" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
Building A Workplace Safety Compliance Application with TwelveLabs and NVIDIA VSS

Nathan Che
This tutorial walks through building a Workplace Safety Compliance Application that uses a fine-tuned YOLO model to chunk live CCTV footage, NVIDIA VSS with Twelve Labs Marengo and Pegasus to generate OSHA compliance reports and efficiency recommendations, and an AI chatbot for real-time workplace safety queries.
This tutorial walks through building a Workplace Safety Compliance Application that uses a fine-tuned YOLO model to chunk live CCTV footage, NVIDIA VSS with Twelve Labs Marengo and Pegasus to generate OSHA compliance reports and efficiency recommendations, and an AI chatbot for real-time workplace safety queries.

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
2025/10/31
15 Minutes
Copy link to article
In this tutorial, you will learn how to build a video intelligence platform that monitors live CCTV cameras in varying workplaces, including factories, construction sites, and more, to find risky employee behaviour or machinery, OSHA compliance violations, and efficiency gaps in near real-time. More importantly, you will learn about the latest TwelveLab’s integration into NVIDIA VSS, allowing you to handle analyzing and summarizing large volumes of video data built for hardware and solutions built on NVIDIA.
Introduction
What if your on-site CCTV cameras transformed to become completely autonomous, with 24/7 surveillance that not only reported back security risks, but detailed reports on specific OSHA compliance issues, efficiency gaps, and risk assessments? 📃
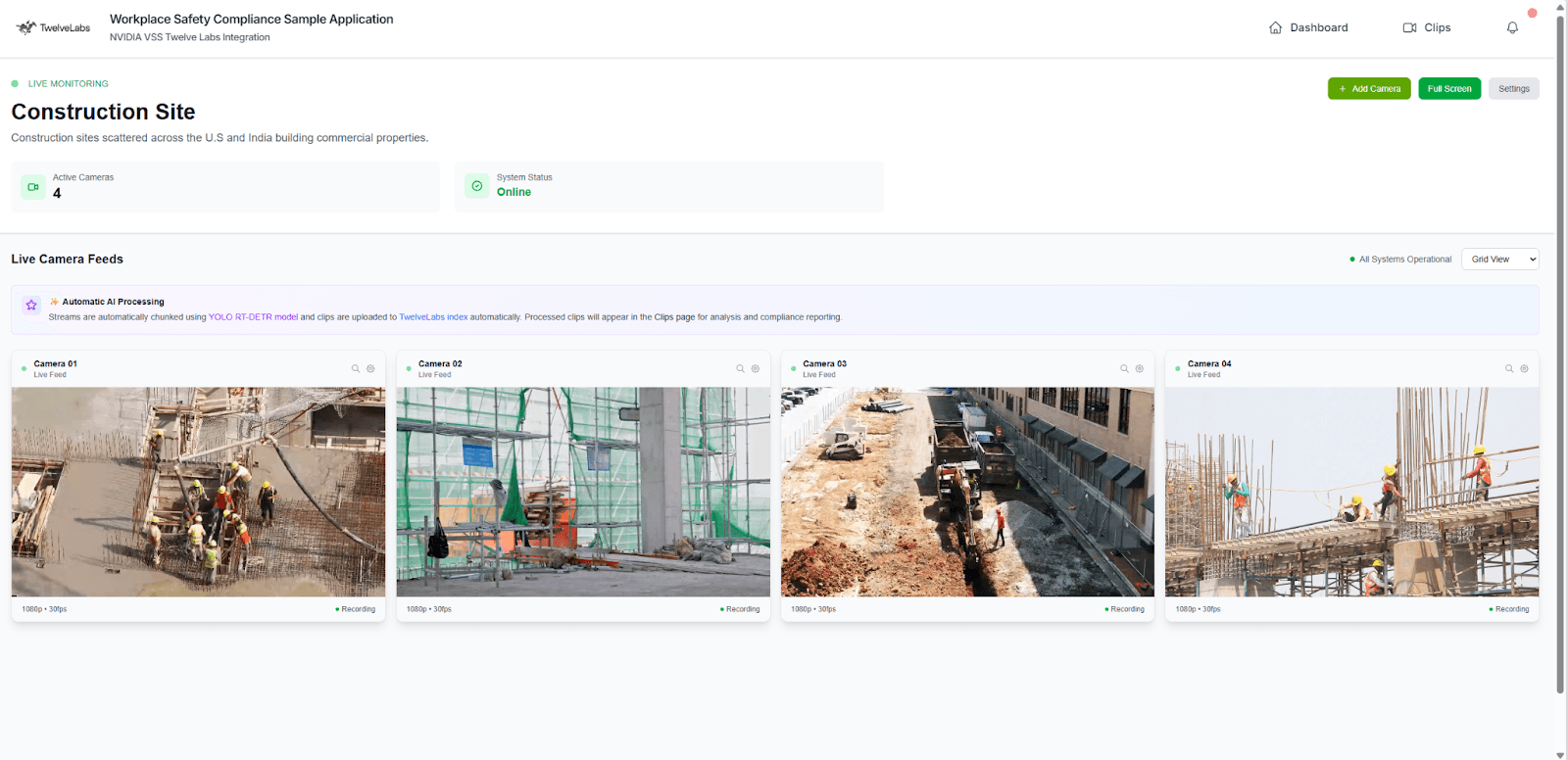
This might sound like magic, but it’s what we’ve built to showcase how TwelveLab’s video intelligence models are changing the way computers understand unstructured data for the recent NVIDIA GTC DC 2025 conference! Best of yet, our models directly integrate with pre-existing NVIDIA frameworks and hardware like NVIDIA Video Search and Summarization (VSS).
Today you’ll learn how this is all possible by not only deploying the application in this step-by-step guide, but also learning the in-depth technical architecture used to build this real-time video intelligence platform. Specifically you will build the platform that transforms live streams into:
OSHA Compliance Reports: Automatically generated with specific regulation and fine references.
Muda (Waste) Recommendations: Designed to support lean management and optimize workspace efficiency.
An Interactive Chatbot: Allows managers to ask detailed questions about their workplace and receive instant, web-sourced feedback and recommendations.
A Dynamic Event Timeline: Enables users to quickly identify what incidents occurred and when.
Contextual AI Actions: AI-generated buttons placed at specific video timestamps and coordinates to highlight inefficiencies, compliance issues, and subtle incidents.
* Note: The concepts and technology here stretch far beyond the workplace and if you’re interested in learning how TwelveLabs can make a difference in your industry, I highly recommend you to check out the Beyond The Workplace section of this blog!
Application Demo
Before we begin coding, please check out the video and deployed application below to get familiarized with what we’ll be building.
Test it out yourself: NVIDIA VSS + Twelve Labs Manufacturing Automation!
GitHub: nathanchess/twelvelabs-nvidia-vss-sample
With that in mind, let’s get started! 😊
Learning Objectives
In this tutorial you will:
Fine tune your own computer vision model on the You Only Look Once (YOLO) object detection algorithm with 15,000+ images for personal protective equipment classification.
Use FFmpeg to convert your MP4 files into live Real Time Streaming Protocol (RTSP) streams to simulate real CCTV cameras.
Learn how TwelveLabs integrates directly into NVIDIA VSS and AWS.
Understand advanced prompt engineering techniques such as chain-of-thought.
Build and run Docker containers to handle asynchronous API operations for video chunk uploading and live stream handling.
Prerequisites
Python 3.8+: Download Python | Python.org
TwelveLabs API Key: Authentication | TwelveLabs
TwelveLabs Index: Python SDK | TwelveLabs
AWS Access Key: Credentials - Boto3 1.40.12 documentation
Docker Installation: Install | Docker Docs
Intermediate understanding of Python, APIs, and JavaScript.
Local Environment Setup
1 - Clone the repository into your local environment
>> git2 - Clone NVIDIA VSS framework (with TwelveLab integration) into your local environment.
>> git3 - Navigate into your AWS console and create a new S3 bucket named “nvidia-vss-source”
Full tutorial here: Creating a general purpose bucket - Amazon Simple Storage Service
This will act as storage for our fake CCTV camera footage!
4 - Add environment variables to frontend and rtsp-stream-worker folder.
TWELVE_LABS_API_KEY=... NEXT_PUBLIC_TWELVELABS_MARENGO_INDEX_ID=... NEXT_PUBLIC_TWELVELABS_PEGASUS_INDEX_ID=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_RTSP_STREAM_WORKER_URL="http://localhost:8000" NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
TWELVE_LABS_API_KEY=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
5 - Build and run Docker containers for both rtsp-stream-worker and NVIDIA VSS
RTSP Stream Worker Instructions: twelvelabs-nvidia-vss-sample/rtsp-stream-worker at main · nathanchess/twelvelabs-nvidia-vss-sample
NVIDIA VSS Instructions: nvidia-vss/src/vss-engine/src/models/twelve_labs at main · james-le-twelve-labs/nvidia-vss
6 - Start frontend sample application using Node Package Manager (NPM).
Inside your GitHub repository, navigate to your frontend folder in console and type the following:
>> npm |
Then navigate to localhost:3000 to access the site.
* Ensure that NPM is installed: Downloading and installing Node.js and npm | npm Docs
Building the CV Pipeline
So how did we achieve near real-time on an infinitely streaming live video?
💡Learning Opportunity: Not only is live stream handling difficult, with limited bandwidth and unstable connection, but also costly!
