" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
商品
Marengo 2.7: 高度なビデオ理解を実現するパイオニア的マルチベクトル埋め込み
ジェフ・キム、マーズ・ハ、ジェームズ・レ
Twelve Labsは、マルチベクトル埋め込みアーキテクチャを採用したマルチモーダルビデオ埋め込みモデル「Marengo 2.7」をリリースします。これにより、前モデルと比較して15%以上の向上が実現し、ビジュアル、音声、モーション、OCR、ロゴ検索をカバーする60のベンチマークデータセットにおいて業界最高水準(SOTA)の結果を達成しています。
Twelve Labsは、マルチベクトル埋め込みアーキテクチャを採用したマルチモーダルビデオ埋め込みモデル「Marengo 2.7」をリリースします。これにより、前モデルと比較して15%以上の向上が実現し、ビジュアル、音声、モーション、OCR、ロゴ検索をカバーする60のベンチマークデータセットにおいて業界最高水準(SOTA)の結果を達成しています。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2024/12/04
18分
記事へのリンクをコピー
1 - はじめに
Twelve Labsは、前身であるMarengo 2.6と比較して15%以上の向上を達成した、新しい最新のマルチモーダル埋め込みモデル「Marengo 2.7」を発表できることを嬉しく思います。
マルチベクトルによるビデオ表現の導入
単一の単語埋め込みで文脈的な意味を効果的に捉えることができるテキストとは異なり、ビデオコンテンツは本質的に、より複雑で多面的です。ビデオクリップには、ビジュアル要素(オブジェクト、シーン、アクション)、時間的ダイナミクス(動き、遷移)、オーディオコンポーネント(音声、環境音、音楽)、そして多くの場合テキスト情報(オーバーレイ、字幕)が同時に含まれています。従来のシングルベクトルアプローチでは、重要な情報を失うことなく、これらすべての多様な側面を1つの表現に効果的に圧縮することに苦労していました。この複雑さにより、ビデオ理解に対するより洗練されたアプローチが必要となります。
この複雑さに対処するため、Marengo 2.7は独自のマルチベクトルアプローチを採用しています。すべてを単一のベクトルに圧縮する代わりに、ビデオのさまざまな側面に対して個別のベクトルを作成します。あるベクトルは視覚的な外見(例:「黒いシャツを着た男性」)を捉え、別のベクトルは動き(例:「手を振っている」)を追跡し、さらに別のベクトルは話された内容(例:「ビデオ基盤モデルは楽しい」)を記憶します。このアプローチにより、モデルは多くの異なるタイプの情報を含むビデオをよりよく理解できるようになり、ビジュアル、モーション、オーディオのすべての側面にわたって、より正確なビデオ分析が可能になります。
60以上のマルチモーダル検索データセットで評価
ビデオ理解モデルの既存のベンチマークは、ビデオ内の主要なイベントを捉えた詳細なナラティブ形式の説明に依存していることがよくあります。しかし、このアプローチは、ユーザーが通常「赤い車を見つけて」や「お祝いのシーンを見せて」といった、より短く曖昧なクエリを投げるような、現実世界の使用パターンを反映していません。また、ユーザーは周辺の詳細、背景要素、またはほんの一瞬しか表示されない特定のオブジェクトを検索することも頻繁にあります。さらに、クエリは複数のモダリティ(視覚要素と音声の手がかり、またはテキストオーバーレイと特定のアクションなど)を組み合わせることがよくあります。このようなベンチマーク評価と実際のユースケースの間の乖離があるため、Marengo 2.7には、より包括的な評価アプローチが必要でした。
現実世界のユースケースを捉える上での既存ベンチマークの限界を理解した上で、私たちは60以上の多様なデータセットを網羅する広範な評価フレームワークを開発しました。このフレームワークは、以下の領域においてモデルの能力を厳格にテストします:
一般的なビジュアル理解
複雑なクエリの理解
小さなオブジェクトの検出
OCR解釈
ロゴ認識
オーディオ処理(会話および非会話)
比類のないイメージ・ツー・ビジュアル検索機能を備えた最先端のパフォーマンス
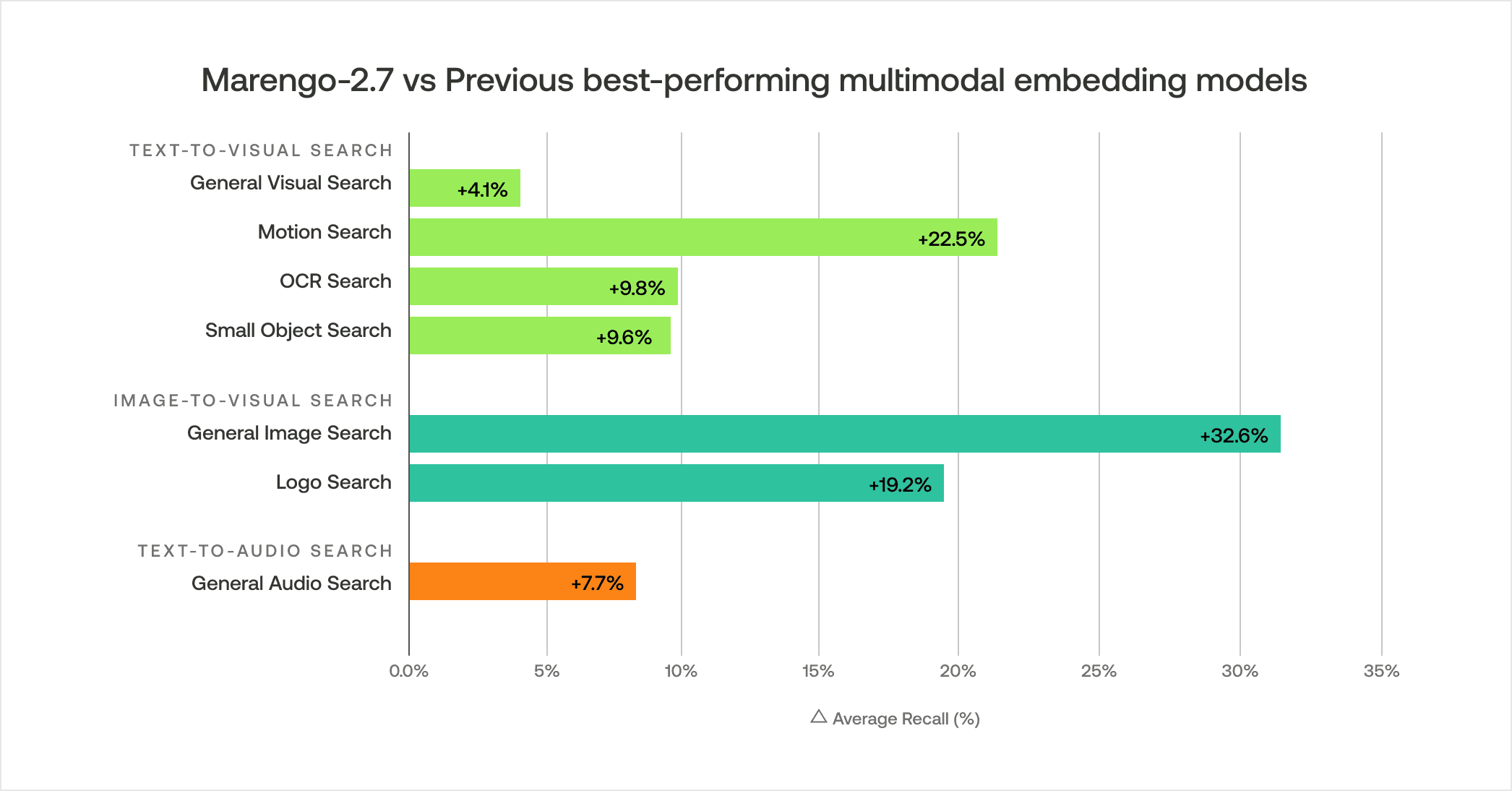
Marengo 2.7は、すべての主要なベンチマークにおいて最先端のパフォーマンスを示しており、特にイメージ・ツー・ビジュアル検索機能において極めて顕著な成果を上げています。すべての指標において強力なパフォーマンスを示している一方で、画像オブジェクト検索と画像ロゴ検索におけるパフォーマンスは、この分野における大きな飛躍を象徴しています。
一般的なテキスト・ツー・ビジュアル検索: MSRVTTおよびCOCOデータセット全体で平均74.9%のパフォーマンスを達成し、外部の最先端(SOTA)モデルを4.6%上回りました。
モーション(テキスト)・ツー・ビジュアル検索: Something Something v2において平均78.1%の再現率を達成し、外部のSOTAモデルを30.0%上回りました。
OCR(テキスト)検索: TextCapsおよびBLIP3-OCRデータセット全体で平均77.0%のパフォーマンスを達成し、外部のSOTAモデルを13.4%上回りました。
小さなオブジェクト(テキスト)・ツー・ビジュアル検索: obj365-medium、bdd-medium、mapillary-mediumデータセット全体で平均52.7%のパフォーマンスを達成し、外部のSOTAモデルを10.1%上回りました。
一般的なイメージ・ツー・ビジュアル検索: obj365-easy、obj365-medium、LaSOTデータセット全体で平均90.6%という極めて優れたパフォーマンスを達成し、外部のSOTAモデルに対して著しい35.0%の向上を示しました。これは、私たちのこれまでで最大のパフォーマンスの飛躍です。
ロゴ(画像)・ツー・ビジュアル検索: OpenLogo、ads-logo、basketball-logoデータセット全体で平均56.0%という素晴らしいパフォーマンスを達成し、外部のSOTAモデルに対して19.2%の向上を遂げ、大幅な進歩を示しました。
一般的なテキスト・ツー・オーディオ検索: AudioCaps、Clotho、GTZANデータセット全体で平均57.7%のパフォーマンスを達成し、Marengo-2.6を7.7%上回りました。
2 - Marengo 2.7の概要
Marengo 2.6の成功をベースに構築された最新のMarengo 2.7ビデオ基盤モデルは、マルチモーダルなビデオ理解における重要な進歩を表しています。また、より精密かつ包括的なビデオコンテンツ分析を可能にする、革新的なマルチベクトルアプローチを導入しています。
2.1 - マルチベクトルアーキテクチャによる統一されたフレームワーク
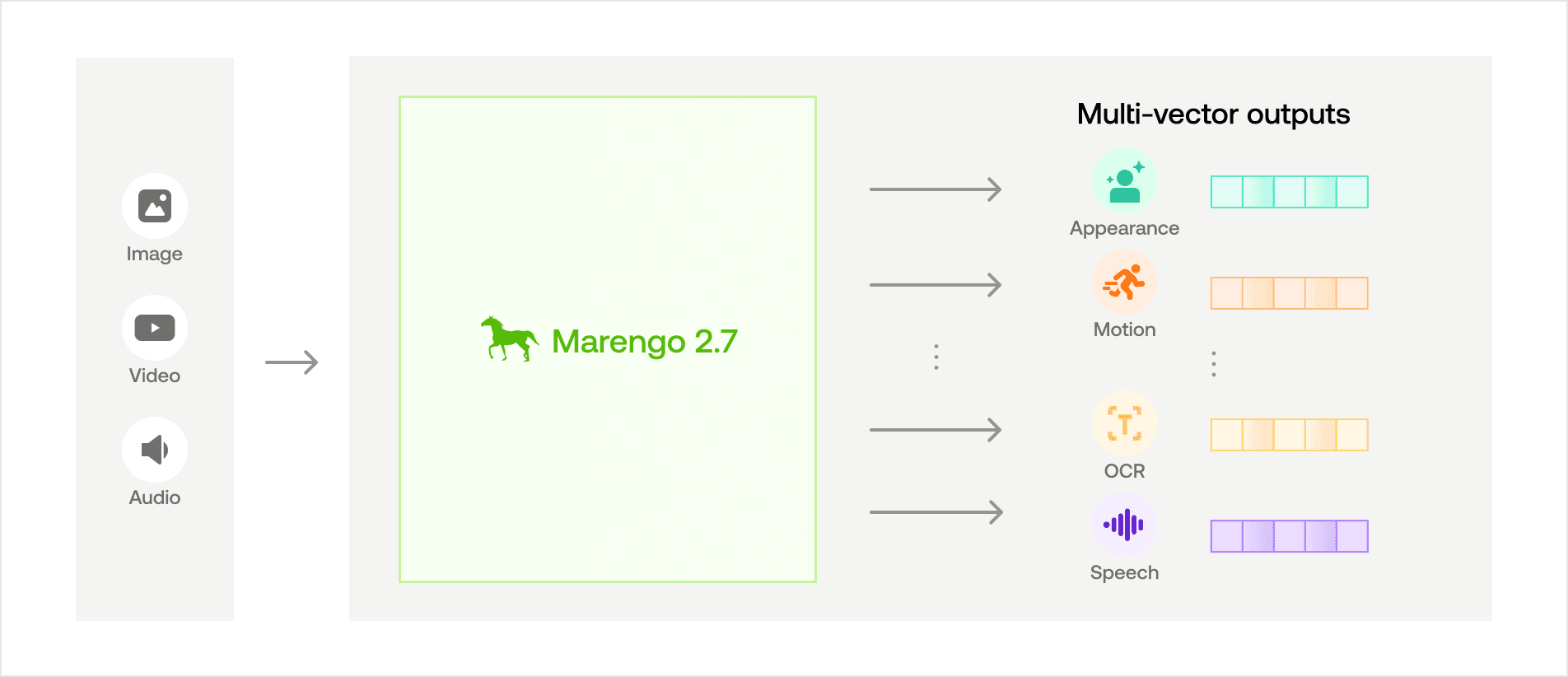
その中核として、Marengo-2.7は、以下を理解することができる、単一の統合されたフレームワークを通じてビデオコンテンツを処理するTransformerベースのアーキテクチャを採用しています:
ビジュアル要素:きめ細かなオブジェクト検出、モーションのダイナミクス、時間的関係、および外観の特徴
オーディオ要素:ネイティブの音声理解、非言語的な音の認識、および音楽の解釈
Marengo-2.7の最大の特徴は、そのユニークなマルチベクトル表現です。すべての情報を単一の埋め込みに圧縮するMarengo-2.6とは異なり、Marengo-2.7は生の入力を複数の特殊なベクトルに分解します。それぞれのベクトルは、視覚的な外見やモーションのダイナミクスから、OCRテキストや音声パターンに至るまで、ビデオコンテンツの異なる側面を独立して捉えます。このきめ細かな表現により、よりニュアンスに富んだ正確なマルチモーダル検索機能が可能になります。このアプローチは、一般的なテキストベースの検索タスクにおいて卓越したパフォーマンスを維持しながら、小さなオブジェクトの検出において特に強みを発揮します。
2.2 - トレーニングとデータ
Marengo 2.7のトレーニングは、包括的なマルチモーダルデータセット上での対照学習(contrastive loss)を用いた自己教師あり学習に焦点を当てています。私たちのビジネスおよび顧客のニーズに基づき、モデルのトレーニングに有益な、膨大で多様なデータセットを注意深くキュレートし、拡張しました。
さらに、独自の大型ビデオ・言語モデルであるPegasusを用いて再キャプション化を行うことで、トレーニングデータを強化しました。このプロセスにより、世界の知識や、複雑な動き、時空間的関係を捉えた高品質な説明が生成されました。これは、非常に堅牢なモデルをトレーニングする上で、テキストによる説明が極めて重要であるという洞察に基づいています(Fan et.al., LaCLIP, 2023.10 および Gu et. al., RWKV-CLIP, 2024.06)。
この包括的なトレーニングデータにより、Marengo 2.7は領域やモダリティを超えた堅牢な理解を蓄積することができます。豊富なビデオコンテンツを通じて、モデルは高度な時間的関係やクロスモーダルな相互作用を学習します。
3 - 定量的評価
Marengo 2.7のパフォーマンスは、60以上のベンチマークデータセットにおいて、主要なマルチモーダル検索モデルや複数のドメインにわたる専門的なソリューションに対して広範に評価されています。私たちの評価フレームワークは、テキスト・ツー・ビジュアル、イメージ・ツー・ビジュアル、およびテキスト・ツー・オーディオの検索機能を網羅しており、モデルのマルチモーダルな理解を包括的に評価します。
3.1 - ベースラインモデル
比較のために、以下の強力なベースラインモデルを選択しました:
Data Filtering Network-H/14-378 (Fang et al, Apple & ワシントン大学, 2023.09): このオープンソースの画像基盤モデルは、CLIPのトレーニング目的に基づいています。378x378の画像解像度で、50億の画像とテキストのペアでトレーニングされました。
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08):このオープンソースのビデオ基盤モデルは、対照学習のトレーニング目的でトレーニングされたビデオViTアーキテクチャに基づいています。1億本のビデオと3億枚の画像からなるデータセットでトレーニングされました。
(商用)Google Vertex Multimodal Embedding API (multimodalembedding@001, 2024.10): Google Cloudが提供するこの商用APIは、画像、ビデオ、テキストのマルチモーダル埋め込みを提供します。Googleのマルチモーダル理解における研究を活用し、大規模な独自のデータセットでトレーニングされています。
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6は、6,000万本のビデオ、5億枚の画像、50万個のオーディオから構成される、キュレートされた包括的なマルチモーダルデータセット上で対照学習を用いてトレーニングされた、独自のビデオ基盤モデルです。
3.2 - 評価データセット
評価フレームワークには、多様なデータセットが利用されています:
テキスト・ツー・ビジュアル データセット
MSRVTT: ウェブドメインのテキスト・ツー・ビデオ評価用の1,000本のビデオ
COCO: テキスト・ツー・イメージ検索用の5,000枚の画像
Something-Something v2: モーション理解用の1,989本のビデオ
TextCaps: OCRに焦点を当てたテキスト・ツー・イメージ検索用の5,000枚の画像
BLIP3-OCR: テキスト・ツー・OCR検索をテストするための、マルチレベルOCRアノテーション付きの9,687枚の画像
カスタムの小さなオブジェクトデータセット: これらは、実際のユーザー行動をよりよく反映するために、画像内の小さなオブジェクト(カバー率1〜10%)を対象とした検索クエリを評価するために私たちが作成したカスタムデータセットです。これらには、Object365-medium(10,000枚の画像)、Mapillary-medium(278枚の画像)、およびBDD-medium(636枚の画像)が含まれます。
テキスト・ツー・オーディオ データセット
AudioCaps および Clotho: テキスト・ツー・一般的なオーディオの評価。AudioCapsは957個のオーディオと4,785個のテキストクエリで構成され、Clothoは1,045個のオーディオと5,225個のテキストクエリで構成されています。
GTZAN: 10個のテンプレートクエリを用いたジャンル分類。
イメージ・ツー・ビジュアル データセット
Object365: バウンディングボックスのアノテーションに基づいて、オブジェクトを「obj365-easy」(画像カバー率 >10%)と「obj365-medium」(カバー率 1–10%)のセットに分割した画像検出データセット。オブジェクトボックスを切り取って、ソース画像をターゲットとする画像クエリを作成しました。
LaSOT: イメージ・ツー・ビデオ検索用に変換されたビデオ追跡データセット
OpenLogo: ロゴドメインにおけるオブジェクト検出データセット。289枚のロゴ画像をクエリ、2,039枚の画像をターゲットとして選択することにより、このデータセットをイメージ・ツー・イメージタスクに変換しました。
カスタムロゴデータセット: さまざまなドメインのビデオコンテンツにおいて特定のロゴを見つけるモデルの能力を評価するために、カスタムアノテーション付きの ads-logo(287本のビデオ、233個のロゴ)および basketball-logo(300本のビデオ、154個のロゴ)データセットを作成しました。
透明性と再現性を確保するため、私たちはビデオ検索用の包括的な評価フレームワークをオープンソース化します。現在の評価データセットは主に機械生成されたものであり、パフォーマンスの傾向を効果的に示していますが、一般公開する前にさらなる洗練と人間による検証が必要です。私たちは、これらがパブリックな研究利用に期待される高い基準を満たすよう、データセットの磨き上げに積極的に取り組んでいます。
3.3 - テキスト・ツー・ビジュアル検索のパフォーマンス
一般的なビジュアル検索
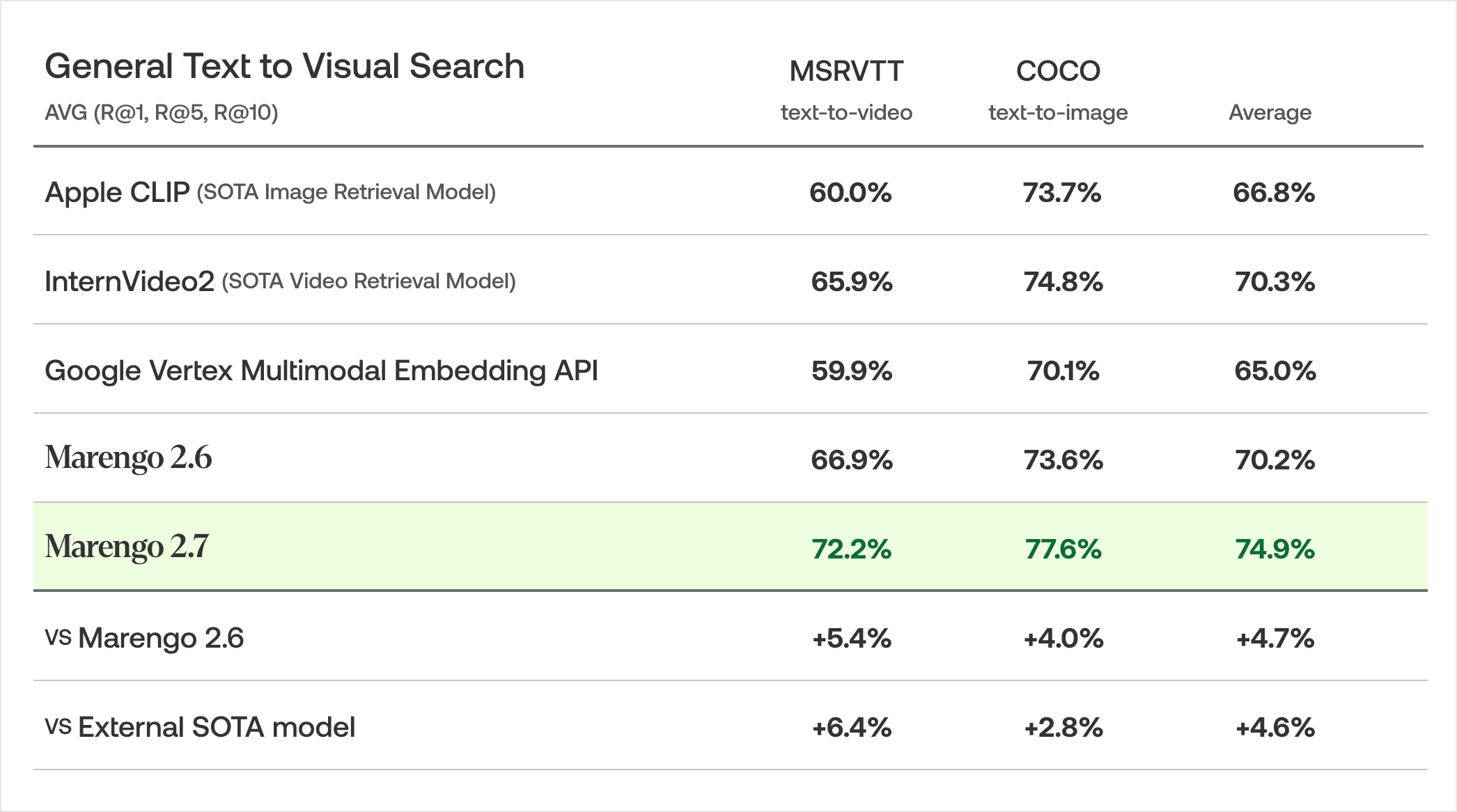
一般的なビジュアル検索において、Marengo 2.7は2つのベンチマークデータセットで平均74.9%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して4.7%の向上、外部のSOTAモデルに対して4.6%のアドバンテージを示しています。
モーション検索
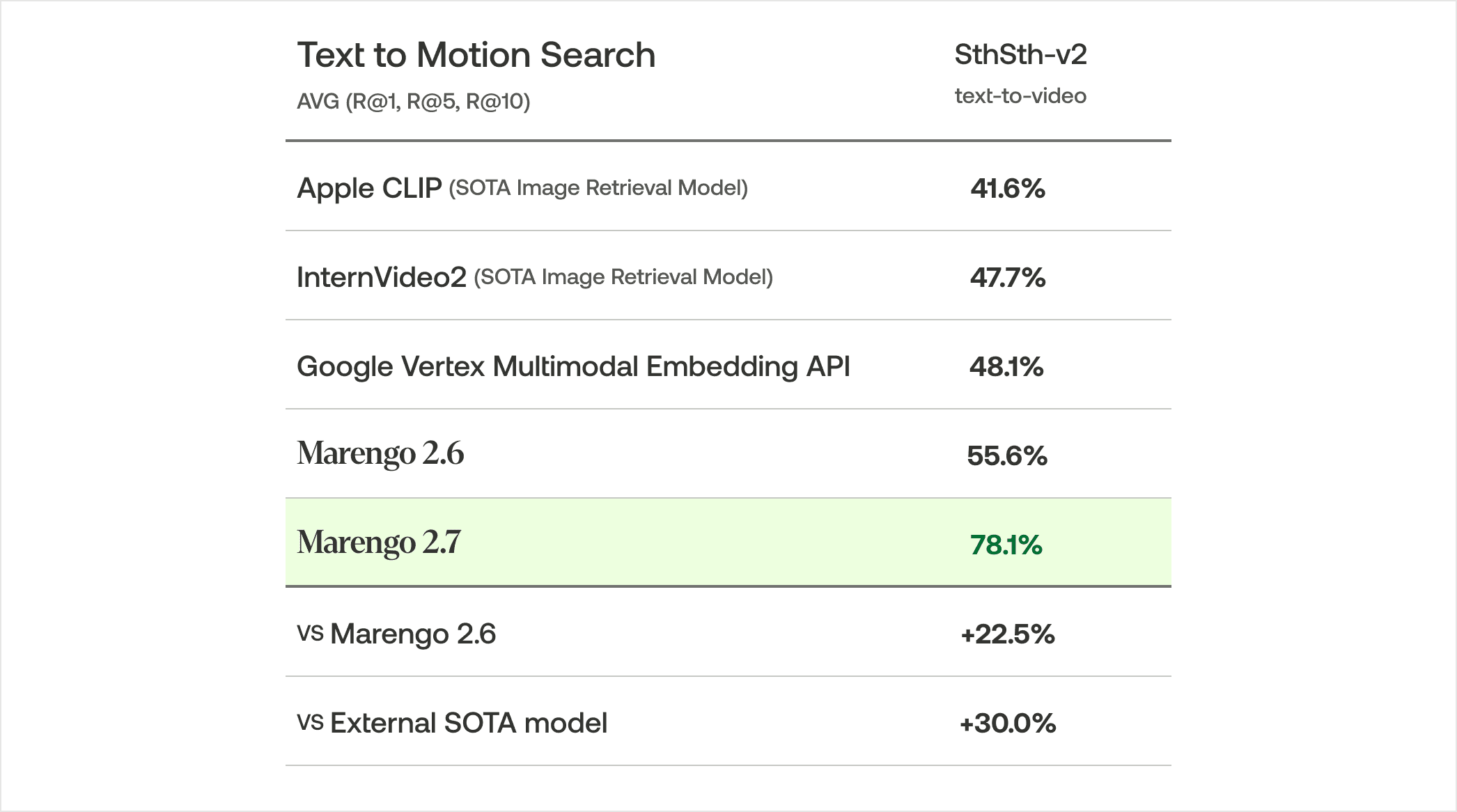
モーション検索において、Marengo 2.7はSomething Something v2で平均78.1%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して22.5%の向上、外部のSOTAモデルに対して30.0%のアドバンテージを示しています。
OCR検索
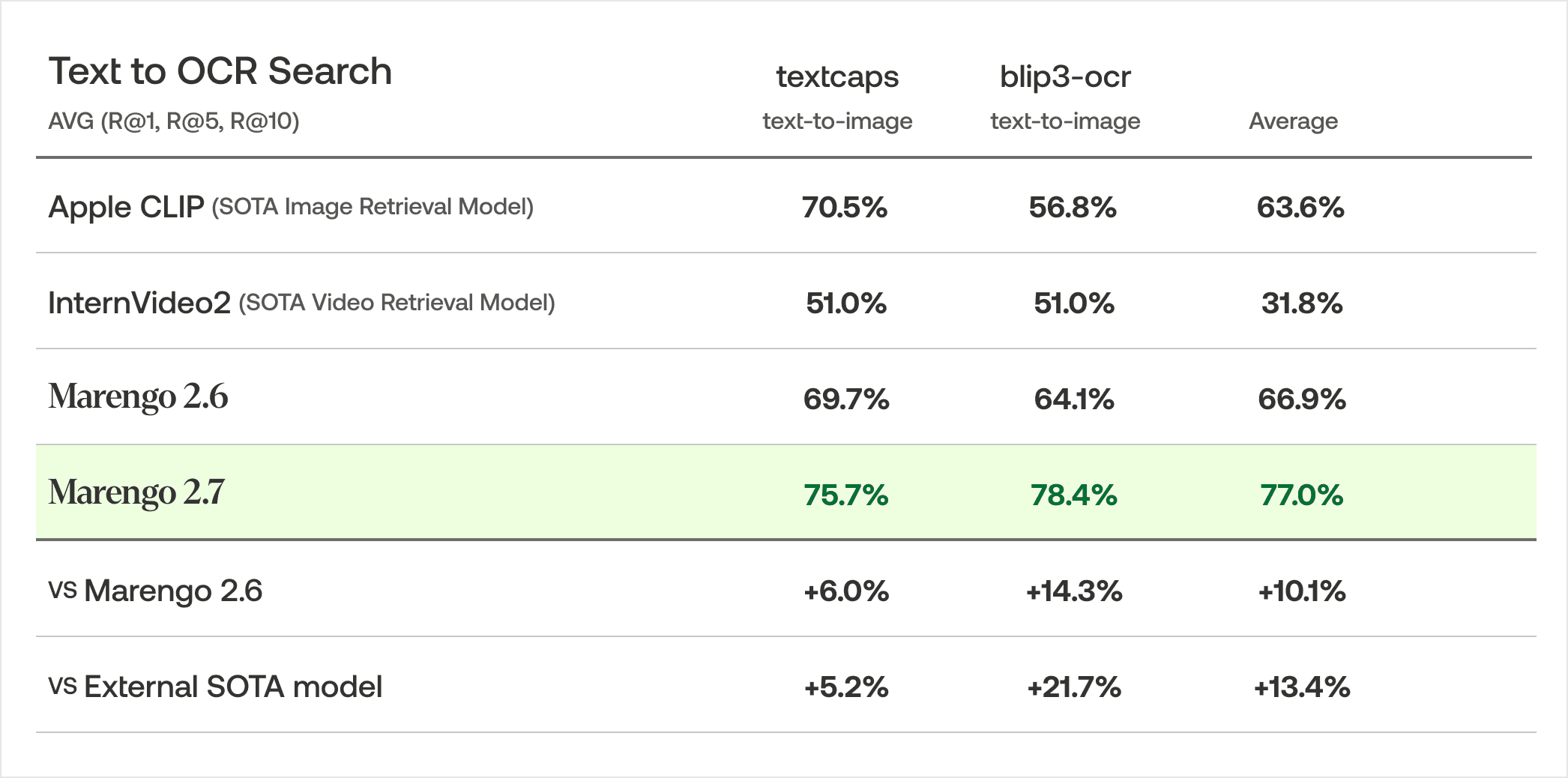
OCR検索において、Marengo 2.7は2つのベンチマークデータセットで平均精度(mAP)77.0%を達成しました。これは、Marengo 2.6と比較して10.1%の向上、外部のSOTAモデルに対して13.4%のアドバンテージを示しています。
小さなオブジェクトの検索
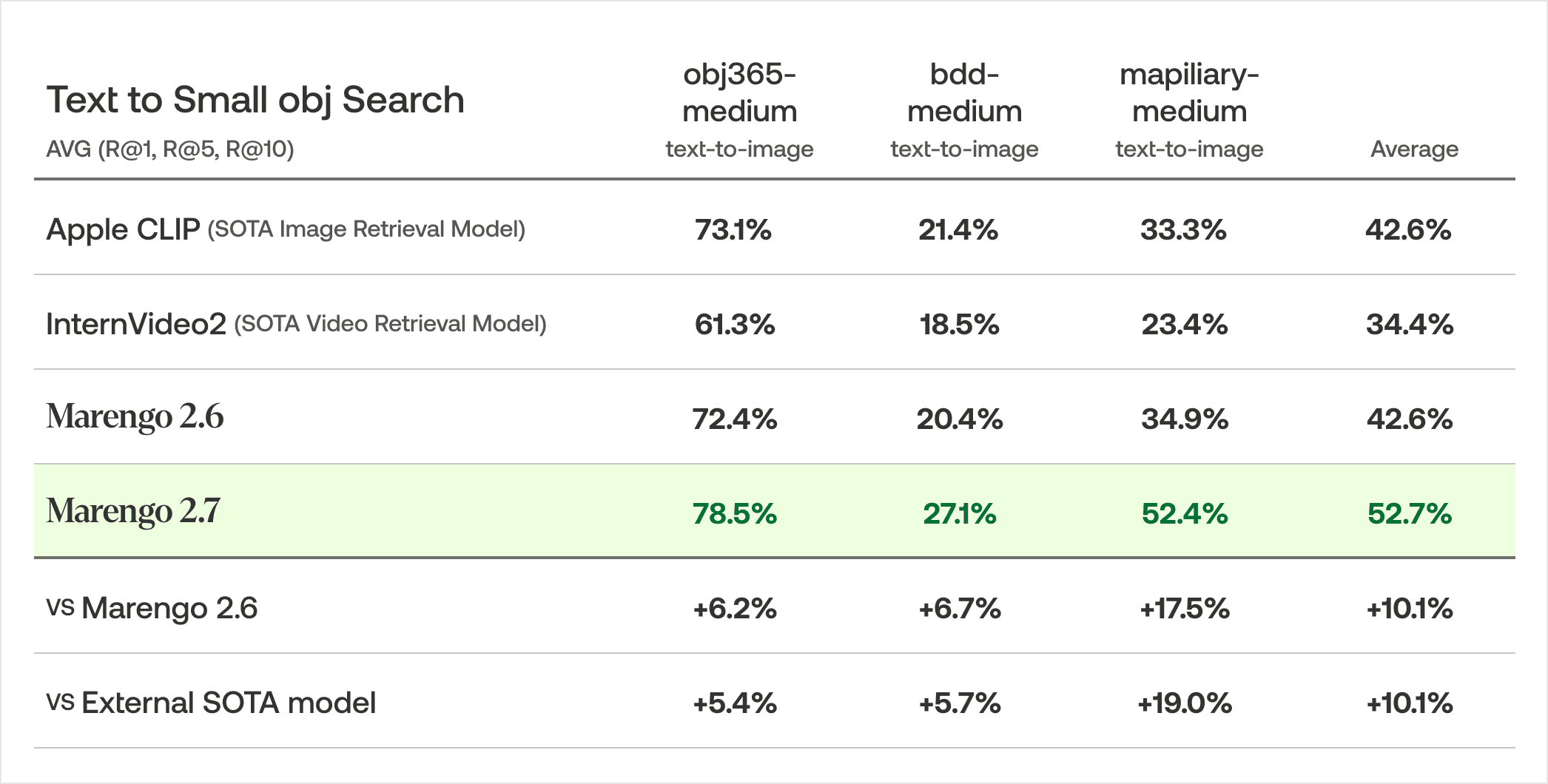
