" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
연구
파운데이션 모델이 멀티모달로 나아가고 있습니다

제임스 러
버트(BERT)와 지피티(GPT) 같은 텍스트 중심의 모델에서 시작된 파운데이션 모델은 이제 언어, 이미지, 비디오를 함께 처리하는 멀티모달 아키텍처로 진화했습니다. 이 글에서는 이러한 패러다임의 변화가 어떻게 일어났는지, 왜 비디오 이해가 인공지능 분야의 가장 도전적인 영역인지, 그리고 이것이 향후 AI 개발의 미래에 어떤 의미를 갖는지 자세히 짚어봅니다.
버트(BERT)와 지피티(GPT) 같은 텍스트 중심의 모델에서 시작된 파운데이션 모델은 이제 언어, 이미지, 비디오를 함께 처리하는 멀티모달 아키텍처로 진화했습니다. 이 글에서는 이러한 패러다임의 변화가 어떻게 일어났는지, 왜 비디오 이해가 인공지능 분야의 가장 도전적인 영역인지, 그리고 이것이 향후 AI 개발의 미래에 어떤 의미를 갖는지 자세히 짚어봅니다.

목차
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2023. 3. 31.
17분
링크 복사하기
파운데이션 모델(예: BERT, GPT-3, CLIP, Codex)의 성장은 시각과 언어 양방향의 모달리티를 결합한 모델에 대한 관심을 크게 높였습니다. 이러한 하이브리드 시각-언어 모델은 이미지 캡셔닝, 이미지 생성, 시각적 질의응답을 포함한 고난도 작업에서 인상적인 성능을 입증해 왔습니다. 최근에는 파운데이션 모델의 작동 원리를 고스란히 적용해 비디오 데이터로부터 학습을 수행하는 새로운 패러다임인 비디오 파운데이션 모델이 등장하고 있습니다.
이 블로그 포스트에서는 파운데이션 모델, 대규모 언어 및 시각-언어 모델, 그리고 비디오 파운데이션 모델의 전반적인 개념을 다룹니다. 파운데이션 모델의 아키텍처, 학습 및 미세 조정(fine-tuning) 패러다임, 그리고 스케일링 법칙(scaling laws)을 살펴봅니다. 또한 시각-언어 모델이 컴퓨터 비전과 자연어 처리의 강점을 어떻게 결합하는지, 그리고 이들이 복잡한 문제를 해결하기 위해 어떻게 활용되고 있는지 논의합니다. 마지막으로 비디오 파운데이션 모델을 집중 조명하며, 이들이 비디오 데이터의 이해와 분석 분야를 어떻게 혁신하고 있는지 살펴보겠습니다.
1. 파운데이션 모델 가볍게 입문하기
파운데이션 모델은 방대한 규모의 데이터로부터 자기지도학습(self-supervision)을 통해 대규모로 학습하는 머신러닝 모델의 한 종류입니다. 핵심 개념은 다양한 수많은 작업에 범용적으로 활용할 수 있는 모델을 만드는 것입니다. 엄청난 양의 데이터로 사전 학습함으로써, 모델은 데이터에 내재된 일반적인 패턴을 학습합니다. 향후 특정 세부 작업에 모델을 적용할 때, 모델은 이 배경지식을 활용해 빠르게 적응할 수 있습니다.
파운데이션 모델은 2012년 이후 주류로 부상한 심층 신경망(deep neural networks)과 오랜 기간 발전해 온 자기지도학습을 기반으로 삼고 있습니다. 최근 두 분야의 기술 혁신 덕분에 한층 더 크고 복잡한 모델 구축이 가능해졌습니다. 이러한 모델들은 명시적인 라벨(label)이 지정되지 않은 대규모의 데이터셋을 바탕으로 대량 학습을 진행합니다.
이 과정을 거쳐 모델은 광범위한 패턴과 논리적 관계를 습득하며, 이는 다양한 작업에 유연하게 활용될 수 있습니다. 이는 자연어 처리, 컴퓨터 비전, 멀티모달 AI 분야의 비약적인 도약을 이끌어 냈습니다. 파운데이션 모델을 활용하면 개별 작업마다 별도의 모델을 처음부터 개발할 필요 없이, 단 하나의 강력한 모델을 다목적으로 활용할 수 있습니다. 결과적으로 개발 시간과 리소스를 크게 아끼고 관련 기술 분야의 발전을 앞당길 수 있습니다.
전이 학습 (Transfer Learning)
전통적인 머신러닝(ML) 모델은 스크래치 단계에서부터 학습을 진행하는 경우가 많아 우수한 성능을 내기 위해 특정 도메인에 특화된 방대한 데이터셋이 필수적이었습니다. 반면, 데이터의 양이 충분하지 않을 때는 전이 학습을 유용하게 활용할 수 있습니다. 전이 학습의 핵심은 한 이미지나 작업에서 이미 학습한 "지식"을 가져와 다른 작업에 적용하는 것으로, 스크래치 단계부터 처음 학습할 때에 비해 필요한 데이터 양을 획기적으로 줄여줍니다. 심층 신경망에서 사전 학습(pre-training)은 전이 학습을 위한 지배적인 접근법입니다. 모델을 원래의 일차적인 작업(예: 도로 위의 차량 감지)으로 먼저 학습시킨 뒤, 우리가 실제로 해결하고자 하는 하위 단계의 타겟 작업(예: 검은색 테슬라 모델 3 감지)에 맞춰 가중치를 미세 조정(fine-tuning)하는 방식입니다.
컴퓨터 비전 분야에서는 2014년부터 이 방식이 활발히 사용되어 왔습니다. 통상적으로 ImageNet 데이터셋으로 모델을 먼저 학습시킨 후, 신경망의 레이어 대부분은 그대로 유지하고 출력층에 가까운 상위 3개 정도의 레이어만 새로운 가중치로 변경해 재정렬합니다. 혹은 모델 전체를 처음부터 끝까지 엔드투엔드로 미세 조정하기도 합니다. 컴퓨터 비전 작업에서 가장 널리 쓰이는 대표적인 사전 학습 모델로는 AlexNet, ResNet, MobileNet, Inception, EfficientNet, 그리고 YOLO 등이 있습니다.
자연어 처리(NLP) 분야에서 사전 학습은 초기에는 주로 첫 단계인 단어 임베딩(word embeddings)에 국한되어 사용되었습니다. 언어 모델의 입력값은 단어입니다. 이 단어 데이터를 벡터 형식으로 인코딩하는 대표적인 방식 중 하나가 바로 원-핫 인코딩(one-hot encoding)입니다. 대규모 단어 행렬이 주어지면 임베딩 매트릭스를 생성하고, 각 단어를 실수 가치의 고차원 벡터 공간에 매핑할 수 있습니다. 이 가공 과정을 거친 매트릭스는 대략 수천 차원 규모로 축소되며, 이때의 각 차원은 단어의 어떠한 의미론적 개념들과 매칭될 수 있습니다.
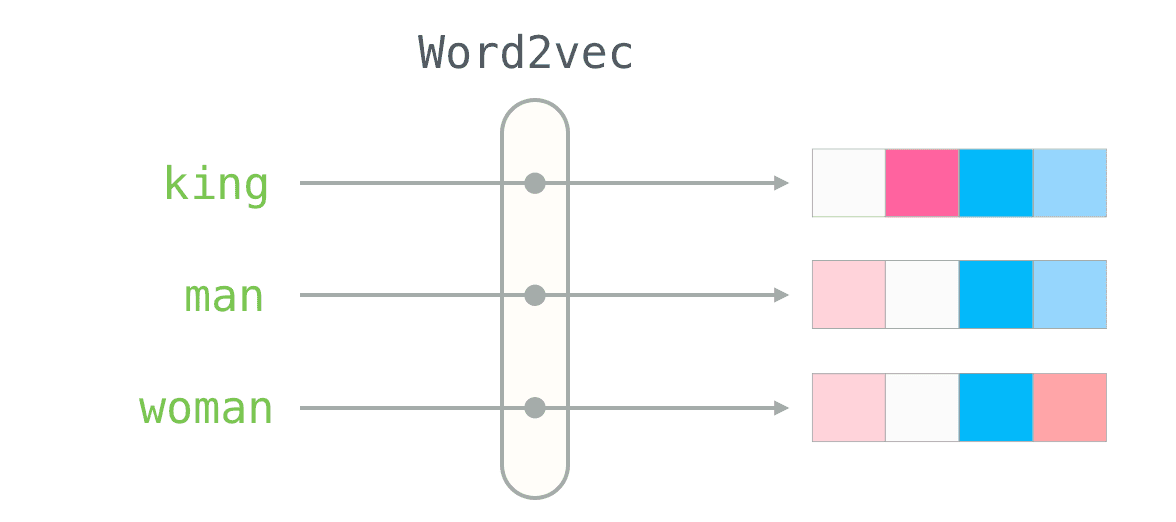
2013년 출시된 Word2Vec이 이러한 방식으로 모델 학습을 진행했습니다. 이 모델은 어떤 단어들이 문장 내에서 얼마나 자주 함께 등장하는지 추적했습니다. 이를 통해 이들 임베딩 벡터 간의 코사인 유사도(cosine similarity)를 극대화하는 방향으로 학습을 유도했습니다. 완성된 벡터 임베딩 공간 위에서는 흥미로운 벡터 산술 연산을 시연해 볼 수도 있었습니다. 예컨대 "왕(king)", "남자(man)", "여자(woman)" 단어 지표를 처리해 수학 연산을 수행하면, 해당 임베딩 공간 내에서 "여왕(queen)"에 가장 인접한 결과 벡터를 얻게 됩니다.
문장 내 문맥에 따라 단어의 역할과 의미가 달라지기 때문에, 정확한 단어 임베딩을 위해서는 더 넓은 문맥 영역을 살펴보는 것이 매우 유익합니다. 이 방식으로 처리하면 하위 태스크 전반의 정확도가 크게 향상됩니다. 2018년에는 ELMo, ULMFiT, GPT를 포함한 여러 모델들이 언어 모델링이 사전 학습에 어떻게 고도로 기여할 수 있는지를 실증적으로 증명해 냈습니다. 이 세 가지 방식 모두 사전 학습된 언어 모델을 활용해 텍스트 분류, 질의응답, 자연어 추론, 상호참조 해결, 시퀀스 라벨링을 비롯한 다양한 NLP 분석 영역에서 뛰어난 성능(SOTA)을 달성해 냈습니다.
트랜스포머(Transformers) = 파운데이션 모델의 핵심 아키텍처

오리지널 트랜스포머 아키텍처는 2017년 논문인 "Attention Is All You Need"에서 최초로 소개되었습니다. 트랜스포머가 등장하기 전까지만 해도 NLP 분야의 최첨단 기술(SOTA)은 LSTM이나 널리 쓰이던 Seq2Seq 아키텍처와 같이 텍스트를 구성하는 단어들을 순서대로 하나씩 처리하는 순환 신경망(RNNs) 기반이었습니다.
트랜스포머가 가져온 핵심 혁신은 바로 언어 처리의 병렬화입니다. 이를 통해 주어진 텍스트 바디의 모든 토큰들을 순차적으로 처리할 필요 없이 동시에 고속으로 분석할 수 있게 되었습니다. 트랜스포머는 이러한 병렬화를 수행하기 위해 AI 알고리즘 메커니즘인 어텐션(attention)에 의존합니다. 어텐션을 통해 모델은 문장 안에서 멀리 떨어져 있는 단어들 간의 상관관계를 파악할 수 있으며, 전체 지문에서 흐름상 집중해야 하는 핵심 단어와 구문을 스마트하게 판단할 수 있습니다.
또한 병렬 처리가 가능해지면서 트랜스포머는 RNN 대비 계산 효율이 압도적으로 우수해졌으며, 이를 바탕으로 더 거대한 데이터셋을 학습하고 더 많은 수의 파라미터(매개변수)를 탑재할 수 있게 되었습니다. 오늘날의 거대 트랜스포머 모델의 성장은 이러한 구조에 기반한 것입니다.
비전 트랜스포머 (Vision Transformers)
그간 컴퓨터 비전 분야에서는 합성곱 신경망(CNN)이 지배적인 아키텍처 자리를 지켜왔습니다. 그러나 트랜스포머가 NLP 진영에서 엄청난 성공을 거두자, 연구자들은 이 강력한 구조를 이미지 데이터 분석에도 이식하기 시작했습니다. 널리 알려진 논문 "An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale"은 트랜스포머의 인코더 블록을 이미지 분류 문제에 성공적으로 적용한 비전 트랜스포머(ViT) 아키텍처를 소개했습니다.

이 연구의 저자는 하나의 전체 이미지를 여러 조각(patch)으로 분할한 뒤, 이 패치들을 선형 임베딩 시퀀스로 변환해 트랜스포머의 입력값으로 제공했습니다. NLP 환경에서 토큰을 다루는 방식과 유사하게 이 이미지 패치들을 개별 입력값으로 취급한 것입니다. 전체 아키텍처는 이미지를 조각내는 스템(stem) 단계, 멀티레이어 트랜스포머 인코더 기반의 바디(body) 단계, 전역 표현을 바탕으로 타겟 출력 라벨로 변환해 주는 MLP(Multi-Layer Perceptron) 헤드로 구성됩니다. ViT는 대규모 학습 시 리소스를 비교적 덜 쓰면서도 여러 이미지 분류 벤치마크셋에서 기존의 최고 성능 기록을 갈아치우거나 넘어서는 쾌거를 달성했습니다.
비전 트랜스포머가 뛰어난 잠재력을 보였음에도 몇 가지 구조적 극복 과제가 남았습니다. 가장 큰 한계는 모델이 고해상도 이미지를 다룰 때 발생합니다. 이미지 크기가 커질수록 필요한 컴퓨팅 리소스가 기하급수적으로 폭증하기 때문입니다. 더불어, ViT의 고정 크기 토큰 방식은 다양한 가변 크기의 시각 요소를 잡아내고 분석하는 작업에는 다소 비효율적이었습니다.
트랜스포머 변형 아키텍처들
오리지널 트랜스포머 아키텍처 발표 이후 많은 후속 연구가 이어졌으며, 연구진들은 앞서 언급한 한계점과 비효율성을 극복하기 위해 아키텍처 수정 보완에 나섰습니다.

2021년 마이크로소프트 연구진은 모든 모달리티에 유연하게 적용할 수 있는 범용 트랜스포머 아키텍처인 Swin Transformer를 발표했습니다. Swin Transformer는 계층형 피처 맵(hierarchical feature maps)과 이동 윈도우 어텐션(shifted window attention)이라는 두 가지 획기적인 개념을 도입했습니다.
1. 이 모델은 조밀한 예측(dense prediction)을 위한 고난도 기법을 구현하기 위해 계층형 피처 맵을 활용합니다. 이미지를 중첩되지 않는 윈도우 단위로 분할한 뒤 각 로컬 윈도우 영역 안에서만 셀프 어텐션을 수행함으로써 선형적인 계산 복잡도를 확보했습니다. 덕분에 Swin Transformer는 다양한 컴퓨터 비전 작업의 우수한 뼈대(backbone)로 자리 잡았습니다.
2. 이동 윈도우(shifted windows) 방식을 결합하여, 이전 레이어의 정보가 윈도우 경계를 가로질러 유기적으로 엮이도록 모델링 역량을 끌어올렸습니다. 이 설계는 실제 하드웨어 Latency가 매우 낮다는 실용적 장점도 갖췄습니다. 하나의 윈도우 안에 속한 모든 쿼리 패치들이 동일한 키(key) 세트를 공유하므로 하드웨어 메모리 접근이 훨씬 수월합니다.
Perceiver는 비슷한 시기에 DeepMind에서 발표한 또 다른 혁신적인 트랜스포머 변형 모델로, 생물학적 감각 시스템에서 영감을 얻어 개발되었습니다. 이미지, 비디오, 오디오는 물론 3D 포인트 클라우드에 이르기까지 정형/비정형의 수많은 입력 데이터 유형을 어텐션 기반 메커니즘을 통해 일관되게 처리합니다. 특정 데이터 도메인에 대한 가설이나 제약에 크게 구애받지 않고 유기적인 멀티모달 처리를 구현해 냅니다.

Perceiver 아키텍처는 일련의 소규모 잠재 유닛(latent units)을 인입해 어텐션 병목 구조를 형성합니다. 이를 통해 네트워크 전체가 올투올(all-to-all) 방식으로 연결되어 계산이 폭증하던 문제를 원천 차단하고 구조를 한 단계 더 깊고 정교하게 쌓을 수 있도록 도왔습니다. 이전 단계의 정보 처리를 기반으로 가장 연계성이 높은 주요 입력 부문에 집중하는 방식입니다. 다만 밀접한 멀티모달 환경에서는 들어오는 정보의 근원이 어느 모달리티인지 구분해 주는 세부 처리가 필수적입니다. 이 모델의 저자들은 구조적 단순함을 유지하기 위해 생물학적 신경망의 '레이블 라인(labeled line)' 전략처럼 각 입력 요소에 고유한 물리적 위치와 결합된 모달리티 피처를 유기적으로 심어 보환해 냈습니다.
2. 거대 언어 모델 (Large Language Models)
오리지널 트랜스포머 연구 성과를 발판 삼아, 최신의 AI 연구진들은 이 기술적 돌파구를 더욱 발전시켰습니다. 그 첫 신호탄은 자연어 처리(NLP) 영역이었습니다.
GPT와 GPT-2가 각각 2018년과 2019년에 세간에 공개되었습니다. 이 이름은 '생성형 사전 학습 트랜스포머(Generative Pre-trained Transformers)'의 약자입니다. 이들은 구조적으로 디코더 전용(decoder-only) 모델이며 마스크드 셀프 어텐션(masked self-attention) 기법을 사용합니다. 마스크드 셀프 어텐션이란 임의의 출력 시퀀스 시점에서 바라볼 때 문맥상 그 이전에 먼저 출현했던 앞쪽 입력 시퀀스 벡터들만을 참고해 관계를 맺도록 제약을 두는 기법입니다. GPT 임베딩 역시 분류(classification) 등의 목적에 다양하게 활용 가능하지만, 이러한 독특한 디코딩 접근 아이디어는 오늘날 ChatGPT와 같은 가장 대중화된 대형 LLM 패밀리의 강력한 모태가 되었습니다.
당시 이 모델 패밀리는 약 8백만 개의 웹 페이지 데이터를 읽고 익혔으며, 최대 모델 크기는 무려 15억 개의 파라미터 수준에 달했습니다. GPT-2가 해결해야 했던 기본 학습 미션은 웹문서의 앞부분 흐름을 읽고 '그다음에 이어질 알맞은 단어를 예측하는 것'이었습니다. 연구팀은 모델 파라미터의 규모가 늘어남에 따라 생성의 정교함과 정확도가 눈에 띄게 수직 상승하는 패턴을 확인했습니다.

BERT도 양방향 인코더 트랜스포머(Bidirectional Encoder Representations for Transformers)라는 이름을 내걸고 비슷한 시기 세상에 모습을 드러냈습니다. 1억 1천만 개의 파라미터 규모로 구축된 이 모델은 순수한 예측 과제를 수행하기 위한 인코더 전용 트랜스포머 구조를 채택하였으며, 기발한 마스크드 언어 모델링(masked-language modeling) 개념을 최초로 선포했습니다. 학습 중 BERT는 입력 문장 임의의 위치에 있는 무작위 단어들을 마스킹 테이프로 가리듯 숨긴 채, 문장 앞뒤 양방향 문맥을 정교하게 훑어 해당 위치의 빈칸에 알맞은 원본 단어가 무엇인지 정확하게 역추적해 내는 미션을 훈련받았습니다.
T5 (Text-to-Text Transformer)는 2020년 구글에 의해 발표되었습니다. 입력값과 출력값이 모두 순수한 가공 텍스트 문자열 형식이기 때문에, 사용자가 해결해 주기를 바라는 특정 가벼운 태스크 미션을 직접 텍스트 명령 형태로 지정할 수 있습니다. T5는 오리지널 정석형 구조인 인코더-디코더 설계를 정교하게 사용했습니다. 위키백과 데이터베이스보다 100배 이상 방대한 스케일의 C4 데이터셋(Colossal Clean Crawled Corpus)으로 집중 무장하여 설계되었으며, 파라미터는 약 100억 개에 육박합니다.
파운데이션 모델 진영의 무어의 법칙: 스케일링 법칙
일반적으로 스케일링 법칙은 가용 컴퓨팅 예산(예: 엄청난 크기의 모델 구조나 더 풍부한 데이터 정제량)을 크게 증강하면 모델의 종합 품질도 한계점이 없이 비례하여 향상된다고 전망합니다. Open AI 연구진은 2020년 트랜스포머 언어 모델의 스케일링 법칙에 관한 깊이 있는 실증 조사를 감행하여, 이러한 규모 확장 규칙이 실재하며 향후 모델 성장을 매우 신뢰성 있게 진단해 준다는 사실을 널리 보여주었습니다. 이들의 결론은 모델 성능 ∝ 데이터 스케일 x 매개변수 규모 x 투자 계산량이라는 명확한 핵심 공식으로 귀결됩니다.

구체적으로 일련의 실험 결과들은 트레이닝 손실값(test loss)이 트레이닝에 동원된 모델의 크기, 학습 데이터셋 부피, 투입된 종합 시스템 연산 자원량에 대응해 일정한 지수 법칙(power law) 패턴을 보임을 증명했으며, 이는 측정 범위가 무려 7자릿수(7 orders of magnitude)를 넘나들 정도로 높은 일관성을 가졌음을 밝혔습니다. 이는 대규모 언어 모델을 빌딩하고 훈련 설정을 최적화할 때, 연관 매개변수들 사이의 역학 관계를 단순한 수학 공식으로 수월하게 설계할 수 있음을 의미합니다. 나아가 핵심 아키텍처 차원의 미세 디테일(예: 네트워크의 가로 폭 대 세로 다층 깊이 비율 등)은 정상적인 바운더리 범주 안에 머물러만 준다면 성능 격차에 거의 유의미한 흔적을 남기지 못했습니다.
도출해 낸 상관 공식과 연구 관측에 근거해 볼 때, 더 거대하게 가공된 초거대 모델일수록 주어진 소스 표본으로부터 유효 지식을 추출해 내는 샘플 효율성이 눈에 띄게 탁월합니다. 다른 각도로 해석하자면, 투자 예산 대비 비용 효율을 극대화하여 스마트하게 훈련하려면 초대형 모델을 설계해 상대적으로 간소하고 정제된 노이즈 리스 데이터셋에서 신속히 가중치를 훈련한 뒤, 과적합이나 정체 국면에 접어들기 한참 전에 학습 회차를 지혜롭게 클로징하는 편이 최적이라는 결론을 선사합니다.

스케일링 법칙 백서가 학계에 공개된 이후, 글로벌 빅테크 기업들 간 언어 모델 기둥을 초대형으로 경쟁 확장하려는 레이스에 본격적으로 불이 붙었습니다. 2020년 공개된 GPT-3는 당대 최고의 성능을 구현했습니다. 이는 이전 GPT-2 세대보다 100배가량 업그레이드되어 자그마치 1,750억 개의 파라미터를 안고 탄생했습니다. 차원이 다른 크기 덕분에 GPT-3 모델은 새로운 도메인의 문제를 맞닥뜨렸을 때 소수 지문 예시를 주거나 아예 예시를 주지 않고 바로 문제를 술술 풀어나가는 퓨샷(Few-shot) 및 제로샷(Zero-shot) 테스트 조건 하에서 미증유의 대처 능력을 과시했습니다. 즉, 제시하는 레퍼런스 사례가 정교할수록 모델 성능은 극대화되며, 무엇보다 모델 구조 자체가 방해 장벽 없이 비대해질수록 본질적인 성능 지각 변동이 더 크게 일어납니다.
구글 리서치팀 역시 이에 발맞춰 "Emergent Abilities of Large Language Models"라는 중대한 분석 논문을 선보였습니다. 소형 모델 진영에서는 아예 부재했거나 침묵 속에 머물러 있던 다양한 복잡 고차원 태스크 해결 능력이 특정 임계 물리 볼륨을 뚫고 넘어선 거대 인프라 위에서 어떻게 기적처럼 돌연 출현(Emergent Abilities)하는지 면밀히 추적한 분석입니다. 연구팀은 하드웨어 연산량 투자 확대 및 지평 성장에 맞춰 다양한 난도의 세부 미션 해결 지표를 관측했습니다. 특정 영역들의 성능은 투자에 따라 아주 점진적이고 선형적으로 추종 성장하기도 하지만, 또 다른 다수의 핵심 복리 미션들에서는 평소 바닥권에 머물던 난해한 문제 돌파력이 모델 크기 700억 파라미터 등의 특정 임계 스케일을 돌파하는 찰나에 급작스럽게 폭발하는 특이점 패턴을 보여주는 놀라운 발견을 소개했습니다.

2022년 딥마인드(DeepMind) 연구진은 가용 예산 제한 범위 내에서 컴퓨팅 효율을 극한으로 끌어올리는 새 장을 열기 위해 "친칠라(Chinchilla)" 스케일링 법칙 청사진을 제시했습니다. 이는 오리지널 OpenAI가 앞서 주창했던 산 식보다 실무 환경에 한 차원 더 정확하게 부합하는 개선된 스케일 공식으로 큰 인정을 받게 되었습니다.
이들은 7천만 개에서 최대 160억 개의 파라미터 범주에 배치한 400여 개 이상의 풍부한 실험 모델들을 50억~5,000억 개의 방대한 데이터 토큰들 위에 다각도로 정교하게 학습시켰습니다. 분석 결과를 기반으로 모델 파라미터 크기 단위 수에 최고 효율로 비례하는 학습 데이터 토큰 요구 균형비를 산출해 새로운 가이드 공식을 완성해 냈습니다. 이들은 최근 런칭된 다수의 주류 신경망 모델들이 실질적 역량 대비 학습 기회 부전, 즉 파라미터 크기에 걸맞은 충분한 양의 풍성한 말뭉치 데이터를 제대로 소화하지 못한 '언더트레이닝(undertrained)' 상태였다고 날카롭게 진단했습니다.
이 가설을 멋지게 실증하기 위해 딥마인드는 2,800억 파라미터를 보유한 기존 대형 모델 Gopher(약 3,000억 데이터 토큰 학습)를 대조군으로 삼아 새 도전 모델 친칠라를 디자인했습니다. 친칠라는 기존 파라미터 크기를 오히려 4분의 1 수준인 700억 파라미터 수준으로 대폭 감량 조정하는 대신, 입맛에 맞게 소화할 소스 데이터 공급량은 무려 4배 이상 증축 공급한 1.4조 토큰을 완전 정독시켰습니다. 결과는 놀라웠습니다. 모델 무게는 비교가 무색할 만큼 가벼워졌음에도 친칠라는 모든 성능 벤치마크 테스트에서 골리앗 같았던 Gopher의 기록들을 시원하게 추월했습니다. 이는 모델 자체의 절대 부피 확장만큼이나 이를 풍성하게 채울 건강한 학습 훈련용 토큰 비중 균형 유지 또한 아주 결정적인 열쇠임을 시장에 일깨워준 귀중한 결과였습니다.
이처럼 전폭적인 이론 무장과 지배적인 스케일링 법칙의 탄생에 힘입어, 학계와 업계에는 더욱 매력적이고 유능한 초거대 언어 모델(LLM)들이 쉴 새 없이 쏟아져 나오게 되었습니다. 이 혁신 리더 모델들은 활성화 경로를 스마트하게 솎아 비용을 아끼는 희소 신경망 모듈(sparse mixture-of-experts) 구조를 가미하거나, 다양한 데이터 소스로부터 파생된 미개발 청정 데이터를 수집 및 주입함으로써 극한의 학습 성과를 견인하고 있습니다. 대표적인 이정표 모델들로는 Megatron-LM(8.3B), GLaM(64B), LaMDA(137B), Megatron-Turing NLG(530B)를 넘어 구글의 자존심이라 불린 PaLM(540B) 등에 이르기까지 방대한 군단이 거론됩니다.
마찬가지로 구글 리서치팀이 주도한 비전 트랜스포머의 스케일 확장 연구(Scaling Vision Transformers)에 의하면, 스케일링 법칙의 강력한 효과는 단순한 자연어 텍스트 처리뿐만 아니라 컴퓨터 비전(CV) 영역에도 한정 없이 고스란히 유효하게 작용함을 가시적으로 입증했습니다. 연구진은 5백만 개부터 20억 파라미터 사이를 종횡무진하는 다채로운 스펙트럼의 ViT 모델들을 구성한 뒤, 1백만 개부터 30억 개 규모의 방대한 이미지 소스 풀 위에서 다채롭게 학습 세션을 벌였습니다. 이때 투입된 총 컴퓨팅 리소스 기여도 범위만 최소 TPUv3 1코어 구동 하루 치 기준 미만에서부터 1만 코어 이상 연속 가동 수준에 육박했습니다. 결론은 단순하고 강력했습니다. 전체 계산 투입 규모와 모델 피지컬 벌크 크기를 이상적인 보폭 비율에 맞춰 나란히 빌드업해 줄 때 학습 효율이 최고조에 달합니다. 준비된 수치에 여유가 있다면, 모델의 체격 자체를 대폭 불리는 것이 정석적인 정답 경로입니다. 또한, 충분한 이미지 수능 자료를 획득한 ViT 모델 패밀리 역시 명료한 지수 하강 피팅 법칙 곡선을 예외 없이 정밀하게 수렴 추종했으며, 벌크 한계점이 높은 거대 모델 진영이 낯선 신규 카테고리에 대한 신속 인지 및 희소 샘플 대응 과제에서도 월등히 강력한 두각을 자랑했습니다.

마지막 흐름으로 오픈 진영의 대표 주자인 LAION AI 소속 오픈 연구자 기여 그룹 역시 CLIP 모델 아키텍처 군을 대입해 실증 검증을 시도했으며, 마찬가지로 완벽한 파워 로우 수렴 법칙 관계가 성립함을 똑같이 재입증해 냈습니다. 이 거대한 관측은 데이터 투입 크기 범위는 물론이고 다채롭게 분류된 수많은 다운스트림 제로샷, 리트리블(retrieval), 소량 샘플 퓨샷 선형 탐침 분류 검증 성능까지 완전히 포괄적으로 아울렀습니다.
3. 거대 시각-언어 모델(Vision-Language Models)의 전성시대
비전 트랜스포머(ViT)의 성공으로 두 아키텍처 세계관의 정교한 결합, 즉 이미지와 텍스트 두 복합 지형의 관계를 포괄적으로 융합 설계하고자 하는 욕구가 폭발했습니다. 이들을 가리키는 시각-언어 모델(Vision-Language Models)들은 인간이 일상적으로 감상하고 대화하는 높은 수준의 캡셔닝, 자율 창작 제너레이팅, 그리고 이미지를 보며 심도 깊게 대화하는 비주얼 질의응답 등의 고난도 테마 미션들에서 극적인 위력을 여실히 증명 중입니다. 일반적으로 이러한 크로스 멀티모달 프레임워크는 대략 3가지 필수 세그먼트로 구성됩니다. 바로 이미지 분석용 인코더, 텍스트 번역 및 해석용 인코더, 그리고 이들 두 핵심 신호 소스로부터 추출된 정보들을 유기적으로 버무려 엮어주는 특화된 연동/융합 전략입니다. 지난 2년간 시각-언어 모델 패러다임을 화려하게 주도해 온 가장 영향력 있는 기념비적 이정표 모델들을 빠르게 점검해 봅시다.
첫 시작으로 2021년 OpenAI 진영은 CLIP (Contrastive Language–Image Pre-training) 모델을 성대하게 데뷔시켰습니다. CLIP의 지혜를 관장하는 배경 자료는 전 세계 웹 서핑을 통해 수집된 총 4억 쌍의 정교한 이미지-텍스트 쌍(image-text pairs)입니다. 언어 정보는 텍스트 트랜스포머가 유려하게 수화하고, 시각 정경은 비전 트랜스포머가 한 땀 한 땀 해독해 낸 다음, 이들을 대조 학습(Contrastive Learning) 원리로 조화롭게 커플링 연동하도록 신경써서 트레이닝을 전개했습니다. 대조 학습은 쉽게 말해 서로 짝이 맞는 정밀 이미지 쌍과 문구 설명의 논리 교차점은 코사인 유사도 벡터를 끌어당겨 완벽하게 포개어지도록 묶고, 연관성이 없는 대상 벡터들은 멀리멀리 밀쳐내는 방식으로 가중치 공간 정합성을 수축 완성해 내는 똑똑한 훈련 노하우입니다.

이 기하학적으로 일치 정교화된 임베딩 공간 지도를 한 번 강력히 확립해 두고 나면, 기계는 훈련 과정에서 한 번도 만나보지 않은 완전히 생소한 실물 스냅샷 이미지나 전례 없는 까다로운 텍스트 서술 유형이 급증 인입되어도 지도가 선사하는 높은 임베딩 위치 정밀도를 바탕으로 높은 연관성을 신속하게 도출해 냅니다. 이를 응용 구현하는 실질적인 전술적 테크닉 경로는 크게 2가지입니다. 첫째는 CLIP이 풍성하게 방출해 내는 정교한 피처 결과 영역 상단에 아주 단순 가벼운 로지스틱 회귀 레이어 한 층만을 슬며시 얹어 최종 미세 조절 분류 성향을 빠르게 유감없이 길들이는 "선형 탐색(linear probe)" 유형입니다. 다른 대안 패스는 타겟 레이블 키워드 항목들을 모조리 기하 임베딩 좌표로 인코딩 세팅한 뒤, 렌더링된 인풋 이미지의 공간 위치 벡터와 어텐션 밀도를 그저 좌표 그대로 자율 매칭하게 두어 추가적인 훈련 계산 단계를 완전 생략해 버리는 경이로운 "제로샷(zero-shot)" 경로 방식입니다. 정밀도 측면에서는 미세 튜닝 유도 과정이 융합된 선형 탐색 쪽이 비교적 약간 더 성과 우위를 보여줍니다.

다만 짚어둘 상세 점은 CLIP 아키텍처 자체가 이미지 투입을 곧바로 자막 대사 텍스트 필드로 전환하거나 그 역방향 생성을 즉각 전담 연산하는 인스턴트 기기는 아니라는 사실입니다. CLIP은 두 세계를 연결하는 공통 분모이자 가교 공간인 고성능 임베딩 맵을 영리하게 직조해 낼 뿐입니다. 그러나 이 공간은 멀티모달 간 서치나 고차원 검색 엔진을 빌딩할 때 절대 빼놓을 수 없는 핵심 도구 역할을 합니다.
그 뒤를 이어 탄생한 구글의 CoCa(Contrastive Captioner) 역시 완벽한 양방향 파운데이션 강자이며 대조 학습 매칭 기반의 스피릿(CLIP)과 텍스트 생성 기반 모델(SimVLM)의 정수들을 맛깔스럽게 통합했습니다. 특유의 인코더-디코더 설계를 개선 적용하여 대조 손실율(contrastive loss) 설계와 캡션 마스킹 생성 손실율(captioning loss)을 똑같은 타임라인 축선에서 동시 트레이닝하도록 유도했습니다. 이것이 주는 극적 보너스는 단일 모달리티 차원의 대국적 임베딩은 물론, 디코더 프레임이 유기적으로 식별해 내는 시각 피처 속 정밀한 미세 영역 레벨 정보까지 하나로 아우르며 독보적인 융합 성과를 달성했습니다.
2022년 말 딥마인드는 세상을 한 번 더 놀라게 한 시각-언어 모델 패키지인 Flamingo를 전격 런칭했습니다. 이 지능 모델 세트는 아주 극소량 부트스트랩 인입 샘플(few-shot) 유도 팁만 몇 가닥 던져주면, 완전히 낯설고 이색적인 지시 업무 시나리오도 귀신같이 응해 냅니다. 이들은 기본적으로 두 가지 뇌 영역으로 구동됩니다. 방대한 시각 정경과 현실 세계 비주얼을 심도 깊게 감상하고 명민하게 관조하는 비전 모델, 그리고 해당 정형 정보들을 단단한 논리와 상식 사슬 기반 위에 가지런히 엮어 정밀한 스토리 추론으로 완결해 줄 대형 언어 모델입니다. 이들은 기존에 이미 사전 습득되어 있던 독립 신경망 영역들의 전문 지식들을 허물없이 결합 소통시킵니다. Flamingo는 거대한 양의 고해상도 그래픽 데이터뿐 아니라 프레임 타임라인 비디오 피처까지 부드럽고 가볍게 시식할 수 있는데, 이는 앞트랙 변형 트랜스포머 파트에서 상술했던 'Perceiver' 지능형 어텐션 아키텍처를 도입하여 미려하게 수렴 정제해 주기 때문입니다.

기술적 혁신 덕분에 Flamingo 아키텍처는 풍부하게 훈련된 개별 비주얼 감각 필터와 하이레벨 어휘 개념을 자유롭게 커플링하고, 실시간으로 복잡하게 섞여 들어오는 오디오 트랙, 장문의 비주얼 시나리오 및 자유 서술 텍스트 단락들을 매끄럽게 처리할 수 있게 되었습니다. 이 패밀리 구조의 왕좌인 Flamingo-80B(800억 파라미터 탑재형) 모델의 경우, 인간의 시각, 언어, 영상 지능이 골고루 교차 융합되어 평가받는 복합 인지 멀티 태스킹 테스트 영역군에서 퓨샷 조건 기준 단숨에 지구상 정점 기록을 정조준 갱신하기도 했습니다.
또한 최근 들어서는 Microsoft, Google, OpenAI가 연달아 하루가 멀다 하고 차세대 특화 거물 시각-언어 플랫폼 패치들을 전 세계에 연쇄 드롭하며 바야흐로 차세대 멀티모달 AI 세대의 절대적인 지평 확장을 한층 속도감 있게 추동하고 있습니다.
마이크로소프트의 Kosmos-1은 단일 모달에 안주하지 않고 매우 섬세하게 주변 이종 자극 피처들을 동시 지각하며, 입력으로 전달되는 미묘한 주변 맥락 문맥들을 신속히 이해하고 지시에 수긍하는 매력적인 멀티모달 트랜스포머 인과 관계 언어 인프라입니다. 앞선 복합 지시 영역들을 고르게 음미하여 부드러운 스태킹 단락을 산출해 내며 이미지 해석, OCR, 질의응답 레이스에서 최우수 레벨 성적표를 자랑했습니다.
구글의 야심작인 PaLM-E는 하드웨어 로봇 구동 및 실제 피지컬 임바디먼트(embodied) 구현까지 능히 아우르도록 사전에 아주 타이트하게 포장 설계된 초특급 피지컬 가미 멀티모달입니다. 현실 감각 도구, 공간 위치 비주얼 감각 채널, 인터넷 급의 어마어마한 상식 지도를 스마트하게 연결해 줍니다. 최종 가동되는 최대 볼륨 버전 PaLM-E-562B 모델은 무려 5,620억 파라미터로 동작하며 복잡한 인지 학습 없이도 현장 비주얼을 감상해 농담을 꼬아 대답하거나, 로봇 기구를 가동하여 주변 공간을 식별하고, 실시간 경로 대화 계획을 즉석에서 플래닝해 움직이는 마법 같은 장면들을 수시로 선사합니다.
마지막 화룡점정으로 OpenAI 사의 GPT-4는 현실에 영감을 준 가장 세련되고 완성도 높은 대주주 거대 멀티모달로, 비주얼 그래픽 정보와 문자 질문들을 혼합 추종해 세밀하고 긴 텍스트 문단을 단숨에 쏟아냅니다. 모의 미국 변호사 시험에서 일반 인간 수험생 상위 10%의 초고득점 합격 컷을 달성하는 기염을 토했으며, 시각 지능 탑재 활성화 조건으로 평가한 국제 생물학 올림피아드 벤치마크 테스트에서는 오답을 거의 찾기 힘든 상위 99%라는 압도적인 기량을 확인시켰습니다.
4. 비디오 파운데이션 모델의 새로운 패러다임
비디오 이해가 그동안 극도로 까다로웠던 프레임 요인들
작금의 사회 속 비디오 콘텐츠 이해 시스템 구축의 필요성은 이미 그 임계 위상을 가늠하기 어려울 만큼 매우 거대해졌습니다. 매 순간 쏟아지는 소셜 플랫폼 미디어 트래픽 폭증 물결뿐만 아니라, 공공 영역 CCTV 지능형 모니터링 분석 강화에 이르기까지 자동화 비디오 추론 역량의 중요성은 날로 절실함을 더해 갑니다. 그러나 전 세계의 무수한 수요 강도에 비해, 텍스트 분석이나 정적 단일 이미지 연구 진영 수준의 풍성한 광명에 들어서기까지 비디오 이해 분야는 다소 외로운 기술적 정체기를 지나왔던 것이 냉정한 사실입니다.
이유는 무엇이었을까요? 비디오 처리가 텍스트나 고정된 사진 이미지 처리에 비해 혁신 도약 속도가 완만했던 주범은 다름 아닌 압도적으로 무거운 컴퓨팅 연산 유발 비용에 기인합니다. 비디오 클립 데이터가 내포한 원시 픽셀들의 바이트 스택 부피와 밀도 수준은 고정 차원 텍스트 단어 행렬이나 단일 프레임 사진 소스와는 아예 스케일 단위부터 다릅니다. 이 문제를 프레임 토큰 한 장 단위당 복잡도가 무려 제곱 배율(quadratic complexity)로 불어나는 민감한 트랜스포머 가동 공식에 무작정 대입한다면, 하드웨어가 겪게 되는 오버헤드 쓰나미는 도저히 손을 쓰기 어려운 난제로 직결되곤 했습니다.
기계가 느끼는 고충을 아주 상세하고 수학적으로 추적해 봅시다. 평범한 10분짜리 가벼운 클립 하나를 재생한다고 할 때, 통상 부드러운 가독성 감상을 위해 초당 30프레임(30 images/sec) 조건 기준 규격이 기본 제공됩니다. 즉 인풋 수치는 단 10분 재생 분량 속에 10 x 3600 x 30프레임 단위 계산 공식을 태워, 실제로는 무려 108만 장에 달하는 방대한 이미지 더미가 실시간 로딩됨을 의미합니다. 트랜스포머 고유 성향인 인풋 제곱 배수 연산 수렴치에 이를 비추어 계산해 보면, 모델이 연산해야 하는 연계 관계의 총매칭 검토량은 100만 제곱 단위인 자그마치 1조 번(1e12) 이상이라는 감당 안 되는 무서운 스택 연산으로 환산되어 버립니다.
주목할 도전점은 단순히 용량이 비대하다는 것 자체에만 있지 않습니다. 비디오 이해 미션만이 갖는 가장 독보적인 장벽은 바로 입체적 시간 축을 횡단하는 가변 템포럴(temporal) 모델링 구현에 있습니다. 비디오 파일은 정적인 2D 단면 프레임에 단순히 가만히 고정 주색되어 머물러 주지 않습니다. 0.1초의 짧은 스팬 단위마다 복합 오브젝트들의 상호작용 위치 상태가 정치가 요동치듯 역동적으로 흘러가며 연산 추적이 지속되어야만 비로소 일관된 스토리가 정립됩니다. 이는 시각 인코더가 평소 만져보지 못한 전혀 새로운 차원의 기차 레일 정합성 매핑 정렬 테크닉을 필수적으로 촉구합니다.
더 나아가 완벽한 사실주의 비디오 감상 영역을 매끄럽게 개척해 내기 위해서는 시선을 강탈하는 격정적 시각 피처 처리뿐 아니라, 해당 배경 타임라인 정중앙에 고스란히 정렬 싱크로나이즈드되어 맞물려 흘러나오는 복합 다차원 오디오 웨이브 큐(audio cues) 분석 능력까지 지체 없이 일괄 처리되어야만 합니다. 비디오 속 누군가 대화하는 보이스 톤, 현장의 다급한 소음, 자동차 경적 소리는 때론 영상 화면 내 가려져 보이지 않던 사각지대의 결정적인 현실 정황 콘텍스트를 시사해 주기도 합니다. 인간은 귀로 듣고 눈으로 감상하며 영화 하나를 온전히 공감하고 파악합니다. 그러므로 현명한 비디오 전용 신경망을 공고히 하려면 시각 장벽 돌파 노력만큼이나 오디오 청각 정보 인지 필터를 비디오 인플루언서 융합 시스템 안으로 매끄럽고 신속하게 블렌딩해 내는 깊이 있는 노하우가 절대적 핵심 기둥입니다.
그렇지만 이러한 높은 난관들에 가로막혀 마냥 멈추어 서있을 수만은 없기에, 전 세계 엘리트 AI 연구팀들은 비디오 이해 분야의 혁신적 수렴 속도를 위해 전력을 지속 투구해 오고 있습니다. 강력한 차세대 범용 시각-언어 파운데이션 강자들의 기술 도약 흐름을 필두로, 이제 비디오 데이터가 지니는 복잡한 맥락 영역을 조율하고 다스리려 하는 참신한 전용 시각 언어 연동 엔진 모델 제형들이 본격적으로 시장 위를 비행하기 시작했습니다. 글로벌 무대의 활기찬 오픈 커뮤니티 역시 이 뜨거운 세부 주제를 관통하는 핵심 연구의 정수를 정조준하며 땀 흘리고 있으며, 이들의 공고한 헌신 끝에 시대를 대변할 정합성 높은 실제 훌륭한 비디오 파운데이션 성과들이 멀지 않은 미래에 우리 삶에 곧 선사될 것이라 굳게 확신합니다.
기지개를 켜는 대세 거대 비디오 전용 지능 모델들

2019년 구글 개발진은 미답지 영역이던 무비디오 시공간 데이터 위에 드디어 자기지도학습을 스마트하게 구가한 시조격 기념비 모델 VideoBERT를 출범시켰습니다. 이미 검증되어 상용 수준으로 안착해 돌던 3종의 성숙 기술 소스 프레임워크들을 기발하게 정비소에 넣어 개조 결합했는데, 첫째는 음성 자동 변환 수신기(ASR), 둘째는 정밀 스페이셜 템포럴 픽셀 정보 처리를 지원하는 비주얼 기어 양자화 분석 필터, 마지막 기조는 이 정렬된 정보 흐름 축을 가지런히 정제해 넘겨받아 차례대로 독파할 클래식 고성능 BERT 모델 축선이었습니다. 이 독보적인 연동 체인을 바탕으로 시각과 언어를 동기화해 관계를 맺어주는 데 탁월한 효과를 보였습니다. 구글 연구진은 비디오의 기획 단계 원시 픽셀 스택을 '비주얼 머스킷 단어'처럼 기능하게 유도하기 위해 원시 프레임을 특화 레이블 토큰셋으로 스마트하게 잘라 표현 벡터 양자화 기술로 다스려 냈습니다. 그 결실로 비디오 이해의 흐름 정답을 매핑하여 역추적하는 캡셔닝 벤치마크 미션을 가볍게 석권하며 시조새로서의 우아한 면모를 과시했습니다.
논문을 통해 화려하게 등극한 All-In-One 역시 사전 학습용으로 명명 설계된 비디오 언어 파운데이션 핵심 주자 중 하나로, 전용 단일 백본 아키텍처 내부에서 가공되지 않은 raw 시각 신호와 텍스트 시그널을 한 타임에 포착해 내는 전무후무한 소화력을 자랑합니다. 추가 컴퓨팅 리소스 폭증 걱정 없이 가볍게 샘플링한 가변 프레임 축선상에서 프레임 정보가 템포럴하게 롤링하며 정합되도록 마이그레이션 기법을 구축하여, 시간 차원 정보 스택 처리를 깔끔히 접수해 냈습니다. 이는 멀티플 옵션 논리 문제 풀이나 시각적 상식 추론 영역 등 4대 난제 부문 전방위에서 우수한 기량을 시원하게 갱신하여 가치를 입증했습니다.

비디오 인지 및 인식(Video recognition)은 기계가 동영상 클립 속을 분 단위로 질주하면서 정교한 주요 행위 오브젝트, 물리적 사건들의 흐름을 정확히 명명 분류하고 트래킹 파악하는 높은 차원에 해당합니다. 이는 스마트 시티, 자율 주행 차량 관제 지평, 몰입형 미디어 제어 산업 등에 이르기까지 실제 필드에서 활용도가 가장 무한한 황금 시장이며 정교한 연산 기술이 활발히 생성되는 곳입니다.
Video MAE는 일반적인 바닐라 비전 트랜스포머가 가진 비디오 표현 능력을 극한까지 끌어올린 자가학습 비디오 사전 훈련 기법입니다. 무작위로 선택된 비디오 큐브를 마스킹하여 감추고, 비대칭 인코더-디코더 구조를 활용해 유실된 큐브를 영리하게 복구해 냅니다. 저자들은 극도로 높은 마스킹 비율과 튜브 마스킹(tube masking) 전략이라는 두 가지 핵심 설계를 도입했으며, 이를 통해 VideoMAE가 정보 중복과 같은 비디오 특유의 비효율성을 극복하고 한 차원 높은 정밀도로 비디오의 대표 특징들을 학습하도록 유도했습니다.

풍부한 인터넷 데이터 소스로부터 대조 조합을 훈련받은 CLIP 시스템의 혜택을 디딤돌 삼아, 자연어 피처 프롬프팅 정보를 가이드 레일로 삼는 전폭적인 비디오 전용 인지 기술을 새로이 구축할 수 있습니다. 이미 폭넓게 학습이 완료된 임베딩 개념 지도를 레퍼런스로 영리하게 차용하는 방식이기에, 복잡한 추가 파라미터 트레이닝 공수를 기적처럼 하이패싱하거나 제로셋에 패치하여 낯선 실전 도메인 작업에 아주 경이로운 연비로 초고속 이식 적용을 매끄럽게 수행해 낼 수 있기 때문입니다.
마이크로소프트의 X-Clip 프레임워크는 정적인 정밀 CLIP 핵심 감각 필터를 동적으로 생동감 넘치게 움직이는 비디오 추론 전용으로 스마트하게 개조 이식한 매력적 아키텍처입니다. 이들의 내부 코어 영역은 크로스 프레임 연소 정보 교환 인터페이스용 트랜스포머 기어 한 축과, 프레임들을 하나로 매끄럽게 컴포지트 통합해 줄 멀티프레임 연계용 트랜스포머 가이드 기어의 이중 탑재입니다. 이들은 메신저 토큰을 주고받아 각 프레임 간의 누락 정보들을 긴밀하게 맞교환하도록 독려합니다. 또한 비디오 속에 담긴 고유 기류 콘텍스트 정보를 명민하게 취합해, 텍스트가 가진 내포 의미가 훨씬 고해상도로 작용하도록 프롬프트 결합을 극대화해 줍니다. 극도로 제한적인 영양 공급 수준의 희소 샘플 피팅 테스트 상황 속에서도 이들이 선보인 최상급 수렴 정밀도는 대단히 기품이 넘칩니다.

사실 컴퓨터 언어나 싱글 단화 크기의 비주얼 파운데이션 리더 기기들에 비하면 현재 비디오 특화 진영의 모델들은 아직 소화하고 해결할 수 있는 액션 세트의 폭과 크로스 결집 영역이 다소 협소한 초창기에 있습니다. 하지만 최근 등판한 위대한 명작 InternVideo는 그간 별개 트랙을 정밀 돌진해 오던 양대 대표 자가학습 자양분, 즉 비디오 마스크 인지 튜브 재생 기반의 모델 기조와 정교한 멀티모달 대조 정보 수렴 인프라를 하나의 매력적인 기어로 용감히 블렌딩했습니다. 이 두 핵심 트랜스포머 간 유기적인 신호 커플링 상호작용 피트를 인입해 냄으로써 대조 학습의 정적인 세련됨과 생성 모델 고유의 유기적 표현력 둘 모두의 핵심 지분을 영리하게 장악해 냈습니다.
InternVideo는 행동 해석, 시각-언어 데이터 정렬 상태 체크, 그리고 무제한 환경 오픈 월드 비디오 응용 지표들을 면밀히 매기는 비디오 종합 성적표(video understanding benchmark) 기준 판에서 유수의 대형 모델들을 훌륭히 압도하며 왕좌를 쟁취했습니다. 이들이 보여준 입체적 기량은 앞으로 비디오 분야 인공지능이 무한 성장해야 할 본질적인 영양분의 청사진 그 자체라 칭할 수 있습니다.
글을 마치며
준비 운동이 온전히 끝나서 기쁜 상태이든 아니든, 이 시대가 명명하는 모든 실용 파운데이션 신경망 기조는 이제 마침내 강력한 멀티모달 시대로 막힘없이 진입하고 있습니다. 마침내 파운데이션 모델이 조만간 세상의 가치 있는 모든 AI 기반 소프트웨어 인프라의 핵심 중추이자 주춧돌로 완전 격상하여 동작하게 됨에 따라, 일선의 유능한 개발 파트너 엔지니어들 역시 매사에 맨땅 부지 위에서 삽질을 시작하기보다 정교하게 예비 훈련된 파운데이션 코어를 기본 축으로 가져와 설치한 다음 세부 타겟 세그먼트만을 빠르게 다듬어 처리하는 흐름을 정석으로 받아들일 것입니다. 다만 이러한 영리한 모델 기조를 가로막는 여전한 최대 적수는 인간 사회 실증 속 빈번히 난입하는 극소수의 이색 데이터 조각들과 이른바 '롱테일(long-tail)'형 예외 예측 불가 돌발 시나리오들일 것입니다. 이 롱테일 과제들은 서로 다른 성향의 이종 자극이 기류 차이를 자아내는 멀티모달 연동 구도 하에서 훨씬 더 혹독하고 지독하게 복잡한 사투를 예고하고 있습니다.
Twelve Labs 연구팀은 바로 그 난공불락의 험난 영역, 즉 실전 롱테일 정황 중심의 입체 멀티모달 비디오 이해를 전담할 가장 신뢰성 높은 최첨단 비디오 기반 파운데이션 모델 패키지를 땀 흘려 설계 중입니다. 우리의 궁극적 미션은 전 세계의 수많은 개발 엔지니어 분들이 마치 두 눈으로 세상을 보고, 양 귀로 다채로운 화음을 즐기며, 뛰어난 상식 사절단처럼 대화하듯 세상을 유기적으로 응시하고 감각 수용하는 지능형 모바일 애플리케이션들을 한껏 세련되게 꽃피울 수 있도록 최고 성능의 고효율 지능형 비디오 이해 인프라를 선물해 드리는 일입니다. 전 세계의 엘리트 동료들과 나누고픈 복합 대형 신경망 멀티모달 구상들의 신선한 팁과 지론들이 가득하지만, 지면 관계상 오늘의 대서사시 포스트는 이쯤으로 정리하겠습니다. 이 멋진 지식 여행의 실제 주인공이자 베타 테스트의 선두 프론티어로서 유쾌한 한 발자국을 저희와 함께 걸어보고 싶으시다면 망설이지 말고 지금 바로 베타 유저 서비스에 조인 신청을 남겨주십시오! 고도로 역동적인 멀티모달 AI의 비약적 흥행 로드를 동반 개척할 정예 Discord 디스코드 커뮤니티 대화방의 활성 파트너 참여 역시 양팔 벌려 언제나 뜨겁게 환영합니다!
이 방대한 지식 기사를 작성하는 과정에서 탁월한 고품질 시각 자료 원천 출처 공유와 밀도 높은 교정 기여 활약을 펼치며 혼신을 다해 지원해 주신 에이든 리(Aiden Lee) 님께 글을 빌려 진심어린 감사의 뜻을 바칩니다!
파운데이션 모델(예: BERT, GPT-3, CLIP, Codex)의 성장은 시각과 언어 양방향의 모달리티를 결합한 모델에 대한 관심을 크게 높였습니다. 이러한 하이브리드 시각-언어 모델은 이미지 캡셔닝, 이미지 생성, 시각적 질의응답을 포함한 고난도 작업에서 인상적인 성능을 입증해 왔습니다. 최근에는 파운데이션 모델의 작동 원리를 고스란히 적용해 비디오 데이터로부터 학습을 수행하는 새로운 패러다임인 비디오 파운데이션 모델이 등장하고 있습니다.
이 블로그 포스트에서는 파운데이션 모델, 대규모 언어 및 시각-언어 모델, 그리고 비디오 파운데이션 모델의 전반적인 개념을 다룹니다. 파운데이션 모델의 아키텍처, 학습 및 미세 조정(fine-tuning) 패러다임, 그리고 스케일링 법칙(scaling laws)을 살펴봅니다. 또한 시각-언어 모델이 컴퓨터 비전과 자연어 처리의 강점을 어떻게 결합하는지, 그리고 이들이 복잡한 문제를 해결하기 위해 어떻게 활용되고 있는지 논의합니다. 마지막으로 비디오 파운데이션 모델을 집중 조명하며, 이들이 비디오 데이터의 이해와 분석 분야를 어떻게 혁신하고 있는지 살펴보겠습니다.
1. 파운데이션 모델 가볍게 입문하기
파운데이션 모델은 방대한 규모의 데이터로부터 자기지도학습(self-supervision)을 통해 대규모로 학습하는 머신러닝 모델의 한 종류입니다. 핵심 개념은 다양한 수많은 작업에 범용적으로 활용할 수 있는 모델을 만드는 것입니다. 엄청난 양의 데이터로 사전 학습함으로써, 모델은 데이터에 내재된 일반적인 패턴을 학습합니다. 향후 특정 세부 작업에 모델을 적용할 때, 모델은 이 배경지식을 활용해 빠르게 적응할 수 있습니다.
파운데이션 모델은 2012년 이후 주류로 부상한 심층 신경망(deep neural networks)과 오랜 기간 발전해 온 자기지도학습을 기반으로 삼고 있습니다. 최근 두 분야의 기술 혁신 덕분에 한층 더 크고 복잡한 모델 구축이 가능해졌습니다. 이러한 모델들은 명시적인 라벨(label)이 지정되지 않은 대규모의 데이터셋을 바탕으로 대량 학습을 진행합니다.
이 과정을 거쳐 모델은 광범위한 패턴과 논리적 관계를 습득하며, 이는 다양한 작업에 유연하게 활용될 수 있습니다. 이는 자연어 처리, 컴퓨터 비전, 멀티모달 AI 분야의 비약적인 도약을 이끌어 냈습니다. 파운데이션 모델을 활용하면 개별 작업마다 별도의 모델을 처음부터 개발할 필요 없이, 단 하나의 강력한 모델을 다목적으로 활용할 수 있습니다. 결과적으로 개발 시간과 리소스를 크게 아끼고 관련 기술 분야의 발전을 앞당길 수 있습니다.
전이 학습 (Transfer Learning)
전통적인 머신러닝(ML) 모델은 스크래치 단계에서부터 학습을 진행하는 경우가 많아 우수한 성능을 내기 위해 특정 도메인에 특화된 방대한 데이터셋이 필수적이었습니다. 반면, 데이터의 양이 충분하지 않을 때는 전이 학습을 유용하게 활용할 수 있습니다. 전이 학습의 핵심은 한 이미지나 작업에서 이미 학습한 "지식"을 가져와 다른 작업에 적용하는 것으로, 스크래치 단계부터 처음 학습할 때에 비해 필요한 데이터 양을 획기적으로 줄여줍니다. 심층 신경망에서 사전 학습(pre-training)은 전이 학습을 위한 지배적인 접근법입니다. 모델을 원래의 일차적인 작업(예: 도로 위의 차량 감지)으로 먼저 학습시킨 뒤, 우리가 실제로 해결하고자 하는 하위 단계의 타겟 작업(예: 검은색 테슬라 모델 3 감지)에 맞춰 가중치를 미세 조정(fine-tuning)하는 방식입니다.
컴퓨터 비전 분야에서는 2014년부터 이 방식이 활발히 사용되어 왔습니다. 통상적으로 ImageNet 데이터셋으로 모델을 먼저 학습시킨 후, 신경망의 레이어 대부분은 그대로 유지하고 출력층에 가까운 상위 3개 정도의 레이어만 새로운 가중치로 변경해 재정렬합니다. 혹은 모델 전체를 처음부터 끝까지 엔드투엔드로 미세 조정하기도 합니다. 컴퓨터 비전 작업에서 가장 널리 쓰이는 대표적인 사전 학습 모델로는 AlexNet, ResNet, MobileNet, Inception, EfficientNet, 그리고 YOLO 등이 있습니다.
자연어 처리(NLP) 분야에서 사전 학습은 초기에는 주로 첫 단계인 단어 임베딩(word embeddings)에 국한되어 사용되었습니다. 언어 모델의 입력값은 단어입니다. 이 단어 데이터를 벡터 형식으로 인코딩하는 대표적인 방식 중 하나가 바로 원-핫 인코딩(one-hot encoding)입니다. 대규모 단어 행렬이 주어지면 임베딩 매트릭스를 생성하고, 각 단어를 실수 가치의 고차원 벡터 공간에 매핑할 수 있습니다. 이 가공 과정을 거친 매트릭스는 대략 수천 차원 규모로 축소되며, 이때의 각 차원은 단어의 어떠한 의미론적 개념들과 매칭될 수 있습니다.
2013년 출시된 Word2Vec이 이러한 방식으로 모델 학습을 진행했습니다. 이 모델은 어떤 단어들이 문장 내에서 얼마나 자주 함께 등장하는지 추적했습니다. 이를 통해 이들 임베딩 벡터 간의 코사인 유사도(cosine similarity)를 극대화하는 방향으로 학습을 유도했습니다. 완성된 벡터 임베딩 공간 위에서는 흥미로운 벡터 산술 연산을 시연해 볼 수도 있었습니다. 예컨대 "왕(king)", "남자(man)", "여자(woman)" 단어 지표를 처리해 수학 연산을 수행하면, 해당 임베딩 공간 내에서 "여왕(queen)"에 가장 인접한 결과 벡터를 얻게 됩니다.
문장 내 문맥에 따라 단어의 역할과 의미가 달라지기 때문에, 정확한 단어 임베딩을 위해서는 더 넓은 문맥 영역을 살펴보는 것이 매우 유익합니다. 이 방식으로 처리하면 하위 태스크 전반의 정확도가 크게 향상됩니다. 2018년에는 ELMo, ULMFiT, GPT를 포함한 여러 모델들이 언어 모델링이 사전 학습에 어떻게 고도로 기여할 수 있는지를 실증적으로 증명해 냈습니다. 이 세 가지 방식 모두 사전 학습된 언어 모델을 활용해 텍스트 분류, 질의응답, 자연어 추론, 상호참조 해결, 시퀀스 라벨링을 비롯한 다양한 NLP 분석 영역에서 뛰어난 성능(SOTA)을 달성해 냈습니다.
트랜스포머(Transformers) = 파운데이션 모델의 핵심 아키텍처
오리지널 트랜스포머 아키텍처는 2017년 논문인 "Attention Is All You Need"에서 최초로 소개되었습니다. 트랜스포머가 등장하기 전까지만 해도 NLP 분야의 최첨단 기술(SOTA)은 LSTM이나 널리 쓰이던 Seq2Seq 아키텍처와 같이 텍스트를 구성하는 단어들을 순서대로 하나씩 처리하는 순환 신경망(RNNs) 기반이었습니다.
트랜스포머가 가져온 핵심 혁신은 바로 언어 처리의 병렬화입니다. 이를 통해 주어진 텍스트 바디의 모든 토큰들을 순차적으로 처리할 필요 없이 동시에 고속으로 분석할 수 있게 되었습니다. 트랜스포머는 이러한 병렬화를 수행하기 위해 AI 알고리즘 메커니즘인 어텐션(attention)에 의존합니다. 어텐션을 통해 모델은 문장 안에서 멀리 떨어져 있는 단어들 간의 상관관계를 파악할 수 있으며, 전체 지문에서 흐름상 집중해야 하는 핵심 단어와 구문을 스마트하게 판단할 수 있습니다.
또한 병렬 처리가 가능해지면서 트랜스포머는 RNN 대비 계산 효율이 압도적으로 우수해졌으며, 이를 바탕으로 더 거대한 데이터셋을 학습하고 더 많은 수의 파라미터(매개변수)를 탑재할 수 있게 되었습니다. 오늘날의 거대 트랜스포머 모델의 성장은 이러한 구조에 기반한 것입니다.
비전 트랜스포머 (Vision Transformers)
그간 컴퓨터 비전 분야에서는 합성곱 신경망(CNN)이 지배적인 아키텍처 자리를 지켜왔습니다. 그러나 트랜스포머가 NLP 진영에서 엄청난 성공을 거두자, 연구자들은 이 강력한 구조를 이미지 데이터 분석에도 이식하기 시작했습니다. 널리 알려진 논문 "An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale"은 트랜스포머의 인코더 블록을 이미지 분류 문제에 성공적으로 적용한 비전 트랜스포머(ViT) 아키텍처를 소개했습니다.
이 연구의 저자는 하나의 전체 이미지를 여러 조각(patch)으로 분할한 뒤, 이 패치들을 선형 임베딩 시퀀스로 변환해 트랜스포머의 입력값으로 제공했습니다. NLP 환경에서 토큰을 다루는 방식과 유사하게 이 이미지 패치들을 개별 입력값으로 취급한 것입니다. 전체 아키텍처는 이미지를 조각내는 스템(stem) 단계, 멀티레이어 트랜스포머 인코더 기반의 바디(body) 단계, 전역 표현을 바탕으로 타겟 출력 라벨로 변환해 주는 MLP(Multi-Layer Perceptron) 헤드로 구성됩니다. ViT는 대규모 학습 시 리소스를 비교적 덜 쓰면서도 여러 이미지 분류 벤치마크셋에서 기존의 최고 성능 기록을 갈아치우거나 넘어서는 쾌거를 달성했습니다.
비전 트랜스포머가 뛰어난 잠재력을 보였음에도 몇 가지 구조적 극복 과제가 남았습니다. 가장 큰 한계는 모델이 고해상도 이미지를 다룰 때 발생합니다. 이미지 크기가 커질수록 필요한 컴퓨팅 리소스가 기하급수적으로 폭증하기 때문입니다. 더불어, ViT의 고정 크기 토큰 방식은 다양한 가변 크기의 시각 요소를 잡아내고 분석하는 작업에는 다소 비효율적이었습니다.
트랜스포머 변형 아키텍처들
오리지널 트랜스포머 아키텍처 발표 이후 많은 후속 연구가 이어졌으며, 연구진들은 앞서 언급한 한계점과 비효율성을 극복하기 위해 아키텍처 수정 보완에 나섰습니다.
2021년 마이크로소프트 연구진은 모든 모달리티에 유연하게 적용할 수 있는 범용 트랜스포머 아키텍처인 Swin Transformer를 발표했습니다. Swin Transformer는 계층형 피처 맵(hierarchical feature maps)과 이동 윈도우 어텐션(shifted window attention)이라는 두 가지 획기적인 개념을 도입했습니다.
1. 이 모델은 조밀한 예측(dense prediction)을 위한 고난도 기법을 구현하기 위해 계층형 피처 맵을 활용합니다. 이미지를 중첩되지 않는 윈도우 단위로 분할한 뒤 각 로컬 윈도우 영역 안에서만 셀프 어텐션을 수행함으로써 선형적인 계산 복잡도를 확보했습니다. 덕분에 Swin Transformer는 다양한 컴퓨터 비전 작업의 우수한 뼈대(backbone)로 자리 잡았습니다.
2. 이동 윈도우(shifted windows) 방식을 결합하여, 이전 레이어의 정보가 윈도우 경계를 가로질러 유기적으로 엮이도록 모델링 역량을 끌어올렸습니다. 이 설계는 실제 하드웨어 Latency가 매우 낮다는 실용적 장점도 갖췄습니다. 하나의 윈도우 안에 속한 모든 쿼리 패치들이 동일한 키(key) 세트를 공유하므로 하드웨어 메모리 접근이 훨씬 수월합니다.
Perceiver는 비슷한 시기에 DeepMind에서 발표한 또 다른 혁신적인 트랜스포머 변형 모델로, 생물학적 감각 시스템에서 영감을 얻어 개발되었습니다. 이미지, 비디오, 오디오는 물론 3D 포인트 클라우드에 이르기까지 정형/비정형의 수많은 입력 데이터 유형을 어텐션 기반 메커니즘을 통해 일관되게 처리합니다. 특정 데이터 도메인에 대한 가설이나 제약에 크게 구애받지 않고 유기적인 멀티모달 처리를 구현해 냅니다.
Perceiver 아키텍처는 일련의 소규모 잠재 유닛(latent units)을 인입해 어텐션 병목 구조를 형성합니다. 이를 통해 네트워크 전체가 올투올(all-to-all) 방식으로 연결되어 계산이 폭증하던 문제를 원천 차단하고 구조를 한 단계 더 깊고 정교하게 쌓을 수 있도록 도왔습니다. 이전 단계의 정보 처리를 기반으로 가장 연계성이 높은 주요 입력 부문에 집중하는 방식입니다. 다만 밀접한 멀티모달 환경에서는 들어오는 정보의 근원이 어느 모달리티인지 구분해 주는 세부 처리가 필수적입니다. 이 모델의 저자들은 구조적 단순함을 유지하기 위해 생물학적 신경망의 '레이블 라인(labeled line)' 전략처럼 각 입력 요소에 고유한 물리적 위치와 결합된 모달리티 피처를 유기적으로 심어 보환해 냈습니다.
2. 거대 언어 모델 (Large Language Models)
오리지널 트랜스포머 연구 성과를 발판 삼아, 최신의 AI 연구진들은 이 기술적 돌파구를 더욱 발전시켰습니다. 그 첫 신호탄은 자연어 처리(NLP) 영역이었습니다.
GPT와 GPT-2가 각각 2018년과 2019년에 세간에 공개되었습니다. 이 이름은 '생성형 사전 학습 트랜스포머(Generative Pre-trained Transformers)'의 약자입니다. 이들은 구조적으로 디코더 전용(decoder-only) 모델이며 마스크드 셀프 어텐션(masked self-attention) 기법을 사용합니다. 마스크드 셀프 어텐션이란 임의의 출력 시퀀스 시점에서 바라볼 때 문맥상 그 이전에 먼저 출현했던 앞쪽 입력 시퀀스 벡터들만을 참고해 관계를 맺도록 제약을 두는 기법입니다. GPT 임베딩 역시 분류(classification) 등의 목적에 다양하게 활용 가능하지만, 이러한 독특한 디코딩 접근 아이디어는 오늘날 ChatGPT와 같은 가장 대중화된 대형 LLM 패밀리의 강력한 모태가 되었습니다.
당시 이 모델 패밀리는 약 8백만 개의 웹 페이지 데이터를 읽고 익혔으며, 최대 모델 크기는 무려 15억 개의 파라미터 수준에 달했습니다. GPT-2가 해결해야 했던 기본 학습 미션은 웹문서의 앞부분 흐름을 읽고 '그다음에 이어질 알맞은 단어를 예측하는 것'이었습니다. 연구팀은 모델 파라미터의 규모가 늘어남에 따라 생성의 정교함과 정확도가 눈에 띄게 수직 상승하는 패턴을 확인했습니다.
BERT도 양방향 인코더 트랜스포머(Bidirectional Encoder Representations for Transformers)라는 이름을 내걸고 비슷한 시기 세상에 모습을 드러냈습니다. 1억 1천만 개의 파라미터 규모로 구축된 이 모델은 순수한 예측 과제를 수행하기 위한 인코더 전용 트랜스포머 구조를 채택하였으며, 기발한 마스크드 언어 모델링(masked-language modeling) 개념을 최초로 선포했습니다. 학습 중 BERT는 입력 문장 임의의 위치에 있는 무작위 단어들을 마스킹 테이프로 가리듯 숨긴 채, 문장 앞뒤 양방향 문맥을 정교하게 훑어 해당 위치의 빈칸에 알맞은 원본 단어가 무엇인지 정확하게 역추적해 내는 미션을 훈련받았습니다.
T5 (Text-to-Text Transformer)는 2020년 구글에 의해 발표되었습니다. 입력값과 출력값이 모두 순수한 가공 텍스트 문자열 형식이기 때문에, 사용자가 해결해 주기를 바라는 특정 가벼운 태스크 미션을 직접 텍스트 명령 형태로 지정할 수 있습니다. T5는 오리지널 정석형 구조인 인코더-디코더 설계를 정교하게 사용했습니다. 위키백과 데이터베이스보다 100배 이상 방대한 스케일의 C4 데이터셋(Colossal Clean Crawled Corpus)으로 집중 무장하여 설계되었으며, 파라미터는 약 100억 개에 육박합니다.
파운데이션 모델 진영의 무어의 법칙: 스케일링 법칙
일반적으로 스케일링 법칙은 가용 컴퓨팅 예산(예: 엄청난 크기의 모델 구조나 더 풍부한 데이터 정제량)을 크게 증강하면 모델의 종합 품질도 한계점이 없이 비례하여 향상된다고 전망합니다. Open AI 연구진은 2020년 트랜스포머 언어 모델의 스케일링 법칙에 관한 깊이 있는 실증 조사를 감행하여, 이러한 규모 확장 규칙이 실재하며 향후 모델 성장을 매우 신뢰성 있게 진단해 준다는 사실을 널리 보여주었습니다. 이들의 결론은 모델 성능 ∝ 데이터 스케일 x 매개변수 규모 x 투자 계산량이라는 명확한 핵심 공식으로 귀결됩니다.
구체적으로 일련의 실험 결과들은 트레이닝 손실값(test loss)이 트레이닝에 동원된 모델의 크기, 학습 데이터셋 부피, 투입된 종합 시스템 연산 자원량에 대응해 일정한 지수 법칙(power law) 패턴을 보임을 증명했으며, 이는 측정 범위가 무려 7자릿수(7 orders of magnitude)를 넘나들 정도로 높은 일관성을 가졌음을 밝혔습니다. 이는 대규모 언어 모델을 빌딩하고 훈련 설정을 최적화할 때, 연관 매개변수들 사이의 역학 관계를 단순한 수학 공식으로 수월하게 설계할 수 있음을 의미합니다. 나아가 핵심 아키텍처 차원의 미세 디테일(예: 네트워크의 가로 폭 대 세로 다층 깊이 비율 등)은 정상적인 바운더리 범주 안에 머물러만 준다면 성능 격차에 거의 유의미한 흔적을 남기지 못했습니다.
도출해 낸 상관 공식과 연구 관측에 근거해 볼 때, 더 거대하게 가공된 초거대 모델일수록 주어진 소스 표본으로부터 유효 지식을 추출해 내는 샘플 효율성이 눈에 띄게 탁월합니다. 다른 각도로 해석하자면, 투자 예산 대비 비용 효율을 극대화하여 스마트하게 훈련하려면 초대형 모델을 설계해 상대적으로 간소하고 정제된 노이즈 리스 데이터셋에서 신속히 가중치를 훈련한 뒤, 과적합이나 정체 국면에 접어들기 한참 전에 학습 회차를 지혜롭게 클로징하는 편이 최적이라는 결론을 선사합니다.
스케일링 법칙 백서가 학계에 공개된 이후, 글로벌 빅테크 기업들 간 언어 모델 기둥을 초대형으로 경쟁 확장하려는 레이스에 본격적으로 불이 붙었습니다. 2020년 공개된 GPT-3는 당대 최고의 성능을 구현했습니다. 이는 이전 GPT-2 세대보다 100배가량 업그레이드되어 자그마치 1,750억 개의 파라미터를 안고 탄생했습니다. 차원이 다른 크기 덕분에 GPT-3 모델은 새로운 도메인의 문제를 맞닥뜨렸을 때 소수 지문 예시를 주거나 아예 예시를 주지 않고 바로 문제를 술술 풀어나가는 퓨샷(Few-shot) 및 제로샷(Zero-shot) 테스트 조건 하에서 미증유의 대처 능력을 과시했습니다. 즉, 제시하는 레퍼런스 사례가 정교할수록 모델 성능은 극대화되며, 무엇보다 모델 구조 자체가 방해 장벽 없이 비대해질수록 본질적인 성능 지각 변동이 더 크게 일어납니다.
구글 리서치팀 역시 이에 발맞춰 "Emergent Abilities of Large Language Models"라는 중대한 분석 논문을 선보였습니다. 소형 모델 진영에서는 아예 부재했거나 침묵 속에 머물러 있던 다양한 복잡 고차원 태스크 해결 능력이 특정 임계 물리 볼륨을 뚫고 넘어선 거대 인프라 위에서 어떻게 기적처럼 돌연 출현(Emergent Abilities)하는지 면밀히 추적한 분석입니다. 연구팀은 하드웨어 연산량 투자 확대 및 지평 성장에 맞춰 다양한 난도의 세부 미션 해결 지표를 관측했습니다. 특정 영역들의 성능은 투자에 따라 아주 점진적이고 선형적으로 추종 성장하기도 하지만, 또 다른 다수의 핵심 복리 미션들에서는 평소 바닥권에 머물던 난해한 문제 돌파력이 모델 크기 700억 파라미터 등의 특정 임계 스케일을 돌파하는 찰나에 급작스럽게 폭발하는 특이점 패턴을 보여주는 놀라운 발견을 소개했습니다.
2022년 딥마인드(DeepMind) 연구진은 가용 예산 제한 범위 내에서 컴퓨팅 효율을 극한으로 끌어올리는 새 장을 열기 위해 "친칠라(Chinchilla)" 스케일링 법칙 청사진을 제시했습니다. 이는 오리지널 OpenAI가 앞서 주창했던 산 식보다 실무 환경에 한 차원 더 정확하게 부합하는 개선된 스케일 공식으로 큰 인정을 받게 되었습니다.
이들은 7천만 개에서 최대 160억 개의 파라미터 범주에 배치한 400여 개 이상의 풍부한 실험 모델들을 50억~5,000억 개의 방대한 데이터 토큰들 위에 다각도로 정교하게 학습시켰습니다. 분석 결과를 기반으로 모델 파라미터 크기 단위 수에 최고 효율로 비례하는 학습 데이터 토큰 요구 균형비를 산출해 새로운 가이드 공식을 완성해 냈습니다. 이들은 최근 런칭된 다수의 주류 신경망 모델들이 실질적 역량 대비 학습 기회 부전, 즉 파라미터 크기에 걸맞은 충분한 양의 풍성한 말뭉치 데이터를 제대로 소화하지 못한 '언더트레이닝(undertrained)' 상태였다고 날카롭게 진단했습니다.
이 가설을 멋지게 실증하기 위해 딥마인드는 2,800억 파라미터를 보유한 기존 대형 모델 Gopher(약 3,000억 데이터 토큰 학습)를 대조군으로 삼아 새 도전 모델 친칠라를 디자인했습니다. 친칠라는 기존 파라미터 크기를 오히려 4분의 1 수준인 700억 파라미터 수준으로 대폭 감량 조정하는 대신, 입맛에 맞게 소화할 소스 데이터 공급량은 무려 4배 이상 증축 공급한 1.4조 토큰을 완전 정독시켰습니다. 결과는 놀라웠습니다. 모델 무게는 비교가 무색할 만큼 가벼워졌음에도 친칠라는 모든 성능 벤치마크 테스트에서 골리앗 같았던 Gopher의 기록들을 시원하게 추월했습니다. 이는 모델 자체의 절대 부피 확장만큼이나 이를 풍성하게 채울 건강한 학습 훈련용 토큰 비중 균형 유지 또한 아주 결정적인 열쇠임을 시장에 일깨워준 귀중한 결과였습니다.
이처럼 전폭적인 이론 무장과 지배적인 스케일링 법칙의 탄생에 힘입어, 학계와 업계에는 더욱 매력적이고 유능한 초거대 언어 모델(LLM)들이 쉴 새 없이 쏟아져 나오게 되었습니다. 이 혁신 리더 모델들은 활성화 경로를 스마트하게 솎아 비용을 아끼는 희소 신경망 모듈(sparse mixture-of-experts) 구조를 가미하거나, 다양한 데이터 소스로부터 파생된 미개발 청정 데이터를 수집 및 주입함으로써 극한의 학습 성과를 견인하고 있습니다. 대표적인 이정표 모델들로는 Megatron-LM(8.3B), GLaM(64B), LaMDA(137B), Megatron-Turing NLG(530B)를 넘어 구글의 자존심이라 불린 PaLM(540B) 등에 이르기까지 방대한 군단이 거론됩니다.
마찬가지로 구글 리서치팀이 주도한 비전 트랜스포머의 스케일 확장 연구(Scaling Vision Transformers)에 의하면, 스케일링 법칙의 강력한 효과는 단순한 자연어 텍스트 처리뿐만 아니라 컴퓨터 비전(CV) 영역에도 한정 없이 고스란히 유효하게 작용함을 가시적으로 입증했습니다. 연구진은 5백만 개부터 20억 파라미터 사이를 종횡무진하는 다채로운 스펙트럼의 ViT 모델들을 구성한 뒤, 1백만 개부터 30억 개 규모의 방대한 이미지 소스 풀 위에서 다채롭게 학습 세션을 벌였습니다. 이때 투입된 총 컴퓨팅 리소스 기여도 범위만 최소 TPUv3 1코어 구동 하루 치 기준 미만에서부터 1만 코어 이상 연속 가동 수준에 육박했습니다. 결론은 단순하고 강력했습니다. 전체 계산 투입 규모와 모델 피지컬 벌크 크기를 이상적인 보폭 비율에 맞춰 나란히 빌드업해 줄 때 학습 효율이 최고조에 달합니다. 준비된 수치에 여유가 있다면, 모델의 체격 자체를 대폭 불리는 것이 정석적인 정답 경로입니다. 또한, 충분한 이미지 수능 자료를 획득한 ViT 모델 패밀리 역시 명료한 지수 하강 피팅 법칙 곡선을 예외 없이 정밀하게 수렴 추종했으며, 벌크 한계점이 높은 거대 모델 진영이 낯선 신규 카테고리에 대한 신속 인지 및 희소 샘플 대응 과제에서도 월등히 강력한 두각을 자랑했습니다.
마지막 흐름으로 오픈 진영의 대표 주자인 LAION AI 소속 오픈 연구자 기여 그룹 역시 CLIP 모델 아키텍처 군을 대입해 실증 검증을 시도했으며, 마찬가지로 완벽한 파워 로우 수렴 법칙 관계가 성립함을 똑같이 재입증해 냈습니다. 이 거대한 관측은 데이터 투입 크기 범위는 물론이고 다채롭게 분류된 수많은 다운스트림 제로샷, 리트리블(retrieval), 소량 샘플 퓨샷 선형 탐침 분류 검증 성능까지 완전히 포괄적으로 아울렀습니다.
3. 거대 시각-언어 모델(Vision-Language Models)의 전성시대
비전 트랜스포머(ViT)의 성공으로 두 아키텍처 세계관의 정교한 결합, 즉 이미지와 텍스트 두 복합 지형의 관계를 포괄적으로 융합 설계하고자 하는 욕구가 폭발했습니다. 이들을 가리키는 시각-언어 모델(Vision-Language Models)들은 인간이 일상적으로 감상하고 대화하는 높은 수준의 캡셔닝, 자율 창작 제너레이팅, 그리고 이미지를 보며 심도 깊게 대화하는 비주얼 질의응답 등의 고난도 테마 미션들에서 극적인 위력을 여실히 증명 중입니다. 일반적으로 이러한 크로스 멀티모달 프레임워크는 대략 3가지 필수 세그먼트로 구성됩니다. 바로 이미지 분석용 인코더, 텍스트 번역 및 해석용 인코더, 그리고 이들 두 핵심 신호 소스로부터 추출된 정보들을 유기적으로 버무려 엮어주는 특화된 연동/융합 전략입니다. 지난 2년간 시각-언어 모델 패러다임을 화려하게 주도해 온 가장 영향력 있는 기념비적 이정표 모델들을 빠르게 점검해 봅시다.
첫 시작으로 2021년 OpenAI 진영은 CLIP (Contrastive Language–Image Pre-training) 모델을 성대하게 데뷔시켰습니다. CLIP의 지혜를 관장하는 배경 자료는 전 세계 웹 서핑을 통해 수집된 총 4억 쌍의 정교한 이미지-텍스트 쌍(image-text pairs)입니다. 언어 정보는 텍스트 트랜스포머가 유려하게 수화하고, 시각 정경은 비전 트랜스포머가 한 땀 한 땀 해독해 낸 다음, 이들을 대조 학습(Contrastive Learning) 원리로 조화롭게 커플링 연동하도록 신경써서 트레이닝을 전개했습니다. 대조 학습은 쉽게 말해 서로 짝이 맞는 정밀 이미지 쌍과 문구 설명의 논리 교차점은 코사인 유사도 벡터를 끌어당겨 완벽하게 포개어지도록 묶고, 연관성이 없는 대상 벡터들은 멀리멀리 밀쳐내는 방식으로 가중치 공간 정합성을 수축 완성해 내는 똑똑한 훈련 노하우입니다.
이 기하학적으로 일치 정교화된 임베딩 공간 지도를 한 번 강력히 확립해 두고 나면, 기계는 훈련 과정에서 한 번도 만나보지 않은 완전히 생소한 실물 스냅샷 이미지나 전례 없는 까다로운 텍스트 서술 유형이 급증 인입되어도 지도가 선사하는 높은 임베딩 위치 정밀도를 바탕으로 높은 연관성을 신속하게 도출해 냅니다. 이를 응용 구현하는 실질적인 전술적 테크닉 경로는 크게 2가지입니다. 첫째는 CLIP이 풍성하게 방출해 내는 정교한 피처 결과 영역 상단에 아주 단순 가벼운 로지스틱 회귀 레이어 한 층만을 슬며시 얹어 최종 미세 조절 분류 성향을 빠르게 유감없이 길들이는 "선형 탐색(linear probe)" 유형입니다. 다른 대안 패스는 타겟 레이블 키워드 항목들을 모조리 기하 임베딩 좌표로 인코딩 세팅한 뒤, 렌더링된 인풋 이미지의 공간 위치 벡터와 어텐션 밀도를 그저 좌표 그대로 자율 매칭하게 두어 추가적인 훈련 계산 단계를 완전 생략해 버리는 경이로운 "제로샷(zero-shot)" 경로 방식입니다. 정밀도 측면에서는 미세 튜닝 유도 과정이 융합된 선형 탐색 쪽이 비교적 약간 더 성과 우위를 보여줍니다.
다만 짚어둘 상세 점은 CLIP 아키텍처 자체가 이미지 투입을 곧바로 자막 대사 텍스트 필드로 전환하거나 그 역방향 생성을 즉각 전담 연산하는 인스턴트 기기는 아니라는 사실입니다. CLIP은 두 세계를 연결하는 공통 분모이자 가교 공간인 고성능 임베딩 맵을 영리하게 직조해 낼 뿐입니다. 그러나 이 공간은 멀티모달 간 서치나 고차원 검색 엔진을 빌딩할 때 절대 빼놓을 수 없는 핵심 도구 역할을 합니다.
그 뒤를 이어 탄생한 구글의 CoCa(Contrastive Captioner) 역시 완벽한 양방향 파운데이션 강자이며 대조 학습 매칭 기반의 스피릿(CLIP)과 텍스트 생성 기반 모델(SimVLM)의 정수들을 맛깔스럽게 통합했습니다. 특유의 인코더-디코더 설계를 개선 적용하여 대조 손실율(contrastive loss) 설계와 캡션 마스킹 생성 손실율(captioning loss)을 똑같은 타임라인 축선에서 동시 트레이닝하도록 유도했습니다. 이것이 주는 극적 보너스는 단일 모달리티 차원의 대국적 임베딩은 물론, 디코더 프레임이 유기적으로 식별해 내는 시각 피처 속 정밀한 미세 영역 레벨 정보까지 하나로 아우르며 독보적인 융합 성과를 달성했습니다.
2022년 말 딥마인드는 세상을 한 번 더 놀라게 한 시각-언어 모델 패키지인 Flamingo를 전격 런칭했습니다. 이 지능 모델 세트는 아주 극소량 부트스트랩 인입 샘플(few-shot) 유도 팁만 몇 가닥 던져주면, 완전히 낯설고 이색적인 지시 업무 시나리오도 귀신같이 응해 냅니다. 이들은 기본적으로 두 가지 뇌 영역으로 구동됩니다. 방대한 시각 정경과 현실 세계 비주얼을 심도 깊게 감상하고 명민하게 관조하는 비전 모델, 그리고 해당 정형 정보들을 단단한 논리와 상식 사슬 기반 위에 가지런히 엮어 정밀한 스토리 추론으로 완결해 줄 대형 언어 모델입니다. 이들은 기존에 이미 사전 습득되어 있던 독립 신경망 영역들의 전문 지식들을 허물없이 결합 소통시킵니다. Flamingo는 거대한 양의 고해상도 그래픽 데이터뿐 아니라 프레임 타임라인 비디오 피처까지 부드럽고 가볍게 시식할 수 있는데, 이는 앞트랙 변형 트랜스포머 파트에서 상술했던 'Perceiver' 지능형 어텐션 아키텍처를 도입하여 미려하게 수렴 정제해 주기 때문입니다.
기술적 혁신 덕분에 Flamingo 아키텍처는 풍부하게 훈련된 개별 비주얼 감각 필터와 하이레벨 어휘 개념을 자유롭게 커플링하고, 실시간으로 복잡하게 섞여 들어오는 오디오 트랙, 장문의 비주얼 시나리오 및 자유 서술 텍스트 단락들을 매끄럽게 처리할 수 있게 되었습니다. 이 패밀리 구조의 왕좌인 Flamingo-80B(800억 파라미터 탑재형) 모델의 경우, 인간의 시각, 언어, 영상 지능이 골고루 교차 융합되어 평가받는 복합 인지 멀티 태스킹 테스트 영역군에서 퓨샷 조건 기준 단숨에 지구상 정점 기록을 정조준 갱신하기도 했습니다.
또한 최근 들어서는 Microsoft, Google, OpenAI가 연달아 하루가 멀다 하고 차세대 특화 거물 시각-언어 플랫폼 패치들을 전 세계에 연쇄 드롭하며 바야흐로 차세대 멀티모달 AI 세대의 절대적인 지평 확장을 한층 속도감 있게 추동하고 있습니다.
마이크로소프트의 Kosmos-1은 단일 모달에 안주하지 않고 매우 섬세하게 주변 이종 자극 피처들을 동시 지각하며, 입력으로 전달되는 미묘한 주변 맥락 문맥들을 신속히 이해하고 지시에 수긍하는 매력적인 멀티모달 트랜스포머 인과 관계 언어 인프라입니다. 앞선 복합 지시 영역들을 고르게 음미하여 부드러운 스태킹 단락을 산출해 내며 이미지 해석, OCR, 질의응답 레이스에서 최우수 레벨 성적표를 자랑했습니다.
구글의 야심작인 PaLM-E는 하드웨어 로봇 구동 및 실제 피지컬 임바디먼트(embodied) 구현까지 능히 아우르도록 사전에 아주 타이트하게 포장 설계된 초특급 피지컬 가미 멀티모달입니다. 현실 감각 도구, 공간 위치 비주얼 감각 채널, 인터넷 급의 어마어마한 상식 지도를 스마트하게 연결해 줍니다. 최종 가동되는 최대 볼륨 버전 PaLM-E-562B 모델은 무려 5,620억 파라미터로 동작하며 복잡한 인지 학습 없이도 현장 비주얼을 감상해 농담을 꼬아 대답하거나, 로봇 기구를 가동하여 주변 공간을 식별하고, 실시간 경로 대화 계획을 즉석에서 플래닝해 움직이는 마법 같은 장면들을 수시로 선사합니다.
마지막 화룡점정으로 OpenAI 사의 GPT-4는 현실에 영감을 준 가장 세련되고 완성도 높은 대주주 거대 멀티모달로, 비주얼 그래픽 정보와 문자 질문들을 혼합 추종해 세밀하고 긴 텍스트 문단을 단숨에 쏟아냅니다. 모의 미국 변호사 시험에서 일반 인간 수험생 상위 10%의 초고득점 합격 컷을 달성하는 기염을 토했으며, 시각 지능 탑재 활성화 조건으로 평가한 국제 생물학 올림피아드 벤치마크 테스트에서는 오답을 거의 찾기 힘든 상위 99%라는 압도적인 기량을 확인시켰습니다.
4. 비디오 파운데이션 모델의 새로운 패러다임
비디오 이해가 그동안 극도로 까다로웠던 프레임 요인들
작금의 사회 속 비디오 콘텐츠 이해 시스템 구축의 필요성은 이미 그 임계 위상을 가늠하기 어려울 만큼 매우 거대해졌습니다. 매 순간 쏟아지는 소셜 플랫폼 미디어 트래픽 폭증 물결뿐만 아니라, 공공 영역 CCTV 지능형 모니터링 분석 강화에 이르기까지 자동화 비디오 추론 역량의 중요성은 날로 절실함을 더해 갑니다. 그러나 전 세계의 무수한 수요 강도에 비해, 텍스트 분석이나 정적 단일 이미지 연구 진영 수준의 풍성한 광명에 들어서기까지 비디오 이해 분야는 다소 외로운 기술적 정체기를 지나왔던 것이 냉정한 사실입니다.
이유는 무엇이었을까요? 비디오 처리가 텍스트나 고정된 사진 이미지 처리에 비해 혁신 도약 속도가 완만했던 주범은 다름 아닌 압도적으로 무거운 컴퓨팅 연산 유발 비용에 기인합니다. 비디오 클립 데이터가 내포한 원시 픽셀들의 바이트 스택 부피와 밀도 수준은 고정 차원 텍스트 단어 행렬이나 단일 프레임 사진 소스와는 아예 스케일 단위부터 다릅니다. 이 문제를 프레임 토큰 한 장 단위당 복잡도가 무려 제곱 배율(quadratic complexity)로 불어나는 민감한 트랜스포머 가동 공식에 무작정 대입한다면, 하드웨어가 겪게 되는 오버헤드 쓰나미는 도저히 손을 쓰기 어려운 난제로 직결되곤 했습니다.
기계가 느끼는 고충을 아주 상세하고 수학적으로 추적해 봅시다. 평범한 10분짜리 가벼운 클립 하나를 재생한다고 할 때, 통상 부드러운 가독성 감상을 위해 초당 30프레임(30 images/sec) 조건 기준 규격이 기본 제공됩니다. 즉 인풋 수치는 단 10분 재생 분량 속에 10 x 3600 x 30프레임 단위 계산 공식을 태워, 실제로는 무려 108만 장에 달하는 방대한 이미지 더미가 실시간 로딩됨을 의미합니다. 트랜스포머 고유 성향인 인풋 제곱 배수 연산 수렴치에 이를 비추어 계산해 보면, 모델이 연산해야 하는 연계 관계의 총매칭 검토량은 100만 제곱 단위인 자그마치 1조 번(1e12) 이상이라는 감당 안 되는 무서운 스택 연산으로 환산되어 버립니다.
주목할 도전점은 단순히 용량이 비대하다는 것 자체에만 있지 않습니다. 비디오 이해 미션만이 갖는 가장 독보적인 장벽은 바로 입체적 시간 축을 횡단하는 가변 템포럴(temporal) 모델링 구현에 있습니다. 비디오 파일은 정적인 2D 단면 프레임에 단순히 가만히 고정 주색되어 머물러 주지 않습니다. 0.1초의 짧은 스팬 단위마다 복합 오브젝트들의 상호작용 위치 상태가 정치가 요동치듯 역동적으로 흘러가며 연산 추적이 지속되어야만 비로소 일관된 스토리가 정립됩니다. 이는 시각 인코더가 평소 만져보지 못한 전혀 새로운 차원의 기차 레일 정합성 매핑 정렬 테크닉을 필수적으로 촉구합니다.
더 나아가 완벽한 사실주의 비디오 감상 영역을 매끄럽게 개척해 내기 위해서는 시선을 강탈하는 격정적 시각 피처 처리뿐 아니라, 해당 배경 타임라인 정중앙에 고스란히 정렬 싱크로나이즈드되어 맞물려 흘러나오는 복합 다차원 오디오 웨이브 큐(audio cues) 분석 능력까지 지체 없이 일괄 처리되어야만 합니다. 비디오 속 누군가 대화하는 보이스 톤, 현장의 다급한 소음, 자동차 경적 소리는 때론 영상 화면 내 가려져 보이지 않던 사각지대의 결정적인 현실 정황 콘텍스트를 시사해 주기도 합니다. 인간은 귀로 듣고 눈으로 감상하며 영화 하나를 온전히 공감하고 파악합니다. 그러므로 현명한 비디오 전용 신경망을 공고히 하려면 시각 장벽 돌파 노력만큼이나 오디오 청각 정보 인지 필터를 비디오 인플루언서 융합 시스템 안으로 매끄럽고 신속하게 블렌딩해 내는 깊이 있는 노하우가 절대적 핵심 기둥입니다.
그렇지만 이러한 높은 난관들에 가로막혀 마냥 멈추어 서있을 수만은 없기에, 전 세계 엘리트 AI 연구팀들은 비디오 이해 분야의 혁신적 수렴 속도를 위해 전력을 지속 투구해 오고 있습니다. 강력한 차세대 범용 시각-언어 파운데이션 강자들의 기술 도약 흐름을 필두로, 이제 비디오 데이터가 지니는 복잡한 맥락 영역을 조율하고 다스리려 하는 참신한 전용 시각 언어 연동 엔진 모델 제형들이 본격적으로 시장 위를 비행하기 시작했습니다. 글로벌 무대의 활기찬 오픈 커뮤니티 역시 이 뜨거운 세부 주제를 관통하는 핵심 연구의 정수를 정조준하며 땀 흘리고 있으며, 이들의 공고한 헌신 끝에 시대를 대변할 정합성 높은 실제 훌륭한 비디오 파운데이션 성과들이 멀지 않은 미래에 우리 삶에 곧 선사될 것이라 굳게 확신합니다.
기지개를 켜는 대세 거대 비디오 전용 지능 모델들
2019년 구글 개발진은 미답지 영역이던 무비디오 시공간 데이터 위에 드디어 자기지도학습을 스마트하게 구가한 시조격 기념비 모델 VideoBERT를 출범시켰습니다. 이미 검증되어 상용 수준으로 안착해 돌던 3종의 성숙 기술 소스 프레임워크들을 기발하게 정비소에 넣어 개조 결합했는데, 첫째는 음성 자동 변환 수신기(ASR), 둘째는 정밀 스페이셜 템포럴 픽셀 정보 처리를 지원하는 비주얼 기어 양자화 분석 필터, 마지막 기조는 이 정렬된 정보 흐름 축을 가지런히 정제해 넘겨받아 차례대로 독파할 클래식 고성능 BERT 모델 축선이었습니다. 이 독보적인 연동 체인을 바탕으로 시각과 언어를 동기화해 관계를 맺어주는 데 탁월한 효과를 보였습니다. 구글 연구진은 비디오의 기획 단계 원시 픽셀 스택을 '비주얼 머스킷 단어'처럼 기능하게 유도하기 위해 원시 프레임을 특화 레이블 토큰셋으로 스마트하게 잘라 표현 벡터 양자화 기술로 다스려 냈습니다. 그 결실로 비디오 이해의 흐름 정답을 매핑하여 역추적하는 캡셔닝 벤치마크 미션을 가볍게 석권하며 시조새로서의 우아한 면모를 과시했습니다.
논문을 통해 화려하게 등극한 All-In-One 역시 사전 학습용으로 명명 설계된 비디오 언어 파운데이션 핵심 주자 중 하나로, 전용 단일 백본 아키텍처 내부에서 가공되지 않은 raw 시각 신호와 텍스트 시그널을 한 타임에 포착해 내는 전무후무한 소화력을 자랑합니다. 추가 컴퓨팅 리소스 폭증 걱정 없이 가볍게 샘플링한 가변 프레임 축선상에서 프레임 정보가 템포럴하게 롤링하며 정합되도록 마이그레이션 기법을 구축하여, 시간 차원 정보 스택 처리를 깔끔히 접수해 냈습니다. 이는 멀티플 옵션 논리 문제 풀이나 시각적 상식 추론 영역 등 4대 난제 부문 전방위에서 우수한 기량을 시원하게 갱신하여 가치를 입증했습니다.
비디오 인지 및 인식(Video recognition)은 기계가 동영상 클립 속을 분 단위로 질주하면서 정교한 주요 행위 오브젝트, 물리적 사건들의 흐름을 정확히 명명 분류하고 트래킹 파악하는 높은 차원에 해당합니다. 이는 스마트 시티, 자율 주행 차량 관제 지평, 몰입형 미디어 제어 산업 등에 이르기까지 실제 필드에서 활용도가 가장 무한한 황금 시장이며 정교한 연산 기술이 활발히 생성되는 곳입니다.
Video MAE는 일반적인 바닐라 비전 트랜스포머가 가진 비디오 표현 능력을 극한까지 끌어올린 자가학습 비디오 사전 훈련 기법입니다. 무작위로 선택된 비디오 큐브를 마스킹하여 감추고, 비대칭 인코더-디코더 구조를 활용해 유실된 큐브를 영리하게 복구해 냅니다. 저자들은 극도로 높은 마스킹 비율과 튜브 마스킹(tube masking) 전략이라는 두 가지 핵심 설계를 도입했으며, 이를 통해 VideoMAE가 정보 중복과 같은 비디오 특유의 비효율성을 극복하고 한 차원 높은 정밀도로 비디오의 대표 특징들을 학습하도록 유도했습니다.
풍부한 인터넷 데이터 소스로부터 대조 조합을 훈련받은 CLIP 시스템의 혜택을 디딤돌 삼아, 자연어 피처 프롬프팅 정보를 가이드 레일로 삼는 전폭적인 비디오 전용 인지 기술을 새로이 구축할 수 있습니다. 이미 폭넓게 학습이 완료된 임베딩 개념 지도를 레퍼런스로 영리하게 차용하는 방식이기에, 복잡한 추가 파라미터 트레이닝 공수를 기적처럼 하이패싱하거나 제로셋에 패치하여 낯선 실전 도메인 작업에 아주 경이로운 연비로 초고속 이식 적용을 매끄럽게 수행해 낼 수 있기 때문입니다.
마이크로소프트의 X-Clip 프레임워크는 정적인 정밀 CLIP 핵심 감각 필터를 동적으로 생동감 넘치게 움직이는 비디오 추론 전용으로 스마트하게 개조 이식한 매력적 아키텍처입니다. 이들의 내부 코어 영역은 크로스 프레임 연소 정보 교환 인터페이스용 트랜스포머 기어 한 축과, 프레임들을 하나로 매끄럽게 컴포지트 통합해 줄 멀티프레임 연계용 트랜스포머 가이드 기어의 이중 탑재입니다. 이들은 메신저 토큰을 주고받아 각 프레임 간의 누락 정보들을 긴밀하게 맞교환하도록 독려합니다. 또한 비디오 속에 담긴 고유 기류 콘텍스트 정보를 명민하게 취합해, 텍스트가 가진 내포 의미가 훨씬 고해상도로 작용하도록 프롬프트 결합을 극대화해 줍니다. 극도로 제한적인 영양 공급 수준의 희소 샘플 피팅 테스트 상황 속에서도 이들이 선보인 최상급 수렴 정밀도는 대단히 기품이 넘칩니다.
사실 컴퓨터 언어나 싱글 단화 크기의 비주얼 파운데이션 리더 기기들에 비하면 현재 비디오 특화 진영의 모델들은 아직 소화하고 해결할 수 있는 액션 세트의 폭과 크로스 결집 영역이 다소 협소한 초창기에 있습니다. 하지만 최근 등판한 위대한 명작 InternVideo는 그간 별개 트랙을 정밀 돌진해 오던 양대 대표 자가학습 자양분, 즉 비디오 마스크 인지 튜브 재생 기반의 모델 기조와 정교한 멀티모달 대조 정보 수렴 인프라를 하나의 매력적인 기어로 용감히 블렌딩했습니다. 이 두 핵심 트랜스포머 간 유기적인 신호 커플링 상호작용 피트를 인입해 냄으로써 대조 학습의 정적인 세련됨과 생성 모델 고유의 유기적 표현력 둘 모두의 핵심 지분을 영리하게 장악해 냈습니다.
InternVideo는 행동 해석, 시각-언어 데이터 정렬 상태 체크, 그리고 무제한 환경 오픈 월드 비디오 응용 지표들을 면밀히 매기는 비디오 종합 성적표(video understanding benchmark) 기준 판에서 유수의 대형 모델들을 훌륭히 압도하며 왕좌를 쟁취했습니다. 이들이 보여준 입체적 기량은 앞으로 비디오 분야 인공지능이 무한 성장해야 할 본질적인 영양분의 청사진 그 자체라 칭할 수 있습니다.
글을 마치며
준비 운동이 온전히 끝나서 기쁜 상태이든 아니든, 이 시대가 명명하는 모든 실용 파운데이션 신경망 기조는 이제 마침내 강력한 멀티모달 시대로 막힘없이 진입하고 있습니다. 마침내 파운데이션 모델이 조만간 세상의 가치 있는 모든 AI 기반 소프트웨어 인프라의 핵심 중추이자 주춧돌로 완전 격상하여 동작하게 됨에 따라, 일선의 유능한 개발 파트너 엔지니어들 역시 매사에 맨땅 부지 위에서 삽질을 시작하기보다 정교하게 예비 훈련된 파운데이션 코어를 기본 축으로 가져와 설치한 다음 세부 타겟 세그먼트만을 빠르게 다듬어 처리하는 흐름을 정석으로 받아들일 것입니다. 다만 이러한 영리한 모델 기조를 가로막는 여전한 최대 적수는 인간 사회 실증 속 빈번히 난입하는 극소수의 이색 데이터 조각들과 이른바 '롱테일(long-tail)'형 예외 예측 불가 돌발 시나리오들일 것입니다. 이 롱테일 과제들은 서로 다른 성향의 이종 자극이 기류 차이를 자아내는 멀티모달 연동 구도 하에서 훨씬 더 혹독하고 지독하게 복잡한 사투를 예고하고 있습니다.
Twelve Labs 연구팀은 바로 그 난공불락의 험난 영역, 즉 실전 롱테일 정황 중심의 입체 멀티모달 비디오 이해를 전담할 가장 신뢰성 높은 최첨단 비디오 기반 파운데이션 모델 패키지를 땀 흘려 설계 중입니다. 우리의 궁극적 미션은 전 세계의 수많은 개발 엔지니어 분들이 마치 두 눈으로 세상을 보고, 양 귀로 다채로운 화음을 즐기며, 뛰어난 상식 사절단처럼 대화하듯 세상을 유기적으로 응시하고 감각 수용하는 지능형 모바일 애플리케이션들을 한껏 세련되게 꽃피울 수 있도록 최고 성능의 고효율 지능형 비디오 이해 인프라를 선물해 드리는 일입니다. 전 세계의 엘리트 동료들과 나누고픈 복합 대형 신경망 멀티모달 구상들의 신선한 팁과 지론들이 가득하지만, 지면 관계상 오늘의 대서사시 포스트는 이쯤으로 정리하겠습니다. 이 멋진 지식 여행의 실제 주인공이자 베타 테스트의 선두 프론티어로서 유쾌한 한 발자국을 저희와 함께 걸어보고 싶으시다면 망설이지 말고 지금 바로 베타 유저 서비스에 조인 신청을 남겨주십시오! 고도로 역동적인 멀티모달 AI의 비약적 흥행 로드를 동반 개척할 정예 Discord 디스코드 커뮤니티 대화방의 활성 파트너 참여 역시 양팔 벌려 언제나 뜨겁게 환영합니다!
이 방대한 지식 기사를 작성하는 과정에서 탁월한 고품질 시각 자료 원천 출처 공유와 밀도 높은 교정 기여 활약을 펼치며 혼신을 다해 지원해 주신 에이든 리(Aiden Lee) 님께 글을 빌려 진심어린 감사의 뜻을 바칩니다!