
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
チュートリアル
SAGEの構築:TwelveLabs埋め込みを用いたセマンティック動画比較

アーヒル・シェイク
このチュートリアルでは、SAGEの構築手順を解説します。SAGEは、Twelve LabsのMarengo 2.7埋め込み(embeddings)を使用して、2秒セグメント単位で2つの動画間の意味的なコンテンツの違いを検出するセマンティック動画比較システムです。S3ストリーミングアップロード、コサイン距離スコアリング、同期化されたサイドバイサイド再生、そしてオプションのOpenAI連携分析などの機能を備えています。
このチュートリアルでは、SAGEの構築手順を解説します。SAGEは、Twelve LabsのMarengo 2.7埋め込み(embeddings)を使用して、2秒セグメント単位で2つの動画間の意味的なコンテンツの違いを検出するセマンティック動画比較システムです。S3ストリーミングアップロード、コサイン距離スコアリング、同期化されたサイドバイサイド再生、そしてオプションのOpenAI連携分析などの機能を備えています。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2026/01/06
17分
記事へのリンクをコピー
はじめに
あなたはトレーニング動画を2つのバージョンで撮影しました。内容は同じ、台本も同じですが、テイクが異なります。一方は照明が良く、もう一方は音声がよりクリアです。フレームごとのピクセル単位の違いだけでなく、コンテンツ、シーンの構成、または視覚要素の実際のセマンティック(意味的)な変化など、それらが正確にどこで異なっているかを素早く特定する必要があります。
従来の動画比較ツールには、根本的な限界があります。それは、意味ではなくピクセルを比較するという点です。これは、動画に以下のような違いがある場合に破綻します。
異なる解像度やアスペクト比
異なるエンコード設定や圧縮率
異なるカメラアングルや位置
照明やカラーグレーディングの違い
時間的なズレ(一方の動画が数秒遅れて始まるなど)
これが、私たちがSAGEを構築した理由です。SAGEは、動画に含まれるピクセルだけでなく、動画の中に何があるかを理解するシステムです。生の動画データを比較する代わりに、SAGEはTwelveLabs Marengoエンベディングを使用して動画セグメントのセマンティック表現を生成し、それらの表現を比較して意味のある違いを検出します。
重要な洞察とは何でしょうか?それは、セマンティックエンベディングは重要な要素を捉えるということです。人が歩いているカットは、同一のピクセルである必要はありません。同じアクションを表現していればよいのです。エンベディングを比較することで、技術的な理由でピクセルが異なる場合でも、動画のコンテンツが異なる場合を検出することができます。
SAGEは完全な比較ワークフローを作成します:
ストリーミングマルチパートアップロードを使用して動画をS3にアップロード(大容量ファイルを効率的に処理)
TwelveLabs Marengo-retrieval-2.7(2秒セグメント)を使用してエンベディングを生成
コサイン類似度を使用してエンベディングを比較(セマンティックな違いを検出)
同期されたタイムライン上で、サイドバイサイドの再生により違いを視覚化
オプションのAIを活用したインサイト(OpenAI連携)で違いを分析
その結果はどうなるでしょうか?単に何が違って見えるかだけでなく、何が変わったかを教えてくれるシステムが実現します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上またはBunがインストールされていること
APIキー:
TwelveLabs APIキー(エンベディング生成用)
OpenAI APIキー(任意、AI分析用)
S3へのアクセスが設定されたAWSアカウント(動画保存用)
リポジトリをクローンするためのGit
Python、FastAPI、Next.js、およびAWS S3に関する基本的な知識
ピクセルレベル比較の問題点
私たちが発見したのは、ピクセルレベルの比較は実世界のシナリオでは破綻するということです。以下の2つの動画を比較することを考えてみましょう:
動画 A: 1080p MP4、30fpsで撮影、H.264エンコード、自然光
動画 B: 720p MP4、24fpsで撮影、H.265エンコード、スタジオ照明
ピクセルレベルの比較では、両方の動画が同じコンテンツを表示していても、ほぼすべてのフレームが「異なる」と判定されます。根本的な問題は何でしょうか?それは、ピクセルは意味を表さないということです。
従来の方式が失敗する理由
従来の動画比較アプローチには、3つの重大な限界があります:
フォーマットの感度:解像度、コーデック、フレームレートの違いにより、誤検出(偽陽性)が発生する
時間的理解の欠如:フレームごとの比較では、時間的なコンテキストが見落とされる
セマンティック認識の欠如:「異なるピクセル」と「異なるコンテンツ」を区別できない
エンベディングによる解決策
TwelveLabs Marengoエンベディングは、動画内に何が含まれているかを表現し、どのようなピクセルが含まれているかを排除することでこれを解決します。各2秒のセグメントは、以下を捉える高次元ベクトルに変換されます:
視覚的コンテンツ(オブジェクト、シーン、アクション)
時間的パターン(動き、トランジション)
セマンティックな意味(見え方ではなく、何が起きているか)
これらのエンベディングを比較することで、単なるピクセルではなく、動画のコンテンツがいつ異なるのかを知ることができます。
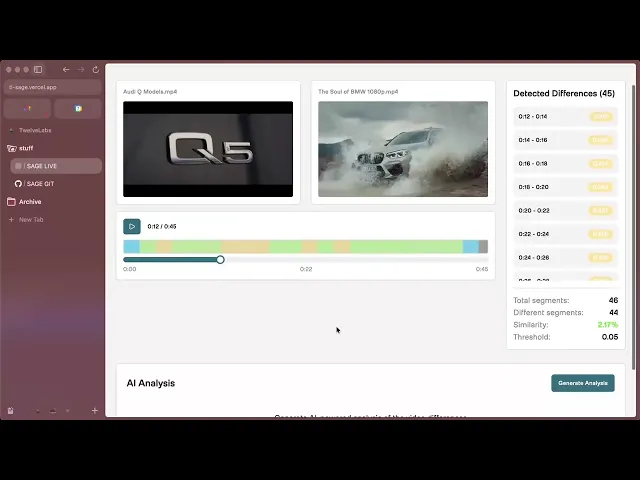
デモアプリケーション
SAGEは、効率的な動画比較ワークフローを提供します:
動画のアップロード:2つの動画(一度に最大2ファイル)をアップロードすると、S3へのアップロードからエンベディング生成の完了まで、リアルタイムのステータス更新で処理プロセスを確認できます。
自動比較:両方の動画の準備が整うと、SAGEはセマンティックエンベディングを使用して自動的に比較を行い、手動でのフレームごとの確認なしにセグメントレベルで違いを特定します。
インタラクティブな分析:同期された左右並列再生、動画の違いを示す色分けされたタイムライン、類似度スコア付きの詳細なセグメントごとの内訳を通じて、違いを探索できます。
このプロセスはリアルタイムで処理されます。エンベディング生成の進行状況を観察し、類似度の割合が即座に計算されるのを確認し、正確なタイムスタンプでタイムライン上の違いを追跡します。違いのマーカーにジャンプして、動画間で具体的に何が変更されたかを正確に確認できます。
完全なデモアプリケーションを探索し、GitHubで完全なソースコードを見つけることができます。または、システムの動作を示すチュートリアル動画をご覧ください:
SAGEの仕組み
SAGEは、AWS S3ストレージ、TwelveLabsエンベディング、および高度なビジュアライゼーションを組み合わせた、洗練された動画比較パイプラインを実装しています:
システムアーキテクチャ
準備手順
1. リポジトリのクローン
コードはこちらで公開されています: https://github.com/aahilshaikh-twlbs/SAGE
git clone https://github.com/aahilshaikh-twlbs/SAGE.git cd
2. バックエンドのセットアップ
cd backend python3 -m venv .venv source .venv/bin/activate # Windows: .venv\Scripts\activate pip install -r requirements.txt cp env.example .env # .envにAPIキーを追加します
3. フロントエンドのセットアップ
cd ../frontend npm install # または bun install cp .env.local.example .env.local # NEXT_PUBLIC_API_URL=http://localhost:8000 を設定します
4. AWS S3の設定
# AWS認証情報を設定します(AWS SSOまたはIAMを使用) aws configure --profile dev # または環境変数を設定します: export AWS_ACCESS_KEY_ID=your_access_key export AWS_SECRET_ACCESS_KEY=your_secret_key export AWS_REGION
5. アプリケーションの起動
# ターミナル 1: バックエンド cd backend python app.py # ターミナル 2: フロントエンド cd frontend npm run dev # または bun dev
これらの手順が完了したら、http://localhost:3000 にアクセスして SAGE に接続してください!
実装解説
SAGEの動画比較システムを支えるコアコンポーネントを順に見ていきましょう。
1. S3へのストリーミング動画アップロード
SAGEは、ストリーミングマルチパートアップロードを使用して、大容量の動画ファイルを効率的に処理します:
async def upload_to_s3_streaming(file: UploadFile) -> str: """メモリの問題を回避するため、ストリーミングを使用してファイルをS3にアップロードします。""" file_key = f"videos/{uuid.uuid4()}_{file.filename}" # 大容量ファイルにはマルチパートアップロードを使用 response = s3_client.create_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, ContentType=file.content_type ) upload_id = response['UploadId'] parts = [] part_number = 1 chunk_size = 10 * 1024 * 1024# 10MBのチャンク while True: chunk = await file.read(chunk_size) if not chunk: break part_response = s3_client.upload_part( Bucket=S3_BUCKET_NAME, Key=file_key, PartNumber=part_number, UploadId=upload_id, Body=chunk ) parts.append({ 'ETag': part_response['ETag'], 'PartNumber': part_number }) part_number += 1 # マルチパートアップロードを完了 s3_client.complete_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, UploadId=upload_id, MultipartUpload={'Parts': parts} ) return f"s3://{S3_BUCKET_NAME}/{file_key}"
主な設計上の決定:
10MBのチャンク:アップロード効率とメモリ使用量のバランスを取ります
ストリーミング:ファイルをチャンクで処理し、ファイル全体をメモリにロードしないようにします
マルチパートアップロード:5GBを超えるファイルに必須であり、100MBを超えるファイルに推奨されます
署名付きURL:TwelveLabsが動画に安全にアクセスできるようにするための一時的なURLを生成します
2. TwelveLabsによるエンベディング生成
SAGEは、TwelveLabsの Marengo-retrieval-2.7 を使用して、非同期でエンベディングを生成します:
async def generate_embeddings_async(embedding_id: str, s3_url: str, api_key: str): """S3からの動画に対して非同期でエンベディングを生成します。""" # TwelveLabsクライアントを取得 tl = get_twelve_labs_client(api_key) # TwelveLabsが動画にアクセスするための署名付きURLを生成 presigned_url = get_s3_presigned_url(s3_url) # 署名付きHTTPS URLを使用してエンベディングタスクを作成 task = tl.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=presigned_url, video_clip_length=2,# 2秒セグメント video_embedding_scopes=["clip", "video"] ) # タイムアウト付きで完了を待つ task.wait_for_done(sleep_interval=5, timeout=1800)# 30分 # 完了したタスクを取得 completed_task = tl.embed.task.retrieve(task.id) # エンベディングが生成されたことを検証 if not completed_task.video_embedding or not completed_task.video_embedding.segments: raise Exception("Embedding generation failed") # エンベディングと動画の長さを保存 embedding_storage[embedding_id].update({ "status": "completed", "embeddings": completed_task.video_embedding, "duration": last_segment.end_offset_sec, "task_id": task.id })
主な特徴:
2秒セグメント:粒度と処理時間のバランスを取ります
非同期処理:ノンブロッキングで、キューを介して複数の動画を処理します
タイムアウト処理:30分のタイムアウトにより、問題のある動画での処理の中断を防ぎます
検証:エンベディングが動画の全編をカバーしていることを確認します
3. セマンティック動画比較
SAGEは、エンベディングにコサイン距離を適用して動画を比較します:
async def compare_local_videos( embedding_id1: str, embedding_id2: str, threshold: float = 0.1, distance_metric: str = "cosine" ): """エンベディングIDを使用して、2つの動画を比較します。""" # エンベディングセグメントを取得 segments1 = extract_segments(embedding_storage[embedding_id1]) segments2 = extract_segments(embedding_storage[embedding_id2]) differing_segments = [] min_segments = min(len(segments1), len(segments2)) # 対応するセグメントを比較 for i in range(min_segments): seg1 = segments1[i] seg2 = segments2[i] # コサイン距離を計算 v1 = np.array(seg1["embedding"], dtype=np.float32) v2 = np.array(seg2["embedding"], dtype=np.float32) dot = np.dot(v1, v2) norm1 = np.linalg.norm(v1) norm2 = np.linalg.norm(v2) distance = 1.0 - (dot / (norm1 * norm2)) if norm1 > 0 and norm2 > 0 else 1.0 # しきい値を超えるセグメントにフラグを立てる if distance > threshold: differing_segments.append({ "start_sec": seg1["start_offset_sec"], "end_sec": seg1["end_offset_sec"], "distance": distance }) return { "differences": differing_segments, "total_segments": min_segments, "differing_segments": len(differing_segments), "similarity_percent": ((min_segments - len(differing_segments)) / min_segments * 100) }
なぜコサイン類似度(距離)なのか?
スケール不変性:正規化されたベクトルは、大きさ(解像度など)の違いを無視します
セマンティック(意味)重視:ピクセル値ではなく、意味の類似性を測定します
解釈の容易さ:0 = 同一、1 = 直交(無関係)、2 = 反対
構成可能なしきい値:さまざまなユースケースに合わせて感度を調整できます
4. 同期されたタイムラインの視覚化
フロントエンドは、同期された再生機能を備えたインタラクティブなタイムラインを作成します:
// 同期された動画再生 const handlePlayPause = () => { if (video1Ref.current && video2Ref.current) { if (isPlaying) { video1Ref.current.pause(); video2Ref.current.pause(); } else { video1Ref.current.play(); video2Ref.current.play(); } setIsPlaying(!isPlaying); } }; // 両方の動画で特定の時間にジャンプ const seekToTime = (time: number) => { const constrainedTime = Math.min( time, Math.min(video1Data.duration, video2Data.duration) ); video1Ref.current.currentTime = constrainedTime; video2Ref.current.currentTime = constrainedTime; setCurrentTime(constrainedTime); }; // 色分けされた相違点マーカー const getSeverityColor = (distance: number) => { if (distance >= 1.5) return 'bg-red-600';// 完全に異なる if (distance >= 1.0) return 'bg-red-500';// 大きく異なる if (distance >= 0.7) return 'bg-orange-500';// かなり異なる if (distance >= 0.5) return 'bg-amber-500';// 中程度に異なる if (distance >= 0.3) return 'bg-yellow-500';// やや異なる if (distance >= 0.1) return 'bg-lime-500';// わずかに異なる return 'bg-cyan-500';// ほぼ同一 };
ビジュアライゼーション機能:
同期された再生:両方の動画が同時に再生/ポーズされます
タイムラインマーカー:色分けされたセグメントで違いの深刻度を表示します
クリックによるシーク:マーカーをクリックすると、その時間に直接ジャンプします
類似度スコア:セグメントから算出した類似度の比率(%)を示します
5. オプションのAIパワー分析
SAGEは、OpenAIを使用して人間が読みやすい分析を生成するオプションを備えています:
async def generate_openai_analysis( embedding_id1: str, embedding_id2: str, differences: List[DifferenceSegment], threshold: float, video_duration: float ): """動画の違いに関するAI駆動の分析を生成します。""" prompt = f""" 以下のデータに基づいて、2つの動画間の違いを分析してください: 视频 1: {embed_data1.get('filename', 'Unknown')} 视频 2: {embed_data2.get('filename', 'Unknown')} 総再生時間: {video_duration:.1f} 秒 類似度しきい値: {threshold} 違いの件数: {len(differences)} これらの時間セグメントで違いが検出されました: {chr(10).join([f"- {d.start_sec:.1f} 秒から {d.end_sec:.1f} 秒 (距離: {d.distance:.3f})" for d in differences[:20]])} 以下を提供してください: 1. これらの違いが何を表している可能性があるかについての簡潔な分析 2. 比較に関する主要なインサイト 3. 重大な違いが発生している注目すべき時間セグメント """ response = openai.ChatCompletion.create( model="gpt-4", messages=[ {"role": "system", "content": "あなたは専門的な動画分析アシスタントです。"}, {"role": "user", "content": prompt} ], max_tokens=500, temperature=0.7 ) return { "analysis": response.choices[0].message.content, "key_insights": extract_insights(response), "time_segments": extract_segments(response) }
主な設計上の決定
1. フレーム単位ではなくセグメント単位の比較の採用
フレーム単位の比較の代わりに2秒セグメントを選択した理由は、主に次の3点です:
時間的コンテキスト:静止フレームだけでなく、動きやアクションを捉えることができます
計算効率:比較回数を削減できます(例:1分間の動画で1800フレームに対して300セグメント)
セマンティックの正確さ:個々のフレームよりも、エンベディングの方が「何が起きているか」を良く理解できます
トレードオフ:時間の精度は低くなりますが(フレーム精度に対して2秒精度)、より意味のある相違点を特定できます。
2. メモリ内処理ではなくストリーミングアップロードの採用
大容量の動画は数ギガバイトに及ぶことがあります。ファイル全体をメモリに読み込むと、サーバーがクラッシュする原因になります:
メモリ安全性:ストリーミングにより、ファイルを10MBのチャンクで処理します
スケーラビリティ:複数の大容量アップロードがあってもサーバーの応答性が維持されます
S3統合:S3に直接アップロードし、TwelveLabs用の署名付きURLを生成します
トレードオフ:アップロードのロジックが複雑になりますが、任意のサイズの動画を処理できるようになります。
3. ユークリッド距離ではなくコサイン類似度(距離)の採用
セマンティックな比較のためにコサイン距離を使用します:
スケール不変性:異なる画質の動画間でも一貫して機能します
セマンティック重視:大きさや強度ではなく、意味の類似性を測定します
解釈が可能:明確なしきい値を設定できます(0.1 = 微細、0.5 = 中程度、1.0 = 重大)
トレードオフ:ユークリッド距離よりも直感的ではありませんが、セマンティックな比較により適しています。
4. 並行型ではなくキューベースの処理の採用
エンベディングの生成には、動画あたり5〜30分かかる場合があります。これを順次処理します:
レート制限対策:TwelveLabs APIのレート制限超過を防ぎます
リソース管理:一度に1つの動画を処理することで、リソース使用量を一定に抑えます
エラーの隔離:失敗した動画が他の処理を阻害しません
トレードオフ:総スループットは遅くなりますが、より信頼性が高く予測可能になります。
5. データベースではなくメモリ内へのエンベディング保存
エンベディングをデータベースに永続化せず、メモリ内に保存します:
パフォーマンス:比較時における高速なアクセス(データベースクエリが不要)
シンプルさ:スキーマ移行やデータベースの管理が不要
一時的な性質:エンベディングはセッション固有であり、永続化の必要性が低いです
トレードオフ:サーバー再起動時にデータが失われますが、比較ワークフローにおいては許容範囲です。
パフォーマンス・エンジニアリング:私たちが学んだこと
SAGEの構築を通じて、大規模な動画処理。を扱うための貴重な教訓を得ました:
80/20の法則の適用
私たちは最適化作業の80%を、以下の3点に費やしました:
ストリーミングアップロード:分割アップロードにより、メモリの枯渇を防ぎます。2GBのファイルをすべてロードしてクラッシュさせるか、ストリーミングしてサーバーを安定させるかの違いはここにあります。
非同期処理:ノンブロッキングのエンベディング生成により、APIの応答性を維持します。ユーザーは、それぞれの完了を待つことなく複数の動画をアップロードできます。
セグメント検証:エンベディングが動画の全範囲をカバーしていることを確認し、サイレントエラーを防ぎます。結果を受け入れる前に、セグメント数、カバレッジ、再生時間を検証します。
うまくいかなかったこと(とその理由)
いくつかの最適化を試みましたが、どれもうまくいきませんでした:
並行エンベディング生成:TwelveLabsのレート制限に当たりました。順次処理の方が信頼性が高いことがわかりました。
エンベディングのキャッシュ:動画はそれぞれユニークであり、キャッシュは役に立ちませんでした。キャッシュするよりも再生成する方が効率的です
フレームレベルの比較:細かすぎて処理が遅く、誤検出が多すぎました。セグメントレベルが最適な妥協点でした。
長時間動画の処理
10分を超える動画には、特別な配慮が必要でした:
タイムアウト管理:30分のタイムアウトにより、問題のある動画でプロセスがハングするのを防ぎます
セグメント検証:セグメントが全編をカバーしているか検証(不完全なエンベディングを捕捉)
エラーメッセージ:サイレントに失敗させるのではなく、明確なエラーを返します(
"Embedding generation incomplete")
この結果、SAGEは10秒から20分までの動画を安定して処理できるようになりました。
この件に関する詳細情報は、私たちの 長時間動画処理ガイド に掲載されています。
データ出力
SAGEは網羅的な比較結果を生成します:
比較指標
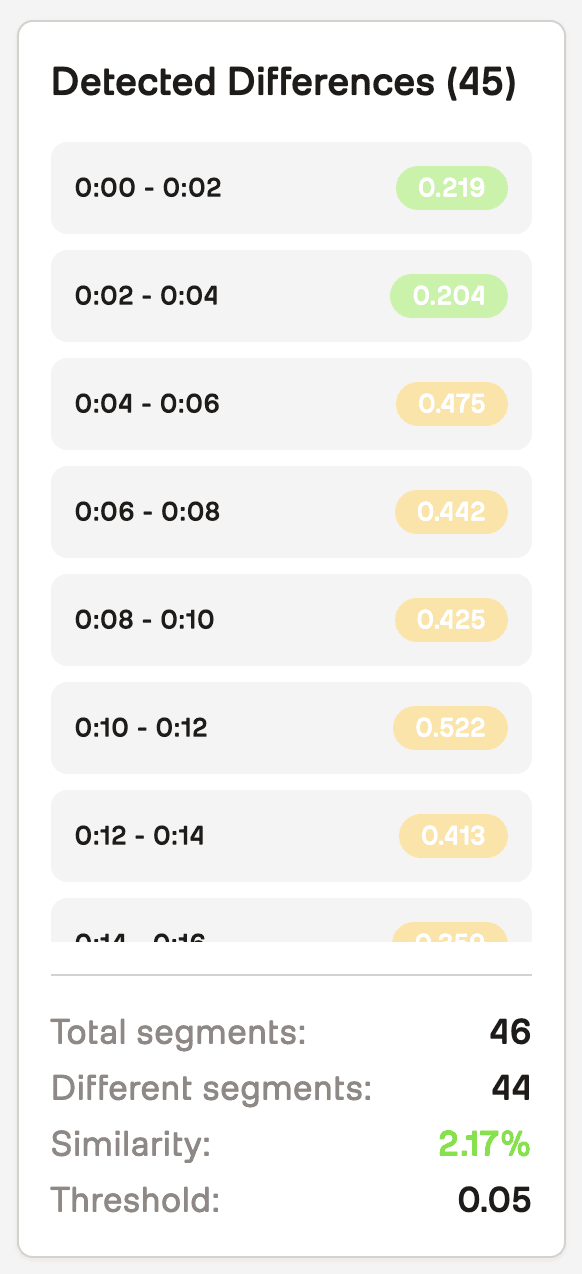
総セグメント数:比較された2秒セグメントの数
不一致セグメント数:設定した閾値を超える距離(違い)があるセグメントの数
類似度の割合(%):
(総セグメント数 - 不一致セグメント数) / 総セグメント数 * 100相違点タイムライン:不一致度スコア付きのタイムスタンプ付きセグメント情報
ビジュアライゼーション

同期された動画プレイヤー:タイムライン付きの左右に並べた動画再生
色分けされたマーカー:重大度(緑 = 類似、赤 = 異なり)のビジュアル表現
インタラクティブなタイムライン:マーカーをクリックして相違点にシーク
相違点リスト:時間セグメントによる詳細な内訳
オプションのAI分析

要約:違いに関するハイレベルな分析
主要なインサイト:注目すべき発見事項の箇条書き表現
時間セグメント:重大な違いが発生している特定の瞬間
使用例
ケース1:2つのトレーニング動画を比較する
シナリオ:製品デモ動画の修正前・修正後バージョンを比較する
# 動画のアップロード POST /upload-and-generate-embeddings { "file": <video_file_1> } POST /upload-and-generate-embeddings { "file": <video_file_2> } # エンベディングの生成を待つ(ステータスエンドポイントをポーリング) GET /embedding-status/{embedding_id} # 動画の比較を行う POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.1
レスポンス:
{ "filename1": "demo_v1.mp4", "filename2": "demo_v2.mp4", "differences": [ { "start_sec": 12.0, "end_sec": 14.0, "distance": 0.342 }, { "start_sec": 45.0, "end_sec": 47.0, "distance": 0.521 } ], "total_segments": 180, "differing_segments": 2, "threshold_used": 0.1, "similarity_percent": 98.89 }
解釈:動画は98.89%類似しています。2つのセグメントが異なっています:
12~14秒:中程度の違い(距離:0.342)
45~47秒:中程度の違い(距離:0.521)
ケース2:かすかな違いを見つけるためにしきい値を微調整する
シナリオ:背景のわずかな変更など、ごくかすかな違いを特定する
# より高い感度のために、低いしきい値を使用します POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.05
結果:背景の微細な変化や照明の調整など、より多くの相違点を探知します。
ケース3:AI分析を生成する
シナリオ:違いに関する、人間にわかりやすい説明を生成する
POST /openai-analysis { "embedding_id1": "...", "embedding_id2": "...", "differences": [...], "threshold": 0.1, "video_duration": 360.0 }
レスポンス:
{ "analysis": "動画は全体的に類似した内容を示していますが、2つの顕著な相違点があります...", "key_insights": [ "テイク間で製品の位置変更がありました", "45秒時点で背景の照明が調整されています" ], "time_segments": [ "12-14 秒: 製品実演のアングル", "45-47 秒: 背景シーンの変更" ] }
現実世界のユースケース
SAGEを構築してテストする中で、このツールが最も価値を発揮する明確なパターンを特定しました:
コンテンツ制作
Before/Afterの比較:編集前と編集後の映像素材を比較する
バージョン管理:動画の改訂プロセスに沿って変更を追跡する
品質保証(QA):異なるパターンの動画間で一貫性を確認する
トレーニング & 教育
取扱説明用動画:更新前と更新後の動画バージョンを比較する
コースの整合性:すべてのレッスンが同じフォーマットを維持しているか確認する
コンテンツのアップデート:改訂された教材のどの部分が変更されたかを特定する
コンプライアンス(法令順守) & 検証
広告表現の検証:承認されたバージョンと実際に放送・配信されたバージョンを比較する
法的文書化:証拠動画などの変更を追跡する
ブランドガイドラインの整合性:マーケティング用動画がブランド規定に合致しているか検証する
このアプローチが効果を発揮する理由(それと機能しない場合)
SAGEはセマンティックな比較(単なるピクセルではなく、動画のコンテンツ意味の違いを検出すること)に優れています。 最もその強みを発揮するのは、以下のような場合です:
強みを発揮する場合:
✅ 動画の技術スペック(解像度、コーデック、フレームレート)が異なる場合
✅ ピクセルではなく、コンテンツ自体の違いを見つけたい場合
✅ 動画の構造が類似している場合(同じ長さ、同じようなシーン)
✅ 違いが意味のある内容である場合(シーンの変化、物体の追加など)
あまり効果的ではない場合:
❌ 動画同士が完全に異なる場合(無関係なコンテンツの比較)
❌ フレーム精度の正確なタイミングが必要な場合(SAGEは2秒セグメント単位です)
❌ 動画の長さが極端に異なる場合(比較は短い方の動画に合わせて切り詰められます)
❌ ピクセルレベルの厳密な同一性検証が必要な場合(代わりに従来の差分取得ツールをご使用ください)
スイートスポット(最適な環境)
SAGEは、同じコンテンツのバリエーション(同じ台本、同じ現場だがテイクが異なる、編集やバージョンが異なるもの)を比較するのに最適です。技術的な違いに左右されることなく、本質的に重要な違いを見つけ出します。
パフォーマンス・ベンチマーク
何百本もの動画を処理して得られた知見を以下に示します:
処理時間
1分間の動画:合計約2〜3分(アップロード + エンベディング)
5分間の動画:合計約5〜8分
10分間の動画:合計約10〜15分
15分間の動画:合計約15〜25分
内訳:アップロードは通常1分未満で完了します。エンベディング生成時間は、動画の長さにほぼ比例して増加します。
比較速度
比較ロジックの計算:動画の長さに関わらず1秒未満
タイムラインのレンダリング:一般的な動画で100ミリ秒未満
動画再生:ブラウザ本来のネイティブパフォーマンス
重要なインサイト:エンベディングが存在していれば、比較処理は一瞬で終わります。処理のボトルネックは比較そのものではなく、エンベディングの生成部分になります。
精度

セマンティック(意味的)相違点:実質的なコンテンツの変化を正確に捉えます
誤検出(偽陽性):適切なしきい値設定(デフォルトの0.1が推奨)で低く抑えられます
検出漏れ(偽陰性):極めて微細な変化は検出されない場合があります(その場合は値を下げてください)

しきい値のガイドライン:
0.05:超高感度(かすかな背景の変化なども特定)
0.1:標準的(感度のバランスに優れる)
0.2:低感度(主要な変化のみ)
0.5:最過保護(劇的なシーン変更のみ)

結論:動画比較の未来
SAGEは、「動画をピクセルではなく意味で比較するとどうなるか?」という実験から始まりました。私たちが発見したのは、セマンティックな比較が動画の「違い」に関する我々の見方を変えるということです。
ピクセルレベルのノイズに翻弄されることなく、コンテンツ自体の変更、シーン構成の違い、本質的なバリエーションといった本当に重要なことに集中できます。そして、フレームの手動比較を自動化することも可能になります。
このアプローチは示唆に富んでいます:
クリエイター向け:手動チェックなしに、以前のバージョンと何が変更されたかを即座に特定
開発者向け:単なる動画ファイルとしてではなく、動画の内容そのものを理解するインテリジェントなアプリ構築
業界全体へ:エンベディングモデルが進化すれば、自動的にこの比較精度も上がっていきます
一番エキサイティングなのは、まだこれが始まりに過ぎないという点です。動画理解モデルの進化に伴い、SAGEの比較能力もレベルアップしていきます。現在はセグメント単位ですが、将来的にはシーンごと、特定オブジェクトの検知、さらには文脈やストーリー構成の理解にまで及ぶかもしれません。
土台はすでに整っています。あとは繰り返しの開発があるのみです。
その他の情報源
GitHub リポジトリ: GitHub上のSAGEページ
TwelveLabs ドキュメント: Marengoエンベディング応用ガイド
AWS S3: マルチパートアップロードのベストプラクティス
コサイン類似度: ベクトルの類似性の理解
付録:技術的詳細
エンベディングモデル
使用モデル:Marengo-retrieval-2.7
セグメント長:2秒
ベクトル次元数:768(セグメントあたり)
スコープ選択:
["clip", "video"](クリップ単位および動画全体の双方)
類似度の数式表現
コサイン距離:
1 - (dot(v1, v2) / (norm(v1) * norm(v2)))範囲:0(完全に同一)から 2(正反対)まで
目安:0-0.1(極めて類似)、0.1-0.3(多少の違い)、0.3-0.7(中程度の相違)、0.7+(著しい相違)
S3 詳細構成
分割サイズ(チャンク):10MB
アップロード方式:常にマルチパートを使用(信頼性向上のため)
署名付きURLの有効期限:1時間(3600秒)
ホスト地域(Region):構成調整(デフォルト:us-east-2)
提供API一覧
POST /validate-key- TwelveLabsのAPI有効性をチェックPOST /upload-and-generate-embeddings- ビデオアップロードとエンベディング生成タスクの開始GET /embedding-status/{embedding_id}- エンベディング生成の現在のステータス判定POST /compare-local-videos- エンベディングIDを用いた、2つの動画の比較実行POST /openai-analysis- 違いを説明するAI分析文章の任意生成GET /serve-video/{video_id}- ブラウザ再生用の署名付きURL生成GET /health- APIサーバのヘルスチェック(動作点検)
はじめに
あなたはトレーニング動画を2つのバージョンで撮影しました。内容は同じ、台本も同じですが、テイクが異なります。一方は照明が良く、もう一方は音声がよりクリアです。フレームごとのピクセル単位の違いだけでなく、コンテンツ、シーンの構成、または視覚要素の実際のセマンティック(意味的)な変化など、それらが正確にどこで異なっているかを素早く特定する必要があります。
従来の動画比較ツールには、根本的な限界があります。それは、意味ではなくピクセルを比較するという点です。これは、動画に以下のような違いがある場合に破綻します。
異なる解像度やアスペクト比
異なるエンコード設定や圧縮率
異なるカメラアングルや位置
照明やカラーグレーディングの違い
時間的なズレ(一方の動画が数秒遅れて始まるなど)
これが、私たちがSAGEを構築した理由です。SAGEは、動画に含まれるピクセルだけでなく、動画の中に何があるかを理解するシステムです。生の動画データを比較する代わりに、SAGEはTwelveLabs Marengoエンベディングを使用して動画セグメントのセマンティック表現を生成し、それらの表現を比較して意味のある違いを検出します。
重要な洞察とは何でしょうか?それは、セマンティックエンベディングは重要な要素を捉えるということです。人が歩いているカットは、同一のピクセルである必要はありません。同じアクションを表現していればよいのです。エンベディングを比較することで、技術的な理由でピクセルが異なる場合でも、動画のコンテンツが異なる場合を検出することができます。
SAGEは完全な比較ワークフローを作成します:
ストリーミングマルチパートアップロードを使用して動画をS3にアップロード(大容量ファイルを効率的に処理)
TwelveLabs Marengo-retrieval-2.7(2秒セグメント)を使用してエンベディングを生成
コサイン類似度を使用してエンベディングを比較(セマンティックな違いを検出)
同期されたタイムライン上で、サイドバイサイドの再生により違いを視覚化
オプションのAIを活用したインサイト(OpenAI連携)で違いを分析
その結果はどうなるでしょうか?単に何が違って見えるかだけでなく、何が変わったかを教えてくれるシステムが実現します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上またはBunがインストールされていること
APIキー:
TwelveLabs APIキー(エンベディング生成用)
OpenAI APIキー(任意、AI分析用)
S3へのアクセスが設定されたAWSアカウント(動画保存用)
リポジトリをクローンするためのGit
Python、FastAPI、Next.js、およびAWS S3に関する基本的な知識
ピクセルレベル比較の問題点
私たちが発見したのは、ピクセルレベルの比較は実世界のシナリオでは破綻するということです。以下の2つの動画を比較することを考えてみましょう:
動画 A: 1080p MP4、30fpsで撮影、H.264エンコード、自然光
動画 B: 720p MP4、24fpsで撮影、H.265エンコード、スタジオ照明
ピクセルレベルの比較では、両方の動画が同じコンテンツを表示していても、ほぼすべてのフレームが「異なる」と判定されます。根本的な問題は何でしょうか?それは、ピクセルは意味を表さないということです。
従来の方式が失敗する理由
従来の動画比較アプローチには、3つの重大な限界があります:
フォーマットの感度:解像度、コーデック、フレームレートの違いにより、誤検出(偽陽性)が発生する
時間的理解の欠如:フレームごとの比較では、時間的なコンテキストが見落とされる
セマンティック認識の欠如:「異なるピクセル」と「異なるコンテンツ」を区別できない
エンベディングによる解決策
TwelveLabs Marengoエンベディングは、動画内に何が含まれているかを表現し、どのようなピクセルが含まれているかを排除することでこれを解決します。各2秒のセグメントは、以下を捉える高次元ベクトルに変換されます:
視覚的コンテンツ(オブジェクト、シーン、アクション)
時間的パターン(動き、トランジション)
セマンティックな意味(見え方ではなく、何が起きているか)
これらのエンベディングを比較することで、単なるピクセルではなく、動画のコンテンツがいつ異なるのかを知ることができます。
デモアプリケーション
SAGEは、効率的な動画比較ワークフローを提供します:
動画のアップロード:2つの動画(一度に最大2ファイル)をアップロードすると、S3へのアップロードからエンベディング生成の完了まで、リアルタイムのステータス更新で処理プロセスを確認できます。
自動比較:両方の動画の準備が整うと、SAGEはセマンティックエンベディングを使用して自動的に比較を行い、手動でのフレームごとの確認なしにセグメントレベルで違いを特定します。
インタラクティブな分析:同期された左右並列再生、動画の違いを示す色分けされたタイムライン、類似度スコア付きの詳細なセグメントごとの内訳を通じて、違いを探索できます。
このプロセスはリアルタイムで処理されます。エンベディング生成の進行状況を観察し、類似度の割合が即座に計算されるのを確認し、正確なタイムスタンプでタイムライン上の違いを追跡します。違いのマーカーにジャンプして、動画間で具体的に何が変更されたかを正確に確認できます。
完全なデモアプリケーションを探索し、GitHubで完全なソースコードを見つけることができます。または、システムの動作を示すチュートリアル動画をご覧ください:
SAGEの仕組み
SAGEは、AWS S3ストレージ、TwelveLabsエンベディング、および高度なビジュアライゼーションを組み合わせた、洗練された動画比較パイプラインを実装しています:
システムアーキテクチャ
準備手順
1. リポジトリのクローン
コードはこちらで公開されています: https://github.com/aahilshaikh-twlbs/SAGE
git clone https://github.com/aahilshaikh-twlbs/SAGE.git cd
2. バックエンドのセットアップ
cd backend python3 -m venv .venv source .venv/bin/activate # Windows: .venv\Scripts\activate pip install -r requirements.txt cp env.example .env # .envにAPIキーを追加します
3. フロントエンドのセットアップ
cd ../frontend npm install # または bun install cp .env.local.example .env.local # NEXT_PUBLIC_API_URL=http://localhost:8000 を設定します
4. AWS S3の設定
# AWS認証情報を設定します(AWS SSOまたはIAMを使用) aws configure --profile dev # または環境変数を設定します: export AWS_ACCESS_KEY_ID=your_access_key export AWS_SECRET_ACCESS_KEY=your_secret_key export AWS_REGION
5. アプリケーションの起動
# ターミナル 1: バックエンド cd backend python app.py # ターミナル 2: フロントエンド cd frontend npm run dev # または bun dev
これらの手順が完了したら、http://localhost:3000 にアクセスして SAGE に接続してください!
実装解説
SAGEの動画比較システムを支えるコアコンポーネントを順に見ていきましょう。
1. S3へのストリーミング動画アップロード
SAGEは、ストリーミングマルチパートアップロードを使用して、大容量の動画ファイルを効率的に処理します:
async def upload_to_s3_streaming(file: UploadFile) -> str: """メモリの問題を回避するため、ストリーミングを使用してファイルをS3にアップロードします。""" file_key = f"videos/{uuid.uuid4()}_{file.filename}" # 大容量ファイルにはマルチパートアップロードを使用 response = s3_client.create_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, ContentType=file.content_type ) upload_id = response['UploadId'] parts = [] part_number = 1 chunk_size = 10 * 1024 * 1024# 10MBのチャンク while True: chunk = await file.read(chunk_size) if not chunk: break part_response = s3_client.upload_part( Bucket=S3_BUCKET_NAME, Key=file_key, PartNumber=part_number, UploadId=upload_id, Body=chunk ) parts.append({ 'ETag': part_response['ETag'], 'PartNumber': part_number }) part_number += 1 # マルチパートアップロードを完了 s3_client.complete_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, UploadId=upload_id, MultipartUpload={'Parts': parts} ) return f"s3://{S3_BUCKET_NAME}/{file_key}"
主な設計上の決定:
10MBのチャンク:アップロード効率とメモリ使用量のバランスを取ります
ストリーミング:ファイルをチャンクで処理し、ファイル全体をメモリにロードしないようにします
マルチパートアップロード:5GBを超えるファイルに必須であり、100MBを超えるファイルに推奨されます
署名付きURL:TwelveLabsが動画に安全にアクセスできるようにするための一時的なURLを生成します
2. TwelveLabsによるエンベディング生成
SAGEは、TwelveLabsの Marengo-retrieval-2.7 を使用して、非同期でエンベディングを生成します:
async def generate_embeddings_async(embedding_id: str, s3_url: str, api_key: str): """S3からの動画に対して非同期でエンベディングを生成します。""" # TwelveLabsクライアントを取得 tl = get_twelve_labs_client(api_key) # TwelveLabsが動画にアクセスするための署名付きURLを生成 presigned_url = get_s3_presigned_url(s3_url) # 署名付きHTTPS URLを使用してエンベディングタスクを作成 task = tl.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=presigned_url, video_clip_length=2,# 2秒セグメント video_embedding_scopes=["clip", "video"] ) # タイムアウト付きで完了を待つ task.wait_for_done(sleep_interval=5, timeout=1800)# 30分 # 完了したタスクを取得 completed_task = tl.embed.task.retrieve(task.id) # エンベディングが生成されたことを検証 if not completed_task.video_embedding or not completed_task.video_embedding.segments: raise Exception("Embedding generation failed") # エンベディングと動画の長さを保存 embedding_storage[embedding_id].update({ "status": "completed", "embeddings": completed_task.video_embedding, "duration": last_segment.end_offset_sec, "task_id": task.id })
主な特徴:
2秒セグメント:粒度と処理時間のバランスを取ります
非同期処理:ノンブロッキングで、キューを介して複数の動画を処理します
タイムアウト処理:30分のタイムアウトにより、問題のある動画での処理の中断を防ぎます
検証:エンベディングが動画の全編をカバーしていることを確認します
3. セマンティック動画比較
SAGEは、エンベディングにコサイン距離を適用して動画を比較します:
async def compare_local_videos( embedding_id1: str, embedding_id2: str, threshold: float = 0.1, distance_metric: str = "cosine" ): """エンベディングIDを使用して、2つの動画を比較します。""" # エンベディングセグメントを取得 segments1 = extract_segments(embedding_storage[embedding_id1]) segments2 = extract_segments(embedding_storage[embedding_id2]) differing_segments = [] min_segments = min(len(segments1), len(segments2)) # 対応するセグメントを比較 for i in range(min_segments): seg1 = segments1[i] seg2 = segments2[i] # コサイン距離を計算 v1 = np.array(seg1["embedding"], dtype=np.float32) v2 = np.array(seg2["embedding"], dtype=np.float32) dot = np.dot(v1, v2) norm1 = np.linalg.norm(v1) norm2 = np.linalg.norm(v2) distance = 1.0 - (dot / (norm1 * norm2)) if norm1 > 0 and norm2 > 0 else 1.0 # しきい値を超えるセグメントにフラグを立てる if distance > threshold: differing_segments.append({ "start_sec": seg1["start_offset_sec"], "end_sec": seg1["end_offset_sec"], "distance": distance }) return { "differences": differing_segments, "total_segments": min_segments, "differing_segments": len(differing_segments), "similarity_percent": ((min_segments - len(differing_segments)) / min_segments * 100) }
なぜコサイン類似度(距離)なのか?
スケール不変性:正規化されたベクトルは、大きさ(解像度など)の違いを無視します
セマンティック(意味)重視:ピクセル値ではなく、意味の類似性を測定します
解釈の容易さ:0 = 同一、1 = 直交(無関係)、2 = 反対
構成可能なしきい値:さまざまなユースケースに合わせて感度を調整できます
4. 同期されたタイムラインの視覚化
フロントエンドは、同期された再生機能を備えたインタラクティブなタイムラインを作成します:
// 同期された動画再生 const handlePlayPause = () => { if (video1Ref.current && video2Ref.current) { if (isPlaying) { video1Ref.current.pause(); video2Ref.current.pause(); } else { video1Ref.current.play(); video2Ref.current.play(); } setIsPlaying(!isPlaying); } }; // 両方の動画で特定の時間にジャンプ const seekToTime = (time: number) => { const constrainedTime = Math.min( time, Math.min(video1Data.duration, video2Data.duration) ); video1Ref.current.currentTime = constrainedTime; video2Ref.current.currentTime = constrainedTime; setCurrentTime(constrainedTime); }; // 色分けされた相違点マーカー const getSeverityColor = (distance: number) => { if (distance >= 1.5) return 'bg-red-600';// 完全に異なる if (distance >= 1.0) return 'bg-red-500';// 大きく異なる if (distance >= 0.7) return 'bg-orange-500';// かなり異なる if (distance >= 0.5) return 'bg-amber-500';// 中程度に異なる if (distance >= 0.3) return 'bg-yellow-500';// やや異なる if (distance >= 0.1) return 'bg-lime-500';// わずかに異なる return 'bg-cyan-500';// ほぼ同一 };
ビジュアライゼーション機能:
同期された再生:両方の動画が同時に再生/ポーズされます
タイムラインマーカー:色分けされたセグメントで違いの深刻度を表示します
クリックによるシーク:マーカーをクリックすると、その時間に直接ジャンプします
類似度スコア:セグメントから算出した類似度の比率(%)を示します
5. オプションのAIパワー分析
SAGEは、OpenAIを使用して人間が読みやすい分析を生成するオプションを備えています:
async def generate_openai_analysis( embedding_id1: str, embedding_id2: str, differences: List[DifferenceSegment], threshold: float, video_duration: float ): """動画の違いに関するAI駆動の分析を生成します。""" prompt = f""" 以下のデータに基づいて、2つの動画間の違いを分析してください: 视频 1: {embed_data1.get('filename', 'Unknown')} 视频 2: {embed_data2.get('filename', 'Unknown')} 総再生時間: {video_duration:.1f} 秒 類似度しきい値: {threshold} 違いの件数: {len(differences)} これらの時間セグメントで違いが検出されました: {chr(10).join([f"- {d.start_sec:.1f} 秒から {d.end_sec:.1f} 秒 (距離: {d.distance:.3f})" for d in differences[:20]])} 以下を提供してください: 1. これらの違いが何を表している可能性があるかについての簡潔な分析 2. 比較に関する主要なインサイト 3. 重大な違いが発生している注目すべき時間セグメント """ response = openai.ChatCompletion.create( model="gpt-4", messages=[ {"role": "system", "content": "あなたは専門的な動画分析アシスタントです。"}, {"role": "user", "content": prompt} ], max_tokens=500, temperature=0.7 ) return { "analysis": response.choices[0].message.content, "key_insights": extract_insights(response), "time_segments": extract_segments(response) }
主な設計上の決定
1. フレーム単位ではなくセグメント単位の比較の採用
フレーム単位の比較の代わりに2秒セグメントを選択した理由は、主に次の3点です:
時間的コンテキスト:静止フレームだけでなく、動きやアクションを捉えることができます
計算効率:比較回数を削減できます(例:1分間の動画で1800フレームに対して300セグメント)
セマンティックの正確さ:個々のフレームよりも、エンベディングの方が「何が起きているか」を良く理解できます
トレードオフ:時間の精度は低くなりますが(フレーム精度に対して2秒精度)、より意味のある相違点を特定できます。
2. メモリ内処理ではなくストリーミングアップロードの採用
大容量の動画は数ギガバイトに及ぶことがあります。ファイル全体をメモリに読み込むと、サーバーがクラッシュする原因になります:
メモリ安全性:ストリーミングにより、ファイルを10MBのチャンクで処理します
スケーラビリティ:複数の大容量アップロードがあってもサーバーの応答性が維持されます
S3統合:S3に直接アップロードし、TwelveLabs用の署名付きURLを生成します
トレードオフ:アップロードのロジックが複雑になりますが、任意のサイズの動画を処理できるようになります。
3. ユークリッド距離ではなくコサイン類似度(距離)の採用
セマンティックな比較のためにコサイン距離を使用します:
スケール不変性:異なる画質の動画間でも一貫して機能します
セマンティック重視:大きさや強度ではなく、意味の類似性を測定します
解釈が可能:明確なしきい値を設定できます(0.1 = 微細、0.5 = 中程度、1.0 = 重大)
トレードオフ:ユークリッド距離よりも直感的ではありませんが、セマンティックな比較により適しています。
4. 並行型ではなくキューベースの処理の採用
エンベディングの生成には、動画あたり5〜30分かかる場合があります。これを順次処理します:
レート制限対策:TwelveLabs APIのレート制限超過を防ぎます
リソース管理:一度に1つの動画を処理することで、リソース使用量を一定に抑えます
エラーの隔離:失敗した動画が他の処理を阻害しません
トレードオフ:総スループットは遅くなりますが、より信頼性が高く予測可能になります。
5. データベースではなくメモリ内へのエンベディング保存
エンベディングをデータベースに永続化せず、メモリ内に保存します:
パフォーマンス:比較時における高速なアクセス(データベースクエリが不要)
シンプルさ:スキーマ移行やデータベースの管理が不要
一時的な性質:エンベディングはセッション固有であり、永続化の必要性が低いです
トレードオフ:サーバー再起動時にデータが失われますが、比較ワークフローにおいては許容範囲です。
パフォーマンス・エンジニアリング:私たちが学んだこと
SAGEの構築を通じて、大規模な動画処理。を扱うための貴重な教訓を得ました:
80/20の法則の適用
私たちは最適化作業の80%を、以下の3点に費やしました:
ストリーミングアップロード:分割アップロードにより、メモリの枯渇を防ぎます。2GBのファイルをすべてロードしてクラッシュさせるか、ストリーミングしてサーバーを安定させるかの違いはここにあります。
非同期処理:ノンブロッキングのエンベディング生成により、APIの応答性を維持します。ユーザーは、それぞれの完了を待つことなく複数の動画をアップロードできます。
セグメント検証:エンベディングが動画の全範囲をカバーしていることを確認し、サイレントエラーを防ぎます。結果を受け入れる前に、セグメント数、カバレッジ、再生時間を検証します。
うまくいかなかったこと(とその理由)
いくつかの最適化を試みましたが、どれもうまくいきませんでした:
並行エンベディング生成:TwelveLabsのレート制限に当たりました。順次処理の方が信頼性が高いことがわかりました。
エンベディングのキャッシュ:動画はそれぞれユニークであり、キャッシュは役に立ちませんでした。キャッシュするよりも再生成する方が効率的です
フレームレベルの比較:細かすぎて処理が遅く、誤検出が多すぎました。セグメントレベルが最適な妥協点でした。
長時間動画の処理
10分を超える動画には、特別な配慮が必要でした:
タイムアウト管理:30分のタイムアウトにより、問題のある動画でプロセスがハングするのを防ぎます
セグメント検証:セグメントが全編をカバーしているか検証(不完全なエンベディングを捕捉)
エラーメッセージ:サイレントに失敗させるのではなく、明確なエラーを返します(
"Embedding generation incomplete")
この結果、SAGEは10秒から20分までの動画を安定して処理できるようになりました。
この件に関する詳細情報は、私たちの 長時間動画処理ガイド に掲載されています。
データ出力
SAGEは網羅的な比較結果を生成します:
比較指標
総セグメント数:比較された2秒セグメントの数
不一致セグメント数:設定した閾値を超える距離(違い)があるセグメントの数
類似度の割合(%):
(総セグメント数 - 不一致セグメント数) / 総セグメント数 * 100相違点タイムライン:不一致度スコア付きのタイムスタンプ付きセグメント情報
ビジュアライゼーション
同期された動画プレイヤー:タイムライン付きの左右に並べた動画再生
色分けされたマーカー:重大度(緑 = 類似、赤 = 異なり)のビジュアル表現
インタラクティブなタイムライン:マーカーをクリックして相違点にシーク
相違点リスト:時間セグメントによる詳細な内訳
オプションのAI分析
要約:違いに関するハイレベルな分析
主要なインサイト:注目すべき発見事項の箇条書き表現
時間セグメント:重大な違いが発生している特定の瞬間
使用例
ケース1:2つのトレーニング動画を比較する
シナリオ:製品デモ動画の修正前・修正後バージョンを比較する
# 動画のアップロード POST /upload-and-generate-embeddings { "file": <video_file_1> } POST /upload-and-generate-embeddings { "file": <video_file_2> } # エンベディングの生成を待つ(ステータスエンドポイントをポーリング) GET /embedding-status/{embedding_id} # 動画の比較を行う POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.1
レスポンス:
{ "filename1": "demo_v1.mp4", "filename2": "demo_v2.mp4", "differences": [ { "start_sec": 12.0, "end_sec": 14.0, "distance": 0.342 }, { "start_sec": 45.0, "end_sec": 47.0, "distance": 0.521 } ], "total_segments": 180, "differing_segments": 2, "threshold_used": 0.1, "similarity_percent": 98.89 }
解釈:動画は98.89%類似しています。2つのセグメントが異なっています:
12~14秒:中程度の違い(距離:0.342)
45~47秒:中程度の違い(距離:0.521)
ケース2:かすかな違いを見つけるためにしきい値を微調整する
シナリオ:背景のわずかな変更など、ごくかすかな違いを特定する
# より高い感度のために、低いしきい値を使用します POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.05
結果:背景の微細な変化や照明の調整など、より多くの相違点を探知します。
ケース3:AI分析を生成する
シナリオ:違いに関する、人間にわかりやすい説明を生成する
POST /openai-analysis { "embedding_id1": "...", "embedding_id2": "...", "differences": [...], "threshold": 0.1, "video_duration": 360.0 }
レスポンス:
{ "analysis": "動画は全体的に類似した内容を示していますが、2つの顕著な相違点があります...", "key_insights": [ "テイク間で製品の位置変更がありました", "45秒時点で背景の照明が調整されています" ], "time_segments": [ "12-14 秒: 製品実演のアングル", "45-47 秒: 背景シーンの変更" ] }
現実世界のユースケース
SAGEを構築してテストする中で、このツールが最も価値を発揮する明確なパターンを特定しました:
コンテンツ制作
Before/Afterの比較:編集前と編集後の映像素材を比較する
バージョン管理:動画の改訂プロセスに沿って変更を追跡する
品質保証(QA):異なるパターンの動画間で一貫性を確認する
トレーニング & 教育
取扱説明用動画:更新前と更新後の動画バージョンを比較する
コースの整合性:すべてのレッスンが同じフォーマットを維持しているか確認する
コンテンツのアップデート:改訂された教材のどの部分が変更されたかを特定する
コンプライアンス(法令順守) & 検証
広告表現の検証:承認されたバージョンと実際に放送・配信されたバージョンを比較する
法的文書化:証拠動画などの変更を追跡する
ブランドガイドラインの整合性:マーケティング用動画がブランド規定に合致しているか検証する
このアプローチが効果を発揮する理由(それと機能しない場合)
SAGEはセマンティックな比較(単なるピクセルではなく、動画のコンテンツ意味の違いを検出すること)に優れています。 最もその強みを発揮するのは、以下のような場合です:
強みを発揮する場合:
✅ 動画の技術スペック(解像度、コーデック、フレームレート)が異なる場合
✅ ピクセルではなく、コンテンツ自体の違いを見つけたい場合
✅ 動画の構造が類似している場合(同じ長さ、同じようなシーン)
✅ 違いが意味のある内容である場合(シーンの変化、物体の追加など)
あまり効果的ではない場合:
❌ 動画同士が完全に異なる場合(無関係なコンテンツの比較)
❌ フレーム精度の正確なタイミングが必要な場合(SAGEは2秒セグメント単位です)
❌ 動画の長さが極端に異なる場合(比較は短い方の動画に合わせて切り詰められます)
❌ ピクセルレベルの厳密な同一性検証が必要な場合(代わりに従来の差分取得ツールをご使用ください)
スイートスポット(最適な環境)
SAGEは、同じコンテンツのバリエーション(同じ台本、同じ現場だがテイクが異なる、編集やバージョンが異なるもの)を比較するのに最適です。技術的な違いに左右されることなく、本質的に重要な違いを見つけ出します。
パフォーマンス・ベンチマーク
何百本もの動画を処理して得られた知見を以下に示します:
処理時間
1分間の動画:合計約2〜3分(アップロード + エンベディング)
5分間の動画:合計約5〜8分
10分間の動画:合計約10〜15分
15分間の動画:合計約15〜25分
内訳:アップロードは通常1分未満で完了します。エンベディング生成時間は、動画の長さにほぼ比例して増加します。
比較速度
比較ロジックの計算:動画の長さに関わらず1秒未満
タイムラインのレンダリング:一般的な動画で100ミリ秒未満
動画再生:ブラウザ本来のネイティブパフォーマンス
重要なインサイト:エンベディングが存在していれば、比較処理は一瞬で終わります。処理のボトルネックは比較そのものではなく、エンベディングの生成部分になります。
精度
セマンティック(意味的)相違点:実質的なコンテンツの変化を正確に捉えます
誤検出(偽陽性):適切なしきい値設定(デフォルトの0.1が推奨)で低く抑えられます
検出漏れ(偽陰性):極めて微細な変化は検出されない場合があります(その場合は値を下げてください)
しきい値のガイドライン:
0.05:超高感度(かすかな背景の変化なども特定)
0.1:標準的(感度のバランスに優れる)
0.2:低感度(主要な変化のみ)
0.5:最過保護(劇的なシーン変更のみ)
結論:動画比較の未来
SAGEは、「動画をピクセルではなく意味で比較するとどうなるか?」という実験から始まりました。私たちが発見したのは、セマンティックな比較が動画の「違い」に関する我々の見方を変えるということです。
ピクセルレベルのノイズに翻弄されることなく、コンテンツ自体の変更、シーン構成の違い、本質的なバリエーションといった本当に重要なことに集中できます。そして、フレームの手動比較を自動化することも可能になります。
このアプローチは示唆に富んでいます:
クリエイター向け:手動チェックなしに、以前のバージョンと何が変更されたかを即座に特定
開発者向け:単なる動画ファイルとしてではなく、動画の内容そのものを理解するインテリジェントなアプリ構築
業界全体へ:エンベディングモデルが進化すれば、自動的にこの比較精度も上がっていきます
一番エキサイティングなのは、まだこれが始まりに過ぎないという点です。動画理解モデルの進化に伴い、SAGEの比較能力もレベルアップしていきます。現在はセグメント単位ですが、将来的にはシーンごと、特定オブジェクトの検知、さらには文脈やストーリー構成の理解にまで及ぶかもしれません。
土台はすでに整っています。あとは繰り返しの開発があるのみです。
その他の情報源
GitHub リポジトリ: GitHub上のSAGEページ
TwelveLabs ドキュメント: Marengoエンベディング応用ガイド
AWS S3: マルチパートアップロードのベストプラクティス
コサイン類似度: ベクトルの類似性の理解
付録:技術的詳細
エンベディングモデル
使用モデル:Marengo-retrieval-2.7
セグメント長:2秒
ベクトル次元数:768(セグメントあたり)
スコープ選択:
["clip", "video"](クリップ単位および動画全体の双方)
類似度の数式表現
コサイン距離:
1 - (dot(v1, v2) / (norm(v1) * norm(v2)))範囲:0(完全に同一)から 2(正反対)まで
目安:0-0.1(極めて類似)、0.1-0.3(多少の違い)、0.3-0.7(中程度の相違)、0.7+(著しい相違)
S3 詳細構成
分割サイズ(チャンク):10MB
アップロード方式:常にマルチパートを使用(信頼性向上のため)
署名付きURLの有効期限:1時間(3600秒)
ホスト地域(Region):構成調整(デフォルト:us-east-2)
提供API一覧
POST /validate-key- TwelveLabsのAPI有効性をチェックPOST /upload-and-generate-embeddings- ビデオアップロードとエンベディング生成タスクの開始GET /embedding-status/{embedding_id}- エンベディング生成の現在のステータス判定POST /compare-local-videos- エンベディングIDを用いた、2つの動画の比較実行POST /openai-analysis- 違いを説明するAI分析文章の任意生成GET /serve-video/{video_id}- ブラウザ再生用の署名付きURL生成GET /health- APIサーバのヘルスチェック(動作点検)
はじめに
あなたはトレーニング動画を2つのバージョンで撮影しました。内容は同じ、台本も同じですが、テイクが異なります。一方は照明が良く、もう一方は音声がよりクリアです。フレームごとのピクセル単位の違いだけでなく、コンテンツ、シーンの構成、または視覚要素の実際のセマンティック(意味的)な変化など、それらが正確にどこで異なっているかを素早く特定する必要があります。
従来の動画比較ツールには、根本的な限界があります。それは、意味ではなくピクセルを比較するという点です。これは、動画に以下のような違いがある場合に破綻します。
異なる解像度やアスペクト比
異なるエンコード設定や圧縮率
異なるカメラアングルや位置
照明やカラーグレーディングの違い
時間的なズレ(一方の動画が数秒遅れて始まるなど)
これが、私たちがSAGEを構築した理由です。SAGEは、動画に含まれるピクセルだけでなく、動画の中に何があるかを理解するシステムです。生の動画データを比較する代わりに、SAGEはTwelveLabs Marengoエンベディングを使用して動画セグメントのセマンティック表現を生成し、それらの表現を比較して意味のある違いを検出します。
重要な洞察とは何でしょうか?それは、セマンティックエンベディングは重要な要素を捉えるということです。人が歩いているカットは、同一のピクセルである必要はありません。同じアクションを表現していればよいのです。エンベディングを比較することで、技術的な理由でピクセルが異なる場合でも、動画のコンテンツが異なる場合を検出することができます。
SAGEは完全な比較ワークフローを作成します:
ストリーミングマルチパートアップロードを使用して動画をS3にアップロード(大容量ファイルを効率的に処理)
TwelveLabs Marengo-retrieval-2.7(2秒セグメント)を使用してエンベディングを生成
コサイン類似度を使用してエンベディングを比較(セマンティックな違いを検出)
同期されたタイムライン上で、サイドバイサイドの再生により違いを視覚化
オプションのAIを活用したインサイト(OpenAI連携)で違いを分析
その結果はどうなるでしょうか?単に何が違って見えるかだけでなく、何が変わったかを教えてくれるシステムが実現します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上またはBunがインストールされていること
APIキー:
TwelveLabs APIキー(エンベディング生成用)
OpenAI APIキー(任意、AI分析用)
S3へのアクセスが設定されたAWSアカウント(動画保存用)
リポジトリをクローンするためのGit
Python、FastAPI、Next.js、およびAWS S3に関する基本的な知識
ピクセルレベル比較の問題点
私たちが発見したのは、ピクセルレベルの比較は実世界のシナリオでは破綻するということです。以下の2つの動画を比較することを考えてみましょう:
動画 A: 1080p MP4、30fpsで撮影、H.264エンコード、自然光
動画 B: 720p MP4、24fpsで撮影、H.265エンコード、スタジオ照明
ピクセルレベルの比較では、両方の動画が同じコンテンツを表示していても、ほぼすべてのフレームが「異なる」と判定されます。根本的な問題は何でしょうか?それは、ピクセルは意味を表さないということです。
従来の方式が失敗する理由
従来の動画比較アプローチには、3つの重大な限界があります:
フォーマットの感度:解像度、コーデック、フレームレートの違いにより、誤検出(偽陽性)が発生する
時間的理解の欠如:フレームごとの比較では、時間的なコンテキストが見落とされる
セマンティック認識の欠如:「異なるピクセル」と「異なるコンテンツ」を区別できない
エンベディングによる解決策
TwelveLabs Marengoエンベディングは、動画内に何が含まれているかを表現し、どのようなピクセルが含まれているかを排除することでこれを解決します。各2秒のセグメントは、以下を捉える高次元ベクトルに変換されます:
視覚的コンテンツ(オブジェクト、シーン、アクション)
時間的パターン(動き、トランジション)
セマンティックな意味(見え方ではなく、何が起きているか)
これらのエンベディングを比較することで、単なるピクセルではなく、動画のコンテンツがいつ異なるのかを知ることができます。
デモアプリケーション
SAGEは、効率的な動画比較ワークフローを提供します:
動画のアップロード:2つの動画(一度に最大2ファイル)をアップロードすると、S3へのアップロードからエンベディング生成の完了まで、リアルタイムのステータス更新で処理プロセスを確認できます。
自動比較:両方の動画の準備が整うと、SAGEはセマンティックエンベディングを使用して自動的に比較を行い、手動でのフレームごとの確認なしにセグメントレベルで違いを特定します。
インタラクティブな分析:同期された左右並列再生、動画の違いを示す色分けされたタイムライン、類似度スコア付きの詳細なセグメントごとの内訳を通じて、違いを探索できます。
このプロセスはリアルタイムで処理されます。エンベディング生成の進行状況を観察し、類似度の割合が即座に計算されるのを確認し、正確なタイムスタンプでタイムライン上の違いを追跡します。違いのマーカーにジャンプして、動画間で具体的に何が変更されたかを正確に確認できます。
完全なデモアプリケーションを探索し、GitHubで完全なソースコードを見つけることができます。または、システムの動作を示すチュートリアル動画をご覧ください:
SAGEの仕組み
SAGEは、AWS S3ストレージ、TwelveLabsエンベディング、および高度なビジュアライゼーションを組み合わせた、洗練された動画比較パイプラインを実装しています:
システムアーキテクチャ
準備手順
1. リポジトリのクローン
コードはこちらで公開されています: https://github.com/aahilshaikh-twlbs/SAGE
git clone https://github.com/aahilshaikh-twlbs/SAGE.git cd
2. バックエンドのセットアップ
cd backend python3 -m venv .venv source .venv/bin/activate # Windows: .venv\Scripts\activate pip install -r requirements.txt cp env.example .env # .envにAPIキーを追加します
3. フロントエンドのセットアップ
cd ../frontend npm install # または bun install cp .env.local.example .env.local # NEXT_PUBLIC_API_URL=http://localhost:8000 を設定します
4. AWS S3の設定
# AWS認証情報を設定します(AWS SSOまたはIAMを使用) aws configure --profile dev # または環境変数を設定します: export AWS_ACCESS_KEY_ID=your_access_key export AWS_SECRET_ACCESS_KEY=your_secret_key export AWS_REGION
5. アプリケーションの起動
# ターミナル 1: バックエンド cd backend python app.py # ターミナル 2: フロントエンド cd frontend npm run dev # または bun dev
これらの手順が完了したら、http://localhost:3000 にアクセスして SAGE に接続してください!
実装解説
SAGEの動画比較システムを支えるコアコンポーネントを順に見ていきましょう。
1. S3へのストリーミング動画アップロード
SAGEは、ストリーミングマルチパートアップロードを使用して、大容量の動画ファイルを効率的に処理します:
async def upload_to_s3_streaming(file: UploadFile) -> str: """メモリの問題を回避するため、ストリーミングを使用してファイルをS3にアップロードします。""" file_key = f"videos/{uuid.uuid4()}_{file.filename}" # 大容量ファイルにはマルチパートアップロードを使用 response = s3_client.create_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, ContentType=file.content_type ) upload_id = response['UploadId'] parts = [] part_number = 1 chunk_size = 10 * 1024 * 1024# 10MBのチャンク while True: chunk = await file.read(chunk_size) if not chunk: break part_response = s3_client.upload_part( Bucket=S3_BUCKET_NAME, Key=file_key, PartNumber=part_number, UploadId=upload_id, Body=chunk ) parts.append({ 'ETag': part_response['ETag'], 'PartNumber': part_number }) part_number += 1 # マルチパートアップロードを完了 s3_client.complete_multipart_upload( Bucket=S3_BUCKET_NAME, Key=file_key, UploadId=upload_id, MultipartUpload={'Parts': parts} ) return f"s3://{S3_BUCKET_NAME}/{file_key}"
主な設計上の決定:
10MBのチャンク:アップロード効率とメモリ使用量のバランスを取ります
ストリーミング:ファイルをチャンクで処理し、ファイル全体をメモリにロードしないようにします
マルチパートアップロード:5GBを超えるファイルに必須であり、100MBを超えるファイルに推奨されます
署名付きURL:TwelveLabsが動画に安全にアクセスできるようにするための一時的なURLを生成します
2. TwelveLabsによるエンベディング生成
SAGEは、TwelveLabsの Marengo-retrieval-2.7 を使用して、非同期でエンベディングを生成します:
async def generate_embeddings_async(embedding_id: str, s3_url: str, api_key: str): """S3からの動画に対して非同期でエンベディングを生成します。""" # TwelveLabsクライアントを取得 tl = get_twelve_labs_client(api_key) # TwelveLabsが動画にアクセスするための署名付きURLを生成 presigned_url = get_s3_presigned_url(s3_url) # 署名付きHTTPS URLを使用してエンベディングタスクを作成 task = tl.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=presigned_url, video_clip_length=2,# 2秒セグメント video_embedding_scopes=["clip", "video"] ) # タイムアウト付きで完了を待つ task.wait_for_done(sleep_interval=5, timeout=1800)# 30分 # 完了したタスクを取得 completed_task = tl.embed.task.retrieve(task.id) # エンベディングが生成されたことを検証 if not completed_task.video_embedding or not completed_task.video_embedding.segments: raise Exception("Embedding generation failed") # エンベディングと動画の長さを保存 embedding_storage[embedding_id].update({ "status": "completed", "embeddings": completed_task.video_embedding, "duration": last_segment.end_offset_sec, "task_id": task.id })
主な特徴:
2秒セグメント:粒度と処理時間のバランスを取ります
非同期処理:ノンブロッキングで、キューを介して複数の動画を処理します
タイムアウト処理:30分のタイムアウトにより、問題のある動画での処理の中断を防ぎます
検証:エンベディングが動画の全編をカバーしていることを確認します
3. セマンティック動画比較
SAGEは、エンベディングにコサイン距離を適用して動画を比較します:
async def compare_local_videos( embedding_id1: str, embedding_id2: str, threshold: float = 0.1, distance_metric: str = "cosine" ): """エンベディングIDを使用して、2つの動画を比較します。""" # エンベディングセグメントを取得 segments1 = extract_segments(embedding_storage[embedding_id1]) segments2 = extract_segments(embedding_storage[embedding_id2]) differing_segments = [] min_segments = min(len(segments1), len(segments2)) # 対応するセグメントを比較 for i in range(min_segments): seg1 = segments1[i] seg2 = segments2[i] # コサイン距離を計算 v1 = np.array(seg1["embedding"], dtype=np.float32) v2 = np.array(seg2["embedding"], dtype=np.float32) dot = np.dot(v1, v2) norm1 = np.linalg.norm(v1) norm2 = np.linalg.norm(v2) distance = 1.0 - (dot / (norm1 * norm2)) if norm1 > 0 and norm2 > 0 else 1.0 # しきい値を超えるセグメントにフラグを立てる if distance > threshold: differing_segments.append({ "start_sec": seg1["start_offset_sec"], "end_sec": seg1["end_offset_sec"], "distance": distance }) return { "differences": differing_segments, "total_segments": min_segments, "differing_segments": len(differing_segments), "similarity_percent": ((min_segments - len(differing_segments)) / min_segments * 100) }
なぜコサイン類似度(距離)なのか?
スケール不変性:正規化されたベクトルは、大きさ(解像度など)の違いを無視します
セマンティック(意味)重視:ピクセル値ではなく、意味の類似性を測定します
解釈の容易さ:0 = 同一、1 = 直交(無関係)、2 = 反対
構成可能なしきい値:さまざまなユースケースに合わせて感度を調整できます
4. 同期されたタイムラインの視覚化
フロントエンドは、同期された再生機能を備えたインタラクティブなタイムラインを作成します:
// 同期された動画再生 const handlePlayPause = () => { if (video1Ref.current && video2Ref.current) { if (isPlaying) { video1Ref.current.pause(); video2Ref.current.pause(); } else { video1Ref.current.play(); video2Ref.current.play(); } setIsPlaying(!isPlaying); } }; // 両方の動画で特定の時間にジャンプ const seekToTime = (time: number) => { const constrainedTime = Math.min( time, Math.min(video1Data.duration, video2Data.duration) ); video1Ref.current.currentTime = constrainedTime; video2Ref.current.currentTime = constrainedTime; setCurrentTime(constrainedTime); }; // 色分けされた相違点マーカー const getSeverityColor = (distance: number) => { if (distance >= 1.5) return 'bg-red-600';// 完全に異なる if (distance >= 1.0) return 'bg-red-500';// 大きく異なる if (distance >= 0.7) return 'bg-orange-500';// かなり異なる if (distance >= 0.5) return 'bg-amber-500';// 中程度に異なる if (distance >= 0.3) return 'bg-yellow-500';// やや異なる if (distance >= 0.1) return 'bg-lime-500';// わずかに異なる return 'bg-cyan-500';// ほぼ同一 };
ビジュアライゼーション機能:
同期された再生:両方の動画が同時に再生/ポーズされます
タイムラインマーカー:色分けされたセグメントで違いの深刻度を表示します
クリックによるシーク:マーカーをクリックすると、その時間に直接ジャンプします
類似度スコア:セグメントから算出した類似度の比率(%)を示します
5. オプションのAIパワー分析
SAGEは、OpenAIを使用して人間が読みやすい分析を生成するオプションを備えています:
async def generate_openai_analysis( embedding_id1: str, embedding_id2: str, differences: List[DifferenceSegment], threshold: float, video_duration: float ): """動画の違いに関するAI駆動の分析を生成します。""" prompt = f""" 以下のデータに基づいて、2つの動画間の違いを分析してください: 视频 1: {embed_data1.get('filename', 'Unknown')} 视频 2: {embed_data2.get('filename', 'Unknown')} 総再生時間: {video_duration:.1f} 秒 類似度しきい値: {threshold} 違いの件数: {len(differences)} これらの時間セグメントで違いが検出されました: {chr(10).join([f"- {d.start_sec:.1f} 秒から {d.end_sec:.1f} 秒 (距離: {d.distance:.3f})" for d in differences[:20]])} 以下を提供してください: 1. これらの違いが何を表している可能性があるかについての簡潔な分析 2. 比較に関する主要なインサイト 3. 重大な違いが発生している注目すべき時間セグメント """ response = openai.ChatCompletion.create( model="gpt-4", messages=[ {"role": "system", "content": "あなたは専門的な動画分析アシスタントです。"}, {"role": "user", "content": prompt} ], max_tokens=500, temperature=0.7 ) return { "analysis": response.choices[0].message.content, "key_insights": extract_insights(response), "time_segments": extract_segments(response) }
主な設計上の決定
1. フレーム単位ではなくセグメント単位の比較の採用
フレーム単位の比較の代わりに2秒セグメントを選択した理由は、主に次の3点です:
時間的コンテキスト:静止フレームだけでなく、動きやアクションを捉えることができます
計算効率:比較回数を削減できます(例:1分間の動画で1800フレームに対して300セグメント)
セマンティックの正確さ:個々のフレームよりも、エンベディングの方が「何が起きているか」を良く理解できます
トレードオフ:時間の精度は低くなりますが(フレーム精度に対して2秒精度)、より意味のある相違点を特定できます。
2. メモリ内処理ではなくストリーミングアップロードの採用
大容量の動画は数ギガバイトに及ぶことがあります。ファイル全体をメモリに読み込むと、サーバーがクラッシュする原因になります:
メモリ安全性:ストリーミングにより、ファイルを10MBのチャンクで処理します
スケーラビリティ:複数の大容量アップロードがあってもサーバーの応答性が維持されます
S3統合:S3に直接アップロードし、TwelveLabs用の署名付きURLを生成します
トレードオフ:アップロードのロジックが複雑になりますが、任意のサイズの動画を処理できるようになります。
3. ユークリッド距離ではなくコサイン類似度(距離)の採用
セマンティックな比較のためにコサイン距離を使用します:
スケール不変性:異なる画質の動画間でも一貫して機能します
セマンティック重視:大きさや強度ではなく、意味の類似性を測定します
解釈が可能:明確なしきい値を設定できます(0.1 = 微細、0.5 = 中程度、1.0 = 重大)
トレードオフ:ユークリッド距離よりも直感的ではありませんが、セマンティックな比較により適しています。
4. 並行型ではなくキューベースの処理の採用
エンベディングの生成には、動画あたり5〜30分かかる場合があります。これを順次処理します:
レート制限対策:TwelveLabs APIのレート制限超過を防ぎます
リソース管理:一度に1つの動画を処理することで、リソース使用量を一定に抑えます
エラーの隔離:失敗した動画が他の処理を阻害しません
トレードオフ:総スループットは遅くなりますが、より信頼性が高く予測可能になります。
5. データベースではなくメモリ内へのエンベディング保存
エンベディングをデータベースに永続化せず、メモリ内に保存します:
パフォーマンス:比較時における高速なアクセス(データベースクエリが不要)
シンプルさ:スキーマ移行やデータベースの管理が不要
一時的な性質:エンベディングはセッション固有であり、永続化の必要性が低いです
トレードオフ:サーバー再起動時にデータが失われますが、比較ワークフローにおいては許容範囲です。
パフォーマンス・エンジニアリング:私たちが学んだこと
SAGEの構築を通じて、大規模な動画処理。を扱うための貴重な教訓を得ました:
80/20の法則の適用
私たちは最適化作業の80%を、以下の3点に費やしました:
ストリーミングアップロード:分割アップロードにより、メモリの枯渇を防ぎます。2GBのファイルをすべてロードしてクラッシュさせるか、ストリーミングしてサーバーを安定させるかの違いはここにあります。
非同期処理:ノンブロッキングのエンベディング生成により、APIの応答性を維持します。ユーザーは、それぞれの完了を待つことなく複数の動画をアップロードできます。
セグメント検証:エンベディングが動画の全範囲をカバーしていることを確認し、サイレントエラーを防ぎます。結果を受け入れる前に、セグメント数、カバレッジ、再生時間を検証します。
うまくいかなかったこと(とその理由)
いくつかの最適化を試みましたが、どれもうまくいきませんでした:
並行エンベディング生成:TwelveLabsのレート制限に当たりました。順次処理の方が信頼性が高いことがわかりました。
エンベディングのキャッシュ:動画はそれぞれユニークであり、キャッシュは役に立ちませんでした。キャッシュするよりも再生成する方が効率的です
フレームレベルの比較:細かすぎて処理が遅く、誤検出が多すぎました。セグメントレベルが最適な妥協点でした。
長時間動画の処理
10分を超える動画には、特別な配慮が必要でした:
タイムアウト管理:30分のタイムアウトにより、問題のある動画でプロセスがハングするのを防ぎます
セグメント検証:セグメントが全編をカバーしているか検証(不完全なエンベディングを捕捉)
エラーメッセージ:サイレントに失敗させるのではなく、明確なエラーを返します(
"Embedding generation incomplete")
この結果、SAGEは10秒から20分までの動画を安定して処理できるようになりました。
この件に関する詳細情報は、私たちの 長時間動画処理ガイド に掲載されています。
データ出力
SAGEは網羅的な比較結果を生成します:
比較指標
総セグメント数:比較された2秒セグメントの数
不一致セグメント数:設定した閾値を超える距離(違い)があるセグメントの数
類似度の割合(%):
(総セグメント数 - 不一致セグメント数) / 総セグメント数 * 100相違点タイムライン:不一致度スコア付きのタイムスタンプ付きセグメント情報
ビジュアライゼーション
同期された動画プレイヤー:タイムライン付きの左右に並べた動画再生
色分けされたマーカー:重大度(緑 = 類似、赤 = 異なり)のビジュアル表現
インタラクティブなタイムライン:マーカーをクリックして相違点にシーク
相違点リスト:時間セグメントによる詳細な内訳
オプションのAI分析
要約:違いに関するハイレベルな分析
主要なインサイト:注目すべき発見事項の箇条書き表現
時間セグメント:重大な違いが発生している特定の瞬間
使用例
ケース1:2つのトレーニング動画を比較する
シナリオ:製品デモ動画の修正前・修正後バージョンを比較する
# 動画のアップロード POST /upload-and-generate-embeddings { "file": <video_file_1> } POST /upload-and-generate-embeddings { "file": <video_file_2> } # エンベディングの生成を待つ(ステータスエンドポイントをポーリング) GET /embedding-status/{embedding_id} # 動画の比較を行う POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.1
レスポンス:
{ "filename1": "demo_v1.mp4", "filename2": "demo_v2.mp4", "differences": [ { "start_sec": 12.0, "end_sec": 14.0, "distance": 0.342 }, { "start_sec": 45.0, "end_sec": 47.0, "distance": 0.521 } ], "total_segments": 180, "differing_segments": 2, "threshold_used": 0.1, "similarity_percent": 98.89 }
解釈:動画は98.89%類似しています。2つのセグメントが異なっています:
12~14秒:中程度の違い(距離:0.342)
45~47秒:中程度の違い(距離:0.521)
ケース2:かすかな違いを見つけるためにしきい値を微調整する
シナリオ:背景のわずかな変更など、ごくかすかな違いを特定する
# より高い感度のために、低いしきい値を使用します POST /compare-local-videos?embedding_id1={id1}&embedding_id2={id2}&threshold=0.05
結果:背景の微細な変化や照明の調整など、より多くの相違点を探知します。
ケース3:AI分析を生成する
シナリオ:違いに関する、人間にわかりやすい説明を生成する
POST /openai-analysis { "embedding_id1": "...", "embedding_id2": "...", "differences": [...], "threshold": 0.1, "video_duration": 360.0 }
レスポンス:
{ "analysis": "動画は全体的に類似した内容を示していますが、2つの顕著な相違点があります...", "key_insights": [ "テイク間で製品の位置変更がありました", "45秒時点で背景の照明が調整されています" ], "time_segments": [ "12-14 秒: 製品実演のアングル", "45-47 秒: 背景シーンの変更" ] }
現実世界のユースケース
SAGEを構築してテストする中で、このツールが最も価値を発揮する明確なパターンを特定しました:
コンテンツ制作
Before/Afterの比較:編集前と編集後の映像素材を比較する
バージョン管理:動画の改訂プロセスに沿って変更を追跡する
品質保証(QA):異なるパターンの動画間で一貫性を確認する
トレーニング & 教育
取扱説明用動画:更新前と更新後の動画バージョンを比較する
コースの整合性:すべてのレッスンが同じフォーマットを維持しているか確認する
コンテンツのアップデート:改訂された教材のどの部分が変更されたかを特定する
コンプライアンス(法令順守) & 検証
広告表現の検証:承認されたバージョンと実際に放送・配信されたバージョンを比較する
法的文書化:証拠動画などの変更を追跡する
ブランドガイドラインの整合性:マーケティング用動画がブランド規定に合致しているか検証する
このアプローチが効果を発揮する理由(それと機能しない場合)
SAGEはセマンティックな比較(単なるピクセルではなく、動画のコンテンツ意味の違いを検出すること)に優れています。 最もその強みを発揮するのは、以下のような場合です:
強みを発揮する場合:
✅ 動画の技術スペック(解像度、コーデック、フレームレート)が異なる場合
✅ ピクセルではなく、コンテンツ自体の違いを見つけたい場合
✅ 動画の構造が類似している場合(同じ長さ、同じようなシーン)
✅ 違いが意味のある内容である場合(シーンの変化、物体の追加など)
あまり効果的ではない場合:
❌ 動画同士が完全に異なる場合(無関係なコンテンツの比較)
❌ フレーム精度の正確なタイミングが必要な場合(SAGEは2秒セグメント単位です)
❌ 動画の長さが極端に異なる場合(比較は短い方の動画に合わせて切り詰められます)
❌ ピクセルレベルの厳密な同一性検証が必要な場合(代わりに従来の差分取得ツールをご使用ください)
スイートスポット(最適な環境)
SAGEは、同じコンテンツのバリエーション(同じ台本、同じ現場だがテイクが異なる、編集やバージョンが異なるもの)を比較するのに最適です。技術的な違いに左右されることなく、本質的に重要な違いを見つけ出します。
パフォーマンス・ベンチマーク
何百本もの動画を処理して得られた知見を以下に示します:
処理時間
1分間の動画:合計約2〜3分(アップロード + エンベディング)
5分間の動画:合計約5〜8分
10分間の動画:合計約10〜15分
15分間の動画:合計約15〜25分
内訳:アップロードは通常1分未満で完了します。エンベディング生成時間は、動画の長さにほぼ比例して増加します。
比較速度
比較ロジックの計算:動画の長さに関わらず1秒未満
タイムラインのレンダリング:一般的な動画で100ミリ秒未満
動画再生:ブラウザ本来のネイティブパフォーマンス
重要なインサイト:エンベディングが存在していれば、比較処理は一瞬で終わります。処理のボトルネックは比較そのものではなく、エンベディングの生成部分になります。
精度
セマンティック(意味的)相違点:実質的なコンテンツの変化を正確に捉えます
誤検出(偽陽性):適切なしきい値設定(デフォルトの0.1が推奨)で低く抑えられます
検出漏れ(偽陰性):極めて微細な変化は検出されない場合があります(その場合は値を下げてください)
しきい値のガイドライン:
0.05:超高感度(かすかな背景の変化なども特定)
0.1:標準的(感度のバランスに優れる)
0.2:低感度(主要な変化のみ)
0.5:最過保護(劇的なシーン変更のみ)
結論:動画比較の未来
SAGEは、「動画をピクセルではなく意味で比較するとどうなるか?」という実験から始まりました。私たちが発見したのは、セマンティックな比較が動画の「違い」に関する我々の見方を変えるということです。
ピクセルレベルのノイズに翻弄されることなく、コンテンツ自体の変更、シーン構成の違い、本質的なバリエーションといった本当に重要なことに集中できます。そして、フレームの手動比較を自動化することも可能になります。
このアプローチは示唆に富んでいます:
クリエイター向け:手動チェックなしに、以前のバージョンと何が変更されたかを即座に特定
開発者向け:単なる動画ファイルとしてではなく、動画の内容そのものを理解するインテリジェントなアプリ構築
業界全体へ:エンベディングモデルが進化すれば、自動的にこの比較精度も上がっていきます
一番エキサイティングなのは、まだこれが始まりに過ぎないという点です。動画理解モデルの進化に伴い、SAGEの比較能力もレベルアップしていきます。現在はセグメント単位ですが、将来的にはシーンごと、特定オブジェクトの検知、さらには文脈やストーリー構成の理解にまで及ぶかもしれません。
土台はすでに整っています。あとは繰り返しの開発があるのみです。
その他の情報源
GitHub リポジトリ: GitHub上のSAGEページ
TwelveLabs ドキュメント: Marengoエンベディング応用ガイド
AWS S3: マルチパートアップロードのベストプラクティス
コサイン類似度: ベクトルの類似性の理解
付録:技術的詳細
エンベディングモデル
使用モデル:Marengo-retrieval-2.7
セグメント長:2秒
ベクトル次元数:768(セグメントあたり)
スコープ選択:
["clip", "video"](クリップ単位および動画全体の双方)
類似度の数式表現
コサイン距離:
1 - (dot(v1, v2) / (norm(v1) * norm(v2)))範囲:0(完全に同一)から 2(正反対)まで
目安:0-0.1(極めて類似)、0.1-0.3(多少の違い)、0.3-0.7(中程度の相違)、0.7+(著しい相違)
S3 詳細構成
分割サイズ(チャンク):10MB
アップロード方式:常にマルチパートを使用(信頼性向上のため)
署名付きURLの有効期限:1時間(3600秒)
ホスト地域(Region):構成調整(デフォルト:us-east-2)
提供API一覧
POST /validate-key- TwelveLabsのAPI有効性をチェックPOST /upload-and-generate-embeddings- ビデオアップロードとエンベディング生成タスクの開始GET /embedding-status/{embedding_id}- エンベディング生成の現在のステータス判定POST /compare-local-videos- エンベディングIDを用いた、2つの動画の比較実行POST /openai-analysis- 違いを説明するAI分析文章の任意生成GET /serve-video/{video_id}- ブラウザ再生用の署名付きURL生成GET /health- APIサーバのヘルスチェック(動作点検)
関連記事




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.