
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
パートナーシップ
TwelveLabsとVespaを活用したマルチベクトル動画検索

ジェームズ・リー
開発者は、Twelve LabsのEmbed APIとVespaを統合し、Marengoでマルチモーダル埋め込みを生成、それをVespa Cloudにインデックスし、BM25レキシカル検索とベクトル類似度を組み合わせたハイブリッドランキングアプローチを用いてクエリを実行することで、セマンティックビデオ検索アプリケーションを構築できます。
開発者は、Twelve LabsのEmbed APIとVespaを統合し、Marengoでマルチモーダル埋め込みを生成、それをVespa Cloudにインデックスし、BM25レキシカル検索とベクトル類似度を組み合わせたハイブリッドランキングアプローチを用いてクエリを実行することで、セマンティックビデオ検索アプリケーションを構築できます。

この記事の内容
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AIを活用してビデオを検索、分析、探索します。
2025/03/03
9分
記事へのリンクをコピー
これを私たちと共同で開発してくれた Zohar Nissare-Houssen 氏と Andreas Eriksen 氏に深く感謝いたします!
はじめに
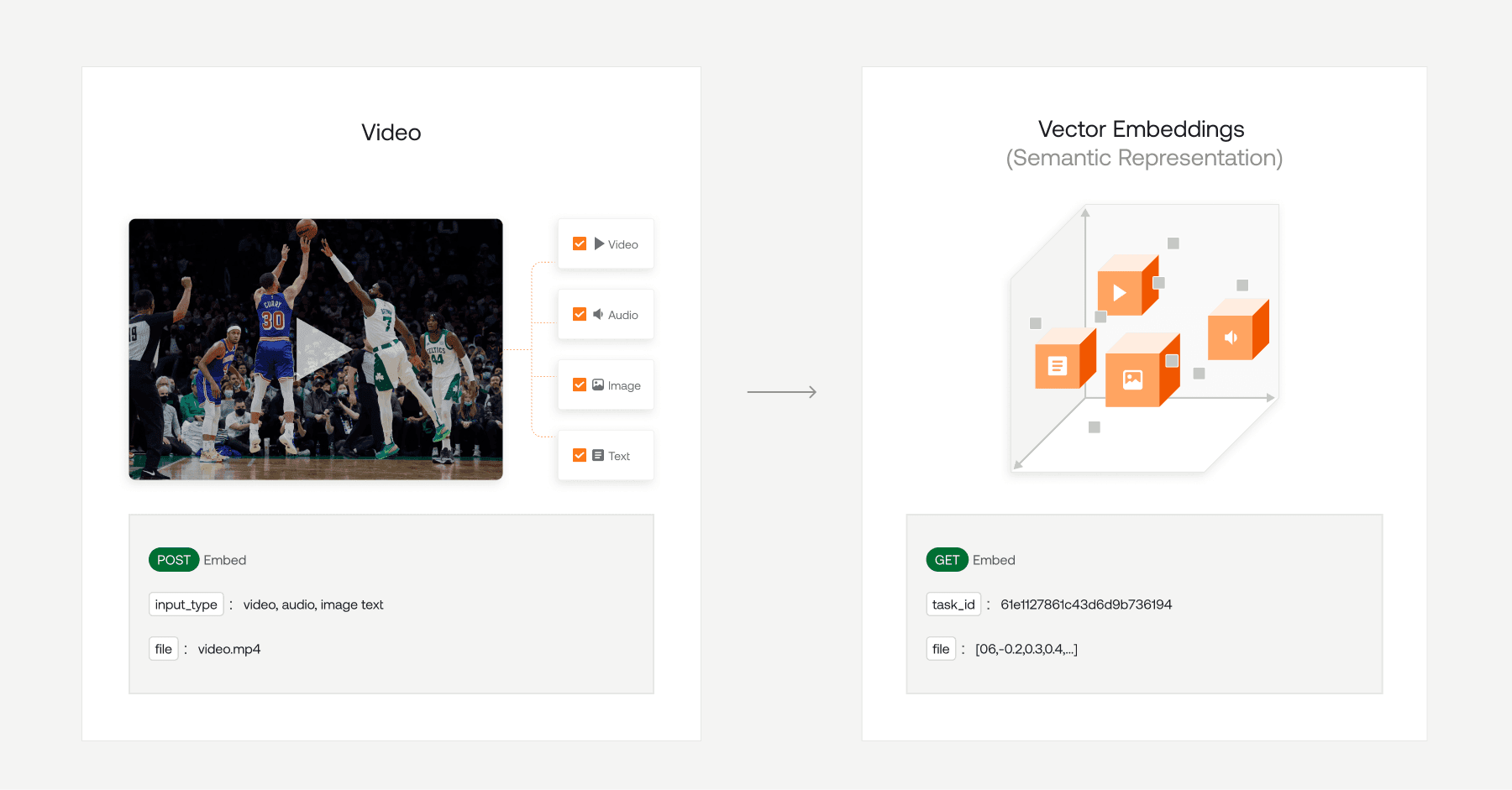
マルチモーダル・コンテンツの時代において、動画データから有意義なインサイトを抽出するには、テキスト、音声、視覚情報などの複数のモーダリティを処理・解釈できる高度なツールが必要です。TwelveLabsの Embed API を使用すると、開発者は視覚表現、発話内容、文脈上のインタラクションを含む、動画コンテンツの本質を凝縮した豊かでマルチモーダルな埋め込み(embeddings)を生成できます。これらの埋め込みは、動画の統一されたベクトル表現を提供することで、セマンティック動画検索のような高度なアプリケーションを実現します。
一方で、 Vespaは、大規模なデータセットに対する低レイテンシの計算向けに設計されたプラットフォームであり、構造化データやベクトルデータのインデックス作成およびクエリ実行に優れています。近似最近傍(ANN)検索のサポートとハイブリッドランキング機能を備えたVespaは、スケーラブルな動画検索ソリューションを展開するための理想的なパートナーです。
このチュートリアルでは、TwelveLabsの Embed API と Vespa を統合して、セマンティック動画検索アプリケーションを構築する方法を説明します。両プラットフォームの強みを組み合わせることで、強力なハイブリッド検索機能を実現しながら、動画の埋め込みとメタデータを効率的にインデックス登録できます。
ステップ 1: セットアップと設定
このセクションでは、TwelveLabsの Embed API と Vespa Cloud を使用してセマンティック動画検索アプリケーションを構築するために必要な環境と設定をセットアップします。セットアッププロセスをステップバイステップで進めていきましょう。
前提条件
始める前に、以下を用意していることを確認してください:
Python 3.7 以上がインストールされていること
APIキーを持つTwelveLabsのアカウント
Vespa Cloudのトライアルアカウント
環境セットアップ
まず、必要な Python パッケージをインストールしましょう:
!pip3 install pyvespa vespacli twelvelabs pandas
次に、必要なパッケージをすべてインポートします:
import os import hashlib import json from vespa.package import ( ApplicationPackage, Field, Schema, Document, HNSW, RankProfile, FieldSet, SecondPhaseRanking, Function, ) from vespa.deployment import VespaCloud from vespa.io import VespaResponse, VespaQueryResponse from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import pandas as pd from datetime import datetime
APIの設定
TwelveLabs Embed API を使用するには、API キーを設定する必要があります:
まだ登録していない場合は、 https://auth.twelvelabs.io/u/signup でサインアップしてください
https://playground.twelvelabs.io/dashboard/api-key に移動して、APIキーを取得します
APIキーを設定します:
TL_API_KEY = os.getenv("TL_API_KEY") or input("Enter your TL_API key: ")
注意: 無料(Free)プランには600分間の動画インデックス作成が含まれており、このチュートリアルを進めるには十分です。
Vespa Cloudのセットアップ
Vespa Cloudをセットアップするには:
https://vespa.ai/free-trial でVespa Cloudトライアルアカウントを作成します
console.vespa-cloud.com にログインし、テナントを作成します
アプリケーションの設定を構成します:
# Replace with your tenant name from the Vespa Cloud Console tenant_name = "vespa-team" # Replace with your application name (does not need to exist yet) application = "videosearch"
接続の確認
TwelveLabsクライアントを初期化して、セットアップが正しくできているかを確認しましょう:
# Initialize Twelve Labs client client = TwelveLabs(api_key=TL_API_KEY) # Test the connection try: client.tasks.list() print("Successfully connected to Twelve Labs API") except Exception as e: print(f"Error connecting to Twelve Labs API: {e}")
これらの設定が完了したら、次のセクションでサンプル動画用の埋め込み(embeddings)生成に進みましょう。
重要: APIキーは安全に保護し、コード内に直接コミットしないようにしてください。本番環境では環境変数や安全なシークレット管理ソリューションの使用を検討してください。
ステップ 2: 属性と埋め込みの生成
このセクションでは、Twelve Labs の Generate API および Embed API を使用して、サンプル動画のマルチモーダルな埋め込みと属性を生成します。ワークフローを説明するために、Internet Archiveから3つの動画を処理します。
動画処理の初期化
まず、動画ソースを設定し、インデックスを作成します:
VIDEO_URLs = [ "https://ia801503.us.archive.org/27/items/hide-and-seek-with-giant-jenny/HnVideoEditor_2022_10_29_205557707.ia.mp4", "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4", "https://dn720401.ca.archive.org/0/items/mr-bean-the-animated-series-holiday-for-teddy/S2E12.ia.mp4", ] # Initialize client and create index client = TwelveLabs(api_key=TL_API_KEY) timestamp = int(datetime.now().timestamp()) index_name = "Vespa_" + str(timestamp) # Create Index with Pegasus 1.2 model index = client.index.create( name=index_name, models=[{"name": "pegasus1.2", "options": ["visual", "audio"]}], addons=["thumbnail"] )
動画のアップロードと処理
それでは、動画をアップロードして処理しましょう:
def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") for video_url in VIDEO_URLs: task = client.task.create(index_id=index.id, url=video_url) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}")
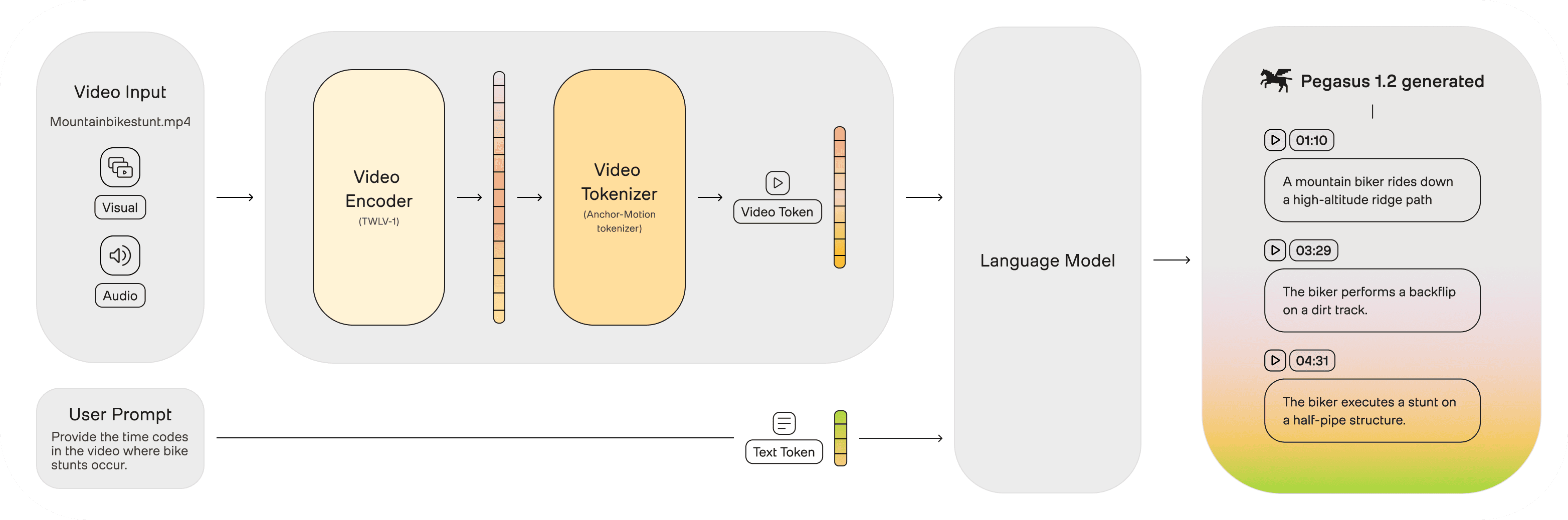
動画属性の生成
各動画の要約とキーワードを生成します:
summaries = [] keywords_array = [] titles = [ "Mr. Bean the Animated Series Holiday for Teddy", "Twas the night before Christmas", "Hide and Seek with Giant Jenny", ] videos = client.index.video.list(index_id) for video in videos: # Generate summary res = client.generate.summarize( video_id=video.id, type="summary", prompt="Generate an abstract of the video serving as metadata on the video, up to five sentences." ) summaries.append(res.summary) # Generate keywords keywords = client.generate.text( video_id=video.id, prompt="Based on this video, I want to generate five keywords for SEO. Provide just the keywords as a comma delimited list." ) keywords_array.append(keywords.data)
マルチモーダル埋め込みの生成
Marengo検索モデルを使用して埋め込みタスクを作成します:
task_ids = [] for url in VIDEO_URLs: task = client.embed.task.create(model_name="Marengo-retrieval-2.7", video_url=url) task_ids.append(str(task.id)) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Embedding failed with status {task.status}")
埋め込みの取得とデータ処理
最後に、生成された埋め込みを取得します:
tasks = [] for task_id in task_ids: task = client.embed.task.retrieve(task_id) tasks.append(task)
生成された埋め込み出力には、以下のような特徴があります:
各動画は6秒間のチャンクに分割されます
各セグメントには1024次元の埋め込みベクトルが含まれます
動画の長さに応じて、1本の動画から37〜242個のセグメントが生成されます
各セグメントには開始・終了オフセットのタイムスタンプが含まれます
時間的文脈をとらえるため、埋め込みスコープは "clip" に設定されます

これらの埋め込みは、映像要素、音声、時間的な関係など、動画のマルチモーダルな側面を捉えています。これらを利用して、Vespaでセマンティック検索を実現します。
ステップ 3: Vespaアプリケーションのデプロイ
このステップでは、VespaアプリケーションパッケージをVespa Cloudにデプロイし、属性や埋め込みを含む処理済みの動画データをアプリケーションにフィード(投入)します。
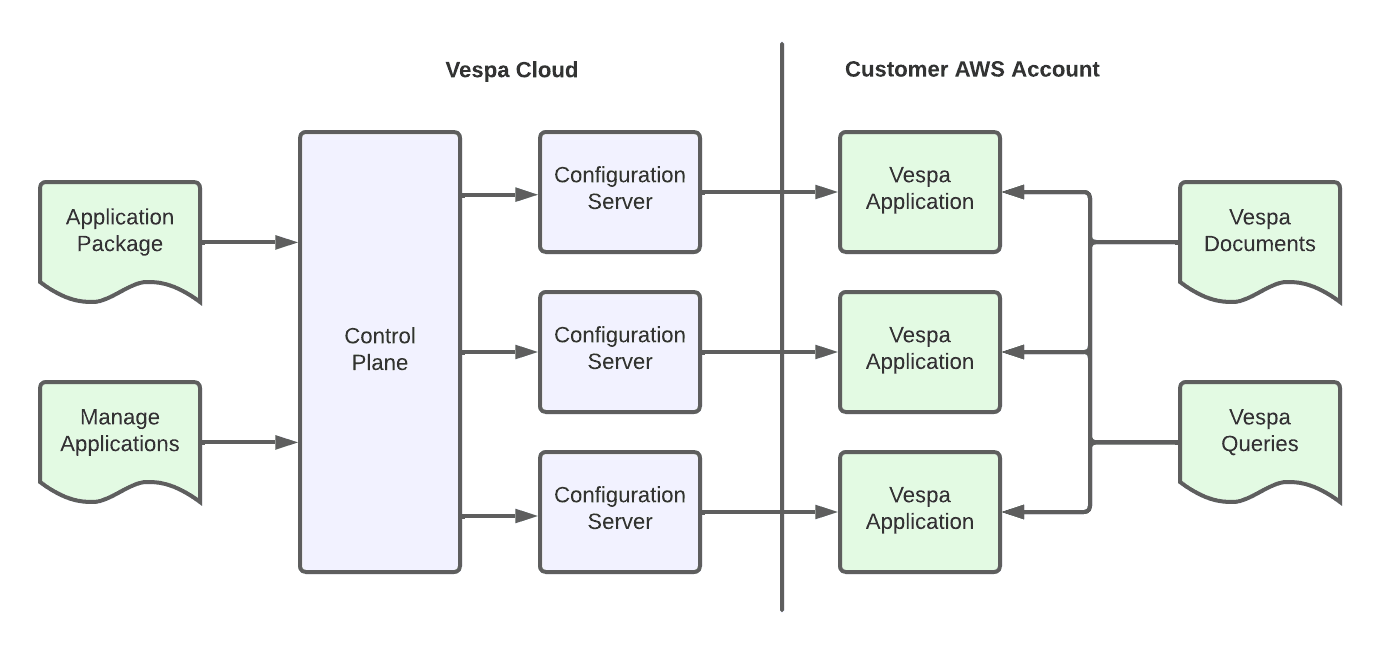
アプリケーションパッケージの作成
Vespaアプリケーションパッケージは、アプリケーションのスキーマと構成を定義します。これには、Twelve Labs Embed API によって生成されたフィールド(動画属性や埋め込みなど)が含まれます。ここでは、 pyvespa を使ってスキーマを定義する方法を示します:
# Define the schema for "videos" videos_schema = Schema( name="videos", document=Document( fields=[ Field(name="video_url", type="string", indexing=["summary"]), Field(name="title", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="keywords", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="video_summary", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="embedding_scope", type="string", indexing=["attribute", "summary"]), Field(name="start_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field(name="end_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field( name="embeddings", type="tensor<float>(p{},x[1024])", indexing=["index", "attribute"], ann=HNSW(distance_metric="angular"), ), ] ), ) # Add fieldsets for search fieldsets = [ FieldSet(name="default", fields=["title", "keywords", "video_summary"]), ] # Define ranking functions mapfunctions = [ Function( name="similarities", expression="""sum(query(q) * attribute(embeddings), x)""", ), Function( name="bm25_score", expression="bm25(title) + bm25(keywords) + bm25(video_summary)", ), ] # Define a hybrid rank profile semantic_rankprofile = RankProfile( name="hybrid", inputs=[("query(q)", "tensor<float>(x[1024])")], first_phase="bm25_score", second_phase=SecondPhaseRanking(expression="closeness(field, embeddings)", rerank_count=10), match_features=["closest(embeddings)"], summary_features=["similarities"], functions=mapfunctions, ) # Add rank profile to schema videos_schema.add_rank_profile(semantic_rankprofile) # Create the application package package = ApplicationPackage(name=application, schema=[videos_schema])
このスキーマは、動画データ(属性と埋め込み)がVespaでどのように格納、インデックス登録、およびクエリ検索されるかを定義しています。
アプリケーションパッケージのデプロイ
アプリケーションパッケージをVespa Cloudにデプロイするには、 VespaCloud を使用して接続を作成し、定義されたパッケージをデプロイします。
from vespa.deployment import VespaCloud # Deploy the application package to Vespa Cloud vespa_cloud = VespaCloud( tenant=tenant_name, application=application, application_package=package, key_content=os.getenv("VESPA_TEAM_API_KEY"), # Replace with your API key content ) app = vespa_cloud.deploy() print("Deployment complete!")

デプロイが完了すると、上記のようなデプロイログが表示されます。アプリケーションは現在稼働しており、データを受け取る準備ができています。
Vespaへのデータ投入(フィード)
次に、 pyvespa を使用して動画データ(属性と埋め込み)をVespaに投入します。各ドキュメントは、URLとセグメントインデックスから派生した一意のIDによって識別され、動画セグメントに対応しています。
フィード用データの準備
import hashlib # Initialize a list to store Vespa feed documents vespa_feed = [] # Reverse VIDEO_URLs since attributes were generated in reverse order VIDEO_URLs.reverse() for i, task in enumerate(tasks): video_url = VIDEO_URLs[i] title = titles[i] keywords = keywords_array[i] summary = summaries[i] start_offsets = [] end_offsets = [] embeddings = {} for index, segment in enumerate(task.video_embedding.segments): start_offsets.append(float(segment.start_offset_sec)) end_offsets.append(float(segment.end_offset_sec)) embeddings[str(index)] = list(map(float, segment.embeddings_float)) # Create unique ID for each segment id_hash = hashlib.md5(f"{video_url}_{index}".encode()).hexdigest() document = { "id": id_hash, "fields": { "video_url": video_url, "title": title, "keywords": keywords, "video_summary": summary, "embedding_scope": segment.embedding_scope, "start_offset_sec": start_offsets, "end_offset_sec": end_offsets, "embeddings": embeddings, }, } vespa_feed.append(document)
Vespaへのデータ投入(フィード)
from vespa.io import VespaResponse def callback(response: VespaResponse, id: str): if not response.is_successful(): print(f"Failed to feed document {id} with status code {response.status_code}: {response.get_json()}") # Feed data synchronously app.feed_iterable(vespa_feed, schema="videos", callback=callback) print("Data feeding complete!")
フィード作業により、すべての動画データがVespaのコンテンツクラスターにインデックス登録されます。ログを確認するか、Vespaインスタンスに問い合わせることで、これを確認できます。
概要
アプリケーションパッケージ: 動画属性と埋め込みを格納するためのスキーマを定義しました。
デプロイ: パッケージを Vespa Cloud にデプロイしました。
データ投入(フィード): デプロイされたアプリケーションに処理済みの動画データをインデックス登録しました。
これでVespaアプリケーションがセマンティック検索に対応できるようになりました!

ステップ 4: セマンティック検索の実行
このステップでは、Vespaに保存されている動画埋め込みに対してセマンティック検索を実行します。検索には、キーワードによるテキスト検索(語彙検索)とベクトル類似度検索を組み合わせたハイブリッドランキングを使用し、最も関連性の高い動画セグメントを取得します。
ハイブリッド検索の実行
クエリの埋め込みの作成
「そりに乗ったサンタクロース(Santa Claus on his sleigh)」というクエリに該当する動画セグメントを検索するために、まずは動画の埋め込みに使用したのと同じモデル(Marengo-retrieval-2.7)を使ってクエリの埋め込みを生成します:
client = TwelveLabs(api_key=TL_API_KEY) user_query = "Santa Claus on his sleigh" # Generate embedding for the query res = client.embed.create( model_name="Marengo-retrieval-2.7", text=user_query, ) print("Created a text embedding") print(f" Model: {res.model_name}") if res.text_embedding is not None and res.text_embedding.segments is not None: q_embedding = res.text_embedding.segments[0].embeddings_float print(f" Embedding Dimension: {len(q_embedding)}") print(f" Sample 5 values from array: {q_embedding[:5]}")
この手法により 1024 次元のクエリ埋め込みが出力されます。これを使用して、Vespa で近傍探索用のクエリを実行します。
Vespaでのハイブリッド検索の実行
Vespa の近似最近傍(ANN)検索機能を使用し、テキスト検索(BM25)とベクトル類似度ランキングを組み合わせます。このクエリにより、ハイブリッドランキングに基づいて最も関連性の高い結果が取得されます:
with app.syncio(connections=1) as session: response: VespaQueryResponse = session.query( yql="select * from videos where userQuery() OR ({targetHits:100}nearestNeighbor(embeddings,q))", query=user_query, ranking="hybrid", hits=1, body={"input.query(q)": q_embedding}, ) assert response.is_successful() # Print the top hit for hit in response.hits: print(json.dumps(hit, indent=4)) # Get full response JSON response.get_json()
ハイブリッドランキングは次のように機能します:
第一段階(First Phase): 動画タイトル、キーワード、要約に基づいたBM25語彙ランキング。
第二段階(Second Phase): クエリの埋め込みと動画の埋め込み間のベクトル類似度を用いたリランキング。
出力ログに示されているように、最も関連度の高い結果(Top Hit)は、これらを組み合わせたスコアが最も高かったセグメントに対応します。
結果をDataFrameに変換して処理する
結果を使いやすくするために、pandas の DataFrame を使って、類似度スコアに基づいて上位 N 個のセグメントを抽出して並べ替えます:
def get_top_n_similarity_matches(data, N=5): """ Extracts top N similarity scores and their corresponding offsets. Args: - data (dict): Input JSON-like structure containing similarities and offsets. - N (int): Number of top similarity scores to return. Returns: - pd.DataFrame: A DataFrame with top N similarity scores and offsets. """ # Extract relevant fields similarities = data["fields"]["summaryfeatures"]["similarities"]["cells"] start_offset_sec = data["fields"]["start_offset_sec"] end_offset_sec = data["fields"]["end_offset_sec"] # Sort by similarity score sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True) # Prepare results for top N matches results = [] for index_str, score in sorted_similarities[:N]: index = int(index_str) if index < len(start_offset_sec): results.append({ "index": index, "similarity_score": score, "start_offset_sec": start_offset_sec[index], "end_offset_sec": end_offset_sec[index], }) return pd.DataFrame(results) # Get top 10 matches df_result = get_top_n_similarity_matches(response.hits[0], N=10) print(df_result)
出力される DataFrame には以下が含まれます:
Index: 動画内でのセグメントを示すインデックス。
Similarity Score: ベクトル類似度に基づく関連性スコア。
Start/End Offsets: 秒単位でのセグメント開始・終了時間境界。
以下の表は、クエリから得られた上位10件の類似検索結果の例です:
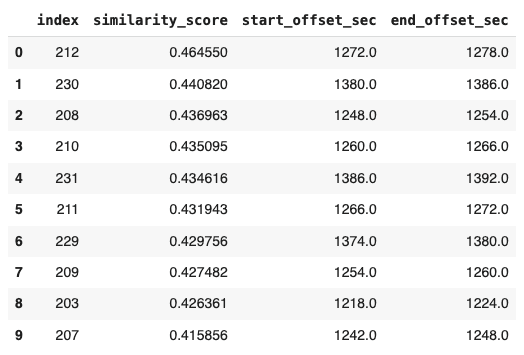
このフォーマットにより、詳細な分析や動画再生において、最も関連性の高い複数のセグメントを素早く特定しやすくなります。
概要
TwelveLabs の Embed API を使用してクエリの埋め込みを生成しました。
Vespa でテキスト検索(BM25)とベクトル類似度に基づいたハイブリッド検索を実行しました。
上位の検索結果を分析しやすいように pandas の DataFrame に変換して処理しました。
このワークフローは、TwelveLabsのマルチモーダル埋め込みとVespaの高度な検索機能を用いて、関連度が高い該当セグメントを効率的に見つけ出す方法を実証しています。
ステップ 5: 結果の確認
このステップでは、関連する動画の区間をグループ化し、整理することで、セマンティック検索の結果を確認します。その後、ノートブックに埋め込まれた動画プレーヤーを使ってビジュアルに結果を再生し、その関連性を評価します。
隣接する類似セグメントの統合
結果をより簡単に確認できるように、同一箇所の連続した動画セグメント(各セグメントの開始・終了時刻に基づく)を一つの範囲として統合する必要があります。また、切り替わりがスムーズになるように、各セグメントの境界に 3 秒間ののりしろ(オーバーラップ)を設けます。以下の関数は、この統合を行い、読みやすさを考慮して時間オフセットを MM:SS 形式に変換します。
例えば、上位の検索結果に重複する時間帯や隣接する時間帯が含まれている場合、この関数はそれらを単一の範囲にマージします。その出力は、以下のようになります:
Consolidated Segments (MM:SS): [('20:15', '20:27'), ('20:39', '21:21'), ('22:51', '23:15'
動画プレーヤーを使用した結果の視覚化
特定されたセグメントを実際に確認するために、ノートブック上に簡単な動画プレーヤーを埋め込みます。統合された時間範囲に手動で進めることも、指定した時間にジャンプするようにプログラムを設定することもできます。
動画プレーヤーの埋め込み
from IPython.display import HTML # Define video URL (replace with your video URL) video_url = "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4" # Define middle point of a segment for playback preview (e.g., first consolidated segment) middle_point = (1272 + 1278) / 2 # Example from top match # Generate HTML for video player video_player = f""" <video id="myVideo" width="640" height="480" controls> <source src="{video_url}" type="video/mp4"> Your browser does not support the video tag. </video """ # Display the video player HTML(video_player)
このコードは、指定された時間(middle_point)から再生を開始するインタラクティブな動画プレーヤーを生成します。興味のある別のポイントに基づいて middle_point の数値を変更して確認できます。
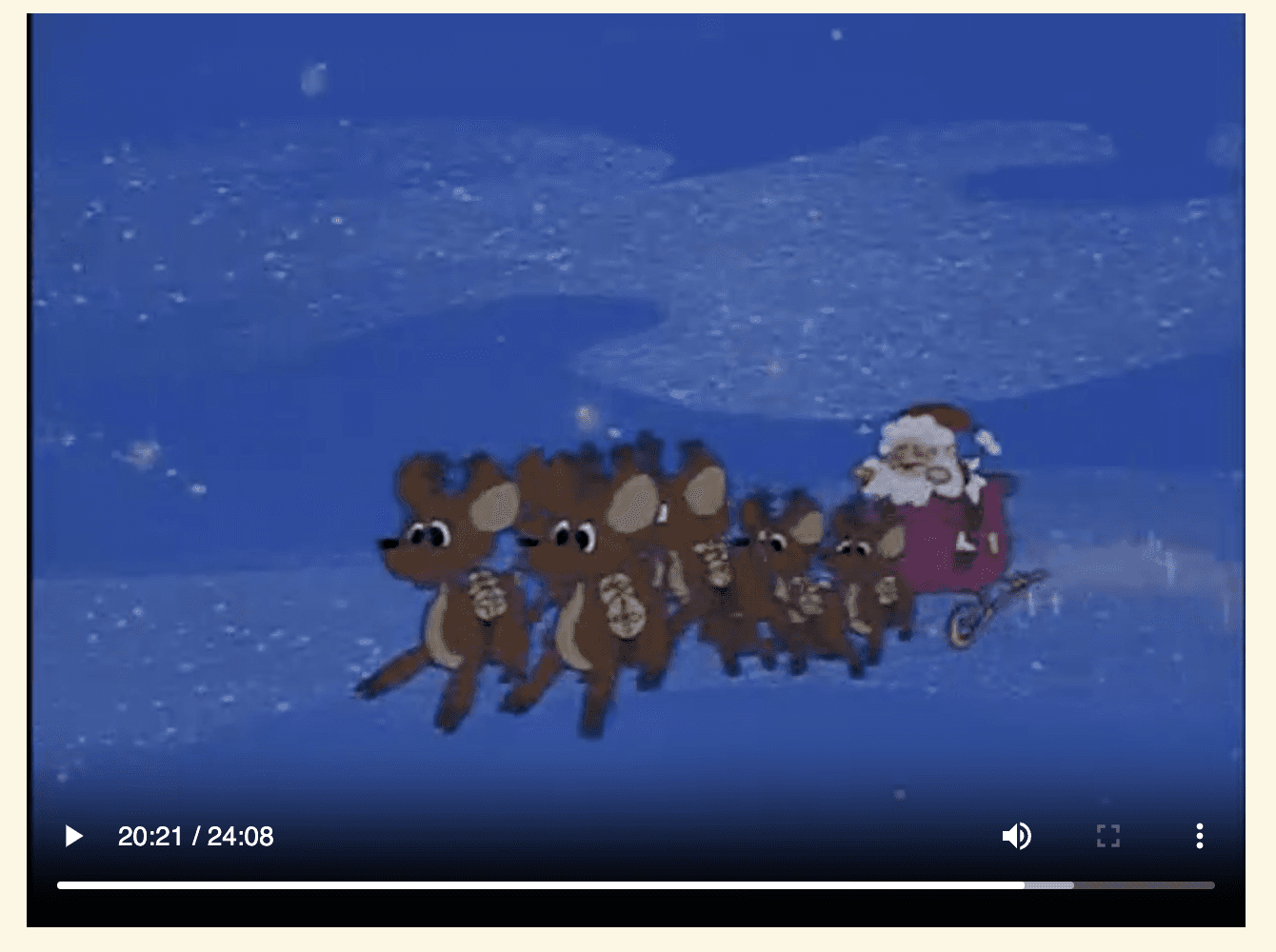
検索結果の評価
プレーヤーが埋め込まれたら、統合された時間範囲を手動またはシークバーで移動しながら、各ビジュアルを視覚的に評価できます。先ほど生成された segments のリストを利用し、クエリとの高い関連が確実視される一致箇所を見つけて再生してください。
例えば:
セグメント:
'20:21' - '21:18'該当シーンの確認: このセグメントには、そりに乗ったサンタクロースがはっきりと映っており、本ハイブリッド探索が関連性の高いコンテンツを正確に認識・抽出できていることが証明されます。
終わりに
TwelveLabsの Embed API と Vespa を組み合わせることで、高度なセマンティック動画検索アプリケーションの実用可能な可能性が大きく広がります。 Embed API は、ビデオの時間軸や文脈的なニュアンスをとらえる豊富なマルチモーダル埋め込みを提供し、Vespa の強力なインデックス登録およびハイブリッド検索機能によって、求める該当箇所を非常に高速で特定できます。
この統合がもたらす主な利点は以下の通りです:
マルチモーダルな理解: TwelveLabs が生成する統一された埋め込みにより、複数のメディア要素にまたがる動画の内容を包括的に表現できます。
優れたスケーラビリティ: 大規模なデータセットでも処理能力が高く、大量のデータが存在するスケール時にも低レイテンシで処理・検索を実行できます。
洗練されたハイブリッド検索: キーワードベースの(BM25)テキスト検索に、ベクトル的な意味類似度(ANN)を掛け合わせることで、目的の箇所の高い識別精度を維持できます。
高度な柔軟性: 開発者は、要件に応じたスキーマ設計、独自のランク構成、様々なクエリロジックを必要に合わせて自由にカスタマイズできます。
本チュートリアルを参照することで、ユーザー体験を飛躍的に向上させ、動画アーカイブなどのコンテンツ検索における新たなアイデアを形にする、スケーラブルで知的な動画検索システムを構築できるようになります。
これを私たちと共同で開発してくれた Zohar Nissare-Houssen 氏と Andreas Eriksen 氏に深く感謝いたします!
はじめに
マルチモーダル・コンテンツの時代において、動画データから有意義なインサイトを抽出するには、テキスト、音声、視覚情報などの複数のモーダリティを処理・解釈できる高度なツールが必要です。TwelveLabsの Embed API を使用すると、開発者は視覚表現、発話内容、文脈上のインタラクションを含む、動画コンテンツの本質を凝縮した豊かでマルチモーダルな埋め込み(embeddings)を生成できます。これらの埋め込みは、動画の統一されたベクトル表現を提供することで、セマンティック動画検索のような高度なアプリケーションを実現します。
一方で、 Vespaは、大規模なデータセットに対する低レイテンシの計算向けに設計されたプラットフォームであり、構造化データやベクトルデータのインデックス作成およびクエリ実行に優れています。近似最近傍(ANN)検索のサポートとハイブリッドランキング機能を備えたVespaは、スケーラブルな動画検索ソリューションを展開するための理想的なパートナーです。
このチュートリアルでは、TwelveLabsの Embed API と Vespa を統合して、セマンティック動画検索アプリケーションを構築する方法を説明します。両プラットフォームの強みを組み合わせることで、強力なハイブリッド検索機能を実現しながら、動画の埋め込みとメタデータを効率的にインデックス登録できます。
ステップ 1: セットアップと設定
このセクションでは、TwelveLabsの Embed API と Vespa Cloud を使用してセマンティック動画検索アプリケーションを構築するために必要な環境と設定をセットアップします。セットアッププロセスをステップバイステップで進めていきましょう。
前提条件
始める前に、以下を用意していることを確認してください:
Python 3.7 以上がインストールされていること
APIキーを持つTwelveLabsのアカウント
Vespa Cloudのトライアルアカウント
環境セットアップ
まず、必要な Python パッケージをインストールしましょう:
!pip3 install pyvespa vespacli twelvelabs pandas
次に、必要なパッケージをすべてインポートします:
import os import hashlib import json from vespa.package import ( ApplicationPackage, Field, Schema, Document, HNSW, RankProfile, FieldSet, SecondPhaseRanking, Function, ) from vespa.deployment import VespaCloud from vespa.io import VespaResponse, VespaQueryResponse from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import pandas as pd from datetime import datetime
APIの設定
TwelveLabs Embed API を使用するには、API キーを設定する必要があります:
まだ登録していない場合は、 https://auth.twelvelabs.io/u/signup でサインアップしてください
https://playground.twelvelabs.io/dashboard/api-key に移動して、APIキーを取得します
APIキーを設定します:
TL_API_KEY = os.getenv("TL_API_KEY") or input("Enter your TL_API key: ")
注意: 無料(Free)プランには600分間の動画インデックス作成が含まれており、このチュートリアルを進めるには十分です。
Vespa Cloudのセットアップ
Vespa Cloudをセットアップするには:
https://vespa.ai/free-trial でVespa Cloudトライアルアカウントを作成します
console.vespa-cloud.com にログインし、テナントを作成します
アプリケーションの設定を構成します:
# Replace with your tenant name from the Vespa Cloud Console tenant_name = "vespa-team" # Replace with your application name (does not need to exist yet) application = "videosearch"
接続の確認
TwelveLabsクライアントを初期化して、セットアップが正しくできているかを確認しましょう:
# Initialize Twelve Labs client client = TwelveLabs(api_key=TL_API_KEY) # Test the connection try: client.tasks.list() print("Successfully connected to Twelve Labs API") except Exception as e: print(f"Error connecting to Twelve Labs API: {e}")
これらの設定が完了したら、次のセクションでサンプル動画用の埋め込み(embeddings)生成に進みましょう。
重要: APIキーは安全に保護し、コード内に直接コミットしないようにしてください。本番環境では環境変数や安全なシークレット管理ソリューションの使用を検討してください。
ステップ 2: 属性と埋め込みの生成
このセクションでは、Twelve Labs の Generate API および Embed API を使用して、サンプル動画のマルチモーダルな埋め込みと属性を生成します。ワークフローを説明するために、Internet Archiveから3つの動画を処理します。
動画処理の初期化
まず、動画ソースを設定し、インデックスを作成します:
VIDEO_URLs = [ "https://ia801503.us.archive.org/27/items/hide-and-seek-with-giant-jenny/HnVideoEditor_2022_10_29_205557707.ia.mp4", "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4", "https://dn720401.ca.archive.org/0/items/mr-bean-the-animated-series-holiday-for-teddy/S2E12.ia.mp4", ] # Initialize client and create index client = TwelveLabs(api_key=TL_API_KEY) timestamp = int(datetime.now().timestamp()) index_name = "Vespa_" + str(timestamp) # Create Index with Pegasus 1.2 model index = client.index.create( name=index_name, models=[{"name": "pegasus1.2", "options": ["visual", "audio"]}], addons=["thumbnail"] )
動画のアップロードと処理
それでは、動画をアップロードして処理しましょう:
def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") for video_url in VIDEO_URLs: task = client.task.create(index_id=index.id, url=video_url) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}")
動画属性の生成
各動画の要約とキーワードを生成します:
summaries = [] keywords_array = [] titles = [ "Mr. Bean the Animated Series Holiday for Teddy", "Twas the night before Christmas", "Hide and Seek with Giant Jenny", ] videos = client.index.video.list(index_id) for video in videos: # Generate summary res = client.generate.summarize( video_id=video.id, type="summary", prompt="Generate an abstract of the video serving as metadata on the video, up to five sentences." ) summaries.append(res.summary) # Generate keywords keywords = client.generate.text( video_id=video.id, prompt="Based on this video, I want to generate five keywords for SEO. Provide just the keywords as a comma delimited list." ) keywords_array.append(keywords.data)
マルチモーダル埋め込みの生成
Marengo検索モデルを使用して埋め込みタスクを作成します:
task_ids = [] for url in VIDEO_URLs: task = client.embed.task.create(model_name="Marengo-retrieval-2.7", video_url=url) task_ids.append(str(task.id)) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Embedding failed with status {task.status}")
埋め込みの取得とデータ処理
最後に、生成された埋め込みを取得します:
tasks = [] for task_id in task_ids: task = client.embed.task.retrieve(task_id) tasks.append(task)
生成された埋め込み出力には、以下のような特徴があります:
各動画は6秒間のチャンクに分割されます
各セグメントには1024次元の埋め込みベクトルが含まれます
動画の長さに応じて、1本の動画から37〜242個のセグメントが生成されます
各セグメントには開始・終了オフセットのタイムスタンプが含まれます
時間的文脈をとらえるため、埋め込みスコープは "clip" に設定されます
これらの埋め込みは、映像要素、音声、時間的な関係など、動画のマルチモーダルな側面を捉えています。これらを利用して、Vespaでセマンティック検索を実現します。
ステップ 3: Vespaアプリケーションのデプロイ
このステップでは、VespaアプリケーションパッケージをVespa Cloudにデプロイし、属性や埋め込みを含む処理済みの動画データをアプリケーションにフィード(投入)します。
アプリケーションパッケージの作成
Vespaアプリケーションパッケージは、アプリケーションのスキーマと構成を定義します。これには、Twelve Labs Embed API によって生成されたフィールド(動画属性や埋め込みなど)が含まれます。ここでは、 pyvespa を使ってスキーマを定義する方法を示します:
# Define the schema for "videos" videos_schema = Schema( name="videos", document=Document( fields=[ Field(name="video_url", type="string", indexing=["summary"]), Field(name="title", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="keywords", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="video_summary", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="embedding_scope", type="string", indexing=["attribute", "summary"]), Field(name="start_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field(name="end_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field( name="embeddings", type="tensor<float>(p{},x[1024])", indexing=["index", "attribute"], ann=HNSW(distance_metric="angular"), ), ] ), ) # Add fieldsets for search fieldsets = [ FieldSet(name="default", fields=["title", "keywords", "video_summary"]), ] # Define ranking functions mapfunctions = [ Function( name="similarities", expression="""sum(query(q) * attribute(embeddings), x)""", ), Function( name="bm25_score", expression="bm25(title) + bm25(keywords) + bm25(video_summary)", ), ] # Define a hybrid rank profile semantic_rankprofile = RankProfile( name="hybrid", inputs=[("query(q)", "tensor<float>(x[1024])")], first_phase="bm25_score", second_phase=SecondPhaseRanking(expression="closeness(field, embeddings)", rerank_count=10), match_features=["closest(embeddings)"], summary_features=["similarities"], functions=mapfunctions, ) # Add rank profile to schema videos_schema.add_rank_profile(semantic_rankprofile) # Create the application package package = ApplicationPackage(name=application, schema=[videos_schema])
このスキーマは、動画データ(属性と埋め込み)がVespaでどのように格納、インデックス登録、およびクエリ検索されるかを定義しています。
アプリケーションパッケージのデプロイ
アプリケーションパッケージをVespa Cloudにデプロイするには、 VespaCloud を使用して接続を作成し、定義されたパッケージをデプロイします。
from vespa.deployment import VespaCloud # Deploy the application package to Vespa Cloud vespa_cloud = VespaCloud( tenant=tenant_name, application=application, application_package=package, key_content=os.getenv("VESPA_TEAM_API_KEY"), # Replace with your API key content ) app = vespa_cloud.deploy() print("Deployment complete!")
デプロイが完了すると、上記のようなデプロイログが表示されます。アプリケーションは現在稼働しており、データを受け取る準備ができています。
Vespaへのデータ投入(フィード)
次に、 pyvespa を使用して動画データ(属性と埋め込み)をVespaに投入します。各ドキュメントは、URLとセグメントインデックスから派生した一意のIDによって識別され、動画セグメントに対応しています。
フィード用データの準備
import hashlib # Initialize a list to store Vespa feed documents vespa_feed = [] # Reverse VIDEO_URLs since attributes were generated in reverse order VIDEO_URLs.reverse() for i, task in enumerate(tasks): video_url = VIDEO_URLs[i] title = titles[i] keywords = keywords_array[i] summary = summaries[i] start_offsets = [] end_offsets = [] embeddings = {} for index, segment in enumerate(task.video_embedding.segments): start_offsets.append(float(segment.start_offset_sec)) end_offsets.append(float(segment.end_offset_sec)) embeddings[str(index)] = list(map(float, segment.embeddings_float)) # Create unique ID for each segment id_hash = hashlib.md5(f"{video_url}_{index}".encode()).hexdigest() document = { "id": id_hash, "fields": { "video_url": video_url, "title": title, "keywords": keywords, "video_summary": summary, "embedding_scope": segment.embedding_scope, "start_offset_sec": start_offsets, "end_offset_sec": end_offsets, "embeddings": embeddings, }, } vespa_feed.append(document)
Vespaへのデータ投入(フィード)
from vespa.io import VespaResponse def callback(response: VespaResponse, id: str): if not response.is_successful(): print(f"Failed to feed document {id} with status code {response.status_code}: {response.get_json()}") # Feed data synchronously app.feed_iterable(vespa_feed, schema="videos", callback=callback) print("Data feeding complete!")
フィード作業により、すべての動画データがVespaのコンテンツクラスターにインデックス登録されます。ログを確認するか、Vespaインスタンスに問い合わせることで、これを確認できます。
概要
アプリケーションパッケージ: 動画属性と埋め込みを格納するためのスキーマを定義しました。
デプロイ: パッケージを Vespa Cloud にデプロイしました。
データ投入(フィード): デプロイされたアプリケーションに処理済みの動画データをインデックス登録しました。
これでVespaアプリケーションがセマンティック検索に対応できるようになりました!
ステップ 4: セマンティック検索の実行
このステップでは、Vespaに保存されている動画埋め込みに対してセマンティック検索を実行します。検索には、キーワードによるテキスト検索(語彙検索)とベクトル類似度検索を組み合わせたハイブリッドランキングを使用し、最も関連性の高い動画セグメントを取得します。
ハイブリッド検索の実行
クエリの埋め込みの作成
「そりに乗ったサンタクロース(Santa Claus on his sleigh)」というクエリに該当する動画セグメントを検索するために、まずは動画の埋め込みに使用したのと同じモデル(Marengo-retrieval-2.7)を使ってクエリの埋め込みを生成します:
client = TwelveLabs(api_key=TL_API_KEY) user_query = "Santa Claus on his sleigh" # Generate embedding for the query res = client.embed.create( model_name="Marengo-retrieval-2.7", text=user_query, ) print("Created a text embedding") print(f" Model: {res.model_name}") if res.text_embedding is not None and res.text_embedding.segments is not None: q_embedding = res.text_embedding.segments[0].embeddings_float print(f" Embedding Dimension: {len(q_embedding)}") print(f" Sample 5 values from array: {q_embedding[:5]}")
この手法により 1024 次元のクエリ埋め込みが出力されます。これを使用して、Vespa で近傍探索用のクエリを実行します。
Vespaでのハイブリッド検索の実行
Vespa の近似最近傍(ANN)検索機能を使用し、テキスト検索(BM25)とベクトル類似度ランキングを組み合わせます。このクエリにより、ハイブリッドランキングに基づいて最も関連性の高い結果が取得されます:
with app.syncio(connections=1) as session: response: VespaQueryResponse = session.query( yql="select * from videos where userQuery() OR ({targetHits:100}nearestNeighbor(embeddings,q))", query=user_query, ranking="hybrid", hits=1, body={"input.query(q)": q_embedding}, ) assert response.is_successful() # Print the top hit for hit in response.hits: print(json.dumps(hit, indent=4)) # Get full response JSON response.get_json()
ハイブリッドランキングは次のように機能します:
第一段階(First Phase): 動画タイトル、キーワード、要約に基づいたBM25語彙ランキング。
第二段階(Second Phase): クエリの埋め込みと動画の埋め込み間のベクトル類似度を用いたリランキング。
出力ログに示されているように、最も関連度の高い結果(Top Hit)は、これらを組み合わせたスコアが最も高かったセグメントに対応します。
結果をDataFrameに変換して処理する
結果を使いやすくするために、pandas の DataFrame を使って、類似度スコアに基づいて上位 N 個のセグメントを抽出して並べ替えます:
def get_top_n_similarity_matches(data, N=5): """ Extracts top N similarity scores and their corresponding offsets. Args: - data (dict): Input JSON-like structure containing similarities and offsets. - N (int): Number of top similarity scores to return. Returns: - pd.DataFrame: A DataFrame with top N similarity scores and offsets. """ # Extract relevant fields similarities = data["fields"]["summaryfeatures"]["similarities"]["cells"] start_offset_sec = data["fields"]["start_offset_sec"] end_offset_sec = data["fields"]["end_offset_sec"] # Sort by similarity score sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True) # Prepare results for top N matches results = [] for index_str, score in sorted_similarities[:N]: index = int(index_str) if index < len(start_offset_sec): results.append({ "index": index, "similarity_score": score, "start_offset_sec": start_offset_sec[index], "end_offset_sec": end_offset_sec[index], }) return pd.DataFrame(results) # Get top 10 matches df_result = get_top_n_similarity_matches(response.hits[0], N=10) print(df_result)
出力される DataFrame には以下が含まれます:
Index: 動画内でのセグメントを示すインデックス。
Similarity Score: ベクトル類似度に基づく関連性スコア。
Start/End Offsets: 秒単位でのセグメント開始・終了時間境界。
以下の表は、クエリから得られた上位10件の類似検索結果の例です:
このフォーマットにより、詳細な分析や動画再生において、最も関連性の高い複数のセグメントを素早く特定しやすくなります。
概要
TwelveLabs の Embed API を使用してクエリの埋め込みを生成しました。
Vespa でテキスト検索(BM25)とベクトル類似度に基づいたハイブリッド検索を実行しました。
上位の検索結果を分析しやすいように pandas の DataFrame に変換して処理しました。
このワークフローは、TwelveLabsのマルチモーダル埋め込みとVespaの高度な検索機能を用いて、関連度が高い該当セグメントを効率的に見つけ出す方法を実証しています。
ステップ 5: 結果の確認
このステップでは、関連する動画の区間をグループ化し、整理することで、セマンティック検索の結果を確認します。その後、ノートブックに埋め込まれた動画プレーヤーを使ってビジュアルに結果を再生し、その関連性を評価します。
隣接する類似セグメントの統合
結果をより簡単に確認できるように、同一箇所の連続した動画セグメント(各セグメントの開始・終了時刻に基づく)を一つの範囲として統合する必要があります。また、切り替わりがスムーズになるように、各セグメントの境界に 3 秒間ののりしろ(オーバーラップ)を設けます。以下の関数は、この統合を行い、読みやすさを考慮して時間オフセットを MM:SS 形式に変換します。
例えば、上位の検索結果に重複する時間帯や隣接する時間帯が含まれている場合、この関数はそれらを単一の範囲にマージします。その出力は、以下のようになります:
Consolidated Segments (MM:SS): [('20:15', '20:27'), ('20:39', '21:21'), ('22:51', '23:15'
動画プレーヤーを使用した結果の視覚化
特定されたセグメントを実際に確認するために、ノートブック上に簡単な動画プレーヤーを埋め込みます。統合された時間範囲に手動で進めることも、指定した時間にジャンプするようにプログラムを設定することもできます。
動画プレーヤーの埋め込み
from IPython.display import HTML # Define video URL (replace with your video URL) video_url = "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4" # Define middle point of a segment for playback preview (e.g., first consolidated segment) middle_point = (1272 + 1278) / 2 # Example from top match # Generate HTML for video player video_player = f""" <video id="myVideo" width="640" height="480" controls> <source src="{video_url}" type="video/mp4"> Your browser does not support the video tag. </video """ # Display the video player HTML(video_player)
このコードは、指定された時間(middle_point)から再生を開始するインタラクティブな動画プレーヤーを生成します。興味のある別のポイントに基づいて middle_point の数値を変更して確認できます。
検索結果の評価
プレーヤーが埋め込まれたら、統合された時間範囲を手動またはシークバーで移動しながら、各ビジュアルを視覚的に評価できます。先ほど生成された segments のリストを利用し、クエリとの高い関連が確実視される一致箇所を見つけて再生してください。
例えば:
セグメント:
'20:21' - '21:18'該当シーンの確認: このセグメントには、そりに乗ったサンタクロースがはっきりと映っており、本ハイブリッド探索が関連性の高いコンテンツを正確に認識・抽出できていることが証明されます。
終わりに
TwelveLabsの Embed API と Vespa を組み合わせることで、高度なセマンティック動画検索アプリケーションの実用可能な可能性が大きく広がります。 Embed API は、ビデオの時間軸や文脈的なニュアンスをとらえる豊富なマルチモーダル埋め込みを提供し、Vespa の強力なインデックス登録およびハイブリッド検索機能によって、求める該当箇所を非常に高速で特定できます。
この統合がもたらす主な利点は以下の通りです:
マルチモーダルな理解: TwelveLabs が生成する統一された埋め込みにより、複数のメディア要素にまたがる動画の内容を包括的に表現できます。
優れたスケーラビリティ: 大規模なデータセットでも処理能力が高く、大量のデータが存在するスケール時にも低レイテンシで処理・検索を実行できます。
洗練されたハイブリッド検索: キーワードベースの(BM25)テキスト検索に、ベクトル的な意味類似度(ANN)を掛け合わせることで、目的の箇所の高い識別精度を維持できます。
高度な柔軟性: 開発者は、要件に応じたスキーマ設計、独自のランク構成、様々なクエリロジックを必要に合わせて自由にカスタマイズできます。
本チュートリアルを参照することで、ユーザー体験を飛躍的に向上させ、動画アーカイブなどのコンテンツ検索における新たなアイデアを形にする、スケーラブルで知的な動画検索システムを構築できるようになります。
これを私たちと共同で開発してくれた Zohar Nissare-Houssen 氏と Andreas Eriksen 氏に深く感謝いたします!
はじめに
マルチモーダル・コンテンツの時代において、動画データから有意義なインサイトを抽出するには、テキスト、音声、視覚情報などの複数のモーダリティを処理・解釈できる高度なツールが必要です。TwelveLabsの Embed API を使用すると、開発者は視覚表現、発話内容、文脈上のインタラクションを含む、動画コンテンツの本質を凝縮した豊かでマルチモーダルな埋め込み(embeddings)を生成できます。これらの埋め込みは、動画の統一されたベクトル表現を提供することで、セマンティック動画検索のような高度なアプリケーションを実現します。
一方で、 Vespaは、大規模なデータセットに対する低レイテンシの計算向けに設計されたプラットフォームであり、構造化データやベクトルデータのインデックス作成およびクエリ実行に優れています。近似最近傍(ANN)検索のサポートとハイブリッドランキング機能を備えたVespaは、スケーラブルな動画検索ソリューションを展開するための理想的なパートナーです。
このチュートリアルでは、TwelveLabsの Embed API と Vespa を統合して、セマンティック動画検索アプリケーションを構築する方法を説明します。両プラットフォームの強みを組み合わせることで、強力なハイブリッド検索機能を実現しながら、動画の埋め込みとメタデータを効率的にインデックス登録できます。
ステップ 1: セットアップと設定
このセクションでは、TwelveLabsの Embed API と Vespa Cloud を使用してセマンティック動画検索アプリケーションを構築するために必要な環境と設定をセットアップします。セットアッププロセスをステップバイステップで進めていきましょう。
前提条件
始める前に、以下を用意していることを確認してください:
Python 3.7 以上がインストールされていること
APIキーを持つTwelveLabsのアカウント
Vespa Cloudのトライアルアカウント
環境セットアップ
まず、必要な Python パッケージをインストールしましょう:
!pip3 install pyvespa vespacli twelvelabs pandas
次に、必要なパッケージをすべてインポートします:
import os import hashlib import json from vespa.package import ( ApplicationPackage, Field, Schema, Document, HNSW, RankProfile, FieldSet, SecondPhaseRanking, Function, ) from vespa.deployment import VespaCloud from vespa.io import VespaResponse, VespaQueryResponse from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import pandas as pd from datetime import datetime
APIの設定
TwelveLabs Embed API を使用するには、API キーを設定する必要があります:
まだ登録していない場合は、 https://auth.twelvelabs.io/u/signup でサインアップしてください
https://playground.twelvelabs.io/dashboard/api-key に移動して、APIキーを取得します
APIキーを設定します:
TL_API_KEY = os.getenv("TL_API_KEY") or input("Enter your TL_API key: ")
注意: 無料(Free)プランには600分間の動画インデックス作成が含まれており、このチュートリアルを進めるには十分です。
Vespa Cloudのセットアップ
Vespa Cloudをセットアップするには:
https://vespa.ai/free-trial でVespa Cloudトライアルアカウントを作成します
console.vespa-cloud.com にログインし、テナントを作成します
アプリケーションの設定を構成します:
# Replace with your tenant name from the Vespa Cloud Console tenant_name = "vespa-team" # Replace with your application name (does not need to exist yet) application = "videosearch"
接続の確認
TwelveLabsクライアントを初期化して、セットアップが正しくできているかを確認しましょう:
# Initialize Twelve Labs client client = TwelveLabs(api_key=TL_API_KEY) # Test the connection try: client.tasks.list() print("Successfully connected to Twelve Labs API") except Exception as e: print(f"Error connecting to Twelve Labs API: {e}")
これらの設定が完了したら、次のセクションでサンプル動画用の埋め込み(embeddings)生成に進みましょう。
重要: APIキーは安全に保護し、コード内に直接コミットしないようにしてください。本番環境では環境変数や安全なシークレット管理ソリューションの使用を検討してください。
ステップ 2: 属性と埋め込みの生成
このセクションでは、Twelve Labs の Generate API および Embed API を使用して、サンプル動画のマルチモーダルな埋め込みと属性を生成します。ワークフローを説明するために、Internet Archiveから3つの動画を処理します。
動画処理の初期化
まず、動画ソースを設定し、インデックスを作成します:
VIDEO_URLs = [ "https://ia801503.us.archive.org/27/items/hide-and-seek-with-giant-jenny/HnVideoEditor_2022_10_29_205557707.ia.mp4", "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4", "https://dn720401.ca.archive.org/0/items/mr-bean-the-animated-series-holiday-for-teddy/S2E12.ia.mp4", ] # Initialize client and create index client = TwelveLabs(api_key=TL_API_KEY) timestamp = int(datetime.now().timestamp()) index_name = "Vespa_" + str(timestamp) # Create Index with Pegasus 1.2 model index = client.index.create( name=index_name, models=[{"name": "pegasus1.2", "options": ["visual", "audio"]}], addons=["thumbnail"] )
動画のアップロードと処理
それでは、動画をアップロードして処理しましょう:
def on_task_update(task: EmbeddingsTask): print(f" Status={task.status}") for video_url in VIDEO_URLs: task = client.task.create(index_id=index.id, url=video_url) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Indexing failed with status {task.status}")
動画属性の生成
各動画の要約とキーワードを生成します:
summaries = [] keywords_array = [] titles = [ "Mr. Bean the Animated Series Holiday for Teddy", "Twas the night before Christmas", "Hide and Seek with Giant Jenny", ] videos = client.index.video.list(index_id) for video in videos: # Generate summary res = client.generate.summarize( video_id=video.id, type="summary", prompt="Generate an abstract of the video serving as metadata on the video, up to five sentences." ) summaries.append(res.summary) # Generate keywords keywords = client.generate.text( video_id=video.id, prompt="Based on this video, I want to generate five keywords for SEO. Provide just the keywords as a comma delimited list." ) keywords_array.append(keywords.data)
マルチモーダル埋め込みの生成
Marengo検索モデルを使用して埋め込みタスクを作成します:
task_ids = [] for url in VIDEO_URLs: task = client.embed.task.create(model_name="Marengo-retrieval-2.7", video_url=url) task_ids.append(str(task.id)) status = task.wait_for_done(sleep_interval=10, callback=on_task_update) if task.status != "ready": raise RuntimeError(f"Embedding failed with status {task.status}")
埋め込みの取得とデータ処理
最後に、生成された埋め込みを取得します:
tasks = [] for task_id in task_ids: task = client.embed.task.retrieve(task_id) tasks.append(task)
生成された埋め込み出力には、以下のような特徴があります:
各動画は6秒間のチャンクに分割されます
各セグメントには1024次元の埋め込みベクトルが含まれます
動画の長さに応じて、1本の動画から37〜242個のセグメントが生成されます
各セグメントには開始・終了オフセットのタイムスタンプが含まれます
時間的文脈をとらえるため、埋め込みスコープは "clip" に設定されます
これらの埋め込みは、映像要素、音声、時間的な関係など、動画のマルチモーダルな側面を捉えています。これらを利用して、Vespaでセマンティック検索を実現します。
ステップ 3: Vespaアプリケーションのデプロイ
このステップでは、VespaアプリケーションパッケージをVespa Cloudにデプロイし、属性や埋め込みを含む処理済みの動画データをアプリケーションにフィード(投入)します。
アプリケーションパッケージの作成
Vespaアプリケーションパッケージは、アプリケーションのスキーマと構成を定義します。これには、Twelve Labs Embed API によって生成されたフィールド(動画属性や埋め込みなど)が含まれます。ここでは、 pyvespa を使ってスキーマを定義する方法を示します:
# Define the schema for "videos" videos_schema = Schema( name="videos", document=Document( fields=[ Field(name="video_url", type="string", indexing=["summary"]), Field(name="title", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="keywords", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="video_summary", type="string", indexing=["index", "summary"], match=["text"], index="enable-bm25"), Field(name="embedding_scope", type="string", indexing=["attribute", "summary"]), Field(name="start_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field(name="end_offset_sec", type="array<float>", indexing=["attribute", "summary"]), Field( name="embeddings", type="tensor<float>(p{},x[1024])", indexing=["index", "attribute"], ann=HNSW(distance_metric="angular"), ), ] ), ) # Add fieldsets for search fieldsets = [ FieldSet(name="default", fields=["title", "keywords", "video_summary"]), ] # Define ranking functions mapfunctions = [ Function( name="similarities", expression="""sum(query(q) * attribute(embeddings), x)""", ), Function( name="bm25_score", expression="bm25(title) + bm25(keywords) + bm25(video_summary)", ), ] # Define a hybrid rank profile semantic_rankprofile = RankProfile( name="hybrid", inputs=[("query(q)", "tensor<float>(x[1024])")], first_phase="bm25_score", second_phase=SecondPhaseRanking(expression="closeness(field, embeddings)", rerank_count=10), match_features=["closest(embeddings)"], summary_features=["similarities"], functions=mapfunctions, ) # Add rank profile to schema videos_schema.add_rank_profile(semantic_rankprofile) # Create the application package package = ApplicationPackage(name=application, schema=[videos_schema])
このスキーマは、動画データ(属性と埋め込み)がVespaでどのように格納、インデックス登録、およびクエリ検索されるかを定義しています。
アプリケーションパッケージのデプロイ
アプリケーションパッケージをVespa Cloudにデプロイするには、 VespaCloud を使用して接続を作成し、定義されたパッケージをデプロイします。
from vespa.deployment import VespaCloud # Deploy the application package to Vespa Cloud vespa_cloud = VespaCloud( tenant=tenant_name, application=application, application_package=package, key_content=os.getenv("VESPA_TEAM_API_KEY"), # Replace with your API key content ) app = vespa_cloud.deploy() print("Deployment complete!")
デプロイが完了すると、上記のようなデプロイログが表示されます。アプリケーションは現在稼働しており、データを受け取る準備ができています。
Vespaへのデータ投入(フィード)
次に、 pyvespa を使用して動画データ(属性と埋め込み)をVespaに投入します。各ドキュメントは、URLとセグメントインデックスから派生した一意のIDによって識別され、動画セグメントに対応しています。
フィード用データの準備
import hashlib # Initialize a list to store Vespa feed documents vespa_feed = [] # Reverse VIDEO_URLs since attributes were generated in reverse order VIDEO_URLs.reverse() for i, task in enumerate(tasks): video_url = VIDEO_URLs[i] title = titles[i] keywords = keywords_array[i] summary = summaries[i] start_offsets = [] end_offsets = [] embeddings = {} for index, segment in enumerate(task.video_embedding.segments): start_offsets.append(float(segment.start_offset_sec)) end_offsets.append(float(segment.end_offset_sec)) embeddings[str(index)] = list(map(float, segment.embeddings_float)) # Create unique ID for each segment id_hash = hashlib.md5(f"{video_url}_{index}".encode()).hexdigest() document = { "id": id_hash, "fields": { "video_url": video_url, "title": title, "keywords": keywords, "video_summary": summary, "embedding_scope": segment.embedding_scope, "start_offset_sec": start_offsets, "end_offset_sec": end_offsets, "embeddings": embeddings, }, } vespa_feed.append(document)
Vespaへのデータ投入(フィード)
from vespa.io import VespaResponse def callback(response: VespaResponse, id: str): if not response.is_successful(): print(f"Failed to feed document {id} with status code {response.status_code}: {response.get_json()}") # Feed data synchronously app.feed_iterable(vespa_feed, schema="videos", callback=callback) print("Data feeding complete!")
フィード作業により、すべての動画データがVespaのコンテンツクラスターにインデックス登録されます。ログを確認するか、Vespaインスタンスに問い合わせることで、これを確認できます。
概要
アプリケーションパッケージ: 動画属性と埋め込みを格納するためのスキーマを定義しました。
デプロイ: パッケージを Vespa Cloud にデプロイしました。
データ投入(フィード): デプロイされたアプリケーションに処理済みの動画データをインデックス登録しました。
これでVespaアプリケーションがセマンティック検索に対応できるようになりました!
ステップ 4: セマンティック検索の実行
このステップでは、Vespaに保存されている動画埋め込みに対してセマンティック検索を実行します。検索には、キーワードによるテキスト検索(語彙検索)とベクトル類似度検索を組み合わせたハイブリッドランキングを使用し、最も関連性の高い動画セグメントを取得します。
ハイブリッド検索の実行
クエリの埋め込みの作成
「そりに乗ったサンタクロース(Santa Claus on his sleigh)」というクエリに該当する動画セグメントを検索するために、まずは動画の埋め込みに使用したのと同じモデル(Marengo-retrieval-2.7)を使ってクエリの埋め込みを生成します:
client = TwelveLabs(api_key=TL_API_KEY) user_query = "Santa Claus on his sleigh" # Generate embedding for the query res = client.embed.create( model_name="Marengo-retrieval-2.7", text=user_query, ) print("Created a text embedding") print(f" Model: {res.model_name}") if res.text_embedding is not None and res.text_embedding.segments is not None: q_embedding = res.text_embedding.segments[0].embeddings_float print(f" Embedding Dimension: {len(q_embedding)}") print(f" Sample 5 values from array: {q_embedding[:5]}")
この手法により 1024 次元のクエリ埋め込みが出力されます。これを使用して、Vespa で近傍探索用のクエリを実行します。
Vespaでのハイブリッド検索の実行
Vespa の近似最近傍(ANN)検索機能を使用し、テキスト検索(BM25)とベクトル類似度ランキングを組み合わせます。このクエリにより、ハイブリッドランキングに基づいて最も関連性の高い結果が取得されます:
with app.syncio(connections=1) as session: response: VespaQueryResponse = session.query( yql="select * from videos where userQuery() OR ({targetHits:100}nearestNeighbor(embeddings,q))", query=user_query, ranking="hybrid", hits=1, body={"input.query(q)": q_embedding}, ) assert response.is_successful() # Print the top hit for hit in response.hits: print(json.dumps(hit, indent=4)) # Get full response JSON response.get_json()
ハイブリッドランキングは次のように機能します:
第一段階(First Phase): 動画タイトル、キーワード、要約に基づいたBM25語彙ランキング。
第二段階(Second Phase): クエリの埋め込みと動画の埋め込み間のベクトル類似度を用いたリランキング。
出力ログに示されているように、最も関連度の高い結果(Top Hit)は、これらを組み合わせたスコアが最も高かったセグメントに対応します。
結果をDataFrameに変換して処理する
結果を使いやすくするために、pandas の DataFrame を使って、類似度スコアに基づいて上位 N 個のセグメントを抽出して並べ替えます:
def get_top_n_similarity_matches(data, N=5): """ Extracts top N similarity scores and their corresponding offsets. Args: - data (dict): Input JSON-like structure containing similarities and offsets. - N (int): Number of top similarity scores to return. Returns: - pd.DataFrame: A DataFrame with top N similarity scores and offsets. """ # Extract relevant fields similarities = data["fields"]["summaryfeatures"]["similarities"]["cells"] start_offset_sec = data["fields"]["start_offset_sec"] end_offset_sec = data["fields"]["end_offset_sec"] # Sort by similarity score sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True) # Prepare results for top N matches results = [] for index_str, score in sorted_similarities[:N]: index = int(index_str) if index < len(start_offset_sec): results.append({ "index": index, "similarity_score": score, "start_offset_sec": start_offset_sec[index], "end_offset_sec": end_offset_sec[index], }) return pd.DataFrame(results) # Get top 10 matches df_result = get_top_n_similarity_matches(response.hits[0], N=10) print(df_result)
出力される DataFrame には以下が含まれます:
Index: 動画内でのセグメントを示すインデックス。
Similarity Score: ベクトル類似度に基づく関連性スコア。
Start/End Offsets: 秒単位でのセグメント開始・終了時間境界。
以下の表は、クエリから得られた上位10件の類似検索結果の例です:
このフォーマットにより、詳細な分析や動画再生において、最も関連性の高い複数のセグメントを素早く特定しやすくなります。
概要
TwelveLabs の Embed API を使用してクエリの埋め込みを生成しました。
Vespa でテキスト検索(BM25)とベクトル類似度に基づいたハイブリッド検索を実行しました。
上位の検索結果を分析しやすいように pandas の DataFrame に変換して処理しました。
このワークフローは、TwelveLabsのマルチモーダル埋め込みとVespaの高度な検索機能を用いて、関連度が高い該当セグメントを効率的に見つけ出す方法を実証しています。
ステップ 5: 結果の確認
このステップでは、関連する動画の区間をグループ化し、整理することで、セマンティック検索の結果を確認します。その後、ノートブックに埋め込まれた動画プレーヤーを使ってビジュアルに結果を再生し、その関連性を評価します。
隣接する類似セグメントの統合
結果をより簡単に確認できるように、同一箇所の連続した動画セグメント(各セグメントの開始・終了時刻に基づく)を一つの範囲として統合する必要があります。また、切り替わりがスムーズになるように、各セグメントの境界に 3 秒間ののりしろ(オーバーラップ)を設けます。以下の関数は、この統合を行い、読みやすさを考慮して時間オフセットを MM:SS 形式に変換します。
例えば、上位の検索結果に重複する時間帯や隣接する時間帯が含まれている場合、この関数はそれらを単一の範囲にマージします。その出力は、以下のようになります:
Consolidated Segments (MM:SS): [('20:15', '20:27'), ('20:39', '21:21'), ('22:51', '23:15'
動画プレーヤーを使用した結果の視覚化
特定されたセグメントを実際に確認するために、ノートブック上に簡単な動画プレーヤーを埋め込みます。統合された時間範囲に手動で進めることも、指定した時間にジャンプするようにプログラムを設定することもできます。
動画プレーヤーの埋め込み
from IPython.display import HTML # Define video URL (replace with your video URL) video_url = "https://ia601401.us.archive.org/1/items/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net/twas-the-night-before-christmas-1974-full-movie-freedownloadvideo.net.mp4" # Define middle point of a segment for playback preview (e.g., first consolidated segment) middle_point = (1272 + 1278) / 2 # Example from top match # Generate HTML for video player video_player = f""" <video id="myVideo" width="640" height="480" controls> <source src="{video_url}" type="video/mp4"> Your browser does not support the video tag. </video """ # Display the video player HTML(video_player)
このコードは、指定された時間(middle_point)から再生を開始するインタラクティブな動画プレーヤーを生成します。興味のある別のポイントに基づいて middle_point の数値を変更して確認できます。
検索結果の評価
プレーヤーが埋め込まれたら、統合された時間範囲を手動またはシークバーで移動しながら、各ビジュアルを視覚的に評価できます。先ほど生成された segments のリストを利用し、クエリとの高い関連が確実視される一致箇所を見つけて再生してください。
例えば:
セグメント:
'20:21' - '21:18'該当シーンの確認: このセグメントには、そりに乗ったサンタクロースがはっきりと映っており、本ハイブリッド探索が関連性の高いコンテンツを正確に認識・抽出できていることが証明されます。
終わりに
TwelveLabsの Embed API と Vespa を組み合わせることで、高度なセマンティック動画検索アプリケーションの実用可能な可能性が大きく広がります。 Embed API は、ビデオの時間軸や文脈的なニュアンスをとらえる豊富なマルチモーダル埋め込みを提供し、Vespa の強力なインデックス登録およびハイブリッド検索機能によって、求める該当箇所を非常に高速で特定できます。
この統合がもたらす主な利点は以下の通りです:
マルチモーダルな理解: TwelveLabs が生成する統一された埋め込みにより、複数のメディア要素にまたがる動画の内容を包括的に表現できます。
優れたスケーラビリティ: 大規模なデータセットでも処理能力が高く、大量のデータが存在するスケール時にも低レイテンシで処理・検索を実行できます。
洗練されたハイブリッド検索: キーワードベースの(BM25)テキスト検索に、ベクトル的な意味類似度(ANN)を掛け合わせることで、目的の箇所の高い識別精度を維持できます。
高度な柔軟性: 開発者は、要件に応じたスキーマ設計、独自のランク構成、様々なクエリロジックを必要に合わせて自由にカスタマイズできます。
本チュートリアルを参照することで、ユーザー体験を飛躍的に向上させ、動画アーカイブなどのコンテンツ検索における新たなアイデアを形にする、スケーラブルで知的な動画検索システムを構築できるようになります。








