
Marengo 3.0 understands every moment in your video data
Search across scenes, objects, speech, actions, and motion
50% storage cost savings and 2x faster indexing
Advanced temporal and spatial reasoning for real video comprehension
Industry-first sports intelligence and entity-level recognition
Composed image plus text queries for precise retrieval
Try it free with your own videos in the Playground
Or book a demo to explore your use case
Marengo 3.0 understands every moment in your video data
Search across scenes, objects, speech, actions, and motion
50% storage cost savings and 2x faster indexing
Advanced temporal and spatial reasoning for real video comprehension
Industry-first sports intelligence and entity-level recognition
Composed image plus text queries for precise retrieval
Try it free with your own videos in the Playground
Or book a demo to explore your use case
Marengo 3.0 understands every moment in your video data
Search across scenes, objects, speech, actions, and motion
50% storage cost savings and 2x faster indexing
Advanced temporal and spatial reasoning for real video comprehension
Industry-first sports intelligence and entity-level recognition
Composed image plus text queries for precise retrieval
Try it free with your own videos in the Playground
Or book a demo to explore your use case
TRUSTED BY
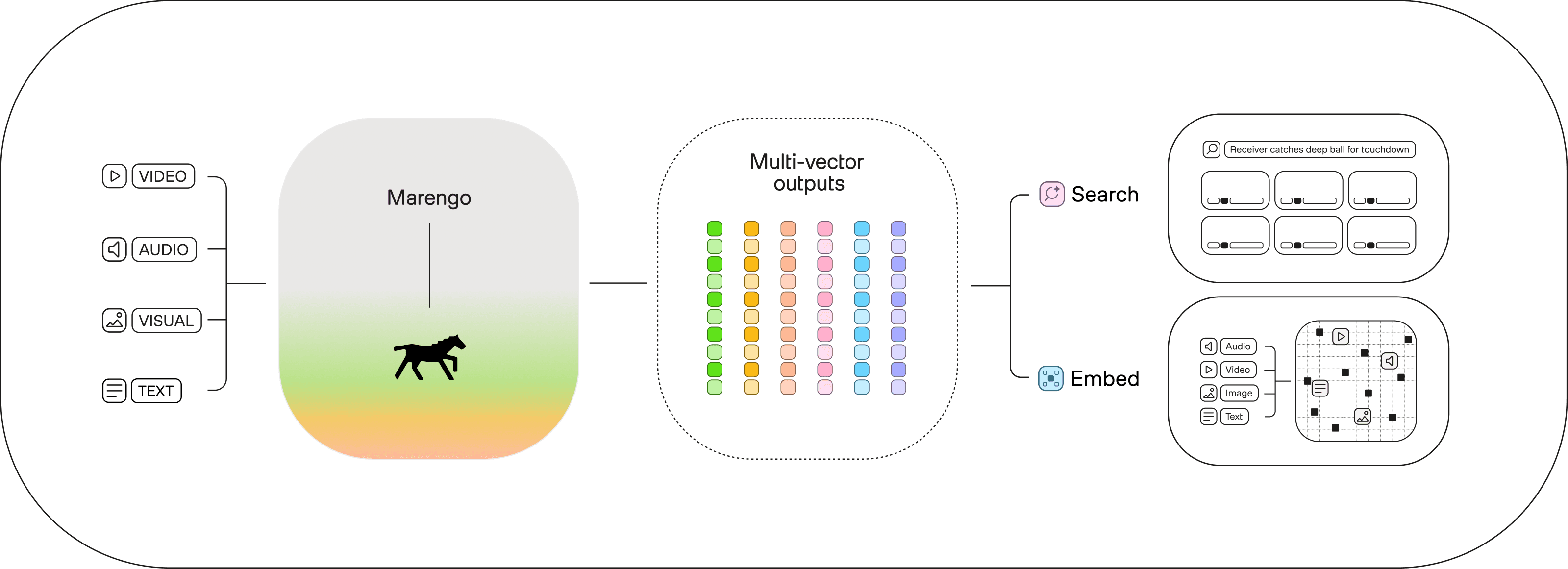
Marengo transforms text, audio, image, and video into numerical representations called embeddings.
Embeddings enable unsurpassed information retrieval. Now, you can perform powerful cross-modal searches – across text, audio, image and video.
This any-to-any retrieval can transform applications. Content discovery, recommendation systems, description and analysis will all change for good.
At TwelveLabs, we’re developing video-native AI systems that can solve problems with human-level reasoning. Helping machines learn about the world — and enabling humans to retrieve, capture, and tell their visual stories better.
Marengo
3.0
Powered Features
Where power meets potential.
" height="31px" id="h_XX9eIa4" transform="translate(0.5 1)" width="31px"/><path d="M 8.824 1.411 C 9.184 1.411 9.538 1.437 9.884 1.486 L 9.761 1.664 L 8.401 2.928 C 5.179 3.156 2.716 5.895 2.83 9.123 C 2.944 12.352 5.594 14.91 8.824 14.911 C 11.453 14.91 13.775 13.199 14.555 10.689 L 16.301 9.468 C 16.101 12.152 14.478 14.522 12.048 15.68 C 9.619 16.837 6.755 16.603 4.545 15.068 L 1.151 19.141 L 0 18.181 L 3.405 14.094 C 1.33 11.924 0.749 8.725 1.929 5.964 C 3.109 3.203 5.821 1.411 8.824 1.411 Z M 14.211 0.177 C 14.259 0.069 14.367 0 14.485 0 C 14.602 0 14.71 0.069 14.758 0.177 L 15.838 2.568 C 15.868 2.634 15.921 2.688 15.988 2.718 L 18.378 3.798 C 18.486 3.846 18.555 3.953 18.555 4.071 C 18.555 4.189 18.486 4.296 18.378 4.345 L 15.988 5.425 C 15.921 5.455 15.868 5.508 15.838 5.575 L 14.758 7.965 C 14.71 8.072 14.602 8.141 14.485 8.141 C 14.367 8.141 14.259 8.072 14.211 7.965 L 13.131 5.575 C 13.101 5.508 13.048 5.455 12.981 5.425 L 10.59 4.345 C 10.482 4.296 10.413 4.189 10.413 4.071 C 10.413 3.953 10.482 3.846 10.59 3.798 L 12.981 2.718 C 13.048 2.688 13.101 2.634 13.131 2.568 Z" fill="rgb(123, 88, 128)" height="19.140720825195313px" id="TNtAf537q" transform="translate(6.5 6.5)" width="18.554721223852766px"/><path d="M 9.1 31 C 4.074 31 0 26.926 0 21.9 L 0 9.1 C 0 4.074 4.074 0 9.1 0 L 21.9 0 C 26.926 0 31 4.074 31 9.1 L 31 21.9 C 31 26.926 26.926 31 21.9 31 Z" fill="transparent" height="31px" id="tL5FaW6u_" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="1" stroke="rgb(123, 88, 128)" transform="translate(0.5 1)" width="31px"/></svg>)
Search
Introducing ‘any-to-any’ search
Marengo’s state-of-the-art ‘any-to-any’ search helps you pinpoint exact moments in vast video libraries, or allow customers to find any video moment within your platform.

Embed
Introducing ‘rich embeddings’
With Marengo, it’s easy to build complex features like semantic search, hybrid search, anomaly detection, and more.


Ready to see your video differently?
Try your own video in our Playground to see next-level video intelligence in action.
Ready to see your video differently?
Try your own video in our Playground to see next-level video intelligence in action.



© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved