" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
チュートリアル
Twelve Labsを使用したBrand Integration Assistant(ブランド統合アシスタント)とAd Break Finder(広告枠検出)アプリの構築

ミラン・キム
このチュートリアルでは、Twelve LabsのAnalyze APIおよびEmbed APIとPineconeを組み合わせて、広告メタデータタグの自動生成、マルチモーダル類似性検索による文脈に沿ったコンテンツ動画の検出、そしてAIが生成したチャプター区切りでのミッドロール広告挿入のシミュレーションを行う「ブランド統合アシスタントおよび広告ブレイクファインダーアプリ」の構築手順を解説します。
このチュートリアルでは、Twelve LabsのAnalyze APIおよびEmbed APIとPineconeを組み合わせて、広告メタデータタグの自動生成、マルチモーダル類似性検索による文脈に沿ったコンテンツ動画の検出、そしてAIが生成したチャプター区切りでのミッドロール広告挿入のシミュレーションを行う「ブランド統合アシスタントおよび広告ブレイクファインダーアプリ」の構築手順を解説します。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2025/07/14
12分
記事へのリンクをコピー
はじめに
視聴者は、見ているコンテンツと一致しない、無関係な広告に圧倒されることがよくあります。この不一致は不満を招き、広告が押し付けがましく感じられたり、タイミングが悪いと感じられたりする原因になります。
ブランド統合アシスタント & 広告挿入点ファインダー アプリは、コンテキストに関連する広告レコメンデーションを提供することでこれを解決し、エンゲージメントの適切な瞬間に、適切な視聴者へ適切なメッセージが届くようにします。
このチュートリアルでは、アプリのコア機能全体における動作方法を学習します:
タグの自動生成: アップロードされた各広告が分析され、トピックカテゴリ、感情、ブランド、ターゲット層(性別・年齢)、場所といった豊かなメタデータが生成され、スマートなフィルタリング、検索、コンテキスト構築が可能になります。
コンテキストに整合したコンテンツの検索: AIを活用した類似性検索を使用して、ビデオとテキストの両方の埋め込み(embeddings)に基づき、広告と意味的に整合しているコンテンツビデオを検索します。
広告挿入点の推奨とシミュレーション: コンテンツをチャプターに自動分割し、ミッドロール広告の挿入をシミュレートすることで、シームレスで没入感のある広告体験を実現します。
前提条件
Twelve Labs プレイグラウンドにサインアップしてAPIキーを生成し、広告用とコンテンツビデオ用にインデックスをそれぞれ2つ作成します。
Pineconeのアカウントを設定し、ビデオ埋め込みを保存するためのインデックスを作成します。
Dimensionsを1024に、MetricをCosineに設定してください
関連するGitHubリポジトリでアプリケーションのソースコードを確認します。
よりスムーズなセットアップと開発体験のために、JavaScript、TypeScript、Next.jsの知識があると役立ちます。
デモ
デモアプリケーションでご自身で試してみるか、以下のクイックデモビデオをご覧になり、実際にどのように機能するか確認してください。 https://www.loom.com/share/233cc8cb66ae44218e3cff69afb772d7
デモ全体のウェビナー録画は以下からご覧いただけます:
アプリの仕組み
アプリの内部には、広告ライブラリ(Ads Library)とコンテキスト整合性分析(Contextual Alignment Analysis)の2つのメインメニューがあります。
広告ライブラリ - ブランドマーケター向けに、自動生成されたタグ付きの広告ビデオを整理して表示します。トピックカテゴリ、感情、ブランド、性別、年齢、場所で広告をフィルタリングしたり、Twelve Labs Search APIを使用してショートテールまたはロングテールのキーワードで検索したりできます。このチュートリアルでは、広告ライブラリ内の自動タグ生成機能に焦点を当てます。
コンテキスト整合性分析 - このセクションでは、各広告に対してコンテキストが最も関連性の高いコンテンツビデオを検索できます。Twelve Labs EMBEDおよびGETビデオAPI(タグおよびビデオ埋め込み用)と、類似性ベースのフィルタリングを行うPineconeによって、親和性の高いコンテンツを表面化させます。
その後、ユーザーはコンテンツビデオを選択し、広告挿入のための自動チャプター生成を行い、チャプターの切り替わりで広告の再生をシミュレートできます。
以下のチュートリアルでは、コンテンツマッチングと広告シミュレーションの両方の機能について詳しく説明します。
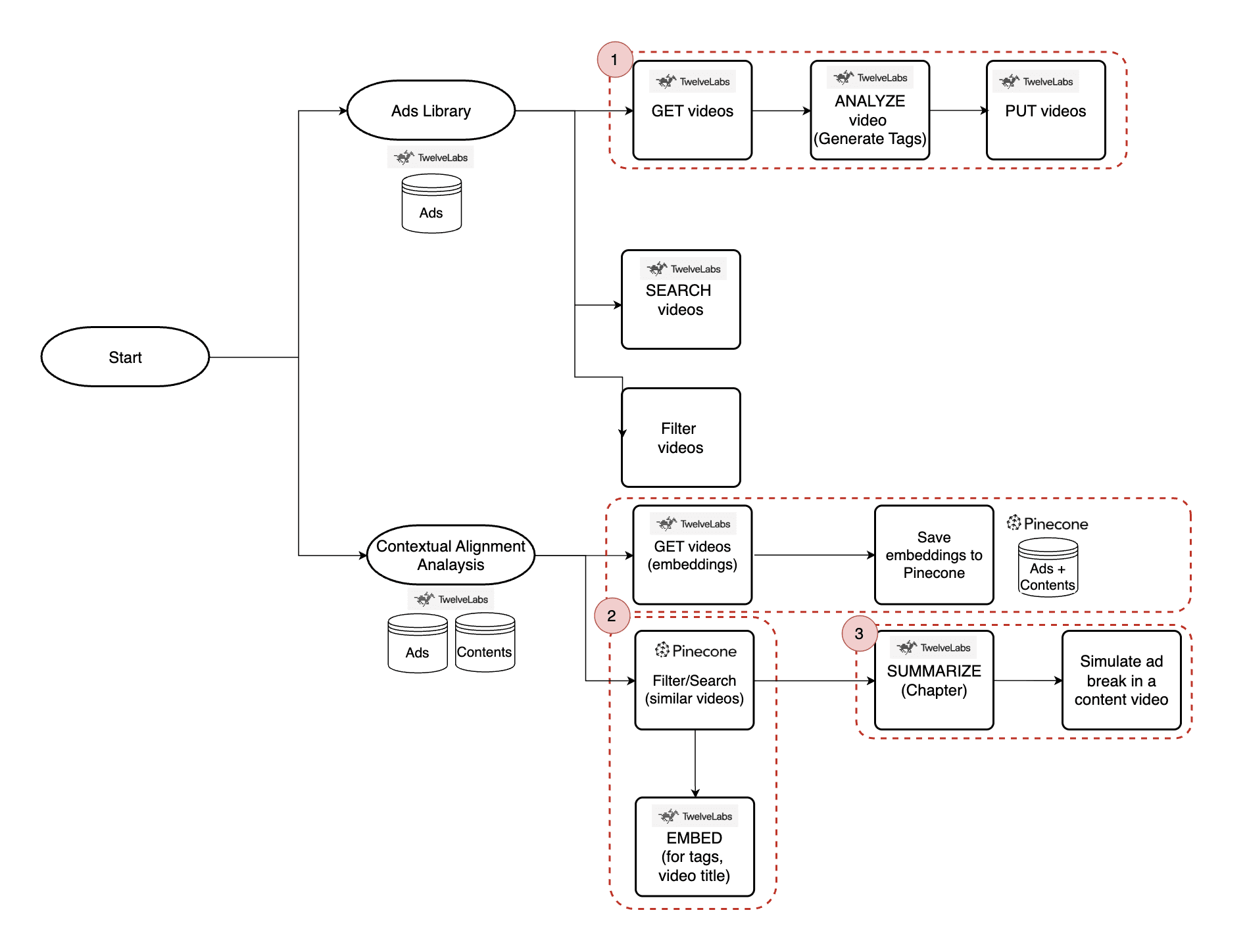
アプリの3つの主要機能とその仕組み
主要機能 1. 自動タグ生成(「広告ライブラリ」内)
広告ライブラリでは、インデックスに登録されたビデオのコレクションをブラウズし、自動生成されたタグを表示できます。これらのタグは、ビデオをトピック、感情、ブランド、ユーザー層などに分類するのに役立ち、これらはすべて Twelve Labs の Analyze API を使用して抽出されます。
ステップ 1 - 各ビデオのタグを生成する
ビデオがロードされ、メタデータが不完全または失われていると判断された場合、システムは generateMetadata を呼び出して、Twelve Labs の Analyze API を使ってタグを取得します。
⭐️Twelve Labs' Analyze API の詳細についてはこちらを参照してください。
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.ts (lines 279-290)
if (!video.user_metadata || Object.keys(video.user_metadata).length === 0 || !video.user_metadata.topic_category && !video.user_metadata.emotions && !video.user_metadata.brands && !video.user_metadata.locations)) { setVideosInProcessing(prev => [...prev, videoId]); const hashtagText = await generateMetadata(videoId); if (hashtagText) { const metadata = parseHashtags(hashtagText);
generateMetadata 関数は、サーバー側のAPI呼び出しをトリガーして Twelve Labs エンジンからAI生成されたタグを要求するカスタムフックです。
これにより、api/analyze/route.ts 内のバックエンドハンドラーがトリガーされ、Twelve Labs の Analyze API 用に構造化された具体的なプロンプトが作成されます。このプロンプトにより、返されるデータが適切に分類され、一貫してフォーマットされるため、簡単にタグに変換してフィルターメニューに表示できます。バックエンドルートの主要な部分は以下のとおりです:
api/analyze/route.ts (lines 1 - 85)
import { NextResponse } from 'next/server'; const API_KEY = process.env.TWELVELABS_API_KEY; const TWELVELABS_API_BASE_URL = process.env.TWELVELABS_API_BASE_URL; export const maxDuration = 60; export async function GET(req: Request) { const { searchParams } = new URL(req.url); const videoId = searchParams.get("videoId"); const prompt = `You are a marketing assistant specialized in generating hashtags for video content. Based on the input video metadata, generate a list of hashtags labeled by category. **Output Format:** Each line must be in the format: [Category]: [Hashtag] (e.g., sector: #beauty) **Allowed Values:** Gender: Male, Female Age: 18-25, 25-34, 35-44, 45-54, 55+ Topic: Beauty, Fashion, Tech, Travel, CPG, Food & Bev, Retail, Other Emotions: sorrow, happiness, laughter, anger, empathy, fear, love, trust, sadness, belonging, guilt, compassion, pride **Instructions:** 1. Use only the values provided in Allowed Values. 2. Do not invent new values except for Brands and Location. Only use values from the Allowed Values. 3. Output must contain at least one hashtag for each of the following categories: - Gender - Age - Topic - Emotions - Location - Brands 4. Do not output any explanations or category names—only return the final hashtag list. **Output Example:** Gender: female Age: 25-34 Topic: beauty Emotions: happiness Location: Los Angeles Brands: Fenty Beauty --- ` … const url = `${TWELVELABS_API_BASE_URL}/analyze`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": API_KEY, }, body: JSON.stringify({ prompt: prompt, video_id: videoId, stream: false }) }; try { const response = await fetch(url, options); …
ステップ 2 - 各ビデオに PUT リクエストを送信して生成されたタグを保存する
/api/analyze ルートを使用してタグを生成したら、次のステップでそれらをインデックスされたライブラリのビデオオブジェクトに保存します。これは、Twelve Labs インデックス内のビデオのメタデータを更新する PUT API コールを通じて行われます。
⭐️ Twelve Labs のUpdate Video Information APIの詳細についてはこちらを参照してください。
この処理は updateVideoMetadata フックによって行われ、最終的に api/videos/metadata/route.ts のバックエンドルートを呼び出します。
❗️カスタムメタデータを保存するには、各ビデオを更新する際にキーに user_metadata を使用していることを確認してください。
api/videos/metadata/route.ts (lines 1-68)
import { NextRequest, NextResponse } from 'next/server'; … export async function PUT(request: NextRequest) { try { // Parse request body const body: MetadataUpdateRequest = await request.json(); const { videoId, indexId, metadata } = body; … // Prepare API request const url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; const requestBody = { user_metadata: { source: metadata.source || '', sector: metadata.sector || '', emotions: metadata.emotions || '', brands: metadata.brands || '', locations: metadata.locations || '', demographics: metadata.demographics || '' } }; const options = { method: 'PUT', headers: { 'Content-Type': 'application/json', 'x-api-key': API_KEY, }, body: JSON.stringify(requestBody) }; // Call Twelve Labs API const response = await fetch(url, options); …
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.tsx (lines 289-292)
if (hashtagText) { const metadata = parseHashtags(hashtagText); await updateVideoMetadata(videoId, adsIndexId, metadata);
📌 user_metadata には何が含まれているか?
保存される user_metadata オブジェクトは、次のような重要フィールドを含んでいます:
{
"gender": "female",
"age": "25-34",
"topic": "beauty",
"emotions": "happiness",
"location": "Los Angeles",
"brands": "Fenty Beauty"
この一貫したフォーマットにより、カテゴリ別フィルター UI、検索、およびダッシュボードでの視覚的グルーピングが可能になります。これらのカスタムメタデータは Twelve Labs から取得されるビデオに埋め込まれているため、GET リクエストを使用して各ビデオを取得し、必要に応じてメタデータを表示できます。
⭐️Twelve Labs' Retrieve Video Information API の詳細についてはこちらを参照してください。
主要機能 2. 類似ビデオの検索(「コンテキスト整合性分析」内)
コンテキスト整合性分析機能は、ビデオとテキストの埋め込み(embeddings)を比較することにより、選択された広告に最も関連のあるコンテンツビデオを見つけるのに役立ちます。これらの埋め込みは以下の通りです:
Twelve Labs によって生成される
類似性検索のために Pinecone を介して保存およびクエリされる
これを可能にするために、以下を確認する必要があります:
すべてのコンテンツビデオに埋め込みが存在すること
選択された広告ビデオに埋め込みが存在すること
すべての埋め込みが同じ Pinecone インデックスに保存されていること
❗️Twelve Labs を通じてビデオをインデックス登録すると、埋め込みが自動的に生成され、Retrieve Video Information API コールで取得できます。
ステップ 1 - コンテンツビデオの埋め込みを処理する
類似性検索を実行する前に、すべてのコンテンツビデオの埋め込みを Pinecone に保存する必要があります。これは、クライアント側の関数 processContentVideoEmbeddings() によって処理されます。
💡 内部フロー
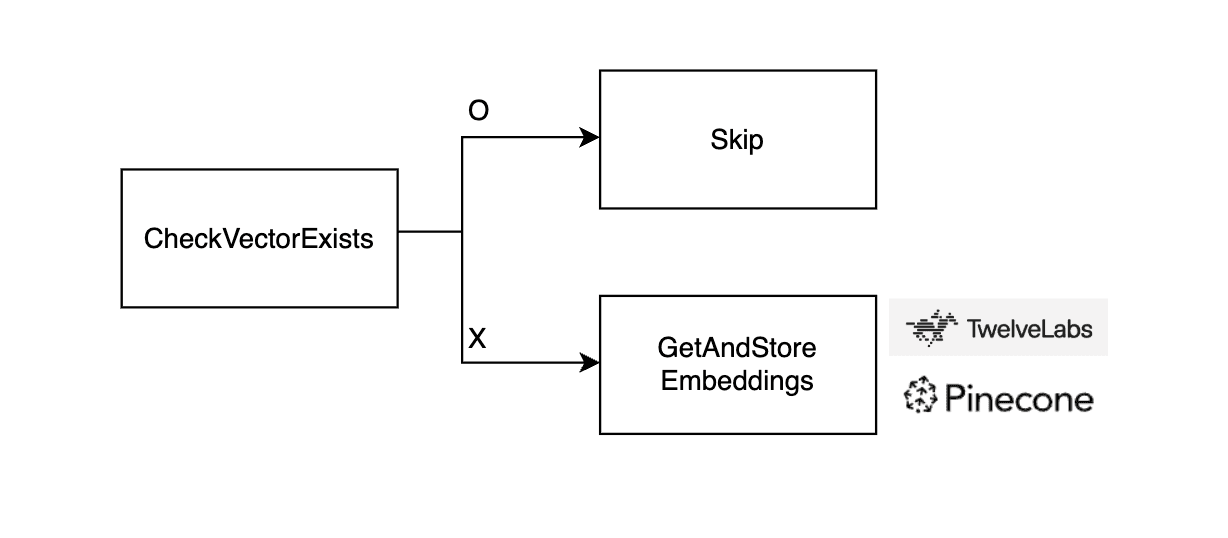
🔧 コア関数
checkVectorExists は、ビデオの埋め込みベクトルがすでに Pinecone に存在するかどうかを確認します。内部的にバックエンドルートを呼び出します。
api/vectors/exists (lines 15-27)
// Fetch vectors using metadata filter instead of direct ID const queryResponse = await index.query({ vector: new Array(1024).fill(0), filter: { tl_video_id: videoId }, topK: 1, includeMetadata: true }); return NextResponse.json({ exists: queryResponse.matches.length > 0 });
埋め込みが存在しない場合は、getAndStoreEmbeddings が以下を行います:
Twelve Labs(/api/videos/[videoId]?embed=true)から埋め込みを取得します
/api/vectors/store を介して Pinecone に保存します
api/videos/[videoId] (lines 77-95)
// Base URL let url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; // Always include embedding query parameters if requested if (requestEmbeddings) { // Include only supported embedding options url += `?embedding_option=visual-text&embedding_option=audio`; } const options = { method: "GET", headers: { "x-api-key": `${API_KEY}`, "Accept": "application/json" }, }; try { const response = await fetch(url, options);
api/vectors/store (lines 126-173)
// Create vectors from embedding segments const vectors = embedding.video_embedding.segments.map((segment: Segment, index: number) => { // Create a meaningful and unique vector ID const vectorId = `${vectorIdBase}_segment${index + 1}`; const vector = { id: vectorId, values: segment.float, metadata: { video_file: actualFileName, video_title: videoTitle, video_segment: index + 1, start_time: segment.start_offset_sec, end_time: segment.end_offset_sec, scope: segment.embedding_scope, tl_video_id: videoId, tl_index_id: indexId, category } }; return vector; }); try { const index = getPineconeIndex(); // Upload vectors in batches const batchSize = 100; const totalBatches = Math.ceil(vectors.length / batchSize); console.log(`🚀 FILENAME DEBUG - Starting vector upload with ${totalBatches} batches...`); for (let i = 0; i < vectors.length; i += batchSize) { const batch = vectors.slice(i, i + batchSize); const batchNumber = Math.floor(i / batchSize) + 1; try { // Test Pinecone connection before upserting try { await index.describeIndexStats(); } catch (statsError) { console.error(`❌ Pinecone connection test failed:`, statsError); throw new Error(`Failed to connect to Pinecone: ${statsError instanceof Error ? statsError.message : 'Unknown error'}`); } // Perform the actual upsert await index.upsert(batch);
ステップ 2 - 選択された広告ビデオの埋め込みを処理する
ユーザーが広告を選択すると、アプリはその埋め込みが準備できているかどうかを自動的にチェックします。このロジックは、選択された広告を監視する useEffect() フック内で実行されます:
contextual-analysis/page.tsx (lines 296-318)
// Automatically check ONLY the ad video embedding when a video is selected useEffect(() => { if (selectedVideoId && !isLoadingEmbeddings) { const cachedStatus = queryClient.getQueryData(['embeddingStatus', selectedVideoId]) as { checked: boolean, ready: boolean } | undefined; if (!cachedStatus?.checked) { setIsLoadingEmbeddings(true); ensureEmbeddings().then(success => { queryClient.setQueryData(['embeddingStatus', selectedVideoId], { checked: true, ready: success }); setEmbeddingsReady(success); setIsLoadingEmbeddings(false); }); } else { setEmbeddingsReady(cachedStatus.ready); } } }, [selectedVideoId, isLoadingEmbeddings, queryClient]);
🔧 コア関数
ensureEmbeddings は checkAndEnsureEmbeddings() を呼び出して以下を行います:
checkVectorExists を介して広告の埋め込みが存在するか確認します
欠落している場合、getAndStoreEmbeddings を使用して生成および保存します
オプションで、同じ呼び出しの中でコンテンツビデオすべてを処理します
❗️checkVectorExists() と getAndStoreEmbeddings() の内部動作についてはステップ 1 ですでに説明しているため、ここでは繰り返さずにそれらを参照します。
ステップ 3 - Pinecone での類似性検索 + TL 検索
すべてのビデオ埋め込み(広告 + コンテンツ)が配置されると、[Run Contextual Analysis(コンテキスト分析の実行)] ボタンをクリックして、以下の2つのタイプの類似性検索を並行して実行します:
テキストからビデオへの検索: 選択された広告のテキストタグ(専門分野や感情など)を使用して、意味的に関連のあるコンテンツビデオを検索します。
ビデオからビデオへの検索: 選択された広告のフレームレベルのビデオ埋め込みを使用して、視覚的/コンテキスト的に類似したコンテンツクリップを検索します。
両方の結果はマージされてスコアリングされ、両方の検索で見つかった一致項目が優先されます。
テキストからビデオへの検索
contextual-analysis/page.tsx (lines 351-384)
const handleContextualAnalysis = async () => { … try { textResults = await textToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); … try { videoResults = await videoToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); …
textToVideoEmbeddingSearch は、選択された広告から専門分野や感情のタグ、およびビデオのタイトルを抽出します。
それらをテキストプロンプトとして api/embeddingSearch/textToVideo ルートに送信します。
Twelve Labs はテキスト埋め込みを生成し、これを使用して Pinecone に意味的に類似したコンテンツビデオをクエリします。
api/embeddingSearch/textToVideo (lines 20-45)
const { data: embedData } = await axios.post(url, formData, { … // extract embedding vector from text_embedding object const textEmbedding = embedData.text_embedding.segments[0].float; … // Get index and search const searchResults = await index.query({ vector: textEmbedding, filter: { // video_type: 'ad', tl_index_id: indexId, scope: 'clip' }, topK: 10, includeMetadata: true, });
ビデオからビデオへの検索
videoToVideoEmbeddingSearch は、選択された広告のフレームレベルのセグメント(ベクトル値)を見つけます。
各セグメントについて、Pinecone 内のコンテンツインデックスに対して類似性クエリを実行します。
各結果は、ビデオ埋め込みにおけるクリップレベルの一致を反映します。
api/embeddingSearch/videoToVideo (lines 22-50)
// First, get the original video's clip embedding const originalClipQuery = await index.query({ filter: { tl_video_id: videoId, scope: 'clip' }, topK: 100, includeMetadata: true, includeValues: true, vector: new Array(1024).fill(0) }); // If we found matching clips, search for similar ads for each match const similarResults = []; if (originalClipQuery.matches.length > 0) { for (const originalClip of originalClipQuery.matches) { const vectorValues = originalClip.values || new Array(1024).fill(0); const queryResult = await index.query({ vector: vectorValues, filter: { tl_index_id: indexId, scope: 'clip' }, topK: 5, includeMetadata: true, }); similarResults.push(queryResult); } }
結果のマージ
両方の検索結果はビデオ ID によってマージされます。ビデオが両方の検索に含まれている場合、そのスコアは 2倍にブーストされます。
contextual-analysis/page.tsx (lines 412-428)
if (combinedResultsMap.has(videoId)) { // This is a match found in both searches - update it const existingResult = combinedResultsMap.get(videoId); // Apply a significant boost for results found in both searches (50% boost) const boostMultiplier = 2; // Combine the scores: use the max of both scores and apply the boost const maxScore = Math.max(existingResult.textScore, result.score); const boostedScore = maxScore * boostMultiplier; combinedResultsMap.set(videoId, { ...existingResult, videoScore: result.score, finalScore: boostedScore, // Boosted score for appearing in both searches source: "BOTH" });
主要機能 3. チャプターを「GENERATE」して広告挿入(ミッドロール)を実装する(「コンテキスト整合性分析」内)
この機能は、選択したコンテンツを意味のあるチャプターに分割し、選択したチャプターの最後に適切な広告を挿入することで、現実のミッドロール広告の挿入をシミュレートし、コンテキストに沿ったビデオレコメンデーション体験を強化します。
ステップ 1 - 選択したコンテンツのチャプターを自動生成する
ユーザーが VideoModal を開くと、アプリは自動的に generateChapters API を呼び出して、選択したコンテンツビデオをセグメント化します。
// Fetch chapters data const { data: chaptersData, isLoading: isChaptersLoading } = useQuery({ queryKey: ["chapters", videoId], queryFn: () => generateChapters(videoId), enabled: isOpen && !!videoId, });
各チャプターには以下が含まれます:
end: チャプターの終了時間(広告キューのポイントとして使用されます)
chapter_title: 生成された短いタイトル
chapter_summary: そのシーンと、それがなぜ広告挿入点として戦略的に適切であるかの説明(1文)
これらのチャプターは チャプタータイムラインバー上 に視覚化され、各ドットが end ポイントを示します。ドットをクリックすると、そのチャプターが終了する直前に広告を挿入するシミュレーションが行われます。
ユーザー体験(UX)の動作:
ドットはチャプター終了マーカーとして表示されます。
ドットをクリックすると、そのキューポイントで 「Show Ad(広告の表示)」 のオーバーレイが表示されます。
広告はスキップ可能で、実際のミッドロール広告のように再生されます。
サーバーロジック:Twelve Labs を介したチャプター生成
チャプターは、カスタムプロンプトとともに Twelve Labs の summarize エンドポイントを使用して生成されます。
api/generateChapters (lines 19-30)
const url = `${TWELVELABS_API_BASE_URL}/summarize`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": `${API_KEY}`, }, body: JSON.stringify({type: "chapter", video_id: videoId, prompt: "Chapterize this video into 3 chapters. For every chapter, describe why it is a strategically appropriate point for placing an advertisement. Do not mention what type of advertisement would be suitable, as the ad content has already been determined. "}) }; try { const response = await fetch(url, options);
クライアント側のヘルパー:generateChapters
React Query でチャプターデータを取得するために使用されます:
export const generateChapters = async (videoId: string): Promise<ChaptersData> => { try { const response = await fetch(`/api/generateChapters?videoId=${videoId}`);
ステップ 2 - 選択したチャプターの区切りで広告を挿入および再生する
ユーザーがチャプターマーカーをクリックすると次のようになります:
コンテンツビデオはチャプターが終了する 3 秒前までシークします。
再生がチャプターの終了時間に達すると、アプリは広告再生シーケンスに移行します。
広告が終了すると、元のコンテンツがチャプターの区切りの直後から再開されます。
チャプターマーカークリックロジック
チャプターマーカーをクリックすると、プレーヤーはそのチャプターが終了する直前にシークし、ミッドロール広告を再生する準備をします。
VideoModal.tsx (lines 102-126)
// Chapter click handler const handleChapterClick = (index: number) => { if (playbackSequence === 'ad') { return; } if (!adVideoDetail?.hls?.video_url) { console.warn("No ad selected. Please select an ad in the contextual analysis page."); return; } if (!chaptersData) return; const chapter = chaptersData.chapters[index]; setSelectedChapter(index); setHasPlayedAd(false); setPlaybackSequence('video'); setShowChapterInfo(true); if (playerRef.current) { // Start 3 seconds before the chapter end time const startTime = Math.max(0, chapter.end - 3); playerRef.current.seekTo(startTime, 'seconds'); } };
進行状況の監視 – チャプター終了時に広告をトリガー
コンテンツの再生中、アプリは現在の再生時間がチャプターのエンドポイントに達したかどうかを確認し、条件が満たされている場合は広告の再生に切り替えます。
// Track video progress const handleProgress = (state: { playedSeconds: number }) => { if (selectedChapter === null || !chaptersData || !adVideoDetail) { return; } const chapter = chaptersData.chapters[selectedChapter]; const timeDiff = state.playedSeconds - chapter.end; const isLastChapter = selectedChapter === chaptersData.chapters.length - 1; if playbackSequence === 'video' && !hasPlayedAd && ((isLastChapter && Math.abs(timeDiff) < 0.5) || (!isLastChapter && timeDiff >= 0)) ) { setPlaybackSequence('ad'); setHasPlayedAd(true); } };
広告再生&コンテンツ再開
広告が終わると、アプリはチャプターが終了した場所から自動的にコンテンツの再生を再開します。
VideoModal.tsx (lines 128-136)
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
これにより、自然な区切りで脈絡(コンテキスト)に関連した広告を表示するのに最適な、スマートな広告挿入が可能な没入型でチャプター対応の視聴体験が創出されます。
まとめ
このチュートリアルでは、埋め込みベクトルの生成と保存から、類似性検索の実行、そして最後にチャプターによるセグメント化を使用したミッドロール広告の挿入シミュレーションまで、コンテキスト分析の流れ全体を追ってきました。Twelve Labs のマルチモーダル埋め込み(multimodal embeddings)と Pinecone のベクトルフィルタリングを組み合わせることで、スマートでコンテンツを認識した広告体験を提供できます。この基盤は、リアルタイムの広告ターゲティング、A/Bテスト、大規模パーソナライズ広告の配信へとさらに拡張できます。
はじめに
視聴者は、見ているコンテンツと一致しない、無関係な広告に圧倒されることがよくあります。この不一致は不満を招き、広告が押し付けがましく感じられたり、タイミングが悪いと感じられたりする原因になります。
ブランド統合アシスタント & 広告挿入点ファインダー アプリは、コンテキストに関連する広告レコメンデーションを提供することでこれを解決し、エンゲージメントの適切な瞬間に、適切な視聴者へ適切なメッセージが届くようにします。
このチュートリアルでは、アプリのコア機能全体における動作方法を学習します:
タグの自動生成: アップロードされた各広告が分析され、トピックカテゴリ、感情、ブランド、ターゲット層(性別・年齢)、場所といった豊かなメタデータが生成され、スマートなフィルタリング、検索、コンテキスト構築が可能になります。
コンテキストに整合したコンテンツの検索: AIを活用した類似性検索を使用して、ビデオとテキストの両方の埋め込み(embeddings)に基づき、広告と意味的に整合しているコンテンツビデオを検索します。
広告挿入点の推奨とシミュレーション: コンテンツをチャプターに自動分割し、ミッドロール広告の挿入をシミュレートすることで、シームレスで没入感のある広告体験を実現します。
前提条件
Twelve Labs プレイグラウンドにサインアップしてAPIキーを生成し、広告用とコンテンツビデオ用にインデックスをそれぞれ2つ作成します。
Pineconeのアカウントを設定し、ビデオ埋め込みを保存するためのインデックスを作成します。
Dimensionsを1024に、MetricをCosineに設定してください
関連するGitHubリポジトリでアプリケーションのソースコードを確認します。
よりスムーズなセットアップと開発体験のために、JavaScript、TypeScript、Next.jsの知識があると役立ちます。
デモ
デモアプリケーションでご自身で試してみるか、以下のクイックデモビデオをご覧になり、実際にどのように機能するか確認してください。 https://www.loom.com/share/233cc8cb66ae44218e3cff69afb772d7
デモ全体のウェビナー録画は以下からご覧いただけます:
アプリの仕組み
アプリの内部には、広告ライブラリ(Ads Library)とコンテキスト整合性分析(Contextual Alignment Analysis)の2つのメインメニューがあります。
広告ライブラリ - ブランドマーケター向けに、自動生成されたタグ付きの広告ビデオを整理して表示します。トピックカテゴリ、感情、ブランド、性別、年齢、場所で広告をフィルタリングしたり、Twelve Labs Search APIを使用してショートテールまたはロングテールのキーワードで検索したりできます。このチュートリアルでは、広告ライブラリ内の自動タグ生成機能に焦点を当てます。
コンテキスト整合性分析 - このセクションでは、各広告に対してコンテキストが最も関連性の高いコンテンツビデオを検索できます。Twelve Labs EMBEDおよびGETビデオAPI(タグおよびビデオ埋め込み用)と、類似性ベースのフィルタリングを行うPineconeによって、親和性の高いコンテンツを表面化させます。
その後、ユーザーはコンテンツビデオを選択し、広告挿入のための自動チャプター生成を行い、チャプターの切り替わりで広告の再生をシミュレートできます。
以下のチュートリアルでは、コンテンツマッチングと広告シミュレーションの両方の機能について詳しく説明します。
アプリの3つの主要機能とその仕組み
主要機能 1. 自動タグ生成(「広告ライブラリ」内)
広告ライブラリでは、インデックスに登録されたビデオのコレクションをブラウズし、自動生成されたタグを表示できます。これらのタグは、ビデオをトピック、感情、ブランド、ユーザー層などに分類するのに役立ち、これらはすべて Twelve Labs の Analyze API を使用して抽出されます。
ステップ 1 - 各ビデオのタグを生成する
ビデオがロードされ、メタデータが不完全または失われていると判断された場合、システムは generateMetadata を呼び出して、Twelve Labs の Analyze API を使ってタグを取得します。
⭐️Twelve Labs' Analyze API の詳細についてはこちらを参照してください。
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.ts (lines 279-290)
if (!video.user_metadata || Object.keys(video.user_metadata).length === 0 || !video.user_metadata.topic_category && !video.user_metadata.emotions && !video.user_metadata.brands && !video.user_metadata.locations)) { setVideosInProcessing(prev => [...prev, videoId]); const hashtagText = await generateMetadata(videoId); if (hashtagText) { const metadata = parseHashtags(hashtagText);
generateMetadata 関数は、サーバー側のAPI呼び出しをトリガーして Twelve Labs エンジンからAI生成されたタグを要求するカスタムフックです。
これにより、api/analyze/route.ts 内のバックエンドハンドラーがトリガーされ、Twelve Labs の Analyze API 用に構造化された具体的なプロンプトが作成されます。このプロンプトにより、返されるデータが適切に分類され、一貫してフォーマットされるため、簡単にタグに変換してフィルターメニューに表示できます。バックエンドルートの主要な部分は以下のとおりです:
api/analyze/route.ts (lines 1 - 85)
import { NextResponse } from 'next/server'; const API_KEY = process.env.TWELVELABS_API_KEY; const TWELVELABS_API_BASE_URL = process.env.TWELVELABS_API_BASE_URL; export const maxDuration = 60; export async function GET(req: Request) { const { searchParams } = new URL(req.url); const videoId = searchParams.get("videoId"); const prompt = `You are a marketing assistant specialized in generating hashtags for video content. Based on the input video metadata, generate a list of hashtags labeled by category. **Output Format:** Each line must be in the format: [Category]: [Hashtag] (e.g., sector: #beauty) **Allowed Values:** Gender: Male, Female Age: 18-25, 25-34, 35-44, 45-54, 55+ Topic: Beauty, Fashion, Tech, Travel, CPG, Food & Bev, Retail, Other Emotions: sorrow, happiness, laughter, anger, empathy, fear, love, trust, sadness, belonging, guilt, compassion, pride **Instructions:** 1. Use only the values provided in Allowed Values. 2. Do not invent new values except for Brands and Location. Only use values from the Allowed Values. 3. Output must contain at least one hashtag for each of the following categories: - Gender - Age - Topic - Emotions - Location - Brands 4. Do not output any explanations or category names—only return the final hashtag list. **Output Example:** Gender: female Age: 25-34 Topic: beauty Emotions: happiness Location: Los Angeles Brands: Fenty Beauty --- ` … const url = `${TWELVELABS_API_BASE_URL}/analyze`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": API_KEY, }, body: JSON.stringify({ prompt: prompt, video_id: videoId, stream: false }) }; try { const response = await fetch(url, options); …
ステップ 2 - 各ビデオに PUT リクエストを送信して生成されたタグを保存する
/api/analyze ルートを使用してタグを生成したら、次のステップでそれらをインデックスされたライブラリのビデオオブジェクトに保存します。これは、Twelve Labs インデックス内のビデオのメタデータを更新する PUT API コールを通じて行われます。
⭐️ Twelve Labs のUpdate Video Information APIの詳細についてはこちらを参照してください。
この処理は updateVideoMetadata フックによって行われ、最終的に api/videos/metadata/route.ts のバックエンドルートを呼び出します。
❗️カスタムメタデータを保存するには、各ビデオを更新する際にキーに user_metadata を使用していることを確認してください。
api/videos/metadata/route.ts (lines 1-68)
import { NextRequest, NextResponse } from 'next/server'; … export async function PUT(request: NextRequest) { try { // Parse request body const body: MetadataUpdateRequest = await request.json(); const { videoId, indexId, metadata } = body; … // Prepare API request const url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; const requestBody = { user_metadata: { source: metadata.source || '', sector: metadata.sector || '', emotions: metadata.emotions || '', brands: metadata.brands || '', locations: metadata.locations || '', demographics: metadata.demographics || '' } }; const options = { method: 'PUT', headers: { 'Content-Type': 'application/json', 'x-api-key': API_KEY, }, body: JSON.stringify(requestBody) }; // Call Twelve Labs API const response = await fetch(url, options); …
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.tsx (lines 289-292)
if (hashtagText) { const metadata = parseHashtags(hashtagText); await updateVideoMetadata(videoId, adsIndexId, metadata);
📌 user_metadata には何が含まれているか?
保存される user_metadata オブジェクトは、次のような重要フィールドを含んでいます:
{
"gender": "female",
"age": "25-34",
"topic": "beauty",
"emotions": "happiness",
"location": "Los Angeles",
"brands": "Fenty Beauty"
この一貫したフォーマットにより、カテゴリ別フィルター UI、検索、およびダッシュボードでの視覚的グルーピングが可能になります。これらのカスタムメタデータは Twelve Labs から取得されるビデオに埋め込まれているため、GET リクエストを使用して各ビデオを取得し、必要に応じてメタデータを表示できます。
⭐️Twelve Labs' Retrieve Video Information API の詳細についてはこちらを参照してください。
主要機能 2. 類似ビデオの検索(「コンテキスト整合性分析」内)
コンテキスト整合性分析機能は、ビデオとテキストの埋め込み(embeddings)を比較することにより、選択された広告に最も関連のあるコンテンツビデオを見つけるのに役立ちます。これらの埋め込みは以下の通りです:
Twelve Labs によって生成される
類似性検索のために Pinecone を介して保存およびクエリされる
これを可能にするために、以下を確認する必要があります:
すべてのコンテンツビデオに埋め込みが存在すること
選択された広告ビデオに埋め込みが存在すること
すべての埋め込みが同じ Pinecone インデックスに保存されていること
❗️Twelve Labs を通じてビデオをインデックス登録すると、埋め込みが自動的に生成され、Retrieve Video Information API コールで取得できます。
ステップ 1 - コンテンツビデオの埋め込みを処理する
類似性検索を実行する前に、すべてのコンテンツビデオの埋め込みを Pinecone に保存する必要があります。これは、クライアント側の関数 processContentVideoEmbeddings() によって処理されます。
💡 内部フロー
🔧 コア関数
checkVectorExists は、ビデオの埋め込みベクトルがすでに Pinecone に存在するかどうかを確認します。内部的にバックエンドルートを呼び出します。
api/vectors/exists (lines 15-27)
// Fetch vectors using metadata filter instead of direct ID const queryResponse = await index.query({ vector: new Array(1024).fill(0), filter: { tl_video_id: videoId }, topK: 1, includeMetadata: true }); return NextResponse.json({ exists: queryResponse.matches.length > 0 });
埋め込みが存在しない場合は、getAndStoreEmbeddings が以下を行います:
Twelve Labs(/api/videos/[videoId]?embed=true)から埋め込みを取得します
/api/vectors/store を介して Pinecone に保存します
api/videos/[videoId] (lines 77-95)
// Base URL let url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; // Always include embedding query parameters if requested if (requestEmbeddings) { // Include only supported embedding options url += `?embedding_option=visual-text&embedding_option=audio`; } const options = { method: "GET", headers: { "x-api-key": `${API_KEY}`, "Accept": "application/json" }, }; try { const response = await fetch(url, options);
api/vectors/store (lines 126-173)
// Create vectors from embedding segments const vectors = embedding.video_embedding.segments.map((segment: Segment, index: number) => { // Create a meaningful and unique vector ID const vectorId = `${vectorIdBase}_segment${index + 1}`; const vector = { id: vectorId, values: segment.float, metadata: { video_file: actualFileName, video_title: videoTitle, video_segment: index + 1, start_time: segment.start_offset_sec, end_time: segment.end_offset_sec, scope: segment.embedding_scope, tl_video_id: videoId, tl_index_id: indexId, category } }; return vector; }); try { const index = getPineconeIndex(); // Upload vectors in batches const batchSize = 100; const totalBatches = Math.ceil(vectors.length / batchSize); console.log(`🚀 FILENAME DEBUG - Starting vector upload with ${totalBatches} batches...`); for (let i = 0; i < vectors.length; i += batchSize) { const batch = vectors.slice(i, i + batchSize); const batchNumber = Math.floor(i / batchSize) + 1; try { // Test Pinecone connection before upserting try { await index.describeIndexStats(); } catch (statsError) { console.error(`❌ Pinecone connection test failed:`, statsError); throw new Error(`Failed to connect to Pinecone: ${statsError instanceof Error ? statsError.message : 'Unknown error'}`); } // Perform the actual upsert await index.upsert(batch);
ステップ 2 - 選択された広告ビデオの埋め込みを処理する
ユーザーが広告を選択すると、アプリはその埋め込みが準備できているかどうかを自動的にチェックします。このロジックは、選択された広告を監視する useEffect() フック内で実行されます:
contextual-analysis/page.tsx (lines 296-318)
// Automatically check ONLY the ad video embedding when a video is selected useEffect(() => { if (selectedVideoId && !isLoadingEmbeddings) { const cachedStatus = queryClient.getQueryData(['embeddingStatus', selectedVideoId]) as { checked: boolean, ready: boolean } | undefined; if (!cachedStatus?.checked) { setIsLoadingEmbeddings(true); ensureEmbeddings().then(success => { queryClient.setQueryData(['embeddingStatus', selectedVideoId], { checked: true, ready: success }); setEmbeddingsReady(success); setIsLoadingEmbeddings(false); }); } else { setEmbeddingsReady(cachedStatus.ready); } } }, [selectedVideoId, isLoadingEmbeddings, queryClient]);
🔧 コア関数
ensureEmbeddings は checkAndEnsureEmbeddings() を呼び出して以下を行います:
checkVectorExists を介して広告の埋め込みが存在するか確認します
欠落している場合、getAndStoreEmbeddings を使用して生成および保存します
オプションで、同じ呼び出しの中でコンテンツビデオすべてを処理します
❗️checkVectorExists() と getAndStoreEmbeddings() の内部動作についてはステップ 1 ですでに説明しているため、ここでは繰り返さずにそれらを参照します。
ステップ 3 - Pinecone での類似性検索 + TL 検索
すべてのビデオ埋め込み(広告 + コンテンツ)が配置されると、[Run Contextual Analysis(コンテキスト分析の実行)] ボタンをクリックして、以下の2つのタイプの類似性検索を並行して実行します:
テキストからビデオへの検索: 選択された広告のテキストタグ(専門分野や感情など)を使用して、意味的に関連のあるコンテンツビデオを検索します。
ビデオからビデオへの検索: 選択された広告のフレームレベルのビデオ埋め込みを使用して、視覚的/コンテキスト的に類似したコンテンツクリップを検索します。
両方の結果はマージされてスコアリングされ、両方の検索で見つかった一致項目が優先されます。
テキストからビデオへの検索
contextual-analysis/page.tsx (lines 351-384)
const handleContextualAnalysis = async () => { … try { textResults = await textToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); … try { videoResults = await videoToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); …
textToVideoEmbeddingSearch は、選択された広告から専門分野や感情のタグ、およびビデオのタイトルを抽出します。
それらをテキストプロンプトとして api/embeddingSearch/textToVideo ルートに送信します。
Twelve Labs はテキスト埋め込みを生成し、これを使用して Pinecone に意味的に類似したコンテンツビデオをクエリします。
api/embeddingSearch/textToVideo (lines 20-45)
const { data: embedData } = await axios.post(url, formData, { … // extract embedding vector from text_embedding object const textEmbedding = embedData.text_embedding.segments[0].float; … // Get index and search const searchResults = await index.query({ vector: textEmbedding, filter: { // video_type: 'ad', tl_index_id: indexId, scope: 'clip' }, topK: 10, includeMetadata: true, });
ビデオからビデオへの検索
videoToVideoEmbeddingSearch は、選択された広告のフレームレベルのセグメント(ベクトル値)を見つけます。
各セグメントについて、Pinecone 内のコンテンツインデックスに対して類似性クエリを実行します。
各結果は、ビデオ埋め込みにおけるクリップレベルの一致を反映します。
api/embeddingSearch/videoToVideo (lines 22-50)
// First, get the original video's clip embedding const originalClipQuery = await index.query({ filter: { tl_video_id: videoId, scope: 'clip' }, topK: 100, includeMetadata: true, includeValues: true, vector: new Array(1024).fill(0) }); // If we found matching clips, search for similar ads for each match const similarResults = []; if (originalClipQuery.matches.length > 0) { for (const originalClip of originalClipQuery.matches) { const vectorValues = originalClip.values || new Array(1024).fill(0); const queryResult = await index.query({ vector: vectorValues, filter: { tl_index_id: indexId, scope: 'clip' }, topK: 5, includeMetadata: true, }); similarResults.push(queryResult); } }
結果のマージ
両方の検索結果はビデオ ID によってマージされます。ビデオが両方の検索に含まれている場合、そのスコアは 2倍にブーストされます。
contextual-analysis/page.tsx (lines 412-428)
if (combinedResultsMap.has(videoId)) { // This is a match found in both searches - update it const existingResult = combinedResultsMap.get(videoId); // Apply a significant boost for results found in both searches (50% boost) const boostMultiplier = 2; // Combine the scores: use the max of both scores and apply the boost const maxScore = Math.max(existingResult.textScore, result.score); const boostedScore = maxScore * boostMultiplier; combinedResultsMap.set(videoId, { ...existingResult, videoScore: result.score, finalScore: boostedScore, // Boosted score for appearing in both searches source: "BOTH" });
主要機能 3. チャプターを「GENERATE」して広告挿入(ミッドロール)を実装する(「コンテキスト整合性分析」内)
この機能は、選択したコンテンツを意味のあるチャプターに分割し、選択したチャプターの最後に適切な広告を挿入することで、現実のミッドロール広告の挿入をシミュレートし、コンテキストに沿ったビデオレコメンデーション体験を強化します。
ステップ 1 - 選択したコンテンツのチャプターを自動生成する
ユーザーが VideoModal を開くと、アプリは自動的に generateChapters API を呼び出して、選択したコンテンツビデオをセグメント化します。
// Fetch chapters data const { data: chaptersData, isLoading: isChaptersLoading } = useQuery({ queryKey: ["chapters", videoId], queryFn: () => generateChapters(videoId), enabled: isOpen && !!videoId, });
各チャプターには以下が含まれます:
end: チャプターの終了時間(広告キューのポイントとして使用されます)
chapter_title: 生成された短いタイトル
chapter_summary: そのシーンと、それがなぜ広告挿入点として戦略的に適切であるかの説明(1文)
これらのチャプターは チャプタータイムラインバー上 に視覚化され、各ドットが end ポイントを示します。ドットをクリックすると、そのチャプターが終了する直前に広告を挿入するシミュレーションが行われます。
ユーザー体験(UX)の動作:
ドットはチャプター終了マーカーとして表示されます。
ドットをクリックすると、そのキューポイントで 「Show Ad(広告の表示)」 のオーバーレイが表示されます。
広告はスキップ可能で、実際のミッドロール広告のように再生されます。
サーバーロジック:Twelve Labs を介したチャプター生成
チャプターは、カスタムプロンプトとともに Twelve Labs の summarize エンドポイントを使用して生成されます。
api/generateChapters (lines 19-30)
const url = `${TWELVELABS_API_BASE_URL}/summarize`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": `${API_KEY}`, }, body: JSON.stringify({type: "chapter", video_id: videoId, prompt: "Chapterize this video into 3 chapters. For every chapter, describe why it is a strategically appropriate point for placing an advertisement. Do not mention what type of advertisement would be suitable, as the ad content has already been determined. "}) }; try { const response = await fetch(url, options);
クライアント側のヘルパー:generateChapters
React Query でチャプターデータを取得するために使用されます:
export const generateChapters = async (videoId: string): Promise<ChaptersData> => { try { const response = await fetch(`/api/generateChapters?videoId=${videoId}`);
ステップ 2 - 選択したチャプターの区切りで広告を挿入および再生する
ユーザーがチャプターマーカーをクリックすると次のようになります:
コンテンツビデオはチャプターが終了する 3 秒前までシークします。
再生がチャプターの終了時間に達すると、アプリは広告再生シーケンスに移行します。
広告が終了すると、元のコンテンツがチャプターの区切りの直後から再開されます。
チャプターマーカークリックロジック
チャプターマーカーをクリックすると、プレーヤーはそのチャプターが終了する直前にシークし、ミッドロール広告を再生する準備をします。
VideoModal.tsx (lines 102-126)
// Chapter click handler const handleChapterClick = (index: number) => { if (playbackSequence === 'ad') { return; } if (!adVideoDetail?.hls?.video_url) { console.warn("No ad selected. Please select an ad in the contextual analysis page."); return; } if (!chaptersData) return; const chapter = chaptersData.chapters[index]; setSelectedChapter(index); setHasPlayedAd(false); setPlaybackSequence('video'); setShowChapterInfo(true); if (playerRef.current) { // Start 3 seconds before the chapter end time const startTime = Math.max(0, chapter.end - 3); playerRef.current.seekTo(startTime, 'seconds'); } };
進行状況の監視 – チャプター終了時に広告をトリガー
コンテンツの再生中、アプリは現在の再生時間がチャプターのエンドポイントに達したかどうかを確認し、条件が満たされている場合は広告の再生に切り替えます。
// Track video progress const handleProgress = (state: { playedSeconds: number }) => { if (selectedChapter === null || !chaptersData || !adVideoDetail) { return; } const chapter = chaptersData.chapters[selectedChapter]; const timeDiff = state.playedSeconds - chapter.end; const isLastChapter = selectedChapter === chaptersData.chapters.length - 1; if playbackSequence === 'video' && !hasPlayedAd && ((isLastChapter && Math.abs(timeDiff) < 0.5) || (!isLastChapter && timeDiff >= 0)) ) { setPlaybackSequence('ad'); setHasPlayedAd(true); } };
広告再生&コンテンツ再開
広告が終わると、アプリはチャプターが終了した場所から自動的にコンテンツの再生を再開します。
VideoModal.tsx (lines 128-136)
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
これにより、自然な区切りで脈絡(コンテキスト)に関連した広告を表示するのに最適な、スマートな広告挿入が可能な没入型でチャプター対応の視聴体験が創出されます。
まとめ
このチュートリアルでは、埋め込みベクトルの生成と保存から、類似性検索の実行、そして最後にチャプターによるセグメント化を使用したミッドロール広告の挿入シミュレーションまで、コンテキスト分析の流れ全体を追ってきました。Twelve Labs のマルチモーダル埋め込み(multimodal embeddings)と Pinecone のベクトルフィルタリングを組み合わせることで、スマートでコンテンツを認識した広告体験を提供できます。この基盤は、リアルタイムの広告ターゲティング、A/Bテスト、大規模パーソナライズ広告の配信へとさらに拡張できます。
はじめに
視聴者は、見ているコンテンツと一致しない、無関係な広告に圧倒されることがよくあります。この不一致は不満を招き、広告が押し付けがましく感じられたり、タイミングが悪いと感じられたりする原因になります。
ブランド統合アシスタント & 広告挿入点ファインダー アプリは、コンテキストに関連する広告レコメンデーションを提供することでこれを解決し、エンゲージメントの適切な瞬間に、適切な視聴者へ適切なメッセージが届くようにします。
このチュートリアルでは、アプリのコア機能全体における動作方法を学習します:
タグの自動生成: アップロードされた各広告が分析され、トピックカテゴリ、感情、ブランド、ターゲット層(性別・年齢)、場所といった豊かなメタデータが生成され、スマートなフィルタリング、検索、コンテキスト構築が可能になります。
コンテキストに整合したコンテンツの検索: AIを活用した類似性検索を使用して、ビデオとテキストの両方の埋め込み(embeddings)に基づき、広告と意味的に整合しているコンテンツビデオを検索します。
広告挿入点の推奨とシミュレーション: コンテンツをチャプターに自動分割し、ミッドロール広告の挿入をシミュレートすることで、シームレスで没入感のある広告体験を実現します。
前提条件
Twelve Labs プレイグラウンドにサインアップしてAPIキーを生成し、広告用とコンテンツビデオ用にインデックスをそれぞれ2つ作成します。
Pineconeのアカウントを設定し、ビデオ埋め込みを保存するためのインデックスを作成します。
Dimensionsを1024に、MetricをCosineに設定してください
関連するGitHubリポジトリでアプリケーションのソースコードを確認します。
よりスムーズなセットアップと開発体験のために、JavaScript、TypeScript、Next.jsの知識があると役立ちます。
デモ
デモアプリケーションでご自身で試してみるか、以下のクイックデモビデオをご覧になり、実際にどのように機能するか確認してください。 https://www.loom.com/share/233cc8cb66ae44218e3cff69afb772d7
デモ全体のウェビナー録画は以下からご覧いただけます:
アプリの仕組み
アプリの内部には、広告ライブラリ(Ads Library)とコンテキスト整合性分析(Contextual Alignment Analysis)の2つのメインメニューがあります。
広告ライブラリ - ブランドマーケター向けに、自動生成されたタグ付きの広告ビデオを整理して表示します。トピックカテゴリ、感情、ブランド、性別、年齢、場所で広告をフィルタリングしたり、Twelve Labs Search APIを使用してショートテールまたはロングテールのキーワードで検索したりできます。このチュートリアルでは、広告ライブラリ内の自動タグ生成機能に焦点を当てます。
コンテキスト整合性分析 - このセクションでは、各広告に対してコンテキストが最も関連性の高いコンテンツビデオを検索できます。Twelve Labs EMBEDおよびGETビデオAPI(タグおよびビデオ埋め込み用)と、類似性ベースのフィルタリングを行うPineconeによって、親和性の高いコンテンツを表面化させます。
その後、ユーザーはコンテンツビデオを選択し、広告挿入のための自動チャプター生成を行い、チャプターの切り替わりで広告の再生をシミュレートできます。
以下のチュートリアルでは、コンテンツマッチングと広告シミュレーションの両方の機能について詳しく説明します。
アプリの3つの主要機能とその仕組み
主要機能 1. 自動タグ生成(「広告ライブラリ」内)
広告ライブラリでは、インデックスに登録されたビデオのコレクションをブラウズし、自動生成されたタグを表示できます。これらのタグは、ビデオをトピック、感情、ブランド、ユーザー層などに分類するのに役立ち、これらはすべて Twelve Labs の Analyze API を使用して抽出されます。
ステップ 1 - 各ビデオのタグを生成する
ビデオがロードされ、メタデータが不完全または失われていると判断された場合、システムは generateMetadata を呼び出して、Twelve Labs の Analyze API を使ってタグを取得します。
⭐️Twelve Labs' Analyze API の詳細についてはこちらを参照してください。
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.ts (lines 279-290)
if (!video.user_metadata || Object.keys(video.user_metadata).length === 0 || !video.user_metadata.topic_category && !video.user_metadata.emotions && !video.user_metadata.brands && !video.user_metadata.locations)) { setVideosInProcessing(prev => [...prev, videoId]); const hashtagText = await generateMetadata(videoId); if (hashtagText) { const metadata = parseHashtags(hashtagText);
generateMetadata 関数は、サーバー側のAPI呼び出しをトリガーして Twelve Labs エンジンからAI生成されたタグを要求するカスタムフックです。
これにより、api/analyze/route.ts 内のバックエンドハンドラーがトリガーされ、Twelve Labs の Analyze API 用に構造化された具体的なプロンプトが作成されます。このプロンプトにより、返されるデータが適切に分類され、一貫してフォーマットされるため、簡単にタグに変換してフィルターメニューに表示できます。バックエンドルートの主要な部分は以下のとおりです:
api/analyze/route.ts (lines 1 - 85)
import { NextResponse } from 'next/server'; const API_KEY = process.env.TWELVELABS_API_KEY; const TWELVELABS_API_BASE_URL = process.env.TWELVELABS_API_BASE_URL; export const maxDuration = 60; export async function GET(req: Request) { const { searchParams } = new URL(req.url); const videoId = searchParams.get("videoId"); const prompt = `You are a marketing assistant specialized in generating hashtags for video content. Based on the input video metadata, generate a list of hashtags labeled by category. **Output Format:** Each line must be in the format: [Category]: [Hashtag] (e.g., sector: #beauty) **Allowed Values:** Gender: Male, Female Age: 18-25, 25-34, 35-44, 45-54, 55+ Topic: Beauty, Fashion, Tech, Travel, CPG, Food & Bev, Retail, Other Emotions: sorrow, happiness, laughter, anger, empathy, fear, love, trust, sadness, belonging, guilt, compassion, pride **Instructions:** 1. Use only the values provided in Allowed Values. 2. Do not invent new values except for Brands and Location. Only use values from the Allowed Values. 3. Output must contain at least one hashtag for each of the following categories: - Gender - Age - Topic - Emotions - Location - Brands 4. Do not output any explanations or category names—only return the final hashtag list. **Output Example:** Gender: female Age: 25-34 Topic: beauty Emotions: happiness Location: Los Angeles Brands: Fenty Beauty --- ` … const url = `${TWELVELABS_API_BASE_URL}/analyze`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": API_KEY, }, body: JSON.stringify({ prompt: prompt, video_id: videoId, stream: false }) }; try { const response = await fetch(url, options); …
ステップ 2 - 各ビデオに PUT リクエストを送信して生成されたタグを保存する
/api/analyze ルートを使用してタグを生成したら、次のステップでそれらをインデックスされたライブラリのビデオオブジェクトに保存します。これは、Twelve Labs インデックス内のビデオのメタデータを更新する PUT API コールを通じて行われます。
⭐️ Twelve Labs のUpdate Video Information APIの詳細についてはこちらを参照してください。
この処理は updateVideoMetadata フックによって行われ、最終的に api/videos/metadata/route.ts のバックエンドルートを呼び出します。
❗️カスタムメタデータを保存するには、各ビデオを更新する際にキーに user_metadata を使用していることを確認してください。
api/videos/metadata/route.ts (lines 1-68)
import { NextRequest, NextResponse } from 'next/server'; … export async function PUT(request: NextRequest) { try { // Parse request body const body: MetadataUpdateRequest = await request.json(); const { videoId, indexId, metadata } = body; … // Prepare API request const url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; const requestBody = { user_metadata: { source: metadata.source || '', sector: metadata.sector || '', emotions: metadata.emotions || '', brands: metadata.brands || '', locations: metadata.locations || '', demographics: metadata.demographics || '' } }; const options = { method: 'PUT', headers: { 'Content-Type': 'application/json', 'x-api-key': API_KEY, }, body: JSON.stringify(requestBody) }; // Call Twelve Labs API const response = await fetch(url, options); …
🔁 使用されている場所
この呼び出しは page.tsx の processVideoMetadataSingle 内にあり、以下のようになっています:
ads-library/page.tsx (lines 289-292)
if (hashtagText) { const metadata = parseHashtags(hashtagText); await updateVideoMetadata(videoId, adsIndexId, metadata);
📌 user_metadata には何が含まれているか?
保存される user_metadata オブジェクトは、次のような重要フィールドを含んでいます:
{
"gender": "female",
"age": "25-34",
"topic": "beauty",
"emotions": "happiness",
"location": "Los Angeles",
"brands": "Fenty Beauty"
この一貫したフォーマットにより、カテゴリ別フィルター UI、検索、およびダッシュボードでの視覚的グルーピングが可能になります。これらのカスタムメタデータは Twelve Labs から取得されるビデオに埋め込まれているため、GET リクエストを使用して各ビデオを取得し、必要に応じてメタデータを表示できます。
⭐️Twelve Labs' Retrieve Video Information API の詳細についてはこちらを参照してください。
主要機能 2. 類似ビデオの検索(「コンテキスト整合性分析」内)
コンテキスト整合性分析機能は、ビデオとテキストの埋め込み(embeddings)を比較することにより、選択された広告に最も関連のあるコンテンツビデオを見つけるのに役立ちます。これらの埋め込みは以下の通りです:
Twelve Labs によって生成される
類似性検索のために Pinecone を介して保存およびクエリされる
これを可能にするために、以下を確認する必要があります:
すべてのコンテンツビデオに埋め込みが存在すること
選択された広告ビデオに埋め込みが存在すること
すべての埋め込みが同じ Pinecone インデックスに保存されていること
❗️Twelve Labs を通じてビデオをインデックス登録すると、埋め込みが自動的に生成され、Retrieve Video Information API コールで取得できます。
ステップ 1 - コンテンツビデオの埋め込みを処理する
類似性検索を実行する前に、すべてのコンテンツビデオの埋め込みを Pinecone に保存する必要があります。これは、クライアント側の関数 processContentVideoEmbeddings() によって処理されます。
💡 内部フロー
🔧 コア関数
checkVectorExists は、ビデオの埋め込みベクトルがすでに Pinecone に存在するかどうかを確認します。内部的にバックエンドルートを呼び出します。
api/vectors/exists (lines 15-27)
// Fetch vectors using metadata filter instead of direct ID const queryResponse = await index.query({ vector: new Array(1024).fill(0), filter: { tl_video_id: videoId }, topK: 1, includeMetadata: true }); return NextResponse.json({ exists: queryResponse.matches.length > 0 });
埋め込みが存在しない場合は、getAndStoreEmbeddings が以下を行います:
Twelve Labs(/api/videos/[videoId]?embed=true)から埋め込みを取得します
/api/vectors/store を介して Pinecone に保存します
api/videos/[videoId] (lines 77-95)
// Base URL let url = `${TWELVELABS_API_BASE_URL}/indexes/${indexId}/videos/${videoId}`; // Always include embedding query parameters if requested if (requestEmbeddings) { // Include only supported embedding options url += `?embedding_option=visual-text&embedding_option=audio`; } const options = { method: "GET", headers: { "x-api-key": `${API_KEY}`, "Accept": "application/json" }, }; try { const response = await fetch(url, options);
api/vectors/store (lines 126-173)
// Create vectors from embedding segments const vectors = embedding.video_embedding.segments.map((segment: Segment, index: number) => { // Create a meaningful and unique vector ID const vectorId = `${vectorIdBase}_segment${index + 1}`; const vector = { id: vectorId, values: segment.float, metadata: { video_file: actualFileName, video_title: videoTitle, video_segment: index + 1, start_time: segment.start_offset_sec, end_time: segment.end_offset_sec, scope: segment.embedding_scope, tl_video_id: videoId, tl_index_id: indexId, category } }; return vector; }); try { const index = getPineconeIndex(); // Upload vectors in batches const batchSize = 100; const totalBatches = Math.ceil(vectors.length / batchSize); console.log(`🚀 FILENAME DEBUG - Starting vector upload with ${totalBatches} batches...`); for (let i = 0; i < vectors.length; i += batchSize) { const batch = vectors.slice(i, i + batchSize); const batchNumber = Math.floor(i / batchSize) + 1; try { // Test Pinecone connection before upserting try { await index.describeIndexStats(); } catch (statsError) { console.error(`❌ Pinecone connection test failed:`, statsError); throw new Error(`Failed to connect to Pinecone: ${statsError instanceof Error ? statsError.message : 'Unknown error'}`); } // Perform the actual upsert await index.upsert(batch);
ステップ 2 - 選択された広告ビデオの埋め込みを処理する
ユーザーが広告を選択すると、アプリはその埋め込みが準備できているかどうかを自動的にチェックします。このロジックは、選択された広告を監視する useEffect() フック内で実行されます:
contextual-analysis/page.tsx (lines 296-318)
// Automatically check ONLY the ad video embedding when a video is selected useEffect(() => { if (selectedVideoId && !isLoadingEmbeddings) { const cachedStatus = queryClient.getQueryData(['embeddingStatus', selectedVideoId]) as { checked: boolean, ready: boolean } | undefined; if (!cachedStatus?.checked) { setIsLoadingEmbeddings(true); ensureEmbeddings().then(success => { queryClient.setQueryData(['embeddingStatus', selectedVideoId], { checked: true, ready: success }); setEmbeddingsReady(success); setIsLoadingEmbeddings(false); }); } else { setEmbeddingsReady(cachedStatus.ready); } } }, [selectedVideoId, isLoadingEmbeddings, queryClient]);
🔧 コア関数
ensureEmbeddings は checkAndEnsureEmbeddings() を呼び出して以下を行います:
checkVectorExists を介して広告の埋め込みが存在するか確認します
欠落している場合、getAndStoreEmbeddings を使用して生成および保存します
オプションで、同じ呼び出しの中でコンテンツビデオすべてを処理します
❗️checkVectorExists() と getAndStoreEmbeddings() の内部動作についてはステップ 1 ですでに説明しているため、ここでは繰り返さずにそれらを参照します。
ステップ 3 - Pinecone での類似性検索 + TL 検索
すべてのビデオ埋め込み(広告 + コンテンツ)が配置されると、[Run Contextual Analysis(コンテキスト分析の実行)] ボタンをクリックして、以下の2つのタイプの類似性検索を並行して実行します:
テキストからビデオへの検索: 選択された広告のテキストタグ(専門分野や感情など)を使用して、意味的に関連のあるコンテンツビデオを検索します。
ビデオからビデオへの検索: 選択された広告のフレームレベルのビデオ埋め込みを使用して、視覚的/コンテキスト的に類似したコンテンツクリップを検索します。
両方の結果はマージされてスコアリングされ、両方の検索で見つかった一致項目が優先されます。
テキストからビデオへの検索
contextual-analysis/page.tsx (lines 351-384)
const handleContextualAnalysis = async () => { … try { textResults = await textToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); … try { videoResults = await videoToVideoEmbeddingSearch(selectedVideoId, adsIndexId, contentIndexId); …
textToVideoEmbeddingSearch は、選択された広告から専門分野や感情のタグ、およびビデオのタイトルを抽出します。
それらをテキストプロンプトとして api/embeddingSearch/textToVideo ルートに送信します。
Twelve Labs はテキスト埋め込みを生成し、これを使用して Pinecone に意味的に類似したコンテンツビデオをクエリします。
api/embeddingSearch/textToVideo (lines 20-45)
const { data: embedData } = await axios.post(url, formData, { … // extract embedding vector from text_embedding object const textEmbedding = embedData.text_embedding.segments[0].float; … // Get index and search const searchResults = await index.query({ vector: textEmbedding, filter: { // video_type: 'ad', tl_index_id: indexId, scope: 'clip' }, topK: 10, includeMetadata: true, });
ビデオからビデオへの検索
videoToVideoEmbeddingSearch は、選択された広告のフレームレベルのセグメント(ベクトル値)を見つけます。
各セグメントについて、Pinecone 内のコンテンツインデックスに対して類似性クエリを実行します。
各結果は、ビデオ埋め込みにおけるクリップレベルの一致を反映します。
api/embeddingSearch/videoToVideo (lines 22-50)
// First, get the original video's clip embedding const originalClipQuery = await index.query({ filter: { tl_video_id: videoId, scope: 'clip' }, topK: 100, includeMetadata: true, includeValues: true, vector: new Array(1024).fill(0) }); // If we found matching clips, search for similar ads for each match const similarResults = []; if (originalClipQuery.matches.length > 0) { for (const originalClip of originalClipQuery.matches) { const vectorValues = originalClip.values || new Array(1024).fill(0); const queryResult = await index.query({ vector: vectorValues, filter: { tl_index_id: indexId, scope: 'clip' }, topK: 5, includeMetadata: true, }); similarResults.push(queryResult); } }
結果のマージ
両方の検索結果はビデオ ID によってマージされます。ビデオが両方の検索に含まれている場合、そのスコアは 2倍にブーストされます。
contextual-analysis/page.tsx (lines 412-428)
if (combinedResultsMap.has(videoId)) { // This is a match found in both searches - update it const existingResult = combinedResultsMap.get(videoId); // Apply a significant boost for results found in both searches (50% boost) const boostMultiplier = 2; // Combine the scores: use the max of both scores and apply the boost const maxScore = Math.max(existingResult.textScore, result.score); const boostedScore = maxScore * boostMultiplier; combinedResultsMap.set(videoId, { ...existingResult, videoScore: result.score, finalScore: boostedScore, // Boosted score for appearing in both searches source: "BOTH" });
主要機能 3. チャプターを「GENERATE」して広告挿入(ミッドロール)を実装する(「コンテキスト整合性分析」内)
この機能は、選択したコンテンツを意味のあるチャプターに分割し、選択したチャプターの最後に適切な広告を挿入することで、現実のミッドロール広告の挿入をシミュレートし、コンテキストに沿ったビデオレコメンデーション体験を強化します。
ステップ 1 - 選択したコンテンツのチャプターを自動生成する
ユーザーが VideoModal を開くと、アプリは自動的に generateChapters API を呼び出して、選択したコンテンツビデオをセグメント化します。
// Fetch chapters data const { data: chaptersData, isLoading: isChaptersLoading } = useQuery({ queryKey: ["chapters", videoId], queryFn: () => generateChapters(videoId), enabled: isOpen && !!videoId, });
各チャプターには以下が含まれます:
end: チャプターの終了時間(広告キューのポイントとして使用されます)
chapter_title: 生成された短いタイトル
chapter_summary: そのシーンと、それがなぜ広告挿入点として戦略的に適切であるかの説明(1文)
これらのチャプターは チャプタータイムラインバー上 に視覚化され、各ドットが end ポイントを示します。ドットをクリックすると、そのチャプターが終了する直前に広告を挿入するシミュレーションが行われます。
ユーザー体験(UX)の動作:
ドットはチャプター終了マーカーとして表示されます。
ドットをクリックすると、そのキューポイントで 「Show Ad(広告の表示)」 のオーバーレイが表示されます。
広告はスキップ可能で、実際のミッドロール広告のように再生されます。
サーバーロジック:Twelve Labs を介したチャプター生成
チャプターは、カスタムプロンプトとともに Twelve Labs の summarize エンドポイントを使用して生成されます。
api/generateChapters (lines 19-30)
const url = `${TWELVELABS_API_BASE_URL}/summarize`; const options = { method: "POST", headers: { "Content-Type": "application/json", "x-api-key": `${API_KEY}`, }, body: JSON.stringify({type: "chapter", video_id: videoId, prompt: "Chapterize this video into 3 chapters. For every chapter, describe why it is a strategically appropriate point for placing an advertisement. Do not mention what type of advertisement would be suitable, as the ad content has already been determined. "}) }; try { const response = await fetch(url, options);
クライアント側のヘルパー:generateChapters
React Query でチャプターデータを取得するために使用されます:
export const generateChapters = async (videoId: string): Promise<ChaptersData> => { try { const response = await fetch(`/api/generateChapters?videoId=${videoId}`);
ステップ 2 - 選択したチャプターの区切りで広告を挿入および再生する
ユーザーがチャプターマーカーをクリックすると次のようになります:
コンテンツビデオはチャプターが終了する 3 秒前までシークします。
再生がチャプターの終了時間に達すると、アプリは広告再生シーケンスに移行します。
広告が終了すると、元のコンテンツがチャプターの区切りの直後から再開されます。
チャプターマーカークリックロジック
チャプターマーカーをクリックすると、プレーヤーはそのチャプターが終了する直前にシークし、ミッドロール広告を再生する準備をします。
VideoModal.tsx (lines 102-126)
// Chapter click handler const handleChapterClick = (index: number) => { if (playbackSequence === 'ad') { return; } if (!adVideoDetail?.hls?.video_url) { console.warn("No ad selected. Please select an ad in the contextual analysis page."); return; } if (!chaptersData) return; const chapter = chaptersData.chapters[index]; setSelectedChapter(index); setHasPlayedAd(false); setPlaybackSequence('video'); setShowChapterInfo(true); if (playerRef.current) { // Start 3 seconds before the chapter end time const startTime = Math.max(0, chapter.end - 3); playerRef.current.seekTo(startTime, 'seconds'); } };
進行状況の監視 – チャプター終了時に広告をトリガー
コンテンツの再生中、アプリは現在の再生時間がチャプターのエンドポイントに達したかどうかを確認し、条件が満たされている場合は広告の再生に切り替えます。
// Track video progress const handleProgress = (state: { playedSeconds: number }) => { if (selectedChapter === null || !chaptersData || !adVideoDetail) { return; } const chapter = chaptersData.chapters[selectedChapter]; const timeDiff = state.playedSeconds - chapter.end; const isLastChapter = selectedChapter === chaptersData.chapters.length - 1; if playbackSequence === 'video' && !hasPlayedAd && ((isLastChapter && Math.abs(timeDiff) < 0.5) || (!isLastChapter && timeDiff >= 0)) ) { setPlaybackSequence('ad'); setHasPlayedAd(true); } };
広告再生&コンテンツ再開
広告が終わると、アプリはチャプターが終了した場所から自動的にコンテンツの再生を再開します。
VideoModal.tsx (lines 128-136)
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
// Ad ended handler const handleAdEnded = () => { if (selectedChapter === null || !chaptersData) return; const chapter = chaptersData.chapters[selectedChapter]; setPlaybackSequence('video'); setReturnToTime(chapter.end); setIsPlaying(true); };
これにより、自然な区切りで脈絡(コンテキスト)に関連した広告を表示するのに最適な、スマートな広告挿入が可能な没入型でチャプター対応の視聴体験が創出されます。
まとめ
このチュートリアルでは、埋め込みベクトルの生成と保存から、類似性検索の実行、そして最後にチャプターによるセグメント化を使用したミッドロール広告の挿入シミュレーションまで、コンテキスト分析の流れ全体を追ってきました。Twelve Labs のマルチモーダル埋め込み(multimodal embeddings)と Pinecone のベクトルフィルタリングを組み合わせることで、スマートでコンテンツを認識した広告体験を提供できます。この基盤は、リアルタイムの広告ターゲティング、A/Bテスト、大規模パーソナライズ広告の配信へとさらに拡張できます。