
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
Building Video Deep Research with TwelveLabs and Perplexity Sonar

Hrishikesh Yadav
This tutorial walks through building the Video Deep Research application, which uses the Twelve Labs Pegasus 1.2 model to analyze video content and Perplexity Sonar to generate citation-backed research insights from the analysis results, with a Next.js frontend and Flask backend supporting both pre-indexed videos and direct uploads.
This tutorial walks through building the Video Deep Research application, which uses the Twelve Labs Pegasus 1.2 model to analyze video content and Perplexity Sonar to generate citation-backed research insights from the analysis results, with a Next.js frontend and Flask backend supporting both pre-indexed videos and direct uploads.

In this article
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2025. 10. 7.
13 Minutes
링크 복사하기
Introduction
What if you could search videos as easily as you search text over the web and get every insight with a trusted citation? 🎥🔍
Today, that’s still a missing piece of the web. Search engines don't consider the videos as the input to get the result. This leaves researchers, creators, and professionals stuck manually going through hours of footage, with no reliable way to extract structured insights or verify them.
Video Deep Research changes the way to look on to the video for the research. By combining TwelveLabs Analyze pegasus-1.2 for semantic video understanding with Sonar by Perplexity for citation-powered knowledge retrieval, it transforms videos into a searchable, trustworthy research resource.
Let’s explore how the Video Deep Research application works and how you can build a similar solution with the video understanding and deep research by using the TwelveLabs Python SDK and Perplexity Sonar.
You can explore the demo of the application here: Video Deep Research Application
Prerequisites
Generate an API key by signing up at the TwelveLabs Playground.
Sign Up on Sonar and generate the API KEY to access the model.
Find the repository for this application on Github Repository.
You should be familiar with Python, Flask, and Next.js
Demo Application
This demo application showcases how video understanding and knowledge retrieval can unlock a completely new way of doing research.
Users can simply upload a video or select from an already indexed video by connecting their TwelveLabs API Key. The application then processes the content, extracts structured insights, and links them to verifiable references, bridging the gap between video and trustworthy research.
Here, you’ll find a detailed walkthrough of the code and the demo so you can build and extend your own Video Deep Research powered application —
Working of the Application
The application supports two modes of interaction -
Using the TwelveLabs API Key: Connect your personal TwelveLabs API Key to access and interact with your own already indexed videos. Once connected, you can select an existing Index ID and respective video.
Upload a Video: When a video is uploaded, the application is designed to automatically use the default TwelveLabs API key for seamless setup. After the upload, the indexing process begins immediately. Once indexing is complete, the most recently uploaded video will be displayed as the latest available content. From this point onward, the query and citation workflow proceeds identically for both interaction modes, following the steps mentioned below.
The complete workflow of the application begins with configuring the TwelveLabs client. This requires setting up the TwelveLabs API key, either by using the environment-provided key or by allowing the user to connect their own key from the client side to access already indexed videos. Once the client is configured, the process follows a sequential flow as outlined below –
Fetch Indexes – Retrieve the list of indexes associated with the connected TwelveLabs account.
Select Video – Choose a video from the desired index for analysis.
Analyze Video – Perform video content analysis on the selected video using the provided query.
Deep Research – Combine the analyzed response with a structured prompt and the user’s query, then pass it to the Sonar research model for deeper reasoning and citation-backed insights.
This structured workflow ensures a smooth progression from video indexing through to advanced research, providing users with detailed, context-aware outputs.
Both approaches are illustrated in the architecture diagram below.

The flow is designed such that once a research response is generated, users can provide follow-up queries to request additional references or deeper insights around the same context. These subsequent queries are routed back into the Sonar research loop, which maintains contextual continuity and expands on the existing knowledge base. This iterative design ensures that each new query builds upon the prior results, allowing for progressively richer and more context-aware research outputs.
Preparation Steps
Obtain your API key from the TwelveLabs Playground and set up your environment variable.
Do create the Index, with the
pegasus-1.2selection via TwelveLabs Playground, and get theindex_idspecifically for this application.Clone the project from Github.
Do obtain the API KEY from the Sonar by Perplexity.
Create a
.envfile containing your TwelveLabs and Sonar credentials. An example of the environment setup can be found here.
Once you've completed these steps, you're ready to start developing!
Walkthrough for the Video Deep-Research App
This tutorial demonstrates how to build an application that can retrieve citations and relevant information from the web based on video content. The project uses Next.js for the frontend and a Flask API (with CORS enabled) for the backend. Our main focus will be on implementing the core backend utility that powers this video deep-research application, along with setting up the complete environment.
For detailed setup instructions and the full code structure, please refer to the README.md file in the GitHub repository.
1 - Workflow for Video Deep-Research Implementation
The most critical step in the workflow is the initialization and handling of the TwelveLabs API key. The application can either load the key directly from the environment for default usage or allow the user to provide their own API key via the client.
backend/service/twelvelabs_service.py (14-36 Line)
class TwelveLabsService: def __init__(self, api_key=None): # If no API key is provided, try to get it from environment variable if api_key is None: api_key = os.environ.get('TWELVELABS_API_KEY', '') self.api_key = api_key # Store API key in the instance self.client = TwelveLabs(api_key=api_key) # Intialize the TwelveLabs client
class TwelveLabsService: def __init__(self, api_key=None): # If no API key is provided, try to get it from environment variable if api_key is None: api_key = os.environ.get('TWELVELABS_API_KEY', '') self.api_key = api_key # Store API key in the instance self.client = TwelveLabs(api_key=api_key) # Intialize the TwelveLabs client
1.1 GET the Indexes
Once the user connects their TwelveLabs API key either through the portal or via the default mode where the key is loaded from the environment, the application retrieves all indexes associated with that account. The retrieved data is then structured and delivered to the frontend for display.
backend/service/twelvelabs_service.py (14-36 Line)
def get_indexes(self): try: print("Fetching indexes...") # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of indexes indexes = self.client.indexes.list() result = [] for index in indexes: # Append a dictionary with relevant index details result.append({ "id": index.id, "name": index.index_name }) print(f"ID: {index.id}") print(f" Name: {index.index_name}") return result except Exception as e: print(f"Error fetching indexes: {e}") return []
def get_indexes(self): try: print("Fetching indexes...") # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of indexes indexes = self.client.indexes.list() result = [] for index in indexes: # Append a dictionary with relevant index details result.append({ "id": index.id, "name": index.index_name }) print(f"ID: {index.id}") print(f" Name: {index.index_name}") return result except Exception as e: print(f"Error fetching indexes: {e}") return []
1.2 GET the list of videos, for respective Index ID
When a user selects an index, the application records the associated index_id. With this index_id, the system invokes the relevant method to fetch and return all videos linked to that index.
backend/service/twelvelabs_service.py (38-70 Line)
def get_videos(self, index_id, page=1): try: # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of videos videos_response = self.client.indexes.videos.list(index_id=index_id, page=page) result = [] for video in videos_response.items: system_metadata = video.system_metadata hls_data = video.hls thumbnail_urls = hls_data.get('thumbnail_urls', []) if hls_data else [] thumbnail_url = thumbnail_urls[0] if thumbnail_urls else None video_url = hls_data.get('video_url') if hls_data else None # Append a dictionary with relevant video details result.append({ "id": video.id, "name": system_metadata.filename if system_metadata and system_metadata.filename else f'Video {video.id}', "duration": system_metadata.duration if system_metadata else 0, "thumbnail_url": thumbnail_url, "video_url": video_url, "width": system_metadata.width if system_metadata else 0, "height": system_metadata.height if system_metadata else 0, "fps": system_metadata.fps if system_metadata else 0, "size": system_metadata.size if system_metadata else 0 }) return result except Exception as e: print(f"Error fetching videos for index {index_id}: {e}") return []
def get_videos(self, index_id, page=1): try: # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of videos videos_response = self.client.indexes.videos.list(index_id=index_id, page=page) result = [] for video in videos_response.items: system_metadata = video.system_metadata hls_data = video.hls thumbnail_urls = hls_data.get('thumbnail_urls', []) if hls_data else [] thumbnail_url = thumbnail_urls[0] if thumbnail_urls else None video_url = hls_data.get('video_url') if hls_data else None # Append a dictionary with relevant video details result.append({ "id": video.id, "name": system_metadata.filename if system_metadata and system_metadata.filename else f'Video {video.id}', "duration": system_metadata.duration if system_metadata else 0, "thumbnail_url": thumbnail_url, "video_url": video_url, "width": system_metadata.width if system_metadata else 0, "height": system_metadata.height if system_metadata else 0, "fps": system_metadata.fps if system_metadata else 0, "size": system_metadata.size if system_metadata else 0 }) return result except Exception as e: print(f"Error fetching videos for index {index_id}: {e}") return []
1.3 Analyze the video content
When a video is selected and a research query is provided by the user, both the video_id and the query are passed to the analyze utility for video understanding. The query is appended to a predefined prompt, which enhances the context and ensures meaningful analyzed response. The prompt used for the video analysis is provided here.
backend/service/twelvelabs_service.py (72-81 Line)
def analyze_video(self, video_id, prompt): try: # Call the TwelveLabs client to analyze the video analysis_response = self.client.analyze( video_id=video_id, prompt=prompt ) return analysis_response.data except Exception as e: print(f"Error analyzing video {video_id}: {e}") raise e
def analyze_video(self, video_id, prompt): try: # Call the TwelveLabs client to analyze the video analysis_response = self.client.analyze( video_id=video_id, prompt=prompt ) return analysis_response.data except Exception as e: print(f"Error analyzing video {video_id}: {e}") raise e
1.4 Deep Research on Analyzed Content
After the initial analysis completes, the workflow proceeds to a deep-research phase powered by the sonar model. The deep_research call constructs a single payload that combines three elements, the user’s original query, the research prompt, and the analysis results and sends that structured input to sonar for further processing. Sonar returns a refined, structured response that includes source citations. The prompt for the deep research prompt can be found here.
backend/service/sonar_service.py (13-52 Line)
def deep_research(self, query, timeout=180): try: # Ensure API key is available if not self.api_key: raise ValueError("API key is required") payload = { "model": "sonar", "messages": [ {"role": "user", "content": query} ] } headers = { "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" } # POST request to the API endpoint with timeout response = requests.post( self.base_url, json=payload, headers=headers, timeout=timeout ) # Check if the response was successful if response.status_code == 200: return response.json() else: print(f"Error: {response.status_code} - {response.text}") return {"error": f"API request failed with status {response.status_code}"} except requests.exceptions.Timeout: print("Request timed out") return {"error": "Request timed out - Sonar research is taking too long"} except requests.exceptions.RequestException as e: print(f"Request error: {e}") return {"error": f"Network error: {str(e)}"} except Exception as e: print(f"Error in deep_research: {e}") return {"error": str(e)}
def deep_research(self, query, timeout=180): try: # Ensure API key is available if not self.api_key: raise ValueError("API key is required") payload = { "model": "sonar", "messages": [ {"role": "user", "content": query} ] } headers = { "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" } # POST request to the API endpoint with timeout response = requests.post( self.base_url, json=payload, headers=headers, timeout=timeout ) # Check if the response was successful if response.status_code == 200: return response.json() else: print(f"Error: {response.status_code} - {response.text}") return {"error": f"API request failed with status {response.status_code}"} except requests.exceptions.Timeout: print("Request timed out") return {"error": "Request timed out - Sonar research is taking too long"} except requests.exceptions.RequestException as e: print(f"Request error: {e}") return {"error": f"Network error: {str(e)}"} except Exception as e: print(f"Error in deep_research: {e}") return {"error": str(e)}
There are multiple Sonar variants available like sonar, sonar-reasoning, and sonar-deep-research. The sonar-deep-research model supports a reasoning_effort setting (low, medium, high), with medium as the default for a balanced trade-off between deep research and speed. Increasing the reasoning effort to “high” produces more citations and deeper insights but also increases response time and token usage, so choose the model and effort level based on the required thoroughness, latency tolerance, and cost.
By simply changing the model name to sonar-deep-research, the system produces more detailed reasoning along with a greater number of citations. This configuration enables deeper research and richer insights compared to the default sonar model. Below is a demonstration of the enhanced response generated —

1.5 Function calling workflow for the research
The workflow begins with the configuration of the TwelveLabs client, ensuring the API key, index ID, and video ID are properly validated. Once the setup is confirmed, the application fetches the video details from the TwelveLabs service. This ensures the selected video context is well-defined before proceeding further. The results are streamed back to the frontend in real-time using yield, which allows the UI to update progressively rather than waiting for the entire process to finish.
Next, the system invokes the analyze_video method of the TwelveLabs service class defined, passing in the selected video_id and the analysis prompt. The output of this analysis is then included into an enhanced research query, structured with a predefined template. This template enforces a markdown based response format as an instruction and ensures that both the analysis result and the user’s query are aligned into a consistent structure. The enhanced query is then sent to the Sonar service for deep research, which produces a refined and citation-backed response.
backend/routes/api_routes.py (31-162 Line)
def generate_workflow(twelvelabs_api_key, index_id, video_id, analysis_prompt, research_query, research_prompt_template): # Input validation if not twelvelabs_api_key: yield json.dumps({'type': 'error', 'message': 'TwelveLabs API key is required'}) + '\n' return if not index_id or not video_id: yield json.dumps({'type': 'error', 'message': 'Index ID and Video ID are required'}) + '\n' return if not research_query: yield json.dumps({'type': 'error', 'message': 'Research query is required'}) + '\n' return try: twelvelabs_service = TwelveLabsService(api_key=twelvelabs_api_key) # Step 1: Get video details yield safe_json_dumps({ 'type': 'progress', 'step': 'video_details', 'message': 'Fetching video details...', 'progress': 0 }) + '\n' video_details = twelvelabs_service.get_video_details(index_id, video_id) if not video_details: yield safe_json_dumps({'type': 'error', 'message': 'Could not retrieve video details'}) + '\n' return yield safe_json_dumps({ 'type': 'data', 'step': 'video_details', 'data': { 'id': video_details.get('_id', ''), 'filename': video_details.get('system_metadata', {}).get('filename', ''), 'duration': video_details.get('system_metadata', {}).get('duration', 0) }, 'progress': 33 }) + '\n' # Step 2: Analyze video yield safe_json_dumps({ 'type': 'progress', 'step': 'analysis', 'message': 'Analyzing video content...', 'progress': 33 }) + '\n' analysis_result = twelvelabs_service.analyze_video(video_id, analysis_prompt) yield safe_json_dumps({ 'type': 'data', 'step': 'analysis', 'data': analysis_result, 'progress': 66 }) + '\n' # Step 3: Research with context yield safe_json_dumps({ 'type': 'progress', 'step': 'research', 'message': 'Conducting deep research...', 'progress': 66 }) + '\n' enhanced_query = research_prompt_template.format( analysis_result=analysis_result, research_query=research_query ) sonar_service = SonarService() research_result = sonar_service.deep_research(enhanced_query, timeout=180) if 'error' in research_result: yield safe_json_dumps({'type': 'error', 'message': f'Research failed: {research_result["error"]}'}) + '\n' return # Extract research content research_content = "" if research_result and research_result.get('choices'): research_content = research_result['choices'][0].get('message', {}).get('content', '') # Send research content in chunks if large max_chunk_size = 10000 if len(research_content) > max_chunk_size: for i in range(0, len(research_content), max_chunk_size): chunk = research_content[i:i + max_chunk_size] is_final = (i + max_chunk_size) >= len(research_content) yield safe_json_dumps({ 'type': 'research_chunk', 'content': chunk, 'is_final': is_final, 'progress': 80 + (i / len(research_content)) * 20 }) + '\n' # Send completion with chunked content indicator yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': '[CHUNKED_CONTENT]' } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' else: # Send completion with research data yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': research_content } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' except Exception as e: yield safe_json_dumps({'type': 'error', 'message': str(e)}) + '\n'
def generate_workflow(twelvelabs_api_key, index_id, video_id, analysis_prompt, research_query, research_prompt_template): # Input validation if not twelvelabs_api_key: yield json.dumps({'type': 'error', 'message': 'TwelveLabs API key is required'}) + '\n' return if not index_id or not video_id: yield json.dumps({'type': 'error', 'message': 'Index ID and Video ID are required'}) + '\n' return if not research_query: yield json.dumps({'type': 'error', 'message': 'Research query is required'}) + '\n' return try: twelvelabs_service = TwelveLabsService(api_key=twelvelabs_api_key) # Step 1: Get video details yield safe_json_dumps({ 'type': 'progress', 'step': 'video_details', 'message': 'Fetching video details...', 'progress': 0 }) + '\n' video_details = twelvelabs_service.get_video_details(index_id, video_id) if not video_details: yield safe_json_dumps({'type': 'error', 'message': 'Could not retrieve video details'}) + '\n' return yield safe_json_dumps({ 'type': 'data', 'step': 'video_details', 'data': { 'id': video_details.get('_id', ''), 'filename': video_details.get('system_metadata', {}).get('filename', ''), 'duration': video_details.get('system_metadata', {}).get('duration', 0) }, 'progress': 33 }) + '\n' # Step 2: Analyze video yield safe_json_dumps({ 'type': 'progress', 'step': 'analysis', 'message': 'Analyzing video content...', 'progress': 33 }) + '\n' analysis_result = twelvelabs_service.analyze_video(video_id, analysis_prompt) yield safe_json_dumps({ 'type': 'data', 'step': 'analysis', 'data': analysis_result, 'progress': 66 }) + '\n' # Step 3: Research with context yield safe_json_dumps({ 'type': 'progress', 'step': 'research', 'message': 'Conducting deep research...', 'progress': 66 }) + '\n' enhanced_query = research_prompt_template.format( analysis_result=analysis_result, research_query=research_query ) sonar_service = SonarService() research_result = sonar_service.deep_research(enhanced_query, timeout=180) if 'error' in research_result: yield safe_json_dumps({'type': 'error', 'message': f'Research failed: {research_result["error"]}'}) + '\n' return # Extract research content research_content = "" if research_result and research_result.get('choices'): research_content = research_result['choices'][0].get('message', {}).get('content', '') # Send research content in chunks if large max_chunk_size = 10000 if len(research_content) > max_chunk_size: for i in range(0, len(research_content), max_chunk_size): chunk = research_content[i:i + max_chunk_size] is_final = (i + max_chunk_size) >= len(research_content) yield safe_json_dumps({ 'type': 'research_chunk', 'content': chunk, 'is_final': is_final, 'progress': 80 + (i / len(research_content)) * 20 }) + '\n' # Send completion with chunked content indicator yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': '[CHUNKED_CONTENT]' } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' else: # Send completion with research data yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': research_content } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' except Exception as e: yield safe_json_dumps({'type': 'error', 'message': str(e)}) + '\n'
To handle large research outputs, the workflow implements response chunking. Since Sonar may return extensive content with detailed reasoning and numerous citations, sending it as one large JSON risks exceeding payload size limits and causing serialization errors. To prevent this, the response is split into manageable chunks which are streamed sequentially. This design ensures scalability, avoids network bottlenecks, and maintains frontend responsiveness.
2 - Video upload indexing workflow essential
In the alternate workflow, instead of relying on pre-indexed videos, the user directly uploads a new video file. The upload_video_file method handles this process by validating the required inputs such as the API key, index ID, and file path. Once validated, it initiates a request to TwelveLabs task endpoint, creating an upload task with the video file attached. If the task creation is successful, a task ID is returned, which is used to monitor the indexing status.
The method then enters a polling loop, periodically checking the task status until it is either completed, failed, or the defined timeout is reached. When the indexing succeeds, the response includes a video_id, which uniquely identifies the uploaded video and makes it immediately available for further analysis. This ensures the uploaded video becomes the latest available video on the portal. In case of failure or timeout, appropriate error messages are returned, providing robust error handling for the upload and indexing process.
backend/service/twelvelabs_service.py (145-207 Line)
def upload_video_file(self, index_id: str, file_path: str, timeout_seconds: int = 900): import sys try: if not self.api_key: return {"error": "Missing TwelveLabs API key"} if not index_id: return {"error": "Missing index_id"} if not os.path.exists(file_path): return {"error": f"File not found: {file_path}"} print(f"Starting upload for file: {file_path}", file=sys.stderr) tasks_url = "https://api.twelvelabs.io/v1.3/tasks" headers = { "x-api-key": self.api_key } # Create upload task with open(file_path, "rb") as f: files = { "video_file": (os.path.basename(file_path), f) } data = { "index_id": index_id } resp = requests.post(tasks_url, headers=headers, files=files, data=data) if resp.status_code not in (200, 201): return {"error": f"Failed to create upload task: {resp.status_code} {resp.text}"} resp_json = resp.json() if resp.text else {} task_id = resp_json.get("id") or resp_json.get("task_id") or resp_json.get("_id") if not task_id: return {"error": f"No task id returned: {resp_json}"} # Poll task until ready import time start_time = time.time() print(f"Starting to poll task {task_id} for completion...", file=sys.stderr) while time.time() - start_time < timeout_seconds: r = requests.get(f"{tasks_url}/{task_id}", headers=headers) if r.status_code != 200: time.sleep(2) continue task = r.json() if r.text else {} status = task.get("status") print(f"Task {task_id} status: {status}", file=sys.stderr) if status in ("ready", "completed"): video_id = task.get("video_id") or (task.get("data") or {}).get("video_id") print(f"Indexing completed successfully! Video ID: {video_id}", file=sys.stderr) return {"status": status, "video_id": video_id, "task": task} if status in ("failed", "error"): print(f"Indexing failed with status: {status}", file=sys.stderr) return {"error": f"Indexing failed with status {status}", "task": task} time.sleep(2) print(f"Upload timed out after {timeout_seconds} seconds", file=sys.stderr) return {"error": "Upload timed out"}
def upload_video_file(self, index_id: str, file_path: str, timeout_seconds: int = 900): import sys try: if not self.api_key: return {"error": "Missing TwelveLabs API key"} if not index_id: return {"error": "Missing index_id"} if not os.path.exists(file_path): return {"error": f"File not found: {file_path}"} print(f"Starting upload for file: {file_path}", file=sys.stderr) tasks_url = "https://api.twelvelabs.io/v1.3/tasks" headers = { "x-api-key": self.api_key } # Create upload task with open(file_path, "rb") as f: files = { "video_file": (os.path.basename(file_path), f) } data = { "index_id": index_id } resp = requests.post(tasks_url, headers=headers, files=files, data=data) if resp.status_code not in (200, 201): return {"error": f"Failed to create upload task: {resp.status_code} {resp.text}"} resp_json = resp.json() if resp.text else {} task_id = resp_json.get("id") or resp_json.get("task_id") or resp_json.get("_id") if not task_id: return {"error": f"No task id returned: {resp_json}"} # Poll task until ready import time start_time = time.time() print(f"Starting to poll task {task_id} for completion...", file=sys.stderr) while time.time() - start_time < timeout_seconds: r = requests.get(f"{tasks_url}/{task_id}", headers=headers) if r.status_code != 200: time.sleep(2) continue task = r.json() if r.text else {} status = task.get("status") print(f"Task {task_id} status: {status}", file=sys.stderr) if status in ("ready", "completed"): video_id = task.get("video_id") or (task.get("data") or {}).get("video_id") print(f"Indexing completed successfully! Video ID: {video_id}", file=sys.stderr) return {"status": status, "video_id": video_id, "task": task} if status in ("failed", "error"): print(f"Indexing failed with status: {status}", file=sys.stderr) return {"error": f"Indexing failed with status {status}", "task": task} time.sleep(2) print(f"Upload timed out after {timeout_seconds} seconds", file=sys.stderr) return {"error": "Upload timed out"}
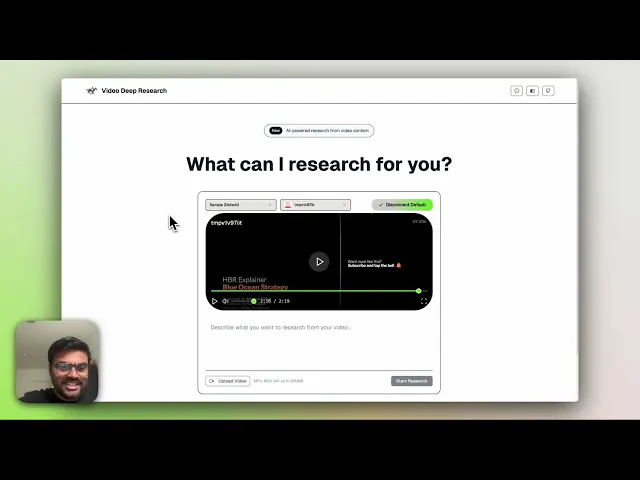
The subsequent workflow pipeline follows the same sequence described earlier, once a video is uploaded and indexed, the generated video_id is passed through the workflow for analysis, research enhancement, and citation-backed response. This ensures consistency between the default mode (pre-indexed videos) and the alternate mode (uploaded videos), while maintaining a unified workflow. Below is a quick demonstration highlighting the process of uploading a video, performing indexing, and executing the complete pipeline —
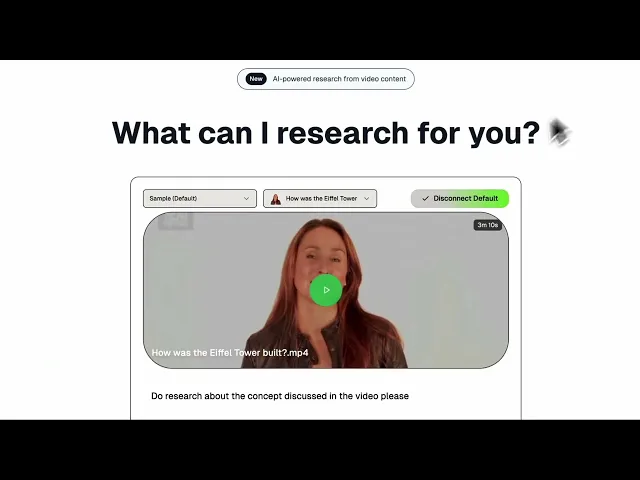
The application supports handling the TwelveLabs API key directly on the client side. This provides users with the flexibility to connect their own API key, enabling them to analyze and conduct research on their previously indexed videos without relying on the default key.
More Ideas to Experiment with the Tutorial
Exploring how video understanding and connected to verifiable research opens the door to even more powerful applications. Here are some experimental directions you can try with TwelveLabs Analyze and Sonar by Perplexity —
🔍 Deep Video Fact-Checking — Automatically verify statements and claims in video content by linking extracted insights to trusted sources and citations.
📑 Semantic Research Review — Generate structured summaries/reviews of video content, highlighting key ideas, references, and actionable insights for faster research.
📚 Enhanced Learning Workflows — Combine video insights with external knowledge repositories to create interactive or guided learning experiences for researchers, students, and content creators.
Conclusion
This tutorial demonstrates how video understanding can transform the way we conduct research and interact with video content. By combining TwelveLabs Analyze for deep video analysis with Sonar by Perplexity for knowledge retrieval and citation, we’ve built a system that turns videos from passive media into structured, citable research tools which empowers researchers, creators, and professionals to explore video content in a meaningful and trustworthy way.
Additional Resources
Learn more about the analyze video engine—Pegasus-1.2. To explore TwelveLabs further and enhance your understanding of video content analysis, check out these resources:
Explore More Use Cases: Visit the Sonar by Perplexity to learn about its deep research capabilities. Small changes in this tutorial can help you explore even more use cases.
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord.
Explore Tutorials: Dive deeper into TwelveLabs capabilities with our comprehensive tutorials
We encourage you to use these resources to expand your knowledge and create innovative applications using TwelveLabs video understanding technology.
Introduction
What if you could search videos as easily as you search text over the web and get every insight with a trusted citation? 🎥🔍
Today, that’s still a missing piece of the web. Search engines don't consider the videos as the input to get the result. This leaves researchers, creators, and professionals stuck manually going through hours of footage, with no reliable way to extract structured insights or verify them.
Video Deep Research changes the way to look on to the video for the research. By combining TwelveLabs Analyze pegasus-1.2 for semantic video understanding with Sonar by Perplexity for citation-powered knowledge retrieval, it transforms videos into a searchable, trustworthy research resource.
Let’s explore how the Video Deep Research application works and how you can build a similar solution with the video understanding and deep research by using the TwelveLabs Python SDK and Perplexity Sonar.
You can explore the demo of the application here: Video Deep Research Application
Prerequisites
Generate an API key by signing up at the TwelveLabs Playground.
Sign Up on Sonar and generate the API KEY to access the model.
Find the repository for this application on Github Repository.
You should be familiar with Python, Flask, and Next.js
Demo Application
This demo application showcases how video understanding and knowledge retrieval can unlock a completely new way of doing research.
Users can simply upload a video or select from an already indexed video by connecting their TwelveLabs API Key. The application then processes the content, extracts structured insights, and links them to verifiable references, bridging the gap between video and trustworthy research.
Here, you’ll find a detailed walkthrough of the code and the demo so you can build and extend your own Video Deep Research powered application —
Working of the Application
The application supports two modes of interaction -
Using the TwelveLabs API Key: Connect your personal TwelveLabs API Key to access and interact with your own already indexed videos. Once connected, you can select an existing Index ID and respective video.
Upload a Video: When a video is uploaded, the application is designed to automatically use the default TwelveLabs API key for seamless setup. After the upload, the indexing process begins immediately. Once indexing is complete, the most recently uploaded video will be displayed as the latest available content. From this point onward, the query and citation workflow proceeds identically for both interaction modes, following the steps mentioned below.
The complete workflow of the application begins with configuring the TwelveLabs client. This requires setting up the TwelveLabs API key, either by using the environment-provided key or by allowing the user to connect their own key from the client side to access already indexed videos. Once the client is configured, the process follows a sequential flow as outlined below –
Fetch Indexes – Retrieve the list of indexes associated with the connected TwelveLabs account.
Select Video – Choose a video from the desired index for analysis.
Analyze Video – Perform video content analysis on the selected video using the provided query.
Deep Research – Combine the analyzed response with a structured prompt and the user’s query, then pass it to the Sonar research model for deeper reasoning and citation-backed insights.
This structured workflow ensures a smooth progression from video indexing through to advanced research, providing users with detailed, context-aware outputs.
Both approaches are illustrated in the architecture diagram below.
The flow is designed such that once a research response is generated, users can provide follow-up queries to request additional references or deeper insights around the same context. These subsequent queries are routed back into the Sonar research loop, which maintains contextual continuity and expands on the existing knowledge base. This iterative design ensures that each new query builds upon the prior results, allowing for progressively richer and more context-aware research outputs.
Preparation Steps
Obtain your API key from the TwelveLabs Playground and set up your environment variable.
Do create the Index, with the
pegasus-1.2selection via TwelveLabs Playground, and get theindex_idspecifically for this application.Clone the project from Github.
Do obtain the API KEY from the Sonar by Perplexity.
Create a
.envfile containing your TwelveLabs and Sonar credentials. An example of the environment setup can be found here.
Once you've completed these steps, you're ready to start developing!
Walkthrough for the Video Deep-Research App
This tutorial demonstrates how to build an application that can retrieve citations and relevant information from the web based on video content. The project uses Next.js for the frontend and a Flask API (with CORS enabled) for the backend. Our main focus will be on implementing the core backend utility that powers this video deep-research application, along with setting up the complete environment.
For detailed setup instructions and the full code structure, please refer to the README.md file in the GitHub repository.
1 - Workflow for Video Deep-Research Implementation
The most critical step in the workflow is the initialization and handling of the TwelveLabs API key. The application can either load the key directly from the environment for default usage or allow the user to provide their own API key via the client.
backend/service/twelvelabs_service.py (14-36 Line)
class TwelveLabsService: def __init__(self, api_key=None): # If no API key is provided, try to get it from environment variable if api_key is None: api_key = os.environ.get('TWELVELABS_API_KEY', '') self.api_key = api_key # Store API key in the instance self.client = TwelveLabs(api_key=api_key) # Intialize the TwelveLabs client
1.1 GET the Indexes
Once the user connects their TwelveLabs API key either through the portal or via the default mode where the key is loaded from the environment, the application retrieves all indexes associated with that account. The retrieved data is then structured and delivered to the frontend for display.
backend/service/twelvelabs_service.py (14-36 Line)
def get_indexes(self): try: print("Fetching indexes...") # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of indexes indexes = self.client.indexes.list() result = [] for index in indexes: # Append a dictionary with relevant index details result.append({ "id": index.id, "name": index.index_name }) print(f"ID: {index.id}") print(f" Name: {index.index_name}") return result except Exception as e: print(f"Error fetching indexes: {e}") return []
1.2 GET the list of videos, for respective Index ID
When a user selects an index, the application records the associated index_id. With this index_id, the system invokes the relevant method to fetch and return all videos linked to that index.
backend/service/twelvelabs_service.py (38-70 Line)
def get_videos(self, index_id, page=1): try: # Check if API key is available if not self.api_key: print("No API key available") return [] # Use TwelveLabs client to get a list of videos videos_response = self.client.indexes.videos.list(index_id=index_id, page=page) result = [] for video in videos_response.items: system_metadata = video.system_metadata hls_data = video.hls thumbnail_urls = hls_data.get('thumbnail_urls', []) if hls_data else [] thumbnail_url = thumbnail_urls[0] if thumbnail_urls else None video_url = hls_data.get('video_url') if hls_data else None # Append a dictionary with relevant video details result.append({ "id": video.id, "name": system_metadata.filename if system_metadata and system_metadata.filename else f'Video {video.id}', "duration": system_metadata.duration if system_metadata else 0, "thumbnail_url": thumbnail_url, "video_url": video_url, "width": system_metadata.width if system_metadata else 0, "height": system_metadata.height if system_metadata else 0, "fps": system_metadata.fps if system_metadata else 0, "size": system_metadata.size if system_metadata else 0 }) return result except Exception as e: print(f"Error fetching videos for index {index_id}: {e}") return []
1.3 Analyze the video content
When a video is selected and a research query is provided by the user, both the video_id and the query are passed to the analyze utility for video understanding. The query is appended to a predefined prompt, which enhances the context and ensures meaningful analyzed response. The prompt used for the video analysis is provided here.
backend/service/twelvelabs_service.py (72-81 Line)
def analyze_video(self, video_id, prompt): try: # Call the TwelveLabs client to analyze the video analysis_response = self.client.analyze( video_id=video_id, prompt=prompt ) return analysis_response.data except Exception as e: print(f"Error analyzing video {video_id}: {e}") raise e
1.4 Deep Research on Analyzed Content
After the initial analysis completes, the workflow proceeds to a deep-research phase powered by the sonar model. The deep_research call constructs a single payload that combines three elements, the user’s original query, the research prompt, and the analysis results and sends that structured input to sonar for further processing. Sonar returns a refined, structured response that includes source citations. The prompt for the deep research prompt can be found here.
backend/service/sonar_service.py (13-52 Line)
def deep_research(self, query, timeout=180): try: # Ensure API key is available if not self.api_key: raise ValueError("API key is required") payload = { "model": "sonar", "messages": [ {"role": "user", "content": query} ] } headers = { "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" } # POST request to the API endpoint with timeout response = requests.post( self.base_url, json=payload, headers=headers, timeout=timeout ) # Check if the response was successful if response.status_code == 200: return response.json() else: print(f"Error: {response.status_code} - {response.text}") return {"error": f"API request failed with status {response.status_code}"} except requests.exceptions.Timeout: print("Request timed out") return {"error": "Request timed out - Sonar research is taking too long"} except requests.exceptions.RequestException as e: print(f"Request error: {e}") return {"error": f"Network error: {str(e)}"} except Exception as e: print(f"Error in deep_research: {e}") return {"error": str(e)}
There are multiple Sonar variants available like sonar, sonar-reasoning, and sonar-deep-research. The sonar-deep-research model supports a reasoning_effort setting (low, medium, high), with medium as the default for a balanced trade-off between deep research and speed. Increasing the reasoning effort to “high” produces more citations and deeper insights but also increases response time and token usage, so choose the model and effort level based on the required thoroughness, latency tolerance, and cost.
By simply changing the model name to sonar-deep-research, the system produces more detailed reasoning along with a greater number of citations. This configuration enables deeper research and richer insights compared to the default sonar model. Below is a demonstration of the enhanced response generated —
1.5 Function calling workflow for the research
The workflow begins with the configuration of the TwelveLabs client, ensuring the API key, index ID, and video ID are properly validated. Once the setup is confirmed, the application fetches the video details from the TwelveLabs service. This ensures the selected video context is well-defined before proceeding further. The results are streamed back to the frontend in real-time using yield, which allows the UI to update progressively rather than waiting for the entire process to finish.
Next, the system invokes the analyze_video method of the TwelveLabs service class defined, passing in the selected video_id and the analysis prompt. The output of this analysis is then included into an enhanced research query, structured with a predefined template. This template enforces a markdown based response format as an instruction and ensures that both the analysis result and the user’s query are aligned into a consistent structure. The enhanced query is then sent to the Sonar service for deep research, which produces a refined and citation-backed response.
backend/routes/api_routes.py (31-162 Line)
def generate_workflow(twelvelabs_api_key, index_id, video_id, analysis_prompt, research_query, research_prompt_template): # Input validation if not twelvelabs_api_key: yield json.dumps({'type': 'error', 'message': 'TwelveLabs API key is required'}) + '\n' return if not index_id or not video_id: yield json.dumps({'type': 'error', 'message': 'Index ID and Video ID are required'}) + '\n' return if not research_query: yield json.dumps({'type': 'error', 'message': 'Research query is required'}) + '\n' return try: twelvelabs_service = TwelveLabsService(api_key=twelvelabs_api_key) # Step 1: Get video details yield safe_json_dumps({ 'type': 'progress', 'step': 'video_details', 'message': 'Fetching video details...', 'progress': 0 }) + '\n' video_details = twelvelabs_service.get_video_details(index_id, video_id) if not video_details: yield safe_json_dumps({'type': 'error', 'message': 'Could not retrieve video details'}) + '\n' return yield safe_json_dumps({ 'type': 'data', 'step': 'video_details', 'data': { 'id': video_details.get('_id', ''), 'filename': video_details.get('system_metadata', {}).get('filename', ''), 'duration': video_details.get('system_metadata', {}).get('duration', 0) }, 'progress': 33 }) + '\n' # Step 2: Analyze video yield safe_json_dumps({ 'type': 'progress', 'step': 'analysis', 'message': 'Analyzing video content...', 'progress': 33 }) + '\n' analysis_result = twelvelabs_service.analyze_video(video_id, analysis_prompt) yield safe_json_dumps({ 'type': 'data', 'step': 'analysis', 'data': analysis_result, 'progress': 66 }) + '\n' # Step 3: Research with context yield safe_json_dumps({ 'type': 'progress', 'step': 'research', 'message': 'Conducting deep research...', 'progress': 66 }) + '\n' enhanced_query = research_prompt_template.format( analysis_result=analysis_result, research_query=research_query ) sonar_service = SonarService() research_result = sonar_service.deep_research(enhanced_query, timeout=180) if 'error' in research_result: yield safe_json_dumps({'type': 'error', 'message': f'Research failed: {research_result["error"]}'}) + '\n' return # Extract research content research_content = "" if research_result and research_result.get('choices'): research_content = research_result['choices'][0].get('message', {}).get('content', '') # Send research content in chunks if large max_chunk_size = 10000 if len(research_content) > max_chunk_size: for i in range(0, len(research_content), max_chunk_size): chunk = research_content[i:i + max_chunk_size] is_final = (i + max_chunk_size) >= len(research_content) yield safe_json_dumps({ 'type': 'research_chunk', 'content': chunk, 'is_final': is_final, 'progress': 80 + (i / len(research_content)) * 20 }) + '\n' # Send completion with chunked content indicator yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': '[CHUNKED_CONTENT]' } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' else: # Send completion with research data yield safe_json_dumps({ 'type': 'complete', 'data': { 'research': { 'choices': [{ 'message': { 'content': research_content } }], 'citations': research_result.get('citations', [])[:10], 'usage': research_result.get('usage', {}) }, 'sources': research_result.get('search_results', [])[:10] }, 'progress': 100 }) + '\n' except Exception as e: yield safe_json_dumps({'type': 'error', 'message': str(e)}) + '\n'
To handle large research outputs, the workflow implements response chunking. Since Sonar may return extensive content with detailed reasoning and numerous citations, sending it as one large JSON risks exceeding payload size limits and causing serialization errors. To prevent this, the response is split into manageable chunks which are streamed sequentially. This design ensures scalability, avoids network bottlenecks, and maintains frontend responsiveness.
2 - Video upload indexing workflow essential
In the alternate workflow, instead of relying on pre-indexed videos, the user directly uploads a new video file. The upload_video_file method handles this process by validating the required inputs such as the API key, index ID, and file path. Once validated, it initiates a request to TwelveLabs task endpoint, creating an upload task with the video file attached. If the task creation is successful, a task ID is returned, which is used to monitor the indexing status.
The method then enters a polling loop, periodically checking the task status until it is either completed, failed, or the defined timeout is reached. When the indexing succeeds, the response includes a video_id, which uniquely identifies the uploaded video and makes it immediately available for further analysis. This ensures the uploaded video becomes the latest available video on the portal. In case of failure or timeout, appropriate error messages are returned, providing robust error handling for the upload and indexing process.
backend/service/twelvelabs_service.py (145-207 Line)
def upload_video_file(self, index_id: str, file_path: str, timeout_seconds: int = 900): import sys try: if not self.api_key: return {"error": "Missing TwelveLabs API key"} if not index_id: return {"error": "Missing index_id"} if not os.path.exists(file_path): return {"error": f"File not found: {file_path}"} print(f"Starting upload for file: {file_path}", file=sys.stderr) tasks_url = "https://api.twelvelabs.io/v1.3/tasks" headers = { "x-api-key": self.api_key } # Create upload task with open(file_path, "rb") as f: files = { "video_file": (os.path.basename(file_path), f) } data = { "index_id": index_id } resp = requests.post(tasks_url, headers=headers, files=files, data=data) if resp.status_code not in (200, 201): return {"error": f"Failed to create upload task: {resp.status_code} {resp.text}"} resp_json = resp.json() if resp.text else {} task_id = resp_json.get("id") or resp_json.get("task_id") or resp_json.get("_id") if not task_id: return {"error": f"No task id returned: {resp_json}"} # Poll task until ready import time start_time = time.time() print(f"Starting to poll task {task_id} for completion...", file=sys.stderr) while time.time() - start_time < timeout_seconds: r = requests.get(f"{tasks_url}/{task_id}", headers=headers) if r.status_code != 200: time.sleep(2) continue task = r.json() if r.text else {} status = task.get("status") print(f"Task {task_id} status: {status}", file=sys.stderr) if status in ("ready", "completed"): video_id = task.get("video_id") or (task.get("data") or {}).get("video_id") print(f"Indexing completed successfully! Video ID: {video_id}", file=sys.stderr) return {"status": status, "video_id": video_id, "task": task} if status in ("failed", "error"): print(f"Indexing failed with status: {status}", file=sys.stderr) return {"error": f"Indexing failed with status {status}", "task": task} time.sleep(2) print(f"Upload timed out after {timeout_seconds} seconds", file=sys.stderr) return {"error": "Upload timed out"}
The subsequent workflow pipeline follows the same sequence described earlier, once a video is uploaded and indexed, the generated video_id is passed through the workflow for analysis, research enhancement, and citation-backed response. This ensures consistency between the default mode (pre-indexed videos) and the alternate mode (uploaded videos), while maintaining a unified workflow. Below is a quick demonstration highlighting the process of uploading a video, performing indexing, and executing the complete pipeline —
The application supports handling the TwelveLabs API key directly on the client side. This provides users with the flexibility to connect their own API key, enabling them to analyze and conduct research on their previously indexed videos without relying on the default key.
More Ideas to Experiment with the Tutorial
Exploring how video understanding and connected to verifiable research opens the door to even more powerful applications. Here are some experimental directions you can try with TwelveLabs Analyze and Sonar by Perplexity —
🔍 Deep Video Fact-Checking — Automatically verify statements and claims in video content by linking extracted insights to trusted sources and citations.
📑 Semantic Research Review — Generate structured summaries/reviews of video content, highlighting key ideas, references, and actionable insights for faster research.
📚 Enhanced Learning Workflows — Combine video insights with external knowledge repositories to create interactive or guided learning experiences for researchers, students, and content creators.
Conclusion
This tutorial demonstrates how video understanding can transform the way we conduct research and interact with video content. By combining TwelveLabs Analyze for deep video analysis with Sonar by Perplexity for knowledge retrieval and citation, we’ve built a system that turns videos from passive media into structured, citable research tools which empowers researchers, creators, and professionals to explore video content in a meaningful and trustworthy way.
Additional Resources
Learn more about the analyze video engine—Pegasus-1.2. To explore TwelveLabs further and enhance your understanding of video content analysis, check out these resources:
Explore More Use Cases: Visit the Sonar by Perplexity to learn about its deep research capabilities. Small changes in this tutorial can help you explore even more use cases.
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord.
Explore Tutorials: Dive deeper into TwelveLabs capabilities with our comprehensive tutorials
We encourage you to use these resources to expand your knowledge and create innovative applications using TwelveLabs video understanding technology.




©
2026년
주식회사 트웰브랩스. All Rights Reserved

©
2026년
주식회사 트웰브랩스. All Rights Reserved

©
2026년
주식회사 트웰브랩스. All Rights Reserved


