
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)

商品
Pegasus 1.5の構築:クリップ単位のQAから時間単位のメタデータへ

キアン・キム、シャノン・ホン
Pegasus 1.5は、ビデオ理解における根本的な転換をもたらします。それは、動画クリップに関する質問に答えることから、ビデオ全体にわたって構造化された時間基準のメタデータを生成することへの移行です。本記事では、時間的セグメンテーション(temporal segmentation)の背後にある技術的課題、TwelveLabsが第一原理から新しい評価指標とデータセットをどのように設計したか、そしてなぜトレーニングをこれらの指標に合わせることが実世界での信頼性にとって重要なのかを詳しく解説します。その結果、ビデオを検索可能でプロダクション環境に対応したデータに変換し、大規模な検索、分析、自動化を可能にするシステムが実現しました。
Pegasus 1.5は、ビデオ理解における根本的な転換をもたらします。それは、動画クリップに関する質問に答えることから、ビデオ全体にわたって構造化された時間基準のメタデータを生成することへの移行です。本記事では、時間的セグメンテーション(temporal segmentation)の背後にある技術的課題、TwelveLabsが第一原理から新しい評価指標とデータセットをどのように設計したか、そしてなぜトレーニングをこれらの指標に合わせることが実世界での信頼性にとって重要なのかを詳しく解説します。その結果、ビデオを検索可能でプロダクション環境に対応したデータに変換し、大規模な検索、分析、自動化を可能にするシステムが実現しました。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2026/04/19
12分
記事へのリンクをコピー
1 - クリップベースの回答から構造化されたビデオインテリジェンスへ
ビデオは最も情報豊かな形態の一つですが、ソフトウェアシステムにとっては最もアクセスしにくいものの一つであり続けています。テキストや画像とは異なり、ビデオにおける意味は単一の瞬間にとどまりません。時間の経過に伴う連続性、マルチモーダルな相互作用、そして因果関係を通じて生まれます。スポーツのプレイが数秒かけて展開され、映画のプロットが数分間に及び、ブランドの登場が視覚的には些細であっても文脈上重要であることがあります。ビデオを大規模に活用するために、システムは何が起こるかだけでなく、それがいつ起こるかについても推論する必要があります。
ここで時間ベースのメタデータが不可欠になります。時間ベースのメタデータは、生のビデオを構造化されタイムスタンプが押されたデータへと変換し、開発者がビデオをクエリ可能かつ計算可能な資産として扱えるようにします。手作業で映像を確認したり、不安定なヒューリスティクスに頼ったりする代わりに、組織は自社ビジネスにとって重要なこと(編集セグメント、スポーツのプレイ、発言者の交代、ブランドの登場など)を定義し、ビデオライブラリ全体からこれらのイベントを自動的に抽出できます。
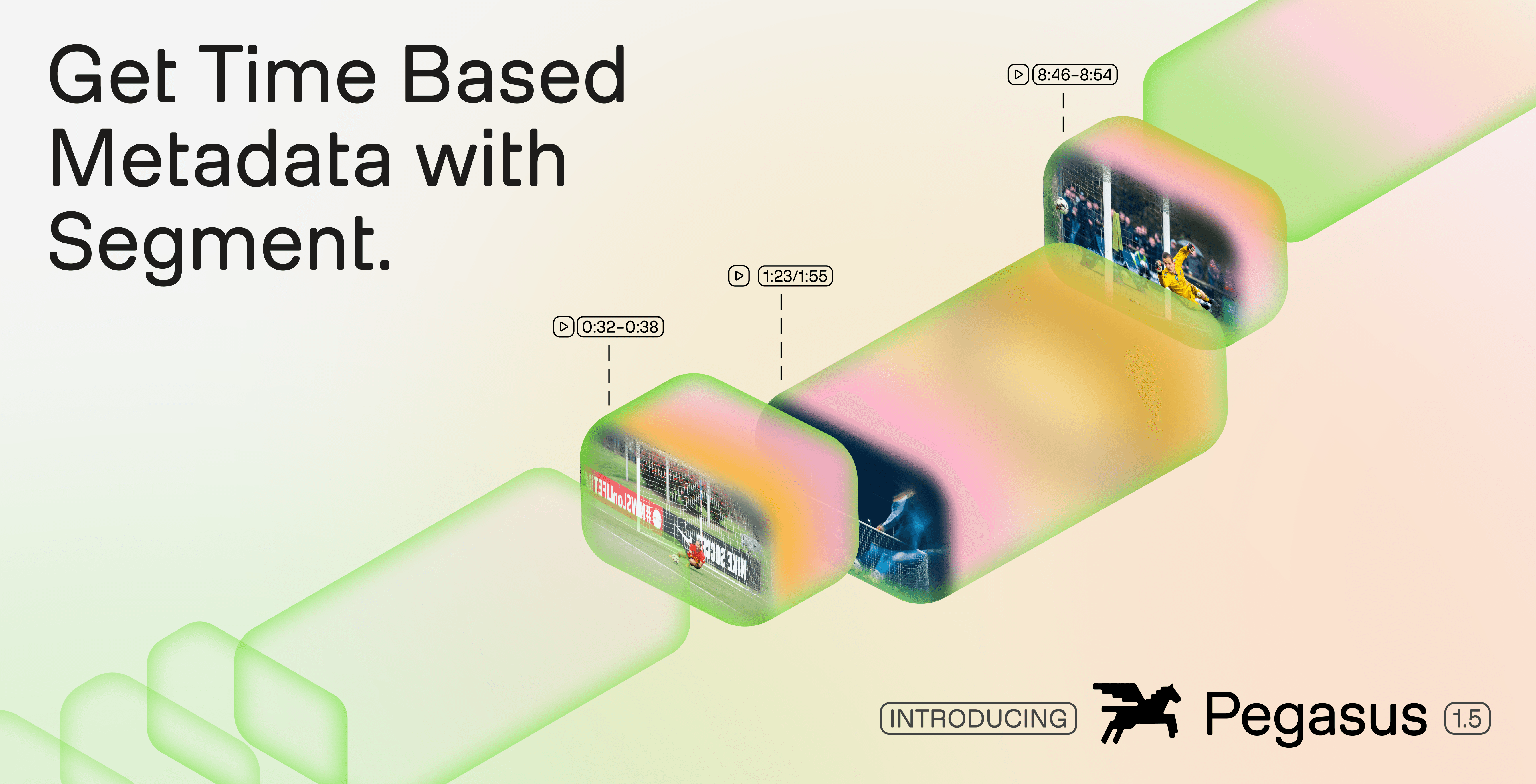
Pegasusの以前のバージョンは、異なる種類の問題に対処していました。Pegasus 1.2はビデオ質問回答 (QA) システムとして設計されました。ユーザーがクリップを提供して質問すると、モデルが回答や要約を返します。このパラダイムは、事実に関するクエリや局所的な理解には適しています。しかし、実際のワークフローにおいては根本的な制限が生じます。それは、ユーザーがどこを探すべきかをあらかじめ知っていなければならないということです。大規模な環境(メディアアーカイブ、ライブスポーツ、配信カタログなど)では、この前提は成り立ちません。
その結果、Pegasus 1.2は、ビデオ全体にわたる体系的なセグメンテーションや、一貫したメタデータ抽出を必要とするワークフローを完全にはサポートできませんでした。モデル駆動型の境界検出が存在しなかったため、ユーザーは関心のある時間領域を定義するために、依然として手動のアノテーションやヒューリスティックな前処理に依存していました。
Pegasus 1.5は根本的な大転換を意味します。事前定義されたクリップに対する質問に回答する代わりに、モデルはユーザー定義のスキーマに従ってビデオ全体を分割し、各セグメントに構造化されたメタデータでラベルを貼り付けます。この変革により、ビデオ理解は検索の問題からデータ生成パイプラインへと移行し、ビデオは分析、自動化、およびエージェントシステムのためのファーストクラスのインプットになります。
2 - 非構造化ビデオのコスト
ビデオコンテンツの爆発的な成長にもかかわらず、ほとんどの組織は依然として非構造化メディアとして管理しています。従来のアプローチは、手動のロギング、キーワードタグ付け、または単純なカット検出アルゴリズムに依存しています。これらの方法では、下流の意思決定に必要な意味的および時間的な複雑さを捉えることができません。
システム側の観点から見ると、課題はビデオの3つの特性に起因します:
時間的曖昧さ: イベントには明確な境界がありません。ニュースストーリーがどこで始まり、スポーツのプレイがどこで終わるかを判断するには、複数のモダリティにわたる文脈的な推論が必要です。
マルチモーダルへの依存: 意味は、視覚的ヒント、音声、オーディオ信号、画面上のテキストの相互作用から生じます。
スキーマの多様性: 組織によって関心を持つイベントは異なるため、柔軟でドメイン特定の定義が必要になります。
信頼性の高い時間ベースのメタデータがなければ、ビデオを簡単にインデックス化、クエリ、あるいはデータパイプラインに統合できず、自動化や分析における価値が制限されます。
生ビデオと構造化データの間の運用上のギャップは、次の比較で説明できます:
図1: 従来のワークフロー
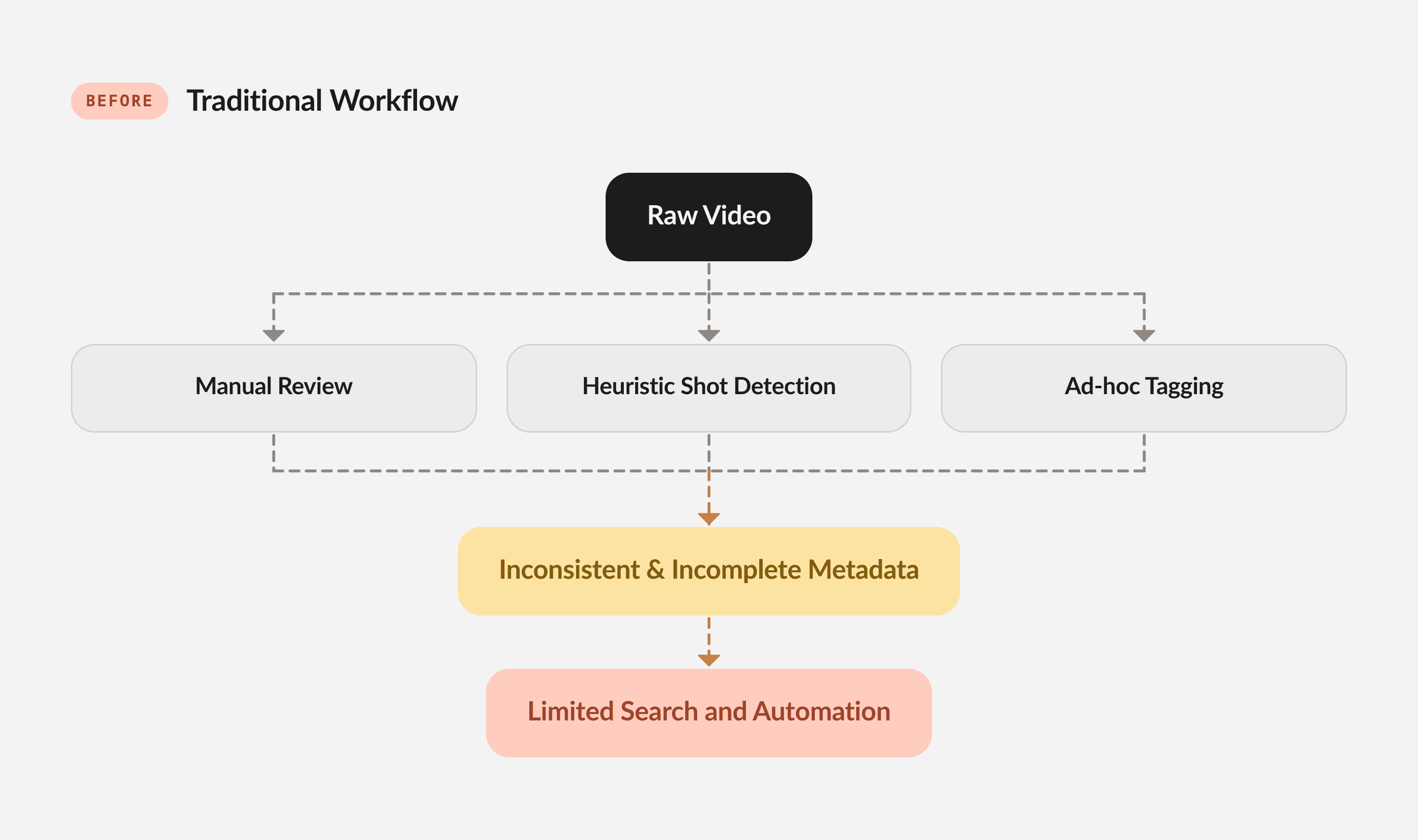
図2: Pegasus 1.5のワークフロー
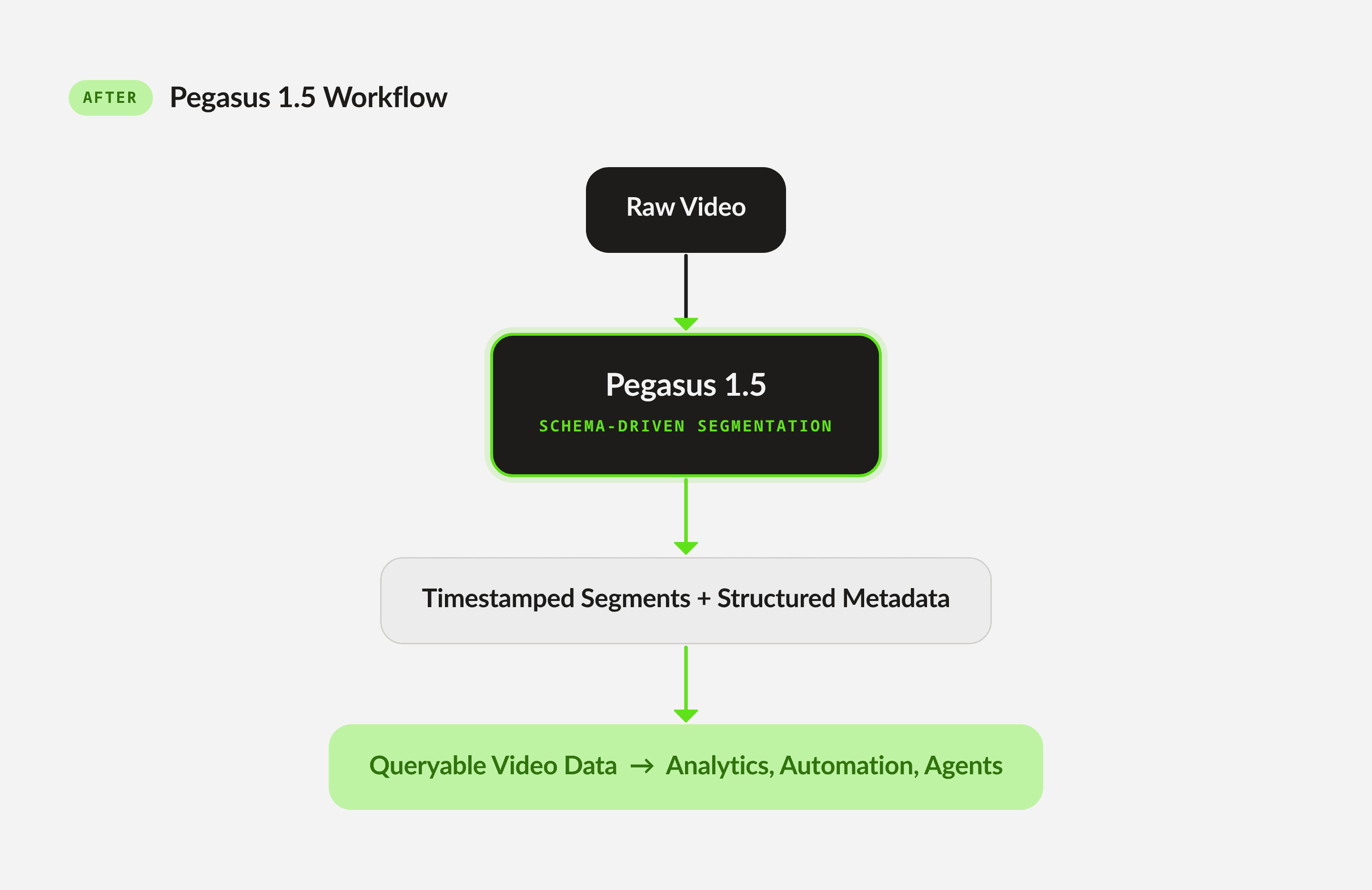
開発者がイベントのボキャブラリを定義できるようにすることで、Pegasus 1.5は時間的推論の負担を人間からモデルへと移行させ、スケーラブルで一貫したメタデータ抽出を実現します。
メディア&エンターテインメントでは、編集チームは長尺のコンテンツを、シーン、トピック、キャラクターの登場などのナビゲーションユニットに分割し、アーカイブ、レコメンデーション、収益化をサポートする必要があります。Pegasus 1.5を使用すると、編集セグメントのスキーマを定義し、カタログ全体から構造化されたメタデータを自動的に抽出できます。これにより、セマンティック検索、ハイライトの自動生成、効率的なコンテンツの再利用が可能になります。
スポーツアナリティクスでは、スポーツ映像内のプレイを特定してラベルを付ける作業は労力がかかり、時間的な制約もあるため、専門家がゲーム全体を確認することがよく求められます。Pegasus 1.5を使用すると、プレイ(ゴール、ファウル、ターンオーバーなど)のスキーマを定義し、正確な時間境界で各インスタンスを自動的に検出できます。これは、リアルタイムのハイライト作成やパフォーマンス分析をサポートします。
ストリーミングプラットフォームでは、ターゲット広告やコンテンツの収益化を可能にするために、ブランドの露出、シーンの切り替わり、文脈に応じた瞬間を特定する必要があります。Pegasus 1.5を使用すると、ブランドの視認性や文脈に即したトリガーのスキーマを定義でき、膨大なライブラリ全体から収益化可能な瞬間を自動的に検出できます。
3 - 技術的基盤: 時間ベースのメタデータの定義
時間ベースのメタデータ (TBM) とは、ビデオの特定の時間的セグメントに関連付けられた構造化情報を指します。各セグメントは正確な開始および終了のタイムスタンプによって定義され、ユーザー定義のスキーマに準拠するメタデータフィールドで強化されます。
形式的には、TBM出力は以下のように表現できます:
Segment = { start_time: float, end_time: float, metadata: { key: value, ... } }
完全な分析は、ユーザーから提供された各セマンティック定義用の、重複しないセグメントのセットで構成されます。この構造により、検索インデックス、分析プラットフォーム、およびエージェントベースのワークフローなどの下流システムとの確実な統合が可能になります。
Pegasus 1.5は、 /analyze APIを通じて、スキーマファーストのインタラクションモデルを導入します。開発者は、モデルに対してオープンエンドの質問をする代わりに、以下を記述するセグメント定義を指定します:
何をもってセグメントとするか(意味的な説明)
どのメタデータフィールドを抽出するか
長さや文脈上の言及などの制限(オプション)
この設計により、本番環境における一貫性、決定性、および統合準備の容易さが保証されます。

これは上記のバスケットボールのビデオに対する /analyze APIリクエストの例です:
{ "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "video": { "type": "url", "url": "https://example.com/video.mp4" }, "response_format": { "type": "segment_definitions", "segment_definitions": [ { "id": "non_gameplay_footage", "description": "画面上のコンテンツが実際の試合プレイではない場合のみセグメントを生成します。", "fields": [ { "name": "description", "type": "string", "description": "ゲームプレイ以外の映像に関する詳細かつ長い説明。" } ] }, { "id": "scoring_plays", "description": "チームが得点したすべての時間をセグメント化します。セグメントは得点プレイ全体とします。", "fields": [ { "name": "points_scored", "type": "string", "description": "プレイ中に得点された点数。", "enum": [ "2pt", "1pt", "3pt" ] }, { "name": "shot_type", "type": "string", "description": "得点プレイにおけるシュートの種類。", "enum": [ "jump_start", "layup", "dunk", "foul_shot" ] }, { "name": "scoring_team", "type": "string", "description": "得点したチームの名前。" } ] }, { "id": "camera_cut", "description": "カメラにハードカット(パッと切り替わる場面)がある瞬間のみセグメント化します。それ以外の場合は現在のセグメントを継続します。", "fields": [ { "name": "camera_angle", "type": "string", "description": "現在のカメラのアングル。", "enum": [ "high", "low", "medium" ] } ] } ] }, "temperature": 0, "min_segment_duration": 2 }
そして、以下が応答の出力例の構造です:
"result": { "generation_id": "5be1b8c6-7e92-43ce-b37d-ba1b53ed1ebe", "data": "{\"gameplay_footage\": [{\"start_time\": 0.0, \"end_time\": 11.0, \"metadata\": {\"description\": \"ロヨラ大学のNCAAチャンピオンシップ優勝を発表するタイトルカードでビデオが始まり、その後に満員の競技場のワイドショットと、コート上の'NCAA Finals 1963'ロゴのクローズアップが続きます。\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"description\": \"短いカットインカットが、観客席の女性が笑顔で熱心に拍手している様子を示しています。\"}}, {\"start_time\": 29.0, \"end_time\": 31.0, \"metadata\": {\"description\": \"カメラがスコアボードにズームし、第2ピリオド残り2:04でスコアが48-50であることを示しています。\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"description\": \"観客席の観客が試合に反応している短いショット。\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"description\": \"カメラが観客席で両腕を上げて祝う2人の男性を捉えています。\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"description\": \"再びスコアボードが表示され、第3ピリオドの残り5:00で54-54と同点のスプリットスコアを示しています。\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"description\": \"群衆のショットが、試合中にファンが歓声を上げて祝っている様子を示しています。\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"description\": \"コート上で2人のチアリーダーがルーティンを披露している様子が表示されます。\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"description\": \"スーツを着た男性が観客席に立ち、拍手を送っている姿が見られます。\"}}, {\"start_time\": 109.0, \"end_time\": 118.0, \"metadata\": {\"description\": \"最後のシュートに続いて、ロヨラの選手とコーチがコートになだれ込み、チャンピオンシップの勝利を祝います。\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"description\": \"最終スコアボードが表示され、タイムアウト時のロヨラの60-58での勝利を示しています。\"}}], \"scoring_plays\": [{\"start_time\": 12.0, \"end_time\": 20.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 23.0, \"end_time\": 28.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 46.0, \"end_time\": 52.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 60.0, \"end_time\": 68.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 71.0, \"end_time\": 76.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 79.0, \"end_time\": 83.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 102.0, \"end_time\": 110.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}], \"camera_cut\": [{\"start_time\": 0.0, \"end_time\": 3.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 3.0, \"end_time\": 10.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 10.0, \"end_time\": 11.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 11.0, \"end_time\": 20.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 22.0, \"end_time\": 28.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 28.0, \"end_time\": 31.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 31.0, \"end_time\": 38.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 38.0, \"end_time\": 45.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 45.0, \"end_time\": 53.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 54.0, \"end_time\": 56.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 58.0, \"end_time\": 68.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 70.0, \"end_time\": 76.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 78.0, \"end_time\": 81.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 83.0, \"end_time\": 88.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 90.0, \"end_time\": 108.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 108.0, \"end_time\": 118.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"camera_angle\": \"medium\"}}]}" "finish_reason": "stop", "usage": { "output_tokens": <number>
レスポンス構造の
1 - クリップベースの回答から構造化されたビデオインテリジェンスへ
ビデオは最も情報豊かな形態の一つですが、ソフトウェアシステムにとっては最もアクセスしにくいものの一つであり続けています。テキストや画像とは異なり、ビデオにおける意味は単一の瞬間にとどまりません。時間の経過に伴う連続性、マルチモーダルな相互作用、そして因果関係を通じて生まれます。スポーツのプレイが数秒かけて展開され、映画のプロットが数分間に及び、ブランドの登場が視覚的には些細であっても文脈上重要であることがあります。ビデオを大規模に活用するために、システムは何が起こるかだけでなく、それがいつ起こるかについても推論する必要があります。
ここで時間ベースのメタデータが不可欠になります。時間ベースのメタデータは、生のビデオを構造化されタイムスタンプが押されたデータへと変換し、開発者がビデオをクエリ可能かつ計算可能な資産として扱えるようにします。手作業で映像を確認したり、不安定なヒューリスティクスに頼ったりする代わりに、組織は自社ビジネスにとって重要なこと(編集セグメント、スポーツのプレイ、発言者の交代、ブランドの登場など)を定義し、ビデオライブラリ全体からこれらのイベントを自動的に抽出できます。
Pegasusの以前のバージョンは、異なる種類の問題に対処していました。Pegasus 1.2はビデオ質問回答 (QA) システムとして設計されました。ユーザーがクリップを提供して質問すると、モデルが回答や要約を返します。このパラダイムは、事実に関するクエリや局所的な理解には適しています。しかし、実際のワークフローにおいては根本的な制限が生じます。それは、ユーザーがどこを探すべきかをあらかじめ知っていなければならないということです。大規模な環境(メディアアーカイブ、ライブスポーツ、配信カタログなど)では、この前提は成り立ちません。
その結果、Pegasus 1.2は、ビデオ全体にわたる体系的なセグメンテーションや、一貫したメタデータ抽出を必要とするワークフローを完全にはサポートできませんでした。モデル駆動型の境界検出が存在しなかったため、ユーザーは関心のある時間領域を定義するために、依然として手動のアノテーションやヒューリスティックな前処理に依存していました。
Pegasus 1.5は根本的な大転換を意味します。事前定義されたクリップに対する質問に回答する代わりに、モデルはユーザー定義のスキーマに従ってビデオ全体を分割し、各セグメントに構造化されたメタデータでラベルを貼り付けます。この変革により、ビデオ理解は検索の問題からデータ生成パイプラインへと移行し、ビデオは分析、自動化、およびエージェントシステムのためのファーストクラスのインプットになります。
2 - 非構造化ビデオのコスト
ビデオコンテンツの爆発的な成長にもかかわらず、ほとんどの組織は依然として非構造化メディアとして管理しています。従来のアプローチは、手動のロギング、キーワードタグ付け、または単純なカット検出アルゴリズムに依存しています。これらの方法では、下流の意思決定に必要な意味的および時間的な複雑さを捉えることができません。
システム側の観点から見ると、課題はビデオの3つの特性に起因します:
時間的曖昧さ: イベントには明確な境界がありません。ニュースストーリーがどこで始まり、スポーツのプレイがどこで終わるかを判断するには、複数のモダリティにわたる文脈的な推論が必要です。
マルチモーダルへの依存: 意味は、視覚的ヒント、音声、オーディオ信号、画面上のテキストの相互作用から生じます。
スキーマの多様性: 組織によって関心を持つイベントは異なるため、柔軟でドメイン特定の定義が必要になります。
信頼性の高い時間ベースのメタデータがなければ、ビデオを簡単にインデックス化、クエリ、あるいはデータパイプラインに統合できず、自動化や分析における価値が制限されます。
生ビデオと構造化データの間の運用上のギャップは、次の比較で説明できます:
図1: 従来のワークフロー
図2: Pegasus 1.5のワークフロー
開発者がイベントのボキャブラリを定義できるようにすることで、Pegasus 1.5は時間的推論の負担を人間からモデルへと移行させ、スケーラブルで一貫したメタデータ抽出を実現します。
メディア&エンターテインメントでは、編集チームは長尺のコンテンツを、シーン、トピック、キャラクターの登場などのナビゲーションユニットに分割し、アーカイブ、レコメンデーション、収益化をサポートする必要があります。Pegasus 1.5を使用すると、編集セグメントのスキーマを定義し、カタログ全体から構造化されたメタデータを自動的に抽出できます。これにより、セマンティック検索、ハイライトの自動生成、効率的なコンテンツの再利用が可能になります。
スポーツアナリティクスでは、スポーツ映像内のプレイを特定してラベルを付ける作業は労力がかかり、時間的な制約もあるため、専門家がゲーム全体を確認することがよく求められます。Pegasus 1.5を使用すると、プレイ(ゴール、ファウル、ターンオーバーなど)のスキーマを定義し、正確な時間境界で各インスタンスを自動的に検出できます。これは、リアルタイムのハイライト作成やパフォーマンス分析をサポートします。
ストリーミングプラットフォームでは、ターゲット広告やコンテンツの収益化を可能にするために、ブランドの露出、シーンの切り替わり、文脈に応じた瞬間を特定する必要があります。Pegasus 1.5を使用すると、ブランドの視認性や文脈に即したトリガーのスキーマを定義でき、膨大なライブラリ全体から収益化可能な瞬間を自動的に検出できます。
3 - 技術的基盤: 時間ベースのメタデータの定義
時間ベースのメタデータ (TBM) とは、ビデオの特定の時間的セグメントに関連付けられた構造化情報を指します。各セグメントは正確な開始および終了のタイムスタンプによって定義され、ユーザー定義のスキーマに準拠するメタデータフィールドで強化されます。
形式的には、TBM出力は以下のように表現できます:
Segment = { start_time: float, end_time: float, metadata: { key: value, ... } }
完全な分析は、ユーザーから提供された各セマンティック定義用の、重複しないセグメントのセットで構成されます。この構造により、検索インデックス、分析プラットフォーム、およびエージェントベースのワークフローなどの下流システムとの確実な統合が可能になります。
Pegasus 1.5は、 /analyze APIを通じて、スキーマファーストのインタラクションモデルを導入します。開発者は、モデルに対してオープンエンドの質問をする代わりに、以下を記述するセグメント定義を指定します:
何をもってセグメントとするか(意味的な説明)
どのメタデータフィールドを抽出するか
長さや文脈上の言及などの制限(オプション)
この設計により、本番環境における一貫性、決定性、および統合準備の容易さが保証されます。
これは上記のバスケットボールのビデオに対する /analyze APIリクエストの例です:
{ "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "video": { "type": "url", "url": "https://example.com/video.mp4" }, "response_format": { "type": "segment_definitions", "segment_definitions": [ { "id": "non_gameplay_footage", "description": "画面上のコンテンツが実際の試合プレイではない場合のみセグメントを生成します。", "fields": [ { "name": "description", "type": "string", "description": "ゲームプレイ以外の映像に関する詳細かつ長い説明。" } ] }, { "id": "scoring_plays", "description": "チームが得点したすべての時間をセグメント化します。セグメントは得点プレイ全体とします。", "fields": [ { "name": "points_scored", "type": "string", "description": "プレイ中に得点された点数。", "enum": [ "2pt", "1pt", "3pt" ] }, { "name": "shot_type", "type": "string", "description": "得点プレイにおけるシュートの種類。", "enum": [ "jump_start", "layup", "dunk", "foul_shot" ] }, { "name": "scoring_team", "type": "string", "description": "得点したチームの名前。" } ] }, { "id": "camera_cut", "description": "カメラにハードカット(パッと切り替わる場面)がある瞬間のみセグメント化します。それ以外の場合は現在のセグメントを継続します。", "fields": [ { "name": "camera_angle", "type": "string", "description": "現在のカメラのアングル。", "enum": [ "high", "low", "medium" ] } ] } ] }, "temperature": 0, "min_segment_duration": 2 }
そして、以下が応答の出力例の構造です:
"result": { "generation_id": "5be1b8c6-7e92-43ce-b37d-ba1b53ed1ebe", "data": "{\"gameplay_footage\": [{\"start_time\": 0.0, \"end_time\": 11.0, \"metadata\": {\"description\": \"ロヨラ大学のNCAAチャンピオンシップ優勝を発表するタイトルカードでビデオが始まり、その後に満員の競技場のワイドショットと、コート上の'NCAA Finals 1963'ロゴのクローズアップが続きます。\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"description\": \"短いカットインカットが、観客席の女性が笑顔で熱心に拍手している様子を示しています。\"}}, {\"start_time\": 29.0, \"end_time\": 31.0, \"metadata\": {\"description\": \"カメラがスコアボードにズームし、第2ピリオド残り2:04でスコアが48-50であることを示しています。\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"description\": \"観客席の観客が試合に反応している短いショット。\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"description\": \"カメラが観客席で両腕を上げて祝う2人の男性を捉えています。\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"description\": \"再びスコアボードが表示され、第3ピリオドの残り5:00で54-54と同点のスプリットスコアを示しています。\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"description\": \"群衆のショットが、試合中にファンが歓声を上げて祝っている様子を示しています。\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"description\": \"コート上で2人のチアリーダーがルーティンを披露している様子が表示されます。\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"description\": \"スーツを着た男性が観客席に立ち、拍手を送っている姿が見られます。\"}}, {\"start_time\": 109.0, \"end_time\": 118.0, \"metadata\": {\"description\": \"最後のシュートに続いて、ロヨラの選手とコーチがコートになだれ込み、チャンピオンシップの勝利を祝います。\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"description\": \"最終スコアボードが表示され、タイムアウト時のロヨラの60-58での勝利を示しています。\"}}], \"scoring_plays\": [{\"start_time\": 12.0, \"end_time\": 20.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 23.0, \"end_time\": 28.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 46.0, \"end_time\": 52.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 60.0, \"end_time\": 68.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 71.0, \"end_time\": 76.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 79.0, \"end_time\": 83.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 102.0, \"end_time\": 110.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}], \"camera_cut\": [{\"start_time\": 0.0, \"end_time\": 3.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 3.0, \"end_time\": 10.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 10.0, \"end_time\": 11.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 11.0, \"end_time\": 20.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 22.0, \"end_time\": 28.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 28.0, \"end_time\": 31.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 31.0, \"end_time\": 38.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 38.0, \"end_time\": 45.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 45.0, \"end_time\": 53.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 54.0, \"end_time\": 56.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 58.0, \"end_time\": 68.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 70.0, \"end_time\": 76.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 78.0, \"end_time\": 81.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 83.0, \"end_time\": 88.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 90.0, \"end_time\": 108.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 108.0, \"end_time\": 118.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"camera_angle\": \"medium\"}}]}" "finish_reason": "stop", "usage": { "output_tokens": <number>
レスポンス構造の
1 - クリップベースの回答から構造化されたビデオインテリジェンスへ
ビデオは最も情報豊かな形態の一つですが、ソフトウェアシステムにとっては最もアクセスしにくいものの一つであり続けています。テキストや画像とは異なり、ビデオにおける意味は単一の瞬間にとどまりません。時間の経過に伴う連続性、マルチモーダルな相互作用、そして因果関係を通じて生まれます。スポーツのプレイが数秒かけて展開され、映画のプロットが数分間に及び、ブランドの登場が視覚的には些細であっても文脈上重要であることがあります。ビデオを大規模に活用するために、システムは何が起こるかだけでなく、それがいつ起こるかについても推論する必要があります。
ここで時間ベースのメタデータが不可欠になります。時間ベースのメタデータは、生のビデオを構造化されタイムスタンプが押されたデータへと変換し、開発者がビデオをクエリ可能かつ計算可能な資産として扱えるようにします。手作業で映像を確認したり、不安定なヒューリスティクスに頼ったりする代わりに、組織は自社ビジネスにとって重要なこと(編集セグメント、スポーツのプレイ、発言者の交代、ブランドの登場など)を定義し、ビデオライブラリ全体からこれらのイベントを自動的に抽出できます。
Pegasusの以前のバージョンは、異なる種類の問題に対処していました。Pegasus 1.2はビデオ質問回答 (QA) システムとして設計されました。ユーザーがクリップを提供して質問すると、モデルが回答や要約を返します。このパラダイムは、事実に関するクエリや局所的な理解には適しています。しかし、実際のワークフローにおいては根本的な制限が生じます。それは、ユーザーがどこを探すべきかをあらかじめ知っていなければならないということです。大規模な環境(メディアアーカイブ、ライブスポーツ、配信カタログなど)では、この前提は成り立ちません。
その結果、Pegasus 1.2は、ビデオ全体にわたる体系的なセグメンテーションや、一貫したメタデータ抽出を必要とするワークフローを完全にはサポートできませんでした。モデル駆動型の境界検出が存在しなかったため、ユーザーは関心のある時間領域を定義するために、依然として手動のアノテーションやヒューリスティックな前処理に依存していました。
Pegasus 1.5は根本的な大転換を意味します。事前定義されたクリップに対する質問に回答する代わりに、モデルはユーザー定義のスキーマに従ってビデオ全体を分割し、各セグメントに構造化されたメタデータでラベルを貼り付けます。この変革により、ビデオ理解は検索の問題からデータ生成パイプラインへと移行し、ビデオは分析、自動化、およびエージェントシステムのためのファーストクラスのインプットになります。
2 - 非構造化ビデオのコスト
ビデオコンテンツの爆発的な成長にもかかわらず、ほとんどの組織は依然として非構造化メディアとして管理しています。従来のアプローチは、手動のロギング、キーワードタグ付け、または単純なカット検出アルゴリズムに依存しています。これらの方法では、下流の意思決定に必要な意味的および時間的な複雑さを捉えることができません。
システム側の観点から見ると、課題はビデオの3つの特性に起因します:
時間的曖昧さ: イベントには明確な境界がありません。ニュースストーリーがどこで始まり、スポーツのプレイがどこで終わるかを判断するには、複数のモダリティにわたる文脈的な推論が必要です。
マルチモーダルへの依存: 意味は、視覚的ヒント、音声、オーディオ信号、画面上のテキストの相互作用から生じます。
スキーマの多様性: 組織によって関心を持つイベントは異なるため、柔軟でドメイン特定の定義が必要になります。
信頼性の高い時間ベースのメタデータがなければ、ビデオを簡単にインデックス化、クエリ、あるいはデータパイプラインに統合できず、自動化や分析における価値が制限されます。
生ビデオと構造化データの間の運用上のギャップは、次の比較で説明できます:
図1: 従来のワークフロー
図2: Pegasus 1.5のワークフロー
開発者がイベントのボキャブラリを定義できるようにすることで、Pegasus 1.5は時間的推論の負担を人間からモデルへと移行させ、スケーラブルで一貫したメタデータ抽出を実現します。
メディア&エンターテインメントでは、編集チームは長尺のコンテンツを、シーン、トピック、キャラクターの登場などのナビゲーションユニットに分割し、アーカイブ、レコメンデーション、収益化をサポートする必要があります。Pegasus 1.5を使用すると、編集セグメントのスキーマを定義し、カタログ全体から構造化されたメタデータを自動的に抽出できます。これにより、セマンティック検索、ハイライトの自動生成、効率的なコンテンツの再利用が可能になります。
スポーツアナリティクスでは、スポーツ映像内のプレイを特定してラベルを付ける作業は労力がかかり、時間的な制約もあるため、専門家がゲーム全体を確認することがよく求められます。Pegasus 1.5を使用すると、プレイ(ゴール、ファウル、ターンオーバーなど)のスキーマを定義し、正確な時間境界で各インスタンスを自動的に検出できます。これは、リアルタイムのハイライト作成やパフォーマンス分析をサポートします。
ストリーミングプラットフォームでは、ターゲット広告やコンテンツの収益化を可能にするために、ブランドの露出、シーンの切り替わり、文脈に応じた瞬間を特定する必要があります。Pegasus 1.5を使用すると、ブランドの視認性や文脈に即したトリガーのスキーマを定義でき、膨大なライブラリ全体から収益化可能な瞬間を自動的に検出できます。
3 - 技術的基盤: 時間ベースのメタデータの定義
時間ベースのメタデータ (TBM) とは、ビデオの特定の時間的セグメントに関連付けられた構造化情報を指します。各セグメントは正確な開始および終了のタイムスタンプによって定義され、ユーザー定義のスキーマに準拠するメタデータフィールドで強化されます。
形式的には、TBM出力は以下のように表現できます:
Segment = { start_time: float, end_time: float, metadata: { key: value, ... } }
完全な分析は、ユーザーから提供された各セマンティック定義用の、重複しないセグメントのセットで構成されます。この構造により、検索インデックス、分析プラットフォーム、およびエージェントベースのワークフローなどの下流システムとの確実な統合が可能になります。
Pegasus 1.5は、 /analyze APIを通じて、スキーマファーストのインタラクションモデルを導入します。開発者は、モデルに対してオープンエンドの質問をする代わりに、以下を記述するセグメント定義を指定します:
何をもってセグメントとするか(意味的な説明)
どのメタデータフィールドを抽出するか
長さや文脈上の言及などの制限(オプション)
この設計により、本番環境における一貫性、決定性、および統合準備の容易さが保証されます。
これは上記のバスケットボールのビデオに対する /analyze APIリクエストの例です:
{ "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "video": { "type": "url", "url": "https://example.com/video.mp4" }, "response_format": { "type": "segment_definitions", "segment_definitions": [ { "id": "non_gameplay_footage", "description": "画面上のコンテンツが実際の試合プレイではない場合のみセグメントを生成します。", "fields": [ { "name": "description", "type": "string", "description": "ゲームプレイ以外の映像に関する詳細かつ長い説明。" } ] }, { "id": "scoring_plays", "description": "チームが得点したすべての時間をセグメント化します。セグメントは得点プレイ全体とします。", "fields": [ { "name": "points_scored", "type": "string", "description": "プレイ中に得点された点数。", "enum": [ "2pt", "1pt", "3pt" ] }, { "name": "shot_type", "type": "string", "description": "得点プレイにおけるシュートの種類。", "enum": [ "jump_start", "layup", "dunk", "foul_shot" ] }, { "name": "scoring_team", "type": "string", "description": "得点したチームの名前。" } ] }, { "id": "camera_cut", "description": "カメラにハードカット(パッと切り替わる場面)がある瞬間のみセグメント化します。それ以外の場合は現在のセグメントを継続します。", "fields": [ { "name": "camera_angle", "type": "string", "description": "現在のカメラのアングル。", "enum": [ "high", "low", "medium" ] } ] } ] }, "temperature": 0, "min_segment_duration": 2 }
そして、以下が応答の出力例の構造です:
"result": { "generation_id": "5be1b8c6-7e92-43ce-b37d-ba1b53ed1ebe", "data": "{\"gameplay_footage\": [{\"start_time\": 0.0, \"end_time\": 11.0, \"metadata\": {\"description\": \"ロヨラ大学のNCAAチャンピオンシップ優勝を発表するタイトルカードでビデオが始まり、その後に満員の競技場のワイドショットと、コート上の'NCAA Finals 1963'ロゴのクローズアップが続きます。\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"description\": \"短いカットインカットが、観客席の女性が笑顔で熱心に拍手している様子を示しています。\"}}, {\"start_time\": 29.0, \"end_time\": 31.0, \"metadata\": {\"description\": \"カメラがスコアボードにズームし、第2ピリオド残り2:04でスコアが48-50であることを示しています。\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"description\": \"観客席の観客が試合に反応している短いショット。\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"description\": \"カメラが観客席で両腕を上げて祝う2人の男性を捉えています。\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"description\": \"再びスコアボードが表示され、第3ピリオドの残り5:00で54-54と同点のスプリットスコアを示しています。\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"description\": \"群衆のショットが、試合中にファンが歓声を上げて祝っている様子を示しています。\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"description\": \"コート上で2人のチアリーダーがルーティンを披露している様子が表示されます。\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"description\": \"スーツを着た男性が観客席に立ち、拍手を送っている姿が見られます。\"}}, {\"start_time\": 109.0, \"end_time\": 118.0, \"metadata\": {\"description\": \"最後のシュートに続いて、ロヨラの選手とコーチがコートになだれ込み、チャンピオンシップの勝利を祝います。\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"description\": \"最終スコアボードが表示され、タイムアウト時のロヨラの60-58での勝利を示しています。\"}}], \"scoring_plays\": [{\"start_time\": 12.0, \"end_time\": 20.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 23.0, \"end_time\": 28.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 46.0, \"end_time\": 52.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 60.0, \"end_time\": 68.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 71.0, \"end_time\": 76.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}, {\"start_time\": 79.0, \"end_time\": 83.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"jump_start\", \"scoring_team\": \"シンシナティ大学ベアキャッツ\"}}, {\"start_time\": 102.0, \"end_time\": 110.0, \"metadata\": {\"points_scored\": \"2pt\", \"shot_type\": \"layup\", \"scoring_team\": \"ロヨラ・ランブラーズ\"}}], \"camera_cut\": [{\"start_time\": 0.0, \"end_time\": 3.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 3.0, \"end_time\": 10.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 10.0, \"end_time\": 11.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 11.0, \"end_time\": 20.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 20.0, \"end_time\": 22.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 22.0, \"end_time\": 28.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 28.0, \"end_time\": 31.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 31.0, \"end_time\": 38.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 38.0, \"end_time\": 45.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 45.0, \"end_time\": 53.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 53.0, \"end_time\": 54.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 54.0, \"end_time\": 56.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 56.0, \"end_time\": 58.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 58.0, \"end_time\": 68.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 68.0, \"end_time\": 70.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 70.0, \"end_time\": 76.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 76.0, \"end_time\": 78.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 78.0, \"end_time\": 81.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 81.0, \"end_time\": 83.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 83.0, \"end_time\": 88.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 88.0, \"end_time\": 90.0, \"metadata\": {\"camera_angle\": \"medium\"}}, {\"start_time\": 90.0, \"end_time\": 108.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 108.0, \"end_time\": 118.0, \"metadata\": {\"camera_angle\": \"high\"}}, {\"start_time\": 118.0, \"end_time\": 121.0, \"metadata\": {\"camera_angle\": \"medium\"}}]}" "finish_reason": "stop", "usage": { "output_tokens": <number>
レスポンス構造の




プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.

プラットフォーム
© 2021
-
2026年
TwelveLabs, Inc. All Rights Reserved.


