제품
Marengo 3.0: Defining Real-World Embedding AI for Videos, Audios, Texts, Images, and Composition of Them

Dan Kim, Jeff Kim, Chris Jeon, Jeremy Kim, Cooper Han, Royce Han
Marengo 3.0 represents a fundamental shift from benchmark optimization to production-grade video understanding. By natively supporting multilingual content, composed queries, hour-long videos, and specialized domains like sports—while maintaining leadership on general benchmarks—we have built a foundation model that scales with real-world complexity.
Marengo 3.0 represents a fundamental shift from benchmark optimization to production-grade video understanding. By natively supporting multilingual content, composed queries, hour-long videos, and specialized domains like sports—while maintaining leadership on general benchmarks—we have built a foundation model that scales with real-world complexity.

뉴스레터 구독하기
최신 영상 AI 소식과 활용 팁, 업계 인사이트까지 한눈에 받아보세요
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2025. 11. 30.
12 Minutes
링크 복사하기
From the TwelveLabs Marengo team. We are excited to introduce Marengo 3.0, a new standard for foundation models that understand the world in all its complexity.
Marengo 3.0 is the foundation model powering Twelve Labs' Embed API and Search API. This post focuses on the core Marengo 3.0 model itself—the embeddings that enable semantic video understanding. (Our Search API adds production components like advanced transcription and hybrid lexical search for even higher accuracy on benchmarks like MSRVTT and VATEX)
Marengo 3.0 advances beyond English-language benchmarks to solve real-world production challenges: multilingual video archives requiring native cross-language search, complex queries combining visual and textual elements, hour-long content that breaks other models, and specialized domains like sports where general models fail.
Marengo 3.0 achieves these capabilities with a 512-dimension embedding—6x more storage-efficient than Amazon Nova (3072d) and 3x better than Google Vertex (1408d). Lower dimensionality directly reduces database costs, accelerates search queries, and enables larger video libraries at the same infrastructure spend, without sacrificing retrieval accuracy.
This post demonstrates how Marengo 3.0 achieves state-of-the-art performance across composed retrieval, multilingual understanding, audio intelligence, sports analysis, OCR, and general benchmarks—establishing production-grade video understanding that scales.
Summary
Every model provider cherry-picks data to claim superiority. But here's what matters for production: Marengo 3.0 delivers superior performance with unparalleled latency while competitors fail or crawl. This isn't just better benchmarks for researchers to argue about; it's the difference between a model that works in production and one that doesn't.
Latency: Where Competitors Break Down
Marengo 3.0 processes videos at speeds that make enterprise-scale deployment practical. The charts below show latency versus composite performance across video lengths:
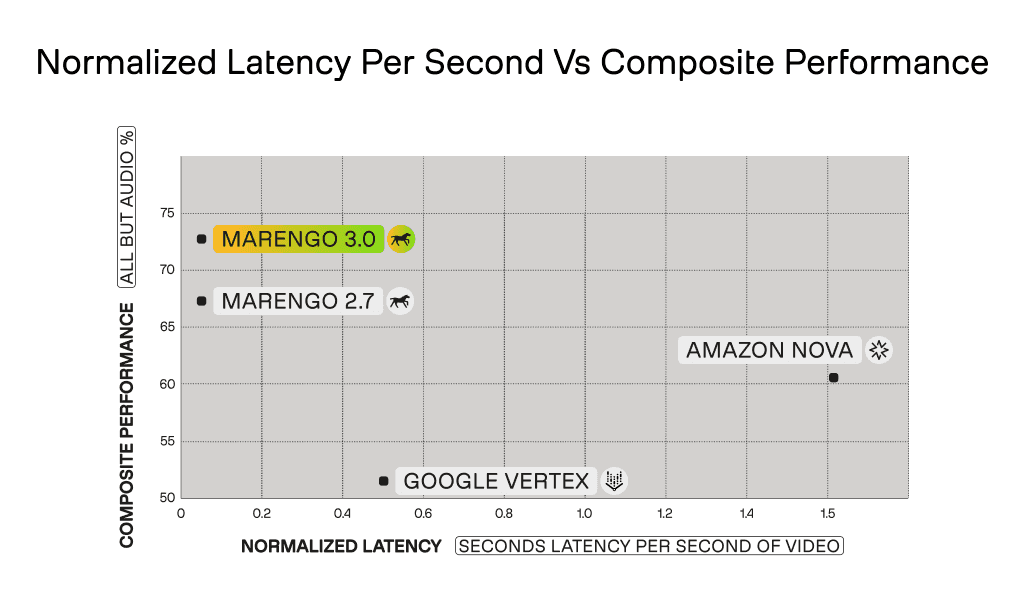
Marengo 3.0 achieves the highest composite performance (73%) while maintaining the fastest normalized latency per second (0.05 seconds/second of video). Google Vertex has a higher latency (~0.5 seconds/second) but with significantly lower performance (52%). Amazon Nova requires >1.5 seconds per second of video—making it 30x slower than Marengo 3.0 while delivering lower accuracy.
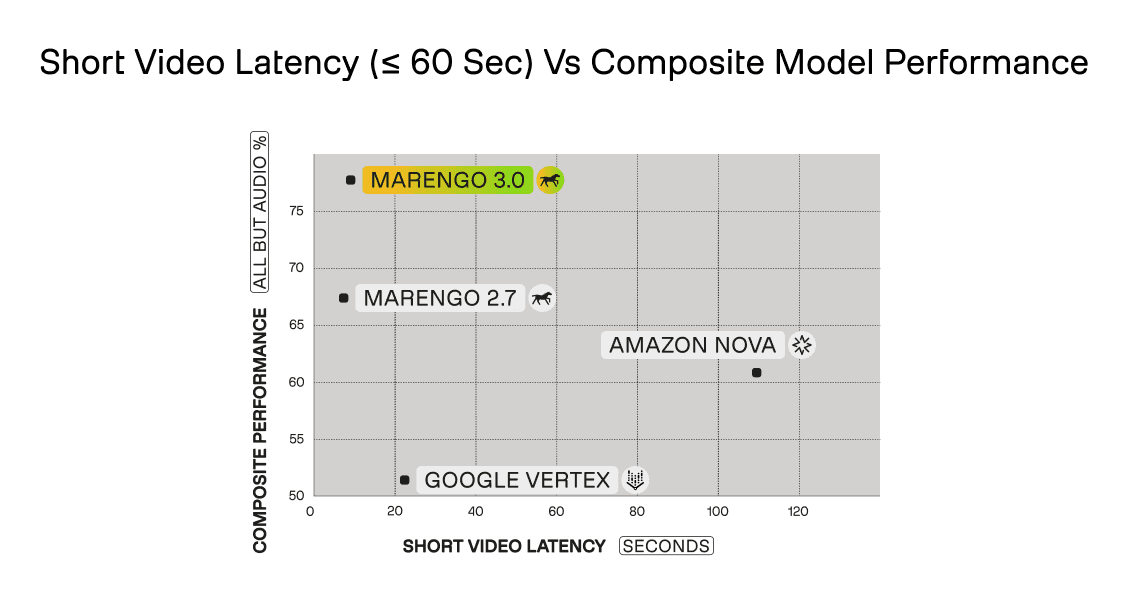
For short videos (≤ 60 seconds), Marengo 3.0 processes content in ~10 seconds with 78% composite performance. Amazon Nova requires ~110 seconds for 61% performance—a 11x latency penalty with 17 percentage point accuracy loss.
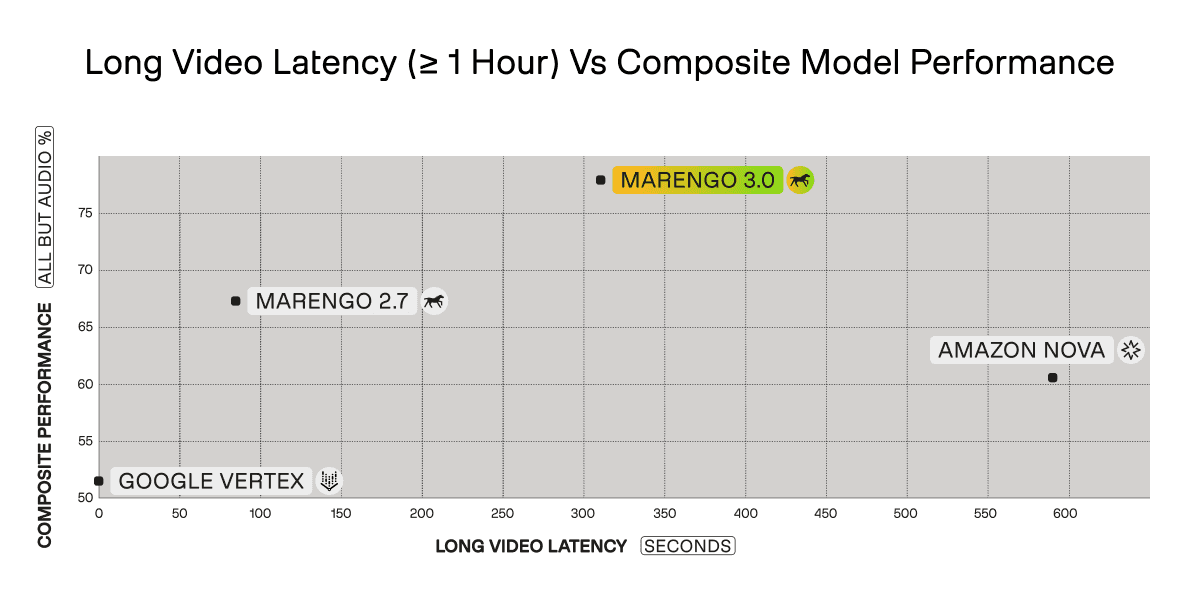
For hour-long videos, Marengo 3.0 processes content in ~310 seconds (slightly more than 5 minutes). Amazon Nova requires 590 seconds (close to 10 minutes)—a 1.9x slowdown that compounds across thousands of videos. Google Vertex's performance degrades dramatically for long content, scoring only 51% composite performance compared to Marengo 3.0's 78%.
These latency differences determine what's deployable. For example, processing a 1,000 hours-long video library with Marengo 3.0 versus Nova means the difference between 86 hours and 164 hours of compute time—impacting both time-to-market and infrastructure costs.
Performance Across All Modalities
Marengo 3.0 doesn't just excel at latency—it leads across video, audio, image, and text understanding:
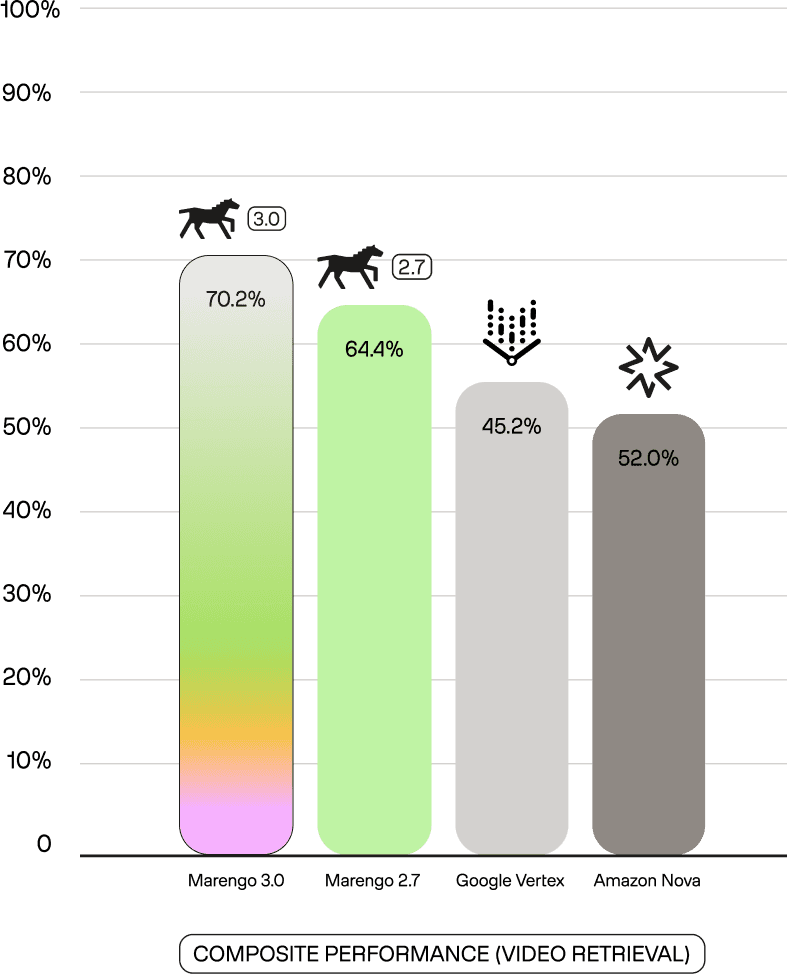
For video retrieval, the composite performance above is the mean across 14 benchmarks: MSRVTT, MSVD, VATEX, YooCook2, DiDemo, QVHighlight, Dense-WebVid-CoVR, tl-abps-basketball, tl-sports-general, tl-american-football, tl-baseball, tl-basketball, tl-ice-hockey, tl-soccer.
Marengo 3.0 achieves 70.2% across general video retrieval, sports understanding, and composed queries—an 5.8 percentage point lead over Marengo 2.7, 25 points over Vertex, and 18.2 points over Nova.
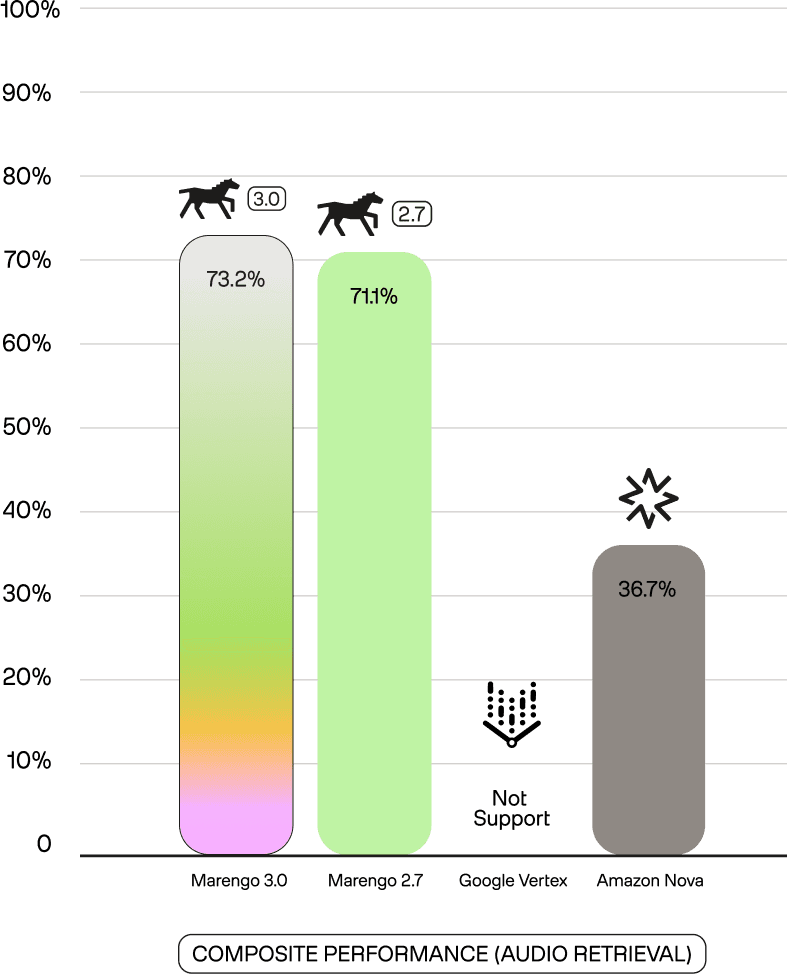
For audio retrieval, the composite performance above is the mean across 3 benchmarks: GTZAN, Clotho, Librispeech.
At 73.2%, Marengo 3.0 maintains Marengo 2.7's audio strength while Nova struggles at 36.7% and Vertex cannot process audio at all.
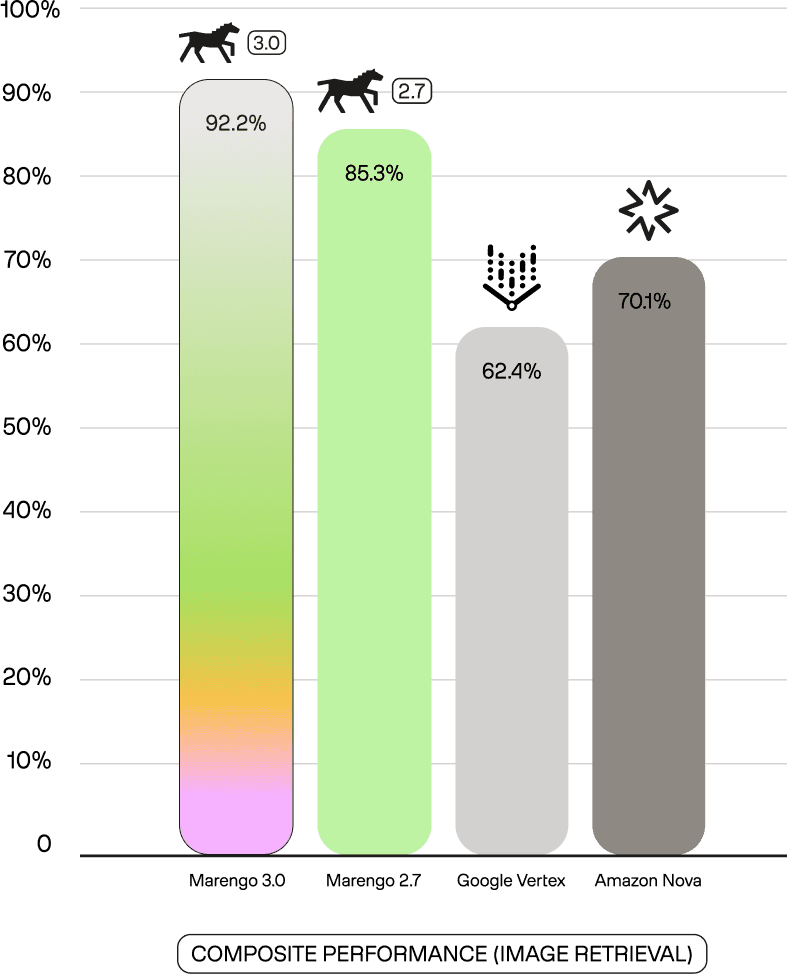
For image retrieval, the composite performance above is the mean across 5 benchmarks: Visual7W-Pointing, Urban1K, TextCaps, Object365-medium, OpenLogo.
92.2% performance demonstrates Marengo 3.0's visual precision on OCR, object recognition, and spatial reasoning tasks - completely outperforming Vertex (62.4%) and Nova (70.1%).
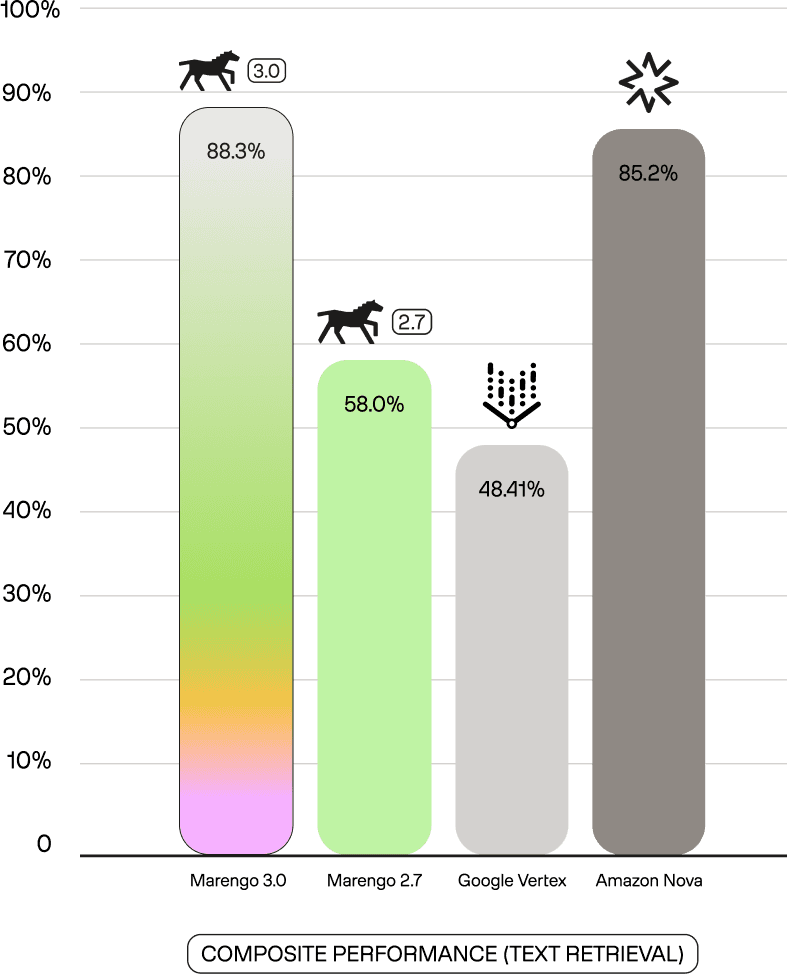
For text retrieval, the composite performance above is the mean across 5 benchmarks: SomethingSomethingv2-MC, Kinetics-700, PasskeyRetrieval, HagridRetrieval, WikipediaRetrieval.
88.3% validates that Marengo 3.0's text encoder rivals specialized text-only models—a 30 percentage point improvement over Marengo 2.7's 58%.
Table of Content
The sections that follow provide detailed evidence for Marengo 3.0's capabilities across:
Composed and Long-Form Retrieval: Combining modalities in queries and processing extended-duration content
Audio and Sports Intelligence: Understanding dynamic content where temporal reasoning dominates
Multilingual and Text Mastery: Native cross-language search and text-only retrieval rivaling specialized models
Advanced Visual Perception: OCR, object recognition, and logo detection at scale
General Benchmark Leadership: State-of-the-art results without trade-offs
Each section includes benchmark results, competitor comparisons, and sample queries demonstrating retrieval quality. Together, these results establish Marengo 3.0 as the only production-grade foundation model that delivers both performance and efficiency at enterprise scale.
Metrics Used in This Post:
R@1,5,10 Avg: Recall at ranks 1, 5, and 10, averaged. Measures how often the correct result appears in the top 1, 5, or 10 results.
mAP: Mean Average Precision. Measures ranking quality across all relevant results.
NDCG@K: Normalized Discounted Cumulative Gain at position K. Measures ranking quality with position-weighted scoring.
1. The Core Capability: Composed and Long-Form Retrieval
Marengo 3.0 is built to handle queries as complex and nuanced as human thought. Marengo 3.0 handles composed queries—searches that combine visual and textual elements to express intent more precisely than either modality alone.
Composed Retrieval (Visual+Text Embedding)
Marengo 3.0 supports composed retrieval by combining image and text inputs into a single query embedding. For example, users can submit an image of a specific player plus the text "scored a jump shot" to retrieve precise action moments from hours of game footage. This capability is unavailable in competing foundation models, which process visual and textual queries separately.
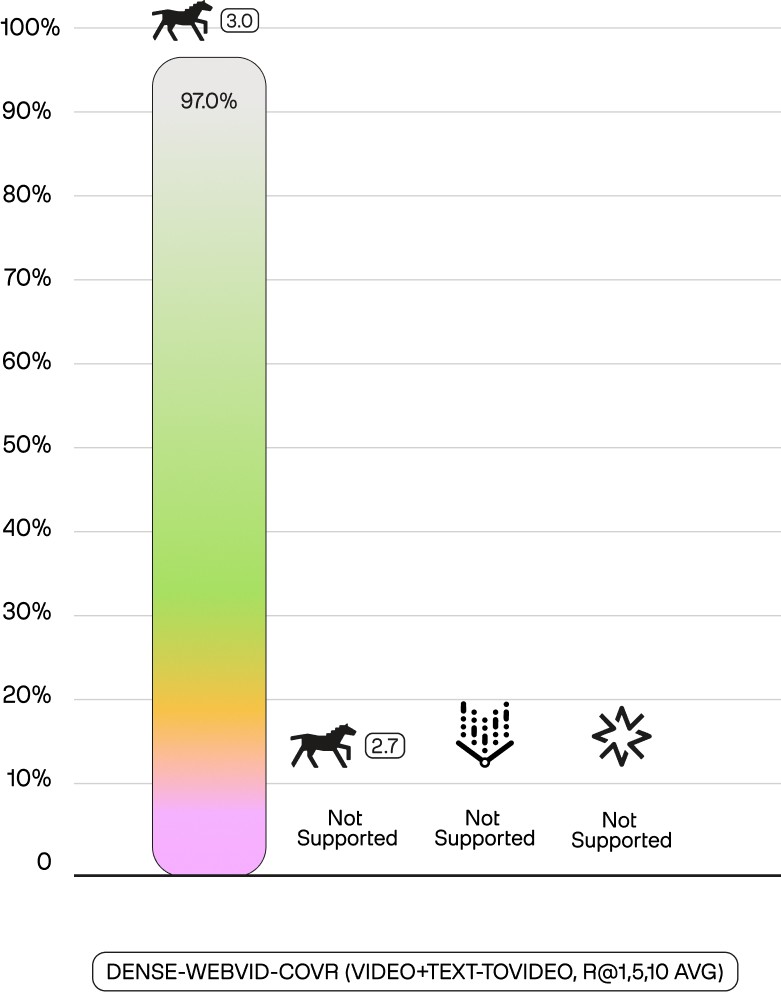
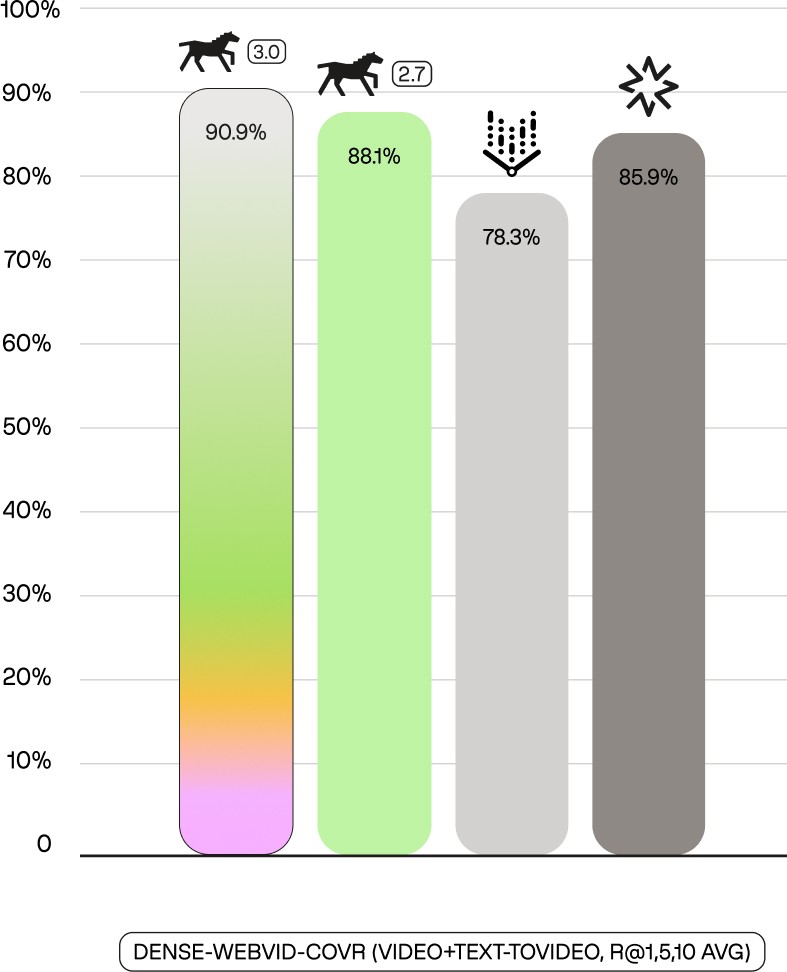
The performance leap is significant. On our in-house action bound person search benchmark (tl-abps-nba), a text-only query achieves a 34.4 mAP. By adding a single image, Marengo 3.0's composed retrieval improves the performance to 38.5 mAP. This leadership is even more pronounced on the Dense-Webvid-CoVR benchmark (which evaluates video+text-to-video retrieval), where Marengo 3.0 achieves a 97.0 score on average in Recall @1, Recall @5, and Recall @10 metrics, a result competitors cannot even attempt.
Text-only queries struggle on these benchmarks because they require disambiguating specific visual attributes (e.g., which player, what action). Composed retrieval provides this disambiguation:
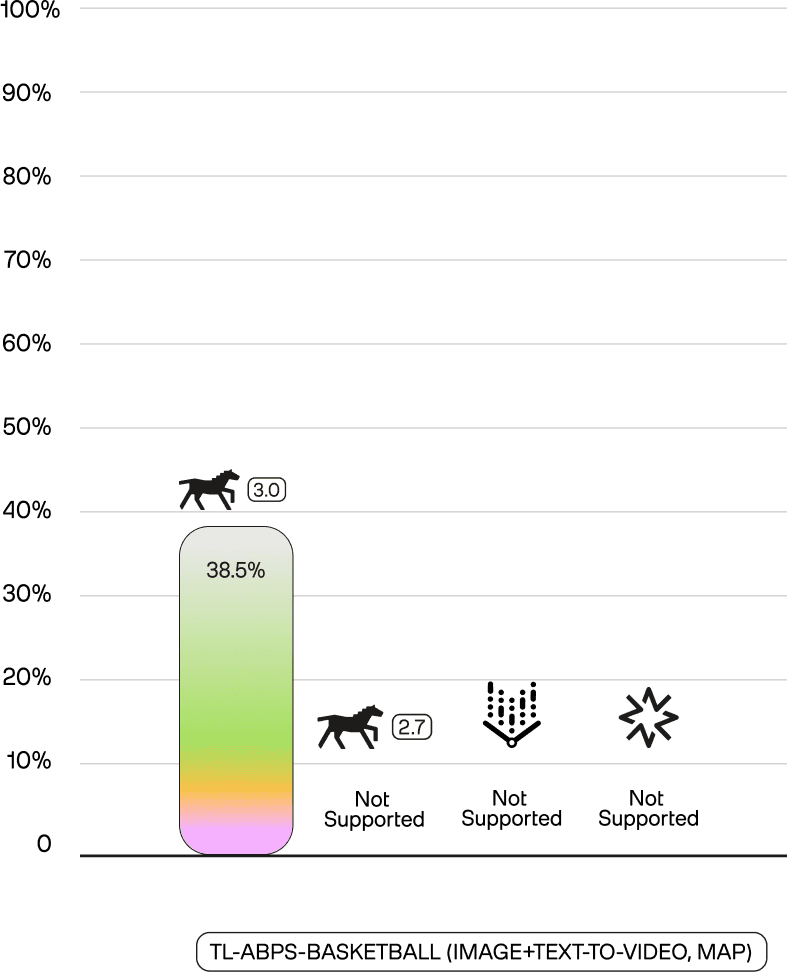
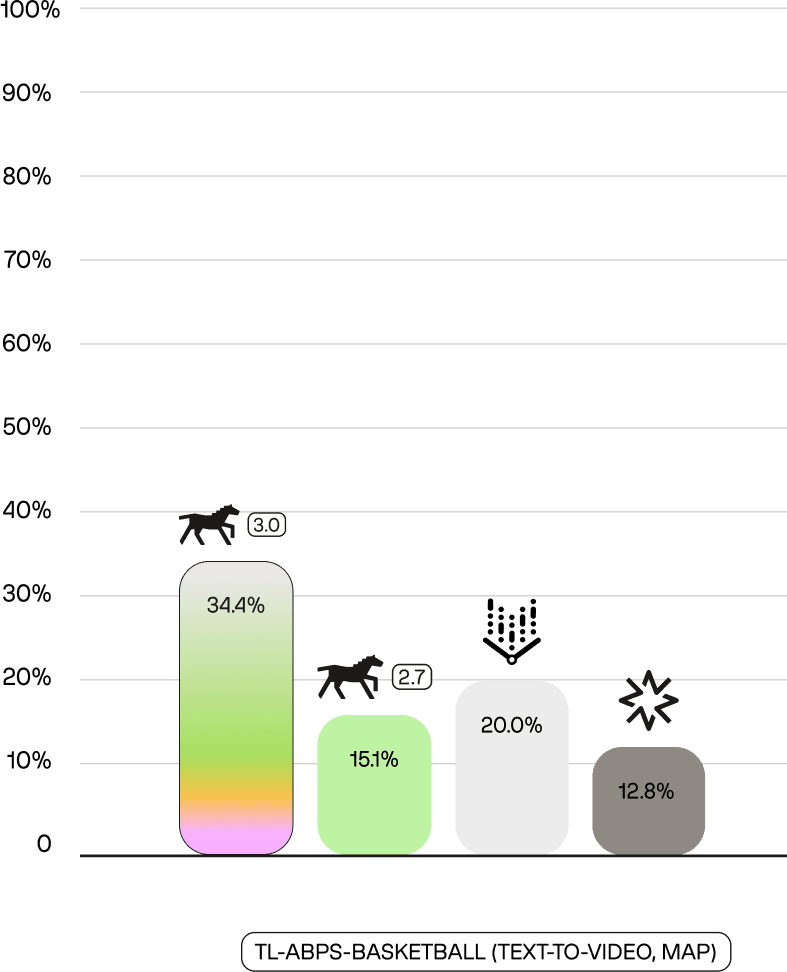
On tl-abps-nba, Marengo 3.0's composed retrieval (38.5 mAP) outperforms even its own text-only mode (34.4 mAP) and substantially exceeds competitors' text-only results (Marengo 2.7: 15.1%, Vertex: 20.0%, Nova: 12.8%).
Beyond combining modalities, Marengo 3.0 excels at processing extended content and complex, descriptive queries—critical for AI agent applications and detailed video search.
As seen in the example results below on Dense-WebVid-CoVR, Marengo 3.0 with composed retrieval (M30 CR) places the correct video at rank 1. Text-only queries (M30, M27, Vertex, Nova) rank the target video lower or miss it entirely, retrieving videos with similar text descriptions but incorrect visual attributes.
Long Query Retrieval
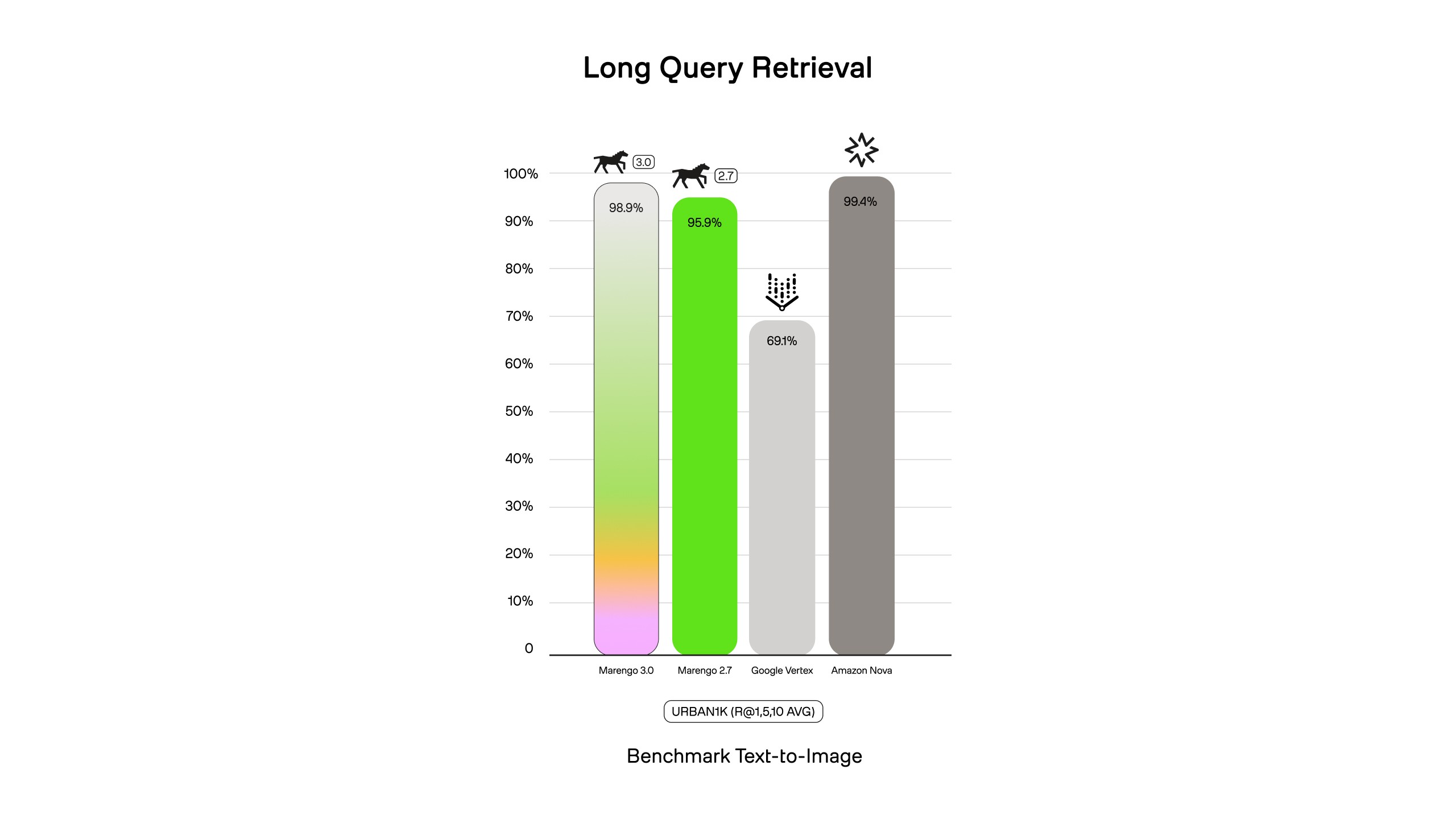
Marengo 3.0 is designed to handle "extended-duration content" and the long, descriptive queries common in AI Agent applications. On Urban1K, Marengo 3.0 and Nova both excel, while other models struggle with context length.
Long-form retrieval is critical for production systems where users provide detailed natural language descriptions ("Find the segment where the person in the red jacket walks past the yellow taxi near the intersection") rather than optimized keyword queries. Agentic systems similarly generate verbose, multi-constraint queries when decomposing complex user intents.
As seen in the example results below on Urban1k, Marengo 3.0 retrieves the correct image at rank 1 despite queries containing 60-80 words with multiple visual details (colors, positions, background elements). Marengo 2.7 ranks the target at position 2-3, while Vertex requires 5 results to surface the correct match.
2. Beyond Visuals: Unmatched Audio and Sports Comprehension
Video understanding requires more than visual analysis—audio (speech, music, sound effects) and rapid motion (sports, action sequences) challenge models that prioritize static image understanding. Marengo 3.0's architecture jointly processes these modalities, enabling accurate retrieval where temporal dynamics dominate.
Audio (Speech & Non-Speech)
Most multimodal models treat audio as an afterthought. Marengo 3.0 treats it as a first-class citizen.
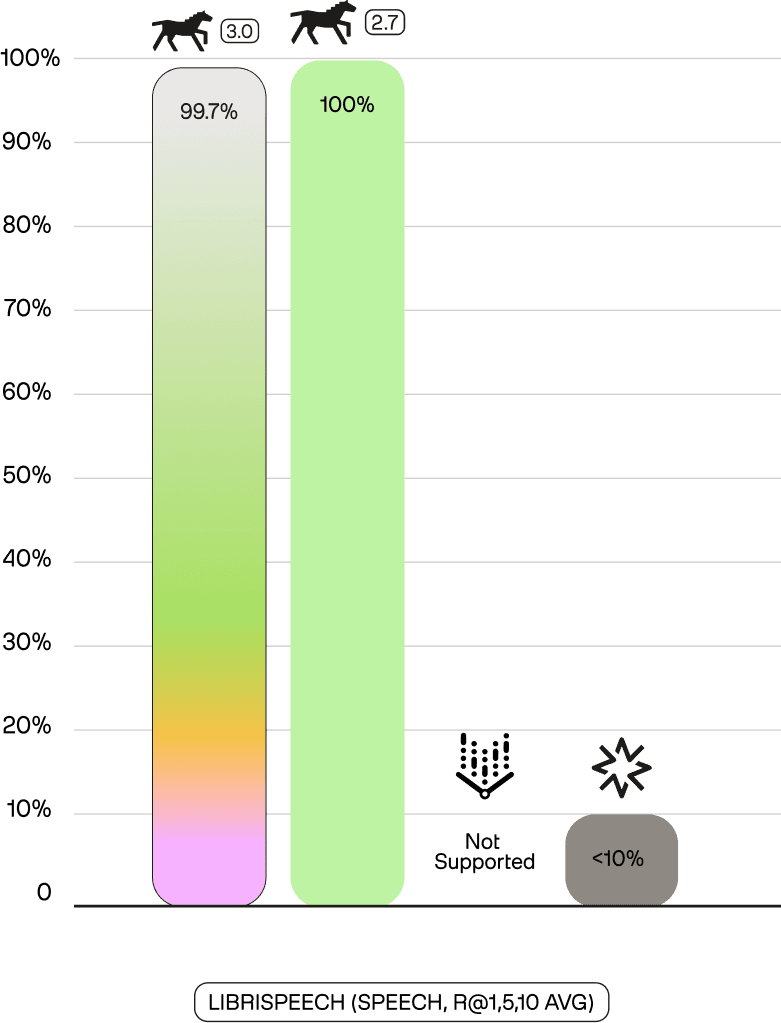
On Librispeech—a speech-to-text retrieval benchmark—Marengo 3.0 achieves 99.7% accuracy (R@1,5,10 Avg), matching Marengo 2.7's 100% and vastly outperforming Amazon Nova (< 10%). Google Vertex does not support audio retrieval. Performance below 10% indicates the model cannot reliably distinguish speech content, functionally lacking the capability.
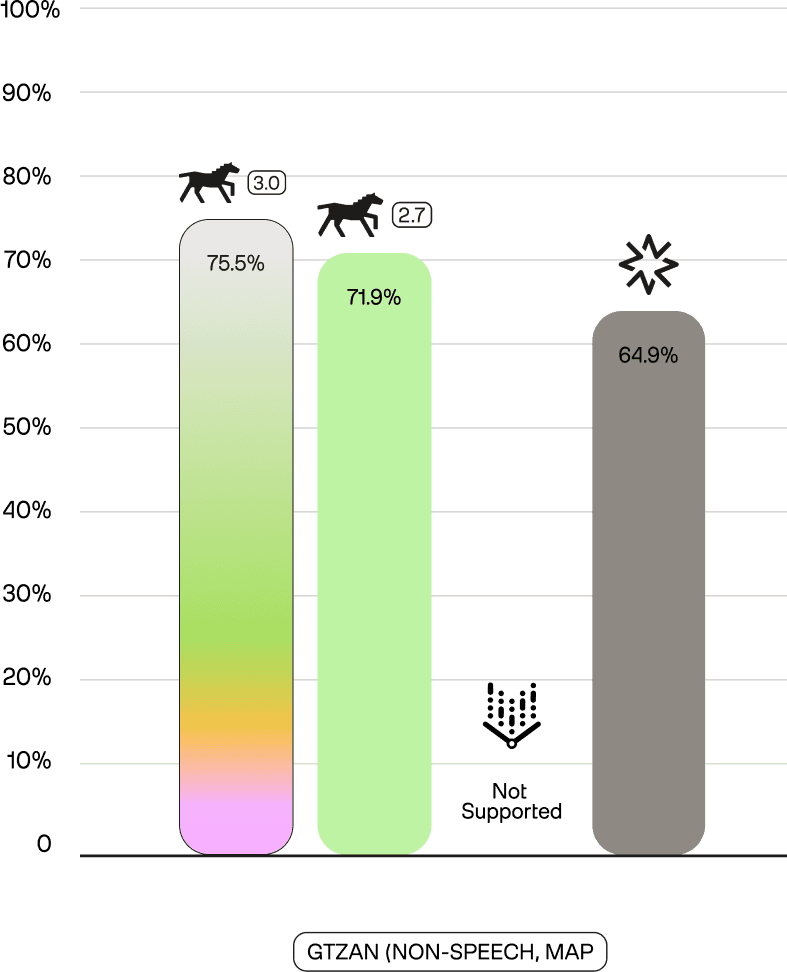
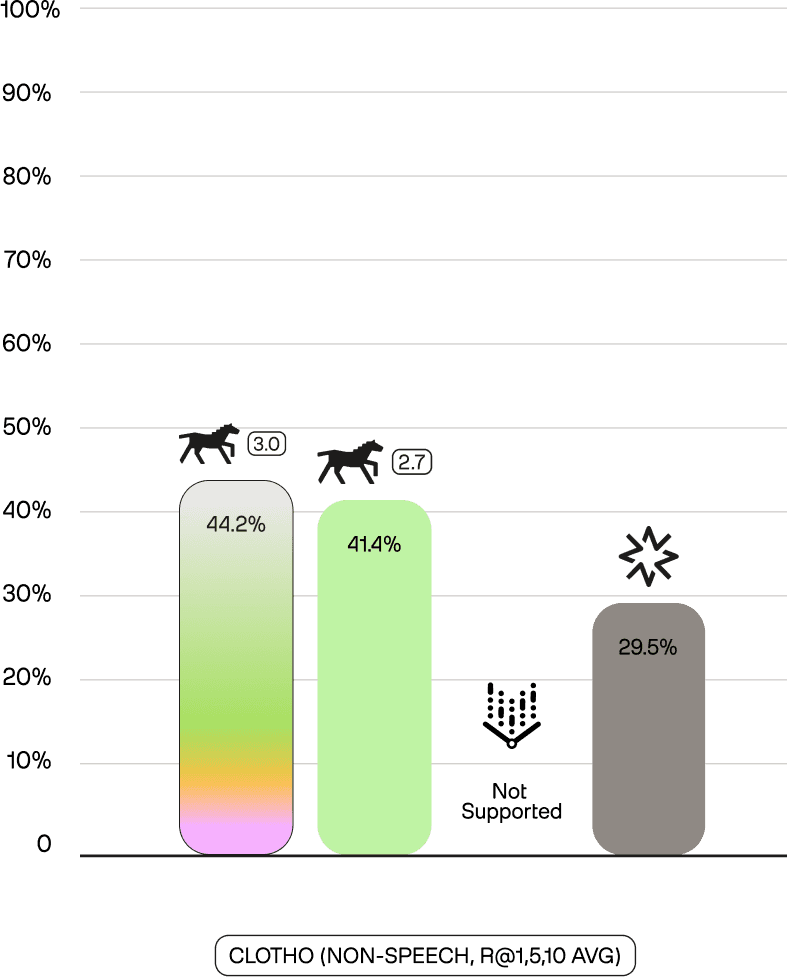
This audio capability extends to non-speech sounds. On GTZAN (music genre recognition, mAP) and Clotho (audio captioning, R@1,5,10 Avg), Marengo 3.0 achieves 75.5% and 44.2%, respectively—improvements over Marengo 2.7 (71.9%, 41.4%) and substantial leads over Nova (64.9%, 29.5%). Vertex does not support non-speech audio tasks.
In the Librispeechresult below, Marengo 3.0 and 2.7 both retrieve the correct speech segment at rank 1, demonstrating strong text-to-speech alignment. Amazon Nova fails to find the target in the top 5, indicating its audio encoder cannot accurately map spoken content to text queries.
On the other hand, the Clotho query require understanding complex auditory scenes. Marengo 3.0 ranks the correct audio clip at position 1, while Marengo 2.7 places it at position 3, and Nova at position 4. This shows Marengo 3.0's improved ability to parse multi-source audio environments.
Sports
Sports video presents extreme challenges for video models: rapid camera motion, occlusions, similar-looking actions (e.g., different types of passes), and domain-specific terminology. Marengo 3.0's temporal modeling and entity recognition enable action-level understanding where general models default to generic labels.
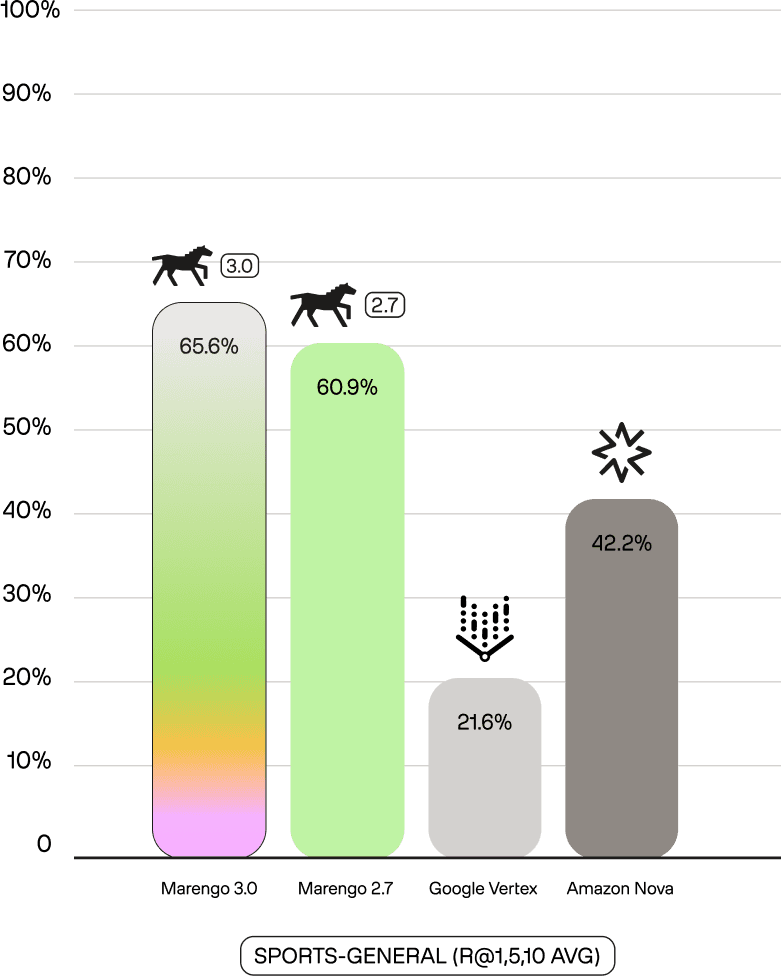
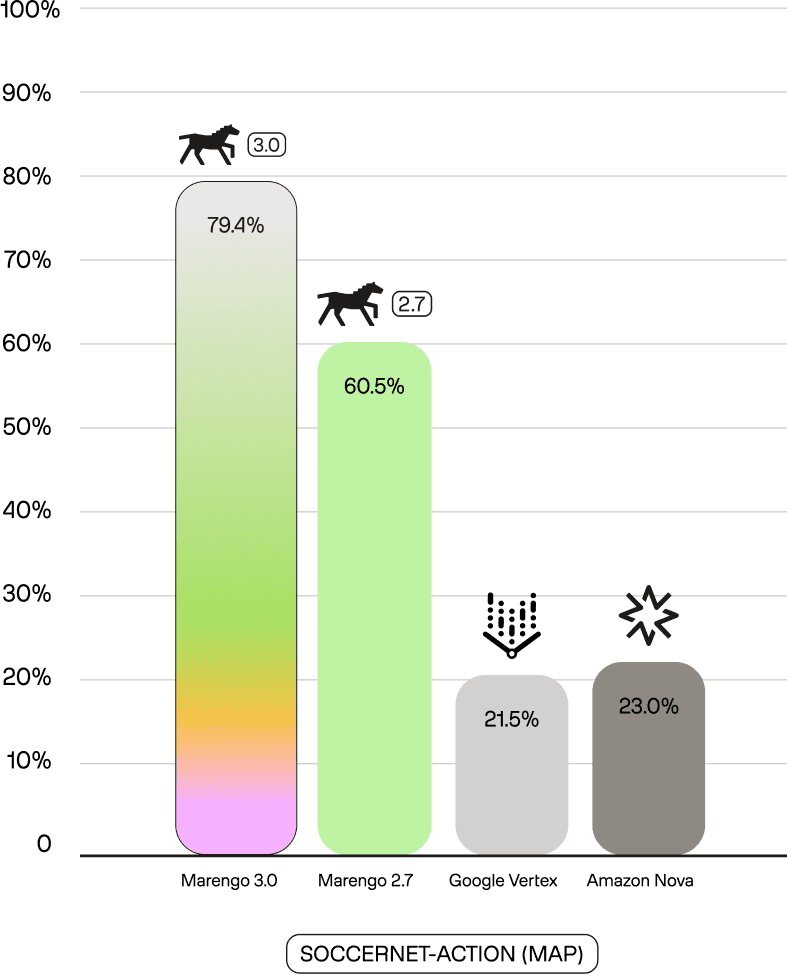
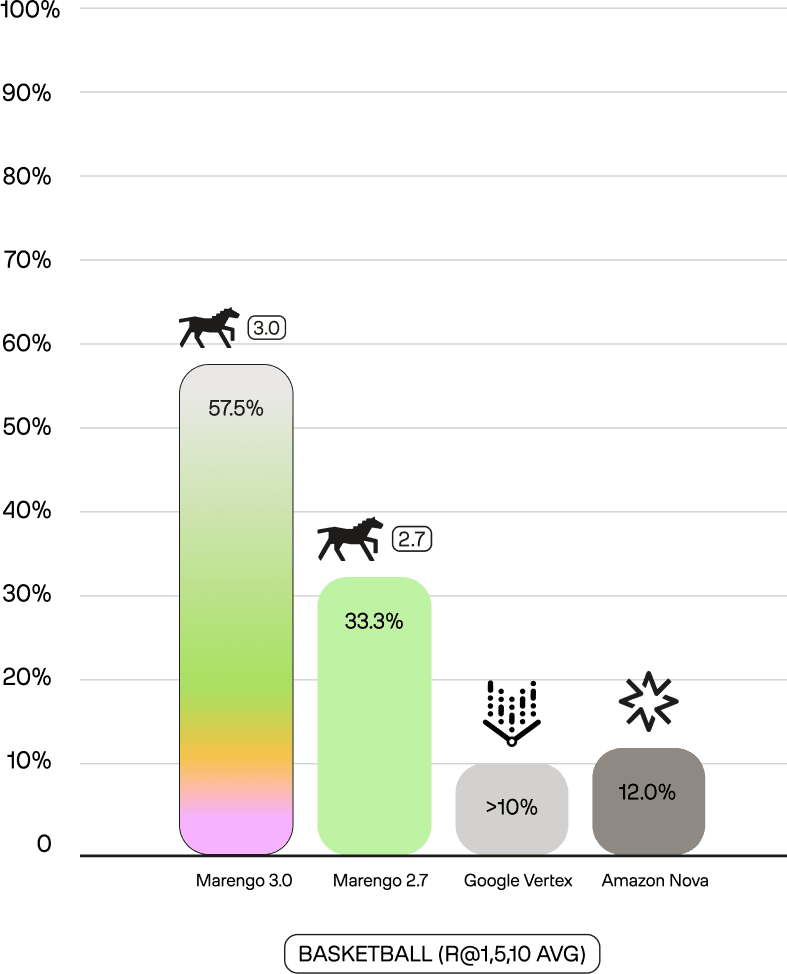
Marengo 3.0's performance shows a commanding lead over all competitors, often by 20-50%p, highlighting its superior motion and context understanding. This lead is not just general; it is dominant in specific sports. On SoccerNet-Action—a public benchmark for soccer action recognition—Marengo 3.0 achieves 79.4 mAP, compared to 23.0 for Nova and 21.5 for Vertex. This 3.5x performance advantage extends to our internal benchmarks: on tl-basketball, which requires distinguishing fine-grained actions (jump shots vs. layups, steals vs. blocks), Marengo 3.0 scores 57.5% (R@1,5,10 Avg) versus 12.0% for Nova. These results demonstrate a deep understanding of complex, specific actions that general models fail to capture.
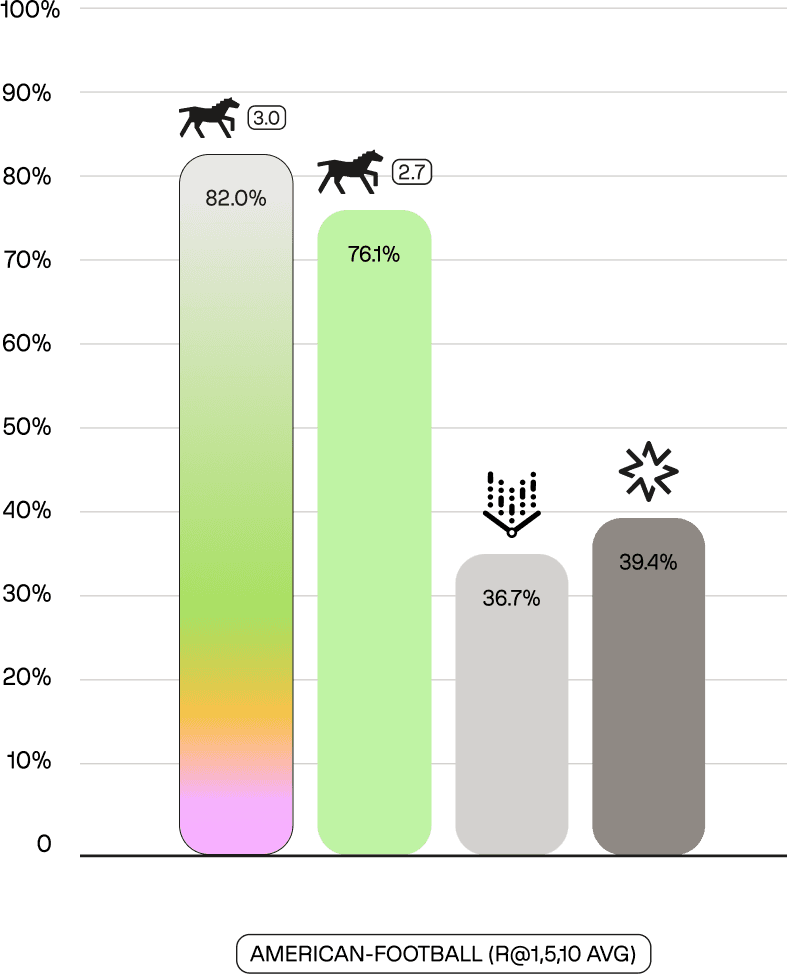
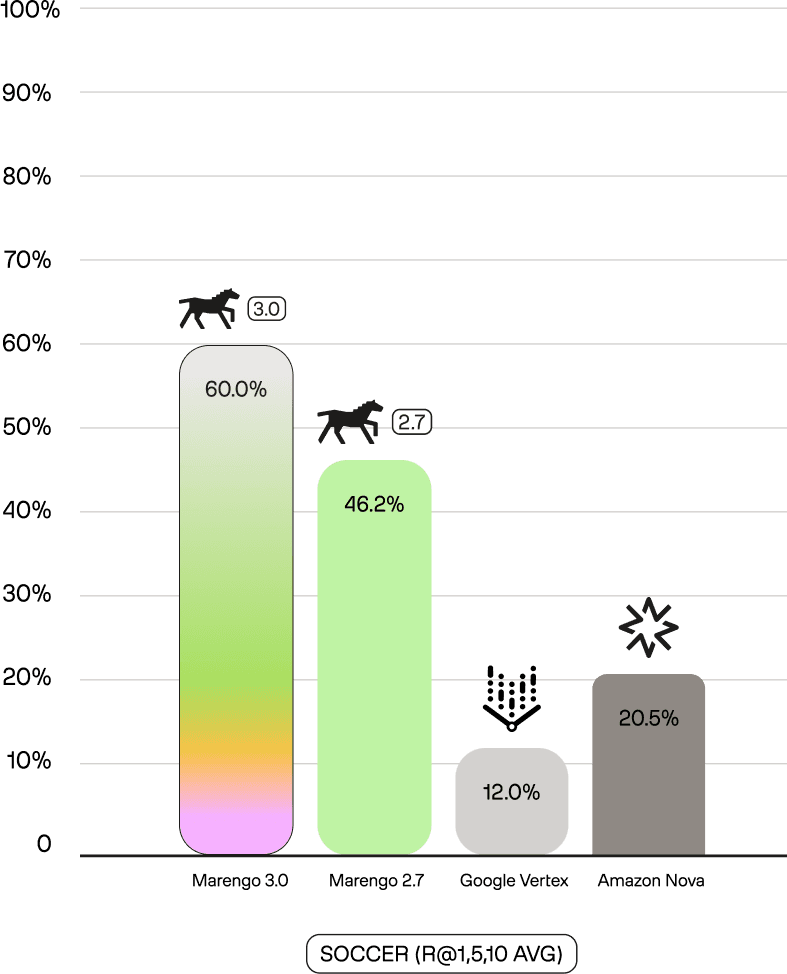
Sports intelligence enables production applications including automated highlight generation, play-by-play search for coaching analysis, and content moderation for league compliance. These use cases require action-level granularity that general-purpose multimodal models cannot provide.
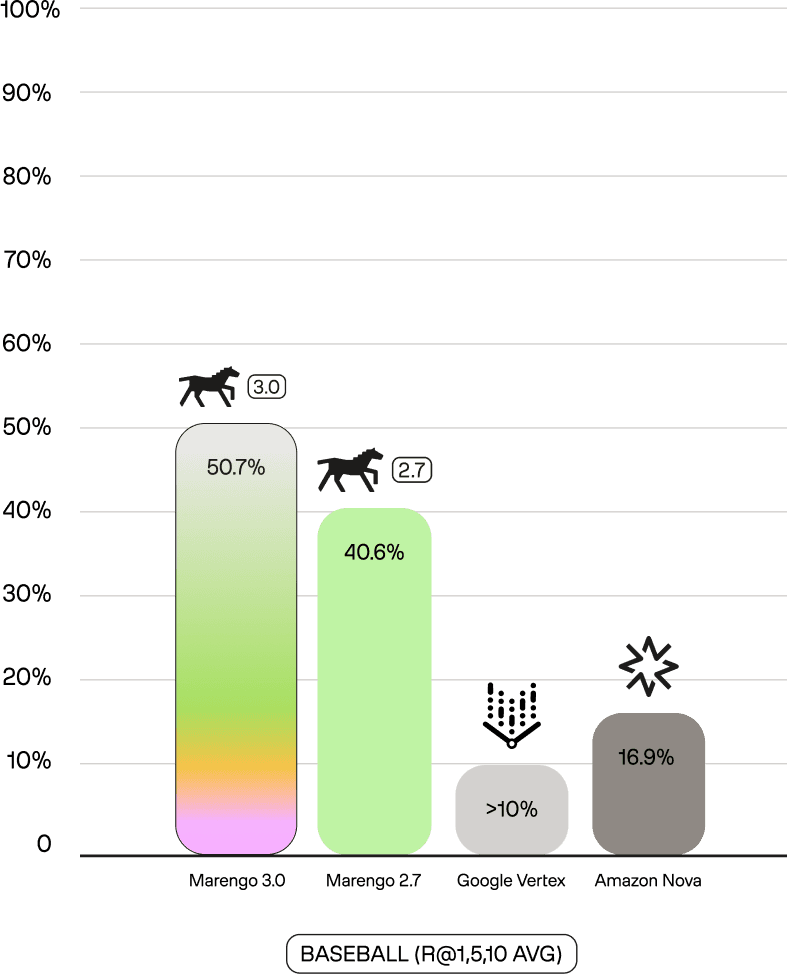
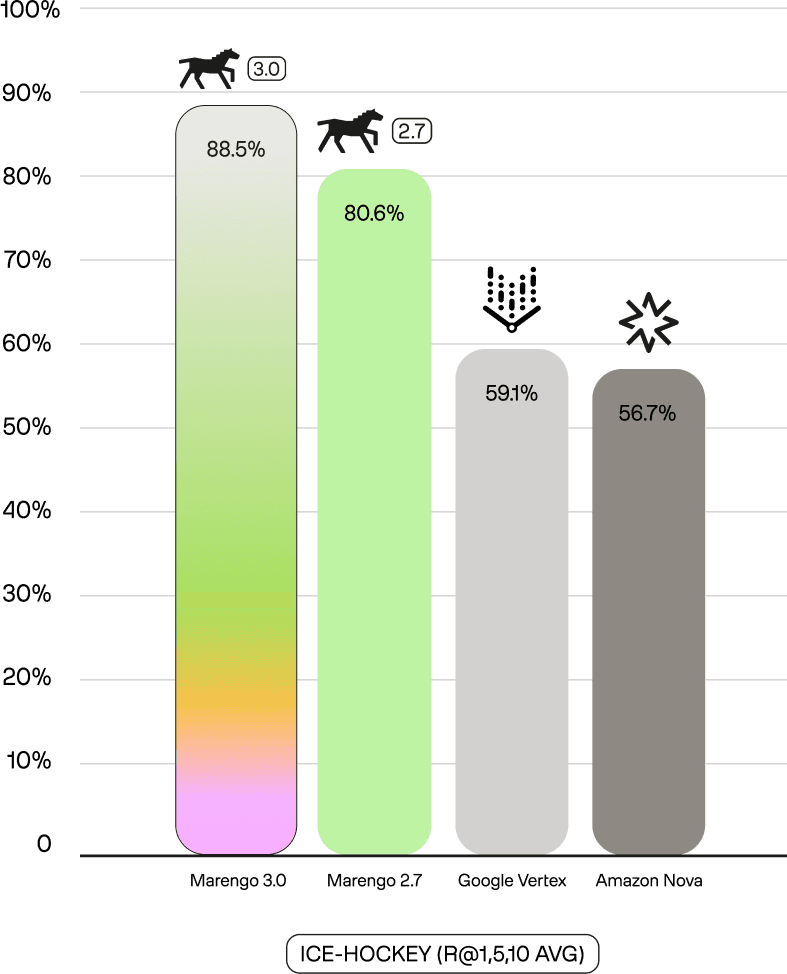
In the example results below on tl-sports-general, multi-clause queries requiring temporal ordering ("initially shows... then shows... at last") and entity tracking (player 11). Marengo 3.0 ranks the correct video at position 1, while competitors struggle to maintain entity consistency across the description.
3. A Truly Unified Space: Multilingual and Text-to-Text Mastery
A "unified embedding model" must excel at text and multilingual understanding, not just treat it as a feature.
Native Multilingual Retrieval
Marengo 3.0 enables native multilingual understanding, allowing semantic retrieval across any combination of modalities (video, audio, text, image) in multiple languages. On the other hand, Marengo 2.7 and Vertex only fully support English.
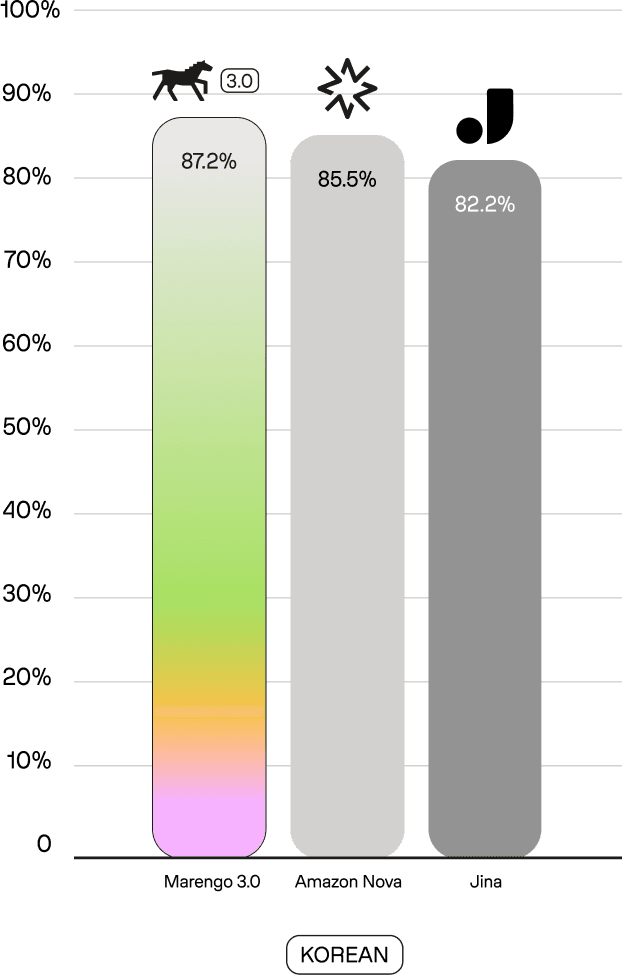
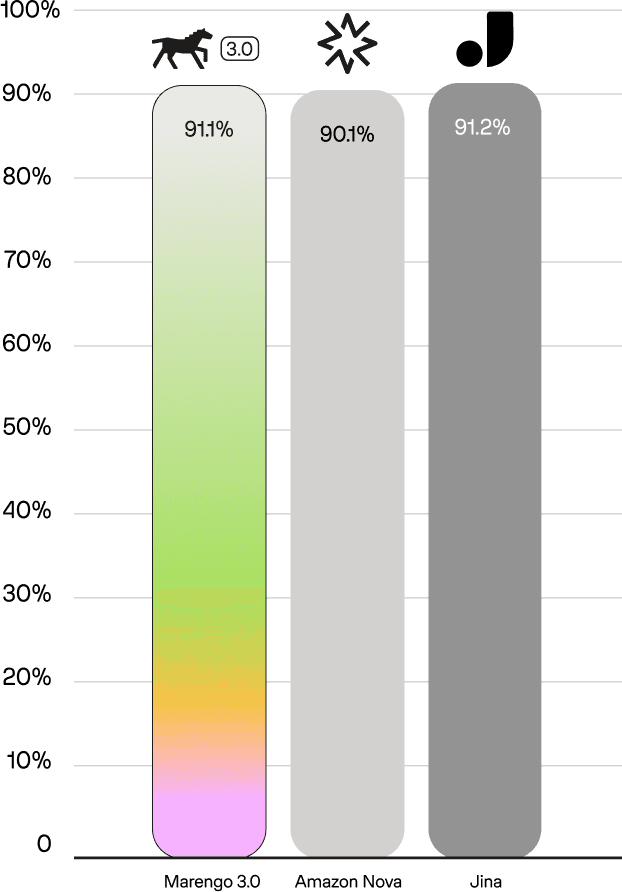
On the Crossmodal 3600 benchmark—which evaluates multilingual text-to-image retrieval—Marengo 3.0 achieves state-of-the-art results in Korean (87.2% R@5), outperforming Amazon Nova (85.5%) and Jina Embeddings v4 (82.2%). In Japanese, Marengo 3.0 reaches 91.1%, matching the best-in-class performance of Jina (91.2%) while outpacing Amazon Nova (90.1%). These results are particularly notable given that Korean and Japanese present unique challenges for multilingual models—both use non-Latin writing systems (Hangul and a mix of Kanji, Hiragana, and Katakana), have grammatical structures that differ substantially from English, and are linguistically distant from the Romance languages where transfer learning from English tends to be more straightforward. Across all evaluated languages, Marengo 3.0 remains highly competitive while offering up to 6x better storage efficiency.
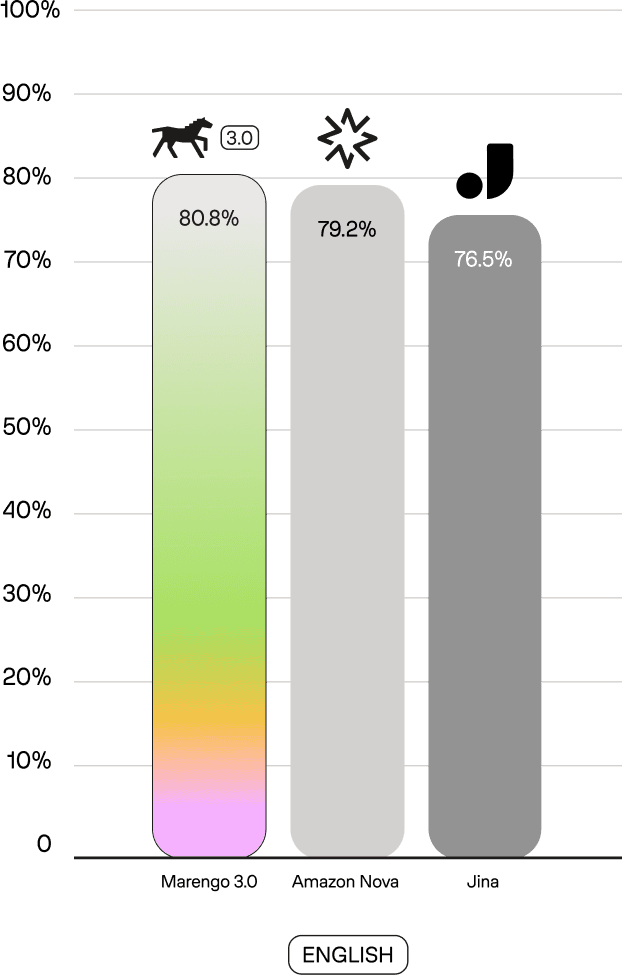
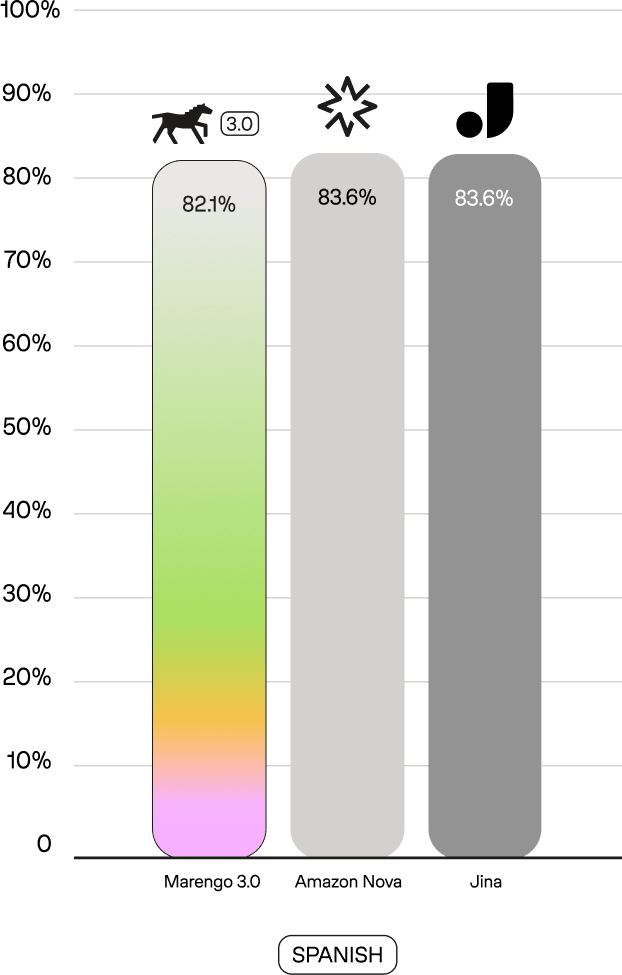
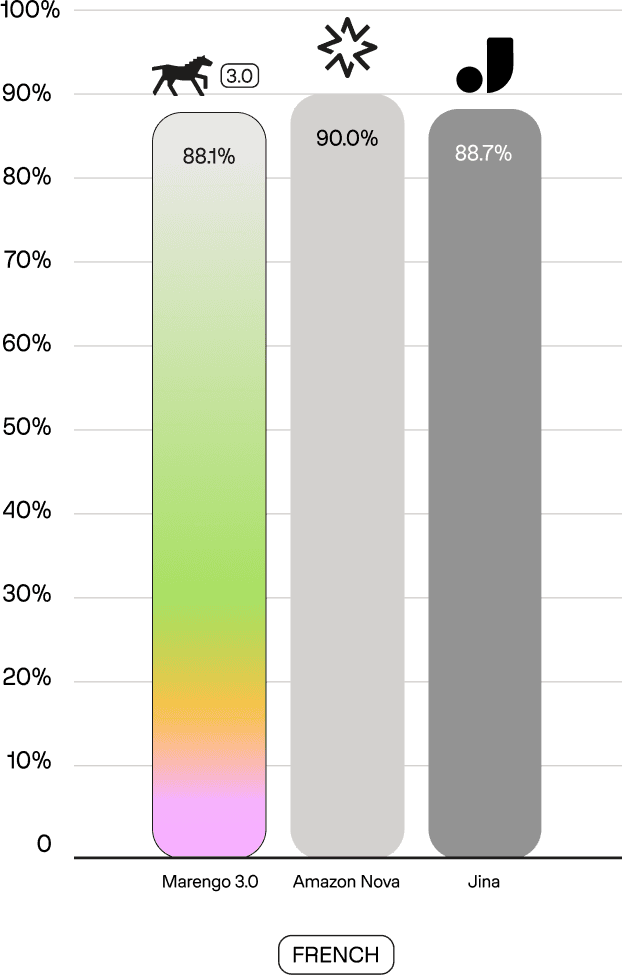
Text-to-Text
Marengo 3.0's text encoder, trained within a multimodal space, demonstrates exceptional capabilities in handling named entities. Unlike traditional text-only models, Marengo 3.0 allocates more attention to entity-related tokens because these key terms must be precisely mapped to visual and audio embeddings. This entity-focused design makes Marengo 3.0 particularly well-suited for applications requiring robust entity recognition and retrieval.
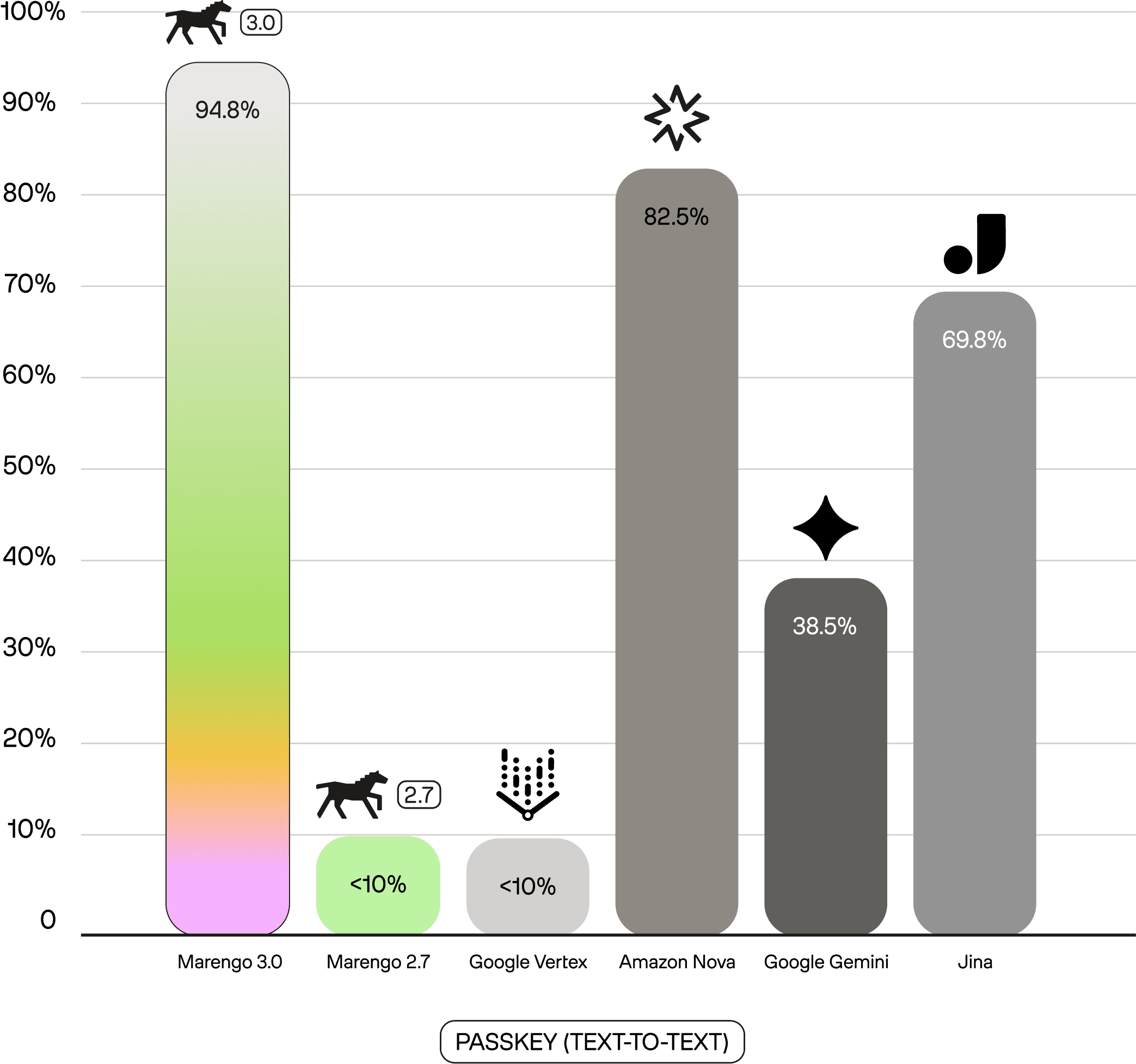
For example, PasskeyRetrievaltests long-context entity extraction: models must locate specific information (e.g., "What is the passkey for Marlon Robles?") buried within very long documents filled with similar distractors. This requires precise entity-value binding across long context windows. Marengo 3.0 achieves 94.4% (NDCG@1) on Passkey, compared to 38.5% for Google's Gemini Embedding (text-only) and 82.5% for Amazon Nova (multimodal). This demonstrates that multimodal training—which grounds entity mentions in visual and auditory contexts—produces more robust entity representations than text-only approaches.
As seen below, a sample document in PasskeyRetrievalcontains 500-1000 words of filler text with multiple name-passkey pairs embedded at various positions. Models must identify the correct pair for the queried name.
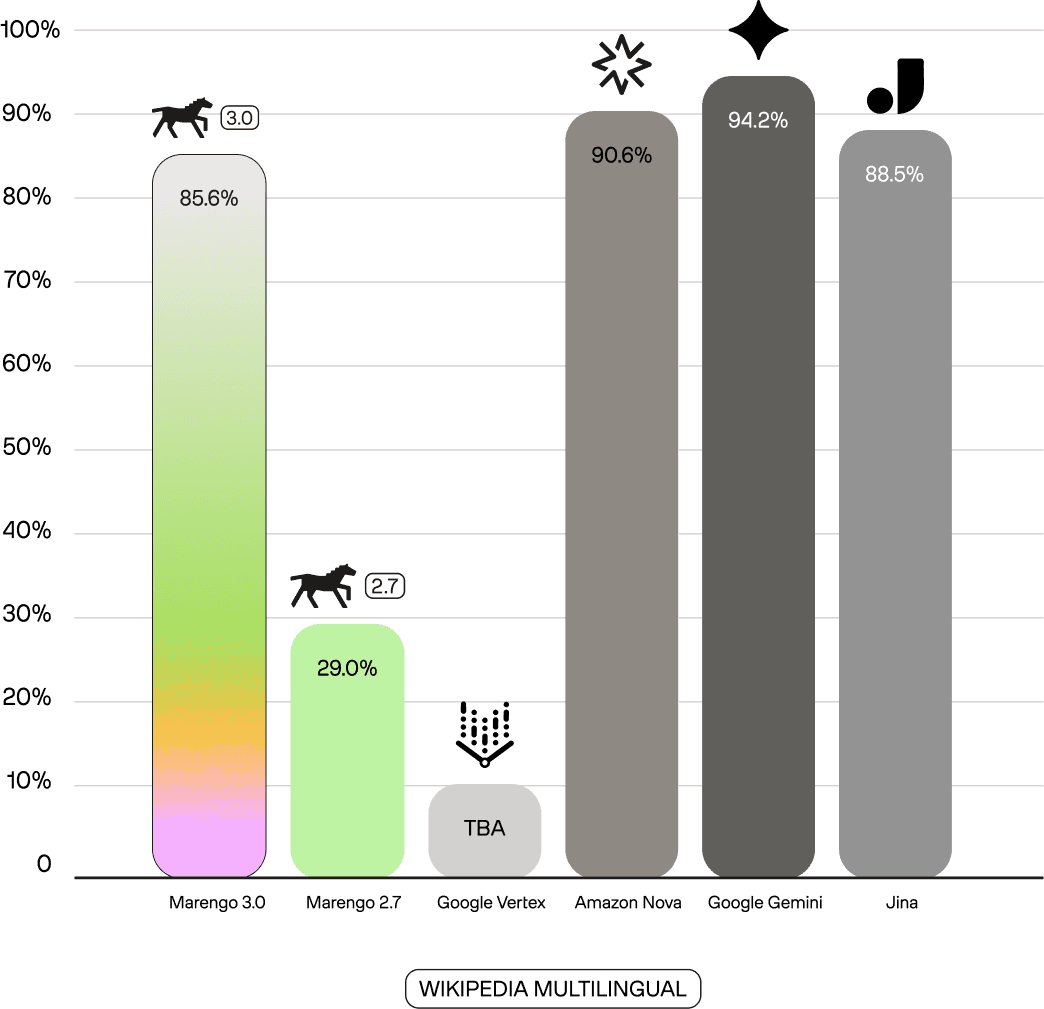
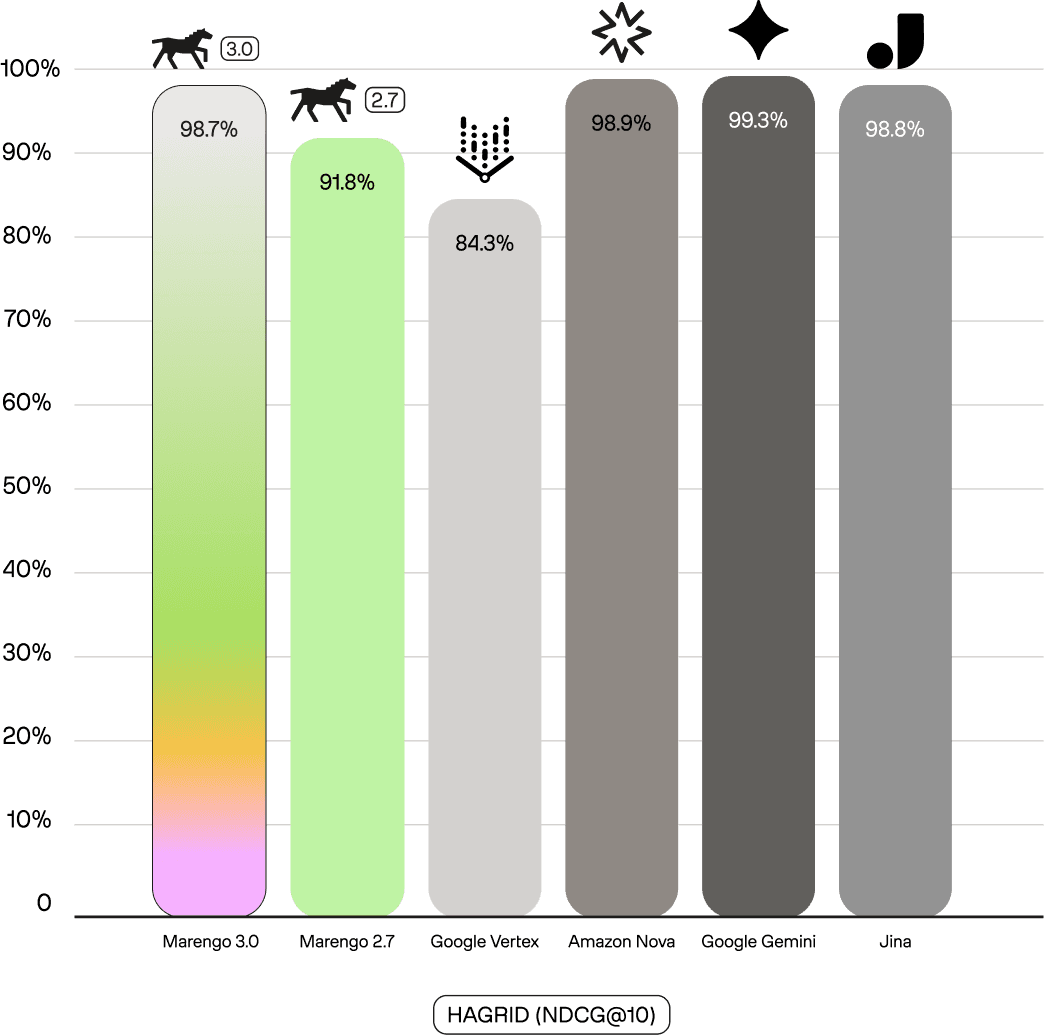
This strength isn't limited to entities. On Wikipedia Multilingual benchmark, Marengo 3.0 achieves 85.6% (NDCG@10), a substantial improvement over Marengo 2.7's 29.0%. This reflects Marengo 3.0's architectural shift to native multilingual training, whereas Marengo 2.7's text encoder was English-centric. On Hagrid(English-only document retrieval), Marengo 3.0 scores 98.7%, competitive with text-only SOTA models like Gemini (99.3%) and Jina v4 (98.8%). This is a remarkable achievement for a lightweight, unified multimodal model.
4. Advanced Visual Perception: OCR and Object Recognition
Marengo 3.0's unified architecture also leads to superior fine-grained visual understanding, from text-in-visual (OCR) to specific objects and logos.
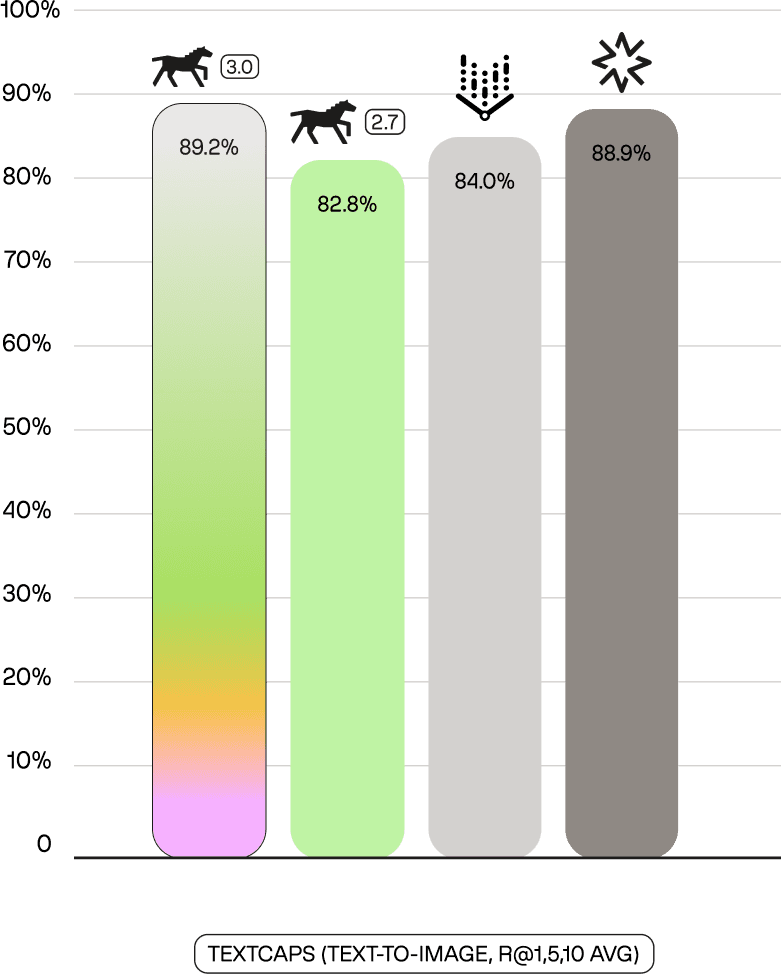
On TextCaps—which evaluates OCR-based image retrieval requiring models to read and understand text in natural scenes—Marengo 3.0 achieves 89.2% (R@1,5,10 Avg), outperforming Amazon Nova (88.9%), Google Vertex (84.0%), and Marengo 2.7 (82.8%).
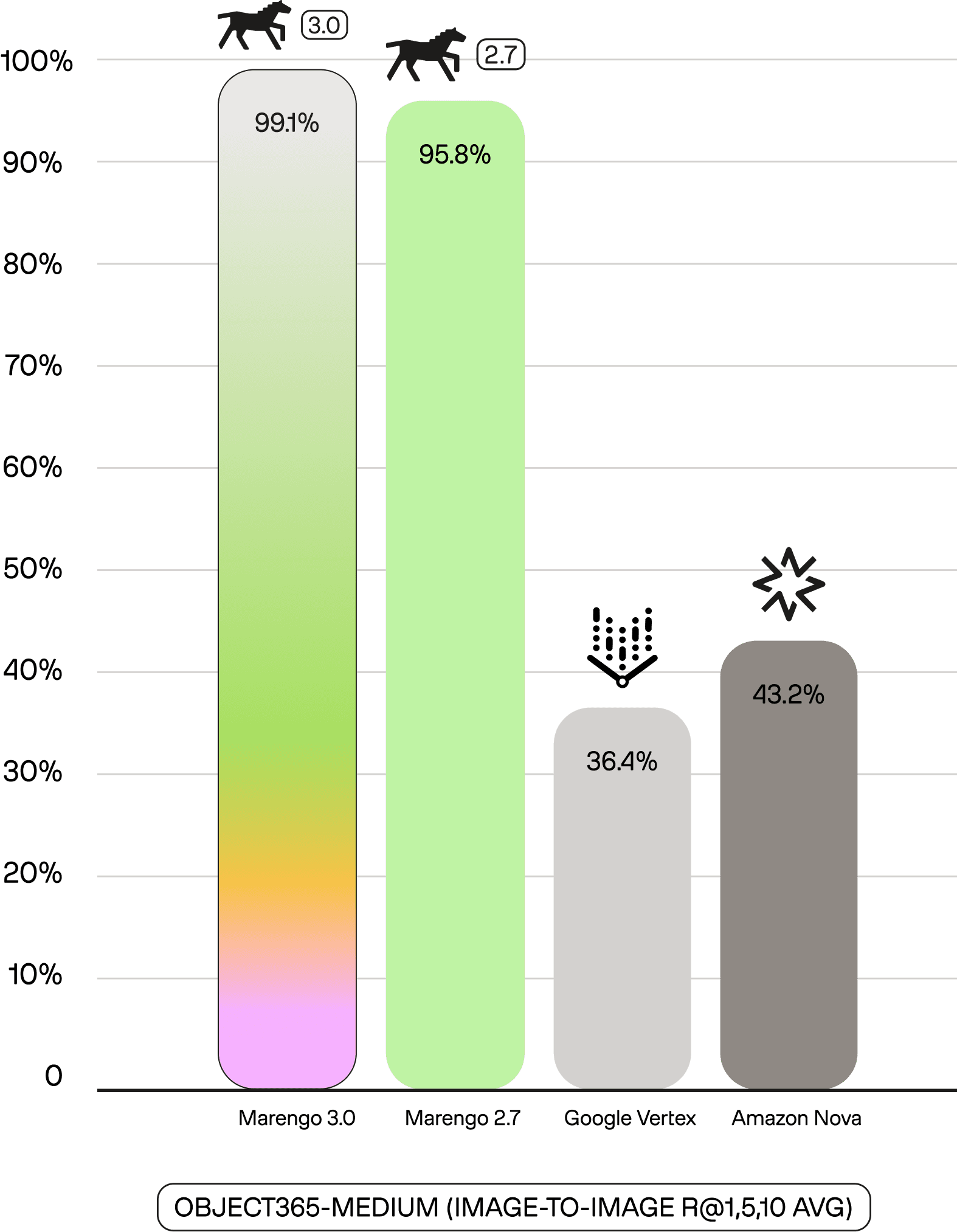
On Object365-medium (general object recognition, image-to-image retrieval), Marengo 3.0 achieves 99.1% (R@1,5,10 Avg), up from 95.8% in Marengo 2.7—approaching near perfect accuracy.
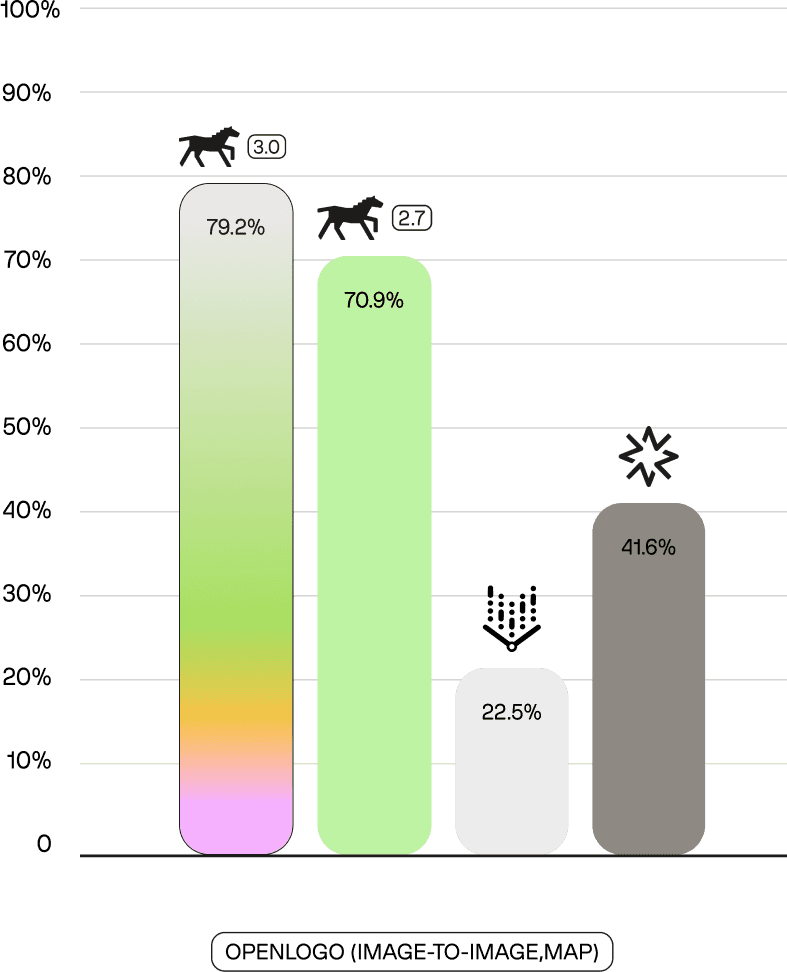
Logo recognition shows even larger gains: on OpenLogo (image-to-image mAP), Marengo 3.0 scores 79.2% compared to Marengo 2.7's 70.9%, a 12% relative improvement. These gains reflect increased training diversity in fine-grained visual categories.
The OpenLogo example below tests logo recognition across varied contexts (different sizes, angles, backgrounds). The "heineken logo" query should retrieve Heineken branding in diverse settings. Marengo 3.0 achieves 5/5 correct results, while competitors miss some instances, indicating weaker logo-specific visual memory.
5. The "No Trade-Off" Proof: SOTA on General Benchmarks
Specialization typically degrades general performance. Models optimized for sports, multilingual content, or composed retrieval often sacrifice accuracy on standard English-language benchmarks like MSRVTT. Marengo 3.0 breaks this pattern: it maintains—and in many cases improves—state-of-the-art results on established benchmarks while adding specialized capabilities.
Marengo 3.0 maintains or surpasses the SOTA status Marengo 2.7 already held on classic academic benchmarks, proving our "no trade-off" design.
General Text-to-Video Retrieval
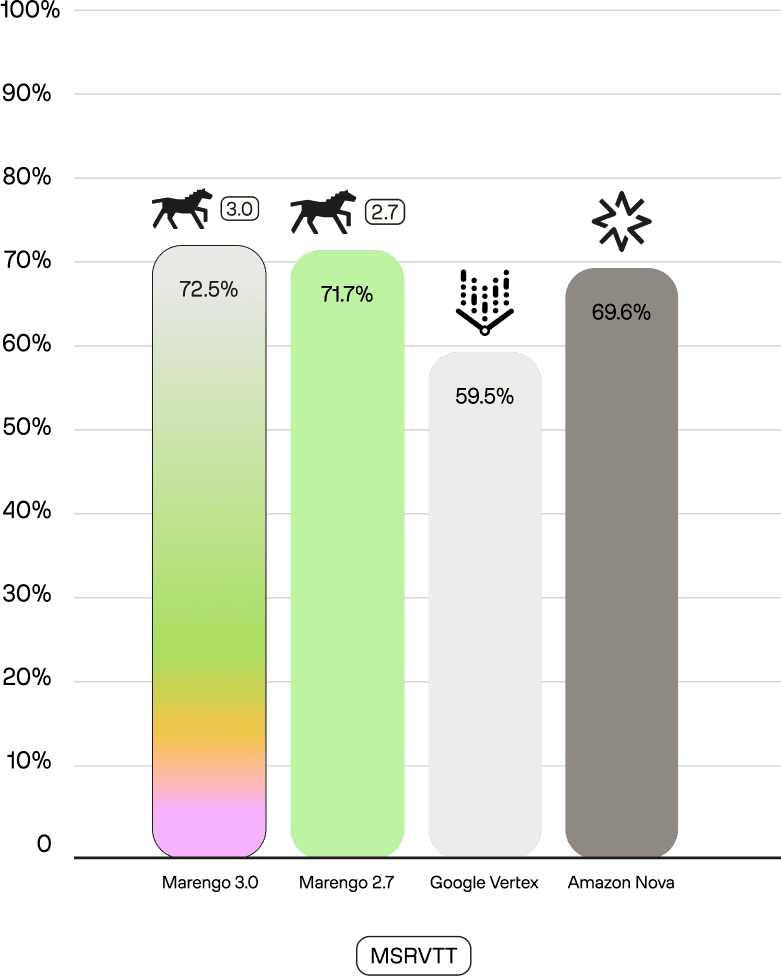
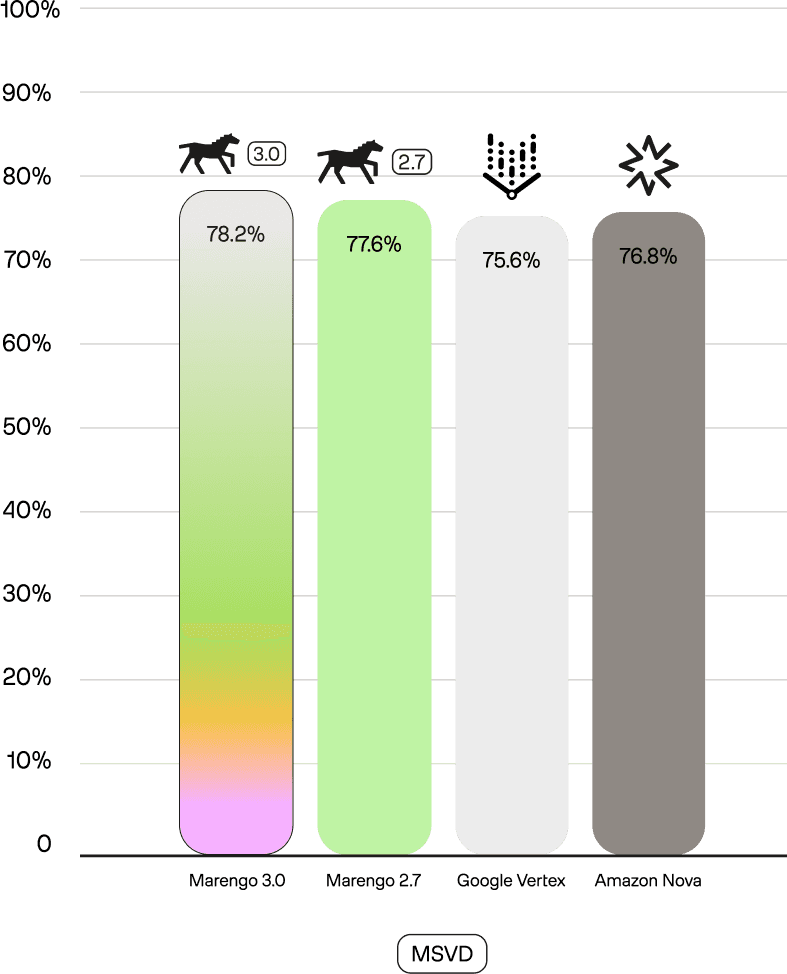
The claim of "no trade-off" is not just about maintaining performance; Marengo 3.0 often improves it. On the gold-standard MSRVTT benchmark, Marengo 3.0 (72.5) beats Marengo 2.7 (71.7), Vertex (59.5), and Nova (69.6). It shows similar state-of-the-art performance on MSVD (78.2) and VATEX (86.4).
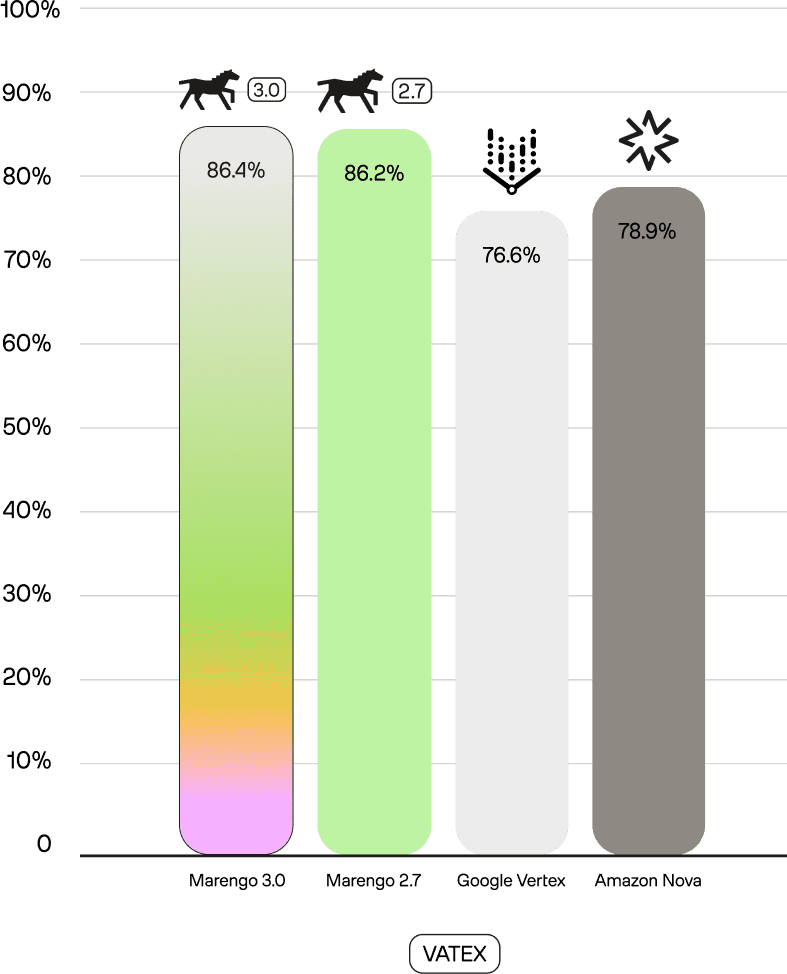
The VATEX query below tests audio-visual alignment, more specifically understanding speech content ("asks it for hugs"). Marengo 3.0 ranks correct videos at position 1, demonstrating that general benchmark improvements don't come at the cost of audio capabilities.
General Video Classification
Video classification benchmarks (assigning videos to predefined categories like "running" or "swimming") test different capabilities than retrieval (finding specific content via natural language). Marengo 3.0 outperforms others in this domain as well.
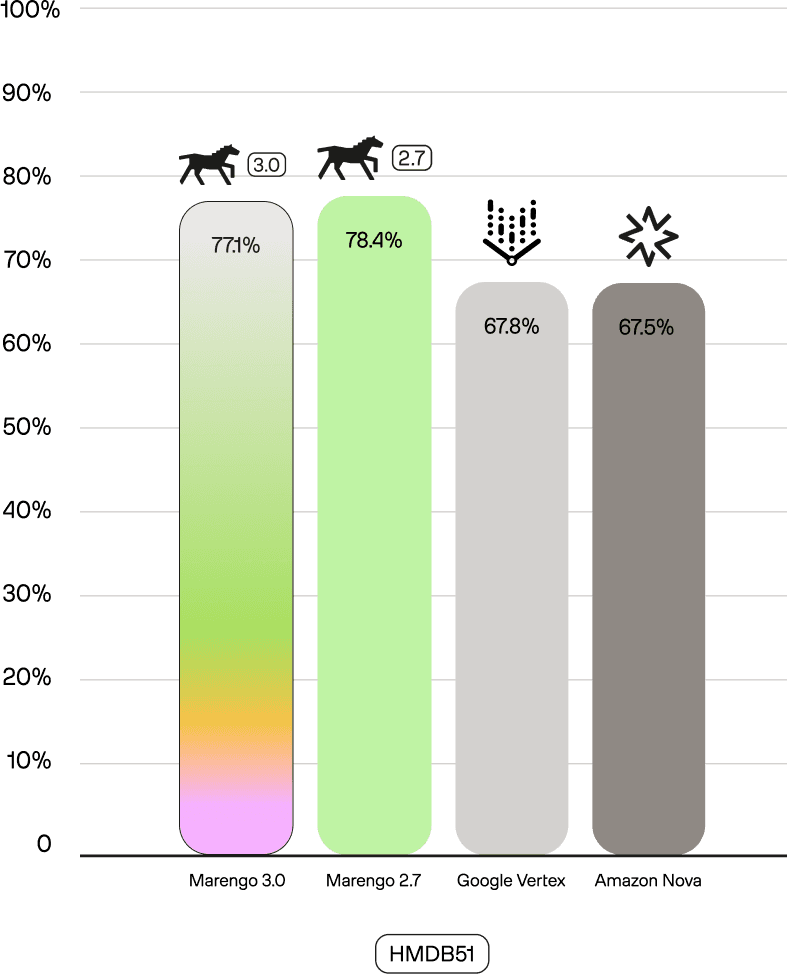
First, Marengo 3.0 outperforms competitors on all classification benchmarks, often by a wide margin.
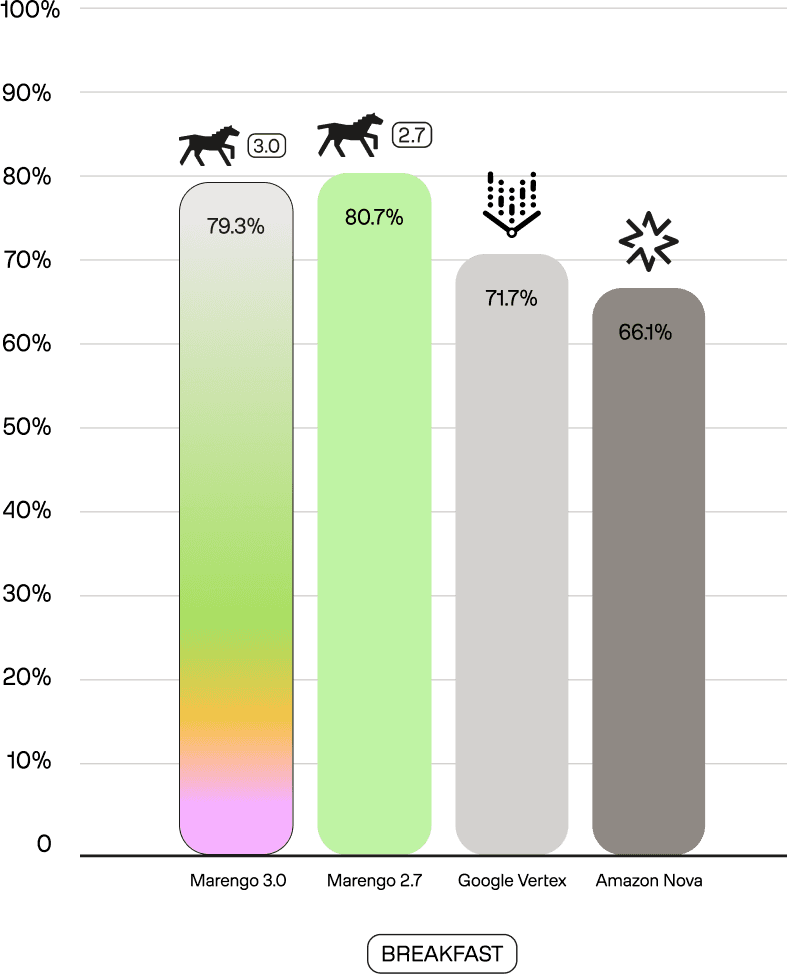
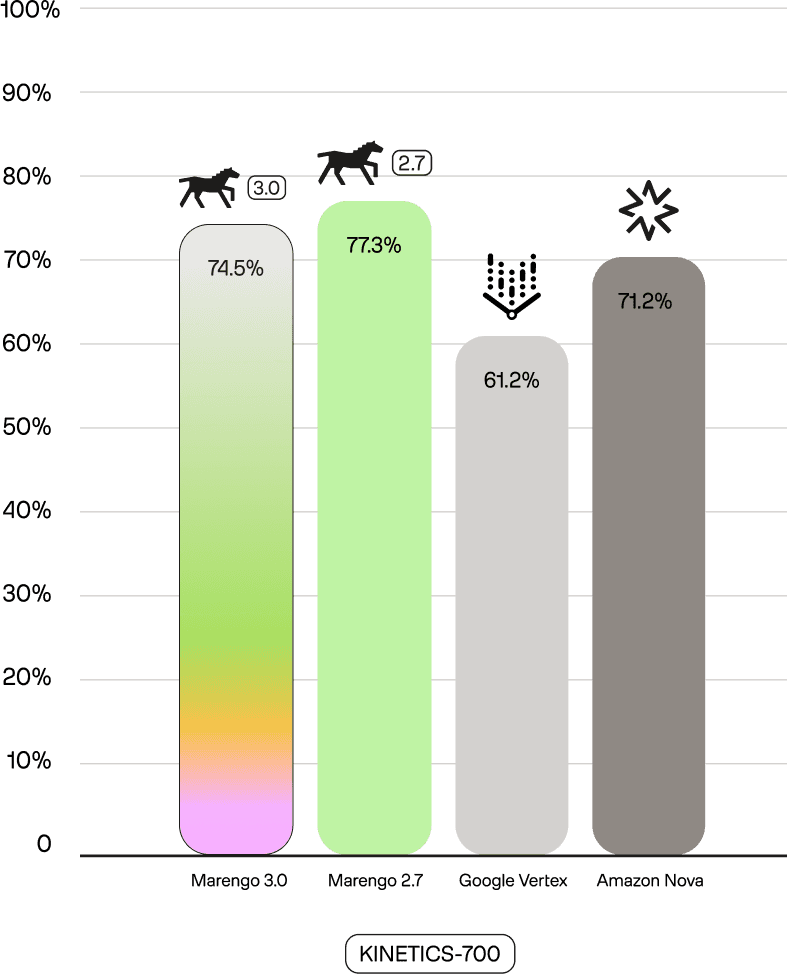
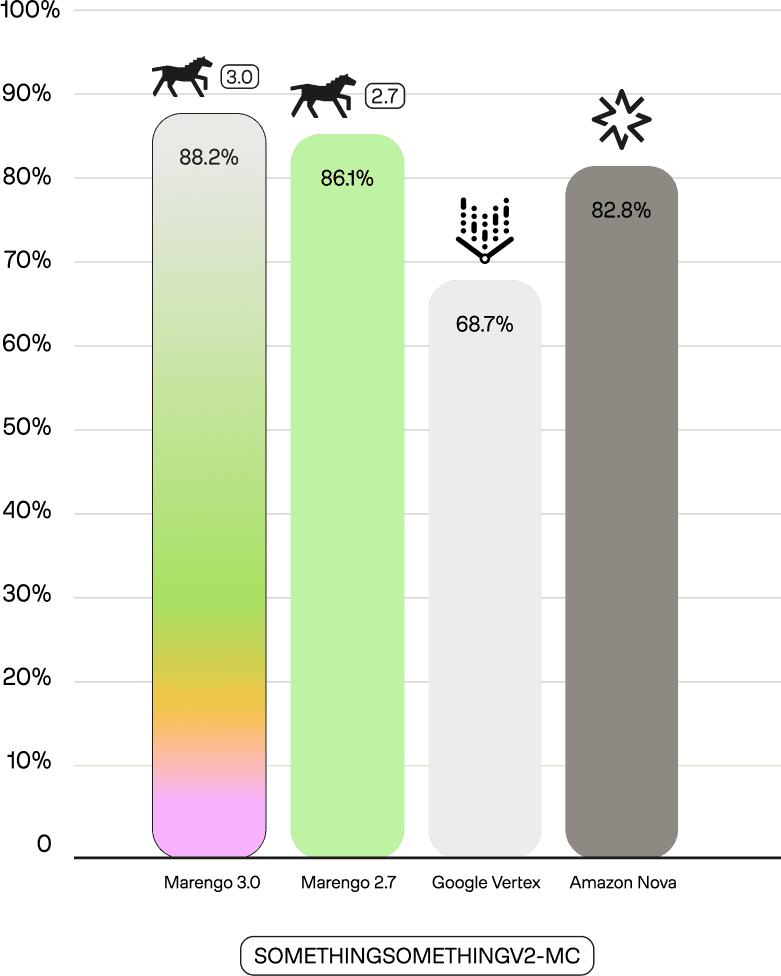
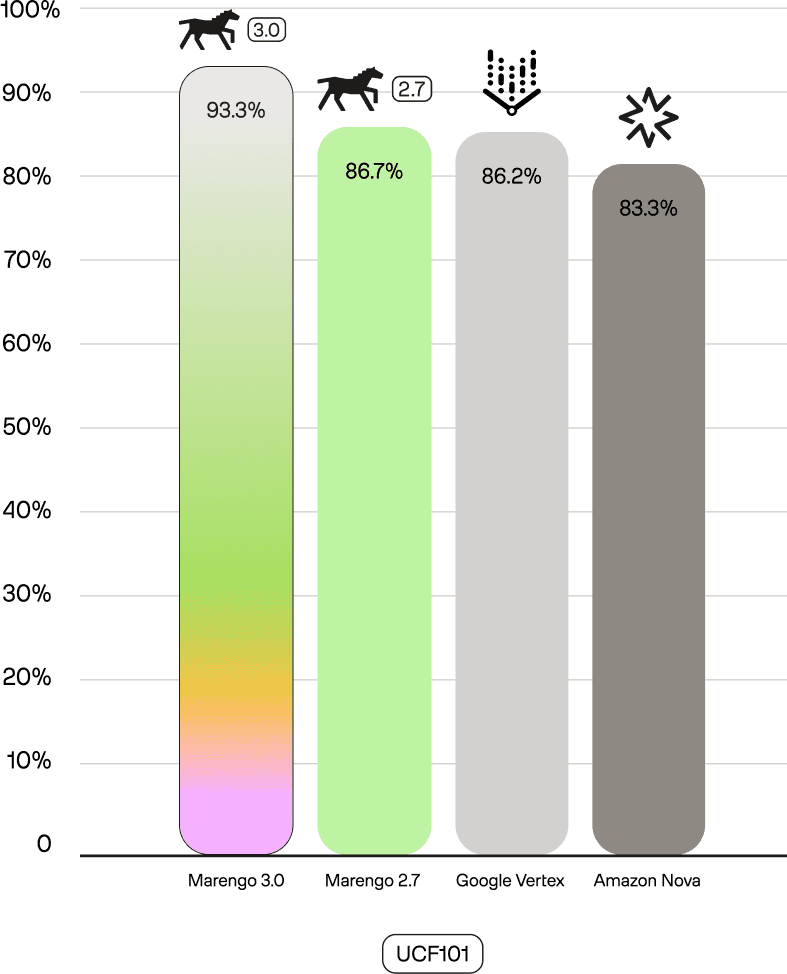
Second, compared to our previous larger Marengo 2.7 (1024d) model, Marengo 3.0 sets new SOTA scores on benchmarks like SomethingSomethingv2-MC (88.2 vs 86.1) and UCF101 (93.3 vs 86.7). This demonstrates our success in shifting the model's focus to real-world tasks while maintaining its powerful core capabilities.
6. The Path Forward
Marengo 3.0 is now available through two deployment options: AWS Bedrock provides enterprise-grade integration with AWS infrastructure (learn more), while TwelveLabs SaaS (Search API and Embed API) offers developer-friendly APIs with Python and Node.js SDKs (learn more). Both deliver the same powerful capabilities with production-proven reliability. If you want to reproduce the results detailed in this technical blog, you'll need to use our SaaS APIs.
Marengo 3.0 establishes the foundation for the next generation of retrieval systems. Work is already underway to extend its capabilities, including:
Hybrid semantic-lexical search for combining embedding-based semantic search with traditional keyword matching for queries requiring exact phrase matches
Extended composed retrieval for even deeper multimodal reasoning
Improved domain adaptation for media, security, and enterprise video
Marengo 3.0 represents a fundamental shift from benchmark optimization to production-grade video understanding. By natively supporting multilingual content, composed queries, hour-long videos, and specialized domains like sports—while maintaining leadership on general benchmarks—we've built a foundation model that scales with real-world complexity.
From the TwelveLabs Marengo team. We are excited to introduce Marengo 3.0, a new standard for foundation models that understand the world in all its complexity.
Marengo 3.0 is the foundation model powering Twelve Labs' Embed API and Search API. This post focuses on the core Marengo 3.0 model itself—the embeddings that enable semantic video understanding. (Our Search API adds production components like advanced transcription and hybrid lexical search for even higher accuracy on benchmarks like MSRVTT and VATEX)
Marengo 3.0 advances beyond English-language benchmarks to solve real-world production challenges: multilingual video archives requiring native cross-language search, complex queries combining visual and textual elements, hour-long content that breaks other models, and specialized domains like sports where general models fail.
Marengo 3.0 achieves these capabilities with a 512-dimension embedding—6x more storage-efficient than Amazon Nova (3072d) and 3x better than Google Vertex (1408d). Lower dimensionality directly reduces database costs, accelerates search queries, and enables larger video libraries at the same infrastructure spend, without sacrificing retrieval accuracy.
This post demonstrates how Marengo 3.0 achieves state-of-the-art performance across composed retrieval, multilingual understanding, audio intelligence, sports analysis, OCR, and general benchmarks—establishing production-grade video understanding that scales.
Summary
Every model provider cherry-picks data to claim superiority. But here's what matters for production: Marengo 3.0 delivers superior performance with unparalleled latency while competitors fail or crawl. This isn't just better benchmarks for researchers to argue about; it's the difference between a model that works in production and one that doesn't.
Latency: Where Competitors Break Down
Marengo 3.0 processes videos at speeds that make enterprise-scale deployment practical. The charts below show latency versus composite performance across video lengths:
Marengo 3.0 achieves the highest composite performance (73%) while maintaining the fastest normalized latency per second (0.05 seconds/second of video). Google Vertex has a higher latency (~0.5 seconds/second) but with significantly lower performance (52%). Amazon Nova requires >1.5 seconds per second of video—making it 30x slower than Marengo 3.0 while delivering lower accuracy.
For short videos (≤ 60 seconds), Marengo 3.0 processes content in ~10 seconds with 78% composite performance. Amazon Nova requires ~110 seconds for 61% performance—a 11x latency penalty with 17 percentage point accuracy loss.
For hour-long videos, Marengo 3.0 processes content in ~310 seconds (slightly more than 5 minutes). Amazon Nova requires 590 seconds (close to 10 minutes)—a 1.9x slowdown that compounds across thousands of videos. Google Vertex's performance degrades dramatically for long content, scoring only 51% composite performance compared to Marengo 3.0's 78%.
These latency differences determine what's deployable. For example, processing a 1,000 hours-long video library with Marengo 3.0 versus Nova means the difference between 86 hours and 164 hours of compute time—impacting both time-to-market and infrastructure costs.
Performance Across All Modalities
Marengo 3.0 doesn't just excel at latency—it leads across video, audio, image, and text understanding:
For video retrieval, the composite performance above is the mean across 14 benchmarks: MSRVTT, MSVD, VATEX, YooCook2, DiDemo, QVHighlight, Dense-WebVid-CoVR, tl-abps-basketball, tl-sports-general, tl-american-football, tl-baseball, tl-basketball, tl-ice-hockey, tl-soccer.
Marengo 3.0 achieves 70.2% across general video retrieval, sports understanding, and composed queries—an 5.8 percentage point lead over Marengo 2.7, 25 points over Vertex, and 18.2 points over Nova.
For audio retrieval, the composite performance above is the mean across 3 benchmarks: GTZAN, Clotho, Librispeech.
At 73.2%, Marengo 3.0 maintains Marengo 2.7's audio strength while Nova struggles at 36.7% and Vertex cannot process audio at all.
For image retrieval, the composite performance above is the mean across 5 benchmarks: Visual7W-Pointing, Urban1K, TextCaps, Object365-medium, OpenLogo.
92.2% performance demonstrates Marengo 3.0's visual precision on OCR, object recognition, and spatial reasoning tasks - completely outperforming Vertex (62.4%) and Nova (70.1%).
For text retrieval, the composite performance above is the mean across 5 benchmarks: SomethingSomethingv2-MC, Kinetics-700, PasskeyRetrieval, HagridRetrieval, WikipediaRetrieval.
88.3% validates that Marengo 3.0's text encoder rivals specialized text-only models—a 30 percentage point improvement over Marengo 2.7's 58%.
Table of Content
The sections that follow provide detailed evidence for Marengo 3.0's capabilities across:
Composed and Long-Form Retrieval: Combining modalities in queries and processing extended-duration content
Audio and Sports Intelligence: Understanding dynamic content where temporal reasoning dominates
Multilingual and Text Mastery: Native cross-language search and text-only retrieval rivaling specialized models
Advanced Visual Perception: OCR, object recognition, and logo detection at scale
General Benchmark Leadership: State-of-the-art results without trade-offs
Each section includes benchmark results, competitor comparisons, and sample queries demonstrating retrieval quality. Together, these results establish Marengo 3.0 as the only production-grade foundation model that delivers both performance and efficiency at enterprise scale.
Metrics Used in This Post:
R@1,5,10 Avg: Recall at ranks 1, 5, and 10, averaged. Measures how often the correct result appears in the top 1, 5, or 10 results.
mAP: Mean Average Precision. Measures ranking quality across all relevant results.
NDCG@K: Normalized Discounted Cumulative Gain at position K. Measures ranking quality with position-weighted scoring.
1. The Core Capability: Composed and Long-Form Retrieval
Marengo 3.0 is built to handle queries as complex and nuanced as human thought. Marengo 3.0 handles composed queries—searches that combine visual and textual elements to express intent more precisely than either modality alone.
Composed Retrieval (Visual+Text Embedding)
Marengo 3.0 supports composed retrieval by combining image and text inputs into a single query embedding. For example, users can submit an image of a specific player plus the text "scored a jump shot" to retrieve precise action moments from hours of game footage. This capability is unavailable in competing foundation models, which process visual and textual queries separately.
The performance leap is significant. On our in-house action bound person search benchmark (tl-abps-nba), a text-only query achieves a 34.4 mAP. By adding a single image, Marengo 3.0's composed retrieval improves the performance to 38.5 mAP. This leadership is even more pronounced on the Dense-Webvid-CoVR benchmark (which evaluates video+text-to-video retrieval), where Marengo 3.0 achieves a 97.0 score on average in Recall @1, Recall @5, and Recall @10 metrics, a result competitors cannot even attempt.
Text-only queries struggle on these benchmarks because they require disambiguating specific visual attributes (e.g., which player, what action). Composed retrieval provides this disambiguation:
On tl-abps-nba, Marengo 3.0's composed retrieval (38.5 mAP) outperforms even its own text-only mode (34.4 mAP) and substantially exceeds competitors' text-only results (Marengo 2.7: 15.1%, Vertex: 20.0%, Nova: 12.8%).
Beyond combining modalities, Marengo 3.0 excels at processing extended content and complex, descriptive queries—critical for AI agent applications and detailed video search.
As seen in the example results below on Dense-WebVid-CoVR, Marengo 3.0 with composed retrieval (M30 CR) places the correct video at rank 1. Text-only queries (M30, M27, Vertex, Nova) rank the target video lower or miss it entirely, retrieving videos with similar text descriptions but incorrect visual attributes.
Long Query Retrieval
Marengo 3.0 is designed to handle "extended-duration content" and the long, descriptive queries common in AI Agent applications. On Urban1K, Marengo 3.0 and Nova both excel, while other models struggle with context length.
Long-form retrieval is critical for production systems where users provide detailed natural language descriptions ("Find the segment where the person in the red jacket walks past the yellow taxi near the intersection") rather than optimized keyword queries. Agentic systems similarly generate verbose, multi-constraint queries when decomposing complex user intents.
As seen in the example results below on Urban1k, Marengo 3.0 retrieves the correct image at rank 1 despite queries containing 60-80 words with multiple visual details (colors, positions, background elements). Marengo 2.7 ranks the target at position 2-3, while Vertex requires 5 results to surface the correct match.
2. Beyond Visuals: Unmatched Audio and Sports Comprehension
Video understanding requires more than visual analysis—audio (speech, music, sound effects) and rapid motion (sports, action sequences) challenge models that prioritize static image understanding. Marengo 3.0's architecture jointly processes these modalities, enabling accurate retrieval where temporal dynamics dominate.
Audio (Speech & Non-Speech)
Most multimodal models treat audio as an afterthought. Marengo 3.0 treats it as a first-class citizen.
On Librispeech—a speech-to-text retrieval benchmark—Marengo 3.0 achieves 99.7% accuracy (R@1,5,10 Avg), matching Marengo 2.7's 100% and vastly outperforming Amazon Nova (< 10%). Google Vertex does not support audio retrieval. Performance below 10% indicates the model cannot reliably distinguish speech content, functionally lacking the capability.
This audio capability extends to non-speech sounds. On GTZAN (music genre recognition, mAP) and Clotho (audio captioning, R@1,5,10 Avg), Marengo 3.0 achieves 75.5% and 44.2%, respectively—improvements over Marengo 2.7 (71.9%, 41.4%) and substantial leads over Nova (64.9%, 29.5%). Vertex does not support non-speech audio tasks.
In the Librispeechresult below, Marengo 3.0 and 2.7 both retrieve the correct speech segment at rank 1, demonstrating strong text-to-speech alignment. Amazon Nova fails to find the target in the top 5, indicating its audio encoder cannot accurately map spoken content to text queries.
On the other hand, the Clotho query require understanding complex auditory scenes. Marengo 3.0 ranks the correct audio clip at position 1, while Marengo 2.7 places it at position 3, and Nova at position 4. This shows Marengo 3.0's improved ability to parse multi-source audio environments.
Sports
Sports video presents extreme challenges for video models: rapid camera motion, occlusions, similar-looking actions (e.g., different types of passes), and domain-specific terminology. Marengo 3.0's temporal modeling and entity recognition enable action-level understanding where general models default to generic labels.
Marengo 3.0's performance shows a commanding lead over all competitors, often by 20-50%p, highlighting its superior motion and context understanding. This lead is not just general; it is dominant in specific sports. On SoccerNet-Action—a public benchmark for soccer action recognition—Marengo 3.0 achieves 79.4 mAP, compared to 23.0 for Nova and 21.5 for Vertex. This 3.5x performance advantage extends to our internal benchmarks: on tl-basketball, which requires distinguishing fine-grained actions (jump shots vs. layups, steals vs. blocks), Marengo 3.0 scores 57.5% (R@1,5,10 Avg) versus 12.0% for Nova. These results demonstrate a deep understanding of complex, specific actions that general models fail to capture.
Sports intelligence enables production applications including automated highlight generation, play-by-play search for coaching analysis, and content moderation for league compliance. These use cases require action-level granularity that general-purpose multimodal models cannot provide.
In the example results below on tl-sports-general, multi-clause queries requiring temporal ordering ("initially shows... then shows... at last") and entity tracking (player 11). Marengo 3.0 ranks the correct video at position 1, while competitors struggle to maintain entity consistency across the description.
3. A Truly Unified Space: Multilingual and Text-to-Text Mastery
A "unified embedding model" must excel at text and multilingual understanding, not just treat it as a feature.
Native Multilingual Retrieval
Marengo 3.0 enables native multilingual understanding, allowing semantic retrieval across any combination of modalities (video, audio, text, image) in multiple languages. On the other hand, Marengo 2.7 and Vertex only fully support English.
On the Crossmodal 3600 benchmark—which evaluates multilingual text-to-image retrieval—Marengo 3.0 achieves state-of-the-art results in Korean (87.2% R@5), outperforming Amazon Nova (85.5%) and Jina Embeddings v4 (82.2%). In Japanese, Marengo 3.0 reaches 91.1%, matching the best-in-class performance of Jina (91.2%) while outpacing Amazon Nova (90.1%). These results are particularly notable given that Korean and Japanese present unique challenges for multilingual models—both use non-Latin writing systems (Hangul and a mix of Kanji, Hiragana, and Katakana), have grammatical structures that differ substantially from English, and are linguistically distant from the Romance languages where transfer learning from English tends to be more straightforward. Across all evaluated languages, Marengo 3.0 remains highly competitive while offering up to 6x better storage efficiency.
Text-to-Text
Marengo 3.0's text encoder, trained within a multimodal space, demonstrates exceptional capabilities in handling named entities. Unlike traditional text-only models, Marengo 3.0 allocates more attention to entity-related tokens because these key terms must be precisely mapped to visual and audio embeddings. This entity-focused design makes Marengo 3.0 particularly well-suited for applications requiring robust entity recognition and retrieval.
For example, PasskeyRetrievaltests long-context entity extraction: models must locate specific information (e.g., "What is the passkey for Marlon Robles?") buried within very long documents filled with similar distractors. This requires precise entity-value binding across long context windows. Marengo 3.0 achieves 94.4% (NDCG@1) on Passkey, compared to 38.5% for Google's Gemini Embedding (text-only) and 82.5% for Amazon Nova (multimodal). This demonstrates that multimodal training—which grounds entity mentions in visual and auditory contexts—produces more robust entity representations than text-only approaches.
As seen below, a sample document in PasskeyRetrievalcontains 500-1000 words of filler text with multiple name-passkey pairs embedded at various positions. Models must identify the correct pair for the queried name.
This strength isn't limited to entities. On Wikipedia Multilingual benchmark, Marengo 3.0 achieves 85.6% (NDCG@10), a substantial improvement over Marengo 2.7's 29.0%. This reflects Marengo 3.0's architectural shift to native multilingual training, whereas Marengo 2.7's text encoder was English-centric. On Hagrid(English-only document retrieval), Marengo 3.0 scores 98.7%, competitive with text-only SOTA models like Gemini (99.3%) and Jina v4 (98.8%). This is a remarkable achievement for a lightweight, unified multimodal model.
4. Advanced Visual Perception: OCR and Object Recognition
Marengo 3.0's unified architecture also leads to superior fine-grained visual understanding, from text-in-visual (OCR) to specific objects and logos.
On TextCaps—which evaluates OCR-based image retrieval requiring models to read and understand text in natural scenes—Marengo 3.0 achieves 89.2% (R@1,5,10 Avg), outperforming Amazon Nova (88.9%), Google Vertex (84.0%), and Marengo 2.7 (82.8%).
On Object365-medium (general object recognition, image-to-image retrieval), Marengo 3.0 achieves 99.1% (R@1,5,10 Avg), up from 95.8% in Marengo 2.7—approaching near perfect accuracy.
Logo recognition shows even larger gains: on OpenLogo (image-to-image mAP), Marengo 3.0 scores 79.2% compared to Marengo 2.7's 70.9%, a 12% relative improvement. These gains reflect increased training diversity in fine-grained visual categories.
The OpenLogo example below tests logo recognition across varied contexts (different sizes, angles, backgrounds). The "heineken logo" query should retrieve Heineken branding in diverse settings. Marengo 3.0 achieves 5/5 correct results, while competitors miss some instances, indicating weaker logo-specific visual memory.
5. The "No Trade-Off" Proof: SOTA on General Benchmarks
Specialization typically degrades general performance. Models optimized for sports, multilingual content, or composed retrieval often sacrifice accuracy on standard English-language benchmarks like MSRVTT. Marengo 3.0 breaks this pattern: it maintains—and in many cases improves—state-of-the-art results on established benchmarks while adding specialized capabilities.
Marengo 3.0 maintains or surpasses the SOTA status Marengo 2.7 already held on classic academic benchmarks, proving our "no trade-off" design.
General Text-to-Video Retrieval
The claim of "no trade-off" is not just about maintaining performance; Marengo 3.0 often improves it. On the gold-standard MSRVTT benchmark, Marengo 3.0 (72.5) beats Marengo 2.7 (71.7), Vertex (59.5), and Nova (69.6). It shows similar state-of-the-art performance on MSVD (78.2) and VATEX (86.4).
The VATEX query below tests audio-visual alignment, more specifically understanding speech content ("asks it for hugs"). Marengo 3.0 ranks correct videos at position 1, demonstrating that general benchmark improvements don't come at the cost of audio capabilities.
General Video Classification
Video classification benchmarks (assigning videos to predefined categories like "running" or "swimming") test different capabilities than retrieval (finding specific content via natural language). Marengo 3.0 outperforms others in this domain as well.
First, Marengo 3.0 outperforms competitors on all classification benchmarks, often by a wide margin.
Second, compared to our previous larger Marengo 2.7 (1024d) model, Marengo 3.0 sets new SOTA scores on benchmarks like SomethingSomethingv2-MC (88.2 vs 86.1) and UCF101 (93.3 vs 86.7). This demonstrates our success in shifting the model's focus to real-world tasks while maintaining its powerful core capabilities.
6. The Path Forward
Marengo 3.0 is now available through two deployment options: AWS Bedrock provides enterprise-grade integration with AWS infrastructure (learn more), while TwelveLabs SaaS (Search API and Embed API) offers developer-friendly APIs with Python and Node.js SDKs (learn more). Both deliver the same powerful capabilities with production-proven reliability. If you want to reproduce the results detailed in this technical blog, you'll need to use our SaaS APIs.
Marengo 3.0 establishes the foundation for the next generation of retrieval systems. Work is already underway to extend its capabilities, including:
Hybrid semantic-lexical search for combining embedding-based semantic search with traditional keyword matching for queries requiring exact phrase matches
Extended composed retrieval for even deeper multimodal reasoning
Improved domain adaptation for media, security, and enterprise video
Marengo 3.0 represents a fundamental shift from benchmark optimization to production-grade video understanding. By natively supporting multilingual content, composed queries, hour-long videos, and specialized domains like sports—while maintaining leadership on general benchmarks—we've built a foundation model that scales with real-world complexity.
From the TwelveLabs Marengo team. We are excited to introduce Marengo 3.0, a new standard for foundation models that understand the world in all its complexity.
Marengo 3.0 is the foundation model powering Twelve Labs' Embed API and Search API. This post focuses on the core Marengo 3.0 model itself—the embeddings that enable semantic video understanding. (Our Search API adds production components like advanced transcription and hybrid lexical search for even higher accuracy on benchmarks like MSRVTT and VATEX)
Marengo 3.0 advances beyond English-language benchmarks to solve real-world production challenges: multilingual video archives requiring native cross-language search, complex queries combining visual and textual elements, hour-long content that breaks other models, and specialized domains like sports where general models fail.
Marengo 3.0 achieves these capabilities with a 512-dimension embedding—6x more storage-efficient than Amazon Nova (3072d) and 3x better than Google Vertex (1408d). Lower dimensionality directly reduces database costs, accelerates search queries, and enables larger video libraries at the same infrastructure spend, without sacrificing retrieval accuracy.
This post demonstrates how Marengo 3.0 achieves state-of-the-art performance across composed retrieval, multilingual understanding, audio intelligence, sports analysis, OCR, and general benchmarks—establishing production-grade video understanding that scales.
Summary
Every model provider cherry-picks data to claim superiority. But here's what matters for production: Marengo 3.0 delivers superior performance with unparalleled latency while competitors fail or crawl. This isn't just better benchmarks for researchers to argue about; it's the difference between a model that works in production and one that doesn't.
Latency: Where Competitors Break Down
Marengo 3.0 processes videos at speeds that make enterprise-scale deployment practical. The charts below show latency versus composite performance across video lengths:
Marengo 3.0 achieves the highest composite performance (73%) while maintaining the fastest normalized latency per second (0.05 seconds/second of video). Google Vertex has a higher latency (~0.5 seconds/second) but with significantly lower performance (52%). Amazon Nova requires >1.5 seconds per second of video—making it 30x slower than Marengo 3.0 while delivering lower accuracy.
For short videos (≤ 60 seconds), Marengo 3.0 processes content in ~10 seconds with 78% composite performance. Amazon Nova requires ~110 seconds for 61% performance—a 11x latency penalty with 17 percentage point accuracy loss.
For hour-long videos, Marengo 3.0 processes content in ~310 seconds (slightly more than 5 minutes). Amazon Nova requires 590 seconds (close to 10 minutes)—a 1.9x slowdown that compounds across thousands of videos. Google Vertex's performance degrades dramatically for long content, scoring only 51% composite performance compared to Marengo 3.0's 78%.
These latency differences determine what's deployable. For example, processing a 1,000 hours-long video library with Marengo 3.0 versus Nova means the difference between 86 hours and 164 hours of compute time—impacting both time-to-market and infrastructure costs.
Performance Across All Modalities
Marengo 3.0 doesn't just excel at latency—it leads across video, audio, image, and text understanding:
For video retrieval, the composite performance above is the mean across 14 benchmarks: MSRVTT, MSVD, VATEX, YooCook2, DiDemo, QVHighlight, Dense-WebVid-CoVR, tl-abps-basketball, tl-sports-general, tl-american-football, tl-baseball, tl-basketball, tl-ice-hockey, tl-soccer.
Marengo 3.0 achieves 70.2% across general video retrieval, sports understanding, and composed queries—an 5.8 percentage point lead over Marengo 2.7, 25 points over Vertex, and 18.2 points over Nova.
For audio retrieval, the composite performance above is the mean across 3 benchmarks: GTZAN, Clotho, Librispeech.
At 73.2%, Marengo 3.0 maintains Marengo 2.7's audio strength while Nova struggles at 36.7% and Vertex cannot process audio at all.
For image retrieval, the composite performance above is the mean across 5 benchmarks: Visual7W-Pointing, Urban1K, TextCaps, Object365-medium, OpenLogo.
92.2% performance demonstrates Marengo 3.0's visual precision on OCR, object recognition, and spatial reasoning tasks - completely outperforming Vertex (62.4%) and Nova (70.1%).
For text retrieval, the composite performance above is the mean across 5 benchmarks: SomethingSomethingv2-MC, Kinetics-700, PasskeyRetrieval, HagridRetrieval, WikipediaRetrieval.
88.3% validates that Marengo 3.0's text encoder rivals specialized text-only models—a 30 percentage point improvement over Marengo 2.7's 58%.
Table of Content
The sections that follow provide detailed evidence for Marengo 3.0's capabilities across:
Composed and Long-Form Retrieval: Combining modalities in queries and processing extended-duration content
Audio and Sports Intelligence: Understanding dynamic content where temporal reasoning dominates
Multilingual and Text Mastery: Native cross-language search and text-only retrieval rivaling specialized models
Advanced Visual Perception: OCR, object recognition, and logo detection at scale
General Benchmark Leadership: State-of-the-art results without trade-offs
Each section includes benchmark results, competitor comparisons, and sample queries demonstrating retrieval quality. Together, these results establish Marengo 3.0 as the only production-grade foundation model that delivers both performance and efficiency at enterprise scale.
Metrics Used in This Post:
R@1,5,10 Avg: Recall at ranks 1, 5, and 10, averaged. Measures how often the correct result appears in the top 1, 5, or 10 results.
mAP: Mean Average Precision. Measures ranking quality across all relevant results.
NDCG@K: Normalized Discounted Cumulative Gain at position K. Measures ranking quality with position-weighted scoring.
1. The Core Capability: Composed and Long-Form Retrieval
Marengo 3.0 is built to handle queries as complex and nuanced as human thought. Marengo 3.0 handles composed queries—searches that combine visual and textual elements to express intent more precisely than either modality alone.
Composed Retrieval (Visual+Text Embedding)
Marengo 3.0 supports composed retrieval by combining image and text inputs into a single query embedding. For example, users can submit an image of a specific player plus the text "scored a jump shot" to retrieve precise action moments from hours of game footage. This capability is unavailable in competing foundation models, which process visual and textual queries separately.
The performance leap is significant. On our in-house action bound person search benchmark (tl-abps-nba), a text-only query achieves a 34.4 mAP. By adding a single image, Marengo 3.0's composed retrieval improves the performance to 38.5 mAP. This leadership is even more pronounced on the Dense-Webvid-CoVR benchmark (which evaluates video+text-to-video retrieval), where Marengo 3.0 achieves a 97.0 score on average in Recall @1, Recall @5, and Recall @10 metrics, a result competitors cannot even attempt.
Text-only queries struggle on these benchmarks because they require disambiguating specific visual attributes (e.g., which player, what action). Composed retrieval provides this disambiguation:
On tl-abps-nba, Marengo 3.0's composed retrieval (38.5 mAP) outperforms even its own text-only mode (34.4 mAP) and substantially exceeds competitors' text-only results (Marengo 2.7: 15.1%, Vertex: 20.0%, Nova: 12.8%).
Beyond combining modalities, Marengo 3.0 excels at processing extended content and complex, descriptive queries—critical for AI agent applications and detailed video search.
As seen in the example results below on Dense-WebVid-CoVR, Marengo 3.0 with composed retrieval (M30 CR) places the correct video at rank 1. Text-only queries (M30, M27, Vertex, Nova) rank the target video lower or miss it entirely, retrieving videos with similar text descriptions but incorrect visual attributes.
Long Query Retrieval
Marengo 3.0 is designed to handle "extended-duration content" and the long, descriptive queries common in AI Agent applications. On Urban1K, Marengo 3.0 and Nova both excel, while other models struggle with context length.
Long-form retrieval is critical for production systems where users provide detailed natural language descriptions ("Find the segment where the person in the red jacket walks past the yellow taxi near the intersection") rather than optimized keyword queries. Agentic systems similarly generate verbose, multi-constraint queries when decomposing complex user intents.
As seen in the example results below on Urban1k, Marengo 3.0 retrieves the correct image at rank 1 despite queries containing 60-80 words with multiple visual details (colors, positions, background elements). Marengo 2.7 ranks the target at position 2-3, while Vertex requires 5 results to surface the correct match.
2. Beyond Visuals: Unmatched Audio and Sports Comprehension
Video understanding requires more than visual analysis—audio (speech, music, sound effects) and rapid motion (sports, action sequences) challenge models that prioritize static image understanding. Marengo 3.0's architecture jointly processes these modalities, enabling accurate retrieval where temporal dynamics dominate.
Audio (Speech & Non-Speech)
Most multimodal models treat audio as an afterthought. Marengo 3.0 treats it as a first-class citizen.
On Librispeech—a speech-to-text retrieval benchmark—Marengo 3.0 achieves 99.7% accuracy (R@1,5,10 Avg), matching Marengo 2.7's 100% and vastly outperforming Amazon Nova (< 10%). Google Vertex does not support audio retrieval. Performance below 10% indicates the model cannot reliably distinguish speech content, functionally lacking the capability.
This audio capability extends to non-speech sounds. On GTZAN (music genre recognition, mAP) and Clotho (audio captioning, R@1,5,10 Avg), Marengo 3.0 achieves 75.5% and 44.2%, respectively—improvements over Marengo 2.7 (71.9%, 41.4%) and substantial leads over Nova (64.9%, 29.5%). Vertex does not support non-speech audio tasks.
In the Librispeechresult below, Marengo 3.0 and 2.7 both retrieve the correct speech segment at rank 1, demonstrating strong text-to-speech alignment. Amazon Nova fails to find the target in the top 5, indicating its audio encoder cannot accurately map spoken content to text queries.
On the other hand, the Clotho query require understanding complex auditory scenes. Marengo 3.0 ranks the correct audio clip at position 1, while Marengo 2.7 places it at position 3, and Nova at position 4. This shows Marengo 3.0's improved ability to parse multi-source audio environments.
Sports
Sports video presents extreme challenges for video models: rapid camera motion, occlusions, similar-looking actions (e.g., different types of passes), and domain-specific terminology. Marengo 3.0's temporal modeling and entity recognition enable action-level understanding where general models default to generic labels.
Marengo 3.0's performance shows a commanding lead over all competitors, often by 20-50%p, highlighting its superior motion and context understanding. This lead is not just general; it is dominant in specific sports. On SoccerNet-Action—a public benchmark for soccer action recognition—Marengo 3.0 achieves 79.4 mAP, compared to 23.0 for Nova and 21.5 for Vertex. This 3.5x performance advantage extends to our internal benchmarks: on tl-basketball, which requires distinguishing fine-grained actions (jump shots vs. layups, steals vs. blocks), Marengo 3.0 scores 57.5% (R@1,5,10 Avg) versus 12.0% for Nova. These results demonstrate a deep understanding of complex, specific actions that general models fail to capture.
Sports intelligence enables production applications including automated highlight generation, play-by-play search for coaching analysis, and content moderation for league compliance. These use cases require action-level granularity that general-purpose multimodal models cannot provide.
In the example results below on tl-sports-general, multi-clause queries requiring temporal ordering ("initially shows... then shows... at last") and entity tracking (player 11). Marengo 3.0 ranks the correct video at position 1, while competitors struggle to maintain entity consistency across the description.
3. A Truly Unified Space: Multilingual and Text-to-Text Mastery
A "unified embedding model" must excel at text and multilingual understanding, not just treat it as a feature.
Native Multilingual Retrieval
Marengo 3.0 enables native multilingual understanding, allowing semantic retrieval across any combination of modalities (video, audio, text, image) in multiple languages. On the other hand, Marengo 2.7 and Vertex only fully support English.
On the Crossmodal 3600 benchmark—which evaluates multilingual text-to-image retrieval—Marengo 3.0 achieves state-of-the-art results in Korean (87.2% R@5), outperforming Amazon Nova (85.5%) and Jina Embeddings v4 (82.2%). In Japanese, Marengo 3.0 reaches 91.1%, matching the best-in-class performance of Jina (91.2%) while outpacing Amazon Nova (90.1%). These results are particularly notable given that Korean and Japanese present unique challenges for multilingual models—both use non-Latin writing systems (Hangul and a mix of Kanji, Hiragana, and Katakana), have grammatical structures that differ substantially from English, and are linguistically distant from the Romance languages where transfer learning from English tends to be more straightforward. Across all evaluated languages, Marengo 3.0 remains highly competitive while offering up to 6x better storage efficiency.
Text-to-Text
Marengo 3.0's text encoder, trained within a multimodal space, demonstrates exceptional capabilities in handling named entities. Unlike traditional text-only models, Marengo 3.0 allocates more attention to entity-related tokens because these key terms must be precisely mapped to visual and audio embeddings. This entity-focused design makes Marengo 3.0 particularly well-suited for applications requiring robust entity recognition and retrieval.
For example, PasskeyRetrievaltests long-context entity extraction: models must locate specific information (e.g., "What is the passkey for Marlon Robles?") buried within very long documents filled with similar distractors. This requires precise entity-value binding across long context windows. Marengo 3.0 achieves 94.4% (NDCG@1) on Passkey, compared to 38.5% for Google's Gemini Embedding (text-only) and 82.5% for Amazon Nova (multimodal). This demonstrates that multimodal training—which grounds entity mentions in visual and auditory contexts—produces more robust entity representations than text-only approaches.
As seen below, a sample document in PasskeyRetrievalcontains 500-1000 words of filler text with multiple name-passkey pairs embedded at various positions. Models must identify the correct pair for the queried name.
This strength isn't limited to entities. On Wikipedia Multilingual benchmark, Marengo 3.0 achieves 85.6% (NDCG@10), a substantial improvement over Marengo 2.7's 29.0%. This reflects Marengo 3.0's architectural shift to native multilingual training, whereas Marengo 2.7's text encoder was English-centric. On Hagrid(English-only document retrieval), Marengo 3.0 scores 98.7%, competitive with text-only SOTA models like Gemini (99.3%) and Jina v4 (98.8%). This is a remarkable achievement for a lightweight, unified multimodal model.
4. Advanced Visual Perception: OCR and Object Recognition
Marengo 3.0's unified architecture also leads to superior fine-grained visual understanding, from text-in-visual (OCR) to specific objects and logos.
On TextCaps—which evaluates OCR-based image retrieval requiring models to read and understand text in natural scenes—Marengo 3.0 achieves 89.2% (R@1,5,10 Avg), outperforming Amazon Nova (88.9%), Google Vertex (84.0%), and Marengo 2.7 (82.8%).
On Object365-medium (general object recognition, image-to-image retrieval), Marengo 3.0 achieves 99.1% (R@1,5,10 Avg), up from 95.8% in Marengo 2.7—approaching near perfect accuracy.
Logo recognition shows even larger gains: on OpenLogo (image-to-image mAP), Marengo 3.0 scores 79.2% compared to Marengo 2.7's 70.9%, a 12% relative improvement. These gains reflect increased training diversity in fine-grained visual categories.
The OpenLogo example below tests logo recognition across varied contexts (different sizes, angles, backgrounds). The "heineken logo" query should retrieve Heineken branding in diverse settings. Marengo 3.0 achieves 5/5 correct results, while competitors miss some instances, indicating weaker logo-specific visual memory.
5. The "No Trade-Off" Proof: SOTA on General Benchmarks
Specialization typically degrades general performance. Models optimized for sports, multilingual content, or composed retrieval often sacrifice accuracy on standard English-language benchmarks like MSRVTT. Marengo 3.0 breaks this pattern: it maintains—and in many cases improves—state-of-the-art results on established benchmarks while adding specialized capabilities.
Marengo 3.0 maintains or surpasses the SOTA status Marengo 2.7 already held on classic academic benchmarks, proving our "no trade-off" design.
General Text-to-Video Retrieval
The claim of "no trade-off" is not just about maintaining performance; Marengo 3.0 often improves it. On the gold-standard MSRVTT benchmark, Marengo 3.0 (72.5) beats Marengo 2.7 (71.7), Vertex (59.5), and Nova (69.6). It shows similar state-of-the-art performance on MSVD (78.2) and VATEX (86.4).
The VATEX query below tests audio-visual alignment, more specifically understanding speech content ("asks it for hugs"). Marengo 3.0 ranks correct videos at position 1, demonstrating that general benchmark improvements don't come at the cost of audio capabilities.
General Video Classification
Video classification benchmarks (assigning videos to predefined categories like "running" or "swimming") test different capabilities than retrieval (finding specific content via natural language). Marengo 3.0 outperforms others in this domain as well.
First, Marengo 3.0 outperforms competitors on all classification benchmarks, often by a wide margin.
Second, compared to our previous larger Marengo 2.7 (1024d) model, Marengo 3.0 sets new SOTA scores on benchmarks like SomethingSomethingv2-MC (88.2 vs 86.1) and UCF101 (93.3 vs 86.7). This demonstrates our success in shifting the model's focus to real-world tasks while maintaining its powerful core capabilities.
6. The Path Forward
Marengo 3.0 is now available through two deployment options: AWS Bedrock provides enterprise-grade integration with AWS infrastructure (learn more), while TwelveLabs SaaS (Search API and Embed API) offers developer-friendly APIs with Python and Node.js SDKs (learn more). Both deliver the same powerful capabilities with production-proven reliability. If you want to reproduce the results detailed in this technical blog, you'll need to use our SaaS APIs.
Marengo 3.0 establishes the foundation for the next generation of retrieval systems. Work is already underway to extend its capabilities, including:
Hybrid semantic-lexical search for combining embedding-based semantic search with traditional keyword matching for queries requiring exact phrase matches
Extended composed retrieval for even deeper multimodal reasoning
Improved domain adaptation for media, security, and enterprise video
Marengo 3.0 represents a fundamental shift from benchmark optimization to production-grade video understanding. By natively supporting multilingual content, composed queries, hour-long videos, and specialized domains like sports—while maintaining leadership on general benchmarks—we've built a foundation model that scales with real-world complexity.







