" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Research
Semantic Content Discovery for a Post-Production World

James Le
Semantic search is transforming media production workflows by using multimodal AI models like Twelve Labs' Marengo to let editors search vast video libraries using natural language, finding content based on meaning and context rather than relying solely on manual metadata tagging.
Semantic search is transforming media production workflows by using multimodal AI models like Twelve Labs' Marengo to let editors search vast video libraries using natural language, finding content based on meaning and context rather than relying solely on manual metadata tagging.

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
May 24, 2024
12 Min
Copy link to article
This blog post is co-authored with Rob Gonsalves - Engineering Fellow at Avid
1 - Introduction
Quickly and easily finding the perfect content in vast media libraries is crucial in the world of media production. Traditionally, this meant manually tagging media assets with keywords, but this method has its limitations in accuracy, scalability, and understanding of the context. Through AI-powered semantic search, which understands the context, meaning, and relationships between media assets by analyzing the content, users can find relevant content based on its semantic meaning— not just keywords.
Thanks to rapid advancements in multimodal AI, semantic search is now a reality in media production. Foundation models help our smart machines understand media content. They power semantic search engines that index media assets, making them searchable based on their semantic content.
Semantic search plays a huge role in media production. It helps media professionals find exactly what they need quickly, saving time and sparking new ideas for content repurposing and creative storytelling. Plus, it can uncover hidden gems that may have been overlooked due to inadequate manual tagging.
In this post, we'll explore the awesome applications and benefits of semantic search in post-production, the key technologies powering it, how it integrates with media asset management systems, and where it's headed in the future.
2 - The Evolution of Semantic Search in Media Production
2.1 - Metadata-Based Search
The transition from metadata-based searches to semantic searches represents a significant advancement in media production workflows.
Avid’s MediaCentral | Production Management and MediaCentral | Asset Management systems have successfully enabled teams of up to hundreds of users to effectively log and search metadata for many years. This has included utilizing AI services from Cloud providers to enrich metadata with automated tagging, speech to text transcription, optical character recognition and more, to generate more searchable data.
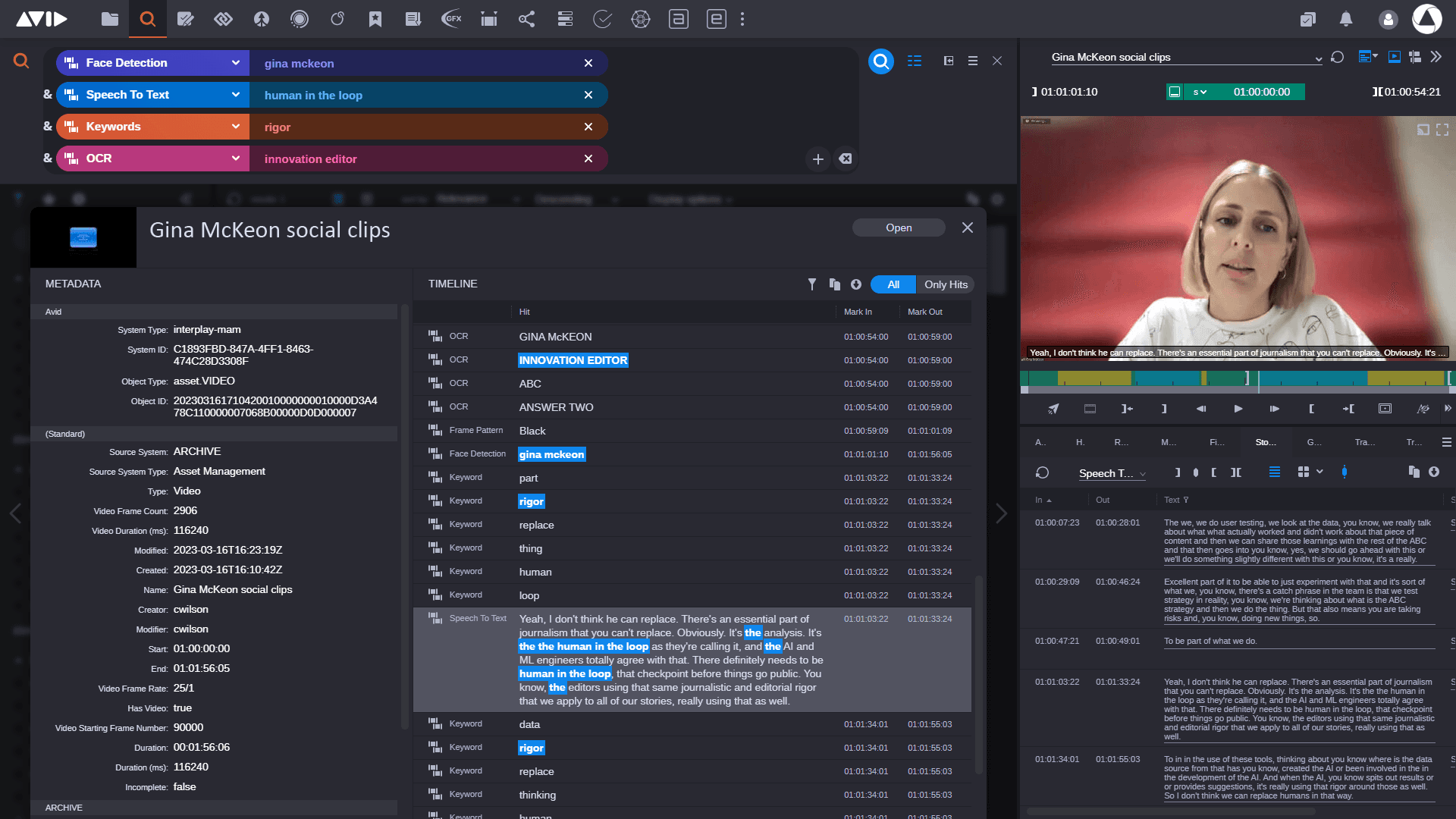
These traditional metadata-based searches rely on manually extracted information or predefined taxonomies, which, while highly effective, can limit the ability to find truly relevant content.
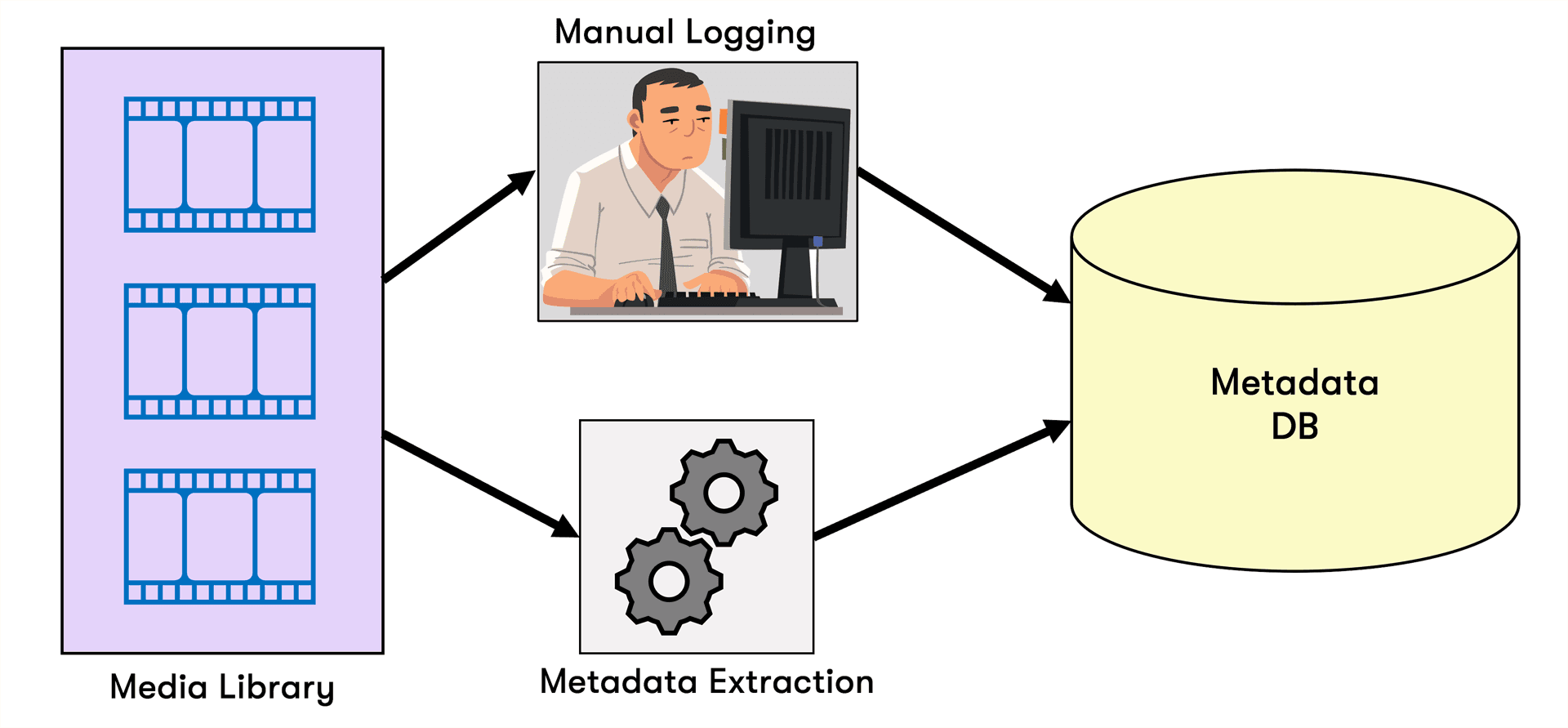
Metadata-based searches traditionally have several limitations:
Manual metadata extraction is time-consuming and prone to human error. Automated metadata extraction can help, but it still relies on predefined taxonomies and keywords, failing to capture the true context and meaning of the content.
These searches only return results that match the exact keywords or metadata, often missing out on related or semantically similar content that could be highly relevant.
2.2 - Semantic Search
In contrast, semantic search leverages state-of-the-art foundation models to understand the actual meaning and context behind the content. By analyzing the visual elements, spoken words, and other data within the media assets, semantic search engines can comprehend the underlying concepts and relationships, rather than relying solely on predefined keywords or taxonomies.
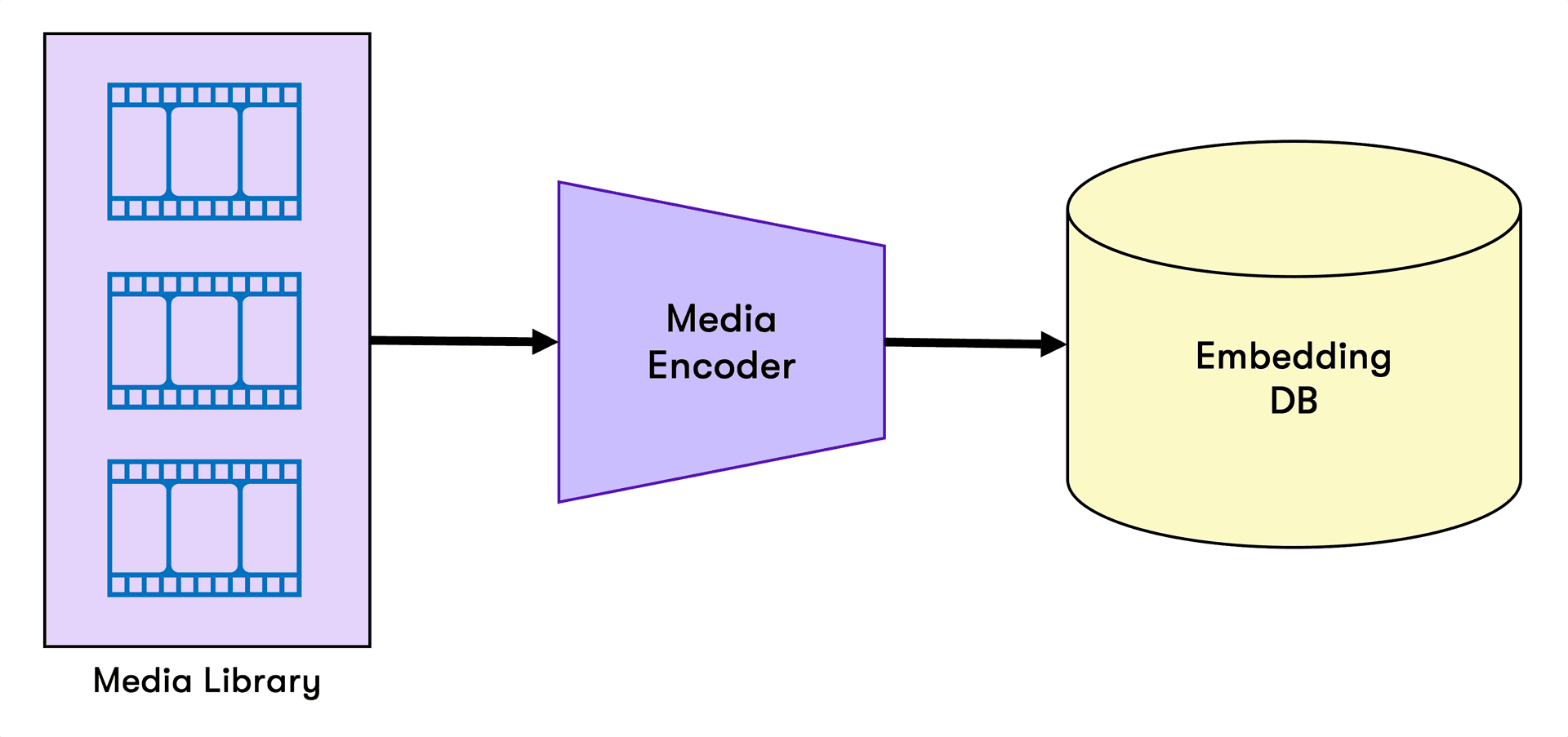
The semantic search process is depicted above:
A media encoder is a tool that takes raw media, such as videos or audio files, and converts them into a format that computer systems can understand and analyze, much like a translator that helps computers "read" media files.
During this process, it extracts features like images, sounds, and words, converting them into numerical representations called embeddings, which serve as digital fingerprints capturing the essence of the content.
These embeddings are stored in an embedding database, a digital library that allows the system to quickly locate and compare similar media files based on these numerical representations, as part of a semantic search.
Twelve Labs offers a powerful Semantic Video Search solution that simultaneously integrates all modalities inside video and captures the complex relationships among them to deliver a more nuanced, humanlike interpretation. That results in much faster and far more accurate video search and retrieval from cloud object storage. Instead of time-consuming and ineffective manual tagging, video editors can use natural language to quickly and accurately search vast media archives to unearth video moments and hidden gems that otherwise might go unnoticed.
The accuracy and efficiency of semantic search are particularly valuable in media production environments, where vast libraries of text, audio, video, and image assets need to be searched and retrieved quickly. By understanding the true meaning and context of the content, semantic search engines can deliver highly relevant results, even when the user's query does not match the exact keywords or metadata associated with the media assets.
3 - Key Technologies Powering Semantic Search
3.1 - The Foundation with CLIP
OpenAI's Contrastive Language-Image Pre-training (CLIP) model is at the heart of modern semantic search capabilities. CLIP is a neural network that learns to encode both images and text into a shared embedding space. By training on a massive dataset of image-text pairs, CLIP develops the ability to associate visual concepts with their linguistic representations.
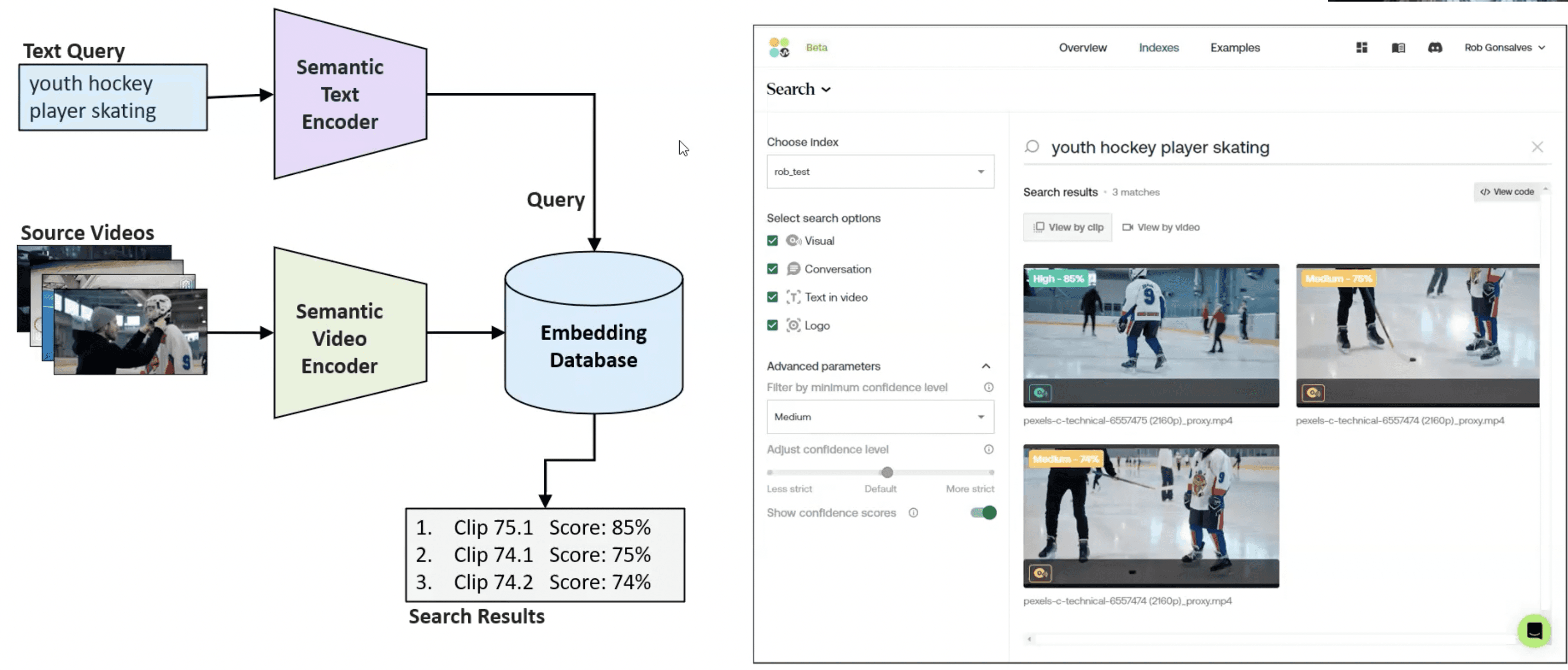
The CLIP model consists of two main components: a visual encoder and a text encoder. The visual encoder, typically a Vision Transformer (ViT), analyzes the image and generates a visual embedding. Simultaneously, the text encoder, a Transformer-based language model, encodes the text input into a textual embedding. These embeddings are then compared, and the model learns to align the visual and textual representations, enabling cross-modal retrieval and understanding. You can see how this works in the diagram below.
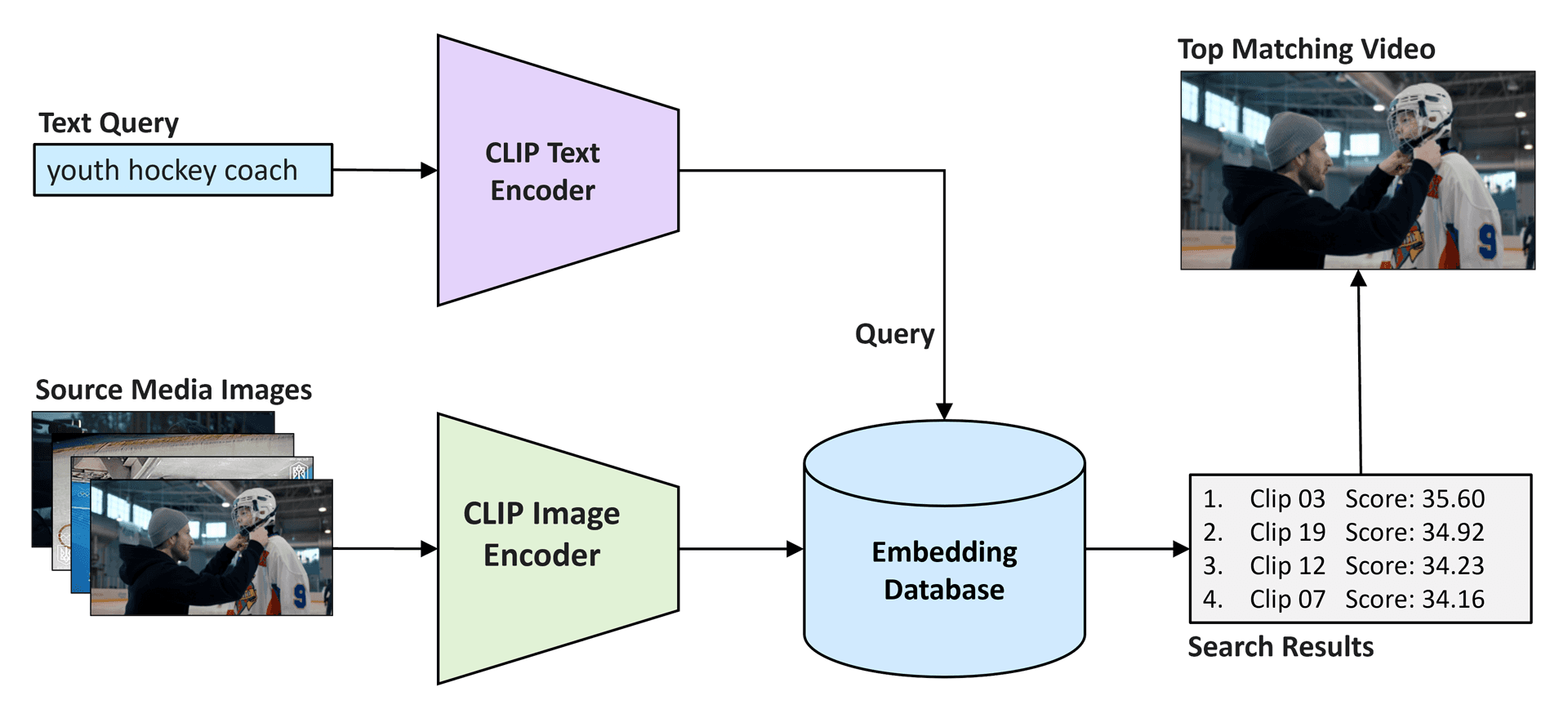
For example, if the user searches for “youth hockey coach,” CLIP encodes this text and compares it to embeddings from the media library to find matches. The system ranks video clips by relevance. The highest-scoring video closely aligns with the search, demonstrating CLIP's ability to understand and retrieve content semantically.
3.2 - CLIP Extensions
Building upon CLIP's success, researchers have developed advanced models to enhance semantic search capabilities across different media formats and languages. One notable extension is Multilingual CLIP, which extends the original CLIP text encoder to support multiple languages. By leveraging techniques like cross-lingual teacher learning, Multilingual CLIP enables cross-lingual search and retrieval, allowing users to query media content using text in various languages.
Another significant development is LAION's CLAP (Contrastive Language-Audio-Visual Pre-training) model, which incorporates audio encoding capabilities into the multi-modal framework. CLAP learns to encode audio waveforms, text data, and visual information into a shared embedding space, enabling a comprehensive semantic understanding of multimedia content.
3.3 - Marengo-2.6

Twelve Labs' Marengo-2.6 model provides advanced video encoding and retrieval capabilities for video search applications. As a state-of-the-art video foundation model, Marengo-2.6 extracts semantic features from video content, allowing users to search for and retrieve relevant video clips based on text queries or reference videos.
Astoundingly, Marengo-2.6's expanded capabilities allow for any-to-any (cross-modality) retrieval tasks, making it a versatile tool for a wide range of applications. This includes text-to-video, text-to-image, text-to-audio, audio-to-video, and image-to-video tasks, bridging different media types. Watch the webinar session below for qualitative demonstration of such capabilities:
These multimodal models work together to enhance media search capabilities across different formats and languages. CLIP and its extensions, such as Multilingual CLIP and CLAP, encode images, text, and audio into searchable embeddings. These embeddings are then stored in embedding databases, enabling efficient retrieval and matching based on semantic similarity. For video content, Marengo-2.6 leverages self-supervised learning with contrastive loss to embed and search video clips based on text queries or reference videos.
By combining these technologies, users can perform semantic searches across vast media libraries, finding relevant content based on their intent and the contextual meaning of their queries.
4 - Applications and Benefits of Semantic Search in Post-Production
Semantic search introduces transformative benefits and applications in post-production tasks. By using advanced foundation models mentioned above, media professionals can easily locate specific clips and images through descriptive queries. For instance, a producer might search for "intense soccer match under rain at night," and the system will retrieve video clips that visually match this description without relying on precise tags.
AI-based systems can provide enhanced analytics and insights through the utilization of clustering and semantic mapping. Semantic search can analyze video frames and cluster them into meaningful groups, allowing editors to quickly find scenes of interest or discover thematic patterns across large datasets. For example, semantic embeddings can be used to plot a 2-dimensional semantic map of video clips, providing a visual representation of content relationships and thematic consistencies. You can see an example of this in the image below.
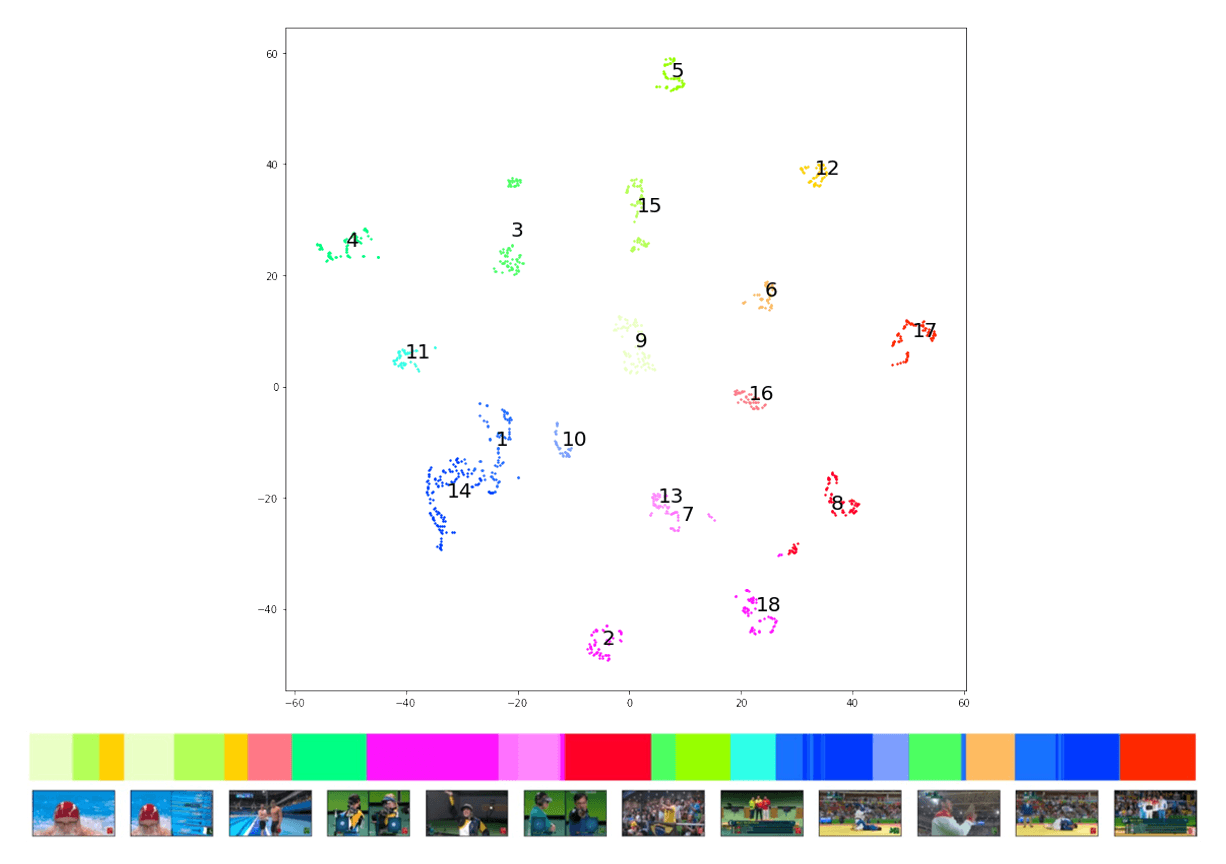
The image shows a representation of CLIP video frame embeddings from a sports highlight reel reduced to two dimensions. You can see how similar frames in the reel are grouped together by semantic similarity, like the swimming shots in groups 9, 15, and 12.
Extending semantic search capabilities to include spoken phrases and ambient sounds enriches the scope of search in audiovisual content. The integration of media embedding models like Marengo from Twelve Labs and LAION’s CLAP enhance the ability to search video and audio content by semantic similarity, not just text match, allowing users to find media that contains specific looks and sounds like bustling cityscapes or serene nature scenes.
5 - Extending Semantic Search for Comprehensive Media Insights
Semantic search extends beyond simple retrieval to provide comprehensive insights and analytics. This capability is exemplified by the potential to create interactive displays from semantic embeddings, enabling producers and editors to derive in-depth analytics from media content. For instance, using media embedding models, users can visually explore how different themes are represented across a media library, identify trends, and predict future content preferences.
Furthermore, semantic search can drastically enhance the process of metadata management in media libraries. Typically, metadata is manually tagged, which is labor-intensive and prone to inconsistencies. By automatically generating rich, descriptive metadata from the content, semantic search tools can ensure that every asset is uniformly described, making it far easier to retrieve and analyze. This automated metadata enrichment process leverages the deep learning capabilities of media embedding models to interpret complex media content, including the mood, themes, and key visual elements, thus providing a richer dataset for further analysis and utilization.
These insights are valuable in understanding the existing content and guiding the creation of new media that aligns with audience interests and ongoing trends. The ability to analyze semantic relationships and cultural contexts within media libraries opens up possibilities for predictive analytics and targeted content recommendations.

6 - Integrating Semantic Search into Media Asset Management Systems
Integrating semantic search technologies into existing media asset management (MAM) systems can significantly enhance the efficiency and effectiveness of media libraries. This integration facilitates more intelligent search capabilities, which can understand the content and context of media files, thereby improving the accessibility and discoverability of assets.
Integration of semantic search into MAM systems also facilitates better archival and retrieval processes, crucial in post-production workflows. For example, when editors need to pull content from archives that span decades, semantic search can quickly filter through various formats and eras to find content that matches current production needs without manual browsing. This capability speeds up the retrieval process and ensures valuable archival footage is more accessible, promoting its reuse and maximizing the value of existing assets. This represents a significant shift from traditional keyword-based systems, which often require extensive manual input and upkeep to remain effective.
Moreover, semantic search can provide context-aware recommendations based on the user's current project or past searches. This feature speeds up the workflow and inspires new creative ideas by exposing editors to potentially relevant content they might not have considered.
Avid has demonstrated research in this area on various proofs of concept at major trade show events such as NAB and IBC. This has included a Recommendation Engine in the web-based application MediaCentral | Cloud UX, where journalists are offered media related to the script which they are writing, or on the audio in a voiceover on a timeline. The system not only offers suggestions based on a literal analysis of the text, it also generates related sentences or phrases based on the context of the script to offer further suggestions.
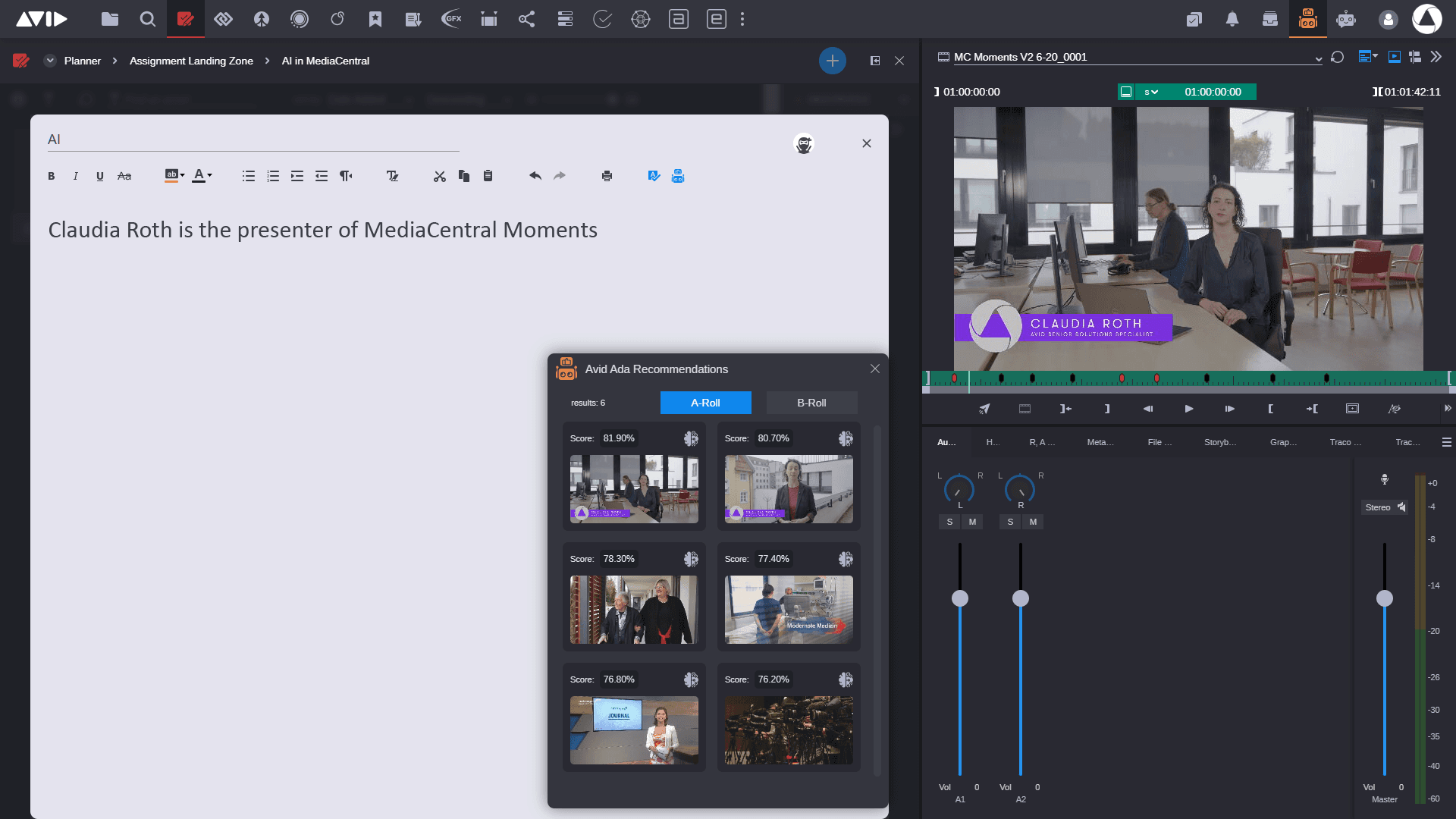
Avid is continuing to implement AI-enabled technologies within a range of products, under the banner of Avid Ada – an overarching framework for AI across its portfolio.
Twelve Labs has integrated with multiple MAM providers to bring video understanding to their users. A notable example is our partnership with Vidispine - An Arvato Systems Brand. We first worked together for a joint client from the sports industry to improve the video browsing experience for the client. The joint solution enables easier navigation through video content and uncovers previously undetectable elements, such as specific moves or player conversations. It quickly became clear that the integration had the potential to be even more.
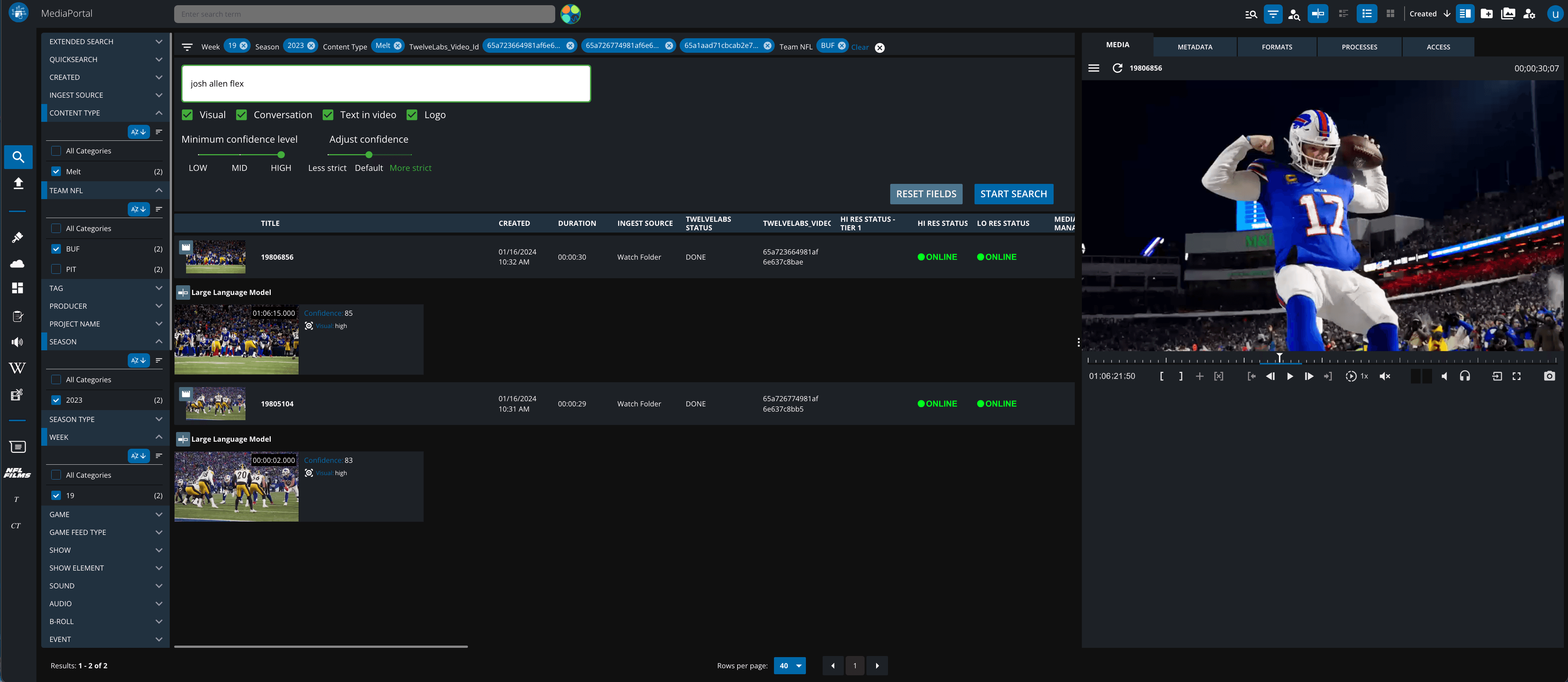
Integrating Twelve Labs’ video-language foundation models in the intuitive user interface of Vidispine’s MediaPortal changes the way users can search for material as it eliminates the need to index all static metadata fields in the core service VidiCore. Vidispine users can now find exact moments within their videos using natural language queries and combine them with metadata from Vidispine applications.
7 - Challenges and Future Directions
While semantic search technologies have made significant strides in recent years, several challenges remain in their implementation and widespread adoption in the media production industry.
7.1 - Challenges
One of the primary challenges is the significant computational power and resources required to effectively process and analyze large volumes of multimedia data. Generating high-quality semantic embeddings and performing complex contextual understanding demands substantial computational resources, including powerful hardware accelerators (GPUs) and ample storage capacity. As media libraries continue to grow exponentially, the computational demands will only increase, necessitating the development of more efficient algorithms and hardware acceleration techniques to make semantic search scalable and practical.
Although current language and vision foundation models have made remarkable progress in understanding context, there is still room for improvement in capturing nuanced meaning, handling ambiguity, and accounting for real-world knowledge. Developing more sophisticated multimodal foundation models that can better grasp the intricate context and relationships within multimedia content will be crucial for enhancing the relevance and accuracy of search results.
Seamlessly integrating and fusing diverse modalities, such as text, images, video, and audio, into a unified semantic search framework presents technical challenges. Advancing methods to align and combine these heterogeneous data sources will be important for delivering comprehensive, cross-modal search capabilities that can effectively leverage the complementary information present in different modalities.

7.2 - Future Directions
Despite these challenges, the future of semantic search in media production holds immense potential and promises to revolutionize the way media professionals search, discover, and utilize content.
The ongoing development of multimodal foundation models, which aim to capture and fuse information across various modalities, could pave the way for more sophisticated semantic search engines. These models (such as Marengo and Pegasus from Twelve Labs), trained on massive multimodal datasets, have the potential to uncover intricate relationships and patterns across different data types, enabling more accurate and comprehensive search capabilities.
Moreover, integrating other forms of production data, such as knowledge graphs, scripts, and transcripts, into a semantic search system can significantly enhance its capabilities. Knowledge graphs can provide a structured representation of relationships between various entities, enriching the search process with contextual information. Scripts and transcripts offer a detailed textual account of media content, allowing the search engine to index and retrieve specific dialogues, scenes, and narrative elements. By leveraging these diverse data sources, semantic search systems can deliver more precise and contextually relevant results, ultimately improving the efficiency of content discovery and utilization in media production.
Furthermore, the incorporation of personalized semantic search, which tailors search results based on user preferences and past behavior, could enhance the relevance and utility of search results in media production environments. By understanding the specific needs and contexts of individual users, personalized semantic search can surface the most pertinent content, facilitating more efficient and effective content discovery and utilization.
8 - Conclusion
Semantic search is definitely the new cool kid on the block in the world of news, broadcast and, of course, post-production. It's all about harnessing the power of advanced AI techniques to understand the deeper meaning and context of media assets. Forget the old school keyword-based search methods, this is a transformative approach that is revolutionizing how we manage and use media in production workflows.
Think about models like OpenAI’s CLIP or innovations like Multilingual CLIP, LAION’s CLAP, and Twelve Labs’ Marengo and continuous advancements from Avid. These are just a few examples of how fast things are moving in this field. They're making the search process more intuitive, helping media professionals find content that matches their creative vision with unprecedented precision and speed. With the amount of digital media out there, being able to quickly find what you need will become increasingly vital.
The journey of semantic search is still unfolding, with each new development adding a whole new level of sophistication and capability. By embracing semantic search, we're making things more efficient and boosting our creative processes, giving content creators a whole new way to tell their stories.
9 - Call to Action
Semantic search technologies are integral to the future of media production. As a media professional, adopting these innovations is crucial.
Use semantic search in all stages of production, from planning to editing.
Test various semantic search models to enhance your content discovery and management. Stay updated on AI advancements in media production through workshops and webinars.
Consider partnering with tech providers and participate in pilot programs to tailor semantic search to your needs. This investment will increase efficiency, creativity, and competitive edge.
Twelve Labs' semantic video search solution stands at the forefront of this revolution. Our video understanding platform seamlessly integrates with existing media asset management systems, empowering their users to navigate vast video libraries with unprecedented ease. Check out our recent integrations with Vidispine, Blackbird, EMAM, Nomad, and Cinesys.
Over the past few years, Avid has conducted research on the use of AI for media production, including semantic media search. They developed Avid Ada, a digital assistant that supports making workflows more efficient. In addition to feeding the results of their research into their product roadmaps, Avid also publishes and shares with the media industry.
This blog post is co-authored with Rob Gonsalves - Engineering Fellow at Avid
1 - Introduction
Quickly and easily finding the perfect content in vast media libraries is crucial in the world of media production. Traditionally, this meant manually tagging media assets with keywords, but this method has its limitations in accuracy, scalability, and understanding of the context. Through AI-powered semantic search, which understands the context, meaning, and relationships between media assets by analyzing the content, users can find relevant content based on its semantic meaning— not just keywords.
Thanks to rapid advancements in multimodal AI, semantic search is now a reality in media production. Foundation models help our smart machines understand media content. They power semantic search engines that index media assets, making them searchable based on their semantic content.
Semantic search plays a huge role in media production. It helps media professionals find exactly what they need quickly, saving time and sparking new ideas for content repurposing and creative storytelling. Plus, it can uncover hidden gems that may have been overlooked due to inadequate manual tagging.
In this post, we'll explore the awesome applications and benefits of semantic search in post-production, the key technologies powering it, how it integrates with media asset management systems, and where it's headed in the future.
2 - The Evolution of Semantic Search in Media Production
2.1 - Metadata-Based Search
The transition from metadata-based searches to semantic searches represents a significant advancement in media production workflows.
Avid’s MediaCentral | Production Management and MediaCentral | Asset Management systems have successfully enabled teams of up to hundreds of users to effectively log and search metadata for many years. This has included utilizing AI services from Cloud providers to enrich metadata with automated tagging, speech to text transcription, optical character recognition and more, to generate more searchable data.
These traditional metadata-based searches rely on manually extracted information or predefined taxonomies, which, while highly effective, can limit the ability to find truly relevant content.
Metadata-based searches traditionally have several limitations:
Manual metadata extraction is time-consuming and prone to human error. Automated metadata extraction can help, but it still relies on predefined taxonomies and keywords, failing to capture the true context and meaning of the content.
These searches only return results that match the exact keywords or metadata, often missing out on related or semantically similar content that could be highly relevant.
2.2 - Semantic Search
In contrast, semantic search leverages state-of-the-art foundation models to understand the actual meaning and context behind the content. By analyzing the visual elements, spoken words, and other data within the media assets, semantic search engines can comprehend the underlying concepts and relationships, rather than relying solely on predefined keywords or taxonomies.
The semantic search process is depicted above:
A media encoder is a tool that takes raw media, such as videos or audio files, and converts them into a format that computer systems can understand and analyze, much like a translator that helps computers "read" media files.
During this process, it extracts features like images, sounds, and words, converting them into numerical representations called embeddings, which serve as digital fingerprints capturing the essence of the content.
These embeddings are stored in an embedding database, a digital library that allows the system to quickly locate and compare similar media files based on these numerical representations, as part of a semantic search.
Twelve Labs offers a powerful Semantic Video Search solution that simultaneously integrates all modalities inside video and captures the complex relationships among them to deliver a more nuanced, humanlike interpretation. That results in much faster and far more accurate video search and retrieval from cloud object storage. Instead of time-consuming and ineffective manual tagging, video editors can use natural language to quickly and accurately search vast media archives to unearth video moments and hidden gems that otherwise might go unnoticed.
The accuracy and efficiency of semantic search are particularly valuable in media production environments, where vast libraries of text, audio, video, and image assets need to be searched and retrieved quickly. By understanding the true meaning and context of the content, semantic search engines can deliver highly relevant results, even when the user's query does not match the exact keywords or metadata associated with the media assets.
3 - Key Technologies Powering Semantic Search
3.1 - The Foundation with CLIP
OpenAI's Contrastive Language-Image Pre-training (CLIP) model is at the heart of modern semantic search capabilities. CLIP is a neural network that learns to encode both images and text into a shared embedding space. By training on a massive dataset of image-text pairs, CLIP develops the ability to associate visual concepts with their linguistic representations.
The CLIP model consists of two main components: a visual encoder and a text encoder. The visual encoder, typically a Vision Transformer (ViT), analyzes the image and generates a visual embedding. Simultaneously, the text encoder, a Transformer-based language model, encodes the text input into a textual embedding. These embeddings are then compared, and the model learns to align the visual and textual representations, enabling cross-modal retrieval and understanding. You can see how this works in the diagram below.
For example, if the user searches for “youth hockey coach,” CLIP encodes this text and compares it to embeddings from the media library to find matches. The system ranks video clips by relevance. The highest-scoring video closely aligns with the search, demonstrating CLIP's ability to understand and retrieve content semantically.
3.2 - CLIP Extensions
Building upon CLIP's success, researchers have developed advanced models to enhance semantic search capabilities across different media formats and languages. One notable extension is Multilingual CLIP, which extends the original CLIP text encoder to support multiple languages. By leveraging techniques like cross-lingual teacher learning, Multilingual CLIP enables cross-lingual search and retrieval, allowing users to query media content using text in various languages.
Another significant development is LAION's CLAP (Contrastive Language-Audio-Visual Pre-training) model, which incorporates audio encoding capabilities into the multi-modal framework. CLAP learns to encode audio waveforms, text data, and visual information into a shared embedding space, enabling a comprehensive semantic understanding of multimedia content.
3.3 - Marengo-2.6
Twelve Labs' Marengo-2.6 model provides advanced video encoding and retrieval capabilities for video search applications. As a state-of-the-art video foundation model, Marengo-2.6 extracts semantic features from video content, allowing users to search for and retrieve relevant video clips based on text queries or reference videos.
Astoundingly, Marengo-2.6's expanded capabilities allow for any-to-any (cross-modality) retrieval tasks, making it a versatile tool for a wide range of applications. This includes text-to-video, text-to-image, text-to-audio, audio-to-video, and image-to-video tasks, bridging different media types. Watch the webinar session below for qualitative demonstration of such capabilities:
These multimodal models work together to enhance media search capabilities across different formats and languages. CLIP and its extensions, such as Multilingual CLIP and CLAP, encode images, text, and audio into searchable embeddings. These embeddings are then stored in embedding databases, enabling efficient retrieval and matching based on semantic similarity. For video content, Marengo-2.6 leverages self-supervised learning with contrastive loss to embed and search video clips based on text queries or reference videos.
By combining these technologies, users can perform semantic searches across vast media libraries, finding relevant content based on their intent and the contextual meaning of their queries.
4 - Applications and Benefits of Semantic Search in Post-Production
Semantic search introduces transformative benefits and applications in post-production tasks. By using advanced foundation models mentioned above, media professionals can easily locate specific clips and images through descriptive queries. For instance, a producer might search for "intense soccer match under rain at night," and the system will retrieve video clips that visually match this description without relying on precise tags.
AI-based systems can provide enhanced analytics and insights through the utilization of clustering and semantic mapping. Semantic search can analyze video frames and cluster them into meaningful groups, allowing editors to quickly find scenes of interest or discover thematic patterns across large datasets. For example, semantic embeddings can be used to plot a 2-dimensional semantic map of video clips, providing a visual representation of content relationships and thematic consistencies. You can see an example of this in the image below.
The image shows a representation of CLIP video frame embeddings from a sports highlight reel reduced to two dimensions. You can see how similar frames in the reel are grouped together by semantic similarity, like the swimming shots in groups 9, 15, and 12.
Extending semantic search capabilities to include spoken phrases and ambient sounds enriches the scope of search in audiovisual content. The integration of media embedding models like Marengo from Twelve Labs and LAION’s CLAP enhance the ability to search video and audio content by semantic similarity, not just text match, allowing users to find media that contains specific looks and sounds like bustling cityscapes or serene nature scenes.
5 - Extending Semantic Search for Comprehensive Media Insights
Semantic search extends beyond simple retrieval to provide comprehensive insights and analytics. This capability is exemplified by the potential to create interactive displays from semantic embeddings, enabling producers and editors to derive in-depth analytics from media content. For instance, using media embedding models, users can visually explore how different themes are represented across a media library, identify trends, and predict future content preferences.
Furthermore, semantic search can drastically enhance the process of metadata management in media libraries. Typically, metadata is manually tagged, which is labor-intensive and prone to inconsistencies. By automatically generating rich, descriptive metadata from the content, semantic search tools can ensure that every asset is uniformly described, making it far easier to retrieve and analyze. This automated metadata enrichment process leverages the deep learning capabilities of media embedding models to interpret complex media content, including the mood, themes, and key visual elements, thus providing a richer dataset for further analysis and utilization.
These insights are valuable in understanding the existing content and guiding the creation of new media that aligns with audience interests and ongoing trends. The ability to analyze semantic relationships and cultural contexts within media libraries opens up possibilities for predictive analytics and targeted content recommendations.
6 - Integrating Semantic Search into Media Asset Management Systems
Integrating semantic search technologies into existing media asset management (MAM) systems can significantly enhance the efficiency and effectiveness of media libraries. This integration facilitates more intelligent search capabilities, which can understand the content and context of media files, thereby improving the accessibility and discoverability of assets.
Integration of semantic search into MAM systems also facilitates better archival and retrieval processes, crucial in post-production workflows. For example, when editors need to pull content from archives that span decades, semantic search can quickly filter through various formats and eras to find content that matches current production needs without manual browsing. This capability speeds up the retrieval process and ensures valuable archival footage is more accessible, promoting its reuse and maximizing the value of existing assets. This represents a significant shift from traditional keyword-based systems, which often require extensive manual input and upkeep to remain effective.
Moreover, semantic search can provide context-aware recommendations based on the user's current project or past searches. This feature speeds up the workflow and inspires new creative ideas by exposing editors to potentially relevant content they might not have considered.
Avid has demonstrated research in this area on various proofs of concept at major trade show events such as NAB and IBC. This has included a Recommendation Engine in the web-based application MediaCentral | Cloud UX, where journalists are offered media related to the script which they are writing, or on the audio in a voiceover on a timeline. The system not only offers suggestions based on a literal analysis of the text, it also generates related sentences or phrases based on the context of the script to offer further suggestions.
Avid is continuing to implement AI-enabled technologies within a range of products, under the banner of Avid Ada – an overarching framework for AI across its portfolio.
Twelve Labs has integrated with multiple MAM providers to bring video understanding to their users. A notable example is our partnership with Vidispine - An Arvato Systems Brand. We first worked together for a joint client from the sports industry to improve the video browsing experience for the client. The joint solution enables easier navigation through video content and uncovers previously undetectable elements, such as specific moves or player conversations. It quickly became clear that the integration had the potential to be even more.
Integrating Twelve Labs’ video-language foundation models in the intuitive user interface of Vidispine’s MediaPortal changes the way users can search for material as it eliminates the need to index all static metadata fields in the core service VidiCore. Vidispine users can now find exact moments within their videos using natural language queries and combine them with metadata from Vidispine applications.
7 - Challenges and Future Directions
While semantic search technologies have made significant strides in recent years, several challenges remain in their implementation and widespread adoption in the media production industry.
7.1 - Challenges
One of the primary challenges is the significant computational power and resources required to effectively process and analyze large volumes of multimedia data. Generating high-quality semantic embeddings and performing complex contextual understanding demands substantial computational resources, including powerful hardware accelerators (GPUs) and ample storage capacity. As media libraries continue to grow exponentially, the computational demands will only increase, necessitating the development of more efficient algorithms and hardware acceleration techniques to make semantic search scalable and practical.
Although current language and vision foundation models have made remarkable progress in understanding context, there is still room for improvement in capturing nuanced meaning, handling ambiguity, and accounting for real-world knowledge. Developing more sophisticated multimodal foundation models that can better grasp the intricate context and relationships within multimedia content will be crucial for enhancing the relevance and accuracy of search results.
Seamlessly integrating and fusing diverse modalities, such as text, images, video, and audio, into a unified semantic search framework presents technical challenges. Advancing methods to align and combine these heterogeneous data sources will be important for delivering comprehensive, cross-modal search capabilities that can effectively leverage the complementary information present in different modalities.
7.2 - Future Directions
Despite these challenges, the future of semantic search in media production holds immense potential and promises to revolutionize the way media professionals search, discover, and utilize content.
The ongoing development of multimodal foundation models, which aim to capture and fuse information across various modalities, could pave the way for more sophisticated semantic search engines. These models (such as Marengo and Pegasus from Twelve Labs), trained on massive multimodal datasets, have the potential to uncover intricate relationships and patterns across different data types, enabling more accurate and comprehensive search capabilities.
Moreover, integrating other forms of production data, such as knowledge graphs, scripts, and transcripts, into a semantic search system can significantly enhance its capabilities. Knowledge graphs can provide a structured representation of relationships between various entities, enriching the search process with contextual information. Scripts and transcripts offer a detailed textual account of media content, allowing the search engine to index and retrieve specific dialogues, scenes, and narrative elements. By leveraging these diverse data sources, semantic search systems can deliver more precise and contextually relevant results, ultimately improving the efficiency of content discovery and utilization in media production.
Furthermore, the incorporation of personalized semantic search, which tailors search results based on user preferences and past behavior, could enhance the relevance and utility of search results in media production environments. By understanding the specific needs and contexts of individual users, personalized semantic search can surface the most pertinent content, facilitating more efficient and effective content discovery and utilization.
8 - Conclusion
Semantic search is definitely the new cool kid on the block in the world of news, broadcast and, of course, post-production. It's all about harnessing the power of advanced AI techniques to understand the deeper meaning and context of media assets. Forget the old school keyword-based search methods, this is a transformative approach that is revolutionizing how we manage and use media in production workflows.
Think about models like OpenAI’s CLIP or innovations like Multilingual CLIP, LAION’s CLAP, and Twelve Labs’ Marengo and continuous advancements from Avid. These are just a few examples of how fast things are moving in this field. They're making the search process more intuitive, helping media professionals find content that matches their creative vision with unprecedented precision and speed. With the amount of digital media out there, being able to quickly find what you need will become increasingly vital.
The journey of semantic search is still unfolding, with each new development adding a whole new level of sophistication and capability. By embracing semantic search, we're making things more efficient and boosting our creative processes, giving content creators a whole new way to tell their stories.
9 - Call to Action
Semantic search technologies are integral to the future of media production. As a media professional, adopting these innovations is crucial.
Use semantic search in all stages of production, from planning to editing.
Test various semantic search models to enhance your content discovery and management. Stay updated on AI advancements in media production through workshops and webinars.
Consider partnering with tech providers and participate in pilot programs to tailor semantic search to your needs. This investment will increase efficiency, creativity, and competitive edge.
Twelve Labs' semantic video search solution stands at the forefront of this revolution. Our video understanding platform seamlessly integrates with existing media asset management systems, empowering their users to navigate vast video libraries with unprecedented ease. Check out our recent integrations with Vidispine, Blackbird, EMAM, Nomad, and Cinesys.
Over the past few years, Avid has conducted research on the use of AI for media production, including semantic media search. They developed Avid Ada, a digital assistant that supports making workflows more efficient. In addition to feeding the results of their research into their product roadmaps, Avid also publishes and shares with the media industry.
Related articles




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved