" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Product
Pegasus 1 Beta: 비디오-언어 모델링의 새로운 기준을 제시
Twelve Labs가 Pegasus-1의 오픈 베타 버전을 출시합니다. 이번 버전은 170억 개의 파라미터를 갖춘 알파 버전에서 한 단계 업그레이드되었으며, 비디오 처리 해상도가 15배 향상되었습니다. 또한, 개선된 학습 기술을 통해 Gemini Pro 1.5를 포함한 타 모델들과의 비교에서 비디오 질문 답변, 요약 및 대화 벤치마크 기준 최상위(SOTA) 수준의 성능을 입증했습니다.
Twelve Labs가 Pegasus-1의 오픈 베타 버전을 출시합니다. 이번 버전은 170억 개의 파라미터를 갖춘 알파 버전에서 한 단계 업그레이드되었으며, 비디오 처리 해상도가 15배 향상되었습니다. 또한, 개선된 학습 기술을 통해 Gemini Pro 1.5를 포함한 타 모델들과의 비교에서 비디오 질문 답변, 요약 및 대화 벤치마크 기준 최상위(SOTA) 수준의 성능을 입증했습니다.

In this article
No headings found on page
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2024. 3. 12.
10분
링크 복사하기
arXiV 및 HuggingFace에서 Pegasus-1 기술 보고서를 확인해 보세요!
1 - 소개 (Introduction)
Twelve Labs의 목표는 혁신적인 멀티모달 AI 모델을 개발하여 비디오 이해 기술을 한 단계 더 진보시키는 것입니다. 이전 포스트인 "Video-to-Text 및 Pegasus-1 (80B) 소개"에서 Pegasus-1 알파 버전을 처음 공개해 드린 바 있습니다. 이 파운데이션 모델은 비디오 입력을 통해 상세한 설명 텍스트를 생성할 수 있습니다. 그리고 오늘, 드디어 Pegasus-1의 오픈 베타 출시 소식을 전해드리게 되어 매우 기쁩니다.
Pegasus-1은 복잡한 비디오 콘텐츠를 이해하고 이를 명확하게 표현하도록 설계되어, 우리가 멀티미디어와 상호작용하고 분석하는 방식을 혁신적으로 변화시킵니다. 약 170억 개의 매개변수(parameter)를 갖춘 이 모델은 멀티모달 AI 분야의 중요한 진전을 의미하며, 독보적인 정확도와 디테일로 비디오 입력으로부터 언어를 처리하고 생성해 냅니다.
이번 업데이트에서는 알파 출시 이후 Pegasus-1에 적용된 다양한 개선 사항을 살펴봅니다. 여기에는 데이터 품질, 비디오 처리 및 학습 방법의 개선이 포함됩니다. 또한 비디오 요약, 질의응답 및 대화 모델링 전반에서 Pegasus-1의 독보적인 성능을 입증하는 주요 상용 및 오픈소스 모델과의 벤치마크 결과도 공유합니다. 정량적 지표를 넘어, Pegasus-1은 한층 강화된 글로벌 상식 지식(world knowledge)과 상세한 시각적 정보를 정교하게 포착하는 능력을 통해 한 차원 높은 정성적 향상을 보여줍니다.
2 - 모델 개요 (Model Overview)
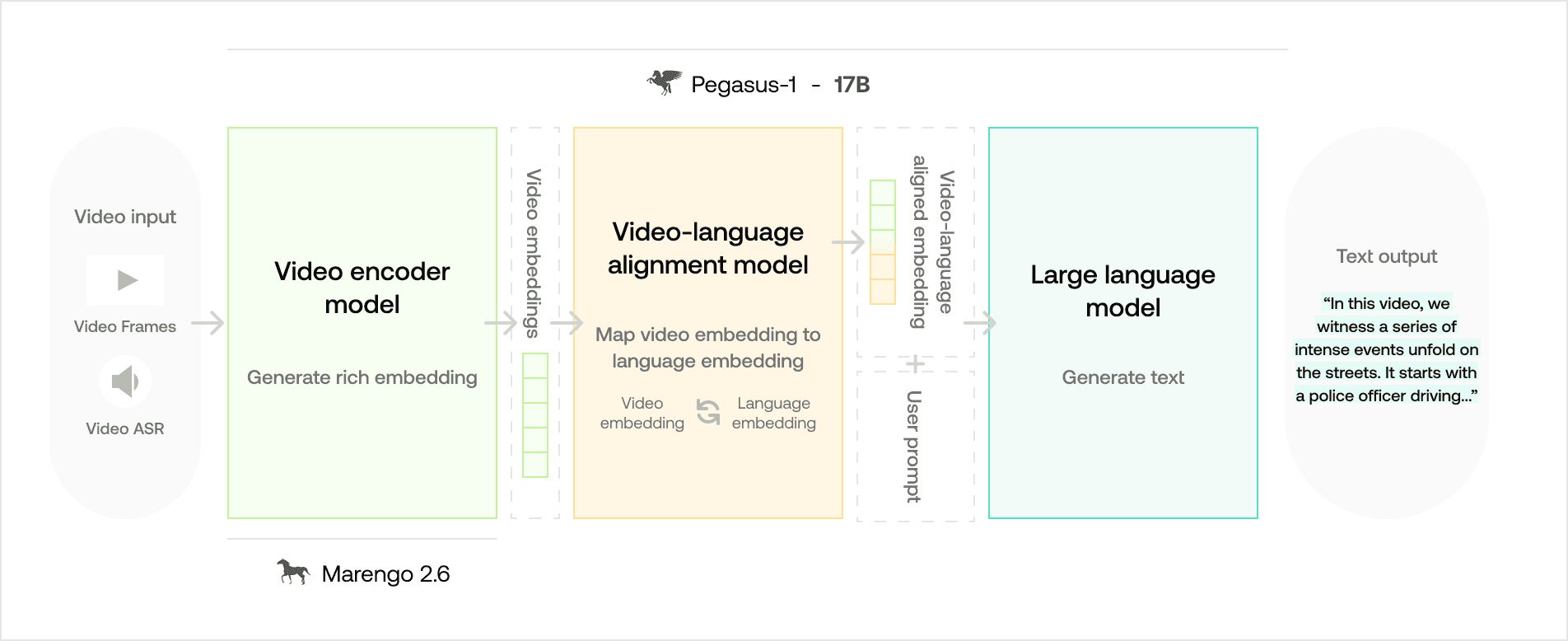
짧게 요약하자면, Pegasus-1은 비디오 콘텐츠와 언어 사이의 간극을 좁혀 기계가 비디오 입력을 바탕으로 텍스트를 해석하고 생성할 수 있도록 설계된 멀티모달 파운데이션 모델입니다. Pegasus-1의 아키텍처는 크게 세 가지 핵심 컴포넌트로 구성됩니다.
비디오 인코더 모델 (Video encoder model)은 비디오 입력을 처리하여 비디오 프레임과 오디오 음성 인식(ASR) 데이터 모두로부터 풍부한 임베딩을 생성합니다. 이 임베딩은 비디오 콘텐츠의 시각적 및 청각적 속성을 압축하여 담아낸 고밀도 표현입니다.
비디오-언어 정렬 모델 (Video-language alignment model)은 비디오 임베딩을 그에 대응하는 언어 임베딩에 매핑하여, 비디오와 텍스트 표현이 일치하는 공유 공간을 생성합니다. 이 정렬 프로세스는 모델이 비디오 속 시각 파일과 이를 설명하는 언어 간의 연관성을 파악하는 데 매우 중요합니다.
대규모 언어 모델 (LLM) 디코더는 이 정렬된 임베딩과 사용자 프롬프트를 입력받아 맥락에 맞춰 자연스럽고 정교한 텍스트 출력을 생성합니다. 이 출력은 설명 위주의 요약부터 비디오 내용에 대한 특정 질문의 답변까지 다양하게 구현됩니다.
알파 버전과 비교했을 때, Pegasus-1 오픈 베타 버전은 약 170억 개의 매개변수를 자랑하며, 비디오 데이터 기반의 텍스트 해석 및 생성 분야에서 가볍고도 강력한 성능을 보여줍니다.
3 - 주요 개선 사항 (Major Improvements)
알파 단계에서 오픈 베타 단계로 진화하면서, 저희는 모델을 지속적으로 정제하고 강화하여 한층 더 정확하고 고도화된 비디오-언어 이해를 제공해 왔습니다. 이러한 개선은 고품질 데이터, 최적화된 비디오 처리, 그리고 정교화된 학습 기법이라는 세 가지 핵심 요소를 통해 이루어졌습니다.
3.1 - 데이터 개선 (Data Improvement)
기존 연구 결과들과 마찬가지로, 저희 역시 단순히 데이터의 절대적인 양을 늘리는 것보다 캡션의 품질과 상세함(granularity)이 모델 성능에 훨씬 더 결정적인 영향을 미친다는 점을 확인했습니다. 일례로, 10만 개의 고품질 비디오-텍스트 쌍(pair)으로 학습된 Pegasus-1은 낮은 품질의 캡션을 가진 대규모 데이터셋(1,000만 개 이상)으로 학습된 동일한 아키텍처의 성능을 한참 능가합니다.
이러한 실험적 근거를 바탕으로, 저희는 앞서 언급한 1,000만 개 이상의 비디오에 대해 고품질 비디오 캡션을 실시간으로 생성할 수 있는 효율적인 데이터 어노테이션 파이프라인을 구축했습니다. 이처럼 방대한 양의 고품질 비디오-텍스트 쌍을 통해 학습을 마친 Pegasus는 타 모델에서는 찾아볼 수 없는 독보적이고 강력한 비디오 이해 성능을 갖추게 되었습니다.
3.2 - 비디오 처리 개선 (Video Processing Improvement)
저희는 공간적 및 시간적 해상도를 모두 최적화하기 위해 비디오 처리 파이프라인에 대대적인 변화를 주었습니다. 프레임당 패치 수(공간적 해상도)를 10배 늘리고 프레임 수(시간적 해상도)를 1.5배 늘려, 결과적으로 비디오당 총 패치 수를 15배나 증가시켰습니다. 이러한 개선 덕분에 Pegasus-1은 프레임당 훨씬 더 풍부한 정보를 포착해 표현할 수 있습니다.
또한, 정성적 및 정량적 분석(특히 질의응답 데이터셋 결과)을 통해 확인된 것처럼 이제 Pegasus-1은 비디오 전체의 내러티브와 맥락을 훨씬 더 명확하고 일관성 있게 파악할 수 있습니다.
3.3 - 학습 기법 개선 (Training Improvement)
멀티모달 파운데이션 모델인 Pegasus-1은 여러 단계에 걸쳐 대규모 멀티모달 데이터셋으로 학습됩니다. 그러나 다단계 학습은 보통 파괴적 망각(catastrophic forgetting)이라 불리는 한계에 부딪히기 쉽습니다. 모델이 새로운 정보를 학습하는 과정에서 이전에 학습했던 기존 정보를 쉽게 잊어버리는 현상입니다. 이러한 현상은 모달리티 간의 순차적 학습 과정을 거치는 멀티모달 모델에서 특히 더 두드러집니다.
이를 해결하기 위해, 저희는 새로운 지식 습득과 기존 정보 보존 사이의 정교한 균형을 유지할 수 있도록 특별히 설계된 전략적 학습 체계(strategic training regimen)를 도입했습니다. 이 접근법의 핵심은 학습 프로세스 전반에 걸쳐 모델 매개변수를 선택적으로 업데이트(unfreezing)하고 학습률(learning rates)을 세밀하게 제어하는 데 있습니다.
Pegasus-1 오픈 베타 버전은 알파 버전과 비교하여 세밀한 시간적 모멘트 포착 기능이 크게 향상되었으며, 환각(hallucination) 현상이 크게 감소하여 다양한 비디오 도메인에 걸쳐 높은 신뢰성과 일관성을 확보했습니다. 또한 확장된 월드 지식을 보여주고, 특정 단일 장면에만 집중하기보다 시간 순서대로 다양한 모멘트를 나열하는 능력이 크게 향상되었습니다.
4 - 정량적 벤치마크 결과
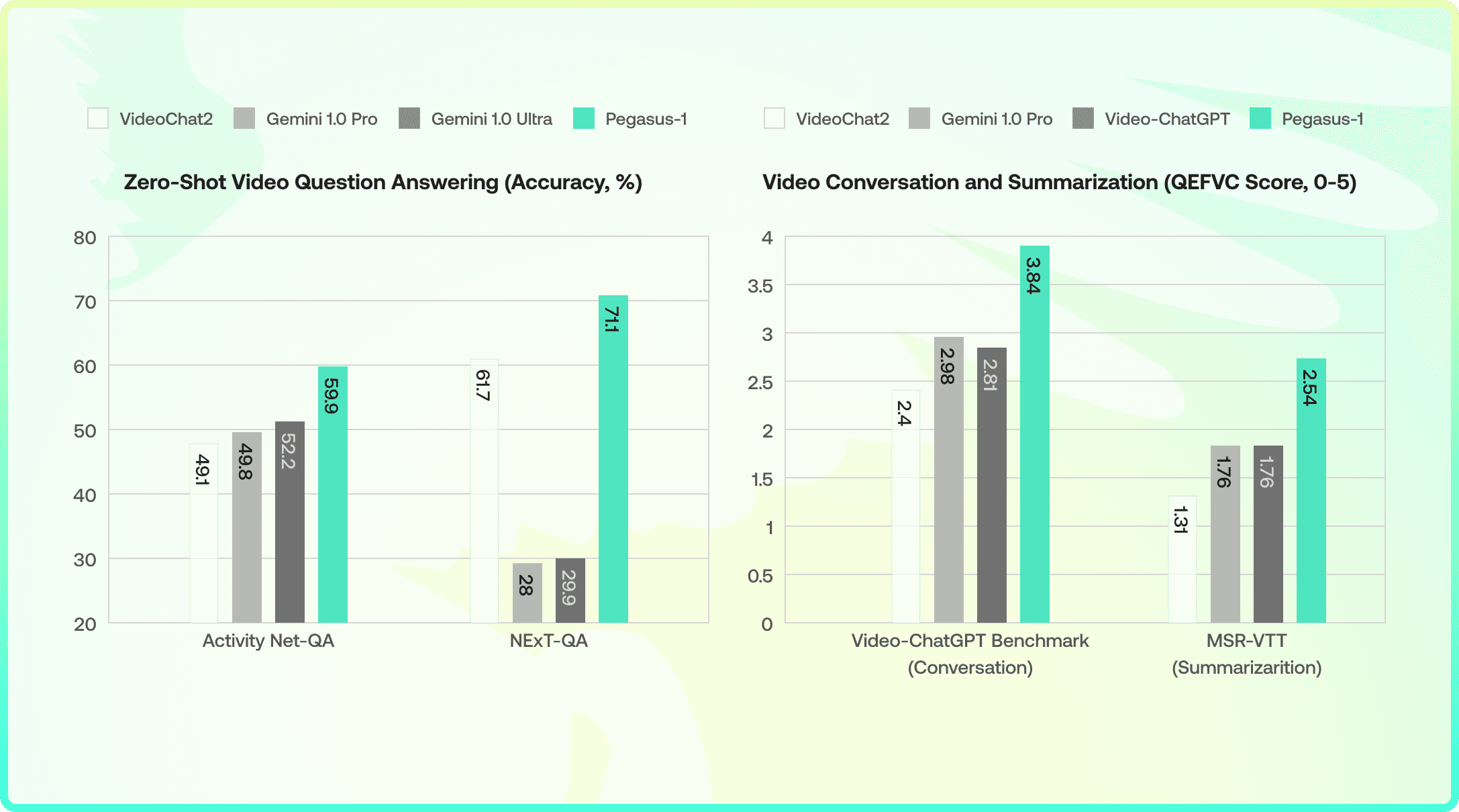
철저히 검증된 당사의 벤치마크 평가를 통해, Pegasus-1은 상용 및 오픈소스 모델 모두를 아우르는 다양한 모델군과 비교 분석되었습니다. 이 섹션에서는 여러 비디오-언어 모델링 태스크에서 타 모델들과 비교한 Pegasus-1의 구체적인 성능 수치를 명확히 제시합니다.
4.1 - 베이스라인 모델 (Baseline Models)
Pegasus-1의 벤치마크 평가에 사용된 베이스라인 모델 목록은 다음과 같습니다.
Gemini Pro (1.5): 2023년 11월에 처음 공개되고 가장 최근인 2024년 2월에 업데이트된 Google DeepMind의 상용 멀티모달 모델로, 뛰어난 비디오-언어 이해 성능으로 잘 알려져 있습니다. 본 비교에는 최신 버전인 Gemini Pro 1.5가 사용되었습니다.
Whisper + ChatGPT-3.5 (OpenAI): 이 조합은 업계에서 흔히 비디오 요약에 사용하는 접근법 중 하나입니다. 최고 수준의 음성 인식 모델(STT)과 LLM을 결합하여 가동되며, 요약은 주로 비디오의 음성 대화 내용을 바탕으로 처리됩니다. 비디오 내의 귀중한 '시각적 정보'를 인지하지 못한다는 치명적인 한계가 있습니다.
Vendor A’s Summary API: 오디오 및 비디오 요약 생성에 널리 사용되는 시중의 상용 제품입니다. Vendor A의 요약 API는 오직 텍스트 트랜스크립션 데이터와 구어체 언어 모델(ASR+ChatGPT3.5와 유사)에 기인하여 결과물을 도출하는 것으로 파악됩니다.
Video-ChatGPT: Maaz 등이 개발한 모델(2023년 6월 출시)로 채팅 인터페이스를 탑재한 비디오 언어 모델입니다. 비디오 프레임을 처리하여 비디오 서사 내의 시각적 이벤트를 파악합니다. 단, 비디오 내의 다이얼로그나 음성 정보는 활용하지 못한다는 점이 피력됩니다.
VideoChat2: Li 등이 개발한 모델(2023년 11월 출시)로, 다양한 지시어 튜닝(instruction-tuning) 데이터를 탑재하여 프로그레시브 멀티모달 학습을 설계한 최고 수준의 오픈소스 멀티모달 LLM입니다.
시각 기반의 이미지-언어 모델인 LLaVA 및 GPT-4V 등은 우리의 비교 대상에서 제외되었습니다. 이 모델들은 당사가 평가하려는 태스크의 핵심 요건인 네이티브 비디오 처리 기능이 결여되어 있기 때문입니다. 구체적인 한계는 아래와 같습니다.
해당 모델들의 상당수는 오직 완벽한 단일 이미지만 인식 가능하여, 대부분의 비디오 벤치마크 데이터셋에서 매우 저조한 성능을 보입니다.
일부 모델(예: GPT-4V)은 여러 이미지를 한 번에 처리할 수 있으나, 한 번에 처리할 수 있는 비디오 프레임 수가 극히 소량(10프레임 이하)에 불과하여 1분이 넘어가는 대부분의 실무 비디오 처리에 한계가 있습니다.
이미지 기반 모델은 비디오 콘텐츠 특유의 유기적이고 역동적인 내러티브 맥락을 온전히 처리하는 데 태생적 한계를 보입니다. 입력을 유기적인 비디오가 아닌 정적인 이미지의 나열로만 학습하기 때문입니다.
또한, 이러한 이미지 기반 모델들이 전체 비디오를 구동 및 처리하기 위해 요구되는 실행 시간은 실제 서비스 및 프로덕션 환경에 적용하기에 지나치게 깁니다. 비디오 속 내러티브의 흐름과 액션을 직관적으로 파악하는 데 필수적인 시간 축(temporal dimension)을 효율적으로 다루는 기술적 설계가 부족하기 때문입니다.
4.2 - 비디오 질의응답 결과 (Video QA)
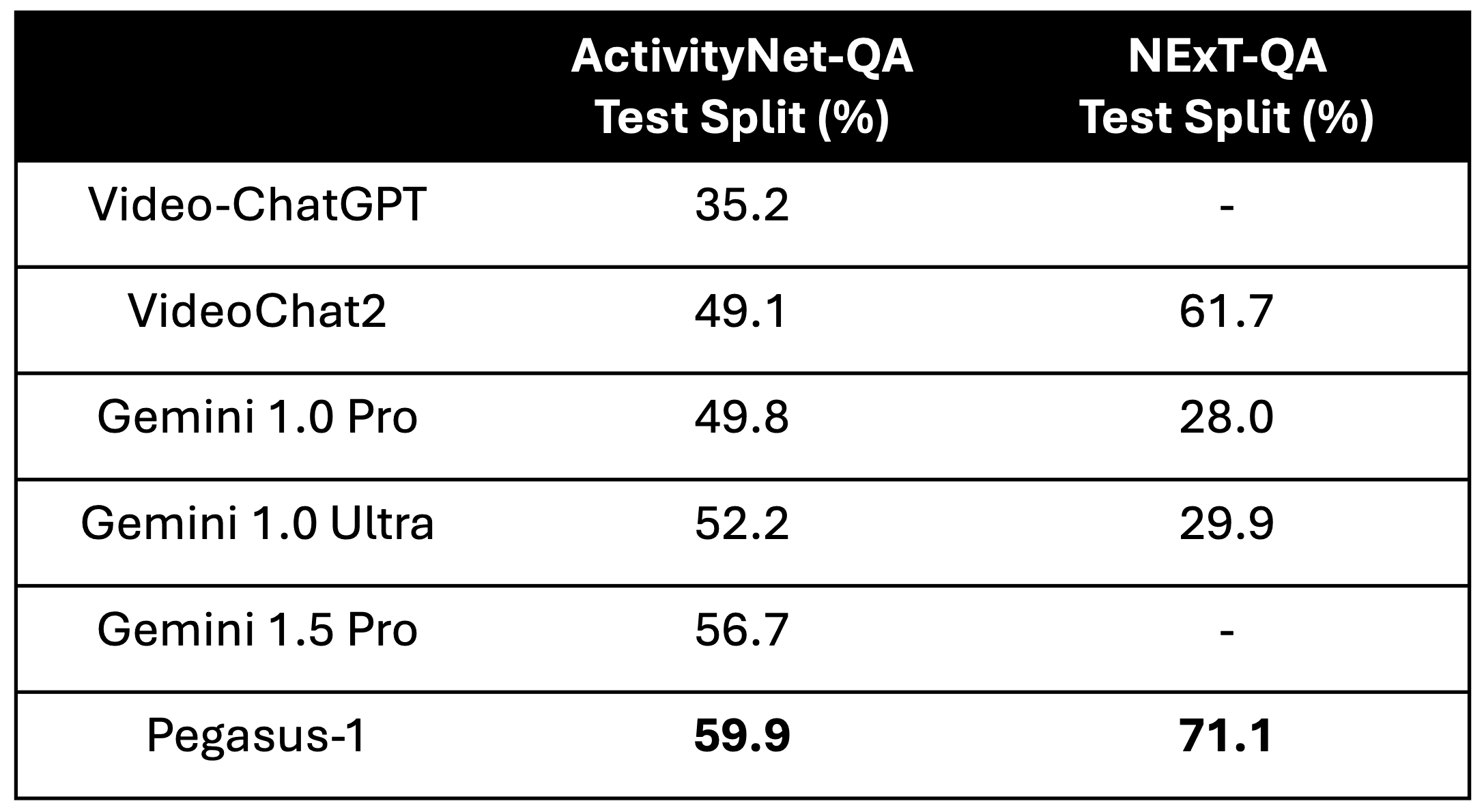
비디오 질의응답(Video QA) 분야에서, Pegasus-1은 별도의 파인튜닝 프로세스 없이도 ActivityNet-QA 및 NExT-QA 벤치마크 모두에서 뛰어난 제로샷(zero-shot) 성능을 달성했습니다. 특정 태스크 전용 학습 없이도, 다양한 도메인의 비디오 내용을 유연하게 일반화하여 핵심 질문에 아주 높은 신뢰도로 올바른 답을 도출합니다.
4.3 - 비디오 대화 결과 (Video Conversations)

Video-ChatGPT 벤치마크(QEFVC라고도 불림) 결과는 비디오 대화를 처리하는 데 있어서 Pegasus-1의 월등한 성능을 여과 없이 표현합니다. 정확성(Correctness), 디테일(Detail), 컨텍스트(Context), 시간 정보 이해(Temporal understanding), 일관성(Consistency) 수치 모두에서 시장 타 모델들을 크게 앞질렀습니다. 특히 Pegasus-1은 정확성에서 3.79, 설명 디테일에서 4.29를 획득하여, 인물 간의 정교한 대화 맥락과 상황적 context를 능숙하게 파악함을 스스로 입증했습니다.
4.4 - 비디오 요약 결과 (Video Summarization)
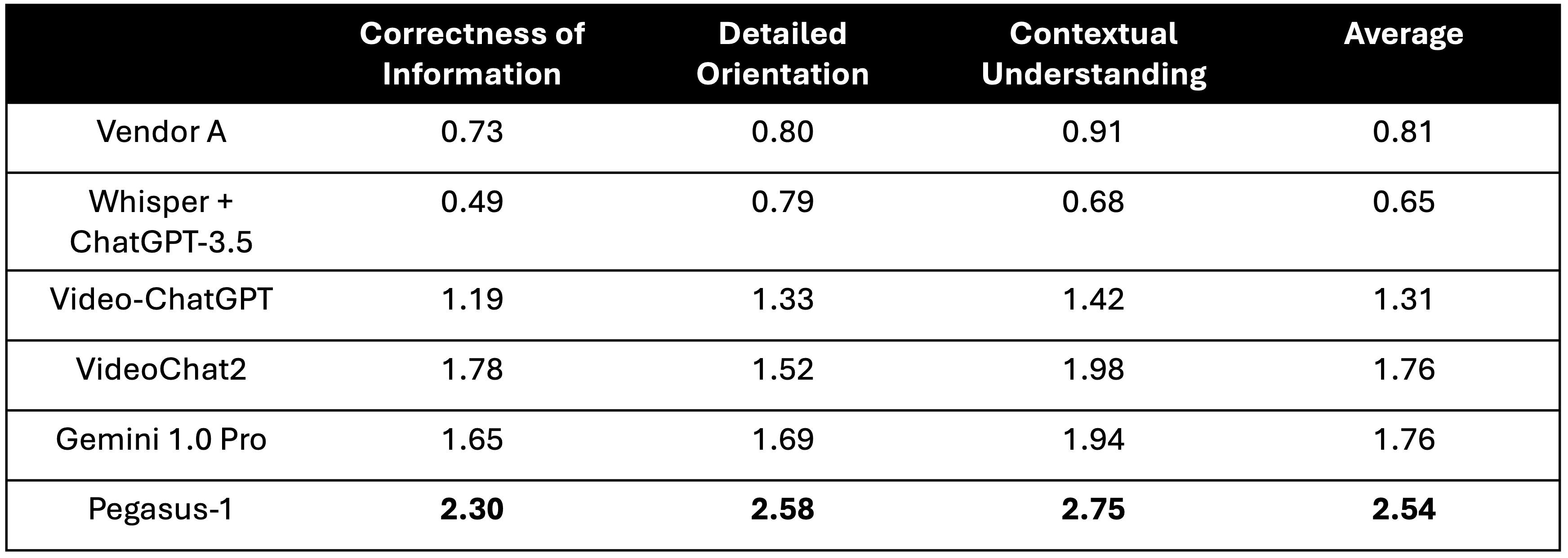
마지막으로, Pegasus-1은 비디오를 요약하는 영역에서도 압도적인 역량을 증명해 보였습니다. MSR-VTT 데이터셋을 대상으로 VideoChatGPT의 상세 평가 지표 시스템을 적용하여 요약 성능 빅매치를 진행했습니다 (요약 태스크 특성상 시간 정보 이해 및 일관성 지표는 제외). 상기 데이터 결과가 증명하듯 Pegasus-1은 모든 정량적 평가에서 경쟁 베이스라인 모델들을 큰 격차로 따돌렸습니다.
이 종합적인 벤치마크 결과를 통해 Pegasus-1은 비디오-언어 처리 모델링 분야의 선두 주자로 우뚝 섰으며, 제로샷 요약 성능과 뛰어난 범용 비디오 태스크 수행 능력에 있어 새로운 글로벌 표준을 정립했습니다.
5 - 구체적인 정성적 사용 예시 (Qualitative Examples)
다양한 도메인에서 엄선되고 무작위로 추출된 실제 케이스를 통해 Pegasus-1의 실제 작동 형태를 직관적으로 체험해 보세요.
이러닝 비디오 (E-Learning Video)
생성된 타이틀 (Generated Title)
텐트 설치하기: 캐나다 국립공원 관리청과 함께하는 캠핑 초보자 가이드
생성된 토픽 (Generated Topic)
캠핑: 캐나다 국립공원에서 안전하게 텐트 치고 고정하기
생성된 해시태그 (Generated Hashtags)
#캠핑, #텐트, #설치하기, #화로대, #안전, #초보캠핑, #캐나다국립공원
생성된 비디오 챕터 (Generated Chapters)
1단계: 사이트 선정 00:00:00 - 00:00:08
적절한 캠핑 사이트를 선택하고 텐트 설치 준비하기.

2단계: 화로 구축 00:00:09 - 00:00:36
조리 및 보온을 위한 안전한 모닥불 화로 만들기.

3단계: 텐트 펼치기 00:00:37 - 00:01:14
텐트를 바닥에 펼쳐놓고 위치 조절하기.

4단계: 지면 고정 00:01:14 - 00:01:48
텐트가 바람에 날아가지 않도록 팩을 사용해 단단히 지면에 고정하기.

5단계: 플라이 시트 장착 00:01:49 - 00:01:54
비와 이슬을 막기 위해 텐트 상단에 레인플라이 씌우기.

6단계: 내부 세팅 00:01:55 - 00:02:16
텐트 내부에 매트와 침구 등 장비를 배치해 편안한 보금자리 만들기.

7단계: 텐트 철수 00:02:17 - 00:02:30
설치된 텐트의 장비를 치우고 안전하게 해체하기.

8단계: 패킹하기 00:02:31 - 00:02:58
텐트를 잘 접어서 전용 가방에 깔끔하게 보관하기.

9단계: 교육 프로그램 알아보기 00:03:00 - 00:03:06
캐나다 국립공원 관리청의 교육 캠페인 소개 안내.

광고 비디오 (Ad Video)

맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 광고가 브랜드의 메시지를 전달하기 위해 인물들의 표정을 어떻게 활용하고 있는지 분석해 줘.
답변(Output): 본 광고는 브랜드 특유의 우아함과 기쁨, 럭셔리한 정취를 전달하기 위해 인물들의 표정을 고도로 기획하여 배치하고 있습니다. 광고 속 모델들은 당당하면서도 따뜻한 미소를 짓고 있는데, 이는 불가리(Bvlgari) 주얼리가 선사하는 내면의 행복감과 착용자의 아름다움을 한층 극대화해 준다는 인상을 심어 줍니다. 이 미소 띤 표정들은 시청자에게 긍정적인 감정을 전달하며 타겟 오디언스와 브랜드 간의 감정적 교감을 즉각적으로 형성합니다.
나아가, 모델들의 차분하고 기품 있는 표정은 브랜드의 클래식하고 정제된 가치를 잘 대변합니다. 주얼리를 클로즈업 사진처럼 다각도로 조명하며 모델의 얼굴과 표정을 함께 교차하여 비춰줌으로써, 디바이스 표면 위에 감도는 긍정적이고 경이로운 무드를 독자에게 은밀히 주입합니다. 이를 통해 시청자의 소망과 욕구를 자극하여 주얼리를 고급스러운 동경의 대상으로서 확고하게 포지셔닝합니다.
비디오의 기본적인 전개에 비추어 볼 때, 이 광고는 다양한 배경 속에서 다채로운 불가리 컬렉션을 선보이는 여성 모델의 시선을 따라 흘러갑니다. 도입부에서는 주얼리와 귀걸이를 착용한 고혹적인 여성의 자태로 시작하는데, 그녀 옆 고목 나무 기둥 부근에 불가리 브랜드 로고가 웅장하게 안착되어 있습니다. 이어 다른 세련된 드레스를 매칭하였으나 동일한 네크리스 컬렉션을 갖춘 채 나무가 늘어선 우아한 저택 도로를 향해 걸어나가는 시퀀스로 자연스럽게 전환됩니다. 이후 화려한 인테리어 속 내부 공간으로 신(scene)이 연결되며, 섬세한 펜던트가 입혀진 목걸이부터 시그니처 링 반지를 감상하는 명확한 스포트라이트를 지속 도출합니다.
동시에 고전적인 럭셔리와 신비로움을 상징하는 공작새 및 깃털 모티브가 장면 곳곳에 은유적으로 개입됩니다. 후반부에 접어들면서 주인공 모델 곁에 매혹적인 보조 인물이 함께 가세하여 컬렉션의 깊이를 입체화합니다. 광고의 대미는 불가리 고유의 인장 로고와 함께 'Wonderful Extravaganza' 및 'Bvlgari Rome'이라는 텍스트가 강렬하게 부각되며 세련되고 웅장한 여운에 마침표를 찍습니다.
요약하자면, 본 광고는 환희와 세련미가 넘치는 미소 표현 기법을 적확하게 사용하고 있습니다. 럭셔리한 인프라와 공작 요소를 매혹적으로 레이어링하여 궁극의 브랜드 헤리티지와 압도적인 수작업 미학을 강력하게 각인시킵니다.
영화 예고편 비디오 (Movie Trailer Video)

맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 비디오를 어린아이들에게 추천해도 괜찮을까?
답변(Output): 비디오 콘텐츠의 입체적인 시각 분석 결과에 근거해 판단할 때, 이 영상을 어린 자녀에게 시청하게 하는 것은 권장되지 않습니다. 영상 전반에 하드보일드 성격의 거친 액션 시퀀스와 무기류 위주의 시각적 긴장 요소, 그리고 성숙한 타겟층을 위한 긴박하고 어두운 무드의 테마가 빈번하게 노출되기 때문입니다. 트레일러의 흐름상 미스터리하고 스릴 있는 범죄 느와르 성향의 영화 혹은 드라마 장르에 속하는 작품으로 강력하게 유추됩니다.
비디오는 타오르는 듯한 주황색 톤의 강렬한 타이틀 카드 디자인으로 문을 열며, 이어 촛불들이 은빛 배경에 매달려 엄숙하고 우스스한 분위기를 내뿜는 성당 내부를 비춥니다. 수트를 단정히 입은 남성이 제단을 지나 위풍당당하게 걸어가고 있고, 그 뒤를 동일한 피트의 신사가 따릅니다. 직후 미스터리한 음모감을 자극하듯 여인과 남성의 밀도 높은 포옹 장면이 조명되어 성인용 멜로 혹은 서스펜스 드라마 서사를 강력하게 암시합니다.
예고편이 진전되면서 가파르고 손에 땀을 쥐게 하는 시퀀스들이 연이어 몰아칩니다. 적대 세력인 두 남성 간의 단호한 신경전 대치 상태, 조심스럽게 포켓 시계를 응시하는 고독한 침묵의 순간, 인물 간의 차갑고 의미심장한 설전, 그리고 어두운 심야 도심의 도로 위를 돌파하는 타이트한 자동차 체이싱 카레이스 트랙 장면 등이 대표적입니다. 도망치는 배후와 더불어 강박적으로 흔들리는 사막 오지 풍경, 폭발의 화마를 유연하게 뚫고 뒤돌아 유유히 걸어나오는 요원들의 백뷰 샷 역시 성인 지향적인 하드 보일드 무비를 완벽하게 가리킵니다.
구체적으로 살상력을 품은 소형 권총 장비를 클로즈업해 유심히 응시하는 빌런의 모습이 수차례 포함되어 심각한 물리적 타격을 암시합니다. 영상의 마무리 연출 역시 강렬합니다. 붉게 타오르는 석양 아래 고독하게 서 있는 에펠탑 주변을 비춘 다음, 제목 텍스트인 "IN MARC A DANCER"와 개봉 예고일 "MARCH 24"가 부상하며 짙은 잔상을 배출하고 마무리됩니다.
즉, 성인 지향적인 타격신과 폭발 등의 위협 수위가 결부된 자극이 포진된 미디어이므로 미취학 및 소아 연령층의 시청에는 적합지 않습니다.
6 - 한계점 (Limitations)
안전성 및 편향 (Safety & Biases): Pegasus-1은 철저한 안전 장치와 필터 프로세스를 바탕으로 정밀 설계되었습니다. 하지만 오픈 필드의 거센 시나리오 하에 구동되는 대형 신경망 특성상, 일정한 통제 범위를 벗어날 경우 부적절한 설명 결과물이 표출될 여지는 소수 존재할 수 있습니다. 당사는 비디오 파운데이션 모델에 대한 완벽한 윤리 검증과 방어망 성장을 위한 안전 연구를 다각도로 고수하고 있습니다. 추후 내부 테스트와 학계 데이터 피드백 분석들이 일단락되는 시점에 보다 입체성 있는 윤리 백서를 대외 공개할 예정입니다.
지원 비디오 제한 (Video Duration): 현재 당사 정식 API는 최소 4초에서 최대 20분 내외 분량의 비디오 스트림 처리를 안정 영역으로 확보하고 있습니다. 비디오의 대규모 로 변형 및 토큰 분석 시 부하를 막기 위해 연산 하드웨어 용량을 감안해 설계한 스펙 라인업입니다. 대규모 영화 및 롱폼 영상의 완벽한 핸들링을 도모하려면 사용자가 프레임 영역을 일정 분절로 분배해 업로드해야 합니다. 향후 업데이트 플랜을 고려하여 초대용량 장기 비디오 포맷도 네이티브하게 온전히 커버 가능한 업데이트가 곧 구축될 예정입니다.
환각 현상 (Hallucinations): Pegasus-1 모델 역시 일반적인 생성 AI처럼 드물게 실시간 오정답 데이터를 정교한 어조로 생성해 내는 환각 문제를 겪을 확률이 존재합니다. 알파 버전에 비해 이 확률을 강력히 낮춘 상태이지만, 매우 섬세하고 정확한 증명이 핵심인 산업 및 연구 도메인 전반에 사용 시 오답 교차 체크 장치를 늘 수반해 실행하시기를 거듭 강조드립니다.
7 - 맺음말 (Closing Remarks)
Pegasus-1이 초기 알파 버전에서 마침내 세련된 오픈 베타 시스템으로 고도화될 수 있었던 핵심 여정 뒤에는 집념 어린 공학적 탐구와 엔지니어링의 정수가 있었습니다. 학습에 개입되는 캡션 데이터를 수동 어노테이션 기법으로 고점까지 정제했고, 비디오 내 시간 축의 거동을 15배 더 압축 처리하는 프레임워크를 이식하여, 과거 기계적 언어가 도달하지 못했던 맥락과 미학적 서사의 이해를 완벽히 구현해 냈습니다.
벤치마크 점수 역시 이를 명료히 증명합니다. 당사의 혁신적 시도는 업계를 압도하는 수준 높은 결과를 실현해 냈으며, 글로벌 테크 대기업들의 생성형 AI 프레임워크 등과 직접 겨뤄 정량적 스코어 상 우위를 점하는 등 화려한 기록을 다수 갈아치웠습니다. Pegasus-1의 이러한 성취는 곧 비디오 AI 기술 패러다임이 맞이할 차세대 도약을 예견하고 있습니다.
완전한 통제를 위한 향후 롱폼 영상 지원 로드맵, 환각 현상 극복 연구, 완벽한 세이프티 수립 등의 남겨진 세밀한 퍼즐 조각들조차 당사 연구진에게는 강력한 성장의 도약대로 작용하고 있습니다. Twelve Labs는 진보된 비디오 인터페이스 기술의 미래 지평을 여러분과 가장 먼저 열기 위해 쉬지 않고 더 거세게 시동을 걸겠습니다.
Twelve Labs 팀
이 놀라운 성과는 모델 및 데이터 연구, 엔지니어링, 프로덕트, 사업 개발에 걸친 수많은 크루들의 유기적인 시너지와 땀방울이 만든 결실입니다. (성명은 알파벳 이름 순으로 기입되었으며, 핵심 기여자는 'Core'로 표기했습니다.)
Model: Aiden Lee, Cooper Han, Flynn Jang (core), Jae Lee, Jay Yi (core), Jeff Kim, Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha, Minjoon Seo, Ray Jung (core), William Go (core)
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders Soyoung Lee, Sue Kim, Travis Couture
관련 자원 및 리소스:
연구나 실무 작업에 본 모델이나 결과를 직간접적으로 이용하시는 파트너와 리서처 분들은 아래 BibTeX 가이드라인 포맷을 적용하여 Twelve Labs 명의로 정식 인용 문구를 삽입해 주시기를 바랍니다.
@misc{pegasus-1-beta, author = {Twelve Labs Team}, title = {Pegasus-1 Open Beta: Setting New Standards in Video-Language Modeling}, url = {https://www.twelvelabs.io/blog/pegasus-1-beta}, year = {2024}}
arXiV 및 HuggingFace에서 Pegasus-1 기술 보고서를 확인해 보세요!
1 - 소개 (Introduction)
Twelve Labs의 목표는 혁신적인 멀티모달 AI 모델을 개발하여 비디오 이해 기술을 한 단계 더 진보시키는 것입니다. 이전 포스트인 "Video-to-Text 및 Pegasus-1 (80B) 소개"에서 Pegasus-1 알파 버전을 처음 공개해 드린 바 있습니다. 이 파운데이션 모델은 비디오 입력을 통해 상세한 설명 텍스트를 생성할 수 있습니다. 그리고 오늘, 드디어 Pegasus-1의 오픈 베타 출시 소식을 전해드리게 되어 매우 기쁩니다.
Pegasus-1은 복잡한 비디오 콘텐츠를 이해하고 이를 명확하게 표현하도록 설계되어, 우리가 멀티미디어와 상호작용하고 분석하는 방식을 혁신적으로 변화시킵니다. 약 170억 개의 매개변수(parameter)를 갖춘 이 모델은 멀티모달 AI 분야의 중요한 진전을 의미하며, 독보적인 정확도와 디테일로 비디오 입력으로부터 언어를 처리하고 생성해 냅니다.
이번 업데이트에서는 알파 출시 이후 Pegasus-1에 적용된 다양한 개선 사항을 살펴봅니다. 여기에는 데이터 품질, 비디오 처리 및 학습 방법의 개선이 포함됩니다. 또한 비디오 요약, 질의응답 및 대화 모델링 전반에서 Pegasus-1의 독보적인 성능을 입증하는 주요 상용 및 오픈소스 모델과의 벤치마크 결과도 공유합니다. 정량적 지표를 넘어, Pegasus-1은 한층 강화된 글로벌 상식 지식(world knowledge)과 상세한 시각적 정보를 정교하게 포착하는 능력을 통해 한 차원 높은 정성적 향상을 보여줍니다.
2 - 모델 개요 (Model Overview)
짧게 요약하자면, Pegasus-1은 비디오 콘텐츠와 언어 사이의 간극을 좁혀 기계가 비디오 입력을 바탕으로 텍스트를 해석하고 생성할 수 있도록 설계된 멀티모달 파운데이션 모델입니다. Pegasus-1의 아키텍처는 크게 세 가지 핵심 컴포넌트로 구성됩니다.
비디오 인코더 모델 (Video encoder model)은 비디오 입력을 처리하여 비디오 프레임과 오디오 음성 인식(ASR) 데이터 모두로부터 풍부한 임베딩을 생성합니다. 이 임베딩은 비디오 콘텐츠의 시각적 및 청각적 속성을 압축하여 담아낸 고밀도 표현입니다.
비디오-언어 정렬 모델 (Video-language alignment model)은 비디오 임베딩을 그에 대응하는 언어 임베딩에 매핑하여, 비디오와 텍스트 표현이 일치하는 공유 공간을 생성합니다. 이 정렬 프로세스는 모델이 비디오 속 시각 파일과 이를 설명하는 언어 간의 연관성을 파악하는 데 매우 중요합니다.
대규모 언어 모델 (LLM) 디코더는 이 정렬된 임베딩과 사용자 프롬프트를 입력받아 맥락에 맞춰 자연스럽고 정교한 텍스트 출력을 생성합니다. 이 출력은 설명 위주의 요약부터 비디오 내용에 대한 특정 질문의 답변까지 다양하게 구현됩니다.
알파 버전과 비교했을 때, Pegasus-1 오픈 베타 버전은 약 170억 개의 매개변수를 자랑하며, 비디오 데이터 기반의 텍스트 해석 및 생성 분야에서 가볍고도 강력한 성능을 보여줍니다.
3 - 주요 개선 사항 (Major Improvements)
알파 단계에서 오픈 베타 단계로 진화하면서, 저희는 모델을 지속적으로 정제하고 강화하여 한층 더 정확하고 고도화된 비디오-언어 이해를 제공해 왔습니다. 이러한 개선은 고품질 데이터, 최적화된 비디오 처리, 그리고 정교화된 학습 기법이라는 세 가지 핵심 요소를 통해 이루어졌습니다.
3.1 - 데이터 개선 (Data Improvement)
기존 연구 결과들과 마찬가지로, 저희 역시 단순히 데이터의 절대적인 양을 늘리는 것보다 캡션의 품질과 상세함(granularity)이 모델 성능에 훨씬 더 결정적인 영향을 미친다는 점을 확인했습니다. 일례로, 10만 개의 고품질 비디오-텍스트 쌍(pair)으로 학습된 Pegasus-1은 낮은 품질의 캡션을 가진 대규모 데이터셋(1,000만 개 이상)으로 학습된 동일한 아키텍처의 성능을 한참 능가합니다.
이러한 실험적 근거를 바탕으로, 저희는 앞서 언급한 1,000만 개 이상의 비디오에 대해 고품질 비디오 캡션을 실시간으로 생성할 수 있는 효율적인 데이터 어노테이션 파이프라인을 구축했습니다. 이처럼 방대한 양의 고품질 비디오-텍스트 쌍을 통해 학습을 마친 Pegasus는 타 모델에서는 찾아볼 수 없는 독보적이고 강력한 비디오 이해 성능을 갖추게 되었습니다.
3.2 - 비디오 처리 개선 (Video Processing Improvement)
저희는 공간적 및 시간적 해상도를 모두 최적화하기 위해 비디오 처리 파이프라인에 대대적인 변화를 주었습니다. 프레임당 패치 수(공간적 해상도)를 10배 늘리고 프레임 수(시간적 해상도)를 1.5배 늘려, 결과적으로 비디오당 총 패치 수를 15배나 증가시켰습니다. 이러한 개선 덕분에 Pegasus-1은 프레임당 훨씬 더 풍부한 정보를 포착해 표현할 수 있습니다.
또한, 정성적 및 정량적 분석(특히 질의응답 데이터셋 결과)을 통해 확인된 것처럼 이제 Pegasus-1은 비디오 전체의 내러티브와 맥락을 훨씬 더 명확하고 일관성 있게 파악할 수 있습니다.
3.3 - 학습 기법 개선 (Training Improvement)
멀티모달 파운데이션 모델인 Pegasus-1은 여러 단계에 걸쳐 대규모 멀티모달 데이터셋으로 학습됩니다. 그러나 다단계 학습은 보통 파괴적 망각(catastrophic forgetting)이라 불리는 한계에 부딪히기 쉽습니다. 모델이 새로운 정보를 학습하는 과정에서 이전에 학습했던 기존 정보를 쉽게 잊어버리는 현상입니다. 이러한 현상은 모달리티 간의 순차적 학습 과정을 거치는 멀티모달 모델에서 특히 더 두드러집니다.
이를 해결하기 위해, 저희는 새로운 지식 습득과 기존 정보 보존 사이의 정교한 균형을 유지할 수 있도록 특별히 설계된 전략적 학습 체계(strategic training regimen)를 도입했습니다. 이 접근법의 핵심은 학습 프로세스 전반에 걸쳐 모델 매개변수를 선택적으로 업데이트(unfreezing)하고 학습률(learning rates)을 세밀하게 제어하는 데 있습니다.
Pegasus-1 오픈 베타 버전은 알파 버전과 비교하여 세밀한 시간적 모멘트 포착 기능이 크게 향상되었으며, 환각(hallucination) 현상이 크게 감소하여 다양한 비디오 도메인에 걸쳐 높은 신뢰성과 일관성을 확보했습니다. 또한 확장된 월드 지식을 보여주고, 특정 단일 장면에만 집중하기보다 시간 순서대로 다양한 모멘트를 나열하는 능력이 크게 향상되었습니다.
4 - 정량적 벤치마크 결과
철저히 검증된 당사의 벤치마크 평가를 통해, Pegasus-1은 상용 및 오픈소스 모델 모두를 아우르는 다양한 모델군과 비교 분석되었습니다. 이 섹션에서는 여러 비디오-언어 모델링 태스크에서 타 모델들과 비교한 Pegasus-1의 구체적인 성능 수치를 명확히 제시합니다.
4.1 - 베이스라인 모델 (Baseline Models)
Pegasus-1의 벤치마크 평가에 사용된 베이스라인 모델 목록은 다음과 같습니다.
Gemini Pro (1.5): 2023년 11월에 처음 공개되고 가장 최근인 2024년 2월에 업데이트된 Google DeepMind의 상용 멀티모달 모델로, 뛰어난 비디오-언어 이해 성능으로 잘 알려져 있습니다. 본 비교에는 최신 버전인 Gemini Pro 1.5가 사용되었습니다.
Whisper + ChatGPT-3.5 (OpenAI): 이 조합은 업계에서 흔히 비디오 요약에 사용하는 접근법 중 하나입니다. 최고 수준의 음성 인식 모델(STT)과 LLM을 결합하여 가동되며, 요약은 주로 비디오의 음성 대화 내용을 바탕으로 처리됩니다. 비디오 내의 귀중한 '시각적 정보'를 인지하지 못한다는 치명적인 한계가 있습니다.
Vendor A’s Summary API: 오디오 및 비디오 요약 생성에 널리 사용되는 시중의 상용 제품입니다. Vendor A의 요약 API는 오직 텍스트 트랜스크립션 데이터와 구어체 언어 모델(ASR+ChatGPT3.5와 유사)에 기인하여 결과물을 도출하는 것으로 파악됩니다.
Video-ChatGPT: Maaz 등이 개발한 모델(2023년 6월 출시)로 채팅 인터페이스를 탑재한 비디오 언어 모델입니다. 비디오 프레임을 처리하여 비디오 서사 내의 시각적 이벤트를 파악합니다. 단, 비디오 내의 다이얼로그나 음성 정보는 활용하지 못한다는 점이 피력됩니다.
VideoChat2: Li 등이 개발한 모델(2023년 11월 출시)로, 다양한 지시어 튜닝(instruction-tuning) 데이터를 탑재하여 프로그레시브 멀티모달 학습을 설계한 최고 수준의 오픈소스 멀티모달 LLM입니다.
시각 기반의 이미지-언어 모델인 LLaVA 및 GPT-4V 등은 우리의 비교 대상에서 제외되었습니다. 이 모델들은 당사가 평가하려는 태스크의 핵심 요건인 네이티브 비디오 처리 기능이 결여되어 있기 때문입니다. 구체적인 한계는 아래와 같습니다.
해당 모델들의 상당수는 오직 완벽한 단일 이미지만 인식 가능하여, 대부분의 비디오 벤치마크 데이터셋에서 매우 저조한 성능을 보입니다.
일부 모델(예: GPT-4V)은 여러 이미지를 한 번에 처리할 수 있으나, 한 번에 처리할 수 있는 비디오 프레임 수가 극히 소량(10프레임 이하)에 불과하여 1분이 넘어가는 대부분의 실무 비디오 처리에 한계가 있습니다.
이미지 기반 모델은 비디오 콘텐츠 특유의 유기적이고 역동적인 내러티브 맥락을 온전히 처리하는 데 태생적 한계를 보입니다. 입력을 유기적인 비디오가 아닌 정적인 이미지의 나열로만 학습하기 때문입니다.
또한, 이러한 이미지 기반 모델들이 전체 비디오를 구동 및 처리하기 위해 요구되는 실행 시간은 실제 서비스 및 프로덕션 환경에 적용하기에 지나치게 깁니다. 비디오 속 내러티브의 흐름과 액션을 직관적으로 파악하는 데 필수적인 시간 축(temporal dimension)을 효율적으로 다루는 기술적 설계가 부족하기 때문입니다.
4.2 - 비디오 질의응답 결과 (Video QA)
비디오 질의응답(Video QA) 분야에서, Pegasus-1은 별도의 파인튜닝 프로세스 없이도 ActivityNet-QA 및 NExT-QA 벤치마크 모두에서 뛰어난 제로샷(zero-shot) 성능을 달성했습니다. 특정 태스크 전용 학습 없이도, 다양한 도메인의 비디오 내용을 유연하게 일반화하여 핵심 질문에 아주 높은 신뢰도로 올바른 답을 도출합니다.
4.3 - 비디오 대화 결과 (Video Conversations)
Video-ChatGPT 벤치마크(QEFVC라고도 불림) 결과는 비디오 대화를 처리하는 데 있어서 Pegasus-1의 월등한 성능을 여과 없이 표현합니다. 정확성(Correctness), 디테일(Detail), 컨텍스트(Context), 시간 정보 이해(Temporal understanding), 일관성(Consistency) 수치 모두에서 시장 타 모델들을 크게 앞질렀습니다. 특히 Pegasus-1은 정확성에서 3.79, 설명 디테일에서 4.29를 획득하여, 인물 간의 정교한 대화 맥락과 상황적 context를 능숙하게 파악함을 스스로 입증했습니다.
4.4 - 비디오 요약 결과 (Video Summarization)
마지막으로, Pegasus-1은 비디오를 요약하는 영역에서도 압도적인 역량을 증명해 보였습니다. MSR-VTT 데이터셋을 대상으로 VideoChatGPT의 상세 평가 지표 시스템을 적용하여 요약 성능 빅매치를 진행했습니다 (요약 태스크 특성상 시간 정보 이해 및 일관성 지표는 제외). 상기 데이터 결과가 증명하듯 Pegasus-1은 모든 정량적 평가에서 경쟁 베이스라인 모델들을 큰 격차로 따돌렸습니다.
이 종합적인 벤치마크 결과를 통해 Pegasus-1은 비디오-언어 처리 모델링 분야의 선두 주자로 우뚝 섰으며, 제로샷 요약 성능과 뛰어난 범용 비디오 태스크 수행 능력에 있어 새로운 글로벌 표준을 정립했습니다.
5 - 구체적인 정성적 사용 예시 (Qualitative Examples)
다양한 도메인에서 엄선되고 무작위로 추출된 실제 케이스를 통해 Pegasus-1의 실제 작동 형태를 직관적으로 체험해 보세요.
이러닝 비디오 (E-Learning Video)
생성된 타이틀 (Generated Title)
텐트 설치하기: 캐나다 국립공원 관리청과 함께하는 캠핑 초보자 가이드
생성된 토픽 (Generated Topic)
캠핑: 캐나다 국립공원에서 안전하게 텐트 치고 고정하기
생성된 해시태그 (Generated Hashtags)
#캠핑, #텐트, #설치하기, #화로대, #안전, #초보캠핑, #캐나다국립공원
생성된 비디오 챕터 (Generated Chapters)
1단계: 사이트 선정 00:00:00 - 00:00:08
적절한 캠핑 사이트를 선택하고 텐트 설치 준비하기.
2단계: 화로 구축 00:00:09 - 00:00:36
조리 및 보온을 위한 안전한 모닥불 화로 만들기.
3단계: 텐트 펼치기 00:00:37 - 00:01:14
텐트를 바닥에 펼쳐놓고 위치 조절하기.
4단계: 지면 고정 00:01:14 - 00:01:48
텐트가 바람에 날아가지 않도록 팩을 사용해 단단히 지면에 고정하기.
5단계: 플라이 시트 장착 00:01:49 - 00:01:54
비와 이슬을 막기 위해 텐트 상단에 레인플라이 씌우기.
6단계: 내부 세팅 00:01:55 - 00:02:16
텐트 내부에 매트와 침구 등 장비를 배치해 편안한 보금자리 만들기.
7단계: 텐트 철수 00:02:17 - 00:02:30
설치된 텐트의 장비를 치우고 안전하게 해체하기.
8단계: 패킹하기 00:02:31 - 00:02:58
텐트를 잘 접어서 전용 가방에 깔끔하게 보관하기.
9단계: 교육 프로그램 알아보기 00:03:00 - 00:03:06
캐나다 국립공원 관리청의 교육 캠페인 소개 안내.
광고 비디오 (Ad Video)
맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 광고가 브랜드의 메시지를 전달하기 위해 인물들의 표정을 어떻게 활용하고 있는지 분석해 줘.
답변(Output): 본 광고는 브랜드 특유의 우아함과 기쁨, 럭셔리한 정취를 전달하기 위해 인물들의 표정을 고도로 기획하여 배치하고 있습니다. 광고 속 모델들은 당당하면서도 따뜻한 미소를 짓고 있는데, 이는 불가리(Bvlgari) 주얼리가 선사하는 내면의 행복감과 착용자의 아름다움을 한층 극대화해 준다는 인상을 심어 줍니다. 이 미소 띤 표정들은 시청자에게 긍정적인 감정을 전달하며 타겟 오디언스와 브랜드 간의 감정적 교감을 즉각적으로 형성합니다.
나아가, 모델들의 차분하고 기품 있는 표정은 브랜드의 클래식하고 정제된 가치를 잘 대변합니다. 주얼리를 클로즈업 사진처럼 다각도로 조명하며 모델의 얼굴과 표정을 함께 교차하여 비춰줌으로써, 디바이스 표면 위에 감도는 긍정적이고 경이로운 무드를 독자에게 은밀히 주입합니다. 이를 통해 시청자의 소망과 욕구를 자극하여 주얼리를 고급스러운 동경의 대상으로서 확고하게 포지셔닝합니다.
비디오의 기본적인 전개에 비추어 볼 때, 이 광고는 다양한 배경 속에서 다채로운 불가리 컬렉션을 선보이는 여성 모델의 시선을 따라 흘러갑니다. 도입부에서는 주얼리와 귀걸이를 착용한 고혹적인 여성의 자태로 시작하는데, 그녀 옆 고목 나무 기둥 부근에 불가리 브랜드 로고가 웅장하게 안착되어 있습니다. 이어 다른 세련된 드레스를 매칭하였으나 동일한 네크리스 컬렉션을 갖춘 채 나무가 늘어선 우아한 저택 도로를 향해 걸어나가는 시퀀스로 자연스럽게 전환됩니다. 이후 화려한 인테리어 속 내부 공간으로 신(scene)이 연결되며, 섬세한 펜던트가 입혀진 목걸이부터 시그니처 링 반지를 감상하는 명확한 스포트라이트를 지속 도출합니다.
동시에 고전적인 럭셔리와 신비로움을 상징하는 공작새 및 깃털 모티브가 장면 곳곳에 은유적으로 개입됩니다. 후반부에 접어들면서 주인공 모델 곁에 매혹적인 보조 인물이 함께 가세하여 컬렉션의 깊이를 입체화합니다. 광고의 대미는 불가리 고유의 인장 로고와 함께 'Wonderful Extravaganza' 및 'Bvlgari Rome'이라는 텍스트가 강렬하게 부각되며 세련되고 웅장한 여운에 마침표를 찍습니다.
요약하자면, 본 광고는 환희와 세련미가 넘치는 미소 표현 기법을 적확하게 사용하고 있습니다. 럭셔리한 인프라와 공작 요소를 매혹적으로 레이어링하여 궁극의 브랜드 헤리티지와 압도적인 수작업 미학을 강력하게 각인시킵니다.
영화 예고편 비디오 (Movie Trailer Video)
맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 비디오를 어린아이들에게 추천해도 괜찮을까?
답변(Output): 비디오 콘텐츠의 입체적인 시각 분석 결과에 근거해 판단할 때, 이 영상을 어린 자녀에게 시청하게 하는 것은 권장되지 않습니다. 영상 전반에 하드보일드 성격의 거친 액션 시퀀스와 무기류 위주의 시각적 긴장 요소, 그리고 성숙한 타겟층을 위한 긴박하고 어두운 무드의 테마가 빈번하게 노출되기 때문입니다. 트레일러의 흐름상 미스터리하고 스릴 있는 범죄 느와르 성향의 영화 혹은 드라마 장르에 속하는 작품으로 강력하게 유추됩니다.
비디오는 타오르는 듯한 주황색 톤의 강렬한 타이틀 카드 디자인으로 문을 열며, 이어 촛불들이 은빛 배경에 매달려 엄숙하고 우스스한 분위기를 내뿜는 성당 내부를 비춥니다. 수트를 단정히 입은 남성이 제단을 지나 위풍당당하게 걸어가고 있고, 그 뒤를 동일한 피트의 신사가 따릅니다. 직후 미스터리한 음모감을 자극하듯 여인과 남성의 밀도 높은 포옹 장면이 조명되어 성인용 멜로 혹은 서스펜스 드라마 서사를 강력하게 암시합니다.
예고편이 진전되면서 가파르고 손에 땀을 쥐게 하는 시퀀스들이 연이어 몰아칩니다. 적대 세력인 두 남성 간의 단호한 신경전 대치 상태, 조심스럽게 포켓 시계를 응시하는 고독한 침묵의 순간, 인물 간의 차갑고 의미심장한 설전, 그리고 어두운 심야 도심의 도로 위를 돌파하는 타이트한 자동차 체이싱 카레이스 트랙 장면 등이 대표적입니다. 도망치는 배후와 더불어 강박적으로 흔들리는 사막 오지 풍경, 폭발의 화마를 유연하게 뚫고 뒤돌아 유유히 걸어나오는 요원들의 백뷰 샷 역시 성인 지향적인 하드 보일드 무비를 완벽하게 가리킵니다.
구체적으로 살상력을 품은 소형 권총 장비를 클로즈업해 유심히 응시하는 빌런의 모습이 수차례 포함되어 심각한 물리적 타격을 암시합니다. 영상의 마무리 연출 역시 강렬합니다. 붉게 타오르는 석양 아래 고독하게 서 있는 에펠탑 주변을 비춘 다음, 제목 텍스트인 "IN MARC A DANCER"와 개봉 예고일 "MARCH 24"가 부상하며 짙은 잔상을 배출하고 마무리됩니다.
즉, 성인 지향적인 타격신과 폭발 등의 위협 수위가 결부된 자극이 포진된 미디어이므로 미취학 및 소아 연령층의 시청에는 적합지 않습니다.
6 - 한계점 (Limitations)
안전성 및 편향 (Safety & Biases): Pegasus-1은 철저한 안전 장치와 필터 프로세스를 바탕으로 정밀 설계되었습니다. 하지만 오픈 필드의 거센 시나리오 하에 구동되는 대형 신경망 특성상, 일정한 통제 범위를 벗어날 경우 부적절한 설명 결과물이 표출될 여지는 소수 존재할 수 있습니다. 당사는 비디오 파운데이션 모델에 대한 완벽한 윤리 검증과 방어망 성장을 위한 안전 연구를 다각도로 고수하고 있습니다. 추후 내부 테스트와 학계 데이터 피드백 분석들이 일단락되는 시점에 보다 입체성 있는 윤리 백서를 대외 공개할 예정입니다.
지원 비디오 제한 (Video Duration): 현재 당사 정식 API는 최소 4초에서 최대 20분 내외 분량의 비디오 스트림 처리를 안정 영역으로 확보하고 있습니다. 비디오의 대규모 로 변형 및 토큰 분석 시 부하를 막기 위해 연산 하드웨어 용량을 감안해 설계한 스펙 라인업입니다. 대규모 영화 및 롱폼 영상의 완벽한 핸들링을 도모하려면 사용자가 프레임 영역을 일정 분절로 분배해 업로드해야 합니다. 향후 업데이트 플랜을 고려하여 초대용량 장기 비디오 포맷도 네이티브하게 온전히 커버 가능한 업데이트가 곧 구축될 예정입니다.
환각 현상 (Hallucinations): Pegasus-1 모델 역시 일반적인 생성 AI처럼 드물게 실시간 오정답 데이터를 정교한 어조로 생성해 내는 환각 문제를 겪을 확률이 존재합니다. 알파 버전에 비해 이 확률을 강력히 낮춘 상태이지만, 매우 섬세하고 정확한 증명이 핵심인 산업 및 연구 도메인 전반에 사용 시 오답 교차 체크 장치를 늘 수반해 실행하시기를 거듭 강조드립니다.
7 - 맺음말 (Closing Remarks)
Pegasus-1이 초기 알파 버전에서 마침내 세련된 오픈 베타 시스템으로 고도화될 수 있었던 핵심 여정 뒤에는 집념 어린 공학적 탐구와 엔지니어링의 정수가 있었습니다. 학습에 개입되는 캡션 데이터를 수동 어노테이션 기법으로 고점까지 정제했고, 비디오 내 시간 축의 거동을 15배 더 압축 처리하는 프레임워크를 이식하여, 과거 기계적 언어가 도달하지 못했던 맥락과 미학적 서사의 이해를 완벽히 구현해 냈습니다.
벤치마크 점수 역시 이를 명료히 증명합니다. 당사의 혁신적 시도는 업계를 압도하는 수준 높은 결과를 실현해 냈으며, 글로벌 테크 대기업들의 생성형 AI 프레임워크 등과 직접 겨뤄 정량적 스코어 상 우위를 점하는 등 화려한 기록을 다수 갈아치웠습니다. Pegasus-1의 이러한 성취는 곧 비디오 AI 기술 패러다임이 맞이할 차세대 도약을 예견하고 있습니다.
완전한 통제를 위한 향후 롱폼 영상 지원 로드맵, 환각 현상 극복 연구, 완벽한 세이프티 수립 등의 남겨진 세밀한 퍼즐 조각들조차 당사 연구진에게는 강력한 성장의 도약대로 작용하고 있습니다. Twelve Labs는 진보된 비디오 인터페이스 기술의 미래 지평을 여러분과 가장 먼저 열기 위해 쉬지 않고 더 거세게 시동을 걸겠습니다.
Twelve Labs 팀
이 놀라운 성과는 모델 및 데이터 연구, 엔지니어링, 프로덕트, 사업 개발에 걸친 수많은 크루들의 유기적인 시너지와 땀방울이 만든 결실입니다. (성명은 알파벳 이름 순으로 기입되었으며, 핵심 기여자는 'Core'로 표기했습니다.)
Model: Aiden Lee, Cooper Han, Flynn Jang (core), Jae Lee, Jay Yi (core), Jeff Kim, Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha, Minjoon Seo, Ray Jung (core), William Go (core)
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders Soyoung Lee, Sue Kim, Travis Couture
관련 자원 및 리소스:
연구나 실무 작업에 본 모델이나 결과를 직간접적으로 이용하시는 파트너와 리서처 분들은 아래 BibTeX 가이드라인 포맷을 적용하여 Twelve Labs 명의로 정식 인용 문구를 삽입해 주시기를 바랍니다.
@misc{pegasus-1-beta, author = {Twelve Labs Team}, title = {Pegasus-1 Open Beta: Setting New Standards in Video-Language Modeling}, url = {https://www.twelvelabs.io/blog/pegasus-1-beta}, year = {2024}}
arXiV 및 HuggingFace에서 Pegasus-1 기술 보고서를 확인해 보세요!
1 - 소개 (Introduction)
Twelve Labs의 목표는 혁신적인 멀티모달 AI 모델을 개발하여 비디오 이해 기술을 한 단계 더 진보시키는 것입니다. 이전 포스트인 "Video-to-Text 및 Pegasus-1 (80B) 소개"에서 Pegasus-1 알파 버전을 처음 공개해 드린 바 있습니다. 이 파운데이션 모델은 비디오 입력을 통해 상세한 설명 텍스트를 생성할 수 있습니다. 그리고 오늘, 드디어 Pegasus-1의 오픈 베타 출시 소식을 전해드리게 되어 매우 기쁩니다.
Pegasus-1은 복잡한 비디오 콘텐츠를 이해하고 이를 명확하게 표현하도록 설계되어, 우리가 멀티미디어와 상호작용하고 분석하는 방식을 혁신적으로 변화시킵니다. 약 170억 개의 매개변수(parameter)를 갖춘 이 모델은 멀티모달 AI 분야의 중요한 진전을 의미하며, 독보적인 정확도와 디테일로 비디오 입력으로부터 언어를 처리하고 생성해 냅니다.
이번 업데이트에서는 알파 출시 이후 Pegasus-1에 적용된 다양한 개선 사항을 살펴봅니다. 여기에는 데이터 품질, 비디오 처리 및 학습 방법의 개선이 포함됩니다. 또한 비디오 요약, 질의응답 및 대화 모델링 전반에서 Pegasus-1의 독보적인 성능을 입증하는 주요 상용 및 오픈소스 모델과의 벤치마크 결과도 공유합니다. 정량적 지표를 넘어, Pegasus-1은 한층 강화된 글로벌 상식 지식(world knowledge)과 상세한 시각적 정보를 정교하게 포착하는 능력을 통해 한 차원 높은 정성적 향상을 보여줍니다.
2 - 모델 개요 (Model Overview)
짧게 요약하자면, Pegasus-1은 비디오 콘텐츠와 언어 사이의 간극을 좁혀 기계가 비디오 입력을 바탕으로 텍스트를 해석하고 생성할 수 있도록 설계된 멀티모달 파운데이션 모델입니다. Pegasus-1의 아키텍처는 크게 세 가지 핵심 컴포넌트로 구성됩니다.
비디오 인코더 모델 (Video encoder model)은 비디오 입력을 처리하여 비디오 프레임과 오디오 음성 인식(ASR) 데이터 모두로부터 풍부한 임베딩을 생성합니다. 이 임베딩은 비디오 콘텐츠의 시각적 및 청각적 속성을 압축하여 담아낸 고밀도 표현입니다.
비디오-언어 정렬 모델 (Video-language alignment model)은 비디오 임베딩을 그에 대응하는 언어 임베딩에 매핑하여, 비디오와 텍스트 표현이 일치하는 공유 공간을 생성합니다. 이 정렬 프로세스는 모델이 비디오 속 시각 파일과 이를 설명하는 언어 간의 연관성을 파악하는 데 매우 중요합니다.
대규모 언어 모델 (LLM) 디코더는 이 정렬된 임베딩과 사용자 프롬프트를 입력받아 맥락에 맞춰 자연스럽고 정교한 텍스트 출력을 생성합니다. 이 출력은 설명 위주의 요약부터 비디오 내용에 대한 특정 질문의 답변까지 다양하게 구현됩니다.
알파 버전과 비교했을 때, Pegasus-1 오픈 베타 버전은 약 170억 개의 매개변수를 자랑하며, 비디오 데이터 기반의 텍스트 해석 및 생성 분야에서 가볍고도 강력한 성능을 보여줍니다.
3 - 주요 개선 사항 (Major Improvements)
알파 단계에서 오픈 베타 단계로 진화하면서, 저희는 모델을 지속적으로 정제하고 강화하여 한층 더 정확하고 고도화된 비디오-언어 이해를 제공해 왔습니다. 이러한 개선은 고품질 데이터, 최적화된 비디오 처리, 그리고 정교화된 학습 기법이라는 세 가지 핵심 요소를 통해 이루어졌습니다.
3.1 - 데이터 개선 (Data Improvement)
기존 연구 결과들과 마찬가지로, 저희 역시 단순히 데이터의 절대적인 양을 늘리는 것보다 캡션의 품질과 상세함(granularity)이 모델 성능에 훨씬 더 결정적인 영향을 미친다는 점을 확인했습니다. 일례로, 10만 개의 고품질 비디오-텍스트 쌍(pair)으로 학습된 Pegasus-1은 낮은 품질의 캡션을 가진 대규모 데이터셋(1,000만 개 이상)으로 학습된 동일한 아키텍처의 성능을 한참 능가합니다.
이러한 실험적 근거를 바탕으로, 저희는 앞서 언급한 1,000만 개 이상의 비디오에 대해 고품질 비디오 캡션을 실시간으로 생성할 수 있는 효율적인 데이터 어노테이션 파이프라인을 구축했습니다. 이처럼 방대한 양의 고품질 비디오-텍스트 쌍을 통해 학습을 마친 Pegasus는 타 모델에서는 찾아볼 수 없는 독보적이고 강력한 비디오 이해 성능을 갖추게 되었습니다.
3.2 - 비디오 처리 개선 (Video Processing Improvement)
저희는 공간적 및 시간적 해상도를 모두 최적화하기 위해 비디오 처리 파이프라인에 대대적인 변화를 주었습니다. 프레임당 패치 수(공간적 해상도)를 10배 늘리고 프레임 수(시간적 해상도)를 1.5배 늘려, 결과적으로 비디오당 총 패치 수를 15배나 증가시켰습니다. 이러한 개선 덕분에 Pegasus-1은 프레임당 훨씬 더 풍부한 정보를 포착해 표현할 수 있습니다.
또한, 정성적 및 정량적 분석(특히 질의응답 데이터셋 결과)을 통해 확인된 것처럼 이제 Pegasus-1은 비디오 전체의 내러티브와 맥락을 훨씬 더 명확하고 일관성 있게 파악할 수 있습니다.
3.3 - 학습 기법 개선 (Training Improvement)
멀티모달 파운데이션 모델인 Pegasus-1은 여러 단계에 걸쳐 대규모 멀티모달 데이터셋으로 학습됩니다. 그러나 다단계 학습은 보통 파괴적 망각(catastrophic forgetting)이라 불리는 한계에 부딪히기 쉽습니다. 모델이 새로운 정보를 학습하는 과정에서 이전에 학습했던 기존 정보를 쉽게 잊어버리는 현상입니다. 이러한 현상은 모달리티 간의 순차적 학습 과정을 거치는 멀티모달 모델에서 특히 더 두드러집니다.
이를 해결하기 위해, 저희는 새로운 지식 습득과 기존 정보 보존 사이의 정교한 균형을 유지할 수 있도록 특별히 설계된 전략적 학습 체계(strategic training regimen)를 도입했습니다. 이 접근법의 핵심은 학습 프로세스 전반에 걸쳐 모델 매개변수를 선택적으로 업데이트(unfreezing)하고 학습률(learning rates)을 세밀하게 제어하는 데 있습니다.
Pegasus-1 오픈 베타 버전은 알파 버전과 비교하여 세밀한 시간적 모멘트 포착 기능이 크게 향상되었으며, 환각(hallucination) 현상이 크게 감소하여 다양한 비디오 도메인에 걸쳐 높은 신뢰성과 일관성을 확보했습니다. 또한 확장된 월드 지식을 보여주고, 특정 단일 장면에만 집중하기보다 시간 순서대로 다양한 모멘트를 나열하는 능력이 크게 향상되었습니다.
4 - 정량적 벤치마크 결과
철저히 검증된 당사의 벤치마크 평가를 통해, Pegasus-1은 상용 및 오픈소스 모델 모두를 아우르는 다양한 모델군과 비교 분석되었습니다. 이 섹션에서는 여러 비디오-언어 모델링 태스크에서 타 모델들과 비교한 Pegasus-1의 구체적인 성능 수치를 명확히 제시합니다.
4.1 - 베이스라인 모델 (Baseline Models)
Pegasus-1의 벤치마크 평가에 사용된 베이스라인 모델 목록은 다음과 같습니다.
Gemini Pro (1.5): 2023년 11월에 처음 공개되고 가장 최근인 2024년 2월에 업데이트된 Google DeepMind의 상용 멀티모달 모델로, 뛰어난 비디오-언어 이해 성능으로 잘 알려져 있습니다. 본 비교에는 최신 버전인 Gemini Pro 1.5가 사용되었습니다.
Whisper + ChatGPT-3.5 (OpenAI): 이 조합은 업계에서 흔히 비디오 요약에 사용하는 접근법 중 하나입니다. 최고 수준의 음성 인식 모델(STT)과 LLM을 결합하여 가동되며, 요약은 주로 비디오의 음성 대화 내용을 바탕으로 처리됩니다. 비디오 내의 귀중한 '시각적 정보'를 인지하지 못한다는 치명적인 한계가 있습니다.
Vendor A’s Summary API: 오디오 및 비디오 요약 생성에 널리 사용되는 시중의 상용 제품입니다. Vendor A의 요약 API는 오직 텍스트 트랜스크립션 데이터와 구어체 언어 모델(ASR+ChatGPT3.5와 유사)에 기인하여 결과물을 도출하는 것으로 파악됩니다.
Video-ChatGPT: Maaz 등이 개발한 모델(2023년 6월 출시)로 채팅 인터페이스를 탑재한 비디오 언어 모델입니다. 비디오 프레임을 처리하여 비디오 서사 내의 시각적 이벤트를 파악합니다. 단, 비디오 내의 다이얼로그나 음성 정보는 활용하지 못한다는 점이 피력됩니다.
VideoChat2: Li 등이 개발한 모델(2023년 11월 출시)로, 다양한 지시어 튜닝(instruction-tuning) 데이터를 탑재하여 프로그레시브 멀티모달 학습을 설계한 최고 수준의 오픈소스 멀티모달 LLM입니다.
시각 기반의 이미지-언어 모델인 LLaVA 및 GPT-4V 등은 우리의 비교 대상에서 제외되었습니다. 이 모델들은 당사가 평가하려는 태스크의 핵심 요건인 네이티브 비디오 처리 기능이 결여되어 있기 때문입니다. 구체적인 한계는 아래와 같습니다.
해당 모델들의 상당수는 오직 완벽한 단일 이미지만 인식 가능하여, 대부분의 비디오 벤치마크 데이터셋에서 매우 저조한 성능을 보입니다.
일부 모델(예: GPT-4V)은 여러 이미지를 한 번에 처리할 수 있으나, 한 번에 처리할 수 있는 비디오 프레임 수가 극히 소량(10프레임 이하)에 불과하여 1분이 넘어가는 대부분의 실무 비디오 처리에 한계가 있습니다.
이미지 기반 모델은 비디오 콘텐츠 특유의 유기적이고 역동적인 내러티브 맥락을 온전히 처리하는 데 태생적 한계를 보입니다. 입력을 유기적인 비디오가 아닌 정적인 이미지의 나열로만 학습하기 때문입니다.
또한, 이러한 이미지 기반 모델들이 전체 비디오를 구동 및 처리하기 위해 요구되는 실행 시간은 실제 서비스 및 프로덕션 환경에 적용하기에 지나치게 깁니다. 비디오 속 내러티브의 흐름과 액션을 직관적으로 파악하는 데 필수적인 시간 축(temporal dimension)을 효율적으로 다루는 기술적 설계가 부족하기 때문입니다.
4.2 - 비디오 질의응답 결과 (Video QA)
비디오 질의응답(Video QA) 분야에서, Pegasus-1은 별도의 파인튜닝 프로세스 없이도 ActivityNet-QA 및 NExT-QA 벤치마크 모두에서 뛰어난 제로샷(zero-shot) 성능을 달성했습니다. 특정 태스크 전용 학습 없이도, 다양한 도메인의 비디오 내용을 유연하게 일반화하여 핵심 질문에 아주 높은 신뢰도로 올바른 답을 도출합니다.
4.3 - 비디오 대화 결과 (Video Conversations)
Video-ChatGPT 벤치마크(QEFVC라고도 불림) 결과는 비디오 대화를 처리하는 데 있어서 Pegasus-1의 월등한 성능을 여과 없이 표현합니다. 정확성(Correctness), 디테일(Detail), 컨텍스트(Context), 시간 정보 이해(Temporal understanding), 일관성(Consistency) 수치 모두에서 시장 타 모델들을 크게 앞질렀습니다. 특히 Pegasus-1은 정확성에서 3.79, 설명 디테일에서 4.29를 획득하여, 인물 간의 정교한 대화 맥락과 상황적 context를 능숙하게 파악함을 스스로 입증했습니다.
4.4 - 비디오 요약 결과 (Video Summarization)
마지막으로, Pegasus-1은 비디오를 요약하는 영역에서도 압도적인 역량을 증명해 보였습니다. MSR-VTT 데이터셋을 대상으로 VideoChatGPT의 상세 평가 지표 시스템을 적용하여 요약 성능 빅매치를 진행했습니다 (요약 태스크 특성상 시간 정보 이해 및 일관성 지표는 제외). 상기 데이터 결과가 증명하듯 Pegasus-1은 모든 정량적 평가에서 경쟁 베이스라인 모델들을 큰 격차로 따돌렸습니다.
이 종합적인 벤치마크 결과를 통해 Pegasus-1은 비디오-언어 처리 모델링 분야의 선두 주자로 우뚝 섰으며, 제로샷 요약 성능과 뛰어난 범용 비디오 태스크 수행 능력에 있어 새로운 글로벌 표준을 정립했습니다.
5 - 구체적인 정성적 사용 예시 (Qualitative Examples)
다양한 도메인에서 엄선되고 무작위로 추출된 실제 케이스를 통해 Pegasus-1의 실제 작동 형태를 직관적으로 체험해 보세요.
이러닝 비디오 (E-Learning Video)
생성된 타이틀 (Generated Title)
텐트 설치하기: 캐나다 국립공원 관리청과 함께하는 캠핑 초보자 가이드
생성된 토픽 (Generated Topic)
캠핑: 캐나다 국립공원에서 안전하게 텐트 치고 고정하기
생성된 해시태그 (Generated Hashtags)
#캠핑, #텐트, #설치하기, #화로대, #안전, #초보캠핑, #캐나다국립공원
생성된 비디오 챕터 (Generated Chapters)
1단계: 사이트 선정 00:00:00 - 00:00:08
적절한 캠핑 사이트를 선택하고 텐트 설치 준비하기.
2단계: 화로 구축 00:00:09 - 00:00:36
조리 및 보온을 위한 안전한 모닥불 화로 만들기.
3단계: 텐트 펼치기 00:00:37 - 00:01:14
텐트를 바닥에 펼쳐놓고 위치 조절하기.
4단계: 지면 고정 00:01:14 - 00:01:48
텐트가 바람에 날아가지 않도록 팩을 사용해 단단히 지면에 고정하기.
5단계: 플라이 시트 장착 00:01:49 - 00:01:54
비와 이슬을 막기 위해 텐트 상단에 레인플라이 씌우기.
6단계: 내부 세팅 00:01:55 - 00:02:16
텐트 내부에 매트와 침구 등 장비를 배치해 편안한 보금자리 만들기.
7단계: 텐트 철수 00:02:17 - 00:02:30
설치된 텐트의 장비를 치우고 안전하게 해체하기.
8단계: 패킹하기 00:02:31 - 00:02:58
텐트를 잘 접어서 전용 가방에 깔끔하게 보관하기.
9단계: 교육 프로그램 알아보기 00:03:00 - 00:03:06
캐나다 국립공원 관리청의 교육 캠페인 소개 안내.
광고 비디오 (Ad Video)
맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 광고가 브랜드의 메시지를 전달하기 위해 인물들의 표정을 어떻게 활용하고 있는지 분석해 줘.
답변(Output): 본 광고는 브랜드 특유의 우아함과 기쁨, 럭셔리한 정취를 전달하기 위해 인물들의 표정을 고도로 기획하여 배치하고 있습니다. 광고 속 모델들은 당당하면서도 따뜻한 미소를 짓고 있는데, 이는 불가리(Bvlgari) 주얼리가 선사하는 내면의 행복감과 착용자의 아름다움을 한층 극대화해 준다는 인상을 심어 줍니다. 이 미소 띤 표정들은 시청자에게 긍정적인 감정을 전달하며 타겟 오디언스와 브랜드 간의 감정적 교감을 즉각적으로 형성합니다.
나아가, 모델들의 차분하고 기품 있는 표정은 브랜드의 클래식하고 정제된 가치를 잘 대변합니다. 주얼리를 클로즈업 사진처럼 다각도로 조명하며 모델의 얼굴과 표정을 함께 교차하여 비춰줌으로써, 디바이스 표면 위에 감도는 긍정적이고 경이로운 무드를 독자에게 은밀히 주입합니다. 이를 통해 시청자의 소망과 욕구를 자극하여 주얼리를 고급스러운 동경의 대상으로서 확고하게 포지셔닝합니다.
비디오의 기본적인 전개에 비추어 볼 때, 이 광고는 다양한 배경 속에서 다채로운 불가리 컬렉션을 선보이는 여성 모델의 시선을 따라 흘러갑니다. 도입부에서는 주얼리와 귀걸이를 착용한 고혹적인 여성의 자태로 시작하는데, 그녀 옆 고목 나무 기둥 부근에 불가리 브랜드 로고가 웅장하게 안착되어 있습니다. 이어 다른 세련된 드레스를 매칭하였으나 동일한 네크리스 컬렉션을 갖춘 채 나무가 늘어선 우아한 저택 도로를 향해 걸어나가는 시퀀스로 자연스럽게 전환됩니다. 이후 화려한 인테리어 속 내부 공간으로 신(scene)이 연결되며, 섬세한 펜던트가 입혀진 목걸이부터 시그니처 링 반지를 감상하는 명확한 스포트라이트를 지속 도출합니다.
동시에 고전적인 럭셔리와 신비로움을 상징하는 공작새 및 깃털 모티브가 장면 곳곳에 은유적으로 개입됩니다. 후반부에 접어들면서 주인공 모델 곁에 매혹적인 보조 인물이 함께 가세하여 컬렉션의 깊이를 입체화합니다. 광고의 대미는 불가리 고유의 인장 로고와 함께 'Wonderful Extravaganza' 및 'Bvlgari Rome'이라는 텍스트가 강렬하게 부각되며 세련되고 웅장한 여운에 마침표를 찍습니다.
요약하자면, 본 광고는 환희와 세련미가 넘치는 미소 표현 기법을 적확하게 사용하고 있습니다. 럭셔리한 인프라와 공작 요소를 매혹적으로 레이어링하여 궁극의 브랜드 헤리티지와 압도적인 수작업 미학을 강력하게 각인시킵니다.
영화 예고편 비디오 (Movie Trailer Video)
맞춤형 프롬프트를 통한 지능형 답변 생성 예시
프롬프트: 이 비디오를 어린아이들에게 추천해도 괜찮을까?
답변(Output): 비디오 콘텐츠의 입체적인 시각 분석 결과에 근거해 판단할 때, 이 영상을 어린 자녀에게 시청하게 하는 것은 권장되지 않습니다. 영상 전반에 하드보일드 성격의 거친 액션 시퀀스와 무기류 위주의 시각적 긴장 요소, 그리고 성숙한 타겟층을 위한 긴박하고 어두운 무드의 테마가 빈번하게 노출되기 때문입니다. 트레일러의 흐름상 미스터리하고 스릴 있는 범죄 느와르 성향의 영화 혹은 드라마 장르에 속하는 작품으로 강력하게 유추됩니다.
비디오는 타오르는 듯한 주황색 톤의 강렬한 타이틀 카드 디자인으로 문을 열며, 이어 촛불들이 은빛 배경에 매달려 엄숙하고 우스스한 분위기를 내뿜는 성당 내부를 비춥니다. 수트를 단정히 입은 남성이 제단을 지나 위풍당당하게 걸어가고 있고, 그 뒤를 동일한 피트의 신사가 따릅니다. 직후 미스터리한 음모감을 자극하듯 여인과 남성의 밀도 높은 포옹 장면이 조명되어 성인용 멜로 혹은 서스펜스 드라마 서사를 강력하게 암시합니다.
예고편이 진전되면서 가파르고 손에 땀을 쥐게 하는 시퀀스들이 연이어 몰아칩니다. 적대 세력인 두 남성 간의 단호한 신경전 대치 상태, 조심스럽게 포켓 시계를 응시하는 고독한 침묵의 순간, 인물 간의 차갑고 의미심장한 설전, 그리고 어두운 심야 도심의 도로 위를 돌파하는 타이트한 자동차 체이싱 카레이스 트랙 장면 등이 대표적입니다. 도망치는 배후와 더불어 강박적으로 흔들리는 사막 오지 풍경, 폭발의 화마를 유연하게 뚫고 뒤돌아 유유히 걸어나오는 요원들의 백뷰 샷 역시 성인 지향적인 하드 보일드 무비를 완벽하게 가리킵니다.
구체적으로 살상력을 품은 소형 권총 장비를 클로즈업해 유심히 응시하는 빌런의 모습이 수차례 포함되어 심각한 물리적 타격을 암시합니다. 영상의 마무리 연출 역시 강렬합니다. 붉게 타오르는 석양 아래 고독하게 서 있는 에펠탑 주변을 비춘 다음, 제목 텍스트인 "IN MARC A DANCER"와 개봉 예고일 "MARCH 24"가 부상하며 짙은 잔상을 배출하고 마무리됩니다.
즉, 성인 지향적인 타격신과 폭발 등의 위협 수위가 결부된 자극이 포진된 미디어이므로 미취학 및 소아 연령층의 시청에는 적합지 않습니다.
6 - 한계점 (Limitations)
안전성 및 편향 (Safety & Biases): Pegasus-1은 철저한 안전 장치와 필터 프로세스를 바탕으로 정밀 설계되었습니다. 하지만 오픈 필드의 거센 시나리오 하에 구동되는 대형 신경망 특성상, 일정한 통제 범위를 벗어날 경우 부적절한 설명 결과물이 표출될 여지는 소수 존재할 수 있습니다. 당사는 비디오 파운데이션 모델에 대한 완벽한 윤리 검증과 방어망 성장을 위한 안전 연구를 다각도로 고수하고 있습니다. 추후 내부 테스트와 학계 데이터 피드백 분석들이 일단락되는 시점에 보다 입체성 있는 윤리 백서를 대외 공개할 예정입니다.
지원 비디오 제한 (Video Duration): 현재 당사 정식 API는 최소 4초에서 최대 20분 내외 분량의 비디오 스트림 처리를 안정 영역으로 확보하고 있습니다. 비디오의 대규모 로 변형 및 토큰 분석 시 부하를 막기 위해 연산 하드웨어 용량을 감안해 설계한 스펙 라인업입니다. 대규모 영화 및 롱폼 영상의 완벽한 핸들링을 도모하려면 사용자가 프레임 영역을 일정 분절로 분배해 업로드해야 합니다. 향후 업데이트 플랜을 고려하여 초대용량 장기 비디오 포맷도 네이티브하게 온전히 커버 가능한 업데이트가 곧 구축될 예정입니다.
환각 현상 (Hallucinations): Pegasus-1 모델 역시 일반적인 생성 AI처럼 드물게 실시간 오정답 데이터를 정교한 어조로 생성해 내는 환각 문제를 겪을 확률이 존재합니다. 알파 버전에 비해 이 확률을 강력히 낮춘 상태이지만, 매우 섬세하고 정확한 증명이 핵심인 산업 및 연구 도메인 전반에 사용 시 오답 교차 체크 장치를 늘 수반해 실행하시기를 거듭 강조드립니다.
7 - 맺음말 (Closing Remarks)
Pegasus-1이 초기 알파 버전에서 마침내 세련된 오픈 베타 시스템으로 고도화될 수 있었던 핵심 여정 뒤에는 집념 어린 공학적 탐구와 엔지니어링의 정수가 있었습니다. 학습에 개입되는 캡션 데이터를 수동 어노테이션 기법으로 고점까지 정제했고, 비디오 내 시간 축의 거동을 15배 더 압축 처리하는 프레임워크를 이식하여, 과거 기계적 언어가 도달하지 못했던 맥락과 미학적 서사의 이해를 완벽히 구현해 냈습니다.
벤치마크 점수 역시 이를 명료히 증명합니다. 당사의 혁신적 시도는 업계를 압도하는 수준 높은 결과를 실현해 냈으며, 글로벌 테크 대기업들의 생성형 AI 프레임워크 등과 직접 겨뤄 정량적 스코어 상 우위를 점하는 등 화려한 기록을 다수 갈아치웠습니다. Pegasus-1의 이러한 성취는 곧 비디오 AI 기술 패러다임이 맞이할 차세대 도약을 예견하고 있습니다.
완전한 통제를 위한 향후 롱폼 영상 지원 로드맵, 환각 현상 극복 연구, 완벽한 세이프티 수립 등의 남겨진 세밀한 퍼즐 조각들조차 당사 연구진에게는 강력한 성장의 도약대로 작용하고 있습니다. Twelve Labs는 진보된 비디오 인터페이스 기술의 미래 지평을 여러분과 가장 먼저 열기 위해 쉬지 않고 더 거세게 시동을 걸겠습니다.
Twelve Labs 팀
이 놀라운 성과는 모델 및 데이터 연구, 엔지니어링, 프로덕트, 사업 개발에 걸친 수많은 크루들의 유기적인 시너지와 땀방울이 만든 결실입니다. (성명은 알파벳 이름 순으로 기입되었으며, 핵심 기여자는 'Core'로 표기했습니다.)
Model: Aiden Lee, Cooper Han, Flynn Jang (core), Jae Lee, Jay Yi (core), Jeff Kim, Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha, Minjoon Seo, Ray Jung (core), William Go (core)
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders Soyoung Lee, Sue Kim, Travis Couture
관련 자원 및 리소스:
연구나 실무 작업에 본 모델이나 결과를 직간접적으로 이용하시는 파트너와 리서처 분들은 아래 BibTeX 가이드라인 포맷을 적용하여 Twelve Labs 명의로 정식 인용 문구를 삽입해 주시기를 바랍니다.
@misc{pegasus-1-beta, author = {Twelve Labs Team}, title = {Pegasus-1 Open Beta: Setting New Standards in Video-Language Modeling}, url = {https://www.twelvelabs.io/blog/pegasus-1-beta}, year = {2024}}








