" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
チュートリアル
複数ソースの法的証拠レポート:AWS BedrockおよびNeMo Retrieverを介したTwelveLabsによる調査プラットフォームの構築

リシケシュ・ヤダフ
開発者は、ビデオインテリジェンス向けのAWS Bedrock経由のTwelve Labs MarengoおよびPegasusと、ドキュメント検索向けのNVIDIA NeMo Retrieverを使用することで、マルチソースの法的証拠調査プラットフォームを構築できます。これにより、12の異なるビデオソースにまたがる自然言語クエリ、カメラフィード間のエンティティ追跡、およびタイムスタンプ付きの結果を伴う自動コンプライアンス分析が可能になります。
開発者は、ビデオインテリジェンス向けのAWS Bedrock経由のTwelve Labs MarengoおよびPegasusと、ドキュメント検索向けのNVIDIA NeMo Retrieverを使用することで、マルチソースの法的証拠調査プラットフォームを構築できます。これにより、12の異なるビデオソースにまたがる自然言語クエリ、カメラフィード間のエンティティ追跡、およびタイムスタンプ付きの結果を伴う自動コンプライアンス分析が可能になります。

この記事の内容
No headings found on page
ニュースレターに登録する
ニュースレターに登録する
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
ビデオ理解に関する最新の技術進歩、チュートリアル、業界の動向をお届けします
AIを活用してビデオを検索、分析、探索します。
2026/04/25
16分
記事へのリンクをコピー
u9002u5165
u30d3u30c7u30aau8a3cu62e0u3092u51e6u7406u3059u308bu6cd5u52d9u30c1u30fcu30e0u306fu3001u66f4u306bu6df1u307eu308bu554fu984cu306bu76f4u9762u3057u3066u3044u307eu3059u30021u3064u306eu4e8bu6848u306bu3001u30c0u30c3u30b7u30e5u30abu30e0u3001u30dcu30c7u30a3u30abu30e0u3001u9632u72afu30abu30e1u30e9uff08CCTVuff09u30b7u30b9u30c6u30e0u3001u30c1u30e3u30a4u30e0u30abu30e1u30e9u3001u4fddu967au7533u8acbu7528u6620u50cfu306au3069u304bu3089u306e40u6642u9593u4ee5u4e0au306eu6620u50cfu304cu542bu307eu308cu308bu3053u3068u304cu3042u308au3001u305du306eu3059u3079u3066u304cu7570u306au308bu30d5u30a9u30fcu30deu30c3u30c8u3001u89e3u50cfu5ea6u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u3059u3002u8abfu67fbu54e1u306fu3001u3053u306eu30b3u30f3u30c6u30f3u30c4u3092u624bu52d5u3067u30ecu30d3u30e5u30fcu3059u308bu30d1u30e9u30eau30fcu30acu30ebu306eu4f5cu696du6642u9593u306b1u6642u9593u3042u305fu308a200uff5e500u30c9u30ebu3092u8cbbu3084u3057u3066u3044u307eu305su30027u756au76eeu306eu30abu30e1u30e9u6620u50cfu306e23u6642u9593u76eeu306bu57cbu3082u308cu305fu81e8u754cu7684u306a10u79d2u306eu30afu30eau30c3u30d7u3092u898bu843du306du308bu3068u3001u88c1u5224u306eu7d50u679cu304cu5909u308fu3063u3066u3057u307eu3044u307eu3059u3002
u524du56deu306eu30a2u30d7u30edu30fcu30c1uff08u624bu52d5u3067u306eu30ecu30d3u30e5u30fcu3001u57fau672cu7684u306au30e1u30bfu30c7u30fcu30bfu306eu30bfu30b0u4ed8u3051u3001u30d5u30ecu30fcu30e0u30d0u30a4u30d5u30ecu30fcu30e0u306eu5206u6790uff09u306fu3001u30b9u30b1u30fcu30e9u30d6u30ebu3067u306fu3042u308au307eu305bu3093u3002u6cd5u52d9u30c1u30fcu30e0u306fu3001u7570u306au308bu30bdu30fcu30b9u3092u540cu6642u306bu691cu7d22u3057u3001u65adu7247u5316u3055u308cu305fu6620u50cfu304bu308fu305fu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3057u3001u3059u3079u3066u306eu30d3u30c7u30aau3092u898bu308bu3053u3068u306au304fu81e8u754cu306au77acu9593u3092u7279u5b9au3059u308bu5fc5u8981u304cu3042u308fu308au307eu3059u3002
u3053u306eu30c1u30e5u30fcu30c8u30eau30a2u30ebu3067u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30eau30b8u30a7u30f3u30b9u306bAWS Bedrocku3092u4ecbu3057u305fTwelveLabsu3092u3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306bNVIDIA NeMo Retrieveru3092u4f7fu7528u3057u3066u3001u6cd5u7684u8a3cu62e0u8abfu67fbu30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u3092u69cbu7bc9u3059u308bu65b9u6cd5u3092u5b9fu6f14u3057u307eu3059u3002u305du306eu7d50u679cu3001u8abfu67fbu54e1u306f12u500bu306eu30d3u30c7u30aau30bdu30fcu30b9u3092u81eau7136u8a00u8a9eu306eu30afu30a8u30eauff08u300cu8d64u3044u30bbu30c0u30f3u3092u898bu3064u3051u308bu300du307eu305fu306fu300cu4ebau7269u304cu5efau7269u306bu5165u3063u305fu306eu306fu3044u3064u304bu8868u793au3059u308buff09u3067u540cu6642u306bu691cu7d22u3067u304du3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu30e9u30f3u30adu30f3u30b0u7d50u679cu3092u5f97u3066u3001u6570u65e5u3067u306fu306au304fu6570u5206u3067u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u4f5cu6210u3067u304du308bu3088u3046u306bu306au308au307eu3059u3002
u69cbu7bc9u3059u308bu3082u306e: u6df7u5728u3059u308bu30d5u30a9u30fcu30deu30c3u30c8u306eu76e3u8996u6620u50cfu3092u53d6u308au8fbcu307fu3001u30bdu30fcu30b9u9593u306eu30bbu30deu30f3u30c6u30a3u30c3u30afu691cu7d22u3092u53efu80fdu306bu3057u3001u81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u884cu3044u3001u7570u306au308bu30d3u30c7u30aau30bdu30fcu30b9u304bu3089u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3059u308bu3001u30deu30ebu30c1u30bdu30fcu30b9u53f8u6cd5u8a3cu62e0u8abfu67fbu30c4u30fcu30ebu3092u69cbu7bc9u3057u307eu3059u3002
u5218u52b9u6642u9593: 40u6642u9593u306eu8a3cu62e0u30ecu30d3u30e5u30fcu304cu3001u7279u5b9au306eu8abfu67fbu3092u884cu30464u6642u9593u306eu4f5cu696du306bu77edu7e2eu3055u308cu307eu305su3002
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306eu30c7u30e2u306fu3053u3061u3089u304bu3089u4f53u9a13u3067u304du307eu3059: u6cd5u7684u8a3cu62e0u8abfu67fbu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
u30bdu30fcu30b9u30b3u30fcu30c9u306fu3053u3061u3089u304bu3089u78bau8a8du3067u304du307eu3059: GitHub u30eau30ddu30b8u30c8u30ea
u30c7u30e2u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
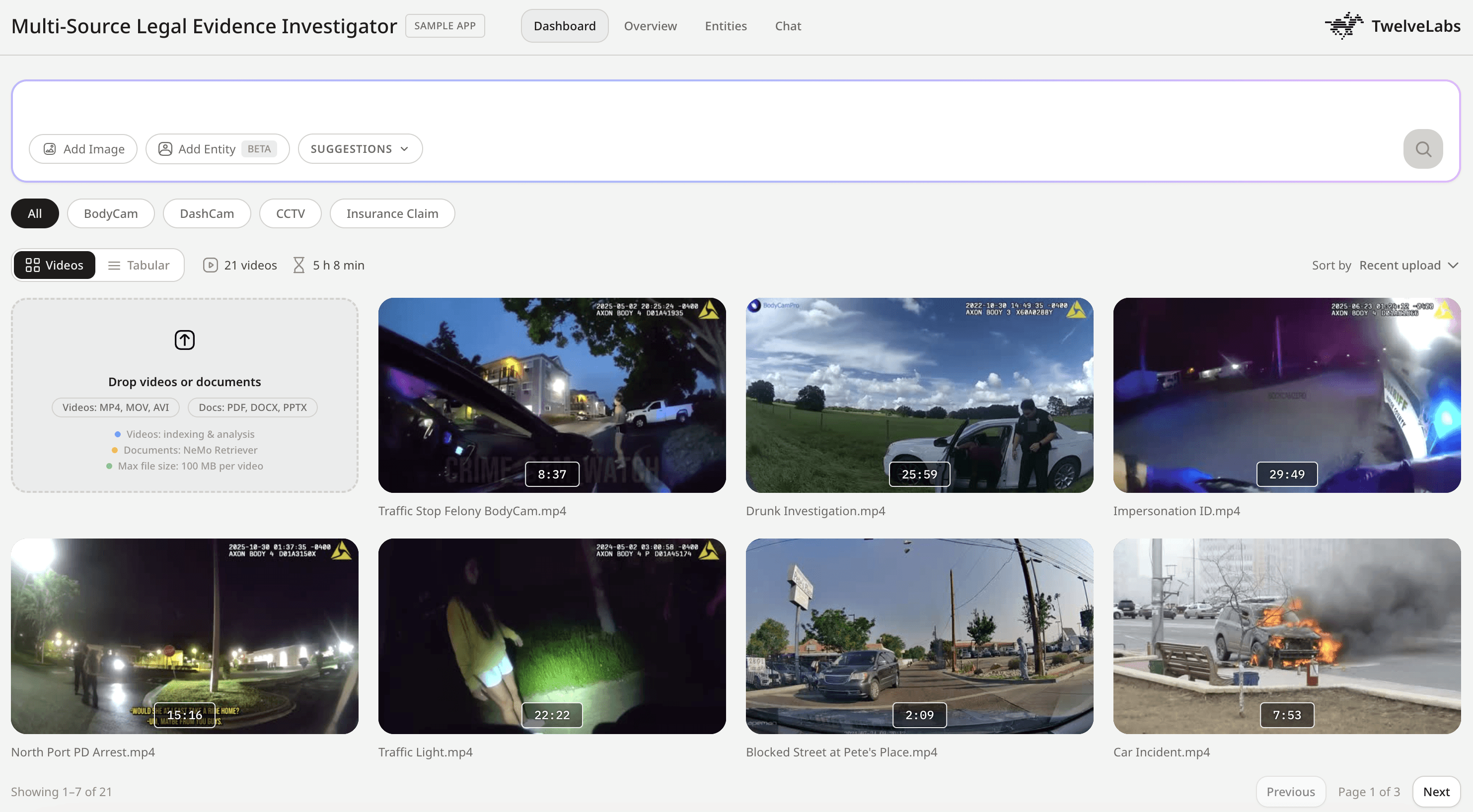
u3053u306eu30c7u30e2u3067u306fu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u304cu8907u6570u306eu30d3u30c7u30aau30bdu30fcu30b9u3092u691cu7d22u3057u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u1e1au754cu306au77acu9593u3092u7279u5b9au3057u3001u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u751fu6210u3057u3001u3055u3089u306bu6df1u3044u8abfu67fbu306eu305fu3081u306eu5bfeu8a71u578bQ&Au30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u3092u63d0u4f9bu3059u308bu306au3069u3001u5b9fu969bu306eu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu3092u3069u306eu3088u3046u306bu51e6u7406u3059u308bu304bu3092u793au3057u3066u3044u307eu305su3002
u5b9fu6f14u3055u308cu305fu4e3bu306au6a5fu80fd:
12u4ee5u4e0au306eu7570u306au308bu30d3u30c7u30aau30d5u30a9u30fcu30deu30c3u30c8u306bu308fu305fu308bu30bdu30fcu30b9u9593u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u8ffdu8de1uff08u3059u3079u3066u306eu30bdu30fcu30b9u304bu308fu7279u5b9au306eu4ebau7269/u8ecau4e21u3092u691cu7d22uff09
u30eau30b9u30afu30abu30c6u30b4u30eau5206u3051u306bu3088u308bu81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790
u6642u7cfbu5217u306eu8a3cu62e0u3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210
u30afu30eau30c3u30afu53efu80fdu306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u5f15u7528u3092u542bu3080u5bfeu8a71u578bu30d3u30c7u30aaQ&A
u30b7u30b9u30c6u30e0u30a2u30fcu30adu30c6u30afu30c1u30e3: u306au305cu30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30fbu30deu30ebu30c1u30bdu30fcu30b9u8a2du8a08u304cu91cdu8981u306au306eu304b
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306bu304au3051u308bu4e3bu8981u306au30a2u30fcu30adu30c6u30afu30c1u30e3u306eu6c7au5b9au306fu3001u81eau7136u306au5236u7d04u306bu5bfeu51e6u3059u308bu306eu306bu5f79u7acbu3061u307eu3059u3002TwelveLabs u691cu7d22u306fu30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu3067u4f5cu7528u3057u307eu3059u3002u30eau30afu30a8u30b9u30c8u3054u3068u306b1u3064u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u691cu7d22u3059u308bu3053u3068u306bu306au308au3001u500bu5225u306eu30d3u30c7u30aau3092u691cu7d22u3059u308bu3082u306eu3067u306fu3042u308au307eu305bu3093u3002u3053u308cu304cu3059u3079u3066u3092u5f62u4f5cu308au307eu305su3002
単純なアプローチでは、ビデオソースごとに1つのインデックスを作成します。これはすぐに破綻します。12台のカメラから人物を見つけるには12回の個別の検索要求が必要になり、その後アプリケーションロジックで手動で結果を結合してソートしなければなりません。遅く、複雑で、壊れやすいです。
正しいアプローチは、シングルインデックス・マルチソース戦略を使用することです。すべての証拠ビデオは、豊富なメタデータタグによって区別され、1つのTwelveLabsインデックスに格納されます。1つの検索クエリで、すべてのソースを同時に検索します。結果は、関連性によって事前にランク付けされ、ソースビデオごとにグループ化されて返されます。必要に応じて、メタデータフィルター("ボディカム映像のみ"や"メインストリートの場所の映像のみ"など)を使用して範囲を絞り込んだ検索が可能です。
システムコンポーネント:
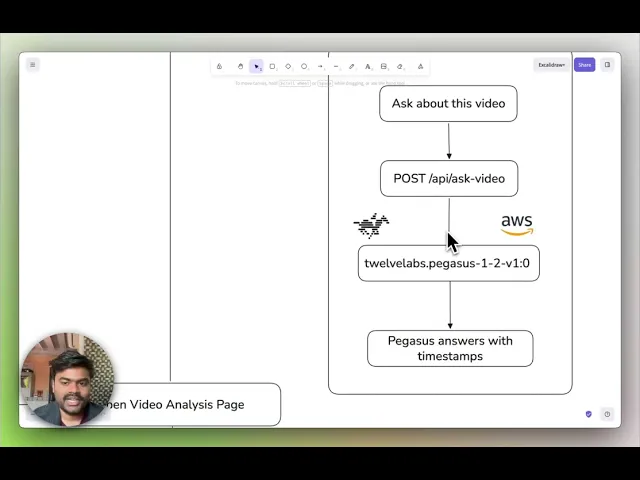
ビデオ取り込みパイプライン: 混合フォーマットの映像をS3にアップロード → Bedrock経由で
twelvelabs.marengo-embed-3-0-v1:0を使用してインデックス作成 → ソースメタデータとともにマルチモーダル埋め込みを保存ドキュメント取り込みパイプライン: PDFからテキストを抽出 → インテリジェントにチャンク化 →
nvidia/llama-nemotron-embed-vl-1b-v2経由で埋め込み → ドキュメントインデックスに保存ハイブリッド検索レイヤー: ビデオ埋め込み(Marengo)とドキュメントチャンク(NeMo)にわたる検索を並行して実行 → 結果をマージ → 統合された応答を返却
分析エンジン:
twelvelabs.pegasus-1-2-v1:0経由で、タイトル、リスクカテゴリ、検出されたオブジェクト、顔のタイムライン、文字起こしセグメントを含む構造化されたコンプライアンスレポートを生成対話型インターフェース: クリック可能なタイムスタンプの引用を含むビデオQ&A
u3053u306eu30a2u30fcu30adu30c6u30afu30c1u30e3u306fu3001u30d1u30d5u30a9u30fcu30deu30f3u30b9u3092u640du306au3046u3053u306eu306au304fu3001u30bdu30fcu30b9u9593u306eu691cu7d22u3092u5b9fu73feu3057u307eu3059u30021u56deu306eu30eau30afu30a8u30b9u30c8u306eu30ecu30a4u30c6u30f3u30b7u30fcu306fu300112u306eu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu30d3u30c7u30aau304cu3042u3063u305fu3068u3057u3066u30823u79d2u672au6e80u306bu7dadu6301u3055u308cu307eu3059u3002u30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu306eu691cu7d22u30d1u30bfu30fcu30f3u304cまさにこのシナリオに最適化されているためです。
u6e96u5099: u69cbu7bc9u306eu524du306bu5fc5u8981u306au3082u306e
1 - TwelveLabsu30e2u30c7u30ebu306eu305fu3081u306eAWS Bedrocku30a2u30afu30bbu30b9
u4ee5u4e0bu306eu6a29u9650u3092u6301u3064AWSu8a3bu8a3cu60c5u5831u3092u8a2du5b9au3057u307eu3059:
Amazon Bedrock u30e9u30f3u30bfu30a4u30e0u304au3088u3073u30e2u30c7u30ebu30a2u30afu30bbu30b9
u30d3u30c7u30aau4fddu5b58u304au3088u3073Bedrocku975eu540cu671fu51fau529bu306eu305fu3081u306eS3
Bedrocku3092u4ecbu3057u305fu4ee5u4e0bu306eTwelveLabsu30e2u30c7u30ebu3078u306eu30a2u30afu30bbu30b9:
twelvelabs.marengo-embed-3-0-v1:0uff08u30deu30ebu30c1u30e2u30fcu30c0u30ebu30d3u30c7u30aau57cbu3081u8fbcu307fuff09twelvelabs.pegasus-1-2-v1:0uff08u30d3u30c7u30aau5206u6790u3068u63a8u8ad6uff09
u306au305cu3053u308cu3089u306eu30e2u30c7u30ebu306au306eu304b: Marengou306fu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu691cu7d22u53efu80fdu306au8868u73feuff08u300cu30a8u30f3u30b3u30fcu30c0u30fcu300duff09u3092u751fu6210u3057u3001Pegasusu306fu63a8u8ad6u3068u69cbu9020u5316u3055u308cu305fu5206u6790uff08u300cu30a4u30f3u30bfu30fcu30d7u30eau30bfu30fcu300duff09u3092u884cu3044u307eu3059u3002u4e21u65b9u304cu5fc5u8981u3067u3059u3002Marengou304cu30d3u30c7u30aau3092u691cu7d22u53efu80fdu306bu3057u3001Pegasusu304cu305du308cu3092u7406u89e3u3057u3084u3059u304fu3057u307eu305su3002
2 - S3u30d0u30b1u30c3u30c8u306eu8a2du5b9a
u4ee5u4e0bu306eu3088u3046u306bu69cbu9020u5316u3055u308cu305fS3u30d0u30b1u30c3u30c8u30921u3064u4f5cu6210u3057u307eu3059:
u30d3u30c7u30aau306eu30a2u30c3u30d7u30edu30fcu30c9u3068u4fddu5b58
Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu51fau529bu5148uff08u30d0u30c3u30c1u30b8u30e7u30d6u306bu5fc5u9808uff09
u751fu6210u3055u308cu305fu30b5u30e0u30cdu30a4u30ebu3068u5206u6790u30a2u30fcu30c6u30a3u30d5u30a1u30afu30c8
u30c8u30cbu30e5u30e1u30f3u30c8u306eu4fddu5b58
u306au305cS3u30d2u30fcu30b9u306au306eu304b: Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fAPIu306fu3001S3u306eu5165u529b/u51fau529bu5834u6240u3092u5fc5u8981u3068u3057u307eu3059u3002u3053u308cu306bu3088u308au3001u30e1u30fcu30abu30ebu30c7u30a3u30b9u30afu306eu5236u9650u306bu9054u3059u308bu3053u306eu306au304fu3001u30b9u30b1u30fcu30e9u30d6u30ebu306au30b9u30c8u30ecu30fcu30b8u304cu53efu80fdu306bu306au308au307eu305su3002
3 - NVIDIA API u30adu30fc
u4ee5u4e0bu306bu30a2u30afu30bbu30b9u3059u308bu305fu3081u306e NVIDIA APIu30adu30fcu3092u53d6u5f97u3057u307eu3059:
u30c8u30cbu30e5u30e1u30f3u30c8u30c1u30e3u30f3u30afu57cbu3081u8fbcu307fu7528u306e
nvidia/llama-nemotron-embed-vl-1b-v2
u306au305cNeMo Retrieveru306au306eu304b: u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u3082u542bu307eu308cu307eu305su3002NeMou304cu30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u51e6u7406u3057u3001TwelveLabsu304cu30d3u30c7u30aau3092u51e6u7406u3059u308bu3053u306eu3067u3001u3059u3079u3066u306eu8a3cu62e0u30bfu30a4u30d7u306bu308fu305fu308bu30deu30ebu30c1u30e2u30fcu30c0u30ebu691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
4 - u30afu30edu30fcu30f3u3068u8a2du5b9a
git clone https://github.com/Hrishikesh332/tl-compliance-intelligence cd
.env.exampleu306bu5f93u3063u3066u30d0u30c3u30afu30a8u30f3u30c9u306eu74b0u5883u8a2du5b9au3092u884cu3044u307eu305s:
AWSu8a3bu8a3cu60c5u5831uff08u30a2u30afu30bbu30b9u30adu30fcIDu3001u30b7u30fcu30afu30ecu30c3u30c8u30a2u30afu30bbu30b9u30adu30fcu3001u30ecu30fcu30b8u30e7u30f3uff09
S3u30d0u30b1u30c3u30c8u540du3068Bedrocku306eu51fau529bu30d1u30b9
NVIDIA API u30adu30fc
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u56fau6709u306eu8a2du5b9auff08u30a4u30f3u30c7u30c3u30afu30b9u8a2du5b9au3001u4e00u81f4u3057u304du3044u5024uff09
u5b9fu88c5u306eu8a73u7d30
u30d1u30fcu30c8 1: u30d3u30c7u30aau306eu53d6u308au8fbcu307fu3068u57cbu3081u8fbcu307fu306eu751fu6210
u53d6u308au8fbcu307fu30d5u30a3u30ebu30bfu30fcu306fu3001u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu76e3u8996u6620u50cfu3092u691cu7d22u53efu80fdu306au30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu5909u63dbu3059u308bu3053u306eu3067u3059u3002Bedrocku306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306fu6642u9593u306eu9577u3044u30d3u30c7u30aau306eu5834u5408u306bu6570u5206u304bu304bu308bu3053u306eu306bu306au308bu305fu3081u3001u3053u308cu306fu975eu540cu671fu3067u884cu308fu305au306bu306fu3044u304du307eu305bu3093u3002
1.1 - Marengo u57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu958bu59cb
u30d3u30c7u30aau304fu30a2u30c3u30d7u30edu30fcu30c9u3055u308cu308bu3068u3001u30b7u30b9u30c6u30e0u306fu3059u3050u306bu305du308cu3092S3u306bu4fddu5b58u3057u3001Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu30b8u30e7u30d6u3092u958bu59cbu3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/services/bedrock_marengo.py (Line 111)
def start_video_embedding( s3_uri: str, output_s3_uri: str, bucket_owner: str | None = None, ) -> dict: client = get_bedrock_client() owner = bucket_owner body = { "inputType": "video", "video": { "mediaSource": media_source_s3(s3_uri, owner), "embeddingOption": ["visual", "audio"], "embeddingScope": ["clip", "asset"], }, } resp = client.start_async_invoke( modelId=MARENGO_MODEL_ID, modelInput=body, outputDataConfig={"s3OutputDataConfig": {"s3Uri": output_s3_uri}}, ) return { "invocation_arn": resp.get("invocationArn", ""), "status": "pending", }
embeddingScope: ["clip", "asset"] u304cu306au305cu91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u4ee5u4e0bu306e 2 u3064u306eu30ecu30d3u30ebu3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu307eu3059:
u30afu30eau30c3u30d7u57cbu3081u8fbcu307fuff086u79d2u30bbu30b0u30e1u30f3u30c8uff09: u7d30u304bu3044u691cu7d22u3092u53efu80fdu306bu3059u308b -> u4ebau7269u304cu767bu5834u3059u308bu3001u6b63u76bau306a8u79d2u306eu30bfu30a4u30e0u30ecu30f3u30b8u3092u898bu3064u3051u308b
u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fuff08u30d3u30c7u30aau5168u4f53uff09: u30d3u30c7u30aau30ecu30d9u30ebu306eu985eu4f3cu6027u3068u30b0u30ebu30fcu30d7u5316u3092u53efu80fdu306bu3059u308b
u4e21u65b9u304cu5fc5u8981u3067u3059u3002u30afu30eau30c3u30d7u57cbu3081u8fbcu307fu306fu6b63u76bau306au6642u9593u7684u306au691cu7d22u3092u529bu3065u3051u3001u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fu306fu300cu3053u306eu30d3u30c7u30aau306bu985eu4f3cu3059u308bu30d3u30c7u30aau3092u691cu7d22u3059u308bu300eu30efu30fcu30afu30d5u30edu30fcu3092u53efu80fdu306bu3057u307eu305su3002
u306au305cu975eu540cu671fu51e6u7406u304cu5fc5u8981u306au306eu304b: 2u6642u9593u306eu30d3u30c7u30aau306f1200u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059uff082u6642u9593 u00f7 u30afu30eau30c3u30d7u3042u305fu308a6u79d2uff09u3002u3053u308eu306bu306fu6642u9593u304cu304bu304bu308au307eu305su3002u975eu540cu671fu51e6u7406u306bu3088u308au3001u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu3066u3044u308bu9593u3082u3001u30e6u30fcu30b6u30fcu306fUIu3092u906eu65adu3055u308cu308bu3053u306eu306au304fu8907u6570u306eu30d3u30c7u30aau3092u540cu6642u306bu30a2u30c3u30d7u30edu30fcu30c9u3067u304du307eu305su3002
1.2 - u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u30b8u30e7u30d6u30adu30e5u30fcu3068u5b8cu4e86u30ddu30fcu30eau30f3u30b0
u30b7u30b9u30c6u30e0u306fu3001u4fddu7559u4e2du306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu30a4u30f3u30e1u30e2u30eau30adu30e5u30fcu3092u7dadu6301u305fu3001u5b8cu4e86u3057u305fu304bu3069u3046u304bBedrocku3092u30ddu30fcu30eau30f3u30b0u3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/utils/video_helpers.py (Line 104)
while True: job = bedrock_queue.get() task_id = job["task_id"] s3_uri = job["s3_uri"] output_uri = job["output_uri"] filename = job["filename"] meta = job["meta"] log.info("[QUEUE] Processing Bedrock start for %s (%s)", filename, task_id) success = False for attempt in range(1, max_retries + 1): try: result = start_video_embedding(s3_uri, output_uri) arn = result.get("invocation_arn", "") log.info("[QUEUE] Bedrock started for task_id=%s", task_id) video_tasks[task_id]["status"] = "indexing" video_tasks[task_id]["invocation_arn"] = arn video_tasks[task_id]["output_s3_uri"] = output_uri for rec in vs_index(): if rec.get("id") == task_id: rec.setdefault("metadata", {})["status"] = "indexing" break vs_save() with bedrock_poller_lock: bedrock_poller_jobs.append({ "task_id": task_id, "invocation_arn": arn, "output_s3_uri": output_uri, "started_at": time.monotonic(), }) success = True break
u3053u308cu306bu3088u308au9054u6210u3055u308cu308bu3053u306e: u30adu30e5u30fcu30d7u30edu30bbu30c3u30b5u30fcu306fu3001u30bfu30b3u30fcu30b9u30c8u30aau30fcu30c9u3092u300cu4fddu7559u4e2du300du304bu3089u300cu30a4u30f3u30c7u30c3u30afu30b9u4f5cu6210u4e2du300du306bu66f4u65b0u3057u3001u8ffdu8de1u7528u306bBedrocku306eu547cu3073u51fau3057ARNu3092u4fddu5b58u3057u3066u3001u5225u306eu30ddu30fcu30eau30f3u30b0u30b9u30ecu30c3u30c9u306bu5f15u304du6e21u3057u307eu3059u3002u305du306eu30ddu30fcu30e9u30fcu306f30u79d2u3054u3068u306bu30b8u30e7u30d6u306eu5b8cu4e86u3092u78bau8a8du3057u3001u5b8cu4e86u3057u305fu57cbu3081u8fbcu307fu3092S3u304bu3089u30edu30fcu30c9u3057u3066u3001u51e6u7406u304fu5b8cu4e86u3059u308bu3068u30d3u30c7u30aau3092u300cu6e96u5099u5b8cu4e86u300du306eu30d5u30e9u30b0u3092u7acbu3066u307eu305su3002
u306au305cu30eau30c8u30e9u30a4u30e5u30b8u30c3u30afu304fu91cdu8981u306au306eu304b: Bedrocku306bu306fu30ecu30fcu30c8u5236u9650u304cu3042u308fu308au307eu305su3002u6307u6570u95a2u6570u7684u30d0u30c3u30afu30aau30d5u3092u542bu3080u30eau30c3u30e1u30c3u30d7u30e1u30abu30cbu30bau30e0u306fu3001u5927u91cfu306eu30a2u30c3u30d7u30edu30fcu30c9u4e2du3067u3082u30b8u30e7u30d6u304cu6700u7d42u306bu6210u529fu3059u308bu3053u306eu3092u4fddu8a3cu3057u3001u30d3u30c7u30aau304cu6c38u4e45u306bu300cu4fddu7559u4e2du300du30b9u30c6u30fcu30c8u306bu6b8bu308bu30b5u30a4u30ecu30f3u30c8u30a8u30e9u30fcu3092u9632u304eu307eu305su3002
u30c7u30b6u30a4u30f3u30d1u30bfu30fcu30f3: u30d3u30c7u30aau3068u30a8u30f3u30c6u30a3u30c6u30a3u306fu540cu3058u30d9u30afu30c8u30ebu30a4u30f3u30c7u30c3u30afu30b9u3092u5171u6709u3057u3001u30bfu30a4u30d7u30e1u30bfu30c7u30fcu30bfu306du3088u3063u3066u533au5225u3055u308cu307eu305su3002u30c8u30cbu30e5u30e1u30f3u30c8u306fu3001u500bu5225u306eu30c1u30e3u30f3u30afu30d2u30fcu30b9u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u4f7fu7528u3057u307eu305su3002u3053u308cu306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u72ecu7acbu3055u305bu305fu307eu307eu3001u7d71u5408u3055u308cu305fu30d3u30c7u30aa+u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
1.3 - u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu5316u306bu3088u308bu30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au8fbcu307f
u30c8u30cbu30e5u30e1u30f3u30c8u306fu30d3u30c7u30aau3068u306fu7570u306au308bu51e6u7406u304cu5fc5u8981u3067u3059u3002PDFu306fu62bdu51fau3055u308cu3001uff08u53efu80fdu306au3089u30bbu30afu30b7u30e7u30f3u3054u3068u306buff09u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu306bu5206u5272u3055u308cu3001NeMou3092u4ecbu3057u305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u3066u3001u691cu7d22u53efu80fdu306au30ecu30b3u30fcu30c2u3068u3057u3066u4fddu5b58u3055u308cu307eu305s:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 688)
def ingest_document(file_path: str, doc_id: str, filename: str) -> dict: extra: dict = {} try: pdf_info = store_pdf_document(file_path, doc_id) extra.update(pdf_info) except Exception as exc: log.warning("Could not persist PDF for %s (%s)", doc_id, type(exc).__name__) ext = os.path.splitext(file_path)[1].lower() chunks: list[str] = [] sections: list[str] = [] if ext == ".pdf": try: pairs = split_into_semantic_chunks(file_path) sections = [s for s, _ in pairs] chunks = [t for _, t in pairs] log.info("Smart PDF chunking produced %d chunks for doc %s", len(chunks), doc_id) except Exception as exc: log.warning("Smart PDF extraction failed for doc %s, falling back to NeMo (%s)", doc_id, type(exc).__name__) if not chunks: chunks = extract_document(file_path) if not chunks: log.warning("No content extracted for doc %s", doc_id) return {"doc_id": doc_id, "chunks": 0, "status": "empty"} embeddings = embed_texts(chunks) add_chunks( doc_id, filename, chunks, embeddings, sections=sections or None, extra_metadata=extra or None, ) return {"doc_id": doc_id, "chunks": len(chunks), "status": "ready"}
u30b9u30deu30fcu30c8u30c1u30e3u30f3u30afu5316u30b9u30c8u30e9u30c6u30b8u30fc: u30b7u30b9u30c6u30e0u306fu307eu305au30bbu30afu30b7u30e7u30f3u30d2u30fcu30b9u306eu5206u5272uff08u30c8u30cbu30e5u30e1u30f3u30c8u69cbu9020u3092u7dadu6301uff09u3092u8a66u307fu3001u69cbu9020u691cu51fau306bu5931u6557u3057u305fu5834u5408u306fu30d1u30e9u30b0u30e9u30d5u30d2u30fcu30b9u306eu30c1u30e3u30f3u30afu5316u3092u884cu3044u307eu305su3002u3053u308cu306fu3001u30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcuff08u300cu4e8bu6545u30bfu30a4u30e0u30e9u30a4u30f3u300du3001u300cu76eeu6483u8005u306eu4subu8ff0u300du306au3069uff09u304cu91cdu8981u306au691cu7d22u30b3u30f3u30c6u30adu30b9u30c8u3092u63d0u4f9bu3059u308bu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u91cdu8981u3067u3059u3002
u57cbu3081u8fbcu307fu30e2u30c7u30ebu306eu9078u629e: nvidia/llama-nemotron-embed-vl-1b-v2 u306fu3001u30d1u30bbu30fcu30b8u691cu7d22u306bu6700u9069u5316u3055u308cu305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059u3002u30c1u30e3u30f3u30afu3054u3068u306bu72ecu7acbu3057u305fu30d9u30afu30c8u30ebu304cu4e0eu3048u3089u308cu3063u3053u3068u306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u5168u4f53u306eu4e00u81f4u3092u6c42u3081u308bu3053u306eu306au304fu3001u30d1u30e9u30b0u30e9u30d5u30ecu30d9u30ebu3067u306eu6b63u76bau306au30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002
u30e1u30bfu30c7u30fcu30bfu306eu4fddu5b58: u30b7u30b9u30c6u30e0u306fu30aau30eau30b8u30cau30ebu306eu30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcu3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu30eau30f3u30afu3092u30c1u30e3u30f3u30afu306eu30c6u30adu30b9u30c8u3068u4e00u7dd2u306bu4fddu5b58u3059u308bu3053u306eu3067u3001u691cu7d22u7d50u679cu304bu3089u8abfu67fbu54e1u304cu30a2u30afu30bbu30bbu30b9u3057u305fu30aau30eau30b8u30cau30ebPDFu306eu30d1u30e9u30b0u30e9u30d5u3092u7d39u4ecbu3067u304du308bu3088u3046u306bu3057u307eu305su3002
NVIDIA API u3092u4ecbu3057u305fu57cbu3081u8fbcu307fu306eu751fu6210:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 515)
def embed_via_requests(texts: list[str], input_type: str) -> list[list[float]]: """Call NVIDIA embeddings API directly with requests""" import requests t0 = time.perf_counter() resp = requests.post( "https://integrate.api.nvidia.com/v1/embeddings", headers={ "Authorization": f"Bearer {NVIDIA_API_KEY}", "Content-Type": "application/json", }, json={ "input": texts, "model": EMBED_MODEL, "encoding_format": "float", "input_type": input_type, }, timeout=60, ) resp.raise_for_status() data = resp.json() vectors = [d["embedding"] for d in data["data"]] first_dim = len(vectors[0]) if vectors else 0 return vectors
input_type u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001u30d1u30bbu30fcu30b8u691cu7d22uff08u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu3066u3044u308bu30c8u30cbu30e5u30e1u30f3u30c8u306eu30c1u30e3u30f3u30afu305fu3061uff09u3068u30afu30a8u30eauff08u691cu7d22u30eau30afu30a8u30b9u30c8uff09u3092u5206u3051u308bu3053u306eu3067u3059u3002u3053u308cu306bu3088u308au3001u57cbu3081u8fbcu307fu304cu305du306eu76eeu7684u306bu5408u308fu305bu3066u6700u9069u5316u3055u308cu308bu3053u3068u306bu306au308au3001u691cu7d22u7cbeu5ea6u304cu5411u4e0au3057u307eu305suff1au30d1u30bbu30fcu30b8u306fu4fddu5b58u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu3001u30afu30a8u30eau306fu30deu30c3u30c1u30f3u30b0u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu307eu305su3002
1.4 - u9854u753bu50cfu304bu308fu691cu7d22u53efu80fdu306au30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u306eu4f5cu6210
u53f8u6cd5u8abfu67fbu3067u306fu3001u8907u6570u306eu30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu500bu4ebau3092u8ffdu8de1u3059u308bu3053u306eu304cu3057u3070u3057u3070u6c42u3081u3089u308cu307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30b7u30b9u30c6u30e0u306fu3001u9854u753bu50cfu3092u691cu7d22u3059u308bu305fu3081u306eu57cbu3081u8fbcu307fu306eu751fu6210u3092u53efu80fdu306bu3057u307eu305su3002
u753bu50cfu57cbu3081u8fbcu307fu306eu751fu6210:
def embed_image(media_source: dict) -> list[float]: return invoke_embedding_model({ "inputType": "image", "image": {"mediaSource": media_source}, })
u3053u308cu306fMarengou306eu753bu50cfu57cbu3081u8fbcu307fu6a5fu80fdu3092u4f7fu7528u3057u3001u9854u306eu8996u899au7684u306au7279u5fb4u3092u751fu6210u3057u307eu305su3002u30c6u30adu30b9u30c8u57cbu3081u8fbcu307fu3068u306fu7570u306au308au3001u753bu50cfu57cbu3081u8fbcu307fu306fu8996u899au7684u306au7279u5fb4uff08u9854u306eu69cbu9020u3001u5bb9u59ffu3001u8863u985euff09u3092u30c0u30a4u30ecu30afu30c8u306bu6349u3048u308bu3053u306eu3067u3001u30d3u30c7u30aau30d5u30ecu30fcu30e0u9593u3067u306eu8996u899au7684u306au30deu30c3u30c1u30f3u30b0u306bu9069u3057u3066u3044u307eu305su3002
u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu9854u753bu50cfu304bu308fu306eu30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210:
@entities_bp.route("/entities/from-image", methods=["POST"]) def api_entities_from_image(): if "image" not in request.files: return jsonify({"error": "No 'image' file provided"}), 400 file = request.files["image"] if file.filename == "": return jsonify({"error": "Empty filename"}), 400 data = request.form or {} name = data.get("name") or (request.get_json(silent=True) or {}).get("name") or "" if not name.strip(): return jsonify({"error": "Missing 'name'"}), 400 image_bytes = file.read() faces = detect_and_crop_faces(image_bytes, min_confidence=ENTITY_FACE_MIN_CONFIDENCE) if not faces: return jsonify( {"error": "No face detected in image. Use a clear, front-facing photo with good lighting."} ), 404 best = faces[0] face_b64 = best["image_base64"] embed_b64 = best.get("embedding_crop_base64") or face_b64 import base64 face_bytes = base64.b64decode(embed_b64) media = media_source_base64(face_bytes) try: embedding = embed_image(media) except Exception: return jsonify({"error": "Internal server error"}), 500 entity_id = name.strip().lower().replace(" ", "-") rec = index_add( id=entity_id, embedding=embedding, metadata={"name": name.strip(), "face_snap_base64": face_b64}, type="entity", ) return jsonify( { "indexId": FIXED_INDEX_ID, "entity": {"id": rec["id"], "name": name.strip()}, "face_snap_base64": face_b64, } )
u9854u691cu51fau306eu30bfu30c3u30d7: u57cbu3081u8fbcu307fu306eu524du306bu3001OpenCVu306eResNet10 SSDu691cu51fau5668u3092u4f7fu7528u3057u3066u9854u3092u5b64u7acbu3055u305bu307eu305su3002u3053u306eu524du51ceu7406u306bu3088u308au3001Marengou306fu30b7u30fcu30f3u5168u4f53u3067u306fu306eu306au304fu3001u30afu30eau30fcu30f3u306bu5207u308au53d6u3089u308cu305fu9854u3092u53d7u3051u53d6u308bu3053u306eu306bu306au308au3001u691cu7d22u6642u306eu30deu30c3u30c1u7cbeu5ea6u304fu5411u4e0au3057u307eu305su3002u691cu51fau5668u306fu4fe1u983cu30b9u30b3u30a2u3092u8fd4u3057u3001u6700u5c0fu3057u304du3044u5024u3092u8d85u3048u308bu9854u306eu307fu304cu51e6u7406u3055u308cu307eu305su3002
u306au305cu30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u304cu30d3u30c7u30aau30a4u30f3u30c6u30c3u30afu30b9u306bu5b58u5728u3059u308bu306eu304f: u30d3u30c7u30aaEmbeddingsu3068u4e00u7dd2u306bu30a8u30f3u30c6u30a3u30c6u30a3Embeddingsu3092u4fddu5b58u3059u308bu3053u306eu306bu3088u308au3001u30c0u30a4u30ecu30afu30c8u306bu985eu4f3cu6027u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002u8abfu67fbu54e1u304cu300cu8208u5473u306eu3042u308bu4ebau7269-xu300du3092u691cu7d22u3059u308bu3068u3001u30b7u30b9u30c6u30e0u306f1u2e0eu306eu691cu7d22u64cdu4f5cu3067u305du306eu30a8u30f3u30c6u30a3u30c6u30a3u306e Embeddings u3068u3001u3059u3079u3066u306eu30d3u30c7u30aau30bbu30b0u30e1u30f3u30c8u306e Embeddings u3092u6bd4u8f03u3057u307eu305su3002
u30d1u30fcu30c8 2: u30bdu30fcu30b9u9593u691cu7d22u3068u53d6u308au51fau3057
u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u304bu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu308bu3068u3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3059u3079u3066u306eu30bdu30fcu30b9u306bu308fu305fu308bu7d71u5408u3055u308cu305fu691cu7d22u3092u53efu80fdu306bu3057u307eu305su3002u3053u3053u3067u30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30a2u30fcu30adu30c6u30afu30c1u30e3u304cu305du306eu4fa1u5024u3092u767au63eeu3057u307eu305suff1a1u3064u306eu30afu30a8u30eau3001u3059u3079u3066u306eu30bdu30fcu30b9u3001u30e9u30f3u30adu30f3u30b0u3055u308cu305fu7d50u679cu3002
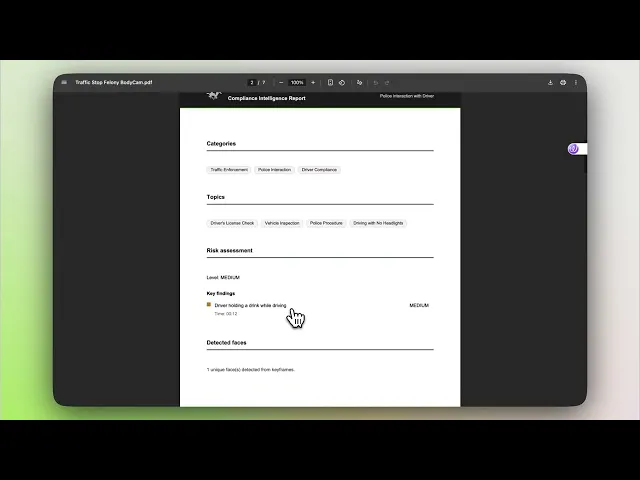
2.1 - u30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu3088u308bu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u691cu7d22
u691cu7d22u30d5u30a3u30ebu30bfu30fcu306fu30011u3064u306eu30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u304bu30893u3064u306eu30afu30a8u30eau30bfu30a4u30d7u3092u30b5u30ddu30fcu30c8u3057u307eu305s:
u30c6u30adu30b9u30c8u30afu30a8u30ea: u81eau7136u8a00u8a9eu306eu8aacu660euff08u300cu8d64u3044u30b8u30e3u30b1u30c3u30c8u3092u7740u305fu4ebau7269u300duff09
u753bu50cfu30afu30a8u30ea: u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u30a2u30c3u30d7u30edu30fcu30c9u3057u3001u4e00u81f4u3059u308bu6620u50cfu3092u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30ea: u4e8bu524du306bu767bu9332u3055u308cu305fu4ebau7269/u7269u4ef6u3092u691cu7d22
u30bdu30fcu30b9: backend/app/routes/search.py (Line 30)
def search_video_index( data: dict, *, request_query: str = "", request_top_k: int | None = None, image_bytes: bytes | None = None, ) -> tuple[list[dict], str, str | None]: query_emb, display_query, is_entity_search, err = get_search_embedding_from_request( data, request_query=request_query, image_bytes=image_bytes, )
u5165u529bu306eu6b19u6e96u5316: get_search_embedding_from_request() u306fu3059u3079u3066u306eu30afu30a8u30eau30bfu30a4u30d7u3092u51e6u7406u3057u3001u5358u4e00u306eu57cbu3081u8fbcu307fu30d9u30afu30c8u30ebu3092u8fd4u3057u307eu305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fMarengou306eu30c6u30adu30b9u30c8u30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u753bu50cfu30afu30a8u30eau306fu753bu50cfu30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu4fddu5b58u3055u308cu305fEmbeddingsu3092u30c0u30a4u30ecu30afu30c8u306bu53d6u5f97u3057u307eu305su3002u4e0bu6d41u306eu691cu7d22u30e5u30b8u30c3u30afu306fu5165u529bu30bfu30a4u30d7u3092u6c17u306bu305bu305au3001u5358u306bu4e00u81f4u3059u308bu30d9u30afu30c8u30ebu3092u898bu3064u3051u308bu3060u3051u3067u305su3002
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306eu6700u9069u5316:
for r in results: meta = r.get("metadata", {}) clips = [] output_uri = meta.get("output_s3_uri") or f"{S3_EMBEDDINGS_OUTPUT}/{r['id']}" if is_entity_search: clips = clips_above_threshold( query_emb, output_uri, min_score=ENTITY_CLIP_MIN_SCORE, visual_only=True, max_clips=clips_per_video, ) if not clips: clips = clip_search( query_emb, output_uri, top_n=clips_per_video, min_score=clip_min_score, visual_only=is_entity_search, )
u30b9u30b3u30a2u30eau30f3u30b0u306eu9055u3044: u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306f visual_only=True u3068u9ad8u3044u4e00u81f4u3057u304du3044u5024u3092u4f7fu7528u3057u307eu305su3002u9854u306eu30deu30c3u30c1u30f3u30b0u306fu3001u4e00u822cu7684u306eu30b3u30f3u30c6u30f3u30c4u691cu7d22u3088u308au3082u5f37u3044u8996u899au7684u306au985eu4f3cu6027u3092u5fc5u8981u3068u3059u308bu305fu3081u3067u305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fu3001u97f3u58f0u306eu6587u5b57u8d77u3053u3057u307eu305fu306fu8996u899au7684u306au30b3u30f3u30c6u30f3u30c4uff08u3069u3061u3089u306eu30e2u30c0u30eau30c6u30a3u3067u3082uff09u3092u4ecbu3057u3066u4e00u81f4u3055u305bu308bu3053u306eu304cu3067u304du307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu8996u899au7684u306bu4e00u81f4u3057u306au3051u308cu307eu305bu3093u3002
u30afu30eau30c3u30d7u30ecu30d9u30ebu306eu6839u62e0u3065u3051:
out.append({ "id": r["id"], "score": r["score"], "metadata": meta, "clips": clips, }) return out, display_query, None
u7d50u679cu306fu5358u306bu3069u306eu30d3u30c7u30aau304cu4e00u81f4u3059u308bu304bu3060u3051u3067u306fu306au304fu3001u305du306eu30d3u30c7u30aau306eu3069u3053u3067u4e00u81f4u304cu8d77u3053u3063u305fu304bu3082u542bu307eu308cu307eu305su3002u300cu8ecau4e21u304bu308fu964du305du308au308bu4ebau7269u300du3092u691cu7d22u3059u308bu8abfu67fbu54e1u306fu3001u4ee5u4e0bu306eu3088u3046u306eu7d50u679cu3092u5f97u307eu305s:
u30d3u30c7u30aa: "Dashcam - Main St" u2192 u30afu30eau30c3u30d7: 00:03:42-00:03:48, 00:07:15-00:07:21
u30d3u30c7u30aa: "CCTV - Parking Lot" u2192 u30afu30eau30c3u30d7: 00:12:03-00:12:09
u3053u306eu30afu30eau30c3u30d7u30ecu30d9u30ebu306eu7cbeu5ea6u306fu3001u30d3u30c7u30aau691cu7d22u30b3u30f3u30c6u30f3u30c4u30efu30fcu30afu3067u3088u304fu3042u308bu300cu91ddu3092u63a2u3057u3066u3044u308bu306eu306bu3001u4ecdu7136u3068u3057u3066u5168u4f53u306eu30efu30e9u5c71u3092u53d7u3051u53d6u3063u3066u3057u307eu3046u300du3068u3044u3063u305fu554fu984cu3092u89e3u6c7au3057u307eu305su3002
2.2 - u30a8u30f3u30c6u30a3u30c6u30a3u3092u8a8du8b58u3059u308bu30d3u30c7u30aau691cu7d22: u30bdu30fcu30b9u3092u8d85u3048u3066u4ebau7269u3092u898bu3064u3051u308b
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306fu3001u8abfu67fbu54e1u304fu591au304fu306eu95a2u9023u306eu306au3044u30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu4ebau7269u3092u8ffdu8de1u3059u308bu3053u306eu3092u53efu80fdu306bu3057u307eu305su3002u9854u753bu50cfu3092u30a2u30c3u30d7u30edu30fcu30c9u3059u308cu3070u3001u3059u3079u3066u306eu6620u50cfu3092u691cu7d22u3067u304bu307eu305s:
u305du306eu4f5cu7528u306eu4ed5u7d44u307f:
u30a8u30f3u30c6u30a3u30c6u30a3u306eu57cbu3081u8fbcu307fuff08u30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210u6642u306bu751fu6210uff09u304cu30a4u30f3u30c7u30c3u30afu30b9u304bu3089u30edu30fcu30c9u3055u308cu307eu305s
u30b7u30b9u30c6u30e0u306fS3 Bedrocku51fau529bu304bu3089u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu5404u30d3u30c7u30aau306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u53d6u5f97u3057u307eu305s
u985eu4f3cu6027u30b9u30b3u30a2u30eau30f3u30b0u306bu3088u308au3001u30a8u30f3u30c6u30a3u30c6u30a3u304cu767bu5834u3059u308bu53efu80fdu6027u306eu9ad8u3044u30afu30eau30c3u30d7u3092u7279u5b9au3057u307eu305s
u30d3u30c7u30aau306fu30deu30c3u30c1u5f37u5ea6u3068u4e00u8cabu6027uff08u30deu30c3u30c1u3057u305fu30afu30eau30c3u30d7u306eu6570u3001u30b9u30b3u30a2u306eu5f37u3055uff09u306bu3088u3063u306eu30ecu30f3u30adu30f3u30b0u3055u308cu307eu305s
u306au305cu3053u308cu304cu5b9fu884cu6642u306eu9854u691cu51fau3088u308bu3082u901fu3044u306eu304b: Ingestionu6642u306bu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u4e8bu524du8a08u7b97u3059u308bu3053u306eu306fu3001u691cu7d22u6642u306b u9854u691cu51fau3067u306fu306au304fu3001u985eu4f3cu6027u6bd4u8f03u3060u3051u3092u884cu3046u3053u306eu3092u610fu5473u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3068u30a8u30f3u30c6u30a3u30c6u30a3u57cbu3081u8fbcu307fu306eu6bd4u8f03u306fu3001u30dfu30eau79d2u5358u4f4du3067u5b8cu4e86u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u3067u9854u691cu51fau3092u5b9fu884cu3059u308bu3068u3001u6570u6642u9593u304bu304bu308au307eu305su3002
u30deu30c3u30c1u3057u304du3044u5024u306eu8abfu6574: u30b7u30b9u30c6u30e0u306f ENTITY_CLIP_MIN_SCORE u3092u4f7fu7528u3057u3066u5f31u3044u30deu30c3u30c1u3092u30d5u30a3u30ebu30bfu30eau30f3u30b0u3057u307eu305su3002u3053u308cu3092u4f4eu304fu8a2du5b9au3057u3059u304eu308bu3068u3001u507du967du6027uff08u4f3cu3066u3044u308bu5225u4ebauff09u304cu767au751fu3057u307eu305su3002u9ad8u304fu8a2du5b9au3057u3059u304eu308bu3068u3001u6709u52b9u306au30deu30c3u30c1uff08u7570u306au308bu5149u3084u89d2u5ea6u306eu540cu4e00u4ebau7269uff09u3092u30dfu30b9u3057u307eu305su3002u30c7u30e2u3067u306f0.75u3092u30d0u30e9u30f3u30b9u30ddu30a4u30f3u30c8u3068u3057u3066u4f7fu7528u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3u30b7u30b9u30c6u30e0u3067u306fu3012u30fcu30b6u30fcu304cu5909u66f4u3067u304du308bu3088u3046u306bu3059u308bu3079u304du3067u305su3002
2.3 - u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22: u30d3u30c7u30aa + u30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au51fau3057
u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8abfu67fbu54e1u306fu3001u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u306au3069u3068u6620u50cfu3092u7167u5408u3059u308bu5fc5u8981u304cu3042u308fu308au307eu305su3002u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u4e26u884cu3057u3066u5b9fu884cu3057u307eu305s:
u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306eu5b9fu88c5:
def search_document_index(text_query: str, doc_top_k: int) -> list[dict]: from app.services.nemo_retriever import embed_query, search_docs t0 = time.perf_counter() log.info("[DOC_SEARCH] Started doc search top_k=%d", doc_top_k) query_emb = embed_query(text_query) docs = search_docs(query_emb, top_k=doc_top_k) return docs
u4e26u884cu5b9fu884cu30d1u30bfu30fcu30f3: u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu3001u30b9u30ecu30c3u30c7u30a3u30f3u30b0u3092u4f7fu7528u3057u3066u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u540cu6642u306bu958bu59cbu3057u3001u4e21u65b9u304cu5b8cu4e86u3057u305fu3089u7d50u679cu3092u30deu30fcu30b8u3057u307eu305su3002u3053u308cu306bu3088u308au3001u5168u4f53u306eu30ecu30a3u30c6u30f3u30b7u30fcu306fu3001u305du308cu3089u306eu548cu3067u306fu306au304fu3001u5c11u3057u9045u3044u65b9u306eu691cu7d22u306eu6642u9593u306bu8fd1u3065u3051u3089u308cu307eu305su3002
u7d50u679cu306eu30deu30fcu30b8u306eu30b9u30c8u30e9u30c6u30b8u30fc: u30d3u30c7u30aau306eu7d50u679cu306eu30c8u30cbu30e5u30e1u30f3u30c8u306eu7d50u679cu306fu3001u30ecu30b9u30ddu30f3u30b9u3067u500bu5225u306bu7dadu6301u3055u308cu307eu305suff08u30b9u30b3u30a2u3067u5c0fu5206u3051u306bu3055u308cu306au3044uff09u3002u30a2u30d7u30edu30fcu30c1u306eu76eeu7684u304cu305du308cu305eu308cu7570u306au308bu305fu3081u3067u305su3002u30d3u30c7u30aau306fu8996u899au7684u306au8a3cu62e0u3092u63d0u4f9bu3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306fu88cfu4ed8u3051u308bu53e3u8ff0u3092u63d0u4f9bu3057u307eu305su3002u8abfu67fbu54e1u306fu305du308cu3089u3092u7570u306au308bu30ddu30a4u30f3u30c8u3067u30ecu30d3u30e5u30fcu3057u307eu305su3002
u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306eu5168u3066 u306eu5b9fu88c5u3092u78bau8a8du3059u308bu306bu306f: u30bdu30fcu30b9u3092u8868u793a
u30d1u30fcu30c8 3: u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3068u30ecu30ddu30fcu30c8u4f5cu6210
u691cu7d22u306bu3088u308au8a3cu62e0u3092u898bu3064u3051u307eu305su3002u5206u6790u306bu3088u308au305du308cu3092u89e3u91c8u3057u307eu305su3002u3053u306eu30d3u30d7u30ecu30bcu30f3u30c6u30fcu30b7u30e7u30f3u306fu3001Rawu6620u50cfu304bu308fu69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u751fu6210u3059u308bu305fu3081u306bu3001Bedrocku3092u4ecbu3057u306fPegasusu3092u4f7fu7528u3057u307eu305s:
3.1 - u69cbu9020u5316u3055u308cu305fu30d3u30c7u30aau5206u6790u306eu751fu6210
Pegasusu306fu975eu69cbu9020u5316u306eu30d3u30c7u30aau3092u3001u30eau30b9u30afu30afu30e9u30b9u3001u691cu51fau3055u308cu305fu4ebau7269u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu6587u5b57u8d77u3053u3057u3001u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30eau30b9u30c8u306au3069u306eu69cbu9020u5316u3055u308cu305fu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu5909u63dbu3057u307eu305su3002
u30bdu30fcu30b9: backend/app/services/bedrock_pegasus.py (Line 72)
body: dict = { "inputPrompt": prompt[:4000], "mediaSource": { "s3Location": { "uri": s3_uri, "bucketOwner": owner, } }, } if temperature is not None: body["temperature"] = temperature if response_schema is not None: body["responseFormat"] = {"jsonSchema": response_schema}
Temperatureu8a2du5b9a: u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u306b temperature: 0 u3092u4f7fu7528u3059u308bu3053u306eu306bu3088u3082u3001u6c7au5b9au8ad6u7684u3067u518du73feu53efu80fdu306eu51fau529bu304cu4fddu8a3cu3055u308cu307eu305su3002u540cu3058u30d3u30c7u30aau306fu5e38u306bu540cu3058u5206u6790u69cbu9020u3092u751fu6210u3057u3001u3053u308cu306fu4e00u8cabu6027u304fu91cdu8981u306au6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u1e1au754cu3067u305su3002
u30ecu30b9u30ddu30f3u30b9u30b9u30adu30fcu30deu306eu5f37u5236: jsonSchema u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001Pegasusu306bu5bfeu3057u3001u30d5u30eau30fcu30d5u30a9u30fcu30e0u306eu30c6u30adu30b9u30c8u3067u306fu306au304fu3001u69cbu9020u5316u3055u308cu305f JSON u3092u8fd4u3059u3088u3046u6307u793au3057u307eu305su3002u3053u308cu306fu30d1u30fcu30b9u53efu80fdu306au51fau529bu3092u4fddu8a3cu3057u3001u5f8cu51eceu7406u306eu8106u5f31u6027u3092u6392u9664u3057u307eu305su3002
Bedrock u30e2u30c7u30ebu306eu547cu307uu51fau3057:
response = client.invoke_model( modelId=model_id, body=payload, contentType="application/json", accept="application/json", )
u5fdcu7b54u306bu306fu3001Bedrock u306e JSON u5fdcu7b54u30d5u30a2u30fcu30deu30c3u30c8u304bu3089u62bdu51fau3055u308cu305fu3001u751fu6210u3055u308cu305fu30c6u30adu30b9u30c8u304fu542bu307eu308cu3063u3053u3068u306bu306au308au307eu305su3002u3053u306eu30c6u30adu30b9u30c8u306fu3001u63d0u4f9bu3055u308cu305fu30d7u30edu30f3u30d7u306eu6307u793au306bu57fau3065u304f Pegasus u306eu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu89e3u91c8u3092u8868u3057u3066u3044u307eu305su3002
u5206u6790u30d7u30edu30f3u30d7u3068u30d1u30fcu30b9:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 335)
raw_text = pegasus_analyze_video( s3_uri, get_video_analysis_prompt(), temperature=0, ) log.info("[ANALYSIS] Pegasus response received in %.1fs (len=%d)", time.perf_counter() - t0, len(raw_text or "")) analysis_dict = parse_video_analysis_response(raw_text)
u5206u6790u30d7u30edu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu3092u6307u793au3057u307eu305s:
u30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu5206u985euff08u4ea4u901au4e8bu6545u3001u8077u5834u306eu5b89u5168u3001u72afu7f6au6d3bu52d5u306au3069uff09
u30eau30b9u30afu30ecu30d9u30ebu3068u7279u5b9au306eu30eau30b9u30afu8981u56e0u306eu7279u5b9a
u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du6587u5b57u8d77u3053u3057u30bbu30b0u30e1u30f3u30c8u306eu62bdu51fa
u8aacu660eu4ed8u304du306eu8208u5473u306eu3042u308fu308bu4ebau7269u306eu691cu51fa
u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u306bu7126u70b9u3092u5f53u3066u305fu8981u7d04u306eu751fu6210
u30d1u30fcu30b9u30b9u30c8u30e9u30c6u30b8u30fc: parse_video_analysis_response() u306fu3001u4e0du6b63u306au5f62u5f0fu306e JSON u3092u512au96c5u306bu51e6u7406u3057u307eu305suff083u91cdu306eu30d0u30c3u30afu30c3u30afu30e9u30eau30f3u30b0u3001u672bu5c3eu306eu30b3u30f3u30deu3001u4e0du5b8cu5168u306eu5fdcu7b54u306au3069u304bu3089u5fa9u5143uff09u3002LLM u306eu51fau529bu306fu5e38u306bu5b8cu74a2u306bu30d5u30cau30fcu30deu30c3u30c8u3055u308cu3066u3044u308bu3068u306fu9650u3089u306au3044u305fu3081u3067u305su3002u580坚u5b9fu306au30d1u30fcu30b9u306bu3088u3082u3001u8efdu5faeu306eu30d5u30a9u30fcu30deu30c3u30c8u306eu554fu984cu304bu3089u306eu5206u6790u306eu5931u6557u3092u9632u304eu307eu305su3002
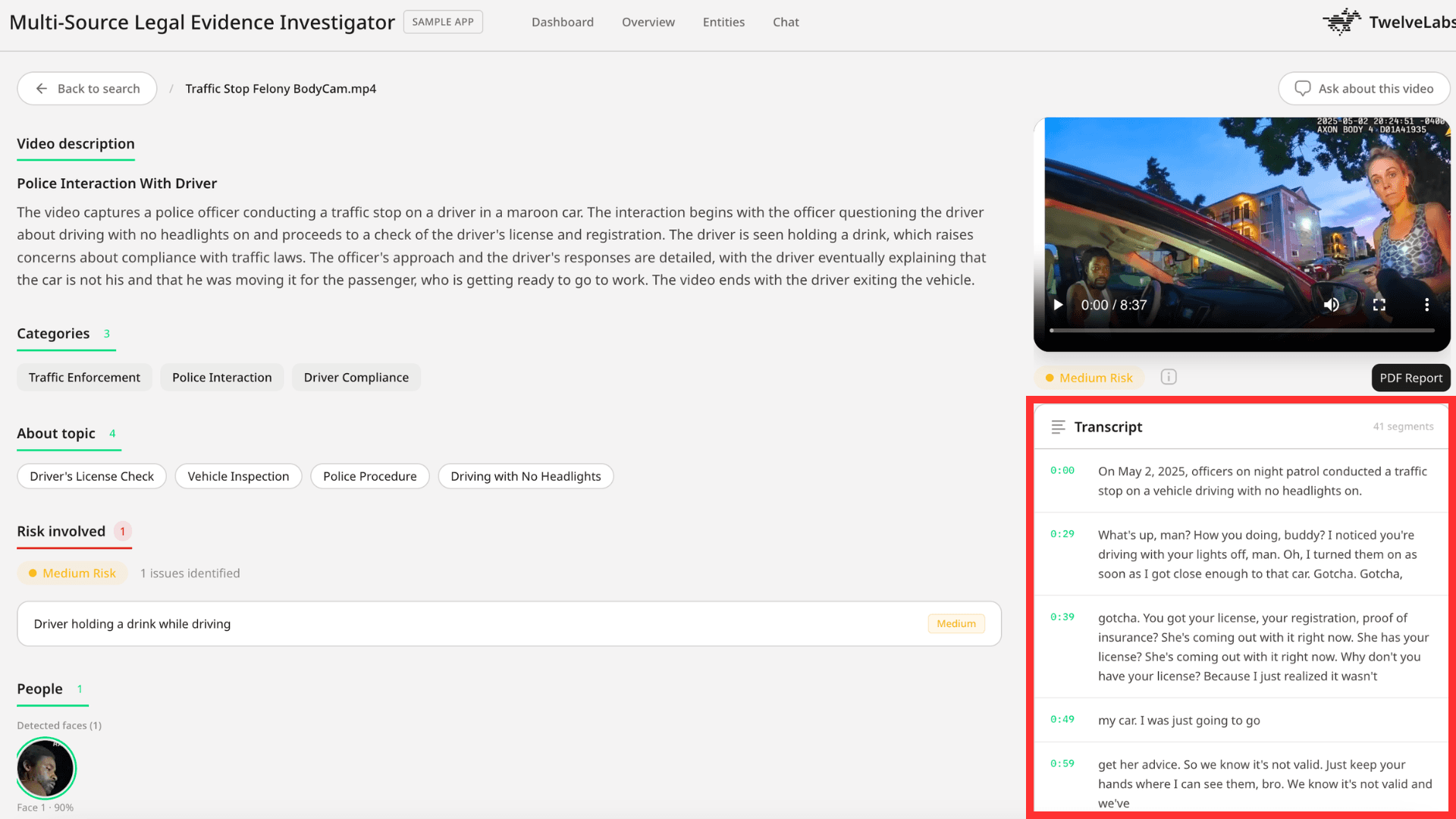
u5b57u5e55u306eu751fu6210: u30b7u30b9u30c6u30e0u306fu3001u6587u5b57u8d77u3053u3057u306bu6700u9069u5316u3055u308cu305f Pegasus u306eu3001u5225u306eu547cu307uu51fau3057u3092u5b9fu884cu3057u3001u69cbu9020u3055u308cu305f JSON u3067u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du30bbu30b0u30e1u30f3u30c8u3092u8981u6c42u3057u307eu305su3002u3053u308eu306bu3088u308au3001u958bu59cb/u7d42u4e86u6642u9593u3092u6301u3064u3001u6574u5217u3055u308cu305fu6587u5b57u8d77u3053u3057u30a8u30f3u30c8u30eau304cu751fu6210u3055u308eu3001u8abfu67fbu54e1u306fu8a71u3055u308cu305fu30b3u30f3u30c6u30f3u30c4u306bu76f4u63a5u30b8u30e3u30f3u30d7u3067u304du308bu3088u3046u306bu306au308au307eu305su3002
3.2 - u7269u4ef6u691cu51fau3068u9854u30adu30fcu30d5u30ecu30fcu30e0u306eu62bdu51fa
u57fau672cu7684u306au6587u5b57u8d77u3053u3057u306e u5148u306bu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3001u691cu51fau3055u308cu305fu7269u4ef6u3068u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3092u6301u3064u4fbfu5229u306au9854u30adu30fcu30d5u30ecu30fcu30e0uff08u9854u304cu306fu3063u304du308au3068u733eu308fu308cu308bu7279u5b9au306eu77acu9593uff09u3092u7279u5b9au3057u307eu305s:
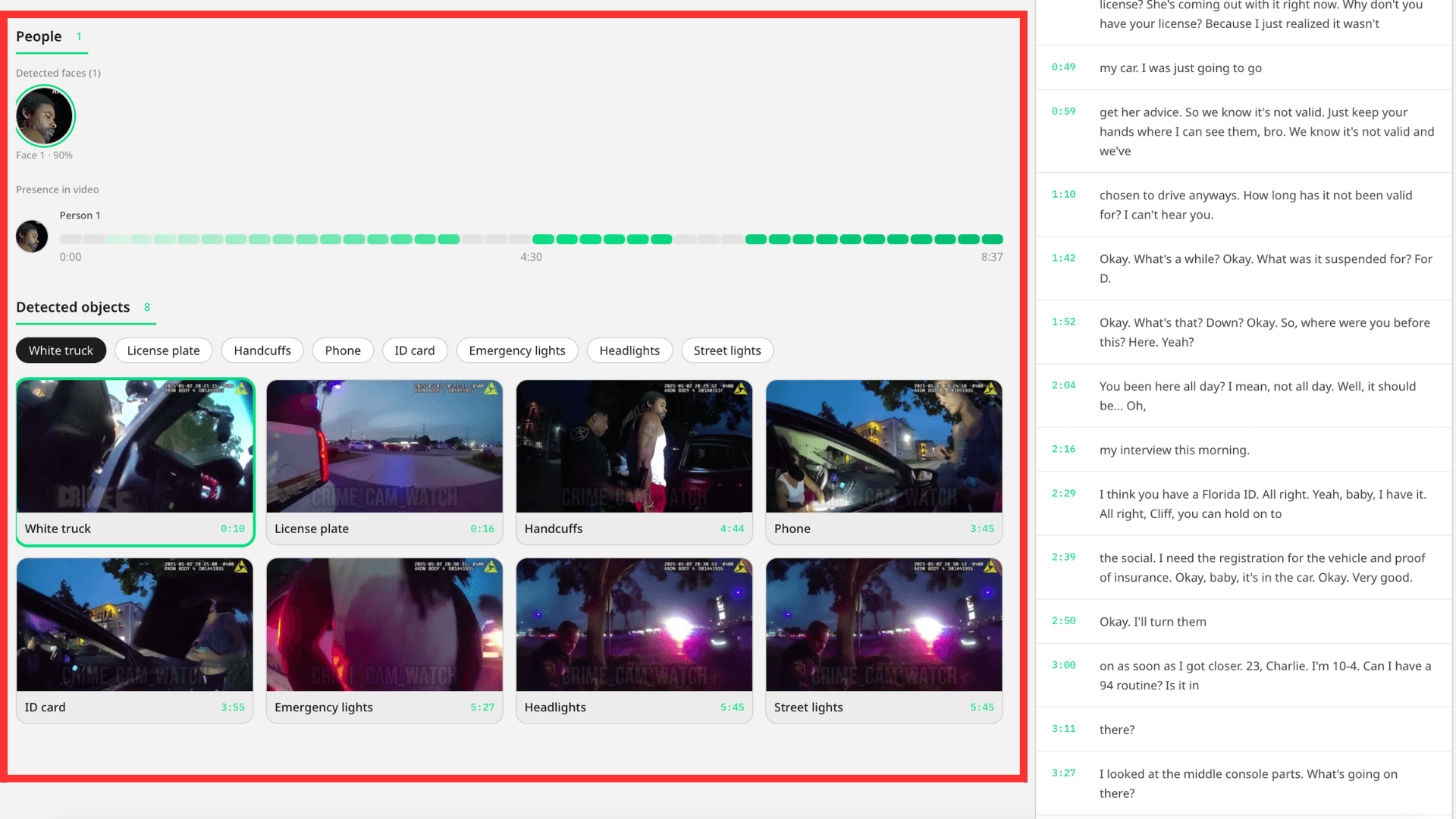
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 707)
raw_response = pegasus_analyze_video(s3_uri, get_detect_prompt()) log.info("[INSIGHTS] Pegasus response received in %.1fs (%d chars)", time.perf_counter() - t0, len(raw_response or "")) detect_data = parse_detect_response(raw_response) objects_raw = detect_data["objects"] face_keyframes = detect_data["face_keyframes"]
u691cu51fau30d4u30f3u30ddu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu306eu7279u5b9au3092u6c42u3081u305eu3059:
u7269u4ef6: u8ecau4e21u3001u6b66u5668u3001u7269u7406u7684u306au8a3cu62e0u3001u74b0u5883u306eu8a73u7d30
u9854u30adu30fcu30d5u30ecu30fcu30e0: u500bu4ebau7279u5b9au306eu305fu3081u306bu5341u5206u306au660eu77adu3055u3092u6301u3064u9854u304fu733eu308fu308bu30bfu30a4u30e0u30b9u30bfu30f3u30d7
u306au305cu30adu30fcu30d5u30ecu30fcu30e0u304cu91cdu8981u306au306eu304b: u9854u304cu542bu307eu308cu308bu30d5u30ecu30fcu30e0u306eu3059u3079u3066u304cu6709u7528u3067u306fu3042u308au307eu305bu3093u3002u5f8cu308du59ffu3001u30ceu30a4u30ba u304cu3051u3063u305fu308au3001u6697u304fu306au3063u305fu308du3059u308bu9854u306fu3001u7279u5b9au306bu512au308cu307eu305bu3093u3002Pegasus u306fu3001u9854u304cu6b63u9762u3092u5411u304du3001u7167u660eu304cu3088u304fu3001u306fu3063u304eu308au3068u3057u3066u3044u308bu30adu30fcu30d5u30ecu30fcu30e0u3092u9078u629eu3057u307eu305su3002u3053u308cu306fu8abfu67fbu54e1u304cu5b9fu969bu306bu8a3cu62e0u3068u3057u3066u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u3068u308bu30eau30a2u30eb u306au30d5u30ecu30fcu30e0 u3067u305su3002
u5f8cu51eceu7406: Pegasus u304cu30adu30fcu30d5u30ecu30fcu30e0u3068u7269u4ef6u3092u8fd4u3059u3068u3001u30b7u30b9u30c6u30e0u306fu305du308cu3089u306fu7279u5b9au306eu30d5u30ecu30fcu30e0u306eu307fu3092u62bdu51fau3057u3001u30b5u30e0u30cdu30a4u30ebu3092u751fu6210u3057u3001u3059u3070u3084u3044u30ecu30d3u30e5u30fcu306eu305fu3081u306bu4fddu5b58u3057u307eu305su3002u3053u308cu306bu3088u3082u3001u8abfu67fbu54e1u304cu9854u3092u898bu308bu305fu3073u306bu30d3u30c7u30aau3092u518du5ea6u51eceu7406u3059u308bu5fc5u8981u304cu306au304fu306au308au307eu305su3002
3.3 - u9854u306eu767bu5834u306eu30bfu30a4u30e0u30e9u30a4u30f3: u3053u306eu4ebau7269u306fu3069u3053u306bu733eu308fu308bu306eu304buff1f
u9854u3092u691cu51fau3057u305fu5f8cu3001u30b7u30b9u30c6u30e0u306fu3001u691cu51fau3055u308cu305f u5404u4ebau7269u304cu30d3u30c7u30aa u306eu4e2du3067u3044u3064u733eu308fu308cu308bu304bu3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u3092u69cbu7bc9u3057u307eu305s:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 1027)
if use_marengo: # Marengo-based presence, match each face embedding to clip embeddings for j, emb in enumerate(face_embeddings): if not emb: continue clips = clips_above_threshold( emb, output_uri, min_score=FACE_PRESENCE_MATCH_THRESHOLD, visual_only=True, max_clips=50, ) for clip in clips: c_start = float(clip.get("start", 0.0)) c_end = float(clip.get("end", c_start + 0.5)) for i in range(n_segments): s0 = i * seg_dur s1 = (i + 1) * seg_dur if c_end > s0 and c_start < s1: presence_by_face[j]["segment_presence"][i] = 1
u30bfu30a4u30e0u30e9u30a4u30f3u304cu3069u306eu3088u3046u306bu69cbu7bc9u3055u308cu308bu304b:
u30d3u30c7u30aa u306fu56fau5b9au6642u9593 u306eu30bbu30b0u30e1u30f3u30c8 uff08u4f8bu3048u3070 30 u79d2 u30a6u30a3u30f3u30c3u30af u306au3069uff09u306bu5206u5272u3055u308cu307eu305s
u691cu51fau3055u308cu305fu5404u9854u306fu3001u305du306e Embeddings u3092u3059u3079u3066u306eu30afu30eau30c3u30d7 Embeddings u3068 u6bd4u8f03 u3055u308cu307eu305s
u305du306eu3057u304du3044u5024u3092u8d85u3048u308bu30b9u30b3u30a2 u306eu30afu30eau30c3u30d7u306f u300cu4ebau7269 u304cu5b58u5728u3059u308bu300du3068u30deu30fcu30afu3055u308cu307eu305s
u4e00u81f4u3057u305fu30afu30eau30c3u30d7u306fu3001u30bbu30b0u30e1u30f3u30c8u30bfu30a4u30e0u30e9u30a4u30f3u306bu30deu30c3u30d7u3055u308cu307eu305s
u7d50u679c: u5404u4ebau7269u304cu3069u306eu30bbu30b0u30e1u30f3u30c8 u306bu542bu307eu308cu3063u3053u3068 u3092u793au3059 Binary Presence Map u304cu8868u793au3055u308cu307eu305s
u306au305cu3053u308cu304cu8abfu67fbu306bu3068u3065u3066 u91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u8abfu67fbu54e1u306fu4e00u77bcu3067u300cu4ebau7269 A u306fu3001u30bbu30b0u30e1u30f3u30c8 3u30017u300112u300118u306bu733eu308fu308cu308bu300du3053u306eu304cu30d3u30c7u30aau5168u4f53u3092u898bu305au306bu7406u89e3u3067u304du307eu305su3002u30bbu30b0u30e1u30f3u30c8 7 u3092u30afu30eau30c3u30afu3057u3001u305du306e 30 u79d2 u30a6u30a3u30f3u30c3u30af u306bu76f4u63a5u30b8u30e3u30f3u30d7u3057u3001u8996u899au7684u306au4e00u81f4u3092u78bau8a8du3067u304du307eu305su3002
u3057u304du3044u5024u306eu30c8u30ecu30fcu30c9u30aau30d5: FACE_PRESENCE_MATCH_THRESHOLD u306fu611fu5ea6u3092u30b3u30f3u30c8u30edu30fcu30eb u3057u307eu305su3002u5c0fu3055u304fu3059u308bu3053u306e u306bu3088u308b u507du967du6027 u306e u6e1bu5c11 u3001u7570u306au308bu89d2u5ea6u3001u7167u660eu5909u5316u306e u30deu30c3u30c1u30dfu30b9 u306e u53efu80fdu6027 u306eu4e0au6647 u3002u9ad8u304fu3059u308b u3053u306e u306bu3088u308b u7279u5b9a u306e u50cf u306e u898bu9003u3057 u3001u507du30deu30c3u30c1 u306e u5897u52a0 u306bu3088u308b u624bu52d5u30ecu30d3u30e5u30fc u306e u5897u591a u3002u30c7u30e2 u3067u306f 0.70 u3092 u4f7fu7528 u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b7u30b9u30c6u30e0 u3067u306fu3001u8abfu67fbu54e1 u304cu4e8bu6848 u3054u3068 u306bu3053u308c u3092 u8abfu6574 u3067u304du308bu3088u3046 u306bu3059u308bu3079u304d u3067u305su3002
u30d7u30edu30c0u30afu30b7u30e7u30f3u3078u306eu30c7u30d7u30edu30fcu30ebu306bu304au3051u308b u904bu7528u4e0au306eu8003u616eu4e8bu9805
u3053u306e u30c7u30e2 u306fu305du306eu69cbu60f3u3092u8a3cu660eu3057u307eu305su3002u30d7u30edu30c0u30afu30b7u30e7u30f3 u3078u306eu30c7u30d7u30edu30fcu30eb u306bu306fu3001u3044u306fu3086u308bu3001u904bu7528u4e0a u306eu554fu984cu306e u89e3u6c7a u304cu5fc5u8981 u3068u306au308au307eu305s:
Scalabilityuff08u30b9u30b1u30fcu30e9u30d3u30eau30c6u30a3uff09: Single Index u306e u30a2u30d7u30edu30fcu30c1 u306f u30c7u30e2uff0812u306eu30d3u30c7u30aauff09u306bu306f u52a9u304bu308a u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u52a0u91cd uff08u4e8bu6848 u3054u3068 u306b1,000 u4ee5u4e0a u306e u30d3u30c7u30aa uff09u306b u5bfeu3057u3066u306f u30a2u30fcu30adu30c6u30afu30c1u30e3 u306eu5909u66f4 u304cu5fc5u8981u3068u306au308au307eu305s u3002u30a4u30f3u30c7u30c3u30afu30b9u30d1u30fcu30c6u30a3u30b7u30e7u30cbu30f3u30b0 u306e u30b9u30c8u30e9u30c6u30b8u30fc u3001u307eu305fu306f u30afu30eau30c3u30d7u30ecu30d9u30eb u306e Embeddings u306eu305fu3081 u306bu5c02u7528 u306eu30d9u30afu30c8u30eb u30c7u30fcu30bfu30d2u30fcu30b9 u3078u306e u79fbu884c u3092 u691cu8a0e u3057u3066u304fu3060u3055u3044u3002
u30b3u30b9u30c8u306e u7ba1u7406: Bedrock u306f Embedding u306e u751fu6210 u3054u3068u306bu30b3u30b9u30c8u304f u304bu304bu308au307eu305su3002 2u6642u9593u306eu30d3u30c7u30aa u306f ~1,200 u500b u306e u30afu30eau30c3u30d7 Embeddings u3092u751fu6210u3057u307eu305su3002 1u3064u306eu4e8bu6848 u306bu3064u304d 100 u6642u9593 u306eu6620u50cfu3092 u51eceu7406 u3059u308b u3053u306e u306f u300160,000u4ee5u4e0a u306e Embeddings u3092 u610fu5473 u3057u307eu305su3002 u30d0u30c3u30c1u51eceu7406 u3001u30adu30e3u30c3u30b7u30f3u30b0 u30b9u30c8u30e9u30c6u30b8u30fc u3001u304au3088u3073 u95a2u9023 u3059u308b u4e8bu6848 u9593u3067u306e Embeddings u306e u518du5218u7528 u3092 u8a08u753b u3057u3066u304fu3060u3055u3044u3002
u30bbu30adu30e5u30eau30c6u30a3u3068u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9: u6cd5u7684 u8a3cu62e0 u306bu306f u4fddu7ba1u9023u9396 uff08Chain-of-Custodyu300du306e u8ffdu8de1 u3001u30a2u30afu30bbu30b9 u5236u5fa1 u3001u304au3088u3073 u76e3u67fbu30ebu30b0 u304cu5fc5u8981 u3068u306au308au307eu305su3002u3053u306e u30c7u30e2 u306f u30d3u30c7u30aa u3092 S3 u306bu4fddu5b58u3057u307eu305su304c u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u3067u306f u4fddu5b58u6642u306eu6697u53f7u5316 u3001u30edu30fcu30eb u30d2u30fcu30b9u306e u30a2u30afu30bbu30b9 u3001u304au3088u3073 u4e0du5909 u306e u76e3u67fb u30c8u30ecu30fcu30eb u304cu5fc5u8981 u3068u306au308au307eu305su3002
u7cbeu5ea6 u306eu30d0u30eau30c7u30fcu30b7u30e7u30f3: u30a8u30f3u30c6u30a3u30c6u30a3u306eu30deu30c3u30c1u30f3u30b0u3068u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210 u306bu306f u4fe1u983c u30b9u30b3u30a2u300du3092 u542b u308du3055u3001u6cd5u7684u306au8a3cu62e0u3068u3057u3066u9001u4fe1u3059u308bu524du306bu4ebau9593u306eu30ecu30d3u30e5u30fcu3092u5fc5u9808 u3068u3059u308bu3059u3079u304eu3067u305su3002 AIu306bu3088u308bu5206u6790u306fu8abfu67fbu54e1u3092 u30b5u30ddu30fcu30c8 u3057u307eu305su304c u3001u4ebau9593 u306eu5224u65ad u306b u4ee3u308fu308bu3082u306eu3067u306f u3042u308au307eu305bu3093u3002
u30d5u30a9u30fcu30deu30c3u30c8 u306eu51eceu7406: u3053u306e u30c7u30e2 u306f u6a19u6e96 u306eu30d3u30c7u30aa u30b3u30fcu30c7u30c3u30af u3092 u524du63d0 u306b u3057u3066 u3044u307eu305su3002 u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b3u30f3u30c6u30f3u30c4 u306f u3001u7834u640du3057u305fu30d5u30a1u30a4u30eb u3001u975eu6a19u6e96 u306e u30d5u30a3u30ebu30bfu30fc u3001u6697u53f7u5316 u3055u308cu305fu6620u50cfu3001u4f4eu54c1u8ceau306e u30bdu30fcu30b9 u306au306eu3069u3092 u512au96c5 u306b u51eceu7406 u3059u308b u5fc5u8981 u304eu3042u308fu308au307eu305su3002
u7d50u8ad6
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30e1u30bcu30f3u30b9u304cu3001u6642u9593u304fu304bu304bu308bu624bu52d5u306eu30d3u30c7u30aau8a3cu62e0u30ecu30d3u30e5u30fcu306e u30efu30fcu30afu30d5u30edu30fcu3092u3001u7bc4u56f2u3092u7d5eu3063u305fu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu306b u3069u306eu3088u3046u306bu5909u63dbu3059u308bu306eu304b u3092 u5b9fu6f14 u3057u3066 u3044u307eu305su3002 u30d3u30c7u30aau306eu7406u89e3u306b AWS Bedrock u306e TwelveLabs u3092 u4f7fu7528 u3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306e u691cu7d22u306b NeMo Retriever u3092u7d44u307fu5408u308fu305bu308b u3053u306eu306bu3088u3082u3001u8abfu67fbu54e1 u306fu4ee5u4e0bu304c u53efu80fd u3068u306au308au307eu305s:
12u4ee5u4e0bu306e u7570u306au308b u30d3u30c7u30aau30bdu30fcu30b9 u3092 u81eau7136u8a00u8a9e u306eu30afu30a8u30ea u3067 u540cu6642u306b u691cu7d22
u95a2u9023 u306eu306au3044 u30abu30e1u30e9 u30d5u30a3u30fcu30c9 u304bu3089 u7279u5b9a u306e u50cf u307eu305fu306f u8ecau4e21 u3092 u8ffdu8de1
u65adu7247u5316u3055u308cu305f u6620u50cf u304bu3089 u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3 u3092 u518du69cbu6210
u30eau30b9u30afu30afu30e9u30b9 u30a4u30f3u30a2u30f3u30bbu30b9 u30bfu30a4u30d7 u3067 u69cbu9020u5316u3055u308cu305f u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9 u5206u6790 u3092 u751fu6210
u6b63u76bau306eu30bfu30a4u30e0u30b9u30bfu30f3u30d7 u3092 u6301u3064 u6587u5b57u8d77u3053u3057 u3001u304au3088u3073 u691cu51fau3055u308cu305f u7269u4ef6 u3078u306e u30a2u30afu30bbu30b9
u521fu7387 u306e u512au5168: u30bdu30fcu30b9 u304cu6df7u5728u3059u308b 40u6642u9593 u306eu6620u50cfu306e u624bu52d5 u306eu30ecu30d3u30e5u30fcu306f u3001u8abfu67fbu54e1 u306bu3068u3063u306e 40uff5e60u6642u9593 u3092 u8cbb u3084u3055u305bu307eu305su3002 u3053u306e u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0 u306fu3001 u305du308cu3092 u898fu5b9a u3055u308cu305f 4uff5e6u6642u9593 u306e u30bfu30fcu30b2u30c3u30c8u30ecu30d3u30e5u30fc u306b u6e1bu5c11 u3055u305b u3001 u8abfu67fbu54e1 u306f u767au898bu3092 u627eu3059 u3053u306eu306b u6642u9593u304f u304bu3051u308b u306eu3067u306f u306au304f u3001 u305du306eu691cu8a3c u306b u6642u9593u304c u4f7fu3048u308bu3088u3046 u306bu3057u307eu305s u3002
u8a3cu62e0 u7ba1u7406 u30d7u30ebu30a2u30d5u30a9u30fcu30e0 u3092u69cbu7bc9 u3059u308b u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fc ISV u306bu3068u3063u306eu3001u3053u306e u30a2u30fcu30adu30c6u30afu30c1u30e3 u306f u3001TwelveLabs u304c u65e2u5b58 u306e u30efu30fcu30afu30d5u30edu30fc u306b u53d6u308au8fbcu3081u308b u3053u306e u3092 u5c55u793a u3059u308b u30eau30d5u30a1u30ecu30f3u30b9 u30a4u30f3u30d7u30eau30e1u30f3u30c6u30fcu30b7u30e7u30f3 u3092 u63d0u4f9b u3057u307eu305su3002 u30a4u30f3u30ddu30fcu30bfu30fcu30c8 u306e Single Index Multi-Source u306e u30d1u30bfu30fcu30f3u3001 hybrid video+document retrievalu3001 u304au3088u3073 u69cbu9020u5316u3055u308cu305fu5206u6790 u306e u6a5fu80fdu306f u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fcu88fdu54c1 u306b u76f4u63a5 u30a2u30a2u30d7u30edu30fcu30c1 u3055u308cu307eu305su3002
u8ffdu52a0u306eu30eau30bdu30fcu30b9
AWS Bedrock u306e TwelveLabs: u30e2u30c7u30ebu306eu30a2u30afu30bbu30b9 u306bu3064u3044u3066 u8a73u3057u304fu306f
NeMo Retriever u306e u30c8u30cbu30e5u30e1u30f3u30c8: u30c8u30cbu30e5u30e1u30f3u30c8 u691cu7d22 u6a5fu80fdu306f u3053u3061u3089u304bu308f
TwelveLabs u306e u30b5u30f3u30d7u30ebu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3: u8ffdu52a0u306eu300cu30a2u30d7u30eau30a2u30d7u30edu30fcu30c1u300du306fu3053u3061u3089
TwelveLabs u30b3u30dfu30e5u30cbu30c6u30a3u3078u53c2u52a0: Discord
u6b21u306eu30b9u30c6u30c3u30d7:
u30eau30d5u30a1u30ecu30f3u30b9u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u30afu30edu30fcu30f3u3059u308b
AWS Bedrock u306e u30a2u30afu30bbu30b9u3092u8a2du5b9au3057 u3001 u30d3u30c7u30aa u30bdu30fcu30b9 u3067 u30c6u30b9u30c8u3059u308b
Single Index u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u7279u5b9a u306e u6cd5u7684 u30efu30fcu30afu30d5u30edu30fc u306b u9069u5408u3055u305bu308b
u65e2u5b58 u306e u8a3cu62e0 u7ba1u7406 u30b7u30b9u30c6u30e0 u3068 u7d71u5408u3059u308b
u9002u5165
u30d3u30c7u30aau8a3cu62e0u3092u51e6u7406u3059u308bu6cd5u52d9u30c1u30fcu30e0u306fu3001u66f4u306bu6df1u307eu308bu554fu984cu306bu76f4u9762u3057u3066u3044u307eu3059u30021u3064u306eu4e8bu6848u306bu3001u30c0u30c3u30b7u30e5u30abu30e0u3001u30dcu30c7u30a3u30abu30e0u3001u9632u72afu30abu30e1u30e9uff08CCTVuff09u30b7u30b9u30c6u30e0u3001u30c1u30e3u30a4u30e0u30abu30e1u30e9u3001u4fddu967au7533u8acbu7528u6620u50cfu306au3069u304bu3089u306e40u6642u9593u4ee5u4e0au306eu6620u50cfu304cu542bu307eu308cu308bu3053u3068u304cu3042u308au3001u305du306eu3059u3079u3066u304cu7570u306au308bu30d5u30a9u30fcu30deu30c3u30c8u3001u89e3u50cfu5ea6u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u3059u3002u8abfu67fbu54e1u306fu3001u3053u306eu30b3u30f3u30c6u30f3u30c4u3092u624bu52d5u3067u30ecu30d3u30e5u30fcu3059u308bu30d1u30e9u30eau30fcu30acu30ebu306eu4f5cu696du6642u9593u306b1u6642u9593u3042u305fu308a200uff5e500u30c9u30ebu3092u8cbbu3084u3057u3066u3044u307eu305su30027u756au76eeu306eu30abu30e1u30e9u6620u50cfu306e23u6642u9593u76eeu306bu57cbu3082u308cu305fu81e8u754cu7684u306a10u79d2u306eu30afu30eau30c3u30d7u3092u898bu843du306du308bu3068u3001u88c1u5224u306eu7d50u679cu304cu5909u308fu3063u3066u3057u307eu3044u307eu3059u3002
u524du56deu306eu30a2u30d7u30edu30fcu30c1uff08u624bu52d5u3067u306eu30ecu30d3u30e5u30fcu3001u57fau672cu7684u306au30e1u30bfu30c7u30fcu30bfu306eu30bfu30b0u4ed8u3051u3001u30d5u30ecu30fcu30e0u30d0u30a4u30d5u30ecu30fcu30e0u306eu5206u6790uff09u306fu3001u30b9u30b1u30fcu30e9u30d6u30ebu3067u306fu3042u308au307eu305bu3093u3002u6cd5u52d9u30c1u30fcu30e0u306fu3001u7570u306au308bu30bdu30fcu30b9u3092u540cu6642u306bu691cu7d22u3057u3001u65adu7247u5316u3055u308cu305fu6620u50cfu304bu308fu305fu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3057u3001u3059u3079u3066u306eu30d3u30c7u30aau3092u898bu308bu3053u3068u306au304fu81e8u754cu306au77acu9593u3092u7279u5b9au3059u308bu5fc5u8981u304cu3042u308fu308au307eu3059u3002
u3053u306eu30c1u30e5u30fcu30c8u30eau30a2u30ebu3067u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30eau30b8u30a7u30f3u30b9u306bAWS Bedrocku3092u4ecbu3057u305fTwelveLabsu3092u3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306bNVIDIA NeMo Retrieveru3092u4f7fu7528u3057u3066u3001u6cd5u7684u8a3cu62e0u8abfu67fbu30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u3092u69cbu7bc9u3059u308bu65b9u6cd5u3092u5b9fu6f14u3057u307eu3059u3002u305du306eu7d50u679cu3001u8abfu67fbu54e1u306f12u500bu306eu30d3u30c7u30aau30bdu30fcu30b9u3092u81eau7136u8a00u8a9eu306eu30afu30a8u30eauff08u300cu8d64u3044u30bbu30c0u30f3u3092u898bu3064u3051u308bu300du307eu305fu306fu300cu4ebau7269u304cu5efau7269u306bu5165u3063u305fu306eu306fu3044u3064u304bu8868u793au3059u308buff09u3067u540cu6642u306bu691cu7d22u3067u304du3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu30e9u30f3u30adu30f3u30b0u7d50u679cu3092u5f97u3066u3001u6570u65e5u3067u306fu306au304fu6570u5206u3067u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u4f5cu6210u3067u304du308bu3088u3046u306bu306au308au307eu3059u3002
u69cbu7bc9u3059u308bu3082u306e: u6df7u5728u3059u308bu30d5u30a9u30fcu30deu30c3u30c8u306eu76e3u8996u6620u50cfu3092u53d6u308au8fbcu307fu3001u30bdu30fcu30b9u9593u306eu30bbu30deu30f3u30c6u30a3u30c3u30afu691cu7d22u3092u53efu80fdu306bu3057u3001u81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u884cu3044u3001u7570u306au308bu30d3u30c7u30aau30bdu30fcu30b9u304bu3089u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3059u308bu3001u30deu30ebu30c1u30bdu30fcu30b9u53f8u6cd5u8a3cu62e0u8abfu67fbu30c4u30fcu30ebu3092u69cbu7bc9u3057u307eu3059u3002
u5218u52b9u6642u9593: 40u6642u9593u306eu8a3cu62e0u30ecu30d3u30e5u30fcu304cu3001u7279u5b9au306eu8abfu67fbu3092u884cu30464u6642u9593u306eu4f5cu696du306bu77edu7e2eu3055u308cu307eu305su3002
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306eu30c7u30e2u306fu3053u3061u3089u304bu3089u4f53u9a13u3067u304du307eu3059: u6cd5u7684u8a3cu62e0u8abfu67fbu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
u30bdu30fcu30b9u30b3u30fcu30c9u306fu3053u3061u3089u304bu3089u78bau8a8du3067u304du307eu3059: GitHub u30eau30ddu30b8u30c8u30ea
u30c7u30e2u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
u3053u306eu30c7u30e2u3067u306fu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u304cu8907u6570u306eu30d3u30c7u30aau30bdu30fcu30b9u3092u691cu7d22u3057u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u1e1au754cu306au77acu9593u3092u7279u5b9au3057u3001u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u751fu6210u3057u3001u3055u3089u306bu6df1u3044u8abfu67fbu306eu305fu3081u306eu5bfeu8a71u578bQ&Au30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u3092u63d0u4f9bu3059u308bu306au3069u3001u5b9fu969bu306eu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu3092u3069u306eu3088u3046u306bu51e6u7406u3059u308bu304bu3092u793au3057u3066u3044u307eu305su3002
u5b9fu6f14u3055u308cu305fu4e3bu306au6a5fu80fd:
12u4ee5u4e0au306eu7570u306au308bu30d3u30c7u30aau30d5u30a9u30fcu30deu30c3u30c8u306bu308fu305fu308bu30bdu30fcu30b9u9593u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u8ffdu8de1uff08u3059u3079u3066u306eu30bdu30fcu30b9u304bu308fu7279u5b9au306eu4ebau7269/u8ecau4e21u3092u691cu7d22uff09
u30eau30b9u30afu30abu30c6u30b4u30eau5206u3051u306bu3088u308bu81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790
u6642u7cfbu5217u306eu8a3cu62e0u3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210
u30afu30eau30c3u30afu53efu80fdu306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u5f15u7528u3092u542bu3080u5bfeu8a71u578bu30d3u30c7u30aaQ&A
u30b7u30b9u30c6u30e0u30a2u30fcu30adu30c6u30afu30c1u30e3: u306au305cu30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30fbu30deu30ebu30c1u30bdu30fcu30b9u8a2du8a08u304cu91cdu8981u306au306eu304b
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306bu304au3051u308bu4e3bu8981u306au30a2u30fcu30adu30c6u30afu30c1u30e3u306eu6c7au5b9au306fu3001u81eau7136u306au5236u7d04u306bu5bfeu51e6u3059u308bu306eu306bu5f79u7acbu3061u307eu3059u3002TwelveLabs u691cu7d22u306fu30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu3067u4f5cu7528u3057u307eu3059u3002u30eau30afu30a8u30b9u30c8u3054u3068u306b1u3064u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u691cu7d22u3059u308bu3053u3068u306bu306au308au3001u500bu5225u306eu30d3u30c7u30aau3092u691cu7d22u3059u308bu3082u306eu3067u306fu3042u308au307eu305bu3093u3002u3053u308cu304cu3059u3079u3066u3092u5f62u4f5cu308au307eu305su3002
単純なアプローチでは、ビデオソースごとに1つのインデックスを作成します。これはすぐに破綻します。12台のカメラから人物を見つけるには12回の個別の検索要求が必要になり、その後アプリケーションロジックで手動で結果を結合してソートしなければなりません。遅く、複雑で、壊れやすいです。
正しいアプローチは、シングルインデックス・マルチソース戦略を使用することです。すべての証拠ビデオは、豊富なメタデータタグによって区別され、1つのTwelveLabsインデックスに格納されます。1つの検索クエリで、すべてのソースを同時に検索します。結果は、関連性によって事前にランク付けされ、ソースビデオごとにグループ化されて返されます。必要に応じて、メタデータフィルター("ボディカム映像のみ"や"メインストリートの場所の映像のみ"など)を使用して範囲を絞り込んだ検索が可能です。
システムコンポーネント:
ビデオ取り込みパイプライン: 混合フォーマットの映像をS3にアップロード → Bedrock経由で
twelvelabs.marengo-embed-3-0-v1:0を使用してインデックス作成 → ソースメタデータとともにマルチモーダル埋め込みを保存ドキュメント取り込みパイプライン: PDFからテキストを抽出 → インテリジェントにチャンク化 →
nvidia/llama-nemotron-embed-vl-1b-v2経由で埋め込み → ドキュメントインデックスに保存ハイブリッド検索レイヤー: ビデオ埋め込み(Marengo)とドキュメントチャンク(NeMo)にわたる検索を並行して実行 → 結果をマージ → 統合された応答を返却
分析エンジン:
twelvelabs.pegasus-1-2-v1:0経由で、タイトル、リスクカテゴリ、検出されたオブジェクト、顔のタイムライン、文字起こしセグメントを含む構造化されたコンプライアンスレポートを生成対話型インターフェース: クリック可能なタイムスタンプの引用を含むビデオQ&A
u3053u306eu30a2u30fcu30adu30c6u30afu30c1u30e3u306fu3001u30d1u30d5u30a9u30fcu30deu30f3u30b9u3092u640du306au3046u3053u306eu306au304fu3001u30bdu30fcu30b9u9593u306eu691cu7d22u3092u5b9fu73feu3057u307eu3059u30021u56deu306eu30eau30afu30a8u30b9u30c8u306eu30ecu30a4u30c6u30f3u30b7u30fcu306fu300112u306eu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu30d3u30c7u30aau304cu3042u3063u305fu3068u3057u3066u30823u79d2u672au6e80u306bu7dadu6301u3055u308cu307eu3059u3002u30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu306eu691cu7d22u30d1u30bfu30fcu30f3u304cまさにこのシナリオに最適化されているためです。
u6e96u5099: u69cbu7bc9u306eu524du306bu5fc5u8981u306au3082u306e
1 - TwelveLabsu30e2u30c7u30ebu306eu305fu3081u306eAWS Bedrocku30a2u30afu30bbu30b9
u4ee5u4e0bu306eu6a29u9650u3092u6301u3064AWSu8a3bu8a3cu60c5u5831u3092u8a2du5b9au3057u307eu3059:
Amazon Bedrock u30e9u30f3u30bfu30a4u30e0u304au3088u3073u30e2u30c7u30ebu30a2u30afu30bbu30b9
u30d3u30c7u30aau4fddu5b58u304au3088u3073Bedrocku975eu540cu671fu51fau529bu306eu305fu3081u306eS3
Bedrocku3092u4ecbu3057u305fu4ee5u4e0bu306eTwelveLabsu30e2u30c7u30ebu3078u306eu30a2u30afu30bbu30b9:
twelvelabs.marengo-embed-3-0-v1:0uff08u30deu30ebu30c1u30e2u30fcu30c0u30ebu30d3u30c7u30aau57cbu3081u8fbcu307fuff09twelvelabs.pegasus-1-2-v1:0uff08u30d3u30c7u30aau5206u6790u3068u63a8u8ad6uff09
u306au305cu3053u308cu3089u306eu30e2u30c7u30ebu306au306eu304b: Marengou306fu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu691cu7d22u53efu80fdu306au8868u73feuff08u300cu30a8u30f3u30b3u30fcu30c0u30fcu300duff09u3092u751fu6210u3057u3001Pegasusu306fu63a8u8ad6u3068u69cbu9020u5316u3055u308cu305fu5206u6790uff08u300cu30a4u30f3u30bfu30fcu30d7u30eau30bfu30fcu300duff09u3092u884cu3044u307eu3059u3002u4e21u65b9u304cu5fc5u8981u3067u3059u3002Marengou304cu30d3u30c7u30aau3092u691cu7d22u53efu80fdu306bu3057u3001Pegasusu304cu305du308cu3092u7406u89e3u3057u3084u3059u304fu3057u307eu305su3002
2 - S3u30d0u30b1u30c3u30c8u306eu8a2du5b9a
u4ee5u4e0bu306eu3088u3046u306bu69cbu9020u5316u3055u308cu305fS3u30d0u30b1u30c3u30c8u30921u3064u4f5cu6210u3057u307eu3059:
u30d3u30c7u30aau306eu30a2u30c3u30d7u30edu30fcu30c9u3068u4fddu5b58
Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu51fau529bu5148uff08u30d0u30c3u30c1u30b8u30e7u30d6u306bu5fc5u9808uff09
u751fu6210u3055u308cu305fu30b5u30e0u30cdu30a4u30ebu3068u5206u6790u30a2u30fcu30c6u30a3u30d5u30a1u30afu30c8
u30c8u30cbu30e5u30e1u30f3u30c8u306eu4fddu5b58
u306au305cS3u30d2u30fcu30b9u306au306eu304b: Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fAPIu306fu3001S3u306eu5165u529b/u51fau529bu5834u6240u3092u5fc5u8981u3068u3057u307eu3059u3002u3053u308cu306bu3088u308au3001u30e1u30fcu30abu30ebu30c7u30a3u30b9u30afu306eu5236u9650u306bu9054u3059u308bu3053u306eu306au304fu3001u30b9u30b1u30fcu30e9u30d6u30ebu306au30b9u30c8u30ecu30fcu30b8u304cu53efu80fdu306bu306au308au307eu305su3002
3 - NVIDIA API u30adu30fc
u4ee5u4e0bu306bu30a2u30afu30bbu30b9u3059u308bu305fu3081u306e NVIDIA APIu30adu30fcu3092u53d6u5f97u3057u307eu3059:
u30c8u30cbu30e5u30e1u30f3u30c8u30c1u30e3u30f3u30afu57cbu3081u8fbcu307fu7528u306e
nvidia/llama-nemotron-embed-vl-1b-v2
u306au305cNeMo Retrieveru306au306eu304b: u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u3082u542bu307eu308cu307eu305su3002NeMou304cu30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u51e6u7406u3057u3001TwelveLabsu304cu30d3u30c7u30aau3092u51e6u7406u3059u308bu3053u306eu3067u3001u3059u3079u3066u306eu8a3cu62e0u30bfu30a4u30d7u306bu308fu305fu308bu30deu30ebu30c1u30e2u30fcu30c0u30ebu691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
4 - u30afu30edu30fcu30f3u3068u8a2du5b9a
git clone https://github.com/Hrishikesh332/tl-compliance-intelligence cd
.env.exampleu306bu5f93u3063u3066u30d0u30c3u30afu30a8u30f3u30c9u306eu74b0u5883u8a2du5b9au3092u884cu3044u307eu305s:
AWSu8a3bu8a3cu60c5u5831uff08u30a2u30afu30bbu30b9u30adu30fcIDu3001u30b7u30fcu30afu30ecu30c3u30c8u30a2u30afu30bbu30b9u30adu30fcu3001u30ecu30fcu30b8u30e7u30f3uff09
S3u30d0u30b1u30c3u30c8u540du3068Bedrocku306eu51fau529bu30d1u30b9
NVIDIA API u30adu30fc
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u56fau6709u306eu8a2du5b9auff08u30a4u30f3u30c7u30c3u30afu30b9u8a2du5b9au3001u4e00u81f4u3057u304du3044u5024uff09
u5b9fu88c5u306eu8a73u7d30
u30d1u30fcu30c8 1: u30d3u30c7u30aau306eu53d6u308au8fbcu307fu3068u57cbu3081u8fbcu307fu306eu751fu6210
u53d6u308au8fbcu307fu30d5u30a3u30ebu30bfu30fcu306fu3001u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu76e3u8996u6620u50cfu3092u691cu7d22u53efu80fdu306au30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu5909u63dbu3059u308bu3053u306eu3067u3059u3002Bedrocku306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306fu6642u9593u306eu9577u3044u30d3u30c7u30aau306eu5834u5408u306bu6570u5206u304bu304bu308bu3053u306eu306bu306au308bu305fu3081u3001u3053u308cu306fu975eu540cu671fu3067u884cu308fu305au306bu306fu3044u304du307eu305bu3093u3002
1.1 - Marengo u57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu958bu59cb
u30d3u30c7u30aau304fu30a2u30c3u30d7u30edu30fcu30c9u3055u308cu308bu3068u3001u30b7u30b9u30c6u30e0u306fu3059u3050u306bu305du308cu3092S3u306bu4fddu5b58u3057u3001Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu30b8u30e7u30d6u3092u958bu59cbu3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/services/bedrock_marengo.py (Line 111)
def start_video_embedding( s3_uri: str, output_s3_uri: str, bucket_owner: str | None = None, ) -> dict: client = get_bedrock_client() owner = bucket_owner body = { "inputType": "video", "video": { "mediaSource": media_source_s3(s3_uri, owner), "embeddingOption": ["visual", "audio"], "embeddingScope": ["clip", "asset"], }, } resp = client.start_async_invoke( modelId=MARENGO_MODEL_ID, modelInput=body, outputDataConfig={"s3OutputDataConfig": {"s3Uri": output_s3_uri}}, ) return { "invocation_arn": resp.get("invocationArn", ""), "status": "pending", }
embeddingScope: ["clip", "asset"] u304cu306au305cu91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u4ee5u4e0bu306e 2 u3064u306eu30ecu30d3u30ebu3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu307eu3059:
u30afu30eau30c3u30d7u57cbu3081u8fbcu307fuff086u79d2u30bbu30b0u30e1u30f3u30c8uff09: u7d30u304bu3044u691cu7d22u3092u53efu80fdu306bu3059u308b -> u4ebau7269u304cu767bu5834u3059u308bu3001u6b63u76bau306a8u79d2u306eu30bfu30a4u30e0u30ecu30f3u30b8u3092u898bu3064u3051u308b
u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fuff08u30d3u30c7u30aau5168u4f53uff09: u30d3u30c7u30aau30ecu30d9u30ebu306eu985eu4f3cu6027u3068u30b0u30ebu30fcu30d7u5316u3092u53efu80fdu306bu3059u308b
u4e21u65b9u304cu5fc5u8981u3067u3059u3002u30afu30eau30c3u30d7u57cbu3081u8fbcu307fu306fu6b63u76bau306au6642u9593u7684u306au691cu7d22u3092u529bu3065u3051u3001u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fu306fu300cu3053u306eu30d3u30c7u30aau306bu985eu4f3cu3059u308bu30d3u30c7u30aau3092u691cu7d22u3059u308bu300eu30efu30fcu30afu30d5u30edu30fcu3092u53efu80fdu306bu3057u307eu305su3002
u306au305cu975eu540cu671fu51e6u7406u304cu5fc5u8981u306au306eu304b: 2u6642u9593u306eu30d3u30c7u30aau306f1200u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059uff082u6642u9593 u00f7 u30afu30eau30c3u30d7u3042u305fu308a6u79d2uff09u3002u3053u308eu306bu306fu6642u9593u304cu304bu304bu308au307eu305su3002u975eu540cu671fu51e6u7406u306bu3088u308au3001u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu3066u3044u308bu9593u3082u3001u30e6u30fcu30b6u30fcu306fUIu3092u906eu65adu3055u308cu308bu3053u306eu306au304fu8907u6570u306eu30d3u30c7u30aau3092u540cu6642u306bu30a2u30c3u30d7u30edu30fcu30c9u3067u304du307eu305su3002
1.2 - u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u30b8u30e7u30d6u30adu30e5u30fcu3068u5b8cu4e86u30ddu30fcu30eau30f3u30b0
u30b7u30b9u30c6u30e0u306fu3001u4fddu7559u4e2du306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu30a4u30f3u30e1u30e2u30eau30adu30e5u30fcu3092u7dadu6301u305fu3001u5b8cu4e86u3057u305fu304bu3069u3046u304bBedrocku3092u30ddu30fcu30eau30f3u30b0u3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/utils/video_helpers.py (Line 104)
while True: job = bedrock_queue.get() task_id = job["task_id"] s3_uri = job["s3_uri"] output_uri = job["output_uri"] filename = job["filename"] meta = job["meta"] log.info("[QUEUE] Processing Bedrock start for %s (%s)", filename, task_id) success = False for attempt in range(1, max_retries + 1): try: result = start_video_embedding(s3_uri, output_uri) arn = result.get("invocation_arn", "") log.info("[QUEUE] Bedrock started for task_id=%s", task_id) video_tasks[task_id]["status"] = "indexing" video_tasks[task_id]["invocation_arn"] = arn video_tasks[task_id]["output_s3_uri"] = output_uri for rec in vs_index(): if rec.get("id") == task_id: rec.setdefault("metadata", {})["status"] = "indexing" break vs_save() with bedrock_poller_lock: bedrock_poller_jobs.append({ "task_id": task_id, "invocation_arn": arn, "output_s3_uri": output_uri, "started_at": time.monotonic(), }) success = True break
u3053u308cu306bu3088u308au9054u6210u3055u308cu308bu3053u306e: u30adu30e5u30fcu30d7u30edu30bbu30c3u30b5u30fcu306fu3001u30bfu30b3u30fcu30b9u30c8u30aau30fcu30c9u3092u300cu4fddu7559u4e2du300du304bu3089u300cu30a4u30f3u30c7u30c3u30afu30b9u4f5cu6210u4e2du300du306bu66f4u65b0u3057u3001u8ffdu8de1u7528u306bBedrocku306eu547cu3073u51fau3057ARNu3092u4fddu5b58u3057u3066u3001u5225u306eu30ddu30fcu30eau30f3u30b0u30b9u30ecu30c3u30c9u306bu5f15u304du6e21u3057u307eu3059u3002u305du306eu30ddu30fcu30e9u30fcu306f30u79d2u3054u3068u306bu30b8u30e7u30d6u306eu5b8cu4e86u3092u78bau8a8du3057u3001u5b8cu4e86u3057u305fu57cbu3081u8fbcu307fu3092S3u304bu3089u30edu30fcu30c9u3057u3066u3001u51e6u7406u304fu5b8cu4e86u3059u308bu3068u30d3u30c7u30aau3092u300cu6e96u5099u5b8cu4e86u300du306eu30d5u30e9u30b0u3092u7acbu3066u307eu305su3002
u306au305cu30eau30c8u30e9u30a4u30e5u30b8u30c3u30afu304fu91cdu8981u306au306eu304b: Bedrocku306bu306fu30ecu30fcu30c8u5236u9650u304cu3042u308fu308au307eu305su3002u6307u6570u95a2u6570u7684u30d0u30c3u30afu30aau30d5u3092u542bu3080u30eau30c3u30e1u30c3u30d7u30e1u30abu30cbu30bau30e0u306fu3001u5927u91cfu306eu30a2u30c3u30d7u30edu30fcu30c9u4e2du3067u3082u30b8u30e7u30d6u304cu6700u7d42u306bu6210u529fu3059u308bu3053u306eu3092u4fddu8a3cu3057u3001u30d3u30c7u30aau304cu6c38u4e45u306bu300cu4fddu7559u4e2du300du30b9u30c6u30fcu30c8u306bu6b8bu308bu30b5u30a4u30ecu30f3u30c8u30a8u30e9u30fcu3092u9632u304eu307eu305su3002
u30c7u30b6u30a4u30f3u30d1u30bfu30fcu30f3: u30d3u30c7u30aau3068u30a8u30f3u30c6u30a3u30c6u30a3u306fu540cu3058u30d9u30afu30c8u30ebu30a4u30f3u30c7u30c3u30afu30b9u3092u5171u6709u3057u3001u30bfu30a4u30d7u30e1u30bfu30c7u30fcu30bfu306du3088u3063u3066u533au5225u3055u308cu307eu305su3002u30c8u30cbu30e5u30e1u30f3u30c8u306fu3001u500bu5225u306eu30c1u30e3u30f3u30afu30d2u30fcu30b9u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u4f7fu7528u3057u307eu305su3002u3053u308cu306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u72ecu7acbu3055u305bu305fu307eu307eu3001u7d71u5408u3055u308cu305fu30d3u30c7u30aa+u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
1.3 - u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu5316u306bu3088u308bu30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au8fbcu307f
u30c8u30cbu30e5u30e1u30f3u30c8u306fu30d3u30c7u30aau3068u306fu7570u306au308bu51e6u7406u304cu5fc5u8981u3067u3059u3002PDFu306fu62bdu51fau3055u308cu3001uff08u53efu80fdu306au3089u30bbu30afu30b7u30e7u30f3u3054u3068u306buff09u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu306bu5206u5272u3055u308cu3001NeMou3092u4ecbu3057u305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u3066u3001u691cu7d22u53efu80fdu306au30ecu30b3u30fcu30c2u3068u3057u3066u4fddu5b58u3055u308cu307eu305s:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 688)
def ingest_document(file_path: str, doc_id: str, filename: str) -> dict: extra: dict = {} try: pdf_info = store_pdf_document(file_path, doc_id) extra.update(pdf_info) except Exception as exc: log.warning("Could not persist PDF for %s (%s)", doc_id, type(exc).__name__) ext = os.path.splitext(file_path)[1].lower() chunks: list[str] = [] sections: list[str] = [] if ext == ".pdf": try: pairs = split_into_semantic_chunks(file_path) sections = [s for s, _ in pairs] chunks = [t for _, t in pairs] log.info("Smart PDF chunking produced %d chunks for doc %s", len(chunks), doc_id) except Exception as exc: log.warning("Smart PDF extraction failed for doc %s, falling back to NeMo (%s)", doc_id, type(exc).__name__) if not chunks: chunks = extract_document(file_path) if not chunks: log.warning("No content extracted for doc %s", doc_id) return {"doc_id": doc_id, "chunks": 0, "status": "empty"} embeddings = embed_texts(chunks) add_chunks( doc_id, filename, chunks, embeddings, sections=sections or None, extra_metadata=extra or None, ) return {"doc_id": doc_id, "chunks": len(chunks), "status": "ready"}
u30b9u30deu30fcu30c8u30c1u30e3u30f3u30afu5316u30b9u30c8u30e9u30c6u30b8u30fc: u30b7u30b9u30c6u30e0u306fu307eu305au30bbu30afu30b7u30e7u30f3u30d2u30fcu30b9u306eu5206u5272uff08u30c8u30cbu30e5u30e1u30f3u30c8u69cbu9020u3092u7dadu6301uff09u3092u8a66u307fu3001u69cbu9020u691cu51fau306bu5931u6557u3057u305fu5834u5408u306fu30d1u30e9u30b0u30e9u30d5u30d2u30fcu30b9u306eu30c1u30e3u30f3u30afu5316u3092u884cu3044u307eu305su3002u3053u308cu306fu3001u30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcuff08u300cu4e8bu6545u30bfu30a4u30e0u30e9u30a4u30f3u300du3001u300cu76eeu6483u8005u306eu4subu8ff0u300du306au3069uff09u304cu91cdu8981u306au691cu7d22u30b3u30f3u30c6u30adu30b9u30c8u3092u63d0u4f9bu3059u308bu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u91cdu8981u3067u3059u3002
u57cbu3081u8fbcu307fu30e2u30c7u30ebu306eu9078u629e: nvidia/llama-nemotron-embed-vl-1b-v2 u306fu3001u30d1u30bbu30fcu30b8u691cu7d22u306bu6700u9069u5316u3055u308cu305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059u3002u30c1u30e3u30f3u30afu3054u3068u306bu72ecu7acbu3057u305fu30d9u30afu30c8u30ebu304cu4e0eu3048u3089u308cu3063u3053u3068u306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u5168u4f53u306eu4e00u81f4u3092u6c42u3081u308bu3053u306eu306au304fu3001u30d1u30e9u30b0u30e9u30d5u30ecu30d9u30ebu3067u306eu6b63u76bau306au30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002
u30e1u30bfu30c7u30fcu30bfu306eu4fddu5b58: u30b7u30b9u30c6u30e0u306fu30aau30eau30b8u30cau30ebu306eu30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcu3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu30eau30f3u30afu3092u30c1u30e3u30f3u30afu306eu30c6u30adu30b9u30c8u3068u4e00u7dd2u306bu4fddu5b58u3059u308bu3053u306eu3067u3001u691cu7d22u7d50u679cu304bu3089u8abfu67fbu54e1u304cu30a2u30afu30bbu30bbu30b9u3057u305fu30aau30eau30b8u30cau30ebPDFu306eu30d1u30e9u30b0u30e9u30d5u3092u7d39u4ecbu3067u304du308bu3088u3046u306bu3057u307eu305su3002
NVIDIA API u3092u4ecbu3057u305fu57cbu3081u8fbcu307fu306eu751fu6210:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 515)
def embed_via_requests(texts: list[str], input_type: str) -> list[list[float]]: """Call NVIDIA embeddings API directly with requests""" import requests t0 = time.perf_counter() resp = requests.post( "https://integrate.api.nvidia.com/v1/embeddings", headers={ "Authorization": f"Bearer {NVIDIA_API_KEY}", "Content-Type": "application/json", }, json={ "input": texts, "model": EMBED_MODEL, "encoding_format": "float", "input_type": input_type, }, timeout=60, ) resp.raise_for_status() data = resp.json() vectors = [d["embedding"] for d in data["data"]] first_dim = len(vectors[0]) if vectors else 0 return vectors
input_type u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001u30d1u30bbu30fcu30b8u691cu7d22uff08u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu3066u3044u308bu30c8u30cbu30e5u30e1u30f3u30c8u306eu30c1u30e3u30f3u30afu305fu3061uff09u3068u30afu30a8u30eauff08u691cu7d22u30eau30afu30a8u30b9u30c8uff09u3092u5206u3051u308bu3053u306eu3067u3059u3002u3053u308cu306bu3088u308au3001u57cbu3081u8fbcu307fu304cu305du306eu76eeu7684u306bu5408u308fu305bu3066u6700u9069u5316u3055u308cu308bu3053u3068u306bu306au308au3001u691cu7d22u7cbeu5ea6u304cu5411u4e0au3057u307eu305suff1au30d1u30bbu30fcu30b8u306fu4fddu5b58u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu3001u30afu30a8u30eau306fu30deu30c3u30c1u30f3u30b0u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu307eu305su3002
1.4 - u9854u753bu50cfu304bu308fu691cu7d22u53efu80fdu306au30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u306eu4f5cu6210
u53f8u6cd5u8abfu67fbu3067u306fu3001u8907u6570u306eu30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu500bu4ebau3092u8ffdu8de1u3059u308bu3053u306eu304cu3057u3070u3057u3070u6c42u3081u3089u308cu307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30b7u30b9u30c6u30e0u306fu3001u9854u753bu50cfu3092u691cu7d22u3059u308bu305fu3081u306eu57cbu3081u8fbcu307fu306eu751fu6210u3092u53efu80fdu306bu3057u307eu305su3002
u753bu50cfu57cbu3081u8fbcu307fu306eu751fu6210:
def embed_image(media_source: dict) -> list[float]: return invoke_embedding_model({ "inputType": "image", "image": {"mediaSource": media_source}, })
u3053u308cu306fMarengou306eu753bu50cfu57cbu3081u8fbcu307fu6a5fu80fdu3092u4f7fu7528u3057u3001u9854u306eu8996u899au7684u306au7279u5fb4u3092u751fu6210u3057u307eu305su3002u30c6u30adu30b9u30c8u57cbu3081u8fbcu307fu3068u306fu7570u306au308au3001u753bu50cfu57cbu3081u8fbcu307fu306fu8996u899au7684u306au7279u5fb4uff08u9854u306eu69cbu9020u3001u5bb9u59ffu3001u8863u985euff09u3092u30c0u30a4u30ecu30afu30c8u306bu6349u3048u308bu3053u306eu3067u3001u30d3u30c7u30aau30d5u30ecu30fcu30e0u9593u3067u306eu8996u899au7684u306au30deu30c3u30c1u30f3u30b0u306bu9069u3057u3066u3044u307eu305su3002
u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu9854u753bu50cfu304bu308fu306eu30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210:
@entities_bp.route("/entities/from-image", methods=["POST"]) def api_entities_from_image(): if "image" not in request.files: return jsonify({"error": "No 'image' file provided"}), 400 file = request.files["image"] if file.filename == "": return jsonify({"error": "Empty filename"}), 400 data = request.form or {} name = data.get("name") or (request.get_json(silent=True) or {}).get("name") or "" if not name.strip(): return jsonify({"error": "Missing 'name'"}), 400 image_bytes = file.read() faces = detect_and_crop_faces(image_bytes, min_confidence=ENTITY_FACE_MIN_CONFIDENCE) if not faces: return jsonify( {"error": "No face detected in image. Use a clear, front-facing photo with good lighting."} ), 404 best = faces[0] face_b64 = best["image_base64"] embed_b64 = best.get("embedding_crop_base64") or face_b64 import base64 face_bytes = base64.b64decode(embed_b64) media = media_source_base64(face_bytes) try: embedding = embed_image(media) except Exception: return jsonify({"error": "Internal server error"}), 500 entity_id = name.strip().lower().replace(" ", "-") rec = index_add( id=entity_id, embedding=embedding, metadata={"name": name.strip(), "face_snap_base64": face_b64}, type="entity", ) return jsonify( { "indexId": FIXED_INDEX_ID, "entity": {"id": rec["id"], "name": name.strip()}, "face_snap_base64": face_b64, } )
u9854u691cu51fau306eu30bfu30c3u30d7: u57cbu3081u8fbcu307fu306eu524du306bu3001OpenCVu306eResNet10 SSDu691cu51fau5668u3092u4f7fu7528u3057u3066u9854u3092u5b64u7acbu3055u305bu307eu305su3002u3053u306eu524du51ceu7406u306bu3088u308au3001Marengou306fu30b7u30fcu30f3u5168u4f53u3067u306fu306eu306au304fu3001u30afu30eau30fcu30f3u306bu5207u308au53d6u3089u308cu305fu9854u3092u53d7u3051u53d6u308bu3053u306eu306bu306au308au3001u691cu7d22u6642u306eu30deu30c3u30c1u7cbeu5ea6u304fu5411u4e0au3057u307eu305su3002u691cu51fau5668u306fu4fe1u983cu30b9u30b3u30a2u3092u8fd4u3057u3001u6700u5c0fu3057u304du3044u5024u3092u8d85u3048u308bu9854u306eu307fu304cu51e6u7406u3055u308cu307eu305su3002
u306au305cu30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u304cu30d3u30c7u30aau30a4u30f3u30c6u30c3u30afu30b9u306bu5b58u5728u3059u308bu306eu304f: u30d3u30c7u30aaEmbeddingsu3068u4e00u7dd2u306bu30a8u30f3u30c6u30a3u30c6u30a3Embeddingsu3092u4fddu5b58u3059u308bu3053u306eu306bu3088u308au3001u30c0u30a4u30ecu30afu30c8u306bu985eu4f3cu6027u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002u8abfu67fbu54e1u304cu300cu8208u5473u306eu3042u308bu4ebau7269-xu300du3092u691cu7d22u3059u308bu3068u3001u30b7u30b9u30c6u30e0u306f1u2e0eu306eu691cu7d22u64cdu4f5cu3067u305du306eu30a8u30f3u30c6u30a3u30c6u30a3u306e Embeddings u3068u3001u3059u3079u3066u306eu30d3u30c7u30aau30bbu30b0u30e1u30f3u30c8u306e Embeddings u3092u6bd4u8f03u3057u307eu305su3002
u30d1u30fcu30c8 2: u30bdu30fcu30b9u9593u691cu7d22u3068u53d6u308au51fau3057
u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u304bu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu308bu3068u3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3059u3079u3066u306eu30bdu30fcu30b9u306bu308fu305fu308bu7d71u5408u3055u308cu305fu691cu7d22u3092u53efu80fdu306bu3057u307eu305su3002u3053u3053u3067u30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30a2u30fcu30adu30c6u30afu30c1u30e3u304cu305du306eu4fa1u5024u3092u767au63eeu3057u307eu305suff1a1u3064u306eu30afu30a8u30eau3001u3059u3079u3066u306eu30bdu30fcu30b9u3001u30e9u30f3u30adu30f3u30b0u3055u308cu305fu7d50u679cu3002
2.1 - u30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu3088u308bu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u691cu7d22
u691cu7d22u30d5u30a3u30ebu30bfu30fcu306fu30011u3064u306eu30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u304bu30893u3064u306eu30afu30a8u30eau30bfu30a4u30d7u3092u30b5u30ddu30fcu30c8u3057u307eu305s:
u30c6u30adu30b9u30c8u30afu30a8u30ea: u81eau7136u8a00u8a9eu306eu8aacu660euff08u300cu8d64u3044u30b8u30e3u30b1u30c3u30c8u3092u7740u305fu4ebau7269u300duff09
u753bu50cfu30afu30a8u30ea: u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u30a2u30c3u30d7u30edu30fcu30c9u3057u3001u4e00u81f4u3059u308bu6620u50cfu3092u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30ea: u4e8bu524du306bu767bu9332u3055u308cu305fu4ebau7269/u7269u4ef6u3092u691cu7d22
u30bdu30fcu30b9: backend/app/routes/search.py (Line 30)
def search_video_index( data: dict, *, request_query: str = "", request_top_k: int | None = None, image_bytes: bytes | None = None, ) -> tuple[list[dict], str, str | None]: query_emb, display_query, is_entity_search, err = get_search_embedding_from_request( data, request_query=request_query, image_bytes=image_bytes, )
u5165u529bu306eu6b19u6e96u5316: get_search_embedding_from_request() u306fu3059u3079u3066u306eu30afu30a8u30eau30bfu30a4u30d7u3092u51e6u7406u3057u3001u5358u4e00u306eu57cbu3081u8fbcu307fu30d9u30afu30c8u30ebu3092u8fd4u3057u307eu305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fMarengou306eu30c6u30adu30b9u30c8u30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u753bu50cfu30afu30a8u30eau306fu753bu50cfu30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu4fddu5b58u3055u308cu305fEmbeddingsu3092u30c0u30a4u30ecu30afu30c8u306bu53d6u5f97u3057u307eu305su3002u4e0bu6d41u306eu691cu7d22u30e5u30b8u30c3u30afu306fu5165u529bu30bfu30a4u30d7u3092u6c17u306bu305bu305au3001u5358u306bu4e00u81f4u3059u308bu30d9u30afu30c8u30ebu3092u898bu3064u3051u308bu3060u3051u3067u305su3002
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306eu6700u9069u5316:
for r in results: meta = r.get("metadata", {}) clips = [] output_uri = meta.get("output_s3_uri") or f"{S3_EMBEDDINGS_OUTPUT}/{r['id']}" if is_entity_search: clips = clips_above_threshold( query_emb, output_uri, min_score=ENTITY_CLIP_MIN_SCORE, visual_only=True, max_clips=clips_per_video, ) if not clips: clips = clip_search( query_emb, output_uri, top_n=clips_per_video, min_score=clip_min_score, visual_only=is_entity_search, )
u30b9u30b3u30a2u30eau30f3u30b0u306eu9055u3044: u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306f visual_only=True u3068u9ad8u3044u4e00u81f4u3057u304du3044u5024u3092u4f7fu7528u3057u307eu305su3002u9854u306eu30deu30c3u30c1u30f3u30b0u306fu3001u4e00u822cu7684u306eu30b3u30f3u30c6u30f3u30c4u691cu7d22u3088u308au3082u5f37u3044u8996u899au7684u306au985eu4f3cu6027u3092u5fc5u8981u3068u3059u308bu305fu3081u3067u305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fu3001u97f3u58f0u306eu6587u5b57u8d77u3053u3057u307eu305fu306fu8996u899au7684u306au30b3u30f3u30c6u30f3u30c4uff08u3069u3061u3089u306eu30e2u30c0u30eau30c6u30a3u3067u3082uff09u3092u4ecbu3057u3066u4e00u81f4u3055u305bu308bu3053u306eu304cu3067u304du307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu8996u899au7684u306bu4e00u81f4u3057u306au3051u308cu307eu305bu3093u3002
u30afu30eau30c3u30d7u30ecu30d9u30ebu306eu6839u62e0u3065u3051:
out.append({ "id": r["id"], "score": r["score"], "metadata": meta, "clips": clips, }) return out, display_query, None
u7d50u679cu306fu5358u306bu3069u306eu30d3u30c7u30aau304cu4e00u81f4u3059u308bu304bu3060u3051u3067u306fu306au304fu3001u305du306eu30d3u30c7u30aau306eu3069u3053u3067u4e00u81f4u304cu8d77u3053u3063u305fu304bu3082u542bu307eu308cu307eu305su3002u300cu8ecau4e21u304bu308fu964du305du308au308bu4ebau7269u300du3092u691cu7d22u3059u308bu8abfu67fbu54e1u306fu3001u4ee5u4e0bu306eu3088u3046u306eu7d50u679cu3092u5f97u307eu305s:
u30d3u30c7u30aa: "Dashcam - Main St" u2192 u30afu30eau30c3u30d7: 00:03:42-00:03:48, 00:07:15-00:07:21
u30d3u30c7u30aa: "CCTV - Parking Lot" u2192 u30afu30eau30c3u30d7: 00:12:03-00:12:09
u3053u306eu30afu30eau30c3u30d7u30ecu30d9u30ebu306eu7cbeu5ea6u306fu3001u30d3u30c7u30aau691cu7d22u30b3u30f3u30c6u30f3u30c4u30efu30fcu30afu3067u3088u304fu3042u308bu300cu91ddu3092u63a2u3057u3066u3044u308bu306eu306bu3001u4ecdu7136u3068u3057u3066u5168u4f53u306eu30efu30e9u5c71u3092u53d7u3051u53d6u3063u3066u3057u307eu3046u300du3068u3044u3063u305fu554fu984cu3092u89e3u6c7au3057u307eu305su3002
2.2 - u30a8u30f3u30c6u30a3u30c6u30a3u3092u8a8du8b58u3059u308bu30d3u30c7u30aau691cu7d22: u30bdu30fcu30b9u3092u8d85u3048u3066u4ebau7269u3092u898bu3064u3051u308b
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306fu3001u8abfu67fbu54e1u304fu591au304fu306eu95a2u9023u306eu306au3044u30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu4ebau7269u3092u8ffdu8de1u3059u308bu3053u306eu3092u53efu80fdu306bu3057u307eu305su3002u9854u753bu50cfu3092u30a2u30c3u30d7u30edu30fcu30c9u3059u308cu3070u3001u3059u3079u3066u306eu6620u50cfu3092u691cu7d22u3067u304bu307eu305s:
u305du306eu4f5cu7528u306eu4ed5u7d44u307f:
u30a8u30f3u30c6u30a3u30c6u30a3u306eu57cbu3081u8fbcu307fuff08u30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210u6642u306bu751fu6210uff09u304cu30a4u30f3u30c7u30c3u30afu30b9u304bu3089u30edu30fcu30c9u3055u308cu307eu305s
u30b7u30b9u30c6u30e0u306fS3 Bedrocku51fau529bu304bu3089u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu5404u30d3u30c7u30aau306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u53d6u5f97u3057u307eu305s
u985eu4f3cu6027u30b9u30b3u30a2u30eau30f3u30b0u306bu3088u308au3001u30a8u30f3u30c6u30a3u30c6u30a3u304cu767bu5834u3059u308bu53efu80fdu6027u306eu9ad8u3044u30afu30eau30c3u30d7u3092u7279u5b9au3057u307eu305s
u30d3u30c7u30aau306fu30deu30c3u30c1u5f37u5ea6u3068u4e00u8cabu6027uff08u30deu30c3u30c1u3057u305fu30afu30eau30c3u30d7u306eu6570u3001u30b9u30b3u30a2u306eu5f37u3055uff09u306bu3088u3063u306eu30ecu30f3u30adu30f3u30b0u3055u308cu307eu305s
u306au305cu3053u308cu304cu5b9fu884cu6642u306eu9854u691cu51fau3088u308bu3082u901fu3044u306eu304b: Ingestionu6642u306bu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u4e8bu524du8a08u7b97u3059u308bu3053u306eu306fu3001u691cu7d22u6642u306b u9854u691cu51fau3067u306fu306au304fu3001u985eu4f3cu6027u6bd4u8f03u3060u3051u3092u884cu3046u3053u306eu3092u610fu5473u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3068u30a8u30f3u30c6u30a3u30c6u30a3u57cbu3081u8fbcu307fu306eu6bd4u8f03u306fu3001u30dfu30eau79d2u5358u4f4du3067u5b8cu4e86u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u3067u9854u691cu51fau3092u5b9fu884cu3059u308bu3068u3001u6570u6642u9593u304bu304bu308au307eu305su3002
u30deu30c3u30c1u3057u304du3044u5024u306eu8abfu6574: u30b7u30b9u30c6u30e0u306f ENTITY_CLIP_MIN_SCORE u3092u4f7fu7528u3057u3066u5f31u3044u30deu30c3u30c1u3092u30d5u30a3u30ebu30bfu30eau30f3u30b0u3057u307eu305su3002u3053u308cu3092u4f4eu304fu8a2du5b9au3057u3059u304eu308bu3068u3001u507du967du6027uff08u4f3cu3066u3044u308bu5225u4ebauff09u304cu767au751fu3057u307eu305su3002u9ad8u304fu8a2du5b9au3057u3059u304eu308bu3068u3001u6709u52b9u306au30deu30c3u30c1uff08u7570u306au308bu5149u3084u89d2u5ea6u306eu540cu4e00u4ebau7269uff09u3092u30dfu30b9u3057u307eu305su3002u30c7u30e2u3067u306f0.75u3092u30d0u30e9u30f3u30b9u30ddu30a4u30f3u30c8u3068u3057u3066u4f7fu7528u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3u30b7u30b9u30c6u30e0u3067u306fu3012u30fcu30b6u30fcu304cu5909u66f4u3067u304du308bu3088u3046u306bu3059u308bu3079u304du3067u305su3002
2.3 - u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22: u30d3u30c7u30aa + u30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au51fau3057
u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8abfu67fbu54e1u306fu3001u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u306au3069u3068u6620u50cfu3092u7167u5408u3059u308bu5fc5u8981u304cu3042u308fu308au307eu305su3002u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u4e26u884cu3057u3066u5b9fu884cu3057u307eu305s:
u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306eu5b9fu88c5:
def search_document_index(text_query: str, doc_top_k: int) -> list[dict]: from app.services.nemo_retriever import embed_query, search_docs t0 = time.perf_counter() log.info("[DOC_SEARCH] Started doc search top_k=%d", doc_top_k) query_emb = embed_query(text_query) docs = search_docs(query_emb, top_k=doc_top_k) return docs
u4e26u884cu5b9fu884cu30d1u30bfu30fcu30f3: u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu3001u30b9u30ecu30c3u30c7u30a3u30f3u30b0u3092u4f7fu7528u3057u3066u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u540cu6642u306bu958bu59cbu3057u3001u4e21u65b9u304cu5b8cu4e86u3057u305fu3089u7d50u679cu3092u30deu30fcu30b8u3057u307eu305su3002u3053u308cu306bu3088u308au3001u5168u4f53u306eu30ecu30a3u30c6u30f3u30b7u30fcu306fu3001u305du308cu3089u306eu548cu3067u306fu306au304fu3001u5c11u3057u9045u3044u65b9u306eu691cu7d22u306eu6642u9593u306bu8fd1u3065u3051u3089u308cu307eu305su3002
u7d50u679cu306eu30deu30fcu30b8u306eu30b9u30c8u30e9u30c6u30b8u30fc: u30d3u30c7u30aau306eu7d50u679cu306eu30c8u30cbu30e5u30e1u30f3u30c8u306eu7d50u679cu306fu3001u30ecu30b9u30ddu30f3u30b9u3067u500bu5225u306bu7dadu6301u3055u308cu307eu305suff08u30b9u30b3u30a2u3067u5c0fu5206u3051u306bu3055u308cu306au3044uff09u3002u30a2u30d7u30edu30fcu30c1u306eu76eeu7684u304cu305du308cu305eu308cu7570u306au308bu305fu3081u3067u305su3002u30d3u30c7u30aau306fu8996u899au7684u306au8a3cu62e0u3092u63d0u4f9bu3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306fu88cfu4ed8u3051u308bu53e3u8ff0u3092u63d0u4f9bu3057u307eu305su3002u8abfu67fbu54e1u306fu305du308cu3089u3092u7570u306au308bu30ddu30a4u30f3u30c8u3067u30ecu30d3u30e5u30fcu3057u307eu305su3002
u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306eu5168u3066 u306eu5b9fu88c5u3092u78bau8a8du3059u308bu306bu306f: u30bdu30fcu30b9u3092u8868u793a
u30d1u30fcu30c8 3: u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3068u30ecu30ddu30fcu30c8u4f5cu6210
u691cu7d22u306bu3088u308au8a3cu62e0u3092u898bu3064u3051u307eu305su3002u5206u6790u306bu3088u308au305du308cu3092u89e3u91c8u3057u307eu305su3002u3053u306eu30d3u30d7u30ecu30bcu30f3u30c6u30fcu30b7u30e7u30f3u306fu3001Rawu6620u50cfu304bu308fu69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u751fu6210u3059u308bu305fu3081u306bu3001Bedrocku3092u4ecbu3057u306fPegasusu3092u4f7fu7528u3057u307eu305s:
3.1 - u69cbu9020u5316u3055u308cu305fu30d3u30c7u30aau5206u6790u306eu751fu6210
Pegasusu306fu975eu69cbu9020u5316u306eu30d3u30c7u30aau3092u3001u30eau30b9u30afu30afu30e9u30b9u3001u691cu51fau3055u308cu305fu4ebau7269u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu6587u5b57u8d77u3053u3057u3001u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30eau30b9u30c8u306au3069u306eu69cbu9020u5316u3055u308cu305fu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu5909u63dbu3057u307eu305su3002
u30bdu30fcu30b9: backend/app/services/bedrock_pegasus.py (Line 72)
body: dict = { "inputPrompt": prompt[:4000], "mediaSource": { "s3Location": { "uri": s3_uri, "bucketOwner": owner, } }, } if temperature is not None: body["temperature"] = temperature if response_schema is not None: body["responseFormat"] = {"jsonSchema": response_schema}
Temperatureu8a2du5b9a: u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u306b temperature: 0 u3092u4f7fu7528u3059u308bu3053u306eu306bu3088u3082u3001u6c7au5b9au8ad6u7684u3067u518du73feu53efu80fdu306eu51fau529bu304cu4fddu8a3cu3055u308cu307eu305su3002u540cu3058u30d3u30c7u30aau306fu5e38u306bu540cu3058u5206u6790u69cbu9020u3092u751fu6210u3057u3001u3053u308cu306fu4e00u8cabu6027u304fu91cdu8981u306au6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u1e1au754cu3067u305su3002
u30ecu30b9u30ddu30f3u30b9u30b9u30adu30fcu30deu306eu5f37u5236: jsonSchema u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001Pegasusu306bu5bfeu3057u3001u30d5u30eau30fcu30d5u30a9u30fcu30e0u306eu30c6u30adu30b9u30c8u3067u306fu306au304fu3001u69cbu9020u5316u3055u308cu305f JSON u3092u8fd4u3059u3088u3046u6307u793au3057u307eu305su3002u3053u308cu306fu30d1u30fcu30b9u53efu80fdu306au51fau529bu3092u4fddu8a3cu3057u3001u5f8cu51eceu7406u306eu8106u5f31u6027u3092u6392u9664u3057u307eu305su3002
Bedrock u30e2u30c7u30ebu306eu547cu307uu51fau3057:
response = client.invoke_model( modelId=model_id, body=payload, contentType="application/json", accept="application/json", )
u5fdcu7b54u306bu306fu3001Bedrock u306e JSON u5fdcu7b54u30d5u30a2u30fcu30deu30c3u30c8u304bu3089u62bdu51fau3055u308cu305fu3001u751fu6210u3055u308cu305fu30c6u30adu30b9u30c8u304fu542bu307eu308cu3063u3053u3068u306bu306au308au307eu305su3002u3053u306eu30c6u30adu30b9u30c8u306fu3001u63d0u4f9bu3055u308cu305fu30d7u30edu30f3u30d7u306eu6307u793au306bu57fau3065u304f Pegasus u306eu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu89e3u91c8u3092u8868u3057u3066u3044u307eu305su3002
u5206u6790u30d7u30edu30f3u30d7u3068u30d1u30fcu30b9:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 335)
raw_text = pegasus_analyze_video( s3_uri, get_video_analysis_prompt(), temperature=0, ) log.info("[ANALYSIS] Pegasus response received in %.1fs (len=%d)", time.perf_counter() - t0, len(raw_text or "")) analysis_dict = parse_video_analysis_response(raw_text)
u5206u6790u30d7u30edu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu3092u6307u793au3057u307eu305s:
u30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu5206u985euff08u4ea4u901au4e8bu6545u3001u8077u5834u306eu5b89u5168u3001u72afu7f6au6d3bu52d5u306au3069uff09
u30eau30b9u30afu30ecu30d9u30ebu3068u7279u5b9au306eu30eau30b9u30afu8981u56e0u306eu7279u5b9a
u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du6587u5b57u8d77u3053u3057u30bbu30b0u30e1u30f3u30c8u306eu62bdu51fa
u8aacu660eu4ed8u304du306eu8208u5473u306eu3042u308fu308bu4ebau7269u306eu691cu51fa
u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u306bu7126u70b9u3092u5f53u3066u305fu8981u7d04u306eu751fu6210
u30d1u30fcu30b9u30b9u30c8u30e9u30c6u30b8u30fc: parse_video_analysis_response() u306fu3001u4e0du6b63u306au5f62u5f0fu306e JSON u3092u512au96c5u306bu51e6u7406u3057u307eu305suff083u91cdu306eu30d0u30c3u30afu30c3u30afu30e9u30eau30f3u30b0u3001u672bu5c3eu306eu30b3u30f3u30deu3001u4e0du5b8cu5168u306eu5fdcu7b54u306au3069u304bu3089u5fa9u5143uff09u3002LLM u306eu51fau529bu306fu5e38u306bu5b8cu74a2u306bu30d5u30cau30fcu30deu30c3u30c8u3055u308cu3066u3044u308bu3068u306fu9650u3089u306au3044u305fu3081u3067u305su3002u580坚u5b9fu306au30d1u30fcu30b9u306bu3088u3082u3001u8efdu5faeu306eu30d5u30a9u30fcu30deu30c3u30c8u306eu554fu984cu304bu3089u306eu5206u6790u306eu5931u6557u3092u9632u304eu307eu305su3002
u5b57u5e55u306eu751fu6210: u30b7u30b9u30c6u30e0u306fu3001u6587u5b57u8d77u3053u3057u306bu6700u9069u5316u3055u308cu305f Pegasus u306eu3001u5225u306eu547cu307uu51fau3057u3092u5b9fu884cu3057u3001u69cbu9020u3055u308cu305f JSON u3067u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du30bbu30b0u30e1u30f3u30c8u3092u8981u6c42u3057u307eu305su3002u3053u308eu306bu3088u308au3001u958bu59cb/u7d42u4e86u6642u9593u3092u6301u3064u3001u6574u5217u3055u308cu305fu6587u5b57u8d77u3053u3057u30a8u30f3u30c8u30eau304cu751fu6210u3055u308eu3001u8abfu67fbu54e1u306fu8a71u3055u308cu305fu30b3u30f3u30c6u30f3u30c4u306bu76f4u63a5u30b8u30e3u30f3u30d7u3067u304du308bu3088u3046u306bu306au308au307eu305su3002
3.2 - u7269u4ef6u691cu51fau3068u9854u30adu30fcu30d5u30ecu30fcu30e0u306eu62bdu51fa
u57fau672cu7684u306au6587u5b57u8d77u3053u3057u306e u5148u306bu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3001u691cu51fau3055u308cu305fu7269u4ef6u3068u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3092u6301u3064u4fbfu5229u306au9854u30adu30fcu30d5u30ecu30fcu30e0uff08u9854u304cu306fu3063u304du308au3068u733eu308fu308cu308bu7279u5b9au306eu77acu9593uff09u3092u7279u5b9au3057u307eu305s:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 707)
raw_response = pegasus_analyze_video(s3_uri, get_detect_prompt()) log.info("[INSIGHTS] Pegasus response received in %.1fs (%d chars)", time.perf_counter() - t0, len(raw_response or "")) detect_data = parse_detect_response(raw_response) objects_raw = detect_data["objects"] face_keyframes = detect_data["face_keyframes"]
u691cu51fau30d4u30f3u30ddu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu306eu7279u5b9au3092u6c42u3081u305eu3059:
u7269u4ef6: u8ecau4e21u3001u6b66u5668u3001u7269u7406u7684u306au8a3cu62e0u3001u74b0u5883u306eu8a73u7d30
u9854u30adu30fcu30d5u30ecu30fcu30e0: u500bu4ebau7279u5b9au306eu305fu3081u306bu5341u5206u306au660eu77adu3055u3092u6301u3064u9854u304fu733eu308fu308bu30bfu30a4u30e0u30b9u30bfu30f3u30d7
u306au305cu30adu30fcu30d5u30ecu30fcu30e0u304cu91cdu8981u306au306eu304b: u9854u304cu542bu307eu308cu308bu30d5u30ecu30fcu30e0u306eu3059u3079u3066u304cu6709u7528u3067u306fu3042u308au307eu305bu3093u3002u5f8cu308du59ffu3001u30ceu30a4u30ba u304cu3051u3063u305fu308au3001u6697u304fu306au3063u305fu308du3059u308bu9854u306fu3001u7279u5b9au306bu512au308cu307eu305bu3093u3002Pegasus u306fu3001u9854u304cu6b63u9762u3092u5411u304du3001u7167u660eu304cu3088u304fu3001u306fu3063u304eu308au3068u3057u3066u3044u308bu30adu30fcu30d5u30ecu30fcu30e0u3092u9078u629eu3057u307eu305su3002u3053u308cu306fu8abfu67fbu54e1u304cu5b9fu969bu306bu8a3cu62e0u3068u3057u3066u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u3068u308bu30eau30a2u30eb u306au30d5u30ecu30fcu30e0 u3067u305su3002
u5f8cu51eceu7406: Pegasus u304cu30adu30fcu30d5u30ecu30fcu30e0u3068u7269u4ef6u3092u8fd4u3059u3068u3001u30b7u30b9u30c6u30e0u306fu305du308cu3089u306fu7279u5b9au306eu30d5u30ecu30fcu30e0u306eu307fu3092u62bdu51fau3057u3001u30b5u30e0u30cdu30a4u30ebu3092u751fu6210u3057u3001u3059u3070u3084u3044u30ecu30d3u30e5u30fcu306eu305fu3081u306bu4fddu5b58u3057u307eu305su3002u3053u308cu306bu3088u3082u3001u8abfu67fbu54e1u304cu9854u3092u898bu308bu305fu3073u306bu30d3u30c7u30aau3092u518du5ea6u51eceu7406u3059u308bu5fc5u8981u304cu306au304fu306au308au307eu305su3002
3.3 - u9854u306eu767bu5834u306eu30bfu30a4u30e0u30e9u30a4u30f3: u3053u306eu4ebau7269u306fu3069u3053u306bu733eu308fu308bu306eu304buff1f
u9854u3092u691cu51fau3057u305fu5f8cu3001u30b7u30b9u30c6u30e0u306fu3001u691cu51fau3055u308cu305f u5404u4ebau7269u304cu30d3u30c7u30aa u306eu4e2du3067u3044u3064u733eu308fu308cu308bu304bu3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u3092u69cbu7bc9u3057u307eu305s:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 1027)
if use_marengo: # Marengo-based presence, match each face embedding to clip embeddings for j, emb in enumerate(face_embeddings): if not emb: continue clips = clips_above_threshold( emb, output_uri, min_score=FACE_PRESENCE_MATCH_THRESHOLD, visual_only=True, max_clips=50, ) for clip in clips: c_start = float(clip.get("start", 0.0)) c_end = float(clip.get("end", c_start + 0.5)) for i in range(n_segments): s0 = i * seg_dur s1 = (i + 1) * seg_dur if c_end > s0 and c_start < s1: presence_by_face[j]["segment_presence"][i] = 1
u30bfu30a4u30e0u30e9u30a4u30f3u304cu3069u306eu3088u3046u306bu69cbu7bc9u3055u308cu308bu304b:
u30d3u30c7u30aa u306fu56fau5b9au6642u9593 u306eu30bbu30b0u30e1u30f3u30c8 uff08u4f8bu3048u3070 30 u79d2 u30a6u30a3u30f3u30c3u30af u306au3069uff09u306bu5206u5272u3055u308cu307eu305s
u691cu51fau3055u308cu305fu5404u9854u306fu3001u305du306e Embeddings u3092u3059u3079u3066u306eu30afu30eau30c3u30d7 Embeddings u3068 u6bd4u8f03 u3055u308cu307eu305s
u305du306eu3057u304du3044u5024u3092u8d85u3048u308bu30b9u30b3u30a2 u306eu30afu30eau30c3u30d7u306f u300cu4ebau7269 u304cu5b58u5728u3059u308bu300du3068u30deu30fcu30afu3055u308cu307eu305s
u4e00u81f4u3057u305fu30afu30eau30c3u30d7u306fu3001u30bbu30b0u30e1u30f3u30c8u30bfu30a4u30e0u30e9u30a4u30f3u306bu30deu30c3u30d7u3055u308cu307eu305s
u7d50u679c: u5404u4ebau7269u304cu3069u306eu30bbu30b0u30e1u30f3u30c8 u306bu542bu307eu308cu3063u3053u3068 u3092u793au3059 Binary Presence Map u304cu8868u793au3055u308cu307eu305s
u306au305cu3053u308cu304cu8abfu67fbu306bu3068u3065u3066 u91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u8abfu67fbu54e1u306fu4e00u77bcu3067u300cu4ebau7269 A u306fu3001u30bbu30b0u30e1u30f3u30c8 3u30017u300112u300118u306bu733eu308fu308cu308bu300du3053u306eu304cu30d3u30c7u30aau5168u4f53u3092u898bu305au306bu7406u89e3u3067u304du307eu305su3002u30bbu30b0u30e1u30f3u30c8 7 u3092u30afu30eau30c3u30afu3057u3001u305du306e 30 u79d2 u30a6u30a3u30f3u30c3u30af u306bu76f4u63a5u30b8u30e3u30f3u30d7u3057u3001u8996u899au7684u306au4e00u81f4u3092u78bau8a8du3067u304du307eu305su3002
u3057u304du3044u5024u306eu30c8u30ecu30fcu30c9u30aau30d5: FACE_PRESENCE_MATCH_THRESHOLD u306fu611fu5ea6u3092u30b3u30f3u30c8u30edu30fcu30eb u3057u307eu305su3002u5c0fu3055u304fu3059u308bu3053u306e u306bu3088u308b u507du967du6027 u306e u6e1bu5c11 u3001u7570u306au308bu89d2u5ea6u3001u7167u660eu5909u5316u306e u30deu30c3u30c1u30dfu30b9 u306e u53efu80fdu6027 u306eu4e0au6647 u3002u9ad8u304fu3059u308b u3053u306e u306bu3088u308b u7279u5b9a u306e u50cf u306e u898bu9003u3057 u3001u507du30deu30c3u30c1 u306e u5897u52a0 u306bu3088u308b u624bu52d5u30ecu30d3u30e5u30fc u306e u5897u591a u3002u30c7u30e2 u3067u306f 0.70 u3092 u4f7fu7528 u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b7u30b9u30c6u30e0 u3067u306fu3001u8abfu67fbu54e1 u304cu4e8bu6848 u3054u3068 u306bu3053u308c u3092 u8abfu6574 u3067u304du308bu3088u3046 u306bu3059u308bu3079u304d u3067u305su3002
u30d7u30edu30c0u30afu30b7u30e7u30f3u3078u306eu30c7u30d7u30edu30fcu30ebu306bu304au3051u308b u904bu7528u4e0au306eu8003u616eu4e8bu9805
u3053u306e u30c7u30e2 u306fu305du306eu69cbu60f3u3092u8a3cu660eu3057u307eu305su3002u30d7u30edu30c0u30afu30b7u30e7u30f3 u3078u306eu30c7u30d7u30edu30fcu30eb u306bu306fu3001u3044u306fu3086u308bu3001u904bu7528u4e0a u306eu554fu984cu306e u89e3u6c7a u304cu5fc5u8981 u3068u306au308au307eu305s:
Scalabilityuff08u30b9u30b1u30fcu30e9u30d3u30eau30c6u30a3uff09: Single Index u306e u30a2u30d7u30edu30fcu30c1 u306f u30c7u30e2uff0812u306eu30d3u30c7u30aauff09u306bu306f u52a9u304bu308a u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u52a0u91cd uff08u4e8bu6848 u3054u3068 u306b1,000 u4ee5u4e0a u306e u30d3u30c7u30aa uff09u306b u5bfeu3057u3066u306f u30a2u30fcu30adu30c6u30afu30c1u30e3 u306eu5909u66f4 u304cu5fc5u8981u3068u306au308au307eu305s u3002u30a4u30f3u30c7u30c3u30afu30b9u30d1u30fcu30c6u30a3u30b7u30e7u30cbu30f3u30b0 u306e u30b9u30c8u30e9u30c6u30b8u30fc u3001u307eu305fu306f u30afu30eau30c3u30d7u30ecu30d9u30eb u306e Embeddings u306eu305fu3081 u306bu5c02u7528 u306eu30d9u30afu30c8u30eb u30c7u30fcu30bfu30d2u30fcu30b9 u3078u306e u79fbu884c u3092 u691cu8a0e u3057u3066u304fu3060u3055u3044u3002
u30b3u30b9u30c8u306e u7ba1u7406: Bedrock u306f Embedding u306e u751fu6210 u3054u3068u306bu30b3u30b9u30c8u304f u304bu304bu308au307eu305su3002 2u6642u9593u306eu30d3u30c7u30aa u306f ~1,200 u500b u306e u30afu30eau30c3u30d7 Embeddings u3092u751fu6210u3057u307eu305su3002 1u3064u306eu4e8bu6848 u306bu3064u304d 100 u6642u9593 u306eu6620u50cfu3092 u51eceu7406 u3059u308b u3053u306e u306f u300160,000u4ee5u4e0a u306e Embeddings u3092 u610fu5473 u3057u307eu305su3002 u30d0u30c3u30c1u51eceu7406 u3001u30adu30e3u30c3u30b7u30f3u30b0 u30b9u30c8u30e9u30c6u30b8u30fc u3001u304au3088u3073 u95a2u9023 u3059u308b u4e8bu6848 u9593u3067u306e Embeddings u306e u518du5218u7528 u3092 u8a08u753b u3057u3066u304fu3060u3055u3044u3002
u30bbu30adu30e5u30eau30c6u30a3u3068u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9: u6cd5u7684 u8a3cu62e0 u306bu306f u4fddu7ba1u9023u9396 uff08Chain-of-Custodyu300du306e u8ffdu8de1 u3001u30a2u30afu30bbu30b9 u5236u5fa1 u3001u304au3088u3073 u76e3u67fbu30ebu30b0 u304cu5fc5u8981 u3068u306au308au307eu305su3002u3053u306e u30c7u30e2 u306f u30d3u30c7u30aa u3092 S3 u306bu4fddu5b58u3057u307eu305su304c u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u3067u306f u4fddu5b58u6642u306eu6697u53f7u5316 u3001u30edu30fcu30eb u30d2u30fcu30b9u306e u30a2u30afu30bbu30b9 u3001u304au3088u3073 u4e0du5909 u306e u76e3u67fb u30c8u30ecu30fcu30eb u304cu5fc5u8981 u3068u306au308au307eu305su3002
u7cbeu5ea6 u306eu30d0u30eau30c7u30fcu30b7u30e7u30f3: u30a8u30f3u30c6u30a3u30c6u30a3u306eu30deu30c3u30c1u30f3u30b0u3068u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210 u306bu306f u4fe1u983c u30b9u30b3u30a2u300du3092 u542b u308du3055u3001u6cd5u7684u306au8a3cu62e0u3068u3057u3066u9001u4fe1u3059u308bu524du306bu4ebau9593u306eu30ecu30d3u30e5u30fcu3092u5fc5u9808 u3068u3059u308bu3059u3079u304eu3067u305su3002 AIu306bu3088u308bu5206u6790u306fu8abfu67fbu54e1u3092 u30b5u30ddu30fcu30c8 u3057u307eu305su304c u3001u4ebau9593 u306eu5224u65ad u306b u4ee3u308fu308bu3082u306eu3067u306f u3042u308au307eu305bu3093u3002
u30d5u30a9u30fcu30deu30c3u30c8 u306eu51eceu7406: u3053u306e u30c7u30e2 u306f u6a19u6e96 u306eu30d3u30c7u30aa u30b3u30fcu30c7u30c3u30af u3092 u524du63d0 u306b u3057u3066 u3044u307eu305su3002 u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b3u30f3u30c6u30f3u30c4 u306f u3001u7834u640du3057u305fu30d5u30a1u30a4u30eb u3001u975eu6a19u6e96 u306e u30d5u30a3u30ebu30bfu30fc u3001u6697u53f7u5316 u3055u308cu305fu6620u50cfu3001u4f4eu54c1u8ceau306e u30bdu30fcu30b9 u306au306eu3069u3092 u512au96c5 u306b u51eceu7406 u3059u308b u5fc5u8981 u304eu3042u308fu308au307eu305su3002
u7d50u8ad6
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30e1u30bcu30f3u30b9u304cu3001u6642u9593u304fu304bu304bu308bu624bu52d5u306eu30d3u30c7u30aau8a3cu62e0u30ecu30d3u30e5u30fcu306e u30efu30fcu30afu30d5u30edu30fcu3092u3001u7bc4u56f2u3092u7d5eu3063u305fu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu306b u3069u306eu3088u3046u306bu5909u63dbu3059u308bu306eu304b u3092 u5b9fu6f14 u3057u3066 u3044u307eu305su3002 u30d3u30c7u30aau306eu7406u89e3u306b AWS Bedrock u306e TwelveLabs u3092 u4f7fu7528 u3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306e u691cu7d22u306b NeMo Retriever u3092u7d44u307fu5408u308fu305bu308b u3053u306eu306bu3088u3082u3001u8abfu67fbu54e1 u306fu4ee5u4e0bu304c u53efu80fd u3068u306au308au307eu305s:
12u4ee5u4e0bu306e u7570u306au308b u30d3u30c7u30aau30bdu30fcu30b9 u3092 u81eau7136u8a00u8a9e u306eu30afu30a8u30ea u3067 u540cu6642u306b u691cu7d22
u95a2u9023 u306eu306au3044 u30abu30e1u30e9 u30d5u30a3u30fcu30c9 u304bu3089 u7279u5b9a u306e u50cf u307eu305fu306f u8ecau4e21 u3092 u8ffdu8de1
u65adu7247u5316u3055u308cu305f u6620u50cf u304bu3089 u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3 u3092 u518du69cbu6210
u30eau30b9u30afu30afu30e9u30b9 u30a4u30f3u30a2u30f3u30bbu30b9 u30bfu30a4u30d7 u3067 u69cbu9020u5316u3055u308cu305f u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9 u5206u6790 u3092 u751fu6210
u6b63u76bau306eu30bfu30a4u30e0u30b9u30bfu30f3u30d7 u3092 u6301u3064 u6587u5b57u8d77u3053u3057 u3001u304au3088u3073 u691cu51fau3055u308cu305f u7269u4ef6 u3078u306e u30a2u30afu30bbu30b9
u521fu7387 u306e u512au5168: u30bdu30fcu30b9 u304cu6df7u5728u3059u308b 40u6642u9593 u306eu6620u50cfu306e u624bu52d5 u306eu30ecu30d3u30e5u30fcu306f u3001u8abfu67fbu54e1 u306bu3068u3063u306e 40uff5e60u6642u9593 u3092 u8cbb u3084u3055u305bu307eu305su3002 u3053u306e u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0 u306fu3001 u305du308cu3092 u898fu5b9a u3055u308cu305f 4uff5e6u6642u9593 u306e u30bfu30fcu30b2u30c3u30c8u30ecu30d3u30e5u30fc u306b u6e1bu5c11 u3055u305b u3001 u8abfu67fbu54e1 u306f u767au898bu3092 u627eu3059 u3053u306eu306b u6642u9593u304f u304bu3051u308b u306eu3067u306f u306au304f u3001 u305du306eu691cu8a3c u306b u6642u9593u304c u4f7fu3048u308bu3088u3046 u306bu3057u307eu305s u3002
u8a3cu62e0 u7ba1u7406 u30d7u30ebu30a2u30d5u30a9u30fcu30e0 u3092u69cbu7bc9 u3059u308b u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fc ISV u306bu3068u3063u306eu3001u3053u306e u30a2u30fcu30adu30c6u30afu30c1u30e3 u306f u3001TwelveLabs u304c u65e2u5b58 u306e u30efu30fcu30afu30d5u30edu30fc u306b u53d6u308au8fbcu3081u308b u3053u306e u3092 u5c55u793a u3059u308b u30eau30d5u30a1u30ecu30f3u30b9 u30a4u30f3u30d7u30eau30e1u30f3u30c6u30fcu30b7u30e7u30f3 u3092 u63d0u4f9b u3057u307eu305su3002 u30a4u30f3u30ddu30fcu30bfu30fcu30c8 u306e Single Index Multi-Source u306e u30d1u30bfu30fcu30f3u3001 hybrid video+document retrievalu3001 u304au3088u3073 u69cbu9020u5316u3055u308cu305fu5206u6790 u306e u6a5fu80fdu306f u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fcu88fdu54c1 u306b u76f4u63a5 u30a2u30a2u30d7u30edu30fcu30c1 u3055u308cu307eu305su3002
u8ffdu52a0u306eu30eau30bdu30fcu30b9
AWS Bedrock u306e TwelveLabs: u30e2u30c7u30ebu306eu30a2u30afu30bbu30b9 u306bu3064u3044u3066 u8a73u3057u304fu306f
NeMo Retriever u306e u30c8u30cbu30e5u30e1u30f3u30c8: u30c8u30cbu30e5u30e1u30f3u30c8 u691cu7d22 u6a5fu80fdu306f u3053u3061u3089u304bu308f
TwelveLabs u306e u30b5u30f3u30d7u30ebu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3: u8ffdu52a0u306eu300cu30a2u30d7u30eau30a2u30d7u30edu30fcu30c1u300du306fu3053u3061u3089
TwelveLabs u30b3u30dfu30e5u30cbu30c6u30a3u3078u53c2u52a0: Discord
u6b21u306eu30b9u30c6u30c3u30d7:
u30eau30d5u30a1u30ecu30f3u30b9u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u30afu30edu30fcu30f3u3059u308b
AWS Bedrock u306e u30a2u30afu30bbu30b9u3092u8a2du5b9au3057 u3001 u30d3u30c7u30aa u30bdu30fcu30b9 u3067 u30c6u30b9u30c8u3059u308b
Single Index u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u7279u5b9a u306e u6cd5u7684 u30efu30fcu30afu30d5u30edu30fc u306b u9069u5408u3055u305bu308b
u65e2u5b58 u306e u8a3cu62e0 u7ba1u7406 u30b7u30b9u30c6u30e0 u3068 u7d71u5408u3059u308b
u9002u5165
u30d3u30c7u30aau8a3cu62e0u3092u51e6u7406u3059u308bu6cd5u52d9u30c1u30fcu30e0u306fu3001u66f4u306bu6df1u307eu308bu554fu984cu306bu76f4u9762u3057u3066u3044u307eu3059u30021u3064u306eu4e8bu6848u306bu3001u30c0u30c3u30b7u30e5u30abu30e0u3001u30dcu30c7u30a3u30abu30e0u3001u9632u72afu30abu30e1u30e9uff08CCTVuff09u30b7u30b9u30c6u30e0u3001u30c1u30e3u30a4u30e0u30abu30e1u30e9u3001u4fddu967au7533u8acbu7528u6620u50cfu306au3069u304bu3089u306e40u6642u9593u4ee5u4e0au306eu6620u50cfu304cu542bu307eu308cu308bu3053u3068u304cu3042u308au3001u305du306eu3059u3079u3066u304cu7570u306au308bu30d5u30a9u30fcu30deu30c3u30c8u3001u89e3u50cfu5ea6u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u3059u3002u8abfu67fbu54e1u306fu3001u3053u306eu30b3u30f3u30c6u30f3u30c4u3092u624bu52d5u3067u30ecu30d3u30e5u30fcu3059u308bu30d1u30e9u30eau30fcu30acu30ebu306eu4f5cu696du6642u9593u306b1u6642u9593u3042u305fu308a200uff5e500u30c9u30ebu3092u8cbbu3084u3057u3066u3044u307eu305su30027u756au76eeu306eu30abu30e1u30e9u6620u50cfu306e23u6642u9593u76eeu306bu57cbu3082u308cu305fu81e8u754cu7684u306a10u79d2u306eu30afu30eau30c3u30d7u3092u898bu843du306du308bu3068u3001u88c1u5224u306eu7d50u679cu304cu5909u308fu3063u3066u3057u307eu3044u307eu3059u3002
u524du56deu306eu30a2u30d7u30edu30fcu30c1uff08u624bu52d5u3067u306eu30ecu30d3u30e5u30fcu3001u57fau672cu7684u306au30e1u30bfu30c7u30fcu30bfu306eu30bfu30b0u4ed8u3051u3001u30d5u30ecu30fcu30e0u30d0u30a4u30d5u30ecu30fcu30e0u306eu5206u6790uff09u306fu3001u30b9u30b1u30fcu30e9u30d6u30ebu3067u306fu3042u308au307eu305bu3093u3002u6cd5u52d9u30c1u30fcu30e0u306fu3001u7570u306au308bu30bdu30fcu30b9u3092u540cu6642u306bu691cu7d22u3057u3001u65adu7247u5316u3055u308cu305fu6620u50cfu304bu308fu305fu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3057u3001u3059u3079u3066u306eu30d3u30c7u30aau3092u898bu308bu3053u3068u306au304fu81e8u754cu306au77acu9593u3092u7279u5b9au3059u308bu5fc5u8981u304cu3042u308fu308au307eu3059u3002
u3053u306eu30c1u30e5u30fcu30c8u30eau30a2u30ebu3067u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30eau30b8u30a7u30f3u30b9u306bAWS Bedrocku3092u4ecbu3057u305fTwelveLabsu3092u3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306bNVIDIA NeMo Retrieveru3092u4f7fu7528u3057u3066u3001u6cd5u7684u8a3cu62e0u8abfu67fbu30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u3092u69cbu7bc9u3059u308bu65b9u6cd5u3092u5b9fu6f14u3057u307eu3059u3002u305du306eu7d50u679cu3001u8abfu67fbu54e1u306f12u500bu306eu30d3u30c7u30aau30bdu30fcu30b9u3092u81eau7136u8a00u8a9eu306eu30afu30a8u30eauff08u300cu8d64u3044u30bbu30c0u30f3u3092u898bu3064u3051u308bu300du307eu305fu306fu300cu4ebau7269u304cu5efau7269u306bu5165u3063u305fu306eu306fu3044u3064u304bu8868u793au3059u308buff09u3067u540cu6642u306bu691cu7d22u3067u304du3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu30e9u30f3u30adu30f3u30b0u7d50u679cu3092u5f97u3066u3001u6570u65e5u3067u306fu306au304fu6570u5206u3067u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u4f5cu6210u3067u304du308bu3088u3046u306bu306au308au307eu3059u3002
u69cbu7bc9u3059u308bu3082u306e: u6df7u5728u3059u308bu30d5u30a9u30fcu30deu30c3u30c8u306eu76e3u8996u6620u50cfu3092u53d6u308au8fbcu307fu3001u30bdu30fcu30b9u9593u306eu30bbu30deu30f3u30c6u30a3u30c3u30afu691cu7d22u3092u53efu80fdu306bu3057u3001u81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u884cu3044u3001u7570u306au308bu30d3u30c7u30aau30bdu30fcu30b9u304bu3089u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3u3092u518du69cbu6210u3059u308bu3001u30deu30ebu30c1u30bdu30fcu30b9u53f8u6cd5u8a3cu62e0u8abfu67fbu30c4u30fcu30ebu3092u69cbu7bc9u3057u307eu3059u3002
u5218u52b9u6642u9593: 40u6642u9593u306eu8a3cu62e0u30ecu30d3u30e5u30fcu304cu3001u7279u5b9au306eu8abfu67fbu3092u884cu30464u6642u9593u306eu4f5cu696du306bu77edu7e2eu3055u308cu307eu305su3002
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306eu30c7u30e2u306fu3053u3061u3089u304bu3089u4f53u9a13u3067u304du307eu3059: u6cd5u7684u8a3cu62e0u8abfu67fbu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
u30bdu30fcu30b9u30b3u30fcu30c9u306fu3053u3061u3089u304bu3089u78bau8a8du3067u304du307eu3059: GitHub u30eau30ddu30b8u30c8u30ea
u30c7u30e2u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3
u3053u306eu30c7u30e2u3067u306fu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u304cu8907u6570u306eu30d3u30c7u30aau30bdu30fcu30b9u3092u691cu7d22u3057u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3067u1e1au754cu306au77acu9593u3092u7279u5b9au3057u3001u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3092u751fu6210u3057u3001u3055u3089u306bu6df1u3044u8abfu67fbu306eu305fu3081u306eu5bfeu8a71u578bQ&Au30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u3092u63d0u4f9bu3059u308bu306au3069u3001u5b9fu969bu306eu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu3092u3069u306eu3088u3046u306bu51e6u7406u3059u308bu304bu3092u793au3057u3066u3044u307eu305su3002
u5b9fu6f14u3055u308cu305fu4e3bu306au6a5fu80fd:
12u4ee5u4e0au306eu7570u306au308bu30d3u30c7u30aau30d5u30a9u30fcu30deu30c3u30c8u306bu308fu305fu308bu30bdu30fcu30b9u9593u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u8ffdu8de1uff08u3059u3079u3066u306eu30bdu30fcu30b9u304bu308fu7279u5b9au306eu4ebau7269/u8ecau4e21u3092u691cu7d22uff09
u30eau30b9u30afu30abu30c6u30b4u30eau5206u3051u306bu3088u308bu81eau52d5u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790
u6642u7cfbu5217u306eu8a3cu62e0u3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210
u30afu30eau30c3u30afu53efu80fdu306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u5f15u7528u3092u542bu3080u5bfeu8a71u578bu30d3u30c7u30aaQ&A
u30b7u30b9u30c6u30e0u30a2u30fcu30adu30c6u30afu30c1u30e3: u306au305cu30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30fbu30deu30ebu30c1u30bdu30fcu30b9u8a2du8a08u304cu91cdu8981u306au306eu304b
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306bu304au3051u308bu4e3bu8981u306au30a2u30fcu30adu30c6u30afu30c1u30e3u306eu6c7au5b9au306fu3001u81eau7136u306au5236u7d04u306bu5bfeu51e6u3059u308bu306eu306bu5f79u7acbu3061u307eu3059u3002TwelveLabs u691cu7d22u306fu30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu3067u4f5cu7528u3057u307eu3059u3002u30eau30afu30a8u30b9u30c8u3054u3068u306b1u3064u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u691cu7d22u3059u308bu3053u3068u306bu306au308au3001u500bu5225u306eu30d3u30c7u30aau3092u691cu7d22u3059u308bu3082u306eu3067u306fu3042u308au307eu305bu3093u3002u3053u308cu304cu3059u3079u3066u3092u5f62u4f5cu308au307eu305su3002
単純なアプローチでは、ビデオソースごとに1つのインデックスを作成します。これはすぐに破綻します。12台のカメラから人物を見つけるには12回の個別の検索要求が必要になり、その後アプリケーションロジックで手動で結果を結合してソートしなければなりません。遅く、複雑で、壊れやすいです。
正しいアプローチは、シングルインデックス・マルチソース戦略を使用することです。すべての証拠ビデオは、豊富なメタデータタグによって区別され、1つのTwelveLabsインデックスに格納されます。1つの検索クエリで、すべてのソースを同時に検索します。結果は、関連性によって事前にランク付けされ、ソースビデオごとにグループ化されて返されます。必要に応じて、メタデータフィルター("ボディカム映像のみ"や"メインストリートの場所の映像のみ"など)を使用して範囲を絞り込んだ検索が可能です。
システムコンポーネント:
ビデオ取り込みパイプライン: 混合フォーマットの映像をS3にアップロード → Bedrock経由で
twelvelabs.marengo-embed-3-0-v1:0を使用してインデックス作成 → ソースメタデータとともにマルチモーダル埋め込みを保存ドキュメント取り込みパイプライン: PDFからテキストを抽出 → インテリジェントにチャンク化 →
nvidia/llama-nemotron-embed-vl-1b-v2経由で埋め込み → ドキュメントインデックスに保存ハイブリッド検索レイヤー: ビデオ埋め込み(Marengo)とドキュメントチャンク(NeMo)にわたる検索を並行して実行 → 結果をマージ → 統合された応答を返却
分析エンジン:
twelvelabs.pegasus-1-2-v1:0経由で、タイトル、リスクカテゴリ、検出されたオブジェクト、顔のタイムライン、文字起こしセグメントを含む構造化されたコンプライアンスレポートを生成対話型インターフェース: クリック可能なタイムスタンプの引用を含むビデオQ&A
u3053u306eu30a2u30fcu30adu30c6u30afu30c1u30e3u306fu3001u30d1u30d5u30a9u30fcu30deu30f3u30b9u3092u640du306au3046u3053u306eu306au304fu3001u30bdu30fcu30b9u9593u306eu691cu7d22u3092u5b9fu73feu3057u307eu3059u30021u56deu306eu30eau30afu30a8u30b9u30c8u306eu30ecu30a4u30c6u30f3u30b7u30fcu306fu300112u306eu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu30d3u30c7u30aau304cu3042u3063u305fu3068u3057u3066u30823u79d2u672au6e80u306bu7dadu6301u3055u308cu307eu3059u3002u30a4u30f3u30c7u30c3u30afu30b9u30ecu30d9u30ebu306eu691cu7d22u30d1u30bfu30fcu30f3u304cまさにこのシナリオに最適化されているためです。
u6e96u5099: u69cbu7bc9u306eu524du306bu5fc5u8981u306au3082u306e
1 - TwelveLabsu30e2u30c7u30ebu306eu305fu3081u306eAWS Bedrocku30a2u30afu30bbu30b9
u4ee5u4e0bu306eu6a29u9650u3092u6301u3064AWSu8a3bu8a3cu60c5u5831u3092u8a2du5b9au3057u307eu3059:
Amazon Bedrock u30e9u30f3u30bfu30a4u30e0u304au3088u3073u30e2u30c7u30ebu30a2u30afu30bbu30b9
u30d3u30c7u30aau4fddu5b58u304au3088u3073Bedrocku975eu540cu671fu51fau529bu306eu305fu3081u306eS3
Bedrocku3092u4ecbu3057u305fu4ee5u4e0bu306eTwelveLabsu30e2u30c7u30ebu3078u306eu30a2u30afu30bbu30b9:
twelvelabs.marengo-embed-3-0-v1:0uff08u30deu30ebu30c1u30e2u30fcu30c0u30ebu30d3u30c7u30aau57cbu3081u8fbcu307fuff09twelvelabs.pegasus-1-2-v1:0uff08u30d3u30c7u30aau5206u6790u3068u63a8u8ad6uff09
u306au305cu3053u308cu3089u306eu30e2u30c7u30ebu306au306eu304b: Marengou306fu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu691cu7d22u53efu80fdu306au8868u73feuff08u300cu30a8u30f3u30b3u30fcu30c0u30fcu300duff09u3092u751fu6210u3057u3001Pegasusu306fu63a8u8ad6u3068u69cbu9020u5316u3055u308cu305fu5206u6790uff08u300cu30a4u30f3u30bfu30fcu30d7u30eau30bfu30fcu300duff09u3092u884cu3044u307eu3059u3002u4e21u65b9u304cu5fc5u8981u3067u3059u3002Marengou304cu30d3u30c7u30aau3092u691cu7d22u53efu80fdu306bu3057u3001Pegasusu304cu305du308cu3092u7406u89e3u3057u3084u3059u304fu3057u307eu305su3002
2 - S3u30d0u30b1u30c3u30c8u306eu8a2du5b9a
u4ee5u4e0bu306eu3088u3046u306bu69cbu9020u5316u3055u308cu305fS3u30d0u30b1u30c3u30c8u30921u3064u4f5cu6210u3057u307eu3059:
u30d3u30c7u30aau306eu30a2u30c3u30d7u30edu30fcu30c9u3068u4fddu5b58
Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu51fau529bu5148uff08u30d0u30c3u30c1u30b8u30e7u30d6u306bu5fc5u9808uff09
u751fu6210u3055u308cu305fu30b5u30e0u30cdu30a4u30ebu3068u5206u6790u30a2u30fcu30c6u30a3u30d5u30a1u30afu30c8
u30c8u30cbu30e5u30e1u30f3u30c8u306eu4fddu5b58
u306au305cS3u30d2u30fcu30b9u306au306eu304b: Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fAPIu306fu3001S3u306eu5165u529b/u51fau529bu5834u6240u3092u5fc5u8981u3068u3057u307eu3059u3002u3053u308cu306bu3088u308au3001u30e1u30fcu30abu30ebu30c7u30a3u30b9u30afu306eu5236u9650u306bu9054u3059u308bu3053u306eu306au304fu3001u30b9u30b1u30fcu30e9u30d6u30ebu306au30b9u30c8u30ecu30fcu30b8u304cu53efu80fdu306bu306au308au307eu305su3002
3 - NVIDIA API u30adu30fc
u4ee5u4e0bu306bu30a2u30afu30bbu30b9u3059u308bu305fu3081u306e NVIDIA APIu30adu30fcu3092u53d6u5f97u3057u307eu3059:
u30c8u30cbu30e5u30e1u30f3u30c8u30c1u30e3u30f3u30afu57cbu3081u8fbcu307fu7528u306e
nvidia/llama-nemotron-embed-vl-1b-v2
u306au305cNeMo Retrieveru306au306eu304b: u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u3082u542bu307eu308cu307eu305su3002NeMou304cu30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u51e6u7406u3057u3001TwelveLabsu304cu30d3u30c7u30aau3092u51e6u7406u3059u308bu3053u306eu3067u3001u3059u3079u3066u306eu8a3cu62e0u30bfu30a4u30d7u306bu308fu305fu308bu30deu30ebu30c1u30e2u30fcu30c0u30ebu691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
4 - u30afu30edu30fcu30f3u3068u8a2du5b9a
git clone https://github.com/Hrishikesh332/tl-compliance-intelligence cd
.env.exampleu306bu5f93u3063u3066u30d0u30c3u30afu30a8u30f3u30c9u306eu74b0u5883u8a2du5b9au3092u884cu3044u307eu305s:
AWSu8a3bu8a3cu60c5u5831uff08u30a2u30afu30bbu30b9u30adu30fcIDu3001u30b7u30fcu30afu30ecu30c3u30c8u30a2u30afu30bbu30b9u30adu30fcu3001u30ecu30fcu30b8u30e7u30f3uff09
S3u30d0u30b1u30c3u30c8u540du3068Bedrocku306eu51fau529bu30d1u30b9
NVIDIA API u30adu30fc
u30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u56fau6709u306eu8a2du5b9auff08u30a4u30f3u30c7u30c3u30afu30b9u8a2du5b9au3001u4e00u81f4u3057u304du3044u5024uff09
u5b9fu88c5u306eu8a73u7d30
u30d1u30fcu30c8 1: u30d3u30c7u30aau306eu53d6u308au8fbcu307fu3068u57cbu3081u8fbcu307fu306eu751fu6210
u53d6u308au8fbcu307fu30d5u30a3u30ebu30bfu30fcu306fu3001u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu76e3u8996u6620u50cfu3092u691cu7d22u53efu80fdu306au30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu5909u63dbu3059u308bu3053u306eu3067u3059u3002Bedrocku306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306fu6642u9593u306eu9577u3044u30d3u30c7u30aau306eu5834u5408u306bu6570u5206u304bu304bu308bu3053u306eu306bu306au308bu305fu3081u3001u3053u308cu306fu975eu540cu671fu3067u884cu308fu305au306bu306fu3044u304du307eu305bu3093u3002
1.1 - Marengo u57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu958bu59cb
u30d3u30c7u30aau304fu30a2u30c3u30d7u30edu30fcu30c9u3055u308cu308bu3068u3001u30b7u30b9u30c6u30e0u306fu3059u3050u306bu305du308cu3092S3u306bu4fddu5b58u3057u3001Bedrocku306eu975eu540cu671fu57cbu3081u8fbcu307fu30b8u30e7u30d6u3092u958bu59cbu3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/services/bedrock_marengo.py (Line 111)
def start_video_embedding( s3_uri: str, output_s3_uri: str, bucket_owner: str | None = None, ) -> dict: client = get_bedrock_client() owner = bucket_owner body = { "inputType": "video", "video": { "mediaSource": media_source_s3(s3_uri, owner), "embeddingOption": ["visual", "audio"], "embeddingScope": ["clip", "asset"], }, } resp = client.start_async_invoke( modelId=MARENGO_MODEL_ID, modelInput=body, outputDataConfig={"s3OutputDataConfig": {"s3Uri": output_s3_uri}}, ) return { "invocation_arn": resp.get("invocationArn", ""), "status": "pending", }
embeddingScope: ["clip", "asset"] u304cu306au305cu91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u4ee5u4e0bu306e 2 u3064u306eu30ecu30d3u30ebu3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu307eu3059:
u30afu30eau30c3u30d7u57cbu3081u8fbcu307fuff086u79d2u30bbu30b0u30e1u30f3u30c8uff09: u7d30u304bu3044u691cu7d22u3092u53efu80fdu306bu3059u308b -> u4ebau7269u304cu767bu5834u3059u308bu3001u6b63u76bau306a8u79d2u306eu30bfu30a4u30e0u30ecu30f3u30b8u3092u898bu3064u3051u308b
u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fuff08u30d3u30c7u30aau5168u4f53uff09: u30d3u30c7u30aau30ecu30d9u30ebu306eu985eu4f3cu6027u3068u30b0u30ebu30fcu30d7u5316u3092u53efu80fdu306bu3059u308b
u4e21u65b9u304cu5fc5u8981u3067u3059u3002u30afu30eau30c3u30d7u57cbu3081u8fbcu307fu306fu6b63u76bau306au6642u9593u7684u306au691cu7d22u3092u529bu3065u3051u3001u30a2u30bbu30c3u30c8u57cbu3081u8fbcu307fu306fu300cu3053u306eu30d3u30c7u30aau306bu985eu4f3cu3059u308bu30d3u30c7u30aau3092u691cu7d22u3059u308bu300eu30efu30fcu30afu30d5u30edu30fcu3092u53efu80fdu306bu3057u307eu305su3002
u306au305cu975eu540cu671fu51e6u7406u304cu5fc5u8981u306au306eu304b: 2u6642u9593u306eu30d3u30c7u30aau306f1200u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059uff082u6642u9593 u00f7 u30afu30eau30c3u30d7u3042u305fu308a6u79d2uff09u3002u3053u308eu306bu306fu6642u9593u304cu304bu304bu308au307eu305su3002u975eu540cu671fu51e6u7406u306bu3088u308au3001u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u3067u57cbu3081u8fbcu307fu304cu751fu6210u3055u308cu3066u3044u308bu9593u3082u3001u30e6u30fcu30b6u30fcu306fUIu3092u906eu65adu3055u308cu308bu3053u306eu306au304fu8907u6570u306eu30d3u30c7u30aau3092u540cu6642u306bu30a2u30c3u30d7u30edu30fcu30c9u3067u304du307eu305su3002
1.2 - u30d0u30c3u30afu30b0u30e9u30a6u30f3u30c9u30b8u30e7u30d6u30adu30e5u30fcu3068u5b8cu4e86u30ddu30fcu30eau30f3u30b0
u30b7u30b9u30c6u30e0u306fu3001u4fddu7559u4e2du306eu57cbu3081u8fbcu307fu30b8u30e7u30d6u306eu30a4u30f3u30e1u30e2u30eau30adu30e5u30fcu3092u7dadu6301u305fu3001u5b8cu4e86u3057u305fu304bu3069u3046u304bBedrocku3092u30ddu30fcu30eau30f3u30b0u3057u307eu305bu3093:
u30bdu30fcu30b9: backend/app/utils/video_helpers.py (Line 104)
while True: job = bedrock_queue.get() task_id = job["task_id"] s3_uri = job["s3_uri"] output_uri = job["output_uri"] filename = job["filename"] meta = job["meta"] log.info("[QUEUE] Processing Bedrock start for %s (%s)", filename, task_id) success = False for attempt in range(1, max_retries + 1): try: result = start_video_embedding(s3_uri, output_uri) arn = result.get("invocation_arn", "") log.info("[QUEUE] Bedrock started for task_id=%s", task_id) video_tasks[task_id]["status"] = "indexing" video_tasks[task_id]["invocation_arn"] = arn video_tasks[task_id]["output_s3_uri"] = output_uri for rec in vs_index(): if rec.get("id") == task_id: rec.setdefault("metadata", {})["status"] = "indexing" break vs_save() with bedrock_poller_lock: bedrock_poller_jobs.append({ "task_id": task_id, "invocation_arn": arn, "output_s3_uri": output_uri, "started_at": time.monotonic(), }) success = True break
u3053u308cu306bu3088u308au9054u6210u3055u308cu308bu3053u306e: u30adu30e5u30fcu30d7u30edu30bbu30c3u30b5u30fcu306fu3001u30bfu30b3u30fcu30b9u30c8u30aau30fcu30c9u3092u300cu4fddu7559u4e2du300du304bu3089u300cu30a4u30f3u30c7u30c3u30afu30b9u4f5cu6210u4e2du300du306bu66f4u65b0u3057u3001u8ffdu8de1u7528u306bBedrocku306eu547cu3073u51fau3057ARNu3092u4fddu5b58u3057u3066u3001u5225u306eu30ddu30fcu30eau30f3u30b0u30b9u30ecu30c3u30c9u306bu5f15u304du6e21u3057u307eu3059u3002u305du306eu30ddu30fcu30e9u30fcu306f30u79d2u3054u3068u306bu30b8u30e7u30d6u306eu5b8cu4e86u3092u78bau8a8du3057u3001u5b8cu4e86u3057u305fu57cbu3081u8fbcu307fu3092S3u304bu3089u30edu30fcu30c9u3057u3066u3001u51e6u7406u304fu5b8cu4e86u3059u308bu3068u30d3u30c7u30aau3092u300cu6e96u5099u5b8cu4e86u300du306eu30d5u30e9u30b0u3092u7acbu3066u307eu305su3002
u306au305cu30eau30c8u30e9u30a4u30e5u30b8u30c3u30afu304fu91cdu8981u306au306eu304b: Bedrocku306bu306fu30ecu30fcu30c8u5236u9650u304cu3042u308fu308au307eu305su3002u6307u6570u95a2u6570u7684u30d0u30c3u30afu30aau30d5u3092u542bu3080u30eau30c3u30e1u30c3u30d7u30e1u30abu30cbu30bau30e0u306fu3001u5927u91cfu306eu30a2u30c3u30d7u30edu30fcu30c9u4e2du3067u3082u30b8u30e7u30d6u304cu6700u7d42u306bu6210u529fu3059u308bu3053u306eu3092u4fddu8a3cu3057u3001u30d3u30c7u30aau304cu6c38u4e45u306bu300cu4fddu7559u4e2du300du30b9u30c6u30fcu30c8u306bu6b8bu308bu30b5u30a4u30ecu30f3u30c8u30a8u30e9u30fcu3092u9632u304eu307eu305su3002
u30c7u30b6u30a4u30f3u30d1u30bfu30fcu30f3: u30d3u30c7u30aau3068u30a8u30f3u30c6u30a3u30c6u30a3u306fu540cu3058u30d9u30afu30c8u30ebu30a4u30f3u30c7u30c3u30afu30b9u3092u5171u6709u3057u3001u30bfu30a4u30d7u30e1u30bfu30c7u30fcu30bfu306du3088u3063u3066u533au5225u3055u308cu307eu305su3002u30c8u30cbu30e5u30e1u30f3u30c8u306fu3001u500bu5225u306eu30c1u30e3u30f3u30afu30d2u30fcu30b9u306eu30a4u30f3u30c7u30c3u30afu30b9u3092u4f7fu7528u3057u307eu305su3002u3053u308cu306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u3092u72ecu7acbu3055u305bu305fu307eu307eu3001u7d71u5408u3055u308cu305fu30d3u30c7u30aa+u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u304cu53efu80fdu306bu306au308au307eu305su3002
1.3 - u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu5316u306bu3088u308bu30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au8fbcu307f
u30c8u30cbu30e5u30e1u30f3u30c8u306fu30d3u30c7u30aau3068u306fu7570u306au308bu51e6u7406u304cu5fc5u8981u3067u3059u3002PDFu306fu62bdu51fau3055u308cu3001uff08u53efu80fdu306au3089u30bbu30afu30b7u30e7u30f3u3054u3068u306buff09u30bbu30deu30f3u30c6u30a3u30c3u30afu30c1u30e3u30f3u30afu306bu5206u5272u3055u308cu3001NeMou3092u4ecbu3057u305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u3066u3001u691cu7d22u53efu80fdu306au30ecu30b3u30fcu30c2u3068u3057u3066u4fddu5b58u3055u308cu307eu305s:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 688)
def ingest_document(file_path: str, doc_id: str, filename: str) -> dict: extra: dict = {} try: pdf_info = store_pdf_document(file_path, doc_id) extra.update(pdf_info) except Exception as exc: log.warning("Could not persist PDF for %s (%s)", doc_id, type(exc).__name__) ext = os.path.splitext(file_path)[1].lower() chunks: list[str] = [] sections: list[str] = [] if ext == ".pdf": try: pairs = split_into_semantic_chunks(file_path) sections = [s for s, _ in pairs] chunks = [t for _, t in pairs] log.info("Smart PDF chunking produced %d chunks for doc %s", len(chunks), doc_id) except Exception as exc: log.warning("Smart PDF extraction failed for doc %s, falling back to NeMo (%s)", doc_id, type(exc).__name__) if not chunks: chunks = extract_document(file_path) if not chunks: log.warning("No content extracted for doc %s", doc_id) return {"doc_id": doc_id, "chunks": 0, "status": "empty"} embeddings = embed_texts(chunks) add_chunks( doc_id, filename, chunks, embeddings, sections=sections or None, extra_metadata=extra or None, ) return {"doc_id": doc_id, "chunks": len(chunks), "status": "ready"}
u30b9u30deu30fcu30c8u30c1u30e3u30f3u30afu5316u30b9u30c8u30e9u30c6u30b8u30fc: u30b7u30b9u30c6u30e0u306fu307eu305au30bbu30afu30b7u30e7u30f3u30d2u30fcu30b9u306eu5206u5272uff08u30c8u30cbu30e5u30e1u30f3u30c8u69cbu9020u3092u7dadu6301uff09u3092u8a66u307fu3001u69cbu9020u691cu51fau306bu5931u6557u3057u305fu5834u5408u306fu30d1u30e9u30b0u30e9u30d5u30d2u30fcu30b9u306eu30c1u30e3u30f3u30afu5316u3092u884cu3044u307eu305su3002u3053u308cu306fu3001u30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcuff08u300cu4e8bu6545u30bfu30a4u30e0u30e9u30a4u30f3u300du3001u300cu76eeu6483u8005u306eu4subu8ff0u300du306au3069uff09u304cu91cdu8981u306au691cu7d22u30b3u30f3u30c6u30adu30b9u30c8u3092u63d0u4f9bu3059u308bu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u91cdu8981u3067u3059u3002
u57cbu3081u8fbcu307fu30e2u30c7u30ebu306eu9078u629e: nvidia/llama-nemotron-embed-vl-1b-v2 u306fu3001u30d1u30bbu30fcu30b8u691cu7d22u306bu6700u9069u5316u3055u308cu305fu57cbu3081u8fbcu307fu3092u751fu6210u3057u307eu3059u3002u30c1u30e3u30f3u30afu3054u3068u306bu72ecu7acbu3057u305fu30d9u30afu30c8u30ebu304cu4e0eu3048u3089u308cu3063u3053u3068u306bu3088u308au3001u30c8u30cbu30e5u30e1u30f3u30c8u5168u4f53u306eu4e00u81f4u3092u6c42u3081u308bu3053u306eu306au304fu3001u30d1u30e9u30b0u30e9u30d5u30ecu30d9u30ebu3067u306eu6b63u76bau306au30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002
u30e1u30bfu30c7u30fcu30bfu306eu4fddu5b58: u30b7u30b9u30c6u30e0u306fu30aau30eau30b8u30cau30ebu306eu30bbu30afu30b7u30e7u30f3u30d8u30c3u30c0u30fcu3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu30eau30f3u30afu3092u30c1u30e3u30f3u30afu306eu30c6u30adu30b9u30c8u3068u4e00u7dd2u306bu4fddu5b58u3059u308bu3053u306eu3067u3001u691cu7d22u7d50u679cu304bu3089u8abfu67fbu54e1u304cu30a2u30afu30bbu30bbu30b9u3057u305fu30aau30eau30b8u30cau30ebPDFu306eu30d1u30e9u30b0u30e9u30d5u3092u7d39u4ecbu3067u304du308bu3088u3046u306bu3057u307eu305su3002
NVIDIA API u3092u4ecbu3057u305fu57cbu3081u8fbcu307fu306eu751fu6210:
u30bdu30fcu30b9: backend/app/services/nemo_retriever.py (Line 515)
def embed_via_requests(texts: list[str], input_type: str) -> list[list[float]]: """Call NVIDIA embeddings API directly with requests""" import requests t0 = time.perf_counter() resp = requests.post( "https://integrate.api.nvidia.com/v1/embeddings", headers={ "Authorization": f"Bearer {NVIDIA_API_KEY}", "Content-Type": "application/json", }, json={ "input": texts, "model": EMBED_MODEL, "encoding_format": "float", "input_type": input_type, }, timeout=60, ) resp.raise_for_status() data = resp.json() vectors = [d["embedding"] for d in data["data"]] first_dim = len(vectors[0]) if vectors else 0 return vectors
input_type u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001u30d1u30bbu30fcu30b8u691cu7d22uff08u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu3066u3044u308bu30c8u30cbu30e5u30e1u30f3u30c8u306eu30c1u30e3u30f3u30afu305fu3061uff09u3068u30afu30a8u30eauff08u691cu7d22u30eau30afu30a8u30b9u30c8uff09u3092u5206u3051u308bu3053u306eu3067u3059u3002u3053u308cu306bu3088u308au3001u57cbu3081u8fbcu307fu304cu305du306eu76eeu7684u306bu5408u308fu305bu3066u6700u9069u5316u3055u308cu308bu3053u3068u306bu306au308au3001u691cu7d22u7cbeu5ea6u304cu5411u4e0au3057u307eu305suff1au30d1u30bbu30fcu30b8u306fu4fddu5b58u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu3001u30afu30a8u30eau306fu30deu30c3u30c1u30f3u30b0u306eu305fu3081u306bu57cbu3081u8fbcu307eu308cu307eu305su3002
1.4 - u9854u753bu50cfu304bu308fu691cu7d22u53efu80fdu306au30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u306eu4f5cu6210
u53f8u6cd5u8abfu67fbu3067u306fu3001u8907u6570u306eu30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu500bu4ebau3092u8ffdu8de1u3059u308bu3053u306eu304cu3057u3070u3057u3070u6c42u3081u3089u308cu307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30b7u30b9u30c6u30e0u306fu3001u9854u753bu50cfu3092u691cu7d22u3059u308bu305fu3081u306eu57cbu3081u8fbcu307fu306eu751fu6210u3092u53efu80fdu306bu3057u307eu305su3002
u753bu50cfu57cbu3081u8fbcu307fu306eu751fu6210:
def embed_image(media_source: dict) -> list[float]: return invoke_embedding_model({ "inputType": "image", "image": {"mediaSource": media_source}, })
u3053u308cu306fMarengou306eu753bu50cfu57cbu3081u8fbcu307fu6a5fu80fdu3092u4f7fu7528u3057u3001u9854u306eu8996u899au7684u306au7279u5fb4u3092u751fu6210u3057u307eu305su3002u30c6u30adu30b9u30c8u57cbu3081u8fbcu307fu3068u306fu7570u306au308au3001u753bu50cfu57cbu3081u8fbcu307fu306fu8996u899au7684u306au7279u5fb4uff08u9854u306eu69cbu9020u3001u5bb9u59ffu3001u8863u985euff09u3092u30c0u30a4u30ecu30afu30c8u306bu6349u3048u308bu3053u306eu3067u3001u30d3u30c7u30aau30d5u30ecu30fcu30e0u9593u3067u306eu8996u899au7684u306au30deu30c3u30c1u30f3u30b0u306bu9069u3057u3066u3044u307eu305su3002
u30a2u30c3u30d7u30edu30fcu30c9u3055u308cu305fu9854u753bu50cfu304bu308fu306eu30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210:
@entities_bp.route("/entities/from-image", methods=["POST"]) def api_entities_from_image(): if "image" not in request.files: return jsonify({"error": "No 'image' file provided"}), 400 file = request.files["image"] if file.filename == "": return jsonify({"error": "Empty filename"}), 400 data = request.form or {} name = data.get("name") or (request.get_json(silent=True) or {}).get("name") or "" if not name.strip(): return jsonify({"error": "Missing 'name'"}), 400 image_bytes = file.read() faces = detect_and_crop_faces(image_bytes, min_confidence=ENTITY_FACE_MIN_CONFIDENCE) if not faces: return jsonify( {"error": "No face detected in image. Use a clear, front-facing photo with good lighting."} ), 404 best = faces[0] face_b64 = best["image_base64"] embed_b64 = best.get("embedding_crop_base64") or face_b64 import base64 face_bytes = base64.b64decode(embed_b64) media = media_source_base64(face_bytes) try: embedding = embed_image(media) except Exception: return jsonify({"error": "Internal server error"}), 500 entity_id = name.strip().lower().replace(" ", "-") rec = index_add( id=entity_id, embedding=embedding, metadata={"name": name.strip(), "face_snap_base64": face_b64}, type="entity", ) return jsonify( { "indexId": FIXED_INDEX_ID, "entity": {"id": rec["id"], "name": name.strip()}, "face_snap_base64": face_b64, } )
u9854u691cu51fau306eu30bfu30c3u30d7: u57cbu3081u8fbcu307fu306eu524du306bu3001OpenCVu306eResNet10 SSDu691cu51fau5668u3092u4f7fu7528u3057u3066u9854u3092u5b64u7acbu3055u305bu307eu305su3002u3053u306eu524du51ceu7406u306bu3088u308au3001Marengou306fu30b7u30fcu30f3u5168u4f53u3067u306fu306eu306au304fu3001u30afu30eau30fcu30f3u306bu5207u308au53d6u3089u308cu305fu9854u3092u53d7u3051u53d6u308bu3053u306eu306bu306au308au3001u691cu7d22u6642u306eu30deu30c3u30c1u7cbeu5ea6u304fu5411u4e0au3057u307eu305su3002u691cu51fau5668u306fu4fe1u983cu30b9u30b3u30a2u3092u8fd4u3057u3001u6700u5c0fu3057u304du3044u5024u3092u8d85u3048u308bu9854u306eu307fu304cu51e6u7406u3055u308cu307eu305su3002
u306au305cu30a8u30f3u30c6u30a3u30c6u30a3u30ecu30b3u30fcu30c2u304cu30d3u30c7u30aau30a4u30f3u30c6u30c3u30afu30b9u306bu5b58u5728u3059u308bu306eu304f: u30d3u30c7u30aaEmbeddingsu3068u4e00u7dd2u306bu30a8u30f3u30c6u30a3u30c6u30a3Embeddingsu3092u4fddu5b58u3059u308bu3053u306eu306bu3088u308au3001u30c0u30a4u30ecu30afu30c8u306bu985eu4f3cu6027u691cu7d22u304fu53efu80fdu306bu306au308au307eu305su3002u8abfu67fbu54e1u304cu300cu8208u5473u306eu3042u308bu4ebau7269-xu300du3092u691cu7d22u3059u308bu3068u3001u30b7u30b9u30c6u30e0u306f1u2e0eu306eu691cu7d22u64cdu4f5cu3067u305du306eu30a8u30f3u30c6u30a3u30c6u30a3u306e Embeddings u3068u3001u3059u3079u3066u306eu30d3u30c7u30aau30bbu30b0u30e1u30f3u30c8u306e Embeddings u3092u6bd4u8f03u3057u307eu305su3002
u30d1u30fcu30c8 2: u30bdu30fcu30b9u9593u691cu7d22u3068u53d6u308au51fau3057
u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u304bu30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu308bu3068u3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3059u3079u3066u306eu30bdu30fcu30b9u306bu308fu305fu308bu7d71u5408u3055u308cu305fu691cu7d22u3092u53efu80fdu306bu3057u307eu305su3002u3053u3053u3067u30b1u30a4u30ba-u30a4u30f3u30c7u30c3u30afu30b9u30a2u30fcu30adu30c6u30afu30c1u30e3u304cu305du306eu4fa1u5024u3092u767au63eeu3057u307eu305suff1a1u3064u306eu30afu30a8u30eau3001u3059u3079u3066u306eu30bdu30fcu30b9u3001u30e9u30f3u30adu30f3u30b0u3055u308cu305fu7d50u679cu3002
2.1 - u30deu30ebu30c1u30e2u30fcu30c0u30ebu57cbu3081u8fbcu307fu306bu3088u308bu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u691cu7d22
u691cu7d22u30d5u30a3u30ebu30bfu30fcu306fu30011u3064u306eu30a4u30f3u30bfu30fcu30d5u30a7u30fcu30b9u304bu30893u3064u306eu30afu30a8u30eau30bfu30a4u30d7u3092u30b5u30ddu30fcu30c8u3057u307eu305s:
u30c6u30adu30b9u30c8u30afu30a8u30ea: u81eau7136u8a00u8a9eu306eu8aacu660euff08u300cu8d64u3044u30b8u30e3u30b1u30c3u30c8u3092u7740u305fu4ebau7269u300duff09
u753bu50cfu30afu30a8u30ea: u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u30a2u30c3u30d7u30edu30fcu30c9u3057u3001u4e00u81f4u3059u308bu6620u50cfu3092u691cu7d22
u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30ea: u4e8bu524du306bu767bu9332u3055u308cu305fu4ebau7269/u7269u4ef6u3092u691cu7d22
u30bdu30fcu30b9: backend/app/routes/search.py (Line 30)
def search_video_index( data: dict, *, request_query: str = "", request_top_k: int | None = None, image_bytes: bytes | None = None, ) -> tuple[list[dict], str, str | None]: query_emb, display_query, is_entity_search, err = get_search_embedding_from_request( data, request_query=request_query, image_bytes=image_bytes, )
u5165u529bu306eu6b19u6e96u5316: get_search_embedding_from_request() u306fu3059u3079u3066u306eu30afu30a8u30eau30bfu30a4u30d7u3092u51e6u7406u3057u3001u5358u4e00u306eu57cbu3081u8fbcu307fu30d9u30afu30c8u30ebu3092u8fd4u3057u307eu305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fMarengou306eu30c6u30adu30b9u30c8u30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u753bu50cfu30afu30a8u30eau306fu753bu50cfu30a8u30f3u30b3u30fcu30c4u30fcu3092u4ecbu3057u3066Embedu3055u308cu3001u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu4fddu5b58u3055u308cu305fEmbeddingsu3092u30c0u30a4u30ecu30afu30c8u306bu53d6u5f97u3057u307eu305su3002u4e0bu6d41u306eu691cu7d22u30e5u30b8u30c3u30afu306fu5165u529bu30bfu30a4u30d7u3092u6c17u306bu305bu305au3001u5358u306bu4e00u81f4u3059u308bu30d9u30afu30c8u30ebu3092u898bu3064u3051u308bu3060u3051u3067u305su3002
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306eu6700u9069u5316:
for r in results: meta = r.get("metadata", {}) clips = [] output_uri = meta.get("output_s3_uri") or f"{S3_EMBEDDINGS_OUTPUT}/{r['id']}" if is_entity_search: clips = clips_above_threshold( query_emb, output_uri, min_score=ENTITY_CLIP_MIN_SCORE, visual_only=True, max_clips=clips_per_video, ) if not clips: clips = clip_search( query_emb, output_uri, top_n=clips_per_video, min_score=clip_min_score, visual_only=is_entity_search, )
u30b9u30b3u30a2u30eau30f3u30b0u306eu9055u3044: u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306f visual_only=True u3068u9ad8u3044u4e00u81f4u3057u304du3044u5024u3092u4f7fu7528u3057u307eu305su3002u9854u306eu30deu30c3u30c1u30f3u30b0u306fu3001u4e00u822cu7684u306eu30b3u30f3u30c6u30f3u30c4u691cu7d22u3088u308au3082u5f37u3044u8996u899au7684u306au985eu4f3cu6027u3092u5fc5u8981u3068u3059u308bu305fu3081u3067u305su3002u30c6u30adu30b9u30c8u30afu30a8u30eau306fu3001u97f3u58f0u306eu6587u5b57u8d77u3053u3057u307eu305fu306fu8996u899au7684u306au30b3u30f3u30c6u30f3u30c4uff08u3069u3061u3089u306eu30e2u30c0u30eau30c6u30a3u3067u3082uff09u3092u4ecbu3057u3066u4e00u81f4u3055u305bu308bu3053u306eu304cu3067u304du307eu305su3002u30a8u30f3u30c6u30a3u30c6u30a3u30afu30a8u30eau306fu8996u899au7684u306bu4e00u81f4u3057u306au3051u308cu307eu305bu3093u3002
u30afu30eau30c3u30d7u30ecu30d9u30ebu306eu6839u62e0u3065u3051:
out.append({ "id": r["id"], "score": r["score"], "metadata": meta, "clips": clips, }) return out, display_query, None
u7d50u679cu306fu5358u306bu3069u306eu30d3u30c7u30aau304cu4e00u81f4u3059u308bu304bu3060u3051u3067u306fu306au304fu3001u305du306eu30d3u30c7u30aau306eu3069u3053u3067u4e00u81f4u304cu8d77u3053u3063u305fu304bu3082u542bu307eu308cu307eu305su3002u300cu8ecau4e21u304bu308fu964du305du308au308bu4ebau7269u300du3092u691cu7d22u3059u308bu8abfu67fbu54e1u306fu3001u4ee5u4e0bu306eu3088u3046u306eu7d50u679cu3092u5f97u307eu305s:
u30d3u30c7u30aa: "Dashcam - Main St" u2192 u30afu30eau30c3u30d7: 00:03:42-00:03:48, 00:07:15-00:07:21
u30d3u30c7u30aa: "CCTV - Parking Lot" u2192 u30afu30eau30c3u30d7: 00:12:03-00:12:09
u3053u306eu30afu30eau30c3u30d7u30ecu30d9u30ebu306eu7cbeu5ea6u306fu3001u30d3u30c7u30aau691cu7d22u30b3u30f3u30c6u30f3u30c4u30efu30fcu30afu3067u3088u304fu3042u308bu300cu91ddu3092u63a2u3057u3066u3044u308bu306eu306bu3001u4ecdu7136u3068u3057u3066u5168u4f53u306eu30efu30e9u5c71u3092u53d7u3051u53d6u3063u3066u3057u307eu3046u300du3068u3044u3063u305fu554fu984cu3092u89e3u6c7au3057u307eu305su3002
2.2 - u30a8u30f3u30c6u30a3u30c6u30a3u3092u8a8du8b58u3059u308bu30d3u30c7u30aau691cu7d22: u30bdu30fcu30b9u3092u8d85u3048u3066u4ebau7269u3092u898bu3064u3051u308b
u30a8u30f3u30c6u30a3u30c6u30a3u691cu7d22u306fu3001u8abfu67fbu54e1u304fu591au304fu306eu95a2u9023u306eu306au3044u30abu30e1u30e9u30bdu30fcu30b9u304bu3089u7279u5b9au306eu4ebau7269u3092u8ffdu8de1u3059u308bu3053u306eu3092u53efu80fdu306bu3057u307eu305su3002u9854u753bu50cfu3092u30a2u30c3u30d7u30edu30fcu30c9u3059u308cu3070u3001u3059u3079u3066u306eu6620u50cfu3092u691cu7d22u3067u304bu307eu305s:
u305du306eu4f5cu7528u306eu4ed5u7d44u307f:
u30a8u30f3u30c6u30a3u30c6u30a3u306eu57cbu3081u8fbcu307fuff08u30a8u30f3u30c6u30a3u30c6u30a3u4f5cu6210u6642u306bu751fu6210uff09u304cu30a4u30f3u30c7u30c3u30afu30b9u304bu3089u30edu30fcu30c9u3055u308cu307eu305s
u30b7u30b9u30c6u30e0u306fS3 Bedrocku51fau529bu304bu3089u30a4u30f3u30c7u30c3u30afu30b9u5316u3055u308cu305fu5404u30d3u30c7u30aau306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u53d6u5f97u3057u307eu305s
u985eu4f3cu6027u30b9u30b3u30a2u30eau30f3u30b0u306bu3088u308au3001u30a8u30f3u30c6u30a3u30c6u30a3u304cu767bu5834u3059u308bu53efu80fdu6027u306eu9ad8u3044u30afu30eau30c3u30d7u3092u7279u5b9au3057u307eu305s
u30d3u30c7u30aau306fu30deu30c3u30c1u5f37u5ea6u3068u4e00u8cabu6027uff08u30deu30c3u30c1u3057u305fu30afu30eau30c3u30d7u306eu6570u3001u30b9u30b3u30a2u306eu5f37u3055uff09u306bu3088u3063u306eu30ecu30f3u30adu30f3u30b0u3055u308cu307eu305s
u306au305cu3053u308cu304cu5b9fu884cu6642u306eu9854u691cu51fau3088u308bu3082u901fu3044u306eu304b: Ingestionu6642u306bu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3092u4e8bu524du8a08u7b97u3059u308bu3053u306eu306fu3001u691cu7d22u6642u306b u9854u691cu51fau3067u306fu306au304fu3001u985eu4f3cu6027u6bd4u8f03u3060u3051u3092u884cu3046u3053u306eu3092u610fu5473u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u57cbu3081u8fbcu307fu3068u30a8u30f3u30c6u30a3u30c6u30a3u57cbu3081u8fbcu307fu306eu6bd4u8f03u306fu3001u30dfu30eau79d2u5358u4f4du3067u5b8cu4e86u3057u307eu305su300210,000u500bu306eu30afu30eau30c3u30d7u3067u9854u691cu51fau3092u5b9fu884cu3059u308bu3068u3001u6570u6642u9593u304bu304bu308au307eu305su3002
u30deu30c3u30c1u3057u304du3044u5024u306eu8abfu6574: u30b7u30b9u30c6u30e0u306f ENTITY_CLIP_MIN_SCORE u3092u4f7fu7528u3057u3066u5f31u3044u30deu30c3u30c1u3092u30d5u30a3u30ebu30bfu30eau30f3u30b0u3057u307eu305su3002u3053u308cu3092u4f4eu304fu8a2du5b9au3057u3059u304eu308bu3068u3001u507du967du6027uff08u4f3cu3066u3044u308bu5225u4ebauff09u304cu767au751fu3057u307eu305su3002u9ad8u304fu8a2du5b9au3057u3059u304eu308bu3068u3001u6709u52b9u306au30deu30c3u30c1uff08u7570u306au308bu5149u3084u89d2u5ea6u306eu540cu4e00u4ebau7269uff09u3092u30dfu30b9u3057u307eu305su3002u30c7u30e2u3067u306f0.75u3092u30d0u30e9u30f3u30b9u30ddu30a4u30f3u30c8u3068u3057u3066u4f7fu7528u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3u30b7u30b9u30c6u30e0u3067u306fu3012u30fcu30b6u30fcu304cu5909u66f4u3067u304du308bu3088u3046u306bu3059u308bu3079u304du3067u305su3002
2.3 - u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22: u30d3u30c7u30aa + u30c8u30cbu30e5u30e1u30f3u30c8u53d6u308au51fau3057
u6cd5u7684u8a3cu62e0u306fu30d3u30c7u30aau3060u3051u3067u306fu3042u308au307eu305bu3093u3002u8abfu67fbu54e1u306fu3001u8b66u5bdfu306eu5831u544au66f8u3001u76eeu6483u8005u306eu4subu8ff0u66f8u3001u4fddu967au7533u8acbu66f8u306au3069u3068u6620u50cfu3092u7167u5408u3059u308bu5fc5u8981u304cu3042u308fu308au307eu305su3002u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u4e26u884cu3057u3066u5b9fu884cu3057u307eu305s:
u30c8u30cbu30e5u30e1u30f3u30c8u691cu7d22u306eu5b9fu88c5:
def search_document_index(text_query: str, doc_top_k: int) -> list[dict]: from app.services.nemo_retriever import embed_query, search_docs t0 = time.perf_counter() log.info("[DOC_SEARCH] Started doc search top_k=%d", doc_top_k) query_emb = embed_query(text_query) docs = search_docs(query_emb, top_k=doc_top_k) return docs
u4e26u884cu5b9fu884cu30d1u30bfu30fcu30f3: u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306fu3001u30b9u30ecu30c3u30c7u30a3u30f3u30b0u3092u4f7fu7528u3057u3066u30d3u30c7u30aau3068u30c8u30cbu30e5u30e1u30f3u30c8u306eu691cu7d22u3092u540cu6642u306bu958bu59cbu3057u3001u4e21u65b9u304cu5b8cu4e86u3057u305fu3089u7d50u679cu3092u30deu30fcu30b8u3057u307eu305su3002u3053u308cu306bu3088u308au3001u5168u4f53u306eu30ecu30a3u30c6u30f3u30b7u30fcu306fu3001u305du308cu3089u306eu548cu3067u306fu306au304fu3001u5c11u3057u9045u3044u65b9u306eu691cu7d22u306eu6642u9593u306bu8fd1u3065u3051u3089u308cu307eu305su3002
u7d50u679cu306eu30deu30fcu30b8u306eu30b9u30c8u30e9u30c6u30b8u30fc: u30d3u30c7u30aau306eu7d50u679cu306eu30c8u30cbu30e5u30e1u30f3u30c8u306eu7d50u679cu306fu3001u30ecu30b9u30ddu30f3u30b9u3067u500bu5225u306bu7dadu6301u3055u308cu307eu305suff08u30b9u30b3u30a2u3067u5c0fu5206u3051u306bu3055u308cu306au3044uff09u3002u30a2u30d7u30edu30fcu30c1u306eu76eeu7684u304cu305du308cu305eu308cu7570u306au308bu305fu3081u3067u305su3002u30d3u30c7u30aau306fu8996u899au7684u306au8a3cu62e0u3092u63d0u4f9bu3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306fu88cfu4ed8u3051u308bu53e3u8ff0u3092u63d0u4f9bu3057u307eu305su3002u8abfu67fbu54e1u306fu305du308cu3089u3092u7570u306au308bu30ddu30a4u30f3u30c8u3067u30ecu30d3u30e5u30fcu3057u307eu305su3002
u30cfu30a4u30d6u30eau30c3u30c9u691cu7d22u306eu5168u3066 u306eu5b9fu88c5u3092u78bau8a8du3059u308bu306bu306f: u30bdu30fcu30b9u3092u8868u793a
u30d1u30fcu30c8 3: u69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u3068u30ecu30ddu30fcu30c8u4f5cu6210
u691cu7d22u306bu3088u308au8a3cu62e0u3092u898bu3064u3051u307eu305su3002u5206u6790u306bu3088u308au305du308cu3092u89e3u91c8u3057u307eu305su3002u3053u306eu30d3u30d7u30ecu30bcu30f3u30c6u30fcu30b7u30e7u30f3u306fu3001Rawu6620u50cfu304bu308fu69cbu9020u5316u3055u308cu305fu30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30ecu30ddu30fcu30c8u3092u751fu6210u3059u308bu305fu3081u306bu3001Bedrocku3092u4ecbu3057u306fPegasusu3092u4f7fu7528u3057u307eu305s:
3.1 - u69cbu9020u5316u3055u308cu305fu30d3u30c7u30aau5206u6790u306eu751fu6210
Pegasusu306fu975eu69cbu9020u5316u306eu30d3u30c7u30aau3092u3001u30eau30b9u30afu30afu30e9u30b9u3001u691cu51fau3055u308cu305fu4ebau7269u3001u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du306eu6587u5b57u8d77u3053u3057u3001u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u30eau30b9u30c8u306au3069u306eu69cbu9020u5316u3055u308cu305fu6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu5909u63dbu3057u307eu305su3002
u30bdu30fcu30b9: backend/app/services/bedrock_pegasus.py (Line 72)
body: dict = { "inputPrompt": prompt[:4000], "mediaSource": { "s3Location": { "uri": s3_uri, "bucketOwner": owner, } }, } if temperature is not None: body["temperature"] = temperature if response_schema is not None: body["responseFormat"] = {"jsonSchema": response_schema}
Temperatureu8a2du5b9a: u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u5206u6790u306b temperature: 0 u3092u4f7fu7528u3059u308bu3053u306eu306bu3088u3082u3001u6c7au5b9au8ad6u7684u3067u518du73feu53efu80fdu306eu51fau529bu304cu4fddu8a3cu3055u308cu307eu305su3002u540cu3058u30d3u30c7u30aau306fu5e38u306bu540cu3058u5206u6790u69cbu9020u3092u751fu6210u3057u3001u3053u308cu306fu4e00u8cabu6027u304fu91cdu8981u306au6cd5u7684u30c8u30cbu30e5u30e1u30f3u30c8u306bu3068u3063u3066u1e1au754cu3067u305su3002
u30ecu30b9u30ddu30f3u30b9u30b9u30adu30fcu30deu306eu5f37u5236: jsonSchema u30d1u30e9u30e1u30fcu30bfu30fcu306fu3001Pegasusu306bu5bfeu3057u3001u30d5u30eau30fcu30d5u30a9u30fcu30e0u306eu30c6u30adu30b9u30c8u3067u306fu306au304fu3001u69cbu9020u5316u3055u308cu305f JSON u3092u8fd4u3059u3088u3046u6307u793au3057u307eu305su3002u3053u308cu306fu30d1u30fcu30b9u53efu80fdu306au51fau529bu3092u4fddu8a3cu3057u3001u5f8cu51eceu7406u306eu8106u5f31u6027u3092u6392u9664u3057u307eu305su3002
Bedrock u30e2u30c7u30ebu306eu547cu307uu51fau3057:
response = client.invoke_model( modelId=model_id, body=payload, contentType="application/json", accept="application/json", )
u5fdcu7b54u306bu306fu3001Bedrock u306e JSON u5fdcu7b54u30d5u30a2u30fcu30deu30c3u30c8u304bu3089u62bdu51fau3055u308cu305fu3001u751fu6210u3055u308cu305fu30c6u30adu30b9u30c8u304fu542bu307eu308cu3063u3053u3068u306bu306au308au307eu305su3002u3053u306eu30c6u30adu30b9u30c8u306fu3001u63d0u4f9bu3055u308cu305fu30d7u30edu30f3u30d7u306eu6307u793au306bu57fau3065u304f Pegasus u306eu30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu89e3u91c8u3092u8868u3057u3066u3044u307eu305su3002
u5206u6790u30d7u30edu30f3u30d7u3068u30d1u30fcu30b9:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 335)
raw_text = pegasus_analyze_video( s3_uri, get_video_analysis_prompt(), temperature=0, ) log.info("[ANALYSIS] Pegasus response received in %.1fs (len=%d)", time.perf_counter() - t0, len(raw_text or "")) analysis_dict = parse_video_analysis_response(raw_text)
u5206u6790u30d7u30edu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu3092u6307u793au3057u307eu305s:
u30d3u30c7u30aau30b3u30f3u30c6u30f3u30c4u306eu5206u985euff08u4ea4u901au4e8bu6545u3001u8077u5834u306eu5b89u5168u3001u72afu7f6au6d3bu52d5u306au3069uff09
u30eau30b9u30afu30ecu30d9u30ebu3068u7279u5b9au306eu30eau30b9u30afu8981u56e0u306eu7279u5b9a
u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du6587u5b57u8d77u3053u3057u30bbu30b0u30e1u30f3u30c8u306eu62bdu51fa
u8aacu660eu4ed8u304du306eu8208u5473u306eu3042u308fu308bu4ebau7269u306eu691cu51fa
u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9u306bu7126u70b9u3092u5f53u3066u305fu8981u7d04u306eu751fu6210
u30d1u30fcu30b9u30b9u30c8u30e9u30c6u30b8u30fc: parse_video_analysis_response() u306fu3001u4e0du6b63u306au5f62u5f0fu306e JSON u3092u512au96c5u306bu51e6u7406u3057u307eu305suff083u91cdu306eu30d0u30c3u30afu30c3u30afu30e9u30eau30f3u30b0u3001u672bu5c3eu306eu30b3u30f3u30deu3001u4e0du5b8cu5168u306eu5fdcu7b54u306au3069u304bu3089u5fa9u5143uff09u3002LLM u306eu51fau529bu306fu5e38u306bu5b8cu74a2u306bu30d5u30cau30fcu30deu30c3u30c8u3055u308cu3066u3044u308bu3068u306fu9650u3089u306au3044u305fu3081u3067u305su3002u580坚u5b9fu306au30d1u30fcu30b9u306bu3088u3082u3001u8efdu5faeu306eu30d5u30a9u30fcu30deu30c3u30c8u306eu554fu984cu304bu3089u306eu5206u6790u306eu5931u6557u3092u9632u304eu307eu305su3002
u5b57u5e55u306eu751fu6210: u30b7u30b9u30c6u30e0u306fu3001u6587u5b57u8d77u3053u3057u306bu6700u9069u5316u3055u308cu305f Pegasus u306eu3001u5225u306eu547cu307uu51fau3057u3092u5b9fu884cu3057u3001u69cbu9020u3055u308cu305f JSON u3067u30bfu30a4u30e0u30b9u30bfu30f3u30d7u4ed8u304du30bbu30b0u30e1u30f3u30c8u3092u8981u6c42u3057u307eu305su3002u3053u308eu306bu3088u308au3001u958bu59cb/u7d42u4e86u6642u9593u3092u6301u3064u3001u6574u5217u3055u308cu305fu6587u5b57u8d77u3053u3057u30a8u30f3u30c8u30eau304cu751fu6210u3055u308eu3001u8abfu67fbu54e1u306fu8a71u3055u308cu305fu30b3u30f3u30c6u30f3u30c4u306bu76f4u63a5u30b8u30e3u30f3u30d7u3067u304du308bu3088u3046u306bu306au308au307eu305su3002
3.2 - u7269u4ef6u691cu51fau3068u9854u30adu30fcu30d5u30ecu30fcu30e0u306eu62bdu51fa
u57fau672cu7684u306au6587u5b57u8d77u3053u3057u306e u5148u306bu3001u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0u306fu3001u691cu51fau3055u308cu305fu7269u4ef6u3068u3001u6b63u76bau306au30bfu30a4u30e0u30b9u30bfu30f3u30d7u3092u6301u3064u4fbfu5229u306au9854u30adu30fcu30d5u30ecu30fcu30e0uff08u9854u304cu306fu3063u304du308au3068u733eu308fu308cu308bu7279u5b9au306eu77acu9593uff09u3092u7279u5b9au3057u307eu305s:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 707)
raw_response = pegasus_analyze_video(s3_uri, get_detect_prompt()) log.info("[INSIGHTS] Pegasus response received in %.1fs (%d chars)", time.perf_counter() - t0, len(raw_response or "")) detect_data = parse_detect_response(raw_response) objects_raw = detect_data["objects"] face_keyframes = detect_data["face_keyframes"]
u691cu51fau30d4u30f3u30ddu30f3u30d7uff08u30bdu30fcu30b9u3092u8868u793auff09u306fu3001Pegasus u306bu4ee5u4e0bu306eu7279u5b9au3092u6c42u3081u305eu3059:
u7269u4ef6: u8ecau4e21u3001u6b66u5668u3001u7269u7406u7684u306au8a3cu62e0u3001u74b0u5883u306eu8a73u7d30
u9854u30adu30fcu30d5u30ecu30fcu30e0: u500bu4ebau7279u5b9au306eu305fu3081u306bu5341u5206u306au660eu77adu3055u3092u6301u3064u9854u304fu733eu308fu308bu30bfu30a4u30e0u30b9u30bfu30f3u30d7
u306au305cu30adu30fcu30d5u30ecu30fcu30e0u304cu91cdu8981u306au306eu304b: u9854u304cu542bu307eu308cu308bu30d5u30ecu30fcu30e0u306eu3059u3079u3066u304cu6709u7528u3067u306fu3042u308au307eu305bu3093u3002u5f8cu308du59ffu3001u30ceu30a4u30ba u304cu3051u3063u305fu308au3001u6697u304fu306au3063u305fu308du3059u308bu9854u306fu3001u7279u5b9au306bu512au308cu307eu305bu3093u3002Pegasus u306fu3001u9854u304cu6b63u9762u3092u5411u304du3001u7167u660eu304cu3088u304fu3001u306fu3063u304eu308au3068u3057u3066u3044u308bu30adu30fcu30d5u30ecu30fcu30e0u3092u9078u629eu3057u307eu305su3002u3053u308cu306fu8abfu67fbu54e1u304cu5b9fu969bu306bu8a3cu62e0u3068u3057u3066u30b9u30afu30eau30fcu30f3u30b7u30e7u30c3u30c8u3092u3068u308bu30eau30a2u30eb u306au30d5u30ecu30fcu30e0 u3067u305su3002
u5f8cu51eceu7406: Pegasus u304cu30adu30fcu30d5u30ecu30fcu30e0u3068u7269u4ef6u3092u8fd4u3059u3068u3001u30b7u30b9u30c6u30e0u306fu305du308cu3089u306fu7279u5b9au306eu30d5u30ecu30fcu30e0u306eu307fu3092u62bdu51fau3057u3001u30b5u30e0u30cdu30a4u30ebu3092u751fu6210u3057u3001u3059u3070u3084u3044u30ecu30d3u30e5u30fcu306eu305fu3081u306bu4fddu5b58u3057u307eu305su3002u3053u308cu306bu3088u3082u3001u8abfu67fbu54e1u304cu9854u3092u898bu308bu305fu3073u306bu30d3u30c7u30aau3092u518du5ea6u51eceu7406u3059u308bu5fc5u8981u304cu306au304fu306au308au307eu305su3002
3.3 - u9854u306eu767bu5834u306eu30bfu30a4u30e0u30e9u30a4u30f3: u3053u306eu4ebau7269u306fu3069u3053u306bu733eu308fu308bu306eu304buff1f
u9854u3092u691cu51fau3057u305fu5f8cu3001u30b7u30b9u30c6u30e0u306fu3001u691cu51fau3055u308cu305f u5404u4ebau7269u304cu30d3u30c7u30aa u306eu4e2du3067u3044u3064u733eu308fu308cu308bu304bu3092u793au3059u30bfu30a4u30e0u30e9u30a4u30f3u3092u69cbu7bc9u3057u307eu305s:
u30bdu30fcu30b9: backend/app/routes/videos.py (Line 1027)
if use_marengo: # Marengo-based presence, match each face embedding to clip embeddings for j, emb in enumerate(face_embeddings): if not emb: continue clips = clips_above_threshold( emb, output_uri, min_score=FACE_PRESENCE_MATCH_THRESHOLD, visual_only=True, max_clips=50, ) for clip in clips: c_start = float(clip.get("start", 0.0)) c_end = float(clip.get("end", c_start + 0.5)) for i in range(n_segments): s0 = i * seg_dur s1 = (i + 1) * seg_dur if c_end > s0 and c_start < s1: presence_by_face[j]["segment_presence"][i] = 1
u30bfu30a4u30e0u30e9u30a4u30f3u304cu3069u306eu3088u3046u306bu69cbu7bc9u3055u308cu308bu304b:
u30d3u30c7u30aa u306fu56fau5b9au6642u9593 u306eu30bbu30b0u30e1u30f3u30c8 uff08u4f8bu3048u3070 30 u79d2 u30a6u30a3u30f3u30c3u30af u306au3069uff09u306bu5206u5272u3055u308cu307eu305s
u691cu51fau3055u308cu305fu5404u9854u306fu3001u305du306e Embeddings u3092u3059u3079u3066u306eu30afu30eau30c3u30d7 Embeddings u3068 u6bd4u8f03 u3055u308cu307eu305s
u305du306eu3057u304du3044u5024u3092u8d85u3048u308bu30b9u30b3u30a2 u306eu30afu30eau30c3u30d7u306f u300cu4ebau7269 u304cu5b58u5728u3059u308bu300du3068u30deu30fcu30afu3055u308cu307eu305s
u4e00u81f4u3057u305fu30afu30eau30c3u30d7u306fu3001u30bbu30b0u30e1u30f3u30c8u30bfu30a4u30e0u30e9u30a4u30f3u306bu30deu30c3u30d7u3055u308cu307eu305s
u7d50u679c: u5404u4ebau7269u304cu3069u306eu30bbu30b0u30e1u30f3u30c8 u306bu542bu307eu308cu3063u3053u3068 u3092u793au3059 Binary Presence Map u304cu8868u793au3055u308cu307eu305s
u306au305cu3053u308cu304cu8abfu67fbu306bu3068u3065u3066 u91cdu8981u306au306eu304b: u3053u308cu306bu3088u308au3001u8abfu67fbu54e1u306fu4e00u77bcu3067u300cu4ebau7269 A u306fu3001u30bbu30b0u30e1u30f3u30c8 3u30017u300112u300118u306bu733eu308fu308cu308bu300du3053u306eu304cu30d3u30c7u30aau5168u4f53u3092u898bu305au306bu7406u89e3u3067u304du307eu305su3002u30bbu30b0u30e1u30f3u30c8 7 u3092u30afu30eau30c3u30afu3057u3001u305du306e 30 u79d2 u30a6u30a3u30f3u30c3u30af u306bu76f4u63a5u30b8u30e3u30f3u30d7u3057u3001u8996u899au7684u306au4e00u81f4u3092u78bau8a8du3067u304du307eu305su3002
u3057u304du3044u5024u306eu30c8u30ecu30fcu30c9u30aau30d5: FACE_PRESENCE_MATCH_THRESHOLD u306fu611fu5ea6u3092u30b3u30f3u30c8u30edu30fcu30eb u3057u307eu305su3002u5c0fu3055u304fu3059u308bu3053u306e u306bu3088u308b u507du967du6027 u306e u6e1bu5c11 u3001u7570u306au308bu89d2u5ea6u3001u7167u660eu5909u5316u306e u30deu30c3u30c1u30dfu30b9 u306e u53efu80fdu6027 u306eu4e0au6647 u3002u9ad8u304fu3059u308b u3053u306e u306bu3088u308b u7279u5b9a u306e u50cf u306e u898bu9003u3057 u3001u507du30deu30c3u30c1 u306e u5897u52a0 u306bu3088u308b u624bu52d5u30ecu30d3u30e5u30fc u306e u5897u591a u3002u30c7u30e2 u3067u306f 0.70 u3092 u4f7fu7528 u3057u3066u3044u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b7u30b9u30c6u30e0 u3067u306fu3001u8abfu67fbu54e1 u304cu4e8bu6848 u3054u3068 u306bu3053u308c u3092 u8abfu6574 u3067u304du308bu3088u3046 u306bu3059u308bu3079u304d u3067u305su3002
u30d7u30edu30c0u30afu30b7u30e7u30f3u3078u306eu30c7u30d7u30edu30fcu30ebu306bu304au3051u308b u904bu7528u4e0au306eu8003u616eu4e8bu9805
u3053u306e u30c7u30e2 u306fu305du306eu69cbu60f3u3092u8a3cu660eu3057u307eu305su3002u30d7u30edu30c0u30afu30b7u30e7u30f3 u3078u306eu30c7u30d7u30edu30fcu30eb u306bu306fu3001u3044u306fu3086u308bu3001u904bu7528u4e0a u306eu554fu984cu306e u89e3u6c7a u304cu5fc5u8981 u3068u306au308au307eu305s:
Scalabilityuff08u30b9u30b1u30fcu30e9u30d3u30eau30c6u30a3uff09: Single Index u306e u30a2u30d7u30edu30fcu30c1 u306f u30c7u30e2uff0812u306eu30d3u30c7u30aauff09u306bu306f u52a9u304bu308a u307eu305su304cu3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u52a0u91cd uff08u4e8bu6848 u3054u3068 u306b1,000 u4ee5u4e0a u306e u30d3u30c7u30aa uff09u306b u5bfeu3057u3066u306f u30a2u30fcu30adu30c6u30afu30c1u30e3 u306eu5909u66f4 u304cu5fc5u8981u3068u306au308au307eu305s u3002u30a4u30f3u30c7u30c3u30afu30b9u30d1u30fcu30c6u30a3u30b7u30e7u30cbu30f3u30b0 u306e u30b9u30c8u30e9u30c6u30b8u30fc u3001u307eu305fu306f u30afu30eau30c3u30d7u30ecu30d9u30eb u306e Embeddings u306eu305fu3081 u306bu5c02u7528 u306eu30d9u30afu30c8u30eb u30c7u30fcu30bfu30d2u30fcu30b9 u3078u306e u79fbu884c u3092 u691cu8a0e u3057u3066u304fu3060u3055u3044u3002
u30b3u30b9u30c8u306e u7ba1u7406: Bedrock u306f Embedding u306e u751fu6210 u3054u3068u306bu30b3u30b9u30c8u304f u304bu304bu308au307eu305su3002 2u6642u9593u306eu30d3u30c7u30aa u306f ~1,200 u500b u306e u30afu30eau30c3u30d7 Embeddings u3092u751fu6210u3057u307eu305su3002 1u3064u306eu4e8bu6848 u306bu3064u304d 100 u6642u9593 u306eu6620u50cfu3092 u51eceu7406 u3059u308b u3053u306e u306f u300160,000u4ee5u4e0a u306e Embeddings u3092 u610fu5473 u3057u307eu305su3002 u30d0u30c3u30c1u51eceu7406 u3001u30adu30e3u30c3u30b7u30f3u30b0 u30b9u30c8u30e9u30c6u30b8u30fc u3001u304au3088u3073 u95a2u9023 u3059u308b u4e8bu6848 u9593u3067u306e Embeddings u306e u518du5218u7528 u3092 u8a08u753b u3057u3066u304fu3060u3055u3044u3002
u30bbu30adu30e5u30eau30c6u30a3u3068u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9: u6cd5u7684 u8a3cu62e0 u306bu306f u4fddu7ba1u9023u9396 uff08Chain-of-Custodyu300du306e u8ffdu8de1 u3001u30a2u30afu30bbu30b9 u5236u5fa1 u3001u304au3088u3073 u76e3u67fbu30ebu30b0 u304cu5fc5u8981 u3068u306au308au307eu305su3002u3053u306e u30c7u30e2 u306f u30d3u30c7u30aa u3092 S3 u306bu4fddu5b58u3057u307eu305su304c u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u3067u306f u4fddu5b58u6642u306eu6697u53f7u5316 u3001u30edu30fcu30eb u30d2u30fcu30b9u306e u30a2u30afu30bbu30b9 u3001u304au3088u3073 u4e0du5909 u306e u76e3u67fb u30c8u30ecu30fcu30eb u304cu5fc5u8981 u3068u306au308au307eu305su3002
u7cbeu5ea6 u306eu30d0u30eau30c7u30fcu30b7u30e7u30f3: u30a8u30f3u30c6u30a3u30c6u30a3u306eu30deu30c3u30c1u30f3u30b0u3068u30bfu30a4u30e0u30e9u30a4u30f3u306eu518du69cbu6210 u306bu306f u4fe1u983c u30b9u30b3u30a2u300du3092 u542b u308du3055u3001u6cd5u7684u306au8a3cu62e0u3068u3057u3066u9001u4fe1u3059u308bu524du306bu4ebau9593u306eu30ecu30d3u30e5u30fcu3092u5fc5u9808 u3068u3059u308bu3059u3079u304eu3067u305su3002 AIu306bu3088u308bu5206u6790u306fu8abfu67fbu54e1u3092 u30b5u30ddu30fcu30c8 u3057u307eu305su304c u3001u4ebau9593 u306eu5224u65ad u306b u4ee3u308fu308bu3082u306eu3067u306f u3042u308au307eu305bu3093u3002
u30d5u30a9u30fcu30deu30c3u30c8 u306eu51eceu7406: u3053u306e u30c7u30e2 u306f u6a19u6e96 u306eu30d3u30c7u30aa u30b3u30fcu30c7u30c3u30af u3092 u524du63d0 u306b u3057u3066 u3044u307eu305su3002 u30d7u30edu30c0u30afu30b7u30e7u30f3 u30b3u30f3u30c6u30f3u30c4 u306f u3001u7834u640du3057u305fu30d5u30a1u30a4u30eb u3001u975eu6a19u6e96 u306e u30d5u30a3u30ebu30bfu30fc u3001u6697u53f7u5316 u3055u308cu305fu6620u50cfu3001u4f4eu54c1u8ceau306e u30bdu30fcu30b9 u306au306eu3069u3092 u512au96c5 u306b u51eceu7406 u3059u308b u5fc5u8981 u304eu3042u308fu308au307eu305su3002
u7d50u8ad6
u3053u306eu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3u306fu3001u30d3u30c7u30aau30a4u30f3u30c6u30e1u30bcu30f3u30b9u304cu3001u6642u9593u304fu304bu304bu308bu624bu52d5u306eu30d3u30c7u30aau8a3cu62e0u30ecu30d3u30e5u30fcu306e u30efu30fcu30afu30d5u30edu30fcu3092u3001u7bc4u56f2u3092u7d5eu3063u305fu8abfu67fbu30efu30fcu30afu30d5u30edu30fcu306b u3069u306eu3088u3046u306bu5909u63dbu3059u308bu306eu304b u3092 u5b9fu6f14 u3057u3066 u3044u307eu305su3002 u30d3u30c7u30aau306eu7406u89e3u306b AWS Bedrock u306e TwelveLabs u3092 u4f7fu7528 u3057u3001u30c8u30cbu30e5u30e1u30f3u30c8u306e u691cu7d22u306b NeMo Retriever u3092u7d44u307fu5408u308fu305bu308b u3053u306eu306bu3088u3082u3001u8abfu67fbu54e1 u306fu4ee5u4e0bu304c u53efu80fd u3068u306au308au307eu305s:
12u4ee5u4e0bu306e u7570u306au308b u30d3u30c7u30aau30bdu30fcu30b9 u3092 u81eau7136u8a00u8a9e u306eu30afu30a8u30ea u3067 u540cu6642u306b u691cu7d22
u95a2u9023 u306eu306au3044 u30abu30e1u30e9 u30d5u30a3u30fcu30c9 u304bu3089 u7279u5b9a u306e u50cf u307eu305fu306f u8ecau4e21 u3092 u8ffdu8de1
u65adu7247u5316u3055u308cu305f u6620u50cf u304bu3089 u6642u7cfbu5217u306eu30bfu30a4u30e0u30e9u30a4u30f3 u3092 u518du69cbu6210
u30eau30b9u30afu30afu30e9u30b9 u30a4u30f3u30a2u30f3u30bbu30b9 u30bfu30a4u30d7 u3067 u69cbu9020u5316u3055u308cu305f u30b3u30f3u30d7u30e9u30a4u30a2u30f3u30b9 u5206u6790 u3092 u751fu6210
u6b63u76bau306eu30bfu30a4u30e0u30b9u30bfu30f3u30d7 u3092 u6301u3064 u6587u5b57u8d77u3053u3057 u3001u304au3088u3073 u691cu51fau3055u308cu305f u7269u4ef6 u3078u306e u30a2u30afu30bbu30b9
u521fu7387 u306e u512au5168: u30bdu30fcu30b9 u304cu6df7u5728u3059u308b 40u6642u9593 u306eu6620u50cfu306e u624bu52d5 u306eu30ecu30d3u30e5u30fcu306f u3001u8abfu67fbu54e1 u306bu3068u3063u306e 40uff5e60u6642u9593 u3092 u8cbb u3084u3055u305bu307eu305su3002 u3053u306e u30d7u30e9u30c3u30c8u30d5u30a9u30fcu30e0 u306fu3001 u305du308cu3092 u898fu5b9a u3055u308cu305f 4uff5e6u6642u9593 u306e u30bfu30fcu30b2u30c3u30c8u30ecu30d3u30e5u30fc u306b u6e1bu5c11 u3055u305b u3001 u8abfu67fbu54e1 u306f u767au898bu3092 u627eu3059 u3053u306eu306b u6642u9593u304f u304bu3051u308b u306eu3067u306f u306au304f u3001 u305du306eu691cu8a3c u306b u6642u9593u304c u4f7fu3048u308bu3088u3046 u306bu3057u307eu305s u3002
u8a3cu62e0 u7ba1u7406 u30d7u30ebu30a2u30d5u30a9u30fcu30e0 u3092u69cbu7bc9 u3059u308b u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fc ISV u306bu3068u3063u306eu3001u3053u306e u30a2u30fcu30adu30c6u30afu30c1u30e3 u306f u3001TwelveLabs u304c u65e2u5b58 u306e u30efu30fcu30afu30d5u30edu30fc u306b u53d6u308au8fbcu3081u308b u3053u306e u3092 u5c55u793a u3059u308b u30eau30d5u30a1u30ecu30f3u30b9 u30a4u30f3u30d7u30eau30e1u30f3u30c6u30fcu30b7u30e7u30f3 u3092 u63d0u4f9b u3057u307eu305su3002 u30a4u30f3u30ddu30fcu30bfu30fcu30c8 u306e Single Index Multi-Source u306e u30d1u30bfu30fcu30f3u3001 hybrid video+document retrievalu3001 u304au3088u3073 u69cbu9020u5316u3055u308cu305fu5206u6790 u306e u6a5fu80fdu306f u3001u30d7u30edu30c0u30afu30b7u30e7u30f3 u306e u6cd5u7684 u30c6u30afu30ceu30ebu30b8u30fcu88fdu54c1 u306b u76f4u63a5 u30a2u30a2u30d7u30edu30fcu30c1 u3055u308cu307eu305su3002
u8ffdu52a0u306eu30eau30bdu30fcu30b9
AWS Bedrock u306e TwelveLabs: u30e2u30c7u30ebu306eu30a2u30afu30bbu30b9 u306bu3064u3044u3066 u8a73u3057u304fu306f
NeMo Retriever u306e u30c8u30cbu30e5u30e1u30f3u30c8: u30c8u30cbu30e5u30e1u30f3u30c8 u691cu7d22 u6a5fu80fdu306f u3053u3061u3089u304bu308f
TwelveLabs u306e u30b5u30f3u30d7u30ebu30a2u30d7u30eau30b1u30fcu30b7u30e7u30f3: u8ffdu52a0u306eu300cu30a2u30d7u30eau30a2u30d7u30edu30fcu30c1u300du306fu3053u3061u3089
TwelveLabs u30b3u30dfu30e5u30cbu30c6u30a3u3078u53c2u52a0: Discord
u6b21u306eu30b9u30c6u30c3u30d7:
u30eau30d5u30a1u30ecu30f3u30b9u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u30afu30edu30fcu30f3u3059u308b
AWS Bedrock u306e u30a2u30afu30bbu30b9u3092u8a2du5b9au3057 u3001 u30d3u30c7u30aa u30bdu30fcu30b9 u3067 u30c6u30b9u30c8u3059u308b
Single Index u30a2u30fcu30adu30c6u30afu30c1u30e3 u3092 u7279u5b9a u306e u6cd5u7684 u30efu30fcu30afu30d5u30edu30fc u306b u9069u5408u3055u305bu308b
u65e2u5b58 u306e u8a3cu62e0 u7ba1u7406 u30b7u30b9u30c6u30e0 u3068 u7d71u5408u3059u308b