" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
チュートリアル
TwelveLabsを使って自動でGDPR準拠のビデオ個人情報マスキングを構築する方法

リシケシュ・ヤダフ
このチュートリアルでは、Twelve Labs上でプロダクション対応のGDPR準拠ビデオ匿名化(モザイク処理)アプリケーションを構築する手順を解説します。エンティティベースの検索を行うMarengo 3.0、タイムスタンプ付きの構造化されたプライバシーメタデータを生成するPegasus 1.5、そして安定した個人特定・追跡モザイク処理のためのローカル顔検出パイプラインを組み合わせます。これにより、レビュー担当者は動画のアップロードから監査対応済みのモザイク処理出力までを単一のインターフェースで完結でき、すべての判断ステップにおける根拠もドキュメント化されます。
このチュートリアルでは、Twelve Labs上でプロダクション対応のGDPR準拠ビデオ匿名化(モザイク処理)アプリケーションを構築する手順を解説します。エンティティベースの検索を行うMarengo 3.0、タイムスタンプ付きの構造化されたプライバシーメタデータを生成するPegasus 1.5、そして安定した個人特定・追跡モザイク処理のためのローカル顔検出パイプラインを組み合わせます。これにより、レビュー担当者は動画のアップロードから監査対応済みのモザイク処理出力までを単一のインターフェースで完結でき、すべての判断ステップにおける根拠もドキュメント化されます。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2026/05/28
13分
記事へのリンクをコピー
イントロダクション
大規模なプライバシーレビューは、単なる編集の問題ではありません。それはインテリジェンス(情報と理解)の問題です。
法的要請が発生し、チームが数時間もの映像から特定の人物の登場箇所をすべて特定し、評価し、マスキング(黒塗り/ぼかし)する必要がある場合、フレームごとの手作業による確認は機能しません。GDPR Enforcement Trackerの記録によると、2026年3月までに2,793件の事例で累計60.6億ユーロ以上の制裁金が科されています。第83条では、最も深刻な違反に対して、最大2,000万ユーロまたは全世界の年間売上高の4%のいずれか高い方の制裁金が依然として認められています。運用のプレッシャーは現実のものであり、手動のワークフローはそれを吸収できるようには作られていません。
GDPRに準拠したマスキングには、3つの要素の連携が必要です。対象となる人物やオブジェクトの正確な特定、コーパス全体からの関連するすべての登場箇所の検索、そして法的な目的に実際に必要な範囲に限定したマスキングです。すべてをただぼかすだけでは、防御可能な戦略とは言えません。規制の「データの最小化」の原則は、全面的な抑制ではなく、正確性を求めています。
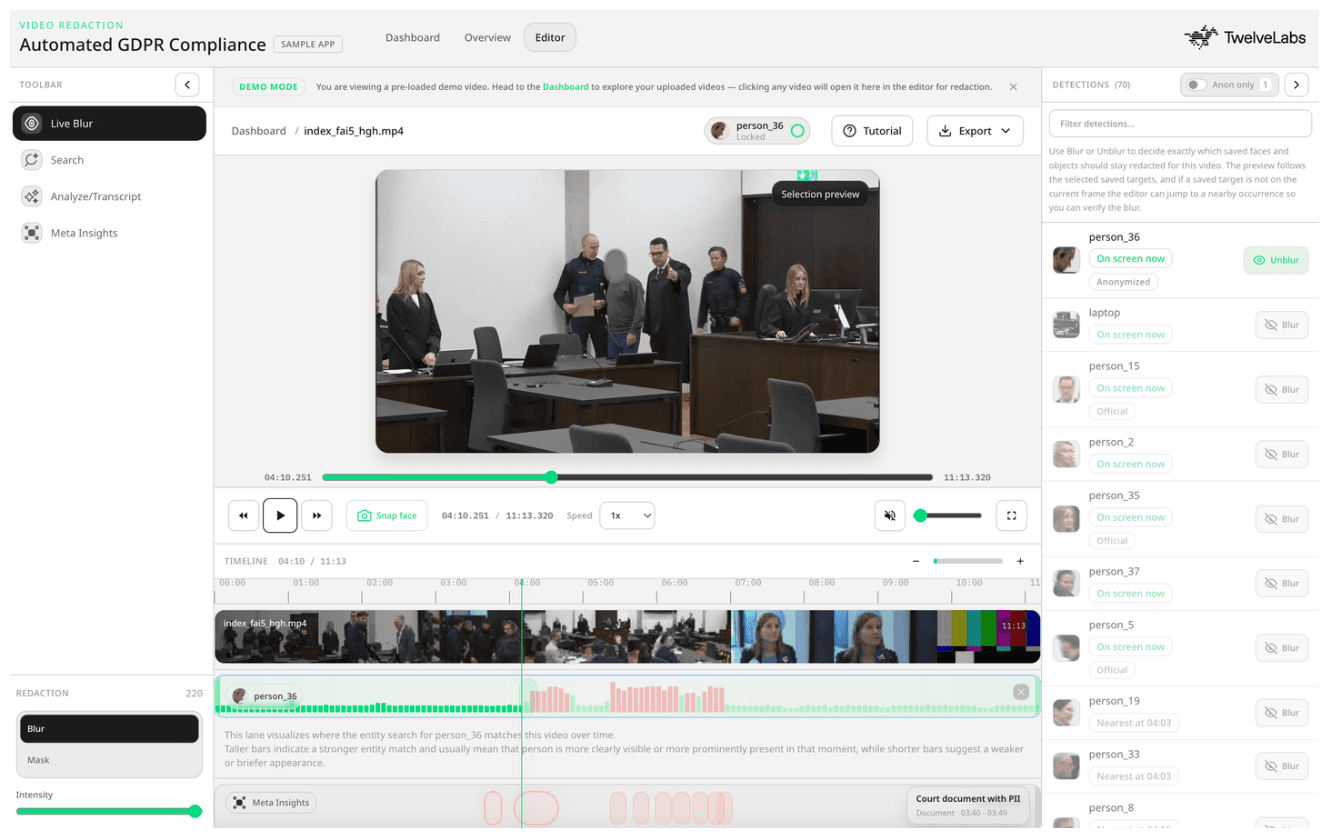
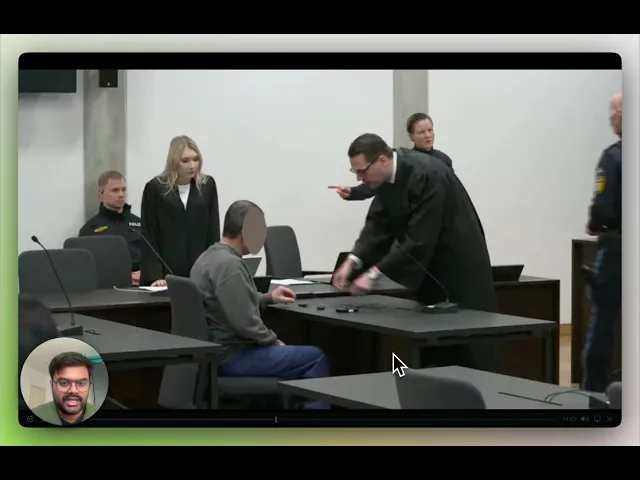
このチュートリアルでは、TwelveLabsをベースに構築された、本番環境対応のGDPRビデオマスキングアプリケーションについて説明します。このアプリケーションは、マルチモーダル検索とエンティティベースの検索にMarengo 3.0を、構造化されたプライバシーメタデータにPegasus 1.5を、そしてフレームレベルのアイデンティティクラスタリングにローカルの顔検出パイプラインを使用しています。その結果、ビデオのアップロードからエクスポート可能なマスキング済み出力までを単一のインターフェースでレビュー担当者が実行できるワークフローが実現します。
デモは tl-gdpr-compliance.vercel.app で体験でき、ソースコードは github.com/Hrishikesh332/tl-GDPR-compliance-redaction で公開されています。
アプリケーションの機能
ほとんどのマスキングツールは手動選択を前提に構築されています。レビュー担当者が映像を視聴し、バウンディングボックスを描き、ぼかし処理されたクリップをエクスポートします。このアプローチは、コーパスが大規模な場合や、人物が複数のクリップにまたがって登場する場合、あるいは法的義務により各マスキングの決定理由を文書化する必要がある場合にはスケールしません。
このアプリケーションは、この問題に対して異なるアプローチをとります。TwelveLabsはワークフロー全体を通じてビデオ理解レイヤーとして機能します。レビュー担当者は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、インデックス化された映像全体を検索できます。Pegasus 1.5は、タイムスタンプ付きのプライバシーメタデータを生成し、レビュー担当者が1フレームも見る前にリスクの高い瞬間を表面化させます。ローカルの顔検出は、検出された顔を安定した個人ごとのアイデンティティにクラスタリングし、エクスポートパイプライン全体で維持します。ぼかしの追跡は、物体の動き、横顔への変化、カメラのカット割りを超えて特定の人物を追跡します。
このワークフローは、映像のアップロードとインデックス登録、自然言語や顔画像を使用した対象の追跡、インタラクティブなタイムライン上でのAI生成プライバシーシステムリスクセグメントのレビュー、個人アイデンティティによるマスキング対象の選択、そして安定した顔固定のマスキングビデオのエクスポートにいたる、レビューサイクル全体をカバーしています。
マスキングパイプラインの内部構造
アプリケーションは、4つの異なる機能を単一のレビューワークフローに接続します。
Marengo 3.0によるマルチモーダル検索により、レビュー担当者はテキストクエリ、画像のアップロード、または登録済みの顔エンティティを使用して、任意の人物、オブジェクト、またはシーンを特定できます。Marengoは関連するクリップセグメントを信頼度スコアとともに返し、インターフェースはこれを最も一致度の高い箇所にレビューマーカーを配置した視覚的なタイムラインレーンとしてレンダリングします。
Pegasus 1.5によるプライバシーメタデータは、プライバシーリスクに焦点を当てたタイムスタンプ付きのセグメントデータを生成します。ビデオ全体の状況を説明するのではなく、顔、文書、ナンバープレート、スクリーン、機密性の高いオブジェクト、保護対象の個人などの特定のカテゴリをターゲットにしたスキーマがPegasusに提供されます。各セグメントには、リスクレベル、マスキング理由、推奨されるアクション、シーン内での役割が含まれます。
ローカル検出とアイデンティティクラスタリングは、Pegasusのタイムスタンプを使用してキーフレームの抽出をガイドします。その後、アプリケーションはローカルの顔検出とInsightFaceエンベディングを実行し、検出された顔をビデオ全体で一貫したIDを持つ安定した個人ごとのアイデンティティにクラスタリングします。
顔固定ぼかしとエクスポートマスキングは、選択された個人の検出履歴をフレームインデックス付きのバウンディングボックスレーンに変換します。エクスポート中、レンダラーは一致する各フレームのそのレーンからぼかしを適用し、安定した、アイデンティティを認識したマスキングビデオを生成します。

環境のセットアップ
構築を開始する前に、以下の前提条件を完了してください。
TwelveLabsアカウントを作成し、APIキーを生成します。Marengo 3.0とPegasus 1.5を有効にしたインデックスを作成し、インデックスIDを記録します。
顔登録とエンティティ検索をサポートするために、TwelveLabsエンティティコレクションを作成します。
Flaskバックエンド用にPython 3を、Reactフロントエンド用にNode.js/npmをインストールします。エクスポート時のビデオ再エンコードにはFFmpegを推奨します。
リポジトリをクローンし、READMEのセットアップ手順に従います。
.env.exampleで定義されている変数を使用して、backend/.envを作成します。
セクション1:TwelveLabsによるエンティティ管理
インデックス化された映像全体から特定の既知の人物を特定するには、単なるテキスト検索以上のものが必要です。顔をTwelveLabsエンティティとして登録すると、再利用可能なアイデンティティ参照が作成され、コンテキストクエリ(ドキュメントの近くにいるこの人物、特定のシーンタイプ内にいる人物、または特定のアクションを行っている人物を見つけるなど)と組み合わせることができます。
これはマスキングの精度にとって重要です。ビデオ内のすべての顔にフラグを立てる代わりに、レビュー担当者は検索を既知のアイデンティティに固定し、その人物が表示されている瞬間のみを抽出できます。
1.1 - エンティティインデックスへの顔アセットの登録
ユーザーが顔画像をアップロードして名前を入力すると、バックエンドはResNet-10顔検出器を使用して顔を検出し、プレビュークロップを生成して、TwelveLabsへの登録用の顔アセットを準備します。
フローには2つのステップがあります。まず顔画像をアセットとしてアップロードし、次に返されたアセットIDを参照する名前付きエンティティを作成します。これにより、視覚的な参照が検索可能なアイデンティティにリンクされます。
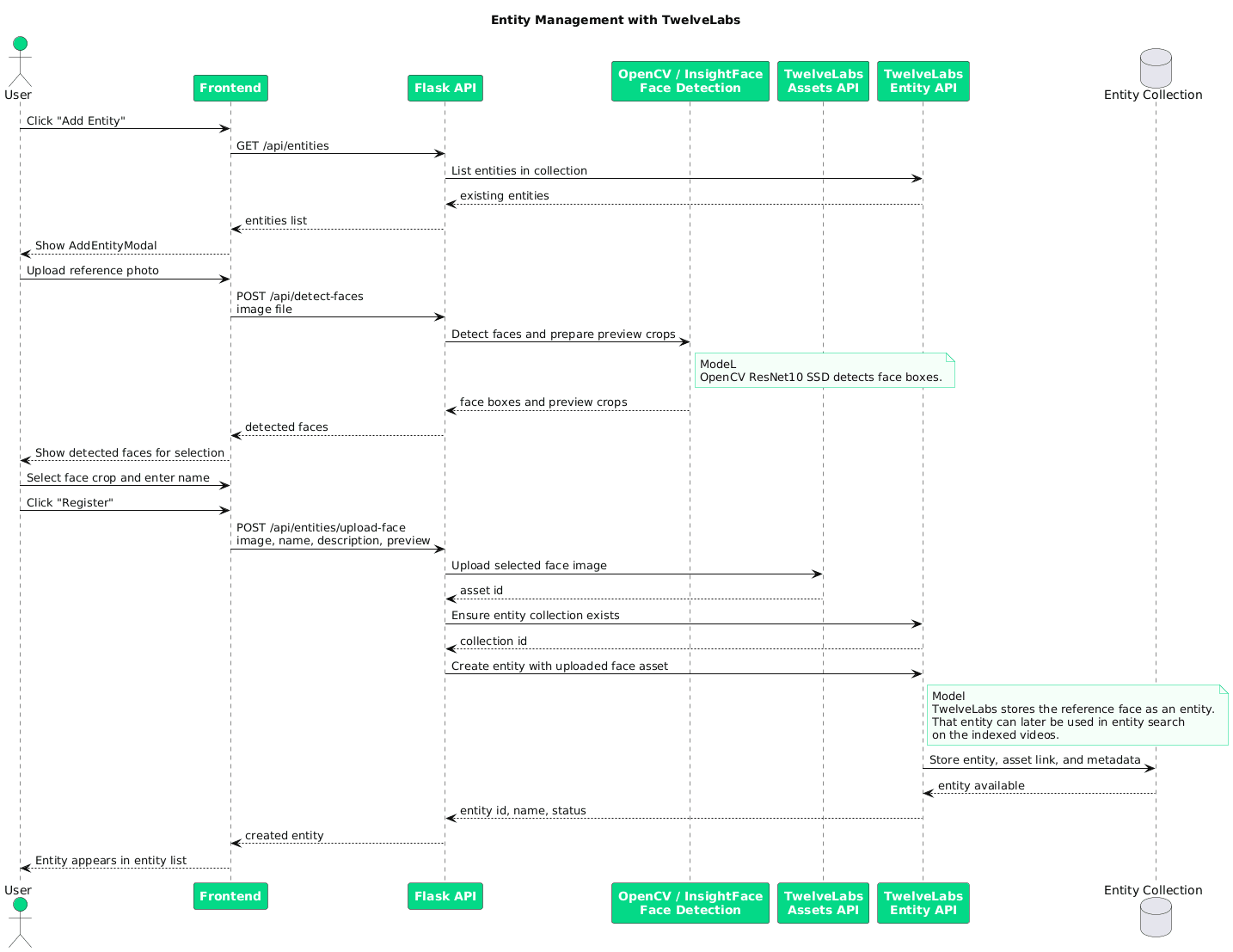
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
登録後、エンティティはコレクション内のインデックス化されたすべてのビデオにわたって、アイデンティティ制約付き検索に使用できるようになります。
1.2 - エンティティとテキストによる検索
検索は、エンティティベース、テキストベース、画像ベースの3つのモードをサポートしています。レビュー担当者は、レビュー開始時に把握している情報量に応じてこれらを組み合わせることができます。
エンティティベースの検索の場合、バックエンドはエンティティIDをTwelveLabsのメンション形式(<@entity_id>)でラップします。ユーザーがテキスト修飾子を追加すると、双方が結合され、検索がアイデンティティとコンテキストの両方によって制限されます。
backend/services/twelvelabs_services (Line 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
画像ベースの検索の場合、バックエンドはquery_media_type="image"として画像を渡し、query_media_fileまたはquery_media_urlのいずれかを指定します。
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 検索タイムラインレーンとレビューマーカー
検索結果は、順位付きリストとしてだけでなく、視覚的なタイムラインレーンとしてもレンダリングされます。各結果セグメントにはstart(開始)とend(終了)の時間があり、フロントエンドはこれをビデオスクラバーにマッピングします。信頼度の高い一致箇所は赤いレビューインジケーターでマークされるため、レビュー担当者は周囲のコンテキストから最も一致度の高い箇所を容易に区別できます。

これにより、検索がレビューワークフローへと変わります。レビュー担当者は検索を行い、タイムラインを検査し、マスキングの決定が必要になる可能性が最も高い瞬間に直接ジャンプできます。
セクション2:検出と顔固定マスキング
検出は、TwelveLabsのビデオ理解をローカルのコンピュータービジョンパイプラインに接続します。すべてのフレームで顔検出を実行するのではなく、Pegasus 1.5が最初に、ビデオ内で人が表示される場所に関する構造化されたメタデータを生成します。バックエンドはこれらのタイムスタンプを使用してキーフレームの抽出をガイドし、検出パスをより高速かつターゲットを絞ったものにします。
検出された顔は、安定した個人ごとのアイデンティティにクラスタリングされます。レビュー担当者は、個々のバウンディングボックスからではなく、それらのアイデンティティから選択します。選択により、エクスポートマスキングに使用される顔固定レーンが駆動されます。
2.1 - TwelveLabsのコンテキストとローカルな顔検出の組み合わせ
パイプラインは、Pegasus構造化分析タスクから始まります。スキーマは2つのセグメントタイプを定義します。face_redaction_target(マスキングが必要になる可能性のある人々用)と scene_segment(より曖昧なシーンのコンテキスト用)です。temperature: 0.1に設定することで、出力を一貫した状態に保ち、自動化されたパイプラインに適したものにします。
backend/services/twelvelabs_services (Line 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasusが人物のメタデータを返すと、アプリケーションはタイムレンジを抽出し、それらのウィンドウからキーフレームをサンプリングします。各キーフレームは detect_faces(..., with_encodings=True) に渡され、InsightFaceを使用して顔を検出し、バウンディングボックスを計算し、鮮明度を評価し、アイデンティティの埋め込みを生成します。
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
各検出データは、埋め込みとともにフレームインデックスとタイムスタンプを保存し、クラスタリングステップで一貫した人物アイデンティティにグループ化できる時間対応のマスキングメタデータを作成します。
2.2 - マスキングターゲットの選択
検出とクラスタリングの後、レビュー担当者は検出された個人のリストから人物のアイデンティティを選択します。その選択は、顔のターゲットとそれらの保存された埋め込みのリストに分解され、エクスポートパイプラインが顔固定追跡のために使用します。
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
リバースマスキング(除くマスキング)は、逆方向で同じアイデンティティ解決を使用します。レビュー担当者が保護したい人を選択すると、エクスポート時に検出された他のすべての顔にぼかしが適用されます。
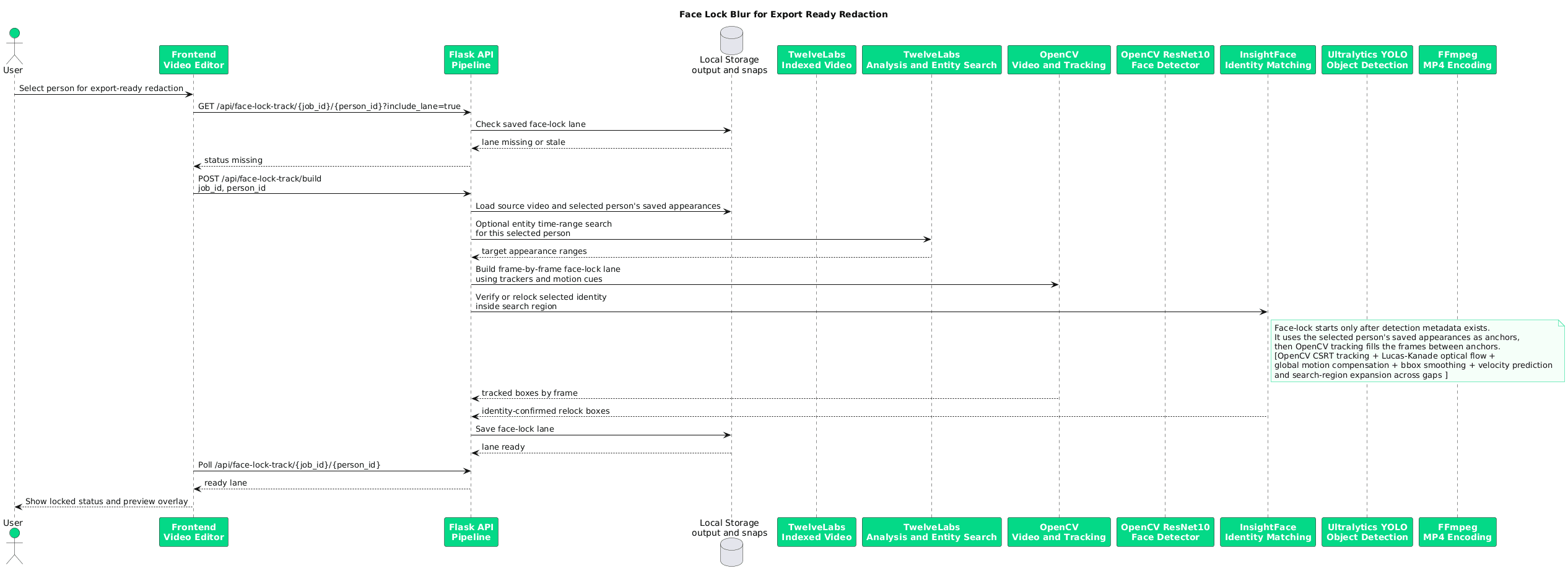
2.3 - 顔固定レーンの構築とマスキングされたエクスポートのレンダリング
選択された各人物アイデンティティについて、パイプラインは build_face_lock_lane(job_id, person_id) を呼び出します。レーンビルダーは、保存されたInsightFaceの外観レコード、TwelveLabsエンティティ検索のタイムレンジ、およびPegasusから保存されたセマンティック人物範囲の3つのソースを利用します。その結果、ビデオ内のそのアイデンティティの全スパンをカバーするレーンドキュメントが作成されます。
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
エクスポート中、レーンはフレームインデックス付きのバウンディングボックスルックアップテーブル(face_lock_bboxes_by_frame)に変換され、YOLOv8-Faceリファインメントでガイドされます。レンダラーはこのテーブルに対して各フレームをチェックし、顔固定バウンディングボックスが登録されている場所にはどこでも apply_detection_redaction を適用します。
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
出力は、フレームごとの手動修正を必要とせずに、動き、部分的なオクルージョン、およびカメラの動きを通じて選択されたアイデンティティを追跡する安定したぼかしです。
セクション3:Pegasus 1.5によるプライバシーメタデータ
Pegasus 1.5はスキーマ駆動型のタイムスタンプベースのメタデータをサポートしています。これは、検出するプライバシーリスクのタイプと、各セグメントに対して返す構造化フィールドを正確に定義できることを意味します。これが、レビューインターフェースの「Meta Insights(メタインサイト)」を動かす仕組みです。
3.1 - プライバシーリスクスキーマの構築
スキーマは、アクション可能なレビューターゲット、すなわち顔、文書、画面、ナンバープレート、機密性の高いテキスト、保護対象の個人にPegasusの出力を集中させる単一のセグメントタイプ privacy_risk_segment を定義します。risk_level、scene_role、redaction_decision、reason などのフィールドは、単にタイムスタンプだけでなく、フラグが立てられた各瞬間の文書化された明確な論拠をレビュー担当者に提供します。
backend/services/pegasus_privacy (Line 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - タイムスタンプ付きプライバシーセグメントの生成
スキーマは analysis_mode: "time_based_metadata" を指定してPegasusに渡されます。これにより、Pegasusは単一のドキュメントの要約ではなく、構造化されたタイムラインとして応答を返すよう指示されます。temperature: 0.1に設定することで出力を決定論的な状態に保ちます。これは、繰り返しの実行において一貫性が求められるコンプライアンスワークフローに非常に重要です。
backend/services/twelvelabs_services (Line 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
バックエンドは情報が空の timeline_events と recommended_actions フィールドを持つ初期ジョブデータを保存し、タスクが完了するまでポーリングします。各Pegasusセグメントは、タイムラインイベント(start_sec、end_sec、severity、category、reason、および redaction_decision)と、次にレビュー担当者が行うべきことを示す推奨アクションの2つのオブジェクトに変換されます。
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - レビューインターフェースとしてのプライバシーメタデータのレンダリング

タイムラインレーンは、各Pegasusイベントを start_sec と end_sec に配置されたクリック可能なホットスポットとしてレンダリングします。ホットスポットをクリックすると、メタインサイトパネルが開き、イベントにフォーカスが当たり、ビデオがそのタイムスタンプにシークされます。
サイドバーには、深刻度、カテゴリ、理由、マスキングの決定、マスキングターゲット、対象の選択、シーンの役割、信頼度、および処理に関するメモなど、完全なイベントメタデータが表示されます。レビュー担当者は、何かが注意を必要とする場所だけでなく、その理由も確認できます。これは、GDPR監査が必要とする文書化された論拠となります。
セクション4:確認のためのオープンエンドなビデオ分析
構造化されたメタデータに加えて、アプリケーションはインデックス付きビデオに対する自由形式のコンテキストの質問をサポートしています。レビュー担当者は、映像全体にどのような機密情報が表示されるか、どの瞬間が最も高いコンプライアンスリスクを伴うか、または特定のタイムスタンプの周囲で何が起こっているかを質問できます。これは、レビュー担当者が探しているものがまだ分かっていない状況で役立ちます。
フロントエンドは、video_id とレビュー担当者のプロンプトを /api/analyze-custom に送信します。バックエンドは、特定の瞬間に言及されるたびにタイムスタンプを要求するフォーマット指示をプロンプトの先頭に追加し、結合されたプロンプトをTwelveLabsのAnalyze(分析)サービスに渡します。
backend/services/twelvelabs_services (Line 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
応答は、ビデオコンテンツに基づいた平易な言葉による分析を返し、タイムスタンプによってレビュー担当者に関連する瞬間に直接リンクします。これにより、「機密情報を見つける必要がある」状態から「見るべき正確な場所はここである」状態へのギャップが埋まります。
このアプローチが可能にすること
歴史的に、ビデオのGDPRコンプライアンスには2つのトレードオフのいずれかが必要でした。遅くて高価な手動レビュープロセスか、法律が必要とする以上のものをマスキングし、その決定理由を明確に説明できない、大雑把な自動化されたアプローチのいずれかです。
このアプリケーションは、異なる道を進みます。Marengo 3.0は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、コーパス全体から適切な瞬間を特定します。Pegasus 1.5は、フラグが立てられた各セグメントについて、文書化された明確な論拠を持つ構造化された、タイムスタンプ付きのプライバシーメタデータを生成します。ローカルの顔検出は、AIに基づいたキーフレームからアイデンティティをクラスタリングします。顔固定レーンは、エクスポート全体で安定したぼかしトラックを維持します。
その結果、マスキングワークフローが、網羅的ではなくピンポイントなものになり、不透明ではなく文書化され、そして手動ではなくスケーラブルなものになります。すべての決定基準点にはレビュー可能な記録があり、これこそが真のコンプライアンスにおいて実際に求められているものです。
参考情報
イントロダクション
大規模なプライバシーレビューは、単なる編集の問題ではありません。それはインテリジェンス(情報と理解)の問題です。
法的要請が発生し、チームが数時間もの映像から特定の人物の登場箇所をすべて特定し、評価し、マスキング(黒塗り/ぼかし)する必要がある場合、フレームごとの手作業による確認は機能しません。GDPR Enforcement Trackerの記録によると、2026年3月までに2,793件の事例で累計60.6億ユーロ以上の制裁金が科されています。第83条では、最も深刻な違反に対して、最大2,000万ユーロまたは全世界の年間売上高の4%のいずれか高い方の制裁金が依然として認められています。運用のプレッシャーは現実のものであり、手動のワークフローはそれを吸収できるようには作られていません。
GDPRに準拠したマスキングには、3つの要素の連携が必要です。対象となる人物やオブジェクトの正確な特定、コーパス全体からの関連するすべての登場箇所の検索、そして法的な目的に実際に必要な範囲に限定したマスキングです。すべてをただぼかすだけでは、防御可能な戦略とは言えません。規制の「データの最小化」の原則は、全面的な抑制ではなく、正確性を求めています。
このチュートリアルでは、TwelveLabsをベースに構築された、本番環境対応のGDPRビデオマスキングアプリケーションについて説明します。このアプリケーションは、マルチモーダル検索とエンティティベースの検索にMarengo 3.0を、構造化されたプライバシーメタデータにPegasus 1.5を、そしてフレームレベルのアイデンティティクラスタリングにローカルの顔検出パイプラインを使用しています。その結果、ビデオのアップロードからエクスポート可能なマスキング済み出力までを単一のインターフェースでレビュー担当者が実行できるワークフローが実現します。
デモは tl-gdpr-compliance.vercel.app で体験でき、ソースコードは github.com/Hrishikesh332/tl-GDPR-compliance-redaction で公開されています。
アプリケーションの機能
ほとんどのマスキングツールは手動選択を前提に構築されています。レビュー担当者が映像を視聴し、バウンディングボックスを描き、ぼかし処理されたクリップをエクスポートします。このアプローチは、コーパスが大規模な場合や、人物が複数のクリップにまたがって登場する場合、あるいは法的義務により各マスキングの決定理由を文書化する必要がある場合にはスケールしません。
このアプリケーションは、この問題に対して異なるアプローチをとります。TwelveLabsはワークフロー全体を通じてビデオ理解レイヤーとして機能します。レビュー担当者は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、インデックス化された映像全体を検索できます。Pegasus 1.5は、タイムスタンプ付きのプライバシーメタデータを生成し、レビュー担当者が1フレームも見る前にリスクの高い瞬間を表面化させます。ローカルの顔検出は、検出された顔を安定した個人ごとのアイデンティティにクラスタリングし、エクスポートパイプライン全体で維持します。ぼかしの追跡は、物体の動き、横顔への変化、カメラのカット割りを超えて特定の人物を追跡します。
このワークフローは、映像のアップロードとインデックス登録、自然言語や顔画像を使用した対象の追跡、インタラクティブなタイムライン上でのAI生成プライバシーシステムリスクセグメントのレビュー、個人アイデンティティによるマスキング対象の選択、そして安定した顔固定のマスキングビデオのエクスポートにいたる、レビューサイクル全体をカバーしています。
マスキングパイプラインの内部構造
アプリケーションは、4つの異なる機能を単一のレビューワークフローに接続します。
Marengo 3.0によるマルチモーダル検索により、レビュー担当者はテキストクエリ、画像のアップロード、または登録済みの顔エンティティを使用して、任意の人物、オブジェクト、またはシーンを特定できます。Marengoは関連するクリップセグメントを信頼度スコアとともに返し、インターフェースはこれを最も一致度の高い箇所にレビューマーカーを配置した視覚的なタイムラインレーンとしてレンダリングします。
Pegasus 1.5によるプライバシーメタデータは、プライバシーリスクに焦点を当てたタイムスタンプ付きのセグメントデータを生成します。ビデオ全体の状況を説明するのではなく、顔、文書、ナンバープレート、スクリーン、機密性の高いオブジェクト、保護対象の個人などの特定のカテゴリをターゲットにしたスキーマがPegasusに提供されます。各セグメントには、リスクレベル、マスキング理由、推奨されるアクション、シーン内での役割が含まれます。
ローカル検出とアイデンティティクラスタリングは、Pegasusのタイムスタンプを使用してキーフレームの抽出をガイドします。その後、アプリケーションはローカルの顔検出とInsightFaceエンベディングを実行し、検出された顔をビデオ全体で一貫したIDを持つ安定した個人ごとのアイデンティティにクラスタリングします。
顔固定ぼかしとエクスポートマスキングは、選択された個人の検出履歴をフレームインデックス付きのバウンディングボックスレーンに変換します。エクスポート中、レンダラーは一致する各フレームのそのレーンからぼかしを適用し、安定した、アイデンティティを認識したマスキングビデオを生成します。
環境のセットアップ
構築を開始する前に、以下の前提条件を完了してください。
TwelveLabsアカウントを作成し、APIキーを生成します。Marengo 3.0とPegasus 1.5を有効にしたインデックスを作成し、インデックスIDを記録します。
顔登録とエンティティ検索をサポートするために、TwelveLabsエンティティコレクションを作成します。
Flaskバックエンド用にPython 3を、Reactフロントエンド用にNode.js/npmをインストールします。エクスポート時のビデオ再エンコードにはFFmpegを推奨します。
リポジトリをクローンし、READMEのセットアップ手順に従います。
.env.exampleで定義されている変数を使用して、backend/.envを作成します。
セクション1:TwelveLabsによるエンティティ管理
インデックス化された映像全体から特定の既知の人物を特定するには、単なるテキスト検索以上のものが必要です。顔をTwelveLabsエンティティとして登録すると、再利用可能なアイデンティティ参照が作成され、コンテキストクエリ(ドキュメントの近くにいるこの人物、特定のシーンタイプ内にいる人物、または特定のアクションを行っている人物を見つけるなど)と組み合わせることができます。
これはマスキングの精度にとって重要です。ビデオ内のすべての顔にフラグを立てる代わりに、レビュー担当者は検索を既知のアイデンティティに固定し、その人物が表示されている瞬間のみを抽出できます。
1.1 - エンティティインデックスへの顔アセットの登録
ユーザーが顔画像をアップロードして名前を入力すると、バックエンドはResNet-10顔検出器を使用して顔を検出し、プレビュークロップを生成して、TwelveLabsへの登録用の顔アセットを準備します。
フローには2つのステップがあります。まず顔画像をアセットとしてアップロードし、次に返されたアセットIDを参照する名前付きエンティティを作成します。これにより、視覚的な参照が検索可能なアイデンティティにリンクされます。
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
登録後、エンティティはコレクション内のインデックス化されたすべてのビデオにわたって、アイデンティティ制約付き検索に使用できるようになります。
1.2 - エンティティとテキストによる検索
検索は、エンティティベース、テキストベース、画像ベースの3つのモードをサポートしています。レビュー担当者は、レビュー開始時に把握している情報量に応じてこれらを組み合わせることができます。
エンティティベースの検索の場合、バックエンドはエンティティIDをTwelveLabsのメンション形式(<@entity_id>)でラップします。ユーザーがテキスト修飾子を追加すると、双方が結合され、検索がアイデンティティとコンテキストの両方によって制限されます。
backend/services/twelvelabs_services (Line 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
画像ベースの検索の場合、バックエンドはquery_media_type="image"として画像を渡し、query_media_fileまたはquery_media_urlのいずれかを指定します。
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 検索タイムラインレーンとレビューマーカー
検索結果は、順位付きリストとしてだけでなく、視覚的なタイムラインレーンとしてもレンダリングされます。各結果セグメントにはstart(開始)とend(終了)の時間があり、フロントエンドはこれをビデオスクラバーにマッピングします。信頼度の高い一致箇所は赤いレビューインジケーターでマークされるため、レビュー担当者は周囲のコンテキストから最も一致度の高い箇所を容易に区別できます。
これにより、検索がレビューワークフローへと変わります。レビュー担当者は検索を行い、タイムラインを検査し、マスキングの決定が必要になる可能性が最も高い瞬間に直接ジャンプできます。
セクション2:検出と顔固定マスキング
検出は、TwelveLabsのビデオ理解をローカルのコンピュータービジョンパイプラインに接続します。すべてのフレームで顔検出を実行するのではなく、Pegasus 1.5が最初に、ビデオ内で人が表示される場所に関する構造化されたメタデータを生成します。バックエンドはこれらのタイムスタンプを使用してキーフレームの抽出をガイドし、検出パスをより高速かつターゲットを絞ったものにします。
検出された顔は、安定した個人ごとのアイデンティティにクラスタリングされます。レビュー担当者は、個々のバウンディングボックスからではなく、それらのアイデンティティから選択します。選択により、エクスポートマスキングに使用される顔固定レーンが駆動されます。
2.1 - TwelveLabsのコンテキストとローカルな顔検出の組み合わせ
パイプラインは、Pegasus構造化分析タスクから始まります。スキーマは2つのセグメントタイプを定義します。face_redaction_target(マスキングが必要になる可能性のある人々用)と scene_segment(より曖昧なシーンのコンテキスト用)です。temperature: 0.1に設定することで、出力を一貫した状態に保ち、自動化されたパイプラインに適したものにします。
backend/services/twelvelabs_services (Line 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasusが人物のメタデータを返すと、アプリケーションはタイムレンジを抽出し、それらのウィンドウからキーフレームをサンプリングします。各キーフレームは detect_faces(..., with_encodings=True) に渡され、InsightFaceを使用して顔を検出し、バウンディングボックスを計算し、鮮明度を評価し、アイデンティティの埋め込みを生成します。
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
各検出データは、埋め込みとともにフレームインデックスとタイムスタンプを保存し、クラスタリングステップで一貫した人物アイデンティティにグループ化できる時間対応のマスキングメタデータを作成します。
2.2 - マスキングターゲットの選択
検出とクラスタリングの後、レビュー担当者は検出された個人のリストから人物のアイデンティティを選択します。その選択は、顔のターゲットとそれらの保存された埋め込みのリストに分解され、エクスポートパイプラインが顔固定追跡のために使用します。
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
リバースマスキング(除くマスキング)は、逆方向で同じアイデンティティ解決を使用します。レビュー担当者が保護したい人を選択すると、エクスポート時に検出された他のすべての顔にぼかしが適用されます。
2.3 - 顔固定レーンの構築とマスキングされたエクスポートのレンダリング
選択された各人物アイデンティティについて、パイプラインは build_face_lock_lane(job_id, person_id) を呼び出します。レーンビルダーは、保存されたInsightFaceの外観レコード、TwelveLabsエンティティ検索のタイムレンジ、およびPegasusから保存されたセマンティック人物範囲の3つのソースを利用します。その結果、ビデオ内のそのアイデンティティの全スパンをカバーするレーンドキュメントが作成されます。
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
エクスポート中、レーンはフレームインデックス付きのバウンディングボックスルックアップテーブル(face_lock_bboxes_by_frame)に変換され、YOLOv8-Faceリファインメントでガイドされます。レンダラーはこのテーブルに対して各フレームをチェックし、顔固定バウンディングボックスが登録されている場所にはどこでも apply_detection_redaction を適用します。
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
出力は、フレームごとの手動修正を必要とせずに、動き、部分的なオクルージョン、およびカメラの動きを通じて選択されたアイデンティティを追跡する安定したぼかしです。
セクション3:Pegasus 1.5によるプライバシーメタデータ
Pegasus 1.5はスキーマ駆動型のタイムスタンプベースのメタデータをサポートしています。これは、検出するプライバシーリスクのタイプと、各セグメントに対して返す構造化フィールドを正確に定義できることを意味します。これが、レビューインターフェースの「Meta Insights(メタインサイト)」を動かす仕組みです。
3.1 - プライバシーリスクスキーマの構築
スキーマは、アクション可能なレビューターゲット、すなわち顔、文書、画面、ナンバープレート、機密性の高いテキスト、保護対象の個人にPegasusの出力を集中させる単一のセグメントタイプ privacy_risk_segment を定義します。risk_level、scene_role、redaction_decision、reason などのフィールドは、単にタイムスタンプだけでなく、フラグが立てられた各瞬間の文書化された明確な論拠をレビュー担当者に提供します。
backend/services/pegasus_privacy (Line 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - タイムスタンプ付きプライバシーセグメントの生成
スキーマは analysis_mode: "time_based_metadata" を指定してPegasusに渡されます。これにより、Pegasusは単一のドキュメントの要約ではなく、構造化されたタイムラインとして応答を返すよう指示されます。temperature: 0.1に設定することで出力を決定論的な状態に保ちます。これは、繰り返しの実行において一貫性が求められるコンプライアンスワークフローに非常に重要です。
backend/services/twelvelabs_services (Line 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
バックエンドは情報が空の timeline_events と recommended_actions フィールドを持つ初期ジョブデータを保存し、タスクが完了するまでポーリングします。各Pegasusセグメントは、タイムラインイベント(start_sec、end_sec、severity、category、reason、および redaction_decision)と、次にレビュー担当者が行うべきことを示す推奨アクションの2つのオブジェクトに変換されます。
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - レビューインターフェースとしてのプライバシーメタデータのレンダリング
タイムラインレーンは、各Pegasusイベントを start_sec と end_sec に配置されたクリック可能なホットスポットとしてレンダリングします。ホットスポットをクリックすると、メタインサイトパネルが開き、イベントにフォーカスが当たり、ビデオがそのタイムスタンプにシークされます。
サイドバーには、深刻度、カテゴリ、理由、マスキングの決定、マスキングターゲット、対象の選択、シーンの役割、信頼度、および処理に関するメモなど、完全なイベントメタデータが表示されます。レビュー担当者は、何かが注意を必要とする場所だけでなく、その理由も確認できます。これは、GDPR監査が必要とする文書化された論拠となります。
セクション4:確認のためのオープンエンドなビデオ分析
構造化されたメタデータに加えて、アプリケーションはインデックス付きビデオに対する自由形式のコンテキストの質問をサポートしています。レビュー担当者は、映像全体にどのような機密情報が表示されるか、どの瞬間が最も高いコンプライアンスリスクを伴うか、または特定のタイムスタンプの周囲で何が起こっているかを質問できます。これは、レビュー担当者が探しているものがまだ分かっていない状況で役立ちます。
フロントエンドは、video_id とレビュー担当者のプロンプトを /api/analyze-custom に送信します。バックエンドは、特定の瞬間に言及されるたびにタイムスタンプを要求するフォーマット指示をプロンプトの先頭に追加し、結合されたプロンプトをTwelveLabsのAnalyze(分析)サービスに渡します。
backend/services/twelvelabs_services (Line 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
応答は、ビデオコンテンツに基づいた平易な言葉による分析を返し、タイムスタンプによってレビュー担当者に関連する瞬間に直接リンクします。これにより、「機密情報を見つける必要がある」状態から「見るべき正確な場所はここである」状態へのギャップが埋まります。
このアプローチが可能にすること
歴史的に、ビデオのGDPRコンプライアンスには2つのトレードオフのいずれかが必要でした。遅くて高価な手動レビュープロセスか、法律が必要とする以上のものをマスキングし、その決定理由を明確に説明できない、大雑把な自動化されたアプローチのいずれかです。
このアプリケーションは、異なる道を進みます。Marengo 3.0は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、コーパス全体から適切な瞬間を特定します。Pegasus 1.5は、フラグが立てられた各セグメントについて、文書化された明確な論拠を持つ構造化された、タイムスタンプ付きのプライバシーメタデータを生成します。ローカルの顔検出は、AIに基づいたキーフレームからアイデンティティをクラスタリングします。顔固定レーンは、エクスポート全体で安定したぼかしトラックを維持します。
その結果、マスキングワークフローが、網羅的ではなくピンポイントなものになり、不透明ではなく文書化され、そして手動ではなくスケーラブルなものになります。すべての決定基準点にはレビュー可能な記録があり、これこそが真のコンプライアンスにおいて実際に求められているものです。
参考情報
イントロダクション
大規模なプライバシーレビューは、単なる編集の問題ではありません。それはインテリジェンス(情報と理解)の問題です。
法的要請が発生し、チームが数時間もの映像から特定の人物の登場箇所をすべて特定し、評価し、マスキング(黒塗り/ぼかし)する必要がある場合、フレームごとの手作業による確認は機能しません。GDPR Enforcement Trackerの記録によると、2026年3月までに2,793件の事例で累計60.6億ユーロ以上の制裁金が科されています。第83条では、最も深刻な違反に対して、最大2,000万ユーロまたは全世界の年間売上高の4%のいずれか高い方の制裁金が依然として認められています。運用のプレッシャーは現実のものであり、手動のワークフローはそれを吸収できるようには作られていません。
GDPRに準拠したマスキングには、3つの要素の連携が必要です。対象となる人物やオブジェクトの正確な特定、コーパス全体からの関連するすべての登場箇所の検索、そして法的な目的に実際に必要な範囲に限定したマスキングです。すべてをただぼかすだけでは、防御可能な戦略とは言えません。規制の「データの最小化」の原則は、全面的な抑制ではなく、正確性を求めています。
このチュートリアルでは、TwelveLabsをベースに構築された、本番環境対応のGDPRビデオマスキングアプリケーションについて説明します。このアプリケーションは、マルチモーダル検索とエンティティベースの検索にMarengo 3.0を、構造化されたプライバシーメタデータにPegasus 1.5を、そしてフレームレベルのアイデンティティクラスタリングにローカルの顔検出パイプラインを使用しています。その結果、ビデオのアップロードからエクスポート可能なマスキング済み出力までを単一のインターフェースでレビュー担当者が実行できるワークフローが実現します。
デモは tl-gdpr-compliance.vercel.app で体験でき、ソースコードは github.com/Hrishikesh332/tl-GDPR-compliance-redaction で公開されています。
アプリケーションの機能
ほとんどのマスキングツールは手動選択を前提に構築されています。レビュー担当者が映像を視聴し、バウンディングボックスを描き、ぼかし処理されたクリップをエクスポートします。このアプローチは、コーパスが大規模な場合や、人物が複数のクリップにまたがって登場する場合、あるいは法的義務により各マスキングの決定理由を文書化する必要がある場合にはスケールしません。
このアプリケーションは、この問題に対して異なるアプローチをとります。TwelveLabsはワークフロー全体を通じてビデオ理解レイヤーとして機能します。レビュー担当者は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、インデックス化された映像全体を検索できます。Pegasus 1.5は、タイムスタンプ付きのプライバシーメタデータを生成し、レビュー担当者が1フレームも見る前にリスクの高い瞬間を表面化させます。ローカルの顔検出は、検出された顔を安定した個人ごとのアイデンティティにクラスタリングし、エクスポートパイプライン全体で維持します。ぼかしの追跡は、物体の動き、横顔への変化、カメラのカット割りを超えて特定の人物を追跡します。
このワークフローは、映像のアップロードとインデックス登録、自然言語や顔画像を使用した対象の追跡、インタラクティブなタイムライン上でのAI生成プライバシーシステムリスクセグメントのレビュー、個人アイデンティティによるマスキング対象の選択、そして安定した顔固定のマスキングビデオのエクスポートにいたる、レビューサイクル全体をカバーしています。
マスキングパイプラインの内部構造
アプリケーションは、4つの異なる機能を単一のレビューワークフローに接続します。
Marengo 3.0によるマルチモーダル検索により、レビュー担当者はテキストクエリ、画像のアップロード、または登録済みの顔エンティティを使用して、任意の人物、オブジェクト、またはシーンを特定できます。Marengoは関連するクリップセグメントを信頼度スコアとともに返し、インターフェースはこれを最も一致度の高い箇所にレビューマーカーを配置した視覚的なタイムラインレーンとしてレンダリングします。
Pegasus 1.5によるプライバシーメタデータは、プライバシーリスクに焦点を当てたタイムスタンプ付きのセグメントデータを生成します。ビデオ全体の状況を説明するのではなく、顔、文書、ナンバープレート、スクリーン、機密性の高いオブジェクト、保護対象の個人などの特定のカテゴリをターゲットにしたスキーマがPegasusに提供されます。各セグメントには、リスクレベル、マスキング理由、推奨されるアクション、シーン内での役割が含まれます。
ローカル検出とアイデンティティクラスタリングは、Pegasusのタイムスタンプを使用してキーフレームの抽出をガイドします。その後、アプリケーションはローカルの顔検出とInsightFaceエンベディングを実行し、検出された顔をビデオ全体で一貫したIDを持つ安定した個人ごとのアイデンティティにクラスタリングします。
顔固定ぼかしとエクスポートマスキングは、選択された個人の検出履歴をフレームインデックス付きのバウンディングボックスレーンに変換します。エクスポート中、レンダラーは一致する各フレームのそのレーンからぼかしを適用し、安定した、アイデンティティを認識したマスキングビデオを生成します。
環境のセットアップ
構築を開始する前に、以下の前提条件を完了してください。
TwelveLabsアカウントを作成し、APIキーを生成します。Marengo 3.0とPegasus 1.5を有効にしたインデックスを作成し、インデックスIDを記録します。
顔登録とエンティティ検索をサポートするために、TwelveLabsエンティティコレクションを作成します。
Flaskバックエンド用にPython 3を、Reactフロントエンド用にNode.js/npmをインストールします。エクスポート時のビデオ再エンコードにはFFmpegを推奨します。
リポジトリをクローンし、READMEのセットアップ手順に従います。
.env.exampleで定義されている変数を使用して、backend/.envを作成します。
セクション1:TwelveLabsによるエンティティ管理
インデックス化された映像全体から特定の既知の人物を特定するには、単なるテキスト検索以上のものが必要です。顔をTwelveLabsエンティティとして登録すると、再利用可能なアイデンティティ参照が作成され、コンテキストクエリ(ドキュメントの近くにいるこの人物、特定のシーンタイプ内にいる人物、または特定のアクションを行っている人物を見つけるなど)と組み合わせることができます。
これはマスキングの精度にとって重要です。ビデオ内のすべての顔にフラグを立てる代わりに、レビュー担当者は検索を既知のアイデンティティに固定し、その人物が表示されている瞬間のみを抽出できます。
1.1 - エンティティインデックスへの顔アセットの登録
ユーザーが顔画像をアップロードして名前を入力すると、バックエンドはResNet-10顔検出器を使用して顔を検出し、プレビュークロップを生成して、TwelveLabsへの登録用の顔アセットを準備します。
フローには2つのステップがあります。まず顔画像をアセットとしてアップロードし、次に返されたアセットIDを参照する名前付きエンティティを作成します。これにより、視覚的な参照が検索可能なアイデンティティにリンクされます。
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
登録後、エンティティはコレクション内のインデックス化されたすべてのビデオにわたって、アイデンティティ制約付き検索に使用できるようになります。
1.2 - エンティティとテキストによる検索
検索は、エンティティベース、テキストベース、画像ベースの3つのモードをサポートしています。レビュー担当者は、レビュー開始時に把握している情報量に応じてこれらを組み合わせることができます。
エンティティベースの検索の場合、バックエンドはエンティティIDをTwelveLabsのメンション形式(<@entity_id>)でラップします。ユーザーがテキスト修飾子を追加すると、双方が結合され、検索がアイデンティティとコンテキストの両方によって制限されます。
backend/services/twelvelabs_services (Line 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
画像ベースの検索の場合、バックエンドはquery_media_type="image"として画像を渡し、query_media_fileまたはquery_media_urlのいずれかを指定します。
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 検索タイムラインレーンとレビューマーカー
検索結果は、順位付きリストとしてだけでなく、視覚的なタイムラインレーンとしてもレンダリングされます。各結果セグメントにはstart(開始)とend(終了)の時間があり、フロントエンドはこれをビデオスクラバーにマッピングします。信頼度の高い一致箇所は赤いレビューインジケーターでマークされるため、レビュー担当者は周囲のコンテキストから最も一致度の高い箇所を容易に区別できます。
これにより、検索がレビューワークフローへと変わります。レビュー担当者は検索を行い、タイムラインを検査し、マスキングの決定が必要になる可能性が最も高い瞬間に直接ジャンプできます。
セクション2:検出と顔固定マスキング
検出は、TwelveLabsのビデオ理解をローカルのコンピュータービジョンパイプラインに接続します。すべてのフレームで顔検出を実行するのではなく、Pegasus 1.5が最初に、ビデオ内で人が表示される場所に関する構造化されたメタデータを生成します。バックエンドはこれらのタイムスタンプを使用してキーフレームの抽出をガイドし、検出パスをより高速かつターゲットを絞ったものにします。
検出された顔は、安定した個人ごとのアイデンティティにクラスタリングされます。レビュー担当者は、個々のバウンディングボックスからではなく、それらのアイデンティティから選択します。選択により、エクスポートマスキングに使用される顔固定レーンが駆動されます。
2.1 - TwelveLabsのコンテキストとローカルな顔検出の組み合わせ
パイプラインは、Pegasus構造化分析タスクから始まります。スキーマは2つのセグメントタイプを定義します。face_redaction_target(マスキングが必要になる可能性のある人々用)と scene_segment(より曖昧なシーンのコンテキスト用)です。temperature: 0.1に設定することで、出力を一貫した状態に保ち、自動化されたパイプラインに適したものにします。
backend/services/twelvelabs_services (Line 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasusが人物のメタデータを返すと、アプリケーションはタイムレンジを抽出し、それらのウィンドウからキーフレームをサンプリングします。各キーフレームは detect_faces(..., with_encodings=True) に渡され、InsightFaceを使用して顔を検出し、バウンディングボックスを計算し、鮮明度を評価し、アイデンティティの埋め込みを生成します。
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
各検出データは、埋め込みとともにフレームインデックスとタイムスタンプを保存し、クラスタリングステップで一貫した人物アイデンティティにグループ化できる時間対応のマスキングメタデータを作成します。
2.2 - マスキングターゲットの選択
検出とクラスタリングの後、レビュー担当者は検出された個人のリストから人物のアイデンティティを選択します。その選択は、顔のターゲットとそれらの保存された埋め込みのリストに分解され、エクスポートパイプラインが顔固定追跡のために使用します。
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
リバースマスキング(除くマスキング)は、逆方向で同じアイデンティティ解決を使用します。レビュー担当者が保護したい人を選択すると、エクスポート時に検出された他のすべての顔にぼかしが適用されます。
2.3 - 顔固定レーンの構築とマスキングされたエクスポートのレンダリング
選択された各人物アイデンティティについて、パイプラインは build_face_lock_lane(job_id, person_id) を呼び出します。レーンビルダーは、保存されたInsightFaceの外観レコード、TwelveLabsエンティティ検索のタイムレンジ、およびPegasusから保存されたセマンティック人物範囲の3つのソースを利用します。その結果、ビデオ内のそのアイデンティティの全スパンをカバーするレーンドキュメントが作成されます。
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
エクスポート中、レーンはフレームインデックス付きのバウンディングボックスルックアップテーブル(face_lock_bboxes_by_frame)に変換され、YOLOv8-Faceリファインメントでガイドされます。レンダラーはこのテーブルに対して各フレームをチェックし、顔固定バウンディングボックスが登録されている場所にはどこでも apply_detection_redaction を適用します。
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
出力は、フレームごとの手動修正を必要とせずに、動き、部分的なオクルージョン、およびカメラの動きを通じて選択されたアイデンティティを追跡する安定したぼかしです。
セクション3:Pegasus 1.5によるプライバシーメタデータ
Pegasus 1.5はスキーマ駆動型のタイムスタンプベースのメタデータをサポートしています。これは、検出するプライバシーリスクのタイプと、各セグメントに対して返す構造化フィールドを正確に定義できることを意味します。これが、レビューインターフェースの「Meta Insights(メタインサイト)」を動かす仕組みです。
3.1 - プライバシーリスクスキーマの構築
スキーマは、アクション可能なレビューターゲット、すなわち顔、文書、画面、ナンバープレート、機密性の高いテキスト、保護対象の個人にPegasusの出力を集中させる単一のセグメントタイプ privacy_risk_segment を定義します。risk_level、scene_role、redaction_decision、reason などのフィールドは、単にタイムスタンプだけでなく、フラグが立てられた各瞬間の文書化された明確な論拠をレビュー担当者に提供します。
backend/services/pegasus_privacy (Line 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - タイムスタンプ付きプライバシーセグメントの生成
スキーマは analysis_mode: "time_based_metadata" を指定してPegasusに渡されます。これにより、Pegasusは単一のドキュメントの要約ではなく、構造化されたタイムラインとして応答を返すよう指示されます。temperature: 0.1に設定することで出力を決定論的な状態に保ちます。これは、繰り返しの実行において一貫性が求められるコンプライアンスワークフローに非常に重要です。
backend/services/twelvelabs_services (Line 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
バックエンドは情報が空の timeline_events と recommended_actions フィールドを持つ初期ジョブデータを保存し、タスクが完了するまでポーリングします。各Pegasusセグメントは、タイムラインイベント(start_sec、end_sec、severity、category、reason、および redaction_decision)と、次にレビュー担当者が行うべきことを示す推奨アクションの2つのオブジェクトに変換されます。
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - レビューインターフェースとしてのプライバシーメタデータのレンダリング
タイムラインレーンは、各Pegasusイベントを start_sec と end_sec に配置されたクリック可能なホットスポットとしてレンダリングします。ホットスポットをクリックすると、メタインサイトパネルが開き、イベントにフォーカスが当たり、ビデオがそのタイムスタンプにシークされます。
サイドバーには、深刻度、カテゴリ、理由、マスキングの決定、マスキングターゲット、対象の選択、シーンの役割、信頼度、および処理に関するメモなど、完全なイベントメタデータが表示されます。レビュー担当者は、何かが注意を必要とする場所だけでなく、その理由も確認できます。これは、GDPR監査が必要とする文書化された論拠となります。
セクション4:確認のためのオープンエンドなビデオ分析
構造化されたメタデータに加えて、アプリケーションはインデックス付きビデオに対する自由形式のコンテキストの質問をサポートしています。レビュー担当者は、映像全体にどのような機密情報が表示されるか、どの瞬間が最も高いコンプライアンスリスクを伴うか、または特定のタイムスタンプの周囲で何が起こっているかを質問できます。これは、レビュー担当者が探しているものがまだ分かっていない状況で役立ちます。
フロントエンドは、video_id とレビュー担当者のプロンプトを /api/analyze-custom に送信します。バックエンドは、特定の瞬間に言及されるたびにタイムスタンプを要求するフォーマット指示をプロンプトの先頭に追加し、結合されたプロンプトをTwelveLabsのAnalyze(分析)サービスに渡します。
backend/services/twelvelabs_services (Line 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
応答は、ビデオコンテンツに基づいた平易な言葉による分析を返し、タイムスタンプによってレビュー担当者に関連する瞬間に直接リンクします。これにより、「機密情報を見つける必要がある」状態から「見るべき正確な場所はここである」状態へのギャップが埋まります。
このアプローチが可能にすること
歴史的に、ビデオのGDPRコンプライアンスには2つのトレードオフのいずれかが必要でした。遅くて高価な手動レビュープロセスか、法律が必要とする以上のものをマスキングし、その決定理由を明確に説明できない、大雑把な自動化されたアプローチのいずれかです。
このアプリケーションは、異なる道を進みます。Marengo 3.0は、テキスト、画像、または登録されたアイデンティティエンティティを使用して、コーパス全体から適切な瞬間を特定します。Pegasus 1.5は、フラグが立てられた各セグメントについて、文書化された明確な論拠を持つ構造化された、タイムスタンプ付きのプライバシーメタデータを生成します。ローカルの顔検出は、AIに基づいたキーフレームからアイデンティティをクラスタリングします。顔固定レーンは、エクスポート全体で安定したぼかしトラックを維持します。
その結果、マスキングワークフローが、網羅的ではなくピンポイントなものになり、不透明ではなく文書化され、そして手動ではなくスケーラブルなものになります。すべての決定基準点にはレビュー可能な記録があり、これこそが真のコンプライアンスにおいて実際に求められているものです。
参考情報








