
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Product
Video-to-Text Arena: From Pixels to Text with Video-Language Models

Hrishikesh Yadav
The Video-to-Text Arena is an open-source benchmarking platform that evaluates and compares multimodal video understanding models including Twelve Labs Pegasus 1.2, GPT-4o, Gemini 2.0 Flash, Gemini 2.5 Pro, and AWS Nova side-by-side across temporal reasoning, scene continuity, audio transcription, and object tracking tasks.
The Video-to-Text Arena is an open-source benchmarking platform that evaluates and compares multimodal video understanding models including Twelve Labs Pegasus 1.2, GPT-4o, Gemini 2.0 Flash, Gemini 2.5 Pro, and AWS Nova side-by-side across temporal reasoning, scene continuity, audio transcription, and object tracking tasks.

In this article
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Nov 17, 2025
9 Minutes
Copy link to article
Introduction
The Video-to-Text Arena is an open-source platform designed to assess the true capabilities of current AI models in understanding video content. It offers a standardized evaluation process, enabling users to compare various multimodal AI models side-by-side. The platform specifically measures how accurately each model translates visual actions, scenes, and events into analyzed text, highlighting which models best capture context, timing, and meaning.
Modern specialized video understanding models are built to process visual, audio, and textual information simultaneously, moving beyond simple concatenation to deep integration of modalities. These models should be capable of sophisticated video understanding, including cause and effect relationships, temporal ordering, and long-range dependencies across video sequences. The Arena's goal is to bring clarity to this field through practical, transparent comparisons.
Currently, the Arena supports models such as Twelve Labs (Pegasus 1.2), OpenAI (GPT-4o), Google (Gemini 2.0 Flash and 2.5 Pro), and AWS (nova-lite-v1:0). This guide focuses on evaluating these models under consistent qualitative conditions to demonstrate their strengths in various video understanding scenarios.
Thanks to its modular architecture, the Arena can easily integrate more models, and contributors are encouraged to add their own. This guide also provides instructions on how to effectively contribute to the Arena.
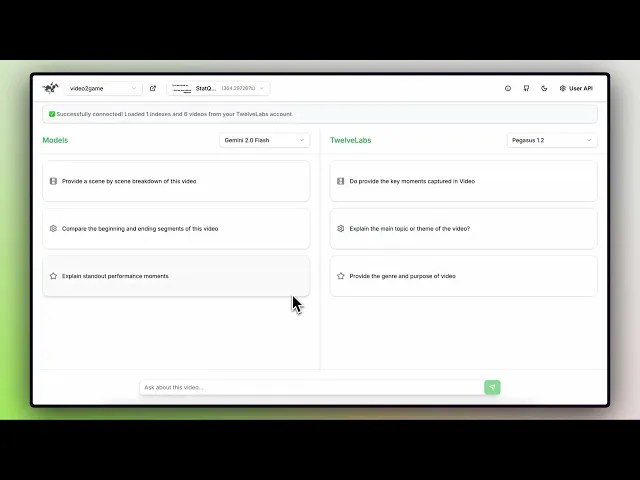
Demo
Below is a demo showing how different models are selected and used for the video analysis to compare their responses with Pegasus-1.2 (TwelveLabs). This setup helps analyze videos across various scenario understanding.
Video Understanding Challenges
Video understanding presents a fundamental temporal challenge, as numerous model pipelines currently sample at approximately one frame per second or even lower, in an effort to minimize computational resources and associated costs. This reduced sampling rate results in a significant information deficit, leading to the omission of rapid actions and brief events, a loss of timestamp granularity, and an impaired synchronization between visual and auditory components, thereby hindering comprehensive video comprehension.
1 - Temporal Reasoning and Sequential Understanding Limitations
Video understanding models encounter substantial difficulties in temporal reasoning and the comprehension of events across video sequences. Models such as GPT-4V exhibit limitations in maintaining coherent temporal understanding when processing extended videos, frequently treating individual frames as discrete snapshots rather than continuous temporal flows. This fundamental constraint arises from frame sampling strategies that downsample videos into sparse representations, leading models to overlook crucial transitional moments and temporal dependencies. While these models generally perform adequately on isolated, moment-specific queries, they demonstrate significant challenges when tasks necessitate a comprehensive understanding of event sequences over time or the tracking of long-range context across several minutes or even hours of video.
2 - Spatial Details Recognition and Object Tracking Deficiencies
Multimodal understanding models exhibit significant deficiencies in spatial reasoning and object tracking within video sequences. Models such as Gemini-2.5-pro and GPT-4o demonstrate a limited capacity to maintain object identity across frames, struggle with in-frame text recognition, and perform poorly in spatial localization tasks. Recent research, specifically the SlowFocus study, indicates that current Vid-LLMs, which process sequences of frames, consume more tokens for higher-quality frames. This creates a trade-off between spatial detail and temporal coverage, preventing Vid-LLMs from simultaneously retaining high-quality frame-level semantic information and comprehensive video-level temporal information. Consequently, numerous failures occur in various scenarios, including tracking specific objects through scene changes, accurately counting objects in high-speed videos, and comprehending precise spatial relationships between objects.
This limitation is exacerbated in longer videos due to memory constraints that necessitate aggressive compression of visual information, thereby hindering accurate scene understanding and leading to token overflow issues.
3 - Hallucination and the Grounding Problems in the Multimodal Context
Video hallucination, a prevalent issue in major multimodal LLMs, results in the generation of factually incorrect information. Benchmarks such as VidHalluc demonstrate the susceptibility of these models to hallucination across three crucial dimensions: action recognition, temporal sequence accuracy, and scene transition understanding. This problem is particularly pronounced in longer videos, where models are required to condense visual information into limited token budgets, leading to over-generalization and fabricated details. A primary approach to mitigate hallucination involves the use of visual encoders capable of discerning subtle differences between similar scenes, combined with LLMs, to ensure strict adherence to visual evidence.
4 - Context Window, Memory and Computational Constraints
Video understanding models encounter limitations concerning context window capacity and computational resource demands. While GPT-4o offers a 128K-token context and Gemini-2.5-Pro supports up to 1M tokens, these capacities remain insufficient for comprehensive, long-form video analysis, given the extensive token requirements for accurate video frame representation. Models inherently struggle to achieve a balance between sampling frequency (temporal resolution) and the overall duration of video they can process. Current methodologies either omit crucial moments by skipping frames or exceed computational thresholds before analysis completion.
As we have explored, the landscape of video understanding models contends with challenges in temporal reasoning and long-form content analysis. The TwelveLabs Pegasus 1.2 model represents an advancement specifically designed to address the fundamental limitations of general-purpose Multimodal Large Language Models (MLLMs). Pegasus 1.2 employs a spatio-temporal comprehension approach that directly confronts the previously discussed challenges. Unlike GPT-4o, Gemini, and Claude, which were primarily developed for general multimodal tasks and subsequently adapted for video understanding, Pegasus 1.2 is purpose-built as a video language model. The model is capable of processing videos up to an hour in length with low latency, high accuracy, and more cost-effective repeated queries to the same video content. Due to its specialized architecture, Pegasus 1.2's ability to process hour-long videos without the accuracy degradation observed in general-purpose MLLMs positions it as the preferred solution for enterprise applications, including content summarization, video captioning, timestamp-accurate event identification, and comprehensive video content analysis.
Qualitative Insights
In this section, we evaluate the video analysis text generated by different models across multiple parameters to assess their video understanding capabilities.
A. Temporal Context Understanding
In this analysis, we focus on temporal context understanding in video content using the example video, “Five Forces of Market Competition,” which visually explains Porter’s Five Forces principle.
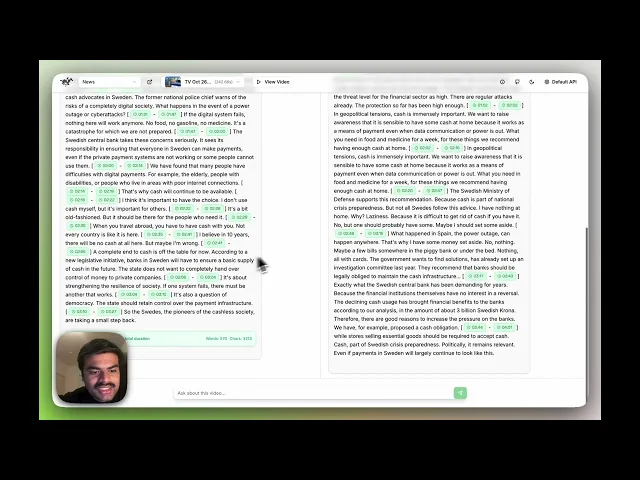
Query – “Describe the sequence of events in the video with timestamps.”

The ensuing analysis contrasts gemini-2.5-pro with pegasus-1.2. The Gemini model produces granular timestamps with high temporal precision, yet it exhibits difficulty in correlating visual segments with their underlying business concepts. Its frame-level segmentation results in a fragmented narration that describes what transpires rather than why. Conversely, Pegasus offers a more conceptually structured and causally coherent explanation, adeptly linking each visual transition to the corresponding competitive force.
While Gemini's precision is advantageous for technical tasks such as event localization, Pegasus surpasses it in interpretability, clarity, and topic relevance, rendering it more appropriate for comprehension and communication.
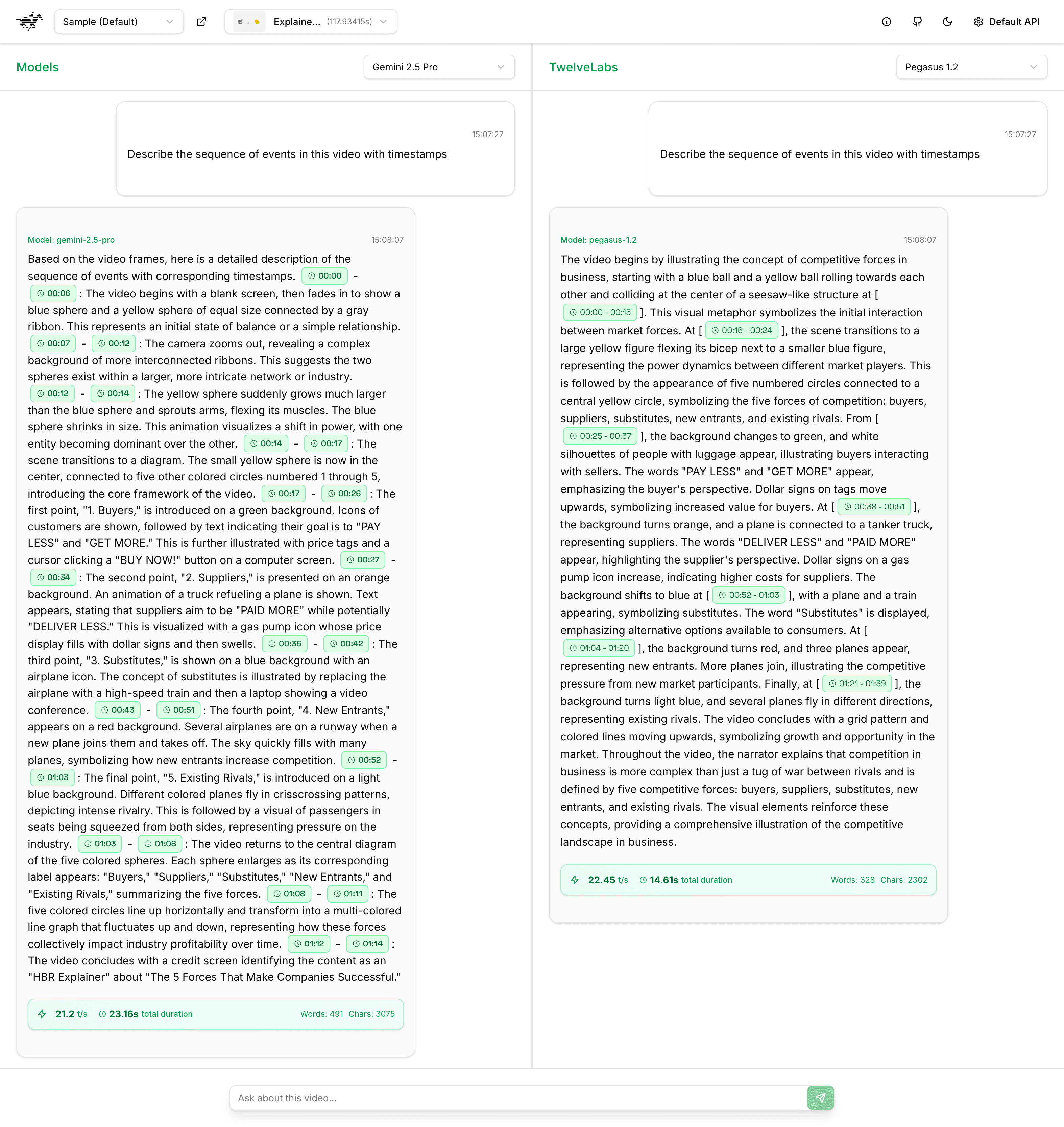
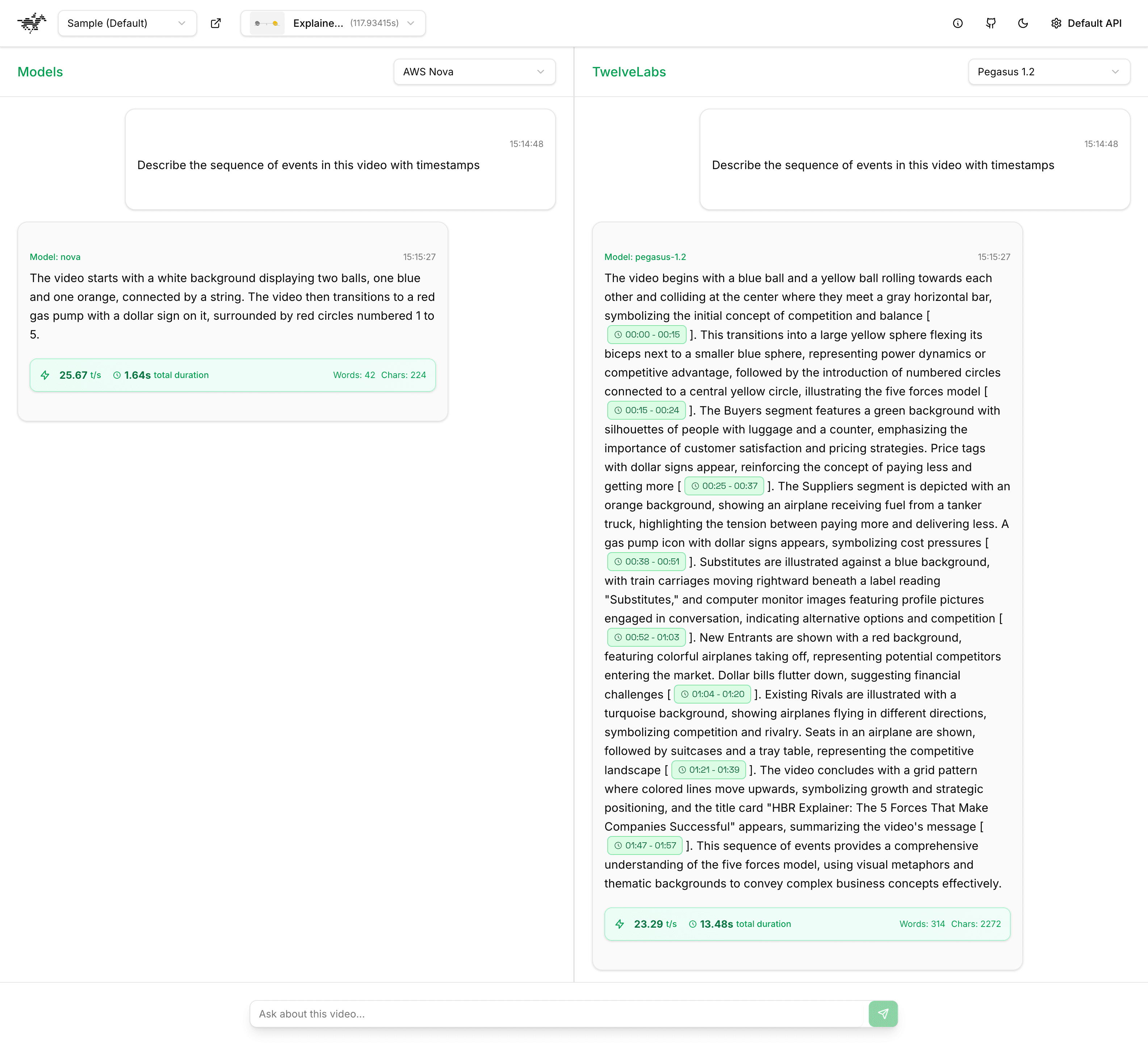
The OpenAI model (GPT-4o) encountered difficulties in processing the video due to its length, which exceeded the token limit when analyzed at a rate of one frame per second. In contrast, AWS Nova (nova-lite-v1:0), as demonstrated below, furnished a superficial temporal summary, characterized by limited detail and an absence of substantive conceptual connections.
B. Scene Transition and Continuity Tracking
For the understanding of the scene transition and the continuity tracking, the video analyzed is titled “How the Eiffel Tower Was Built”.
Query – “For each transition, describe how context changes.”

Upon analysis, the Gemini (gemini-2.5-pro) response is characterized by its extensive and repetitive nature, exhibiting poor structural organization. This results in lengthy paragraphs that combine multiple transitions without distinct timestamp separations. The absence of adequate formatting and contextual clarity hinders the ability to easily trace the narrative progression from one stage of construction to the next.
Conversely, Pegasus offers a well-organized and visually coherent response. Each transition is presented with a bold title, a concise description, and precise timestamps. The inclusion of timestamps further enhances readability, facilitating the identification and comprehension of how the video's context evolves across the various stages of the Eiffel Tower's construction.

When the identical task was executed using AWS Nova, the model encountered difficulty in accurately interpreting the query and consequently failed to provide the anticipated response. Its output consisted of general titles that did not adequately represent the video's transitions or shifts in context. As a result, the response lacked both pertinence and thoroughness, offering only superficial information without effectively elucidating the contextual changes throughout the video.

C. Dialogue and Audio Content in Video
Most Multimodal Large Language Models (MLLMs) are not yet fully adapted to comprehend or interpret the audio component within videos. Specifically, AWS Nova’s (nova-lite-v1:0) video understanding currently lacks audio support, thereby restricting its capacity to capture spoken content, tone, or background context. Consequently, this section will qualitatively evaluate audio content understanding, examining the efficacy with which different models can interpret, transcribe, and explain the spoken and auditory elements present in video data.
An open-source video from a German news channel was analyzed herein.
Query — “Could you please transcribe the content with the proper timestamp. Needed for directly to be added as a transcript file. Just provide the words which are there in the audio. The timestamp of the format [mm:ss - mm:ss]”

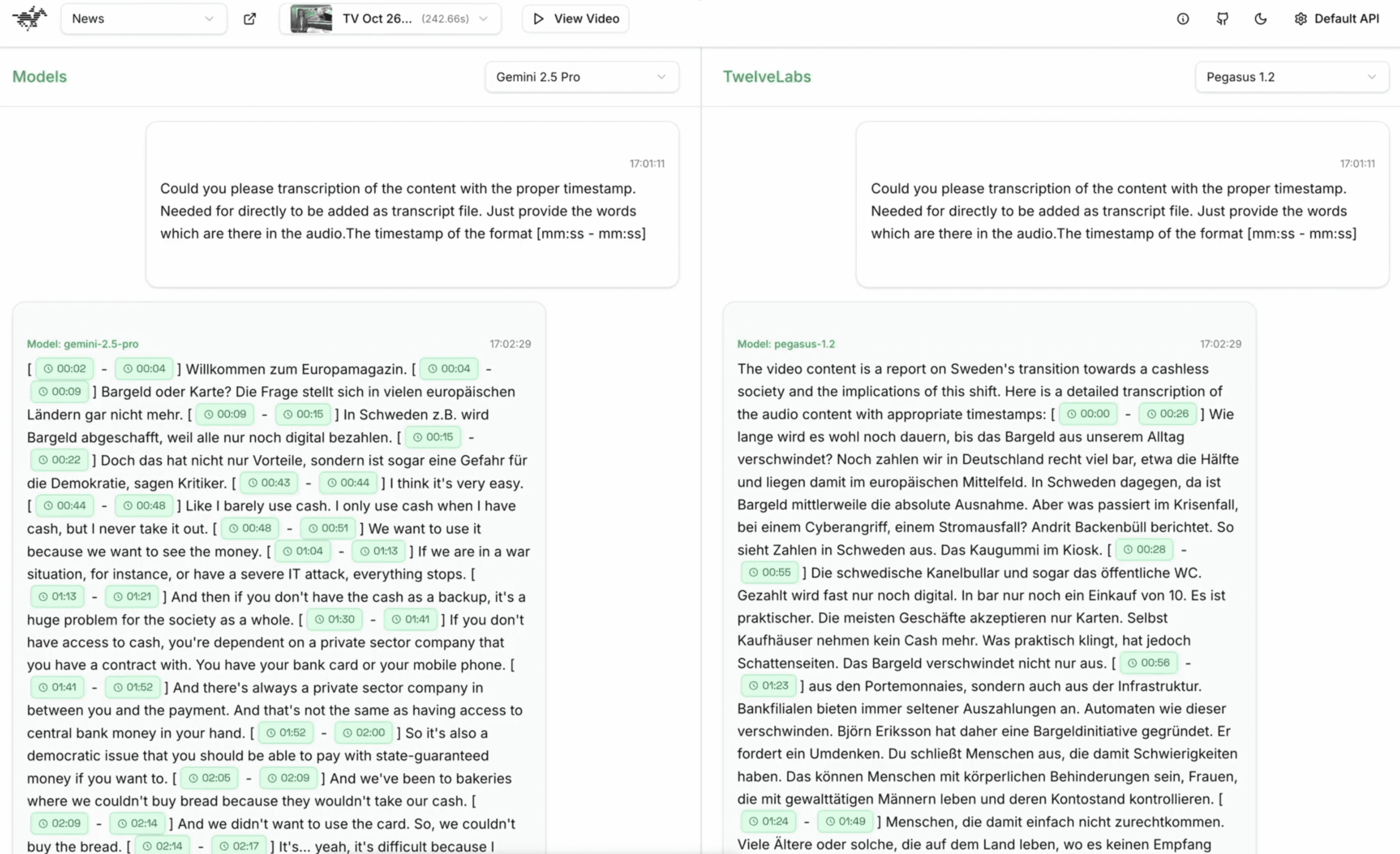
The analysis indicates that Pegasus 1.2 significantly surpasses Gemini 2.5 Pro in both accuracy and adherence to the specified format.
While Gemini provides timestamps in the requested [mm:ss – mm:ss] format, its transcription is fragmented and excessively segmented, resulting in incomplete, choppy, and contextually disjointed content. Furthermore, Gemini's timestamps are inconsistent with the video duration (the input video is approximately 4 minutes, yet Gemini's output covers only about 3 minutes). Another observed issue is that, given the original video language was German, Gemini initiates transcription in German before switching to English, thereby compromising consistency.
In contrast, the Pegasus 1.2 output presents a comprehensive and continuous transcription with longer, coherent dialogue segments. It maintains the original language throughout and provides accurately aligned timestamps, capturing full sentences and preserving the natural conversational flow.

When presented with a request for English transcription within the same query, Gemini again demonstrated subpar performance, yielding an abstract summary rather than an accurate transliterated transcript. It paraphrased and condensed the content, failing to accurately reflect the spoken dialogue, and its timestamps remained imprecise. In contrast, Pegasus delivered an accurate transliterated transcription with appropriately formatted timestamps, suitable for direct export and subsequent production use.
D. Object & Entity Fidelity
The objective of this analysis is to evaluate the model's capacity to identify and comprehend objects and entities within a video. For the experimental setup, a video illustrating the task of placing objects inside a circle was utilized.
Query – "Kindly provide the start of the second circle task, the list of product names within that circle, and the total amount."

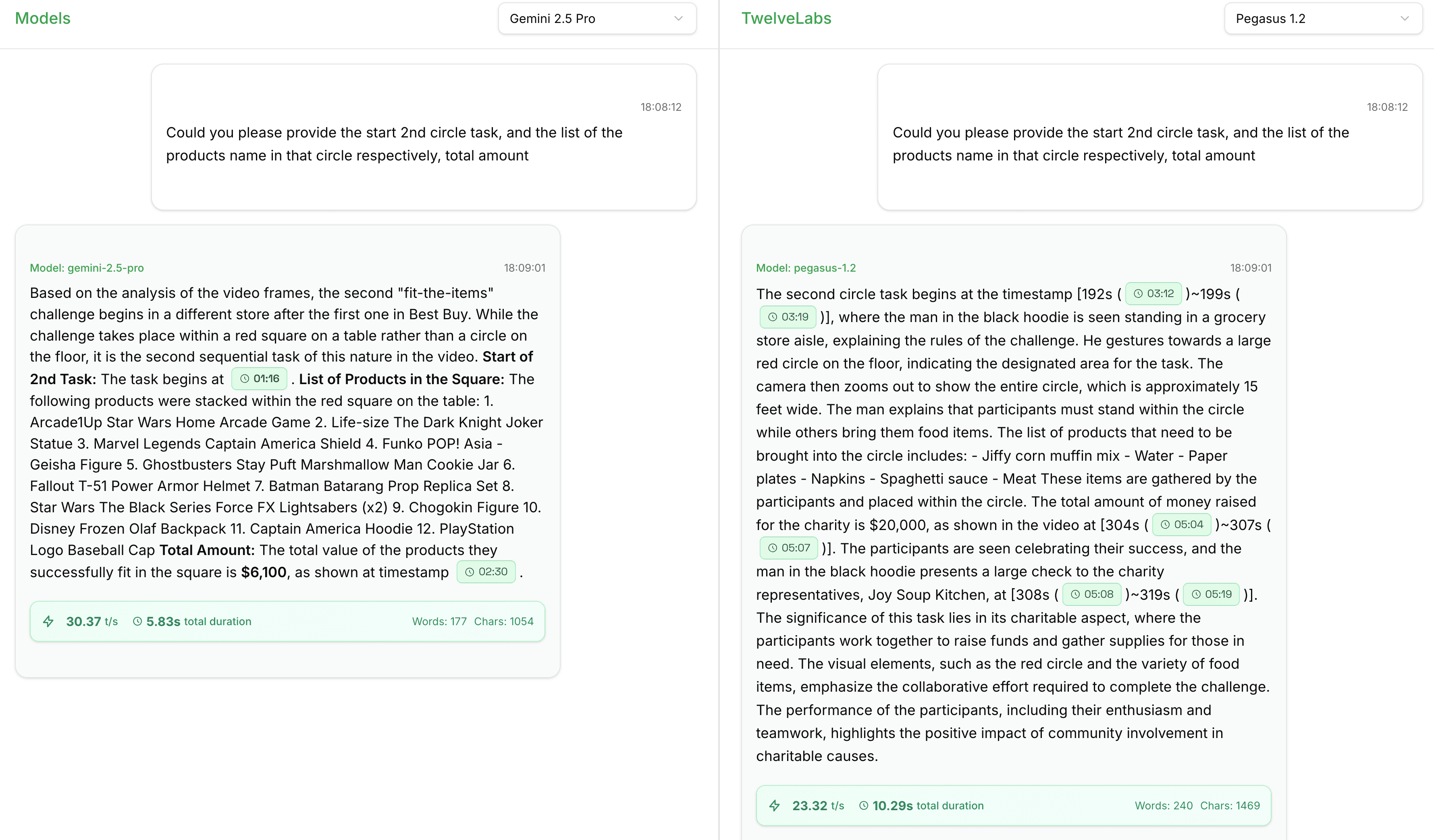
In the preceding analysis, Pegasus 1.2 demonstrates significantly superior accuracy, whereas Gemini 2.5 Pro completely fails. Despite the user's explicit request for information regarding the "2nd circle task," Gemini incorrectly identifies its location as a "red square on a table" and provides a list of 12 products, which appears to correspond to the initial challenge. Gemini's response reveals a fundamental lack of understanding concerning spatial and temporal sequencing within the video. Conversely, Pegasus accurately identifies the second circle task, providing precise timestamps [192s-199s], correctly describes its occurrence on the floor of a grocery store aisle (not a table), and furnishes the correct product list.
Pegasus also accurately identifies the total amount as $20,000 (with timestamps [304s-307s]), while Gemini erroneously reports $6,100. Pegasus's content is factually accurate, while Gemini's entire response addresses the incorrect question, thereby demonstrating poor video comprehension and object tracking.
E. Contextual Reasoning and Descriptiveness
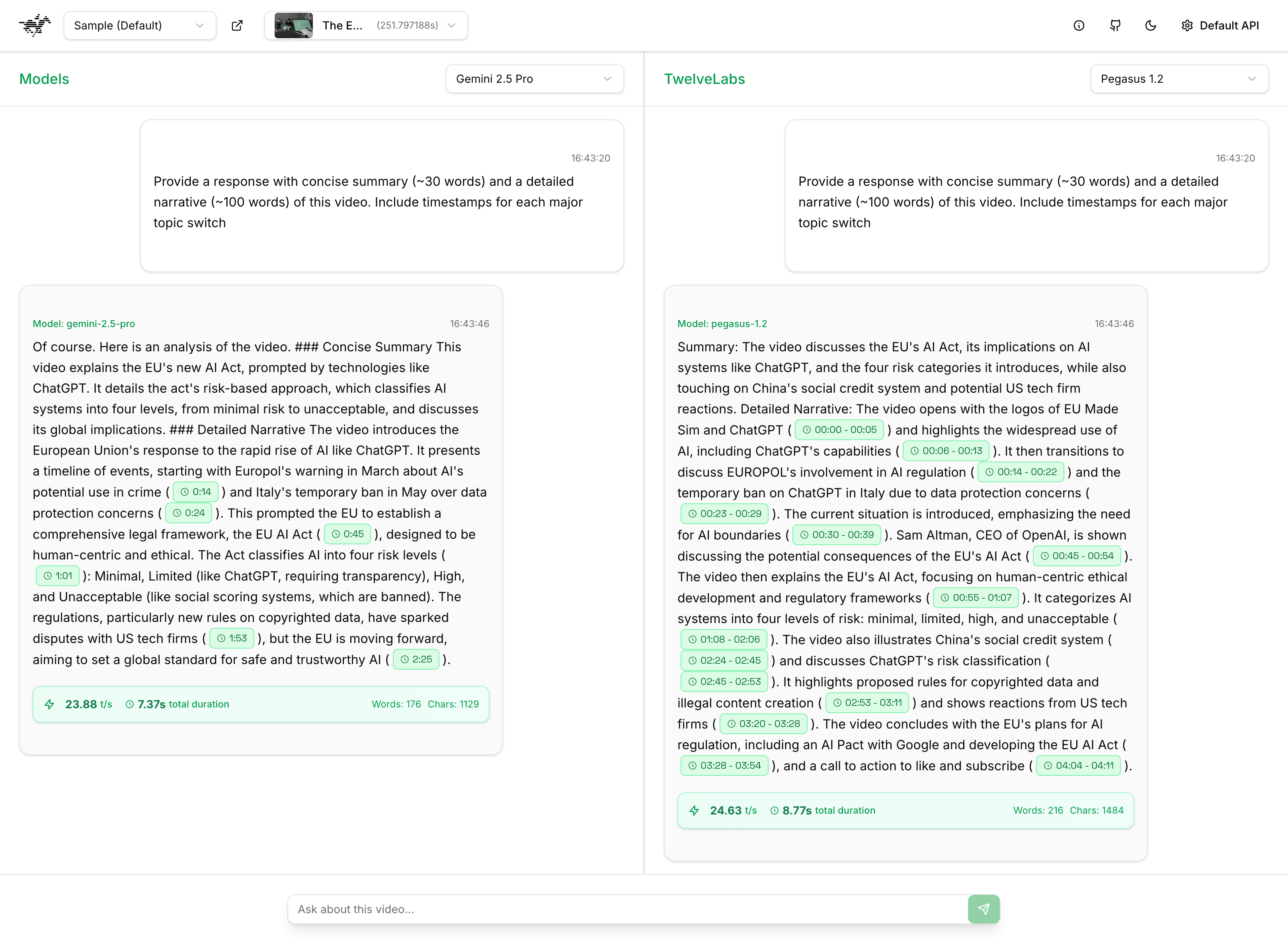
This evaluation will assess the system's proficiency in comprehending input queries and generating comprehensive, contextually relevant responses. The test's foundational content is a video elucidating the EU AI Act. Our analysis will concentrate on the system's capacity to interpret the subject matter and furnish thorough, accurate, and pertinent insights derived from the content.
Query — "Furnish a response comprising a concise summary (approximately 30 words) and an elaborate narrative (approximately 100 words) of this video. Incorporate timestamps for each principal topic transition."

The following analysis indicates that Pegasus 1.2 exhibits superior contextual reasoning and descriptive capabilities when compared to both Gemini 2.5 Pro and AWS Nova. Pegasus provides a comprehensive and coherent narrative, accurately referencing individuals such as Sam Altman, CEO of OpenAI, and establishing meaningful connections between concepts, including the EU AI Act, ChatGPT’s risk classification, and China's social credit system. In contrast, Gemini 2.5 Pro, while competent, offers a more fragmented explanation with reduced depth and fewer contextual links.
AWS Nova consistently demonstrates a significant deficiency in contextual comprehension, offering only superficial descriptions of visual elements, such as "a woman in a dark background" and "a man standing in front of a map." It provides no substantive interpretation of the EU AI Act discussion, lacking analytical depth beyond basic scene recognition.
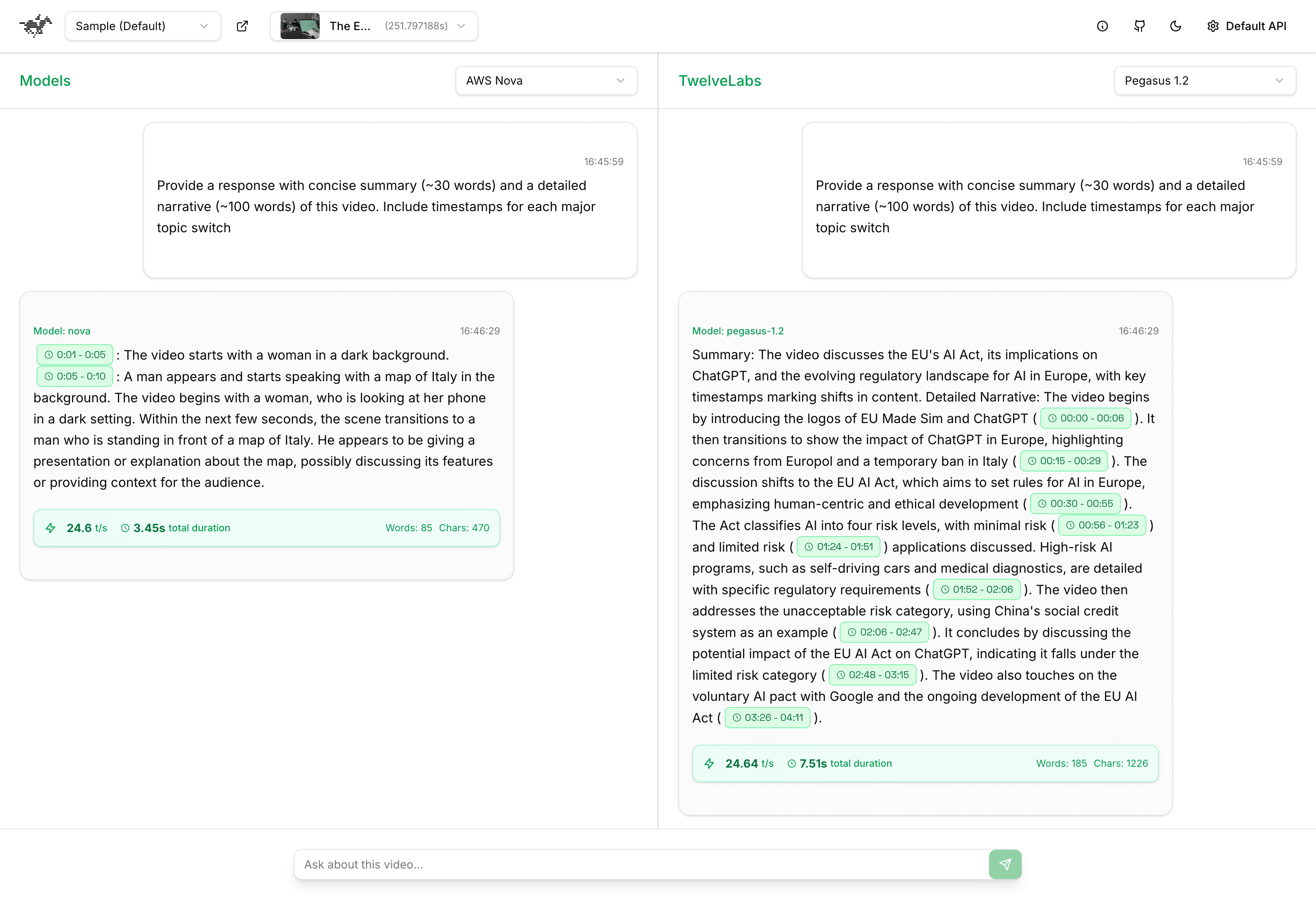
Pegasus 1.2, in contrast, effectively timestamps transitions and articulates the regulatory framework, risk tiers, and policy implications in a well-structured and logically coherent manner. Pegasus not only identifies the subject matter but also synthesizes the evolving discussion across the video timeline, transforming raw information into a clear and informative narrative. AWS Nova, however, demonstrates limited capability beyond object identification, exhibiting minimal understanding of the video's thematic significance or legal context.
How to contribute to the Video-to-Text Arena codebase
To list a model or any other video understanding/multimodal model for comparison on the platform, integrate it within approximately 30 lines of code in the video-to-text Arena. The following steps and files require updates to integrate a new model and ensure its visibility in the user interface.
Any Multimodal Large Language Models (MLLMs) adapted for video understanding or any other specialized video model can be integrated into the platform. Each model can be mapped to its own dedicated processing utility, defined within the same class structure. The diagram below illustrates the utilization of different models across the platform, along with their corresponding processing pipelines.
Preparation Steps
Obtain your API key from the TwelveLabs Playground and configure your environment variable.
Clone the project from Github Repo.
Create a .env file to store your TwelveLabs API KEY.
Upon completion of these steps, you're ready to start developing!
Backend Setup
Step 1: Create Model Class
A new model class should be created, with its associated processing utilities defined within this class. The class may be defined as a separate model file within the models/ folder.
Step 2: Update Configuration
Integrate your model's configuration into config.py, primarily specifying the inference API and the Base URL of the endpoint.
Step 3: Register your Model
Update models/__init__.py to reference the newly defined model's class.
Step 4: Integrate with Main Application
Modify app.py to incorporate your new model by defining its class within the model_dict.
Step 5: Add API Route
Update routes/api_routes.py to include your model in the routes by defining it within the model_dict.
The backend server is now fully configured. Only minimal frontend adjustments are required to make the newly defined model visible.
Frontend Setup
Step 1: Update API Service Type Definitions
Add your model to the ModelStatus interface in lib/api.ts.
Step 2: Update Model Availability Functions
The components/model-evaluation-platform.tsx component manages model selection. Update the model availability functions by defining the newly integrated model function.
The newly added model will subsequently appear in the arena, ready for exploration and experimentation.
Conclusion
At TwelveLabs, our Pegasus-1.2 model stands at the forefront of specialized video understanding, uniquely engineered to overcome the inherent limitations of general-purpose Multimodal LLMs. Pegasus meticulously captures the profound nuances of video, discerning contextual information, temporal relationships, and subtle visual cues that other AI systems often miss.
The seamless integration of Pegasus with advanced tool-use and autonomous workflows marks a new era in intelligent video processing. This synergy empowers our model to move beyond mere analysis, actively interpreting, reasoning about, and ultimately acting upon video content. This groundbreaking capability unlocks a multitude of transformative applications, revolutionizing how our users interact with and leverage video data.
For example, in content moderation, Pegasus autonomously identifies and flags inappropriate or harmful content, significantly enhancing the efficiency and accuracy of platform safety measures for our clients. In entertainment, personalized video recommendations powered by Pegasus become far more precise and engaging, catering to individual tastes by understanding the underlying themes and emotions within videos. Furthermore, intelligent scene-based editing leverages Pegasus to automate complex video production tasks, allowing for the seamless creation of highlight reels, dynamic transitions, and contextually aware cuts, thereby streamlining the creative process and opening new possibilities for video storytelling. The ability of Pegasus to not just understand but also interact with and manipulate video content represents a significant leap forward in video understanding, with far-reaching implications across various industries and applications that we are proud to enable.
Additional Resources
Learn more about the analyze video engine—Pegasus-1.2. To explore TwelveLabs further and enhance your understanding of video content analysis, check out these resources:
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord.
Explore Sample Apps: Dive deeper into TwelveLabs capabilities with our comprehensive tutorials
We encourage you to use these resources to expand your knowledge and create innovative applications using TwelveLabs video understanding technology.
Introduction
The Video-to-Text Arena is an open-source platform designed to assess the true capabilities of current AI models in understanding video content. It offers a standardized evaluation process, enabling users to compare various multimodal AI models side-by-side. The platform specifically measures how accurately each model translates visual actions, scenes, and events into analyzed text, highlighting which models best capture context, timing, and meaning.
Modern specialized video understanding models are built to process visual, audio, and textual information simultaneously, moving beyond simple concatenation to deep integration of modalities. These models should be capable of sophisticated video understanding, including cause and effect relationships, temporal ordering, and long-range dependencies across video sequences. The Arena's goal is to bring clarity to this field through practical, transparent comparisons.
Currently, the Arena supports models such as Twelve Labs (Pegasus 1.2), OpenAI (GPT-4o), Google (Gemini 2.0 Flash and 2.5 Pro), and AWS (nova-lite-v1:0). This guide focuses on evaluating these models under consistent qualitative conditions to demonstrate their strengths in various video understanding scenarios.
Thanks to its modular architecture, the Arena can easily integrate more models, and contributors are encouraged to add their own. This guide also provides instructions on how to effectively contribute to the Arena.
Demo
Below is a demo showing how different models are selected and used for the video analysis to compare their responses with Pegasus-1.2 (TwelveLabs). This setup helps analyze videos across various scenario understanding.
Video Understanding Challenges
Video understanding presents a fundamental temporal challenge, as numerous model pipelines currently sample at approximately one frame per second or even lower, in an effort to minimize computational resources and associated costs. This reduced sampling rate results in a significant information deficit, leading to the omission of rapid actions and brief events, a loss of timestamp granularity, and an impaired synchronization between visual and auditory components, thereby hindering comprehensive video comprehension.
1 - Temporal Reasoning and Sequential Understanding Limitations
Video understanding models encounter substantial difficulties in temporal reasoning and the comprehension of events across video sequences. Models such as GPT-4V exhibit limitations in maintaining coherent temporal understanding when processing extended videos, frequently treating individual frames as discrete snapshots rather than continuous temporal flows. This fundamental constraint arises from frame sampling strategies that downsample videos into sparse representations, leading models to overlook crucial transitional moments and temporal dependencies. While these models generally perform adequately on isolated, moment-specific queries, they demonstrate significant challenges when tasks necessitate a comprehensive understanding of event sequences over time or the tracking of long-range context across several minutes or even hours of video.
2 - Spatial Details Recognition and Object Tracking Deficiencies
Multimodal understanding models exhibit significant deficiencies in spatial reasoning and object tracking within video sequences. Models such as Gemini-2.5-pro and GPT-4o demonstrate a limited capacity to maintain object identity across frames, struggle with in-frame text recognition, and perform poorly in spatial localization tasks. Recent research, specifically the SlowFocus study, indicates that current Vid-LLMs, which process sequences of frames, consume more tokens for higher-quality frames. This creates a trade-off between spatial detail and temporal coverage, preventing Vid-LLMs from simultaneously retaining high-quality frame-level semantic information and comprehensive video-level temporal information. Consequently, numerous failures occur in various scenarios, including tracking specific objects through scene changes, accurately counting objects in high-speed videos, and comprehending precise spatial relationships between objects.
This limitation is exacerbated in longer videos due to memory constraints that necessitate aggressive compression of visual information, thereby hindering accurate scene understanding and leading to token overflow issues.
3 - Hallucination and the Grounding Problems in the Multimodal Context
Video hallucination, a prevalent issue in major multimodal LLMs, results in the generation of factually incorrect information. Benchmarks such as VidHalluc demonstrate the susceptibility of these models to hallucination across three crucial dimensions: action recognition, temporal sequence accuracy, and scene transition understanding. This problem is particularly pronounced in longer videos, where models are required to condense visual information into limited token budgets, leading to over-generalization and fabricated details. A primary approach to mitigate hallucination involves the use of visual encoders capable of discerning subtle differences between similar scenes, combined with LLMs, to ensure strict adherence to visual evidence.
4 - Context Window, Memory and Computational Constraints
Video understanding models encounter limitations concerning context window capacity and computational resource demands. While GPT-4o offers a 128K-token context and Gemini-2.5-Pro supports up to 1M tokens, these capacities remain insufficient for comprehensive, long-form video analysis, given the extensive token requirements for accurate video frame representation. Models inherently struggle to achieve a balance between sampling frequency (temporal resolution) and the overall duration of video they can process. Current methodologies either omit crucial moments by skipping frames or exceed computational thresholds before analysis completion.
As we have explored, the landscape of video understanding models contends with challenges in temporal reasoning and long-form content analysis. The TwelveLabs Pegasus 1.2 model represents an advancement specifically designed to address the fundamental limitations of general-purpose Multimodal Large Language Models (MLLMs). Pegasus 1.2 employs a spatio-temporal comprehension approach that directly confronts the previously discussed challenges. Unlike GPT-4o, Gemini, and Claude, which were primarily developed for general multimodal tasks and subsequently adapted for video understanding, Pegasus 1.2 is purpose-built as a video language model. The model is capable of processing videos up to an hour in length with low latency, high accuracy, and more cost-effective repeated queries to the same video content. Due to its specialized architecture, Pegasus 1.2's ability to process hour-long videos without the accuracy degradation observed in general-purpose MLLMs positions it as the preferred solution for enterprise applications, including content summarization, video captioning, timestamp-accurate event identification, and comprehensive video content analysis.
Qualitative Insights
In this section, we evaluate the video analysis text generated by different models across multiple parameters to assess their video understanding capabilities.
A. Temporal Context Understanding
In this analysis, we focus on temporal context understanding in video content using the example video, “Five Forces of Market Competition,” which visually explains Porter’s Five Forces principle.
Query – “Describe the sequence of events in the video with timestamps.”
The ensuing analysis contrasts gemini-2.5-pro with pegasus-1.2. The Gemini model produces granular timestamps with high temporal precision, yet it exhibits difficulty in correlating visual segments with their underlying business concepts. Its frame-level segmentation results in a fragmented narration that describes what transpires rather than why. Conversely, Pegasus offers a more conceptually structured and causally coherent explanation, adeptly linking each visual transition to the corresponding competitive force.
While Gemini's precision is advantageous for technical tasks such as event localization, Pegasus surpasses it in interpretability, clarity, and topic relevance, rendering it more appropriate for comprehension and communication.
The OpenAI model (GPT-4o) encountered difficulties in processing the video due to its length, which exceeded the token limit when analyzed at a rate of one frame per second. In contrast, AWS Nova (nova-lite-v1:0), as demonstrated below, furnished a superficial temporal summary, characterized by limited detail and an absence of substantive conceptual connections.
B. Scene Transition and Continuity Tracking
For the understanding of the scene transition and the continuity tracking, the video analyzed is titled “How the Eiffel Tower Was Built”.
Query – “For each transition, describe how context changes.”
Upon analysis, the Gemini (gemini-2.5-pro) response is characterized by its extensive and repetitive nature, exhibiting poor structural organization. This results in lengthy paragraphs that combine multiple transitions without distinct timestamp separations. The absence of adequate formatting and contextual clarity hinders the ability to easily trace the narrative progression from one stage of construction to the next.
Conversely, Pegasus offers a well-organized and visually coherent response. Each transition is presented with a bold title, a concise description, and precise timestamps. The inclusion of timestamps further enhances readability, facilitating the identification and comprehension of how the video's context evolves across the various stages of the Eiffel Tower's construction.
When the identical task was executed using AWS Nova, the model encountered difficulty in accurately interpreting the query and consequently failed to provide the anticipated response. Its output consisted of general titles that did not adequately represent the video's transitions or shifts in context. As a result, the response lacked both pertinence and thoroughness, offering only superficial information without effectively elucidating the contextual changes throughout the video.
C. Dialogue and Audio Content in Video
Most Multimodal Large Language Models (MLLMs) are not yet fully adapted to comprehend or interpret the audio component within videos. Specifically, AWS Nova’s (nova-lite-v1:0) video understanding currently lacks audio support, thereby restricting its capacity to capture spoken content, tone, or background context. Consequently, this section will qualitatively evaluate audio content understanding, examining the efficacy with which different models can interpret, transcribe, and explain the spoken and auditory elements present in video data.
An open-source video from a German news channel was analyzed herein.
Query — “Could you please transcribe the content with the proper timestamp. Needed for directly to be added as a transcript file. Just provide the words which are there in the audio. The timestamp of the format [mm:ss - mm:ss]”
The analysis indicates that Pegasus 1.2 significantly surpasses Gemini 2.5 Pro in both accuracy and adherence to the specified format.
While Gemini provides timestamps in the requested [mm:ss – mm:ss] format, its transcription is fragmented and excessively segmented, resulting in incomplete, choppy, and contextually disjointed content. Furthermore, Gemini's timestamps are inconsistent with the video duration (the input video is approximately 4 minutes, yet Gemini's output covers only about 3 minutes). Another observed issue is that, given the original video language was German, Gemini initiates transcription in German before switching to English, thereby compromising consistency.
In contrast, the Pegasus 1.2 output presents a comprehensive and continuous transcription with longer, coherent dialogue segments. It maintains the original language throughout and provides accurately aligned timestamps, capturing full sentences and preserving the natural conversational flow.
When presented with a request for English transcription within the same query, Gemini again demonstrated subpar performance, yielding an abstract summary rather than an accurate transliterated transcript. It paraphrased and condensed the content, failing to accurately reflect the spoken dialogue, and its timestamps remained imprecise. In contrast, Pegasus delivered an accurate transliterated transcription with appropriately formatted timestamps, suitable for direct export and subsequent production use.
D. Object & Entity Fidelity
The objective of this analysis is to evaluate the model's capacity to identify and comprehend objects and entities within a video. For the experimental setup, a video illustrating the task of placing objects inside a circle was utilized.
Query – "Kindly provide the start of the second circle task, the list of product names within that circle, and the total amount."
In the preceding analysis, Pegasus 1.2 demonstrates significantly superior accuracy, whereas Gemini 2.5 Pro completely fails. Despite the user's explicit request for information regarding the "2nd circle task," Gemini incorrectly identifies its location as a "red square on a table" and provides a list of 12 products, which appears to correspond to the initial challenge. Gemini's response reveals a fundamental lack of understanding concerning spatial and temporal sequencing within the video. Conversely, Pegasus accurately identifies the second circle task, providing precise timestamps [192s-199s], correctly describes its occurrence on the floor of a grocery store aisle (not a table), and furnishes the correct product list.
Pegasus also accurately identifies the total amount as $20,000 (with timestamps [304s-307s]), while Gemini erroneously reports $6,100. Pegasus's content is factually accurate, while Gemini's entire response addresses the incorrect question, thereby demonstrating poor video comprehension and object tracking.
E. Contextual Reasoning and Descriptiveness
This evaluation will assess the system's proficiency in comprehending input queries and generating comprehensive, contextually relevant responses. The test's foundational content is a video elucidating the EU AI Act. Our analysis will concentrate on the system's capacity to interpret the subject matter and furnish thorough, accurate, and pertinent insights derived from the content.
Query — "Furnish a response comprising a concise summary (approximately 30 words) and an elaborate narrative (approximately 100 words) of this video. Incorporate timestamps for each principal topic transition."
The following analysis indicates that Pegasus 1.2 exhibits superior contextual reasoning and descriptive capabilities when compared to both Gemini 2.5 Pro and AWS Nova. Pegasus provides a comprehensive and coherent narrative, accurately referencing individuals such as Sam Altman, CEO of OpenAI, and establishing meaningful connections between concepts, including the EU AI Act, ChatGPT’s risk classification, and China's social credit system. In contrast, Gemini 2.5 Pro, while competent, offers a more fragmented explanation with reduced depth and fewer contextual links.
AWS Nova consistently demonstrates a significant deficiency in contextual comprehension, offering only superficial descriptions of visual elements, such as "a woman in a dark background" and "a man standing in front of a map." It provides no substantive interpretation of the EU AI Act discussion, lacking analytical depth beyond basic scene recognition.
Pegasus 1.2, in contrast, effectively timestamps transitions and articulates the regulatory framework, risk tiers, and policy implications in a well-structured and logically coherent manner. Pegasus not only identifies the subject matter but also synthesizes the evolving discussion across the video timeline, transforming raw information into a clear and informative narrative. AWS Nova, however, demonstrates limited capability beyond object identification, exhibiting minimal understanding of the video's thematic significance or legal context.
How to contribute to the Video-to-Text Arena codebase
To list a model or any other video understanding/multimodal model for comparison on the platform, integrate it within approximately 30 lines of code in the video-to-text Arena. The following steps and files require updates to integrate a new model and ensure its visibility in the user interface.
Any Multimodal Large Language Models (MLLMs) adapted for video understanding or any other specialized video model can be integrated into the platform. Each model can be mapped to its own dedicated processing utility, defined within the same class structure. The diagram below illustrates the utilization of different models across the platform, along with their corresponding processing pipelines.
Preparation Steps
Obtain your API key from the TwelveLabs Playground and configure your environment variable.
Clone the project from Github Repo.
Create a .env file to store your TwelveLabs API KEY.
Upon completion of these steps, you're ready to start developing!
Backend Setup
Step 1: Create Model Class
A new model class should be created, with its associated processing utilities defined within this class. The class may be defined as a separate model file within the models/ folder.
Step 2: Update Configuration
Integrate your model's configuration into config.py, primarily specifying the inference API and the Base URL of the endpoint.
Step 3: Register your Model
Update models/__init__.py to reference the newly defined model's class.
Step 4: Integrate with Main Application
Modify app.py to incorporate your new model by defining its class within the model_dict.
Step 5: Add API Route
Update routes/api_routes.py to include your model in the routes by defining it within the model_dict.
The backend server is now fully configured. Only minimal frontend adjustments are required to make the newly defined model visible.
Frontend Setup
Step 1: Update API Service Type Definitions
Add your model to the ModelStatus interface in lib/api.ts.
Step 2: Update Model Availability Functions
The components/model-evaluation-platform.tsx component manages model selection. Update the model availability functions by defining the newly integrated model function.
The newly added model will subsequently appear in the arena, ready for exploration and experimentation.
Conclusion
At TwelveLabs, our Pegasus-1.2 model stands at the forefront of specialized video understanding, uniquely engineered to overcome the inherent limitations of general-purpose Multimodal LLMs. Pegasus meticulously captures the profound nuances of video, discerning contextual information, temporal relationships, and subtle visual cues that other AI systems often miss.
The seamless integration of Pegasus with advanced tool-use and autonomous workflows marks a new era in intelligent video processing. This synergy empowers our model to move beyond mere analysis, actively interpreting, reasoning about, and ultimately acting upon video content. This groundbreaking capability unlocks a multitude of transformative applications, revolutionizing how our users interact with and leverage video data.
For example, in content moderation, Pegasus autonomously identifies and flags inappropriate or harmful content, significantly enhancing the efficiency and accuracy of platform safety measures for our clients. In entertainment, personalized video recommendations powered by Pegasus become far more precise and engaging, catering to individual tastes by understanding the underlying themes and emotions within videos. Furthermore, intelligent scene-based editing leverages Pegasus to automate complex video production tasks, allowing for the seamless creation of highlight reels, dynamic transitions, and contextually aware cuts, thereby streamlining the creative process and opening new possibilities for video storytelling. The ability of Pegasus to not just understand but also interact with and manipulate video content represents a significant leap forward in video understanding, with far-reaching implications across various industries and applications that we are proud to enable.
Additional Resources
Learn more about the analyze video engine—Pegasus-1.2. To explore TwelveLabs further and enhance your understanding of video content analysis, check out these resources:
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord.
Explore Sample Apps: Dive deeper into TwelveLabs capabilities with our comprehensive tutorials
We encourage you to use these resources to expand your knowledge and create innovative applications using TwelveLabs video understanding technology.




Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved


