" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
パートナーシップ
マルチモーダルAIを極める:Twelve Labs + Databricks Mosaic AIによる高度なビデオ理解ビデオ高度理解

ジェームズ・リー
この記事では、Twelve LabsのEmbed APIとDatabricks Mosaic AI Vector Searchを統合して、類似検索や推奨システムを含む高度なビデオ理解アプリケーションを構築する方法を、開発者向けに解説します。また、パフォーマンスの最適化、スケーリング、モニターにおける考慮事項についても取り上げます。
この記事では、Twelve LabsのEmbed APIとDatabricks Mosaic AI Vector Searchを統合して、類似検索や推奨システムを含む高度なビデオ理解アプリケーションを構築する方法を、開発者向けに解説します。また、パフォーマンスの最適化、スケーリング、モニターにおける考慮事項についても取り上げます。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2024/08/30
14分
記事へのリンクをコピー
概要
Twelve LabsのEmbed APIを使用すると、開発者は高度なビデオ理解のユースケースを動かすためのマルチモーダル埋め込みを取得できます。これには、セマンティックビデオ検索やデータキュレーションから、コンテンツ推奨、ビデオRAGシステムまでが含まれます。
Twelve Labsを使用すると、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の間の関係を捉える文脈ベクトル表現を生成できます。Databricks Mosaic AIのVector Searchは、高次元ベクトルのインデックス作成とクエリ実行のための、堅牢でスケーラブルなインフラストラクチャを提供します。
このブログ記事では、これらの相補的な技術を活用して、ビデオAIアプリケーションの新たな可能性を切り拓く方法を説明します。
このチュートリアルの作成にあたり、ご協力いただいたDatabricksのNina Williams氏、Austin Zaccor氏、Fernanda Heredia氏、およびEmily Hutson氏に深く感謝いたします!
なぜ Twelve Labs + Databricks Mosaic AI なのか?
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchと統合することで、大規模なビデオデータセットの効率的な処理や、正確なマルチモーダルコンテンツの表現といった、ビデオAIにおける主要な課題に対応できます。この統合により、高度なビデオアプリケーションの開発時間と必要なリソースを削減し、膨大なビデオライブラリ全体にわたる複雑なクエリを可能にするとともに、ワークフロー全体の効率を向上させます。
マルチモーダルデータを処理するための統合されたアプローチは特に注目に値します。テキスト、画像、音声の分析のために別々のモデルを使い分ける代わりに、ビデオコンテンツの本質を丸ごと捉える、単一の一貫した表現を扱えるようになります。これにより、展開アーキテクチャが簡素化されるだけでなく、洗練されたコンテンツ推奨システムから高度なビデオ検索エンジン、自動コンテンツモデレーションツールまで、よりニュアンスに富んだ文脈対応のアプリケーションが実現します。
さらに、この統合によりDatabricksエコシステムの機能が拡張され、ビデオ理解を既存のデータパイプラインや機械学習ワークフローにシームレスに組み込めるようになります。企業がリアルタイムのビデオ分析を開発している場合でも、大規模なコンテンツ分類システムを構築している場合でも、あるいは生成AIの新しいアプリケーションを模索している場合でも、この組み合わせソリューションは強力な基盤を提供します。これにより、ビデオAIで実現可能な価値の限界を押し広げ、メディアやエンターテインメントからセキュリティ、ヘルスケアに至るまでの業界において、イノベーションと問題解決の新しい道を切り拓きます。
Twelve Labs の Embed API を理解する
Twelve LabsのEmbed APIは、ビデオコンテンツ専用に設計されたマルチモーダル埋め込み技術における大きな進歩を表しています。フレームごとの分析や異なるモダリティごとの個別のモデルに依存する従来のアプローチとは異なり、このAPIは、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の複雑な相互作用を捉える文脈ベクトル表現を生成します。これは、当社の最先端のマルチモーダル基盤モデル Marengo-2.6をベースに構築されています。
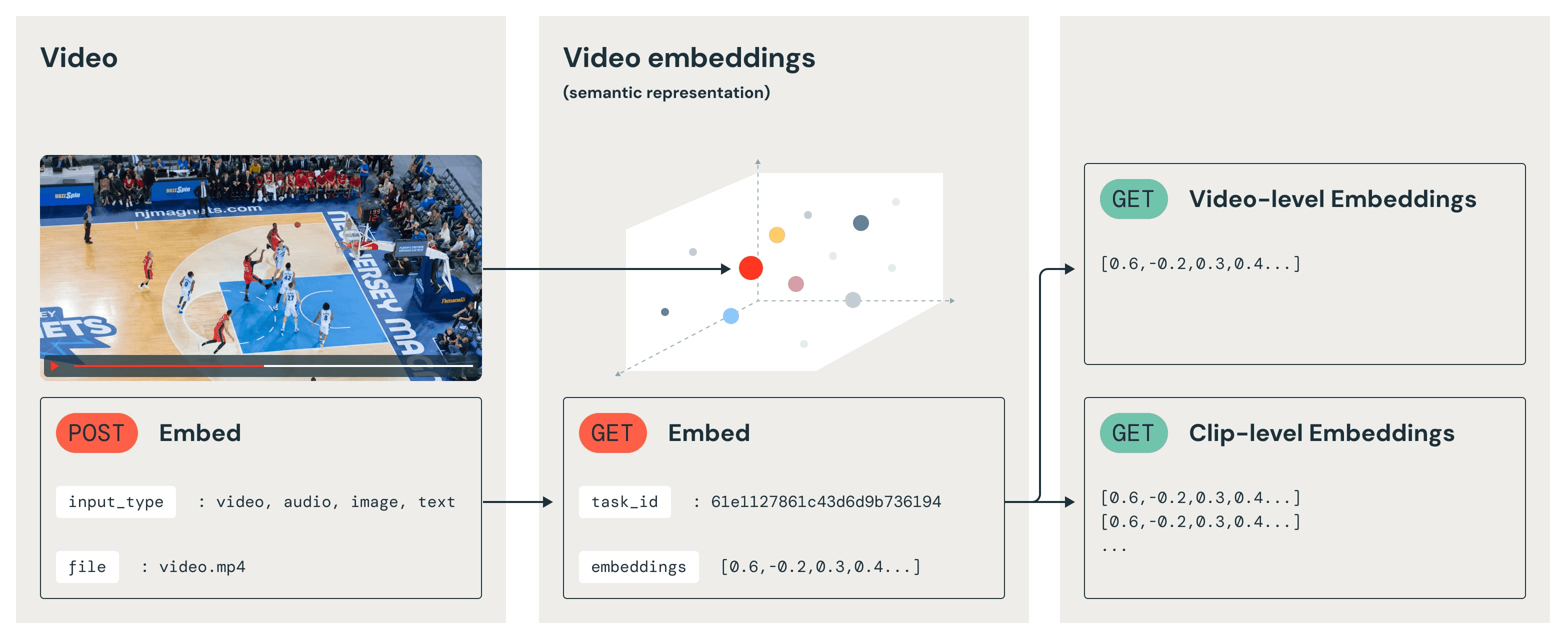
Embed APIは、ビデオデータを扱うAIエンジニアにとって特に強力となるいくつかの重要な機能を提供します。第一に、ビデオに存在するあらゆるモダリティに柔軟に対応できるため、テキスト専用や画像専用の個別のモデルを用意する必要がありません。第二に、動き、アクション、時系列の情報を考慮するビデオネイティブなアプローチを採用しており、ビデオコンテンツのより正確で時系列的に一貫した解釈を保証します。最後に、すべてのモダリティからの埋め込みを統合する統一されたベクトル空間を作成し、ビデオコンテンツのより包括的な理解を促進します。
AIエンジニアにとって、Embed APIはビデオ理解タスクにおいて新しい可能性を切り拓きます。これにより、より高度なコンテンツ分析、向上したセマンティック検索機能、および強化された推奨システムが可能になります。文脈に沿った微細な合図や異なるモダリティ間の長時間の相互作用を捉えるAPIの能力は、感情認識、文脈を考慮したコンテンツモデレーション、高度なビデオ検索システムなど、ビデオコンテンツのニュアンス豊かな理解を必要とするアプリケーションで特に価値を発揮します。
前提条件
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchに統合する前に、以下の前提条件を満たしていることを確認してください。
ワークスペースの作成と管理のアクセス権を持つDatabricksアカウント。(無料トライアルは https://databricks.com/try-databricks から登録できます)
Pythonプログラミングおよび基本的なデータサイエンスの概念についての知識。
Twelve LabsのAPIキー。(playground.twelvelabs.io で登録してください)
ベクトル埋め込みと類似性検索の概念に関する基本的な理解。
(オプション)AWS上でDatabricksを使用する場合はAWSアカウント。AzureまたはGoogle Cloud上でDatabricksを使用する場合は不要です。
注意:Embed APIは現在プライベートベータ版ですが、すべてのユーザーがこのフォームに記入するだけでアクセスをリクエストできます。通常、数時間以内に確認メールが届き、Embed APIの使用を開始できるようになります。
ステップ 1: 環境のセットアップ
まず、Databricks環境をセットアップし、必要なライブラリをインストールします。
1 - 新しいDatabricksワークスペースを作成する:
https://accounts.cloud.databricks.com/ からDatabricksアカウントにログインします。
Databricksドキュメントに記載されている手順に従って、新しいワークスペースを作成します: https://docs.databricks.com/en/getting-started/index.html
2 - 新しいクラスターを作成するか、既存のクラスターに接続する:
このアプリケーションには、ほぼすべてのMLクラスターが機能します。以下の設定は、最適なコストパフォーマンスを求める方向けに提供されています。
「Compute」タブで「Create compute」をクリックします。
「Single node」を選択し、Runtimeには「14.3 LTS ML non-GPU」を選択します。
クラスターのポリシーとアクセスモードはデフォルトのままで構いません。
ノードタイプとして「r6i.xlarge」を選択します。
これにより、メモリ使用率を最大化しつつ、コストはAWS上でわずか$0.252/時、Databricksで割引適用前で1.02 DBU/時となります。
また、テストした中で最も高速なオプションの一つでした。
他のすべてのオプションはデフォルトのままで構いません。
下部にある「Create compute」をクリックし、ワークスペースに戻ります。
3 - Databricksワークスペースに新しいノートブックを作成する:
ワークスペースで「Create」をクリックし、「Notebook」を選択します。
ノートブックに名前を付けます(例: "TwelveLabs_MosaicAI_VectorSearch_Integration")
デフォルト言語としてPythonを選択します。
4 - Twelve Labs および Mosaic AI Vector Search の SDK をインストールする:
ノートブックの最初のセルで、次のコマンドを実行します。
%pip install twelvelabs databricks-vectorsearch
5 - Twelve Labs の認証を設定する:
次のセルに、以下のコードを追加します。
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
注意:セキュリティを強化するため、APIキーをハードコードしたり環境変数を使用したりするのではなく、Databricksのシークレット機能を使用して保存することをお勧めします。
ステップ 2: マルチモーダル埋め込みを生成する
提供されているgenerate_embedding関数を使用して、Twelve Labs Embed APIでマルチモーダル埋め込みを生成します。この関数は、Databricks内のSpark DataFrameで効率的に動作するようにPandasユーザー定義関数(UDF)として設計されています。これは、埋め込みタスクの作成、進行状況の監視、および結果の取得のプロセスをカプセル化しています。
次に、ビデオURLを文字列として受け取り、Twelve Labs Embed APIを呼び出して配列<float>を返すprocess_url関数を作成します。
以下に実装方法と使用方法を示します。
UDFの定義:
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
ビデオURLを含むサンプルDataFrameの作成:
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
埋め込みを生成するためのUDFの適用:
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
結果の表示:
df_with_embeddings.show(truncate=False)
このプロセスにより、DataFrame内の各ビデオURLに対して、視覚情報、音声情報、およびテキスト情報を含む、ビデオコンテンツのマルチモーダルな本質を捉えたマルチモーダル埋め込みが生成されます。
大規模なビデオデータセットの場合、埋め込みの生成は計算負荷が高く、時間がかかることがある点に注意してください。本番スケールのアプリケーションでは、バッチ処理や分散処理の戦略を実装することを検討してください。さらに、APIエラーやネットワークの問題を処理するために、適切なエラーハンドリングとログ記録が導入されていることを確認してください。
ステップ 3: ビデオ埋め込み用の Delta テーブルを作成する
次に、ビデオメタデータと、Twelve Labs Embed APIによって生成された埋め込みを保存するためのソースDeltaテーブルを作成します。このテーブルは、Databricks Mosaic AI Vector SearchにおけるVector Searchインデックスの基礎として機能します。
まず、ビデオのURLとメタデータを含むソースDataFrameを作成します:
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
次に、SQLを使用してDeltaテーブルのスキーマを定義します:
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
テーブルでChange Data Feedが有効になっていることに注意してください。これは、Vector Searchインデックスを作成および維持するために非常に重要です。
では、先ほど定義したget_video_embeddings関数を使用して、ビデオの埋め込みを生成します:
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
このステップは、ビデオの数や長さによっては少し時間がかかる場合があります。
埋め込みが生成されたら、データをDeltaテーブルに書き込みます:
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
最後に、埋め込みを含むDataFrameを表示して、データを確認します:
display(embeddings_df)
この手順により、Vector Search機能のための強力な基盤が構築されます。Deltaテーブルは自動的にVector Searchインデックスと同期されるため、ビデオデータセットに対する更新や追加は即座に検索結果に反映されます。
覚えておくべきいくつかの重要なポイント:
id列は自動生成され、各ビデオに一意の識別子を提供します。embedding列は、Twelve Labs Embed APIによって生成された各ビデオの高次元ベクトル表現を格納します。Change Data Feedを有効にすることで、Databricksはテーブル内の変更を効率的に追跡できます。これは、最新のVector Searchインデックスを維持するために不可欠です。
ステップ 4: Mosaic AI Vector Search を設定する
このステップでは、ビデオ埋め込みを処理できるようにDatabricks Mosaic AI Vector Searchをセットアップします。これには、Vector Searchエンドポイントと、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexの作成が含まれます。
まず、Vector Searchエンドポイントを作成します:
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
このコードは、新しいVector Searchエンドポイントを作成するか、同じ名前の既存のエンドポイントを置き換えます。このエンドポイントは、Vector Search操作用のアクセスポイントとして機能します。
次に、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexを作成します:
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
このコードは、ソースDeltaテーブルにリンクするDelta Sync Indexを作成します。ソーステーブルに加えられた変更から数秒以内にインデックスを自動的に更新したい場合(Vector Searchの結果が常に最新であることを保証する)、pipeline_type="CONTINUOUS"を設定します。
インデックスが作成され、正しく同期されていることを確認するには、次のコードを使用して手動で同期を呼び出します:
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
このコードを使用すると、インデックスのステータスを確認し、必要に応じて手動で同期を行うことができます。本番環境では、ソースDeltaテーブルの変更に基づいて自動的に同期するようにパイプラインを設定する方が好ましいでしょう。
覚えておくべき重要事項:
Vector Searchエンドポイントは、Vector Search操作のアクセスポイントとして機能します。
Delta Sync IndexはソースDeltaテーブルと自動的に同期し、常に最新の検索結果を保証します。
embedding_dimensionは、Twelve LabsのEmbed APIによって生成された埋め込みの次元数(1024)に一致させる必要があります。primary_keyは「id」に設定します。これはソーステーブルの一意の識別子に対応している必要があります。embedding_vector_columnは「embedding」に設定します。これはソーステーブル内のビデオ埋め込みが含まれる列名と一致する必要があります。
ステップ 5: 類似性検索を実装する
次のステップは、設定されたMosaic AI Vector SearchインデックスとTwelve Labs Embed APIを使用して類似性検索機能を実装することです。これにより、マルチモーダル埋め込みのパワーを活用し、指定したテキストクエリに類似したビデオを見つけることができます。
まず、Twelve Labs Embed APIを使用して、テキストクエリの埋め込みを取得する関数を定義します:
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
この関数はテキストクエリを受け取り、ビデオ埋め込みと同じモデルを使用してその埋め込みを生成し、ベクトル空間での互換性を確保します。
次に、類似性検索関数を実装します:
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
この関数は、テキストクエリと返される結果の数を受け取ります。クエリの埋め込みを生成し、Mosaic AI Vector Searchインデックスを使用して類似するビデオを検索します。
検索結果を解析して表示するには、次のヘルパー関数を使用します:
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
では、これらをすべて組み合わせて、サンプル検索を実行してみましょう:
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
このコードは、Twelve Labsの類似性検索関数を使用して「A dragon」というクエリに関連するビデオを検索する方法を示しています。その後、検索結果を解析し、ユーザーフレンドリーな形式で表示します。
覚えておくべき重要事項:
get_text_embedding関数は、ビデオ埋め込みと同じTwelve Labsモデルを使用するため、互換性が保証されます。similarity_search関数は、テキストから埋め込みへの変換とVector Searchを組み合わせて、類似するビデオを見つけます。ネットワークの問題やAPIの変更が検索プロセスに影響を与える可能性があるため、エラーハンドリングは不可欠です。
parse_search_results関数は、生のAPI応答をより扱いやすい形式に変換するのに役立ちます。similarity_search関数のnum_resultsパラメータを調整して、返される結果の数を制御できます。
この実装により、ビデオデータセット全体の強力なセマンティック検索機能が有効になります。ユーザーは、Twelve Labs Embed APIによって生成された豊かなマルチモーダル埋め込みを活用して、自然言語クエリを使用して関連するビデオを見つけることができるようになります。
ステップ 6: ビデオ推奨システムを構築する
次に、Twelve Labs Embed APIとDatabricks Mosaic AI Vector Searchによって生成されたマルチモーダル埋め込みを使用して、基本的なビデオ推奨システムを作成します。このシステムは、埋め込みの類似性に基づいて、指定されたビデオに類似したビデオを提示します。
まず、簡単な推奨機能を実装します:
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
この実装は以下の仕組みで動きます:
get_video_recommendations関数は、ビデオIDと返すべき推奨ビデオの件数を受け取ります。指定されたビデオの埋め込みをソースDeltaテーブルから取得します。
この埋め込みを使用して類似性検索を実行し、最も類似しているビデオを見つけます。
同じビデオが推奨されないように、結果から入力ビデオを削除します(結果に含まれる場合)。
display_recommendationsヘルパー関数は、推奨ビデオのリストをユーザーフレンドリーな形で整形し、出力します。
この推奨システムを使用するには:
videos_source_embeddingsテーブルに、有効な埋め込みを持つビデオが保存されていることを確認します。データセット内の有効なビデオIDを指定して、
get_video_recommendations関数を呼び出します。関数は類似度に基づいた推奨ビデオのリストを表示します。
この基本的な推奨システムは、コンテンツベースのビデオ推奨においてマルチモーダル埋め込みをどのように活用するかを示しています。これは、いくつかの方法で拡張および改善できます:
パーソナライズされた推奨を行うために、ユーザーの好みや視聴履歴を組み込みます。
多様な推奨結果を保証するために、偶発性メカニズムを実装します。
ビデオメタデータ(ジャンル、長さ、投稿日など)に基づくフィルタリングを追加します。
頻繁にリクエストされる推奨ビデオのパフォーマンスを向上させるために、キャッシュメカニズムを実装します。
推奨の品質は、ビデオデータセットの規模と多様性、さらにはTwelve Labs Embed APIが生成する埋め込みの正確性に依存することに注意してください。システムに登録するビデオを増やすにつれて、推奨結果はさらに高い関連性と多様性を持つようになります。
この統合を次のレベルに引き上げる
インデックスの更新と同期
ビデオライブラリが拡大し進化するにつれて、Vector Searchインデックスを最新の状態に維持することが極めて重要です。Mosaic AI Vector SearchはソースDeltaテーブルとのシームレスな同期を提供し、推奨結果や検索結果に常に最新データを反映させることができます。
インデックス更新と同期における重要な考慮事項:
増分更新:Delta Lakeの変更データフィード(Change Data Feed)を活用し、インデックス内の変更されたレコード、または新しいレコードのみを効率的に更新します。
定期同期のスケジュール:Databricksのワークフローオーケストレーションツールを使用し、定期的な同期ジョブを実行してインデックスの鮮度を維持します。
リアルタイム更新:時間に極めてシリズなアプリケーションでは、Databricks Mosaic AIのストリーミング機能を使用した準リアルタイムのインデックス更新の実装を検討してください。
バージョン管理:Delta Lakeのタイムトラベル機能を利用してインデックスの複数のバージョンを維持し、必要に応じて簡単にロールバックできるようにします。
同期ステータスの監視:同期の成功を追跡し、更新処理での問題をすばやく特定するために、ログ記録やアラートの仕組みを実装します。
これらの手法を習得することで、TwelveLabsのビデオ埋め込みを常に最新に保ち、高度な検索と推奨のユースケースにいつでも対応できるようにします。
パフォーマンスとスケーリングの最適化
自身のビデオ分析パイプラインが成長するにつれ、パフォーマンスの最適化を継続し、ソリューションをスケールアップさせることが重要になります。Databricksの分散コンピューティング機能は、Twelve Labsの効率的な埋め込み生成と連携することで、大規模なビデオ処理タスクの処理に耐えうる堅牢な基盤を提供します。
ソリューションを最適化しスケーリングするための主なアプローチ:
分散処理:DatabricksのSparkクラスターを活用して、複数のノード間で埋め込みの生成タスクやインデックス構築タスクを並列化します。
キャッシュ戦略:アクセス頻度が高い埋め込みに対してインテリジェントなキャッシュ処理を導入し、APIの呼び出しを減らして応答時間を短縮します。
バッチ処理:大規模なビデオライブラリに対しては、ピーク時以外の時間帯に埋め込みを生成してインデックスを更新するバッチ処理ワークフローを実装します。
クエリの最適化:
num_resultsなどのパラメータを調整し、効率的なフィルタリング手法を駆使して、Vector Searchクエリを微調整します。インデックスのパーティショニング:超大規模なデータセットの場合は、クエリのレスポンスを高め、よりきめ細かい更新を可能にするために、インデックスのパーティショニング戦略を調査します。
オートスケーリング:Databricksのオートスケーリング機能を利用し、ワークロードの処理需要に合わせてコンピューティングリソースを動的に調整します。
エッジコンピューティング:遅延(レイテンシ)を気にするアプリケーションの場合は、モデルの軽量版をデータソースの近くにデプロイすることを検討します。
これらの最適化手法を導入することで、優れたパフォーマンスとコスト効率を両立させながら、増え続けるビデオライブラリと増加するユーザー需要に対処することが可能になります。
モニタリングと分析
ビデオ理解パイプラインの継続的な成功を収めるためには、堅牢な監視(モニタリング)とデータ分析の仕組みが欠かせません。Databricksは、システムのパフォーマンス、ユーザー行動、ビジネスインパクトを追跡するための強力なツールを提供しています。
監視と分析で重点を置くべき主な領域:
パフォーマンスメトリクス:クエリの遅延、埋め込み生成までの時間、インデックス同期にかかる時間などの主要業績評価指標(KPI)を追跡します。
利用ログの分析:ユーザーの操作履歴、よく使われる検索クエリ、頻繁にレコメンドされるビデオを分析し、ユーザー行動の洞察を得ます。
品質評価:システムによる自動評価指標と実際のユーザーフィードバックを活用し、検索結果や推奨結果の関連度を評価するフィードバックループを構築します。
リソース使用状況:コンピューティングリソース、APIコール数、ストレージ利用量を継続的に監視し、コストとパフォーマンスを最適化します。
エラー追跡:パイプライン内で発生した不具合を迅速に検知・解決するために、包括的なログ記録と警告システム(アラート)を整備します。
A/Bテスト:Databricksの検証機能を活用し、さまざまな埋め込みモデル、検索アルゴリズム、またはレコメンドモデルを試験評価(テスト)します。
ビジネス目標の検証:ビデオ解析により実現した機能を、ユーザーの滞在状況(エンゲージメント)、視聴時間、成約率などの最終的なKGIに紐付けます。
法規制・規約遵守:ビデオ処理処理パイプラインが個人情報保護規制やコンテンツモデレーションのガイドラインに適合しているかを継続的に確認します。
これらすべての監視手法を施すことで、ビデオパイプラインの働きとその成果について価値の高い情報を手にすることができます。このアプローチに基づく改善を絶えず繰り返すことで、Twelve Labsの高度なビデオ構造化機能とDatabricks Data Intelligence Platformの統合価値を、データに基づいて実証できるようになります。
まとめ
Twelve Labs と Databricks Mosaic AI は、洗練された映像コンテンツの構造化と、高度なデータ抽出タスクのための一貫した統合開発フレームワークを提供します。この統合技術により、マルチモーダルなビデオ表現ベクトルの抽出と実効性の高いベクトル検索(Vector Search)を活用し、開発者は独自のビデオ解析、レコメンド、検索システムを作り上げることが可能になります。
このチュートリアルでは、開発に必要な環境構築から、マルチモーダル情報のベクトル展開、ベクトルエンジンへの登録、類似コンテンツ検索、レコメンデーションの実装に必要な基本ロジックを解説しました。さらに実用に必要なスケーラブルな管理システム設計、最適化手法、信頼性向上のための監視方法まで包括的に言及しています。
映像データが爆発的に増加する現在、それらをシステムに最適化させて価値を効率よく発掘する術(すべ)は不可欠です。本ドキュメントは、この難解なプロジェクトを克服するための強力な設計方法論を提供するものです。ぜひそれらの機能をテストし、応用的課題を検討しながら、映像理解を進化させる開発コミュニティを共に盛り上げましょう。
さらに学びたい方のための情報ソース
これらの連携方法をさらに深く探索するために、以下の情報をぜひご一読ください。
これらのお役立ち情報を手元に置くことで、最先端のAIビデオテクノロジーを活用し、Twelve Labs と Databricks をベースにした独自のイノベーティブなシステムの構築を進めていきましょう。
概要
Twelve LabsのEmbed APIを使用すると、開発者は高度なビデオ理解のユースケースを動かすためのマルチモーダル埋め込みを取得できます。これには、セマンティックビデオ検索やデータキュレーションから、コンテンツ推奨、ビデオRAGシステムまでが含まれます。
Twelve Labsを使用すると、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の間の関係を捉える文脈ベクトル表現を生成できます。Databricks Mosaic AIのVector Searchは、高次元ベクトルのインデックス作成とクエリ実行のための、堅牢でスケーラブルなインフラストラクチャを提供します。
このブログ記事では、これらの相補的な技術を活用して、ビデオAIアプリケーションの新たな可能性を切り拓く方法を説明します。
このチュートリアルの作成にあたり、ご協力いただいたDatabricksのNina Williams氏、Austin Zaccor氏、Fernanda Heredia氏、およびEmily Hutson氏に深く感謝いたします!
なぜ Twelve Labs + Databricks Mosaic AI なのか?
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchと統合することで、大規模なビデオデータセットの効率的な処理や、正確なマルチモーダルコンテンツの表現といった、ビデオAIにおける主要な課題に対応できます。この統合により、高度なビデオアプリケーションの開発時間と必要なリソースを削減し、膨大なビデオライブラリ全体にわたる複雑なクエリを可能にするとともに、ワークフロー全体の効率を向上させます。
マルチモーダルデータを処理するための統合されたアプローチは特に注目に値します。テキスト、画像、音声の分析のために別々のモデルを使い分ける代わりに、ビデオコンテンツの本質を丸ごと捉える、単一の一貫した表現を扱えるようになります。これにより、展開アーキテクチャが簡素化されるだけでなく、洗練されたコンテンツ推奨システムから高度なビデオ検索エンジン、自動コンテンツモデレーションツールまで、よりニュアンスに富んだ文脈対応のアプリケーションが実現します。
さらに、この統合によりDatabricksエコシステムの機能が拡張され、ビデオ理解を既存のデータパイプラインや機械学習ワークフローにシームレスに組み込めるようになります。企業がリアルタイムのビデオ分析を開発している場合でも、大規模なコンテンツ分類システムを構築している場合でも、あるいは生成AIの新しいアプリケーションを模索している場合でも、この組み合わせソリューションは強力な基盤を提供します。これにより、ビデオAIで実現可能な価値の限界を押し広げ、メディアやエンターテインメントからセキュリティ、ヘルスケアに至るまでの業界において、イノベーションと問題解決の新しい道を切り拓きます。
Twelve Labs の Embed API を理解する
Twelve LabsのEmbed APIは、ビデオコンテンツ専用に設計されたマルチモーダル埋め込み技術における大きな進歩を表しています。フレームごとの分析や異なるモダリティごとの個別のモデルに依存する従来のアプローチとは異なり、このAPIは、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の複雑な相互作用を捉える文脈ベクトル表現を生成します。これは、当社の最先端のマルチモーダル基盤モデル Marengo-2.6をベースに構築されています。
Embed APIは、ビデオデータを扱うAIエンジニアにとって特に強力となるいくつかの重要な機能を提供します。第一に、ビデオに存在するあらゆるモダリティに柔軟に対応できるため、テキスト専用や画像専用の個別のモデルを用意する必要がありません。第二に、動き、アクション、時系列の情報を考慮するビデオネイティブなアプローチを採用しており、ビデオコンテンツのより正確で時系列的に一貫した解釈を保証します。最後に、すべてのモダリティからの埋め込みを統合する統一されたベクトル空間を作成し、ビデオコンテンツのより包括的な理解を促進します。
AIエンジニアにとって、Embed APIはビデオ理解タスクにおいて新しい可能性を切り拓きます。これにより、より高度なコンテンツ分析、向上したセマンティック検索機能、および強化された推奨システムが可能になります。文脈に沿った微細な合図や異なるモダリティ間の長時間の相互作用を捉えるAPIの能力は、感情認識、文脈を考慮したコンテンツモデレーション、高度なビデオ検索システムなど、ビデオコンテンツのニュアンス豊かな理解を必要とするアプリケーションで特に価値を発揮します。
前提条件
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchに統合する前に、以下の前提条件を満たしていることを確認してください。
ワークスペースの作成と管理のアクセス権を持つDatabricksアカウント。(無料トライアルは https://databricks.com/try-databricks から登録できます)
Pythonプログラミングおよび基本的なデータサイエンスの概念についての知識。
Twelve LabsのAPIキー。(playground.twelvelabs.io で登録してください)
ベクトル埋め込みと類似性検索の概念に関する基本的な理解。
(オプション)AWS上でDatabricksを使用する場合はAWSアカウント。AzureまたはGoogle Cloud上でDatabricksを使用する場合は不要です。
注意:Embed APIは現在プライベートベータ版ですが、すべてのユーザーがこのフォームに記入するだけでアクセスをリクエストできます。通常、数時間以内に確認メールが届き、Embed APIの使用を開始できるようになります。
ステップ 1: 環境のセットアップ
まず、Databricks環境をセットアップし、必要なライブラリをインストールします。
1 - 新しいDatabricksワークスペースを作成する:
https://accounts.cloud.databricks.com/ からDatabricksアカウントにログインします。
Databricksドキュメントに記載されている手順に従って、新しいワークスペースを作成します: https://docs.databricks.com/en/getting-started/index.html
2 - 新しいクラスターを作成するか、既存のクラスターに接続する:
このアプリケーションには、ほぼすべてのMLクラスターが機能します。以下の設定は、最適なコストパフォーマンスを求める方向けに提供されています。
「Compute」タブで「Create compute」をクリックします。
「Single node」を選択し、Runtimeには「14.3 LTS ML non-GPU」を選択します。
クラスターのポリシーとアクセスモードはデフォルトのままで構いません。
ノードタイプとして「r6i.xlarge」を選択します。
これにより、メモリ使用率を最大化しつつ、コストはAWS上でわずか$0.252/時、Databricksで割引適用前で1.02 DBU/時となります。
また、テストした中で最も高速なオプションの一つでした。
他のすべてのオプションはデフォルトのままで構いません。
下部にある「Create compute」をクリックし、ワークスペースに戻ります。
3 - Databricksワークスペースに新しいノートブックを作成する:
ワークスペースで「Create」をクリックし、「Notebook」を選択します。
ノートブックに名前を付けます(例: "TwelveLabs_MosaicAI_VectorSearch_Integration")
デフォルト言語としてPythonを選択します。
4 - Twelve Labs および Mosaic AI Vector Search の SDK をインストールする:
ノートブックの最初のセルで、次のコマンドを実行します。
%pip install twelvelabs databricks-vectorsearch
5 - Twelve Labs の認証を設定する:
次のセルに、以下のコードを追加します。
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
注意:セキュリティを強化するため、APIキーをハードコードしたり環境変数を使用したりするのではなく、Databricksのシークレット機能を使用して保存することをお勧めします。
ステップ 2: マルチモーダル埋め込みを生成する
提供されているgenerate_embedding関数を使用して、Twelve Labs Embed APIでマルチモーダル埋め込みを生成します。この関数は、Databricks内のSpark DataFrameで効率的に動作するようにPandasユーザー定義関数(UDF)として設計されています。これは、埋め込みタスクの作成、進行状況の監視、および結果の取得のプロセスをカプセル化しています。
次に、ビデオURLを文字列として受け取り、Twelve Labs Embed APIを呼び出して配列<float>を返すprocess_url関数を作成します。
以下に実装方法と使用方法を示します。
UDFの定義:
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
ビデオURLを含むサンプルDataFrameの作成:
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
埋め込みを生成するためのUDFの適用:
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
結果の表示:
df_with_embeddings.show(truncate=False)
このプロセスにより、DataFrame内の各ビデオURLに対して、視覚情報、音声情報、およびテキスト情報を含む、ビデオコンテンツのマルチモーダルな本質を捉えたマルチモーダル埋め込みが生成されます。
大規模なビデオデータセットの場合、埋め込みの生成は計算負荷が高く、時間がかかることがある点に注意してください。本番スケールのアプリケーションでは、バッチ処理や分散処理の戦略を実装することを検討してください。さらに、APIエラーやネットワークの問題を処理するために、適切なエラーハンドリングとログ記録が導入されていることを確認してください。
ステップ 3: ビデオ埋め込み用の Delta テーブルを作成する
次に、ビデオメタデータと、Twelve Labs Embed APIによって生成された埋め込みを保存するためのソースDeltaテーブルを作成します。このテーブルは、Databricks Mosaic AI Vector SearchにおけるVector Searchインデックスの基礎として機能します。
まず、ビデオのURLとメタデータを含むソースDataFrameを作成します:
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
次に、SQLを使用してDeltaテーブルのスキーマを定義します:
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
テーブルでChange Data Feedが有効になっていることに注意してください。これは、Vector Searchインデックスを作成および維持するために非常に重要です。
では、先ほど定義したget_video_embeddings関数を使用して、ビデオの埋め込みを生成します:
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
このステップは、ビデオの数や長さによっては少し時間がかかる場合があります。
埋め込みが生成されたら、データをDeltaテーブルに書き込みます:
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
最後に、埋め込みを含むDataFrameを表示して、データを確認します:
display(embeddings_df)
この手順により、Vector Search機能のための強力な基盤が構築されます。Deltaテーブルは自動的にVector Searchインデックスと同期されるため、ビデオデータセットに対する更新や追加は即座に検索結果に反映されます。
覚えておくべきいくつかの重要なポイント:
id列は自動生成され、各ビデオに一意の識別子を提供します。embedding列は、Twelve Labs Embed APIによって生成された各ビデオの高次元ベクトル表現を格納します。Change Data Feedを有効にすることで、Databricksはテーブル内の変更を効率的に追跡できます。これは、最新のVector Searchインデックスを維持するために不可欠です。
ステップ 4: Mosaic AI Vector Search を設定する
このステップでは、ビデオ埋め込みを処理できるようにDatabricks Mosaic AI Vector Searchをセットアップします。これには、Vector Searchエンドポイントと、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexの作成が含まれます。
まず、Vector Searchエンドポイントを作成します:
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
このコードは、新しいVector Searchエンドポイントを作成するか、同じ名前の既存のエンドポイントを置き換えます。このエンドポイントは、Vector Search操作用のアクセスポイントとして機能します。
次に、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexを作成します:
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
このコードは、ソースDeltaテーブルにリンクするDelta Sync Indexを作成します。ソーステーブルに加えられた変更から数秒以内にインデックスを自動的に更新したい場合(Vector Searchの結果が常に最新であることを保証する)、pipeline_type="CONTINUOUS"を設定します。
インデックスが作成され、正しく同期されていることを確認するには、次のコードを使用して手動で同期を呼び出します:
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
このコードを使用すると、インデックスのステータスを確認し、必要に応じて手動で同期を行うことができます。本番環境では、ソースDeltaテーブルの変更に基づいて自動的に同期するようにパイプラインを設定する方が好ましいでしょう。
覚えておくべき重要事項:
Vector Searchエンドポイントは、Vector Search操作のアクセスポイントとして機能します。
Delta Sync IndexはソースDeltaテーブルと自動的に同期し、常に最新の検索結果を保証します。
embedding_dimensionは、Twelve LabsのEmbed APIによって生成された埋め込みの次元数(1024)に一致させる必要があります。primary_keyは「id」に設定します。これはソーステーブルの一意の識別子に対応している必要があります。embedding_vector_columnは「embedding」に設定します。これはソーステーブル内のビデオ埋め込みが含まれる列名と一致する必要があります。
ステップ 5: 類似性検索を実装する
次のステップは、設定されたMosaic AI Vector SearchインデックスとTwelve Labs Embed APIを使用して類似性検索機能を実装することです。これにより、マルチモーダル埋め込みのパワーを活用し、指定したテキストクエリに類似したビデオを見つけることができます。
まず、Twelve Labs Embed APIを使用して、テキストクエリの埋め込みを取得する関数を定義します:
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
この関数はテキストクエリを受け取り、ビデオ埋め込みと同じモデルを使用してその埋め込みを生成し、ベクトル空間での互換性を確保します。
次に、類似性検索関数を実装します:
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
この関数は、テキストクエリと返される結果の数を受け取ります。クエリの埋め込みを生成し、Mosaic AI Vector Searchインデックスを使用して類似するビデオを検索します。
検索結果を解析して表示するには、次のヘルパー関数を使用します:
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
では、これらをすべて組み合わせて、サンプル検索を実行してみましょう:
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
このコードは、Twelve Labsの類似性検索関数を使用して「A dragon」というクエリに関連するビデオを検索する方法を示しています。その後、検索結果を解析し、ユーザーフレンドリーな形式で表示します。
覚えておくべき重要事項:
get_text_embedding関数は、ビデオ埋め込みと同じTwelve Labsモデルを使用するため、互換性が保証されます。similarity_search関数は、テキストから埋め込みへの変換とVector Searchを組み合わせて、類似するビデオを見つけます。ネットワークの問題やAPIの変更が検索プロセスに影響を与える可能性があるため、エラーハンドリングは不可欠です。
parse_search_results関数は、生のAPI応答をより扱いやすい形式に変換するのに役立ちます。similarity_search関数のnum_resultsパラメータを調整して、返される結果の数を制御できます。
この実装により、ビデオデータセット全体の強力なセマンティック検索機能が有効になります。ユーザーは、Twelve Labs Embed APIによって生成された豊かなマルチモーダル埋め込みを活用して、自然言語クエリを使用して関連するビデオを見つけることができるようになります。
ステップ 6: ビデオ推奨システムを構築する
次に、Twelve Labs Embed APIとDatabricks Mosaic AI Vector Searchによって生成されたマルチモーダル埋め込みを使用して、基本的なビデオ推奨システムを作成します。このシステムは、埋め込みの類似性に基づいて、指定されたビデオに類似したビデオを提示します。
まず、簡単な推奨機能を実装します:
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
この実装は以下の仕組みで動きます:
get_video_recommendations関数は、ビデオIDと返すべき推奨ビデオの件数を受け取ります。指定されたビデオの埋め込みをソースDeltaテーブルから取得します。
この埋め込みを使用して類似性検索を実行し、最も類似しているビデオを見つけます。
同じビデオが推奨されないように、結果から入力ビデオを削除します(結果に含まれる場合)。
display_recommendationsヘルパー関数は、推奨ビデオのリストをユーザーフレンドリーな形で整形し、出力します。
この推奨システムを使用するには:
videos_source_embeddingsテーブルに、有効な埋め込みを持つビデオが保存されていることを確認します。データセット内の有効なビデオIDを指定して、
get_video_recommendations関数を呼び出します。関数は類似度に基づいた推奨ビデオのリストを表示します。
この基本的な推奨システムは、コンテンツベースのビデオ推奨においてマルチモーダル埋め込みをどのように活用するかを示しています。これは、いくつかの方法で拡張および改善できます:
パーソナライズされた推奨を行うために、ユーザーの好みや視聴履歴を組み込みます。
多様な推奨結果を保証するために、偶発性メカニズムを実装します。
ビデオメタデータ(ジャンル、長さ、投稿日など)に基づくフィルタリングを追加します。
頻繁にリクエストされる推奨ビデオのパフォーマンスを向上させるために、キャッシュメカニズムを実装します。
推奨の品質は、ビデオデータセットの規模と多様性、さらにはTwelve Labs Embed APIが生成する埋め込みの正確性に依存することに注意してください。システムに登録するビデオを増やすにつれて、推奨結果はさらに高い関連性と多様性を持つようになります。
この統合を次のレベルに引き上げる
インデックスの更新と同期
ビデオライブラリが拡大し進化するにつれて、Vector Searchインデックスを最新の状態に維持することが極めて重要です。Mosaic AI Vector SearchはソースDeltaテーブルとのシームレスな同期を提供し、推奨結果や検索結果に常に最新データを反映させることができます。
インデックス更新と同期における重要な考慮事項:
増分更新:Delta Lakeの変更データフィード(Change Data Feed)を活用し、インデックス内の変更されたレコード、または新しいレコードのみを効率的に更新します。
定期同期のスケジュール:Databricksのワークフローオーケストレーションツールを使用し、定期的な同期ジョブを実行してインデックスの鮮度を維持します。
リアルタイム更新:時間に極めてシリズなアプリケーションでは、Databricks Mosaic AIのストリーミング機能を使用した準リアルタイムのインデックス更新の実装を検討してください。
バージョン管理:Delta Lakeのタイムトラベル機能を利用してインデックスの複数のバージョンを維持し、必要に応じて簡単にロールバックできるようにします。
同期ステータスの監視:同期の成功を追跡し、更新処理での問題をすばやく特定するために、ログ記録やアラートの仕組みを実装します。
これらの手法を習得することで、TwelveLabsのビデオ埋め込みを常に最新に保ち、高度な検索と推奨のユースケースにいつでも対応できるようにします。
パフォーマンスとスケーリングの最適化
自身のビデオ分析パイプラインが成長するにつれ、パフォーマンスの最適化を継続し、ソリューションをスケールアップさせることが重要になります。Databricksの分散コンピューティング機能は、Twelve Labsの効率的な埋め込み生成と連携することで、大規模なビデオ処理タスクの処理に耐えうる堅牢な基盤を提供します。
ソリューションを最適化しスケーリングするための主なアプローチ:
分散処理:DatabricksのSparkクラスターを活用して、複数のノード間で埋め込みの生成タスクやインデックス構築タスクを並列化します。
キャッシュ戦略:アクセス頻度が高い埋め込みに対してインテリジェントなキャッシュ処理を導入し、APIの呼び出しを減らして応答時間を短縮します。
バッチ処理:大規模なビデオライブラリに対しては、ピーク時以外の時間帯に埋め込みを生成してインデックスを更新するバッチ処理ワークフローを実装します。
クエリの最適化:
num_resultsなどのパラメータを調整し、効率的なフィルタリング手法を駆使して、Vector Searchクエリを微調整します。インデックスのパーティショニング:超大規模なデータセットの場合は、クエリのレスポンスを高め、よりきめ細かい更新を可能にするために、インデックスのパーティショニング戦略を調査します。
オートスケーリング:Databricksのオートスケーリング機能を利用し、ワークロードの処理需要に合わせてコンピューティングリソースを動的に調整します。
エッジコンピューティング:遅延(レイテンシ)を気にするアプリケーションの場合は、モデルの軽量版をデータソースの近くにデプロイすることを検討します。
これらの最適化手法を導入することで、優れたパフォーマンスとコスト効率を両立させながら、増え続けるビデオライブラリと増加するユーザー需要に対処することが可能になります。
モニタリングと分析
ビデオ理解パイプラインの継続的な成功を収めるためには、堅牢な監視(モニタリング)とデータ分析の仕組みが欠かせません。Databricksは、システムのパフォーマンス、ユーザー行動、ビジネスインパクトを追跡するための強力なツールを提供しています。
監視と分析で重点を置くべき主な領域:
パフォーマンスメトリクス:クエリの遅延、埋め込み生成までの時間、インデックス同期にかかる時間などの主要業績評価指標(KPI)を追跡します。
利用ログの分析:ユーザーの操作履歴、よく使われる検索クエリ、頻繁にレコメンドされるビデオを分析し、ユーザー行動の洞察を得ます。
品質評価:システムによる自動評価指標と実際のユーザーフィードバックを活用し、検索結果や推奨結果の関連度を評価するフィードバックループを構築します。
リソース使用状況:コンピューティングリソース、APIコール数、ストレージ利用量を継続的に監視し、コストとパフォーマンスを最適化します。
エラー追跡:パイプライン内で発生した不具合を迅速に検知・解決するために、包括的なログ記録と警告システム(アラート)を整備します。
A/Bテスト:Databricksの検証機能を活用し、さまざまな埋め込みモデル、検索アルゴリズム、またはレコメンドモデルを試験評価(テスト)します。
ビジネス目標の検証:ビデオ解析により実現した機能を、ユーザーの滞在状況(エンゲージメント)、視聴時間、成約率などの最終的なKGIに紐付けます。
法規制・規約遵守:ビデオ処理処理パイプラインが個人情報保護規制やコンテンツモデレーションのガイドラインに適合しているかを継続的に確認します。
これらすべての監視手法を施すことで、ビデオパイプラインの働きとその成果について価値の高い情報を手にすることができます。このアプローチに基づく改善を絶えず繰り返すことで、Twelve Labsの高度なビデオ構造化機能とDatabricks Data Intelligence Platformの統合価値を、データに基づいて実証できるようになります。
まとめ
Twelve Labs と Databricks Mosaic AI は、洗練された映像コンテンツの構造化と、高度なデータ抽出タスクのための一貫した統合開発フレームワークを提供します。この統合技術により、マルチモーダルなビデオ表現ベクトルの抽出と実効性の高いベクトル検索(Vector Search)を活用し、開発者は独自のビデオ解析、レコメンド、検索システムを作り上げることが可能になります。
このチュートリアルでは、開発に必要な環境構築から、マルチモーダル情報のベクトル展開、ベクトルエンジンへの登録、類似コンテンツ検索、レコメンデーションの実装に必要な基本ロジックを解説しました。さらに実用に必要なスケーラブルな管理システム設計、最適化手法、信頼性向上のための監視方法まで包括的に言及しています。
映像データが爆発的に増加する現在、それらをシステムに最適化させて価値を効率よく発掘する術(すべ)は不可欠です。本ドキュメントは、この難解なプロジェクトを克服するための強力な設計方法論を提供するものです。ぜひそれらの機能をテストし、応用的課題を検討しながら、映像理解を進化させる開発コミュニティを共に盛り上げましょう。
さらに学びたい方のための情報ソース
これらの連携方法をさらに深く探索するために、以下の情報をぜひご一読ください。
これらのお役立ち情報を手元に置くことで、最先端のAIビデオテクノロジーを活用し、Twelve Labs と Databricks をベースにした独自のイノベーティブなシステムの構築を進めていきましょう。
概要
Twelve LabsのEmbed APIを使用すると、開発者は高度なビデオ理解のユースケースを動かすためのマルチモーダル埋め込みを取得できます。これには、セマンティックビデオ検索やデータキュレーションから、コンテンツ推奨、ビデオRAGシステムまでが含まれます。
Twelve Labsを使用すると、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の間の関係を捉える文脈ベクトル表現を生成できます。Databricks Mosaic AIのVector Searchは、高次元ベクトルのインデックス作成とクエリ実行のための、堅牢でスケーラブルなインフラストラクチャを提供します。
このブログ記事では、これらの相補的な技術を活用して、ビデオAIアプリケーションの新たな可能性を切り拓く方法を説明します。
このチュートリアルの作成にあたり、ご協力いただいたDatabricksのNina Williams氏、Austin Zaccor氏、Fernanda Heredia氏、およびEmily Hutson氏に深く感謝いたします!
なぜ Twelve Labs + Databricks Mosaic AI なのか?
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchと統合することで、大規模なビデオデータセットの効率的な処理や、正確なマルチモーダルコンテンツの表現といった、ビデオAIにおける主要な課題に対応できます。この統合により、高度なビデオアプリケーションの開発時間と必要なリソースを削減し、膨大なビデオライブラリ全体にわたる複雑なクエリを可能にするとともに、ワークフロー全体の効率を向上させます。
マルチモーダルデータを処理するための統合されたアプローチは特に注目に値します。テキスト、画像、音声の分析のために別々のモデルを使い分ける代わりに、ビデオコンテンツの本質を丸ごと捉える、単一の一貫した表現を扱えるようになります。これにより、展開アーキテクチャが簡素化されるだけでなく、洗練されたコンテンツ推奨システムから高度なビデオ検索エンジン、自動コンテンツモデレーションツールまで、よりニュアンスに富んだ文脈対応のアプリケーションが実現します。
さらに、この統合によりDatabricksエコシステムの機能が拡張され、ビデオ理解を既存のデータパイプラインや機械学習ワークフローにシームレスに組み込めるようになります。企業がリアルタイムのビデオ分析を開発している場合でも、大規模なコンテンツ分類システムを構築している場合でも、あるいは生成AIの新しいアプリケーションを模索している場合でも、この組み合わせソリューションは強力な基盤を提供します。これにより、ビデオAIで実現可能な価値の限界を押し広げ、メディアやエンターテインメントからセキュリティ、ヘルスケアに至るまでの業界において、イノベーションと問題解決の新しい道を切り拓きます。
Twelve Labs の Embed API を理解する
Twelve LabsのEmbed APIは、ビデオコンテンツ専用に設計されたマルチモーダル埋め込み技術における大きな進歩を表しています。フレームごとの分析や異なるモダリティごとの個別のモデルに依存する従来のアプローチとは異なり、このAPIは、ビデオ内の視覚的表現、ボディランゲージ、話し言葉、および全体的な文脈の複雑な相互作用を捉える文脈ベクトル表現を生成します。これは、当社の最先端のマルチモーダル基盤モデル Marengo-2.6をベースに構築されています。
Embed APIは、ビデオデータを扱うAIエンジニアにとって特に強力となるいくつかの重要な機能を提供します。第一に、ビデオに存在するあらゆるモダリティに柔軟に対応できるため、テキスト専用や画像専用の個別のモデルを用意する必要がありません。第二に、動き、アクション、時系列の情報を考慮するビデオネイティブなアプローチを採用しており、ビデオコンテンツのより正確で時系列的に一貫した解釈を保証します。最後に、すべてのモダリティからの埋め込みを統合する統一されたベクトル空間を作成し、ビデオコンテンツのより包括的な理解を促進します。
AIエンジニアにとって、Embed APIはビデオ理解タスクにおいて新しい可能性を切り拓きます。これにより、より高度なコンテンツ分析、向上したセマンティック検索機能、および強化された推奨システムが可能になります。文脈に沿った微細な合図や異なるモダリティ間の長時間の相互作用を捉えるAPIの能力は、感情認識、文脈を考慮したコンテンツモデレーション、高度なビデオ検索システムなど、ビデオコンテンツのニュアンス豊かな理解を必要とするアプリケーションで特に価値を発揮します。
前提条件
Twelve LabsのEmbed APIをDatabricks Mosaic AI Vector Searchに統合する前に、以下の前提条件を満たしていることを確認してください。
ワークスペースの作成と管理のアクセス権を持つDatabricksアカウント。(無料トライアルは https://databricks.com/try-databricks から登録できます)
Pythonプログラミングおよび基本的なデータサイエンスの概念についての知識。
Twelve LabsのAPIキー。(playground.twelvelabs.io で登録してください)
ベクトル埋め込みと類似性検索の概念に関する基本的な理解。
(オプション)AWS上でDatabricksを使用する場合はAWSアカウント。AzureまたはGoogle Cloud上でDatabricksを使用する場合は不要です。
注意:Embed APIは現在プライベートベータ版ですが、すべてのユーザーがこのフォームに記入するだけでアクセスをリクエストできます。通常、数時間以内に確認メールが届き、Embed APIの使用を開始できるようになります。
ステップ 1: 環境のセットアップ
まず、Databricks環境をセットアップし、必要なライブラリをインストールします。
1 - 新しいDatabricksワークスペースを作成する:
https://accounts.cloud.databricks.com/ からDatabricksアカウントにログインします。
Databricksドキュメントに記載されている手順に従って、新しいワークスペースを作成します: https://docs.databricks.com/en/getting-started/index.html
2 - 新しいクラスターを作成するか、既存のクラスターに接続する:
このアプリケーションには、ほぼすべてのMLクラスターが機能します。以下の設定は、最適なコストパフォーマンスを求める方向けに提供されています。
「Compute」タブで「Create compute」をクリックします。
「Single node」を選択し、Runtimeには「14.3 LTS ML non-GPU」を選択します。
クラスターのポリシーとアクセスモードはデフォルトのままで構いません。
ノードタイプとして「r6i.xlarge」を選択します。
これにより、メモリ使用率を最大化しつつ、コストはAWS上でわずか$0.252/時、Databricksで割引適用前で1.02 DBU/時となります。
また、テストした中で最も高速なオプションの一つでした。
他のすべてのオプションはデフォルトのままで構いません。
下部にある「Create compute」をクリックし、ワークスペースに戻ります。
3 - Databricksワークスペースに新しいノートブックを作成する:
ワークスペースで「Create」をクリックし、「Notebook」を選択します。
ノートブックに名前を付けます(例: "TwelveLabs_MosaicAI_VectorSearch_Integration")
デフォルト言語としてPythonを選択します。
4 - Twelve Labs および Mosaic AI Vector Search の SDK をインストールする:
ノートブックの最初のセルで、次のコマンドを実行します。
%pip install twelvelabs databricks-vectorsearch
5 - Twelve Labs の認証を設定する:
次のセルに、以下のコードを追加します。
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
注意:セキュリティを強化するため、APIキーをハードコードしたり環境変数を使用したりするのではなく、Databricksのシークレット機能を使用して保存することをお勧めします。
ステップ 2: マルチモーダル埋め込みを生成する
提供されているgenerate_embedding関数を使用して、Twelve Labs Embed APIでマルチモーダル埋め込みを生成します。この関数は、Databricks内のSpark DataFrameで効率的に動作するようにPandasユーザー定義関数(UDF)として設計されています。これは、埋め込みタスクの作成、進行状況の監視、および結果の取得のプロセスをカプセル化しています。
次に、ビデオURLを文字列として受け取り、Twelve Labs Embed APIを呼び出して配列<float>を返すprocess_url関数を作成します。
以下に実装方法と使用方法を示します。
UDFの定義:
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
ビデオURLを含むサンプルDataFrameの作成:
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
埋め込みを生成するためのUDFの適用:
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
結果の表示:
df_with_embeddings.show(truncate=False)
このプロセスにより、DataFrame内の各ビデオURLに対して、視覚情報、音声情報、およびテキスト情報を含む、ビデオコンテンツのマルチモーダルな本質を捉えたマルチモーダル埋め込みが生成されます。
大規模なビデオデータセットの場合、埋め込みの生成は計算負荷が高く、時間がかかることがある点に注意してください。本番スケールのアプリケーションでは、バッチ処理や分散処理の戦略を実装することを検討してください。さらに、APIエラーやネットワークの問題を処理するために、適切なエラーハンドリングとログ記録が導入されていることを確認してください。
ステップ 3: ビデオ埋め込み用の Delta テーブルを作成する
次に、ビデオメタデータと、Twelve Labs Embed APIによって生成された埋め込みを保存するためのソースDeltaテーブルを作成します。このテーブルは、Databricks Mosaic AI Vector SearchにおけるVector Searchインデックスの基礎として機能します。
まず、ビデオのURLとメタデータを含むソースDataFrameを作成します:
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
次に、SQLを使用してDeltaテーブルのスキーマを定義します:
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
テーブルでChange Data Feedが有効になっていることに注意してください。これは、Vector Searchインデックスを作成および維持するために非常に重要です。
では、先ほど定義したget_video_embeddings関数を使用して、ビデオの埋め込みを生成します:
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
このステップは、ビデオの数や長さによっては少し時間がかかる場合があります。
埋め込みが生成されたら、データをDeltaテーブルに書き込みます:
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
最後に、埋め込みを含むDataFrameを表示して、データを確認します:
display(embeddings_df)
この手順により、Vector Search機能のための強力な基盤が構築されます。Deltaテーブルは自動的にVector Searchインデックスと同期されるため、ビデオデータセットに対する更新や追加は即座に検索結果に反映されます。
覚えておくべきいくつかの重要なポイント:
id列は自動生成され、各ビデオに一意の識別子を提供します。embedding列は、Twelve Labs Embed APIによって生成された各ビデオの高次元ベクトル表現を格納します。Change Data Feedを有効にすることで、Databricksはテーブル内の変更を効率的に追跡できます。これは、最新のVector Searchインデックスを維持するために不可欠です。
ステップ 4: Mosaic AI Vector Search を設定する
このステップでは、ビデオ埋め込みを処理できるようにDatabricks Mosaic AI Vector Searchをセットアップします。これには、Vector Searchエンドポイントと、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexの作成が含まれます。
まず、Vector Searchエンドポイントを作成します:
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
このコードは、新しいVector Searchエンドポイントを作成するか、同じ名前の既存のエンドポイントを置き換えます。このエンドポイントは、Vector Search操作用のアクセスポイントとして機能します。
次に、videos_source_embeddings Deltaテーブルと自動的に同期するDelta Sync Indexを作成します:
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
このコードは、ソースDeltaテーブルにリンクするDelta Sync Indexを作成します。ソーステーブルに加えられた変更から数秒以内にインデックスを自動的に更新したい場合(Vector Searchの結果が常に最新であることを保証する)、pipeline_type="CONTINUOUS"を設定します。
インデックスが作成され、正しく同期されていることを確認するには、次のコードを使用して手動で同期を呼び出します:
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
このコードを使用すると、インデックスのステータスを確認し、必要に応じて手動で同期を行うことができます。本番環境では、ソースDeltaテーブルの変更に基づいて自動的に同期するようにパイプラインを設定する方が好ましいでしょう。
覚えておくべき重要事項:
Vector Searchエンドポイントは、Vector Search操作のアクセスポイントとして機能します。
Delta Sync IndexはソースDeltaテーブルと自動的に同期し、常に最新の検索結果を保証します。
embedding_dimensionは、Twelve LabsのEmbed APIによって生成された埋め込みの次元数(1024)に一致させる必要があります。primary_keyは「id」に設定します。これはソーステーブルの一意の識別子に対応している必要があります。embedding_vector_columnは「embedding」に設定します。これはソーステーブル内のビデオ埋め込みが含まれる列名と一致する必要があります。
ステップ 5: 類似性検索を実装する
次のステップは、設定されたMosaic AI Vector SearchインデックスとTwelve Labs Embed APIを使用して類似性検索機能を実装することです。これにより、マルチモーダル埋め込みのパワーを活用し、指定したテキストクエリに類似したビデオを見つけることができます。
まず、Twelve Labs Embed APIを使用して、テキストクエリの埋め込みを取得する関数を定義します:
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
この関数はテキストクエリを受け取り、ビデオ埋め込みと同じモデルを使用してその埋め込みを生成し、ベクトル空間での互換性を確保します。
次に、類似性検索関数を実装します:
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
この関数は、テキストクエリと返される結果の数を受け取ります。クエリの埋め込みを生成し、Mosaic AI Vector Searchインデックスを使用して類似するビデオを検索します。
検索結果を解析して表示するには、次のヘルパー関数を使用します:
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
では、これらをすべて組み合わせて、サンプル検索を実行してみましょう:
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
このコードは、Twelve Labsの類似性検索関数を使用して「A dragon」というクエリに関連するビデオを検索する方法を示しています。その後、検索結果を解析し、ユーザーフレンドリーな形式で表示します。
覚えておくべき重要事項:
get_text_embedding関数は、ビデオ埋め込みと同じTwelve Labsモデルを使用するため、互換性が保証されます。similarity_search関数は、テキストから埋め込みへの変換とVector Searchを組み合わせて、類似するビデオを見つけます。ネットワークの問題やAPIの変更が検索プロセスに影響を与える可能性があるため、エラーハンドリングは不可欠です。
parse_search_results関数は、生のAPI応答をより扱いやすい形式に変換するのに役立ちます。similarity_search関数のnum_resultsパラメータを調整して、返される結果の数を制御できます。
この実装により、ビデオデータセット全体の強力なセマンティック検索機能が有効になります。ユーザーは、Twelve Labs Embed APIによって生成された豊かなマルチモーダル埋め込みを活用して、自然言語クエリを使用して関連するビデオを見つけることができるようになります。
ステップ 6: ビデオ推奨システムを構築する
次に、Twelve Labs Embed APIとDatabricks Mosaic AI Vector Searchによって生成されたマルチモーダル埋め込みを使用して、基本的なビデオ推奨システムを作成します。このシステムは、埋め込みの類似性に基づいて、指定されたビデオに類似したビデオを提示します。
まず、簡単な推奨機能を実装します:
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
この実装は以下の仕組みで動きます:
get_video_recommendations関数は、ビデオIDと返すべき推奨ビデオの件数を受け取ります。指定されたビデオの埋め込みをソースDeltaテーブルから取得します。
この埋め込みを使用して類似性検索を実行し、最も類似しているビデオを見つけます。
同じビデオが推奨されないように、結果から入力ビデオを削除します(結果に含まれる場合)。
display_recommendationsヘルパー関数は、推奨ビデオのリストをユーザーフレンドリーな形で整形し、出力します。
この推奨システムを使用するには:
videos_source_embeddingsテーブルに、有効な埋め込みを持つビデオが保存されていることを確認します。データセット内の有効なビデオIDを指定して、
get_video_recommendations関数を呼び出します。関数は類似度に基づいた推奨ビデオのリストを表示します。
この基本的な推奨システムは、コンテンツベースのビデオ推奨においてマルチモーダル埋め込みをどのように活用するかを示しています。これは、いくつかの方法で拡張および改善できます:
パーソナライズされた推奨を行うために、ユーザーの好みや視聴履歴を組み込みます。
多様な推奨結果を保証するために、偶発性メカニズムを実装します。
ビデオメタデータ(ジャンル、長さ、投稿日など)に基づくフィルタリングを追加します。
頻繁にリクエストされる推奨ビデオのパフォーマンスを向上させるために、キャッシュメカニズムを実装します。
推奨の品質は、ビデオデータセットの規模と多様性、さらにはTwelve Labs Embed APIが生成する埋め込みの正確性に依存することに注意してください。システムに登録するビデオを増やすにつれて、推奨結果はさらに高い関連性と多様性を持つようになります。
この統合を次のレベルに引き上げる
インデックスの更新と同期
ビデオライブラリが拡大し進化するにつれて、Vector Searchインデックスを最新の状態に維持することが極めて重要です。Mosaic AI Vector SearchはソースDeltaテーブルとのシームレスな同期を提供し、推奨結果や検索結果に常に最新データを反映させることができます。
インデックス更新と同期における重要な考慮事項:
増分更新:Delta Lakeの変更データフィード(Change Data Feed)を活用し、インデックス内の変更されたレコード、または新しいレコードのみを効率的に更新します。
定期同期のスケジュール:Databricksのワークフローオーケストレーションツールを使用し、定期的な同期ジョブを実行してインデックスの鮮度を維持します。
リアルタイム更新:時間に極めてシリズなアプリケーションでは、Databricks Mosaic AIのストリーミング機能を使用した準リアルタイムのインデックス更新の実装を検討してください。
バージョン管理:Delta Lakeのタイムトラベル機能を利用してインデックスの複数のバージョンを維持し、必要に応じて簡単にロールバックできるようにします。
同期ステータスの監視:同期の成功を追跡し、更新処理での問題をすばやく特定するために、ログ記録やアラートの仕組みを実装します。
これらの手法を習得することで、TwelveLabsのビデオ埋め込みを常に最新に保ち、高度な検索と推奨のユースケースにいつでも対応できるようにします。
パフォーマンスとスケーリングの最適化
自身のビデオ分析パイプラインが成長するにつれ、パフォーマンスの最適化を継続し、ソリューションをスケールアップさせることが重要になります。Databricksの分散コンピューティング機能は、Twelve Labsの効率的な埋め込み生成と連携することで、大規模なビデオ処理タスクの処理に耐えうる堅牢な基盤を提供します。
ソリューションを最適化しスケーリングするための主なアプローチ:
分散処理:DatabricksのSparkクラスターを活用して、複数のノード間で埋め込みの生成タスクやインデックス構築タスクを並列化します。
キャッシュ戦略:アクセス頻度が高い埋め込みに対してインテリジェントなキャッシュ処理を導入し、APIの呼び出しを減らして応答時間を短縮します。
バッチ処理:大規模なビデオライブラリに対しては、ピーク時以外の時間帯に埋め込みを生成してインデックスを更新するバッチ処理ワークフローを実装します。
クエリの最適化:
num_resultsなどのパラメータを調整し、効率的なフィルタリング手法を駆使して、Vector Searchクエリを微調整します。インデックスのパーティショニング:超大規模なデータセットの場合は、クエリのレスポンスを高め、よりきめ細かい更新を可能にするために、インデックスのパーティショニング戦略を調査します。
オートスケーリング:Databricksのオートスケーリング機能を利用し、ワークロードの処理需要に合わせてコンピューティングリソースを動的に調整します。
エッジコンピューティング:遅延(レイテンシ)を気にするアプリケーションの場合は、モデルの軽量版をデータソースの近くにデプロイすることを検討します。
これらの最適化手法を導入することで、優れたパフォーマンスとコスト効率を両立させながら、増え続けるビデオライブラリと増加するユーザー需要に対処することが可能になります。
モニタリングと分析
ビデオ理解パイプラインの継続的な成功を収めるためには、堅牢な監視(モニタリング)とデータ分析の仕組みが欠かせません。Databricksは、システムのパフォーマンス、ユーザー行動、ビジネスインパクトを追跡するための強力なツールを提供しています。
監視と分析で重点を置くべき主な領域:
パフォーマンスメトリクス:クエリの遅延、埋め込み生成までの時間、インデックス同期にかかる時間などの主要業績評価指標(KPI)を追跡します。
利用ログの分析:ユーザーの操作履歴、よく使われる検索クエリ、頻繁にレコメンドされるビデオを分析し、ユーザー行動の洞察を得ます。
品質評価:システムによる自動評価指標と実際のユーザーフィードバックを活用し、検索結果や推奨結果の関連度を評価するフィードバックループを構築します。
リソース使用状況:コンピューティングリソース、APIコール数、ストレージ利用量を継続的に監視し、コストとパフォーマンスを最適化します。
エラー追跡:パイプライン内で発生した不具合を迅速に検知・解決するために、包括的なログ記録と警告システム(アラート)を整備します。
A/Bテスト:Databricksの検証機能を活用し、さまざまな埋め込みモデル、検索アルゴリズム、またはレコメンドモデルを試験評価(テスト)します。
ビジネス目標の検証:ビデオ解析により実現した機能を、ユーザーの滞在状況(エンゲージメント)、視聴時間、成約率などの最終的なKGIに紐付けます。
法規制・規約遵守:ビデオ処理処理パイプラインが個人情報保護規制やコンテンツモデレーションのガイドラインに適合しているかを継続的に確認します。
これらすべての監視手法を施すことで、ビデオパイプラインの働きとその成果について価値の高い情報を手にすることができます。このアプローチに基づく改善を絶えず繰り返すことで、Twelve Labsの高度なビデオ構造化機能とDatabricks Data Intelligence Platformの統合価値を、データに基づいて実証できるようになります。
まとめ
Twelve Labs と Databricks Mosaic AI は、洗練された映像コンテンツの構造化と、高度なデータ抽出タスクのための一貫した統合開発フレームワークを提供します。この統合技術により、マルチモーダルなビデオ表現ベクトルの抽出と実効性の高いベクトル検索(Vector Search)を活用し、開発者は独自のビデオ解析、レコメンド、検索システムを作り上げることが可能になります。
このチュートリアルでは、開発に必要な環境構築から、マルチモーダル情報のベクトル展開、ベクトルエンジンへの登録、類似コンテンツ検索、レコメンデーションの実装に必要な基本ロジックを解説しました。さらに実用に必要なスケーラブルな管理システム設計、最適化手法、信頼性向上のための監視方法まで包括的に言及しています。
映像データが爆発的に増加する現在、それらをシステムに最適化させて価値を効率よく発掘する術(すべ)は不可欠です。本ドキュメントは、この難解なプロジェクトを克服するための強力な設計方法論を提供するものです。ぜひそれらの機能をテストし、応用的課題を検討しながら、映像理解を進化させる開発コミュニティを共に盛り上げましょう。
さらに学びたい方のための情報ソース
これらの連携方法をさらに深く探索するために、以下の情報をぜひご一読ください。
これらのお役立ち情報を手元に置くことで、最先端のAIビデオテクノロジーを活用し、Twelve Labs と Databricks をベースにした独自のイノベーティブなシステムの構築を進めていきましょう。








