
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
チュートリアル
Twelve Labsのシンプルな検索APIを使用して、ビデオ内の特定の瞬間を見つける方法

アンキット・カレ
開発者はTwelve Labs Search APIを使用することで、手作業で映像をスクラブすることなく、自然言語のクエリを使用して動画内の正確な瞬間をピンポイントで特定できます。このチュートリアルでは、動画のインデックス作成、視覚、会話、画面上のテキストにわたるセマンティック検索の実行、およびFlaskアプリでの検索結果の表示について手順を追って説明します。
開発者はTwelve Labs Search APIを使用することで、手作業で映像をスクラブすることなく、自然言語のクエリを使用して動画内の正確な瞬間をピンポイントで特定できます。このチュートリアルでは、動画のインデックス作成、視覚、会話、画面上のテキストにわたるセマンティック検索の実行、およびFlaskアプリでの検索結果の表示について手順を追って説明します。

この記事の内容
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2023/04/07
15分
記事へのリンクをコピー
最近、Twelve LabsはGTC 2023におけるマルチモーダルAIのパイオニアとして取り上げられました。GTC 2023のビデオを見ている時、共同創業者のSoyoungが、自社が紹介されているセグメントを探すのに苦労して髪をかきむしっているのを目にしました。この経験から、自社のAPIを使ってビデオ内を検索するという課題に取り組むモチベーションが湧きました。そこで、今週末の楽しさ満載の個人プロジェクトのチュートリアルとして、Twelve Labsの検索APIを使用してビデオ内の特定の瞬間を見つけるプロセスをご案内します。
ビデオ内の検索をより快適にするためのシンプルな設計図😎
はじめに
Twelve Labsは、ビデオ理解のパワーを活用したアプリケーションの作成を支援するために設計された、一連のAPIの形でマルチモーダル基盤モデルを提供しています。このブログ記事では、Twelve Labs APIを使用して、自然言語のクエリでビデオ内の特定の興味深い瞬間をシームレスに見つける方法を探ります。大学院時代に作成した、「Machine Learning is Everywhere(機械学習はどこにでもある)」というタイトルの面白いビデオをローカルドライブからアップロードします。その名の通り、この80秒のビデオは、生活のあらゆる側面におけるMLの偏在性を示しています。このビデオでは、プロの卓球選手がKukaロボットと対戦する様子や、スケートボードのトリックを行う人物のイベント要約にMLが使用されている様子などのMLアプリケーションが紹介されています。Twelve Labs APIの力を借りて、シンプルな自然言語クエリを使用してビデオ内の特定のシーンを見つける方法をデモします。
このチュートリアルでは、シンプルな検索APIについての緩やかな導入を目的としているため、シングルビデオ内の瞬間を検索することに焦点を当て、軽量でユーザーフレンドリーなFlaskフレームワークを使用してデモアプリを作成するという、最小限の構成にしています。しかし、このプラットフォームは、数百、あるいは数千のビデオのアップロードに対応し、それらの中から特定の瞬間を見つけ出せるようにスケールする十分な機能を備えています。それでは、本格的な楽しみに向けて飛び込んでいきましょう!
クイックオーバービュー
前提条件: Twelve Labs APIスイートを使用するためのサインアップと、デモアプリケーションを作成するために必要なパッケージのインストール
ビデオのアップロード: 素晴らしいビデオをお持ちですか?それらをTwelve Labsプラットフォームに送信すれば、効率的にインデックスが作成され、検索体験が格段に簡単になります!
セマンティックビデオ検索: シンプルな自然言語クエリで、ビデオ内の思い出の瞬間を探し出します
デモアプリの作成: Flaskを使用してHTMLテンプレートをレンダリングする便利なPythonスクリプトを作成し、検索結果を表示する洗練されたHTMLページをデザインします
💡 ところで、開発者ではない方がこの記事を読まれていても、心配は無用です!Jupyter Notebookのすぐに使えるリンクを用意しており、プロセス全体を実行して結果を得ることができます。さらに、コードを1行も書かずにセマンティックビデオ検索の力を体験できる弊社のPlaygroundもぜひお試しください。無料クレジットが必要な場合は、お気軽にご連絡ください😄。
前提条件
このチュートリアルでは、Jupyter Notebookを使用します。ローカルコンピューターにすでにJupyter、Python、およびPipがセットアップされていることを前提としています。何か問題が発生した場合は、最も迅速にレスポンスが可能な弊社のDiscordサーバーでお気軽にご相談ください 🚅🏎️⚡️。Discordがお好みに合わない場合は、メールでお問い合わせいただくこともできます。Twelve Labsのアカウントを作成すると、APIダッシュボードにアクセスしてAPIキーを取得できます。このデモでは既存のアカウントを使用します。API呼び出しを行うには、シークレットキーを使用し、API URLを指定するだけです。さらに、環境変数を使用して、アプリケーションに設定の詳細を渡すことができます。
<pre><code class="bash">%env API_KEY=<your_API_key> %env API_URL=https://api.twelvelabs.io/v1.1 </code></pre>
依存関係のインストール:
<pre><code class="python">pip install requests pip install flask </code></pre>
ビデオのアップロード
最初のステップとして、ビデオ理解機能を活用するために、ローカルコンピューターからTwelve Labsプラットフォームにビデオをアップロードした方法を解説します。
インポート:
<pre><code class="python">import os import requests import glob from pprint import pprint </code></pre
以下のようにして、APIのURLとAPIキーを取得します。
<pre><code class="python">API_URL = os.getenv("API_URL") assert API_URL </code></pre
<pre><code class="python">API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre
Index API
次のステップでは、Index APIを使用してビデオインデックスを作成します。ビデオインデックスは、1つ以上のビデオをグループ化し、いくつかの共通の検索プロパティを設定する方法であり、これにより、インデックスにアップロードされたビデオに対してセマンティック検索を実行できるようになります。
インデックスは以下のフィールドによって定義されます:
<ul> <li><b>名前</b></li> <li><b>エンジン</b> - 現在、ビデオ理解のための最新のマルチモーダル基盤モデルであるMarengo2を提供しています</li> <li>1つ以上の<b>インデックス作成オプション</b>:</li> <ul> <li><b>visual</b>: このオプションを選択すると、APIサービスはビデオのマルチモーダルな視覚・音響分析を実行し、オブジェクト、アクション、音、動き、場所、状況に応じたイベント、および複雑な視覚・音響テキストの説明によって検索できるようになります。ビジュアル検索の例としては、大歓声の群衆やオフィスを去る疲れ切った開発者などが挙げられます😆。</li> <li><b>conversation</b>: このオプションを選択すると、APIはビデオから説明(書き起こしテキスト)を抽出し、そのテキストに対してセマンティックな自然言語処理(NLP)分析を実行します。これにより、検索している会話が行われているビデオ内の正確な瞬間を特定できます。インデックス化されたビデオ内で行われる会話を検索する例としては、兄弟に嘘をついた瞬間などが挙げられます😜。</li> <li><b>text_in_video</b>: このオプションを選択すると、APIサービスは文字認識(OCR)を実行し、標識、ラベル、字幕、ロゴ、プレゼンテーション、ドキュメントなど、ビデオ内に表示されるテキストを検索できるようにします。この場合、サッカーの試合中に登場するブランドなどを検索することができます🏈。</li></ul></ul>
インデックスの作成:
<pre><code class="python"># `/indexes` エンドポイントの URL を構築します INDEXES_URL = f"{API_URL}/indexes" # インデックスの名前を指定します INDEX_NAME = "My University Days" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } # data という名前の辞書を宣言します data = { "engine_id": "marengo2", "index_options": ["visual", "conversation", "text_in_video"], "index_name": INDEX_NAME, } # インデックスを作成します response = requests.post(INDEXES_URL, headers=headers, json=data) # インデックスの一意の識別子を保存します INDEX_ID = response.json().get('_id') # ステータスコードとレスポンスをプリントします print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
ビデオをアップロードするためのTask API
Twelve Labs プラットフォームは、作成されたインデックスにビデオをアップロードし、アップロードプロセスのステータスを監視するためのTask APIを提供しています。
<pre><code class="python">TASKS_URL = f"{API_URL}/tasks" file_name = "Machine Learning is Everywhere" # インデックス化されたビデオはこのファイル名になります file_path = "ml.mp4" # アップロードするビデオのファイル名 file_stream = open(file_path,"rb") data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] response = requests.post(TASKS_URL, headers=headers, data=data, files=file_param </code></pre
ビデオをアップロードすると、システムは自動的にビデオ・インデックス作成プロセスを開始します。Twelve Labsは、「ビデオ・インデックス作成」の概念について、マルチモーダル基盤モデルを使用して時間的コンテキストを組み込み、動き、オブジェクト、音、画面上のテキスト、ビデオからの音声などの情報を抽出して、強力なビデオ埋め込み(embeddings)を生成することだと説明しています。これにより、日常的な言葉を使ってビデオ内の特定の瞬間を見つけたり、指定されたラベルやプロンプトに基づいてビデオセグメントを分類したりすることが可能になります。
ビデオ・インデックス作成プロセスの監視:
<pre><code class="python">import time # 開始時間を定義します start = time.time() print("Start uploading video") # インデックスプロセスを監視します TASK_STATUS_URL = f"{API_URL}/tasks/{TASK_ID}" while True: response = requests.get(TASK_STATUS_URL, headers=headers) STATUS = response.json().get("status") if STATUS == "ready": print(f"Status code: {STATUS}") break time.sleep(10) # 終了時間を定義します end = time.time() print("Finish uploading video") print("Time elapsed (in seconds): ", end - start) </code></pre
<pre><code class="python"># ビデオの一意の識別子を取得します VIDEO_ID = response.json().get('video_id') # ステータスコード、ビデオの一意の識別子、 およびレスポンスをプリントします print(f"VIDEO ID: {VIDEO_ID}") pprint(response.json()) </code></pre
<pre><code class="language-plaintext">VIDEO ID: 642621ffffa3551fb6d2f### {'_id': '642621fc3205dc8a48ba8###', 'created_at': '2023-03-30T23:57:48.877Z', 'estimated_time': '2023-03-30T23:59:58.312Z', 'index_id': '###621fb7b1f2230dfcd6###', 'metadata': {'duration': 80.32, 'filename': 'Machine Learning is Everywhere', 'height': 720, 'width': 1280}, 'status': 'ready', 'type': 'index_task_info', 'updated_at': '2023-03-31T00:00:34.412Z', 'video_id': '642621ffffa3551fb6d2f###'} </code></pre
アプリに既存インデックスの一意の識別子を渡すための別の環境変数を作成します:
<pre><code class="python">%env ENV_INDEX_ID = ###621fb7b1f2230dfcd6### </code></pre
こちらはインデックス内のすべてのビデオの一覧です。今回はシンプルにするためにビデオを1つだけインデックス化しましたが、無料クレジットを使用すれば最大10時間分のビデオコンテンツをアップロードできます。
<pre><code class="python"># 既存のインデックスの一意の識別子を取得します INDEX_ID = os.getenv("ENV_INDEX_ID") # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY, } # インデックス内のすべてのビデオをリストします INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=headers) print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
<pre><code class="python">Status code: 200 {'data': [{'_id': '642621ffffa3551fb6d2f###', 'created_at': '2023-03-30T23:57:48Z', 'metadata': {'duration': 80.32, 'engine_id': 'marengo2', 'filename': 'Machine Learning is Everywhere', 'fps': 25, 'height': 720, 'size': 11877525, 'width': 1280}, 'updated_at': '2023-03-30T23:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 80.32, 'total_page': 1, 'total_results': 1}} </code></pre
セマンティックビデオ検索、すなわち特定の瞬間の検索
システムがビデオのインデックス作成とビデオ埋め込みの生成を完了すると、これらを活用して検索APIで特定の瞬間を見つけることができます。このAPIは、入力したクエリのセマンティックな意味に対応する、関連ビデオ内の正確な開始・終了タイムコードを特定します。選択したインデックスの作成オプションに応じて、セマンティックビデオ検索に同じオプションのサブセットから選択できます。例えば、インデックスのすべてのオプションを有効にした場合、視覚・聴覚的な検索、会話の検索、ビデオ内に表示されるテキストの検索が可能になります。インデックスレベルと検索レベルの両方で同じオプションのセットを提供する理由は、ビデオコンテンツの分析にプラットフォームをどのように利用したいか、また現在のコンテキストに適したオプションを組み合わせてビデオコンテンツ全体をどのように検索したいかを柔軟に決定できるようにするためです。
まずは、シンプルな自然言語クエリ「a guy doing a trick on a skateboard(スケートボードでトリックを決める男)」を使ったビジュアル検索から始めましょう。
<pre><code class="bash">Status code: 200 {'data': [{'confidence': 'high', 'end': 49.34375, 'metadata': [{'type': 'visual'}], 'score': 83.24, 'start': 41.65625, 'video_id': '642621ffffa3551fb6d2f###'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-03-31T22:41:42Z', 'total_results': 1}, 'search_pool': {'index_id': '642621fb7b1f2230dfcd####', 'total_count': 1, 'total_duration': 80}} </code></pre
対応するビデオセグメント:

この機能は、モデルがビデオコンテンツを人間のように理解している様子を示しているため、とても興奮します。上のスクリーンショットでわかるように、システムは抽出したかった正確な瞬間を見事に特定しています。
別のクエリとして「a guy playing table tennis with a robotic arm(ロボットアームと卓球をする男)」を試して、システムがさらに魔法のような力を発揮する様子を見てみましょう。
<pre><code class="python"># `/search` エンドポイントの URL を構築します SEARCH_URL = f"{API_URL}/search/" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } query = "a guy playing table tennis with a robotic arm" # `data` という名前の辞書を宣言します data = { "query": query, # 検索クエリを指定します "index_id": INDEX_ID, # インデックスの一意の識別子を指定します "search_options": ["visual"], # 検索オプションを指定します } # 検索リクエストを行います response = requests.post(SEARCH_URL, headers=headers, json=data) print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre
出力:
<pre><code class="python">{'data': [{'confidence': 'high', 'end': 14.6875, 'metadata': [{'type': 'visual'}], 'score': 90.62, 'start': 9.75, 'video_id': '642621ffffa3551fb6d2####'}, {'confidence': 'high', 'end': 9.75, 'metadata': [{'type': 'visual'}], 'score': 89.74, 'start': 4.5, 'video_id': '642621ffffa3551fb6d2####'}], </code></pre
対応するビデオセグメント:


ビンゴ!今回もシステムは魅力的な瞬間を正確に特定しました。
💡ここで、楽しいミニ課題です。"a breakthrough in machine learning would be worth ten Microsofts(機械学習におけるブレイクスルーはマイクロソフト10社分の価値がある)"を検索し、検索オプションを `["text_in_video"]` に設定してみてください。
これらのJSONレスポンスを、開始点と終了点を手動で確認することなく最大限に活用するには、愛情込めて作られた素晴らしいインデックスページが必要です。そうすれば、検索リクエストのJSON出力を対応するビデオに直接送信できます。さあ、取りかかりましょう!
デモアプリの作成
この素晴らしいビデオ理解の冒険にお付き合いいただきありがとうございます 🎉🥳👏!最後のステップに到達しました。ここでは、Flaskベースのシンプルなアプリを作成し、前のステップの検索結果を取得して美しいウェブページに表示し、リクエストした正確な瞬間を披露します。ちなみに、私はデータサイエンスのバックグラウンドがあり、Pythonが大好きなのでFlaskを選びました。さらに、Flaskは軽量なPythonベースのフレームワークであり、このチュートリアルのニーズに合致しています。もちろん、お好みに合わせて他のフレームワークを選んでいただいてもかまいません。
最初のステップは、Jupyter Notebookに必要なインポートを行うことです。
<pre><code class="python">import json import pickle </code></pre
検索APIから収集したすべての開始および終了タイムスタンプを保持する、"starts "と "ends "という2つのリストを生成します。
<pre><code class="python">data = response.json() starts = [] ends = [] for item in data['data']: starts.append(item['start']) ends.append(item['end']) print("starts:", starts) print("ends:", ends) </code></pre
<pre><code class="bash">starts: [34.90625, 0, 62.5625] ends: [39.21875, 4.5, 65.90625] </code></pre
必要なタイムスタンプを取得し、同じビデオを自身のYouTubeチャンネルにアップロードしたので、それらを使用する方法はいくつかあります。ローカルディスクからビデオを取得してウェブページでお気に入りのクリップを表示することもできますし、YouTubeチャンネルのビデオURLをそのまま使用して同じ結果を得ることもできます。後者の方がより魅力的なので、アップロードしたビデオと同じYouTubeの埋め込みコードを使用し、開始と終了のタイムスタンプを渡すことにします。このようにして、検索した正確なビデオセグメントが表示されるようになります。少し注意点として、YouTubeの埋め込みコードは、開始および終了パラメータに整数値のみをサポートしているため、これらの値を丸める必要があります。
<pre><code class="bash">starts_int = [int(f) for f in starts] ends_int = [int(f) for f in ends] </code></pre
作成するFlaskアプリのファイルに渡せるよう、入力したクエリと一緒にこれらのリストを素早くシリアライズ(pickle)しておきましょう。これは、これから作成するFlaskアプリのファイルにパラメータを渡す際に役立ちます。
<pre><code class="python">with open("lists.pkl", "wb") as f: pickle.dump((starts_int, ends_int, query), f) </code></pre>
これで、Flaskを使用してこれらのパラメータを渡す設定がすべて整いました。
Flaskアプリを作成する手順
1. 新しいFlaskプロジェクトの作成: プロジェクト用の新しいディレクトリを作成し、Flaskアプリのメインファイルとなる新しいPythonファイルを作成します。
<pre><code class="bash">mkdir my_flask_app cd my_flask_app touch app.py </code></pre>
Flaskアプリファイルとテンプレートの準備ができると、ディレクトリ構造は次のようになります。
<pre><code class="markdown">my_flask_app/ │ app.py │ ml.mp4 │ └───templates/ │ index.html </code></pre>
アップロードするビデオファイルを `my_flask_app` ディレクトリ内に保存しておきます。
2. Flaskアプリのコードを作成する: **app.py** ファイルに、Flaskアプリのコードを記述する必要があります。以下は、Jinja2テンプレートを使用して、タイムスタンプのリストが使用されている 'index.html' ファイルをレンダリングするFlaskアプリです。
<pre><code class="python">from flask import Flask, render_template import pickle with open("lists.pkl", "rb") as f: starts, ends, query = pickle.load(f) app = Flask(__name__) @app.route("/") def index(): return render_template("index.html", starts=starts, ends=ends, query=query) if __name__ == "__main__": app.run(debug=True) </code></pre
3. templatesディレクトリの作成: FlaskでJinja2テンプレートを使用するには、Flaskアプリと同じディレクトリに **templates** ディレクトリを作成する必要があります。このディレクトリにJinja2テンプレートを保存します。
<pre><code class="bash">mkdir templates </code></pre>
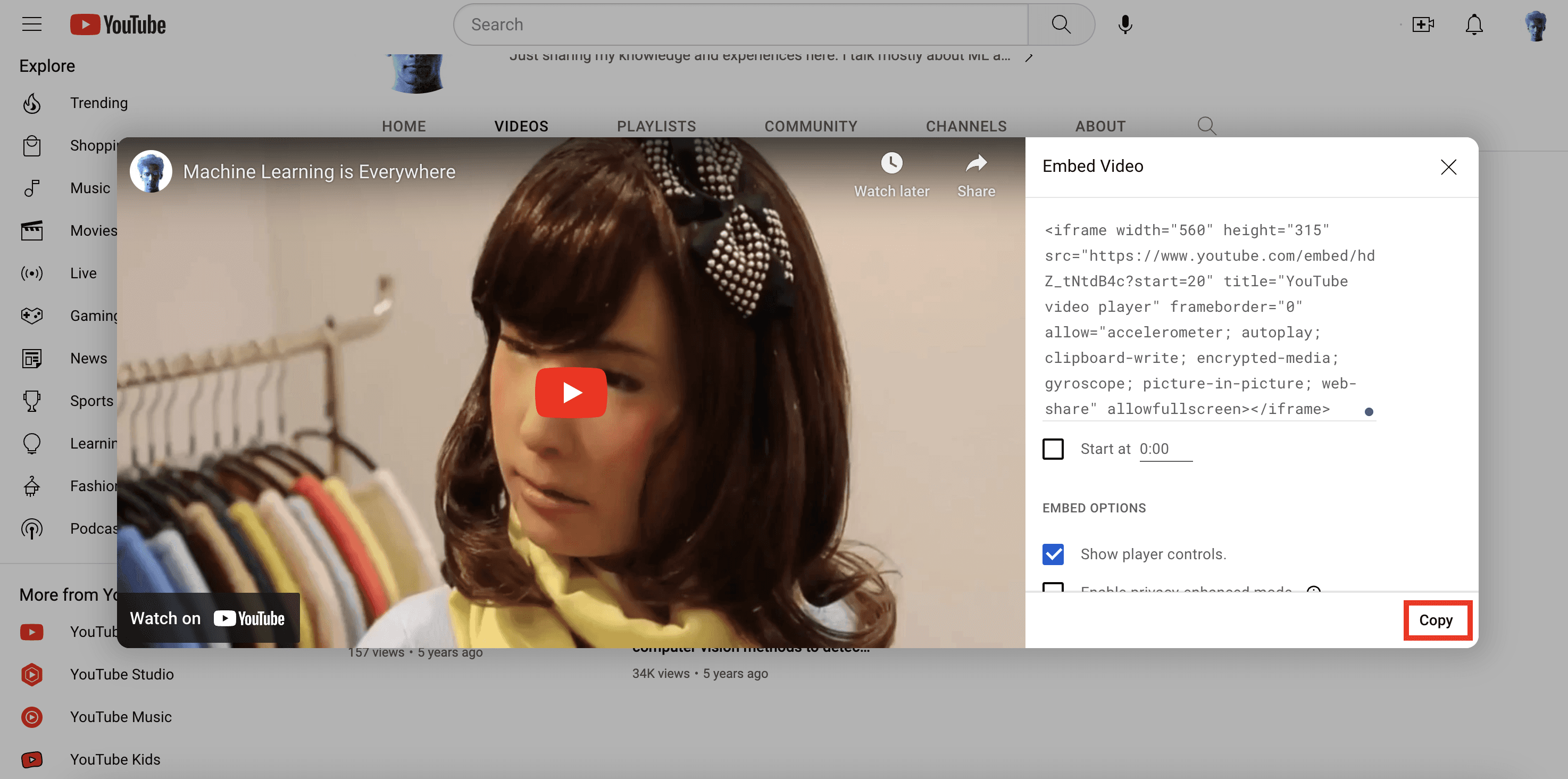
パズルの最後のピースは、検索クエリに一致したすべてのビデオセグメントを表示する `index.html` ページです。HTMLファイルを作成する前に、私のYouTubeチャンネルから「ビデオの埋め込み」コードを素早く取得しましょう。
4. Jinja2テンプレートの作成: Jinja2テンプレートを作成するには、**templates** ディレクトリにHTMLファイルを作成する必要があります。
<pre><code class="bash">touch index.html </code></pre>
以下は、Jinja2テンプレートのシンプルな例です。HTMLファイル内に、アプリファイルから渡されたリストとクエリ文字列を反復処理できるようにするコードが組み込まれています。
<pre><code class="language-html"><html> <head> <style> body { background-color: #F2F2F2; font-family: Arial, sans-serif; text-align: center; } h1 { margin-top: 40px; } .video-container { display: flex; flex-wrap: wrap; padding: 40px; justify-content: center; } .video-item { display: flex; flex-direction: column; align-items: center; width: 50%; height: 600px; margin: 20px; text-align: center; } .video-item iframe { width: 80%; height: 380px; margin: 20px; } .video-item p { font-size: 16px; margin-top: 10px; font-weight: bold; } </style> </head> <body> <h1>My Favorite Scenes</h1> <div class="video-container"> {% for i in range(starts|length) %} <div class="video-item"> <iframe width="560" height="315" src="https://www.youtube.com/embed/hdZ_tNtdB4c?start={{ starts[i] }}&end={{ ends[i] }}" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in- picture" allowfullscreen></iframe> <p>Start: {{ starts[i] }} | End: {{ ends[i] }}</p> <p>Query: {{ query }}</p> </div> {% endfor %} </div> </body> </html> </code></pre>
パーフェクト!Jupyter Notebookの最後のセルを実行しましょう。
<pre><code class="python">%run app.py </code></pre>
すべてが期待通りに進んでいることを示す、以下のような出力が表示されるはずです😊:
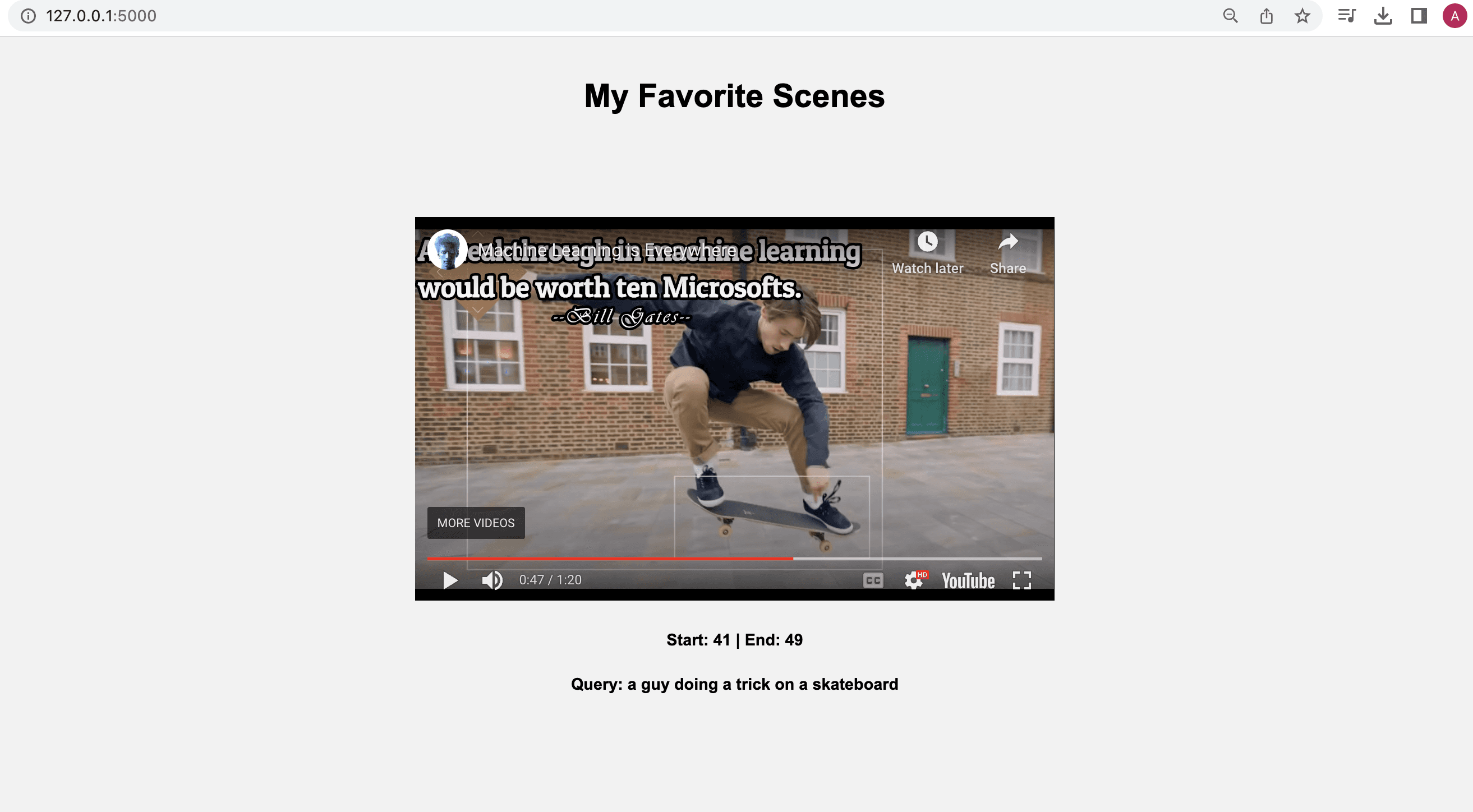
URLリンク http://127.0.0.1:5000 をクリックすると、検索クエリに応じて、以下のように出力されます。
ビデオを再生すると、指定したタイムスタンプに従って再生され、ビデオ内で探し出したかった特定の瞬間やセグメントが強調表示されます。
Jupyter Notebookを含むフォルダと、手元のコンピュータでローカルにチュートリアルを実行するために必要なすべてのファイルへのリンクはこちらです - https://tinyurl.com/twelvelabs
探求してほしい楽しいアクティビティ:
検索オプション(visual、conversation、text-in-video)のさまざまな組み合わせを試してみて、結果がどのように変化するかを確認してください。
複数のビデオをアップロードし、それに応じてコードを調整して、これらすべてのビデオを同時に検索できるようにします。
プロの開発者スキルを発揮して、ユーザーが `index.html` ページからクエリを入力し、リアルタイムで結果を取得できるようにコードを強化します。
次にすること
次回の記事では、演算子のセットを使用して複数のシンプルなクエリを組み合わせたり、ビデオのコレクション全体を検索したりする方法について詳しく説明します。今後の投稿を楽しみにしていてください!
最後に、マルチモーダル基盤モデルに関心を共有する同志たちとつながるために、当社のDiscordコミュニティにぜひご参加ください。アイデアを交換したり、質問したり、お互いから学び合ったりするのに最適な場所です!
最近、Twelve LabsはGTC 2023におけるマルチモーダルAIのパイオニアとして取り上げられました。GTC 2023のビデオを見ている時、共同創業者のSoyoungが、自社が紹介されているセグメントを探すのに苦労して髪をかきむしっているのを目にしました。この経験から、自社のAPIを使ってビデオ内を検索するという課題に取り組むモチベーションが湧きました。そこで、今週末の楽しさ満載の個人プロジェクトのチュートリアルとして、Twelve Labsの検索APIを使用してビデオ内の特定の瞬間を見つけるプロセスをご案内します。
ビデオ内の検索をより快適にするためのシンプルな設計図😎
はじめに
Twelve Labsは、ビデオ理解のパワーを活用したアプリケーションの作成を支援するために設計された、一連のAPIの形でマルチモーダル基盤モデルを提供しています。このブログ記事では、Twelve Labs APIを使用して、自然言語のクエリでビデオ内の特定の興味深い瞬間をシームレスに見つける方法を探ります。大学院時代に作成した、「Machine Learning is Everywhere(機械学習はどこにでもある)」というタイトルの面白いビデオをローカルドライブからアップロードします。その名の通り、この80秒のビデオは、生活のあらゆる側面におけるMLの偏在性を示しています。このビデオでは、プロの卓球選手がKukaロボットと対戦する様子や、スケートボードのトリックを行う人物のイベント要約にMLが使用されている様子などのMLアプリケーションが紹介されています。Twelve Labs APIの力を借りて、シンプルな自然言語クエリを使用してビデオ内の特定のシーンを見つける方法をデモします。
このチュートリアルでは、シンプルな検索APIについての緩やかな導入を目的としているため、シングルビデオ内の瞬間を検索することに焦点を当て、軽量でユーザーフレンドリーなFlaskフレームワークを使用してデモアプリを作成するという、最小限の構成にしています。しかし、このプラットフォームは、数百、あるいは数千のビデオのアップロードに対応し、それらの中から特定の瞬間を見つけ出せるようにスケールする十分な機能を備えています。それでは、本格的な楽しみに向けて飛び込んでいきましょう!
クイックオーバービュー
前提条件: Twelve Labs APIスイートを使用するためのサインアップと、デモアプリケーションを作成するために必要なパッケージのインストール
ビデオのアップロード: 素晴らしいビデオをお持ちですか?それらをTwelve Labsプラットフォームに送信すれば、効率的にインデックスが作成され、検索体験が格段に簡単になります!
セマンティックビデオ検索: シンプルな自然言語クエリで、ビデオ内の思い出の瞬間を探し出します
デモアプリの作成: Flaskを使用してHTMLテンプレートをレンダリングする便利なPythonスクリプトを作成し、検索結果を表示する洗練されたHTMLページをデザインします
💡 ところで、開発者ではない方がこの記事を読まれていても、心配は無用です!Jupyter Notebookのすぐに使えるリンクを用意しており、プロセス全体を実行して結果を得ることができます。さらに、コードを1行も書かずにセマンティックビデオ検索の力を体験できる弊社のPlaygroundもぜひお試しください。無料クレジットが必要な場合は、お気軽にご連絡ください😄。
前提条件
このチュートリアルでは、Jupyter Notebookを使用します。ローカルコンピューターにすでにJupyter、Python、およびPipがセットアップされていることを前提としています。何か問題が発生した場合は、最も迅速にレスポンスが可能な弊社のDiscordサーバーでお気軽にご相談ください 🚅🏎️⚡️。Discordがお好みに合わない場合は、メールでお問い合わせいただくこともできます。Twelve Labsのアカウントを作成すると、APIダッシュボードにアクセスしてAPIキーを取得できます。このデモでは既存のアカウントを使用します。API呼び出しを行うには、シークレットキーを使用し、API URLを指定するだけです。さらに、環境変数を使用して、アプリケーションに設定の詳細を渡すことができます。
<pre><code class="bash">%env API_KEY=<your_API_key> %env API_URL=https://api.twelvelabs.io/v1.1 </code></pre>
依存関係のインストール:
<pre><code class="python">pip install requests pip install flask </code></pre>
ビデオのアップロード
最初のステップとして、ビデオ理解機能を活用するために、ローカルコンピューターからTwelve Labsプラットフォームにビデオをアップロードした方法を解説します。
インポート:
<pre><code class="python">import os import requests import glob from pprint import pprint </code></pre
以下のようにして、APIのURLとAPIキーを取得します。
<pre><code class="python">API_URL = os.getenv("API_URL") assert API_URL </code></pre
<pre><code class="python">API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre
Index API
次のステップでは、Index APIを使用してビデオインデックスを作成します。ビデオインデックスは、1つ以上のビデオをグループ化し、いくつかの共通の検索プロパティを設定する方法であり、これにより、インデックスにアップロードされたビデオに対してセマンティック検索を実行できるようになります。
インデックスは以下のフィールドによって定義されます:
<ul> <li><b>名前</b></li> <li><b>エンジン</b> - 現在、ビデオ理解のための最新のマルチモーダル基盤モデルであるMarengo2を提供しています</li> <li>1つ以上の<b>インデックス作成オプション</b>:</li> <ul> <li><b>visual</b>: このオプションを選択すると、APIサービスはビデオのマルチモーダルな視覚・音響分析を実行し、オブジェクト、アクション、音、動き、場所、状況に応じたイベント、および複雑な視覚・音響テキストの説明によって検索できるようになります。ビジュアル検索の例としては、大歓声の群衆やオフィスを去る疲れ切った開発者などが挙げられます😆。</li> <li><b>conversation</b>: このオプションを選択すると、APIはビデオから説明(書き起こしテキスト)を抽出し、そのテキストに対してセマンティックな自然言語処理(NLP)分析を実行します。これにより、検索している会話が行われているビデオ内の正確な瞬間を特定できます。インデックス化されたビデオ内で行われる会話を検索する例としては、兄弟に嘘をついた瞬間などが挙げられます😜。</li> <li><b>text_in_video</b>: このオプションを選択すると、APIサービスは文字認識(OCR)を実行し、標識、ラベル、字幕、ロゴ、プレゼンテーション、ドキュメントなど、ビデオ内に表示されるテキストを検索できるようにします。この場合、サッカーの試合中に登場するブランドなどを検索することができます🏈。</li></ul></ul>
インデックスの作成:
<pre><code class="python"># `/indexes` エンドポイントの URL を構築します INDEXES_URL = f"{API_URL}/indexes" # インデックスの名前を指定します INDEX_NAME = "My University Days" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } # data という名前の辞書を宣言します data = { "engine_id": "marengo2", "index_options": ["visual", "conversation", "text_in_video"], "index_name": INDEX_NAME, } # インデックスを作成します response = requests.post(INDEXES_URL, headers=headers, json=data) # インデックスの一意の識別子を保存します INDEX_ID = response.json().get('_id') # ステータスコードとレスポンスをプリントします print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
ビデオをアップロードするためのTask API
Twelve Labs プラットフォームは、作成されたインデックスにビデオをアップロードし、アップロードプロセスのステータスを監視するためのTask APIを提供しています。
<pre><code class="python">TASKS_URL = f"{API_URL}/tasks" file_name = "Machine Learning is Everywhere" # インデックス化されたビデオはこのファイル名になります file_path = "ml.mp4" # アップロードするビデオのファイル名 file_stream = open(file_path,"rb") data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] response = requests.post(TASKS_URL, headers=headers, data=data, files=file_param </code></pre
ビデオをアップロードすると、システムは自動的にビデオ・インデックス作成プロセスを開始します。Twelve Labsは、「ビデオ・インデックス作成」の概念について、マルチモーダル基盤モデルを使用して時間的コンテキストを組み込み、動き、オブジェクト、音、画面上のテキスト、ビデオからの音声などの情報を抽出して、強力なビデオ埋め込み(embeddings)を生成することだと説明しています。これにより、日常的な言葉を使ってビデオ内の特定の瞬間を見つけたり、指定されたラベルやプロンプトに基づいてビデオセグメントを分類したりすることが可能になります。
ビデオ・インデックス作成プロセスの監視:
<pre><code class="python">import time # 開始時間を定義します start = time.time() print("Start uploading video") # インデックスプロセスを監視します TASK_STATUS_URL = f"{API_URL}/tasks/{TASK_ID}" while True: response = requests.get(TASK_STATUS_URL, headers=headers) STATUS = response.json().get("status") if STATUS == "ready": print(f"Status code: {STATUS}") break time.sleep(10) # 終了時間を定義します end = time.time() print("Finish uploading video") print("Time elapsed (in seconds): ", end - start) </code></pre
<pre><code class="python"># ビデオの一意の識別子を取得します VIDEO_ID = response.json().get('video_id') # ステータスコード、ビデオの一意の識別子、 およびレスポンスをプリントします print(f"VIDEO ID: {VIDEO_ID}") pprint(response.json()) </code></pre
<pre><code class="language-plaintext">VIDEO ID: 642621ffffa3551fb6d2f### {'_id': '642621fc3205dc8a48ba8###', 'created_at': '2023-03-30T23:57:48.877Z', 'estimated_time': '2023-03-30T23:59:58.312Z', 'index_id': '###621fb7b1f2230dfcd6###', 'metadata': {'duration': 80.32, 'filename': 'Machine Learning is Everywhere', 'height': 720, 'width': 1280}, 'status': 'ready', 'type': 'index_task_info', 'updated_at': '2023-03-31T00:00:34.412Z', 'video_id': '642621ffffa3551fb6d2f###'} </code></pre
アプリに既存インデックスの一意の識別子を渡すための別の環境変数を作成します:
<pre><code class="python">%env ENV_INDEX_ID = ###621fb7b1f2230dfcd6### </code></pre
こちらはインデックス内のすべてのビデオの一覧です。今回はシンプルにするためにビデオを1つだけインデックス化しましたが、無料クレジットを使用すれば最大10時間分のビデオコンテンツをアップロードできます。
<pre><code class="python"># 既存のインデックスの一意の識別子を取得します INDEX_ID = os.getenv("ENV_INDEX_ID") # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY, } # インデックス内のすべてのビデオをリストします INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=headers) print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
<pre><code class="python">Status code: 200 {'data': [{'_id': '642621ffffa3551fb6d2f###', 'created_at': '2023-03-30T23:57:48Z', 'metadata': {'duration': 80.32, 'engine_id': 'marengo2', 'filename': 'Machine Learning is Everywhere', 'fps': 25, 'height': 720, 'size': 11877525, 'width': 1280}, 'updated_at': '2023-03-30T23:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 80.32, 'total_page': 1, 'total_results': 1}} </code></pre
セマンティックビデオ検索、すなわち特定の瞬間の検索
システムがビデオのインデックス作成とビデオ埋め込みの生成を完了すると、これらを活用して検索APIで特定の瞬間を見つけることができます。このAPIは、入力したクエリのセマンティックな意味に対応する、関連ビデオ内の正確な開始・終了タイムコードを特定します。選択したインデックスの作成オプションに応じて、セマンティックビデオ検索に同じオプションのサブセットから選択できます。例えば、インデックスのすべてのオプションを有効にした場合、視覚・聴覚的な検索、会話の検索、ビデオ内に表示されるテキストの検索が可能になります。インデックスレベルと検索レベルの両方で同じオプションのセットを提供する理由は、ビデオコンテンツの分析にプラットフォームをどのように利用したいか、また現在のコンテキストに適したオプションを組み合わせてビデオコンテンツ全体をどのように検索したいかを柔軟に決定できるようにするためです。
まずは、シンプルな自然言語クエリ「a guy doing a trick on a skateboard(スケートボードでトリックを決める男)」を使ったビジュアル検索から始めましょう。
<pre><code class="bash">Status code: 200 {'data': [{'confidence': 'high', 'end': 49.34375, 'metadata': [{'type': 'visual'}], 'score': 83.24, 'start': 41.65625, 'video_id': '642621ffffa3551fb6d2f###'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-03-31T22:41:42Z', 'total_results': 1}, 'search_pool': {'index_id': '642621fb7b1f2230dfcd####', 'total_count': 1, 'total_duration': 80}} </code></pre
対応するビデオセグメント:
この機能は、モデルがビデオコンテンツを人間のように理解している様子を示しているため、とても興奮します。上のスクリーンショットでわかるように、システムは抽出したかった正確な瞬間を見事に特定しています。
別のクエリとして「a guy playing table tennis with a robotic arm(ロボットアームと卓球をする男)」を試して、システムがさらに魔法のような力を発揮する様子を見てみましょう。
<pre><code class="python"># `/search` エンドポイントの URL を構築します SEARCH_URL = f"{API_URL}/search/" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } query = "a guy playing table tennis with a robotic arm" # `data` という名前の辞書を宣言します data = { "query": query, # 検索クエリを指定します "index_id": INDEX_ID, # インデックスの一意の識別子を指定します "search_options": ["visual"], # 検索オプションを指定します } # 検索リクエストを行います response = requests.post(SEARCH_URL, headers=headers, json=data) print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre
出力:
<pre><code class="python">{'data': [{'confidence': 'high', 'end': 14.6875, 'metadata': [{'type': 'visual'}], 'score': 90.62, 'start': 9.75, 'video_id': '642621ffffa3551fb6d2####'}, {'confidence': 'high', 'end': 9.75, 'metadata': [{'type': 'visual'}], 'score': 89.74, 'start': 4.5, 'video_id': '642621ffffa3551fb6d2####'}], </code></pre
対応するビデオセグメント:
ビンゴ!今回もシステムは魅力的な瞬間を正確に特定しました。
💡ここで、楽しいミニ課題です。"a breakthrough in machine learning would be worth ten Microsofts(機械学習におけるブレイクスルーはマイクロソフト10社分の価値がある)"を検索し、検索オプションを `["text_in_video"]` に設定してみてください。
これらのJSONレスポンスを、開始点と終了点を手動で確認することなく最大限に活用するには、愛情込めて作られた素晴らしいインデックスページが必要です。そうすれば、検索リクエストのJSON出力を対応するビデオに直接送信できます。さあ、取りかかりましょう!
デモアプリの作成
この素晴らしいビデオ理解の冒険にお付き合いいただきありがとうございます 🎉🥳👏!最後のステップに到達しました。ここでは、Flaskベースのシンプルなアプリを作成し、前のステップの検索結果を取得して美しいウェブページに表示し、リクエストした正確な瞬間を披露します。ちなみに、私はデータサイエンスのバックグラウンドがあり、Pythonが大好きなのでFlaskを選びました。さらに、Flaskは軽量なPythonベースのフレームワークであり、このチュートリアルのニーズに合致しています。もちろん、お好みに合わせて他のフレームワークを選んでいただいてもかまいません。
最初のステップは、Jupyter Notebookに必要なインポートを行うことです。
<pre><code class="python">import json import pickle </code></pre
検索APIから収集したすべての開始および終了タイムスタンプを保持する、"starts "と "ends "という2つのリストを生成します。
<pre><code class="python">data = response.json() starts = [] ends = [] for item in data['data']: starts.append(item['start']) ends.append(item['end']) print("starts:", starts) print("ends:", ends) </code></pre
<pre><code class="bash">starts: [34.90625, 0, 62.5625] ends: [39.21875, 4.5, 65.90625] </code></pre
必要なタイムスタンプを取得し、同じビデオを自身のYouTubeチャンネルにアップロードしたので、それらを使用する方法はいくつかあります。ローカルディスクからビデオを取得してウェブページでお気に入りのクリップを表示することもできますし、YouTubeチャンネルのビデオURLをそのまま使用して同じ結果を得ることもできます。後者の方がより魅力的なので、アップロードしたビデオと同じYouTubeの埋め込みコードを使用し、開始と終了のタイムスタンプを渡すことにします。このようにして、検索した正確なビデオセグメントが表示されるようになります。少し注意点として、YouTubeの埋め込みコードは、開始および終了パラメータに整数値のみをサポートしているため、これらの値を丸める必要があります。
<pre><code class="bash">starts_int = [int(f) for f in starts] ends_int = [int(f) for f in ends] </code></pre
作成するFlaskアプリのファイルに渡せるよう、入力したクエリと一緒にこれらのリストを素早くシリアライズ(pickle)しておきましょう。これは、これから作成するFlaskアプリのファイルにパラメータを渡す際に役立ちます。
<pre><code class="python">with open("lists.pkl", "wb") as f: pickle.dump((starts_int, ends_int, query), f) </code></pre>
これで、Flaskを使用してこれらのパラメータを渡す設定がすべて整いました。
Flaskアプリを作成する手順
1. 新しいFlaskプロジェクトの作成: プロジェクト用の新しいディレクトリを作成し、Flaskアプリのメインファイルとなる新しいPythonファイルを作成します。
<pre><code class="bash">mkdir my_flask_app cd my_flask_app touch app.py </code></pre>
Flaskアプリファイルとテンプレートの準備ができると、ディレクトリ構造は次のようになります。
<pre><code class="markdown">my_flask_app/ │ app.py │ ml.mp4 │ └───templates/ │ index.html </code></pre>
アップロードするビデオファイルを `my_flask_app` ディレクトリ内に保存しておきます。
2. Flaskアプリのコードを作成する: **app.py** ファイルに、Flaskアプリのコードを記述する必要があります。以下は、Jinja2テンプレートを使用して、タイムスタンプのリストが使用されている 'index.html' ファイルをレンダリングするFlaskアプリです。
<pre><code class="python">from flask import Flask, render_template import pickle with open("lists.pkl", "rb") as f: starts, ends, query = pickle.load(f) app = Flask(__name__) @app.route("/") def index(): return render_template("index.html", starts=starts, ends=ends, query=query) if __name__ == "__main__": app.run(debug=True) </code></pre
3. templatesディレクトリの作成: FlaskでJinja2テンプレートを使用するには、Flaskアプリと同じディレクトリに **templates** ディレクトリを作成する必要があります。このディレクトリにJinja2テンプレートを保存します。
<pre><code class="bash">mkdir templates </code></pre>
パズルの最後のピースは、検索クエリに一致したすべてのビデオセグメントを表示する `index.html` ページです。HTMLファイルを作成する前に、私のYouTubeチャンネルから「ビデオの埋め込み」コードを素早く取得しましょう。
4. Jinja2テンプレートの作成: Jinja2テンプレートを作成するには、**templates** ディレクトリにHTMLファイルを作成する必要があります。
<pre><code class="bash">touch index.html </code></pre>
以下は、Jinja2テンプレートのシンプルな例です。HTMLファイル内に、アプリファイルから渡されたリストとクエリ文字列を反復処理できるようにするコードが組み込まれています。
<pre><code class="language-html"><html> <head> <style> body { background-color: #F2F2F2; font-family: Arial, sans-serif; text-align: center; } h1 { margin-top: 40px; } .video-container { display: flex; flex-wrap: wrap; padding: 40px; justify-content: center; } .video-item { display: flex; flex-direction: column; align-items: center; width: 50%; height: 600px; margin: 20px; text-align: center; } .video-item iframe { width: 80%; height: 380px; margin: 20px; } .video-item p { font-size: 16px; margin-top: 10px; font-weight: bold; } </style> </head> <body> <h1>My Favorite Scenes</h1> <div class="video-container"> {% for i in range(starts|length) %} <div class="video-item"> <iframe width="560" height="315" src="https://www.youtube.com/embed/hdZ_tNtdB4c?start={{ starts[i] }}&end={{ ends[i] }}" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in- picture" allowfullscreen></iframe> <p>Start: {{ starts[i] }} | End: {{ ends[i] }}</p> <p>Query: {{ query }}</p> </div> {% endfor %} </div> </body> </html> </code></pre>
パーフェクト!Jupyter Notebookの最後のセルを実行しましょう。
<pre><code class="python">%run app.py </code></pre>
すべてが期待通りに進んでいることを示す、以下のような出力が表示されるはずです😊:
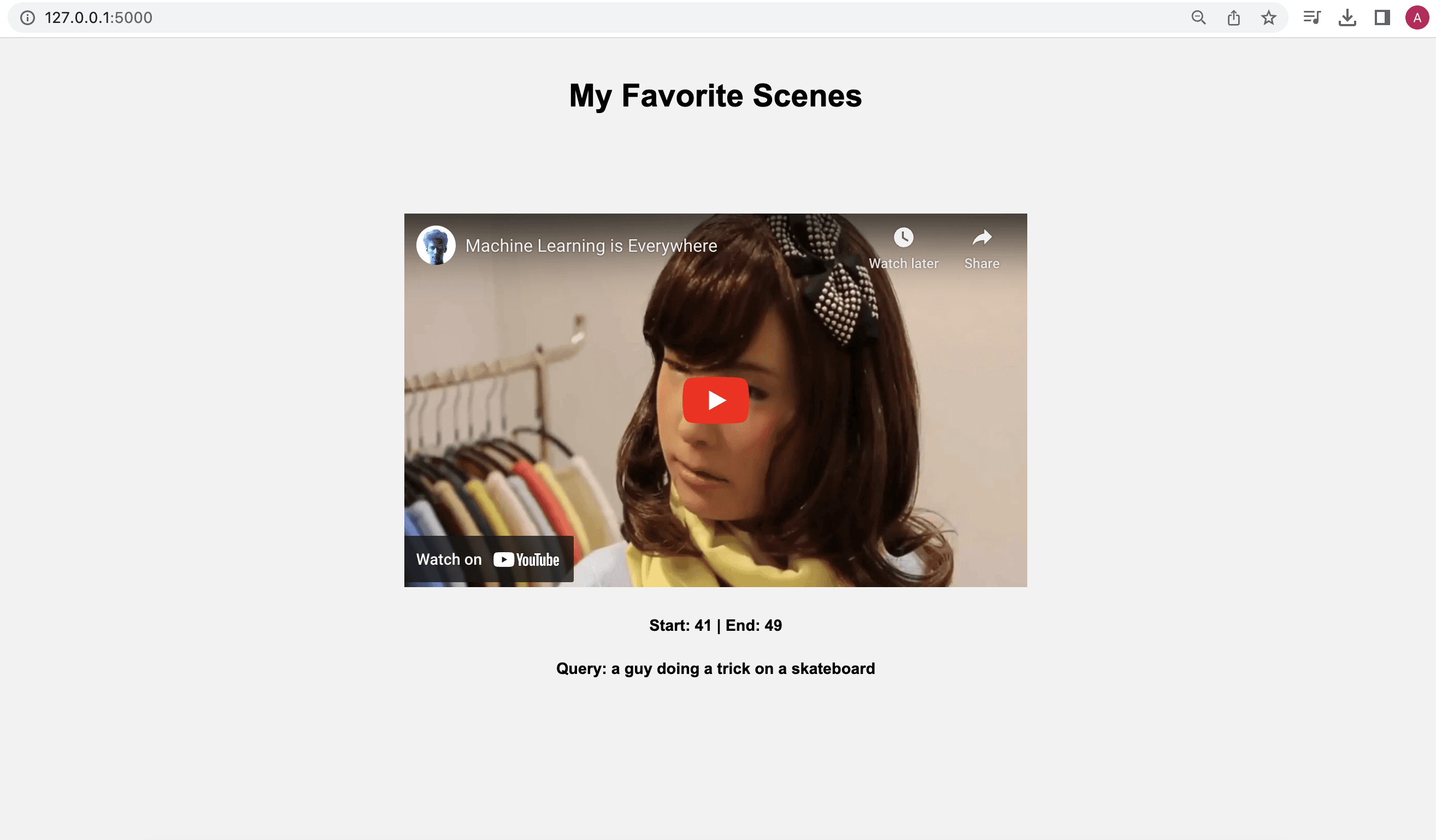
URLリンク http://127.0.0.1:5000 をクリックすると、検索クエリに応じて、以下のように出力されます。
ビデオを再生すると、指定したタイムスタンプに従って再生され、ビデオ内で探し出したかった特定の瞬間やセグメントが強調表示されます。
Jupyter Notebookを含むフォルダと、手元のコンピュータでローカルにチュートリアルを実行するために必要なすべてのファイルへのリンクはこちらです - https://tinyurl.com/twelvelabs
探求してほしい楽しいアクティビティ:
検索オプション(visual、conversation、text-in-video)のさまざまな組み合わせを試してみて、結果がどのように変化するかを確認してください。
複数のビデオをアップロードし、それに応じてコードを調整して、これらすべてのビデオを同時に検索できるようにします。
プロの開発者スキルを発揮して、ユーザーが `index.html` ページからクエリを入力し、リアルタイムで結果を取得できるようにコードを強化します。
次にすること
次回の記事では、演算子のセットを使用して複数のシンプルなクエリを組み合わせたり、ビデオのコレクション全体を検索したりする方法について詳しく説明します。今後の投稿を楽しみにしていてください!
最後に、マルチモーダル基盤モデルに関心を共有する同志たちとつながるために、当社のDiscordコミュニティにぜひご参加ください。アイデアを交換したり、質問したり、お互いから学び合ったりするのに最適な場所です!
最近、Twelve LabsはGTC 2023におけるマルチモーダルAIのパイオニアとして取り上げられました。GTC 2023のビデオを見ている時、共同創業者のSoyoungが、自社が紹介されているセグメントを探すのに苦労して髪をかきむしっているのを目にしました。この経験から、自社のAPIを使ってビデオ内を検索するという課題に取り組むモチベーションが湧きました。そこで、今週末の楽しさ満載の個人プロジェクトのチュートリアルとして、Twelve Labsの検索APIを使用してビデオ内の特定の瞬間を見つけるプロセスをご案内します。
ビデオ内の検索をより快適にするためのシンプルな設計図😎
はじめに
Twelve Labsは、ビデオ理解のパワーを活用したアプリケーションの作成を支援するために設計された、一連のAPIの形でマルチモーダル基盤モデルを提供しています。このブログ記事では、Twelve Labs APIを使用して、自然言語のクエリでビデオ内の特定の興味深い瞬間をシームレスに見つける方法を探ります。大学院時代に作成した、「Machine Learning is Everywhere(機械学習はどこにでもある)」というタイトルの面白いビデオをローカルドライブからアップロードします。その名の通り、この80秒のビデオは、生活のあらゆる側面におけるMLの偏在性を示しています。このビデオでは、プロの卓球選手がKukaロボットと対戦する様子や、スケートボードのトリックを行う人物のイベント要約にMLが使用されている様子などのMLアプリケーションが紹介されています。Twelve Labs APIの力を借りて、シンプルな自然言語クエリを使用してビデオ内の特定のシーンを見つける方法をデモします。
このチュートリアルでは、シンプルな検索APIについての緩やかな導入を目的としているため、シングルビデオ内の瞬間を検索することに焦点を当て、軽量でユーザーフレンドリーなFlaskフレームワークを使用してデモアプリを作成するという、最小限の構成にしています。しかし、このプラットフォームは、数百、あるいは数千のビデオのアップロードに対応し、それらの中から特定の瞬間を見つけ出せるようにスケールする十分な機能を備えています。それでは、本格的な楽しみに向けて飛び込んでいきましょう!
クイックオーバービュー
前提条件: Twelve Labs APIスイートを使用するためのサインアップと、デモアプリケーションを作成するために必要なパッケージのインストール
ビデオのアップロード: 素晴らしいビデオをお持ちですか?それらをTwelve Labsプラットフォームに送信すれば、効率的にインデックスが作成され、検索体験が格段に簡単になります!
セマンティックビデオ検索: シンプルな自然言語クエリで、ビデオ内の思い出の瞬間を探し出します
デモアプリの作成: Flaskを使用してHTMLテンプレートをレンダリングする便利なPythonスクリプトを作成し、検索結果を表示する洗練されたHTMLページをデザインします
💡 ところで、開発者ではない方がこの記事を読まれていても、心配は無用です!Jupyter Notebookのすぐに使えるリンクを用意しており、プロセス全体を実行して結果を得ることができます。さらに、コードを1行も書かずにセマンティックビデオ検索の力を体験できる弊社のPlaygroundもぜひお試しください。無料クレジットが必要な場合は、お気軽にご連絡ください😄。
前提条件
このチュートリアルでは、Jupyter Notebookを使用します。ローカルコンピューターにすでにJupyter、Python、およびPipがセットアップされていることを前提としています。何か問題が発生した場合は、最も迅速にレスポンスが可能な弊社のDiscordサーバーでお気軽にご相談ください 🚅🏎️⚡️。Discordがお好みに合わない場合は、メールでお問い合わせいただくこともできます。Twelve Labsのアカウントを作成すると、APIダッシュボードにアクセスしてAPIキーを取得できます。このデモでは既存のアカウントを使用します。API呼び出しを行うには、シークレットキーを使用し、API URLを指定するだけです。さらに、環境変数を使用して、アプリケーションに設定の詳細を渡すことができます。
<pre><code class="bash">%env API_KEY=<your_API_key> %env API_URL=https://api.twelvelabs.io/v1.1 </code></pre>
依存関係のインストール:
<pre><code class="python">pip install requests pip install flask </code></pre>
ビデオのアップロード
最初のステップとして、ビデオ理解機能を活用するために、ローカルコンピューターからTwelve Labsプラットフォームにビデオをアップロードした方法を解説します。
インポート:
<pre><code class="python">import os import requests import glob from pprint import pprint </code></pre
以下のようにして、APIのURLとAPIキーを取得します。
<pre><code class="python">API_URL = os.getenv("API_URL") assert API_URL </code></pre
<pre><code class="python">API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre
Index API
次のステップでは、Index APIを使用してビデオインデックスを作成します。ビデオインデックスは、1つ以上のビデオをグループ化し、いくつかの共通の検索プロパティを設定する方法であり、これにより、インデックスにアップロードされたビデオに対してセマンティック検索を実行できるようになります。
インデックスは以下のフィールドによって定義されます:
<ul> <li><b>名前</b></li> <li><b>エンジン</b> - 現在、ビデオ理解のための最新のマルチモーダル基盤モデルであるMarengo2を提供しています</li> <li>1つ以上の<b>インデックス作成オプション</b>:</li> <ul> <li><b>visual</b>: このオプションを選択すると、APIサービスはビデオのマルチモーダルな視覚・音響分析を実行し、オブジェクト、アクション、音、動き、場所、状況に応じたイベント、および複雑な視覚・音響テキストの説明によって検索できるようになります。ビジュアル検索の例としては、大歓声の群衆やオフィスを去る疲れ切った開発者などが挙げられます😆。</li> <li><b>conversation</b>: このオプションを選択すると、APIはビデオから説明(書き起こしテキスト)を抽出し、そのテキストに対してセマンティックな自然言語処理(NLP)分析を実行します。これにより、検索している会話が行われているビデオ内の正確な瞬間を特定できます。インデックス化されたビデオ内で行われる会話を検索する例としては、兄弟に嘘をついた瞬間などが挙げられます😜。</li> <li><b>text_in_video</b>: このオプションを選択すると、APIサービスは文字認識(OCR)を実行し、標識、ラベル、字幕、ロゴ、プレゼンテーション、ドキュメントなど、ビデオ内に表示されるテキストを検索できるようにします。この場合、サッカーの試合中に登場するブランドなどを検索することができます🏈。</li></ul></ul>
インデックスの作成:
<pre><code class="python"># `/indexes` エンドポイントの URL を構築します INDEXES_URL = f"{API_URL}/indexes" # インデックスの名前を指定します INDEX_NAME = "My University Days" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } # data という名前の辞書を宣言します data = { "engine_id": "marengo2", "index_options": ["visual", "conversation", "text_in_video"], "index_name": INDEX_NAME, } # インデックスを作成します response = requests.post(INDEXES_URL, headers=headers, json=data) # インデックスの一意の識別子を保存します INDEX_ID = response.json().get('_id') # ステータスコードとレスポンスをプリントします print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
ビデオをアップロードするためのTask API
Twelve Labs プラットフォームは、作成されたインデックスにビデオをアップロードし、アップロードプロセスのステータスを監視するためのTask APIを提供しています。
<pre><code class="python">TASKS_URL = f"{API_URL}/tasks" file_name = "Machine Learning is Everywhere" # インデックス化されたビデオはこのファイル名になります file_path = "ml.mp4" # アップロードするビデオのファイル名 file_stream = open(file_path,"rb") data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] response = requests.post(TASKS_URL, headers=headers, data=data, files=file_param </code></pre
ビデオをアップロードすると、システムは自動的にビデオ・インデックス作成プロセスを開始します。Twelve Labsは、「ビデオ・インデックス作成」の概念について、マルチモーダル基盤モデルを使用して時間的コンテキストを組み込み、動き、オブジェクト、音、画面上のテキスト、ビデオからの音声などの情報を抽出して、強力なビデオ埋め込み(embeddings)を生成することだと説明しています。これにより、日常的な言葉を使ってビデオ内の特定の瞬間を見つけたり、指定されたラベルやプロンプトに基づいてビデオセグメントを分類したりすることが可能になります。
ビデオ・インデックス作成プロセスの監視:
<pre><code class="python">import time # 開始時間を定義します start = time.time() print("Start uploading video") # インデックスプロセスを監視します TASK_STATUS_URL = f"{API_URL}/tasks/{TASK_ID}" while True: response = requests.get(TASK_STATUS_URL, headers=headers) STATUS = response.json().get("status") if STATUS == "ready": print(f"Status code: {STATUS}") break time.sleep(10) # 終了時間を定義します end = time.time() print("Finish uploading video") print("Time elapsed (in seconds): ", end - start) </code></pre
<pre><code class="python"># ビデオの一意の識別子を取得します VIDEO_ID = response.json().get('video_id') # ステータスコード、ビデオの一意の識別子、 およびレスポンスをプリントします print(f"VIDEO ID: {VIDEO_ID}") pprint(response.json()) </code></pre
<pre><code class="language-plaintext">VIDEO ID: 642621ffffa3551fb6d2f### {'_id': '642621fc3205dc8a48ba8###', 'created_at': '2023-03-30T23:57:48.877Z', 'estimated_time': '2023-03-30T23:59:58.312Z', 'index_id': '###621fb7b1f2230dfcd6###', 'metadata': {'duration': 80.32, 'filename': 'Machine Learning is Everywhere', 'height': 720, 'width': 1280}, 'status': 'ready', 'type': 'index_task_info', 'updated_at': '2023-03-31T00:00:34.412Z', 'video_id': '642621ffffa3551fb6d2f###'} </code></pre
アプリに既存インデックスの一意の識別子を渡すための別の環境変数を作成します:
<pre><code class="python">%env ENV_INDEX_ID = ###621fb7b1f2230dfcd6### </code></pre
こちらはインデックス内のすべてのビデオの一覧です。今回はシンプルにするためにビデオを1つだけインデックス化しましたが、無料クレジットを使用すれば最大10時間分のビデオコンテンツをアップロードできます。
<pre><code class="python"># 既存のインデックスの一意の識別子を取得します INDEX_ID = os.getenv("ENV_INDEX_ID") # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY, } # インデックス内のすべてのビデオをリストします INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=headers) print(f'Status code: {response.status_code}') pprint(response.json()) </code></pre
<pre><code class="python">Status code: 200 {'data': [{'_id': '642621ffffa3551fb6d2f###', 'created_at': '2023-03-30T23:57:48Z', 'metadata': {'duration': 80.32, 'engine_id': 'marengo2', 'filename': 'Machine Learning is Everywhere', 'fps': 25, 'height': 720, 'size': 11877525, 'width': 1280}, 'updated_at': '2023-03-30T23:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 80.32, 'total_page': 1, 'total_results': 1}} </code></pre
セマンティックビデオ検索、すなわち特定の瞬間の検索
システムがビデオのインデックス作成とビデオ埋め込みの生成を完了すると、これらを活用して検索APIで特定の瞬間を見つけることができます。このAPIは、入力したクエリのセマンティックな意味に対応する、関連ビデオ内の正確な開始・終了タイムコードを特定します。選択したインデックスの作成オプションに応じて、セマンティックビデオ検索に同じオプションのサブセットから選択できます。例えば、インデックスのすべてのオプションを有効にした場合、視覚・聴覚的な検索、会話の検索、ビデオ内に表示されるテキストの検索が可能になります。インデックスレベルと検索レベルの両方で同じオプションのセットを提供する理由は、ビデオコンテンツの分析にプラットフォームをどのように利用したいか、また現在のコンテキストに適したオプションを組み合わせてビデオコンテンツ全体をどのように検索したいかを柔軟に決定できるようにするためです。
まずは、シンプルな自然言語クエリ「a guy doing a trick on a skateboard(スケートボードでトリックを決める男)」を使ったビジュアル検索から始めましょう。
<pre><code class="bash">Status code: 200 {'data': [{'confidence': 'high', 'end': 49.34375, 'metadata': [{'type': 'visual'}], 'score': 83.24, 'start': 41.65625, 'video_id': '642621ffffa3551fb6d2f###'}], 'page_info': {'limit_per_page': 10, 'page_expired_at': '2023-03-31T22:41:42Z', 'total_results': 1}, 'search_pool': {'index_id': '642621fb7b1f2230dfcd####', 'total_count': 1, 'total_duration': 80}} </code></pre
対応するビデオセグメント:
この機能は、モデルがビデオコンテンツを人間のように理解している様子を示しているため、とても興奮します。上のスクリーンショットでわかるように、システムは抽出したかった正確な瞬間を見事に特定しています。
別のクエリとして「a guy playing table tennis with a robotic arm(ロボットアームと卓球をする男)」を試して、システムがさらに魔法のような力を発揮する様子を見てみましょう。
<pre><code class="python"># `/search` エンドポイントの URL を構築します SEARCH_URL = f"{API_URL}/search/" # リクエストのヘッダーを設定します headers = { "x-api-key": API_KEY } query = "a guy playing table tennis with a robotic arm" # `data` という名前の辞書を宣言します data = { "query": query, # 検索クエリを指定します "index_id": INDEX_ID, # インデックスの一意の識別子を指定します "search_options": ["visual"], # 検索オプションを指定します } # 検索リクエストを行います response = requests.post(SEARCH_URL, headers=headers, json=data) print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre
出力:
<pre><code class="python">{'data': [{'confidence': 'high', 'end': 14.6875, 'metadata': [{'type': 'visual'}], 'score': 90.62, 'start': 9.75, 'video_id': '642621ffffa3551fb6d2####'}, {'confidence': 'high', 'end': 9.75, 'metadata': [{'type': 'visual'}], 'score': 89.74, 'start': 4.5, 'video_id': '642621ffffa3551fb6d2####'}], </code></pre
対応するビデオセグメント:
ビンゴ!今回もシステムは魅力的な瞬間を正確に特定しました。
💡ここで、楽しいミニ課題です。"a breakthrough in machine learning would be worth ten Microsofts(機械学習におけるブレイクスルーはマイクロソフト10社分の価値がある)"を検索し、検索オプションを `["text_in_video"]` に設定してみてください。
これらのJSONレスポンスを、開始点と終了点を手動で確認することなく最大限に活用するには、愛情込めて作られた素晴らしいインデックスページが必要です。そうすれば、検索リクエストのJSON出力を対応するビデオに直接送信できます。さあ、取りかかりましょう!
デモアプリの作成
この素晴らしいビデオ理解の冒険にお付き合いいただきありがとうございます 🎉🥳👏!最後のステップに到達しました。ここでは、Flaskベースのシンプルなアプリを作成し、前のステップの検索結果を取得して美しいウェブページに表示し、リクエストした正確な瞬間を披露します。ちなみに、私はデータサイエンスのバックグラウンドがあり、Pythonが大好きなのでFlaskを選びました。さらに、Flaskは軽量なPythonベースのフレームワークであり、このチュートリアルのニーズに合致しています。もちろん、お好みに合わせて他のフレームワークを選んでいただいてもかまいません。
最初のステップは、Jupyter Notebookに必要なインポートを行うことです。
<pre><code class="python">import json import pickle </code></pre
検索APIから収集したすべての開始および終了タイムスタンプを保持する、"starts "と "ends "という2つのリストを生成します。
<pre><code class="python">data = response.json() starts = [] ends = [] for item in data['data']: starts.append(item['start']) ends.append(item['end']) print("starts:", starts) print("ends:", ends) </code></pre
<pre><code class="bash">starts: [34.90625, 0, 62.5625] ends: [39.21875, 4.5, 65.90625] </code></pre
必要なタイムスタンプを取得し、同じビデオを自身のYouTubeチャンネルにアップロードしたので、それらを使用する方法はいくつかあります。ローカルディスクからビデオを取得してウェブページでお気に入りのクリップを表示することもできますし、YouTubeチャンネルのビデオURLをそのまま使用して同じ結果を得ることもできます。後者の方がより魅力的なので、アップロードしたビデオと同じYouTubeの埋め込みコードを使用し、開始と終了のタイムスタンプを渡すことにします。このようにして、検索した正確なビデオセグメントが表示されるようになります。少し注意点として、YouTubeの埋め込みコードは、開始および終了パラメータに整数値のみをサポートしているため、これらの値を丸める必要があります。
<pre><code class="bash">starts_int = [int(f) for f in starts] ends_int = [int(f) for f in ends] </code></pre
作成するFlaskアプリのファイルに渡せるよう、入力したクエリと一緒にこれらのリストを素早くシリアライズ(pickle)しておきましょう。これは、これから作成するFlaskアプリのファイルにパラメータを渡す際に役立ちます。
<pre><code class="python">with open("lists.pkl", "wb") as f: pickle.dump((starts_int, ends_int, query), f) </code></pre>
これで、Flaskを使用してこれらのパラメータを渡す設定がすべて整いました。
Flaskアプリを作成する手順
1. 新しいFlaskプロジェクトの作成: プロジェクト用の新しいディレクトリを作成し、Flaskアプリのメインファイルとなる新しいPythonファイルを作成します。
<pre><code class="bash">mkdir my_flask_app cd my_flask_app touch app.py </code></pre>
Flaskアプリファイルとテンプレートの準備ができると、ディレクトリ構造は次のようになります。
<pre><code class="markdown">my_flask_app/ │ app.py │ ml.mp4 │ └───templates/ │ index.html </code></pre>
アップロードするビデオファイルを `my_flask_app` ディレクトリ内に保存しておきます。
2. Flaskアプリのコードを作成する: **app.py** ファイルに、Flaskアプリのコードを記述する必要があります。以下は、Jinja2テンプレートを使用して、タイムスタンプのリストが使用されている 'index.html' ファイルをレンダリングするFlaskアプリです。
<pre><code class="python">from flask import Flask, render_template import pickle with open("lists.pkl", "rb") as f: starts, ends, query = pickle.load(f) app = Flask(__name__) @app.route("/") def index(): return render_template("index.html", starts=starts, ends=ends, query=query) if __name__ == "__main__": app.run(debug=True) </code></pre
3. templatesディレクトリの作成: FlaskでJinja2テンプレートを使用するには、Flaskアプリと同じディレクトリに **templates** ディレクトリを作成する必要があります。このディレクトリにJinja2テンプレートを保存します。
<pre><code class="bash">mkdir templates </code></pre>
パズルの最後のピースは、検索クエリに一致したすべてのビデオセグメントを表示する `index.html` ページです。HTMLファイルを作成する前に、私のYouTubeチャンネルから「ビデオの埋め込み」コードを素早く取得しましょう。
4. Jinja2テンプレートの作成: Jinja2テンプレートを作成するには、**templates** ディレクトリにHTMLファイルを作成する必要があります。
<pre><code class="bash">touch index.html </code></pre>
以下は、Jinja2テンプレートのシンプルな例です。HTMLファイル内に、アプリファイルから渡されたリストとクエリ文字列を反復処理できるようにするコードが組み込まれています。
<pre><code class="language-html"><html> <head> <style> body { background-color: #F2F2F2; font-family: Arial, sans-serif; text-align: center; } h1 { margin-top: 40px; } .video-container { display: flex; flex-wrap: wrap; padding: 40px; justify-content: center; } .video-item { display: flex; flex-direction: column; align-items: center; width: 50%; height: 600px; margin: 20px; text-align: center; } .video-item iframe { width: 80%; height: 380px; margin: 20px; } .video-item p { font-size: 16px; margin-top: 10px; font-weight: bold; } </style> </head> <body> <h1>My Favorite Scenes</h1> <div class="video-container"> {% for i in range(starts|length) %} <div class="video-item"> <iframe width="560" height="315" src="https://www.youtube.com/embed/hdZ_tNtdB4c?start={{ starts[i] }}&end={{ ends[i] }}" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in- picture" allowfullscreen></iframe> <p>Start: {{ starts[i] }} | End: {{ ends[i] }}</p> <p>Query: {{ query }}</p> </div> {% endfor %} </div> </body> </html> </code></pre>
パーフェクト!Jupyter Notebookの最後のセルを実行しましょう。
<pre><code class="python">%run app.py </code></pre>
すべてが期待通りに進んでいることを示す、以下のような出力が表示されるはずです😊:
URLリンク http://127.0.0.1:5000 をクリックすると、検索クエリに応じて、以下のように出力されます。
ビデオを再生すると、指定したタイムスタンプに従って再生され、ビデオ内で探し出したかった特定の瞬間やセグメントが強調表示されます。
Jupyter Notebookを含むフォルダと、手元のコンピュータでローカルにチュートリアルを実行するために必要なすべてのファイルへのリンクはこちらです - https://tinyurl.com/twelvelabs
探求してほしい楽しいアクティビティ:
検索オプション(visual、conversation、text-in-video)のさまざまな組み合わせを試してみて、結果がどのように変化するかを確認してください。
複数のビデオをアップロードし、それに応じてコードを調整して、これらすべてのビデオを同時に検索できるようにします。
プロの開発者スキルを発揮して、ユーザーが `index.html` ページからクエリを入力し、リアルタイムで結果を取得できるようにコードを強化します。
次にすること
次回の記事では、演算子のセットを使用して複数のシンプルなクエリを組み合わせたり、ビデオのコレクション全体を検索したりする方法について詳しく説明します。今後の投稿を楽しみにしていてください!
最後に、マルチモーダル基盤モデルに関心を共有する同志たちとつながるために、当社のDiscordコミュニティにぜひご参加ください。アイデアを交換したり、質問したり、お互いから学び合ったりするのに最適な場所です!








