
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)

パートナーシップ
ビデオからベクトルへ:TwelveLabsとLangflowで構築するスマートビデオエージェント

ジェームズ・リー
開発者は、Twelve LabsとLangflowを使用し、ビデオインデックス作成および質問回答用のPegasusとマルチモーダル埋め込み用のMarengoを組み合わせることで、ビデオ対応のAIエージェントを構築できます。これにより、セマンティックビデオ検索からAstraDBベクトルストレージを使用した完全なRAGシステムに至るまでのワークフローがカバーされます。
開発者は、Twelve LabsとLangflowを使用し、ビデオインデックス作成および質問回答用のPegasusとマルチモーダル埋め込み用のMarengoを組み合わせることで、ビデオ対応のAIエージェントを構築できます。これにより、セマンティックビデオ検索からAstraDBベクトルストレージを使用した完全なRAGシステムに至るまでのワークフローがカバーされます。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2025/06/04
12分
記事へのリンクをコピー
Langflow/DataStaxチーム(Melissa Herrera、Eric Hare、Gokul Krishnaa、Alejandro Cantarero)のコラボレーションに深く感謝いたします!
ワークフロー全体を紹介しているMelissaによる以下のチュートリアルもぜひご覧ください 👇
1 - はじめにと概要
ビデオAIのワイルドな世界へようこそ!ここでは、あなた自身と同じように、アプリが動画で何が起こっているかを「見る」ことができます! 🎬
このチュートリアルは、TwelveLabsとLangflowを使って次世代のビデオパワードエージェントを構築するためのゴールインチケットです。コンピュータビジョンの博士号は必要ありません。好奇心といくつかのビデオクリップさえあれば準備完了です。

なぜ重要なのか?
TwelveLabsは「頭脳」を提供します。当社のPegasus(ペガサス)およびMarengo(マレンゴ)モデルにより、コードがビデオコンテンツを理解、インデックス化、チャットできるようになり、質問への回答、重要な瞬間の特定、スマートな要約生成などが可能になります。Langflowはあなたの遊び場です。アイデアをAIワークフローに変換し、即座にAPIとして提供できるビジュアルビルダーです。これらを組み合わせることで、ビデオ検索エンジン、コンテンツモデレーションボット、あるいはテキスト、画像、動画を処理できるマルチモーダルアシスタントなど、ビデオAIソリューションの作成、テスト、デプロイが簡単になります。
内容は?
このチュートリアルでは、初心者からビデオのプロへと成長できます。環境をセットアップし、LangflowにおけるTwelveLabsコンポーネントをマスターし、ビデオとのチャット、ビデオ埋め込み(Embeddings)の生成と保存、さらにはビデオライブラリから質問を取得して回答する本格的なRAGシステムの構築といった実践的なフローを構築します。その過程で、ベストプラクティスを学び、画期的なユースケースを発見し、独自のビデオ対応アプリを構築するインスピレーションを得ることができます。
それでは、ポップコーンを用意し、コードエディタを立ち上げて、AIワークフローを真のビデオススマートにしていきましょう! 🚀🍿
2 - 開発環境のセットアップ
TwelveLabsとLangflowで開発を開始するために環境を準備しましょう。
Langflowのインストール
pipを使用してLangflowをインストールします:
pip install langflowLangflowサーバーを起動します:
langflow runブラウザで
http://127.0.0.1:7860にアクセスし、LangflowのUIを開きます。

TwelveLabs API認証情報の取得
まだアカウントをお持ちでない場合は、 TwelveLabsプラットフォーム でアカウントを作成します。
プロファイル設定に移動し、新しいAPIキーを作成します。
TwelveLabsサービスへのリクエストの認証に必要となるため、APIキーを書き留めておきます。
TwelveLabsコンポーネントの確認
Langflowのインターフェースで、「+」ボタンをクリックして新しいフローを作成します。
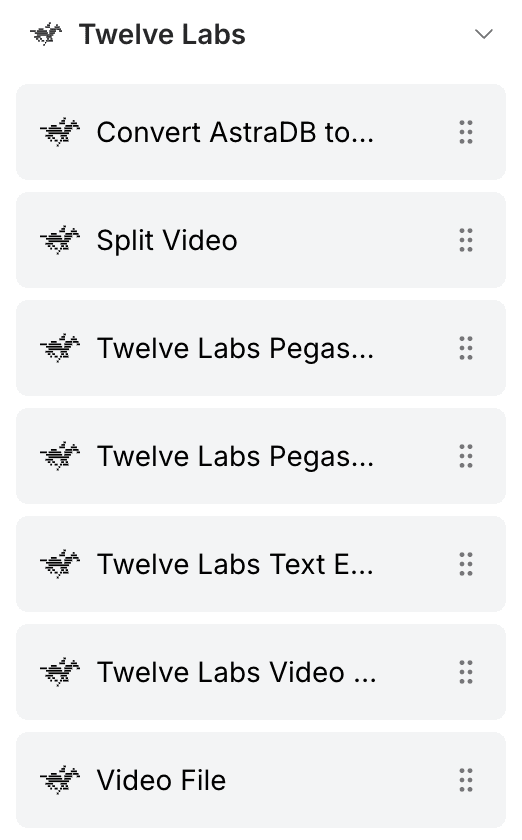
コンポーネントサイドバーを開き、「TwelveLabs」を検索します。以下のコンポーネントが表示されるはずです:
Video File(ビデオファイル)
Split Video(ビデオ分割)
Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)
Twelve Labs Pegasus(Twelve Labs Pegasus)
Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)
Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)
Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)
これらのコンポーネントが表示されない場合は、Langflowが最新バージョンにアップデートされているか確認してください。
サンプル動画の準備
このチュートリアルでのテスト用に、2〜3個の短いビデオクリップ(それぞれ1〜3分)を用意します。MP4、MOV、AVIなどの一般的なフォーマットがサポートされています。
学習時のパフォーマンスを最適化するために、視覚的コンテンツが明確で、シーンがはっきり分かれている動画を使用してください。これにより、ビデオ理解機能の効果をより実感できます。
チュートリアル中に見つけやすいよう、サンプル動画専用のフォルダを作成します。
トラブルシューティングのヒント
TwelveLabsコンポーネントで問題が発生した場合:
API認証: APIキーが正しく入力されており、有効期限が切れていないことを確認してください。
ビデオ処理: ビデオがサポートされているフォーマットであり、サイズが大きすぎないことを確認してください。処理を高速化するため、まずは100MB未満のクリップから始めてください。
コンポーネントの読み込み: コンポーネントが表示されない場合は、Langflowを再起動するか、コンソールでエラーメッセージを確認してください。
依存関係: 統合にはビデオ処理のためにFFmpegが必要です。まだインストールされていない場合は、システムのパッケージマネージャーを使用してインストールしてください。
環境がセットアップできたら、TwelveLabsとLangflowを使って強力なビデオ対応AIワークフローの構築を始める準備は完了です。
3 - LangflowにおけるTwelveLabsコンポーネントの理解
Langflowに、AIワークフローで高度なビデオ理解機能を可能にする7つの強力なTwelveLabsコンポーネントが加わりました。これらのコンポーネントは、動画の処理、埋め込みの生成、ビデオコンテンツのインデックス作成、そして視覚コンテンツとの自然言語によるインタラクションを実現するために相互に連携します。
3.1 - Video File(ビデオファイル)コンポーネント

Video Fileコンポーネントは、Langflowにおけるビデオ処理ワークフローのエントリポイントとして機能します。MP4、AVI、MOV、MKVなど、幅広い一般的なビデオフォーマットに対応しているため、様々なビデオソースに対して汎用性があります。実装は簡単で、ビデオファイルへのパスを指定するだけで、コンポーネントはファイルパスと重要なメタデータの両方を含むDataオブジェクトを返します。開発中のパフォーマンスを最適化するため、まずは100MB未満のビデオから始めることをお勧めします。
3.2 - Split Video(ビデオ分割)コンポーネント

この強力なコンポーネントは、長尺のビデオをインテリジェントに小さく扱いやすいクリップに分割(セグメント化)します。いくつかのパラメータを通じて分割プロセスを微調整できます。希望するクリップの長さを秒単位で設定し、最後のクリップの処理方法(切り捨て、前のコンテンツとのオーバーラップ、またはそのまま保持)を選択し、元のビデオをクリップと並行して保持するかどうかを決定します。このコンポーネントは、詳細なメタデータを含むDataオブジェクトのコレクションとしてクリップを出力します。検索および理解タスクで最良の結果を得るには、6秒から30秒の長さのクリップを作成することをお勧めします。
3.3 - Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)コンポーネント

ビデオインデックス作成の中核を担うのが、Pegasus Index Videoコンポーネントです。TwelveLabsのPegasus APIと連携し、ビデオコンテンツの検索可能なインデックスを作成します。APIキーとビデオデータ(通常はSplit Videoコンポーネントから取得)を提供すると、固有のvideo_idとindex_id識別子を含むインデックス付きビデオデータを生成します。このインデックス作成ステップは、Pegasusコンポーネントでクエリを実行する前に不可欠です。
3.4 - Twelve Labs Pegasus コンポーネント
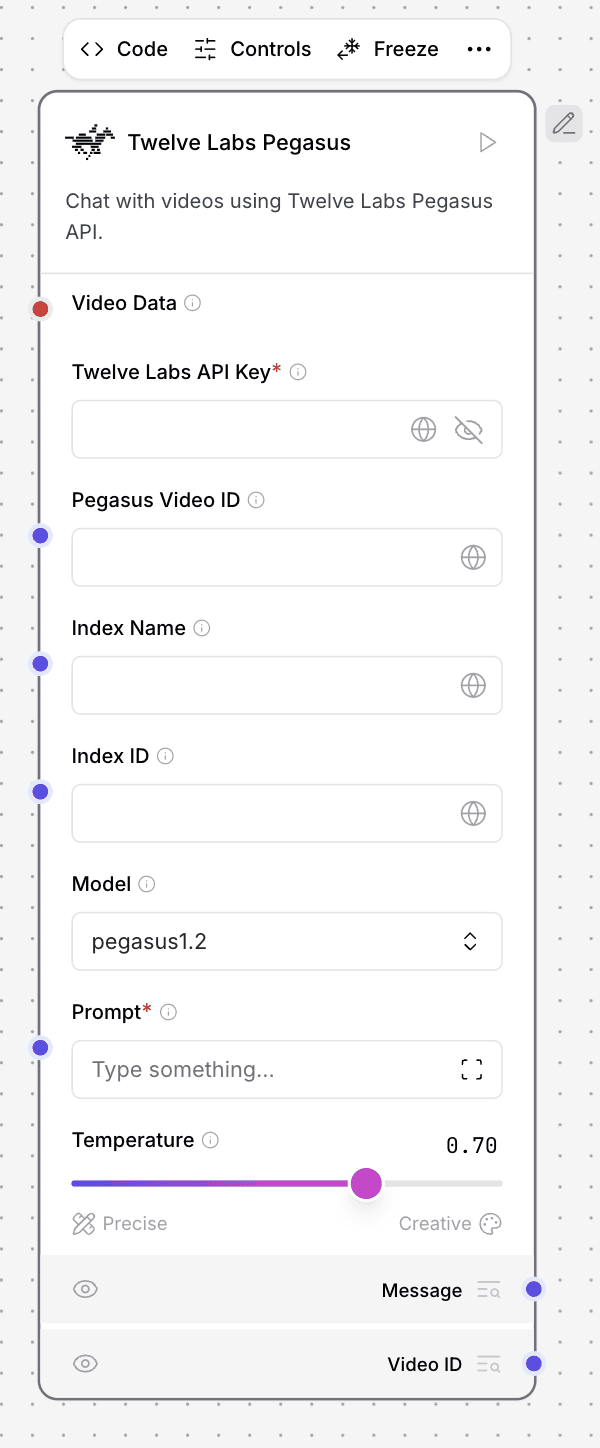
Pegasusコンポーネントは、インデックス作成されたビデオコンテンツとの高度な自然言語インタラクションを可能にします。構成には、APIキー、クエリテキスト、および関連するビデオ識別子とインデックス識別子が必要です。インテリジェントな推論レイヤーとして機能し、クエリのコンテキストとビデオコンテンツの両方を処理して、対話的な応答を生成します。このコンポーネントは、自然言語の理解とビデオコンテンツ分析のギャップを真に埋めるものです。
3.5 - Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)コンポーネント

TwelveLabsのMarengoモデルを活用して、このコンポーネントはテキスト入力からベクトル埋め込みを生成します。APIキーが必要で、現在はMarengo-retrieval-2.7モデルをサポートしています。出力はベクトルデータベースと完全に互換性があるため、洗練された検索システムに最適です。アプリケーションにおける一貫性を保つため、テキストコンポーネントとビデオコンポーネントの両方で同じ埋め込みモデルを使用することをお勧めします。
3.6 - Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)コンポーネント
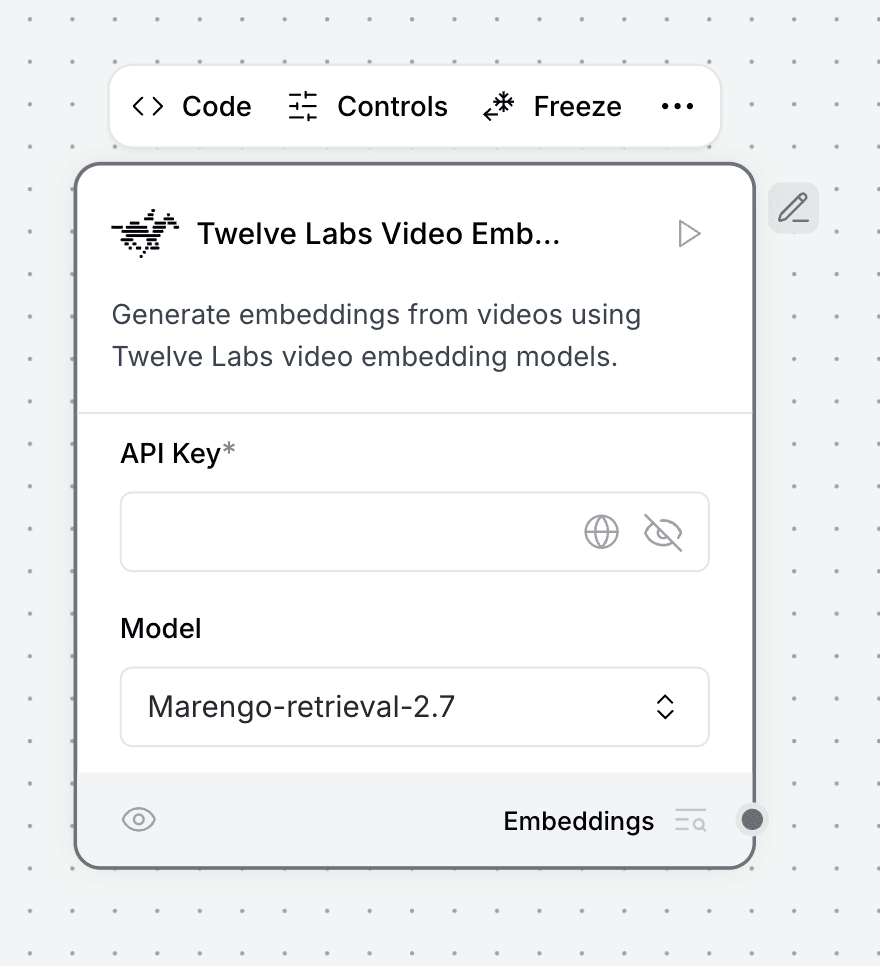
テキスト版と同様に、Video Embeddingsコンポーネントはビデオコンテンツの密なベクトル表現を作成します。テキスト埋め込みコンポーネントと同じ構成パターンを共有しますが、ビデオファイルの処理に特化しています。得られる埋め込みにより、動画間またはテキストと動画コンテンツ間の強力なセマンティック類似性検索が可能になり、マルチモーダルアプリケーションの刺激的な可能性が広がります。
3.7 - Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)コンポーネント
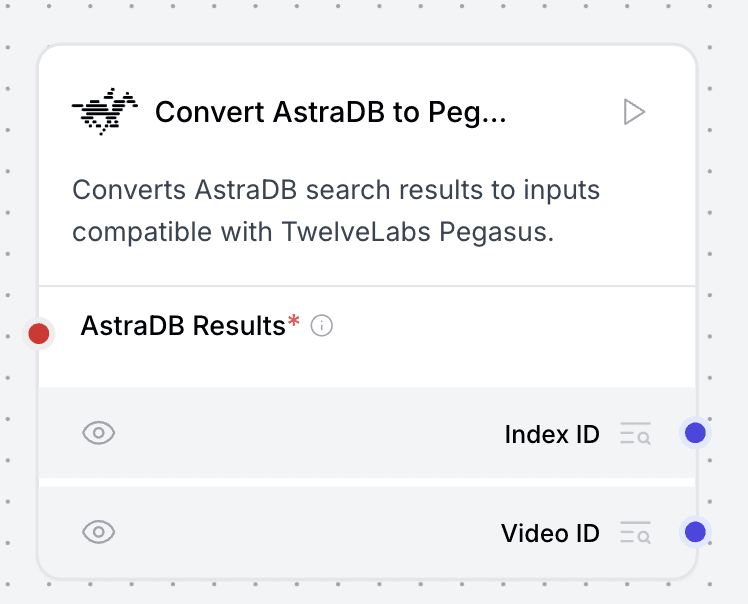
この重要なコネクタコンポーネントは、ベクトルデータベースの操作とTwelveLabsコンポーネント間の架け橋となります。AstraDBからの検索結果を処理し、重要なvideo_idとindex_idの情報を抽出して、Pegasusコンポーネントに適した形式に適切に変換します。このコンポーネントは、ビデオコンテンツを使用したRAG(検索拡張生成)パターンを実装する際に特に価値があり、ベクトルデータベースとビデオ処理パイプライン間のスムーズなデータフローを保証します。
これらのコンポーネントは、シームレスに連携するように設計されています。たとえば、以下のようにしてビデオ検索エンジンを作成できます:
Video Fileでビデオを読み込む
Split Videoで扱いやすいチャンクに分割する
Pegasus Index Videoでインデックスを作成する
Video Embeddingsで埋め込みを生成する
AstraDBなどのベクトルデータベースに保存する
Convert AstraDB to Pegasus Inputで関連するクリップを取得する
Twelve Labs Pegasusで質問に答える
ワークフローを構築する際は、これらのコンポーネントを、読み込みや処理からインデックス作成、埋め込み、検索に至るまで、ビデオ理解の様々な側面を処理するビルディングブロックとして考えてください。
4 - Pegasusでのビデオチャット:最初の対話型ビデオワークフロー
このセクションでは、Twelve Labs Pegasusモデルを使用してビデオと「チャット」できる基本的なLangflowワークフローの作成手順を説明します。このフローは、ビデオ処理、インデックス作成、および自然言語クエリの直接的な統合を示しています。
参照画像に示されている「Pegasus Chat with Video」フローにより、ビデオをアップロードし、Twelve Labsによって自動的にインデックス化され、その後チャットインターフェースを通じてその内容について質問することができます。

以下の手順に従ってこのフローを構築してください:
ビデオのアップロード:
Video FileコンポーネントをLangflowキャンバスにドラッグします。Video Fileコンポーネントのプロパティで、サンプルビデオファイル(例:画像に示されているbig_buck_bunny_720.mp4)をアップロードするためにクリックします。このコンポーネントがビデオを読み込み、他のコンポーネントで利用できるようにします。
ビデオデータをPegasusに接続:
Twelve Labs Pegasusコンポーネントをキャンバスに追加します。Video FileコンポーネントのData出力(赤丸)を、Twelve Labs PegasusコンポーネントのVideo Data入力(赤丸)に接続します。これにより、Pegasusコンポーネントに処理対象のビデオを伝えます。
Pegasusコンポーネントの構成:
Twelve Labs Pegasusコンポーネントにおいて:指定されたフィールドに Twelve Labs APIキー を入力します。
Index Name (インデックス名)を指定します。これは、作成されるビデオインデックスに対して任意に選択した分かりやすい名前で構いません(例:「bunny-test-index」)。
Model はデフォルトで
pegasus1.2のようなPegasusモデルになります。特定のモデル要件がない限り、通常はそのままにしておいて構いません。
開発者向け注意:
Index IDを指定せずにVideo DataとIndex Nameを提供すると、Pegasusコンポーネントは新規ビデオに対してTwelve Labsでのビデオインデックス自動作成プロセスを開始します。このプロセス中にTwelve Labsによってvideo_idおよびindex_idが作成されます。
ユーザー入力の有効化:
Chat Inputコンポーネントをキャンバスに追加します。Chat Inputコンポーネントの出力を、Twelve Labs PegasusコンポーネントのPrompt入力(画像で「Receiving input」とラベル付けされた、青丸)に接続します。これにより、Pegasusモデルに送信される質問を入力できるようになります。
チャット応答の表示:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントのMessage出力(青丸)を、このChat Outputコンポーネントの入力に接続します。これにより、Pegasusモデルからの回答が表示されます。
任意:再チャット用のビデオIDの出力:
その後のチャットセッションで同じビデオの再インデックス作成を避けるために、Twelve Labsによって生成された
Video IDとIndex IDをキャプチャできます。もう一つの
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのVideo ID出力(青丸)を、この新しいChat Outputコンポーネントに接続します。開発者のヒント:同じビデオを使用した将来のセッションでは、以前に生成された
Video IDとIndex IDを、それぞれTwelve Labs PegasusコンポーネントのPegasus Video IDおよびIndex IDフィールドに直接入力できます。これにより、再インデックス作成ステップをバイパスし、インタラクションを高速化できます。Video DataとIndex Nameのみを提供した場合は、再インデックス作成されます。
プレイグラウンドでのテスト:
Langflowプレイグラウンドを開きます(通常は右側のサイドバーにあるチャットバブルアイコンをクリックします)。
ビデオに関する質問をチャットインターフェースに入力します(例:「ビデオに写っている動物は何ですか?」、「主役を説明してください。」)。
Pegasusコンポーネントがビデオを処理し(初回の場合)、インデックスを作成し、ビデオの内容に基づいて質問に答えます。応答は接続された
Chat Outputに表示されます。
このシンプルながら強力なフローは、TwelveLabsのビデオ理解をインタラクティブなLangflowエージェントに直接統合する方法の基本例として役立ちます。これで、ほぼリアルタイムでビデオの内容について質問を投げ、回答を得ることができます。
5 - MarengoとAstraDBによるビデオ埋め込み:セマンティック・ビデオ・インデックスの構築
このセクションでは、TwelveLabsのMarengoモデルを使用してビデオ埋め込みを生成し、その後これらの埋め込みをDataStax AstraDBに保存するためのLangflowワークフローの構築方法を詳しく説明します。これは、ビデオライブラリに対するセマンティック検索を有効にしたり、ビデオコンテンツを使用した高度な検索拡張生成(RAG)システムを構築したりするために不可欠なステップです。
提供されている参照画像に示されているように、このワークフローは、ビデオを取り込んで埋め込みを生成し、これらの埋め込みをビデオのメタデータとともにAstraDBコレクションに保存します。
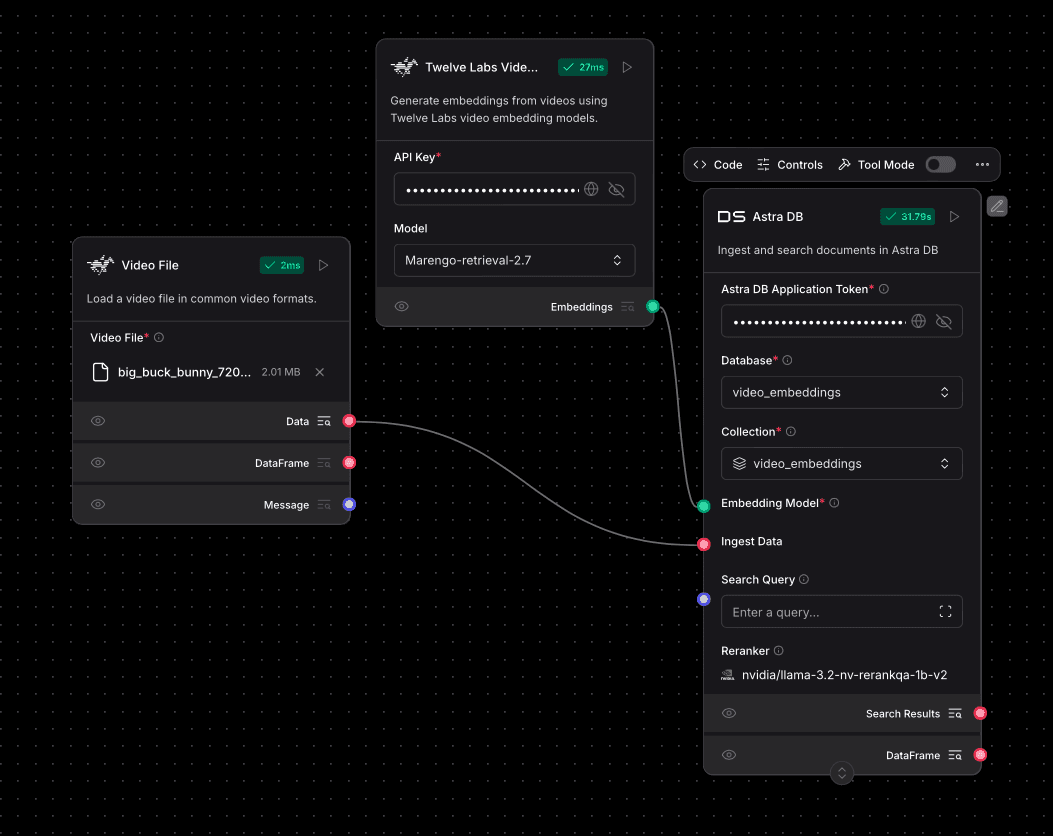
5.1 - 事前準備:AstraDBのセットアップ
Langflowのフローを構築する前に、AstraDB環境が準備できていることを確認してください:
AstraDBデータベースの作成:
まだお持ちでない場合は、サインアップして DataStax AstraDB 上に新しいサーバーレスデータベースを作成します。
データベースの初期作成については、AstraDBのセットアップガイドに従ってください。
アプリケーション・トークンの生成:
AstraDBコンソールの「Database Details(データベースの詳細)」セクションに移動します。
適切な権限(例:Database Administrator、またはコレクションへの接続・読み書きを許可するロール)を持つアプリケーション・トークン(Application Token)を生成します。Langflowコンポーネントで必要になるため、このトークンを安全に保存してください。
video_embeddingsコレクションの作成:AstraDBデータベース内に新しいコレクションを作成します。名前は
video_embeddingsなどにすると良いでしょう。極めて重要:このコレクションをベクトル検索(Vector Search)に対応するように構成します。これには通常、以下が含まれます:
コレクションがベクトルを保存するように指定すること。
ベクトルの次元数(Dimension)を 1024 に設定すること。これは、TwelveLabsのMarengoモデル(画像に示されている
Marengo-retrieval-2.7など)によって生成される埋め込みの次元数です。
ベクトル検索の有効化および次元数の設定に関する詳細な手順については、コレクション管理に関するAstraDBのドキュメントを参照してください。
5.2 - Langflowワークフローの構築
AstraDBがセットアップされたら、Langflowで以下のフローを構築します:
動画のアップロード:
Video Fileコンポーネントをキャンバスにドラッグします。希望のビデオファイル(例:画像で使われている
big_buck_bunny_720.mp4)をアップロードして構成します。このコンポーネントにより、ビデオデータがワークフローからアクセス可能になります。
ビデオ埋め込み生成の構成:
Twelve Labs Video Embeddingsコンポーネントをキャンバスに追加します。API Keyフィールドに Twelve Labs APIキー を入力します。Model が
Marengo-retrieval-2.7(または別の互換性のあるMarengoモデル)に設定されていることを確認します。このコンポーネントがビデオを処理し、密なベクトル埋め込みを生成します。
取り込み用AstraDBの構成:
DS Astra DBコンポーネント(または画像に示されているAstra DBコンポーネント)をキャンバスに追加します。対応するフィールドに Astra DB アプリケーション・トークン を入力します。
ベクトル対応コレクションを作成した Database 名を指定します。
作成した Collection 名(例:
video_embeddings)を入力します。
埋め込みをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力(緑丸)を、DS Astra DBコンポーネントのEmbedding Model入力(緑丸)に接続します。開発者向け注意:この接続は、AstraDBに対して受信データを埋め込みとして解釈する 方法 を伝えるものですが、埋め込み自体を提供するわけではありません。実際の埋め込みは、取り込まれるデータとともに渡されます。
取り込み用ビデオデータの接続:
Video FileコンポーネントからのData出力(赤丸)を、DS Astra DBコンポーネントのIngest Data入力(赤丸)に接続します。開発者向け注意:データが
Ingest Data入力に渡されると、このフローのように埋め込みモデルが構成されているか埋め込みコンポーネントに接続されている場合、Astra DBコンポーネントは入力データの埋め込みを期待または生成します。このセットアップでは、Twelve Labs Video Embeddingsコンポーネントが埋め込み生成を処理し、その出力(元のデータと埋め込みを含む)がDS Astra DBに渡されます。
フローを実行して埋め込みと取り込みを行う:
プロセスを開始するには、通常、このチェーンの最後のコンポーネントである
DS Astra DBコンポーネントを「実行」または有効化します。Langflowでは、コンポーネント上の再生/実行アイコンをクリックするか、より大きな実行可能グラフの一部としてフロー全体を構築して開始します。実行されると、
Video Fileコンポーネントがビデオを読み込みます。次に、Twelve Labs Video Embeddingsコンポーネントがこのビデオデータを受け取り(フローを通じて暗黙的に、またはVideo Data入力が接続されている場合は明示的に受け取り。スクリーンショットのコンポーネントでは示されていませんが)、埋め込みを生成します。最後に、DS Astra DBコンポーネントがビデオデータ(上流コンポーネントあるいは自身の内部ロジックによって埋め込みが豊富化されたもの)を受け取り、指定されたAstraDBコレクションに取り込みます。
このフローを実行すると、ビデオの内容はAstraDBコレクション内のベクトル埋め込みとして表現され、セマンティック検索や類似性比較、RAGアプリケーションのナレッジベースとして活用できる状態になります。AstraDBコレクションに直接クエリを実行して、データが保存されているか確認することができます。
6 - ビデオコンテンツを使用した高度なRAG実装
ビデオのための堅牢な検索拡張生成(RAG)システムを構築するには、ビデオコンテンツの処理やインデックス作成から、セマンティック検索や文脈に応じた理解の有効化にいたるまで、いくつかの段階があります。このセクションは2つのパートに分かれています。まず、ビデオを分割し、そのクリップに対してTwelve Labs Pegasusでインデックスを作成し、Marengoで埋め込みを生成し、それらすべてをAstraDBに保存することで、ビデオデータを準備することに焦点を当てます。
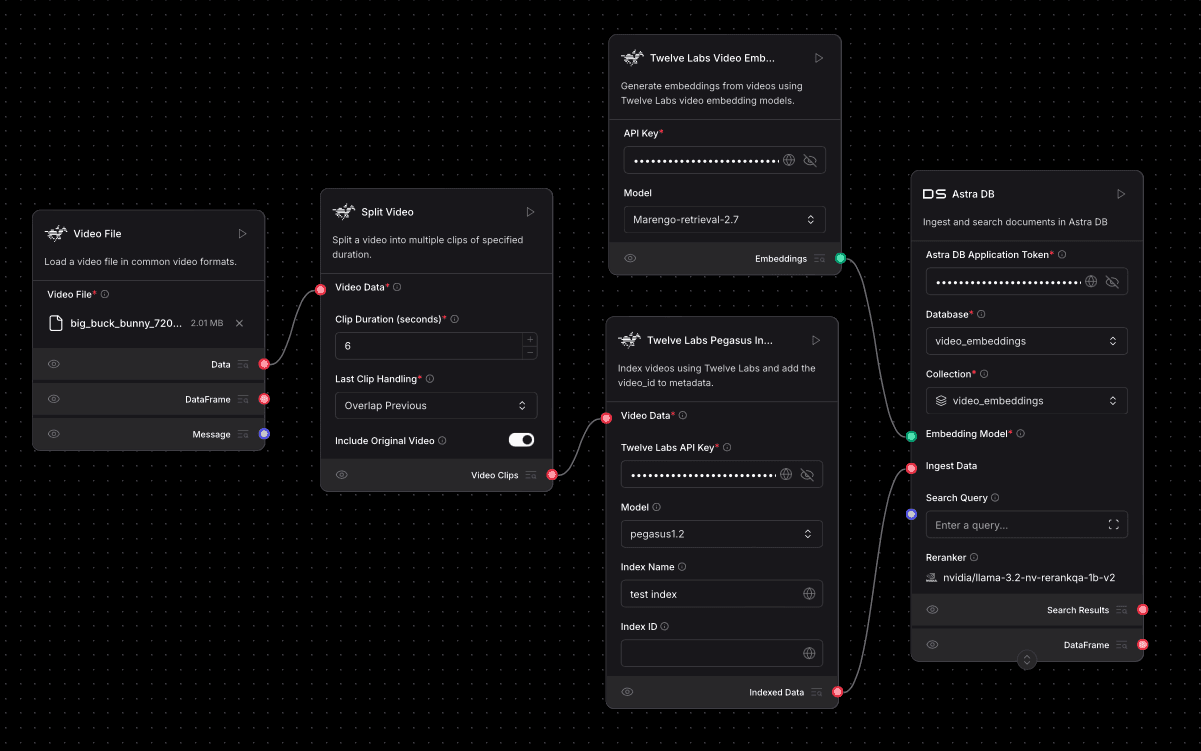
パート1:ビデオを分割し、Pegasusでクリップのインデックスを作成し、埋め込みをAstra DBに保存する
この最初のフローは、画像に示されているように、ビデオRAGシステムの基礎となります。ソースビデオを管理可能なクリップに分割処理し、Pegasusからのインデックス情報でこれらのクリップを充実させ、Marengoを使用して対応するベクトル埋め込みを生成し、最後にこの包括的なデータセットを効率的な検索のためにAstraDBに保存します。
このデータ取り込み用パイプラインの構築手順は以下の通りです:
ソースビデオのアップロード:
まず、
Video FileコンポーネントをLangflowキャンバスにドラッグします。動画をアップロードして構成します(例:画像に示されている
big_buck_bunny_720...)。このコンポーネントは生のビデオデータを出力します。
動画をクリップに分割:
Split Videoコンポーネントを追加します。Video FileコンポーネントからのData出力を、Split VideoコンポーネントのVideo Data入力に接続します。Split Videoコンポーネントを構成します:Clip Duration (seconds): 各ビデオセグメントの長さを定義するためにこれを設定します。画像では
6秒になっており、きめ細かな分析に適した開始値です。コンテンツに合わせてこれを調整できます(たとえば、大まかなシーンセグメンテーションには30秒が適している場合があります)。Last Clip Handling: クリップの長さを一定にするために、画像にある
Overlap Previous(前のクリップと重ねる)のようなオプションを選択するか、お好みに応じてTruncate(切り捨て)やKeep Short(短いまま保持)を選択します。Include Original Video: セグメントを扱うことになるRAG処理用クリップを作成する場合、通常はこれをオフ(画像のとおり)にします。
Pegasusでクリップのインデックス作成:
Twelve Labs Pegasus Index Videoコンポーネントを導入します。Split VideoコンポーネントからのVideo Clips出力を、Twelve Labs Pegasus Index VideoコンポーネントのVideo Data入力に接続します。このコンポーネントは各クリップを処理します。コンポーネントの設定において:
Twelve Labs APIキーを入力します。
Index Name (例:画像の
test index)を指定します。これにより、Twelve Labs内でインデックス作成されたコンテンツを整理しやすくなります。コンポーネントはIndexed Dataを出力します。これには元のクリップデータと、Pegasusによって割り当てられたvideo_idおよびindex_idが含まれます。Model はデフォルトでPegasusモデル(例:
pegasus1.2)になります。
Marengoによるビデオ埋め込みの生成:
Twelve Labs Video Embeddingsコンポーネントを追加します。ここでも Twelve Labs APIキー を入力します。
Model に
Marengo-retrieval-2.7(画像に示されているモデル)か、お好みのMarengo埋め込みモデルを設定します。極めて重要:
Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、Twelve Labs Video Embeddingsコンポーネントの(暗黙的または明示的な)ビデオデータ入力に接続します。開発者向け注意:画像ではこのコンポーネントに直接「Video Data」という名前の入力が表示されていませんが、埋め込みコンポーネントは処理対象のビデオクリップを受け取る必要があります。Indexed Dataがこれらのクリップを運びます。
保存先AstraDBの構成:
DS Astra DBコンポーネントをキャンバスに配置します。Astra DB アプリケーション・トークン を入力します。
ビデオデータと埋め込みが保存される、ターゲットとなる Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。このコレクションが、使用するMarengoモデル(Marengo-retrieval-2.7の場合は1024)に一致する次元数で、ベクトル検索向けに構成されていることを確認してください。
埋め込みとデータをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBに埋め込みベクトルの解釈方法を伝えます。Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、DS Astra DBコンポーネントのIngest Data入力に接続します。これにより、ビデオクリップ(Pegasusのvideo_idとindex_idで充実化されたデータ)と、生成されたそれらの埋め込みが、保存先へと送信されます。
取り込みフローの実行:
フローを実行します。
Video Fileが読み込まれ、Split Videoによって分割されます。各クリップは、インデックス作成のためにTwelve Labs Pegasus Index Videoに送信されます。得られたIndexed Data(クリップ + Pegasus ID)はTwelve Labs Video Embeddingsに渡され、Marengo埋め込みが生成されます。最後に、DS Astra DBコンポーネントがこの包括的なデータ(クリップ、Pegasusインデックス情報、Marengoベクトル埋め込み)を、指定されたコレクションに取り込みます。
このフローが完了すると、AstraDBコレクションに、個々のベクトル埋め込みおよびPegasusの識別子が紐付けられた、インデックス作成済みビデオクリップが含まれ、RAGシステムの取得パートへの準備が整います。
パート2:ビデオ埋め込みへのクエリ実行と、Pegasusを使用したビデオチャット
ビデオクリップが処理され、Pegasusによってインデックスが作成され、それらのMarengo埋め込みがAstraDBに保存され終わったら(パート1で詳述)、この2つ目のフローはRAGの「取得(ミリバール)」と「生成」の側面を示します。参照画像にあるように、まずユーザーのテキスト質問(クエリ)を埋め込みに変換し、それを使用して関連するビデオクリップをAstraDBから検索します。これらのクリップからの情報は、コンテキストに基づいた回答を生成するためにTwelve Labs Pegasusモデルに渡されます。
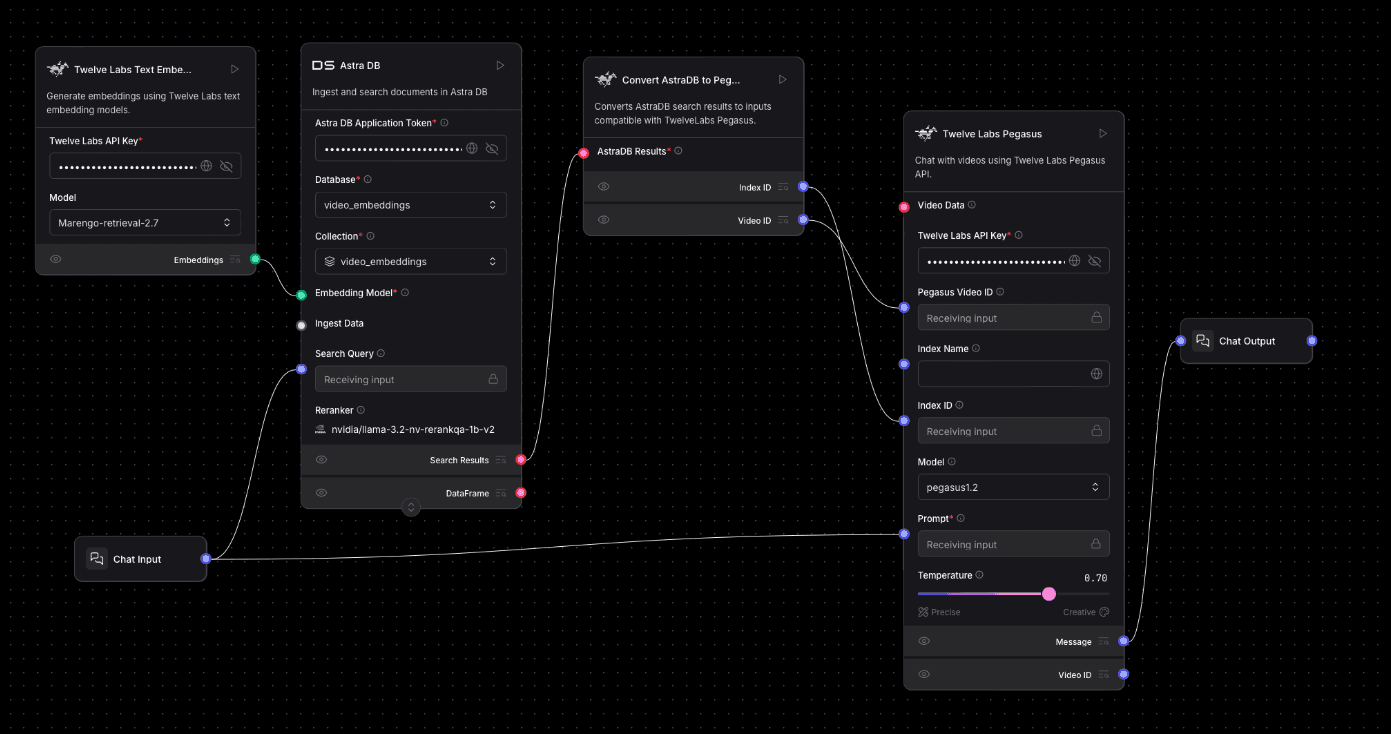
以下はこの取得および質問応答パイプラインの構築手順です:
ユーザーのクエリ入力と埋め込み:
Chat Inputコンポーネントをキャンバスに追加します。これは、ユーザーが質問を入力する場所になります。Twelve Labs Text Embeddingsコンポーネントを追加します。Twelve Labs APIキーを入力します。
Model に
Marengo-retrieval-2.7(またはパート1でビデオクリップの埋め込みに使用したのと同じMarengoモデル)を設定します。
Chat Inputコンポーネントの出力を、Twelve Labs Text Embeddingsコンポーネントのテキスト入力に接続します。これにより、ユーザーのクエリがベクトル埋め込みに確実に変換されます。
AstraDBでのセマンティック検索:
DS Astra DBコンポーネントを追加します。Astra DB アプリケーション・トークン を入力します。
ビデオクリップの埋め込みが保存されている Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。Twelve Labs Text EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBにクエリ埋め込みが提供されます。Chat Inputコンポーネントの出力(生のテキストクエリ)を、DS Astra DBコンポーネントのSearch Query入力に接続します。開発者向け注意:クエリの埋め込みはEmbedding Modelに渡されますが、Search Query入力自体は、構成によってはキーワードフィルタリングやその他のハイブリッド検索戦略、あるいは単に提供されたクエリ埋め込みを使用して何に対してベクトル検索を行うかを知るために、AstraDBによって利用される場合があります。
DS Astra DBコンポーネントは、コレクション内で類似性検索を実行し、最も関連性の高いビデオクリップ(またはパート1から保存されている場合は、video_idやindex_idを含むメタデータ)であるSearch Resultsを返します。
AstraDBの結果をPegasus入力用に変換:
Convert AstraDB to Pegasus Inputコンポーネントを追加します。DS Astra DBコンポーネントからのSearch Results出力(多くの場合ドキュメントのメタデータを含む赤丸)を、このコンバータコンポーネントのAstraDB Results入力に接続します。このユーティリティコンポーネントは非常に重要です。AstraDBの検索結果から
Index IDとVideo IDを抽出します。これは、Pegasusコンポーネントが「チャット」対象となる特定のインデックス作成済みビデオセグメントを識別するために必須となります。
文脈に応じたQ&Aに向けてPegasusを準備:
Twelve Labs Pegasusコンポーネントを追加します。Twelve Labs APIキーを入力します。
希望のPegasusの Model を選択します(デフォルトは
pegasus1.2です)。
Convert AstraDB to Pegasus InputコンポーネントからのIndex ID出力を、Twelve Labs PegasusコンポーネントのIndex ID入力(「Receiving input」とラベルされた端子)に接続します。Convert AstraDB to Pegasus InputコンポーネントからのVideo ID出力を、Twelve Labs PegasusコンポーネントのPegasus Video ID入力(「Receiving input」とラベルされた端子)に接続します。開発者向け注意:ビデオデータがその場で直接インデックス作成のために提供される「Pegasus Chat with Video」フローとは異なり、ここではAstraDBから取得した すでにインデックス作成されている コンテンツの特定の
Pegasus Video IDとIndex IDを提供しています。PegasusコンポーネントのVideo Data入力はこのRAG検索フローでは未接続のままになります。
元のクエリをPegasusに渡す:
元の
Chat Inputコンポーネント(ユーザーの質問を保持しているもの)の出力を、Twelve Labs PegasusコンポーネントのPrompt入力(「Receiving input」とラベルされた端子)に直接接続します。これにより、Pegasusは取得したビデオセグメントの文脈を使用して、どの質問に答えるべきかを認識できます。
Pegasusの応答を表示する:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのMessage出力を、このChat Outputコンポーネントの入力に接続します。これにより、AIが生成した回答が表示されます。
ビデオRAGシステムのテスト:
Langflowのプレイグラウンド(チャットインターフェース)を開きます。
パート1で処理したビデオコンテンツに関連する質問を入力します(例:「冒頭でウサギに何が起こりますか?」、「蝶が出てくるシーンを見せてください。」)。
フローは以下のように実行されます:
あなたの質問が
Chat Inputによってキャプチャされます。Twelve Labs Text Embeddingsが質問をベクトルに変換します。DS Astra DBがそのベクトルを使用して、データベースから最もセマンティックに類似したビデオクリップを見つけます。Convert AstraDB to Pegasus Inputが、上位に取得されたクリップのvideo_idおよびindex_idを抽出します。Twelve Labs PegasusがこれらのID(どのビデオセグメントに焦点を当てるかを指示)と元の質問(そのセグメントに関して何を回答すべきかを指示)を受け取ります。Pegasusが、あなたの質問に関連する指定のビデオセグメントを分析し、回答を生成します。
回答が
Chat Outputを介して表示されます。
この2パートからなるRAGアーキテクチャにより、大規模なビデオライブラリから関連する重要な瞬間を対話形式で取得し、それを基にやり取りできる、洗練されたスケーラブルなビデオ理解アプリケーションを構築できます。
7 - 特別なユースケースとパフォーマンスのベストプラクティス
TwelveLabsとLangflowの連携によるビデオ機能は、価値の高いビジネスアプリケーションを数多く展開させます。不適切な動画セグメントを自動的にフラグ付け、または要約するコンテンツモデレーションシステム、大規模なアーカイブから関連のある瞬間を表面化させるビデオ検索エンジン、さらには動画、テキスト、画像の理解をブレンドしたマルチモーダルアシスタントを構築し、より豊かなユーザーエクスペリエンスを提供できます。これらのユースケースは、動画に対する迅速な洞察や自動分析が、生産性、コンプライアンス、ユーザー維持を直接左右する、メディア、教育、カスタマーサポートなどの業界に最適です。
ビデオ対応ワークフローで信頼性の高いビジネス結果を提供するには、パフォーマンスとコストの最適化に注力してください。動画セグメントをバッチ処理する、あるいは不要な再処理を防ぐためにキャッシュを使用することで、APIのフットプリントを抑え、また詳細度と計算効率のバランスが取れるクリップの長さを選びましょう。ビデオライブラリの増加に伴い高速なクエリ応答を維持するため、AstraDBと埋め込みパイプラインを監視し、より精密な結果を得るために、ベクトル類似性にメタデータフィルタリングを組み合わせたハイブリッド検索戦略を検討してください。
これらのベストプラクティスに従うことで、ビデオAIソリューションにおけるスケーラビリティ、正確性、費用対効果を最大化できます。これにより、組織は大規模なビデオから実行可能な洞察を抽出し、市場における競争優位性を維持することができます。
8 - まとめと次のステップ
おめでとうございます。これであなたもビデオマスターです! 🎬✨
TwelveLabsとLangflowの強力なコンビを使用して、本当にビデオを見て理解するAIエージェントを構築する力をアンロックできました。次世代のスマートなビデオ検索エンジンを作成する、大規模なコンテンツモデレーション、あるいはマルチモーダルアシスタントの開発など、生のフッテージを実用的な洞察(そしてちょっとした魔法のような体験)に変えるツールが手に入りました。
それでは、次に何をしましょう?
独自の創造的なフローを実験したり、さまざまな種類のビデオで限界に挑戦したり、最もクールなプロジェクトをコミュニティで共有してみましょう。TwelveLabsとLangflowのロードマップで発表される刺激的な新機能に注目し、ディスカッションへの参加もお忘れなく。あなたのアイデアとフィードバックが、ビデオAIの未来を形作ります!
さあ、素晴らしいものを構築しに出発しましょう。ビデオの宇宙があなたの探索を待っています! 🚀🎥
追加リソース
TwelveLabs ドキュメント: https://docs.twelvelabs.io/
Langflow ドキュメント: https://docs.langflow.org/
LangflowにおけるTwelveLabsコンポーネント: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md
Langflow/DataStaxチーム(Melissa Herrera、Eric Hare、Gokul Krishnaa、Alejandro Cantarero)のコラボレーションに深く感謝いたします!
ワークフロー全体を紹介しているMelissaによる以下のチュートリアルもぜひご覧ください 👇
1 - はじめにと概要
ビデオAIのワイルドな世界へようこそ!ここでは、あなた自身と同じように、アプリが動画で何が起こっているかを「見る」ことができます! 🎬
このチュートリアルは、TwelveLabsとLangflowを使って次世代のビデオパワードエージェントを構築するためのゴールインチケットです。コンピュータビジョンの博士号は必要ありません。好奇心といくつかのビデオクリップさえあれば準備完了です。
なぜ重要なのか?
TwelveLabsは「頭脳」を提供します。当社のPegasus(ペガサス)およびMarengo(マレンゴ)モデルにより、コードがビデオコンテンツを理解、インデックス化、チャットできるようになり、質問への回答、重要な瞬間の特定、スマートな要約生成などが可能になります。Langflowはあなたの遊び場です。アイデアをAIワークフローに変換し、即座にAPIとして提供できるビジュアルビルダーです。これらを組み合わせることで、ビデオ検索エンジン、コンテンツモデレーションボット、あるいはテキスト、画像、動画を処理できるマルチモーダルアシスタントなど、ビデオAIソリューションの作成、テスト、デプロイが簡単になります。
内容は?
このチュートリアルでは、初心者からビデオのプロへと成長できます。環境をセットアップし、LangflowにおけるTwelveLabsコンポーネントをマスターし、ビデオとのチャット、ビデオ埋め込み(Embeddings)の生成と保存、さらにはビデオライブラリから質問を取得して回答する本格的なRAGシステムの構築といった実践的なフローを構築します。その過程で、ベストプラクティスを学び、画期的なユースケースを発見し、独自のビデオ対応アプリを構築するインスピレーションを得ることができます。
それでは、ポップコーンを用意し、コードエディタを立ち上げて、AIワークフローを真のビデオススマートにしていきましょう! 🚀🍿
2 - 開発環境のセットアップ
TwelveLabsとLangflowで開発を開始するために環境を準備しましょう。
Langflowのインストール
pipを使用してLangflowをインストールします:
pip install langflowLangflowサーバーを起動します:
langflow runブラウザで
http://127.0.0.1:7860にアクセスし、LangflowのUIを開きます。
TwelveLabs API認証情報の取得
まだアカウントをお持ちでない場合は、 TwelveLabsプラットフォーム でアカウントを作成します。
プロファイル設定に移動し、新しいAPIキーを作成します。
TwelveLabsサービスへのリクエストの認証に必要となるため、APIキーを書き留めておきます。
TwelveLabsコンポーネントの確認
Langflowのインターフェースで、「+」ボタンをクリックして新しいフローを作成します。
コンポーネントサイドバーを開き、「TwelveLabs」を検索します。以下のコンポーネントが表示されるはずです:
Video File(ビデオファイル)
Split Video(ビデオ分割)
Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)
Twelve Labs Pegasus(Twelve Labs Pegasus)
Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)
Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)
Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)
これらのコンポーネントが表示されない場合は、Langflowが最新バージョンにアップデートされているか確認してください。
サンプル動画の準備
このチュートリアルでのテスト用に、2〜3個の短いビデオクリップ(それぞれ1〜3分)を用意します。MP4、MOV、AVIなどの一般的なフォーマットがサポートされています。
学習時のパフォーマンスを最適化するために、視覚的コンテンツが明確で、シーンがはっきり分かれている動画を使用してください。これにより、ビデオ理解機能の効果をより実感できます。
チュートリアル中に見つけやすいよう、サンプル動画専用のフォルダを作成します。
トラブルシューティングのヒント
TwelveLabsコンポーネントで問題が発生した場合:
API認証: APIキーが正しく入力されており、有効期限が切れていないことを確認してください。
ビデオ処理: ビデオがサポートされているフォーマットであり、サイズが大きすぎないことを確認してください。処理を高速化するため、まずは100MB未満のクリップから始めてください。
コンポーネントの読み込み: コンポーネントが表示されない場合は、Langflowを再起動するか、コンソールでエラーメッセージを確認してください。
依存関係: 統合にはビデオ処理のためにFFmpegが必要です。まだインストールされていない場合は、システムのパッケージマネージャーを使用してインストールしてください。
環境がセットアップできたら、TwelveLabsとLangflowを使って強力なビデオ対応AIワークフローの構築を始める準備は完了です。
3 - LangflowにおけるTwelveLabsコンポーネントの理解
Langflowに、AIワークフローで高度なビデオ理解機能を可能にする7つの強力なTwelveLabsコンポーネントが加わりました。これらのコンポーネントは、動画の処理、埋め込みの生成、ビデオコンテンツのインデックス作成、そして視覚コンテンツとの自然言語によるインタラクションを実現するために相互に連携します。
3.1 - Video File(ビデオファイル)コンポーネント
Video Fileコンポーネントは、Langflowにおけるビデオ処理ワークフローのエントリポイントとして機能します。MP4、AVI、MOV、MKVなど、幅広い一般的なビデオフォーマットに対応しているため、様々なビデオソースに対して汎用性があります。実装は簡単で、ビデオファイルへのパスを指定するだけで、コンポーネントはファイルパスと重要なメタデータの両方を含むDataオブジェクトを返します。開発中のパフォーマンスを最適化するため、まずは100MB未満のビデオから始めることをお勧めします。
3.2 - Split Video(ビデオ分割)コンポーネント
この強力なコンポーネントは、長尺のビデオをインテリジェントに小さく扱いやすいクリップに分割(セグメント化)します。いくつかのパラメータを通じて分割プロセスを微調整できます。希望するクリップの長さを秒単位で設定し、最後のクリップの処理方法(切り捨て、前のコンテンツとのオーバーラップ、またはそのまま保持)を選択し、元のビデオをクリップと並行して保持するかどうかを決定します。このコンポーネントは、詳細なメタデータを含むDataオブジェクトのコレクションとしてクリップを出力します。検索および理解タスクで最良の結果を得るには、6秒から30秒の長さのクリップを作成することをお勧めします。
3.3 - Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)コンポーネント
ビデオインデックス作成の中核を担うのが、Pegasus Index Videoコンポーネントです。TwelveLabsのPegasus APIと連携し、ビデオコンテンツの検索可能なインデックスを作成します。APIキーとビデオデータ(通常はSplit Videoコンポーネントから取得)を提供すると、固有のvideo_idとindex_id識別子を含むインデックス付きビデオデータを生成します。このインデックス作成ステップは、Pegasusコンポーネントでクエリを実行する前に不可欠です。
3.4 - Twelve Labs Pegasus コンポーネント
Pegasusコンポーネントは、インデックス作成されたビデオコンテンツとの高度な自然言語インタラクションを可能にします。構成には、APIキー、クエリテキスト、および関連するビデオ識別子とインデックス識別子が必要です。インテリジェントな推論レイヤーとして機能し、クエリのコンテキストとビデオコンテンツの両方を処理して、対話的な応答を生成します。このコンポーネントは、自然言語の理解とビデオコンテンツ分析のギャップを真に埋めるものです。
3.5 - Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)コンポーネント
TwelveLabsのMarengoモデルを活用して、このコンポーネントはテキスト入力からベクトル埋め込みを生成します。APIキーが必要で、現在はMarengo-retrieval-2.7モデルをサポートしています。出力はベクトルデータベースと完全に互換性があるため、洗練された検索システムに最適です。アプリケーションにおける一貫性を保つため、テキストコンポーネントとビデオコンポーネントの両方で同じ埋め込みモデルを使用することをお勧めします。
3.6 - Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)コンポーネント
テキスト版と同様に、Video Embeddingsコンポーネントはビデオコンテンツの密なベクトル表現を作成します。テキスト埋め込みコンポーネントと同じ構成パターンを共有しますが、ビデオファイルの処理に特化しています。得られる埋め込みにより、動画間またはテキストと動画コンテンツ間の強力なセマンティック類似性検索が可能になり、マルチモーダルアプリケーションの刺激的な可能性が広がります。
3.7 - Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)コンポーネント
この重要なコネクタコンポーネントは、ベクトルデータベースの操作とTwelveLabsコンポーネント間の架け橋となります。AstraDBからの検索結果を処理し、重要なvideo_idとindex_idの情報を抽出して、Pegasusコンポーネントに適した形式に適切に変換します。このコンポーネントは、ビデオコンテンツを使用したRAG(検索拡張生成)パターンを実装する際に特に価値があり、ベクトルデータベースとビデオ処理パイプライン間のスムーズなデータフローを保証します。
これらのコンポーネントは、シームレスに連携するように設計されています。たとえば、以下のようにしてビデオ検索エンジンを作成できます:
Video Fileでビデオを読み込む
Split Videoで扱いやすいチャンクに分割する
Pegasus Index Videoでインデックスを作成する
Video Embeddingsで埋め込みを生成する
AstraDBなどのベクトルデータベースに保存する
Convert AstraDB to Pegasus Inputで関連するクリップを取得する
Twelve Labs Pegasusで質問に答える
ワークフローを構築する際は、これらのコンポーネントを、読み込みや処理からインデックス作成、埋め込み、検索に至るまで、ビデオ理解の様々な側面を処理するビルディングブロックとして考えてください。
4 - Pegasusでのビデオチャット:最初の対話型ビデオワークフロー
このセクションでは、Twelve Labs Pegasusモデルを使用してビデオと「チャット」できる基本的なLangflowワークフローの作成手順を説明します。このフローは、ビデオ処理、インデックス作成、および自然言語クエリの直接的な統合を示しています。
参照画像に示されている「Pegasus Chat with Video」フローにより、ビデオをアップロードし、Twelve Labsによって自動的にインデックス化され、その後チャットインターフェースを通じてその内容について質問することができます。
以下の手順に従ってこのフローを構築してください:
ビデオのアップロード:
Video FileコンポーネントをLangflowキャンバスにドラッグします。Video Fileコンポーネントのプロパティで、サンプルビデオファイル(例:画像に示されているbig_buck_bunny_720.mp4)をアップロードするためにクリックします。このコンポーネントがビデオを読み込み、他のコンポーネントで利用できるようにします。
ビデオデータをPegasusに接続:
Twelve Labs Pegasusコンポーネントをキャンバスに追加します。Video FileコンポーネントのData出力(赤丸)を、Twelve Labs PegasusコンポーネントのVideo Data入力(赤丸)に接続します。これにより、Pegasusコンポーネントに処理対象のビデオを伝えます。
Pegasusコンポーネントの構成:
Twelve Labs Pegasusコンポーネントにおいて:指定されたフィールドに Twelve Labs APIキー を入力します。
Index Name (インデックス名)を指定します。これは、作成されるビデオインデックスに対して任意に選択した分かりやすい名前で構いません(例:「bunny-test-index」)。
Model はデフォルトで
pegasus1.2のようなPegasusモデルになります。特定のモデル要件がない限り、通常はそのままにしておいて構いません。
開発者向け注意:
Index IDを指定せずにVideo DataとIndex Nameを提供すると、Pegasusコンポーネントは新規ビデオに対してTwelve Labsでのビデオインデックス自動作成プロセスを開始します。このプロセス中にTwelve Labsによってvideo_idおよびindex_idが作成されます。
ユーザー入力の有効化:
Chat Inputコンポーネントをキャンバスに追加します。Chat Inputコンポーネントの出力を、Twelve Labs PegasusコンポーネントのPrompt入力(画像で「Receiving input」とラベル付けされた、青丸)に接続します。これにより、Pegasusモデルに送信される質問を入力できるようになります。
チャット応答の表示:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントのMessage出力(青丸)を、このChat Outputコンポーネントの入力に接続します。これにより、Pegasusモデルからの回答が表示されます。
任意:再チャット用のビデオIDの出力:
その後のチャットセッションで同じビデオの再インデックス作成を避けるために、Twelve Labsによって生成された
Video IDとIndex IDをキャプチャできます。もう一つの
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのVideo ID出力(青丸)を、この新しいChat Outputコンポーネントに接続します。開発者のヒント:同じビデオを使用した将来のセッションでは、以前に生成された
Video IDとIndex IDを、それぞれTwelve Labs PegasusコンポーネントのPegasus Video IDおよびIndex IDフィールドに直接入力できます。これにより、再インデックス作成ステップをバイパスし、インタラクションを高速化できます。Video DataとIndex Nameのみを提供した場合は、再インデックス作成されます。
プレイグラウンドでのテスト:
Langflowプレイグラウンドを開きます(通常は右側のサイドバーにあるチャットバブルアイコンをクリックします)。
ビデオに関する質問をチャットインターフェースに入力します(例:「ビデオに写っている動物は何ですか?」、「主役を説明してください。」)。
Pegasusコンポーネントがビデオを処理し(初回の場合)、インデックスを作成し、ビデオの内容に基づいて質問に答えます。応答は接続された
Chat Outputに表示されます。
このシンプルながら強力なフローは、TwelveLabsのビデオ理解をインタラクティブなLangflowエージェントに直接統合する方法の基本例として役立ちます。これで、ほぼリアルタイムでビデオの内容について質問を投げ、回答を得ることができます。
5 - MarengoとAstraDBによるビデオ埋め込み:セマンティック・ビデオ・インデックスの構築
このセクションでは、TwelveLabsのMarengoモデルを使用してビデオ埋め込みを生成し、その後これらの埋め込みをDataStax AstraDBに保存するためのLangflowワークフローの構築方法を詳しく説明します。これは、ビデオライブラリに対するセマンティック検索を有効にしたり、ビデオコンテンツを使用した高度な検索拡張生成(RAG)システムを構築したりするために不可欠なステップです。
提供されている参照画像に示されているように、このワークフローは、ビデオを取り込んで埋め込みを生成し、これらの埋め込みをビデオのメタデータとともにAstraDBコレクションに保存します。
5.1 - 事前準備:AstraDBのセットアップ
Langflowのフローを構築する前に、AstraDB環境が準備できていることを確認してください:
AstraDBデータベースの作成:
まだお持ちでない場合は、サインアップして DataStax AstraDB 上に新しいサーバーレスデータベースを作成します。
データベースの初期作成については、AstraDBのセットアップガイドに従ってください。
アプリケーション・トークンの生成:
AstraDBコンソールの「Database Details(データベースの詳細)」セクションに移動します。
適切な権限(例:Database Administrator、またはコレクションへの接続・読み書きを許可するロール)を持つアプリケーション・トークン(Application Token)を生成します。Langflowコンポーネントで必要になるため、このトークンを安全に保存してください。
video_embeddingsコレクションの作成:AstraDBデータベース内に新しいコレクションを作成します。名前は
video_embeddingsなどにすると良いでしょう。極めて重要:このコレクションをベクトル検索(Vector Search)に対応するように構成します。これには通常、以下が含まれます:
コレクションがベクトルを保存するように指定すること。
ベクトルの次元数(Dimension)を 1024 に設定すること。これは、TwelveLabsのMarengoモデル(画像に示されている
Marengo-retrieval-2.7など)によって生成される埋め込みの次元数です。
ベクトル検索の有効化および次元数の設定に関する詳細な手順については、コレクション管理に関するAstraDBのドキュメントを参照してください。
5.2 - Langflowワークフローの構築
AstraDBがセットアップされたら、Langflowで以下のフローを構築します:
動画のアップロード:
Video Fileコンポーネントをキャンバスにドラッグします。希望のビデオファイル(例:画像で使われている
big_buck_bunny_720.mp4)をアップロードして構成します。このコンポーネントにより、ビデオデータがワークフローからアクセス可能になります。
ビデオ埋め込み生成の構成:
Twelve Labs Video Embeddingsコンポーネントをキャンバスに追加します。API Keyフィールドに Twelve Labs APIキー を入力します。Model が
Marengo-retrieval-2.7(または別の互換性のあるMarengoモデル)に設定されていることを確認します。このコンポーネントがビデオを処理し、密なベクトル埋め込みを生成します。
取り込み用AstraDBの構成:
DS Astra DBコンポーネント(または画像に示されているAstra DBコンポーネント)をキャンバスに追加します。対応するフィールドに Astra DB アプリケーション・トークン を入力します。
ベクトル対応コレクションを作成した Database 名を指定します。
作成した Collection 名(例:
video_embeddings)を入力します。
埋め込みをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力(緑丸)を、DS Astra DBコンポーネントのEmbedding Model入力(緑丸)に接続します。開発者向け注意:この接続は、AstraDBに対して受信データを埋め込みとして解釈する 方法 を伝えるものですが、埋め込み自体を提供するわけではありません。実際の埋め込みは、取り込まれるデータとともに渡されます。
取り込み用ビデオデータの接続:
Video FileコンポーネントからのData出力(赤丸)を、DS Astra DBコンポーネントのIngest Data入力(赤丸)に接続します。開発者向け注意:データが
Ingest Data入力に渡されると、このフローのように埋め込みモデルが構成されているか埋め込みコンポーネントに接続されている場合、Astra DBコンポーネントは入力データの埋め込みを期待または生成します。このセットアップでは、Twelve Labs Video Embeddingsコンポーネントが埋め込み生成を処理し、その出力(元のデータと埋め込みを含む)がDS Astra DBに渡されます。
フローを実行して埋め込みと取り込みを行う:
プロセスを開始するには、通常、このチェーンの最後のコンポーネントである
DS Astra DBコンポーネントを「実行」または有効化します。Langflowでは、コンポーネント上の再生/実行アイコンをクリックするか、より大きな実行可能グラフの一部としてフロー全体を構築して開始します。実行されると、
Video Fileコンポーネントがビデオを読み込みます。次に、Twelve Labs Video Embeddingsコンポーネントがこのビデオデータを受け取り(フローを通じて暗黙的に、またはVideo Data入力が接続されている場合は明示的に受け取り。スクリーンショットのコンポーネントでは示されていませんが)、埋め込みを生成します。最後に、DS Astra DBコンポーネントがビデオデータ(上流コンポーネントあるいは自身の内部ロジックによって埋め込みが豊富化されたもの)を受け取り、指定されたAstraDBコレクションに取り込みます。
このフローを実行すると、ビデオの内容はAstraDBコレクション内のベクトル埋め込みとして表現され、セマンティック検索や類似性比較、RAGアプリケーションのナレッジベースとして活用できる状態になります。AstraDBコレクションに直接クエリを実行して、データが保存されているか確認することができます。
6 - ビデオコンテンツを使用した高度なRAG実装
ビデオのための堅牢な検索拡張生成(RAG)システムを構築するには、ビデオコンテンツの処理やインデックス作成から、セマンティック検索や文脈に応じた理解の有効化にいたるまで、いくつかの段階があります。このセクションは2つのパートに分かれています。まず、ビデオを分割し、そのクリップに対してTwelve Labs Pegasusでインデックスを作成し、Marengoで埋め込みを生成し、それらすべてをAstraDBに保存することで、ビデオデータを準備することに焦点を当てます。
パート1:ビデオを分割し、Pegasusでクリップのインデックスを作成し、埋め込みをAstra DBに保存する
この最初のフローは、画像に示されているように、ビデオRAGシステムの基礎となります。ソースビデオを管理可能なクリップに分割処理し、Pegasusからのインデックス情報でこれらのクリップを充実させ、Marengoを使用して対応するベクトル埋め込みを生成し、最後にこの包括的なデータセットを効率的な検索のためにAstraDBに保存します。
このデータ取り込み用パイプラインの構築手順は以下の通りです:
ソースビデオのアップロード:
まず、
Video FileコンポーネントをLangflowキャンバスにドラッグします。動画をアップロードして構成します(例:画像に示されている
big_buck_bunny_720...)。このコンポーネントは生のビデオデータを出力します。
動画をクリップに分割:
Split Videoコンポーネントを追加します。Video FileコンポーネントからのData出力を、Split VideoコンポーネントのVideo Data入力に接続します。Split Videoコンポーネントを構成します:Clip Duration (seconds): 各ビデオセグメントの長さを定義するためにこれを設定します。画像では
6秒になっており、きめ細かな分析に適した開始値です。コンテンツに合わせてこれを調整できます(たとえば、大まかなシーンセグメンテーションには30秒が適している場合があります)。Last Clip Handling: クリップの長さを一定にするために、画像にある
Overlap Previous(前のクリップと重ねる)のようなオプションを選択するか、お好みに応じてTruncate(切り捨て)やKeep Short(短いまま保持)を選択します。Include Original Video: セグメントを扱うことになるRAG処理用クリップを作成する場合、通常はこれをオフ(画像のとおり)にします。
Pegasusでクリップのインデックス作成:
Twelve Labs Pegasus Index Videoコンポーネントを導入します。Split VideoコンポーネントからのVideo Clips出力を、Twelve Labs Pegasus Index VideoコンポーネントのVideo Data入力に接続します。このコンポーネントは各クリップを処理します。コンポーネントの設定において:
Twelve Labs APIキーを入力します。
Index Name (例:画像の
test index)を指定します。これにより、Twelve Labs内でインデックス作成されたコンテンツを整理しやすくなります。コンポーネントはIndexed Dataを出力します。これには元のクリップデータと、Pegasusによって割り当てられたvideo_idおよびindex_idが含まれます。Model はデフォルトでPegasusモデル(例:
pegasus1.2)になります。
Marengoによるビデオ埋め込みの生成:
Twelve Labs Video Embeddingsコンポーネントを追加します。ここでも Twelve Labs APIキー を入力します。
Model に
Marengo-retrieval-2.7(画像に示されているモデル)か、お好みのMarengo埋め込みモデルを設定します。極めて重要:
Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、Twelve Labs Video Embeddingsコンポーネントの(暗黙的または明示的な)ビデオデータ入力に接続します。開発者向け注意:画像ではこのコンポーネントに直接「Video Data」という名前の入力が表示されていませんが、埋め込みコンポーネントは処理対象のビデオクリップを受け取る必要があります。Indexed Dataがこれらのクリップを運びます。
保存先AstraDBの構成:
DS Astra DBコンポーネントをキャンバスに配置します。Astra DB アプリケーション・トークン を入力します。
ビデオデータと埋め込みが保存される、ターゲットとなる Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。このコレクションが、使用するMarengoモデル(Marengo-retrieval-2.7の場合は1024)に一致する次元数で、ベクトル検索向けに構成されていることを確認してください。
埋め込みとデータをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBに埋め込みベクトルの解釈方法を伝えます。Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、DS Astra DBコンポーネントのIngest Data入力に接続します。これにより、ビデオクリップ(Pegasusのvideo_idとindex_idで充実化されたデータ)と、生成されたそれらの埋め込みが、保存先へと送信されます。
取り込みフローの実行:
フローを実行します。
Video Fileが読み込まれ、Split Videoによって分割されます。各クリップは、インデックス作成のためにTwelve Labs Pegasus Index Videoに送信されます。得られたIndexed Data(クリップ + Pegasus ID)はTwelve Labs Video Embeddingsに渡され、Marengo埋め込みが生成されます。最後に、DS Astra DBコンポーネントがこの包括的なデータ(クリップ、Pegasusインデックス情報、Marengoベクトル埋め込み)を、指定されたコレクションに取り込みます。
このフローが完了すると、AstraDBコレクションに、個々のベクトル埋め込みおよびPegasusの識別子が紐付けられた、インデックス作成済みビデオクリップが含まれ、RAGシステムの取得パートへの準備が整います。
パート2:ビデオ埋め込みへのクエリ実行と、Pegasusを使用したビデオチャット
ビデオクリップが処理され、Pegasusによってインデックスが作成され、それらのMarengo埋め込みがAstraDBに保存され終わったら(パート1で詳述)、この2つ目のフローはRAGの「取得(ミリバール)」と「生成」の側面を示します。参照画像にあるように、まずユーザーのテキスト質問(クエリ)を埋め込みに変換し、それを使用して関連するビデオクリップをAstraDBから検索します。これらのクリップからの情報は、コンテキストに基づいた回答を生成するためにTwelve Labs Pegasusモデルに渡されます。
以下はこの取得および質問応答パイプラインの構築手順です:
ユーザーのクエリ入力と埋め込み:
Chat Inputコンポーネントをキャンバスに追加します。これは、ユーザーが質問を入力する場所になります。Twelve Labs Text Embeddingsコンポーネントを追加します。Twelve Labs APIキーを入力します。
Model に
Marengo-retrieval-2.7(またはパート1でビデオクリップの埋め込みに使用したのと同じMarengoモデル)を設定します。
Chat Inputコンポーネントの出力を、Twelve Labs Text Embeddingsコンポーネントのテキスト入力に接続します。これにより、ユーザーのクエリがベクトル埋め込みに確実に変換されます。
AstraDBでのセマンティック検索:
DS Astra DBコンポーネントを追加します。Astra DB アプリケーション・トークン を入力します。
ビデオクリップの埋め込みが保存されている Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。Twelve Labs Text EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBにクエリ埋め込みが提供されます。Chat Inputコンポーネントの出力(生のテキストクエリ)を、DS Astra DBコンポーネントのSearch Query入力に接続します。開発者向け注意:クエリの埋め込みはEmbedding Modelに渡されますが、Search Query入力自体は、構成によってはキーワードフィルタリングやその他のハイブリッド検索戦略、あるいは単に提供されたクエリ埋め込みを使用して何に対してベクトル検索を行うかを知るために、AstraDBによって利用される場合があります。
DS Astra DBコンポーネントは、コレクション内で類似性検索を実行し、最も関連性の高いビデオクリップ(またはパート1から保存されている場合は、video_idやindex_idを含むメタデータ)であるSearch Resultsを返します。
AstraDBの結果をPegasus入力用に変換:
Convert AstraDB to Pegasus Inputコンポーネントを追加します。DS Astra DBコンポーネントからのSearch Results出力(多くの場合ドキュメントのメタデータを含む赤丸)を、このコンバータコンポーネントのAstraDB Results入力に接続します。このユーティリティコンポーネントは非常に重要です。AstraDBの検索結果から
Index IDとVideo IDを抽出します。これは、Pegasusコンポーネントが「チャット」対象となる特定のインデックス作成済みビデオセグメントを識別するために必須となります。
文脈に応じたQ&Aに向けてPegasusを準備:
Twelve Labs Pegasusコンポーネントを追加します。Twelve Labs APIキーを入力します。
希望のPegasusの Model を選択します(デフォルトは
pegasus1.2です)。
Convert AstraDB to Pegasus InputコンポーネントからのIndex ID出力を、Twelve Labs PegasusコンポーネントのIndex ID入力(「Receiving input」とラベルされた端子)に接続します。Convert AstraDB to Pegasus InputコンポーネントからのVideo ID出力を、Twelve Labs PegasusコンポーネントのPegasus Video ID入力(「Receiving input」とラベルされた端子)に接続します。開発者向け注意:ビデオデータがその場で直接インデックス作成のために提供される「Pegasus Chat with Video」フローとは異なり、ここではAstraDBから取得した すでにインデックス作成されている コンテンツの特定の
Pegasus Video IDとIndex IDを提供しています。PegasusコンポーネントのVideo Data入力はこのRAG検索フローでは未接続のままになります。
元のクエリをPegasusに渡す:
元の
Chat Inputコンポーネント(ユーザーの質問を保持しているもの)の出力を、Twelve Labs PegasusコンポーネントのPrompt入力(「Receiving input」とラベルされた端子)に直接接続します。これにより、Pegasusは取得したビデオセグメントの文脈を使用して、どの質問に答えるべきかを認識できます。
Pegasusの応答を表示する:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのMessage出力を、このChat Outputコンポーネントの入力に接続します。これにより、AIが生成した回答が表示されます。
ビデオRAGシステムのテスト:
Langflowのプレイグラウンド(チャットインターフェース)を開きます。
パート1で処理したビデオコンテンツに関連する質問を入力します(例:「冒頭でウサギに何が起こりますか?」、「蝶が出てくるシーンを見せてください。」)。
フローは以下のように実行されます:
あなたの質問が
Chat Inputによってキャプチャされます。Twelve Labs Text Embeddingsが質問をベクトルに変換します。DS Astra DBがそのベクトルを使用して、データベースから最もセマンティックに類似したビデオクリップを見つけます。Convert AstraDB to Pegasus Inputが、上位に取得されたクリップのvideo_idおよびindex_idを抽出します。Twelve Labs PegasusがこれらのID(どのビデオセグメントに焦点を当てるかを指示)と元の質問(そのセグメントに関して何を回答すべきかを指示)を受け取ります。Pegasusが、あなたの質問に関連する指定のビデオセグメントを分析し、回答を生成します。
回答が
Chat Outputを介して表示されます。
この2パートからなるRAGアーキテクチャにより、大規模なビデオライブラリから関連する重要な瞬間を対話形式で取得し、それを基にやり取りできる、洗練されたスケーラブルなビデオ理解アプリケーションを構築できます。
7 - 特別なユースケースとパフォーマンスのベストプラクティス
TwelveLabsとLangflowの連携によるビデオ機能は、価値の高いビジネスアプリケーションを数多く展開させます。不適切な動画セグメントを自動的にフラグ付け、または要約するコンテンツモデレーションシステム、大規模なアーカイブから関連のある瞬間を表面化させるビデオ検索エンジン、さらには動画、テキスト、画像の理解をブレンドしたマルチモーダルアシスタントを構築し、より豊かなユーザーエクスペリエンスを提供できます。これらのユースケースは、動画に対する迅速な洞察や自動分析が、生産性、コンプライアンス、ユーザー維持を直接左右する、メディア、教育、カスタマーサポートなどの業界に最適です。
ビデオ対応ワークフローで信頼性の高いビジネス結果を提供するには、パフォーマンスとコストの最適化に注力してください。動画セグメントをバッチ処理する、あるいは不要な再処理を防ぐためにキャッシュを使用することで、APIのフットプリントを抑え、また詳細度と計算効率のバランスが取れるクリップの長さを選びましょう。ビデオライブラリの増加に伴い高速なクエリ応答を維持するため、AstraDBと埋め込みパイプラインを監視し、より精密な結果を得るために、ベクトル類似性にメタデータフィルタリングを組み合わせたハイブリッド検索戦略を検討してください。
これらのベストプラクティスに従うことで、ビデオAIソリューションにおけるスケーラビリティ、正確性、費用対効果を最大化できます。これにより、組織は大規模なビデオから実行可能な洞察を抽出し、市場における競争優位性を維持することができます。
8 - まとめと次のステップ
おめでとうございます。これであなたもビデオマスターです! 🎬✨
TwelveLabsとLangflowの強力なコンビを使用して、本当にビデオを見て理解するAIエージェントを構築する力をアンロックできました。次世代のスマートなビデオ検索エンジンを作成する、大規模なコンテンツモデレーション、あるいはマルチモーダルアシスタントの開発など、生のフッテージを実用的な洞察(そしてちょっとした魔法のような体験)に変えるツールが手に入りました。
それでは、次に何をしましょう?
独自の創造的なフローを実験したり、さまざまな種類のビデオで限界に挑戦したり、最もクールなプロジェクトをコミュニティで共有してみましょう。TwelveLabsとLangflowのロードマップで発表される刺激的な新機能に注目し、ディスカッションへの参加もお忘れなく。あなたのアイデアとフィードバックが、ビデオAIの未来を形作ります!
さあ、素晴らしいものを構築しに出発しましょう。ビデオの宇宙があなたの探索を待っています! 🚀🎥
追加リソース
TwelveLabs ドキュメント: https://docs.twelvelabs.io/
Langflow ドキュメント: https://docs.langflow.org/
LangflowにおけるTwelveLabsコンポーネント: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md
Langflow/DataStaxチーム(Melissa Herrera、Eric Hare、Gokul Krishnaa、Alejandro Cantarero)のコラボレーションに深く感謝いたします!
ワークフロー全体を紹介しているMelissaによる以下のチュートリアルもぜひご覧ください 👇
1 - はじめにと概要
ビデオAIのワイルドな世界へようこそ!ここでは、あなた自身と同じように、アプリが動画で何が起こっているかを「見る」ことができます! 🎬
このチュートリアルは、TwelveLabsとLangflowを使って次世代のビデオパワードエージェントを構築するためのゴールインチケットです。コンピュータビジョンの博士号は必要ありません。好奇心といくつかのビデオクリップさえあれば準備完了です。
なぜ重要なのか?
TwelveLabsは「頭脳」を提供します。当社のPegasus(ペガサス)およびMarengo(マレンゴ)モデルにより、コードがビデオコンテンツを理解、インデックス化、チャットできるようになり、質問への回答、重要な瞬間の特定、スマートな要約生成などが可能になります。Langflowはあなたの遊び場です。アイデアをAIワークフローに変換し、即座にAPIとして提供できるビジュアルビルダーです。これらを組み合わせることで、ビデオ検索エンジン、コンテンツモデレーションボット、あるいはテキスト、画像、動画を処理できるマルチモーダルアシスタントなど、ビデオAIソリューションの作成、テスト、デプロイが簡単になります。
内容は?
このチュートリアルでは、初心者からビデオのプロへと成長できます。環境をセットアップし、LangflowにおけるTwelveLabsコンポーネントをマスターし、ビデオとのチャット、ビデオ埋め込み(Embeddings)の生成と保存、さらにはビデオライブラリから質問を取得して回答する本格的なRAGシステムの構築といった実践的なフローを構築します。その過程で、ベストプラクティスを学び、画期的なユースケースを発見し、独自のビデオ対応アプリを構築するインスピレーションを得ることができます。
それでは、ポップコーンを用意し、コードエディタを立ち上げて、AIワークフローを真のビデオススマートにしていきましょう! 🚀🍿
2 - 開発環境のセットアップ
TwelveLabsとLangflowで開発を開始するために環境を準備しましょう。
Langflowのインストール
pipを使用してLangflowをインストールします:
pip install langflowLangflowサーバーを起動します:
langflow runブラウザで
http://127.0.0.1:7860にアクセスし、LangflowのUIを開きます。
TwelveLabs API認証情報の取得
まだアカウントをお持ちでない場合は、 TwelveLabsプラットフォーム でアカウントを作成します。
プロファイル設定に移動し、新しいAPIキーを作成します。
TwelveLabsサービスへのリクエストの認証に必要となるため、APIキーを書き留めておきます。
TwelveLabsコンポーネントの確認
Langflowのインターフェースで、「+」ボタンをクリックして新しいフローを作成します。
コンポーネントサイドバーを開き、「TwelveLabs」を検索します。以下のコンポーネントが表示されるはずです:
Video File(ビデオファイル)
Split Video(ビデオ分割)
Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)
Twelve Labs Pegasus(Twelve Labs Pegasus)
Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)
Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)
Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)
これらのコンポーネントが表示されない場合は、Langflowが最新バージョンにアップデートされているか確認してください。
サンプル動画の準備
このチュートリアルでのテスト用に、2〜3個の短いビデオクリップ(それぞれ1〜3分)を用意します。MP4、MOV、AVIなどの一般的なフォーマットがサポートされています。
学習時のパフォーマンスを最適化するために、視覚的コンテンツが明確で、シーンがはっきり分かれている動画を使用してください。これにより、ビデオ理解機能の効果をより実感できます。
チュートリアル中に見つけやすいよう、サンプル動画専用のフォルダを作成します。
トラブルシューティングのヒント
TwelveLabsコンポーネントで問題が発生した場合:
API認証: APIキーが正しく入力されており、有効期限が切れていないことを確認してください。
ビデオ処理: ビデオがサポートされているフォーマットであり、サイズが大きすぎないことを確認してください。処理を高速化するため、まずは100MB未満のクリップから始めてください。
コンポーネントの読み込み: コンポーネントが表示されない場合は、Langflowを再起動するか、コンソールでエラーメッセージを確認してください。
依存関係: 統合にはビデオ処理のためにFFmpegが必要です。まだインストールされていない場合は、システムのパッケージマネージャーを使用してインストールしてください。
環境がセットアップできたら、TwelveLabsとLangflowを使って強力なビデオ対応AIワークフローの構築を始める準備は完了です。
3 - LangflowにおけるTwelveLabsコンポーネントの理解
Langflowに、AIワークフローで高度なビデオ理解機能を可能にする7つの強力なTwelveLabsコンポーネントが加わりました。これらのコンポーネントは、動画の処理、埋め込みの生成、ビデオコンテンツのインデックス作成、そして視覚コンテンツとの自然言語によるインタラクションを実現するために相互に連携します。
3.1 - Video File(ビデオファイル)コンポーネント
Video Fileコンポーネントは、Langflowにおけるビデオ処理ワークフローのエントリポイントとして機能します。MP4、AVI、MOV、MKVなど、幅広い一般的なビデオフォーマットに対応しているため、様々なビデオソースに対して汎用性があります。実装は簡単で、ビデオファイルへのパスを指定するだけで、コンポーネントはファイルパスと重要なメタデータの両方を含むDataオブジェクトを返します。開発中のパフォーマンスを最適化するため、まずは100MB未満のビデオから始めることをお勧めします。
3.2 - Split Video(ビデオ分割)コンポーネント
この強力なコンポーネントは、長尺のビデオをインテリジェントに小さく扱いやすいクリップに分割(セグメント化)します。いくつかのパラメータを通じて分割プロセスを微調整できます。希望するクリップの長さを秒単位で設定し、最後のクリップの処理方法(切り捨て、前のコンテンツとのオーバーラップ、またはそのまま保持)を選択し、元のビデオをクリップと並行して保持するかどうかを決定します。このコンポーネントは、詳細なメタデータを含むDataオブジェクトのコレクションとしてクリップを出力します。検索および理解タスクで最良の結果を得るには、6秒から30秒の長さのクリップを作成することをお勧めします。
3.3 - Twelve Labs Pegasus Index Video(Twelve Labs Pegasus ビデオインデックス作成)コンポーネント
ビデオインデックス作成の中核を担うのが、Pegasus Index Videoコンポーネントです。TwelveLabsのPegasus APIと連携し、ビデオコンテンツの検索可能なインデックスを作成します。APIキーとビデオデータ(通常はSplit Videoコンポーネントから取得)を提供すると、固有のvideo_idとindex_id識別子を含むインデックス付きビデオデータを生成します。このインデックス作成ステップは、Pegasusコンポーネントでクエリを実行する前に不可欠です。
3.4 - Twelve Labs Pegasus コンポーネント
Pegasusコンポーネントは、インデックス作成されたビデオコンテンツとの高度な自然言語インタラクションを可能にします。構成には、APIキー、クエリテキスト、および関連するビデオ識別子とインデックス識別子が必要です。インテリジェントな推論レイヤーとして機能し、クエリのコンテキストとビデオコンテンツの両方を処理して、対話的な応答を生成します。このコンポーネントは、自然言語の理解とビデオコンテンツ分析のギャップを真に埋めるものです。
3.5 - Twelve Labs Text Embeddings(Twelve Labs テキスト埋め込み)コンポーネント
TwelveLabsのMarengoモデルを活用して、このコンポーネントはテキスト入力からベクトル埋め込みを生成します。APIキーが必要で、現在はMarengo-retrieval-2.7モデルをサポートしています。出力はベクトルデータベースと完全に互換性があるため、洗練された検索システムに最適です。アプリケーションにおける一貫性を保つため、テキストコンポーネントとビデオコンポーネントの両方で同じ埋め込みモデルを使用することをお勧めします。
3.6 - Twelve Labs Video Embeddings(Twelve Labs ビデオ埋め込み)コンポーネント
テキスト版と同様に、Video Embeddingsコンポーネントはビデオコンテンツの密なベクトル表現を作成します。テキスト埋め込みコンポーネントと同じ構成パターンを共有しますが、ビデオファイルの処理に特化しています。得られる埋め込みにより、動画間またはテキストと動画コンテンツ間の強力なセマンティック類似性検索が可能になり、マルチモーダルアプリケーションの刺激的な可能性が広がります。
3.7 - Convert AstraDB to Pegasus Input(AstraDBからPegasus入力への変換)コンポーネント
この重要なコネクタコンポーネントは、ベクトルデータベースの操作とTwelveLabsコンポーネント間の架け橋となります。AstraDBからの検索結果を処理し、重要なvideo_idとindex_idの情報を抽出して、Pegasusコンポーネントに適した形式に適切に変換します。このコンポーネントは、ビデオコンテンツを使用したRAG(検索拡張生成)パターンを実装する際に特に価値があり、ベクトルデータベースとビデオ処理パイプライン間のスムーズなデータフローを保証します。
これらのコンポーネントは、シームレスに連携するように設計されています。たとえば、以下のようにしてビデオ検索エンジンを作成できます:
Video Fileでビデオを読み込む
Split Videoで扱いやすいチャンクに分割する
Pegasus Index Videoでインデックスを作成する
Video Embeddingsで埋め込みを生成する
AstraDBなどのベクトルデータベースに保存する
Convert AstraDB to Pegasus Inputで関連するクリップを取得する
Twelve Labs Pegasusで質問に答える
ワークフローを構築する際は、これらのコンポーネントを、読み込みや処理からインデックス作成、埋め込み、検索に至るまで、ビデオ理解の様々な側面を処理するビルディングブロックとして考えてください。
4 - Pegasusでのビデオチャット:最初の対話型ビデオワークフロー
このセクションでは、Twelve Labs Pegasusモデルを使用してビデオと「チャット」できる基本的なLangflowワークフローの作成手順を説明します。このフローは、ビデオ処理、インデックス作成、および自然言語クエリの直接的な統合を示しています。
参照画像に示されている「Pegasus Chat with Video」フローにより、ビデオをアップロードし、Twelve Labsによって自動的にインデックス化され、その後チャットインターフェースを通じてその内容について質問することができます。
以下の手順に従ってこのフローを構築してください:
ビデオのアップロード:
Video FileコンポーネントをLangflowキャンバスにドラッグします。Video Fileコンポーネントのプロパティで、サンプルビデオファイル(例:画像に示されているbig_buck_bunny_720.mp4)をアップロードするためにクリックします。このコンポーネントがビデオを読み込み、他のコンポーネントで利用できるようにします。
ビデオデータをPegasusに接続:
Twelve Labs Pegasusコンポーネントをキャンバスに追加します。Video FileコンポーネントのData出力(赤丸)を、Twelve Labs PegasusコンポーネントのVideo Data入力(赤丸)に接続します。これにより、Pegasusコンポーネントに処理対象のビデオを伝えます。
Pegasusコンポーネントの構成:
Twelve Labs Pegasusコンポーネントにおいて:指定されたフィールドに Twelve Labs APIキー を入力します。
Index Name (インデックス名)を指定します。これは、作成されるビデオインデックスに対して任意に選択した分かりやすい名前で構いません(例:「bunny-test-index」)。
Model はデフォルトで
pegasus1.2のようなPegasusモデルになります。特定のモデル要件がない限り、通常はそのままにしておいて構いません。
開発者向け注意:
Index IDを指定せずにVideo DataとIndex Nameを提供すると、Pegasusコンポーネントは新規ビデオに対してTwelve Labsでのビデオインデックス自動作成プロセスを開始します。このプロセス中にTwelve Labsによってvideo_idおよびindex_idが作成されます。
ユーザー入力の有効化:
Chat Inputコンポーネントをキャンバスに追加します。Chat Inputコンポーネントの出力を、Twelve Labs PegasusコンポーネントのPrompt入力(画像で「Receiving input」とラベル付けされた、青丸)に接続します。これにより、Pegasusモデルに送信される質問を入力できるようになります。
チャット応答の表示:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントのMessage出力(青丸)を、このChat Outputコンポーネントの入力に接続します。これにより、Pegasusモデルからの回答が表示されます。
任意:再チャット用のビデオIDの出力:
その後のチャットセッションで同じビデオの再インデックス作成を避けるために、Twelve Labsによって生成された
Video IDとIndex IDをキャプチャできます。もう一つの
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのVideo ID出力(青丸)を、この新しいChat Outputコンポーネントに接続します。開発者のヒント:同じビデオを使用した将来のセッションでは、以前に生成された
Video IDとIndex IDを、それぞれTwelve Labs PegasusコンポーネントのPegasus Video IDおよびIndex IDフィールドに直接入力できます。これにより、再インデックス作成ステップをバイパスし、インタラクションを高速化できます。Video DataとIndex Nameのみを提供した場合は、再インデックス作成されます。
プレイグラウンドでのテスト:
Langflowプレイグラウンドを開きます(通常は右側のサイドバーにあるチャットバブルアイコンをクリックします)。
ビデオに関する質問をチャットインターフェースに入力します(例:「ビデオに写っている動物は何ですか?」、「主役を説明してください。」)。
Pegasusコンポーネントがビデオを処理し(初回の場合)、インデックスを作成し、ビデオの内容に基づいて質問に答えます。応答は接続された
Chat Outputに表示されます。
このシンプルながら強力なフローは、TwelveLabsのビデオ理解をインタラクティブなLangflowエージェントに直接統合する方法の基本例として役立ちます。これで、ほぼリアルタイムでビデオの内容について質問を投げ、回答を得ることができます。
5 - MarengoとAstraDBによるビデオ埋め込み:セマンティック・ビデオ・インデックスの構築
このセクションでは、TwelveLabsのMarengoモデルを使用してビデオ埋め込みを生成し、その後これらの埋め込みをDataStax AstraDBに保存するためのLangflowワークフローの構築方法を詳しく説明します。これは、ビデオライブラリに対するセマンティック検索を有効にしたり、ビデオコンテンツを使用した高度な検索拡張生成(RAG)システムを構築したりするために不可欠なステップです。
提供されている参照画像に示されているように、このワークフローは、ビデオを取り込んで埋め込みを生成し、これらの埋め込みをビデオのメタデータとともにAstraDBコレクションに保存します。
5.1 - 事前準備:AstraDBのセットアップ
Langflowのフローを構築する前に、AstraDB環境が準備できていることを確認してください:
AstraDBデータベースの作成:
まだお持ちでない場合は、サインアップして DataStax AstraDB 上に新しいサーバーレスデータベースを作成します。
データベースの初期作成については、AstraDBのセットアップガイドに従ってください。
アプリケーション・トークンの生成:
AstraDBコンソールの「Database Details(データベースの詳細)」セクションに移動します。
適切な権限(例:Database Administrator、またはコレクションへの接続・読み書きを許可するロール)を持つアプリケーション・トークン(Application Token)を生成します。Langflowコンポーネントで必要になるため、このトークンを安全に保存してください。
video_embeddingsコレクションの作成:AstraDBデータベース内に新しいコレクションを作成します。名前は
video_embeddingsなどにすると良いでしょう。極めて重要:このコレクションをベクトル検索(Vector Search)に対応するように構成します。これには通常、以下が含まれます:
コレクションがベクトルを保存するように指定すること。
ベクトルの次元数(Dimension)を 1024 に設定すること。これは、TwelveLabsのMarengoモデル(画像に示されている
Marengo-retrieval-2.7など)によって生成される埋め込みの次元数です。
ベクトル検索の有効化および次元数の設定に関する詳細な手順については、コレクション管理に関するAstraDBのドキュメントを参照してください。
5.2 - Langflowワークフローの構築
AstraDBがセットアップされたら、Langflowで以下のフローを構築します:
動画のアップロード:
Video Fileコンポーネントをキャンバスにドラッグします。希望のビデオファイル(例:画像で使われている
big_buck_bunny_720.mp4)をアップロードして構成します。このコンポーネントにより、ビデオデータがワークフローからアクセス可能になります。
ビデオ埋め込み生成の構成:
Twelve Labs Video Embeddingsコンポーネントをキャンバスに追加します。API Keyフィールドに Twelve Labs APIキー を入力します。Model が
Marengo-retrieval-2.7(または別の互換性のあるMarengoモデル)に設定されていることを確認します。このコンポーネントがビデオを処理し、密なベクトル埋め込みを生成します。
取り込み用AstraDBの構成:
DS Astra DBコンポーネント(または画像に示されているAstra DBコンポーネント)をキャンバスに追加します。対応するフィールドに Astra DB アプリケーション・トークン を入力します。
ベクトル対応コレクションを作成した Database 名を指定します。
作成した Collection 名(例:
video_embeddings)を入力します。
埋め込みをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力(緑丸)を、DS Astra DBコンポーネントのEmbedding Model入力(緑丸)に接続します。開発者向け注意:この接続は、AstraDBに対して受信データを埋め込みとして解釈する 方法 を伝えるものですが、埋め込み自体を提供するわけではありません。実際の埋め込みは、取り込まれるデータとともに渡されます。
取り込み用ビデオデータの接続:
Video FileコンポーネントからのData出力(赤丸)を、DS Astra DBコンポーネントのIngest Data入力(赤丸)に接続します。開発者向け注意:データが
Ingest Data入力に渡されると、このフローのように埋め込みモデルが構成されているか埋め込みコンポーネントに接続されている場合、Astra DBコンポーネントは入力データの埋め込みを期待または生成します。このセットアップでは、Twelve Labs Video Embeddingsコンポーネントが埋め込み生成を処理し、その出力(元のデータと埋め込みを含む)がDS Astra DBに渡されます。
フローを実行して埋め込みと取り込みを行う:
プロセスを開始するには、通常、このチェーンの最後のコンポーネントである
DS Astra DBコンポーネントを「実行」または有効化します。Langflowでは、コンポーネント上の再生/実行アイコンをクリックするか、より大きな実行可能グラフの一部としてフロー全体を構築して開始します。実行されると、
Video Fileコンポーネントがビデオを読み込みます。次に、Twelve Labs Video Embeddingsコンポーネントがこのビデオデータを受け取り(フローを通じて暗黙的に、またはVideo Data入力が接続されている場合は明示的に受け取り。スクリーンショットのコンポーネントでは示されていませんが)、埋め込みを生成します。最後に、DS Astra DBコンポーネントがビデオデータ(上流コンポーネントあるいは自身の内部ロジックによって埋め込みが豊富化されたもの)を受け取り、指定されたAstraDBコレクションに取り込みます。
このフローを実行すると、ビデオの内容はAstraDBコレクション内のベクトル埋め込みとして表現され、セマンティック検索や類似性比較、RAGアプリケーションのナレッジベースとして活用できる状態になります。AstraDBコレクションに直接クエリを実行して、データが保存されているか確認することができます。
6 - ビデオコンテンツを使用した高度なRAG実装
ビデオのための堅牢な検索拡張生成(RAG)システムを構築するには、ビデオコンテンツの処理やインデックス作成から、セマンティック検索や文脈に応じた理解の有効化にいたるまで、いくつかの段階があります。このセクションは2つのパートに分かれています。まず、ビデオを分割し、そのクリップに対してTwelve Labs Pegasusでインデックスを作成し、Marengoで埋め込みを生成し、それらすべてをAstraDBに保存することで、ビデオデータを準備することに焦点を当てます。
パート1:ビデオを分割し、Pegasusでクリップのインデックスを作成し、埋め込みをAstra DBに保存する
この最初のフローは、画像に示されているように、ビデオRAGシステムの基礎となります。ソースビデオを管理可能なクリップに分割処理し、Pegasusからのインデックス情報でこれらのクリップを充実させ、Marengoを使用して対応するベクトル埋め込みを生成し、最後にこの包括的なデータセットを効率的な検索のためにAstraDBに保存します。
このデータ取り込み用パイプラインの構築手順は以下の通りです:
ソースビデオのアップロード:
まず、
Video FileコンポーネントをLangflowキャンバスにドラッグします。動画をアップロードして構成します(例:画像に示されている
big_buck_bunny_720...)。このコンポーネントは生のビデオデータを出力します。
動画をクリップに分割:
Split Videoコンポーネントを追加します。Video FileコンポーネントからのData出力を、Split VideoコンポーネントのVideo Data入力に接続します。Split Videoコンポーネントを構成します:Clip Duration (seconds): 各ビデオセグメントの長さを定義するためにこれを設定します。画像では
6秒になっており、きめ細かな分析に適した開始値です。コンテンツに合わせてこれを調整できます(たとえば、大まかなシーンセグメンテーションには30秒が適している場合があります)。Last Clip Handling: クリップの長さを一定にするために、画像にある
Overlap Previous(前のクリップと重ねる)のようなオプションを選択するか、お好みに応じてTruncate(切り捨て)やKeep Short(短いまま保持)を選択します。Include Original Video: セグメントを扱うことになるRAG処理用クリップを作成する場合、通常はこれをオフ(画像のとおり)にします。
Pegasusでクリップのインデックス作成:
Twelve Labs Pegasus Index Videoコンポーネントを導入します。Split VideoコンポーネントからのVideo Clips出力を、Twelve Labs Pegasus Index VideoコンポーネントのVideo Data入力に接続します。このコンポーネントは各クリップを処理します。コンポーネントの設定において:
Twelve Labs APIキーを入力します。
Index Name (例:画像の
test index)を指定します。これにより、Twelve Labs内でインデックス作成されたコンテンツを整理しやすくなります。コンポーネントはIndexed Dataを出力します。これには元のクリップデータと、Pegasusによって割り当てられたvideo_idおよびindex_idが含まれます。Model はデフォルトでPegasusモデル(例:
pegasus1.2)になります。
Marengoによるビデオ埋め込みの生成:
Twelve Labs Video Embeddingsコンポーネントを追加します。ここでも Twelve Labs APIキー を入力します。
Model に
Marengo-retrieval-2.7(画像に示されているモデル)か、お好みのMarengo埋め込みモデルを設定します。極めて重要:
Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、Twelve Labs Video Embeddingsコンポーネントの(暗黙的または明示的な)ビデオデータ入力に接続します。開発者向け注意:画像ではこのコンポーネントに直接「Video Data」という名前の入力が表示されていませんが、埋め込みコンポーネントは処理対象のビデオクリップを受け取る必要があります。Indexed Dataがこれらのクリップを運びます。
保存先AstraDBの構成:
DS Astra DBコンポーネントをキャンバスに配置します。Astra DB アプリケーション・トークン を入力します。
ビデオデータと埋め込みが保存される、ターゲットとなる Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。このコレクションが、使用するMarengoモデル(Marengo-retrieval-2.7の場合は1024)に一致する次元数で、ベクトル検索向けに構成されていることを確認してください。
埋め込みとデータをAstraDBに接続:
Twelve Labs Video EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBに埋め込みベクトルの解釈方法を伝えます。Twelve Labs Pegasus Index VideoコンポーネントからのIndexed Data出力を、DS Astra DBコンポーネントのIngest Data入力に接続します。これにより、ビデオクリップ(Pegasusのvideo_idとindex_idで充実化されたデータ)と、生成されたそれらの埋め込みが、保存先へと送信されます。
取り込みフローの実行:
フローを実行します。
Video Fileが読み込まれ、Split Videoによって分割されます。各クリップは、インデックス作成のためにTwelve Labs Pegasus Index Videoに送信されます。得られたIndexed Data(クリップ + Pegasus ID)はTwelve Labs Video Embeddingsに渡され、Marengo埋め込みが生成されます。最後に、DS Astra DBコンポーネントがこの包括的なデータ(クリップ、Pegasusインデックス情報、Marengoベクトル埋め込み)を、指定されたコレクションに取り込みます。
このフローが完了すると、AstraDBコレクションに、個々のベクトル埋め込みおよびPegasusの識別子が紐付けられた、インデックス作成済みビデオクリップが含まれ、RAGシステムの取得パートへの準備が整います。
パート2:ビデオ埋め込みへのクエリ実行と、Pegasusを使用したビデオチャット
ビデオクリップが処理され、Pegasusによってインデックスが作成され、それらのMarengo埋め込みがAstraDBに保存され終わったら(パート1で詳述)、この2つ目のフローはRAGの「取得(ミリバール)」と「生成」の側面を示します。参照画像にあるように、まずユーザーのテキスト質問(クエリ)を埋め込みに変換し、それを使用して関連するビデオクリップをAstraDBから検索します。これらのクリップからの情報は、コンテキストに基づいた回答を生成するためにTwelve Labs Pegasusモデルに渡されます。
以下はこの取得および質問応答パイプラインの構築手順です:
ユーザーのクエリ入力と埋め込み:
Chat Inputコンポーネントをキャンバスに追加します。これは、ユーザーが質問を入力する場所になります。Twelve Labs Text Embeddingsコンポーネントを追加します。Twelve Labs APIキーを入力します。
Model に
Marengo-retrieval-2.7(またはパート1でビデオクリップの埋め込みに使用したのと同じMarengoモデル)を設定します。
Chat Inputコンポーネントの出力を、Twelve Labs Text Embeddingsコンポーネントのテキスト入力に接続します。これにより、ユーザーのクエリがベクトル埋め込みに確実に変換されます。
AstraDBでのセマンティック検索:
DS Astra DBコンポーネントを追加します。Astra DB アプリケーション・トークン を入力します。
ビデオクリップの埋め込みが保存されている Database (例:
video_embeddings)および Collection (例:video_embeddings)を選択します。Twelve Labs Text EmbeddingsコンポーネントからのEmbeddings出力を、DS Astra DBコンポーネントのEmbedding Model入力に接続します。これにより、AstraDBにクエリ埋め込みが提供されます。Chat Inputコンポーネントの出力(生のテキストクエリ)を、DS Astra DBコンポーネントのSearch Query入力に接続します。開発者向け注意:クエリの埋め込みはEmbedding Modelに渡されますが、Search Query入力自体は、構成によってはキーワードフィルタリングやその他のハイブリッド検索戦略、あるいは単に提供されたクエリ埋め込みを使用して何に対してベクトル検索を行うかを知るために、AstraDBによって利用される場合があります。
DS Astra DBコンポーネントは、コレクション内で類似性検索を実行し、最も関連性の高いビデオクリップ(またはパート1から保存されている場合は、video_idやindex_idを含むメタデータ)であるSearch Resultsを返します。
AstraDBの結果をPegasus入力用に変換:
Convert AstraDB to Pegasus Inputコンポーネントを追加します。DS Astra DBコンポーネントからのSearch Results出力(多くの場合ドキュメントのメタデータを含む赤丸)を、このコンバータコンポーネントのAstraDB Results入力に接続します。このユーティリティコンポーネントは非常に重要です。AstraDBの検索結果から
Index IDとVideo IDを抽出します。これは、Pegasusコンポーネントが「チャット」対象となる特定のインデックス作成済みビデオセグメントを識別するために必須となります。
文脈に応じたQ&Aに向けてPegasusを準備:
Twelve Labs Pegasusコンポーネントを追加します。Twelve Labs APIキーを入力します。
希望のPegasusの Model を選択します(デフォルトは
pegasus1.2です)。
Convert AstraDB to Pegasus InputコンポーネントからのIndex ID出力を、Twelve Labs PegasusコンポーネントのIndex ID入力(「Receiving input」とラベルされた端子)に接続します。Convert AstraDB to Pegasus InputコンポーネントからのVideo ID出力を、Twelve Labs PegasusコンポーネントのPegasus Video ID入力(「Receiving input」とラベルされた端子)に接続します。開発者向け注意:ビデオデータがその場で直接インデックス作成のために提供される「Pegasus Chat with Video」フローとは異なり、ここではAstraDBから取得した すでにインデックス作成されている コンテンツの特定の
Pegasus Video IDとIndex IDを提供しています。PegasusコンポーネントのVideo Data入力はこのRAG検索フローでは未接続のままになります。
元のクエリをPegasusに渡す:
元の
Chat Inputコンポーネント(ユーザーの質問を保持しているもの)の出力を、Twelve Labs PegasusコンポーネントのPrompt入力(「Receiving input」とラベルされた端子)に直接接続します。これにより、Pegasusは取得したビデオセグメントの文脈を使用して、どの質問に答えるべきかを認識できます。
Pegasusの応答を表示する:
Chat Outputコンポーネントを追加します。Twelve Labs PegasusコンポーネントからのMessage出力を、このChat Outputコンポーネントの入力に接続します。これにより、AIが生成した回答が表示されます。
ビデオRAGシステムのテスト:
Langflowのプレイグラウンド(チャットインターフェース)を開きます。
パート1で処理したビデオコンテンツに関連する質問を入力します(例:「冒頭でウサギに何が起こりますか?」、「蝶が出てくるシーンを見せてください。」)。
フローは以下のように実行されます:
あなたの質問が
Chat Inputによってキャプチャされます。Twelve Labs Text Embeddingsが質問をベクトルに変換します。DS Astra DBがそのベクトルを使用して、データベースから最もセマンティックに類似したビデオクリップを見つけます。Convert AstraDB to Pegasus Inputが、上位に取得されたクリップのvideo_idおよびindex_idを抽出します。Twelve Labs PegasusがこれらのID(どのビデオセグメントに焦点を当てるかを指示)と元の質問(そのセグメントに関して何を回答すべきかを指示)を受け取ります。Pegasusが、あなたの質問に関連する指定のビデオセグメントを分析し、回答を生成します。
回答が
Chat Outputを介して表示されます。
この2パートからなるRAGアーキテクチャにより、大規模なビデオライブラリから関連する重要な瞬間を対話形式で取得し、それを基にやり取りできる、洗練されたスケーラブルなビデオ理解アプリケーションを構築できます。
7 - 特別なユースケースとパフォーマンスのベストプラクティス
TwelveLabsとLangflowの連携によるビデオ機能は、価値の高いビジネスアプリケーションを数多く展開させます。不適切な動画セグメントを自動的にフラグ付け、または要約するコンテンツモデレーションシステム、大規模なアーカイブから関連のある瞬間を表面化させるビデオ検索エンジン、さらには動画、テキスト、画像の理解をブレンドしたマルチモーダルアシスタントを構築し、より豊かなユーザーエクスペリエンスを提供できます。これらのユースケースは、動画に対する迅速な洞察や自動分析が、生産性、コンプライアンス、ユーザー維持を直接左右する、メディア、教育、カスタマーサポートなどの業界に最適です。
ビデオ対応ワークフローで信頼性の高いビジネス結果を提供するには、パフォーマンスとコストの最適化に注力してください。動画セグメントをバッチ処理する、あるいは不要な再処理を防ぐためにキャッシュを使用することで、APIのフットプリントを抑え、また詳細度と計算効率のバランスが取れるクリップの長さを選びましょう。ビデオライブラリの増加に伴い高速なクエリ応答を維持するため、AstraDBと埋め込みパイプラインを監視し、より精密な結果を得るために、ベクトル類似性にメタデータフィルタリングを組み合わせたハイブリッド検索戦略を検討してください。
これらのベストプラクティスに従うことで、ビデオAIソリューションにおけるスケーラビリティ、正確性、費用対効果を最大化できます。これにより、組織は大規模なビデオから実行可能な洞察を抽出し、市場における競争優位性を維持することができます。
8 - まとめと次のステップ
おめでとうございます。これであなたもビデオマスターです! 🎬✨
TwelveLabsとLangflowの強力なコンビを使用して、本当にビデオを見て理解するAIエージェントを構築する力をアンロックできました。次世代のスマートなビデオ検索エンジンを作成する、大規模なコンテンツモデレーション、あるいはマルチモーダルアシスタントの開発など、生のフッテージを実用的な洞察(そしてちょっとした魔法のような体験)に変えるツールが手に入りました。
それでは、次に何をしましょう?
独自の創造的なフローを実験したり、さまざまな種類のビデオで限界に挑戦したり、最もクールなプロジェクトをコミュニティで共有してみましょう。TwelveLabsとLangflowのロードマップで発表される刺激的な新機能に注目し、ディスカッションへの参加もお忘れなく。あなたのアイデアとフィードバックが、ビデオAIの未来を形作ります!
さあ、素晴らしいものを構築しに出発しましょう。ビデオの宇宙があなたの探索を待っています! 🚀🎥
追加リソース
TwelveLabs ドキュメント: https://docs.twelvelabs.io/
Langflow ドキュメント: https://docs.langflow.org/
LangflowにおけるTwelveLabsコンポーネント: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.


