" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Partnerships
Semantic Video Search Engine with TwelveLabs and ApertureDB

James Le
Learn how to build a semantic video search engine with the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search.
Learn how to build a semantic video search engine with the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
2024/10/11
10 min
Copy link to article
This tutorial demonstrates how to build a semantic video search engine with the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. The Twelve Labs Embed API, powered by the state-of-the-art Marengo-2.6 video foundation model, generates multimodal embeddings that capture the essence of video content, including visual expressions, spoken words, and contextual information. These embeddings enable highly accurate and efficient semantic search capabilities when combined with ApertureDB, a graph-vector database optimized for computer vision and machine learning applications.
By following this workflow, developers and data scientists will learn how to leverage the TwelveLabs Embed API to create rich video embeddings and seamlessly integrate them along with the source videos into ApertureDB, for semantic search. This workflow showcases the potential for building sophisticated video analysis and retrieval systems, opening up new possibilities for content discovery, recommendation engines, and video-based applications across various industries.
Setup and Installations
In this section, we will install the necessary libraries and dependencies required for integrating the TwelveLabs Embed API with ApertureDB. This includes the installation of the requests library for making API calls, the aperturedb Python SDK for interacting with the ApertureDB service, and the twelvelabs Python SDK for accessing the TwelveLabs Embed API.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
After running the above code, you will have all the necessary libraries installed and ready for use in the subsequent steps of the notebook.
Configure API Key
In this section, we'll set up the necessary API keys for both TwelveLabs and ApertureDB. We'll use Google Colab's userdata feature to securely store and retrieve these keys.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
To use this code, you need to set up your API keys in Google Colab's Secrets:
Go to the left sidebar in your Colab notebook.
Click on the "Key" icon to open the "Secrets" panel.
Add two secrets:some text
Key: TL_API_KEY, Value: Your TwelveLabs API key
Key: ADB_PASSWORD, Value: Your ApertureDB password
This approach ensures that your API keys are securely stored and not exposed in your notebook. The code checks if the keys are properly set and raises an error if they're missing, helping you troubleshoot any configuration issues.
Generate Video Embeddings with TwelveLabs Embed API
In this section, we'll demonstrate how to generate video embeddings using the TwelveLabs Embed API. This API is powered by Marengo-2.6, Twelve Labs' state-of-the-art video foundation model designed for any-to-any retrieval tasks. Marengo-2.6 enables the creation of multimodal embeddings that capture the essence of video content, including visual expressions, body language, spoken words, and overall context.
Let's set up the TwelveLabs client and define a function to generate embeddings:
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
This code demonstrates the process of generating video embeddings using the TwelveLabs Embed API. Here's a breakdown of what's happening:
We initialize the TwelveLabs client with our API key.
The generate_embedding function creates an embedding task using the Marengo-2.6 engine, which is optimized for video understanding and retrieval tasks.
We monitor the task progress and wait for it to complete.
Once the task is done, we retrieve the results and extract the embeddings.
The embeddings are returned along with metadata such as the time range they correspond to and their scope.
The Marengo-2.6 model used by the Embed API offers several advantages:
Multimodal understanding: It captures the interplay between visual, audio, and textual elements in the video.
Temporal awareness: Unlike static image models, Marengo-2.6 accounts for motion, action, and temporal information in videos.
Flexible segmentation: The API can generate embeddings for different segments of a video or a single embedding for the entire video.
State-of-the-art performance: It provides more accurate and temporally coherent interpretations of video content compared to traditional approaches.
By using this API, developers can easily create contextual vector representations of their videos, enabling advanced search and analysis capabilities in their applications.
Insert Embeddings into ApertureDB
ApertureDB allows us to store and manage multimodal data, including videos, clips, and their associated embeddings. In this section, we demonstrate how to insert the video embeddings generated by the TwelveLabs Embed API into ApertureDB. This step is crucial for enabling efficient semantic video search.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
This code demonstrates the process of inserting the video embeddings into ApertureDB:
We define custom data models (ClipEmbeddingModel and VideoClipsModel) to represent the structure of our video data, including clips and their associated embeddings.
The create_video_object_with_clips function creates a video object with its associated clips and embeddings, which, in ApertureDB, gets represented in a connected graph schema as shown in the figure below.
We instantiate an ApertureDB client using the provided credentials.
A descriptor set (collection) is created to store the embeddings. This set defines the search space for our embeddings.
Finally, we create a video object that includes all the clips and their corresponding embeddings, and insert it into ApertureDB.
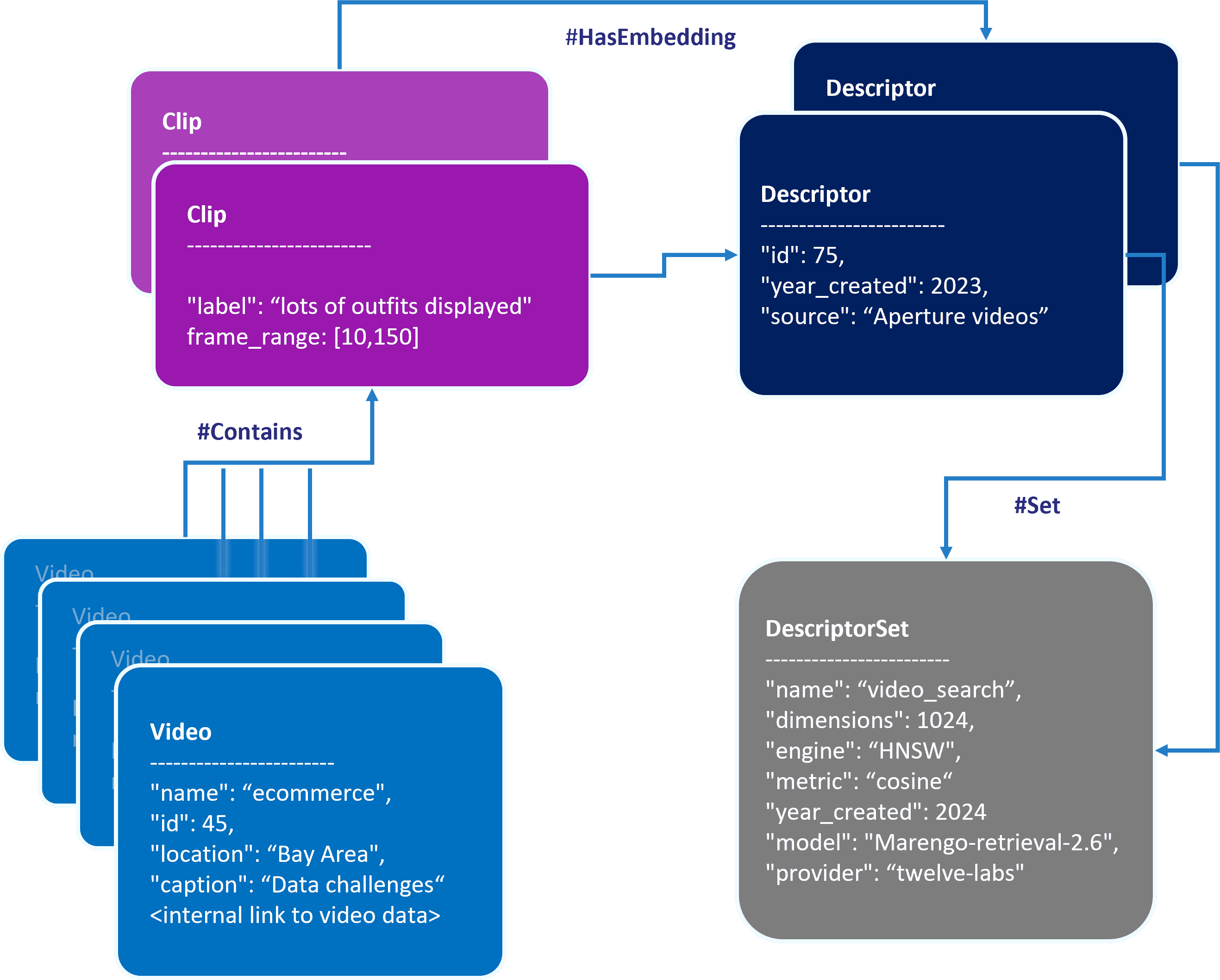
The schema created with adding the data as described above
By structuring the data this way, we maintain the temporal information of each embedding within the video, allowing for more precise semantic search capabilities. Each clip is associated with its specific time range and embedding, enabling granular search and retrieval of video segments.
Perform Semantic Video Search
In this section, we'll demonstrate how to perform a semantic video search using the embeddings stored in ApertureDB. We'll use a text query to find relevant video clips based on their semantic similarity.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
This code performs the following steps:
Generates a text embedding for our search query using the Twelve Labs Embed API.
Uses ApertureDB's Descriptors class to find similar embeddings in the "marengo26" descriptor set.
Retrieves the video clips connected to the most similar embeddings.
Display Results
Now, we'll display the search results, showing the metadata of the clips and the corresponding video segments.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
This code:
Iterates through the found clips.
Displays metadata for each clip, including start and end times, and the video URL.
Uses the display_video_mp4 function to show the actual video segment corresponding to each clip.
Conclusion
This tutorial has demonstrated the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. By leveraging TwelveLabs' state-of-the-art Marengo-2.6 video foundation model, we've shown how to generate rich, multimodal embeddings that capture the essence of video content. These embeddings, when combined with ApertureDB's efficient multimodal data storage and vector search capabilities, enable highly accurate and context-aware video search functionalities.
The workflow presented here opens up new possibilities for content discovery, recommendation engines, and video-based applications across various industries. By understanding the semantic content of videos, developers can create more intuitive and powerful search experiences that go beyond simple keyword matching.
Next Steps
To further enhance this semantic video search system, consider exploring the following avenues:
Optimize embedding generation: Experiment with different video segmentation strategies to balance granularity and performance.
Enhance search capabilities: Implement more advanced query techniques, such as multimodal queries combining text, image, and audio inputs. TwelveLabs Embed API will soon support image and audio embedding generation. ApertureDB already supports representation of images and multimodal embeddings.
Scale the system: Test the performance with larger video datasets and optimize for high-volume queries.
Implement user feedback: Incorporate user interactions to refine search results over time.
Explore additional use cases: Adapt this workflow for specific applications like content moderation, video summarization, or personalized recommendations.
By building upon this foundation, developers can create sophisticated video analysis and retrieval systems that push the boundaries of what's possible in video understanding and search technology.
Appendix
For your reference and further exploration:
We'd love to see what you build! Share your projects and experiences with the TwelveLabs and ApertureDB communities. Happy coding!
This tutorial demonstrates how to build a semantic video search engine with the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. The Twelve Labs Embed API, powered by the state-of-the-art Marengo-2.6 video foundation model, generates multimodal embeddings that capture the essence of video content, including visual expressions, spoken words, and contextual information. These embeddings enable highly accurate and efficient semantic search capabilities when combined with ApertureDB, a graph-vector database optimized for computer vision and machine learning applications.
By following this workflow, developers and data scientists will learn how to leverage the TwelveLabs Embed API to create rich video embeddings and seamlessly integrate them along with the source videos into ApertureDB, for semantic search. This workflow showcases the potential for building sophisticated video analysis and retrieval systems, opening up new possibilities for content discovery, recommendation engines, and video-based applications across various industries.
Setup and Installations
In this section, we will install the necessary libraries and dependencies required for integrating the TwelveLabs Embed API with ApertureDB. This includes the installation of the requests library for making API calls, the aperturedb Python SDK for interacting with the ApertureDB service, and the twelvelabs Python SDK for accessing the TwelveLabs Embed API.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
After running the above code, you will have all the necessary libraries installed and ready for use in the subsequent steps of the notebook.
Configure API Key
In this section, we'll set up the necessary API keys for both TwelveLabs and ApertureDB. We'll use Google Colab's userdata feature to securely store and retrieve these keys.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
To use this code, you need to set up your API keys in Google Colab's Secrets:
Go to the left sidebar in your Colab notebook.
Click on the "Key" icon to open the "Secrets" panel.
Add two secrets:some text
Key: TL_API_KEY, Value: Your TwelveLabs API key
Key: ADB_PASSWORD, Value: Your ApertureDB password
This approach ensures that your API keys are securely stored and not exposed in your notebook. The code checks if the keys are properly set and raises an error if they're missing, helping you troubleshoot any configuration issues.
Generate Video Embeddings with TwelveLabs Embed API
In this section, we'll demonstrate how to generate video embeddings using the TwelveLabs Embed API. This API is powered by Marengo-2.6, Twelve Labs' state-of-the-art video foundation model designed for any-to-any retrieval tasks. Marengo-2.6 enables the creation of multimodal embeddings that capture the essence of video content, including visual expressions, body language, spoken words, and overall context.
Let's set up the TwelveLabs client and define a function to generate embeddings:
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
This code demonstrates the process of generating video embeddings using the TwelveLabs Embed API. Here's a breakdown of what's happening:
We initialize the TwelveLabs client with our API key.
The generate_embedding function creates an embedding task using the Marengo-2.6 engine, which is optimized for video understanding and retrieval tasks.
We monitor the task progress and wait for it to complete.
Once the task is done, we retrieve the results and extract the embeddings.
The embeddings are returned along with metadata such as the time range they correspond to and their scope.
The Marengo-2.6 model used by the Embed API offers several advantages:
Multimodal understanding: It captures the interplay between visual, audio, and textual elements in the video.
Temporal awareness: Unlike static image models, Marengo-2.6 accounts for motion, action, and temporal information in videos.
Flexible segmentation: The API can generate embeddings for different segments of a video or a single embedding for the entire video.
State-of-the-art performance: It provides more accurate and temporally coherent interpretations of video content compared to traditional approaches.
By using this API, developers can easily create contextual vector representations of their videos, enabling advanced search and analysis capabilities in their applications.
Insert Embeddings into ApertureDB
ApertureDB allows us to store and manage multimodal data, including videos, clips, and their associated embeddings. In this section, we demonstrate how to insert the video embeddings generated by the TwelveLabs Embed API into ApertureDB. This step is crucial for enabling efficient semantic video search.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
This code demonstrates the process of inserting the video embeddings into ApertureDB:
We define custom data models (ClipEmbeddingModel and VideoClipsModel) to represent the structure of our video data, including clips and their associated embeddings.
The create_video_object_with_clips function creates a video object with its associated clips and embeddings, which, in ApertureDB, gets represented in a connected graph schema as shown in the figure below.
We instantiate an ApertureDB client using the provided credentials.
A descriptor set (collection) is created to store the embeddings. This set defines the search space for our embeddings.
Finally, we create a video object that includes all the clips and their corresponding embeddings, and insert it into ApertureDB.
The schema created with adding the data as described above
By structuring the data this way, we maintain the temporal information of each embedding within the video, allowing for more precise semantic search capabilities. Each clip is associated with its specific time range and embedding, enabling granular search and retrieval of video segments.
Perform Semantic Video Search
In this section, we'll demonstrate how to perform a semantic video search using the embeddings stored in ApertureDB. We'll use a text query to find relevant video clips based on their semantic similarity.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
This code performs the following steps:
Generates a text embedding for our search query using the Twelve Labs Embed API.
Uses ApertureDB's Descriptors class to find similar embeddings in the "marengo26" descriptor set.
Retrieves the video clips connected to the most similar embeddings.
Display Results
Now, we'll display the search results, showing the metadata of the clips and the corresponding video segments.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
This code:
Iterates through the found clips.
Displays metadata for each clip, including start and end times, and the video URL.
Uses the display_video_mp4 function to show the actual video segment corresponding to each clip.
Conclusion
This tutorial has demonstrated the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. By leveraging TwelveLabs' state-of-the-art Marengo-2.6 video foundation model, we've shown how to generate rich, multimodal embeddings that capture the essence of video content. These embeddings, when combined with ApertureDB's efficient multimodal data storage and vector search capabilities, enable highly accurate and context-aware video search functionalities.
