" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
트웰브랩스
Cutting Edge Isn’t Plug-and-Play: Customizing FlashAttention-4 on B300

Sam Choi
정말 Cutting Edge를 달리고 싶다면, 더 이상 Plug and Play는 가능하지 않습니다. 저희는 필요할 때 직접 문제를 풀며 계속해서 빠르게 달려가는 팀이 되려고 합니다.
정말 Cutting Edge를 달리고 싶다면, 더 이상 Plug and Play는 가능하지 않습니다. 저희는 필요할 때 직접 문제를 풀며 계속해서 빠르게 달려가는 팀이 되려고 합니다.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
2026/05/29
10 mins
Copy link to article
B300이 왜 H100보다 느리지?
첫 B300 학습에서 들었던 생각입니다. Spec Sheet 기준 이전 세대 (Hopper, H100) 대비 3.5배의 VRAM, 2배 이상의 Max FLOPs이어야 하는데, model forward/backward가 오히려 느려졌어요. 원인을 찾기 위해 코드를 파고들다 보니, 문제는 Transformer의 핵심, attention에 있었습니다. 더 정확히는, attention을 빠르게 해주는 Flash Attention Kernel이 문제였어요.
그동안은 Hopper 전용으로 튜닝된 Flash Attention 3 (FA3) Kernel을 쓰고 있었습니다. 그런데 Blackwell 구조인 B300에서는 해당 커널을 사용할 수 없었고, 이보다 더 generic한 이전 세대 커널, 즉 Flash Attention 2 (FA2)로 fallback하고 있었어요. 하드웨어는 한 세대 진보했지만, 소프트웨어는 한 세대 퇴보한 셈이죠.
다행히 Blackwell 용으로 작성된 Flash Attention 4 (FA4)가 당시 pre-release로 공개돼 있었어요. FA3가 그랬던 것처럼, FA4 역시 Blackwell에서 이전 커널 대비 큰 폭의 성능 개선을 목표로 한 rewrite였습니다. 그러나 안타깝게도, 저희가 바로 가져와서 쓰는 건 불가능했습니다. 저희 모델이 쓰는 attention head dimension은 당시 FA4 지원 목록 밖에 있었기 때문이에요.
일반적으로 이 시점에 내릴 수 있는 결정은 두 가지 중 하나입니다.
FA4가 지원하는 head dimension에 맞춰 모델 재설계.
아키텍처는 유지하고, 더 오래된 fallback 커널 사용.
저희가 내린 결정은 둘다 아닌, 3번. 저희 모델의 head dimension에 맞게 커널을 직접 작성하는 것이었어요.
이 글은 Research Scientist가 커널 작성에 직접 뛰어들면서, 최신 하드웨어가 왜 plug-and-play가 아닌지, 그리고 모델 팀이 필요한 성능을 얻기 위해 어디까지 내려가야 하는지를 배운 기록입니다.
Flash Attention Recap & 왜 매 세대 다시 쓰여야 하나
필요한 만큼만 짧게 짚어보겠습니다.
Attention을 그대로 계산하면, score matrix S = Q · Kᵀ # [..., T_q, T_k] 전체를 HBM (GPU 메인 메모리) 에 만들어야 해요. Sequence length가 커질수록, 실제 matmul 연산보다 결과값을 메모리에 적고 다시 읽는 데에 더 많은 시간을 쓰게 됩니다. FlashAttention의 아이디어는 해당 matmul들을 sequence 축에 대해 더 작은 “연산 조각”으로 쪼개서 (tiling) matrix 중간값들을 HBM에 쓰지 않고도 attention 연산이 가능하게 한 것이었습니다. 덕분에 수학적으로는 동일하지만, 훨씬 적은 메모리 트래픽을 사용하고 속도도 챙길 수 있게 되었어요.
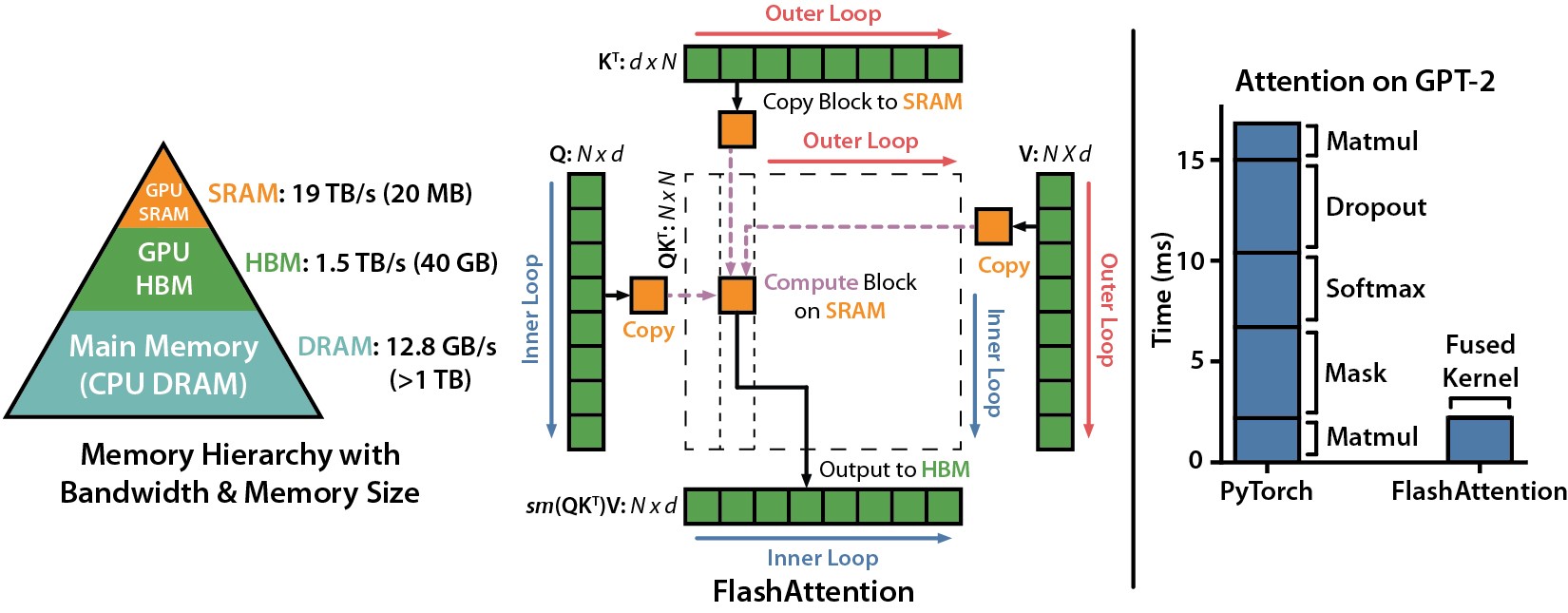
Image reference: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, Dao et al., 2022
문제는, 가장 효율적으로 "연산을 쪼개는" 방식이 GPU architecture 마다 달라진다는 점입니다. Tensor Core가 커지기도 하고, 새로운 memory class가 생기고, 새로운 instruction이 생기기도 하면서, 이전 세대에 optimal했던 Flash Attention 커널이 다음 세대에선 동작하지 않거나, 최대 효율을 뽑아내지 못하게 돼요.
FA2는 Ampere 시대에 작성되었고, 범용적이어서 이후 세대에서도 동작은 하지만 최대 효율을 뽑진 못해요.
FA3는 Hopper 전용 rewrite이에요 (H100, H200). Hopper가 아닌 GPU 에서는 동작하지 않아요.
FA4는 Blackwell 전용 rewrite이에요 (B200, B300). Blackwell에서 새로 도입된 TMEM (Processor 에 직결되어있는 메모리)과 2-CTA MMA (두 CTA가 협력해 하나의 matmul을 수행하는 방식)를 활용해요.
FA4 의 또 다른 특징은 바로 C++/CUTLASS가 아니라 CuTe-DSL(CUTLASS의 building block 위에 얹힌 Python frontend)로 쓰여있다는 점이에요. 덕분에 tooling 및 compile이 용이해졌고, 이게 이전 세대 대비 직접 커널 개발에 뛰어들 수 있게 하는 주요한 역할을 했습니다.
당시 (2026년 3월) 공개된 Blackwell 용 FA4 는 자주 쓰이는 몇 가지 head dimension에 대한 지원만 들어있었어요. 그 외의 shape에 대해서는 AssertionError가 발생했습니다.
GPU 용어 정리
블로그를 이해하는 데 필수적인 B300 관련 GPU 용어 및 개념들만 정리하고 넘어가겠습니다.
Tensor Core / MMA — 행렬 곱(matmul)을 한 instruction으로 처리하는 전용 회로. 정식 이름은 Matrix Multiply-Accumulate —
D = A · B + C형태예요. 최신 GPU에서 attention 산수의 거의 전부가 여기서 일어나요.TMEM (Tensor Memory) — Blackwell이 추가한 새로운 memory class. Tensor Core 와 직접 연결되어 있어서 MMA의 중간값들을 적어놓는 빠른 on-chip scratchpad로 쓰여요. 빠른 대신 예산이 빡빡해서, 무엇을 언제 올려놓을지가 커널 설계의 핵심이 됩니다.
Producer/Consumer — GPU programming에서는 데이터를 메모리에 올리는 Producer, 메모리에서 데이터를 읽는 Consumer라는 컨셉이 있습니다. 이 둘은 동시에 같은 메모리 buffer에 작업할 수 없습니다.
실제 구현해야 했던 것들
저는 숙련된 kernel engineer가 아니다보니, 처음부터 instruction-level 디테일로 들어가지는 못했습니다. 먼저 "무엇이 느린가", "왜 기존 경로가 안 맞는가", "어떤 자원이 부족한가"를 high-level로 이해해야 했어요. 그다음에야 실제 디버깅이 가능했습니다.
그래서 일반적인 ML 연구자의 입장에서 각 작업의 갈래부터 먼저 설명하고, 구현적인 디테일을 풀어보겠습니다.
Phase 1. Forward Pass
Blackwell에서 중요한 건 TMEM을 얼마나 잘 사용하느냐입니다. 기존 FA4 forward kernel은 MMA stage를 double buffering하고 있었는데요, 두 개의 stage를 TMEM 안에 유지해 두고 현재 stage를 계산하는 동안 다음 stage를 준비해 stall을 줄이는 방식입니다. 그런데 저희 모델의 shape에서는 두 번째 stage까지 TMEM에 유지하면 예산이 넘었습니다.
해결책은 생각보다 단순했어요. Double buffering을 끄고 single buffering으로 바꾸니 TMEM 예산 안에 들어왔습니다. 자연스럽게 "그러면 pipeline stall이 생겨서 느려지지 않나?"라는 생각이 들 수 있지만, 여기서는 먼저 kernel이 Blackwell 경로로 정상 dispatch 되는 것이 중요했습니다. 실제 측정에서도 forward는 기대했던 대로, SDPA 대비 약 2배 가량 빨라졌습니다.

하지만 여기까지는 반쪽짜리 kernel이었어요. 학습에는 backward가 필요하니까요.
Phase 1.1. Backward Pass Fallback
다음으로 시도한 건 backward에서만 fa2로의 fallback이었습니다. 정확도의 문제는 없었지만, end-to-end 속도는 sdpa 보다도 느렸습니다. 일단 올바르게 돌아가는 baseline을 설정하는 것이 주된 목표였기 때문에, 빠르게 다음 단계로 넘어갔습니다.
Phase 2. Chunked Backward, TMEM 예산 안으로
Backward는 forward 보다 더 많은 중간값들을 동시에 들고 있어야 합니다. 저희 shape에서는 이 모든 것을 한 번에 TMEM 안에 배치할 수 없었습니다.
그래서 backward gradient를 sequence 축에서의 tiling과 더불어 head dim 축에서도 여러 slice로 쪼개는 방향으로 갔습니다. 각 kernel이 head dimension의 일부 slice를 맡고, 그 slice에 해당하는 gradient를 계산합니다. 이렇게 하면 한 번에 필요한 TMEM 양이 줄어들어요.
다만 이건 쉬운 문제가 아니었습니다. Gradient를 메모리에 저장하는 단위는 slice로 나눌 수 있지만, score matrix와 softmax 관련 값들은 현재 slice만으로 계산할 수 없습니다. 각 score의 원소는 head axis 전체에 대한 dot product이기 때문이에요. 그래서 각 slice kernel 안에서도, 현재 tile에 해당하는 score를 head axis 전체에 대해 다시 구성해야 정확한 값을 구할 수 있었습니다.
조금 더 디테일하게 풀어볼게요.
각 kernel invocation이 head dimension의 한 slice를 담당해요. 그 slice에 해당하는 dQ, dK, dV 를 해당 invocation이 계산하고 씁니다. 다만 dQ는 KV tile을 돌면서 같은 slice accumulator에 계속 더해지는 값입니다.
dQ와 dK 를 구하기 위해선 dS를 구해야 하고, 이를 위해선 score matrix S를 다시 만들어야 합니다. S = Q · Kᵀ이고, Q와 K의 전체 head dim에 대한 dot product이기 때문에, head dimension slice 한 조각만으로 S를 만들게 되면 틀린 값을 구하게 됩니다. 그래서 현재 slice에 대한 gradient만 저장하게끔 하더라도, 다른 slice의 값들도 가져와야 합니다.
저희의 chunked backward를 짧은 pseudo-code로 쓰면 다음과 같습니다. 여기서 O와 LSE는 forward 에서 저장해 둔 값입니다. Shape 표기는 Bq를 query tile row 수, Bk를 key/value tile row 수, H를 전체 head axis, Hc를 현재 invocation이 맡은 slice의 크기로 두겠습니다.
# Inside the q, kv loops, Q/dO/O mean the current Q tile, # and K/V mean the current KV tile. # Q, dO, O: [Bq, H], K, V: [Bk, H] # S_tile, P_tile, dP_tile, dS_tile: [Bq, Bk] # c: current slice on the head axis, width Hc for each Q tile q: for each KV tile k,v: S_tile = 0 # [Bq, Bk] dP_tile = 0 # [Bq, Bk] for each head-axis slice h: S_tile += Q[h] @ K[h].T # partial score contribution dP_tile += dO[h] @ V[h]
여기서 핵심은 S_tile와 dP_tile입니다. 둘 다 head-axis slice 하나로는 완성되지 않고, h에 대해 for-loop을 돌며 partial matmul을 더해야 현재 tile에 대해 정확한 값을 구할 수 있습니다. P_tile은 이렇게 구한 S_tile과, forward에서 저장해 둔 LSE로 만듭니다. 그래서 current KV tile만 보고도 full softmax row에 맞게 normalize 된 값을 얻을 수 있어요.
Chunked backward에서는 의도했던 대로 dQ, dK, dV를 slice 별로 나눠 씁니다. 하지만 S, P, delta, dP, dS는 [Bq, Bk], 즉 tile 전체에 대한 값입니다. 그래서 각 invocation 안에서도 Q/K/V/dO 의 다른 slice contribution을 다시 읽고 누적해야 합니다.
필요한 buffer도 이 구조에서 나옵니다.
Input tiles:
Q,K,V,dO. 현재 output slice 뿐 아니라S_tile와dP_tile를 재구성하기 위한 같은 head의 다른 slice의 값들도 필요합니다.Scratch buffer:
S/P,dP/dS. Shape은[Bq, Bk]입니다. 즉, 현재 tile 전체에 대한 gradient입니다.Output accumulator: 현재 invocation이 책임지는
dQ[c],dK[c],dV[c]slice.

버그 헌팅
큰 흐름은 위에서 얘기한 대로지만, 사실 커널이 복잡해질수록 대부분의 시간은 버그 해결이었습니다. 그중 가장 오래 걸렸던 버그 해결 과정에 대해서 풀어보겠습니다.
Correctness 이슈가 대부분 잡힌 다음에도 커널은 가장 짧은 sequence length에서만 통과했고 그보다 긴 sequence length에서는 hang이 걸렸어요. 원인은 데이터를 로드하는 Producer와 사용하는 Consumer 사이의 deadlock이었습니다. 위 pseudo-code만 보면 놓치기 쉽지만, 실제 데이터를 메모리에 올리고 내리는 instruction 순서의 문제였고, 이 순서를 재배치함으로써 해결할 수 있었습니다.
GPU 커널에서는 데이터를 메모리에 로드하는 producer와 데이터를 가져다 연산하는 consumer 사이에서 누가 어떤 buffer를 읽고 쓸 수 있는지 명시적으로 맞춰줘야 합니다. 특히 buffer가 하나뿐일 때는 producer가 다음 로드를 시작하려면 consumer가 현재 buffer를 완전히 놓아줘야 해요. 이 순서가 어긋나면 같은 resource를 두고 서로가 서로를 기다리는 deadlock이 생깁니다.
해당 버그가 정확히 그 케이스였습니다. 위 pseudo-code에 맞춰 말하면, 하나의 q, kv score tile을 처리하는 동안 consumer는 같은 K tile을 두 번 읽습니다. 먼저 S_tile += Q[h] @ K[h].T에서 읽고, dS_tile이 만들어진 뒤 다시 dQ[c] += dS_tile @ K[c]에서 읽어요. 그런데 backward kernel의 실제 schedule에서는 그 사이에 다음 sequence tile 계산을 준비하려고 producer가 같은 SMEM K input buffer를 새 K tile로 채우려 했습니다.
조금 더 디테일하게는, chunked backward에서 이 K input buffer는 stage가 하나뿐이었습니다. 일반적으로는 stage를 여럿 두어 producer와 consumer가 서로 다른 stage를 동시에 작업하게 하지만, 여기서는 on-chip buffer 예산이 빡빡해서 그렇게 하지 못했습니다. 발견하는게 특히 어려웠던 이유는 dependency chain이 생각보다 길었기 때문이었어요. S_tile을 만든 직후에는 K를 다 쓴 것처럼 보이지만, dS_tile = P_tile * (dP_tile - delta)를 계산한 뒤 dQ[c] += dS_tile @ K[c]를 만들 때 같은 K input tile을 다시 읽어야 합니다.
그런데 실제 schedule에서는 다음 tile을 준비하는 producer가 같은 SMEM buffer에 다음 K tile을 덮어쓰려 합니다. 하지만 consumer가 현재 K tile을 아직 잡고 있기 때문에 producer는 acquire 할 수 없습니다. Consumer 입장에서도 뒤의 dQ[c] += dS_tile @ K[c] matmul이 그 K tile을 다시 읽어야 하기 때문에 release 할 수 없구요. 전형적인 single-stage deadlock이었습니다.
해법은 꽤나 직관적이에요. Main loop를 reorder해서, producer가 다음 K tile을 load하기 전에 consumer가 현재 K tile을 필요로 하는 matmul들을 모두 끝내게 만들면 됩니다.
이렇듯 대부분의 버그는 알고리즘 자체의 로직이 아니었습니다. 실제 하드웨어의 구조 및 제약에 맞추는 것, 해당 과정에서의 발생할 수 있는 memory / matmul scheduling 실수들이 대부분이었고, 오랫동안 Python 위에서 비교적 편안하게 코딩하던 연구자 입장에서는 매우 신선하고 어려운 작업들이었습니다.

성능
환경에 따라 절대 숫자는 달라질 수 있으니, raw FLOPS 대신 같은 내부 benchmark 안에서의 상대 성능을 보겠습니다.
Forward만 FA4로 보내고 backward를 fallback으로 보내는 방식은 학습에 쓸 수 없었습니다. Forward 자체는 SDPA 대비 대략 2배 빨라졌지만, backward가 너무 느려서 학습 전체로 보면 이득이 사라졌어요.
Custom backward path를 구현하고 나서는 긴 sequence 영역에서 SDPA 대비 확실한 이득이 나왔습니다. 짧은 sequence에서는 여러 invocation과 후처리 overhead 때문에 여전히 손해가 있었지만, 저희가 중요하게 보는 긴 sequence 학습 구간에서는 결과가 뒤집혔습니다.

최종적으로 저희는 B300에서 FA4 kernel을 실제 Video LLM 학습에 쓸 수 있는 수준까지 끌어올렸고, 100k 이상의 packed sequence를 사용하는 실제 End-to-End 학습에서 약 30% 가량의 MFU 상승을 이끌어냈습니다.
성공적으로 개발을 마무리할 수 있었던 이유
GPU kernel level까지 다뤄본 ML 연구자는 많지 않습니다. 그런 상황에서 저희 팀이 GPU kernel을 직접 작성하는 선택을 내리고, 성공적으로 개발할 수 있었던 데에는 몇 가지 중요한 이유가 있었습니다.
첫째는 CuTe-DSL 이에요. FA4가 C++/CUTLASS가 아니라 CuTe-DSL (Python frontend)로 쓰여 있다는 건 나이브하게는 Python이 더 친숙한 ML Researcher/Engineer에게 심리적인 진입장벽을 낮춰주는 효과가 있어요. 물론 실질적으로 더 큰 차이는 iteration loop입니다. Kernel shape을 바꾸고, compile하고, 작은 test slice를 돌려보고, 다시 고치는 loop가 C++ template stack 전체를 직접 만질 때보다 훨씬 빨랐습니다.
물론 Python frontend라고 해서 kernel 개발이 쉬워지는 건 아닙니다. frontend만 Python일 뿐, 여전히 GPU Programming이긴 하니까요. single-stage deadlock, 2-CTA layout, TMEM budget 등을 구성하는 것은 동일하게 필요한 작업이었습니다. 다만 실패했을 때 돌아오는 Error message 및 feedback이 더 이해하기 쉬웠습니다. Research Scientist 입장에서는 이 차이가 컸어요.
둘째는 Test Suite 입니다. FlashAttention 레포에는 fully-parametrized correctness suite 가 들어 있습니다. dtype, sequence length, MHA / GQA / MQA, causal / non-causal, varlen 여부처럼 커널 path 를 바꾸는 축들을 넓게 커버해요. 이 suite가 없었다면, "한 workload에서는 맞아 보이는 kernel" 을 "정말 쓸 수 있는 kernel"로 착각했을 가능성이 큽니다.
셋째는 coding agent 였어요. 위의 버그 헌팅 대부분은 긴 iterative session으로 굴러갔습니다. 사람이 가설을 고르고, agent가 diff를 구현해서 관련 test slice를 돌리고, 사람이 결과를 읽고 다음 가설을 고르는 식이에요. Test suite가 좋지 않으면 이 loop는 무용지물입니다. Agent가 자기 변경이 도움이 됐는지를 알 수 없으니까요. 이 test suite에서는 loop가 빡빡하게 돌았습니다.
최신 장비를 사용한다는 건
연구실에서는 최신 하드웨어를 사용할 기회가 많지 않다 보니, 대부분의 경우 내가 사용하는 GPU 에 대한 최적화된 kernel은 누군가가 만들어놓은 경우가 많았습니다. 하지만 industry에서는 항상 그렇진 않습니다. 특히 스타트업처럼 모든게 빠르게 변화하는 환경에서는 더더욱 그렇습니다. 새로운 하드웨어가 출시되고, 누군가가 그 위에 내가 원하는 Kernel을 만들어주기까지, 길면 연 단위의 시간이 걸리는 그 기간 동안엔 공백이 발생하게 돼요. 그때, "지원되는 커널로 연구의 한계를 정하든, 직접 작성하든"의 선택지를 마주하게 됩니다.
모든 모델링 팀이 kernel까지 작성할 필요는 없습니다. 하지만 정말 Cutting Edge를 달리고 싶다면, 더 이상 Plug and Play는 가능하지 않습니다. 저희는 필요할 때 직접 문제를 풀며 계속해서 빠르게 달려가는 팀이 되려고 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]
B300이 왜 H100보다 느리지?
첫 B300 학습에서 들었던 생각입니다. Spec Sheet 기준 이전 세대 (Hopper, H100) 대비 3.5배의 VRAM, 2배 이상의 Max FLOPs이어야 하는데, model forward/backward가 오히려 느려졌어요. 원인을 찾기 위해 코드를 파고들다 보니, 문제는 Transformer의 핵심, attention에 있었습니다. 더 정확히는, attention을 빠르게 해주는 Flash Attention Kernel이 문제였어요.
그동안은 Hopper 전용으로 튜닝된 Flash Attention 3 (FA3) Kernel을 쓰고 있었습니다. 그런데 Blackwell 구조인 B300에서는 해당 커널을 사용할 수 없었고, 이보다 더 generic한 이전 세대 커널, 즉 Flash Attention 2 (FA2)로 fallback하고 있었어요. 하드웨어는 한 세대 진보했지만, 소프트웨어는 한 세대 퇴보한 셈이죠.
다행히 Blackwell 용으로 작성된 Flash Attention 4 (FA4)가 당시 pre-release로 공개돼 있었어요. FA3가 그랬던 것처럼, FA4 역시 Blackwell에서 이전 커널 대비 큰 폭의 성능 개선을 목표로 한 rewrite였습니다. 그러나 안타깝게도, 저희가 바로 가져와서 쓰는 건 불가능했습니다. 저희 모델이 쓰는 attention head dimension은 당시 FA4 지원 목록 밖에 있었기 때문이에요.
일반적으로 이 시점에 내릴 수 있는 결정은 두 가지 중 하나입니다.
FA4가 지원하는 head dimension에 맞춰 모델 재설계.
아키텍처는 유지하고, 더 오래된 fallback 커널 사용.
저희가 내린 결정은 둘다 아닌, 3번. 저희 모델의 head dimension에 맞게 커널을 직접 작성하는 것이었어요.
이 글은 Research Scientist가 커널 작성에 직접 뛰어들면서, 최신 하드웨어가 왜 plug-and-play가 아닌지, 그리고 모델 팀이 필요한 성능을 얻기 위해 어디까지 내려가야 하는지를 배운 기록입니다.
Flash Attention Recap & 왜 매 세대 다시 쓰여야 하나
필요한 만큼만 짧게 짚어보겠습니다.
Attention을 그대로 계산하면, score matrix S = Q · Kᵀ # [..., T_q, T_k] 전체를 HBM (GPU 메인 메모리) 에 만들어야 해요. Sequence length가 커질수록, 실제 matmul 연산보다 결과값을 메모리에 적고 다시 읽는 데에 더 많은 시간을 쓰게 됩니다. FlashAttention의 아이디어는 해당 matmul들을 sequence 축에 대해 더 작은 “연산 조각”으로 쪼개서 (tiling) matrix 중간값들을 HBM에 쓰지 않고도 attention 연산이 가능하게 한 것이었습니다. 덕분에 수학적으로는 동일하지만, 훨씬 적은 메모리 트래픽을 사용하고 속도도 챙길 수 있게 되었어요.
Image reference: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, Dao et al., 2022
문제는, 가장 효율적으로 "연산을 쪼개는" 방식이 GPU architecture 마다 달라진다는 점입니다. Tensor Core가 커지기도 하고, 새로운 memory class가 생기고, 새로운 instruction이 생기기도 하면서, 이전 세대에 optimal했던 Flash Attention 커널이 다음 세대에선 동작하지 않거나, 최대 효율을 뽑아내지 못하게 돼요.
FA2는 Ampere 시대에 작성되었고, 범용적이어서 이후 세대에서도 동작은 하지만 최대 효율을 뽑진 못해요.
FA3는 Hopper 전용 rewrite이에요 (H100, H200). Hopper가 아닌 GPU 에서는 동작하지 않아요.
FA4는 Blackwell 전용 rewrite이에요 (B200, B300). Blackwell에서 새로 도입된 TMEM (Processor 에 직결되어있는 메모리)과 2-CTA MMA (두 CTA가 협력해 하나의 matmul을 수행하는 방식)를 활용해요.
FA4 의 또 다른 특징은 바로 C++/CUTLASS가 아니라 CuTe-DSL(CUTLASS의 building block 위에 얹힌 Python frontend)로 쓰여있다는 점이에요. 덕분에 tooling 및 compile이 용이해졌고, 이게 이전 세대 대비 직접 커널 개발에 뛰어들 수 있게 하는 주요한 역할을 했습니다.
당시 (2026년 3월) 공개된 Blackwell 용 FA4 는 자주 쓰이는 몇 가지 head dimension에 대한 지원만 들어있었어요. 그 외의 shape에 대해서는 AssertionError가 발생했습니다.
GPU 용어 정리
블로그를 이해하는 데 필수적인 B300 관련 GPU 용어 및 개념들만 정리하고 넘어가겠습니다.
Tensor Core / MMA — 행렬 곱(matmul)을 한 instruction으로 처리하는 전용 회로. 정식 이름은 Matrix Multiply-Accumulate —
D = A · B + C형태예요. 최신 GPU에서 attention 산수의 거의 전부가 여기서 일어나요.TMEM (Tensor Memory) — Blackwell이 추가한 새로운 memory class. Tensor Core 와 직접 연결되어 있어서 MMA의 중간값들을 적어놓는 빠른 on-chip scratchpad로 쓰여요. 빠른 대신 예산이 빡빡해서, 무엇을 언제 올려놓을지가 커널 설계의 핵심이 됩니다.
Producer/Consumer — GPU programming에서는 데이터를 메모리에 올리는 Producer, 메모리에서 데이터를 읽는 Consumer라는 컨셉이 있습니다. 이 둘은 동시에 같은 메모리 buffer에 작업할 수 없습니다.
실제 구현해야 했던 것들
저는 숙련된 kernel engineer가 아니다보니, 처음부터 instruction-level 디테일로 들어가지는 못했습니다. 먼저 "무엇이 느린가", "왜 기존 경로가 안 맞는가", "어떤 자원이 부족한가"를 high-level로 이해해야 했어요. 그다음에야 실제 디버깅이 가능했습니다.
그래서 일반적인 ML 연구자의 입장에서 각 작업의 갈래부터 먼저 설명하고, 구현적인 디테일을 풀어보겠습니다.
Phase 1. Forward Pass
Blackwell에서 중요한 건 TMEM을 얼마나 잘 사용하느냐입니다. 기존 FA4 forward kernel은 MMA stage를 double buffering하고 있었는데요, 두 개의 stage를 TMEM 안에 유지해 두고 현재 stage를 계산하는 동안 다음 stage를 준비해 stall을 줄이는 방식입니다. 그런데 저희 모델의 shape에서는 두 번째 stage까지 TMEM에 유지하면 예산이 넘었습니다.
해결책은 생각보다 단순했어요. Double buffering을 끄고 single buffering으로 바꾸니 TMEM 예산 안에 들어왔습니다. 자연스럽게 "그러면 pipeline stall이 생겨서 느려지지 않나?"라는 생각이 들 수 있지만, 여기서는 먼저 kernel이 Blackwell 경로로 정상 dispatch 되는 것이 중요했습니다. 실제 측정에서도 forward는 기대했던 대로, SDPA 대비 약 2배 가량 빨라졌습니다.
하지만 여기까지는 반쪽짜리 kernel이었어요. 학습에는 backward가 필요하니까요.
Phase 1.1. Backward Pass Fallback
다음으로 시도한 건 backward에서만 fa2로의 fallback이었습니다. 정확도의 문제는 없었지만, end-to-end 속도는 sdpa 보다도 느렸습니다. 일단 올바르게 돌아가는 baseline을 설정하는 것이 주된 목표였기 때문에, 빠르게 다음 단계로 넘어갔습니다.
Phase 2. Chunked Backward, TMEM 예산 안으로
Backward는 forward 보다 더 많은 중간값들을 동시에 들고 있어야 합니다. 저희 shape에서는 이 모든 것을 한 번에 TMEM 안에 배치할 수 없었습니다.
그래서 backward gradient를 sequence 축에서의 tiling과 더불어 head dim 축에서도 여러 slice로 쪼개는 방향으로 갔습니다. 각 kernel이 head dimension의 일부 slice를 맡고, 그 slice에 해당하는 gradient를 계산합니다. 이렇게 하면 한 번에 필요한 TMEM 양이 줄어들어요.
다만 이건 쉬운 문제가 아니었습니다. Gradient를 메모리에 저장하는 단위는 slice로 나눌 수 있지만, score matrix와 softmax 관련 값들은 현재 slice만으로 계산할 수 없습니다. 각 score의 원소는 head axis 전체에 대한 dot product이기 때문이에요. 그래서 각 slice kernel 안에서도, 현재 tile에 해당하는 score를 head axis 전체에 대해 다시 구성해야 정확한 값을 구할 수 있었습니다.
조금 더 디테일하게 풀어볼게요.
각 kernel invocation이 head dimension의 한 slice를 담당해요. 그 slice에 해당하는 dQ, dK, dV 를 해당 invocation이 계산하고 씁니다. 다만 dQ는 KV tile을 돌면서 같은 slice accumulator에 계속 더해지는 값입니다.
dQ와 dK 를 구하기 위해선 dS를 구해야 하고, 이를 위해선 score matrix S를 다시 만들어야 합니다. S = Q · Kᵀ이고, Q와 K의 전체 head dim에 대한 dot product이기 때문에, head dimension slice 한 조각만으로 S를 만들게 되면 틀린 값을 구하게 됩니다. 그래서 현재 slice에 대한 gradient만 저장하게끔 하더라도, 다른 slice의 값들도 가져와야 합니다.
저희의 chunked backward를 짧은 pseudo-code로 쓰면 다음과 같습니다. 여기서 O와 LSE는 forward 에서 저장해 둔 값입니다. Shape 표기는 Bq를 query tile row 수, Bk를 key/value tile row 수, H를 전체 head axis, Hc를 현재 invocation이 맡은 slice의 크기로 두겠습니다.
# Inside the q, kv loops, Q/dO/O mean the current Q tile, # and K/V mean the current KV tile. # Q, dO, O: [Bq, H], K, V: [Bk, H] # S_tile, P_tile, dP_tile, dS_tile: [Bq, Bk] # c: current slice on the head axis, width Hc for each Q tile q: for each KV tile k,v: S_tile = 0 # [Bq, Bk] dP_tile = 0 # [Bq, Bk] for each head-axis slice h: S_tile += Q[h] @ K[h].T # partial score contribution dP_tile += dO[h] @ V[h]
여기서 핵심은 S_tile와 dP_tile입니다. 둘 다 head-axis slice 하나로는 완성되지 않고, h에 대해 for-loop을 돌며 partial matmul을 더해야 현재 tile에 대해 정확한 값을 구할 수 있습니다. P_tile은 이렇게 구한 S_tile과, forward에서 저장해 둔 LSE로 만듭니다. 그래서 current KV tile만 보고도 full softmax row에 맞게 normalize 된 값을 얻을 수 있어요.
Chunked backward에서는 의도했던 대로 dQ, dK, dV를 slice 별로 나눠 씁니다. 하지만 S, P, delta, dP, dS는 [Bq, Bk], 즉 tile 전체에 대한 값입니다. 그래서 각 invocation 안에서도 Q/K/V/dO 의 다른 slice contribution을 다시 읽고 누적해야 합니다.
필요한 buffer도 이 구조에서 나옵니다.
Input tiles:
Q,K,V,dO. 현재 output slice 뿐 아니라S_tile와dP_tile를 재구성하기 위한 같은 head의 다른 slice의 값들도 필요합니다.Scratch buffer:
S/P,dP/dS. Shape은[Bq, Bk]입니다. 즉, 현재 tile 전체에 대한 gradient입니다.Output accumulator: 현재 invocation이 책임지는
dQ[c],dK[c],dV[c]slice.
버그 헌팅
큰 흐름은 위에서 얘기한 대로지만, 사실 커널이 복잡해질수록 대부분의 시간은 버그 해결이었습니다. 그중 가장 오래 걸렸던 버그 해결 과정에 대해서 풀어보겠습니다.
Correctness 이슈가 대부분 잡힌 다음에도 커널은 가장 짧은 sequence length에서만 통과했고 그보다 긴 sequence length에서는 hang이 걸렸어요. 원인은 데이터를 로드하는 Producer와 사용하는 Consumer 사이의 deadlock이었습니다. 위 pseudo-code만 보면 놓치기 쉽지만, 실제 데이터를 메모리에 올리고 내리는 instruction 순서의 문제였고, 이 순서를 재배치함으로써 해결할 수 있었습니다.
GPU 커널에서는 데이터를 메모리에 로드하는 producer와 데이터를 가져다 연산하는 consumer 사이에서 누가 어떤 buffer를 읽고 쓸 수 있는지 명시적으로 맞춰줘야 합니다. 특히 buffer가 하나뿐일 때는 producer가 다음 로드를 시작하려면 consumer가 현재 buffer를 완전히 놓아줘야 해요. 이 순서가 어긋나면 같은 resource를 두고 서로가 서로를 기다리는 deadlock이 생깁니다.
해당 버그가 정확히 그 케이스였습니다. 위 pseudo-code에 맞춰 말하면, 하나의 q, kv score tile을 처리하는 동안 consumer는 같은 K tile을 두 번 읽습니다. 먼저 S_tile += Q[h] @ K[h].T에서 읽고, dS_tile이 만들어진 뒤 다시 dQ[c] += dS_tile @ K[c]에서 읽어요. 그런데 backward kernel의 실제 schedule에서는 그 사이에 다음 sequence tile 계산을 준비하려고 producer가 같은 SMEM K input buffer를 새 K tile로 채우려 했습니다.
조금 더 디테일하게는, chunked backward에서 이 K input buffer는 stage가 하나뿐이었습니다. 일반적으로는 stage를 여럿 두어 producer와 consumer가 서로 다른 stage를 동시에 작업하게 하지만, 여기서는 on-chip buffer 예산이 빡빡해서 그렇게 하지 못했습니다. 발견하는게 특히 어려웠던 이유는 dependency chain이 생각보다 길었기 때문이었어요. S_tile을 만든 직후에는 K를 다 쓴 것처럼 보이지만, dS_tile = P_tile * (dP_tile - delta)를 계산한 뒤 dQ[c] += dS_tile @ K[c]를 만들 때 같은 K input tile을 다시 읽어야 합니다.
그런데 실제 schedule에서는 다음 tile을 준비하는 producer가 같은 SMEM buffer에 다음 K tile을 덮어쓰려 합니다. 하지만 consumer가 현재 K tile을 아직 잡고 있기 때문에 producer는 acquire 할 수 없습니다. Consumer 입장에서도 뒤의 dQ[c] += dS_tile @ K[c] matmul이 그 K tile을 다시 읽어야 하기 때문에 release 할 수 없구요. 전형적인 single-stage deadlock이었습니다.
해법은 꽤나 직관적이에요. Main loop를 reorder해서, producer가 다음 K tile을 load하기 전에 consumer가 현재 K tile을 필요로 하는 matmul들을 모두 끝내게 만들면 됩니다.
이렇듯 대부분의 버그는 알고리즘 자체의 로직이 아니었습니다. 실제 하드웨어의 구조 및 제약에 맞추는 것, 해당 과정에서의 발생할 수 있는 memory / matmul scheduling 실수들이 대부분이었고, 오랫동안 Python 위에서 비교적 편안하게 코딩하던 연구자 입장에서는 매우 신선하고 어려운 작업들이었습니다.
성능
환경에 따라 절대 숫자는 달라질 수 있으니, raw FLOPS 대신 같은 내부 benchmark 안에서의 상대 성능을 보겠습니다.
Forward만 FA4로 보내고 backward를 fallback으로 보내는 방식은 학습에 쓸 수 없었습니다. Forward 자체는 SDPA 대비 대략 2배 빨라졌지만, backward가 너무 느려서 학습 전체로 보면 이득이 사라졌어요.
Custom backward path를 구현하고 나서는 긴 sequence 영역에서 SDPA 대비 확실한 이득이 나왔습니다. 짧은 sequence에서는 여러 invocation과 후처리 overhead 때문에 여전히 손해가 있었지만, 저희가 중요하게 보는 긴 sequence 학습 구간에서는 결과가 뒤집혔습니다.
최종적으로 저희는 B300에서 FA4 kernel을 실제 Video LLM 학습에 쓸 수 있는 수준까지 끌어올렸고, 100k 이상의 packed sequence를 사용하는 실제 End-to-End 학습에서 약 30% 가량의 MFU 상승을 이끌어냈습니다.
성공적으로 개발을 마무리할 수 있었던 이유
GPU kernel level까지 다뤄본 ML 연구자는 많지 않습니다. 그런 상황에서 저희 팀이 GPU kernel을 직접 작성하는 선택을 내리고, 성공적으로 개발할 수 있었던 데에는 몇 가지 중요한 이유가 있었습니다.
첫째는 CuTe-DSL 이에요. FA4가 C++/CUTLASS가 아니라 CuTe-DSL (Python frontend)로 쓰여 있다는 건 나이브하게는 Python이 더 친숙한 ML Researcher/Engineer에게 심리적인 진입장벽을 낮춰주는 효과가 있어요. 물론 실질적으로 더 큰 차이는 iteration loop입니다. Kernel shape을 바꾸고, compile하고, 작은 test slice를 돌려보고, 다시 고치는 loop가 C++ template stack 전체를 직접 만질 때보다 훨씬 빨랐습니다.
물론 Python frontend라고 해서 kernel 개발이 쉬워지는 건 아닙니다. frontend만 Python일 뿐, 여전히 GPU Programming이긴 하니까요. single-stage deadlock, 2-CTA layout, TMEM budget 등을 구성하는 것은 동일하게 필요한 작업이었습니다. 다만 실패했을 때 돌아오는 Error message 및 feedback이 더 이해하기 쉬웠습니다. Research Scientist 입장에서는 이 차이가 컸어요.
둘째는 Test Suite 입니다. FlashAttention 레포에는 fully-parametrized correctness suite 가 들어 있습니다. dtype, sequence length, MHA / GQA / MQA, causal / non-causal, varlen 여부처럼 커널 path 를 바꾸는 축들을 넓게 커버해요. 이 suite가 없었다면, "한 workload에서는 맞아 보이는 kernel" 을 "정말 쓸 수 있는 kernel"로 착각했을 가능성이 큽니다.
셋째는 coding agent 였어요. 위의 버그 헌팅 대부분은 긴 iterative session으로 굴러갔습니다. 사람이 가설을 고르고, agent가 diff를 구현해서 관련 test slice를 돌리고, 사람이 결과를 읽고 다음 가설을 고르는 식이에요. Test suite가 좋지 않으면 이 loop는 무용지물입니다. Agent가 자기 변경이 도움이 됐는지를 알 수 없으니까요. 이 test suite에서는 loop가 빡빡하게 돌았습니다.
최신 장비를 사용한다는 건
연구실에서는 최신 하드웨어를 사용할 기회가 많지 않다 보니, 대부분의 경우 내가 사용하는 GPU 에 대한 최적화된 kernel은 누군가가 만들어놓은 경우가 많았습니다. 하지만 industry에서는 항상 그렇진 않습니다. 특히 스타트업처럼 모든게 빠르게 변화하는 환경에서는 더더욱 그렇습니다. 새로운 하드웨어가 출시되고, 누군가가 그 위에 내가 원하는 Kernel을 만들어주기까지, 길면 연 단위의 시간이 걸리는 그 기간 동안엔 공백이 발생하게 돼요. 그때, "지원되는 커널로 연구의 한계를 정하든, 직접 작성하든"의 선택지를 마주하게 됩니다.
모든 모델링 팀이 kernel까지 작성할 필요는 없습니다. 하지만 정말 Cutting Edge를 달리고 싶다면, 더 이상 Plug and Play는 가능하지 않습니다. 저희는 필요할 때 직접 문제를 풀며 계속해서 빠르게 달려가는 팀이 되려고 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]
B300이 왜 H100보다 느리지?
첫 B300 학습에서 들었던 생각입니다. Spec Sheet 기준 이전 세대 (Hopper, H100) 대비 3.5배의 VRAM, 2배 이상의 Max FLOPs이어야 하는데, model forward/backward가 오히려 느려졌어요. 원인을 찾기 위해 코드를 파고들다 보니, 문제는 Transformer의 핵심, attention에 있었습니다. 더 정확히는, attention을 빠르게 해주는 Flash Attention Kernel이 문제였어요.
그동안은 Hopper 전용으로 튜닝된 Flash Attention 3 (FA3) Kernel을 쓰고 있었습니다. 그런데 Blackwell 구조인 B300에서는 해당 커널을 사용할 수 없었고, 이보다 더 generic한 이전 세대 커널, 즉 Flash Attention 2 (FA2)로 fallback하고 있었어요. 하드웨어는 한 세대 진보했지만, 소프트웨어는 한 세대 퇴보한 셈이죠.
다행히 Blackwell 용으로 작성된 Flash Attention 4 (FA4)가 당시 pre-release로 공개돼 있었어요. FA3가 그랬던 것처럼, FA4 역시 Blackwell에서 이전 커널 대비 큰 폭의 성능 개선을 목표로 한 rewrite였습니다. 그러나 안타깝게도, 저희가 바로 가져와서 쓰는 건 불가능했습니다. 저희 모델이 쓰는 attention head dimension은 당시 FA4 지원 목록 밖에 있었기 때문이에요.
일반적으로 이 시점에 내릴 수 있는 결정은 두 가지 중 하나입니다.
FA4가 지원하는 head dimension에 맞춰 모델 재설계.
아키텍처는 유지하고, 더 오래된 fallback 커널 사용.
저희가 내린 결정은 둘다 아닌, 3번. 저희 모델의 head dimension에 맞게 커널을 직접 작성하는 것이었어요.
이 글은 Research Scientist가 커널 작성에 직접 뛰어들면서, 최신 하드웨어가 왜 plug-and-play가 아닌지, 그리고 모델 팀이 필요한 성능을 얻기 위해 어디까지 내려가야 하는지를 배운 기록입니다.
Flash Attention Recap & 왜 매 세대 다시 쓰여야 하나
필요한 만큼만 짧게 짚어보겠습니다.
Attention을 그대로 계산하면, score matrix S = Q · Kᵀ # [..., T_q, T_k] 전체를 HBM (GPU 메인 메모리) 에 만들어야 해요. Sequence length가 커질수록, 실제 matmul 연산보다 결과값을 메모리에 적고 다시 읽는 데에 더 많은 시간을 쓰게 됩니다. FlashAttention의 아이디어는 해당 matmul들을 sequence 축에 대해 더 작은 “연산 조각”으로 쪼개서 (tiling) matrix 중간값들을 HBM에 쓰지 않고도 attention 연산이 가능하게 한 것이었습니다. 덕분에 수학적으로는 동일하지만, 훨씬 적은 메모리 트래픽을 사용하고 속도도 챙길 수 있게 되었어요.
Image reference: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, Dao et al., 2022
문제는, 가장 효율적으로 "연산을 쪼개는" 방식이 GPU architecture 마다 달라진다는 점입니다. Tensor Core가 커지기도 하고, 새로운 memory class가 생기고, 새로운 instruction이 생기기도 하면서, 이전 세대에 optimal했던 Flash Attention 커널이 다음 세대에선 동작하지 않거나, 최대 효율을 뽑아내지 못하게 돼요.
FA2는 Ampere 시대에 작성되었고, 범용적이어서 이후 세대에서도 동작은 하지만 최대 효율을 뽑진 못해요.
FA3는 Hopper 전용 rewrite이에요 (H100, H200). Hopper가 아닌 GPU 에서는 동작하지 않아요.
FA4는 Blackwell 전용 rewrite이에요 (B200, B300). Blackwell에서 새로 도입된 TMEM (Processor 에 직결되어있는 메모리)과 2-CTA MMA (두 CTA가 협력해 하나의 matmul을 수행하는 방식)를 활용해요.
FA4 의 또 다른 특징은 바로 C++/CUTLASS가 아니라 CuTe-DSL(CUTLASS의 building block 위에 얹힌 Python frontend)로 쓰여있다는 점이에요. 덕분에 tooling 및 compile이 용이해졌고, 이게 이전 세대 대비 직접 커널 개발에 뛰어들 수 있게 하는 주요한 역할을 했습니다.
당시 (2026년 3월) 공개된 Blackwell 용 FA4 는 자주 쓰이는 몇 가지 head dimension에 대한 지원만 들어있었어요. 그 외의 shape에 대해서는 AssertionError가 발생했습니다.
GPU 용어 정리
블로그를 이해하는 데 필수적인 B300 관련 GPU 용어 및 개념들만 정리하고 넘어가겠습니다.
Tensor Core / MMA — 행렬 곱(matmul)을 한 instruction으로 처리하는 전용 회로. 정식 이름은 Matrix Multiply-Accumulate —
D = A · B + C형태예요. 최신 GPU에서 attention 산수의 거의 전부가 여기서 일어나요.TMEM (Tensor Memory) — Blackwell이 추가한 새로운 memory class. Tensor Core 와 직접 연결되어 있어서 MMA의 중간값들을 적어놓는 빠른 on-chip scratchpad로 쓰여요. 빠른 대신 예산이 빡빡해서, 무엇을 언제 올려놓을지가 커널 설계의 핵심이 됩니다.
Producer/Consumer — GPU programming에서는 데이터를 메모리에 올리는 Producer, 메모리에서 데이터를 읽는 Consumer라는 컨셉이 있습니다. 이 둘은 동시에 같은 메모리 buffer에 작업할 수 없습니다.
실제 구현해야 했던 것들
저는 숙련된 kernel engineer가 아니다보니, 처음부터 instruction-level 디테일로 들어가지는 못했습니다. 먼저 "무엇이 느린가", "왜 기존 경로가 안 맞는가", "어떤 자원이 부족한가"를 high-level로 이해해야 했어요. 그다음에야 실제 디버깅이 가능했습니다.
그래서 일반적인 ML 연구자의 입장에서 각 작업의 갈래부터 먼저 설명하고, 구현적인 디테일을 풀어보겠습니다.
Phase 1. Forward Pass
Blackwell에서 중요한 건 TMEM을 얼마나 잘 사용하느냐입니다. 기존 FA4 forward kernel은 MMA stage를 double buffering하고 있었는데요, 두 개의 stage를 TMEM 안에 유지해 두고 현재 stage를 계산하는 동안 다음 stage를 준비해 stall을 줄이는 방식입니다. 그런데 저희 모델의 shape에서는 두 번째 stage까지 TMEM에 유지하면 예산이 넘었습니다.
해결책은 생각보다 단순했어요. Double buffering을 끄고 single buffering으로 바꾸니 TMEM 예산 안에 들어왔습니다. 자연스럽게 "그러면 pipeline stall이 생겨서 느려지지 않나?"라는 생각이 들 수 있지만, 여기서는 먼저 kernel이 Blackwell 경로로 정상 dispatch 되는 것이 중요했습니다. 실제 측정에서도 forward는 기대했던 대로, SDPA 대비 약 2배 가량 빨라졌습니다.
하지만 여기까지는 반쪽짜리 kernel이었어요. 학습에는 backward가 필요하니까요.
Phase 1.1. Backward Pass Fallback
다음으로 시도한 건 backward에서만 fa2로의 fallback이었습니다. 정확도의 문제는 없었지만, end-to-end 속도는 sdpa 보다도 느렸습니다. 일단 올바르게 돌아가는 baseline을 설정하는 것이 주된 목표였기 때문에, 빠르게 다음 단계로 넘어갔습니다.
Phase 2. Chunked Backward, TMEM 예산 안으로
Backward는 forward 보다 더 많은 중간값들을 동시에 들고 있어야 합니다. 저희 shape에서는 이 모든 것을 한 번에 TMEM 안에 배치할 수 없었습니다.
그래서 backward gradient를 sequence 축에서의 tiling과 더불어 head dim 축에서도 여러 slice로 쪼개는 방향으로 갔습니다. 각 kernel이 head dimension의 일부 slice를 맡고, 그 slice에 해당하는 gradient를 계산합니다. 이렇게 하면 한 번에 필요한 TMEM 양이 줄어들어요.
다만 이건 쉬운 문제가 아니었습니다. Gradient를 메모리에 저장하는 단위는 slice로 나눌 수 있지만, score matrix와 softmax 관련 값들은 현재 slice만으로 계산할 수 없습니다. 각 score의 원소는 head axis 전체에 대한 dot product이기 때문이에요. 그래서 각 slice kernel 안에서도, 현재 tile에 해당하는 score를 head axis 전체에 대해 다시 구성해야 정확한 값을 구할 수 있었습니다.
조금 더 디테일하게 풀어볼게요.
각 kernel invocation이 head dimension의 한 slice를 담당해요. 그 slice에 해당하는 dQ, dK, dV 를 해당 invocation이 계산하고 씁니다. 다만 dQ는 KV tile을 돌면서 같은 slice accumulator에 계속 더해지는 값입니다.
dQ와 dK 를 구하기 위해선 dS를 구해야 하고, 이를 위해선 score matrix S를 다시 만들어야 합니다. S = Q · Kᵀ이고, Q와 K의 전체 head dim에 대한 dot product이기 때문에, head dimension slice 한 조각만으로 S를 만들게 되면 틀린 값을 구하게 됩니다. 그래서 현재 slice에 대한 gradient만 저장하게끔 하더라도, 다른 slice의 값들도 가져와야 합니다.
저희의 chunked backward를 짧은 pseudo-code로 쓰면 다음과 같습니다. 여기서 O와 LSE는 forward 에서 저장해 둔 값입니다. Shape 표기는 Bq를 query tile row 수, Bk를 key/value tile row 수, H를 전체 head axis, Hc를 현재 invocation이 맡은 slice의 크기로 두겠습니다.
# Inside the q, kv loops, Q/dO/O mean the current Q tile, # and K/V mean the current KV tile. # Q, dO, O: [Bq, H], K, V: [Bk, H] # S_tile, P_tile, dP_tile, dS_tile: [Bq, Bk] # c: current slice on the head axis, width Hc for each Q tile q: for each KV tile k,v: S_tile = 0 # [Bq, Bk] dP_tile = 0 # [Bq, Bk] for each head-axis slice h: S_tile += Q[h] @ K[h].T # partial score contribution dP_tile += dO[h] @ V[h]
여기서 핵심은 S_tile와 dP_tile입니다. 둘 다 head-axis slice 하나로는 완성되지 않고, h에 대해 for-loop을 돌며 partial matmul을 더해야 현재 tile에 대해 정확한 값을 구할 수 있습니다. P_tile은 이렇게 구한 S_tile과, forward에서 저장해 둔 LSE로 만듭니다. 그래서 current KV tile만 보고도 full softmax row에 맞게 normalize 된 값을 얻을 수 있어요.
Chunked backward에서는 의도했던 대로 dQ, dK, dV를 slice 별로 나눠 씁니다. 하지만 S, P, delta, dP, dS는 [Bq, Bk], 즉 tile 전체에 대한 값입니다. 그래서 각 invocation 안에서도 Q/K/V/dO 의 다른 slice contribution을 다시 읽고 누적해야 합니다.
필요한 buffer도 이 구조에서 나옵니다.
Input tiles:
Q,K,V,dO. 현재 output slice 뿐 아니라S_tile와dP_tile를 재구성하기 위한 같은 head의 다른 slice의 값들도 필요합니다.Scratch buffer:
S/P,dP/dS. Shape은[Bq, Bk]입니다. 즉, 현재 tile 전체에 대한 gradient입니다.Output accumulator: 현재 invocation이 책임지는
dQ[c],dK[c],dV[c]slice.
버그 헌팅
큰 흐름은 위에서 얘기한 대로지만, 사실 커널이 복잡해질수록 대부분의 시간은 버그 해결이었습니다. 그중 가장 오래 걸렸던 버그 해결 과정에 대해서 풀어보겠습니다.
Correctness 이슈가 대부분 잡힌 다음에도 커널은 가장 짧은 sequence length에서만 통과했고 그보다 긴 sequence length에서는 hang이 걸렸어요. 원인은 데이터를 로드하는 Producer와 사용하는 Consumer 사이의 deadlock이었습니다. 위 pseudo-code만 보면 놓치기 쉽지만, 실제 데이터를 메모리에 올리고 내리는 instruction 순서의 문제였고, 이 순서를 재배치함으로써 해결할 수 있었습니다.
GPU 커널에서는 데이터를 메모리에 로드하는 producer와 데이터를 가져다 연산하는 consumer 사이에서 누가 어떤 buffer를 읽고 쓸 수 있는지 명시적으로 맞춰줘야 합니다. 특히 buffer가 하나뿐일 때는 producer가 다음 로드를 시작하려면 consumer가 현재 buffer를 완전히 놓아줘야 해요. 이 순서가 어긋나면 같은 resource를 두고 서로가 서로를 기다리는 deadlock이 생깁니다.
해당 버그가 정확히 그 케이스였습니다. 위 pseudo-code에 맞춰 말하면, 하나의 q, kv score tile을 처리하는 동안 consumer는 같은 K tile을 두 번 읽습니다. 먼저 S_tile += Q[h] @ K[h].T에서 읽고, dS_tile이 만들어진 뒤 다시 dQ[c] += dS_tile @ K[c]에서 읽어요. 그런데 backward kernel의 실제 schedule에서는 그 사이에 다음 sequence tile 계산을 준비하려고 producer가 같은 SMEM K input buffer를 새 K tile로 채우려 했습니다.
조금 더 디테일하게는, chunked backward에서 이 K input buffer는 stage가 하나뿐이었습니다. 일반적으로는 stage를 여럿 두어 producer와 consumer가 서로 다른 stage를 동시에 작업하게 하지만, 여기서는 on-chip buffer 예산이 빡빡해서 그렇게 하지 못했습니다. 발견하는게 특히 어려웠던 이유는 dependency chain이 생각보다 길었기 때문이었어요. S_tile을 만든 직후에는 K를 다 쓴 것처럼 보이지만, dS_tile = P_tile * (dP_tile - delta)를 계산한 뒤 dQ[c] += dS_tile @ K[c]를 만들 때 같은 K input tile을 다시 읽어야 합니다.
그런데 실제 schedule에서는 다음 tile을 준비하는 producer가 같은 SMEM buffer에 다음 K tile을 덮어쓰려 합니다. 하지만 consumer가 현재 K tile을 아직 잡고 있기 때문에 producer는 acquire 할 수 없습니다. Consumer 입장에서도 뒤의 dQ[c] += dS_tile @ K[c] matmul이 그 K tile을 다시 읽어야 하기 때문에 release 할 수 없구요. 전형적인 single-stage deadlock이었습니다.
해법은 꽤나 직관적이에요. Main loop를 reorder해서, producer가 다음 K tile을 load하기 전에 consumer가 현재 K tile을 필요로 하는 matmul들을 모두 끝내게 만들면 됩니다.
이렇듯 대부분의 버그는 알고리즘 자체의 로직이 아니었습니다. 실제 하드웨어의 구조 및 제약에 맞추는 것, 해당 과정에서의 발생할 수 있는 memory / matmul scheduling 실수들이 대부분이었고, 오랫동안 Python 위에서 비교적 편안하게 코딩하던 연구자 입장에서는 매우 신선하고 어려운 작업들이었습니다.
성능
환경에 따라 절대 숫자는 달라질 수 있으니, raw FLOPS 대신 같은 내부 benchmark 안에서의 상대 성능을 보겠습니다.
Forward만 FA4로 보내고 backward를 fallback으로 보내는 방식은 학습에 쓸 수 없었습니다. Forward 자체는 SDPA 대비 대략 2배 빨라졌지만, backward가 너무 느려서 학습 전체로 보면 이득이 사라졌어요.
Custom backward path를 구현하고 나서는 긴 sequence 영역에서 SDPA 대비 확실한 이득이 나왔습니다. 짧은 sequence에서는 여러 invocation과 후처리 overhead 때문에 여전히 손해가 있었지만, 저희가 중요하게 보는 긴 sequence 학습 구간에서는 결과가 뒤집혔습니다.
최종적으로 저희는 B300에서 FA4 kernel을 실제 Video LLM 학습에 쓸 수 있는 수준까지 끌어올렸고, 100k 이상의 packed sequence를 사용하는 실제 End-to-End 학습에서 약 30% 가량의 MFU 상승을 이끌어냈습니다.
성공적으로 개발을 마무리할 수 있었던 이유
GPU kernel level까지 다뤄본 ML 연구자는 많지 않습니다. 그런 상황에서 저희 팀이 GPU kernel을 직접 작성하는 선택을 내리고, 성공적으로 개발할 수 있었던 데에는 몇 가지 중요한 이유가 있었습니다.
첫째는 CuTe-DSL 이에요. FA4가 C++/CUTLASS가 아니라 CuTe-DSL (Python frontend)로 쓰여 있다는 건 나이브하게는 Python이 더 친숙한 ML Researcher/Engineer에게 심리적인 진입장벽을 낮춰주는 효과가 있어요. 물론 실질적으로 더 큰 차이는 iteration loop입니다. Kernel shape을 바꾸고, compile하고, 작은 test slice를 돌려보고, 다시 고치는 loop가 C++ template stack 전체를 직접 만질 때보다 훨씬 빨랐습니다.
물론 Python frontend라고 해서 kernel 개발이 쉬워지는 건 아닙니다. frontend만 Python일 뿐, 여전히 GPU Programming이긴 하니까요. single-stage deadlock, 2-CTA layout, TMEM budget 등을 구성하는 것은 동일하게 필요한 작업이었습니다. 다만 실패했을 때 돌아오는 Error message 및 feedback이 더 이해하기 쉬웠습니다. Research Scientist 입장에서는 이 차이가 컸어요.
둘째는 Test Suite 입니다. FlashAttention 레포에는 fully-parametrized correctness suite 가 들어 있습니다. dtype, sequence length, MHA / GQA / MQA, causal / non-causal, varlen 여부처럼 커널 path 를 바꾸는 축들을 넓게 커버해요. 이 suite가 없었다면, "한 workload에서는 맞아 보이는 kernel" 을 "정말 쓸 수 있는 kernel"로 착각했을 가능성이 큽니다.
셋째는 coding agent 였어요. 위의 버그 헌팅 대부분은 긴 iterative session으로 굴러갔습니다. 사람이 가설을 고르고, agent가 diff를 구현해서 관련 test slice를 돌리고, 사람이 결과를 읽고 다음 가설을 고르는 식이에요. Test suite가 좋지 않으면 이 loop는 무용지물입니다. Agent가 자기 변경이 도움이 됐는지를 알 수 없으니까요. 이 test suite에서는 loop가 빡빡하게 돌았습니다.
최신 장비를 사용한다는 건
연구실에서는 최신 하드웨어를 사용할 기회가 많지 않다 보니, 대부분의 경우 내가 사용하는 GPU 에 대한 최적화된 kernel은 누군가가 만들어놓은 경우가 많았습니다. 하지만 industry에서는 항상 그렇진 않습니다. 특히 스타트업처럼 모든게 빠르게 변화하는 환경에서는 더더욱 그렇습니다. 새로운 하드웨어가 출시되고, 누군가가 그 위에 내가 원하는 Kernel을 만들어주기까지, 길면 연 단위의 시간이 걸리는 그 기간 동안엔 공백이 발생하게 돼요. 그때, "지원되는 커널로 연구의 한계를 정하든, 직접 작성하든"의 선택지를 마주하게 됩니다.
모든 모델링 팀이 kernel까지 작성할 필요는 없습니다. 하지만 정말 Cutting Edge를 달리고 싶다면, 더 이상 Plug and Play는 가능하지 않습니다. 저희는 필요할 때 직접 문제를 풀며 계속해서 빠르게 달려가는 팀이 되려고 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]
Related articles



プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved

プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved




プラットフォーム
Enterprise
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved