" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
ビデオインテリジェンスはエージェンティック(自律エージェント型)へ

ジェームズ・リー
Twelve LabsのJockeyは、受動的なビデオ分析から自律型ビデオインテリジェンスへの移行を象徴しています。ビデオ基盤モデルとLLMベースの推論を組み合わせることで、ユーザーは自然言語を通じて、複雑なマルチステップのワークフローにわたり、ビデオコンテンツの検索、編集、生成を行うことができます。
Twelve LabsのJockeyは、受動的なビデオ分析から自律型ビデオインテリジェンスへの移行を象徴しています。ビデオ基盤モデルとLLMベースの推論を組み合わせることで、ユーザーは自然言語を通じて、複雑なマルチステップのワークフローにわたり、ビデオコンテンツの検索、編集、生成を行うことができます。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2025/04/04
読了時間:30分
記事へのリンクをコピー
TLDR: エージェント型ビデオ・インテリジェンスの台頭
私たちは地殻変動を目撃しています。ビデオAIは、単なる基本的な分析ツールから、文脈を理解し、コンテンツについて推論し、複雑なクリエイティブタスクを実行できる知的なコラボレーターへと進化しています。
TwelveLabsのJockeyは、単なるもう一つのAIツールではありません。私たちのビデオネイティブな基盤モデルをシンフォニーのように指揮し、混沌としたビデオワークフローを調和のとれたクリエイティブなプロセスへと変える、洗練されたオーケストレーターです。
使いにくいビデオインターフェースは忘れてください。これらの新しいビデオエージェントは、あなたの言葉を理解しながら、ビジュアルを直接操作できるようにし、ついに人間の創造性とマシンの効率性の間のギャップを埋めます。
技術的なビデオツールと格闘する日々は残りわずかです。AIアシスタントに「
最も魅力的な顧客のストーリーを見つけて」と伝えるだけで、完璧なハイライトリールが構築されるのを見る様子を想像してみてください。ビデオコンテンツに埋もれている企業にとって、これは単なるアップグレードではなく、自然な対話を通じて、圧倒的なメディアライブラリをアクセシブルで実用的な資産へと変貌させる革命です。
NotebookLMが生成したこちらの会話から、この記事を音声で聴くことができます:https://soundcloud.com/james-le-56344460/agentic-video-intelligence
1 - はじめに:ビデオ・インテリジェンスの進化
2025年、私たちはマシンがビジュアルメディアを理解し操作する方法における、根本的な転換の瀬戸際に立っています。日々、様々なプラットフォームに数十億時間ものビデオコンテンツがアップロードされる中、限られたコンテンツと定義済みのタスクの時代に向けて設計された従来の処理ツールは、時代遅れになりつつあります。このコンテンツの爆発的増加は、前例のない機会と、途方もない課題の両方を生み出しました。
ビデオ基盤モデルの登場により、私たちの能力は単純なフレームごとのビデオ分析から、高度な空間理解や時間的推論へと進化しました。しかし、生のモデル能力と現実世界のアプリケーションとの間には、依然として重要なギャップが存在しています。ここで登場するのがエージェント型ビデオ・インテリジェンス(agentic video intelligence)です。これは、受動的な分析から、ビデオコンテンツに対する能動的で目標指向のインタラクションへのパラダイムシフトを表しています。これらのシステムは、エージェントプランニングのフレームワークを通じてビデオ基盤モデルと大規模言語モデルを組み合わせ、ビデオの中に何が映っているかだけでなく、なぜそれが重要で、どのような行動をとるべきかまで理解するAIシステムを創り出します。
TwelveLabsでは、Jockeyを通じてこれらの課題に取り組んでいます。Jockeyは、専用のエージェントアーキテクチャを通じて、ビデオ基盤モデルとLLMベースの推論を組み合わせた対話型ビデオエージェントです。この記事では、エンジニアリングとデザインの両方の視点から技術的なイノベーションを検証することにより、ビデオインテリジェンスがいかにエージェント型(ジェンティック)になりつつあるかを探ります。メディア制作からスポーツのハイライト生成に至るまで、このシフトにより、これまでは不可能だったコンテンツ作成と分析への全く新しいアプローチが可能になります。次世代のビデオアプリケーションを構築する組織にとって、これは人間の創造性とマシンの効率性を組み合わせる変革の機会となります。ビデオインテリジェンスの革命は、単に近づいているだけではありません。すでにここにあります。そしてそれは、エージェント型なのです。
2 - LLM領域におけるAIエージェントの台頭
大規模言語モデル(LLM)の登場は、理解し、計画し、行動できる自律型エージェントを可能にすることで、AIに革命をもたらしました。これらのLLM搭載エージェントは、自然言語をインターフェースとして使用し、目標を理解し、高度な推論とツールの統合を通じて複雑なタスクを実行できます。この能力は、基本的なプロンプトエンジニアリングから、思考の連鎖(Chain-of-Thought)プロンプティングを活用するより高度なアプローチへと進化し、エージェントが複雑な問題を段階的に分解できるようになりました。

ソース:https://www.letta.com/blog/ai-agents-stack
Open AI Agents SDK、Letta、LangGraphのような高度なエージェントフレームワークが、信頼性の高いエージェントを構築するための重要なインフラストラクチャとして台頭してきました。これらのフレームワークは、計画、ツール統合、メモリ管理、自己内省などの重要な機能を実装しています。近代的なエージェントアーキテクチャは、認知機能を専門的なコンポーネント(戦略のためのプランナー、アクションのためのエグゼキューター、評価のためのクリティック)に分離し、ますます複雑なタスクを処理できるようにしています。
現実世界のアプリケーションにおいて、LLMエージェントは非常に適応能力が高いことが証明されています。彼らは、LLMの推論能力とドメイン固有のツールやワークフローを組み合わせることで、ソフトウェア開発やカスタマーサービスから調査の統合にいたるまで、多様なタスクを実行できます。このアーキテクチャにより、従来の自動化よりも柔軟に複雑な問題空間をナビゲートしながら、生のLLM出力よりも高い信頼性を提供することができます。

ソース:https://weaviate.io/blog/what-are-agentic-workflows#planning-pattern
この分野では、エージェントの成功を牽引するいくつかの主要なデザインパターンが特定されています。これらには、タスクの分解(目標を管理可能なステップに分割する)、再帰的推論(中間結果に論理を適用する)、ツールの拡張(APIを介して機能を拡張する)、およびヒューマン・イン・ザ・ループのコラボレーション(ユーザーフィードバックを取り入れる)が含まれます。これらのパターンは異なるドメインを横断して機能し、効果的なエージェント設計のためのコア原則を確立しています。
LLMエージェント開発から得られたこれらの知見は、ビデオインテリジェンスシステムに極めて重要な指針を与えてくれます。基盤モデルは、特定のタスク要件に沿った構造化されたアーキテクチャ内で最も効果的に機能することを示しています。また、信頼性の向上には、明確な「計画」と「振り返り(内省)」が重要であることを強調しています。最も重要なのは、最も効果的なシステムとは自動化と人間とのコラボレーションのバランスをとることであり、マシンの知能と人間の知性の両方を活用する真のパートナーシップを築いているという点です。ビデオエージェントを開発するにあたり、これらの原則は、ビジュアルメディアの理解と操作という独自の課題を乗り越える手助けとなります。
3 - ビデオエージェントの登場:新しいパラダイム
ビデオ基盤モデルとLLMベースのエージェントアーキテクチャの融合により、ビデオエージェントが誕生しました。これは、かつてない洗練された方法でビジュアルメディアを理解、操作、および推理するために独自に設計されたシステムです。これまでの前身システムとは異なり、これらのエージェントは単にビデオコンテンツを分析するだけではありません。ビジュアルナラティブ、時間的関係、およびマルチモーダルな文脈に関する専門知識を活用し、目的を持ってビデオと対話します。この新しいパラダイムは、意味理解の欠如した従来のビデオ処理パイプラインや、ビデオコンテンツに固有の複雑な時間的・空間的次元への対応に苦労する汎用AIエージェントの双方の根本的な限界を解消します。
ビデオエージェントが際立っているのは、ビデオインテリジェンス特有の課題を克服できる能力です。ビデオデータは、視覚、音声、時間的要素を組み合わせた高次元空間に存在するため、テキストや静止画に必要なものを超えた専門的な知覚能力が必要です。計算需要はビデオの長さや解像度に応じて劇的にスケールするため、アテンション(注意)とメモリに対する効率的なアプローチが必要になります。そしておそらく何よりも重要であるのは、ビデオの理解には、フレームレベルの詳細から、シーンレベルの構成、さらにはナラティブ(物語)レベルの構造にいたるまで、複数の時間スケールにわたる推論を同時に行うことが求められるという点です。これは、他のドメインではほとんど必要とされない能力です。OmAgentのようなシステムは、マルチモーダルRAGと分割統治法(divide-and-conquer)的な推論アプローチを組み合わせた革新的なアーキテクチャを通じて、これらの課題に対するソリューションの先駆けとなりました。
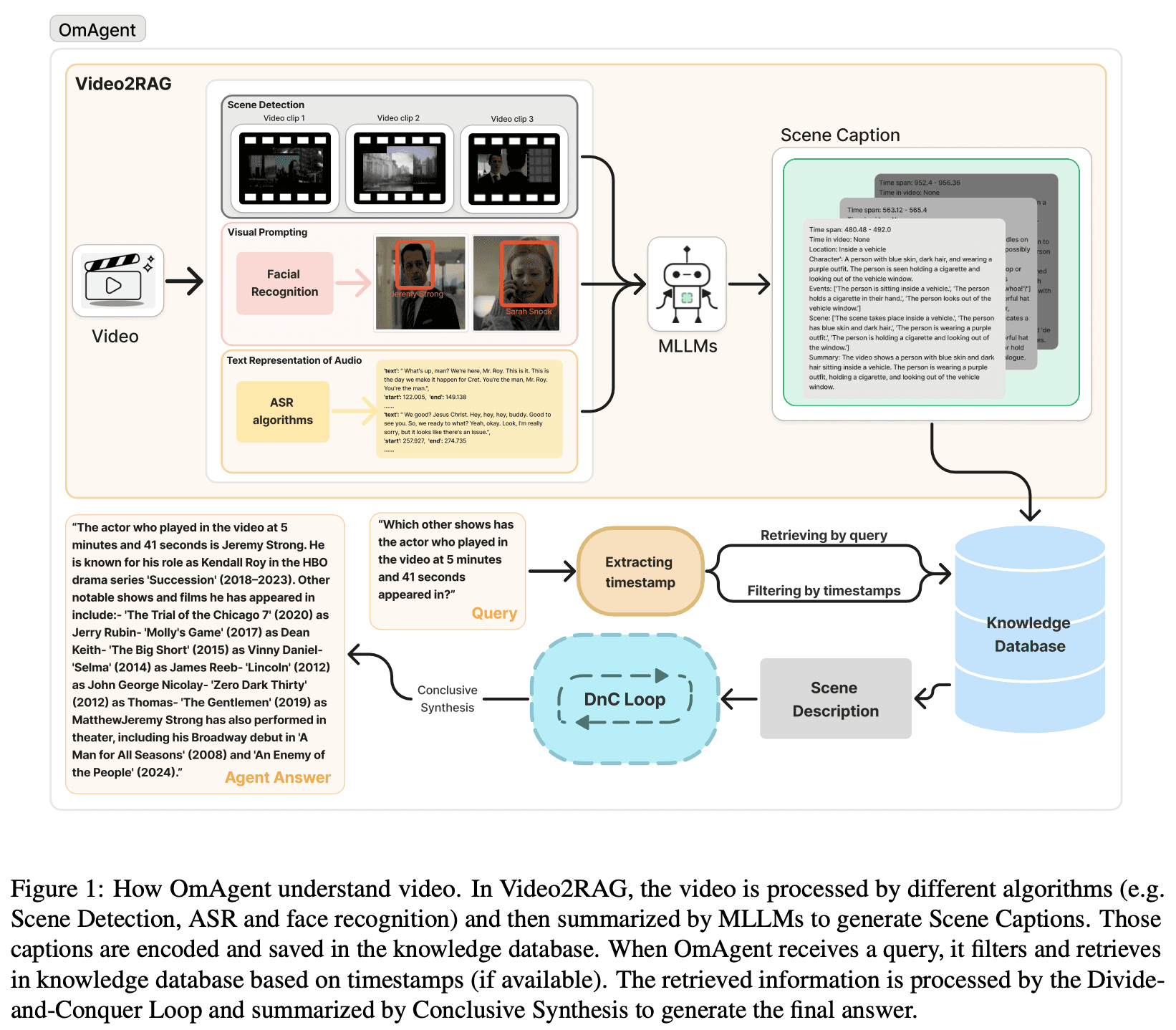
近年の学術的な成果によりこのシフトは加速しており、研究者たちはビデオ理解のためのエージェント型(ジェンティック)フレームワークにますます注目しています。北京大学の論文「VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding」は、メモリメカニズムがどのように時間的推論を強化できるかを示しており、スタンフォード大学による「VideoAgent: Long-form Video Understanding with Large Language Model as Agent」の研究では、長尺ビデオから関連情報を効率的に検索・集約する方法について探求しています。これらのアプローチは共通の洞察を共有しています。すなわち、すべてのビデオコンテンツを網羅的に処理するのではなく、効果的なエージェントは、何が重要であるかを推論し、関連するセグメントに選択的に注意を向け、反復的な分析を通じて動的に理解を構築していくべきであるという点です。

ソース:https://wxh1996.github.io/VideoAgent-Website/
また、LLMの推論とビデオ専用のツールを組み合わせたLAVEのような作品もあります。これらのシステムは通常、マルチモーダル特徴を抽出する知覚システム、ビデオの文脈を保存・読み出すメモリメカニズム、複雑なクエリを分解する計画モジュール、そしてビデオ処理ツールとのインターフェースとなる実行コンポーネントなど、専門的なコンポーネントを中心にワークフローを構築しています。このモジュール性により、基盤モデルの強みと、ビデオコンテンツおよび編集操作に関するドメイン固有の知識を組み合わせることができます。
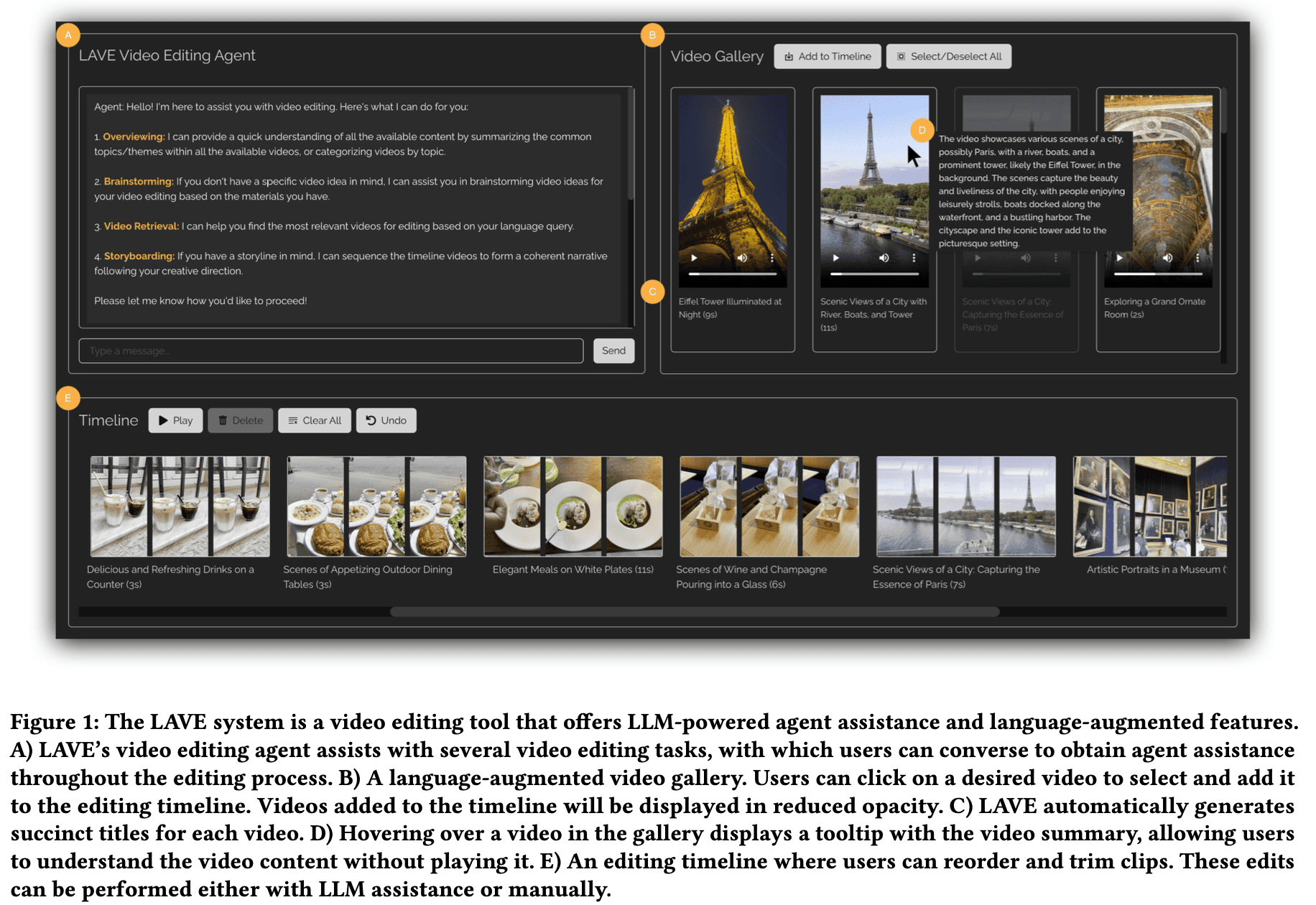
ソース:https://arxiv.org/abs/2402.10294
ビデオエージェントが研究プロトタイプからプロダクションシステムへと進化するに従い、コンテンツ作成、メディア分析、および情報検索における現実世界の課題にますます対処できるようになっています。放送、映画制作、ソーシャルメディアの初期導入企業は、ハイライト生成、コンテンツモデレーション、プロモーション用クリップの作成など、従来手動で行われていたタスクを自動化するために、すでにこれらの能力を活用しています。最も先進的なシステムは、ビデオの表面的なコンテンツだけでなく、その背景にある目的、スタイル、そして叙事的な構成まで理解しつつある初期の能力を示しています。これにより、複雑なツールを操作するというよりも、知識豊富なアシスタントとコラボレーションしているかのような対話が可能になります。受動的な分析から能動的なコラボレーションへのこの移行は、おそらくマルチモーダルAIの出現以来、ビデオインテリジェンスにおける最も重要なパラダイムシフトを表しています。
4 - TwelveLabsのアプローチ:ビデオエージェントフレームワークとしてのJockey
昨年から開発が進められてきたJockeyは、ビデオインテリジェンスにおける大きな進化を象徴しています。これはTwelveLabsの核となるビデオ基盤モデルの土台の上に構築され、複雑性のギャップに対処するために不可欠なオーケストレーション層を追加したものです。その根幹として、Jockeyは当社の2つの強力なビデオネイティブモデルを活用しています。すなわち、セマンティックビデオ検索のためのMarengo 2.7と、高度なビデオ・トゥ・テキスト(動画からテキストへの変換)理解のためのPegasus 1.2です。Jockeyはこれらのモデルを置き換えるのではなく、各コンポーネントの強みに応じて認知タスクを分配するプランナー・ワーカー・リフレクター(計画・実行・内省)アーキテクチャを通じて戦略的にこれらを調整します。計画と推論にはLLMを使用し、知覚負荷の高い操作は専用のビデオモデルに委ねています。

このアーキテクチャは、ビデオインテリジェンスにおける根本的な課題を解決します。基盤モデルは知覚や推論タスクに優れていますが、複雑なワークフローのシーケンス(順序立て)に苦戦することがよくあります。Jockeyのマルチエージェント型アプローチは、詳細な実行シーケンスを作成する「プランナー」、ビデオAPIと直接やり取りする専門の「ワーカー」、そしてアクションステップを要約する「リフレクター」を実装することで、この制限に対処します。この関心事の分離により、各コンポーネントは自身が最も得意とする機能に集中できます。LLMが推論や自然言語の理解を処理し、ビデオ基盤モデルが複雑なマルチモーダル分析を管理します。
Jockeyを特に強力にしているのは、複雑な、複数ステップにわたるワークフロー全体でコンテキスト(文脈)を維持する能力です。例えばビデオのハイライト作成において、Jockeyは単純に一度の検索処理を実行するだけではありません。正確な基準に沿って検索をシーケンス化(順序化)し、結果セットを賢く組み合わせ、ユーザーの本来の意図を反映したポストプロセス(後処理)操作を適用します。システムはLangGraph上に構築されたグラフベースのフレームワークを通じて永続的な状態を維持するため、複数の操作を跨いでクリップを追跡し、細分化されたサブタスクを実行している間も全体のタスク目的を把握し続けることができます。

ソース:https://github.com/twelvelabs-io/tl-jockey/blob/main/jockey/stirrups/stirrup.py
Jockeyの設計では、本番環境への導入に不可欠な特性である適応性を優先しています。そのモジュール式アーキテクチャにより、プロンプト駆動の動作調整から全く新しいワーカーモジュールの追加にいたるまで、複数のレベルでカスタマイズが可能です。これにより、開発者はコアシステムの信頼性を維持しながら、特定のワークフローに合わせてJockeyの機能を拡張することができます。
5 - Jockeyに透明性をもたらす
効果的なビデオエージェントの作成は、一般的なLLMアプリケーションとは異なり、ビデオ操作に特有のユニークなエンジニアリング上の課題をもたらします。特に顕著な課題は、クリップの抽出や結合といった複雑な操作における、ビデオ処理パイプラインのパフォーマンス最適化です。私たちが採用したアプローチは以下の二通りです:
第一に、
base_search()、process_clips()、およびdownload_remaining()のような個別のステップを独立して処理する関数ディスパッチャーを使用した、非同期処理パイプラインの設計。第二に、インターフェースに表示される透明な「思考(Thinking)」状態を通じて、これらの処理ステージをユーザーに開示すること(詳細はセクション6を参照)。
この透明性は単なるステータスの更新に留まりません。システムがどのようにして結論に至ったかを明らかにし、各瞬間においてどの処理コンポーネントが活用されているかを示すことで、必要不可欠な信頼関係を築き上げます。

Jockeyの開発を通じて、私たちは、たとえ応答時間がわずかに長くなったとしても、自らの推論プロセスを説明してくれるシステムに対して、ユーザーがより強い信頼を寄せるようになることを学びました。この洞察は、私たちのUIデザインに根本的な影響を与えており、処理状態や、それぞれのクエリに適用されている具体的なモデルコンポーネント(Marengoの検索機能か、あるいはPegasusのコンテクスト理解か)を明示的に表示するようにしました。この透明性は、ブラックボックスなソリューションではなく、検証可能なプロセスを必要とするエンタープライズクライアントと連携する際に特に重要です。
Jockeyの将来的な拡張は、双方向思考システムとなる予定です。これはエージェントの処理ステップを表示するだけでなく、ユーザーがそれらのステップを直接修正できるようにするものです。この機能により、Jockeyは受動的なツールから、ユーザーがインタラクティブにクエリを洗練させたり(日本のカメレオンから日本のトカゲへ変更)、処理決定を検証したり、エージェントのフォーカスを方向転換させたりできる協調的パートナーへと変わります。つまり、出力をただ受け入れるのではなく、AIを「操縦(ステアリング)」できるようになるのです。このアプローチは、MLSEチームと共同で行った成果や他のエンタープライズ顧客からのフィードバックと一致しています。彼らは、ビデオコンテンツのような価値の高いクリエイティブアセットを扱う際、純粋な自動化のスピードよりも、プロセスを理解しコントロールできることを一貫して優先しています。

ソース:https://www.latent.space/p/why-mcp-won
Model Context Protocol(MCP)フレームワークは、特にサードパーティ統合を拡大していく中で、Jockeyの将来の進化に興味深い可能性をもたらします。MCPは、Jockeyのコアコンポーネントと、外部サービス、例えばビデオ生成ツール(RunwayML、Luma Labs)、オーディオ生成ソフトウェア(ElevenLabs、Suno)、さらにはシーン分割やオブジェクトトラッキング(MetaのSAM)といった高度なビデオ操作タスクとの間に、標準化された統合レイヤーを提供する可能性があります。
統合先ごとにカスタムコネクタを作成する代わりに、MCPを使用することで、ツールの呼び出し、文脈(コンテキスト)の共有、およびレスポンス処理のための統一されたインターフェースを定義できます。このアプローチは、n×m個の統合問題(n個のエージェントフレームワーク×m個のツール)を、より管理しやすいn+m個の問題へと変換し、システム拡張性を高めつつ、実装の複雑さを劇的に軽減します。
Jockeyに関して言えば、MCPはより洗練されたワークフローを可能にする可能性があります。例えば、Marengoを介して特定されたクリップを、外部の画質向上ツールへとシームレスに渡し、次にナレーション用の生成オーディオサービスへ、そして最終的に編集システムへと引き渡すことができます。これらの一連の流れを、すべてのプロセスにわたって一貫したコンテキストを維持したまま、実行できるようになります。
6 - マルチモーダルインターフェースの力
従来のビデオインターフェースは一般的に、視覚的な文脈を無視したテキストベースの検索か、またはインタラクティブな機能が最小限に抑えられたビデオプレイヤーのどちらか一つの選択をユーザーに強いてきました。 Jockeyは、対話的なインテラクションとビデオネイティブな要素を組み合わせた、根本的にマルチモーダルなインターフェースを通じてこの関係性を再定義し、片方をもう片方に無理に合わせるのではなく、両方のモダリティを第一級の市民として扱います。以下のスクリーンショットに示されているインターフェースはこのアプローチを実証しています。対話エリアが自然言語を通じてユーザーの意図を汲み取り、ビジュアルな「思考表示」がエージェントの推論プロセスを明らかにし、ビデオギャラリーがタイムスタンプや説明などの関連する文脈とともに結果を提示します。この統一された体験により、ユーザーは抽象度の高いゴール(困難を克服した人々の心に響くストーリーを探して)の表現から、ビジュアル結果へのダイレクトな操作へとシームレスに移行できます。
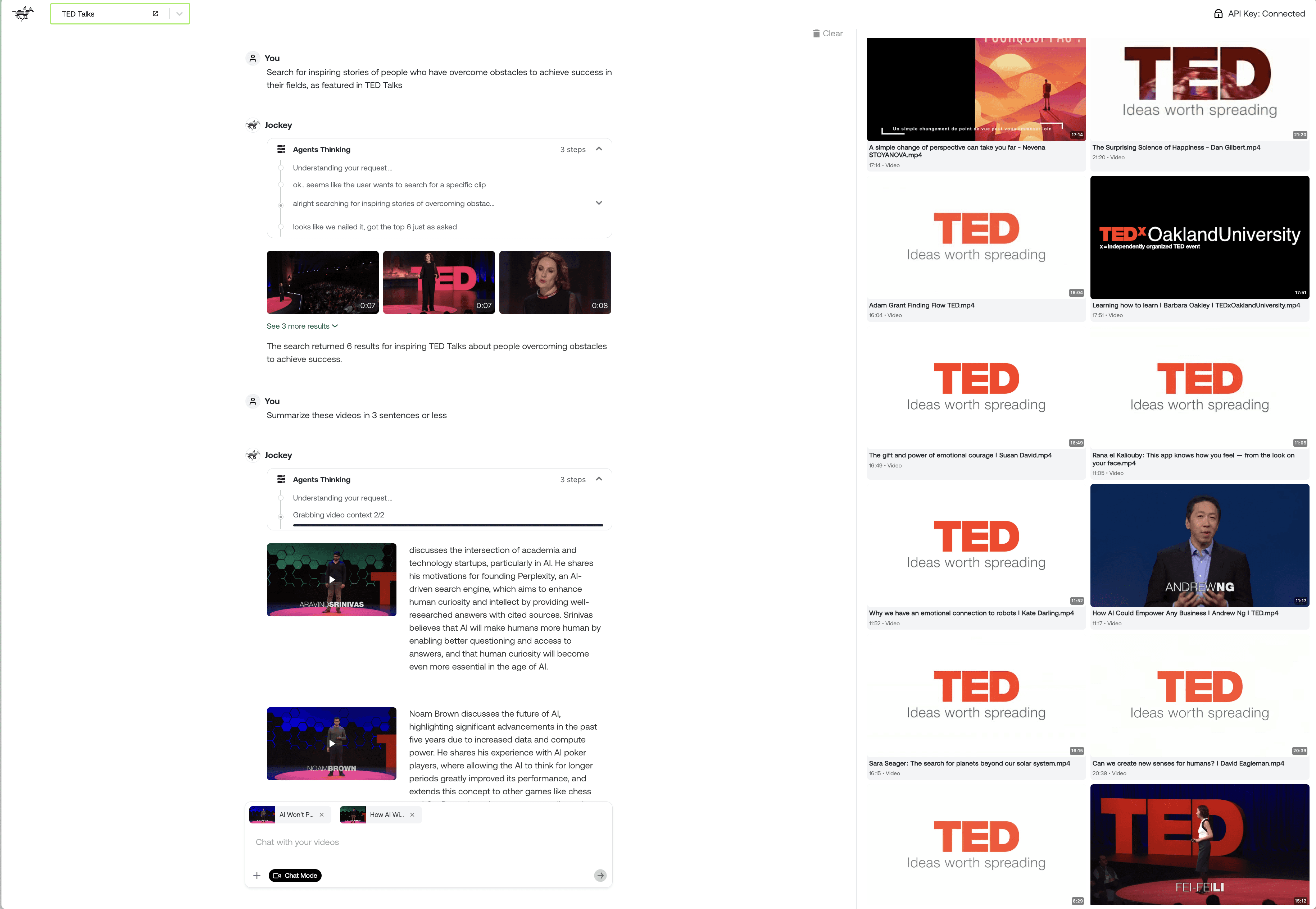
このアプローチを強力なものにしているのは、テキスト要素とビジュアル要素の間を流れる、双方向の情報フローです。ユーザーが自然言語のクエリを入力すると、Jockeyはテキストによる説明と、関連するビデオセグメントへの直接リンクの双方を含む回答を返し、詳細なタイムスタンプによって映像内のどこの場所でその具体的なコンセプトが出現するかを示します。この時間的アンカー(紐付け)が、Jockeyのテキスト回答と、参照されている実際のビデオコンテンツとの間に、明確な架け橋を築き上げます。
さらに、ユーザーはサムネイルを通してビデオセグメントを直接操作できるため、ナビゲーション体験が向上します。これにより、それぞれのモダリティが互いを高め合う好循環が生まれます。言語は意図を指定する際の精度を提供し、ビジュアル要素はテキストで伝えるのが非効率な豊かさと文脈を提供します。例えば、以下のスクリーンショットは、Jockeyがエージェントの思考ステップをタイムスタンプ付きのビデオセグメントの隣にどのように表示するかを示しており、ユーザーがどのようなコンテンツが見つかったかだけでなく、なぜそれが選ばれたのかを理解する手助けをします。
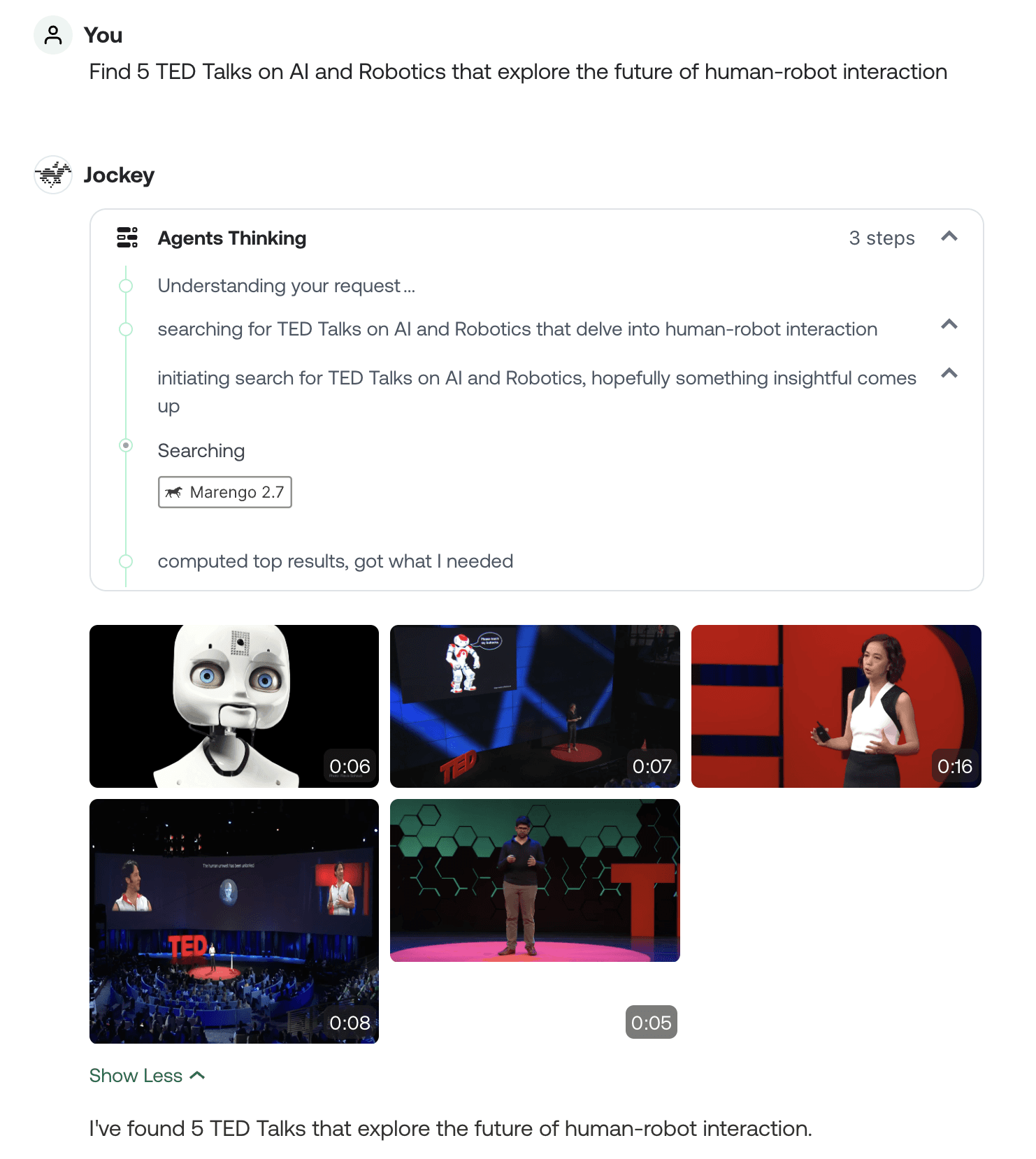
このインターフェースは、ビデオインタラクションに特有のいくつかの認知的な課題に対処しています。ビデオコンテンツは本質的に時間的なものであり、情報が密に詰まっているため、ユーザーがテキストで行うようにスキャンしたり、ブラウズしたり、比較したりすることが困難です。Jockeyのマルチモーダルアプローチは、複数の入口を提供することでこれらの課題を軽減します。ユーザーはサムネイルを通して視覚的にブラウズしたり、エージェントが生成した要約に目を通したり、あるいはコンセプトの説明に基づいて特定の瞬間へとパッと直接ジャンプしたりできます。これらのアプローチを組み合わせることで、インターフェースはユーザーの認知負荷を大幅に削減し、複数のビデオを同時に処理する場合でも文脈を維持できるようにします。それは、以下のスクリーンショットで、ユーザーが検索結果を確認した後に「これらのビデオをエモーショナルなトーンで要約して」と依頼している箇所で見ることができます。

最も重要なのは、このインターフェースが単なるクエリ応答パターンを超えて、真の協調的ワークスペースへと進化している点です。以下のスクリーンショットに示すエージェントの思考表示は、Jockeyが難解なタスクを リクエストの理解 や ビデオコンテキストの取得 といった個別のステップへとどのように分解するかを示しており、透明性を生み出すことでユーザーの信頼を築き、タイムリーな介入を可能にします。この透明性は、アルゴリズムの確信度(番号付きのステップを介して)と思考プロセスの両方の表示にまで及び、ユーザーがシステムへの依存度を調整し、人間の判断が必要となる場面において情報に基づいた決定を下せるようにします。ワークフローのどの時点であってもエージェントのアプローチを中断、リダイレクト、または洗練できる機能と組み合わせることで、従来のビデオインターフェースにありがちだったトランザクション(取引)的なモデルではなく、真に協調的な関係が創り出されます。

このマルチモーダルアプローチの将来の進化は、私たちが「フロー認識型の弾道(flow-aware trajectories)」と呼ぶ方向へと向かっています。これは、ユーザーのワークフローの中で生まれつつあるパターンに基づいて、ユーザーが次に行うであろうアクションを先回りして予測するインターフェースのことです(詳細はセクション8を参照)。上のスクリーンショットのエージェントによる段階的な推論に示されているように、Jockeyは会話のやり取り全体でコンテキストを維持し、これまでの対話を踏まえて構築していくことで、すでにこの方向における初期の能力を示しています。これらの能力が成熟するにつれて、インターフェースはエージェントとツールの間の境界線をますます曖昧にし、ユーザーの創造的な流れ(フロー)を損なうことなく、ニーズを先回りして予測し、代替アプローチを提案し、専門的な細部を処理する、ユーザーの創作プロセスの延長線となることでしょう。これは、単にリクエストを処理するインターフェースから、創造的かつ分析的なプロセスに主体的に貢献する、本当の意味での「共同作業者」への根本的な転換を表しています。
7 - コンテンツ作成の変革:エンタープライズメディアワークフローに向けたJockeyのビジョン
エンタープライズメディアの領域は、制作リソースが横ばいであるにもかかわらず、コンテンツへの需要が指数関数的に増加するという、前例のない課題に直面しています。マーケティングチームは、フォーマット要件や視聴者の期待値が異なる、多様な複数のプラットフォームに向けて、より多くのビデオコンテンツを制作しなければなりません。ドキュメンタリー映画の製作者は、何百時間ものフッテージ(映像素材)から関連する瞬間を見つけ出す必要があります。企業の広報部門は、グローバル市場全体で一貫したメッセージングを維持することに苦慮しています。これらのワークフローには、共通のペインポイントがあります。それらは時間がかかり、専門的なスキルを必要とし、伝統的なアプローチでは効率的にスケールしないという点です.
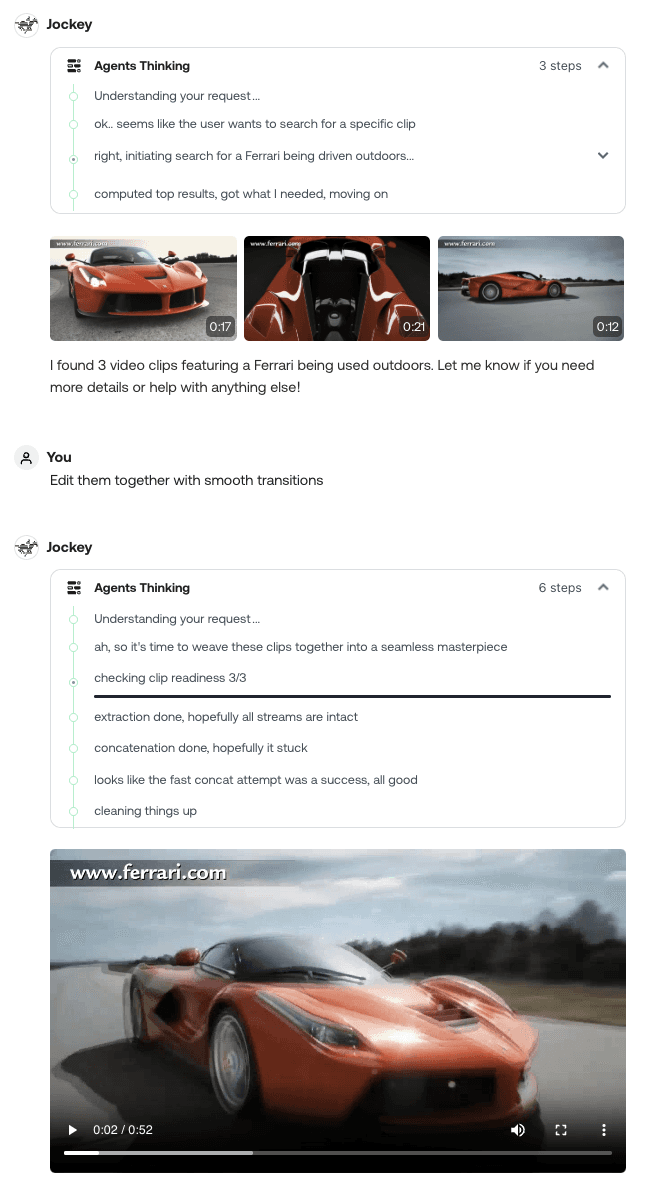
Jockeyのビジョンは、企業がビデオコンテンツと関わる方法を再定義することによって、これらの課題に対処します。既存のプロセスを単に自動化するのではなく、Jockeyは、その対話型インターフェースとビデオ理解機能のインテリジェントなオーケストレーションを通じて、コンテンツワークフローに新しい可能性を生み出します。例えば、製品デモンストレーションビデオを作成しているマーケティングチームは、Jockeyに対して「製品が屋外で使用されているクリップを見つけて」と指示し、次に「それらをスムーズなトランジションで編集して」と伝えることができます。この自然言語によるアプローチは、制作スピードを低下させがちな専門的な障壁を取り除き、チームが機械的な作業ではなく、創造的な決定に集中することを可能にします。
特に魅力的な用途の一つに、Jockeyが即座に価値を発揮できる、広告およびマーケティングのワークフローが挙げられます。クリエイティブチームは、ブランドメッセージやキャンペーンのテーマに合致する瞬間を特定するために、生の映像素材をレビューするのに何時間も費やすことがよくあります。Jockeyは、街中(屋外)の環境で私たちのロゴが目立つように表示されているシーンを特定して、または 製品を使って人々が興奮を表現しているクリップを見つけてといった自然言語のクエリを使って、ビデオライブラリを検索できるようにすることで、このプロセスを変革します。エージェントはMarengoのマルチモーダルな理解力を活用して関連する映像を呼び出し、Pegasusのコンテクスト認識力を駆使してそれらの瞬間をまとまりのあるシーケンスへと組み立てるため、コンセプトから完成したアセットへと至るまでの時間を劇的に削減します。

Jockeyのアプローチが持つ真のパワーは、エンド・ツー・エンド(始点から終点まで)のクリエイティブワークフローにおいて顕著に現れます。新製品の発表ビデオ制作を任された企業広報チームを例に挙げてみましょう。従来、これには絵コンテの作成、撮影、映像素材のアーカイブ整理、ラフカットの編集、グラフィックスの追加、ナレーションの収録、そして配信に向けた最終調整が必要であり、それぞれのステップごとに異なる専門家やツールが介入していました。Jockeyの目指すビジョンは、自然言語の指示を通じて、チームが関連フッテージを呼び出し、初期カットを組み立て、付随する音声を生成し、配信可能なアセットを用意できるようにすることで、これらのワークフローを統合することです。まだ初期の段階にありますが、Jockeyの開発ロードマップには、関連ツールとのサードパーティ連携を通じてこれらの機能を拡張していくことが含まれています。これにより、組織に対して技術的な制限に自らのワークフローを合わせるよう強いるのではなく、企業の要件に合わせて適応していく総合的なプラットフォームを創り出します。
8 - ビデオエージェントの未来:私たちのビジョンとロードマップ
ビデオエージェントの将来的な進化は、段階的な改善を超えて、人間がビジュアルメディアとやり取りする方法を根本的に変革する、3つの主要な原則に導かれます。Jockeyを通じて、私たちはビデオインテリジェンスが、自動化と人間による創造的な主体性のバランスを保ちつつ、ニーズを先回りして予測し、個人の好みに適応する、創造的および分析的なワークフローの自然な拡張となるようなビジョンに向かって構築を進めています。

フロー認識型の弾道(Flow-Aware Trajectories)は、クリエイティブな勢い(モーメンタム)を維持するために、ユーザーが必要とするものを数ステップ先回りして予測するシステムであり、当社の第一の指針となる原則です。実用的な場面において、これはJockeyがハイライト作成中に次に必要とされるクリップを予測し、コンテンツに基づいて適切なトランジションを提案し、ユーザーの編集パターンに沿ったラフカットを事前に組み立てることを意味します。これらの機能が成熟するにつれて、エディターはクリエイティブな作業プロセスを邪魔されることが少なくなり、システムが技術的な細部を処理している間も自らの表現の方向性を保ち続けることができます。例えば、スポーツのプロデューサーであれば、観客の反応に基づいて重要なプレイを自動的に提案し、一定のペースを維持し、ストーリーの流れを担保したハイライトパッケージをJockeyを使って作成することができ、その間プロデューサー自身は最終的な選択に関するクリエイティブな権限を握り続けることができます。

文脈的メタ学習(Contextual Meta-Learning)は、Jockeyが対話のたびに進化し、プロジェクトやセッションの違いを越えて、ユーザーの好みに関する永続的な理解を構築できるようにするものです。あらゆる操作に明確な指示を毎回求める代わりに、システムは、好まれるトランジションのスタイル、代表的なシーン構成、または一般的な編集シーケンスなど、ユーザーの行動パターンを認識し、それに応じて提案を適応させていきます。これにより、システムが時間の経過とともにより価値を高め、プロジェクト特有の要件を記憶して、フィードバックに適応していく好循環が生まれます。定期的に発生する種類のコンテンツ(週次のスポーツハイライトや製品レビューなど)を扱う組織は、Jockeyが明確な指示なしに関連性の高いコンテンツを優先し、一貫したスタイリングを適用することを学習するため、ワークフローがますます効率的になることを実感するでしょう。

大規模なマルチモーダルインテリジェンス(Multimodal Intelligence at Scale)により、Jockeyは、ガチガチに固まったルールに頼ることなく、ビデオ、オーディオ、およびテキスト要素を横断する高度な結びつきを構築できます。この原則により、単なる視覚的な類似性だけでなくテーマとしての関連性に基づいてシーンを呼び出したり、複数のクリップにわたるナラティブの流れを分析したり、感情的に共鳴するシーケンスを自動的に特定したりする複雑な操作が可能になります。ナレーション用の音声生成、別パターンのシーン用のビデオ生成、あるいはプレゼンテーション用のアバター作成といったサードパーティの追加機能を統合していく中で、Jockeyはこれらの専門ツールをまとまりのあるワークフローへとオーケストレートし、操作全体でコンテキストを維持し、最終的な出力における一貫した品質を保証します。この統合ロードマップには、セグメンテーション、背景の置き換え、シンセティックメディア(合成メディア)生成、および音声作成のリーディングツールとの提携が含まれており、ユーザーに複雑な技術の統合管理を求めることなく、Jockeyの機能を大幅に拡張します。
ツールから協調的パートナーへのJockeyの進化は、組織がビデオ資産にアプローチする方法におけるパラダイムシフトを表しています。これら3つの原則にフォーカスし、拡張可能な機能のエコシステムを構築することで、私たちは技術的な制約にユーザーを合わせるのではなく、人々が本来ビデオコンテンツについて検討する自然な思考プロセスに適応するプラットフォームを創り出しています。このプラットフォーム上で開発を行うエンジニアにとって、Jockeyはバラバラのモデルを統合する複雑さに煩わされることなく、高度なビデオインテリジェンスを活用したアプリケーションを提供する機会を与えます。ビジュアルコンテンツの制作体制をスケールさせたい企業にとっては、確立されたワークフローを尊重しつつ、効率性を劇的に変革する、一貫した高品質な出力の土台を提供します。
9 - 結論:ビデオエージェント革命への参加
ビデオ基盤モデルとエージェントアーキテクチャの融合は、ビデオコンテンツの制作、分析、および配信方法における根本的なシフトを体現しています。Jockeyは、ビデオを専門的な専門知識を要する一枚岩のメディアとして扱うことから脱却し、多様なワークフローやクリエイティブなニーズに合わせることができるプログラミング可能なリソースへと移行できることを示しています。インテリジェントなタスク割り当て、ネイティブなビデオ処理、そして人間と協調するデザインの組み合わせを通じて、かつては労働集約的であったタスクを、流動的で対話的なやり取りへと変貌させ、創作的な主導権を確保したまま、制作時間を劇的に短縮します。
現時点におけるJockeyの限界を、アルファステージの概念実証(Proof-of-Concept)として認めることは重要です。エージェントは時として最適な結果を得るために特定の言い回しを必要としたり、時に複雑なクエリに苦労したりすることがあり、特定のワークフロー向けへの最適化もまだ完了していません。Jockeyを支えるエージェントフレームワーク自体も急速に進化を遂げており、業界全体の開発者たちが計画、メモリ管理、およびマルチモーダル推論に向けた異なるアプローチをテストしている段階です。しかしながら、これらの限界は、根本的な障害ではなく、より有能で直感的なビデオインテリジェンスへと到達するための、明確な開発プロセスにおける通過点に過ぎません。
Jockeyの早期アクセスのために、この未来を一緒に形作っていくよう皆様を招待します。私たちは、私たちの技術を積極的にテストし、貴重なフィードバックを提供してくださる、熱意ある初期導入企業(アーリーアダプター)を特に求めています。こちらのフォームから興味をお知らせください:https://form.typeform.com/to/JCKz0aBA
制作ワークフローの合理化を目指すコンテンツ制作者であれ、ビデオインテリジェンスを自社のアプリケーションに組み込みたい開発者であれ、あるいはビデオ運用体制を拡充させたい企業であれ、皆様のフィードバックや活用ケースは開発の優先順位へと直接影響を与えます。この限定アルファテストに参加していただくことで、最先端のビデオエージェント技術を直接手にするだけでなく、ビジュアルメディアの扱い方におけるより大きな変革に寄与することができます。ビデオエージェントの革命は、単に来るべき予定を指しているのではなく、まさに今ここに起きており、皆様の視点こそがその先の道を切り開く力となるのです。
この記事の執筆にあたり、コメント、フィードバック、および提案を寄せてくれたTwelveLabsの同僚たち(Kingston Yip、Simon Shim、Simon Lecointe、Yeonhoo Park、Sean Barclay、Sunny Nguyen)に感謝を捧げます。
TLDR: エージェント型ビデオ・インテリジェンスの台頭
私たちは地殻変動を目撃しています。ビデオAIは、単なる基本的な分析ツールから、文脈を理解し、コンテンツについて推論し、複雑なクリエイティブタスクを実行できる知的なコラボレーターへと進化しています。
TwelveLabsのJockeyは、単なるもう一つのAIツールではありません。私たちのビデオネイティブな基盤モデルをシンフォニーのように指揮し、混沌としたビデオワークフローを調和のとれたクリエイティブなプロセスへと変える、洗練されたオーケストレーターです。
使いにくいビデオインターフェースは忘れてください。これらの新しいビデオエージェントは、あなたの言葉を理解しながら、ビジュアルを直接操作できるようにし、ついに人間の創造性とマシンの効率性の間のギャップを埋めます。
技術的なビデオツールと格闘する日々は残りわずかです。AIアシスタントに「
最も魅力的な顧客のストーリーを見つけて」と伝えるだけで、完璧なハイライトリールが構築されるのを見る様子を想像してみてください。ビデオコンテンツに埋もれている企業にとって、これは単なるアップグレードではなく、自然な対話を通じて、圧倒的なメディアライブラリをアクセシブルで実用的な資産へと変貌させる革命です。
NotebookLMが生成したこちらの会話から、この記事を音声で聴くことができます:https://soundcloud.com/james-le-56344460/agentic-video-intelligence
1 - はじめに:ビデオ・インテリジェンスの進化
2025年、私たちはマシンがビジュアルメディアを理解し操作する方法における、根本的な転換の瀬戸際に立っています。日々、様々なプラットフォームに数十億時間ものビデオコンテンツがアップロードされる中、限られたコンテンツと定義済みのタスクの時代に向けて設計された従来の処理ツールは、時代遅れになりつつあります。このコンテンツの爆発的増加は、前例のない機会と、途方もない課題の両方を生み出しました。
ビデオ基盤モデルの登場により、私たちの能力は単純なフレームごとのビデオ分析から、高度な空間理解や時間的推論へと進化しました。しかし、生のモデル能力と現実世界のアプリケーションとの間には、依然として重要なギャップが存在しています。ここで登場するのがエージェント型ビデオ・インテリジェンス(agentic video intelligence)です。これは、受動的な分析から、ビデオコンテンツに対する能動的で目標指向のインタラクションへのパラダイムシフトを表しています。これらのシステムは、エージェントプランニングのフレームワークを通じてビデオ基盤モデルと大規模言語モデルを組み合わせ、ビデオの中に何が映っているかだけでなく、なぜそれが重要で、どのような行動をとるべきかまで理解するAIシステムを創り出します。
TwelveLabsでは、Jockeyを通じてこれらの課題に取り組んでいます。Jockeyは、専用のエージェントアーキテクチャを通じて、ビデオ基盤モデルとLLMベースの推論を組み合わせた対話型ビデオエージェントです。この記事では、エンジニアリングとデザインの両方の視点から技術的なイノベーションを検証することにより、ビデオインテリジェンスがいかにエージェント型(ジェンティック)になりつつあるかを探ります。メディア制作からスポーツのハイライト生成に至るまで、このシフトにより、これまでは不可能だったコンテンツ作成と分析への全く新しいアプローチが可能になります。次世代のビデオアプリケーションを構築する組織にとって、これは人間の創造性とマシンの効率性を組み合わせる変革の機会となります。ビデオインテリジェンスの革命は、単に近づいているだけではありません。すでにここにあります。そしてそれは、エージェント型なのです。
2 - LLM領域におけるAIエージェントの台頭
大規模言語モデル(LLM)の登場は、理解し、計画し、行動できる自律型エージェントを可能にすることで、AIに革命をもたらしました。これらのLLM搭載エージェントは、自然言語をインターフェースとして使用し、目標を理解し、高度な推論とツールの統合を通じて複雑なタスクを実行できます。この能力は、基本的なプロンプトエンジニアリングから、思考の連鎖(Chain-of-Thought)プロンプティングを活用するより高度なアプローチへと進化し、エージェントが複雑な問題を段階的に分解できるようになりました。
ソース:https://www.letta.com/blog/ai-agents-stack
Open AI Agents SDK、Letta、LangGraphのような高度なエージェントフレームワークが、信頼性の高いエージェントを構築するための重要なインフラストラクチャとして台頭してきました。これらのフレームワークは、計画、ツール統合、メモリ管理、自己内省などの重要な機能を実装しています。近代的なエージェントアーキテクチャは、認知機能を専門的なコンポーネント(戦略のためのプランナー、アクションのためのエグゼキューター、評価のためのクリティック)に分離し、ますます複雑なタスクを処理できるようにしています。
現実世界のアプリケーションにおいて、LLMエージェントは非常に適応能力が高いことが証明されています。彼らは、LLMの推論能力とドメイン固有のツールやワークフローを組み合わせることで、ソフトウェア開発やカスタマーサービスから調査の統合にいたるまで、多様なタスクを実行できます。このアーキテクチャにより、従来の自動化よりも柔軟に複雑な問題空間をナビゲートしながら、生のLLM出力よりも高い信頼性を提供することができます。
ソース:https://weaviate.io/blog/what-are-agentic-workflows#planning-pattern
この分野では、エージェントの成功を牽引するいくつかの主要なデザインパターンが特定されています。これらには、タスクの分解(目標を管理可能なステップに分割する)、再帰的推論(中間結果に論理を適用する)、ツールの拡張(APIを介して機能を拡張する)、およびヒューマン・イン・ザ・ループのコラボレーション(ユーザーフィードバックを取り入れる)が含まれます。これらのパターンは異なるドメインを横断して機能し、効果的なエージェント設計のためのコア原則を確立しています。
LLMエージェント開発から得られたこれらの知見は、ビデオインテリジェンスシステムに極めて重要な指針を与えてくれます。基盤モデルは、特定のタスク要件に沿った構造化されたアーキテクチャ内で最も効果的に機能することを示しています。また、信頼性の向上には、明確な「計画」と「振り返り(内省)」が重要であることを強調しています。最も重要なのは、最も効果的なシステムとは自動化と人間とのコラボレーションのバランスをとることであり、マシンの知能と人間の知性の両方を活用する真のパートナーシップを築いているという点です。ビデオエージェントを開発するにあたり、これらの原則は、ビジュアルメディアの理解と操作という独自の課題を乗り越える手助けとなります。
3 - ビデオエージェントの登場:新しいパラダイム
ビデオ基盤モデルとLLMベースのエージェントアーキテクチャの融合により、ビデオエージェントが誕生しました。これは、かつてない洗練された方法でビジュアルメディアを理解、操作、および推理するために独自に設計されたシステムです。これまでの前身システムとは異なり、これらのエージェントは単にビデオコンテンツを分析するだけではありません。ビジュアルナラティブ、時間的関係、およびマルチモーダルな文脈に関する専門知識を活用し、目的を持ってビデオと対話します。この新しいパラダイムは、意味理解の欠如した従来のビデオ処理パイプラインや、ビデオコンテンツに固有の複雑な時間的・空間的次元への対応に苦労する汎用AIエージェントの双方の根本的な限界を解消します。
ビデオエージェントが際立っているのは、ビデオインテリジェンス特有の課題を克服できる能力です。ビデオデータは、視覚、音声、時間的要素を組み合わせた高次元空間に存在するため、テキストや静止画に必要なものを超えた専門的な知覚能力が必要です。計算需要はビデオの長さや解像度に応じて劇的にスケールするため、アテンション(注意)とメモリに対する効率的なアプローチが必要になります。そしておそらく何よりも重要であるのは、ビデオの理解には、フレームレベルの詳細から、シーンレベルの構成、さらにはナラティブ(物語)レベルの構造にいたるまで、複数の時間スケールにわたる推論を同時に行うことが求められるという点です。これは、他のドメインではほとんど必要とされない能力です。OmAgentのようなシステムは、マルチモーダルRAGと分割統治法(divide-and-conquer)的な推論アプローチを組み合わせた革新的なアーキテクチャを通じて、これらの課題に対するソリューションの先駆けとなりました。
近年の学術的な成果によりこのシフトは加速しており、研究者たちはビデオ理解のためのエージェント型(ジェンティック)フレームワークにますます注目しています。北京大学の論文「VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding」は、メモリメカニズムがどのように時間的推論を強化できるかを示しており、スタンフォード大学による「VideoAgent: Long-form Video Understanding with Large Language Model as Agent」の研究では、長尺ビデオから関連情報を効率的に検索・集約する方法について探求しています。これらのアプローチは共通の洞察を共有しています。すなわち、すべてのビデオコンテンツを網羅的に処理するのではなく、効果的なエージェントは、何が重要であるかを推論し、関連するセグメントに選択的に注意を向け、反復的な分析を通じて動的に理解を構築していくべきであるという点です。
ソース:https://wxh1996.github.io/VideoAgent-Website/
また、LLMの推論とビデオ専用のツールを組み合わせたLAVEのような作品もあります。これらのシステムは通常、マルチモーダル特徴を抽出する知覚システム、ビデオの文脈を保存・読み出すメモリメカニズム、複雑なクエリを分解する計画モジュール、そしてビデオ処理ツールとのインターフェースとなる実行コンポーネントなど、専門的なコンポーネントを中心にワークフローを構築しています。このモジュール性により、基盤モデルの強みと、ビデオコンテンツおよび編集操作に関するドメイン固有の知識を組み合わせることができます。
ソース:https://arxiv.org/abs/2402.10294
ビデオエージェントが研究プロトタイプからプロダクションシステムへと進化するに従い、コンテンツ作成、メディア分析、および情報検索における現実世界の課題にますます対処できるようになっています。放送、映画制作、ソーシャルメディアの初期導入企業は、ハイライト生成、コンテンツモデレーション、プロモーション用クリップの作成など、従来手動で行われていたタスクを自動化するために、すでにこれらの能力を活用しています。最も先進的なシステムは、ビデオの表面的なコンテンツだけでなく、その背景にある目的、スタイル、そして叙事的な構成まで理解しつつある初期の能力を示しています。これにより、複雑なツールを操作するというよりも、知識豊富なアシスタントとコラボレーションしているかのような対話が可能になります。受動的な分析から能動的なコラボレーションへのこの移行は、おそらくマルチモーダルAIの出現以来、ビデオインテリジェンスにおける最も重要なパラダイムシフトを表しています。
4 - TwelveLabsのアプローチ:ビデオエージェントフレームワークとしてのJockey
昨年から開発が進められてきたJockeyは、ビデオインテリジェンスにおける大きな進化を象徴しています。これはTwelveLabsの核となるビデオ基盤モデルの土台の上に構築され、複雑性のギャップに対処するために不可欠なオーケストレーション層を追加したものです。その根幹として、Jockeyは当社の2つの強力なビデオネイティブモデルを活用しています。すなわち、セマンティックビデオ検索のためのMarengo 2.7と、高度なビデオ・トゥ・テキスト(動画からテキストへの変換)理解のためのPegasus 1.2です。Jockeyはこれらのモデルを置き換えるのではなく、各コンポーネントの強みに応じて認知タスクを分配するプランナー・ワーカー・リフレクター(計画・実行・内省)アーキテクチャを通じて戦略的にこれらを調整します。計画と推論にはLLMを使用し、知覚負荷の高い操作は専用のビデオモデルに委ねています。
このアーキテクチャは、ビデオインテリジェンスにおける根本的な課題を解決します。基盤モデルは知覚や推論タスクに優れていますが、複雑なワークフローのシーケンス(順序立て)に苦戦することがよくあります。Jockeyのマルチエージェント型アプローチは、詳細な実行シーケンスを作成する「プランナー」、ビデオAPIと直接やり取りする専門の「ワーカー」、そしてアクションステップを要約する「リフレクター」を実装することで、この制限に対処します。この関心事の分離により、各コンポーネントは自身が最も得意とする機能に集中できます。LLMが推論や自然言語の理解を処理し、ビデオ基盤モデルが複雑なマルチモーダル分析を管理します。
Jockeyを特に強力にしているのは、複雑な、複数ステップにわたるワークフロー全体でコンテキスト(文脈)を維持する能力です。例えばビデオのハイライト作成において、Jockeyは単純に一度の検索処理を実行するだけではありません。正確な基準に沿って検索をシーケンス化(順序化)し、結果セットを賢く組み合わせ、ユーザーの本来の意図を反映したポストプロセス(後処理)操作を適用します。システムはLangGraph上に構築されたグラフベースのフレームワークを通じて永続的な状態を維持するため、複数の操作を跨いでクリップを追跡し、細分化されたサブタスクを実行している間も全体のタスク目的を把握し続けることができます。
ソース:https://github.com/twelvelabs-io/tl-jockey/blob/main/jockey/stirrups/stirrup.py
Jockeyの設計では、本番環境への導入に不可欠な特性である適応性を優先しています。そのモジュール式アーキテクチャにより、プロンプト駆動の動作調整から全く新しいワーカーモジュールの追加にいたるまで、複数のレベルでカスタマイズが可能です。これにより、開発者はコアシステムの信頼性を維持しながら、特定のワークフローに合わせてJockeyの機能を拡張することができます。
5 - Jockeyに透明性をもたらす
効果的なビデオエージェントの作成は、一般的なLLMアプリケーションとは異なり、ビデオ操作に特有のユニークなエンジニアリング上の課題をもたらします。特に顕著な課題は、クリップの抽出や結合といった複雑な操作における、ビデオ処理パイプラインのパフォーマンス最適化です。私たちが採用したアプローチは以下の二通りです:
第一に、
base_search()、process_clips()、およびdownload_remaining()のような個別のステップを独立して処理する関数ディスパッチャーを使用した、非同期処理パイプラインの設計。第二に、インターフェースに表示される透明な「思考(Thinking)」状態を通じて、これらの処理ステージをユーザーに開示すること(詳細はセクション6を参照)。
この透明性は単なるステータスの更新に留まりません。システムがどのようにして結論に至ったかを明らかにし、各瞬間においてどの処理コンポーネントが活用されているかを示すことで、必要不可欠な信頼関係を築き上げます。
Jockeyの開発を通じて、私たちは、たとえ応答時間がわずかに長くなったとしても、自らの推論プロセスを説明してくれるシステムに対して、ユーザーがより強い信頼を寄せるようになることを学びました。この洞察は、私たちのUIデザインに根本的な影響を与えており、処理状態や、それぞれのクエリに適用されている具体的なモデルコンポーネント(Marengoの検索機能か、あるいはPegasusのコンテクスト理解か)を明示的に表示するようにしました。この透明性は、ブラックボックスなソリューションではなく、検証可能なプロセスを必要とするエンタープライズクライアントと連携する際に特に重要です。
Jockeyの将来的な拡張は、双方向思考システムとなる予定です。これはエージェントの処理ステップを表示するだけでなく、ユーザーがそれらのステップを直接修正できるようにするものです。この機能により、Jockeyは受動的なツールから、ユーザーがインタラクティブにクエリを洗練させたり(日本のカメレオンから日本のトカゲへ変更)、処理決定を検証したり、エージェントのフォーカスを方向転換させたりできる協調的パートナーへと変わります。つまり、出力をただ受け入れるのではなく、AIを「操縦(ステアリング)」できるようになるのです。このアプローチは、MLSEチームと共同で行った成果や他のエンタープライズ顧客からのフィードバックと一致しています。彼らは、ビデオコンテンツのような価値の高いクリエイティブアセットを扱う際、純粋な自動化のスピードよりも、プロセスを理解しコントロールできることを一貫して優先しています。
ソース:https://www.latent.space/p/why-mcp-won
Model Context Protocol(MCP)フレームワークは、特にサードパーティ統合を拡大していく中で、Jockeyの将来の進化に興味深い可能性をもたらします。MCPは、Jockeyのコアコンポーネントと、外部サービス、例えばビデオ生成ツール(RunwayML、Luma Labs)、オーディオ生成ソフトウェア(ElevenLabs、Suno)、さらにはシーン分割やオブジェクトトラッキング(MetaのSAM)といった高度なビデオ操作タスクとの間に、標準化された統合レイヤーを提供する可能性があります。
統合先ごとにカスタムコネクタを作成する代わりに、MCPを使用することで、ツールの呼び出し、文脈(コンテキスト)の共有、およびレスポンス処理のための統一されたインターフェースを定義できます。このアプローチは、n×m個の統合問題(n個のエージェントフレームワーク×m個のツール)を、より管理しやすいn+m個の問題へと変換し、システム拡張性を高めつつ、実装の複雑さを劇的に軽減します。
Jockeyに関して言えば、MCPはより洗練されたワークフローを可能にする可能性があります。例えば、Marengoを介して特定されたクリップを、外部の画質向上ツールへとシームレスに渡し、次にナレーション用の生成オーディオサービスへ、そして最終的に編集システムへと引き渡すことができます。これらの一連の流れを、すべてのプロセスにわたって一貫したコンテキストを維持したまま、実行できるようになります。
6 - マルチモーダルインターフェースの力
従来のビデオインターフェースは一般的に、視覚的な文脈を無視したテキストベースの検索か、またはインタラクティブな機能が最小限に抑えられたビデオプレイヤーのどちらか一つの選択をユーザーに強いてきました。 Jockeyは、対話的なインテラクションとビデオネイティブな要素を組み合わせた、根本的にマルチモーダルなインターフェースを通じてこの関係性を再定義し、片方をもう片方に無理に合わせるのではなく、両方のモダリティを第一級の市民として扱います。以下のスクリーンショットに示されているインターフェースはこのアプローチを実証しています。対話エリアが自然言語を通じてユーザーの意図を汲み取り、ビジュアルな「思考表示」がエージェントの推論プロセスを明らかにし、ビデオギャラリーがタイムスタンプや説明などの関連する文脈とともに結果を提示します。この統一された体験により、ユーザーは抽象度の高いゴール(困難を克服した人々の心に響くストーリーを探して)の表現から、ビジュアル結果へのダイレクトな操作へとシームレスに移行できます。
このアプローチを強力なものにしているのは、テキスト要素とビジュアル要素の間を流れる、双方向の情報フローです。ユーザーが自然言語のクエリを入力すると、Jockeyはテキストによる説明と、関連するビデオセグメントへの直接リンクの双方を含む回答を返し、詳細なタイムスタンプによって映像内のどこの場所でその具体的なコンセプトが出現するかを示します。この時間的アンカー(紐付け)が、Jockeyのテキスト回答と、参照されている実際のビデオコンテンツとの間に、明確な架け橋を築き上げます。
さらに、ユーザーはサムネイルを通してビデオセグメントを直接操作できるため、ナビゲーション体験が向上します。これにより、それぞれのモダリティが互いを高め合う好循環が生まれます。言語は意図を指定する際の精度を提供し、ビジュアル要素はテキストで伝えるのが非効率な豊かさと文脈を提供します。例えば、以下のスクリーンショットは、Jockeyがエージェントの思考ステップをタイムスタンプ付きのビデオセグメントの隣にどのように表示するかを示しており、ユーザーがどのようなコンテンツが見つかったかだけでなく、なぜそれが選ばれたのかを理解する手助けをします。
このインターフェースは、ビデオインタラクションに特有のいくつかの認知的な課題に対処しています。ビデオコンテンツは本質的に時間的なものであり、情報が密に詰まっているため、ユーザーがテキストで行うようにスキャンしたり、ブラウズしたり、比較したりすることが困難です。Jockeyのマルチモーダルアプローチは、複数の入口を提供することでこれらの課題を軽減します。ユーザーはサムネイルを通して視覚的にブラウズしたり、エージェントが生成した要約に目を通したり、あるいはコンセプトの説明に基づいて特定の瞬間へとパッと直接ジャンプしたりできます。これらのアプローチを組み合わせることで、インターフェースはユーザーの認知負荷を大幅に削減し、複数のビデオを同時に処理する場合でも文脈を維持できるようにします。それは、以下のスクリーンショットで、ユーザーが検索結果を確認した後に「これらのビデオをエモーショナルなトーンで要約して」と依頼している箇所で見ることができます。
最も重要なのは、このインターフェースが単なるクエリ応答パターンを超えて、真の協調的ワークスペースへと進化している点です。以下のスクリーンショットに示すエージェントの思考表示は、Jockeyが難解なタスクを リクエストの理解 や ビデオコンテキストの取得 といった個別のステップへとどのように分解するかを示しており、透明性を生み出すことでユーザーの信頼を築き、タイムリーな介入を可能にします。この透明性は、アルゴリズムの確信度(番号付きのステップを介して)と思考プロセスの両方の表示にまで及び、ユーザーがシステムへの依存度を調整し、人間の判断が必要となる場面において情報に基づいた決定を下せるようにします。ワークフローのどの時点であってもエージェントのアプローチを中断、リダイレクト、または洗練できる機能と組み合わせることで、従来のビデオインターフェースにありがちだったトランザクション(取引)的なモデルではなく、真に協調的な関係が創り出されます。
このマルチモーダルアプローチの将来の進化は、私たちが「フロー認識型の弾道(flow-aware trajectories)」と呼ぶ方向へと向かっています。これは、ユーザーのワークフローの中で生まれつつあるパターンに基づいて、ユーザーが次に行うであろうアクションを先回りして予測するインターフェースのことです(詳細はセクション8を参照)。上のスクリーンショットのエージェントによる段階的な推論に示されているように、Jockeyは会話のやり取り全体でコンテキストを維持し、これまでの対話を踏まえて構築していくことで、すでにこの方向における初期の能力を示しています。これらの能力が成熟するにつれて、インターフェースはエージェントとツールの間の境界線をますます曖昧にし、ユーザーの創造的な流れ(フロー)を損なうことなく、ニーズを先回りして予測し、代替アプローチを提案し、専門的な細部を処理する、ユーザーの創作プロセスの延長線となることでしょう。これは、単にリクエストを処理するインターフェースから、創造的かつ分析的なプロセスに主体的に貢献する、本当の意味での「共同作業者」への根本的な転換を表しています。
7 - コンテンツ作成の変革:エンタープライズメディアワークフローに向けたJockeyのビジョン
エンタープライズメディアの領域は、制作リソースが横ばいであるにもかかわらず、コンテンツへの需要が指数関数的に増加するという、前例のない課題に直面しています。マーケティングチームは、フォーマット要件や視聴者の期待値が異なる、多様な複数のプラットフォームに向けて、より多くのビデオコンテンツを制作しなければなりません。ドキュメンタリー映画の製作者は、何百時間ものフッテージ(映像素材)から関連する瞬間を見つけ出す必要があります。企業の広報部門は、グローバル市場全体で一貫したメッセージングを維持することに苦慮しています。これらのワークフローには、共通のペインポイントがあります。それらは時間がかかり、専門的なスキルを必要とし、伝統的なアプローチでは効率的にスケールしないという点です.
Jockeyのビジョンは、企業がビデオコンテンツと関わる方法を再定義することによって、これらの課題に対処します。既存のプロセスを単に自動化するのではなく、Jockeyは、その対話型インターフェースとビデオ理解機能のインテリジェントなオーケストレーションを通じて、コンテンツワークフローに新しい可能性を生み出します。例えば、製品デモンストレーションビデオを作成しているマーケティングチームは、Jockeyに対して「製品が屋外で使用されているクリップを見つけて」と指示し、次に「それらをスムーズなトランジションで編集して」と伝えることができます。この自然言語によるアプローチは、制作スピードを低下させがちな専門的な障壁を取り除き、チームが機械的な作業ではなく、創造的な決定に集中することを可能にします。
特に魅力的な用途の一つに、Jockeyが即座に価値を発揮できる、広告およびマーケティングのワークフローが挙げられます。クリエイティブチームは、ブランドメッセージやキャンペーンのテーマに合致する瞬間を特定するために、生の映像素材をレビューするのに何時間も費やすことがよくあります。Jockeyは、街中(屋外)の環境で私たちのロゴが目立つように表示されているシーンを特定して、または 製品を使って人々が興奮を表現しているクリップを見つけてといった自然言語のクエリを使って、ビデオライブラリを検索できるようにすることで、このプロセスを変革します。エージェントはMarengoのマルチモーダルな理解力を活用して関連する映像を呼び出し、Pegasusのコンテクスト認識力を駆使してそれらの瞬間をまとまりのあるシーケンスへと組み立てるため、コンセプトから完成したアセットへと至るまでの時間を劇的に削減します。
Jockeyのアプローチが持つ真のパワーは、エンド・ツー・エンド(始点から終点まで)のクリエイティブワークフローにおいて顕著に現れます。新製品の発表ビデオ制作を任された企業広報チームを例に挙げてみましょう。従来、これには絵コンテの作成、撮影、映像素材のアーカイブ整理、ラフカットの編集、グラフィックスの追加、ナレーションの収録、そして配信に向けた最終調整が必要であり、それぞれのステップごとに異なる専門家やツールが介入していました。Jockeyの目指すビジョンは、自然言語の指示を通じて、チームが関連フッテージを呼び出し、初期カットを組み立て、付随する音声を生成し、配信可能なアセットを用意できるようにすることで、これらのワークフローを統合することです。まだ初期の段階にありますが、Jockeyの開発ロードマップには、関連ツールとのサードパーティ連携を通じてこれらの機能を拡張していくことが含まれています。これにより、組織に対して技術的な制限に自らのワークフローを合わせるよう強いるのではなく、企業の要件に合わせて適応していく総合的なプラットフォームを創り出します。
8 - ビデオエージェントの未来:私たちのビジョンとロードマップ
ビデオエージェントの将来的な進化は、段階的な改善を超えて、人間がビジュアルメディアとやり取りする方法を根本的に変革する、3つの主要な原則に導かれます。Jockeyを通じて、私たちはビデオインテリジェンスが、自動化と人間による創造的な主体性のバランスを保ちつつ、ニーズを先回りして予測し、個人の好みに適応する、創造的および分析的なワークフローの自然な拡張となるようなビジョンに向かって構築を進めています。
フロー認識型の弾道(Flow-Aware Trajectories)は、クリエイティブな勢い(モーメンタム)を維持するために、ユーザーが必要とするものを数ステップ先回りして予測するシステムであり、当社の第一の指針となる原則です。実用的な場面において、これはJockeyがハイライト作成中に次に必要とされるクリップを予測し、コンテンツに基づいて適切なトランジションを提案し、ユーザーの編集パターンに沿ったラフカットを事前に組み立てることを意味します。これらの機能が成熟するにつれて、エディターはクリエイティブな作業プロセスを邪魔されることが少なくなり、システムが技術的な細部を処理している間も自らの表現の方向性を保ち続けることができます。例えば、スポーツのプロデューサーであれば、観客の反応に基づいて重要なプレイを自動的に提案し、一定のペースを維持し、ストーリーの流れを担保したハイライトパッケージをJockeyを使って作成することができ、その間プロデューサー自身は最終的な選択に関するクリエイティブな権限を握り続けることができます。
文脈的メタ学習(Contextual Meta-Learning)は、Jockeyが対話のたびに進化し、プロジェクトやセッションの違いを越えて、ユーザーの好みに関する永続的な理解を構築できるようにするものです。あらゆる操作に明確な指示を毎回求める代わりに、システムは、好まれるトランジションのスタイル、代表的なシーン構成、または一般的な編集シーケンスなど、ユーザーの行動パターンを認識し、それに応じて提案を適応させていきます。これにより、システムが時間の経過とともにより価値を高め、プロジェクト特有の要件を記憶して、フィードバックに適応していく好循環が生まれます。定期的に発生する種類のコンテンツ(週次のスポーツハイライトや製品レビューなど)を扱う組織は、Jockeyが明確な指示なしに関連性の高いコンテンツを優先し、一貫したスタイリングを適用することを学習するため、ワークフローがますます効率的になることを実感するでしょう。
大規模なマルチモーダルインテリジェンス(Multimodal Intelligence at Scale)により、Jockeyは、ガチガチに固まったルールに頼ることなく、ビデオ、オーディオ、およびテキスト要素を横断する高度な結びつきを構築できます。この原則により、単なる視覚的な類似性だけでなくテーマとしての関連性に基づいてシーンを呼び出したり、複数のクリップにわたるナラティブの流れを分析したり、感情的に共鳴するシーケンスを自動的に特定したりする複雑な操作が可能になります。ナレーション用の音声生成、別パターンのシーン用のビデオ生成、あるいはプレゼンテーション用のアバター作成といったサードパーティの追加機能を統合していく中で、Jockeyはこれらの専門ツールをまとまりのあるワークフローへとオーケストレートし、操作全体でコンテキストを維持し、最終的な出力における一貫した品質を保証します。この統合ロードマップには、セグメンテーション、背景の置き換え、シンセティックメディア(合成メディア)生成、および音声作成のリーディングツールとの提携が含まれており、ユーザーに複雑な技術の統合管理を求めることなく、Jockeyの機能を大幅に拡張します。
ツールから協調的パートナーへのJockeyの進化は、組織がビデオ資産にアプローチする方法におけるパラダイムシフトを表しています。これら3つの原則にフォーカスし、拡張可能な機能のエコシステムを構築することで、私たちは技術的な制約にユーザーを合わせるのではなく、人々が本来ビデオコンテンツについて検討する自然な思考プロセスに適応するプラットフォームを創り出しています。このプラットフォーム上で開発を行うエンジニアにとって、Jockeyはバラバラのモデルを統合する複雑さに煩わされることなく、高度なビデオインテリジェンスを活用したアプリケーションを提供する機会を与えます。ビジュアルコンテンツの制作体制をスケールさせたい企業にとっては、確立されたワークフローを尊重しつつ、効率性を劇的に変革する、一貫した高品質な出力の土台を提供します。
9 - 結論:ビデオエージェント革命への参加
ビデオ基盤モデルとエージェントアーキテクチャの融合は、ビデオコンテンツの制作、分析、および配信方法における根本的なシフトを体現しています。Jockeyは、ビデオを専門的な専門知識を要する一枚岩のメディアとして扱うことから脱却し、多様なワークフローやクリエイティブなニーズに合わせることができるプログラミング可能なリソースへと移行できることを示しています。インテリジェントなタスク割り当て、ネイティブなビデオ処理、そして人間と協調するデザインの組み合わせを通じて、かつては労働集約的であったタスクを、流動的で対話的なやり取りへと変貌させ、創作的な主導権を確保したまま、制作時間を劇的に短縮します。
現時点におけるJockeyの限界を、アルファステージの概念実証(Proof-of-Concept)として認めることは重要です。エージェントは時として最適な結果を得るために特定の言い回しを必要としたり、時に複雑なクエリに苦労したりすることがあり、特定のワークフロー向けへの最適化もまだ完了していません。Jockeyを支えるエージェントフレームワーク自体も急速に進化を遂げており、業界全体の開発者たちが計画、メモリ管理、およびマルチモーダル推論に向けた異なるアプローチをテストしている段階です。しかしながら、これらの限界は、根本的な障害ではなく、より有能で直感的なビデオインテリジェンスへと到達するための、明確な開発プロセスにおける通過点に過ぎません。
Jockeyの早期アクセスのために、この未来を一緒に形作っていくよう皆様を招待します。私たちは、私たちの技術を積極的にテストし、貴重なフィードバックを提供してくださる、熱意ある初期導入企業(アーリーアダプター)を特に求めています。こちらのフォームから興味をお知らせください:https://form.typeform.com/to/JCKz0aBA
制作ワークフローの合理化を目指すコンテンツ制作者であれ、ビデオインテリジェンスを自社のアプリケーションに組み込みたい開発者であれ、あるいはビデオ運用体制を拡充させたい企業であれ、皆様のフィードバックや活用ケースは開発の優先順位へと直接影響を与えます。この限定アルファテストに参加していただくことで、最先端のビデオエージェント技術を直接手にするだけでなく、ビジュアルメディアの扱い方におけるより大きな変革に寄与することができます。ビデオエージェントの革命は、単に来るべき予定を指しているのではなく、まさに今ここに起きており、皆様の視点こそがその先の道を切り開く力となるのです。
この記事の執筆にあたり、コメント、フィードバック、および提案を寄せてくれたTwelveLabsの同僚たち(Kingston Yip、Simon Shim、Simon Lecointe、Yeonhoo Park、Sean Barclay、Sunny Nguyen)に感謝を捧げます。