小さなオブジェクトの検索において、Marengo 2.7は3つのカスタムベンチマークデータセットで平均72.7%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して10.14%の向上、外部のSOTAモデルに対して10.08%のアドバンテージを示しています。
3.4 - イメージ・ツー・ビジュアル検索のパフォーマンス
一般(小さなオブジェクト)検索
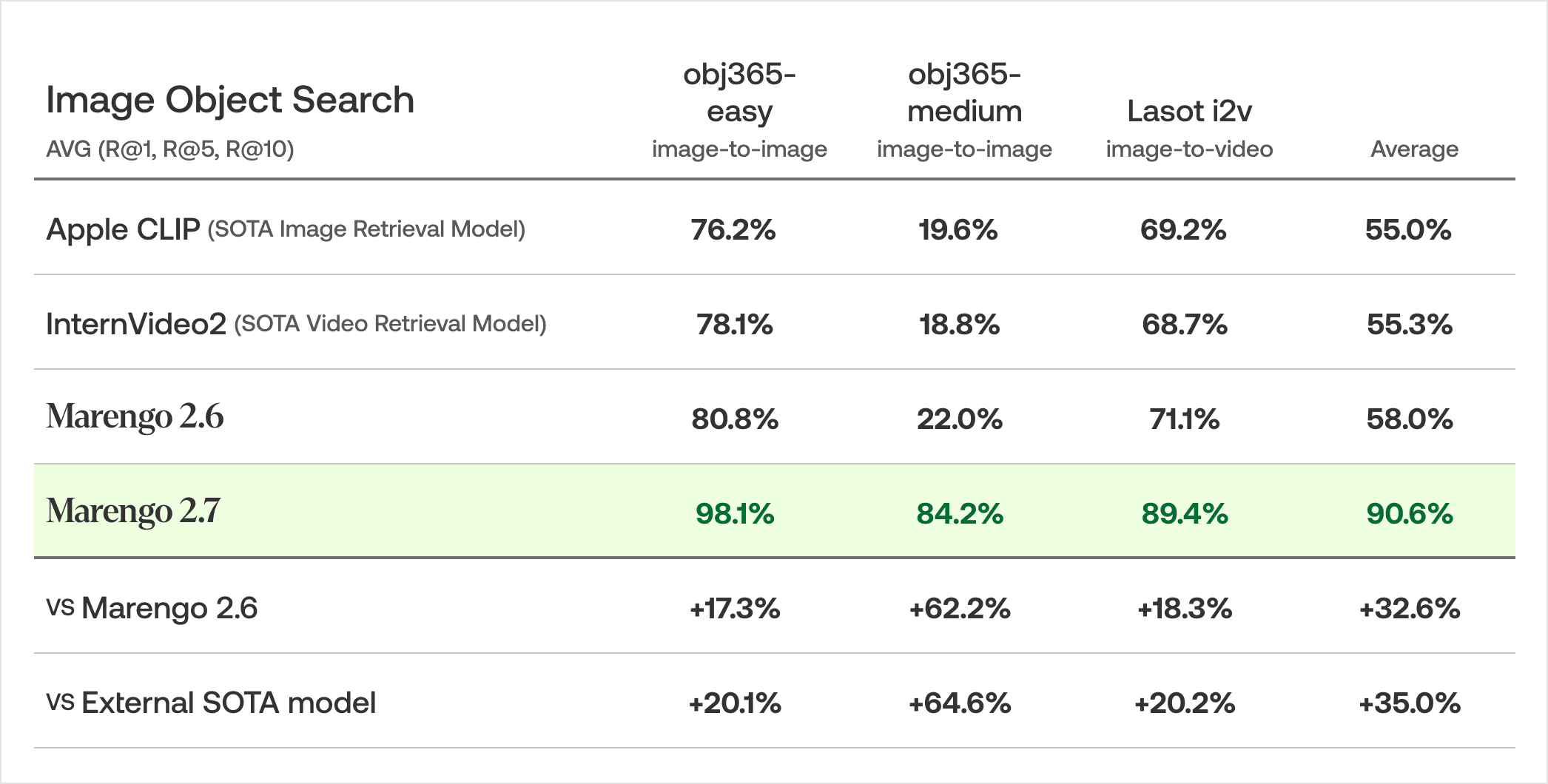
オブジェクト検索において、Marengo 2.7は3つのベンチマークデータセットで平均90.6%の再現率を達成しました。この結果は、Marengo 2.6(32.6%向上)と外部のSOTAモデル(35.0%向上)の双方に対する向上を示しています。
ロゴ検索
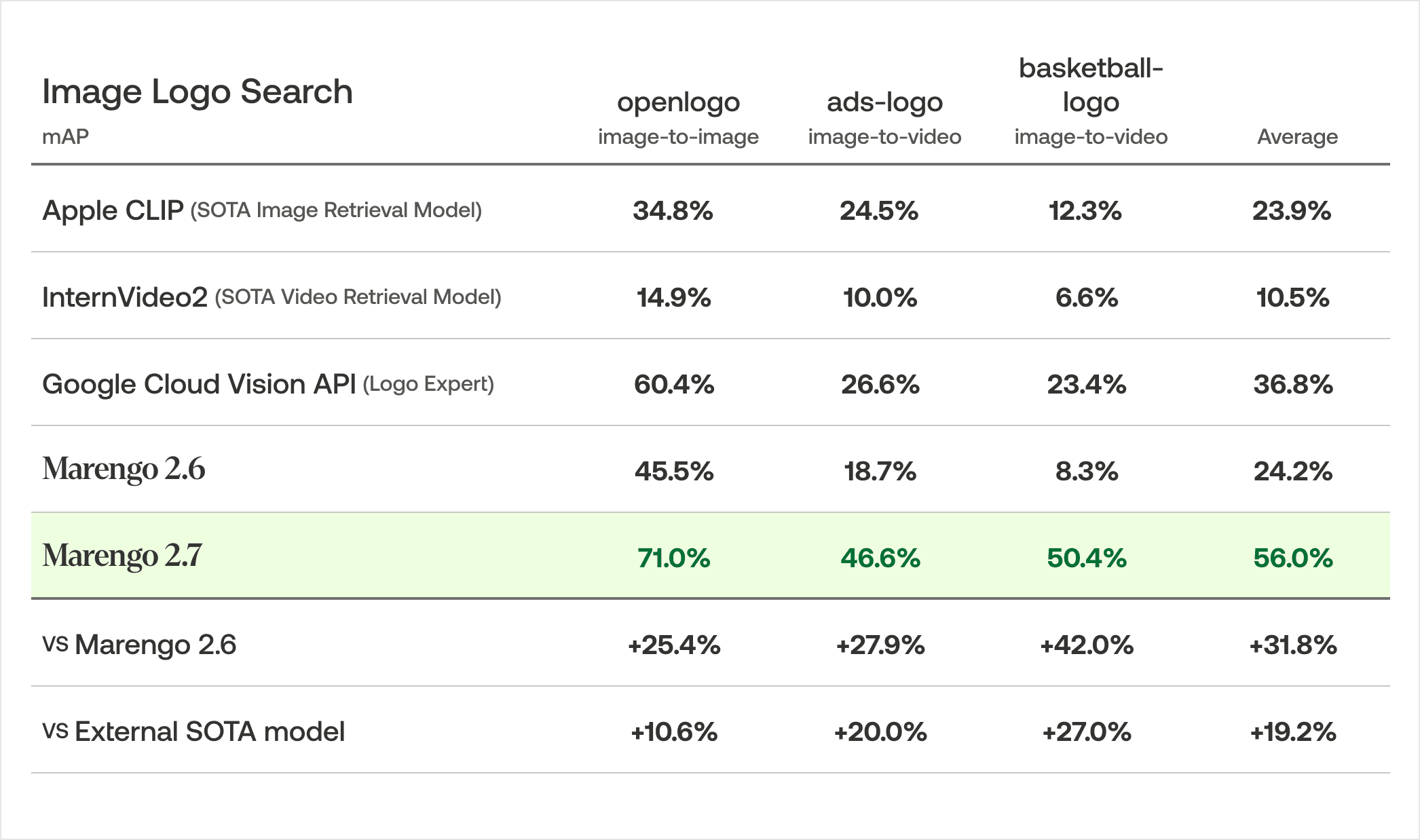
ロゴ検索において、Marengo 2.7は3つのベンチマークデータセットで平均平均精度(mAP)56.0%を達成しました。これは、前身モデルと比較して31.8%の向上、外部のSOTAモデルに対して19.2%のアドバンテージを示しています。なお、言及されている上記のロゴ専門モデル(Logo Expert Model)はGoogle Cloud Vision API - Detect Logosを指します。
3.5 - テキスト・ツー・オーディオ検索のパフォーマンス
一般的なオーディオ検索
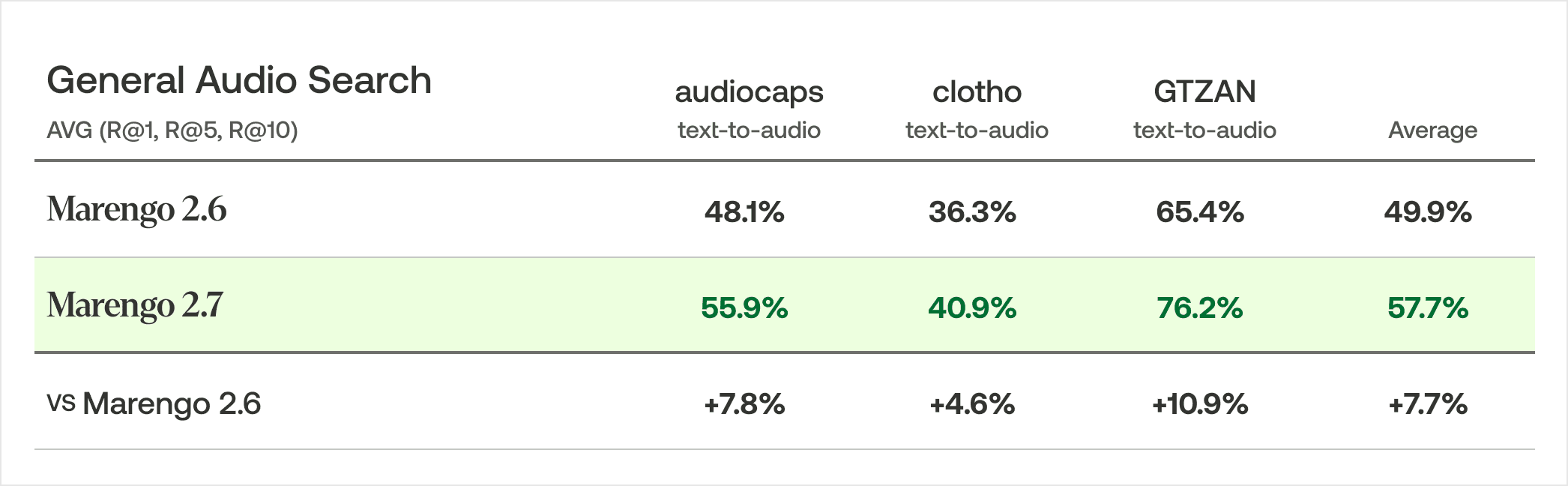
一般的なオーディオ検索において、Marengo 2.7は3つのベンチマークデータセットで平均57.7%の再現率を達成しました。これは、Marengo 2.6と比較して7.7%の向上を示しています。
4 - 質的評価結果
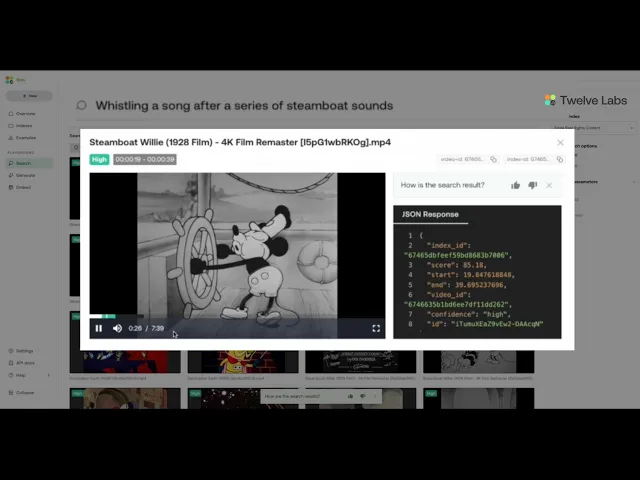
異なる検索モダリティにわたるMarengo 2.7の機能を説明するために、実際のパフォーマンスを示すいくつかの代表的な例を紹介します。
テキスト・ツー・ビジュアル (Marengo 2.7)
このモデルは、2つの例を通じて複雑なイベントやシーンに対する洗練された理解を示しています:
複数のアクションを伴う詳細なスポートのプレイ
クエリ: 複数のニューイングランド・ペイトリオッツの選手がパントをプレッシャーをかけてブロックし、ボールがアウトオブバウンズに転がり、ターンオーバーオンダウンズになる。
上位3件の結果:
都市環境における連続的な視覚的要素
クエリ: 車がBEST BUY、Jeepディーラー、そしてTHE HOME DEPOTの前を通り過ぎている。
上位3件の結果:
イメージ・ツー・ビデオ (Marengo 2.7)
Marengo 2.7は低解像度の画像(64x64)での検索に対応しながら、ビデオフレームの背景にある小さなロゴやオブジェクトを見つけるなど、驚異的な結果を達成します。そのビジュアル検索機能を見てみましょう:
ロゴ検出
クエリ(画像): 複雑な視野角でチェース銀行(Chase bank)のロゴを特定する

上位3件の結果:
オブジェクト検索
クエリ(画像): 棚の上のクロロックス(Clorox)除菌ワイプを特定する

上位3件の結果:
テキスト・ツー・オーディオ (Marengo 2.7)
このモデルの音声理解は、以下を通じて紹介されます:
音声理解: 会話コンテンツの処理とマッチング
クエリ 1: “何が起きているか教えて”
上位3件の結果:
クエリ 2: “ゴルフカートに立っている間、それぞれのゴルフバッグが与えられたフィールドでどのように機能するか、よりよく理解してもらうための方法をいくつか考案しました。”
上位3件の結果:
クエリ 3: “自宅や職場でタブレットを使用しており、物理キーボードを使うのが好きな母のために、キーボードの購入を計画していました。”
上位3件の結果:
楽器認識: 特定の音楽的要素の特定 (”バイオリンの音”)
上位3件の結果:
これらの例は、異なるモダリティにわたって高い精度を維持しながら、多様なクエリタイプを処理するMarengo 2.7の能力を示しています。
5 - 限界と今後の課題
Marengo 2.7は複数のモダリティにわたって大幅な向上を示しているものの、包括的なビデオ理解を達成するにはいくつかの課題が残されています。
複雑なシーンの理解
主要なアクションやオブジェクトの特定には優れていますが、ビデオ内で同時に発生する背景の微妙な活動や並行するイベントを見落とす可能性があります。
視覚的な完全一致の課題
このモデルは、特にわずかに異なる文脈で複数回出現する可能性のあるオブジェクトや人物の特定のインスタンスを検索する際に、視覚的な完全一致を見つけることに苦労することがあります。
クエリの解釈
Marengo 2.7はほとんどのクエリを効果的に処理しますが、以下のような場合に課題に直面することがあります:
複数の時間的関係を伴う細かく構成されたクエリ
単純なケースを超えた複雑な否定パターン
抽象的な推論や世界の知識を必要とするクエリ
ロゴ検索、会話検索、OCR検索におけるパフォーマンス
さらに、Marengo 2.7は、特にロゴがフレームの1%未満しか占めていない場合や、難しい視野角に表示されている場合のテキスト・ツー・ロゴ検索シナリオにおいて限界を示しています。
会話やOCRの検索においては、強いアクセントのある話し言葉、重複する会話、珍しいフォントや向きのテキストに苦労することがあります。これらの課題は、特にライティング条件が悪い、または複雑な背景を持つ現実世界のシナリオで顕著になります。
これらの制限は、マルチモーダルなビデオ理解の能力を向上させ続ける中での、今後の研究開発の当然の課題です。現在進行中の取り組みは、クロスモーダルな理解や時間的推論における現在の強みを維持しながら、これらの課題に対処することに焦点を当てています。
6 - 結論
Marengo 2.7は、マルチモーダルビデオ理解における大きな飛躍を意味し、映像、音声、テキストモダリティ全体で大きな向上を示しています。革新的なマルチベクトルアプローチと包括的な評価フレームワークを通じて、さまざまなユースケースにおいて高精度を維持しながら、複雑なビデオ理解タスクにおいて最先端のパフォーマンスを達成できることを実証しました。
この分野における透明性と再現性をサポートするため、包括的な評価フレームワークとともに、詳細なテクニカルレポートを公開する予定です。60以上のデータセットにわたるテストを含むこのフレームワークは、オープンソース化され定期的にメンテナンスされるため、研究者や実践者の方が私たちの結果を検証し、マルチモーダルなビデオ理解の進歩に貢献できるようになります。
謝辞
これは、サイエンス、エンジニアリング、プロダクト、ビジネス開発、オペレーションを含む複数の機能横断グループによる共同チームの成果です。Twelve Labs Research Science部門のMarengoチームの共同執筆によるものです。
リソース
1 - はじめに
Twelve Labsは、前身であるMarengo 2.6と比較して15%以上の向上を達成した、新しい最新のマルチモーダル埋め込みモデル「Marengo 2.7」を発表できることを嬉しく思います。
マルチベクトルによるビデオ表現の導入
単一の単語埋め込みで文脈的な意味を効果的に捉えることができるテキストとは異なり、ビデオコンテンツは本質的に、より複雑で多面的です。ビデオクリップには、ビジュアル要素(オブジェクト、シーン、アクション)、時間的ダイナミクス(動き、遷移)、オーディオコンポーネント(音声、環境音、音楽)、そして多くの場合テキスト情報(オーバーレイ、字幕)が同時に含まれています。従来のシングルベクトルアプローチでは、重要な情報を失うことなく、これらすべての多様な側面を1つの表現に効果的に圧縮することに苦労していました。この複雑さにより、ビデオ理解に対するより洗練されたアプローチが必要となります。