Let’s prove it with some simple math. Take TwelveLab’s multimodal model Marengo. How much would it cost if we were to process a full 24 hour worth of video content into an index? Marengo: ($.042/min + %.0015/min) * 1440 minutes = $60.48
$60.48 per day would definitely not be sustainable for a fleet of cameras, something very common in the public and security sector to cover every inch of a property. Note: Feel free to run your own calculations at the TwelveLabs pricing calculator: https://www.twelvelabs.io/pricing-calculator |
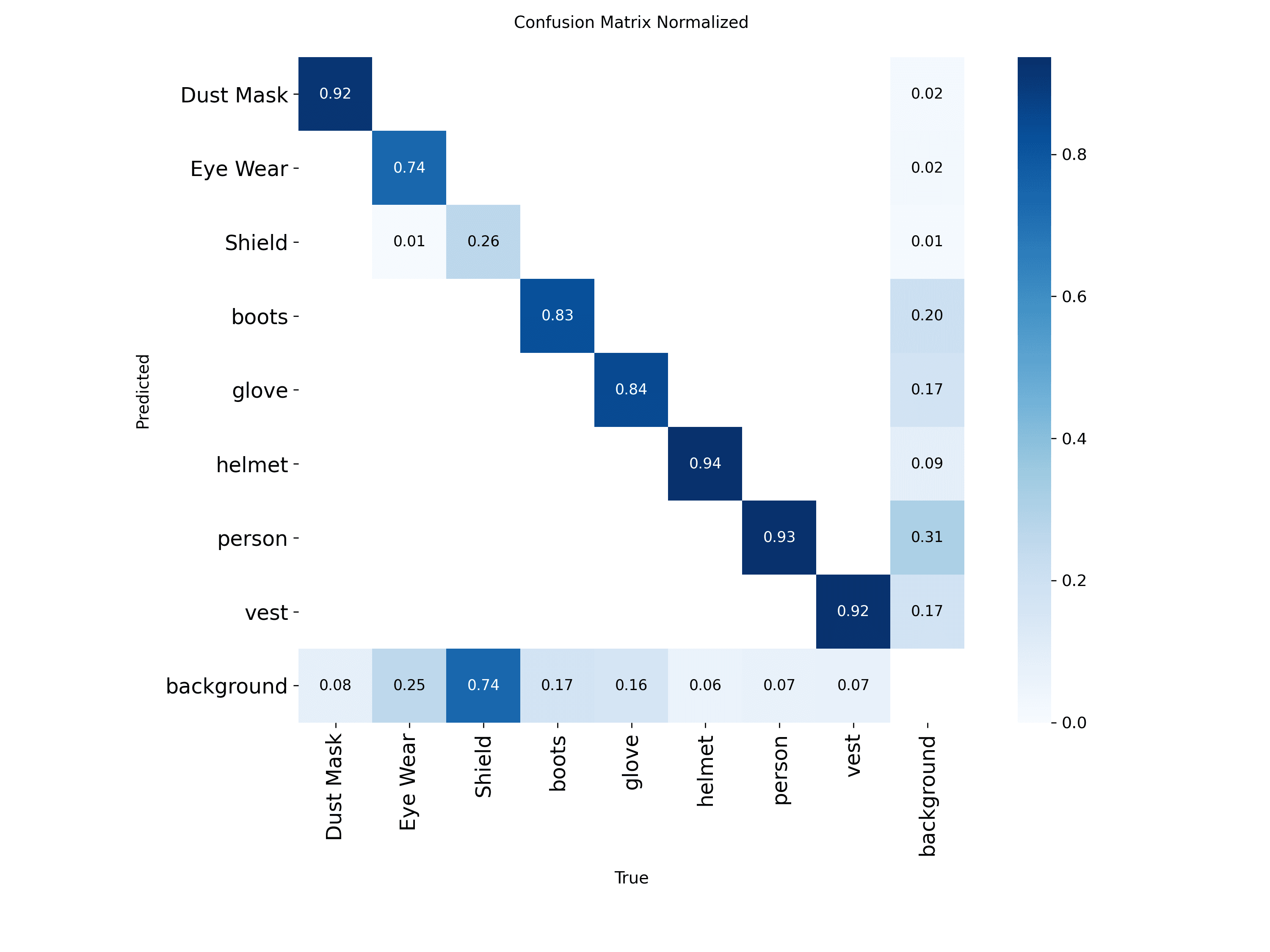
So how do we solve this pricing issue? Well, the answer lies in chunking and pre-processing! Of course the constraints and environment you are dealing with may be different, but I ended up fine–tuning a YOLO model on personal protective equipment (PPE) detection. Here are the results:
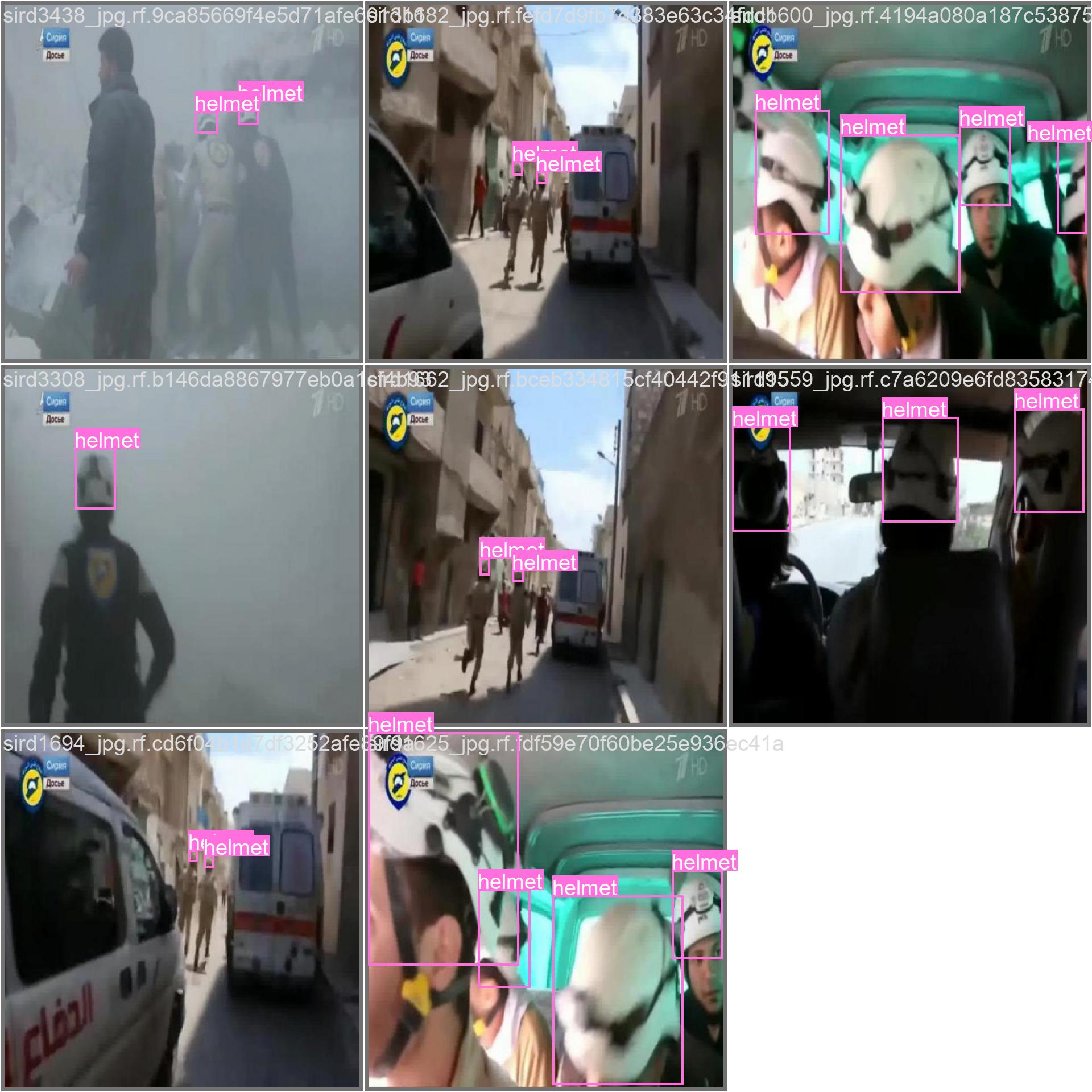
Above we can see the model in action, identifying helmets in a variety of different environments, angles, and lighting. By having a diverse training dataset of over 15,000+ images and augmenting the images to have different colors, angles, etc. we ended up getting >90% accuracy on common PPE items like vests, helmets, gloves, boots, and more!
💡Learning Opportunity: Though out of the scope of this blog, if you would like to view the training scripts and learn how to build one from scratch feel free to check out the /cv_model's README in the repository: https://github.com/nathanchess/twelvelabs-nvidia-vss-sample/tree/main/cv_model
So here’s how it’s used for cost-saving and video chunking:
/rtsp-stream-worker/main.py (Lines 357 - 391)
def analyze_video(self, video_source: str): people_count, ppe_count = 0, 0 results = self.model.predict(frame, conf=0.25, iou=0.45, max_det=1000) processed_frame = self._draw_boxes(frame, results) for box in results[0].boxes: class_id = int(box.cls[0]) class_name = self.model.model.names[class_id] if class_name == "Person": people_count += 1 else: ppe_count += 1 # Write frame to output video video_writer.write(processed_frame) video_capture.release() video_writer.release() return new_video_source else: raise FileNotFoundError(f"Video file not found: {video_source}")
The code block simply above simply aggregates the number of people with protective gear seen in the frame. This data can then be used to create a custom chunking algorithm, tailored to a variety of workplace needs. Specifically, only video chunks of interest (missing PPE) will be fed into our multimodal model, reducing the 24 hour video content into minutes or even seconds of computation power.
Think about the type of PPE / compliance issues that may arise depending on the setting:
Food Processing Manufacturer: May require all employees to have a pair of gloves.
Medical Facilities: Require certain people to have face masks and gloves.
Construction Sites: Require a full set of PPE.
By having this customizability, individual factories can gain significant savings cost with this platform, while still maintaining high accuracy!
* Note: This does seem like a lot of upfront work, hence in the “Connecting with NVIDIA VSS” section, we will talk about how you can use pre-built video chunking algorithms in the NVIDIA VSS framework!
Creating a Fake Camera with Real-Time Streaming Protocol
Great, so now we have the chunking algorithm down ready to help with the pre-processing and cost saving for our live video streams. But how about the streams themselves?
Well upon a quick Google search you’ll notice it’s quite difficult to find open-source cameras linked to real factories, workplaces, etc. Which is why we’ll have to build our own in Python!
💡Learning Opportunity: What are the required components to simulate a fake camera?
To build a robust and realistic "fake" camera stream that mimics a real-world IP camera, we need to create a pipeline that handles content, broadcasting, and distribution. For our project, this pipeline consists of four main components:
|
Let’s see these components in action below in the technical architecture:
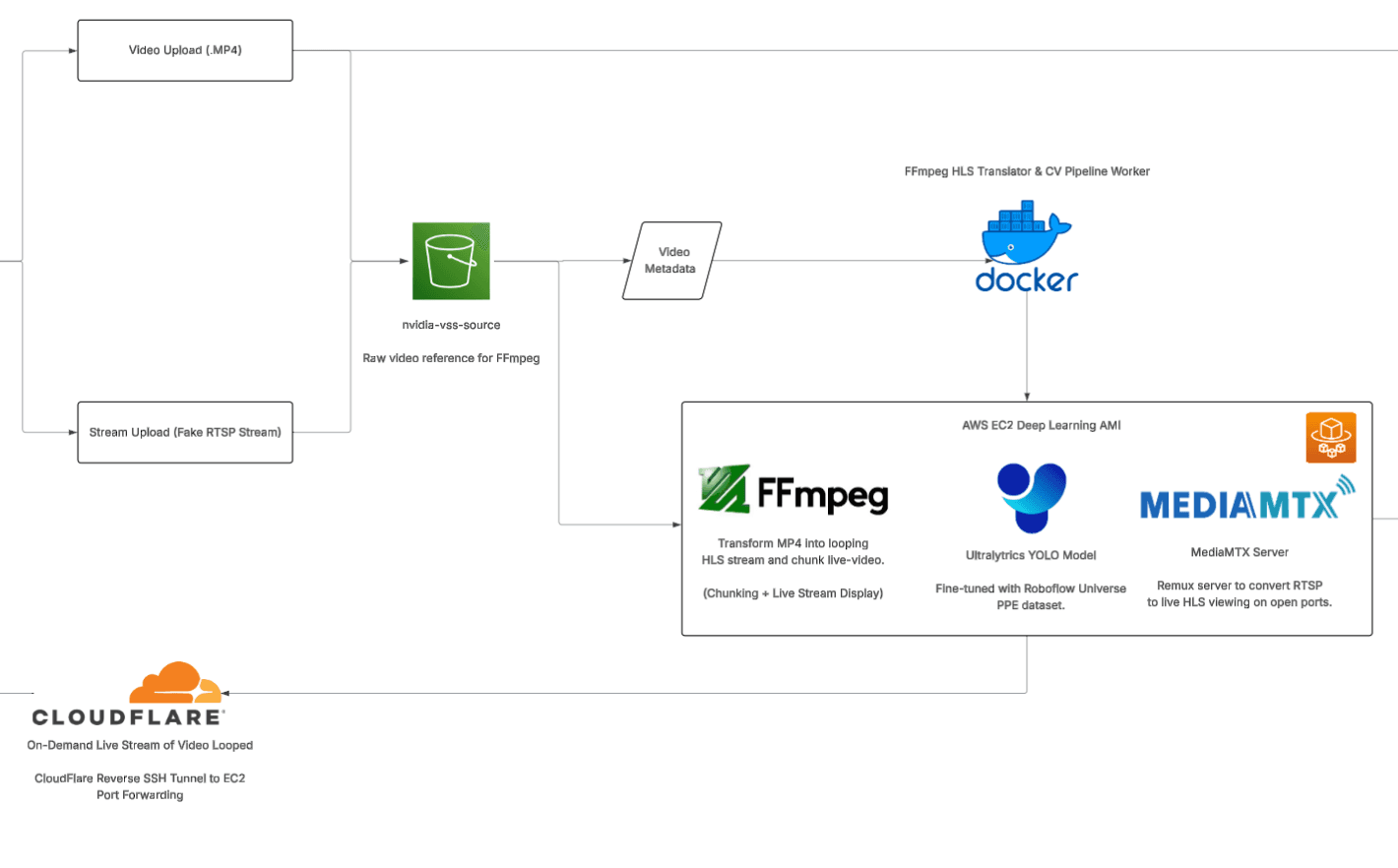
Technical Architecture Diagram: LucidChart (Click to view in full-screen)
This backend service is deployed on a monolithic architecture, meaning all our code is centralized into one codebase, and in our case a singular Deep Learning AMI EC2 instance! Let me briefly explain each piece of technology.
AWS S3 Buckets: This serves as the source video content for our simulated content. Put simply, just hold our MP4 files.
FFmpeg: This is the engine of our virtual camera. FFmpeg is a command-line powerhouse that does the heavy lifting:
It pulls the .mp4 file from S3.
It puts that file on an infinite loop (-stream_loop -1).
Most importantly, it transcodes this file in real-time into an RTSP (Real-Time Streaming Protocol) feed.
💡Learning Opportunity: RTSP is the native language of most IP security cameras. By creating an RTSP stream, FFmpeg is perfectly simulating a high-end camera broadcasting 24/7 onto our server's local network. Read more here: What is an RTSP Camera? – Real Time Streaming Protocol Explained Cloud based and Central Management
MediaMTX: This is our universal translator and distribution hub. The problem? Web browsers cannot play the RTSP stream that FFmpeg creates. MediaMTX is a brilliant, zero-dependency server that:
Ingests the single RTSP feed from FFmpeg.
Repackages it instantly into multiple web-friendly formats.
For our project, we use HLS (HTTP Live Streaming). MediaMTX automatically chops the live video into small, 10-second video files (.ts) and creates a "playlist" file (.m3u8) that tells the video player where to find the next chunk. This is the modern standard that allows any web browser or mobile app to play our stream smoothly.
Finetuned YOLO Model: This our previous chunking algorithm at play! As FFmpeg loops and encodes the video into RTSP format, we will use this fine-tuned model to detect objects inside the video.
CloudFlare SSH Tunnels: This is our secure gateway to the public internet. Our EC2 instance is completely locked down—it has zero open inbound ports, making it invisible to scanners and attackers.
💡Learning Opportunity: So how does the outside world see our HLS stream? Cloudflare's lightweight cloudflared agent creates a secure, outbound-only tunnel from our EC2 instance to the Cloudflare network. Cloudflare then acts as the public-facing entry point, giving us a stable URL (e.g., live.myproject.com), free SSL, DDoS protection, and caching, all without us ever needing a static IP or configuring a single firewall rule.
The end product? Highly secure HTTP Live Streaming protocols that can be easily connected to any common video player or website.
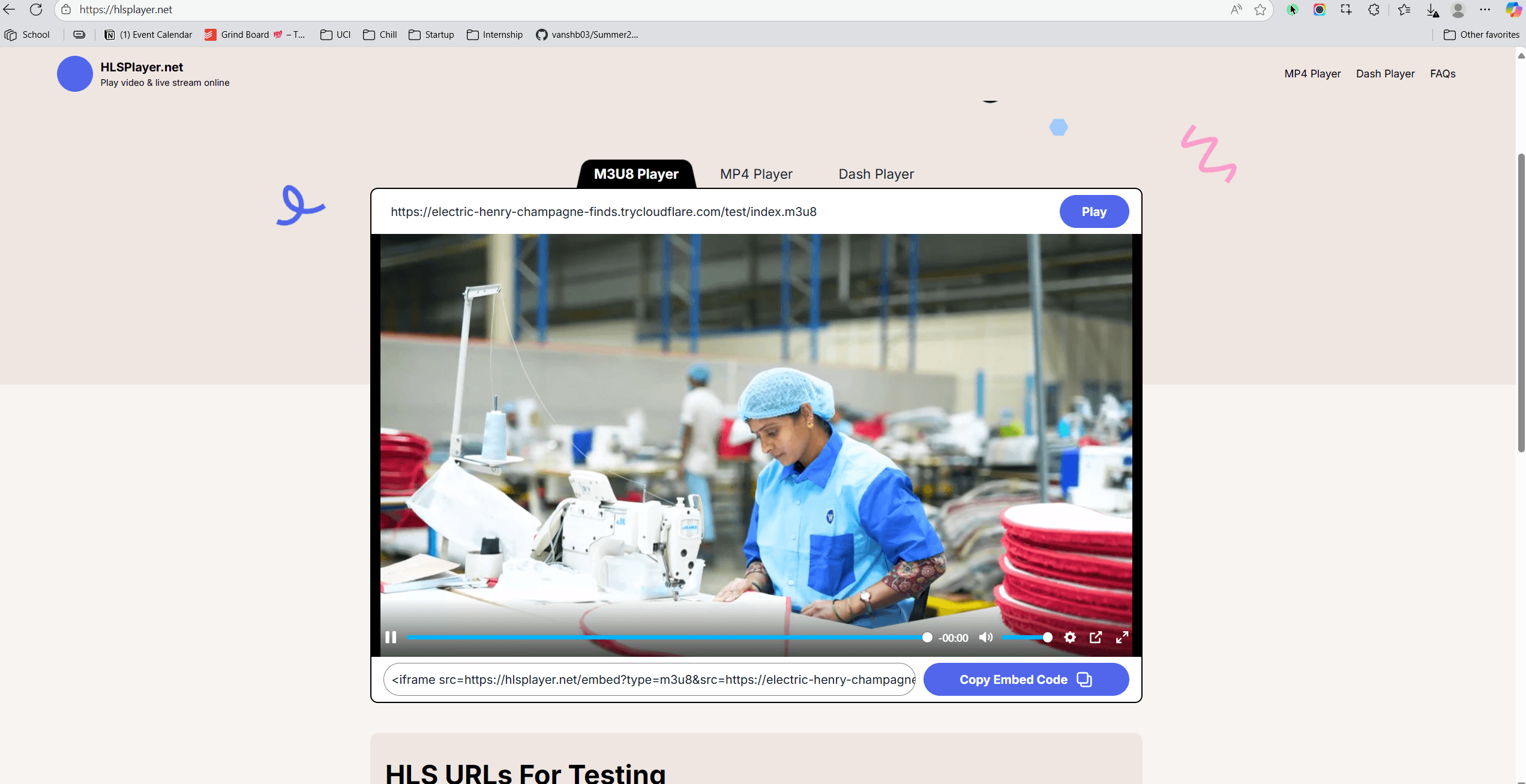
Notice how the temporary cloudflare URL generated works on public sites like hlsplayer.net ☺️! This means that our HLS URL is not only public, but formatted into a proper .m3u8 file, allowing any video player to find the next chunk properly.
Connecting with NVIDIA VSS
Great so now we have our fake cameras up and running and the pre-processing algorithm deployed onto our AWS EC2. Time to wrap things up by integrating arguably the most important part, a highly intelligent and context-aware video intelligence model to process chunks of interest. This is where NVIDIA VSS’s TwelveLabs integration steps in.
💡Learning Opportunity: Before jumping into the code and technical architecture, it’s important to understand what NVIDIA VSS even is and the tools it provides to those that build software on top of NVIDIA hardware.
