
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
파트너십
Mastering Multimodal AI: Advanced Video Understanding with Twelve Labs + Databricks Mosaic AI

James Le
This article guides developers through integrating Twelve Labs' Embed API with Databricks Mosaic AI Vector Search to create advanced video understanding applications, including similarity search and recommendation systems, while addressing performance optimization, scaling, and monitoring considerations.
This article guides developers through integrating Twelve Labs' Embed API with Databricks Mosaic AI Vector Search to create advanced video understanding applications, including similarity search and recommendation systems, while addressing performance optimization, scaling, and monitoring considerations.

In this article
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2024. 8. 30.
14 Min
링크 복사하기
Short Summary
Twelve Labs Embed API enables developers to get multimodal embeddings that power advanced video understanding use cases, from semantic video search and data curation to content recommendation and video RAG systems.
With Twelve Labs, contextual vector representations can be generated that capture the relationship between visual expressions, body language, spoken words, and overall context within videos. Databricks Mosaic AI Vector Search provides a robust, scalable infrastructure for indexing and querying high-dimensional vectors.
This blog post will guide you through harnessing these complementary technologies to unlock new possibilities in video AI applications.
Big thanks to Nina Williams, Austin Zaccor, Fernanda Heredia, and Emily Hutson from Databricks for collaborating with us on this tutorial!
Why Twelve Labs + Databricks Mosaic AI?
Integrating Twelve Labs Embed API with Databricks Mosaic AI Vector Search addresses key challenges in video AI, such as efficient processing of large-scale video datasets and accurate multimodal content representation. This integration reduces development time and resource needs for advanced video applications, enabling complex queries across vast video libraries and enhancing overall workflow efficiency.
The unified approach to handling multimodal data is particularly noteworthy. Instead of juggling separate models for text, image, and audio analysis, users can now work with a single, coherent representation that captures the essence of video content in its entirety. This not only simplifies deployment architecture but also enables more nuanced and context-aware applications, from sophisticated content recommendation systems to advanced video search engines and automated content moderation tools.
Moreover, this integration extends the capabilities of the Databricks ecosystem, allowing seamless incorporation of video understanding into existing data pipelines and machine learning workflows. Whether companies are developing real-time video analytics, building large-scale content classification systems, or exploring novel applications in Generative AI, this combined solution provides a powerful foundation. It pushes the boundaries of what's possible in video AI, opening up new avenues for innovation and problem-solving in industries ranging from media and entertainment to security and healthcare.
Understanding Twelve Labs' Embed API
Twelve Labs' Embed API represents a significant advancement in multimodal embedding technology, specifically designed for video content. Unlike traditional approaches that rely on frame-by-frame analysis or separate models for different modalities, this API generates contextual vector representations that capture the intricate interplay of visual expressions, body language, spoken words, and overall context within videos. It is powered by our state-of-the-art multimodal foundation model Marengo-2.6.
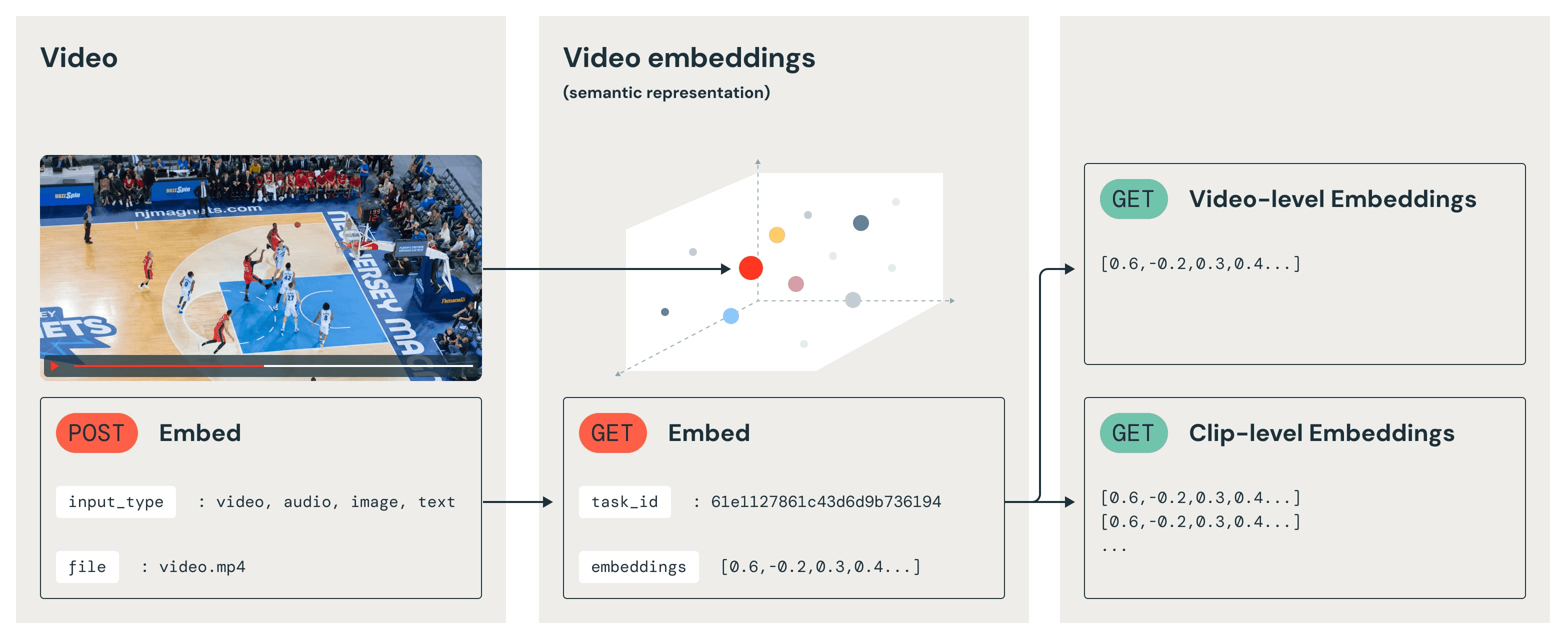
The Embed API offers several key features that make it particularly powerful for AI engineers working with video data. First, it provides flexibility for any modality present in videos, eliminating the need for separate text-only or image-only models. Second, it employs a video-native approach that accounts for motion, action, and temporal information, ensuring a more accurate and temporally coherent interpretation of video content. Lastly, it creates a unified vector space that integrates embeddings from all modalities, facilitating a more holistic understanding of the video content.
For AI engineers, the Embed API opens up new possibilities in video understanding tasks. It enables more sophisticated content analysis, improved semantic search capabilities, and enhanced recommendation systems. The API's ability to capture subtle cues and interactions between different modalities over time makes it particularly valuable for applications requiring a nuanced understanding of video content, such as emotion recognition, context-aware content moderation, and advanced video retrieval systems.
Prerequisites
Before integrating Twelve Labs Embed API with Databricks Mosaic AI Vector Search, be sure you have the following prerequisites:
A Databricks account with access to create and manage workspaces. (You can sign up for a free trial at https://databricks.com/try-databricks)
Familiarity with Python programming and basic data science concepts.
A Twelve Labs API key. (Sign up at playground.twelvelabs.io)
Basic understanding of vector embeddings and similarity search concepts.
(Optional) An AWS account if using Databricks on AWS. This is not required if using Databricks on Azure or Google Cloud.
Note: The Embed API is currently in private beta but any user can request access by simply filling this form. Usually within a few hours, you will receive a confirmation email that you can now start using the Embed API.
Step 1: Set Up the Environment
To begin, set up the Databricks environment and install the necessary libraries:
1 - Create a new Databricks workspace:
Log in to your Databricks account at https://accounts.cloud.databricks.com/
Follow the steps outlined in the Databricks documentation to create a new workspace: https://docs.databricks.com/en/getting-started/index.html
2 - Create a new cluster or connect to an existing cluster:
Almost any ML cluster will work for this application. The below settings are provided for those seeking optimal price performance.
In your Compute tab, click “Create compute”
Select “Single node” and Runtime: 14.3 LTS ML non-GPU
The cluster policy and access mode can be left as the default
Select “r6i.xlarge” as the Node type
This will maximize memory utilization while only costing $0.252/hr on AWS and 1.02 DBU/hr on Databricks before any discounting
It was also one of the fastest options we tested
All other options can be left as the default
Click “Create compute” at the bottom and return to your workspace
3 - Create a new notebook in your Databricks workspace:
In your workspace, click "Create" and select "Notebook"
Name your notebook (e.g., "TwelveLabs_MosaicAI_VectorSearch_Integration")
Choose Python as the default language
4 - Install the Twelve Labs and Mosaic AI Vector Search SDKs:
In the first cell of your notebook, run the following command:
%pip install twelvelabs databricks-vectorsearch
%pip install twelvelabs databricks-vectorsearch
5 - Set up Twelve Labs authentication:
In the next cell, add the following code:
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
Note: For enhanced security, it's recommended to use Databricks secrets to store your API key rather than hardcoding it or using environment variables.
Step 2: Generate Multimodal Embeddings
Use the provided generate_embedding function to generate multimodal embeddings using Twelve Labs Embed API. This function is designed as a Pandas user-defined function (UDF) to work efficiently with Spark DataFrames in Databricks. It encapsulates the process of creating an embedding task, monitoring its progress, and retrieving the results.
Next, create a process_url function, which takes the video URL as string input and invokes a wrapper call to the Twelve Labs Embed API - returning an array<float>.
Here's how to implement and use it:
Define the UDF:
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
Create a sample DataFrame with video URLs:
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
Apply the UDF to generate embeddings:
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
Display the results:
df_with_embeddings.show(truncate=False)
df_with_embeddings.show(truncate=False)
This process will generate multimodal embeddings for each video URL in a DataFrame that will capture the multimodal essence of the video content, including visual, audio, and textual information.
Remember that generating embeddings can be computationally intensive and time-consuming for large video datasets. Consider implementing batching or distributed processing strategies for production-scale applications. Additionally, ensure that you have appropriate error handling and logging in place to manage potential API failures or network issues.
Step 3: Create a Delta Table for Video Embeddings
Now, create a source Delta Table to store video metadata and the embeddings generated by Twelve Labs Embed API. This table will serve as the foundation for a Vector Search index in Databricks Mosaic AI Vector Search.
First, create a source DataFrame with video URLs and metadata:
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
Next, declare the schema for the Delta table using SQL:
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
Note that Change Data Feed has been enabled on the table, which is crucial for creating and maintaining the Vector Search index.
Now, generate embeddings for your videos using the get_video_embeddings function defined earlier:
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
This step may take some time, depending on the number and length of your videos.
With your embeddings generated, now you can write the data to your Delta Table:
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
Finally, verify your data by displaying the DataFrame with embeddings:
display(embeddings_df)
display(embeddings_df)
This step creates a robust foundation for Vector Search capabilities. The Delta Table will automatically stay in sync with the Vector Search index, ensuring that any updates or additions to our video dataset are reflected in your search results.
Some key points to remember:
The
idcolumn is auto-generated, providing a unique identifier for each video.The
embeddingcolumn stores the high-dimensional vector representation of each video, generated by Twelve Labs Embed API.Enabling Change Data Feed allows Databricks to efficiently track changes in the table, which is crucial for maintaining an up-to-date Vector Search index.
Step 4: Configure Mosaic AI Vector Search
In this step, set up Databricks Mosaic AI Vector Search to work with video embeddings. This involves creating a Vector Search endpoint and a Delta Sync Index that will automatically stay in sync with your videos_source_embeddings Delta table.
First, create a Vector Search endpoint:
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
This code creates a new Vector Search endpoint or replaces an existing one with the same name. The endpoint will serve as the access point for your Vector Search operations.
Next, create a Delta Sync Index that will automatically stay in sync with your videos_source_embeddings Delta table:
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
This code creates a Delta Sync Index that links to your source Delta table. If you want the index to automatically update within seconds of changes made to the source table (ensuring your Vector Search results are always up-to-date), then set pipeline_type="CONTINUOUS".
To verify that the index has been created and is syncing correctly, use the following code to trigger the sync:
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
This code allows you to check the status of your index and manually trigger a sync if needed. In production, you may prefer to set the pipeline to sync automatically based on changes to the source Delta table.
Key points to remember:
The Vector Search endpoint serves as the access point for Vector Search operations.
The Delta Sync Index automatically stays in sync with the source Delta table, ensuring up-to-date search results.
The
embedding_dimensionshould match the dimension of the embeddings generated by Twelve Labs' Embed API (1024).The
primary_keyis set to "id", which should correspond to the unique identifier in our source table.The
embedding_vector_columnis set to "embedding," which should match the column name in our source table containing the video embeddings.
Step 5: Implementing Similarity Search
The next step is to implement similarity search functionality using your configured Mosaic AI Vector Search index and Twelve Labs Embed API. This will allow you to find videos similar to a given text query by leveraging the power of multimodal embeddings.
First, define a function to get the embedding for a text query using Twelve Labs Embed API:
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
This function takes a text query and returns its embedding using the same model as video embeddings, ensuring compatibility in the vector space.
Next, implement the similarity search function:
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
This function takes a text query and the number of results to return. It generates an embedding for the query, and then uses the Mosaic AI Vector Search index to find similar videos.
To parse and display the search results, use the following helper function:
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
Now, put it all together and perform a sample search:
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
This code demonstrates how to use Twelve Labs’ similarity search function to find videos related to the query "A dragon". It then parses and displays the results in a user-friendly format.
Key points to remember:
The
get_text_embeddingfunction uses the same Twelve Labs model as our video embeddings, ensuring compatibility.The
similarity_searchfunction combines text-to-embedding conversion with Vector Search to find similar videos.Error handling is crucial, as network issues or API changes could affect the search process.
The
parse_search_resultsfunction helps convert the raw API response into a more usable format.You can adjust the
num_resultsparameter in thesimilarity_searchfunction to control the number of results returned.
This implementation enables powerful semantic search capabilities across your video dataset. Users can now find relevant videos using natural language queries, leveraging the rich multimodal embeddings generated by Twelve Labs Embed API.
Step 6: Build a Video Recommendation System
Now, it’s time to create a basic video recommendation system using the multimodal embeddings generated by Twelve Labs Embed API and Databricks Mosaic AI Vector Search. This system will suggest videos similar to a given video based on their embedding similarities.
First, implement a simple recommendation function:
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
This implementation does the following:
The
get_video_recommendationsfunction takes a video ID and the number of recommendations to return.It retrieves the embedding for the given video from a source Delta table.
Using this embedding, it performs a similarity search to find the most similar videos.
The function removes the input video from the results (if present) to avoid recommending the same video.
The
display_recommendationshelper function formats and prints the recommendations in a user-friendly manner.
To use this recommendation system:
Ensure you have videos in your
videos_source_embeddingstable with valid embeddings.Call the
get_video_recommendationsfunction with a valid video ID from your dataset.The function will return and display a list of recommended videos based on similarity.
This basic recommendation system demonstrates how to leverage multimodal embeddings for content-based video recommendations. It can be extended and improved in several ways:
Incorporate user preferences and viewing history for personalized recommendations.
Implement diversity mechanisms to ensure varied recommendations.
Add filters based on video metadata (e.g., genre, length, upload date).
Implement caching mechanisms for frequently requested recommendations to improve performance.
Remember that the quality of recommendations depends on the size and diversity of your video dataset, as well as the accuracy of the embeddings generated by Twelve Labs Embed API. As you add more videos to your system, the recommendations should become more relevant and diverse.
Take this Integration to the Next Level
Update and Sync the Index
As your video library grows and evolves, it's crucial to keep your Vector Search index up-to-date. Mosaic AI Vector Search offers seamless synchronization with your source Delta table, ensuring that recommendations and search results always reflect the latest data.
Key considerations for index updates and synchronization:
Incremental updates: Leverage Delta Lake's change data feed to efficiently update only the modified or new records in your index.
Scheduled syncs: Implement regular synchronization jobs using Databricks workflow orchestration tools to maintain index freshness.
Real-time updates: For time-sensitive applications, consider implementing near real-time index updates using Databricks Mosaic AI streaming capabilities.
Version management: Utilize Delta Lake's time travel feature to maintain multiple versions of your index, allowing for easy rollbacks if needed.
Monitoring sync status: Implement logging and alerting mechanisms to track successful syncs and quickly identify any issues in the update process.
By mastering these techniques, you'll ensure that your TwelveLabs video embeddings are always current and readily available for advanced search and recommendation use cases.
Optimize Performance and Scaling
As your video analysis pipeline grows, it is important to continue optimizing performance and scaling your solution. Distributed computing capabilities from Databricks, combined with efficient embedding generation from Twelve Labs, provide a robust foundation for handling large-scale video processing tasks.
Consider these strategies for optimizing and scaling your solution:
Distributed processing: Leverage Databricks Spark clusters to parallelize embedding generation and indexing tasks across multiple nodes.
Caching strategies: Implement intelligent caching mechanisms for frequently accessed embeddings to reduce API calls and improve response times.
Batch processing: For large video libraries, implement batch processing workflows to generate embeddings and update indexes during off-peak hours.
Query optimization: Fine-tune Vector Search queries by adjusting parameters like
num_resultsand implementing efficient filtering techniques.Index partitioning: For massive datasets, explore index partitioning strategies to improve query performance and enable more granular updates.
Auto-scaling: Utilize Databricks auto-scaling features to dynamically adjust computational resources based on workload demands.
Edge computing: For latency-sensitive applications, consider deploying lightweight versions of your models closer to the data source.
By implementing these optimization techniques, you'll be well-equipped to handle growing video libraries and increasing user demands while maintaining high performance and cost efficiency.
Monitoring and Analytics
Implementing robust monitoring and analytics is essential to ensuring the ongoing success of your video understanding pipeline. Databricks provides powerful tools for tracking system performance, user engagement, and business impact.
Key areas to focus on for monitoring and analytics:
Performance metrics: Track key performance indicators such as query latency, embedding generation time, and index update duration.
Usage analytics: Monitor user interactions, popular search queries, and frequently recommended videos to gain insights into user behavior.
Quality assessment: Implement feedback loops to evaluate the relevance of search results and recommendations, using both automated metrics and user feedback.
Resource utilization: Keep an eye on computational resource usage, API call volumes, and storage consumption to optimize costs and performance.
Error tracking: Set up comprehensive error logging and alerting to quickly identify and resolve issues in the pipeline.
A/B testing: Utilize experimentation capabilities from Databricks to test different embedding models, search algorithms, or recommendation strategies.
Business impact analysis: Correlate video understanding capabilities with key business metrics like user engagement, content consumption, or conversion rates.
Compliance monitoring: Ensure your video processing pipeline adheres to data privacy regulations and content moderation guidelines.
By implementing a comprehensive monitoring and analytics strategy, you'll gain valuable insights into your video understanding pipeline's performance and impact. This data-driven approach will enable continuous improvement and help you demonstrate the value of integrating advanced video understanding capabilities from Twelve Labs with the Databricks Data Intelligence Platform.
Conclusion
Twelve Labs and Databricks Mosaic AI provide a robust framework for advanced video understanding and analysis. This integration leverages multimodal embeddings and efficient Vector Search capabilities, enabling developers to construct sophisticated video search, recommendation, and analysis systems.
This tutorial has walked through the technical steps of setting up the environment, generating embeddings, configuring Vector Search, and implementing basic search and recommendation functionalities. It also addresses key considerations for scaling, optimizing, and monitoring your solution.
In the evolving landscape of video content, the ability to extract precise insights from this medium is critical. This integration equips developers with the tools to address complex video understanding tasks. We encourage you to explore the technical capabilities, experiment with advanced use cases, and contribute to the community of AI engineers advancing video understanding technology.
Additional Resources
To further explore and leverage this integration, consider the following resources:
These resources will help you stay at the forefront of video AI technology and continue to build innovative solutions using Twelve Labs and Databricks.
Short Summary
Twelve Labs Embed API enables developers to get multimodal embeddings that power advanced video understanding use cases, from semantic video search and data curation to content recommendation and video RAG systems.
With Twelve Labs, contextual vector representations can be generated that capture the relationship between visual expressions, body language, spoken words, and overall context within videos. Databricks Mosaic AI Vector Search provides a robust, scalable infrastructure for indexing and querying high-dimensional vectors.
This blog post will guide you through harnessing these complementary technologies to unlock new possibilities in video AI applications.
Big thanks to Nina Williams, Austin Zaccor, Fernanda Heredia, and Emily Hutson from Databricks for collaborating with us on this tutorial!
Why Twelve Labs + Databricks Mosaic AI?
Integrating Twelve Labs Embed API with Databricks Mosaic AI Vector Search addresses key challenges in video AI, such as efficient processing of large-scale video datasets and accurate multimodal content representation. This integration reduces development time and resource needs for advanced video applications, enabling complex queries across vast video libraries and enhancing overall workflow efficiency.
The unified approach to handling multimodal data is particularly noteworthy. Instead of juggling separate models for text, image, and audio analysis, users can now work with a single, coherent representation that captures the essence of video content in its entirety. This not only simplifies deployment architecture but also enables more nuanced and context-aware applications, from sophisticated content recommendation systems to advanced video search engines and automated content moderation tools.
Moreover, this integration extends the capabilities of the Databricks ecosystem, allowing seamless incorporation of video understanding into existing data pipelines and machine learning workflows. Whether companies are developing real-time video analytics, building large-scale content classification systems, or exploring novel applications in Generative AI, this combined solution provides a powerful foundation. It pushes the boundaries of what's possible in video AI, opening up new avenues for innovation and problem-solving in industries ranging from media and entertainment to security and healthcare.
Understanding Twelve Labs' Embed API
Twelve Labs' Embed API represents a significant advancement in multimodal embedding technology, specifically designed for video content. Unlike traditional approaches that rely on frame-by-frame analysis or separate models for different modalities, this API generates contextual vector representations that capture the intricate interplay of visual expressions, body language, spoken words, and overall context within videos. It is powered by our state-of-the-art multimodal foundation model Marengo-2.6.
The Embed API offers several key features that make it particularly powerful for AI engineers working with video data. First, it provides flexibility for any modality present in videos, eliminating the need for separate text-only or image-only models. Second, it employs a video-native approach that accounts for motion, action, and temporal information, ensuring a more accurate and temporally coherent interpretation of video content. Lastly, it creates a unified vector space that integrates embeddings from all modalities, facilitating a more holistic understanding of the video content.
For AI engineers, the Embed API opens up new possibilities in video understanding tasks. It enables more sophisticated content analysis, improved semantic search capabilities, and enhanced recommendation systems. The API's ability to capture subtle cues and interactions between different modalities over time makes it particularly valuable for applications requiring a nuanced understanding of video content, such as emotion recognition, context-aware content moderation, and advanced video retrieval systems.
Prerequisites
Before integrating Twelve Labs Embed API with Databricks Mosaic AI Vector Search, be sure you have the following prerequisites:
A Databricks account with access to create and manage workspaces. (You can sign up for a free trial at https://databricks.com/try-databricks)
Familiarity with Python programming and basic data science concepts.
A Twelve Labs API key. (Sign up at playground.twelvelabs.io)
Basic understanding of vector embeddings and similarity search concepts.
(Optional) An AWS account if using Databricks on AWS. This is not required if using Databricks on Azure or Google Cloud.
Note: The Embed API is currently in private beta but any user can request access by simply filling this form. Usually within a few hours, you will receive a confirmation email that you can now start using the Embed API.
Step 1: Set Up the Environment
To begin, set up the Databricks environment and install the necessary libraries:
1 - Create a new Databricks workspace:
Log in to your Databricks account at https://accounts.cloud.databricks.com/
Follow the steps outlined in the Databricks documentation to create a new workspace: https://docs.databricks.com/en/getting-started/index.html
2 - Create a new cluster or connect to an existing cluster:
Almost any ML cluster will work for this application. The below settings are provided for those seeking optimal price performance.
In your Compute tab, click “Create compute”
Select “Single node” and Runtime: 14.3 LTS ML non-GPU
The cluster policy and access mode can be left as the default
Select “r6i.xlarge” as the Node type
This will maximize memory utilization while only costing $0.252/hr on AWS and 1.02 DBU/hr on Databricks before any discounting
It was also one of the fastest options we tested
All other options can be left as the default
Click “Create compute” at the bottom and return to your workspace
3 - Create a new notebook in your Databricks workspace:
In your workspace, click "Create" and select "Notebook"
Name your notebook (e.g., "TwelveLabs_MosaicAI_VectorSearch_Integration")
Choose Python as the default language
4 - Install the Twelve Labs and Mosaic AI Vector Search SDKs:
In the first cell of your notebook, run the following command:
%pip install twelvelabs databricks-vectorsearch
5 - Set up Twelve Labs authentication:
In the next cell, add the following code:
from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
Note: For enhanced security, it's recommended to use Databricks secrets to store your API key rather than hardcoding it or using environment variables.
Step 2: Generate Multimodal Embeddings
Use the provided generate_embedding function to generate multimodal embeddings using Twelve Labs Embed API. This function is designed as a Pandas user-defined function (UDF) to work efficiently with Spark DataFrames in Databricks. It encapsulates the process of creating an embedding task, monitoring its progress, and retrieving the results.
Next, create a process_url function, which takes the video URL as string input and invokes a wrapper call to the Twelve Labs Embed API - returning an array<float>.
Here's how to implement and use it:
Define the UDF:
from pyspark.sql.functions import pandas_udf from pyspark.sql.types import ArrayType, FloatType from twelvelabs.models.embed import EmbeddingsTask import pandas as pd @pandas_udf(ArrayType(FloatType())) def get_video_embeddings(urls: pd.Series) -> pd.Series: def generate_embedding(video_url): twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) task.wait_for_done() task_result = twelvelabs_client.embed.task.retrieve(task.id) embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings def process_url(url): embeddings = generate_embedding(url) return embeddings[0]['embedding'] if embeddings else None return urls.apply(process_url)
Create a sample DataFrame with video URLs:
video_urls = [ "https://example.com/video1.mp4", "https://example.com/video2.mp4", "https://example.com/video3.mp4" ] df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
Apply the UDF to generate embeddings:
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
Display the results:
df_with_embeddings.show(truncate=False)
This process will generate multimodal embeddings for each video URL in a DataFrame that will capture the multimodal essence of the video content, including visual, audio, and textual information.
Remember that generating embeddings can be computationally intensive and time-consuming for large video datasets. Consider implementing batching or distributed processing strategies for production-scale applications. Additionally, ensure that you have appropriate error handling and logging in place to manage potential API failures or network issues.
Step 3: Create a Delta Table for Video Embeddings
Now, create a source Delta Table to store video metadata and the embeddings generated by Twelve Labs Embed API. This table will serve as the foundation for a Vector Search index in Databricks Mosaic AI Vector Search.
First, create a source DataFrame with video URLs and metadata:
from pyspark.sql import Row # Create a list of sample video URLs and metadata video_data = [ Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'), Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny') ] # Create a DataFrame from the list source_df = spark.createDataFrame(video_data) source_df.show()
Next, declare the schema for the Delta table using SQL:
%sql CREATE TABLE IF NOT EXISTS videos_source_embeddings ( id BIGINT GENERATED BY DEFAULT AS IDENTITY, url STRING, title STRING, embedding ARRAY<FLOAT> ) TBLPROPERTIES (delta.enableChangeDataFeed = true)
Note that Change Data Feed has been enabled on the table, which is crucial for creating and maintaining the Vector Search index.
Now, generate embeddings for your videos using the get_video_embeddings function defined earlier:
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
This step may take some time, depending on the number and length of your videos.
With your embeddings generated, now you can write the data to your Delta Table:
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
Finally, verify your data by displaying the DataFrame with embeddings:
display(embeddings_df)
This step creates a robust foundation for Vector Search capabilities. The Delta Table will automatically stay in sync with the Vector Search index, ensuring that any updates or additions to our video dataset are reflected in your search results.
Some key points to remember:
The
idcolumn is auto-generated, providing a unique identifier for each video.The
embeddingcolumn stores the high-dimensional vector representation of each video, generated by Twelve Labs Embed API.Enabling Change Data Feed allows Databricks to efficiently track changes in the table, which is crucial for maintaining an up-to-date Vector Search index.
Step 4: Configure Mosaic AI Vector Search
In this step, set up Databricks Mosaic AI Vector Search to work with video embeddings. This involves creating a Vector Search endpoint and a Delta Sync Index that will automatically stay in sync with your videos_source_embeddings Delta table.
First, create a Vector Search endpoint:
from databricks.vector_search.client import VectorSearchClient # Initialize the Vector Search client and name the endpoint mosaic_client = VectorSearchClient() endpoint_name = "twelve_labs_video_endpoint" # Delete the existing endpoint if it exists try: mosaic_client.delete_endpoint(endpoint_name) print(f"Deleted existing endpoint: {endpoint_name}") except Exception: pass # Ignore non-existing endpoints # Create the new endpoint endpoint = mosaic_client.create_endpoint( name=endpoint_name, endpoint_type="STANDARD" )
This code creates a new Vector Search endpoint or replaces an existing one with the same name. The endpoint will serve as the access point for your Vector Search operations.
Next, create a Delta Sync Index that will automatically stay in sync with your videos_source_embeddings Delta table:
# Define the source table name and index name source_table_name = "twelvelabs.default.videos_source_embeddings" index_name = "twelvelabs.default.video_embeddings_index" index = mosaic_client.create_delta_sync_index( endpoint_name="twelve_labs_video_endpoint", source_table_name=source_table_name, index_name=index_name, primary_key="id", embedding_dimension=1024, embedding_vector_column="embedding", pipeline_type="TRIGGERED" ) print(f"Created index: {index.name}")
This code creates a Delta Sync Index that links to your source Delta table. If you want the index to automatically update within seconds of changes made to the source table (ensuring your Vector Search results are always up-to-date), then set pipeline_type="CONTINUOUS".
To verify that the index has been created and is syncing correctly, use the following code to trigger the sync:
# Check the status of the index; this may take some time index_status = mosaic_client.get_index( endpoint_name="twelve_labs_video_endpoint", index_name="twelvelabs.default.video_embeddings_index" ) print(f"Index status: {index_status}") # Manually trigger the index sync try: index.sync() print("Index sync triggered successfully.") except Exception as e: print(f"Error triggering index sync: {str(e)}")
This code allows you to check the status of your index and manually trigger a sync if needed. In production, you may prefer to set the pipeline to sync automatically based on changes to the source Delta table.
Key points to remember:
The Vector Search endpoint serves as the access point for Vector Search operations.
The Delta Sync Index automatically stays in sync with the source Delta table, ensuring up-to-date search results.
The
embedding_dimensionshould match the dimension of the embeddings generated by Twelve Labs' Embed API (1024).The
primary_keyis set to "id", which should correspond to the unique identifier in our source table.The
embedding_vector_columnis set to "embedding," which should match the column name in our source table containing the video embeddings.
Step 5: Implementing Similarity Search
The next step is to implement similarity search functionality using your configured Mosaic AI Vector Search index and Twelve Labs Embed API. This will allow you to find videos similar to a given text query by leveraging the power of multimodal embeddings.
First, define a function to get the embedding for a text query using Twelve Labs Embed API:
def get_text_embedding(text_query): # Twelve Labs Embed API supports text-to-embedding text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text=text_query, text_truncate="start" ) return text_embedding.text_embedding.float
This function takes a text query and returns its embedding using the same model as video embeddings, ensuring compatibility in the vector space.
Next, implement the similarity search function:
def similarity_search(query_text, num_results=5): # Initialize the Vector Search client and get the query embedding mosaic_client = VectorSearchClient() query_embedding = get_text_embedding(query_text) print(f"Query embedding generated: {len(query_embedding)} dimensions") # Perform the similarity search results = index.similarity_search( query_vector=query_embedding, num_results=num_results, columns=["id", "url", "title"] ) return results
This function takes a text query and the number of results to return. It generates an embedding for the query, and then uses the Mosaic AI Vector Search index to find similar videos.
To parse and display the search results, use the following helper function:
def parse_search_results(raw_results): try: data_array = raw_results['result']['data_array'] columns = [col['name'] for col in raw_results['manifest']['columns']] return [dict(zip(columns, row)) for row in data_array] except KeyError: print("Unexpected result format:", raw_results) return []
Now, put it all together and perform a sample search:
# Example usage query = "A dragon" raw_results = similarity_search(query) # Parse and print the search results search_results = parse_search_results(raw_results) if search_results: print(f"Top {len(search_results)} videos similar to the query: '{query}'") for i, result in enumerate(search_results, 1): print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}") else: print("No valid search results returned.")
This code demonstrates how to use Twelve Labs’ similarity search function to find videos related to the query "A dragon". It then parses and displays the results in a user-friendly format.
Key points to remember:
The
get_text_embeddingfunction uses the same Twelve Labs model as our video embeddings, ensuring compatibility.The
similarity_searchfunction combines text-to-embedding conversion with Vector Search to find similar videos.Error handling is crucial, as network issues or API changes could affect the search process.
The
parse_search_resultsfunction helps convert the raw API response into a more usable format.You can adjust the
num_resultsparameter in thesimilarity_searchfunction to control the number of results returned.
This implementation enables powerful semantic search capabilities across your video dataset. Users can now find relevant videos using natural language queries, leveraging the rich multimodal embeddings generated by Twelve Labs Embed API.
Step 6: Build a Video Recommendation System
Now, it’s time to create a basic video recommendation system using the multimodal embeddings generated by Twelve Labs Embed API and Databricks Mosaic AI Vector Search. This system will suggest videos similar to a given video based on their embedding similarities.
First, implement a simple recommendation function:
def get_video_recommendations(video_id, num_recommendations=5): # Initialize the Vector Search client mosaic_client = VectorSearchClient() # First, retrieve the embedding for the given video_id source_df = spark.table("videos_source_embeddings") video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first() if not video_embedding: print(f"No video found with id: {video_id}") return [] # Perform similarity search using the video's embedding try: results = index.similarity_search( query_vector=video_embedding["embedding"], num_results=num_recommendations + 1, # +1 to account for the input video columns=["id", "url", "title"] ) # Parse the results recommendations = parse_search_results(results) # Remove the input video from recommendations if present recommendations = [r for r in recommendations if r.get('id') != video_id] return recommendations[:num_recommendations] except Exception as e: print(f"Error during recommendation: {e}") return [] # Helper function to display recommendations def display_recommendations(recommendations): if recommendations: print(f"Top {len(recommendations)} recommended videos:") for i, video in enumerate(recommendations, 1): print(f"{i}. Title: {video.get('title', 'N/A')}") print(f" URL: {video.get('url', 'N/A')}") print(f" Similarity Score: {video.get('score', 'N/A')}") print() else: print("No recommendations found.") # Example usage video_id = 1 # Assuming this is a valid video ID in your dataset recommendations = get_video_recommendations(video_id) display_recommendations(recommendations)
This implementation does the following:
The
get_video_recommendationsfunction takes a video ID and the number of recommendations to return.It retrieves the embedding for the given video from a source Delta table.
Using this embedding, it performs a similarity search to find the most similar videos.
The function removes the input video from the results (if present) to avoid recommending the same video.
The
display_recommendationshelper function formats and prints the recommendations in a user-friendly manner.
To use this recommendation system:
Ensure you have videos in your
videos_source_embeddingstable with valid embeddings.Call the
get_video_recommendationsfunction with a valid video ID from your dataset.The function will return and display a list of recommended videos based on similarity.
This basic recommendation system demonstrates how to leverage multimodal embeddings for content-based video recommendations. It can be extended and improved in several ways:
Incorporate user preferences and viewing history for personalized recommendations.
Implement diversity mechanisms to ensure varied recommendations.
Add filters based on video metadata (e.g., genre, length, upload date).
Implement caching mechanisms for frequently requested recommendations to improve performance.
Remember that the quality of recommendations depends on the size and diversity of your video dataset, as well as the accuracy of the embeddings generated by Twelve Labs Embed API. As you add more videos to your system, the recommendations should become more relevant and diverse.
Take this Integration to the Next Level
Update and Sync the Index
As your video library grows and evolves, it's crucial to keep your Vector Search index up-to-date. Mosaic AI Vector Search offers seamless synchronization with your source Delta table, ensuring that recommendations and search results always reflect the latest data.
Key considerations for index updates and synchronization:
Incremental updates: Leverage Delta Lake's change data feed to efficiently update only the modified or new records in your index.
Scheduled syncs: Implement regular synchronization jobs using Databricks workflow orchestration tools to maintain index freshness.
Real-time updates: For time-sensitive applications, consider implementing near real-time index updates using Databricks Mosaic AI streaming capabilities.
Version management: Utilize Delta Lake's time travel feature to maintain multiple versions of your index, allowing for easy rollbacks if needed.
Monitoring sync status: Implement logging and alerting mechanisms to track successful syncs and quickly identify any issues in the update process.
By mastering these techniques, you'll ensure that your TwelveLabs video embeddings are always current and readily available for advanced search and recommendation use cases.
Optimize Performance and Scaling
As your video analysis pipeline grows, it is important to continue optimizing performance and scaling your solution. Distributed computing capabilities from Databricks, combined with efficient embedding generation from Twelve Labs, provide a robust foundation for handling large-scale video processing tasks.
Consider these strategies for optimizing and scaling your solution:
Distributed processing: Leverage Databricks Spark clusters to parallelize embedding generation and indexing tasks across multiple nodes.
Caching strategies: Implement intelligent caching mechanisms for frequently accessed embeddings to reduce API calls and improve response times.
Batch processing: For large video libraries, implement batch processing workflows to generate embeddings and update indexes during off-peak hours.
Query optimization: Fine-tune Vector Search queries by adjusting parameters like
num_resultsand implementing efficient filtering techniques.Index partitioning: For massive datasets, explore index partitioning strategies to improve query performance and enable more granular updates.
Auto-scaling: Utilize Databricks auto-scaling features to dynamically adjust computational resources based on workload demands.
Edge computing: For latency-sensitive applications, consider deploying lightweight versions of your models closer to the data source.
By implementing these optimization techniques, you'll be well-equipped to handle growing video libraries and increasing user demands while maintaining high performance and cost efficiency.
Monitoring and Analytics
Implementing robust monitoring and analytics is essential to ensuring the ongoing success of your video understanding pipeline. Databricks provides powerful tools for tracking system performance, user engagement, and business impact.
Key areas to focus on for monitoring and analytics:
Performance metrics: Track key performance indicators such as query latency, embedding generation time, and index update duration.
Usage analytics: Monitor user interactions, popular search queries, and frequently recommended videos to gain insights into user behavior.
Quality assessment: Implement feedback loops to evaluate the relevance of search results and recommendations, using both automated metrics and user feedback.
Resource utilization: Keep an eye on computational resource usage, API call volumes, and storage consumption to optimize costs and performance.
Error tracking: Set up comprehensive error logging and alerting to quickly identify and resolve issues in the pipeline.
A/B testing: Utilize experimentation capabilities from Databricks to test different embedding models, search algorithms, or recommendation strategies.
Business impact analysis: Correlate video understanding capabilities with key business metrics like user engagement, content consumption, or conversion rates.
Compliance monitoring: Ensure your video processing pipeline adheres to data privacy regulations and content moderation guidelines.
By implementing a comprehensive monitoring and analytics strategy, you'll gain valuable insights into your video understanding pipeline's performance and impact. This data-driven approach will enable continuous improvement and help you demonstrate the value of integrating advanced video understanding capabilities from Twelve Labs with the Databricks Data Intelligence Platform.
Conclusion
Twelve Labs and Databricks Mosaic AI provide a robust framework for advanced video understanding and analysis. This integration leverages multimodal embeddings and efficient Vector Search capabilities, enabling developers to construct sophisticated video search, recommendation, and analysis systems.
This tutorial has walked through the technical steps of setting up the environment, generating embeddings, configuring Vector Search, and implementing basic search and recommendation functionalities. It also addresses key considerations for scaling, optimizing, and monitoring your solution.
In the evolving landscape of video content, the ability to extract precise insights from this medium is critical. This integration equips developers with the tools to address complex video understanding tasks. We encourage you to explore the technical capabilities, experiment with advanced use cases, and contribute to the community of AI engineers advancing video understanding technology.
Additional Resources
To further explore and leverage this integration, consider the following resources:
These resources will help you stay at the forefront of video AI technology and continue to build innovative solutions using Twelve Labs and Databricks.




©
2026년
주식회사 트웰브랩스. All Rights Reserved

©
2026년
주식회사 트웰브랩스. All Rights Reserved

©
2026년
주식회사 트웰브랩스. All Rights Reserved