この複雑さに対処するため、Marengo 2.7は独自のマルチベクトルアプローチを採用しています。すべてを単一のベクトルに圧縮する代わりに、ビデオのさまざまな側面に対して個別のベクトルを作成します。あるベクトルは視覚的な外見(例:「黒いシャツを着た男性」)を捉え、別のベクトルは動き(例:「手を振っている」)を追跡し、さらに別のベクトルは話された内容(例:「ビデオ基盤モデルは楽しい」)を記憶します。このアプローチにより、モデルは多くの異なるタイプの情報を含むビデオをよりよく理解できるようになり、ビジュアル、モーション、オーディオのすべての側面にわたって、より正確なビデオ分析が可能になります。
60以上のマルチモーダル検索データセットで評価
ビデオ理解モデルの既存のベンチマークは、ビデオ内の主要なイベントを捉えた詳細なナラティブ形式の説明に依存していることがよくあります。しかし、このアプローチは、ユーザーが通常「赤い車を見つけて」や「お祝いのシーンを見せて」といった、より短く曖昧なクエリを投げるような、現実世界の使用パターンを反映していません。また、ユーザーは周辺の詳細、背景要素、またはほんの一瞬しか表示されない特定のオブジェクトを検索することも頻繁にあります。さらに、クエリは複数のモダリティ(視覚要素と音声の手がかり、またはテキストオーバーレイと特定のアクションなど)を組み合わせることがよくあります。このようなベンチマーク評価と実際のユースケースの間の乖離があるため、Marengo 2.7には、より包括的な評価アプローチが必要でした。
現実世界のユースケースを捉える上での既存ベンチマークの限界を理解した上で、私たちは60以上の多様なデータセットを網羅する広範な評価フレームワークを開発しました。このフレームワークは、以下の領域においてモデルの能力を厳格にテストします:
一般的なビジュアル理解
複雑なクエリの理解
小さなオブジェクトの検出
OCR解釈
ロゴ認識
オーディオ処理(会話および非会話)
比類のないイメージ・ツー・ビジュアル検索機能を備えた最先端のパフォーマンス
Marengo 2.7は、すべての主要なベンチマークにおいて最先端のパフォーマンスを示しており、特にイメージ・ツー・ビジュアル検索機能において極めて顕著な成果を上げています。すべての指標において強力なパフォーマンスを示している一方で、画像オブジェクト検索と画像ロゴ検索におけるパフォーマンスは、この分野における大きな飛躍を象徴しています。
一般的なテキスト・ツー・ビジュアル検索: MSRVTTおよびCOCOデータセット全体で平均74.9%のパフォーマンスを達成し、外部の最先端(SOTA)モデルを4.6%上回りました。
モーション(テキスト)・ツー・ビジュアル検索: Something Something v2において平均78.1%の再現率を達成し、外部のSOTAモデルを30.0%上回りました。
OCR(テキスト)検索: TextCapsおよびBLIP3-OCRデータセット全体で平均77.0%のパフォーマンスを達成し、外部のSOTAモデルを13.4%上回りました。
小さなオブジェクト(テキスト)・ツー・ビジュアル検索: obj365-medium、bdd-medium、mapillary-mediumデータセット全体で平均52.7%のパフォーマンスを達成し、外部のSOTAモデルを10.1%上回りました。
一般的なイメージ・ツー・ビジュアル検索: obj365-easy、obj365-medium、LaSOTデータセット全体で平均90.6%という極めて優れたパフォーマンスを達成し、外部のSOTAモデルに対して著しい35.0%の向上を示しました。これは、私たちのこれまでで最大のパフォーマンスの飛躍です。
ロゴ(画像)・ツー・ビジュアル検索: OpenLogo、ads-logo、basketball-logoデータセット全体で平均56.0%という素晴らしいパフォーマンスを達成し、外部のSOTAモデルに対して19.2%の向上を遂げ、大幅な進歩を示しました。
一般的なテキスト・ツー・オーディオ検索: AudioCaps、Clotho、GTZANデータセット全体で平均57.7%のパフォーマンスを達成し、Marengo-2.6を7.7%上回りました。
2 - Marengo 2.7の概要
Marengo 2.6の成功をベースに構築された最新のMarengo 2.7ビデオ基盤モデルは、マルチモーダルなビデオ理解における重要な進歩を表しています。また、より精密かつ包括的なビデオコンテンツ分析を可能にする、革新的なマルチベクトルアプローチを導入しています。
2.1 - マルチベクトルアーキテクチャによる統一されたフレームワーク
その中核として、Marengo-2.7は、以下を理解することができる、単一の統合されたフレームワークを通じてビデオコンテンツを処理するTransformerベースのアーキテクチャを採用しています:
ビジュアル要素:きめ細かなオブジェクト検出、モーションのダイナミクス、時間的関係、および外観の特徴
オーディオ要素:ネイティブの音声理解、非言語的な音の認識、および音楽の解釈
Marengo-2.7の最大の特徴は、そのユニークなマルチベクトル表現です。すべての情報を単一の埋め込みに圧縮するMarengo-2.6とは異なり、Marengo-2.7は生の入力を複数の特殊なベクトルに分解します。それぞれのベクトルは、視覚的な外見やモーションのダイナミクスから、OCRテキストや音声パターンに至るまで、ビデオコンテンツの異なる側面を独立して捉えます。このきめ細かな表現により、よりニュアンスに富んだ正確なマルチモーダル検索機能が可能になります。このアプローチは、一般的なテキストベースの検索タスクにおいて卓越したパフォーマンスを維持しながら、小さなオブジェクトの検出において特に強みを発揮します。
2.2 - トレーニングとデータ
Marengo 2.7のトレーニングは、包括的なマルチモーダルデータセット上での対照学習(contrastive loss)を用いた自己教師あり学習に焦点を当てています。私たちのビジネスおよび顧客のニーズに基づき、モデルのトレーニングに有益な、膨大で多様なデータセットを注意深くキュレートし、拡張しました。
さらに、独自の大型ビデオ・言語モデルであるPegasusを用いて再キャプション化を行うことで、トレーニングデータを強化しました。このプロセスにより、世界の知識や、複雑な動き、時空間的関係を捉えた高品質な説明が生成されました。これは、非常に堅牢なモデルをトレーニングする上で、テキストによる説明が極めて重要であるという洞察に基づいています(Fan et.al., LaCLIP, 2023.10 および Gu et. al., RWKV-CLIP, 2024.06)。
この包括的なトレーニングデータにより、Marengo 2.7は領域やモダリティを超えた堅牢な理解を蓄積することができます。豊富なビデオコンテンツを通じて、モデルは高度な時間的関係やクロスモーダルな相互作用を学習します。
3 - 定量的評価
Marengo 2.7のパフォーマンスは、60以上のベンチマークデータセットにおいて、主要なマルチモーダル検索モデルや複数のドメインにわたる専門的なソリューションに対して広範に評価されています。私たちの評価フレームワークは、テキスト・ツー・ビジュアル、イメージ・ツー・ビジュアル、およびテキスト・ツー・オーディオの検索機能を網羅しており、モデルのマルチモーダルな理解を包括的に評価します。
3.1 - ベースラインモデル
比較のために、以下の強力なベースラインモデルを選択しました:
Data Filtering Network-H/14-378 (Fang et al, Apple & ワシントン大学, 2023.09): このオープンソースの画像基盤モデルは、CLIPのトレーニング目的に基づいています。378x378の画像解像度で、50億の画像とテキストのペアでトレーニングされました。
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08):このオープンソースのビデオ基盤モデルは、対照学習のトレーニング目的でトレーニングされたビデオViTアーキテクチャに基づいています。1億本のビデオと3億枚の画像からなるデータセットでトレーニングされました。
(商用)Google Vertex Multimodal Embedding API (multimodalembedding@001, 2024.10): Google Cloudが提供するこの商用APIは、画像、ビデオ、テキストのマルチモーダル埋め込みを提供します。Googleのマルチモーダル理解における研究を活用し、大規模な独自のデータセットでトレーニングされています。
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6は、6,000万本のビデオ、5億枚の画像、50万個のオーディオから構成される、キュレートされた包括的なマルチモーダルデータセット上で対照学習を用いてトレーニングされた、独自のビデオ基盤モデルです。
3.2 - 評価データセット
評価フレームワークには、多様なデータセットが利用されています:
テキスト・ツー・ビジュアル データセット
MSRVTT: ウェブドメインのテキスト・ツー・ビデオ評価用の1,000本のビデオ
COCO: テキスト・ツー・イメージ検索用の5,000枚の画像
Something-Something v2: モーション理解用の1,989本のビデオ
TextCaps: OCRに焦点を当てたテキスト・ツー・イメージ検索用の5,000枚の画像
BLIP3-OCR: テキスト・ツー・OCR検索をテストするための、マルチレベルOCRアノテーション付きの9,687枚の画像
カスタムの小さなオブジェクトデータセット: これらは、実際のユーザー行動をよりよく反映するために、画像内の小さなオブジェクト(カバー率1〜10%)を対象とした検索クエリを評価するために私たちが作成したカスタムデータセットです。これらには、Object365-medium(10,000枚の画像)、Mapillary-medium(278枚の画像)、およびBDD-medium(636枚の画像)が含まれます。
テキスト・ツー・オーディオ データセット
AudioCaps および Clotho: テキスト・ツー・一般的なオーディオの評価。AudioCapsは957個のオーディオと4,785個のテキストクエリで構成され、Clothoは1,045個のオーディオと5,225個のテキストクエリで構成されています。
GTZAN: 10個のテンプレートクエリを用いたジャンル分類。
イメージ・ツー・ビジュアル データセット
Object365: バウンディングボックスのアノテーションに基づいて、オブジェクトを「obj365-easy」(画像カバー率 >10%)と「obj365-medium」(カバー率 1–10%)のセットに分割した画像検出データセット。オブジェクトボックスを切り取って、ソース画像をターゲットとする画像クエリを作成しました。
LaSOT: イメージ・ツー・ビデオ検索用に変換されたビデオ追跡データセット
OpenLogo: ロゴドメインにおけるオブジェクト検出データセット。289枚のロゴ画像をクエリ、2,039枚の画像をターゲットとして選択することにより、このデータセットをイメージ・ツー・イメージタスクに変換しました。
カスタムロゴデータセット: さまざまなドメインのビデオコンテンツにおいて特定のロゴを見つけるモデルの能力を評価するために、カスタムアノテーション付きの ads-logo(287本のビデオ、233個のロゴ)および basketball-logo(300本のビデオ、154個のロゴ)データセットを作成しました。
透明性と再現性を確保するため、私たちはビデオ検索用の包括的な評価フレームワークをオープンソース化します。現在の評価データセットは主に機械生成されたものであり、パフォーマンスの傾向を効果的に示していますが、一般公開する前にさらなる洗練と人間による検証が必要です。私たちは、これらがパブリックな研究利用に期待される高い基準を満たすよう、データセットの磨き上げに積極的に取り組んでいます。
3.3 - テキスト・ツー・ビジュアル検索のパフォーマンス
一般的なビジュアル検索
一般的なビジュアル検索において、Marengo 2.7は2つのベンチマークデータセットで平均74.9%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して4.7%の向上、外部のSOTAモデルに対して4.6%のアドバンテージを示しています。
モーション検索
モーション検索において、Marengo 2.7はSomething Something v2で平均78.1%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して22.5%の向上、外部のSOTAモデルに対して30.0%のアドバンテージを示しています。
OCR検索
OCR検索において、Marengo 2.7は2つのベンチマークデータセットで平均精度(mAP)77.0%を達成しました。これは、Marengo 2.6と比較して10.1%の向上、外部のSOTAモデルに対して13.4%のアドバンテージを示しています。
小さなオブジェクトの検索
小さなオブジェクトの検索において、Marengo 2.7は3つのカスタムベンチマークデータセットで平均72.7%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して10.14%の向上、外部のSOTAモデルに対して10.08%のアドバンテージを示しています。
3.4 - イメージ・ツー・ビジュアル検索のパフォーマンス
一般(小さなオブジェクト)検索
オブジェクト検索において、Marengo 2.7は3つのベンチマークデータセットで平均90.6%の再現率を達成しました。この結果は、Marengo 2.6(32.6%向上)と外部のSOTAモデル(35.0%向上)の双方に対する向上を示しています。
ロゴ検索
ロゴ検索において、Marengo 2.7は3つのベンチマークデータセットで平均平均精度(mAP)56.0%を達成しました。これは、前身モデルと比較して31.8%の向上、外部のSOTAモデルに対して19.2%のアドバンテージを示しています。なお、言及されている上記のロゴ専門モデル(Logo Expert Model)はGoogle Cloud Vision API - Detect Logosを指します。
3.5 - テキスト・ツー・オーディオ検索のパフォーマンス
一般的なオーディオ検索
一般的なオーディオ検索において、Marengo 2.7は3つのベンチマークデータセットで平均57.7%の再現率を達成しました。これは、Marengo 2.6と比較して7.7%の向上を示しています。
4 - 質的評価結果
異なる検索モダリティにわたるMarengo 2.7の機能を説明するために、実際のパフォーマンスを示すいくつかの代表的な例を紹介します。
テキスト・ツー・ビジュアル (Marengo 2.7)
このモデルは、2つの例を通じて複雑なイベントやシーンに対する洗練された理解を示しています:
複数のアクションを伴う詳細なスポートのプレイ
クエリ: 複数のニューイングランド・ペイトリオッツの選手がパントをプレッシャーをかけてブロックし、ボールがアウトオブバウンズに転がり、ターンオーバーオンダウンズになる。
上位3件の結果:
都市環境における連続的な視覚的要素
クエリ: 車がBEST BUY、Jeepディーラー、そしてTHE HOME DEPOTの前を通り過ぎている。
上位3件の結果:
イメージ・ツー・ビデオ (Marengo 2.7)
Marengo 2.7は低解像度の画像(64x64)での検索に対応しながら、ビデオフレームの背景にある小さなロゴやオブジェクトを見つけるなど、驚異的な結果を達成します。そのビジュアル検索機能を見てみましょう:
ロゴ検出
クエリ(画像): 複雑な視野角でチェース銀行(Chase bank)のロゴを特定する
上位3件の結果:
オブジェクト検索
クエリ(画像): 棚の上のクロロックス(Clorox)除菌ワイプを特定する
上位3件の結果:
テキスト・ツー・オーディオ (Marengo 2.7)
このモデルの音声理解は、以下を通じて紹介されます:
音声理解: 会話コンテンツの処理とマッチング
クエリ 1: “何が起きているか教えて”
上位3件の結果:
クエリ 2: “ゴルフカートに立っている間、それぞれのゴルフバッグが与えられたフィールドでどのように機能するか、よりよく理解してもらうための方法をいくつか考案しました。”
上位3件の結果:
クエリ 3: “自宅や職場でタブレットを使用しており、物理キーボードを使うのが好きな母のために、キーボードの購入を計画していました。”
上位3件の結果:
楽器認識: 特定の音楽的要素の特定 (”バイオリンの音”)
上位3件の結果:
これらの例は、異なるモダリティにわたって高い精度を維持しながら、多様なクエリタイプを処理するMarengo 2.7の能力を示しています。
5 - 限界と今後の課題
Marengo 2.7は複数のモダリティにわたって大幅な向上を示しているものの、包括的なビデオ理解を達成するにはいくつかの課題が残されています。
複雑なシーンの理解
主要なアクションやオブジェクトの特定には優れていますが、ビデオ内で同時に発生する背景の微妙な活動や並行するイベントを見落とす可能性があります。
視覚的な完全一致の課題
このモデルは、特にわずかに異なる文脈で複数回出現する可能性のあるオブジェクトや人物の特定のインスタンスを検索する際に、視覚的な完全一致を見つけることに苦労することがあります。
クエリの解釈
Marengo 2.7はほとんどのクエリを効果的に処理しますが、以下のような場合に課題に直面することがあります:
複数の時間的関係を伴う細かく構成されたクエリ
単純なケースを超えた複雑な否定パターン
抽象的な推論や世界の知識を必要とするクエリ
ロゴ検索、会話検索、OCR検索におけるパフォーマンス
さらに、Marengo 2.7は、特にロゴがフレームの1%未満しか占めていない場合や、難しい視野角に表示されている場合のテキスト・ツー・ロゴ検索シナリオにおいて限界を示しています。
会話やOCRの検索においては、強いアクセントのある話し言葉、重複する会話、珍しいフォントや向きのテキストに苦労することがあります。これらの課題は、特にライティング条件が悪い、または複雑な背景を持つ現実世界のシナリオで顕著になります。
これらの制限は、マルチモーダルなビデオ理解の能力を向上させ続ける中での、今後の研究開発の当然の課題です。現在進行中の取り組みは、クロスモーダルな理解や時間的推論における現在の強みを維持しながら、これらの課題に対処することに焦点を当てています。
6 - 結論
Marengo 2.7は、マルチモーダルビデオ理解における大きな飛躍を意味し、映像、音声、テキストモダリティ全体で大きな向上を示しています。革新的なマルチベクトルアプローチと包括的な評価フレームワークを通じて、さまざまなユースケースにおいて高精度を維持しながら、複雑なビデオ理解タスクにおいて最先端のパフォーマンスを達成できることを実証しました。
この分野における透明性と再現性をサポートするため、包括的な評価フレームワークとともに、詳細なテクニカルレポートを公開する予定です。60以上のデータセットにわたるテストを含むこのフレームワークは、オープンソース化され定期的にメンテナンスされるため、研究者や実践者の方が私たちの結果を検証し、マルチモーダルなビデオ理解の進歩に貢献できるようになります。
謝辞
これは、サイエンス、エンジニアリング、プロダクト、ビジネス開発、オペレーションを含む複数の機能横断グループによる共同チームの成果です。Twelve Labs Research Science部門のMarengoチームの共同執筆によるものです。
リソース
1 - はじめに
Twelve Labsは、前身であるMarengo 2.6と比較して15%以上の向上を達成した、新しい最新のマルチモーダル埋め込みモデル「Marengo 2.7」を発表できることを嬉しく思います。
マルチベクトルによるビデオ表現の導入
単一の単語埋め込みで文脈的な意味を効果的に捉えることができるテキストとは異なり、ビデオコンテンツは本質的に、より複雑で多面的です。ビデオクリップには、ビジュアル要素(オブジェクト、シーン、アクション)、時間的ダイナミクス(動き、遷移)、オーディオコンポーネント(音声、環境音、音楽)、そして多くの場合テキスト情報(オーバーレイ、字幕)が同時に含まれています。従来のシングルベクトルアプローチでは、重要な情報を失うことなく、これらすべての多様な側面を1つの表現に効果的に圧縮することに苦労していました。この複雑さにより、ビデオ理解に対するより洗練されたアプローチが必要となります。
この複雑さに対処するため、Marengo 2.7は独自のマルチベクトルアプローチを採用しています。すべてを単一のベクトルに圧縮する代わりに、ビデオのさまざまな側面に対して個別のベクトルを作成します。あるベクトルは視覚的な外見(例:「黒いシャツを着た男性」)を捉え、別のベクトルは動き(例:「手を振っている」)を追跡し、さらに別のベクトルは話された内容(例:「ビデオ基盤モデルは楽しい」)を記憶します。このアプローチにより、モデルは多くの異なるタイプの情報を含むビデオをよりよく理解できるようになり、ビジュアル、モーション、オーディオのすべての側面にわたって、より正確なビデオ分析が可能になります。
60以上のマルチモーダル検索データセットで評価
ビデオ理解モデルの既存のベンチマークは、ビデオ内の主要なイベントを捉えた詳細なナラティブ形式の説明に依存していることがよくあります。しかし、このアプローチは、ユーザーが通常「赤い車を見つけて」や「お祝いのシーンを見せて」といった、より短く曖昧なクエリを投げるような、現実世界の使用パターンを反映していません。また、ユーザーは周辺の詳細、背景要素、またはほんの一瞬しか表示されない特定のオブジェクトを検索することも頻繁にあります。さらに、クエリは複数のモダリティ(視覚要素と音声の手がかり、またはテキストオーバーレイと特定のアクションなど)を組み合わせることがよくあります。このようなベンチマーク評価と実際のユースケースの間の乖離があるため、Marengo 2.7には、より包括的な評価アプローチが必要でした。
現実世界のユースケースを捉える上での既存ベンチマークの限界を理解した上で、私たちは60以上の多様なデータセットを網羅する広範な評価フレームワークを開発しました。このフレームワークは、以下の領域においてモデルの能力を厳格にテストします:
一般的なビジュアル理解
複雑なクエリの理解
小さなオブジェクトの検出
OCR解釈
ロゴ認識
オーディオ処理(会話および非会話)
比類のないイメージ・ツー・ビジュアル検索機能を備えた最先端のパフォーマンス
Marengo 2.7は、すべての主要なベンチマークにおいて最先端のパフォーマンスを示しており、特にイメージ・ツー・ビジュアル検索機能において極めて顕著な成果を上げています。すべての指標において強力なパフォーマンスを示している一方で、画像オブジェクト検索と画像ロゴ検索におけるパフォーマンスは、この分野における大きな飛躍を象徴しています。
一般的なテキスト・ツー・ビジュアル検索: MSRVTTおよびCOCOデータセット全体で平均74.9%のパフォーマンスを達成し、外部の最先端(SOTA)モデルを4.6%上回りました。
モーション(テキスト)・ツー・ビジュアル検索: Something Something v2において平均78.1%の再現率を達成し、外部のSOTAモデルを30.0%上回りました。
OCR(テキスト)検索: TextCapsおよびBLIP3-OCRデータセット全体で平均77.0%のパフォーマンスを達成し、外部のSOTAモデルを13.4%上回りました。
小さなオブジェクト(テキスト)・ツー・ビジュアル検索: obj365-medium、bdd-medium、mapillary-mediumデータセット全体で平均52.7%のパフォーマンスを達成し、外部のSOTAモデルを10.1%上回りました。
一般的なイメージ・ツー・ビジュアル検索: obj365-easy、obj365-medium、LaSOTデータセット全体で平均90.6%という極めて優れたパフォーマンスを達成し、外部のSOTAモデルに対して著しい35.0%の向上を示しました。これは、私たちのこれまでで最大のパフォーマンスの飛躍です。
ロゴ(画像)・ツー・ビジュアル検索: OpenLogo、ads-logo、basketball-logoデータセット全体で平均56.0%という素晴らしいパフォーマンスを達成し、外部のSOTAモデルに対して19.2%の向上を遂げ、大幅な進歩を示しました。
一般的なテキスト・ツー・オーディオ検索: AudioCaps、Clotho、GTZANデータセット全体で平均57.7%のパフォーマンスを達成し、Marengo-2.6を7.7%上回りました。
2 - Marengo 2.7の概要
Marengo 2.6の成功をベースに構築された最新のMarengo 2.7ビデオ基盤モデルは、マルチモーダルなビデオ理解における重要な進歩を表しています。また、より精密かつ包括的なビデオコンテンツ分析を可能にする、革新的なマルチベクトルアプローチを導入しています。
2.1 - マルチベクトルアーキテクチャによる統一されたフレームワーク
その中核として、Marengo-2.7は、以下を理解することができる、単一の統合されたフレームワークを通じてビデオコンテンツを処理するTransformerベースのアーキテクチャを採用しています:
ビジュアル要素:きめ細かなオブジェクト検出、モーションのダイナミクス、時間的関係、および外観の特徴
オーディオ要素:ネイティブの音声理解、非言語的な音の認識、および音楽の解釈
Marengo-2.7の最大の特徴は、そのユニークなマルチベクトル表現です。すべての情報を単一の埋め込みに圧縮するMarengo-2.6とは異なり、Marengo-2.7は生の入力を複数の特殊なベクトルに分解します。それぞれのベクトルは、視覚的な外見やモーションのダイナミクスから、OCRテキストや音声パターンに至るまで、ビデオコンテンツの異なる側面を独立して捉えます。このきめ細かな表現により、よりニュアンスに富んだ正確なマルチモーダル検索機能が可能になります。このアプローチは、一般的なテキストベースの検索タスクにおいて卓越したパフォーマンスを維持しながら、小さなオブジェクトの検出において特に強みを発揮します。
2.2 - トレーニングとデータ
Marengo 2.7のトレーニングは、包括的なマルチモーダルデータセット上での対照学習(contrastive loss)を用いた自己教師あり学習に焦点を当てています。私たちのビジネスおよび顧客のニーズに基づき、モデルのトレーニングに有益な、膨大で多様なデータセットを注意深くキュレートし、拡張しました。
さらに、独自の大型ビデオ・言語モデルであるPegasusを用いて再キャプション化を行うことで、トレーニングデータを強化しました。このプロセスにより、世界の知識や、複雑な動き、時空間的関係を捉えた高品質な説明が生成されました。これは、非常に堅牢なモデルをトレーニングする上で、テキストによる説明が極めて重要であるという洞察に基づいています(Fan et.al., LaCLIP, 2023.10 および Gu et. al., RWKV-CLIP, 2024.06)。
この包括的なトレーニングデータにより、Marengo 2.7は領域やモダリティを超えた堅牢な理解を蓄積することができます。豊富なビデオコンテンツを通じて、モデルは高度な時間的関係やクロスモーダルな相互作用を学習します。
3 - 定量的評価
Marengo 2.7のパフォーマンスは、60以上のベンチマークデータセットにおいて、主要なマルチモーダル検索モデルや複数のドメインにわたる専門的なソリューションに対して広範に評価されています。私たちの評価フレームワークは、テキスト・ツー・ビジュアル、イメージ・ツー・ビジュアル、およびテキスト・ツー・オーディオの検索機能を網羅しており、モデルのマルチモーダルな理解を包括的に評価します。
3.1 - ベースラインモデル
比較のために、以下の強力なベースラインモデルを選択しました:
Data Filtering Network-H/14-378 (Fang et al, Apple & ワシントン大学, 2023.09): このオープンソースの画像基盤モデルは、CLIPのトレーニング目的に基づいています。378x378の画像解像度で、50億の画像とテキストのペアでトレーニングされました。
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08):このオープンソースのビデオ基盤モデルは、対照学習のトレーニング目的でトレーニングされたビデオViTアーキテクチャに基づいています。1億本のビデオと3億枚の画像からなるデータセットでトレーニングされました。
(商用)Google Vertex Multimodal Embedding API (multimodalembedding@001, 2024.10): Google Cloudが提供するこの商用APIは、画像、ビデオ、テキストのマルチモーダル埋め込みを提供します。Googleのマルチモーダル理解における研究を活用し、大規模な独自のデータセットでトレーニングされています。
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6は、6,000万本のビデオ、5億枚の画像、50万個のオーディオから構成される、キュレートされた包括的なマルチモーダルデータセット上で対照学習を用いてトレーニングされた、独自のビデオ基盤モデルです。
3.2 - 評価データセット
評価フレームワークには、多様なデータセットが利用されています:
テキスト・ツー・ビジュアル データセット
MSRVTT: ウェブドメインのテキスト・ツー・ビデオ評価用の1,000本のビデオ
COCO: テキスト・ツー・イメージ検索用の5,000枚の画像
Something-Something v2: モーション理解用の1,989本のビデオ
TextCaps: OCRに焦点を当てたテキスト・ツー・イメージ検索用の5,000枚の画像
BLIP3-OCR: テキスト・ツー・OCR検索をテストするための、マルチレベルOCRアノテーション付きの9,687枚の画像
カスタムの小さなオブジェクトデータセット: これらは、実際のユーザー行動をよりよく反映するために、画像内の小さなオブジェクト(カバー率1〜10%)を対象とした検索クエリを評価するために私たちが作成したカスタムデータセットです。これらには、Object365-medium(10,000枚の画像)、Mapillary-medium(278枚の画像)、およびBDD-medium(636枚の画像)が含まれます。
テキスト・ツー・オーディオ データセット
AudioCaps および Clotho: テキスト・ツー・一般的なオーディオの評価。AudioCapsは957個のオーディオと4,785個のテキストクエリで構成され、Clothoは1,045個のオーディオと5,225個のテキストクエリで構成されています。
GTZAN: 10個のテンプレートクエリを用いたジャンル分類。
イメージ・ツー・ビジュアル データセット
Object365: バウンディングボックスのアノテーションに基づいて、オブジェクトを「obj365-easy」(画像カバー率 >10%)と「obj365-medium」(カバー率 1–10%)のセットに分割した画像検出データセット。オブジェクトボックスを切り取って、ソース画像をターゲットとする画像クエリを作成しました。
LaSOT: イメージ・ツー・ビデオ検索用に変換されたビデオ追跡データセット
OpenLogo: ロゴドメインにおけるオブジェクト検出データセット。289枚のロゴ画像をクエリ、2,039枚の画像をターゲットとして選択することにより、このデータセットをイメージ・ツー・イメージタスクに変換しました。
カスタムロゴデータセット: さまざまなドメインのビデオコンテンツにおいて特定のロゴを見つけるモデルの能力を評価するために、カスタムアノテーション付きの ads-logo(287本のビデオ、233個のロゴ)および basketball-logo(300本のビデオ、154個のロゴ)データセットを作成しました。
透明性と再現性を確保するため、私たちはビデオ検索用の包括的な評価フレームワークをオープンソース化します。現在の評価データセットは主に機械生成されたものであり、パフォーマンスの傾向を効果的に示していますが、一般公開する前にさらなる洗練と人間による検証が必要です。私たちは、これらがパブリックな研究利用に期待される高い基準を満たすよう、データセットの磨き上げに積極的に取り組んでいます。
3.3 - テキスト・ツー・ビジュアル検索のパフォーマンス
一般的なビジュアル検索
一般的なビジュアル検索において、Marengo 2.7は2つのベンチマークデータセットで平均74.9%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して4.7%の向上、外部のSOTAモデルに対して4.6%のアドバンテージを示しています。
モーション検索
モーション検索において、Marengo 2.7はSomething Something v2で平均78.1%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して22.5%の向上、外部のSOTAモデルに対して30.0%のアドバンテージを示しています。
OCR検索
OCR検索において、Marengo 2.7は2つのベンチマークデータセットで平均精度(mAP)77.0%を達成しました。これは、Marengo 2.6と比較して10.1%の向上、外部のSOTAモデルに対して13.4%のアドバンテージを示しています。
小さなオブジェクトの検索
小さなオブジェクトの検索において、Marengo 2.7は3つのカスタムベンチマークデータセットで平均72.7%の再現率を達成しました。これらの結果は、Marengo 2.6と比較して10.14%の向上、外部のSOTAモデルに対して10.08%のアドバンテージを示しています。
3.4 - イメージ・ツー・ビジュアル検索のパフォーマンス
一般(小さなオブジェクト)検索
オブジェクト検索において、Marengo 2.7は3つのベンチマークデータセットで平均90.6%の再現率を達成しました。この結果は、Marengo 2.6(32.6%向上)と外部のSOTAモデル(35.0%向上)の双方に対する向上を示しています。
ロゴ検索
ロゴ検索において、Marengo 2.7は3つのベンチマークデータセットで平均平均精度(mAP)56.0%を達成しました。これは、前身モデルと比較して31.8%の向上、外部のSOTAモデルに対して19.2%のアドバンテージを示しています。なお、言及されている上記のロゴ専門モデル(Logo Expert Model)はGoogle Cloud Vision API - Detect Logosを指します。
3.5 - テキスト・ツー・オーディオ検索のパフォーマンス
一般的なオーディオ検索
一般的なオーディオ検索において、Marengo 2.7は3つのベンチマークデータセットで平均57.7%の再現率を達成しました。これは、Marengo 2.6と比較して7.7%の向上を示しています。
4 - 質的評価結果
異なる検索モダリティにわたるMarengo 2.7の機能を説明するために、実際のパフォーマンスを示すいくつかの代表的な例を紹介します。
テキスト・ツー・ビジュアル (Marengo 2.7)
このモデルは、2つの例を通じて複雑なイベントやシーンに対する洗練された理解を示しています:
複数のアクションを伴う詳細なスポートのプレイ
クエリ: 複数のニューイングランド・ペイトリオッツの選手がパントをプレッシャーをかけてブロックし、ボールがアウトオブバウンズに転がり、ターンオーバーオンダウンズになる。
上位3件の結果:
都市環境における連続的な視覚的要素
クエリ: 車がBEST BUY、Jeepディーラー、そしてTHE HOME DEPOTの前を通り過ぎている。
上位3件の結果:
イメージ・ツー・ビデオ (Marengo 2.7)
Marengo 2.7は低解像度の画像(64x64)での検索に対応しながら、ビデオフレームの背景にある小さなロゴやオブジェクトを見つけるなど、驚異的な結果を達成します。そのビジュアル検索機能を見てみましょう:
ロゴ検出
クエリ(画像): 複雑な視野角でチェース銀行(Chase bank)のロゴを特定する
上位3件の結果:
オブジェクト検索
クエリ(画像): 棚の上のクロロックス(Clorox)除菌ワイプを特定する
上位3件の結果:
テキスト・ツー・オーディオ (Marengo 2.7)
このモデルの音声理解は、以下を通じて紹介されます:
音声理解: 会話コンテンツの処理とマッチング
クエリ 1: “何が起きているか教えて”
上位3件の結果:
クエリ 2: “ゴルフカートに立っている間、それぞれのゴルフバッグが与えられたフィールドでどのように機能するか、よりよく理解してもらうための方法をいくつか考案しました。”
上位3件の結果:
クエリ 3: “自宅や職場でタブレットを使用しており、物理キーボードを使うのが好きな母のために、キーボードの購入を計画していました。”
上位3件の結果:
楽器認識: 特定の音楽的要素の特定 (”バイオリンの音”)
上位3件の結果:
これらの例は、異なるモダリティにわたって高い精度を維持しながら、多様なクエリタイプを処理するMarengo 2.7の能力を示しています。
5 - 限界と今後の課題
Marengo 2.7は複数のモダリティにわたって大幅な向上を示しているものの、包括的なビデオ理解を達成するにはいくつかの課題が残されています。
複雑なシーンの理解
主要なアクションやオブジェクトの特定には優れていますが、ビデオ内で同時に発生する背景の微妙な活動や並行するイベントを見落とす可能性があります。
視覚的な完全一致の課題
このモデルは、特にわずかに異なる文脈で複数回出現する可能性のあるオブジェクトや人物の特定のインスタンスを検索する際に、視覚的な完全一致を見つけることに苦労することがあります。
クエリの解釈
Marengo 2.7はほとんどのクエリを効果的に処理しますが、以下のような場合に課題に直面することがあります:
複数の時間的関係を伴う細かく構成されたクエリ
単純なケースを超えた複雑な否定パターン
抽象的な推論や世界の知識を必要とするクエリ
ロゴ検索、会話検索、OCR検索におけるパフォーマンス
さらに、Marengo 2.7は、特にロゴがフレームの1%未満しか占めていない場合や、難しい視野角に表示されている場合のテキスト・ツー・ロゴ検索シナリオにおいて限界を示しています。
会話やOCRの検索においては、強いアクセントのある話し言葉、重複する会話、珍しいフォントや向きのテキストに苦労することがあります。これらの課題は、特にライティング条件が悪い、または複雑な背景を持つ現実世界のシナリオで顕著になります。
これらの制限は、マルチモーダルなビデオ理解の能力を向上させ続ける中での、今後の研究開発の当然の課題です。現在進行中の取り組みは、クロスモーダルな理解や時間的推論における現在の強みを維持しながら、これらの課題に対処することに焦点を当てています。
6 - 結論
Marengo 2.7は、マルチモーダルビデオ理解における大きな飛躍を意味し、映像、音声、テキストモダリティ全体で大きな向上を示しています。革新的なマルチベクトルアプローチと包括的な評価フレームワークを通じて、さまざまなユースケースにおいて高精度を維持しながら、複雑なビデオ理解タスクにおいて最先端のパフォーマンスを達成できることを実証しました。
この分野における透明性と再現性をサポートするため、包括的な評価フレームワークとともに、詳細なテクニカルレポートを公開する予定です。60以上のデータセットにわたるテストを含むこのフレームワークは、オープンソース化され定期的にメンテナンスされるため、研究者や実践者の方が私たちの結果を検証し、マルチモーダルなビデオ理解の進歩に貢献できるようになります。
謝辞
これは、サイエンス、エンジニアリング、プロダクト、ビジネス開発、オペレーションを含む複数の機能横断グループによる共同チームの成果です。Twelve Labs Research Science部門のMarengoチームの共同執筆によるものです。