VSS stands for Video Search and Summarization. Essentially this is not a single NVIDIA software like CUDA, rather it is a NVIDIA AI Blueprint, giving developers a quick way to deploy powerful AI agents that can understand, search, and summarize video content. It does so with:
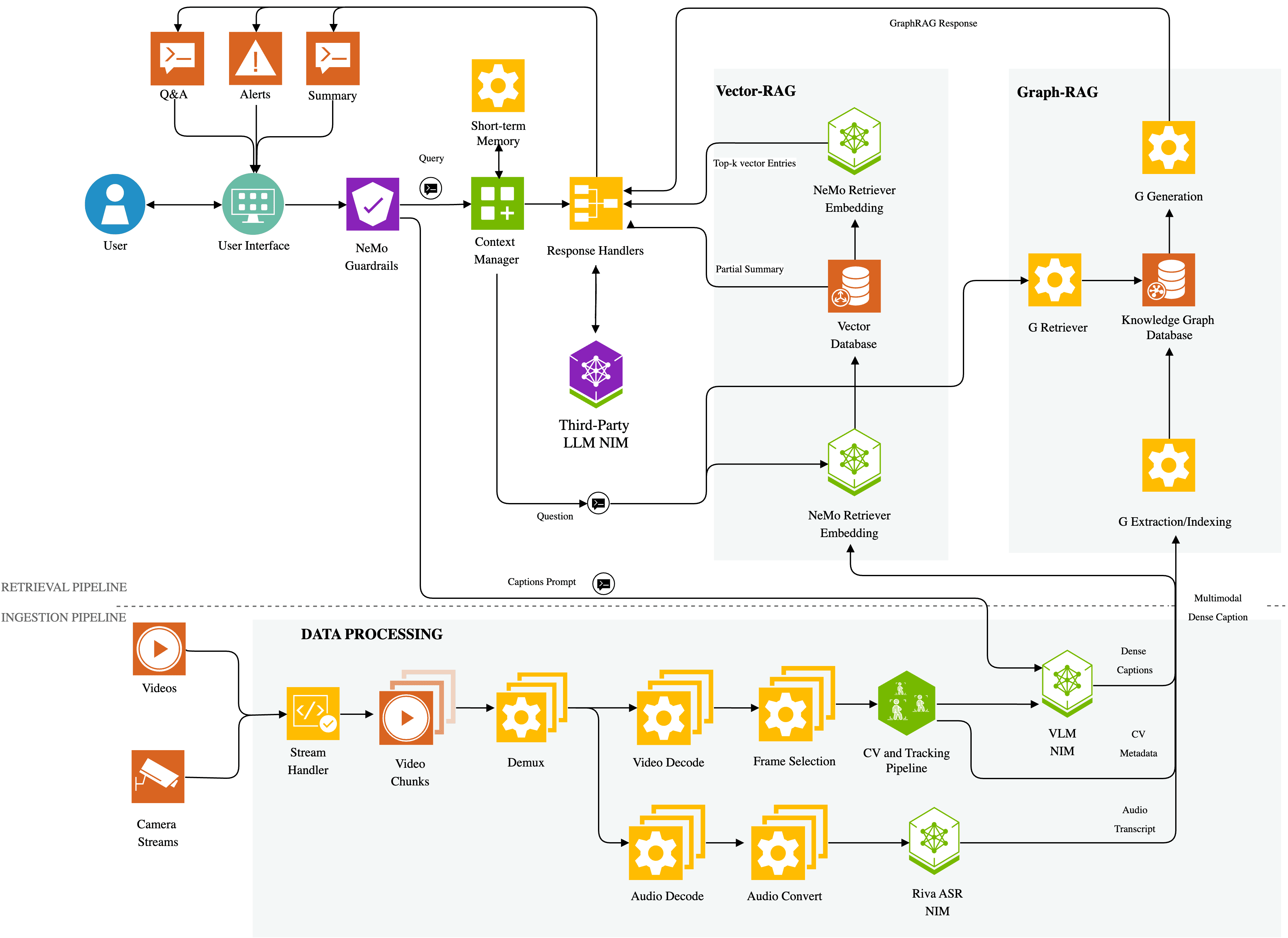
Vision Language Models (VLMs): This is the "seeing" and "understanding" part. VSS provides a pipeline to feed video frames into VLMs, which then generate rich, text-based descriptions (dense captions) of what is happening in each video chunk.
Large Language Models (LLMs): This is the "reasoning" and "communication" part. The text descriptions from the VLM are fed to an LLM, which is what allows you to perform summarization and have a natural language Q&A session.
Retrieval-Augmented Generation (RAG): VSS doesn't just pass data to an LLM; it uses a technique called RAG. It stores the generated video descriptions in a specialized database (a vector or graph database). When you ask a question, it first retrieves the most relevant video chunks from the database and then augments the LLM's prompt with this specific context, leading to highly accurate, data-grounded answers.
GPU-Accelerated Ingestion: It provides a high-performance pipeline for pulling in video (from files or live RTSP streams), decoding it, and preparing it for the AI models, all using the power of NVIDIA GPUs.
Computer Vision (CV) Pipeline Integration: VSS is designed to work with (not just replace) traditional CV. Developers can integrate object detection and tracking models (like YOLO or those in the NVIDIA DeepStream SDK). This adds critical metadata (e.g., "person_1," "box_5") that the VLM and LLM can use to provide even more specific and accurate answers.
Audio Transcription: The blueprint also includes tools to process the audio track from videos, converting speech into text. This adds another layer of searchable data, allowing you to query what was said in a video, not just what was seen.
NVIDIA NIMs (NVIDIA Inference Microservices): Instead of forcing developers to build and optimize their own AI model servers, VSS is often powered by NIMs. These are pre-packaged, optimized, and containerized microservices that make deploying the VLMs and LLMs as simple as running a container.
This NVIDIA VSS blueprint is incredibly powerful, but as you can see, it's also a lot to build, deploy, and manage. You're responsible for the VLM, the LLM, the audio transcription pipeline, the CV pipeline, and the RAG database—all running on your own infrastructure.
This is precisely where TwelveLabs provides a massive accelerator.
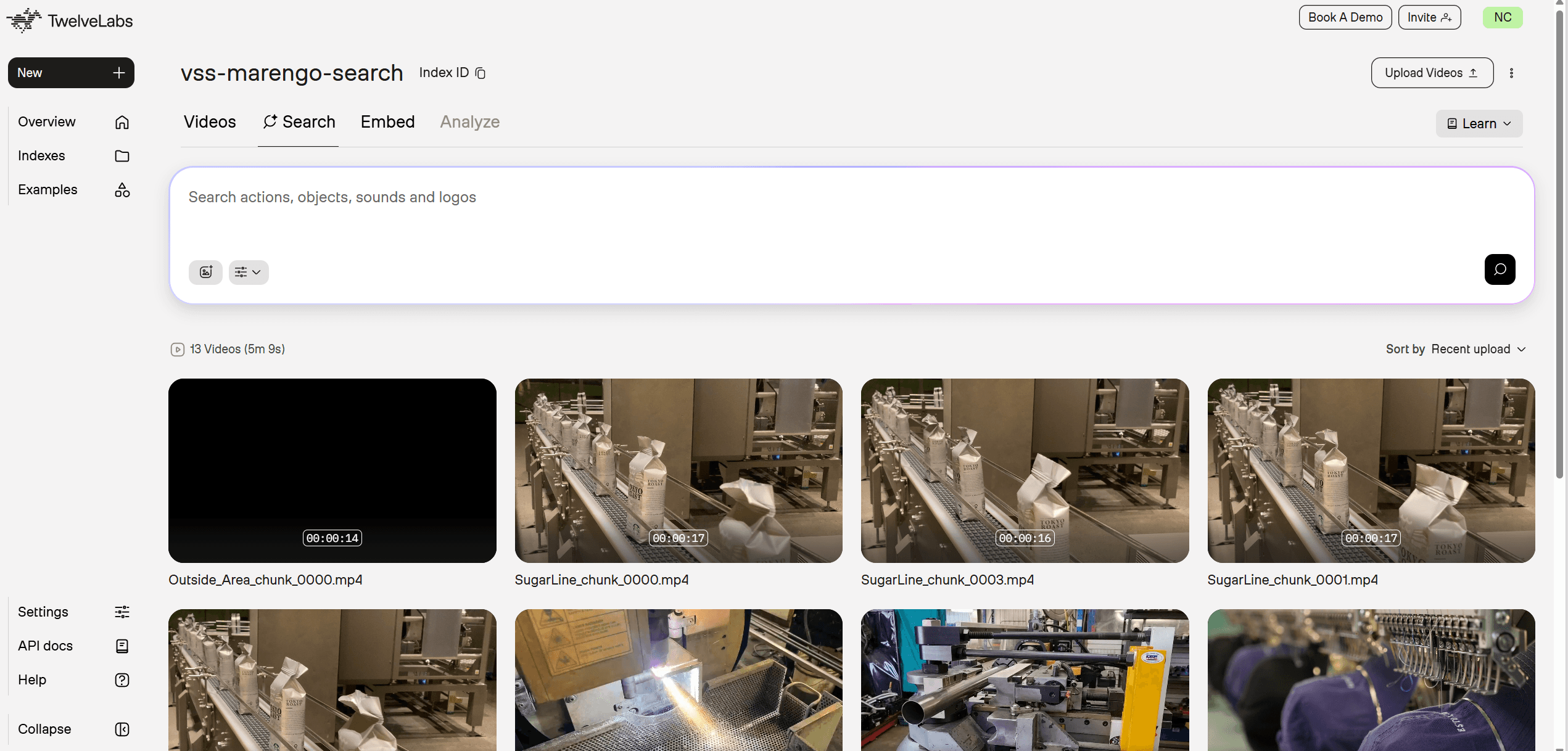
TwelveLabs Playground Index Search Capability (TwelveLabs | Home)
Imagine abstracting away all that complexity. Instead of managing a half-dozen different models and services, you get a complete remote deployment that handles everything for you. The intelligent chunking, the computer vision, the VLM analysis, the audio transcription, and the large-language-model reasoning are all unified into a single, powerful platform, accessible via a simple API. You send the video stream, and TwelveLabs returns the insights.
But here’s the most powerful part: this isn't an all-or-nothing replacement.
The true value is in modularity. Our architecture is designed to be highly configurable, allowing you to create hybrid NVIDIA-based AI workflows.
With this knowledge, let’s go ahead and look at how our technical architecture leverages the complete remote deployment in NVIDIA VSS.

Technical Architecture Diagram: LucidChart (Click to view in full-screen)
Simply put, the uploaded video chunks are passed in two steps.
AWS S3 Bucket (nvidia-vss-streams): Storing it in an external container, outside of the multimodal model, allows to have long-term forensics data for incidents, reporting, etc.
NVIDIA VSS TwelveLabs Integration: The uploaded video content is then further passed to NVIDIA VSS, where it will undergo a series of processes:

Index Creation: Create new dedicated index(es) for both the TwelveLabs Marengo and Pegasus model.
Video Storage: Store videos into indexes, allowing it to be ready to be searched, embedded, and summarized. Feel free to view all video capabilities offered by TwelveLabs here: TwelveLabs | Product Overview
The various features of the page then simply search and summarize the video content uploaded via. NVIDIA VSS API Endpoints! Let’s see how it works in action.
Example Feature 1: AI Compliance Chatbot — Jade.
This is the right panel on the screenshot below and essentially allows factory owners to instantly investigate video chunks deeper with unstructured queries. Whether that be questions about an incident, possible improvements, or local OSHA compliances based on geolocation, they can get answers immediately specific to their factory.

This was built on TwelveLabs' powerful Pegasus conversational model, with extra chat history prompt engineering!
/frontend/src/app/components/ClipChat.js (Lines 49-72)
const typingId = Date.now(); setChatHistory(prev => [...prev, { role: 'assistant', text: '', date: Date.now(), typing: true, _id: typingId }]); try { const prompt = `You are Jade, an expert safety and compliance officer. Here is the chat history: ${chatHistory.map(m => `${m.role}: ${m.text}`).join('\n')}; The user asks: ${message}; The user's geolocation is unknown, please reference general safety and compliance standards. If the user asks about safety, compliance, or improvements, you should always reference the user's geolocation and the laws in that area when providing your response. Do not mention the coordinates, just the location and city. Be highly detailed and specific, by referencing specific machines, processes, and equipment you see in the video and the second. `; const resp = await fetch('/api/analysis', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ videoId, userQuery: prompt }) });
* Notice: The remote deployment allowed your chunked video to effortlessly be prompted in realistically under 4 lines (excluding the prompt itself, which can at times get huge).
Example Feature 2: On-Demand Compliance Report & Video Metadata.
Factory owners can instantly generate full business-ready compliance reports with details like OSHA compliance (specific violations), potential fines, corrective actions, and efficiency recommendations.
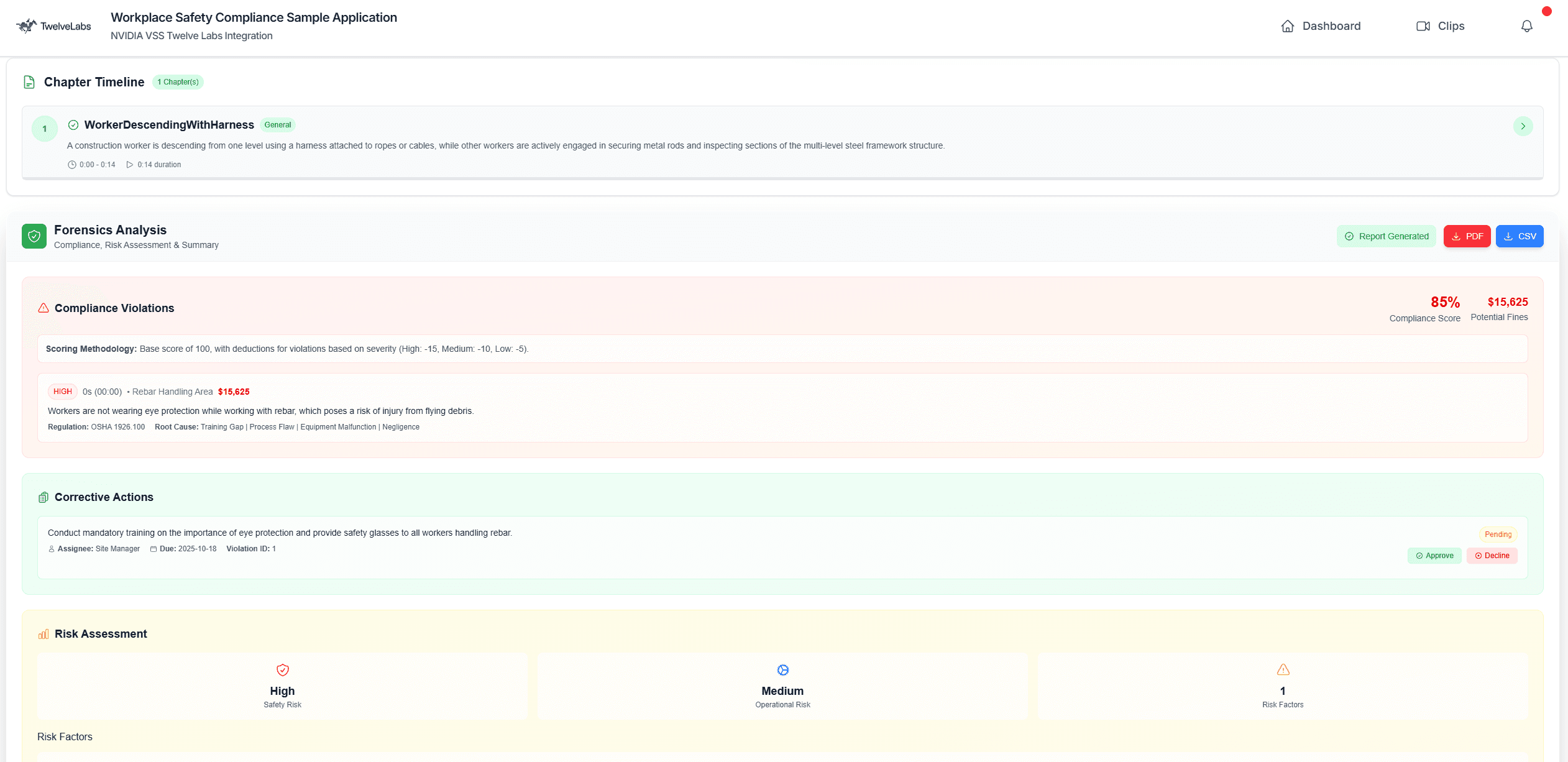
/frontend/src/app/clips/[id]/page.js (Lines 328 - 331)
const response = await fetch(`/api/analysis/${clipData['pegasusId']}`, { method: 'GET', headers: { 'Content-Type': 'application/json' } })
This was built on TwelveLabs' powerful Marengo search and summarization model, which allowed us to instantly generate detailed summaries of our video content with preset prompts!
And, that’s it! You have just built a platform that transforms live stream video content into searchable, summarized, and embedded structured content with the help of the NVIDIA VSS TwelveLabs integration with no additional hardware, GPU, or training costs 🥳.
Conclusion
Great thanks for reading along! You not only built an end-to-end real-time surveillance platform that could benefit millions of companies in the public sector, but learned about NVIDIA VSS and how the recent TwelveLabs integration can help bring your video-intensive projects from ideation to code in hours.
Check out some more in-depth resources regarding this project here:
Technical Architecture Diagram: LucidApp
Technical Design Document: [NVIDIA GTC] - Manufacturing Automation Technical Design
NVIDIA VSS TwelveLabs Integration Repo: james-le-twelve-labs/nvidia-vss: Blueprint for Ingesting massive volumes of live or archived videos and extract insights for summarization and interactive Q&A
Project Repo: nathanchess/twelvelabs-nvidia-vss-sample
Demo Video: NVIDIA VSS TwelveLabs Integration: Manufacturing Automation
In this tutorial, you will learn how to build a video intelligence platform that monitors live CCTV cameras in varying workplaces, including factories, construction sites, and more, to find risky employee behaviour or machinery, OSHA compliance violations, and efficiency gaps in near real-time. More importantly, you will learn about the latest TwelveLab’s integration into NVIDIA VSS, allowing you to handle analyzing and summarizing large volumes of video data built for hardware and solutions built on NVIDIA.
Introduction
What if your on-site CCTV cameras transformed to become completely autonomous, with 24/7 surveillance that not only reported back security risks, but detailed reports on specific OSHA compliance issues, efficiency gaps, and risk assessments? 📃
This might sound like magic, but it’s what we’ve built to showcase how TwelveLab’s video intelligence models are changing the way computers understand unstructured data for the recent NVIDIA GTC DC 2025 conference! Best of yet, our models directly integrate with pre-existing NVIDIA frameworks and hardware like NVIDIA Video Search and Summarization (VSS).
Today you’ll learn how this is all possible by not only deploying the application in this step-by-step guide, but also learning the in-depth technical architecture used to build this real-time video intelligence platform. Specifically you will build the platform that transforms live streams into:
OSHA Compliance Reports: Automatically generated with specific regulation and fine references.
Muda (Waste) Recommendations: Designed to support lean management and optimize workspace efficiency.
An Interactive Chatbot: Allows managers to ask detailed questions about their workplace and receive instant, web-sourced feedback and recommendations.
A Dynamic Event Timeline: Enables users to quickly identify what incidents occurred and when.
Contextual AI Actions: AI-generated buttons placed at specific video timestamps and coordinates to highlight inefficiencies, compliance issues, and subtle incidents.
* Note: The concepts and technology here stretch far beyond the workplace and if you’re interested in learning how TwelveLabs can make a difference in your industry, I highly recommend you to check out the Beyond The Workplace section of this blog!
Application Demo
Before we begin coding, please check out the video and deployed application below to get familiarized with what we’ll be building.
Test it out yourself: NVIDIA VSS + Twelve Labs Manufacturing Automation!
GitHub: nathanchess/twelvelabs-nvidia-vss-sample
With that in mind, let’s get started! 😊
Learning Objectives
In this tutorial you will:
Fine tune your own computer vision model on the You Only Look Once (YOLO) object detection algorithm with 15,000+ images for personal protective equipment classification.
Use FFmpeg to convert your MP4 files into live Real Time Streaming Protocol (RTSP) streams to simulate real CCTV cameras.
Learn how TwelveLabs integrates directly into NVIDIA VSS and AWS.
Understand advanced prompt engineering techniques such as chain-of-thought.
Build and run Docker containers to handle asynchronous API operations for video chunk uploading and live stream handling.
Prerequisites
Python 3.8+: Download Python | Python.org
TwelveLabs API Key: Authentication | TwelveLabs
TwelveLabs Index: Python SDK | TwelveLabs
AWS Access Key: Credentials - Boto3 1.40.12 documentation
Docker Installation: Install | Docker Docs
Intermediate understanding of Python, APIs, and JavaScript.
Local Environment Setup
1 - Clone the repository into your local environment
>> git2 - Clone NVIDIA VSS framework (with TwelveLab integration) into your local environment.
>> git3 - Navigate into your AWS console and create a new S3 bucket named “nvidia-vss-source”
Full tutorial here: Creating a general purpose bucket - Amazon Simple Storage Service
This will act as storage for our fake CCTV camera footage!
4 - Add environment variables to frontend and rtsp-stream-worker folder.
TWELVE_LABS_API_KEY=... NEXT_PUBLIC_TWELVELABS_MARENGO_INDEX_ID=... NEXT_PUBLIC_TWELVELABS_PEGASUS_INDEX_ID=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_RTSP_STREAM_WORKER_URL="http://localhost:8000" NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
TWELVE_LABS_API_KEY=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
5 - Build and run Docker containers for both rtsp-stream-worker and NVIDIA VSS
RTSP Stream Worker Instructions: twelvelabs-nvidia-vss-sample/rtsp-stream-worker at main · nathanchess/twelvelabs-nvidia-vss-sample
NVIDIA VSS Instructions: nvidia-vss/src/vss-engine/src/models/twelve_labs at main · james-le-twelve-labs/nvidia-vss
6 - Start frontend sample application using Node Package Manager (NPM).
Inside your GitHub repository, navigate to your frontend folder in console and type the following:
>> npm |
Then navigate to localhost:3000 to access the site.
* Ensure that NPM is installed: Downloading and installing Node.js and npm | npm Docs
Building the CV Pipeline
So how did we achieve near real-time on an infinitely streaming live video?
💡Learning Opportunity: Not only is live stream handling difficult, with limited bandwidth and unstable connection, but also costly!
Let’s prove it with some simple math. Take TwelveLab’s multimodal model Marengo. How much would it cost if we were to process a full 24 hour worth of video content into an index? Marengo: ($.042/min + %.0015/min) * 1440 minutes = $60.48
$60.48 per day would definitely not be sustainable for a fleet of cameras, something very common in the public and security sector to cover every inch of a property. Note: Feel free to run your own calculations at the TwelveLabs pricing calculator: https://www.twelvelabs.io/pricing-calculator |
So how do we solve this pricing issue? Well, the answer lies in chunking and pre-processing! Of course the constraints and environment you are dealing with may be different, but I ended up fine–tuning a YOLO model on personal protective equipment (PPE) detection. Here are the results:
Above we can see the model in action, identifying helmets in a variety of different environments, angles, and lighting. By having a diverse training dataset of over 15,000+ images and augmenting the images to have different colors, angles, etc. we ended up getting >90% accuracy on common PPE items like vests, helmets, gloves, boots, and more!
💡Learning Opportunity: Though out of the scope of this blog, if you would like to view the training scripts and learn how to build one from scratch feel free to check out the /cv_model's README in the repository: https://github.com/nathanchess/twelvelabs-nvidia-vss-sample/tree/main/cv_model
So here’s how it’s used for cost-saving and video chunking:
/rtsp-stream-worker/main.py (Lines 357 - 391)
def analyze_video(self, video_source: str): people_count, ppe_count = 0, 0 results = self.model.predict(frame, conf=0.25, iou=0.45, max_det=1000) processed_frame = self._draw_boxes(frame, results) for box in results[0].boxes: class_id = int(box.cls[0]) class_name = self.model.model.names[class_id] if class_name == "Person": people_count += 1 else: ppe_count += 1 # Write frame to output video video_writer.write(processed_frame) video_capture.release() video_writer.release() return new_video_source else: raise FileNotFoundError(f"Video file not found: {video_source}")
The code block simply above simply aggregates the number of people with protective gear seen in the frame. This data can then be used to create a custom chunking algorithm, tailored to a variety of workplace needs. Specifically, only video chunks of interest (missing PPE) will be fed into our multimodal model, reducing the 24 hour video content into minutes or even seconds of computation power.
Think about the type of PPE / compliance issues that may arise depending on the setting:
Food Processing Manufacturer: May require all employees to have a pair of gloves.
Medical Facilities: Require certain people to have face masks and gloves.
Construction Sites: Require a full set of PPE.
By having this customizability, individual factories can gain significant savings cost with this platform, while still maintaining high accuracy!
* Note: This does seem like a lot of upfront work, hence in the “Connecting with NVIDIA VSS” section, we will talk about how you can use pre-built video chunking algorithms in the NVIDIA VSS framework!
Creating a Fake Camera with Real-Time Streaming Protocol
Great, so now we have the chunking algorithm down ready to help with the pre-processing and cost saving for our live video streams. But how about the streams themselves?
Well upon a quick Google search you’ll notice it’s quite difficult to find open-source cameras linked to real factories, workplaces, etc. Which is why we’ll have to build our own in Python!
💡Learning Opportunity: What are the required components to simulate a fake camera?
To build a robust and realistic "fake" camera stream that mimics a real-world IP camera, we need to create a pipeline that handles content, broadcasting, and distribution. For our project, this pipeline consists of four main components:
|
Let’s see these components in action below in the technical architecture:
Technical Architecture Diagram: LucidChart (Click to view in full-screen)
This backend service is deployed on a monolithic architecture, meaning all our code is centralized into one codebase, and in our case a singular Deep Learning AMI EC2 instance! Let me briefly explain each piece of technology.
AWS S3 Buckets: This serves as the source video content for our simulated content. Put simply, just hold our MP4 files.
FFmpeg: This is the engine of our virtual camera. FFmpeg is a command-line powerhouse that does the heavy lifting:
It pulls the .mp4 file from S3.
It puts that file on an infinite loop (-stream_loop -1).
Most importantly, it transcodes this file in real-time into an RTSP (Real-Time Streaming Protocol) feed.
💡Learning Opportunity: RTSP is the native language of most IP security cameras. By creating an RTSP stream, FFmpeg is perfectly simulating a high-end camera broadcasting 24/7 onto our server's local network. Read more here: What is an RTSP Camera? – Real Time Streaming Protocol Explained Cloud based and Central Management
MediaMTX: This is our universal translator and distribution hub. The problem? Web browsers cannot play the RTSP stream that FFmpeg creates. MediaMTX is a brilliant, zero-dependency server that:
Ingests the single RTSP feed from FFmpeg.
Repackages it instantly into multiple web-friendly formats.
For our project, we use HLS (HTTP Live Streaming). MediaMTX automatically chops the live video into small, 10-second video files (.ts) and creates a "playlist" file (.m3u8) that tells the video player where to find the next chunk. This is the modern standard that allows any web browser or mobile app to play our stream smoothly.
Finetuned YOLO Model: This our previous chunking algorithm at play! As FFmpeg loops and encodes the video into RTSP format, we will use this fine-tuned model to detect objects inside the video.
CloudFlare SSH Tunnels: This is our secure gateway to the public internet. Our EC2 instance is completely locked down—it has zero open inbound ports, making it invisible to scanners and attackers.
💡Learning Opportunity: So how does the outside world see our HLS stream? Cloudflare's lightweight cloudflared agent creates a secure, outbound-only tunnel from our EC2 instance to the Cloudflare network. Cloudflare then acts as the public-facing entry point, giving us a stable URL (e.g., live.myproject.com), free SSL, DDoS protection, and caching, all without us ever needing a static IP or configuring a single firewall rule.
The end product? Highly secure HTTP Live Streaming protocols that can be easily connected to any common video player or website.
Notice how the temporary cloudflare URL generated works on public sites like hlsplayer.net ☺️! This means that our HLS URL is not only public, but formatted into a proper .m3u8 file, allowing any video player to find the next chunk properly.
Connecting with NVIDIA VSS
Great so now we have our fake cameras up and running and the pre-processing algorithm deployed onto our AWS EC2. Time to wrap things up by integrating arguably the most important part, a highly intelligent and context-aware video intelligence model to process chunks of interest. This is where NVIDIA VSS’s TwelveLabs integration steps in.
💡Learning Opportunity: Before jumping into the code and technical architecture, it’s important to understand what NVIDIA VSS even is and the tools it provides to those that build software on top of NVIDIA hardware.
VSS stands for Video Search and Summarization. Essentially this is not a single NVIDIA software like CUDA, rather it is a NVIDIA AI Blueprint, giving developers a quick way to deploy powerful AI agents that can understand, search, and summarize video content. It does so with:
Vision Language Models (VLMs): This is the "seeing" and "understanding" part. VSS provides a pipeline to feed video frames into VLMs, which then generate rich, text-based descriptions (dense captions) of what is happening in each video chunk.
Large Language Models (LLMs): This is the "reasoning" and "communication" part. The text descriptions from the VLM are fed to an LLM, which is what allows you to perform summarization and have a natural language Q&A session.
Retrieval-Augmented Generation (RAG): VSS doesn't just pass data to an LLM; it uses a technique called RAG. It stores the generated video descriptions in a specialized database (a vector or graph database). When you ask a question, it first retrieves the most relevant video chunks from the database and then augments the LLM's prompt with this specific context, leading to highly accurate, data-grounded answers.
GPU-Accelerated Ingestion: It provides a high-performance pipeline for pulling in video (from files or live RTSP streams), decoding it, and preparing it for the AI models, all using the power of NVIDIA GPUs.
Computer Vision (CV) Pipeline Integration: VSS is designed to work with (not just replace) traditional CV. Developers can integrate object detection and tracking models (like YOLO or those in the NVIDIA DeepStream SDK). This adds critical metadata (e.g., "person_1," "box_5") that the VLM and LLM can use to provide even more specific and accurate answers.
Audio Transcription: The blueprint also includes tools to process the audio track from videos, converting speech into text. This adds another layer of searchable data, allowing you to query what was said in a video, not just what was seen.
NVIDIA NIMs (NVIDIA Inference Microservices): Instead of forcing developers to build and optimize their own AI model servers, VSS is often powered by NIMs. These are pre-packaged, optimized, and containerized microservices that make deploying the VLMs and LLMs as simple as running a container.
This NVIDIA VSS blueprint is incredibly powerful, but as you can see, it's also a lot to build, deploy, and manage. You're responsible for the VLM, the LLM, the audio transcription pipeline, the CV pipeline, and the RAG database—all running on your own infrastructure.
This is precisely where TwelveLabs provides a massive accelerator.
TwelveLabs Playground Index Search Capability (TwelveLabs | Home)
Imagine abstracting away all that complexity. Instead of managing a half-dozen different models and services, you get a complete remote deployment that handles everything for you. The intelligent chunking, the computer vision, the VLM analysis, the audio transcription, and the large-language-model reasoning are all unified into a single, powerful platform, accessible via a simple API. You send the video stream, and TwelveLabs returns the insights.
But here’s the most powerful part: this isn't an all-or-nothing replacement.
The true value is in modularity. Our architecture is designed to be highly configurable, allowing you to create hybrid NVIDIA-based AI workflows.
With this knowledge, let’s go ahead and look at how our technical architecture leverages the complete remote deployment in NVIDIA VSS.
Technical Architecture Diagram: LucidChart (Click to view in full-screen)
Simply put, the uploaded video chunks are passed in two steps.
AWS S3 Bucket (nvidia-vss-streams): Storing it in an external container, outside of the multimodal model, allows to have long-term forensics data for incidents, reporting, etc.
NVIDIA VSS TwelveLabs Integration: The uploaded video content is then further passed to NVIDIA VSS, where it will undergo a series of processes:
Index Creation: Create new dedicated index(es) for both the TwelveLabs Marengo and Pegasus model.
Video Storage: Store videos into indexes, allowing it to be ready to be searched, embedded, and summarized. Feel free to view all video capabilities offered by TwelveLabs here: TwelveLabs | Product Overview
The various features of the page then simply search and summarize the video content uploaded via. NVIDIA VSS API Endpoints! Let’s see how it works in action.
Example Feature 1: AI Compliance Chatbot — Jade.
This is the right panel on the screenshot below and essentially allows factory owners to instantly investigate video chunks deeper with unstructured queries. Whether that be questions about an incident, possible improvements, or local OSHA compliances based on geolocation, they can get answers immediately specific to their factory.
This was built on TwelveLabs' powerful Pegasus conversational model, with extra chat history prompt engineering!
/frontend/src/app/components/ClipChat.js (Lines 49-72)
const typingId = Date.now(); setChatHistory(prev => [...prev, { role: 'assistant', text: '', date: Date.now(), typing: true, _id: typingId }]); try { const prompt = `You are Jade, an expert safety and compliance officer. Here is the chat history: ${chatHistory.map(m => `${m.role}: ${m.text}`).join('\n')}; The user asks: ${message}; The user's geolocation is unknown, please reference general safety and compliance standards. If the user asks about safety, compliance, or improvements, you should always reference the user's geolocation and the laws in that area when providing your response. Do not mention the coordinates, just the location and city. Be highly detailed and specific, by referencing specific machines, processes, and equipment you see in the video and the second. `; const resp = await fetch('/api/analysis', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ videoId, userQuery: prompt }) });
* Notice: The remote deployment allowed your chunked video to effortlessly be prompted in realistically under 4 lines (excluding the prompt itself, which can at times get huge).
Example Feature 2: On-Demand Compliance Report & Video Metadata.
Factory owners can instantly generate full business-ready compliance reports with details like OSHA compliance (specific violations), potential fines, corrective actions, and efficiency recommendations.
/frontend/src/app/clips/[id]/page.js (Lines 328 - 331)
const response = await fetch(`/api/analysis/${clipData['pegasusId']}`, { method: 'GET', headers: { 'Content-Type': 'application/json' } })
This was built on TwelveLabs' powerful Marengo search and summarization model, which allowed us to instantly generate detailed summaries of our video content with preset prompts!
And, that’s it! You have just built a platform that transforms live stream video content into searchable, summarized, and embedded structured content with the help of the NVIDIA VSS TwelveLabs integration with no additional hardware, GPU, or training costs 🥳.
Conclusion
Great thanks for reading along! You not only built an end-to-end real-time surveillance platform that could benefit millions of companies in the public sector, but learned about NVIDIA VSS and how the recent TwelveLabs integration can help bring your video-intensive projects from ideation to code in hours.
Check out some more in-depth resources regarding this project here:
Technical Architecture Diagram: LucidApp
Technical Design Document: [NVIDIA GTC] - Manufacturing Automation Technical Design
NVIDIA VSS TwelveLabs Integration Repo: james-le-twelve-labs/nvidia-vss: Blueprint for Ingesting massive volumes of live or archived videos and extract insights for summarization and interactive Q&A
Project Repo: nathanchess/twelvelabs-nvidia-vss-sample
Demo Video: NVIDIA VSS TwelveLabs Integration: Manufacturing Automation
In this tutorial, you will learn how to build a video intelligence platform that monitors live CCTV cameras in varying workplaces, including factories, construction sites, and more, to find risky employee behaviour or machinery, OSHA compliance violations, and efficiency gaps in near real-time. More importantly, you will learn about the latest TwelveLab’s integration into NVIDIA VSS, allowing you to handle analyzing and summarizing large volumes of video data built for hardware and solutions built on NVIDIA.
Introduction
What if your on-site CCTV cameras transformed to become completely autonomous, with 24/7 surveillance that not only reported back security risks, but detailed reports on specific OSHA compliance issues, efficiency gaps, and risk assessments? 📃
This might sound like magic, but it’s what we’ve built to showcase how TwelveLab’s video intelligence models are changing the way computers understand unstructured data for the recent NVIDIA GTC DC 2025 conference! Best of yet, our models directly integrate with pre-existing NVIDIA frameworks and hardware like NVIDIA Video Search and Summarization (VSS).
Today you’ll learn how this is all possible by not only deploying the application in this step-by-step guide, but also learning the in-depth technical architecture used to build this real-time video intelligence platform. Specifically you will build the platform that transforms live streams into:
OSHA Compliance Reports: Automatically generated with specific regulation and fine references.
Muda (Waste) Recommendations: Designed to support lean management and optimize workspace efficiency.
An Interactive Chatbot: Allows managers to ask detailed questions about their workplace and receive instant, web-sourced feedback and recommendations.
A Dynamic Event Timeline: Enables users to quickly identify what incidents occurred and when.
Contextual AI Actions: AI-generated buttons placed at specific video timestamps and coordinates to highlight inefficiencies, compliance issues, and subtle incidents.
* Note: The concepts and technology here stretch far beyond the workplace and if you’re interested in learning how TwelveLabs can make a difference in your industry, I highly recommend you to check out the Beyond The Workplace section of this blog!
Application Demo
Before we begin coding, please check out the video and deployed application below to get familiarized with what we’ll be building.
Test it out yourself: NVIDIA VSS + Twelve Labs Manufacturing Automation!
GitHub: nathanchess/twelvelabs-nvidia-vss-sample
With that in mind, let’s get started! 😊
Learning Objectives
In this tutorial you will:
Fine tune your own computer vision model on the You Only Look Once (YOLO) object detection algorithm with 15,000+ images for personal protective equipment classification.
Use FFmpeg to convert your MP4 files into live Real Time Streaming Protocol (RTSP) streams to simulate real CCTV cameras.
Learn how TwelveLabs integrates directly into NVIDIA VSS and AWS.
Understand advanced prompt engineering techniques such as chain-of-thought.
Build and run Docker containers to handle asynchronous API operations for video chunk uploading and live stream handling.
Prerequisites
Python 3.8+: Download Python | Python.org
TwelveLabs API Key: Authentication | TwelveLabs
TwelveLabs Index: Python SDK | TwelveLabs
AWS Access Key: Credentials - Boto3 1.40.12 documentation
Docker Installation: Install | Docker Docs
Intermediate understanding of Python, APIs, and JavaScript.
Local Environment Setup
1 - Clone the repository into your local environment
>> git2 - Clone NVIDIA VSS framework (with TwelveLab integration) into your local environment.
>> git3 - Navigate into your AWS console and create a new S3 bucket named “nvidia-vss-source”
Full tutorial here: Creating a general purpose bucket - Amazon Simple Storage Service
This will act as storage for our fake CCTV camera footage!
4 - Add environment variables to frontend and rtsp-stream-worker folder.
TWELVE_LABS_API_KEY=... NEXT_PUBLIC_TWELVELABS_MARENGO_INDEX_ID=... NEXT_PUBLIC_TWELVELABS_PEGASUS_INDEX_ID=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_RTSP_STREAM_WORKER_URL="http://localhost:8000" NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
TWELVE_LABS_API_KEY=... AWS_ACCESS_KEY_ID=... AWS_SECRET_ACCESS_KEY=... AWS_S3_BUCKET_NAME=nvidia-vss-source AWS_REGION=us-east-1 NEXT_PUBLIC_VSS_BASE_URL="http://127.0.0.1:8080"
5 - Build and run Docker containers for both rtsp-stream-worker and NVIDIA VSS
RTSP Stream Worker Instructions: twelvelabs-nvidia-vss-sample/rtsp-stream-worker at main · nathanchess/twelvelabs-nvidia-vss-sample
NVIDIA VSS Instructions: nvidia-vss/src/vss-engine/src/models/twelve_labs at main · james-le-twelve-labs/nvidia-vss
6 - Start frontend sample application using Node Package Manager (NPM).
Inside your GitHub repository, navigate to your frontend folder in console and type the following:
>> npm |
Then navigate to localhost:3000 to access the site.
* Ensure that NPM is installed: Downloading and installing Node.js and npm | npm Docs
Building the CV Pipeline
So how did we achieve near real-time on an infinitely streaming live video?
💡Learning Opportunity: Not only is live stream handling difficult, with limited bandwidth and unstable connection, but also costly!
Let’s prove it with some simple math. Take TwelveLab’s multimodal model Marengo. How much would it cost if we were to process a full 24 hour worth of video content into an index? Marengo: ($.042/min + %.0015/min) * 1440 minutes = $60.48
$60.48 per day would definitely not be sustainable for a fleet of cameras, something very common in the public and security sector to cover every inch of a property. Note: Feel free to run your own calculations at the TwelveLabs pricing calculator: https://www.twelvelabs.io/pricing-calculator |
So how do we solve this pricing issue? Well, the answer lies in chunking and pre-processing! Of course the constraints and environment you are dealing with may be different, but I ended up fine–tuning a YOLO model on personal protective equipment (PPE) detection. Here are the results:
Above we can see the model in action, identifying helmets in a variety of different environments, angles, and lighting. By having a diverse training dataset of over 15,000+ images and augmenting the images to have different colors, angles, etc. we ended up getting >90% accuracy on common PPE items like vests, helmets, gloves, boots, and more!
💡Learning Opportunity: Though out of the scope of this blog, if you would like to view the training scripts and learn how to build one from scratch feel free to check out the /cv_model's README in the repository: https://github.com/nathanchess/twelvelabs-nvidia-vss-sample/tree/main/cv_model
So here’s how it’s used for cost-saving and video chunking:
/rtsp-stream-worker/main.py (Lines 357 - 391)
def analyze_video(self, video_source: str): people_count, ppe_count = 0, 0 results = self.model.predict(frame, conf=0.25, iou=0.45, max_det=1000) processed_frame = self._draw_boxes(frame, results) for box in results[0].boxes: class_id = int(box.cls[0]) class_name = self.model.model.names[class_id] if class_name == "Person": people_count += 1 else: ppe_count += 1 # Write frame to output video video_writer.write(processed_frame) video_capture.release() video_writer.release() return new_video_source else: raise FileNotFoundError(f"Video file not found: {video_source}")
The code block simply above simply aggregates the number of people with protective gear seen in the frame. This data can then be used to create a custom chunking algorithm, tailored to a variety of workplace needs. Specifically, only video chunks of interest (missing PPE) will be fed into our multimodal model, reducing the 24 hour video content into minutes or even seconds of computation power.
Think about the type of PPE / compliance issues that may arise depending on the setting:
Food Processing Manufacturer: May require all employees to have a pair of gloves.
Medical Facilities: Require certain people to have face masks and gloves.
Construction Sites: Require a full set of PPE.
By having this customizability, individual factories can gain significant savings cost with this platform, while still maintaining high accuracy!
* Note: This does seem like a lot of upfront work, hence in the “Connecting with NVIDIA VSS” section, we will talk about how you can use pre-built video chunking algorithms in the NVIDIA VSS framework!
Creating a Fake Camera with Real-Time Streaming Protocol
Great, so now we have the chunking algorithm down ready to help with the pre-processing and cost saving for our live video streams. But how about the streams themselves?
Well upon a quick Google search you’ll notice it’s quite difficult to find open-source cameras linked to real factories, workplaces, etc. Which is why we’ll have to build our own in Python!
💡Learning Opportunity: What are the required components to simulate a fake camera?
To build a robust and realistic "fake" camera stream that mimics a real-world IP camera, we need to create a pipeline that handles content, broadcasting, and distribution. For our project, this pipeline consists of four main components:
|
Let’s see these components in action below in the technical architecture:
Technical Architecture Diagram: LucidChart (Click to view in full-screen)
This backend service is deployed on a monolithic architecture, meaning all our code is centralized into one codebase, and in our case a singular Deep Learning AMI EC2 instance! Let me briefly explain each piece of technology.
AWS S3 Buckets: This serves as the source video content for our simulated content. Put simply, just hold our MP4 files.
FFmpeg: This is the engine of our virtual camera. FFmpeg is a command-line powerhouse that does the heavy lifting:
It pulls the .mp4 file from S3.
It puts that file on an infinite loop (-stream_loop -1).
Most importantly, it transcodes this file in real-time into an RTSP (Real-Time Streaming Protocol) feed.
💡Learning Opportunity: RTSP is the native language of most IP security cameras. By creating an RTSP stream, FFmpeg is perfectly simulating a high-end camera broadcasting 24/7 onto our server's local network. Read more here: What is an RTSP Camera? – Real Time Streaming Protocol Explained Cloud based and Central Management
MediaMTX: This is our universal translator and distribution hub. The problem? Web browsers cannot play the RTSP stream that FFmpeg creates. MediaMTX is a brilliant, zero-dependency server that:
Ingests the single RTSP feed from FFmpeg.
Repackages it instantly into multiple web-friendly formats.
For our project, we use HLS (HTTP Live Streaming). MediaMTX automatically chops the live video into small, 10-second video files (.ts) and creates a "playlist" file (.m3u8) that tells the video player where to find the next chunk. This is the modern standard that allows any web browser or mobile app to play our stream smoothly.
Finetuned YOLO Model: This our previous chunking algorithm at play! As FFmpeg loops and encodes the video into RTSP format, we will use this fine-tuned model to detect objects inside the video.
CloudFlare SSH Tunnels: This is our secure gateway to the public internet. Our EC2 instance is completely locked down—it has zero open inbound ports, making it invisible to scanners and attackers.
💡Learning Opportunity: So how does the outside world see our HLS stream? Cloudflare's lightweight cloudflared agent creates a secure, outbound-only tunnel from our EC2 instance to the Cloudflare network. Cloudflare then acts as the public-facing entry point, giving us a stable URL (e.g., live.myproject.com), free SSL, DDoS protection, and caching, all without us ever needing a static IP or configuring a single firewall rule.
The end product? Highly secure HTTP Live Streaming protocols that can be easily connected to any common video player or website.
Notice how the temporary cloudflare URL generated works on public sites like hlsplayer.net ☺️! This means that our HLS URL is not only public, but formatted into a proper .m3u8 file, allowing any video player to find the next chunk properly.
Connecting with NVIDIA VSS
Great so now we have our fake cameras up and running and the pre-processing algorithm deployed onto our AWS EC2. Time to wrap things up by integrating arguably the most important part, a highly intelligent and context-aware video intelligence model to process chunks of interest. This is where NVIDIA VSS’s TwelveLabs integration steps in.
💡Learning Opportunity: Before jumping into the code and technical architecture, it’s important to understand what NVIDIA VSS even is and the tools it provides to those that build software on top of NVIDIA hardware.
VSS stands for Video Search and Summarization. Essentially this is not a single NVIDIA software like CUDA, rather it is a NVIDIA AI Blueprint, giving developers a quick way to deploy powerful AI agents that can understand, search, and summarize video content. It does so with:
Vision Language Models (VLMs): This is the "seeing" and "understanding" part. VSS provides a pipeline to feed video frames into VLMs, which then generate rich, text-based descriptions (dense captions) of what is happening in each video chunk.
Large Language Models (LLMs): This is the "reasoning" and "communication" part. The text descriptions from the VLM are fed to an LLM, which is what allows you to perform summarization and have a natural language Q&A session.
Retrieval-Augmented Generation (RAG): VSS doesn't just pass data to an LLM; it uses a technique called RAG. It stores the generated video descriptions in a specialized database (a vector or graph database). When you ask a question, it first retrieves the most relevant video chunks from the database and then augments the LLM's prompt with this specific context, leading to highly accurate, data-grounded answers.
GPU-Accelerated Ingestion: It provides a high-performance pipeline for pulling in video (from files or live RTSP streams), decoding it, and preparing it for the AI models, all using the power of NVIDIA GPUs.
Computer Vision (CV) Pipeline Integration: VSS is designed to work with (not just replace) traditional CV. Developers can integrate object detection and tracking models (like YOLO or those in the NVIDIA DeepStream SDK). This adds critical metadata (e.g., "person_1," "box_5") that the VLM and LLM can use to provide even more specific and accurate answers.
Audio Transcription: The blueprint also includes tools to process the audio track from videos, converting speech into text. This adds another layer of searchable data, allowing you to query what was said in a video, not just what was seen.
NVIDIA NIMs (NVIDIA Inference Microservices): Instead of forcing developers to build and optimize their own AI model servers, VSS is often powered by NIMs. These are pre-packaged, optimized, and containerized microservices that make deploying the VLMs and LLMs as simple as running a container.
This NVIDIA VSS blueprint is incredibly powerful, but as you can see, it's also a lot to build, deploy, and manage. You're responsible for the VLM, the LLM, the audio transcription pipeline, the CV pipeline, and the RAG database—all running on your own infrastructure.
This is precisely where TwelveLabs provides a massive accelerator.
TwelveLabs Playground Index Search Capability (TwelveLabs | Home)
Imagine abstracting away all that complexity. Instead of managing a half-dozen different models and services, you get a complete remote deployment that handles everything for you. The intelligent chunking, the computer vision, the VLM analysis, the audio transcription, and the large-language-model reasoning are all unified into a single, powerful platform, accessible via a simple API. You send the video stream, and TwelveLabs returns the insights.
But here’s the most powerful part: this isn't an all-or-nothing replacement.
The true value is in modularity. Our architecture is designed to be highly configurable, allowing you to create hybrid NVIDIA-based AI workflows.
With this knowledge, let’s go ahead and look at how our technical architecture leverages the complete remote deployment in NVIDIA VSS.
Technical Architecture Diagram: LucidChart (Click to view in full-screen)
Simply put, the uploaded video chunks are passed in two steps.
AWS S3 Bucket (nvidia-vss-streams): Storing it in an external container, outside of the multimodal model, allows to have long-term forensics data for incidents, reporting, etc.
NVIDIA VSS TwelveLabs Integration: The uploaded video content is then further passed to NVIDIA VSS, where it will undergo a series of processes:
Index Creation: Create new dedicated index(es) for both the TwelveLabs Marengo and Pegasus model.
Video Storage: Store videos into indexes, allowing it to be ready to be searched, embedded, and summarized. Feel free to view all video capabilities offered by TwelveLabs here: TwelveLabs | Product Overview
The various features of the page then simply search and summarize the video content uploaded via. NVIDIA VSS API Endpoints! Let’s see how it works in action.
Example Feature 1: AI Compliance Chatbot — Jade.
This is the right panel on the screenshot below and essentially allows factory owners to instantly investigate video chunks deeper with unstructured queries. Whether that be questions about an incident, possible improvements, or local OSHA compliances based on geolocation, they can get answers immediately specific to their factory.
This was built on TwelveLabs' powerful Pegasus conversational model, with extra chat history prompt engineering!
/frontend/src/app/components/ClipChat.js (Lines 49-72)
const typingId = Date.now(); setChatHistory(prev => [...prev, { role: 'assistant', text: '', date: Date.now(), typing: true, _id: typingId }]); try { const prompt = `You are Jade, an expert safety and compliance officer. Here is the chat history: ${chatHistory.map(m => `${m.role}: ${m.text}`).join('\n')}; The user asks: ${message}; The user's geolocation is unknown, please reference general safety and compliance standards. If the user asks about safety, compliance, or improvements, you should always reference the user's geolocation and the laws in that area when providing your response. Do not mention the coordinates, just the location and city. Be highly detailed and specific, by referencing specific machines, processes, and equipment you see in the video and the second. `; const resp = await fetch('/api/analysis', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ videoId, userQuery: prompt }) });
* Notice: The remote deployment allowed your chunked video to effortlessly be prompted in realistically under 4 lines (excluding the prompt itself, which can at times get huge).
Example Feature 2: On-Demand Compliance Report & Video Metadata.
Factory owners can instantly generate full business-ready compliance reports with details like OSHA compliance (specific violations), potential fines, corrective actions, and efficiency recommendations.
/frontend/src/app/clips/[id]/page.js (Lines 328 - 331)
const response = await fetch(`/api/analysis/${clipData['pegasusId']}`, { method: 'GET', headers: { 'Content-Type': 'application/json' } })
This was built on TwelveLabs' powerful Marengo search and summarization model, which allowed us to instantly generate detailed summaries of our video content with preset prompts!
And, that’s it! You have just built a platform that transforms live stream video content into searchable, summarized, and embedded structured content with the help of the NVIDIA VSS TwelveLabs integration with no additional hardware, GPU, or training costs 🥳.
Conclusion
Great thanks for reading along! You not only built an end-to-end real-time surveillance platform that could benefit millions of companies in the public sector, but learned about NVIDIA VSS and how the recent TwelveLabs integration can help bring your video-intensive projects from ideation to code in hours.
Check out some more in-depth resources regarding this project here:
Technical Architecture Diagram: LucidApp
Technical Design Document: [NVIDIA GTC] - Manufacturing Automation Technical Design
NVIDIA VSS TwelveLabs Integration Repo: james-le-twelve-labs/nvidia-vss: Blueprint for Ingesting massive volumes of live or archived videos and extract insights for summarization and interactive Q&A
Project Repo: nathanchess/twelvelabs-nvidia-vss-sample
Demo Video: NVIDIA VSS TwelveLabs Integration: Manufacturing Automation
Related articles



プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved

プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved




プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved