" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
TwelveLabs를 활용한 자동 GDPR 준수 비디오 비식별화(Redaction) 시스템 구축 방법

흐리시케시 야다브 (Hrishikesh Yadav)
이 튜토리얼에서는 Twelve Labs를 활용해 상용 수준의 GDPR 비디오 비식별화(모자이크) 애플리케이션을 구축하는 과정을 단계별로 알아봅니다. 엔티티 기반 검색을 위한 Marengo 3.0, 구조화된 타임스탬프 기반 프라이버시 메타데이터 생성을 위한 Pegasus 1.5, 그리고 안정적인 신원 고정 블러 트랙을 위한 로컬 얼굴 감지 파이프라인을 결합합니다. 이를 통해 검토자는 단일 인터페이스에서 업로드부터 감사 준비가 완료된 비식별화 출력물까지 한 번에 처리할 수 있으며, 모든 의사 결정 시점마다 기록된 근거를 확인할 수 있습니다.
이 튜토리얼에서는 Twelve Labs를 활용해 상용 수준의 GDPR 비디오 비식별화(모자이크) 애플리케이션을 구축하는 과정을 단계별로 알아봅니다. 엔티티 기반 검색을 위한 Marengo 3.0, 구조화된 타임스탬프 기반 프라이버시 메타데이터 생성을 위한 Pegasus 1.5, 그리고 안정적인 신원 고정 블러 트랙을 위한 로컬 얼굴 감지 파이프라인을 결합합니다. 이를 통해 검토자는 단일 인터페이스에서 업로드부터 감사 준비가 완료된 비식별화 출력물까지 한 번에 처리할 수 있으며, 모든 의사 결정 시점마다 기록된 근거를 확인할 수 있습니다.

In this article
No headings found on page
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2026. 5. 28.
13분
링크 복사하기
소개
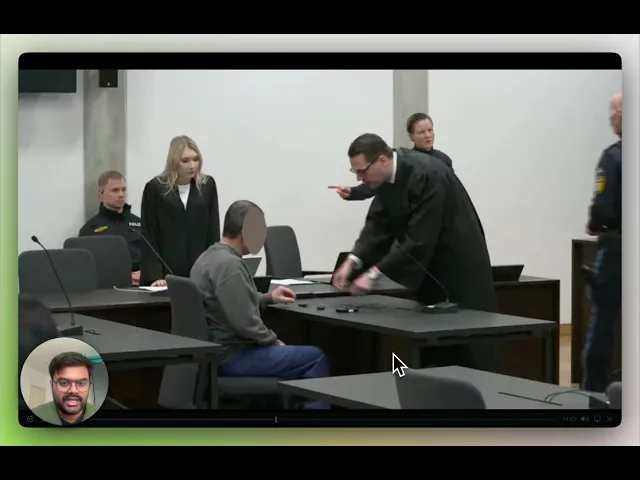
대규모 개인정보 검토는 단순한 편집의 문제가 아닙니다. 이는 지능의 문제입니다.
법적 요청이 접수되어 팀이 수시간 분량의 영상 내에서 특정 인물이 나타나는 모든 지점을 찾아내고, 평가하며, 이를 마스킹해야 할 때, 프레임 단위로 수동 검토하는 방식은 기능하지 않습니다. GDPR 위반 추적기(Enforcement Tracker)에 따르면 2026년 3월까지 누적 벌금은 2,793건의 사례에 걸쳐 60억 6천만 유로를 넘어섰습니다. 가장 심각한 위반의 경우 제83조에 따라 여전히 최대 2,000만 유로 또는 글로벌 연간 매출액의 4%에 달하는 벌금이 부과될 수 있습니다. 운영상의 압박은 실질적이며, 기존의 수동 워크플로우는 이를 감당할 수 없도록 설계되어 있습니다.
GDPR을 준수하는 영상 마스킹 작업을 위해서는 올바른 사람이나 사물에 대한 정확한 식별, 전체 아카이브에서 관련 등장 장면을 빠짐없이 찾아내는 검색 능력, 그리고 법적 목적이 실제로 요구하는 범위로 제한된 마스킹 작업이라는 세 가지 요소가 유기적으로 작동해야 합니다. 영상 전체를 무조건 흐리게 처리하는 방식(블러 처리)은 정당한 방어 전략이 될 수 없습니다. 규정의 데이터 최소화 원칙은 일괄적인 억제가 아니라 정밀한 제어를 요구합니다.
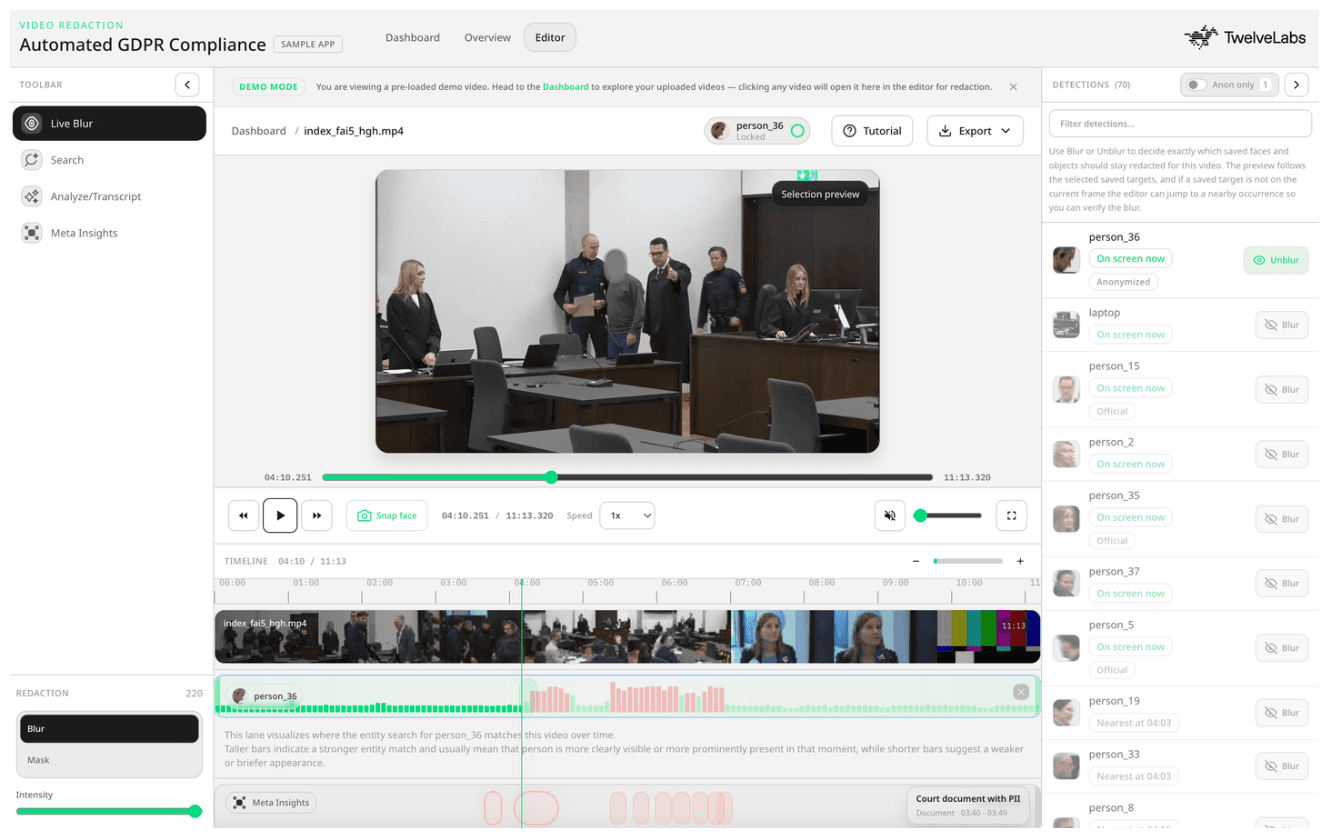
본 튜토리얼에서는 TwelveLabs 플랫폼을 기반으로 구축된, 즉시 프로덕션 환경에 배포 가능한 GDPR 준수 비디오 마스킹 애플리케이션을 단계별로 살펴봅니다. 이 애플리케이션은 멀티모달 검색 및 객체 기반 정보 취득을 위해 Marengo 3.0을 사용하고, 구조화된 개인정보 메타데이터 생성을 위해 Pegasus 1.5를 활용하며, 프레임 레벨의 신원 클러스터링을 위해 로컬 얼굴 감지 파이프라인을 구축했습니다. 그 결과, 단일 인터페이스 안에서 리뷰어가 영상을 업로드하는 단계부터 에디팅이 끝난 최종 마스킹 영상으로 내보내기 단계까지 매끄럽게 처리하는 워크플로우가 완성됩니다.
실제 배포된 서비스는 tl-gdpr-compliance.vercel.app에서 직접 체험해 보실 수 있으며, 전체 소스 코드는 github.com/Hrishikesh332/tl-GDPR-compliance-redaction에서 확인하실 수 있습니다.
애플리케이션이 하는 일
대부분의 마스킹 도구는 수동 선택 방식으로 구축되어 있습니다. 리뷰어가 영상을 시청하면서 바운딩 박스(영역 표시상자)를 그리고, 흐리게 처리된 클립을 내보내는 방식입니다. 하지만 영상 자료의 양이 방대하거나, 대상 인물이 여러 클립에 걸쳐 등장할 때, 혹은 법적 의무 사항으로 각 마스킹 결정에 대한 조치 사유를 문서화해야 할 때는 이러한 방식이 적용되지 않습니다.
이 애플리케이션은 이 문제에 다르게 접근합니다. TwelveLabs는 워크플로우의 모든 단계에서 비디오 이해 레이어의 역할을 수행합니다. 리뷰어는 텍스트, 이미지 또는 등록된 인물 객체를 사용하여 색인된 결과 전체를 검색할 수 있습니다. Pegasus 1.5는 타임스탬프가 포함된 개인정보 메타데이터를 자동 생성하여 리뷰어가 첫 프레임을 시청하기도 전에 리스크가 높은 순간들을 수면 위로 끌어올립니다. 또한 로컬 얼굴 감지 기능을 사용하여 감지된 얼굴 정보를 안정적인 개별 인물 신원으로 클러스트링하며, 이는 내보내기 파이프라인까지 그대로 유지됩니다. 블러 처리 경로는 대상 인물의 움직임, 프로필 회전, 카메라 전환 등의 변화가 발생하더라도 끝까지 추적합니다.
이 워크플로우는 영상 업로드 및 색인 생성, 자연어 또는 얼굴 이미지를 이용한 대상 검색, 대화형 타임라인에서 AI가 생성한 개인정보 위험 구간 검토, 인물 신원별 마스킹 대상 선택, 얼굴 고정형 마스킹이 적용된 최종 영상 내보내기 등 전체 리뷰 라이프 사이클을 완전히 커버합니다.
마스킹 파이프라인 살펴보기
본 애플리케이션은 네 가지 고유한 역량을 단일 검토 워크플로우로 유기적으로 결합합니다.
Marengo 3.0 기반 멀티모달 검색을 통해 리뷰어는 텍스트 쿼리, 이미지 업로드 또는 등록된 얼굴 객체를 사용하여 모든 인물, 사물 또는 장면을 손쉽게 찾을 수 있습니다. Marengo는 신뢰도 점수와 함께 관련 영상 세그먼트를 반환하며, 인터페이스는 이를 시각적 타임라인 레이어 위에 매칭률이 가장 높은 리뷰 마커로 표시해 줍니다.
Pegasus 1.5 기반 개인정보 메타데이터는 개인정보 위험 요소를 타겟으로 타임스탬프가 지정된 세그먼트 데이터를 생성합니다. 영상 전체를 장황하게 묘사하는 대신, Pegasus는 얼굴, 문서, 차량 번호판, 모니터 스크린, 민감한 객체, 보호 대상자 등 사전에 정의된 특정 항목들을 집중 분석하도록 설계되었습니다. 각 세그먼트에는 위험 수준, 마스킹 사유, 권장 조치 및 장면 내 역할이 포함됩니다.
로컬 감지 및 신원 클러스터링은 Pegasus가 제공하는 타임스탬프 정보를 가이드삼아 핵심 프레임(Keyframe)을 정확히 추출합니다. 그 후 로컬 얼굴 감지 및 InsightFace 임베딩 기술을 사용하여 감지된 얼굴을 안정적인 개별 인물로 분류하고, 전체 비디오에 걸쳐 일관된 ID를 부여합니다.
페이스락 블러 기술 및 편집 내보내기는 선택한 인물의 추적 기록 데이터를 프레임 단위로 인덱싱된 바운딩 박스 경로로 변환합니다. 최종 영상을 내보내는 동안, 렌더러는 전달받은 해당 경로에 맞춰 매칭되는 각 프레임에 블러 효과를 적용하고, 끊임없이 대상을 정밀 추적하는 고품질의 마스킹 영상을 완성해 냅니다.

개발 환경 설정하기
개발을 시작하기 전 다음의 사전 단계를 진행하세요.
TwelveLabs 계정을 생성하고 API 키를 발급 받으세요. Marengo 3.0 및 Pegasus 1.5 엔진이 활성화된 새로운 인덱스(Index)를 생성하고 인덱스 ID를 기록해 둡니다.
얼굴 수집 및 실체 검색 기능을 활용할 수 있도록 TwelveLabs 엔터티 컬렉션(Entity Collection)을 생성하세요.
Flask 백엔드 실행을 위해 Python 3을 설치하고, React 프론트엔드를 위해 Node.js/npm을 설치하십시오. 영상 내보내기 시 원활한 인코딩을 위해 FFmpeg 설치를 강력히 권장합니다.
저장소(Repository)를 클론한 뒤 README 파일의 설정 가이드를 따르세요.
.env.example 파일에 기술된 변수 정의를 복사하여 backend/.env 파일을 생성합니다.
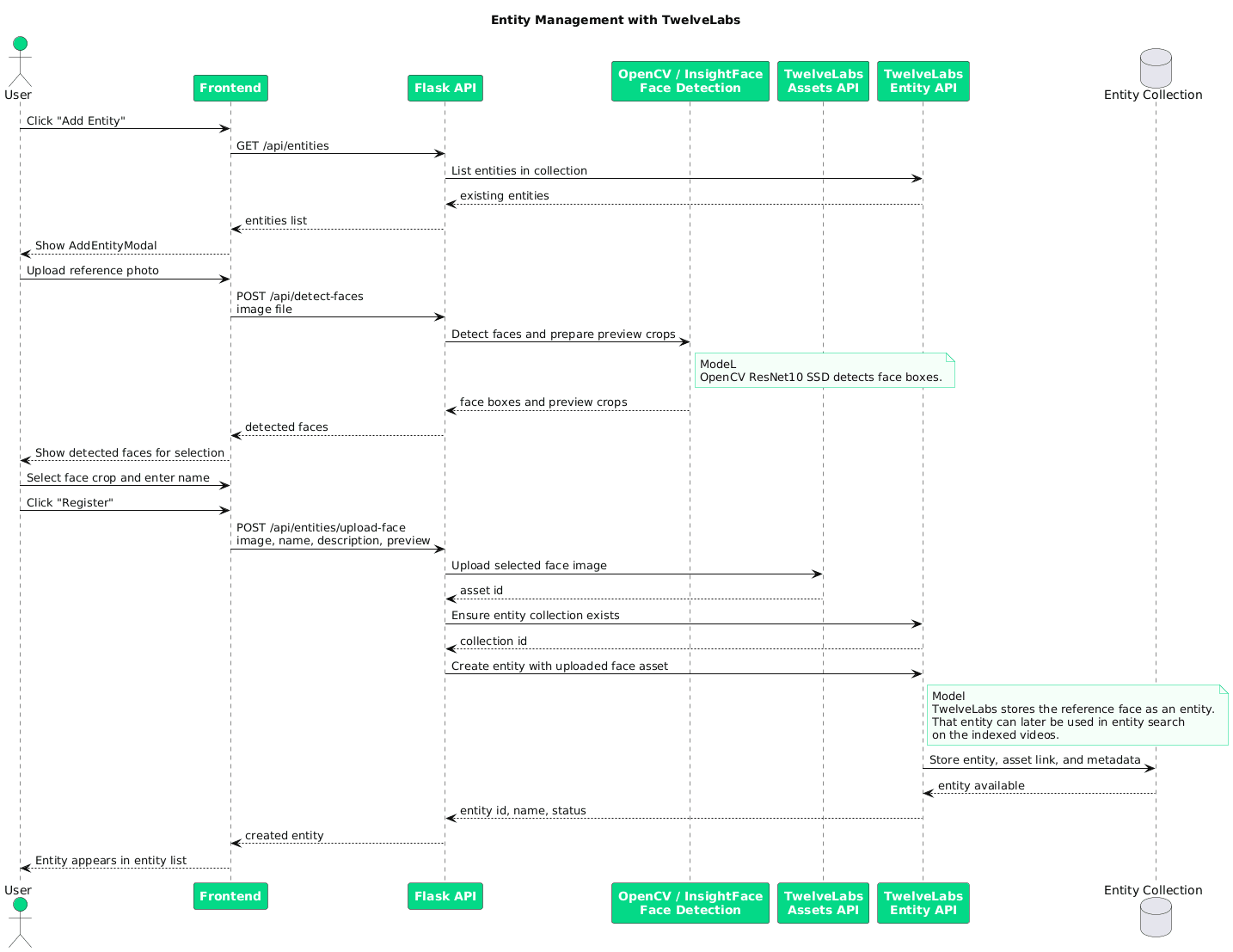
단원 1: TwelveLabs를 활용한 엔터티 관리
영상 속 인물 중 명확히 확인된 특정 개인을 대규모 아카이브에서 추적하는 일은 일반적인 텍스트 검색 이상의 정밀도를 요구합니다. 얼굴 데이터를 TwelveLabs 엔터티(Entity)로 먼저 등록하면 재사용 가능한 신원 식별 정보가 생성되며, 이는 컨텍스트 쿼리와 결합되어 뛰어난 성향을 발휘합니다. 예를 들어 '특정 문서 근처에 있는 이 인물', '특정 장면 속에 서 있는 이 사람', 혹은 '동일한 행동을 하는 누군가'와 같은 검색이 가능해집니다.
이 기법은 마스킹의 정밀도에 결정적인 차이를 만들어 냅니다. 영상 안의 모든 무작위 얼굴들에 주의를 분산시키는 대신, 리뷰어는 타겟이 되는 신원 정보를 명확히 앵커링하고 해당 인물이 명확히 노출되는 정밀한 프레임들만 빠르고 확실하게 검출할 수 있습니다.
1.1 - 엔터티 인덱스에 얼굴 에셋 등록하기
사용자가 얼굴 사진을 업로드하고 이름을 지정하면, 백엔드 엔진은 ResNet-10 기반 얼굴 감지기를 탐색하여 얼굴 영역을 인식하고, 미리보기용 크롭 이미지를 제작한 뒤, TwelveLabs에 등록할 준비를 마칩니다.
이 흐름은 두 개의 단계로 이루어집니다. 첫째는 얼굴 이미지를 에셋으로 업로드하는 것, 둘째는 반환된 에셋 ID를 매핑 데이터 삼아 정형 인물 엔터티를 새로 만드는 것입니다. 이로써 시각 정보와 검색 가능한 신원이 긴밀하게 바인딩됩니다.
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
등록 절차가 마무리되면 컬렉션 내에 인덱싱된 모든 비디오 영상에서 이 엔터티 ID를 바탕으로 신원이 특정한 제어가 가해진 정밀한 검색이 자유롭게 진행됩니다.
1.2 - 엔터티 및 텍스트 융합 검색
검색 시스템은 엔터티 기반, 텍스트 기반, 이미지 기반의 세 가지 모드를 유연하게 제공합니다. 리뷰어는 수집된 초기 정보 수준에 따라 이 기법들을 최적의 방식으로 조합해 활용할 수 있습니다.
엔터티 기반 검색 시, 백엔드는 엔터티 ID를 TwelveLabs가 사전에 인식하는 맨션 구문형식(<@entity_id>)으로 래핑 처리합니다. 사용자가 여기에 구체적인 텍스트 한정자까지 덧붙인 경우 이 구문들이 유기적으로 결합되어 신원과 맥락 모두를 정확히 교집합 삼아 제어된 결과를 찾습니다.
backend/services/twelvelabs_services (라인 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
이미지 기반 검색의 경우, 백엔드는 이미지를 query_media_type="image" 형식에 맞춰 지정하고, 실질 데이터 전달을 위해 query_media_file 혹은 query_media_url을 파라미터로 제공하게 됩니다.
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 타임라인 검색 레이어 및 검사 플래그
검색 반환치는 단순히 점수 순서대로 나란히 늘어서는 것이라 아니라, 직접 조작 가능한 타임라인상에 시각 자료로 펼쳐집니다. 각 결과 세그먼트는 start와 end 시간 정보를 가지며, UX 단에서는 비디오 재생 탐색바 위에 매핑됩니다. 특히 높은 유사율을 나타내는 위치들은 눈에 도드라지는 붉은색 검사 인디케이터로 부각되어 주변 데이터 흐름 속에서 신속히 필터링하도록 돕습니다.

이를 통해 단순 검색 작업은 즉시 프로의 검토 워크플로우로 격상됩니다. 분석 담당자는 검색창을 확인하고, 매칭률이 기록된 최적의 핫스팟으로 타임라인을 클릭 한 번에 뛰어넘어 정밀한 편집 판정을 내릴 수 있습니다.
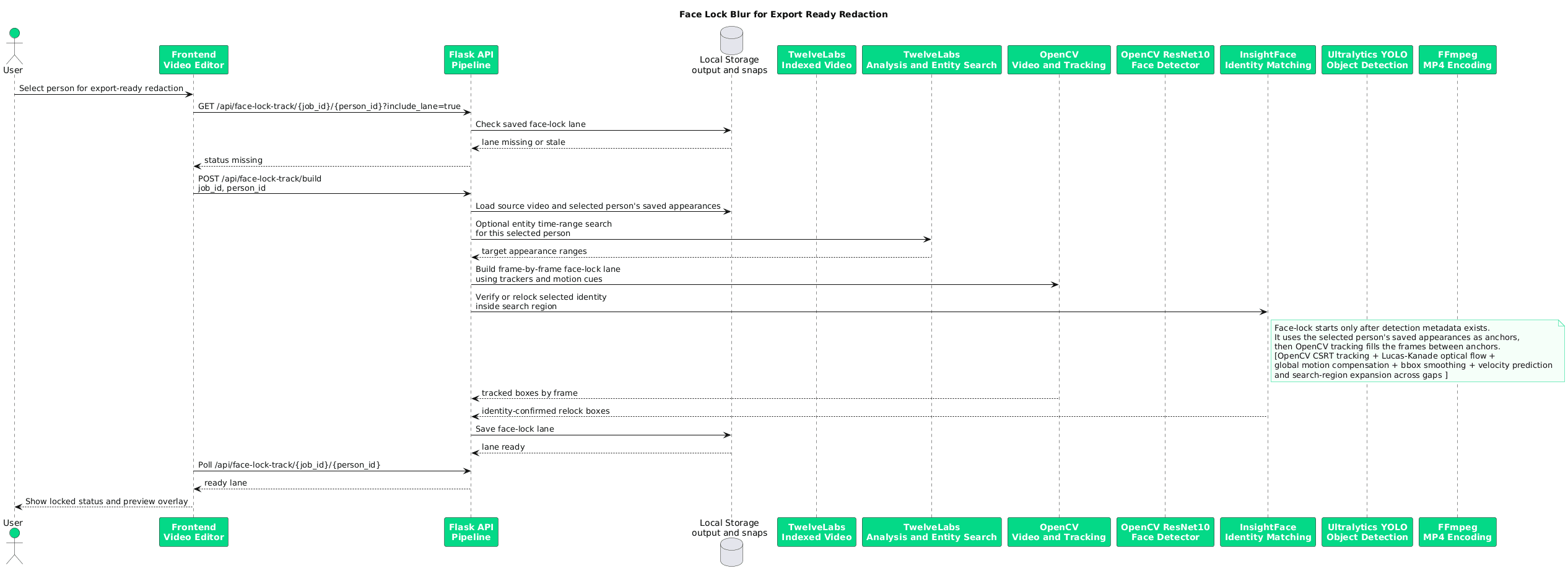
단원 2: 탐색 분석 및 차량/인물 페이스락 마스킹
인식 작업은 TwelveLabs의 고차원 비디오 가치 해석 능력과 로컬단 컴퓨터 비전 기술의 장점을 매끄럽게 연결해 줍니다. 굳이 비효율적으로 비디오 전체의 모든 프랙션 프레임마다 디텍터를 가동할 필요가 없습니다. Pegasus 1.5가 선제적으로 사람들이 집중 출몰하는 위치를 수집하여 구조화된 시점에 특정한 메타데이터로 알려주기 때문입니다. 백엔드는 이 시간 프레임 정보를 키포인트 삼아 핵심 프레임 추출을 최적으로 유도함으로써 컴퓨팅 부하를 줄이고 훨씬 정밀하고 빠른 감지 과정을 안내합니다.
추출된 개별 얼굴은 일관되고 흐트러짐 없는 고정 인물 ID로 클러스터링을 겪습니다. 리뷰어는 무작위로 흐트러진 바운딩 박스가 아니라 정제된 고정 인물 목록에서 타켓팅 대상을 정확히 고르게 됩니다. 이 지시가 내보내기 단계에서 대상을 단단히 실시간 바인딩 고정하는 페이스락 레인의 기반이 됩니다.
2.1 - TwelveLabs의 맥락 정보와 로컬 안면 인식을 유연히 동기화하기
파이프라인 시작점은 Pegasus의 구조화된 상세 분석 프로세스입니다. 정보 구조 프로필은 크게 감사 관찰이 권유되는 face_redaction_target과 정형 시퀀스를 커버할 scene_segment의 두 유형으로 나누어 스키마를 구성합니다. temperature: 0.1 값을 설정함으로써 출력 일관성이 최대한 높여지고 자동 가동 자동화 파이프라인 친화적인 안정성을 보유하게 만듭니다.
backend/services/twelvelabs_services (라인 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasus가 인물 메타데이터를 전해 주면 애플리케이션은 타깃 영역의 전체 프레임을 슬라이싱한 뒤 정밀 핵심프레임 추출을 단락별로 실시합니다. 각각의 분할 프레임은 detect_faces(..., with_encodings=True) 파이프로 도달하며 InsightFace 기법을 작동시켜 실질 얼굴 지점 탐색, 바운딩 박스 생성, 선명도 수치 감별, 인물 고유 임베딩 코드를 구성합니다.
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
각 감색된 결과값은 프레임 번호 및 타임스탬프와 임베딩 정보를 함께 내재화하여 정형 데이터를 구축하게 되며, 이로써 이후의 클러스트링 단계를 거치며 완전하고 균일한 인물 고유성 파악의 초석이 마련됩니다.
2.2 - 마스킹 적용 타겟 정밀 지정
감지 및 클러스터링 단계를 다 마치면, 검토 담당자는 정리되어 인덱싱된 탐색 인물들의 사진 목록 중에서 선명하게 타겟 대상을 점 찍을 수 있습니다. 해당 명령이 지목되면 신뢰도 높은 페이스 디테일과 이미 기억된 특징적 임베딩 데이터가 한 묶음으로 매핑되어 추후 내보내기 렌더러 파이프라인에서 신뢰 높은 타겟 락(lock) 메커니즘을 유도합니다.
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
이 같은 정보는 흔히 역마스킹(Reverse Redaction)이라 불리는 보호 절차에서도 기막힌 편의성을 자랑합니다. 누군가를 역으로 체크하면, 일러둔 보존 대상을 안전하게 보존하고, 발견된 주변의 남은 모든 미등록 타지인의 정보들만 역지정 블러로 신속하고 안전하게 지워 냅니다.
2.3 - 페이스락 레인(Lane) 생성 및 블러 마스킹 최종 내보내기
선택된 인물 신원에 대해 파이프라인은 build_face_lock_lane(job_id, person_id) 함수를 호출합니다. 레인 빌더는 InsightFace 안면 특징 정보, TwelveLabs 엔터티 검색 시간 범위, Pegasus가 분석 추출한 지능형 타임라인 영역의 세 가지 핵심 채널 데이터를 통합 교정합니다. 이를 정밀 결합하여 비디오 전체에 결쳐 해당 대상을 명확히 마킹할 종합 좌표 지도가 최종 편찬됩니다.
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
내보내기 작업을 진척시킬 때 구성된 타켓 차트는 프레임 단위 탐색용 매핑 룩업테이블(face_lock_bboxes_by_frame) 형식으로 정렬된 후, YOLOv8-Face 리파인먼트 교정 모델을 거쳐 정밀도가 최고도로 향상됩니다. 렌더러가 프레임을 전개하는 도중 해당 차트 테이블에서 표식을 구별하면, 즉시 apply_detection_redaction을 실행하여 부드러운 안티 앨리어싱이 밀착 가공된 마스킹 작업을 프레임마다 완벽하게 입힙니다.
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
이와 같은 설계는 대상 추적에 끊김이 생기지 않는 안정적인 블러 효과를 제공해 줍니다. 화면 속 인물이 급격히 흔들리거나, 물체 뒤로 장시간 가려지거나, 화면 기법인 씬이 갑자기 튀며 변경되는 와중에도 매번 수작업 씬 미세 조율 없이 완벽한 정밀 밀착 트래킹을 수행합니다.
단원 3: Pegasus 1.5와 함께하는 정밀 개인정보 메타데이터 인터페이스
Pegasus 1.5는 스키마 구조 기반의 시간 타임스탬프 메타데이터 출력을 안정되게 지원합니다. 이는 해당 애플리케이션으로 하여금 어떠한 영역들을 민감 요소로 판단하고 가공해서 전달해야 할 지 세세한 룰과 조치 사유를 완벽히 통제할 권리를 선사합니다. 이 장치가 리뷰어 웹 인터페이스의 '메타 인사이트'를 직관적으로 끌어주는 고성능 동력 엔진입니다.
3.1 - 리스크 스키마 빌딩
스키마 정보의 핵심은 세그먼트 속성을 privacy_risk_segment 단일 단위로 정확하게 매칭시켜 주는 부분에 있습니다. 얼굴, 일반 서류, 디스플레이 영역, 지목 차량 번호판, 민감 텍스트, 그리고 법률상 보호 조치가 선결되어야 할 중요 대상에 이르기까지, 불필요한 영역은 일절 소외시키고 실무 가치가 높은 타깃에만 Pegasus의 추론 자원을 몰아주기 위함입니다. 여기에 risk_level, scene_role, redaction_decision, reason 등을 디테일하게 탑재함으로써 담당자에게 정보 탐독 플래그 판단은 물론 법적 근거가 되는 조치 증빙 로그 기록의 근거도 함께 제공합니다.
backend/services/pegasus_privacy (라인 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - 타임스탬프 정보 연동으로 데이터 출력
해당 스키마 프로필은 analysis_mode: "time_based_metadata" 인자를 정밀하게 껴안고 Pegasus 추론 엔진으로 직접 전송됩니다. 해당 세그먼트들이 대범하고 광범위한 서술에 지배받지 않고 타임 스탬프 인덱스로 세밀히 슬라이싱된 메타데이터 군집으로 도달하도록 지킴과 동시에, temperature: 0.1 지정을 주어 결정론적 정확성을 수반하게 만듭니다. 컴플라이언스 업무에서 가장 중요한 예측 가능하고 반복 신뢰 높은 실행력을 유지하려는 정밀한 엔지니어링 세팅입니다.
backend/services/twelvelabs_services (라인 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
백엔드 서비스는 초기에 임시 빈 디코더 정보 timeline_events와 recommended_actions를 생성해 임시 잡(job)을 선점해 놓은 뒤, 비동기 호출 타겟 완료를 정교하게 폴링합니다. 회신이 도달하면 각 마킹 구간들은 즉시 궤적이 결부된 타임라인 정보 구조(start_sec, end_sec, 심각도 severity, 유형 category, 사건 사유 reason, 마킹 판정 redaction_decision) 및 이를 지지할 담당자 조치 권고안 등으로 깔끔하게 분할 래핑됩니다.
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - 개인정보 메타데이터를 통합 심사 제어판으로 시각화

유저 타임라인 궤적 위에서 Pegasus의 도출 결과들은 start_sec부터 end_sec까지 부드럽게 칠해진 상호작용 클릭 핫스팟 형태로 수려하게 수놓아집니다. 해당 핫스팟 바위를 탭하여 누르면 사이드바에 유기 연동된 '메타 인사이트' 제어판이 자동으로 열리고, 시각 포커싱과 비디오 재생 타임라인 시점이 해당 사건 시작 시간으로 번개처럼 점프합니다.
해당 패널은 사건의 모든 미세 필트인 정보(리스크 수준, 관련 카테고리 기재, 소명 논거 사유, 마스킹 처리 판단, 구체적 블러 타겟 설정, 검토 권고안 등)를 소상히 디스플레이합니다. 검토 실무자는 문제 부위의 위치는 물론 '왜 이 사유가 감식 판별 조치 사유로 등록되었는가?'에 대한 심층 정보까지 함께 취급하게 됩니다. 이것이 차후 기업의 외부 GDPR 법률 컴플라이언스 감사 부서에 바로 제출 가능한 최고 가치의 증빙 사유서가 되어 줍니다.
단원 4: 검토 업무를 위한 오픈형 심층 비디오 문답
구조화된 정형 지침 추출 이외에도, 본 앱은 담당 리뷰어의 판단 지평을 확장시켜 줄 자유 문답 형태의 내추럴 컨텍스트 다이얼로그 또한 폭넓게 안아줍니다. 영상 검수자는 '해당 비디오 전체의 리스크 요소를 심층 평가해 줘', '어떤 시점의 클립이 가장 법적 마킹 분쟁 소지가 높은지 논증해 줘' 같은 개방형 문답이나 세부 씬을 묻는 작업을 바로 던질 수 있습니다. 어떤 것을 어떻게 집중 필터해야 할 지 구상이 미처 서지 않은 초입 리뷰어에게 아주 완벽한 해결사 노릇을 수행합니다.
프론트 UI는 수신된 video_id와 자유 질의 텍스트가 담은 페이로드를 품고 /api/analyze-custom으로 호조를 시작합니다. 백엔드 시스템은 질의에 답할 때 매번 추적 가능한 시간 인덱스 정보를 함께 서술로 녹여내어 리턴하도록 지시하는 포맷 규칙 구조물(ANALYZE_FORMAT_INSTRUCTION)을 템플릿 마크업 삼아 앞단에 끼워 넣은 뒤, TwelveLabs Analyze 서비스로 전송 처리합니다.
backend/services/twelvelabs_services (라인 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
연동 완료 시 사용자는 실존하는 프레임 정보와 강하게 연계된 자연어 설명을 풍요롭게 소화하게 되며 타임스탬프를 원 터치로 공략해 즉각 해당 위치로 비디오를 돌릴 수 있게 됩니다. "이 영상에서 리스크 요소를 살펴야지"라는 막연한 미션에서 "여기가 바로 그 순간이고 이런 수치로 지목되었구나"로 즉시 실현 전환해 줍니다.
이 접근 방식이 가능해진 미래
과거의 비디오 영상 GDPR 준수 조치들은 항상 극단적인 두 타협점 속에서 선택을 강요받곤 했습니다. 느리고 터무니없이 막대한 예산이 소모되는 수작업 검열을 어쩔 수 없이 지탱하거나, 규정이 전제하는 보전 가치보다 과한 영역을 블러로 막무가내 덮여 가렸으나 법적 감사의 사유를 명시하지 못하는 난도 높은 자동 머신들에 머무르는 대안이었습니다.
정교히 다듬어진 이 파이프라인은 두 문제의 완벽한 가교가 됩니다. Marengo 3.0은 텍스트 표현, 실물 소스 사진, 사전에 명기 등록해 놓은 엔터티 군집을 거치며 영상 자료 속 최적의 사건 순간들을 가혹하고 빠짐없이 가져옵니다. Pegasus 1.5는 기꺼이 모든 구간마다 확실하게 법률적 명시 사유가 부연된 고품질의 타임라인 메타데이터를 영리하게 구축합니다. 로컬 안면 감 인식 시스템은 AI 가이드 기반 핵심 프레임을 효율적으로 건네받아 오차 없는 얼굴 정체성을 구축해 마침내 페이스락 트랙이 적용된 완벽한 블러 비디오 영상 내보내기를 지탱해 줍니다.
이로써 우리는 전체를 망치는 블라인드가 아닌 아주 필요한 구획만 매섭고 확실히 지워 내는 고차원 마스킹 시스템을 소유하게 되며, 수동의 한계를 상회하고, 철저한 법률 감사 증빙 추적이 일상화된 컴플라이언스를 마주할 수 있습니다. 비즈니스 리스크를 합리적인 프로세스 영역으로 정복하고 지배할 완벽한 기술적 준비입니다.
학습 참고 자료 및 공식 리소스
소개
대규모 개인정보 검토는 단순한 편집의 문제가 아닙니다. 이는 지능의 문제입니다.
법적 요청이 접수되어 팀이 수시간 분량의 영상 내에서 특정 인물이 나타나는 모든 지점을 찾아내고, 평가하며, 이를 마스킹해야 할 때, 프레임 단위로 수동 검토하는 방식은 기능하지 않습니다. GDPR 위반 추적기(Enforcement Tracker)에 따르면 2026년 3월까지 누적 벌금은 2,793건의 사례에 걸쳐 60억 6천만 유로를 넘어섰습니다. 가장 심각한 위반의 경우 제83조에 따라 여전히 최대 2,000만 유로 또는 글로벌 연간 매출액의 4%에 달하는 벌금이 부과될 수 있습니다. 운영상의 압박은 실질적이며, 기존의 수동 워크플로우는 이를 감당할 수 없도록 설계되어 있습니다.
GDPR을 준수하는 영상 마스킹 작업을 위해서는 올바른 사람이나 사물에 대한 정확한 식별, 전체 아카이브에서 관련 등장 장면을 빠짐없이 찾아내는 검색 능력, 그리고 법적 목적이 실제로 요구하는 범위로 제한된 마스킹 작업이라는 세 가지 요소가 유기적으로 작동해야 합니다. 영상 전체를 무조건 흐리게 처리하는 방식(블러 처리)은 정당한 방어 전략이 될 수 없습니다. 규정의 데이터 최소화 원칙은 일괄적인 억제가 아니라 정밀한 제어를 요구합니다.
본 튜토리얼에서는 TwelveLabs 플랫폼을 기반으로 구축된, 즉시 프로덕션 환경에 배포 가능한 GDPR 준수 비디오 마스킹 애플리케이션을 단계별로 살펴봅니다. 이 애플리케이션은 멀티모달 검색 및 객체 기반 정보 취득을 위해 Marengo 3.0을 사용하고, 구조화된 개인정보 메타데이터 생성을 위해 Pegasus 1.5를 활용하며, 프레임 레벨의 신원 클러스터링을 위해 로컬 얼굴 감지 파이프라인을 구축했습니다. 그 결과, 단일 인터페이스 안에서 리뷰어가 영상을 업로드하는 단계부터 에디팅이 끝난 최종 마스킹 영상으로 내보내기 단계까지 매끄럽게 처리하는 워크플로우가 완성됩니다.
실제 배포된 서비스는 tl-gdpr-compliance.vercel.app에서 직접 체험해 보실 수 있으며, 전체 소스 코드는 github.com/Hrishikesh332/tl-GDPR-compliance-redaction에서 확인하실 수 있습니다.
애플리케이션이 하는 일
대부분의 마스킹 도구는 수동 선택 방식으로 구축되어 있습니다. 리뷰어가 영상을 시청하면서 바운딩 박스(영역 표시상자)를 그리고, 흐리게 처리된 클립을 내보내는 방식입니다. 하지만 영상 자료의 양이 방대하거나, 대상 인물이 여러 클립에 걸쳐 등장할 때, 혹은 법적 의무 사항으로 각 마스킹 결정에 대한 조치 사유를 문서화해야 할 때는 이러한 방식이 적용되지 않습니다.
이 애플리케이션은 이 문제에 다르게 접근합니다. TwelveLabs는 워크플로우의 모든 단계에서 비디오 이해 레이어의 역할을 수행합니다. 리뷰어는 텍스트, 이미지 또는 등록된 인물 객체를 사용하여 색인된 결과 전체를 검색할 수 있습니다. Pegasus 1.5는 타임스탬프가 포함된 개인정보 메타데이터를 자동 생성하여 리뷰어가 첫 프레임을 시청하기도 전에 리스크가 높은 순간들을 수면 위로 끌어올립니다. 또한 로컬 얼굴 감지 기능을 사용하여 감지된 얼굴 정보를 안정적인 개별 인물 신원으로 클러스트링하며, 이는 내보내기 파이프라인까지 그대로 유지됩니다. 블러 처리 경로는 대상 인물의 움직임, 프로필 회전, 카메라 전환 등의 변화가 발생하더라도 끝까지 추적합니다.
이 워크플로우는 영상 업로드 및 색인 생성, 자연어 또는 얼굴 이미지를 이용한 대상 검색, 대화형 타임라인에서 AI가 생성한 개인정보 위험 구간 검토, 인물 신원별 마스킹 대상 선택, 얼굴 고정형 마스킹이 적용된 최종 영상 내보내기 등 전체 리뷰 라이프 사이클을 완전히 커버합니다.
마스킹 파이프라인 살펴보기
본 애플리케이션은 네 가지 고유한 역량을 단일 검토 워크플로우로 유기적으로 결합합니다.
Marengo 3.0 기반 멀티모달 검색을 통해 리뷰어는 텍스트 쿼리, 이미지 업로드 또는 등록된 얼굴 객체를 사용하여 모든 인물, 사물 또는 장면을 손쉽게 찾을 수 있습니다. Marengo는 신뢰도 점수와 함께 관련 영상 세그먼트를 반환하며, 인터페이스는 이를 시각적 타임라인 레이어 위에 매칭률이 가장 높은 리뷰 마커로 표시해 줍니다.
Pegasus 1.5 기반 개인정보 메타데이터는 개인정보 위험 요소를 타겟으로 타임스탬프가 지정된 세그먼트 데이터를 생성합니다. 영상 전체를 장황하게 묘사하는 대신, Pegasus는 얼굴, 문서, 차량 번호판, 모니터 스크린, 민감한 객체, 보호 대상자 등 사전에 정의된 특정 항목들을 집중 분석하도록 설계되었습니다. 각 세그먼트에는 위험 수준, 마스킹 사유, 권장 조치 및 장면 내 역할이 포함됩니다.
로컬 감지 및 신원 클러스터링은 Pegasus가 제공하는 타임스탬프 정보를 가이드삼아 핵심 프레임(Keyframe)을 정확히 추출합니다. 그 후 로컬 얼굴 감지 및 InsightFace 임베딩 기술을 사용하여 감지된 얼굴을 안정적인 개별 인물로 분류하고, 전체 비디오에 걸쳐 일관된 ID를 부여합니다.
페이스락 블러 기술 및 편집 내보내기는 선택한 인물의 추적 기록 데이터를 프레임 단위로 인덱싱된 바운딩 박스 경로로 변환합니다. 최종 영상을 내보내는 동안, 렌더러는 전달받은 해당 경로에 맞춰 매칭되는 각 프레임에 블러 효과를 적용하고, 끊임없이 대상을 정밀 추적하는 고품질의 마스킹 영상을 완성해 냅니다.
개발 환경 설정하기
개발을 시작하기 전 다음의 사전 단계를 진행하세요.
TwelveLabs 계정을 생성하고 API 키를 발급 받으세요. Marengo 3.0 및 Pegasus 1.5 엔진이 활성화된 새로운 인덱스(Index)를 생성하고 인덱스 ID를 기록해 둡니다.
얼굴 수집 및 실체 검색 기능을 활용할 수 있도록 TwelveLabs 엔터티 컬렉션(Entity Collection)을 생성하세요.
Flask 백엔드 실행을 위해 Python 3을 설치하고, React 프론트엔드를 위해 Node.js/npm을 설치하십시오. 영상 내보내기 시 원활한 인코딩을 위해 FFmpeg 설치를 강력히 권장합니다.
저장소(Repository)를 클론한 뒤 README 파일의 설정 가이드를 따르세요.
.env.example 파일에 기술된 변수 정의를 복사하여 backend/.env 파일을 생성합니다.
단원 1: TwelveLabs를 활용한 엔터티 관리
영상 속 인물 중 명확히 확인된 특정 개인을 대규모 아카이브에서 추적하는 일은 일반적인 텍스트 검색 이상의 정밀도를 요구합니다. 얼굴 데이터를 TwelveLabs 엔터티(Entity)로 먼저 등록하면 재사용 가능한 신원 식별 정보가 생성되며, 이는 컨텍스트 쿼리와 결합되어 뛰어난 성향을 발휘합니다. 예를 들어 '특정 문서 근처에 있는 이 인물', '특정 장면 속에 서 있는 이 사람', 혹은 '동일한 행동을 하는 누군가'와 같은 검색이 가능해집니다.
이 기법은 마스킹의 정밀도에 결정적인 차이를 만들어 냅니다. 영상 안의 모든 무작위 얼굴들에 주의를 분산시키는 대신, 리뷰어는 타겟이 되는 신원 정보를 명확히 앵커링하고 해당 인물이 명확히 노출되는 정밀한 프레임들만 빠르고 확실하게 검출할 수 있습니다.
1.1 - 엔터티 인덱스에 얼굴 에셋 등록하기
사용자가 얼굴 사진을 업로드하고 이름을 지정하면, 백엔드 엔진은 ResNet-10 기반 얼굴 감지기를 탐색하여 얼굴 영역을 인식하고, 미리보기용 크롭 이미지를 제작한 뒤, TwelveLabs에 등록할 준비를 마칩니다.
이 흐름은 두 개의 단계로 이루어집니다. 첫째는 얼굴 이미지를 에셋으로 업로드하는 것, 둘째는 반환된 에셋 ID를 매핑 데이터 삼아 정형 인물 엔터티를 새로 만드는 것입니다. 이로써 시각 정보와 검색 가능한 신원이 긴밀하게 바인딩됩니다.
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
등록 절차가 마무리되면 컬렉션 내에 인덱싱된 모든 비디오 영상에서 이 엔터티 ID를 바탕으로 신원이 특정한 제어가 가해진 정밀한 검색이 자유롭게 진행됩니다.
1.2 - 엔터티 및 텍스트 융합 검색
검색 시스템은 엔터티 기반, 텍스트 기반, 이미지 기반의 세 가지 모드를 유연하게 제공합니다. 리뷰어는 수집된 초기 정보 수준에 따라 이 기법들을 최적의 방식으로 조합해 활용할 수 있습니다.
엔터티 기반 검색 시, 백엔드는 엔터티 ID를 TwelveLabs가 사전에 인식하는 맨션 구문형식(<@entity_id>)으로 래핑 처리합니다. 사용자가 여기에 구체적인 텍스트 한정자까지 덧붙인 경우 이 구문들이 유기적으로 결합되어 신원과 맥락 모두를 정확히 교집합 삼아 제어된 결과를 찾습니다.
backend/services/twelvelabs_services (라인 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
이미지 기반 검색의 경우, 백엔드는 이미지를 query_media_type="image" 형식에 맞춰 지정하고, 실질 데이터 전달을 위해 query_media_file 혹은 query_media_url을 파라미터로 제공하게 됩니다.
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 타임라인 검색 레이어 및 검사 플래그
검색 반환치는 단순히 점수 순서대로 나란히 늘어서는 것이라 아니라, 직접 조작 가능한 타임라인상에 시각 자료로 펼쳐집니다. 각 결과 세그먼트는 start와 end 시간 정보를 가지며, UX 단에서는 비디오 재생 탐색바 위에 매핑됩니다. 특히 높은 유사율을 나타내는 위치들은 눈에 도드라지는 붉은색 검사 인디케이터로 부각되어 주변 데이터 흐름 속에서 신속히 필터링하도록 돕습니다.
이를 통해 단순 검색 작업은 즉시 프로의 검토 워크플로우로 격상됩니다. 분석 담당자는 검색창을 확인하고, 매칭률이 기록된 최적의 핫스팟으로 타임라인을 클릭 한 번에 뛰어넘어 정밀한 편집 판정을 내릴 수 있습니다.
단원 2: 탐색 분석 및 차량/인물 페이스락 마스킹
인식 작업은 TwelveLabs의 고차원 비디오 가치 해석 능력과 로컬단 컴퓨터 비전 기술의 장점을 매끄럽게 연결해 줍니다. 굳이 비효율적으로 비디오 전체의 모든 프랙션 프레임마다 디텍터를 가동할 필요가 없습니다. Pegasus 1.5가 선제적으로 사람들이 집중 출몰하는 위치를 수집하여 구조화된 시점에 특정한 메타데이터로 알려주기 때문입니다. 백엔드는 이 시간 프레임 정보를 키포인트 삼아 핵심 프레임 추출을 최적으로 유도함으로써 컴퓨팅 부하를 줄이고 훨씬 정밀하고 빠른 감지 과정을 안내합니다.
추출된 개별 얼굴은 일관되고 흐트러짐 없는 고정 인물 ID로 클러스터링을 겪습니다. 리뷰어는 무작위로 흐트러진 바운딩 박스가 아니라 정제된 고정 인물 목록에서 타켓팅 대상을 정확히 고르게 됩니다. 이 지시가 내보내기 단계에서 대상을 단단히 실시간 바인딩 고정하는 페이스락 레인의 기반이 됩니다.
2.1 - TwelveLabs의 맥락 정보와 로컬 안면 인식을 유연히 동기화하기
파이프라인 시작점은 Pegasus의 구조화된 상세 분석 프로세스입니다. 정보 구조 프로필은 크게 감사 관찰이 권유되는 face_redaction_target과 정형 시퀀스를 커버할 scene_segment의 두 유형으로 나누어 스키마를 구성합니다. temperature: 0.1 값을 설정함으로써 출력 일관성이 최대한 높여지고 자동 가동 자동화 파이프라인 친화적인 안정성을 보유하게 만듭니다.
backend/services/twelvelabs_services (라인 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasus가 인물 메타데이터를 전해 주면 애플리케이션은 타깃 영역의 전체 프레임을 슬라이싱한 뒤 정밀 핵심프레임 추출을 단락별로 실시합니다. 각각의 분할 프레임은 detect_faces(..., with_encodings=True) 파이프로 도달하며 InsightFace 기법을 작동시켜 실질 얼굴 지점 탐색, 바운딩 박스 생성, 선명도 수치 감별, 인물 고유 임베딩 코드를 구성합니다.
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
각 감색된 결과값은 프레임 번호 및 타임스탬프와 임베딩 정보를 함께 내재화하여 정형 데이터를 구축하게 되며, 이로써 이후의 클러스트링 단계를 거치며 완전하고 균일한 인물 고유성 파악의 초석이 마련됩니다.
2.2 - 마스킹 적용 타겟 정밀 지정
감지 및 클러스터링 단계를 다 마치면, 검토 담당자는 정리되어 인덱싱된 탐색 인물들의 사진 목록 중에서 선명하게 타겟 대상을 점 찍을 수 있습니다. 해당 명령이 지목되면 신뢰도 높은 페이스 디테일과 이미 기억된 특징적 임베딩 데이터가 한 묶음으로 매핑되어 추후 내보내기 렌더러 파이프라인에서 신뢰 높은 타겟 락(lock) 메커니즘을 유도합니다.
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
이 같은 정보는 흔히 역마스킹(Reverse Redaction)이라 불리는 보호 절차에서도 기막힌 편의성을 자랑합니다. 누군가를 역으로 체크하면, 일러둔 보존 대상을 안전하게 보존하고, 발견된 주변의 남은 모든 미등록 타지인의 정보들만 역지정 블러로 신속하고 안전하게 지워 냅니다.
2.3 - 페이스락 레인(Lane) 생성 및 블러 마스킹 최종 내보내기
선택된 인물 신원에 대해 파이프라인은 build_face_lock_lane(job_id, person_id) 함수를 호출합니다. 레인 빌더는 InsightFace 안면 특징 정보, TwelveLabs 엔터티 검색 시간 범위, Pegasus가 분석 추출한 지능형 타임라인 영역의 세 가지 핵심 채널 데이터를 통합 교정합니다. 이를 정밀 결합하여 비디오 전체에 결쳐 해당 대상을 명확히 마킹할 종합 좌표 지도가 최종 편찬됩니다.
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
내보내기 작업을 진척시킬 때 구성된 타켓 차트는 프레임 단위 탐색용 매핑 룩업테이블(face_lock_bboxes_by_frame) 형식으로 정렬된 후, YOLOv8-Face 리파인먼트 교정 모델을 거쳐 정밀도가 최고도로 향상됩니다. 렌더러가 프레임을 전개하는 도중 해당 차트 테이블에서 표식을 구별하면, 즉시 apply_detection_redaction을 실행하여 부드러운 안티 앨리어싱이 밀착 가공된 마스킹 작업을 프레임마다 완벽하게 입힙니다.
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
이와 같은 설계는 대상 추적에 끊김이 생기지 않는 안정적인 블러 효과를 제공해 줍니다. 화면 속 인물이 급격히 흔들리거나, 물체 뒤로 장시간 가려지거나, 화면 기법인 씬이 갑자기 튀며 변경되는 와중에도 매번 수작업 씬 미세 조율 없이 완벽한 정밀 밀착 트래킹을 수행합니다.
단원 3: Pegasus 1.5와 함께하는 정밀 개인정보 메타데이터 인터페이스
Pegasus 1.5는 스키마 구조 기반의 시간 타임스탬프 메타데이터 출력을 안정되게 지원합니다. 이는 해당 애플리케이션으로 하여금 어떠한 영역들을 민감 요소로 판단하고 가공해서 전달해야 할 지 세세한 룰과 조치 사유를 완벽히 통제할 권리를 선사합니다. 이 장치가 리뷰어 웹 인터페이스의 '메타 인사이트'를 직관적으로 끌어주는 고성능 동력 엔진입니다.
3.1 - 리스크 스키마 빌딩
스키마 정보의 핵심은 세그먼트 속성을 privacy_risk_segment 단일 단위로 정확하게 매칭시켜 주는 부분에 있습니다. 얼굴, 일반 서류, 디스플레이 영역, 지목 차량 번호판, 민감 텍스트, 그리고 법률상 보호 조치가 선결되어야 할 중요 대상에 이르기까지, 불필요한 영역은 일절 소외시키고 실무 가치가 높은 타깃에만 Pegasus의 추론 자원을 몰아주기 위함입니다. 여기에 risk_level, scene_role, redaction_decision, reason 등을 디테일하게 탑재함으로써 담당자에게 정보 탐독 플래그 판단은 물론 법적 근거가 되는 조치 증빙 로그 기록의 근거도 함께 제공합니다.
backend/services/pegasus_privacy (라인 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - 타임스탬프 정보 연동으로 데이터 출력
해당 스키마 프로필은 analysis_mode: "time_based_metadata" 인자를 정밀하게 껴안고 Pegasus 추론 엔진으로 직접 전송됩니다. 해당 세그먼트들이 대범하고 광범위한 서술에 지배받지 않고 타임 스탬프 인덱스로 세밀히 슬라이싱된 메타데이터 군집으로 도달하도록 지킴과 동시에, temperature: 0.1 지정을 주어 결정론적 정확성을 수반하게 만듭니다. 컴플라이언스 업무에서 가장 중요한 예측 가능하고 반복 신뢰 높은 실행력을 유지하려는 정밀한 엔지니어링 세팅입니다.
backend/services/twelvelabs_services (라인 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
백엔드 서비스는 초기에 임시 빈 디코더 정보 timeline_events와 recommended_actions를 생성해 임시 잡(job)을 선점해 놓은 뒤, 비동기 호출 타겟 완료를 정교하게 폴링합니다. 회신이 도달하면 각 마킹 구간들은 즉시 궤적이 결부된 타임라인 정보 구조(start_sec, end_sec, 심각도 severity, 유형 category, 사건 사유 reason, 마킹 판정 redaction_decision) 및 이를 지지할 담당자 조치 권고안 등으로 깔끔하게 분할 래핑됩니다.
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - 개인정보 메타데이터를 통합 심사 제어판으로 시각화
유저 타임라인 궤적 위에서 Pegasus의 도출 결과들은 start_sec부터 end_sec까지 부드럽게 칠해진 상호작용 클릭 핫스팟 형태로 수려하게 수놓아집니다. 해당 핫스팟 바위를 탭하여 누르면 사이드바에 유기 연동된 '메타 인사이트' 제어판이 자동으로 열리고, 시각 포커싱과 비디오 재생 타임라인 시점이 해당 사건 시작 시간으로 번개처럼 점프합니다.
해당 패널은 사건의 모든 미세 필트인 정보(리스크 수준, 관련 카테고리 기재, 소명 논거 사유, 마스킹 처리 판단, 구체적 블러 타겟 설정, 검토 권고안 등)를 소상히 디스플레이합니다. 검토 실무자는 문제 부위의 위치는 물론 '왜 이 사유가 감식 판별 조치 사유로 등록되었는가?'에 대한 심층 정보까지 함께 취급하게 됩니다. 이것이 차후 기업의 외부 GDPR 법률 컴플라이언스 감사 부서에 바로 제출 가능한 최고 가치의 증빙 사유서가 되어 줍니다.
단원 4: 검토 업무를 위한 오픈형 심층 비디오 문답
구조화된 정형 지침 추출 이외에도, 본 앱은 담당 리뷰어의 판단 지평을 확장시켜 줄 자유 문답 형태의 내추럴 컨텍스트 다이얼로그 또한 폭넓게 안아줍니다. 영상 검수자는 '해당 비디오 전체의 리스크 요소를 심층 평가해 줘', '어떤 시점의 클립이 가장 법적 마킹 분쟁 소지가 높은지 논증해 줘' 같은 개방형 문답이나 세부 씬을 묻는 작업을 바로 던질 수 있습니다. 어떤 것을 어떻게 집중 필터해야 할 지 구상이 미처 서지 않은 초입 리뷰어에게 아주 완벽한 해결사 노릇을 수행합니다.
프론트 UI는 수신된 video_id와 자유 질의 텍스트가 담은 페이로드를 품고 /api/analyze-custom으로 호조를 시작합니다. 백엔드 시스템은 질의에 답할 때 매번 추적 가능한 시간 인덱스 정보를 함께 서술로 녹여내어 리턴하도록 지시하는 포맷 규칙 구조물(ANALYZE_FORMAT_INSTRUCTION)을 템플릿 마크업 삼아 앞단에 끼워 넣은 뒤, TwelveLabs Analyze 서비스로 전송 처리합니다.
backend/services/twelvelabs_services (라인 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
연동 완료 시 사용자는 실존하는 프레임 정보와 강하게 연계된 자연어 설명을 풍요롭게 소화하게 되며 타임스탬프를 원 터치로 공략해 즉각 해당 위치로 비디오를 돌릴 수 있게 됩니다. "이 영상에서 리스크 요소를 살펴야지"라는 막연한 미션에서 "여기가 바로 그 순간이고 이런 수치로 지목되었구나"로 즉시 실현 전환해 줍니다.
이 접근 방식이 가능해진 미래
과거의 비디오 영상 GDPR 준수 조치들은 항상 극단적인 두 타협점 속에서 선택을 강요받곤 했습니다. 느리고 터무니없이 막대한 예산이 소모되는 수작업 검열을 어쩔 수 없이 지탱하거나, 규정이 전제하는 보전 가치보다 과한 영역을 블러로 막무가내 덮여 가렸으나 법적 감사의 사유를 명시하지 못하는 난도 높은 자동 머신들에 머무르는 대안이었습니다.
정교히 다듬어진 이 파이프라인은 두 문제의 완벽한 가교가 됩니다. Marengo 3.0은 텍스트 표현, 실물 소스 사진, 사전에 명기 등록해 놓은 엔터티 군집을 거치며 영상 자료 속 최적의 사건 순간들을 가혹하고 빠짐없이 가져옵니다. Pegasus 1.5는 기꺼이 모든 구간마다 확실하게 법률적 명시 사유가 부연된 고품질의 타임라인 메타데이터를 영리하게 구축합니다. 로컬 안면 감 인식 시스템은 AI 가이드 기반 핵심 프레임을 효율적으로 건네받아 오차 없는 얼굴 정체성을 구축해 마침내 페이스락 트랙이 적용된 완벽한 블러 비디오 영상 내보내기를 지탱해 줍니다.
이로써 우리는 전체를 망치는 블라인드가 아닌 아주 필요한 구획만 매섭고 확실히 지워 내는 고차원 마스킹 시스템을 소유하게 되며, 수동의 한계를 상회하고, 철저한 법률 감사 증빙 추적이 일상화된 컴플라이언스를 마주할 수 있습니다. 비즈니스 리스크를 합리적인 프로세스 영역으로 정복하고 지배할 완벽한 기술적 준비입니다.
학습 참고 자료 및 공식 리소스
소개
대규모 개인정보 검토는 단순한 편집의 문제가 아닙니다. 이는 지능의 문제입니다.
법적 요청이 접수되어 팀이 수시간 분량의 영상 내에서 특정 인물이 나타나는 모든 지점을 찾아내고, 평가하며, 이를 마스킹해야 할 때, 프레임 단위로 수동 검토하는 방식은 기능하지 않습니다. GDPR 위반 추적기(Enforcement Tracker)에 따르면 2026년 3월까지 누적 벌금은 2,793건의 사례에 걸쳐 60억 6천만 유로를 넘어섰습니다. 가장 심각한 위반의 경우 제83조에 따라 여전히 최대 2,000만 유로 또는 글로벌 연간 매출액의 4%에 달하는 벌금이 부과될 수 있습니다. 운영상의 압박은 실질적이며, 기존의 수동 워크플로우는 이를 감당할 수 없도록 설계되어 있습니다.
GDPR을 준수하는 영상 마스킹 작업을 위해서는 올바른 사람이나 사물에 대한 정확한 식별, 전체 아카이브에서 관련 등장 장면을 빠짐없이 찾아내는 검색 능력, 그리고 법적 목적이 실제로 요구하는 범위로 제한된 마스킹 작업이라는 세 가지 요소가 유기적으로 작동해야 합니다. 영상 전체를 무조건 흐리게 처리하는 방식(블러 처리)은 정당한 방어 전략이 될 수 없습니다. 규정의 데이터 최소화 원칙은 일괄적인 억제가 아니라 정밀한 제어를 요구합니다.
본 튜토리얼에서는 TwelveLabs 플랫폼을 기반으로 구축된, 즉시 프로덕션 환경에 배포 가능한 GDPR 준수 비디오 마스킹 애플리케이션을 단계별로 살펴봅니다. 이 애플리케이션은 멀티모달 검색 및 객체 기반 정보 취득을 위해 Marengo 3.0을 사용하고, 구조화된 개인정보 메타데이터 생성을 위해 Pegasus 1.5를 활용하며, 프레임 레벨의 신원 클러스터링을 위해 로컬 얼굴 감지 파이프라인을 구축했습니다. 그 결과, 단일 인터페이스 안에서 리뷰어가 영상을 업로드하는 단계부터 에디팅이 끝난 최종 마스킹 영상으로 내보내기 단계까지 매끄럽게 처리하는 워크플로우가 완성됩니다.
실제 배포된 서비스는 tl-gdpr-compliance.vercel.app에서 직접 체험해 보실 수 있으며, 전체 소스 코드는 github.com/Hrishikesh332/tl-GDPR-compliance-redaction에서 확인하실 수 있습니다.
애플리케이션이 하는 일
대부분의 마스킹 도구는 수동 선택 방식으로 구축되어 있습니다. 리뷰어가 영상을 시청하면서 바운딩 박스(영역 표시상자)를 그리고, 흐리게 처리된 클립을 내보내는 방식입니다. 하지만 영상 자료의 양이 방대하거나, 대상 인물이 여러 클립에 걸쳐 등장할 때, 혹은 법적 의무 사항으로 각 마스킹 결정에 대한 조치 사유를 문서화해야 할 때는 이러한 방식이 적용되지 않습니다.
이 애플리케이션은 이 문제에 다르게 접근합니다. TwelveLabs는 워크플로우의 모든 단계에서 비디오 이해 레이어의 역할을 수행합니다. 리뷰어는 텍스트, 이미지 또는 등록된 인물 객체를 사용하여 색인된 결과 전체를 검색할 수 있습니다. Pegasus 1.5는 타임스탬프가 포함된 개인정보 메타데이터를 자동 생성하여 리뷰어가 첫 프레임을 시청하기도 전에 리스크가 높은 순간들을 수면 위로 끌어올립니다. 또한 로컬 얼굴 감지 기능을 사용하여 감지된 얼굴 정보를 안정적인 개별 인물 신원으로 클러스트링하며, 이는 내보내기 파이프라인까지 그대로 유지됩니다. 블러 처리 경로는 대상 인물의 움직임, 프로필 회전, 카메라 전환 등의 변화가 발생하더라도 끝까지 추적합니다.
이 워크플로우는 영상 업로드 및 색인 생성, 자연어 또는 얼굴 이미지를 이용한 대상 검색, 대화형 타임라인에서 AI가 생성한 개인정보 위험 구간 검토, 인물 신원별 마스킹 대상 선택, 얼굴 고정형 마스킹이 적용된 최종 영상 내보내기 등 전체 리뷰 라이프 사이클을 완전히 커버합니다.
마스킹 파이프라인 살펴보기
본 애플리케이션은 네 가지 고유한 역량을 단일 검토 워크플로우로 유기적으로 결합합니다.
Marengo 3.0 기반 멀티모달 검색을 통해 리뷰어는 텍스트 쿼리, 이미지 업로드 또는 등록된 얼굴 객체를 사용하여 모든 인물, 사물 또는 장면을 손쉽게 찾을 수 있습니다. Marengo는 신뢰도 점수와 함께 관련 영상 세그먼트를 반환하며, 인터페이스는 이를 시각적 타임라인 레이어 위에 매칭률이 가장 높은 리뷰 마커로 표시해 줍니다.
Pegasus 1.5 기반 개인정보 메타데이터는 개인정보 위험 요소를 타겟으로 타임스탬프가 지정된 세그먼트 데이터를 생성합니다. 영상 전체를 장황하게 묘사하는 대신, Pegasus는 얼굴, 문서, 차량 번호판, 모니터 스크린, 민감한 객체, 보호 대상자 등 사전에 정의된 특정 항목들을 집중 분석하도록 설계되었습니다. 각 세그먼트에는 위험 수준, 마스킹 사유, 권장 조치 및 장면 내 역할이 포함됩니다.
로컬 감지 및 신원 클러스터링은 Pegasus가 제공하는 타임스탬프 정보를 가이드삼아 핵심 프레임(Keyframe)을 정확히 추출합니다. 그 후 로컬 얼굴 감지 및 InsightFace 임베딩 기술을 사용하여 감지된 얼굴을 안정적인 개별 인물로 분류하고, 전체 비디오에 걸쳐 일관된 ID를 부여합니다.
페이스락 블러 기술 및 편집 내보내기는 선택한 인물의 추적 기록 데이터를 프레임 단위로 인덱싱된 바운딩 박스 경로로 변환합니다. 최종 영상을 내보내는 동안, 렌더러는 전달받은 해당 경로에 맞춰 매칭되는 각 프레임에 블러 효과를 적용하고, 끊임없이 대상을 정밀 추적하는 고품질의 마스킹 영상을 완성해 냅니다.
개발 환경 설정하기
개발을 시작하기 전 다음의 사전 단계를 진행하세요.
TwelveLabs 계정을 생성하고 API 키를 발급 받으세요. Marengo 3.0 및 Pegasus 1.5 엔진이 활성화된 새로운 인덱스(Index)를 생성하고 인덱스 ID를 기록해 둡니다.
얼굴 수집 및 실체 검색 기능을 활용할 수 있도록 TwelveLabs 엔터티 컬렉션(Entity Collection)을 생성하세요.
Flask 백엔드 실행을 위해 Python 3을 설치하고, React 프론트엔드를 위해 Node.js/npm을 설치하십시오. 영상 내보내기 시 원활한 인코딩을 위해 FFmpeg 설치를 강력히 권장합니다.
저장소(Repository)를 클론한 뒤 README 파일의 설정 가이드를 따르세요.
.env.example 파일에 기술된 변수 정의를 복사하여 backend/.env 파일을 생성합니다.
단원 1: TwelveLabs를 활용한 엔터티 관리
영상 속 인물 중 명확히 확인된 특정 개인을 대규모 아카이브에서 추적하는 일은 일반적인 텍스트 검색 이상의 정밀도를 요구합니다. 얼굴 데이터를 TwelveLabs 엔터티(Entity)로 먼저 등록하면 재사용 가능한 신원 식별 정보가 생성되며, 이는 컨텍스트 쿼리와 결합되어 뛰어난 성향을 발휘합니다. 예를 들어 '특정 문서 근처에 있는 이 인물', '특정 장면 속에 서 있는 이 사람', 혹은 '동일한 행동을 하는 누군가'와 같은 검색이 가능해집니다.
이 기법은 마스킹의 정밀도에 결정적인 차이를 만들어 냅니다. 영상 안의 모든 무작위 얼굴들에 주의를 분산시키는 대신, 리뷰어는 타겟이 되는 신원 정보를 명확히 앵커링하고 해당 인물이 명확히 노출되는 정밀한 프레임들만 빠르고 확실하게 검출할 수 있습니다.
1.1 - 엔터티 인덱스에 얼굴 에셋 등록하기
사용자가 얼굴 사진을 업로드하고 이름을 지정하면, 백엔드 엔진은 ResNet-10 기반 얼굴 감지기를 탐색하여 얼굴 영역을 인식하고, 미리보기용 크롭 이미지를 제작한 뒤, TwelveLabs에 등록할 준비를 마칩니다.
이 흐름은 두 개의 단계로 이루어집니다. 첫째는 얼굴 이미지를 에셋으로 업로드하는 것, 둘째는 반환된 에셋 ID를 매핑 데이터 삼아 정형 인물 엔터티를 새로 만드는 것입니다. 이로써 시각 정보와 검색 가능한 신원이 긴밀하게 바인딩됩니다.
asset_id = twelvelabs_service.upload_face_asset(tmp.name) metadata = {"name": name} if preview_base64: metadata["face_snap_base64"] = preview_base64 entity_result = twelvelabs_service.create_entity( name=name, asset_ids=[asset_id], description=description or f"Face entity: {name}", metadata=metadata,
등록 절차가 마무리되면 컬렉션 내에 인덱싱된 모든 비디오 영상에서 이 엔터티 ID를 바탕으로 신원이 특정한 제어가 가해진 정밀한 검색이 자유롭게 진행됩니다.
1.2 - 엔터티 및 텍스트 융합 검색
검색 시스템은 엔터티 기반, 텍스트 기반, 이미지 기반의 세 가지 모드를 유연하게 제공합니다. 리뷰어는 수집된 초기 정보 수준에 따라 이 기법들을 최적의 방식으로 조합해 활용할 수 있습니다.
엔터티 기반 검색 시, 백엔드는 엔터티 ID를 TwelveLabs가 사전에 인식하는 맨션 구문형식(<@entity_id>)으로 래핑 처리합니다. 사용자가 여기에 구체적인 텍스트 한정자까지 덧붙인 경우 이 구문들이 유기적으로 결합되어 신원과 맥락 모두를 정확히 교집합 삼아 제어된 결과를 찾습니다.
backend/services/twelvelabs_services (라인 1214)
def entity_search(entity_id, query_suffix="", index_id=None): client = get_client() idx = resolve_index_id(index_id) query_text = f"<@{entity_id}>" if query_suffix: query_text = f"<@{entity_id}> {query_suffix}" logger.info("Entity search: %s", query_text) response = client.search.query( index_id=idx, search_options=["visual"], query_text=query_text, group_by="video", sort_option="score", page_limit=50, ) return serialize_search_results(response)
이미지 기반 검색의 경우, 백엔드는 이미지를 query_media_type="image" 형식에 맞춰 지정하고, 실질 데이터 전달을 위해 query_media_file 혹은 query_media_url을 파라미터로 제공하게 됩니다.
if image_url: response = client.search.query( **kwargs, query_media_type="image", query_media_url=image_url, ) if image_path: with open(image_path, "rb") as image_file: response = client.search.query( **kwargs, query_media_type="image", query_media_file=image_file, )
1.3 - 타임라인 검색 레이어 및 검사 플래그
검색 반환치는 단순히 점수 순서대로 나란히 늘어서는 것이라 아니라, 직접 조작 가능한 타임라인상에 시각 자료로 펼쳐집니다. 각 결과 세그먼트는 start와 end 시간 정보를 가지며, UX 단에서는 비디오 재생 탐색바 위에 매핑됩니다. 특히 높은 유사율을 나타내는 위치들은 눈에 도드라지는 붉은색 검사 인디케이터로 부각되어 주변 데이터 흐름 속에서 신속히 필터링하도록 돕습니다.
이를 통해 단순 검색 작업은 즉시 프로의 검토 워크플로우로 격상됩니다. 분석 담당자는 검색창을 확인하고, 매칭률이 기록된 최적의 핫스팟으로 타임라인을 클릭 한 번에 뛰어넘어 정밀한 편집 판정을 내릴 수 있습니다.
단원 2: 탐색 분석 및 차량/인물 페이스락 마스킹
인식 작업은 TwelveLabs의 고차원 비디오 가치 해석 능력과 로컬단 컴퓨터 비전 기술의 장점을 매끄럽게 연결해 줍니다. 굳이 비효율적으로 비디오 전체의 모든 프랙션 프레임마다 디텍터를 가동할 필요가 없습니다. Pegasus 1.5가 선제적으로 사람들이 집중 출몰하는 위치를 수집하여 구조화된 시점에 특정한 메타데이터로 알려주기 때문입니다. 백엔드는 이 시간 프레임 정보를 키포인트 삼아 핵심 프레임 추출을 최적으로 유도함으로써 컴퓨팅 부하를 줄이고 훨씬 정밀하고 빠른 감지 과정을 안내합니다.
추출된 개별 얼굴은 일관되고 흐트러짐 없는 고정 인물 ID로 클러스터링을 겪습니다. 리뷰어는 무작위로 흐트러진 바운딩 박스가 아니라 정제된 고정 인물 목록에서 타켓팅 대상을 정확히 고르게 됩니다. 이 지시가 내보내기 단계에서 대상을 단단히 실시간 바인딩 고정하는 페이스락 레인의 기반이 됩니다.
2.1 - TwelveLabs의 맥락 정보와 로컬 안면 인식을 유연히 동기화하기
파이프라인 시작점은 Pegasus의 구조화된 상세 분석 프로세스입니다. 정보 구조 프로필은 크게 감사 관찰이 권유되는 face_redaction_target과 정형 시퀀스를 커버할 scene_segment의 두 유형으로 나누어 스키마를 구성합니다. temperature: 0.1 값을 설정함으로써 출력 일관성이 최대한 높여지고 자동 가동 자동화 파이프라인 친화적인 안정성을 보유하게 만듭니다.
backend/services/twelvelabs_services (라인 102)
PIPELINE_METADATA_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "face_redaction_target", "description": ( "Return people segments for face redaction decisions. Create one segment per " "distinct face/person for each continuous time range where their face is visible " "enough to matter for redaction." ), "fields": [ {"name": "name", "type": "string"}, {"name": "description", "type": "string"}, {"name": "should_anonymize", "type": "boolean"}, {"name": "is_official", "type": "boolean"}, {"name": "review_required", "type": "boolean"}, {"name": "redaction_reason", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, { "id": "scene_segment", "fields": [ {"name": "description", "type": "string"}, {"name": "confidence", "type": "number"}, ], }, ], }
body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": PIPELINE_METADATA_RESPONSE_FORMAT, "temperature": 0.1, }
Pegasus가 인물 메타데이터를 전해 주면 애플리케이션은 타깃 영역의 전체 프레임을 슬라이싱한 뒤 정밀 핵심프레임 추출을 단락별로 실시합니다. 각각의 분할 프레임은 detect_faces(..., with_encodings=True) 파이프로 도달하며 InsightFace 기법을 작동시켜 실질 얼굴 지점 탐색, 바운딩 박스 생성, 선명도 수치 감별, 인물 고유 임베딩 코드를 구성합니다.
for kf in keyframes: faces = detect_faces(kf["frame"], with_encodings=True) for f in faces: f["frame_idx"] = kf["frame_idx"] f["timestamp"] = kf["timestamp"] all_faces.append(f)
각 감색된 결과값은 프레임 번호 및 타임스탬프와 임베딩 정보를 함께 내재화하여 정형 데이터를 구축하게 되며, 이로써 이후의 클러스트링 단계를 거치며 완전하고 균일한 인물 고유성 파악의 초석이 마련됩니다.
2.2 - 마스킹 적용 타겟 정밀 지정
감지 및 클러스터링 단계를 다 마치면, 검토 담당자는 정리되어 인덱싱된 탐색 인물들의 사진 목록 중에서 선명하게 타겟 대상을 점 찍을 수 있습니다. 해당 명령이 지목되면 신뢰도 높은 페이스 디테일과 이미 기억된 특징적 임베딩 데이터가 한 묶음으로 매핑되어 추후 내보내기 렌더러 파이프라인에서 신뢰 높은 타겟 락(lock) 메커니즘을 유도합니다.
if person_ids: enriched = get_enriched_faces(job_id) or {} unique_faces = job.get("unique_faces") or enriched.get("unique_faces", []) for index, face in enumerate(unique_faces): stable_person_id = ensure_face_identity(face, fallback_index=index) if stable_person_id not in person_ids: continue face_targets.append(face) encoding = face.get("encoding") if encoding: face_encodings.append(encoding) matched_ids.append(stable_person_id)
이 같은 정보는 흔히 역마스킹(Reverse Redaction)이라 불리는 보호 절차에서도 기막힌 편의성을 자랑합니다. 누군가를 역으로 체크하면, 일러둔 보존 대상을 안전하게 보존하고, 발견된 주변의 남은 모든 미등록 타지인의 정보들만 역지정 블러로 신속하고 안전하게 지워 냅니다.
2.3 - 페이스락 레인(Lane) 생성 및 블러 마스킹 최종 내보내기
선택된 인물 신원에 대해 파이프라인은 build_face_lock_lane(job_id, person_id) 함수를 호출합니다. 레인 빌더는 InsightFace 안면 특징 정보, TwelveLabs 엔터티 검색 시간 범위, Pegasus가 분석 추출한 지능형 타임라인 영역의 세 가지 핵심 채널 데이터를 통합 교정합니다. 이를 정밀 결합하여 비디오 전체에 결쳐 해당 대상을 명확히 마킹할 종합 좌표 지도가 최종 편찬됩니다.
face_lock_tracks = {} if face_targets and not reverse_face_redaction: from services.face_lock_track import build_face_lock_lane for face in face_targets: person_id = get_face_identity(face) if not person_id: continue lane_doc = build_face_lock_lane(job_id, person_id) if lane_doc: face_lock_tracks[person_id] = lane_doc
appearances = collect_person_appearances(selected_face) video_id = str(job.get("twelvelabs_video_id") or "").strip() entity_ranges = get_entity_search_ranges(selected_face, video_id) saved_person_ranges = get_face_semantic_time_ranges(selected_face) semantic_ranges = entity_ranges + saved_person_ranges segments = build_face_lock_segments( appearances, semantic_ranges, fps, total_frames, duration_sec, )
내보내기 작업을 진척시킬 때 구성된 타켓 차트는 프레임 단위 탐색용 매핑 룩업테이블(face_lock_bboxes_by_frame) 형식으로 정렬된 후, YOLOv8-Face 리파인먼트 교정 모델을 거쳐 정밀도가 최고도로 향상됩니다. 렌더러가 프레임을 전개하는 도중 해당 차트 테이블에서 표식을 구별하면, 즉시 apply_detection_redaction을 실행하여 부드러운 안티 앨리어싱이 밀착 가공된 마스킹 작업을 프레임마다 완벽하게 입힙니다.
if face_lock_bboxes_by_frame and not preview_only: for entry in face_lock_bboxes_by_frame.get(frame_idx, ()): lane_bbox = entry.get("bbox") if lane_bbox: apply_detection_redaction(frame, lane_bbox, "face")
이와 같은 설계는 대상 추적에 끊김이 생기지 않는 안정적인 블러 효과를 제공해 줍니다. 화면 속 인물이 급격히 흔들리거나, 물체 뒤로 장시간 가려지거나, 화면 기법인 씬이 갑자기 튀며 변경되는 와중에도 매번 수작업 씬 미세 조율 없이 완벽한 정밀 밀착 트래킹을 수행합니다.
단원 3: Pegasus 1.5와 함께하는 정밀 개인정보 메타데이터 인터페이스
Pegasus 1.5는 스키마 구조 기반의 시간 타임스탬프 메타데이터 출력을 안정되게 지원합니다. 이는 해당 애플리케이션으로 하여금 어떠한 영역들을 민감 요소로 판단하고 가공해서 전달해야 할 지 세세한 룰과 조치 사유를 완벽히 통제할 권리를 선사합니다. 이 장치가 리뷰어 웹 인터페이스의 '메타 인사이트'를 직관적으로 끌어주는 고성능 동력 엔진입니다.
3.1 - 리스크 스키마 빌딩
스키마 정보의 핵심은 세그먼트 속성을 privacy_risk_segment 단일 단위로 정확하게 매칭시켜 주는 부분에 있습니다. 얼굴, 일반 서류, 디스플레이 영역, 지목 차량 번호판, 민감 텍스트, 그리고 법률상 보호 조치가 선결되어야 할 중요 대상에 이르기까지, 불필요한 영역은 일절 소외시키고 실무 가치가 높은 타깃에만 Pegasus의 추론 자원을 몰아주기 위함입니다. 여기에 risk_level, scene_role, redaction_decision, reason 등을 디테일하게 탑재함으로써 담당자에게 정보 탐독 플래그 판단은 물론 법적 근거가 되는 조치 증빙 로그 기록의 근거도 함께 제공합니다.
backend/services/pegasus_privacy (라인 75)
PEGASUS_RESPONSE_FORMAT = { "type": "segment_definitions", "segment_definitions": [ { "id": "privacy_risk_segment", "description": ( f"{PEGASUS_PRIVACY_PROMPT} Do not create broad background or crowd segments. Each " "segment must be narrow, actionable, and tied to one visible target that should be " "redacted or reviewed with care." ), "fields": [ { "name": "privacy_category", "type": "string", "description": ( "One of person, face, screen, document, text, license_plate, logo, object, scene. " "Use scene only when the whole frame contains sensitive material; do not use it " "for ordinary courtroom background." ), "enum": ["person", "face", "screen", "document", "text", "license_plate", "logo", "object", "scene"], }, { "name": "risk_level", "type": "string", "description": "One of low, medium, high.", "enum": ["low", "medium", "high"], }, { "name": "label", "type": "string", "description": "Short target name, for example Main verdict subject, Protected witness, Visible ID, Phone screen, or License plate.", }, { "name": "description", "type": "string", "description": "What is visible and why this exact target needs redaction or careful review.", }, { "name": "reason", "type": "string", "description": ( "Specific reason this item should be redacted. For courtroom people, state why this is " "the main verdict subject or another protected/private person; do not include generic " "courtroom observers." ), }, { "name": "scene_role", "type": "string", "description": ( "Role of the target in context. Use verdict_subject, defendant, respondent, or accused for " "the main person whose verdict is being discussed. Ordinary judges, lawyers, clerks, officers, " "jury, audience, reporters, and bystanders should not be segmented." ), "enum": [ "verdict_subject", "defendant", "respondent", "accused", "protected_witness", "victim", "minor", "private_non_party", "sensitive_item", "unknown", ], # More Segments Defined ... } ], } ], }
3.2 - 타임스탬프 정보 연동으로 데이터 출력
해당 스키마 프로필은 analysis_mode: "time_based_metadata" 인자를 정밀하게 껴안고 Pegasus 추론 엔진으로 직접 전송됩니다. 해당 세그먼트들이 대범하고 광범위한 서술에 지배받지 않고 타임 스탬프 인덱스로 세밀히 슬라이싱된 메타데이터 군집으로 도달하도록 지킴과 동시에, temperature: 0.1 지정을 주어 결정론적 정확성을 수반하게 만듭니다. 컴플라이언스 업무에서 가장 중요한 예측 가능하고 반복 신뢰 높은 실행력을 유지하려는 정밀한 엔지니어링 세팅입니다.
backend/services/twelvelabs_services (라인 1044)
def create_pegasus_privacy_task(asset_id, *, response_format): """Create a Pegasus 1.5 async structured-analysis task from an existing asset id.""" body = { "video": { "type": "asset_id", "asset_id": asset_id, }, "model_name": "pegasus1.5", "analysis_mode": "time_based_metadata", "response_format": response_format, "temperature": 0.1, }
백엔드 서비스는 초기에 임시 빈 디코더 정보 timeline_events와 recommended_actions를 생성해 임시 잡(job)을 선점해 놓은 뒤, 비동기 호출 타겟 완료를 정교하게 폴링합니다. 회신이 도달하면 각 마킹 구간들은 즉시 궤적이 결부된 타임라인 정보 구조(start_sec, end_sec, 심각도 severity, 유형 category, 사건 사유 reason, 마킹 판정 redaction_decision) 및 이를 지지할 담당자 조치 권고안 등으로 깔끔하게 분할 래핑됩니다.
event = { "id": event_id, "start_sec": round(start_sec, 3), "end_sec": round(end_sec, 3), "severity": severity, "category": category, "label": label[:120], "description": description[:600], "reason": reason[:600], "redaction_target": redaction_target[:120] or None, "scene_role": scene_role[:120] or None, "redaction_decision": redaction_decision[:120] or None, "subject_selection": subject_selection[:120] or None, "confidence": round(confidence, 3), "review_required": True, "recommended_action_ids": [action_id], }
3.3 - 개인정보 메타데이터를 통합 심사 제어판으로 시각화
유저 타임라인 궤적 위에서 Pegasus의 도출 결과들은 start_sec부터 end_sec까지 부드럽게 칠해진 상호작용 클릭 핫스팟 형태로 수려하게 수놓아집니다. 해당 핫스팟 바위를 탭하여 누르면 사이드바에 유기 연동된 '메타 인사이트' 제어판이 자동으로 열리고, 시각 포커싱과 비디오 재생 타임라인 시점이 해당 사건 시작 시간으로 번개처럼 점프합니다.
해당 패널은 사건의 모든 미세 필트인 정보(리스크 수준, 관련 카테고리 기재, 소명 논거 사유, 마스킹 처리 판단, 구체적 블러 타겟 설정, 검토 권고안 등)를 소상히 디스플레이합니다. 검토 실무자는 문제 부위의 위치는 물론 '왜 이 사유가 감식 판별 조치 사유로 등록되었는가?'에 대한 심층 정보까지 함께 취급하게 됩니다. 이것이 차후 기업의 외부 GDPR 법률 컴플라이언스 감사 부서에 바로 제출 가능한 최고 가치의 증빙 사유서가 되어 줍니다.
단원 4: 검토 업무를 위한 오픈형 심층 비디오 문답
구조화된 정형 지침 추출 이외에도, 본 앱은 담당 리뷰어의 판단 지평을 확장시켜 줄 자유 문답 형태의 내추럴 컨텍스트 다이얼로그 또한 폭넓게 안아줍니다. 영상 검수자는 '해당 비디오 전체의 리스크 요소를 심층 평가해 줘', '어떤 시점의 클립이 가장 법적 마킹 분쟁 소지가 높은지 논증해 줘' 같은 개방형 문답이나 세부 씬을 묻는 작업을 바로 던질 수 있습니다. 어떤 것을 어떻게 집중 필터해야 할 지 구상이 미처 서지 않은 초입 리뷰어에게 아주 완벽한 해결사 노릇을 수행합니다.
프론트 UI는 수신된 video_id와 자유 질의 텍스트가 담은 페이로드를 품고 /api/analyze-custom으로 호조를 시작합니다. 백엔드 시스템은 질의에 답할 때 매번 추적 가능한 시간 인덱스 정보를 함께 서술로 녹여내어 리턴하도록 지시하는 포맷 규칙 구조물(ANALYZE_FORMAT_INSTRUCTION)을 템플릿 마크업 삼아 앞단에 끼워 넣은 뒤, TwelveLabs Analyze 서비스로 전송 처리합니다.
backend/services/twelvelabs_services (라인 666)
def analyze_video_custom(video_id, prompt): client = get_client() logger.info("Custom analysis on video %s", video_id) enhanced_prompt = f"{ANALYZE_FORMAT_INSTRUCTION}\n\n{prompt}" result = client.analyze( video_id=video_id, prompt=enhanced_prompt, temperature=0.2, request_options={"timeout_in_seconds": TWELVELABS_ANALYZE_TIMEOUT_SEC}, ) return {"data": result.data, "id": result.id}
연동 완료 시 사용자는 실존하는 프레임 정보와 강하게 연계된 자연어 설명을 풍요롭게 소화하게 되며 타임스탬프를 원 터치로 공략해 즉각 해당 위치로 비디오를 돌릴 수 있게 됩니다. "이 영상에서 리스크 요소를 살펴야지"라는 막연한 미션에서 "여기가 바로 그 순간이고 이런 수치로 지목되었구나"로 즉시 실현 전환해 줍니다.
이 접근 방식이 가능해진 미래
과거의 비디오 영상 GDPR 준수 조치들은 항상 극단적인 두 타협점 속에서 선택을 강요받곤 했습니다. 느리고 터무니없이 막대한 예산이 소모되는 수작업 검열을 어쩔 수 없이 지탱하거나, 규정이 전제하는 보전 가치보다 과한 영역을 블러로 막무가내 덮여 가렸으나 법적 감사의 사유를 명시하지 못하는 난도 높은 자동 머신들에 머무르는 대안이었습니다.
정교히 다듬어진 이 파이프라인은 두 문제의 완벽한 가교가 됩니다. Marengo 3.0은 텍스트 표현, 실물 소스 사진, 사전에 명기 등록해 놓은 엔터티 군집을 거치며 영상 자료 속 최적의 사건 순간들을 가혹하고 빠짐없이 가져옵니다. Pegasus 1.5는 기꺼이 모든 구간마다 확실하게 법률적 명시 사유가 부연된 고품질의 타임라인 메타데이터를 영리하게 구축합니다. 로컬 안면 감 인식 시스템은 AI 가이드 기반 핵심 프레임을 효율적으로 건네받아 오차 없는 얼굴 정체성을 구축해 마침내 페이스락 트랙이 적용된 완벽한 블러 비디오 영상 내보내기를 지탱해 줍니다.
이로써 우리는 전체를 망치는 블라인드가 아닌 아주 필요한 구획만 매섭고 확실히 지워 내는 고차원 마스킹 시스템을 소유하게 되며, 수동의 한계를 상회하고, 철저한 법률 감사 증빙 추적이 일상화된 컴플라이언스를 마주할 수 있습니다. 비즈니스 리스크를 합리적인 프로세스 영역으로 정복하고 지배할 완벽한 기술적 준비입니다.
학습 참고 자료 및 공식 리소스








