" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
チュートリアル
Twelve Labs と Milvus を使用したマルチモーダル検索拡張生成(RAG)アプリケーションの構築

リシケシュ・ヤダフ
このチュートリアルでは、Fashion AIチャットアプリケーションの構築手順を解説します。このアプリケーションは、Twelve LabsのEmbed API(Marengo 2.7)とMilvusを使用することで、テキスト、画像、動画ベースの商品検索を可能にし、さらにGPT-3.5を活用したRAG(検索拡張生成)システムによって、取得したマルチモーダル埋め込みから会話形式のファッション提案を生成します。
このチュートリアルでは、Fashion AIチャットアプリケーションの構築手順を解説します。このアプリケーションは、Twelve LabsのEmbed API(Marengo 2.7)とMilvusを使用することで、テキスト、画像、動画ベースの商品検索を可能にし、さらにGPT-3.5を活用したRAG(検索拡張生成)システムによって、取得したマルチモーダル埋め込みから会話形式のファッション提案を生成します。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2025/01/22
13分
記事へのリンクをコピー
はじめに
言葉だけでなく視覚的な好みまで理解してくれる専属のファッションアドバイザーが、24時間365日いつでも利用できたらどうなるか、考えたことはありますか?気に入ったコーディネートの写真を見せるだけで、AIが瞬時に似たスタイルの提案をしてくれたり、憧れのルックを言葉で伝えるだけで、それにマッチするコーディネートの提案を受け取ったりすることを想像してみてください 👚
当社のFashion AIアシスタントアプリケーションは、次世代の製品発見(プロダクトディスカバリー)のために構築されています。このチュートリアルでは、マルチモーダルな検索と対話型AIを組み合わせた、当社の高度なファッション推薦システムについて説明します。このシステムは、 TwelveLabs EmbedのMarengo-retrieval-2.7モデルを使用して、テキストとビデオコンテンツの両方から埋め込み(embeddings)を生成し、異なるデータタイプ間でのシームレスな検索を可能にします。
このアプリケーションは、効率的な類似性検索を行うためのベクトルデータベースとして Milvusを使用し、自然言語処理のためにOpenAIのgpt-3.5を統合しています。テキストと画像両方の入力からファッションに関するクエリを処理し、関連する製品説明と正確なビデオタイムスタンプを見つけ出し、ユーザーが探しているアイテムがビデオ内のどこに登場するかを正確に示します。
この強力な組み合わせにより、テキストとビジュアルの両方のクエリを理解し、マルチモーダルなコンテンツで強化された文脈に沿った回答を提供するシステムが構築されます。
このアプリケーションがどのように機能するのか、そして TwelveLabs Python SDKおよび Milvus Python SDKを使用して同様のソリューションをどのように構築できるかを見ていきましょう。
アプリケーションのデモはこちらからお試しいただけます: Fashion AI Chat App。
コードにアクセスしてアプリを直接試してみたい場合は、こちらの Replit Templateをご利用いただけます。
前提条件
Twelve Labs Playgroundに登録して、APIキーを生成します。
設定ガイドに従って、Milvusサーバーのインストールとセットアップを行います。
このアプリケーションのリポジトリは Fashion AI Chat Applicationにあります。
Python、Streamlit、CSSについて、ある程度の知識があらかじめ必要となります。
アプリケーションの仕組み
ここでは、アプリケーションの動作の概要と、そのコンポーネントがどのように相互作用するかを示します。
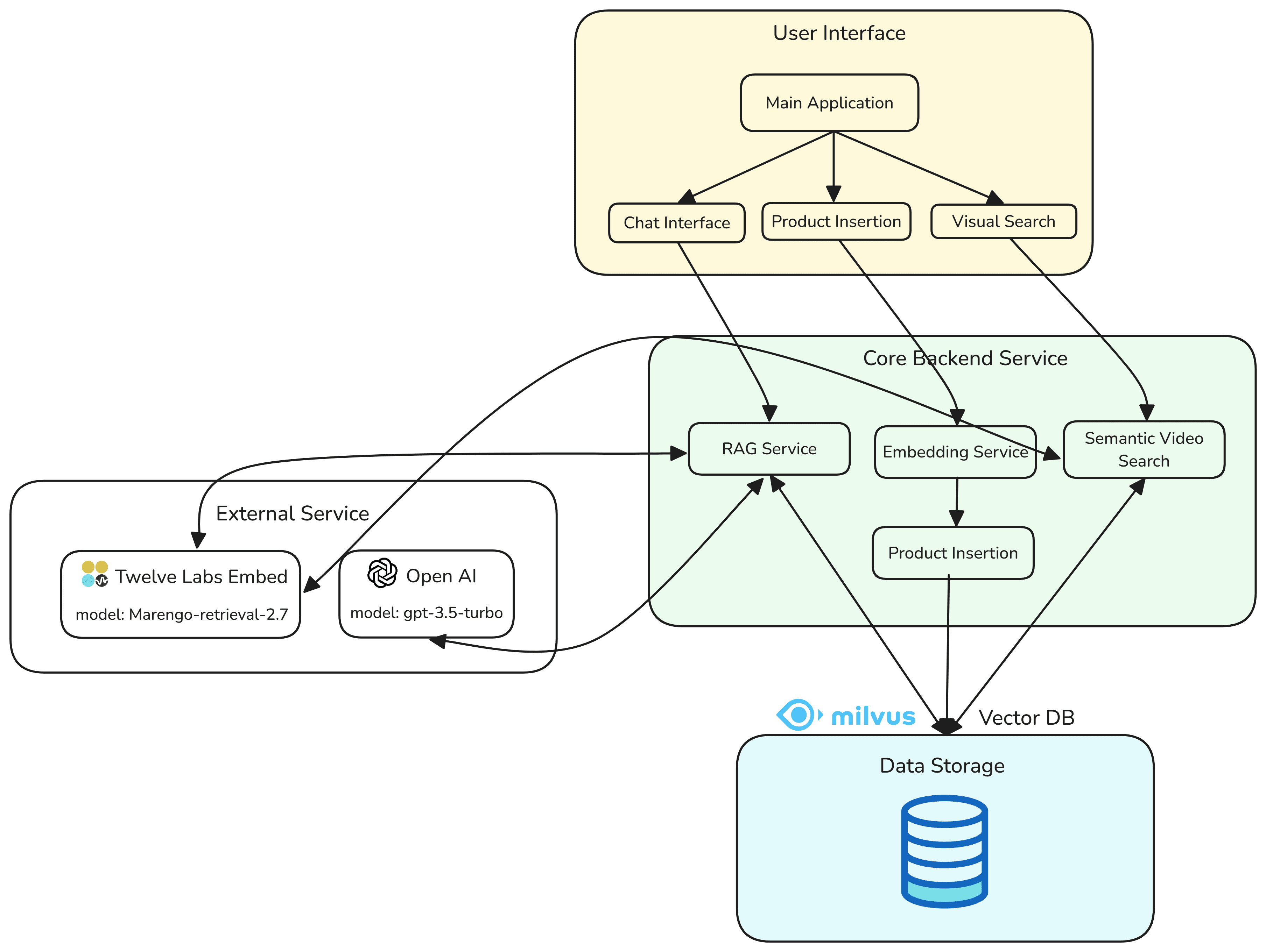
このアプリケーションには、3つの主な機能があります:
埋め込みの生成とMilvusベクトルデータベースへの挿入
クエリ画像からビデオセグメントへの検索
マルチモーダル検索(テキストおよびビデオセグメント)のための、対話型Retrieval Augmented Generation (RAG)
このチュートリアルアプリケーションでは、Twelve Labs Embed - Marengo-retrieval-2.7を使用して、製品カタログデータをベクトルデータベースに格納する方法を示します。テキストとビデオコンテンツの両方に該当する埋め込みは、同一のMilvusベクトルデータベースのコレクションに保存されます。わかりやすさと再利用性を考慮して、Twelve Labsの埋め込み関数は各ユーティリティ関数内で定義されています。
アプリケーションを期待通りに動作させるには、埋め込みデータをコレクションに挿入する必要があります。または、このアプリケーションで使用されているこちらの提供サンプルデータを参照することもできます。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数に設定します。
GitHubからプロジェクトをクローンするか、 Replit Templateを使用します。事前に定義された仮想環境が付属しているため、Replitテンプレートの使用をお勧めします。セットアップ時にはシークレットファイルを追加することを忘れずに、 Replit のシークレットキーに関するドキュメントを参照してください。
Twelve Labs、Milvus接続、およびLLMモデル用のOpenAI APIキーを含む
.envファイルを作成します。
Milvusベクトルデータベースの認証情報にはZilliz Cloudを使用した設定を行っていますが、他の接続方法については 設定ガイドでも確認できます。
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
これらの手順が完了したら、開発を始める準備は完了です!
ファッションチャットアプリケーションの実装解説
このチュートリアルでは、最小限のフロントエンドを備えたStreamlitアプリケーションを作成します。ディレクトリ構造を見てみましょう:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit アプリケーションの作成
セットアップが完了したところで、Streamlitアプリケーションを構築していきましょう。
仮想環境の作成に必要なすべての依存関係は、こちらで確認できます: requirements.txt
Pythonの仮想環境を作成し、次のコマンドを使用してアプリケーションの環境をセットアップします:
pip install -r requirements.txt
ユーティリティ関数の定義
このセクションでは、中心となるロジックと実装が含まれている utility.pyについて説明します。各サブセクションを詳しく処理していきましょう:
1 - 接続のセットアップ
最初のステップでは、環境変数をロードし、LLMアクセスのためのOpenAI、コレクション管理のためのMilvus、そしてTwelve Labsの初期化のための接続を確立します。
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API を使用した埋め込みの生成
このセクションでは、マルチモーダル検索用の Marengo-retrieval-2.7 モデルを搭載したTwelve Labs SDKを使用した埋め込み生成について説明します。このソリューションは、効率的な検索埋め込みを作成するために、テキストとビデオの処理を統合しています。
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
このプロセスは、一貫性があり意味のある埋め込みを保証するために、テキストを構造化およびフォーマットすることから始まります。次に動画の埋め込みが行われ、ステータスの監視や進捗の追跡が処理されます。各ビデオセグメントは6秒に設定されています(video_clip_length=6)。
メタデータの追跡は、トレーサビリティを維持し、正確なビデオセグメントおよびテキスト検索を可能にするために不可欠です。その後、結果はMilvusベクトルデータベースのコレクションに格納されます。
3 - Milvus ベクトルデータベースへの埋め込みの挿入
ベクトルデータベースは、高次元の埋め込みデータを効率的に保存、検索することができます。このセクションでは、適切なメタデータ管理およびエラーハンドリングを行いつつ、テキストとビデオ両方の埋め込みをMilvusベクトルデータベースに挿入する方法を説明します。
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID、ベクトル、メタデータを定義した後、同じコレクション空間内で異なるフォーマットに対応できるようにするために embedding_type を指定します。その後、データは collection.insert メソッドを使用して挿入されます。
4 - 画像から動画を検索するためのセマンティック検索の実装
画像クエリによるセマンティック検索により、類似するビデオコンテンツを探すことができます。この実装は、Twelve Labsの埋め込み機能とMilvusのベクトル検索を組み合わせています。ユーティリティ関数であるsearched_similar_videosがどのように機能するかを以下に示します:
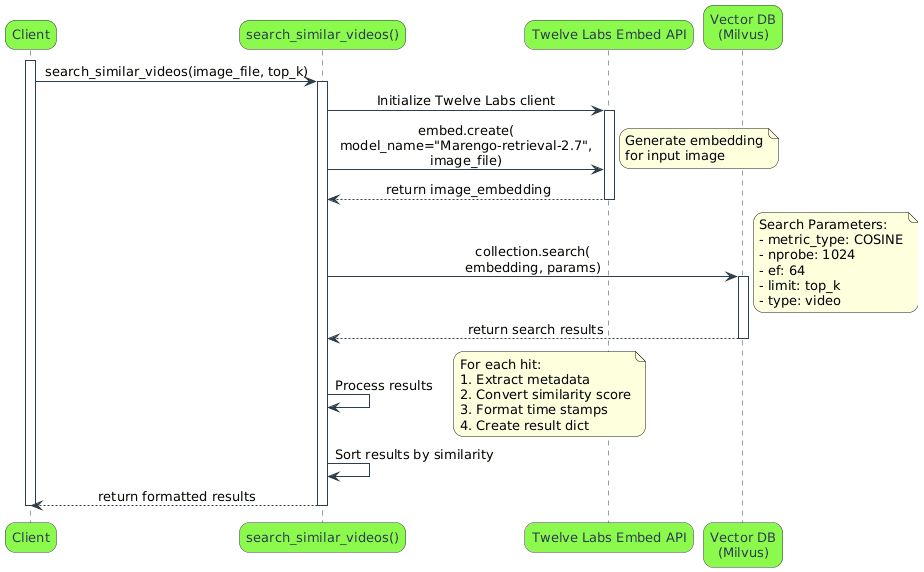
まず、システムは製品画像をロードして読み込み、類似する製品が含まれるビデオセグメントを探します。次にTwelve Labsの埋め込み(embed)が画像を埋め込みに変換し、Milvusコレクションに格納された動画埋め込みに対してセマンティック検索を実行します。
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
検索には、速度と精度のバランスを取るために、コサイン類似度とクラスターパラメータが使用されます。collection.search が embedding_type == 'video' やその他のパラメータとともに実行されると、指定された数の製品ビデオセグメントを検索(リトリーブ)します。
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
システムは結果を処理し、明確にするために類似度のスコアを割合(%)に変換し、メタデータを構造化された辞書形式に整理します。
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
ソートされた結果は、画面に表示することができます。UIの実装はvision_searchで確認できます。
5 - RAG (Retrieval Augmented Generation) システムの開発
このセクションでは、ファッションアシスタントの文脈における質問応答に焦点を当て、マルチモーダル検索とLLM (gpt-3.5) を組み合わせて文脈に即した回答を作成します。効果的なパーソナライズ化のために、メタデータを持つテキストおよび動画データからのマルチモーダル検索を重視しています。get_rag_response関数がRAG機能を実装しています。
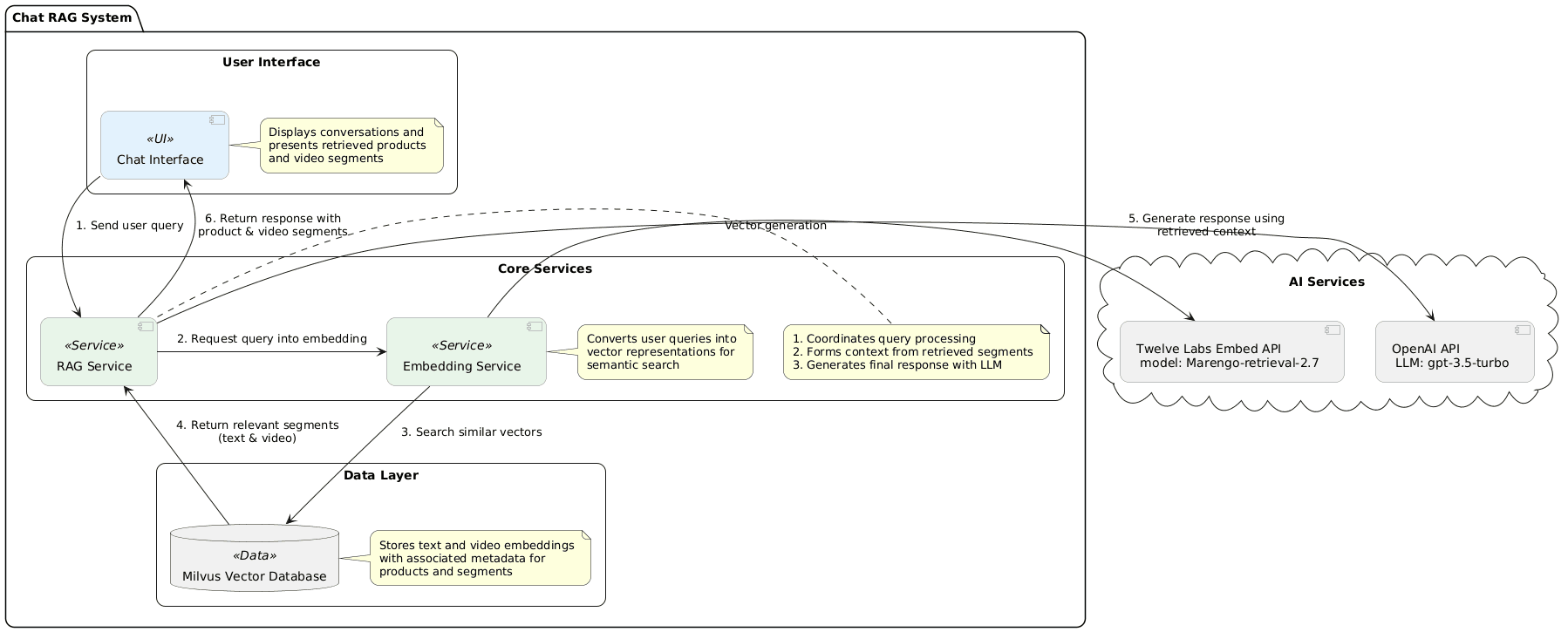
プロセスは、Twelve Labsの埋め込みでMarengo-retrieval-2.7エンジンを使用してユーザーの質問と文脈をテキスト埋め込みに変換し、データベース全体に対するセマンティック検索を可能にすることから始まります。
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
セマンティック検索のパラメータを設定した後、システムはテキストと動画セグメントに対して別々にコレクション検索を実行します。動画セグメント検索では、テキストクエリに最も関連するセグメントを見つけ出し、ユーザーに包括的な探索オプションを提供します。
expr メソッドにより検索条件が絞り込まれ、テキスト検索と動画検索で異なるリミット値が適用されます。典型的な検索では、メタデータを持つ2つのテキスト製品と3つの関連ビデオセグメントを検索します。
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
結果の処理中、システムは各セグメントからメタデータを抽出し、類似度のスコアを割合(%)に変換し、製品の詳細を構造化された辞書形式に整理します。
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
関連する情報を収集した後、システムはRetrieval Augmented Generation(検索拡張生成)のステップに進みます。検索されたコンテキスト(文脈情報)は、効率的なLLM処理のために構造化されます。
システムは、システムプロンプトとユーザープロンプトの両方を定義します。システムプロンプトはファッションアドバイザーとしての役割を確立し、ユーザープロンプトはユーザーのクエリとデータベースから取得したコンテキストを組み合わせます。コンテキスト取得が失敗した場合のエラーハンドリングも含まれています。
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
text_context には検索された情報が含まれます。gpt-3.5-turbo を使用して、システムはシステムプロンプトで指定されたように、説明、提案、ユーザー向けのガイダンスを含む応答を生成します。その応答は、アクセスしやすい辞書構造にフォーマットされます。UI実装の詳細については、appを参照してください。
デモアプリケーション
このデモは、データベース挿入の簡略化、効率的なマルチモーダル検索の有効化、そしてユーザーのための検索機能の向上の3つの主な目的を持ったパーツに分かれています。
データベースへのテキストおよびビデオ埋め込みの生成と挿入
LLMとのチャット対話を通じたマルチモーダルデータの検索
関連するビデオセグメントを見つけるための、製品画像ベースの検索
製品データカタログには、製品ID、テキスト、説明、リンク、およびビデオURLなどのフィールドが含まれます。テキストデータは埋め込みに変換され、その他のデータはメタデータとして保存されます。動画セグメントについて、システムは動画URLを処理します。すべての埋め込みは単一のコレクションに保存されます。
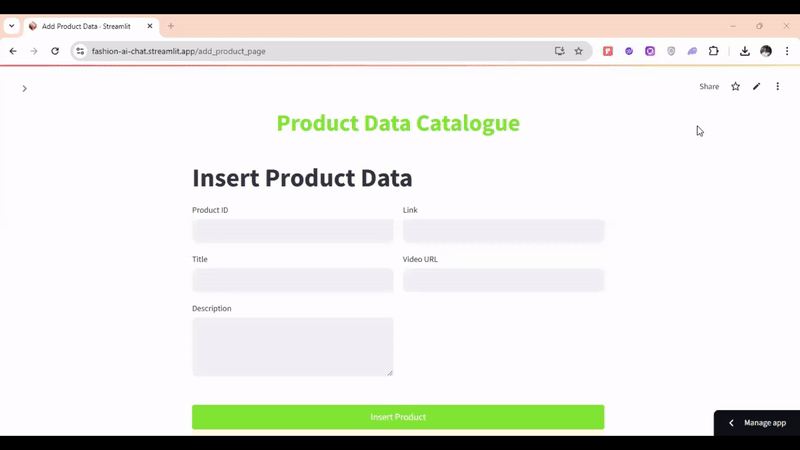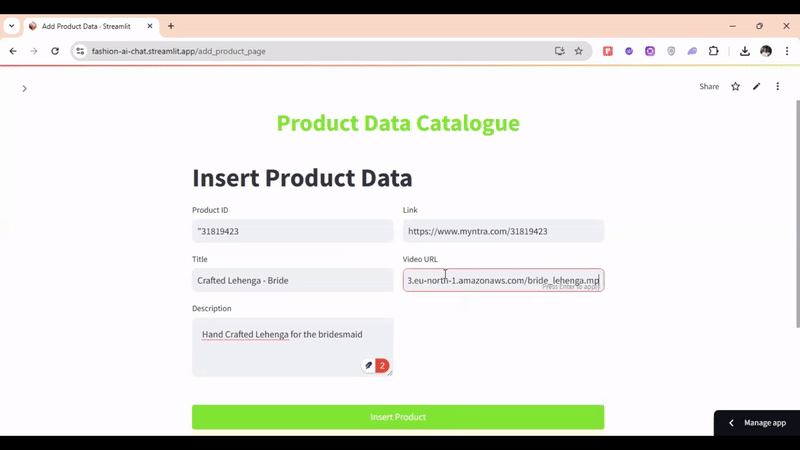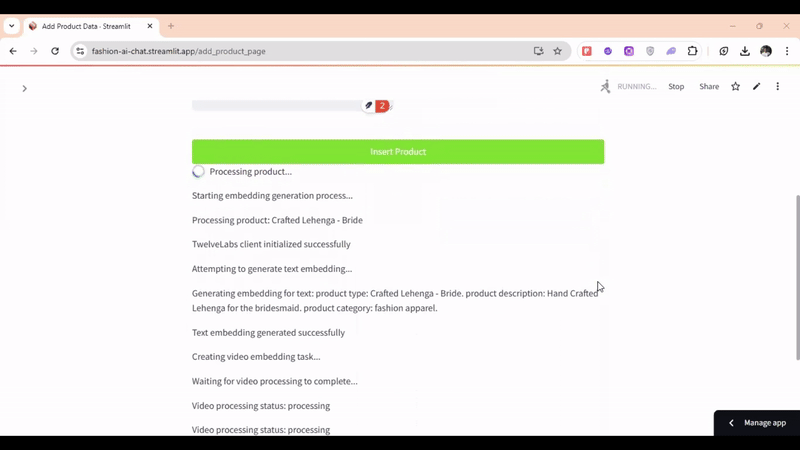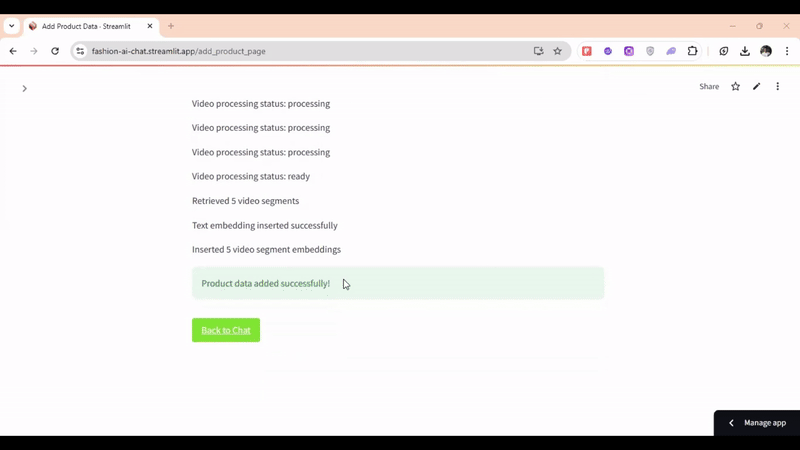
マルチモーダル検索の例として、「メンズの黒いTシャツを探しています」というクエリがあります。
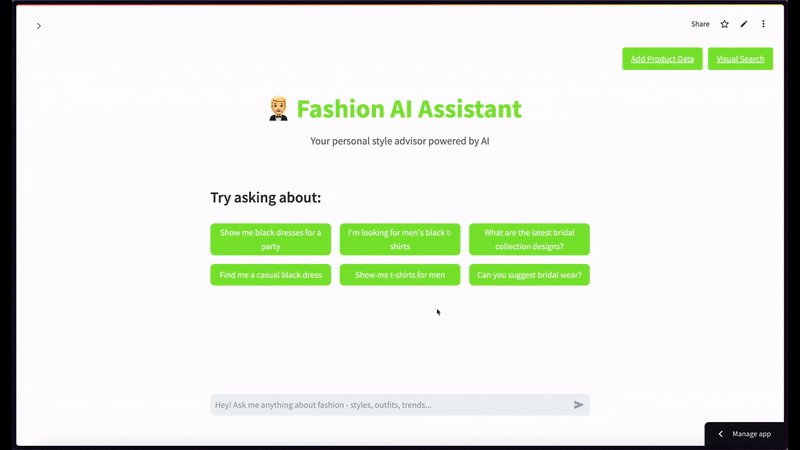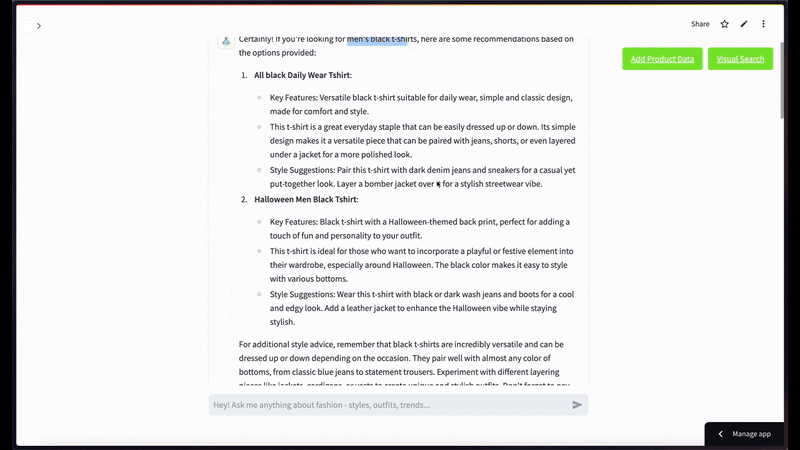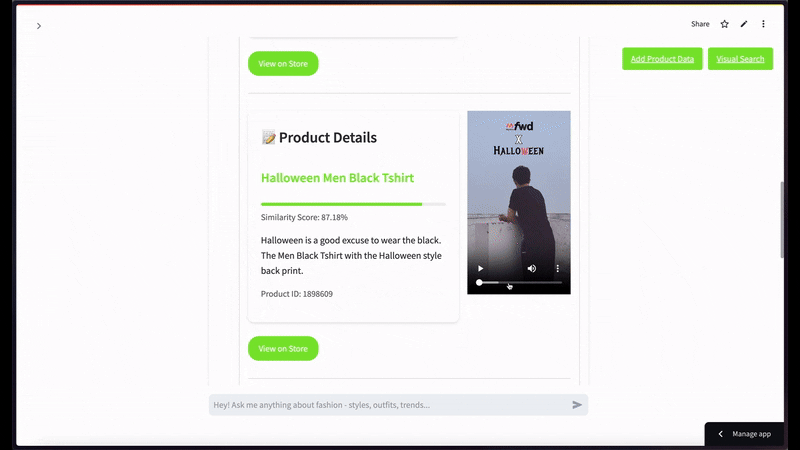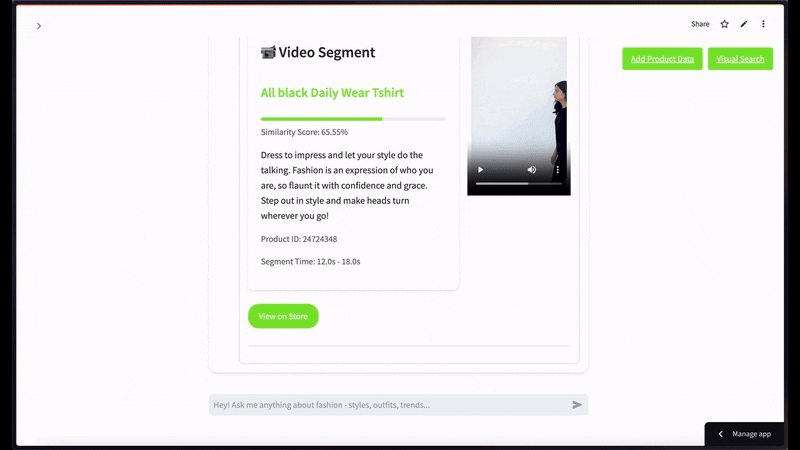
セマンティックビデオ検索では、黒いTシャツの画像をクエリとして使用し、上位2件の結果を表示する場合のようになります。
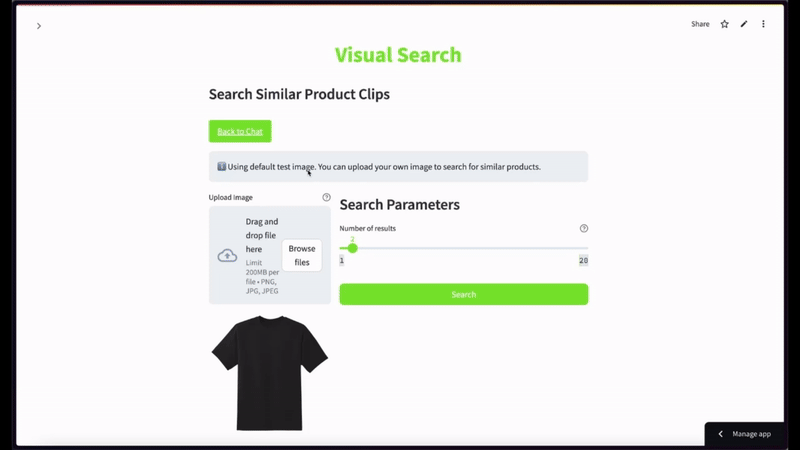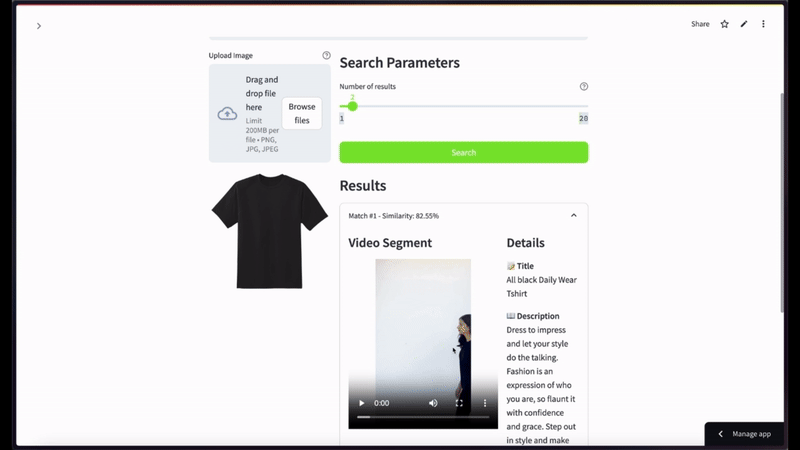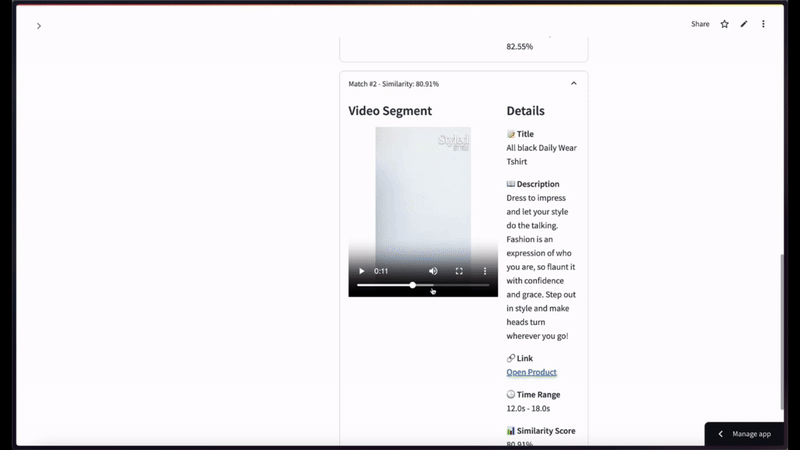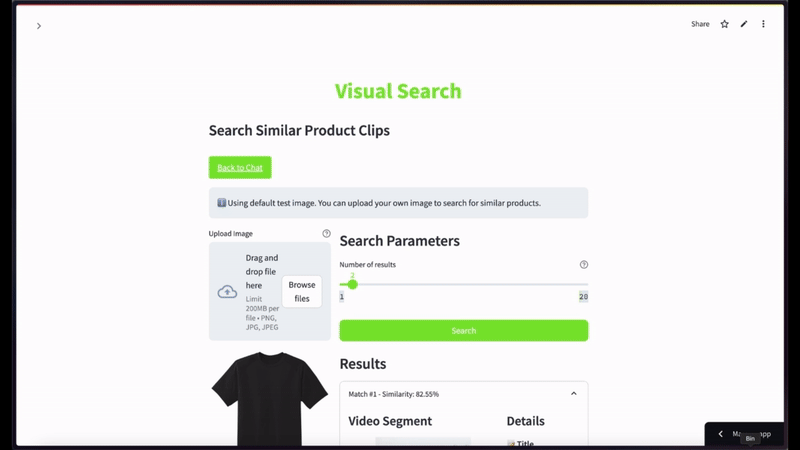
チュートリアルを応用するためのその他のアイデア
アプリケーションの仕組みと開発プロセスを理解することは、ユーザーのニーズを捉えた革新的な製品を作成するのに役立ちます。ビデオコンテンツクリエイター向けの応用可能なユースケースを提案します:
🛍️ Eコマース:テキストおよび画像クエリを用いた商品検索とおすすめ機能の強化
🎵 音楽ディスカバリー:オーディオクリップやユーザーの好みに基づいて、似た曲、アーティスト、またはジャンルを検索
🎥 インテリジェント動画検索エンジン:視覚および音声コンテンツに基づいて動画を検索し、コンテンツクリエイター、ジャーナリスト、研究者を支援
🗺️ パーソナライズされた旅行プランナー:ユーザーの好み、レビュー、目的地のデータに基づいて旅行の旅程を作成
📚 教育リソース管理:ドキュメント、プレゼンテーション、ビデオなどの学習教材を、学習内容のニーズに基づいて整理して検索
結論
このチュートリアルでは、Twelve LabsとMilvusベクトルデータベースによって駆動する埋め込みを介した、マルチモーダル検索プロセスの実装を示しました。この実装は、視覚とテキストデータの両方を処理するスケーラブルなアプリケーションを構築する方法を開発者に示しています。チュートリアルにお付き合いいただきありがとうございました。ユーザーエクスペリエンスの向上やさまざまな課題を解決するためのご意見やアイデアを歓迎します。
追加リソース
埋め込み生成エンジンであるMarengo-retrieval-2.7についてさらに詳しく。Twelve Labsをさらに探索し、ビデオコンテンツ解析への理解を深めるには、以下のリソースを確認してください:
Discord コミュニティ:開発者や熱心なファンが集まる活気あるコミュニティに参加して、アイデアを議論したり、質問したり、プロジェクトをシェアしましょう。Twelve Labs Discordに参加する
サンプルアプリケーション:次のプロジェクトのインスピレーションを得たり、新しい実装テクニックを学ぶためのさまざまなサンプルアプリケーションを探索できます
チュートリアルの探索:包括的なチュートリアルを通じて、Twelve Labsの実力をさらに深く知ることができます
これらのリソースを活用して知識を広げ、Twelve Labsのシステムビデオ理解テクノロジーを使用した革新的なアプリケーションを作成することをお勧めします。
はじめに
言葉だけでなく視覚的な好みまで理解してくれる専属のファッションアドバイザーが、24時間365日いつでも利用できたらどうなるか、考えたことはありますか?気に入ったコーディネートの写真を見せるだけで、AIが瞬時に似たスタイルの提案をしてくれたり、憧れのルックを言葉で伝えるだけで、それにマッチするコーディネートの提案を受け取ったりすることを想像してみてください 👚
当社のFashion AIアシスタントアプリケーションは、次世代の製品発見(プロダクトディスカバリー)のために構築されています。このチュートリアルでは、マルチモーダルな検索と対話型AIを組み合わせた、当社の高度なファッション推薦システムについて説明します。このシステムは、 TwelveLabs EmbedのMarengo-retrieval-2.7モデルを使用して、テキストとビデオコンテンツの両方から埋め込み(embeddings)を生成し、異なるデータタイプ間でのシームレスな検索を可能にします。
このアプリケーションは、効率的な類似性検索を行うためのベクトルデータベースとして Milvusを使用し、自然言語処理のためにOpenAIのgpt-3.5を統合しています。テキストと画像両方の入力からファッションに関するクエリを処理し、関連する製品説明と正確なビデオタイムスタンプを見つけ出し、ユーザーが探しているアイテムがビデオ内のどこに登場するかを正確に示します。
この強力な組み合わせにより、テキストとビジュアルの両方のクエリを理解し、マルチモーダルなコンテンツで強化された文脈に沿った回答を提供するシステムが構築されます。
このアプリケーションがどのように機能するのか、そして TwelveLabs Python SDKおよび Milvus Python SDKを使用して同様のソリューションをどのように構築できるかを見ていきましょう。
アプリケーションのデモはこちらからお試しいただけます: Fashion AI Chat App。
コードにアクセスしてアプリを直接試してみたい場合は、こちらの Replit Templateをご利用いただけます。
前提条件
Twelve Labs Playgroundに登録して、APIキーを生成します。
設定ガイドに従って、Milvusサーバーのインストールとセットアップを行います。
このアプリケーションのリポジトリは Fashion AI Chat Applicationにあります。
Python、Streamlit、CSSについて、ある程度の知識があらかじめ必要となります。
アプリケーションの仕組み
ここでは、アプリケーションの動作の概要と、そのコンポーネントがどのように相互作用するかを示します。
このアプリケーションには、3つの主な機能があります:
埋め込みの生成とMilvusベクトルデータベースへの挿入
クエリ画像からビデオセグメントへの検索
マルチモーダル検索(テキストおよびビデオセグメント)のための、対話型Retrieval Augmented Generation (RAG)
このチュートリアルアプリケーションでは、Twelve Labs Embed - Marengo-retrieval-2.7を使用して、製品カタログデータをベクトルデータベースに格納する方法を示します。テキストとビデオコンテンツの両方に該当する埋め込みは、同一のMilvusベクトルデータベースのコレクションに保存されます。わかりやすさと再利用性を考慮して、Twelve Labsの埋め込み関数は各ユーティリティ関数内で定義されています。
アプリケーションを期待通りに動作させるには、埋め込みデータをコレクションに挿入する必要があります。または、このアプリケーションで使用されているこちらの提供サンプルデータを参照することもできます。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数に設定します。
GitHubからプロジェクトをクローンするか、 Replit Templateを使用します。事前に定義された仮想環境が付属しているため、Replitテンプレートの使用をお勧めします。セットアップ時にはシークレットファイルを追加することを忘れずに、 Replit のシークレットキーに関するドキュメントを参照してください。
Twelve Labs、Milvus接続、およびLLMモデル用のOpenAI APIキーを含む
.envファイルを作成します。
Milvusベクトルデータベースの認証情報にはZilliz Cloudを使用した設定を行っていますが、他の接続方法については 設定ガイドでも確認できます。
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
これらの手順が完了したら、開発を始める準備は完了です!
ファッションチャットアプリケーションの実装解説
このチュートリアルでは、最小限のフロントエンドを備えたStreamlitアプリケーションを作成します。ディレクトリ構造を見てみましょう:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit アプリケーションの作成
セットアップが完了したところで、Streamlitアプリケーションを構築していきましょう。
仮想環境の作成に必要なすべての依存関係は、こちらで確認できます: requirements.txt
Pythonの仮想環境を作成し、次のコマンドを使用してアプリケーションの環境をセットアップします:
pip install -r requirements.txt
ユーティリティ関数の定義
このセクションでは、中心となるロジックと実装が含まれている utility.pyについて説明します。各サブセクションを詳しく処理していきましょう:
1 - 接続のセットアップ
最初のステップでは、環境変数をロードし、LLMアクセスのためのOpenAI、コレクション管理のためのMilvus、そしてTwelve Labsの初期化のための接続を確立します。
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API を使用した埋め込みの生成
このセクションでは、マルチモーダル検索用の Marengo-retrieval-2.7 モデルを搭載したTwelve Labs SDKを使用した埋め込み生成について説明します。このソリューションは、効率的な検索埋め込みを作成するために、テキストとビデオの処理を統合しています。
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
このプロセスは、一貫性があり意味のある埋め込みを保証するために、テキストを構造化およびフォーマットすることから始まります。次に動画の埋め込みが行われ、ステータスの監視や進捗の追跡が処理されます。各ビデオセグメントは6秒に設定されています(video_clip_length=6)。
メタデータの追跡は、トレーサビリティを維持し、正確なビデオセグメントおよびテキスト検索を可能にするために不可欠です。その後、結果はMilvusベクトルデータベースのコレクションに格納されます。
3 - Milvus ベクトルデータベースへの埋め込みの挿入
ベクトルデータベースは、高次元の埋め込みデータを効率的に保存、検索することができます。このセクションでは、適切なメタデータ管理およびエラーハンドリングを行いつつ、テキストとビデオ両方の埋め込みをMilvusベクトルデータベースに挿入する方法を説明します。
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID、ベクトル、メタデータを定義した後、同じコレクション空間内で異なるフォーマットに対応できるようにするために embedding_type を指定します。その後、データは collection.insert メソッドを使用して挿入されます。
4 - 画像から動画を検索するためのセマンティック検索の実装
画像クエリによるセマンティック検索により、類似するビデオコンテンツを探すことができます。この実装は、Twelve Labsの埋め込み機能とMilvusのベクトル検索を組み合わせています。ユーティリティ関数であるsearched_similar_videosがどのように機能するかを以下に示します:
まず、システムは製品画像をロードして読み込み、類似する製品が含まれるビデオセグメントを探します。次にTwelve Labsの埋め込み(embed)が画像を埋め込みに変換し、Milvusコレクションに格納された動画埋め込みに対してセマンティック検索を実行します。
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
検索には、速度と精度のバランスを取るために、コサイン類似度とクラスターパラメータが使用されます。collection.search が embedding_type == 'video' やその他のパラメータとともに実行されると、指定された数の製品ビデオセグメントを検索(リトリーブ)します。
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
システムは結果を処理し、明確にするために類似度のスコアを割合(%)に変換し、メタデータを構造化された辞書形式に整理します。
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
ソートされた結果は、画面に表示することができます。UIの実装はvision_searchで確認できます。
5 - RAG (Retrieval Augmented Generation) システムの開発
このセクションでは、ファッションアシスタントの文脈における質問応答に焦点を当て、マルチモーダル検索とLLM (gpt-3.5) を組み合わせて文脈に即した回答を作成します。効果的なパーソナライズ化のために、メタデータを持つテキストおよび動画データからのマルチモーダル検索を重視しています。get_rag_response関数がRAG機能を実装しています。
プロセスは、Twelve Labsの埋め込みでMarengo-retrieval-2.7エンジンを使用してユーザーの質問と文脈をテキスト埋め込みに変換し、データベース全体に対するセマンティック検索を可能にすることから始まります。
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
セマンティック検索のパラメータを設定した後、システムはテキストと動画セグメントに対して別々にコレクション検索を実行します。動画セグメント検索では、テキストクエリに最も関連するセグメントを見つけ出し、ユーザーに包括的な探索オプションを提供します。
expr メソッドにより検索条件が絞り込まれ、テキスト検索と動画検索で異なるリミット値が適用されます。典型的な検索では、メタデータを持つ2つのテキスト製品と3つの関連ビデオセグメントを検索します。
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
結果の処理中、システムは各セグメントからメタデータを抽出し、類似度のスコアを割合(%)に変換し、製品の詳細を構造化された辞書形式に整理します。
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
関連する情報を収集した後、システムはRetrieval Augmented Generation(検索拡張生成)のステップに進みます。検索されたコンテキスト(文脈情報)は、効率的なLLM処理のために構造化されます。
システムは、システムプロンプトとユーザープロンプトの両方を定義します。システムプロンプトはファッションアドバイザーとしての役割を確立し、ユーザープロンプトはユーザーのクエリとデータベースから取得したコンテキストを組み合わせます。コンテキスト取得が失敗した場合のエラーハンドリングも含まれています。
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
text_context には検索された情報が含まれます。gpt-3.5-turbo を使用して、システムはシステムプロンプトで指定されたように、説明、提案、ユーザー向けのガイダンスを含む応答を生成します。その応答は、アクセスしやすい辞書構造にフォーマットされます。UI実装の詳細については、appを参照してください。
デモアプリケーション
このデモは、データベース挿入の簡略化、効率的なマルチモーダル検索の有効化、そしてユーザーのための検索機能の向上の3つの主な目的を持ったパーツに分かれています。
データベースへのテキストおよびビデオ埋め込みの生成と挿入
LLMとのチャット対話を通じたマルチモーダルデータの検索
関連するビデオセグメントを見つけるための、製品画像ベースの検索
製品データカタログには、製品ID、テキスト、説明、リンク、およびビデオURLなどのフィールドが含まれます。テキストデータは埋め込みに変換され、その他のデータはメタデータとして保存されます。動画セグメントについて、システムは動画URLを処理します。すべての埋め込みは単一のコレクションに保存されます。
マルチモーダル検索の例として、「メンズの黒いTシャツを探しています」というクエリがあります。
セマンティックビデオ検索では、黒いTシャツの画像をクエリとして使用し、上位2件の結果を表示する場合のようになります。
チュートリアルを応用するためのその他のアイデア
アプリケーションの仕組みと開発プロセスを理解することは、ユーザーのニーズを捉えた革新的な製品を作成するのに役立ちます。ビデオコンテンツクリエイター向けの応用可能なユースケースを提案します:
🛍️ Eコマース:テキストおよび画像クエリを用いた商品検索とおすすめ機能の強化
🎵 音楽ディスカバリー:オーディオクリップやユーザーの好みに基づいて、似た曲、アーティスト、またはジャンルを検索
🎥 インテリジェント動画検索エンジン:視覚および音声コンテンツに基づいて動画を検索し、コンテンツクリエイター、ジャーナリスト、研究者を支援
🗺️ パーソナライズされた旅行プランナー:ユーザーの好み、レビュー、目的地のデータに基づいて旅行の旅程を作成
📚 教育リソース管理:ドキュメント、プレゼンテーション、ビデオなどの学習教材を、学習内容のニーズに基づいて整理して検索
結論
このチュートリアルでは、Twelve LabsとMilvusベクトルデータベースによって駆動する埋め込みを介した、マルチモーダル検索プロセスの実装を示しました。この実装は、視覚とテキストデータの両方を処理するスケーラブルなアプリケーションを構築する方法を開発者に示しています。チュートリアルにお付き合いいただきありがとうございました。ユーザーエクスペリエンスの向上やさまざまな課題を解決するためのご意見やアイデアを歓迎します。
追加リソース
埋め込み生成エンジンであるMarengo-retrieval-2.7についてさらに詳しく。Twelve Labsをさらに探索し、ビデオコンテンツ解析への理解を深めるには、以下のリソースを確認してください:
Discord コミュニティ:開発者や熱心なファンが集まる活気あるコミュニティに参加して、アイデアを議論したり、質問したり、プロジェクトをシェアしましょう。Twelve Labs Discordに参加する
サンプルアプリケーション:次のプロジェクトのインスピレーションを得たり、新しい実装テクニックを学ぶためのさまざまなサンプルアプリケーションを探索できます
チュートリアルの探索:包括的なチュートリアルを通じて、Twelve Labsの実力をさらに深く知ることができます
これらのリソースを活用して知識を広げ、Twelve Labsのシステムビデオ理解テクノロジーを使用した革新的なアプリケーションを作成することをお勧めします。
はじめに
言葉だけでなく視覚的な好みまで理解してくれる専属のファッションアドバイザーが、24時間365日いつでも利用できたらどうなるか、考えたことはありますか?気に入ったコーディネートの写真を見せるだけで、AIが瞬時に似たスタイルの提案をしてくれたり、憧れのルックを言葉で伝えるだけで、それにマッチするコーディネートの提案を受け取ったりすることを想像してみてください 👚
当社のFashion AIアシスタントアプリケーションは、次世代の製品発見(プロダクトディスカバリー)のために構築されています。このチュートリアルでは、マルチモーダルな検索と対話型AIを組み合わせた、当社の高度なファッション推薦システムについて説明します。このシステムは、 TwelveLabs EmbedのMarengo-retrieval-2.7モデルを使用して、テキストとビデオコンテンツの両方から埋め込み(embeddings)を生成し、異なるデータタイプ間でのシームレスな検索を可能にします。
このアプリケーションは、効率的な類似性検索を行うためのベクトルデータベースとして Milvusを使用し、自然言語処理のためにOpenAIのgpt-3.5を統合しています。テキストと画像両方の入力からファッションに関するクエリを処理し、関連する製品説明と正確なビデオタイムスタンプを見つけ出し、ユーザーが探しているアイテムがビデオ内のどこに登場するかを正確に示します。
この強力な組み合わせにより、テキストとビジュアルの両方のクエリを理解し、マルチモーダルなコンテンツで強化された文脈に沿った回答を提供するシステムが構築されます。
このアプリケーションがどのように機能するのか、そして TwelveLabs Python SDKおよび Milvus Python SDKを使用して同様のソリューションをどのように構築できるかを見ていきましょう。
アプリケーションのデモはこちらからお試しいただけます: Fashion AI Chat App。
コードにアクセスしてアプリを直接試してみたい場合は、こちらの Replit Templateをご利用いただけます。
前提条件
Twelve Labs Playgroundに登録して、APIキーを生成します。
設定ガイドに従って、Milvusサーバーのインストールとセットアップを行います。
このアプリケーションのリポジトリは Fashion AI Chat Applicationにあります。
Python、Streamlit、CSSについて、ある程度の知識があらかじめ必要となります。
アプリケーションの仕組み
ここでは、アプリケーションの動作の概要と、そのコンポーネントがどのように相互作用するかを示します。
このアプリケーションには、3つの主な機能があります:
埋め込みの生成とMilvusベクトルデータベースへの挿入
クエリ画像からビデオセグメントへの検索
マルチモーダル検索(テキストおよびビデオセグメント)のための、対話型Retrieval Augmented Generation (RAG)
このチュートリアルアプリケーションでは、Twelve Labs Embed - Marengo-retrieval-2.7を使用して、製品カタログデータをベクトルデータベースに格納する方法を示します。テキストとビデオコンテンツの両方に該当する埋め込みは、同一のMilvusベクトルデータベースのコレクションに保存されます。わかりやすさと再利用性を考慮して、Twelve Labsの埋め込み関数は各ユーティリティ関数内で定義されています。
アプリケーションを期待通りに動作させるには、埋め込みデータをコレクションに挿入する必要があります。または、このアプリケーションで使用されているこちらの提供サンプルデータを参照することもできます。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数に設定します。
GitHubからプロジェクトをクローンするか、 Replit Templateを使用します。事前に定義された仮想環境が付属しているため、Replitテンプレートの使用をお勧めします。セットアップ時にはシークレットファイルを追加することを忘れずに、 Replit のシークレットキーに関するドキュメントを参照してください。
Twelve Labs、Milvus接続、およびLLMモデル用のOpenAI APIキーを含む
.envファイルを作成します。
Milvusベクトルデータベースの認証情報にはZilliz Cloudを使用した設定を行っていますが、他の接続方法については 設定ガイドでも確認できます。
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
これらの手順が完了したら、開発を始める準備は完了です!
ファッションチャットアプリケーションの実装解説
このチュートリアルでは、最小限のフロントエンドを備えたStreamlitアプリケーションを作成します。ディレクトリ構造を見てみましょう:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit アプリケーションの作成
セットアップが完了したところで、Streamlitアプリケーションを構築していきましょう。
仮想環境の作成に必要なすべての依存関係は、こちらで確認できます: requirements.txt
Pythonの仮想環境を作成し、次のコマンドを使用してアプリケーションの環境をセットアップします:
pip install -r requirements.txt
ユーティリティ関数の定義
このセクションでは、中心となるロジックと実装が含まれている utility.pyについて説明します。各サブセクションを詳しく処理していきましょう:
1 - 接続のセットアップ
最初のステップでは、環境変数をロードし、LLMアクセスのためのOpenAI、コレクション管理のためのMilvus、そしてTwelve Labsの初期化のための接続を確立します。
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API を使用した埋め込みの生成
このセクションでは、マルチモーダル検索用の Marengo-retrieval-2.7 モデルを搭載したTwelve Labs SDKを使用した埋め込み生成について説明します。このソリューションは、効率的な検索埋め込みを作成するために、テキストとビデオの処理を統合しています。
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
このプロセスは、一貫性があり意味のある埋め込みを保証するために、テキストを構造化およびフォーマットすることから始まります。次に動画の埋め込みが行われ、ステータスの監視や進捗の追跡が処理されます。各ビデオセグメントは6秒に設定されています(video_clip_length=6)。
メタデータの追跡は、トレーサビリティを維持し、正確なビデオセグメントおよびテキスト検索を可能にするために不可欠です。その後、結果はMilvusベクトルデータベースのコレクションに格納されます。
3 - Milvus ベクトルデータベースへの埋め込みの挿入
ベクトルデータベースは、高次元の埋め込みデータを効率的に保存、検索することができます。このセクションでは、適切なメタデータ管理およびエラーハンドリングを行いつつ、テキストとビデオ両方の埋め込みをMilvusベクトルデータベースに挿入する方法を説明します。
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID、ベクトル、メタデータを定義した後、同じコレクション空間内で異なるフォーマットに対応できるようにするために embedding_type を指定します。その後、データは collection.insert メソッドを使用して挿入されます。
4 - 画像から動画を検索するためのセマンティック検索の実装
画像クエリによるセマンティック検索により、類似するビデオコンテンツを探すことができます。この実装は、Twelve Labsの埋め込み機能とMilvusのベクトル検索を組み合わせています。ユーティリティ関数であるsearched_similar_videosがどのように機能するかを以下に示します:
まず、システムは製品画像をロードして読み込み、類似する製品が含まれるビデオセグメントを探します。次にTwelve Labsの埋め込み(embed)が画像を埋め込みに変換し、Milvusコレクションに格納された動画埋め込みに対してセマンティック検索を実行します。
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
検索には、速度と精度のバランスを取るために、コサイン類似度とクラスターパラメータが使用されます。collection.search が embedding_type == 'video' やその他のパラメータとともに実行されると、指定された数の製品ビデオセグメントを検索(リトリーブ)します。
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
システムは結果を処理し、明確にするために類似度のスコアを割合(%)に変換し、メタデータを構造化された辞書形式に整理します。
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
ソートされた結果は、画面に表示することができます。UIの実装はvision_searchで確認できます。
5 - RAG (Retrieval Augmented Generation) システムの開発
このセクションでは、ファッションアシスタントの文脈における質問応答に焦点を当て、マルチモーダル検索とLLM (gpt-3.5) を組み合わせて文脈に即した回答を作成します。効果的なパーソナライズ化のために、メタデータを持つテキストおよび動画データからのマルチモーダル検索を重視しています。get_rag_response関数がRAG機能を実装しています。
プロセスは、Twelve Labsの埋め込みでMarengo-retrieval-2.7エンジンを使用してユーザーの質問と文脈をテキスト埋め込みに変換し、データベース全体に対するセマンティック検索を可能にすることから始まります。
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
セマンティック検索のパラメータを設定した後、システムはテキストと動画セグメントに対して別々にコレクション検索を実行します。動画セグメント検索では、テキストクエリに最も関連するセグメントを見つけ出し、ユーザーに包括的な探索オプションを提供します。
expr メソッドにより検索条件が絞り込まれ、テキスト検索と動画検索で異なるリミット値が適用されます。典型的な検索では、メタデータを持つ2つのテキスト製品と3つの関連ビデオセグメントを検索します。
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
結果の処理中、システムは各セグメントからメタデータを抽出し、類似度のスコアを割合(%)に変換し、製品の詳細を構造化された辞書形式に整理します。
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
関連する情報を収集した後、システムはRetrieval Augmented Generation(検索拡張生成)のステップに進みます。検索されたコンテキスト(文脈情報)は、効率的なLLM処理のために構造化されます。
システムは、システムプロンプトとユーザープロンプトの両方を定義します。システムプロンプトはファッションアドバイザーとしての役割を確立し、ユーザープロンプトはユーザーのクエリとデータベースから取得したコンテキストを組み合わせます。コンテキスト取得が失敗した場合のエラーハンドリングも含まれています。
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
text_context には検索された情報が含まれます。gpt-3.5-turbo を使用して、システムはシステムプロンプトで指定されたように、説明、提案、ユーザー向けのガイダンスを含む応答を生成します。その応答は、アクセスしやすい辞書構造にフォーマットされます。UI実装の詳細については、appを参照してください。
デモアプリケーション
このデモは、データベース挿入の簡略化、効率的なマルチモーダル検索の有効化、そしてユーザーのための検索機能の向上の3つの主な目的を持ったパーツに分かれています。
データベースへのテキストおよびビデオ埋め込みの生成と挿入
LLMとのチャット対話を通じたマルチモーダルデータの検索
関連するビデオセグメントを見つけるための、製品画像ベースの検索
製品データカタログには、製品ID、テキスト、説明、リンク、およびビデオURLなどのフィールドが含まれます。テキストデータは埋め込みに変換され、その他のデータはメタデータとして保存されます。動画セグメントについて、システムは動画URLを処理します。すべての埋め込みは単一のコレクションに保存されます。
マルチモーダル検索の例として、「メンズの黒いTシャツを探しています」というクエリがあります。
セマンティックビデオ検索では、黒いTシャツの画像をクエリとして使用し、上位2件の結果を表示する場合のようになります。
チュートリアルを応用するためのその他のアイデア
アプリケーションの仕組みと開発プロセスを理解することは、ユーザーのニーズを捉えた革新的な製品を作成するのに役立ちます。ビデオコンテンツクリエイター向けの応用可能なユースケースを提案します:
🛍️ Eコマース:テキストおよび画像クエリを用いた商品検索とおすすめ機能の強化
🎵 音楽ディスカバリー:オーディオクリップやユーザーの好みに基づいて、似た曲、アーティスト、またはジャンルを検索
🎥 インテリジェント動画検索エンジン:視覚および音声コンテンツに基づいて動画を検索し、コンテンツクリエイター、ジャーナリスト、研究者を支援
🗺️ パーソナライズされた旅行プランナー:ユーザーの好み、レビュー、目的地のデータに基づいて旅行の旅程を作成
📚 教育リソース管理:ドキュメント、プレゼンテーション、ビデオなどの学習教材を、学習内容のニーズに基づいて整理して検索
結論
このチュートリアルでは、Twelve LabsとMilvusベクトルデータベースによって駆動する埋め込みを介した、マルチモーダル検索プロセスの実装を示しました。この実装は、視覚とテキストデータの両方を処理するスケーラブルなアプリケーションを構築する方法を開発者に示しています。チュートリアルにお付き合いいただきありがとうございました。ユーザーエクスペリエンスの向上やさまざまな課題を解決するためのご意見やアイデアを歓迎します。
追加リソース
埋め込み生成エンジンであるMarengo-retrieval-2.7についてさらに詳しく。Twelve Labsをさらに探索し、ビデオコンテンツ解析への理解を深めるには、以下のリソースを確認してください:
Discord コミュニティ:開発者や熱心なファンが集まる活気あるコミュニティに参加して、アイデアを議論したり、質問したり、プロジェクトをシェアしましょう。Twelve Labs Discordに参加する
サンプルアプリケーション:次のプロジェクトのインスピレーションを得たり、新しい実装テクニックを学ぶためのさまざまなサンプルアプリケーションを探索できます
チュートリアルの探索:包括的なチュートリアルを通じて、Twelve Labsの実力をさらに深く知ることができます
これらのリソースを活用して知識を広げ、Twelve Labsのシステムビデオ理解テクノロジーを使用した革新的なアプリケーションを作成することをお勧めします。








