" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
TWLV-I:ビデオ基盤モデルの包括的評価による分析と洞察
ルーカス・リー、キリアン・ベク、ジェームズ・レ
Twelve Labsは、外観と動作の理解を両立させ、アクション認識、時間的アクションローカリゼーション、および時空間アクションローカリゼーションのベンチマークにおいて最先端のモデルを凌駕またはそれと同等の性能を発揮する、新しいビデオ基盤モデルおよび評価フレームワークである「TWLV-I」を発表しました。
Twelve Labsは、外観と動作の理解を両立させ、アクション認識、時間的アクションローカリゼーション、および時空間アクションローカリゼーションのベンチマークにおいて最先端のモデルを凌駕またはそれと同等の性能を発揮する、新しいビデオ基盤モデルおよび評価フレームワークである「TWLV-I」を発表しました。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2024/09/22
20分
記事へのリンクをコピー
TWLV-Iの技術レポートをarXiVおよびHuggingFaceでご確認ください! コードはGitHubで公開されています:https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
包括的な評価フレームワーク:Twelve Labsは、外観と動きの両方の分析を重視した、ビデオ理解のための堅牢な評価フレームワークを提供します。
TWLV-Iモデル:当社の新しいビデオ基盤モデル(TWLV-I)は、これら2つの側面をバランスよく捉えることに優れており、最先端のモデルと同等以上の性能を発揮します。
タスクパフォーマンス:TWLV-Iは、動作認識、時間の動作ローカライズ、および空間・時間の動作ローカライズにおいて強力な結果を示しており、その汎用性の高さが浮き彫りになっています。
可視化による洞察:t-SNEおよびLDAの可視化により、TWLV-Iは他のモデルと比較して、優れたクラスタリング能力と動きの識別能力を備えていることが明らかになりました。
今後の方向性:TWLV-Iの汎用性と適用性を高めるために、モデル規模の拡張、画像埋め込みの改善、およびモダリティの拡張を重視します。
今後の研究への指針:提案された手法は、ビデオ理解における新たな基準を設定し、この分野における今後の研究開発を導くことを目的としています。
1 - イントロダクション
今日のデジタル環境において、ビデオは普遍的な言語であり、文化を超えて複雑なアイデアや感情をシームレスに伝えています。この豊かなメディアを正確に解釈するには、堅牢なビデオ理解システムの構築が不可欠です。複数の画像のシーケンスであるビデオには、各フレームの外観を認識することと、時間の経過とともに展開する動きを理解することの、2つの焦点を当てる必要があります。
Twelve Labsでは、ビデオ理解におけるこれら2つの側面に対応する包括的な評価フレームワークの必要性を認識しています。私たちの目標は、外観と動きの両方の能力を正確に測定する評価手法を確立することにより、この分野における今後の研究の明確な方向性を提示することです。
1.1 - 基盤モデルとビデオ理解
基盤モデル(FM)は、特定の領域内の多様なタスクをモデルが処理できるようにすることで、AIに革命をもたらしました。言語および画像基盤モデルが大きな進歩を遂げた一方で、ビデオ理解には特有の課題が存在します。既存のビデオ基盤モデルは、クラスタリングや分類タスクの限界からも明らかなように、外観と動きの両方を効果的に捉えることができない場合が多々あります。
1.2 - TWLV-Iと評価フレームワークの紹介
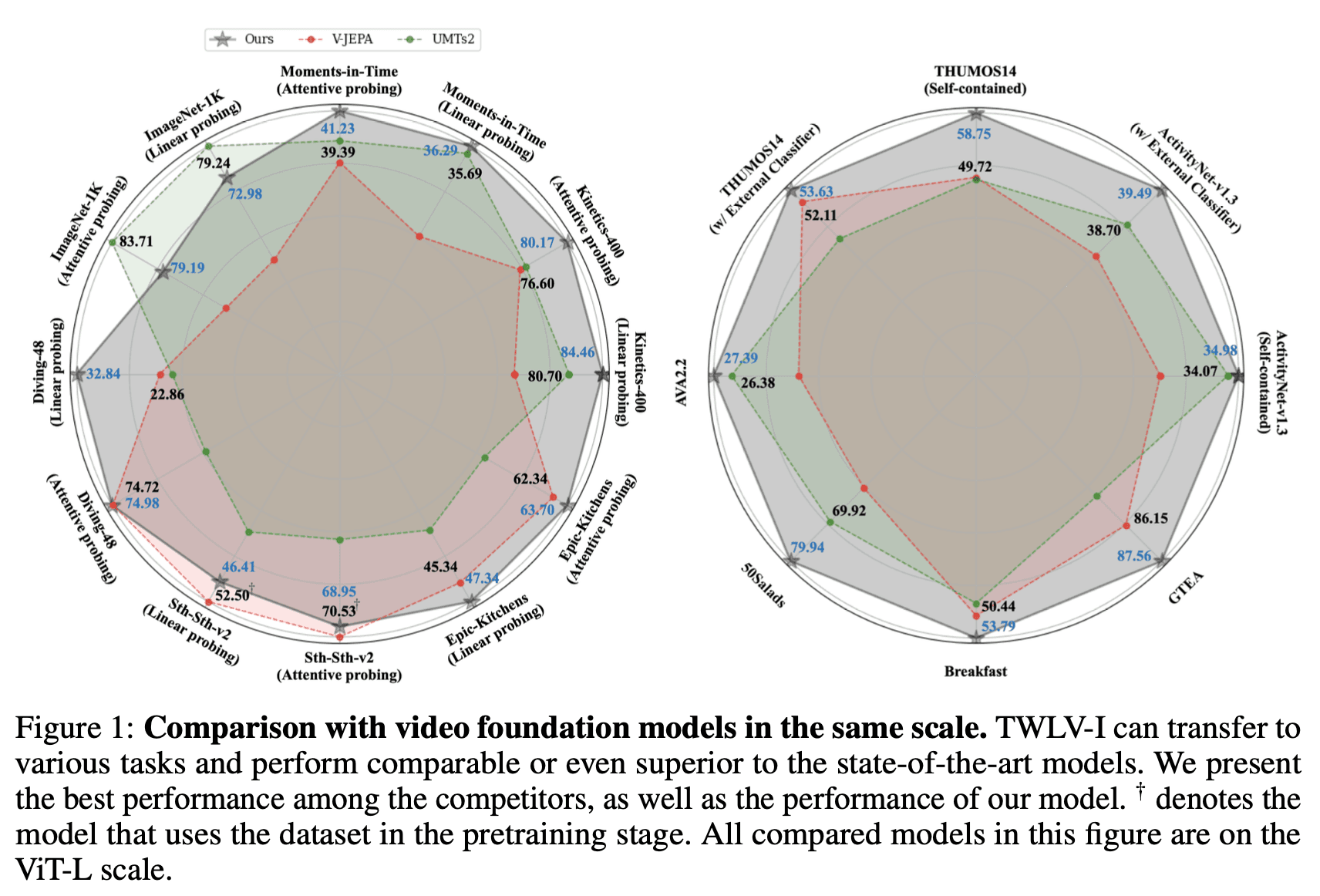
これらの課題に対処するため、私たちは図1に示すように、外観ベースおよび動きベースの両方のタスクで卓越するように設計されたTWLV-Iを導入します。さらに重要なこととして、TWLV-Iの能力を評価するだけでなく、今後のモデルのベンチマークを設定する堅牢な評価フレームワークを提案します。
私たちのフレームワークには、動作認識、時間の動作ローカライズ、空間・時間の動作ローカライズなど、ビデオ理解の特定の側面を評価するために細心の注意を払って設計された様々なタスクが含まれています。この包括的なアプローチを通じて、バランスのとれた能力の重要性を強調し、業界をより包括的なモデル開発へと導くことを目指しています。
ビデオモデルの性能と適切な評価の両方に焦点を当てることで、私たちはビデオ研究におけるマイルストーンを提示し、このダイナミックな分野における今後の進歩と革新への道を切り開くことを熱望しています。
2 - TWLV-I & ビデオ基盤モデル評価フレームワーク
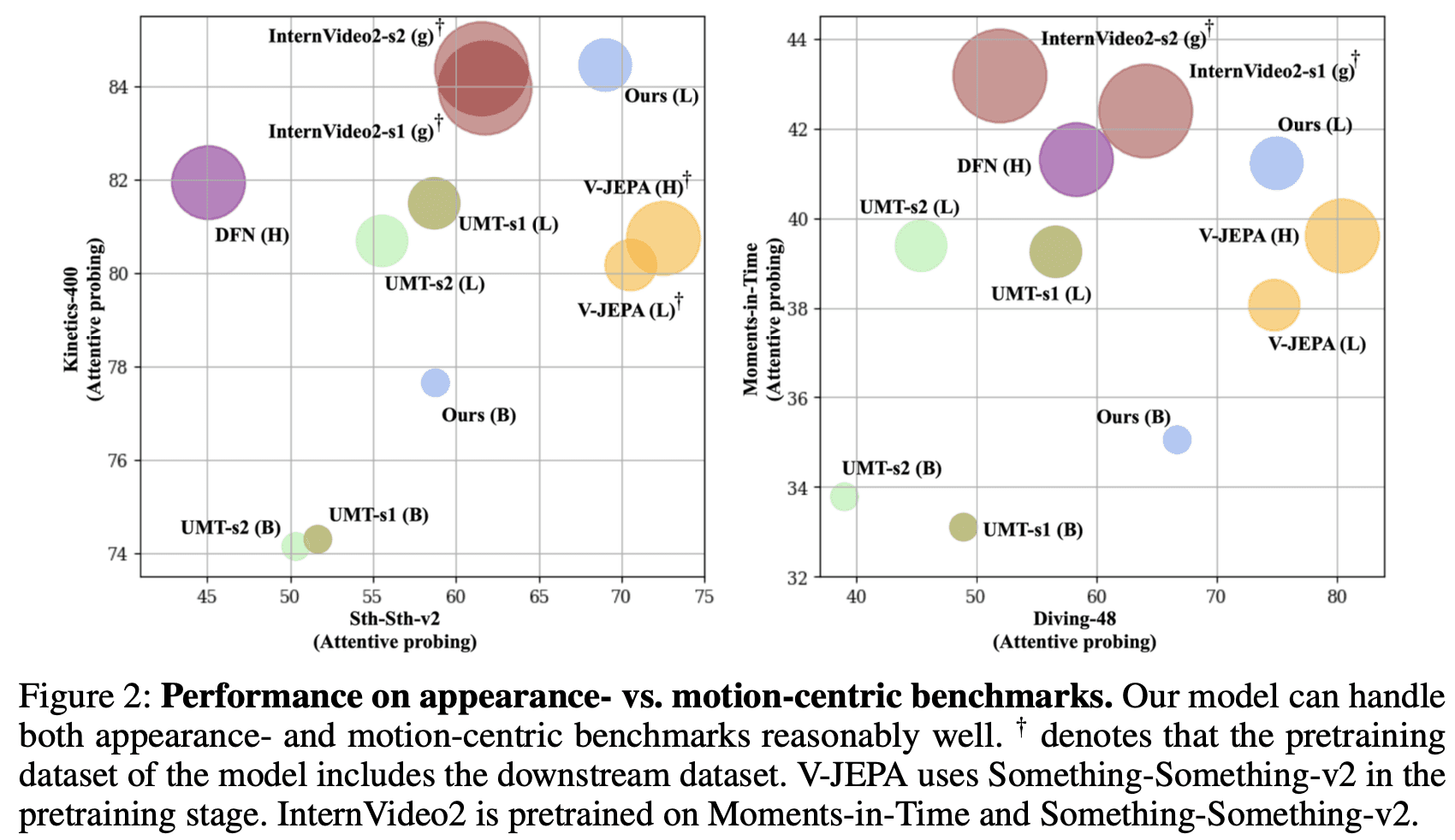
TWLV-Iのアーキテクチャとトレーニングプロセスは、外観と動きの両方の理解に対するニーズのバランスをとりながら、ビデオ理解に特有の課題に対処するように設計されています。図2は、外観中心のベンチマーク(Kinetics-400)と、動き中心のベンチマーク(SSv2およびDiving-48)におけるTWLV-Iのパフォーマンスの視覚的な比較を示しています。このプロットは、TWLV-Iのバランスの取れた能力を示しており、両方のタイプのタスクを高度に処理できることを実証しています。
このサブセクションでは、TWLV-Iのトレーニング手法とフレームサンプリング技術の主要な側面について詳しく説明します。
2.1 - アーキテクチャ
TWLV-Iは、Visual Transformer(ViT)アーキテクチャに基づいて構築されており、ビジュアルデータを処理するその強力な能力を活用しています。私たちは、次の2つのバリアントを実装しています:
ViT-B (Base): 8600万個のパラメータを持つモデル
ViT-L (Large): 3億700万個のパラメータに拡張されたバージョン
入力されたビデオは複数のパッチにトークン化され、これらはトランスフォーマー層を介して処理されます。このプロセスにより、パッチごとの埋め込みが取得され、その後プーリングされて、入力ビデオのトータルな埋め込みが生成されます。
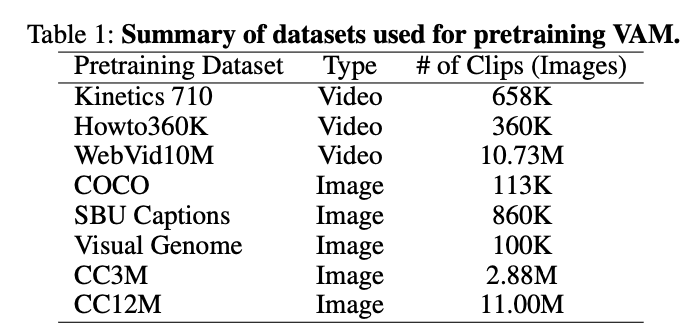
2.2 - 事前トレーニングデータセット
堅牢で汎用性の高いビデオ理解を実現するために、TWLV-Iは表1に詳しく説明されている多様なデータセットで事前トレーニングされています:
ビデオデータセット:
Kinetics 710(65.8万動画クリップ)
HowTo360K(36万動画クリップ、HowTo100Mのサブセット)
WebVid10M(1073万動画クリップ)
画像データセット(合計1500万画像):
COCO(11.3万画像)
SBU Captions(86万画像)
Visual Genome(10万画像)
CC3M(288万画像)
CC12M(1100万画像)
このビデオデータセットと画像データセットの組み合わせにより、動きのダイナミクスと静的なビジュアル特徴の両方を理解するTWLV-Iの能力が向上します。
2.3 - トレーニング目的
TWLV-Iは、基礎的なトレーニングアプローチとしてマスクモデリングモデルを採用しています。しかし、動きと外観の両方の理解においてモデルの性能を最適化するために、再構成ターゲットを多様化しています。この戦略は、様々なビデオ理解タスクにわたって優れた性能を発揮できる、頑健なモデルの作成を目的としています。モデルは、この目的と前述のデータセットを使用してゼロからトレーニングされます。
2.4 - フレームサンプリング
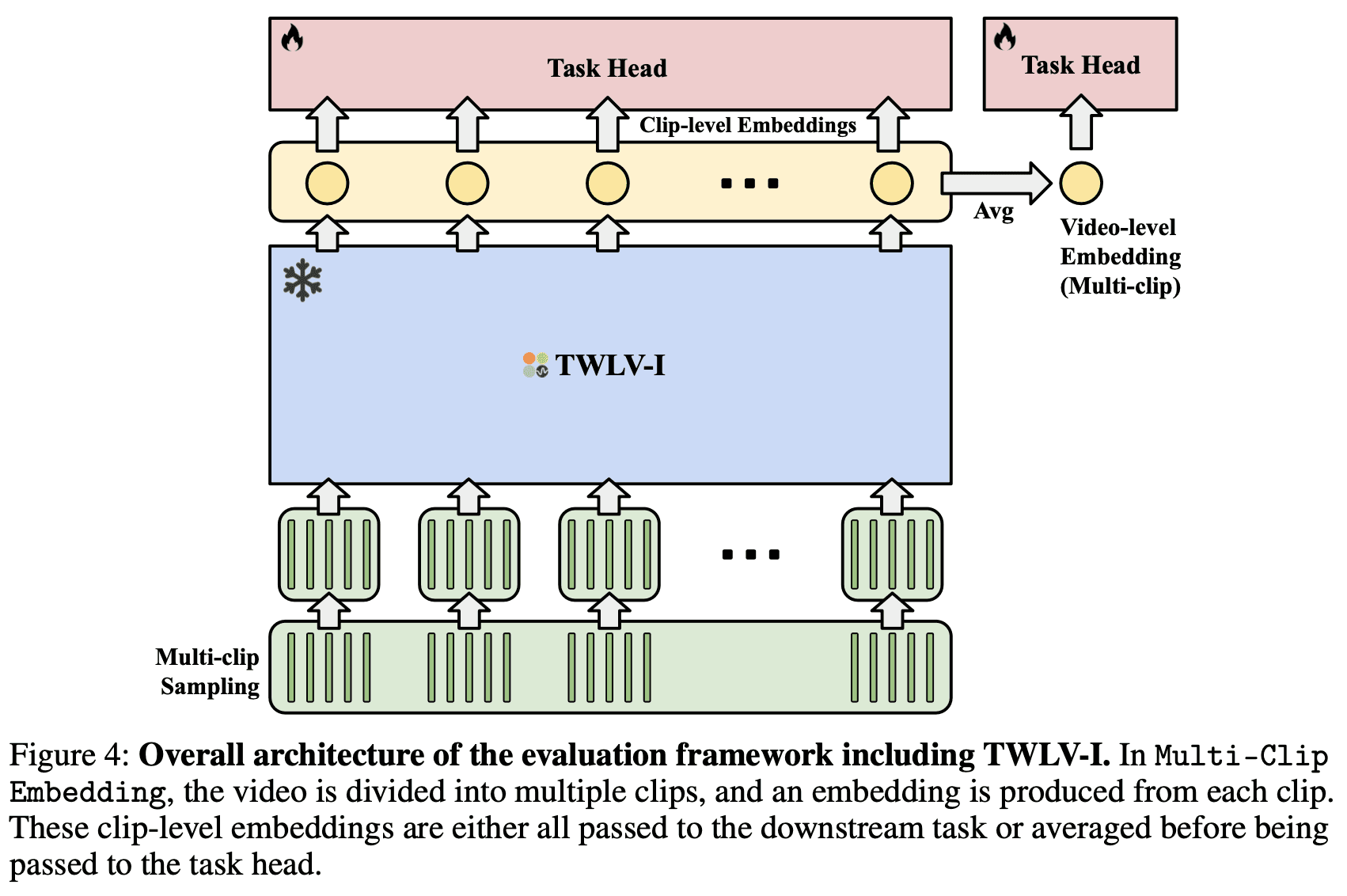
フレームサンプリングのプロセスは、ViTアーキテクチャの計算上の制約があるため非常に重要です。トークンの数が増えると、計算の複雑さ(二次関数的)も増します。これを処理するため、私たちはMulti-Clip Embedding(マルチクリップ埋め込み、図4を参照)と呼ばれる戦略的なフレームサンプリング技術を採用しています:
クリップの分割:入力されたビデオは、それぞれ長さがT秒のM個のクリップに分割されます。
フレームの選択:各クリップからNフレームがサンプリングされます。
埋め込み生成:このプロセスにより、ビデオ1本につきM個の埋め込みが作成されます。
柔軟な表現:埋め込みの数はビデオの長さに比例して増加するため、可変長のビデオ処理が可能になります。
単一の埋め込みオプション:ビデオ全体を表すために単一の埋め込みが必要とされる場合は、M個の埋め込みを平均化します。
このアプローチにより、TWLV-Iは短期および長期の時間的ダイナミクスの両方を捉える能力を維持しながら、様々な長さのビデオを効率的に処理できます。
強力なViTアーキテクチャと、多様な事前トレーニングデータセット、および革新的なフレームサンプリング技術を組み合わせることで、TWLV-Iは複雑なビデオ理解タスクに対処する十分な能力を備えています。この強固な土台により、TWLV-Iは外観中心および動き中心の両方のベンチマークにわたって堅牢に機能することができ、それについては本評価フレームワークの以降のセクションで詳しく見ていきます。
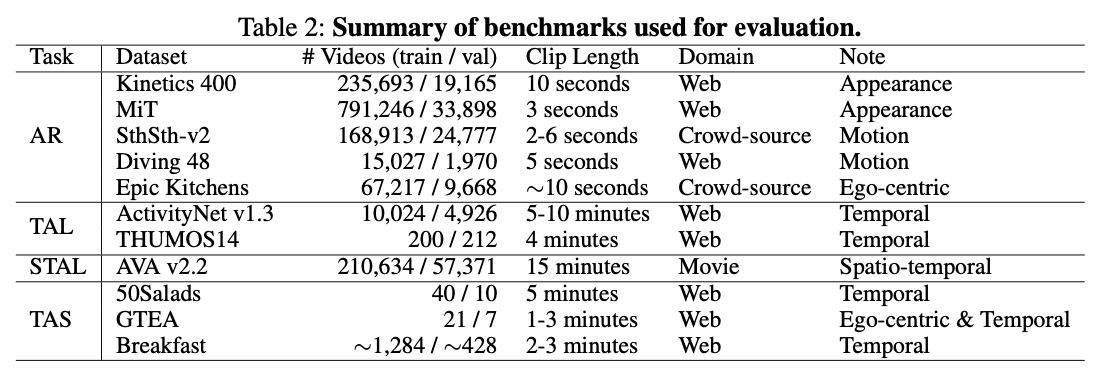
3 - 動作認識
動作認識(Action Recognition; AR)はビデオ理解における基本的なタスクであり、ビデオを定義済みの人間の動作カテゴリに分類することを目的としています。このタスクは、外観と動きの両方の理解を必要とするため、ビデオ基盤モデルの性能を評価するための重要なベンチマークとなっています。
3.1 - ベンチマーク
私たちは、それぞれ異なる特徴を持つ、代表的な5つのARベンチマークにおいてTWLV-Iの性能を評価しました:
Kinetics-400 (K400):外観ベースの動作に焦点を当てた大規模データセット
Something-Something-v2 (SSv2):時間的関係を重視した動き中心のデータセット
Moments-in-Time (MiT):多様な動作カテゴリを持つ、もう1つの外観重視のデータセット
Diving-48 (DV48):ダイビングの動作に特化した、詳細かつ動き中心のデータセット
Epic-Kitchens (EK):日々の台所での活動を捉えた一人称視点(自我中心)のデータセット
これらのベンチマークは包括的な評価環境を提供し、外観重視および動き中心の両方のシナリオにわたってTWLV-Iの能力を評価できるようにします。
3.2 - 評価手法
私たちは、動作認識タスクにおける標準的な手法であるマルチビュー分類法を採用しています:
入力ビデオを空間的にリサイズし、要求される解像度に適合させます
空間次元に沿ってm個、時間次元に沿ってn個のクリップを一様にサンプリングし、合計m × n個のクリップを作成します
各クリップのクラス確率を算出します
確率を平均化して最終的な出力を取得します
このアプローチにより、入力ビデオの異なる空間的および時間的セグメントにわたるモデルの性能が徹底的に評価されます。
3.3 - リニアプロービング(線形評価)
リニアプロービングは、モデル全体をファインチューニングすることなく、学習された表現の品質を評価するために使用される技術です。以下のステップを含みます:
特徴抽出器(バックボーンモデル)を固定(フリーズ)します
フリーズされた特徴の上に線形分類器を配置してトレーニングします
線形分類器は、埋め込みベクトルの次元数から動作クラスの数へのマッピングを行う重み行列で構成されます。
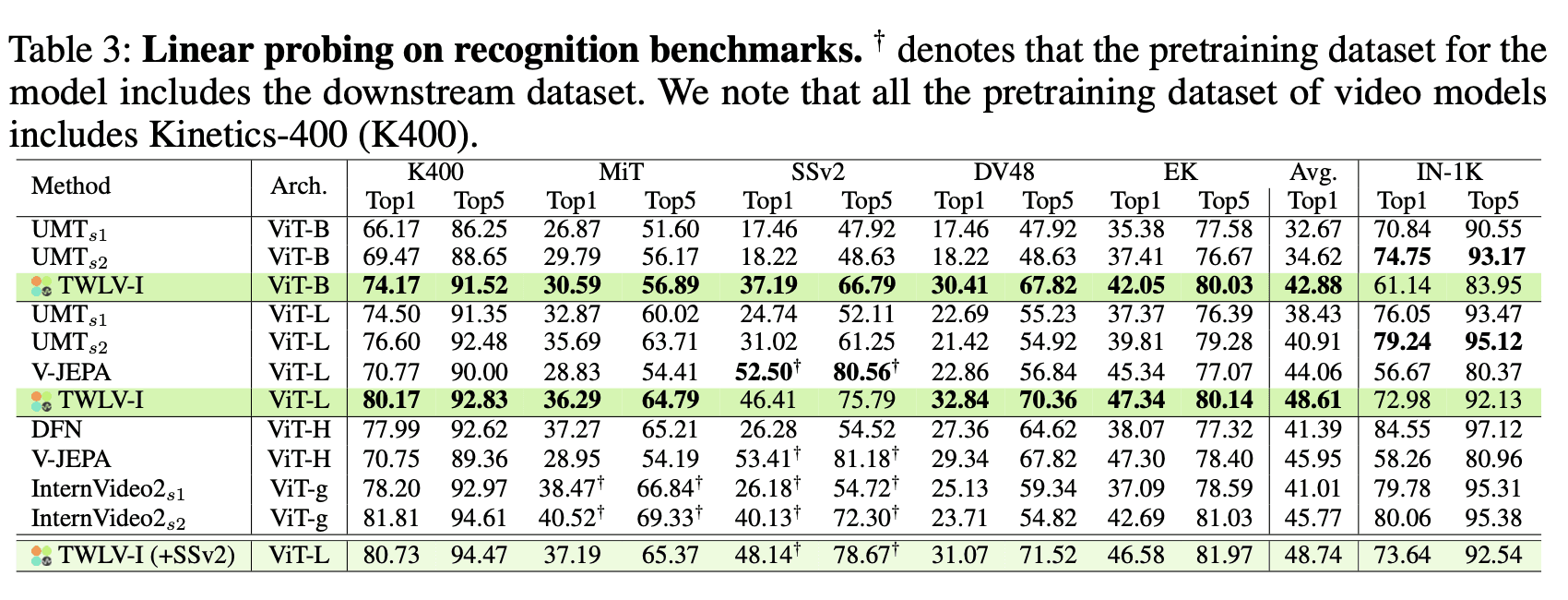
結果と分析
表3は、様々なベンチマークとモデルにおけるリニアプロービングの結果を示しています。主な観察結果は以下の通りです:
TWLV-Iはすべてのベンチマーク、特にそのアーキテクチャ規模(ViT-BおよびViT-L)において強力なパフォーマンスを示しています。
SSv2において、TWLV-Iは、事前トレーニングにSSv2を含んでいるV-JEPAを除き、ViT-H (DFN) や ViT-g (InternVideo2) などのより大規模なモデルを凌駕しています。
TWLV-IのViT-Lモデルは、EKおよびDV48のベンチマークにおいて、より大規模な他モデルを上回る結果を示しています。
これらの結果は、単純な線形分類器を使用して評価した場合であっても、TWLV-Iが様々な動作認識タスクにうまく汎用できる、豊かな表現特徴を学習できていることを裏付けています。
3.4 - アテンティブプロービング(注意評価)
リニアプロービングはクリップごとの埋め込み精度についての洞察を提供しますが、特にパッチレベルの教師あり学習で訓練されたモデルにおいて、その真能力を完全に捉えきれない場合があります。この制限に対処するため、私たちは以下を含むアテンティブプロービングを導入します:
フリーズされたモデルの上に、学習可能なクラストークンを持つ単一のアテンション層を導入してトレーニングします
出力されたクラストークンを線形分類器に入力します
Top-1精度を測定します
この手法により、モデルのパッチ単位での表現能力をより詳細に評価することが可能になります。
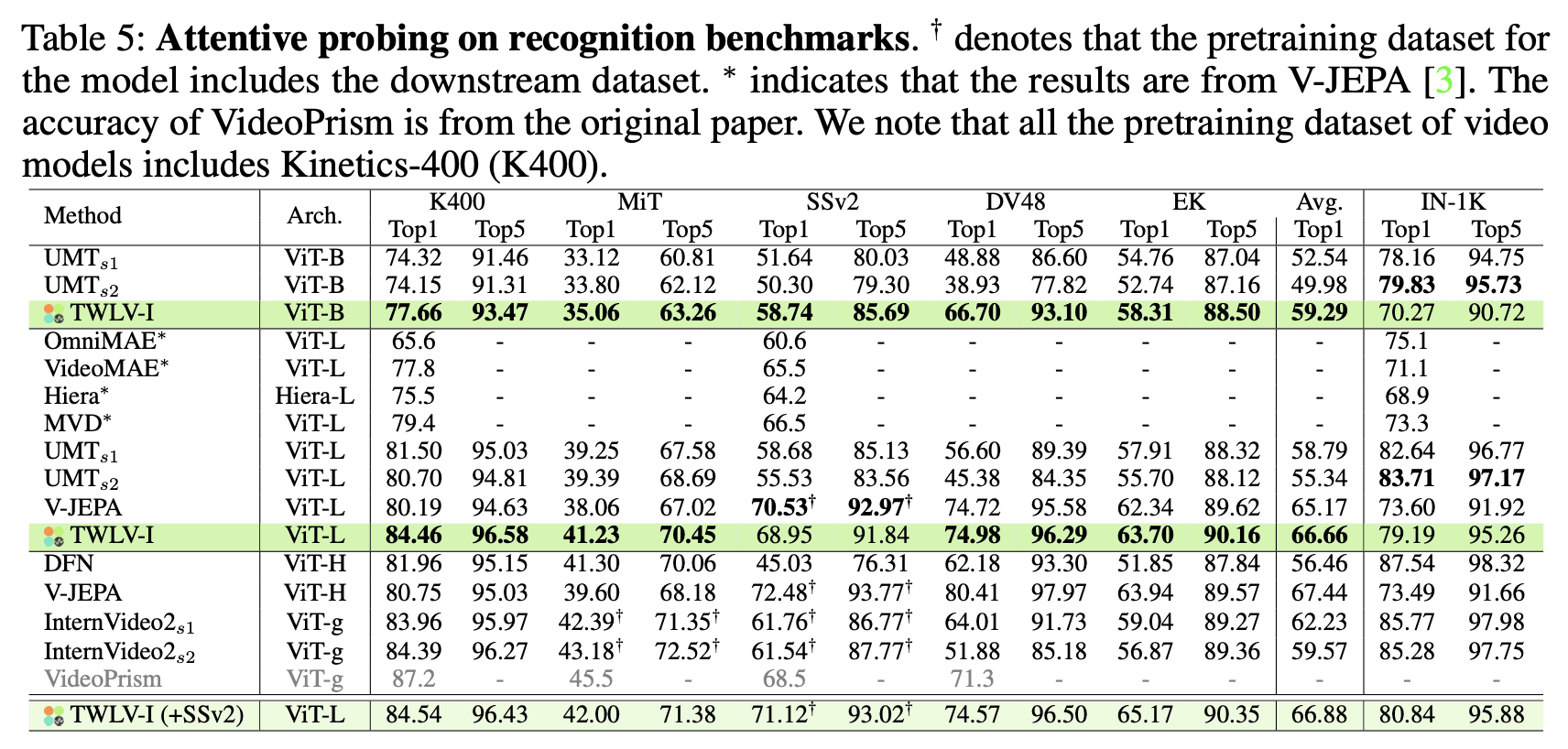
結果と分析
表5は、アテンティブプロービングの結果を示しています。主な発見は以下の通りです:
TWLV-Iは、外観重視および動き中心の両方のベンチマークにわたって、他のモデルと比較して優れた性能を達成しています。
アテンティブプロービングにおける強力なパフォーマンスは、TWLV-Iが同等のモデル群に比べて、より詳細で豊かなパッチ単位の表現をそなえていることを示唆しています。
3.5 - K近傍法(K-Nearest Neighbors)
勾配法に基づく評価での潜在的な偏り(バイアス)を排除し、パラメータフリーな状態で埋め込みの品質を評価するため、私たちはK近傍法(KNN)分類タスクを採用しています。このノンパラメトリックなアプローチにより、異なるモデルアーキテクチャ間で埋め込みベクトルをより公正に比較することができます。
私たちは、以下の2つの手法で埋め込みを生成します:
一律の埋め込み(Uniform Embedding):ビデオ全体に対して1つの埋め込みベクトルを生成します。
マルチクリップ埋め込み(Multi-Clip Embedding):ビデオ全体にわたる2秒間のクリップから複数の埋め込みを生成します。
マルチクリップ埋め込みでは、2つの評価戦略を採用しています:
ビデオレベル:すべてのクリップの埋め込みを平均化して、単一のビデオ表現を作成します。
クリップレベル:各クリップが獲得した投票を合計して、最終的なクラスを決定します。
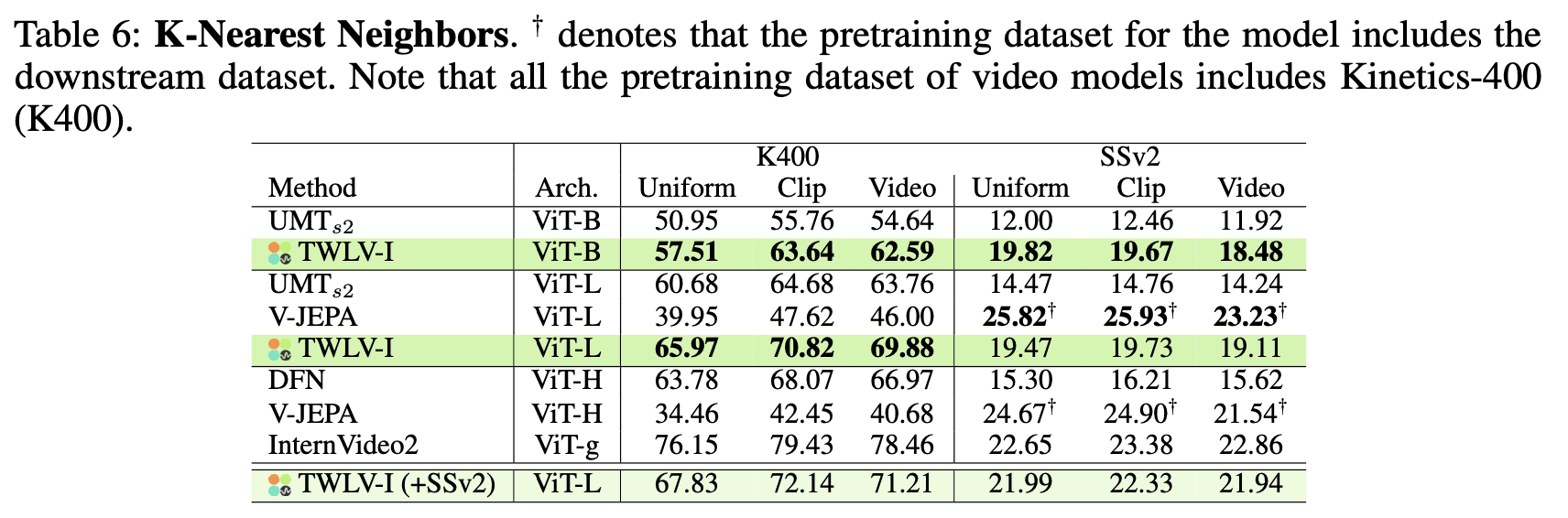
結果と分析
表6は、異なるモデルおよび埋め込み戦略におけるKNN分類の結果を示しています。主な観察結果は以下の通りです:
TWLV-Iは、Kinetics-400(K400)およびSomething-Something-v2(SSv2)の双方のデータセットにおいて、特に対象モデルが同等規模のものと比較した際に、極めて競争力のある性能を示しています。
Uniform(一律)埋め込みの設定において、TWLV-I-ViT-BはK400で57.51%、SSv2で19.82%のTop-1精度を達成し、同一のアーキテクチャを持つUMT_s2を凌駕しています。
TWLV-I-ViT-Lは強力な結果を示しており、K400で65.97%、SSv2で19.47%のTop-1精度を達成し、いくつかのより大規模なモデルを上回っています。
それにもかかわらず、アテンティブプロービングでの結果とは異なり、KNN評価においてTWLV-IはK400およびSSv2の双方でInternVideo2に一歩及ばない結果となりました。これは以下を示唆しています:
TWLV-Iの埋め込みをノンパラメトリックな方法で活用する余地がまだ残されていること。
特に長時間のビデオ(単一クリップの長さを大幅に超えるもの)について、その埋め込みを効果的に表現する方法に関する更なる研究が必要であること。
これらの結果は、ビデオ表現の複雑さと、異なる評価手法のすべてにわたって普遍的に強力な埋め込みを構築することの難しさを物語っています。
3.6 - SSv2を用いた事前トレーニング
V-JEPAなどのモデルとの公平な比較を行い、事前トレーニングに動き中心のデータを取り込むことの影響を評価するため、私たちはSomething-Something-v2 (SSv2) データセットをTWLV-Iの事前トレーニングフェーズに組み込む追加の実験を行いました。
私たちは、元のデータセット群に加えて事前トレーニング用データにSSv2を組み込み、TWLV-I(ViT-Lアーキテクチャ)のバリアントをトレーニングしました。これにより、この追加データが様々なベンチマークや評価に与える影響を直接比較できます。
結果と分析
このSSv2を組み込んで拡張されたモデルの評価結果は、表3、表5、および表6の下部に示されています。主な発見は以下の通りです:
SSv2パフォーマンスの進歩:すべての評価方法(リニアプロービング、アテンティブプロービング、およびKNN)を通じて、そのモデルはSSv2ベンチマークにおいて大幅な進化を遂げています。たとえば、リニアプロービング(表3)では、SSv2でのTop-1精度が46.41%から48.14%に上昇しました。
全体の総合的性能向上:事前トレーニングにSSv2を含めることで、他のベンチマークにおいても性能向上が見られました。これは、動き中心のデータを追加したことで、モデルの全体的なビデオ理解能力が向上したことを示唆しています。
専門特化モデルとの比較:性能が改善されたものの、動き中心のSSv2における事前トレーニング拡張モデルのKNN性能は、同テスト上で依然としてV-JEPAおよびInternVideo2に対して遅れをとっています。これは、TWLV-Iのパッチレベルの表現能力は強力である一方、ビデオレベルでの表現力には改善の余地があることを示しています。
表現性能におけるトレードオフ:結果は、TWLV-Iのパッチレベルとビデオレベルの表現において、潜在的な不均衡がある可能性を浮き彫りにしています。この顕著なギャップへの対処は、今後のモデル拡張に際しての重要フォーカスとなるはずです。
これらの発見は、堅牢なビデオ基盤モデルの開発において多様な事前トレーニングデータの存在が極めて重要であることを強調しています。また、外観中心のベンチマークでの高い性能を維持しつつ、動き中心のタスクにおいて特定の専門モデルにより良く対抗するために、TWLV-Iを改良できる具体的な領域を指示してくれています。
4 - ImageNet 分類
ビデオ基盤モデルの汎用性と、それらが一般的な画像認識モデルとして機能する可能性を評価するために、ImageNet分類タスクにおけるTWLV-Iの性能評価を行いました。このベンチマークは、静止画像を処理・理解するモデルの能力についての洞察を提供し、これは包括的なビデオ理解システムを構築する上でも不可欠な要素です。
4.1 - 結果と分析
ImageNetの分類結果は、表3(リニアプロービング)および表5(アテンティブプロービング)の最後の列に示されています。主な観察結果は以下の通りです:
外観中心のタスクとの相関関係:一般的に、外観中心の動画動作認識タスク(例: Kinetics-400)で優れたスコアを達成するモデルは、ImageNetベンチマークにおいても強力な性能を発揮します。この相関関係は、ビデオ理解のために学習された特徴が、静止画分類タスクにも効果的に転移できることを示唆しています。
TWLV-Iのパフォーマンス:
リニアプロービング(表3)において、TWLV-I-ViT-LはImageNetで72.98%のTop-1精度を達成し、競争力はあるもののトップには至っていません。
アテンティブプロービング(表5)では、TWLV-I-ViT-Lは79.19%のTop-1精度へと性能が向上しており、アテンションメカニズムを介した学習済み特徴のさらなる有効活用を示してくれています。
専門特化モデルとの比較:TWLV-Iはビデオベースのタスクにおいて強固なパフォーマンスを発揮している一方で、いくつかの特定目的のモデルと比較するとImageNet分類のスコアには目に見えるギャップがあります。たとえば、InternVideo2はImageNetにおいてTWLV-Iを大幅に上回っていますが、ビデオ動作認識タスクにおいてはその性能差は狭まり、場合によっては逆転することもあります。
4.2 - 示唆と洞察
これらの観察に基づき、私たちは次の洞察を得ました:
静止画像処理における制約:結果から、TWLV-Iは、当該タスクに最適化されたモデルと比較して、静止画像の処理についてある程度の制限があることが示されています。これは、モデルの将来のアップグレード段階における改善余地があることを示します。
動作情報の活用能力:ImageNetのスコア差をよそに、ビデオタスクにおいてTWLV-Iと他モデルとの性能ギャップが縮まることは、TWLV-Iがビデオ理解において動作情報を非常に効果的に活用していることを示唆しています。この能力は外観ベースの特徴保管と補完し合い、結果として強力なトータルビデオ分析性能をもたらします。
ビデオと画像能力の均衡化:TWLV-Iを単なる動画特化モデルから、さらに前へと進化させるために、今後の研究ではその強力なビデオ分析能力を損なうことなく、単一画像を理解する能力を強化することに焦点を当てるべきです。
総括として、TWLV-Iはビデオ理解タスクにおいて強力な性能を示しているものの、ImageNet分類結果は、静止画像処理におけるいくつかの改良すべき領域を示しています。これらの制約に対処することで、ビデオと画像の双方のドメインにわたって秀でた、より包括的な視覚基盤モデルの実現につながる可能性があります。
5 - 時間の動作ローカライズ
時間の動作ローカライズ(Temporal Action Localization; TAL)はビデオ理解における重要なタスクであり、トリミングされていない一連のビデオの中から特定の動作を特定し、時間的位置を特定することを含みます。このタスクは自動運転、スポーツ分析、コンテンツに基づくビデオ検索などの応用において特に重要です。TALでは、モデルが長くて複雑なビデオを分析し、その中で発生する各動作の時間的な境界と対応するクラス分類ラベルを正確に判定することが求められます。
5.1 - 評価の視点
TALは、主に以下の2つの主要な視点からビデオ基盤モデルを評価します:
時間的感度:関心のある動作が特定のタイムステップで発生したかどうかを識別する能力。
インスタンス識別能力:フレームごとのセグメントを、完全な一つの動作インスタンスに識別またはグループ化する能力。
TALは本質的に動作中心のタスクとして設計されていますが、私たちの分析によれば、これら2つの側面の効果的な達成において、外観と動きの双方の能力が相乗的に寄与していることが明らかになりました。
5.2 - 手法
私たちは、TWLV-Iおよび他の動画基盤モデルを、以下の2つの著名なTALデータセットにおいて評価しました:
ActivityNet-v1.3
THUMOS14
検出用のヘッドとしてはActionFormerを採用しました。そして、以下の2つの異なる検証方法で評価を行いました:
自己完結型(Self-contained):モデルの外部サポートを受けることなく、自ら単独で分類と回帰の両方を実行します。
外部分類器併用型(w/ External Classifier):モデルは二値分類を行い、実際の動作クラスの予測は外部の分類器が行います。
特徴の抽出は、「フレームサンプリング」セクションで説明したマルチクリップ埋め込み手法に従って行われました。
5.3 - 結果と分析
表9と表10はそれぞれ、THUMOS14およびActivityNet-v1.3における包括的な結果を示しています。
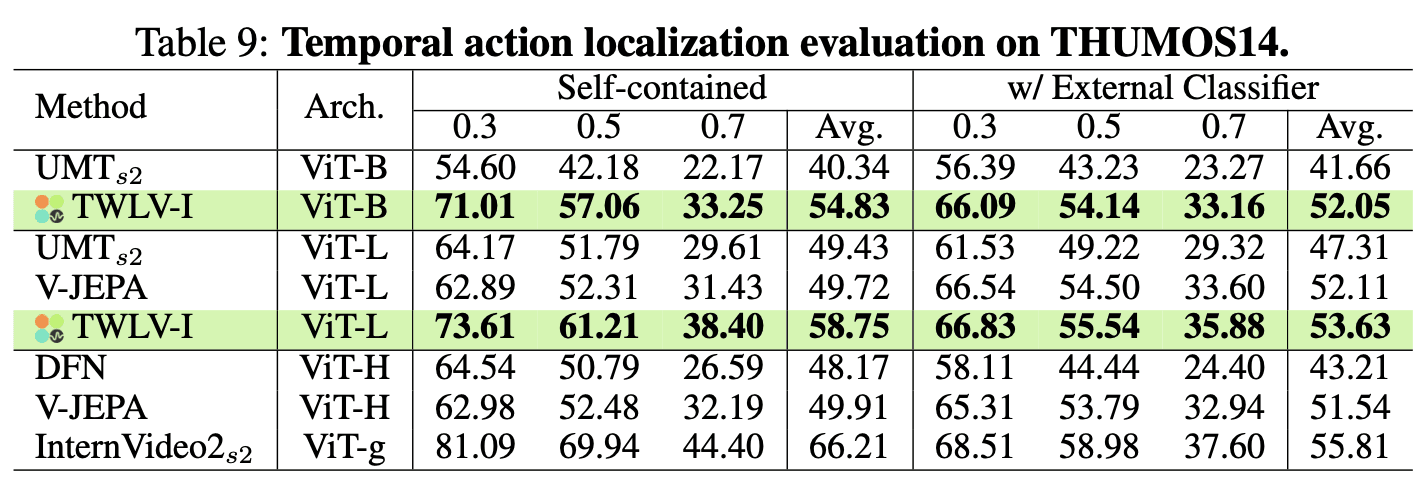
THUMOS14(表9)
TWLV-I(当社モデル)は、すべての検証指標において、同一スケールの他のモデルを一貫して上回る性能を示しています。
TWLV-I-ViT-Lは、自己完結型設定で58.75%、外部分類器併用設定で53.63%という最高の平均mAPを達成しました。
特筆すべきは、TWLV-I-ViT-LがDFNやV-JEPA (ViT-H) のようなより大規模なモデルををも凌駕している点であり、その優れた汎用・一般化能力を証明しています。
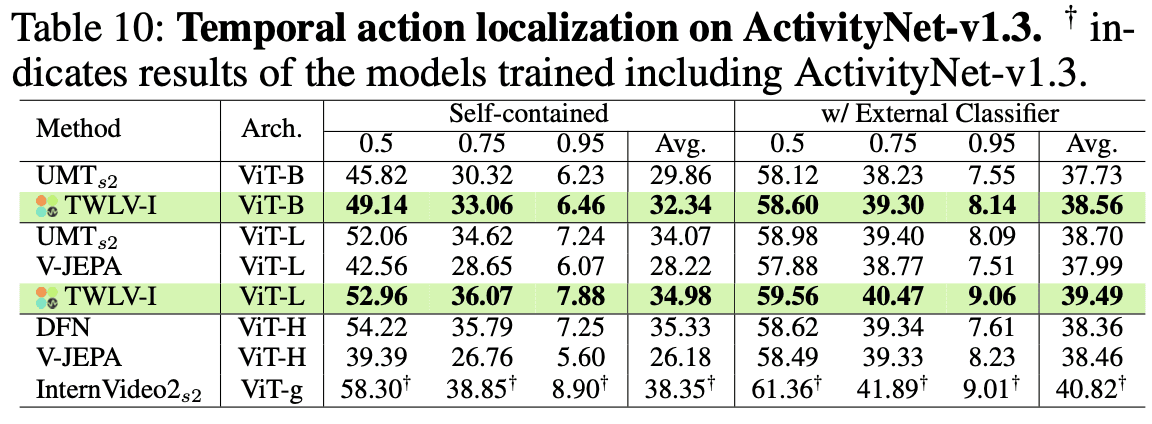
ActivityNet-v1.3(表10)
TWLV-Iはここでも、そのアーキテクチャの規模感において屈指のパフォーマンスを示しています。
TWLV-I-ViT-Lは、平均mAPで34.98%(自己完結型)および39.49%(外部分類器併用型)を記録しました。
驚くべきことに、TWLV-Iは厳格なIoU閾値(例: 0.95)において極めて優れた性能を発揮しており、並外れた時間的感度を有していることが示されています。
5.4 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
スケール効率:TWLV-Iのパフォーマンス、特にViT-Lの規模感において他社大容量モデルを打ち負かしている現状は、その効率的な設計アーキテクチャとトレーニング手法を明白に証明しています。
時間的精密さ:極めて厳しい基準である厳格なIoU閾値(ActivityNetにおける0.95等)での高スコア獲得は、TWLV-Iが誇る突出した時間的感度の鋭さを証明しています。
モデル規模の影響:InternVideo2のトップパフォーマンス、特に自己完結型の評価における実績は、TALタスクにおいて分類と時間的境界の回帰を同時に実行する際、モデルの規模拡張が大きく利益をもたらすことを示唆しています。
評価戦略:単に「動きの理解」のみに的を絞って正確に測定したい場合は、外部分類器との併用が推奨されます。一方で、外観の理解度をも包含するより網羅的な評価を望む場合は、自己完結型のアプローチが求められます。
汎化能力:異なる複数のデータセットおよび評価方法にわたるTWLV-Iの終始強力なパフォーマンスは、時間の動作ローカライズ分野における主要バックボーンとしての屈強さを表しています。
これらの結果は、時間の動作ローカライズという極めて複雑な課題に対するTWLV-Iの抜群の有用性を物語っており、時間的感度と動作のまとまり認識の双方においてバランスよく実力を備えていることを明確に示しています。様々なスケールや多様な測定環境において現れたその高い適合能力は、ビデオ理解全般を支える汎用的ベース基盤としての高いポテンシャルを示しています。
6 - 空間・時間の動作ローカライズ
空間・時間の動作ローカライズ(Spatio-Temporal Action Localization; STAL)は、ビデオの中の特定の動作を認識するだけでなく、編集されていないビデオ系列内の空間(画面中のどこか)および時間(いつ発生したか)の双方を正確に検知・特定する、高度で複合的な難関課題です。この課題はアクションの精密な分析が必要とされるシーンで重要視され、外観と動き双方の完全な統合理解がモデル側に問われます。
6.1 - データセットと評価
私たちは、1本あたり15分間の映画から切り出された430個の動画クリップで構成されているAVA v2.2データセットを用いてモデル検証を行っています。キーフレームは毎秒付与され、学習用セットに210,634枚、検証用セットに57,371枚のラベル付きフレームが含まれています。データセットには、各俳優に紐付けられた80個の原子的な基本動作ラベルが含まれています。
この動作評価では、最新のv2.2アノテーションを使用し、Intersection over Union (IoU)の閾値0.5におけるフレーム平均精度(Frame Average Precision; fAP)を取得して比較しています。私たちはエンドツーエンドのSTALフレームワークを採用し、バックボーン側のビジュアルモデル部分を固定した状態でデコーダの追加トレーニングを実行しました。
6.2 - 結果と分析

表11は、STALタスクにおける性能評価を示しています。主な観察結果は以下の通りです:
他モデルとの対比:TWLV-I、UMT、およびInternVideo2は、DFNやV-JEPAより優れた性能を発揮しています。DFNとV-JEPAは他の種類のタスクで全く異なる極端なスコア傾向を見せていましたが、物体としての人物特定と、時間的な動作認識の双方をクリアする必要があるSTALタスクにおいては、その性能は似たような値にとどまっています。
検出局所化における難点:
V-JEPA:人物などのインスタンスの特定そのものに手こずり、それが後続の動作認識スコアにも波及して悪影響を与えています。
DFN:得意とする外観の精緻な理解力により、対象が画像のどこにいるのかを素早く特定できていますが、時間情報の解釈の限界から、そこでどのような動作が行われているかの認識で誤答しています。
TWLV-Iの特徴的な強み:
TWLV-Iは、物体の外観と動作中の物理的変化を極めて高いレベルで調和よく理解することで、STALタスクにおける確固たる強さを現しています。
ViT-Lモデルにおいて、TWLV-IはfAP@0.5で27.39を達成しました。これはDFNやV-JEPAを大きくリードし、より構造の大きい巨体モデル群であるInternVideo2の記録に肉薄する性能スコアです。
6.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
調和のとれた深い読解:今回の好成績は、TWLV-Iが時空間情報を極めて適切に理解できていることを示す十分な証拠であり、精度の高い時空間ローカライズを実現する上でも要となります。
全般的なビデオ判定価値:終始シームレスにエンドツーエンドで行われるSTAL検定は、空間と時間の2つの次元におけるパフォーマンスを高い再現性を持って明らかにする包括的なモデル審査手法と言えます。
手法の有効性検証:TWLV-IがUMTやInternVideo2と並んで好成績を残している現状は、空間位置特定と動作分析の2つの異なる目標を同時に処理する能力の現れであり、外観のみ、あるいは動作のみといった限定的な一方を追求した他社モデルとは一線を画しています。
これらの裏付けは、時空間の複雑なシーンを正確に記述する必要がある高度な難題(STAL等)を解決するために、外観情報と動作変化情報の双方が一つの脳(モデル)の中にバランスよく統合されていることが如何に決定的であるかを語っています。
7 - 時間の動作セグメンテーション
時間の動作セグメンテーション(Temporal Action Segmentation; TAS)は、編集されていない長時間のビデオから人間の複雑な活動の全貌を読み解くために非常に重要とされている応用課題です。セキュリティ監視、ハイライト映像などの要約作成、作業スキルの機械的審査など、広範な産業でその活躍が期待されています。TASでは、トリミングされていないビデオを入力として直接流し込み、それぞれのフレームに一連の正しいアクションのクラス分類ラベルを追加していく作業を行います。
7.1 - 表記比較基準とアプローチ
私たちは、TASの性能を判定すべく以下の3つの高難度検証基準を用意しました:
50Salads:調理の手順において、細々とした変化を伴う複雑な一連の処理を含んでいます。
GTEA:一人称の目の高さで撮影した、複雑な身の回り仕事の一連のプロセスを記録しています。
Breakfast:引いた位置からも撮影された、全身でキッチン作業をこなす長時間の全体構成データです。
TASのデコーダ部分としてはASFormerを使用しました。閾値10、25、および50のもとで測定されたF1スコアの平均値を「mF1」として評価に採用しています。マルチクリップ埋め込みを用いて特徴を抽出し、空間次元プーリングを施すことで時間軸のみを滑らかに残しています。
7.2 - 結果と分析
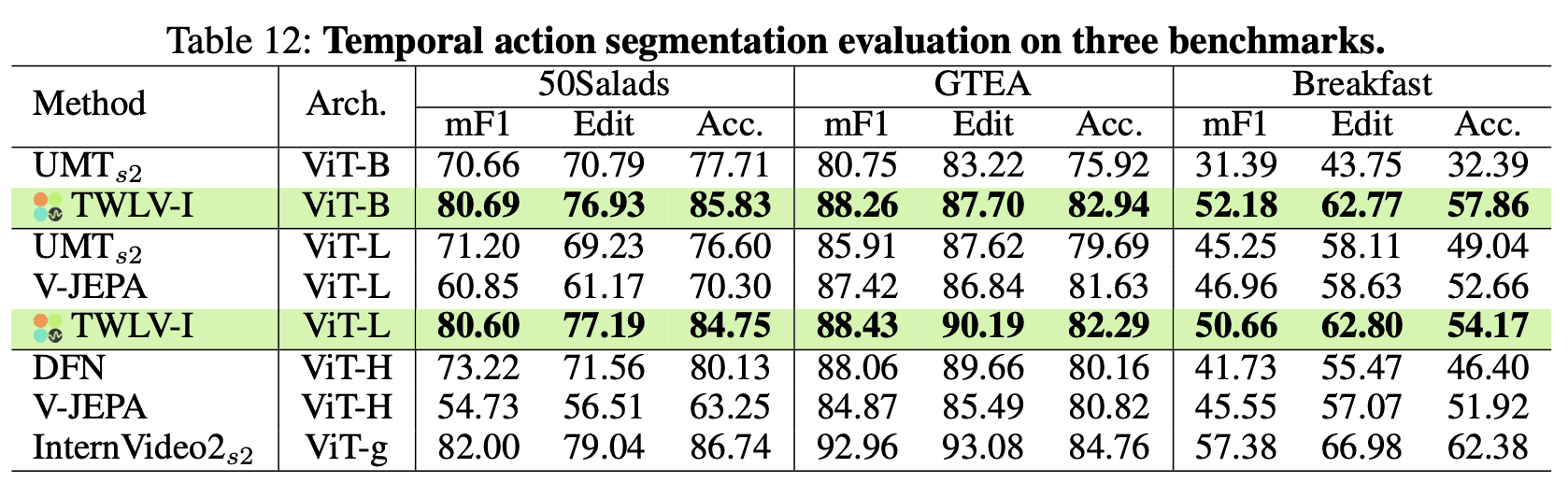
表12は、これら3つのテスト条件のもとで実施したTAS試験の結果を詳細を伝えています:
50Salads:TWLV-Iは、ViT-Bで80.69、ViT-Lで80.60のmF1スコアをマークしました。これは、UMTやDFNといった外観重視モデルや、動作変化を専門としたV-JEPAをも完全に跳ね除ける数値です。また、エディットおよび予測適合率の項目についても、TWLV-Iの手法が正解データ配列に極めて整合していることを明らかにしています。
GTEA:TWLV-Iはさらに強さを示し、ViT-Bで88.26、ViT-Lで88.43のmF1スコアを記録して競合を大きく引き離しました。これは、一瞬で移り変わるアクションの正確なセグメンテーションを必要とする、一人称主観視点の動画において真価が浮き彫りになることを証明しています。
Breakfast:被写体が遥か遠くにフレームインする視野角の広いこのシーンでも、TWLV-Iは実力を落とすことなく、ViT-Bで52.18、ViT-Lで50.66という好ましいmF1スコアを獲得しています。目まぐるしく変化するカメラ視野の切り替わりに対しても、その対応柔軟性が高水準に維持されています。
7.3 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
完成されたオールラウンダーとしての実力:データの多様性によらずあらゆる分類群で最高峰に位置するTWLV-Iの一貫した強さは、外観の把握力と動作の持続変化を漏らさず記述する能力のバランスが非常に良好であることを意味しています。
実際の推移への適合精度:エディットスコアおよびmF1スコアが高水準にまとまっていることは、TWLV-Iが予測したアクションの流れ全体(系列)が、実際のビデオ内で人間の動作した現実の順序に正確に合致していることを意味し、将来的なオンサイト実装における安全・信頼性の高さを示しています。
視野角変化に対する屈強さ:上空からの撮影、手元を映す一人称主観カメラなど、極端な画角変更があっても他製品以上のスコアを叩き出し続ける事実は、いかなる用途でも現場を選びにくい柔軟性のある頑丈なモデルであることを実証しています。
InternVideo2とのベンチマーク性能比較:特定のアングルのデータにおいて、TWLV-IはInternVideo2に類似する好成績を取り分けて現していますが、広範囲にまたがる複数データセットを前にしても性能がブレることのなく、常に一貫した優秀さを維持する確実性は、総合的なポテンシャルの高さをはっきりと映し出しています。
これらの評価により、時系列動作セグメンテーション(TAS)の非常に挑戦的な検証において、TWLV-Iがビデオ解析を応用可能とする多大なる可能性を備えていることが確かに認められました。
8 - 埋め込み空間の可視化
TWLV-Iや他社基盤モデルのビジュアル表現能力がどのように構造化されているかを詳しく探索するため、私たちはt-SNEおよび線形判別分析(LDA)を用いたビジュアル確認実験を実施しました。これにより、作成された埋め込みベクトルが「外観情報」と「動き情報」の各々の側面をどれほど精緻に描写できているかが理解できます。
8.1 - t-SNEを用いた各評価データセット上のマッピング
t-SNEを用いて、Kinetics-400 (K400) および Something-Something-v2 (SSv2) 検証用セットにおける埋め込みベクトル分布をマッピングしました。また、色分けは異なるアクションクラスを表しています。
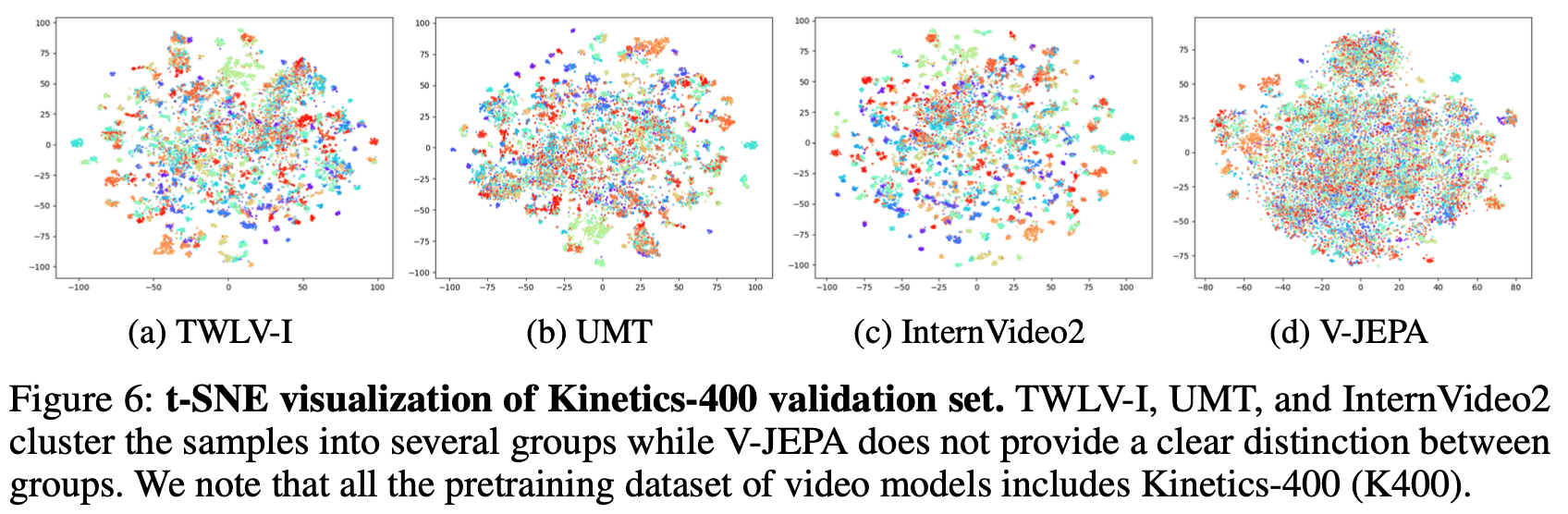
Kinetics-400(図6)
TWLV-I, UMT, および InternVideo2:これらのモデルは同じ特性をもつ動作どうしが1つのブロックのように固まりを構築し、境界線を容易に引くことができるきれいなクラスタリングを示しました。これは、外観に基づいて表現が異なる多数の動作群を驚くほどきれいに判定できていることを意味します。
V-JEPA:打って変わって、各動作クラスをごちゃ混ぜに描いてしまい、特徴空間を明確に分割することができていません。静止構造(外観ターゲット)をきれいに捕捉できていない性質が読み取れます。
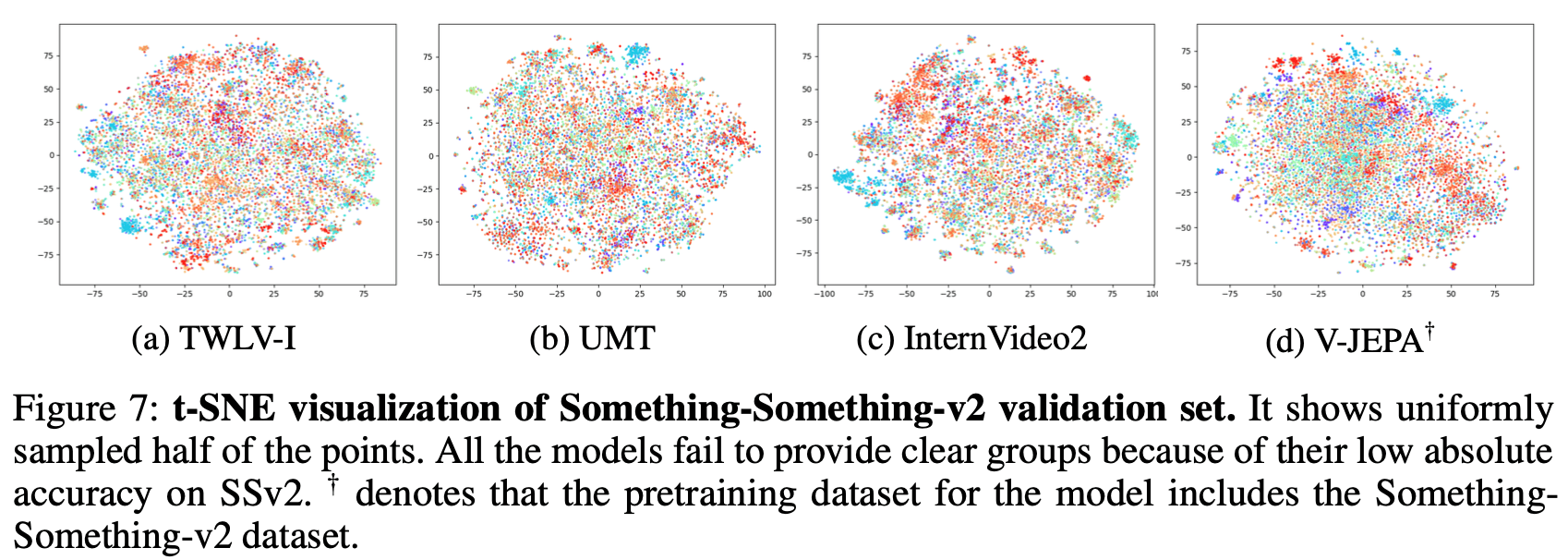
Something-Something-v2(図7)
全モデルの傾向:面白いことに、TWLV-IやV-JEPAも含め、どのモデルもSSv2のような高度に動きが重視されるデータセットにおいては、一目で分かるようなクラスタリングを表示できませんでした。これは、他の手法に比べ、そもそもSSv2の分類スコアがどの製品でも総じて低い実情と重なっています。
そのことが暗示する意味:このプロットによる描画結果は、動きそのものの質的違いを明確なベクトルのまとまりの中に落とし込んで表現することが技術的に如何に困難であるかを雄弁に物語っており、ブレイクスルーを呼び起こす今後の革新的アプローチが待ち望まれます。
8.2 - 動作の方向に対する感度検証
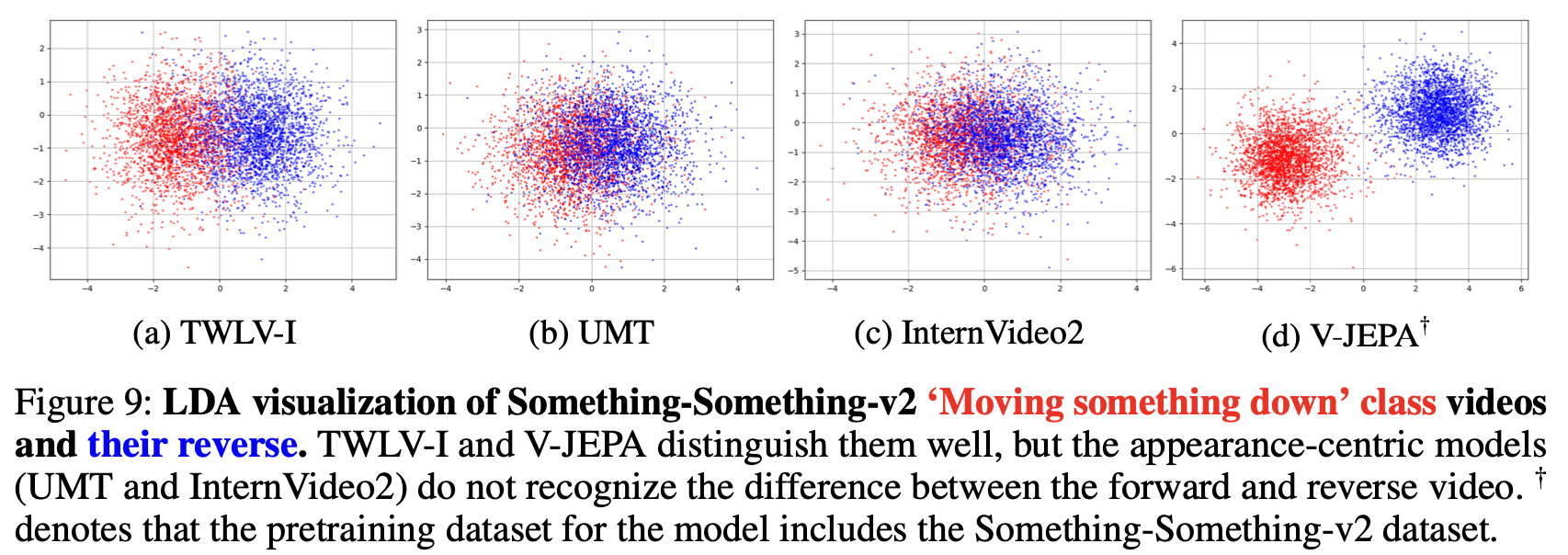
よりミクロなレベルにおいて、モデルが動きをどのように知覚しているかを理解するために、私たちはSSv2から「何かを押し上げる」「何かを引き下げる」といった、動作の物理的方向の読解が無ければおよそ解答不可能な、特定の動作ペアに注目しました。
私たちは、通常の正再生動画から切り出した動画ベクトルと、それを時間軸に対して逆転させた逆再生動画の埋め込みベクトルを抽出し、線形判別分析(LDA)を用いてプロットしました。この検証では、外観が全く同じである動画どうしの順逆方向について、純粋に時間的経過の順序だけでその差異を埋め込みベクトル空間上で分離できるかどうかをテストできます。
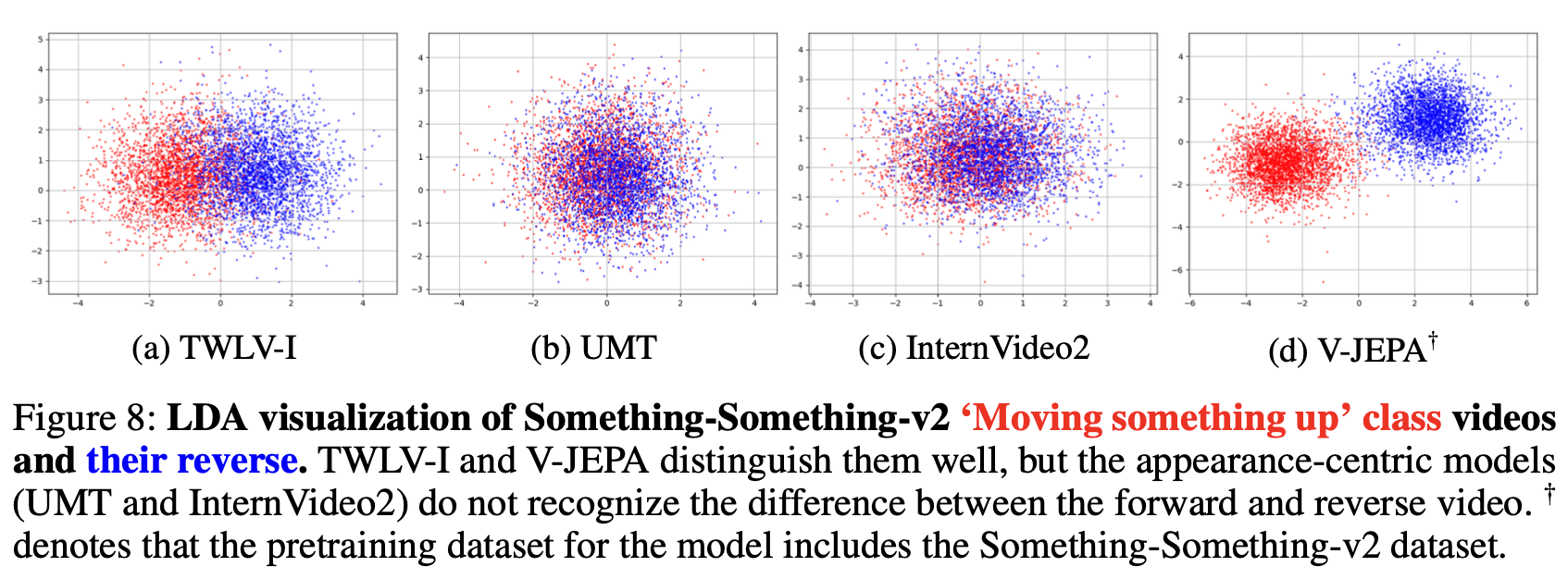
結果(図8および図9)
TWLV-I:正再生と逆再生の動画が交じることなく極めて良好に二極反転の空間位置を保っており、時間方向の違いをベクトルの差異の形で確実に記述できていることを実証しています。
V-JEPA:ここでも正逆識別において最も広い距離感(明確さ)を獲得しています。これは、同モデルが事前トレーニング時から意図的にSSv2データセットを多量に摂取している実績に起因すると考えられます。
UMT および InternVideo2:埋め込みの正負領域での重複が大きく分離困難に陥っています。これは、静止画像の精緻な理解を得意とする一方で、時間方向に対してはほぼ感度を持たない(動作変化に対して無頓着な)設計上の構造を示しています。
8.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
外観と運動変化を同時に記述する能力:TWLV-Iは、静止画を基準とする認識分類力(K400の図から顕著)と、動作方向による時間秩序変化の知覚力(順逆分析から顕著)の双方を高レベルで併せ持つ、類稀なるオールラウンド性能を持っていることがビジュアルからも明らかになりました。
動作の質的表現(モデリング)のための課題:SSv2のクラスタリングで全ての競合が描いたカオティックなプロット図は、運動表現のみで多様なクラス群をきれいに定常分離していく作業が今なおどれほど高難易度であるかを示し、ビデオ分野における最大のテーマとして残されています。
時間変化に対する鋭敏な解釈力:正逆方向のビデオを即座に引き裂くTWLV-Iのおおきな分離能力は、ただ物理的な情報を見るだけでなく、動画ならではの微細な時間フレームの前後変化にまで高い感度で反応を返せていることを意味し、高度な動作記述の足がかりとなります。
各社モデルの個別得意分野:プロットにより、それぞれの製品群が得意とする設計方針の違いが鮮明になり、外観を高度に見抜くモデルがある一方で、時間的運動のみをうまく感知するような尖った得意領域に特化するなどの現状が浮き彫りになり得ます。
これらの特徴的な視覚マッピングによる可視化手法は、TWLV-Iの脳がどのように特徴を獲得しているかを視覚的に雄弁に説いてくれており、今後の改善策を計画するための重要な技術基盤となります。
9 - 今後の開発テーマ
今後の展望として、TWLV-Iの実用拡大、およびビデオ基盤モデル一般を劇的に変革し、応用領域を広げるためのいくつかの有望な発展レーンが存在します。これらは、モデル能力の大幅補強、スコア改善、さらに多領域における産業実装の加速を目指すものです。
9.1 - モデルスケールの拡張
これまでのところ、主に以下の2つのモジュール構成を中心にリリースしてきました:ViT-BおよびViT-L。しかしながら、当社のTWLV-I-ViT-Lは、一回り体が大きい他社製のViT-HやViT-gの記録と同等、場合によってはそれを超える良好な数値を叩き出しています。この効率の良さは、今後モデルを拡張した場合、さらなる大幅なポテンシャル向上の余白があることを意味します:
極大規模アーキテクチャの導入:TWLV-Iをより極大サイズのモデルへと引き上げることで、多様な検証ベンチマークにおけるスコアを飛躍的にレベルアップさせることが大いに期待されます。
内製の極大データセットの構築:自社で囲い込みを行って獲得した並外れた規模の大容量学習資源を使用することで、さらに柔軟であらゆる変化に強い強固なベースを育むことが可能です。これは未体験の難題や新たなシーンをモデルが難なく見抜く手助けとなります。
高効率スケーリング設計:スパースアテンション構造やMixture-of-Experts (MoE) と言われるマルチネットワーク構造などの高効率スケーリング手法を採用することで、開発リソース資源を際限なく食いつぶすことなく、極端な機能アップグレードを安定して実現させられます。
9.2 - 画像埋め込み機能の大幅強化
TWLV-Iはビデオに関わる項目で強い優位性を現したものの、単一の画像そのものの埋め込みを表現する精度に関しては、さらに向上させられる余地が残っています:
静止フレームの読解力強化:ビデオから切り出した1枚のフレームそのものを正確に把握する精度を強化することは非常に合理的です。この能力が磨かれれば、ビデオの得意さと画像の得意さが統合され、TWLV-Iは総合的に完璧なビジュアル認識プラットフォームとなり得ます。
転移学習アプローチの探索:動画上で構築された「動作変化を前提とした知覚表現」を、うまく静止画における分類タスクの補助特徴へと転移する学習アプローチが構築できれば、一般的な画像AIタスクにおける信頼性を容易に格上げできます。
単一フレームワークでの統合学習:同一のシステム構成のままで、ビデオからの入力と静止画からの入力のいずれでも変わらぬ適合率をたたき出す、シームレスな統合アーキテクチャの変更を推進します。
9.3 - モダリティレンジの拡張
さらに、TWLV-Iとしての利便性を全方位的にレベルアップさせ、AI産業自体の需要とより強固に噛み合わせるために、モダリティレンジを着実に拡張することが非常に重要です:
マルチモダルの活用促進:ビデオと引き当てられる文章推薦(ビデオテキスト検索)や、動画を正確に文字に直すビデオキャプションなど、極めて複雑な多元タスクを処理できるように改良します。これにより、卓越した映像把握力を生かしたまま、テキストと調和的に交信できるようになります。
ビデオLMMとしての位置づけ構築:TWLV-Iの構造をビジュアル側にとって最適なビジョンエンコーダとして位置付け、先進的なビデオ・大規模言語モデル(VLM)との高水準な接ぎ木を実現します。高度なテキスト理解力とのシームレスな融合が可能となります。
音声特徴の統合理解:動画内の時間変化に伴う「音声変化(オーディオ)」を映像と時間補正した状態で統合することで、音と映像のタイミングマッチング、音の出どころイベントの検出など、さらに応用度をました技術を実現します。
テスト手法の体系化と基準設定:これらの極めて応用的なマルチモダル性能について、信頼性高くスコア検証していけるよう、独自の統合的な判定テスト手法や新たな検証基準を設け、その安定性を保証していきます。
これらの将来像を追うことで、TWLV-Iが提供するバリューを「ビデオ専用のベース」から、「様々な周辺状況に対して瞬時に協調できる究極の知覚システム」へと引き上げることを想定しています。この発展は、現在実現されている機能群での性能を引き上げるのみならず、自動応答アシスタント、次世代のコンテンツクリエイト事業、革新的な人間とロボットのインターフェース構築といった未来的な産業へ決定的な道を開きます。
10 - おわりに
私たちは今回の体系的なビデオ検証において、絵画的な美しさ(外観)と移り変わる変化(動き)の2つの要素の調和が、映像解釈という広大で豊かな目的をクリアするためにいかに決定的であるかを詳述してきました。私たちの取り組みは、以下の素晴らしいブレイクスルーと発見をもたらしています:
多角的で包括的な測定規格:動画の時間的ローカライズから一連のアクションシーケンス抽出まで、あらゆる側面においてモデルの能力を均一な視点で測定できる、信頼性の高い規格を提供しています。
既存モデルの顕著な改善余白:一連の周到な検証プロセスにより、他モデル群が動作と外観のいずれか一方のみの知覚に依存し、両者を共にハイパフォーマンスに両立することがいかに苦手であるかを明らかにし、この分野におけるミッシングリンクを特定しました。
満を持してのTWLV-Iの紹介:これらの業界の不均衡に対して最適な解を与えるべく、外観と動作の両方を同時に、そして高解像度に把握する新世代のアプローチ「TWLV-I」を投入しました。
抜群の埋め込み品質:TWLV-Iが生む埋め込みベクトルは、高度な下流タスクを非常に簡便にいなす高い適用力を見せており、実用化の検証コストを劇的に圧縮します。
汎用的で強力な検証用フレームワーク:本ブログでお披露目された多様な検証とプロット比較法は、今後のビデオ基盤モデルの基礎テスト規格となる得るよう、業界コミュニティへ開示されています。
将来のイノベーションプラン:今後の研究をドライブするために、モデルの大容量化、画像識別のブラッシュアップ、さらには音響やテキスト等の他系統とのマルチリンガル的な統合を進めていきます。
業界の目指すべき座標の提示:外観性能のみの偏重、動きのみの過学習を克服し、双方をひとつの体にバランスよく共存させる姿勢を示すことで、ビデオ理解領域が目指すべき進路を設定できたと自負しています。
要約すれば、TWLV-Iは万能型でかつ不屈の動画基盤モデルを作るうえで、記念碑的な飛躍を示すモデルです。外観知覚と動作知覚を絶妙に調和させることで、これまで想像さえ難しかった、高次元の動画理解と多角的な用途への扉が開かれました。私たちは、ここで開示された評価スキームやアイデアが多くの研究者をエンパワーし、新しい視点、そしてより本質に迫るアプローチで今後の課題に取り組んでもらえることを切に願っています。
この先、こうした完璧な統合基盤がさらに成熟していくプロセスは、ビデオを取り扱う多くのソフトウェア群のブレイクスルーにつながり、AIが生活シーンを支える究極のパートナーへと変貌していくために重要となります。私たちは世界中のリサーチャーとともにこの挑戦の地盤を盤石なものとし、ビデオAIが切り開く素晴らしい未来へのフロンティアを共に開いていくことを歓迎します。
Twelve Labs チーム
本研究開発は、Twelve Labs ML ResearchおよびML Dataチームの厚い支援のもと、核となる以下の主要執筆者たちの均等な(equal contributionという素晴らしい連携による)献身的な貢献を通じて達成されました。
主要な執筆者・研究代表
Hyeongmin Lee, MLリサーチャー(Research Scientist)
Jin-Young Kim, MLリサーチャー(Research Scientist)
Kyungjune Baek, MLリサーチャー(Research Scientist)
Jihwan Kim, MLリサーチャー(Research Scientist)
Aiden Lee, 最高技術責任者(CTO)
コントリビューター(アルファベット順表記)
Aaron (Jangwon) Lee, MLデータ・インターン\
Calvin (Minjoon) Seo, チーフサイエンティスト(Chief Scientist)
Cooper (Seokjin) Han, MLリサーチャー(Research Scientist)
Daniel (GeunOh) Kim, MLデータエンジニア
Flynn (Jiho) Jang, MLリサーチャー(Research Scientist)
Ian (Soonwoo) Kwon, MLリサーチャー(Research Scientist)
Jay Suh, MLデータエンジニア
Jay (Jaehyuk) Yi, MLリサーチャー(Research Scientist)
Jayden (Junwan) Kim, リサーチ・インターン
Jeff (Jongseok) Kim, MLリサーチャー(Research Scientist)
Kyle (Seungjoon) Park, MLリサーチャー(Research Scientist)
Leo (Daewoo) Kim, MLリサーチャー(Research Scientist)
Mars (Seongsu) Ha, MLリサーチャー(Research Scientist)
Max (JongMok) Kim, MLリサーチャー(Research Scientist)
Ray (Raehyuk) Jung, MLリサーチャー(Research Scientist)
William (Hyojun) Go, MLリサーチャー(Research Scientist)
引用
本プロジェクトおよび私たちの論文が皆様の研究の助けとなりましたら、ぜひスターボタンを押して引用をお願いいたします:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }
TWLV-Iの技術レポートをarXiVおよびHuggingFaceでご確認ください! コードはGitHubで公開されています:https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
包括的な評価フレームワーク:Twelve Labsは、外観と動きの両方の分析を重視した、ビデオ理解のための堅牢な評価フレームワークを提供します。
TWLV-Iモデル:当社の新しいビデオ基盤モデル(TWLV-I)は、これら2つの側面をバランスよく捉えることに優れており、最先端のモデルと同等以上の性能を発揮します。
タスクパフォーマンス:TWLV-Iは、動作認識、時間の動作ローカライズ、および空間・時間の動作ローカライズにおいて強力な結果を示しており、その汎用性の高さが浮き彫りになっています。
可視化による洞察:t-SNEおよびLDAの可視化により、TWLV-Iは他のモデルと比較して、優れたクラスタリング能力と動きの識別能力を備えていることが明らかになりました。
今後の方向性:TWLV-Iの汎用性と適用性を高めるために、モデル規模の拡張、画像埋め込みの改善、およびモダリティの拡張を重視します。
今後の研究への指針:提案された手法は、ビデオ理解における新たな基準を設定し、この分野における今後の研究開発を導くことを目的としています。
1 - イントロダクション
今日のデジタル環境において、ビデオは普遍的な言語であり、文化を超えて複雑なアイデアや感情をシームレスに伝えています。この豊かなメディアを正確に解釈するには、堅牢なビデオ理解システムの構築が不可欠です。複数の画像のシーケンスであるビデオには、各フレームの外観を認識することと、時間の経過とともに展開する動きを理解することの、2つの焦点を当てる必要があります。
Twelve Labsでは、ビデオ理解におけるこれら2つの側面に対応する包括的な評価フレームワークの必要性を認識しています。私たちの目標は、外観と動きの両方の能力を正確に測定する評価手法を確立することにより、この分野における今後の研究の明確な方向性を提示することです。
1.1 - 基盤モデルとビデオ理解
基盤モデル(FM)は、特定の領域内の多様なタスクをモデルが処理できるようにすることで、AIに革命をもたらしました。言語および画像基盤モデルが大きな進歩を遂げた一方で、ビデオ理解には特有の課題が存在します。既存のビデオ基盤モデルは、クラスタリングや分類タスクの限界からも明らかなように、外観と動きの両方を効果的に捉えることができない場合が多々あります。
1.2 - TWLV-Iと評価フレームワークの紹介
これらの課題に対処するため、私たちは図1に示すように、外観ベースおよび動きベースの両方のタスクで卓越するように設計されたTWLV-Iを導入します。さらに重要なこととして、TWLV-Iの能力を評価するだけでなく、今後のモデルのベンチマークを設定する堅牢な評価フレームワークを提案します。
私たちのフレームワークには、動作認識、時間の動作ローカライズ、空間・時間の動作ローカライズなど、ビデオ理解の特定の側面を評価するために細心の注意を払って設計された様々なタスクが含まれています。この包括的なアプローチを通じて、バランスのとれた能力の重要性を強調し、業界をより包括的なモデル開発へと導くことを目指しています。
ビデオモデルの性能と適切な評価の両方に焦点を当てることで、私たちはビデオ研究におけるマイルストーンを提示し、このダイナミックな分野における今後の進歩と革新への道を切り開くことを熱望しています。
2 - TWLV-I & ビデオ基盤モデル評価フレームワーク
TWLV-Iのアーキテクチャとトレーニングプロセスは、外観と動きの両方の理解に対するニーズのバランスをとりながら、ビデオ理解に特有の課題に対処するように設計されています。図2は、外観中心のベンチマーク(Kinetics-400)と、動き中心のベンチマーク(SSv2およびDiving-48)におけるTWLV-Iのパフォーマンスの視覚的な比較を示しています。このプロットは、TWLV-Iのバランスの取れた能力を示しており、両方のタイプのタスクを高度に処理できることを実証しています。
このサブセクションでは、TWLV-Iのトレーニング手法とフレームサンプリング技術の主要な側面について詳しく説明します。
2.1 - アーキテクチャ
TWLV-Iは、Visual Transformer(ViT)アーキテクチャに基づいて構築されており、ビジュアルデータを処理するその強力な能力を活用しています。私たちは、次の2つのバリアントを実装しています:
ViT-B (Base): 8600万個のパラメータを持つモデル
ViT-L (Large): 3億700万個のパラメータに拡張されたバージョン
入力されたビデオは複数のパッチにトークン化され、これらはトランスフォーマー層を介して処理されます。このプロセスにより、パッチごとの埋め込みが取得され、その後プーリングされて、入力ビデオのトータルな埋め込みが生成されます。
2.2 - 事前トレーニングデータセット
堅牢で汎用性の高いビデオ理解を実現するために、TWLV-Iは表1に詳しく説明されている多様なデータセットで事前トレーニングされています:
ビデオデータセット:
Kinetics 710(65.8万動画クリップ)
HowTo360K(36万動画クリップ、HowTo100Mのサブセット)
WebVid10M(1073万動画クリップ)
画像データセット(合計1500万画像):
COCO(11.3万画像)
SBU Captions(86万画像)
Visual Genome(10万画像)
CC3M(288万画像)
CC12M(1100万画像)
このビデオデータセットと画像データセットの組み合わせにより、動きのダイナミクスと静的なビジュアル特徴の両方を理解するTWLV-Iの能力が向上します。
2.3 - トレーニング目的
TWLV-Iは、基礎的なトレーニングアプローチとしてマスクモデリングモデルを採用しています。しかし、動きと外観の両方の理解においてモデルの性能を最適化するために、再構成ターゲットを多様化しています。この戦略は、様々なビデオ理解タスクにわたって優れた性能を発揮できる、頑健なモデルの作成を目的としています。モデルは、この目的と前述のデータセットを使用してゼロからトレーニングされます。
2.4 - フレームサンプリング
フレームサンプリングのプロセスは、ViTアーキテクチャの計算上の制約があるため非常に重要です。トークンの数が増えると、計算の複雑さ(二次関数的)も増します。これを処理するため、私たちはMulti-Clip Embedding(マルチクリップ埋め込み、図4を参照)と呼ばれる戦略的なフレームサンプリング技術を採用しています:
クリップの分割:入力されたビデオは、それぞれ長さがT秒のM個のクリップに分割されます。
フレームの選択:各クリップからNフレームがサンプリングされます。
埋め込み生成:このプロセスにより、ビデオ1本につきM個の埋め込みが作成されます。
柔軟な表現:埋め込みの数はビデオの長さに比例して増加するため、可変長のビデオ処理が可能になります。
単一の埋め込みオプション:ビデオ全体を表すために単一の埋め込みが必要とされる場合は、M個の埋め込みを平均化します。
このアプローチにより、TWLV-Iは短期および長期の時間的ダイナミクスの両方を捉える能力を維持しながら、様々な長さのビデオを効率的に処理できます。
強力なViTアーキテクチャと、多様な事前トレーニングデータセット、および革新的なフレームサンプリング技術を組み合わせることで、TWLV-Iは複雑なビデオ理解タスクに対処する十分な能力を備えています。この強固な土台により、TWLV-Iは外観中心および動き中心の両方のベンチマークにわたって堅牢に機能することができ、それについては本評価フレームワークの以降のセクションで詳しく見ていきます。
3 - 動作認識
動作認識(Action Recognition; AR)はビデオ理解における基本的なタスクであり、ビデオを定義済みの人間の動作カテゴリに分類することを目的としています。このタスクは、外観と動きの両方の理解を必要とするため、ビデオ基盤モデルの性能を評価するための重要なベンチマークとなっています。
3.1 - ベンチマーク
私たちは、それぞれ異なる特徴を持つ、代表的な5つのARベンチマークにおいてTWLV-Iの性能を評価しました:
Kinetics-400 (K400):外観ベースの動作に焦点を当てた大規模データセット
Something-Something-v2 (SSv2):時間的関係を重視した動き中心のデータセット
Moments-in-Time (MiT):多様な動作カテゴリを持つ、もう1つの外観重視のデータセット
Diving-48 (DV48):ダイビングの動作に特化した、詳細かつ動き中心のデータセット
Epic-Kitchens (EK):日々の台所での活動を捉えた一人称視点(自我中心)のデータセット
これらのベンチマークは包括的な評価環境を提供し、外観重視および動き中心の両方のシナリオにわたってTWLV-Iの能力を評価できるようにします。
3.2 - 評価手法
私たちは、動作認識タスクにおける標準的な手法であるマルチビュー分類法を採用しています:
入力ビデオを空間的にリサイズし、要求される解像度に適合させます
空間次元に沿ってm個、時間次元に沿ってn個のクリップを一様にサンプリングし、合計m × n個のクリップを作成します
各クリップのクラス確率を算出します
確率を平均化して最終的な出力を取得します
このアプローチにより、入力ビデオの異なる空間的および時間的セグメントにわたるモデルの性能が徹底的に評価されます。
3.3 - リニアプロービング(線形評価)
リニアプロービングは、モデル全体をファインチューニングすることなく、学習された表現の品質を評価するために使用される技術です。以下のステップを含みます:
特徴抽出器(バックボーンモデル)を固定(フリーズ)します
フリーズされた特徴の上に線形分類器を配置してトレーニングします
線形分類器は、埋め込みベクトルの次元数から動作クラスの数へのマッピングを行う重み行列で構成されます。
結果と分析
表3は、様々なベンチマークとモデルにおけるリニアプロービングの結果を示しています。主な観察結果は以下の通りです:
TWLV-Iはすべてのベンチマーク、特にそのアーキテクチャ規模(ViT-BおよびViT-L)において強力なパフォーマンスを示しています。
SSv2において、TWLV-Iは、事前トレーニングにSSv2を含んでいるV-JEPAを除き、ViT-H (DFN) や ViT-g (InternVideo2) などのより大規模なモデルを凌駕しています。
TWLV-IのViT-Lモデルは、EKおよびDV48のベンチマークにおいて、より大規模な他モデルを上回る結果を示しています。
これらの結果は、単純な線形分類器を使用して評価した場合であっても、TWLV-Iが様々な動作認識タスクにうまく汎用できる、豊かな表現特徴を学習できていることを裏付けています。
3.4 - アテンティブプロービング(注意評価)
リニアプロービングはクリップごとの埋め込み精度についての洞察を提供しますが、特にパッチレベルの教師あり学習で訓練されたモデルにおいて、その真能力を完全に捉えきれない場合があります。この制限に対処するため、私たちは以下を含むアテンティブプロービングを導入します:
フリーズされたモデルの上に、学習可能なクラストークンを持つ単一のアテンション層を導入してトレーニングします
出力されたクラストークンを線形分類器に入力します
Top-1精度を測定します
この手法により、モデルのパッチ単位での表現能力をより詳細に評価することが可能になります。
結果と分析
表5は、アテンティブプロービングの結果を示しています。主な発見は以下の通りです:
TWLV-Iは、外観重視および動き中心の両方のベンチマークにわたって、他のモデルと比較して優れた性能を達成しています。
アテンティブプロービングにおける強力なパフォーマンスは、TWLV-Iが同等のモデル群に比べて、より詳細で豊かなパッチ単位の表現をそなえていることを示唆しています。
3.5 - K近傍法(K-Nearest Neighbors)
勾配法に基づく評価での潜在的な偏り(バイアス)を排除し、パラメータフリーな状態で埋め込みの品質を評価するため、私たちはK近傍法(KNN)分類タスクを採用しています。このノンパラメトリックなアプローチにより、異なるモデルアーキテクチャ間で埋め込みベクトルをより公正に比較することができます。
私たちは、以下の2つの手法で埋め込みを生成します:
一律の埋め込み(Uniform Embedding):ビデオ全体に対して1つの埋め込みベクトルを生成します。
マルチクリップ埋め込み(Multi-Clip Embedding):ビデオ全体にわたる2秒間のクリップから複数の埋め込みを生成します。
マルチクリップ埋め込みでは、2つの評価戦略を採用しています:
ビデオレベル:すべてのクリップの埋め込みを平均化して、単一のビデオ表現を作成します。
クリップレベル:各クリップが獲得した投票を合計して、最終的なクラスを決定します。
結果と分析
表6は、異なるモデルおよび埋め込み戦略におけるKNN分類の結果を示しています。主な観察結果は以下の通りです:
TWLV-Iは、Kinetics-400(K400)およびSomething-Something-v2(SSv2)の双方のデータセットにおいて、特に対象モデルが同等規模のものと比較した際に、極めて競争力のある性能を示しています。
Uniform(一律)埋め込みの設定において、TWLV-I-ViT-BはK400で57.51%、SSv2で19.82%のTop-1精度を達成し、同一のアーキテクチャを持つUMT_s2を凌駕しています。
TWLV-I-ViT-Lは強力な結果を示しており、K400で65.97%、SSv2で19.47%のTop-1精度を達成し、いくつかのより大規模なモデルを上回っています。
それにもかかわらず、アテンティブプロービングでの結果とは異なり、KNN評価においてTWLV-IはK400およびSSv2の双方でInternVideo2に一歩及ばない結果となりました。これは以下を示唆しています:
TWLV-Iの埋め込みをノンパラメトリックな方法で活用する余地がまだ残されていること。
特に長時間のビデオ(単一クリップの長さを大幅に超えるもの)について、その埋め込みを効果的に表現する方法に関する更なる研究が必要であること。
これらの結果は、ビデオ表現の複雑さと、異なる評価手法のすべてにわたって普遍的に強力な埋め込みを構築することの難しさを物語っています。
3.6 - SSv2を用いた事前トレーニング
V-JEPAなどのモデルとの公平な比較を行い、事前トレーニングに動き中心のデータを取り込むことの影響を評価するため、私たちはSomething-Something-v2 (SSv2) データセットをTWLV-Iの事前トレーニングフェーズに組み込む追加の実験を行いました。
私たちは、元のデータセット群に加えて事前トレーニング用データにSSv2を組み込み、TWLV-I(ViT-Lアーキテクチャ)のバリアントをトレーニングしました。これにより、この追加データが様々なベンチマークや評価に与える影響を直接比較できます。
結果と分析
このSSv2を組み込んで拡張されたモデルの評価結果は、表3、表5、および表6の下部に示されています。主な発見は以下の通りです:
SSv2パフォーマンスの進歩:すべての評価方法(リニアプロービング、アテンティブプロービング、およびKNN)を通じて、そのモデルはSSv2ベンチマークにおいて大幅な進化を遂げています。たとえば、リニアプロービング(表3)では、SSv2でのTop-1精度が46.41%から48.14%に上昇しました。
全体の総合的性能向上:事前トレーニングにSSv2を含めることで、他のベンチマークにおいても性能向上が見られました。これは、動き中心のデータを追加したことで、モデルの全体的なビデオ理解能力が向上したことを示唆しています。
専門特化モデルとの比較:性能が改善されたものの、動き中心のSSv2における事前トレーニング拡張モデルのKNN性能は、同テスト上で依然としてV-JEPAおよびInternVideo2に対して遅れをとっています。これは、TWLV-Iのパッチレベルの表現能力は強力である一方、ビデオレベルでの表現力には改善の余地があることを示しています。
表現性能におけるトレードオフ:結果は、TWLV-Iのパッチレベルとビデオレベルの表現において、潜在的な不均衡がある可能性を浮き彫りにしています。この顕著なギャップへの対処は、今後のモデル拡張に際しての重要フォーカスとなるはずです。
これらの発見は、堅牢なビデオ基盤モデルの開発において多様な事前トレーニングデータの存在が極めて重要であることを強調しています。また、外観中心のベンチマークでの高い性能を維持しつつ、動き中心のタスクにおいて特定の専門モデルにより良く対抗するために、TWLV-Iを改良できる具体的な領域を指示してくれています。
4 - ImageNet 分類
ビデオ基盤モデルの汎用性と、それらが一般的な画像認識モデルとして機能する可能性を評価するために、ImageNet分類タスクにおけるTWLV-Iの性能評価を行いました。このベンチマークは、静止画像を処理・理解するモデルの能力についての洞察を提供し、これは包括的なビデオ理解システムを構築する上でも不可欠な要素です。
4.1 - 結果と分析
ImageNetの分類結果は、表3(リニアプロービング)および表5(アテンティブプロービング)の最後の列に示されています。主な観察結果は以下の通りです:
外観中心のタスクとの相関関係:一般的に、外観中心の動画動作認識タスク(例: Kinetics-400)で優れたスコアを達成するモデルは、ImageNetベンチマークにおいても強力な性能を発揮します。この相関関係は、ビデオ理解のために学習された特徴が、静止画分類タスクにも効果的に転移できることを示唆しています。
TWLV-Iのパフォーマンス:
リニアプロービング(表3)において、TWLV-I-ViT-LはImageNetで72.98%のTop-1精度を達成し、競争力はあるもののトップには至っていません。
アテンティブプロービング(表5)では、TWLV-I-ViT-Lは79.19%のTop-1精度へと性能が向上しており、アテンションメカニズムを介した学習済み特徴のさらなる有効活用を示してくれています。
専門特化モデルとの比較:TWLV-Iはビデオベースのタスクにおいて強固なパフォーマンスを発揮している一方で、いくつかの特定目的のモデルと比較するとImageNet分類のスコアには目に見えるギャップがあります。たとえば、InternVideo2はImageNetにおいてTWLV-Iを大幅に上回っていますが、ビデオ動作認識タスクにおいてはその性能差は狭まり、場合によっては逆転することもあります。
4.2 - 示唆と洞察
これらの観察に基づき、私たちは次の洞察を得ました:
静止画像処理における制約:結果から、TWLV-Iは、当該タスクに最適化されたモデルと比較して、静止画像の処理についてある程度の制限があることが示されています。これは、モデルの将来のアップグレード段階における改善余地があることを示します。
動作情報の活用能力:ImageNetのスコア差をよそに、ビデオタスクにおいてTWLV-Iと他モデルとの性能ギャップが縮まることは、TWLV-Iがビデオ理解において動作情報を非常に効果的に活用していることを示唆しています。この能力は外観ベースの特徴保管と補完し合い、結果として強力なトータルビデオ分析性能をもたらします。
ビデオと画像能力の均衡化:TWLV-Iを単なる動画特化モデルから、さらに前へと進化させるために、今後の研究ではその強力なビデオ分析能力を損なうことなく、単一画像を理解する能力を強化することに焦点を当てるべきです。
総括として、TWLV-Iはビデオ理解タスクにおいて強力な性能を示しているものの、ImageNet分類結果は、静止画像処理におけるいくつかの改良すべき領域を示しています。これらの制約に対処することで、ビデオと画像の双方のドメインにわたって秀でた、より包括的な視覚基盤モデルの実現につながる可能性があります。
5 - 時間の動作ローカライズ
時間の動作ローカライズ(Temporal Action Localization; TAL)はビデオ理解における重要なタスクであり、トリミングされていない一連のビデオの中から特定の動作を特定し、時間的位置を特定することを含みます。このタスクは自動運転、スポーツ分析、コンテンツに基づくビデオ検索などの応用において特に重要です。TALでは、モデルが長くて複雑なビデオを分析し、その中で発生する各動作の時間的な境界と対応するクラス分類ラベルを正確に判定することが求められます。
5.1 - 評価の視点
TALは、主に以下の2つの主要な視点からビデオ基盤モデルを評価します:
時間的感度:関心のある動作が特定のタイムステップで発生したかどうかを識別する能力。
インスタンス識別能力:フレームごとのセグメントを、完全な一つの動作インスタンスに識別またはグループ化する能力。
TALは本質的に動作中心のタスクとして設計されていますが、私たちの分析によれば、これら2つの側面の効果的な達成において、外観と動きの双方の能力が相乗的に寄与していることが明らかになりました。
5.2 - 手法
私たちは、TWLV-Iおよび他の動画基盤モデルを、以下の2つの著名なTALデータセットにおいて評価しました:
ActivityNet-v1.3
THUMOS14
検出用のヘッドとしてはActionFormerを採用しました。そして、以下の2つの異なる検証方法で評価を行いました:
自己完結型(Self-contained):モデルの外部サポートを受けることなく、自ら単独で分類と回帰の両方を実行します。
外部分類器併用型(w/ External Classifier):モデルは二値分類を行い、実際の動作クラスの予測は外部の分類器が行います。
特徴の抽出は、「フレームサンプリング」セクションで説明したマルチクリップ埋め込み手法に従って行われました。
5.3 - 結果と分析
表9と表10はそれぞれ、THUMOS14およびActivityNet-v1.3における包括的な結果を示しています。
THUMOS14(表9)
TWLV-I(当社モデル)は、すべての検証指標において、同一スケールの他のモデルを一貫して上回る性能を示しています。
TWLV-I-ViT-Lは、自己完結型設定で58.75%、外部分類器併用設定で53.63%という最高の平均mAPを達成しました。
特筆すべきは、TWLV-I-ViT-LがDFNやV-JEPA (ViT-H) のようなより大規模なモデルををも凌駕している点であり、その優れた汎用・一般化能力を証明しています。
ActivityNet-v1.3(表10)
TWLV-Iはここでも、そのアーキテクチャの規模感において屈指のパフォーマンスを示しています。
TWLV-I-ViT-Lは、平均mAPで34.98%(自己完結型)および39.49%(外部分類器併用型)を記録しました。
驚くべきことに、TWLV-Iは厳格なIoU閾値(例: 0.95)において極めて優れた性能を発揮しており、並外れた時間的感度を有していることが示されています。
5.4 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
スケール効率:TWLV-Iのパフォーマンス、特にViT-Lの規模感において他社大容量モデルを打ち負かしている現状は、その効率的な設計アーキテクチャとトレーニング手法を明白に証明しています。
時間的精密さ:極めて厳しい基準である厳格なIoU閾値(ActivityNetにおける0.95等)での高スコア獲得は、TWLV-Iが誇る突出した時間的感度の鋭さを証明しています。
モデル規模の影響:InternVideo2のトップパフォーマンス、特に自己完結型の評価における実績は、TALタスクにおいて分類と時間的境界の回帰を同時に実行する際、モデルの規模拡張が大きく利益をもたらすことを示唆しています。
評価戦略:単に「動きの理解」のみに的を絞って正確に測定したい場合は、外部分類器との併用が推奨されます。一方で、外観の理解度をも包含するより網羅的な評価を望む場合は、自己完結型のアプローチが求められます。
汎化能力:異なる複数のデータセットおよび評価方法にわたるTWLV-Iの終始強力なパフォーマンスは、時間の動作ローカライズ分野における主要バックボーンとしての屈強さを表しています。
これらの結果は、時間の動作ローカライズという極めて複雑な課題に対するTWLV-Iの抜群の有用性を物語っており、時間的感度と動作のまとまり認識の双方においてバランスよく実力を備えていることを明確に示しています。様々なスケールや多様な測定環境において現れたその高い適合能力は、ビデオ理解全般を支える汎用的ベース基盤としての高いポテンシャルを示しています。
6 - 空間・時間の動作ローカライズ
空間・時間の動作ローカライズ(Spatio-Temporal Action Localization; STAL)は、ビデオの中の特定の動作を認識するだけでなく、編集されていないビデオ系列内の空間(画面中のどこか)および時間(いつ発生したか)の双方を正確に検知・特定する、高度で複合的な難関課題です。この課題はアクションの精密な分析が必要とされるシーンで重要視され、外観と動き双方の完全な統合理解がモデル側に問われます。
6.1 - データセットと評価
私たちは、1本あたり15分間の映画から切り出された430個の動画クリップで構成されているAVA v2.2データセットを用いてモデル検証を行っています。キーフレームは毎秒付与され、学習用セットに210,634枚、検証用セットに57,371枚のラベル付きフレームが含まれています。データセットには、各俳優に紐付けられた80個の原子的な基本動作ラベルが含まれています。
この動作評価では、最新のv2.2アノテーションを使用し、Intersection over Union (IoU)の閾値0.5におけるフレーム平均精度(Frame Average Precision; fAP)を取得して比較しています。私たちはエンドツーエンドのSTALフレームワークを採用し、バックボーン側のビジュアルモデル部分を固定した状態でデコーダの追加トレーニングを実行しました。
6.2 - 結果と分析
表11は、STALタスクにおける性能評価を示しています。主な観察結果は以下の通りです:
他モデルとの対比:TWLV-I、UMT、およびInternVideo2は、DFNやV-JEPAより優れた性能を発揮しています。DFNとV-JEPAは他の種類のタスクで全く異なる極端なスコア傾向を見せていましたが、物体としての人物特定と、時間的な動作認識の双方をクリアする必要があるSTALタスクにおいては、その性能は似たような値にとどまっています。
検出局所化における難点:
V-JEPA:人物などのインスタンスの特定そのものに手こずり、それが後続の動作認識スコアにも波及して悪影響を与えています。
DFN:得意とする外観の精緻な理解力により、対象が画像のどこにいるのかを素早く特定できていますが、時間情報の解釈の限界から、そこでどのような動作が行われているかの認識で誤答しています。
TWLV-Iの特徴的な強み:
TWLV-Iは、物体の外観と動作中の物理的変化を極めて高いレベルで調和よく理解することで、STALタスクにおける確固たる強さを現しています。
ViT-Lモデルにおいて、TWLV-IはfAP@0.5で27.39を達成しました。これはDFNやV-JEPAを大きくリードし、より構造の大きい巨体モデル群であるInternVideo2の記録に肉薄する性能スコアです。
6.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
調和のとれた深い読解:今回の好成績は、TWLV-Iが時空間情報を極めて適切に理解できていることを示す十分な証拠であり、精度の高い時空間ローカライズを実現する上でも要となります。
全般的なビデオ判定価値:終始シームレスにエンドツーエンドで行われるSTAL検定は、空間と時間の2つの次元におけるパフォーマンスを高い再現性を持って明らかにする包括的なモデル審査手法と言えます。
手法の有効性検証:TWLV-IがUMTやInternVideo2と並んで好成績を残している現状は、空間位置特定と動作分析の2つの異なる目標を同時に処理する能力の現れであり、外観のみ、あるいは動作のみといった限定的な一方を追求した他社モデルとは一線を画しています。
これらの裏付けは、時空間の複雑なシーンを正確に記述する必要がある高度な難題(STAL等)を解決するために、外観情報と動作変化情報の双方が一つの脳(モデル)の中にバランスよく統合されていることが如何に決定的であるかを語っています。
7 - 時間の動作セグメンテーション
時間の動作セグメンテーション(Temporal Action Segmentation; TAS)は、編集されていない長時間のビデオから人間の複雑な活動の全貌を読み解くために非常に重要とされている応用課題です。セキュリティ監視、ハイライト映像などの要約作成、作業スキルの機械的審査など、広範な産業でその活躍が期待されています。TASでは、トリミングされていないビデオを入力として直接流し込み、それぞれのフレームに一連の正しいアクションのクラス分類ラベルを追加していく作業を行います。
7.1 - 表記比較基準とアプローチ
私たちは、TASの性能を判定すべく以下の3つの高難度検証基準を用意しました:
50Salads:調理の手順において、細々とした変化を伴う複雑な一連の処理を含んでいます。
GTEA:一人称の目の高さで撮影した、複雑な身の回り仕事の一連のプロセスを記録しています。
Breakfast:引いた位置からも撮影された、全身でキッチン作業をこなす長時間の全体構成データです。
TASのデコーダ部分としてはASFormerを使用しました。閾値10、25、および50のもとで測定されたF1スコアの平均値を「mF1」として評価に採用しています。マルチクリップ埋め込みを用いて特徴を抽出し、空間次元プーリングを施すことで時間軸のみを滑らかに残しています。
7.2 - 結果と分析
表12は、これら3つのテスト条件のもとで実施したTAS試験の結果を詳細を伝えています:
50Salads:TWLV-Iは、ViT-Bで80.69、ViT-Lで80.60のmF1スコアをマークしました。これは、UMTやDFNといった外観重視モデルや、動作変化を専門としたV-JEPAをも完全に跳ね除ける数値です。また、エディットおよび予測適合率の項目についても、TWLV-Iの手法が正解データ配列に極めて整合していることを明らかにしています。
GTEA:TWLV-Iはさらに強さを示し、ViT-Bで88.26、ViT-Lで88.43のmF1スコアを記録して競合を大きく引き離しました。これは、一瞬で移り変わるアクションの正確なセグメンテーションを必要とする、一人称主観視点の動画において真価が浮き彫りになることを証明しています。
Breakfast:被写体が遥か遠くにフレームインする視野角の広いこのシーンでも、TWLV-Iは実力を落とすことなく、ViT-Bで52.18、ViT-Lで50.66という好ましいmF1スコアを獲得しています。目まぐるしく変化するカメラ視野の切り替わりに対しても、その対応柔軟性が高水準に維持されています。
7.3 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
完成されたオールラウンダーとしての実力:データの多様性によらずあらゆる分類群で最高峰に位置するTWLV-Iの一貫した強さは、外観の把握力と動作の持続変化を漏らさず記述する能力のバランスが非常に良好であることを意味しています。
実際の推移への適合精度:エディットスコアおよびmF1スコアが高水準にまとまっていることは、TWLV-Iが予測したアクションの流れ全体(系列)が、実際のビデオ内で人間の動作した現実の順序に正確に合致していることを意味し、将来的なオンサイト実装における安全・信頼性の高さを示しています。
視野角変化に対する屈強さ:上空からの撮影、手元を映す一人称主観カメラなど、極端な画角変更があっても他製品以上のスコアを叩き出し続ける事実は、いかなる用途でも現場を選びにくい柔軟性のある頑丈なモデルであることを実証しています。
InternVideo2とのベンチマーク性能比較:特定のアングルのデータにおいて、TWLV-IはInternVideo2に類似する好成績を取り分けて現していますが、広範囲にまたがる複数データセットを前にしても性能がブレることのなく、常に一貫した優秀さを維持する確実性は、総合的なポテンシャルの高さをはっきりと映し出しています。
これらの評価により、時系列動作セグメンテーション(TAS)の非常に挑戦的な検証において、TWLV-Iがビデオ解析を応用可能とする多大なる可能性を備えていることが確かに認められました。
8 - 埋め込み空間の可視化
TWLV-Iや他社基盤モデルのビジュアル表現能力がどのように構造化されているかを詳しく探索するため、私たちはt-SNEおよび線形判別分析(LDA)を用いたビジュアル確認実験を実施しました。これにより、作成された埋め込みベクトルが「外観情報」と「動き情報」の各々の側面をどれほど精緻に描写できているかが理解できます。
8.1 - t-SNEを用いた各評価データセット上のマッピング
t-SNEを用いて、Kinetics-400 (K400) および Something-Something-v2 (SSv2) 検証用セットにおける埋め込みベクトル分布をマッピングしました。また、色分けは異なるアクションクラスを表しています。
Kinetics-400(図6)
TWLV-I, UMT, および InternVideo2:これらのモデルは同じ特性をもつ動作どうしが1つのブロックのように固まりを構築し、境界線を容易に引くことができるきれいなクラスタリングを示しました。これは、外観に基づいて表現が異なる多数の動作群を驚くほどきれいに判定できていることを意味します。
V-JEPA:打って変わって、各動作クラスをごちゃ混ぜに描いてしまい、特徴空間を明確に分割することができていません。静止構造(外観ターゲット)をきれいに捕捉できていない性質が読み取れます。
Something-Something-v2(図7)
全モデルの傾向:面白いことに、TWLV-IやV-JEPAも含め、どのモデルもSSv2のような高度に動きが重視されるデータセットにおいては、一目で分かるようなクラスタリングを表示できませんでした。これは、他の手法に比べ、そもそもSSv2の分類スコアがどの製品でも総じて低い実情と重なっています。
そのことが暗示する意味:このプロットによる描画結果は、動きそのものの質的違いを明確なベクトルのまとまりの中に落とし込んで表現することが技術的に如何に困難であるかを雄弁に物語っており、ブレイクスルーを呼び起こす今後の革新的アプローチが待ち望まれます。
8.2 - 動作の方向に対する感度検証
よりミクロなレベルにおいて、モデルが動きをどのように知覚しているかを理解するために、私たちはSSv2から「何かを押し上げる」「何かを引き下げる」といった、動作の物理的方向の読解が無ければおよそ解答不可能な、特定の動作ペアに注目しました。
私たちは、通常の正再生動画から切り出した動画ベクトルと、それを時間軸に対して逆転させた逆再生動画の埋め込みベクトルを抽出し、線形判別分析(LDA)を用いてプロットしました。この検証では、外観が全く同じである動画どうしの順逆方向について、純粋に時間的経過の順序だけでその差異を埋め込みベクトル空間上で分離できるかどうかをテストできます。
結果(図8および図9)
TWLV-I:正再生と逆再生の動画が交じることなく極めて良好に二極反転の空間位置を保っており、時間方向の違いをベクトルの差異の形で確実に記述できていることを実証しています。
V-JEPA:ここでも正逆識別において最も広い距離感(明確さ)を獲得しています。これは、同モデルが事前トレーニング時から意図的にSSv2データセットを多量に摂取している実績に起因すると考えられます。
UMT および InternVideo2:埋め込みの正負領域での重複が大きく分離困難に陥っています。これは、静止画像の精緻な理解を得意とする一方で、時間方向に対してはほぼ感度を持たない(動作変化に対して無頓着な)設計上の構造を示しています。
8.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
外観と運動変化を同時に記述する能力:TWLV-Iは、静止画を基準とする認識分類力(K400の図から顕著)と、動作方向による時間秩序変化の知覚力(順逆分析から顕著)の双方を高レベルで併せ持つ、類稀なるオールラウンド性能を持っていることがビジュアルからも明らかになりました。
動作の質的表現(モデリング)のための課題:SSv2のクラスタリングで全ての競合が描いたカオティックなプロット図は、運動表現のみで多様なクラス群をきれいに定常分離していく作業が今なおどれほど高難易度であるかを示し、ビデオ分野における最大のテーマとして残されています。
時間変化に対する鋭敏な解釈力:正逆方向のビデオを即座に引き裂くTWLV-Iのおおきな分離能力は、ただ物理的な情報を見るだけでなく、動画ならではの微細な時間フレームの前後変化にまで高い感度で反応を返せていることを意味し、高度な動作記述の足がかりとなります。
各社モデルの個別得意分野:プロットにより、それぞれの製品群が得意とする設計方針の違いが鮮明になり、外観を高度に見抜くモデルがある一方で、時間的運動のみをうまく感知するような尖った得意領域に特化するなどの現状が浮き彫りになり得ます。
これらの特徴的な視覚マッピングによる可視化手法は、TWLV-Iの脳がどのように特徴を獲得しているかを視覚的に雄弁に説いてくれており、今後の改善策を計画するための重要な技術基盤となります。
9 - 今後の開発テーマ
今後の展望として、TWLV-Iの実用拡大、およびビデオ基盤モデル一般を劇的に変革し、応用領域を広げるためのいくつかの有望な発展レーンが存在します。これらは、モデル能力の大幅補強、スコア改善、さらに多領域における産業実装の加速を目指すものです。
9.1 - モデルスケールの拡張
これまでのところ、主に以下の2つのモジュール構成を中心にリリースしてきました:ViT-BおよびViT-L。しかしながら、当社のTWLV-I-ViT-Lは、一回り体が大きい他社製のViT-HやViT-gの記録と同等、場合によってはそれを超える良好な数値を叩き出しています。この効率の良さは、今後モデルを拡張した場合、さらなる大幅なポテンシャル向上の余白があることを意味します:
極大規模アーキテクチャの導入:TWLV-Iをより極大サイズのモデルへと引き上げることで、多様な検証ベンチマークにおけるスコアを飛躍的にレベルアップさせることが大いに期待されます。
内製の極大データセットの構築:自社で囲い込みを行って獲得した並外れた規模の大容量学習資源を使用することで、さらに柔軟であらゆる変化に強い強固なベースを育むことが可能です。これは未体験の難題や新たなシーンをモデルが難なく見抜く手助けとなります。
高効率スケーリング設計:スパースアテンション構造やMixture-of-Experts (MoE) と言われるマルチネットワーク構造などの高効率スケーリング手法を採用することで、開発リソース資源を際限なく食いつぶすことなく、極端な機能アップグレードを安定して実現させられます。
9.2 - 画像埋め込み機能の大幅強化
TWLV-Iはビデオに関わる項目で強い優位性を現したものの、単一の画像そのものの埋め込みを表現する精度に関しては、さらに向上させられる余地が残っています:
静止フレームの読解力強化:ビデオから切り出した1枚のフレームそのものを正確に把握する精度を強化することは非常に合理的です。この能力が磨かれれば、ビデオの得意さと画像の得意さが統合され、TWLV-Iは総合的に完璧なビジュアル認識プラットフォームとなり得ます。
転移学習アプローチの探索:動画上で構築された「動作変化を前提とした知覚表現」を、うまく静止画における分類タスクの補助特徴へと転移する学習アプローチが構築できれば、一般的な画像AIタスクにおける信頼性を容易に格上げできます。
単一フレームワークでの統合学習:同一のシステム構成のままで、ビデオからの入力と静止画からの入力のいずれでも変わらぬ適合率をたたき出す、シームレスな統合アーキテクチャの変更を推進します。
9.3 - モダリティレンジの拡張
さらに、TWLV-Iとしての利便性を全方位的にレベルアップさせ、AI産業自体の需要とより強固に噛み合わせるために、モダリティレンジを着実に拡張することが非常に重要です:
マルチモダルの活用促進:ビデオと引き当てられる文章推薦(ビデオテキスト検索)や、動画を正確に文字に直すビデオキャプションなど、極めて複雑な多元タスクを処理できるように改良します。これにより、卓越した映像把握力を生かしたまま、テキストと調和的に交信できるようになります。
ビデオLMMとしての位置づけ構築:TWLV-Iの構造をビジュアル側にとって最適なビジョンエンコーダとして位置付け、先進的なビデオ・大規模言語モデル(VLM)との高水準な接ぎ木を実現します。高度なテキスト理解力とのシームレスな融合が可能となります。
音声特徴の統合理解:動画内の時間変化に伴う「音声変化(オーディオ)」を映像と時間補正した状態で統合することで、音と映像のタイミングマッチング、音の出どころイベントの検出など、さらに応用度をました技術を実現します。
テスト手法の体系化と基準設定:これらの極めて応用的なマルチモダル性能について、信頼性高くスコア検証していけるよう、独自の統合的な判定テスト手法や新たな検証基準を設け、その安定性を保証していきます。
これらの将来像を追うことで、TWLV-Iが提供するバリューを「ビデオ専用のベース」から、「様々な周辺状況に対して瞬時に協調できる究極の知覚システム」へと引き上げることを想定しています。この発展は、現在実現されている機能群での性能を引き上げるのみならず、自動応答アシスタント、次世代のコンテンツクリエイト事業、革新的な人間とロボットのインターフェース構築といった未来的な産業へ決定的な道を開きます。
10 - おわりに
私たちは今回の体系的なビデオ検証において、絵画的な美しさ(外観)と移り変わる変化(動き)の2つの要素の調和が、映像解釈という広大で豊かな目的をクリアするためにいかに決定的であるかを詳述してきました。私たちの取り組みは、以下の素晴らしいブレイクスルーと発見をもたらしています:
多角的で包括的な測定規格:動画の時間的ローカライズから一連のアクションシーケンス抽出まで、あらゆる側面においてモデルの能力を均一な視点で測定できる、信頼性の高い規格を提供しています。
既存モデルの顕著な改善余白:一連の周到な検証プロセスにより、他モデル群が動作と外観のいずれか一方のみの知覚に依存し、両者を共にハイパフォーマンスに両立することがいかに苦手であるかを明らかにし、この分野におけるミッシングリンクを特定しました。
満を持してのTWLV-Iの紹介:これらの業界の不均衡に対して最適な解を与えるべく、外観と動作の両方を同時に、そして高解像度に把握する新世代のアプローチ「TWLV-I」を投入しました。
抜群の埋め込み品質:TWLV-Iが生む埋め込みベクトルは、高度な下流タスクを非常に簡便にいなす高い適用力を見せており、実用化の検証コストを劇的に圧縮します。
汎用的で強力な検証用フレームワーク:本ブログでお披露目された多様な検証とプロット比較法は、今後のビデオ基盤モデルの基礎テスト規格となる得るよう、業界コミュニティへ開示されています。
将来のイノベーションプラン:今後の研究をドライブするために、モデルの大容量化、画像識別のブラッシュアップ、さらには音響やテキスト等の他系統とのマルチリンガル的な統合を進めていきます。
業界の目指すべき座標の提示:外観性能のみの偏重、動きのみの過学習を克服し、双方をひとつの体にバランスよく共存させる姿勢を示すことで、ビデオ理解領域が目指すべき進路を設定できたと自負しています。
要約すれば、TWLV-Iは万能型でかつ不屈の動画基盤モデルを作るうえで、記念碑的な飛躍を示すモデルです。外観知覚と動作知覚を絶妙に調和させることで、これまで想像さえ難しかった、高次元の動画理解と多角的な用途への扉が開かれました。私たちは、ここで開示された評価スキームやアイデアが多くの研究者をエンパワーし、新しい視点、そしてより本質に迫るアプローチで今後の課題に取り組んでもらえることを切に願っています。
この先、こうした完璧な統合基盤がさらに成熟していくプロセスは、ビデオを取り扱う多くのソフトウェア群のブレイクスルーにつながり、AIが生活シーンを支える究極のパートナーへと変貌していくために重要となります。私たちは世界中のリサーチャーとともにこの挑戦の地盤を盤石なものとし、ビデオAIが切り開く素晴らしい未来へのフロンティアを共に開いていくことを歓迎します。
Twelve Labs チーム
本研究開発は、Twelve Labs ML ResearchおよびML Dataチームの厚い支援のもと、核となる以下の主要執筆者たちの均等な(equal contributionという素晴らしい連携による)献身的な貢献を通じて達成されました。
主要な執筆者・研究代表
Hyeongmin Lee, MLリサーチャー(Research Scientist)
Jin-Young Kim, MLリサーチャー(Research Scientist)
Kyungjune Baek, MLリサーチャー(Research Scientist)
Jihwan Kim, MLリサーチャー(Research Scientist)
Aiden Lee, 最高技術責任者(CTO)
コントリビューター(アルファベット順表記)
Aaron (Jangwon) Lee, MLデータ・インターン\
Calvin (Minjoon) Seo, チーフサイエンティスト(Chief Scientist)
Cooper (Seokjin) Han, MLリサーチャー(Research Scientist)
Daniel (GeunOh) Kim, MLデータエンジニア
Flynn (Jiho) Jang, MLリサーチャー(Research Scientist)
Ian (Soonwoo) Kwon, MLリサーチャー(Research Scientist)
Jay Suh, MLデータエンジニア
Jay (Jaehyuk) Yi, MLリサーチャー(Research Scientist)
Jayden (Junwan) Kim, リサーチ・インターン
Jeff (Jongseok) Kim, MLリサーチャー(Research Scientist)
Kyle (Seungjoon) Park, MLリサーチャー(Research Scientist)
Leo (Daewoo) Kim, MLリサーチャー(Research Scientist)
Mars (Seongsu) Ha, MLリサーチャー(Research Scientist)
Max (JongMok) Kim, MLリサーチャー(Research Scientist)
Ray (Raehyuk) Jung, MLリサーチャー(Research Scientist)
William (Hyojun) Go, MLリサーチャー(Research Scientist)
引用
本プロジェクトおよび私たちの論文が皆様の研究の助けとなりましたら、ぜひスターボタンを押して引用をお願いいたします:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }
TWLV-Iの技術レポートをarXiVおよびHuggingFaceでご確認ください! コードはGitHubで公開されています:https://github.com/twelvelabs-io/video-embeddings-evaluation-framework
TLDR
包括的な評価フレームワーク:Twelve Labsは、外観と動きの両方の分析を重視した、ビデオ理解のための堅牢な評価フレームワークを提供します。
TWLV-Iモデル:当社の新しいビデオ基盤モデル(TWLV-I)は、これら2つの側面をバランスよく捉えることに優れており、最先端のモデルと同等以上の性能を発揮します。
タスクパフォーマンス:TWLV-Iは、動作認識、時間の動作ローカライズ、および空間・時間の動作ローカライズにおいて強力な結果を示しており、その汎用性の高さが浮き彫りになっています。
可視化による洞察:t-SNEおよびLDAの可視化により、TWLV-Iは他のモデルと比較して、優れたクラスタリング能力と動きの識別能力を備えていることが明らかになりました。
今後の方向性:TWLV-Iの汎用性と適用性を高めるために、モデル規模の拡張、画像埋め込みの改善、およびモダリティの拡張を重視します。
今後の研究への指針:提案された手法は、ビデオ理解における新たな基準を設定し、この分野における今後の研究開発を導くことを目的としています。
1 - イントロダクション
今日のデジタル環境において、ビデオは普遍的な言語であり、文化を超えて複雑なアイデアや感情をシームレスに伝えています。この豊かなメディアを正確に解釈するには、堅牢なビデオ理解システムの構築が不可欠です。複数の画像のシーケンスであるビデオには、各フレームの外観を認識することと、時間の経過とともに展開する動きを理解することの、2つの焦点を当てる必要があります。
Twelve Labsでは、ビデオ理解におけるこれら2つの側面に対応する包括的な評価フレームワークの必要性を認識しています。私たちの目標は、外観と動きの両方の能力を正確に測定する評価手法を確立することにより、この分野における今後の研究の明確な方向性を提示することです。
1.1 - 基盤モデルとビデオ理解
基盤モデル(FM)は、特定の領域内の多様なタスクをモデルが処理できるようにすることで、AIに革命をもたらしました。言語および画像基盤モデルが大きな進歩を遂げた一方で、ビデオ理解には特有の課題が存在します。既存のビデオ基盤モデルは、クラスタリングや分類タスクの限界からも明らかなように、外観と動きの両方を効果的に捉えることができない場合が多々あります。
1.2 - TWLV-Iと評価フレームワークの紹介
これらの課題に対処するため、私たちは図1に示すように、外観ベースおよび動きベースの両方のタスクで卓越するように設計されたTWLV-Iを導入します。さらに重要なこととして、TWLV-Iの能力を評価するだけでなく、今後のモデルのベンチマークを設定する堅牢な評価フレームワークを提案します。
私たちのフレームワークには、動作認識、時間の動作ローカライズ、空間・時間の動作ローカライズなど、ビデオ理解の特定の側面を評価するために細心の注意を払って設計された様々なタスクが含まれています。この包括的なアプローチを通じて、バランスのとれた能力の重要性を強調し、業界をより包括的なモデル開発へと導くことを目指しています。
ビデオモデルの性能と適切な評価の両方に焦点を当てることで、私たちはビデオ研究におけるマイルストーンを提示し、このダイナミックな分野における今後の進歩と革新への道を切り開くことを熱望しています。
2 - TWLV-I & ビデオ基盤モデル評価フレームワーク
TWLV-Iのアーキテクチャとトレーニングプロセスは、外観と動きの両方の理解に対するニーズのバランスをとりながら、ビデオ理解に特有の課題に対処するように設計されています。図2は、外観中心のベンチマーク(Kinetics-400)と、動き中心のベンチマーク(SSv2およびDiving-48)におけるTWLV-Iのパフォーマンスの視覚的な比較を示しています。このプロットは、TWLV-Iのバランスの取れた能力を示しており、両方のタイプのタスクを高度に処理できることを実証しています。
このサブセクションでは、TWLV-Iのトレーニング手法とフレームサンプリング技術の主要な側面について詳しく説明します。
2.1 - アーキテクチャ
TWLV-Iは、Visual Transformer(ViT)アーキテクチャに基づいて構築されており、ビジュアルデータを処理するその強力な能力を活用しています。私たちは、次の2つのバリアントを実装しています:
ViT-B (Base): 8600万個のパラメータを持つモデル
ViT-L (Large): 3億700万個のパラメータに拡張されたバージョン
入力されたビデオは複数のパッチにトークン化され、これらはトランスフォーマー層を介して処理されます。このプロセスにより、パッチごとの埋め込みが取得され、その後プーリングされて、入力ビデオのトータルな埋め込みが生成されます。
2.2 - 事前トレーニングデータセット
堅牢で汎用性の高いビデオ理解を実現するために、TWLV-Iは表1に詳しく説明されている多様なデータセットで事前トレーニングされています:
ビデオデータセット:
Kinetics 710(65.8万動画クリップ)
HowTo360K(36万動画クリップ、HowTo100Mのサブセット)
WebVid10M(1073万動画クリップ)
画像データセット(合計1500万画像):
COCO(11.3万画像)
SBU Captions(86万画像)
Visual Genome(10万画像)
CC3M(288万画像)
CC12M(1100万画像)
このビデオデータセットと画像データセットの組み合わせにより、動きのダイナミクスと静的なビジュアル特徴の両方を理解するTWLV-Iの能力が向上します。
2.3 - トレーニング目的
TWLV-Iは、基礎的なトレーニングアプローチとしてマスクモデリングモデルを採用しています。しかし、動きと外観の両方の理解においてモデルの性能を最適化するために、再構成ターゲットを多様化しています。この戦略は、様々なビデオ理解タスクにわたって優れた性能を発揮できる、頑健なモデルの作成を目的としています。モデルは、この目的と前述のデータセットを使用してゼロからトレーニングされます。
2.4 - フレームサンプリング
フレームサンプリングのプロセスは、ViTアーキテクチャの計算上の制約があるため非常に重要です。トークンの数が増えると、計算の複雑さ(二次関数的)も増します。これを処理するため、私たちはMulti-Clip Embedding(マルチクリップ埋め込み、図4を参照)と呼ばれる戦略的なフレームサンプリング技術を採用しています:
クリップの分割:入力されたビデオは、それぞれ長さがT秒のM個のクリップに分割されます。
フレームの選択:各クリップからNフレームがサンプリングされます。
埋め込み生成:このプロセスにより、ビデオ1本につきM個の埋め込みが作成されます。
柔軟な表現:埋め込みの数はビデオの長さに比例して増加するため、可変長のビデオ処理が可能になります。
単一の埋め込みオプション:ビデオ全体を表すために単一の埋め込みが必要とされる場合は、M個の埋め込みを平均化します。
このアプローチにより、TWLV-Iは短期および長期の時間的ダイナミクスの両方を捉える能力を維持しながら、様々な長さのビデオを効率的に処理できます。
強力なViTアーキテクチャと、多様な事前トレーニングデータセット、および革新的なフレームサンプリング技術を組み合わせることで、TWLV-Iは複雑なビデオ理解タスクに対処する十分な能力を備えています。この強固な土台により、TWLV-Iは外観中心および動き中心の両方のベンチマークにわたって堅牢に機能することができ、それについては本評価フレームワークの以降のセクションで詳しく見ていきます。
3 - 動作認識
動作認識(Action Recognition; AR)はビデオ理解における基本的なタスクであり、ビデオを定義済みの人間の動作カテゴリに分類することを目的としています。このタスクは、外観と動きの両方の理解を必要とするため、ビデオ基盤モデルの性能を評価するための重要なベンチマークとなっています。
3.1 - ベンチマーク
私たちは、それぞれ異なる特徴を持つ、代表的な5つのARベンチマークにおいてTWLV-Iの性能を評価しました:
Kinetics-400 (K400):外観ベースの動作に焦点を当てた大規模データセット
Something-Something-v2 (SSv2):時間的関係を重視した動き中心のデータセット
Moments-in-Time (MiT):多様な動作カテゴリを持つ、もう1つの外観重視のデータセット
Diving-48 (DV48):ダイビングの動作に特化した、詳細かつ動き中心のデータセット
Epic-Kitchens (EK):日々の台所での活動を捉えた一人称視点(自我中心)のデータセット
これらのベンチマークは包括的な評価環境を提供し、外観重視および動き中心の両方のシナリオにわたってTWLV-Iの能力を評価できるようにします。
3.2 - 評価手法
私たちは、動作認識タスクにおける標準的な手法であるマルチビュー分類法を採用しています:
入力ビデオを空間的にリサイズし、要求される解像度に適合させます
空間次元に沿ってm個、時間次元に沿ってn個のクリップを一様にサンプリングし、合計m × n個のクリップを作成します
各クリップのクラス確率を算出します
確率を平均化して最終的な出力を取得します
このアプローチにより、入力ビデオの異なる空間的および時間的セグメントにわたるモデルの性能が徹底的に評価されます。
3.3 - リニアプロービング(線形評価)
リニアプロービングは、モデル全体をファインチューニングすることなく、学習された表現の品質を評価するために使用される技術です。以下のステップを含みます:
特徴抽出器(バックボーンモデル)を固定(フリーズ)します
フリーズされた特徴の上に線形分類器を配置してトレーニングします
線形分類器は、埋め込みベクトルの次元数から動作クラスの数へのマッピングを行う重み行列で構成されます。
結果と分析
表3は、様々なベンチマークとモデルにおけるリニアプロービングの結果を示しています。主な観察結果は以下の通りです:
TWLV-Iはすべてのベンチマーク、特にそのアーキテクチャ規模(ViT-BおよびViT-L)において強力なパフォーマンスを示しています。
SSv2において、TWLV-Iは、事前トレーニングにSSv2を含んでいるV-JEPAを除き、ViT-H (DFN) や ViT-g (InternVideo2) などのより大規模なモデルを凌駕しています。
TWLV-IのViT-Lモデルは、EKおよびDV48のベンチマークにおいて、より大規模な他モデルを上回る結果を示しています。
これらの結果は、単純な線形分類器を使用して評価した場合であっても、TWLV-Iが様々な動作認識タスクにうまく汎用できる、豊かな表現特徴を学習できていることを裏付けています。
3.4 - アテンティブプロービング(注意評価)
リニアプロービングはクリップごとの埋め込み精度についての洞察を提供しますが、特にパッチレベルの教師あり学習で訓練されたモデルにおいて、その真能力を完全に捉えきれない場合があります。この制限に対処するため、私たちは以下を含むアテンティブプロービングを導入します:
フリーズされたモデルの上に、学習可能なクラストークンを持つ単一のアテンション層を導入してトレーニングします
出力されたクラストークンを線形分類器に入力します
Top-1精度を測定します
この手法により、モデルのパッチ単位での表現能力をより詳細に評価することが可能になります。
結果と分析
表5は、アテンティブプロービングの結果を示しています。主な発見は以下の通りです:
TWLV-Iは、外観重視および動き中心の両方のベンチマークにわたって、他のモデルと比較して優れた性能を達成しています。
アテンティブプロービングにおける強力なパフォーマンスは、TWLV-Iが同等のモデル群に比べて、より詳細で豊かなパッチ単位の表現をそなえていることを示唆しています。
3.5 - K近傍法(K-Nearest Neighbors)
勾配法に基づく評価での潜在的な偏り(バイアス)を排除し、パラメータフリーな状態で埋め込みの品質を評価するため、私たちはK近傍法(KNN)分類タスクを採用しています。このノンパラメトリックなアプローチにより、異なるモデルアーキテクチャ間で埋め込みベクトルをより公正に比較することができます。
私たちは、以下の2つの手法で埋め込みを生成します:
一律の埋め込み(Uniform Embedding):ビデオ全体に対して1つの埋め込みベクトルを生成します。
マルチクリップ埋め込み(Multi-Clip Embedding):ビデオ全体にわたる2秒間のクリップから複数の埋め込みを生成します。
マルチクリップ埋め込みでは、2つの評価戦略を採用しています:
ビデオレベル:すべてのクリップの埋め込みを平均化して、単一のビデオ表現を作成します。
クリップレベル:各クリップが獲得した投票を合計して、最終的なクラスを決定します。
結果と分析
表6は、異なるモデルおよび埋め込み戦略におけるKNN分類の結果を示しています。主な観察結果は以下の通りです:
TWLV-Iは、Kinetics-400(K400)およびSomething-Something-v2(SSv2)の双方のデータセットにおいて、特に対象モデルが同等規模のものと比較した際に、極めて競争力のある性能を示しています。
Uniform(一律)埋め込みの設定において、TWLV-I-ViT-BはK400で57.51%、SSv2で19.82%のTop-1精度を達成し、同一のアーキテクチャを持つUMT_s2を凌駕しています。
TWLV-I-ViT-Lは強力な結果を示しており、K400で65.97%、SSv2で19.47%のTop-1精度を達成し、いくつかのより大規模なモデルを上回っています。
それにもかかわらず、アテンティブプロービングでの結果とは異なり、KNN評価においてTWLV-IはK400およびSSv2の双方でInternVideo2に一歩及ばない結果となりました。これは以下を示唆しています:
TWLV-Iの埋め込みをノンパラメトリックな方法で活用する余地がまだ残されていること。
特に長時間のビデオ(単一クリップの長さを大幅に超えるもの)について、その埋め込みを効果的に表現する方法に関する更なる研究が必要であること。
これらの結果は、ビデオ表現の複雑さと、異なる評価手法のすべてにわたって普遍的に強力な埋め込みを構築することの難しさを物語っています。
3.6 - SSv2を用いた事前トレーニング
V-JEPAなどのモデルとの公平な比較を行い、事前トレーニングに動き中心のデータを取り込むことの影響を評価するため、私たちはSomething-Something-v2 (SSv2) データセットをTWLV-Iの事前トレーニングフェーズに組み込む追加の実験を行いました。
私たちは、元のデータセット群に加えて事前トレーニング用データにSSv2を組み込み、TWLV-I(ViT-Lアーキテクチャ)のバリアントをトレーニングしました。これにより、この追加データが様々なベンチマークや評価に与える影響を直接比較できます。
結果と分析
このSSv2を組み込んで拡張されたモデルの評価結果は、表3、表5、および表6の下部に示されています。主な発見は以下の通りです:
SSv2パフォーマンスの進歩:すべての評価方法(リニアプロービング、アテンティブプロービング、およびKNN)を通じて、そのモデルはSSv2ベンチマークにおいて大幅な進化を遂げています。たとえば、リニアプロービング(表3)では、SSv2でのTop-1精度が46.41%から48.14%に上昇しました。
全体の総合的性能向上:事前トレーニングにSSv2を含めることで、他のベンチマークにおいても性能向上が見られました。これは、動き中心のデータを追加したことで、モデルの全体的なビデオ理解能力が向上したことを示唆しています。
専門特化モデルとの比較:性能が改善されたものの、動き中心のSSv2における事前トレーニング拡張モデルのKNN性能は、同テスト上で依然としてV-JEPAおよびInternVideo2に対して遅れをとっています。これは、TWLV-Iのパッチレベルの表現能力は強力である一方、ビデオレベルでの表現力には改善の余地があることを示しています。
表現性能におけるトレードオフ:結果は、TWLV-Iのパッチレベルとビデオレベルの表現において、潜在的な不均衡がある可能性を浮き彫りにしています。この顕著なギャップへの対処は、今後のモデル拡張に際しての重要フォーカスとなるはずです。
これらの発見は、堅牢なビデオ基盤モデルの開発において多様な事前トレーニングデータの存在が極めて重要であることを強調しています。また、外観中心のベンチマークでの高い性能を維持しつつ、動き中心のタスクにおいて特定の専門モデルにより良く対抗するために、TWLV-Iを改良できる具体的な領域を指示してくれています。
4 - ImageNet 分類
ビデオ基盤モデルの汎用性と、それらが一般的な画像認識モデルとして機能する可能性を評価するために、ImageNet分類タスクにおけるTWLV-Iの性能評価を行いました。このベンチマークは、静止画像を処理・理解するモデルの能力についての洞察を提供し、これは包括的なビデオ理解システムを構築する上でも不可欠な要素です。
4.1 - 結果と分析
ImageNetの分類結果は、表3(リニアプロービング)および表5(アテンティブプロービング)の最後の列に示されています。主な観察結果は以下の通りです:
外観中心のタスクとの相関関係:一般的に、外観中心の動画動作認識タスク(例: Kinetics-400)で優れたスコアを達成するモデルは、ImageNetベンチマークにおいても強力な性能を発揮します。この相関関係は、ビデオ理解のために学習された特徴が、静止画分類タスクにも効果的に転移できることを示唆しています。
TWLV-Iのパフォーマンス:
リニアプロービング(表3)において、TWLV-I-ViT-LはImageNetで72.98%のTop-1精度を達成し、競争力はあるもののトップには至っていません。
アテンティブプロービング(表5)では、TWLV-I-ViT-Lは79.19%のTop-1精度へと性能が向上しており、アテンションメカニズムを介した学習済み特徴のさらなる有効活用を示してくれています。
専門特化モデルとの比較:TWLV-Iはビデオベースのタスクにおいて強固なパフォーマンスを発揮している一方で、いくつかの特定目的のモデルと比較するとImageNet分類のスコアには目に見えるギャップがあります。たとえば、InternVideo2はImageNetにおいてTWLV-Iを大幅に上回っていますが、ビデオ動作認識タスクにおいてはその性能差は狭まり、場合によっては逆転することもあります。
4.2 - 示唆と洞察
これらの観察に基づき、私たちは次の洞察を得ました:
静止画像処理における制約:結果から、TWLV-Iは、当該タスクに最適化されたモデルと比較して、静止画像の処理についてある程度の制限があることが示されています。これは、モデルの将来のアップグレード段階における改善余地があることを示します。
動作情報の活用能力:ImageNetのスコア差をよそに、ビデオタスクにおいてTWLV-Iと他モデルとの性能ギャップが縮まることは、TWLV-Iがビデオ理解において動作情報を非常に効果的に活用していることを示唆しています。この能力は外観ベースの特徴保管と補完し合い、結果として強力なトータルビデオ分析性能をもたらします。
ビデオと画像能力の均衡化:TWLV-Iを単なる動画特化モデルから、さらに前へと進化させるために、今後の研究ではその強力なビデオ分析能力を損なうことなく、単一画像を理解する能力を強化することに焦点を当てるべきです。
総括として、TWLV-Iはビデオ理解タスクにおいて強力な性能を示しているものの、ImageNet分類結果は、静止画像処理におけるいくつかの改良すべき領域を示しています。これらの制約に対処することで、ビデオと画像の双方のドメインにわたって秀でた、より包括的な視覚基盤モデルの実現につながる可能性があります。
5 - 時間の動作ローカライズ
時間の動作ローカライズ(Temporal Action Localization; TAL)はビデオ理解における重要なタスクであり、トリミングされていない一連のビデオの中から特定の動作を特定し、時間的位置を特定することを含みます。このタスクは自動運転、スポーツ分析、コンテンツに基づくビデオ検索などの応用において特に重要です。TALでは、モデルが長くて複雑なビデオを分析し、その中で発生する各動作の時間的な境界と対応するクラス分類ラベルを正確に判定することが求められます。
5.1 - 評価の視点
TALは、主に以下の2つの主要な視点からビデオ基盤モデルを評価します:
時間的感度:関心のある動作が特定のタイムステップで発生したかどうかを識別する能力。
インスタンス識別能力:フレームごとのセグメントを、完全な一つの動作インスタンスに識別またはグループ化する能力。
TALは本質的に動作中心のタスクとして設計されていますが、私たちの分析によれば、これら2つの側面の効果的な達成において、外観と動きの双方の能力が相乗的に寄与していることが明らかになりました。
5.2 - 手法
私たちは、TWLV-Iおよび他の動画基盤モデルを、以下の2つの著名なTALデータセットにおいて評価しました:
ActivityNet-v1.3
THUMOS14
検出用のヘッドとしてはActionFormerを採用しました。そして、以下の2つの異なる検証方法で評価を行いました:
自己完結型(Self-contained):モデルの外部サポートを受けることなく、自ら単独で分類と回帰の両方を実行します。
外部分類器併用型(w/ External Classifier):モデルは二値分類を行い、実際の動作クラスの予測は外部の分類器が行います。
特徴の抽出は、「フレームサンプリング」セクションで説明したマルチクリップ埋め込み手法に従って行われました。
5.3 - 結果と分析
表9と表10はそれぞれ、THUMOS14およびActivityNet-v1.3における包括的な結果を示しています。
THUMOS14(表9)
TWLV-I(当社モデル)は、すべての検証指標において、同一スケールの他のモデルを一貫して上回る性能を示しています。
TWLV-I-ViT-Lは、自己完結型設定で58.75%、外部分類器併用設定で53.63%という最高の平均mAPを達成しました。
特筆すべきは、TWLV-I-ViT-LがDFNやV-JEPA (ViT-H) のようなより大規模なモデルををも凌駕している点であり、その優れた汎用・一般化能力を証明しています。
ActivityNet-v1.3(表10)
TWLV-Iはここでも、そのアーキテクチャの規模感において屈指のパフォーマンスを示しています。
TWLV-I-ViT-Lは、平均mAPで34.98%(自己完結型)および39.49%(外部分類器併用型)を記録しました。
驚くべきことに、TWLV-Iは厳格なIoU閾値(例: 0.95)において極めて優れた性能を発揮しており、並外れた時間的感度を有していることが示されています。
5.4 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
スケール効率:TWLV-Iのパフォーマンス、特にViT-Lの規模感において他社大容量モデルを打ち負かしている現状は、その効率的な設計アーキテクチャとトレーニング手法を明白に証明しています。
時間的精密さ:極めて厳しい基準である厳格なIoU閾値(ActivityNetにおける0.95等)での高スコア獲得は、TWLV-Iが誇る突出した時間的感度の鋭さを証明しています。
モデル規模の影響:InternVideo2のトップパフォーマンス、特に自己完結型の評価における実績は、TALタスクにおいて分類と時間的境界の回帰を同時に実行する際、モデルの規模拡張が大きく利益をもたらすことを示唆しています。
評価戦略:単に「動きの理解」のみに的を絞って正確に測定したい場合は、外部分類器との併用が推奨されます。一方で、外観の理解度をも包含するより網羅的な評価を望む場合は、自己完結型のアプローチが求められます。
汎化能力:異なる複数のデータセットおよび評価方法にわたるTWLV-Iの終始強力なパフォーマンスは、時間の動作ローカライズ分野における主要バックボーンとしての屈強さを表しています。
これらの結果は、時間の動作ローカライズという極めて複雑な課題に対するTWLV-Iの抜群の有用性を物語っており、時間的感度と動作のまとまり認識の双方においてバランスよく実力を備えていることを明確に示しています。様々なスケールや多様な測定環境において現れたその高い適合能力は、ビデオ理解全般を支える汎用的ベース基盤としての高いポテンシャルを示しています。
6 - 空間・時間の動作ローカライズ
空間・時間の動作ローカライズ(Spatio-Temporal Action Localization; STAL)は、ビデオの中の特定の動作を認識するだけでなく、編集されていないビデオ系列内の空間(画面中のどこか)および時間(いつ発生したか)の双方を正確に検知・特定する、高度で複合的な難関課題です。この課題はアクションの精密な分析が必要とされるシーンで重要視され、外観と動き双方の完全な統合理解がモデル側に問われます。
6.1 - データセットと評価
私たちは、1本あたり15分間の映画から切り出された430個の動画クリップで構成されているAVA v2.2データセットを用いてモデル検証を行っています。キーフレームは毎秒付与され、学習用セットに210,634枚、検証用セットに57,371枚のラベル付きフレームが含まれています。データセットには、各俳優に紐付けられた80個の原子的な基本動作ラベルが含まれています。
この動作評価では、最新のv2.2アノテーションを使用し、Intersection over Union (IoU)の閾値0.5におけるフレーム平均精度(Frame Average Precision; fAP)を取得して比較しています。私たちはエンドツーエンドのSTALフレームワークを採用し、バックボーン側のビジュアルモデル部分を固定した状態でデコーダの追加トレーニングを実行しました。
6.2 - 結果と分析
表11は、STALタスクにおける性能評価を示しています。主な観察結果は以下の通りです:
他モデルとの対比:TWLV-I、UMT、およびInternVideo2は、DFNやV-JEPAより優れた性能を発揮しています。DFNとV-JEPAは他の種類のタスクで全く異なる極端なスコア傾向を見せていましたが、物体としての人物特定と、時間的な動作認識の双方をクリアする必要があるSTALタスクにおいては、その性能は似たような値にとどまっています。
検出局所化における難点:
V-JEPA:人物などのインスタンスの特定そのものに手こずり、それが後続の動作認識スコアにも波及して悪影響を与えています。
DFN:得意とする外観の精緻な理解力により、対象が画像のどこにいるのかを素早く特定できていますが、時間情報の解釈の限界から、そこでどのような動作が行われているかの認識で誤答しています。
TWLV-Iの特徴的な強み:
TWLV-Iは、物体の外観と動作中の物理的変化を極めて高いレベルで調和よく理解することで、STALタスクにおける確固たる強さを現しています。
ViT-Lモデルにおいて、TWLV-IはfAP@0.5で27.39を達成しました。これはDFNやV-JEPAを大きくリードし、より構造の大きい巨体モデル群であるInternVideo2の記録に肉薄する性能スコアです。
6.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
調和のとれた深い読解:今回の好成績は、TWLV-Iが時空間情報を極めて適切に理解できていることを示す十分な証拠であり、精度の高い時空間ローカライズを実現する上でも要となります。
全般的なビデオ判定価値:終始シームレスにエンドツーエンドで行われるSTAL検定は、空間と時間の2つの次元におけるパフォーマンスを高い再現性を持って明らかにする包括的なモデル審査手法と言えます。
手法の有効性検証:TWLV-IがUMTやInternVideo2と並んで好成績を残している現状は、空間位置特定と動作分析の2つの異なる目標を同時に処理する能力の現れであり、外観のみ、あるいは動作のみといった限定的な一方を追求した他社モデルとは一線を画しています。
これらの裏付けは、時空間の複雑なシーンを正確に記述する必要がある高度な難題(STAL等)を解決するために、外観情報と動作変化情報の双方が一つの脳(モデル)の中にバランスよく統合されていることが如何に決定的であるかを語っています。
7 - 時間の動作セグメンテーション
時間の動作セグメンテーション(Temporal Action Segmentation; TAS)は、編集されていない長時間のビデオから人間の複雑な活動の全貌を読み解くために非常に重要とされている応用課題です。セキュリティ監視、ハイライト映像などの要約作成、作業スキルの機械的審査など、広範な産業でその活躍が期待されています。TASでは、トリミングされていないビデオを入力として直接流し込み、それぞれのフレームに一連の正しいアクションのクラス分類ラベルを追加していく作業を行います。
7.1 - 表記比較基準とアプローチ
私たちは、TASの性能を判定すべく以下の3つの高難度検証基準を用意しました:
50Salads:調理の手順において、細々とした変化を伴う複雑な一連の処理を含んでいます。
GTEA:一人称の目の高さで撮影した、複雑な身の回り仕事の一連のプロセスを記録しています。
Breakfast:引いた位置からも撮影された、全身でキッチン作業をこなす長時間の全体構成データです。
TASのデコーダ部分としてはASFormerを使用しました。閾値10、25、および50のもとで測定されたF1スコアの平均値を「mF1」として評価に採用しています。マルチクリップ埋め込みを用いて特徴を抽出し、空間次元プーリングを施すことで時間軸のみを滑らかに残しています。
7.2 - 結果と分析
表12は、これら3つのテスト条件のもとで実施したTAS試験の結果を詳細を伝えています:
50Salads:TWLV-Iは、ViT-Bで80.69、ViT-Lで80.60のmF1スコアをマークしました。これは、UMTやDFNといった外観重視モデルや、動作変化を専門としたV-JEPAをも完全に跳ね除ける数値です。また、エディットおよび予測適合率の項目についても、TWLV-Iの手法が正解データ配列に極めて整合していることを明らかにしています。
GTEA:TWLV-Iはさらに強さを示し、ViT-Bで88.26、ViT-Lで88.43のmF1スコアを記録して競合を大きく引き離しました。これは、一瞬で移り変わるアクションの正確なセグメンテーションを必要とする、一人称主観視点の動画において真価が浮き彫りになることを証明しています。
Breakfast:被写体が遥か遠くにフレームインする視野角の広いこのシーンでも、TWLV-Iは実力を落とすことなく、ViT-Bで52.18、ViT-Lで50.66という好ましいmF1スコアを獲得しています。目まぐるしく変化するカメラ視野の切り替わりに対しても、その対応柔軟性が高水準に維持されています。
7.3 - 主要な洞察
これらの結果に基づき、私たちは次の洞察を得ました:
完成されたオールラウンダーとしての実力:データの多様性によらずあらゆる分類群で最高峰に位置するTWLV-Iの一貫した強さは、外観の把握力と動作の持続変化を漏らさず記述する能力のバランスが非常に良好であることを意味しています。
実際の推移への適合精度:エディットスコアおよびmF1スコアが高水準にまとまっていることは、TWLV-Iが予測したアクションの流れ全体(系列)が、実際のビデオ内で人間の動作した現実の順序に正確に合致していることを意味し、将来的なオンサイト実装における安全・信頼性の高さを示しています。
視野角変化に対する屈強さ:上空からの撮影、手元を映す一人称主観カメラなど、極端な画角変更があっても他製品以上のスコアを叩き出し続ける事実は、いかなる用途でも現場を選びにくい柔軟性のある頑丈なモデルであることを実証しています。
InternVideo2とのベンチマーク性能比較:特定のアングルのデータにおいて、TWLV-IはInternVideo2に類似する好成績を取り分けて現していますが、広範囲にまたがる複数データセットを前にしても性能がブレることのなく、常に一貫した優秀さを維持する確実性は、総合的なポテンシャルの高さをはっきりと映し出しています。
これらの評価により、時系列動作セグメンテーション(TAS)の非常に挑戦的な検証において、TWLV-Iがビデオ解析を応用可能とする多大なる可能性を備えていることが確かに認められました。
8 - 埋め込み空間の可視化
TWLV-Iや他社基盤モデルのビジュアル表現能力がどのように構造化されているかを詳しく探索するため、私たちはt-SNEおよび線形判別分析(LDA)を用いたビジュアル確認実験を実施しました。これにより、作成された埋め込みベクトルが「外観情報」と「動き情報」の各々の側面をどれほど精緻に描写できているかが理解できます。
8.1 - t-SNEを用いた各評価データセット上のマッピング
t-SNEを用いて、Kinetics-400 (K400) および Something-Something-v2 (SSv2) 検証用セットにおける埋め込みベクトル分布をマッピングしました。また、色分けは異なるアクションクラスを表しています。
Kinetics-400(図6)
TWLV-I, UMT, および InternVideo2:これらのモデルは同じ特性をもつ動作どうしが1つのブロックのように固まりを構築し、境界線を容易に引くことができるきれいなクラスタリングを示しました。これは、外観に基づいて表現が異なる多数の動作群を驚くほどきれいに判定できていることを意味します。
V-JEPA:打って変わって、各動作クラスをごちゃ混ぜに描いてしまい、特徴空間を明確に分割することができていません。静止構造(外観ターゲット)をきれいに捕捉できていない性質が読み取れます。
Something-Something-v2(図7)
全モデルの傾向:面白いことに、TWLV-IやV-JEPAも含め、どのモデルもSSv2のような高度に動きが重視されるデータセットにおいては、一目で分かるようなクラスタリングを表示できませんでした。これは、他の手法に比べ、そもそもSSv2の分類スコアがどの製品でも総じて低い実情と重なっています。
そのことが暗示する意味:このプロットによる描画結果は、動きそのものの質的違いを明確なベクトルのまとまりの中に落とし込んで表現することが技術的に如何に困難であるかを雄弁に物語っており、ブレイクスルーを呼び起こす今後の革新的アプローチが待ち望まれます。
8.2 - 動作の方向に対する感度検証
よりミクロなレベルにおいて、モデルが動きをどのように知覚しているかを理解するために、私たちはSSv2から「何かを押し上げる」「何かを引き下げる」といった、動作の物理的方向の読解が無ければおよそ解答不可能な、特定の動作ペアに注目しました。
私たちは、通常の正再生動画から切り出した動画ベクトルと、それを時間軸に対して逆転させた逆再生動画の埋め込みベクトルを抽出し、線形判別分析(LDA)を用いてプロットしました。この検証では、外観が全く同じである動画どうしの順逆方向について、純粋に時間的経過の順序だけでその差異を埋め込みベクトル空間上で分離できるかどうかをテストできます。
結果(図8および図9)
TWLV-I:正再生と逆再生の動画が交じることなく極めて良好に二極反転の空間位置を保っており、時間方向の違いをベクトルの差異の形で確実に記述できていることを実証しています。
V-JEPA:ここでも正逆識別において最も広い距離感(明確さ)を獲得しています。これは、同モデルが事前トレーニング時から意図的にSSv2データセットを多量に摂取している実績に起因すると考えられます。
UMT および InternVideo2:埋め込みの正負領域での重複が大きく分離困難に陥っています。これは、静止画像の精緻な理解を得意とする一方で、時間方向に対してはほぼ感度を持たない(動作変化に対して無頓着な)設計上の構造を示しています。
8.3 - 主要な洞察
これらの観察に基づき、私たちは次の洞察を得ました:
外観と運動変化を同時に記述する能力:TWLV-Iは、静止画を基準とする認識分類力(K400の図から顕著)と、動作方向による時間秩序変化の知覚力(順逆分析から顕著)の双方を高レベルで併せ持つ、類稀なるオールラウンド性能を持っていることがビジュアルからも明らかになりました。
動作の質的表現(モデリング)のための課題:SSv2のクラスタリングで全ての競合が描いたカオティックなプロット図は、運動表現のみで多様なクラス群をきれいに定常分離していく作業が今なおどれほど高難易度であるかを示し、ビデオ分野における最大のテーマとして残されています。
時間変化に対する鋭敏な解釈力:正逆方向のビデオを即座に引き裂くTWLV-Iのおおきな分離能力は、ただ物理的な情報を見るだけでなく、動画ならではの微細な時間フレームの前後変化にまで高い感度で反応を返せていることを意味し、高度な動作記述の足がかりとなります。
各社モデルの個別得意分野:プロットにより、それぞれの製品群が得意とする設計方針の違いが鮮明になり、外観を高度に見抜くモデルがある一方で、時間的運動のみをうまく感知するような尖った得意領域に特化するなどの現状が浮き彫りになり得ます。
これらの特徴的な視覚マッピングによる可視化手法は、TWLV-Iの脳がどのように特徴を獲得しているかを視覚的に雄弁に説いてくれており、今後の改善策を計画するための重要な技術基盤となります。
9 - 今後の開発テーマ
今後の展望として、TWLV-Iの実用拡大、およびビデオ基盤モデル一般を劇的に変革し、応用領域を広げるためのいくつかの有望な発展レーンが存在します。これらは、モデル能力の大幅補強、スコア改善、さらに多領域における産業実装の加速を目指すものです。
9.1 - モデルスケールの拡張
これまでのところ、主に以下の2つのモジュール構成を中心にリリースしてきました:ViT-BおよびViT-L。しかしながら、当社のTWLV-I-ViT-Lは、一回り体が大きい他社製のViT-HやViT-gの記録と同等、場合によってはそれを超える良好な数値を叩き出しています。この効率の良さは、今後モデルを拡張した場合、さらなる大幅なポテンシャル向上の余白があることを意味します:
極大規模アーキテクチャの導入:TWLV-Iをより極大サイズのモデルへと引き上げることで、多様な検証ベンチマークにおけるスコアを飛躍的にレベルアップさせることが大いに期待されます。
内製の極大データセットの構築:自社で囲い込みを行って獲得した並外れた規模の大容量学習資源を使用することで、さらに柔軟であらゆる変化に強い強固なベースを育むことが可能です。これは未体験の難題や新たなシーンをモデルが難なく見抜く手助けとなります。
高効率スケーリング設計:スパースアテンション構造やMixture-of-Experts (MoE) と言われるマルチネットワーク構造などの高効率スケーリング手法を採用することで、開発リソース資源を際限なく食いつぶすことなく、極端な機能アップグレードを安定して実現させられます。
9.2 - 画像埋め込み機能の大幅強化
TWLV-Iはビデオに関わる項目で強い優位性を現したものの、単一の画像そのものの埋め込みを表現する精度に関しては、さらに向上させられる余地が残っています:
静止フレームの読解力強化:ビデオから切り出した1枚のフレームそのものを正確に把握する精度を強化することは非常に合理的です。この能力が磨かれれば、ビデオの得意さと画像の得意さが統合され、TWLV-Iは総合的に完璧なビジュアル認識プラットフォームとなり得ます。
転移学習アプローチの探索:動画上で構築された「動作変化を前提とした知覚表現」を、うまく静止画における分類タスクの補助特徴へと転移する学習アプローチが構築できれば、一般的な画像AIタスクにおける信頼性を容易に格上げできます。
単一フレームワークでの統合学習:同一のシステム構成のままで、ビデオからの入力と静止画からの入力のいずれでも変わらぬ適合率をたたき出す、シームレスな統合アーキテクチャの変更を推進します。
9.3 - モダリティレンジの拡張
さらに、TWLV-Iとしての利便性を全方位的にレベルアップさせ、AI産業自体の需要とより強固に噛み合わせるために、モダリティレンジを着実に拡張することが非常に重要です:
マルチモダルの活用促進:ビデオと引き当てられる文章推薦(ビデオテキスト検索)や、動画を正確に文字に直すビデオキャプションなど、極めて複雑な多元タスクを処理できるように改良します。これにより、卓越した映像把握力を生かしたまま、テキストと調和的に交信できるようになります。
ビデオLMMとしての位置づけ構築:TWLV-Iの構造をビジュアル側にとって最適なビジョンエンコーダとして位置付け、先進的なビデオ・大規模言語モデル(VLM)との高水準な接ぎ木を実現します。高度なテキスト理解力とのシームレスな融合が可能となります。
音声特徴の統合理解:動画内の時間変化に伴う「音声変化(オーディオ)」を映像と時間補正した状態で統合することで、音と映像のタイミングマッチング、音の出どころイベントの検出など、さらに応用度をました技術を実現します。
テスト手法の体系化と基準設定:これらの極めて応用的なマルチモダル性能について、信頼性高くスコア検証していけるよう、独自の統合的な判定テスト手法や新たな検証基準を設け、その安定性を保証していきます。
これらの将来像を追うことで、TWLV-Iが提供するバリューを「ビデオ専用のベース」から、「様々な周辺状況に対して瞬時に協調できる究極の知覚システム」へと引き上げることを想定しています。この発展は、現在実現されている機能群での性能を引き上げるのみならず、自動応答アシスタント、次世代のコンテンツクリエイト事業、革新的な人間とロボットのインターフェース構築といった未来的な産業へ決定的な道を開きます。
10 - おわりに
私たちは今回の体系的なビデオ検証において、絵画的な美しさ(外観)と移り変わる変化(動き)の2つの要素の調和が、映像解釈という広大で豊かな目的をクリアするためにいかに決定的であるかを詳述してきました。私たちの取り組みは、以下の素晴らしいブレイクスルーと発見をもたらしています:
多角的で包括的な測定規格:動画の時間的ローカライズから一連のアクションシーケンス抽出まで、あらゆる側面においてモデルの能力を均一な視点で測定できる、信頼性の高い規格を提供しています。
既存モデルの顕著な改善余白:一連の周到な検証プロセスにより、他モデル群が動作と外観のいずれか一方のみの知覚に依存し、両者を共にハイパフォーマンスに両立することがいかに苦手であるかを明らかにし、この分野におけるミッシングリンクを特定しました。
満を持してのTWLV-Iの紹介:これらの業界の不均衡に対して最適な解を与えるべく、外観と動作の両方を同時に、そして高解像度に把握する新世代のアプローチ「TWLV-I」を投入しました。
抜群の埋め込み品質:TWLV-Iが生む埋め込みベクトルは、高度な下流タスクを非常に簡便にいなす高い適用力を見せており、実用化の検証コストを劇的に圧縮します。
汎用的で強力な検証用フレームワーク:本ブログでお披露目された多様な検証とプロット比較法は、今後のビデオ基盤モデルの基礎テスト規格となる得るよう、業界コミュニティへ開示されています。
将来のイノベーションプラン:今後の研究をドライブするために、モデルの大容量化、画像識別のブラッシュアップ、さらには音響やテキスト等の他系統とのマルチリンガル的な統合を進めていきます。
業界の目指すべき座標の提示:外観性能のみの偏重、動きのみの過学習を克服し、双方をひとつの体にバランスよく共存させる姿勢を示すことで、ビデオ理解領域が目指すべき進路を設定できたと自負しています。
要約すれば、TWLV-Iは万能型でかつ不屈の動画基盤モデルを作るうえで、記念碑的な飛躍を示すモデルです。外観知覚と動作知覚を絶妙に調和させることで、これまで想像さえ難しかった、高次元の動画理解と多角的な用途への扉が開かれました。私たちは、ここで開示された評価スキームやアイデアが多くの研究者をエンパワーし、新しい視点、そしてより本質に迫るアプローチで今後の課題に取り組んでもらえることを切に願っています。
この先、こうした完璧な統合基盤がさらに成熟していくプロセスは、ビデオを取り扱う多くのソフトウェア群のブレイクスルーにつながり、AIが生活シーンを支える究極のパートナーへと変貌していくために重要となります。私たちは世界中のリサーチャーとともにこの挑戦の地盤を盤石なものとし、ビデオAIが切り開く素晴らしい未来へのフロンティアを共に開いていくことを歓迎します。
Twelve Labs チーム
本研究開発は、Twelve Labs ML ResearchおよびML Dataチームの厚い支援のもと、核となる以下の主要執筆者たちの均等な(equal contributionという素晴らしい連携による)献身的な貢献を通じて達成されました。
主要な執筆者・研究代表
Hyeongmin Lee, MLリサーチャー(Research Scientist)
Jin-Young Kim, MLリサーチャー(Research Scientist)
Kyungjune Baek, MLリサーチャー(Research Scientist)
Jihwan Kim, MLリサーチャー(Research Scientist)
Aiden Lee, 最高技術責任者(CTO)
コントリビューター(アルファベット順表記)
Aaron (Jangwon) Lee, MLデータ・インターン\
Calvin (Minjoon) Seo, チーフサイエンティスト(Chief Scientist)
Cooper (Seokjin) Han, MLリサーチャー(Research Scientist)
Daniel (GeunOh) Kim, MLデータエンジニア
Flynn (Jiho) Jang, MLリサーチャー(Research Scientist)
Ian (Soonwoo) Kwon, MLリサーチャー(Research Scientist)
Jay Suh, MLデータエンジニア
Jay (Jaehyuk) Yi, MLリサーチャー(Research Scientist)
Jayden (Junwan) Kim, リサーチ・インターン
Jeff (Jongseok) Kim, MLリサーチャー(Research Scientist)
Kyle (Seungjoon) Park, MLリサーチャー(Research Scientist)
Leo (Daewoo) Kim, MLリサーチャー(Research Scientist)
Mars (Seongsu) Ha, MLリサーチャー(Research Scientist)
Max (JongMok) Kim, MLリサーチャー(Research Scientist)
Ray (Raehyuk) Jung, MLリサーチャー(Research Scientist)
William (Hyojun) Go, MLリサーチャー(Research Scientist)
引用
本プロジェクトおよび私たちの論文が皆様の研究の助けとなりましたら、ぜひスターボタンを押して引用をお願いいたします:
@inproceedings{twelvelabs2024twlv, title={TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models}, author={Twelve Labs}, year={2024} }








