" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
Twelve Labs와 Milvus로 멀티모달 RAG(검색 증강 생성) 애플리케이션 구축하기

흐리시케시 야다브 (Hrishikesh Yadav)
이 튜토리얼에서는 Marengo 2.7 기반의 Twelve Labs Embed API와 Milvus를 활용하여 텍스트, 이미지, 비디오 기반의 상품 검색을 구현하고, GPT-3.5 기반의 RAG 시스템을 통해 검색된 멀티모달 임베딩으로부터 대화형 패션 추천을 생성하는 '패션 AI 챗 애플리케이션(Fashion AI Chat Application)'의 구축 과정을 자세히 설명합니다.
이 튜토리얼에서는 Marengo 2.7 기반의 Twelve Labs Embed API와 Milvus를 활용하여 텍스트, 이미지, 비디오 기반의 상품 검색을 구현하고, GPT-3.5 기반의 RAG 시스템을 통해 검색된 멀티모달 임베딩으로부터 대화형 패션 추천을 생성하는 '패션 AI 챗 애플리케이션(Fashion AI Chat Application)'의 구축 과정을 자세히 설명합니다.

In this article
No headings found on page
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2025. 1. 22.
13분
링크 복사하기
소개
언제 어디서나 나의 말뿐 아니라 시각적 취향까지도 온전히 이해하는 개인 패션 어드바이저가 있다면 어떨지 상상해 보셨나요? 마음에 드는 의상 사진을 보여주면 AI가 유사한 스타일을 즉시 제안해 주거나, 꿈꾸던 룩을 묘사하면 딱 맞는 코디를 추천해 주는 세상을 경험해 보세요 👚
Twelve Labs의 패션 AI 어시스턴트 애플리케이션은 차세대 상품 검색을 위해 설계되었습니다. 본 튜토리얼에서는 멀티모달 검색과 대화형 AI를 결합한 고도화된 패션 추천 시스템을 살펴봅니다. 이 시스템은 TwelveLabs Embed - Marengo-retrieval-2.7 모델을 활용하여 텍스트와 비디오 콘텐츠 모두에서 벡터 임베딩을 생성하므로, 서로 다른 데이터 타입 간에도 매끄러운 검색이 가능합니다.
본 애플리케이션은 효율적인 유사도 검색을 위한 벡터 데이터베이스로 Milvus를 사용하며, 자연어 처리를 위해 OpenAI의 gpt-3.5를 통합했습니다. 텍스트와 이미지 입력을 통해 패션 관련 질의를 처리하고, 관련 상품 설명과 함께 정확한 비디오 타임스탬프를 찾아내어 사용자가 원하는 아이템이 영상의 어느 부분에 등장하는지 정확히 보여줍니다.
이 강력한 조합을 통해 텍스트와 시각적 질의를 모두 이해하고, 멀티모달 콘텐츠로 풍부해진 맥락 맞춤형 답변을 제공하는 시스템이 완성됩니다.
이 애플리케이션이 어떻게 작동하는지 살펴보고, TwelveLabs Python SDK 및 Milvus Python SDK를 활용해 유사한 솔루션을 직접 구축하는 방법을 알아보겠습니다.
애플리케이션 데모는 여기에서 확인하실 수 있습니다: 패션 AI 챗 앱 데모.
코드를 직접 확인하고 앱을 실행해 보고 싶다면 다음 Replit 템플릿을 활용하세요.
사전 준비 사항
Twelve Labs Playground에 가입하여 API 키를 생성합니다.
설치 가이드에 따라 Milvus 서버를 설치하고 설정합니다.
이 애플리케이션의 소스 코드는 패션 AI 챗 애플리케이션 저장소에서 확인하실 수 있습니다.
Python, Streamlit, CSS에 대한 기본적인 이해가 필요합니다.
애플리케이션 작동 원리
애플리케이션이 작동하는 방식과 각 구성 요소가 상호작용하는 흐름은 다음과 같습니다:
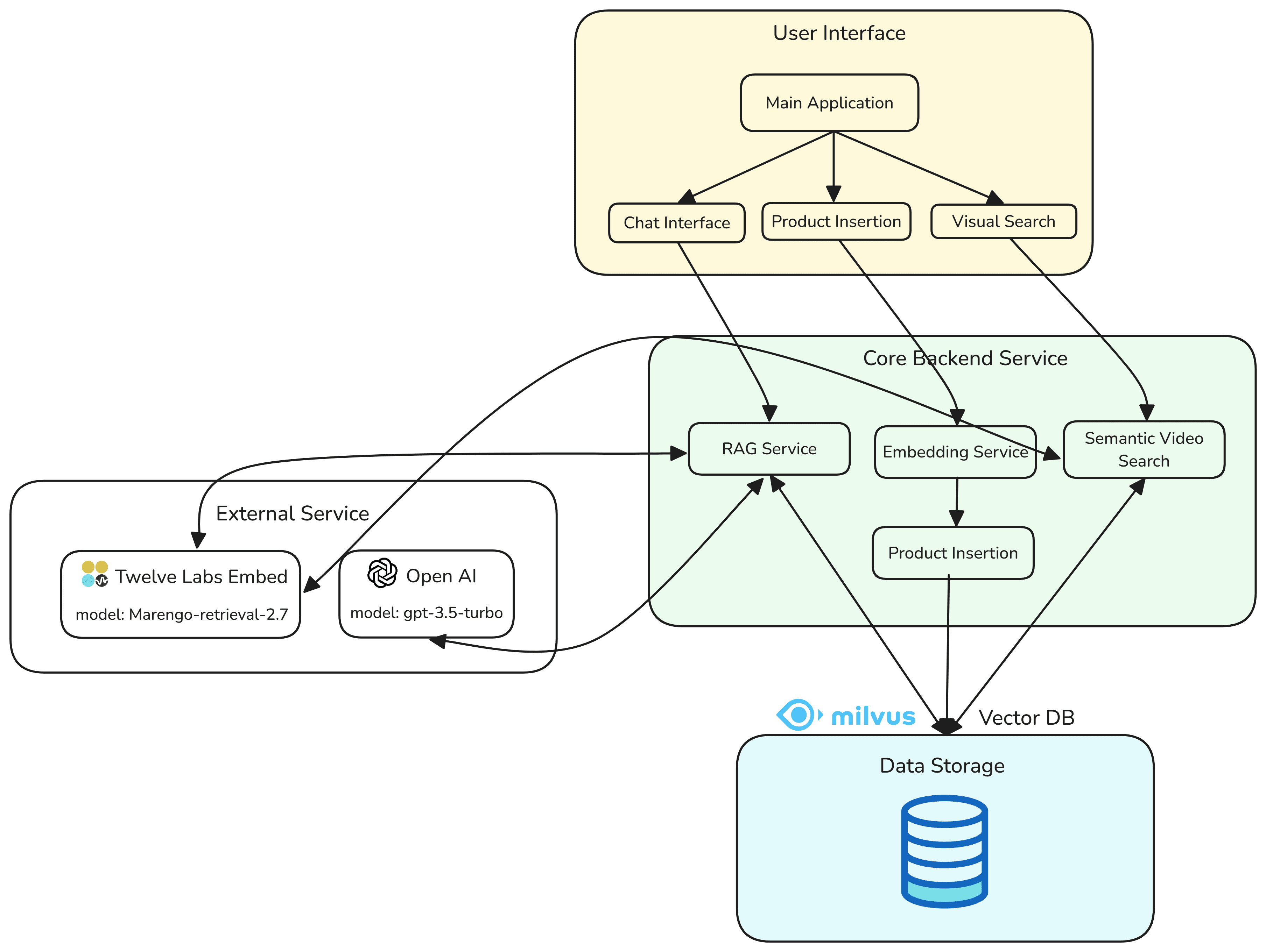
이 애플리케이션은 크게 세 가지 주요 기능을 제공합니다:
임베딩 생성 및 Milvus 벡터 데이터베이스 삽입
쿼리 이미지 기반 비디오 구간(Segment) 검색
멀티모달 검색(텍스트 및 비디오 구간)을 위한 검색 증강 생성(RAG)
본 튜토리얼 앱은 Twelve Labs Embed - Marengo-retrieval-2.7 모델을 사용하여 상품 카탈로그 데이터를 벡터 데이터베이스에 저장하는 방법을 보여줍니다. 텍스트와 비디오 콘텐츠의 임베딩은 동일한 Milvus 벡터 데이터베이스 컬렉션에 함께 저장됩니다. 코드의 명확성과 재사용성을 위해 Twelve Labs 임베딩 생성 함수는 각 유틸리티 함수 내에 정의되어 있습니다.
애플리케이션을 정상적으로 작동시키려면 임베딩 데이터를 컬렉션에 추가해야 합니다. 직접 구축하는 대신 본 애플리케이션에 사용된 샘플 데이터를 여기에서 다운로드하여 활용할 수도 있습니다.
준비 동작
Twelve Labs Playground에서 API 키를 발급받아 환경 변수로 설정합니다.
GitHub에서 프로젝트를 복제하거나 Replit 템플릿을 사용하세요. 가상 환경이 미리 구성되어 있는 Replit 템플릿 사용을 권장합니다. 설정 중에 시크릿 파일을 추가하고 Replit 보안 키 문서를 참고하는 것을 잊지 마세요.
Twelve Labs, Milvus 연결 정보, 그리고 LLM 모델용 OpenAI API 키를 포함하는
.env파일을 생성합니다.
Milvus 벡터 데이터베이스의 경우 Zilliz Cloud를 기준으로 자격 증명이 구성되어 있으나, 다른 연결 방식은 설치 가이드를 참고하시기 바랍니다.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
이 단계들을 완료하셨다면 이제 본격적인 개발을 시작할 준비가 되었습니다!
패션 챗 애플리케이션 가이드
이번 튜토리얼에서는 직관적이고 심플한 프론트엔드를 갖춘 Streamlit 애플리케이션을 만들어 보겠습니다. 프로젝트의 디렉토리 구조는 다음과 같습니다:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit 애플리케이션 만들기
환경 설정이 끝났으니 이제 Streamlit 애플리케이션을 구축할 차례입니다.
가상 환경 구성을 위해 필요한 종속성 목록은 다음에서 확인하실 수 있습니다: requirements.txt
파이썬 가상 환경을 생성한 후, 아래 명령어를 실행하여 애플리케이션에 필요한 패키지들을 설치하세요:
pip install -r requirements.txt
유틸리티 함수 정의하기
이 섹션에서는 핵심 비즈니스 로직과 구현체가 포함된 utils.py 파일을 설명합니다. 각 세부 단계를 차례로 살펴보겠습니다:
1 - 연결(Connection) 설정
첫 번째 단계로 환경 변수를 로드하고 LLM 접근을 위한 OpenAI, 컬렉션 관리를 위한 Milvus, 그리고 Twelve Labs SDK 초기화를 진행하여 연결을 수립합니다.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API를 사용한 임베딩 생성
이 섹션에서는 Twelve Labs SDK의 Marengo-retrieval-2.7 모델을 사용하여 멀티모달 검색을 위한 임베딩을 생성하는 방법에 대해 설명합니다. 텍스트와 비디오 프로세싱을 통합하여 고성능 검색 임베딩을 원활하게 생성합니다.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
이 프로세스는 일관되고 유의미한 임베딩을 확보하기 위해 텍스트의 구조를 잡고 포맷팅하는 데서 출발합니다. 이어 상태 모니터링 및 진행 상황 추적과 함께 비디오 임베딩이 순차적으로 작동합니다. 이 튜토리얼에서 각 비디오 세그먼트는 6초 단위(video_clip_length=6)로 분할 및 인코딩되도록 설정되었습니다.
추적 가능성을 유지하고 정확한 비디오 세그먼트 및 텍스트 검색을 구현하기 위해서는 메타데이터 관리가 필수적입니다. 임베딩 작업이 끝나면 그 결과물은 Milvus 벡터 데이터베이스 컬렉션에 바로 저장됩니다.
3 - Milvus 벡터 데이터베이스에 임베딩 저장하기
벡터 데이터베이스는 고차원의 임베딩 데이터를 효율적으로 저장하고 초고속으로 조회할 수 있게 돕습니다. 본 단락에서는 적절한 메타데이터 관리와 예외 처리 프로세스를 통해 텍스트 및 비디오 임베딩을 Milvus 컬렉션에 동시에 밀어 넣는 방법을 살펴봅니다.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID, 벡터, 메타데이터를 올바르게 정의한 뒤, 동일한 컬렉션 공간 내에서도 포맷이 다른 데이터를 유연하게 다룰 수 있도록 embedding_type 필드를 별도로 명시해 줍니다. 최종 가공된 데이터는 collection.insert 메소드를 통해 일괄 반영됩니다.
4 - 이미지 대 비디오 검색을 위한 시맨틱 검색 구현
이미지 입력을 쿼리로 삼아 시맨틱 검색을 수행하면 이와 유사한 성격의 비디오 내 장면들을 손쉽게 골라낼 수 있습니다. 이 과정은 Twelve Labs 임베딩 기능과 Milvus의 벡터 유사도 검색 메커니즘이 조화롭게 결합되어 동작합니다. 아래는 유틸리티 함수인 searched_similar_videos가 동작하는 원리 구조입니다:
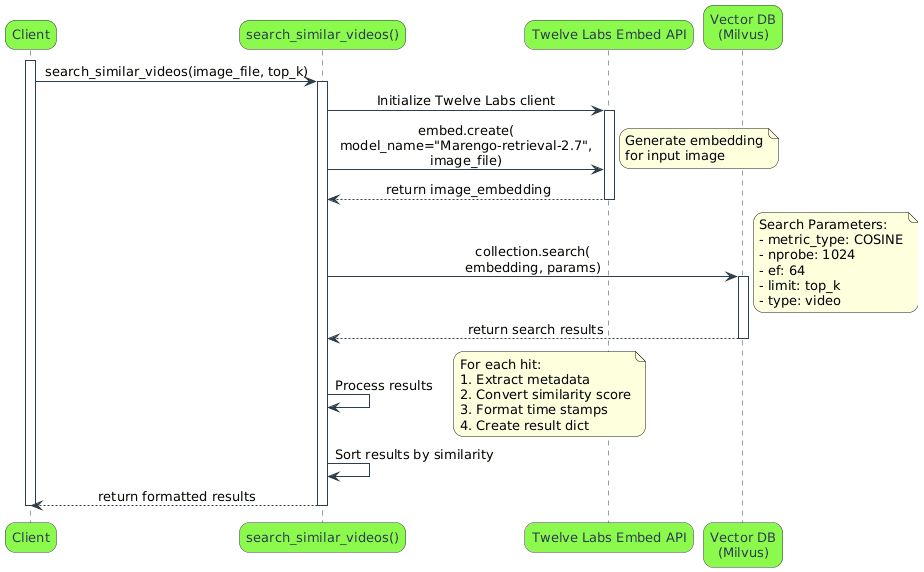
먼저, 시스템은 제공된 상품 이미지를 읽어 들인 뒤, 해당 상품과 시각적으로 유사한 상품이 포함된 비디오 세그먼트를 찾기 시작합니다. Twelve Labs Embed API를 통해 이 이미지를 밀도 높은 임베딩 벡터로 정형화한 후, Milvus 컬렉션에 적재되어 있던 비디오 임베딩과의 정밀한 비교 연산을 수행합니다.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
검색 모듈은 코사인 유사도(Cosine Similarity) 평가지표와 고차원 탐색용 인덱스 인자를 적용하여, 반환 주기와 정확도 간 최적의 균형값을 잡을 수 있도록 제어합니다. embedding_type == 'video' 속성과 여타 필요한 논리 표현을 활용해 collection.search를 수행하면, 매칭률이 높은 비디오 세그먼트들을 원하는 개수만큼 깔끔하게 회수해 줍니다.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
마지막으로 이 유사도 지수를 사용자가 파악하기 가장 편안한 형태인 '백분율(%)' 정보로 다듬고, 타임라인 구간 정보 등 제반 메타데이터를 정제된 사전식 구조로 조립합니다.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
정렬이 마무리된 결과 데이터는 사용자 인터페이스를 통해 훌륭하게 출력될 수 있습니다. UI 구현부는 visual_search.py 파일에서 확인하실 수 있습니다.
5 - 검색 증강 생성(RAG) 시스템 설계하기
이 섹션에서는 패션 어시스턴트 컨텍스트에서 질의응답을 구현하는 데 초점을 맞추며, 멀티모달 검색과 LLM(gpt-3.5)을 결합하여 맥락에 부합하는 응답을 제공합니다. 효과적인 개인화를 유도하기 위해 텍스트와 비디오 등의 원천 데이터로부터 메타데이터 정보를 밀도 높게 이끌어 내는 과정이 핵심입니다. 이 흐름의 핵심 기능은 get_rag_response 함수로 제어합니다.
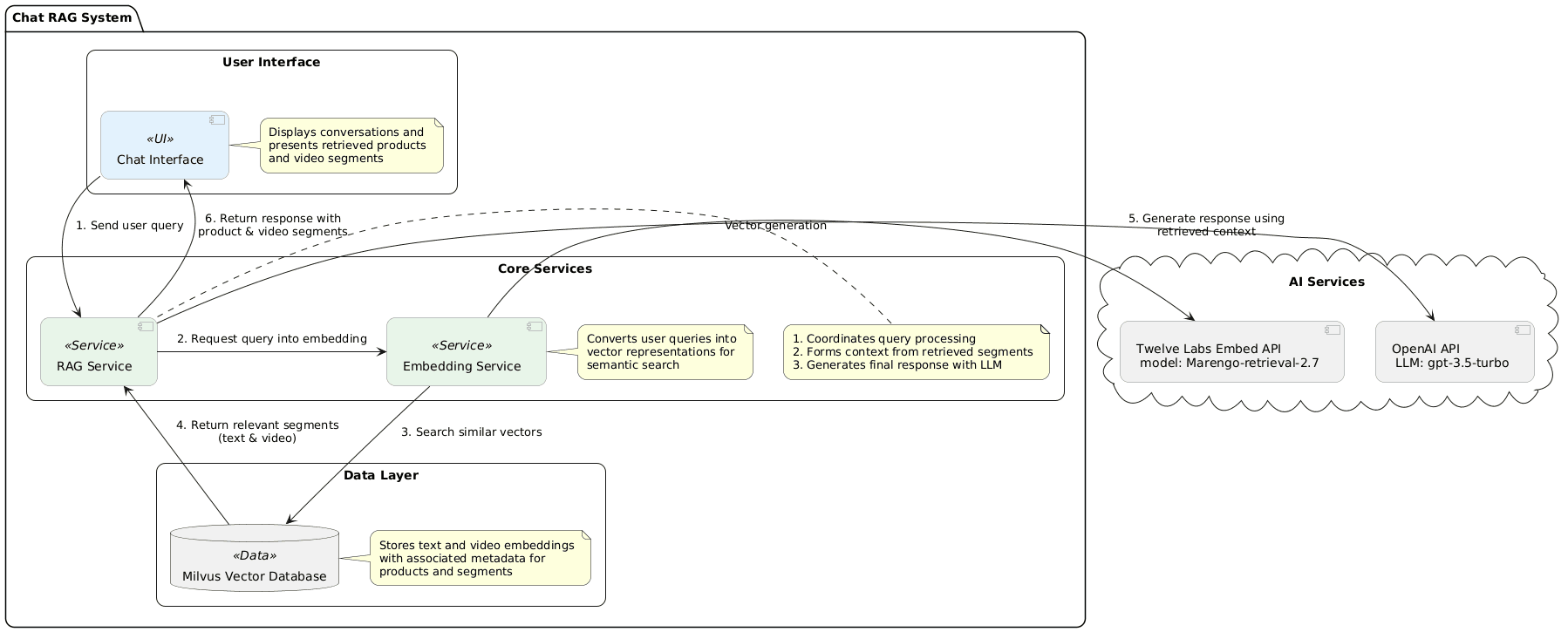
동작 시 가장 먼저, 사용자 질문과 맥락을 Twelve Labs의 Marengo-retrieval-2.7 임베딩 모델로 전송하여 벡터 데이터로 가공해 시맨틱 조회가 가능하도록 사전 작업을 마칩니다.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
시맨틱 검색 매개변수를 구성한 후, 시스템은 텍스트 및 비디오 세그먼트에 대해 각각 데이터베이스를 독자적으로 조회합니다. 이때 연관 비디오 구간까지 동시에 필터링하여 사용자에게 매우 다채로운 입체적인 탐색 옵션을 보장하게 됩니다.
expr 처리를 통해 검출 조건을 통교히 가다듬고, 각각 텍스트 중심은 2개, 비디오 구간 측은 3개 매장 정도로 일치 정합 제한 한도를 적절히 다듬어 줍니다.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
이어서 결과물을 객체화하는 동안 메타정보를 온전히 취득하고, 획득 유사 점수를 알기 쉬운 백분율 정보로 순화하여 수려하게 구조화합니다.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
유의미한 정보 자산이 전부 수집되고 나면, LLM 모델 지능과 안전하게 결합할 대화형 RAG 준비 단계로 자연스럽게 이동합니다. 정형화된 Context 형태로 전처리되어 언어 모델에 정갈하게 정렬 인가됩니다.
시스템 프롬프트(System Prompt)와 유저 프롬프트(User Prompt)를 세밀하게 정의합니다. 시스템 프롬프트는 전문 패션 조언가로서 가이드의 역할을 설정하고, 유저 프롬프트는 실제 질문 요구사항을 실시간 탐색 영역에 단단히 결합합니다. 중간 조회 오류나 부재 등의 상황을 방지하기 위한 안전 예외 구문도 유연하게 준비합니다.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
준비된 text_context 데이터를 활용해, gpt-3.5-turbo 모델이 지시에 따라 일관성 있고 풍부한 스타일 팁을 담은 최종 자연어 응답을 구조화해 출력합니다. 유려하게 포장된 사전(dictionary) 형태의 결과를 프론트엔드로 즉시 넘겨주어 화면에 띄울 수 있도록 설계되었습니다. UI 세부 사항은 app.py에서 직접 감상해 보시기 바랍니다.
데모 애플리케이션
이 데모 프로그램은 크게 3개의 실용 컴포넌트로 나뉘어 작동하며, 데이터 관리자 편익 및 역동적인 대화형 멀티모달 서비스 기획자들에게 최적의 사용 가치를 제공하도록 기획되었습니다.
검색 질의 대상이 될 원본 텍스트 및 비디오 임베딩의 빠른 생성 및 데이터베이스 삽입 처리
LLM 및 멀티모달 정렬 기법을 적용한 채팅 상호작용 기반의 맞춤 결과 추려내기
시각적 제품 스크린샷 이미지 입력을 수단으로 한 고성능 비디오 세그먼트 매칭
우리가 다룰 데이터 모델 카탈로그 정보에는 기본 일련번호를 시작으로 메타 내용물, 상세 연동 커머스 외부 링크 및 비디오 고유 원천 URL 등의 실용 구성 요소가 포함되어 조화롭게 정렬됩니다. 이 흐름을 거쳐 비디오 정보는 세그먼트 벡터로 변환되고 나머지 설명 정보는 고유 속성 메타에 통합된 후 결국 원형 컬렉션 하나에 수려히 조립 적재됩니다.
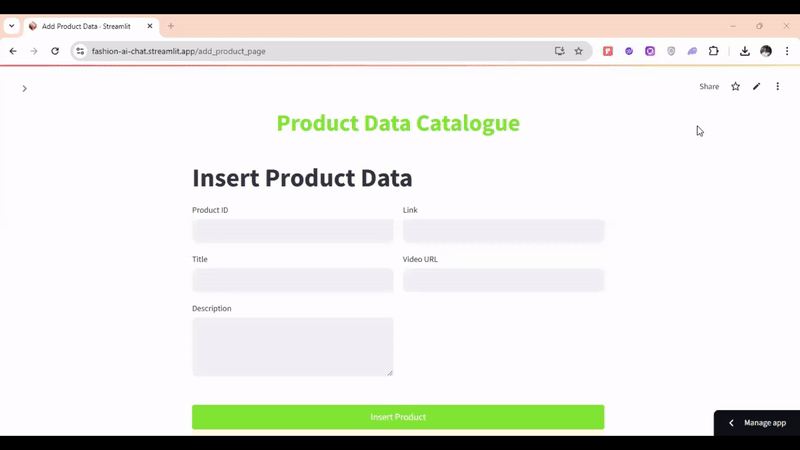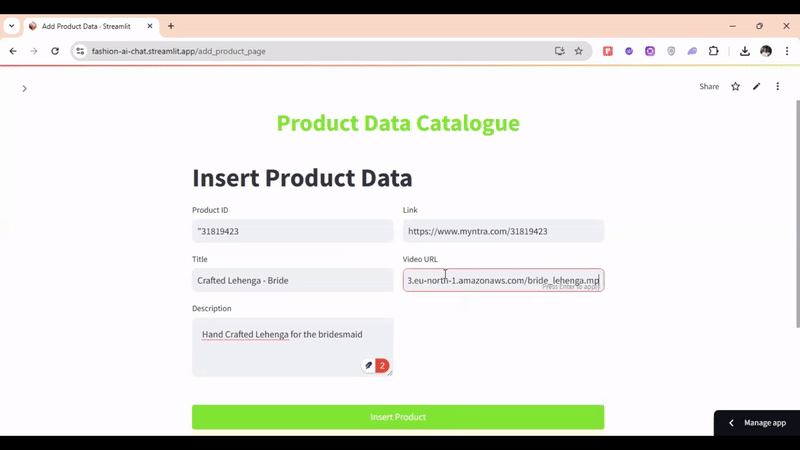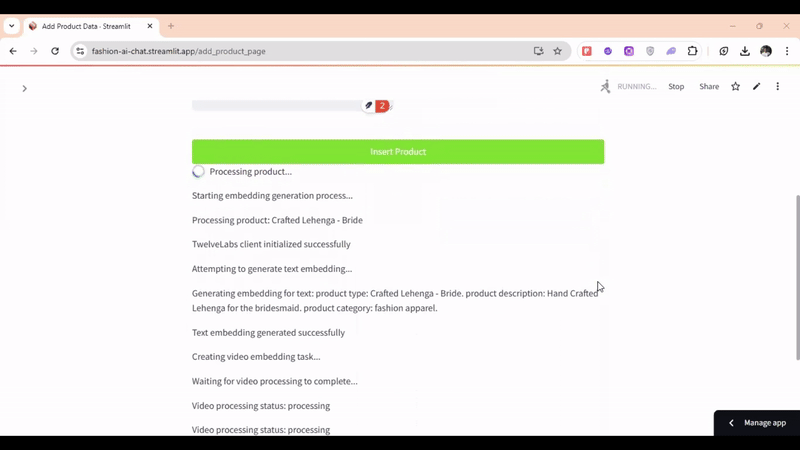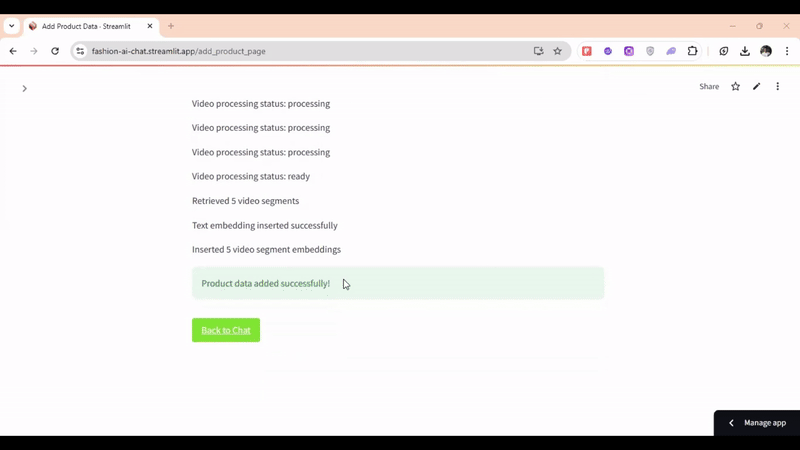
멀티모달 대화형 질문 예시로, "남성용 검은색 티셔츠 종류 좀 보여줘"라고 질문했을 때의 반환 장면입니다 —
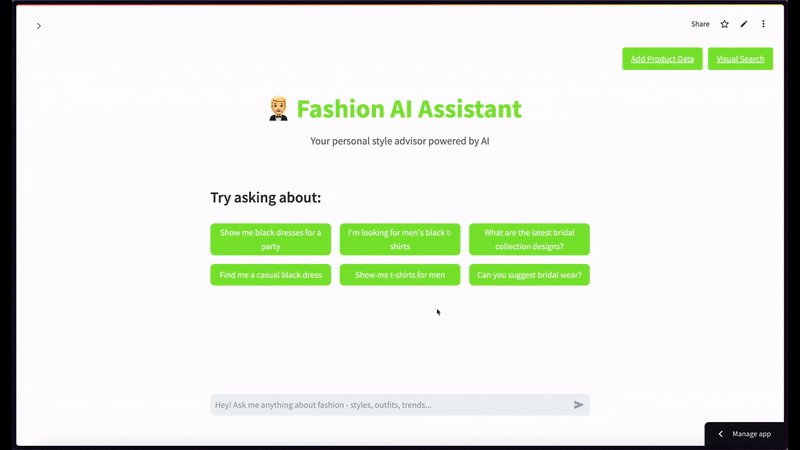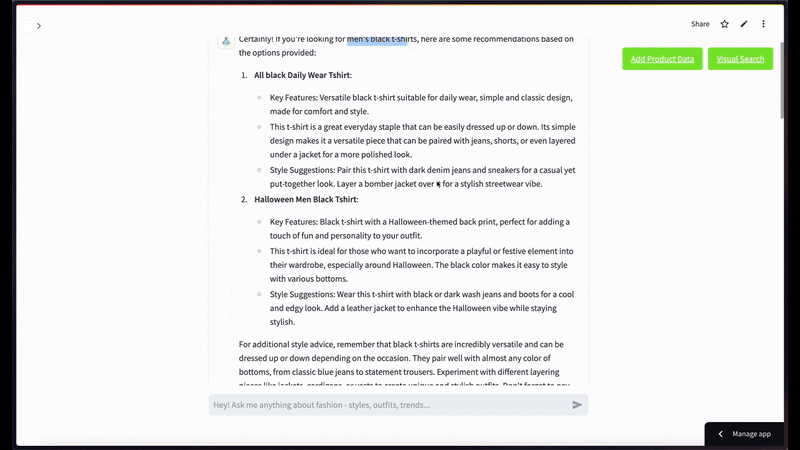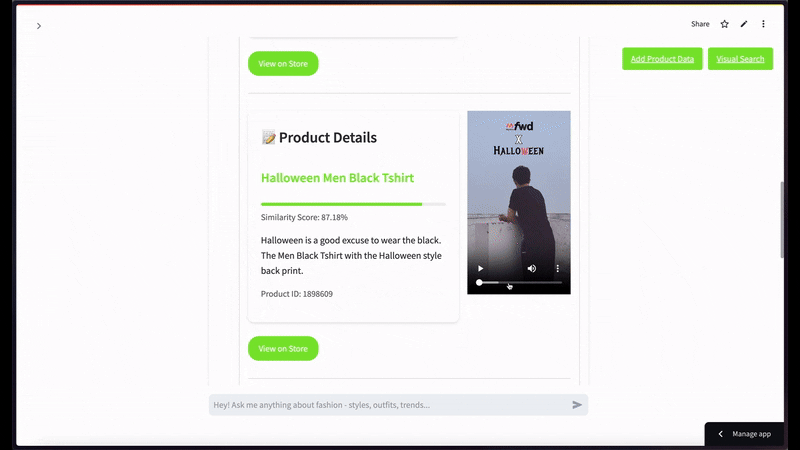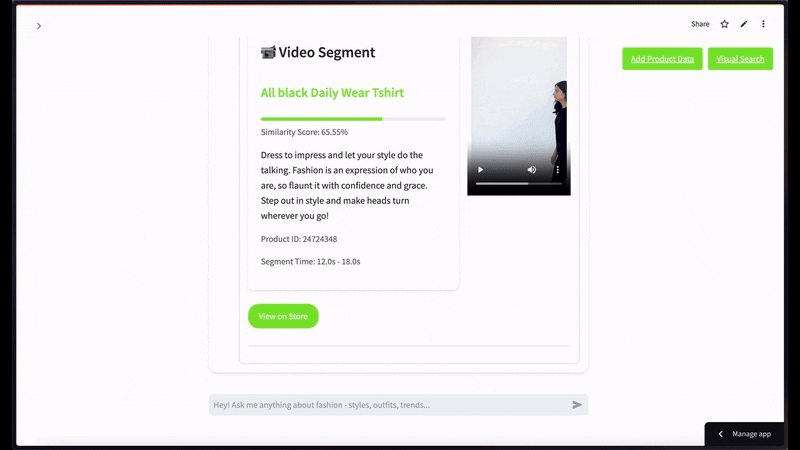
만약 사용자가 검은색 반소매 티셔츠 화상을 넣고 상위 2건 정도로 시맨틱 비디오 검색을 한정 요청했을 때 표출되는 유려한 캡처 씬입니다 —
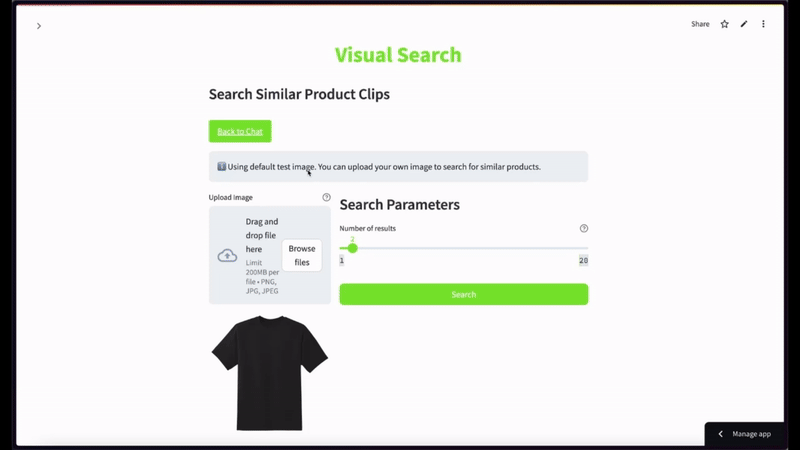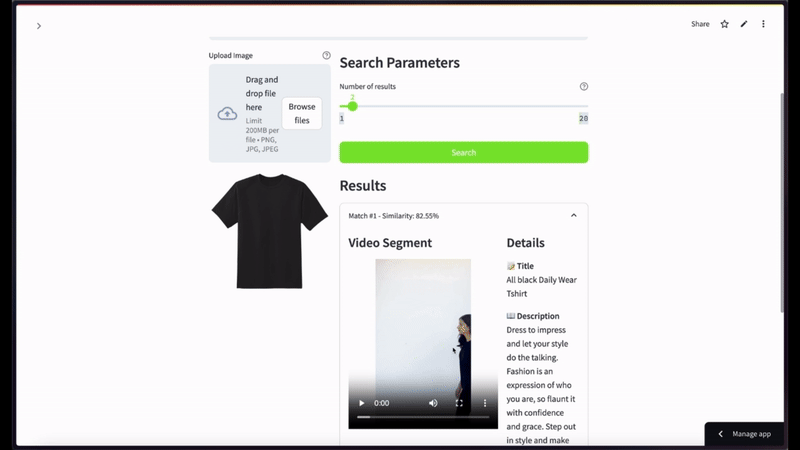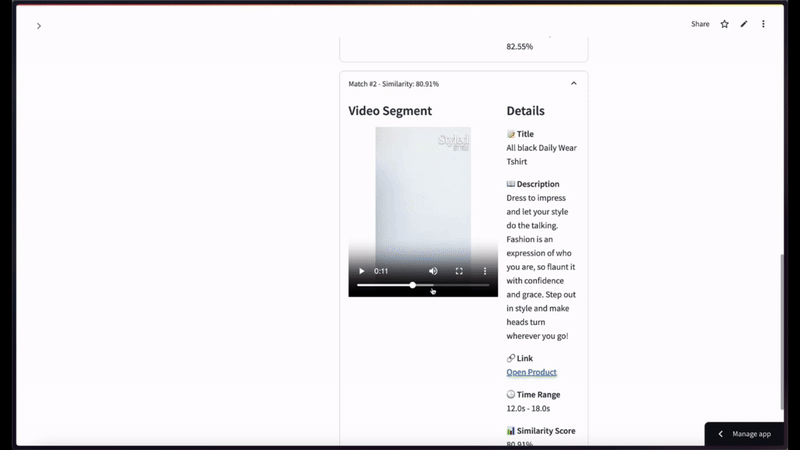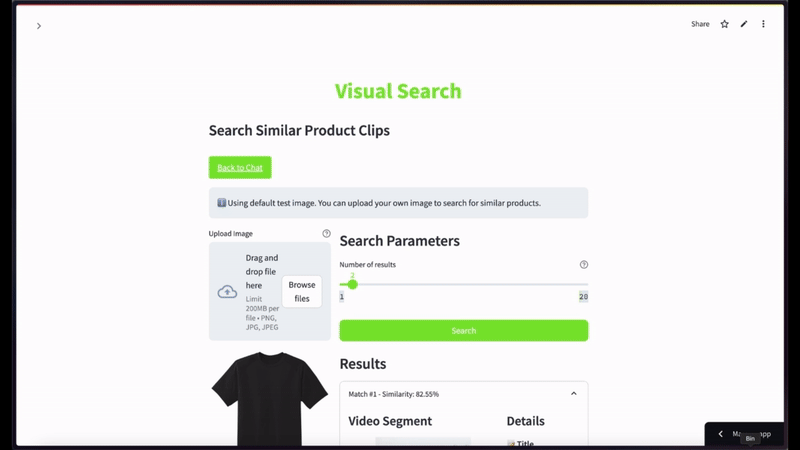
한 걸음 더 나아가기: 비즈니스 응용 아이디어
이 가이드를 통해 애플리케이션의 핵심 원리와 흐름을 이해하셨다면, 실제 서비스 현장에서 사용자의 여러 페인 포인트를 날렵하게 처리할 다양하고 혁신적인 비즈니스 장치로 활용 또는 이식하실 수 있습니다. 응용해 볼 수 있는 대표 시나리오들은 다음과 같습니다:
🛍️ 개인화 이커머스 솔루션: 텍스트 및 실시간 사진 전송 질의 과정을 결합하여 시각 패턴에 지극히 부합하는 초밀착 상품 필터 정합 구현
🎵 음원 및 취향 미디어 매칭: 단순 분위기 텍스트 묘사나 유사 멜로디 파형 등을 도구로 고도화된 음원 소스 큐레이션망 기획
🎥 똑똑해진 지능형 비디오 포털: 영상 크리에이터, 뉴스 편집국 및 미디어 연구원들을 위해 다량의 영상 아카이브 속 시각 및 오디오 신호를 짚어 정밀 추적해 주는 전문 검색 엔진 개발
🗺️ 사용자 맞춤형 여행 코디 구축: 개인 가계부 정보나 선호 관광 스타일, 리뷰 텍스트를 파악해 최적의 이동 동선 컨텍스트 수립
📚 통합 에듀테크 콘텐츠 클러스터 정비: 방대하게 분산된 프레젠테이션 파일, 비디오 클립 강의 및 실습 텍스트 자료를 내용물 핵심 키워드로 연동 정리해 탐색 능률 최상화
마치며
이 튜토리얼은 Twelve Labs API와 Milvus 벡터 데이터베이스 결합을 통해 다차원 임베딩 기반의 멀티모달 검색이 실제 비즈니스 모델로 어떻게 정교하게 안착할 수 있는지 실질적인 모범 사례를 보였습니다. 개발자는 이 단순하지만 막강한 통합 아키텍처를 발판 삼아 방대한 동영상 자산과 텍스트를 세련되게 요리할 고성능 애플리케이션을 유연하게 발굴할 수 있습니다. 여정을 함께해 주셔서 감사드리며, 실제 제품에서 맞닥뜨릴 여러 한계를 슬기롭게 돌파할 훌륭한 응용 도전을 언제나 뜨겁게 응원합니다.
추가 리소스
고도화된 비디오 의미 이해를 선도하는 Marengo-retrieval-2.7 임베딩 엔진에 관해 자세한 정보가 필요하거나, Twelve Labs의 고성능 멀티모달 AI 분석 기술을 깊이 있게 학습하려면 다음 공간들을 방문해 보시기 바랍니다:
공식 Discord 개발자 커뮤니티: 업계 다양한 엔지니어 및 기술 애호가들과 토론하고, 다양한 사용 팁과 크리에이티브한 영감을 역동적으로 교환해 보세요.
쇼케이스 가이드: 실전 비즈니스 영감을 불어넣어 줄 참신하고 흥미로운 실전 응용 앱 형태의 샘플 데모를 다양하게 연구하고 빌드해 보세요.
튜토리얼 보관소: 입문 코드 수준부터 대규모 구조 구축 훈련 단계까지, 유용한 핵심 노하우 기술 아티클로 전문 지식의 지평을 한 차원 더 넓히세요.
Twelve Labs의 탁월한 비디오 이해 AI 솔루션을 토대로 혁신의 문을 활짝 열어 가시기를 기대합니다.
소개
언제 어디서나 나의 말뿐 아니라 시각적 취향까지도 온전히 이해하는 개인 패션 어드바이저가 있다면 어떨지 상상해 보셨나요? 마음에 드는 의상 사진을 보여주면 AI가 유사한 스타일을 즉시 제안해 주거나, 꿈꾸던 룩을 묘사하면 딱 맞는 코디를 추천해 주는 세상을 경험해 보세요 👚
Twelve Labs의 패션 AI 어시스턴트 애플리케이션은 차세대 상품 검색을 위해 설계되었습니다. 본 튜토리얼에서는 멀티모달 검색과 대화형 AI를 결합한 고도화된 패션 추천 시스템을 살펴봅니다. 이 시스템은 TwelveLabs Embed - Marengo-retrieval-2.7 모델을 활용하여 텍스트와 비디오 콘텐츠 모두에서 벡터 임베딩을 생성하므로, 서로 다른 데이터 타입 간에도 매끄러운 검색이 가능합니다.
본 애플리케이션은 효율적인 유사도 검색을 위한 벡터 데이터베이스로 Milvus를 사용하며, 자연어 처리를 위해 OpenAI의 gpt-3.5를 통합했습니다. 텍스트와 이미지 입력을 통해 패션 관련 질의를 처리하고, 관련 상품 설명과 함께 정확한 비디오 타임스탬프를 찾아내어 사용자가 원하는 아이템이 영상의 어느 부분에 등장하는지 정확히 보여줍니다.
이 강력한 조합을 통해 텍스트와 시각적 질의를 모두 이해하고, 멀티모달 콘텐츠로 풍부해진 맥락 맞춤형 답변을 제공하는 시스템이 완성됩니다.
이 애플리케이션이 어떻게 작동하는지 살펴보고, TwelveLabs Python SDK 및 Milvus Python SDK를 활용해 유사한 솔루션을 직접 구축하는 방법을 알아보겠습니다.
애플리케이션 데모는 여기에서 확인하실 수 있습니다: 패션 AI 챗 앱 데모.
코드를 직접 확인하고 앱을 실행해 보고 싶다면 다음 Replit 템플릿을 활용하세요.
사전 준비 사항
Twelve Labs Playground에 가입하여 API 키를 생성합니다.
설치 가이드에 따라 Milvus 서버를 설치하고 설정합니다.
이 애플리케이션의 소스 코드는 패션 AI 챗 애플리케이션 저장소에서 확인하실 수 있습니다.
Python, Streamlit, CSS에 대한 기본적인 이해가 필요합니다.
애플리케이션 작동 원리
애플리케이션이 작동하는 방식과 각 구성 요소가 상호작용하는 흐름은 다음과 같습니다:
이 애플리케이션은 크게 세 가지 주요 기능을 제공합니다:
임베딩 생성 및 Milvus 벡터 데이터베이스 삽입
쿼리 이미지 기반 비디오 구간(Segment) 검색
멀티모달 검색(텍스트 및 비디오 구간)을 위한 검색 증강 생성(RAG)
본 튜토리얼 앱은 Twelve Labs Embed - Marengo-retrieval-2.7 모델을 사용하여 상품 카탈로그 데이터를 벡터 데이터베이스에 저장하는 방법을 보여줍니다. 텍스트와 비디오 콘텐츠의 임베딩은 동일한 Milvus 벡터 데이터베이스 컬렉션에 함께 저장됩니다. 코드의 명확성과 재사용성을 위해 Twelve Labs 임베딩 생성 함수는 각 유틸리티 함수 내에 정의되어 있습니다.
애플리케이션을 정상적으로 작동시키려면 임베딩 데이터를 컬렉션에 추가해야 합니다. 직접 구축하는 대신 본 애플리케이션에 사용된 샘플 데이터를 여기에서 다운로드하여 활용할 수도 있습니다.
준비 동작
Twelve Labs Playground에서 API 키를 발급받아 환경 변수로 설정합니다.
GitHub에서 프로젝트를 복제하거나 Replit 템플릿을 사용하세요. 가상 환경이 미리 구성되어 있는 Replit 템플릿 사용을 권장합니다. 설정 중에 시크릿 파일을 추가하고 Replit 보안 키 문서를 참고하는 것을 잊지 마세요.
Twelve Labs, Milvus 연결 정보, 그리고 LLM 모델용 OpenAI API 키를 포함하는
.env파일을 생성합니다.
Milvus 벡터 데이터베이스의 경우 Zilliz Cloud를 기준으로 자격 증명이 구성되어 있으나, 다른 연결 방식은 설치 가이드를 참고하시기 바랍니다.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
이 단계들을 완료하셨다면 이제 본격적인 개발을 시작할 준비가 되었습니다!
패션 챗 애플리케이션 가이드
이번 튜토리얼에서는 직관적이고 심플한 프론트엔드를 갖춘 Streamlit 애플리케이션을 만들어 보겠습니다. 프로젝트의 디렉토리 구조는 다음과 같습니다:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit 애플리케이션 만들기
환경 설정이 끝났으니 이제 Streamlit 애플리케이션을 구축할 차례입니다.
가상 환경 구성을 위해 필요한 종속성 목록은 다음에서 확인하실 수 있습니다: requirements.txt
파이썬 가상 환경을 생성한 후, 아래 명령어를 실행하여 애플리케이션에 필요한 패키지들을 설치하세요:
pip install -r requirements.txt
유틸리티 함수 정의하기
이 섹션에서는 핵심 비즈니스 로직과 구현체가 포함된 utils.py 파일을 설명합니다. 각 세부 단계를 차례로 살펴보겠습니다:
1 - 연결(Connection) 설정
첫 번째 단계로 환경 변수를 로드하고 LLM 접근을 위한 OpenAI, 컬렉션 관리를 위한 Milvus, 그리고 Twelve Labs SDK 초기화를 진행하여 연결을 수립합니다.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API를 사용한 임베딩 생성
이 섹션에서는 Twelve Labs SDK의 Marengo-retrieval-2.7 모델을 사용하여 멀티모달 검색을 위한 임베딩을 생성하는 방법에 대해 설명합니다. 텍스트와 비디오 프로세싱을 통합하여 고성능 검색 임베딩을 원활하게 생성합니다.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
이 프로세스는 일관되고 유의미한 임베딩을 확보하기 위해 텍스트의 구조를 잡고 포맷팅하는 데서 출발합니다. 이어 상태 모니터링 및 진행 상황 추적과 함께 비디오 임베딩이 순차적으로 작동합니다. 이 튜토리얼에서 각 비디오 세그먼트는 6초 단위(video_clip_length=6)로 분할 및 인코딩되도록 설정되었습니다.
추적 가능성을 유지하고 정확한 비디오 세그먼트 및 텍스트 검색을 구현하기 위해서는 메타데이터 관리가 필수적입니다. 임베딩 작업이 끝나면 그 결과물은 Milvus 벡터 데이터베이스 컬렉션에 바로 저장됩니다.
3 - Milvus 벡터 데이터베이스에 임베딩 저장하기
벡터 데이터베이스는 고차원의 임베딩 데이터를 효율적으로 저장하고 초고속으로 조회할 수 있게 돕습니다. 본 단락에서는 적절한 메타데이터 관리와 예외 처리 프로세스를 통해 텍스트 및 비디오 임베딩을 Milvus 컬렉션에 동시에 밀어 넣는 방법을 살펴봅니다.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID, 벡터, 메타데이터를 올바르게 정의한 뒤, 동일한 컬렉션 공간 내에서도 포맷이 다른 데이터를 유연하게 다룰 수 있도록 embedding_type 필드를 별도로 명시해 줍니다. 최종 가공된 데이터는 collection.insert 메소드를 통해 일괄 반영됩니다.
4 - 이미지 대 비디오 검색을 위한 시맨틱 검색 구현
이미지 입력을 쿼리로 삼아 시맨틱 검색을 수행하면 이와 유사한 성격의 비디오 내 장면들을 손쉽게 골라낼 수 있습니다. 이 과정은 Twelve Labs 임베딩 기능과 Milvus의 벡터 유사도 검색 메커니즘이 조화롭게 결합되어 동작합니다. 아래는 유틸리티 함수인 searched_similar_videos가 동작하는 원리 구조입니다:
먼저, 시스템은 제공된 상품 이미지를 읽어 들인 뒤, 해당 상품과 시각적으로 유사한 상품이 포함된 비디오 세그먼트를 찾기 시작합니다. Twelve Labs Embed API를 통해 이 이미지를 밀도 높은 임베딩 벡터로 정형화한 후, Milvus 컬렉션에 적재되어 있던 비디오 임베딩과의 정밀한 비교 연산을 수행합니다.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
검색 모듈은 코사인 유사도(Cosine Similarity) 평가지표와 고차원 탐색용 인덱스 인자를 적용하여, 반환 주기와 정확도 간 최적의 균형값을 잡을 수 있도록 제어합니다. embedding_type == 'video' 속성과 여타 필요한 논리 표현을 활용해 collection.search를 수행하면, 매칭률이 높은 비디오 세그먼트들을 원하는 개수만큼 깔끔하게 회수해 줍니다.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
마지막으로 이 유사도 지수를 사용자가 파악하기 가장 편안한 형태인 '백분율(%)' 정보로 다듬고, 타임라인 구간 정보 등 제반 메타데이터를 정제된 사전식 구조로 조립합니다.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
정렬이 마무리된 결과 데이터는 사용자 인터페이스를 통해 훌륭하게 출력될 수 있습니다. UI 구현부는 visual_search.py 파일에서 확인하실 수 있습니다.
5 - 검색 증강 생성(RAG) 시스템 설계하기
이 섹션에서는 패션 어시스턴트 컨텍스트에서 질의응답을 구현하는 데 초점을 맞추며, 멀티모달 검색과 LLM(gpt-3.5)을 결합하여 맥락에 부합하는 응답을 제공합니다. 효과적인 개인화를 유도하기 위해 텍스트와 비디오 등의 원천 데이터로부터 메타데이터 정보를 밀도 높게 이끌어 내는 과정이 핵심입니다. 이 흐름의 핵심 기능은 get_rag_response 함수로 제어합니다.
동작 시 가장 먼저, 사용자 질문과 맥락을 Twelve Labs의 Marengo-retrieval-2.7 임베딩 모델로 전송하여 벡터 데이터로 가공해 시맨틱 조회가 가능하도록 사전 작업을 마칩니다.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
시맨틱 검색 매개변수를 구성한 후, 시스템은 텍스트 및 비디오 세그먼트에 대해 각각 데이터베이스를 독자적으로 조회합니다. 이때 연관 비디오 구간까지 동시에 필터링하여 사용자에게 매우 다채로운 입체적인 탐색 옵션을 보장하게 됩니다.
expr 처리를 통해 검출 조건을 통교히 가다듬고, 각각 텍스트 중심은 2개, 비디오 구간 측은 3개 매장 정도로 일치 정합 제한 한도를 적절히 다듬어 줍니다.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
이어서 결과물을 객체화하는 동안 메타정보를 온전히 취득하고, 획득 유사 점수를 알기 쉬운 백분율 정보로 순화하여 수려하게 구조화합니다.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
유의미한 정보 자산이 전부 수집되고 나면, LLM 모델 지능과 안전하게 결합할 대화형 RAG 준비 단계로 자연스럽게 이동합니다. 정형화된 Context 형태로 전처리되어 언어 모델에 정갈하게 정렬 인가됩니다.
시스템 프롬프트(System Prompt)와 유저 프롬프트(User Prompt)를 세밀하게 정의합니다. 시스템 프롬프트는 전문 패션 조언가로서 가이드의 역할을 설정하고, 유저 프롬프트는 실제 질문 요구사항을 실시간 탐색 영역에 단단히 결합합니다. 중간 조회 오류나 부재 등의 상황을 방지하기 위한 안전 예외 구문도 유연하게 준비합니다.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
준비된 text_context 데이터를 활용해, gpt-3.5-turbo 모델이 지시에 따라 일관성 있고 풍부한 스타일 팁을 담은 최종 자연어 응답을 구조화해 출력합니다. 유려하게 포장된 사전(dictionary) 형태의 결과를 프론트엔드로 즉시 넘겨주어 화면에 띄울 수 있도록 설계되었습니다. UI 세부 사항은 app.py에서 직접 감상해 보시기 바랍니다.
데모 애플리케이션
이 데모 프로그램은 크게 3개의 실용 컴포넌트로 나뉘어 작동하며, 데이터 관리자 편익 및 역동적인 대화형 멀티모달 서비스 기획자들에게 최적의 사용 가치를 제공하도록 기획되었습니다.
검색 질의 대상이 될 원본 텍스트 및 비디오 임베딩의 빠른 생성 및 데이터베이스 삽입 처리
LLM 및 멀티모달 정렬 기법을 적용한 채팅 상호작용 기반의 맞춤 결과 추려내기
시각적 제품 스크린샷 이미지 입력을 수단으로 한 고성능 비디오 세그먼트 매칭
우리가 다룰 데이터 모델 카탈로그 정보에는 기본 일련번호를 시작으로 메타 내용물, 상세 연동 커머스 외부 링크 및 비디오 고유 원천 URL 등의 실용 구성 요소가 포함되어 조화롭게 정렬됩니다. 이 흐름을 거쳐 비디오 정보는 세그먼트 벡터로 변환되고 나머지 설명 정보는 고유 속성 메타에 통합된 후 결국 원형 컬렉션 하나에 수려히 조립 적재됩니다.
멀티모달 대화형 질문 예시로, "남성용 검은색 티셔츠 종류 좀 보여줘"라고 질문했을 때의 반환 장면입니다 —
만약 사용자가 검은색 반소매 티셔츠 화상을 넣고 상위 2건 정도로 시맨틱 비디오 검색을 한정 요청했을 때 표출되는 유려한 캡처 씬입니다 —
한 걸음 더 나아가기: 비즈니스 응용 아이디어
이 가이드를 통해 애플리케이션의 핵심 원리와 흐름을 이해하셨다면, 실제 서비스 현장에서 사용자의 여러 페인 포인트를 날렵하게 처리할 다양하고 혁신적인 비즈니스 장치로 활용 또는 이식하실 수 있습니다. 응용해 볼 수 있는 대표 시나리오들은 다음과 같습니다:
🛍️ 개인화 이커머스 솔루션: 텍스트 및 실시간 사진 전송 질의 과정을 결합하여 시각 패턴에 지극히 부합하는 초밀착 상품 필터 정합 구현
🎵 음원 및 취향 미디어 매칭: 단순 분위기 텍스트 묘사나 유사 멜로디 파형 등을 도구로 고도화된 음원 소스 큐레이션망 기획
🎥 똑똑해진 지능형 비디오 포털: 영상 크리에이터, 뉴스 편집국 및 미디어 연구원들을 위해 다량의 영상 아카이브 속 시각 및 오디오 신호를 짚어 정밀 추적해 주는 전문 검색 엔진 개발
🗺️ 사용자 맞춤형 여행 코디 구축: 개인 가계부 정보나 선호 관광 스타일, 리뷰 텍스트를 파악해 최적의 이동 동선 컨텍스트 수립
📚 통합 에듀테크 콘텐츠 클러스터 정비: 방대하게 분산된 프레젠테이션 파일, 비디오 클립 강의 및 실습 텍스트 자료를 내용물 핵심 키워드로 연동 정리해 탐색 능률 최상화
마치며
이 튜토리얼은 Twelve Labs API와 Milvus 벡터 데이터베이스 결합을 통해 다차원 임베딩 기반의 멀티모달 검색이 실제 비즈니스 모델로 어떻게 정교하게 안착할 수 있는지 실질적인 모범 사례를 보였습니다. 개발자는 이 단순하지만 막강한 통합 아키텍처를 발판 삼아 방대한 동영상 자산과 텍스트를 세련되게 요리할 고성능 애플리케이션을 유연하게 발굴할 수 있습니다. 여정을 함께해 주셔서 감사드리며, 실제 제품에서 맞닥뜨릴 여러 한계를 슬기롭게 돌파할 훌륭한 응용 도전을 언제나 뜨겁게 응원합니다.
추가 리소스
고도화된 비디오 의미 이해를 선도하는 Marengo-retrieval-2.7 임베딩 엔진에 관해 자세한 정보가 필요하거나, Twelve Labs의 고성능 멀티모달 AI 분석 기술을 깊이 있게 학습하려면 다음 공간들을 방문해 보시기 바랍니다:
공식 Discord 개발자 커뮤니티: 업계 다양한 엔지니어 및 기술 애호가들과 토론하고, 다양한 사용 팁과 크리에이티브한 영감을 역동적으로 교환해 보세요.
쇼케이스 가이드: 실전 비즈니스 영감을 불어넣어 줄 참신하고 흥미로운 실전 응용 앱 형태의 샘플 데모를 다양하게 연구하고 빌드해 보세요.
튜토리얼 보관소: 입문 코드 수준부터 대규모 구조 구축 훈련 단계까지, 유용한 핵심 노하우 기술 아티클로 전문 지식의 지평을 한 차원 더 넓히세요.
Twelve Labs의 탁월한 비디오 이해 AI 솔루션을 토대로 혁신의 문을 활짝 열어 가시기를 기대합니다.
소개
언제 어디서나 나의 말뿐 아니라 시각적 취향까지도 온전히 이해하는 개인 패션 어드바이저가 있다면 어떨지 상상해 보셨나요? 마음에 드는 의상 사진을 보여주면 AI가 유사한 스타일을 즉시 제안해 주거나, 꿈꾸던 룩을 묘사하면 딱 맞는 코디를 추천해 주는 세상을 경험해 보세요 👚
Twelve Labs의 패션 AI 어시스턴트 애플리케이션은 차세대 상품 검색을 위해 설계되었습니다. 본 튜토리얼에서는 멀티모달 검색과 대화형 AI를 결합한 고도화된 패션 추천 시스템을 살펴봅니다. 이 시스템은 TwelveLabs Embed - Marengo-retrieval-2.7 모델을 활용하여 텍스트와 비디오 콘텐츠 모두에서 벡터 임베딩을 생성하므로, 서로 다른 데이터 타입 간에도 매끄러운 검색이 가능합니다.
본 애플리케이션은 효율적인 유사도 검색을 위한 벡터 데이터베이스로 Milvus를 사용하며, 자연어 처리를 위해 OpenAI의 gpt-3.5를 통합했습니다. 텍스트와 이미지 입력을 통해 패션 관련 질의를 처리하고, 관련 상품 설명과 함께 정확한 비디오 타임스탬프를 찾아내어 사용자가 원하는 아이템이 영상의 어느 부분에 등장하는지 정확히 보여줍니다.
이 강력한 조합을 통해 텍스트와 시각적 질의를 모두 이해하고, 멀티모달 콘텐츠로 풍부해진 맥락 맞춤형 답변을 제공하는 시스템이 완성됩니다.
이 애플리케이션이 어떻게 작동하는지 살펴보고, TwelveLabs Python SDK 및 Milvus Python SDK를 활용해 유사한 솔루션을 직접 구축하는 방법을 알아보겠습니다.
애플리케이션 데모는 여기에서 확인하실 수 있습니다: 패션 AI 챗 앱 데모.
코드를 직접 확인하고 앱을 실행해 보고 싶다면 다음 Replit 템플릿을 활용하세요.
사전 준비 사항
Twelve Labs Playground에 가입하여 API 키를 생성합니다.
설치 가이드에 따라 Milvus 서버를 설치하고 설정합니다.
이 애플리케이션의 소스 코드는 패션 AI 챗 애플리케이션 저장소에서 확인하실 수 있습니다.
Python, Streamlit, CSS에 대한 기본적인 이해가 필요합니다.
애플리케이션 작동 원리
애플리케이션이 작동하는 방식과 각 구성 요소가 상호작용하는 흐름은 다음과 같습니다:
이 애플리케이션은 크게 세 가지 주요 기능을 제공합니다:
임베딩 생성 및 Milvus 벡터 데이터베이스 삽입
쿼리 이미지 기반 비디오 구간(Segment) 검색
멀티모달 검색(텍스트 및 비디오 구간)을 위한 검색 증강 생성(RAG)
본 튜토리얼 앱은 Twelve Labs Embed - Marengo-retrieval-2.7 모델을 사용하여 상품 카탈로그 데이터를 벡터 데이터베이스에 저장하는 방법을 보여줍니다. 텍스트와 비디오 콘텐츠의 임베딩은 동일한 Milvus 벡터 데이터베이스 컬렉션에 함께 저장됩니다. 코드의 명확성과 재사용성을 위해 Twelve Labs 임베딩 생성 함수는 각 유틸리티 함수 내에 정의되어 있습니다.
애플리케이션을 정상적으로 작동시키려면 임베딩 데이터를 컬렉션에 추가해야 합니다. 직접 구축하는 대신 본 애플리케이션에 사용된 샘플 데이터를 여기에서 다운로드하여 활용할 수도 있습니다.
준비 동작
Twelve Labs Playground에서 API 키를 발급받아 환경 변수로 설정합니다.
GitHub에서 프로젝트를 복제하거나 Replit 템플릿을 사용하세요. 가상 환경이 미리 구성되어 있는 Replit 템플릿 사용을 권장합니다. 설정 중에 시크릿 파일을 추가하고 Replit 보안 키 문서를 참고하는 것을 잊지 마세요.
Twelve Labs, Milvus 연결 정보, 그리고 LLM 모델용 OpenAI API 키를 포함하는
.env파일을 생성합니다.
Milvus 벡터 데이터베이스의 경우 Zilliz Cloud를 기준으로 자격 증명이 구성되어 있으나, 다른 연결 방식은 설치 가이드를 참고하시기 바랍니다.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
이 단계들을 완료하셨다면 이제 본격적인 개발을 시작할 준비가 되었습니다!
패션 챗 애플리케이션 가이드
이번 튜토리얼에서는 직관적이고 심플한 프론트엔드를 갖춘 Streamlit 애플리케이션을 만들어 보겠습니다. 프로젝트의 디렉토리 구조는 다음과 같습니다:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Streamlit 애플리케이션 만들기
환경 설정이 끝났으니 이제 Streamlit 애플리케이션을 구축할 차례입니다.
가상 환경 구성을 위해 필요한 종속성 목록은 다음에서 확인하실 수 있습니다: requirements.txt
파이썬 가상 환경을 생성한 후, 아래 명령어를 실행하여 애플리케이션에 필요한 패키지들을 설치하세요:
pip install -r requirements.txt
유틸리티 함수 정의하기
이 섹션에서는 핵심 비즈니스 로직과 구현체가 포함된 utils.py 파일을 설명합니다. 각 세부 단계를 차례로 살펴보겠습니다:
1 - 연결(Connection) 설정
첫 번째 단계로 환경 변수를 로드하고 LLM 접근을 위한 OpenAI, 컬렉션 관리를 위한 Milvus, 그리고 Twelve Labs SDK 초기화를 진행하여 연결을 수립합니다.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Twelve Labs Embed API를 사용한 임베딩 생성
이 섹션에서는 Twelve Labs SDK의 Marengo-retrieval-2.7 모델을 사용하여 멀티모달 검색을 위한 임베딩을 생성하는 방법에 대해 설명합니다. 텍스트와 비디오 프로세싱을 통합하여 고성능 검색 임베딩을 원활하게 생성합니다.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
이 프로세스는 일관되고 유의미한 임베딩을 확보하기 위해 텍스트의 구조를 잡고 포맷팅하는 데서 출발합니다. 이어 상태 모니터링 및 진행 상황 추적과 함께 비디오 임베딩이 순차적으로 작동합니다. 이 튜토리얼에서 각 비디오 세그먼트는 6초 단위(video_clip_length=6)로 분할 및 인코딩되도록 설정되었습니다.
추적 가능성을 유지하고 정확한 비디오 세그먼트 및 텍스트 검색을 구현하기 위해서는 메타데이터 관리가 필수적입니다. 임베딩 작업이 끝나면 그 결과물은 Milvus 벡터 데이터베이스 컬렉션에 바로 저장됩니다.
3 - Milvus 벡터 데이터베이스에 임베딩 저장하기
벡터 데이터베이스는 고차원의 임베딩 데이터를 효율적으로 저장하고 초고속으로 조회할 수 있게 돕습니다. 본 단락에서는 적절한 메타데이터 관리와 예외 처리 프로세스를 통해 텍스트 및 비디오 임베딩을 Milvus 컬렉션에 동시에 밀어 넣는 방법을 살펴봅니다.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
ID, 벡터, 메타데이터를 올바르게 정의한 뒤, 동일한 컬렉션 공간 내에서도 포맷이 다른 데이터를 유연하게 다룰 수 있도록 embedding_type 필드를 별도로 명시해 줍니다. 최종 가공된 데이터는 collection.insert 메소드를 통해 일괄 반영됩니다.
4 - 이미지 대 비디오 검색을 위한 시맨틱 검색 구현
이미지 입력을 쿼리로 삼아 시맨틱 검색을 수행하면 이와 유사한 성격의 비디오 내 장면들을 손쉽게 골라낼 수 있습니다. 이 과정은 Twelve Labs 임베딩 기능과 Milvus의 벡터 유사도 검색 메커니즘이 조화롭게 결합되어 동작합니다. 아래는 유틸리티 함수인 searched_similar_videos가 동작하는 원리 구조입니다:
먼저, 시스템은 제공된 상품 이미지를 읽어 들인 뒤, 해당 상품과 시각적으로 유사한 상품이 포함된 비디오 세그먼트를 찾기 시작합니다. Twelve Labs Embed API를 통해 이 이미지를 밀도 높은 임베딩 벡터로 정형화한 후, Milvus 컬렉션에 적재되어 있던 비디오 임베딩과의 정밀한 비교 연산을 수행합니다.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
검색 모듈은 코사인 유사도(Cosine Similarity) 평가지표와 고차원 탐색용 인덱스 인자를 적용하여, 반환 주기와 정확도 간 최적의 균형값을 잡을 수 있도록 제어합니다. embedding_type == 'video' 속성과 여타 필요한 논리 표현을 활용해 collection.search를 수행하면, 매칭률이 높은 비디오 세그먼트들을 원하는 개수만큼 깔끔하게 회수해 줍니다.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
마지막으로 이 유사도 지수를 사용자가 파악하기 가장 편안한 형태인 '백분율(%)' 정보로 다듬고, 타임라인 구간 정보 등 제반 메타데이터를 정제된 사전식 구조로 조립합니다.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
정렬이 마무리된 결과 데이터는 사용자 인터페이스를 통해 훌륭하게 출력될 수 있습니다. UI 구현부는 visual_search.py 파일에서 확인하실 수 있습니다.
5 - 검색 증강 생성(RAG) 시스템 설계하기
이 섹션에서는 패션 어시스턴트 컨텍스트에서 질의응답을 구현하는 데 초점을 맞추며, 멀티모달 검색과 LLM(gpt-3.5)을 결합하여 맥락에 부합하는 응답을 제공합니다. 효과적인 개인화를 유도하기 위해 텍스트와 비디오 등의 원천 데이터로부터 메타데이터 정보를 밀도 높게 이끌어 내는 과정이 핵심입니다. 이 흐름의 핵심 기능은 get_rag_response 함수로 제어합니다.
동작 시 가장 먼저, 사용자 질문과 맥락을 Twelve Labs의 Marengo-retrieval-2.7 임베딩 모델로 전송하여 벡터 데이터로 가공해 시맨틱 조회가 가능하도록 사전 작업을 마칩니다.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
시맨틱 검색 매개변수를 구성한 후, 시스템은 텍스트 및 비디오 세그먼트에 대해 각각 데이터베이스를 독자적으로 조회합니다. 이때 연관 비디오 구간까지 동시에 필터링하여 사용자에게 매우 다채로운 입체적인 탐색 옵션을 보장하게 됩니다.
expr 처리를 통해 검출 조건을 통교히 가다듬고, 각각 텍스트 중심은 2개, 비디오 구간 측은 3개 매장 정도로 일치 정합 제한 한도를 적절히 다듬어 줍니다.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
이어서 결과물을 객체화하는 동안 메타정보를 온전히 취득하고, 획득 유사 점수를 알기 쉬운 백분율 정보로 순화하여 수려하게 구조화합니다.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
유의미한 정보 자산이 전부 수집되고 나면, LLM 모델 지능과 안전하게 결합할 대화형 RAG 준비 단계로 자연스럽게 이동합니다. 정형화된 Context 형태로 전처리되어 언어 모델에 정갈하게 정렬 인가됩니다.
시스템 프롬프트(System Prompt)와 유저 프롬프트(User Prompt)를 세밀하게 정의합니다. 시스템 프롬프트는 전문 패션 조언가로서 가이드의 역할을 설정하고, 유저 프롬프트는 실제 질문 요구사항을 실시간 탐색 영역에 단단히 결합합니다. 중간 조회 오류나 부재 등의 상황을 방지하기 위한 안전 예외 구문도 유연하게 준비합니다.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
준비된 text_context 데이터를 활용해, gpt-3.5-turbo 모델이 지시에 따라 일관성 있고 풍부한 스타일 팁을 담은 최종 자연어 응답을 구조화해 출력합니다. 유려하게 포장된 사전(dictionary) 형태의 결과를 프론트엔드로 즉시 넘겨주어 화면에 띄울 수 있도록 설계되었습니다. UI 세부 사항은 app.py에서 직접 감상해 보시기 바랍니다.
데모 애플리케이션
이 데모 프로그램은 크게 3개의 실용 컴포넌트로 나뉘어 작동하며, 데이터 관리자 편익 및 역동적인 대화형 멀티모달 서비스 기획자들에게 최적의 사용 가치를 제공하도록 기획되었습니다.
검색 질의 대상이 될 원본 텍스트 및 비디오 임베딩의 빠른 생성 및 데이터베이스 삽입 처리
LLM 및 멀티모달 정렬 기법을 적용한 채팅 상호작용 기반의 맞춤 결과 추려내기
시각적 제품 스크린샷 이미지 입력을 수단으로 한 고성능 비디오 세그먼트 매칭
우리가 다룰 데이터 모델 카탈로그 정보에는 기본 일련번호를 시작으로 메타 내용물, 상세 연동 커머스 외부 링크 및 비디오 고유 원천 URL 등의 실용 구성 요소가 포함되어 조화롭게 정렬됩니다. 이 흐름을 거쳐 비디오 정보는 세그먼트 벡터로 변환되고 나머지 설명 정보는 고유 속성 메타에 통합된 후 결국 원형 컬렉션 하나에 수려히 조립 적재됩니다.
멀티모달 대화형 질문 예시로, "남성용 검은색 티셔츠 종류 좀 보여줘"라고 질문했을 때의 반환 장면입니다 —
만약 사용자가 검은색 반소매 티셔츠 화상을 넣고 상위 2건 정도로 시맨틱 비디오 검색을 한정 요청했을 때 표출되는 유려한 캡처 씬입니다 —
한 걸음 더 나아가기: 비즈니스 응용 아이디어
이 가이드를 통해 애플리케이션의 핵심 원리와 흐름을 이해하셨다면, 실제 서비스 현장에서 사용자의 여러 페인 포인트를 날렵하게 처리할 다양하고 혁신적인 비즈니스 장치로 활용 또는 이식하실 수 있습니다. 응용해 볼 수 있는 대표 시나리오들은 다음과 같습니다:
🛍️ 개인화 이커머스 솔루션: 텍스트 및 실시간 사진 전송 질의 과정을 결합하여 시각 패턴에 지극히 부합하는 초밀착 상품 필터 정합 구현
🎵 음원 및 취향 미디어 매칭: 단순 분위기 텍스트 묘사나 유사 멜로디 파형 등을 도구로 고도화된 음원 소스 큐레이션망 기획
🎥 똑똑해진 지능형 비디오 포털: 영상 크리에이터, 뉴스 편집국 및 미디어 연구원들을 위해 다량의 영상 아카이브 속 시각 및 오디오 신호를 짚어 정밀 추적해 주는 전문 검색 엔진 개발
🗺️ 사용자 맞춤형 여행 코디 구축: 개인 가계부 정보나 선호 관광 스타일, 리뷰 텍스트를 파악해 최적의 이동 동선 컨텍스트 수립
📚 통합 에듀테크 콘텐츠 클러스터 정비: 방대하게 분산된 프레젠테이션 파일, 비디오 클립 강의 및 실습 텍스트 자료를 내용물 핵심 키워드로 연동 정리해 탐색 능률 최상화
마치며
이 튜토리얼은 Twelve Labs API와 Milvus 벡터 데이터베이스 결합을 통해 다차원 임베딩 기반의 멀티모달 검색이 실제 비즈니스 모델로 어떻게 정교하게 안착할 수 있는지 실질적인 모범 사례를 보였습니다. 개발자는 이 단순하지만 막강한 통합 아키텍처를 발판 삼아 방대한 동영상 자산과 텍스트를 세련되게 요리할 고성능 애플리케이션을 유연하게 발굴할 수 있습니다. 여정을 함께해 주셔서 감사드리며, 실제 제품에서 맞닥뜨릴 여러 한계를 슬기롭게 돌파할 훌륭한 응용 도전을 언제나 뜨겁게 응원합니다.
추가 리소스
고도화된 비디오 의미 이해를 선도하는 Marengo-retrieval-2.7 임베딩 엔진에 관해 자세한 정보가 필요하거나, Twelve Labs의 고성능 멀티모달 AI 분석 기술을 깊이 있게 학습하려면 다음 공간들을 방문해 보시기 바랍니다:
공식 Discord 개발자 커뮤니티: 업계 다양한 엔지니어 및 기술 애호가들과 토론하고, 다양한 사용 팁과 크리에이티브한 영감을 역동적으로 교환해 보세요.
쇼케이스 가이드: 실전 비즈니스 영감을 불어넣어 줄 참신하고 흥미로운 실전 응용 앱 형태의 샘플 데모를 다양하게 연구하고 빌드해 보세요.
튜토리얼 보관소: 입문 코드 수준부터 대규모 구조 구축 훈련 단계까지, 유용한 핵심 노하우 기술 아티클로 전문 지식의 지평을 한 차원 더 넓히세요.
Twelve Labs의 탁월한 비디오 이해 AI 솔루션을 토대로 혁신의 문을 활짝 열어 가시기를 기대합니다.








