" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
ポストプロダクション界のためのセマンティックコンテンツディックコンテンツ発見

ジェームズ・リー
セマンティック検索は、Twelve LabsのMarengoのようなマルチモーダルAIモデルを使用することで、メディア制作のワークフローを変革しています。これにより、編集者は自然言語を使って膨大なビデオライブラリを検索し、手動のメタデータタグ付けだけに頼ることなく、意味や文脈に基づいてコンテンツを見つけることができます。
セマンティック検索は、Twelve LabsのMarengoのようなマルチモーダルAIモデルを使用することで、メディア制作のワークフローを変革しています。これにより、編集者は自然言語を使って膨大なビデオライブラリを検索し、手動のメタデータタグ付けだけに頼ることなく、意味や文脈に基づいてコンテンツを見つけることができます。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2024/05/24
12分
記事へのリンクをコピー
このブログ記事は、Avidのエンジニアリング・フェローであるRob Gonsalves氏との共同執筆です。
1 - はじめに
膨大なメディアライブラリの中から、完璧なコンテンツを素早く簡単に見つけ出すことは、メディア制作の世界において極めて重要です。従来は、メディアアセットにキーワードを手動でタグ付けしていましたが、この方法には正確性、拡張性、文脈の理解に限界がありました。コンテンツを分析することでメディアアセット間の文脈、意味、関係性を理解するAI駆動のセマンティック検索により、ユーザーはキーワードだけでなく、セマンティックな意味に基づいて関連コンテンツを見つけることができます。
マルチモーダルAIの急速な進歩のおかげで、セマンティック検索は今やメディア制作における現実となっています。基盤モデルは、スマートなマシンがメディアコンテンツを理解するのを助けます。これらはメディアアセットをインデックス化するセマンティック検索エンジンを動かし、セマンティックコンテンツに基づいて検索できるようにします。
セマンティック検索は、メディア制作において大きな役割を果たします。メディアのプロフェッショナルが必要なものを素早く見つけるのを助け、時間を節約し、コンテンツの再利用やクリエイティブなストーリーテリングのための新しいアイデアを刺激します。さらに、不適切な手動タグ付けのために見落とされていたかもしれない、隠れた名作を発見することもできます。
この投稿では、ポストプロダクションにおけるセマンティック検索の素晴らしいアプリケーションとメリット、それを支える主要技術、メディアアセット管理システムとの統合方法、そして今後の方向性について探っていきます。
2 - メディア制作におけるセマンティック検索の進化
2.1 - メタデータに基づく検索
メタデータに基づく検索からセマンティック検索への移行は、メディア制作ワークフローにおける大きな進歩を意味します。
AvidのMediaCentral | Production ManagementおよびMediaCentral | Asset Managementシステムは、長年にわたり、最大数百人のユーザーからなるチームがメタデータを効果的に記録および検索できるようにしてきました。これには、クラウドプロバイダーのAIサービスを活用して、自動タグ付け、音声のテキスト書き起こし、光学文字認識などでメタデータを豊かにし、より検索しやすいデータを生成することが含まれています。
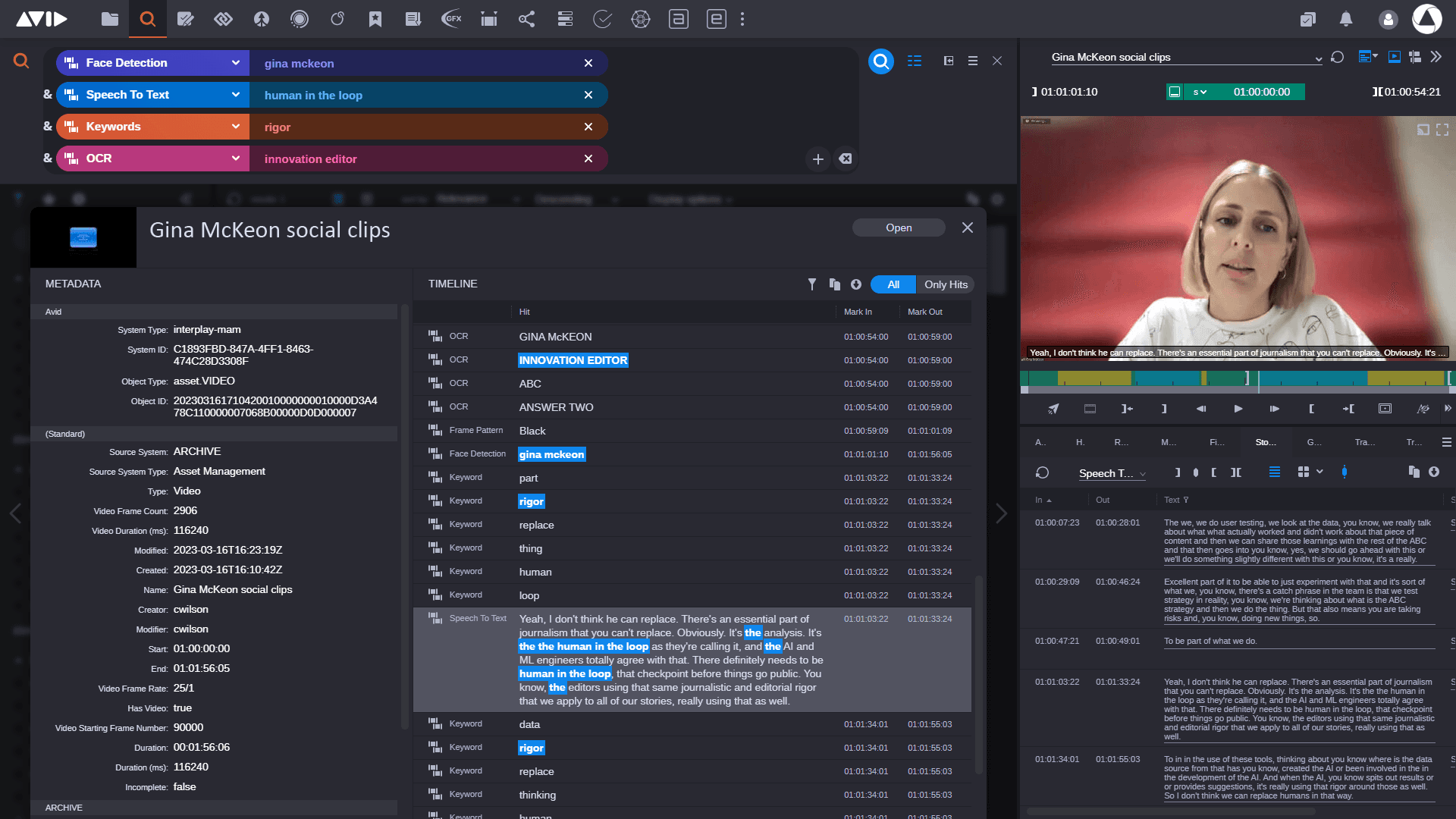
これらの従来のメタデータに基づく検索は、手動で抽出された情報や事前に定義されたタクソノミーに依存しており、非常に効果的ではあるものの、本当に論理的に関連のあるコンテンツを見つける能力を制限することがあります。
メタデータに基づく検索には、従来いくつかの限界があります:
手動でのメタデータ抽出は、時間がかかり、人的エラーが発生しやすいです。自動メタデータ抽出は役立ちますが、依然として事前に定義されたタクソノミーやキーワードに依存しているため、コンテンツの真の文脈や意味を捉えることができません。
これらの検索は、正確なキーワードまたはメタデータに一致する結果のみを返すため、非常に関連性の高い、関連するコンテンツやセマンティックに類似したコンテンツを見落とすことがよくあります。
2.2 - セマンティック検索
対照的に、セマンティック検索は、最先端の基盤モデルを活用して、コンテンツの背景にある実際の意味や文脈を理解します。メディアアセット内の視覚的要素、話された言葉、その他のデータを分析することにより、セマンティック検索エンジンは、事前に定義されたキーワードやタクソノミーだけに頼るのではなく、根底にある概念や関係性を理解することができます。
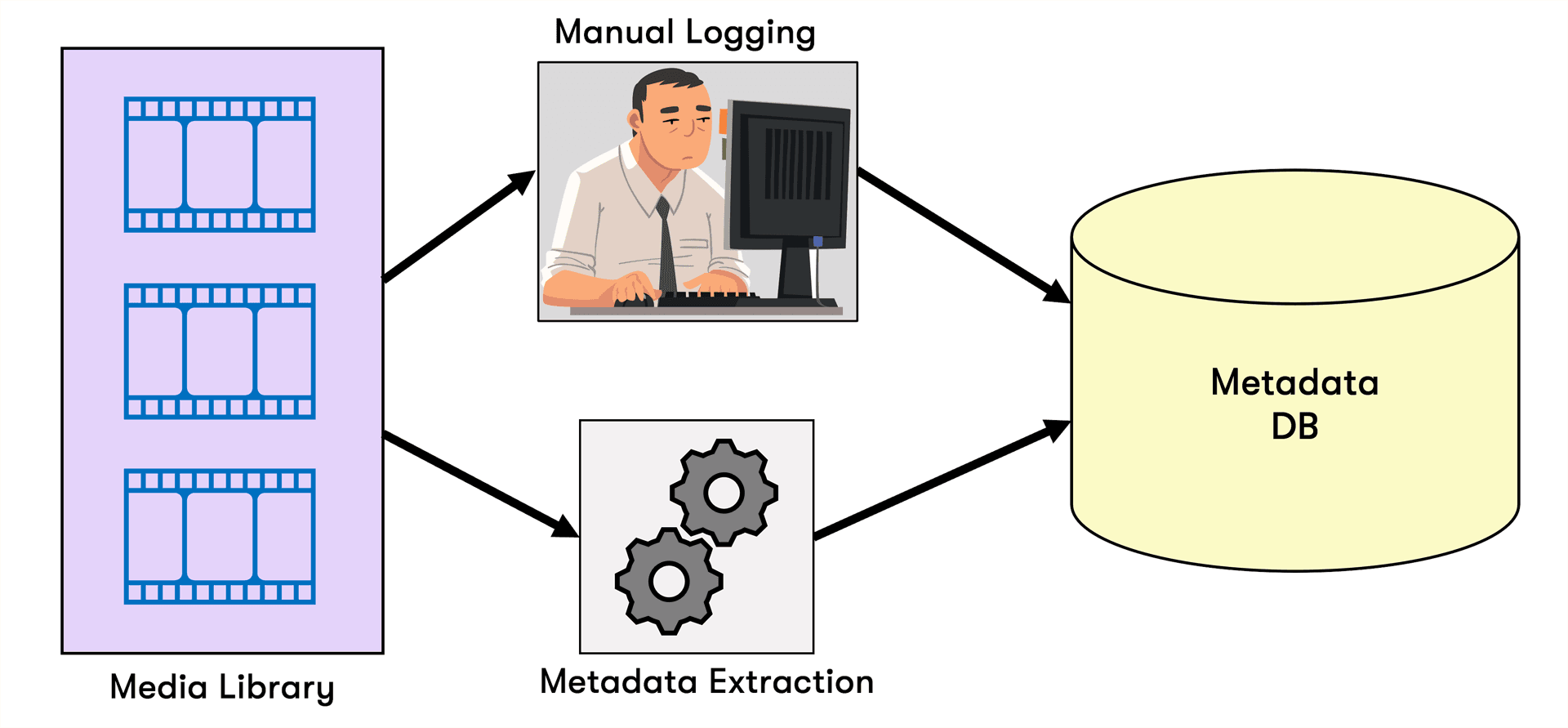
セマンティック検索のプロセスは、上記のように描かれています:
メディアエンコーダーは、ビデオやオーディオファイルなどの生のメディアを、コンピュータシステムが理解・分析できる形式に変換するツールであり、コンピュータがメディアファイルを「読む」のを助ける翻訳者のようなものです。
このプロセスの間に、画像、音、言葉などの特徴を抽出し、それらを埋め込み(embeddings)と呼ばれる数値表現に変換します。これは、コンテンツの本質を捉えるデジタル指紋として機能します。
これらの埋め込みは、セマンティック検索の一環として、システムがこれらの数値表現に基づいて類似のメディアファイルを素早く特定し、比較できるようにするデジタルライブラリである埋め込みデータベースに保存されます。
Twelve Labsは、ビデオ内のすべてのモダリティを同時に統合し、それらの間の複雑な関係性を捉えて、よりニュアンスに富んだ、人間のような解釈を提供する、強力なセマンティックビデオ検索ソリューションを提供しています。その結果、クラウドオブジェクトストレージからのビデオ検索・取得が大幅に高速化され、はるかに正確になります。時間がかかり非効率的な手動タグ付けの代わりに、ビデオエディターは自然言語を使用して、膨大なメディアアーカイブを迅速かつ正確に検索し、そうしなければ気付かれなかったかもしれないビデオの瞬間や隠れた名作を発見できます。
セマンティック検索の正確性と効率性は、テキスト、オーディオ、ビデオ、画像などの膨大なアセットライブラリを迅速に検索して取得する必要があるメディア制作環境において、特に価値があります。コンテンツの真の意味と文脈を理解することで、セマンティック検索エンジンは、ユーザーのクエリがメディアアセットに関連付けられた正確なキーワードやメタデータと一致しない場合でも、非常に関連性の高い結果を提供できます。
3 - セマンティック検索を支える主要技術
3.1 - CLIPによる基礎
OpenAIのContrastive Language-Image Pre-training(CLIP)モデルは、現代のセマンティック検索機能の中心にあります。CLIPは、画像とテキストの両方を共有の埋め込み空間にエンコードすることを学習するニューラルネットワークです。画像とテキストのペアの大規模なデータセットでトレーニングすることで、CLIPは視覚的な概念をその言語的表現と関連付ける能力を開発します。
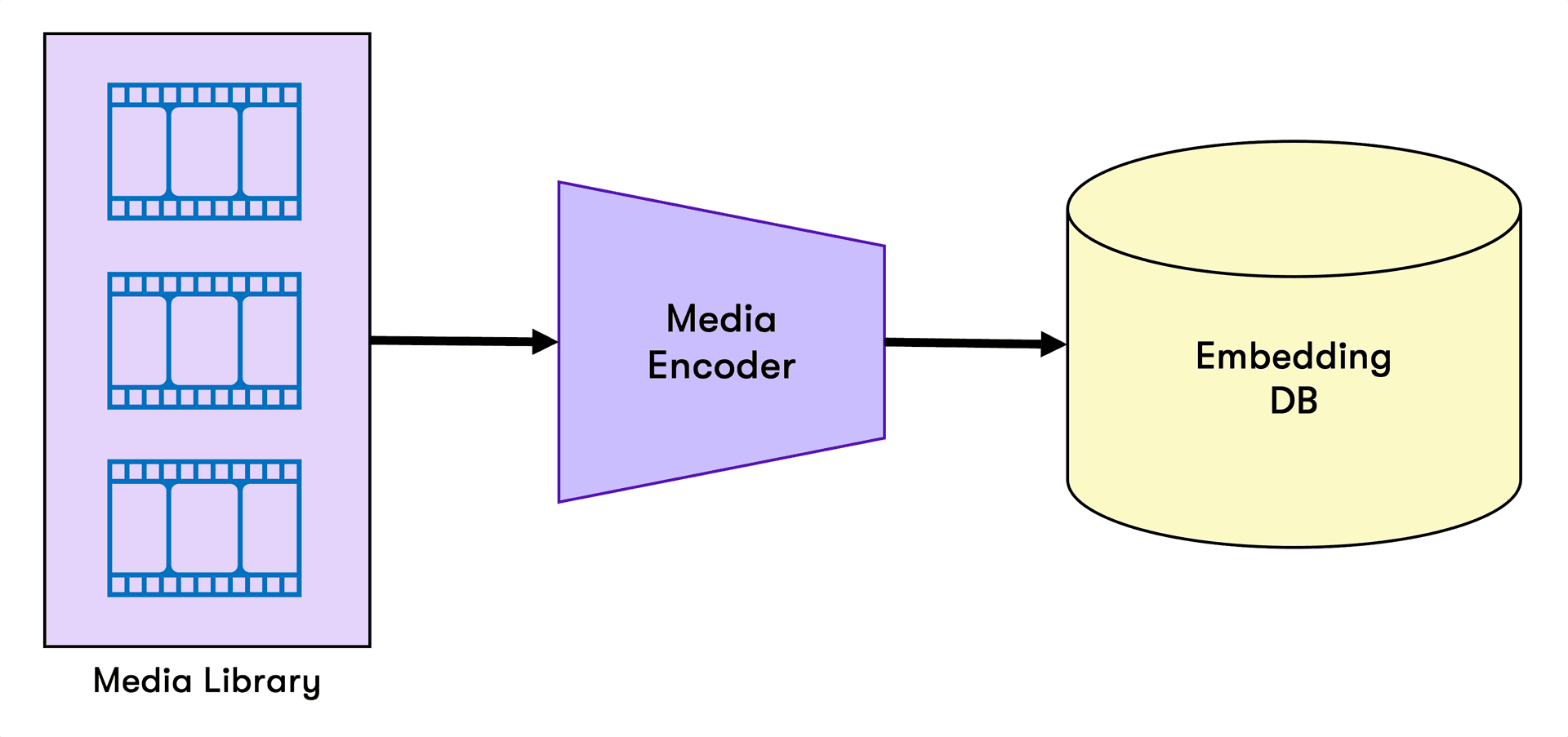
CLIPモデルは主に、ビジュアルエンコーダーとテキストエンコーダーの2つのコンポーネントで構成されています。ビジュアルエンコーダー(通常はVision Transformer(ViT))は、画像を分析してビジュアルな埋め込みを生成します。同時に、テキストエンコーダー(Transformerベースの言語モデル)は、テキスト入力をテキストの埋め込みにエンコードします。その後、これらの埋め込みが比較され、モデルは視覚的表現とテキスト表現をアライメントすることを学習し、モーダル間の検索と理解を可能にします。これがどのように機能するかは、以下の図で見ることができます。
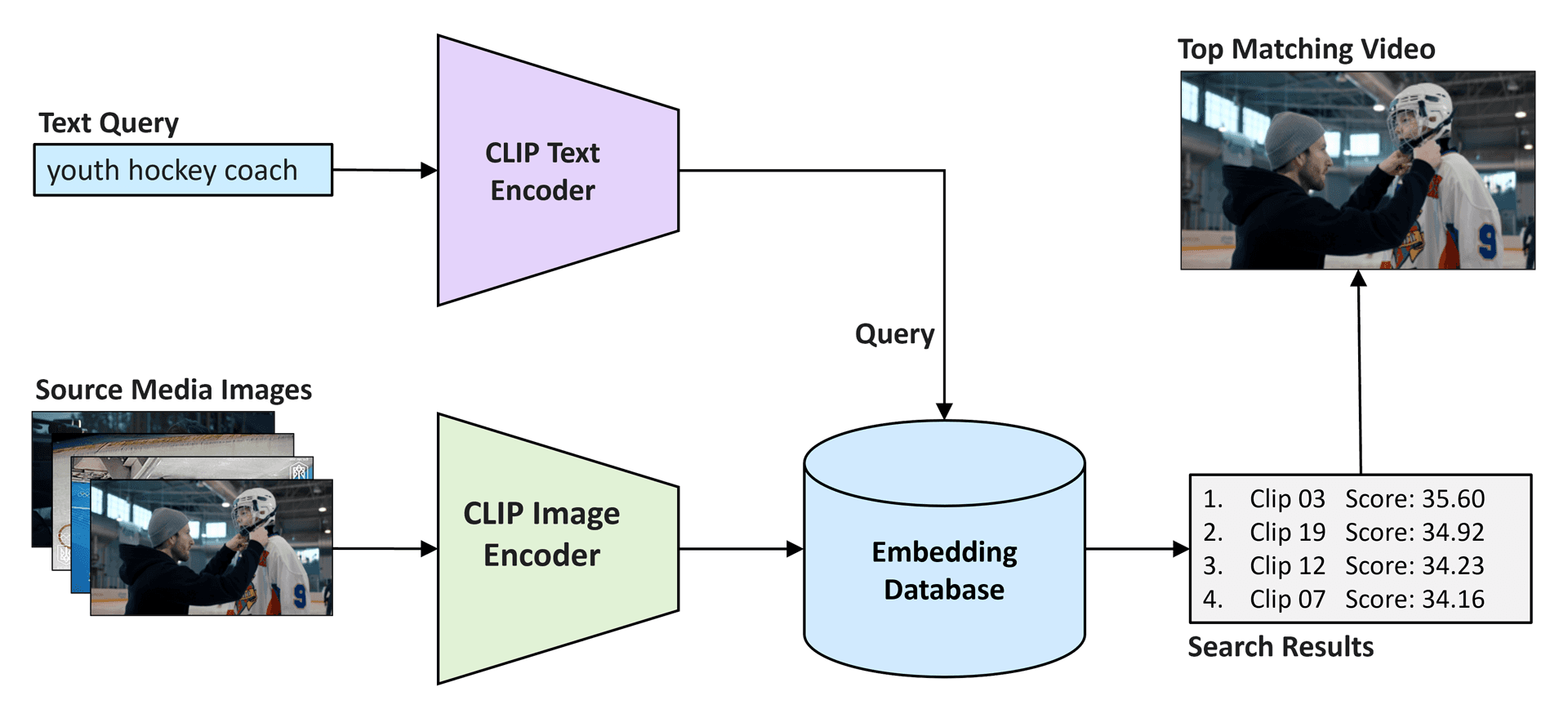
例えば、ユーザーが「ユースホッケーのコーチ」と検索すると、CLIPはこのテキストをエンコードし、メディアライブラリの埋め込みと比較して一致するものを探します。システムは関連性によってビデオクリップをランク付けします。最もスコアの高いビデオは検索と密接に一致し、セマンティックにコンテンツを理解して取得するCLIPの能力を示しています。
3.2 - CLIPの拡張
CLIPの成功に基づき、研究者たちは異なるメディアフォーマットや言語にわたってセマンティック検索機能を強化するための高度なモデルを開発してきました。注目すべき拡張の一つは、元のCLIPテキストエンコーダーを拡張して複数の言語をサポートするMultilingual CLIPです。多言語教師学習(cross-lingual teacher learning)のような技術を活用することで、Multilingual CLIPは多言語での検索と取得を可能にし、ユーザーは様々な言語のテキストを使用してメディアコンテンツにクエリを実行できます。
もう一つの重要な進展は、オーディオエンコーディング機能をマルチモーダルフレームワークに組み込んだLAIONのCLAP(Contrastive Language-Audio-Visual Pre-training)モデルです。CLAPは、オーディオ波形、テキストデータ、および視覚情報を共有の埋め込み空間にエンコードすることを学習し、マルチメディアコンテンツの包括的なセマンティック理解を可能にします。
3.3 - Marengo-2.6

Twelve LabsのMarengo-2.6モデルは、ビデオ検索アプリケーション向けに高度なビデオエンコーディングおよび取得機能を提供します。最先端のビデオ基盤モデルとして、Marengo-2.6はビデオコンテンツからセマンティック特徴を抽出し、ユーザーがテキストクエリや参照ビデオに基づいて関連するビデオクリップを検索・取得できるようにします。
驚くべきことに、Marengo-2.6の拡張された機能は、あらゆる(クロスモダリティ)取得タスクに対応しており、幅広いアプリケーションに対応する汎用ツールとなっています。これには、テキストからビデオ、テキストから画像、テキストからオーディオ、オーディオからビデオ、および画像からビデオのタスクが含まれ、異なるメディアタイプを繋ぎます。これらの能力の質的な実証については、以下のウェビナーセッションをご覧ください:
これらのマルチモーダルモデルは連携して、異なるフォーマットや言語にわたるメディア検索機能を拡張します。CLIPとその拡張(Multilingual CLIPやCLAPなど)は、画像、テキスト、オーディオを検索可能な埋め込みにエンコードします。これらの埋め込みはその後、埋め込みデータベースに保存され、セマンティックな類似性に基づいた効率的な取得とマッチングを可能にします。ビデオコンテンツについては、Marengo-2.6が対照エントロピー損失を用いた自己教師あり学習を活用し、テキストクエリや参照ビデオに基づいてビデオクリップを埋め込み、検索します。
これらの技術を組み合わせることで、ユーザーは膨大なメディアライブラリ全体でセマンティック検索を実行し、意図やクエリの文脈的な意味に基づいて関連性の高いコンテンツを見つけることができます。
4 - ポストプロダクションにおけるセマンティック検索の応用と利点
セマンティック検索は、ポストプロダクションのタスクに革新的なメリットとアプリケーションをもたらします。上記の高度な基盤モデルを使用することで、メディアのプロフェッショナルは説明的なクエリを通じて特定のクリップや画像を簡単に特定できます。例えば、プロデューサーが「夜の雨の中の激しいサッカーの試合」と検索すると、システムは正確なタグに頼ることなく、この説明に視覚的に一致するビデオクリップを取得します。
AIベースのシステムは、クラスタリングとセマンティックマッピングの活用を通じて、高度な分析とインサイトを提供できます。セマンティック検索は、ビデオフレームを分析し、それらを意味のあるグループにクラスタリングすることができるため、エディターは興味のあるシーンを素早く見つけたり、大規模なデータセット全体でテーマのパターンを発見したりできます。例えば、セマンティック埋め込みを使用してビデオクリップの2次元セマンティックマップをプロットし、コンテンツの関係性やテーマの一貫性を視覚的に表現することができます。これの例を以下の画像で確認できます。
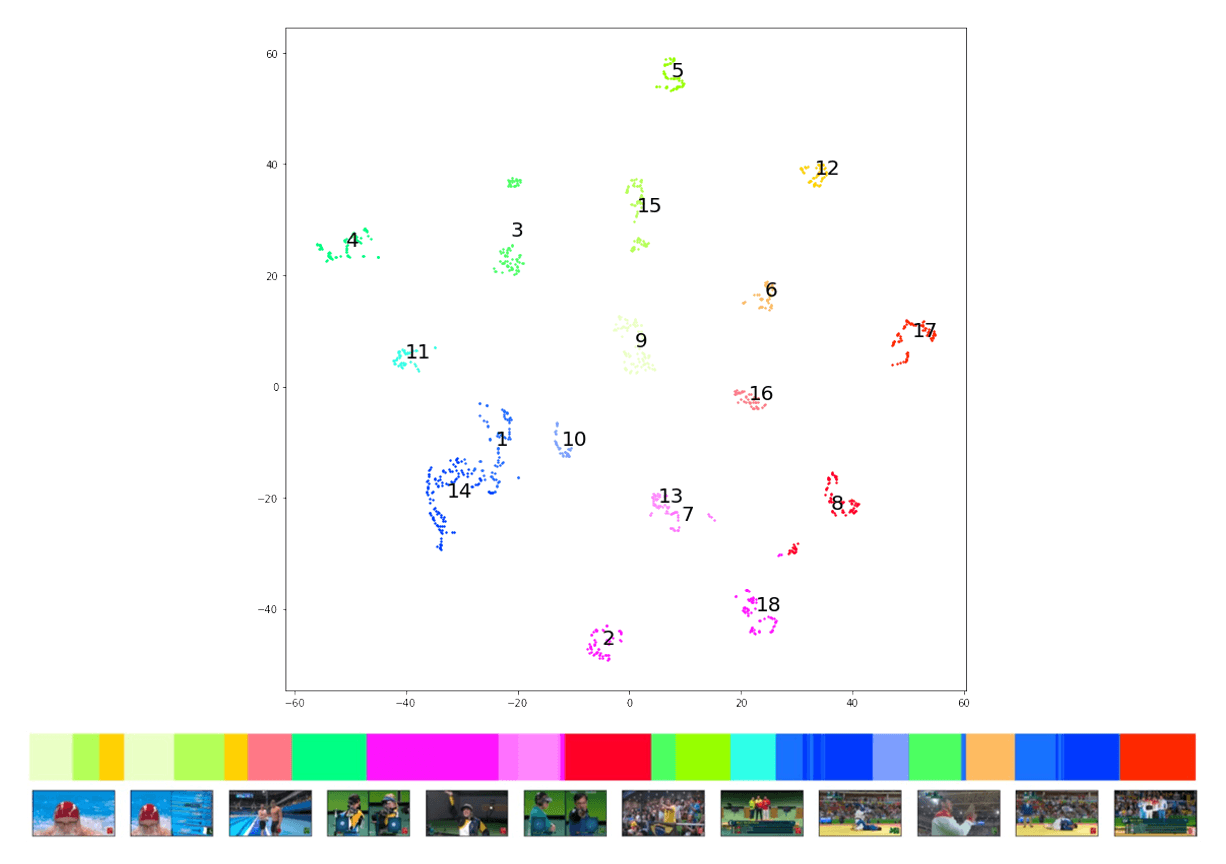
画像は、スポーツのハイライトリールからのCLIPビデオフレーム埋め込みを2次元に削減した表現を示しています。グループ9、15、12のスイミングのショットのように、リール内の類似のフレームがセマンティックな類似性によってどのようにグループ化されているかを確認できます。
話されたフレーズや環境音を含むようにセマンティック検索機能を拡張することで、オーディオビジュアルコンテンツにおける検索の範囲が豊かになります。Twelve LabsのMarengoやLAIONのCLAPのようなメディア埋め込みモデルの統合により、単なるテキストの一致ではなく、セマンティックな類似性によってビデオおよびオーディオコンテンツを検索する能力が向上し、ユーザーは賑やかな街並みや静かな自然の風景のプロットなどの特定の外観や音を含むメディアを見つけることができます。
5 - 包括的なメディアインサイトのためのセマンティック検索の拡張
セマンティック検索は、単純な取得を超えて、包括的なインサイトと分析を提供します。この機能は、セマンティック埋め込みからインタラクティブなディスプレイを作成し、プロデューサーやエディターがメディアコンテンツから深い分析を導き出すことを可能にする可能性によって実証されています。例えば、メディア埋め込みモデルを使用することで、ユーザーは異なるテーマがメディアライブラリ全体でどのように表現されているかを視覚的に探索し、トレンドを特定し、将来のコンテンツの好みを予測することができます。
さらに、セマンティック検索は、メディアライブラリにおけるメタデータ管理のプロセスを劇的に向上させることができます。通常、メタデータは手動でタグ付けされますが、これは労働集約的であり、不整合が生じやすいものです。コンテンツから豊かで説明的なメタデータを自動的に生成することで、セマンティック検索ツールはすべてのアセットが均一に説明されることを保証し、取得や分析を大幅に容易にします。この自動化されたメタデータ強化プロセスは、メディア埋め込みモデルのディープラーニング機能を活用して、気分、テーマ、主要な視覚要素を含む複雑なメディアコンテンツを解釈し、さらなる分析や活用のためのより豊かなデータセットを提供します。
これらのインサイトは、既存のコンテンツを理解し、視聴者の関心や進行中のトレンドに合致する新しいメディアの作成を導く上で価値があります。メディアライブラリ内のセマンティックな関係や文化的文脈を分析する能力は、予測分析やターゲットを絞ったコンテンツ推奨の可能性を切り拓きます。

6 - メディアアセット管理システムへのセマンティック検索の統合
セマンティック検索技術を既存のメディアアセット管理(MAM)システムに統合することは、メディアライブラリの効率性と効果を大幅に高めることができます。この統合により、メディアファイルのコンテンツと文脈を理解できるよりインテリジェントな検索機能が促進され、アセットのアクセス性と発見しやすさが向上します。
MAMシステムへのセマンティック検索の統合は、ポストプロダクションワークフローにおいて極めて重要な、より優れたアーカイブと取得プロセスをも促します。例えば、エディターが数十年にわたるアーカイブからコンテンツを取り出す必要がある場合、セマンティック検索は手動でブラウジングすることなく、現在の制作ニーズに一致するコンテンツを見つけるために、様々な形式や時代を迅速にフィルタリングできます。この機能は取得プロセスをスピードアップし、価値あるアーカイブ映像へのアクセスを容易にし、その再利用を促進して既存アセットの価値を最大化します。これは、効果を維持するために広範な手動入力と維持管理を必要とすることが多い従来のキーワードベースのシステムからの大きな転換を意味します。
さらに、セマンティック検索は、ユーザーの現在のプロジェクトや過去の検索に基づいて、文脈を認識した推奨(レコメンデーション)を提供できます。この機能はワークフローをスピードアップし、エディターが考慮していなかったかもしれない関連性の高いコンテンツに触れさせることで、新しいクリエイティブなアイデアを着想させます。
Avidは、NABやIBCなどの主要なトレードショーイベントにおける様々な概念実証(PoC)で、この分野の研究を実証してきました。これには、ウェブベースのアプリケーション「MediaCentral | Cloud UX」におけるレコメンデーションエンジンが含まれており、ジャーナリストが執筆中のスクリプトや、タイムライン上のナレーション音声に関連するメディアが提供されます。システムは、テキストの文字通りの分析に基づいて提案を行うだけでなく、スクリプトの文脈に基づいて関連する文やフレーズを生成し、さらなる提案を提供します。
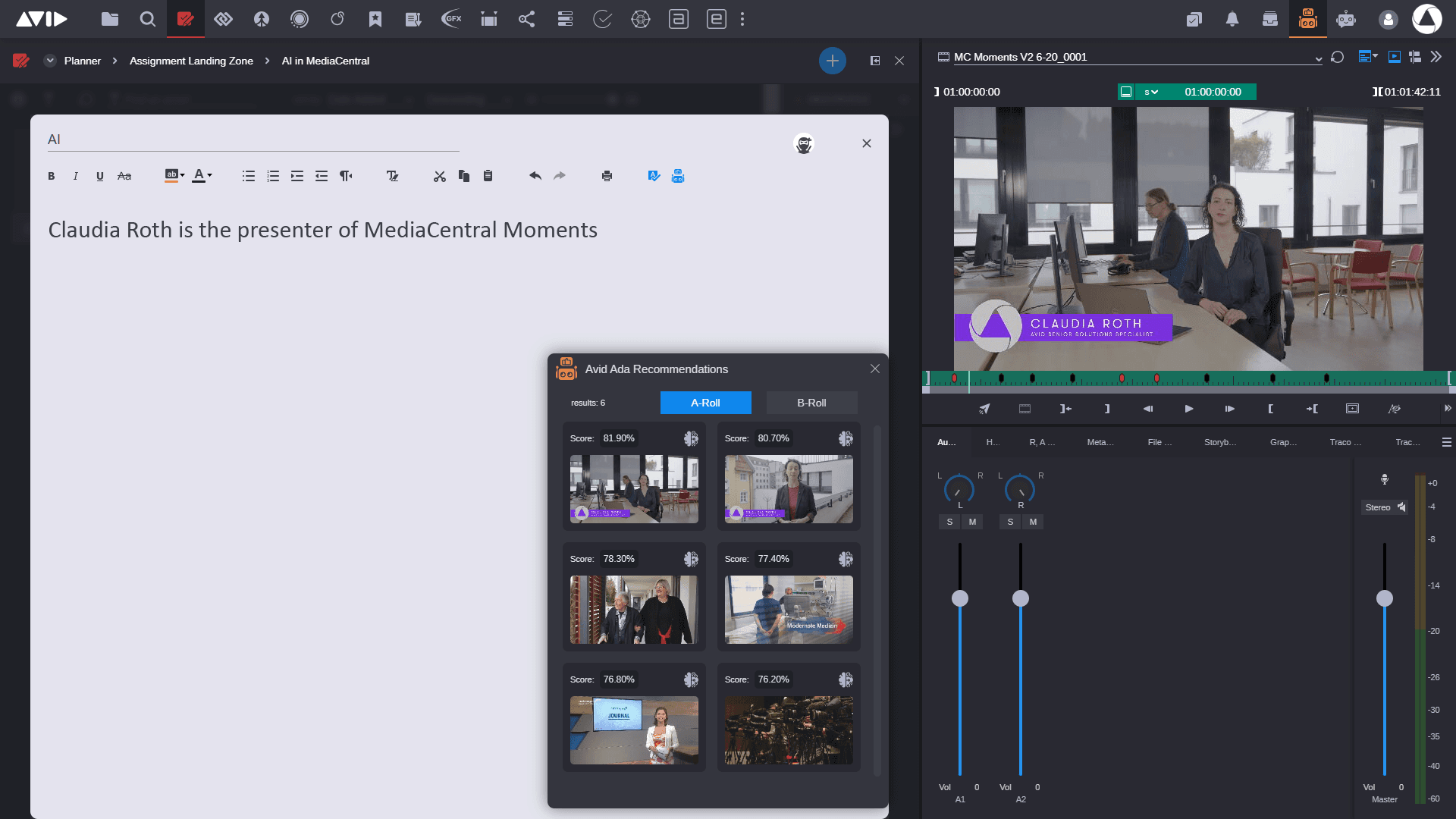
Avidは、同社のポートフォリオ全体でおけるAIの包括的なフレームワークであるAvid Adaの傘下で、幅広い製品へのAI対応技術の実装を継続しています。
Twelve Labsは、ユーザーにビデオ理解を提供するために、複数のMAMプロバイダーと統合しています。注目すべき例は、Vidispine - An Arvato Systems Brandとのパートナーシップです。私たちはまず、スポーツ業界の共通のクライアント向けに連携し、クライアントのビデオ閲覧体験を向上させました。この共同ソリューションにより、ビデオコンテンツ内のナビゲーションが容易になり、特定の動きやプレイヤーの会話など、これまで検出できなかった要素が明らかになりました。この統合には、それ以上の可能性があることがすぐに明らかになりました。
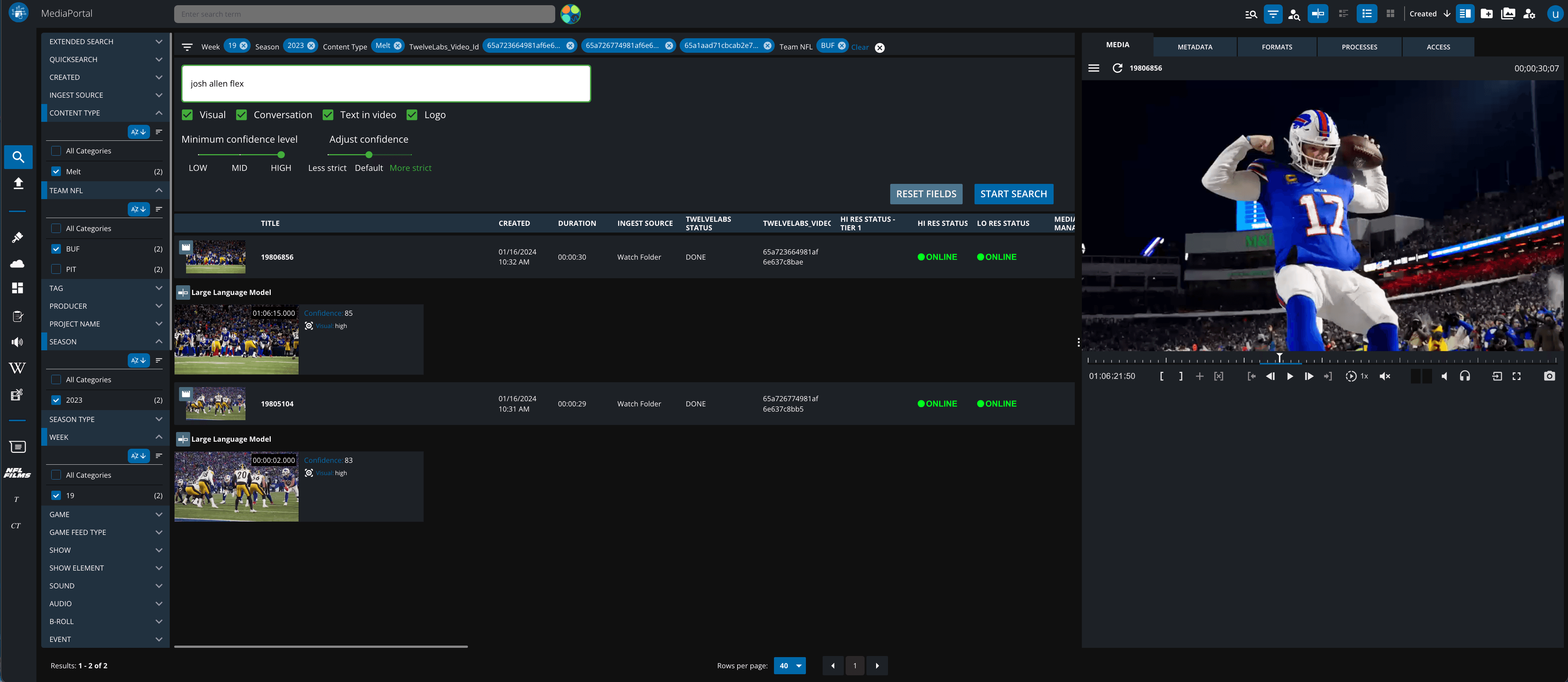
VidispineのMediaPortalの直感的なユーザーインターフェースにTwelve Labsのビデオ言語基盤モデルを統合することで、コアサービスであるVidiCoreですべての静的メタデータフィールドをインデックス化する必要がなくなるため、ユーザーの素材検索方法が変わります。Vidispineのユーザーは、自然言語クエリを使用してビデオ内の正確な瞬間を見つけ、それをVidispineアプリケーションのメタデータと組み合わせることができるようになりました。
7 - 課題と今後の方向性
セマンティック検索技術は近年大きな進歩を遂げているものの、メディア制作業界における実装と広範な採用には、依然としていくつかの課題が存在します。
7.1 - 課題
主な課題の一つは、大量のマルチメディアデータを効果的に処理および分析するために必要な、極めて大きな計算能力とリソースです。高品質のセマンティック埋め込みを生成し、複雑な文脈理解を実行するには、強力なハードウェアアクセラレータ(GPU)や十分なストレージ容量を含む、多大な計算リソースが必要とされます。メディアライブラリが指数関数的に成長し続ける中、計算需要は増すばかりであり、セマンティック検索を拡張可能で実用的なものにするためには、より効率的なアルゴリズムとハードウェア加速技術の開発が必要不可欠です。
現在の言語・視覚の基盤モデルは文脈の理解において目覚ましい進歩を遂げていますが、ニュアンスのある意味の捉え、曖昧さの処理、現実世界の知識の考慮という点では、まだ改善の余地があります。マルチメディアコンテンツ内の複雑な文脈や関係性をよりよく把握できる、より洗練されたマルチモーダル基盤モデルを開発することが、検索結果の関連性と正確性を高めるために極めて重要です。
また、テキスト、画像、ビデオ、オーディオといった多様なモダリティを、統一されたセマンティック検索フレームワークにシームレスに統合し融合させることには、技術的な課題があります。これらの異種データソースをアライメントし、組み合わせる方法を進歩させることは、異なるモダリティに存在する相補的な情報を効果的に活用できる、包括的でクロスモーダルな検索機能を提供するために重要です。

7.2 - 今後の方向性
これらの課題にもかかわらず、メディア制作におけるセマンティック検索の未来は、計り知れない可能性を秘めており、メディアのプロフェッショナルがコンテンツを検索、発見、活用する方法に革命をもたらすことを約束しています。
様々なモダリティにわたる情報を捉えて融合させることを目指す、マルチモーダル基盤モデルの継続的な開発は、より洗練されたセマンティック検索エンジンへの道を切り拓く可能性があります。大規模なマルチモーダルデータセットでトレーニングされたこれらのモデル(Twelve LabsのMarengoやPegasusなど)は、異なるデータタイプにまたがる複雑な関係性やパターンを明らかにする可能性を秘めており、より正確で包括的な検索機能を可能にします。
さらに、ナレッジグラフ、スクリプト、文字起こしなどの他の形式の制作データをセマンティック検索システムに統合することで、その機能が大幅に向上します。ナレッジグラフは、様々なエンティティ間の関係性の構造化された表現を提供し、文脈情報で検索プロセスを豊かにすることができます。スクリプトや文字起こしは、メディアコンテンツの詳細なテキスト記録を提供し、検索エンジンが特定のダイアログ、シーン、ナラティブ要素をインデックス化して取得できるようにします。これらの多様なデータソースを活用することで、セマンティック検索システムはより正確で文脈に関連した結果を提供でき、最終的にはメディア制作におけるコンテンツ発見と活用の効率を向上させます。
さらに、ユーザーの好みや過去の行動に基づいて検索結果を調整する、パーソナライズされたセマンティック検索の導入は、メディア制作環境における検索結果の関連性と実用性を高める可能性があります。個々のユーザーの特定のニーズや文脈を理解することで、パーソナライズされたセマンティック検索は最も適切なコンテンツを表面化させ、より効率的で効果的なコンテンツの発見と活用を促進します。
8 - 結論
セマンティック検索は、ニュース、放送、そしてもちろんポストプロダクションの世界において、間違いなく期待の新星です。これは、メディアアセットのより深い意味と文脈を理解するために、高度なAI技術の力を活用することに他なりません。従来のキーワードベースの検索手法を忘れさせる、これは制作ワークフローにおけるメディアの管理と利用方法を革新する、変革的なアプローチです。
OpenAIのCLIPのようなモデルや、Multilingual CLIP、LAIONのCLAP、Twelve LabsのMarengo、そしてAvidからの継続的な好進展などのイノベーションについて考えてみてください。これらは、この分野がどれほど速く動いているかを示すほんの数例に過ぎません。これらは検索プロセスをより直感的なものにし、メディアのプロフェッショナルが前例のない精度とスピードで自己のクリエイティブなビジョンに合致するコンテンツを見つけるのを助けています。デジタルメディアの量がこれほど増えている中、必要なものを素早く見つけられることは、ますます重要になっていくでしょう。
セマンティック検索の道のりはまだ続いており、新しい開発が行われるたびに、全く新しいレベルの洗練度と機能が追加されています。セマンティック検索を受け入れることで、私たちは効率を高め、クリエイティブなプロセスを促進し、コンテンツクリエイターにストーリーを語るための全く新しい方法を提供しています。
9 - アクションへの呼びかけ
セマンティック検索技術は、メディア制作の未来に不可欠です。メディアのプロフェッショナルとして、これらのイノベーションを採用することは極めて重要です。
企画から編集まで、制作のすべての段階でセマンティック検索を使用してください。
コンテンツの発見と管理を強化するために、様々なセマンティック検索モデルをテストしてください。ワークショップやウェビナーを通じて、メディア制作におけるAIの進歩に関する最新情報を常に入手してください。
セマンティック検索をニーズに合わせるために、技術プロバイダーとの提携やパイロットプログラムへの参加を検討してください。この投資は、効率性、創造性、そして競争優位性を高めることになります。
Twelve Labsのセマンティックビデオ検索ソリューションは、この革命の最前線に立っています。当社のビデオ理解プラットフォームは既存のメディアアセット管理システムとシームレスに統合し、ユーザーが前例のない容易さで膨大なビデオライブラリをナビゲートできるようにします。Vidispine、Blackbird、EMAM、Nomad、Cinesysとの最近の統合実績をご覧ください。
過去数年にわたり、Avidはセマンティックメディア検索を含む、メディア制作向けのAI活用に関する研究を実施してきました。彼らはワークフローの効率化をサポートするデジタルアシスタント「Avid Ada」を開発しました。研究成果を製品ロードマップに反映させることに加え、Avidはメディア業界に向けて研究成果の公開と共有も行っています。
このブログ記事は、Avidのエンジニアリング・フェローであるRob Gonsalves氏との共同執筆です。
1 - はじめに
膨大なメディアライブラリの中から、完璧なコンテンツを素早く簡単に見つけ出すことは、メディア制作の世界において極めて重要です。従来は、メディアアセットにキーワードを手動でタグ付けしていましたが、この方法には正確性、拡張性、文脈の理解に限界がありました。コンテンツを分析することでメディアアセット間の文脈、意味、関係性を理解するAI駆動のセマンティック検索により、ユーザーはキーワードだけでなく、セマンティックな意味に基づいて関連コンテンツを見つけることができます。
マルチモーダルAIの急速な進歩のおかげで、セマンティック検索は今やメディア制作における現実となっています。基盤モデルは、スマートなマシンがメディアコンテンツを理解するのを助けます。これらはメディアアセットをインデックス化するセマンティック検索エンジンを動かし、セマンティックコンテンツに基づいて検索できるようにします。
セマンティック検索は、メディア制作において大きな役割を果たします。メディアのプロフェッショナルが必要なものを素早く見つけるのを助け、時間を節約し、コンテンツの再利用やクリエイティブなストーリーテリングのための新しいアイデアを刺激します。さらに、不適切な手動タグ付けのために見落とされていたかもしれない、隠れた名作を発見することもできます。
この投稿では、ポストプロダクションにおけるセマンティック検索の素晴らしいアプリケーションとメリット、それを支える主要技術、メディアアセット管理システムとの統合方法、そして今後の方向性について探っていきます。
2 - メディア制作におけるセマンティック検索の進化
2.1 - メタデータに基づく検索
メタデータに基づく検索からセマンティック検索への移行は、メディア制作ワークフローにおける大きな進歩を意味します。
AvidのMediaCentral | Production ManagementおよびMediaCentral | Asset Managementシステムは、長年にわたり、最大数百人のユーザーからなるチームがメタデータを効果的に記録および検索できるようにしてきました。これには、クラウドプロバイダーのAIサービスを活用して、自動タグ付け、音声のテキスト書き起こし、光学文字認識などでメタデータを豊かにし、より検索しやすいデータを生成することが含まれています。
これらの従来のメタデータに基づく検索は、手動で抽出された情報や事前に定義されたタクソノミーに依存しており、非常に効果的ではあるものの、本当に論理的に関連のあるコンテンツを見つける能力を制限することがあります。
メタデータに基づく検索には、従来いくつかの限界があります:
手動でのメタデータ抽出は、時間がかかり、人的エラーが発生しやすいです。自動メタデータ抽出は役立ちますが、依然として事前に定義されたタクソノミーやキーワードに依存しているため、コンテンツの真の文脈や意味を捉えることができません。
これらの検索は、正確なキーワードまたはメタデータに一致する結果のみを返すため、非常に関連性の高い、関連するコンテンツやセマンティックに類似したコンテンツを見落とすことがよくあります。
2.2 - セマンティック検索
対照的に、セマンティック検索は、最先端の基盤モデルを活用して、コンテンツの背景にある実際の意味や文脈を理解します。メディアアセット内の視覚的要素、話された言葉、その他のデータを分析することにより、セマンティック検索エンジンは、事前に定義されたキーワードやタクソノミーだけに頼るのではなく、根底にある概念や関係性を理解することができます。
セマンティック検索のプロセスは、上記のように描かれています:
メディアエンコーダーは、ビデオやオーディオファイルなどの生のメディアを、コンピュータシステムが理解・分析できる形式に変換するツールであり、コンピュータがメディアファイルを「読む」のを助ける翻訳者のようなものです。
このプロセスの間に、画像、音、言葉などの特徴を抽出し、それらを埋め込み(embeddings)と呼ばれる数値表現に変換します。これは、コンテンツの本質を捉えるデジタル指紋として機能します。
これらの埋め込みは、セマンティック検索の一環として、システムがこれらの数値表現に基づいて類似のメディアファイルを素早く特定し、比較できるようにするデジタルライブラリである埋め込みデータベースに保存されます。
Twelve Labsは、ビデオ内のすべてのモダリティを同時に統合し、それらの間の複雑な関係性を捉えて、よりニュアンスに富んだ、人間のような解釈を提供する、強力なセマンティックビデオ検索ソリューションを提供しています。その結果、クラウドオブジェクトストレージからのビデオ検索・取得が大幅に高速化され、はるかに正確になります。時間がかかり非効率的な手動タグ付けの代わりに、ビデオエディターは自然言語を使用して、膨大なメディアアーカイブを迅速かつ正確に検索し、そうしなければ気付かれなかったかもしれないビデオの瞬間や隠れた名作を発見できます。
セマンティック検索の正確性と効率性は、テキスト、オーディオ、ビデオ、画像などの膨大なアセットライブラリを迅速に検索して取得する必要があるメディア制作環境において、特に価値があります。コンテンツの真の意味と文脈を理解することで、セマンティック検索エンジンは、ユーザーのクエリがメディアアセットに関連付けられた正確なキーワードやメタデータと一致しない場合でも、非常に関連性の高い結果を提供できます。
3 - セマンティック検索を支える主要技術
3.1 - CLIPによる基礎
OpenAIのContrastive Language-Image Pre-training(CLIP)モデルは、現代のセマンティック検索機能の中心にあります。CLIPは、画像とテキストの両方を共有の埋め込み空間にエンコードすることを学習するニューラルネットワークです。画像とテキストのペアの大規模なデータセットでトレーニングすることで、CLIPは視覚的な概念をその言語的表現と関連付ける能力を開発します。
CLIPモデルは主に、ビジュアルエンコーダーとテキストエンコーダーの2つのコンポーネントで構成されています。ビジュアルエンコーダー(通常はVision Transformer(ViT))は、画像を分析してビジュアルな埋め込みを生成します。同時に、テキストエンコーダー(Transformerベースの言語モデル)は、テキスト入力をテキストの埋め込みにエンコードします。その後、これらの埋め込みが比較され、モデルは視覚的表現とテキスト表現をアライメントすることを学習し、モーダル間の検索と理解を可能にします。これがどのように機能するかは、以下の図で見ることができます。
例えば、ユーザーが「ユースホッケーのコーチ」と検索すると、CLIPはこのテキストをエンコードし、メディアライブラリの埋め込みと比較して一致するものを探します。システムは関連性によってビデオクリップをランク付けします。最もスコアの高いビデオは検索と密接に一致し、セマンティックにコンテンツを理解して取得するCLIPの能力を示しています。
3.2 - CLIPの拡張
CLIPの成功に基づき、研究者たちは異なるメディアフォーマットや言語にわたってセマンティック検索機能を強化するための高度なモデルを開発してきました。注目すべき拡張の一つは、元のCLIPテキストエンコーダーを拡張して複数の言語をサポートするMultilingual CLIPです。多言語教師学習(cross-lingual teacher learning)のような技術を活用することで、Multilingual CLIPは多言語での検索と取得を可能にし、ユーザーは様々な言語のテキストを使用してメディアコンテンツにクエリを実行できます。
もう一つの重要な進展は、オーディオエンコーディング機能をマルチモーダルフレームワークに組み込んだLAIONのCLAP(Contrastive Language-Audio-Visual Pre-training)モデルです。CLAPは、オーディオ波形、テキストデータ、および視覚情報を共有の埋め込み空間にエンコードすることを学習し、マルチメディアコンテンツの包括的なセマンティック理解を可能にします。
3.3 - Marengo-2.6
Twelve LabsのMarengo-2.6モデルは、ビデオ検索アプリケーション向けに高度なビデオエンコーディングおよび取得機能を提供します。最先端のビデオ基盤モデルとして、Marengo-2.6はビデオコンテンツからセマンティック特徴を抽出し、ユーザーがテキストクエリや参照ビデオに基づいて関連するビデオクリップを検索・取得できるようにします。
驚くべきことに、Marengo-2.6の拡張された機能は、あらゆる(クロスモダリティ)取得タスクに対応しており、幅広いアプリケーションに対応する汎用ツールとなっています。これには、テキストからビデオ、テキストから画像、テキストからオーディオ、オーディオからビデオ、および画像からビデオのタスクが含まれ、異なるメディアタイプを繋ぎます。これらの能力の質的な実証については、以下のウェビナーセッションをご覧ください:
これらのマルチモーダルモデルは連携して、異なるフォーマットや言語にわたるメディア検索機能を拡張します。CLIPとその拡張(Multilingual CLIPやCLAPなど)は、画像、テキスト、オーディオを検索可能な埋め込みにエンコードします。これらの埋め込みはその後、埋め込みデータベースに保存され、セマンティックな類似性に基づいた効率的な取得とマッチングを可能にします。ビデオコンテンツについては、Marengo-2.6が対照エントロピー損失を用いた自己教師あり学習を活用し、テキストクエリや参照ビデオに基づいてビデオクリップを埋め込み、検索します。
これらの技術を組み合わせることで、ユーザーは膨大なメディアライブラリ全体でセマンティック検索を実行し、意図やクエリの文脈的な意味に基づいて関連性の高いコンテンツを見つけることができます。
4 - ポストプロダクションにおけるセマンティック検索の応用と利点
セマンティック検索は、ポストプロダクションのタスクに革新的なメリットとアプリケーションをもたらします。上記の高度な基盤モデルを使用することで、メディアのプロフェッショナルは説明的なクエリを通じて特定のクリップや画像を簡単に特定できます。例えば、プロデューサーが「夜の雨の中の激しいサッカーの試合」と検索すると、システムは正確なタグに頼ることなく、この説明に視覚的に一致するビデオクリップを取得します。
AIベースのシステムは、クラスタリングとセマンティックマッピングの活用を通じて、高度な分析とインサイトを提供できます。セマンティック検索は、ビデオフレームを分析し、それらを意味のあるグループにクラスタリングすることができるため、エディターは興味のあるシーンを素早く見つけたり、大規模なデータセット全体でテーマのパターンを発見したりできます。例えば、セマンティック埋め込みを使用してビデオクリップの2次元セマンティックマップをプロットし、コンテンツの関係性やテーマの一貫性を視覚的に表現することができます。これの例を以下の画像で確認できます。
画像は、スポーツのハイライトリールからのCLIPビデオフレーム埋め込みを2次元に削減した表現を示しています。グループ9、15、12のスイミングのショットのように、リール内の類似のフレームがセマンティックな類似性によってどのようにグループ化されているかを確認できます。
話されたフレーズや環境音を含むようにセマンティック検索機能を拡張することで、オーディオビジュアルコンテンツにおける検索の範囲が豊かになります。Twelve LabsのMarengoやLAIONのCLAPのようなメディア埋め込みモデルの統合により、単なるテキストの一致ではなく、セマンティックな類似性によってビデオおよびオーディオコンテンツを検索する能力が向上し、ユーザーは賑やかな街並みや静かな自然の風景のプロットなどの特定の外観や音を含むメディアを見つけることができます。
5 - 包括的なメディアインサイトのためのセマンティック検索の拡張
セマンティック検索は、単純な取得を超えて、包括的なインサイトと分析を提供します。この機能は、セマンティック埋め込みからインタラクティブなディスプレイを作成し、プロデューサーやエディターがメディアコンテンツから深い分析を導き出すことを可能にする可能性によって実証されています。例えば、メディア埋め込みモデルを使用することで、ユーザーは異なるテーマがメディアライブラリ全体でどのように表現されているかを視覚的に探索し、トレンドを特定し、将来のコンテンツの好みを予測することができます。
さらに、セマンティック検索は、メディアライブラリにおけるメタデータ管理のプロセスを劇的に向上させることができます。通常、メタデータは手動でタグ付けされますが、これは労働集約的であり、不整合が生じやすいものです。コンテンツから豊かで説明的なメタデータを自動的に生成することで、セマンティック検索ツールはすべてのアセットが均一に説明されることを保証し、取得や分析を大幅に容易にします。この自動化されたメタデータ強化プロセスは、メディア埋め込みモデルのディープラーニング機能を活用して、気分、テーマ、主要な視覚要素を含む複雑なメディアコンテンツを解釈し、さらなる分析や活用のためのより豊かなデータセットを提供します。
これらのインサイトは、既存のコンテンツを理解し、視聴者の関心や進行中のトレンドに合致する新しいメディアの作成を導く上で価値があります。メディアライブラリ内のセマンティックな関係や文化的文脈を分析する能力は、予測分析やターゲットを絞ったコンテンツ推奨の可能性を切り拓きます。
6 - メディアアセット管理システムへのセマンティック検索の統合
セマンティック検索技術を既存のメディアアセット管理(MAM)システムに統合することは、メディアライブラリの効率性と効果を大幅に高めることができます。この統合により、メディアファイルのコンテンツと文脈を理解できるよりインテリジェントな検索機能が促進され、アセットのアクセス性と発見しやすさが向上します。
MAMシステムへのセマンティック検索の統合は、ポストプロダクションワークフローにおいて極めて重要な、より優れたアーカイブと取得プロセスをも促します。例えば、エディターが数十年にわたるアーカイブからコンテンツを取り出す必要がある場合、セマンティック検索は手動でブラウジングすることなく、現在の制作ニーズに一致するコンテンツを見つけるために、様々な形式や時代を迅速にフィルタリングできます。この機能は取得プロセスをスピードアップし、価値あるアーカイブ映像へのアクセスを容易にし、その再利用を促進して既存アセットの価値を最大化します。これは、効果を維持するために広範な手動入力と維持管理を必要とすることが多い従来のキーワードベースのシステムからの大きな転換を意味します。
さらに、セマンティック検索は、ユーザーの現在のプロジェクトや過去の検索に基づいて、文脈を認識した推奨(レコメンデーション)を提供できます。この機能はワークフローをスピードアップし、エディターが考慮していなかったかもしれない関連性の高いコンテンツに触れさせることで、新しいクリエイティブなアイデアを着想させます。
Avidは、NABやIBCなどの主要なトレードショーイベントにおける様々な概念実証(PoC)で、この分野の研究を実証してきました。これには、ウェブベースのアプリケーション「MediaCentral | Cloud UX」におけるレコメンデーションエンジンが含まれており、ジャーナリストが執筆中のスクリプトや、タイムライン上のナレーション音声に関連するメディアが提供されます。システムは、テキストの文字通りの分析に基づいて提案を行うだけでなく、スクリプトの文脈に基づいて関連する文やフレーズを生成し、さらなる提案を提供します。
Avidは、同社のポートフォリオ全体でおけるAIの包括的なフレームワークであるAvid Adaの傘下で、幅広い製品へのAI対応技術の実装を継続しています。
Twelve Labsは、ユーザーにビデオ理解を提供するために、複数のMAMプロバイダーと統合しています。注目すべき例は、Vidispine - An Arvato Systems Brandとのパートナーシップです。私たちはまず、スポーツ業界の共通のクライアント向けに連携し、クライアントのビデオ閲覧体験を向上させました。この共同ソリューションにより、ビデオコンテンツ内のナビゲーションが容易になり、特定の動きやプレイヤーの会話など、これまで検出できなかった要素が明らかになりました。この統合には、それ以上の可能性があることがすぐに明らかになりました。
VidispineのMediaPortalの直感的なユーザーインターフェースにTwelve Labsのビデオ言語基盤モデルを統合することで、コアサービスであるVidiCoreですべての静的メタデータフィールドをインデックス化する必要がなくなるため、ユーザーの素材検索方法が変わります。Vidispineのユーザーは、自然言語クエリを使用してビデオ内の正確な瞬間を見つけ、それをVidispineアプリケーションのメタデータと組み合わせることができるようになりました。
7 - 課題と今後の方向性
セマンティック検索技術は近年大きな進歩を遂げているものの、メディア制作業界における実装と広範な採用には、依然としていくつかの課題が存在します。
7.1 - 課題
主な課題の一つは、大量のマルチメディアデータを効果的に処理および分析するために必要な、極めて大きな計算能力とリソースです。高品質のセマンティック埋め込みを生成し、複雑な文脈理解を実行するには、強力なハードウェアアクセラレータ(GPU)や十分なストレージ容量を含む、多大な計算リソースが必要とされます。メディアライブラリが指数関数的に成長し続ける中、計算需要は増すばかりであり、セマンティック検索を拡張可能で実用的なものにするためには、より効率的なアルゴリズムとハードウェア加速技術の開発が必要不可欠です。
現在の言語・視覚の基盤モデルは文脈の理解において目覚ましい進歩を遂げていますが、ニュアンスのある意味の捉え、曖昧さの処理、現実世界の知識の考慮という点では、まだ改善の余地があります。マルチメディアコンテンツ内の複雑な文脈や関係性をよりよく把握できる、より洗練されたマルチモーダル基盤モデルを開発することが、検索結果の関連性と正確性を高めるために極めて重要です。
また、テキスト、画像、ビデオ、オーディオといった多様なモダリティを、統一されたセマンティック検索フレームワークにシームレスに統合し融合させることには、技術的な課題があります。これらの異種データソースをアライメントし、組み合わせる方法を進歩させることは、異なるモダリティに存在する相補的な情報を効果的に活用できる、包括的でクロスモーダルな検索機能を提供するために重要です。
7.2 - 今後の方向性
これらの課題にもかかわらず、メディア制作におけるセマンティック検索の未来は、計り知れない可能性を秘めており、メディアのプロフェッショナルがコンテンツを検索、発見、活用する方法に革命をもたらすことを約束しています。
様々なモダリティにわたる情報を捉えて融合させることを目指す、マルチモーダル基盤モデルの継続的な開発は、より洗練されたセマンティック検索エンジンへの道を切り拓く可能性があります。大規模なマルチモーダルデータセットでトレーニングされたこれらのモデル(Twelve LabsのMarengoやPegasusなど)は、異なるデータタイプにまたがる複雑な関係性やパターンを明らかにする可能性を秘めており、より正確で包括的な検索機能を可能にします。
さらに、ナレッジグラフ、スクリプト、文字起こしなどの他の形式の制作データをセマンティック検索システムに統合することで、その機能が大幅に向上します。ナレッジグラフは、様々なエンティティ間の関係性の構造化された表現を提供し、文脈情報で検索プロセスを豊かにすることができます。スクリプトや文字起こしは、メディアコンテンツの詳細なテキスト記録を提供し、検索エンジンが特定のダイアログ、シーン、ナラティブ要素をインデックス化して取得できるようにします。これらの多様なデータソースを活用することで、セマンティック検索システムはより正確で文脈に関連した結果を提供でき、最終的にはメディア制作におけるコンテンツ発見と活用の効率を向上させます。
さらに、ユーザーの好みや過去の行動に基づいて検索結果を調整する、パーソナライズされたセマンティック検索の導入は、メディア制作環境における検索結果の関連性と実用性を高める可能性があります。個々のユーザーの特定のニーズや文脈を理解することで、パーソナライズされたセマンティック検索は最も適切なコンテンツを表面化させ、より効率的で効果的なコンテンツの発見と活用を促進します。
8 - 結論
セマンティック検索は、ニュース、放送、そしてもちろんポストプロダクションの世界において、間違いなく期待の新星です。これは、メディアアセットのより深い意味と文脈を理解するために、高度なAI技術の力を活用することに他なりません。従来のキーワードベースの検索手法を忘れさせる、これは制作ワークフローにおけるメディアの管理と利用方法を革新する、変革的なアプローチです。
OpenAIのCLIPのようなモデルや、Multilingual CLIP、LAIONのCLAP、Twelve LabsのMarengo、そしてAvidからの継続的な好進展などのイノベーションについて考えてみてください。これらは、この分野がどれほど速く動いているかを示すほんの数例に過ぎません。これらは検索プロセスをより直感的なものにし、メディアのプロフェッショナルが前例のない精度とスピードで自己のクリエイティブなビジョンに合致するコンテンツを見つけるのを助けています。デジタルメディアの量がこれほど増えている中、必要なものを素早く見つけられることは、ますます重要になっていくでしょう。
セマンティック検索の道のりはまだ続いており、新しい開発が行われるたびに、全く新しいレベルの洗練度と機能が追加されています。セマンティック検索を受け入れることで、私たちは効率を高め、クリエイティブなプロセスを促進し、コンテンツクリエイターにストーリーを語るための全く新しい方法を提供しています。
9 - アクションへの呼びかけ
セマンティック検索技術は、メディア制作の未来に不可欠です。メディアのプロフェッショナルとして、これらのイノベーションを採用することは極めて重要です。
企画から編集まで、制作のすべての段階でセマンティック検索を使用してください。
コンテンツの発見と管理を強化するために、様々なセマンティック検索モデルをテストしてください。ワークショップやウェビナーを通じて、メディア制作におけるAIの進歩に関する最新情報を常に入手してください。
セマンティック検索をニーズに合わせるために、技術プロバイダーとの提携やパイロットプログラムへの参加を検討してください。この投資は、効率性、創造性、そして競争優位性を高めることになります。
Twelve Labsのセマンティックビデオ検索ソリューションは、この革命の最前線に立っています。当社のビデオ理解プラットフォームは既存のメディアアセット管理システムとシームレスに統合し、ユーザーが前例のない容易さで膨大なビデオライブラリをナビゲートできるようにします。Vidispine、Blackbird、EMAM、Nomad、Cinesysとの最近の統合実績をご覧ください。
過去数年にわたり、Avidはセマンティックメディア検索を含む、メディア制作向けのAI活用に関する研究を実施してきました。彼らはワークフローの効率化をサポートするデジタルアシスタント「Avid Ada」を開発しました。研究成果を製品ロードマップに反映させることに加え、Avidはメディア業界に向けて研究成果の公開と共有も行っています。