The workflow presented here opens up new possibilities for content discovery, recommendation engines, and video-based applications across various industries. By understanding the semantic content of videos, developers can create more intuitive and powerful search experiences that go beyond simple keyword matching.
Next Steps
To further enhance this semantic video search system, consider exploring the following avenues:
Optimize embedding generation: Experiment with different video segmentation strategies to balance granularity and performance.
Enhance search capabilities: Implement more advanced query techniques, such as multimodal queries combining text, image, and audio inputs. TwelveLabs Embed API will soon support image and audio embedding generation. ApertureDB already supports representation of images and multimodal embeddings.
Scale the system: Test the performance with larger video datasets and optimize for high-volume queries.
Implement user feedback: Incorporate user interactions to refine search results over time.
Explore additional use cases: Adapt this workflow for specific applications like content moderation, video summarization, or personalized recommendations.
By building upon this foundation, developers can create sophisticated video analysis and retrieval systems that push the boundaries of what's possible in video understanding and search technology.
Appendix
For your reference and further exploration:
We'd love to see what you build! Share your projects and experiences with the TwelveLabs and ApertureDB communities. Happy coding!
This tutorial demonstrates how to build a semantic video search engine with the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. The Twelve Labs Embed API, powered by the state-of-the-art Marengo-2.6 video foundation model, generates multimodal embeddings that capture the essence of video content, including visual expressions, spoken words, and contextual information. These embeddings enable highly accurate and efficient semantic search capabilities when combined with ApertureDB, a graph-vector database optimized for computer vision and machine learning applications.
By following this workflow, developers and data scientists will learn how to leverage the TwelveLabs Embed API to create rich video embeddings and seamlessly integrate them along with the source videos into ApertureDB, for semantic search. This workflow showcases the potential for building sophisticated video analysis and retrieval systems, opening up new possibilities for content discovery, recommendation engines, and video-based applications across various industries.
Setup and Installations
In this section, we will install the necessary libraries and dependencies required for integrating the TwelveLabs Embed API with ApertureDB. This includes the installation of the requests library for making API calls, the aperturedb Python SDK for interacting with the ApertureDB service, and the twelvelabs Python SDK for accessing the TwelveLabs Embed API.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
After running the above code, you will have all the necessary libraries installed and ready for use in the subsequent steps of the notebook.
Configure API Key
In this section, we'll set up the necessary API keys for both TwelveLabs and ApertureDB. We'll use Google Colab's userdata feature to securely store and retrieve these keys.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
To use this code, you need to set up your API keys in Google Colab's Secrets:
Go to the left sidebar in your Colab notebook.
Click on the "Key" icon to open the "Secrets" panel.
Add two secrets:some text
Key: TL_API_KEY, Value: Your TwelveLabs API key
Key: ADB_PASSWORD, Value: Your ApertureDB password
This approach ensures that your API keys are securely stored and not exposed in your notebook. The code checks if the keys are properly set and raises an error if they're missing, helping you troubleshoot any configuration issues.
Generate Video Embeddings with TwelveLabs Embed API
In this section, we'll demonstrate how to generate video embeddings using the TwelveLabs Embed API. This API is powered by Marengo-2.6, Twelve Labs' state-of-the-art video foundation model designed for any-to-any retrieval tasks. Marengo-2.6 enables the creation of multimodal embeddings that capture the essence of video content, including visual expressions, body language, spoken words, and overall context.
Let's set up the TwelveLabs client and define a function to generate embeddings:
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
This code demonstrates the process of generating video embeddings using the TwelveLabs Embed API. Here's a breakdown of what's happening:
We initialize the TwelveLabs client with our API key.
The generate_embedding function creates an embedding task using the Marengo-2.6 engine, which is optimized for video understanding and retrieval tasks.
We monitor the task progress and wait for it to complete.
Once the task is done, we retrieve the results and extract the embeddings.
The embeddings are returned along with metadata such as the time range they correspond to and their scope.
