
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
Research
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Lucas Lee, Kilian Baek, James Le
Twelve Labs introduces TWLV-I, a new video foundation model and evaluation framework that balances both appearance and motion understanding, outperforming or matching state-of-the-art models across action recognition, temporal action localization, and spatio-temporal action localization benchmarks.
Twelve Labs introduces TWLV-I, a new video foundation model and evaluation framework that balances both appearance and motion understanding, outperforming or matching state-of-the-art models across action recognition, temporal action localization, and spatio-temporal action localization benchmarks.

In this article
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Sep 22, 2024
20 Min
Copy link to article
Check out the TWLV-I technical report on arXiV and HuggingFace! The code is available on GitHub: https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
Comprehensive Evaluation Framework: Twelve Labs introduces a robust evaluation framework for video understanding, emphasizing both appearance and motion analysis.
TWLV-I Model: Our new video foundation model (TWLV-I) excels in balancing these dual aspects, outperforming or matching state-of-the-art models.
Task Performance: TWLV-I shows strong results across action recognition, temporal action localization, and spatio-temporal action localization, highlighting its versatility.
Visualization Insights: t-SNE and LDA visualizations reveal TWLV-I's superior clustering and motion distinguishability capabilities compared to other models.
Future Directions: Emphasizes scaling up, improving image embedding, and expanding modalities to enhance TWLV-I's versatility and applicability.
Guiding Future Research: The proposed methodologies aim to set a new standard in video understanding, guiding future research and development in the field.
1 - Introduction
In today's digital landscape, video serves as a universal language, seamlessly conveying complex ideas and emotions across cultures. Developing robust video understanding systems is crucial for accurately interpreting this rich medium. Videos, as sequences of images, require a dual focus: recognizing the appearance in each frame and understanding the motion that unfolds over time.
At Twelve Labs, we recognize the need for a comprehensive evaluation framework that addresses these dual aspects of video understanding. Our goal is to set a clear direction for future research in this field by establishing methodologies that accurately measure both appearance and motion capabilities.
1.1 - Foundation Models and Video Understanding
Foundation Models (FMs) have revolutionized AI by enabling models to handle diverse tasks within a domain. While Language and Image Foundation Models have made significant strides, video understanding presents unique challenges. Existing Video Foundation Models often fall short in effectively capturing both appearance and motion, as evidenced by limitations in clustering and classification tasks.
1.2 - Introducing TWLV-I and Our Evaluation Framework
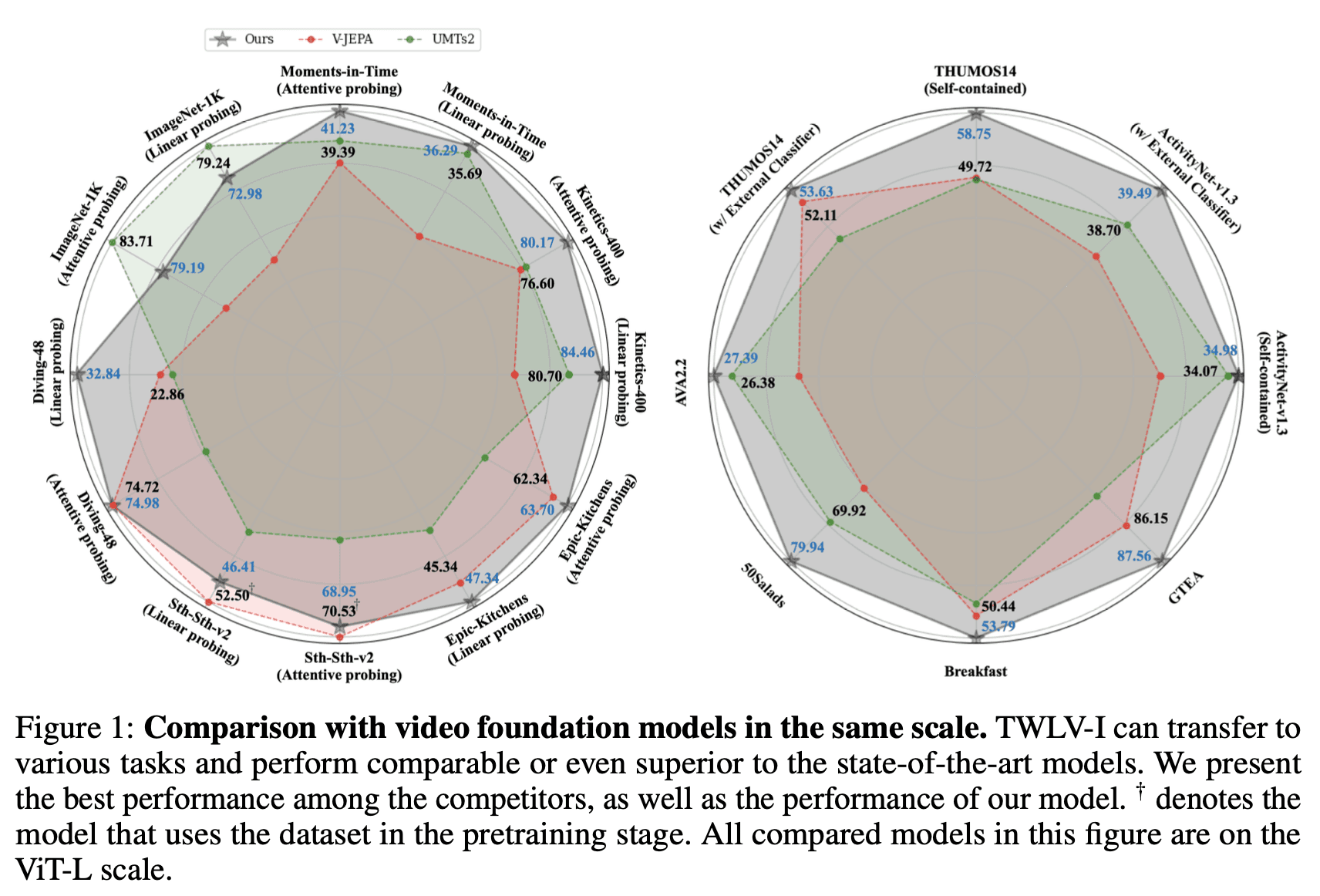
To address these challenges, we introduce TWLV-I - designed to excel in both appearance and motion-based tasks, as shown in Figure 1. More importantly, we propose a robust evaluation framework that not only assesses TWLV-I's capabilities but also sets a benchmark for future models.
Our framework includes a range of tasks such as action recognition, temporal action localization, and spatio-temporal action localization, each meticulously designed to evaluate specific aspects of video understanding. Through this comprehensive approach, we aim to highlight the importance of balanced capabilities and guide the field towards more holistic model development.
By focusing on both the performance and proper evaluation of video models, we aspire to present a milestone in video research, paving the way for future advancements and innovations in this dynamic field.
2 - TWLV-I & Video Foundation Model Evaluation Framework
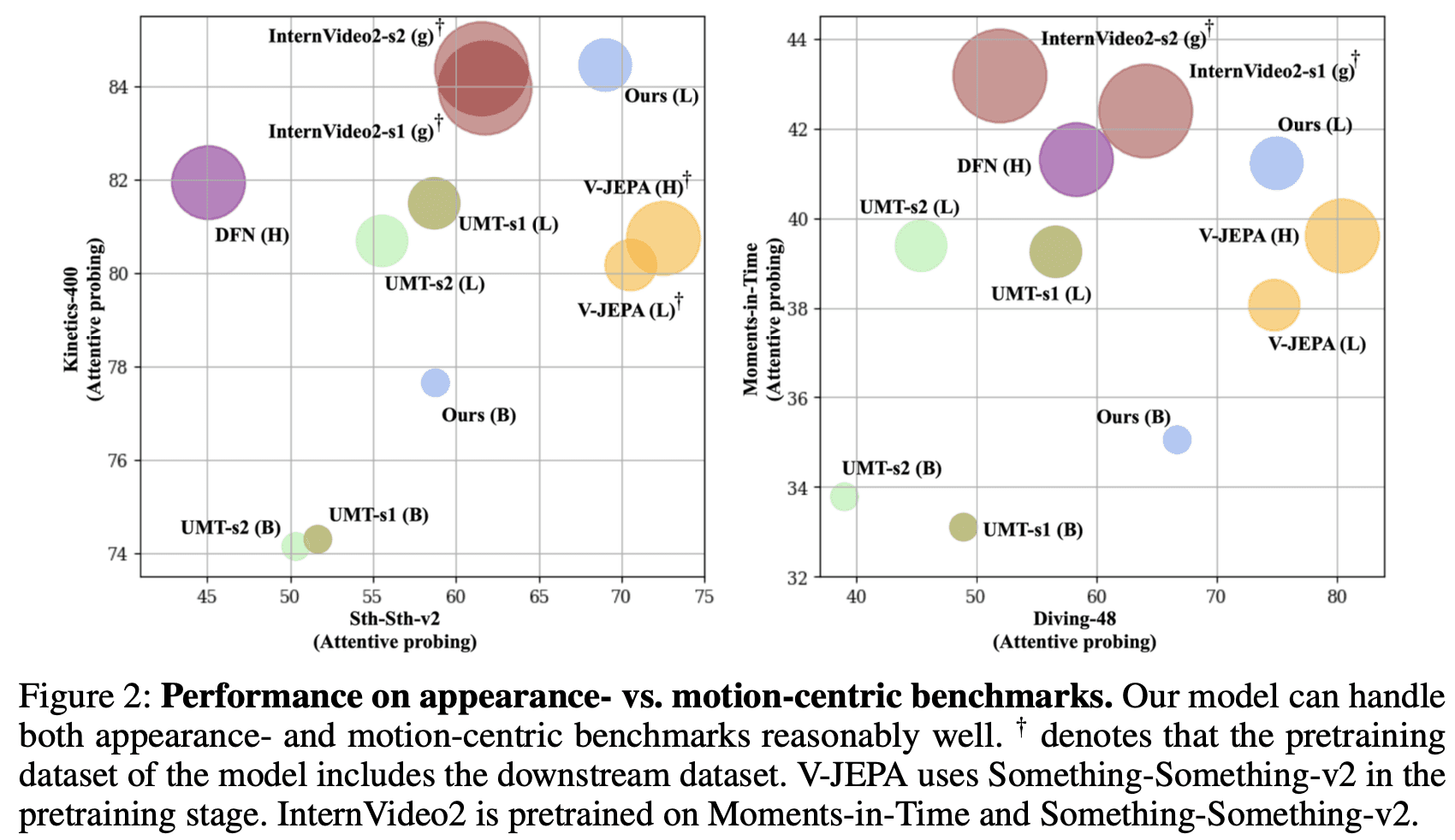
TWLV-I's architecture and training process are designed to address the unique challenges of video understanding, balancing the need for both appearance and motion comprehension. Figure 2 provides a visual comparison of TWLV-I's performance on appearance-centric (Kinetics-400) versus motion-centric (SSv2 and Diving-48) benchmarks. The plot demonstrates TWLV-I's balanced capabilities, handling both types of tasks reasonably well.
This subsection delves into the key aspects of TWLV-I's training methodology and frame sampling techniques.
2.1 - Architecture
TWLV-I is built upon the Vision Transformer (ViT) architecture, leveraging its powerful ability to process visual data. We implement two variants:
ViT-B (Base): A model with 86 million parameters
ViT-L (Large): An expanded version with 307 million parameters
The input video is tokenized into multiple patches, which are then processed through the transformer layers. This process yields patch-wise embeddings that are subsequently pooled to generate the overall embedding for the input video.
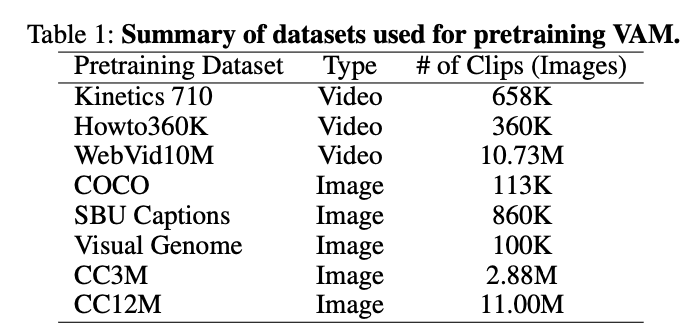
2.2 - Pretraining Dataset
To ensure robust and versatile video understanding, TWLV-I is pretrained on a diverse set of datasets, as detailed in Table 1:
Video datasets:
Kinetics 710 (658K clips)
HowTo360K (360K clips, a subset of HowTo100M)
WebVid10M (10.73M clips)
Image datasets (total of 15M images):
COCO (113K images)
SBU Captions (860K images)
Visual Genome (100K images)
CC3M (2.88M images)
CC12M (11.00M images)
This combination of video and image datasets enhances TWLV-I's ability to understand both motion dynamics and static visual features.
2.3 - Training Objective
TWLV-I employs a masked modeling schema as its foundational training approach. However, to optimize the model's performance in both motion and appearance understanding, we diversify the reconstruction targets. This strategy aims to create a robust model capable of excelling across various video understanding tasks. The model is trained from scratch using this objective and the aforementioned datasets.
2.4 - Frame Sampling
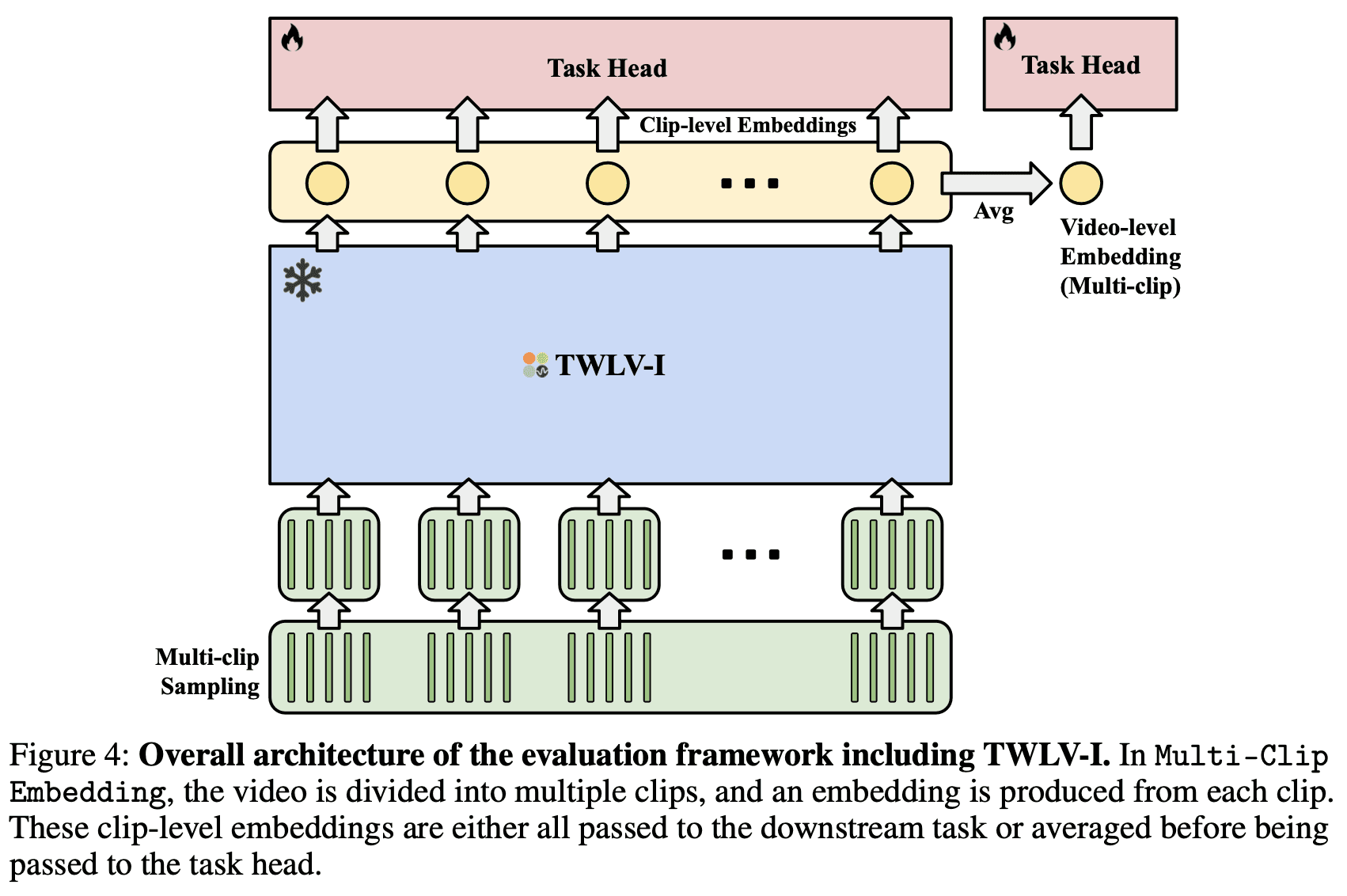
The frame sampling process is crucial due to the computational constraints of the ViT architecture. As the number of tokens increases, so does the computational complexity (quadratically). To manage this, we employ a strategic frame sampling technique called Multi-Clip Embedding (shown in Figure 4):
Clip Division: An input video is divided into M clips, each T seconds long.
Frame Selection: N frames are sampled from each clip.
Embedding Generation: This process results in M embeddings per video.
Flexible Representation: The number of embeddings increases proportionally with video length, allowing for variable-length video processing.
Single Embedding Option: When a single embedding is required to represent the entire video, we average the M embeddings.
This approach allows TWLV-I to handle videos of varying lengths efficiently while maintaining the ability to capture both short-term and long-term temporal dynamics.
By combining a powerful ViT architecture with a diverse pretraining dataset and an innovative frame sampling technique, TWLV-I is well-equipped to handle the complexities of video understanding tasks. This foundation enables TWLV-I to perform robustly across both appearance-centric and motion-centric benchmarks, as we will explore in subsequent sections of this evaluation framework.
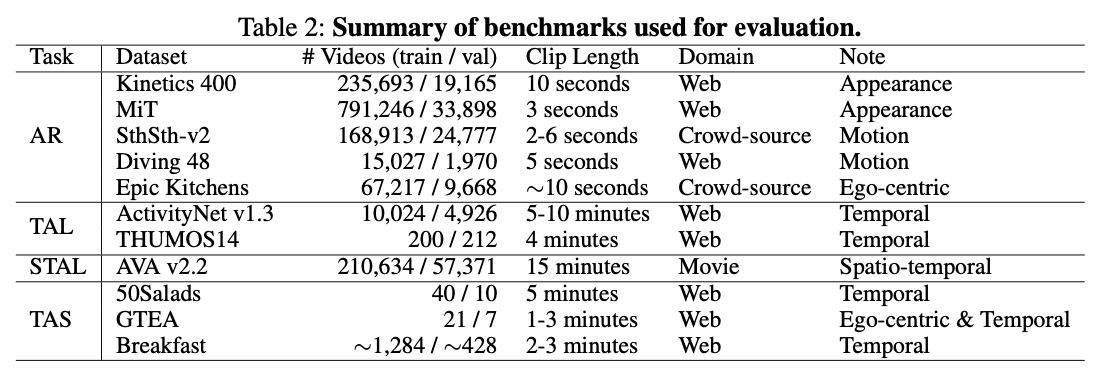
3 - Action Recognition
Action Recognition (AR) is a fundamental task in video understanding, aiming to classify videos into predefined human action categories. This task serves as a crucial benchmark for evaluating the performance of video foundation models, as it requires both appearance and motion understanding.
3.1 - Benchmarks
We evaluate TWLV-I's performance on five representative AR benchmarks, each with its unique characteristics:
Kinetics-400 (K400): A large-scale dataset focusing on appearance-based actions
Something-Something-v2 (SSv2): A motion-centric dataset emphasizing temporal relationships
Moments-in-Time (MiT): Another appearance-focused dataset with diverse action categories
Diving-48 (DV48): A fine-grained, motion-centric dataset of diving actions
Epic-Kitchens (EK): An egocentric dataset capturing daily kitchen activities
These benchmarks provide a comprehensive evaluation landscape, allowing us to assess TWLV-I's capabilities across both appearance-focused and motion-centric scenarios.
3.2 - Evaluation Methodology
We employ a multi-view classification method, which is standard in action recognition tasks:
Spatial resizing of input videos to match the required input resolution
Uniform sampling of m clips along the spatial dimension and n clips along the temporal dimension, resulting in m × n total clips
Calculation of class probabilities for each clip
Averaging of probabilities to obtain the final output
This approach ensures a thorough evaluation of the model's performance across different spatial and temporal segments of the input videos.
3.3 - Linear Probing
Linear probing is a technique used to evaluate the quality of learned representations without fine-tuning the entire model. It involves:
Freezing the feature extractor (backbone model)
Training a linear classifier on top of the frozen features
The linear classifier consists of a weight matrix that maps the embedding vector dimension to the number of action classes.
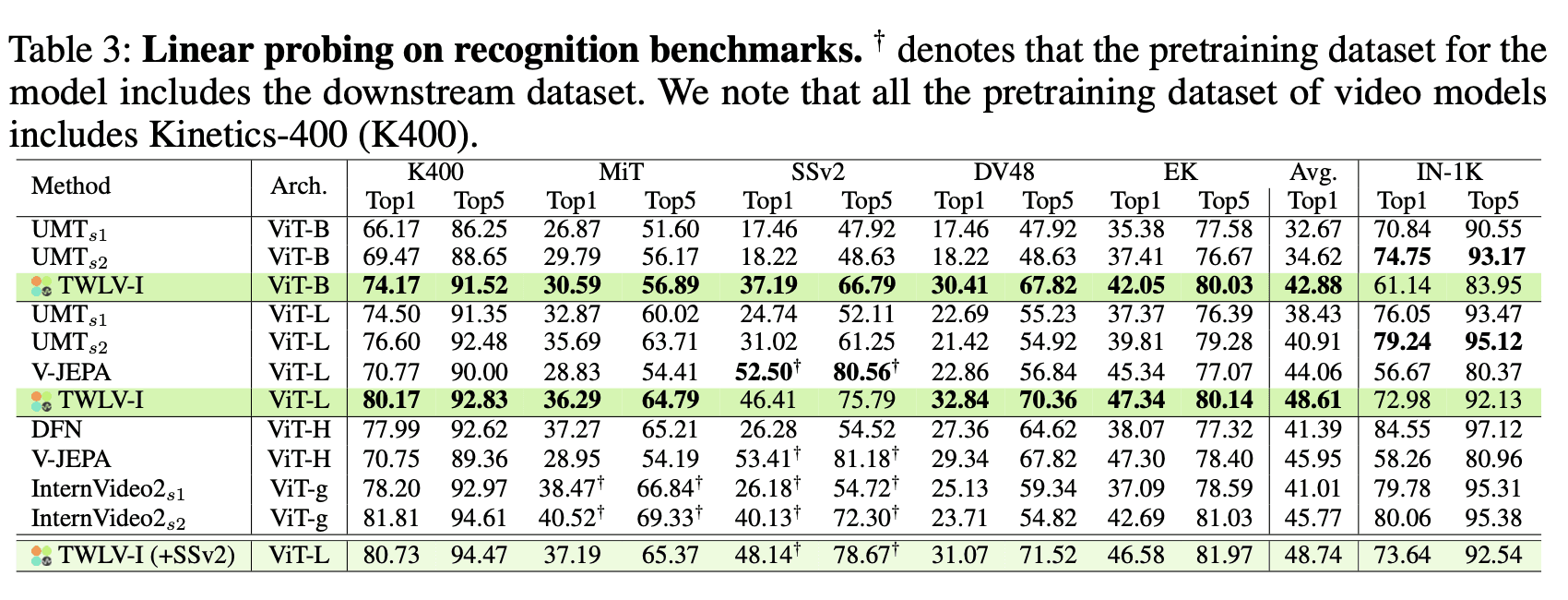
Results and Analysis
Table 3 presents the linear probing results across various benchmarks and models. Key observations include:
TWLV-I demonstrates strong performance across all benchmarks, particularly within its architecture scale (ViT-B and ViT-L).
For SSv2, TWLV-I outperforms larger models like ViT-H (DFN) and ViT-g (InternVideo2), with the exception of V-JEPA, which includes SSv2 in its pretraining.
TWLV-I's ViT-L variant surpasses larger-scale models on EK and DV48 benchmarks.
These results highlight TWLV-I's ability to learn rich, generalizable features that transfer well to various action recognition tasks, even when evaluated using a simple linear classifier.
3.4 - Attentive Probing
While linear probing provides insights into clip-wise embedding quality, it may not fully capture the models' capabilities, especially for those trained with patch-level supervision. To address this limitation, we introduce attentive probing, which involves:
Training a single attention layer with a learnable class token on top of the frozen model
Passing the output class token through a linear classifier
Measuring the top-1 accuracy
This method allows for a more nuanced evaluation of the models' patch-wise representation capabilities.
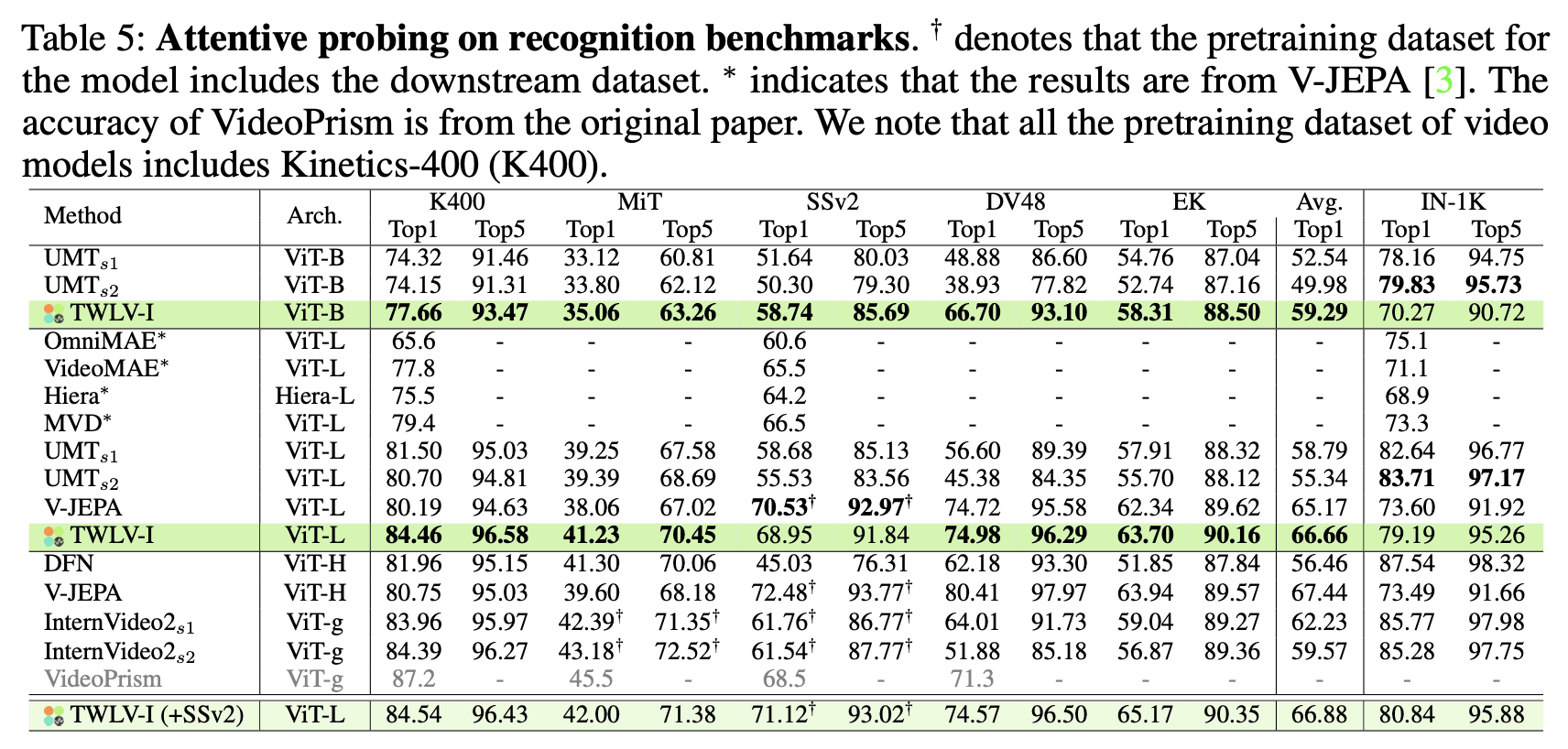
Results and Analysis
Table 5 showcases the attentive probing results. Key findings include:
TWLV-I achieves superior performance across both appearance- and motion-centric benchmarks compared to other models.
The strong performance in attentive probing suggests that TWLV-I possesses richer patch-wise representations compared to its counterparts.
3.5 - K-Nearest Neighbors
To provide a parameter-free evaluation of embedding quality and address potential biases in gradient-based methods, we employ the K-Nearest Neighbors (KNN) classification task. This non-parametric approach offers a fair comparison of embedding vectors across different model architectures.
We generate embeddings using two methods:
Uniform Embedding: A single embedding vector for the entire video.
Multi-Clip Embedding: Multiple embeddings from 2-second clips throughout the video.
For Multi-Clip Embedding, we employ two evaluation strategies:
Video-level: Averaging all clip embeddings to create a single video representation.
Clip-level: Summing votes received by each clip to determine the final class.
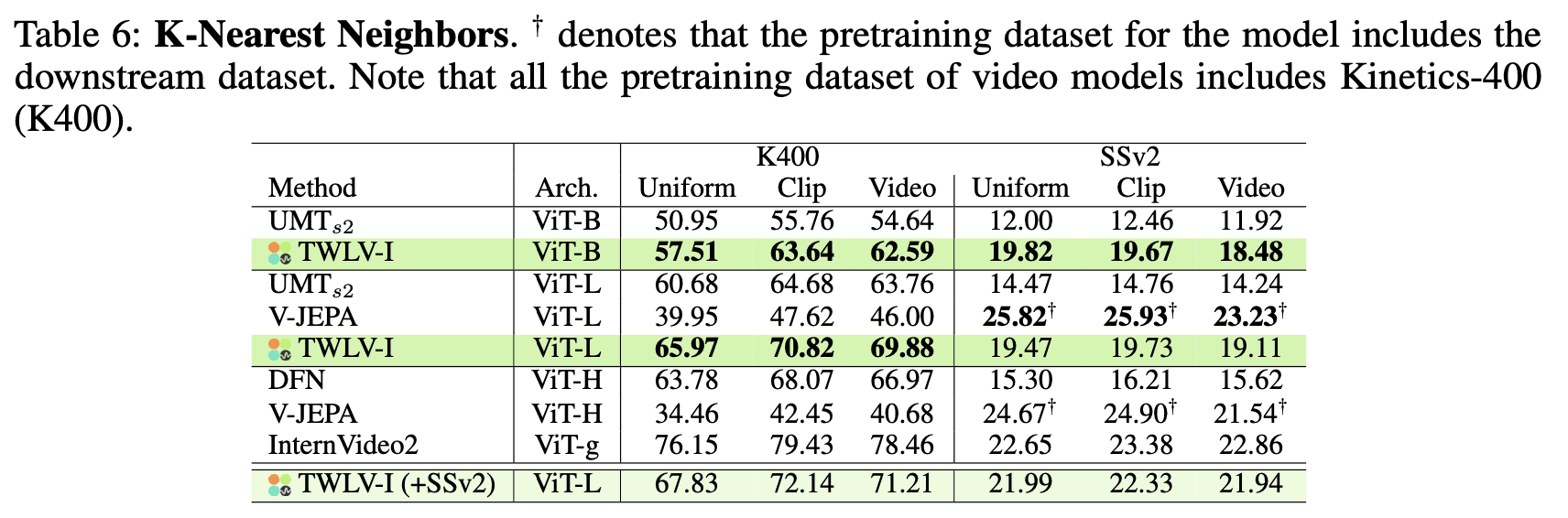
Results and Analysis
Table 6 presents the KNN classification results across different models and embedding strategies. Key observations include:
TWLV-I demonstrates competitive performance on both Kinetics-400 (K400) and Something-Something-v2 (SSv2) datasets, particularly when compared to models of similar scale.
In the Uniform embedding setting, TWLV-I-ViT-B achieves 57.51% and 19.82% top-1 accuracy on K400 and SSv2 respectively, outperforming UMT_s2 with the same architecture.
TWLV-I-ViT-L shows strong results, with 65.97% and 19.47% top-1 accuracy on K400 and SSv2, surpassing several larger models.
However, unlike the attentive probing results, TWLV-I underperforms compared to InternVideo2 on both K400 and SSv2 in the KNN evaluation. This suggests:
There's room for improvement in utilizing TWLV-I's embeddings in a non-parametric manner.
The need for further research on effectively representing embeddings for longer videos, especially those extending beyond a single clip length.
These results highlight the complexity of video representation and the challenges in creating a universally strong embedding across different evaluation methodologies.
3.6 - Pre-Training with SSv2
To ensure a fair comparison with models like V-JEPA and to assess the impact of including motion-centric data in pretraining, we conducted an additional experiment by incorporating the Something-Something-v2 (SSv2) dataset into TWLV-I's pretraining phase.
We trained a variant of TWLV-I (ViT-L architecture) including SSv2 in its pretraining dataset alongside the original datasets. This allows us to directly compare the impact of this additional data on various benchmarks and evaluation methods.
Results and Analysis
The results of this SSv2-enhanced model are presented at the bottom of Tables 3, 5, and 6. Key findings include:
Improved SSv2 Performance: Across all evaluation methods (linear probing, attentive probing, and KNN), the model shows significant improvements on the SSv2 benchmark. For example, in linear probing (Table 3), the top-1 accuracy on SSv2 increases from 46.41% to 48.14%.
General Performance Boost: The inclusion of SSv2 in pretraining leads to performance gains across other benchmarks as well. This suggests that the additional motion-centric data enhances the model's overall video understanding capabilities.
Comparison with Specialized Models: Despite the improvements, the KNN performance of our SSv2-enhanced model still lags behind V-JEPA and InternVideo2 on SSv2. This indicates that while TWLV-I's patch-level representations are strong, there's room for improvement in video-level representations.
Trade-offs in Representation: The results highlight a potential imbalance between TWLV-I's patch-level and video-level representations. Addressing this discrepancy should be a key focus for future enhancements to the model.
These findings underscore the importance of diverse pretraining data in developing robust video foundation models. They also point to specific areas where TWLV-I can be improved to better compete with specialized models on motion-centric tasks while maintaining its strong performance on appearance-based benchmarks.
4 - ImageNet Classification
To assess the versatility of video foundation models and their potential to function as general vision models, we evaluated TWLV-I's performance on the ImageNet classification task. This benchmark provides insights into the model's ability to process and understand static images, which is crucial for a comprehensive video understanding system.
4.1 - Results and Analysis
The ImageNet classification results are presented in the last columns of Table 3 (linear probing) and Table 5 (attentive probing). Key observations include:
Correlation with Appearance-Centric Tasks: Generally, models that excel in appearance-centric action recognition tasks (e.g., Kinetics-400) also demonstrate strong performance on the ImageNet benchmark. This correlation suggests that the features learned for video understanding can transfer effectively to static image classification.
TWLV-I's Performance:
In linear probing (Table 3), TWLV-I-ViT-L achieves 72.98% Top-1 accuracy on ImageNet, which is competitive but not leading.
For attentive probing (Table 5), TWLV-I-ViT-L shows improved performance with 79.19% Top-1 accuracy, indicating better utilization of learned features through attention mechanisms.
Comparison with Specialized Models: While TWLV-I shows strong performance on video-based tasks, there's a noticeable gap in ImageNet classification compared to some specialized models. For instance, InternVideo2 significantly outperforms TWLV-I on ImageNet, although this gap narrows or even reverses in video action recognition tasks.
4.2 - Implications and Insights
Given such observations, we deduce the following insights:
Static Image Processing Limitations: The results suggest that TWLV-I has some limitations in processing static images compared to models optimized for this task. This indicates an area for potential improvement in future iterations of the model.
Motion Information Utilization: The narrowing performance gap between TWLV-I and other models in video tasks, despite lower ImageNet scores, suggests that TWLV-I effectively leverages motion information for video understanding. This ability complements its appearance-based features, resulting in strong overall video analysis performance.
Balancing Video and Image Capabilities: To evolve TWLV-I beyond being solely a video model, future research should focus on enhancing its ability to understand single images without compromising its strong video analysis capabilities.
Overall, while TWLV-I demonstrates strong capabilities in video understanding tasks, the ImageNet classification results highlight areas for improvement in static image processing. Addressing these limitations could lead to a more comprehensive visual foundation model capable of excelling across both video and image domains.
5 - Temporal Action Localization
Temporal Action Localization (TAL) is a critical task in video understanding that involves identifying and localizing specific actions within untrimmed videos. This task is particularly important for applications in autonomous driving, sports analysis, and content-based video retrieval. TAL requires models to analyze long, complex videos and precisely determine both the temporal boundaries and class labels of distinct actions occurring within them.
5.1 - Evaluation Perspectives
TAL evaluates video foundation models from two key perspectives:
Temporal Sensitivity: The ability to identify if an action of interest occurs at a specific time step.
Instance Discrimination: The capability to distinguish or group frame-wise segments into complete action instances.
While TAL is primarily designed as a motion-centric task, our analysis reveals that both appearance and motion capabilities contribute to achieving these aspects effectively.
5.2 - Methodology
We evaluated TWLV-I and other video foundation models on two prominent TAL datasets:
ActivityNet-v1.3
THUMOS14
For the detection head, we employed ActionFormer. Our evaluation used two distinct methods:
Self-contained: The model performs both classification and regression without external assistance.
w/ External Classifier: The model conducts binary classification, while an external classifier predicts the action class.
Feature extraction followed the Multi-Clip Embedding method described in the "Frame Sampling" section.
5.3 - Results and Analysis
Tables 9 and 10 present the comprehensive results for THUMOS14 and ActivityNet-v1.3, respectively.
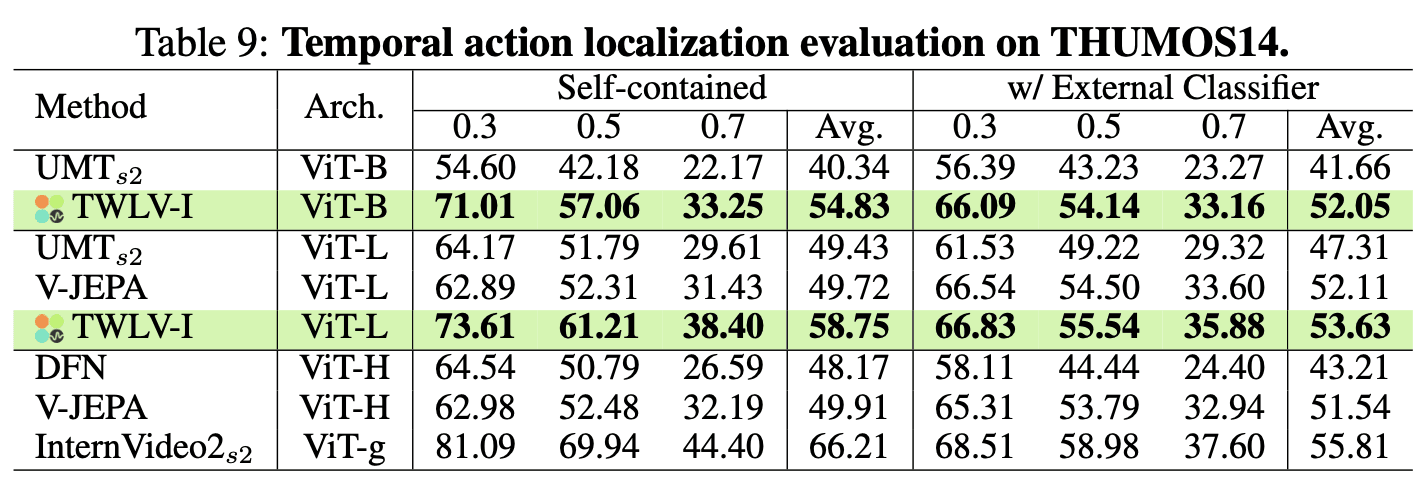
THUMOS14 (Table 9)
TWLV-I (our model) consistently outperforms other models of the same scale across all metrics.
TWLV-I-ViT-L achieves the highest average mAP of 58.75% in the self-contained setting and 53.63% with an external classifier.
Notably, TWLV-I-ViT-L surpasses larger models like DFN and V-JEPA (ViT-H), demonstrating its robust generalization capabilities.
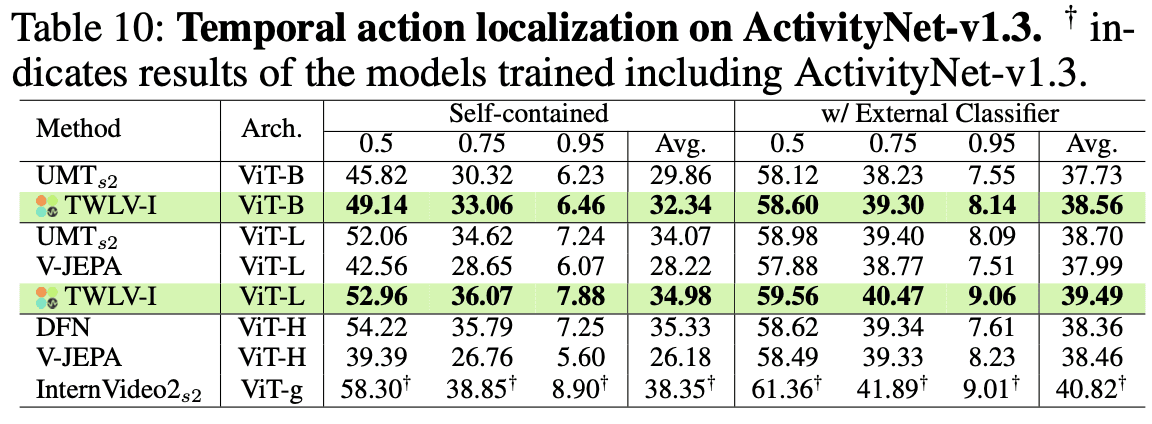
ActivityNet-v1.3 (Table 10)
TWLV-I again shows superior performance within its architecture scale.
TWLV-I-ViT-L achieves an average mAP of 34.98% (self-contained) and 39.49% (w/ external classifier).
Remarkably, TWLV-I performs exceptionally well at strict IoU thresholds (e.g., 0.95), indicating strong temporal sensitivity.
5.4 - Key Insights
Given such observations, we deduce the following insights:
Scale Efficiency: TWLV-I's performance, especially at the ViT-L scale, outperforming larger models, highlights its efficient architecture and training methodology.
Temporal Precision: High performance at strict IoU thresholds (e.g., 0.95 in ActivityNet) demonstrates TWLV-I's superior temporal sensitivity.
Model Scale Impact: InternVideo2's top performance, particularly in self-contained evaluation, suggests that TAL benefits from larger model scales, especially when performing both classification and boundary regression simultaneously.
Evaluation Strategy: For a focused assessment of motion understanding, using an external classifier is recommended. However, for a comprehensive evaluation including appearance capabilities, the self-contained approach is preferable.
Generalization Capability: TWLV-I's strong performance across different datasets and evaluation methods indicates its robustness as a backbone for temporal localization tasks.
These results underscore TWLV-I's effectiveness in tackling the complex task of temporal action localization, showcasing its balanced capabilities in both temporal sensitivity and instance discrimination. The model's performance across various scales and evaluation methods demonstrates its potential as a versatile foundation for video understanding tasks.
6 - Spatio-Temporal Action Localization
Spatio-Temporal Action Localization (STAL) is a complex task that evaluates a model's ability to not only recognize actions but also accurately localize them in both space and time within untrimmed videos. This task is crucial for applications requiring detailed action analysis, as it demands a comprehensive understanding of both appearance and motion.
6.1 - Dataset and Evaluation
We evaluate models using the AVA v2.2 dataset, which consists of 430 movie clips, each 15 minutes long. Keyframes are annotated every second, resulting in 210,634 labeled frames in the training set and 57,371 in the validation set. The dataset includes 80 atomic actions labeled for each actor.
For evaluation, we report the Frame Average Precision (fAP) at an Intersection over Union (IoU) threshold of 0.5, using the latest v2.2 annotations. We adopt an end-to-end STAL framework, training the decoder while keeping the vision backbone frozen.
6.2 - Results and Analysis

Table 11 presents the evaluation results for the STAL task. Key observations include:
Comparison with Other Models: TWLV-I, along with UMT and InternVideo2, outperforms DFN and V-JEPA. While DFN and V-JEPA exhibit opposite trends in other tasks, they show similar performance in STAL due to the dual requirements of instance localization and action recognition.
Challenges in Instance Localization:
V-JEPA: Struggles with instance localization, which impairs its ability to perform action recognition effectively.
DFN: Excels in localizing instances due to its strong appearance understanding but fails in action recognition due to limited temporal understanding.
Strengths of TWLV-I:
TWLV-I demonstrates a balanced understanding of both appearance and motion, allowing it to perform well in STAL.
At the ViT-L scale, TWLV-I achieves a fAP@0.5 of 27.39, outperforming both DFN and V-JEPA and closely matching the performance of larger models like InternVideo2.
6.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Understanding: The results confirm that TWLV-I effectively understands spatio-temporal information, crucial for accurate STAL.
Comprehensive Evaluation: The STAL task, conducted in an end-to-end manner, serves as a robust measure of a model's ability to understand video comprehensively, encompassing both spatial and temporal dimensions.
Model Validation: The performance of TWLV-I, alongside UMT and InternVideo2, highlights its capability to handle the dual challenges of localization and recognition, setting it apart from models with a singular focus on appearance or motion.
These findings underscore the importance of a balanced approach to video understanding, where both appearance and motion are integrated to achieve superior performance in complex tasks like STAL.
7 - Temporal Action Segmentation
Temporal Action Segmentation (TAS) is a crucial task for understanding and analyzing human activities in complex, extended videos. It has a wide range of applications, including video surveillance, summarization, and skill assessment. TAS involves processing untrimmed video inputs to generate a sequence of action class labels for each frame.
7.1 - Benchmarks and Methodology
We evaluate TAS using three challenging benchmarks:
50Salads: Focuses on fine-grained actions in cooking scenarios.
GTEA: Captures egocentric views of daily activities.
Breakfast: Encompasses a broader view, including full-body actions.
For TAS, we employ ASFormer as the detection head. We report the average F1 scores at thresholds of 10, 25, and 50, referred to as ‘mF1’. Features are extracted using the Multi-Clip Embedding method and aggregated with spatial pooling to retain only the temporal axis.
7.2 - Results and Analysis
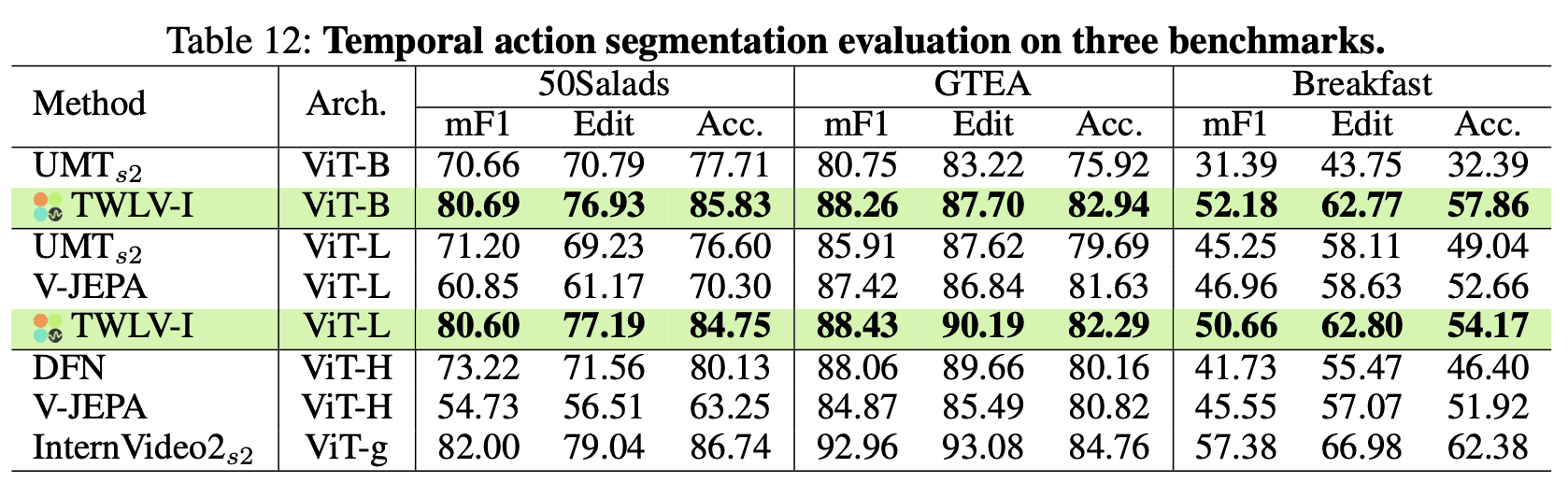
Table 12 presents the TAS evaluation results across the three benchmarks:
50Salads: TWLV-I achieves an mF1 score of 80.69 with ViT-B and 80.60 with ViT-L, outperforming both appearance-centric models like UMT and DFN and the motion-centric model V-JEPA. The Edit and accuracy scores also reflect TWLV-I's strong alignment with ground-truth sequences.
GTEA: TWLV-I excels with an mF1 score of 88.26 (ViT-B) and 88.43 (ViT-L), surpassing all baselines. This demonstrates its robust performance in egocentric views, where precise action segmentation is critical.
Breakfast: Despite the broader view, TWLV-I maintains strong performance, achieving mF1 scores of 52.18 (ViT-B) and 50.66 (ViT-L). This highlights its versatility across different camera perspectives.
7.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Capabilities: TWLV-I's superior performance across all datasets indicates a well-balanced understanding of both appearance and motion, crucial for accurate action segmentation.
Alignment with Ground Truth: High Edit and mF1 scores suggest that TWLV-I's predictions closely match the actual sequences of actions, enhancing its reliability for real-world applications.
Versatility Across Views: The model's ability to outperform baselines in various camera views, including top-down and egocentric perspectives, underscores its adaptability and robustness.
Comparison with InternVideo2: While TWLV-I performs comparably to InternVideo2 in specific views, its consistent excellence across different datasets and perspectives highlights its comprehensive capabilities.
These results affirm the effectiveness of our model in tackling the complex task of temporal action segmentation, showcasing its potential for diverse applications in video analysis.
8 - Embedding Visualization
To gain deeper insights into the representational capabilities of TWLV-I and other video foundation models, we conducted visualization experiments using t-SNE and Linear Discriminant Analysis (LDA). These visualizations provide valuable information about the models' ability to capture both appearance-based and motion-based features.
8.1 - t-SNE Visualization on Benchmark Datasets
We used t-SNE to visualize the embedding spaces of the Kinetics-400 (K400) and Something-Something-v2 (SSv2) validation sets, with different colors representing different action classes.
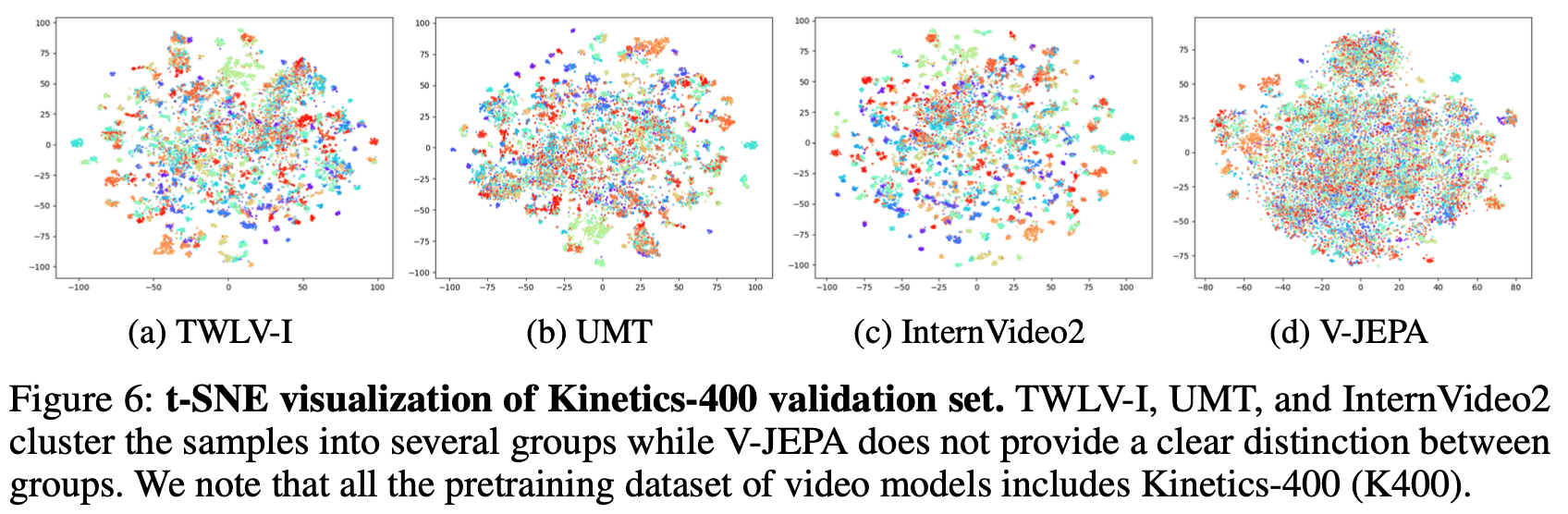
Kinetics-400 (Figure 6)
TWLV-I, UMT, and InternVideo2: These models demonstrate clear clustering of samples, with distinct decision boundaries for most classes. This indicates a strong ability to differentiate between various appearance-based actions.
V-JEPA: In contrast, V-JEPA fails to cluster the samples into distinct groups, suggesting limitations in capturing appearance-based features effectively.
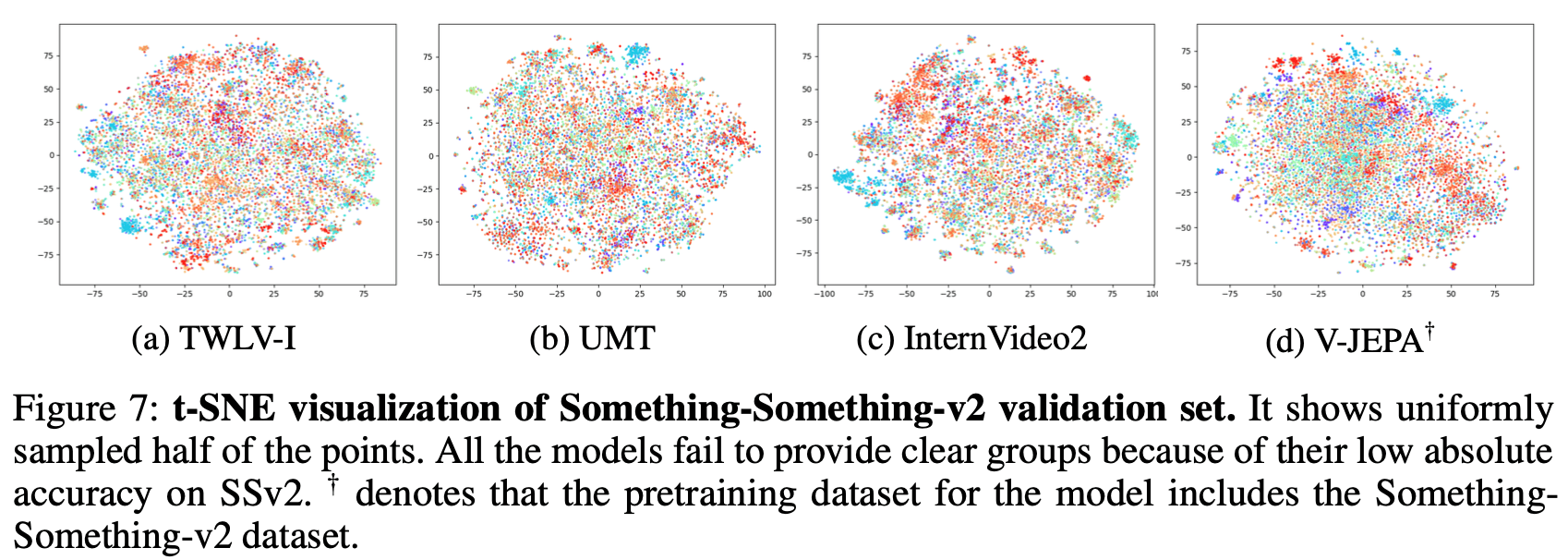
Something-Something-v2 (Figure 7)
All Models: Interestingly, none of the models, including TWLV-I and V-JEPA, show effective clustering of classes in the SSv2 dataset. This aligns with the generally lower classification performance on SSv2 compared to K400.
Implications: The lack of clear clustering in SSv2 visualizations highlights the challenges in representing motion-centric actions and underscores the need for further research to improve performance on such benchmarks.
8.2 - Directional Motion Distinguishability
To better understand the models' capabilities in capturing motion information, we focused on specific classes within SSv2 that require understanding directional motion, such as "Moving something up" and "Moving something down".
We visualized embeddings of original videos and their temporally flipped versions using Linear Discriminant Analysis (LDA). This approach allows us to assess whether models can encode directional motion information in their embedding vectors, independent of appearance.
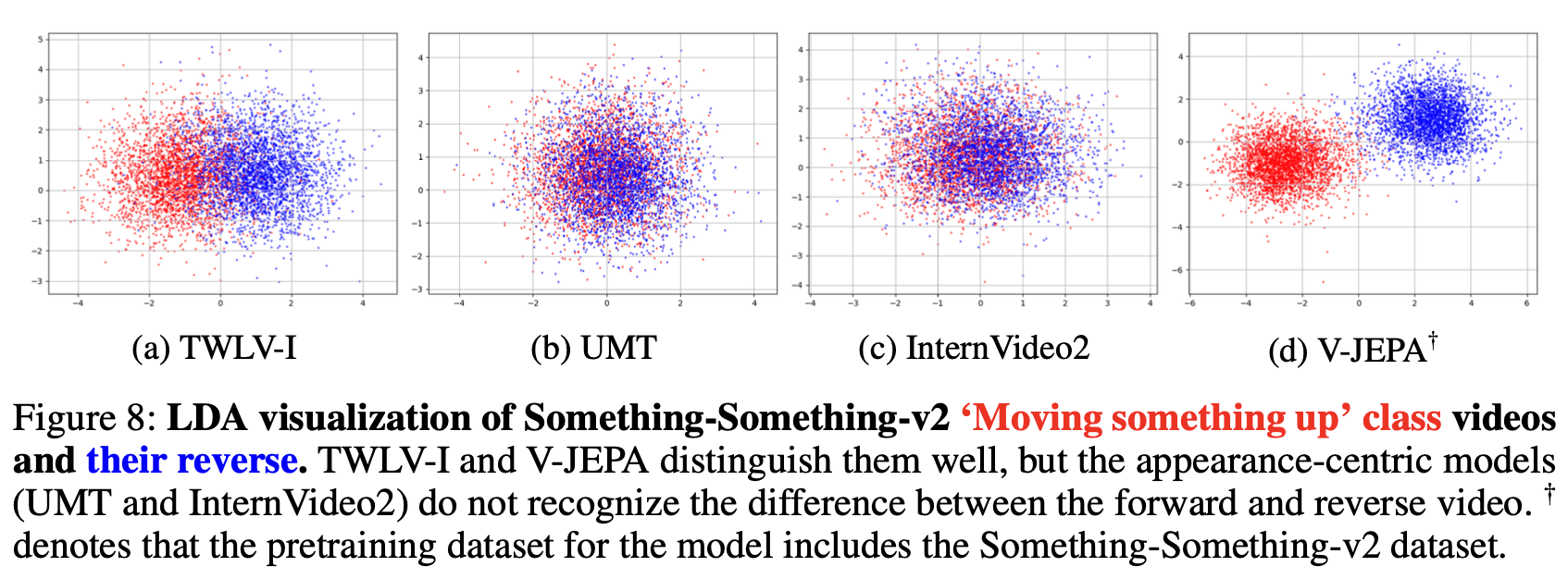
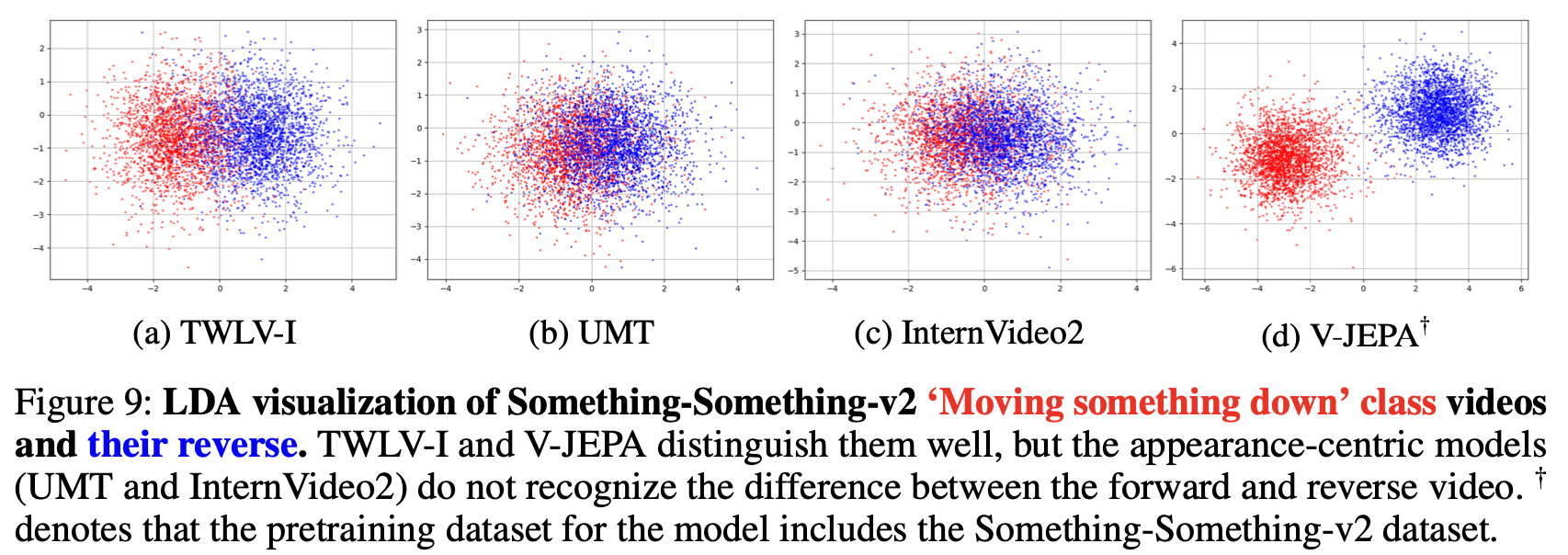
Results (Figures 8 and 9)
TWLV-I: Demonstrates good separation between forward and reverse videos, indicating effective encoding of directional motion information.
V-JEPA: Shows the highest distinguishability between forward and reverse videos, likely due to its pretraining on the SSv2 dataset.
UMT and InternVideo2: Provide non-separable embeddings for forward and reverse videos, suggesting a limitation in capturing directional motion information despite their strong appearance understanding capabilities.
8.3 - Key Insights
Given such observations, we deduce the following insights:
Appearance vs. Motion Understanding: TWLV-I shows a balanced capability in capturing both appearance-based features (evident in K400 visualization) and motion-based features (demonstrated in directional motion analysis).
Challenges in Motion-Centric Tasks: The difficulty in clustering SSv2 classes highlights the complexity of representing motion-centric actions, a challenge faced by all evaluated models.
Directional Motion Encoding: TWLV-I's ability to distinguish between forward and reverse videos indicates its effectiveness in encoding fine-grained motion information, a crucial aspect for comprehensive video understanding.
Model Specialization: The results reveal the strengths and limitations of different models, with some excelling in appearance-based tasks while struggling with motion-centric challenges.
These visualizations provide valuable insights into the representational capabilities of TWLV-I and other video foundation models, highlighting areas of strength and identifying opportunities for further improvement in capturing complex motion dynamics.
9 - Future Directions
As we look ahead, there are several promising avenues for further development and enhancement of TWLV-I and video foundation models in general. These directions aim to expand the model's capabilities, improve its performance, and broaden its applicability across various domains of visual understanding.
9.1 - Scaling Up
Our current focus has been on two primary scales of models: ViT-B and ViT-L. The ViT-L variant of TWLV-I has already demonstrated performance comparable to, and in some cases surpassing, larger models such as ViT-H or ViT-g. This success suggests significant potential for further improvements through scaling:
Increased Model Size: Expanding TWLV-I to even larger architectures could potentially yield substantial performance gains across various tasks.
Large-Scale Datasets: Utilizing extensive, in-house collected datasets for training could lead to the development of more general and robust models. This approach could help in capturing a wider range of visual concepts and scenarios.
Efficient Scaling Techniques: Exploring methods to scale the model efficiently, such as sparse attention mechanisms or mixture-of-experts architectures, could allow for increased model capacity without proportional increases in computational requirements.
9.2 - Enhancing Image Embedding Capabilities
While TWLV-I has shown strong performance in video-related tasks, there's room for improvement in its image embedding capabilities:
Single-Frame Processing: Enhancing TWLV-I's ability to process and understand single-frame inputs (i.e., images) is crucial. This improvement would bridge the gap between video and image understanding, making TWLV-I a more versatile visual foundation model.
Transfer Learning: Developing techniques to effectively transfer knowledge from video understanding to image tasks could lead to improved performance in image-specific applications.
Unified Architecture: Exploring architectural modifications that allow for seamless processing of both videos and images within the same model framework.
9.3 - Expanding Modality
To further enhance TWLV-I's versatility and align it with broader applications in AI, expanding its modality is a key direction:
Multimodal Tasks: Extending TWLV-I to handle multimodal tasks such as video-text retrieval and video captioning. This expansion would require aligning the model with text domains while maintaining its strong unimodal video understanding capabilities.
Video-Language Models: Developing TWLV-I as a more effective vision encoder for video-language models, enabling better integration with language processing tasks.
Audio Integration: Incorporating audio processing capabilities to enable tasks such as audio-visual synchronization and sound event detection in videos.
Evaluation Methodologies: Proposing and standardizing comprehensive evaluation methodologies for these multimodal tasks to ensure thorough assessment and validation of model performance.
By pursuing these future directions, we aim to evolve TWLV-I from a specialized video foundation model to a comprehensive visual understanding system capable of handling a wide range of tasks across different modalities. This evolution will not only enhance the model's performance in existing applications but also open up new possibilities in fields such as human-computer interaction, content creation, and advanced AI assistants.
10 - Conclusion
In this comprehensive exploration of video understanding, we have emphasized the critical importance of both appearance and motion as fundamental elements in comprehending visual content. Our research has led to several key outcomes and insights:
Dual-Aspect Evaluation: We have presented methodologies for measuring both appearance and motion capabilities across various tasks, providing a holistic approach to assessing video foundation models.
Limitations of Existing Models: Through rigorous experiments, we have demonstrated that many existing models struggle to excel in both appearance and motion understanding simultaneously, highlighting a significant gap in the field.
Introduction of TWLV-I: In response to these challenges, we have proposed TWLV-I, a novel approach that demonstrates robust performance in both motion and appearance-based tasks.
Versatile Embeddings: The embeddings generated by TWLV-I show promise for wide-ranging applications and further research in various downstream tasks, potentially accelerating progress in video understanding.
Evaluation Framework: The evaluation and analysis methods introduced in this post offer a comprehensive framework for assessing video foundation models, which we hope will be widely adopted in the field.
Future Directions: Our work points towards potential avenues for future research, including scaling up model size, enhancing image embedding capabilities, and expanding into multimodal tasks.
Guiding the Field: By addressing both appearance and motion aspects, our approach aims to set a new standard and direction for the video understanding domain.
In conclusion, TWLV-I represents a significant step forward in creating more versatile and robust video foundation models. By balancing the capabilities of appearance and motion understanding, it opens up new possibilities for advanced video analysis and comprehension. We anticipate that the methodologies and insights presented here will drive further innovations in video AI and inspire researchers to approach video understanding with a more holistic perspective.
As we move forward, the continued development and refinement of such comprehensive models will be crucial in unlocking the full potential of video understanding technologies across various applications, from content analysis and creation to advanced AI assistants and beyond. We invite the research community to build upon these foundations, pushing the boundaries of what's possible in the realm of video AI.
Twelve Labs Team
This work was achieved through the combined efforts (equal contribution) of the core contributors, with significant support from the Twelve Labs ML Research and ML Data teams.
Core Contributors
Hyeongmin Lee, Research Scientist
Jin-Young Kim, Research Scientist
Kyungjune Baek, Research Scientist
Jihwan Kim, Research Scientist
Aiden Lee, CTO
Contributors (first-name alphabetical order)
Aaron (Jangwon) Lee, ML Data Intern\
Calvin (Minjoon) Seo, Chief Scientist
Cooper (Seokjin) Han, Research Scientist
Daniel (GeunOh) Kim, ML Data Engineer
Flynn (Jiho) Jang, Research Scientist
Ian (Soonwoo) Kwon, Research Scientist
Jay Suh, ML Data Engineer
Jay (Jaehyuk) Yi, Research Scientist
Jayden (Junwan) Kim, Research Intern
Jeff (Jongseok) Kim, Research Scientist
Kyle (Seungjoon) Park, Research Scientist
Leo (Daewoo) Kim, Research Scientist
Mars (Seongsu) Ha, Research Scientist
Max (JongMok) Kim, Research Scientist
Ray (Raehyuk) Jung, Research Scientist
William (Hyojun) Go, Research Scientist
Citation
If you think this project is helpful, please feel free to leave a star and cite our paper:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }
Check out the TWLV-I technical report on arXiV and HuggingFace! The code is available on GitHub: https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
Comprehensive Evaluation Framework: Twelve Labs introduces a robust evaluation framework for video understanding, emphasizing both appearance and motion analysis.
TWLV-I Model: Our new video foundation model (TWLV-I) excels in balancing these dual aspects, outperforming or matching state-of-the-art models.
Task Performance: TWLV-I shows strong results across action recognition, temporal action localization, and spatio-temporal action localization, highlighting its versatility.
Visualization Insights: t-SNE and LDA visualizations reveal TWLV-I's superior clustering and motion distinguishability capabilities compared to other models.
Future Directions: Emphasizes scaling up, improving image embedding, and expanding modalities to enhance TWLV-I's versatility and applicability.
Guiding Future Research: The proposed methodologies aim to set a new standard in video understanding, guiding future research and development in the field.
1 - Introduction
In today's digital landscape, video serves as a universal language, seamlessly conveying complex ideas and emotions across cultures. Developing robust video understanding systems is crucial for accurately interpreting this rich medium. Videos, as sequences of images, require a dual focus: recognizing the appearance in each frame and understanding the motion that unfolds over time.
At Twelve Labs, we recognize the need for a comprehensive evaluation framework that addresses these dual aspects of video understanding. Our goal is to set a clear direction for future research in this field by establishing methodologies that accurately measure both appearance and motion capabilities.
1.1 - Foundation Models and Video Understanding
Foundation Models (FMs) have revolutionized AI by enabling models to handle diverse tasks within a domain. While Language and Image Foundation Models have made significant strides, video understanding presents unique challenges. Existing Video Foundation Models often fall short in effectively capturing both appearance and motion, as evidenced by limitations in clustering and classification tasks.
1.2 - Introducing TWLV-I and Our Evaluation Framework
To address these challenges, we introduce TWLV-I - designed to excel in both appearance and motion-based tasks, as shown in Figure 1. More importantly, we propose a robust evaluation framework that not only assesses TWLV-I's capabilities but also sets a benchmark for future models.
Our framework includes a range of tasks such as action recognition, temporal action localization, and spatio-temporal action localization, each meticulously designed to evaluate specific aspects of video understanding. Through this comprehensive approach, we aim to highlight the importance of balanced capabilities and guide the field towards more holistic model development.
By focusing on both the performance and proper evaluation of video models, we aspire to present a milestone in video research, paving the way for future advancements and innovations in this dynamic field.
2 - TWLV-I & Video Foundation Model Evaluation Framework
TWLV-I's architecture and training process are designed to address the unique challenges of video understanding, balancing the need for both appearance and motion comprehension. Figure 2 provides a visual comparison of TWLV-I's performance on appearance-centric (Kinetics-400) versus motion-centric (SSv2 and Diving-48) benchmarks. The plot demonstrates TWLV-I's balanced capabilities, handling both types of tasks reasonably well.
This subsection delves into the key aspects of TWLV-I's training methodology and frame sampling techniques.
2.1 - Architecture
TWLV-I is built upon the Vision Transformer (ViT) architecture, leveraging its powerful ability to process visual data. We implement two variants:
ViT-B (Base): A model with 86 million parameters
ViT-L (Large): An expanded version with 307 million parameters
The input video is tokenized into multiple patches, which are then processed through the transformer layers. This process yields patch-wise embeddings that are subsequently pooled to generate the overall embedding for the input video.
2.2 - Pretraining Dataset
To ensure robust and versatile video understanding, TWLV-I is pretrained on a diverse set of datasets, as detailed in Table 1:
Video datasets:
Kinetics 710 (658K clips)
HowTo360K (360K clips, a subset of HowTo100M)
WebVid10M (10.73M clips)
Image datasets (total of 15M images):
COCO (113K images)
SBU Captions (860K images)
Visual Genome (100K images)
CC3M (2.88M images)
CC12M (11.00M images)
This combination of video and image datasets enhances TWLV-I's ability to understand both motion dynamics and static visual features.
2.3 - Training Objective
TWLV-I employs a masked modeling schema as its foundational training approach. However, to optimize the model's performance in both motion and appearance understanding, we diversify the reconstruction targets. This strategy aims to create a robust model capable of excelling across various video understanding tasks. The model is trained from scratch using this objective and the aforementioned datasets.
2.4 - Frame Sampling
The frame sampling process is crucial due to the computational constraints of the ViT architecture. As the number of tokens increases, so does the computational complexity (quadratically). To manage this, we employ a strategic frame sampling technique called Multi-Clip Embedding (shown in Figure 4):
Clip Division: An input video is divided into M clips, each T seconds long.
Frame Selection: N frames are sampled from each clip.
Embedding Generation: This process results in M embeddings per video.
Flexible Representation: The number of embeddings increases proportionally with video length, allowing for variable-length video processing.
Single Embedding Option: When a single embedding is required to represent the entire video, we average the M embeddings.
This approach allows TWLV-I to handle videos of varying lengths efficiently while maintaining the ability to capture both short-term and long-term temporal dynamics.
By combining a powerful ViT architecture with a diverse pretraining dataset and an innovative frame sampling technique, TWLV-I is well-equipped to handle the complexities of video understanding tasks. This foundation enables TWLV-I to perform robustly across both appearance-centric and motion-centric benchmarks, as we will explore in subsequent sections of this evaluation framework.
3 - Action Recognition
Action Recognition (AR) is a fundamental task in video understanding, aiming to classify videos into predefined human action categories. This task serves as a crucial benchmark for evaluating the performance of video foundation models, as it requires both appearance and motion understanding.
3.1 - Benchmarks
We evaluate TWLV-I's performance on five representative AR benchmarks, each with its unique characteristics:
Kinetics-400 (K400): A large-scale dataset focusing on appearance-based actions
Something-Something-v2 (SSv2): A motion-centric dataset emphasizing temporal relationships
Moments-in-Time (MiT): Another appearance-focused dataset with diverse action categories
Diving-48 (DV48): A fine-grained, motion-centric dataset of diving actions
Epic-Kitchens (EK): An egocentric dataset capturing daily kitchen activities
These benchmarks provide a comprehensive evaluation landscape, allowing us to assess TWLV-I's capabilities across both appearance-focused and motion-centric scenarios.
3.2 - Evaluation Methodology
We employ a multi-view classification method, which is standard in action recognition tasks:
Spatial resizing of input videos to match the required input resolution
Uniform sampling of m clips along the spatial dimension and n clips along the temporal dimension, resulting in m × n total clips
Calculation of class probabilities for each clip
Averaging of probabilities to obtain the final output
This approach ensures a thorough evaluation of the model's performance across different spatial and temporal segments of the input videos.
3.3 - Linear Probing
Linear probing is a technique used to evaluate the quality of learned representations without fine-tuning the entire model. It involves:
Freezing the feature extractor (backbone model)
Training a linear classifier on top of the frozen features
The linear classifier consists of a weight matrix that maps the embedding vector dimension to the number of action classes.
Results and Analysis
Table 3 presents the linear probing results across various benchmarks and models. Key observations include:
TWLV-I demonstrates strong performance across all benchmarks, particularly within its architecture scale (ViT-B and ViT-L).
For SSv2, TWLV-I outperforms larger models like ViT-H (DFN) and ViT-g (InternVideo2), with the exception of V-JEPA, which includes SSv2 in its pretraining.
TWLV-I's ViT-L variant surpasses larger-scale models on EK and DV48 benchmarks.
These results highlight TWLV-I's ability to learn rich, generalizable features that transfer well to various action recognition tasks, even when evaluated using a simple linear classifier.
3.4 - Attentive Probing
While linear probing provides insights into clip-wise embedding quality, it may not fully capture the models' capabilities, especially for those trained with patch-level supervision. To address this limitation, we introduce attentive probing, which involves:
Training a single attention layer with a learnable class token on top of the frozen model
Passing the output class token through a linear classifier
Measuring the top-1 accuracy
This method allows for a more nuanced evaluation of the models' patch-wise representation capabilities.
Results and Analysis
Table 5 showcases the attentive probing results. Key findings include:
TWLV-I achieves superior performance across both appearance- and motion-centric benchmarks compared to other models.
The strong performance in attentive probing suggests that TWLV-I possesses richer patch-wise representations compared to its counterparts.
3.5 - K-Nearest Neighbors
To provide a parameter-free evaluation of embedding quality and address potential biases in gradient-based methods, we employ the K-Nearest Neighbors (KNN) classification task. This non-parametric approach offers a fair comparison of embedding vectors across different model architectures.
We generate embeddings using two methods:
Uniform Embedding: A single embedding vector for the entire video.
Multi-Clip Embedding: Multiple embeddings from 2-second clips throughout the video.
For Multi-Clip Embedding, we employ two evaluation strategies:
Video-level: Averaging all clip embeddings to create a single video representation.
Clip-level: Summing votes received by each clip to determine the final class.
Results and Analysis
Table 6 presents the KNN classification results across different models and embedding strategies. Key observations include:
TWLV-I demonstrates competitive performance on both Kinetics-400 (K400) and Something-Something-v2 (SSv2) datasets, particularly when compared to models of similar scale.
In the Uniform embedding setting, TWLV-I-ViT-B achieves 57.51% and 19.82% top-1 accuracy on K400 and SSv2 respectively, outperforming UMT_s2 with the same architecture.
TWLV-I-ViT-L shows strong results, with 65.97% and 19.47% top-1 accuracy on K400 and SSv2, surpassing several larger models.
However, unlike the attentive probing results, TWLV-I underperforms compared to InternVideo2 on both K400 and SSv2 in the KNN evaluation. This suggests:
There's room for improvement in utilizing TWLV-I's embeddings in a non-parametric manner.
The need for further research on effectively representing embeddings for longer videos, especially those extending beyond a single clip length.
These results highlight the complexity of video representation and the challenges in creating a universally strong embedding across different evaluation methodologies.
3.6 - Pre-Training with SSv2
To ensure a fair comparison with models like V-JEPA and to assess the impact of including motion-centric data in pretraining, we conducted an additional experiment by incorporating the Something-Something-v2 (SSv2) dataset into TWLV-I's pretraining phase.
We trained a variant of TWLV-I (ViT-L architecture) including SSv2 in its pretraining dataset alongside the original datasets. This allows us to directly compare the impact of this additional data on various benchmarks and evaluation methods.
Results and Analysis
The results of this SSv2-enhanced model are presented at the bottom of Tables 3, 5, and 6. Key findings include:
Improved SSv2 Performance: Across all evaluation methods (linear probing, attentive probing, and KNN), the model shows significant improvements on the SSv2 benchmark. For example, in linear probing (Table 3), the top-1 accuracy on SSv2 increases from 46.41% to 48.14%.
General Performance Boost: The inclusion of SSv2 in pretraining leads to performance gains across other benchmarks as well. This suggests that the additional motion-centric data enhances the model's overall video understanding capabilities.
Comparison with Specialized Models: Despite the improvements, the KNN performance of our SSv2-enhanced model still lags behind V-JEPA and InternVideo2 on SSv2. This indicates that while TWLV-I's patch-level representations are strong, there's room for improvement in video-level representations.
Trade-offs in Representation: The results highlight a potential imbalance between TWLV-I's patch-level and video-level representations. Addressing this discrepancy should be a key focus for future enhancements to the model.
These findings underscore the importance of diverse pretraining data in developing robust video foundation models. They also point to specific areas where TWLV-I can be improved to better compete with specialized models on motion-centric tasks while maintaining its strong performance on appearance-based benchmarks.
4 - ImageNet Classification
To assess the versatility of video foundation models and their potential to function as general vision models, we evaluated TWLV-I's performance on the ImageNet classification task. This benchmark provides insights into the model's ability to process and understand static images, which is crucial for a comprehensive video understanding system.
4.1 - Results and Analysis
The ImageNet classification results are presented in the last columns of Table 3 (linear probing) and Table 5 (attentive probing). Key observations include:
Correlation with Appearance-Centric Tasks: Generally, models that excel in appearance-centric action recognition tasks (e.g., Kinetics-400) also demonstrate strong performance on the ImageNet benchmark. This correlation suggests that the features learned for video understanding can transfer effectively to static image classification.
TWLV-I's Performance:
In linear probing (Table 3), TWLV-I-ViT-L achieves 72.98% Top-1 accuracy on ImageNet, which is competitive but not leading.
For attentive probing (Table 5), TWLV-I-ViT-L shows improved performance with 79.19% Top-1 accuracy, indicating better utilization of learned features through attention mechanisms.
Comparison with Specialized Models: While TWLV-I shows strong performance on video-based tasks, there's a noticeable gap in ImageNet classification compared to some specialized models. For instance, InternVideo2 significantly outperforms TWLV-I on ImageNet, although this gap narrows or even reverses in video action recognition tasks.
4.2 - Implications and Insights
Given such observations, we deduce the following insights:
Static Image Processing Limitations: The results suggest that TWLV-I has some limitations in processing static images compared to models optimized for this task. This indicates an area for potential improvement in future iterations of the model.
Motion Information Utilization: The narrowing performance gap between TWLV-I and other models in video tasks, despite lower ImageNet scores, suggests that TWLV-I effectively leverages motion information for video understanding. This ability complements its appearance-based features, resulting in strong overall video analysis performance.
Balancing Video and Image Capabilities: To evolve TWLV-I beyond being solely a video model, future research should focus on enhancing its ability to understand single images without compromising its strong video analysis capabilities.
Overall, while TWLV-I demonstrates strong capabilities in video understanding tasks, the ImageNet classification results highlight areas for improvement in static image processing. Addressing these limitations could lead to a more comprehensive visual foundation model capable of excelling across both video and image domains.
5 - Temporal Action Localization
Temporal Action Localization (TAL) is a critical task in video understanding that involves identifying and localizing specific actions within untrimmed videos. This task is particularly important for applications in autonomous driving, sports analysis, and content-based video retrieval. TAL requires models to analyze long, complex videos and precisely determine both the temporal boundaries and class labels of distinct actions occurring within them.
5.1 - Evaluation Perspectives
TAL evaluates video foundation models from two key perspectives:
Temporal Sensitivity: The ability to identify if an action of interest occurs at a specific time step.
Instance Discrimination: The capability to distinguish or group frame-wise segments into complete action instances.
While TAL is primarily designed as a motion-centric task, our analysis reveals that both appearance and motion capabilities contribute to achieving these aspects effectively.
5.2 - Methodology
We evaluated TWLV-I and other video foundation models on two prominent TAL datasets:
ActivityNet-v1.3
THUMOS14
For the detection head, we employed ActionFormer. Our evaluation used two distinct methods:
Self-contained: The model performs both classification and regression without external assistance.
w/ External Classifier: The model conducts binary classification, while an external classifier predicts the action class.
Feature extraction followed the Multi-Clip Embedding method described in the "Frame Sampling" section.
5.3 - Results and Analysis
Tables 9 and 10 present the comprehensive results for THUMOS14 and ActivityNet-v1.3, respectively.
THUMOS14 (Table 9)
TWLV-I (our model) consistently outperforms other models of the same scale across all metrics.
TWLV-I-ViT-L achieves the highest average mAP of 58.75% in the self-contained setting and 53.63% with an external classifier.
Notably, TWLV-I-ViT-L surpasses larger models like DFN and V-JEPA (ViT-H), demonstrating its robust generalization capabilities.
ActivityNet-v1.3 (Table 10)
TWLV-I again shows superior performance within its architecture scale.
TWLV-I-ViT-L achieves an average mAP of 34.98% (self-contained) and 39.49% (w/ external classifier).
Remarkably, TWLV-I performs exceptionally well at strict IoU thresholds (e.g., 0.95), indicating strong temporal sensitivity.
5.4 - Key Insights
Given such observations, we deduce the following insights:
Scale Efficiency: TWLV-I's performance, especially at the ViT-L scale, outperforming larger models, highlights its efficient architecture and training methodology.
Temporal Precision: High performance at strict IoU thresholds (e.g., 0.95 in ActivityNet) demonstrates TWLV-I's superior temporal sensitivity.
Model Scale Impact: InternVideo2's top performance, particularly in self-contained evaluation, suggests that TAL benefits from larger model scales, especially when performing both classification and boundary regression simultaneously.
Evaluation Strategy: For a focused assessment of motion understanding, using an external classifier is recommended. However, for a comprehensive evaluation including appearance capabilities, the self-contained approach is preferable.
Generalization Capability: TWLV-I's strong performance across different datasets and evaluation methods indicates its robustness as a backbone for temporal localization tasks.
These results underscore TWLV-I's effectiveness in tackling the complex task of temporal action localization, showcasing its balanced capabilities in both temporal sensitivity and instance discrimination. The model's performance across various scales and evaluation methods demonstrates its potential as a versatile foundation for video understanding tasks.
6 - Spatio-Temporal Action Localization
Spatio-Temporal Action Localization (STAL) is a complex task that evaluates a model's ability to not only recognize actions but also accurately localize them in both space and time within untrimmed videos. This task is crucial for applications requiring detailed action analysis, as it demands a comprehensive understanding of both appearance and motion.
6.1 - Dataset and Evaluation
We evaluate models using the AVA v2.2 dataset, which consists of 430 movie clips, each 15 minutes long. Keyframes are annotated every second, resulting in 210,634 labeled frames in the training set and 57,371 in the validation set. The dataset includes 80 atomic actions labeled for each actor.
For evaluation, we report the Frame Average Precision (fAP) at an Intersection over Union (IoU) threshold of 0.5, using the latest v2.2 annotations. We adopt an end-to-end STAL framework, training the decoder while keeping the vision backbone frozen.
6.2 - Results and Analysis
Table 11 presents the evaluation results for the STAL task. Key observations include:
Comparison with Other Models: TWLV-I, along with UMT and InternVideo2, outperforms DFN and V-JEPA. While DFN and V-JEPA exhibit opposite trends in other tasks, they show similar performance in STAL due to the dual requirements of instance localization and action recognition.
Challenges in Instance Localization:
V-JEPA: Struggles with instance localization, which impairs its ability to perform action recognition effectively.
DFN: Excels in localizing instances due to its strong appearance understanding but fails in action recognition due to limited temporal understanding.
Strengths of TWLV-I:
TWLV-I demonstrates a balanced understanding of both appearance and motion, allowing it to perform well in STAL.
At the ViT-L scale, TWLV-I achieves a fAP@0.5 of 27.39, outperforming both DFN and V-JEPA and closely matching the performance of larger models like InternVideo2.
6.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Understanding: The results confirm that TWLV-I effectively understands spatio-temporal information, crucial for accurate STAL.
Comprehensive Evaluation: The STAL task, conducted in an end-to-end manner, serves as a robust measure of a model's ability to understand video comprehensively, encompassing both spatial and temporal dimensions.
Model Validation: The performance of TWLV-I, alongside UMT and InternVideo2, highlights its capability to handle the dual challenges of localization and recognition, setting it apart from models with a singular focus on appearance or motion.
These findings underscore the importance of a balanced approach to video understanding, where both appearance and motion are integrated to achieve superior performance in complex tasks like STAL.
7 - Temporal Action Segmentation
Temporal Action Segmentation (TAS) is a crucial task for understanding and analyzing human activities in complex, extended videos. It has a wide range of applications, including video surveillance, summarization, and skill assessment. TAS involves processing untrimmed video inputs to generate a sequence of action class labels for each frame.
7.1 - Benchmarks and Methodology
We evaluate TAS using three challenging benchmarks:
50Salads: Focuses on fine-grained actions in cooking scenarios.
GTEA: Captures egocentric views of daily activities.
Breakfast: Encompasses a broader view, including full-body actions.
For TAS, we employ ASFormer as the detection head. We report the average F1 scores at thresholds of 10, 25, and 50, referred to as ‘mF1’. Features are extracted using the Multi-Clip Embedding method and aggregated with spatial pooling to retain only the temporal axis.
7.2 - Results and Analysis
Table 12 presents the TAS evaluation results across the three benchmarks:
50Salads: TWLV-I achieves an mF1 score of 80.69 with ViT-B and 80.60 with ViT-L, outperforming both appearance-centric models like UMT and DFN and the motion-centric model V-JEPA. The Edit and accuracy scores also reflect TWLV-I's strong alignment with ground-truth sequences.
GTEA: TWLV-I excels with an mF1 score of 88.26 (ViT-B) and 88.43 (ViT-L), surpassing all baselines. This demonstrates its robust performance in egocentric views, where precise action segmentation is critical.
Breakfast: Despite the broader view, TWLV-I maintains strong performance, achieving mF1 scores of 52.18 (ViT-B) and 50.66 (ViT-L). This highlights its versatility across different camera perspectives.
7.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Capabilities: TWLV-I's superior performance across all datasets indicates a well-balanced understanding of both appearance and motion, crucial for accurate action segmentation.
Alignment with Ground Truth: High Edit and mF1 scores suggest that TWLV-I's predictions closely match the actual sequences of actions, enhancing its reliability for real-world applications.
Versatility Across Views: The model's ability to outperform baselines in various camera views, including top-down and egocentric perspectives, underscores its adaptability and robustness.
Comparison with InternVideo2: While TWLV-I performs comparably to InternVideo2 in specific views, its consistent excellence across different datasets and perspectives highlights its comprehensive capabilities.
These results affirm the effectiveness of our model in tackling the complex task of temporal action segmentation, showcasing its potential for diverse applications in video analysis.
8 - Embedding Visualization
To gain deeper insights into the representational capabilities of TWLV-I and other video foundation models, we conducted visualization experiments using t-SNE and Linear Discriminant Analysis (LDA). These visualizations provide valuable information about the models' ability to capture both appearance-based and motion-based features.
8.1 - t-SNE Visualization on Benchmark Datasets
We used t-SNE to visualize the embedding spaces of the Kinetics-400 (K400) and Something-Something-v2 (SSv2) validation sets, with different colors representing different action classes.
Kinetics-400 (Figure 6)
TWLV-I, UMT, and InternVideo2: These models demonstrate clear clustering of samples, with distinct decision boundaries for most classes. This indicates a strong ability to differentiate between various appearance-based actions.
V-JEPA: In contrast, V-JEPA fails to cluster the samples into distinct groups, suggesting limitations in capturing appearance-based features effectively.
Something-Something-v2 (Figure 7)
All Models: Interestingly, none of the models, including TWLV-I and V-JEPA, show effective clustering of classes in the SSv2 dataset. This aligns with the generally lower classification performance on SSv2 compared to K400.
Implications: The lack of clear clustering in SSv2 visualizations highlights the challenges in representing motion-centric actions and underscores the need for further research to improve performance on such benchmarks.
8.2 - Directional Motion Distinguishability
To better understand the models' capabilities in capturing motion information, we focused on specific classes within SSv2 that require understanding directional motion, such as "Moving something up" and "Moving something down".
We visualized embeddings of original videos and their temporally flipped versions using Linear Discriminant Analysis (LDA). This approach allows us to assess whether models can encode directional motion information in their embedding vectors, independent of appearance.
Results (Figures 8 and 9)
TWLV-I: Demonstrates good separation between forward and reverse videos, indicating effective encoding of directional motion information.
V-JEPA: Shows the highest distinguishability between forward and reverse videos, likely due to its pretraining on the SSv2 dataset.
UMT and InternVideo2: Provide non-separable embeddings for forward and reverse videos, suggesting a limitation in capturing directional motion information despite their strong appearance understanding capabilities.
8.3 - Key Insights
Given such observations, we deduce the following insights:
Appearance vs. Motion Understanding: TWLV-I shows a balanced capability in capturing both appearance-based features (evident in K400 visualization) and motion-based features (demonstrated in directional motion analysis).
Challenges in Motion-Centric Tasks: The difficulty in clustering SSv2 classes highlights the complexity of representing motion-centric actions, a challenge faced by all evaluated models.
Directional Motion Encoding: TWLV-I's ability to distinguish between forward and reverse videos indicates its effectiveness in encoding fine-grained motion information, a crucial aspect for comprehensive video understanding.
Model Specialization: The results reveal the strengths and limitations of different models, with some excelling in appearance-based tasks while struggling with motion-centric challenges.
These visualizations provide valuable insights into the representational capabilities of TWLV-I and other video foundation models, highlighting areas of strength and identifying opportunities for further improvement in capturing complex motion dynamics.
9 - Future Directions
As we look ahead, there are several promising avenues for further development and enhancement of TWLV-I and video foundation models in general. These directions aim to expand the model's capabilities, improve its performance, and broaden its applicability across various domains of visual understanding.
9.1 - Scaling Up
Our current focus has been on two primary scales of models: ViT-B and ViT-L. The ViT-L variant of TWLV-I has already demonstrated performance comparable to, and in some cases surpassing, larger models such as ViT-H or ViT-g. This success suggests significant potential for further improvements through scaling:
Increased Model Size: Expanding TWLV-I to even larger architectures could potentially yield substantial performance gains across various tasks.
Large-Scale Datasets: Utilizing extensive, in-house collected datasets for training could lead to the development of more general and robust models. This approach could help in capturing a wider range of visual concepts and scenarios.
Efficient Scaling Techniques: Exploring methods to scale the model efficiently, such as sparse attention mechanisms or mixture-of-experts architectures, could allow for increased model capacity without proportional increases in computational requirements.
9.2 - Enhancing Image Embedding Capabilities
While TWLV-I has shown strong performance in video-related tasks, there's room for improvement in its image embedding capabilities:
Single-Frame Processing: Enhancing TWLV-I's ability to process and understand single-frame inputs (i.e., images) is crucial. This improvement would bridge the gap between video and image understanding, making TWLV-I a more versatile visual foundation model.
Transfer Learning: Developing techniques to effectively transfer knowledge from video understanding to image tasks could lead to improved performance in image-specific applications.
Unified Architecture: Exploring architectural modifications that allow for seamless processing of both videos and images within the same model framework.
9.3 - Expanding Modality
To further enhance TWLV-I's versatility and align it with broader applications in AI, expanding its modality is a key direction:
Multimodal Tasks: Extending TWLV-I to handle multimodal tasks such as video-text retrieval and video captioning. This expansion would require aligning the model with text domains while maintaining its strong unimodal video understanding capabilities.
Video-Language Models: Developing TWLV-I as a more effective vision encoder for video-language models, enabling better integration with language processing tasks.
Audio Integration: Incorporating audio processing capabilities to enable tasks such as audio-visual synchronization and sound event detection in videos.
Evaluation Methodologies: Proposing and standardizing comprehensive evaluation methodologies for these multimodal tasks to ensure thorough assessment and validation of model performance.
By pursuing these future directions, we aim to evolve TWLV-I from a specialized video foundation model to a comprehensive visual understanding system capable of handling a wide range of tasks across different modalities. This evolution will not only enhance the model's performance in existing applications but also open up new possibilities in fields such as human-computer interaction, content creation, and advanced AI assistants.
10 - Conclusion
In this comprehensive exploration of video understanding, we have emphasized the critical importance of both appearance and motion as fundamental elements in comprehending visual content. Our research has led to several key outcomes and insights:
Dual-Aspect Evaluation: We have presented methodologies for measuring both appearance and motion capabilities across various tasks, providing a holistic approach to assessing video foundation models.
Limitations of Existing Models: Through rigorous experiments, we have demonstrated that many existing models struggle to excel in both appearance and motion understanding simultaneously, highlighting a significant gap in the field.
Introduction of TWLV-I: In response to these challenges, we have proposed TWLV-I, a novel approach that demonstrates robust performance in both motion and appearance-based tasks.
Versatile Embeddings: The embeddings generated by TWLV-I show promise for wide-ranging applications and further research in various downstream tasks, potentially accelerating progress in video understanding.
Evaluation Framework: The evaluation and analysis methods introduced in this post offer a comprehensive framework for assessing video foundation models, which we hope will be widely adopted in the field.
Future Directions: Our work points towards potential avenues for future research, including scaling up model size, enhancing image embedding capabilities, and expanding into multimodal tasks.
Guiding the Field: By addressing both appearance and motion aspects, our approach aims to set a new standard and direction for the video understanding domain.
In conclusion, TWLV-I represents a significant step forward in creating more versatile and robust video foundation models. By balancing the capabilities of appearance and motion understanding, it opens up new possibilities for advanced video analysis and comprehension. We anticipate that the methodologies and insights presented here will drive further innovations in video AI and inspire researchers to approach video understanding with a more holistic perspective.
As we move forward, the continued development and refinement of such comprehensive models will be crucial in unlocking the full potential of video understanding technologies across various applications, from content analysis and creation to advanced AI assistants and beyond. We invite the research community to build upon these foundations, pushing the boundaries of what's possible in the realm of video AI.
Twelve Labs Team
This work was achieved through the combined efforts (equal contribution) of the core contributors, with significant support from the Twelve Labs ML Research and ML Data teams.
Core Contributors
Hyeongmin Lee, Research Scientist
Jin-Young Kim, Research Scientist
Kyungjune Baek, Research Scientist
Jihwan Kim, Research Scientist
Aiden Lee, CTO
Contributors (first-name alphabetical order)
Aaron (Jangwon) Lee, ML Data Intern\
Calvin (Minjoon) Seo, Chief Scientist
Cooper (Seokjin) Han, Research Scientist
Daniel (GeunOh) Kim, ML Data Engineer
Flynn (Jiho) Jang, Research Scientist
Ian (Soonwoo) Kwon, Research Scientist
Jay Suh, ML Data Engineer
Jay (Jaehyuk) Yi, Research Scientist
Jayden (Junwan) Kim, Research Intern
Jeff (Jongseok) Kim, Research Scientist
Kyle (Seungjoon) Park, Research Scientist
Leo (Daewoo) Kim, Research Scientist
Mars (Seongsu) Ha, Research Scientist
Max (JongMok) Kim, Research Scientist
Ray (Raehyuk) Jung, Research Scientist
William (Hyojun) Go, Research Scientist
Citation
If you think this project is helpful, please feel free to leave a star and cite our paper:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }
Check out the TWLV-I technical report on arXiV and HuggingFace! The code is available on GitHub: https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
Comprehensive Evaluation Framework: Twelve Labs introduces a robust evaluation framework for video understanding, emphasizing both appearance and motion analysis.
TWLV-I Model: Our new video foundation model (TWLV-I) excels in balancing these dual aspects, outperforming or matching state-of-the-art models.
Task Performance: TWLV-I shows strong results across action recognition, temporal action localization, and spatio-temporal action localization, highlighting its versatility.
Visualization Insights: t-SNE and LDA visualizations reveal TWLV-I's superior clustering and motion distinguishability capabilities compared to other models.
Future Directions: Emphasizes scaling up, improving image embedding, and expanding modalities to enhance TWLV-I's versatility and applicability.
Guiding Future Research: The proposed methodologies aim to set a new standard in video understanding, guiding future research and development in the field.
1 - Introduction
In today's digital landscape, video serves as a universal language, seamlessly conveying complex ideas and emotions across cultures. Developing robust video understanding systems is crucial for accurately interpreting this rich medium. Videos, as sequences of images, require a dual focus: recognizing the appearance in each frame and understanding the motion that unfolds over time.
At Twelve Labs, we recognize the need for a comprehensive evaluation framework that addresses these dual aspects of video understanding. Our goal is to set a clear direction for future research in this field by establishing methodologies that accurately measure both appearance and motion capabilities.
1.1 - Foundation Models and Video Understanding
Foundation Models (FMs) have revolutionized AI by enabling models to handle diverse tasks within a domain. While Language and Image Foundation Models have made significant strides, video understanding presents unique challenges. Existing Video Foundation Models often fall short in effectively capturing both appearance and motion, as evidenced by limitations in clustering and classification tasks.
1.2 - Introducing TWLV-I and Our Evaluation Framework
To address these challenges, we introduce TWLV-I - designed to excel in both appearance and motion-based tasks, as shown in Figure 1. More importantly, we propose a robust evaluation framework that not only assesses TWLV-I's capabilities but also sets a benchmark for future models.
Our framework includes a range of tasks such as action recognition, temporal action localization, and spatio-temporal action localization, each meticulously designed to evaluate specific aspects of video understanding. Through this comprehensive approach, we aim to highlight the importance of balanced capabilities and guide the field towards more holistic model development.
By focusing on both the performance and proper evaluation of video models, we aspire to present a milestone in video research, paving the way for future advancements and innovations in this dynamic field.
2 - TWLV-I & Video Foundation Model Evaluation Framework
TWLV-I's architecture and training process are designed to address the unique challenges of video understanding, balancing the need for both appearance and motion comprehension. Figure 2 provides a visual comparison of TWLV-I's performance on appearance-centric (Kinetics-400) versus motion-centric (SSv2 and Diving-48) benchmarks. The plot demonstrates TWLV-I's balanced capabilities, handling both types of tasks reasonably well.
This subsection delves into the key aspects of TWLV-I's training methodology and frame sampling techniques.
2.1 - Architecture
TWLV-I is built upon the Vision Transformer (ViT) architecture, leveraging its powerful ability to process visual data. We implement two variants:
ViT-B (Base): A model with 86 million parameters
ViT-L (Large): An expanded version with 307 million parameters
The input video is tokenized into multiple patches, which are then processed through the transformer layers. This process yields patch-wise embeddings that are subsequently pooled to generate the overall embedding for the input video.
2.2 - Pretraining Dataset
To ensure robust and versatile video understanding, TWLV-I is pretrained on a diverse set of datasets, as detailed in Table 1:
Video datasets:
Kinetics 710 (658K clips)
HowTo360K (360K clips, a subset of HowTo100M)
WebVid10M (10.73M clips)
Image datasets (total of 15M images):
COCO (113K images)
SBU Captions (860K images)
Visual Genome (100K images)
CC3M (2.88M images)
CC12M (11.00M images)
This combination of video and image datasets enhances TWLV-I's ability to understand both motion dynamics and static visual features.
2.3 - Training Objective
TWLV-I employs a masked modeling schema as its foundational training approach. However, to optimize the model's performance in both motion and appearance understanding, we diversify the reconstruction targets. This strategy aims to create a robust model capable of excelling across various video understanding tasks. The model is trained from scratch using this objective and the aforementioned datasets.
2.4 - Frame Sampling
The frame sampling process is crucial due to the computational constraints of the ViT architecture. As the number of tokens increases, so does the computational complexity (quadratically). To manage this, we employ a strategic frame sampling technique called Multi-Clip Embedding (shown in Figure 4):
Clip Division: An input video is divided into M clips, each T seconds long.
Frame Selection: N frames are sampled from each clip.
Embedding Generation: This process results in M embeddings per video.
Flexible Representation: The number of embeddings increases proportionally with video length, allowing for variable-length video processing.
Single Embedding Option: When a single embedding is required to represent the entire video, we average the M embeddings.
This approach allows TWLV-I to handle videos of varying lengths efficiently while maintaining the ability to capture both short-term and long-term temporal dynamics.
By combining a powerful ViT architecture with a diverse pretraining dataset and an innovative frame sampling technique, TWLV-I is well-equipped to handle the complexities of video understanding tasks. This foundation enables TWLV-I to perform robustly across both appearance-centric and motion-centric benchmarks, as we will explore in subsequent sections of this evaluation framework.
3 - Action Recognition
Action Recognition (AR) is a fundamental task in video understanding, aiming to classify videos into predefined human action categories. This task serves as a crucial benchmark for evaluating the performance of video foundation models, as it requires both appearance and motion understanding.
3.1 - Benchmarks
We evaluate TWLV-I's performance on five representative AR benchmarks, each with its unique characteristics:
Kinetics-400 (K400): A large-scale dataset focusing on appearance-based actions
Something-Something-v2 (SSv2): A motion-centric dataset emphasizing temporal relationships
Moments-in-Time (MiT): Another appearance-focused dataset with diverse action categories
Diving-48 (DV48): A fine-grained, motion-centric dataset of diving actions
Epic-Kitchens (EK): An egocentric dataset capturing daily kitchen activities
These benchmarks provide a comprehensive evaluation landscape, allowing us to assess TWLV-I's capabilities across both appearance-focused and motion-centric scenarios.
3.2 - Evaluation Methodology
We employ a multi-view classification method, which is standard in action recognition tasks:
Spatial resizing of input videos to match the required input resolution
Uniform sampling of m clips along the spatial dimension and n clips along the temporal dimension, resulting in m × n total clips
Calculation of class probabilities for each clip
Averaging of probabilities to obtain the final output
This approach ensures a thorough evaluation of the model's performance across different spatial and temporal segments of the input videos.
3.3 - Linear Probing
Linear probing is a technique used to evaluate the quality of learned representations without fine-tuning the entire model. It involves:
Freezing the feature extractor (backbone model)
Training a linear classifier on top of the frozen features
The linear classifier consists of a weight matrix that maps the embedding vector dimension to the number of action classes.
Results and Analysis
Table 3 presents the linear probing results across various benchmarks and models. Key observations include:
TWLV-I demonstrates strong performance across all benchmarks, particularly within its architecture scale (ViT-B and ViT-L).
For SSv2, TWLV-I outperforms larger models like ViT-H (DFN) and ViT-g (InternVideo2), with the exception of V-JEPA, which includes SSv2 in its pretraining.
TWLV-I's ViT-L variant surpasses larger-scale models on EK and DV48 benchmarks.
These results highlight TWLV-I's ability to learn rich, generalizable features that transfer well to various action recognition tasks, even when evaluated using a simple linear classifier.
3.4 - Attentive Probing
While linear probing provides insights into clip-wise embedding quality, it may not fully capture the models' capabilities, especially for those trained with patch-level supervision. To address this limitation, we introduce attentive probing, which involves:
Training a single attention layer with a learnable class token on top of the frozen model
Passing the output class token through a linear classifier
Measuring the top-1 accuracy
This method allows for a more nuanced evaluation of the models' patch-wise representation capabilities.
Results and Analysis
Table 5 showcases the attentive probing results. Key findings include:
TWLV-I achieves superior performance across both appearance- and motion-centric benchmarks compared to other models.
The strong performance in attentive probing suggests that TWLV-I possesses richer patch-wise representations compared to its counterparts.
3.5 - K-Nearest Neighbors
To provide a parameter-free evaluation of embedding quality and address potential biases in gradient-based methods, we employ the K-Nearest Neighbors (KNN) classification task. This non-parametric approach offers a fair comparison of embedding vectors across different model architectures.
We generate embeddings using two methods:
Uniform Embedding: A single embedding vector for the entire video.
Multi-Clip Embedding: Multiple embeddings from 2-second clips throughout the video.
For Multi-Clip Embedding, we employ two evaluation strategies:
Video-level: Averaging all clip embeddings to create a single video representation.
Clip-level: Summing votes received by each clip to determine the final class.
Results and Analysis
Table 6 presents the KNN classification results across different models and embedding strategies. Key observations include:
TWLV-I demonstrates competitive performance on both Kinetics-400 (K400) and Something-Something-v2 (SSv2) datasets, particularly when compared to models of similar scale.
In the Uniform embedding setting, TWLV-I-ViT-B achieves 57.51% and 19.82% top-1 accuracy on K400 and SSv2 respectively, outperforming UMT_s2 with the same architecture.
TWLV-I-ViT-L shows strong results, with 65.97% and 19.47% top-1 accuracy on K400 and SSv2, surpassing several larger models.
However, unlike the attentive probing results, TWLV-I underperforms compared to InternVideo2 on both K400 and SSv2 in the KNN evaluation. This suggests:
There's room for improvement in utilizing TWLV-I's embeddings in a non-parametric manner.
The need for further research on effectively representing embeddings for longer videos, especially those extending beyond a single clip length.
These results highlight the complexity of video representation and the challenges in creating a universally strong embedding across different evaluation methodologies.
3.6 - Pre-Training with SSv2
To ensure a fair comparison with models like V-JEPA and to assess the impact of including motion-centric data in pretraining, we conducted an additional experiment by incorporating the Something-Something-v2 (SSv2) dataset into TWLV-I's pretraining phase.
We trained a variant of TWLV-I (ViT-L architecture) including SSv2 in its pretraining dataset alongside the original datasets. This allows us to directly compare the impact of this additional data on various benchmarks and evaluation methods.
Results and Analysis
The results of this SSv2-enhanced model are presented at the bottom of Tables 3, 5, and 6. Key findings include:
Improved SSv2 Performance: Across all evaluation methods (linear probing, attentive probing, and KNN), the model shows significant improvements on the SSv2 benchmark. For example, in linear probing (Table 3), the top-1 accuracy on SSv2 increases from 46.41% to 48.14%.
General Performance Boost: The inclusion of SSv2 in pretraining leads to performance gains across other benchmarks as well. This suggests that the additional motion-centric data enhances the model's overall video understanding capabilities.
Comparison with Specialized Models: Despite the improvements, the KNN performance of our SSv2-enhanced model still lags behind V-JEPA and InternVideo2 on SSv2. This indicates that while TWLV-I's patch-level representations are strong, there's room for improvement in video-level representations.
Trade-offs in Representation: The results highlight a potential imbalance between TWLV-I's patch-level and video-level representations. Addressing this discrepancy should be a key focus for future enhancements to the model.
These findings underscore the importance of diverse pretraining data in developing robust video foundation models. They also point to specific areas where TWLV-I can be improved to better compete with specialized models on motion-centric tasks while maintaining its strong performance on appearance-based benchmarks.
4 - ImageNet Classification
To assess the versatility of video foundation models and their potential to function as general vision models, we evaluated TWLV-I's performance on the ImageNet classification task. This benchmark provides insights into the model's ability to process and understand static images, which is crucial for a comprehensive video understanding system.
4.1 - Results and Analysis
The ImageNet classification results are presented in the last columns of Table 3 (linear probing) and Table 5 (attentive probing). Key observations include:
Correlation with Appearance-Centric Tasks: Generally, models that excel in appearance-centric action recognition tasks (e.g., Kinetics-400) also demonstrate strong performance on the ImageNet benchmark. This correlation suggests that the features learned for video understanding can transfer effectively to static image classification.
TWLV-I's Performance:
In linear probing (Table 3), TWLV-I-ViT-L achieves 72.98% Top-1 accuracy on ImageNet, which is competitive but not leading.
For attentive probing (Table 5), TWLV-I-ViT-L shows improved performance with 79.19% Top-1 accuracy, indicating better utilization of learned features through attention mechanisms.
Comparison with Specialized Models: While TWLV-I shows strong performance on video-based tasks, there's a noticeable gap in ImageNet classification compared to some specialized models. For instance, InternVideo2 significantly outperforms TWLV-I on ImageNet, although this gap narrows or even reverses in video action recognition tasks.
4.2 - Implications and Insights
Given such observations, we deduce the following insights:
Static Image Processing Limitations: The results suggest that TWLV-I has some limitations in processing static images compared to models optimized for this task. This indicates an area for potential improvement in future iterations of the model.
Motion Information Utilization: The narrowing performance gap between TWLV-I and other models in video tasks, despite lower ImageNet scores, suggests that TWLV-I effectively leverages motion information for video understanding. This ability complements its appearance-based features, resulting in strong overall video analysis performance.
Balancing Video and Image Capabilities: To evolve TWLV-I beyond being solely a video model, future research should focus on enhancing its ability to understand single images without compromising its strong video analysis capabilities.
Overall, while TWLV-I demonstrates strong capabilities in video understanding tasks, the ImageNet classification results highlight areas for improvement in static image processing. Addressing these limitations could lead to a more comprehensive visual foundation model capable of excelling across both video and image domains.
5 - Temporal Action Localization
Temporal Action Localization (TAL) is a critical task in video understanding that involves identifying and localizing specific actions within untrimmed videos. This task is particularly important for applications in autonomous driving, sports analysis, and content-based video retrieval. TAL requires models to analyze long, complex videos and precisely determine both the temporal boundaries and class labels of distinct actions occurring within them.
5.1 - Evaluation Perspectives
TAL evaluates video foundation models from two key perspectives:
Temporal Sensitivity: The ability to identify if an action of interest occurs at a specific time step.
Instance Discrimination: The capability to distinguish or group frame-wise segments into complete action instances.
While TAL is primarily designed as a motion-centric task, our analysis reveals that both appearance and motion capabilities contribute to achieving these aspects effectively.
5.2 - Methodology
We evaluated TWLV-I and other video foundation models on two prominent TAL datasets:
ActivityNet-v1.3
THUMOS14
For the detection head, we employed ActionFormer. Our evaluation used two distinct methods:
Self-contained: The model performs both classification and regression without external assistance.
w/ External Classifier: The model conducts binary classification, while an external classifier predicts the action class.
Feature extraction followed the Multi-Clip Embedding method described in the "Frame Sampling" section.
5.3 - Results and Analysis
Tables 9 and 10 present the comprehensive results for THUMOS14 and ActivityNet-v1.3, respectively.
THUMOS14 (Table 9)
TWLV-I (our model) consistently outperforms other models of the same scale across all metrics.
TWLV-I-ViT-L achieves the highest average mAP of 58.75% in the self-contained setting and 53.63% with an external classifier.
Notably, TWLV-I-ViT-L surpasses larger models like DFN and V-JEPA (ViT-H), demonstrating its robust generalization capabilities.
ActivityNet-v1.3 (Table 10)
TWLV-I again shows superior performance within its architecture scale.
TWLV-I-ViT-L achieves an average mAP of 34.98% (self-contained) and 39.49% (w/ external classifier).
Remarkably, TWLV-I performs exceptionally well at strict IoU thresholds (e.g., 0.95), indicating strong temporal sensitivity.
5.4 - Key Insights
Given such observations, we deduce the following insights:
Scale Efficiency: TWLV-I's performance, especially at the ViT-L scale, outperforming larger models, highlights its efficient architecture and training methodology.
Temporal Precision: High performance at strict IoU thresholds (e.g., 0.95 in ActivityNet) demonstrates TWLV-I's superior temporal sensitivity.
Model Scale Impact: InternVideo2's top performance, particularly in self-contained evaluation, suggests that TAL benefits from larger model scales, especially when performing both classification and boundary regression simultaneously.
Evaluation Strategy: For a focused assessment of motion understanding, using an external classifier is recommended. However, for a comprehensive evaluation including appearance capabilities, the self-contained approach is preferable.
Generalization Capability: TWLV-I's strong performance across different datasets and evaluation methods indicates its robustness as a backbone for temporal localization tasks.
These results underscore TWLV-I's effectiveness in tackling the complex task of temporal action localization, showcasing its balanced capabilities in both temporal sensitivity and instance discrimination. The model's performance across various scales and evaluation methods demonstrates its potential as a versatile foundation for video understanding tasks.
6 - Spatio-Temporal Action Localization
Spatio-Temporal Action Localization (STAL) is a complex task that evaluates a model's ability to not only recognize actions but also accurately localize them in both space and time within untrimmed videos. This task is crucial for applications requiring detailed action analysis, as it demands a comprehensive understanding of both appearance and motion.
6.1 - Dataset and Evaluation
We evaluate models using the AVA v2.2 dataset, which consists of 430 movie clips, each 15 minutes long. Keyframes are annotated every second, resulting in 210,634 labeled frames in the training set and 57,371 in the validation set. The dataset includes 80 atomic actions labeled for each actor.
For evaluation, we report the Frame Average Precision (fAP) at an Intersection over Union (IoU) threshold of 0.5, using the latest v2.2 annotations. We adopt an end-to-end STAL framework, training the decoder while keeping the vision backbone frozen.
6.2 - Results and Analysis
Table 11 presents the evaluation results for the STAL task. Key observations include:
Comparison with Other Models: TWLV-I, along with UMT and InternVideo2, outperforms DFN and V-JEPA. While DFN and V-JEPA exhibit opposite trends in other tasks, they show similar performance in STAL due to the dual requirements of instance localization and action recognition.
Challenges in Instance Localization:
V-JEPA: Struggles with instance localization, which impairs its ability to perform action recognition effectively.
DFN: Excels in localizing instances due to its strong appearance understanding but fails in action recognition due to limited temporal understanding.
Strengths of TWLV-I:
TWLV-I demonstrates a balanced understanding of both appearance and motion, allowing it to perform well in STAL.
At the ViT-L scale, TWLV-I achieves a fAP@0.5 of 27.39, outperforming both DFN and V-JEPA and closely matching the performance of larger models like InternVideo2.
6.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Understanding: The results confirm that TWLV-I effectively understands spatio-temporal information, crucial for accurate STAL.
Comprehensive Evaluation: The STAL task, conducted in an end-to-end manner, serves as a robust measure of a model's ability to understand video comprehensively, encompassing both spatial and temporal dimensions.
Model Validation: The performance of TWLV-I, alongside UMT and InternVideo2, highlights its capability to handle the dual challenges of localization and recognition, setting it apart from models with a singular focus on appearance or motion.
These findings underscore the importance of a balanced approach to video understanding, where both appearance and motion are integrated to achieve superior performance in complex tasks like STAL.
7 - Temporal Action Segmentation
Temporal Action Segmentation (TAS) is a crucial task for understanding and analyzing human activities in complex, extended videos. It has a wide range of applications, including video surveillance, summarization, and skill assessment. TAS involves processing untrimmed video inputs to generate a sequence of action class labels for each frame.
7.1 - Benchmarks and Methodology
We evaluate TAS using three challenging benchmarks:
50Salads: Focuses on fine-grained actions in cooking scenarios.
GTEA: Captures egocentric views of daily activities.
Breakfast: Encompasses a broader view, including full-body actions.
For TAS, we employ ASFormer as the detection head. We report the average F1 scores at thresholds of 10, 25, and 50, referred to as ‘mF1’. Features are extracted using the Multi-Clip Embedding method and aggregated with spatial pooling to retain only the temporal axis.
7.2 - Results and Analysis
Table 12 presents the TAS evaluation results across the three benchmarks:
50Salads: TWLV-I achieves an mF1 score of 80.69 with ViT-B and 80.60 with ViT-L, outperforming both appearance-centric models like UMT and DFN and the motion-centric model V-JEPA. The Edit and accuracy scores also reflect TWLV-I's strong alignment with ground-truth sequences.
GTEA: TWLV-I excels with an mF1 score of 88.26 (ViT-B) and 88.43 (ViT-L), surpassing all baselines. This demonstrates its robust performance in egocentric views, where precise action segmentation is critical.
Breakfast: Despite the broader view, TWLV-I maintains strong performance, achieving mF1 scores of 52.18 (ViT-B) and 50.66 (ViT-L). This highlights its versatility across different camera perspectives.
7.3 - Key Insights
Given such observations, we deduce the following insights:
Balanced Capabilities: TWLV-I's superior performance across all datasets indicates a well-balanced understanding of both appearance and motion, crucial for accurate action segmentation.
Alignment with Ground Truth: High Edit and mF1 scores suggest that TWLV-I's predictions closely match the actual sequences of actions, enhancing its reliability for real-world applications.
Versatility Across Views: The model's ability to outperform baselines in various camera views, including top-down and egocentric perspectives, underscores its adaptability and robustness.
Comparison with InternVideo2: While TWLV-I performs comparably to InternVideo2 in specific views, its consistent excellence across different datasets and perspectives highlights its comprehensive capabilities.
These results affirm the effectiveness of our model in tackling the complex task of temporal action segmentation, showcasing its potential for diverse applications in video analysis.
8 - Embedding Visualization
To gain deeper insights into the representational capabilities of TWLV-I and other video foundation models, we conducted visualization experiments using t-SNE and Linear Discriminant Analysis (LDA). These visualizations provide valuable information about the models' ability to capture both appearance-based and motion-based features.
8.1 - t-SNE Visualization on Benchmark Datasets
We used t-SNE to visualize the embedding spaces of the Kinetics-400 (K400) and Something-Something-v2 (SSv2) validation sets, with different colors representing different action classes.
Kinetics-400 (Figure 6)
TWLV-I, UMT, and InternVideo2: These models demonstrate clear clustering of samples, with distinct decision boundaries for most classes. This indicates a strong ability to differentiate between various appearance-based actions.
V-JEPA: In contrast, V-JEPA fails to cluster the samples into distinct groups, suggesting limitations in capturing appearance-based features effectively.
Something-Something-v2 (Figure 7)
All Models: Interestingly, none of the models, including TWLV-I and V-JEPA, show effective clustering of classes in the SSv2 dataset. This aligns with the generally lower classification performance on SSv2 compared to K400.
Implications: The lack of clear clustering in SSv2 visualizations highlights the challenges in representing motion-centric actions and underscores the need for further research to improve performance on such benchmarks.
8.2 - Directional Motion Distinguishability
To better understand the models' capabilities in capturing motion information, we focused on specific classes within SSv2 that require understanding directional motion, such as "Moving something up" and "Moving something down".
We visualized embeddings of original videos and their temporally flipped versions using Linear Discriminant Analysis (LDA). This approach allows us to assess whether models can encode directional motion information in their embedding vectors, independent of appearance.
Results (Figures 8 and 9)
TWLV-I: Demonstrates good separation between forward and reverse videos, indicating effective encoding of directional motion information.
V-JEPA: Shows the highest distinguishability between forward and reverse videos, likely due to its pretraining on the SSv2 dataset.
UMT and InternVideo2: Provide non-separable embeddings for forward and reverse videos, suggesting a limitation in capturing directional motion information despite their strong appearance understanding capabilities.
8.3 - Key Insights
Given such observations, we deduce the following insights:
Appearance vs. Motion Understanding: TWLV-I shows a balanced capability in capturing both appearance-based features (evident in K400 visualization) and motion-based features (demonstrated in directional motion analysis).
Challenges in Motion-Centric Tasks: The difficulty in clustering SSv2 classes highlights the complexity of representing motion-centric actions, a challenge faced by all evaluated models.
Directional Motion Encoding: TWLV-I's ability to distinguish between forward and reverse videos indicates its effectiveness in encoding fine-grained motion information, a crucial aspect for comprehensive video understanding.
Model Specialization: The results reveal the strengths and limitations of different models, with some excelling in appearance-based tasks while struggling with motion-centric challenges.
These visualizations provide valuable insights into the representational capabilities of TWLV-I and other video foundation models, highlighting areas of strength and identifying opportunities for further improvement in capturing complex motion dynamics.
9 - Future Directions
As we look ahead, there are several promising avenues for further development and enhancement of TWLV-I and video foundation models in general. These directions aim to expand the model's capabilities, improve its performance, and broaden its applicability across various domains of visual understanding.
9.1 - Scaling Up
Our current focus has been on two primary scales of models: ViT-B and ViT-L. The ViT-L variant of TWLV-I has already demonstrated performance comparable to, and in some cases surpassing, larger models such as ViT-H or ViT-g. This success suggests significant potential for further improvements through scaling:
Increased Model Size: Expanding TWLV-I to even larger architectures could potentially yield substantial performance gains across various tasks.
Large-Scale Datasets: Utilizing extensive, in-house collected datasets for training could lead to the development of more general and robust models. This approach could help in capturing a wider range of visual concepts and scenarios.
Efficient Scaling Techniques: Exploring methods to scale the model efficiently, such as sparse attention mechanisms or mixture-of-experts architectures, could allow for increased model capacity without proportional increases in computational requirements.
9.2 - Enhancing Image Embedding Capabilities
While TWLV-I has shown strong performance in video-related tasks, there's room for improvement in its image embedding capabilities:
Single-Frame Processing: Enhancing TWLV-I's ability to process and understand single-frame inputs (i.e., images) is crucial. This improvement would bridge the gap between video and image understanding, making TWLV-I a more versatile visual foundation model.
Transfer Learning: Developing techniques to effectively transfer knowledge from video understanding to image tasks could lead to improved performance in image-specific applications.
Unified Architecture: Exploring architectural modifications that allow for seamless processing of both videos and images within the same model framework.
9.3 - Expanding Modality
To further enhance TWLV-I's versatility and align it with broader applications in AI, expanding its modality is a key direction:
Multimodal Tasks: Extending TWLV-I to handle multimodal tasks such as video-text retrieval and video captioning. This expansion would require aligning the model with text domains while maintaining its strong unimodal video understanding capabilities.
Video-Language Models: Developing TWLV-I as a more effective vision encoder for video-language models, enabling better integration with language processing tasks.
Audio Integration: Incorporating audio processing capabilities to enable tasks such as audio-visual synchronization and sound event detection in videos.
Evaluation Methodologies: Proposing and standardizing comprehensive evaluation methodologies for these multimodal tasks to ensure thorough assessment and validation of model performance.
By pursuing these future directions, we aim to evolve TWLV-I from a specialized video foundation model to a comprehensive visual understanding system capable of handling a wide range of tasks across different modalities. This evolution will not only enhance the model's performance in existing applications but also open up new possibilities in fields such as human-computer interaction, content creation, and advanced AI assistants.
10 - Conclusion
In this comprehensive exploration of video understanding, we have emphasized the critical importance of both appearance and motion as fundamental elements in comprehending visual content. Our research has led to several key outcomes and insights:
Dual-Aspect Evaluation: We have presented methodologies for measuring both appearance and motion capabilities across various tasks, providing a holistic approach to assessing video foundation models.
Limitations of Existing Models: Through rigorous experiments, we have demonstrated that many existing models struggle to excel in both appearance and motion understanding simultaneously, highlighting a significant gap in the field.
Introduction of TWLV-I: In response to these challenges, we have proposed TWLV-I, a novel approach that demonstrates robust performance in both motion and appearance-based tasks.
Versatile Embeddings: The embeddings generated by TWLV-I show promise for wide-ranging applications and further research in various downstream tasks, potentially accelerating progress in video understanding.
Evaluation Framework: The evaluation and analysis methods introduced in this post offer a comprehensive framework for assessing video foundation models, which we hope will be widely adopted in the field.
Future Directions: Our work points towards potential avenues for future research, including scaling up model size, enhancing image embedding capabilities, and expanding into multimodal tasks.
Guiding the Field: By addressing both appearance and motion aspects, our approach aims to set a new standard and direction for the video understanding domain.
In conclusion, TWLV-I represents a significant step forward in creating more versatile and robust video foundation models. By balancing the capabilities of appearance and motion understanding, it opens up new possibilities for advanced video analysis and comprehension. We anticipate that the methodologies and insights presented here will drive further innovations in video AI and inspire researchers to approach video understanding with a more holistic perspective.
As we move forward, the continued development and refinement of such comprehensive models will be crucial in unlocking the full potential of video understanding technologies across various applications, from content analysis and creation to advanced AI assistants and beyond. We invite the research community to build upon these foundations, pushing the boundaries of what's possible in the realm of video AI.
Twelve Labs Team
This work was achieved through the combined efforts (equal contribution) of the core contributors, with significant support from the Twelve Labs ML Research and ML Data teams.
Core Contributors
Hyeongmin Lee, Research Scientist
Jin-Young Kim, Research Scientist
Kyungjune Baek, Research Scientist
Jihwan Kim, Research Scientist
Aiden Lee, CTO
Contributors (first-name alphabetical order)
Aaron (Jangwon) Lee, ML Data Intern\
Calvin (Minjoon) Seo, Chief Scientist
Cooper (Seokjin) Han, Research Scientist
Daniel (GeunOh) Kim, ML Data Engineer
Flynn (Jiho) Jang, Research Scientist
Ian (Soonwoo) Kwon, Research Scientist
Jay Suh, ML Data Engineer
Jay (Jaehyuk) Yi, Research Scientist
Jayden (Junwan) Kim, Research Intern
Jeff (Jongseok) Kim, Research Scientist
Kyle (Seungjoon) Park, Research Scientist
Leo (Daewoo) Kim, Research Scientist
Mars (Seongsu) Ha, Research Scientist
Max (JongMok) Kim, Research Scientist
Ray (Raehyuk) Jung, Research Scientist
William (Hyojun) Go, Research Scientist
Citation
If you think this project is helpful, please feel free to leave a star and cite our paper:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }
Related articles




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved