" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
파트너십
TwelveLabs와 ApertureDB를 활용한 시맨틱 비디오 검색 엔진

제임스 러
개발자는 Twelve Labs의 Embed API를 ApertureDB와 통합하여 시맨틱 비디오 검색 엔진을 구축할 수 있습니다. Marengo 2.6을 통해 멀티모달 비디오 임베딩을 생성하고 이를 ApertureDB의 그래프-벡터 데이터베이스에 저장한 뒤, 자연어로 쿼리하여 정확한 타임스탬프와 함께 일치하는 비디오 클립을 찾아낼 수 있습니다.
개발자는 Twelve Labs의 Embed API를 ApertureDB와 통합하여 시맨틱 비디오 검색 엔진을 구축할 수 있습니다. Marengo 2.6을 통해 멀티모달 비디오 임베딩을 생성하고 이를 ApertureDB의 그래프-벡터 데이터베이스에 저장한 뒤, 자연어로 쿼리하여 정확한 타임스탬프와 함께 일치하는 비디오 클립을 찾아낼 수 있습니다.

In this article
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2024. 10. 11.
10분
링크 복사하기
이 튜토리얼에서는 TwelveLabs의 Embed API와 ApertureDB의 강력한 통합을 활용하여 고급 의미론적(semantic) 비디오 검색 엔진을 빌드하는 방법을 설명합니다. 최첨단 비디오 파운데이션 모델인 Marengo-2.6 기반의 Twelve Labs Embed API는 시각적 표현, 음성, 문맥 정보를 포함한 비디오 콘텐츠의 본질을 포착하는 다중모드 임베딩(multimodal embeddings)을 생성합니다. 이러한 임베딩을 컴퓨터 비전 및 머신러닝 애플리케이션에 최적화된 그래프-벡터 데이터베이스인 ApertureDB와 결합하면 매우 정확하고 효율적인 의미론적 검색 기능을 구현할 수 있습니다.
이 워크플로우를 통해 개발자와 데이터 과학자는 TwelveLabs Embed API를 활용하여 풍부한 비디오 임베딩을 생성하고, 이를 원본 비디오와 함께 ApertureDB에 원활하게 통합하여 의미론적 검색을 수행하는 방법을 배울 수 있습니다. 이 워크플로우는 정교한 비디오 분석 및 검색 시스템 빌드의 가능성을 보여주며, 다양한 산업 전반에서 콘텐츠 검색, 추천 엔진, 비디오 기반 애플리케이션의 새로운 가능성을 열어줍니다.
설치 및 환경 설정
이 섹션에서는 TwelveLabs Embed API와 ApertureDB를 통합하는 데 필요한 필수 라이브러리와 종속성을 설치합니다. 여기에는 API 호출을 위한 requests 라이브러리, ApertureDB 서비스와 상호작용하기 위한 aperturedb Python SDK, TwelveLabs Embed API에 액세스하기 위한 twelvelabs Python SDK 설치가 포함됩니다.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
위 코드를 실행하면 다음 단계의 노트북에서 사용할 수 있도록 필요한 모든 라이브러리가 명확히 설치되고 준비됩니다.
API 키 설정
이 섹션에서는 TwelveLabs 및 ApertureDB에 필요한 API 키를 설정합니다. 이러한 키를 안전하게 저장하고 불러오기 위해 Google Colab의 userdata 기능을 사용합니다.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
이 코드를 사용하려면 Google Colab의 ‘Secret(비밀)’에 API 키를 설정해야 합니다.
Colab 노트북의 왼쪽 사이드바 메뉴로 이동합니다.
열쇠 모양 아이콘을 클릭하여 "Secrets" 패널을 엽니다.
다음 두 가지의 비밀값을 추가합니다.
Key: TL_API_KEY, Value: 사용자의 TwelveLabs API 키
Key: ADB_PASSWORD, Value: 사용자의 ApertureDB 비밀번호
이 방식을 사용하면 API 키를 노트북에 노출하지 않고 안전하게 보호할 수 있습니다. 코드가 키의 설정 여부를 검증하고, 누락된 경우 에러를 발생시켜 구성 문제를 쉽게 해결할 수 있도록 도와줍니다.
TwelveLabs Embed API로 비디오 임베딩 생성하기
이 섹션에서는 TwelveLabs Embed API를 사용하여 비디오 임베딩을 생성하는 방법을 보여줍니다. 이 API는 임의 검색(any-to-any retrieval) 태스크를 위해 설계된 Twelve Labs의 최첨단 비디오 파운데이션 모델인 Marengo-2.6을 기반으로 합니다. Marengo-2.6은 시각적 표현, 제스처, 발화, 전반적인 맥락을 포함한 비디오 콘텐츠의 본질을 완벽하게 포착하는 다중모드 임베딩 생성을 지원합니다.
TwelveLabs 클라이언트를 설정하고 임베딩을 생성하는 함수를 정의해 보겠습니다.
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
이 코드는 TwelveLabs Embed API를 활용해 비디오 임베딩을 생성하는 전체 프로세스를 보여줍니다. 각 단계별 역할은 다음과 같습니다.
API 키를 사용해 TwelveLabs 클라이언트를 초기화합니다.
generate_embedding 함수는 비디오 이해 및 검색 테스크에 최적화된 Marengo-2.6 엔진을 사용하여 임베딩 작업(task)을 만듭니다.
작업 진행 상황을 모니터링하며 프로세스가 완료될 때까지 대기합니다.
작업이 완료되면 결과를 검색하고 임베딩을 추출합니다.
추출된 임베딩은 해당 시간 범위 및 분석 범위(scope) 등의 메타데이터와 함께 반환됩니다.
Embed API에서 사용하는 Marengo-2.6 모델은 다음과 같은 강력한 장점을 제공합니다.
다중모드(Multimodal) 이해: 비디오 생태계의 시각, 오디오 및 텍스트 요소 간의 상호작용을 그대로 포착합니다.
시간의 흐름 파악(Temporal awareness): 정적인 이미지 모델과 달리 Marengo-2.6은 비디오 내의 움직임, 액션, 시간 경과에 따른 정보를 정밀하게 추적합니다.
유연한 세그멘테이션: 비디오의 특정 구간별로 각각 임베딩을 생성하거나, 비디오 전체를 아우르는 단일 임베딩을 커스텀하게 생성할 수 있습니다.
업계 최고의 성능: 전통적인 비디오 모델에 비해 비디오 콘텐츠를 시간에 맞춰 훨씬 정밀하고 일관되게 해석해 냅니다.
이 API를 활용하면 개발자는 비디오 데이터의 문맥적 벡터 표현을 손쉽게 생성하여 자체 애플리케이션 내에 정밀한 검색 및 분석 기능을 성공적으로 이식할 수 있습니다.
ApertureDB에 임베딩 업로드하기
ApertureDB는 비디오, 클립, 그리고 이에 결합된 임베딩을 포함한 리치 미디어 데이터를 지능적으로 관리합니다. 이 섹션에서는 TwelveLabs Embed API가 생성한 비디오 임베딩을 ApertureDB에 업로드하는 방법을 구현합니다. 이 단계는 속도감 있고 혁신적인 세만틱 비디오 검색을 구현하기 위한 핵심 연결 고리입니다.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
이 코드는 준비된 임베딩을 ApertureDB로 마이그레이션 및 인서트하는 로직입니다.
커스텀 데이터 모델(ClipEmbeddingModel 및 VideoClipsModel)을 명확하게 정의하여 클립 및 연관 데이터가 포함된 비디오 데이터의 전체 구조를 스키마 형식으로 구조화합니다.
create_video_object_with_clips 함수는 클립과 해당 임베딩이 포함된 비디오 인스턴스를 동적으로 찍어냅니다. 이는 파일 아래 그림과 같이 ApertureDB 내에서 유기적으로 연결된 그래프 네트워크 구조(connected graph schema)로 변환됩니다.
사전에 전달된 인증 자격 정보를 통해 ApertureDB 클라이언트를 활성화합니다.
업로드할 임베딩을 수용할 디스크립터 세트(컬렉션)를 프로비저닝합니다. 이 세트가 임베딩 검색 대상의 메인 인덱스 역할을 수행하게 됩니다.
마지막 단계로 모든 클립 세그먼트와 맵핑된 임베딩 정보가 통합된 완성형 비디오 객체를 생성한 후 ApertureDB 데이터베이스에 완전히 적재합니다.
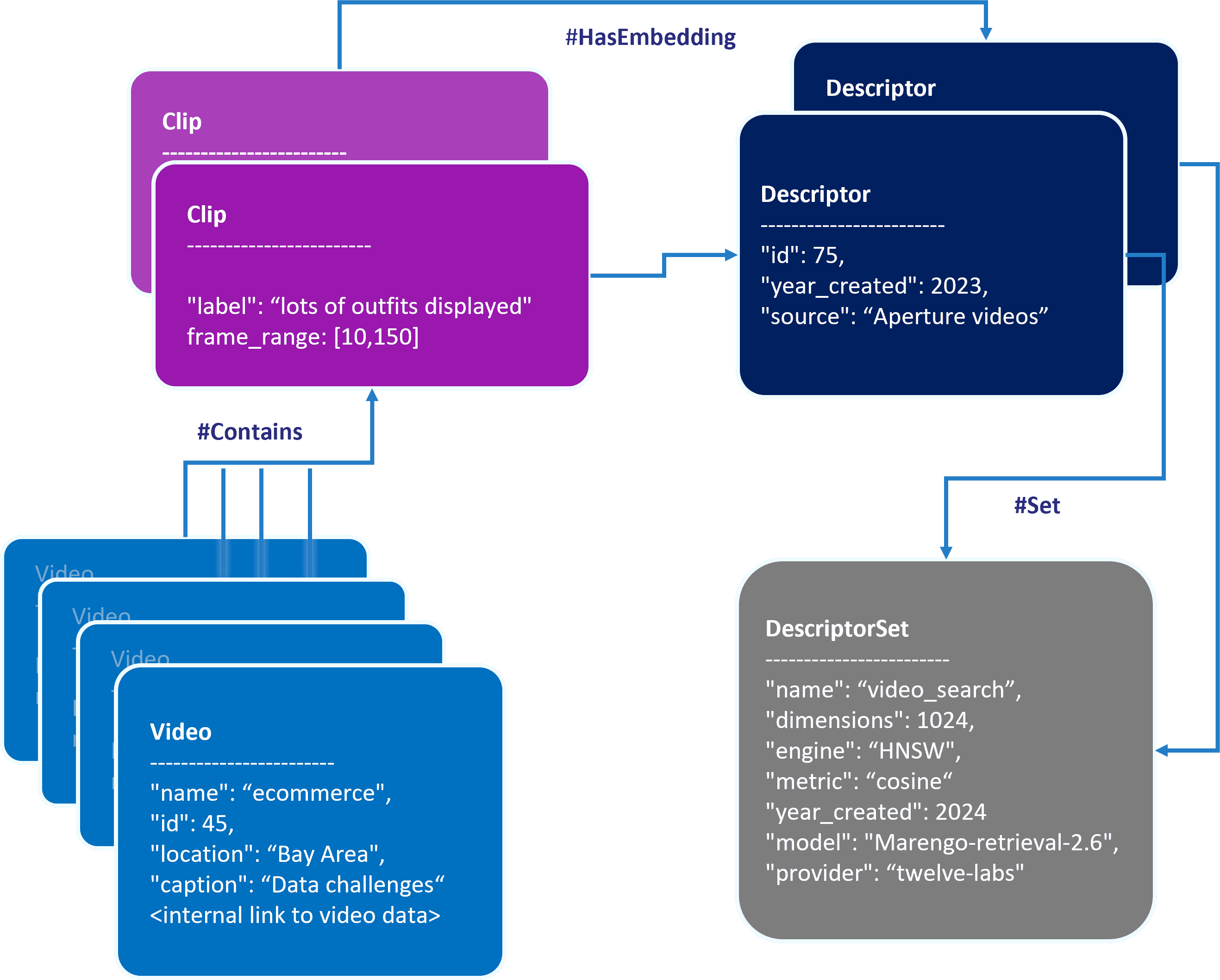
위 방식에 따라 데이터 삽입 완료 시 구축되는 데이터 스키마 형태
비디오 데이터를 이처럼 정교하게 구성해 두면, 동영상 안의 개별 임베딩들이 지닌 시각적·시간적 전후 정보가 그대로 완벽하게 보존됩니다. 따라서 더 정확하며 세분화된 세만틱 검색 시스템을 구축할 수 있습니다. 각 클립은 고유한 시간대 데이터 및 임베딩 벡터와 다이렉트로 매칭되어 있어, 타겟 비디오 세그먼트를 마이크로 단위로 세밀하게 끄집어낼 수 있게 돕습니다.
우수한 성능의 세만틱 비디오 검색 수행하기
이번 장에서는 ApertureDB 서비스 내부의 임베딩 저장소를 무대로 삼아 실제 세만틱 비디오 검색(semantic video search)을 가볍게 수행해보고자 합니다. 자연어 기반의 텍스트 쿼리를 입력해 의미적 유사도가 아주 높은 대표 비디오 클립을 정교하게 발굴해 낼 것입니다.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
이 코드는 다음 단계를 정교하게 실행합니다.
TwelveLabs Embed API를 사용해 찾고자 하는 영문 텍스트 입력을 문맥이 듬뿍 담긴 고차원 텍스트 임베딩으로 전환합니다.
ApertureDB의 Descriptors 클래스 장치를 이용해 미리 적재된 "marengo26" 데이터베이스 내에서 이와 가장 가까운 수학적 거리를 지닌 유력 임베딩들을 선별해냅니다.
선별된 임베딩들과 물리적으로 연결 고리를 가진 정답 영상 클립 객체들을 안전하게 트래킹하여 잡아냅니다.
결과 출력 데이터 시각화하기
최종 매칭된 유의미한 검색 결과를 출력해 실제 비디오 조각들의 메타데이터와 영상 프레임 분석 세그먼트를 렌더링해 봅니다.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
해당 코드 영역은 다음과 같은 역할을 수행합니다.
추려진 영웅 클립 집합 리스트를 순서대로 루프를 돌며 스캔합니다.
각 비디오 클립의 시작/종료 세컨드 구간 값 및 원래 호스팅되고 있던 웹 비디오 URL 등의 메타데이터를 정갈하게 뿌려줍니다.
display_video_mp4 도구 함수를 터치해 실제 세그먼트를 플레이어로 불러와 즉각 플레이할 수 있게 표시해 줍니다.
마치며
이 튜토리얼에서는 TwelveLabs의 차세대 Embed API 환경과 ApertureDB의 백엔드 연동을 이용해 고도화된 세만틱 비디오 검색 기능을 완벽히 구현해 보았습니다. 동영상 시장의 고질적인 문맥 이해 문제를 고해상도로 해결해 내는 TwelveLabs의 독보적인 Marengo-2.6 비디오 파운데이션 모델을 기반으로 비디오 전반의 시퀀스를 지능적인 다중모드 임베딩으로 추출해 냈습니다. 이 정교한 임베딩 세트들이 대규모 인메모리 관리 및 인덱스 검색에 용이한 ApertureDB 플랫폼의 벡터 엔진 영역과 조우할 때, 그 어떤 고전적인 기술보다 의미적으로 일치하는 콘텐츠를 칼같이 정밀해진 실시간 검색 기술로 뽑아낼 수 있습니다.
오늘 설계해 본 이상적인 프로세스는 기업들의 다양한 영상 추천 코어 아키텍처 및 미디어 탐색 시스템의 지평을 활짝 열어줄 것입니다. 비디오 원천 콘텐츠의 속내 깊은 내용까지 AI 모델이 완벽하게 동기화하여 이해하게 함으로써 개발자들은 단순히 수작업된 태그 키워드 매칭이나 텍스트 검색에 머물렀던 구시대 방식을 너머, 유저가 원하는 신차원의 비디오 내비게이션 경험을 쉽고 매끄럽게 구축할 수 있을 것입니다.
다음 단계로 나아가기
이 고급형 세만틱 비디오 검색(semantic video search) 시스템의 아키텍처 완성도를 극대화화기 위해 아래와 같은 확장 개발 도전을 적극적으로 권장합니다.
임베딩 제너레이션 파인튜닝: 비디오의 클리핑 세그먼트를 쪼개는 다양한 방법론들을 비교 적용하여 데이터의 유실 없는 최적의 분석 프레임을 도출해 보세요.
쿼리 탐색 기능의 극대화: 단순한 문자 검색에서 한발 더 나아가 텍스트, 이미지, 서라운드 오디오 등을 복합 연동하는 멀티모달 패턴 쿼리 레이아웃을 도입해 보세요. TwelveLabs Embed API 제품군은 완벽한 이미지 세력 연계 및 오디오 임베딩(audio embedding) 지원 엔진 출시를 정조준하고 있습니다. 이에 발맞춰 ApertureDB 역시 이러한 통합 다중모드 벡터에 대한 유연한 맵핑 스토리지 구조를 완전하게 갖추고 있습니다.
프로덕션 크기의 대용량 아키텍처 빌딩: 실제 초대형 메가 바이트급 비디오 데이터셋을 로드하고 밀려드는 동시 사용자 트래픽 쿼리를 밀리 세컨드 단위로 정밀하게 쳐내는 성능 최적화를 감행해 보세요.
사용자 상호작용 피드백 반영: 최종 유저의 행동 반응 로그를 수집하여 추천 및 검색의 신뢰 정교함을 더욱 연마하는 선순환 루프를 빌드해 보세요.
무궁무진한 버티컬 비즈니스 모델로의 파생: 이번 지식을 디딤돌 삼아 스마트한 콘텐츠 모니터링 모더레이션 패트롤 엔진, 실시간 영상 하이라이트 요약 봇, 혹은 완벽히 초개인화된 맞춤 광고 추천 분야로 응용해 보세요.
이 탄탄한 기반 위에 여러분의 창의력을 더해 비디오 기술의 한계를 시험하고, 영상 데이터가 담고 있는 무수한 숨은 가치를 실현하는 최고의 인텔리전트 서비스를 직접 경험해 가시길 바랍니다.
부록 자료
여러분의 더 깊이 있는 탐구 여정을 돕기 위해 공식 개발 레퍼런스를 공유합니다.
개발자 여러분이 이 통합 솔루션으로 어떤 혁신을 만들어낼지 무척 기대됩니다! 구현 과정 중에 얻은 멋진 아이디어와 값진 질문들은 TwelveLabs 및 ApertureDB 글로벌 엔지니어 커뮤니티 공간에 언제든 편히 공유하고 논의해 보세요. 즐거운 코딩 되시길 응원합니다!
이 튜토리얼에서는 TwelveLabs의 Embed API와 ApertureDB의 강력한 통합을 활용하여 고급 의미론적(semantic) 비디오 검색 엔진을 빌드하는 방법을 설명합니다. 최첨단 비디오 파운데이션 모델인 Marengo-2.6 기반의 Twelve Labs Embed API는 시각적 표현, 음성, 문맥 정보를 포함한 비디오 콘텐츠의 본질을 포착하는 다중모드 임베딩(multimodal embeddings)을 생성합니다. 이러한 임베딩을 컴퓨터 비전 및 머신러닝 애플리케이션에 최적화된 그래프-벡터 데이터베이스인 ApertureDB와 결합하면 매우 정확하고 효율적인 의미론적 검색 기능을 구현할 수 있습니다.
이 워크플로우를 통해 개발자와 데이터 과학자는 TwelveLabs Embed API를 활용하여 풍부한 비디오 임베딩을 생성하고, 이를 원본 비디오와 함께 ApertureDB에 원활하게 통합하여 의미론적 검색을 수행하는 방법을 배울 수 있습니다. 이 워크플로우는 정교한 비디오 분석 및 검색 시스템 빌드의 가능성을 보여주며, 다양한 산업 전반에서 콘텐츠 검색, 추천 엔진, 비디오 기반 애플리케이션의 새로운 가능성을 열어줍니다.
설치 및 환경 설정
이 섹션에서는 TwelveLabs Embed API와 ApertureDB를 통합하는 데 필요한 필수 라이브러리와 종속성을 설치합니다. 여기에는 API 호출을 위한 requests 라이브러리, ApertureDB 서비스와 상호작용하기 위한 aperturedb Python SDK, TwelveLabs Embed API에 액세스하기 위한 twelvelabs Python SDK 설치가 포함됩니다.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
위 코드를 실행하면 다음 단계의 노트북에서 사용할 수 있도록 필요한 모든 라이브러리가 명확히 설치되고 준비됩니다.
API 키 설정
이 섹션에서는 TwelveLabs 및 ApertureDB에 필요한 API 키를 설정합니다. 이러한 키를 안전하게 저장하고 불러오기 위해 Google Colab의 userdata 기능을 사용합니다.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
이 코드를 사용하려면 Google Colab의 ‘Secret(비밀)’에 API 키를 설정해야 합니다.
Colab 노트북의 왼쪽 사이드바 메뉴로 이동합니다.
열쇠 모양 아이콘을 클릭하여 "Secrets" 패널을 엽니다.
다음 두 가지의 비밀값을 추가합니다.
Key: TL_API_KEY, Value: 사용자의 TwelveLabs API 키
Key: ADB_PASSWORD, Value: 사용자의 ApertureDB 비밀번호
이 방식을 사용하면 API 키를 노트북에 노출하지 않고 안전하게 보호할 수 있습니다. 코드가 키의 설정 여부를 검증하고, 누락된 경우 에러를 발생시켜 구성 문제를 쉽게 해결할 수 있도록 도와줍니다.
TwelveLabs Embed API로 비디오 임베딩 생성하기
이 섹션에서는 TwelveLabs Embed API를 사용하여 비디오 임베딩을 생성하는 방법을 보여줍니다. 이 API는 임의 검색(any-to-any retrieval) 태스크를 위해 설계된 Twelve Labs의 최첨단 비디오 파운데이션 모델인 Marengo-2.6을 기반으로 합니다. Marengo-2.6은 시각적 표현, 제스처, 발화, 전반적인 맥락을 포함한 비디오 콘텐츠의 본질을 완벽하게 포착하는 다중모드 임베딩 생성을 지원합니다.
TwelveLabs 클라이언트를 설정하고 임베딩을 생성하는 함수를 정의해 보겠습니다.
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
이 코드는 TwelveLabs Embed API를 활용해 비디오 임베딩을 생성하는 전체 프로세스를 보여줍니다. 각 단계별 역할은 다음과 같습니다.
API 키를 사용해 TwelveLabs 클라이언트를 초기화합니다.
generate_embedding 함수는 비디오 이해 및 검색 테스크에 최적화된 Marengo-2.6 엔진을 사용하여 임베딩 작업(task)을 만듭니다.
작업 진행 상황을 모니터링하며 프로세스가 완료될 때까지 대기합니다.
작업이 완료되면 결과를 검색하고 임베딩을 추출합니다.
추출된 임베딩은 해당 시간 범위 및 분석 범위(scope) 등의 메타데이터와 함께 반환됩니다.
Embed API에서 사용하는 Marengo-2.6 모델은 다음과 같은 강력한 장점을 제공합니다.
다중모드(Multimodal) 이해: 비디오 생태계의 시각, 오디오 및 텍스트 요소 간의 상호작용을 그대로 포착합니다.
시간의 흐름 파악(Temporal awareness): 정적인 이미지 모델과 달리 Marengo-2.6은 비디오 내의 움직임, 액션, 시간 경과에 따른 정보를 정밀하게 추적합니다.
유연한 세그멘테이션: 비디오의 특정 구간별로 각각 임베딩을 생성하거나, 비디오 전체를 아우르는 단일 임베딩을 커스텀하게 생성할 수 있습니다.
업계 최고의 성능: 전통적인 비디오 모델에 비해 비디오 콘텐츠를 시간에 맞춰 훨씬 정밀하고 일관되게 해석해 냅니다.
이 API를 활용하면 개발자는 비디오 데이터의 문맥적 벡터 표현을 손쉽게 생성하여 자체 애플리케이션 내에 정밀한 검색 및 분석 기능을 성공적으로 이식할 수 있습니다.
ApertureDB에 임베딩 업로드하기
ApertureDB는 비디오, 클립, 그리고 이에 결합된 임베딩을 포함한 리치 미디어 데이터를 지능적으로 관리합니다. 이 섹션에서는 TwelveLabs Embed API가 생성한 비디오 임베딩을 ApertureDB에 업로드하는 방법을 구현합니다. 이 단계는 속도감 있고 혁신적인 세만틱 비디오 검색을 구현하기 위한 핵심 연결 고리입니다.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
이 코드는 준비된 임베딩을 ApertureDB로 마이그레이션 및 인서트하는 로직입니다.
커스텀 데이터 모델(ClipEmbeddingModel 및 VideoClipsModel)을 명확하게 정의하여 클립 및 연관 데이터가 포함된 비디오 데이터의 전체 구조를 스키마 형식으로 구조화합니다.
create_video_object_with_clips 함수는 클립과 해당 임베딩이 포함된 비디오 인스턴스를 동적으로 찍어냅니다. 이는 파일 아래 그림과 같이 ApertureDB 내에서 유기적으로 연결된 그래프 네트워크 구조(connected graph schema)로 변환됩니다.
사전에 전달된 인증 자격 정보를 통해 ApertureDB 클라이언트를 활성화합니다.
업로드할 임베딩을 수용할 디스크립터 세트(컬렉션)를 프로비저닝합니다. 이 세트가 임베딩 검색 대상의 메인 인덱스 역할을 수행하게 됩니다.
마지막 단계로 모든 클립 세그먼트와 맵핑된 임베딩 정보가 통합된 완성형 비디오 객체를 생성한 후 ApertureDB 데이터베이스에 완전히 적재합니다.
위 방식에 따라 데이터 삽입 완료 시 구축되는 데이터 스키마 형태
비디오 데이터를 이처럼 정교하게 구성해 두면, 동영상 안의 개별 임베딩들이 지닌 시각적·시간적 전후 정보가 그대로 완벽하게 보존됩니다. 따라서 더 정확하며 세분화된 세만틱 검색 시스템을 구축할 수 있습니다. 각 클립은 고유한 시간대 데이터 및 임베딩 벡터와 다이렉트로 매칭되어 있어, 타겟 비디오 세그먼트를 마이크로 단위로 세밀하게 끄집어낼 수 있게 돕습니다.
우수한 성능의 세만틱 비디오 검색 수행하기
이번 장에서는 ApertureDB 서비스 내부의 임베딩 저장소를 무대로 삼아 실제 세만틱 비디오 검색(semantic video search)을 가볍게 수행해보고자 합니다. 자연어 기반의 텍스트 쿼리를 입력해 의미적 유사도가 아주 높은 대표 비디오 클립을 정교하게 발굴해 낼 것입니다.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
이 코드는 다음 단계를 정교하게 실행합니다.
TwelveLabs Embed API를 사용해 찾고자 하는 영문 텍스트 입력을 문맥이 듬뿍 담긴 고차원 텍스트 임베딩으로 전환합니다.
ApertureDB의 Descriptors 클래스 장치를 이용해 미리 적재된 "marengo26" 데이터베이스 내에서 이와 가장 가까운 수학적 거리를 지닌 유력 임베딩들을 선별해냅니다.
선별된 임베딩들과 물리적으로 연결 고리를 가진 정답 영상 클립 객체들을 안전하게 트래킹하여 잡아냅니다.
결과 출력 데이터 시각화하기
최종 매칭된 유의미한 검색 결과를 출력해 실제 비디오 조각들의 메타데이터와 영상 프레임 분석 세그먼트를 렌더링해 봅니다.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
해당 코드 영역은 다음과 같은 역할을 수행합니다.
추려진 영웅 클립 집합 리스트를 순서대로 루프를 돌며 스캔합니다.
각 비디오 클립의 시작/종료 세컨드 구간 값 및 원래 호스팅되고 있던 웹 비디오 URL 등의 메타데이터를 정갈하게 뿌려줍니다.
display_video_mp4 도구 함수를 터치해 실제 세그먼트를 플레이어로 불러와 즉각 플레이할 수 있게 표시해 줍니다.
마치며
이 튜토리얼에서는 TwelveLabs의 차세대 Embed API 환경과 ApertureDB의 백엔드 연동을 이용해 고도화된 세만틱 비디오 검색 기능을 완벽히 구현해 보았습니다. 동영상 시장의 고질적인 문맥 이해 문제를 고해상도로 해결해 내는 TwelveLabs의 독보적인 Marengo-2.6 비디오 파운데이션 모델을 기반으로 비디오 전반의 시퀀스를 지능적인 다중모드 임베딩으로 추출해 냈습니다. 이 정교한 임베딩 세트들이 대규모 인메모리 관리 및 인덱스 검색에 용이한 ApertureDB 플랫폼의 벡터 엔진 영역과 조우할 때, 그 어떤 고전적인 기술보다 의미적으로 일치하는 콘텐츠를 칼같이 정밀해진 실시간 검색 기술로 뽑아낼 수 있습니다.
오늘 설계해 본 이상적인 프로세스는 기업들의 다양한 영상 추천 코어 아키텍처 및 미디어 탐색 시스템의 지평을 활짝 열어줄 것입니다. 비디오 원천 콘텐츠의 속내 깊은 내용까지 AI 모델이 완벽하게 동기화하여 이해하게 함으로써 개발자들은 단순히 수작업된 태그 키워드 매칭이나 텍스트 검색에 머물렀던 구시대 방식을 너머, 유저가 원하는 신차원의 비디오 내비게이션 경험을 쉽고 매끄럽게 구축할 수 있을 것입니다.
다음 단계로 나아가기
이 고급형 세만틱 비디오 검색(semantic video search) 시스템의 아키텍처 완성도를 극대화화기 위해 아래와 같은 확장 개발 도전을 적극적으로 권장합니다.
임베딩 제너레이션 파인튜닝: 비디오의 클리핑 세그먼트를 쪼개는 다양한 방법론들을 비교 적용하여 데이터의 유실 없는 최적의 분석 프레임을 도출해 보세요.
쿼리 탐색 기능의 극대화: 단순한 문자 검색에서 한발 더 나아가 텍스트, 이미지, 서라운드 오디오 등을 복합 연동하는 멀티모달 패턴 쿼리 레이아웃을 도입해 보세요. TwelveLabs Embed API 제품군은 완벽한 이미지 세력 연계 및 오디오 임베딩(audio embedding) 지원 엔진 출시를 정조준하고 있습니다. 이에 발맞춰 ApertureDB 역시 이러한 통합 다중모드 벡터에 대한 유연한 맵핑 스토리지 구조를 완전하게 갖추고 있습니다.
프로덕션 크기의 대용량 아키텍처 빌딩: 실제 초대형 메가 바이트급 비디오 데이터셋을 로드하고 밀려드는 동시 사용자 트래픽 쿼리를 밀리 세컨드 단위로 정밀하게 쳐내는 성능 최적화를 감행해 보세요.
사용자 상호작용 피드백 반영: 최종 유저의 행동 반응 로그를 수집하여 추천 및 검색의 신뢰 정교함을 더욱 연마하는 선순환 루프를 빌드해 보세요.
무궁무진한 버티컬 비즈니스 모델로의 파생: 이번 지식을 디딤돌 삼아 스마트한 콘텐츠 모니터링 모더레이션 패트롤 엔진, 실시간 영상 하이라이트 요약 봇, 혹은 완벽히 초개인화된 맞춤 광고 추천 분야로 응용해 보세요.
이 탄탄한 기반 위에 여러분의 창의력을 더해 비디오 기술의 한계를 시험하고, 영상 데이터가 담고 있는 무수한 숨은 가치를 실현하는 최고의 인텔리전트 서비스를 직접 경험해 가시길 바랍니다.
부록 자료
여러분의 더 깊이 있는 탐구 여정을 돕기 위해 공식 개발 레퍼런스를 공유합니다.
개발자 여러분이 이 통합 솔루션으로 어떤 혁신을 만들어낼지 무척 기대됩니다! 구현 과정 중에 얻은 멋진 아이디어와 값진 질문들은 TwelveLabs 및 ApertureDB 글로벌 엔지니어 커뮤니티 공간에 언제든 편히 공유하고 논의해 보세요. 즐거운 코딩 되시길 응원합니다!
이 튜토리얼에서는 TwelveLabs의 Embed API와 ApertureDB의 강력한 통합을 활용하여 고급 의미론적(semantic) 비디오 검색 엔진을 빌드하는 방법을 설명합니다. 최첨단 비디오 파운데이션 모델인 Marengo-2.6 기반의 Twelve Labs Embed API는 시각적 표현, 음성, 문맥 정보를 포함한 비디오 콘텐츠의 본질을 포착하는 다중모드 임베딩(multimodal embeddings)을 생성합니다. 이러한 임베딩을 컴퓨터 비전 및 머신러닝 애플리케이션에 최적화된 그래프-벡터 데이터베이스인 ApertureDB와 결합하면 매우 정확하고 효율적인 의미론적 검색 기능을 구현할 수 있습니다.
이 워크플로우를 통해 개발자와 데이터 과학자는 TwelveLabs Embed API를 활용하여 풍부한 비디오 임베딩을 생성하고, 이를 원본 비디오와 함께 ApertureDB에 원활하게 통합하여 의미론적 검색을 수행하는 방법을 배울 수 있습니다. 이 워크플로우는 정교한 비디오 분석 및 검색 시스템 빌드의 가능성을 보여주며, 다양한 산업 전반에서 콘텐츠 검색, 추천 엔진, 비디오 기반 애플리케이션의 새로운 가능성을 열어줍니다.
설치 및 환경 설정
이 섹션에서는 TwelveLabs Embed API와 ApertureDB를 통합하는 데 필요한 필수 라이브러리와 종속성을 설치합니다. 여기에는 API 호출을 위한 requests 라이브러리, ApertureDB 서비스와 상호작용하기 위한 aperturedb Python SDK, TwelveLabs Embed API에 액세스하기 위한 twelvelabs Python SDK 설치가 포함됩니다.
# Install necessary libraries and dependencies !pip install requests !pip install aperturedb !pip install twelvelabs # Import required modules import requests import aperturedb import twelvelabs
위 코드를 실행하면 다음 단계의 노트북에서 사용할 수 있도록 필요한 모든 라이브러리가 명확히 설치되고 준비됩니다.
API 키 설정
이 섹션에서는 TwelveLabs 및 ApertureDB에 필요한 API 키를 설정합니다. 이러한 키를 안전하게 저장하고 불러오기 위해 Google Colab의 userdata 기능을 사용합니다.
from google.colab import userdata # Configure Twelve Labs TL_API_KEY = userdata.get('TL_API_KEY') # Configure ApertureDB ADB_PASSWORD = userdata.get('ADB_PASSWORD') # Verify that the keys are properly set if not TL_API_KEY: raise ValueError("Twelve Labs API key not found. Please set it in Colab's Secrets.") if not ADB_PASSWORD: raise ValueError("ApertureDB password not found. Please set it in Colab's Secrets.") print("API keys successfully configured.")
이 코드를 사용하려면 Google Colab의 ‘Secret(비밀)’에 API 키를 설정해야 합니다.
Colab 노트북의 왼쪽 사이드바 메뉴로 이동합니다.
열쇠 모양 아이콘을 클릭하여 "Secrets" 패널을 엽니다.
다음 두 가지의 비밀값을 추가합니다.
Key: TL_API_KEY, Value: 사용자의 TwelveLabs API 키
Key: ADB_PASSWORD, Value: 사용자의 ApertureDB 비밀번호
이 방식을 사용하면 API 키를 노트북에 노출하지 않고 안전하게 보호할 수 있습니다. 코드가 키의 설정 여부를 검증하고, 누락된 경우 에러를 발생시켜 구성 문제를 쉽게 해결할 수 있도록 도와줍니다.
TwelveLabs Embed API로 비디오 임베딩 생성하기
이 섹션에서는 TwelveLabs Embed API를 사용하여 비디오 임베딩을 생성하는 방법을 보여줍니다. 이 API는 임의 검색(any-to-any retrieval) 태스크를 위해 설계된 Twelve Labs의 최첨단 비디오 파운데이션 모델인 Marengo-2.6을 기반으로 합니다. Marengo-2.6은 시각적 표현, 제스처, 발화, 전반적인 맥락을 포함한 비디오 콘텐츠의 본질을 완벽하게 포착하는 다중모드 임베딩 생성을 지원합니다.
TwelveLabs 클라이언트를 설정하고 임베딩을 생성하는 함수를 정의해 보겠습니다.
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TL_API_KEY) def generate_embedding(video_url): # Create an embedding task task = twelvelabs_client.embed.task.create( engine_name="Marengo-retrieval-2.6", video_url=video_url ) print(f"Created task: id={task.id} engine_name={task.engine_name} status={task.status}") # Define a callback function to monitor task progress def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") # Wait for the task to complete status = task.wait_for_done( sleep_interval=2, callback=on_task_update ) print(f"Embedding done: {status}") # Retrieve the task result task_result = twelvelabs_client.embed.task.retrieve(task.id) # Extract and return the embeddings embeddings = [] for v in task_result.video_embeddings: embeddings.append({ 'embedding': v.embedding.float, 'start_offset_sec': v.start_offset_sec, 'end_offset_sec': v.end_offset_sec, 'embedding_scope': v.embedding_scope }) return embeddings, task_result # Example usage video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" # Generate embeddings for the video embeddings, task_result = generate_embedding(video_url) print(f"Generated {len(embeddings)} embeddings for the video") for i, emb in enumerate(embeddings): print(f"Embedding {i+1}:") print(f" Scope: {emb['embedding_scope']}") print(f" Time range: {emb['start_offset_sec']} - {emb['end_offset_sec']} seconds") print(f" Embedding vector (first 5 values): {emb['embedding'][:5]}") print()
이 코드는 TwelveLabs Embed API를 활용해 비디오 임베딩을 생성하는 전체 프로세스를 보여줍니다. 각 단계별 역할은 다음과 같습니다.
API 키를 사용해 TwelveLabs 클라이언트를 초기화합니다.
generate_embedding 함수는 비디오 이해 및 검색 테스크에 최적화된 Marengo-2.6 엔진을 사용하여 임베딩 작업(task)을 만듭니다.
작업 진행 상황을 모니터링하며 프로세스가 완료될 때까지 대기합니다.
작업이 완료되면 결과를 검색하고 임베딩을 추출합니다.
추출된 임베딩은 해당 시간 범위 및 분석 범위(scope) 등의 메타데이터와 함께 반환됩니다.
Embed API에서 사용하는 Marengo-2.6 모델은 다음과 같은 강력한 장점을 제공합니다.
다중모드(Multimodal) 이해: 비디오 생태계의 시각, 오디오 및 텍스트 요소 간의 상호작용을 그대로 포착합니다.
시간의 흐름 파악(Temporal awareness): 정적인 이미지 모델과 달리 Marengo-2.6은 비디오 내의 움직임, 액션, 시간 경과에 따른 정보를 정밀하게 추적합니다.
유연한 세그멘테이션: 비디오의 특정 구간별로 각각 임베딩을 생성하거나, 비디오 전체를 아우르는 단일 임베딩을 커스텀하게 생성할 수 있습니다.
업계 최고의 성능: 전통적인 비디오 모델에 비해 비디오 콘텐츠를 시간에 맞춰 훨씬 정밀하고 일관되게 해석해 냅니다.
이 API를 활용하면 개발자는 비디오 데이터의 문맥적 벡터 표현을 손쉽게 생성하여 자체 애플리케이션 내에 정밀한 검색 및 분석 기능을 성공적으로 이식할 수 있습니다.
ApertureDB에 임베딩 업로드하기
ApertureDB는 비디오, 클립, 그리고 이에 결합된 임베딩을 포함한 리치 미디어 데이터를 지능적으로 관리합니다. 이 섹션에서는 TwelveLabs Embed API가 생성한 비디오 임베딩을 ApertureDB에 업로드하는 방법을 구현합니다. 이 단계는 속도감 있고 혁신적인 세만틱 비디오 검색을 구현하기 위한 핵심 연결 고리입니다.
from typing import List from aperturedb.DataModels import VideoDataModel, ClipDataModel, DescriptorDataModel, DescriptorSetDataModel from aperturedb.CommonLibrary import create_connector, execute_query from aperturedb.Query import generate_add_query from aperturedb.Query import RangeType from aperturedb.Connector import Connector import json # Define data models for the association of Video, Video Clips, and Embeddings class ClipEmbeddingModel(ClipDataModel): embedding: DescriptorDataModel class VideoClipsModel(VideoDataModel): title: str description: str clips: List[ClipEmbeddingModel] = [] def create_video_object_with_clips(URL: str, clips, collection): video = VideoClipsModel(url=URL, title="Ecommerce v2.5", description="Ecommerce v2.5 video with clips by Marengo26") for clip in clips: video.clips.append(ClipEmbeddingModel( range_type=RangeType.TIME, start=clip['start_offset_sec'], stop=clip['end_offset_sec'], embedding=DescriptorDataModel( vector=clip['embedding'], set=collection) )) return video video_url = "https://storage.googleapis.com/ad-demos-datasets/videos/Ecommerce%20v2.5.mp4" clips = embeddings # Instantiate an ApertureDB client aperturedb_client = Connector( host="workshop.datasets.gcp.cloud.aperturedata.io", user="admin", password=ADB_PASSWORD ) # Create a descriptor set (collection) collection = DescriptorSetDataModel( name="marengo26", dimensions=len(clips[0]['embedding'])) q, blobs, c = generate_add_query(collection) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Descriptor set creation: {result=}, {response=}") # Create and insert the video object with clips and embeddings video = create_video_object_with_clips(video_url, clips, collection) q, blobs, c = generate_add_query(video) result, response, blobs = execute_query(query=q, blobs=blobs, client=aperturedb_client) print(f"Video insertion: {result=}, {response=}")
이 코드는 준비된 임베딩을 ApertureDB로 마이그레이션 및 인서트하는 로직입니다.
커스텀 데이터 모델(ClipEmbeddingModel 및 VideoClipsModel)을 명확하게 정의하여 클립 및 연관 데이터가 포함된 비디오 데이터의 전체 구조를 스키마 형식으로 구조화합니다.
create_video_object_with_clips 함수는 클립과 해당 임베딩이 포함된 비디오 인스턴스를 동적으로 찍어냅니다. 이는 파일 아래 그림과 같이 ApertureDB 내에서 유기적으로 연결된 그래프 네트워크 구조(connected graph schema)로 변환됩니다.
사전에 전달된 인증 자격 정보를 통해 ApertureDB 클라이언트를 활성화합니다.
업로드할 임베딩을 수용할 디스크립터 세트(컬렉션)를 프로비저닝합니다. 이 세트가 임베딩 검색 대상의 메인 인덱스 역할을 수행하게 됩니다.
마지막 단계로 모든 클립 세그먼트와 맵핑된 임베딩 정보가 통합된 완성형 비디오 객체를 생성한 후 ApertureDB 데이터베이스에 완전히 적재합니다.
위 방식에 따라 데이터 삽입 완료 시 구축되는 데이터 스키마 형태
비디오 데이터를 이처럼 정교하게 구성해 두면, 동영상 안의 개별 임베딩들이 지닌 시각적·시간적 전후 정보가 그대로 완벽하게 보존됩니다. 따라서 더 정확하며 세분화된 세만틱 검색 시스템을 구축할 수 있습니다. 각 클립은 고유한 시간대 데이터 및 임베딩 벡터와 다이렉트로 매칭되어 있어, 타겟 비디오 세그먼트를 마이크로 단위로 세밀하게 끄집어낼 수 있게 돕습니다.
우수한 성능의 세만틱 비디오 검색 수행하기
이번 장에서는 ApertureDB 서비스 내부의 임베딩 저장소를 무대로 삼아 실제 세만틱 비디오 검색(semantic video search)을 가볍게 수행해보고자 합니다. 자연어 기반의 텍스트 쿼리를 입력해 의미적 유사도가 아주 높은 대표 비디오 클립을 정교하게 발굴해 낼 것입니다.
import struct from aperturedb.Descriptors import Descriptors from aperturedb.Query import ObjectType from aperturedb.NotebookHelpers import display_video_mp4 from IPython.display import display # Generate a text embedding for our search query text_embedding = twelvelabs_client.embed.create( engine_name="Marengo-retrieval-2.6", text="Show me the part which has lot of outfits being displayed", text_truncate="none" ) print("Created a text embedding") print(f" Engine: {text_embedding.engine_name}") print(f" Embedding: {text_embedding.text_embedding.float[:5]}...") # Display first 5 values # Define the descriptor set we'll search in descriptorset = "marengo26" # Find similar descriptors to the text embedding descriptors = Descriptors(aperturedb_client) descriptors.find_similar( descriptorset, text_embedding.text_embedding.float, k_neighbors=3, distances=True ) # Find connected clips to the descriptors clip_descriptors = descriptors.get_connected_entities(ObjectType.CLIP) print(f"Found {len(clip_descriptors)} relevant clips")
이 코드는 다음 단계를 정교하게 실행합니다.
TwelveLabs Embed API를 사용해 찾고자 하는 영문 텍스트 입력을 문맥이 듬뿍 담긴 고차원 텍스트 임베딩으로 전환합니다.
ApertureDB의 Descriptors 클래스 장치를 이용해 미리 적재된 "marengo26" 데이터베이스 내에서 이와 가장 가까운 수학적 거리를 지닌 유력 임베딩들을 선별해냅니다.
선별된 임베딩들과 물리적으로 연결 고리를 가진 정답 영상 클립 객체들을 안전하게 트래킹하여 잡아냅니다.
결과 출력 데이터 시각화하기
최종 매칭된 유의미한 검색 결과를 출력해 실제 비디오 조각들의 메타데이터와 영상 프레임 분석 세그먼트를 렌더링해 봅니다.
# Show the metadata of the clips and the corresponding video segments for i, clips in enumerate(clip_descriptors, 1): print(f"\nResult {i}:") for clip in clips: print(f"Clip metadata:") print(f" Start time: {clip.start} seconds") print(f" End time: {clip.stop} seconds") print(f" Video URL: {clip.url}") # Display the video clip print("Displaying video clip:") display_video_mp4(clips.get_blob(clip)) print("\n" + "-"*50 + "\n")
해당 코드 영역은 다음과 같은 역할을 수행합니다.
추려진 영웅 클립 집합 리스트를 순서대로 루프를 돌며 스캔합니다.
각 비디오 클립의 시작/종료 세컨드 구간 값 및 원래 호스팅되고 있던 웹 비디오 URL 등의 메타데이터를 정갈하게 뿌려줍니다.
display_video_mp4 도구 함수를 터치해 실제 세그먼트를 플레이어로 불러와 즉각 플레이할 수 있게 표시해 줍니다.
마치며
이 튜토리얼에서는 TwelveLabs의 차세대 Embed API 환경과 ApertureDB의 백엔드 연동을 이용해 고도화된 세만틱 비디오 검색 기능을 완벽히 구현해 보았습니다. 동영상 시장의 고질적인 문맥 이해 문제를 고해상도로 해결해 내는 TwelveLabs의 독보적인 Marengo-2.6 비디오 파운데이션 모델을 기반으로 비디오 전반의 시퀀스를 지능적인 다중모드 임베딩으로 추출해 냈습니다. 이 정교한 임베딩 세트들이 대규모 인메모리 관리 및 인덱스 검색에 용이한 ApertureDB 플랫폼의 벡터 엔진 영역과 조우할 때, 그 어떤 고전적인 기술보다 의미적으로 일치하는 콘텐츠를 칼같이 정밀해진 실시간 검색 기술로 뽑아낼 수 있습니다.
오늘 설계해 본 이상적인 프로세스는 기업들의 다양한 영상 추천 코어 아키텍처 및 미디어 탐색 시스템의 지평을 활짝 열어줄 것입니다. 비디오 원천 콘텐츠의 속내 깊은 내용까지 AI 모델이 완벽하게 동기화하여 이해하게 함으로써 개발자들은 단순히 수작업된 태그 키워드 매칭이나 텍스트 검색에 머물렀던 구시대 방식을 너머, 유저가 원하는 신차원의 비디오 내비게이션 경험을 쉽고 매끄럽게 구축할 수 있을 것입니다.
다음 단계로 나아가기
이 고급형 세만틱 비디오 검색(semantic video search) 시스템의 아키텍처 완성도를 극대화화기 위해 아래와 같은 확장 개발 도전을 적극적으로 권장합니다.
임베딩 제너레이션 파인튜닝: 비디오의 클리핑 세그먼트를 쪼개는 다양한 방법론들을 비교 적용하여 데이터의 유실 없는 최적의 분석 프레임을 도출해 보세요.
쿼리 탐색 기능의 극대화: 단순한 문자 검색에서 한발 더 나아가 텍스트, 이미지, 서라운드 오디오 등을 복합 연동하는 멀티모달 패턴 쿼리 레이아웃을 도입해 보세요. TwelveLabs Embed API 제품군은 완벽한 이미지 세력 연계 및 오디오 임베딩(audio embedding) 지원 엔진 출시를 정조준하고 있습니다. 이에 발맞춰 ApertureDB 역시 이러한 통합 다중모드 벡터에 대한 유연한 맵핑 스토리지 구조를 완전하게 갖추고 있습니다.
프로덕션 크기의 대용량 아키텍처 빌딩: 실제 초대형 메가 바이트급 비디오 데이터셋을 로드하고 밀려드는 동시 사용자 트래픽 쿼리를 밀리 세컨드 단위로 정밀하게 쳐내는 성능 최적화를 감행해 보세요.
사용자 상호작용 피드백 반영: 최종 유저의 행동 반응 로그를 수집하여 추천 및 검색의 신뢰 정교함을 더욱 연마하는 선순환 루프를 빌드해 보세요.
무궁무진한 버티컬 비즈니스 모델로의 파생: 이번 지식을 디딤돌 삼아 스마트한 콘텐츠 모니터링 모더레이션 패트롤 엔진, 실시간 영상 하이라이트 요약 봇, 혹은 완벽히 초개인화된 맞춤 광고 추천 분야로 응용해 보세요.
이 탄탄한 기반 위에 여러분의 창의력을 더해 비디오 기술의 한계를 시험하고, 영상 데이터가 담고 있는 무수한 숨은 가치를 실현하는 최고의 인텔리전트 서비스를 직접 경험해 가시길 바랍니다.
부록 자료
여러분의 더 깊이 있는 탐구 여정을 돕기 위해 공식 개발 레퍼런스를 공유합니다.
개발자 여러분이 이 통합 솔루션으로 어떤 혁신을 만들어낼지 무척 기대됩니다! 구현 과정 중에 얻은 멋진 아이디어와 값진 질문들은 TwelveLabs 및 ApertureDB 글로벌 엔지니어 커뮤니티 공간에 언제든 편히 공유하고 논의해 보세요. 즐거운 코딩 되시길 응원합니다!









