
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
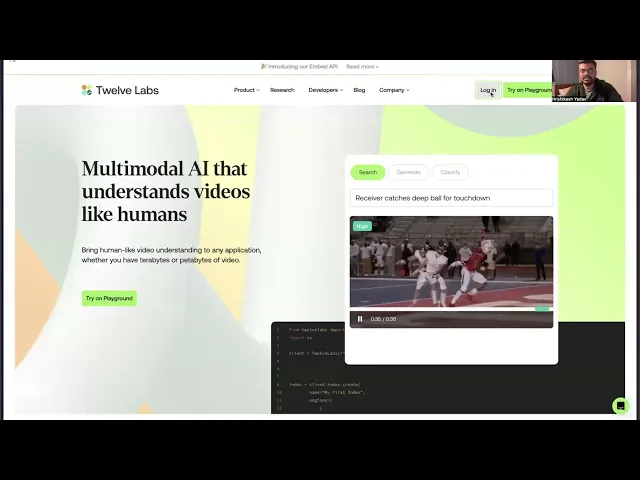
チュートリアル
Twelve Labsを使用した多言語ビデオ文字起こしアプリの構築

リシケシュ・ヤダフ
このチュートリアルでは、「マルチリンガル・ビデオ・トランスクライバー」の構築プロセスを順を追って解説します。このツールは、Twelve Labs APIを使用することで、手動での文字起こしや翻訳作業を行うことなく、任意の言語でタイムスタンプ付きの文字起こしを作成し、初心者のレベル、中級者のレベル、上級者のレベルに合わせた出力の複雑さの調整を可能にします。
このチュートリアルでは、「マルチリンガル・ビデオ・トランスクライバー」の構築プロセスを順を追って解説します。このツールは、Twelve Labs APIを使用することで、手動での文字起こしや翻訳作業を行うことなく、任意の言語でタイムスタンプ付きの文字起こしを作成し、初心者のレベル、中級者のレベル、上級者のレベルに合わせた出力の複雑さの調整を可能にします。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2024/11/19
10分
記事へのリンクをコピー
異なる言語の動画コンテンツを理解するのに苦労していませんか?あるいは、世界中のオーディエンスに向けてコンテンツをアクセシブルにすることに難しさを感じていませんか? 🌍
このチュートリアルでは、「マルチリンガル動画文字起こしアプリケーション(MultiLingual Video Transcriber Application)」を紹介し、その開発プロセスについて解説します。このアプリケーションは、Twelve LabsのAIモデルを活用して動画を理解し、複数の言語でシームレスな文字起こしを提供します。
このプログラムのユニークな点は、ユーザーが選択した習得レベル(初級、中級、上級)に合わせて文字起こしの内容を調整できることです。ユーザーは選択したレベルに最適化された文字起こしや翻訳テキストを受け取ることができます。さらに、このアプリケーションは正確なタイムスタンプを提供するため、ユーザーは発話された言葉と文字起こしテキストの同期を追うことができます。この機能により、コンテンツのナビゲーションや理解が容易になります。このアプリケーションの仕組みと、TwelveLabs Python SDKを使用して同様のソリューションを構築する方法について探っていきましょう。
アプリケーションのデモは、こちらから体験できます:動画マルチリンガル文字起こしデモ(Video Multilingual Transcriber)
コードにアクセスしてアプリを直接試してみたい場合は、こちらのReplit テンプレートをご利用ください。
前提条件
Twelve Labs Playgroundにサインアップして、APIキーを生成します。
このアプリケーションのリポジトリは Video Multilingual Transcriber で確認できます。
Flask、HTML、CSS、JavaScriptに関する基本的な知識があることを前提としています。
アプリケーションの仕組み
このセクションでは、マルチリンガル動画文字起こしアプリケーションを開発するための処理の流れを説明します。このプロセスは、動画を取得し、ユーザーの好みに応じて様々な言語と習得レベルの文字起こしを生成します。単なる単純な文字起こしにとどまらず、より包括的なソリューションを提供します。
システム構成は、フロントエンド層、バックエンド層、ストレージ層、そしてTwelveLabsサービスの4つの主要コンポーネントで構築されています。仕組みは次の通りです:ユーザーが(外国語の可能性がある)動画をアップロードし、希望する翻訳言語と習得レベル(初級、中級、上級)を選択します。
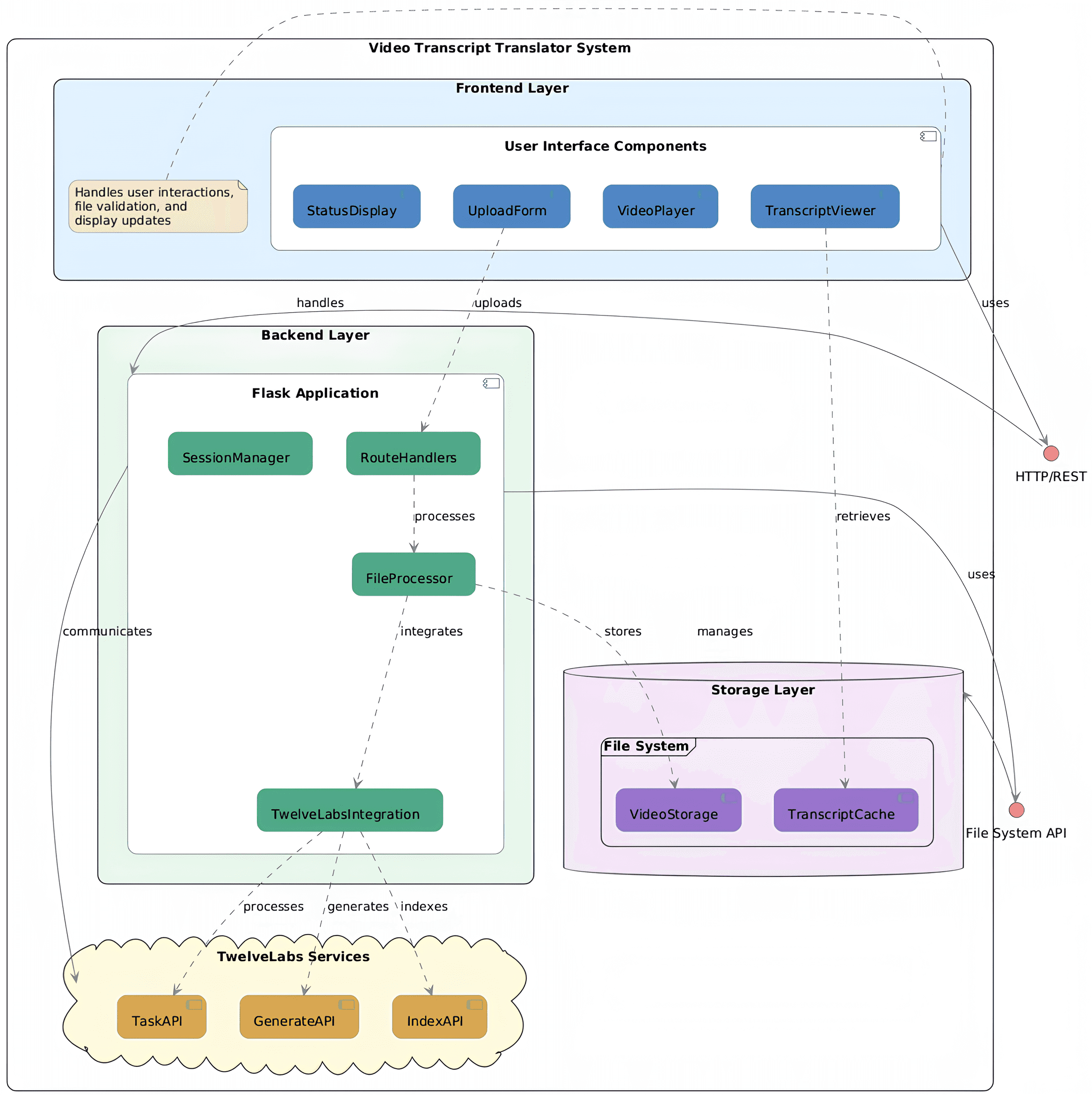
動画アップロード後に「送信(submit)」ボタンをクリックすると、インデックスID(Index ID)が生成され、今後の使用に備えてセッション状態で保存されます。次に、システムは動画をアップロードしてタスクID(Task ID)を作成し、インデックス処理が完了するとビデオID(Video ID)が取得されます。インデックス処理のエンベディングエンジンにはMarengo 2.6が使用され、文字起こしの生成には、Generate APIを介してPegasus 1.1エンジン(ジェネレーティブエンジン)が使用されます。
ユーザーの利便性を高めるため、アプリケーションは文字起こしとともにタイムスタンプを生成します。この機能により、文字起こしテキストと動画再生の間でインタラクティブな同期が可能になります。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数を準備します。
Githubからプロジェクトをクローンするか、Replit テンプレートを使用します。
メインファイルと同じ階層に、APIキーを設定した
.envファイルを作成します。
API_KEY=your_api_key_here
これらの手順が完了したら、いよいよアプリケーションの開発を開始しましょう!
VidScribe - 動画マルチリンガル文字起こしアプリのウォークスルー
このチュートリアルでは、最小限のフロントエンドを持つFlaskアプリケーションを構築します。ディレクトリ構造は以下の通りです:
. ├── app.py ├── requirements.txt ├── static │ ├── style.css │ └── main.js ├── templates │ └── index.html └── uploads
Flaskアプリケーションの作成
準備手順が完了したので、Flaskアプリケーションを実装します。これにより、動画をアップロードしてユーザーの好みに応じた様々な言語の文字起こしを生成するためのシンプルな方法が構築できます。
仮想環境を準備して作成するために必要な依存関係は、こちらで確認できます:requirements.txt
Pythonの仮想環境を作成し、次のコマンドを実行してアプリケーションの環境をセットアップします:
pip install -r
1 - メインアプリケーションの構築
このセクションでは、重要なロジックと指示フローが含まれるメインアプリケーションのユーティリティ機能に焦点を当てます。メインアプリケーションをいくつかのセクションに分解して説明します:
インデックスの作成
結果の生成
アップロード用コンポーネント
1.1 - インデックスの作成
ここでは、Twelve Labs SDKを使用してインデックスを構成する方法について説明します。このFlaskアプリケーションは、ユーザーが動画をアップロードして様々な目的のために処理できるようにします。本番環境で確実に動作するように、安全なファイル名の処理システムとセッション管理を採用しています。
# 必要なモジュールのインポート from flask import Flask, render_template, request, jsonify, send_from_directory, session from werkzeug.utils import secure_filename import os import uuid from twelvelabs import TwelveLabs from twelvelabs.models.task import Task from dotenv import load_dotenv load_dotenv() # 環境変数からTwelve LabsのAPIキーを読み込む API_KEY = os.getenv("API_KEY") app = Flask(__name__) app.secret_key = os.urandom(24) UPLOAD_FOLDER = 'uploads' ALLOWED_EXTENSIONS = {'mp4', 'avi', 'mov'} app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024 # Twelve Labs SDK クライアントの初期化 client = TwelveLabs(api_key=API_KEY) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS @app.route('/') def index(): return render_template('index.html') # ステータス確認用のユーティリティ関数 def on_task_update(task: Task): print(f"Status={task.status}") def process_video(filepath, language, difficulty): try: if 'index_id' not in session: # インデックス名の設定 index_name = f"Translate{uuid.uuid4().hex[:8]}" # エンジンの定義 engines = [ { "name": "pegasus1.1", "options": ["visual", "conversation"] }, { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] } ] # 設定を適用したインデックスの作成 index = client.index.create( name=index_name, engines=engines ) # インデックスIDをセッションに格納し、後の処理で再利用できるようにする session['index_id'] = index.id print(f"Created new index with ID: {index.id}") else: print(f"Using existing index with ID: {session['index_id']}") # タスクの作成 task = client.task.create(index_id=session['index_id'], file=filepath) task.wait_for_done(sleep_interval=5, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}") print(f"The unique identifier of your video is {task.video_id}.")
セッション状態を管理して、インデックスIDの作成を堅牢に処理します。UUIDによってインデックス名にランダムな番号が付加され、セッションごとに一意のインデックス名が作成されます。この新しいインデックスIDは、後で参照できるようにセッションに保存されます。
インデックス構成では、2つのエンジンを定義しています。動画のインデックス作成にはMarengo 2.6(エンベディングエンジン)を使用し、インデックスされた動画にアクセスして自由形式のプロンプトなどに基づいてコンテンツを生成するためにPegasus 1.1(ジェネレーティブエンジン)を使用します。
タスクを作成するには、インデックスIDと動画ファイルのパスを指定します。タスクの処理ステータスは `task.status` を使って追跡できます。インデックス作成が完了すると、次のステップで生成されたビデオIDが使用されます。
1.2 - 結果の生成
このセクションでは、ユーザーが選択した難易度レベルと希望する言語設定に基づいて、インデックス化された動画からテキストを生成する部分を扱います。私たちのプロンプトエンジニアリングシステムは、正確なタイムスタンプと翻訳を維持しながら、ユーザーの理解レベルに合わせて動画文字起こしの複雑さと詳細度を調整します。
# 難易度レベルに応じたアップデートされたプロンプト difficulty_prompts = { "beginner": "Provide a simplified and easy-to-understand", "intermediate": "Provide a moderately detailed", "advanced": "Provide a comprehensive and detailed" } # ユーザーフォームから取得した難易度レベルを格納 base_prompt = difficulty_prompts.get(difficulty, difficulty_prompts["intermediate"]) # 生成のためのオープンエンドプロンプト prompt = f"Provide the Only Transcript in the Translated {language.capitalize()} Language, {base_prompt} level with the timestamp duration (in the format of ss : ss) of the Indexed Video Content." res = client.generate.text(video_id=task.video_id, prompt=prompt, temperature=0.25) print(res) return { 'status': 'ready', 'message': 'File processed successfully', 'transcript': res.data, 'video_path': f'/uploads/{os.path.basename(filepath)}' } except Exception as e: print(f"Error processing video: {str(e)}") return {'status': 'error', 'message': str(e)}
辞書(dictionary)を用いたアプローチで難易度レベルを適切なプロンプトテンプレートにマッピングし、デフォルトのフォールバックとして中級レベルを設定します。一貫性があり信頼性の高い出力生成を実現するために、システムのTemperature値を0.25と低く維持しています。レスポンスには、タイムスタンプ付きの処理済み文字起こしデータが含まれます。
1.3 - アップロード用コンポーネント
このセクションでは、Flaskアプリケーションで安全なファイルアップロードのエンドポイントを生成および管理し、ユーザーからのファイル送信を処理する方法について解説します。このコンポーネントは、ファイルのアップロードプロセスを管理し、ファイルタイプを検証し、言語や難易度の設定を処理します。さらに、ワークフロー全体の適切なエラーハンドリングを維持しながら、アップロードされた動画の安全な保存を保証します。
# ファイルアップロードを処理するルート - POSTリクエストのみを許可 @app.route('/upload', methods=['POST']) def upload_file(): # リクエストにファイルが含まれているか確認 if 'file' not in request.files: return jsonify({'status': 'error', 'message': 'No file part'}), 400 # リクエストからファイルを取得 file = request.files['file'] # フォームデータから抽出した言語設定、未指定の場合はデフォルトでドイツ語を設定 language = request.form.get('language', 'german') difficulty = request.form.get('difficulty', 'intermediate') # ファイルが実際に選択されているか検証 if file.filename == '': return jsonify({'status': 'error', 'message': 'No selected file'}), 400 # 許可されたファイル拡張子であるか確認し、処理を進行 if file and allowed_file(file.filename): filename = secure_filename(file.filename) filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename) file.save(filepath) # 設定された言語と難易度で動画処理を実行 result = process_video(filepath, language, difficulty) # 処理結果をJSON応答として送信 return jsonify(result) # 許可されていないファイルタイプの場合はエラーを返す return jsonify({'status': 'error', 'message': 'File type not allowed'}), 400 # アップロードされたファイルを提供する配信ルート @app.route('/uploads/<filename>') def uploaded_file(filename): return send_from_directory(app.config['UPLOAD_FOLDER'], filename)
動画ファイルと関連するメタデータを処理するためのアップロード先エンドポイントを提供しています。このアップロードルートでは、安全なファイル名処理としてWerkzeugの secure_filename ユーティリティを使用し、適切なHTTPステータスコードを返す堅牢なエラーチェックを実装しています。言語や難易度の設定が指定されない場合、システムはそれぞれドイツ語と中級(intermediate)に設定します。また、ファイルを配信するルートがあることで、指定のディレクトリを通じてアップロード動画への安全なアクセスが可能になり、アクセス制限とファイルシステムのセキュリティが保護されます。
2 - JavaScriptによるコンポーネント処理
このセクションでは、app.jsファイルに含まれる主要な処理ユーティリティについて解説します。このJavaScriptファイルは、ファイルのアップロード、フォーム送信、タイムスタンプ付きの文字起こしデータと動画の同期再生、エラーハンドリング、そしてその他の画面のステータス管理を処理します。main.jsを以下の2つのセクションに分解して説明します:
ファイルのアップロードと検証
文字起こしデータのパース処理
2.1 - ファイルのアップロードと検証
このセクションでは、クライアントサイドでの包括的な検証および送信処理の構成について紹介します。アップロード処理中に動画ファイルを検証し、選択ファイルの削除に対応し、フォームを非同期通信で送信する仕組みが組み込まれています。
// アップロードされたファイルの検証 function validateFile(file) { const validTypes = ['video/mp4', 'video/avi', 'video/quicktime']; const maxSize = 100 * 1024 * 1024; // 100MB if (!validTypes.includes(file.type)) { updateStatus('有効な動画ファイル(MP4, AVI, もしくは MOV)を選択してください', 'error'); return false; } if (file.size > maxSize) { updateStatus('ファイルサイズは100MB未満にしてください', 'error'); return false; } return true; } // 選択されたファイルの削除処理を行うユーティリティ関数 function handleFileRemove(e) { e.preventDefault(); fileInput.value = ''; selectedFile.classList.add('hidden'); uploadPrompt.textContent = '動画を選ぶか、ここにドラッグしてください'; updateStatus('', ''); } // フォーム送信の処理 async function handleFormSubmit(e) { e.preventDefault(); const formData = new FormData(e.target); if (!fileInput.files || !fileInput.files[0]) { updateStatus('まず始めにファイルを選択してください', 'error'); return; } const loadingOverlay = document.getElementById('loading-overlay'); loadingOverlay.classList.remove('hidden'); updateStatus('ファイルをアップロードして処理中...', 'loading'); // 過去の結果表示を切り替える hideResult(); try { // フォームとともにPOSTリクエストを作成してエンドポイントへ送信 const response = await fetch('/upload', { method: 'POST', body: formData }); // JSONレスポンスのパース const data = await response.json(); console.log('Server response:', data); // アップロードと処理に成功したか確認 if (response.ok && data.status === 'ready') { // 状態表示を完了に切り替えて取得データを反映表示 updateStatus('処理が完了しました!', 'success'); showResult(); displayTranscript(data.transcript); displayVideo(data.video_path); } else { // 処理に失敗した場合はエラーをスローする throw new Error(data.message || 'データ処理中にエラーが発生しました'); } } catch (error) { // エラーを検知してログを出力し表示 console.error('Error:', error); updateStatus(`Error: ${error.message}`, 'error'); } finally { // 処理が完了したら成否に関わらずローディング画面を非表示にする loadingOverlay.classList.add('hidden'); } }
validateFile 関数により正しい形式の動画フォーマットと許容されるサイズ以外の不正なファイルが除外され、handleFileRemove が呼び出されると選択されていたファイルの削除と共にステータス表示がリセットされます。また、handleFormSubmit が非同期処理としての送信を仲介し、適切なエラー制御やロード時の進行状況を処理します。
この処理には、状況に合わせた表示を画面上に反映するために、ローディングオーバーレイの有効化・完了通知メッセージの切り替え・エラー発生時の通知表示といった細やかなステータス制御が含まれています。アップロードの各種段階で、常に一貫した使いやすさを提供します。
2.2 - オープンエンドプロンプトを処理する文字起こしパースの処理
このセクションでは、頑健な文字起こしパーサー(解析処理)のJavascript記述に焦点を当てます。このプログラムは、生成AIの自由なテキスト回答において検出される、様々な形式のタイムスタンプ情報や構文構成を網羅し、各構成の時間ベース位置に整合させてテキストを適切に配列します。
この処理により原型のテキストを構造化配列データに編集することで動画プレーヤーと文字起こしテキストのタイムラグの同期表現を行い、文字起こしの際に想定される例外部分や形式のブレに対する汎用的な適応を備えます。
// Parses a transcript string into structured data with timestamps and text function parseTranscript(transcript) { console.log('Raw transcript:', transcript); // Initialize Map to store unique entries (prevents duplicates) const entries = new Map(); if (!transcript) { console.error('Empty transcript received'); return []; } // Extract data from JSON response and handle escapes let transcriptText = transcript; try { if (typeof transcript === 'string' && (transcript.includes('"id":') || transcript.includes("'id':"))) { const dataMatch = transcript.match(/['"]data['"]\s*:\s*['"]([^]+?)['"]\s*$/); if (dataMatch && dataMatch[1]) { transcriptText = dataMatch[1] .replace(/\\n/g, '\n') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\'); } } } catch (e) { console.error('Error parsing JSON response:', e); } // Different timestamp patterns const patterns = [ // HH:MM - HH:MM : "text" /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*["']([^"']+)["']/g, // HH:MM - HH:MM: text /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*([^"\n]+)/g, // Simple format with quotes /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*["']([^"']+)["']/g ]; // Try each pattern against the transcript text for parsing for (const pattern of patterns) { let match; while ((match = pattern.exec(transcriptText)) !== null) { try { const [_, startMin, startSec, endMin, endSec, text] = match; // Convert timestamps to seconds const startTime = parseInt(startMin) * 60 + parseInt(startSec); const endTime = parseInt(endMin) * 60 + parseInt(endSec); // Skip invalid timestamps if (isNaN(startTime) || isNaN(endTime)) continue; // Clean up theo transcript text, if appears const cleanText = text .replace(/^["'\s]+|["'\s]+$/g, '') .replace(/\\n/g, ' ') .replace(/\*\*/g, '') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\') .replace(/\s+/g, ' ') .trim(); if (cleanText && !cleanText.includes('Note:')) { const key = `${startTime}-${cleanText.substring(0, 50)}`; entries.set(key, { start: startTime, end: endTime, text: cleanText }); } } catch (e) { console.error('Error processing match:', e); continue; } } } // Convert Map to Array and sort by start time const sortedEntries = Array.from(entries.values()) .sort((a, b) => a.start - b.start); // Log processed result console.log('Parsed entries:', sortedEntries); return sortedEntries; }
パースを機能させるために、各種パターンに対応する正規表現を使用し、時間指定を秒表記へと変換し、タイム表示に伴う不要ノイズを取り除くよう文字列処理を行います。Map型オブジェクトを用いて重複登録を抑止しつつ時系列を適正順に構成します。また、任意のタイミングで稼働追跡ができるようにデバッグを意識した実用的なログ記述が散りばめられています。
この最終生成物を配列としてまとめることで、動画再生プレーヤーや字幕描写処理等にそのまま適用でき、正確なタイミングで画面文字起こしを表示させることができます。
上で説明されたJavaScriptファイルのコード全体は、こちらのapp.jsファイルからご確認いただけます。
デモアプリケーションの実行
初めに、対象とする翻訳変換先の言語および希望する難易度習得レベルを画面から選択し、動画をアップロードします。アップロードが完了すると、自動的にインデックス化処理が開始されます。

インデックス作成と準備タスクが完了したら、動画IDを介してユーザーの選択設定に合わせて文字起こし文を生成します。下図は、Twelve Labs SDKを用いた生成結果を表示するデモ画面です。

Twelve Labsをさらに深く試してみたい場合は、教育用途、コンテンツ配信制作、その他の分野で動画認識を活用した独自ソリューションのアイデア生成などを進めてみてください。
このチュートリアルを応用するさらなるアイデア
マルチリンガル文字起こしアプリの基本構成を理解することで、多種多様なアイデアの着想やビジネス実用に向けた発展、新たな動画処理機能の開発などが可能になります。以下に、ユーザーの動画利用体験を豊かにする実用的な活用案を紹介します:
🌍 グローバルコンテンツクリエイター: 瞬時に多言語翻訳をまとめて自動文字起こしとして生成し、即時動画の現地ローカライズを進めオーディエンス層をグローバルに広げます。
🎓 国際遠隔教育・レッスンプログラム: ウェブ講義等の動画から自動で他国言語の字幕を作成し、生徒の語学学習レベル(初〜上級)に合わせて理解補助を行い、リソースの制限を軽減します。
💼 多国籍ビジネスにおけるミーティング効率化: 多国間のリモートビデオ面談を一斉にローカル言語へと書き出し、スムーズな多国間商談の要約や確認を可能にします。
まとめ
Twelve Labsを使用した、マルチリンガル動画自動文字起こしアプリケーションの開発と仕組みについてのチュートリアルに最後までお付き合いいただき、ありがとうございました。動画を高度に理解して処理する機能と、今回のアプリ構成フローを組み合わせることで、皆様の新しいアプリ開発の発想に繋がれば幸いです。機能追加や開発上の課題に対する皆様からの積極的なご意見をお待ちしています。
その他のドキュメント関連リソース
動画理解とテキスト生成処理に使用している各エンジンの仕様詳細は、こちらの資料をご覧ください:Marengo 2.6 (エンベディングエンジン) および Pegasus 1.1 (ジェネレーティブエンジン)。また、Twelve Labsを活用するためのリソースや動画データ解析の学習のために、以下の便利なコンテンツをご覧ください:
Discord コミュニティ: 開発仲間が多く籍を置く公式Discordにぜひ登録してください。不明点に関するQ&Aや開発アイデアの進捗共有などが活発に行われています。
サンプルアプリケーション群: すぐに試して理解を深められるアイデア別の導入デモなどを、次の開発のきっかけにお役立てください。
チュートリアル閲覧: Twelve Labsが有する多様なマルチメディア理解機能をさらに深く引き出すための方法を、詳細な手順書とともに追求できます。
ぜひこれらの公式リソースをフルに活用いただき、Twelve Labsの高度な映像理解技術によるまったく新しい革新的ビデオアプリケーションの創出に挑戦してください。
異なる言語の動画コンテンツを理解するのに苦労していませんか?あるいは、世界中のオーディエンスに向けてコンテンツをアクセシブルにすることに難しさを感じていませんか? 🌍
このチュートリアルでは、「マルチリンガル動画文字起こしアプリケーション(MultiLingual Video Transcriber Application)」を紹介し、その開発プロセスについて解説します。このアプリケーションは、Twelve LabsのAIモデルを活用して動画を理解し、複数の言語でシームレスな文字起こしを提供します。
このプログラムのユニークな点は、ユーザーが選択した習得レベル(初級、中級、上級)に合わせて文字起こしの内容を調整できることです。ユーザーは選択したレベルに最適化された文字起こしや翻訳テキストを受け取ることができます。さらに、このアプリケーションは正確なタイムスタンプを提供するため、ユーザーは発話された言葉と文字起こしテキストの同期を追うことができます。この機能により、コンテンツのナビゲーションや理解が容易になります。このアプリケーションの仕組みと、TwelveLabs Python SDKを使用して同様のソリューションを構築する方法について探っていきましょう。
アプリケーションのデモは、こちらから体験できます:動画マルチリンガル文字起こしデモ(Video Multilingual Transcriber)
コードにアクセスしてアプリを直接試してみたい場合は、こちらのReplit テンプレートをご利用ください。
前提条件
Twelve Labs Playgroundにサインアップして、APIキーを生成します。
このアプリケーションのリポジトリは Video Multilingual Transcriber で確認できます。
Flask、HTML、CSS、JavaScriptに関する基本的な知識があることを前提としています。
アプリケーションの仕組み
このセクションでは、マルチリンガル動画文字起こしアプリケーションを開発するための処理の流れを説明します。このプロセスは、動画を取得し、ユーザーの好みに応じて様々な言語と習得レベルの文字起こしを生成します。単なる単純な文字起こしにとどまらず、より包括的なソリューションを提供します。
システム構成は、フロントエンド層、バックエンド層、ストレージ層、そしてTwelveLabsサービスの4つの主要コンポーネントで構築されています。仕組みは次の通りです:ユーザーが(外国語の可能性がある)動画をアップロードし、希望する翻訳言語と習得レベル(初級、中級、上級)を選択します。
動画アップロード後に「送信(submit)」ボタンをクリックすると、インデックスID(Index ID)が生成され、今後の使用に備えてセッション状態で保存されます。次に、システムは動画をアップロードしてタスクID(Task ID)を作成し、インデックス処理が完了するとビデオID(Video ID)が取得されます。インデックス処理のエンベディングエンジンにはMarengo 2.6が使用され、文字起こしの生成には、Generate APIを介してPegasus 1.1エンジン(ジェネレーティブエンジン)が使用されます。
ユーザーの利便性を高めるため、アプリケーションは文字起こしとともにタイムスタンプを生成します。この機能により、文字起こしテキストと動画再生の間でインタラクティブな同期が可能になります。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数を準備します。
Githubからプロジェクトをクローンするか、Replit テンプレートを使用します。
メインファイルと同じ階層に、APIキーを設定した
.envファイルを作成します。
API_KEY=your_api_key_here
これらの手順が完了したら、いよいよアプリケーションの開発を開始しましょう!
VidScribe - 動画マルチリンガル文字起こしアプリのウォークスルー
このチュートリアルでは、最小限のフロントエンドを持つFlaskアプリケーションを構築します。ディレクトリ構造は以下の通りです:
. ├── app.py ├── requirements.txt ├── static │ ├── style.css │ └── main.js ├── templates │ └── index.html └── uploads
Flaskアプリケーションの作成
準備手順が完了したので、Flaskアプリケーションを実装します。これにより、動画をアップロードしてユーザーの好みに応じた様々な言語の文字起こしを生成するためのシンプルな方法が構築できます。
仮想環境を準備して作成するために必要な依存関係は、こちらで確認できます:requirements.txt
Pythonの仮想環境を作成し、次のコマンドを実行してアプリケーションの環境をセットアップします:
pip install -r
1 - メインアプリケーションの構築
このセクションでは、重要なロジックと指示フローが含まれるメインアプリケーションのユーティリティ機能に焦点を当てます。メインアプリケーションをいくつかのセクションに分解して説明します:
インデックスの作成
結果の生成
アップロード用コンポーネント
1.1 - インデックスの作成
ここでは、Twelve Labs SDKを使用してインデックスを構成する方法について説明します。このFlaskアプリケーションは、ユーザーが動画をアップロードして様々な目的のために処理できるようにします。本番環境で確実に動作するように、安全なファイル名の処理システムとセッション管理を採用しています。
# 必要なモジュールのインポート from flask import Flask, render_template, request, jsonify, send_from_directory, session from werkzeug.utils import secure_filename import os import uuid from twelvelabs import TwelveLabs from twelvelabs.models.task import Task from dotenv import load_dotenv load_dotenv() # 環境変数からTwelve LabsのAPIキーを読み込む API_KEY = os.getenv("API_KEY") app = Flask(__name__) app.secret_key = os.urandom(24) UPLOAD_FOLDER = 'uploads' ALLOWED_EXTENSIONS = {'mp4', 'avi', 'mov'} app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024 # Twelve Labs SDK クライアントの初期化 client = TwelveLabs(api_key=API_KEY) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS @app.route('/') def index(): return render_template('index.html') # ステータス確認用のユーティリティ関数 def on_task_update(task: Task): print(f"Status={task.status}") def process_video(filepath, language, difficulty): try: if 'index_id' not in session: # インデックス名の設定 index_name = f"Translate{uuid.uuid4().hex[:8]}" # エンジンの定義 engines = [ { "name": "pegasus1.1", "options": ["visual", "conversation"] }, { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] } ] # 設定を適用したインデックスの作成 index = client.index.create( name=index_name, engines=engines ) # インデックスIDをセッションに格納し、後の処理で再利用できるようにする session['index_id'] = index.id print(f"Created new index with ID: {index.id}") else: print(f"Using existing index with ID: {session['index_id']}") # タスクの作成 task = client.task.create(index_id=session['index_id'], file=filepath) task.wait_for_done(sleep_interval=5, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}") print(f"The unique identifier of your video is {task.video_id}.")
セッション状態を管理して、インデックスIDの作成を堅牢に処理します。UUIDによってインデックス名にランダムな番号が付加され、セッションごとに一意のインデックス名が作成されます。この新しいインデックスIDは、後で参照できるようにセッションに保存されます。
インデックス構成では、2つのエンジンを定義しています。動画のインデックス作成にはMarengo 2.6(エンベディングエンジン)を使用し、インデックスされた動画にアクセスして自由形式のプロンプトなどに基づいてコンテンツを生成するためにPegasus 1.1(ジェネレーティブエンジン)を使用します。
タスクを作成するには、インデックスIDと動画ファイルのパスを指定します。タスクの処理ステータスは `task.status` を使って追跡できます。インデックス作成が完了すると、次のステップで生成されたビデオIDが使用されます。
1.2 - 結果の生成
このセクションでは、ユーザーが選択した難易度レベルと希望する言語設定に基づいて、インデックス化された動画からテキストを生成する部分を扱います。私たちのプロンプトエンジニアリングシステムは、正確なタイムスタンプと翻訳を維持しながら、ユーザーの理解レベルに合わせて動画文字起こしの複雑さと詳細度を調整します。
# 難易度レベルに応じたアップデートされたプロンプト difficulty_prompts = { "beginner": "Provide a simplified and easy-to-understand", "intermediate": "Provide a moderately detailed", "advanced": "Provide a comprehensive and detailed" } # ユーザーフォームから取得した難易度レベルを格納 base_prompt = difficulty_prompts.get(difficulty, difficulty_prompts["intermediate"]) # 生成のためのオープンエンドプロンプト prompt = f"Provide the Only Transcript in the Translated {language.capitalize()} Language, {base_prompt} level with the timestamp duration (in the format of ss : ss) of the Indexed Video Content." res = client.generate.text(video_id=task.video_id, prompt=prompt, temperature=0.25) print(res) return { 'status': 'ready', 'message': 'File processed successfully', 'transcript': res.data, 'video_path': f'/uploads/{os.path.basename(filepath)}' } except Exception as e: print(f"Error processing video: {str(e)}") return {'status': 'error', 'message': str(e)}
辞書(dictionary)を用いたアプローチで難易度レベルを適切なプロンプトテンプレートにマッピングし、デフォルトのフォールバックとして中級レベルを設定します。一貫性があり信頼性の高い出力生成を実現するために、システムのTemperature値を0.25と低く維持しています。レスポンスには、タイムスタンプ付きの処理済み文字起こしデータが含まれます。
1.3 - アップロード用コンポーネント
このセクションでは、Flaskアプリケーションで安全なファイルアップロードのエンドポイントを生成および管理し、ユーザーからのファイル送信を処理する方法について解説します。このコンポーネントは、ファイルのアップロードプロセスを管理し、ファイルタイプを検証し、言語や難易度の設定を処理します。さらに、ワークフロー全体の適切なエラーハンドリングを維持しながら、アップロードされた動画の安全な保存を保証します。
# ファイルアップロードを処理するルート - POSTリクエストのみを許可 @app.route('/upload', methods=['POST']) def upload_file(): # リクエストにファイルが含まれているか確認 if 'file' not in request.files: return jsonify({'status': 'error', 'message': 'No file part'}), 400 # リクエストからファイルを取得 file = request.files['file'] # フォームデータから抽出した言語設定、未指定の場合はデフォルトでドイツ語を設定 language = request.form.get('language', 'german') difficulty = request.form.get('difficulty', 'intermediate') # ファイルが実際に選択されているか検証 if file.filename == '': return jsonify({'status': 'error', 'message': 'No selected file'}), 400 # 許可されたファイル拡張子であるか確認し、処理を進行 if file and allowed_file(file.filename): filename = secure_filename(file.filename) filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename) file.save(filepath) # 設定された言語と難易度で動画処理を実行 result = process_video(filepath, language, difficulty) # 処理結果をJSON応答として送信 return jsonify(result) # 許可されていないファイルタイプの場合はエラーを返す return jsonify({'status': 'error', 'message': 'File type not allowed'}), 400 # アップロードされたファイルを提供する配信ルート @app.route('/uploads/<filename>') def uploaded_file(filename): return send_from_directory(app.config['UPLOAD_FOLDER'], filename)
動画ファイルと関連するメタデータを処理するためのアップロード先エンドポイントを提供しています。このアップロードルートでは、安全なファイル名処理としてWerkzeugの secure_filename ユーティリティを使用し、適切なHTTPステータスコードを返す堅牢なエラーチェックを実装しています。言語や難易度の設定が指定されない場合、システムはそれぞれドイツ語と中級(intermediate)に設定します。また、ファイルを配信するルートがあることで、指定のディレクトリを通じてアップロード動画への安全なアクセスが可能になり、アクセス制限とファイルシステムのセキュリティが保護されます。
2 - JavaScriptによるコンポーネント処理
このセクションでは、app.jsファイルに含まれる主要な処理ユーティリティについて解説します。このJavaScriptファイルは、ファイルのアップロード、フォーム送信、タイムスタンプ付きの文字起こしデータと動画の同期再生、エラーハンドリング、そしてその他の画面のステータス管理を処理します。main.jsを以下の2つのセクションに分解して説明します:
ファイルのアップロードと検証
文字起こしデータのパース処理
2.1 - ファイルのアップロードと検証
このセクションでは、クライアントサイドでの包括的な検証および送信処理の構成について紹介します。アップロード処理中に動画ファイルを検証し、選択ファイルの削除に対応し、フォームを非同期通信で送信する仕組みが組み込まれています。
// アップロードされたファイルの検証 function validateFile(file) { const validTypes = ['video/mp4', 'video/avi', 'video/quicktime']; const maxSize = 100 * 1024 * 1024; // 100MB if (!validTypes.includes(file.type)) { updateStatus('有効な動画ファイル(MP4, AVI, もしくは MOV)を選択してください', 'error'); return false; } if (file.size > maxSize) { updateStatus('ファイルサイズは100MB未満にしてください', 'error'); return false; } return true; } // 選択されたファイルの削除処理を行うユーティリティ関数 function handleFileRemove(e) { e.preventDefault(); fileInput.value = ''; selectedFile.classList.add('hidden'); uploadPrompt.textContent = '動画を選ぶか、ここにドラッグしてください'; updateStatus('', ''); } // フォーム送信の処理 async function handleFormSubmit(e) { e.preventDefault(); const formData = new FormData(e.target); if (!fileInput.files || !fileInput.files[0]) { updateStatus('まず始めにファイルを選択してください', 'error'); return; } const loadingOverlay = document.getElementById('loading-overlay'); loadingOverlay.classList.remove('hidden'); updateStatus('ファイルをアップロードして処理中...', 'loading'); // 過去の結果表示を切り替える hideResult(); try { // フォームとともにPOSTリクエストを作成してエンドポイントへ送信 const response = await fetch('/upload', { method: 'POST', body: formData }); // JSONレスポンスのパース const data = await response.json(); console.log('Server response:', data); // アップロードと処理に成功したか確認 if (response.ok && data.status === 'ready') { // 状態表示を完了に切り替えて取得データを反映表示 updateStatus('処理が完了しました!', 'success'); showResult(); displayTranscript(data.transcript); displayVideo(data.video_path); } else { // 処理に失敗した場合はエラーをスローする throw new Error(data.message || 'データ処理中にエラーが発生しました'); } } catch (error) { // エラーを検知してログを出力し表示 console.error('Error:', error); updateStatus(`Error: ${error.message}`, 'error'); } finally { // 処理が完了したら成否に関わらずローディング画面を非表示にする loadingOverlay.classList.add('hidden'); } }
validateFile 関数により正しい形式の動画フォーマットと許容されるサイズ以外の不正なファイルが除外され、handleFileRemove が呼び出されると選択されていたファイルの削除と共にステータス表示がリセットされます。また、handleFormSubmit が非同期処理としての送信を仲介し、適切なエラー制御やロード時の進行状況を処理します。
この処理には、状況に合わせた表示を画面上に反映するために、ローディングオーバーレイの有効化・完了通知メッセージの切り替え・エラー発生時の通知表示といった細やかなステータス制御が含まれています。アップロードの各種段階で、常に一貫した使いやすさを提供します。
2.2 - オープンエンドプロンプトを処理する文字起こしパースの処理
このセクションでは、頑健な文字起こしパーサー(解析処理)のJavascript記述に焦点を当てます。このプログラムは、生成AIの自由なテキスト回答において検出される、様々な形式のタイムスタンプ情報や構文構成を網羅し、各構成の時間ベース位置に整合させてテキストを適切に配列します。
この処理により原型のテキストを構造化配列データに編集することで動画プレーヤーと文字起こしテキストのタイムラグの同期表現を行い、文字起こしの際に想定される例外部分や形式のブレに対する汎用的な適応を備えます。
// Parses a transcript string into structured data with timestamps and text function parseTranscript(transcript) { console.log('Raw transcript:', transcript); // Initialize Map to store unique entries (prevents duplicates) const entries = new Map(); if (!transcript) { console.error('Empty transcript received'); return []; } // Extract data from JSON response and handle escapes let transcriptText = transcript; try { if (typeof transcript === 'string' && (transcript.includes('"id":') || transcript.includes("'id':"))) { const dataMatch = transcript.match(/['"]data['"]\s*:\s*['"]([^]+?)['"]\s*$/); if (dataMatch && dataMatch[1]) { transcriptText = dataMatch[1] .replace(/\\n/g, '\n') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\'); } } } catch (e) { console.error('Error parsing JSON response:', e); } // Different timestamp patterns const patterns = [ // HH:MM - HH:MM : "text" /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*["']([^"']+)["']/g, // HH:MM - HH:MM: text /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*([^"\n]+)/g, // Simple format with quotes /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*["']([^"']+)["']/g ]; // Try each pattern against the transcript text for parsing for (const pattern of patterns) { let match; while ((match = pattern.exec(transcriptText)) !== null) { try { const [_, startMin, startSec, endMin, endSec, text] = match; // Convert timestamps to seconds const startTime = parseInt(startMin) * 60 + parseInt(startSec); const endTime = parseInt(endMin) * 60 + parseInt(endSec); // Skip invalid timestamps if (isNaN(startTime) || isNaN(endTime)) continue; // Clean up theo transcript text, if appears const cleanText = text .replace(/^["'\s]+|["'\s]+$/g, '') .replace(/\\n/g, ' ') .replace(/\*\*/g, '') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\') .replace(/\s+/g, ' ') .trim(); if (cleanText && !cleanText.includes('Note:')) { const key = `${startTime}-${cleanText.substring(0, 50)}`; entries.set(key, { start: startTime, end: endTime, text: cleanText }); } } catch (e) { console.error('Error processing match:', e); continue; } } } // Convert Map to Array and sort by start time const sortedEntries = Array.from(entries.values()) .sort((a, b) => a.start - b.start); // Log processed result console.log('Parsed entries:', sortedEntries); return sortedEntries; }
パースを機能させるために、各種パターンに対応する正規表現を使用し、時間指定を秒表記へと変換し、タイム表示に伴う不要ノイズを取り除くよう文字列処理を行います。Map型オブジェクトを用いて重複登録を抑止しつつ時系列を適正順に構成します。また、任意のタイミングで稼働追跡ができるようにデバッグを意識した実用的なログ記述が散りばめられています。
この最終生成物を配列としてまとめることで、動画再生プレーヤーや字幕描写処理等にそのまま適用でき、正確なタイミングで画面文字起こしを表示させることができます。
上で説明されたJavaScriptファイルのコード全体は、こちらのapp.jsファイルからご確認いただけます。
デモアプリケーションの実行
初めに、対象とする翻訳変換先の言語および希望する難易度習得レベルを画面から選択し、動画をアップロードします。アップロードが完了すると、自動的にインデックス化処理が開始されます。
インデックス作成と準備タスクが完了したら、動画IDを介してユーザーの選択設定に合わせて文字起こし文を生成します。下図は、Twelve Labs SDKを用いた生成結果を表示するデモ画面です。
Twelve Labsをさらに深く試してみたい場合は、教育用途、コンテンツ配信制作、その他の分野で動画認識を活用した独自ソリューションのアイデア生成などを進めてみてください。
このチュートリアルを応用するさらなるアイデア
マルチリンガル文字起こしアプリの基本構成を理解することで、多種多様なアイデアの着想やビジネス実用に向けた発展、新たな動画処理機能の開発などが可能になります。以下に、ユーザーの動画利用体験を豊かにする実用的な活用案を紹介します:
🌍 グローバルコンテンツクリエイター: 瞬時に多言語翻訳をまとめて自動文字起こしとして生成し、即時動画の現地ローカライズを進めオーディエンス層をグローバルに広げます。
🎓 国際遠隔教育・レッスンプログラム: ウェブ講義等の動画から自動で他国言語の字幕を作成し、生徒の語学学習レベル(初〜上級)に合わせて理解補助を行い、リソースの制限を軽減します。
💼 多国籍ビジネスにおけるミーティング効率化: 多国間のリモートビデオ面談を一斉にローカル言語へと書き出し、スムーズな多国間商談の要約や確認を可能にします。
まとめ
Twelve Labsを使用した、マルチリンガル動画自動文字起こしアプリケーションの開発と仕組みについてのチュートリアルに最後までお付き合いいただき、ありがとうございました。動画を高度に理解して処理する機能と、今回のアプリ構成フローを組み合わせることで、皆様の新しいアプリ開発の発想に繋がれば幸いです。機能追加や開発上の課題に対する皆様からの積極的なご意見をお待ちしています。
その他のドキュメント関連リソース
動画理解とテキスト生成処理に使用している各エンジンの仕様詳細は、こちらの資料をご覧ください:Marengo 2.6 (エンベディングエンジン) および Pegasus 1.1 (ジェネレーティブエンジン)。また、Twelve Labsを活用するためのリソースや動画データ解析の学習のために、以下の便利なコンテンツをご覧ください:
Discord コミュニティ: 開発仲間が多く籍を置く公式Discordにぜひ登録してください。不明点に関するQ&Aや開発アイデアの進捗共有などが活発に行われています。
サンプルアプリケーション群: すぐに試して理解を深められるアイデア別の導入デモなどを、次の開発のきっかけにお役立てください。
チュートリアル閲覧: Twelve Labsが有する多様なマルチメディア理解機能をさらに深く引き出すための方法を、詳細な手順書とともに追求できます。
ぜひこれらの公式リソースをフルに活用いただき、Twelve Labsの高度な映像理解技術によるまったく新しい革新的ビデオアプリケーションの創出に挑戦してください。
異なる言語の動画コンテンツを理解するのに苦労していませんか?あるいは、世界中のオーディエンスに向けてコンテンツをアクセシブルにすることに難しさを感じていませんか? 🌍
このチュートリアルでは、「マルチリンガル動画文字起こしアプリケーション(MultiLingual Video Transcriber Application)」を紹介し、その開発プロセスについて解説します。このアプリケーションは、Twelve LabsのAIモデルを活用して動画を理解し、複数の言語でシームレスな文字起こしを提供します。
このプログラムのユニークな点は、ユーザーが選択した習得レベル(初級、中級、上級)に合わせて文字起こしの内容を調整できることです。ユーザーは選択したレベルに最適化された文字起こしや翻訳テキストを受け取ることができます。さらに、このアプリケーションは正確なタイムスタンプを提供するため、ユーザーは発話された言葉と文字起こしテキストの同期を追うことができます。この機能により、コンテンツのナビゲーションや理解が容易になります。このアプリケーションの仕組みと、TwelveLabs Python SDKを使用して同様のソリューションを構築する方法について探っていきましょう。
アプリケーションのデモは、こちらから体験できます:動画マルチリンガル文字起こしデモ(Video Multilingual Transcriber)
コードにアクセスしてアプリを直接試してみたい場合は、こちらのReplit テンプレートをご利用ください。
前提条件
Twelve Labs Playgroundにサインアップして、APIキーを生成します。
このアプリケーションのリポジトリは Video Multilingual Transcriber で確認できます。
Flask、HTML、CSS、JavaScriptに関する基本的な知識があることを前提としています。
アプリケーションの仕組み
このセクションでは、マルチリンガル動画文字起こしアプリケーションを開発するための処理の流れを説明します。このプロセスは、動画を取得し、ユーザーの好みに応じて様々な言語と習得レベルの文字起こしを生成します。単なる単純な文字起こしにとどまらず、より包括的なソリューションを提供します。
システム構成は、フロントエンド層、バックエンド層、ストレージ層、そしてTwelveLabsサービスの4つの主要コンポーネントで構築されています。仕組みは次の通りです:ユーザーが(外国語の可能性がある)動画をアップロードし、希望する翻訳言語と習得レベル(初級、中級、上級)を選択します。
動画アップロード後に「送信(submit)」ボタンをクリックすると、インデックスID(Index ID)が生成され、今後の使用に備えてセッション状態で保存されます。次に、システムは動画をアップロードしてタスクID(Task ID)を作成し、インデックス処理が完了するとビデオID(Video ID)が取得されます。インデックス処理のエンベディングエンジンにはMarengo 2.6が使用され、文字起こしの生成には、Generate APIを介してPegasus 1.1エンジン(ジェネレーティブエンジン)が使用されます。
ユーザーの利便性を高めるため、アプリケーションは文字起こしとともにタイムスタンプを生成します。この機能により、文字起こしテキストと動画再生の間でインタラクティブな同期が可能になります。
準備手順
Twelve Labs PlaygroundからAPIキーを取得し、環境変数を準備します。
Githubからプロジェクトをクローンするか、Replit テンプレートを使用します。
メインファイルと同じ階層に、APIキーを設定した
.envファイルを作成します。
API_KEY=your_api_key_here
これらの手順が完了したら、いよいよアプリケーションの開発を開始しましょう!
VidScribe - 動画マルチリンガル文字起こしアプリのウォークスルー
このチュートリアルでは、最小限のフロントエンドを持つFlaskアプリケーションを構築します。ディレクトリ構造は以下の通りです:
. ├── app.py ├── requirements.txt ├── static │ ├── style.css │ └── main.js ├── templates │ └── index.html └── uploads
Flaskアプリケーションの作成
準備手順が完了したので、Flaskアプリケーションを実装します。これにより、動画をアップロードしてユーザーの好みに応じた様々な言語の文字起こしを生成するためのシンプルな方法が構築できます。
仮想環境を準備して作成するために必要な依存関係は、こちらで確認できます:requirements.txt
Pythonの仮想環境を作成し、次のコマンドを実行してアプリケーションの環境をセットアップします:
pip install -r
1 - メインアプリケーションの構築
このセクションでは、重要なロジックと指示フローが含まれるメインアプリケーションのユーティリティ機能に焦点を当てます。メインアプリケーションをいくつかのセクションに分解して説明します:
インデックスの作成
結果の生成
アップロード用コンポーネント
1.1 - インデックスの作成
ここでは、Twelve Labs SDKを使用してインデックスを構成する方法について説明します。このFlaskアプリケーションは、ユーザーが動画をアップロードして様々な目的のために処理できるようにします。本番環境で確実に動作するように、安全なファイル名の処理システムとセッション管理を採用しています。
# 必要なモジュールのインポート from flask import Flask, render_template, request, jsonify, send_from_directory, session from werkzeug.utils import secure_filename import os import uuid from twelvelabs import TwelveLabs from twelvelabs.models.task import Task from dotenv import load_dotenv load_dotenv() # 環境変数からTwelve LabsのAPIキーを読み込む API_KEY = os.getenv("API_KEY") app = Flask(__name__) app.secret_key = os.urandom(24) UPLOAD_FOLDER = 'uploads' ALLOWED_EXTENSIONS = {'mp4', 'avi', 'mov'} app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024 # Twelve Labs SDK クライアントの初期化 client = TwelveLabs(api_key=API_KEY) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS @app.route('/') def index(): return render_template('index.html') # ステータス確認用のユーティリティ関数 def on_task_update(task: Task): print(f"Status={task.status}") def process_video(filepath, language, difficulty): try: if 'index_id' not in session: # インデックス名の設定 index_name = f"Translate{uuid.uuid4().hex[:8]}" # エンジンの定義 engines = [ { "name": "pegasus1.1", "options": ["visual", "conversation"] }, { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] } ] # 設定を適用したインデックスの作成 index = client.index.create( name=index_name, engines=engines ) # インデックスIDをセッションに格納し、後の処理で再利用できるようにする session['index_id'] = index.id print(f"Created new index with ID: {index.id}") else: print(f"Using existing index with ID: {session['index_id']}") # タスクの作成 task = client.task.create(index_id=session['index_id'], file=filepath) task.wait_for_done(sleep_interval=5, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}") print(f"The unique identifier of your video is {task.video_id}.")
セッション状態を管理して、インデックスIDの作成を堅牢に処理します。UUIDによってインデックス名にランダムな番号が付加され、セッションごとに一意のインデックス名が作成されます。この新しいインデックスIDは、後で参照できるようにセッションに保存されます。
インデックス構成では、2つのエンジンを定義しています。動画のインデックス作成にはMarengo 2.6(エンベディングエンジン)を使用し、インデックスされた動画にアクセスして自由形式のプロンプトなどに基づいてコンテンツを生成するためにPegasus 1.1(ジェネレーティブエンジン)を使用します。
タスクを作成するには、インデックスIDと動画ファイルのパスを指定します。タスクの処理ステータスは `task.status` を使って追跡できます。インデックス作成が完了すると、次のステップで生成されたビデオIDが使用されます。
1.2 - 結果の生成
このセクションでは、ユーザーが選択した難易度レベルと希望する言語設定に基づいて、インデックス化された動画からテキストを生成する部分を扱います。私たちのプロンプトエンジニアリングシステムは、正確なタイムスタンプと翻訳を維持しながら、ユーザーの理解レベルに合わせて動画文字起こしの複雑さと詳細度を調整します。
# 難易度レベルに応じたアップデートされたプロンプト difficulty_prompts = { "beginner": "Provide a simplified and easy-to-understand", "intermediate": "Provide a moderately detailed", "advanced": "Provide a comprehensive and detailed" } # ユーザーフォームから取得した難易度レベルを格納 base_prompt = difficulty_prompts.get(difficulty, difficulty_prompts["intermediate"]) # 生成のためのオープンエンドプロンプト prompt = f"Provide the Only Transcript in the Translated {language.capitalize()} Language, {base_prompt} level with the timestamp duration (in the format of ss : ss) of the Indexed Video Content." res = client.generate.text(video_id=task.video_id, prompt=prompt, temperature=0.25) print(res) return { 'status': 'ready', 'message': 'File processed successfully', 'transcript': res.data, 'video_path': f'/uploads/{os.path.basename(filepath)}' } except Exception as e: print(f"Error processing video: {str(e)}") return {'status': 'error', 'message': str(e)}
辞書(dictionary)を用いたアプローチで難易度レベルを適切なプロンプトテンプレートにマッピングし、デフォルトのフォールバックとして中級レベルを設定します。一貫性があり信頼性の高い出力生成を実現するために、システムのTemperature値を0.25と低く維持しています。レスポンスには、タイムスタンプ付きの処理済み文字起こしデータが含まれます。
1.3 - アップロード用コンポーネント
このセクションでは、Flaskアプリケーションで安全なファイルアップロードのエンドポイントを生成および管理し、ユーザーからのファイル送信を処理する方法について解説します。このコンポーネントは、ファイルのアップロードプロセスを管理し、ファイルタイプを検証し、言語や難易度の設定を処理します。さらに、ワークフロー全体の適切なエラーハンドリングを維持しながら、アップロードされた動画の安全な保存を保証します。
# ファイルアップロードを処理するルート - POSTリクエストのみを許可 @app.route('/upload', methods=['POST']) def upload_file(): # リクエストにファイルが含まれているか確認 if 'file' not in request.files: return jsonify({'status': 'error', 'message': 'No file part'}), 400 # リクエストからファイルを取得 file = request.files['file'] # フォームデータから抽出した言語設定、未指定の場合はデフォルトでドイツ語を設定 language = request.form.get('language', 'german') difficulty = request.form.get('difficulty', 'intermediate') # ファイルが実際に選択されているか検証 if file.filename == '': return jsonify({'status': 'error', 'message': 'No selected file'}), 400 # 許可されたファイル拡張子であるか確認し、処理を進行 if file and allowed_file(file.filename): filename = secure_filename(file.filename) filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename) file.save(filepath) # 設定された言語と難易度で動画処理を実行 result = process_video(filepath, language, difficulty) # 処理結果をJSON応答として送信 return jsonify(result) # 許可されていないファイルタイプの場合はエラーを返す return jsonify({'status': 'error', 'message': 'File type not allowed'}), 400 # アップロードされたファイルを提供する配信ルート @app.route('/uploads/<filename>') def uploaded_file(filename): return send_from_directory(app.config['UPLOAD_FOLDER'], filename)
動画ファイルと関連するメタデータを処理するためのアップロード先エンドポイントを提供しています。このアップロードルートでは、安全なファイル名処理としてWerkzeugの secure_filename ユーティリティを使用し、適切なHTTPステータスコードを返す堅牢なエラーチェックを実装しています。言語や難易度の設定が指定されない場合、システムはそれぞれドイツ語と中級(intermediate)に設定します。また、ファイルを配信するルートがあることで、指定のディレクトリを通じてアップロード動画への安全なアクセスが可能になり、アクセス制限とファイルシステムのセキュリティが保護されます。
2 - JavaScriptによるコンポーネント処理
このセクションでは、app.jsファイルに含まれる主要な処理ユーティリティについて解説します。このJavaScriptファイルは、ファイルのアップロード、フォーム送信、タイムスタンプ付きの文字起こしデータと動画の同期再生、エラーハンドリング、そしてその他の画面のステータス管理を処理します。main.jsを以下の2つのセクションに分解して説明します:
ファイルのアップロードと検証
文字起こしデータのパース処理
2.1 - ファイルのアップロードと検証
このセクションでは、クライアントサイドでの包括的な検証および送信処理の構成について紹介します。アップロード処理中に動画ファイルを検証し、選択ファイルの削除に対応し、フォームを非同期通信で送信する仕組みが組み込まれています。
// アップロードされたファイルの検証 function validateFile(file) { const validTypes = ['video/mp4', 'video/avi', 'video/quicktime']; const maxSize = 100 * 1024 * 1024; // 100MB if (!validTypes.includes(file.type)) { updateStatus('有効な動画ファイル(MP4, AVI, もしくは MOV)を選択してください', 'error'); return false; } if (file.size > maxSize) { updateStatus('ファイルサイズは100MB未満にしてください', 'error'); return false; } return true; } // 選択されたファイルの削除処理を行うユーティリティ関数 function handleFileRemove(e) { e.preventDefault(); fileInput.value = ''; selectedFile.classList.add('hidden'); uploadPrompt.textContent = '動画を選ぶか、ここにドラッグしてください'; updateStatus('', ''); } // フォーム送信の処理 async function handleFormSubmit(e) { e.preventDefault(); const formData = new FormData(e.target); if (!fileInput.files || !fileInput.files[0]) { updateStatus('まず始めにファイルを選択してください', 'error'); return; } const loadingOverlay = document.getElementById('loading-overlay'); loadingOverlay.classList.remove('hidden'); updateStatus('ファイルをアップロードして処理中...', 'loading'); // 過去の結果表示を切り替える hideResult(); try { // フォームとともにPOSTリクエストを作成してエンドポイントへ送信 const response = await fetch('/upload', { method: 'POST', body: formData }); // JSONレスポンスのパース const data = await response.json(); console.log('Server response:', data); // アップロードと処理に成功したか確認 if (response.ok && data.status === 'ready') { // 状態表示を完了に切り替えて取得データを反映表示 updateStatus('処理が完了しました!', 'success'); showResult(); displayTranscript(data.transcript); displayVideo(data.video_path); } else { // 処理に失敗した場合はエラーをスローする throw new Error(data.message || 'データ処理中にエラーが発生しました'); } } catch (error) { // エラーを検知してログを出力し表示 console.error('Error:', error); updateStatus(`Error: ${error.message}`, 'error'); } finally { // 処理が完了したら成否に関わらずローディング画面を非表示にする loadingOverlay.classList.add('hidden'); } }
validateFile 関数により正しい形式の動画フォーマットと許容されるサイズ以外の不正なファイルが除外され、handleFileRemove が呼び出されると選択されていたファイルの削除と共にステータス表示がリセットされます。また、handleFormSubmit が非同期処理としての送信を仲介し、適切なエラー制御やロード時の進行状況を処理します。
この処理には、状況に合わせた表示を画面上に反映するために、ローディングオーバーレイの有効化・完了通知メッセージの切り替え・エラー発生時の通知表示といった細やかなステータス制御が含まれています。アップロードの各種段階で、常に一貫した使いやすさを提供します。
2.2 - オープンエンドプロンプトを処理する文字起こしパースの処理
このセクションでは、頑健な文字起こしパーサー(解析処理)のJavascript記述に焦点を当てます。このプログラムは、生成AIの自由なテキスト回答において検出される、様々な形式のタイムスタンプ情報や構文構成を網羅し、各構成の時間ベース位置に整合させてテキストを適切に配列します。
この処理により原型のテキストを構造化配列データに編集することで動画プレーヤーと文字起こしテキストのタイムラグの同期表現を行い、文字起こしの際に想定される例外部分や形式のブレに対する汎用的な適応を備えます。
// Parses a transcript string into structured data with timestamps and text function parseTranscript(transcript) { console.log('Raw transcript:', transcript); // Initialize Map to store unique entries (prevents duplicates) const entries = new Map(); if (!transcript) { console.error('Empty transcript received'); return []; } // Extract data from JSON response and handle escapes let transcriptText = transcript; try { if (typeof transcript === 'string' && (transcript.includes('"id":') || transcript.includes("'id':"))) { const dataMatch = transcript.match(/['"]data['"]\s*:\s*['"]([^]+?)['"]\s*$/); if (dataMatch && dataMatch[1]) { transcriptText = dataMatch[1] .replace(/\\n/g, '\n') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\'); } } } catch (e) { console.error('Error parsing JSON response:', e); } // Different timestamp patterns const patterns = [ // HH:MM - HH:MM : "text" /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*["']([^"']+)["']/g, // HH:MM - HH:MM: text /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*:\s*([^"\n]+)/g, // Simple format with quotes /(\d{2}):(\d{2})\s*-\s*(\d{2}):(\d{2})\s*["']([^"']+)["']/g ]; // Try each pattern against the transcript text for parsing for (const pattern of patterns) { let match; while ((match = pattern.exec(transcriptText)) !== null) { try { const [_, startMin, startSec, endMin, endSec, text] = match; // Convert timestamps to seconds const startTime = parseInt(startMin) * 60 + parseInt(startSec); const endTime = parseInt(endMin) * 60 + parseInt(endSec); // Skip invalid timestamps if (isNaN(startTime) || isNaN(endTime)) continue; // Clean up theo transcript text, if appears const cleanText = text .replace(/^["'\s]+|["'\s]+$/g, '') .replace(/\\n/g, ' ') .replace(/\*\*/g, '') .replace(/\\'/g, "'") .replace(/\\"/g, '"') .replace(/\\\\/g, '\\') .replace(/\s+/g, ' ') .trim(); if (cleanText && !cleanText.includes('Note:')) { const key = `${startTime}-${cleanText.substring(0, 50)}`; entries.set(key, { start: startTime, end: endTime, text: cleanText }); } } catch (e) { console.error('Error processing match:', e); continue; } } } // Convert Map to Array and sort by start time const sortedEntries = Array.from(entries.values()) .sort((a, b) => a.start - b.start); // Log processed result console.log('Parsed entries:', sortedEntries); return sortedEntries; }
パースを機能させるために、各種パターンに対応する正規表現を使用し、時間指定を秒表記へと変換し、タイム表示に伴う不要ノイズを取り除くよう文字列処理を行います。Map型オブジェクトを用いて重複登録を抑止しつつ時系列を適正順に構成します。また、任意のタイミングで稼働追跡ができるようにデバッグを意識した実用的なログ記述が散りばめられています。
この最終生成物を配列としてまとめることで、動画再生プレーヤーや字幕描写処理等にそのまま適用でき、正確なタイミングで画面文字起こしを表示させることができます。
上で説明されたJavaScriptファイルのコード全体は、こちらのapp.jsファイルからご確認いただけます。
デモアプリケーションの実行
初めに、対象とする翻訳変換先の言語および希望する難易度習得レベルを画面から選択し、動画をアップロードします。アップロードが完了すると、自動的にインデックス化処理が開始されます。
インデックス作成と準備タスクが完了したら、動画IDを介してユーザーの選択設定に合わせて文字起こし文を生成します。下図は、Twelve Labs SDKを用いた生成結果を表示するデモ画面です。
Twelve Labsをさらに深く試してみたい場合は、教育用途、コンテンツ配信制作、その他の分野で動画認識を活用した独自ソリューションのアイデア生成などを進めてみてください。
このチュートリアルを応用するさらなるアイデア
マルチリンガル文字起こしアプリの基本構成を理解することで、多種多様なアイデアの着想やビジネス実用に向けた発展、新たな動画処理機能の開発などが可能になります。以下に、ユーザーの動画利用体験を豊かにする実用的な活用案を紹介します:
🌍 グローバルコンテンツクリエイター: 瞬時に多言語翻訳をまとめて自動文字起こしとして生成し、即時動画の現地ローカライズを進めオーディエンス層をグローバルに広げます。
🎓 国際遠隔教育・レッスンプログラム: ウェブ講義等の動画から自動で他国言語の字幕を作成し、生徒の語学学習レベル(初〜上級)に合わせて理解補助を行い、リソースの制限を軽減します。
💼 多国籍ビジネスにおけるミーティング効率化: 多国間のリモートビデオ面談を一斉にローカル言語へと書き出し、スムーズな多国間商談の要約や確認を可能にします。
まとめ
Twelve Labsを使用した、マルチリンガル動画自動文字起こしアプリケーションの開発と仕組みについてのチュートリアルに最後までお付き合いいただき、ありがとうございました。動画を高度に理解して処理する機能と、今回のアプリ構成フローを組み合わせることで、皆様の新しいアプリ開発の発想に繋がれば幸いです。機能追加や開発上の課題に対する皆様からの積極的なご意見をお待ちしています。
その他のドキュメント関連リソース
動画理解とテキスト生成処理に使用している各エンジンの仕様詳細は、こちらの資料をご覧ください:Marengo 2.6 (エンベディングエンジン) および Pegasus 1.1 (ジェネレーティブエンジン)。また、Twelve Labsを活用するためのリソースや動画データ解析の学習のために、以下の便利なコンテンツをご覧ください:
Discord コミュニティ: 開発仲間が多く籍を置く公式Discordにぜひ登録してください。不明点に関するQ&Aや開発アイデアの進捗共有などが活発に行われています。
サンプルアプリケーション群: すぐに試して理解を深められるアイデア別の導入デモなどを、次の開発のきっかけにお役立てください。
チュートリアル閲覧: Twelve Labsが有する多様なマルチメディア理解機能をさらに深く引き出すための方法を、詳細な手順書とともに追求できます。
ぜひこれらの公式リソースをフルに活用いただき、Twelve Labsの高度な映像理解技術によるまったく新しい革新的ビデオアプリケーションの創出に挑戦してください。
関連記事




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.