
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)

Partnerships
From Video to Vector: Building Smart Video Agents with TwelveLabs and Langflow

James Le
Developers can build video-powered AI agents using Twelve Labs and Langflow by combining Pegasus for video indexing and question answering with Marengo for multimodal embeddings, covering workflows from semantic video search to full RAG systems with AstraDB vector storage.
Developers can build video-powered AI agents using Twelve Labs and Langflow by combining Pegasus for video indexing and question answering with Marengo for multimodal embeddings, covering workflows from semantic video search to full RAG systems with AstraDB vector storage.

In this article
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Jun 4, 2025
12 Min
Copy link to article
We'd like to give a huge thanks to the team at Langflow/DataStax (Melissa Herrera, Eric Hare, Gokul Krishnaa, and Alejandro Cantarero) for the collaboration!
Please also watch this tutorial from Melissa below that showcases the entire workflows 👇
1 - Introduction and Overview
Welcome to the wild world of video AI, where your apps can finally “see” what’s happening in videos—just like you do! 🎬
This tutorial is your golden ticket to building next-level video-powered agents with TwelveLabs and Langflow. No need for a PhD in computer vision—just bring your curiosity and a few video clips to the party.

Why should you care?
TwelveLabs brings the brains: our Pegasus and Marengo models let your code understand, index, and chat with video content—answering questions, finding key moments, and even generating smart summaries. Langflow is your playground: a visual builder that turns your ideas into AI workflows and instantly serves them as APIs. Together, they make it easy to create, test, and deploy video AI solutions—whether you’re building a video search engine, a content moderation bot, or a multimodal assistant that can handle text, images, and videos.
What’s inside?
In this tutorial, you’ll go from zero to video hero. You’ll set up your environment, master the TwelveLabs components in Langflow, and build real-world flows—like chatting with videos, generating and storing video embeddings, and even crafting a full-blown RAG system that retrieves and answers questions from your video library. Along the way, you’ll pick up best practices, discover killer use cases, and get inspired to build your own video-powered apps.
So grab some popcorn, fire up your code editor, and let’s make your AI workflows truly video-smart! 🚀🍿
2 - Setting Up Your Development Environment
Let's prepare your environment to start building with TwelveLabs and Langflow.
Installing Langflow
Install Langflow using pip:
pip install langflowStart the Langflow server:
langflow runAccess the Langflow UI by navigating to
http://127.0.0.1:7860in your browser.

Obtaining TwelveLabs API Credentials
Create an account on the TwelveLabs platform if you don't already have one.
Navigate to your profile settings and create a new API key.
Make note of your API key as you'll need it to authenticate requests to TwelveLabs services.
Verifying TwelveLabs Components
In the Langflow interface, create a new flow by clicking the "+" button.
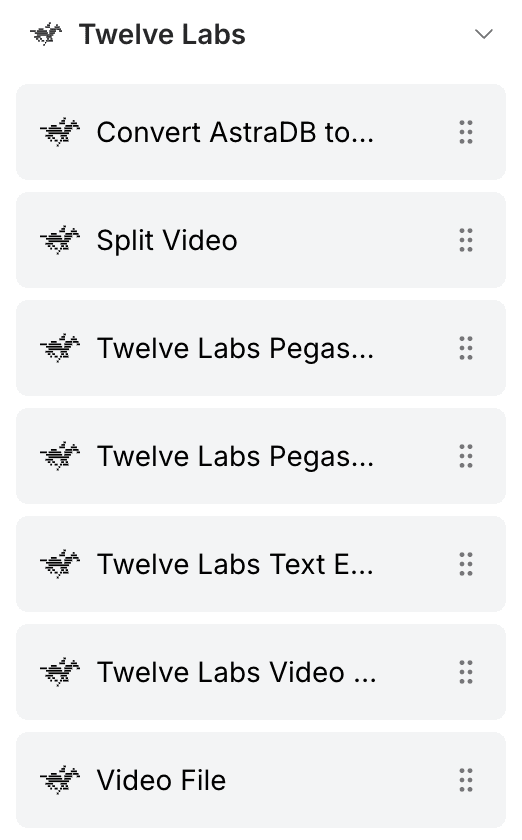
Open the component sidebar and search for "TwelveLabs". You should see the following components:
Video File
Split Video
Twelve Labs Pegasus Index Video
Twelve Labs Pegasus
Twelve Labs Text Embeddings
Twelve Labs Video Embeddings
Convert AstraDB to Pegasus Input
If you don't see these components, ensure Langflow is updated to the latest version.
Preparing Sample Videos
Select 2-3 short video clips (1-3 minutes each) for testing during this tutorial. Common formats like MP4, MOV, and AVI are supported.
For optimal performance during learning, use videos with clear visual content and distinct scenes. This helps demonstrate the video understanding capabilities more effectively.
Create a dedicated folder for your sample videos so they're easy to locate during the tutorial.
Troubleshooting Tips
If you encounter issues with the TwelveLabs components:
API Authentication: Verify your API key is correctly entered and has not expired.
Video Processing: Ensure your videos are in supported formats and aren't too large. Start with clips under 100MB for faster processing.
Component Loading: If components don't appear, try restarting Langflow or checking the console for error messages.
Dependencies: The integration requires FFmpeg for video processing. Install it using your system's package manager if not already available.
With your environment set up, you're ready to start building powerful video-enabled AI workflows with TwelveLabs and Langflow.
3 - Understanding TwelveLabs Components in Langflow
Langflow now includes seven powerful TwelveLabs components that enable advanced video understanding capabilities in your AI workflows. These components work together to process videos, generate embeddings, index video content, and enable natural language interactions with visual content.
3.1 - Video File Component

The Video File Component serves as your entry point for video processing workflows in Langflow. It handles a wide range of common video formats including MP4, AVI, MOV, and MKV, making it versatile for different video sources. Implementation is straightforward - simply provide a path to your video file, and the component returns a Data object containing both the file path and essential metadata. For optimal performance during development, we recommend starting with videos under 100MB.
3.2 - Split Video Component

This powerful component intelligently segments longer videos into smaller, more manageable clips. You can fine-tune the splitting process through several parameters: set your desired clip duration in seconds, choose how to handle the final clip (truncate, overlap with previous content, or keep as-is), and decide whether to retain the original video alongside the clips. The component outputs a collection of clips as Data objects, complete with detailed metadata. For best results in retrieval and understanding tasks, we recommend creating clips between 6 and 30 seconds in length.
3.3 - Twelve Labs Pegasus Index Video Component

At the heart of video indexing lies the Pegasus Index Video Component. It interfaces with TwelveLabs' Pegasus API to create searchable indexes of your video content. After providing your API key and video data (typically from the Split Video component), it generates indexed video data complete with unique video_id and index_id identifiers. This indexing step is crucial before performing any queries with the Pegasus component.
3.4 - Twelve Labs Pegasus Component
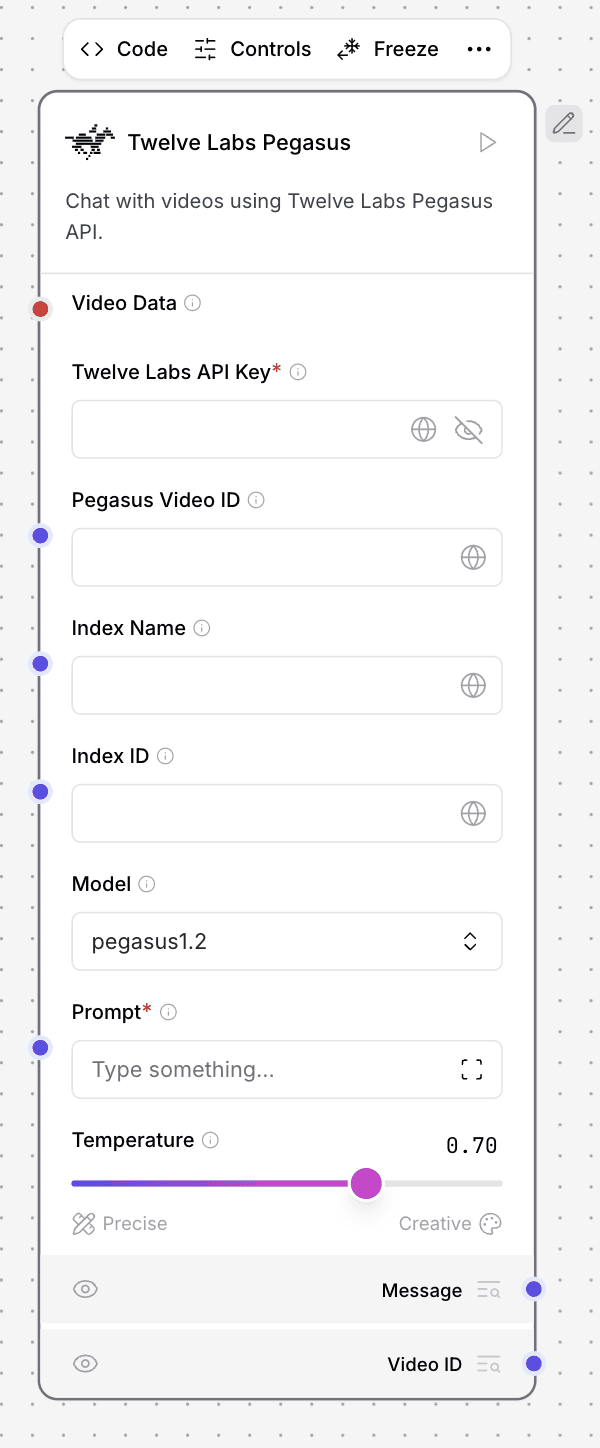
The Pegasus Component enables sophisticated natural language interaction with your indexed video content. Configuration requires your API key, the query text, and the relevant video and index identifiers. Acting as an intelligent reasoning layer, it processes both the query context and video content to generate conversational responses. This component truly bridges the gap between natural language understanding and video content analysis.
3.5 - Twelve Labs Text Embeddings Component

Leveraging TwelveLabs' Marengo model, this component generates vector embeddings from text input. It requires your API key and currently supports the Marengo-retrieval-2.7 model. The output is fully compatible with vector databases, making it perfect for sophisticated retrieval systems. For consistency in your applications, we recommend using the same embedding models across both text and video components.
3.6 - Twelve Labs Video Embeddings Component
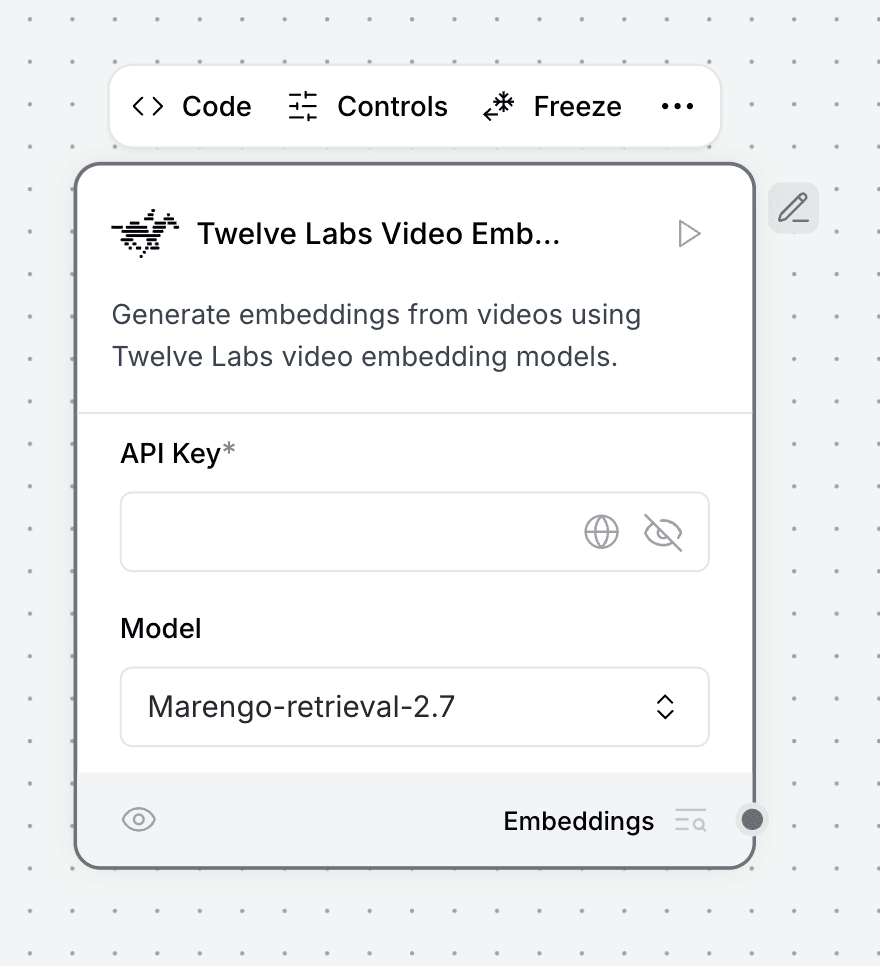
Similar to its text counterpart, the Video Embeddings Component creates dense vector representations of video content. It shares the same configuration pattern as the text embeddings component but specializes in processing video files. The resulting embeddings enable powerful semantic similarity searches between videos or between text and video content, opening up exciting possibilities for multimodal applications.
3.7 - Convert AstraDB to Pegasus Input Component
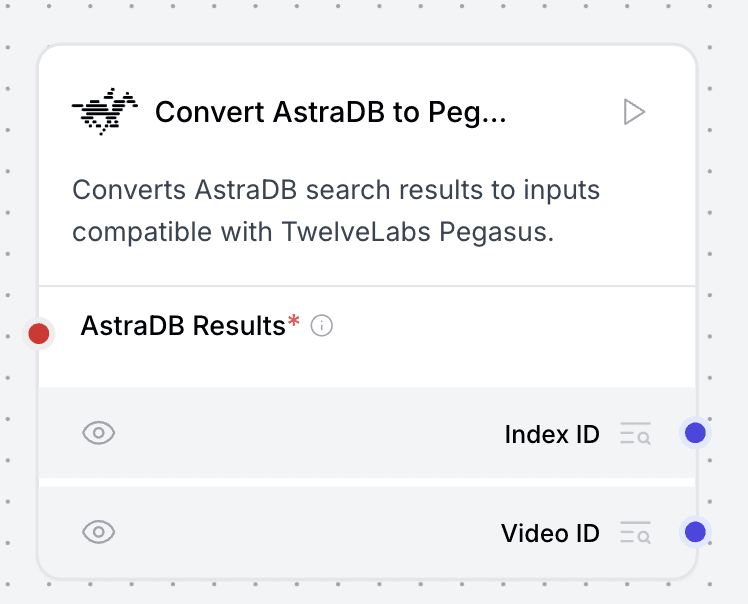
This essential connector component bridges the gap between vector database operations and TwelveLabs components. It processes search results from AstraDB, extracting crucial video_id and index_id information, and formats them properly for the Pegasus component. This component becomes particularly valuable when implementing RAG (Retrieval Augmented Generation) patterns with video content, ensuring smooth data flow between your vector database and video processing pipeline.
These components are designed to work together seamlessly. For example, you can create a video search engine by:
Loading videos with Video File
Splitting them into digestible chunks with Split Video
Indexing them with Pegasus Index Video
Generating embeddings with Video Embeddings
Storing in a vector database like AstraDB
Retrieving relevant clips with Convert AstraDB to Pegasus Input
Answering questions with Twelve Labs Pegasus
When building your workflows, think of these components as building blocks that handle different aspects of video understanding-from loading and processing to indexing, embedding, and retrieval.
4 - Pegasus Chat with Video: Your First Interactive Video Workflow
This section guides you through creating a fundamental Langflow workflow that allows you to "chat" with a video using the Twelve Labs Pegasus model. This flow demonstrates the direct integration of video processing, indexing, and natural language querying.
The "Pegasus Chat with Video" flow, as shown in the reference image, enables you to upload a video, have it automatically indexed by Twelve Labs, and then ask questions about its content through a chat interface.

Follow these steps to build this flow:
Upload Your Video:
Drag a
Video Filecomponent onto the Langflow canvas.In the
Video Filecomponent's properties, click to upload one of your sample video files (e.g.,big_buck_bunny_720.mp4as shown in the image). This component will load your video and make it available to other components.
Connect Video Data to Pegasus:
Add a
Twelve Labs Pegasuscomponent to the canvas.Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theVideo Datainput (the red dot) on theTwelve Labs Pegasuscomponent. This tells the Pegasus component which video to process.
Configure Pegasus Component:
In the
Twelve Labs Pegasuscomponent:Enter your Twelve Labs API Key in the designated field.
Provide an Index Name. This can be any descriptive name you choose for the video index that will be created (e.g., "bunny-test-index").
The Model will default to a Pegasus model like
pegasus1.2. You can typically leave this as is unless you have specific model requirements.
Developer Note: When you provide
Video Dataand anIndex Namewithout anIndex ID, the Pegasus component will automatically initiate the video indexing process with Twelve Labs for the new video. Thevideo_idandindex_idwill be generated by Twelve Labs during this process.
Enable User Input:
Add a
Chat Inputcomponent to the canvas.Connect the output of the
Chat Inputcomponent to thePromptinput (the blue dot, labeled "Receiving input" in the image) of theTwelve Labs Pegasuscomponent. This allows you to type questions that will be sent to the Pegasus model.
Display Chat Responses:
Add a
Chat Outputcomponent.Connect the
Messageoutput (the blue dot) from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent1. This will display the answers from the Pegasus model.
Optional: Output Video ID for Re-chatting:
To avoid re-indexing the same video for subsequent chat sessions, you can capture the
Video IDandIndex IDgenerated by Twelve Labs.Add another
Chat Outputcomponent.Connect the
Video IDoutput (the blue dot) from theTwelve Labs Pegasuscomponent to this newChat Outputcomponent1.Developer Tip: In future sessions with the same video, you can directly input the previously generated
Video IDandIndex IDinto thePegasus Video IDandIndex IDfields of theTwelve Labs Pegasuscomponent, respectively. This bypasses the re-indexing step, making interactions faster. If you only provide theVideo DataandIndex Name, it will re-index.
Test in the Playground:
Open the Langflow playground (usually by clicking the chat bubble icon on the right sidebar).
Type a question about your video into the chat interface (e.g., "What animal is in the video?", "Describe the main character.").
The Pegasus component will process your video (if it's the first time), index it, and then answer your question based on the video's content. The response will appear in the connected
Chat Output.
This simple yet powerful flow serves as a foundational example of how to integrate TwelveLabs' video understanding directly into an interactive Langflow agent. You can now ask questions and get answers about the content of your videos in near real-time.
5 - Video Embeddings with Marengo and AstraDB: Building Your Semantic Video Index
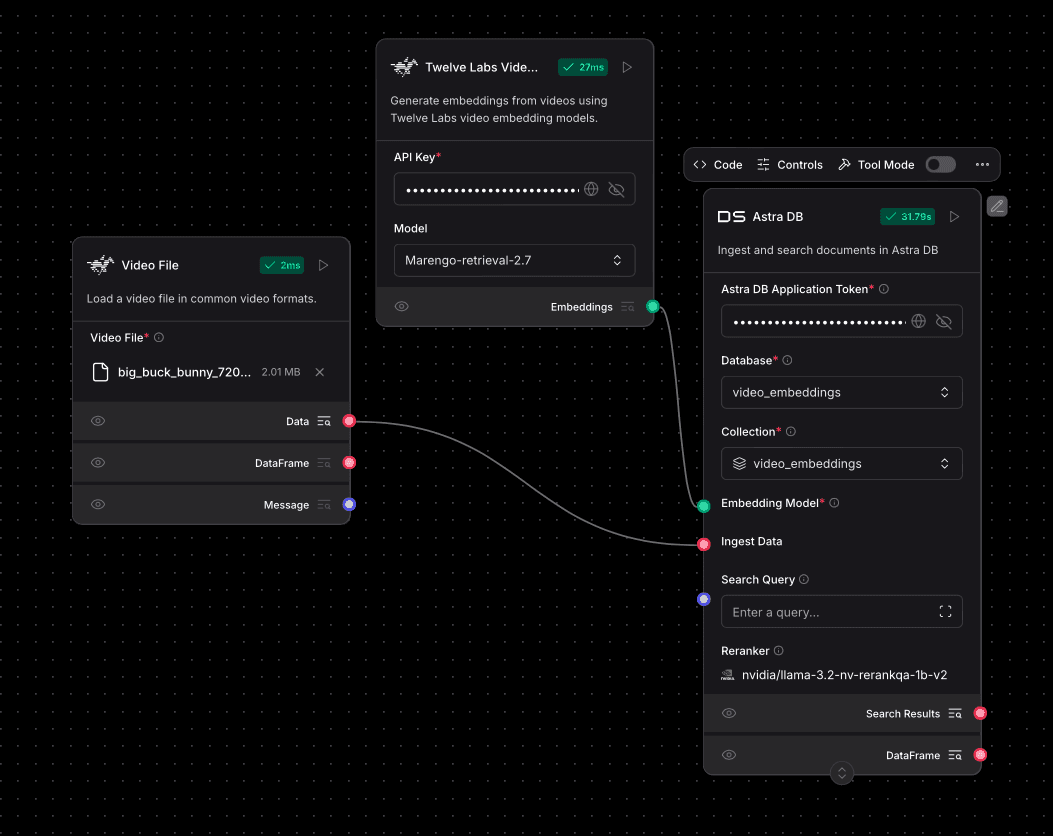
This section details how to construct a Langflow workflow to generate video embeddings using TwelveLabs' Marengo model and subsequently store these embeddings in DataStax AstraDB. This is a crucial step for enabling semantic search over your video library or for building advanced Retrieval Augmented Generation (RAG) systems with video content.
The workflow, as illustrated in the provided reference image, ingests a video, generates its embeddings, and then stores these embeddings along with video metadata in an AstraDB collection.
5.1 - Prerequisites: Setting up AstraDB
Before building the Langflow flow, ensure your AstraDB environment is ready:
Create an AstraDB Database:
If you don't have one, sign up and create a new serverless database on DataStax AstraDB.
Follow the AstraDB setup guides for initial database creation.
Generate an Application Token:
Navigate to your Database Details section in the AstraDB console.
Generate an Application Token with appropriate permissions (e.g., Database Administrator or a role that allows read/write to your collections). Securely store this token, as you'll need it for the Langflow component.
Create a
video_embeddingsCollection:Within your AstraDB database, create a new collection. You might name it
video_embeddingsor similar.Crucially, configure this collection to support vector search. This typically involves:
Specifying that the collection will store vectors.
Setting the vector dimension to 1024, which is the dimension for embeddings generated by TwelveLabs' Marengo models (like
Marengo-retrieval-2.7shown in the image1).
Refer to the AstraDB documentation on collection management for detailed steps on enabling vector search and setting dimensions.
5.2 - Building the Langflow Flow
Once AstraDB is set up, construct the following flow in Langflow:
Upload Your Video:
Drag a
Video Filecomponent onto the canvas.Configure it by uploading your desired video file (e.g.,
big_buck_bunny_720.mp4as seen in the image1). This component makes the video data accessible to the workflow.
Configure Video Embeddings Generation:
Add a
Twelve Labs Video Embeddingscomponent to the canvas.Enter your Twelve Labs API Key in the
API Keyfield.Ensure the Model is set to
Marengo-retrieval-2.7(or another compatible Marengo model). This component will process the video and generate dense vector embeddings.
Configure AstraDB for Ingestion:
Add a
DS Astra DBcomponent (orAstra DBas shown in the image1) to the canvas.Input your Astra DB Application Token into the corresponding field.
Specify the Database name where you created your vector-enabled collection.
Enter the name of your Collection (e.g.,
video_embeddings).
Connect Embeddings to AstraDB:
Connect the
Embeddingsoutput (the green dot) from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput (the green dot) on theDS Astra DBcomponent1.Developer Note: This connection tells AstraDB how to interpret the incoming data as embeddings, but it doesn't provide the embeddings themselves. The actual embeddings come with the data to be ingested.
Connect Video Data for Ingestion:
Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theIngest Datainput (the red dot) on theDS Astra DBcomponent1.Developer Note: When data is passed to the
Ingest Datainput, theAstra DBcomponent, if configured with an embedding model or connected to an embedding component as in this flow, will expect or generate embeddings for the incoming data. In this setup, theTwelve Labs Video Embeddingscomponent handles the embedding generation, and its output (which includes the embedding along with original data) is passed toDS Astra DB.
Run the Flow to Embed and Ingest:
To trigger the process, you typically "run" or activate the final component in this chain, which is the
DS Astra DBcomponent. In Langflow, this might involve clicking a play/run button on the component or initiating the flow if it's part of a larger executable graph.Upon execution, the
Video Filecomponent loads the video. TheTwelve Labs Video Embeddingscomponent then receives this video data (often implicitly through the flow or explicitly if theVideo Datainput is connected, though not shown for this component in the screenshot), generates the embeddings. Finally, theDS Astra DBcomponent takes the video data (now enriched with embeddings by the upstream component or by its own internal logic if the embedding component is connected to itsEmbedding Modelinput) and ingests it into the specified AstraDB collection.
After running this flow, your video's content will be represented as vector embeddings within your AstraDB collection, ready for semantic search, similarity comparisons, and as a knowledge base for RAG applications. You can verify this by querying your AstraDB collection directly.
6 - Advanced RAG Implementation with Video Content
Building a robust Retrieval Augmented Generation (RAG) system for video involves several stages, from processing and indexing your video content to enabling semantic search and contextual understanding. This section is broken into two parts. First, we'll focus on preparing your video data by splitting it, indexing the clips with Twelve Labs Pegasus, generating embeddings with Marengo, and storing everything in AstraDB.
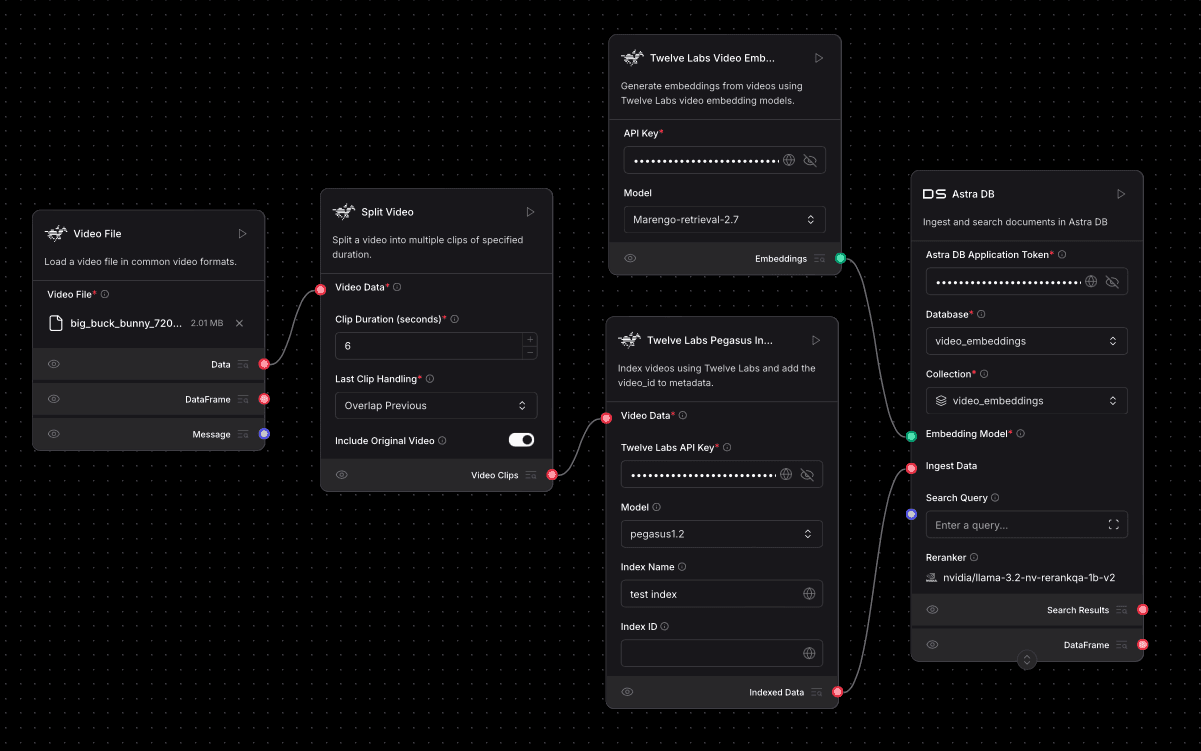
Part 1: Split Video, Index Clips with Pegasus, and Save Embeddings to Astra DB
This initial flow, illustrated in the provided image, is the foundation of your video RAG system. It processes a source video into manageable clips, enriches these clips with indexing information from Pegasus, generates corresponding vector embeddings using Marengo, and finally stores this comprehensive dataset in AstraDB for efficient retrieval.
Here's how to construct this ingestion pipeline:
Upload Source Video:
Begin by dragging a
Video Filecomponent onto your Langflow canvas.Configure it by uploading your video (e.g.,
big_buck_bunny_720...as shown in the image). This component outputs the raw video data.
Split Video into Clips:
Add a
Split Videocomponent.Connect the
Dataoutput from theVideo Filecomponent to theVideo Datainput of theSplit Videocomponent.Configure the
Split Videocomponent:Clip Duration (seconds): Set this to define the length of each video segment. The image shows
6seconds, which is a good starting point for granular analysis. You can adjust this based on your content; for instance, 30 seconds might be suitable for broader scene segmentation.Last Clip Handling: Choose an option like
Overlap Previous(as in the image) to ensure consistent clip lengths, or selectTruncateorKeep Shortbased on your preference.Include Original Video: Typically, this is turned off (as in the image) when processing clips for RAG, as you'll be working with the segments.
Index Clips with Pegasus:
Introduce a
Twelve Labs Pegasus Index Videocomponent.Connect the
Video Clipsoutput from theSplit Videocomponent to theVideo Datainput of theTwelve Labs Pegasus Index Videocomponent. This component will process each clip.In the component's settings:
Enter your Twelve Labs API Key.
Specify an Index Name (e.g.,
test indexin the image). This helps organize your indexed content within Twelve Labs. The component will outputIndexed Data, which includes the original clip data along with thevideo_idandindex_idassigned by Pegasus.The Model will default to a Pegasus model (e.g.,
pegasus1.2).
Generate Video Embeddings with Marengo:
Add a
Twelve Labs Video Embeddingscomponent.Enter your Twelve Labs API Key here as well.
Set the Model to
Marengo-retrieval-2.7(as shown in the image) or your preferred Marengo embedding model.Crucially, connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to the (implicit or explicit) video data input of theTwelve Labs Video Embeddingscomponent. Developer Note: While the image doesn't show a direct named "Video Data" input on this component, the embeddings component needs to receive the video clips to process. TheIndexed Datacarries these clips.
Configure AstraDB for Storage:
Place a
DS Astra DBcomponent onto the canvas.Enter your Astra DB Application Token.
Select your target Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where the video data and embeddings will be stored. Ensure this collection is configured for vector search with a dimension matching your Marengo model (1024 forMarengo-retrieval-2.7).
Connect Embeddings and Data to AstraDB:
Connect the
Embeddingsoutput from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput on theDS Astra DBcomponent. This tells AstraDB how to interpret the embedding vectors.Connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to theIngest Datainput on theDS Astra DBcomponent. This sends the video clips (now enriched with Pegasusvideo_idandindex_id) along with their generated embeddings to be stored.
Run the Ingestion Flow:
Execute the flow. The
Video Fileis loaded, split bySplit Video. Each clip is then sent toTwelve Labs Pegasus Index Videofor indexing. The resultingIndexed Data(clips + Pegasus IDs) is passed toTwelve Labs Video Embeddingsto generate Marengo embeddings. Finally, theDS Astra DBcomponent ingests this comprehensive data: the clips, their Pegasus index information, and their Marengo vector embeddings into your specified collection.
After this flow completes, your AstraDB collection will contain indexed video clips, each associated with its vector embedding and Pegasus identifiers, ready for the retrieval part of your RAG system.
Part 2: Query Video Embeddings and Chat with Video using Pegasus
With your video clips processed, indexed by Pegasus, and their Marengo embeddings stored in AstraDB (as detailed in Part 1), this second flow demonstrates the retrieval and generation aspects of RAG. As shown in the reference image, a user's text query is first embedded, then used to search AstraDB for relevant video clips. The information from these clips is then passed to the Twelve Labs Pegasus model to generate a contextual answer.
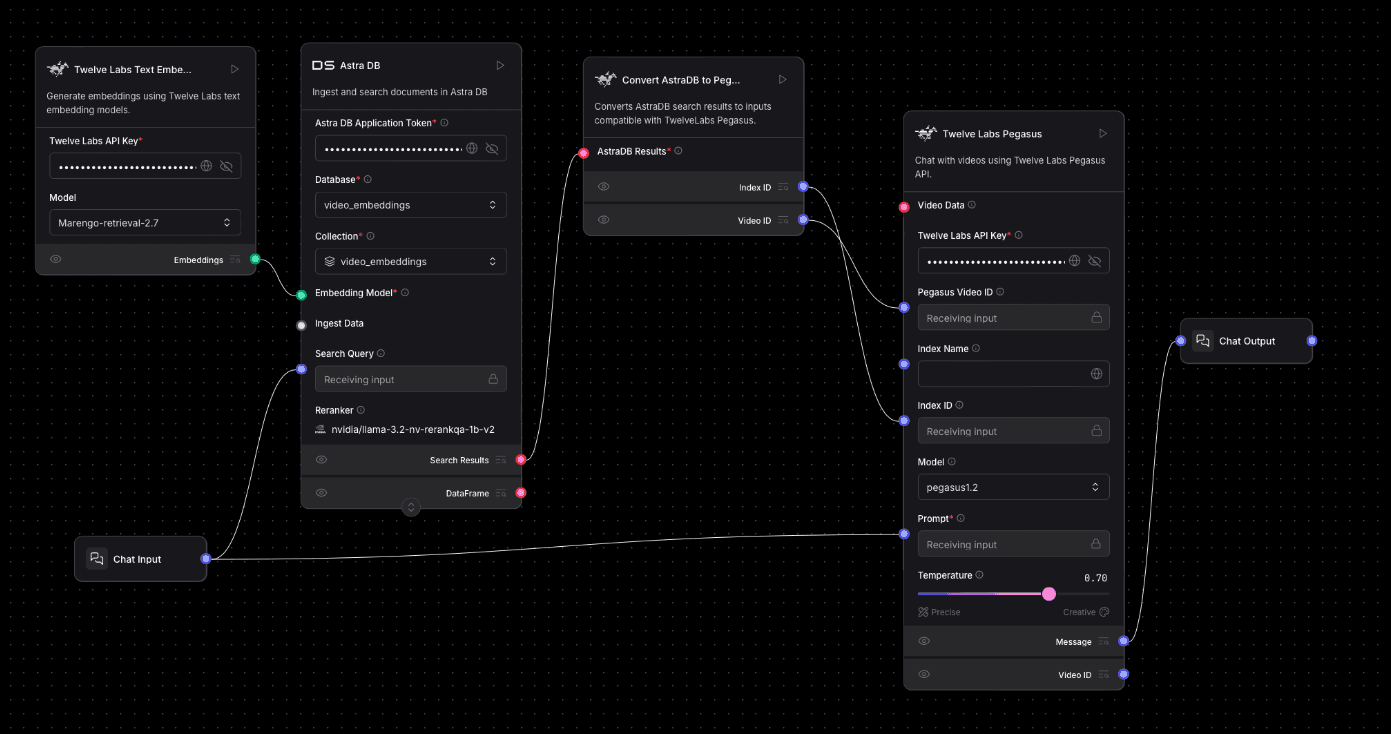
Here's how to build this retrieval and question-answering pipeline:
User Query Input and Embedding:
Add a
Chat Inputcomponent to the canvas. This will be where the user types their question.Add a
Twelve Labs Text Embeddingscomponent.Enter your Twelve Labs API Key.
Set the Model to
Marengo-retrieval-2.7(or the same Marengo model used in Part 1 for embedding the video clips).
Connect the output of the
Chat Inputcomponent to the text input of theTwelve Labs Text Embeddingscomponent. This ensures the user's query is converted into a vector embedding.
Semantic Search in AstraDB:
Add a
DS Astra DBcomponent.Enter your Astra DB Application Token.
Select the Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where your video clip embeddings are stored.Connect the
Embeddingsoutput from theTwelve Labs Text Embeddingscomponent to theEmbedding Modelinput of theDS Astra DBcomponent. This provides AstraDB with the query embedding.Connect the output of the
Chat Inputcomponent (the raw text query) to theSearch Queryinput of theDS Astra DBcomponent. Developer Note: While the embedding of the query is passed toEmbedding Model, theSearch Queryinput itself might be used by AstraDB for keyword filtering or other hybrid search strategies if configured, or simply to know what to perform the vector search against using the provided query embedding.
The
DS Astra DBcomponent will perform a similarity search in your collection, returning theSearch Resultswhich are the most relevant video clips (or their metadata, includingvideo_idandindex_idif stored from Part 1).
Convert AstraDB Results for Pegasus:
Add a
Convert AstraDB to Pegasus Inputcomponent.Connect the
Search Resultsoutput (the red dot, often carrying document metadata) from theDS Astra DBcomponent to theAstraDB Resultsinput of this converter component.This utility component is crucial: it extracts the
Index IDandVideo IDfrom the AstraDB search results, which are necessary for the Pegasus component to identify which specific indexed video segment to "chat" with.
Prepare Pegasus for Contextual Q&A:
Add a
Twelve Labs Pegasuscomponent.Enter your Twelve Labs API Key.
Select the desired Pegasus Model (e.g.,
pegasus1.2is the default).
Connect the
Index IDoutput from theConvert AstraDB to Pegasus Inputcomponent to theIndex IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Connect the
Video IDoutput from theConvert AstraDB to Pegasus Inputcomponent to thePegasus Video IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Developer Note: Unlike the "Pegasus Chat with Video" flow where video data might be directly provided for on-the-fly indexing, here we are providing specific
Pegasus Video IDandIndex IDfor already indexed content retrieved from AstraDB. TheVideo Datainput on the Pegasus component remains unconnected in this RAG retrieval flow.
Pass Original Query to Pegasus:
Connect the output of the original
Chat Inputcomponent (the one holding the user's question) directly to thePromptinput (labeled "Receiving input") of theTwelve Labs Pegasuscomponent. This ensures Pegasus knows what question to answer using the context of the retrieved video segment.
Display Pegasus's Response:
Add a
Chat Outputcomponent.Connect the
Messageoutput from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent. This will display the AI-generated answer.
Test Your Video RAG System:
Open the Langflow playground (chat interface).
Ask a question related to the content of the videos you processed in Part 1 (e.g., "What happens to the bunny at the beginning?", "Show me scenes with butterflies.").
The flow will execute as follows:
Your question is captured by
Chat Input.Twelve Labs Text Embeddingsconverts your question into a vector.DS Astra DBuses this vector to find the most semantically similar video clip(s) from your database.Convert AstraDB to Pegasus Inputextracts thevideo_idandindex_idof the top retrieved clip(s).Twelve Labs Pegasusreceives these IDs (telling it which video segment to focus on) and your original question (telling it what to answer about that segment).Pegasus analyzes the specified video segment in relation to your question and generates an answer.
The answer is displayed via
Chat Output.
This two-part RAG architecture allows you to build sophisticated, scalable video understanding applications where users can conversationally retrieve and interact with relevant moments from a large video library.
7 - Specialized Use Cases & Performance Best Practices
TwelveLabs and Langflow’s combined video capabilities unlock a range of high-value business applications. You can build content moderation systems that automatically flag or summarize inappropriate video segments, video search engines that surface relevant moments from large archives, or even multimodal assistants that blend video, text, and image understanding for richer user experiences. These use cases are ideal for industries like media, education, and customer support, where quick access to video insights and automated analysis directly drive productivity, compliance, and user engagement.
To ensure your video-enabled workflows deliver reliable business results, focus on optimizing performance and cost. Manage API usage by batching video segments or using caching to avoid redundant processing, and choose clip durations that balance detail with computational efficiency. Monitor your AstraDB and embedding pipelines to maintain fast query responses as your video library grows, and consider hybrid search strategies that combine vector similarity with metadata filtering for more precise results.
By following these best practices, you maximize the scalability, accuracy, and cost-effectiveness of your video AI solutions—helping your organization extract actionable insights from video at scale and maintain a competitive edge in the market.
8 - Conclusion and Next Steps
Congratulations, video wizard! 🎬✨
You’ve just unlocked the power to build AI agents that truly see and understand video, using the dynamic duo of TwelveLabs and Langflow. Whether you’re creating the next smart video search engine, moderating content at scale, or crafting multimodal assistants, you’re now equipped with the tools to turn raw footage into actionable insights—and maybe even a little magic.
So what’s next?
Try experimenting with your own creative flows, push the limits with different video types, or share your coolest projects with the community. Keep an eye on the TwelveLabs and Langflow roadmaps for exciting new features, and don’t forget to join the conversation—your ideas and feedback help shape the future of video AI!
Go forth and build something amazing. The video universe is yours to explore! 🚀🎥
Additional Resources
TwelveLabs Docs: https://docs.twelvelabs.io/
Langflow Docs: https://docs.langflow.org/
TwelveLabs Components in Langflow: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md
We'd like to give a huge thanks to the team at Langflow/DataStax (Melissa Herrera, Eric Hare, Gokul Krishnaa, and Alejandro Cantarero) for the collaboration!
Please also watch this tutorial from Melissa below that showcases the entire workflows 👇
1 - Introduction and Overview
Welcome to the wild world of video AI, where your apps can finally “see” what’s happening in videos—just like you do! 🎬
This tutorial is your golden ticket to building next-level video-powered agents with TwelveLabs and Langflow. No need for a PhD in computer vision—just bring your curiosity and a few video clips to the party.
Why should you care?
TwelveLabs brings the brains: our Pegasus and Marengo models let your code understand, index, and chat with video content—answering questions, finding key moments, and even generating smart summaries. Langflow is your playground: a visual builder that turns your ideas into AI workflows and instantly serves them as APIs. Together, they make it easy to create, test, and deploy video AI solutions—whether you’re building a video search engine, a content moderation bot, or a multimodal assistant that can handle text, images, and videos.
What’s inside?
In this tutorial, you’ll go from zero to video hero. You’ll set up your environment, master the TwelveLabs components in Langflow, and build real-world flows—like chatting with videos, generating and storing video embeddings, and even crafting a full-blown RAG system that retrieves and answers questions from your video library. Along the way, you’ll pick up best practices, discover killer use cases, and get inspired to build your own video-powered apps.
So grab some popcorn, fire up your code editor, and let’s make your AI workflows truly video-smart! 🚀🍿
2 - Setting Up Your Development Environment
Let's prepare your environment to start building with TwelveLabs and Langflow.
Installing Langflow
Install Langflow using pip:
pip install langflowStart the Langflow server:
langflow runAccess the Langflow UI by navigating to
http://127.0.0.1:7860in your browser.
Obtaining TwelveLabs API Credentials
Create an account on the TwelveLabs platform if you don't already have one.
Navigate to your profile settings and create a new API key.
Make note of your API key as you'll need it to authenticate requests to TwelveLabs services.
Verifying TwelveLabs Components
In the Langflow interface, create a new flow by clicking the "+" button.
Open the component sidebar and search for "TwelveLabs". You should see the following components:
Video File
Split Video
Twelve Labs Pegasus Index Video
Twelve Labs Pegasus
Twelve Labs Text Embeddings
Twelve Labs Video Embeddings
Convert AstraDB to Pegasus Input
If you don't see these components, ensure Langflow is updated to the latest version.
Preparing Sample Videos
Select 2-3 short video clips (1-3 minutes each) for testing during this tutorial. Common formats like MP4, MOV, and AVI are supported.
For optimal performance during learning, use videos with clear visual content and distinct scenes. This helps demonstrate the video understanding capabilities more effectively.
Create a dedicated folder for your sample videos so they're easy to locate during the tutorial.
Troubleshooting Tips
If you encounter issues with the TwelveLabs components:
API Authentication: Verify your API key is correctly entered and has not expired.
Video Processing: Ensure your videos are in supported formats and aren't too large. Start with clips under 100MB for faster processing.
Component Loading: If components don't appear, try restarting Langflow or checking the console for error messages.
Dependencies: The integration requires FFmpeg for video processing. Install it using your system's package manager if not already available.
With your environment set up, you're ready to start building powerful video-enabled AI workflows with TwelveLabs and Langflow.
3 - Understanding TwelveLabs Components in Langflow
Langflow now includes seven powerful TwelveLabs components that enable advanced video understanding capabilities in your AI workflows. These components work together to process videos, generate embeddings, index video content, and enable natural language interactions with visual content.
3.1 - Video File Component
The Video File Component serves as your entry point for video processing workflows in Langflow. It handles a wide range of common video formats including MP4, AVI, MOV, and MKV, making it versatile for different video sources. Implementation is straightforward - simply provide a path to your video file, and the component returns a Data object containing both the file path and essential metadata. For optimal performance during development, we recommend starting with videos under 100MB.
3.2 - Split Video Component
This powerful component intelligently segments longer videos into smaller, more manageable clips. You can fine-tune the splitting process through several parameters: set your desired clip duration in seconds, choose how to handle the final clip (truncate, overlap with previous content, or keep as-is), and decide whether to retain the original video alongside the clips. The component outputs a collection of clips as Data objects, complete with detailed metadata. For best results in retrieval and understanding tasks, we recommend creating clips between 6 and 30 seconds in length.
3.3 - Twelve Labs Pegasus Index Video Component
At the heart of video indexing lies the Pegasus Index Video Component. It interfaces with TwelveLabs' Pegasus API to create searchable indexes of your video content. After providing your API key and video data (typically from the Split Video component), it generates indexed video data complete with unique video_id and index_id identifiers. This indexing step is crucial before performing any queries with the Pegasus component.
3.4 - Twelve Labs Pegasus Component
The Pegasus Component enables sophisticated natural language interaction with your indexed video content. Configuration requires your API key, the query text, and the relevant video and index identifiers. Acting as an intelligent reasoning layer, it processes both the query context and video content to generate conversational responses. This component truly bridges the gap between natural language understanding and video content analysis.
3.5 - Twelve Labs Text Embeddings Component
Leveraging TwelveLabs' Marengo model, this component generates vector embeddings from text input. It requires your API key and currently supports the Marengo-retrieval-2.7 model. The output is fully compatible with vector databases, making it perfect for sophisticated retrieval systems. For consistency in your applications, we recommend using the same embedding models across both text and video components.
3.6 - Twelve Labs Video Embeddings Component
Similar to its text counterpart, the Video Embeddings Component creates dense vector representations of video content. It shares the same configuration pattern as the text embeddings component but specializes in processing video files. The resulting embeddings enable powerful semantic similarity searches between videos or between text and video content, opening up exciting possibilities for multimodal applications.
3.7 - Convert AstraDB to Pegasus Input Component
This essential connector component bridges the gap between vector database operations and TwelveLabs components. It processes search results from AstraDB, extracting crucial video_id and index_id information, and formats them properly for the Pegasus component. This component becomes particularly valuable when implementing RAG (Retrieval Augmented Generation) patterns with video content, ensuring smooth data flow between your vector database and video processing pipeline.
These components are designed to work together seamlessly. For example, you can create a video search engine by:
Loading videos with Video File
Splitting them into digestible chunks with Split Video
Indexing them with Pegasus Index Video
Generating embeddings with Video Embeddings
Storing in a vector database like AstraDB
Retrieving relevant clips with Convert AstraDB to Pegasus Input
Answering questions with Twelve Labs Pegasus
When building your workflows, think of these components as building blocks that handle different aspects of video understanding-from loading and processing to indexing, embedding, and retrieval.
4 - Pegasus Chat with Video: Your First Interactive Video Workflow
This section guides you through creating a fundamental Langflow workflow that allows you to "chat" with a video using the Twelve Labs Pegasus model. This flow demonstrates the direct integration of video processing, indexing, and natural language querying.
The "Pegasus Chat with Video" flow, as shown in the reference image, enables you to upload a video, have it automatically indexed by Twelve Labs, and then ask questions about its content through a chat interface.
Follow these steps to build this flow:
Upload Your Video:
Drag a
Video Filecomponent onto the Langflow canvas.In the
Video Filecomponent's properties, click to upload one of your sample video files (e.g.,big_buck_bunny_720.mp4as shown in the image). This component will load your video and make it available to other components.
Connect Video Data to Pegasus:
Add a
Twelve Labs Pegasuscomponent to the canvas.Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theVideo Datainput (the red dot) on theTwelve Labs Pegasuscomponent. This tells the Pegasus component which video to process.
Configure Pegasus Component:
In the
Twelve Labs Pegasuscomponent:Enter your Twelve Labs API Key in the designated field.
Provide an Index Name. This can be any descriptive name you choose for the video index that will be created (e.g., "bunny-test-index").
The Model will default to a Pegasus model like
pegasus1.2. You can typically leave this as is unless you have specific model requirements.
Developer Note: When you provide
Video Dataand anIndex Namewithout anIndex ID, the Pegasus component will automatically initiate the video indexing process with Twelve Labs for the new video. Thevideo_idandindex_idwill be generated by Twelve Labs during this process.
Enable User Input:
Add a
Chat Inputcomponent to the canvas.Connect the output of the
Chat Inputcomponent to thePromptinput (the blue dot, labeled "Receiving input" in the image) of theTwelve Labs Pegasuscomponent. This allows you to type questions that will be sent to the Pegasus model.
Display Chat Responses:
Add a
Chat Outputcomponent.Connect the
Messageoutput (the blue dot) from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent1. This will display the answers from the Pegasus model.
Optional: Output Video ID for Re-chatting:
To avoid re-indexing the same video for subsequent chat sessions, you can capture the
Video IDandIndex IDgenerated by Twelve Labs.Add another
Chat Outputcomponent.Connect the
Video IDoutput (the blue dot) from theTwelve Labs Pegasuscomponent to this newChat Outputcomponent1.Developer Tip: In future sessions with the same video, you can directly input the previously generated
Video IDandIndex IDinto thePegasus Video IDandIndex IDfields of theTwelve Labs Pegasuscomponent, respectively. This bypasses the re-indexing step, making interactions faster. If you only provide theVideo DataandIndex Name, it will re-index.
Test in the Playground:
Open the Langflow playground (usually by clicking the chat bubble icon on the right sidebar).
Type a question about your video into the chat interface (e.g., "What animal is in the video?", "Describe the main character.").
The Pegasus component will process your video (if it's the first time), index it, and then answer your question based on the video's content. The response will appear in the connected
Chat Output.
This simple yet powerful flow serves as a foundational example of how to integrate TwelveLabs' video understanding directly into an interactive Langflow agent. You can now ask questions and get answers about the content of your videos in near real-time.
5 - Video Embeddings with Marengo and AstraDB: Building Your Semantic Video Index
This section details how to construct a Langflow workflow to generate video embeddings using TwelveLabs' Marengo model and subsequently store these embeddings in DataStax AstraDB. This is a crucial step for enabling semantic search over your video library or for building advanced Retrieval Augmented Generation (RAG) systems with video content.
The workflow, as illustrated in the provided reference image, ingests a video, generates its embeddings, and then stores these embeddings along with video metadata in an AstraDB collection.
5.1 - Prerequisites: Setting up AstraDB
Before building the Langflow flow, ensure your AstraDB environment is ready:
Create an AstraDB Database:
If you don't have one, sign up and create a new serverless database on DataStax AstraDB.
Follow the AstraDB setup guides for initial database creation.
Generate an Application Token:
Navigate to your Database Details section in the AstraDB console.
Generate an Application Token with appropriate permissions (e.g., Database Administrator or a role that allows read/write to your collections). Securely store this token, as you'll need it for the Langflow component.
Create a
video_embeddingsCollection:Within your AstraDB database, create a new collection. You might name it
video_embeddingsor similar.Crucially, configure this collection to support vector search. This typically involves:
Specifying that the collection will store vectors.
Setting the vector dimension to 1024, which is the dimension for embeddings generated by TwelveLabs' Marengo models (like
Marengo-retrieval-2.7shown in the image1).
Refer to the AstraDB documentation on collection management for detailed steps on enabling vector search and setting dimensions.
5.2 - Building the Langflow Flow
Once AstraDB is set up, construct the following flow in Langflow:
Upload Your Video:
Drag a
Video Filecomponent onto the canvas.Configure it by uploading your desired video file (e.g.,
big_buck_bunny_720.mp4as seen in the image1). This component makes the video data accessible to the workflow.
Configure Video Embeddings Generation:
Add a
Twelve Labs Video Embeddingscomponent to the canvas.Enter your Twelve Labs API Key in the
API Keyfield.Ensure the Model is set to
Marengo-retrieval-2.7(or another compatible Marengo model). This component will process the video and generate dense vector embeddings.
Configure AstraDB for Ingestion:
Add a
DS Astra DBcomponent (orAstra DBas shown in the image1) to the canvas.Input your Astra DB Application Token into the corresponding field.
Specify the Database name where you created your vector-enabled collection.
Enter the name of your Collection (e.g.,
video_embeddings).
Connect Embeddings to AstraDB:
Connect the
Embeddingsoutput (the green dot) from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput (the green dot) on theDS Astra DBcomponent1.Developer Note: This connection tells AstraDB how to interpret the incoming data as embeddings, but it doesn't provide the embeddings themselves. The actual embeddings come with the data to be ingested.
Connect Video Data for Ingestion:
Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theIngest Datainput (the red dot) on theDS Astra DBcomponent1.Developer Note: When data is passed to the
Ingest Datainput, theAstra DBcomponent, if configured with an embedding model or connected to an embedding component as in this flow, will expect or generate embeddings for the incoming data. In this setup, theTwelve Labs Video Embeddingscomponent handles the embedding generation, and its output (which includes the embedding along with original data) is passed toDS Astra DB.
Run the Flow to Embed and Ingest:
To trigger the process, you typically "run" or activate the final component in this chain, which is the
DS Astra DBcomponent. In Langflow, this might involve clicking a play/run button on the component or initiating the flow if it's part of a larger executable graph.Upon execution, the
Video Filecomponent loads the video. TheTwelve Labs Video Embeddingscomponent then receives this video data (often implicitly through the flow or explicitly if theVideo Datainput is connected, though not shown for this component in the screenshot), generates the embeddings. Finally, theDS Astra DBcomponent takes the video data (now enriched with embeddings by the upstream component or by its own internal logic if the embedding component is connected to itsEmbedding Modelinput) and ingests it into the specified AstraDB collection.
After running this flow, your video's content will be represented as vector embeddings within your AstraDB collection, ready for semantic search, similarity comparisons, and as a knowledge base for RAG applications. You can verify this by querying your AstraDB collection directly.
6 - Advanced RAG Implementation with Video Content
Building a robust Retrieval Augmented Generation (RAG) system for video involves several stages, from processing and indexing your video content to enabling semantic search and contextual understanding. This section is broken into two parts. First, we'll focus on preparing your video data by splitting it, indexing the clips with Twelve Labs Pegasus, generating embeddings with Marengo, and storing everything in AstraDB.
Part 1: Split Video, Index Clips with Pegasus, and Save Embeddings to Astra DB
This initial flow, illustrated in the provided image, is the foundation of your video RAG system. It processes a source video into manageable clips, enriches these clips with indexing information from Pegasus, generates corresponding vector embeddings using Marengo, and finally stores this comprehensive dataset in AstraDB for efficient retrieval.
Here's how to construct this ingestion pipeline:
Upload Source Video:
Begin by dragging a
Video Filecomponent onto your Langflow canvas.Configure it by uploading your video (e.g.,
big_buck_bunny_720...as shown in the image). This component outputs the raw video data.
Split Video into Clips:
Add a
Split Videocomponent.Connect the
Dataoutput from theVideo Filecomponent to theVideo Datainput of theSplit Videocomponent.Configure the
Split Videocomponent:Clip Duration (seconds): Set this to define the length of each video segment. The image shows
6seconds, which is a good starting point for granular analysis. You can adjust this based on your content; for instance, 30 seconds might be suitable for broader scene segmentation.Last Clip Handling: Choose an option like
Overlap Previous(as in the image) to ensure consistent clip lengths, or selectTruncateorKeep Shortbased on your preference.Include Original Video: Typically, this is turned off (as in the image) when processing clips for RAG, as you'll be working with the segments.
Index Clips with Pegasus:
Introduce a
Twelve Labs Pegasus Index Videocomponent.Connect the
Video Clipsoutput from theSplit Videocomponent to theVideo Datainput of theTwelve Labs Pegasus Index Videocomponent. This component will process each clip.In the component's settings:
Enter your Twelve Labs API Key.
Specify an Index Name (e.g.,
test indexin the image). This helps organize your indexed content within Twelve Labs. The component will outputIndexed Data, which includes the original clip data along with thevideo_idandindex_idassigned by Pegasus.The Model will default to a Pegasus model (e.g.,
pegasus1.2).
Generate Video Embeddings with Marengo:
Add a
Twelve Labs Video Embeddingscomponent.Enter your Twelve Labs API Key here as well.
Set the Model to
Marengo-retrieval-2.7(as shown in the image) or your preferred Marengo embedding model.Crucially, connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to the (implicit or explicit) video data input of theTwelve Labs Video Embeddingscomponent. Developer Note: While the image doesn't show a direct named "Video Data" input on this component, the embeddings component needs to receive the video clips to process. TheIndexed Datacarries these clips.
Configure AstraDB for Storage:
Place a
DS Astra DBcomponent onto the canvas.Enter your Astra DB Application Token.
Select your target Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where the video data and embeddings will be stored. Ensure this collection is configured for vector search with a dimension matching your Marengo model (1024 forMarengo-retrieval-2.7).
Connect Embeddings and Data to AstraDB:
Connect the
Embeddingsoutput from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput on theDS Astra DBcomponent. This tells AstraDB how to interpret the embedding vectors.Connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to theIngest Datainput on theDS Astra DBcomponent. This sends the video clips (now enriched with Pegasusvideo_idandindex_id) along with their generated embeddings to be stored.
Run the Ingestion Flow:
Execute the flow. The
Video Fileis loaded, split bySplit Video. Each clip is then sent toTwelve Labs Pegasus Index Videofor indexing. The resultingIndexed Data(clips + Pegasus IDs) is passed toTwelve Labs Video Embeddingsto generate Marengo embeddings. Finally, theDS Astra DBcomponent ingests this comprehensive data: the clips, their Pegasus index information, and their Marengo vector embeddings into your specified collection.
After this flow completes, your AstraDB collection will contain indexed video clips, each associated with its vector embedding and Pegasus identifiers, ready for the retrieval part of your RAG system.
Part 2: Query Video Embeddings and Chat with Video using Pegasus
With your video clips processed, indexed by Pegasus, and their Marengo embeddings stored in AstraDB (as detailed in Part 1), this second flow demonstrates the retrieval and generation aspects of RAG. As shown in the reference image, a user's text query is first embedded, then used to search AstraDB for relevant video clips. The information from these clips is then passed to the Twelve Labs Pegasus model to generate a contextual answer.
Here's how to build this retrieval and question-answering pipeline:
User Query Input and Embedding:
Add a
Chat Inputcomponent to the canvas. This will be where the user types their question.Add a
Twelve Labs Text Embeddingscomponent.Enter your Twelve Labs API Key.
Set the Model to
Marengo-retrieval-2.7(or the same Marengo model used in Part 1 for embedding the video clips).
Connect the output of the
Chat Inputcomponent to the text input of theTwelve Labs Text Embeddingscomponent. This ensures the user's query is converted into a vector embedding.
Semantic Search in AstraDB:
Add a
DS Astra DBcomponent.Enter your Astra DB Application Token.
Select the Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where your video clip embeddings are stored.Connect the
Embeddingsoutput from theTwelve Labs Text Embeddingscomponent to theEmbedding Modelinput of theDS Astra DBcomponent. This provides AstraDB with the query embedding.Connect the output of the
Chat Inputcomponent (the raw text query) to theSearch Queryinput of theDS Astra DBcomponent. Developer Note: While the embedding of the query is passed toEmbedding Model, theSearch Queryinput itself might be used by AstraDB for keyword filtering or other hybrid search strategies if configured, or simply to know what to perform the vector search against using the provided query embedding.
The
DS Astra DBcomponent will perform a similarity search in your collection, returning theSearch Resultswhich are the most relevant video clips (or their metadata, includingvideo_idandindex_idif stored from Part 1).
Convert AstraDB Results for Pegasus:
Add a
Convert AstraDB to Pegasus Inputcomponent.Connect the
Search Resultsoutput (the red dot, often carrying document metadata) from theDS Astra DBcomponent to theAstraDB Resultsinput of this converter component.This utility component is crucial: it extracts the
Index IDandVideo IDfrom the AstraDB search results, which are necessary for the Pegasus component to identify which specific indexed video segment to "chat" with.
Prepare Pegasus for Contextual Q&A:
Add a
Twelve Labs Pegasuscomponent.Enter your Twelve Labs API Key.
Select the desired Pegasus Model (e.g.,
pegasus1.2is the default).
Connect the
Index IDoutput from theConvert AstraDB to Pegasus Inputcomponent to theIndex IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Connect the
Video IDoutput from theConvert AstraDB to Pegasus Inputcomponent to thePegasus Video IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Developer Note: Unlike the "Pegasus Chat with Video" flow where video data might be directly provided for on-the-fly indexing, here we are providing specific
Pegasus Video IDandIndex IDfor already indexed content retrieved from AstraDB. TheVideo Datainput on the Pegasus component remains unconnected in this RAG retrieval flow.
Pass Original Query to Pegasus:
Connect the output of the original
Chat Inputcomponent (the one holding the user's question) directly to thePromptinput (labeled "Receiving input") of theTwelve Labs Pegasuscomponent. This ensures Pegasus knows what question to answer using the context of the retrieved video segment.
Display Pegasus's Response:
Add a
Chat Outputcomponent.Connect the
Messageoutput from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent. This will display the AI-generated answer.
Test Your Video RAG System:
Open the Langflow playground (chat interface).
Ask a question related to the content of the videos you processed in Part 1 (e.g., "What happens to the bunny at the beginning?", "Show me scenes with butterflies.").
The flow will execute as follows:
Your question is captured by
Chat Input.Twelve Labs Text Embeddingsconverts your question into a vector.DS Astra DBuses this vector to find the most semantically similar video clip(s) from your database.Convert AstraDB to Pegasus Inputextracts thevideo_idandindex_idof the top retrieved clip(s).Twelve Labs Pegasusreceives these IDs (telling it which video segment to focus on) and your original question (telling it what to answer about that segment).Pegasus analyzes the specified video segment in relation to your question and generates an answer.
The answer is displayed via
Chat Output.
This two-part RAG architecture allows you to build sophisticated, scalable video understanding applications where users can conversationally retrieve and interact with relevant moments from a large video library.
7 - Specialized Use Cases & Performance Best Practices
TwelveLabs and Langflow’s combined video capabilities unlock a range of high-value business applications. You can build content moderation systems that automatically flag or summarize inappropriate video segments, video search engines that surface relevant moments from large archives, or even multimodal assistants that blend video, text, and image understanding for richer user experiences. These use cases are ideal for industries like media, education, and customer support, where quick access to video insights and automated analysis directly drive productivity, compliance, and user engagement.
To ensure your video-enabled workflows deliver reliable business results, focus on optimizing performance and cost. Manage API usage by batching video segments or using caching to avoid redundant processing, and choose clip durations that balance detail with computational efficiency. Monitor your AstraDB and embedding pipelines to maintain fast query responses as your video library grows, and consider hybrid search strategies that combine vector similarity with metadata filtering for more precise results.
By following these best practices, you maximize the scalability, accuracy, and cost-effectiveness of your video AI solutions—helping your organization extract actionable insights from video at scale and maintain a competitive edge in the market.
8 - Conclusion and Next Steps
Congratulations, video wizard! 🎬✨
You’ve just unlocked the power to build AI agents that truly see and understand video, using the dynamic duo of TwelveLabs and Langflow. Whether you’re creating the next smart video search engine, moderating content at scale, or crafting multimodal assistants, you’re now equipped with the tools to turn raw footage into actionable insights—and maybe even a little magic.
So what’s next?
Try experimenting with your own creative flows, push the limits with different video types, or share your coolest projects with the community. Keep an eye on the TwelveLabs and Langflow roadmaps for exciting new features, and don’t forget to join the conversation—your ideas and feedback help shape the future of video AI!
Go forth and build something amazing. The video universe is yours to explore! 🚀🎥
Additional Resources
TwelveLabs Docs: https://docs.twelvelabs.io/
Langflow Docs: https://docs.langflow.org/
TwelveLabs Components in Langflow: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md
We'd like to give a huge thanks to the team at Langflow/DataStax (Melissa Herrera, Eric Hare, Gokul Krishnaa, and Alejandro Cantarero) for the collaboration!
Please also watch this tutorial from Melissa below that showcases the entire workflows 👇
1 - Introduction and Overview
Welcome to the wild world of video AI, where your apps can finally “see” what’s happening in videos—just like you do! 🎬
This tutorial is your golden ticket to building next-level video-powered agents with TwelveLabs and Langflow. No need for a PhD in computer vision—just bring your curiosity and a few video clips to the party.
Why should you care?
TwelveLabs brings the brains: our Pegasus and Marengo models let your code understand, index, and chat with video content—answering questions, finding key moments, and even generating smart summaries. Langflow is your playground: a visual builder that turns your ideas into AI workflows and instantly serves them as APIs. Together, they make it easy to create, test, and deploy video AI solutions—whether you’re building a video search engine, a content moderation bot, or a multimodal assistant that can handle text, images, and videos.
What’s inside?
In this tutorial, you’ll go from zero to video hero. You’ll set up your environment, master the TwelveLabs components in Langflow, and build real-world flows—like chatting with videos, generating and storing video embeddings, and even crafting a full-blown RAG system that retrieves and answers questions from your video library. Along the way, you’ll pick up best practices, discover killer use cases, and get inspired to build your own video-powered apps.
So grab some popcorn, fire up your code editor, and let’s make your AI workflows truly video-smart! 🚀🍿
2 - Setting Up Your Development Environment
Let's prepare your environment to start building with TwelveLabs and Langflow.
Installing Langflow
Install Langflow using pip:
pip install langflowStart the Langflow server:
langflow runAccess the Langflow UI by navigating to
http://127.0.0.1:7860in your browser.
Obtaining TwelveLabs API Credentials
Create an account on the TwelveLabs platform if you don't already have one.
Navigate to your profile settings and create a new API key.
Make note of your API key as you'll need it to authenticate requests to TwelveLabs services.
Verifying TwelveLabs Components
In the Langflow interface, create a new flow by clicking the "+" button.
Open the component sidebar and search for "TwelveLabs". You should see the following components:
Video File
Split Video
Twelve Labs Pegasus Index Video
Twelve Labs Pegasus
Twelve Labs Text Embeddings
Twelve Labs Video Embeddings
Convert AstraDB to Pegasus Input
If you don't see these components, ensure Langflow is updated to the latest version.
Preparing Sample Videos
Select 2-3 short video clips (1-3 minutes each) for testing during this tutorial. Common formats like MP4, MOV, and AVI are supported.
For optimal performance during learning, use videos with clear visual content and distinct scenes. This helps demonstrate the video understanding capabilities more effectively.
Create a dedicated folder for your sample videos so they're easy to locate during the tutorial.
Troubleshooting Tips
If you encounter issues with the TwelveLabs components:
API Authentication: Verify your API key is correctly entered and has not expired.
Video Processing: Ensure your videos are in supported formats and aren't too large. Start with clips under 100MB for faster processing.
Component Loading: If components don't appear, try restarting Langflow or checking the console for error messages.
Dependencies: The integration requires FFmpeg for video processing. Install it using your system's package manager if not already available.
With your environment set up, you're ready to start building powerful video-enabled AI workflows with TwelveLabs and Langflow.
3 - Understanding TwelveLabs Components in Langflow
Langflow now includes seven powerful TwelveLabs components that enable advanced video understanding capabilities in your AI workflows. These components work together to process videos, generate embeddings, index video content, and enable natural language interactions with visual content.
3.1 - Video File Component
The Video File Component serves as your entry point for video processing workflows in Langflow. It handles a wide range of common video formats including MP4, AVI, MOV, and MKV, making it versatile for different video sources. Implementation is straightforward - simply provide a path to your video file, and the component returns a Data object containing both the file path and essential metadata. For optimal performance during development, we recommend starting with videos under 100MB.
3.2 - Split Video Component
This powerful component intelligently segments longer videos into smaller, more manageable clips. You can fine-tune the splitting process through several parameters: set your desired clip duration in seconds, choose how to handle the final clip (truncate, overlap with previous content, or keep as-is), and decide whether to retain the original video alongside the clips. The component outputs a collection of clips as Data objects, complete with detailed metadata. For best results in retrieval and understanding tasks, we recommend creating clips between 6 and 30 seconds in length.
3.3 - Twelve Labs Pegasus Index Video Component
At the heart of video indexing lies the Pegasus Index Video Component. It interfaces with TwelveLabs' Pegasus API to create searchable indexes of your video content. After providing your API key and video data (typically from the Split Video component), it generates indexed video data complete with unique video_id and index_id identifiers. This indexing step is crucial before performing any queries with the Pegasus component.
3.4 - Twelve Labs Pegasus Component
The Pegasus Component enables sophisticated natural language interaction with your indexed video content. Configuration requires your API key, the query text, and the relevant video and index identifiers. Acting as an intelligent reasoning layer, it processes both the query context and video content to generate conversational responses. This component truly bridges the gap between natural language understanding and video content analysis.
3.5 - Twelve Labs Text Embeddings Component
Leveraging TwelveLabs' Marengo model, this component generates vector embeddings from text input. It requires your API key and currently supports the Marengo-retrieval-2.7 model. The output is fully compatible with vector databases, making it perfect for sophisticated retrieval systems. For consistency in your applications, we recommend using the same embedding models across both text and video components.
3.6 - Twelve Labs Video Embeddings Component
Similar to its text counterpart, the Video Embeddings Component creates dense vector representations of video content. It shares the same configuration pattern as the text embeddings component but specializes in processing video files. The resulting embeddings enable powerful semantic similarity searches between videos or between text and video content, opening up exciting possibilities for multimodal applications.
3.7 - Convert AstraDB to Pegasus Input Component
This essential connector component bridges the gap between vector database operations and TwelveLabs components. It processes search results from AstraDB, extracting crucial video_id and index_id information, and formats them properly for the Pegasus component. This component becomes particularly valuable when implementing RAG (Retrieval Augmented Generation) patterns with video content, ensuring smooth data flow between your vector database and video processing pipeline.
These components are designed to work together seamlessly. For example, you can create a video search engine by:
Loading videos with Video File
Splitting them into digestible chunks with Split Video
Indexing them with Pegasus Index Video
Generating embeddings with Video Embeddings
Storing in a vector database like AstraDB
Retrieving relevant clips with Convert AstraDB to Pegasus Input
Answering questions with Twelve Labs Pegasus
When building your workflows, think of these components as building blocks that handle different aspects of video understanding-from loading and processing to indexing, embedding, and retrieval.
4 - Pegasus Chat with Video: Your First Interactive Video Workflow
This section guides you through creating a fundamental Langflow workflow that allows you to "chat" with a video using the Twelve Labs Pegasus model. This flow demonstrates the direct integration of video processing, indexing, and natural language querying.
The "Pegasus Chat with Video" flow, as shown in the reference image, enables you to upload a video, have it automatically indexed by Twelve Labs, and then ask questions about its content through a chat interface.
Follow these steps to build this flow:
Upload Your Video:
Drag a
Video Filecomponent onto the Langflow canvas.In the
Video Filecomponent's properties, click to upload one of your sample video files (e.g.,big_buck_bunny_720.mp4as shown in the image). This component will load your video and make it available to other components.
Connect Video Data to Pegasus:
Add a
Twelve Labs Pegasuscomponent to the canvas.Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theVideo Datainput (the red dot) on theTwelve Labs Pegasuscomponent. This tells the Pegasus component which video to process.
Configure Pegasus Component:
In the
Twelve Labs Pegasuscomponent:Enter your Twelve Labs API Key in the designated field.
Provide an Index Name. This can be any descriptive name you choose for the video index that will be created (e.g., "bunny-test-index").
The Model will default to a Pegasus model like
pegasus1.2. You can typically leave this as is unless you have specific model requirements.
Developer Note: When you provide
Video Dataand anIndex Namewithout anIndex ID, the Pegasus component will automatically initiate the video indexing process with Twelve Labs for the new video. Thevideo_idandindex_idwill be generated by Twelve Labs during this process.
Enable User Input:
Add a
Chat Inputcomponent to the canvas.Connect the output of the
Chat Inputcomponent to thePromptinput (the blue dot, labeled "Receiving input" in the image) of theTwelve Labs Pegasuscomponent. This allows you to type questions that will be sent to the Pegasus model.
Display Chat Responses:
Add a
Chat Outputcomponent.Connect the
Messageoutput (the blue dot) from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent1. This will display the answers from the Pegasus model.
Optional: Output Video ID for Re-chatting:
To avoid re-indexing the same video for subsequent chat sessions, you can capture the
Video IDandIndex IDgenerated by Twelve Labs.Add another
Chat Outputcomponent.Connect the
Video IDoutput (the blue dot) from theTwelve Labs Pegasuscomponent to this newChat Outputcomponent1.Developer Tip: In future sessions with the same video, you can directly input the previously generated
Video IDandIndex IDinto thePegasus Video IDandIndex IDfields of theTwelve Labs Pegasuscomponent, respectively. This bypasses the re-indexing step, making interactions faster. If you only provide theVideo DataandIndex Name, it will re-index.
Test in the Playground:
Open the Langflow playground (usually by clicking the chat bubble icon on the right sidebar).
Type a question about your video into the chat interface (e.g., "What animal is in the video?", "Describe the main character.").
The Pegasus component will process your video (if it's the first time), index it, and then answer your question based on the video's content. The response will appear in the connected
Chat Output.
This simple yet powerful flow serves as a foundational example of how to integrate TwelveLabs' video understanding directly into an interactive Langflow agent. You can now ask questions and get answers about the content of your videos in near real-time.
5 - Video Embeddings with Marengo and AstraDB: Building Your Semantic Video Index
This section details how to construct a Langflow workflow to generate video embeddings using TwelveLabs' Marengo model and subsequently store these embeddings in DataStax AstraDB. This is a crucial step for enabling semantic search over your video library or for building advanced Retrieval Augmented Generation (RAG) systems with video content.
The workflow, as illustrated in the provided reference image, ingests a video, generates its embeddings, and then stores these embeddings along with video metadata in an AstraDB collection.
5.1 - Prerequisites: Setting up AstraDB
Before building the Langflow flow, ensure your AstraDB environment is ready:
Create an AstraDB Database:
If you don't have one, sign up and create a new serverless database on DataStax AstraDB.
Follow the AstraDB setup guides for initial database creation.
Generate an Application Token:
Navigate to your Database Details section in the AstraDB console.
Generate an Application Token with appropriate permissions (e.g., Database Administrator or a role that allows read/write to your collections). Securely store this token, as you'll need it for the Langflow component.
Create a
video_embeddingsCollection:Within your AstraDB database, create a new collection. You might name it
video_embeddingsor similar.Crucially, configure this collection to support vector search. This typically involves:
Specifying that the collection will store vectors.
Setting the vector dimension to 1024, which is the dimension for embeddings generated by TwelveLabs' Marengo models (like
Marengo-retrieval-2.7shown in the image1).
Refer to the AstraDB documentation on collection management for detailed steps on enabling vector search and setting dimensions.
5.2 - Building the Langflow Flow
Once AstraDB is set up, construct the following flow in Langflow:
Upload Your Video:
Drag a
Video Filecomponent onto the canvas.Configure it by uploading your desired video file (e.g.,
big_buck_bunny_720.mp4as seen in the image1). This component makes the video data accessible to the workflow.
Configure Video Embeddings Generation:
Add a
Twelve Labs Video Embeddingscomponent to the canvas.Enter your Twelve Labs API Key in the
API Keyfield.Ensure the Model is set to
Marengo-retrieval-2.7(or another compatible Marengo model). This component will process the video and generate dense vector embeddings.
Configure AstraDB for Ingestion:
Add a
DS Astra DBcomponent (orAstra DBas shown in the image1) to the canvas.Input your Astra DB Application Token into the corresponding field.
Specify the Database name where you created your vector-enabled collection.
Enter the name of your Collection (e.g.,
video_embeddings).
Connect Embeddings to AstraDB:
Connect the
Embeddingsoutput (the green dot) from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput (the green dot) on theDS Astra DBcomponent1.Developer Note: This connection tells AstraDB how to interpret the incoming data as embeddings, but it doesn't provide the embeddings themselves. The actual embeddings come with the data to be ingested.
Connect Video Data for Ingestion:
Connect the
Dataoutput (the red dot) from theVideo Filecomponent to theIngest Datainput (the red dot) on theDS Astra DBcomponent1.Developer Note: When data is passed to the
Ingest Datainput, theAstra DBcomponent, if configured with an embedding model or connected to an embedding component as in this flow, will expect or generate embeddings for the incoming data. In this setup, theTwelve Labs Video Embeddingscomponent handles the embedding generation, and its output (which includes the embedding along with original data) is passed toDS Astra DB.
Run the Flow to Embed and Ingest:
To trigger the process, you typically "run" or activate the final component in this chain, which is the
DS Astra DBcomponent. In Langflow, this might involve clicking a play/run button on the component or initiating the flow if it's part of a larger executable graph.Upon execution, the
Video Filecomponent loads the video. TheTwelve Labs Video Embeddingscomponent then receives this video data (often implicitly through the flow or explicitly if theVideo Datainput is connected, though not shown for this component in the screenshot), generates the embeddings. Finally, theDS Astra DBcomponent takes the video data (now enriched with embeddings by the upstream component or by its own internal logic if the embedding component is connected to itsEmbedding Modelinput) and ingests it into the specified AstraDB collection.
After running this flow, your video's content will be represented as vector embeddings within your AstraDB collection, ready for semantic search, similarity comparisons, and as a knowledge base for RAG applications. You can verify this by querying your AstraDB collection directly.
6 - Advanced RAG Implementation with Video Content
Building a robust Retrieval Augmented Generation (RAG) system for video involves several stages, from processing and indexing your video content to enabling semantic search and contextual understanding. This section is broken into two parts. First, we'll focus on preparing your video data by splitting it, indexing the clips with Twelve Labs Pegasus, generating embeddings with Marengo, and storing everything in AstraDB.
Part 1: Split Video, Index Clips with Pegasus, and Save Embeddings to Astra DB
This initial flow, illustrated in the provided image, is the foundation of your video RAG system. It processes a source video into manageable clips, enriches these clips with indexing information from Pegasus, generates corresponding vector embeddings using Marengo, and finally stores this comprehensive dataset in AstraDB for efficient retrieval.
Here's how to construct this ingestion pipeline:
Upload Source Video:
Begin by dragging a
Video Filecomponent onto your Langflow canvas.Configure it by uploading your video (e.g.,
big_buck_bunny_720...as shown in the image). This component outputs the raw video data.
Split Video into Clips:
Add a
Split Videocomponent.Connect the
Dataoutput from theVideo Filecomponent to theVideo Datainput of theSplit Videocomponent.Configure the
Split Videocomponent:Clip Duration (seconds): Set this to define the length of each video segment. The image shows
6seconds, which is a good starting point for granular analysis. You can adjust this based on your content; for instance, 30 seconds might be suitable for broader scene segmentation.Last Clip Handling: Choose an option like
Overlap Previous(as in the image) to ensure consistent clip lengths, or selectTruncateorKeep Shortbased on your preference.Include Original Video: Typically, this is turned off (as in the image) when processing clips for RAG, as you'll be working with the segments.
Index Clips with Pegasus:
Introduce a
Twelve Labs Pegasus Index Videocomponent.Connect the
Video Clipsoutput from theSplit Videocomponent to theVideo Datainput of theTwelve Labs Pegasus Index Videocomponent. This component will process each clip.In the component's settings:
Enter your Twelve Labs API Key.
Specify an Index Name (e.g.,
test indexin the image). This helps organize your indexed content within Twelve Labs. The component will outputIndexed Data, which includes the original clip data along with thevideo_idandindex_idassigned by Pegasus.The Model will default to a Pegasus model (e.g.,
pegasus1.2).
Generate Video Embeddings with Marengo:
Add a
Twelve Labs Video Embeddingscomponent.Enter your Twelve Labs API Key here as well.
Set the Model to
Marengo-retrieval-2.7(as shown in the image) or your preferred Marengo embedding model.Crucially, connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to the (implicit or explicit) video data input of theTwelve Labs Video Embeddingscomponent. Developer Note: While the image doesn't show a direct named "Video Data" input on this component, the embeddings component needs to receive the video clips to process. TheIndexed Datacarries these clips.
Configure AstraDB for Storage:
Place a
DS Astra DBcomponent onto the canvas.Enter your Astra DB Application Token.
Select your target Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where the video data and embeddings will be stored. Ensure this collection is configured for vector search with a dimension matching your Marengo model (1024 forMarengo-retrieval-2.7).
Connect Embeddings and Data to AstraDB:
Connect the
Embeddingsoutput from theTwelve Labs Video Embeddingscomponent to theEmbedding Modelinput on theDS Astra DBcomponent. This tells AstraDB how to interpret the embedding vectors.Connect the
Indexed Dataoutput from theTwelve Labs Pegasus Index Videocomponent to theIngest Datainput on theDS Astra DBcomponent. This sends the video clips (now enriched with Pegasusvideo_idandindex_id) along with their generated embeddings to be stored.
Run the Ingestion Flow:
Execute the flow. The
Video Fileis loaded, split bySplit Video. Each clip is then sent toTwelve Labs Pegasus Index Videofor indexing. The resultingIndexed Data(clips + Pegasus IDs) is passed toTwelve Labs Video Embeddingsto generate Marengo embeddings. Finally, theDS Astra DBcomponent ingests this comprehensive data: the clips, their Pegasus index information, and their Marengo vector embeddings into your specified collection.
After this flow completes, your AstraDB collection will contain indexed video clips, each associated with its vector embedding and Pegasus identifiers, ready for the retrieval part of your RAG system.
Part 2: Query Video Embeddings and Chat with Video using Pegasus
With your video clips processed, indexed by Pegasus, and their Marengo embeddings stored in AstraDB (as detailed in Part 1), this second flow demonstrates the retrieval and generation aspects of RAG. As shown in the reference image, a user's text query is first embedded, then used to search AstraDB for relevant video clips. The information from these clips is then passed to the Twelve Labs Pegasus model to generate a contextual answer.
Here's how to build this retrieval and question-answering pipeline:
User Query Input and Embedding:
Add a
Chat Inputcomponent to the canvas. This will be where the user types their question.Add a
Twelve Labs Text Embeddingscomponent.Enter your Twelve Labs API Key.
Set the Model to
Marengo-retrieval-2.7(or the same Marengo model used in Part 1 for embedding the video clips).
Connect the output of the
Chat Inputcomponent to the text input of theTwelve Labs Text Embeddingscomponent. This ensures the user's query is converted into a vector embedding.
Semantic Search in AstraDB:
Add a
DS Astra DBcomponent.Enter your Astra DB Application Token.
Select the Database (e.g.,
video_embeddings) and Collection (e.g.,video_embeddings) where your video clip embeddings are stored.Connect the
Embeddingsoutput from theTwelve Labs Text Embeddingscomponent to theEmbedding Modelinput of theDS Astra DBcomponent. This provides AstraDB with the query embedding.Connect the output of the
Chat Inputcomponent (the raw text query) to theSearch Queryinput of theDS Astra DBcomponent. Developer Note: While the embedding of the query is passed toEmbedding Model, theSearch Queryinput itself might be used by AstraDB for keyword filtering or other hybrid search strategies if configured, or simply to know what to perform the vector search against using the provided query embedding.
The
DS Astra DBcomponent will perform a similarity search in your collection, returning theSearch Resultswhich are the most relevant video clips (or their metadata, includingvideo_idandindex_idif stored from Part 1).
Convert AstraDB Results for Pegasus:
Add a
Convert AstraDB to Pegasus Inputcomponent.Connect the
Search Resultsoutput (the red dot, often carrying document metadata) from theDS Astra DBcomponent to theAstraDB Resultsinput of this converter component.This utility component is crucial: it extracts the
Index IDandVideo IDfrom the AstraDB search results, which are necessary for the Pegasus component to identify which specific indexed video segment to "chat" with.
Prepare Pegasus for Contextual Q&A:
Add a
Twelve Labs Pegasuscomponent.Enter your Twelve Labs API Key.
Select the desired Pegasus Model (e.g.,
pegasus1.2is the default).
Connect the
Index IDoutput from theConvert AstraDB to Pegasus Inputcomponent to theIndex IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Connect the
Video IDoutput from theConvert AstraDB to Pegasus Inputcomponent to thePegasus Video IDinput (labeled "Receiving input") on theTwelve Labs Pegasuscomponent.Developer Note: Unlike the "Pegasus Chat with Video" flow where video data might be directly provided for on-the-fly indexing, here we are providing specific
Pegasus Video IDandIndex IDfor already indexed content retrieved from AstraDB. TheVideo Datainput on the Pegasus component remains unconnected in this RAG retrieval flow.
Pass Original Query to Pegasus:
Connect the output of the original
Chat Inputcomponent (the one holding the user's question) directly to thePromptinput (labeled "Receiving input") of theTwelve Labs Pegasuscomponent. This ensures Pegasus knows what question to answer using the context of the retrieved video segment.
Display Pegasus's Response:
Add a
Chat Outputcomponent.Connect the
Messageoutput from theTwelve Labs Pegasuscomponent to the input of thisChat Outputcomponent. This will display the AI-generated answer.
Test Your Video RAG System:
Open the Langflow playground (chat interface).
Ask a question related to the content of the videos you processed in Part 1 (e.g., "What happens to the bunny at the beginning?", "Show me scenes with butterflies.").
The flow will execute as follows:
Your question is captured by
Chat Input.Twelve Labs Text Embeddingsconverts your question into a vector.DS Astra DBuses this vector to find the most semantically similar video clip(s) from your database.Convert AstraDB to Pegasus Inputextracts thevideo_idandindex_idof the top retrieved clip(s).Twelve Labs Pegasusreceives these IDs (telling it which video segment to focus on) and your original question (telling it what to answer about that segment).Pegasus analyzes the specified video segment in relation to your question and generates an answer.
The answer is displayed via
Chat Output.
This two-part RAG architecture allows you to build sophisticated, scalable video understanding applications where users can conversationally retrieve and interact with relevant moments from a large video library.
7 - Specialized Use Cases & Performance Best Practices
TwelveLabs and Langflow’s combined video capabilities unlock a range of high-value business applications. You can build content moderation systems that automatically flag or summarize inappropriate video segments, video search engines that surface relevant moments from large archives, or even multimodal assistants that blend video, text, and image understanding for richer user experiences. These use cases are ideal for industries like media, education, and customer support, where quick access to video insights and automated analysis directly drive productivity, compliance, and user engagement.
To ensure your video-enabled workflows deliver reliable business results, focus on optimizing performance and cost. Manage API usage by batching video segments or using caching to avoid redundant processing, and choose clip durations that balance detail with computational efficiency. Monitor your AstraDB and embedding pipelines to maintain fast query responses as your video library grows, and consider hybrid search strategies that combine vector similarity with metadata filtering for more precise results.
By following these best practices, you maximize the scalability, accuracy, and cost-effectiveness of your video AI solutions—helping your organization extract actionable insights from video at scale and maintain a competitive edge in the market.
8 - Conclusion and Next Steps
Congratulations, video wizard! 🎬✨
You’ve just unlocked the power to build AI agents that truly see and understand video, using the dynamic duo of TwelveLabs and Langflow. Whether you’re creating the next smart video search engine, moderating content at scale, or crafting multimodal assistants, you’re now equipped with the tools to turn raw footage into actionable insights—and maybe even a little magic.
So what’s next?
Try experimenting with your own creative flows, push the limits with different video types, or share your coolest projects with the community. Keep an eye on the TwelveLabs and Langflow roadmaps for exciting new features, and don’t forget to join the conversation—your ideas and feedback help shape the future of video AI!
Go forth and build something amazing. The video universe is yours to explore! 🚀🎥
Additional Resources
TwelveLabs Docs: https://docs.twelvelabs.io/
Langflow Docs: https://docs.langflow.org/
TwelveLabs Components in Langflow: https://github.com/twelvelabs-io/twelvelabs-developer-experience/blob/main/integrations/Langflow/TWELVE_LABS_COMPONENTS_README.md




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved


