
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
チュートリアル
Twelve Labs APIを使用してビデオOCRを実行する方法

アンキット・カレ
Twelve Labs APIを使用すると、OCRインフラを構築・保守することなく、動画からの画面上テキストの抽出や、インデックス化された動画ライブラリ全体でのテキストベースの検索が可能になります。このチュートリアルでは、動画レベルのテキスト抽出とインデックスレベルの動画内テキスト検索の両方をカバーし、結果を表示するためのFlaskアプリも紹介します。
Twelve Labs APIを使用すると、OCRインフラを構築・保守することなく、動画からの画面上テキストの抽出や、インデックス化された動画ライブラリ全体でのテキストベースの検索が可能になります。このチュートリアルでは、動画レベルのテキスト抽出とインデックスレベルの動画内テキスト検索の両方をカバーし、結果を表示するためのFlaskアプリも紹介します。

この記事の内容
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2023/05/19
13分
記事へのリンクをコピー
ビデオ光学文字認識(OCR)は、コンピュータビジョンと機械学習アルゴリズムを使用してビデオフレームからテキストを検出および抽出する技術です。ビデオOCRを使用すると、ビデオコンテンツを簡単に精査し、特定の単語、フレーズ、さらには文全体が画面に表示される正確な瞬間をピンポイントで特定できます。コンテンツ検索やナビゲーションの合理化から、コンテンツ分析の深化、広告配置の最適化、コンテンツの要約、SEOの強化、コンプライアンスとモニタリングの確保にいたるまで、その用途を想像してみてください。
ビデオOCRで認識できる要素の例は以下の通りです:
プレゼンテーションや会議中のスライドコンテンツ
広告、映画、テレビ番組などで画面上に紹介される製品名
スポーツ中継中にユニフォームに表示される選手名やチーム名
会議やカンファレンス中に表示される名札や名前
講義ビデオ内のホワイトボードへの落書き
ビデオ映像内に写り込んでいる文書
画面上に表示される手書きテキスト
ナンバープレートの番号や建物名
映画やインタビュー内の字幕、キャプション、エンディングクレジット
このチュートリアルでは、Twelve Labsプラットフォームが2つの異なるレベルでビデオOCRをどのように実現しているかを探ります。ビデオレベルでは、ビデオ全体を一度に処理し、そこに含まれるあらゆるテキスト情報を活用します。一方、インデックスレベルのアプローチでは焦点を絞り込み、特定のキーワードまたはキーワードのクラスターに狙いを定めます。これらは自然言語クエリとして入力され、Twelve Labsプラットフォーム上でインデックス化されたビデオライブラリ全体から包括的な検索を行うために使用されます。
さらに嬉しいことに、Twelve Labs APIを利用すれば、OCRプロセスの実装や維持といった細かな作業を心配することなく、これらすべてを達成できます。開発からインフラストラクチャ、さらには継続的なサポートに至るまで、私たちがお客様をバックアップします。それでは準備を整えて、ビデオOCRの領域へのエキサイティングな探検へと一緒に出発しましょう。
前提条件
Twelve Labsプラットフォームは現在オープンベータ段階にあり、新規登録時に最大10時間分の無料ビデオインデックス作成クレジットを提供しています。このチュートリアルに進む前に、登録を済ませてTwelve Labsプラットフォームの基本的な側面に慣れておくと有利です。ビデオインデックス作成、インデックスオプション、Task API、検索オプションなどの理解は、このチュートリアルをスムーズに進める上で不可欠です。これらについては、私の最初のチュートリアルで詳しく説明しています。ただし、途中で行き詰まったり迷ったりした場合は、遠慮なくお問い合わせください。ちなみに、Discordがお好みのプラットフォームであれば、私たちのDiscordサーバーでの応答時間は驚くほど速い 🚅🏎️⚡️ です。
チュートリアルの簡単な流れ
前回の説明に続き、ビデオOCRに2つの異なる角度とレベルから取り組みます。したがって、このチュートリアルを2つの極めて重要なセクションに分け、最後にすべてを統合して実際に動作するデモWebアプリを作成するフィナーレへと進みます:
ビデオOCR - 3つのステッププロセス
特定のビデオから認識されたすべてのテキストを抽出するプロセスは、次の3つのステップで構成されます:
ビデオインデックス作成 - このステップに驚きはありません。過去のチュートリアルを読んできた方にとって、このステップは馴染みのある友人のように感じられるはずです。
ビデオの一意識別子の取得 - Twelve Labsプラットフォームがビデオのインデックス作成を完了したら、OCRが必要なビデオの一意の識別子を取得します。
画面に表示されるテキストの抽出 - 作成した特定のインデックスと、OCRが必要なビデオに関連付けられたビデオIDを使用して、ビデオをピンポイントで特定します。APIが面倒な処理をすべて行い、求めている結果を提供します。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
ビデオOCRにより、ビデオ全体を精査してすべてのテキストのインスタンスを抽出することができました。今度は、ビデオ内テキスト検索機能により、入力または検索されたテキストが出現する正確な瞬間やビデオのスニペットに焦点を当てることができます。これにより、大量のビデオカタログを調査する時間が大幅に短縮され、ビデオ再生中に画面に表示されるテキストと検索用語の一致に基づいた正確な検索結果が得られます。
最初のチュートリアルでは、自然言語クエリと、ビジュアル(オーディオビジュアル検索)、会話(対話検索)、ビデオ内テキスト(OCR)などのさまざまな検索オプションを使用して、インデックス化されたビデオ内のコンテンツ検索について掘り下げました。このチュートリアルでは、アプローチを再利用し、OCR技術のみを活用してビデオ内のテキストを検索します。処理時間とコストを最適化するために、text_in_videoインデックスオプションのみを使用してインデックスを作成します。その後、text_in_video検索オプションを使用して検索クエリを実行し、インデックス化されたビデオ内で関連するテキストの一致を検出します。
デモアプリの構築
これらをすべてまとめるために、APIエンドポイントから得られたデータをWebページに表示し、シンプルなHTMLページを提供するFlaskベースのデモアプリを立ち上げます。ビデオOCRの結果は、タイムスタンプと関連テキストを表示してきれいに表形式でまとめられ、テキスト検索では使用したクエリとそれに対応して見つかったビデオセグメントが表示されます。
ビデオOCR - 3つのステッププロセス
分かりやすくするために、既存のアカウントを使用して2つのビデオのみをインデックスにアップロードしました。お気軽に新規登録してください。現在オープンベータ期間中のため、最大10時間のビデオコンテンツをインデックス化できる無料クレジットを差し上げます。それ以上の要件がある場合は、デベロッパープランへのアップグレードについて料金ページをご確認ください。
ビデオインデックス作成
ここでは、Jupyter Notebookに含める必要のある重要な要素について掘り下げます。これには、必要なインポート、API URLの定義、インデックスの作成、ローカルファイルシステムからのビデオのアップロードによるインデックス作成プロセスの開始が含まれます:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= tlk_2FGGACN2TFAH1N2H1HBXR0BDQ9GV !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes INDEX_ID = create_index(index_name = "extract_text", index_options=["text_in_video"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {INDEX_ID}") </code></pre>
先ほど作成したインデックスに2つのビデオをアップロードします。ビデオのタイトルは「A Brief History of Film」(Film Thought Projectの提供、https://www.youtube.com/watch?v=utntGgcsZWI で視聴可能)と「GPT - Explained!」(CodeEmporiumの提供、https://www.youtube.com/watch?v=3IweGfgytgY で視聴可能)です。これらのビデオをそれぞれのYouTubeチャンネルからダウンロードし、ローカルハードドライブの「static」という名前のフォルダに保存しました。これらのローカルファイルを使用して、Twelve Labsプラットフォームにビデオをインデックス化します:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
ビデオの一意の識別子の取得
それでは、インデックス内のすべてのビデオをリストアップしてみましょう。これにより、特定のビデオのビデオIDを保持し、そのビデオに埋め込まれているすべてのテキストを抽出することができます。さらに、前のチュートリアルでの方法と同様に、Flaskアプリケーションに後で提供できるように設計された、ビデオIDとそれぞれのタイトルのリストを組み立てます。
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='644a73aa8b1dd6cde172a933' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
出力:
<pre><code class="python">{'data': [{'_id': '###a917186daab572f349243', 'created_at': '2023-04-27T14:18:48Z', 'metadata': {'duration': 1300.173875, 'engine_id': 'marengo2.5', 'filename': 'A Brief History of Film.mp4', 'fps': 23.976023976023978, 'height': 720, 'size': 188214297, 'width': 1280}, 'updated_at': '2023-04-27T14:20:11Z'}, {'_id': '###3da86daab572f349241', 'created_at': '2023-04-27T13:08:19Z', 'metadata': {'duration': 550.7, 'engine_id': 'marengo2.5', 'filename': 'GPT - Explained!.mp4', 'fps': 30, 'height': 720, 'size': 22838593, 'width': 1152}, 'updated_at': '2023-04-27T13:08:42Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 5402.873875, 'total_page': 1, 'total_results': 3}} [{'video_id': '###a849b86daab572f349242', 'video_name': 'A Brief History of Film.mp4'}, {'video_id': '###a73da86daab572f349241', 'video_name': 'GPT - Explained!.mp4'}] </code></pre>
画面に表示されるテキストの抽出
計画を実行に移す時が来ました!選択したビデオからすべてのテキストコンテンツの抽出を進めます:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' TEXT_IN_VIDEO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/text-in-video" response = requests.get(TEXT_IN_VIDEO_URL, headers=default_header) print (f"Status code: {response.status_code}") ocr_data = response.json() pprint (ocr_data) </code></pre>
出力:
<pre><code class="python">Status code: 200 {'data': [{'end': 3, 'start': 1, 'value': 'Film Thought Project'}, {'end': 6, 'start': 5, 'value': 'Film'}, {'end': 22, 'start': 18, 'value': "'L'arrivée d'un train en gare de La Ciotat"}, {'end': 28, 'start': 18, 'value': 'Year:'}, {'end': 28, 'start': 23, 'value': '2015'}, {'end': 28, 'start': 23, 'value': 'Production Co.'}, {'end': 28, 'start': 23, 'value': 'Alejandro G. Iñárritu'}, {'end': 28, 'start': 23, 'value': 'Regency Enterprises'}, {'end': 28, 'start': 23, 'value': "'The Revenant'"}, {'end': 30, 'start': 29, 'value': "Let's"}, {'end': 40, 'start': 32, 'value': 'Film:'}, {'end': 34, 'start': 33, 'value': 'Film Thought Project'}, {'end': 40, 'start': 35, 'value': 'Director:'}, {'end': 40, 'start': 35, 'value': 'Production Co.'}, {'end': 40, 'start': 36, 'value': 'Alfred Hitchcock'}, {'end': 40, 'start': 36, 'value': '1958'}, {'end': 40, 'start': 36, 'value': 'Alfred J. Hitchcock Productions'}, {'end': 40, 'start': 37, 'value': 'Year:'}, {'end': 40, 'start': 38, 'value': "'Vertigo'"}, {'end': 45, 'start': 44, 'value': 'PRESS START'}, {'end': 46, 'start': 45, 'value': '2020'}, {'end': 47, 'start': 46, 'value': '2018'}, {'end': 48, 'start': 47, 'value': '1975'}, {'end': 53, 'start': 49, 'value': '1870s'}, {'end': 61, 'start': 67, 'value': 'Eadweard Muybridge'}, {'end': 69, 'start': 75, 'value': 'See you soon'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
ご覧の通り、APIは画面上のすべてのテキストを一行ずつ、見事に抽出しました。これらのテキストをメタデータとして保存し、コンテンツのフィルタリング、分類、検索などの下流のワークフローに利用することができます。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
インデックス化されたビデオのコレクション内から、該当するテキストの一致を検出するために、text_in_video検索オプションを利用して検索クエリを実行します:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "horse", "search_options": [ "text_in_video" ] } # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) search_data = response.json() </code></pre>
出力:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 64, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 63, 'video_id': '###a849b86daab572f349242'}, {'confidence': 'high', 'end': 91, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 88, 'video_id': '###a849b86daab572f349242'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-05-12T00:03:43Z', 'total_results': 2}, 'search_pool': {'index_id': '###a73aa8b1dd6cde172a933', 'total_count': 3, 'total_duration': 5403}} </code></pre>
💡ビデオ内テキスト検索機能は、ビデオの再生中に画面に視覚的に表示されるテキストと、入力されたクエリが(必ずしも一言一句同じでなくても)一致する、インデックス化されたビデオ内のすべての出現箇所を特定するように設計されていることに留意してください。たとえば、「horse moving(動く馬)」と入力すると、システムは画面上のテキストが「horse in motion(動いている馬)」となっているインスタンスを識別します。ただし、この一致の信頼度(confidence level)は、「horse in motion」と入力した場合に比べて低くなります。信頼度は、入力された自然言語クエリと一致した単語の割合に依存します。たとえば、3語中2語が一致した場合は、1語しか一致しなかった場合よりも信頼度が高くなります。
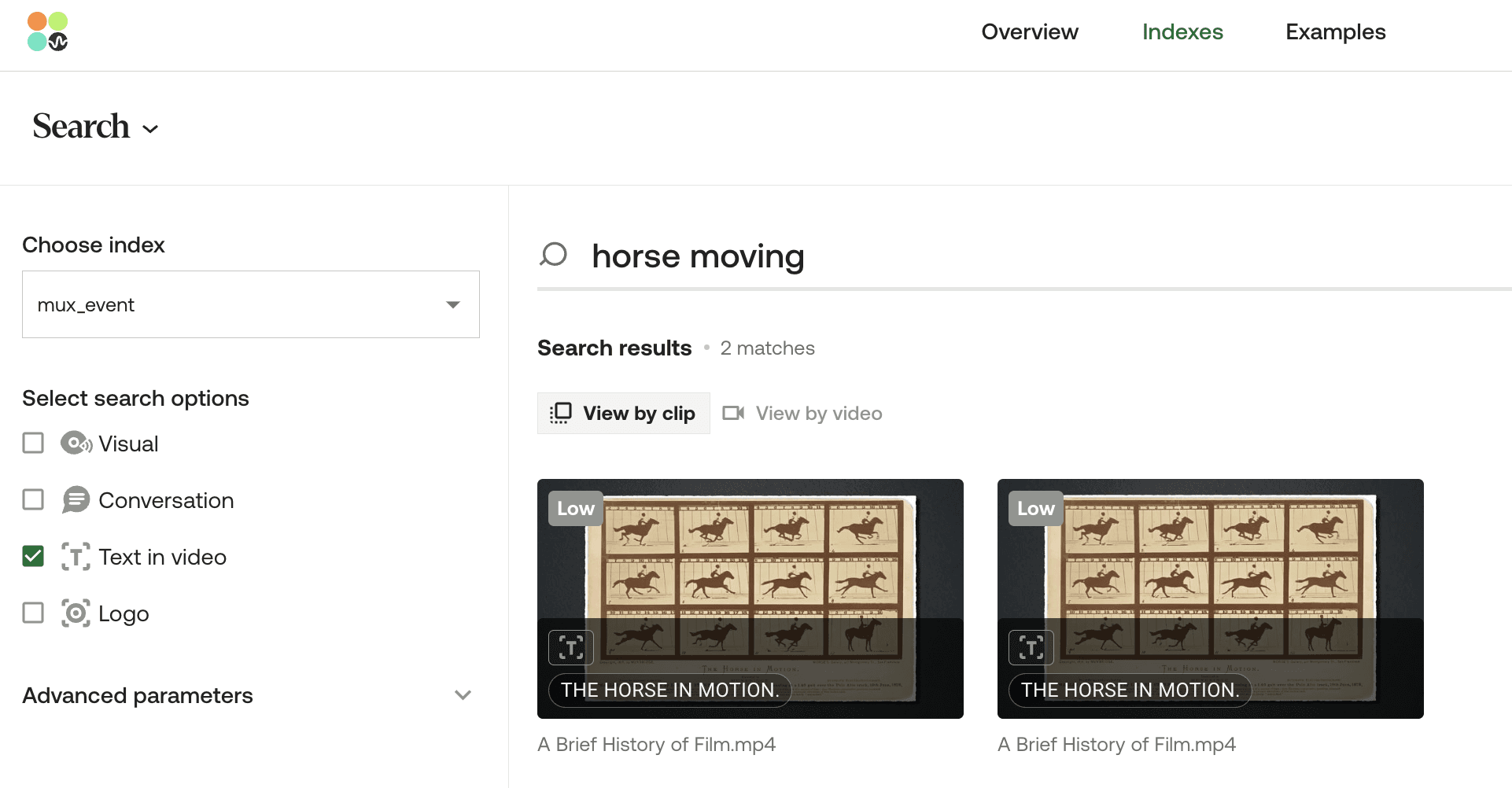
指定されたクエリに対するTwelve Labs Playground'のビデオ内テキスト検索結果
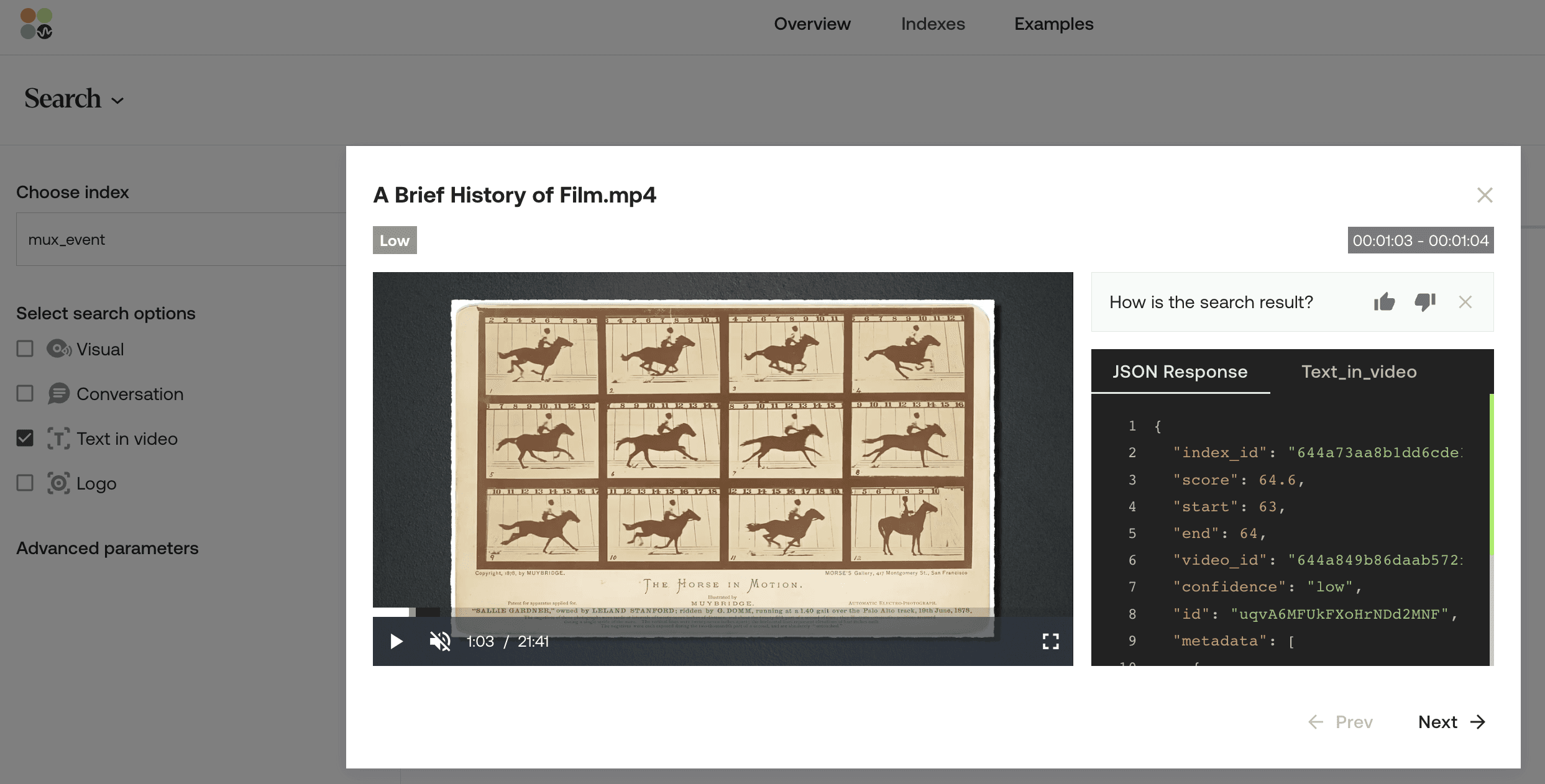
入力クエリに一致し、再生されている特定のビデオの瞬間
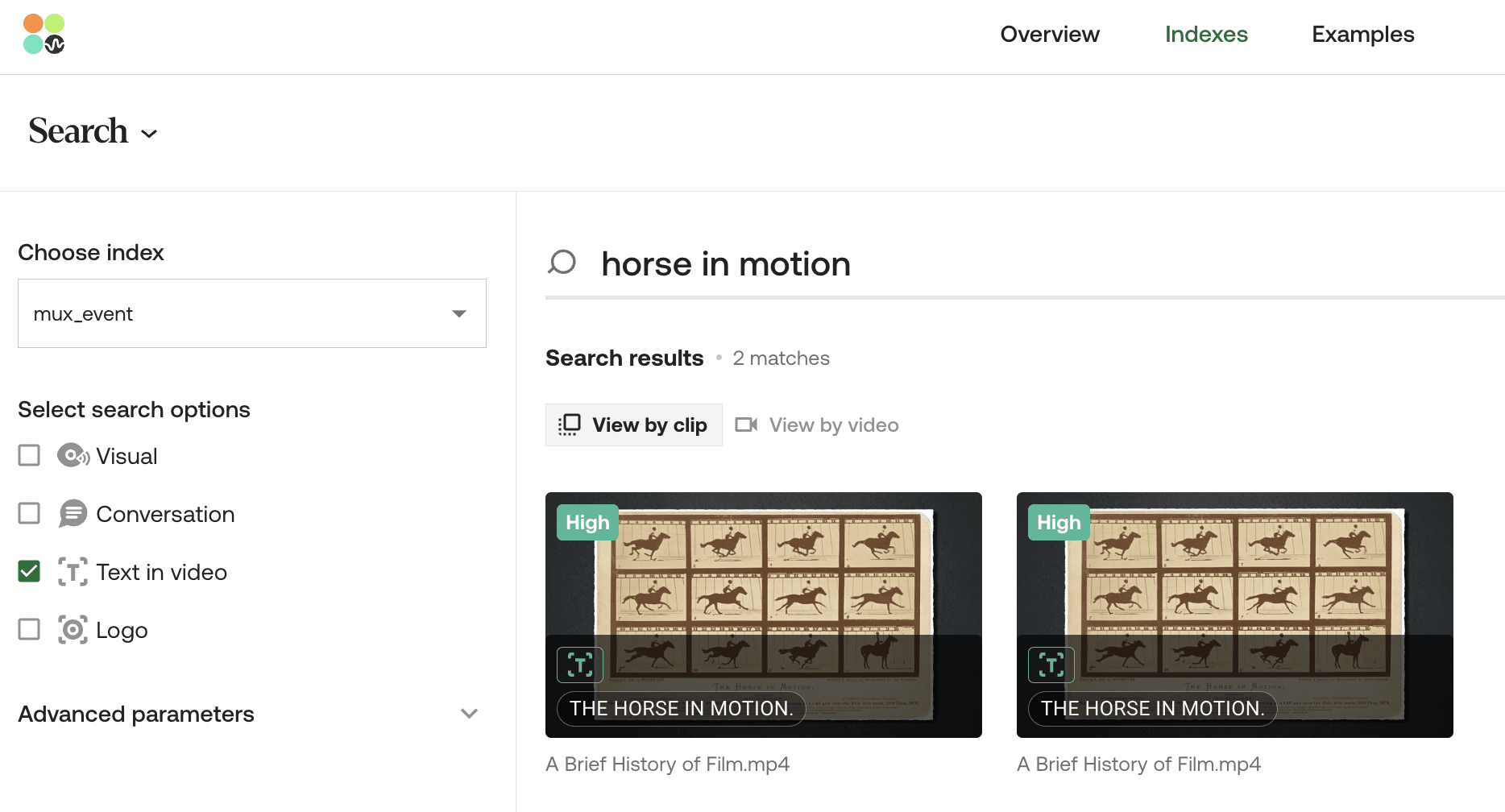
モデルの信頼度は、クエリが画面上のテキストと完全に一致した瞬間に向上します
結果をきれいに表示できるよう、Flaskアプリケーション用のデータを準備します:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
出力:
<pre><code class="python"> {'###a849b86daab572f349242': [{'confidence': 'high', 'end': 64, 'start': 63, 'text': 'THE HORSE IN MOTION.'}, {'confidence': 'high', 'end': 91, 'start': 88, 'text': 'THE HORSE IN MOTION.'}]} </code></pre>
ビデオOCR結果用の追加データ準備。続けていつもの手順通り、すべてを pickle でシリアライズします:
<pre><code class="python">video_id = ocr_data.get('id') data_list = ocr_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
デモアプリの構築
いよいよ、ビデオOCRの冒険の最終段階です。すべての要素をまとめて結果を可視化します。ローカルフォルダからビデオを取得し、Jupyter Notebookから送信されたシリアライズデータ(pickle)を読み込む標準的な構成のほかに、今回はタイムスタンプを「秒のみ」の形式から「分:秒」の形式へ変換するという追加の要件があります。これにより、Webページ上でのデータビジュアライゼーションがより直感的になります。以下は app.py ファイルのコードです:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML テンプレート
次に、最後のパーツである Jinja-2 ベースの HTML テンプレートコードを作成します。これは、Flask の app.py ファイルを通じて送信したすべてのデータを利用します。私たちの最初のタスクは、ビデオ OCR の結果を表示することです。ビデオプレイヤーはビデオの全時間をカバーし、その下には、その時間帯に画面上で発見された開始、終了、およびテキスト。分かりやすくするために、タイムスタンプは「分:秒」の形式で表示され、クリック可能にすることで、特定のタイムスタンプにジャンプして、そこからビデオを再生できるようにします。タイムスタンプを JavaScript 関数 playVideo に渡す際には、再び「秒」単位に変換していることに注意してください。これは、この関数がビデオ再生のために秒のみの形式でタイムスタンプを受け取るように構成されているためです。
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Video OCR</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Video OCR</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Text-in-video Search Results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Flask アプリの実行
素晴らしい!Jupyter notebook の最後のセルを実行して、Flask アプリを起動しましょう:
<pre><code class="python">%run app.py </code></pre>
すべてが予想通りに進んだことを確認する、以下のような出力が表示されるはずです 😊:

URLリンク http://127.0.0.1:5000 をクリックすると、以下のWebページが表示されます:
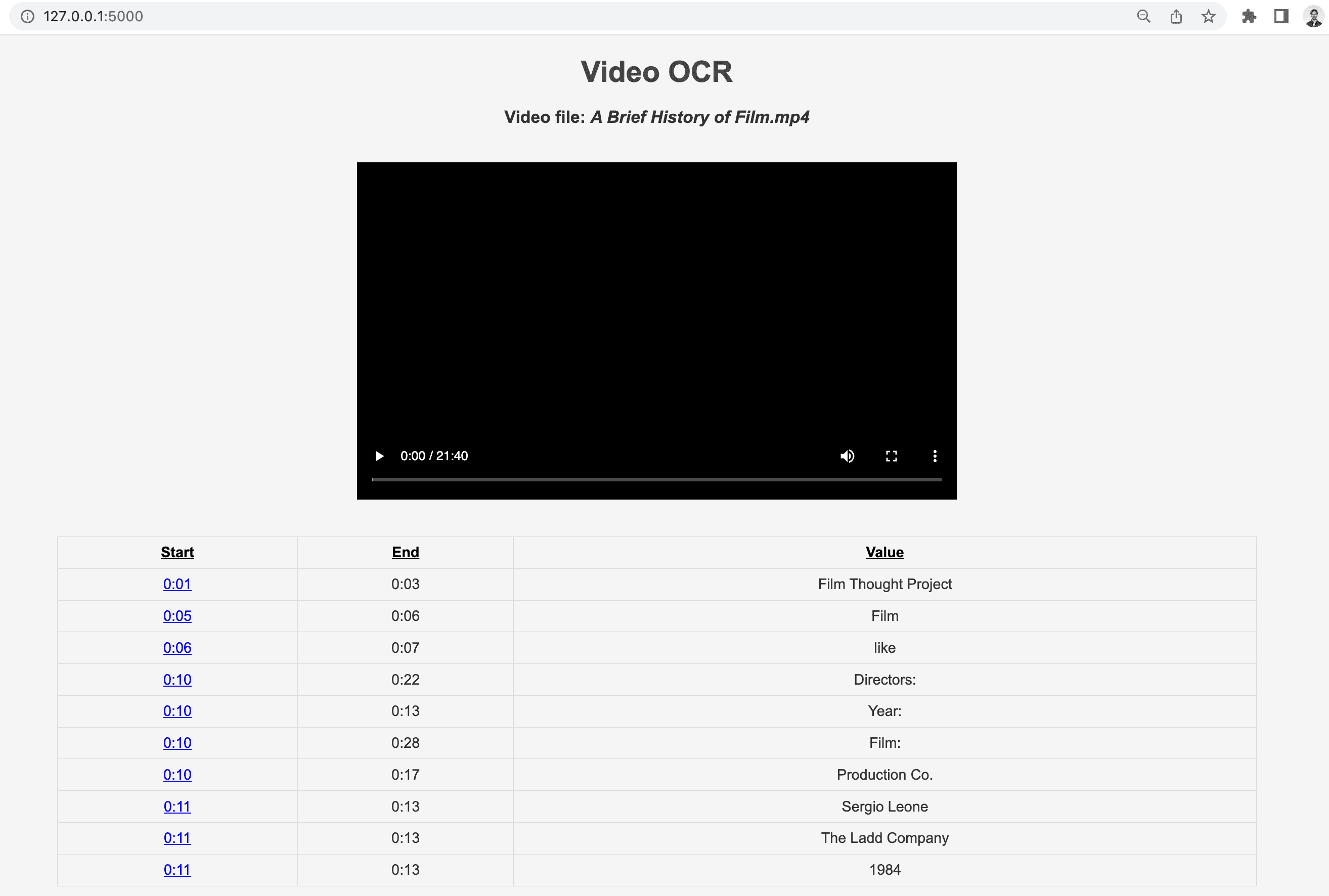

このチュートリアルで作成した完全なコードが含まれる Jupyter Notebook はこちらです - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
アウトロ
今後もさらにスリリングなコンテンツが予定されています。まだ参加していない方は、マルチモーダルAIに熱意を抱く人々が集まる活気ある Discordコミュニティ のメンバーになることを心より歓迎いたします。
ビデオ光学文字認識(OCR)は、コンピュータビジョンと機械学習アルゴリズムを使用してビデオフレームからテキストを検出および抽出する技術です。ビデオOCRを使用すると、ビデオコンテンツを簡単に精査し、特定の単語、フレーズ、さらには文全体が画面に表示される正確な瞬間をピンポイントで特定できます。コンテンツ検索やナビゲーションの合理化から、コンテンツ分析の深化、広告配置の最適化、コンテンツの要約、SEOの強化、コンプライアンスとモニタリングの確保にいたるまで、その用途を想像してみてください。
ビデオOCRで認識できる要素の例は以下の通りです:
プレゼンテーションや会議中のスライドコンテンツ
広告、映画、テレビ番組などで画面上に紹介される製品名
スポーツ中継中にユニフォームに表示される選手名やチーム名
会議やカンファレンス中に表示される名札や名前
講義ビデオ内のホワイトボードへの落書き
ビデオ映像内に写り込んでいる文書
画面上に表示される手書きテキスト
ナンバープレートの番号や建物名
映画やインタビュー内の字幕、キャプション、エンディングクレジット
このチュートリアルでは、Twelve Labsプラットフォームが2つの異なるレベルでビデオOCRをどのように実現しているかを探ります。ビデオレベルでは、ビデオ全体を一度に処理し、そこに含まれるあらゆるテキスト情報を活用します。一方、インデックスレベルのアプローチでは焦点を絞り込み、特定のキーワードまたはキーワードのクラスターに狙いを定めます。これらは自然言語クエリとして入力され、Twelve Labsプラットフォーム上でインデックス化されたビデオライブラリ全体から包括的な検索を行うために使用されます。
さらに嬉しいことに、Twelve Labs APIを利用すれば、OCRプロセスの実装や維持といった細かな作業を心配することなく、これらすべてを達成できます。開発からインフラストラクチャ、さらには継続的なサポートに至るまで、私たちがお客様をバックアップします。それでは準備を整えて、ビデオOCRの領域へのエキサイティングな探検へと一緒に出発しましょう。
前提条件
Twelve Labsプラットフォームは現在オープンベータ段階にあり、新規登録時に最大10時間分の無料ビデオインデックス作成クレジットを提供しています。このチュートリアルに進む前に、登録を済ませてTwelve Labsプラットフォームの基本的な側面に慣れておくと有利です。ビデオインデックス作成、インデックスオプション、Task API、検索オプションなどの理解は、このチュートリアルをスムーズに進める上で不可欠です。これらについては、私の最初のチュートリアルで詳しく説明しています。ただし、途中で行き詰まったり迷ったりした場合は、遠慮なくお問い合わせください。ちなみに、Discordがお好みのプラットフォームであれば、私たちのDiscordサーバーでの応答時間は驚くほど速い 🚅🏎️⚡️ です。
チュートリアルの簡単な流れ
前回の説明に続き、ビデオOCRに2つの異なる角度とレベルから取り組みます。したがって、このチュートリアルを2つの極めて重要なセクションに分け、最後にすべてを統合して実際に動作するデモWebアプリを作成するフィナーレへと進みます:
ビデオOCR - 3つのステッププロセス
特定のビデオから認識されたすべてのテキストを抽出するプロセスは、次の3つのステップで構成されます:
ビデオインデックス作成 - このステップに驚きはありません。過去のチュートリアルを読んできた方にとって、このステップは馴染みのある友人のように感じられるはずです。
ビデオの一意識別子の取得 - Twelve Labsプラットフォームがビデオのインデックス作成を完了したら、OCRが必要なビデオの一意の識別子を取得します。
画面に表示されるテキストの抽出 - 作成した特定のインデックスと、OCRが必要なビデオに関連付けられたビデオIDを使用して、ビデオをピンポイントで特定します。APIが面倒な処理をすべて行い、求めている結果を提供します。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
ビデオOCRにより、ビデオ全体を精査してすべてのテキストのインスタンスを抽出することができました。今度は、ビデオ内テキスト検索機能により、入力または検索されたテキストが出現する正確な瞬間やビデオのスニペットに焦点を当てることができます。これにより、大量のビデオカタログを調査する時間が大幅に短縮され、ビデオ再生中に画面に表示されるテキストと検索用語の一致に基づいた正確な検索結果が得られます。
最初のチュートリアルでは、自然言語クエリと、ビジュアル(オーディオビジュアル検索)、会話(対話検索)、ビデオ内テキスト(OCR)などのさまざまな検索オプションを使用して、インデックス化されたビデオ内のコンテンツ検索について掘り下げました。このチュートリアルでは、アプローチを再利用し、OCR技術のみを活用してビデオ内のテキストを検索します。処理時間とコストを最適化するために、text_in_videoインデックスオプションのみを使用してインデックスを作成します。その後、text_in_video検索オプションを使用して検索クエリを実行し、インデックス化されたビデオ内で関連するテキストの一致を検出します。
デモアプリの構築
これらをすべてまとめるために、APIエンドポイントから得られたデータをWebページに表示し、シンプルなHTMLページを提供するFlaskベースのデモアプリを立ち上げます。ビデオOCRの結果は、タイムスタンプと関連テキストを表示してきれいに表形式でまとめられ、テキスト検索では使用したクエリとそれに対応して見つかったビデオセグメントが表示されます。
ビデオOCR - 3つのステッププロセス
分かりやすくするために、既存のアカウントを使用して2つのビデオのみをインデックスにアップロードしました。お気軽に新規登録してください。現在オープンベータ期間中のため、最大10時間のビデオコンテンツをインデックス化できる無料クレジットを差し上げます。それ以上の要件がある場合は、デベロッパープランへのアップグレードについて料金ページをご確認ください。
ビデオインデックス作成
ここでは、Jupyter Notebookに含める必要のある重要な要素について掘り下げます。これには、必要なインポート、API URLの定義、インデックスの作成、ローカルファイルシステムからのビデオのアップロードによるインデックス作成プロセスの開始が含まれます:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= tlk_2FGGACN2TFAH1N2H1HBXR0BDQ9GV !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes INDEX_ID = create_index(index_name = "extract_text", index_options=["text_in_video"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {INDEX_ID}") </code></pre>
先ほど作成したインデックスに2つのビデオをアップロードします。ビデオのタイトルは「A Brief History of Film」(Film Thought Projectの提供、https://www.youtube.com/watch?v=utntGgcsZWI で視聴可能)と「GPT - Explained!」(CodeEmporiumの提供、https://www.youtube.com/watch?v=3IweGfgytgY で視聴可能)です。これらのビデオをそれぞれのYouTubeチャンネルからダウンロードし、ローカルハードドライブの「static」という名前のフォルダに保存しました。これらのローカルファイルを使用して、Twelve Labsプラットフォームにビデオをインデックス化します:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
ビデオの一意の識別子の取得
それでは、インデックス内のすべてのビデオをリストアップしてみましょう。これにより、特定のビデオのビデオIDを保持し、そのビデオに埋め込まれているすべてのテキストを抽出することができます。さらに、前のチュートリアルでの方法と同様に、Flaskアプリケーションに後で提供できるように設計された、ビデオIDとそれぞれのタイトルのリストを組み立てます。
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='644a73aa8b1dd6cde172a933' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
出力:
<pre><code class="python">{'data': [{'_id': '###a917186daab572f349243', 'created_at': '2023-04-27T14:18:48Z', 'metadata': {'duration': 1300.173875, 'engine_id': 'marengo2.5', 'filename': 'A Brief History of Film.mp4', 'fps': 23.976023976023978, 'height': 720, 'size': 188214297, 'width': 1280}, 'updated_at': '2023-04-27T14:20:11Z'}, {'_id': '###3da86daab572f349241', 'created_at': '2023-04-27T13:08:19Z', 'metadata': {'duration': 550.7, 'engine_id': 'marengo2.5', 'filename': 'GPT - Explained!.mp4', 'fps': 30, 'height': 720, 'size': 22838593, 'width': 1152}, 'updated_at': '2023-04-27T13:08:42Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 5402.873875, 'total_page': 1, 'total_results': 3}} [{'video_id': '###a849b86daab572f349242', 'video_name': 'A Brief History of Film.mp4'}, {'video_id': '###a73da86daab572f349241', 'video_name': 'GPT - Explained!.mp4'}] </code></pre>
画面に表示されるテキストの抽出
計画を実行に移す時が来ました!選択したビデオからすべてのテキストコンテンツの抽出を進めます:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' TEXT_IN_VIDEO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/text-in-video" response = requests.get(TEXT_IN_VIDEO_URL, headers=default_header) print (f"Status code: {response.status_code}") ocr_data = response.json() pprint (ocr_data) </code></pre>
出力:
<pre><code class="python">Status code: 200 {'data': [{'end': 3, 'start': 1, 'value': 'Film Thought Project'}, {'end': 6, 'start': 5, 'value': 'Film'}, {'end': 22, 'start': 18, 'value': "'L'arrivée d'un train en gare de La Ciotat"}, {'end': 28, 'start': 18, 'value': 'Year:'}, {'end': 28, 'start': 23, 'value': '2015'}, {'end': 28, 'start': 23, 'value': 'Production Co.'}, {'end': 28, 'start': 23, 'value': 'Alejandro G. Iñárritu'}, {'end': 28, 'start': 23, 'value': 'Regency Enterprises'}, {'end': 28, 'start': 23, 'value': "'The Revenant'"}, {'end': 30, 'start': 29, 'value': "Let's"}, {'end': 40, 'start': 32, 'value': 'Film:'}, {'end': 34, 'start': 33, 'value': 'Film Thought Project'}, {'end': 40, 'start': 35, 'value': 'Director:'}, {'end': 40, 'start': 35, 'value': 'Production Co.'}, {'end': 40, 'start': 36, 'value': 'Alfred Hitchcock'}, {'end': 40, 'start': 36, 'value': '1958'}, {'end': 40, 'start': 36, 'value': 'Alfred J. Hitchcock Productions'}, {'end': 40, 'start': 37, 'value': 'Year:'}, {'end': 40, 'start': 38, 'value': "'Vertigo'"}, {'end': 45, 'start': 44, 'value': 'PRESS START'}, {'end': 46, 'start': 45, 'value': '2020'}, {'end': 47, 'start': 46, 'value': '2018'}, {'end': 48, 'start': 47, 'value': '1975'}, {'end': 53, 'start': 49, 'value': '1870s'}, {'end': 61, 'start': 67, 'value': 'Eadweard Muybridge'}, {'end': 69, 'start': 75, 'value': 'See you soon'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
ご覧の通り、APIは画面上のすべてのテキストを一行ずつ、見事に抽出しました。これらのテキストをメタデータとして保存し、コンテンツのフィルタリング、分類、検索などの下流のワークフローに利用することができます。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
インデックス化されたビデオのコレクション内から、該当するテキストの一致を検出するために、text_in_video検索オプションを利用して検索クエリを実行します:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "horse", "search_options": [ "text_in_video" ] } # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) search_data = response.json() </code></pre>
出力:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 64, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 63, 'video_id': '###a849b86daab572f349242'}, {'confidence': 'high', 'end': 91, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 88, 'video_id': '###a849b86daab572f349242'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-05-12T00:03:43Z', 'total_results': 2}, 'search_pool': {'index_id': '###a73aa8b1dd6cde172a933', 'total_count': 3, 'total_duration': 5403}} </code></pre>
💡ビデオ内テキスト検索機能は、ビデオの再生中に画面に視覚的に表示されるテキストと、入力されたクエリが(必ずしも一言一句同じでなくても)一致する、インデックス化されたビデオ内のすべての出現箇所を特定するように設計されていることに留意してください。たとえば、「horse moving(動く馬)」と入力すると、システムは画面上のテキストが「horse in motion(動いている馬)」となっているインスタンスを識別します。ただし、この一致の信頼度(confidence level)は、「horse in motion」と入力した場合に比べて低くなります。信頼度は、入力された自然言語クエリと一致した単語の割合に依存します。たとえば、3語中2語が一致した場合は、1語しか一致しなかった場合よりも信頼度が高くなります。
指定されたクエリに対するTwelve Labs Playground'のビデオ内テキスト検索結果
入力クエリに一致し、再生されている特定のビデオの瞬間
モデルの信頼度は、クエリが画面上のテキストと完全に一致した瞬間に向上します
結果をきれいに表示できるよう、Flaskアプリケーション用のデータを準備します:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
出力:
<pre><code class="python"> {'###a849b86daab572f349242': [{'confidence': 'high', 'end': 64, 'start': 63, 'text': 'THE HORSE IN MOTION.'}, {'confidence': 'high', 'end': 91, 'start': 88, 'text': 'THE HORSE IN MOTION.'}]} </code></pre>
ビデオOCR結果用の追加データ準備。続けていつもの手順通り、すべてを pickle でシリアライズします:
<pre><code class="python">video_id = ocr_data.get('id') data_list = ocr_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
デモアプリの構築
いよいよ、ビデオOCRの冒険の最終段階です。すべての要素をまとめて結果を可視化します。ローカルフォルダからビデオを取得し、Jupyter Notebookから送信されたシリアライズデータ(pickle)を読み込む標準的な構成のほかに、今回はタイムスタンプを「秒のみ」の形式から「分:秒」の形式へ変換するという追加の要件があります。これにより、Webページ上でのデータビジュアライゼーションがより直感的になります。以下は app.py ファイルのコードです:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML テンプレート
次に、最後のパーツである Jinja-2 ベースの HTML テンプレートコードを作成します。これは、Flask の app.py ファイルを通じて送信したすべてのデータを利用します。私たちの最初のタスクは、ビデオ OCR の結果を表示することです。ビデオプレイヤーはビデオの全時間をカバーし、その下には、その時間帯に画面上で発見された開始、終了、およびテキスト。分かりやすくするために、タイムスタンプは「分:秒」の形式で表示され、クリック可能にすることで、特定のタイムスタンプにジャンプして、そこからビデオを再生できるようにします。タイムスタンプを JavaScript 関数 playVideo に渡す際には、再び「秒」単位に変換していることに注意してください。これは、この関数がビデオ再生のために秒のみの形式でタイムスタンプを受け取るように構成されているためです。
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Video OCR</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Video OCR</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Text-in-video Search Results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Flask アプリの実行
素晴らしい!Jupyter notebook の最後のセルを実行して、Flask アプリを起動しましょう:
<pre><code class="python">%run app.py </code></pre>
すべてが予想通りに進んだことを確認する、以下のような出力が表示されるはずです 😊:
URLリンク http://127.0.0.1:5000 をクリックすると、以下のWebページが表示されます:
このチュートリアルで作成した完全なコードが含まれる Jupyter Notebook はこちらです - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
アウトロ
今後もさらにスリリングなコンテンツが予定されています。まだ参加していない方は、マルチモーダルAIに熱意を抱く人々が集まる活気ある Discordコミュニティ のメンバーになることを心より歓迎いたします。
ビデオ光学文字認識(OCR)は、コンピュータビジョンと機械学習アルゴリズムを使用してビデオフレームからテキストを検出および抽出する技術です。ビデオOCRを使用すると、ビデオコンテンツを簡単に精査し、特定の単語、フレーズ、さらには文全体が画面に表示される正確な瞬間をピンポイントで特定できます。コンテンツ検索やナビゲーションの合理化から、コンテンツ分析の深化、広告配置の最適化、コンテンツの要約、SEOの強化、コンプライアンスとモニタリングの確保にいたるまで、その用途を想像してみてください。
ビデオOCRで認識できる要素の例は以下の通りです:
プレゼンテーションや会議中のスライドコンテンツ
広告、映画、テレビ番組などで画面上に紹介される製品名
スポーツ中継中にユニフォームに表示される選手名やチーム名
会議やカンファレンス中に表示される名札や名前
講義ビデオ内のホワイトボードへの落書き
ビデオ映像内に写り込んでいる文書
画面上に表示される手書きテキスト
ナンバープレートの番号や建物名
映画やインタビュー内の字幕、キャプション、エンディングクレジット
このチュートリアルでは、Twelve Labsプラットフォームが2つの異なるレベルでビデオOCRをどのように実現しているかを探ります。ビデオレベルでは、ビデオ全体を一度に処理し、そこに含まれるあらゆるテキスト情報を活用します。一方、インデックスレベルのアプローチでは焦点を絞り込み、特定のキーワードまたはキーワードのクラスターに狙いを定めます。これらは自然言語クエリとして入力され、Twelve Labsプラットフォーム上でインデックス化されたビデオライブラリ全体から包括的な検索を行うために使用されます。
さらに嬉しいことに、Twelve Labs APIを利用すれば、OCRプロセスの実装や維持といった細かな作業を心配することなく、これらすべてを達成できます。開発からインフラストラクチャ、さらには継続的なサポートに至るまで、私たちがお客様をバックアップします。それでは準備を整えて、ビデオOCRの領域へのエキサイティングな探検へと一緒に出発しましょう。
前提条件
Twelve Labsプラットフォームは現在オープンベータ段階にあり、新規登録時に最大10時間分の無料ビデオインデックス作成クレジットを提供しています。このチュートリアルに進む前に、登録を済ませてTwelve Labsプラットフォームの基本的な側面に慣れておくと有利です。ビデオインデックス作成、インデックスオプション、Task API、検索オプションなどの理解は、このチュートリアルをスムーズに進める上で不可欠です。これらについては、私の最初のチュートリアルで詳しく説明しています。ただし、途中で行き詰まったり迷ったりした場合は、遠慮なくお問い合わせください。ちなみに、Discordがお好みのプラットフォームであれば、私たちのDiscordサーバーでの応答時間は驚くほど速い 🚅🏎️⚡️ です。
チュートリアルの簡単な流れ
前回の説明に続き、ビデオOCRに2つの異なる角度とレベルから取り組みます。したがって、このチュートリアルを2つの極めて重要なセクションに分け、最後にすべてを統合して実際に動作するデモWebアプリを作成するフィナーレへと進みます:
ビデオOCR - 3つのステッププロセス
特定のビデオから認識されたすべてのテキストを抽出するプロセスは、次の3つのステップで構成されます:
ビデオインデックス作成 - このステップに驚きはありません。過去のチュートリアルを読んできた方にとって、このステップは馴染みのある友人のように感じられるはずです。
ビデオの一意識別子の取得 - Twelve Labsプラットフォームがビデオのインデックス作成を完了したら、OCRが必要なビデオの一意の識別子を取得します。
画面に表示されるテキストの抽出 - 作成した特定のインデックスと、OCRが必要なビデオに関連付けられたビデオIDを使用して、ビデオをピンポイントで特定します。APIが面倒な処理をすべて行い、求めている結果を提供します。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
ビデオOCRにより、ビデオ全体を精査してすべてのテキストのインスタンスを抽出することができました。今度は、ビデオ内テキスト検索機能により、入力または検索されたテキストが出現する正確な瞬間やビデオのスニペットに焦点を当てることができます。これにより、大量のビデオカタログを調査する時間が大幅に短縮され、ビデオ再生中に画面に表示されるテキストと検索用語の一致に基づいた正確な検索結果が得られます。
最初のチュートリアルでは、自然言語クエリと、ビジュアル(オーディオビジュアル検索)、会話(対話検索)、ビデオ内テキスト(OCR)などのさまざまな検索オプションを使用して、インデックス化されたビデオ内のコンテンツ検索について掘り下げました。このチュートリアルでは、アプローチを再利用し、OCR技術のみを活用してビデオ内のテキストを検索します。処理時間とコストを最適化するために、text_in_videoインデックスオプションのみを使用してインデックスを作成します。その後、text_in_video検索オプションを使用して検索クエリを実行し、インデックス化されたビデオ内で関連するテキストの一致を検出します。
デモアプリの構築
これらをすべてまとめるために、APIエンドポイントから得られたデータをWebページに表示し、シンプルなHTMLページを提供するFlaskベースのデモアプリを立ち上げます。ビデオOCRの結果は、タイムスタンプと関連テキストを表示してきれいに表形式でまとめられ、テキスト検索では使用したクエリとそれに対応して見つかったビデオセグメントが表示されます。
ビデオOCR - 3つのステッププロセス
分かりやすくするために、既存のアカウントを使用して2つのビデオのみをインデックスにアップロードしました。お気軽に新規登録してください。現在オープンベータ期間中のため、最大10時間のビデオコンテンツをインデックス化できる無料クレジットを差し上げます。それ以上の要件がある場合は、デベロッパープランへのアップグレードについて料金ページをご確認ください。
ビデオインデックス作成
ここでは、Jupyter Notebookに含める必要のある重要な要素について掘り下げます。これには、必要なインポート、API URLの定義、インデックスの作成、ローカルファイルシステムからのビデオのアップロードによるインデックス作成プロセスの開始が含まれます:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= tlk_2FGGACN2TFAH1N2H1HBXR0BDQ9GV !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes INDEX_ID = create_index(index_name = "extract_text", index_options=["text_in_video"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {INDEX_ID}") </code></pre>
先ほど作成したインデックスに2つのビデオをアップロードします。ビデオのタイトルは「A Brief History of Film」(Film Thought Projectの提供、https://www.youtube.com/watch?v=utntGgcsZWI で視聴可能)と「GPT - Explained!」(CodeEmporiumの提供、https://www.youtube.com/watch?v=3IweGfgytgY で視聴可能)です。これらのビデオをそれぞれのYouTubeチャンネルからダウンロードし、ローカルハードドライブの「static」という名前のフォルダに保存しました。これらのローカルファイルを使用して、Twelve Labsプラットフォームにビデオをインデックス化します:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
ビデオの一意の識別子の取得
それでは、インデックス内のすべてのビデオをリストアップしてみましょう。これにより、特定のビデオのビデオIDを保持し、そのビデオに埋め込まれているすべてのテキストを抽出することができます。さらに、前のチュートリアルでの方法と同様に、Flaskアプリケーションに後で提供できるように設計された、ビデオIDとそれぞれのタイトルのリストを組み立てます。
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='644a73aa8b1dd6cde172a933' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
出力:
<pre><code class="python">{'data': [{'_id': '###a917186daab572f349243', 'created_at': '2023-04-27T14:18:48Z', 'metadata': {'duration': 1300.173875, 'engine_id': 'marengo2.5', 'filename': 'A Brief History of Film.mp4', 'fps': 23.976023976023978, 'height': 720, 'size': 188214297, 'width': 1280}, 'updated_at': '2023-04-27T14:20:11Z'}, {'_id': '###3da86daab572f349241', 'created_at': '2023-04-27T13:08:19Z', 'metadata': {'duration': 550.7, 'engine_id': 'marengo2.5', 'filename': 'GPT - Explained!.mp4', 'fps': 30, 'height': 720, 'size': 22838593, 'width': 1152}, 'updated_at': '2023-04-27T13:08:42Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 5402.873875, 'total_page': 1, 'total_results': 3}} [{'video_id': '###a849b86daab572f349242', 'video_name': 'A Brief History of Film.mp4'}, {'video_id': '###a73da86daab572f349241', 'video_name': 'GPT - Explained!.mp4'}] </code></pre>
画面に表示されるテキストの抽出
計画を実行に移す時が来ました!選択したビデオからすべてのテキストコンテンツの抽出を進めます:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' TEXT_IN_VIDEO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/text-in-video" response = requests.get(TEXT_IN_VIDEO_URL, headers=default_header) print (f"Status code: {response.status_code}") ocr_data = response.json() pprint (ocr_data) </code></pre>
出力:
<pre><code class="python">Status code: 200 {'data': [{'end': 3, 'start': 1, 'value': 'Film Thought Project'}, {'end': 6, 'start': 5, 'value': 'Film'}, {'end': 22, 'start': 18, 'value': "'L'arrivée d'un train en gare de La Ciotat"}, {'end': 28, 'start': 18, 'value': 'Year:'}, {'end': 28, 'start': 23, 'value': '2015'}, {'end': 28, 'start': 23, 'value': 'Production Co.'}, {'end': 28, 'start': 23, 'value': 'Alejandro G. Iñárritu'}, {'end': 28, 'start': 23, 'value': 'Regency Enterprises'}, {'end': 28, 'start': 23, 'value': "'The Revenant'"}, {'end': 30, 'start': 29, 'value': "Let's"}, {'end': 40, 'start': 32, 'value': 'Film:'}, {'end': 34, 'start': 33, 'value': 'Film Thought Project'}, {'end': 40, 'start': 35, 'value': 'Director:'}, {'end': 40, 'start': 35, 'value': 'Production Co.'}, {'end': 40, 'start': 36, 'value': 'Alfred Hitchcock'}, {'end': 40, 'start': 36, 'value': '1958'}, {'end': 40, 'start': 36, 'value': 'Alfred J. Hitchcock Productions'}, {'end': 40, 'start': 37, 'value': 'Year:'}, {'end': 40, 'start': 38, 'value': "'Vertigo'"}, {'end': 45, 'start': 44, 'value': 'PRESS START'}, {'end': 46, 'start': 45, 'value': '2020'}, {'end': 47, 'start': 46, 'value': '2018'}, {'end': 48, 'start': 47, 'value': '1975'}, {'end': 53, 'start': 49, 'value': '1870s'}, {'end': 61, 'start': 67, 'value': 'Eadweard Muybridge'}, {'end': 69, 'start': 75, 'value': 'See you soon'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
ご覧の通り、APIは画面上のすべてのテキストを一行ずつ、見事に抽出しました。これらのテキストをメタデータとして保存し、コンテンツのフィルタリング、分類、検索などの下流のワークフローに利用することができます。
ビデオ内テキスト検索 - インデックスされたすべてのビデオ内から特定のテキストを検索する
インデックス化されたビデオのコレクション内から、該当するテキストの一致を検出するために、text_in_video検索オプションを利用して検索クエリを実行します:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "horse", "search_options": [ "text_in_video" ] } # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) search_data = response.json() </code></pre>
出力:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 64, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 63, 'video_id': '###a849b86daab572f349242'}, {'confidence': 'high', 'end': 91, 'metadata': [{'text': 'THE HORSE IN MOTION.', 'type': 'text_in_video'}], 'score': 92.28, 'start': 88, 'video_id': '###a849b86daab572f349242'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-05-12T00:03:43Z', 'total_results': 2}, 'search_pool': {'index_id': '###a73aa8b1dd6cde172a933', 'total_count': 3, 'total_duration': 5403}} </code></pre>
💡ビデオ内テキスト検索機能は、ビデオの再生中に画面に視覚的に表示されるテキストと、入力されたクエリが(必ずしも一言一句同じでなくても)一致する、インデックス化されたビデオ内のすべての出現箇所を特定するように設計されていることに留意してください。たとえば、「horse moving(動く馬)」と入力すると、システムは画面上のテキストが「horse in motion(動いている馬)」となっているインスタンスを識別します。ただし、この一致の信頼度(confidence level)は、「horse in motion」と入力した場合に比べて低くなります。信頼度は、入力された自然言語クエリと一致した単語の割合に依存します。たとえば、3語中2語が一致した場合は、1語しか一致しなかった場合よりも信頼度が高くなります。
指定されたクエリに対するTwelve Labs Playground'のビデオ内テキスト検索結果
入力クエリに一致し、再生されている特定のビデオの瞬間
モデルの信頼度は、クエリが画面上のテキストと完全に一致した瞬間に向上します
結果をきれいに表示できるよう、Flaskアプリケーション用のデータを準備します:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
出力:
<pre><code class="python"> {'###a849b86daab572f349242': [{'confidence': 'high', 'end': 64, 'start': 63, 'text': 'THE HORSE IN MOTION.'}, {'confidence': 'high', 'end': 91, 'start': 88, 'text': 'THE HORSE IN MOTION.'}]} </code></pre>
ビデオOCR結果用の追加データ準備。続けていつもの手順通り、すべてを pickle でシリアライズします:
<pre><code class="python">video_id = ocr_data.get('id') data_list = ocr_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
デモアプリの構築
いよいよ、ビデオOCRの冒険の最終段階です。すべての要素をまとめて結果を可視化します。ローカルフォルダからビデオを取得し、Jupyter Notebookから送信されたシリアライズデータ(pickle)を読み込む標準的な構成のほかに、今回はタイムスタンプを「秒のみ」の形式から「分:秒」の形式へ変換するという追加の要件があります。これにより、Webページ上でのデータビジュアライゼーションがより直感的になります。以下は app.py ファイルのコードです:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML テンプレート
次に、最後のパーツである Jinja-2 ベースの HTML テンプレートコードを作成します。これは、Flask の app.py ファイルを通じて送信したすべてのデータを利用します。私たちの最初のタスクは、ビデオ OCR の結果を表示することです。ビデオプレイヤーはビデオの全時間をカバーし、その下には、その時間帯に画面上で発見された開始、終了、およびテキスト。分かりやすくするために、タイムスタンプは「分:秒」の形式で表示され、クリック可能にすることで、特定のタイムスタンプにジャンプして、そこからビデオを再生できるようにします。タイムスタンプを JavaScript 関数 playVideo に渡す際には、再び「秒」単位に変換していることに注意してください。これは、この関数がビデオ再生のために秒のみの形式でタイムスタンプを受け取るように構成されているためです。
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Video OCR</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Video OCR</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Text-in-video Search Results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Flask アプリの実行
素晴らしい!Jupyter notebook の最後のセルを実行して、Flask アプリを起動しましょう:
<pre><code class="python">%run app.py </code></pre>
すべてが予想通りに進んだことを確認する、以下のような出力が表示されるはずです 😊:
URLリンク http://127.0.0.1:5000 をクリックすると、以下のWebページが表示されます:
このチュートリアルで作成した完全なコードが含まれる Jupyter Notebook はこちらです - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
アウトロ
今後もさらにスリリングなコンテンツが予定されています。まだ参加していない方は、マルチモーダルAIに熱意を抱く人々が集まる活気ある Discordコミュニティ のメンバーになることを心より歓迎いたします。








