
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
チュートリアル
Recurserの構築:Twelve LabsとGoogle Veoを使用した反復的なAI動画エンハンスメント

アーヒル・シェイク
このチュートリアルでは、Twelve LabsのMarengoを使用して15のカテゴリにわたる250件のチェックでアーティファクトを検出し、Pegasusでビデオコンテンツを説明し、Google Geminiを使用してVeo 2による再生成を繰り返しながらビデオが100%の写真のようなリアルな品質スコアに達するまで生成プロンプトを自動的に改善する、反復型AIビデオエンハンスメントシステム「Recurser」の構築プロセスを詳しく説明します。
このチュートリアルでは、Twelve LabsのMarengoを使用して15のカテゴリにわたる250件のチェックでアーティファクトを検出し、Pegasusでビデオコンテンツを説明し、Google Geminiを使用してVeo 2による再生成を繰り返しながらビデオが100%の写真のようなリアルな品質スコアに達するまで生成プロンプトを自動的に改善する、反復型AIビデオエンハンスメントシステム「Recurser」の構築プロセスを詳しく説明します。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2026/01/13
18分
記事へのリンクをコピー
はじめに
Google GeminiのVeo2で動画を生成したところだとします。一見すると、プロンプトも良く、構図もシッカリしていて、なかなかの出来映えに見えます。しかし、何かがおかしい。よく観察してみると、猫の毛の動きが不自然だったり、影と照明の方向が合っていなかったり、どこか合成っぽさを醸し出す不気味な谷現象(不気味の谷効果)に気づくはずです。
問題は何か? ほとんどのAI動画生成はワンショット(一発勝負)のプロセスである点です。一度生成し、プロンプトを少し調整して、また生成する。しかし、実際に何が間違っているかをどうやって知るのでしょうか?そして、より重要なのは、すべてのフレームを手動で確認することに何時間も費やすことなく、どのようにそれを修正するかという点です。
だからこそ、私たちはRecurserを開発しました。これは、AIの問題を検出するだけでなく、スマートな反復(イテレーション)を通じて能動的に修正する自動化システムです。何が間違っているかを推測する代わりに、RecurserはAI動画理解(Video Understanding)を使用して特定の問題を見つけ出し、プロンプトを自動的に改善して、動画がリアルに見えるまでより良いバージョンを再生成します。
重要な気づきとは? プロンプトを修正することは、動画を直接修正するよりも強力であるということです。 従来のポストプロセッシング(後処理)は、すでに生成されたものにしか対処できませんが、プロンプトを改善することは根本原因に対処することになり、次の生成が根本的に良くなることを保証します。
Recurserはフィードバックループを作成します:
TwelveLabs Marengoを使用して問題を検出(Detect)する(250以上の異なる問題をチェック)
TwelveLabs Pegasusを使用して動画内のコンテンツを理解(Understand)する(動画をテキストの説明に変換)
Google Geminiを使用してプロンプトを改善(Improve)する(プロンプトをより良くする)
Veo2で再生成(Regenerate)する(改善されたプロンプトで新しい動画を作成)
品質が100%に達するか、最大反復回数に達するまで繰り返す(Repeat)
その結果、最初は60%の品質からスタートした動画が、ユーザーが何もすることなく、1〜3回の反復を経て体系的に100%まで向上します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上がインストールされていること
API キー:
TwelveLabs API キー (PegasusおよびMarengo用)
Google Gemini API キー (プロンプト補強用)
Google Veo 2.0 へのアクセス権(動画生成用)
リポジトリを複製するための Git
Python、FastAPI、Next.js に関する基本的な知識
ワンショット生成の問題点
私たちが発見したのは次のような点です: AI動画生成モデルは常に同じ結果を出力するとは限りません。 同じプロンプトを2回実行すると、異なる動画が生成されます。しかしそれ以上に、モデルは一見大丈夫に見えても、近くで観察すると明らかになる欠陥を作り出すことがよくあります。
「庭で紅茶を飲む猫」の動画を生成するシナリオを考えてみましょう。最初の生成物には以下のような問題が含まれている可能性があります:
不自然な毛並みの動き(モーション・アーティファクト)
フレーム間での不整合な照明(テンポラル・アーティファクト)
わずかにロボットのような猫の行動(ビヘイビアル・アーティファクト)
従来のアプローチでは、次のいずれかになります:
欠陥を受け入れる(十分に目立たない場合)
少し異なるプロンプトを手動で再生成する(試行錯誤)
後処理フィルターを適用する(特定の問題のみを修正)
Recurserは異なるアプローチを取ります。 すべての問題を見つけ出し、それらを一度に解決するためにプロンプトを自動的に改善します。 各繰り返しは前回の繰り返しから学習するため、改善が段階的に積み重なっていきます。
デモアプリケーション
Recurserには3つのエントリポイントが用意されています:
プロンプトから生成(Generate from Prompt):新しく開始します。テキスト説明を入力するだけで、Recurserが複数回の反復を通じて自動的にプロンプトを改良する様子を見ることができます
既存の動画をアップロード(Upload Existing Video):「惜しい」動画がありますか?それをアップロードして、Recurserに完璧な状態に磨き上げてもらいましょう
プレイグラウンドから選択(Select from Playground):あらかじめインデックス化された動画をブラウズし、すぐに品質を向上させます
魔法はリアルタイムで起こります。反復ごとに品質スコアが改善されるのを見守り、どのアーティファクトが見つかり、どのようにプロンプトが強化されたかの詳細なログを確認し、「明らかにAI」から「実物と区別がつかない」までのプロセスを追跡できます。
完全なデモアプリケーションを探索し、すべてのソースコードを GitHub で確認できます。また、コードの動作に関するチュートリアル動画もご覧いただけます。 -
Recurserの仕組み
Recurserは、複数のAIサービスを組み合わせた、高度な反復型のエンハンスメント・パイプラインを実装しています:
システムアーキテクチャ
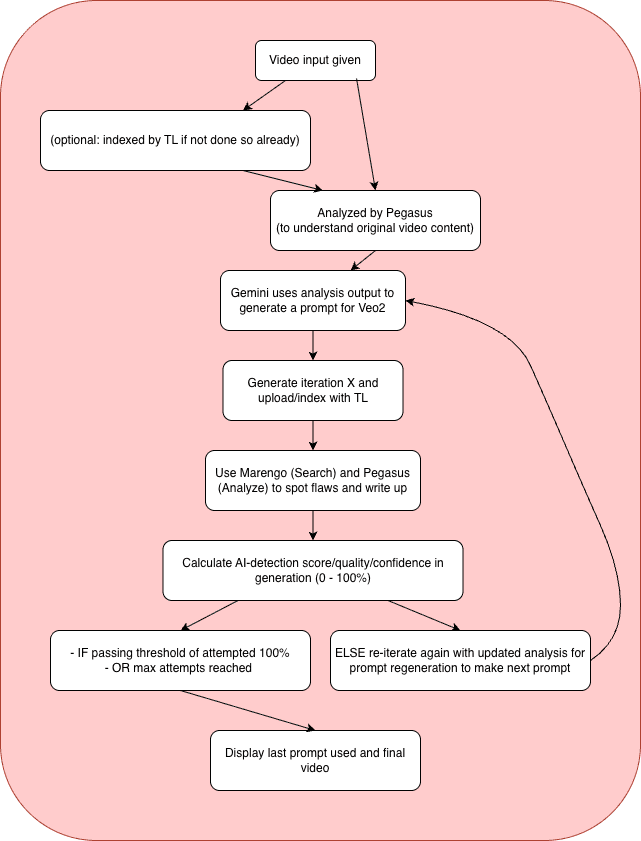
準備手順
1 - リポジトリをクローンする
git clone https://github.com/aahilshaikh-twlbs/Recurser.git cd
2 - バックエンドのセットアップ
cd backend pip3 install -r requirements.txt --break-system-packages cp .env.example .env # .envにAPIキーを追加してください
3 - フロントエンドのセットアップ
cd ../frontend npm install cp .env.local.example .env.local # BACKEND_URL=http://localhost:8000 を設定してください
4 - APIキーの設定
Playground から TwelveLabs の API キーを取得します
AI Studio から Google Gemini の API キーを取得します
Marengo と Pegasus の両方のパワーが有効化された TwelveLabs のインデックスを作成します
アプリケーションで使用するために作成したインデックスIDをメモしておきます
5 - アプリケーションの起動
# ターミナル 1: バックエンド cd backend uvicorn app:app --host 0.0.0.0 --port 8000 --reload # ターミナル 2: フロントエンド cd frontend npm
これらのステップが完了すれば、開発を始める準備は完了です!
実装コードの構成解説
Recurserの反復的な品質改善システムを支えるコアコンポーネントを見ていきましょう。
1. 反復型の動画生成ループ
Recurserの中心となるのは generate_iterative_video メソッドで、これがエンハンスメントプロセス全体を統括します:
このループは、以下のいずれかの条件が満たされるまで継続します:
async def generate_iterative_video(prompt: str, video_id: int, max_iterations: int = 3): """メインループ: 生成 → 分析 → 改善 → 繰り返し""" current_prompt = prompt current_iteration = 1 while current_iteration <= max_iterations: # ステップ 1: 現在のプロンプトで動画を生成await generate_video(current_prompt, video_id, current_iteration) # ステップ 2: 動画がインデックスされるのを待機 (30秒)await asyncio.sleep(30) # ステップ 3: AIアーティファクトを検出するために動画を分析 ai_analysis = await detect_ai_generation(video_id) quality_score = ai_analysis.get('quality_score', 0.0) # ステップ 4: 完了したか確認 (100% = 完璧)if quality_score >= 100.0: break# 成功!動画はリアルに見えます # ステップ 5: 次の反復のためにプロンプトを改善if current_iteration < max_iterations: current_prompt = await enhance_prompt(current_prompt, ai_analysis) current_iteration += 1 return current_prompt# 最終的に改善されたプロンプトを返す
品質スコアが100%に達したとき(動画が写真のようにリアルとみなされた場合)
最大イテレーション件数に到達したとき
エラーが発生したとき
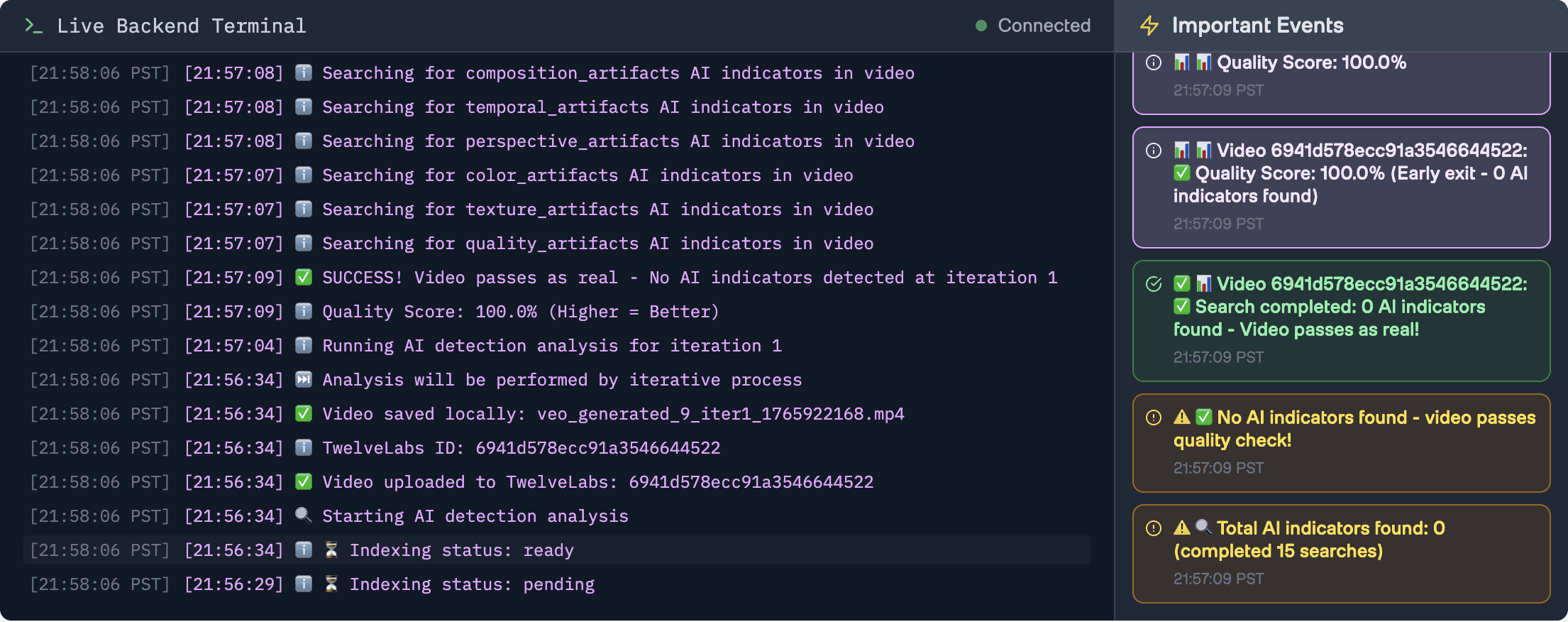
2. Marengoを使用したAIアーティファクト検出
Marengo 検索は、15のカテゴリ(顔の問題、おかしな動き、照明の乱れなど)全体で250以上の異なるAIの問題を検出します。効率を高めるために、関連するチェックを以下のようにグループ化しています:
async def _search_for_ai_indicators(search_client, index_id: str, video_id: str): """Marengoを使用してAIの痕跡を探す - 15つのカテゴリにグループ化""" # 15カテゴリのアーティファクト(顔、動き、照明など)をチェックします ai_detection_categories = { "facial_artifacts": "不自然な顔の対称性、ロボットのような表情", "motion_artifacts": "ぎこちない動き、機械的なトラッキング", "lighting_artifacts": "不整合な照明、人工的な影", # ... あと12つのカテゴリ } all_results = [] # 包括的な検出のために、これら15種すべてのカテゴリをチェックしますfor category, query_text in ai_detection_categories.items(): # このカテゴリのアーティファクトを検索 results = search_client.query( index_id=index_id, search_options=["visual", "audio"], query_text=query_text, filter=json.dumps({"id": [video_id]}) ) if results and results.data: all_results.extend(results.data) return all_results# 検出されたアーティファクトのリストを返す
主要な最適化:
包括的な検出(Comprehensive Detection):漏れのない確実に検出するために15のカテゴリすべてをチェックします。以前は、問題が1つも見つからなかった場合に8回の検索(全体の半分以上)を終えた時点で早期終了するヒューリスティックを採用していましたが、潜在的なすべての問題を保証するためにこれを廃止しました。これは完璧な動画である場合、8回ではなく15回のAPI呼び出しが発生することを意味しますが、後の方のカテゴリにのみ現れる曖昧なアーティファクトを見逃さないことを保証します。
バッチ化されたクエリ(Batched Queries):効率化のために関連する検索ワードをまとめてカテゴリ化します
定期的な完了確認(Periodic Completion Checks):動画がすでに完了したかを5回の検索ごとに検証します(別のプロセスによってすでに完了とマークされている場合にループを完全に停止する別個のチェック)
3. Pegasusによる動画内容分析
Pegasusは動画をテキストに変換します。動画を観て何が描かれているかを説明してくれます。これは、どこを改善すべきかを理解するのに役立ちます:
async def _analyze_with_pegasus_content(analyze_client, video_id: str): """Pegasusが動画を観察し、描かれている内容を説明します""" # Pegasusに対しての質問を2つ投げかけます: prompts = [ "この動画内のすべてを説明してください:オブジェクト、動き、照明、雰囲気", "この動画にはどのような技術的課題(画質、一貫性など)がありますか?" ] analysis_results = [] for prompt in prompts: response = analyze_client.analyze( video_id=video_id, prompt=prompt, temperature=0.2# 値が低いほど一貫した返答が得られます ) analysis_results.append({ 'content_description': response.data }) return analysis_results# 動画のテキスト説明を返す
スマートな最適化: Marengoによる検索でインジケーター(指標)が0個であった場合、動画はすでに品質チェックに合格しているため、本検出サービスはPegasusによる解析をスキップします:
# 早期終了(Early exit): 検索からの異常値が0だった場合、クオリティは100%です - Pegasus分析をスキップします if len(search_results) == 0 and preliminary_quality_score >= 100.0: logger.info(f"✅ 早期終了: 検索結果が0件のため品質は100%です。高速対応のためにPegasus分析をスキップします") log_detailed(video_id, f"✅ クオリティスコア: 100.0% (早期終了 - AIの痕跡は検出されませんでした)", "SUCCESS") # Pegasus抜きの最小限の詳細ログを作成 detailed_logs = AIDetectionService._create_detailed_logs( search_results, [], 100.0 ) return { "search_results": search_results, "analysis_results": [], "quality_score": 100.0, "detailed_logs": detailed_logs }
4. 品質スコア評価システム
本システムは検出された痕跡に基づき、最終的な総合品質スコア(0〜100%)を割り出します。スコアリングロジックは、欠陥が一切見つからなかった場合は満点が得られるように設計されています:
def _calculate_quality_score(search_results, analysis_results): """100%からスタートし、見つかった問題ごとに減点する""" # 問題なし = 満点(100.0) if not search_results and not analysis_results: return 100.0 # 欠陥検出1点につき3%減点 (減点の上限は最大50%) search_penalty = min(len(search_results) * 3, 50) # 記述された品質の課題についてPegasus分析をチェックする analysis_penalty = 0 if analysis_results: # 分析内から "artificial(人工的)", "blurry(不鮮明)", "inconsistent(整合性無し)" などのキーワードを検索する quality_keywords = ['artificial', 'synthetic', 'blurry', 'inconsistent', 'robotic'] issues_found = sum(1 for result in analysis_results if any(keyword in str(result).lower() for keyword in quality_keywords)) analysis_penalty = min(issues_found * 8, 50) # 最終スコア: 100からすべての減点を差し引く (0を下回ることはない) quality_score = max(100 - search_penalty - analysis_penalty, 0) return quality_score
スコアリング判定のロジック:
AIの異常検知 0件: クオリティスコア 100%(完璧。動画が一見実写に見えるレベル)
検出された検索インジケーターあたり: 3%減点(最大合計50%減点)
コンテンツ解析による欠点指摘: 最大でさらに50%のペナルティ減点
最終スコア: 0%を下限とする
5. Geminiを使用したプロンプト改善
品質がターゲット値に満たない場合、Geminiが検出結果を踏まえて改良プロンプトを出力します:
async def _generate_enhanced_prompt(original_prompt: str, analysis_results: dict): """指摘されたエラーに基づき、Geminiを利用して改善プロンプトを生成""" client = Client(api_key=GEMINI_API_KEY) # Geminiに指示: 「オリジナルのプロンプトと検出された欠陥がこれです。改善してください。」 enhancement_request = f""" 元のプロンプト: {original_prompt} 見つかった問題点: {json.dumps(analysis_results, indent=2)} これらの問題を修正した、より優れたプロンプトを作成してください。より自然でリアルな表現にしてください。 他のテキストは含めず、新しいプロンプトのみを返してください。 """ response = client.models.generate_content( model='gemini-2.5-flash', contents=enhancement_request ) return response.text.strip() if response.text else original_prompt
なぜこの仕組みが機能するのか(そして機能しないときはどんなときか)
Recurserを構築して広範にテストした結果、非常に興味深い事実が明らかになりました。 すべての動画で反復改善が必要とされるわけではありません。 最初の試行でほぼ完璧な仕上がりに達するものもあれば、実用に堪える品質に達するまでに3〜5回の対話を要するプロンプトもあります。
反復の最も効果的な領域
テストを巡る中で以下の明確なパターンが確認されました:
単純なシーン (単一の被写体、静止した背景): 初回実行でいきなり100%になるケース多し
複雑なシーン (複数の被写体、ダイナミックな照明): 通常は2〜3回の反復が必要
珍しいプロンプト(クリエイティブな、または現実的にあり得ないシチュエーション): 4〜5回やり直す必要があったり、伸び代が頭打ちになるケースもあります
重要な発見は何か? 早いタイミングでの判定。 100%基準を満たした段階ですぐにイテレーションを中止する「早期終了」を導入することで、すでに十分完璧に達している動画の無駄な生成コストと処理時間の温存が可能になります。
なぜプロンプト改善が後処理(ポストプロセッシング)に勝るのか
最初は、生成後の動画に対してフィルターを適用したり、ノイズの低減やすべてのフレームのズレの補正を行う方法を研究しましたが、すぐに以下の懸念に気がつきました:
後処理加工では本質的な課題の修正に至れない—もしAIモデル側が動画の意図を根本から勘違いして生成していた場合、フィルターは無意味です
プロンプトの改善は根本原因への対策である—再生成を指示するたび、より正しい理解のタスクを出発点にできます
良い学習の積み重ね—イテレーション2はイテレーション1の結果を踏まえて学び、イテレーション3は前2つのアプローチから補強されます
しかし、Recurserは万能薬というわけではありません。以下のケースで最も高い価値を発揮します:
✅ 明確な創作イメージを持っている時(最初の出力がうまく噛み合わなかったとしても)
✅ 繰り返しの漸進プロセスに時間をかけられる場合(反復ごとに2〜5分)
✅ 目指す一定のクオリティ基準を定めている(デフォルトで100%ですがカスタマイズも可能)
逆に以下のような場面では効果が薄いです:
❌ 元の入力アイデアそのものに破綻があるとき(酷いアイデアはどのような最適化でも救えません)
❌ 即時即座の結果を今すぐ必要としているとき(対話型のプロンプト更新では数ミリ秒のスピード出力は困難です)
❌ 予算コストをシビアに削減しなければならない時(イテレーションの度、生成および検出APIの呼び出し費用が伴います)
開発上の重要な基本思考
1. 「検出」と「生成」の責任分離
私たちはAI検出(TwelveLabs)の層と動画生成の層(Veo2)の機能を完全に分けて設計しています。これは構造的な整理に留まらず、明確な開発戦略に基づいています:
別の動画AIエンジンとの連動: 将来的にVeo2からVeo3、あるいはこれとは異なる別の動画AIモデルへと移行を検討する場合も、本検出システムのロジックを1文字も修正する必要がありません
運用負荷の削減: 画質の判定に必要な検出側のコストは動画を丸ごと再生成する処理コストに比べ大幅に安いため、心置きなく詳細にチェックがかけられます
独立したボトルネック対策: 重い処理を行う検出と動画生成のサーバーのリソース分散を、柔軟に調整できます
2. 動作の即時性よりも、妥協のない徹底した検知力の優先
チェックから抜けが生まれるリスクを完全に排除するため、安易な速度アップ措置より検出の総合的な精査能力を大切にしています。ここでの主要なアプローチは以下の通りです:
Marengoによる厳重な診断: チェック基準を満たすよう、15種すべての分類カテゴリを満遍なく走らせます。15項目のすべての検索を終える前に、8回(半数以上)で異常がなかった場合は途中で打ち切る初期の実装がありましたが、最後の方に予期せぬノイズや品質低下が偏って検出されるパターンがあったため、完璧な解析を行うためにこれを排除しました。これにより完璧な動画であっても、8回ではなく15回のAPIリクエストを回す動作になりますが、判定クオリティを最重要視する開発意義を支える重要な要素です。
Pegasusの解析スキップ: Marengoの15すべてのチェックに1件も引っかからなかった場合に限り、Pegasusの動画記述API呼び出しを全カットしてスキップします。これが現在の開発において大きな処理時間、費用の最適化要素となっています。
完了確認の頻度: 5回の検索を行うたびに、別の処理過程が該当の並列動画について「完了」を出していないかをチェックしています。
つまり、最初から完璧な100%基準を満たした動画はPegasusに不必要な情報収集をしに行かなくなるため最速で生成が完了する一方で、何らかの修正点を含む動画に対しては抜け漏れなく15種すべてを評価できる一貫性を備えています。
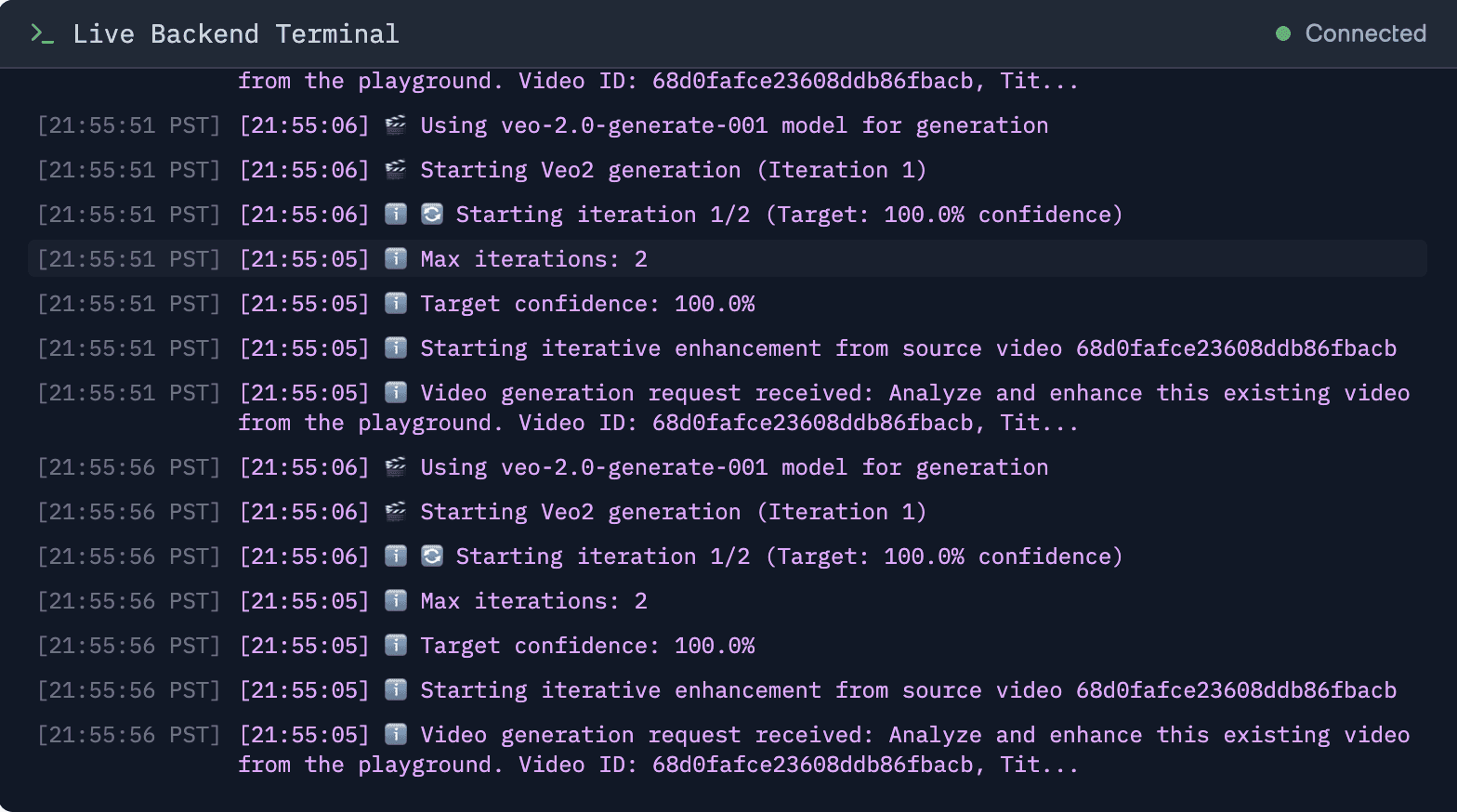
3. WebSocketを利用しないリアルタイム性の追及
私たちのデプロイサーバー(Vercel)ではWebSocketの使用が限定的だったため、定期的に何度もリクエストをかけて状況をリアルタイム並みに近づける「ポーリング」を採用しました:
一時的ログ追記用の保持配列(バッファ): バックエンド側の多様な挙動のログを最大で直近200件分リングバッファ内に保管しています
洗練されたAPIポーリング: 切断処理とサーバー負荷軽減を挟みつつ、1秒単位の超密着型リクエストを実行します
ノイズとなる定形メッセージの除外: 代わり映えしない単なるクエリ呼び出し状況などはクライアントに通知せず、意思決定を必要とする主要イベントのみを強調して流します
これにより、完全な双方向常時接続のない通信環境でも、ユーザーはバックアイランドでのログ動作変更を1-2秒以内で目の当たりにすることができます。
4. 1度で完璧ではなく、耐障害性と途中経過の保存(Graceful Degradation)の優先
AI環境においては予期しないトラブルが突発的に発生します(レート制限、API側の機能遅延や一時的なダウン、回線のタイムアウトエラー)。これらを完全に防ぐシステムよりも、「システムエラーが起きた状況でも諦めず進行する」復元力の仕組みをベースに構築を行いました:
Pegasus呼び出し時のタイムアウト処理: 記述失敗を検知した場合、システムエラーで丸ごとプログラムクラッシュさせず、代替ロギングに切り替えて次に進みます
APIの制限通知検出: 適切な待ち時間、リトライのリカバリー動作を自動で挟み込みます
一部検索の取り落とし時の処理: 例えば15種チェックのうち14件が正常終了していた場合は、手元のデータ領域だけで計算してループを推し進めます
私たちの基本設計思想: 不完全な結果は、何も結果を得られないことよりも優れている。
仕組みをさらに加速させるための開発ティップス
Recurserの構築プロセスは、AI技術を高速化するための多くの有益な学びとなりました。実際に速度や有用性に繋がった要素を紹介します:
AIパイプラインに適用される 80/20 の法則
最適化に投下した全エネルギーの約8割は、次の3つのアプローチに注ぎ込まれました:
条件付きPegasus分析: Marengo検索結果に何一つつまずくポイントがなかった(異常痕跡0)ケースでは、Pegasusの重厚な分析フェイズの一切をパスすることで動画あたり約0.05ドルのコストを削減、待機時間も30秒以上一気に削減されました。
知的な検索単位のパッケージ化(Batching): クエリ状態のごく細かなDB更新を、毎検索、個別で毎回走らせず、5件のチェックの節目に見直す形を取ることで、アクセス処理にかかるオーバーヘッドを15分の1以下まで圧縮。何よりメインスレッドの詰まりを完全に防げるようになりました。
徹底した包括的チェックの維持: 早期終了の条件に逃げず、15種すべての要素をきっちり調べ抜く方式に決断しました。完璧な動画に対して多少多くクエリ枠を消費する仕様となりましたが、何よりも優先度が高い精度面の抜けを封じるという絶対的なメリットを手に入れることができました。
機能しなかったアプローチとその理由
開発段階の検証、試験環境を経て、ボツとなり取り下げる判断に至った幾つかの最適化設計もあります:
検索の複数並列化(Parallelization): 15種類のすべてのカテゴリを完全に同時に投げる試みを行いましたが、プロバイダ側APIの同時呼び出し過多の制限エラー(レートリミット)を多発したため、確実に処理を分散させるシーケンシャル型(逐次処理)が安全であるという設計に戻しました。
内容の一時記憶保存(キャッシュ)の維持: 近い、または同様な構成の動画のときにPegasusの中身情報を同じにしようと一時記録(キャッシュ)を使い回す仕組みを検証しましたが、AIの動画はミリ秒違うだけで全く異なる出力アーティファクトを引き起こしかねず、誤検知の原因になり再利用性は極めて低かったです。
フレームを一定間隔で飛ばす削減(サンプリング): チェック時間短縮を目的に動画の前後一部の切り出し分析のみを行う実装テストを行いましたが、動画に発生する特有の映像破綻や乱れは切り詰めた前後の瞬間にだけ突然現れるパターンなどを検出できなくなってしまったため、フルフレームチェックの仕組みに固定しました。
フロントエンド: 見過ごされていた性能問題の引き金
フロントエンド側はただ情報を流し込むだけのUIではなく、リアルタイムな状態変更を受け続けるモニタリング基盤です。ここに以下の快適化設計を組みました:
循環ログ表示の設計: 過去データの最大配列上限にキャップを設け、ブラウザクラッシュや深刻なメモリリークを起こすバグを取り除きました(チェック中に10,000行以上の生データ描画処理に耐えるためです)
動画再生ユニットの一元化: 役割別に3系統用意されていた動画再生コンポーネントを、柔軟にあらゆるシチュエーションを描写できる単一のプレイヤーへ集約しました。ライブラリ読み込みサイズが削減され、ページの再レンダリング処理が非常に早く完了する恩恵を受けられました。
デバッグのノイズカット: 内部動作で生じているシステムAPIのチェックコールなど、ユーザーが見ても意味の分からない詳細ログの80%以上をユーザー用の画面出力ログからフィルターで遮断しました。
こうした最適化により、どれほど重たい何往復もの繰り返し実行プロセスが発生している最中でも、ブラウザ側の操作は常に機敏さを維持できるようになりました。
各種データ出力
Recurserは生成した動画に対して体系的で詳細な出力結果を用意します:
動画関連メタデータ(情報の保存)
最適化済み動画(Final Video): 繰り返し判定のなかで最大の評価をマークした極上の1本です
全ての反復履歴(All Iterations): どの時点からスタートし、どのような変化を遂げたのかを全て巻き戻して検証できます
一連の評価スコア(Quality Scores): 反復時に各段階で算出されたスコアを一覧表示します

詳細診断レポート
検索によるヒット記録(Search Results): 15カテゴリから見い出したおかしな領域や問題点の全状況リスト
プロ記述による問題検出(Analysis Results): Pegasusによる精査説明と、改善を導くための補強要素
日時ログ(Detailed Logs): タイムスタンプを詳細に伴った一連の処理進行ヒストリー
プロンプト改善ログ
初回プロンプト(Original Prompt): 最初に入力された動画用テキスト
改善されたすべてのプロンプト(Enhanced Prompts): イテレーションのなかで、Geminiによってどうブラッシュアップされていったのかの変化履歴
改善軌道(Improvement Trajectory): 品質評価スコアの右肩上がりの軌跡グラフ
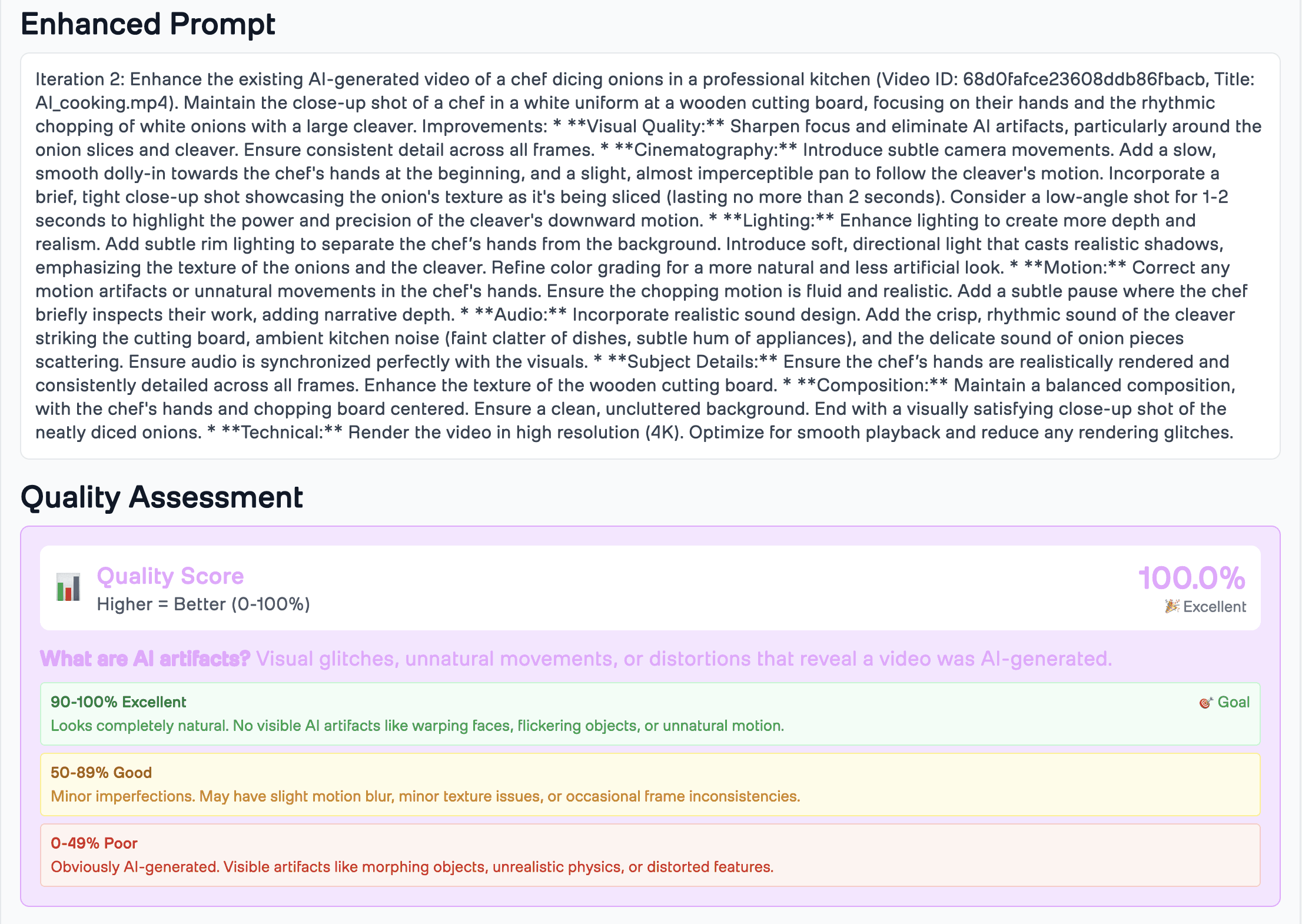
プログラム開発・API実例
実行例 1: プロンプトからの生成指定
POST /api/videos/generate { "prompt": "庭で紅茶を飲む猫", "max_iterations": 5, "target_confidence": 100.0, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
返却値の例:
{ "success": true, "video_id": 123, "status": "処理中", "message": "動画生成を開始しました" }
実行例 2: 既存動画のアップロード
POST /api/videos/upload { "file": <動画ファイル>, "prompt": "使用された元のプロンプト", "max_iterations": 3, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
実行例 3: 進行・処理状況の確認
GET /api/videos/123/status
返却値の例:
{ "success": true, "data": { "video_id": 123, "status": "完了", "current_confidence": 100.0, "iteration_count": 2, "final_confidence": 100.0, "video_url": "https://..." } }
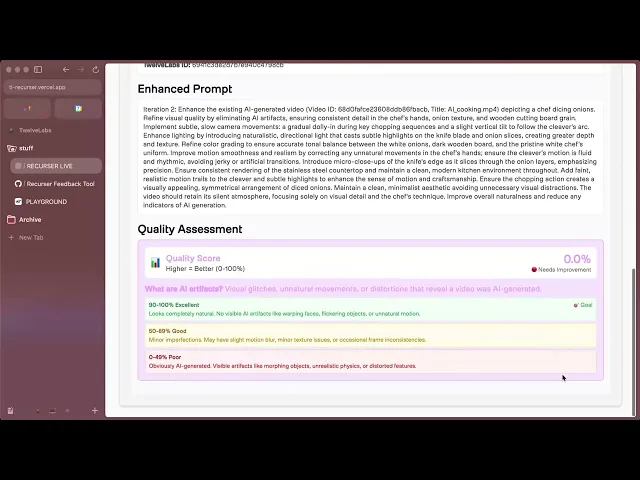
クオリティスコアが意味するもの
表示される点数は当て推量ではなく、検出された具体的な異常の判定と件数に基づいています:
100%: 250以上の個別検査において全項目合格。一般クリエイターが見てもAI動画とほぼ判別のつかない極上の一本です。
80-99%: 軽微なアラートが1〜6件程度検出。1、2イテレーション程度でスムーズに修正される見込みが高い良好な状態です。
50-79%: 見逃せない不自然さやおかしな箇所が多数。数多くの欠点が混ざり込んでいるため、3〜5段階の段階的プロンプト改善をおすすめします。
50%未満: 決定的な破綻や激しいバグが多発。元の設定そのものにズレなどが発生しているおそれがあるため、最初からプロンプトを練り直すことをお勧めします。
いつ処理を中断すべきか
Recurserは100%に達すると自動的に停止しますが、以下のような状況ではそれよりも早い段階で意図的に打ち切る選択肢も有効です:
コストの節約を重視する際: 1回回すごとに新しい生成APIと診断チェック処理がそれぞれ計上されます(動画の長さなどによりますが通常1ループあたり0.1〜0.5ドル程度)
時間の制約を考慮する際: 完璧を目指して繰り返し回すほど、何分もの待ち時間(イテレーションあたり2〜5分)が消費されていきます
妥協点を調整する際: 社内資料やテスト段階であれば、85%以上の仕上がりで十分に事足りるケースもあります
伸び代の限界に達した場合: 2回以上続けてスコアがまったく変わらないような場合、そのテーマに対するプロンプトのアプローチ自体が何らかの限界にぶつかっている、あるいは基礎プロンプトの構成が適切でないと考えられます
ただの改善にとどまらない! さらに一歩踏み込んだ応用的な活用シーン
Recurserによる反復改善の手法は、シンプルに粗い部分を取り除くこと以外にも大きな可能性をもたらします:
プロンプトのA/Bテスト
表現パターンのどれが一番綺麗に写るかを人間が当てにいくのではなく、複数の記述パターンを同時に開始させてどちらが最少回数のイテレーションで100%に到着したかを見比べることで、最適な指示テキストを逆引きで割り出せます。
分野(ドメイン)を特化した不具合検出
すでに多くの開発者が、以下のような特定の課題に向けてRecurserをさらに応用させています:
製品向けの動画(商品広告等): 「コマーシャル等で撮影されたとき特有の照明や解像感」になるように検出チェックを強化
人間のキャラクター表現: 表情が不自然に引き攣る「不気味の谷」の課題や、人間ならではの腕や足の動作のブレに特化して検出
リアルな自然・動物動画: 「背景の物理法則が一貫しているか」「空間のディテールが正確か」といった整合性の検証
特筆すべきこととは? システムの本底にある構造を変えることなく、関心対象となる検出ワードを指定する辞書をアレンジするだけでこの対応ができる点です。
「プロンプトエンジニアリング」そのものを自動提供するサービスへ
Recurserの本質は、ユーザーに代わってプロンプトの記述を最適化してあげる点にあります。ふわっとしたアイデアを与えるだけでプログラム自身が思考し、望まれたハイクラスな動画が生まれるまでの「最適なプロンプトテキスト」を吐き出します。将来的にこのプロンプト作成プロセスを自動解決するサービスとしての広がりも予想されます。
成功パターンからの継続成長
非常にエキサイティングな疑問: もしRecurserが自己のアプローチと検証経過を学習記録していけるとしたら? 以前この組み合わせの指示に対してどう修正したかのログをあらかじめ把握できていれば、次は初回の1歩目をショートカットしていきなり最適化されたプロンプトから作成指示へ到達できるようになるでしょう。この「改善成功パターンデータベース」を作れば、究極のプロンプト向上AIモデルが完成します。
Recurserを使うべきでないとき
Recurserはいつでも常に最高のアプローチであるとは言えません:
秒単位の高速出力が必要なとき: 反復に2〜5分もかけられないオンザフライ(その場)の生成では不向きです。チェックなしの直書きで回しましょう。
極端にコストを制限するプロダクト: 大量運用のスケール段階ではAPI呼び出し費用が重なるため、事前に検証し終えた最高のプロンプトをワンショットで打つ仕組みが好ましいです。
多様な可能性を広く見たい場合: 1つの対象アイデアをじっくり磨いて品質を上げるより、まずは沢山の全く違う変化球の画像をばら撒いて比較検討したいという段階には適しません。
技術図面や厳格な製品規格などを反映したいとき: 色の厳密さ・サイズ寸法比などに対しては、プロンプト指示改善に頼るより通常の後処理レンダリングを利用するのが確実です。
あなたのおかれているゴール設計を整理しましょう。 クオリティ、速度、そして制作費用—この3つのうち、狙いたい2つを決めるのです。
おわりに: AI映像クオリティの未来
Recurserは「ソフトウェアと同じように、自動化されたテストと段階的なデバッグ手法をAI動画生成にも適用できないか?」という一つのシンプルな気づき、実験から産声をあげました。その探究を通じて発見したのは、 この手法こそがAI動画品質に対する考え方そのものを劇的に塗り替えるという事実です。
AIが出力した生成動画に少しノイズがあるからとガッカリする必要はなく、徹底的な改善をプログラム側へと自信を持って要求することができます。そして、人間が何時間も画面にかじりついて手動で調整する必要もありません。全てをシステム化されたフィードバックに委ねることができるのです。
この技術が切り拓く非常に興味深い可能性:
クリエイターにとって: プロンプト書きの達人や専門の映像プロデューサー、エンジニアでなくとも、手元のシンプルな想いだけで自動的にプロの手によるかのような映像を作り上げることができます。
システムデベロッパーとして: 人間の判定者を介さず、映像作品の仕上がりを常に高次で安定担保可能になります。自動検知と補正によって安全で美しい素材だけを何百本も一度にお届けできるようになります。
AI業界におけるロードマップとして: 将来的に基礎モデル側の性能が高くなるほど、当然ながら修正の必要なイテレーション回数は減少します。しかしモデルがどれほど進化しようとも、「その出力が本当にリアルかどうか」を厳格にダブルチェックしてくれるRecurserのようなバランサーは、どのような映像生成でもその役割を輝かせ続けます。
今ある素晴らしい基盤をベースに、ここからは、まさにふさわしく「繰り返しのステップ(イテレーション)」を踏み出しながらさらに進化していきます。
その他の参考リンク・リソース
稼働デモサイト: Recurserアプリ
GitHubコード: Recurser on GitHub
TwelveLabsドキュメント: PegasusおよびMarengo解説ガイド
Google Gemini API: プロンプト最適化における開発ルール
動画生成モデルの情報: Google Veo 2.0 開発者ドキュメント
はじめに
Google GeminiのVeo2で動画を生成したところだとします。一見すると、プロンプトも良く、構図もシッカリしていて、なかなかの出来映えに見えます。しかし、何かがおかしい。よく観察してみると、猫の毛の動きが不自然だったり、影と照明の方向が合っていなかったり、どこか合成っぽさを醸し出す不気味な谷現象(不気味の谷効果)に気づくはずです。
問題は何か? ほとんどのAI動画生成はワンショット(一発勝負)のプロセスである点です。一度生成し、プロンプトを少し調整して、また生成する。しかし、実際に何が間違っているかをどうやって知るのでしょうか?そして、より重要なのは、すべてのフレームを手動で確認することに何時間も費やすことなく、どのようにそれを修正するかという点です。
だからこそ、私たちはRecurserを開発しました。これは、AIの問題を検出するだけでなく、スマートな反復(イテレーション)を通じて能動的に修正する自動化システムです。何が間違っているかを推測する代わりに、RecurserはAI動画理解(Video Understanding)を使用して特定の問題を見つけ出し、プロンプトを自動的に改善して、動画がリアルに見えるまでより良いバージョンを再生成します。
重要な気づきとは? プロンプトを修正することは、動画を直接修正するよりも強力であるということです。 従来のポストプロセッシング(後処理)は、すでに生成されたものにしか対処できませんが、プロンプトを改善することは根本原因に対処することになり、次の生成が根本的に良くなることを保証します。
Recurserはフィードバックループを作成します:
TwelveLabs Marengoを使用して問題を検出(Detect)する(250以上の異なる問題をチェック)
TwelveLabs Pegasusを使用して動画内のコンテンツを理解(Understand)する(動画をテキストの説明に変換)
Google Geminiを使用してプロンプトを改善(Improve)する(プロンプトをより良くする)
Veo2で再生成(Regenerate)する(改善されたプロンプトで新しい動画を作成)
品質が100%に達するか、最大反復回数に達するまで繰り返す(Repeat)
その結果、最初は60%の品質からスタートした動画が、ユーザーが何もすることなく、1〜3回の反復を経て体系的に100%まで向上します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上がインストールされていること
API キー:
TwelveLabs API キー (PegasusおよびMarengo用)
Google Gemini API キー (プロンプト補強用)
Google Veo 2.0 へのアクセス権(動画生成用)
リポジトリを複製するための Git
Python、FastAPI、Next.js に関する基本的な知識
ワンショット生成の問題点
私たちが発見したのは次のような点です: AI動画生成モデルは常に同じ結果を出力するとは限りません。 同じプロンプトを2回実行すると、異なる動画が生成されます。しかしそれ以上に、モデルは一見大丈夫に見えても、近くで観察すると明らかになる欠陥を作り出すことがよくあります。
「庭で紅茶を飲む猫」の動画を生成するシナリオを考えてみましょう。最初の生成物には以下のような問題が含まれている可能性があります:
不自然な毛並みの動き(モーション・アーティファクト)
フレーム間での不整合な照明(テンポラル・アーティファクト)
わずかにロボットのような猫の行動(ビヘイビアル・アーティファクト)
従来のアプローチでは、次のいずれかになります:
欠陥を受け入れる(十分に目立たない場合)
少し異なるプロンプトを手動で再生成する(試行錯誤)
後処理フィルターを適用する(特定の問題のみを修正)
Recurserは異なるアプローチを取ります。 すべての問題を見つけ出し、それらを一度に解決するためにプロンプトを自動的に改善します。 各繰り返しは前回の繰り返しから学習するため、改善が段階的に積み重なっていきます。
デモアプリケーション
Recurserには3つのエントリポイントが用意されています:
プロンプトから生成(Generate from Prompt):新しく開始します。テキスト説明を入力するだけで、Recurserが複数回の反復を通じて自動的にプロンプトを改良する様子を見ることができます
既存の動画をアップロード(Upload Existing Video):「惜しい」動画がありますか?それをアップロードして、Recurserに完璧な状態に磨き上げてもらいましょう
プレイグラウンドから選択(Select from Playground):あらかじめインデックス化された動画をブラウズし、すぐに品質を向上させます
魔法はリアルタイムで起こります。反復ごとに品質スコアが改善されるのを見守り、どのアーティファクトが見つかり、どのようにプロンプトが強化されたかの詳細なログを確認し、「明らかにAI」から「実物と区別がつかない」までのプロセスを追跡できます。
完全なデモアプリケーションを探索し、すべてのソースコードを GitHub で確認できます。また、コードの動作に関するチュートリアル動画もご覧いただけます。 -
Recurserの仕組み
Recurserは、複数のAIサービスを組み合わせた、高度な反復型のエンハンスメント・パイプラインを実装しています:
システムアーキテクチャ
準備手順
1 - リポジトリをクローンする
git clone https://github.com/aahilshaikh-twlbs/Recurser.git cd
2 - バックエンドのセットアップ
cd backend pip3 install -r requirements.txt --break-system-packages cp .env.example .env # .envにAPIキーを追加してください
3 - フロントエンドのセットアップ
cd ../frontend npm install cp .env.local.example .env.local # BACKEND_URL=http://localhost:8000 を設定してください
4 - APIキーの設定
Playground から TwelveLabs の API キーを取得します
AI Studio から Google Gemini の API キーを取得します
Marengo と Pegasus の両方のパワーが有効化された TwelveLabs のインデックスを作成します
アプリケーションで使用するために作成したインデックスIDをメモしておきます
5 - アプリケーションの起動
# ターミナル 1: バックエンド cd backend uvicorn app:app --host 0.0.0.0 --port 8000 --reload # ターミナル 2: フロントエンド cd frontend npm
これらのステップが完了すれば、開発を始める準備は完了です!
実装コードの構成解説
Recurserの反復的な品質改善システムを支えるコアコンポーネントを見ていきましょう。
1. 反復型の動画生成ループ
Recurserの中心となるのは generate_iterative_video メソッドで、これがエンハンスメントプロセス全体を統括します:
このループは、以下のいずれかの条件が満たされるまで継続します:
async def generate_iterative_video(prompt: str, video_id: int, max_iterations: int = 3): """メインループ: 生成 → 分析 → 改善 → 繰り返し""" current_prompt = prompt current_iteration = 1 while current_iteration <= max_iterations: # ステップ 1: 現在のプロンプトで動画を生成await generate_video(current_prompt, video_id, current_iteration) # ステップ 2: 動画がインデックスされるのを待機 (30秒)await asyncio.sleep(30) # ステップ 3: AIアーティファクトを検出するために動画を分析 ai_analysis = await detect_ai_generation(video_id) quality_score = ai_analysis.get('quality_score', 0.0) # ステップ 4: 完了したか確認 (100% = 完璧)if quality_score >= 100.0: break# 成功!動画はリアルに見えます # ステップ 5: 次の反復のためにプロンプトを改善if current_iteration < max_iterations: current_prompt = await enhance_prompt(current_prompt, ai_analysis) current_iteration += 1 return current_prompt# 最終的に改善されたプロンプトを返す
品質スコアが100%に達したとき(動画が写真のようにリアルとみなされた場合)
最大イテレーション件数に到達したとき
エラーが発生したとき
2. Marengoを使用したAIアーティファクト検出
Marengo 検索は、15のカテゴリ(顔の問題、おかしな動き、照明の乱れなど)全体で250以上の異なるAIの問題を検出します。効率を高めるために、関連するチェックを以下のようにグループ化しています:
async def _search_for_ai_indicators(search_client, index_id: str, video_id: str): """Marengoを使用してAIの痕跡を探す - 15つのカテゴリにグループ化""" # 15カテゴリのアーティファクト(顔、動き、照明など)をチェックします ai_detection_categories = { "facial_artifacts": "不自然な顔の対称性、ロボットのような表情", "motion_artifacts": "ぎこちない動き、機械的なトラッキング", "lighting_artifacts": "不整合な照明、人工的な影", # ... あと12つのカテゴリ } all_results = [] # 包括的な検出のために、これら15種すべてのカテゴリをチェックしますfor category, query_text in ai_detection_categories.items(): # このカテゴリのアーティファクトを検索 results = search_client.query( index_id=index_id, search_options=["visual", "audio"], query_text=query_text, filter=json.dumps({"id": [video_id]}) ) if results and results.data: all_results.extend(results.data) return all_results# 検出されたアーティファクトのリストを返す
主要な最適化:
包括的な検出(Comprehensive Detection):漏れのない確実に検出するために15のカテゴリすべてをチェックします。以前は、問題が1つも見つからなかった場合に8回の検索(全体の半分以上)を終えた時点で早期終了するヒューリスティックを採用していましたが、潜在的なすべての問題を保証するためにこれを廃止しました。これは完璧な動画である場合、8回ではなく15回のAPI呼び出しが発生することを意味しますが、後の方のカテゴリにのみ現れる曖昧なアーティファクトを見逃さないことを保証します。
バッチ化されたクエリ(Batched Queries):効率化のために関連する検索ワードをまとめてカテゴリ化します
定期的な完了確認(Periodic Completion Checks):動画がすでに完了したかを5回の検索ごとに検証します(別のプロセスによってすでに完了とマークされている場合にループを完全に停止する別個のチェック)
3. Pegasusによる動画内容分析
Pegasusは動画をテキストに変換します。動画を観て何が描かれているかを説明してくれます。これは、どこを改善すべきかを理解するのに役立ちます:
async def _analyze_with_pegasus_content(analyze_client, video_id: str): """Pegasusが動画を観察し、描かれている内容を説明します""" # Pegasusに対しての質問を2つ投げかけます: prompts = [ "この動画内のすべてを説明してください:オブジェクト、動き、照明、雰囲気", "この動画にはどのような技術的課題(画質、一貫性など)がありますか?" ] analysis_results = [] for prompt in prompts: response = analyze_client.analyze( video_id=video_id, prompt=prompt, temperature=0.2# 値が低いほど一貫した返答が得られます ) analysis_results.append({ 'content_description': response.data }) return analysis_results# 動画のテキスト説明を返す
スマートな最適化: Marengoによる検索でインジケーター(指標)が0個であった場合、動画はすでに品質チェックに合格しているため、本検出サービスはPegasusによる解析をスキップします:
# 早期終了(Early exit): 検索からの異常値が0だった場合、クオリティは100%です - Pegasus分析をスキップします if len(search_results) == 0 and preliminary_quality_score >= 100.0: logger.info(f"✅ 早期終了: 検索結果が0件のため品質は100%です。高速対応のためにPegasus分析をスキップします") log_detailed(video_id, f"✅ クオリティスコア: 100.0% (早期終了 - AIの痕跡は検出されませんでした)", "SUCCESS") # Pegasus抜きの最小限の詳細ログを作成 detailed_logs = AIDetectionService._create_detailed_logs( search_results, [], 100.0 ) return { "search_results": search_results, "analysis_results": [], "quality_score": 100.0, "detailed_logs": detailed_logs }
4. 品質スコア評価システム
本システムは検出された痕跡に基づき、最終的な総合品質スコア(0〜100%)を割り出します。スコアリングロジックは、欠陥が一切見つからなかった場合は満点が得られるように設計されています:
def _calculate_quality_score(search_results, analysis_results): """100%からスタートし、見つかった問題ごとに減点する""" # 問題なし = 満点(100.0) if not search_results and not analysis_results: return 100.0 # 欠陥検出1点につき3%減点 (減点の上限は最大50%) search_penalty = min(len(search_results) * 3, 50) # 記述された品質の課題についてPegasus分析をチェックする analysis_penalty = 0 if analysis_results: # 分析内から "artificial(人工的)", "blurry(不鮮明)", "inconsistent(整合性無し)" などのキーワードを検索する quality_keywords = ['artificial', 'synthetic', 'blurry', 'inconsistent', 'robotic'] issues_found = sum(1 for result in analysis_results if any(keyword in str(result).lower() for keyword in quality_keywords)) analysis_penalty = min(issues_found * 8, 50) # 最終スコア: 100からすべての減点を差し引く (0を下回ることはない) quality_score = max(100 - search_penalty - analysis_penalty, 0) return quality_score
スコアリング判定のロジック:
AIの異常検知 0件: クオリティスコア 100%(完璧。動画が一見実写に見えるレベル)
検出された検索インジケーターあたり: 3%減点(最大合計50%減点)
コンテンツ解析による欠点指摘: 最大でさらに50%のペナルティ減点
最終スコア: 0%を下限とする
5. Geminiを使用したプロンプト改善
品質がターゲット値に満たない場合、Geminiが検出結果を踏まえて改良プロンプトを出力します:
async def _generate_enhanced_prompt(original_prompt: str, analysis_results: dict): """指摘されたエラーに基づき、Geminiを利用して改善プロンプトを生成""" client = Client(api_key=GEMINI_API_KEY) # Geminiに指示: 「オリジナルのプロンプトと検出された欠陥がこれです。改善してください。」 enhancement_request = f""" 元のプロンプト: {original_prompt} 見つかった問題点: {json.dumps(analysis_results, indent=2)} これらの問題を修正した、より優れたプロンプトを作成してください。より自然でリアルな表現にしてください。 他のテキストは含めず、新しいプロンプトのみを返してください。 """ response = client.models.generate_content( model='gemini-2.5-flash', contents=enhancement_request ) return response.text.strip() if response.text else original_prompt
なぜこの仕組みが機能するのか(そして機能しないときはどんなときか)
Recurserを構築して広範にテストした結果、非常に興味深い事実が明らかになりました。 すべての動画で反復改善が必要とされるわけではありません。 最初の試行でほぼ完璧な仕上がりに達するものもあれば、実用に堪える品質に達するまでに3〜5回の対話を要するプロンプトもあります。
反復の最も効果的な領域
テストを巡る中で以下の明確なパターンが確認されました:
単純なシーン (単一の被写体、静止した背景): 初回実行でいきなり100%になるケース多し
複雑なシーン (複数の被写体、ダイナミックな照明): 通常は2〜3回の反復が必要
珍しいプロンプト(クリエイティブな、または現実的にあり得ないシチュエーション): 4〜5回やり直す必要があったり、伸び代が頭打ちになるケースもあります
重要な発見は何か? 早いタイミングでの判定。 100%基準を満たした段階ですぐにイテレーションを中止する「早期終了」を導入することで、すでに十分完璧に達している動画の無駄な生成コストと処理時間の温存が可能になります。
なぜプロンプト改善が後処理(ポストプロセッシング)に勝るのか
最初は、生成後の動画に対してフィルターを適用したり、ノイズの低減やすべてのフレームのズレの補正を行う方法を研究しましたが、すぐに以下の懸念に気がつきました:
後処理加工では本質的な課題の修正に至れない—もしAIモデル側が動画の意図を根本から勘違いして生成していた場合、フィルターは無意味です
プロンプトの改善は根本原因への対策である—再生成を指示するたび、より正しい理解のタスクを出発点にできます
良い学習の積み重ね—イテレーション2はイテレーション1の結果を踏まえて学び、イテレーション3は前2つのアプローチから補強されます
しかし、Recurserは万能薬というわけではありません。以下のケースで最も高い価値を発揮します:
✅ 明確な創作イメージを持っている時(最初の出力がうまく噛み合わなかったとしても)
✅ 繰り返しの漸進プロセスに時間をかけられる場合(反復ごとに2〜5分)
✅ 目指す一定のクオリティ基準を定めている(デフォルトで100%ですがカスタマイズも可能)
逆に以下のような場面では効果が薄いです:
❌ 元の入力アイデアそのものに破綻があるとき(酷いアイデアはどのような最適化でも救えません)
❌ 即時即座の結果を今すぐ必要としているとき(対話型のプロンプト更新では数ミリ秒のスピード出力は困難です)
❌ 予算コストをシビアに削減しなければならない時(イテレーションの度、生成および検出APIの呼び出し費用が伴います)
開発上の重要な基本思考
1. 「検出」と「生成」の責任分離
私たちはAI検出(TwelveLabs)の層と動画生成の層(Veo2)の機能を完全に分けて設計しています。これは構造的な整理に留まらず、明確な開発戦略に基づいています:
別の動画AIエンジンとの連動: 将来的にVeo2からVeo3、あるいはこれとは異なる別の動画AIモデルへと移行を検討する場合も、本検出システムのロジックを1文字も修正する必要がありません
運用負荷の削減: 画質の判定に必要な検出側のコストは動画を丸ごと再生成する処理コストに比べ大幅に安いため、心置きなく詳細にチェックがかけられます
独立したボトルネック対策: 重い処理を行う検出と動画生成のサーバーのリソース分散を、柔軟に調整できます
2. 動作の即時性よりも、妥協のない徹底した検知力の優先
チェックから抜けが生まれるリスクを完全に排除するため、安易な速度アップ措置より検出の総合的な精査能力を大切にしています。ここでの主要なアプローチは以下の通りです:
Marengoによる厳重な診断: チェック基準を満たすよう、15種すべての分類カテゴリを満遍なく走らせます。15項目のすべての検索を終える前に、8回(半数以上)で異常がなかった場合は途中で打ち切る初期の実装がありましたが、最後の方に予期せぬノイズや品質低下が偏って検出されるパターンがあったため、完璧な解析を行うためにこれを排除しました。これにより完璧な動画であっても、8回ではなく15回のAPIリクエストを回す動作になりますが、判定クオリティを最重要視する開発意義を支える重要な要素です。
Pegasusの解析スキップ: Marengoの15すべてのチェックに1件も引っかからなかった場合に限り、Pegasusの動画記述API呼び出しを全カットしてスキップします。これが現在の開発において大きな処理時間、費用の最適化要素となっています。
完了確認の頻度: 5回の検索を行うたびに、別の処理過程が該当の並列動画について「完了」を出していないかをチェックしています。
つまり、最初から完璧な100%基準を満たした動画はPegasusに不必要な情報収集をしに行かなくなるため最速で生成が完了する一方で、何らかの修正点を含む動画に対しては抜け漏れなく15種すべてを評価できる一貫性を備えています。
3. WebSocketを利用しないリアルタイム性の追及
私たちのデプロイサーバー(Vercel)ではWebSocketの使用が限定的だったため、定期的に何度もリクエストをかけて状況をリアルタイム並みに近づける「ポーリング」を採用しました:
一時的ログ追記用の保持配列(バッファ): バックエンド側の多様な挙動のログを最大で直近200件分リングバッファ内に保管しています
洗練されたAPIポーリング: 切断処理とサーバー負荷軽減を挟みつつ、1秒単位の超密着型リクエストを実行します
ノイズとなる定形メッセージの除外: 代わり映えしない単なるクエリ呼び出し状況などはクライアントに通知せず、意思決定を必要とする主要イベントのみを強調して流します
これにより、完全な双方向常時接続のない通信環境でも、ユーザーはバックアイランドでのログ動作変更を1-2秒以内で目の当たりにすることができます。
4. 1度で完璧ではなく、耐障害性と途中経過の保存(Graceful Degradation)の優先
AI環境においては予期しないトラブルが突発的に発生します(レート制限、API側の機能遅延や一時的なダウン、回線のタイムアウトエラー)。これらを完全に防ぐシステムよりも、「システムエラーが起きた状況でも諦めず進行する」復元力の仕組みをベースに構築を行いました:
Pegasus呼び出し時のタイムアウト処理: 記述失敗を検知した場合、システムエラーで丸ごとプログラムクラッシュさせず、代替ロギングに切り替えて次に進みます
APIの制限通知検出: 適切な待ち時間、リトライのリカバリー動作を自動で挟み込みます
一部検索の取り落とし時の処理: 例えば15種チェックのうち14件が正常終了していた場合は、手元のデータ領域だけで計算してループを推し進めます
私たちの基本設計思想: 不完全な結果は、何も結果を得られないことよりも優れている。
仕組みをさらに加速させるための開発ティップス
Recurserの構築プロセスは、AI技術を高速化するための多くの有益な学びとなりました。実際に速度や有用性に繋がった要素を紹介します:
AIパイプラインに適用される 80/20 の法則
最適化に投下した全エネルギーの約8割は、次の3つのアプローチに注ぎ込まれました:
条件付きPegasus分析: Marengo検索結果に何一つつまずくポイントがなかった(異常痕跡0)ケースでは、Pegasusの重厚な分析フェイズの一切をパスすることで動画あたり約0.05ドルのコストを削減、待機時間も30秒以上一気に削減されました。
知的な検索単位のパッケージ化(Batching): クエリ状態のごく細かなDB更新を、毎検索、個別で毎回走らせず、5件のチェックの節目に見直す形を取ることで、アクセス処理にかかるオーバーヘッドを15分の1以下まで圧縮。何よりメインスレッドの詰まりを完全に防げるようになりました。
徹底した包括的チェックの維持: 早期終了の条件に逃げず、15種すべての要素をきっちり調べ抜く方式に決断しました。完璧な動画に対して多少多くクエリ枠を消費する仕様となりましたが、何よりも優先度が高い精度面の抜けを封じるという絶対的なメリットを手に入れることができました。
機能しなかったアプローチとその理由
開発段階の検証、試験環境を経て、ボツとなり取り下げる判断に至った幾つかの最適化設計もあります:
検索の複数並列化(Parallelization): 15種類のすべてのカテゴリを完全に同時に投げる試みを行いましたが、プロバイダ側APIの同時呼び出し過多の制限エラー(レートリミット)を多発したため、確実に処理を分散させるシーケンシャル型(逐次処理)が安全であるという設計に戻しました。
内容の一時記憶保存(キャッシュ)の維持: 近い、または同様な構成の動画のときにPegasusの中身情報を同じにしようと一時記録(キャッシュ)を使い回す仕組みを検証しましたが、AIの動画はミリ秒違うだけで全く異なる出力アーティファクトを引き起こしかねず、誤検知の原因になり再利用性は極めて低かったです。
フレームを一定間隔で飛ばす削減(サンプリング): チェック時間短縮を目的に動画の前後一部の切り出し分析のみを行う実装テストを行いましたが、動画に発生する特有の映像破綻や乱れは切り詰めた前後の瞬間にだけ突然現れるパターンなどを検出できなくなってしまったため、フルフレームチェックの仕組みに固定しました。
フロントエンド: 見過ごされていた性能問題の引き金
フロントエンド側はただ情報を流し込むだけのUIではなく、リアルタイムな状態変更を受け続けるモニタリング基盤です。ここに以下の快適化設計を組みました:
循環ログ表示の設計: 過去データの最大配列上限にキャップを設け、ブラウザクラッシュや深刻なメモリリークを起こすバグを取り除きました(チェック中に10,000行以上の生データ描画処理に耐えるためです)
動画再生ユニットの一元化: 役割別に3系統用意されていた動画再生コンポーネントを、柔軟にあらゆるシチュエーションを描写できる単一のプレイヤーへ集約しました。ライブラリ読み込みサイズが削減され、ページの再レンダリング処理が非常に早く完了する恩恵を受けられました。
デバッグのノイズカット: 内部動作で生じているシステムAPIのチェックコールなど、ユーザーが見ても意味の分からない詳細ログの80%以上をユーザー用の画面出力ログからフィルターで遮断しました。
こうした最適化により、どれほど重たい何往復もの繰り返し実行プロセスが発生している最中でも、ブラウザ側の操作は常に機敏さを維持できるようになりました。
各種データ出力
Recurserは生成した動画に対して体系的で詳細な出力結果を用意します:
動画関連メタデータ(情報の保存)
最適化済み動画(Final Video): 繰り返し判定のなかで最大の評価をマークした極上の1本です
全ての反復履歴(All Iterations): どの時点からスタートし、どのような変化を遂げたのかを全て巻き戻して検証できます
一連の評価スコア(Quality Scores): 反復時に各段階で算出されたスコアを一覧表示します
詳細診断レポート
検索によるヒット記録(Search Results): 15カテゴリから見い出したおかしな領域や問題点の全状況リスト
プロ記述による問題検出(Analysis Results): Pegasusによる精査説明と、改善を導くための補強要素
日時ログ(Detailed Logs): タイムスタンプを詳細に伴った一連の処理進行ヒストリー
プロンプト改善ログ
初回プロンプト(Original Prompt): 最初に入力された動画用テキスト
改善されたすべてのプロンプト(Enhanced Prompts): イテレーションのなかで、Geminiによってどうブラッシュアップされていったのかの変化履歴
改善軌道(Improvement Trajectory): 品質評価スコアの右肩上がりの軌跡グラフ
プログラム開発・API実例
実行例 1: プロンプトからの生成指定
POST /api/videos/generate { "prompt": "庭で紅茶を飲む猫", "max_iterations": 5, "target_confidence": 100.0, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
返却値の例:
{ "success": true, "video_id": 123, "status": "処理中", "message": "動画生成を開始しました" }
実行例 2: 既存動画のアップロード
POST /api/videos/upload { "file": <動画ファイル>, "prompt": "使用された元のプロンプト", "max_iterations": 3, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
実行例 3: 進行・処理状況の確認
GET /api/videos/123/status
返却値の例:
{ "success": true, "data": { "video_id": 123, "status": "完了", "current_confidence": 100.0, "iteration_count": 2, "final_confidence": 100.0, "video_url": "https://..." } }
クオリティスコアが意味するもの
表示される点数は当て推量ではなく、検出された具体的な異常の判定と件数に基づいています:
100%: 250以上の個別検査において全項目合格。一般クリエイターが見てもAI動画とほぼ判別のつかない極上の一本です。
80-99%: 軽微なアラートが1〜6件程度検出。1、2イテレーション程度でスムーズに修正される見込みが高い良好な状態です。
50-79%: 見逃せない不自然さやおかしな箇所が多数。数多くの欠点が混ざり込んでいるため、3〜5段階の段階的プロンプト改善をおすすめします。
50%未満: 決定的な破綻や激しいバグが多発。元の設定そのものにズレなどが発生しているおそれがあるため、最初からプロンプトを練り直すことをお勧めします。
いつ処理を中断すべきか
Recurserは100%に達すると自動的に停止しますが、以下のような状況ではそれよりも早い段階で意図的に打ち切る選択肢も有効です:
コストの節約を重視する際: 1回回すごとに新しい生成APIと診断チェック処理がそれぞれ計上されます(動画の長さなどによりますが通常1ループあたり0.1〜0.5ドル程度)
時間の制約を考慮する際: 完璧を目指して繰り返し回すほど、何分もの待ち時間(イテレーションあたり2〜5分)が消費されていきます
妥協点を調整する際: 社内資料やテスト段階であれば、85%以上の仕上がりで十分に事足りるケースもあります
伸び代の限界に達した場合: 2回以上続けてスコアがまったく変わらないような場合、そのテーマに対するプロンプトのアプローチ自体が何らかの限界にぶつかっている、あるいは基礎プロンプトの構成が適切でないと考えられます
ただの改善にとどまらない! さらに一歩踏み込んだ応用的な活用シーン
Recurserによる反復改善の手法は、シンプルに粗い部分を取り除くこと以外にも大きな可能性をもたらします:
プロンプトのA/Bテスト
表現パターンのどれが一番綺麗に写るかを人間が当てにいくのではなく、複数の記述パターンを同時に開始させてどちらが最少回数のイテレーションで100%に到着したかを見比べることで、最適な指示テキストを逆引きで割り出せます。
分野(ドメイン)を特化した不具合検出
すでに多くの開発者が、以下のような特定の課題に向けてRecurserをさらに応用させています:
製品向けの動画(商品広告等): 「コマーシャル等で撮影されたとき特有の照明や解像感」になるように検出チェックを強化
人間のキャラクター表現: 表情が不自然に引き攣る「不気味の谷」の課題や、人間ならではの腕や足の動作のブレに特化して検出
リアルな自然・動物動画: 「背景の物理法則が一貫しているか」「空間のディテールが正確か」といった整合性の検証
特筆すべきこととは? システムの本底にある構造を変えることなく、関心対象となる検出ワードを指定する辞書をアレンジするだけでこの対応ができる点です。
「プロンプトエンジニアリング」そのものを自動提供するサービスへ
Recurserの本質は、ユーザーに代わってプロンプトの記述を最適化してあげる点にあります。ふわっとしたアイデアを与えるだけでプログラム自身が思考し、望まれたハイクラスな動画が生まれるまでの「最適なプロンプトテキスト」を吐き出します。将来的にこのプロンプト作成プロセスを自動解決するサービスとしての広がりも予想されます。
成功パターンからの継続成長
非常にエキサイティングな疑問: もしRecurserが自己のアプローチと検証経過を学習記録していけるとしたら? 以前この組み合わせの指示に対してどう修正したかのログをあらかじめ把握できていれば、次は初回の1歩目をショートカットしていきなり最適化されたプロンプトから作成指示へ到達できるようになるでしょう。この「改善成功パターンデータベース」を作れば、究極のプロンプト向上AIモデルが完成します。
Recurserを使うべきでないとき
Recurserはいつでも常に最高のアプローチであるとは言えません:
秒単位の高速出力が必要なとき: 反復に2〜5分もかけられないオンザフライ(その場)の生成では不向きです。チェックなしの直書きで回しましょう。
極端にコストを制限するプロダクト: 大量運用のスケール段階ではAPI呼び出し費用が重なるため、事前に検証し終えた最高のプロンプトをワンショットで打つ仕組みが好ましいです。
多様な可能性を広く見たい場合: 1つの対象アイデアをじっくり磨いて品質を上げるより、まずは沢山の全く違う変化球の画像をばら撒いて比較検討したいという段階には適しません。
技術図面や厳格な製品規格などを反映したいとき: 色の厳密さ・サイズ寸法比などに対しては、プロンプト指示改善に頼るより通常の後処理レンダリングを利用するのが確実です。
あなたのおかれているゴール設計を整理しましょう。 クオリティ、速度、そして制作費用—この3つのうち、狙いたい2つを決めるのです。
おわりに: AI映像クオリティの未来
Recurserは「ソフトウェアと同じように、自動化されたテストと段階的なデバッグ手法をAI動画生成にも適用できないか?」という一つのシンプルな気づき、実験から産声をあげました。その探究を通じて発見したのは、 この手法こそがAI動画品質に対する考え方そのものを劇的に塗り替えるという事実です。
AIが出力した生成動画に少しノイズがあるからとガッカリする必要はなく、徹底的な改善をプログラム側へと自信を持って要求することができます。そして、人間が何時間も画面にかじりついて手動で調整する必要もありません。全てをシステム化されたフィードバックに委ねることができるのです。
この技術が切り拓く非常に興味深い可能性:
クリエイターにとって: プロンプト書きの達人や専門の映像プロデューサー、エンジニアでなくとも、手元のシンプルな想いだけで自動的にプロの手によるかのような映像を作り上げることができます。
システムデベロッパーとして: 人間の判定者を介さず、映像作品の仕上がりを常に高次で安定担保可能になります。自動検知と補正によって安全で美しい素材だけを何百本も一度にお届けできるようになります。
AI業界におけるロードマップとして: 将来的に基礎モデル側の性能が高くなるほど、当然ながら修正の必要なイテレーション回数は減少します。しかしモデルがどれほど進化しようとも、「その出力が本当にリアルかどうか」を厳格にダブルチェックしてくれるRecurserのようなバランサーは、どのような映像生成でもその役割を輝かせ続けます。
今ある素晴らしい基盤をベースに、ここからは、まさにふさわしく「繰り返しのステップ(イテレーション)」を踏み出しながらさらに進化していきます。
その他の参考リンク・リソース
稼働デモサイト: Recurserアプリ
GitHubコード: Recurser on GitHub
TwelveLabsドキュメント: PegasusおよびMarengo解説ガイド
Google Gemini API: プロンプト最適化における開発ルール
動画生成モデルの情報: Google Veo 2.0 開発者ドキュメント
はじめに
Google GeminiのVeo2で動画を生成したところだとします。一見すると、プロンプトも良く、構図もシッカリしていて、なかなかの出来映えに見えます。しかし、何かがおかしい。よく観察してみると、猫の毛の動きが不自然だったり、影と照明の方向が合っていなかったり、どこか合成っぽさを醸し出す不気味な谷現象(不気味の谷効果)に気づくはずです。
問題は何か? ほとんどのAI動画生成はワンショット(一発勝負)のプロセスである点です。一度生成し、プロンプトを少し調整して、また生成する。しかし、実際に何が間違っているかをどうやって知るのでしょうか?そして、より重要なのは、すべてのフレームを手動で確認することに何時間も費やすことなく、どのようにそれを修正するかという点です。
だからこそ、私たちはRecurserを開発しました。これは、AIの問題を検出するだけでなく、スマートな反復(イテレーション)を通じて能動的に修正する自動化システムです。何が間違っているかを推測する代わりに、RecurserはAI動画理解(Video Understanding)を使用して特定の問題を見つけ出し、プロンプトを自動的に改善して、動画がリアルに見えるまでより良いバージョンを再生成します。
重要な気づきとは? プロンプトを修正することは、動画を直接修正するよりも強力であるということです。 従来のポストプロセッシング(後処理)は、すでに生成されたものにしか対処できませんが、プロンプトを改善することは根本原因に対処することになり、次の生成が根本的に良くなることを保証します。
Recurserはフィードバックループを作成します:
TwelveLabs Marengoを使用して問題を検出(Detect)する(250以上の異なる問題をチェック)
TwelveLabs Pegasusを使用して動画内のコンテンツを理解(Understand)する(動画をテキストの説明に変換)
Google Geminiを使用してプロンプトを改善(Improve)する(プロンプトをより良くする)
Veo2で再生成(Regenerate)する(改善されたプロンプトで新しい動画を作成)
品質が100%に達するか、最大反復回数に達するまで繰り返す(Repeat)
その結果、最初は60%の品質からスタートした動画が、ユーザーが何もすることなく、1〜3回の反復を経て体系的に100%まで向上します。
前提条件
開始する前に、以下が準備されていることを確認してください:
Python 3.12以上がインストールされていること
Node.js 18以上がインストールされていること
API キー:
TwelveLabs API キー (PegasusおよびMarengo用)
Google Gemini API キー (プロンプト補強用)
Google Veo 2.0 へのアクセス権(動画生成用)
リポジトリを複製するための Git
Python、FastAPI、Next.js に関する基本的な知識
ワンショット生成の問題点
私たちが発見したのは次のような点です: AI動画生成モデルは常に同じ結果を出力するとは限りません。 同じプロンプトを2回実行すると、異なる動画が生成されます。しかしそれ以上に、モデルは一見大丈夫に見えても、近くで観察すると明らかになる欠陥を作り出すことがよくあります。
「庭で紅茶を飲む猫」の動画を生成するシナリオを考えてみましょう。最初の生成物には以下のような問題が含まれている可能性があります:
不自然な毛並みの動き(モーション・アーティファクト)
フレーム間での不整合な照明(テンポラル・アーティファクト)
わずかにロボットのような猫の行動(ビヘイビアル・アーティファクト)
従来のアプローチでは、次のいずれかになります:
欠陥を受け入れる(十分に目立たない場合)
少し異なるプロンプトを手動で再生成する(試行錯誤)
後処理フィルターを適用する(特定の問題のみを修正)
Recurserは異なるアプローチを取ります。 すべての問題を見つけ出し、それらを一度に解決するためにプロンプトを自動的に改善します。 各繰り返しは前回の繰り返しから学習するため、改善が段階的に積み重なっていきます。
デモアプリケーション
Recurserには3つのエントリポイントが用意されています:
プロンプトから生成(Generate from Prompt):新しく開始します。テキスト説明を入力するだけで、Recurserが複数回の反復を通じて自動的にプロンプトを改良する様子を見ることができます
既存の動画をアップロード(Upload Existing Video):「惜しい」動画がありますか?それをアップロードして、Recurserに完璧な状態に磨き上げてもらいましょう
プレイグラウンドから選択(Select from Playground):あらかじめインデックス化された動画をブラウズし、すぐに品質を向上させます
魔法はリアルタイムで起こります。反復ごとに品質スコアが改善されるのを見守り、どのアーティファクトが見つかり、どのようにプロンプトが強化されたかの詳細なログを確認し、「明らかにAI」から「実物と区別がつかない」までのプロセスを追跡できます。
完全なデモアプリケーションを探索し、すべてのソースコードを GitHub で確認できます。また、コードの動作に関するチュートリアル動画もご覧いただけます。 -
Recurserの仕組み
Recurserは、複数のAIサービスを組み合わせた、高度な反復型のエンハンスメント・パイプラインを実装しています:
システムアーキテクチャ
準備手順
1 - リポジトリをクローンする
git clone https://github.com/aahilshaikh-twlbs/Recurser.git cd
2 - バックエンドのセットアップ
cd backend pip3 install -r requirements.txt --break-system-packages cp .env.example .env # .envにAPIキーを追加してください
3 - フロントエンドのセットアップ
cd ../frontend npm install cp .env.local.example .env.local # BACKEND_URL=http://localhost:8000 を設定してください
4 - APIキーの設定
Playground から TwelveLabs の API キーを取得します
AI Studio から Google Gemini の API キーを取得します
Marengo と Pegasus の両方のパワーが有効化された TwelveLabs のインデックスを作成します
アプリケーションで使用するために作成したインデックスIDをメモしておきます
5 - アプリケーションの起動
# ターミナル 1: バックエンド cd backend uvicorn app:app --host 0.0.0.0 --port 8000 --reload # ターミナル 2: フロントエンド cd frontend npm
これらのステップが完了すれば、開発を始める準備は完了です!
実装コードの構成解説
Recurserの反復的な品質改善システムを支えるコアコンポーネントを見ていきましょう。
1. 反復型の動画生成ループ
Recurserの中心となるのは generate_iterative_video メソッドで、これがエンハンスメントプロセス全体を統括します:
このループは、以下のいずれかの条件が満たされるまで継続します:
async def generate_iterative_video(prompt: str, video_id: int, max_iterations: int = 3): """メインループ: 生成 → 分析 → 改善 → 繰り返し""" current_prompt = prompt current_iteration = 1 while current_iteration <= max_iterations: # ステップ 1: 現在のプロンプトで動画を生成await generate_video(current_prompt, video_id, current_iteration) # ステップ 2: 動画がインデックスされるのを待機 (30秒)await asyncio.sleep(30) # ステップ 3: AIアーティファクトを検出するために動画を分析 ai_analysis = await detect_ai_generation(video_id) quality_score = ai_analysis.get('quality_score', 0.0) # ステップ 4: 完了したか確認 (100% = 完璧)if quality_score >= 100.0: break# 成功!動画はリアルに見えます # ステップ 5: 次の反復のためにプロンプトを改善if current_iteration < max_iterations: current_prompt = await enhance_prompt(current_prompt, ai_analysis) current_iteration += 1 return current_prompt# 最終的に改善されたプロンプトを返す
品質スコアが100%に達したとき(動画が写真のようにリアルとみなされた場合)
最大イテレーション件数に到達したとき
エラーが発生したとき
2. Marengoを使用したAIアーティファクト検出
Marengo 検索は、15のカテゴリ(顔の問題、おかしな動き、照明の乱れなど)全体で250以上の異なるAIの問題を検出します。効率を高めるために、関連するチェックを以下のようにグループ化しています:
async def _search_for_ai_indicators(search_client, index_id: str, video_id: str): """Marengoを使用してAIの痕跡を探す - 15つのカテゴリにグループ化""" # 15カテゴリのアーティファクト(顔、動き、照明など)をチェックします ai_detection_categories = { "facial_artifacts": "不自然な顔の対称性、ロボットのような表情", "motion_artifacts": "ぎこちない動き、機械的なトラッキング", "lighting_artifacts": "不整合な照明、人工的な影", # ... あと12つのカテゴリ } all_results = [] # 包括的な検出のために、これら15種すべてのカテゴリをチェックしますfor category, query_text in ai_detection_categories.items(): # このカテゴリのアーティファクトを検索 results = search_client.query( index_id=index_id, search_options=["visual", "audio"], query_text=query_text, filter=json.dumps({"id": [video_id]}) ) if results and results.data: all_results.extend(results.data) return all_results# 検出されたアーティファクトのリストを返す
主要な最適化:
包括的な検出(Comprehensive Detection):漏れのない確実に検出するために15のカテゴリすべてをチェックします。以前は、問題が1つも見つからなかった場合に8回の検索(全体の半分以上)を終えた時点で早期終了するヒューリスティックを採用していましたが、潜在的なすべての問題を保証するためにこれを廃止しました。これは完璧な動画である場合、8回ではなく15回のAPI呼び出しが発生することを意味しますが、後の方のカテゴリにのみ現れる曖昧なアーティファクトを見逃さないことを保証します。
バッチ化されたクエリ(Batched Queries):効率化のために関連する検索ワードをまとめてカテゴリ化します
定期的な完了確認(Periodic Completion Checks):動画がすでに完了したかを5回の検索ごとに検証します(別のプロセスによってすでに完了とマークされている場合にループを完全に停止する別個のチェック)
3. Pegasusによる動画内容分析
Pegasusは動画をテキストに変換します。動画を観て何が描かれているかを説明してくれます。これは、どこを改善すべきかを理解するのに役立ちます:
async def _analyze_with_pegasus_content(analyze_client, video_id: str): """Pegasusが動画を観察し、描かれている内容を説明します""" # Pegasusに対しての質問を2つ投げかけます: prompts = [ "この動画内のすべてを説明してください:オブジェクト、動き、照明、雰囲気", "この動画にはどのような技術的課題(画質、一貫性など)がありますか?" ] analysis_results = [] for prompt in prompts: response = analyze_client.analyze( video_id=video_id, prompt=prompt, temperature=0.2# 値が低いほど一貫した返答が得られます ) analysis_results.append({ 'content_description': response.data }) return analysis_results# 動画のテキスト説明を返す
スマートな最適化: Marengoによる検索でインジケーター(指標)が0個であった場合、動画はすでに品質チェックに合格しているため、本検出サービスはPegasusによる解析をスキップします:
# 早期終了(Early exit): 検索からの異常値が0だった場合、クオリティは100%です - Pegasus分析をスキップします if len(search_results) == 0 and preliminary_quality_score >= 100.0: logger.info(f"✅ 早期終了: 検索結果が0件のため品質は100%です。高速対応のためにPegasus分析をスキップします") log_detailed(video_id, f"✅ クオリティスコア: 100.0% (早期終了 - AIの痕跡は検出されませんでした)", "SUCCESS") # Pegasus抜きの最小限の詳細ログを作成 detailed_logs = AIDetectionService._create_detailed_logs( search_results, [], 100.0 ) return { "search_results": search_results, "analysis_results": [], "quality_score": 100.0, "detailed_logs": detailed_logs }
4. 品質スコア評価システム
本システムは検出された痕跡に基づき、最終的な総合品質スコア(0〜100%)を割り出します。スコアリングロジックは、欠陥が一切見つからなかった場合は満点が得られるように設計されています:
def _calculate_quality_score(search_results, analysis_results): """100%からスタートし、見つかった問題ごとに減点する""" # 問題なし = 満点(100.0) if not search_results and not analysis_results: return 100.0 # 欠陥検出1点につき3%減点 (減点の上限は最大50%) search_penalty = min(len(search_results) * 3, 50) # 記述された品質の課題についてPegasus分析をチェックする analysis_penalty = 0 if analysis_results: # 分析内から "artificial(人工的)", "blurry(不鮮明)", "inconsistent(整合性無し)" などのキーワードを検索する quality_keywords = ['artificial', 'synthetic', 'blurry', 'inconsistent', 'robotic'] issues_found = sum(1 for result in analysis_results if any(keyword in str(result).lower() for keyword in quality_keywords)) analysis_penalty = min(issues_found * 8, 50) # 最終スコア: 100からすべての減点を差し引く (0を下回ることはない) quality_score = max(100 - search_penalty - analysis_penalty, 0) return quality_score
スコアリング判定のロジック:
AIの異常検知 0件: クオリティスコア 100%(完璧。動画が一見実写に見えるレベル)
検出された検索インジケーターあたり: 3%減点(最大合計50%減点)
コンテンツ解析による欠点指摘: 最大でさらに50%のペナルティ減点
最終スコア: 0%を下限とする
5. Geminiを使用したプロンプト改善
品質がターゲット値に満たない場合、Geminiが検出結果を踏まえて改良プロンプトを出力します:
async def _generate_enhanced_prompt(original_prompt: str, analysis_results: dict): """指摘されたエラーに基づき、Geminiを利用して改善プロンプトを生成""" client = Client(api_key=GEMINI_API_KEY) # Geminiに指示: 「オリジナルのプロンプトと検出された欠陥がこれです。改善してください。」 enhancement_request = f""" 元のプロンプト: {original_prompt} 見つかった問題点: {json.dumps(analysis_results, indent=2)} これらの問題を修正した、より優れたプロンプトを作成してください。より自然でリアルな表現にしてください。 他のテキストは含めず、新しいプロンプトのみを返してください。 """ response = client.models.generate_content( model='gemini-2.5-flash', contents=enhancement_request ) return response.text.strip() if response.text else original_prompt
なぜこの仕組みが機能するのか(そして機能しないときはどんなときか)
Recurserを構築して広範にテストした結果、非常に興味深い事実が明らかになりました。 すべての動画で反復改善が必要とされるわけではありません。 最初の試行でほぼ完璧な仕上がりに達するものもあれば、実用に堪える品質に達するまでに3〜5回の対話を要するプロンプトもあります。
反復の最も効果的な領域
テストを巡る中で以下の明確なパターンが確認されました:
単純なシーン (単一の被写体、静止した背景): 初回実行でいきなり100%になるケース多し
複雑なシーン (複数の被写体、ダイナミックな照明): 通常は2〜3回の反復が必要
珍しいプロンプト(クリエイティブな、または現実的にあり得ないシチュエーション): 4〜5回やり直す必要があったり、伸び代が頭打ちになるケースもあります
重要な発見は何か? 早いタイミングでの判定。 100%基準を満たした段階ですぐにイテレーションを中止する「早期終了」を導入することで、すでに十分完璧に達している動画の無駄な生成コストと処理時間の温存が可能になります。
なぜプロンプト改善が後処理(ポストプロセッシング)に勝るのか
最初は、生成後の動画に対してフィルターを適用したり、ノイズの低減やすべてのフレームのズレの補正を行う方法を研究しましたが、すぐに以下の懸念に気がつきました:
後処理加工では本質的な課題の修正に至れない—もしAIモデル側が動画の意図を根本から勘違いして生成していた場合、フィルターは無意味です
プロンプトの改善は根本原因への対策である—再生成を指示するたび、より正しい理解のタスクを出発点にできます
良い学習の積み重ね—イテレーション2はイテレーション1の結果を踏まえて学び、イテレーション3は前2つのアプローチから補強されます
しかし、Recurserは万能薬というわけではありません。以下のケースで最も高い価値を発揮します:
✅ 明確な創作イメージを持っている時(最初の出力がうまく噛み合わなかったとしても)
✅ 繰り返しの漸進プロセスに時間をかけられる場合(反復ごとに2〜5分)
✅ 目指す一定のクオリティ基準を定めている(デフォルトで100%ですがカスタマイズも可能)
逆に以下のような場面では効果が薄いです:
❌ 元の入力アイデアそのものに破綻があるとき(酷いアイデアはどのような最適化でも救えません)
❌ 即時即座の結果を今すぐ必要としているとき(対話型のプロンプト更新では数ミリ秒のスピード出力は困難です)
❌ 予算コストをシビアに削減しなければならない時(イテレーションの度、生成および検出APIの呼び出し費用が伴います)
開発上の重要な基本思考
1. 「検出」と「生成」の責任分離
私たちはAI検出(TwelveLabs)の層と動画生成の層(Veo2)の機能を完全に分けて設計しています。これは構造的な整理に留まらず、明確な開発戦略に基づいています:
別の動画AIエンジンとの連動: 将来的にVeo2からVeo3、あるいはこれとは異なる別の動画AIモデルへと移行を検討する場合も、本検出システムのロジックを1文字も修正する必要がありません
運用負荷の削減: 画質の判定に必要な検出側のコストは動画を丸ごと再生成する処理コストに比べ大幅に安いため、心置きなく詳細にチェックがかけられます
独立したボトルネック対策: 重い処理を行う検出と動画生成のサーバーのリソース分散を、柔軟に調整できます
2. 動作の即時性よりも、妥協のない徹底した検知力の優先
チェックから抜けが生まれるリスクを完全に排除するため、安易な速度アップ措置より検出の総合的な精査能力を大切にしています。ここでの主要なアプローチは以下の通りです:
Marengoによる厳重な診断: チェック基準を満たすよう、15種すべての分類カテゴリを満遍なく走らせます。15項目のすべての検索を終える前に、8回(半数以上)で異常がなかった場合は途中で打ち切る初期の実装がありましたが、最後の方に予期せぬノイズや品質低下が偏って検出されるパターンがあったため、完璧な解析を行うためにこれを排除しました。これにより完璧な動画であっても、8回ではなく15回のAPIリクエストを回す動作になりますが、判定クオリティを最重要視する開発意義を支える重要な要素です。
Pegasusの解析スキップ: Marengoの15すべてのチェックに1件も引っかからなかった場合に限り、Pegasusの動画記述API呼び出しを全カットしてスキップします。これが現在の開発において大きな処理時間、費用の最適化要素となっています。
完了確認の頻度: 5回の検索を行うたびに、別の処理過程が該当の並列動画について「完了」を出していないかをチェックしています。
つまり、最初から完璧な100%基準を満たした動画はPegasusに不必要な情報収集をしに行かなくなるため最速で生成が完了する一方で、何らかの修正点を含む動画に対しては抜け漏れなく15種すべてを評価できる一貫性を備えています。
3. WebSocketを利用しないリアルタイム性の追及
私たちのデプロイサーバー(Vercel)ではWebSocketの使用が限定的だったため、定期的に何度もリクエストをかけて状況をリアルタイム並みに近づける「ポーリング」を採用しました:
一時的ログ追記用の保持配列(バッファ): バックエンド側の多様な挙動のログを最大で直近200件分リングバッファ内に保管しています
洗練されたAPIポーリング: 切断処理とサーバー負荷軽減を挟みつつ、1秒単位の超密着型リクエストを実行します
ノイズとなる定形メッセージの除外: 代わり映えしない単なるクエリ呼び出し状況などはクライアントに通知せず、意思決定を必要とする主要イベントのみを強調して流します
これにより、完全な双方向常時接続のない通信環境でも、ユーザーはバックアイランドでのログ動作変更を1-2秒以内で目の当たりにすることができます。
4. 1度で完璧ではなく、耐障害性と途中経過の保存(Graceful Degradation)の優先
AI環境においては予期しないトラブルが突発的に発生します(レート制限、API側の機能遅延や一時的なダウン、回線のタイムアウトエラー)。これらを完全に防ぐシステムよりも、「システムエラーが起きた状況でも諦めず進行する」復元力の仕組みをベースに構築を行いました:
Pegasus呼び出し時のタイムアウト処理: 記述失敗を検知した場合、システムエラーで丸ごとプログラムクラッシュさせず、代替ロギングに切り替えて次に進みます
APIの制限通知検出: 適切な待ち時間、リトライのリカバリー動作を自動で挟み込みます
一部検索の取り落とし時の処理: 例えば15種チェックのうち14件が正常終了していた場合は、手元のデータ領域だけで計算してループを推し進めます
私たちの基本設計思想: 不完全な結果は、何も結果を得られないことよりも優れている。
仕組みをさらに加速させるための開発ティップス
Recurserの構築プロセスは、AI技術を高速化するための多くの有益な学びとなりました。実際に速度や有用性に繋がった要素を紹介します:
AIパイプラインに適用される 80/20 の法則
最適化に投下した全エネルギーの約8割は、次の3つのアプローチに注ぎ込まれました:
条件付きPegasus分析: Marengo検索結果に何一つつまずくポイントがなかった(異常痕跡0)ケースでは、Pegasusの重厚な分析フェイズの一切をパスすることで動画あたり約0.05ドルのコストを削減、待機時間も30秒以上一気に削減されました。
知的な検索単位のパッケージ化(Batching): クエリ状態のごく細かなDB更新を、毎検索、個別で毎回走らせず、5件のチェックの節目に見直す形を取ることで、アクセス処理にかかるオーバーヘッドを15分の1以下まで圧縮。何よりメインスレッドの詰まりを完全に防げるようになりました。
徹底した包括的チェックの維持: 早期終了の条件に逃げず、15種すべての要素をきっちり調べ抜く方式に決断しました。完璧な動画に対して多少多くクエリ枠を消費する仕様となりましたが、何よりも優先度が高い精度面の抜けを封じるという絶対的なメリットを手に入れることができました。
機能しなかったアプローチとその理由
開発段階の検証、試験環境を経て、ボツとなり取り下げる判断に至った幾つかの最適化設計もあります:
検索の複数並列化(Parallelization): 15種類のすべてのカテゴリを完全に同時に投げる試みを行いましたが、プロバイダ側APIの同時呼び出し過多の制限エラー(レートリミット)を多発したため、確実に処理を分散させるシーケンシャル型(逐次処理)が安全であるという設計に戻しました。
内容の一時記憶保存(キャッシュ)の維持: 近い、または同様な構成の動画のときにPegasusの中身情報を同じにしようと一時記録(キャッシュ)を使い回す仕組みを検証しましたが、AIの動画はミリ秒違うだけで全く異なる出力アーティファクトを引き起こしかねず、誤検知の原因になり再利用性は極めて低かったです。
フレームを一定間隔で飛ばす削減(サンプリング): チェック時間短縮を目的に動画の前後一部の切り出し分析のみを行う実装テストを行いましたが、動画に発生する特有の映像破綻や乱れは切り詰めた前後の瞬間にだけ突然現れるパターンなどを検出できなくなってしまったため、フルフレームチェックの仕組みに固定しました。
フロントエンド: 見過ごされていた性能問題の引き金
フロントエンド側はただ情報を流し込むだけのUIではなく、リアルタイムな状態変更を受け続けるモニタリング基盤です。ここに以下の快適化設計を組みました:
循環ログ表示の設計: 過去データの最大配列上限にキャップを設け、ブラウザクラッシュや深刻なメモリリークを起こすバグを取り除きました(チェック中に10,000行以上の生データ描画処理に耐えるためです)
動画再生ユニットの一元化: 役割別に3系統用意されていた動画再生コンポーネントを、柔軟にあらゆるシチュエーションを描写できる単一のプレイヤーへ集約しました。ライブラリ読み込みサイズが削減され、ページの再レンダリング処理が非常に早く完了する恩恵を受けられました。
デバッグのノイズカット: 内部動作で生じているシステムAPIのチェックコールなど、ユーザーが見ても意味の分からない詳細ログの80%以上をユーザー用の画面出力ログからフィルターで遮断しました。
こうした最適化により、どれほど重たい何往復もの繰り返し実行プロセスが発生している最中でも、ブラウザ側の操作は常に機敏さを維持できるようになりました。
各種データ出力
Recurserは生成した動画に対して体系的で詳細な出力結果を用意します:
動画関連メタデータ(情報の保存)
最適化済み動画(Final Video): 繰り返し判定のなかで最大の評価をマークした極上の1本です
全ての反復履歴(All Iterations): どの時点からスタートし、どのような変化を遂げたのかを全て巻き戻して検証できます
一連の評価スコア(Quality Scores): 反復時に各段階で算出されたスコアを一覧表示します
詳細診断レポート
検索によるヒット記録(Search Results): 15カテゴリから見い出したおかしな領域や問題点の全状況リスト
プロ記述による問題検出(Analysis Results): Pegasusによる精査説明と、改善を導くための補強要素
日時ログ(Detailed Logs): タイムスタンプを詳細に伴った一連の処理進行ヒストリー
プロンプト改善ログ
初回プロンプト(Original Prompt): 最初に入力された動画用テキスト
改善されたすべてのプロンプト(Enhanced Prompts): イテレーションのなかで、Geminiによってどうブラッシュアップされていったのかの変化履歴
改善軌道(Improvement Trajectory): 品質評価スコアの右肩上がりの軌跡グラフ
プログラム開発・API実例
実行例 1: プロンプトからの生成指定
POST /api/videos/generate { "prompt": "庭で紅茶を飲む猫", "max_iterations": 5, "target_confidence": 100.0, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
返却値の例:
{ "success": true, "video_id": 123, "status": "処理中", "message": "動画生成を開始しました" }
実行例 2: 既存動画のアップロード
POST /api/videos/upload { "file": <動画ファイル>, "prompt": "使用された元のプロンプト", "max_iterations": 3, "index_id": "あなたのインデックスID", "twelvelabs_api_key": "あなたのAPIキー" }
実行例 3: 進行・処理状況の確認
GET /api/videos/123/status
返却値の例:
{ "success": true, "data": { "video_id": 123, "status": "完了", "current_confidence": 100.0, "iteration_count": 2, "final_confidence": 100.0, "video_url": "https://..." } }
クオリティスコアが意味するもの
表示される点数は当て推量ではなく、検出された具体的な異常の判定と件数に基づいています:
100%: 250以上の個別検査において全項目合格。一般クリエイターが見てもAI動画とほぼ判別のつかない極上の一本です。
80-99%: 軽微なアラートが1〜6件程度検出。1、2イテレーション程度でスムーズに修正される見込みが高い良好な状態です。
50-79%: 見逃せない不自然さやおかしな箇所が多数。数多くの欠点が混ざり込んでいるため、3〜5段階の段階的プロンプト改善をおすすめします。
50%未満: 決定的な破綻や激しいバグが多発。元の設定そのものにズレなどが発生しているおそれがあるため、最初からプロンプトを練り直すことをお勧めします。
いつ処理を中断すべきか
Recurserは100%に達すると自動的に停止しますが、以下のような状況ではそれよりも早い段階で意図的に打ち切る選択肢も有効です:
コストの節約を重視する際: 1回回すごとに新しい生成APIと診断チェック処理がそれぞれ計上されます(動画の長さなどによりますが通常1ループあたり0.1〜0.5ドル程度)
時間の制約を考慮する際: 完璧を目指して繰り返し回すほど、何分もの待ち時間(イテレーションあたり2〜5分)が消費されていきます
妥協点を調整する際: 社内資料やテスト段階であれば、85%以上の仕上がりで十分に事足りるケースもあります
伸び代の限界に達した場合: 2回以上続けてスコアがまったく変わらないような場合、そのテーマに対するプロンプトのアプローチ自体が何らかの限界にぶつかっている、あるいは基礎プロンプトの構成が適切でないと考えられます
ただの改善にとどまらない! さらに一歩踏み込んだ応用的な活用シーン
Recurserによる反復改善の手法は、シンプルに粗い部分を取り除くこと以外にも大きな可能性をもたらします:
プロンプトのA/Bテスト
表現パターンのどれが一番綺麗に写るかを人間が当てにいくのではなく、複数の記述パターンを同時に開始させてどちらが最少回数のイテレーションで100%に到着したかを見比べることで、最適な指示テキストを逆引きで割り出せます。
分野(ドメイン)を特化した不具合検出
すでに多くの開発者が、以下のような特定の課題に向けてRecurserをさらに応用させています:
製品向けの動画(商品広告等): 「コマーシャル等で撮影されたとき特有の照明や解像感」になるように検出チェックを強化
人間のキャラクター表現: 表情が不自然に引き攣る「不気味の谷」の課題や、人間ならではの腕や足の動作のブレに特化して検出
リアルな自然・動物動画: 「背景の物理法則が一貫しているか」「空間のディテールが正確か」といった整合性の検証
特筆すべきこととは? システムの本底にある構造を変えることなく、関心対象となる検出ワードを指定する辞書をアレンジするだけでこの対応ができる点です。
「プロンプトエンジニアリング」そのものを自動提供するサービスへ
Recurserの本質は、ユーザーに代わってプロンプトの記述を最適化してあげる点にあります。ふわっとしたアイデアを与えるだけでプログラム自身が思考し、望まれたハイクラスな動画が生まれるまでの「最適なプロンプトテキスト」を吐き出します。将来的にこのプロンプト作成プロセスを自動解決するサービスとしての広がりも予想されます。
成功パターンからの継続成長
非常にエキサイティングな疑問: もしRecurserが自己のアプローチと検証経過を学習記録していけるとしたら? 以前この組み合わせの指示に対してどう修正したかのログをあらかじめ把握できていれば、次は初回の1歩目をショートカットしていきなり最適化されたプロンプトから作成指示へ到達できるようになるでしょう。この「改善成功パターンデータベース」を作れば、究極のプロンプト向上AIモデルが完成します。
Recurserを使うべきでないとき
Recurserはいつでも常に最高のアプローチであるとは言えません:
秒単位の高速出力が必要なとき: 反復に2〜5分もかけられないオンザフライ(その場)の生成では不向きです。チェックなしの直書きで回しましょう。
極端にコストを制限するプロダクト: 大量運用のスケール段階ではAPI呼び出し費用が重なるため、事前に検証し終えた最高のプロンプトをワンショットで打つ仕組みが好ましいです。
多様な可能性を広く見たい場合: 1つの対象アイデアをじっくり磨いて品質を上げるより、まずは沢山の全く違う変化球の画像をばら撒いて比較検討したいという段階には適しません。
技術図面や厳格な製品規格などを反映したいとき: 色の厳密さ・サイズ寸法比などに対しては、プロンプト指示改善に頼るより通常の後処理レンダリングを利用するのが確実です。
あなたのおかれているゴール設計を整理しましょう。 クオリティ、速度、そして制作費用—この3つのうち、狙いたい2つを決めるのです。
おわりに: AI映像クオリティの未来
Recurserは「ソフトウェアと同じように、自動化されたテストと段階的なデバッグ手法をAI動画生成にも適用できないか?」という一つのシンプルな気づき、実験から産声をあげました。その探究を通じて発見したのは、 この手法こそがAI動画品質に対する考え方そのものを劇的に塗り替えるという事実です。
AIが出力した生成動画に少しノイズがあるからとガッカリする必要はなく、徹底的な改善をプログラム側へと自信を持って要求することができます。そして、人間が何時間も画面にかじりついて手動で調整する必要もありません。全てをシステム化されたフィードバックに委ねることができるのです。
この技術が切り拓く非常に興味深い可能性:
クリエイターにとって: プロンプト書きの達人や専門の映像プロデューサー、エンジニアでなくとも、手元のシンプルな想いだけで自動的にプロの手によるかのような映像を作り上げることができます。
システムデベロッパーとして: 人間の判定者を介さず、映像作品の仕上がりを常に高次で安定担保可能になります。自動検知と補正によって安全で美しい素材だけを何百本も一度にお届けできるようになります。
AI業界におけるロードマップとして: 将来的に基礎モデル側の性能が高くなるほど、当然ながら修正の必要なイテレーション回数は減少します。しかしモデルがどれほど進化しようとも、「その出力が本当にリアルかどうか」を厳格にダブルチェックしてくれるRecurserのようなバランサーは、どのような映像生成でもその役割を輝かせ続けます。
今ある素晴らしい基盤をベースに、ここからは、まさにふさわしく「繰り返しのステップ(イテレーション)」を踏み出しながらさらに進化していきます。
その他の参考リンク・リソース
稼働デモサイト: Recurserアプリ
GitHubコード: Recurser on GitHub
TwelveLabsドキュメント: PegasusおよびMarengo解説ガイド
Google Gemini API: プロンプト最適化における開発ルール
動画生成モデルの情報: Google Veo 2.0 開発者ドキュメント




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.


