" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
パートナーシップ
マルチモーダルビデオ理解のためのTwelveLabs Embed APIとSnowflake Cortexの統合

ジェームズ・リー
開発者は、Twelve LabsのEmbed APIをSnowflake Cortexと統合し、マルチモーダルなビデオ埋め込みをSnowflake本来のVECTORデータ型に保存し、Snowflake Cortex Completeを使用して取得したビデオクリップや書き起こしから要約を生成することで、セマンティックなビデオ検索および要約のワークフローを構築できます。
開発者は、Twelve LabsのEmbed APIをSnowflake Cortexと統合し、マルチモーダルなビデオ埋め込みをSnowflake本来のVECTORデータ型に保存し、Snowflake Cortex Completeを使用して取得したビデオクリップや書き起こしから要約を生成することで、セマンティックなビデオ検索および要約のワークフローを構築できます。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2025/03/26
8分
記事へのリンクをコピー
このチュートリアルの基礎となる、SnowflakeとTwelveLabsを使用したAIビデオ検索に関するクイックスタートガイドを作成してくださったSnowflakeチームのDash Desai氏に深く感謝いたします。
1 - はじめに
このチュートリアルでは、Snowflake CortexとTwelveLabs Embed APIを使用して、強力なビデオ検索および要約ワークフローを作成する方法を実演します。これら両製品の高度な機能を組み合わせることで、開発者はマルチモーダルなビデオ理解を実現し、セマンティック検索、検索拡張生成(RAG)、コンテンツ推奨などのアプリケーションを開発できるようになります。
クラウドストレージに保存されたビデオは、TwelveLabs Embed APIを使用して処理され、視覚、音声、テキストの情報をカプセル化したマルチモーダルな埋め込み(embeddings)が生成されます。これらの埋め込みはVECTORデータ型を利用してSnowflakeのテーブルに保存され、VECTOR_COSINE_SIMILARITYなどの関数を使用した効率的な類似性検索が可能になります。テキストクエリは埋め込みに変換され、最も関連性の高いビデオクリップが取得されます。さらに、MoviePyによる音声抽出やOpenAIのWhisperモデルを使用した文字起こしなどの追加処理が行われます。最後に、Snowflake Cortex Completeを活用して、ビデオの詳細、タイムスタンプ、文字起こしテキスト、コンテキストの洞察などの結果を要約します。
参考: Snowflake + TwelveLabs: データクラウドにおけるビデオAI
なぜSnowflake Container Runtimeを使用するのか?
Container Runtime上のSnowflake Notebooksは、Snowflake内で直接、高度な機械学習ワークフローを実行するための柔軟な環境を提供します。Snowpark Container Servicesを搭載したこのランタイムは、GPUやCPUなどの最適化されたコンピュートリソースを使用して、Pythonベースのデータサイエンスのタスクをサポートします。これにより、外部インフラの依存関係に悩まされることなく、外部ライブラリやツールをシームレスに統合し、TwelveLabs Embed APIのワークフローを実用化するのに最適です。
なぜTwelveLabs Embed APIを使用するのか?
TwelveLabs Embed APIを使用すると、開発者はビデオ用の最先端のマルチモーダルな埋め込みを作成できます。従来のテキストのみ、または画像ベースのモデルとは異なり、このAPIは視覚的な表情、話し言葉、ジェスチャーなどのモダリティ全体にわたる時空間的な関係性を捉えます。この統合されたアプローチにより、テキストからビデオへの検索、異常検知、ハイブリッドRAGワークフローなどのアプリケーションで正確なビデオ理解が可能になります。

ワークフローの主な特徴
マルチモーダルな埋め込み:視覚、音声、テキストのモダリティ全体にわたってビデオのコンテキストを捉える埋め込みを生成します。
効率的な検索:Snowflakeの
VECTORデータ型を使用して類似性検索を実行し、関連するビデオセグメントを高速に取得します。音声の文字起こし:一致したクリップから音声を抽出し、Whisperを使用して文字起こしを行うことで、アクセシビリティを向上させます。
要約:Snowflake Cortex Completeを活用して、ビデオのメタデータと文字起こしを実用的な洞察に要約します。
このチュートリアルに従うことで、開発者はSnowflakeとTwelveLabsの堅牢なインフラを活用しながら、ビデオ理解のためのスケーラブルなAI搭載アプリケーションを構築できます。
2 - 前提条件
開始する前に、以下が準備されていることを確認してください(詳細はこちらのクイックスタートセットアップを参照)。
Snowflakeアカウント:
Container Runtimeが有効化されたSnowflakeアカウントへのアクセス。この機能により、Pythonベースの機械学習ワークフローをSnowflake内で直接実行できます。
Snowsightでユーザーロールを
DASH_CONTAINER_RUNTIME_ROLEに切り替えます。
TwelveLabsのAPIキー:
TwelveLabsのアカウントを登録し、APIキーを取得します。
Python環境:
Snowpark Pythonおよび必要なライブラリ(
httpx、pydantic、moviepyなど)の知識。
サンプルビデオデータ:
テスト用の公開アクセス可能なビデオURLのリスト。このガイドでは3つのサンプルビデオが提供されています。
ノートブックの設定:
提供されているGitHubリンクから
Gen_AI_Video_Search.ipynbノートブックをダウンロードし、Snowflakeアカウントにインポートします。
環境設定:
TwelveLabs APIにアクセスするために、Snowflakeに外部アクセス統合とシークレットが設定されていることを確認します。
3 - ステップバイステップガイド
ステップ 1: 必要なライブラリのインストール
ノートブックの最初のセルで、TwelveLabs、Whisper、MoviePyを含むすべての必要なPythonパッケージをインストールします。
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
これにより、埋め込み生成、音声処理、文字起こしのタスクに必要なすべての依存関係が利用可能になります。
ステップ 2: ライブラリのインポート
2番目のセルで、インストールしたライブラリを環境にインポートします。これには、埋め込み生成用のTwelveLabs、Snowflakeと対話するためのSnowpark、およびフロントエンドアプリケーション用のStreamlitが含まれます。
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
これにより、Snowflakeセッションが初期化され、埋め込みの作成と処理に必要なツールがセットアップされます。
ステップ 3: ビデオURLの提示
3番目のセルで、処理する公開アクセス可能なビデオURLのリストを定義します。これらのビデオは、埋め込みを生成するための入力として機能します。
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
ステップ 4: 埋め込み生成用のSnowpark UDTFを作成する
次に、TwelveLabs Embed APIを使用して埋め込みを生成するために、Snowparkでユーザー定義テーブル関数(UDTF)create_video_embeddingsを定義および登録します。
このステップの主要な構成要素は次のとおりです。
環境に
twelvelabs.zipパッケージを追加する。安全なAPIアクセスのための外部アクセス統合とシークレットを指定する。
埋め込み用にVECTORデータ型を持つ出力スキーマを定義する。
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
ステップ 5: 埋め込みを生成してSnowflakeに保存する
SnowparkのDataFrameを使用してビデオURLのリストを並行して処理し、生成された埋め込みを video_embeddings というSnowflakeテーブルに保存します。
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
ステップ 6: ビデオクリップの文字起こし
OpenAIのWhisperモデルをダウンロードし、ビデオのダウンロード、音声クリップの抽出、およびそれらの文字起こしを行うヘルパー関数を定義します。
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
これらの関数は、後で類似性検索中に取得されたビデオクリップを処理するために使用されます。
ステップ 7: 類似性検索関数の定義
Snowflake内の VECTOR_COSINE_SIMILARITY を使用して、テキストクエリと保存されたビデオ埋め込みの間の類似性スコアを計算する similarity_scores 関数を作成します。
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
ステップ 8: Streamlitアプリケーションの構築
以下を行うインタラクティブなStreamlitアプリを開発します。
ユーザー入力を受け付ける(検索テキスト、最大結果数)。
similarity_scoresを使用して、一致するビデオクリップを取得する。Whisperを使用して各クリップを文字起こしする。
Snowflake Cortex Completeを使用して結果を要約する。
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
検索の例
「Welcome home, Buster」のようなクエリを検索すると、アプリには以下のように表示されます。
ビデオURL
クリップの開始/終了時間
類似性スコア
文字起こしされたテキスト
Cortex Completeによって生成された要約
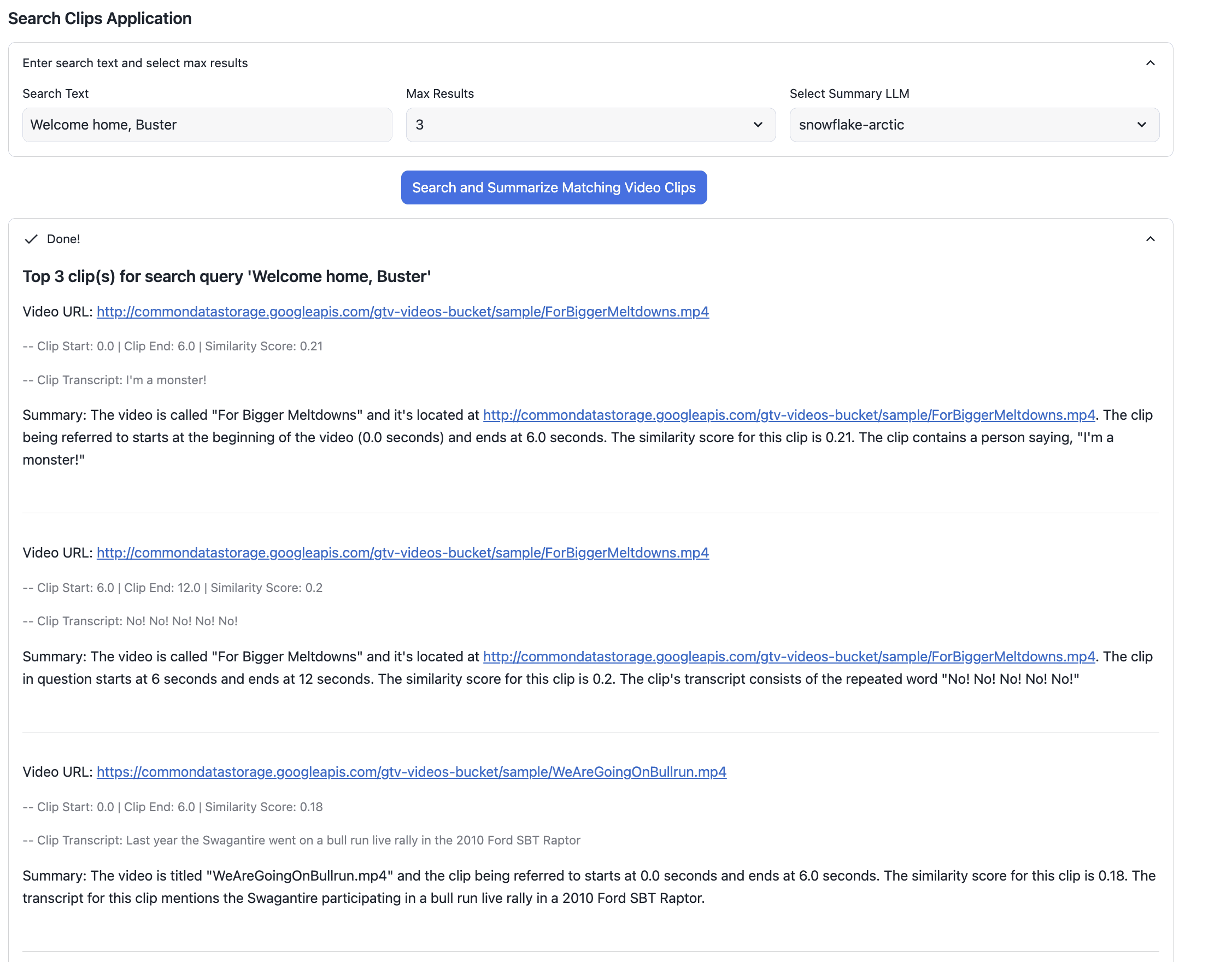
上記に表示されている最上位の結果は、こちらのビデオのものです。白いバナーに「Welcome home, Buster」という文字がはっきりと強調表示されているのがわかります。

別の検索クエリ「A white car and a black car」(白い車と黒い車)を試して、アプリの表示を確認してみましょう。
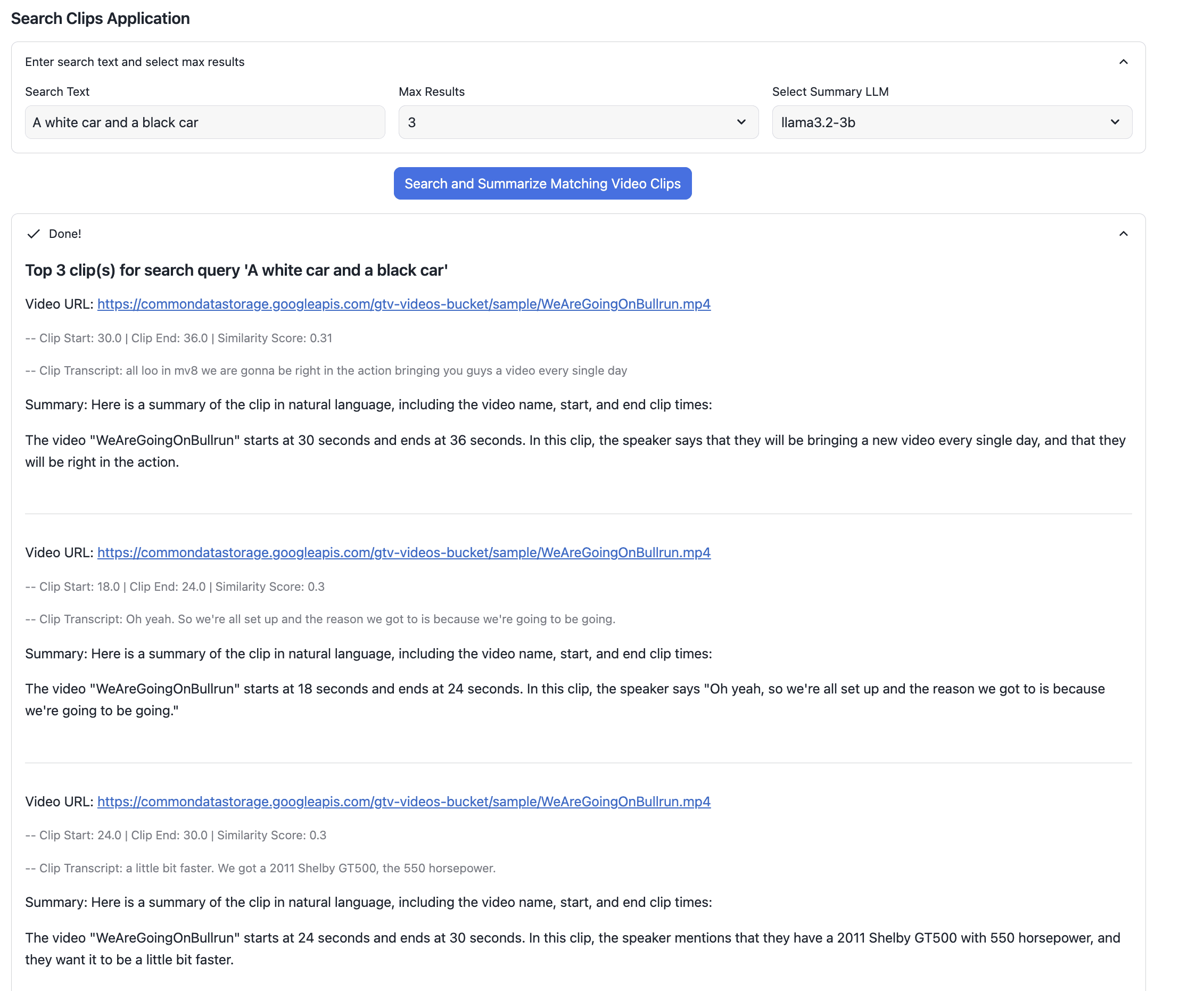
上記に表示されている最上位の結果は、こちらのビデオのものです。フレームの中に白い車と黒い車が映っているのがはっきりと確認できます。

4 - ユースケースとメリット
上記のワークフローにより、開発者は革新的なビデオアプリケーションを構築できます。
文脈に沿ったパーソナライズ広告:TwelveLabsのマルチモーダルな埋め込みとSnowflakeのユーザーデータを組み合わせることで、ブランドセーフティが確保された、文脈に適したビデオ広告を配信できます。ビデオコンテキストを深く理解することで、安全基準を維持しながら、広告をユーザーの好みに合わせることができます。
ビデオ検索エンジン:自然言語クエリをビデオ埋め込みと一致させて、正確な結果を返す高度な検索アプリケーションを作成できます。
コンテンツモデレーション:視覚、音声、テキスト要素を分析することにより、不適切または機密性の高いコンテンツがないかビデオライブラリを審査します。
推奨システム:文脈理解と視聴パターンに基づくビデオ推奨を通じて、ユーザーのエンゲージメントを高めます。
トレーニングデータのキュレーション:ビデオ埋め込み分析を介して、マルチモーダルなビデオデータセット向けに多様で代表的なサンプルを選択します。
TwelveLabsとSnowflakeの統合は、ビデオ理解機能の強化を通じて極めて大きなビジネス価値をもたらします。TwelveLabsのマルチモーダルな埋め込みは、視覚、音声、テキストを文脈に沿って捉えることで、ビデオコンテンツの包括的な分析を可能にします。この統合ではSnowflakeのContainer Runtimeを活用してスケーラブルなネイティブ環境を構築するため、運用上の複雑さが大幅に軽減されます。また、SnowflakeのVECTORデータ型を使用して埋め込みを保存および処理できるため、効率的な類似性検索や、そこから派生する下流のAIアプリケーションが可能になります。
開発者の観点からは、並行ビデオ処理用のSnowpark Python UDTFを介して簡素化されたワークフローが提供されるため、生産性が向上します。開発者は、低遅延でリアルタイムのセマンティック検索を実装したり、高度な要約タスクにSnowflake Cortex Completeを活用したりすることもできます。
最後に、このソリューションは、低レイテンシで埋め込みを生成するTwelveLabsの最先端のビデオネイティブモデルと、Snowflakeの堅牢なインフラを組み合わせることで、優れたパフォーマンスと信頼性を提供し、セキュアでスループットの高い処理能力を保証します。
5 - 結論
TwelveLabs Embed APIとSnowflake Cortexの統合により、開発者はビデオデータの可能性を最大限に引き出すことができます。高度なマルチモーダルビデオ理解と、SnowflakeのスケーラブルなAIデータクラウドを組み合わせることで、企業は検索、パーソナライズ、モデレーションなどのための革新的なアプリケーションを作成できるようになります。このパートナーシップは、TwelveLabsの最先端技術とSnowflakeのエンタープライズグレードのインフラとの相乗効果を示しており、開発者と組織の双方に大きな価値をもたらします。
行動への呼びかけ
ビデオデータを実用的なインテリジェンスに変換する準備はよろしいですか?
統合を試す:TwelveLabs Embed API オープンベータ版にサインアップして、今すぐSnowflakeで独自のAI搭載ビデオアプリケーションの構築を始めましょう。
さらなるユースケースを探索する:Snowflakeクイックスタートガイドにアクセスして、ビジネスニーズに合わせた同様のワークフローを実装する方法を学んでください。
コミュニティに参加する:この統合に関するフィードバックを、TwelveLabsのDiscordやSnowflake開発者コミュニティフォーラムで共有してください。
このチュートリアルの基礎となる、SnowflakeとTwelveLabsを使用したAIビデオ検索に関するクイックスタートガイドを作成してくださったSnowflakeチームのDash Desai氏に深く感謝いたします。
1 - はじめに
このチュートリアルでは、Snowflake CortexとTwelveLabs Embed APIを使用して、強力なビデオ検索および要約ワークフローを作成する方法を実演します。これら両製品の高度な機能を組み合わせることで、開発者はマルチモーダルなビデオ理解を実現し、セマンティック検索、検索拡張生成(RAG)、コンテンツ推奨などのアプリケーションを開発できるようになります。
クラウドストレージに保存されたビデオは、TwelveLabs Embed APIを使用して処理され、視覚、音声、テキストの情報をカプセル化したマルチモーダルな埋め込み(embeddings)が生成されます。これらの埋め込みはVECTORデータ型を利用してSnowflakeのテーブルに保存され、VECTOR_COSINE_SIMILARITYなどの関数を使用した効率的な類似性検索が可能になります。テキストクエリは埋め込みに変換され、最も関連性の高いビデオクリップが取得されます。さらに、MoviePyによる音声抽出やOpenAIのWhisperモデルを使用した文字起こしなどの追加処理が行われます。最後に、Snowflake Cortex Completeを活用して、ビデオの詳細、タイムスタンプ、文字起こしテキスト、コンテキストの洞察などの結果を要約します。
参考: Snowflake + TwelveLabs: データクラウドにおけるビデオAI
なぜSnowflake Container Runtimeを使用するのか?
Container Runtime上のSnowflake Notebooksは、Snowflake内で直接、高度な機械学習ワークフローを実行するための柔軟な環境を提供します。Snowpark Container Servicesを搭載したこのランタイムは、GPUやCPUなどの最適化されたコンピュートリソースを使用して、Pythonベースのデータサイエンスのタスクをサポートします。これにより、外部インフラの依存関係に悩まされることなく、外部ライブラリやツールをシームレスに統合し、TwelveLabs Embed APIのワークフローを実用化するのに最適です。
なぜTwelveLabs Embed APIを使用するのか?
TwelveLabs Embed APIを使用すると、開発者はビデオ用の最先端のマルチモーダルな埋め込みを作成できます。従来のテキストのみ、または画像ベースのモデルとは異なり、このAPIは視覚的な表情、話し言葉、ジェスチャーなどのモダリティ全体にわたる時空間的な関係性を捉えます。この統合されたアプローチにより、テキストからビデオへの検索、異常検知、ハイブリッドRAGワークフローなどのアプリケーションで正確なビデオ理解が可能になります。
ワークフローの主な特徴
マルチモーダルな埋め込み:視覚、音声、テキストのモダリティ全体にわたってビデオのコンテキストを捉える埋め込みを生成します。
効率的な検索:Snowflakeの
VECTORデータ型を使用して類似性検索を実行し、関連するビデオセグメントを高速に取得します。音声の文字起こし:一致したクリップから音声を抽出し、Whisperを使用して文字起こしを行うことで、アクセシビリティを向上させます。
要約:Snowflake Cortex Completeを活用して、ビデオのメタデータと文字起こしを実用的な洞察に要約します。
このチュートリアルに従うことで、開発者はSnowflakeとTwelveLabsの堅牢なインフラを活用しながら、ビデオ理解のためのスケーラブルなAI搭載アプリケーションを構築できます。
2 - 前提条件
開始する前に、以下が準備されていることを確認してください(詳細はこちらのクイックスタートセットアップを参照)。
Snowflakeアカウント:
Container Runtimeが有効化されたSnowflakeアカウントへのアクセス。この機能により、Pythonベースの機械学習ワークフローをSnowflake内で直接実行できます。
Snowsightでユーザーロールを
DASH_CONTAINER_RUNTIME_ROLEに切り替えます。
TwelveLabsのAPIキー:
TwelveLabsのアカウントを登録し、APIキーを取得します。
Python環境:
Snowpark Pythonおよび必要なライブラリ(
httpx、pydantic、moviepyなど)の知識。
サンプルビデオデータ:
テスト用の公開アクセス可能なビデオURLのリスト。このガイドでは3つのサンプルビデオが提供されています。
ノートブックの設定:
提供されているGitHubリンクから
Gen_AI_Video_Search.ipynbノートブックをダウンロードし、Snowflakeアカウントにインポートします。
環境設定:
TwelveLabs APIにアクセスするために、Snowflakeに外部アクセス統合とシークレットが設定されていることを確認します。
3 - ステップバイステップガイド
ステップ 1: 必要なライブラリのインストール
ノートブックの最初のセルで、TwelveLabs、Whisper、MoviePyを含むすべての必要なPythonパッケージをインストールします。
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
これにより、埋め込み生成、音声処理、文字起こしのタスクに必要なすべての依存関係が利用可能になります。
ステップ 2: ライブラリのインポート
2番目のセルで、インストールしたライブラリを環境にインポートします。これには、埋め込み生成用のTwelveLabs、Snowflakeと対話するためのSnowpark、およびフロントエンドアプリケーション用のStreamlitが含まれます。
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
これにより、Snowflakeセッションが初期化され、埋め込みの作成と処理に必要なツールがセットアップされます。
ステップ 3: ビデオURLの提示
3番目のセルで、処理する公開アクセス可能なビデオURLのリストを定義します。これらのビデオは、埋め込みを生成するための入力として機能します。
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
ステップ 4: 埋め込み生成用のSnowpark UDTFを作成する
次に、TwelveLabs Embed APIを使用して埋め込みを生成するために、Snowparkでユーザー定義テーブル関数(UDTF)create_video_embeddingsを定義および登録します。
このステップの主要な構成要素は次のとおりです。
環境に
twelvelabs.zipパッケージを追加する。安全なAPIアクセスのための外部アクセス統合とシークレットを指定する。
埋め込み用にVECTORデータ型を持つ出力スキーマを定義する。
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
ステップ 5: 埋め込みを生成してSnowflakeに保存する
SnowparkのDataFrameを使用してビデオURLのリストを並行して処理し、生成された埋め込みを video_embeddings というSnowflakeテーブルに保存します。
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
ステップ 6: ビデオクリップの文字起こし
OpenAIのWhisperモデルをダウンロードし、ビデオのダウンロード、音声クリップの抽出、およびそれらの文字起こしを行うヘルパー関数を定義します。
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
これらの関数は、後で類似性検索中に取得されたビデオクリップを処理するために使用されます。
ステップ 7: 類似性検索関数の定義
Snowflake内の VECTOR_COSINE_SIMILARITY を使用して、テキストクエリと保存されたビデオ埋め込みの間の類似性スコアを計算する similarity_scores 関数を作成します。
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
ステップ 8: Streamlitアプリケーションの構築
以下を行うインタラクティブなStreamlitアプリを開発します。
ユーザー入力を受け付ける(検索テキスト、最大結果数)。
similarity_scoresを使用して、一致するビデオクリップを取得する。Whisperを使用して各クリップを文字起こしする。
Snowflake Cortex Completeを使用して結果を要約する。
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
検索の例
「Welcome home, Buster」のようなクエリを検索すると、アプリには以下のように表示されます。
ビデオURL
クリップの開始/終了時間
類似性スコア
文字起こしされたテキスト
Cortex Completeによって生成された要約
上記に表示されている最上位の結果は、こちらのビデオのものです。白いバナーに「Welcome home, Buster」という文字がはっきりと強調表示されているのがわかります。
別の検索クエリ「A white car and a black car」(白い車と黒い車)を試して、アプリの表示を確認してみましょう。
上記に表示されている最上位の結果は、こちらのビデオのものです。フレームの中に白い車と黒い車が映っているのがはっきりと確認できます。
4 - ユースケースとメリット
上記のワークフローにより、開発者は革新的なビデオアプリケーションを構築できます。
文脈に沿ったパーソナライズ広告:TwelveLabsのマルチモーダルな埋め込みとSnowflakeのユーザーデータを組み合わせることで、ブランドセーフティが確保された、文脈に適したビデオ広告を配信できます。ビデオコンテキストを深く理解することで、安全基準を維持しながら、広告をユーザーの好みに合わせることができます。
ビデオ検索エンジン:自然言語クエリをビデオ埋め込みと一致させて、正確な結果を返す高度な検索アプリケーションを作成できます。
コンテンツモデレーション:視覚、音声、テキスト要素を分析することにより、不適切または機密性の高いコンテンツがないかビデオライブラリを審査します。
推奨システム:文脈理解と視聴パターンに基づくビデオ推奨を通じて、ユーザーのエンゲージメントを高めます。
トレーニングデータのキュレーション:ビデオ埋め込み分析を介して、マルチモーダルなビデオデータセット向けに多様で代表的なサンプルを選択します。
TwelveLabsとSnowflakeの統合は、ビデオ理解機能の強化を通じて極めて大きなビジネス価値をもたらします。TwelveLabsのマルチモーダルな埋め込みは、視覚、音声、テキストを文脈に沿って捉えることで、ビデオコンテンツの包括的な分析を可能にします。この統合ではSnowflakeのContainer Runtimeを活用してスケーラブルなネイティブ環境を構築するため、運用上の複雑さが大幅に軽減されます。また、SnowflakeのVECTORデータ型を使用して埋め込みを保存および処理できるため、効率的な類似性検索や、そこから派生する下流のAIアプリケーションが可能になります。
開発者の観点からは、並行ビデオ処理用のSnowpark Python UDTFを介して簡素化されたワークフローが提供されるため、生産性が向上します。開発者は、低遅延でリアルタイムのセマンティック検索を実装したり、高度な要約タスクにSnowflake Cortex Completeを活用したりすることもできます。
最後に、このソリューションは、低レイテンシで埋め込みを生成するTwelveLabsの最先端のビデオネイティブモデルと、Snowflakeの堅牢なインフラを組み合わせることで、優れたパフォーマンスと信頼性を提供し、セキュアでスループットの高い処理能力を保証します。
5 - 結論
TwelveLabs Embed APIとSnowflake Cortexの統合により、開発者はビデオデータの可能性を最大限に引き出すことができます。高度なマルチモーダルビデオ理解と、SnowflakeのスケーラブルなAIデータクラウドを組み合わせることで、企業は検索、パーソナライズ、モデレーションなどのための革新的なアプリケーションを作成できるようになります。このパートナーシップは、TwelveLabsの最先端技術とSnowflakeのエンタープライズグレードのインフラとの相乗効果を示しており、開発者と組織の双方に大きな価値をもたらします。
行動への呼びかけ
ビデオデータを実用的なインテリジェンスに変換する準備はよろしいですか?
統合を試す:TwelveLabs Embed API オープンベータ版にサインアップして、今すぐSnowflakeで独自のAI搭載ビデオアプリケーションの構築を始めましょう。
さらなるユースケースを探索する:Snowflakeクイックスタートガイドにアクセスして、ビジネスニーズに合わせた同様のワークフローを実装する方法を学んでください。
コミュニティに参加する:この統合に関するフィードバックを、TwelveLabsのDiscordやSnowflake開発者コミュニティフォーラムで共有してください。
このチュートリアルの基礎となる、SnowflakeとTwelveLabsを使用したAIビデオ検索に関するクイックスタートガイドを作成してくださったSnowflakeチームのDash Desai氏に深く感謝いたします。
1 - はじめに
このチュートリアルでは、Snowflake CortexとTwelveLabs Embed APIを使用して、強力なビデオ検索および要約ワークフローを作成する方法を実演します。これら両製品の高度な機能を組み合わせることで、開発者はマルチモーダルなビデオ理解を実現し、セマンティック検索、検索拡張生成(RAG)、コンテンツ推奨などのアプリケーションを開発できるようになります。
クラウドストレージに保存されたビデオは、TwelveLabs Embed APIを使用して処理され、視覚、音声、テキストの情報をカプセル化したマルチモーダルな埋め込み(embeddings)が生成されます。これらの埋め込みはVECTORデータ型を利用してSnowflakeのテーブルに保存され、VECTOR_COSINE_SIMILARITYなどの関数を使用した効率的な類似性検索が可能になります。テキストクエリは埋め込みに変換され、最も関連性の高いビデオクリップが取得されます。さらに、MoviePyによる音声抽出やOpenAIのWhisperモデルを使用した文字起こしなどの追加処理が行われます。最後に、Snowflake Cortex Completeを活用して、ビデオの詳細、タイムスタンプ、文字起こしテキスト、コンテキストの洞察などの結果を要約します。
参考: Snowflake + TwelveLabs: データクラウドにおけるビデオAI
なぜSnowflake Container Runtimeを使用するのか?
Container Runtime上のSnowflake Notebooksは、Snowflake内で直接、高度な機械学習ワークフローを実行するための柔軟な環境を提供します。Snowpark Container Servicesを搭載したこのランタイムは、GPUやCPUなどの最適化されたコンピュートリソースを使用して、Pythonベースのデータサイエンスのタスクをサポートします。これにより、外部インフラの依存関係に悩まされることなく、外部ライブラリやツールをシームレスに統合し、TwelveLabs Embed APIのワークフローを実用化するのに最適です。
なぜTwelveLabs Embed APIを使用するのか?
TwelveLabs Embed APIを使用すると、開発者はビデオ用の最先端のマルチモーダルな埋め込みを作成できます。従来のテキストのみ、または画像ベースのモデルとは異なり、このAPIは視覚的な表情、話し言葉、ジェスチャーなどのモダリティ全体にわたる時空間的な関係性を捉えます。この統合されたアプローチにより、テキストからビデオへの検索、異常検知、ハイブリッドRAGワークフローなどのアプリケーションで正確なビデオ理解が可能になります。
ワークフローの主な特徴
マルチモーダルな埋め込み:視覚、音声、テキストのモダリティ全体にわたってビデオのコンテキストを捉える埋め込みを生成します。
効率的な検索:Snowflakeの
VECTORデータ型を使用して類似性検索を実行し、関連するビデオセグメントを高速に取得します。音声の文字起こし:一致したクリップから音声を抽出し、Whisperを使用して文字起こしを行うことで、アクセシビリティを向上させます。
要約:Snowflake Cortex Completeを活用して、ビデオのメタデータと文字起こしを実用的な洞察に要約します。
このチュートリアルに従うことで、開発者はSnowflakeとTwelveLabsの堅牢なインフラを活用しながら、ビデオ理解のためのスケーラブルなAI搭載アプリケーションを構築できます。
2 - 前提条件
開始する前に、以下が準備されていることを確認してください(詳細はこちらのクイックスタートセットアップを参照)。
Snowflakeアカウント:
Container Runtimeが有効化されたSnowflakeアカウントへのアクセス。この機能により、Pythonベースの機械学習ワークフローをSnowflake内で直接実行できます。
Snowsightでユーザーロールを
DASH_CONTAINER_RUNTIME_ROLEに切り替えます。
TwelveLabsのAPIキー:
TwelveLabsのアカウントを登録し、APIキーを取得します。
Python環境:
Snowpark Pythonおよび必要なライブラリ(
httpx、pydantic、moviepyなど)の知識。
サンプルビデオデータ:
テスト用の公開アクセス可能なビデオURLのリスト。このガイドでは3つのサンプルビデオが提供されています。
ノートブックの設定:
提供されているGitHubリンクから
Gen_AI_Video_Search.ipynbノートブックをダウンロードし、Snowflakeアカウントにインポートします。
環境設定:
TwelveLabs APIにアクセスするために、Snowflakeに外部アクセス統合とシークレットが設定されていることを確認します。
3 - ステップバイステップガイド
ステップ 1: 必要なライブラリのインストール
ノートブックの最初のセルで、TwelveLabs、Whisper、MoviePyを含むすべての必要なPythonパッケージをインストールします。
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
これにより、埋め込み生成、音声処理、文字起こしのタスクに必要なすべての依存関係が利用可能になります。
ステップ 2: ライブラリのインポート
2番目のセルで、インストールしたライブラリを環境にインポートします。これには、埋め込み生成用のTwelveLabs、Snowflakeと対話するためのSnowpark、およびフロントエンドアプリケーション用のStreamlitが含まれます。
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
これにより、Snowflakeセッションが初期化され、埋め込みの作成と処理に必要なツールがセットアップされます。
ステップ 3: ビデオURLの提示
3番目のセルで、処理する公開アクセス可能なビデオURLのリストを定義します。これらのビデオは、埋め込みを生成するための入力として機能します。
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
ステップ 4: 埋め込み生成用のSnowpark UDTFを作成する
次に、TwelveLabs Embed APIを使用して埋め込みを生成するために、Snowparkでユーザー定義テーブル関数(UDTF)create_video_embeddingsを定義および登録します。
このステップの主要な構成要素は次のとおりです。
環境に
twelvelabs.zipパッケージを追加する。安全なAPIアクセスのための外部アクセス統合とシークレットを指定する。
埋め込み用にVECTORデータ型を持つ出力スキーマを定義する。
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
ステップ 5: 埋め込みを生成してSnowflakeに保存する
SnowparkのDataFrameを使用してビデオURLのリストを並行して処理し、生成された埋め込みを video_embeddings というSnowflakeテーブルに保存します。
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
ステップ 6: ビデオクリップの文字起こし
OpenAIのWhisperモデルをダウンロードし、ビデオのダウンロード、音声クリップの抽出、およびそれらの文字起こしを行うヘルパー関数を定義します。
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
これらの関数は、後で類似性検索中に取得されたビデオクリップを処理するために使用されます。
ステップ 7: 類似性検索関数の定義
Snowflake内の VECTOR_COSINE_SIMILARITY を使用して、テキストクエリと保存されたビデオ埋め込みの間の類似性スコアを計算する similarity_scores 関数を作成します。
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
ステップ 8: Streamlitアプリケーションの構築
以下を行うインタラクティブなStreamlitアプリを開発します。
ユーザー入力を受け付ける(検索テキスト、最大結果数)。
similarity_scoresを使用して、一致するビデオクリップを取得する。Whisperを使用して各クリップを文字起こしする。
Snowflake Cortex Completeを使用して結果を要約する。
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
検索の例
「Welcome home, Buster」のようなクエリを検索すると、アプリには以下のように表示されます。
ビデオURL
クリップの開始/終了時間
類似性スコア
文字起こしされたテキスト
Cortex Completeによって生成された要約
上記に表示されている最上位の結果は、こちらのビデオのものです。白いバナーに「Welcome home, Buster」という文字がはっきりと強調表示されているのがわかります。
別の検索クエリ「A white car and a black car」(白い車と黒い車)を試して、アプリの表示を確認してみましょう。
上記に表示されている最上位の結果は、こちらのビデオのものです。フレームの中に白い車と黒い車が映っているのがはっきりと確認できます。
4 - ユースケースとメリット
上記のワークフローにより、開発者は革新的なビデオアプリケーションを構築できます。
文脈に沿ったパーソナライズ広告:TwelveLabsのマルチモーダルな埋め込みとSnowflakeのユーザーデータを組み合わせることで、ブランドセーフティが確保された、文脈に適したビデオ広告を配信できます。ビデオコンテキストを深く理解することで、安全基準を維持しながら、広告をユーザーの好みに合わせることができます。
ビデオ検索エンジン:自然言語クエリをビデオ埋め込みと一致させて、正確な結果を返す高度な検索アプリケーションを作成できます。
コンテンツモデレーション:視覚、音声、テキスト要素を分析することにより、不適切または機密性の高いコンテンツがないかビデオライブラリを審査します。
推奨システム:文脈理解と視聴パターンに基づくビデオ推奨を通じて、ユーザーのエンゲージメントを高めます。
トレーニングデータのキュレーション:ビデオ埋め込み分析を介して、マルチモーダルなビデオデータセット向けに多様で代表的なサンプルを選択します。
TwelveLabsとSnowflakeの統合は、ビデオ理解機能の強化を通じて極めて大きなビジネス価値をもたらします。TwelveLabsのマルチモーダルな埋め込みは、視覚、音声、テキストを文脈に沿って捉えることで、ビデオコンテンツの包括的な分析を可能にします。この統合ではSnowflakeのContainer Runtimeを活用してスケーラブルなネイティブ環境を構築するため、運用上の複雑さが大幅に軽減されます。また、SnowflakeのVECTORデータ型を使用して埋め込みを保存および処理できるため、効率的な類似性検索や、そこから派生する下流のAIアプリケーションが可能になります。
開発者の観点からは、並行ビデオ処理用のSnowpark Python UDTFを介して簡素化されたワークフローが提供されるため、生産性が向上します。開発者は、低遅延でリアルタイムのセマンティック検索を実装したり、高度な要約タスクにSnowflake Cortex Completeを活用したりすることもできます。
最後に、このソリューションは、低レイテンシで埋め込みを生成するTwelveLabsの最先端のビデオネイティブモデルと、Snowflakeの堅牢なインフラを組み合わせることで、優れたパフォーマンスと信頼性を提供し、セキュアでスループットの高い処理能力を保証します。
5 - 結論
TwelveLabs Embed APIとSnowflake Cortexの統合により、開発者はビデオデータの可能性を最大限に引き出すことができます。高度なマルチモーダルビデオ理解と、SnowflakeのスケーラブルなAIデータクラウドを組み合わせることで、企業は検索、パーソナライズ、モデレーションなどのための革新的なアプリケーションを作成できるようになります。このパートナーシップは、TwelveLabsの最先端技術とSnowflakeのエンタープライズグレードのインフラとの相乗効果を示しており、開発者と組織の双方に大きな価値をもたらします。
行動への呼びかけ
ビデオデータを実用的なインテリジェンスに変換する準備はよろしいですか?
統合を試す:TwelveLabs Embed API オープンベータ版にサインアップして、今すぐSnowflakeで独自のAI搭載ビデオアプリケーションの構築を始めましょう。
さらなるユースケースを探索する:Snowflakeクイックスタートガイドにアクセスして、ビジネスニーズに合わせた同様のワークフローを実装する方法を学んでください。
コミュニティに参加する:この統合に関するフィードバックを、TwelveLabsのDiscordやSnowflake開発者コミュニティフォーラムで共有してください。








