" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Product
Video-to-Text 및 Pegasus-1(80B)을 소개합니다
에이든 리, 재 리
Twelve Labs는 3억 개 이상의 비디오-텍스트 쌍으로 학습된 800억 매개변수 규모의 비디오-언어 파운데이션 모델인 Pegasus-1을 출시합니다. 이와 함께 비디오 요약 벤치마크에서 이전의 최고 성능 모델(SOTA)을 최대 61%까지 능가하는 새로운 Video-to-Text API 제품군을 선보입니다.
Twelve Labs는 3억 개 이상의 비디오-텍스트 쌍으로 학습된 800억 매개변수 규모의 비디오-언어 파운데이션 모델인 Pegasus-1을 출시합니다. 이와 함께 비디오 요약 벤치마크에서 이전의 최고 성능 모델(SOTA)을 최대 61%까지 능가하는 새로운 Video-to-Text API 제품군을 선보입니다.

In this article
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2023. 10. 23.
8분
링크 복사하기
요약
제품: Twelve Labs가 최신 비디오-언어 파운데이션 모델인 Pegasus-1과 함께 비디오-텍스트 API 신규 제품군(Gist API, Summary API, Generate API)을 발표합니다.
제품 및 연구 철학: 비디오 이해를 단순히 이미지나 음성 이해 문제로 재구성하는 기존의 많은 방식들과 달리, Twelve Labs는 다음 네 가지 핵심 원칙을 바탕으로 한 "비디오 우선(Video First)" 전략을 채택하고 있습니다: 효율적인 장편 비디오 처리, 멀티모달 이해, 비디오 네이티브 임베딩, 비디오 및 언어 임베딩 간의 긴밀한 정렬
새로운 모델: Pegasus-1은 약 80B(800억 개)의 매개변수를 가지고 있으며 비디오 인코더, 비디오-언어 정렬 모델, 언어 디코더라는 세 가지 모델 구성 요소가 함께 공동 학습되었습니다.
데이터셋: Twelve Labs는 다양하고 정교하게 정제된 3억 개 이상의 비디오-텍스트 쌍을 수집했으며, 이는 비디오-언어 파운데이션 모델 학습을 위한 세계 최대 규모의 비디오-텍스트 코퍼스 중 하나입니다. 본 기술 보고서는 3,500만 개의 비디오-텍스트 쌍과 10억 개 이상의 이미지-텍스트 쌍으로 구성된 10%의 서브셋에서 진행된 초기 학습 학습 실행을 기반으로 합니다.
최신(SOTA) 비디오-언어 모델 대비 성능: 이전의 최신(SOTA) 비디오-언어 모델과 비교했을 때, Pegasus-1은 QEFVC 품질 점수(Maaz et al., 2023) 기준 MSR-VTT 데이터셋(Xu et al., 2016)에서 61%의 상대적 성능 향상을, 비디오 설명(Video Descriptions) 데이터셋(Maaz et al., 2023)에서 47%의 성능 향상을 보여줍니다. 저희가 제안하는 평가 지표인 VidFactScore로 평가했을 때, MSR-VTT 데이터셋에서는 절대 F1 Score 기준 20%의 상승을, 비디오 설명 데이터셋에서는 14%의 성능 향상을 보여줍니다.
ASR+LLM 모델 대비 성능: ASR+LLM은 비디오-텍스트 변환 문제를 해결하기 위해 널리 채택되는 방식입니다. Whisper-ChatGPT(OpenAI) 및 업계 선두의 상용 ASR+LLM 제품과 비교했을 때, Pegasus-1은 MSR-VTT에서 79%, 비디오 설명 데이터셋에서 188% 더 우수한 성능을 나타냅니다. VidFactScore-F1으로 평가 시, MSR-VTT 데이터셋에서 25%, 비디오 설명 데이터셋에서 33%의 절대 성능 이점을 보여줍니다.
Pegasus-1 API 액세스: Pegasus 기반 비디오-텍스트 API의 대기 명단(Waitlist) 등록 링크입니다.
연구 지평의 확장: 비디오 임베딩을 넘어 생성형 모델로
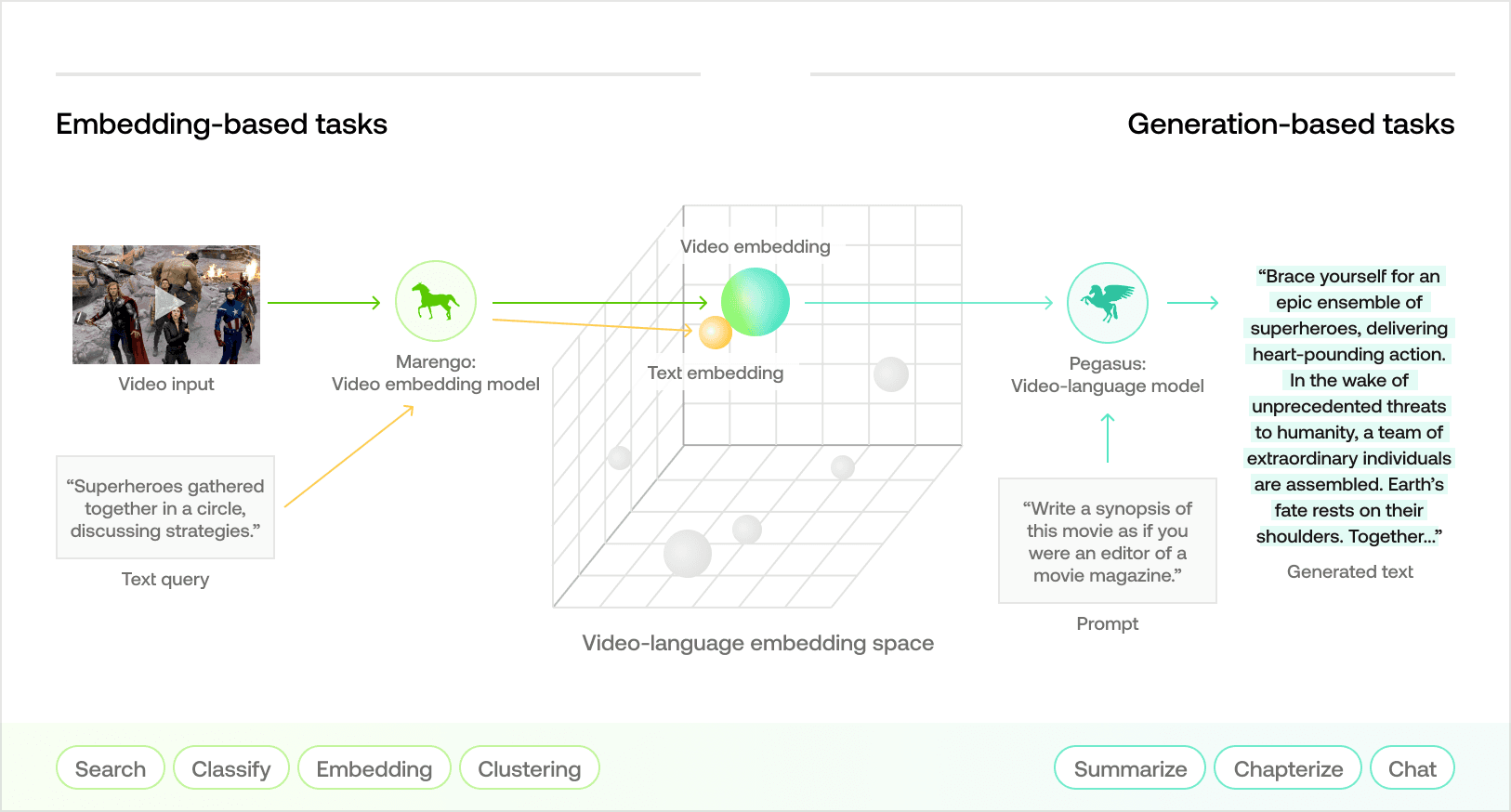
샌프란시스코 베이 에어리어에 본사를 둔 AI 연구 및 제품 개발 기업 Twelve Labs는 멀티모달 비디오 이해의 최전선에 서 있습니다. 오늘 우리는 최신 비디오-언어 파운데이션 모델인 Pegasus-1의 최첨단 비디오-텍스트 생성 기능을 공개하게 되어 매우 기쁩니다. 이는 다양한 다운스트림 비디오 이해 작업에 맞춤화된 종합 API 제품군을 제공하겠다는 우리의 약속을 보여줍니다. 저희 포트폴리오는 자연어 기반의 비디오 모먼트 검색부터 분류, 그리고 이번에 새로 출시된 프롬프트 기반의 비디오-텍스트 생성 기능에 이르기까지 폭넓게 아우르고 있습니다.
우리의 비디오 우선(Video-First) 정신
비디오 데이터는 단일 포맷 내에 여러 모달리티(시각, 청각 등)를 포함하고 있다는 점에서 매우 흥미롭습니다. 우리는 비디오를 진정으로 이해하기 위해서는 시각적 인지의 복잡성과 오디오 및 텍스트의 순차적이고 맥락적인 미묘한 차이를 결합하는 완전히 새로운 접근 방식이 필요하다고 믿습니다. 뛰어난 성능의 이미지 및 언어 모델이 등장함에 따라, 비디오 이해 분야의 주류 접근 방식은 이를 이미지나 음성 이해 문제로 재정의하는 것이었습니다. 전형적인 프레임워크는 비디오에서 프레임을 샘플링하여 비전-언어 모델에 입력하는 형식을 취합니다.
비디오 길이가 짧은 경우에는 이러한 접근 방식이 유효할 수 있지만(대부분의 비전-언어 모델이 1분 미만의 짧은 비디오 클립에 집중하는 이유이기도 합니다), 실제 환경의 비디오 대부분은 1분을 초과하며 수 시간까지 쉽게 늘어납니다. 이러한 비디오에 기존의 "이미지 우선(image-first)" 방식을 사용하면 비디오 하나당 수만 장의 이미지를 처리해야 합니다. 이는 시공간 정보의 의미를 기껏해야 대략적으로만 포착하는 방대한 양의 이미지-텍스트 임베딩을 다뤄야 함을 뜻합니다. 이는 성능, 지연 시간(latency), 비용 측면에서 많은 실제 애플리케이션에 적용하기가 어렵습니다. 더 나아가, 이러한 주류 방법론은 비디오 콘텐츠의 포괄적인 이해를 위해 시각 및 음성을 포함한 청각적 요소를 함께 공동으로 분석하는 것이 핵심이라는 비디오 본연의 멀티모달 특성을 간과하고 있습니다.
이러한 비디오 데이터의 근본적인 특성을 염두에 두고, Twelve Labs는 모델, 데이터, ML 시스템을 오직 비디오 데이터의 처리와 이해에만 전념하도록 하는 "비디오 우선(Video First)" 전략을 채택했습니다. 이는 다른 많은 생성형 AI 기업에서 관찰되는 일반적인 "언어/이미지 우선" 접근 방식과 극명한 대조를 이룹니다. 저희의 "비디오 우선" 정신을 강화하는 네 가지 핵심 원칙은 비디오-언어 파운데이션 모델의 설계와 ML 시스템 아키텍처 구축의 나침반 역할을 하고 있습니다.
효율적인 장편 비디오 처리: 저희 모델과 시스템은 짧은 10초짜리 클립부터 수 시간에 이르는 방대한 콘텐츠까지 다양한 길이의 비디오를 최적화하여 처리할 수 있어야 합니다.
멀티모달 이해: 저희 모델은 시각, 오디오, 음성 정보를 종합적으로 합성할 수 있어야 합니다.
비디오 네이티브 임베딩: 공간적 관계에만 집중하는 이미지 네이티브 임베딩(예: CLIP)에 의존하는 대신, 비디오의 시공간적 정보를 유기적이고 통합된 방식으로 담아낼 수 있는 비디오 네이티브 임베딩이 필요하다고 믿습니다.
비디오 네이티브 임베딩과 언어 모델 간의 긴밀한 정렬: 이미지-텍스트 정렬을 넘어, 대규모 비디오-텍스트 코퍼스와 비디오-텍스트 명령(instruction) 데이터셋에 대한 광범위한 학습을 통해 모델이 깊이 있는 비디오-언어 정렬을 달성하도록 해야 합니다.
새로운 비디오-텍스트 생성 능력과 인터페이스
개발자들은 단 한 번의 API 호출만으로 Pegasus-1 모델에 프롬프트를 입력하여 비디오 데이터로부터 특정 텍스트 출력을 생성할 수 있습니다. 음성-텍스트 변환(STT)을 사용하거나 시각 프레임 데이터에만 의존하는 기존 솔루션들과 달리, Pegasus-1은 시각, 오디오, 음성 정보를 통합하여 비디오로부터 한층 더 종합적인 텍스트를 생성하며 비디오 요약 벤치마크에서 새로운 업계 최고 수준(SOTA)의 성능을 달성했습니다. (아래 평가 및 결과 섹션 참조)

Gist API와 Summary API에는 사용자가 따로 프롬프트를 입력하지 않아도 즉시 작동할 수 있도록 관련 프롬프트가 기본 탑재되어 있습니다. Gist API는 제목, 주제, 관련 해시태그 목록과 같이 간결한 형태의 텍스트 결과를 생성할 수 있습니다. Summary API는 비디오 요약, 챕터 구분, 하이라이트 생성에 특화되어 설계되었습니다. 더 맞춤화된 출력을 원하시는 경우, 실험 단계인 Generate API를 통해 불릿 포인트 형태부터 보고서 스타일, 비디오 내용에 기반한 창의적인 노래 가사에 이르기까지 다양한 형식과 스타일을 요구하는 양방향 프롬프트를 입력할 수 있습니다.
예시 1: Gist API 및 Summary API를 통해 비디오에서 짧은 보고서 생성하기.

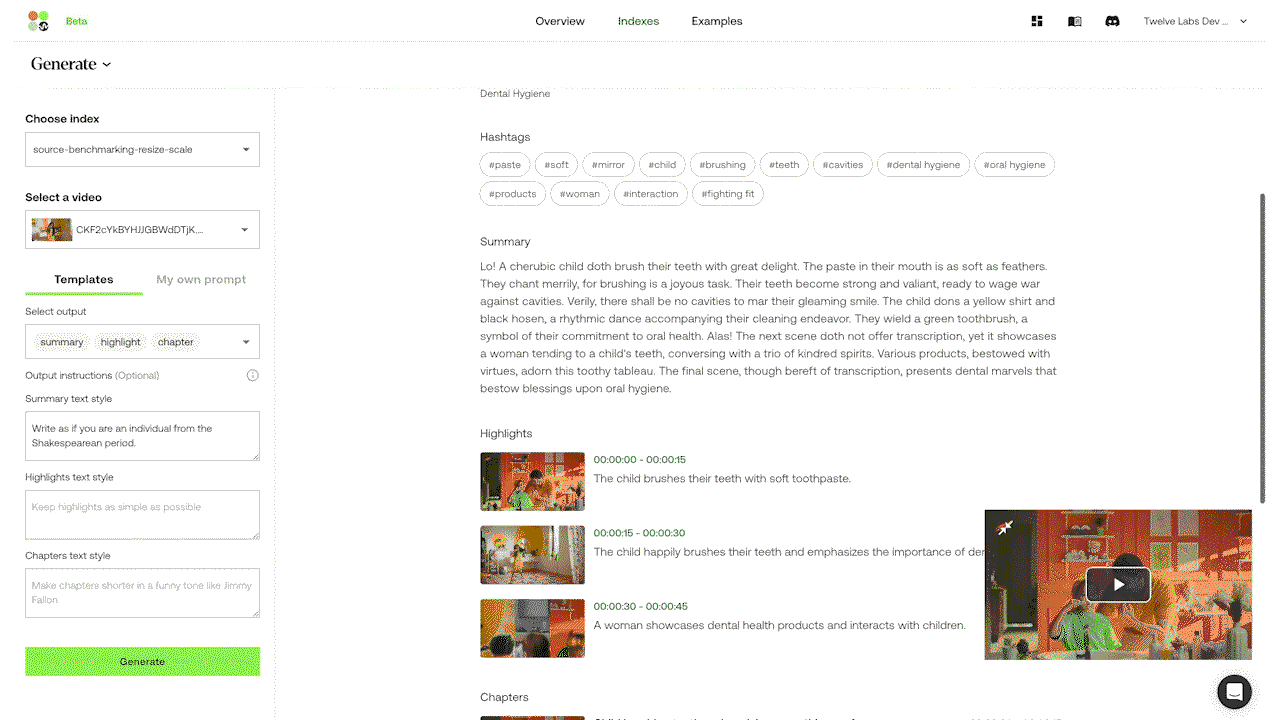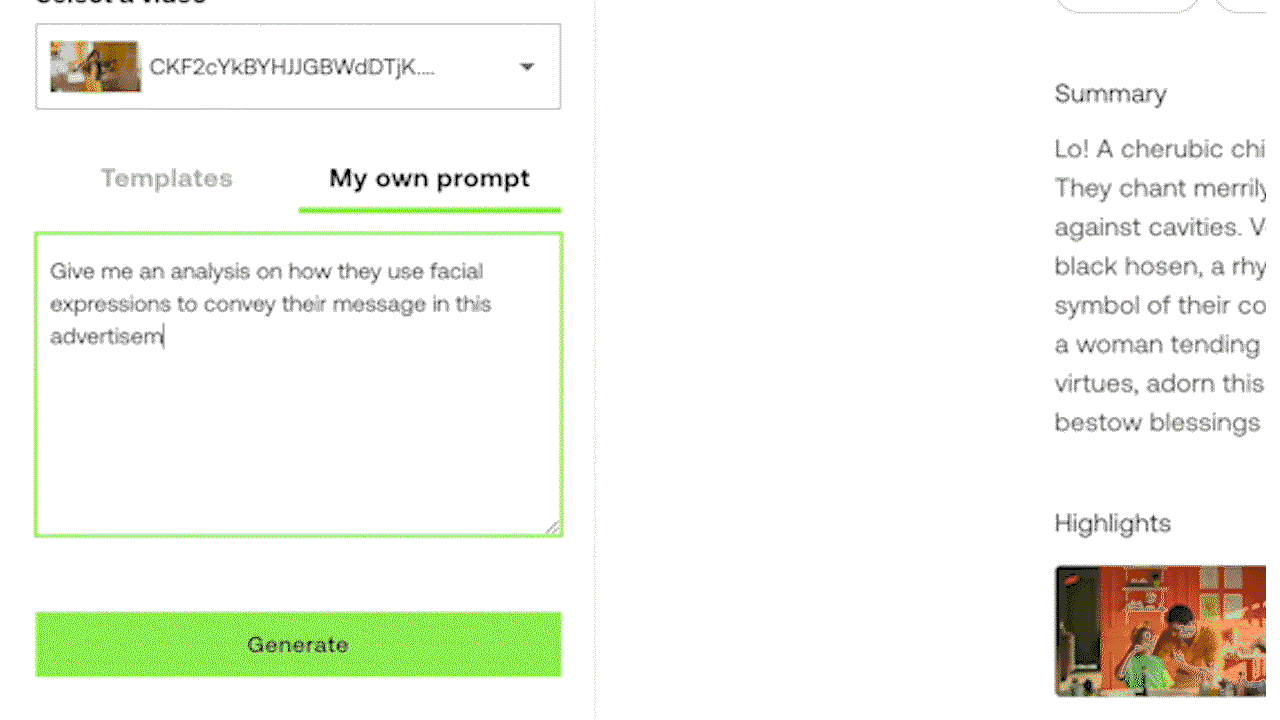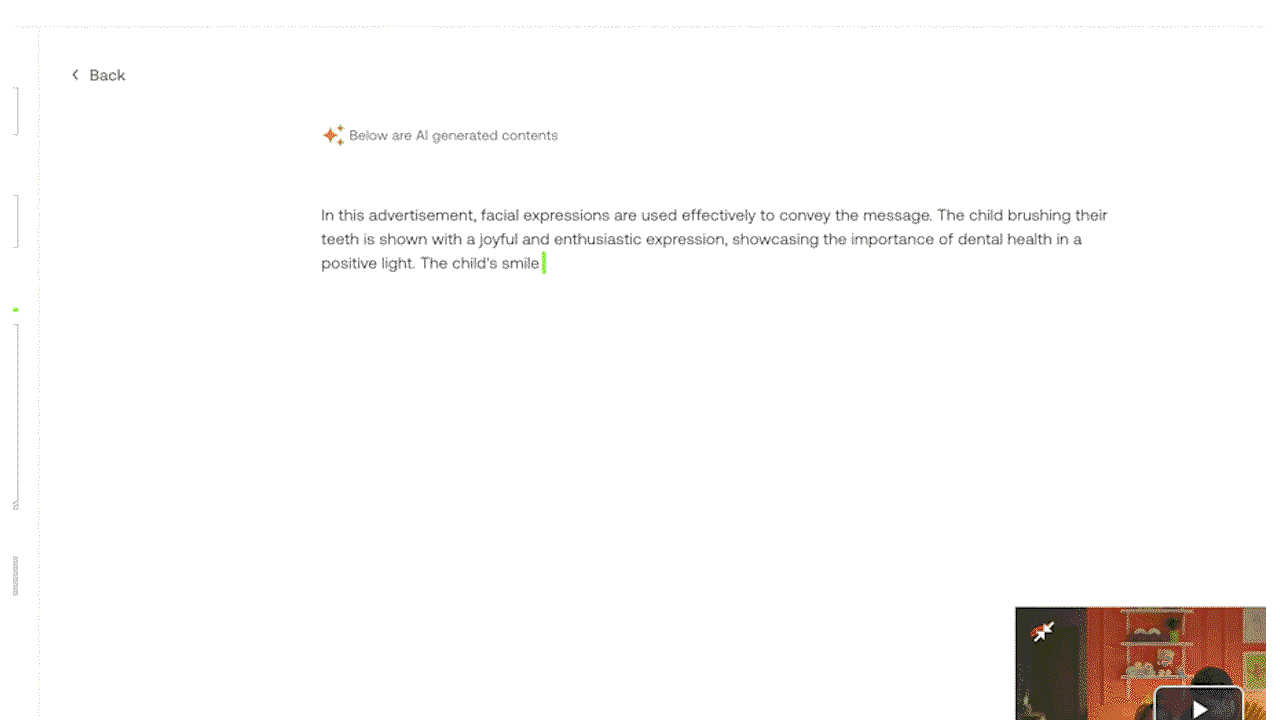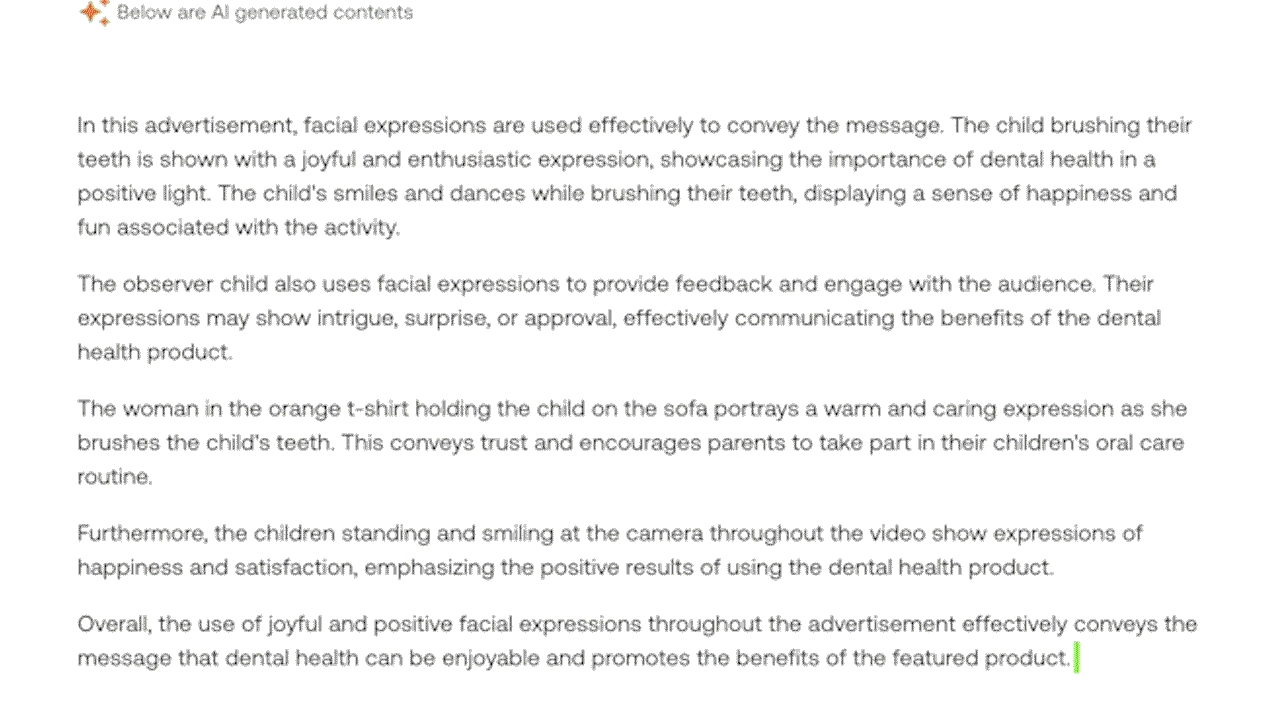
예시 2: Summary API에 스타일 지정 프롬프트를 전달하여 비디오 요약 생성하기.
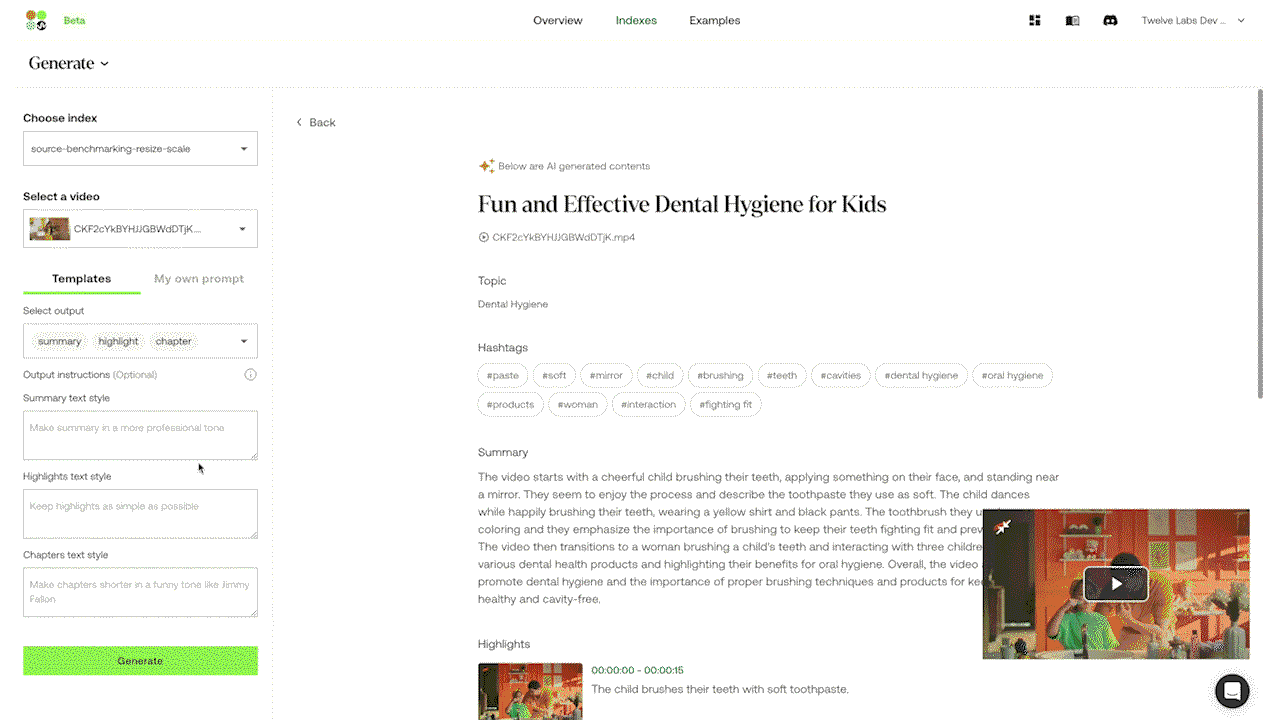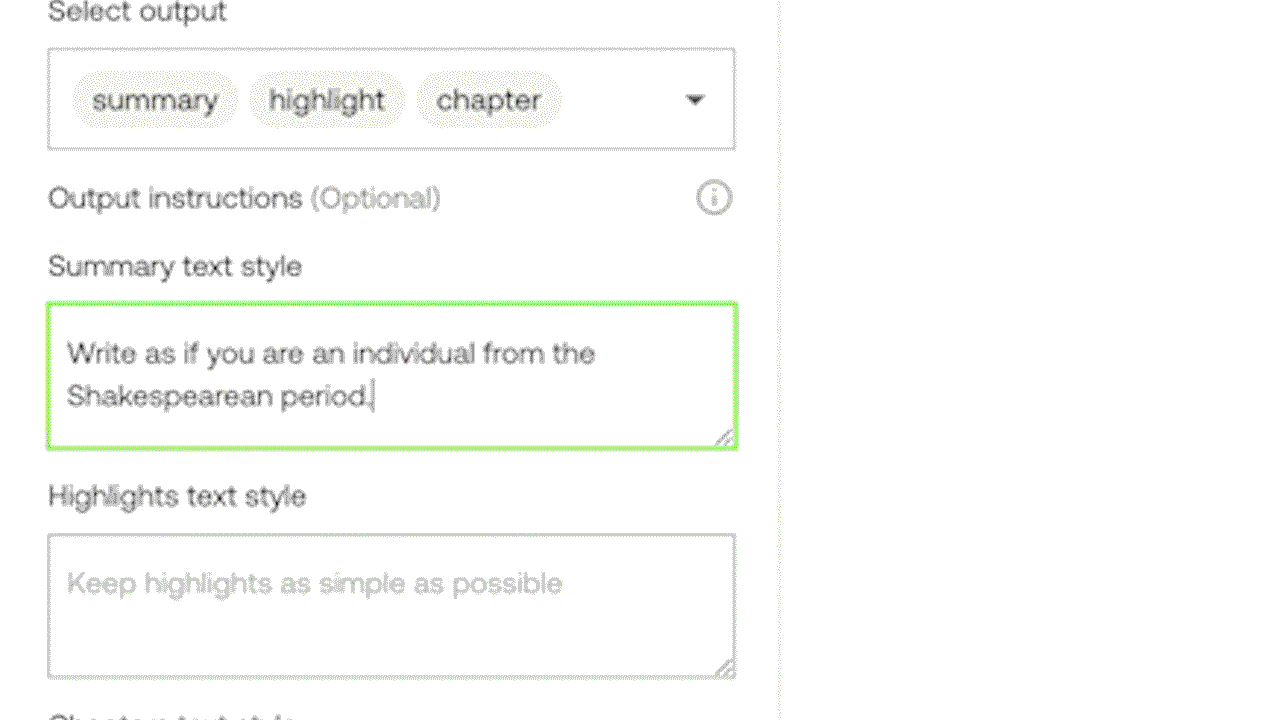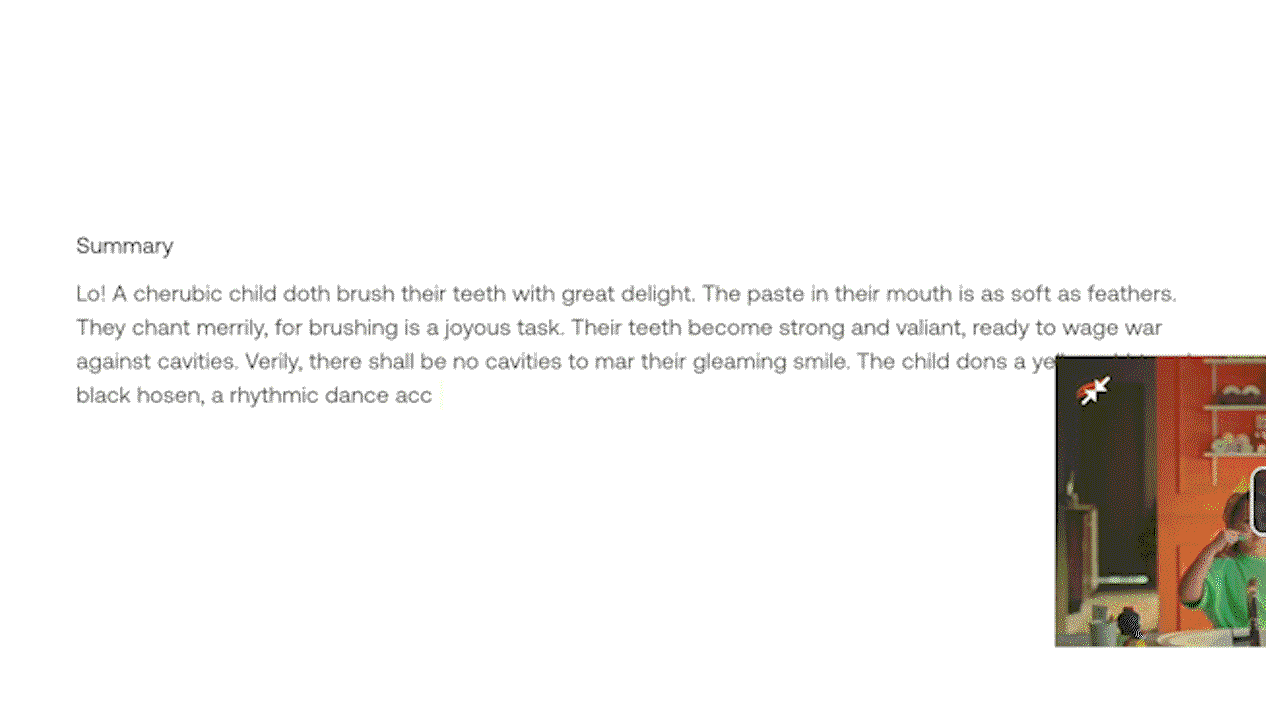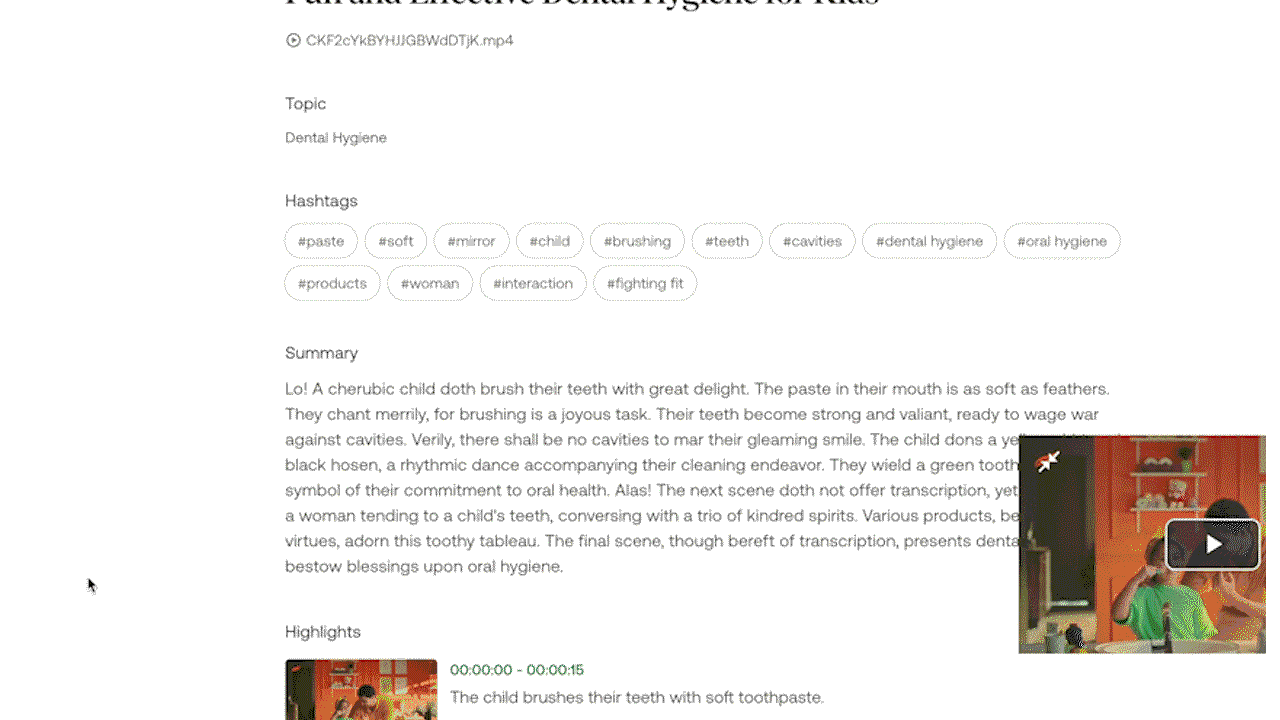
예시 3: 실험 중인 Generate API를 활용한 프롬프트 지시로 맞춤형 텍스트 출력 생성하기.
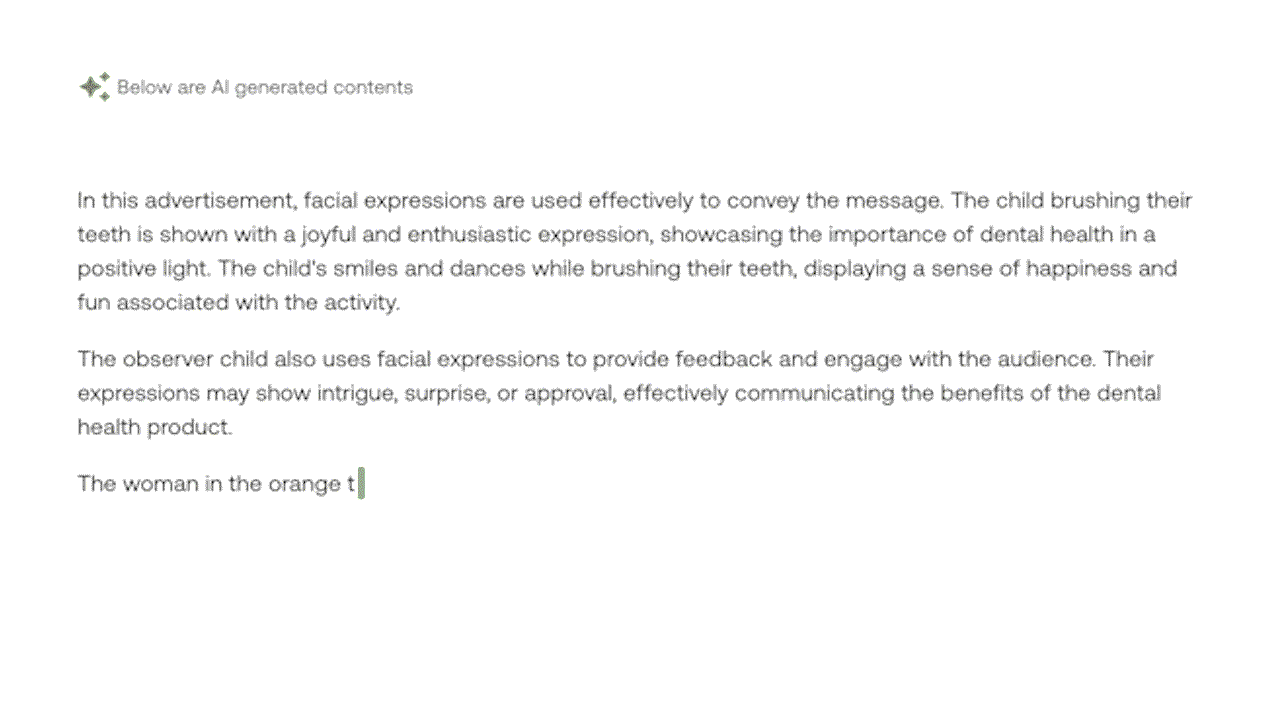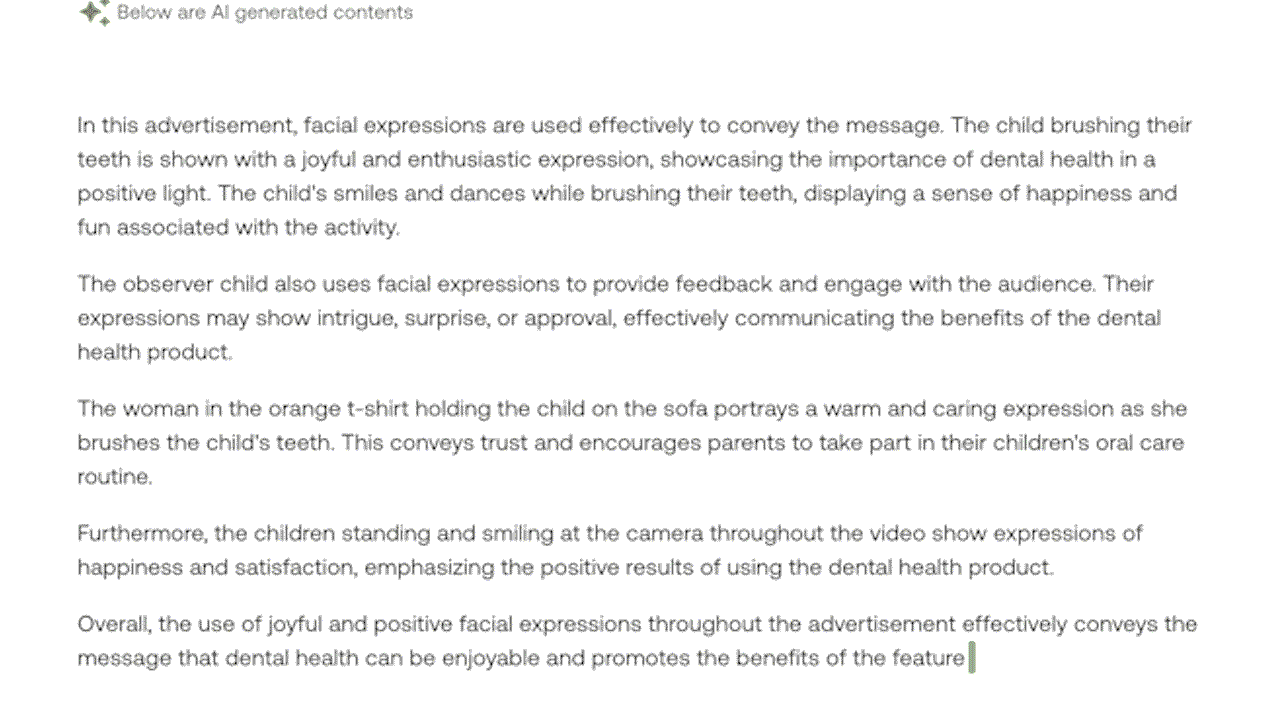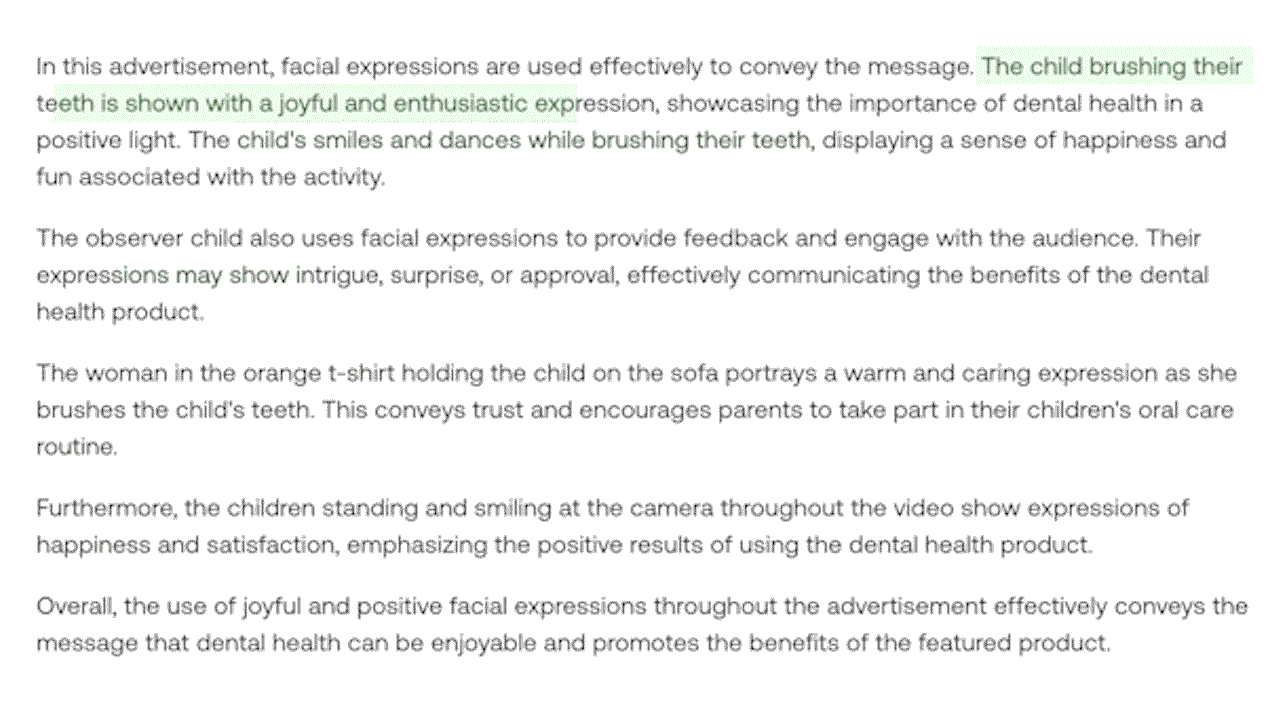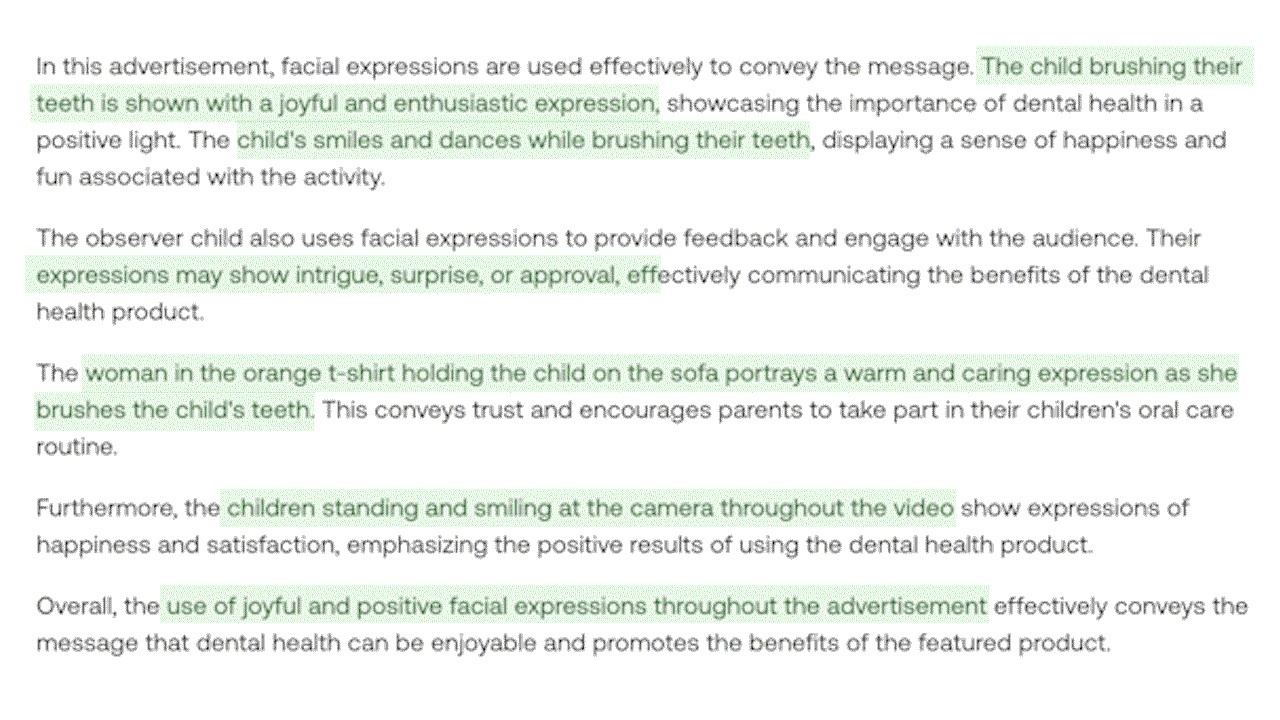
예시 4: 비디오 안의 시각, 음성, 청각적 단서를 통합하는 멀티모달 이해 과정의 예시. (녹색으로 강조된 부분: 시각 정보)
Pegasus-1 (80B) 모델 개요
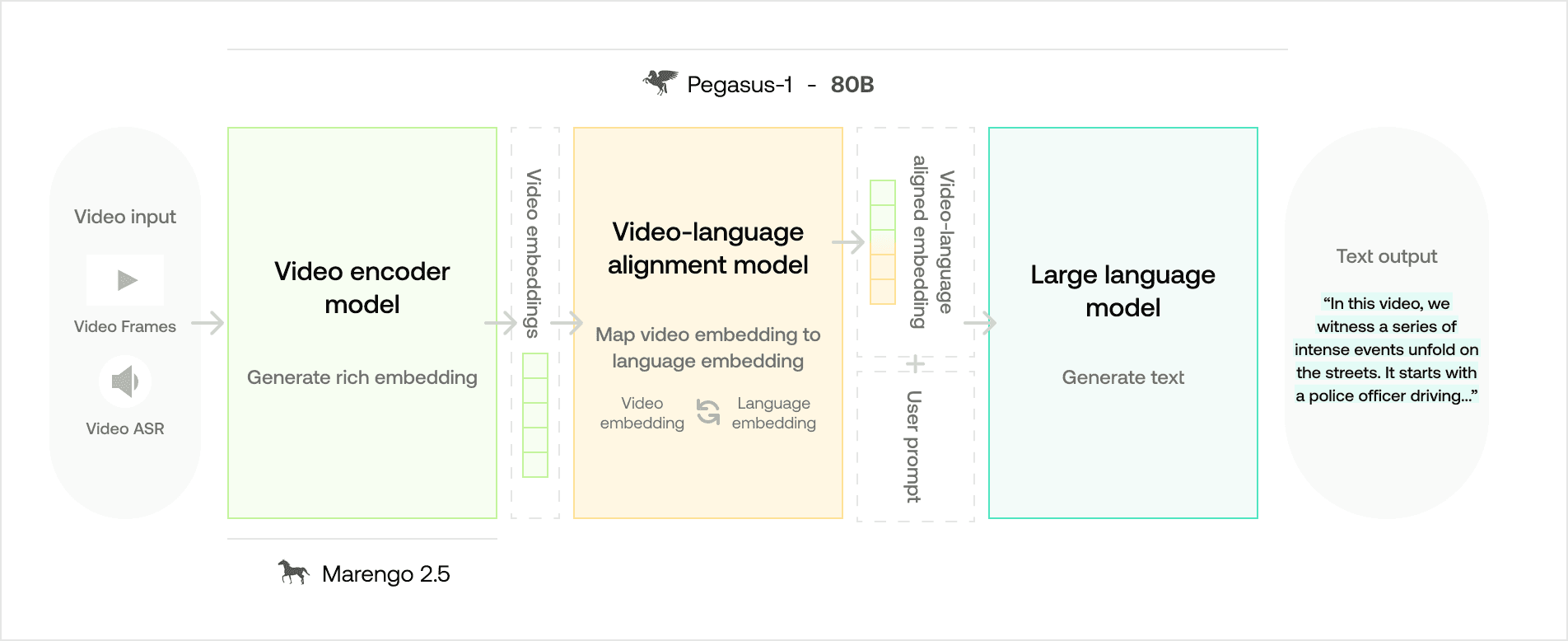
개별 구성 모델들의 세부 기능 및 전체 아키텍처
Pegasus-1 모델은 각각 비디오 네이티브 임베딩 생성, 비디오-언어 정렬 임베딩 생성, 텍스트 출력을 담당하는 세 가지 주요 컴포넌트로 구성되어 있습니다.
1. 비디오 인코더 모델 - 기존 Marengo 임베딩 모델에서 파생
입력: 비디오
출력: 비디오 임베딩(시각, 오디오, 음성 정보 포함)
기능: 비디오 인코더의 목적은 비디오에서 복잡하고 정밀한 세부 정보를 수집하는 것입니다. 비디오 프레임과 그 시간적 관계를 평가하여 관련 시각 정보를 확보하는 동시에 오디오 신호와 음성 정보를 함께 처리합니다.
2. 비디오-언어 정렬(Alignment) 모델
입력: 비디오 임베딩
출력: 비디오-언어 정렬 임베딩
기능: 정렬 모델의 주요 임무는 비디오 임베딩과 언어 모델 영역 간의 가교 역할을 하는 것입니다. 이를 통해 언어 모델이 비디오 임베딩을 텍스트 토큰을 이해하는 것과 유사한 방식으로 해석할 수 있도록 돕습니다.
3. 대규모 언어 모델 - 디코더 모델
입력: 비디오-언어 정렬 임베딩, 사용자 프롬프트
출력: 텍스트
기능: 광범위한 지식 베이스를 활용하여, 언어 모델은 입력된 사용자 프롬프트를 바탕으로 정렬 임베딩을 해석합니다. 그 후 이 정보를 일관성 있고 사람이 읽기 쉬운 자연스러운 텍스트로 디코딩합니다.
모델 매개변수(Parameters) 및 규모
Pegasus-1 모델은 총 약 80B(800억 개)의 매개변수를 보유하고 있습니다. Marengo 임베딩 모델의 크기를 포함하여 각 개별 컴포넌트의 상세한 매개변수 분포는 현재 시점에는 공개되지 않습니다.
학습 및 미세조정(Fine-tuning) 데이터셋
비디오-언어 파운데이션 모델용 학습 데이터: 3억 개 이상의 비디오-텍스트 쌍 라이브러리에서 3,500만 개의 비디오(TL-35M으로 명명)와 10억 개 이상의 이미지로 구성된 10%의 서브셋 가공 및 선별을 마쳤습니다. 첫 학습 단계로서 충분히 큰 규모라고 생각하며, 향후 학습은 TL-100M에서 진행할 예정입니다. 저희가 파악하기로, 이는 비디오-언어 파운데이션 모델 학습을 위해 정교하게 선별된 비디오-텍스트 코퍼스로는 최대 규모입니다. 더 폭넓은 학술적 연구 지원을 위해 소규모 데이터셋을 오픈소스로 공개하는 방안을 고려 중입니다. 관심이 있으신 분은 research@twelvelabs.io로 문의해 주시기 바랍니다.
미세조정(Fine-tuning) 데이터셋: 앞서 언급한 비디오-언어 파운데이션 모델의 지시 이행(instruction-following) 능력을 강화하려면 고품질의 비디오-텍스트 미세조정 데이터셋이 필수적입니다. 저희의 데이터 선정 기준은 도메인의 다양성, 텍스트 주석(annotation)의 포괄성 및 정밀도라는 세 가지 주요 측면에 중점을 두고 있습니다. 본 데이터셋 내 각 비디오에 부여된 텍스트 주석의 평균 길이는 비슷한 길이의 기존 공개 비디오 데이터셋에 비해 두 배 더 깁니다. 또한, 정확성을 기하기 위해 주석 데이터에 대해 여러 차례의 검증 및 보정 단계를 거칩니다. 비록 이러한 접근법이 단위 주석 비용을 증가시키지만, 이전 연구(Zhou et al., 2023)에서 밝혀진 바와 같이 가치 있는 성과를 위해 단순량적 팽창보다 미세조정 데이터셋의 고품질 표준 유지를 더 중시했습니다.
성능에 영향을 미치는 요인들
예상하는 바와 같이, 모델의 종합적인 성능은 각 컴포넌트의 성능과 강력한 상관관계가 있습니다. 개별 구성 모델이 전체 품질 향상에 주는 구체적인 기여도는 여전히 연구 중인 영역입니다. 향후 더 심층적인 이해를 위해 대대적인 소거 실험(ablation study)을 진행하고 발견한 사실들을 공유해 드릴 예정입니다.
비디오 인코더 모델: 현재 당사의 Search 및 Classify API의 기반인 Marengo 2.5 모델(2023년 3월 기준, 1억 개 이상 비디오 / 10억 개 이상 이미지 포함)을 토대로 파생된 비디오 인코더 모델은 임베딩 기반의 비디오 분류 및 검색 작업에서 최고 수준의 결과를 기록하고 있습니다. 비디오로부터 추출할 수 있는 정보의 깊이는 본질적으로 이 비디오 인코더 모델에 의해 상한선이 정해집니다. Marengo 모델에 대한 더욱 상세한 내용은 차기 버전 Marengo 2.6 출시와 함께 다가올 보고서에서 다뤄질 예정입니다.
비디오-언어 정렬 모델: 이 모델은 파운데이션 모델 학습과 지시 미세조정 과정에서 비디오-언어 정렬 전문 지식을 학습합니다. 저희 언어 모델이 비디오 임베딩과 원활히 조화될 수 있는 핵심 경계가 바로 이 정렬 메커니즘을 통해 구축됩니다.
대규모 언어 모델 (디코더 모델): 언어 모델의 역량은 사전 학습 단계에서 축적한 풍부한 지식을 바탕으로 정의됩니다. 결과물인 출력 텍스트의 완성도는 모델 자체의 지식, 제공된 사용자 프롬프트, 그리고 비디오-언어 정렬 임베딩을 어떻게 조화롭게 합성해내느냐에 달려 있습니다.
평가 및 결과


Twelve Labs는 Pegasus-1 모델을 포함하여 전반적인 선진 기술들이 책임감 있게 배포되도록 보장하는 것의 중요성을 무겁게 인지하고 있습니다. 당사는 정확성, 세부 묘사 정밀도, 맥락적 이해도, 안전성, 유용성 등 미세한 다각적 관점에서 모든 개발 모델들의 벤치마크 테스트를 진행할 수 있는 종합적이고 투명한 데이터셋 및 평가 체계를 마련하고자 헌신하고 있습니다. 현재 비디오-언어 모델의 안전성과 유용성을 구체적으로 정량화하기 위한 고유 평가 지표를 조율 중이며, 결과는 즉각 공유될 예정입니다. 이번 블로그를 통해 예비 분석 결과를 우선 전해드리게 되어 대단히 고무적이며, 더욱 심화된 보고서 역시 차후 발표할 계획입니다. 이번 평가는 Pegasus-1 프리뷰 버전을 바탕으로 하였습니다.
저희 평가 코드베이스는 여기에서 확인하실 수 있습니다.
비교 모델군
당사의 모델과 비교할 타사 모델군은 크게 세 가지 고유 카테고리로 분류하였습니다.
Video-ChatGPT (Maaz et al., 2023): 오픈 소스 형태로 공개되어 있으며 채팅 인터페이스를 탑재한 현시점 최신(SOTA) 수준의 대표적인 비디오-언어 모델입니다. 비디오 내 위상과 시각적 사건들을 다루기 위해 영상 프레임을 가공해 해석하지만, 비디오 속에 발생하는 대화 정보는 직접적으로 활용하지 못하는 특징을 보입니다.
Whisper + ChatGPT-3.5 (OpenAI): 비디오 요약 작업을 위해 널리 상용화되어 쓰이는 이종 모델 간 대표적인 하이브리드 조합 중 하나입니다. 최고 수준의 음성 인식 기술(STT) 및 대형 언어 모델의 힘을 합쳐 결과물을 도출하지만, 주된 소스가 청각 음성 트랙에 전적으로 치우쳐져 있어 비디오 내의 귀중한 시각 맥락을 놓치게 된다는 중대한 맹점이 존재합니다.
A사의 요약(Summary) API: 오디오 및 비디오 요약본 생성을 목표로 시장에서 활발히 채택해 사용 중인 대표적인 상용 솔루션입니다. A사의 솔루션은 비디오 요약 결과를 전달할 때 시각 정보를 완전 배제한 채 오직 텍스트 전사(TTS/ASR) 기록과 언어 모델에만 의존(ASR+ChatGPT 3.5 기반 방식과 유사)하는 것으로 분석됩니다.
데이터셋
MSR-VTT 데이터셋 (Xu et al., 2016): 모델이 10초에서 40초 사이의 짧은 비디오 클립에 대한 캡션이나 묘사 결과를 얼마나 훌륭히 생성해 내는지 가늠하게 돕는 널리 쓰이는 표준 비디오 캡셔닝 벤치마크 데이터셋입니다. 각 비디오에 인간 검수자가 작성한 20개 문장이 매칭되어 있으며, 최대한 상세한 세부를 끌어내고자 LLM(ChatGPT)을 통한 통합 정제 단계를 밟아 촘촘한 최종 통합 기술서 한 문단으로 가공해 활용했습니다. 본 평가는 총 1,000개 클립으로 조율된 JSFusion 검증용 분할(Test Split) 상에서 엄격히 이행되었습니다.
Video-ChatGPT 비디오 설명(Descriptions) 데이터셋 (Maaz et al., 2023): 대다수 비디오-텍스트 성능 평가는 위에 소개한 MSR-VTT와 같은 단문 중심의 비디오 가공 캡션 데이터에 크게 의존하는 경향을 보여왔습니다. 이러한 단편 캡셔닝이 훌륭한 나침반이 될 순 있으나 실제 작업 환경에 상존하는 다양한 형태의 장편 비디오를 완벽히 예측 평가하기란 불가능에 가깝습니다. 이에 따라, 저희는 Video-ChatGPT 비디오 설명 데이터셋을 평가 과정에 추가했습니다. 본 데이터셋은 ActivityNet 소스의 500개 비디오 가량으로 구성되어 있으며, 전문 검수 인력에 의해 정밀 제작된 풍부한 내용의 요약 정보가 포함되어 있습니다. 일반적인 짧은 가공식 캡션들과 달리 30초에서 수 분에 이르는 길이감을 가지며, 모든 결과는 시각 및 음향 정보를 종합 보완한 5~8개 수준의 완성도 높은 풀 세부 문단 요약으로 구성되어 있습니다.
평가 지표
비디오 기반 대화 모델을 위한 정량적 평가 프레임워크 (QEFVC)(Maaz et al., 2023) 기준에 따라 당사는 정보의 정확성(Correctness), 세부 묘사 능력(Detail Orientation), 맥락 이해(Contextual Understanding) 등 세 영역에 초점을 맞추어 검증을 진행했습니다. 이를 위해, 정밀 지시 미세조정을 마친 우수한 평가용 언어 모델(GPT-4)을 선택해 정답 레퍼런스 기준 대비 각 기준의 완성도를 질의 분석하도록 유도했습니다. 최종적 전반 성능 수치 도출을 유도하기 위해 3대 지표값을 산술평균 하였으며, 이를 공식 QEFVC 품질 스코어라 명명했습니다.
이 평가 시스템이 타 모델들과의 비교를 매우 매끄럽게 돕는 것은 사실이지만 완벽한 만능 해법은 아닙니다. 언어 모델을 활용하는 제반 평가의 불확실성을 가리킨 기존 동종 학계 유수 연구 결과들은, 평가 모델(GPT-4 등) 하나에만 전적으로 의존하는 수치 도출이 편향이나 기만적 평가 오류를 낼 위험이 있음을 주의 깊게 지적해 왔습니다. 또한 세부 평가 단위를 미시적으로 정교화할수록 평가 수치의 정확 신뢰도와 일관성이 대폭 상승한다는 점 역시 증명된 바 있습니다 (Ye et al., 2023). 이에 영감을 받아 전사적 팩트 체크 스코어링 체계인 FActScore(Min et al., 2023)를 참고해, 비디오 요약 결과의 퀄리티를 더욱 깊고 조밀하게 계측 분석할 독자적 신규 평가 방법론인 VidFactScore(비디오 사실성 스코어)를 선언 및 적용했습니다.
모델의 모든 비디오 대상 출력안과 인간 요약 정답 쌍을 세밀한 이산형 단일 사실 구조들로 잘개 쪼갭니다. 예를 들자면 "한 남자와 여성이 힘차게 뛰어가고 있다"라는 큰 흐름의 진술을 문법적으로 해석해 "남자가 뛰고 있다", "여자가 뛰고 있다" 등의 독립 원자 단위 사실로 분절하는 방식입니다. 이 가공 여정 역시 적절한 훈련과 전용 프롬프트를 이식받은 GPT-4 등의 지시형 언어 모델 기재를 적용해 진행합니다.
분석 평가를 앞둔 실제 자동 생성 비디오 요약본 또한 정확히 같은 방식으로 미시적인 원자 단위 사실형 조각들로 각각 분리하는 흐름을 거쳐 갑니다.
가장 잘 정돈된 완성형 요약본이란 (1) 원래 들어있어야 할 정답 기준의 주요 팩트 요소들을 최대한 빠짐없이 반영하고, (2) 오리지널 원본 소스에 전혀 부합하지 않는 잘못된 거짓 팩트 주장을 최소화하는 요건을 만족해야 합니다. 이 유무 판단 단계 역시 완벽히 프로그래밍된 프롬프트 검인 명령을 장착 완료한 지시 조정형 언어 모델의 엄정 판별을 거칩니다.
정밀 수식화 과정을 대입할 시, (1)은 생성 예측과 정답 세트 간 합치된 사실 총량이 원본 전체 팩트 중 얼마의 기여율을 차지하는가의 계통 분모인 재현율(Recall Rate)과 긴밀히 연결됩니다. 반대로 (2)는 실제 예측 생성본이라 내놓은 글의 팩트 조각들 수 중 진짜 원본 사실에 들어있던 정확 조각의 순수 비중이 얼마인지를 확인하는 정밀도(Precision)에 매칭됩니다. 이 재현율과 정밀도 두 값의 종합 조화평균값인 F1 스코어는 각 모델들의 참 성능 편차를 완벽히 식별해 주는 최상의 직관 평가 좌표를 제안합니다.
성능 평가 결과


최신 업계 최선두 경쟁 구도(SOTA)를 지키던 VideoChatGPT 모델과의 상호 정량 비교 테스트 과정에서, Pegasus-1은 기존 QEFVC 품질 점수 기준 MSR-VTT 상에서 무려 61%의 상대적인 성능 우수성을 달성 하였을 뿐만 아니라, 장편 비디오 설명 데이터셋 테스트 부문에서도 47% 가량 눈에 띄게 큰 연적 격차의 성능 점수 발전을 보여주었습니다. 또한 텍스트 기반 번역 하이브리드 조합군(Whisper+ChatGPT 및 A사 솔루션 그룹) 대비 격차의 한계는 더욱 거대하게 전개되었는데, Pegasus-1이 타 모델들을 압도하며 MSR-VTT 데이터셋에서는 79%, 고난도의 비디오 설명 데이터셋 파트에서는 188%라는 경이로운 지표 우월성을 증명해 보였습니다.


새로 연구 대입한 독자적인 VidFactScore-F1 계측 시스템 상에서 또한, Pegasus-1은 VideoChatGPT 대비 MSR-VTT 환경에서 20%의 절대적 성능 향상을, 장편 비디오 설명 데이터셋 파트에선 14%의 성능 격차 상승률을 기록하며 판정승을 거두었습니다. 이 역시 단순 번역 의존성 하이브리드 조합군과 정밀 계측을 비교 시, MSR-VTT 데이터셋 평가부문에서 25% 상승, 비디오 설명 데이터셋 환경에 있어서는 33%의 절대 우위 점수를 따내는 눈부신 성취를 거두었습니다. 본 검증 결과들은 당사가 신규 제안하는 VidFactScore 평가지표 체계가 기성 학계의 주류 흐름인 QEFVC 분석 메커니즘과 완벽히 궤를 함께하는 높은 정밀 인과성을 보유하고 있음을 한치 오차 없이 명징하게 나타냅니다.
한 가지 무척 고무적이었던 점은, 주로 인물 음성에 극단적으로 전도될 것이라 예상했던 스탠드업 코미디 콘서트 녹화 영상물이나 대학 전공 강의 비디오와 같은 경우였습니다. 이러한 극단적 스피치 비중의 상황에서도 자사의 통합 솔루션 모델은 기존 ASR+LLM 하이브리드 아키텍처 모델군들을 거뜬히 추월하는 면모를 보여주었습니다. 흔히 '이런 음성 전용 콘셉트 비디오들의 제어에는 음성 텍스트 변환(ASR) 하나만으로도 완전히 충분할 것'이라 예단하기 쉽지만, 당사의 상세 비교 시험은 그 편견을 완벽히 반증해 냅니다. 비록 무대 위 아주 짧은 동작의 흐름(예: 무대 위서 스탠드업 쇼를 이어가는 한 남성의 제스처 포착, 혹은 청중들의 교감 리액션 모먼트 스케치)과 같은 미세 수준의 시각 정보다 할지라도, 이 정보가 단순 음성 데이터 트랙과 실시간 복합 결합할 때, 말뜻에 담긴 표현의 입체감을 전방위 확대하여 한층 조밀하고 완전무결한 고급 비디오 핵심 요약을 정련해 내게 됩니다. 결과가 반증하듯, 진정한 형태의 깊은 공간적 비디오 분석 및 맥락 이해는 단지 청각 데이터를 문자로 옮겨내는 얕은 음성 청해 단계를 한참 뛰어넘는 고급 예술입니다. 온전한 이해를 담보하기 위해 시각과 음성을 아우르는 복합 멀티모달 프레임워크 설계가 필수불가결하다는 주장의 선명한 실증입니다. 하단에 기재된 사외 실전 적용형 예시(In-the-wild Examples) 중 "리액션 비디오(Reaction Video)" 실제 비교 파트가 그 해답을 잘 설명해 줄 것입니다.
사외 실전 적용형 예시 (In-the-wild examples)
아래 사례들은 기존의 타사 솔루션들과 비교해 Pegasus-1 모델이 보여주는 뛰어난 역량을 선보이고자 다양한 도메인에서 무작위로 추출 및 가공 처리한 실제 가용 예시들입니다.
자동 생성된 텍스트 출력물 내에는 아래와 같은 한계점들이 잠재적으로 포함될 수 있음을 투명하게 사전 공지해 드립니다.
환각 현상 (Hallucinations: 실제 비디오 상에는 직접 노출 혹은 입증되지 않은 미지의 개연 팩트들을 모델 스스로의 지레짐작과 내부 확률 맥락에 의해 개연성 있는 소설 형태로 창작해 가공해 내는 현상)
사용자가 제시한 명령 프롬프트나 맥락 질문 구조 자체를 명확히 이해하지 못해 다소 동문서답에 가까운 부적합한 출력을 내는 일종의 이탈 오류
특정 편향이나 편견(Biases)의 개입 가능성
이와 관련된 귀중한 모든 피드백 수집 경로를 상시 늘려가고 있으며, 지적 및 보정 요청 사항들은 가까운 시일 내 업데이트 개발에 성실히 투영 및 개선해 가도록 최선을 다할 것입니다.
요약
제품: Twelve Labs가 최신 비디오-언어 파운데이션 모델인 Pegasus-1과 함께 비디오-텍스트 API 신규 제품군(Gist API, Summary API, Generate API)을 발표합니다.
제품 및 연구 철학: 비디오 이해를 단순히 이미지나 음성 이해 문제로 재구성하는 기존의 많은 방식들과 달리, Twelve Labs는 다음 네 가지 핵심 원칙을 바탕으로 한 "비디오 우선(Video First)" 전략을 채택하고 있습니다: 효율적인 장편 비디오 처리, 멀티모달 이해, 비디오 네이티브 임베딩, 비디오 및 언어 임베딩 간의 긴밀한 정렬
새로운 모델: Pegasus-1은 약 80B(800억 개)의 매개변수를 가지고 있으며 비디오 인코더, 비디오-언어 정렬 모델, 언어 디코더라는 세 가지 모델 구성 요소가 함께 공동 학습되었습니다.
데이터셋: Twelve Labs는 다양하고 정교하게 정제된 3억 개 이상의 비디오-텍스트 쌍을 수집했으며, 이는 비디오-언어 파운데이션 모델 학습을 위한 세계 최대 규모의 비디오-텍스트 코퍼스 중 하나입니다. 본 기술 보고서는 3,500만 개의 비디오-텍스트 쌍과 10억 개 이상의 이미지-텍스트 쌍으로 구성된 10%의 서브셋에서 진행된 초기 학습 학습 실행을 기반으로 합니다.
최신(SOTA) 비디오-언어 모델 대비 성능: 이전의 최신(SOTA) 비디오-언어 모델과 비교했을 때, Pegasus-1은 QEFVC 품질 점수(Maaz et al., 2023) 기준 MSR-VTT 데이터셋(Xu et al., 2016)에서 61%의 상대적 성능 향상을, 비디오 설명(Video Descriptions) 데이터셋(Maaz et al., 2023)에서 47%의 성능 향상을 보여줍니다. 저희가 제안하는 평가 지표인 VidFactScore로 평가했을 때, MSR-VTT 데이터셋에서는 절대 F1 Score 기준 20%의 상승을, 비디오 설명 데이터셋에서는 14%의 성능 향상을 보여줍니다.
ASR+LLM 모델 대비 성능: ASR+LLM은 비디오-텍스트 변환 문제를 해결하기 위해 널리 채택되는 방식입니다. Whisper-ChatGPT(OpenAI) 및 업계 선두의 상용 ASR+LLM 제품과 비교했을 때, Pegasus-1은 MSR-VTT에서 79%, 비디오 설명 데이터셋에서 188% 더 우수한 성능을 나타냅니다. VidFactScore-F1으로 평가 시, MSR-VTT 데이터셋에서 25%, 비디오 설명 데이터셋에서 33%의 절대 성능 이점을 보여줍니다.
Pegasus-1 API 액세스: Pegasus 기반 비디오-텍스트 API의 대기 명단(Waitlist) 등록 링크입니다.
연구 지평의 확장: 비디오 임베딩을 넘어 생성형 모델로
샌프란시스코 베이 에어리어에 본사를 둔 AI 연구 및 제품 개발 기업 Twelve Labs는 멀티모달 비디오 이해의 최전선에 서 있습니다. 오늘 우리는 최신 비디오-언어 파운데이션 모델인 Pegasus-1의 최첨단 비디오-텍스트 생성 기능을 공개하게 되어 매우 기쁩니다. 이는 다양한 다운스트림 비디오 이해 작업에 맞춤화된 종합 API 제품군을 제공하겠다는 우리의 약속을 보여줍니다. 저희 포트폴리오는 자연어 기반의 비디오 모먼트 검색부터 분류, 그리고 이번에 새로 출시된 프롬프트 기반의 비디오-텍스트 생성 기능에 이르기까지 폭넓게 아우르고 있습니다.
우리의 비디오 우선(Video-First) 정신
비디오 데이터는 단일 포맷 내에 여러 모달리티(시각, 청각 등)를 포함하고 있다는 점에서 매우 흥미롭습니다. 우리는 비디오를 진정으로 이해하기 위해서는 시각적 인지의 복잡성과 오디오 및 텍스트의 순차적이고 맥락적인 미묘한 차이를 결합하는 완전히 새로운 접근 방식이 필요하다고 믿습니다. 뛰어난 성능의 이미지 및 언어 모델이 등장함에 따라, 비디오 이해 분야의 주류 접근 방식은 이를 이미지나 음성 이해 문제로 재정의하는 것이었습니다. 전형적인 프레임워크는 비디오에서 프레임을 샘플링하여 비전-언어 모델에 입력하는 형식을 취합니다.
비디오 길이가 짧은 경우에는 이러한 접근 방식이 유효할 수 있지만(대부분의 비전-언어 모델이 1분 미만의 짧은 비디오 클립에 집중하는 이유이기도 합니다), 실제 환경의 비디오 대부분은 1분을 초과하며 수 시간까지 쉽게 늘어납니다. 이러한 비디오에 기존의 "이미지 우선(image-first)" 방식을 사용하면 비디오 하나당 수만 장의 이미지를 처리해야 합니다. 이는 시공간 정보의 의미를 기껏해야 대략적으로만 포착하는 방대한 양의 이미지-텍스트 임베딩을 다뤄야 함을 뜻합니다. 이는 성능, 지연 시간(latency), 비용 측면에서 많은 실제 애플리케이션에 적용하기가 어렵습니다. 더 나아가, 이러한 주류 방법론은 비디오 콘텐츠의 포괄적인 이해를 위해 시각 및 음성을 포함한 청각적 요소를 함께 공동으로 분석하는 것이 핵심이라는 비디오 본연의 멀티모달 특성을 간과하고 있습니다.
이러한 비디오 데이터의 근본적인 특성을 염두에 두고, Twelve Labs는 모델, 데이터, ML 시스템을 오직 비디오 데이터의 처리와 이해에만 전념하도록 하는 "비디오 우선(Video First)" 전략을 채택했습니다. 이는 다른 많은 생성형 AI 기업에서 관찰되는 일반적인 "언어/이미지 우선" 접근 방식과 극명한 대조를 이룹니다. 저희의 "비디오 우선" 정신을 강화하는 네 가지 핵심 원칙은 비디오-언어 파운데이션 모델의 설계와 ML 시스템 아키텍처 구축의 나침반 역할을 하고 있습니다.
효율적인 장편 비디오 처리: 저희 모델과 시스템은 짧은 10초짜리 클립부터 수 시간에 이르는 방대한 콘텐츠까지 다양한 길이의 비디오를 최적화하여 처리할 수 있어야 합니다.
멀티모달 이해: 저희 모델은 시각, 오디오, 음성 정보를 종합적으로 합성할 수 있어야 합니다.
비디오 네이티브 임베딩: 공간적 관계에만 집중하는 이미지 네이티브 임베딩(예: CLIP)에 의존하는 대신, 비디오의 시공간적 정보를 유기적이고 통합된 방식으로 담아낼 수 있는 비디오 네이티브 임베딩이 필요하다고 믿습니다.
비디오 네이티브 임베딩과 언어 모델 간의 긴밀한 정렬: 이미지-텍스트 정렬을 넘어, 대규모 비디오-텍스트 코퍼스와 비디오-텍스트 명령(instruction) 데이터셋에 대한 광범위한 학습을 통해 모델이 깊이 있는 비디오-언어 정렬을 달성하도록 해야 합니다.
새로운 비디오-텍스트 생성 능력과 인터페이스
개발자들은 단 한 번의 API 호출만으로 Pegasus-1 모델에 프롬프트를 입력하여 비디오 데이터로부터 특정 텍스트 출력을 생성할 수 있습니다. 음성-텍스트 변환(STT)을 사용하거나 시각 프레임 데이터에만 의존하는 기존 솔루션들과 달리, Pegasus-1은 시각, 오디오, 음성 정보를 통합하여 비디오로부터 한층 더 종합적인 텍스트를 생성하며 비디오 요약 벤치마크에서 새로운 업계 최고 수준(SOTA)의 성능을 달성했습니다. (아래 평가 및 결과 섹션 참조)
Gist API와 Summary API에는 사용자가 따로 프롬프트를 입력하지 않아도 즉시 작동할 수 있도록 관련 프롬프트가 기본 탑재되어 있습니다. Gist API는 제목, 주제, 관련 해시태그 목록과 같이 간결한 형태의 텍스트 결과를 생성할 수 있습니다. Summary API는 비디오 요약, 챕터 구분, 하이라이트 생성에 특화되어 설계되었습니다. 더 맞춤화된 출력을 원하시는 경우, 실험 단계인 Generate API를 통해 불릿 포인트 형태부터 보고서 스타일, 비디오 내용에 기반한 창의적인 노래 가사에 이르기까지 다양한 형식과 스타일을 요구하는 양방향 프롬프트를 입력할 수 있습니다.
예시 1: Gist API 및 Summary API를 통해 비디오에서 짧은 보고서 생성하기.
예시 2: Summary API에 스타일 지정 프롬프트를 전달하여 비디오 요약 생성하기.
예시 3: 실험 중인 Generate API를 활용한 프롬프트 지시로 맞춤형 텍스트 출력 생성하기.
예시 4: 비디오 안의 시각, 음성, 청각적 단서를 통합하는 멀티모달 이해 과정의 예시. (녹색으로 강조된 부분: 시각 정보)
Pegasus-1 (80B) 모델 개요
개별 구성 모델들의 세부 기능 및 전체 아키텍처
Pegasus-1 모델은 각각 비디오 네이티브 임베딩 생성, 비디오-언어 정렬 임베딩 생성, 텍스트 출력을 담당하는 세 가지 주요 컴포넌트로 구성되어 있습니다.
1. 비디오 인코더 모델 - 기존 Marengo 임베딩 모델에서 파생
입력: 비디오
출력: 비디오 임베딩(시각, 오디오, 음성 정보 포함)
기능: 비디오 인코더의 목적은 비디오에서 복잡하고 정밀한 세부 정보를 수집하는 것입니다. 비디오 프레임과 그 시간적 관계를 평가하여 관련 시각 정보를 확보하는 동시에 오디오 신호와 음성 정보를 함께 처리합니다.
2. 비디오-언어 정렬(Alignment) 모델
입력: 비디오 임베딩
출력: 비디오-언어 정렬 임베딩
기능: 정렬 모델의 주요 임무는 비디오 임베딩과 언어 모델 영역 간의 가교 역할을 하는 것입니다. 이를 통해 언어 모델이 비디오 임베딩을 텍스트 토큰을 이해하는 것과 유사한 방식으로 해석할 수 있도록 돕습니다.
3. 대규모 언어 모델 - 디코더 모델
입력: 비디오-언어 정렬 임베딩, 사용자 프롬프트
출력: 텍스트
기능: 광범위한 지식 베이스를 활용하여, 언어 모델은 입력된 사용자 프롬프트를 바탕으로 정렬 임베딩을 해석합니다. 그 후 이 정보를 일관성 있고 사람이 읽기 쉬운 자연스러운 텍스트로 디코딩합니다.
모델 매개변수(Parameters) 및 규모
Pegasus-1 모델은 총 약 80B(800억 개)의 매개변수를 보유하고 있습니다. Marengo 임베딩 모델의 크기를 포함하여 각 개별 컴포넌트의 상세한 매개변수 분포는 현재 시점에는 공개되지 않습니다.
학습 및 미세조정(Fine-tuning) 데이터셋
비디오-언어 파운데이션 모델용 학습 데이터: 3억 개 이상의 비디오-텍스트 쌍 라이브러리에서 3,500만 개의 비디오(TL-35M으로 명명)와 10억 개 이상의 이미지로 구성된 10%의 서브셋 가공 및 선별을 마쳤습니다. 첫 학습 단계로서 충분히 큰 규모라고 생각하며, 향후 학습은 TL-100M에서 진행할 예정입니다. 저희가 파악하기로, 이는 비디오-언어 파운데이션 모델 학습을 위해 정교하게 선별된 비디오-텍스트 코퍼스로는 최대 규모입니다. 더 폭넓은 학술적 연구 지원을 위해 소규모 데이터셋을 오픈소스로 공개하는 방안을 고려 중입니다. 관심이 있으신 분은 research@twelvelabs.io로 문의해 주시기 바랍니다.
미세조정(Fine-tuning) 데이터셋: 앞서 언급한 비디오-언어 파운데이션 모델의 지시 이행(instruction-following) 능력을 강화하려면 고품질의 비디오-텍스트 미세조정 데이터셋이 필수적입니다. 저희의 데이터 선정 기준은 도메인의 다양성, 텍스트 주석(annotation)의 포괄성 및 정밀도라는 세 가지 주요 측면에 중점을 두고 있습니다. 본 데이터셋 내 각 비디오에 부여된 텍스트 주석의 평균 길이는 비슷한 길이의 기존 공개 비디오 데이터셋에 비해 두 배 더 깁니다. 또한, 정확성을 기하기 위해 주석 데이터에 대해 여러 차례의 검증 및 보정 단계를 거칩니다. 비록 이러한 접근법이 단위 주석 비용을 증가시키지만, 이전 연구(Zhou et al., 2023)에서 밝혀진 바와 같이 가치 있는 성과를 위해 단순량적 팽창보다 미세조정 데이터셋의 고품질 표준 유지를 더 중시했습니다.
성능에 영향을 미치는 요인들
예상하는 바와 같이, 모델의 종합적인 성능은 각 컴포넌트의 성능과 강력한 상관관계가 있습니다. 개별 구성 모델이 전체 품질 향상에 주는 구체적인 기여도는 여전히 연구 중인 영역입니다. 향후 더 심층적인 이해를 위해 대대적인 소거 실험(ablation study)을 진행하고 발견한 사실들을 공유해 드릴 예정입니다.
비디오 인코더 모델: 현재 당사의 Search 및 Classify API의 기반인 Marengo 2.5 모델(2023년 3월 기준, 1억 개 이상 비디오 / 10억 개 이상 이미지 포함)을 토대로 파생된 비디오 인코더 모델은 임베딩 기반의 비디오 분류 및 검색 작업에서 최고 수준의 결과를 기록하고 있습니다. 비디오로부터 추출할 수 있는 정보의 깊이는 본질적으로 이 비디오 인코더 모델에 의해 상한선이 정해집니다. Marengo 모델에 대한 더욱 상세한 내용은 차기 버전 Marengo 2.6 출시와 함께 다가올 보고서에서 다뤄질 예정입니다.
비디오-언어 정렬 모델: 이 모델은 파운데이션 모델 학습과 지시 미세조정 과정에서 비디오-언어 정렬 전문 지식을 학습합니다. 저희 언어 모델이 비디오 임베딩과 원활히 조화될 수 있는 핵심 경계가 바로 이 정렬 메커니즘을 통해 구축됩니다.
대규모 언어 모델 (디코더 모델): 언어 모델의 역량은 사전 학습 단계에서 축적한 풍부한 지식을 바탕으로 정의됩니다. 결과물인 출력 텍스트의 완성도는 모델 자체의 지식, 제공된 사용자 프롬프트, 그리고 비디오-언어 정렬 임베딩을 어떻게 조화롭게 합성해내느냐에 달려 있습니다.
평가 및 결과
Twelve Labs는 Pegasus-1 모델을 포함하여 전반적인 선진 기술들이 책임감 있게 배포되도록 보장하는 것의 중요성을 무겁게 인지하고 있습니다. 당사는 정확성, 세부 묘사 정밀도, 맥락적 이해도, 안전성, 유용성 등 미세한 다각적 관점에서 모든 개발 모델들의 벤치마크 테스트를 진행할 수 있는 종합적이고 투명한 데이터셋 및 평가 체계를 마련하고자 헌신하고 있습니다. 현재 비디오-언어 모델의 안전성과 유용성을 구체적으로 정량화하기 위한 고유 평가 지표를 조율 중이며, 결과는 즉각 공유될 예정입니다. 이번 블로그를 통해 예비 분석 결과를 우선 전해드리게 되어 대단히 고무적이며, 더욱 심화된 보고서 역시 차후 발표할 계획입니다. 이번 평가는 Pegasus-1 프리뷰 버전을 바탕으로 하였습니다.
저희 평가 코드베이스는 여기에서 확인하실 수 있습니다.
비교 모델군
당사의 모델과 비교할 타사 모델군은 크게 세 가지 고유 카테고리로 분류하였습니다.
Video-ChatGPT (Maaz et al., 2023): 오픈 소스 형태로 공개되어 있으며 채팅 인터페이스를 탑재한 현시점 최신(SOTA) 수준의 대표적인 비디오-언어 모델입니다. 비디오 내 위상과 시각적 사건들을 다루기 위해 영상 프레임을 가공해 해석하지만, 비디오 속에 발생하는 대화 정보는 직접적으로 활용하지 못하는 특징을 보입니다.
Whisper + ChatGPT-3.5 (OpenAI): 비디오 요약 작업을 위해 널리 상용화되어 쓰이는 이종 모델 간 대표적인 하이브리드 조합 중 하나입니다. 최고 수준의 음성 인식 기술(STT) 및 대형 언어 모델의 힘을 합쳐 결과물을 도출하지만, 주된 소스가 청각 음성 트랙에 전적으로 치우쳐져 있어 비디오 내의 귀중한 시각 맥락을 놓치게 된다는 중대한 맹점이 존재합니다.
A사의 요약(Summary) API: 오디오 및 비디오 요약본 생성을 목표로 시장에서 활발히 채택해 사용 중인 대표적인 상용 솔루션입니다. A사의 솔루션은 비디오 요약 결과를 전달할 때 시각 정보를 완전 배제한 채 오직 텍스트 전사(TTS/ASR) 기록과 언어 모델에만 의존(ASR+ChatGPT 3.5 기반 방식과 유사)하는 것으로 분석됩니다.
데이터셋
MSR-VTT 데이터셋 (Xu et al., 2016): 모델이 10초에서 40초 사이의 짧은 비디오 클립에 대한 캡션이나 묘사 결과를 얼마나 훌륭히 생성해 내는지 가늠하게 돕는 널리 쓰이는 표준 비디오 캡셔닝 벤치마크 데이터셋입니다. 각 비디오에 인간 검수자가 작성한 20개 문장이 매칭되어 있으며, 최대한 상세한 세부를 끌어내고자 LLM(ChatGPT)을 통한 통합 정제 단계를 밟아 촘촘한 최종 통합 기술서 한 문단으로 가공해 활용했습니다. 본 평가는 총 1,000개 클립으로 조율된 JSFusion 검증용 분할(Test Split) 상에서 엄격히 이행되었습니다.
Video-ChatGPT 비디오 설명(Descriptions) 데이터셋 (Maaz et al., 2023): 대다수 비디오-텍스트 성능 평가는 위에 소개한 MSR-VTT와 같은 단문 중심의 비디오 가공 캡션 데이터에 크게 의존하는 경향을 보여왔습니다. 이러한 단편 캡셔닝이 훌륭한 나침반이 될 순 있으나 실제 작업 환경에 상존하는 다양한 형태의 장편 비디오를 완벽히 예측 평가하기란 불가능에 가깝습니다. 이에 따라, 저희는 Video-ChatGPT 비디오 설명 데이터셋을 평가 과정에 추가했습니다. 본 데이터셋은 ActivityNet 소스의 500개 비디오 가량으로 구성되어 있으며, 전문 검수 인력에 의해 정밀 제작된 풍부한 내용의 요약 정보가 포함되어 있습니다. 일반적인 짧은 가공식 캡션들과 달리 30초에서 수 분에 이르는 길이감을 가지며, 모든 결과는 시각 및 음향 정보를 종합 보완한 5~8개 수준의 완성도 높은 풀 세부 문단 요약으로 구성되어 있습니다.
평가 지표
비디오 기반 대화 모델을 위한 정량적 평가 프레임워크 (QEFVC)(Maaz et al., 2023) 기준에 따라 당사는 정보의 정확성(Correctness), 세부 묘사 능력(Detail Orientation), 맥락 이해(Contextual Understanding) 등 세 영역에 초점을 맞추어 검증을 진행했습니다. 이를 위해, 정밀 지시 미세조정을 마친 우수한 평가용 언어 모델(GPT-4)을 선택해 정답 레퍼런스 기준 대비 각 기준의 완성도를 질의 분석하도록 유도했습니다. 최종적 전반 성능 수치 도출을 유도하기 위해 3대 지표값을 산술평균 하였으며, 이를 공식 QEFVC 품질 스코어라 명명했습니다.
이 평가 시스템이 타 모델들과의 비교를 매우 매끄럽게 돕는 것은 사실이지만 완벽한 만능 해법은 아닙니다. 언어 모델을 활용하는 제반 평가의 불확실성을 가리킨 기존 동종 학계 유수 연구 결과들은, 평가 모델(GPT-4 등) 하나에만 전적으로 의존하는 수치 도출이 편향이나 기만적 평가 오류를 낼 위험이 있음을 주의 깊게 지적해 왔습니다. 또한 세부 평가 단위를 미시적으로 정교화할수록 평가 수치의 정확 신뢰도와 일관성이 대폭 상승한다는 점 역시 증명된 바 있습니다 (Ye et al., 2023). 이에 영감을 받아 전사적 팩트 체크 스코어링 체계인 FActScore(Min et al., 2023)를 참고해, 비디오 요약 결과의 퀄리티를 더욱 깊고 조밀하게 계측 분석할 독자적 신규 평가 방법론인 VidFactScore(비디오 사실성 스코어)를 선언 및 적용했습니다.
모델의 모든 비디오 대상 출력안과 인간 요약 정답 쌍을 세밀한 이산형 단일 사실 구조들로 잘개 쪼갭니다. 예를 들자면 "한 남자와 여성이 힘차게 뛰어가고 있다"라는 큰 흐름의 진술을 문법적으로 해석해 "남자가 뛰고 있다", "여자가 뛰고 있다" 등의 독립 원자 단위 사실로 분절하는 방식입니다. 이 가공 여정 역시 적절한 훈련과 전용 프롬프트를 이식받은 GPT-4 등의 지시형 언어 모델 기재를 적용해 진행합니다.
분석 평가를 앞둔 실제 자동 생성 비디오 요약본 또한 정확히 같은 방식으로 미시적인 원자 단위 사실형 조각들로 각각 분리하는 흐름을 거쳐 갑니다.
가장 잘 정돈된 완성형 요약본이란 (1) 원래 들어있어야 할 정답 기준의 주요 팩트 요소들을 최대한 빠짐없이 반영하고, (2) 오리지널 원본 소스에 전혀 부합하지 않는 잘못된 거짓 팩트 주장을 최소화하는 요건을 만족해야 합니다. 이 유무 판단 단계 역시 완벽히 프로그래밍된 프롬프트 검인 명령을 장착 완료한 지시 조정형 언어 모델의 엄정 판별을 거칩니다.
정밀 수식화 과정을 대입할 시, (1)은 생성 예측과 정답 세트 간 합치된 사실 총량이 원본 전체 팩트 중 얼마의 기여율을 차지하는가의 계통 분모인 재현율(Recall Rate)과 긴밀히 연결됩니다. 반대로 (2)는 실제 예측 생성본이라 내놓은 글의 팩트 조각들 수 중 진짜 원본 사실에 들어있던 정확 조각의 순수 비중이 얼마인지를 확인하는 정밀도(Precision)에 매칭됩니다. 이 재현율과 정밀도 두 값의 종합 조화평균값인 F1 스코어는 각 모델들의 참 성능 편차를 완벽히 식별해 주는 최상의 직관 평가 좌표를 제안합니다.
성능 평가 결과
최신 업계 최선두 경쟁 구도(SOTA)를 지키던 VideoChatGPT 모델과의 상호 정량 비교 테스트 과정에서, Pegasus-1은 기존 QEFVC 품질 점수 기준 MSR-VTT 상에서 무려 61%의 상대적인 성능 우수성을 달성 하였을 뿐만 아니라, 장편 비디오 설명 데이터셋 테스트 부문에서도 47% 가량 눈에 띄게 큰 연적 격차의 성능 점수 발전을 보여주었습니다. 또한 텍스트 기반 번역 하이브리드 조합군(Whisper+ChatGPT 및 A사 솔루션 그룹) 대비 격차의 한계는 더욱 거대하게 전개되었는데, Pegasus-1이 타 모델들을 압도하며 MSR-VTT 데이터셋에서는 79%, 고난도의 비디오 설명 데이터셋 파트에서는 188%라는 경이로운 지표 우월성을 증명해 보였습니다.
새로 연구 대입한 독자적인 VidFactScore-F1 계측 시스템 상에서 또한, Pegasus-1은 VideoChatGPT 대비 MSR-VTT 환경에서 20%의 절대적 성능 향상을, 장편 비디오 설명 데이터셋 파트에선 14%의 성능 격차 상승률을 기록하며 판정승을 거두었습니다. 이 역시 단순 번역 의존성 하이브리드 조합군과 정밀 계측을 비교 시, MSR-VTT 데이터셋 평가부문에서 25% 상승, 비디오 설명 데이터셋 환경에 있어서는 33%의 절대 우위 점수를 따내는 눈부신 성취를 거두었습니다. 본 검증 결과들은 당사가 신규 제안하는 VidFactScore 평가지표 체계가 기성 학계의 주류 흐름인 QEFVC 분석 메커니즘과 완벽히 궤를 함께하는 높은 정밀 인과성을 보유하고 있음을 한치 오차 없이 명징하게 나타냅니다.
한 가지 무척 고무적이었던 점은, 주로 인물 음성에 극단적으로 전도될 것이라 예상했던 스탠드업 코미디 콘서트 녹화 영상물이나 대학 전공 강의 비디오와 같은 경우였습니다. 이러한 극단적 스피치 비중의 상황에서도 자사의 통합 솔루션 모델은 기존 ASR+LLM 하이브리드 아키텍처 모델군들을 거뜬히 추월하는 면모를 보여주었습니다. 흔히 '이런 음성 전용 콘셉트 비디오들의 제어에는 음성 텍스트 변환(ASR) 하나만으로도 완전히 충분할 것'이라 예단하기 쉽지만, 당사의 상세 비교 시험은 그 편견을 완벽히 반증해 냅니다. 비록 무대 위 아주 짧은 동작의 흐름(예: 무대 위서 스탠드업 쇼를 이어가는 한 남성의 제스처 포착, 혹은 청중들의 교감 리액션 모먼트 스케치)과 같은 미세 수준의 시각 정보다 할지라도, 이 정보가 단순 음성 데이터 트랙과 실시간 복합 결합할 때, 말뜻에 담긴 표현의 입체감을 전방위 확대하여 한층 조밀하고 완전무결한 고급 비디오 핵심 요약을 정련해 내게 됩니다. 결과가 반증하듯, 진정한 형태의 깊은 공간적 비디오 분석 및 맥락 이해는 단지 청각 데이터를 문자로 옮겨내는 얕은 음성 청해 단계를 한참 뛰어넘는 고급 예술입니다. 온전한 이해를 담보하기 위해 시각과 음성을 아우르는 복합 멀티모달 프레임워크 설계가 필수불가결하다는 주장의 선명한 실증입니다. 하단에 기재된 사외 실전 적용형 예시(In-the-wild Examples) 중 "리액션 비디오(Reaction Video)" 실제 비교 파트가 그 해답을 잘 설명해 줄 것입니다.
사외 실전 적용형 예시 (In-the-wild examples)
아래 사례들은 기존의 타사 솔루션들과 비교해 Pegasus-1 모델이 보여주는 뛰어난 역량을 선보이고자 다양한 도메인에서 무작위로 추출 및 가공 처리한 실제 가용 예시들입니다.
자동 생성된 텍스트 출력물 내에는 아래와 같은 한계점들이 잠재적으로 포함될 수 있음을 투명하게 사전 공지해 드립니다.
환각 현상 (Hallucinations: 실제 비디오 상에는 직접 노출 혹은 입증되지 않은 미지의 개연 팩트들을 모델 스스로의 지레짐작과 내부 확률 맥락에 의해 개연성 있는 소설 형태로 창작해 가공해 내는 현상)
사용자가 제시한 명령 프롬프트나 맥락 질문 구조 자체를 명확히 이해하지 못해 다소 동문서답에 가까운 부적합한 출력을 내는 일종의 이탈 오류
특정 편향이나 편견(Biases)의 개입 가능성
이와 관련된 귀중한 모든 피드백 수집 경로를 상시 늘려가고 있으며, 지적 및 보정 요청 사항들은 가까운 시일 내 업데이트 개발에 성실히 투영 및 개선해 가도록 최선을 다할 것입니다.









