" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
基盤モデル(Foundation Models)の何が特別なのでしょうか?

ジェームズ・リー
基盤モデルは、大量のタスク固有のトレーニングデータを必要とせずに一般化する能力を通じて、メディア・エンターテインメント、スポーツ分析、ヘルスケアをすでに変革している実世界のアプリケーションにおいて、テキスト、ビジョン、音声、ビデオにわたる特定のタスクに合わせて微調整できる、事前にトレーニングされた大規模なAIシステムです。
基盤モデルは、大量のタスク固有のトレーニングデータを必要とせずに一般化する能力を通じて、メディア・エンターテインメント、スポーツ分析、ヘルスケアをすでに変革している実世界のアプリケーションにおいて、テキスト、ビジョン、音声、ビデオにわたる特定のタスクに合わせて微調整できる、事前にトレーニングされた大規模なAIシステムです。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2023/04/11
6分
記事へのリンクをコピー
2022年にスタンフォード大学が基盤モデル(Foundation Models)の概念を提唱して以来、これはほぼすべてのビジネス分野において最もホットなトレンドの1つとなっています。これらのモデルは、一般大衆に広く浸透した初めてのモデルです。簡単に言えば、基盤モデルとは、特定のタスクに合わせてさらに微調整(ファインチューニング)できる、事前学習済みの超大型機械学習モデルであり、幅広いタスクにおいて最先端のパフォーマンスを達成しています。
しかし、技術用語に不慣れな読者にとって、基盤モデルの能力やその応用の可能性を理解するのは難しい場合があります。そこで、この刺激的な技術をより身近で、より多くの人々に理解しやすくするための解説を用意しました。前回の記事では技術的な視点から掘り下げましたが、今回の記事では基盤モデルの能力をわかりやすい言葉で紐解き、それらが現実世界の課題を解決するためにどのように活用できるか、具体的な例を挙げて紹介します。
1 - 基盤モデルの概要
1.1 - なぜ今なのか?
基盤モデルは、幅広い領域や業界にわたって柔軟に、そして再利用できるように設計された、巨大かつ複雑なモデルです。これらのモデルが機能する背景には、「転移学習」と「スケール(規模)」という2つの要素があります。
転移学習
転移学習とは、機械学習(ML)において、あるタスクで得られた知識を別の関連するタスクに活用する手法です。これにより、新しいタスクごとに大量のデータを用意する必要性が減り、モデルをより迅速に学習させることができ、MLモデルのパフォーマンスを向上させることができます。転移学習は、推薦システムにおけるコールドスタート問題、ロボティクスにおけるシミュレーション、多言語間の翻訳など、現実世界の多くのアプリケーションの解決に役立っています。さらに詳しく知りたい方は、Georgianによるこのブログポストにて、具体的な例を交えながら転移学習を簡潔に説明しています。
スケール(規模)
スケールこそが、基盤モデルを強力にする要因です。それには以下の3つの要素が必要でした:
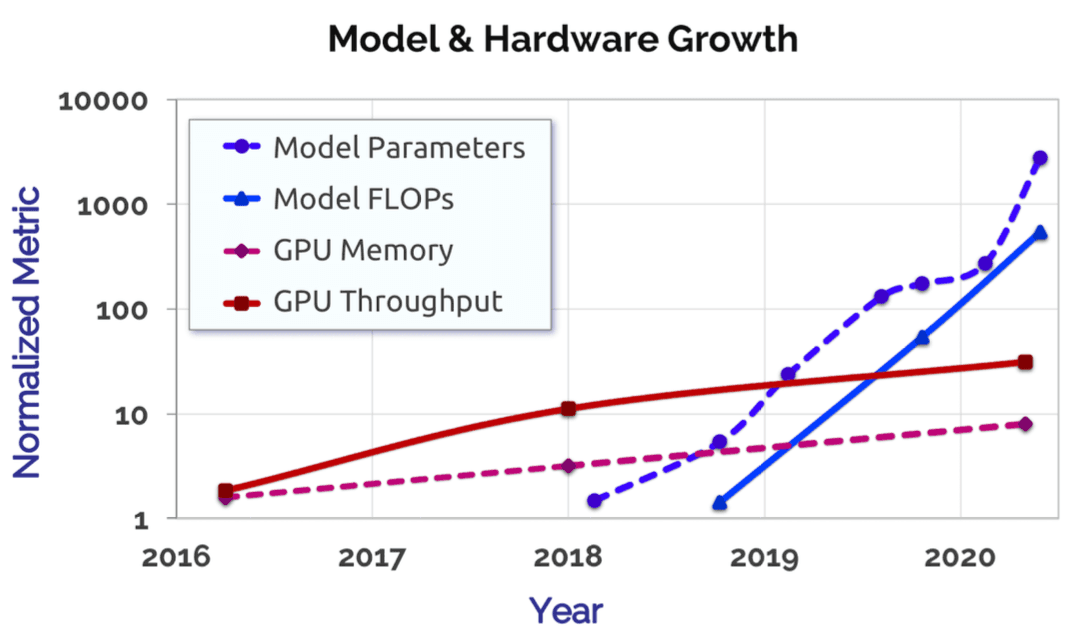
コンピュータハードウェアの向上:GPUの採用により、ディープラーニングモデルの性能が劇的に向上しました。GPUは並列計算を実行できるため、ディープニューラルネットワークのトレーニングに伴う数学的処理に最適です。過去5年間で、より大規模な基盤モデルをサポートするために、GPUのスループットとメモリは10倍に増加しました。
高度に並列化されたアーキテクチャ:Transformerアーキテクチャにより、大規模なディープラーニングネットワークがハードウェアの並列性を活かせるようになりました。これにより、Transformerネットワークは、入力データ全体の中で大きく離れた要素間の長期的な依存関係や高次の相互作用を捉えることができます。これについては、マルチモーダル基盤モデルに関する前回の記事で詳しく説明しました。
膨大な量のトレーニングデータ:大規模なデータセットと、データ収集およびアノテーション技術の向上により、より大きく強力な基盤モデルの開発が可能になりました。GPT-2は40ギガバイトのデータでトレーニングされましたが、GPT-3はインターネットの大部分を含む570ギガバイトのデータでトレーニングされました。また、多くの企業や組織は公開されていない独自のデータセットを保有しており、これらを利用して大規模モデルをトレーニングしています。別のアプローチとして、文全体の意味を保ちながら単語やフレーズをランダムに置き換えるなどの手法により、既存のデータセットを拡張するデータ拡張(データオーグメンテーション)もあります。
1.2 - 技術的な恩恵
汎用性(Generalizability)
これらのモデルの背景にあるエンジニアリングは素晴らしいものですが、AI研究者やエンジニアが最も興奮しているのは、その汎用性です。汎用性とは、十分にトレーニングされた基盤モデルが、(追加のトレーニングや微調整を行うことなく)これまでに見たことのないデータに基づいて正確な予測を行い、一貫性のあるテキストや画像を生成できる能力を指します。これは、モデルがすでに大規模なデータセットで共同学習されており、多くの異なるタスクに役立つ基本的な特徴を習得しているためです。
対照的に、従来の機械学習モデルは、特定のタスクで高いパフォーマンスを発揮するために、大量のラベル付きデータを必要とします。このラベル貼りのプロセスには時間とコストがかかります。さらに、適切なアーキテクチャを設計し、複数のトレーニングサイクルを繰り返す必要があるため、モデルの拡張性や汎用性が制限されます。
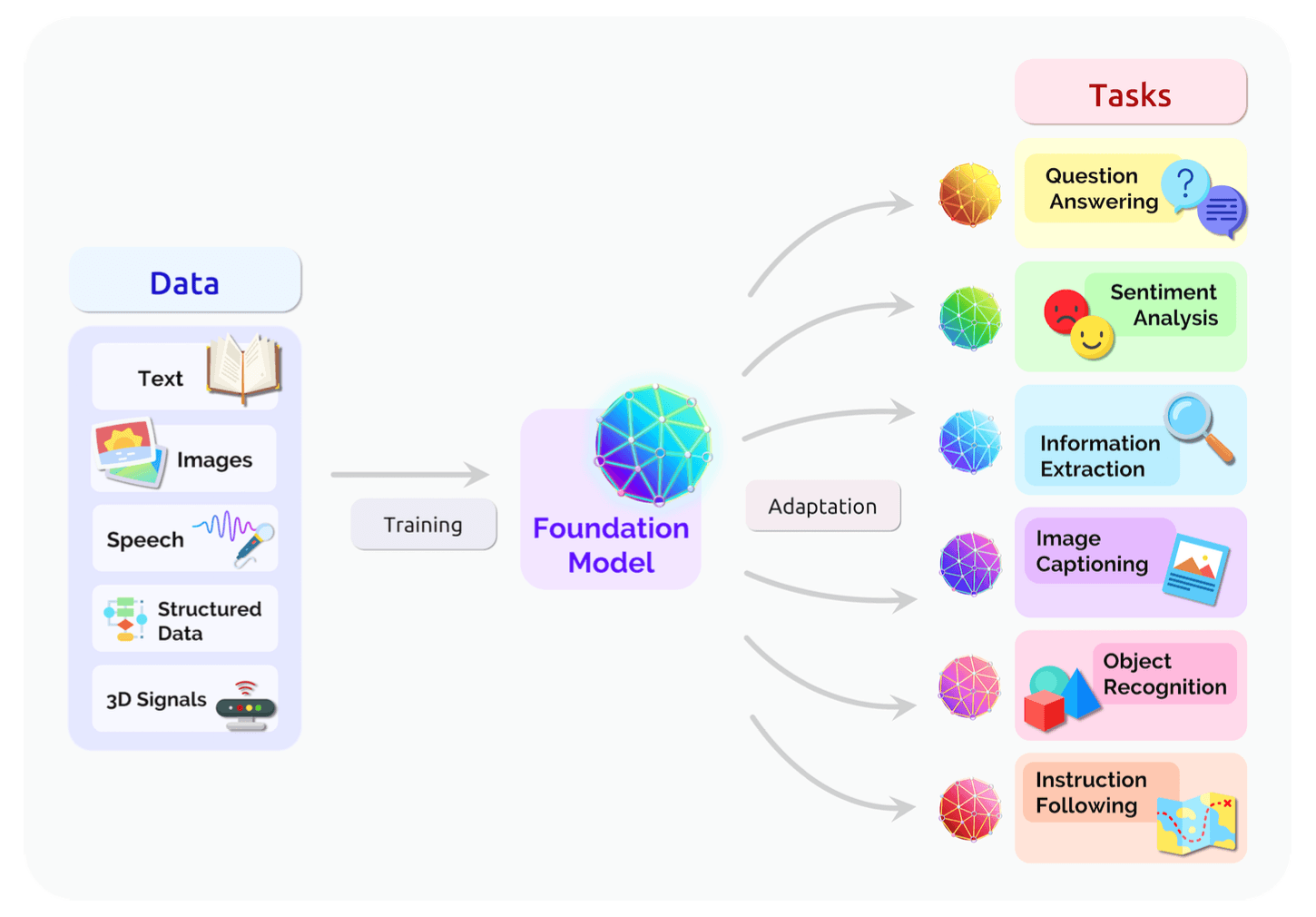
基盤モデルは、テキスト、画像、音声、表形式データ、タンパク質配列、有機分子、強化学習など、幅広いモダリティにわたる様々な研究ベンチマークにおいて、最先端(State-of-the-Art)の性能を達成しています。さらに、一部の領域(ビデオなど)ではデータが自然にマルチモーダルであるため、マルチモーダル基盤モデルは領域に関する関連情報を効果的に組み合わせ、複数のモードが関わるタスクに適応します。
微調整(ファインチューニング)
一般的な知識でトレーニングされた標準的な基盤モデルは、特定の専門領域のタスクにおいては苦戦することがあります。ビジネスリーダーが安心して実務で使用できるレベルまでモデルの性能を高めるには、微調整用のデータを収集して準備する必要があります。例えば、BloombergGPTは、Bloomberg社によって開発された基盤モデルです。このモデルは膨大な金融テキストデータや金融に特化した知識ソースで事前学習されており、金融の自然言語処理を実行したり、既存の知識や参照元から推論して不完全な業界特有のフレーズを補完したりすることができます。
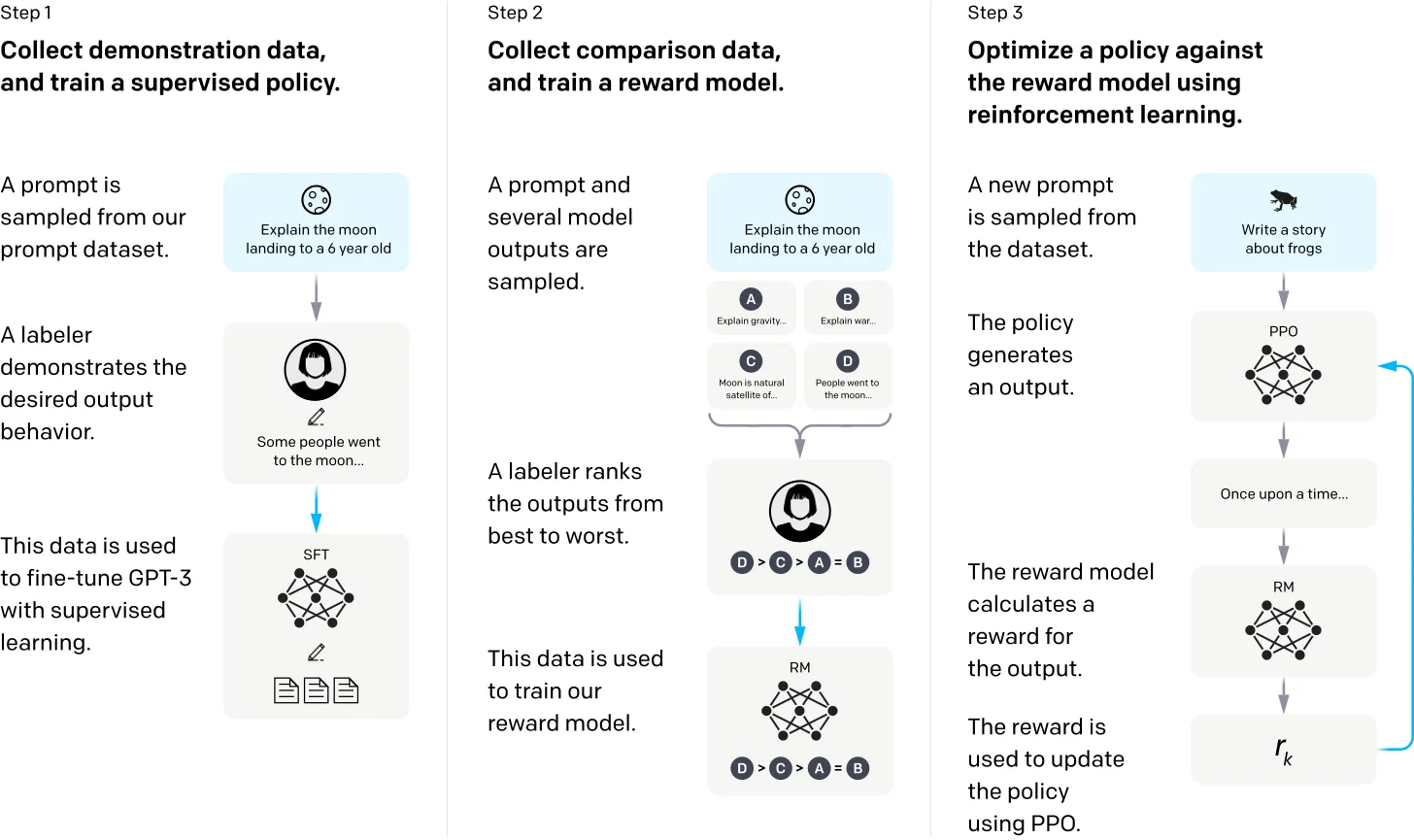
基盤モデルを微調整するための最もわかりやすいアプローチは、ユースケースに応じた大規模な専門領域向けトレーニングデータセットを作成し、それにモデルを適応させることです。また、最近人気を集めている別のアプローチとして、人間のフィードバックからの強化学習を意味する「RLHF」があります。大まかに言えば、事前学習済みのLLMを人間のプロファレンス(好みの情報)を用いて微調整し、望ましい出力を生成させるというコンセプトです。詳細については、Molly Welchによるこのブログポストが、RLHFとその応用について優れた概要を提供しています。
1.3 - 経済的メリット
基盤モデルは、市場投入までの時間の短縮、生産性の向上、および収益の増加によって、エンタープライズ企業に利益をもたらすことができます。かつてない汎用性を持つこれらの強力なモデルを民主化することで、コミュニティは、個人、開発者、および企業が自前でゼロから構築することなく、これらの能力を活用できるようにします。これは、私たちが自分たちで発電機を作る代わりに、近くの発電所から電力を引き出すのと似ています。
これらのモデルは、コンテンツの作成や編集など、手作業とクリエイティブなタスクの両方を企業が自動化するのに役立ちます。これにより、製品やサービスの開発と反復(イテレーション)が加速されます。また、顧客サポートを提供し、よくある質問に答えるチャットボットやバーチャルアシスタントの開発にも使用できます。これにより、企業はリソースを節約しながら自社の目標を達成することができます。
従来のSaaSから基盤モデルへ移行する際、売上原価の計算はより複雑になる可能性がありますが、基盤モデルを活用したアプリケーションははるかにインテリジェントになると期待されています。これにより、顧客に超パーソナライズされた体験を提供することが可能になり、結果として収益の増加につながります。
2 - 基盤モデルの種類
2.1 - 言語
基盤モデルは自然言語処理(NLP)の分野に多大な影響を与えました。例えば、OpenAIのGPT-3(Generative Pre-trained Transformer 3)は、人間のような言語を生成できることでよく知られている基盤モデルです。このモデルは膨大なテキストデータでトレーニングされており、テキスト生成、質問回答、要約など、言語に関連する様々なタスクに適応させることができます。これはOpenAIのChatGPTの基礎となりました。
GPT-3は、高品質なニュース記事やブログの作成、アポイントメントのスケジュール調整、詩の生成、ある言語から別の言語への翻訳など、様々な方法で活用できます。
2.2 - 画像(ビジョン)
コンピュータビジョン分野における最初の基盤モデルは、OpenAIによるCLIP(Contrastive Language–Image Pre-training)のリリースでした。CLIPモデルは4億組の画像とキャプションのペアでトレーニングされており、言語と画像の関係を理解することができます。つまり、モデルは画像の内容を理解し、人間の言葉でその説明を生成できます。例えば、モデルに猫の写真を見せると、それが猫であることを示し、その色や他の特徴を説明することができます。言語と画像の両方を理解するCLIPの能力には、画像認識、キャプション生成、さらにはアートの生成や製品デザインといったクリエイティブなタスクなど、多くの潜在的な用途があります。

さらに、Stable Diffusionは、テキストから画像を生成できるオープンソースのプロジェクトです。これは、シンプルなテキストによる説明に基づいて、リアルで高品質な画像を生成する独自のアルゴリズム(潜在拡散モデルと呼ばれる)を使用しています。人間のアーティストが作成したかのような見事な画像を生成できる能力により、このプロジェクトは大きな注目を集めています。最大の利点は、無料で使用でき、画像生成を実験してみたい人なら誰でもダウンロードできる点です。アーティスト、開発者、あるいは単にAIに興味がある人であっても、Stable Diffusionを探索し、テキストによる説明からどのような画像を作成できるか試すことができます。
2.3 - 音声
言語や画像に加えて、基盤モデルは音声も処理できます。OpenAIのWhisperは、多くの異なるアクセントや言語の話し言葉を理解できる音声基盤モデルです。騒がしい環境であっても、話し言葉を正確かつ迅速に書き起こすことができます。Whisperは68万時間以上の音声からなる大規模なデータセットでトレーニングされており、話し言葉を認識する上で人間レベルの精度を達成することに貢献しました。
Whisperは、デジタルアシスタント、書き起こしソフトウェア、さらには車内やその他の騒音の多い環境など、幅広いアプリケーションで活用される可能性を秘めています。
2.4 - ビデオ
最後に、ビデオデータを処理するための基盤モデルも開発されています。これらのモデルは、映像要素と音声要素を含むビデオの内容を理解するように設計されています。ビデオのアノテーション、要約、検索など、様々なメタデータ生成アプリケーションに使用できます。例えば、ビデオデータ用の基盤モデルをトレーニングして、ビデオ内の特定のオブジェクト、アクション、またはシーンを認識させることができます。これにより、ビデオのタグやキャプションを自動的に生成し、検索や共有を容易にできます。

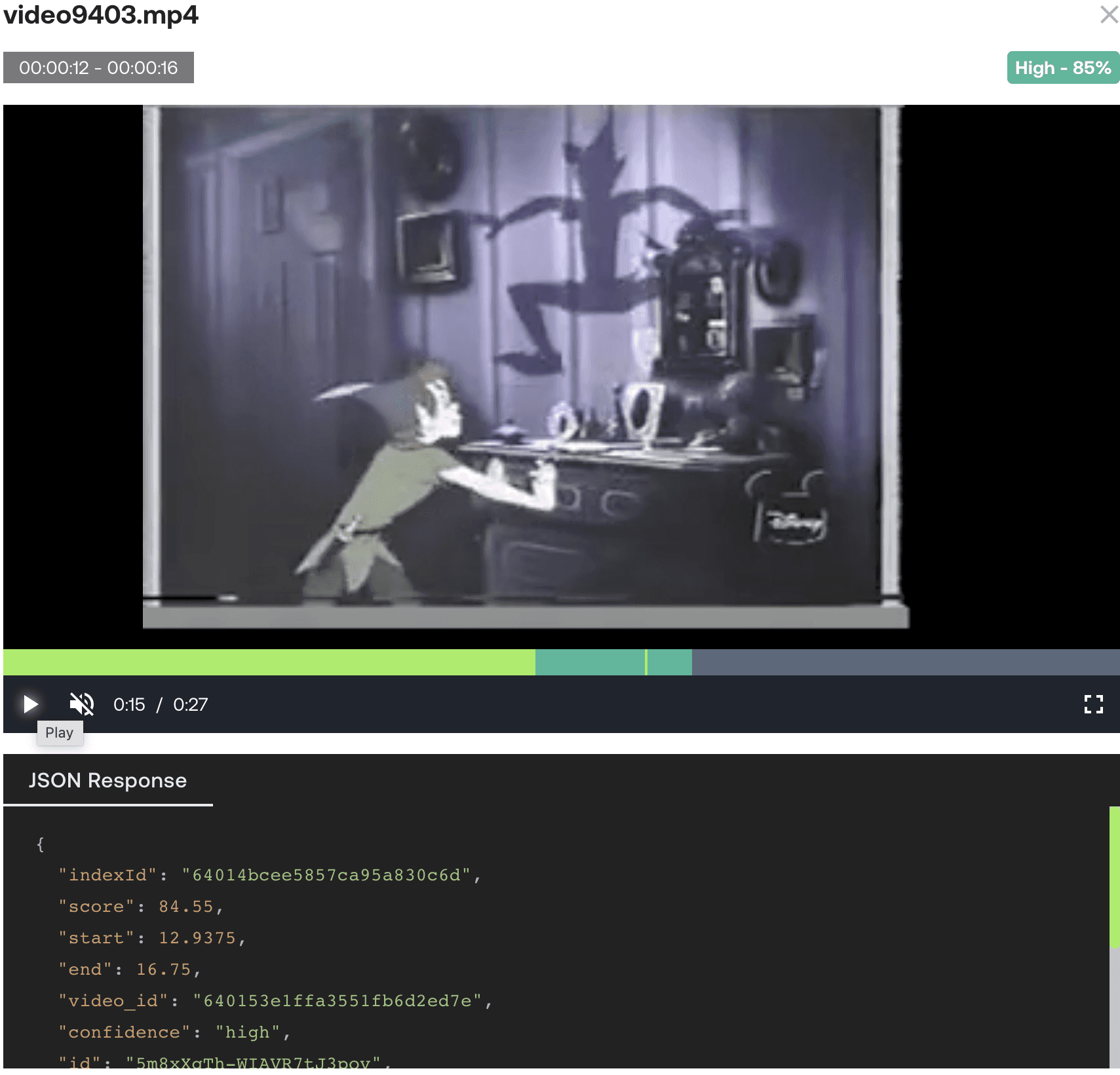
Twelve Labsでは、私たちはロングテールなマルチモーダルビデオ理解のための基盤モデルを構築しています。当社のVideo Understanding APIは、ビデオ検索や分類など、ビデオデータを処理および分析するための強力なツールを開発者に提供します。当社の基盤モデルは特定の用途向けにさらに微調整できるため、様々な業界に高度に適応させることができます。
3 - 潜在的なアプリケーション
基盤モデルは、メディア・エンターテインメントからスポーツ分析、コンシューマー向けヘルスケアまで、幅広い業界に適用できます。以下は、すでに実用に至っている興味深いAIアプリケーションであり、基盤モデルを使用することで簡単に再現(および改善)できます。
3.1 - メディア・エンターテインメント
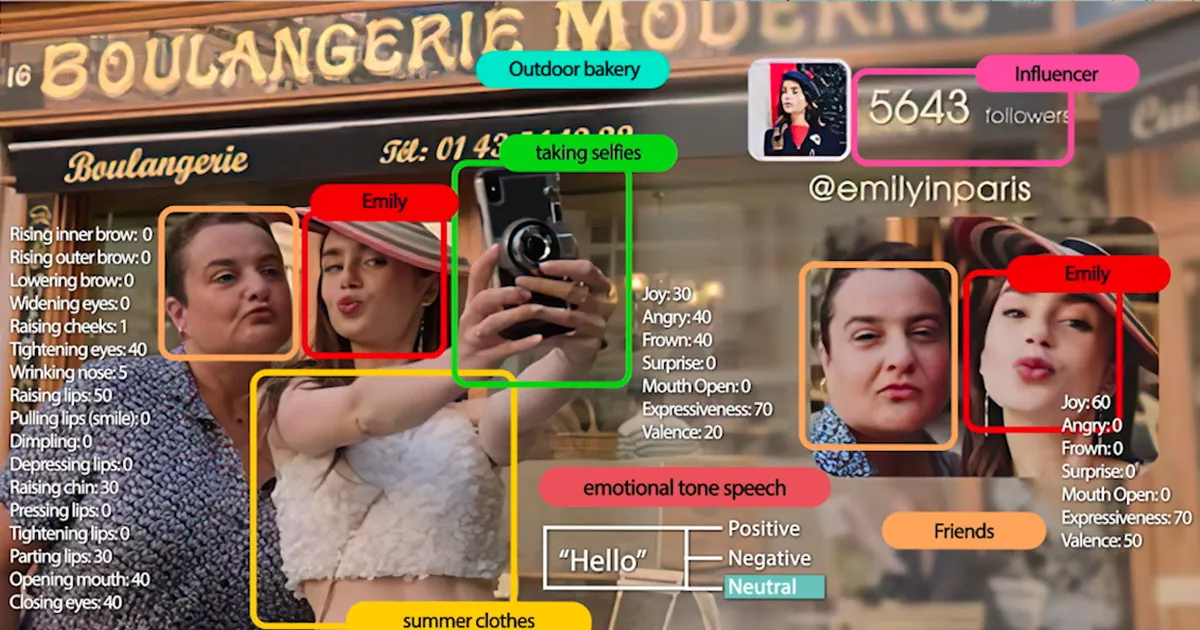
エンターテインメント業界の企業はAIを活用して、よりパーソナライズされ、魅力的な消費者体験を作り出しています。一例としてNetflixが挙げられます。同社は、テレビ番組、予告編、映画、プロモーションアートなどのより良いメディアをクリエイターが制作できるようにAIを活用しています。彼らは、登場人物、ストーリー、感情、シネマトリガーを分類するビデオ理解モデルを導入しており、特定の映像を見つけやすくしています。これにより、クリエイターは映像を何時間もかけて分類する作業から解放され、クリエイティブな意思決定に集中できるようになります。
基盤モデルは、登場人物や感情の分類など、同様のユースケースを解決できます。これにより、これらのモデルの精度と効率が向上し、クリエイターは何時間も分類作業に費やすことなく、特定の映像を迅速に見つけることができます。
また、基盤モデルは、より没入感が高くリアルなコンテンツの作成にも使用できます。例えばゲーム業界では、ノンプレイヤーキャラクター(NPC)をよりインテリジェントでリアルにするのに役立ちます。Ubisoftは、NPCのダイアログを自動的に生成するGhostwriterと呼ばれる新しいAIツールを開発しました。一方でRobloxは、クリエイターが没入感のある3D体験を構築するためのRoblox Studioというプラットフォームを提供しています。
3.2 - スポーツ分析
スポーツ分析において、AIはボールや選手の動きを追跡するのに役立ちます。カタールで開催された2022 FIFAワールドカップでは、オフサイドの反則を検出するための半自動オフサイドテクノロジーなど、AIが様々な役割で活用されました。この技術は、ビデオフィードやセンサーからデータを収集し、審判がオフサイド位置についてより正確な判定を下せるよう支援するものです。スタジアムの屋根の下には12台の追跡カメラが設置され、ボールと、選手の姿勢やボールの位置など毎秒29個のデータポイントを追跡しました。
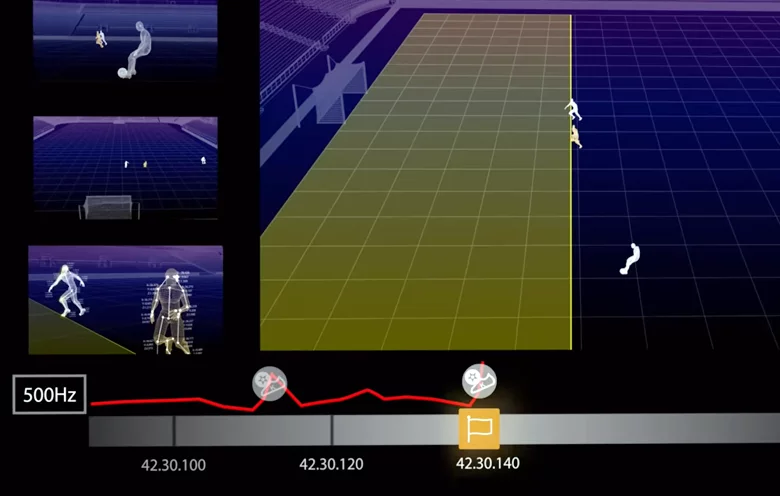
基盤モデルを使用することで、FIFAは半自動オフサイドテクノロジーの精度と効率を向上させることができます。長年にわたって収集されたサッカーの映像で基盤モデルを微調整することにより、選手の位置や動きによってオフサイドになるなど、様々なオフサイドの状況を認識させることができます。さらに、オフサイドになる可能性を予測し、審判がより備えを万全にし、誤審を未然に防ぐのにも役立ちます。
3.3 - ヘルスケア
一般消費者向けのヘルスケアにおいて、AIは保険金の請求手続き、事務処理の処理、医師の診察時のメモ作成など、特定の作業を代行することで、医療従事者が時間を管理しやすくなるようにしています。さらに、AIは年齢、病歴、遺伝情報などの様々な要素に基づいて、患者の経過予測をサポートします。医師はこの情報を使用して、パーソナライズされた治療計画を作成できます。このトピックについてもっと学びたい場合は、Eric Topolの著書『Deep Medicine』をお読みください。
基盤モデルは、レントゲンやMRIなどの医療画像の分析に使用できます。例えば、医療画像から腫瘍や骨折などの異常な箇所を発見するように基盤モデルをトレーニングでき、これにより医師がより迅速かつ正確に疾患を診断し、治療するのに役立ちます。
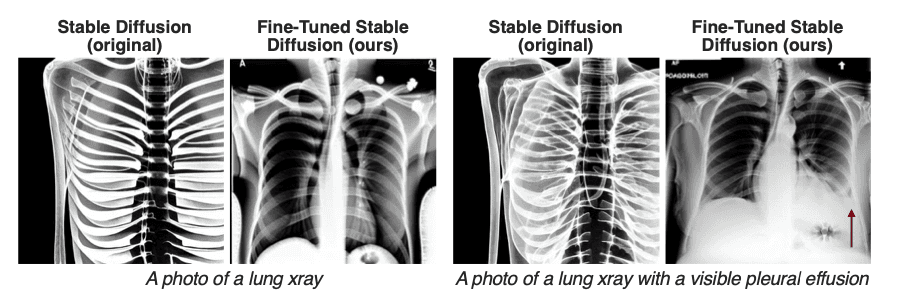
ケアの支援に加えて、基盤モデルは医療の画期的な進歩のスピードを大幅に加速させます。生物学におけるデータ量は膨大であり、人間が複雑な生物学的システムの仕組みをすべて追跡することは困難です。しかし、すでにこのデータを分析し、経路(パスウェイ)を推論し、病原体の標的を探索し、それに応じて薬を設計できるソフトウェアが存在します。AlphaFoldの画期的な技術を基盤とする技術を持つIsomorphic Labsは、AIを創薬に適用し、医療が人々を助け、治癒する方法に革命をもたらしています。
結論
上記で紹介したアプリケーションは、個人的に非常に興味深いものであり、これらはこれから変革が起こるであろう数千の例のほんの一部にすぎません。基盤モデルの可能性は本当に刺激的であり、まだ想像すらされていない無数の未知の機会を提供してくれます。これらの機会は確実に開かれ、創造的な人々が自らのアイデアを記録的な早さで具体的で魅力的な製品へと変化させることができるようになるでしょう。
基盤モデルを実用に投入する前に考慮すべき制限事項もあります。1つのリスクは、事前学習データに含まれていなかったニッチなタスクや特定のタスクにおいて、十分なパフォーマンスを発揮できない可能性があることです。そのため、性能を向上させるためには、特定のタスクにより関連性の高いデータを用いてモデルを微調整する必要があるかもしれません。さらに、基盤モデルはプレトレーニングに使用されたデータに存在する偏見(バイアス)を無意識に永続させてしまう可能性があります。これらのバイアスを防ぎ、軽減することは活発な研究分野であり、事前学習済みモデルにおけるバイアスの影響を低減するために利用できるベストプラクティスが存在します(これらについては今後の記事で取り上げる予定です)。
基盤モデル全般についてお話ししてみたい方は、是非私たちのDiscordコミュニティに参加して、マルチモーダルAIについて語り合いましょう!
2022年にスタンフォード大学が基盤モデル(Foundation Models)の概念を提唱して以来、これはほぼすべてのビジネス分野において最もホットなトレンドの1つとなっています。これらのモデルは、一般大衆に広く浸透した初めてのモデルです。簡単に言えば、基盤モデルとは、特定のタスクに合わせてさらに微調整(ファインチューニング)できる、事前学習済みの超大型機械学習モデルであり、幅広いタスクにおいて最先端のパフォーマンスを達成しています。
しかし、技術用語に不慣れな読者にとって、基盤モデルの能力やその応用の可能性を理解するのは難しい場合があります。そこで、この刺激的な技術をより身近で、より多くの人々に理解しやすくするための解説を用意しました。前回の記事では技術的な視点から掘り下げましたが、今回の記事では基盤モデルの能力をわかりやすい言葉で紐解き、それらが現実世界の課題を解決するためにどのように活用できるか、具体的な例を挙げて紹介します。
1 - 基盤モデルの概要
1.1 - なぜ今なのか?
基盤モデルは、幅広い領域や業界にわたって柔軟に、そして再利用できるように設計された、巨大かつ複雑なモデルです。これらのモデルが機能する背景には、「転移学習」と「スケール(規模)」という2つの要素があります。
転移学習
転移学習とは、機械学習(ML)において、あるタスクで得られた知識を別の関連するタスクに活用する手法です。これにより、新しいタスクごとに大量のデータを用意する必要性が減り、モデルをより迅速に学習させることができ、MLモデルのパフォーマンスを向上させることができます。転移学習は、推薦システムにおけるコールドスタート問題、ロボティクスにおけるシミュレーション、多言語間の翻訳など、現実世界の多くのアプリケーションの解決に役立っています。さらに詳しく知りたい方は、Georgianによるこのブログポストにて、具体的な例を交えながら転移学習を簡潔に説明しています。
スケール(規模)
スケールこそが、基盤モデルを強力にする要因です。それには以下の3つの要素が必要でした:
コンピュータハードウェアの向上:GPUの採用により、ディープラーニングモデルの性能が劇的に向上しました。GPUは並列計算を実行できるため、ディープニューラルネットワークのトレーニングに伴う数学的処理に最適です。過去5年間で、より大規模な基盤モデルをサポートするために、GPUのスループットとメモリは10倍に増加しました。
高度に並列化されたアーキテクチャ:Transformerアーキテクチャにより、大規模なディープラーニングネットワークがハードウェアの並列性を活かせるようになりました。これにより、Transformerネットワークは、入力データ全体の中で大きく離れた要素間の長期的な依存関係や高次の相互作用を捉えることができます。これについては、マルチモーダル基盤モデルに関する前回の記事で詳しく説明しました。
膨大な量のトレーニングデータ:大規模なデータセットと、データ収集およびアノテーション技術の向上により、より大きく強力な基盤モデルの開発が可能になりました。GPT-2は40ギガバイトのデータでトレーニングされましたが、GPT-3はインターネットの大部分を含む570ギガバイトのデータでトレーニングされました。また、多くの企業や組織は公開されていない独自のデータセットを保有しており、これらを利用して大規模モデルをトレーニングしています。別のアプローチとして、文全体の意味を保ちながら単語やフレーズをランダムに置き換えるなどの手法により、既存のデータセットを拡張するデータ拡張(データオーグメンテーション)もあります。
1.2 - 技術的な恩恵
汎用性(Generalizability)
これらのモデルの背景にあるエンジニアリングは素晴らしいものですが、AI研究者やエンジニアが最も興奮しているのは、その汎用性です。汎用性とは、十分にトレーニングされた基盤モデルが、(追加のトレーニングや微調整を行うことなく)これまでに見たことのないデータに基づいて正確な予測を行い、一貫性のあるテキストや画像を生成できる能力を指します。これは、モデルがすでに大規模なデータセットで共同学習されており、多くの異なるタスクに役立つ基本的な特徴を習得しているためです。
対照的に、従来の機械学習モデルは、特定のタスクで高いパフォーマンスを発揮するために、大量のラベル付きデータを必要とします。このラベル貼りのプロセスには時間とコストがかかります。さらに、適切なアーキテクチャを設計し、複数のトレーニングサイクルを繰り返す必要があるため、モデルの拡張性や汎用性が制限されます。
基盤モデルは、テキスト、画像、音声、表形式データ、タンパク質配列、有機分子、強化学習など、幅広いモダリティにわたる様々な研究ベンチマークにおいて、最先端(State-of-the-Art)の性能を達成しています。さらに、一部の領域(ビデオなど)ではデータが自然にマルチモーダルであるため、マルチモーダル基盤モデルは領域に関する関連情報を効果的に組み合わせ、複数のモードが関わるタスクに適応します。
微調整(ファインチューニング)
一般的な知識でトレーニングされた標準的な基盤モデルは、特定の専門領域のタスクにおいては苦戦することがあります。ビジネスリーダーが安心して実務で使用できるレベルまでモデルの性能を高めるには、微調整用のデータを収集して準備する必要があります。例えば、BloombergGPTは、Bloomberg社によって開発された基盤モデルです。このモデルは膨大な金融テキストデータや金融に特化した知識ソースで事前学習されており、金融の自然言語処理を実行したり、既存の知識や参照元から推論して不完全な業界特有のフレーズを補完したりすることができます。
基盤モデルを微調整するための最もわかりやすいアプローチは、ユースケースに応じた大規模な専門領域向けトレーニングデータセットを作成し、それにモデルを適応させることです。また、最近人気を集めている別のアプローチとして、人間のフィードバックからの強化学習を意味する「RLHF」があります。大まかに言えば、事前学習済みのLLMを人間のプロファレンス(好みの情報)を用いて微調整し、望ましい出力を生成させるというコンセプトです。詳細については、Molly Welchによるこのブログポストが、RLHFとその応用について優れた概要を提供しています。
1.3 - 経済的メリット
基盤モデルは、市場投入までの時間の短縮、生産性の向上、および収益の増加によって、エンタープライズ企業に利益をもたらすことができます。かつてない汎用性を持つこれらの強力なモデルを民主化することで、コミュニティは、個人、開発者、および企業が自前でゼロから構築することなく、これらの能力を活用できるようにします。これは、私たちが自分たちで発電機を作る代わりに、近くの発電所から電力を引き出すのと似ています。
これらのモデルは、コンテンツの作成や編集など、手作業とクリエイティブなタスクの両方を企業が自動化するのに役立ちます。これにより、製品やサービスの開発と反復(イテレーション)が加速されます。また、顧客サポートを提供し、よくある質問に答えるチャットボットやバーチャルアシスタントの開発にも使用できます。これにより、企業はリソースを節約しながら自社の目標を達成することができます。
従来のSaaSから基盤モデルへ移行する際、売上原価の計算はより複雑になる可能性がありますが、基盤モデルを活用したアプリケーションははるかにインテリジェントになると期待されています。これにより、顧客に超パーソナライズされた体験を提供することが可能になり、結果として収益の増加につながります。
2 - 基盤モデルの種類
2.1 - 言語
基盤モデルは自然言語処理(NLP)の分野に多大な影響を与えました。例えば、OpenAIのGPT-3(Generative Pre-trained Transformer 3)は、人間のような言語を生成できることでよく知られている基盤モデルです。このモデルは膨大なテキストデータでトレーニングされており、テキスト生成、質問回答、要約など、言語に関連する様々なタスクに適応させることができます。これはOpenAIのChatGPTの基礎となりました。
GPT-3は、高品質なニュース記事やブログの作成、アポイントメントのスケジュール調整、詩の生成、ある言語から別の言語への翻訳など、様々な方法で活用できます。
2.2 - 画像(ビジョン)
コンピュータビジョン分野における最初の基盤モデルは、OpenAIによるCLIP(Contrastive Language–Image Pre-training)のリリースでした。CLIPモデルは4億組の画像とキャプションのペアでトレーニングされており、言語と画像の関係を理解することができます。つまり、モデルは画像の内容を理解し、人間の言葉でその説明を生成できます。例えば、モデルに猫の写真を見せると、それが猫であることを示し、その色や他の特徴を説明することができます。言語と画像の両方を理解するCLIPの能力には、画像認識、キャプション生成、さらにはアートの生成や製品デザインといったクリエイティブなタスクなど、多くの潜在的な用途があります。
さらに、Stable Diffusionは、テキストから画像を生成できるオープンソースのプロジェクトです。これは、シンプルなテキストによる説明に基づいて、リアルで高品質な画像を生成する独自のアルゴリズム(潜在拡散モデルと呼ばれる)を使用しています。人間のアーティストが作成したかのような見事な画像を生成できる能力により、このプロジェクトは大きな注目を集めています。最大の利点は、無料で使用でき、画像生成を実験してみたい人なら誰でもダウンロードできる点です。アーティスト、開発者、あるいは単にAIに興味がある人であっても、Stable Diffusionを探索し、テキストによる説明からどのような画像を作成できるか試すことができます。
2.3 - 音声
言語や画像に加えて、基盤モデルは音声も処理できます。OpenAIのWhisperは、多くの異なるアクセントや言語の話し言葉を理解できる音声基盤モデルです。騒がしい環境であっても、話し言葉を正確かつ迅速に書き起こすことができます。Whisperは68万時間以上の音声からなる大規模なデータセットでトレーニングされており、話し言葉を認識する上で人間レベルの精度を達成することに貢献しました。
Whisperは、デジタルアシスタント、書き起こしソフトウェア、さらには車内やその他の騒音の多い環境など、幅広いアプリケーションで活用される可能性を秘めています。
2.4 - ビデオ
最後に、ビデオデータを処理するための基盤モデルも開発されています。これらのモデルは、映像要素と音声要素を含むビデオの内容を理解するように設計されています。ビデオのアノテーション、要約、検索など、様々なメタデータ生成アプリケーションに使用できます。例えば、ビデオデータ用の基盤モデルをトレーニングして、ビデオ内の特定のオブジェクト、アクション、またはシーンを認識させることができます。これにより、ビデオのタグやキャプションを自動的に生成し、検索や共有を容易にできます。
Twelve Labsでは、私たちはロングテールなマルチモーダルビデオ理解のための基盤モデルを構築しています。当社のVideo Understanding APIは、ビデオ検索や分類など、ビデオデータを処理および分析するための強力なツールを開発者に提供します。当社の基盤モデルは特定の用途向けにさらに微調整できるため、様々な業界に高度に適応させることができます。
3 - 潜在的なアプリケーション
基盤モデルは、メディア・エンターテインメントからスポーツ分析、コンシューマー向けヘルスケアまで、幅広い業界に適用できます。以下は、すでに実用に至っている興味深いAIアプリケーションであり、基盤モデルを使用することで簡単に再現(および改善)できます。
3.1 - メディア・エンターテインメント
エンターテインメント業界の企業はAIを活用して、よりパーソナライズされ、魅力的な消費者体験を作り出しています。一例としてNetflixが挙げられます。同社は、テレビ番組、予告編、映画、プロモーションアートなどのより良いメディアをクリエイターが制作できるようにAIを活用しています。彼らは、登場人物、ストーリー、感情、シネマトリガーを分類するビデオ理解モデルを導入しており、特定の映像を見つけやすくしています。これにより、クリエイターは映像を何時間もかけて分類する作業から解放され、クリエイティブな意思決定に集中できるようになります。
基盤モデルは、登場人物や感情の分類など、同様のユースケースを解決できます。これにより、これらのモデルの精度と効率が向上し、クリエイターは何時間も分類作業に費やすことなく、特定の映像を迅速に見つけることができます。
また、基盤モデルは、より没入感が高くリアルなコンテンツの作成にも使用できます。例えばゲーム業界では、ノンプレイヤーキャラクター(NPC)をよりインテリジェントでリアルにするのに役立ちます。Ubisoftは、NPCのダイアログを自動的に生成するGhostwriterと呼ばれる新しいAIツールを開発しました。一方でRobloxは、クリエイターが没入感のある3D体験を構築するためのRoblox Studioというプラットフォームを提供しています。
3.2 - スポーツ分析
スポーツ分析において、AIはボールや選手の動きを追跡するのに役立ちます。カタールで開催された2022 FIFAワールドカップでは、オフサイドの反則を検出するための半自動オフサイドテクノロジーなど、AIが様々な役割で活用されました。この技術は、ビデオフィードやセンサーからデータを収集し、審判がオフサイド位置についてより正確な判定を下せるよう支援するものです。スタジアムの屋根の下には12台の追跡カメラが設置され、ボールと、選手の姿勢やボールの位置など毎秒29個のデータポイントを追跡しました。
基盤モデルを使用することで、FIFAは半自動オフサイドテクノロジーの精度と効率を向上させることができます。長年にわたって収集されたサッカーの映像で基盤モデルを微調整することにより、選手の位置や動きによってオフサイドになるなど、様々なオフサイドの状況を認識させることができます。さらに、オフサイドになる可能性を予測し、審判がより備えを万全にし、誤審を未然に防ぐのにも役立ちます。
3.3 - ヘルスケア
一般消費者向けのヘルスケアにおいて、AIは保険金の請求手続き、事務処理の処理、医師の診察時のメモ作成など、特定の作業を代行することで、医療従事者が時間を管理しやすくなるようにしています。さらに、AIは年齢、病歴、遺伝情報などの様々な要素に基づいて、患者の経過予測をサポートします。医師はこの情報を使用して、パーソナライズされた治療計画を作成できます。このトピックについてもっと学びたい場合は、Eric Topolの著書『Deep Medicine』をお読みください。
基盤モデルは、レントゲンやMRIなどの医療画像の分析に使用できます。例えば、医療画像から腫瘍や骨折などの異常な箇所を発見するように基盤モデルをトレーニングでき、これにより医師がより迅速かつ正確に疾患を診断し、治療するのに役立ちます。
ケアの支援に加えて、基盤モデルは医療の画期的な進歩のスピードを大幅に加速させます。生物学におけるデータ量は膨大であり、人間が複雑な生物学的システムの仕組みをすべて追跡することは困難です。しかし、すでにこのデータを分析し、経路(パスウェイ)を推論し、病原体の標的を探索し、それに応じて薬を設計できるソフトウェアが存在します。AlphaFoldの画期的な技術を基盤とする技術を持つIsomorphic Labsは、AIを創薬に適用し、医療が人々を助け、治癒する方法に革命をもたらしています。
結論
上記で紹介したアプリケーションは、個人的に非常に興味深いものであり、これらはこれから変革が起こるであろう数千の例のほんの一部にすぎません。基盤モデルの可能性は本当に刺激的であり、まだ想像すらされていない無数の未知の機会を提供してくれます。これらの機会は確実に開かれ、創造的な人々が自らのアイデアを記録的な早さで具体的で魅力的な製品へと変化させることができるようになるでしょう。
基盤モデルを実用に投入する前に考慮すべき制限事項もあります。1つのリスクは、事前学習データに含まれていなかったニッチなタスクや特定のタスクにおいて、十分なパフォーマンスを発揮できない可能性があることです。そのため、性能を向上させるためには、特定のタスクにより関連性の高いデータを用いてモデルを微調整する必要があるかもしれません。さらに、基盤モデルはプレトレーニングに使用されたデータに存在する偏見(バイアス)を無意識に永続させてしまう可能性があります。これらのバイアスを防ぎ、軽減することは活発な研究分野であり、事前学習済みモデルにおけるバイアスの影響を低減するために利用できるベストプラクティスが存在します(これらについては今後の記事で取り上げる予定です)。
基盤モデル全般についてお話ししてみたい方は、是非私たちのDiscordコミュニティに参加して、マルチモーダルAIについて語り合いましょう!
2022年にスタンフォード大学が基盤モデル(Foundation Models)の概念を提唱して以来、これはほぼすべてのビジネス分野において最もホットなトレンドの1つとなっています。これらのモデルは、一般大衆に広く浸透した初めてのモデルです。簡単に言えば、基盤モデルとは、特定のタスクに合わせてさらに微調整(ファインチューニング)できる、事前学習済みの超大型機械学習モデルであり、幅広いタスクにおいて最先端のパフォーマンスを達成しています。
しかし、技術用語に不慣れな読者にとって、基盤モデルの能力やその応用の可能性を理解するのは難しい場合があります。そこで、この刺激的な技術をより身近で、より多くの人々に理解しやすくするための解説を用意しました。前回の記事では技術的な視点から掘り下げましたが、今回の記事では基盤モデルの能力をわかりやすい言葉で紐解き、それらが現実世界の課題を解決するためにどのように活用できるか、具体的な例を挙げて紹介します。
1 - 基盤モデルの概要
1.1 - なぜ今なのか?
基盤モデルは、幅広い領域や業界にわたって柔軟に、そして再利用できるように設計された、巨大かつ複雑なモデルです。これらのモデルが機能する背景には、「転移学習」と「スケール(規模)」という2つの要素があります。
転移学習
転移学習とは、機械学習(ML)において、あるタスクで得られた知識を別の関連するタスクに活用する手法です。これにより、新しいタスクごとに大量のデータを用意する必要性が減り、モデルをより迅速に学習させることができ、MLモデルのパフォーマンスを向上させることができます。転移学習は、推薦システムにおけるコールドスタート問題、ロボティクスにおけるシミュレーション、多言語間の翻訳など、現実世界の多くのアプリケーションの解決に役立っています。さらに詳しく知りたい方は、Georgianによるこのブログポストにて、具体的な例を交えながら転移学習を簡潔に説明しています。
スケール(規模)
スケールこそが、基盤モデルを強力にする要因です。それには以下の3つの要素が必要でした:
コンピュータハードウェアの向上:GPUの採用により、ディープラーニングモデルの性能が劇的に向上しました。GPUは並列計算を実行できるため、ディープニューラルネットワークのトレーニングに伴う数学的処理に最適です。過去5年間で、より大規模な基盤モデルをサポートするために、GPUのスループットとメモリは10倍に増加しました。
高度に並列化されたアーキテクチャ:Transformerアーキテクチャにより、大規模なディープラーニングネットワークがハードウェアの並列性を活かせるようになりました。これにより、Transformerネットワークは、入力データ全体の中で大きく離れた要素間の長期的な依存関係や高次の相互作用を捉えることができます。これについては、マルチモーダル基盤モデルに関する前回の記事で詳しく説明しました。
膨大な量のトレーニングデータ:大規模なデータセットと、データ収集およびアノテーション技術の向上により、より大きく強力な基盤モデルの開発が可能になりました。GPT-2は40ギガバイトのデータでトレーニングされましたが、GPT-3はインターネットの大部分を含む570ギガバイトのデータでトレーニングされました。また、多くの企業や組織は公開されていない独自のデータセットを保有しており、これらを利用して大規模モデルをトレーニングしています。別のアプローチとして、文全体の意味を保ちながら単語やフレーズをランダムに置き換えるなどの手法により、既存のデータセットを拡張するデータ拡張(データオーグメンテーション)もあります。
1.2 - 技術的な恩恵
汎用性(Generalizability)
これらのモデルの背景にあるエンジニアリングは素晴らしいものですが、AI研究者やエンジニアが最も興奮しているのは、その汎用性です。汎用性とは、十分にトレーニングされた基盤モデルが、(追加のトレーニングや微調整を行うことなく)これまでに見たことのないデータに基づいて正確な予測を行い、一貫性のあるテキストや画像を生成できる能力を指します。これは、モデルがすでに大規模なデータセットで共同学習されており、多くの異なるタスクに役立つ基本的な特徴を習得しているためです。
対照的に、従来の機械学習モデルは、特定のタスクで高いパフォーマンスを発揮するために、大量のラベル付きデータを必要とします。このラベル貼りのプロセスには時間とコストがかかります。さらに、適切なアーキテクチャを設計し、複数のトレーニングサイクルを繰り返す必要があるため、モデルの拡張性や汎用性が制限されます。
基盤モデルは、テキスト、画像、音声、表形式データ、タンパク質配列、有機分子、強化学習など、幅広いモダリティにわたる様々な研究ベンチマークにおいて、最先端(State-of-the-Art)の性能を達成しています。さらに、一部の領域(ビデオなど)ではデータが自然にマルチモーダルであるため、マルチモーダル基盤モデルは領域に関する関連情報を効果的に組み合わせ、複数のモードが関わるタスクに適応します。
微調整(ファインチューニング)
一般的な知識でトレーニングされた標準的な基盤モデルは、特定の専門領域のタスクにおいては苦戦することがあります。ビジネスリーダーが安心して実務で使用できるレベルまでモデルの性能を高めるには、微調整用のデータを収集して準備する必要があります。例えば、BloombergGPTは、Bloomberg社によって開発された基盤モデルです。このモデルは膨大な金融テキストデータや金融に特化した知識ソースで事前学習されており、金融の自然言語処理を実行したり、既存の知識や参照元から推論して不完全な業界特有のフレーズを補完したりすることができます。
基盤モデルを微調整するための最もわかりやすいアプローチは、ユースケースに応じた大規模な専門領域向けトレーニングデータセットを作成し、それにモデルを適応させることです。また、最近人気を集めている別のアプローチとして、人間のフィードバックからの強化学習を意味する「RLHF」があります。大まかに言えば、事前学習済みのLLMを人間のプロファレンス(好みの情報)を用いて微調整し、望ましい出力を生成させるというコンセプトです。詳細については、Molly Welchによるこのブログポストが、RLHFとその応用について優れた概要を提供しています。
1.3 - 経済的メリット
基盤モデルは、市場投入までの時間の短縮、生産性の向上、および収益の増加によって、エンタープライズ企業に利益をもたらすことができます。かつてない汎用性を持つこれらの強力なモデルを民主化することで、コミュニティは、個人、開発者、および企業が自前でゼロから構築することなく、これらの能力を活用できるようにします。これは、私たちが自分たちで発電機を作る代わりに、近くの発電所から電力を引き出すのと似ています。
これらのモデルは、コンテンツの作成や編集など、手作業とクリエイティブなタスクの両方を企業が自動化するのに役立ちます。これにより、製品やサービスの開発と反復(イテレーション)が加速されます。また、顧客サポートを提供し、よくある質問に答えるチャットボットやバーチャルアシスタントの開発にも使用できます。これにより、企業はリソースを節約しながら自社の目標を達成することができます。
従来のSaaSから基盤モデルへ移行する際、売上原価の計算はより複雑になる可能性がありますが、基盤モデルを活用したアプリケーションははるかにインテリジェントになると期待されています。これにより、顧客に超パーソナライズされた体験を提供することが可能になり、結果として収益の増加につながります。
2 - 基盤モデルの種類
2.1 - 言語
基盤モデルは自然言語処理(NLP)の分野に多大な影響を与えました。例えば、OpenAIのGPT-3(Generative Pre-trained Transformer 3)は、人間のような言語を生成できることでよく知られている基盤モデルです。このモデルは膨大なテキストデータでトレーニングされており、テキスト生成、質問回答、要約など、言語に関連する様々なタスクに適応させることができます。これはOpenAIのChatGPTの基礎となりました。
GPT-3は、高品質なニュース記事やブログの作成、アポイントメントのスケジュール調整、詩の生成、ある言語から別の言語への翻訳など、様々な方法で活用できます。
2.2 - 画像(ビジョン)
コンピュータビジョン分野における最初の基盤モデルは、OpenAIによるCLIP(Contrastive Language–Image Pre-training)のリリースでした。CLIPモデルは4億組の画像とキャプションのペアでトレーニングされており、言語と画像の関係を理解することができます。つまり、モデルは画像の内容を理解し、人間の言葉でその説明を生成できます。例えば、モデルに猫の写真を見せると、それが猫であることを示し、その色や他の特徴を説明することができます。言語と画像の両方を理解するCLIPの能力には、画像認識、キャプション生成、さらにはアートの生成や製品デザインといったクリエイティブなタスクなど、多くの潜在的な用途があります。
さらに、Stable Diffusionは、テキストから画像を生成できるオープンソースのプロジェクトです。これは、シンプルなテキストによる説明に基づいて、リアルで高品質な画像を生成する独自のアルゴリズム(潜在拡散モデルと呼ばれる)を使用しています。人間のアーティストが作成したかのような見事な画像を生成できる能力により、このプロジェクトは大きな注目を集めています。最大の利点は、無料で使用でき、画像生成を実験してみたい人なら誰でもダウンロードできる点です。アーティスト、開発者、あるいは単にAIに興味がある人であっても、Stable Diffusionを探索し、テキストによる説明からどのような画像を作成できるか試すことができます。
2.3 - 音声
言語や画像に加えて、基盤モデルは音声も処理できます。OpenAIのWhisperは、多くの異なるアクセントや言語の話し言葉を理解できる音声基盤モデルです。騒がしい環境であっても、話し言葉を正確かつ迅速に書き起こすことができます。Whisperは68万時間以上の音声からなる大規模なデータセットでトレーニングされており、話し言葉を認識する上で人間レベルの精度を達成することに貢献しました。
Whisperは、デジタルアシスタント、書き起こしソフトウェア、さらには車内やその他の騒音の多い環境など、幅広いアプリケーションで活用される可能性を秘めています。
2.4 - ビデオ
最後に、ビデオデータを処理するための基盤モデルも開発されています。これらのモデルは、映像要素と音声要素を含むビデオの内容を理解するように設計されています。ビデオのアノテーション、要約、検索など、様々なメタデータ生成アプリケーションに使用できます。例えば、ビデオデータ用の基盤モデルをトレーニングして、ビデオ内の特定のオブジェクト、アクション、またはシーンを認識させることができます。これにより、ビデオのタグやキャプションを自動的に生成し、検索や共有を容易にできます。
Twelve Labsでは、私たちはロングテールなマルチモーダルビデオ理解のための基盤モデルを構築しています。当社のVideo Understanding APIは、ビデオ検索や分類など、ビデオデータを処理および分析するための強力なツールを開発者に提供します。当社の基盤モデルは特定の用途向けにさらに微調整できるため、様々な業界に高度に適応させることができます。
3 - 潜在的なアプリケーション
基盤モデルは、メディア・エンターテインメントからスポーツ分析、コンシューマー向けヘルスケアまで、幅広い業界に適用できます。以下は、すでに実用に至っている興味深いAIアプリケーションであり、基盤モデルを使用することで簡単に再現(および改善)できます。
3.1 - メディア・エンターテインメント
エンターテインメント業界の企業はAIを活用して、よりパーソナライズされ、魅力的な消費者体験を作り出しています。一例としてNetflixが挙げられます。同社は、テレビ番組、予告編、映画、プロモーションアートなどのより良いメディアをクリエイターが制作できるようにAIを活用しています。彼らは、登場人物、ストーリー、感情、シネマトリガーを分類するビデオ理解モデルを導入しており、特定の映像を見つけやすくしています。これにより、クリエイターは映像を何時間もかけて分類する作業から解放され、クリエイティブな意思決定に集中できるようになります。
基盤モデルは、登場人物や感情の分類など、同様のユースケースを解決できます。これにより、これらのモデルの精度と効率が向上し、クリエイターは何時間も分類作業に費やすことなく、特定の映像を迅速に見つけることができます。
また、基盤モデルは、より没入感が高くリアルなコンテンツの作成にも使用できます。例えばゲーム業界では、ノンプレイヤーキャラクター(NPC)をよりインテリジェントでリアルにするのに役立ちます。Ubisoftは、NPCのダイアログを自動的に生成するGhostwriterと呼ばれる新しいAIツールを開発しました。一方でRobloxは、クリエイターが没入感のある3D体験を構築するためのRoblox Studioというプラットフォームを提供しています。
3.2 - スポーツ分析
スポーツ分析において、AIはボールや選手の動きを追跡するのに役立ちます。カタールで開催された2022 FIFAワールドカップでは、オフサイドの反則を検出するための半自動オフサイドテクノロジーなど、AIが様々な役割で活用されました。この技術は、ビデオフィードやセンサーからデータを収集し、審判がオフサイド位置についてより正確な判定を下せるよう支援するものです。スタジアムの屋根の下には12台の追跡カメラが設置され、ボールと、選手の姿勢やボールの位置など毎秒29個のデータポイントを追跡しました。
基盤モデルを使用することで、FIFAは半自動オフサイドテクノロジーの精度と効率を向上させることができます。長年にわたって収集されたサッカーの映像で基盤モデルを微調整することにより、選手の位置や動きによってオフサイドになるなど、様々なオフサイドの状況を認識させることができます。さらに、オフサイドになる可能性を予測し、審判がより備えを万全にし、誤審を未然に防ぐのにも役立ちます。
3.3 - ヘルスケア
一般消費者向けのヘルスケアにおいて、AIは保険金の請求手続き、事務処理の処理、医師の診察時のメモ作成など、特定の作業を代行することで、医療従事者が時間を管理しやすくなるようにしています。さらに、AIは年齢、病歴、遺伝情報などの様々な要素に基づいて、患者の経過予測をサポートします。医師はこの情報を使用して、パーソナライズされた治療計画を作成できます。このトピックについてもっと学びたい場合は、Eric Topolの著書『Deep Medicine』をお読みください。
基盤モデルは、レントゲンやMRIなどの医療画像の分析に使用できます。例えば、医療画像から腫瘍や骨折などの異常な箇所を発見するように基盤モデルをトレーニングでき、これにより医師がより迅速かつ正確に疾患を診断し、治療するのに役立ちます。
ケアの支援に加えて、基盤モデルは医療の画期的な進歩のスピードを大幅に加速させます。生物学におけるデータ量は膨大であり、人間が複雑な生物学的システムの仕組みをすべて追跡することは困難です。しかし、すでにこのデータを分析し、経路(パスウェイ)を推論し、病原体の標的を探索し、それに応じて薬を設計できるソフトウェアが存在します。AlphaFoldの画期的な技術を基盤とする技術を持つIsomorphic Labsは、AIを創薬に適用し、医療が人々を助け、治癒する方法に革命をもたらしています。
結論
上記で紹介したアプリケーションは、個人的に非常に興味深いものであり、これらはこれから変革が起こるであろう数千の例のほんの一部にすぎません。基盤モデルの可能性は本当に刺激的であり、まだ想像すらされていない無数の未知の機会を提供してくれます。これらの機会は確実に開かれ、創造的な人々が自らのアイデアを記録的な早さで具体的で魅力的な製品へと変化させることができるようになるでしょう。
基盤モデルを実用に投入する前に考慮すべき制限事項もあります。1つのリスクは、事前学習データに含まれていなかったニッチなタスクや特定のタスクにおいて、十分なパフォーマンスを発揮できない可能性があることです。そのため、性能を向上させるためには、特定のタスクにより関連性の高いデータを用いてモデルを微調整する必要があるかもしれません。さらに、基盤モデルはプレトレーニングに使用されたデータに存在する偏見(バイアス)を無意識に永続させてしまう可能性があります。これらのバイアスを防ぎ、軽減することは活発な研究分野であり、事前学習済みモデルにおけるバイアスの影響を低減するために利用できるベストプラクティスが存在します(これらについては今後の記事で取り上げる予定です)。
基盤モデル全般についてお話ししてみたい方は、是非私たちのDiscordコミュニティに参加して、マルチモーダルAIについて語り合いましょう!