The Marengo-2.6 model used by the Embed API offers several advantages:
Multimodal understanding: It captures the interplay between visual, audio, and textual elements in the video.
Temporal awareness: Unlike static image models, Marengo-2.6 accounts for motion, action, and temporal information in videos.
Flexible segmentation: The API can generate embeddings for different segments of a video or a single embedding for the entire video.
State-of-the-art performance: It provides more accurate and temporally coherent interpretations of video content compared to traditional approaches.
By using this API, developers can easily create contextual vector representations of their videos, enabling advanced search and analysis capabilities in their applications.
Insert Embeddings into ApertureDB
ApertureDB allows us to store and manage multimodal data, including videos, clips, and their associated embeddings. In this section, we demonstrate how to insert the video embeddings generated by the TwelveLabs Embed API into ApertureDB. This step is crucial for enabling efficient semantic video search.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
This code demonstrates the process of inserting the video embeddings into ApertureDB:
We define custom data models (ClipEmbeddingModel and VideoClipsModel) to represent the structure of our video data, including clips and their associated embeddings.
The create_video_object_with_clips function creates a video object with its associated clips and embeddings, which, in ApertureDB, gets represented in a connected graph schema as shown in the figure below.
We instantiate an ApertureDB client using the provided credentials.
A descriptor set (collection) is created to store the embeddings. This set defines the search space for our embeddings.
Finally, we create a video object that includes all the clips and their corresponding embeddings, and insert it into ApertureDB.
The schema created with adding the data as described above
By structuring the data this way, we maintain the temporal information of each embedding within the video, allowing for more precise semantic search capabilities. Each clip is associated with its specific time range and embedding, enabling granular search and retrieval of video segments.
Perform Semantic Video Search
In this section, we'll demonstrate how to perform a semantic video search using the embeddings stored in ApertureDB. We'll use a text query to find relevant video clips based on their semantic similarity.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
This code performs the following steps:
Generates a text embedding for our search query using the Twelve Labs Embed API.
Uses ApertureDB's Descriptors class to find similar embeddings in the "marengo26" descriptor set.
Retrieves the video clips connected to the most similar embeddings.
Display Results
Now, we'll display the search results, showing the metadata of the clips and the corresponding video segments.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
This code:
Iterates through the found clips.
Displays metadata for each clip, including start and end times, and the video URL.
Uses the display_video_mp4 function to show the actual video segment corresponding to each clip.
Conclusion
This tutorial has demonstrated the powerful integration of TwelveLabs' Embed API with ApertureDB for advanced semantic video search. By leveraging TwelveLabs' state-of-the-art Marengo-2.6 video foundation model, we've shown how to generate rich, multimodal embeddings that capture the essence of video content. These embeddings, when combined with ApertureDB's efficient multimodal data storage and vector search capabilities, enable highly accurate and context-aware video search functionalities.
The workflow presented here opens up new possibilities for content discovery, recommendation engines, and video-based applications across various industries. By understanding the semantic content of videos, developers can create more intuitive and powerful search experiences that go beyond simple keyword matching.
Next Steps
To further enhance this semantic video search system, consider exploring the following avenues:
Optimize embedding generation: Experiment with different video segmentation strategies to balance granularity and performance.
Enhance search capabilities: Implement more advanced query techniques, such as multimodal queries combining text, image, and audio inputs. TwelveLabs Embed API will soon support image and audio embedding generation. ApertureDB already supports representation of images and multimodal embeddings.
Scale the system: Test the performance with larger video datasets and optimize for high-volume queries.
Implement user feedback: Incorporate user interactions to refine search results over time.
Explore additional use cases: Adapt this workflow for specific applications like content moderation, video summarization, or personalized recommendations.
By building upon this foundation, developers can create sophisticated video analysis and retrieval systems that push the boundaries of what's possible in video understanding and search technology.
Appendix
For your reference and further exploration:
We'd love to see what you build! Share your projects and experiences with the TwelveLabs and ApertureDB communities. Happy coding!
Related articles



プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved

プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved




プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved