" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
リサーチ
基盤モデルはマルチモーダル化しています

ジェームズ・リー
基盤モデルは、BERTやGPTのようなテキストのみのシステムから、言語、画像、動画を共に処理するマルチモーダルなアーキテクチャへと進化しました。この記事では、その移行がどのようにして起こったのか、なぜ動画理解が最も困難な未開拓領域であるのか、そしてそれが今後のAI開発の未来にとって何を意味するのかを詳しく解説します。
基盤モデルは、BERTやGPTのようなテキストのみのシステムから、言語、画像、動画を共に処理するマルチモーダルなアーキテクチャへと進化しました。この記事では、その移行がどのようにして起こったのか、なぜ動画理解が最も困難な未開拓領域であるのか、そしてそれが今後のAI開発の未来にとって何を意味するのかを詳しく解説します。

この記事の内容
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2023/03/31
17分
記事へのリンクをコピー
BERT、GPT-3、CLIP、Codexといった基盤モデル(Foundation Models)の成功により、視覚と言語のモダリティを組み合わせたモデルへの関心が高まっています。これらのハイブリッドな視覚言語モデルは、画像キャプション生成、画像生成、視覚的質問応答などの困難なタスクにおいて素晴らしい能力を示しています。最近では、基盤モデルの原理を用いてビデオデータから学習する、ビデオ基盤モデルという新たなパラダイムが登場しています。
このブログ記事では、基盤モデル、大規模言語モデルおよび視覚言語モデル、そしてビデオ基盤モデルの概要について説明します。基盤モデルのアーキテクチャ、そのトレーニングとファインチューニングのパラダイム、およびスケーリング則(Scaling Laws)について探ります。さらに、視覚言語モデルがどのようにコンピュータビジョンと自然言語処理の力を組み合わせ、複雑な問題の解決に使用されているかについて解説します。最後に、ビデオ基盤モデルと、それがビデオデータの理解と分析をどのように革新しているかについて考察します。
1. 基盤モデルへの緩やかな導入
基盤モデルとは、大規模な自己教師あり学習を用いて、幅広いデータから学習する機械学習モデルの一種です。そのアイデアは、多くの異なるタスクに使用できるモデルを作成することです。大量のデータでトレーニングすることにより、モデルはデータ内の一般的なパターンを学習できます。モデルが特定のタスクに使用されるとき、この知識を利用して迅速に適応することができます。
基盤モデルは、2012年以来普及している深層ニューラルネットワークと、ほぼ同じくらい前から存在する自己教師あり学習を使用しています。両分野における最近の進歩により、より大きく、より複雑なモデルの作成が可能になりました。これらのモデルは、明示的なラベルがないことが多い膨大なデータでトレーニングされます。
その結果、幅広いパターンや関係性を学習できるモデルが得られ、これは多くのタスクに活用できます。これにより、自然言語処理、コンピュータビジョン、マルチモーダルAIが大幅に向上しました。基盤モデルを使用すると、タスクごとに異なるモデルを作成するのではなく、多くのタスクに使用できる1つのモデルを作成できます。これにより、時間とリソースを節約し、多くの分野での進歩を加速させることができます。
転移学習(Transfer Learning)
従来の機械学習(ML)モデルは、ゼロから(それに近い状態で)トレーニングされ、良好なパフォーマンスを発揮するためにドメイン固有の大量のデータセットを必要とします。しかし、データの量が少ない場合は、転移学習のメリットを活用できます。転移学習のアイデアは、あるタスクから学習した「知識」を別のタスクに適用することで、ゼロからトレーニングするほど多くのデータを必要としないようにすることです。深層ニューラルネットワークでは、事前トレーニングが転移学習の支配的なアプローチです。オリジナルのタスク(例:道路上の車を検出する)でモデルをトレーニングし、関心のある別の下流タスク(例:黒いテスラ モデル3を検出する)に合わせてファインチューニングします。
私たちは2014年からコンピュータビジョンの分野でこれを行ってきました。通常は、ImageNetでモデルをトレーニングし、ほとんどのレイヤーを保持したまま、上位3つほどのレイヤーを新しく学習した重みに置き換えます。あるいは、モデルをエンドツーエンドでファインチューニングすることもできます。コンピュータビジョンタスク向けに最も人気のある事前トレーニング済みモデルには、AlexNet、ResNet、MobileNet、Inception、EfficientNet、YOLOなどがあります。
自然言語処理(NLP)において、事前トレーニングは当初、最初のステップである単語埋め込み(Word Embeddings)のみに限定されていました。言語モデルへの入力は単語です。それらを(単語としてではなく)ベクトルとしてエンコードする1つの方法は、ワンホットエンコーディングによるものです。単語の巨大な行列が与えられた場合、埋め込み行列を作成し、各単語を実数値ベクトル空間に埋め込むことができます。この新しい行列は、数千倍規模の次元に削減されます。おそらく、それらの次元はいくつかの意味的概念に対応しています。
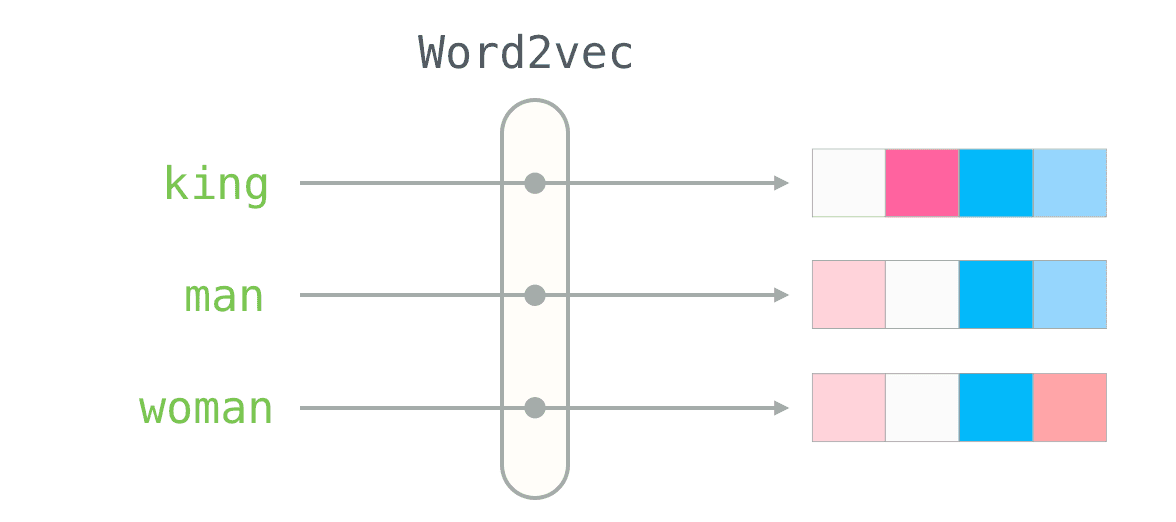
Word2Vecは、2013年にこのようなモデルをトレーニングしました。これは、頻繁に共起する単語を調べました。学習の目的は、それらの埋め込み間のコサイン類似度を最大化することでした。これらの埋め込みに対して、ベクトル演算のクールなデモを行うことができました。たとえば、「王(king)」「男(man)」「女(woman)」という単語を埋め込むと、ベクトル演算を行って、この埋め込み空間内で「女王(queen)」という単語に近いベクトルを得ることができます。
単語は文脈(コンテキスト)によって文中で異なる役割を果たす可能性があるため、単語を正しく埋め込むには、より多くの文脈を確認することが有用です。これを行うと、すべての下流タスクの精度が向上します。2018年には、ELMo、ULMFiT、GPTを含むいくつかのモデルが、言語モデリングを事前トレーニングにどのように使用できるかを実証的に示しました。これら3つの手法は、事前トレーニング済みの言語モデルを採用して、テキスト分類、質問応答、自然言語推論、共参照解決、シーケンスラベル付けなど、NLPの多様なタスクにおいて最先端の結果を達成しました。
Transformers = 基盤モデルの基盤となるアーキテクチャ

Transformersのオリジナル版は、2017年の論文「Attention Is All You Need」で紹介されました。Transformersが登場する前、NLPの最先端技術は、LSTMや広く普及しているSeq2Seqアーキテクチャなどのリカレントニューラルネットワーク(RNN)に基づいており、これらはデータを逐次的(シーケンシャル)に、つまり単語が現れる順に1単語ずつ処理していました。
Transformersの革新性は、言語処理を並列化することにあります。これにより、特定のテキスト本体内のすべてのトークンを、順次ではなく同時に分析できます。Transformersはこの並列化をサポートするために、アテンション(Attention)と呼ばれるAIメカニズムに依存しています。アテンションにより、モデルはテキスト内で遠く離れていても単語間の関係を考慮し、一節の中でどの単語やフレーズに最も注意を払うべきかを決定することができます。
また、並列化により、TransformersはRNNよりも計算効率が大幅に向上し、より大きなデータセットでのトレーニングや、より多くのパラメータを備えた構築が可能になります。今日のTransformerモデルは、その巨大なサイズが特徴です。
Vision Transformers
畳み込みニューラルネットワーク(CNN)は、コンピュータビジョンの分野で支配的なアーキテクチャでした。しかし、NLPにおけるTransformersの成功を受けて、研究者たちはこのアーキテクチャを画像データに適応させ始めました。「An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale」という論文では、Transformerアーキテクチャのエンコーダーブロックを画像分類問題に適用する、Vision Transformer(ViT)アーキテクチャを紹介しています。

この研究の著者は、画像をパッチに分割し、これらのパッチの線形埋め込みシーケンスをTransformerへの入力として提供しました。NLP設定におけるトークンと同様に、これらの画像パッチは入力として扱われます。このアーキテクチャには、画像をパッチ化するステム、マルチレイヤーTransformerエンコーダーに基づくボディ、およびグローバル表現を出力ラベルに変換する多層パーセプトロン(MLP)ヘッドが含まれています。ViTは、事前トレーニングのコストを比較的低く抑えながら、多くの画像分類データセットで最先端の結果を達成または更新しています。
ViTは可能性を示しているものの、いくつかの問題もあります。1つの重要な問題は、高解像度の画像にうまく対応できないことです。なぜなら、画像サイズに伴って急速に増加する膨大な計算パワーを必要とするためです。さらに、ViTの固定スケールのトークンは、様々なサイズの視覚要素を伴うタスクには有用ではありません。
Transformerの変種
オリジナルのTransformerアーキテクチャに続いて研究開発が活発に行われ、そのほとんどは上記のような欠点に対処するために標準的なTransformerアーキテクチャを改良したものでした。

2021年、Microsoftの研究者たちは、あらゆるモダリティに適用できる汎用的なTransformerアーキテクチャであるSwin Transformerを発表しました。Swin Transformerは、階層型特徴マップ(Hierarchical feature maps)とシフトウィンドウアテンション(Shifted window attention)という2つの概念を導入しました。
1. このモデルは、高密度な予測のための高度な技術を可能にするために、階層型特徴マップを使用します。画像を分割する重複しないウィンドウ内でローカルにセルフアテンションを計算することにより、線形の計算複雑性を達成しています。これにより、Swin Transformerは様々なビジョンタスクの優れたバックボーンとなっています。
2. シフトウィンドウの使用は、先行するレイヤーのウィンドウを橋渡しすることで、モデリング能力を高めます。この戦略は、実世界のレイテンシ(遅延)の点でも効率的です。ウィンドウ内のすべてのクエリパッチが同じキーセットを共有するため、ハードウェアでのメモリアクセスが容易になります。
Perceiverは、同時期にDeepMindによって作成された別のTransformer変種であり、生物学的なシステムからインスピレーションを得ています。アテンションに基づく原理を使用して、画像、ビデオ、オーディオ、ポイントクラウドなど、様々なタイプの入力を処理します。また、ドメインに関する特定の仮定に依存することなく、複数タイプの入力の組み合わせを処理できます。

Perceiverアーキテクチャは、アテンションのボトルネックを形成する小さな潜在ユニット(Latent units)のセットを導入しています。これにより、総当たり(all-to-all)のアテンションの問題が解消され、非常に深いモデルが可能になります。先行するステップの情報に基づいて、最も関連性の高い入力に注意を向けます。しかし、マルチモーダルの文脈では、あるモダリティからの入力と別のモダリティからの入力を区別することが重要です。明示的な構造の欠如を補うために、著者らは、生物学的ニューラルネットワークで使用される「標識線」戦略と同様に、すべての入力要素に位置およびモダリティ固有の特徴を関連付けています。
2. 大規模言語モデル(Large Language Models)
オリジナルのTransformer論文に続いて、主要なAI研究者たちがこの基礎的な画期的成果を発展させることで、NLPドメインを皮切りに活発なイノベーションが起こりました。
GPTとGPT-2はそれぞれ2018年と2019年に登場しました。その名前は「Generative Pre-trained Transformers(生成的な事前トレーニング済みTransformers)」を意味します。これらはデコーダーのみのモデル(decoder-only models)であり、マスクされたセルフアテンション(masked self-attention)を使用します。これは、出力シーケンスのある時点において、シーケンス内のその時点より前に現れた2つの入力シーケンスベクトルにのみ注意を向けることができることを意味します。GPTの埋め込みは分類にも使用できますが、GPTのアプローチは、chatGPTなど、今日の最もよく知られている大規模LLMの核心となっています。
これらのモデルは800万のウェブページでトレーニングされました。最大のモデルは15億のパラメータを持っています。GPT-2がトレーニングされたタスクは、ウェブ上のこれらのテキストすべてにおいて、次の単語を予測することです。彼らは、パラメータ数が増えるにつれて、これがますますうまく機能することを発見しました。

BERTは、Transformersの双方向エンコーダー表現(Bidirectional Encoder Representations for Transformers)として、ほぼ同時期に登場しました。1億1000万のパラメータを持つこれは、予測モデリングタスク向けに設計されたエンコーダーのみのTransformerであり、マスク付き言語モデリング(masked-language modeling)という独自の概念を導入しています。トレーニング中、BERTはシーケンス内のランダムな単語をマスクし、マスクされた単語が何であるかを予測しなければなりません。
T5 (Text-to-Text Transformer)は2020年に登場しました。インプットとアウトプットはいずれもテキスト文字列(Text strings)であるため、モデルが実行する想定のタスクを指定することができます。T5はエンコーダー・デコーダー型のアーキテクチャを持っています。これは、Wikipediaの100倍以上の規模を持つC4データセット(Colossal Clean Crawled Corpus)でトレーニングされました。約100億のパラメータを持っています。
基盤モデルのムーアの法則:スケーリング則
一般的に、スケーリング則(Scaling laws)は、計算バジェット(計算予算)を拡大し続ける(例:モデルを大きくする、またはデータを増やす)につれて、モデルの品質が向上し続けることを予測します。OpenAIは、2020年にTransformer言語モデルのスケーリング則を最初に調査し、スケーリング則が将来のパフォーマンスを予測できることを示しました。彼らの発見は、パフォーマンス ∝ データサイズ x パラメータサイズ x 計算量サイズであることを示しています。

より具体的には、実験により、テストの損失値(Test loss)が、トレーニングに使用されるモデルサイズ、データセットサイズ、および計算量に対して、7桁以上の大きさにわたるトレンドをカバーするべき乗則(Power law)に従うことが明らかになりました。これは、これらの変数間の関係が単純な方程式で説明できることを示唆しており、大規模言語モデルの最適なトレーニング構成を決定するために使用できます。さらに、実験では、ネットワークの幅や深さなどの他の建築的詳細は、広い範囲において影響が最小限であることが示されています。
実験と導出された方程式に基づいて、大容量モデルはサンプル効率が著しく高くなります。言い換えれば、最適な計算効率を達成するトレーニングには、比較的少ない量のデータで非常に大きなモデルをトレーニングし、収束するかなり前にトレーニングを停止することが含まれます。

スケーリング則の論文が発表されて以来、言語モデルの規模を拡大することへの関心が著しく高まりました。2020年における最先端モデルの1つがGPT-3でした。これは1750億のパラメータを持ち、GPT/GPT-2の100倍の大きさでした。そのサイズにより、GPT-3はFew-shot(少数の例示)学習やZero-shot(例示なし)学習において前例のない能力を示します。モデルに与える例が多いほど、そのパフォーマンスは向上します。そして、モデルが大きければ大きいほど、その実力はさらに向上します。
Googleは「Emergent Abilities of Large Language Models」という重要な論文を発表しました。この論文では、小規模なモデルには存在しないが、大規模なモデルに現れる「創発的能力(Emergent abilities)」について探求しています。この論文では、スケールの影響を分析した研究を検証し、様々な計算資源でトレーニングされた異なるサイズのモデルを比較しています。多くのタスクにおいて、モデルの挙動はスケールに伴って予測通りに成長するか、あるいは特定のスケール閾値(たとえば700億パラメータ以上)で、ランダムなパフォーマンスからランダムを超えるものへと予測不可能な形で急上昇します。

2022年、DeepMindは計算最適化されたモデルを作成するための「Chinchilla」スケーリング則を提案しました。これは、OpenAIが最初に提案したものよりも正確なスケーリング則の公式です。
彼らは、7000万から160億のパラメータを持つ400以上の言語モデルを、50億から5000億のトークンでトレーニングしました。モデルパラメータ数から導かれる最適なデータ量を予測することで、モデルおよびトレーニングセットのサイズの公式を導き出しました。ほとんどの大規模言語モデルは「過小トレーニング(undertrained)」状態にあり、十分なデータを見ていないことを意味します。
これを検証するために、彼らは2800億のパラメータと3000億のトークンを持つ別の大型モデル、Gopherをトレーニングしました。Chinchillaを使用することで、彼らはパラメータ数を700億に減らす一方、データを4倍の1.4兆トークンに増やしました。パラメータ数が少ないにもかかわらず、ChinchillaはGopherのパフォーマンスを上回り、モデルサイズとトレーニングトークンが等しく重要であることを示唆しました。
スケーリング則のフォーマルおよび実証的な分析以来、さらに多くの言語モデル(LLM)がリリースされています。これらのモデルは、モデルサイズのスケーリング、スパースにアクティベートされたモジュールの使用、およびより多様なソースからの巨大なデータセットでのトレーニングにより、多くのタスクで最先端のFew-shot結果を達成しています。注目すべき例としては、Megatron-LM(83億パラメータ)、GLaM(640億パラメータ)、LaMDA(1370億パラメータ)、Megatron-Turing NLG(5300億パラメータ)、およびPaLM(5400億パラメータ)があります。
GoogleによるScaling Vision Transformersは、スケーリング則がNLPタスクだけでなく、CV(コンピュータビジョン)タスクにも適用されることを示しています。著者らは、500万から20億のパラメータを持つVision Transformerモデル、100万から30億のトレーニング画像を持つデータセット、および1 TPUv3コア日未満から10,000コア日を超える計算バジェットを用いて実験を行いました。彼らの発見は、総計算量とモデルサイズを同時にスケーリングすることが効果的であることを示しています。追加の計算量が利用可能である場合に、モデルのサイズを拡大することが最適です。さらに、十分なトレーニングデータを持つVision Transformerモデルはおおむねべき乗則に従い、より大きなモデルはFew-shot学習においてより良いパフォーマンスを発揮します。

最後に、LAION AIのチームは、CLIPモデルファミリーのスケーリング則の再現を試みました。この調査でも、スケール(モデル、データ、および確認されたサンプル数)と、ゼロショット分類、検索、フューショットおよびフルショットの線形プロービング、ファインチューニングを含む幅広い設定における下流タスクのパフォーマンスとの間に、べき乗則の関係があることを発見しました。
3. 大型視覚言語モデルの台頭
Vision Transformerアーキテクチャのおかげで、視覚と言語のモダリティを組み合わせたモデルへの関心が高まっています。これらのハイブリッドな視覚言語モデルは、画像キャプション生成、画像生成、視覚的質問応答などの挑戦的なタスクで印象的な能力を発揮しています。一般的に、これらは、画像エンコーダー、テキストエンコーダー、そして2つのエンコーダーからの情報を融合する戦略という3つの主要要素で構成されています。過去2年間の視覚言語モデル研究において、最もよく知られているモデルのいくつかを見てみましょう。
2021年、OpenAIはCLIP (Contrastive Language–Image Pre-training)を発表しました。CLIPへの入力は、インターネットから収集された4億組の画像とテキストペアです。テキストをTransformersを用いてエンコードし、画像をVision Transformersを用いてエンコードし、そしてコントラスティブ学習(対照学習)を適用してモデルをトレーニングします。コントラスティブトレーニングは、コサイン類似度を使用して正しい画像とテキストのペアを一致させます。

この強力なトレーニング済みモデルを使用すると、未確認のデータであっても、埋め込みを用いて画像とテキストをマッピングできます。これを行うには2つの方法があります。1つの方法は、推論を実行した後にCLIPが出力する特徴量の上に、シンプルなロジスティック回帰モデルをトレーニングする「線形プローブ(Linear probe)」を使用することです。あるいは、すべてのテキストラベルをエンコードしてそれらをエンコードされた画像と比較する「ゼロショット(Zero-shot)」技術を使用することもできます。線形プローブのアプローチの方がわずかに優れています。

明確にしておくと、CLIPは画像からテキスト、またはその逆へと直接変換するわけではありません。埋め込み(Embeddings)を使用します。しかし、この埋め込み空間は、モダリティを横断した検索を実行する上で非常に便利です。
CoCa(Contrastive Captionerの略)は、コントラスティブ学習(CLIP)と生成学習(SimVLM)を組み合わせた、Googleによるもう1つの基盤モデルです。コントラスティブ(対照)損失とキャプショニング損失の両方で修正・トレーニングされたエンコーダー・デコーダー構造を採用しています。これにより、単一モダリティ(unimodal)の画像およびテキストの埋め込みからグローバルな表現を学習できるだけでなく、マルチモーダルデコーダーからきめ細かな領域レベルの特徴も学習できます。
2022年後半、DeepMindはFlamingoと呼ばれる視覚言語モデル(Visual Language Models)のグループを作成しました。これらのモデルは、わずかなインプットとアウトプットの例を示すだけで、多種多様なタスクを実行できます。それらは、視覚的なシーンを理解できるビジョンモデルと、推論を支援する言語モデルという2つの部分で構成されています。モデルは、事前トレーニングの知識を利用して連携します。また、多くの視覚的入力特徴を分析して少数の視覚トークンを生成できるPerceiverアーキテクチャ(Transformersの変種のセクションで解説)のおかげで、Flamingoモデルは高品質な画像やビデオを取り込むことも可能です。

これらの新しいアーキテクチャの革新のおかげで、Flamingoモデルは、視覚と言語のための強力な事前トレーニング済みモデルを接続し、ビジュアルとテキストデータが混合したシーケンスを処理し、画像やビデオを入力として容易に使用することができます。800億のパラメータを持つ最大バージョンのFlamingo-80Bは、言語、画像、およびビデオの理解を伴う多くのタスクのFew-shot学習において、新たな記録を樹立しました。
Microsoft、Google、およびOpenAIは、ここ数週間の間に各自の大型視覚言語モデルをリリースし、これによりマルチモーダルAIへのトレンドをさらに推進しています。
Microsoftは、様々なモダリティを認識し、文脈を学習し、指示に従うことができるマルチモーダル言語モデル、Kosmos-1をリリースしました。このモデルは、それ以前のコンテキストに基づいてテキストを生成し、Transformerベースの因果関係(causal)言語モデルを使用して、テキストやその他のモダリティを処理します。多種多様なデータを用いてトレーニングされており、言語の理解と作成、画像の認識、および画像に基づく質問への回答を含む、様々なシナリオにおいて優れた性能を発揮しています。
GoogleのPaLM-Eは、インターネット規模の言語、ビジョン、および視覚言語ドメインを含む、様々な情報源からの観察および様々な形態(embodiments)に基づいて、多様な推論タスクを処理できる具体化された(embodied)マルチモーダル言語モデルです。最大のPaLM-EモデルであるPaLM-E-562Bは5620億のパラメータを持ち、事前トレーニングなしで異なる事柄について推論できます。たとえば、画像に基づいてジョークを言ったり、認識、対話、計画などのロボットタスクを実行したりできます。
最後に、OpenAIのGPT-4は、画像とテキスト入力を処理し、テキスト出力を生成できる大規模マルチモーダルモデルです。模擬司法試験で上位10%、生物学オリンピック(画像あり)で上位1%の成績を収めました。
4. ビデオ基盤モデルの新たなパラダイム
ビデオ理解における課題
私たちの社会において、ビデオ理解タスクの重要性はますます高まっています。ソーシャルメディアプラットフォーム上での動画コンテンツの増加や、公共スペースでの監視カメラの使用増加に伴い、自動化されたビデオ理解システムへの需要が高まっています。しかし、この問題が重要であるにもかかわらず、テキストや画像の理解タスクに比べて、受けてきた注目は比較的少ないものでした。
ビデオ処理がテキストや画像の処理ほど注目されてこなかった理由の1つは、それに伴う非常に高い計算負荷にあります。ビデオはテキストや画像に比べてサイズがはるかに大きく、分析には大幅に多くの処理能力が必要です。この問題は、トークンの長さに対して2乗(二次関数的)の複雑さを持つTransformerアーキテクチャでは、さらに顕著になります。
例として、通常1秒あたり30フレーム(画像)を持つ10分間の動画を想定してみましょう。これは、そのビデオに10 * 3600 * 30枚、つまり1,080,000枚(約100万枚)の画像が含まれていることを意味します。Transformerの2乗の複雑さを考慮すると、必要となる総計算量は100万の2乗(1e12)になります。
さらに、ビデオ理解は、時系列モデリング(Temporal modeling)というユニークな課題をもたらします。テキストや画像とは異なり、ビデオには分析の際に考慮しなければならない「時間」の次元が含まれています。これには、他のモダリティでは一般的に使用されない、専用の技術やモデルが必要となります。
最後に、ビデオクリップに表示される視覚情報に加えて、追加の処理を必要とする同期された音声キュー(オーディオの手がかり)があります。これらの音声キューには、ビデオ内で発生する音や会話が含まれ、視聴者に追加のコンテキストや情報を提供します。これらの音声キューは、ビデオに示される視覚情報と「同じくらい重要」であることが多く、見過ごされるべきではないことに留意することが重要です。したがって、これらの音声キューの処理はビデオ分析の極めて重要な側面であり、視覚分析と同レベルの注意を払う必要があります。
いくつかの課題はあるものの、ビデオ理解の研究は着実に進歩しています。視覚言語モデルが効果的であり、マルチモーダルのトレンドが出現しているため、この問題に対処するためにいくつかの言語・視覚基盤モデルが提案されています。活発な研究コミュニティがこのテーマに取り組んでいます。しかし、現実世界のアプリケーションで十分に機能する堅牢で信頼性の高いビデオ理解システムを開発するには、まださらなる取り組みが必要です。
新興の大規模ビデオモデル

2019年、Googleはビデオに自己教師あり学習を適用したVideoBERTを発表しました。これは、音声自動認識、時空間的視覚特徴のためのベクトル量子化、およびトークンシーケンス用のBERTモデルという、3つの既存の手法を使用していました。これらが連携して、視覚ドメインと文脈ドメインの関係性をモデル化しました。ビデオでBERTを機能させるために、著者らはベクトル量子化を使用して生のビデオデータを「視覚的単語」に変換しました。これにより、モデルはビデオの重要な部分と、それらが時間とともにどのように変化するかに焦点を当てることができます。VideoBERTは、ビデオキャプション生成テストにおいて他のモデルを凌駕しました。
「All-In-One」は事前トレーニング向けに設計されたビデオ言語モデルであり、統合されたバックボーンアーキテクチャにおいて、生の視覚・テキストシグナルからビデオ言語の表現を捉えます。追加のパラメータを投入したり時間的複雑性を増大させたりすることなく、疎にサンプリングされたフレームの時系列表現を捉えるために、時系列トークンローリング操作(temporal token rolling operation)を使用します。このモデルは、ビデオ質問応答、テキストからビデオへの検索、複数選択、および視覚的常識推論という4つの下流のビデオ言語タスクにおいて、優れたパフォーマンスを発揮します。

ビデオ認識(Video recognition)には、ビデオ内のオブジェクト、アクション、およびイベントの特定および分類が含まれます。これには、セキュリティシステム、自動運転車、エンターテインメント業界など、多くの実用的なアプリケーションがあります。そのため、これは進化し続けている研究分野であり、新しい開発が定期的に行われています。
Video MAEは、ビデオ認識に向けてバニラ(標準的)なVision Transformerの可能性を引き出す、自己教師ありビデオ事前トレーニング手法です。これはランダムなチューブ(時空間ブロック)をマスクし、欠損した部分を非対称エンコーダー・デコーダー構造で再構築します。著者らは、より代表的な特徴を学習するようにVideoMAEを動機付ける2つの重要な設計(極端に高いマスク比率とチューブマスキング戦略)を導入し、これにより時間的な冗長性と相関に関する課題に対処しました。

Web上の大量の画像・テキストデータを使用して視覚言語を表現することをCLIPが学習するのと同じように、自然言語による教師あり学習を使用することで、素晴らしいビデオ認識方法を学ぶことができます。モデルを事前トレーニングすれば、モデルが学習した視覚的概念を指し示すために自然言語を使用できるため、追加のトレーニングをほとんど、あるいはまったく行うことなく、モデルを他のタスクに簡単に移行できます。
MicrosoftのX-Clipフレームワークは、言語イメージモデルを一般的なビデオ認識に適応させます。これは、クロスフレーム通信Transformerと、マルチフレーム統合Transformerという2つのコンポーネントで構成されています。前者はフレーム間メッセージトークンを使用して情報を交換することを可能にし、後者はフレームレベルの表現をビデオレベルへと転送します。X-CLIPは、ビデオ固有の提示スキームを通じてテキストプロンプトを強化するために、ビデオコンテンツ情報を使用します。完全教師あり、ゼロショット、およびフューショット実験において、X-CLIPは限定されたラベル付きデータにもかかわらず、優れたパフォーマンスを発揮します。

言語や画像の基盤モデルと比較して、現在のビデオ基盤モデルはビデオおよびビデオ言語タスクのサポートが限られています。しかし、InternVideoと呼ばれる新しい研究は、マスクされたビデオモデリングとマルチモーダルなコントラスティブ(対照)学習という、2つの一般的な自己教師あり学習パラダイムを組み合わせています。これら2つのTransformersから新しい特徴を導き出すために学習可能な相互作用を使用し、生成学習とコントラスティブ学習の両方の利点を組み合わせています。
InternVideoは、アクション理解、ビデオ言語アライメント、およびオープンワールドビデオアプリケーションにおけるタスクを含む、ビデオ理解のベンチマークにおいて他のモデルを圧倒しました。これらのタスクは、汎用的なビデオ認識の核心となる能力を表しています。
結論
あなたが準備できているかどうかにかかわらず、基盤モデルはマルチモーダル化しつつあります。基盤モデルはやがてすべてのAI搭載ソフトウェアの基礎として機能するようになるため、開発者は事前トレーニング済みの基盤モデルから始めて、それを狭い範囲のタスクにファインチューニングするケースがますます増えるでしょう。しかし、これらのモデルにとって最も困難な状況は、これまでに見たことのない「ロングテール(滅多に発生しない)」イベントです。これらのロングテールイベントは、マルチモーダルの設定下では解決が一段と複雑になります。
Twelve Labsでは、ロングテールのマルチモーダルビデオ理解のための基盤モデルを構築しています。私たちのビジョンは、最も強力なビデオ理解インフラを提供することで、開発者が私たちのように世界を見て、聴いて、理解できるプログラムを構築できるように支援することです。マルチモーダルな大規模ニューラルネットワークについてはさらに多くのアイデアがありますが、この記事はすでにかなり長くなってしまいました。これについて語り合うことに興味がある方は、ぜひベータユーザーとしてご登録ください!さらに、私たちのDiscordコミュニティに参加して、マルチモーダルAIにまつわるすべてのことについて話し合いましょう!
この膨大な記事の情報提供および様々な草案の校正をしてくれたAiden Leeに感謝します。
BERT、GPT-3、CLIP、Codexといった基盤モデル(Foundation Models)の成功により、視覚と言語のモダリティを組み合わせたモデルへの関心が高まっています。これらのハイブリッドな視覚言語モデルは、画像キャプション生成、画像生成、視覚的質問応答などの困難なタスクにおいて素晴らしい能力を示しています。最近では、基盤モデルの原理を用いてビデオデータから学習する、ビデオ基盤モデルという新たなパラダイムが登場しています。
このブログ記事では、基盤モデル、大規模言語モデルおよび視覚言語モデル、そしてビデオ基盤モデルの概要について説明します。基盤モデルのアーキテクチャ、そのトレーニングとファインチューニングのパラダイム、およびスケーリング則(Scaling Laws)について探ります。さらに、視覚言語モデルがどのようにコンピュータビジョンと自然言語処理の力を組み合わせ、複雑な問題の解決に使用されているかについて解説します。最後に、ビデオ基盤モデルと、それがビデオデータの理解と分析をどのように革新しているかについて考察します。
1. 基盤モデルへの緩やかな導入
基盤モデルとは、大規模な自己教師あり学習を用いて、幅広いデータから学習する機械学習モデルの一種です。そのアイデアは、多くの異なるタスクに使用できるモデルを作成することです。大量のデータでトレーニングすることにより、モデルはデータ内の一般的なパターンを学習できます。モデルが特定のタスクに使用されるとき、この知識を利用して迅速に適応することができます。
基盤モデルは、2012年以来普及している深層ニューラルネットワークと、ほぼ同じくらい前から存在する自己教師あり学習を使用しています。両分野における最近の進歩により、より大きく、より複雑なモデルの作成が可能になりました。これらのモデルは、明示的なラベルがないことが多い膨大なデータでトレーニングされます。
その結果、幅広いパターンや関係性を学習できるモデルが得られ、これは多くのタスクに活用できます。これにより、自然言語処理、コンピュータビジョン、マルチモーダルAIが大幅に向上しました。基盤モデルを使用すると、タスクごとに異なるモデルを作成するのではなく、多くのタスクに使用できる1つのモデルを作成できます。これにより、時間とリソースを節約し、多くの分野での進歩を加速させることができます。
転移学習(Transfer Learning)
従来の機械学習(ML)モデルは、ゼロから(それに近い状態で)トレーニングされ、良好なパフォーマンスを発揮するためにドメイン固有の大量のデータセットを必要とします。しかし、データの量が少ない場合は、転移学習のメリットを活用できます。転移学習のアイデアは、あるタスクから学習した「知識」を別のタスクに適用することで、ゼロからトレーニングするほど多くのデータを必要としないようにすることです。深層ニューラルネットワークでは、事前トレーニングが転移学習の支配的なアプローチです。オリジナルのタスク(例:道路上の車を検出する)でモデルをトレーニングし、関心のある別の下流タスク(例:黒いテスラ モデル3を検出する)に合わせてファインチューニングします。
私たちは2014年からコンピュータビジョンの分野でこれを行ってきました。通常は、ImageNetでモデルをトレーニングし、ほとんどのレイヤーを保持したまま、上位3つほどのレイヤーを新しく学習した重みに置き換えます。あるいは、モデルをエンドツーエンドでファインチューニングすることもできます。コンピュータビジョンタスク向けに最も人気のある事前トレーニング済みモデルには、AlexNet、ResNet、MobileNet、Inception、EfficientNet、YOLOなどがあります。
自然言語処理(NLP)において、事前トレーニングは当初、最初のステップである単語埋め込み(Word Embeddings)のみに限定されていました。言語モデルへの入力は単語です。それらを(単語としてではなく)ベクトルとしてエンコードする1つの方法は、ワンホットエンコーディングによるものです。単語の巨大な行列が与えられた場合、埋め込み行列を作成し、各単語を実数値ベクトル空間に埋め込むことができます。この新しい行列は、数千倍規模の次元に削減されます。おそらく、それらの次元はいくつかの意味的概念に対応しています。
Word2Vecは、2013年にこのようなモデルをトレーニングしました。これは、頻繁に共起する単語を調べました。学習の目的は、それらの埋め込み間のコサイン類似度を最大化することでした。これらの埋め込みに対して、ベクトル演算のクールなデモを行うことができました。たとえば、「王(king)」「男(man)」「女(woman)」という単語を埋め込むと、ベクトル演算を行って、この埋め込み空間内で「女王(queen)」という単語に近いベクトルを得ることができます。
単語は文脈(コンテキスト)によって文中で異なる役割を果たす可能性があるため、単語を正しく埋め込むには、より多くの文脈を確認することが有用です。これを行うと、すべての下流タスクの精度が向上します。2018年には、ELMo、ULMFiT、GPTを含むいくつかのモデルが、言語モデリングを事前トレーニングにどのように使用できるかを実証的に示しました。これら3つの手法は、事前トレーニング済みの言語モデルを採用して、テキスト分類、質問応答、自然言語推論、共参照解決、シーケンスラベル付けなど、NLPの多様なタスクにおいて最先端の結果を達成しました。
Transformers = 基盤モデルの基盤となるアーキテクチャ
Transformersのオリジナル版は、2017年の論文「Attention Is All You Need」で紹介されました。Transformersが登場する前、NLPの最先端技術は、LSTMや広く普及しているSeq2Seqアーキテクチャなどのリカレントニューラルネットワーク(RNN)に基づいており、これらはデータを逐次的(シーケンシャル)に、つまり単語が現れる順に1単語ずつ処理していました。
Transformersの革新性は、言語処理を並列化することにあります。これにより、特定のテキスト本体内のすべてのトークンを、順次ではなく同時に分析できます。Transformersはこの並列化をサポートするために、アテンション(Attention)と呼ばれるAIメカニズムに依存しています。アテンションにより、モデルはテキスト内で遠く離れていても単語間の関係を考慮し、一節の中でどの単語やフレーズに最も注意を払うべきかを決定することができます。
また、並列化により、TransformersはRNNよりも計算効率が大幅に向上し、より大きなデータセットでのトレーニングや、より多くのパラメータを備えた構築が可能になります。今日のTransformerモデルは、その巨大なサイズが特徴です。
Vision Transformers
畳み込みニューラルネットワーク(CNN)は、コンピュータビジョンの分野で支配的なアーキテクチャでした。しかし、NLPにおけるTransformersの成功を受けて、研究者たちはこのアーキテクチャを画像データに適応させ始めました。「An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale」という論文では、Transformerアーキテクチャのエンコーダーブロックを画像分類問題に適用する、Vision Transformer(ViT)アーキテクチャを紹介しています。
この研究の著者は、画像をパッチに分割し、これらのパッチの線形埋め込みシーケンスをTransformerへの入力として提供しました。NLP設定におけるトークンと同様に、これらの画像パッチは入力として扱われます。このアーキテクチャには、画像をパッチ化するステム、マルチレイヤーTransformerエンコーダーに基づくボディ、およびグローバル表現を出力ラベルに変換する多層パーセプトロン(MLP)ヘッドが含まれています。ViTは、事前トレーニングのコストを比較的低く抑えながら、多くの画像分類データセットで最先端の結果を達成または更新しています。
ViTは可能性を示しているものの、いくつかの問題もあります。1つの重要な問題は、高解像度の画像にうまく対応できないことです。なぜなら、画像サイズに伴って急速に増加する膨大な計算パワーを必要とするためです。さらに、ViTの固定スケールのトークンは、様々なサイズの視覚要素を伴うタスクには有用ではありません。
Transformerの変種
オリジナルのTransformerアーキテクチャに続いて研究開発が活発に行われ、そのほとんどは上記のような欠点に対処するために標準的なTransformerアーキテクチャを改良したものでした。
2021年、Microsoftの研究者たちは、あらゆるモダリティに適用できる汎用的なTransformerアーキテクチャであるSwin Transformerを発表しました。Swin Transformerは、階層型特徴マップ(Hierarchical feature maps)とシフトウィンドウアテンション(Shifted window attention)という2つの概念を導入しました。
1. このモデルは、高密度な予測のための高度な技術を可能にするために、階層型特徴マップを使用します。画像を分割する重複しないウィンドウ内でローカルにセルフアテンションを計算することにより、線形の計算複雑性を達成しています。これにより、Swin Transformerは様々なビジョンタスクの優れたバックボーンとなっています。
2. シフトウィンドウの使用は、先行するレイヤーのウィンドウを橋渡しすることで、モデリング能力を高めます。この戦略は、実世界のレイテンシ(遅延)の点でも効率的です。ウィンドウ内のすべてのクエリパッチが同じキーセットを共有するため、ハードウェアでのメモリアクセスが容易になります。
Perceiverは、同時期にDeepMindによって作成された別のTransformer変種であり、生物学的なシステムからインスピレーションを得ています。アテンションに基づく原理を使用して、画像、ビデオ、オーディオ、ポイントクラウドなど、様々なタイプの入力を処理します。また、ドメインに関する特定の仮定に依存することなく、複数タイプの入力の組み合わせを処理できます。
Perceiverアーキテクチャは、アテンションのボトルネックを形成する小さな潜在ユニット(Latent units)のセットを導入しています。これにより、総当たり(all-to-all)のアテンションの問題が解消され、非常に深いモデルが可能になります。先行するステップの情報に基づいて、最も関連性の高い入力に注意を向けます。しかし、マルチモーダルの文脈では、あるモダリティからの入力と別のモダリティからの入力を区別することが重要です。明示的な構造の欠如を補うために、著者らは、生物学的ニューラルネットワークで使用される「標識線」戦略と同様に、すべての入力要素に位置およびモダリティ固有の特徴を関連付けています。
2. 大規模言語モデル(Large Language Models)
オリジナルのTransformer論文に続いて、主要なAI研究者たちがこの基礎的な画期的成果を発展させることで、NLPドメインを皮切りに活発なイノベーションが起こりました。
GPTとGPT-2はそれぞれ2018年と2019年に登場しました。その名前は「Generative Pre-trained Transformers(生成的な事前トレーニング済みTransformers)」を意味します。これらはデコーダーのみのモデル(decoder-only models)であり、マスクされたセルフアテンション(masked self-attention)を使用します。これは、出力シーケンスのある時点において、シーケンス内のその時点より前に現れた2つの入力シーケンスベクトルにのみ注意を向けることができることを意味します。GPTの埋め込みは分類にも使用できますが、GPTのアプローチは、chatGPTなど、今日の最もよく知られている大規模LLMの核心となっています。
これらのモデルは800万のウェブページでトレーニングされました。最大のモデルは15億のパラメータを持っています。GPT-2がトレーニングされたタスクは、ウェブ上のこれらのテキストすべてにおいて、次の単語を予測することです。彼らは、パラメータ数が増えるにつれて、これがますますうまく機能することを発見しました。
BERTは、Transformersの双方向エンコーダー表現(Bidirectional Encoder Representations for Transformers)として、ほぼ同時期に登場しました。1億1000万のパラメータを持つこれは、予測モデリングタスク向けに設計されたエンコーダーのみのTransformerであり、マスク付き言語モデリング(masked-language modeling)という独自の概念を導入しています。トレーニング中、BERTはシーケンス内のランダムな単語をマスクし、マスクされた単語が何であるかを予測しなければなりません。
T5 (Text-to-Text Transformer)は2020年に登場しました。インプットとアウトプットはいずれもテキスト文字列(Text strings)であるため、モデルが実行する想定のタスクを指定することができます。T5はエンコーダー・デコーダー型のアーキテクチャを持っています。これは、Wikipediaの100倍以上の規模を持つC4データセット(Colossal Clean Crawled Corpus)でトレーニングされました。約100億のパラメータを持っています。
基盤モデルのムーアの法則:スケーリング則
一般的に、スケーリング則(Scaling laws)は、計算バジェット(計算予算)を拡大し続ける(例:モデルを大きくする、またはデータを増やす)につれて、モデルの品質が向上し続けることを予測します。OpenAIは、2020年にTransformer言語モデルのスケーリング則を最初に調査し、スケーリング則が将来のパフォーマンスを予測できることを示しました。彼らの発見は、パフォーマンス ∝ データサイズ x パラメータサイズ x 計算量サイズであることを示しています。
より具体的には、実験により、テストの損失値(Test loss)が、トレーニングに使用されるモデルサイズ、データセットサイズ、および計算量に対して、7桁以上の大きさにわたるトレンドをカバーするべき乗則(Power law)に従うことが明らかになりました。これは、これらの変数間の関係が単純な方程式で説明できることを示唆しており、大規模言語モデルの最適なトレーニング構成を決定するために使用できます。さらに、実験では、ネットワークの幅や深さなどの他の建築的詳細は、広い範囲において影響が最小限であることが示されています。
実験と導出された方程式に基づいて、大容量モデルはサンプル効率が著しく高くなります。言い換えれば、最適な計算効率を達成するトレーニングには、比較的少ない量のデータで非常に大きなモデルをトレーニングし、収束するかなり前にトレーニングを停止することが含まれます。
スケーリング則の論文が発表されて以来、言語モデルの規模を拡大することへの関心が著しく高まりました。2020年における最先端モデルの1つがGPT-3でした。これは1750億のパラメータを持ち、GPT/GPT-2の100倍の大きさでした。そのサイズにより、GPT-3はFew-shot(少数の例示)学習やZero-shot(例示なし)学習において前例のない能力を示します。モデルに与える例が多いほど、そのパフォーマンスは向上します。そして、モデルが大きければ大きいほど、その実力はさらに向上します。
Googleは「Emergent Abilities of Large Language Models」という重要な論文を発表しました。この論文では、小規模なモデルには存在しないが、大規模なモデルに現れる「創発的能力(Emergent abilities)」について探求しています。この論文では、スケールの影響を分析した研究を検証し、様々な計算資源でトレーニングされた異なるサイズのモデルを比較しています。多くのタスクにおいて、モデルの挙動はスケールに伴って予測通りに成長するか、あるいは特定のスケール閾値(たとえば700億パラメータ以上)で、ランダムなパフォーマンスからランダムを超えるものへと予測不可能な形で急上昇します。
2022年、DeepMindは計算最適化されたモデルを作成するための「Chinchilla」スケーリング則を提案しました。これは、OpenAIが最初に提案したものよりも正確なスケーリング則の公式です。
彼らは、7000万から160億のパラメータを持つ400以上の言語モデルを、50億から5000億のトークンでトレーニングしました。モデルパラメータ数から導かれる最適なデータ量を予測することで、モデルおよびトレーニングセットのサイズの公式を導き出しました。ほとんどの大規模言語モデルは「過小トレーニング(undertrained)」状態にあり、十分なデータを見ていないことを意味します。
これを検証するために、彼らは2800億のパラメータと3000億のトークンを持つ別の大型モデル、Gopherをトレーニングしました。Chinchillaを使用することで、彼らはパラメータ数を700億に減らす一方、データを4倍の1.4兆トークンに増やしました。パラメータ数が少ないにもかかわらず、ChinchillaはGopherのパフォーマンスを上回り、モデルサイズとトレーニングトークンが等しく重要であることを示唆しました。
スケーリング則のフォーマルおよび実証的な分析以来、さらに多くの言語モデル(LLM)がリリースされています。これらのモデルは、モデルサイズのスケーリング、スパースにアクティベートされたモジュールの使用、およびより多様なソースからの巨大なデータセットでのトレーニングにより、多くのタスクで最先端のFew-shot結果を達成しています。注目すべき例としては、Megatron-LM(83億パラメータ)、GLaM(640億パラメータ)、LaMDA(1370億パラメータ)、Megatron-Turing NLG(5300億パラメータ)、およびPaLM(5400億パラメータ)があります。
GoogleによるScaling Vision Transformersは、スケーリング則がNLPタスクだけでなく、CV(コンピュータビジョン)タスクにも適用されることを示しています。著者らは、500万から20億のパラメータを持つVision Transformerモデル、100万から30億のトレーニング画像を持つデータセット、および1 TPUv3コア日未満から10,000コア日を超える計算バジェットを用いて実験を行いました。彼らの発見は、総計算量とモデルサイズを同時にスケーリングすることが効果的であることを示しています。追加の計算量が利用可能である場合に、モデルのサイズを拡大することが最適です。さらに、十分なトレーニングデータを持つVision Transformerモデルはおおむねべき乗則に従い、より大きなモデルはFew-shot学習においてより良いパフォーマンスを発揮します。
最後に、LAION AIのチームは、CLIPモデルファミリーのスケーリング則の再現を試みました。この調査でも、スケール(モデル、データ、および確認されたサンプル数)と、ゼロショット分類、検索、フューショットおよびフルショットの線形プロービング、ファインチューニングを含む幅広い設定における下流タスクのパフォーマンスとの間に、べき乗則の関係があることを発見しました。
3. 大型視覚言語モデルの台頭
Vision Transformerアーキテクチャのおかげで、視覚と言語のモダリティを組み合わせたモデルへの関心が高まっています。これらのハイブリッドな視覚言語モデルは、画像キャプション生成、画像生成、視覚的質問応答などの挑戦的なタスクで印象的な能力を発揮しています。一般的に、これらは、画像エンコーダー、テキストエンコーダー、そして2つのエンコーダーからの情報を融合する戦略という3つの主要要素で構成されています。過去2年間の視覚言語モデル研究において、最もよく知られているモデルのいくつかを見てみましょう。
2021年、OpenAIはCLIP (Contrastive Language–Image Pre-training)を発表しました。CLIPへの入力は、インターネットから収集された4億組の画像とテキストペアです。テキストをTransformersを用いてエンコードし、画像をVision Transformersを用いてエンコードし、そしてコントラスティブ学習(対照学習)を適用してモデルをトレーニングします。コントラスティブトレーニングは、コサイン類似度を使用して正しい画像とテキストのペアを一致させます。
この強力なトレーニング済みモデルを使用すると、未確認のデータであっても、埋め込みを用いて画像とテキストをマッピングできます。これを行うには2つの方法があります。1つの方法は、推論を実行した後にCLIPが出力する特徴量の上に、シンプルなロジスティック回帰モデルをトレーニングする「線形プローブ(Linear probe)」を使用することです。あるいは、すべてのテキストラベルをエンコードしてそれらをエンコードされた画像と比較する「ゼロショット(Zero-shot)」技術を使用することもできます。線形プローブのアプローチの方がわずかに優れています。
明確にしておくと、CLIPは画像からテキスト、またはその逆へと直接変換するわけではありません。埋め込み(Embeddings)を使用します。しかし、この埋め込み空間は、モダリティを横断した検索を実行する上で非常に便利です。
CoCa(Contrastive Captionerの略)は、コントラスティブ学習(CLIP)と生成学習(SimVLM)を組み合わせた、Googleによるもう1つの基盤モデルです。コントラスティブ(対照)損失とキャプショニング損失の両方で修正・トレーニングされたエンコーダー・デコーダー構造を採用しています。これにより、単一モダリティ(unimodal)の画像およびテキストの埋め込みからグローバルな表現を学習できるだけでなく、マルチモーダルデコーダーからきめ細かな領域レベルの特徴も学習できます。
2022年後半、DeepMindはFlamingoと呼ばれる視覚言語モデル(Visual Language Models)のグループを作成しました。これらのモデルは、わずかなインプットとアウトプットの例を示すだけで、多種多様なタスクを実行できます。それらは、視覚的なシーンを理解できるビジョンモデルと、推論を支援する言語モデルという2つの部分で構成されています。モデルは、事前トレーニングの知識を利用して連携します。また、多くの視覚的入力特徴を分析して少数の視覚トークンを生成できるPerceiverアーキテクチャ(Transformersの変種のセクションで解説)のおかげで、Flamingoモデルは高品質な画像やビデオを取り込むことも可能です。
これらの新しいアーキテクチャの革新のおかげで、Flamingoモデルは、視覚と言語のための強力な事前トレーニング済みモデルを接続し、ビジュアルとテキストデータが混合したシーケンスを処理し、画像やビデオを入力として容易に使用することができます。800億のパラメータを持つ最大バージョンのFlamingo-80Bは、言語、画像、およびビデオの理解を伴う多くのタスクのFew-shot学習において、新たな記録を樹立しました。
Microsoft、Google、およびOpenAIは、ここ数週間の間に各自の大型視覚言語モデルをリリースし、これによりマルチモーダルAIへのトレンドをさらに推進しています。
Microsoftは、様々なモダリティを認識し、文脈を学習し、指示に従うことができるマルチモーダル言語モデル、Kosmos-1をリリースしました。このモデルは、それ以前のコンテキストに基づいてテキストを生成し、Transformerベースの因果関係(causal)言語モデルを使用して、テキストやその他のモダリティを処理します。多種多様なデータを用いてトレーニングされており、言語の理解と作成、画像の認識、および画像に基づく質問への回答を含む、様々なシナリオにおいて優れた性能を発揮しています。
GoogleのPaLM-Eは、インターネット規模の言語、ビジョン、および視覚言語ドメインを含む、様々な情報源からの観察および様々な形態(embodiments)に基づいて、多様な推論タスクを処理できる具体化された(embodied)マルチモーダル言語モデルです。最大のPaLM-EモデルであるPaLM-E-562Bは5620億のパラメータを持ち、事前トレーニングなしで異なる事柄について推論できます。たとえば、画像に基づいてジョークを言ったり、認識、対話、計画などのロボットタスクを実行したりできます。
最後に、OpenAIのGPT-4は、画像とテキスト入力を処理し、テキスト出力を生成できる大規模マルチモーダルモデルです。模擬司法試験で上位10%、生物学オリンピック(画像あり)で上位1%の成績を収めました。
4. ビデオ基盤モデルの新たなパラダイム
ビデオ理解における課題
私たちの社会において、ビデオ理解タスクの重要性はますます高まっています。ソーシャルメディアプラットフォーム上での動画コンテンツの増加や、公共スペースでの監視カメラの使用増加に伴い、自動化されたビデオ理解システムへの需要が高まっています。しかし、この問題が重要であるにもかかわらず、テキストや画像の理解タスクに比べて、受けてきた注目は比較的少ないものでした。
ビデオ処理がテキストや画像の処理ほど注目されてこなかった理由の1つは、それに伴う非常に高い計算負荷にあります。ビデオはテキストや画像に比べてサイズがはるかに大きく、分析には大幅に多くの処理能力が必要です。この問題は、トークンの長さに対して2乗(二次関数的)の複雑さを持つTransformerアーキテクチャでは、さらに顕著になります。
例として、通常1秒あたり30フレーム(画像)を持つ10分間の動画を想定してみましょう。これは、そのビデオに10 * 3600 * 30枚、つまり1,080,000枚(約100万枚)の画像が含まれていることを意味します。Transformerの2乗の複雑さを考慮すると、必要となる総計算量は100万の2乗(1e12)になります。
さらに、ビデオ理解は、時系列モデリング(Temporal modeling)というユニークな課題をもたらします。テキストや画像とは異なり、ビデオには分析の際に考慮しなければならない「時間」の次元が含まれています。これには、他のモダリティでは一般的に使用されない、専用の技術やモデルが必要となります。
最後に、ビデオクリップに表示される視覚情報に加えて、追加の処理を必要とする同期された音声キュー(オーディオの手がかり)があります。これらの音声キューには、ビデオ内で発生する音や会話が含まれ、視聴者に追加のコンテキストや情報を提供します。これらの音声キューは、ビデオに示される視覚情報と「同じくらい重要」であることが多く、見過ごされるべきではないことに留意することが重要です。したがって、これらの音声キューの処理はビデオ分析の極めて重要な側面であり、視覚分析と同レベルの注意を払う必要があります。
いくつかの課題はあるものの、ビデオ理解の研究は着実に進歩しています。視覚言語モデルが効果的であり、マルチモーダルのトレンドが出現しているため、この問題に対処するためにいくつかの言語・視覚基盤モデルが提案されています。活発な研究コミュニティがこのテーマに取り組んでいます。しかし、現実世界のアプリケーションで十分に機能する堅牢で信頼性の高いビデオ理解システムを開発するには、まださらなる取り組みが必要です。
新興の大規模ビデオモデル
2019年、Googleはビデオに自己教師あり学習を適用したVideoBERTを発表しました。これは、音声自動認識、時空間的視覚特徴のためのベクトル量子化、およびトークンシーケンス用のBERTモデルという、3つの既存の手法を使用していました。これらが連携して、視覚ドメインと文脈ドメインの関係性をモデル化しました。ビデオでBERTを機能させるために、著者らはベクトル量子化を使用して生のビデオデータを「視覚的単語」に変換しました。これにより、モデルはビデオの重要な部分と、それらが時間とともにどのように変化するかに焦点を当てることができます。VideoBERTは、ビデオキャプション生成テストにおいて他のモデルを凌駕しました。
「All-In-One」は事前トレーニング向けに設計されたビデオ言語モデルであり、統合されたバックボーンアーキテクチャにおいて、生の視覚・テキストシグナルからビデオ言語の表現を捉えます。追加のパラメータを投入したり時間的複雑性を増大させたりすることなく、疎にサンプリングされたフレームの時系列表現を捉えるために、時系列トークンローリング操作(temporal token rolling operation)を使用します。このモデルは、ビデオ質問応答、テキストからビデオへの検索、複数選択、および視覚的常識推論という4つの下流のビデオ言語タスクにおいて、優れたパフォーマンスを発揮します。
ビデオ認識(Video recognition)には、ビデオ内のオブジェクト、アクション、およびイベントの特定および分類が含まれます。これには、セキュリティシステム、自動運転車、エンターテインメント業界など、多くの実用的なアプリケーションがあります。そのため、これは進化し続けている研究分野であり、新しい開発が定期的に行われています。
Video MAEは、ビデオ認識に向けてバニラ(標準的)なVision Transformerの可能性を引き出す、自己教師ありビデオ事前トレーニング手法です。これはランダムなチューブ(時空間ブロック)をマスクし、欠損した部分を非対称エンコーダー・デコーダー構造で再構築します。著者らは、より代表的な特徴を学習するようにVideoMAEを動機付ける2つの重要な設計(極端に高いマスク比率とチューブマスキング戦略)を導入し、これにより時間的な冗長性と相関に関する課題に対処しました。
Web上の大量の画像・テキストデータを使用して視覚言語を表現することをCLIPが学習するのと同じように、自然言語による教師あり学習を使用することで、素晴らしいビデオ認識方法を学ぶことができます。モデルを事前トレーニングすれば、モデルが学習した視覚的概念を指し示すために自然言語を使用できるため、追加のトレーニングをほとんど、あるいはまったく行うことなく、モデルを他のタスクに簡単に移行できます。
MicrosoftのX-Clipフレームワークは、言語イメージモデルを一般的なビデオ認識に適応させます。これは、クロスフレーム通信Transformerと、マルチフレーム統合Transformerという2つのコンポーネントで構成されています。前者はフレーム間メッセージトークンを使用して情報を交換することを可能にし、後者はフレームレベルの表現をビデオレベルへと転送します。X-CLIPは、ビデオ固有の提示スキームを通じてテキストプロンプトを強化するために、ビデオコンテンツ情報を使用します。完全教師あり、ゼロショット、およびフューショット実験において、X-CLIPは限定されたラベル付きデータにもかかわらず、優れたパフォーマンスを発揮します。
言語や画像の基盤モデルと比較して、現在のビデオ基盤モデルはビデオおよびビデオ言語タスクのサポートが限られています。しかし、InternVideoと呼ばれる新しい研究は、マスクされたビデオモデリングとマルチモーダルなコントラスティブ(対照)学習という、2つの一般的な自己教師あり学習パラダイムを組み合わせています。これら2つのTransformersから新しい特徴を導き出すために学習可能な相互作用を使用し、生成学習とコントラスティブ学習の両方の利点を組み合わせています。
InternVideoは、アクション理解、ビデオ言語アライメント、およびオープンワールドビデオアプリケーションにおけるタスクを含む、ビデオ理解のベンチマークにおいて他のモデルを圧倒しました。これらのタスクは、汎用的なビデオ認識の核心となる能力を表しています。
結論
あなたが準備できているかどうかにかかわらず、基盤モデルはマルチモーダル化しつつあります。基盤モデルはやがてすべてのAI搭載ソフトウェアの基礎として機能するようになるため、開発者は事前トレーニング済みの基盤モデルから始めて、それを狭い範囲のタスクにファインチューニングするケースがますます増えるでしょう。しかし、これらのモデルにとって最も困難な状況は、これまでに見たことのない「ロングテール(滅多に発生しない)」イベントです。これらのロングテールイベントは、マルチモーダルの設定下では解決が一段と複雑になります。
Twelve Labsでは、ロングテールのマルチモーダルビデオ理解のための基盤モデルを構築しています。私たちのビジョンは、最も強力なビデオ理解インフラを提供することで、開発者が私たちのように世界を見て、聴いて、理解できるプログラムを構築できるように支援することです。マルチモーダルな大規模ニューラルネットワークについてはさらに多くのアイデアがありますが、この記事はすでにかなり長くなってしまいました。これについて語り合うことに興味がある方は、ぜひベータユーザーとしてご登録ください!さらに、私たちのDiscordコミュニティに参加して、マルチモーダルAIにまつわるすべてのことについて話し合いましょう!
この膨大な記事の情報提供および様々な草案の校正をしてくれたAiden Leeに感謝します。








