" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
ビデオ言語モデルの現状:第1回NeurIPSワークショップからの研究インサイト

ジェームズ・リー
Twelve Labsは、初開催となるNeurIPS 2024 Video-Language Model Workshop(ビデオ言語モデルワークショップ)を主催し、Meta、Runway、Microsoft、および主要大学の研究者を募り、時間的推論、マルチモーダル統合、ベンチマーキング、そして汎用世界モデル構築への道程など、ビデオ理解における核心的な課題に取り組みました。
Twelve Labsは、初開催となるNeurIPS 2024 Video-Language Model Workshop(ビデオ言語モデルワークショップ)を主催し、Meta、Runway、Microsoft、および主要大学の研究者を募り、時間的推論、マルチモーダル統合、ベンチマーキング、そして汎用世界モデル構築への道程など、ビデオ理解における核心的な課題に取り組みました。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2024/12/31
24分
記事へのリンクをコピー
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップは、急速に進化を遂げる動画の理解と生成という分野において極めて重要な契機となりました。冒頭の挨拶では、当社CTOのエイデン・リーが、動画理解(ビデオからテキストへの変換)と動画生成(テキストからビデオへの変換)という2大重要領域を横断して盛り上がりを見せる、ビデオ言語モデルへの関心の高まりを強調しました。

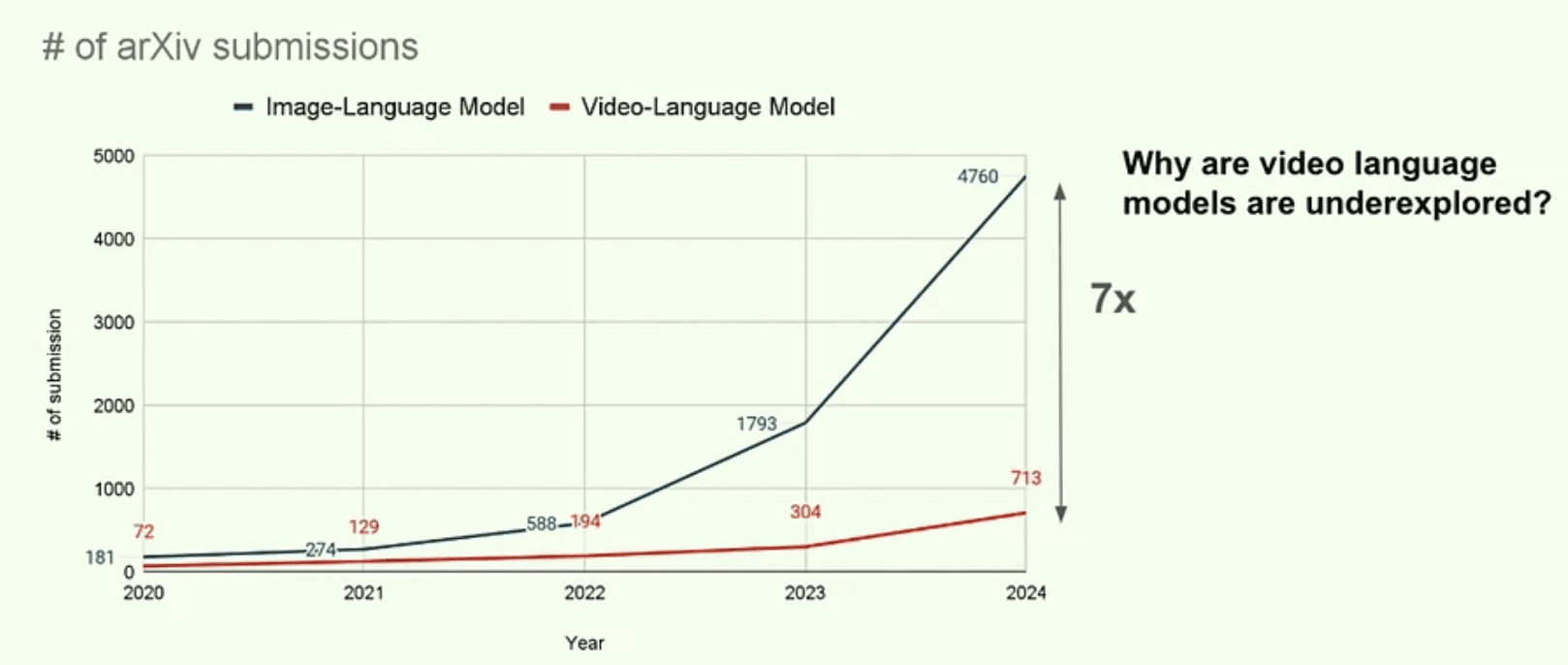
これらの技術は、コンテンツ制作や広告、ヘルスケア、ロボティクスなど、多岐にわたるセクターで応用されています。視覚と言語を統合するビジョン言語モデルの研究は指数関数的な成長を見せているものの、この分野は未だいくつかの重大な課題に直面しています:
特に高品質な動画とテキストのペアにおけるデータ不足
動画の保存および処理におけるスケールと複雑性の問題
視覚、音声、テキストといった複数モダリティの統合における課題
ビデオと言語のアライメントのベンチマーク測定および評価の難しさ
当ワークショップは、多様な研究者を一堂に集めて、現在の障害について議論し、開かれた共同研究を促進し、現実社会で応用できる動画基盤モデルの開発を加速させることを目的として開催されました。
1 - 一人称(エゴセントリック)視点の動画と言語の理解 - Dima Damen
ディマ・ダメン(Dima Damen)教授による包括的な解説では、一人称視点動画と言語の理解における4つの最先端のアスペクトを探究しました。教授の研究はEPIC-KITCHENSデータセットから着想を得ており、画期的なアプローチをいくつも導入しています。
類似のアクションに対するユニークなキャプション記述
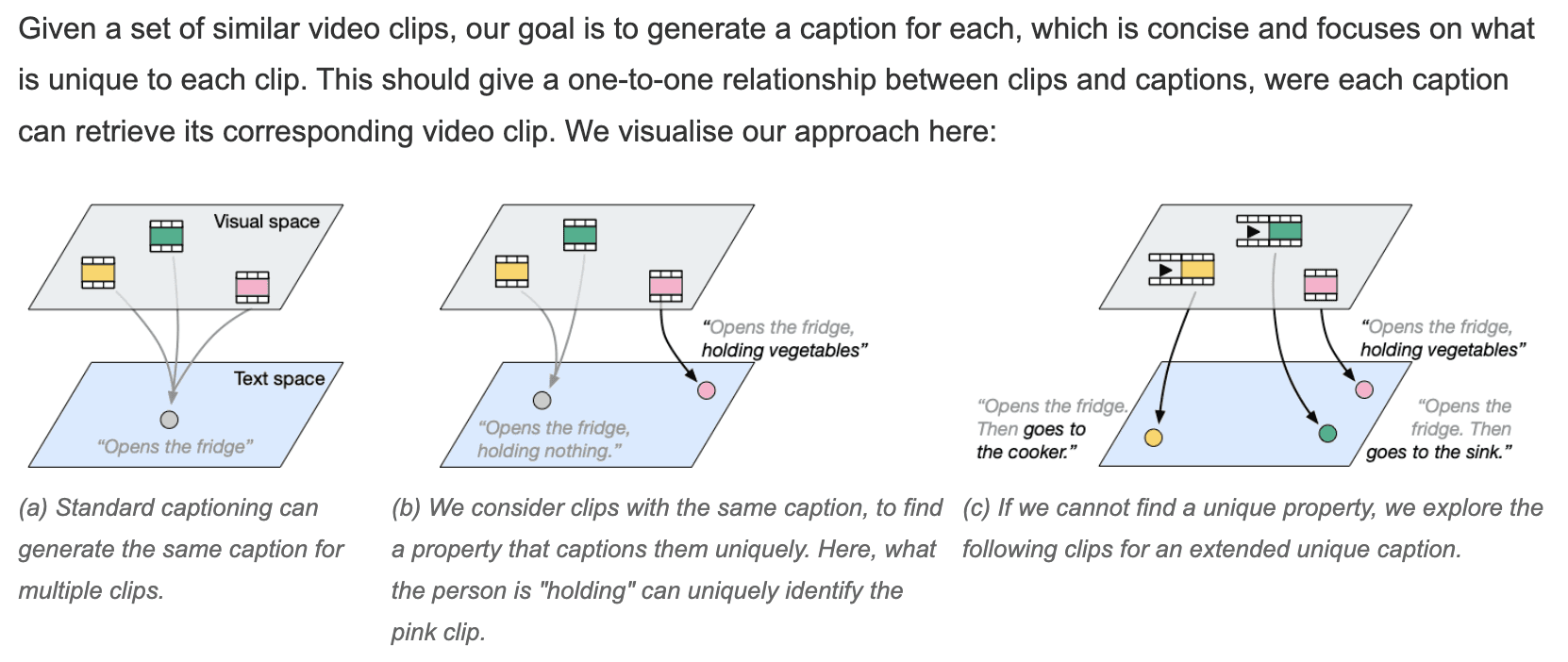
ACCV 2024で最優秀論文賞を受賞した論文「It's Just Another Day(いつもと変わらない日常)」は、動画キャプション作成における根本的な課題、すなわち、既存の手法が類似する複数のクリップを独立して処理した際に全く同じキャプションを生成してしまう傾向に対処するものです。
この研究の根底にある重要な知見は、「日常生活は繰り返しであっても、類似したアクションに対しては異なる説明が必要である」ということです。研究チームは、以下の特徴を持つ「識別プロンプトによるキャプション生成(CDP - Captioning by Discriminative Prompting)」と呼ばれる斬新なアプローチを提案しています:
クリップを個別に切り離して見るのではなく、連動させて評価する
識別プロンプト群を活用して他と異なる固有のキャプションを生成する
ビデオからテキスト、およびテキストからビデオへの双方の検索評価指標を用いて評価を行う
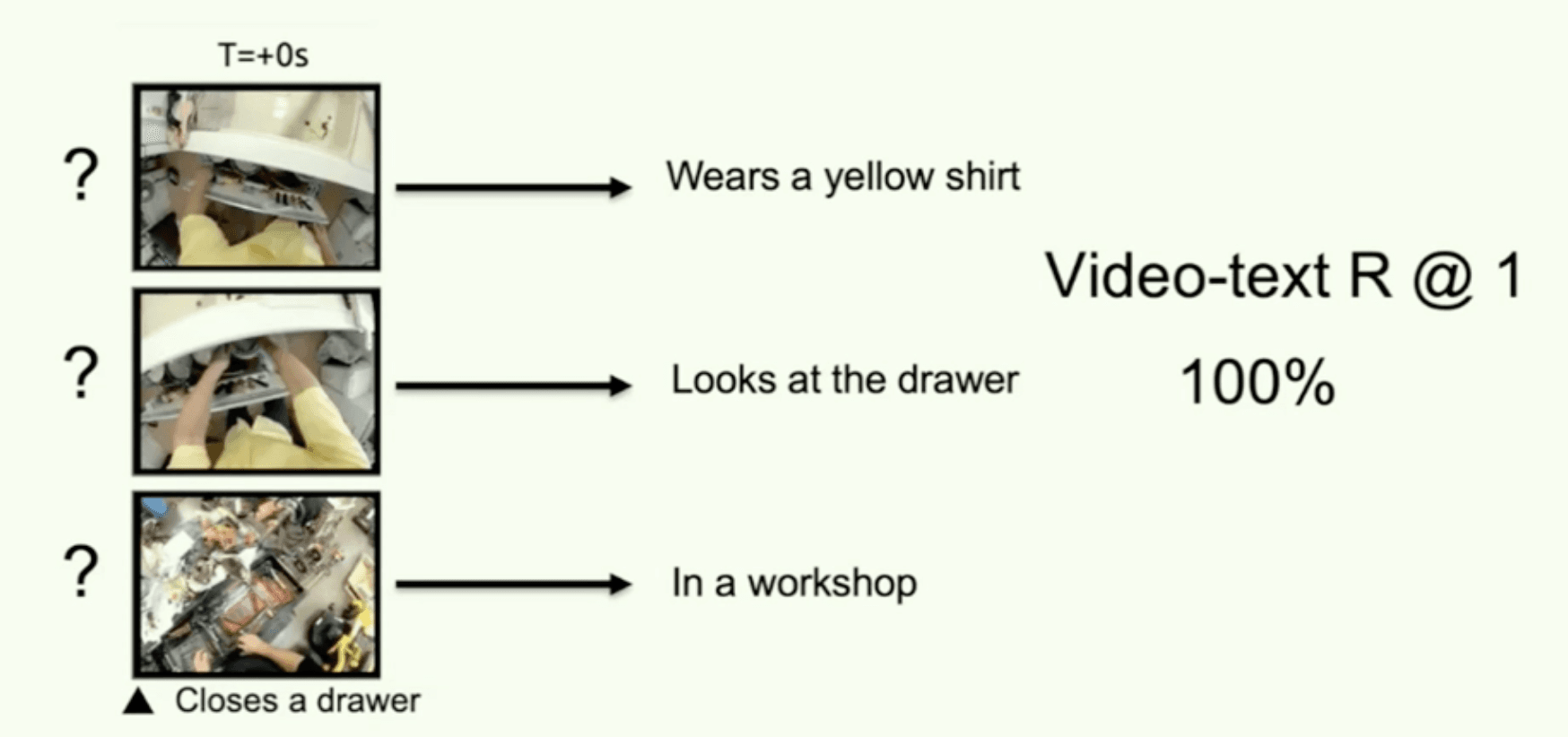
この手法は、Ego4Dからの一人称視点動画とタイムループ映画という2つのドメインで評価されました。CDPをLaViLa VCLMキャプショナーに適用したところ、意味論的な正確性を維持したまま、生成されるキャプションの独自性が大幅に向上しました。
言語を用いたドメイン般化
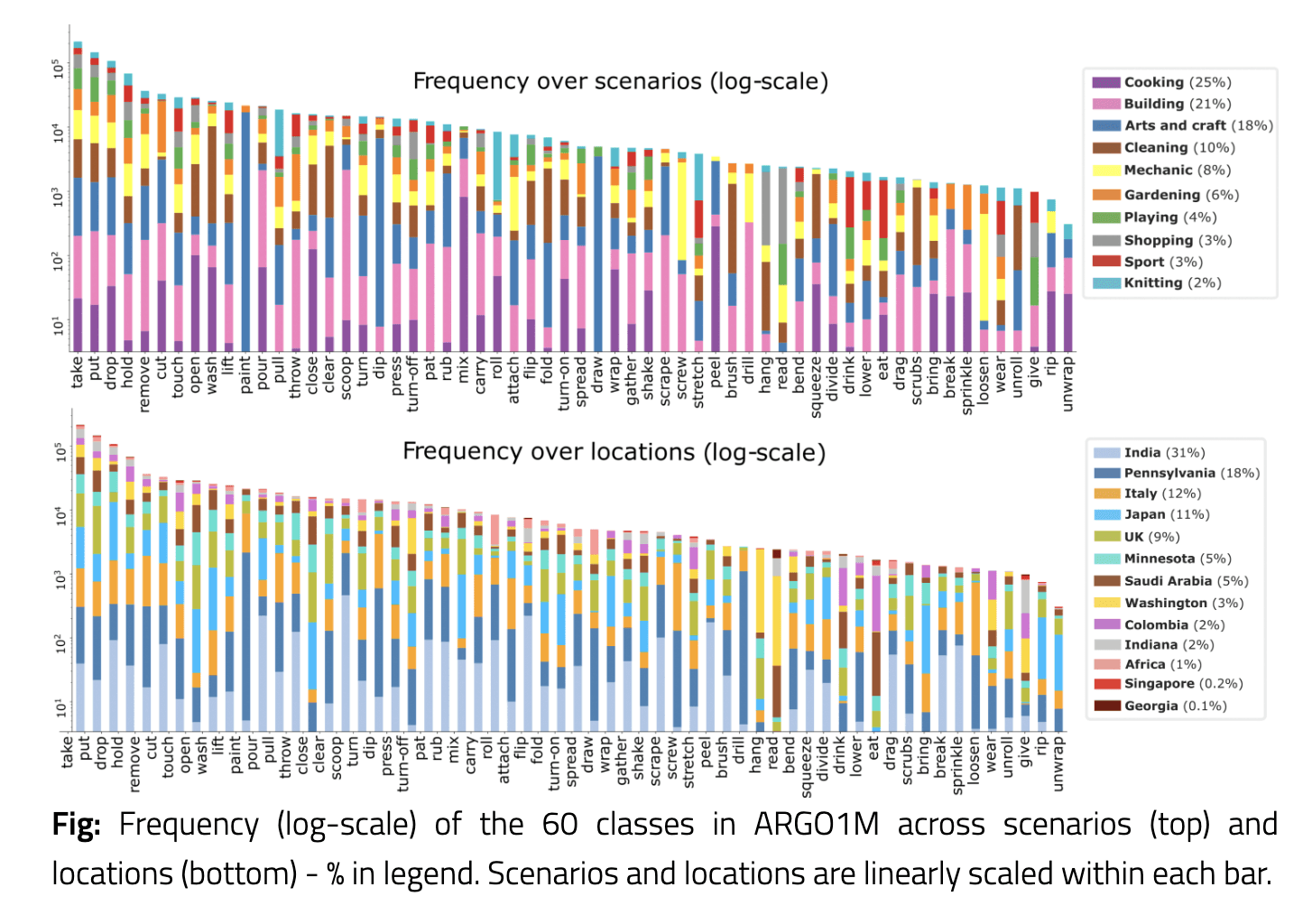
主要な成果として挙げられるのが、シナリオや場所を横断した「行動認識般化(Action Recognition Generalization)」に特化して構築された初のデータセットであるARGO1Mデータセットです。このデータセットには以下の特徴があります:
60の行動クラスをカバーする105万個の行動クリップ
13の異なるロケーションからの録画データ
標準仕様としての10秒間のクリップ尺
同論文「What can a cook in Italy teach a mechanic in India?(イタリアの料理人はインドの整備士に何を教えられるか?)」では、以下の2つの主要な再構成技術を利用する相互インスタンス再構成(CIR - Cross-Instance Reconstruction)を導入しています:
テキストでのナレーションを利用した動画とテキストの関連付け再構成
行動クラス認識のために訓練された分類の再構成
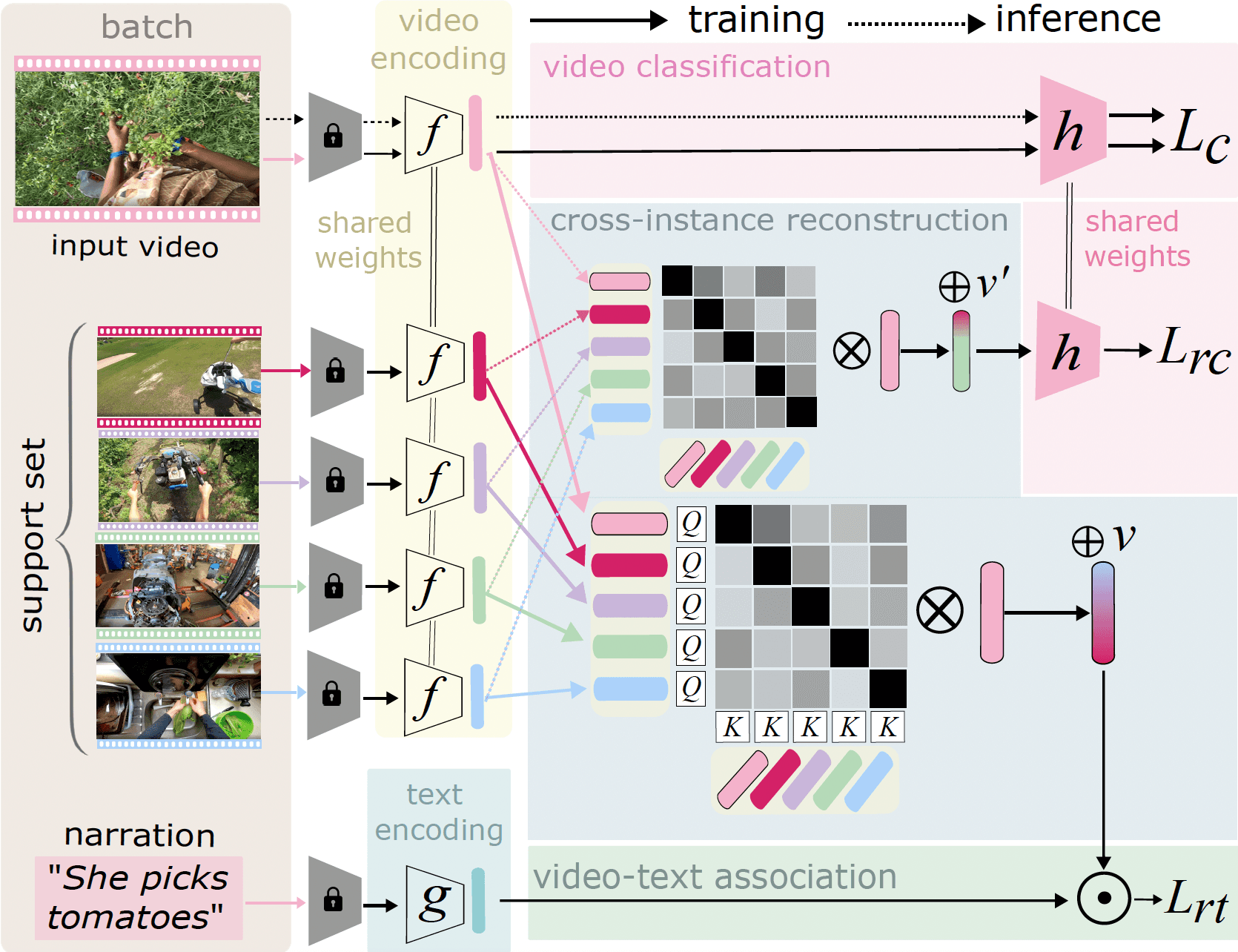
CIRは複数の異なるシナリオや場所における行動を加重結合して表すことで、堅牢なクロスドメイン般化を可能にしています。
手とオブジェクトのインタラクション指示参照
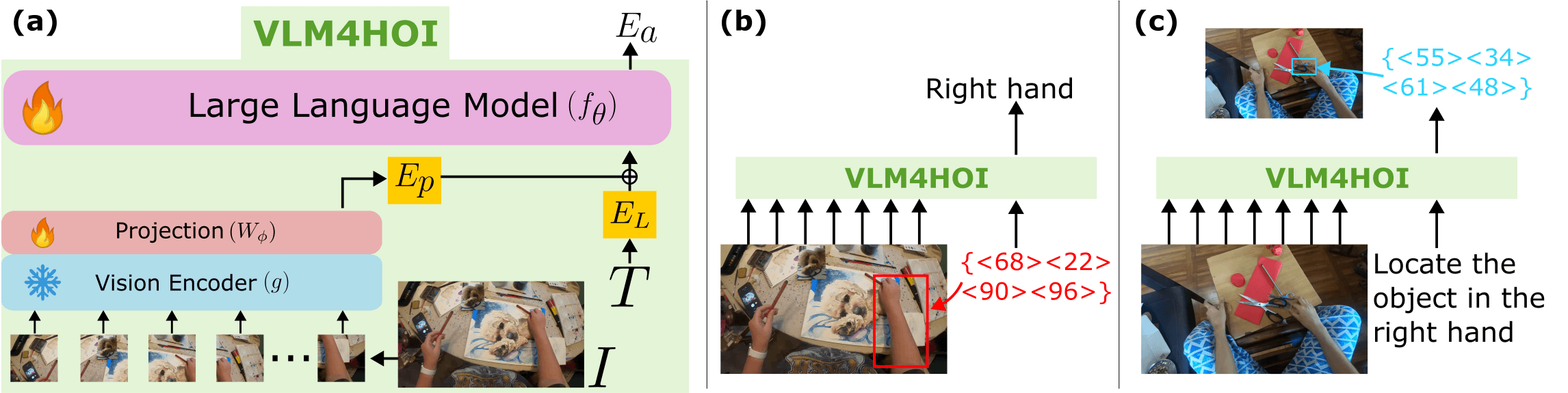
HOI-Refプロジェクトは、一人称視点画像における手とオブジェクトのインタラクション指示(HOI: hand-object interaction referral)に適した洗練されたモデル「VLM4HOI」を導入しました。このモデルのアーキテクチャには以下が含まれます:
画像処理に対応するビジョンエンコーダー(g)と投影レイヤー(Wφ)
言語モデルの埋め込み空間との統合
両手およびインタラクションが発生した対象物の双方を同定する能力
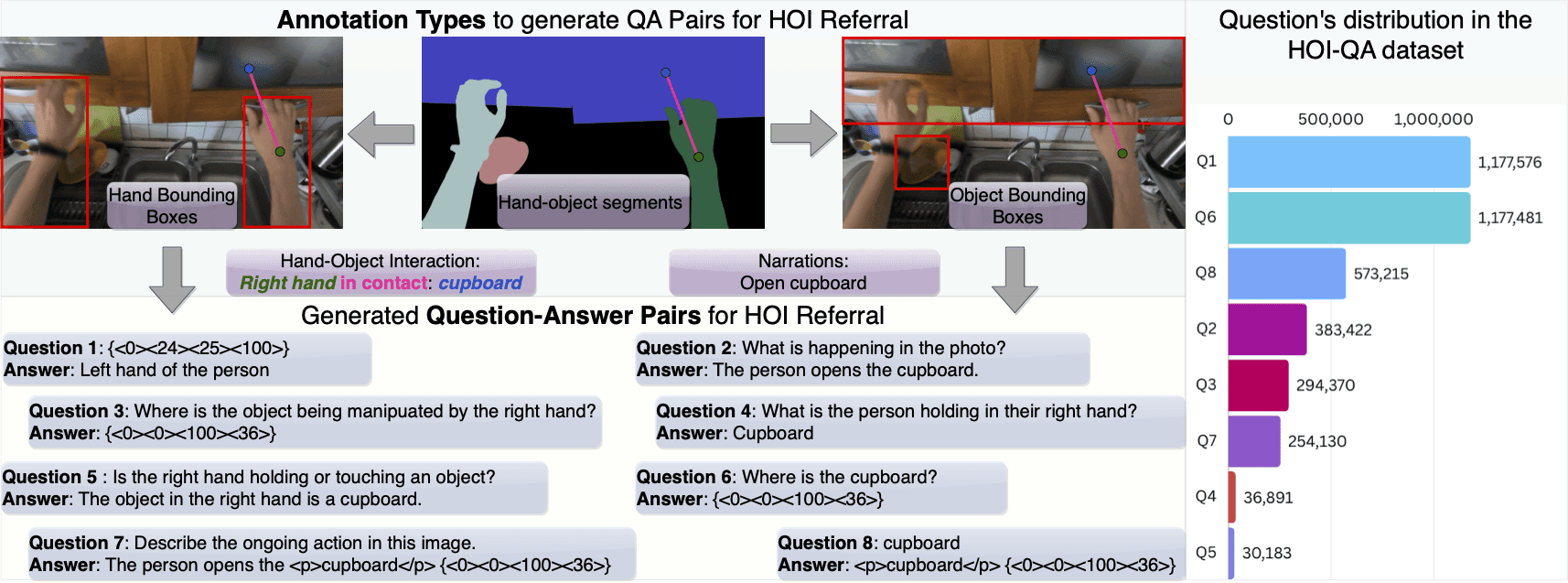
研究チームは、390万問の質問回答ペアを収録する包括的なデータセット「HOI-QA」を開発しました。これは以下に焦点を当てています:
手とオブジェクトの空間認識および指示参照
手とオブジェクトのインタラクションに関する理解
直接的参照(Direct Referral)とインタラクションを介した参照(Interaction Referral)性能の対比
オーディオと言ジュアルのセマンティック統合
このセクションでは、本分野に対する2つの重要な貢献が発表されました:
EPIC-SOUNDSデータセット
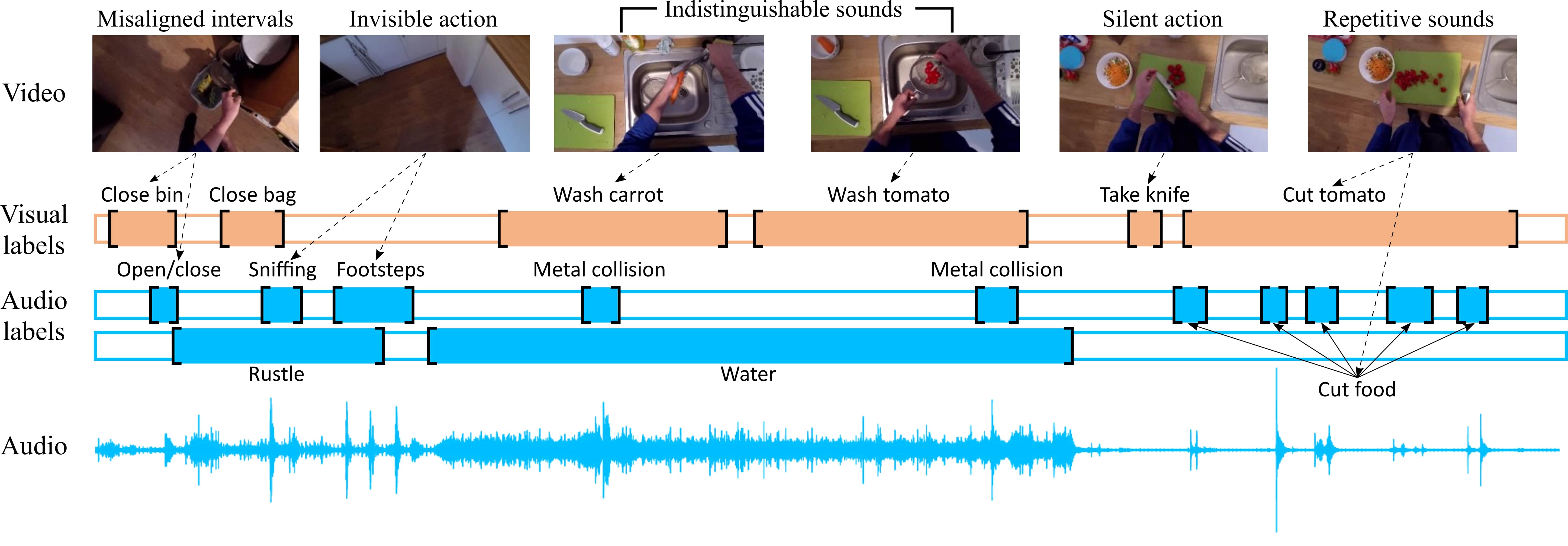
この大規模データセットは、EPIC-KITCHENS-100の一人称視点ビデオから音声アノテーションを抽出したもので、以下の特徴を備えています:
検知可能な音声イベントや行動を捉えた75,900件のセグメント
44個の異なる行動クラス
物体の衝突音に対する詳細な材質別アノテーション
聞き取り分け可能な音声セグメントに対する時間軸ラベル付け
TIM (Time Interval Machine)
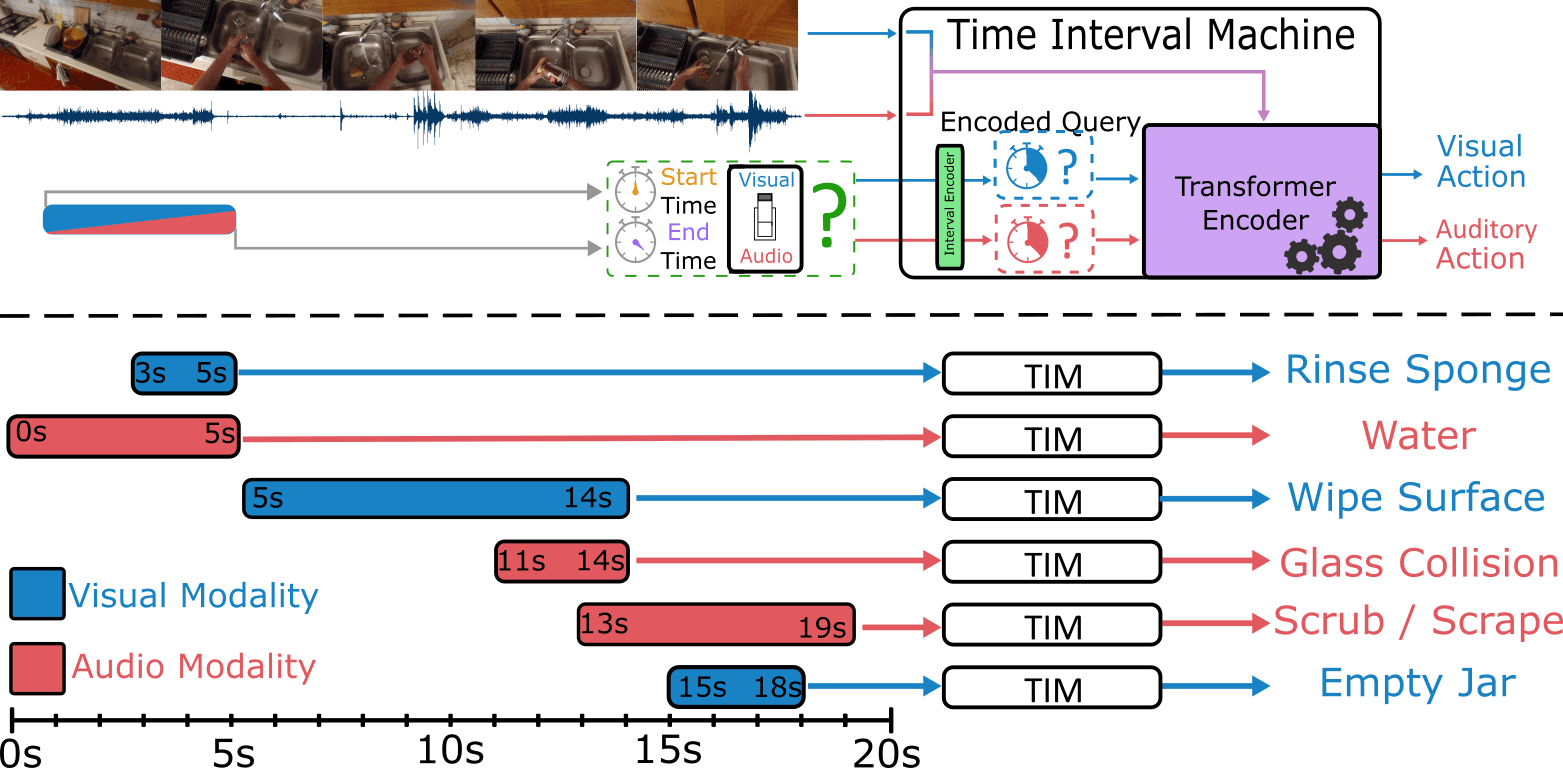
TIMは、長尺動画中において音声イベントと視覚イベント間で時間的な広がり(長さ)が異なるという問題に対処する、画期的な技術を提示します。主な機能は以下の通りです:
モダリティ固有の時間区間(Time Interval)を処理するトランスフォーマーエンコーダー
特定の間隔およびその周辺のコンテキストの双方に対応するアテンション機構
複数のベンチマークにおいてState-of-the-Art(最高水準)を誇るパフォーマンス
このモデルは以下に示す驚異的な結果を達成しました:
EPIC-KITCHENSにおける上位1位(top-1)行動認識の正確性を2.9%向上
Perception TestおよびAVEデータセットにおける卓越したパフォーマンス
高密度でマルチスケールなインターバルクエリを用いた行動検出への適応化に成功
これら一連の進歩は、特に視覚・テキスト・音声の複雑な関係性の相互処理において、一人称視点の動画コンテンツを理解し処理する能力が大きく進歩したことを一貫して示しています。Dima教授の研究グループによるプロジェクトは、一人称動画理解におけるマルチモダリティ統合の課題解決に向けた、包括的なフレームワークを提示しています。
2 - 言語と映像を用いた高難度ビデオ理解 - Gedas Bertasius
ゲダス・ベルタシウス(Gedas Bertasius)教授は、高度な動画理解タスクにおけるビデオ言語モデル(VLM)の目覚ましい進歩と同時に、現在の限界についても光を当てました。LLMやVLMのおかげで動画理解が大幅に向上したことを受け入れつつも、近代的なVLMが未だ複雑な動画の意図や文脈の正確な読解という点においては、依然として根本的な課題にぶつかっていることを指摘して警告しました。
長尺ビデオの理解における問題の解消
最も重要な技術的課題の1つとして挙げられたのが、現在のモデルが長期の動画シーケンス全体から関連性の高いコンテンツがどこにあるかを特定(局所化)するのに手を焼いている点です。Bertasius教授は、動画内の長距離にわたる相互関係を効率的にモデリングする優れた手法として「構造化状態空間モデル(S4: Structured State-Space Models)」を挙げました(こちらの研究やこちらの研究に示されています)。ただし、S4モデルへの入力トークンごとにパラメータが固定されているため、シーケンス(一連の流れ)の特定の場所にピンポイントに注意を向けるようなタスクを苦手としている点を指摘しました。
BIMBA: セレクティブスキャン圧縮

BIMBAは、動的に(データに依存する形で)隠れ状態にどのインプット情報を残すかを選択する選好スキャンアルゴリズム(別名Mamba)を取り込むことで、こうした制限に対処します。このモデルには以下の特長があります:
双方向の選択型スキャン機構を活用した時空間トークンセレクター
精緻なコンテンツ選択を可能にするインターリーブ形式の視覚クエリ
適応的なプロセシングに対応する、インプットに依存する状態変数パラメータ
長尺動画を、高い情報量を凝縮した短いトークンシーケンスに効率的に圧縮する性能

EgoSchemaベンチマーク上での検証において、BIMBAは動画の質問回答タスクに際して最も重要となるパートの抽出で卓越した強みを見せました。定性的なアウトプットにおいても、特定のクエリに対して関連するセグメントを精度高く検出していることが実証されました。
LLoVi: 長尺向けVideoQA用のLLMフレームワーク
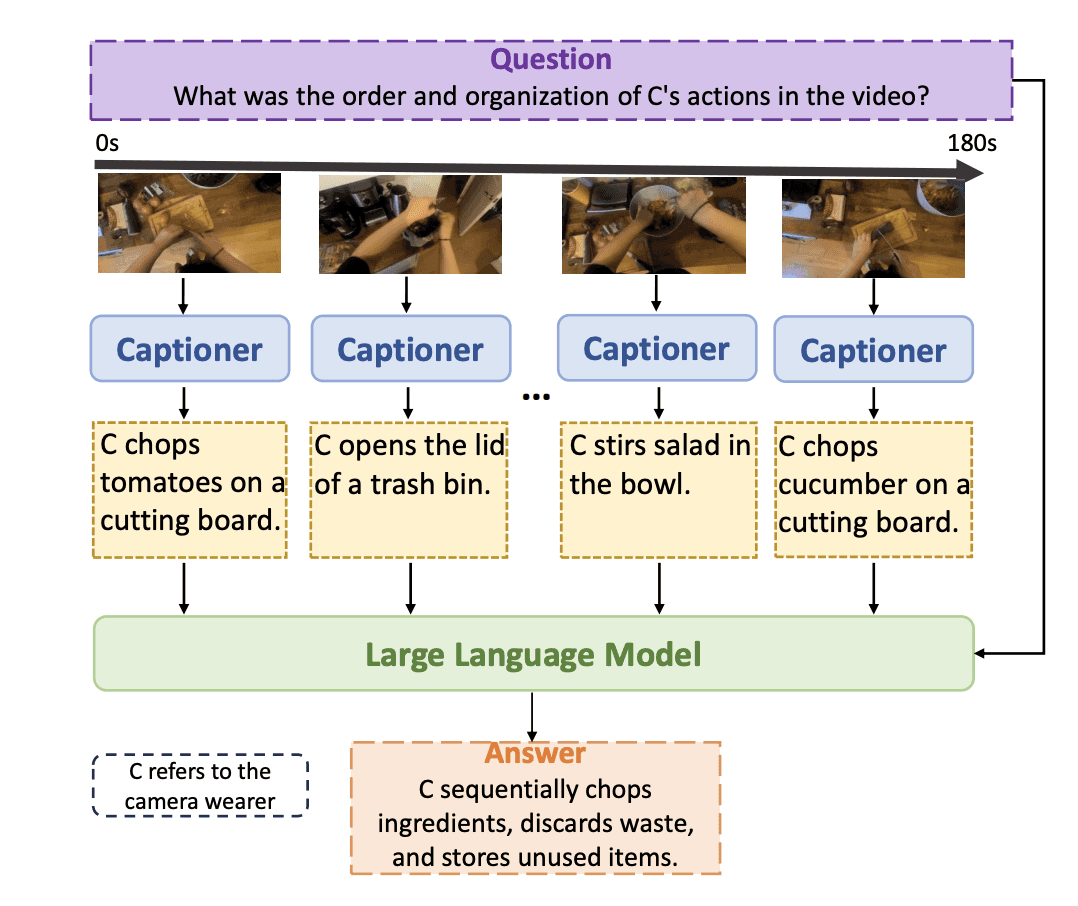
LLoViフロンティアは、長尺動画に対するQ&Aに対してシンプルながら非常に有効な、以下の2ステップから成るワークフローを提供します:
ステージ1: ビデオプロセシング
長尺ビデオから複数の短いクリップ映像を抽出する
各クリップに対してキャプションを付与する
時間記述の流れの順序をそのまま保持する
ステージ2: 質問への回答(Q&A)
時間順に並べられた時系列キャプションをLLMへインプットする
革新的な2周回の要約プロンプト(Summarization Prompt)を使用する
複雑な問いに対する推論回答の品質を高める
EgoSchemaによる評価結果は、長尺動画コンテンツを取り扱う上でLLoViがいかに実用的であるかを示しましたが、Bertasius教授は、このモデルが映像よりもテキスト(言語)側で最大1,750倍多いパラメータを使っている点に言及し、処理効率性や元映像に含まれていた情報の劣化について問題を提起しました。
テキストだけに依存しないアプローチへの回帰
Bertasius教授は、映像そのものを純粋に言語だけで表現することの限界を強く語り、テキストでの解説や短文サマリーだけでは、本来の動画に存在する芳醇な情報資源を劇的に失わせていると注意喚起しました。

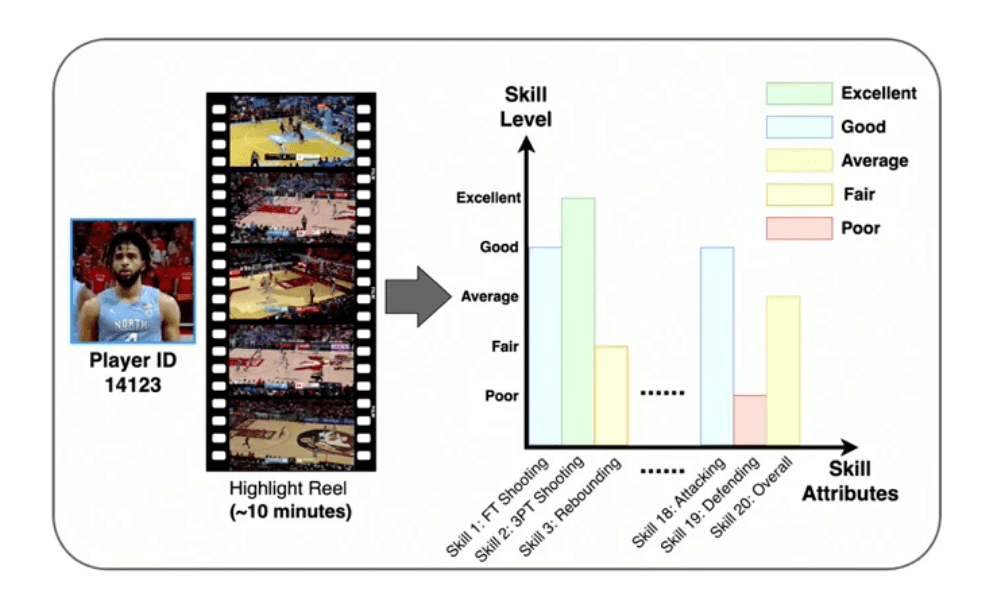
BASKET: 高解像のスキル評価データセット
こうした制約を取り払うために、本講演では「BASKET」と呼ばれる、単なる言語の説明を越えた、高解像度の運動性能や技能評価に焦点を当てた新しい包括データセットを紹介しました。これ以下のデータが含まれます:
累計4,400時間以上の映像データ
4大陸にわたる30カ国以上から収集された32,232人のプレーヤーデータ
バスケットボールにおける20種類の精緻なスキル区分
1人のプレーヤーにつき8〜10分の動画ハイライト集
評価スポーツとしてバスケットボールが選ばれた背景には、いくつかの明確なメリットがあります:
4億人以上の世界的なファン層を持つ普及性
多様な国の参加者がいること
豊富な既存ビデオ映像素材へのアクセシビリティ
時間情報を追うモデルを要する、非常に複雑で微量なスキルアクション
よく似たユニフォーム・アピアランスの競技者を識別するための精微な視覚アライメントが必要とされること
検証結果:
現在最高峰とされる最新鋭のAIベースモデルでも、ハイレベルなスキルの高精度な評価には及ばない
本テストにおいて正解率30%に達したモデルは皆無であった
動画の高度な全推論理解において、人間の能力と現状のAIの間にまだ絶望的なギャップがあることが鮮明に確認された
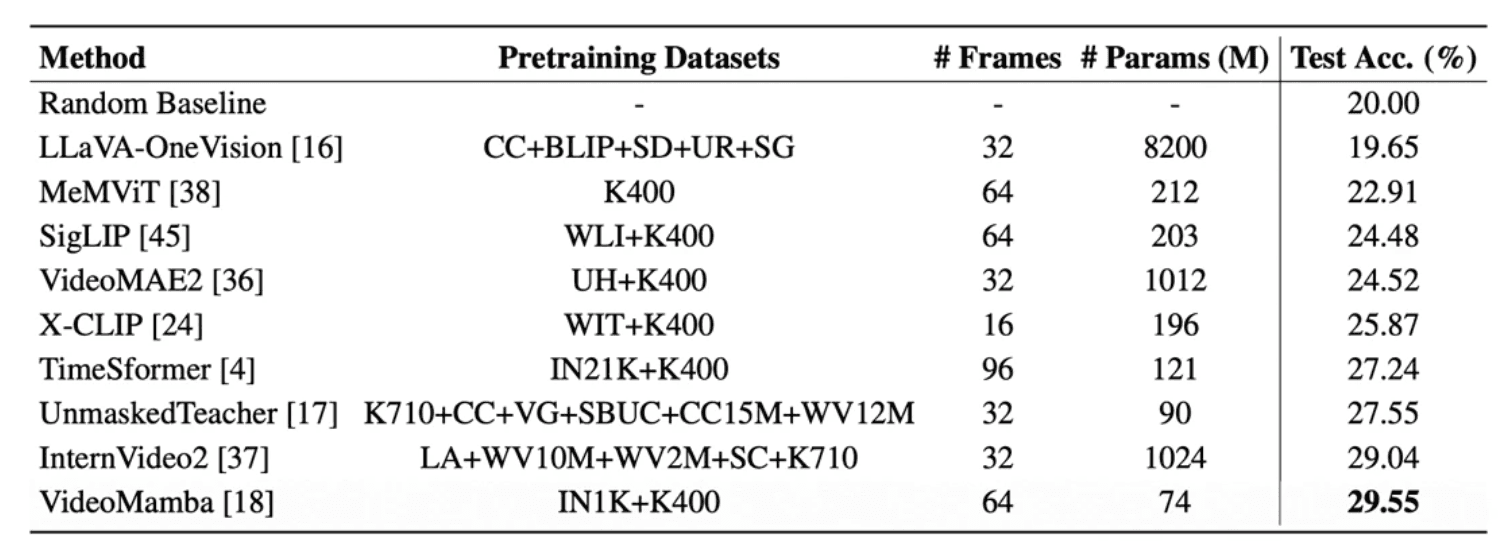
結論・今後の展望
LLMを土台とした動画読解能力は飛躍的に進化しているが、これを言語フォーマットに翻訳しにくいタスクに対しては、これまでの言語メインの基盤やインターネット由来の大量のビデオ・キャプションの恩恵が限定的になること
LLMの高すぎる対話力と古い試験評価法(ベンチマーク)が、実際の動画認識モデル自体の設計上の脆さを覆い隠してしまっている可能性があること
既存の評価尺度が必ずしも動画理解プロセスの難度をフルに測定できていない可能性
言語的な理解だけでなく、言語を介さない純粋に視覚的な認識をこなせる高性能アーキテクチャの併発が必須開発要素となる
3 - 現在のマルチモーダルビジアルモデルはどこまでスマートか? - Yong Jae Lee
ヨンジェ・リー(Yong Jae Lee)教授によるセッションは、既存の多様なモーダルを扱うビデオモデルのポテンシャルに対する一般的な見解に一石を投じる内容でした。コミュニティの関心がこぞって1時間を越えるような長尺に終始する中、Lee教授は最もシンプルな短尺(10秒未満)の動画であっても「時間の反実仮想プロセス」を処理する能力が極めて困難である点を強調しました。この探求心とその仮説は、「Vinoground」と「Matryoshka Multimodal Models(マトリョーシカマルチモーダルモデル)」という2つの歴史的成果に結実しました。
Vinoground: 時間推論に向けた新ベンチマークの誕生

画像ベースの多様な概念の構成関係を反実仮想的(Counterfactual)に突き詰めて試験する「Winoground」からヒントを得て、これを拡張してビデオの時系列向けに構築さたのがこのVinogroundです。先頭の「W」が動画を象徴する「V」へと文字遊びされています。動画の最大特性である、時の流れへの正確な推論能力へと焦点を向けています。
この試験検証データは、正確な動的把握をモデルに求めるために、幾つもの厳しい縛りを持って構築されています:
「たった数枚の代表フレームだけを見る」といったチート技術が適用できないように、シングルフレームの偏りを極限まで廃止して動画の連続性を重視する
テキスト文面の文字面だけの語順ルールからの類推を不可能にする(真の目の知能を求める)
全ビデオ素材に人工のシンセティックデータを使わず、自然な実写動画を採用する
アクションの前後を精確に整理し追える「順序推論能力」を求める
モデルにさらなる検証を課すため、動画ペアに対応する文面の説明テキストは「出現する英単語は全て同一であり、単語の配列(順序)のみが異なる」という厳しい構成になっています。好例として「男が女に話しかける前に、女に手を振った」対「男が女に手を振る前に、女に話しかけた」です。これにより、既存のAIが浅はかなパターンの類似性に溺れるのを許さず、時間経過の正確な動的事象を正確に捉えるモデルであるかをあぶり出します。
アプローチ・技術構築
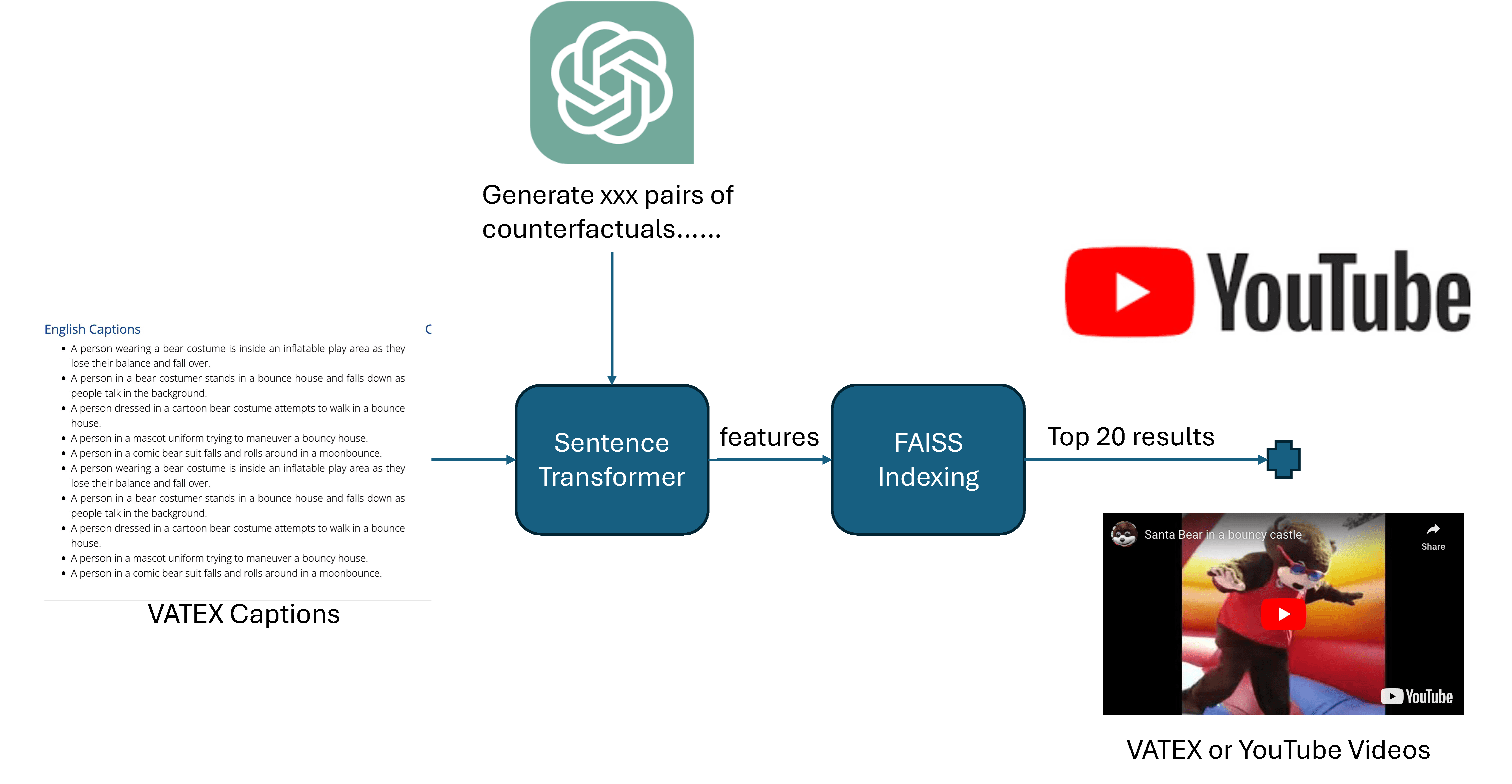
この高品質キュレーション工程では、まずGPT-4を用いて時系列に反するダミーペア文面セットを自動生成しました。これに対し、Sentence Transformerや高速な探索を行うFAISSライブラリを活用しつつ、既存のVATEXライブラリを索引として活用することで、条件にマッチする最適なビデオとマッチングを施します。データベースに適当な事例が見つからない場合は、YouTubeを直接捜索してフィットする実写映像を引き当てました。
本ベンチマークは丁寧に選び抜かれた500の映像とテキストのセットから成り、以下を含みます:
行動、オブジェクト、名詞が同じ場合の時系列的対比(例:「男は食事をしてからテレビを見た」対「男はテレビを見てから食事をした」)
物体の形態や状態が変化する変換プロセス(例:「水が氷になる過程」対「氷が水に溶ける過程」)
対象物の位置関係の知能を問う空間ダイナミクス
多層評価のための分析フレームワーク

正確な分析を提供できるよう、測定時には異なる3つのスコアを使用します:
テキストスコア:テキスト上の僅かな構成の相違をモデルが理解できているかを測る指標
ビデオスコア:視覚的に何が起きているかを識別しているかを測る指標
グループスコア:全体のタイムライン情報を統合して理解したかを判定する指標
Matryoshka Multimodal Models (M3: マトリョーシカマルチモーダルモデル)
次に披露された大きなイノベーションが、既存の最先端AIがトークンに溺れてしまっている問題への対処法です。視覚特徴を切り出した際のトークン数が過剰であるがために、ビジョン言語モデル(LMM)の駆動コストが高騰するばかりか、最たる要所への注目度(Attention)が分散、低下していました。これに対するアンサーとして登場したのが、このMatryoshka Multimodal Models(M3)です。
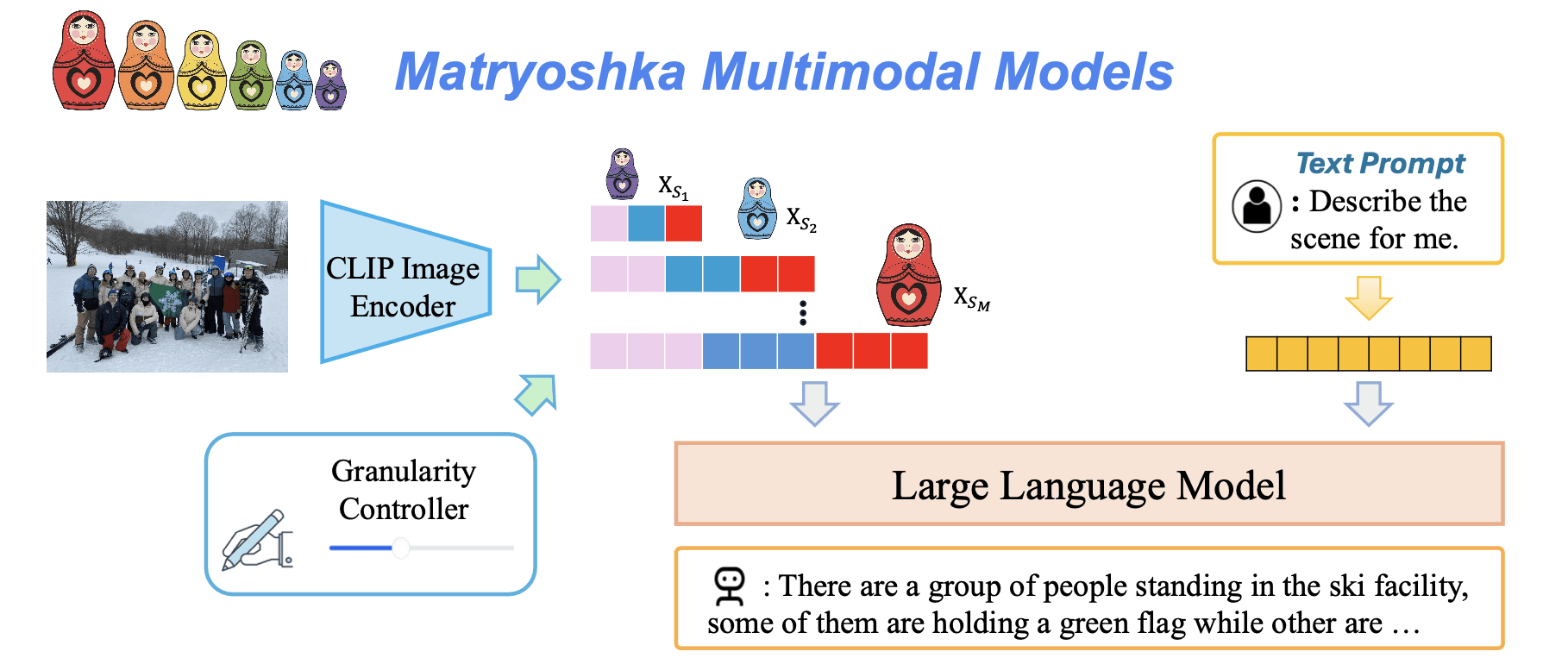
アーキテクチャの特徴
M3の構造の仕組みは美しくシンプルのひとことです。異なるスケールの視覚トークン群に対し、並行して生成ロス(Loss)の平均値を一括処理して学習を行います。プーリングを用いて粒度の階層化(粗い解像度から、きめ細かな解像度まで)を設定し、入れ子状に入れ込まれたデータを入れ替えて使用することができます。
システム側の利点
これは以下のような実用的なメリットを生み出します:
極力通常のLMM設定および学習データを使用するため余分な学習コードや調整が要らず、余分なスケール専用の空間エンコーディング機構の初期立ち上げも省くことができます。また、分析制御性が高まり、実行推論時においてインスタンス単位で視覚データのきめ細かさの粒度を自律調節できる点が魅力です。最後に、データセット検証機として働くため、古いCOCOのようなシンプルなタスクでは576枚もあるトークン中、実はたった「9枚」程度のビジョントークンさえあれば十分に既存と同様のクオリティを出せることが実証され可視化されました。
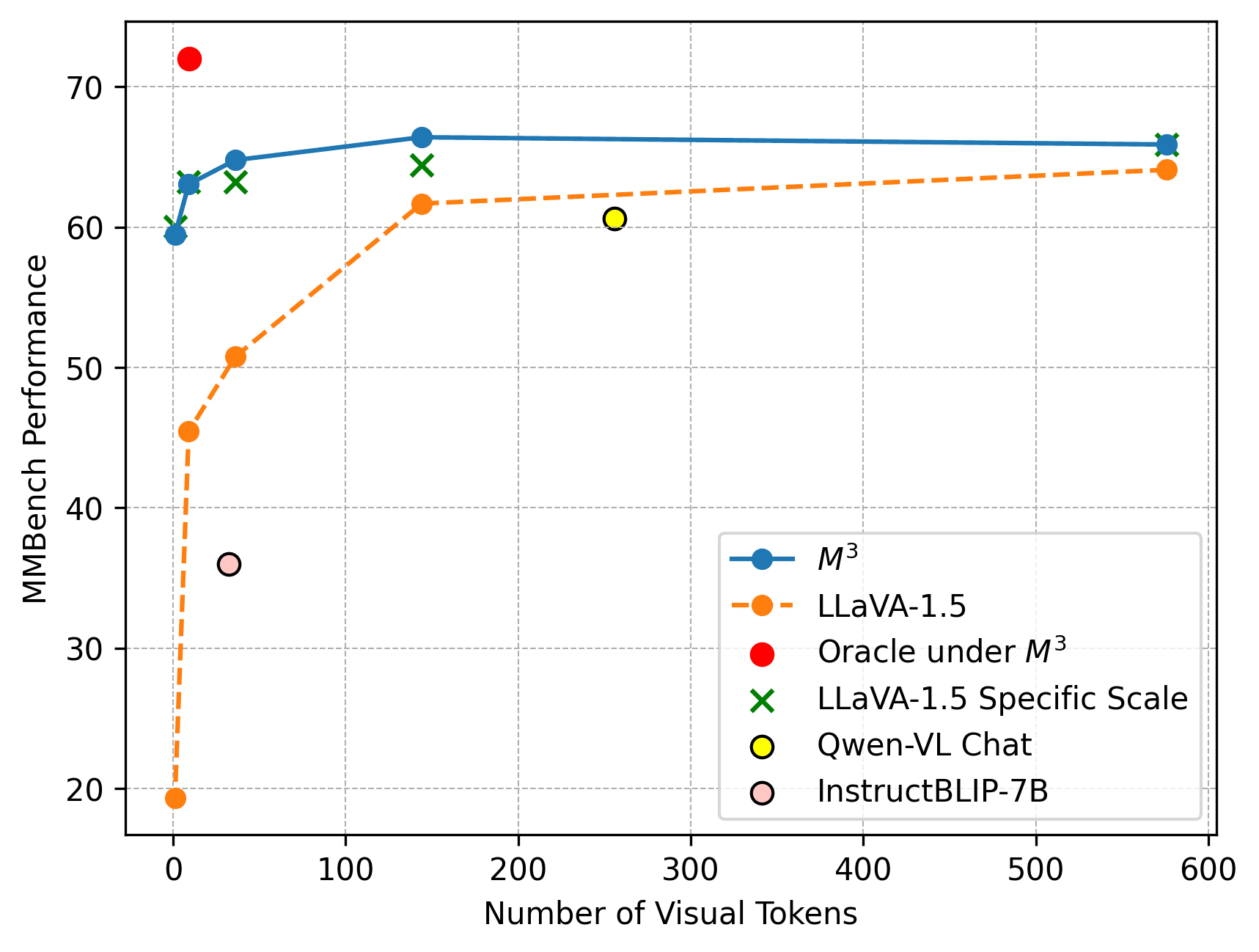
実証成績
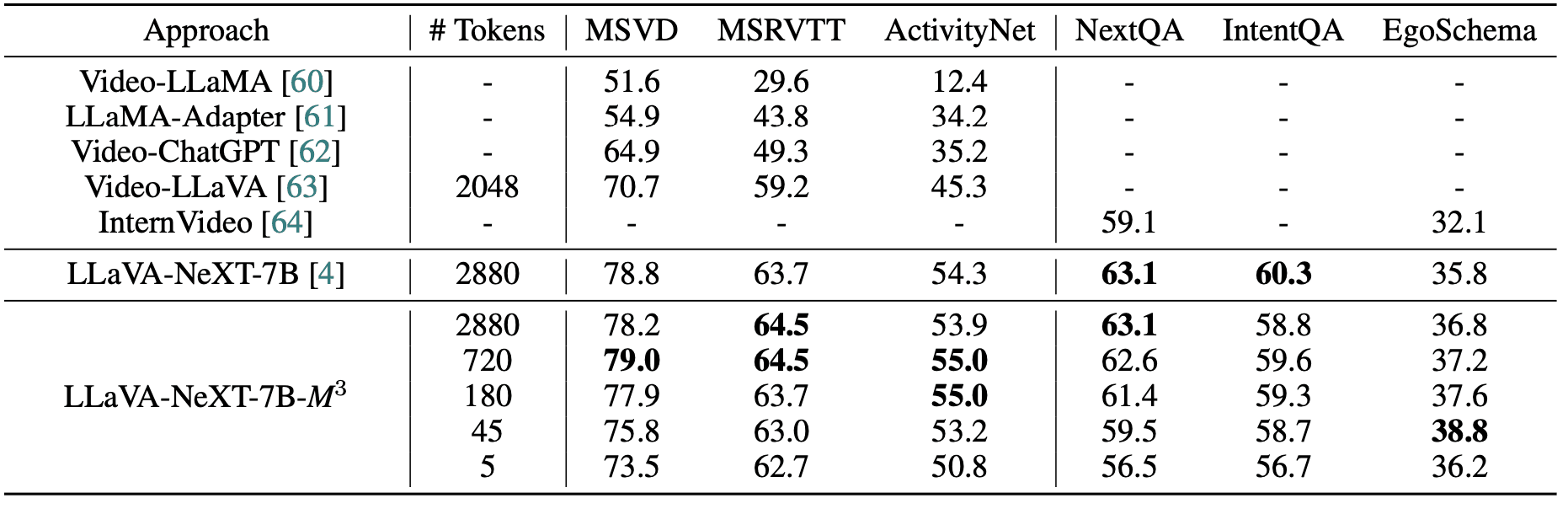
MMBench等での負荷テストで、幾つもの重大な事実が確認されました。例えば、本設計(M3)を「LLaVA-1.5-7B」に施したモデルは、特定スケールだけで固定学習したモデル群対比で同等以上の実力をマークしながら、要求するリソース(学習資源)を格段に減少させています。最も目覚ましい点は、わずか9枚のトークンしかないM3が、InstructBLIPやQwen-VLといった巨頭モデルを上回ったデータです。
実タスクでは、余分なビジュアルトークンはむしろ弊害を生むことがわかっています。検証した6つのメインタスク中、4領域において720〜180トークンで制御した方が、全マックス容量を投入するよりも高い精度を叩き出しており、過多なシグナル情報が生成推論において「単なるノイズ」となっていた仮説が裏付けられました。ActivityNet、IntentQA、EgoSchemaに至っては、画像の1グリッドからたった9箇所(合計わずか45トークン)を使うだけで、2880トークンの全負荷使用時とわずか1%未満の成績の差に踏み止まりました。
業界への影響と今後のマイルストーン
本セッションはAIモデルが抱える動画分析分野でのリアルな実像を炙り出しました。一見輝かしい成果を出しているように映る近代モデルたちですが、未だ人間の持つ深い時系列認識とは乖離があります。Vinogroundの結果は、短い単純動画に仕組まれたわずかな前後情報の変化ですら、最先端AIの前に立ち塞がっている現実を物語ります。しかし一方でM3は、視覚データの無駄を省いた「ミニマルな情報設計」が、力任せな超大容量インプット以上に有効となり得ることを確証する、未来の光明を投げかけています。
4 - MovieGen: 動画創出に挑む最高峰のビデオ基盤モデル - Ishan Misra
イシャン・ミスラ(Ishan Misra)氏の登壇では、Metaが総力を挙げるMovieGenプロジェクトについて解説されました。テキストプロンプトをインプットに、一貫性のある動画へ落とし込む課題に対する最先端ソリューションです。その裾野はアマ作家のSNSクリエイティブワーク、部分動画エディット、映画クオリティのアニメ、リアルシミュレーション、さらにはハリウッド規模のビッグメディア生産ラインにまで及びます。
動画生成の進化史
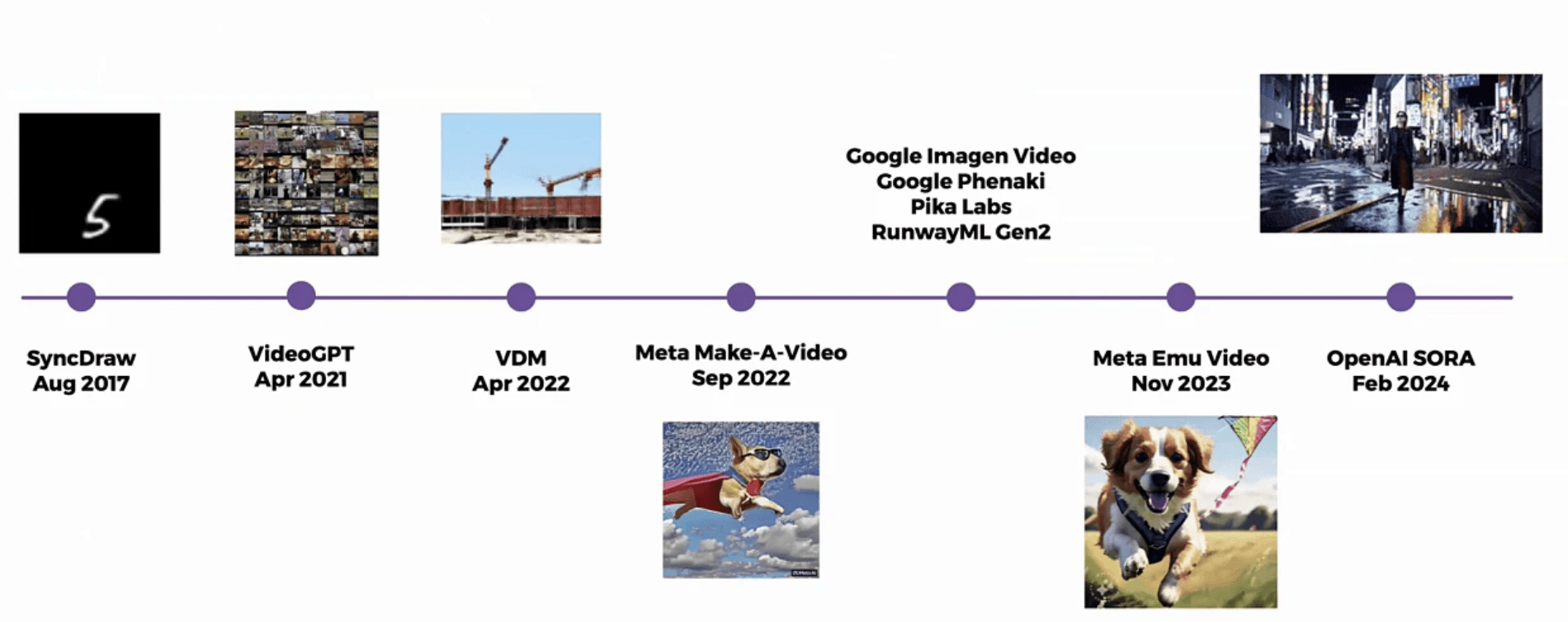
セッションの幕開けとして、歴史上の動画生成モデルのタイムラインを一望することで、MovieGenがこれまでの開発遺産を土台にいかに急加速して成長してきたかが紹介されました。過去の歩みをたどることで、単純なパターン合成から、物理法則・ストーリーの一貫性を追求した生成モデルへいかに進化したかが浮き彫りになります。
動画生成における核心的テーマ
これまでの映画モデル生成には、取り払うべき多くの壁がありました。第一は、次元が著しく低い単なる「文章入力(テキスト)」から、圧倒的な情報密度の差がある「高画質映像データ」へと次元変換する処理。第二は、数秒から数十秒までの時間に渡り、同一アクターや周辺環境の破綻をなくして連続性を担保し続ける安定性。第三は、凄まじい計算能力とストレージ使用量を要する中で、実行処理ロスを減らし全体のパイプラインをスリムに仕上げるハード面の課題です。
アーキテクチャの革新
1. システム形態
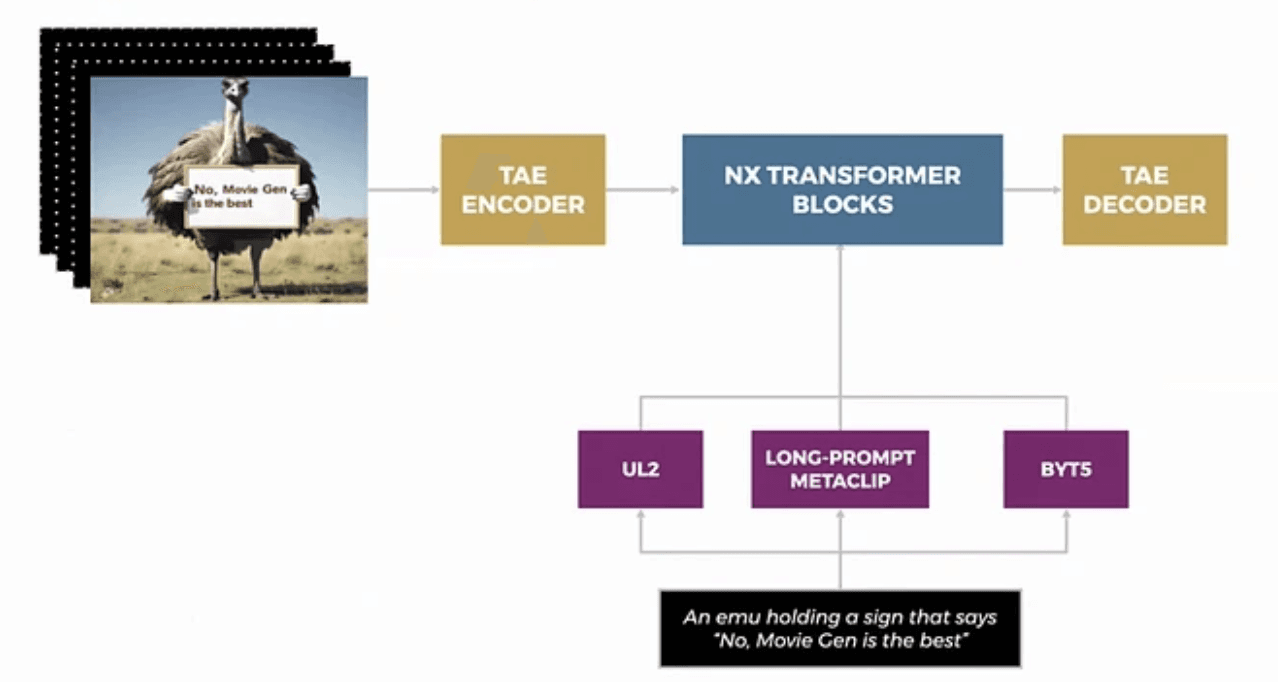
MovieGenのアーキテクチャ設計は、従来の概念を一段階超えるものです。テキストプロンプトに内包された情緒や複雑な命令要件を逃さず、エンコーダーが細部に至る意図を捕捉する仕組みが追加されています。土台にはLLaMA系トランスフォーマーブロックが採用され、時系列データ展開向けに高度にチューンアップされているため、トレーニング中の破綻が極めて低く抑えられています。
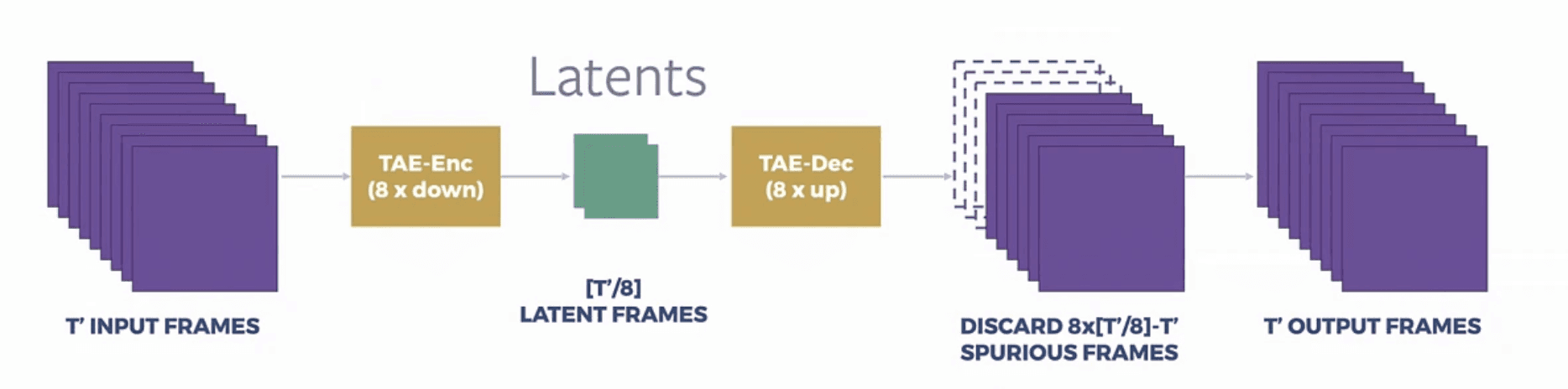
最大のブレイクスルーが「潜在特徴(Latent)圧縮」のアプローチです。MovieGenは、高さ・幅および時間を考慮した次元比を維持しながら最大で「8倍」に凝縮し、これによって全体の配列シークエンスの長さに対しては実質「512分の1」という超圧縮を実現しました。この機能は画像や動画像といった媒体に関係なく等しく適用可能であり、多様なサイズの配列を破綻を抑えたまま処理可能にします。
2. トレーニング手法
モデル本体には、拡散(ディフュージョン)トランスフォーマー(DiT)向けのスケーリング、および各種シフト変数に変更を施した改良版LLaMAブロックを採用しています。これによって全体の拡大トレーニング時における安全度(ロバストネス)が生まれ、静止画と動画の両方の素材パラメータを完全に同一プロセスで一括同時処理し、固定コンポーネントを配置する手間を排除しました。エンドツーエンドの一貫アプローチのおかげで、モデルは静的な画像でも、動的なクリップでも一貫した理解を獲得しています。
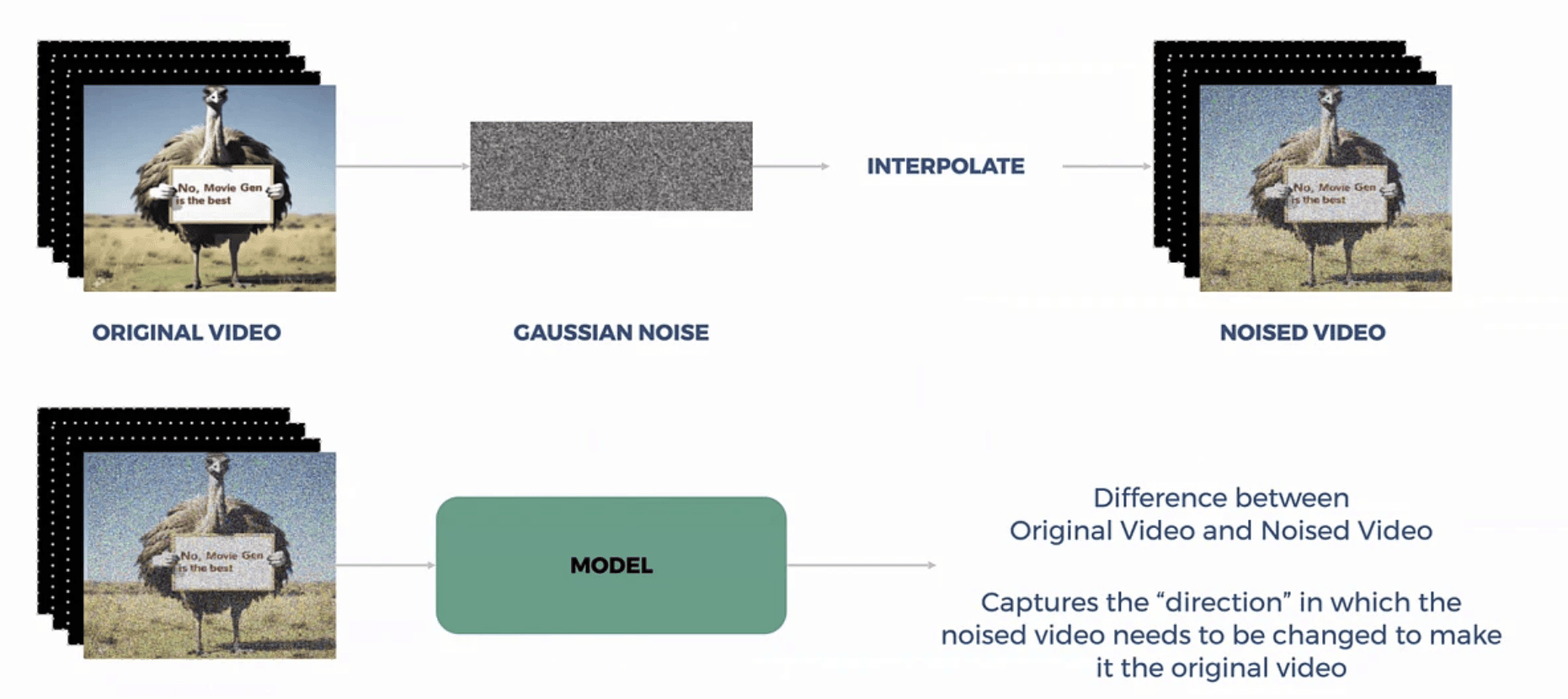
3. 「Flow Matching(フロー・マッチング)」技術

本論文においても特権的な技術とされるのが、従来のディフュージョンの代わりとなる独自のフロー・マッチングの実装です。数式上は「v-prediction」に近似しているものの、多数の明白な技術優位性をもたらします。拡散モデルで見られるような「確率的な微分方程式(SDE)」の求解を迫られる代わりに、フロー・マッチングは一貫性のある「常微分方程式(ODE)」を解く形式のため、推論回路が軽量かつシンプルになります。自然と「端末シグナル対雑音比ゼロ」特性が得られ、生成映像のクオリティおよび推論動作スピ―ドが格段にスピードアップしています。
データ・スケールの探求
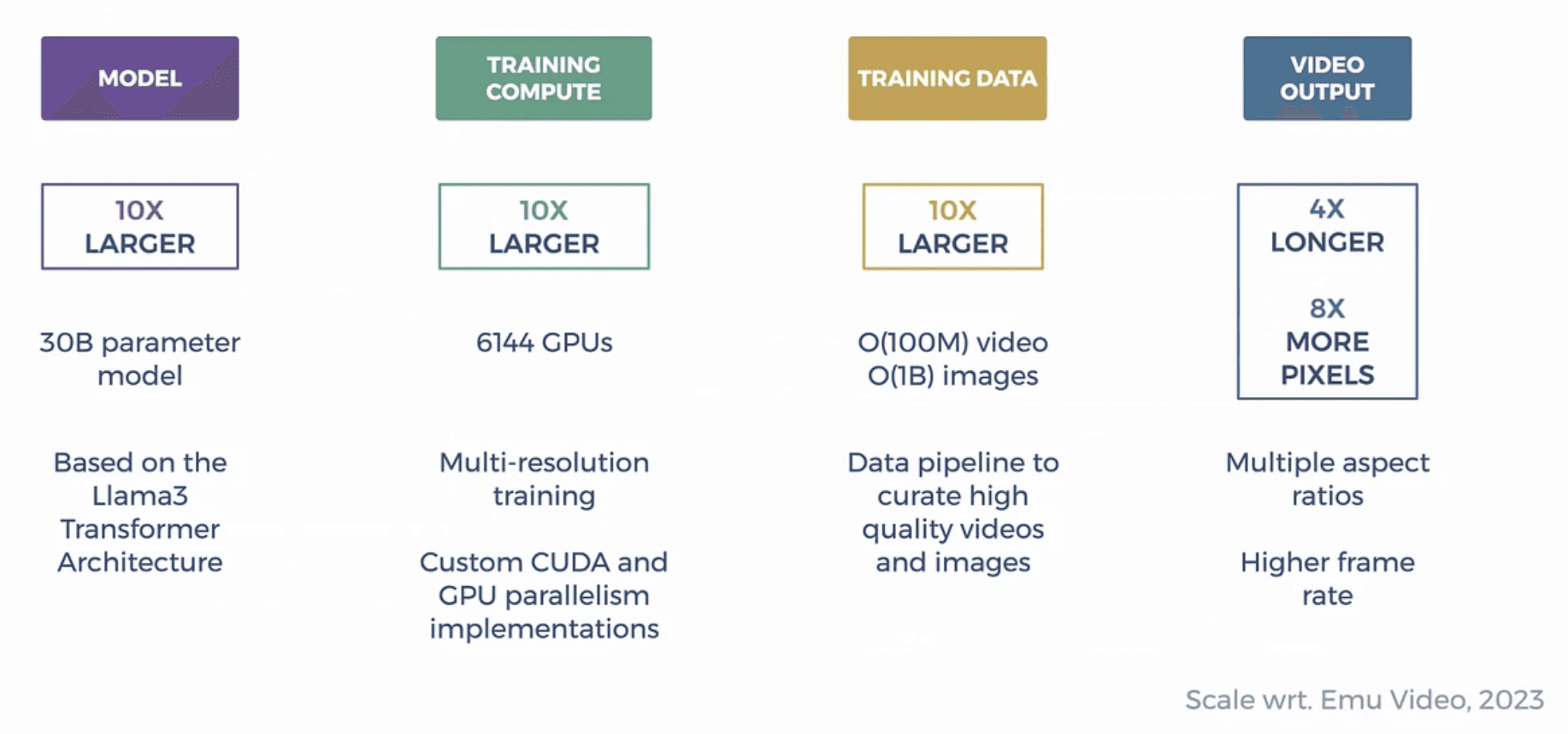
MovieGenの開発プロセスには、データスケールと演算の最大化に向けたエンジニアの凄まじい労力が詰まっています。約1億個にのぼる長短様々のビデオ映像アセットに加え、10億枚クラスの画像データセットが使われ、モデルの汎化能力を最高潮にまで高めています。また、動画用の一貫キャプション自動作成用に「LLaMA-3」を導入。これによりプロンプト命令の忠実度が高まりました。
MovieGen Bench:真価を問うテストスイート
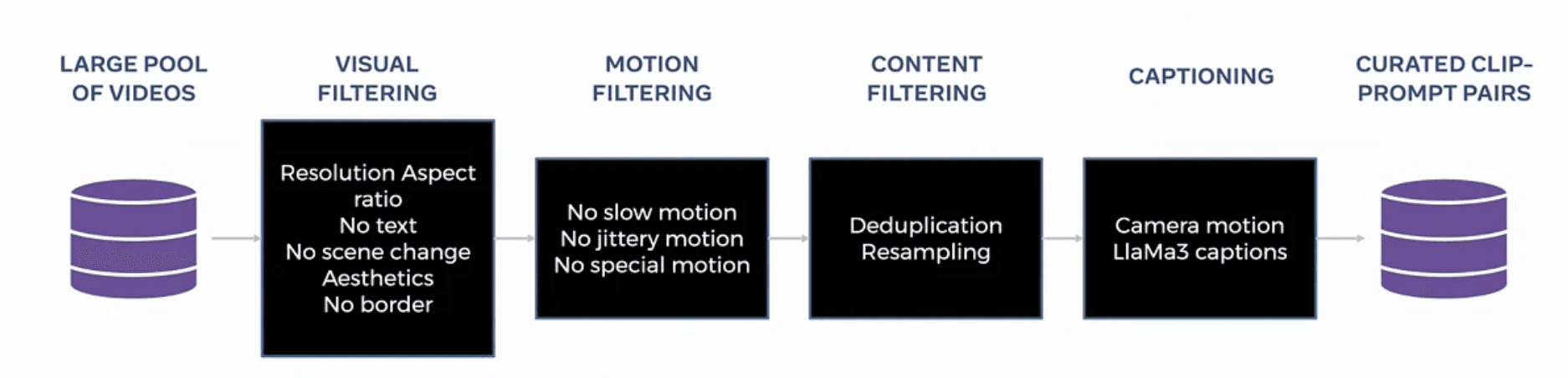
Meta開発チームは、従来の検査アセットに勝る大規模な評価体系であるMovieGen Benchを新規リリースしました。このコレクションは一部の優れた結果だけを集めた、いわゆる「チェリーピック(手加減)」なしの実ビデオ1,000アセットで構築され、GitHubでパブリック公開されており、従来ベンチ比で約3倍のスケールを持ちます。この計測において「バリデーション誤差」と「実際の人間側のクオリティ評価」が良いシグナルで同期しており、指標の再現性が担保されているのが特徴です。
データ結果とその先の未来
測定された実データからは、いくつかの重要なファクトが浮き彫りになりました。全体のクオリティ、および現実世界に近いシミュレーション能力(リアリティ)の両部門でトップマークに近い結果を記録し、特に実写を模したテキスト・トゥ・画像の合成能力で並外れた進歩を見せました。また、最もエキサイティングな洞察として「動画生成モデルの成長スケーリング則(Scaling Laws)が、LLaMA-3で辿った変遷と全く同一の成長パスを描き続けており、未だ飽和点に達していない」ことが究明されました。
しかしMisra氏は、MovieGenがどれだけ素晴らしくとも、未だ人間レベルの高度な物理干渉や認知のすべてを内包して出力する段階には及ばない領域もあること、世界の深い因果の般化については現在も検証中の部分が多いと、オープンかつ有益な総括でプレゼンを締めくくりました。
5 - マルチモーダル・自律型アクションモデルへのパス - Jianwei Yang
ジェンウェイ・ヤン(Jianwei Yang)氏のセッションは、既存AI開発における「認識(純粋な動画コンテンツのパッシブな理解)」のみに偏重した姿勢を揺さぶり、自律的で主体的(Agentic)なアクションをこなせる相互連携の必要価値を訴えました。「過去を理解すること」と「未来に向けて的確に動作を生成すること」の両輪をこなせる、マルチモーダルなビデオ認識をベースとしたWebエージェント、先端ロボ、完全自動操縦向けのロードマップが力強く提唱されました。
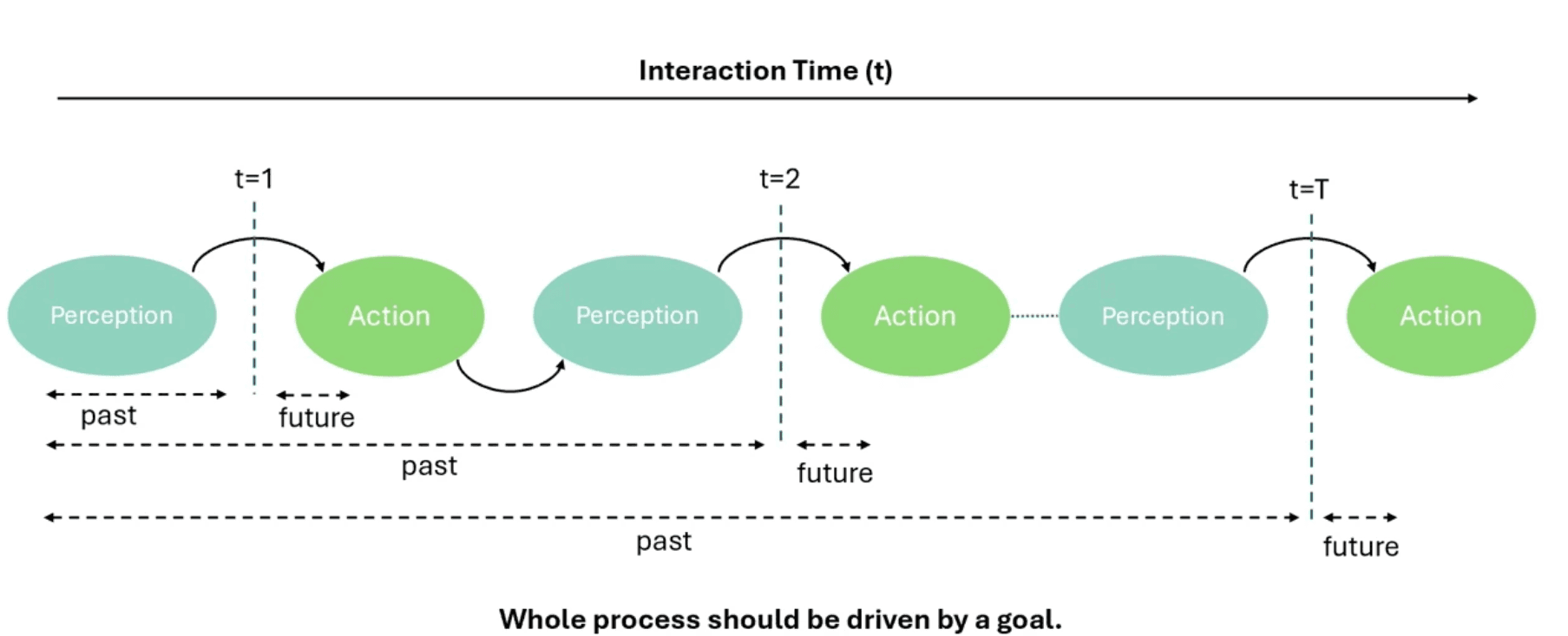
過去を捉える:より強化された空間アライメント認識
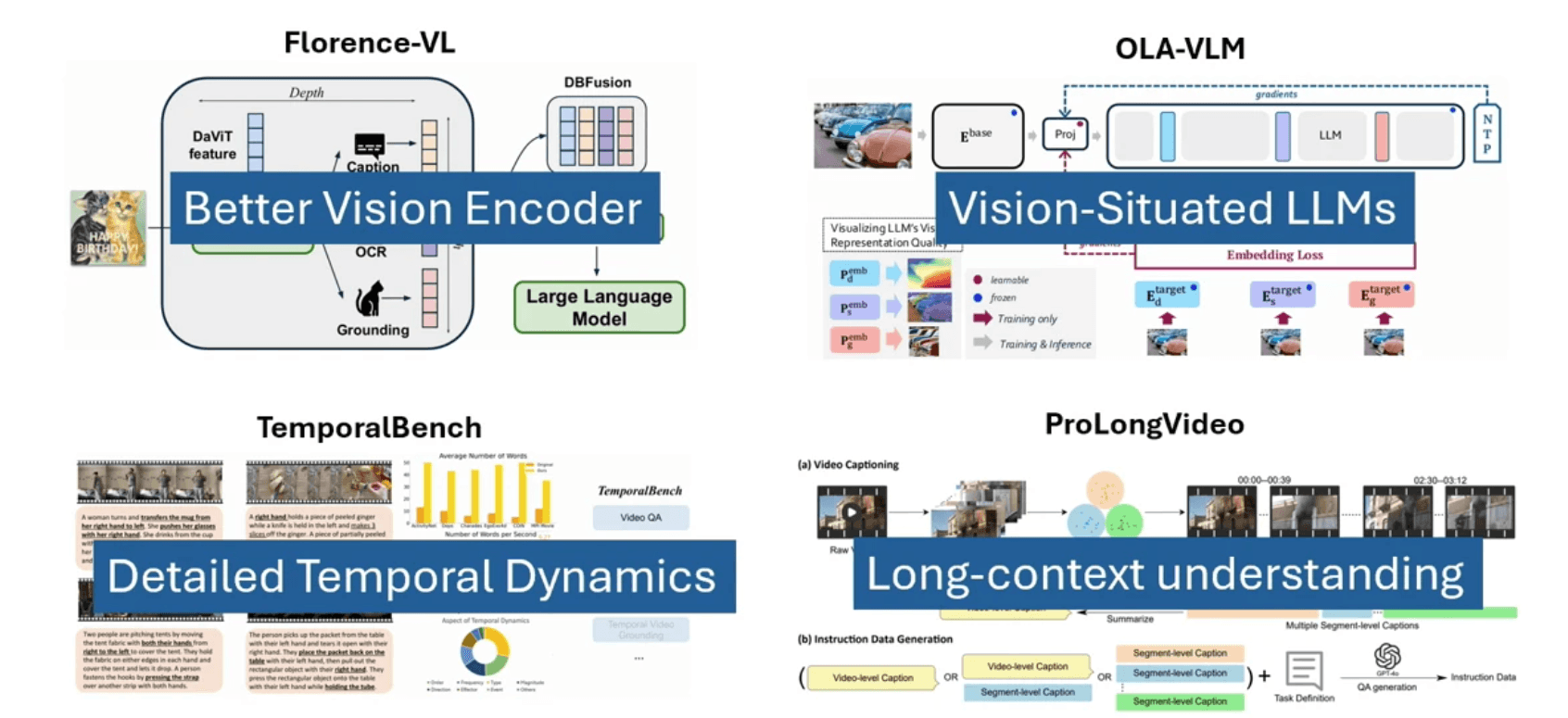
Florence-VL: 表現を極めた視覚統合LMM
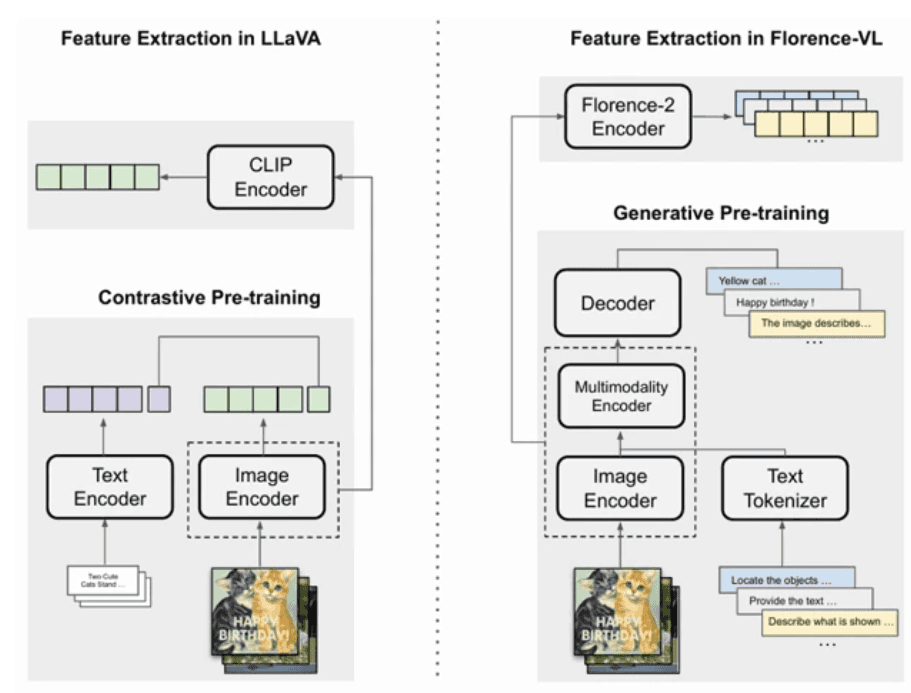
Florence-v2は、テキスト指示に同期して動く視覚ジェネレーティブAIにおいて大きな金字塔となっています。特徴的な空間ピクセル情報の種類に応じて多様なプロンプトの出し分けを行い、複雑なイメージ情報をパズルをパズルのピースを埋めるようにより強固に再構築します。この特徴変換時におけるアライメントロス(ビジョン側とLLM側の損失)を緻密に測定することで、システムは定量的な分析を強められます。
OLA-VLM: 多層特徴のダイレクト統合
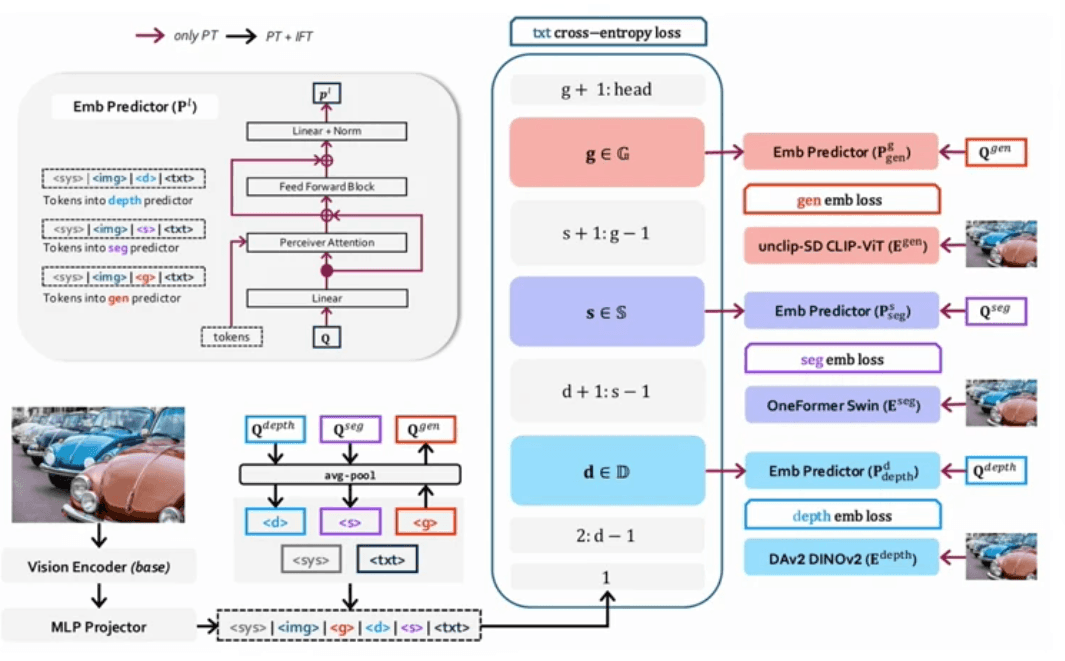
OLA-VLMは、画像が宿す深いエッセンスを取りこぼさないために、1つのソース画像につき異なる3つの個別特徴チャネルを使用して、マルチモーダルLLMの表現能力を最大化します:
対象間の奥行き情報を示す、高精度な「デプス特徴(Depth features)」
輪郭・領域をしぼる「セグメンテーション特徴」
画像をより豊かに視覚表現するための「Unclip-SD特徴」
研究チームは、テキストを用いた十分な監督学習が、画像知覚に必要な中間特徴を格段に豊かにすることを突き止めました。さらに「教師役(Teacher)」となるハイスペックモデルから、LLM側の特徴空間へと直接パラメータ最適化(指導)を行わせることで、さらに完成度を安定させています。
動きの細部に切り込む:ミクロな時間ダイナミクス評価
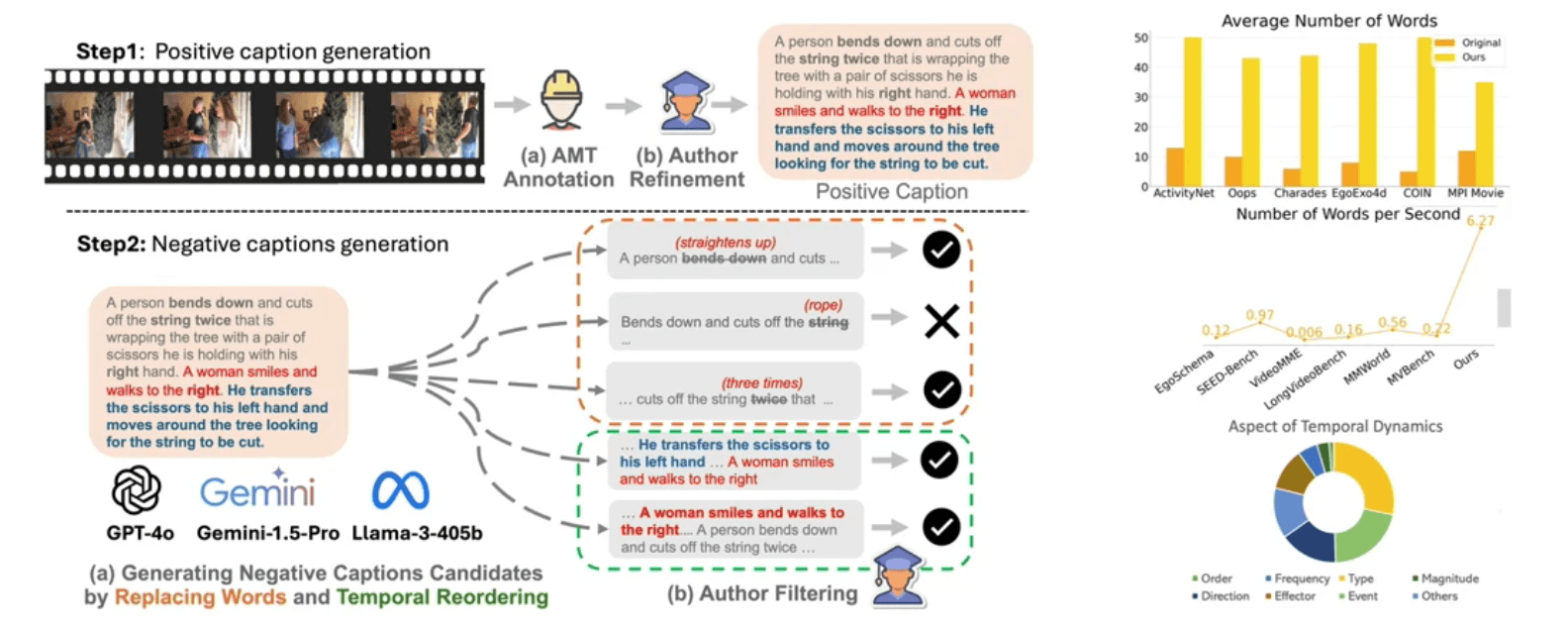
TemporalBenchプロジェクトは、動画理解における根本要素に挑戦します。映像とは個々のフレームの集積ではなく、きわめて綿密な時間軸のアクション変化(ダイナミクス)そのものである、という点です。この評価ベンチマークにより、ビデオモデルが僅かな動作変化を見通せているかを詳細に検証することが可能になります。
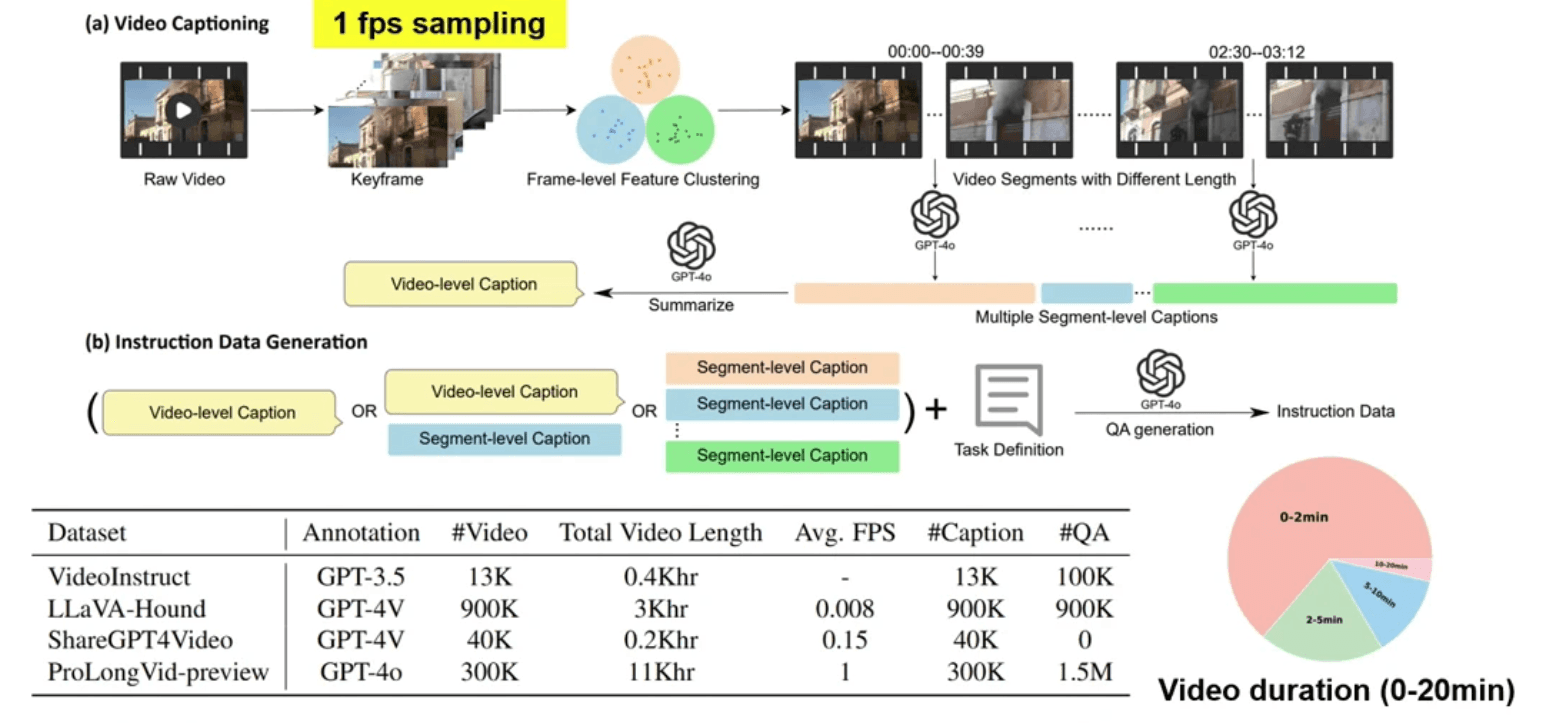
これと対をなす「ProLongVid」と呼ばれる研究では、以下の「成長拡大の2次元軸(スケーリング)」にスポットを当てました:
命令合成プロセスにおけるビデオ実データの「長さ(時間の拡張)」:長時間の長い流れを見落とさないためのトレーニング
学習・推論中の「コンテキスト長(Context Length)」の引き上げ:ストーリー全体の文脈を一挙にモデルが見失わないようにする改良
未来に向けて動く:主体的(Agentic)な自律行動を促す動画AI
TraceVLA: ビジュアルトレースプロンプティング
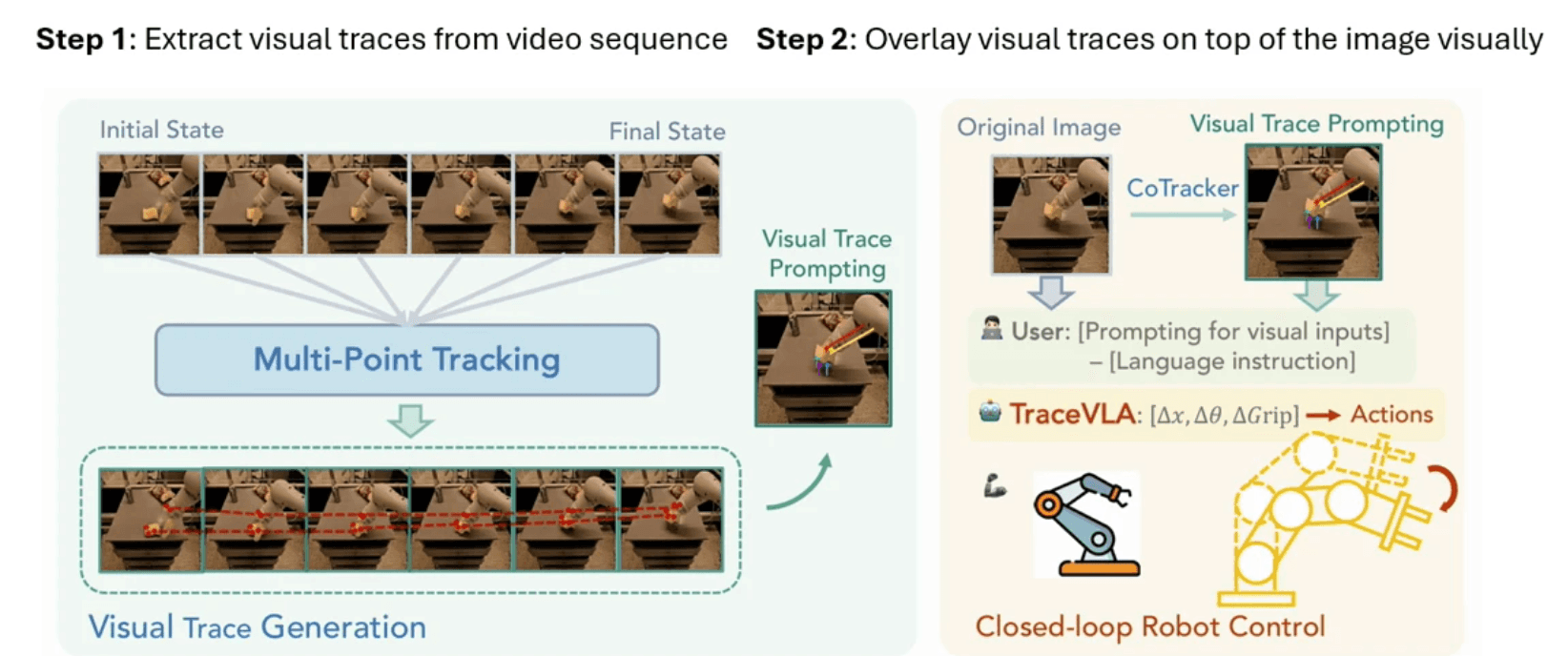
TraceVLAは、ロボティクスのポリシー(制御)において時空間情報を持たせるための優れたインサイトを提示します。「これまでの行動経緯(インプットの過去)をモデルが精密に反芻することで、次に引き起こすアクション(未来予測)がより正確になる」という合理的な仮説に基づいています。この機構は、現在のマルチモーダル変換においてよく起こるいくつかの摩擦を取り除きます:
複数画像を一堂に送り込むと、切り出しトークンの量が劇増して動作スピードが著しく鈍化する一方、一般的なビジュアルエンコーダーは連続するフレーム間の小さなズレやミリ単位の差分(オプティカル・フロー)を高精度に評価できないこと。
テキストプロンプト(記述による指示)は簡単ではあるものの、物理空間上のきわめて高精度な移動ベクトルやピンポイントの静的座標の指定には力及ばないこと。
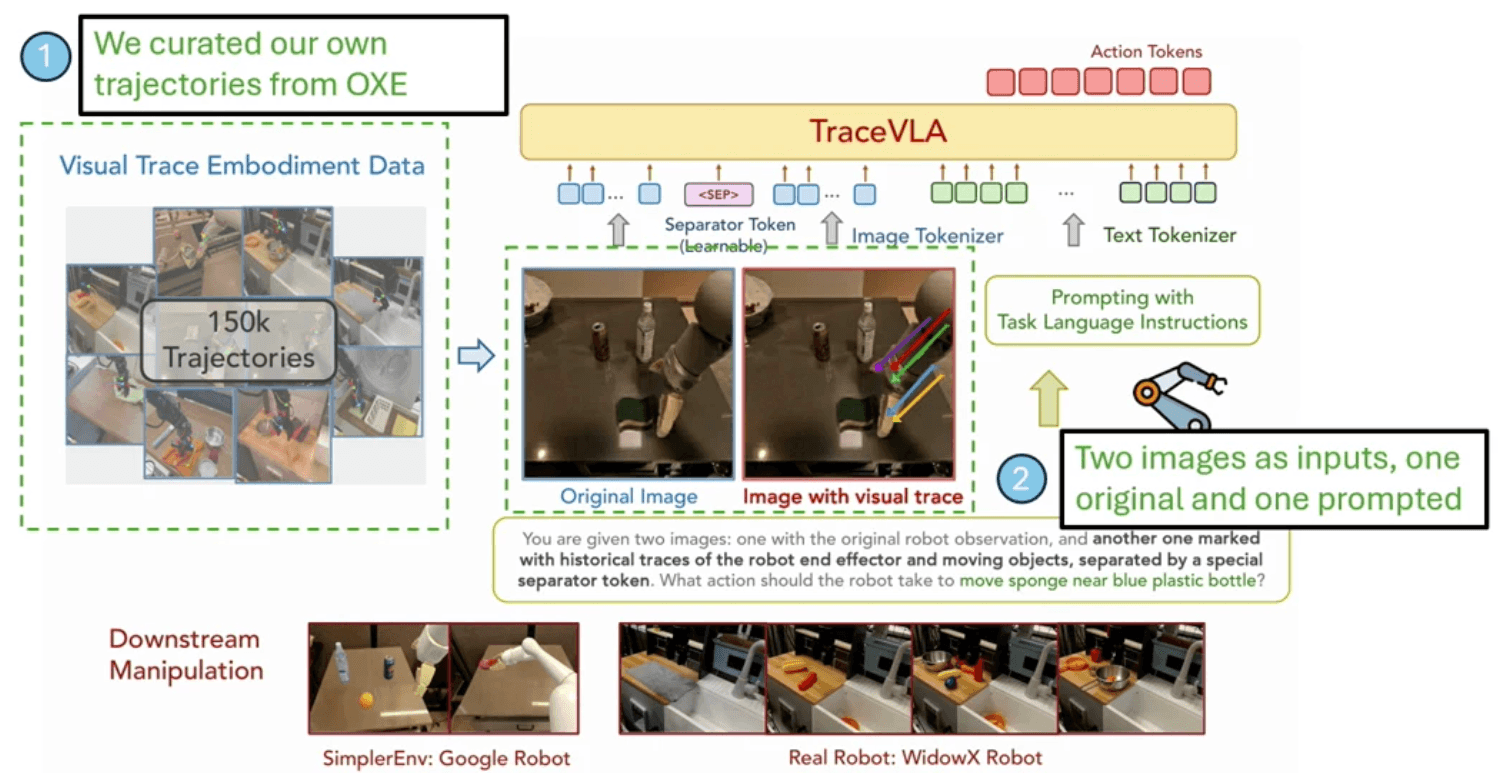
この障壁に対し、視覚的なインジケータ(プロンプトマーク)に直接作用させる画期的な「Set-of-Markプロンプト」を採用することで、現在の観測値と過去の行動軌跡との間のつながりをモデル内にシームレスに確立します。
LAPA: 言語無きビデオからアクションの「事前能力」を引き出す
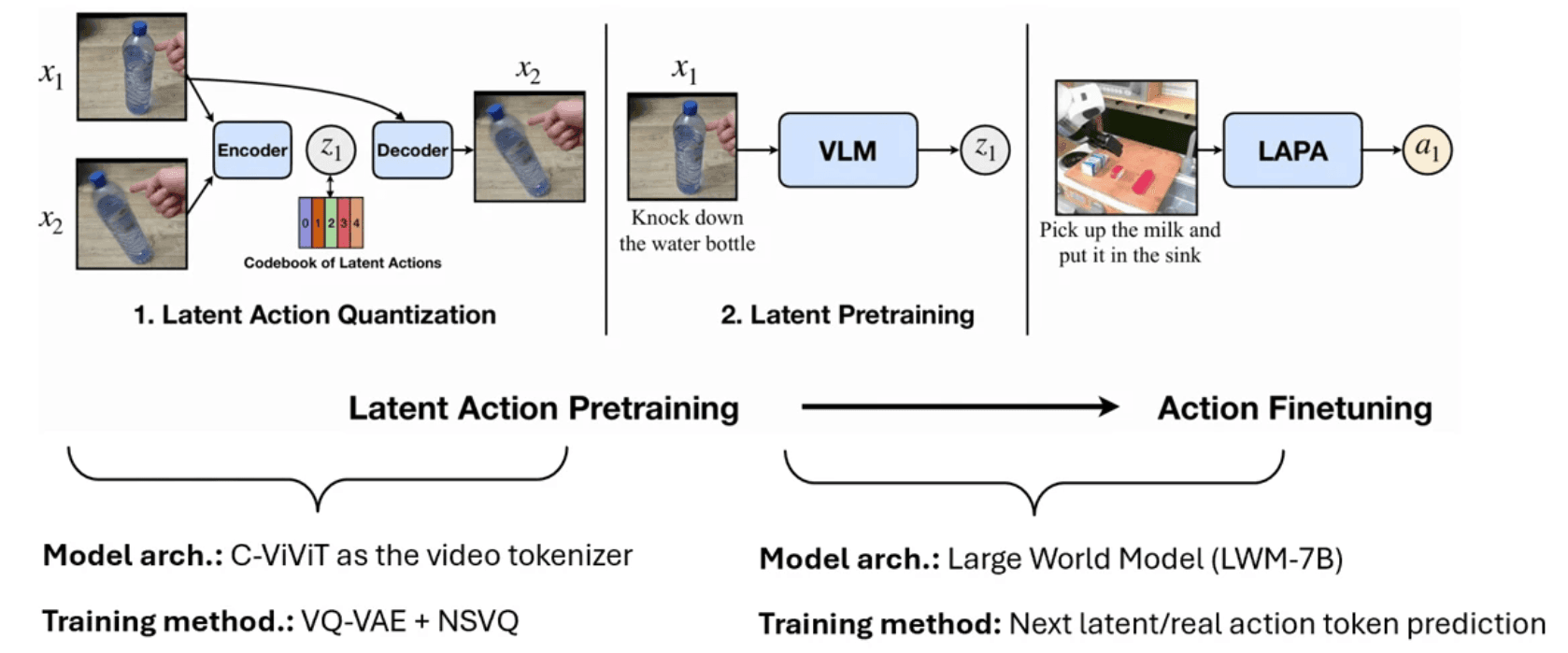
LAPAは、アノテーションされていないありのままの大規模動画から、スマートにロボット関節コマンドや環境運動に必要な基本能力をプリトレイン(学習)させておく革新的な手法です。アクションコマンドがラベル付けされていないロボットデータや、一般的な人間向けのレクチャー動画(How-to動画)の両方を効果的に活用して学習します。「sthv2データセット」を用いたテストでは、ゼロからトレーニングをかけた従来のアプローチを圧倒するパフォーマンスを叩き出したものの、最初からロボ機器特化データだけで仕込んだプロフェッショナルな挙動比では若干の性能差を残し、今後に向けての課題を示しました。
MAGMA:運動神経を宿すマクロ自律基盤AI
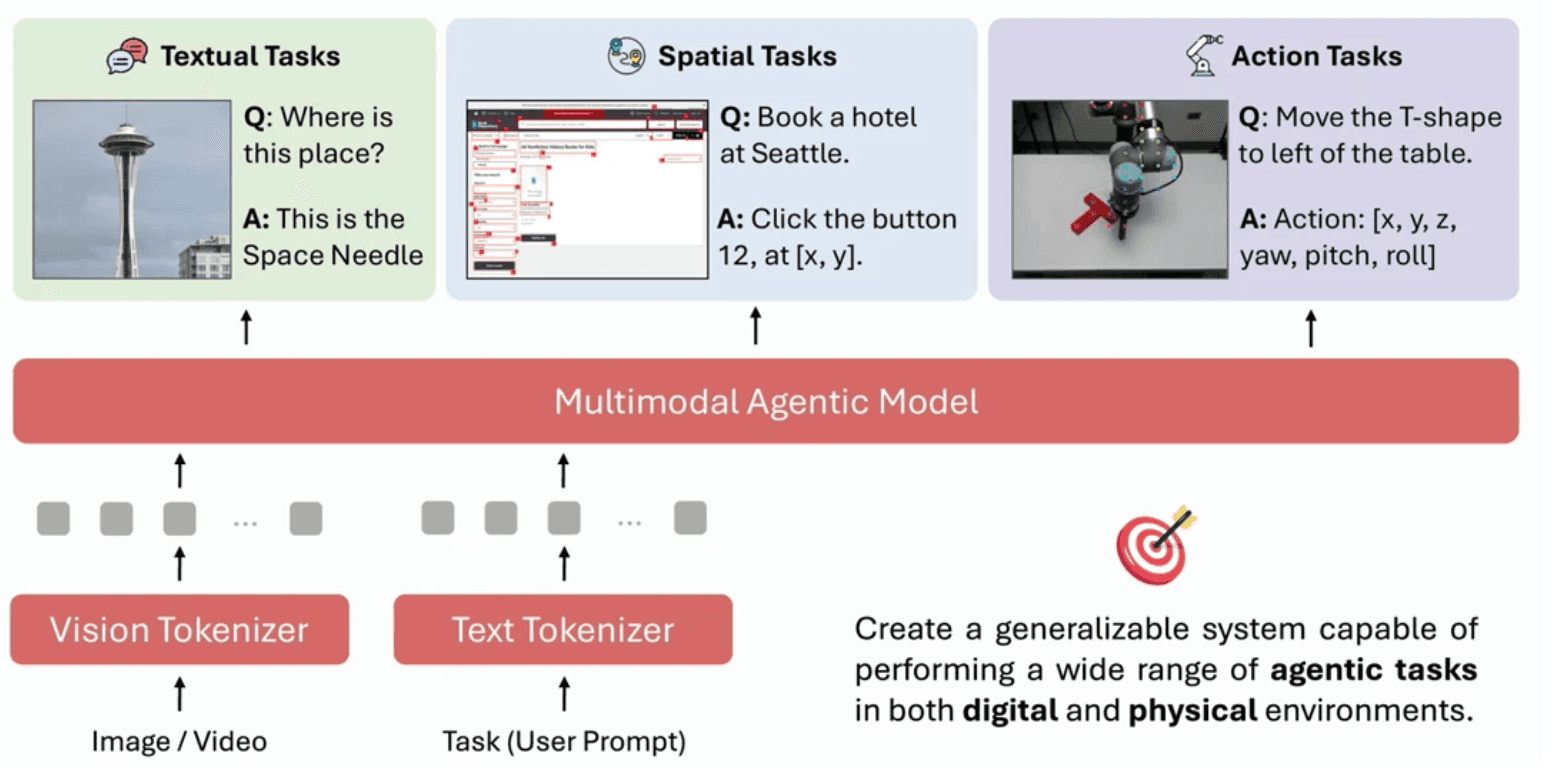
MAGMAは、動的画像をベースとするスマートシステムの中枢となるために、実質的な画像群・動画像群・ロボ操縦ログデータを横断して構築されました。「見る(理解)」と「動く(行動)」の相互作用にこだわり、時間の動きに特化した監視方法(Temporal Motion Supervision)やアクション出力変換を備えます。仕込まれたタスク設定はロボの歩道パス(Trajectory Planning)、およびこれに伴う新環境での柔軟なタスク適応(般化)といった創発的挙動を引き出すべく綿密に組まれています。
「アクティブ・エージェント(主体的知能)」の定義更新

Yang氏はセッションの結びに、マルチモーダルAIエージェントの定義を新たに再定義して宣言しました:「AIエージェントとは、自律的に周辺環境を検知かつ作用して、設定されたゴール(目標)の達成をこなせる主体であり、絶え間ない試行錯誤と蓄積知識(世界の経験値)を用いて日々自己の実行タスクパフォーマンスを高めていける組織体のことである。」この定義には最も主要となる3ファクターが組み込まれています:
エージェントが2次元画面の「ピクセル認知」を越え、奥行きや障害物の立体的な「3次元座標認識(3D)」へ覚醒することの必要性
主体を開発する中で、モデルフリー手法(対症療法的な動作)と、世界モデル構築(物理因果モデルを用いた先回り思考)をいかに高いレベルで融和させるか
単なるトリガー応答を越え、何手先まで計算して進む「プランニング推論」をシステムに宿すことの重要性
今後越えるべき障壁・課題
Yang氏は、映像素材が隠し持つ膨大なデータ資産を引き出すためにも、スケーリング則をさらに推し進めたスケールアップへのこだわりが必要不可欠だとしました。次に向かうべき主要ロードマップとして以下を掲げました:
マルチモーダル自律行動特性(Agentic):さらに高度なロボ制御と干渉
マルチモーダル推論演算(Reasoning):バラバラなマルチモダリティから正確な理論を組み立てる脳の構築
マルチモーダル統合理解(Understanding):混沌とした外界情報からの精度の高いシーンコンテクスト把握
マルチモーダル自己理解(Self-Awareness):現在のモデルの認知レベルを客観視し不確実な判断を自律調整するメタ認知力の獲得
登壇の最後においてもっとも客観的なファクトとして、ビジョンAIが近年劇的に性能を高めていることは認めつつも、「人間の持つ高度な物理運動および思考には及ばないこと。高ダイナミクス映像、ディテールの不変性、時間秩序に関しては、潤沢なインターネット上の生データ対比で、本当の意味でクリーンな動画・テキストペアの蓄積が極端に足りていないことが現状のボトルネックの一つである」と警告しました。
6 - 動画生成基盤から、宇宙をシミュレートする本物の世界モデル(World Models)へ - Doyup Lee
ドユプ・リー(Doyup Lee)氏は、Runwayがこれまで重ねてきた動画生成開発のプロセスを踏まえ、私たちが次に突き進むべき「General World Models(一般世界モデル)」への壮大なパスを語り、その根底にある核心的ロマン「いかにして自律知能は物理世界を目を通じて正しく認識し得るか?」を説き起こしました。Runwayが誇る高度な動画生成テクノロジーの蓄積されたノウハウを交えた、AIにおけるビジュアル認識と想像力の関連性を探究するセッションです。
視覚的知能の本質を読み解く
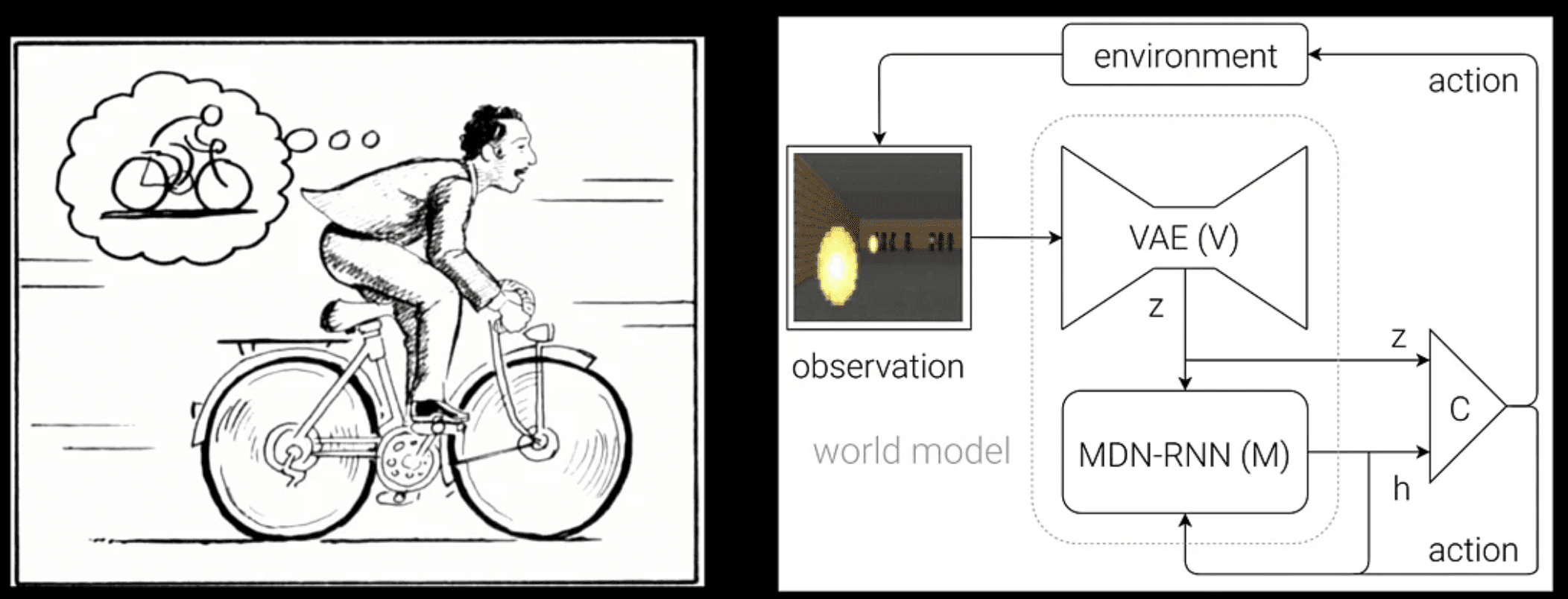
Lee氏は、我々がいう「視覚認識(見る力)」とは何かという点について、世界モデルのシミュレーション能力および人間の「想像力(Imagination)」との深い結びつきを通じて論じました。彼はHa & Schmidhuber(2018)による世界モデルに関する代表論文を引用し、当時の成果が特定のシミュレーター環境内部などの閉じた世界においては高い予測精度をマークした一方で、現実の複雑で不確実な実世界での適用に苦慮した点を回顧しました。従来のビデオ認識手法、例えば画像の解説テキスト化、視覚Q&A(VQA)、特定エリア分割(Semantic Segmentation)などは、基本として人間の定義した言葉(ラベル名)と物体の関連付けに終始しており、取り込める世界の深い真実の一端を拾い損ねている限界を説きました。
プラトン的表現仮説(The Platonic Representation Hypothesis)
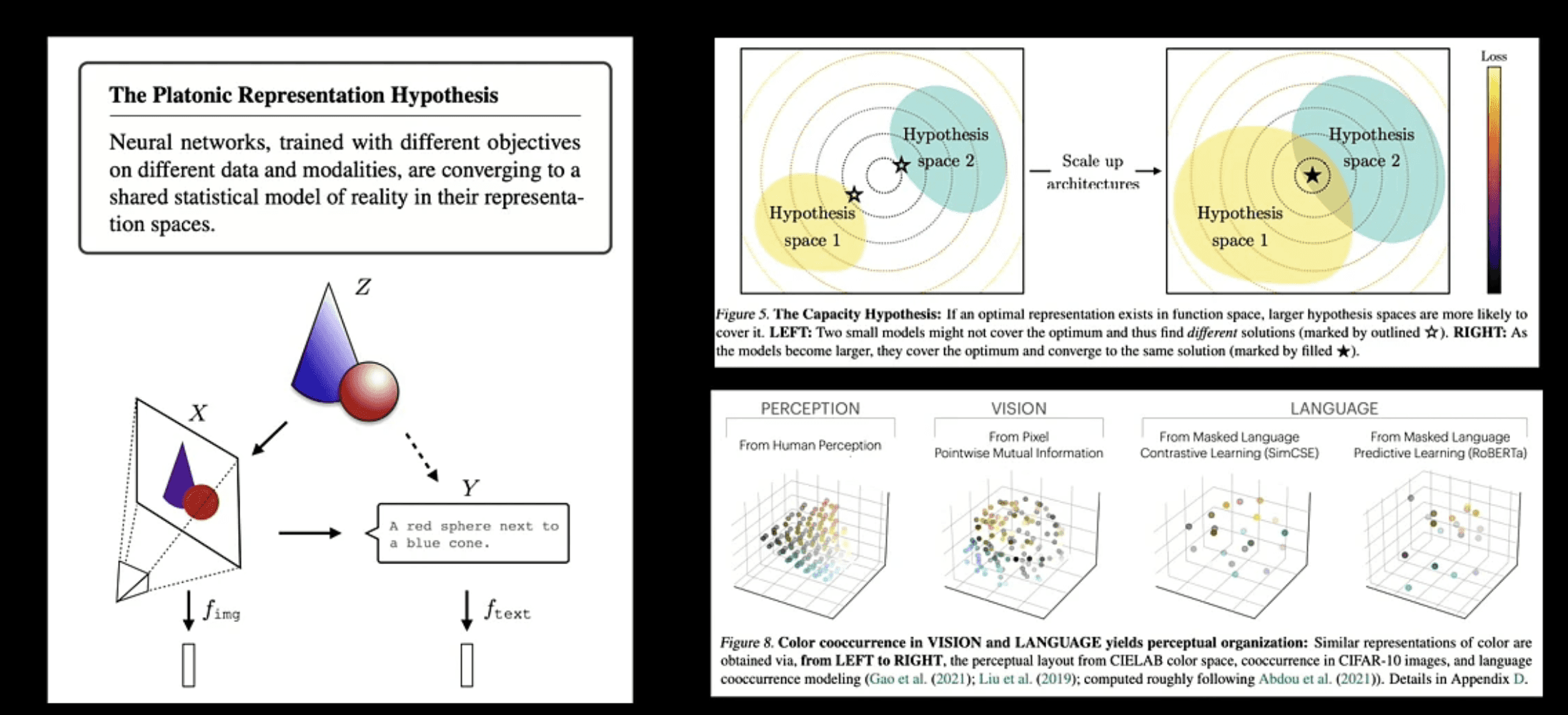
Lee氏がプレゼンの理論基盤としたものに「プラトン的表現仮説(Huh et al., ICML 2024)」があります。これは視覚認知としてAIが満たすべき以下の3つの絶対要素を明快にしたものです:
動画のタイムラインの展開(先、何が起こるか)について極めて高い予測変換能力を持ち、ダイナミクスを真に理解していること
世界の広大さを写し取った、かつ多様な、膨大の映像アセットに絶え間なくアクセスし学習に組み込めること
人間の持つ世界の概念構造や共通認識、行動期待とズレのないアライメント(整合性)をクリアしていること
汎用世界モデル構築に向けた『5つの極意』
1. 「苦い教訓(The Bitter Lesson)」への回帰
Lee氏は、AIの進化において有名な「苦い教訓(Bitter Lesson)」を今一度噛み締めることの重大さを語りました。大抵の場合、特定のルールや手仕事で最適化した専門の設計アプローチよりも、圧倒的な大容量計算リソース(Compute)と一般的な学習による拡大を信じた開発の方が最後にはすべてのタスクで卓越したパフォーマンスを収める、という法則です。この基本方針が、モデル開発における柔軟で無駄のない、スケーラブルな構成を生み出します。
2. 極めて高品質な、超巨大スケールのデータ素材
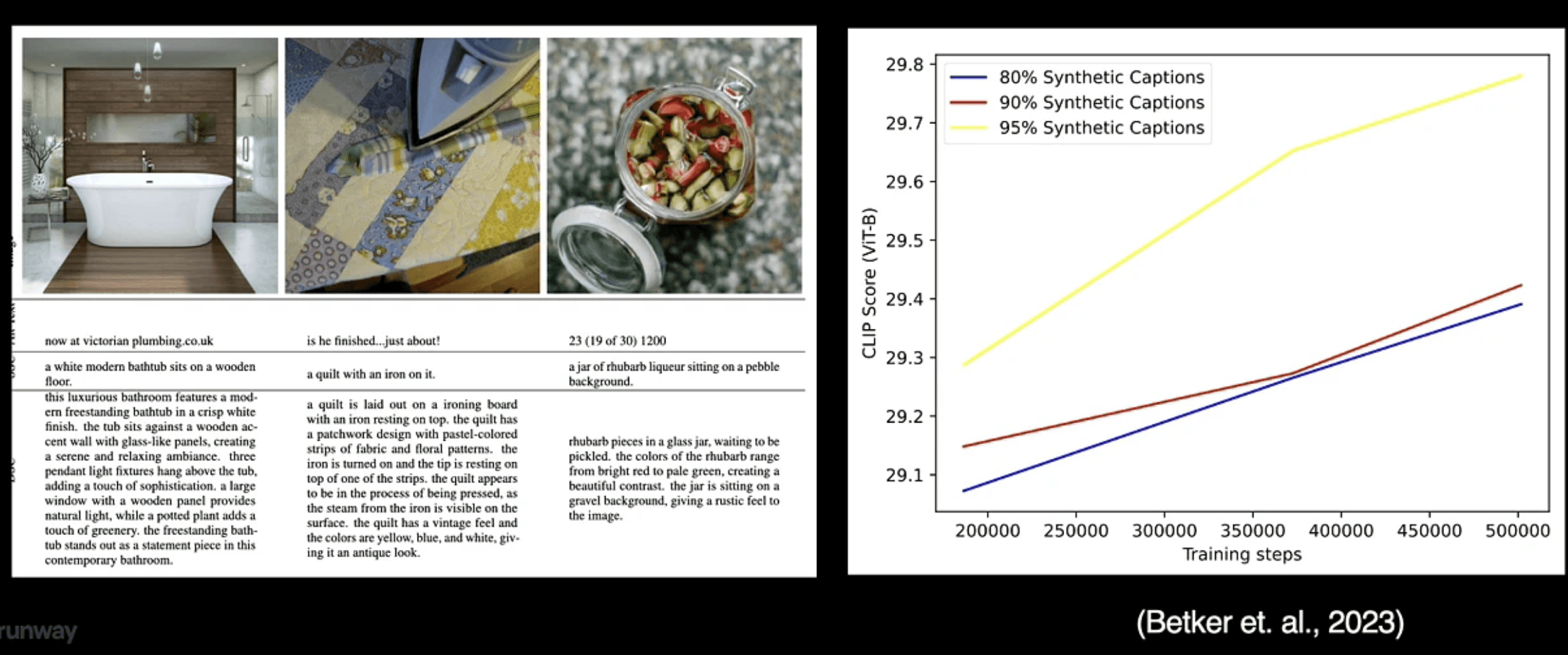
発表では、インプットデータが有する素材純度の僅かな違いが、モデル全体の学習効率と実用パフォーマンスを劇的に左右する事実がデータ付きで示されました。Lee氏は、アノテーションキャプションの品質を最高レベルに保つことで、画像および動画モデルの双方が著しい成績のブーストアップを記録することを示しました。しかし一方で、インターネット上の膨大なデータの山から、どうやって低コストで高品質な長尺キャプションタグ(詳細説明)を作り引き出すかは最大の難題であり、アノテーション工程のブレイクスルーが模索されています。
3. relational inductive bias(関係帰納バイアス)の無いスケーラブルアーキテクチャ
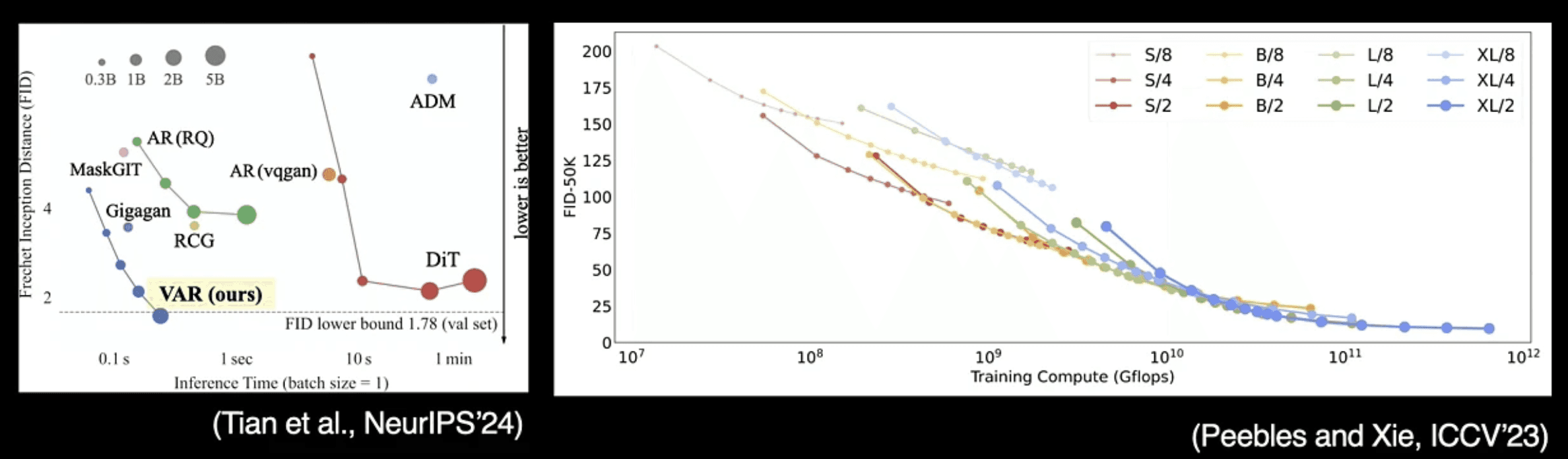
異なるデータ表現間に恣意的な関係性を規定しない、優れたモデル構造を選択すべきことが語られました。これに伴い、演算資源の経済的活用、および学習中の無駄を実証データに基づいて管理・予測するための「ニューラル・スケーリング則」の技術的解説がなされました。これにより、限度あるマシン(プロセッサ)リソースを無駄に食い潰すことなく、成長を設計通りに最大化できます。
4. 分散学習の極限スケール最適化
巨大プラットフォームを用いたマルチノードの並列事前学習においては、マシン全体の演算資源効率を示す指標「Model FLOPS Utilization(MFU: モデル使用演算率)」の最大化が最たる関心事になります。Lee氏は、全理論上の演算ポテンシャルのうち実際に何パーセントを高効率に引き出せているかがシステム最適化の主因であるとし、以下を含むディープなエンジニアリング施策を挙げました:
低精度(FP8/FP16等)演算のスムーズな実装、および演算の最大化
最適化を極めたカスタムCUDAカーネルの自社開発
高度なパラレリズム(並列化:データ並列、モデル並列、パイプライン並列等)の極地
ネットワーク遅延やマシントラブルをリアルタイムに回避する最先端クラスマネジメントシステム
5. 部門を超えたクロスファンクショナルなワンチーム統合
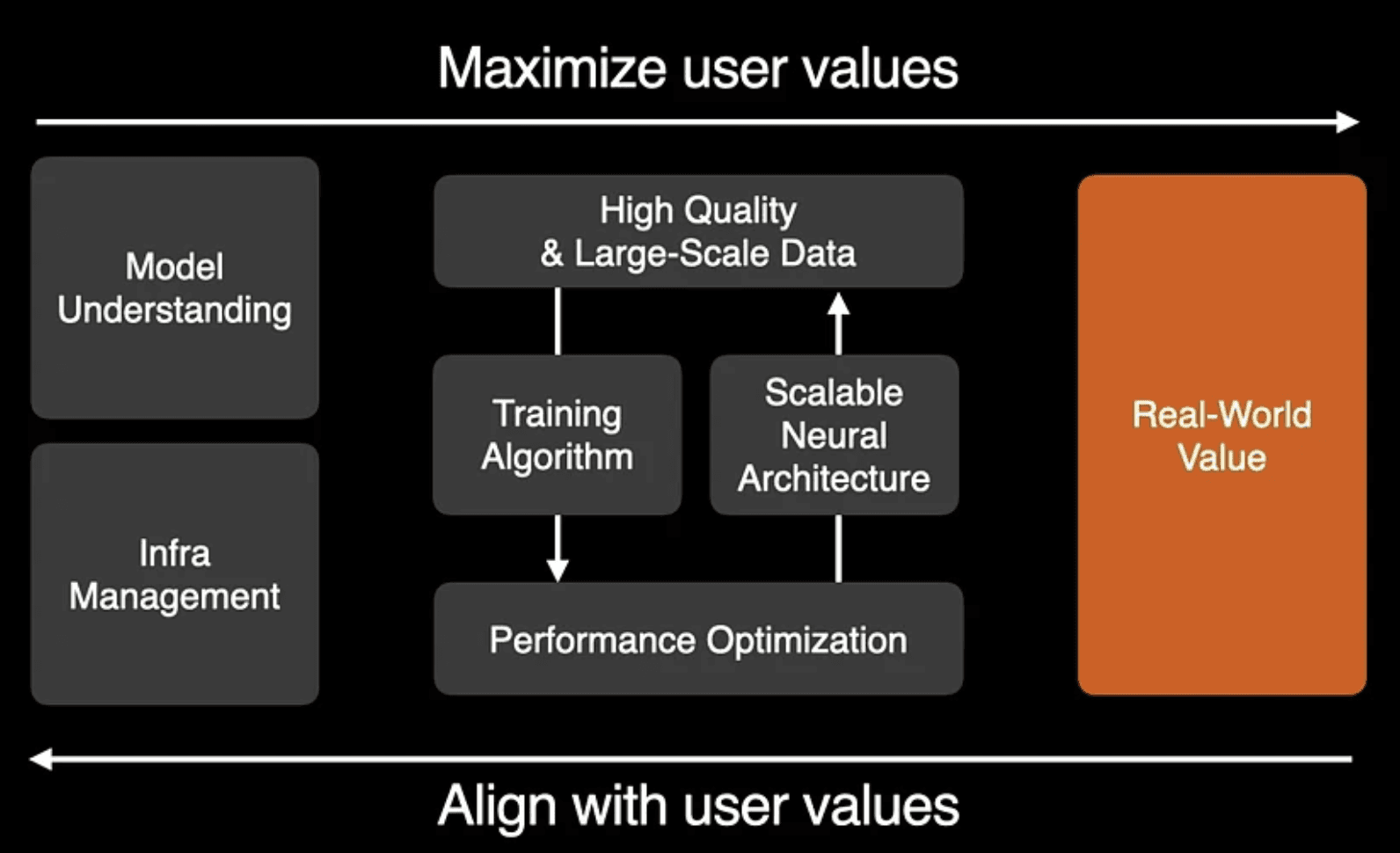
Lee氏は、ここまでの規模の最先端開発とはもはや一介のAI研究部門だけで到底なし得るものではなく、ハード・運用・データ・デザイン・クリエイティブのすべてが完全に連携した総合システムとして回る組織こそが勝機を見出すとしました。それぞれのフィードバックが無駄なく瞬時に交差する組織形態のガイドマップを共有しました。
Runway開発の次世代動画生成モデルたち
Gen-3 Alpha
Lee氏は、2024年6月にリリースされクリエイティブ業界震撼をもたらしたRunwayのGen-3 Alphaモデルを改めて提示深く掘り下げ。ユーザーのあらゆる細かな自然言語記述から、映画クラスの動的なシチュエーションを描き切る能力に秀でています。しかしながら、このGen-3の中にある、物理シミュレーション理解やコンセプチュアルな一般世界の予測モデル能力については、我々人間にとっても未だ分析段階のフロンティアであるとしました。
Runway開発部隊は、この巨大ビジュアル生成の奥深くを確かめるため、以下のような領域について分析研究を日々進めています:
現実世界を司る「物理的な重力や衝突法則」をモデルがいかに獲得して実行しているか
文字のフォント、崩れのない正確きわまる画像レンダリング限界
未知のイメージやキャラクター概念同士の混合描写力(概念の一般化)
思い通りの映像を描くための「直感制御コントロールツール」
Lee氏は、ただ出力するお祈り運搬式の生成ではなく、クリエイターが映像を自らの指先のように自在にコントロールするための優れた直感ツール群もお披露目しました:
イメージを特定のスタイル調に出発点を限定するキーフレーム設定(Keyframe conditioning)
既存シチュエーション・パイプラインにシームレスに入り込む生成VFXテクノロジー
3次元の立体的なパースを狂わせないで駆動するカメラワークコントローラー(3Dカメラ制御)
描いた部分の「動きの種類」や「スピード方向性」を指定ブラシで部分制御するモーションブラシ(Motion Brush)
画像構造やレイアウト指定に合わせるための構造化条件(Structural conditioning)
動画の領域外を拡張しシーンを書き足すアウトペインティング(Out-painting)
Act-One: 命を吹き込む表現のイノベーション
本発表の最も熱いピークにおいて実演されたのが、人物の演技、表情、魂ともいえるき微細なニュアンスを完全に再現・生成する仕組みである Act-Oneのハイレベルデモでした。Gen-3のモデル実力の上に乗る形をとり、人間のキャラクターアクターの演技、顔全体の躍動、心理描写を完全に模倣移転して、異なるキャラクターへと生成することを驚愕のタイムライン処理クオリティを達成しながら可能にしています。

ビジョンと今後のビッグ課題
リー氏はセッションの括りとして、私たち人間の知的世界を描写する絶対の不変メディアは「言語」と「映像」の双璧であるとしました。言語は全抽象世界のインデックス情報を有し、映像は無限に広がる全ビジュアル空間の膨大な実態シグナルを保持します。私たちはこれまでの比ではない圧倒的に膨大なデータを集積・活用して、本当の意味で現実世界およびそのインタラクション全体を包摂する真の世界モデルへ舵を切る準備ができているとして、Runwayが挑み続ける高みを示しました。

プレゼンは究極のフロンティアである、人間の定義・認識・想像力を一段回以上飛び越える、高次元の一般世界モデル(General World Models)の具現化という大いなる約束を持って幕を閉じました。我々はこの開発を以下の多軸から挑戦します:
最高のスケーリングとそれを耐え抜くモデルアーキテクチャの革新
データ合成とキュレーションのクオリティ革命
マシンの持てる全クロックを活用する驚異的な演算最適化
誰もをアーティストに変える、直感的かつ精巧な画風コントロール手法の拡張
プロの撮影シーン、インフラ、CGクリエイティブワークへのシームレスな統合
動画言語モデルの行く末:我々が共に見つめる視線の先へ
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップ(Video-Language Model Workshop)は、動画理解のエキサイティングな進化進捗と、未開のクリアされるべき課題の双方を劇的にあぶり出しました。業界で技術革新に挑むプレイヤーのひとりであり、本祭の企画・共同オーガナイザーでもあるTwelve Labs(トゥエルブラボ)は、この傑出したスピーカー陣が投げかけた鋭い洞察を大切に受け止めています。
浮き彫りとなった重要コアテーマ

ワークショップ中、いくつもの重要検討事項が会場を震わせました。ディマ・ダメン(Dima Damen)教授は一人称視点カメラから見たミクロな連続アクション(時間軸の微細ダイナミクス)の処理の価値を訴え、ゲダス・ベルタシウス(Gedas Bertasius)教授は文字依存の世界観を脱し「テキストフォーマットで定義しきれない純粋ビジュアル」を読み取るモデルの重要性を主張しました。ヨンジェ・リー(Yong Jae Lee)教授が見せた、ほんの10秒足らずのショートビデオに潜む反実仮想の僅かな時間情報の取り扱いでさえ、最新鋭のLLaVAやフロンティアモデルが軒並み苦汁をなめている事実は、大きな話題となりました。
またジェンウェイ・ヤン(Jianwei Yang)氏が見せた「体性を宿した能動アクションモデル(マルチモーダルエージェント)」と、イシャン・ミスラ(Ishan Misra)氏が率いたMovieGen開発による次世代生成ワークフローは、単なるテキスト記述を越えた先にある新しいエンタメの在り方、自動生産システムへの展望を一望させてくれました。さらにドユプ・リー(Doyup Lee)氏が宣言した「一般世界モデル」への歩みは、生成モデル自身がこの宇宙をシミュレートする本物の頭脳へと変革し得る偉大な可能性を裏付けました。
テック企業としての現状理解と私たちの歩む道
Twelve Labs(トゥエルブラボ)において、ここでの課題は私たちの開発実務での経験にこの上なく一致します。当社が長年磨き続けている超高性能動画特徴埋め込みモデルである「Marengo(マレンゴ)」や、映像を流暢なテキストコミュニケーションへと直結させるビデオ対話基盤LMM「Pegasus(ペガサス)」の開発は、まさに登壇した教授陣が説いたマルチモダリティの統合、極めて洗練されたタイムラインの追跡、極地を極めるデータフィルタリングとトレーニングの価値そのものから生まれ育ったプロダクトたちだからです。
ここで展開した白熱した議論は、我々が日々磨いている開発の羅針盤が正確であることを指し示しています:
動画の奥深さに多次元アプローチをかける「マルチベクトル(Multi-vector)埋め込み」テクノロジー
短い閃きのようなアクションから、大河ドラマのような長尺小説の流れまで破綻せずに記憶し処理する高度なタイムライン追跡設計
ピクセル特徴(Visual)、環境情報、セリフや会話・歌(Audio)、そして物語の文字コンテキスト(Text)を美しいハーモニーのようにひとまとめに対象化するマルチモーダル統合処理
これまでの画一的な言語ベースの試験測定を越え、モデルに真の知恵を強烈に問う次世代のロバスト評価指標の創出
未来へ向かう最高の青写真
動画と言語モデルが融和して進化を遂げた先にある世界は、圧倒的な希望に満ち溢れています。私たちはこれから先:
より深く複雑な劇中ストーリー展開や、裏を読ませるような反実仮想を含む時間推論を完全にマスターするビデオ認識脳
社会常識、物理ルール、および人間としての道徳観といった、私たちの持つ「現実の教養」を正しく内包した視覚ビジョン能力
長尺を扱うモデル動作コストを最小限に抑え抜きつつ、最初から最後までの時間連動力を高精度に維持できる洗練された高効率トランスフォーマー設計
最先端を追い求める学会・大学研究の知恵と、実際のスケーラビリティ処理を背負うインフラ実業界(エンタープライズ)との間のこれまでになく太い連携
このワークショップは、学界と産業界双方のエキスパートたちが一堂に会し、こうした数々の野心的な技術的障壁に対して「チーム一体」となって立ち向かうための大きな第一歩となります。これまでの自負、常套手段を越え、真に私たちが目を惹かれる知能システムの誕生を目指し、Twelve Labsはこれからも開かれたテクノロジーコミュニティを愛し、責任ある行動と絶え間ない実験開発を惜しみません。
ここから始まる道のりは険しく、しかしワクワクする発見に満ちています。本日を彩った最高の頭脳たちの知見をバトンに、アカデミズムとビジネスが手を携えて進むことで、この先のビデオ言語モデルが我々の暮らしを、そして「私たちがこの現実世界をどのように知覚し、繋がり、高めあうか」を劇的にアップグレードしてくれる日の到来がより早く、かつ確かに近づいてくるのです。
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップは、急速に進化を遂げる動画の理解と生成という分野において極めて重要な契機となりました。冒頭の挨拶では、当社CTOのエイデン・リーが、動画理解(ビデオからテキストへの変換)と動画生成(テキストからビデオへの変換)という2大重要領域を横断して盛り上がりを見せる、ビデオ言語モデルへの関心の高まりを強調しました。
これらの技術は、コンテンツ制作や広告、ヘルスケア、ロボティクスなど、多岐にわたるセクターで応用されています。視覚と言語を統合するビジョン言語モデルの研究は指数関数的な成長を見せているものの、この分野は未だいくつかの重大な課題に直面しています:
特に高品質な動画とテキストのペアにおけるデータ不足
動画の保存および処理におけるスケールと複雑性の問題
視覚、音声、テキストといった複数モダリティの統合における課題
ビデオと言語のアライメントのベンチマーク測定および評価の難しさ
当ワークショップは、多様な研究者を一堂に集めて、現在の障害について議論し、開かれた共同研究を促進し、現実社会で応用できる動画基盤モデルの開発を加速させることを目的として開催されました。
1 - 一人称(エゴセントリック)視点の動画と言語の理解 - Dima Damen
ディマ・ダメン(Dima Damen)教授による包括的な解説では、一人称視点動画と言語の理解における4つの最先端のアスペクトを探究しました。教授の研究はEPIC-KITCHENSデータセットから着想を得ており、画期的なアプローチをいくつも導入しています。
類似のアクションに対するユニークなキャプション記述
ACCV 2024で最優秀論文賞を受賞した論文「It's Just Another Day(いつもと変わらない日常)」は、動画キャプション作成における根本的な課題、すなわち、既存の手法が類似する複数のクリップを独立して処理した際に全く同じキャプションを生成してしまう傾向に対処するものです。
この研究の根底にある重要な知見は、「日常生活は繰り返しであっても、類似したアクションに対しては異なる説明が必要である」ということです。研究チームは、以下の特徴を持つ「識別プロンプトによるキャプション生成(CDP - Captioning by Discriminative Prompting)」と呼ばれる斬新なアプローチを提案しています:
クリップを個別に切り離して見るのではなく、連動させて評価する
識別プロンプト群を活用して他と異なる固有のキャプションを生成する
ビデオからテキスト、およびテキストからビデオへの双方の検索評価指標を用いて評価を行う
この手法は、Ego4Dからの一人称視点動画とタイムループ映画という2つのドメインで評価されました。CDPをLaViLa VCLMキャプショナーに適用したところ、意味論的な正確性を維持したまま、生成されるキャプションの独自性が大幅に向上しました。
言語を用いたドメイン般化
主要な成果として挙げられるのが、シナリオや場所を横断した「行動認識般化(Action Recognition Generalization)」に特化して構築された初のデータセットであるARGO1Mデータセットです。このデータセットには以下の特徴があります:
60の行動クラスをカバーする105万個の行動クリップ
13の異なるロケーションからの録画データ
標準仕様としての10秒間のクリップ尺
同論文「What can a cook in Italy teach a mechanic in India?(イタリアの料理人はインドの整備士に何を教えられるか?)」では、以下の2つの主要な再構成技術を利用する相互インスタンス再構成(CIR - Cross-Instance Reconstruction)を導入しています:
テキストでのナレーションを利用した動画とテキストの関連付け再構成
行動クラス認識のために訓練された分類の再構成
CIRは複数の異なるシナリオや場所における行動を加重結合して表すことで、堅牢なクロスドメイン般化を可能にしています。
手とオブジェクトのインタラクション指示参照
HOI-Refプロジェクトは、一人称視点画像における手とオブジェクトのインタラクション指示(HOI: hand-object interaction referral)に適した洗練されたモデル「VLM4HOI」を導入しました。このモデルのアーキテクチャには以下が含まれます:
画像処理に対応するビジョンエンコーダー(g)と投影レイヤー(Wφ)
言語モデルの埋め込み空間との統合
両手およびインタラクションが発生した対象物の双方を同定する能力
研究チームは、390万問の質問回答ペアを収録する包括的なデータセット「HOI-QA」を開発しました。これは以下に焦点を当てています:
手とオブジェクトの空間認識および指示参照
手とオブジェクトのインタラクションに関する理解
直接的参照(Direct Referral)とインタラクションを介した参照(Interaction Referral)性能の対比
オーディオと言ジュアルのセマンティック統合
このセクションでは、本分野に対する2つの重要な貢献が発表されました:
EPIC-SOUNDSデータセット
この大規模データセットは、EPIC-KITCHENS-100の一人称視点ビデオから音声アノテーションを抽出したもので、以下の特徴を備えています:
検知可能な音声イベントや行動を捉えた75,900件のセグメント
44個の異なる行動クラス
物体の衝突音に対する詳細な材質別アノテーション
聞き取り分け可能な音声セグメントに対する時間軸ラベル付け
TIM (Time Interval Machine)
TIMは、長尺動画中において音声イベントと視覚イベント間で時間的な広がり(長さ)が異なるという問題に対処する、画期的な技術を提示します。主な機能は以下の通りです:
モダリティ固有の時間区間(Time Interval)を処理するトランスフォーマーエンコーダー
特定の間隔およびその周辺のコンテキストの双方に対応するアテンション機構
複数のベンチマークにおいてState-of-the-Art(最高水準)を誇るパフォーマンス
このモデルは以下に示す驚異的な結果を達成しました:
EPIC-KITCHENSにおける上位1位(top-1)行動認識の正確性を2.9%向上
Perception TestおよびAVEデータセットにおける卓越したパフォーマンス
高密度でマルチスケールなインターバルクエリを用いた行動検出への適応化に成功
これら一連の進歩は、特に視覚・テキスト・音声の複雑な関係性の相互処理において、一人称視点の動画コンテンツを理解し処理する能力が大きく進歩したことを一貫して示しています。Dima教授の研究グループによるプロジェクトは、一人称動画理解におけるマルチモダリティ統合の課題解決に向けた、包括的なフレームワークを提示しています。
2 - 言語と映像を用いた高難度ビデオ理解 - Gedas Bertasius
ゲダス・ベルタシウス(Gedas Bertasius)教授は、高度な動画理解タスクにおけるビデオ言語モデル(VLM)の目覚ましい進歩と同時に、現在の限界についても光を当てました。LLMやVLMのおかげで動画理解が大幅に向上したことを受け入れつつも、近代的なVLMが未だ複雑な動画の意図や文脈の正確な読解という点においては、依然として根本的な課題にぶつかっていることを指摘して警告しました。
長尺ビデオの理解における問題の解消
最も重要な技術的課題の1つとして挙げられたのが、現在のモデルが長期の動画シーケンス全体から関連性の高いコンテンツがどこにあるかを特定(局所化)するのに手を焼いている点です。Bertasius教授は、動画内の長距離にわたる相互関係を効率的にモデリングする優れた手法として「構造化状態空間モデル(S4: Structured State-Space Models)」を挙げました(こちらの研究やこちらの研究に示されています)。ただし、S4モデルへの入力トークンごとにパラメータが固定されているため、シーケンス(一連の流れ)の特定の場所にピンポイントに注意を向けるようなタスクを苦手としている点を指摘しました。
BIMBA: セレクティブスキャン圧縮
BIMBAは、動的に(データに依存する形で)隠れ状態にどのインプット情報を残すかを選択する選好スキャンアルゴリズム(別名Mamba)を取り込むことで、こうした制限に対処します。このモデルには以下の特長があります:
双方向の選択型スキャン機構を活用した時空間トークンセレクター
精緻なコンテンツ選択を可能にするインターリーブ形式の視覚クエリ
適応的なプロセシングに対応する、インプットに依存する状態変数パラメータ
長尺動画を、高い情報量を凝縮した短いトークンシーケンスに効率的に圧縮する性能
EgoSchemaベンチマーク上での検証において、BIMBAは動画の質問回答タスクに際して最も重要となるパートの抽出で卓越した強みを見せました。定性的なアウトプットにおいても、特定のクエリに対して関連するセグメントを精度高く検出していることが実証されました。
LLoVi: 長尺向けVideoQA用のLLMフレームワーク
LLoViフロンティアは、長尺動画に対するQ&Aに対してシンプルながら非常に有効な、以下の2ステップから成るワークフローを提供します:
ステージ1: ビデオプロセシング
長尺ビデオから複数の短いクリップ映像を抽出する
各クリップに対してキャプションを付与する
時間記述の流れの順序をそのまま保持する
ステージ2: 質問への回答(Q&A)
時間順に並べられた時系列キャプションをLLMへインプットする
革新的な2周回の要約プロンプト(Summarization Prompt)を使用する
複雑な問いに対する推論回答の品質を高める
EgoSchemaによる評価結果は、長尺動画コンテンツを取り扱う上でLLoViがいかに実用的であるかを示しましたが、Bertasius教授は、このモデルが映像よりもテキスト(言語)側で最大1,750倍多いパラメータを使っている点に言及し、処理効率性や元映像に含まれていた情報の劣化について問題を提起しました。
テキストだけに依存しないアプローチへの回帰
Bertasius教授は、映像そのものを純粋に言語だけで表現することの限界を強く語り、テキストでの解説や短文サマリーだけでは、本来の動画に存在する芳醇な情報資源を劇的に失わせていると注意喚起しました。
BASKET: 高解像のスキル評価データセット
こうした制約を取り払うために、本講演では「BASKET」と呼ばれる、単なる言語の説明を越えた、高解像度の運動性能や技能評価に焦点を当てた新しい包括データセットを紹介しました。これ以下のデータが含まれます:
累計4,400時間以上の映像データ
4大陸にわたる30カ国以上から収集された32,232人のプレーヤーデータ
バスケットボールにおける20種類の精緻なスキル区分
1人のプレーヤーにつき8〜10分の動画ハイライト集
評価スポーツとしてバスケットボールが選ばれた背景には、いくつかの明確なメリットがあります:
4億人以上の世界的なファン層を持つ普及性
多様な国の参加者がいること
豊富な既存ビデオ映像素材へのアクセシビリティ
時間情報を追うモデルを要する、非常に複雑で微量なスキルアクション
よく似たユニフォーム・アピアランスの競技者を識別するための精微な視覚アライメントが必要とされること
検証結果:
現在最高峰とされる最新鋭のAIベースモデルでも、ハイレベルなスキルの高精度な評価には及ばない
本テストにおいて正解率30%に達したモデルは皆無であった
動画の高度な全推論理解において、人間の能力と現状のAIの間にまだ絶望的なギャップがあることが鮮明に確認された
結論・今後の展望
LLMを土台とした動画読解能力は飛躍的に進化しているが、これを言語フォーマットに翻訳しにくいタスクに対しては、これまでの言語メインの基盤やインターネット由来の大量のビデオ・キャプションの恩恵が限定的になること
LLMの高すぎる対話力と古い試験評価法(ベンチマーク)が、実際の動画認識モデル自体の設計上の脆さを覆い隠してしまっている可能性があること
既存の評価尺度が必ずしも動画理解プロセスの難度をフルに測定できていない可能性
言語的な理解だけでなく、言語を介さない純粋に視覚的な認識をこなせる高性能アーキテクチャの併発が必須開発要素となる
3 - 現在のマルチモーダルビジアルモデルはどこまでスマートか? - Yong Jae Lee
ヨンジェ・リー(Yong Jae Lee)教授によるセッションは、既存の多様なモーダルを扱うビデオモデルのポテンシャルに対する一般的な見解に一石を投じる内容でした。コミュニティの関心がこぞって1時間を越えるような長尺に終始する中、Lee教授は最もシンプルな短尺(10秒未満)の動画であっても「時間の反実仮想プロセス」を処理する能力が極めて困難である点を強調しました。この探求心とその仮説は、「Vinoground」と「Matryoshka Multimodal Models(マトリョーシカマルチモーダルモデル)」という2つの歴史的成果に結実しました。
Vinoground: 時間推論に向けた新ベンチマークの誕生
画像ベースの多様な概念の構成関係を反実仮想的(Counterfactual)に突き詰めて試験する「Winoground」からヒントを得て、これを拡張してビデオの時系列向けに構築さたのがこのVinogroundです。先頭の「W」が動画を象徴する「V」へと文字遊びされています。動画の最大特性である、時の流れへの正確な推論能力へと焦点を向けています。
この試験検証データは、正確な動的把握をモデルに求めるために、幾つもの厳しい縛りを持って構築されています:
「たった数枚の代表フレームだけを見る」といったチート技術が適用できないように、シングルフレームの偏りを極限まで廃止して動画の連続性を重視する
テキスト文面の文字面だけの語順ルールからの類推を不可能にする(真の目の知能を求める)
全ビデオ素材に人工のシンセティックデータを使わず、自然な実写動画を採用する
アクションの前後を精確に整理し追える「順序推論能力」を求める
モデルにさらなる検証を課すため、動画ペアに対応する文面の説明テキストは「出現する英単語は全て同一であり、単語の配列(順序)のみが異なる」という厳しい構成になっています。好例として「男が女に話しかける前に、女に手を振った」対「男が女に手を振る前に、女に話しかけた」です。これにより、既存のAIが浅はかなパターンの類似性に溺れるのを許さず、時間経過の正確な動的事象を正確に捉えるモデルであるかをあぶり出します。
アプローチ・技術構築
この高品質キュレーション工程では、まずGPT-4を用いて時系列に反するダミーペア文面セットを自動生成しました。これに対し、Sentence Transformerや高速な探索を行うFAISSライブラリを活用しつつ、既存のVATEXライブラリを索引として活用することで、条件にマッチする最適なビデオとマッチングを施します。データベースに適当な事例が見つからない場合は、YouTubeを直接捜索してフィットする実写映像を引き当てました。
本ベンチマークは丁寧に選び抜かれた500の映像とテキストのセットから成り、以下を含みます:
行動、オブジェクト、名詞が同じ場合の時系列的対比(例:「男は食事をしてからテレビを見た」対「男はテレビを見てから食事をした」)
物体の形態や状態が変化する変換プロセス(例:「水が氷になる過程」対「氷が水に溶ける過程」)
対象物の位置関係の知能を問う空間ダイナミクス
多層評価のための分析フレームワーク
正確な分析を提供できるよう、測定時には異なる3つのスコアを使用します:
テキストスコア:テキスト上の僅かな構成の相違をモデルが理解できているかを測る指標
ビデオスコア:視覚的に何が起きているかを識別しているかを測る指標
グループスコア:全体のタイムライン情報を統合して理解したかを判定する指標
Matryoshka Multimodal Models (M3: マトリョーシカマルチモーダルモデル)
次に披露された大きなイノベーションが、既存の最先端AIがトークンに溺れてしまっている問題への対処法です。視覚特徴を切り出した際のトークン数が過剰であるがために、ビジョン言語モデル(LMM)の駆動コストが高騰するばかりか、最たる要所への注目度(Attention)が分散、低下していました。これに対するアンサーとして登場したのが、このMatryoshka Multimodal Models(M3)です。
アーキテクチャの特徴
M3の構造の仕組みは美しくシンプルのひとことです。異なるスケールの視覚トークン群に対し、並行して生成ロス(Loss)の平均値を一括処理して学習を行います。プーリングを用いて粒度の階層化(粗い解像度から、きめ細かな解像度まで)を設定し、入れ子状に入れ込まれたデータを入れ替えて使用することができます。
システム側の利点
これは以下のような実用的なメリットを生み出します:
極力通常のLMM設定および学習データを使用するため余分な学習コードや調整が要らず、余分なスケール専用の空間エンコーディング機構の初期立ち上げも省くことができます。また、分析制御性が高まり、実行推論時においてインスタンス単位で視覚データのきめ細かさの粒度を自律調節できる点が魅力です。最後に、データセット検証機として働くため、古いCOCOのようなシンプルなタスクでは576枚もあるトークン中、実はたった「9枚」程度のビジョントークンさえあれば十分に既存と同様のクオリティを出せることが実証され可視化されました。
実証成績
MMBench等での負荷テストで、幾つもの重大な事実が確認されました。例えば、本設計(M3)を「LLaVA-1.5-7B」に施したモデルは、特定スケールだけで固定学習したモデル群対比で同等以上の実力をマークしながら、要求するリソース(学習資源)を格段に減少させています。最も目覚ましい点は、わずか9枚のトークンしかないM3が、InstructBLIPやQwen-VLといった巨頭モデルを上回ったデータです。
実タスクでは、余分なビジュアルトークンはむしろ弊害を生むことがわかっています。検証した6つのメインタスク中、4領域において720〜180トークンで制御した方が、全マックス容量を投入するよりも高い精度を叩き出しており、過多なシグナル情報が生成推論において「単なるノイズ」となっていた仮説が裏付けられました。ActivityNet、IntentQA、EgoSchemaに至っては、画像の1グリッドからたった9箇所(合計わずか45トークン)を使うだけで、2880トークンの全負荷使用時とわずか1%未満の成績の差に踏み止まりました。
業界への影響と今後のマイルストーン
本セッションはAIモデルが抱える動画分析分野でのリアルな実像を炙り出しました。一見輝かしい成果を出しているように映る近代モデルたちですが、未だ人間の持つ深い時系列認識とは乖離があります。Vinogroundの結果は、短い単純動画に仕組まれたわずかな前後情報の変化ですら、最先端AIの前に立ち塞がっている現実を物語ります。しかし一方でM3は、視覚データの無駄を省いた「ミニマルな情報設計」が、力任せな超大容量インプット以上に有効となり得ることを確証する、未来の光明を投げかけています。
4 - MovieGen: 動画創出に挑む最高峰のビデオ基盤モデル - Ishan Misra
イシャン・ミスラ(Ishan Misra)氏の登壇では、Metaが総力を挙げるMovieGenプロジェクトについて解説されました。テキストプロンプトをインプットに、一貫性のある動画へ落とし込む課題に対する最先端ソリューションです。その裾野はアマ作家のSNSクリエイティブワーク、部分動画エディット、映画クオリティのアニメ、リアルシミュレーション、さらにはハリウッド規模のビッグメディア生産ラインにまで及びます。
動画生成の進化史
セッションの幕開けとして、歴史上の動画生成モデルのタイムラインを一望することで、MovieGenがこれまでの開発遺産を土台にいかに急加速して成長してきたかが紹介されました。過去の歩みをたどることで、単純なパターン合成から、物理法則・ストーリーの一貫性を追求した生成モデルへいかに進化したかが浮き彫りになります。
動画生成における核心的テーマ
これまでの映画モデル生成には、取り払うべき多くの壁がありました。第一は、次元が著しく低い単なる「文章入力(テキスト)」から、圧倒的な情報密度の差がある「高画質映像データ」へと次元変換する処理。第二は、数秒から数十秒までの時間に渡り、同一アクターや周辺環境の破綻をなくして連続性を担保し続ける安定性。第三は、凄まじい計算能力とストレージ使用量を要する中で、実行処理ロスを減らし全体のパイプラインをスリムに仕上げるハード面の課題です。
アーキテクチャの革新
1. システム形態
MovieGenのアーキテクチャ設計は、従来の概念を一段階超えるものです。テキストプロンプトに内包された情緒や複雑な命令要件を逃さず、エンコーダーが細部に至る意図を捕捉する仕組みが追加されています。土台にはLLaMA系トランスフォーマーブロックが採用され、時系列データ展開向けに高度にチューンアップされているため、トレーニング中の破綻が極めて低く抑えられています。
最大のブレイクスルーが「潜在特徴(Latent)圧縮」のアプローチです。MovieGenは、高さ・幅および時間を考慮した次元比を維持しながら最大で「8倍」に凝縮し、これによって全体の配列シークエンスの長さに対しては実質「512分の1」という超圧縮を実現しました。この機能は画像や動画像といった媒体に関係なく等しく適用可能であり、多様なサイズの配列を破綻を抑えたまま処理可能にします。
2. トレーニング手法
モデル本体には、拡散(ディフュージョン)トランスフォーマー(DiT)向けのスケーリング、および各種シフト変数に変更を施した改良版LLaMAブロックを採用しています。これによって全体の拡大トレーニング時における安全度(ロバストネス)が生まれ、静止画と動画の両方の素材パラメータを完全に同一プロセスで一括同時処理し、固定コンポーネントを配置する手間を排除しました。エンドツーエンドの一貫アプローチのおかげで、モデルは静的な画像でも、動的なクリップでも一貫した理解を獲得しています。
3. 「Flow Matching(フロー・マッチング)」技術
本論文においても特権的な技術とされるのが、従来のディフュージョンの代わりとなる独自のフロー・マッチングの実装です。数式上は「v-prediction」に近似しているものの、多数の明白な技術優位性をもたらします。拡散モデルで見られるような「確率的な微分方程式(SDE)」の求解を迫られる代わりに、フロー・マッチングは一貫性のある「常微分方程式(ODE)」を解く形式のため、推論回路が軽量かつシンプルになります。自然と「端末シグナル対雑音比ゼロ」特性が得られ、生成映像のクオリティおよび推論動作スピ―ドが格段にスピードアップしています。
データ・スケールの探求
MovieGenの開発プロセスには、データスケールと演算の最大化に向けたエンジニアの凄まじい労力が詰まっています。約1億個にのぼる長短様々のビデオ映像アセットに加え、10億枚クラスの画像データセットが使われ、モデルの汎化能力を最高潮にまで高めています。また、動画用の一貫キャプション自動作成用に「LLaMA-3」を導入。これによりプロンプト命令の忠実度が高まりました。
MovieGen Bench:真価を問うテストスイート
Meta開発チームは、従来の検査アセットに勝る大規模な評価体系であるMovieGen Benchを新規リリースしました。このコレクションは一部の優れた結果だけを集めた、いわゆる「チェリーピック(手加減)」なしの実ビデオ1,000アセットで構築され、GitHubでパブリック公開されており、従来ベンチ比で約3倍のスケールを持ちます。この計測において「バリデーション誤差」と「実際の人間側のクオリティ評価」が良いシグナルで同期しており、指標の再現性が担保されているのが特徴です。
データ結果とその先の未来
測定された実データからは、いくつかの重要なファクトが浮き彫りになりました。全体のクオリティ、および現実世界に近いシミュレーション能力(リアリティ)の両部門でトップマークに近い結果を記録し、特に実写を模したテキスト・トゥ・画像の合成能力で並外れた進歩を見せました。また、最もエキサイティングな洞察として「動画生成モデルの成長スケーリング則(Scaling Laws)が、LLaMA-3で辿った変遷と全く同一の成長パスを描き続けており、未だ飽和点に達していない」ことが究明されました。
しかしMisra氏は、MovieGenがどれだけ素晴らしくとも、未だ人間レベルの高度な物理干渉や認知のすべてを内包して出力する段階には及ばない領域もあること、世界の深い因果の般化については現在も検証中の部分が多いと、オープンかつ有益な総括でプレゼンを締めくくりました。
5 - マルチモーダル・自律型アクションモデルへのパス - Jianwei Yang
ジェンウェイ・ヤン(Jianwei Yang)氏のセッションは、既存AI開発における「認識(純粋な動画コンテンツのパッシブな理解)」のみに偏重した姿勢を揺さぶり、自律的で主体的(Agentic)なアクションをこなせる相互連携の必要価値を訴えました。「過去を理解すること」と「未来に向けて的確に動作を生成すること」の両輪をこなせる、マルチモーダルなビデオ認識をベースとしたWebエージェント、先端ロボ、完全自動操縦向けのロードマップが力強く提唱されました。
過去を捉える:より強化された空間アライメント認識
Florence-VL: 表現を極めた視覚統合LMM
Florence-v2は、テキスト指示に同期して動く視覚ジェネレーティブAIにおいて大きな金字塔となっています。特徴的な空間ピクセル情報の種類に応じて多様なプロンプトの出し分けを行い、複雑なイメージ情報をパズルをパズルのピースを埋めるようにより強固に再構築します。この特徴変換時におけるアライメントロス(ビジョン側とLLM側の損失)を緻密に測定することで、システムは定量的な分析を強められます。
OLA-VLM: 多層特徴のダイレクト統合
OLA-VLMは、画像が宿す深いエッセンスを取りこぼさないために、1つのソース画像につき異なる3つの個別特徴チャネルを使用して、マルチモーダルLLMの表現能力を最大化します:
対象間の奥行き情報を示す、高精度な「デプス特徴(Depth features)」
輪郭・領域をしぼる「セグメンテーション特徴」
画像をより豊かに視覚表現するための「Unclip-SD特徴」
研究チームは、テキストを用いた十分な監督学習が、画像知覚に必要な中間特徴を格段に豊かにすることを突き止めました。さらに「教師役(Teacher)」となるハイスペックモデルから、LLM側の特徴空間へと直接パラメータ最適化(指導)を行わせることで、さらに完成度を安定させています。
動きの細部に切り込む:ミクロな時間ダイナミクス評価
TemporalBenchプロジェクトは、動画理解における根本要素に挑戦します。映像とは個々のフレームの集積ではなく、きわめて綿密な時間軸のアクション変化(ダイナミクス)そのものである、という点です。この評価ベンチマークにより、ビデオモデルが僅かな動作変化を見通せているかを詳細に検証することが可能になります。
これと対をなす「ProLongVid」と呼ばれる研究では、以下の「成長拡大の2次元軸(スケーリング)」にスポットを当てました:
命令合成プロセスにおけるビデオ実データの「長さ(時間の拡張)」:長時間の長い流れを見落とさないためのトレーニング
学習・推論中の「コンテキスト長(Context Length)」の引き上げ:ストーリー全体の文脈を一挙にモデルが見失わないようにする改良
未来に向けて動く:主体的(Agentic)な自律行動を促す動画AI
TraceVLA: ビジュアルトレースプロンプティング
TraceVLAは、ロボティクスのポリシー(制御)において時空間情報を持たせるための優れたインサイトを提示します。「これまでの行動経緯(インプットの過去)をモデルが精密に反芻することで、次に引き起こすアクション(未来予測)がより正確になる」という合理的な仮説に基づいています。この機構は、現在のマルチモーダル変換においてよく起こるいくつかの摩擦を取り除きます:
複数画像を一堂に送り込むと、切り出しトークンの量が劇増して動作スピードが著しく鈍化する一方、一般的なビジュアルエンコーダーは連続するフレーム間の小さなズレやミリ単位の差分(オプティカル・フロー)を高精度に評価できないこと。
テキストプロンプト(記述による指示)は簡単ではあるものの、物理空間上のきわめて高精度な移動ベクトルやピンポイントの静的座標の指定には力及ばないこと。
この障壁に対し、視覚的なインジケータ(プロンプトマーク)に直接作用させる画期的な「Set-of-Markプロンプト」を採用することで、現在の観測値と過去の行動軌跡との間のつながりをモデル内にシームレスに確立します。
LAPA: 言語無きビデオからアクションの「事前能力」を引き出す
LAPAは、アノテーションされていないありのままの大規模動画から、スマートにロボット関節コマンドや環境運動に必要な基本能力をプリトレイン(学習)させておく革新的な手法です。アクションコマンドがラベル付けされていないロボットデータや、一般的な人間向けのレクチャー動画(How-to動画)の両方を効果的に活用して学習します。「sthv2データセット」を用いたテストでは、ゼロからトレーニングをかけた従来のアプローチを圧倒するパフォーマンスを叩き出したものの、最初からロボ機器特化データだけで仕込んだプロフェッショナルな挙動比では若干の性能差を残し、今後に向けての課題を示しました。
MAGMA:運動神経を宿すマクロ自律基盤AI
MAGMAは、動的画像をベースとするスマートシステムの中枢となるために、実質的な画像群・動画像群・ロボ操縦ログデータを横断して構築されました。「見る(理解)」と「動く(行動)」の相互作用にこだわり、時間の動きに特化した監視方法(Temporal Motion Supervision)やアクション出力変換を備えます。仕込まれたタスク設定はロボの歩道パス(Trajectory Planning)、およびこれに伴う新環境での柔軟なタスク適応(般化)といった創発的挙動を引き出すべく綿密に組まれています。
「アクティブ・エージェント(主体的知能)」の定義更新
Yang氏はセッションの結びに、マルチモーダルAIエージェントの定義を新たに再定義して宣言しました:「AIエージェントとは、自律的に周辺環境を検知かつ作用して、設定されたゴール(目標)の達成をこなせる主体であり、絶え間ない試行錯誤と蓄積知識(世界の経験値)を用いて日々自己の実行タスクパフォーマンスを高めていける組織体のことである。」この定義には最も主要となる3ファクターが組み込まれています:
エージェントが2次元画面の「ピクセル認知」を越え、奥行きや障害物の立体的な「3次元座標認識(3D)」へ覚醒することの必要性
主体を開発する中で、モデルフリー手法(対症療法的な動作)と、世界モデル構築(物理因果モデルを用いた先回り思考)をいかに高いレベルで融和させるか
単なるトリガー応答を越え、何手先まで計算して進む「プランニング推論」をシステムに宿すことの重要性
今後越えるべき障壁・課題
Yang氏は、映像素材が隠し持つ膨大なデータ資産を引き出すためにも、スケーリング則をさらに推し進めたスケールアップへのこだわりが必要不可欠だとしました。次に向かうべき主要ロードマップとして以下を掲げました:
マルチモーダル自律行動特性(Agentic):さらに高度なロボ制御と干渉
マルチモーダル推論演算(Reasoning):バラバラなマルチモダリティから正確な理論を組み立てる脳の構築
マルチモーダル統合理解(Understanding):混沌とした外界情報からの精度の高いシーンコンテクスト把握
マルチモーダル自己理解(Self-Awareness):現在のモデルの認知レベルを客観視し不確実な判断を自律調整するメタ認知力の獲得
登壇の最後においてもっとも客観的なファクトとして、ビジョンAIが近年劇的に性能を高めていることは認めつつも、「人間の持つ高度な物理運動および思考には及ばないこと。高ダイナミクス映像、ディテールの不変性、時間秩序に関しては、潤沢なインターネット上の生データ対比で、本当の意味でクリーンな動画・テキストペアの蓄積が極端に足りていないことが現状のボトルネックの一つである」と警告しました。
6 - 動画生成基盤から、宇宙をシミュレートする本物の世界モデル(World Models)へ - Doyup Lee
ドユプ・リー(Doyup Lee)氏は、Runwayがこれまで重ねてきた動画生成開発のプロセスを踏まえ、私たちが次に突き進むべき「General World Models(一般世界モデル)」への壮大なパスを語り、その根底にある核心的ロマン「いかにして自律知能は物理世界を目を通じて正しく認識し得るか?」を説き起こしました。Runwayが誇る高度な動画生成テクノロジーの蓄積されたノウハウを交えた、AIにおけるビジュアル認識と想像力の関連性を探究するセッションです。
視覚的知能の本質を読み解く
Lee氏は、我々がいう「視覚認識(見る力)」とは何かという点について、世界モデルのシミュレーション能力および人間の「想像力(Imagination)」との深い結びつきを通じて論じました。彼はHa & Schmidhuber(2018)による世界モデルに関する代表論文を引用し、当時の成果が特定のシミュレーター環境内部などの閉じた世界においては高い予測精度をマークした一方で、現実の複雑で不確実な実世界での適用に苦慮した点を回顧しました。従来のビデオ認識手法、例えば画像の解説テキスト化、視覚Q&A(VQA)、特定エリア分割(Semantic Segmentation)などは、基本として人間の定義した言葉(ラベル名)と物体の関連付けに終始しており、取り込める世界の深い真実の一端を拾い損ねている限界を説きました。
プラトン的表現仮説(The Platonic Representation Hypothesis)
Lee氏がプレゼンの理論基盤としたものに「プラトン的表現仮説(Huh et al., ICML 2024)」があります。これは視覚認知としてAIが満たすべき以下の3つの絶対要素を明快にしたものです:
動画のタイムラインの展開(先、何が起こるか)について極めて高い予測変換能力を持ち、ダイナミクスを真に理解していること
世界の広大さを写し取った、かつ多様な、膨大の映像アセットに絶え間なくアクセスし学習に組み込めること
人間の持つ世界の概念構造や共通認識、行動期待とズレのないアライメント(整合性)をクリアしていること
汎用世界モデル構築に向けた『5つの極意』
1. 「苦い教訓(The Bitter Lesson)」への回帰
Lee氏は、AIの進化において有名な「苦い教訓(Bitter Lesson)」を今一度噛み締めることの重大さを語りました。大抵の場合、特定のルールや手仕事で最適化した専門の設計アプローチよりも、圧倒的な大容量計算リソース(Compute)と一般的な学習による拡大を信じた開発の方が最後にはすべてのタスクで卓越したパフォーマンスを収める、という法則です。この基本方針が、モデル開発における柔軟で無駄のない、スケーラブルな構成を生み出します。
2. 極めて高品質な、超巨大スケールのデータ素材
発表では、インプットデータが有する素材純度の僅かな違いが、モデル全体の学習効率と実用パフォーマンスを劇的に左右する事実がデータ付きで示されました。Lee氏は、アノテーションキャプションの品質を最高レベルに保つことで、画像および動画モデルの双方が著しい成績のブーストアップを記録することを示しました。しかし一方で、インターネット上の膨大なデータの山から、どうやって低コストで高品質な長尺キャプションタグ(詳細説明)を作り引き出すかは最大の難題であり、アノテーション工程のブレイクスルーが模索されています。
3. relational inductive bias(関係帰納バイアス)の無いスケーラブルアーキテクチャ
異なるデータ表現間に恣意的な関係性を規定しない、優れたモデル構造を選択すべきことが語られました。これに伴い、演算資源の経済的活用、および学習中の無駄を実証データに基づいて管理・予測するための「ニューラル・スケーリング則」の技術的解説がなされました。これにより、限度あるマシン(プロセッサ)リソースを無駄に食い潰すことなく、成長を設計通りに最大化できます。
4. 分散学習の極限スケール最適化
巨大プラットフォームを用いたマルチノードの並列事前学習においては、マシン全体の演算資源効率を示す指標「Model FLOPS Utilization(MFU: モデル使用演算率)」の最大化が最たる関心事になります。Lee氏は、全理論上の演算ポテンシャルのうち実際に何パーセントを高効率に引き出せているかがシステム最適化の主因であるとし、以下を含むディープなエンジニアリング施策を挙げました:
低精度(FP8/FP16等)演算のスムーズな実装、および演算の最大化
最適化を極めたカスタムCUDAカーネルの自社開発
高度なパラレリズム(並列化:データ並列、モデル並列、パイプライン並列等)の極地
ネットワーク遅延やマシントラブルをリアルタイムに回避する最先端クラスマネジメントシステム
5. 部門を超えたクロスファンクショナルなワンチーム統合
Lee氏は、ここまでの規模の最先端開発とはもはや一介のAI研究部門だけで到底なし得るものではなく、ハード・運用・データ・デザイン・クリエイティブのすべてが完全に連携した総合システムとして回る組織こそが勝機を見出すとしました。それぞれのフィードバックが無駄なく瞬時に交差する組織形態のガイドマップを共有しました。
Runway開発の次世代動画生成モデルたち
Gen-3 Alpha
Lee氏は、2024年6月にリリースされクリエイティブ業界震撼をもたらしたRunwayのGen-3 Alphaモデルを改めて提示深く掘り下げ。ユーザーのあらゆる細かな自然言語記述から、映画クラスの動的なシチュエーションを描き切る能力に秀でています。しかしながら、このGen-3の中にある、物理シミュレーション理解やコンセプチュアルな一般世界の予測モデル能力については、我々人間にとっても未だ分析段階のフロンティアであるとしました。
Runway開発部隊は、この巨大ビジュアル生成の奥深くを確かめるため、以下のような領域について分析研究を日々進めています:
現実世界を司る「物理的な重力や衝突法則」をモデルがいかに獲得して実行しているか
文字のフォント、崩れのない正確きわまる画像レンダリング限界
未知のイメージやキャラクター概念同士の混合描写力(概念の一般化)
思い通りの映像を描くための「直感制御コントロールツール」
Lee氏は、ただ出力するお祈り運搬式の生成ではなく、クリエイターが映像を自らの指先のように自在にコントロールするための優れた直感ツール群もお披露目しました:
イメージを特定のスタイル調に出発点を限定するキーフレーム設定(Keyframe conditioning)
既存シチュエーション・パイプラインにシームレスに入り込む生成VFXテクノロジー
3次元の立体的なパースを狂わせないで駆動するカメラワークコントローラー(3Dカメラ制御)
描いた部分の「動きの種類」や「スピード方向性」を指定ブラシで部分制御するモーションブラシ(Motion Brush)
画像構造やレイアウト指定に合わせるための構造化条件(Structural conditioning)
動画の領域外を拡張しシーンを書き足すアウトペインティング(Out-painting)
Act-One: 命を吹き込む表現のイノベーション
本発表の最も熱いピークにおいて実演されたのが、人物の演技、表情、魂ともいえるき微細なニュアンスを完全に再現・生成する仕組みである Act-Oneのハイレベルデモでした。Gen-3のモデル実力の上に乗る形をとり、人間のキャラクターアクターの演技、顔全体の躍動、心理描写を完全に模倣移転して、異なるキャラクターへと生成することを驚愕のタイムライン処理クオリティを達成しながら可能にしています。
ビジョンと今後のビッグ課題
リー氏はセッションの括りとして、私たち人間の知的世界を描写する絶対の不変メディアは「言語」と「映像」の双璧であるとしました。言語は全抽象世界のインデックス情報を有し、映像は無限に広がる全ビジュアル空間の膨大な実態シグナルを保持します。私たちはこれまでの比ではない圧倒的に膨大なデータを集積・活用して、本当の意味で現実世界およびそのインタラクション全体を包摂する真の世界モデルへ舵を切る準備ができているとして、Runwayが挑み続ける高みを示しました。
プレゼンは究極のフロンティアである、人間の定義・認識・想像力を一段回以上飛び越える、高次元の一般世界モデル(General World Models)の具現化という大いなる約束を持って幕を閉じました。我々はこの開発を以下の多軸から挑戦します:
最高のスケーリングとそれを耐え抜くモデルアーキテクチャの革新
データ合成とキュレーションのクオリティ革命
マシンの持てる全クロックを活用する驚異的な演算最適化
誰もをアーティストに変える、直感的かつ精巧な画風コントロール手法の拡張
プロの撮影シーン、インフラ、CGクリエイティブワークへのシームレスな統合
動画言語モデルの行く末:我々が共に見つめる視線の先へ
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップ(Video-Language Model Workshop)は、動画理解のエキサイティングな進化進捗と、未開のクリアされるべき課題の双方を劇的にあぶり出しました。業界で技術革新に挑むプレイヤーのひとりであり、本祭の企画・共同オーガナイザーでもあるTwelve Labs(トゥエルブラボ)は、この傑出したスピーカー陣が投げかけた鋭い洞察を大切に受け止めています。
浮き彫りとなった重要コアテーマ
ワークショップ中、いくつもの重要検討事項が会場を震わせました。ディマ・ダメン(Dima Damen)教授は一人称視点カメラから見たミクロな連続アクション(時間軸の微細ダイナミクス)の処理の価値を訴え、ゲダス・ベルタシウス(Gedas Bertasius)教授は文字依存の世界観を脱し「テキストフォーマットで定義しきれない純粋ビジュアル」を読み取るモデルの重要性を主張しました。ヨンジェ・リー(Yong Jae Lee)教授が見せた、ほんの10秒足らずのショートビデオに潜む反実仮想の僅かな時間情報の取り扱いでさえ、最新鋭のLLaVAやフロンティアモデルが軒並み苦汁をなめている事実は、大きな話題となりました。
またジェンウェイ・ヤン(Jianwei Yang)氏が見せた「体性を宿した能動アクションモデル(マルチモーダルエージェント)」と、イシャン・ミスラ(Ishan Misra)氏が率いたMovieGen開発による次世代生成ワークフローは、単なるテキスト記述を越えた先にある新しいエンタメの在り方、自動生産システムへの展望を一望させてくれました。さらにドユプ・リー(Doyup Lee)氏が宣言した「一般世界モデル」への歩みは、生成モデル自身がこの宇宙をシミュレートする本物の頭脳へと変革し得る偉大な可能性を裏付けました。
テック企業としての現状理解と私たちの歩む道
Twelve Labs(トゥエルブラボ)において、ここでの課題は私たちの開発実務での経験にこの上なく一致します。当社が長年磨き続けている超高性能動画特徴埋め込みモデルである「Marengo(マレンゴ)」や、映像を流暢なテキストコミュニケーションへと直結させるビデオ対話基盤LMM「Pegasus(ペガサス)」の開発は、まさに登壇した教授陣が説いたマルチモダリティの統合、極めて洗練されたタイムラインの追跡、極地を極めるデータフィルタリングとトレーニングの価値そのものから生まれ育ったプロダクトたちだからです。
ここで展開した白熱した議論は、我々が日々磨いている開発の羅針盤が正確であることを指し示しています:
動画の奥深さに多次元アプローチをかける「マルチベクトル(Multi-vector)埋め込み」テクノロジー
短い閃きのようなアクションから、大河ドラマのような長尺小説の流れまで破綻せずに記憶し処理する高度なタイムライン追跡設計
ピクセル特徴(Visual)、環境情報、セリフや会話・歌(Audio)、そして物語の文字コンテキスト(Text)を美しいハーモニーのようにひとまとめに対象化するマルチモーダル統合処理
これまでの画一的な言語ベースの試験測定を越え、モデルに真の知恵を強烈に問う次世代のロバスト評価指標の創出
未来へ向かう最高の青写真
動画と言語モデルが融和して進化を遂げた先にある世界は、圧倒的な希望に満ち溢れています。私たちはこれから先:
より深く複雑な劇中ストーリー展開や、裏を読ませるような反実仮想を含む時間推論を完全にマスターするビデオ認識脳
社会常識、物理ルール、および人間としての道徳観といった、私たちの持つ「現実の教養」を正しく内包した視覚ビジョン能力
長尺を扱うモデル動作コストを最小限に抑え抜きつつ、最初から最後までの時間連動力を高精度に維持できる洗練された高効率トランスフォーマー設計
最先端を追い求める学会・大学研究の知恵と、実際のスケーラビリティ処理を背負うインフラ実業界(エンタープライズ)との間のこれまでになく太い連携
このワークショップは、学界と産業界双方のエキスパートたちが一堂に会し、こうした数々の野心的な技術的障壁に対して「チーム一体」となって立ち向かうための大きな第一歩となります。これまでの自負、常套手段を越え、真に私たちが目を惹かれる知能システムの誕生を目指し、Twelve Labsはこれからも開かれたテクノロジーコミュニティを愛し、責任ある行動と絶え間ない実験開発を惜しみません。
ここから始まる道のりは険しく、しかしワクワクする発見に満ちています。本日を彩った最高の頭脳たちの知見をバトンに、アカデミズムとビジネスが手を携えて進むことで、この先のビデオ言語モデルが我々の暮らしを、そして「私たちがこの現実世界をどのように知覚し、繋がり、高めあうか」を劇的にアップグレードしてくれる日の到来がより早く、かつ確かに近づいてくるのです。
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップは、急速に進化を遂げる動画の理解と生成という分野において極めて重要な契機となりました。冒頭の挨拶では、当社CTOのエイデン・リーが、動画理解(ビデオからテキストへの変換)と動画生成(テキストからビデオへの変換)という2大重要領域を横断して盛り上がりを見せる、ビデオ言語モデルへの関心の高まりを強調しました。
これらの技術は、コンテンツ制作や広告、ヘルスケア、ロボティクスなど、多岐にわたるセクターで応用されています。視覚と言語を統合するビジョン言語モデルの研究は指数関数的な成長を見せているものの、この分野は未だいくつかの重大な課題に直面しています:
特に高品質な動画とテキストのペアにおけるデータ不足
動画の保存および処理におけるスケールと複雑性の問題
視覚、音声、テキストといった複数モダリティの統合における課題
ビデオと言語のアライメントのベンチマーク測定および評価の難しさ
当ワークショップは、多様な研究者を一堂に集めて、現在の障害について議論し、開かれた共同研究を促進し、現実社会で応用できる動画基盤モデルの開発を加速させることを目的として開催されました。
1 - 一人称(エゴセントリック)視点の動画と言語の理解 - Dima Damen
ディマ・ダメン(Dima Damen)教授による包括的な解説では、一人称視点動画と言語の理解における4つの最先端のアスペクトを探究しました。教授の研究はEPIC-KITCHENSデータセットから着想を得ており、画期的なアプローチをいくつも導入しています。
類似のアクションに対するユニークなキャプション記述
ACCV 2024で最優秀論文賞を受賞した論文「It's Just Another Day(いつもと変わらない日常)」は、動画キャプション作成における根本的な課題、すなわち、既存の手法が類似する複数のクリップを独立して処理した際に全く同じキャプションを生成してしまう傾向に対処するものです。
この研究の根底にある重要な知見は、「日常生活は繰り返しであっても、類似したアクションに対しては異なる説明が必要である」ということです。研究チームは、以下の特徴を持つ「識別プロンプトによるキャプション生成(CDP - Captioning by Discriminative Prompting)」と呼ばれる斬新なアプローチを提案しています:
クリップを個別に切り離して見るのではなく、連動させて評価する
識別プロンプト群を活用して他と異なる固有のキャプションを生成する
ビデオからテキスト、およびテキストからビデオへの双方の検索評価指標を用いて評価を行う
この手法は、Ego4Dからの一人称視点動画とタイムループ映画という2つのドメインで評価されました。CDPをLaViLa VCLMキャプショナーに適用したところ、意味論的な正確性を維持したまま、生成されるキャプションの独自性が大幅に向上しました。
言語を用いたドメイン般化
主要な成果として挙げられるのが、シナリオや場所を横断した「行動認識般化(Action Recognition Generalization)」に特化して構築された初のデータセットであるARGO1Mデータセットです。このデータセットには以下の特徴があります:
60の行動クラスをカバーする105万個の行動クリップ
13の異なるロケーションからの録画データ
標準仕様としての10秒間のクリップ尺
同論文「What can a cook in Italy teach a mechanic in India?(イタリアの料理人はインドの整備士に何を教えられるか?)」では、以下の2つの主要な再構成技術を利用する相互インスタンス再構成(CIR - Cross-Instance Reconstruction)を導入しています:
テキストでのナレーションを利用した動画とテキストの関連付け再構成
行動クラス認識のために訓練された分類の再構成
CIRは複数の異なるシナリオや場所における行動を加重結合して表すことで、堅牢なクロスドメイン般化を可能にしています。
手とオブジェクトのインタラクション指示参照
HOI-Refプロジェクトは、一人称視点画像における手とオブジェクトのインタラクション指示(HOI: hand-object interaction referral)に適した洗練されたモデル「VLM4HOI」を導入しました。このモデルのアーキテクチャには以下が含まれます:
画像処理に対応するビジョンエンコーダー(g)と投影レイヤー(Wφ)
言語モデルの埋め込み空間との統合
両手およびインタラクションが発生した対象物の双方を同定する能力
研究チームは、390万問の質問回答ペアを収録する包括的なデータセット「HOI-QA」を開発しました。これは以下に焦点を当てています:
手とオブジェクトの空間認識および指示参照
手とオブジェクトのインタラクションに関する理解
直接的参照(Direct Referral)とインタラクションを介した参照(Interaction Referral)性能の対比
オーディオと言ジュアルのセマンティック統合
このセクションでは、本分野に対する2つの重要な貢献が発表されました:
EPIC-SOUNDSデータセット
この大規模データセットは、EPIC-KITCHENS-100の一人称視点ビデオから音声アノテーションを抽出したもので、以下の特徴を備えています:
検知可能な音声イベントや行動を捉えた75,900件のセグメント
44個の異なる行動クラス
物体の衝突音に対する詳細な材質別アノテーション
聞き取り分け可能な音声セグメントに対する時間軸ラベル付け
TIM (Time Interval Machine)
TIMは、長尺動画中において音声イベントと視覚イベント間で時間的な広がり(長さ)が異なるという問題に対処する、画期的な技術を提示します。主な機能は以下の通りです:
モダリティ固有の時間区間(Time Interval)を処理するトランスフォーマーエンコーダー
特定の間隔およびその周辺のコンテキストの双方に対応するアテンション機構
複数のベンチマークにおいてState-of-the-Art(最高水準)を誇るパフォーマンス
このモデルは以下に示す驚異的な結果を達成しました:
EPIC-KITCHENSにおける上位1位(top-1)行動認識の正確性を2.9%向上
Perception TestおよびAVEデータセットにおける卓越したパフォーマンス
高密度でマルチスケールなインターバルクエリを用いた行動検出への適応化に成功
これら一連の進歩は、特に視覚・テキスト・音声の複雑な関係性の相互処理において、一人称視点の動画コンテンツを理解し処理する能力が大きく進歩したことを一貫して示しています。Dima教授の研究グループによるプロジェクトは、一人称動画理解におけるマルチモダリティ統合の課題解決に向けた、包括的なフレームワークを提示しています。
2 - 言語と映像を用いた高難度ビデオ理解 - Gedas Bertasius
ゲダス・ベルタシウス(Gedas Bertasius)教授は、高度な動画理解タスクにおけるビデオ言語モデル(VLM)の目覚ましい進歩と同時に、現在の限界についても光を当てました。LLMやVLMのおかげで動画理解が大幅に向上したことを受け入れつつも、近代的なVLMが未だ複雑な動画の意図や文脈の正確な読解という点においては、依然として根本的な課題にぶつかっていることを指摘して警告しました。
長尺ビデオの理解における問題の解消
最も重要な技術的課題の1つとして挙げられたのが、現在のモデルが長期の動画シーケンス全体から関連性の高いコンテンツがどこにあるかを特定(局所化)するのに手を焼いている点です。Bertasius教授は、動画内の長距離にわたる相互関係を効率的にモデリングする優れた手法として「構造化状態空間モデル(S4: Structured State-Space Models)」を挙げました(こちらの研究やこちらの研究に示されています)。ただし、S4モデルへの入力トークンごとにパラメータが固定されているため、シーケンス(一連の流れ)の特定の場所にピンポイントに注意を向けるようなタスクを苦手としている点を指摘しました。
BIMBA: セレクティブスキャン圧縮
BIMBAは、動的に(データに依存する形で)隠れ状態にどのインプット情報を残すかを選択する選好スキャンアルゴリズム(別名Mamba)を取り込むことで、こうした制限に対処します。このモデルには以下の特長があります:
双方向の選択型スキャン機構を活用した時空間トークンセレクター
精緻なコンテンツ選択を可能にするインターリーブ形式の視覚クエリ
適応的なプロセシングに対応する、インプットに依存する状態変数パラメータ
長尺動画を、高い情報量を凝縮した短いトークンシーケンスに効率的に圧縮する性能
EgoSchemaベンチマーク上での検証において、BIMBAは動画の質問回答タスクに際して最も重要となるパートの抽出で卓越した強みを見せました。定性的なアウトプットにおいても、特定のクエリに対して関連するセグメントを精度高く検出していることが実証されました。
LLoVi: 長尺向けVideoQA用のLLMフレームワーク
LLoViフロンティアは、長尺動画に対するQ&Aに対してシンプルながら非常に有効な、以下の2ステップから成るワークフローを提供します:
ステージ1: ビデオプロセシング
長尺ビデオから複数の短いクリップ映像を抽出する
各クリップに対してキャプションを付与する
時間記述の流れの順序をそのまま保持する
ステージ2: 質問への回答(Q&A)
時間順に並べられた時系列キャプションをLLMへインプットする
革新的な2周回の要約プロンプト(Summarization Prompt)を使用する
複雑な問いに対する推論回答の品質を高める
EgoSchemaによる評価結果は、長尺動画コンテンツを取り扱う上でLLoViがいかに実用的であるかを示しましたが、Bertasius教授は、このモデルが映像よりもテキスト(言語)側で最大1,750倍多いパラメータを使っている点に言及し、処理効率性や元映像に含まれていた情報の劣化について問題を提起しました。
テキストだけに依存しないアプローチへの回帰
Bertasius教授は、映像そのものを純粋に言語だけで表現することの限界を強く語り、テキストでの解説や短文サマリーだけでは、本来の動画に存在する芳醇な情報資源を劇的に失わせていると注意喚起しました。
BASKET: 高解像のスキル評価データセット
こうした制約を取り払うために、本講演では「BASKET」と呼ばれる、単なる言語の説明を越えた、高解像度の運動性能や技能評価に焦点を当てた新しい包括データセットを紹介しました。これ以下のデータが含まれます:
累計4,400時間以上の映像データ
4大陸にわたる30カ国以上から収集された32,232人のプレーヤーデータ
バスケットボールにおける20種類の精緻なスキル区分
1人のプレーヤーにつき8〜10分の動画ハイライト集
評価スポーツとしてバスケットボールが選ばれた背景には、いくつかの明確なメリットがあります:
4億人以上の世界的なファン層を持つ普及性
多様な国の参加者がいること
豊富な既存ビデオ映像素材へのアクセシビリティ
時間情報を追うモデルを要する、非常に複雑で微量なスキルアクション
よく似たユニフォーム・アピアランスの競技者を識別するための精微な視覚アライメントが必要とされること
検証結果:
現在最高峰とされる最新鋭のAIベースモデルでも、ハイレベルなスキルの高精度な評価には及ばない
本テストにおいて正解率30%に達したモデルは皆無であった
動画の高度な全推論理解において、人間の能力と現状のAIの間にまだ絶望的なギャップがあることが鮮明に確認された
結論・今後の展望
LLMを土台とした動画読解能力は飛躍的に進化しているが、これを言語フォーマットに翻訳しにくいタスクに対しては、これまでの言語メインの基盤やインターネット由来の大量のビデオ・キャプションの恩恵が限定的になること
LLMの高すぎる対話力と古い試験評価法(ベンチマーク)が、実際の動画認識モデル自体の設計上の脆さを覆い隠してしまっている可能性があること
既存の評価尺度が必ずしも動画理解プロセスの難度をフルに測定できていない可能性
言語的な理解だけでなく、言語を介さない純粋に視覚的な認識をこなせる高性能アーキテクチャの併発が必須開発要素となる
3 - 現在のマルチモーダルビジアルモデルはどこまでスマートか? - Yong Jae Lee
ヨンジェ・リー(Yong Jae Lee)教授によるセッションは、既存の多様なモーダルを扱うビデオモデルのポテンシャルに対する一般的な見解に一石を投じる内容でした。コミュニティの関心がこぞって1時間を越えるような長尺に終始する中、Lee教授は最もシンプルな短尺(10秒未満)の動画であっても「時間の反実仮想プロセス」を処理する能力が極めて困難である点を強調しました。この探求心とその仮説は、「Vinoground」と「Matryoshka Multimodal Models(マトリョーシカマルチモーダルモデル)」という2つの歴史的成果に結実しました。
Vinoground: 時間推論に向けた新ベンチマークの誕生
画像ベースの多様な概念の構成関係を反実仮想的(Counterfactual)に突き詰めて試験する「Winoground」からヒントを得て、これを拡張してビデオの時系列向けに構築さたのがこのVinogroundです。先頭の「W」が動画を象徴する「V」へと文字遊びされています。動画の最大特性である、時の流れへの正確な推論能力へと焦点を向けています。
この試験検証データは、正確な動的把握をモデルに求めるために、幾つもの厳しい縛りを持って構築されています:
「たった数枚の代表フレームだけを見る」といったチート技術が適用できないように、シングルフレームの偏りを極限まで廃止して動画の連続性を重視する
テキスト文面の文字面だけの語順ルールからの類推を不可能にする(真の目の知能を求める)
全ビデオ素材に人工のシンセティックデータを使わず、自然な実写動画を採用する
アクションの前後を精確に整理し追える「順序推論能力」を求める
モデルにさらなる検証を課すため、動画ペアに対応する文面の説明テキストは「出現する英単語は全て同一であり、単語の配列(順序)のみが異なる」という厳しい構成になっています。好例として「男が女に話しかける前に、女に手を振った」対「男が女に手を振る前に、女に話しかけた」です。これにより、既存のAIが浅はかなパターンの類似性に溺れるのを許さず、時間経過の正確な動的事象を正確に捉えるモデルであるかをあぶり出します。
アプローチ・技術構築
この高品質キュレーション工程では、まずGPT-4を用いて時系列に反するダミーペア文面セットを自動生成しました。これに対し、Sentence Transformerや高速な探索を行うFAISSライブラリを活用しつつ、既存のVATEXライブラリを索引として活用することで、条件にマッチする最適なビデオとマッチングを施します。データベースに適当な事例が見つからない場合は、YouTubeを直接捜索してフィットする実写映像を引き当てました。
本ベンチマークは丁寧に選び抜かれた500の映像とテキストのセットから成り、以下を含みます:
行動、オブジェクト、名詞が同じ場合の時系列的対比(例:「男は食事をしてからテレビを見た」対「男はテレビを見てから食事をした」)
物体の形態や状態が変化する変換プロセス(例:「水が氷になる過程」対「氷が水に溶ける過程」)
対象物の位置関係の知能を問う空間ダイナミクス
多層評価のための分析フレームワーク
正確な分析を提供できるよう、測定時には異なる3つのスコアを使用します:
テキストスコア:テキスト上の僅かな構成の相違をモデルが理解できているかを測る指標
ビデオスコア:視覚的に何が起きているかを識別しているかを測る指標
グループスコア:全体のタイムライン情報を統合して理解したかを判定する指標
Matryoshka Multimodal Models (M3: マトリョーシカマルチモーダルモデル)
次に披露された大きなイノベーションが、既存の最先端AIがトークンに溺れてしまっている問題への対処法です。視覚特徴を切り出した際のトークン数が過剰であるがために、ビジョン言語モデル(LMM)の駆動コストが高騰するばかりか、最たる要所への注目度(Attention)が分散、低下していました。これに対するアンサーとして登場したのが、このMatryoshka Multimodal Models(M3)です。
アーキテクチャの特徴
M3の構造の仕組みは美しくシンプルのひとことです。異なるスケールの視覚トークン群に対し、並行して生成ロス(Loss)の平均値を一括処理して学習を行います。プーリングを用いて粒度の階層化(粗い解像度から、きめ細かな解像度まで)を設定し、入れ子状に入れ込まれたデータを入れ替えて使用することができます。
システム側の利点
これは以下のような実用的なメリットを生み出します:
極力通常のLMM設定および学習データを使用するため余分な学習コードや調整が要らず、余分なスケール専用の空間エンコーディング機構の初期立ち上げも省くことができます。また、分析制御性が高まり、実行推論時においてインスタンス単位で視覚データのきめ細かさの粒度を自律調節できる点が魅力です。最後に、データセット検証機として働くため、古いCOCOのようなシンプルなタスクでは576枚もあるトークン中、実はたった「9枚」程度のビジョントークンさえあれば十分に既存と同様のクオリティを出せることが実証され可視化されました。
実証成績
MMBench等での負荷テストで、幾つもの重大な事実が確認されました。例えば、本設計(M3)を「LLaVA-1.5-7B」に施したモデルは、特定スケールだけで固定学習したモデル群対比で同等以上の実力をマークしながら、要求するリソース(学習資源)を格段に減少させています。最も目覚ましい点は、わずか9枚のトークンしかないM3が、InstructBLIPやQwen-VLといった巨頭モデルを上回ったデータです。
実タスクでは、余分なビジュアルトークンはむしろ弊害を生むことがわかっています。検証した6つのメインタスク中、4領域において720〜180トークンで制御した方が、全マックス容量を投入するよりも高い精度を叩き出しており、過多なシグナル情報が生成推論において「単なるノイズ」となっていた仮説が裏付けられました。ActivityNet、IntentQA、EgoSchemaに至っては、画像の1グリッドからたった9箇所(合計わずか45トークン)を使うだけで、2880トークンの全負荷使用時とわずか1%未満の成績の差に踏み止まりました。
業界への影響と今後のマイルストーン
本セッションはAIモデルが抱える動画分析分野でのリアルな実像を炙り出しました。一見輝かしい成果を出しているように映る近代モデルたちですが、未だ人間の持つ深い時系列認識とは乖離があります。Vinogroundの結果は、短い単純動画に仕組まれたわずかな前後情報の変化ですら、最先端AIの前に立ち塞がっている現実を物語ります。しかし一方でM3は、視覚データの無駄を省いた「ミニマルな情報設計」が、力任せな超大容量インプット以上に有効となり得ることを確証する、未来の光明を投げかけています。
4 - MovieGen: 動画創出に挑む最高峰のビデオ基盤モデル - Ishan Misra
イシャン・ミスラ(Ishan Misra)氏の登壇では、Metaが総力を挙げるMovieGenプロジェクトについて解説されました。テキストプロンプトをインプットに、一貫性のある動画へ落とし込む課題に対する最先端ソリューションです。その裾野はアマ作家のSNSクリエイティブワーク、部分動画エディット、映画クオリティのアニメ、リアルシミュレーション、さらにはハリウッド規模のビッグメディア生産ラインにまで及びます。
動画生成の進化史
セッションの幕開けとして、歴史上の動画生成モデルのタイムラインを一望することで、MovieGenがこれまでの開発遺産を土台にいかに急加速して成長してきたかが紹介されました。過去の歩みをたどることで、単純なパターン合成から、物理法則・ストーリーの一貫性を追求した生成モデルへいかに進化したかが浮き彫りになります。
動画生成における核心的テーマ
これまでの映画モデル生成には、取り払うべき多くの壁がありました。第一は、次元が著しく低い単なる「文章入力(テキスト)」から、圧倒的な情報密度の差がある「高画質映像データ」へと次元変換する処理。第二は、数秒から数十秒までの時間に渡り、同一アクターや周辺環境の破綻をなくして連続性を担保し続ける安定性。第三は、凄まじい計算能力とストレージ使用量を要する中で、実行処理ロスを減らし全体のパイプラインをスリムに仕上げるハード面の課題です。
アーキテクチャの革新
1. システム形態
MovieGenのアーキテクチャ設計は、従来の概念を一段階超えるものです。テキストプロンプトに内包された情緒や複雑な命令要件を逃さず、エンコーダーが細部に至る意図を捕捉する仕組みが追加されています。土台にはLLaMA系トランスフォーマーブロックが採用され、時系列データ展開向けに高度にチューンアップされているため、トレーニング中の破綻が極めて低く抑えられています。
最大のブレイクスルーが「潜在特徴(Latent)圧縮」のアプローチです。MovieGenは、高さ・幅および時間を考慮した次元比を維持しながら最大で「8倍」に凝縮し、これによって全体の配列シークエンスの長さに対しては実質「512分の1」という超圧縮を実現しました。この機能は画像や動画像といった媒体に関係なく等しく適用可能であり、多様なサイズの配列を破綻を抑えたまま処理可能にします。
2. トレーニング手法
モデル本体には、拡散(ディフュージョン)トランスフォーマー(DiT)向けのスケーリング、および各種シフト変数に変更を施した改良版LLaMAブロックを採用しています。これによって全体の拡大トレーニング時における安全度(ロバストネス)が生まれ、静止画と動画の両方の素材パラメータを完全に同一プロセスで一括同時処理し、固定コンポーネントを配置する手間を排除しました。エンドツーエンドの一貫アプローチのおかげで、モデルは静的な画像でも、動的なクリップでも一貫した理解を獲得しています。
3. 「Flow Matching(フロー・マッチング)」技術
本論文においても特権的な技術とされるのが、従来のディフュージョンの代わりとなる独自のフロー・マッチングの実装です。数式上は「v-prediction」に近似しているものの、多数の明白な技術優位性をもたらします。拡散モデルで見られるような「確率的な微分方程式(SDE)」の求解を迫られる代わりに、フロー・マッチングは一貫性のある「常微分方程式(ODE)」を解く形式のため、推論回路が軽量かつシンプルになります。自然と「端末シグナル対雑音比ゼロ」特性が得られ、生成映像のクオリティおよび推論動作スピ―ドが格段にスピードアップしています。
データ・スケールの探求
MovieGenの開発プロセスには、データスケールと演算の最大化に向けたエンジニアの凄まじい労力が詰まっています。約1億個にのぼる長短様々のビデオ映像アセットに加え、10億枚クラスの画像データセットが使われ、モデルの汎化能力を最高潮にまで高めています。また、動画用の一貫キャプション自動作成用に「LLaMA-3」を導入。これによりプロンプト命令の忠実度が高まりました。
MovieGen Bench:真価を問うテストスイート
Meta開発チームは、従来の検査アセットに勝る大規模な評価体系であるMovieGen Benchを新規リリースしました。このコレクションは一部の優れた結果だけを集めた、いわゆる「チェリーピック(手加減)」なしの実ビデオ1,000アセットで構築され、GitHubでパブリック公開されており、従来ベンチ比で約3倍のスケールを持ちます。この計測において「バリデーション誤差」と「実際の人間側のクオリティ評価」が良いシグナルで同期しており、指標の再現性が担保されているのが特徴です。
データ結果とその先の未来
測定された実データからは、いくつかの重要なファクトが浮き彫りになりました。全体のクオリティ、および現実世界に近いシミュレーション能力(リアリティ)の両部門でトップマークに近い結果を記録し、特に実写を模したテキスト・トゥ・画像の合成能力で並外れた進歩を見せました。また、最もエキサイティングな洞察として「動画生成モデルの成長スケーリング則(Scaling Laws)が、LLaMA-3で辿った変遷と全く同一の成長パスを描き続けており、未だ飽和点に達していない」ことが究明されました。
しかしMisra氏は、MovieGenがどれだけ素晴らしくとも、未だ人間レベルの高度な物理干渉や認知のすべてを内包して出力する段階には及ばない領域もあること、世界の深い因果の般化については現在も検証中の部分が多いと、オープンかつ有益な総括でプレゼンを締めくくりました。
5 - マルチモーダル・自律型アクションモデルへのパス - Jianwei Yang
ジェンウェイ・ヤン(Jianwei Yang)氏のセッションは、既存AI開発における「認識(純粋な動画コンテンツのパッシブな理解)」のみに偏重した姿勢を揺さぶり、自律的で主体的(Agentic)なアクションをこなせる相互連携の必要価値を訴えました。「過去を理解すること」と「未来に向けて的確に動作を生成すること」の両輪をこなせる、マルチモーダルなビデオ認識をベースとしたWebエージェント、先端ロボ、完全自動操縦向けのロードマップが力強く提唱されました。
過去を捉える:より強化された空間アライメント認識
Florence-VL: 表現を極めた視覚統合LMM
Florence-v2は、テキスト指示に同期して動く視覚ジェネレーティブAIにおいて大きな金字塔となっています。特徴的な空間ピクセル情報の種類に応じて多様なプロンプトの出し分けを行い、複雑なイメージ情報をパズルをパズルのピースを埋めるようにより強固に再構築します。この特徴変換時におけるアライメントロス(ビジョン側とLLM側の損失)を緻密に測定することで、システムは定量的な分析を強められます。
OLA-VLM: 多層特徴のダイレクト統合
OLA-VLMは、画像が宿す深いエッセンスを取りこぼさないために、1つのソース画像につき異なる3つの個別特徴チャネルを使用して、マルチモーダルLLMの表現能力を最大化します:
対象間の奥行き情報を示す、高精度な「デプス特徴(Depth features)」
輪郭・領域をしぼる「セグメンテーション特徴」
画像をより豊かに視覚表現するための「Unclip-SD特徴」
研究チームは、テキストを用いた十分な監督学習が、画像知覚に必要な中間特徴を格段に豊かにすることを突き止めました。さらに「教師役(Teacher)」となるハイスペックモデルから、LLM側の特徴空間へと直接パラメータ最適化(指導)を行わせることで、さらに完成度を安定させています。
動きの細部に切り込む:ミクロな時間ダイナミクス評価
TemporalBenchプロジェクトは、動画理解における根本要素に挑戦します。映像とは個々のフレームの集積ではなく、きわめて綿密な時間軸のアクション変化(ダイナミクス)そのものである、という点です。この評価ベンチマークにより、ビデオモデルが僅かな動作変化を見通せているかを詳細に検証することが可能になります。
これと対をなす「ProLongVid」と呼ばれる研究では、以下の「成長拡大の2次元軸(スケーリング)」にスポットを当てました:
命令合成プロセスにおけるビデオ実データの「長さ(時間の拡張)」:長時間の長い流れを見落とさないためのトレーニング
学習・推論中の「コンテキスト長(Context Length)」の引き上げ:ストーリー全体の文脈を一挙にモデルが見失わないようにする改良
未来に向けて動く:主体的(Agentic)な自律行動を促す動画AI
TraceVLA: ビジュアルトレースプロンプティング
TraceVLAは、ロボティクスのポリシー(制御)において時空間情報を持たせるための優れたインサイトを提示します。「これまでの行動経緯(インプットの過去)をモデルが精密に反芻することで、次に引き起こすアクション(未来予測)がより正確になる」という合理的な仮説に基づいています。この機構は、現在のマルチモーダル変換においてよく起こるいくつかの摩擦を取り除きます:
複数画像を一堂に送り込むと、切り出しトークンの量が劇増して動作スピードが著しく鈍化する一方、一般的なビジュアルエンコーダーは連続するフレーム間の小さなズレやミリ単位の差分(オプティカル・フロー)を高精度に評価できないこと。
テキストプロンプト(記述による指示)は簡単ではあるものの、物理空間上のきわめて高精度な移動ベクトルやピンポイントの静的座標の指定には力及ばないこと。
この障壁に対し、視覚的なインジケータ(プロンプトマーク)に直接作用させる画期的な「Set-of-Markプロンプト」を採用することで、現在の観測値と過去の行動軌跡との間のつながりをモデル内にシームレスに確立します。
LAPA: 言語無きビデオからアクションの「事前能力」を引き出す
LAPAは、アノテーションされていないありのままの大規模動画から、スマートにロボット関節コマンドや環境運動に必要な基本能力をプリトレイン(学習)させておく革新的な手法です。アクションコマンドがラベル付けされていないロボットデータや、一般的な人間向けのレクチャー動画(How-to動画)の両方を効果的に活用して学習します。「sthv2データセット」を用いたテストでは、ゼロからトレーニングをかけた従来のアプローチを圧倒するパフォーマンスを叩き出したものの、最初からロボ機器特化データだけで仕込んだプロフェッショナルな挙動比では若干の性能差を残し、今後に向けての課題を示しました。
MAGMA:運動神経を宿すマクロ自律基盤AI
MAGMAは、動的画像をベースとするスマートシステムの中枢となるために、実質的な画像群・動画像群・ロボ操縦ログデータを横断して構築されました。「見る(理解)」と「動く(行動)」の相互作用にこだわり、時間の動きに特化した監視方法(Temporal Motion Supervision)やアクション出力変換を備えます。仕込まれたタスク設定はロボの歩道パス(Trajectory Planning)、およびこれに伴う新環境での柔軟なタスク適応(般化)といった創発的挙動を引き出すべく綿密に組まれています。
「アクティブ・エージェント(主体的知能)」の定義更新
Yang氏はセッションの結びに、マルチモーダルAIエージェントの定義を新たに再定義して宣言しました:「AIエージェントとは、自律的に周辺環境を検知かつ作用して、設定されたゴール(目標)の達成をこなせる主体であり、絶え間ない試行錯誤と蓄積知識(世界の経験値)を用いて日々自己の実行タスクパフォーマンスを高めていける組織体のことである。」この定義には最も主要となる3ファクターが組み込まれています:
エージェントが2次元画面の「ピクセル認知」を越え、奥行きや障害物の立体的な「3次元座標認識(3D)」へ覚醒することの必要性
主体を開発する中で、モデルフリー手法(対症療法的な動作)と、世界モデル構築(物理因果モデルを用いた先回り思考)をいかに高いレベルで融和させるか
単なるトリガー応答を越え、何手先まで計算して進む「プランニング推論」をシステムに宿すことの重要性
今後越えるべき障壁・課題
Yang氏は、映像素材が隠し持つ膨大なデータ資産を引き出すためにも、スケーリング則をさらに推し進めたスケールアップへのこだわりが必要不可欠だとしました。次に向かうべき主要ロードマップとして以下を掲げました:
マルチモーダル自律行動特性(Agentic):さらに高度なロボ制御と干渉
マルチモーダル推論演算(Reasoning):バラバラなマルチモダリティから正確な理論を組み立てる脳の構築
マルチモーダル統合理解(Understanding):混沌とした外界情報からの精度の高いシーンコンテクスト把握
マルチモーダル自己理解(Self-Awareness):現在のモデルの認知レベルを客観視し不確実な判断を自律調整するメタ認知力の獲得
登壇の最後においてもっとも客観的なファクトとして、ビジョンAIが近年劇的に性能を高めていることは認めつつも、「人間の持つ高度な物理運動および思考には及ばないこと。高ダイナミクス映像、ディテールの不変性、時間秩序に関しては、潤沢なインターネット上の生データ対比で、本当の意味でクリーンな動画・テキストペアの蓄積が極端に足りていないことが現状のボトルネックの一つである」と警告しました。
6 - 動画生成基盤から、宇宙をシミュレートする本物の世界モデル(World Models)へ - Doyup Lee
ドユプ・リー(Doyup Lee)氏は、Runwayがこれまで重ねてきた動画生成開発のプロセスを踏まえ、私たちが次に突き進むべき「General World Models(一般世界モデル)」への壮大なパスを語り、その根底にある核心的ロマン「いかにして自律知能は物理世界を目を通じて正しく認識し得るか?」を説き起こしました。Runwayが誇る高度な動画生成テクノロジーの蓄積されたノウハウを交えた、AIにおけるビジュアル認識と想像力の関連性を探究するセッションです。
視覚的知能の本質を読み解く
Lee氏は、我々がいう「視覚認識(見る力)」とは何かという点について、世界モデルのシミュレーション能力および人間の「想像力(Imagination)」との深い結びつきを通じて論じました。彼はHa & Schmidhuber(2018)による世界モデルに関する代表論文を引用し、当時の成果が特定のシミュレーター環境内部などの閉じた世界においては高い予測精度をマークした一方で、現実の複雑で不確実な実世界での適用に苦慮した点を回顧しました。従来のビデオ認識手法、例えば画像の解説テキスト化、視覚Q&A(VQA)、特定エリア分割(Semantic Segmentation)などは、基本として人間の定義した言葉(ラベル名)と物体の関連付けに終始しており、取り込める世界の深い真実の一端を拾い損ねている限界を説きました。
プラトン的表現仮説(The Platonic Representation Hypothesis)
Lee氏がプレゼンの理論基盤としたものに「プラトン的表現仮説(Huh et al., ICML 2024)」があります。これは視覚認知としてAIが満たすべき以下の3つの絶対要素を明快にしたものです:
動画のタイムラインの展開(先、何が起こるか)について極めて高い予測変換能力を持ち、ダイナミクスを真に理解していること
世界の広大さを写し取った、かつ多様な、膨大の映像アセットに絶え間なくアクセスし学習に組み込めること
人間の持つ世界の概念構造や共通認識、行動期待とズレのないアライメント(整合性)をクリアしていること
汎用世界モデル構築に向けた『5つの極意』
1. 「苦い教訓(The Bitter Lesson)」への回帰
Lee氏は、AIの進化において有名な「苦い教訓(Bitter Lesson)」を今一度噛み締めることの重大さを語りました。大抵の場合、特定のルールや手仕事で最適化した専門の設計アプローチよりも、圧倒的な大容量計算リソース(Compute)と一般的な学習による拡大を信じた開発の方が最後にはすべてのタスクで卓越したパフォーマンスを収める、という法則です。この基本方針が、モデル開発における柔軟で無駄のない、スケーラブルな構成を生み出します。
2. 極めて高品質な、超巨大スケールのデータ素材
発表では、インプットデータが有する素材純度の僅かな違いが、モデル全体の学習効率と実用パフォーマンスを劇的に左右する事実がデータ付きで示されました。Lee氏は、アノテーションキャプションの品質を最高レベルに保つことで、画像および動画モデルの双方が著しい成績のブーストアップを記録することを示しました。しかし一方で、インターネット上の膨大なデータの山から、どうやって低コストで高品質な長尺キャプションタグ(詳細説明)を作り引き出すかは最大の難題であり、アノテーション工程のブレイクスルーが模索されています。
3. relational inductive bias(関係帰納バイアス)の無いスケーラブルアーキテクチャ
異なるデータ表現間に恣意的な関係性を規定しない、優れたモデル構造を選択すべきことが語られました。これに伴い、演算資源の経済的活用、および学習中の無駄を実証データに基づいて管理・予測するための「ニューラル・スケーリング則」の技術的解説がなされました。これにより、限度あるマシン(プロセッサ)リソースを無駄に食い潰すことなく、成長を設計通りに最大化できます。
4. 分散学習の極限スケール最適化
巨大プラットフォームを用いたマルチノードの並列事前学習においては、マシン全体の演算資源効率を示す指標「Model FLOPS Utilization(MFU: モデル使用演算率)」の最大化が最たる関心事になります。Lee氏は、全理論上の演算ポテンシャルのうち実際に何パーセントを高効率に引き出せているかがシステム最適化の主因であるとし、以下を含むディープなエンジニアリング施策を挙げました:
低精度(FP8/FP16等)演算のスムーズな実装、および演算の最大化
最適化を極めたカスタムCUDAカーネルの自社開発
高度なパラレリズム(並列化:データ並列、モデル並列、パイプライン並列等)の極地
ネットワーク遅延やマシントラブルをリアルタイムに回避する最先端クラスマネジメントシステム
5. 部門を超えたクロスファンクショナルなワンチーム統合
Lee氏は、ここまでの規模の最先端開発とはもはや一介のAI研究部門だけで到底なし得るものではなく、ハード・運用・データ・デザイン・クリエイティブのすべてが完全に連携した総合システムとして回る組織こそが勝機を見出すとしました。それぞれのフィードバックが無駄なく瞬時に交差する組織形態のガイドマップを共有しました。
Runway開発の次世代動画生成モデルたち
Gen-3 Alpha
Lee氏は、2024年6月にリリースされクリエイティブ業界震撼をもたらしたRunwayのGen-3 Alphaモデルを改めて提示深く掘り下げ。ユーザーのあらゆる細かな自然言語記述から、映画クラスの動的なシチュエーションを描き切る能力に秀でています。しかしながら、このGen-3の中にある、物理シミュレーション理解やコンセプチュアルな一般世界の予測モデル能力については、我々人間にとっても未だ分析段階のフロンティアであるとしました。
Runway開発部隊は、この巨大ビジュアル生成の奥深くを確かめるため、以下のような領域について分析研究を日々進めています:
現実世界を司る「物理的な重力や衝突法則」をモデルがいかに獲得して実行しているか
文字のフォント、崩れのない正確きわまる画像レンダリング限界
未知のイメージやキャラクター概念同士の混合描写力(概念の一般化)
思い通りの映像を描くための「直感制御コントロールツール」
Lee氏は、ただ出力するお祈り運搬式の生成ではなく、クリエイターが映像を自らの指先のように自在にコントロールするための優れた直感ツール群もお披露目しました:
イメージを特定のスタイル調に出発点を限定するキーフレーム設定(Keyframe conditioning)
既存シチュエーション・パイプラインにシームレスに入り込む生成VFXテクノロジー
3次元の立体的なパースを狂わせないで駆動するカメラワークコントローラー(3Dカメラ制御)
描いた部分の「動きの種類」や「スピード方向性」を指定ブラシで部分制御するモーションブラシ(Motion Brush)
画像構造やレイアウト指定に合わせるための構造化条件(Structural conditioning)
動画の領域外を拡張しシーンを書き足すアウトペインティング(Out-painting)
Act-One: 命を吹き込む表現のイノベーション
本発表の最も熱いピークにおいて実演されたのが、人物の演技、表情、魂ともいえるき微細なニュアンスを完全に再現・生成する仕組みである Act-Oneのハイレベルデモでした。Gen-3のモデル実力の上に乗る形をとり、人間のキャラクターアクターの演技、顔全体の躍動、心理描写を完全に模倣移転して、異なるキャラクターへと生成することを驚愕のタイムライン処理クオリティを達成しながら可能にしています。
ビジョンと今後のビッグ課題
リー氏はセッションの括りとして、私たち人間の知的世界を描写する絶対の不変メディアは「言語」と「映像」の双璧であるとしました。言語は全抽象世界のインデックス情報を有し、映像は無限に広がる全ビジュアル空間の膨大な実態シグナルを保持します。私たちはこれまでの比ではない圧倒的に膨大なデータを集積・活用して、本当の意味で現実世界およびそのインタラクション全体を包摂する真の世界モデルへ舵を切る準備ができているとして、Runwayが挑み続ける高みを示しました。
プレゼンは究極のフロンティアである、人間の定義・認識・想像力を一段回以上飛び越える、高次元の一般世界モデル(General World Models)の具現化という大いなる約束を持って幕を閉じました。我々はこの開発を以下の多軸から挑戦します:
最高のスケーリングとそれを耐え抜くモデルアーキテクチャの革新
データ合成とキュレーションのクオリティ革命
マシンの持てる全クロックを活用する驚異的な演算最適化
誰もをアーティストに変える、直感的かつ精巧な画風コントロール手法の拡張
プロの撮影シーン、インフラ、CGクリエイティブワークへのシームレスな統合
動画言語モデルの行く末:我々が共に見つめる視線の先へ
第1回 NeurIPS 2024 ビデオ言語モデル・ワークショップ(Video-Language Model Workshop)は、動画理解のエキサイティングな進化進捗と、未開のクリアされるべき課題の双方を劇的にあぶり出しました。業界で技術革新に挑むプレイヤーのひとりであり、本祭の企画・共同オーガナイザーでもあるTwelve Labs(トゥエルブラボ)は、この傑出したスピーカー陣が投げかけた鋭い洞察を大切に受け止めています。
浮き彫りとなった重要コアテーマ
ワークショップ中、いくつもの重要検討事項が会場を震わせました。ディマ・ダメン(Dima Damen)教授は一人称視点カメラから見たミクロな連続アクション(時間軸の微細ダイナミクス)の処理の価値を訴え、ゲダス・ベルタシウス(Gedas Bertasius)教授は文字依存の世界観を脱し「テキストフォーマットで定義しきれない純粋ビジュアル」を読み取るモデルの重要性を主張しました。ヨンジェ・リー(Yong Jae Lee)教授が見せた、ほんの10秒足らずのショートビデオに潜む反実仮想の僅かな時間情報の取り扱いでさえ、最新鋭のLLaVAやフロンティアモデルが軒並み苦汁をなめている事実は、大きな話題となりました。
またジェンウェイ・ヤン(Jianwei Yang)氏が見せた「体性を宿した能動アクションモデル(マルチモーダルエージェント)」と、イシャン・ミスラ(Ishan Misra)氏が率いたMovieGen開発による次世代生成ワークフローは、単なるテキスト記述を越えた先にある新しいエンタメの在り方、自動生産システムへの展望を一望させてくれました。さらにドユプ・リー(Doyup Lee)氏が宣言した「一般世界モデル」への歩みは、生成モデル自身がこの宇宙をシミュレートする本物の頭脳へと変革し得る偉大な可能性を裏付けました。
テック企業としての現状理解と私たちの歩む道
Twelve Labs(トゥエルブラボ)において、ここでの課題は私たちの開発実務での経験にこの上なく一致します。当社が長年磨き続けている超高性能動画特徴埋め込みモデルである「Marengo(マレンゴ)」や、映像を流暢なテキストコミュニケーションへと直結させるビデオ対話基盤LMM「Pegasus(ペガサス)」の開発は、まさに登壇した教授陣が説いたマルチモダリティの統合、極めて洗練されたタイムラインの追跡、極地を極めるデータフィルタリングとトレーニングの価値そのものから生まれ育ったプロダクトたちだからです。
ここで展開した白熱した議論は、我々が日々磨いている開発の羅針盤が正確であることを指し示しています:
動画の奥深さに多次元アプローチをかける「マルチベクトル(Multi-vector)埋め込み」テクノロジー
短い閃きのようなアクションから、大河ドラマのような長尺小説の流れまで破綻せずに記憶し処理する高度なタイムライン追跡設計
ピクセル特徴(Visual)、環境情報、セリフや会話・歌(Audio)、そして物語の文字コンテキスト(Text)を美しいハーモニーのようにひとまとめに対象化するマルチモーダル統合処理
これまでの画一的な言語ベースの試験測定を越え、モデルに真の知恵を強烈に問う次世代のロバスト評価指標の創出
未来へ向かう最高の青写真
動画と言語モデルが融和して進化を遂げた先にある世界は、圧倒的な希望に満ち溢れています。私たちはこれから先:
より深く複雑な劇中ストーリー展開や、裏を読ませるような反実仮想を含む時間推論を完全にマスターするビデオ認識脳
社会常識、物理ルール、および人間としての道徳観といった、私たちの持つ「現実の教養」を正しく内包した視覚ビジョン能力
長尺を扱うモデル動作コストを最小限に抑え抜きつつ、最初から最後までの時間連動力を高精度に維持できる洗練された高効率トランスフォーマー設計
最先端を追い求める学会・大学研究の知恵と、実際のスケーラビリティ処理を背負うインフラ実業界(エンタープライズ)との間のこれまでになく太い連携
このワークショップは、学界と産業界双方のエキスパートたちが一堂に会し、こうした数々の野心的な技術的障壁に対して「チーム一体」となって立ち向かうための大きな第一歩となります。これまでの自負、常套手段を越え、真に私たちが目を惹かれる知能システムの誕生を目指し、Twelve Labsはこれからも開かれたテクノロジーコミュニティを愛し、責任ある行動と絶え間ない実験開発を惜しみません。
ここから始まる道のりは険しく、しかしワクワクする発見に満ちています。本日を彩った最高の頭脳たちの知見をバトンに、アカデミズムとビジネスが手を携えて進むことで、この先のビデオ言語モデルが我々の暮らしを、そして「私たちがこの現実世界をどのように知覚し、繋がり、高めあうか」を劇的にアップグレードしてくれる日の到来がより早く、かつ確かに近づいてくるのです。








