" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
商品
Video-To-Text(動画テキスト化)とPegasus-1(80B)のご紹介
エイデン・リー、ジェ・リー
Twelve Labsは、3億以上のビデオとテキストのペアでトレーニングされた800億パラメータのビデオ言語基盤モデル「Pegasus-1」をローンチします。これに合わせて、ビデオ要約のベンチマークにおいて従来の最先端技術を最大61%上回る新しい一連のVideo-to-Text APIも提供開始します。
Twelve Labsは、3億以上のビデオとテキストのペアでトレーニングされた800億パラメータのビデオ言語基盤モデル「Pegasus-1」をローンチします。これに合わせて、ビデオ要約のベンチマークにおいて従来の最先端技術を最大61%上回る新しい一連のVideo-to-Text APIも提供開始します。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2023/10/23
8分
記事へのリンクをコピー
概要
プロダクト: Twelve Labsは、最新のビデオ言語基盤モデルであるPegasus-1と、新しいVideo-to-Text APIスイート(Gist API、Summary API、Generate API)を発表します。
プロダクトおよび研究哲学: ビデオ理解を画像や音声の理解問題として再構成する多くの既存手法とは異なり、Twelve Labsは「ビデオファースト」戦略を採用し、4つのコア原則(効率的な長尺ビデオ処理、マルチモーダルな理解、ビデオネイティブな埋め込み、ビデオと言語埋め込みの深いアライメント)を掲げています。
新しいモデル: Pegasus-1は約800億(80B)のパラメータを持ち、ビデオエンコーダ、ビデオ言語アライメントモデル、言語デコーダという3つのモデルコンポーネントが共にトレーニングされています。
データセット: Twelve Labsは、厳選された3億件以上の多様なビデオとテキストのペアを収集しました。これは、ビデオ言語基盤モデルのトレーニング用としては世界最大級のビデオ・テキストコーパスです。本技術レポートは、そのうちの10%にあたる3500万件のビデオ・テキストペアと10億件以上の画像・テキストペアからなるサブセットを用いて実施された初期トレーニングランに基づいています。
SOTAビデオ言語モデルとの性能比較: 従来の最先端(SOTA)ビデオ言語モデルと比較して、Pegasus-1は、QEFVC品質スコア(Maaz et al., 2023)で測定した結果、MSR-VTTデータセット(Xu et al., 2016)で61%の相対的な改善、Video Descriptionsデータセット(Maaz et al., 2023)で47%の向上を示しています。当社が提案する評価指標であるVidFactScoreでの評価では、MSR-VTTデータセットで絶対値20%のF1スコア向上、Video Descriptionデータセットで14%の向上を示しました。
ASR+LLMモデルとの性能比較: ASR+LLMは、Video-to-Textタスクに取り組むために広く採用されているアプローチです。Whisper-ChatGPT(OpenAI)および主要な商用ASR+LLM製品と比較して、Pegasus-1はMSR-VTTで79%、Video Descriptionsデータセットで188%優れたパフォーマンスを発揮します。VidFactScore-F1での評価では、MSR-VTTデータセットで絶対値25%の向上、Video Descriptionデータセットで33%の向上を示しています。
Pegasus-1へのAPIアクセス: Pegasusを搭載したVideo-to-Text APIのウェイティングリストのリンクはこちらです。
研究の視野を広げる:ビデオ埋め込みから生成モデルへ
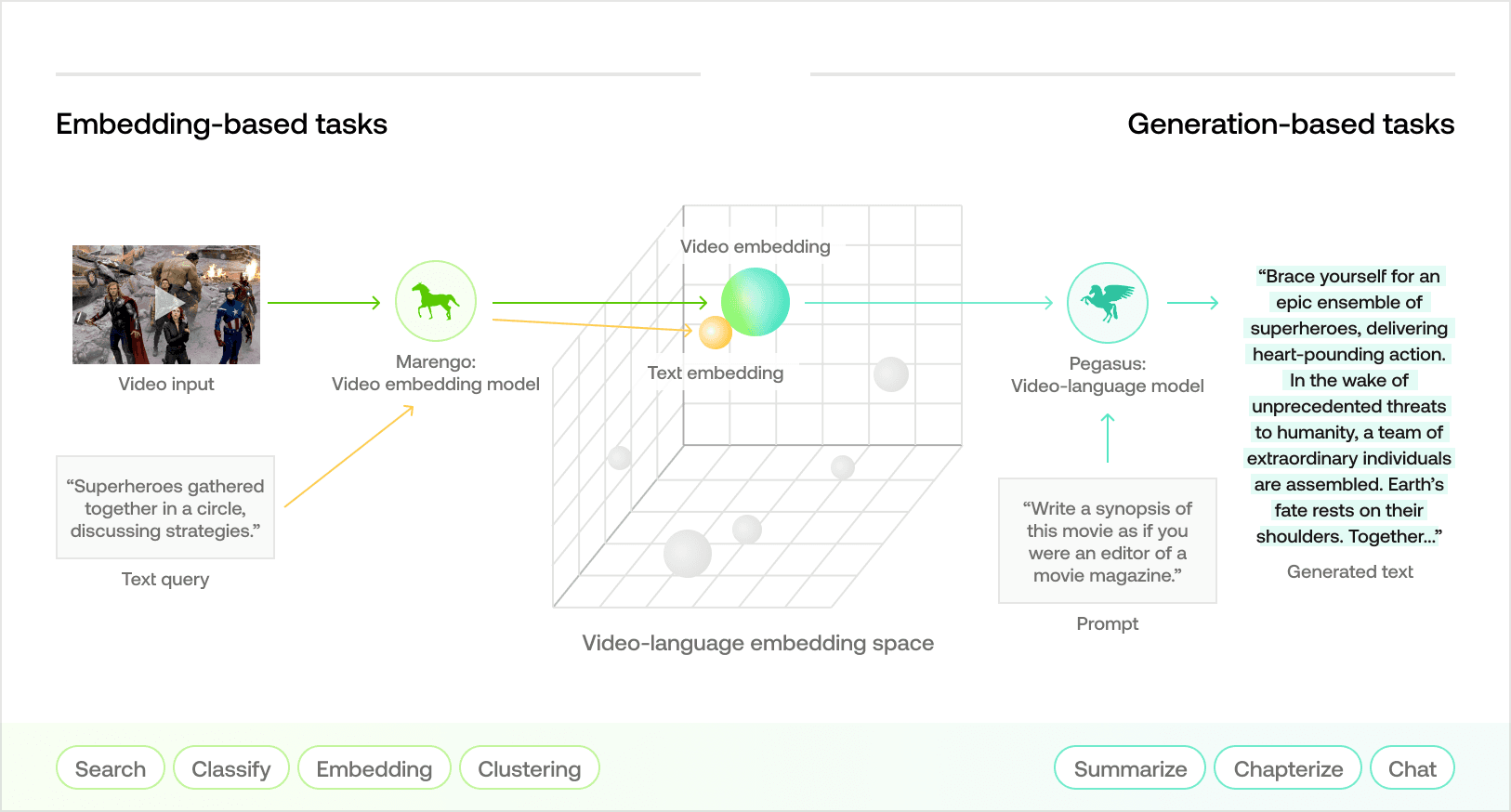
サンフランシスコ・ベイエリアを拠点とするAI研究・プロダクト開発企業であるTwelve Labsは、マルチモーダルなビデオ理解の最前線に立っています。本日、私たちは最新のビデオ言語基盤モデルであるPegasus-1の最先端のビデオ・テキスト生成機能を発表できることを嬉しく思います。これは、さまざまな下流のビデオ理解タスクに合わせてカスタマイズされた包括的なAPIスイートを提供するという、私たちのコミットメントを示すものです。私たちのスイートは、自然言語ベースのビデオモーメント検索から分類、そして今回の最新リリースによるプロンプトベースのビデオ・テキスト生成にまで及びます。
私たちの「ビデオファースト」精神
ビデオデータは、単一のフォーマット内に複数のモダリティを含んでいるため非常に興味深いものです。私たちは、ビデオ理解には、視覚知覚の複雑さと、音声およびテキストの順序的・文脈的なニュアンスを融合させる新しい取り組みが必要であると考えています。優れた画像モデルや言語モデルの台頭に伴い、ビデオ理解の主要なアプローチは、それを画像や音声の理解問題として再構成することでした。一般的なフレームワークでは、ビデオからフレームをサンプリングしてビジョン言語モデルに入力します。
このアプローチは短いビデオには有効かもしれませんが(ほとんどのビジョン言語モデルが1分未満のビデオクリップに焦点を当てているのはそのためです)、現実世界のビデオのほとんどは1分を超え、容易に数時間に及ぶことがあります。このようなビデオに対して単純な「画像ファースト」のアプローチを使用することは、ビデオごとに数万枚の画像を処理することを意味し、結果として、時空間情報の意味論をよくて大まかに捉えているに過ぎない膨大な数の画像・テキスト埋め込みを操作しなければならなくなります。これは、パフォーマンス、レイテンシ、コストの観点から、多くのアプリケーションにおいて不経済です。さらに、主流の設計手法はビデオのマルチモーダルな特性を見落としており、コンテンツを包括的に理解するためには、音声(会話を含む)と視覚要素の両方の共同分析が不可欠です。
ビデオデータの基本的な特性を念頭に置き、Twelve Labsは「ビデオファースト」戦略を採用し、モデル、データ、およびMLシステムをビデオデータの処理と理解のみに焦点を当てて構築しています。 これは、多くのジェネレーティブAIプレイヤーに見られる一般的な「言語/画像ファースト」のアプローチとは対照的です。4つの中心的な原則が当社の「ビデオファースト」精神を支え、ビデオ言語基盤モデルの設計とMLシステムのアーキテクチャの双方を導いています。
効率的な長尺ビデオ処理: 当社のモデルとシステムは、短い10秒のクリップから、数時間に及ぶ膨大なコンテンツまで、多様な長さのビデオを管理できるように最適化されていなければなりません。
マルチモーダルな理解: 当社のモデルは、視覚、音声、およびスピーチ情報を統合できなければなりません。
ビデオネイティブな埋め込み: 空間的な関係に焦点を当てた画像ネイティブな埋め込み(例:CLIP)に依存するのではなく、ビデオの時空間情報を全体的な方法で組み込むことができるビデオネイティブな埋め込みの必要性を信じています。
ビデオネイティブ埋め込みと言語モデルの深いアライメント: 画像とテキストのアライメントを超えて、当社のモデルは、大規模なビデオ・テキストコーパスおよびビデオ・テキスト指示データセットでの広範なトレーニングを通じて、深いビデオ言語アライメントを経なければなりません。
新しいVideo-to-Text機能とインターフェース
デベロッパーは、1回のAPIコールでPegasus-1モデルを促し、ビデオデータから特定のテキスト出力を生成できます。音声からテキストへの変換を利用するか、視覚的なフレームデータのみに依存する既存のソリューションとは異なり、Pegasus-1は視覚、音声、スピーチの情報を統合して、ビデオからより包括的なテキストを生成し、ビデオ要約のベンチマークにおいて新たな最先端のパフォーマンスを達成しています。(下記の「評価と結果」セクションを参照。)

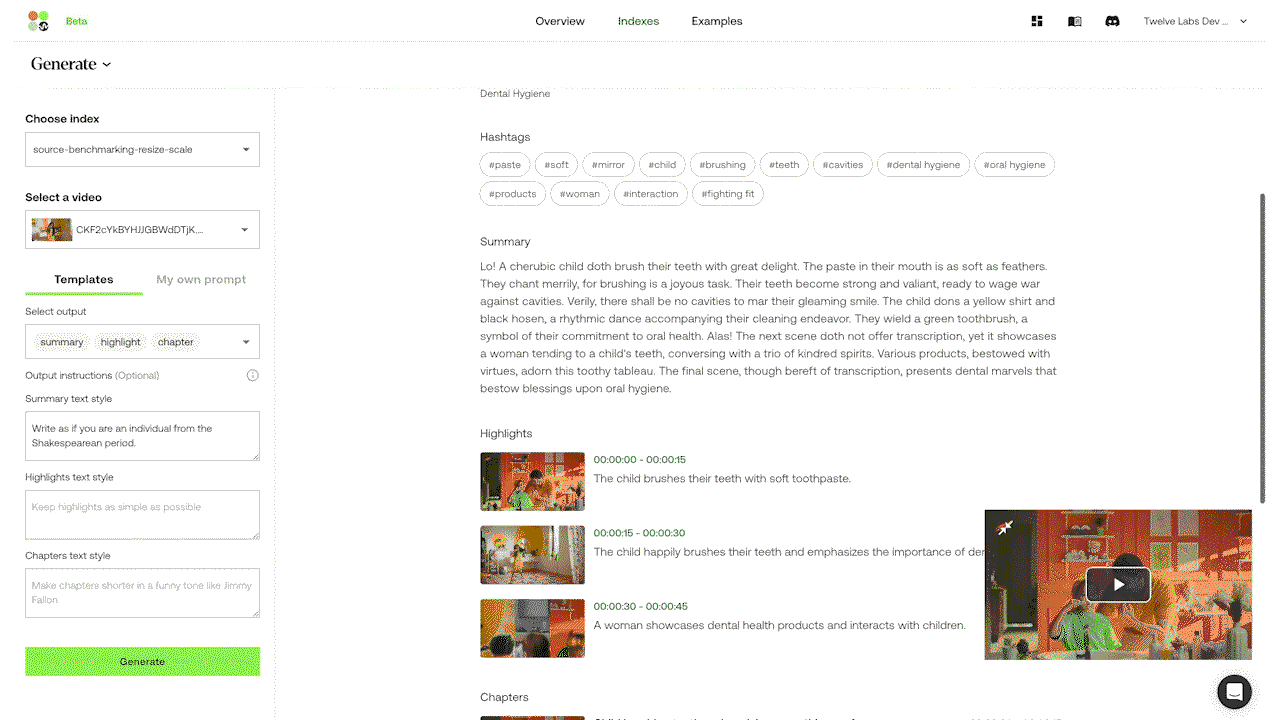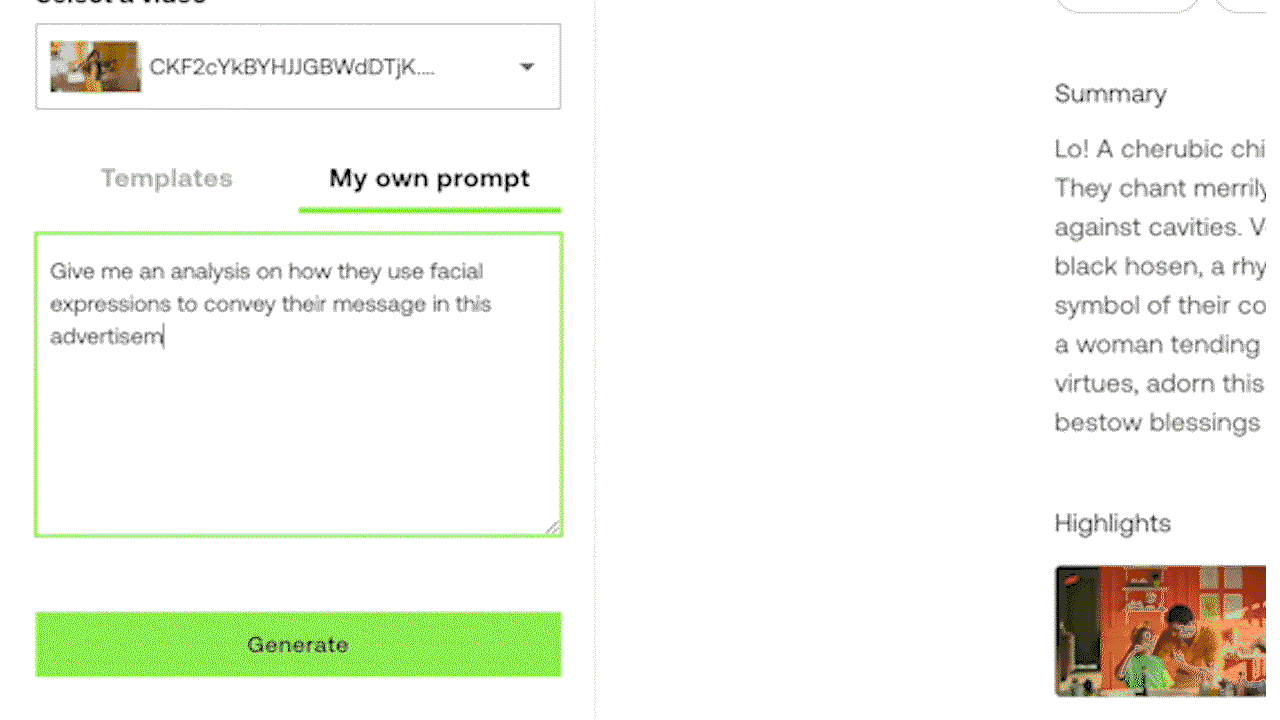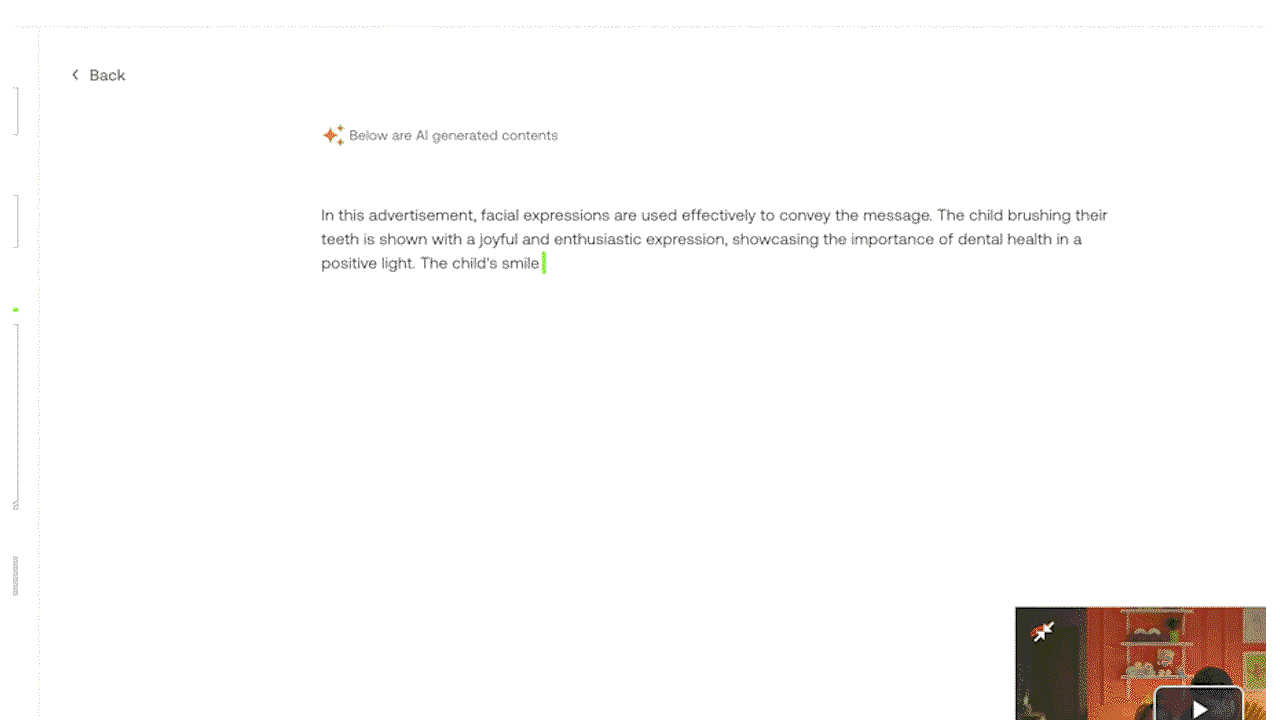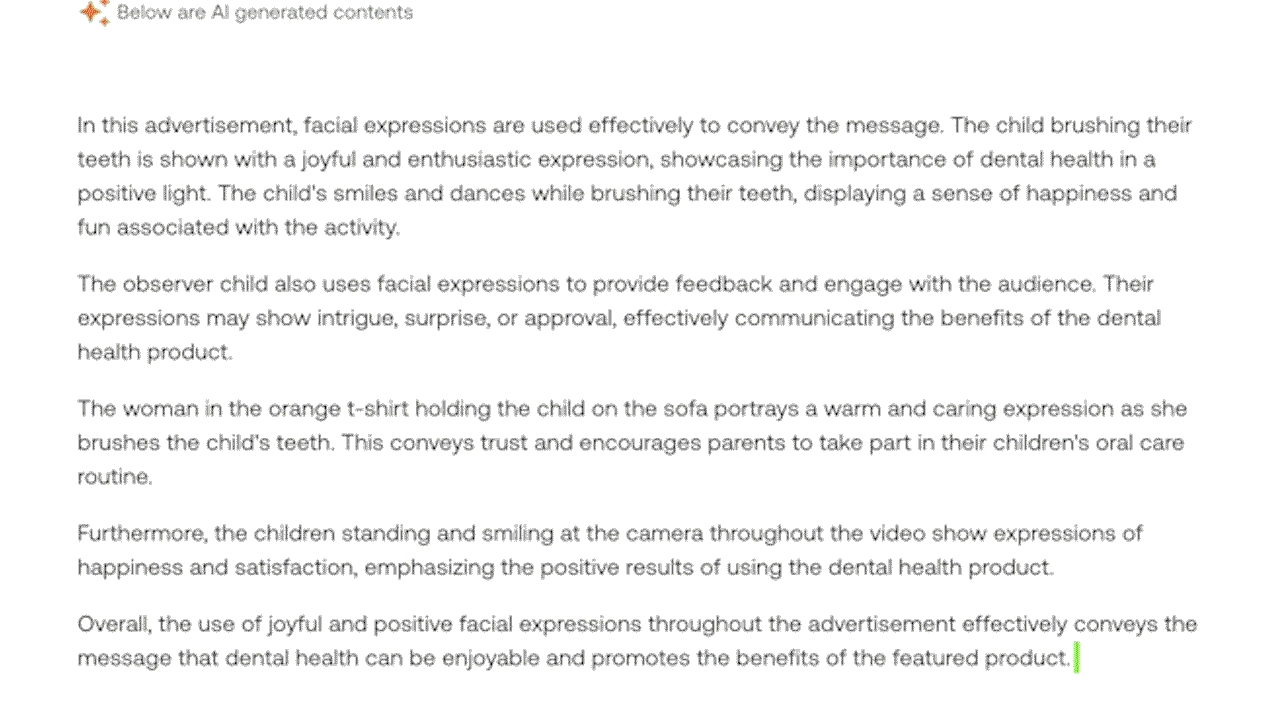
Gist APIとSummary APIにはあらかじめ関連するプロンプトがプリロードされているため、ユーザーがプロンプトを入力しなくても、すぐに使用することができます。Gist APIは、タイトル、トピック、関連ハッシュタグのリストなどの簡潔なテキスト出力を生成できます。Summary APIは、ビデオのサマリー、章、ハイライトを生成するように設計されています。カスタマイズされた出力のために、実験的なGenerate APIを使用すると、ユーザーは箇条書きからレポート、さらにはビデオの内容に基づいたクリエイティブな歌詞に至るまで、特定のフォーマットやスタイルを指定することができます。
例1: Gist APIおよびSummary APIを介してビデオから短いレポートを生成する。

例2: Summary APIにスタイリングプロンプトを渡してビデオサマリーを生成する。
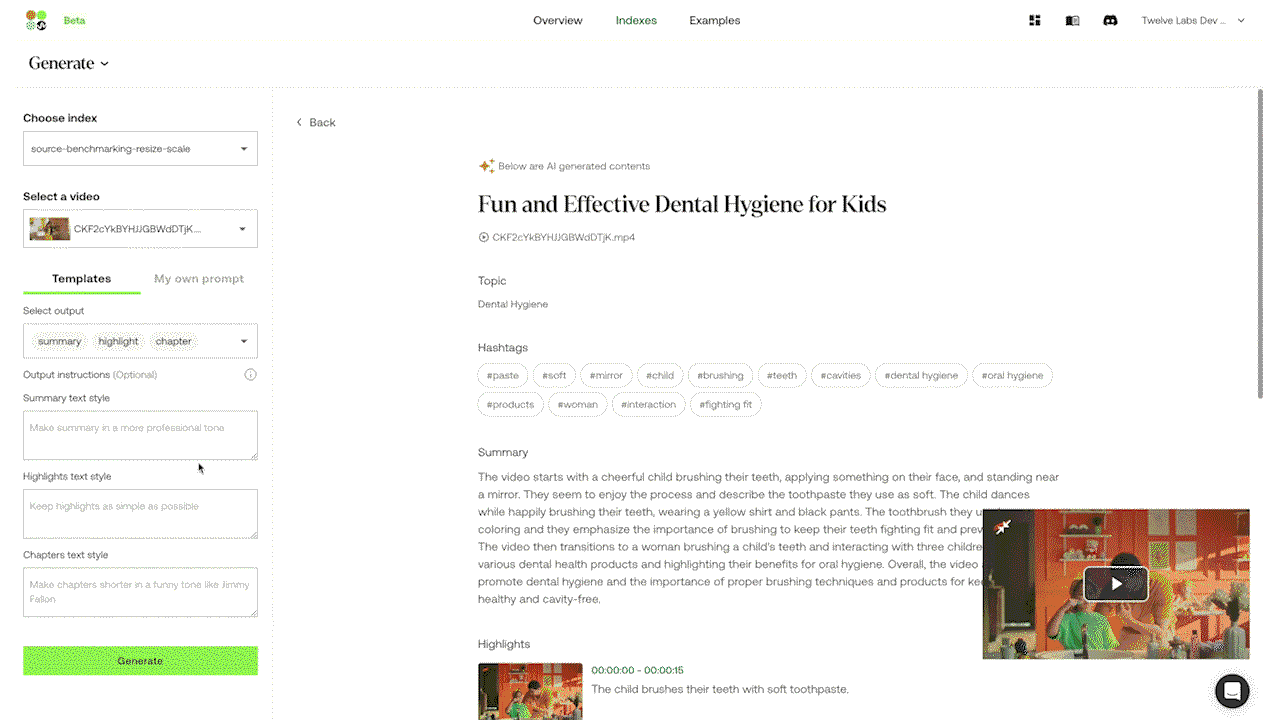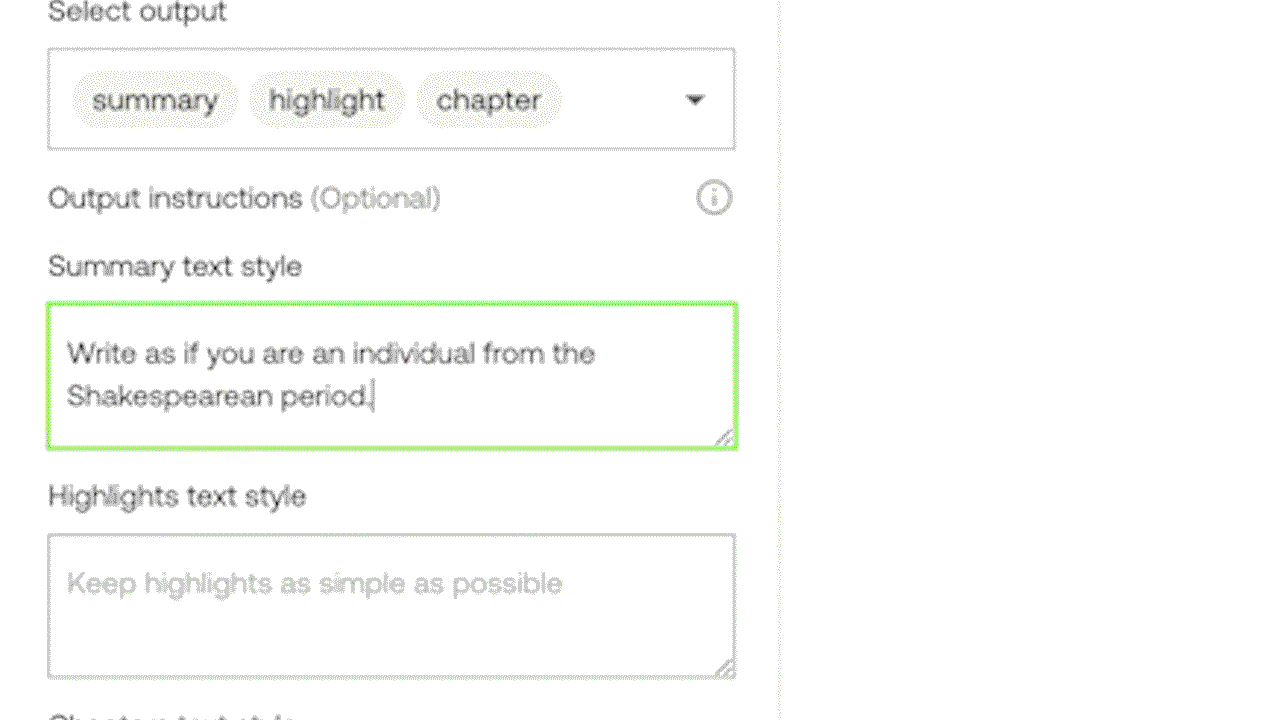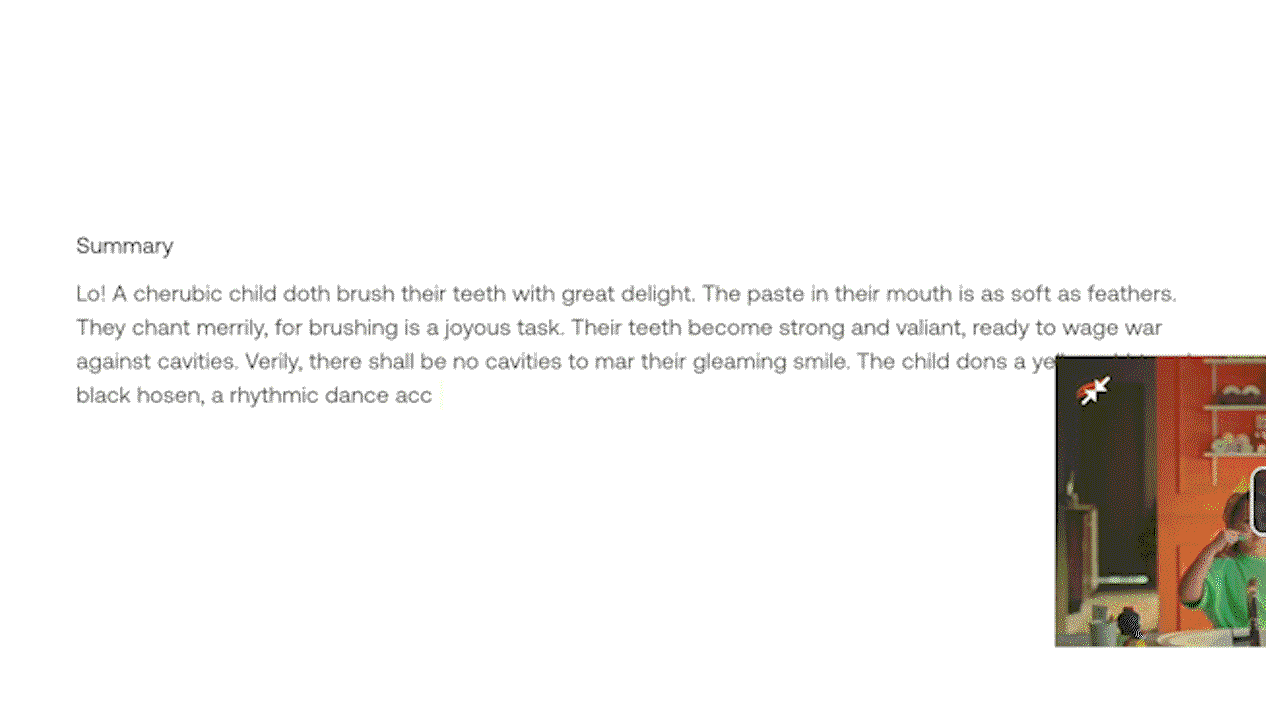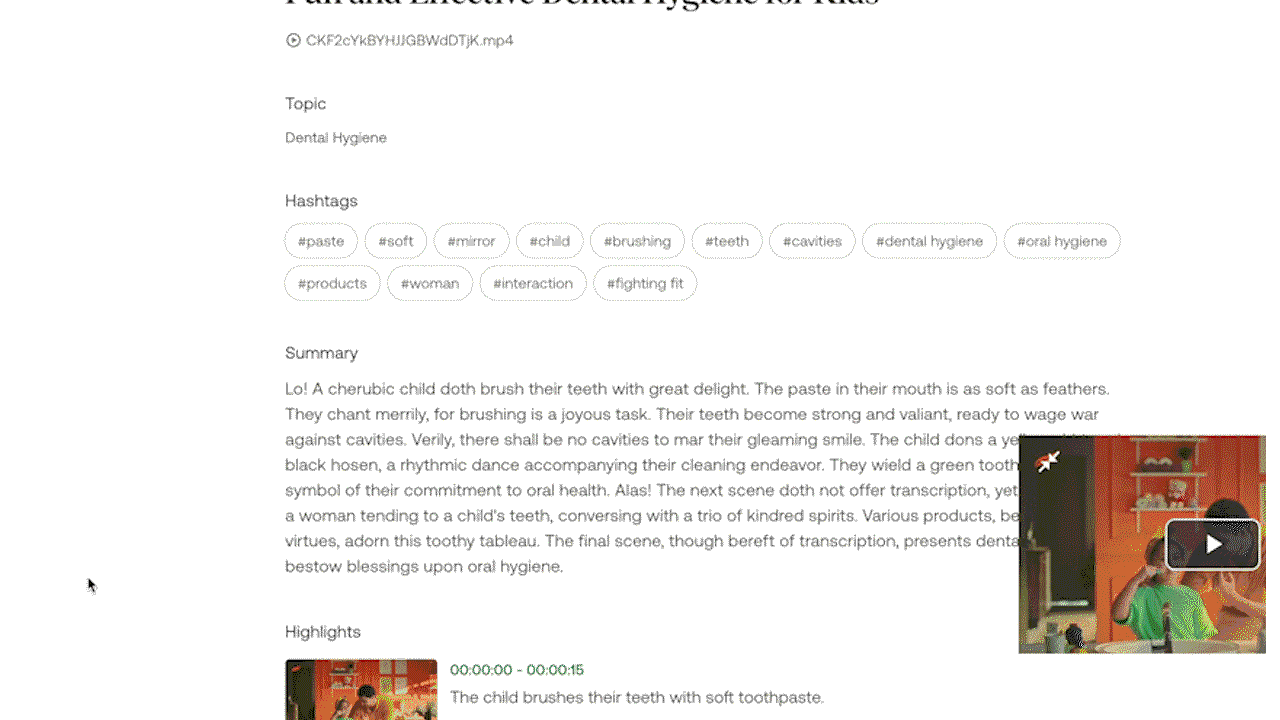
例3: 実験的なGenerate APIによるプロンプト入力で、カスタマイズされたテキスト出力を生成する。
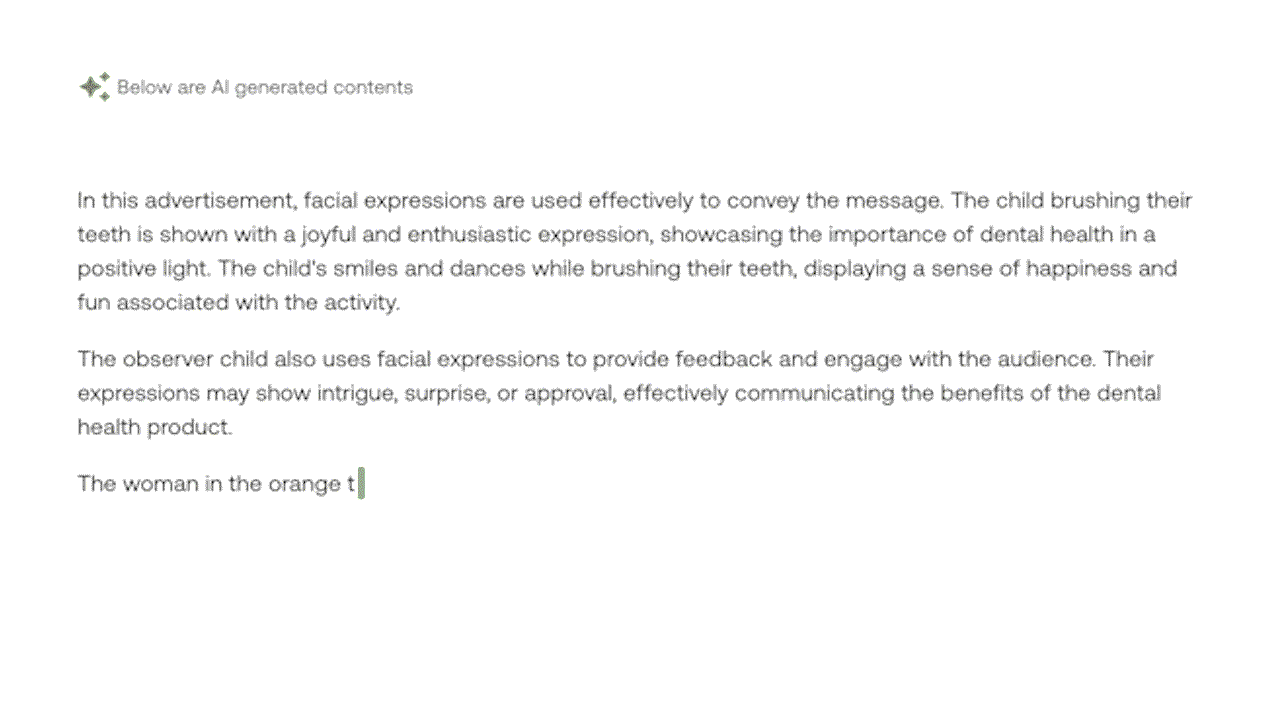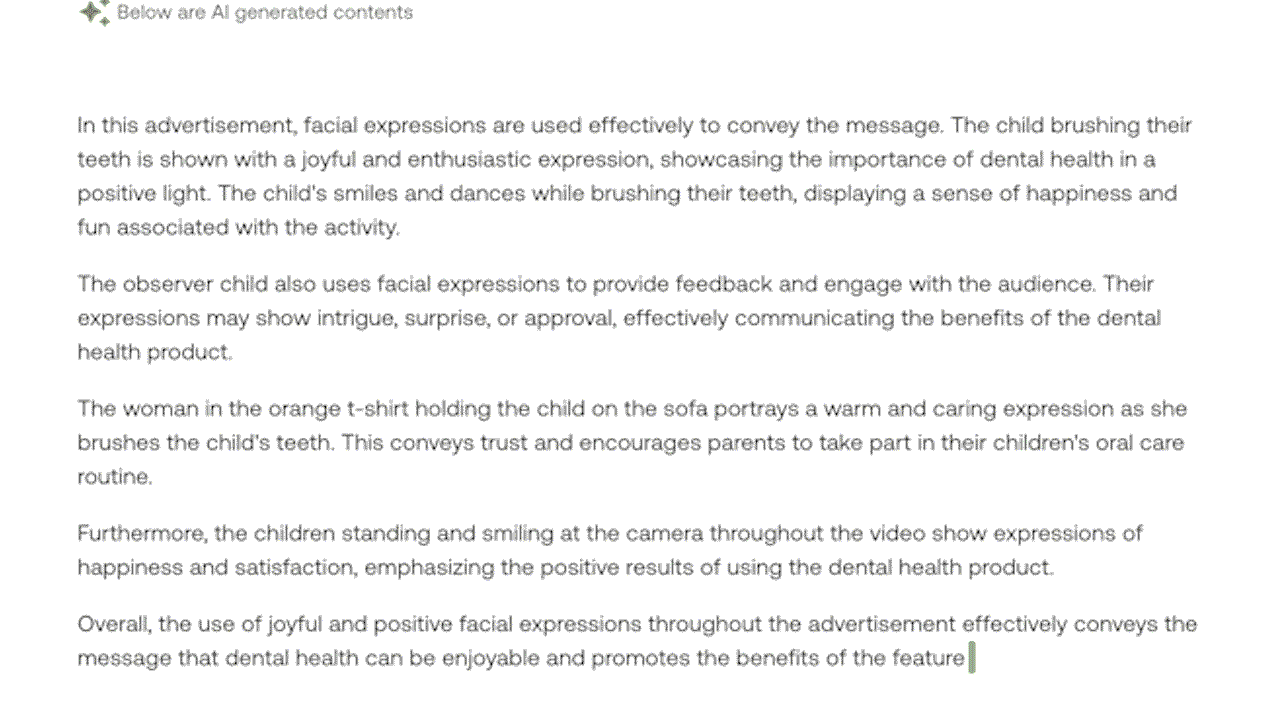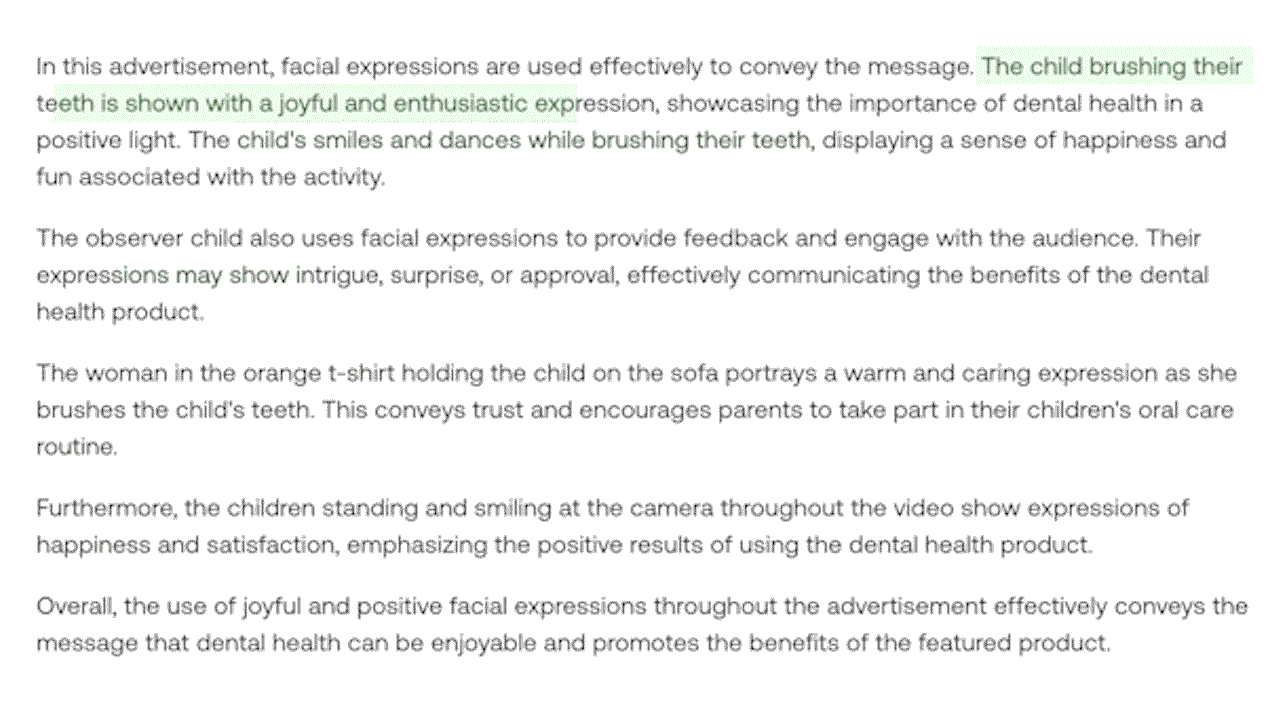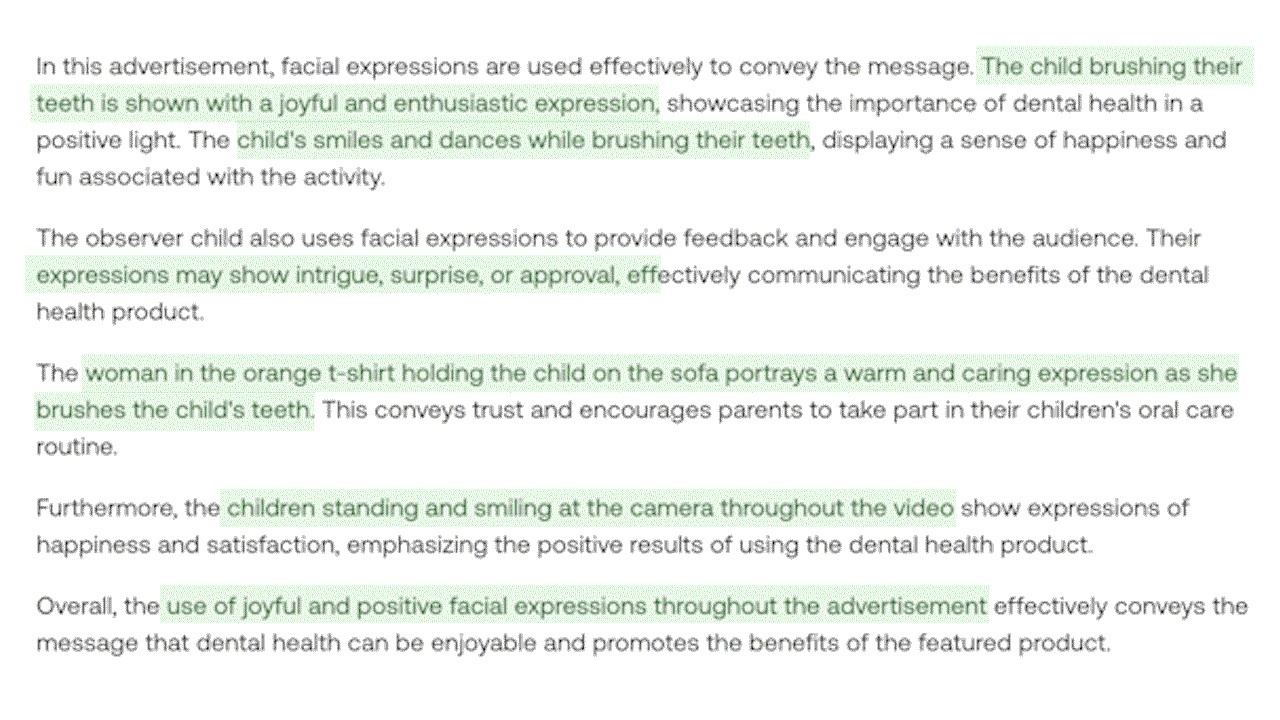
例4: ビデオ内の視覚、音声、発話の手がかりを組み込んだマルチモーダルな理解を実証する。(緑色でハイライト:視覚情報)
Pegasus-1 (80B) モデルの概要
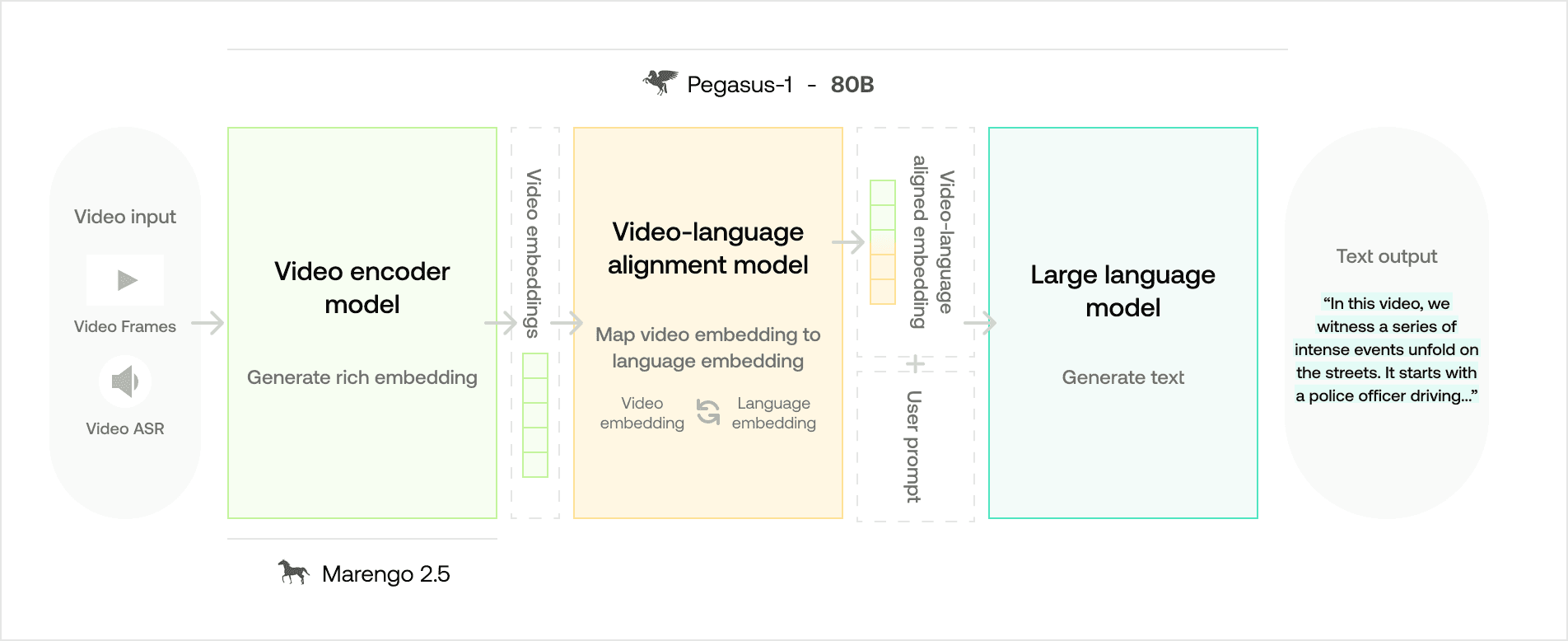
構成モデルの機能と全体的なアーキテクチャ
Pegasus-1モデルは、それぞれビデオネイティブな埋め込み、ビデオと言語がアライメントされた埋め込み、およびテキスト出力を生成するタスクを担う3つの主要コンポーネントを中心に構成されています。
1. ビデオエンコーダモデル - 既存のMarengo埋め込みモデルに由来
入力: ビデオ
出力: ビデオ埋め込み(視覚、音声、スピーチ情報を統合)
機能: ビデオエンコーダの目的は、ビデオから複雑な詳細情報を収集することです。フレームとその時間的関係を評価して関連する視覚情報を取得すると同時に、音声信号とスピーチ情報を処理します。
2. ビデオ言語アライメントモデル
入力: ビデオ埋め込み
出力: ビデオと言語のアライメントが取れた埋め込み
機能: アライメントモデルの主なタスクは、ビデオ埋め込みと言語モデルのドメインを架橋することです。これにより、言語モデルがテキストトークンを理解するのと同じように、ビデオ埋め込みを解釈できるようになります。
3. 大規模言語モデル - デコーダモデル
入力: ビデオと言語のアライメントが取れた埋め込み、ユーザープロンプト
出力: テキスト
機能: その広範なナレッジベースを活用し、言語モデルは入力されたユーザープロンプトに基づいて、アライメントされた埋め込みを解釈します。その後、この情報を一貫性のある人間が読めるテキストにデコードします。
モデルのパラメータと規模
Pegasus-1モデルは、合計で約800億(80B)のパラメータを持っています。Marengo埋め込みモデルのサイズを含む、個々のコンポーネントの詳細なパラメータ構成は現時点では公開されていません。
トレーニングおよび微調整(ファインチューニング)用データセット
ビデオ言語基盤モデルのトレーニングデータ: 3億件以上のビデオ・テキストのペアのコレクションから、10%のサブセットを処理して抽出し、3500万件のビデオ(TL-35Mと表記)と10億件以上の画像で構成されるデータを作成しました。最初のトレーニングランとしてはこれで十分に大きな規模であると考えており、後続のトレーニングはTL-100Mで実施する予定です。私たちの知る限り、これはビデオ言語基盤モデルのトレーニング用として厳選された、世界最大のビデオ・テキストコーパスです。 より広範な研究活動をサポートするため、これより小規模なデータセットのオープンソース化を検討しています。ご興味のある方は、research@twelvelabs.ioまでご連絡ください。
ファインチューニングデータセット: 前述のビデオ言語基盤モデルの指示追従能力を強化するためには、高品質なvideo-to-textファインチューニングデータセットが不可欠です。当社の選択基準は、ドメインの多様性、テキストアノテーションの網羅性と正確性の3つの主要な側面にあります。平均して、当社のデータセットの各ビデオに関連付けられているテキストアノテーションは、同様の長さのビデオを対象とする既存のオープンデータセットのアノテーションの2倍の長さです。さらに、正確性を保証するために、アノテーションは数回にわたる検証と修正プロセスを経ています。このアプローチによりアノテーションの単価は上昇しますが、先行研究(Zhou et al., 2023)で観察された重要性を考慮し、単にデータセットのサイズを大きくするよりも、ファインチューニングデータセットの品質において高い水準を維持することを優先しました。
パフォーマンスに影響を与える要因
予想される通り、モデル全体のパフォーマンスは、各コンポーネントのパフォーマンスと強く相関しています。各構成モデルが全体の品質にどの程度影響しているかは、未だ未解決の課題です。より深い理解を得るために、今後、広範なアブレーション研究(要素別検証)を実施し、その知見を共有する予定です。
ビデオエンコーダモデル: 現在のSearchおよびClassify APIを駆動している当社のMarengo 2.5モデル(2023年3月、1億本以上のビデオ / 10億枚以上の画像)から派生したビデオエンコーダモデルは、ビデオ分類や検索などの埋め込みベースのタスクにおいて最先端の結果を達成しています。ビデオから抽出可能な情報の深さは、本質的にビデオエンコーダモデルによって上限が画定されます。Marengoモデルの詳細については、次回のMarengo 2.6のリリースに伴う今後のレポートで特集される予定です。
ビデオ言語アライメントモデル: このモデルは、基盤モデルのトレーニングおよびインストラクションファインチューニングの過程で、ビデオ言語アライメント能力を獲得します。当社の言語モデルがビデオ埋め込みとどの程度インターフェースできるかは、このアライメントメカニズムによって規定されます。
大規模言語モデル(デコーダモデル): 当社の言語モデルの能力は、トレーニングフェーズで獲得した知識によって枠組みが形成されます。得られるテキスト出力の質は、モデルの知識、ユーザープロンプト、およびビデオ言語がアライメントされた埋め込みを統合する能力によって支配されます。
評価と結果


Twelve Labsは、当社のPegasus-1モデルを含む、高度な技術の責任ある展開を保証することの重要性を認識しています。私たちは、正確さ、詳細さ、文脈の理解、安全性、および有用性を含むきめ細かいカテゴリーにわたって、すべてのモデルをベンチマーク評価する包括的かつ透明性の高いデータセットと評価フレームワークの開発に取り組んでいます。現在、ビデオ言語モデルにおける安全性と有用性に特化した指標を開発中であり、その結果は間もなく共有される予定です。本ブログでお見せするのは暫定的な結果であり、より詳細なレポートは今後リリースされる予定です。評価はPegasus-1のプレビューバージョンに基づいています。
当社の評価コードベースは、こちらでご覧いただけます。
比較モデル
当社のモデルを、3つの異なるモデル(または製品)カテゴリと比較します。
Video-ChatGPT (Maaz et al., 2023): このオープンソースモデルは、チャットインターフェースを備えた現在の最先端(SOTA)ビデオ言語モデルです。このモデルは、ビデオフレームを処理してビデオ内の視覚的イベントをキャプチャします。ただし、ビデオ内の会話情報は利用しません。
Whisper + ChatGPT-3.5 (OpenAI): この組み合わせは、ビデオ要約のために最も広く採用されているアプローチの1つです。最先端の音声テキスト変換技術と大規模言語モデルを活用することで、要約は主にビデオの音声コンテンツから導き出されます。大きな欠点は、ビデオ内の貴重な視覚情報が見落とされることです。
ベンダーAのSummary API: 音声およびビデオ要約生成のために広く採用されているコマーシャル製品です。ベンダーAのSummary APIは、文字起こしデータと言語モデル(ASR+ChatGPT3.5に類似)のみに基づいてビデオサマリーを出力していると見られます。
データセット
MSR-VTTデータセット(Xu et al., 2016): MSR-VTTは、10〜40秒の短いビデオクリップに対する説明文やキャプションを生成するモデルの能力を評価するために広く使用されているビデオ解説データセットです。各ビデオには、人間のアノテーターによって20個の文がアノテーションされています。可能な限り詳細を捉えるため、LLM(ChatGPT)を使用して20個の個別のキャプションを1つの高密度なバリエーション豊かな説明文に結合しています。当社の評価は、1,000件のビデオクリップで構成されるJSFusion Test Splitで実施されています。
Video-ChatGPT Video Descriptionsデータセット(Maaz et al., 2023): Video-to-textの評価では、上記のようなMSR-VTTデータセットをはじめ、主にビデオキャプションデータセットが使用されています。これら短いビデオ説明は基準を提供してくれるものの、現実世界の文脈で多く見られる長尺ビデオ向けのテキスト生成を評価するには不十分です。これを踏まえ、私たちは当社のモデルについて、Video-ChatGPT Video Descriptionデータセットの追加評価を行いました。このデータセットには、ActivityNetの500件のビデオが含まれており、これらすべてに人間が書き下ろした詳細なサマリーがアノテーションされています。従来のキャプションデータセットとは異なり、このデータセット内のビデオは30秒から数分に及び、各ビデオには、視覚要素と音声要素の両方を要約した、5〜8文からなる高密度の要約が含まれています。
指標
ビデオベースの対話モデルのための定量的評価フレームワーク(QEFVC)(Maaz et al., 2023)に従い、情報の正確性、詳細指向性、および文脈の理解という3つの分野でモデルを評価します。これを実施するために、インストラクションチューニングされた言語モデル(例:GPT-4)に対して、参照サマリーを基準とした各評価基準について尋ねます。全体的なパフォーマンスを定量化するため、3つのスコアを平均したものをQEFVC品質スコアとして定義します。
この評価指標は既存のモデルとの比較に便利な手段を提供するものの、いくつかの課題も存在します。言語モデルの評価に関する過去の研究では、モデル予測スコアをGPT-4のみに依存することは、不正確な評価につながりやすいことが指摘されています。また、評価を可能な限り細かく(きめ細かく)行うことで、評価の一貫性と精度が向上することも観察されています(Ye et al., 2023)。これを念頭に置き、FActScore(Min et al., 2023)に着想を得て、ビデオサマリーの品質をより細分化した形で評価する洗練された評価手法VidFactScore(Video Factual Score)を導入します。
それぞれの「ビデオと参照サマリー」のペアについて、参照サマリーを個別の個の事実に分解します。たとえば、「男性と女性が走っている。」という文は、「男性が走っている。」と「女性が走っている。」に分割されます。このセグメンテーションは、適切なプロンプトを与えたGPT-4などのインストラクションチューニングされた言語モデルによって行われます。
モデルが生成したサマリー情報も、同様に分割されます。
理想的な予測サマリーは、(1)参照元の事実の大部分を含んでおり、(2)参照元にない事実の混入を最小限に抑えている必要があります。事実が存在するか省略されているかの判定は、適切なプロンプトを伴うインストラクションチューニング言語モデルを通じて実現されます。
定量的な観点から見ると、(1)は再現率(Recall Rate)に対応し、予測と参照の間で共有される事実の、参照内の全事実に対する割合を算出します。(2)は適合率(Precision)に対応し、予測の全事実に対する共有された事実の割合を算出します。この2つの数値の調和平均であるF1は、モデルの比較のための直接的な指標を提供します。
結果


現在の最先端モデル(VideoChatGPT)との比較では、Pegasus-1は、QEFVC品質スコアで測定した結果、MSR-VTTデータセットで61%の相対的な改善、Video Descriptionデータセットで47%の向上を示しました。ASR+LLMモデル群(Whisper+ChatGPTやベンダーAなどのモデルを含む)に対しては、パフォーマンスの差はさらに広がり、Pegasus-1はMSR-VTTで79%、Video Descriptionデータセットで188%優れたパフォーマンスを発揮しました。


新しく提案されたVidFactScore-F1指標で評価すると、Pegasus-1はVideoChatGPTと比較して、MSR-VTTデータセットで絶対値20%の向上、Video Descriptionsデータセットで14%の向上を示しました。ASR+LLMモデル群を基準とした場合、その差はMSR-VTTデータセットで25%、Video Descriptionsデータセットで33%に上りました。これらの結果は、VidFactScoreが、QEFVCフレームワークに基づく評価と十分に一致し、強い相関関係にあることを一貫して示唆しています。
お笑いのライブ(スタンドアップコメディ)や講義など、主に音声に依存するビデオに関して、非常に興味深い観察が得られました。このようなシナリオであっても、私たちのモデルはASR+LLMモデルを凌駕します。一般的に「こうしたビデオにはASRだけで十分」と思われるかもしれませんが、私たちの調査結果は異なる結果を示しています。私たちは、たとえ最小限の視覚的ヒント(たとえば、「スタンドアップコメディを行っている男性」や「リアクションビデオ(反応動画)」など)であっても、発話データを豊かにし、より正確で網羅的な要約をもたらすことができると仮定しています。 このような結果は、ビデオ comprehending(深い理解)が単なる音声理解を超えるものであるという考えを裏付けています。包括的な理解を達成するには、視覚と音声の双方のモダリティを組み込むことが不可欠であることが浮き彫りになりました。以下の「野生(実環境)の例」セクションの「リアクションビデオ」を参照してください。
実環境の例 (In-the-wild examples)
これらは、既存のアプローチと比較したPegasus-1の能力を説明するために、多様なドメインからランダムに選択されたサンプルの例です。
生成された出力には以下のものが含まれる可能性があることにご注意ください。
ハルシネーション(ビデオに事実として描かれていないにもかかわらず、一貫したストーリーを作り上げてしまうこと)
プロンプトや質問を理解できなかったことによる不適切な回答
偏見(バイアス)
皆様からのフィードバックを歓迎いたします。近い将来にこれらに対処できるよう最善を尽くします。
概要
プロダクト: Twelve Labsは、最新のビデオ言語基盤モデルであるPegasus-1と、新しいVideo-to-Text APIスイート(Gist API、Summary API、Generate API)を発表します。
プロダクトおよび研究哲学: ビデオ理解を画像や音声の理解問題として再構成する多くの既存手法とは異なり、Twelve Labsは「ビデオファースト」戦略を採用し、4つのコア原則(効率的な長尺ビデオ処理、マルチモーダルな理解、ビデオネイティブな埋め込み、ビデオと言語埋め込みの深いアライメント)を掲げています。
新しいモデル: Pegasus-1は約800億(80B)のパラメータを持ち、ビデオエンコーダ、ビデオ言語アライメントモデル、言語デコーダという3つのモデルコンポーネントが共にトレーニングされています。
データセット: Twelve Labsは、厳選された3億件以上の多様なビデオとテキストのペアを収集しました。これは、ビデオ言語基盤モデルのトレーニング用としては世界最大級のビデオ・テキストコーパスです。本技術レポートは、そのうちの10%にあたる3500万件のビデオ・テキストペアと10億件以上の画像・テキストペアからなるサブセットを用いて実施された初期トレーニングランに基づいています。
SOTAビデオ言語モデルとの性能比較: 従来の最先端(SOTA)ビデオ言語モデルと比較して、Pegasus-1は、QEFVC品質スコア(Maaz et al., 2023)で測定した結果、MSR-VTTデータセット(Xu et al., 2016)で61%の相対的な改善、Video Descriptionsデータセット(Maaz et al., 2023)で47%の向上を示しています。当社が提案する評価指標であるVidFactScoreでの評価では、MSR-VTTデータセットで絶対値20%のF1スコア向上、Video Descriptionデータセットで14%の向上を示しました。
ASR+LLMモデルとの性能比較: ASR+LLMは、Video-to-Textタスクに取り組むために広く採用されているアプローチです。Whisper-ChatGPT(OpenAI)および主要な商用ASR+LLM製品と比較して、Pegasus-1はMSR-VTTで79%、Video Descriptionsデータセットで188%優れたパフォーマンスを発揮します。VidFactScore-F1での評価では、MSR-VTTデータセットで絶対値25%の向上、Video Descriptionデータセットで33%の向上を示しています。
Pegasus-1へのAPIアクセス: Pegasusを搭載したVideo-to-Text APIのウェイティングリストのリンクはこちらです。
研究の視野を広げる:ビデオ埋め込みから生成モデルへ
サンフランシスコ・ベイエリアを拠点とするAI研究・プロダクト開発企業であるTwelve Labsは、マルチモーダルなビデオ理解の最前線に立っています。本日、私たちは最新のビデオ言語基盤モデルであるPegasus-1の最先端のビデオ・テキスト生成機能を発表できることを嬉しく思います。これは、さまざまな下流のビデオ理解タスクに合わせてカスタマイズされた包括的なAPIスイートを提供するという、私たちのコミットメントを示すものです。私たちのスイートは、自然言語ベースのビデオモーメント検索から分類、そして今回の最新リリースによるプロンプトベースのビデオ・テキスト生成にまで及びます。
私たちの「ビデオファースト」精神
ビデオデータは、単一のフォーマット内に複数のモダリティを含んでいるため非常に興味深いものです。私たちは、ビデオ理解には、視覚知覚の複雑さと、音声およびテキストの順序的・文脈的なニュアンスを融合させる新しい取り組みが必要であると考えています。優れた画像モデルや言語モデルの台頭に伴い、ビデオ理解の主要なアプローチは、それを画像や音声の理解問題として再構成することでした。一般的なフレームワークでは、ビデオからフレームをサンプリングしてビジョン言語モデルに入力します。
このアプローチは短いビデオには有効かもしれませんが(ほとんどのビジョン言語モデルが1分未満のビデオクリップに焦点を当てているのはそのためです)、現実世界のビデオのほとんどは1分を超え、容易に数時間に及ぶことがあります。このようなビデオに対して単純な「画像ファースト」のアプローチを使用することは、ビデオごとに数万枚の画像を処理することを意味し、結果として、時空間情報の意味論をよくて大まかに捉えているに過ぎない膨大な数の画像・テキスト埋め込みを操作しなければならなくなります。これは、パフォーマンス、レイテンシ、コストの観点から、多くのアプリケーションにおいて不経済です。さらに、主流の設計手法はビデオのマルチモーダルな特性を見落としており、コンテンツを包括的に理解するためには、音声(会話を含む)と視覚要素の両方の共同分析が不可欠です。
ビデオデータの基本的な特性を念頭に置き、Twelve Labsは「ビデオファースト」戦略を採用し、モデル、データ、およびMLシステムをビデオデータの処理と理解のみに焦点を当てて構築しています。 これは、多くのジェネレーティブAIプレイヤーに見られる一般的な「言語/画像ファースト」のアプローチとは対照的です。4つの中心的な原則が当社の「ビデオファースト」精神を支え、ビデオ言語基盤モデルの設計とMLシステムのアーキテクチャの双方を導いています。
効率的な長尺ビデオ処理: 当社のモデルとシステムは、短い10秒のクリップから、数時間に及ぶ膨大なコンテンツまで、多様な長さのビデオを管理できるように最適化されていなければなりません。
マルチモーダルな理解: 当社のモデルは、視覚、音声、およびスピーチ情報を統合できなければなりません。
ビデオネイティブな埋め込み: 空間的な関係に焦点を当てた画像ネイティブな埋め込み(例:CLIP)に依存するのではなく、ビデオの時空間情報を全体的な方法で組み込むことができるビデオネイティブな埋め込みの必要性を信じています。
ビデオネイティブ埋め込みと言語モデルの深いアライメント: 画像とテキストのアライメントを超えて、当社のモデルは、大規模なビデオ・テキストコーパスおよびビデオ・テキスト指示データセットでの広範なトレーニングを通じて、深いビデオ言語アライメントを経なければなりません。
新しいVideo-to-Text機能とインターフェース
デベロッパーは、1回のAPIコールでPegasus-1モデルを促し、ビデオデータから特定のテキスト出力を生成できます。音声からテキストへの変換を利用するか、視覚的なフレームデータのみに依存する既存のソリューションとは異なり、Pegasus-1は視覚、音声、スピーチの情報を統合して、ビデオからより包括的なテキストを生成し、ビデオ要約のベンチマークにおいて新たな最先端のパフォーマンスを達成しています。(下記の「評価と結果」セクションを参照。)
Gist APIとSummary APIにはあらかじめ関連するプロンプトがプリロードされているため、ユーザーがプロンプトを入力しなくても、すぐに使用することができます。Gist APIは、タイトル、トピック、関連ハッシュタグのリストなどの簡潔なテキスト出力を生成できます。Summary APIは、ビデオのサマリー、章、ハイライトを生成するように設計されています。カスタマイズされた出力のために、実験的なGenerate APIを使用すると、ユーザーは箇条書きからレポート、さらにはビデオの内容に基づいたクリエイティブな歌詞に至るまで、特定のフォーマットやスタイルを指定することができます。
例1: Gist APIおよびSummary APIを介してビデオから短いレポートを生成する。
例2: Summary APIにスタイリングプロンプトを渡してビデオサマリーを生成する。
例3: 実験的なGenerate APIによるプロンプト入力で、カスタマイズされたテキスト出力を生成する。
例4: ビデオ内の視覚、音声、発話の手がかりを組み込んだマルチモーダルな理解を実証する。(緑色でハイライト:視覚情報)
Pegasus-1 (80B) モデルの概要
構成モデルの機能と全体的なアーキテクチャ
Pegasus-1モデルは、それぞれビデオネイティブな埋め込み、ビデオと言語がアライメントされた埋め込み、およびテキスト出力を生成するタスクを担う3つの主要コンポーネントを中心に構成されています。
1. ビデオエンコーダモデル - 既存のMarengo埋め込みモデルに由来
入力: ビデオ
出力: ビデオ埋め込み(視覚、音声、スピーチ情報を統合)
機能: ビデオエンコーダの目的は、ビデオから複雑な詳細情報を収集することです。フレームとその時間的関係を評価して関連する視覚情報を取得すると同時に、音声信号とスピーチ情報を処理します。
2. ビデオ言語アライメントモデル
入力: ビデオ埋め込み
出力: ビデオと言語のアライメントが取れた埋め込み
機能: アライメントモデルの主なタスクは、ビデオ埋め込みと言語モデルのドメインを架橋することです。これにより、言語モデルがテキストトークンを理解するのと同じように、ビデオ埋め込みを解釈できるようになります。
3. 大規模言語モデル - デコーダモデル
入力: ビデオと言語のアライメントが取れた埋め込み、ユーザープロンプト
出力: テキスト
機能: その広範なナレッジベースを活用し、言語モデルは入力されたユーザープロンプトに基づいて、アライメントされた埋め込みを解釈します。その後、この情報を一貫性のある人間が読めるテキストにデコードします。
モデルのパラメータと規模
Pegasus-1モデルは、合計で約800億(80B)のパラメータを持っています。Marengo埋め込みモデルのサイズを含む、個々のコンポーネントの詳細なパラメータ構成は現時点では公開されていません。
トレーニングおよび微調整(ファインチューニング)用データセット
ビデオ言語基盤モデルのトレーニングデータ: 3億件以上のビデオ・テキストのペアのコレクションから、10%のサブセットを処理して抽出し、3500万件のビデオ(TL-35Mと表記)と10億件以上の画像で構成されるデータを作成しました。最初のトレーニングランとしてはこれで十分に大きな規模であると考えており、後続のトレーニングはTL-100Mで実施する予定です。私たちの知る限り、これはビデオ言語基盤モデルのトレーニング用として厳選された、世界最大のビデオ・テキストコーパスです。 より広範な研究活動をサポートするため、これより小規模なデータセットのオープンソース化を検討しています。ご興味のある方は、research@twelvelabs.ioまでご連絡ください。
ファインチューニングデータセット: 前述のビデオ言語基盤モデルの指示追従能力を強化するためには、高品質なvideo-to-textファインチューニングデータセットが不可欠です。当社の選択基準は、ドメインの多様性、テキストアノテーションの網羅性と正確性の3つの主要な側面にあります。平均して、当社のデータセットの各ビデオに関連付けられているテキストアノテーションは、同様の長さのビデオを対象とする既存のオープンデータセットのアノテーションの2倍の長さです。さらに、正確性を保証するために、アノテーションは数回にわたる検証と修正プロセスを経ています。このアプローチによりアノテーションの単価は上昇しますが、先行研究(Zhou et al., 2023)で観察された重要性を考慮し、単にデータセットのサイズを大きくするよりも、ファインチューニングデータセットの品質において高い水準を維持することを優先しました。
パフォーマンスに影響を与える要因
予想される通り、モデル全体のパフォーマンスは、各コンポーネントのパフォーマンスと強く相関しています。各構成モデルが全体の品質にどの程度影響しているかは、未だ未解決の課題です。より深い理解を得るために、今後、広範なアブレーション研究(要素別検証)を実施し、その知見を共有する予定です。
ビデオエンコーダモデル: 現在のSearchおよびClassify APIを駆動している当社のMarengo 2.5モデル(2023年3月、1億本以上のビデオ / 10億枚以上の画像)から派生したビデオエンコーダモデルは、ビデオ分類や検索などの埋め込みベースのタスクにおいて最先端の結果を達成しています。ビデオから抽出可能な情報の深さは、本質的にビデオエンコーダモデルによって上限が画定されます。Marengoモデルの詳細については、次回のMarengo 2.6のリリースに伴う今後のレポートで特集される予定です。
ビデオ言語アライメントモデル: このモデルは、基盤モデルのトレーニングおよびインストラクションファインチューニングの過程で、ビデオ言語アライメント能力を獲得します。当社の言語モデルがビデオ埋め込みとどの程度インターフェースできるかは、このアライメントメカニズムによって規定されます。
大規模言語モデル(デコーダモデル): 当社の言語モデルの能力は、トレーニングフェーズで獲得した知識によって枠組みが形成されます。得られるテキスト出力の質は、モデルの知識、ユーザープロンプト、およびビデオ言語がアライメントされた埋め込みを統合する能力によって支配されます。
評価と結果
Twelve Labsは、当社のPegasus-1モデルを含む、高度な技術の責任ある展開を保証することの重要性を認識しています。私たちは、正確さ、詳細さ、文脈の理解、安全性、および有用性を含むきめ細かいカテゴリーにわたって、すべてのモデルをベンチマーク評価する包括的かつ透明性の高いデータセットと評価フレームワークの開発に取り組んでいます。現在、ビデオ言語モデルにおける安全性と有用性に特化した指標を開発中であり、その結果は間もなく共有される予定です。本ブログでお見せするのは暫定的な結果であり、より詳細なレポートは今後リリースされる予定です。評価はPegasus-1のプレビューバージョンに基づいています。
当社の評価コードベースは、こちらでご覧いただけます。
比較モデル
当社のモデルを、3つの異なるモデル(または製品)カテゴリと比較します。
Video-ChatGPT (Maaz et al., 2023): このオープンソースモデルは、チャットインターフェースを備えた現在の最先端(SOTA)ビデオ言語モデルです。このモデルは、ビデオフレームを処理してビデオ内の視覚的イベントをキャプチャします。ただし、ビデオ内の会話情報は利用しません。
Whisper + ChatGPT-3.5 (OpenAI): この組み合わせは、ビデオ要約のために最も広く採用されているアプローチの1つです。最先端の音声テキスト変換技術と大規模言語モデルを活用することで、要約は主にビデオの音声コンテンツから導き出されます。大きな欠点は、ビデオ内の貴重な視覚情報が見落とされることです。
ベンダーAのSummary API: 音声およびビデオ要約生成のために広く採用されているコマーシャル製品です。ベンダーAのSummary APIは、文字起こしデータと言語モデル(ASR+ChatGPT3.5に類似)のみに基づいてビデオサマリーを出力していると見られます。
データセット
MSR-VTTデータセット(Xu et al., 2016): MSR-VTTは、10〜40秒の短いビデオクリップに対する説明文やキャプションを生成するモデルの能力を評価するために広く使用されているビデオ解説データセットです。各ビデオには、人間のアノテーターによって20個の文がアノテーションされています。可能な限り詳細を捉えるため、LLM(ChatGPT)を使用して20個の個別のキャプションを1つの高密度なバリエーション豊かな説明文に結合しています。当社の評価は、1,000件のビデオクリップで構成されるJSFusion Test Splitで実施されています。
Video-ChatGPT Video Descriptionsデータセット(Maaz et al., 2023): Video-to-textの評価では、上記のようなMSR-VTTデータセットをはじめ、主にビデオキャプションデータセットが使用されています。これら短いビデオ説明は基準を提供してくれるものの、現実世界の文脈で多く見られる長尺ビデオ向けのテキスト生成を評価するには不十分です。これを踏まえ、私たちは当社のモデルについて、Video-ChatGPT Video Descriptionデータセットの追加評価を行いました。このデータセットには、ActivityNetの500件のビデオが含まれており、これらすべてに人間が書き下ろした詳細なサマリーがアノテーションされています。従来のキャプションデータセットとは異なり、このデータセット内のビデオは30秒から数分に及び、各ビデオには、視覚要素と音声要素の両方を要約した、5〜8文からなる高密度の要約が含まれています。
指標
ビデオベースの対話モデルのための定量的評価フレームワーク(QEFVC)(Maaz et al., 2023)に従い、情報の正確性、詳細指向性、および文脈の理解という3つの分野でモデルを評価します。これを実施するために、インストラクションチューニングされた言語モデル(例:GPT-4)に対して、参照サマリーを基準とした各評価基準について尋ねます。全体的なパフォーマンスを定量化するため、3つのスコアを平均したものをQEFVC品質スコアとして定義します。
この評価指標は既存のモデルとの比較に便利な手段を提供するものの、いくつかの課題も存在します。言語モデルの評価に関する過去の研究では、モデル予測スコアをGPT-4のみに依存することは、不正確な評価につながりやすいことが指摘されています。また、評価を可能な限り細かく(きめ細かく)行うことで、評価の一貫性と精度が向上することも観察されています(Ye et al., 2023)。これを念頭に置き、FActScore(Min et al., 2023)に着想を得て、ビデオサマリーの品質をより細分化した形で評価する洗練された評価手法VidFactScore(Video Factual Score)を導入します。
それぞれの「ビデオと参照サマリー」のペアについて、参照サマリーを個別の個の事実に分解します。たとえば、「男性と女性が走っている。」という文は、「男性が走っている。」と「女性が走っている。」に分割されます。このセグメンテーションは、適切なプロンプトを与えたGPT-4などのインストラクションチューニングされた言語モデルによって行われます。
モデルが生成したサマリー情報も、同様に分割されます。
理想的な予測サマリーは、(1)参照元の事実の大部分を含んでおり、(2)参照元にない事実の混入を最小限に抑えている必要があります。事実が存在するか省略されているかの判定は、適切なプロンプトを伴うインストラクションチューニング言語モデルを通じて実現されます。
定量的な観点から見ると、(1)は再現率(Recall Rate)に対応し、予測と参照の間で共有される事実の、参照内の全事実に対する割合を算出します。(2)は適合率(Precision)に対応し、予測の全事実に対する共有された事実の割合を算出します。この2つの数値の調和平均であるF1は、モデルの比較のための直接的な指標を提供します。
結果
現在の最先端モデル(VideoChatGPT)との比較では、Pegasus-1は、QEFVC品質スコアで測定した結果、MSR-VTTデータセットで61%の相対的な改善、Video Descriptionデータセットで47%の向上を示しました。ASR+LLMモデル群(Whisper+ChatGPTやベンダーAなどのモデルを含む)に対しては、パフォーマンスの差はさらに広がり、Pegasus-1はMSR-VTTで79%、Video Descriptionデータセットで188%優れたパフォーマンスを発揮しました。
新しく提案されたVidFactScore-F1指標で評価すると、Pegasus-1はVideoChatGPTと比較して、MSR-VTTデータセットで絶対値20%の向上、Video Descriptionsデータセットで14%の向上を示しました。ASR+LLMモデル群を基準とした場合、その差はMSR-VTTデータセットで25%、Video Descriptionsデータセットで33%に上りました。これらの結果は、VidFactScoreが、QEFVCフレームワークに基づく評価と十分に一致し、強い相関関係にあることを一貫して示唆しています。
お笑いのライブ(スタンドアップコメディ)や講義など、主に音声に依存するビデオに関して、非常に興味深い観察が得られました。このようなシナリオであっても、私たちのモデルはASR+LLMモデルを凌駕します。一般的に「こうしたビデオにはASRだけで十分」と思われるかもしれませんが、私たちの調査結果は異なる結果を示しています。私たちは、たとえ最小限の視覚的ヒント(たとえば、「スタンドアップコメディを行っている男性」や「リアクションビデオ(反応動画)」など)であっても、発話データを豊かにし、より正確で網羅的な要約をもたらすことができると仮定しています。 このような結果は、ビデオ comprehending(深い理解)が単なる音声理解を超えるものであるという考えを裏付けています。包括的な理解を達成するには、視覚と音声の双方のモダリティを組み込むことが不可欠であることが浮き彫りになりました。以下の「野生(実環境)の例」セクションの「リアクションビデオ」を参照してください。
実環境の例 (In-the-wild examples)
これらは、既存のアプローチと比較したPegasus-1の能力を説明するために、多様なドメインからランダムに選択されたサンプルの例です。
生成された出力には以下のものが含まれる可能性があることにご注意ください。
ハルシネーション(ビデオに事実として描かれていないにもかかわらず、一貫したストーリーを作り上げてしまうこと)
プロンプトや質問を理解できなかったことによる不適切な回答
偏見(バイアス)
皆様からのフィードバックを歓迎いたします。近い将来にこれらに対処できるよう最善を尽くします。








