" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
트웰브랩스
요청 수만 세는 레이트 리미터로는 부족했습니다

Henry Choi
요청 하나의 비용이 수백 배씩 차이 나는 영상 AI에서는, 익숙한 문제도 다시 풀어야 했습니다. 한정된 리소스를 가지고 공정성과 안정성을 어떻게 동시 충족시킬 수 있을 것인가. 저희가 매일 부딪혀 푸는 문제들은 이런 디테일까지 고려되어야 합니다.
요청 하나의 비용이 수백 배씩 차이 나는 영상 AI에서는, 익숙한 문제도 다시 풀어야 했습니다. 한정된 리소스를 가지고 공정성과 안정성을 어떻게 동시 충족시킬 수 있을 것인가. 저희가 매일 부딪혀 푸는 문제들은 이런 디테일까지 고려되어야 합니다.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Jun 19, 2026
10 mins
Copy link to article
들어가며
API 레이트 리미팅(rate limiting)이라고 하면 보통 규모(scale)의 문제를 떠올립니다. 트래픽이 몰려도 분산 환경에서 카운터를 정확하고 빠르게 세는 것 — 어려움은 거기에 있다고들 하고, 실제로 많은 경우 그렇습니다.
저희도 처음엔 간단하게 접근했습니다. 초기 TwelveLabs API는 엔드포인트별로 "초당 N건, 시간당 M건" 같은 단순한 요청 수 제한만 두고 있었거든요.
그런데 영상 AI에서는 진짜 난제가 다른 곳에 숨어 있었습니다. 10초 길이의 숏폼 영상을 분석하는 요청과 2시간 길이의 영화를 분석하는 요청이 있다고 가정해 보겠습니다. 둘 다 시스템상으로는 '1건'의 요청이지만, 소비되는 컴퓨팅 자원은 수백 배 차이가 날 수도 있습니다. 즉, 단순히 요청의 개수만 세는 방식은 더 이상 공정하지 않았습니다.
측정 가능한 형태로 부하를 분산할 수 없다면, 자연스럽게 뒤에 있는 ML 서비스 역시 위험에 노출될 가능성이 생깁니다. 레이트 리밋의 진짜 목적은 한 사용자의 과도한 워크로드가 GPU 추론 같은 공유 자원을 잠식해, 다른 모든 사용자의 요청까지 느려지거나 실패하게 만드는 'Noisy Neighbor' 상황을 막는 것이었습니다. 실제로 한 고객의 워크로드가 폭주하면서 다운스트림 서비스를 과부하 시켜, 그 고객과 무관한 사용자들에게까지 장애가 번지는 아찔한 경험을 하기도 했습니다.
TwelveLabs API는 영상 인덱싱, 검색, 영상 정보 추출, 임베딩(embedding) 등 다양한 엔드포인트를 제공하며, 각각의 비용 구조가 전부 다릅니다. Search는 인덱스 스캔 비용이 주인 반면, Indexing/Embedding은 영상 길이에 따른 벡터 추출 비용이 지배적입니다. Analyze 엔드포인트는 모델이 뱉어내는 출력 토큰(output token) 수에 따라 다시 한번 비용이 비례하여 증가합니다.
하나의 잣대로 이 모든 것을 제한하는 건 무리가 있었습니다.
이 글에서는 저희가 이러한 문제를 해결하기 위해 '다차원 레이트 리미터'를 설계하고 구현하며 내린 결정들을 공유하려 합니다.
—————————————————————————————————
문제 정의
비용 비대칭
TwelveLabs API의 각 엔드포인트는 리소스를 소모하는 형태가 완전히 다릅니다.
Operation | 주요 비용 요소 |
|---|---|
Search | 요청 수 (request count) |
Indexing / Embedding | 요청 수 + 미디어 길이 (duration) |
Analyze | 요청 수 + 미디어 길이 + 출력 토큰 수 (output tokens) |
요청 수 제한만으로는 Heavy 유저의 리소스 독점을 막을 수 없었습니다. 유저 A가 숏폼 형태의 짧은 영상 100개를 인덱싱하고, 유저 B가 2시간짜리 영상 5개를 인덱싱한다고 해봅시다. 요청 수 기준으로는 A가 20배 더 많이 쓴 것이지만, 실제 리소스 소비는 B가 훨씬 클 수 있습니다.
엔터프라이즈 온보딩 속도
비즈니스가 성장하면서 전용 한도(Dedicated Limit)를 요구하는 엔터프라이즈 고객이 빠르게 늘어났습니다. 엔터프라이즈 고객이 온보딩하는 경우에는, 요청에 따라 전용 한도를 빠르게 적용해야 하는 경우가 많습니다. 운영을 더 쉽고 빠르게 하기 위해서는 코드 배포 없이 DB에 규칙을 하나 추가하는 것과 같은 간단한 방법이 필요했습니다.
결론적으로 저희에게 필요한 것은 요청 수(request count), 영상 길이(duration), 출력 토큰(output token)의 세 축을 동시에 제어할 수 있는 시스템이었습니다.

—————————————————————————————————
핵심 설계 결정들
1. 다차원 제한(Multi-dimensional rate limit): 차원(dimension)을 1급 개념으로
가장 먼저 정해야 했던 것은 "여러 종류의 비용을 어떤 방식으로 표현할 것인가"였습니다.
저희의 선택은 비용의 종류 자체를 1급 개념(first-class)으로 끌어올리는 것이었습니다. 서로 다른 비용 축을 각각 독립된 차원으로 정의하고, 이를 규칙 모델의 정식 필드로 새겨 넣었습니다.
const ( DimensionRequestCount Dimension = "request_count" DimensionDuration Dimension = "duration" DimensionOutputTokenCount Dimension = "output_token_count"
차원은 단순한 enum 값이 아니라 규칙(rule)의 정식 속성입니다. 규칙은 자신이 어떤 차원을 제한하는지를 알고 있고, 조회 키에도 이 차원 이름이 포함됩니다. 그래서 각 차원은 완전히 독립적으로 규칙을 가질 수 있습니다.
같은 차원에 여러 시간 윈도우가 공존할 수도 있습니다 — 예를 들어 요청 수에 "분당 60건"과 "일일 1,000건" 규칙이 동시에 적용되는 식입니다. 두 규칙 모두 통과해야 요청이 허용됩니다.
차원을 도입하면서 ‘무엇을 셀 것인가’를 하나의 일관된 모델로 정리했습니다. 기존에는 요청 횟수(request count) 하나만 셌다면, 이제는 요청 수·길이(초)·출력 토큰을 아우르는, 차원별로 ‘측정 가능한 숫자’라는 같은 형태가 된 셈입니다.
비용 축을 이러한 방식으로 분리하면 두 가지 장점을 얻을 수 있습니다. 첫째, 확장이 단순 더하기로 끝납니다. 입력 토근 수 같이 새로운 비용 축이 필요해지면, 기존 로직을 건드릴 필요 없이 새로운 차원을 하나 더 정의해 주기만 하면 됩니다. 둘째, 운영과 커뮤니케이션 측면 모두에서 직관적입니다. 특정 차단이 일어났을 때 어떤 축에서 제한이 발생했는지를 바로 파악할 수 있기 때문에, "분당 요청 수 초과"처럼 차단 사유가 사람이 쉽게 이해할 수 있는 형태로 표현됩니다.
2. 세션 기반 평가와 롤백 전략
차원을 분리하고 나니 또 다른 난관이 기다리고 있었습니다. 하나의 요청 안에서 각 차원의 비용이 확정되는 시점이 제각각 다르다는 점이었습니다.
'요청 수'는 요청이 들어오는 시점에 바로 알 수 있습니다. 항상 1이기 때문입니다. 하지만 '출력 토큰(output token) 수'는 실제 연산 작업이 끝나야만 비로소 알 수 있습니다. 영상 분석에 소요되는 시간(Duration)도 마찬가지로, 실제 영상을 분석하기 전까지는 정확한 소비량을 알 수 없습니다.
하나의 API 요청 안에서 여러 차원이 서로 다른 시점에 평가되는 구조이므로, 이것을 하나의 생명주기로 묶어야 일관된 롤백이 가능했습니다.
이를 해결하기 위해 저희는 요청마다 고유한 세션(session)을 열어서, 각 차원을 순차적으로 평가하고, 요청이 실패하면 소비한 할당량을 취소하는 구조를 만들었습니다.
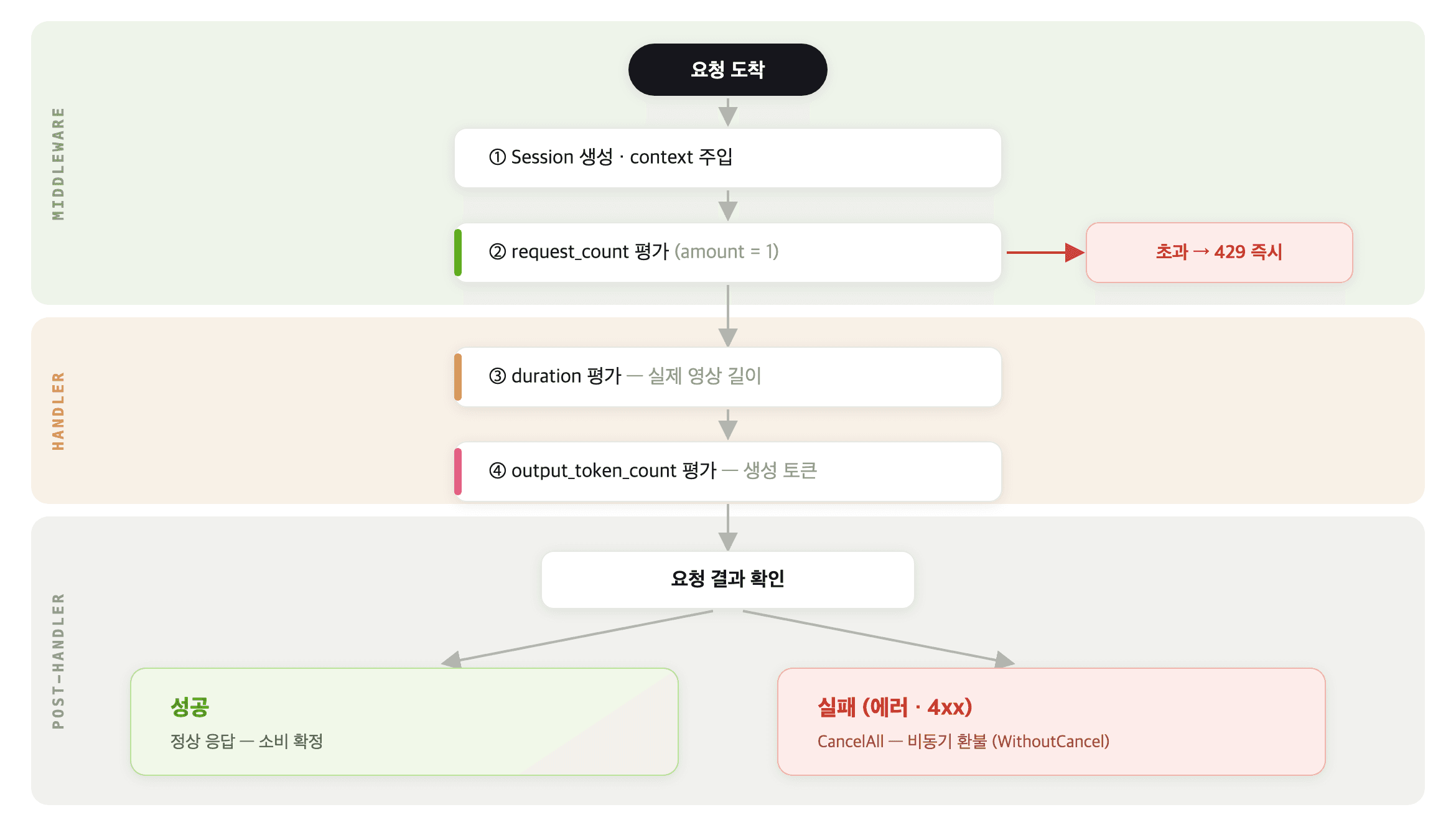
세션 내부에서는 성공한 모든 평가 기록을 별도의 자료구조로 추적합니다. 취소가 필요해지면 이 세션에 기록된 목록을 역순으로 순회하면서 각각의 소비를 되돌립니다.
[요청 실패 시] 세션에 기록된 성공 평가를 역순 순회 └─ 각 디멘션의 소비량을 환불(refund) · 별도 goroutine · 비동기(non-blocking) · 원 요청 context와 무관하게 끝까지 실행
3. 규칙 우선순위와 실시간 반영
레이트 리미팅 규칙의 우선순위를 어떻게 결정할 것인가도 중요한 설계 포인트였습니다.
저희는 다차원 레이트 리미터의 도입과 함께 티어를 세분화하며 3단계 우선순위를 도입했습니다.
💡 잠깐, 여기서 티어(rate tier)란?
전용 한도를 받는 엔터프라이즈 고객을 제외하면, 대부분의 사용자는 '티어'(rate tier) 단위로 관리됩니다. 티어는 미리 정의된 한도 묶음으로, 저희 시스템에서는 Free Tier와 함께 Tier 1·2·3을 미리 구분해 두었습니다. 각 티어에 어떤 한도를 줄지는 가격·플랜 같은 비즈니스 결정에서 내려오고, 그 값들을 하나의 프리셋으로 정의하기 때문에, "이 사용자의 한도가 얼마인가"는 사실상 "이 사용자가 어느 티어인가"의 문제가 됩니다.
정리하면 한도는 두 층으로 정해집니다 — 기본은 티어, 엔터프라이즈 같은 예외는 그 위에 얹는 커스텀 규칙. 뒤에 나오는 다이어그램의 한도 값이나 "규칙 우선순위" 이야기는 모두 이 티어 구조를 전제로 합니다.
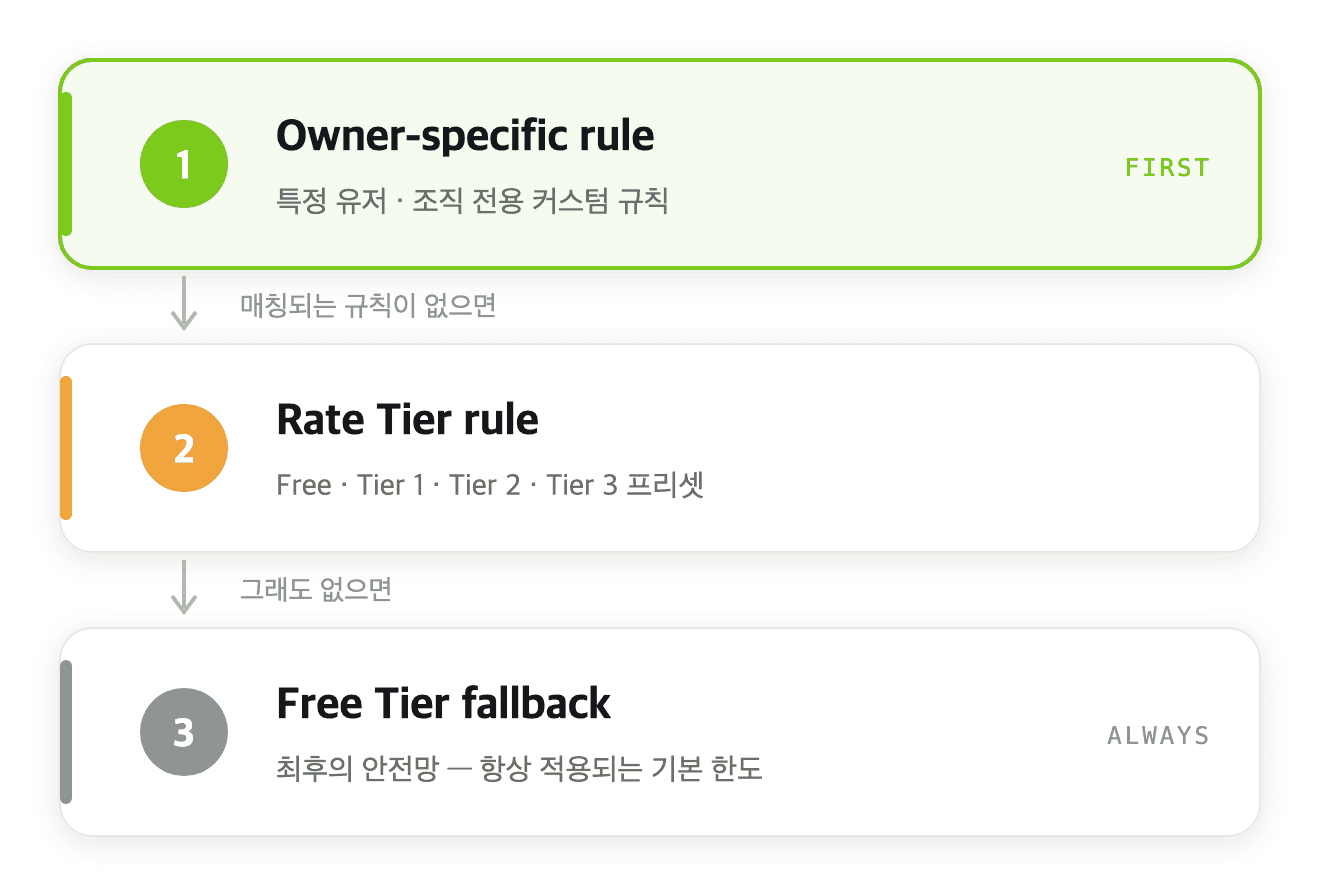
핵심 기능 중 하나는 "코드 배포 없이 즉시 적용"이 가능하다는 것입니다. 엔터프라이즈 고객이 온보딩되면 백오피스를 통해 owner-specific 규칙 하나만 추가하면 됩니다. 티어 기반 규칙도 마찬가지로, 유저가 플랜을 업그레이드하면 별도 배포 없이 새 티어의 규칙이 적용됩니다.
규칙은 인메모리 캐시(in-memory cache)에 인덱싱되어 있어 조회에 대한 시간복잡도는 O(1)입니다. 주기적으로 DB에서 갱신해 최신 상태를 유지합니다.
한 가지 더 말씀을 드리자면, 티어는 사용자의 직전 달 사용량에 따라 자동으로 변경됩니다. 그래서 규칙 조회는 "이 사용자가 지금 어느 티어인가"를 런타임에 반영해야 하고, 급격한 한도 감소로 인해 사용자가 예상치 못한 서비스 거부를 맞이하지 않게 유예 기간(grace period)을 둡니다.
그 외 설계 레이어들
- 소비량을 카운터로 (Consumed, not Remaining)
버킷의 카운터는 소비할 때마다 값을 깎는 게 아니라 쌓는 쪽으로 구현했습니다. 버킷에는 사용량(consumed)만 저장하고, 허용 여부는 읽는 시점에 consumed + amount ≤ limit로 판단합니다.
잔여량(remaining)을 저장해두고 깎아 나가는 방식과 결과는 같지만, 운영 관점에서는 전혀 다릅니다.
운영 중 한도 변경의 복잡성을 없앱니다.
limit은 저장된 값이 아니라 비교 시점에 적용되는 정책 값이라, 운영 중 한도를 변경할 필요성이 생겼을 때 (i.e, 100 → 200), 올리는 즉시 반영됩니다. 깎는 방식은 한도가 이미 각 키에 녹아 있어서, 한도를 바꾸는 순간 이미 누적된remaining을 어떻게 재계산할지가 문제가 됩니다.초기화가 단순합니다. 새 키는 0(= 키 없음)에서 시작하면 끝입니다. 깎는 방식은 키를 만들 때 한도 값으로 seed해야 하고, 그러려면 그 시점의 한도를 알아야 해서 결국 위 문제와 다시 엮입니다.
결국 한도는 규칙(데이터)에만 존재하고, 버킷은 소비량만 셉니다. 앞서 말한 “코드 배포 없이 한도를 즉시 바꾼다”가 가능한 것도 이 구조 덕분입니다.
- 첫 요청 시 초기화 (Lazy Initialization)
버킷 초기화 전략도 고민이었습니다. 모든 유저의 버킷을 미리 만들어 두는 것이 개념적으로 단순할 수 있지만, 저희는 **지연 초기화(lazy initialization)**를 선택했습니다.
버킷이 Redis에 아직 없으면 consumed=0으로 초기화한 뒤 첫 소비를 시도합니다.
이유는 단순합니다. 전체 키의 개수는 유저 수 × 차원 수 × 규칙 수로 계산됩니다. 즉, 서비스가 확장할수록 키가 폭발적으로 늘어나게 되는 구조입니다. 사전 할당은 Redis 메모리와 운영 복잡도 모두에서 비현실적이었습니다. 게다가 lazy init은 단순히 키 수를 줄이는 것을 넘어, 실제로 요청을 보내는 활성 사용자에 대해서만 키를 만듭니다. 또한 버킷마다 TTL을 걸어 일정 시간이 지나면 비활성 사용자의 메모리를 자동으로 회수할 수 있게끔 하였습니다.
- 장애 시 허용 정책 (Fail-Open)
규칙 조회 실패, Redis 장애, 전략 실행 에러 등 다양한 장애 상황에 대한 대비 정책도 필요했습니다. 저희는 모두 로그를 남기고 통과시키는 fail-open 정책을 선택했습니다.
res, err := s.rateLimiter.RunStrategy(ruleCtx, req, rl.Strategy) if err != nil { logger.Error(ctx, fmt.Errorf("ratelimit strategy failed: %w", err)) metrics.Incr("ratelimit.fail_open", tags...) continue // Fail-open on error
레이트 리미터는 방어 장치이지 핵심 비즈니스 로직이 아닙니다. 레이트 리미터가 죽어서 서비스 전체가 멈추는 건 더 나쁜 결과이기 때문입니다. 레이트 리미터가 단일 장애점으로 작동해서는 안됩니다.
물론 여기에도 위험은 존재합니다. 페일오픈 중에는 레이트 리미팅이 사실상 없는 상태이므로 남용 가능성이 있습니다. 다만 이 점은 모니터링과 알림(alerting)으로 보완하고 있습니다.
- 초과 허용 vs 즉시 거절
마지막으로, 한도를 초과하는 요청을 어떻게 처리할 것인지에 대한 고민이 필요했습니다.
저희는 차원에 따라 다른 정책을 적용합니다.
request_count: 즉시 거절(hard deny) — 초과 즉시 거절duration,output_token_count: 허용 후 잠금(allow-and-lock) — 약간의 초과를 허용하되, 그 초과분을 부채(debt)로 기록하고 상환 전까지 후속 요청을 차단
비용 예측이 가능한지 여부가 이 두 정책을 나누는 기준이 됩니다.
요청 수는 항상 한 개씩 증가합니다. 새 요청을 처리하기 전에 즉각적으로 요청의 차단 여부에 대한 판단이 가능합니다. 하지만 duration이나 출력 토큰은 요청의 처리 중, 혹은 처리가 끝난 이후에야 실제 소비량을 알 수 있습니다. 이 경우에는 필요한 경우 약간의 부채를 허용하도록 구성하였습니다.
부채 메커니즘은 이렇게 동작합니다.
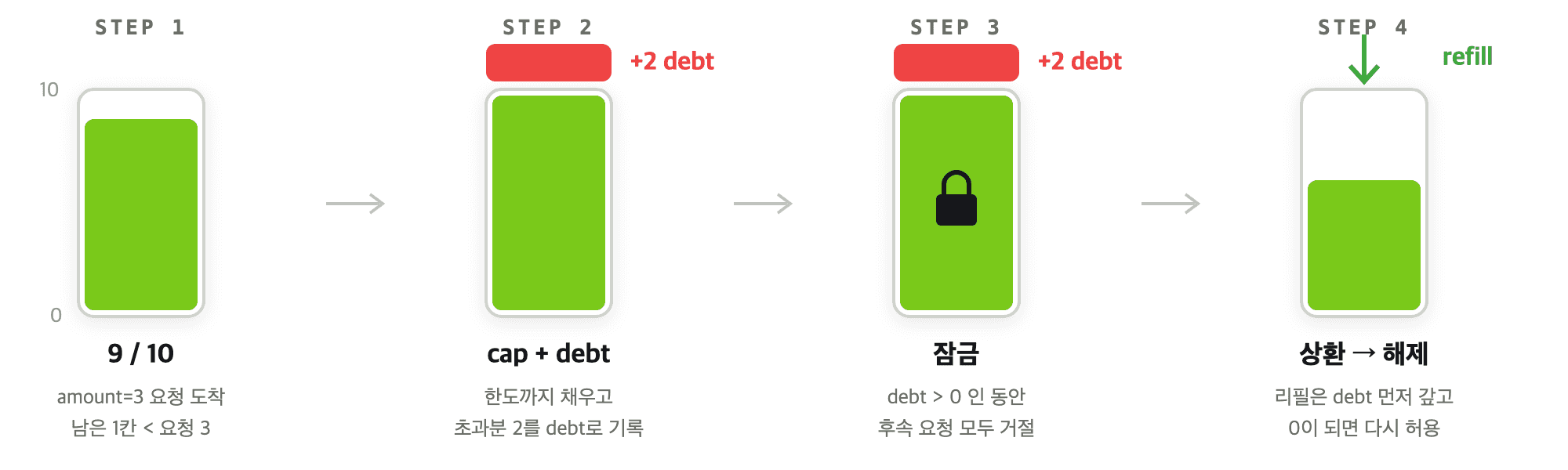
단, 부채가 한도의 일정 비율을 초과하면 초과분도 거절합니다. 극단적인 남용을 방지하기 위한 안전장치입니다.
—————————————————————————————————
구현
전체 구조
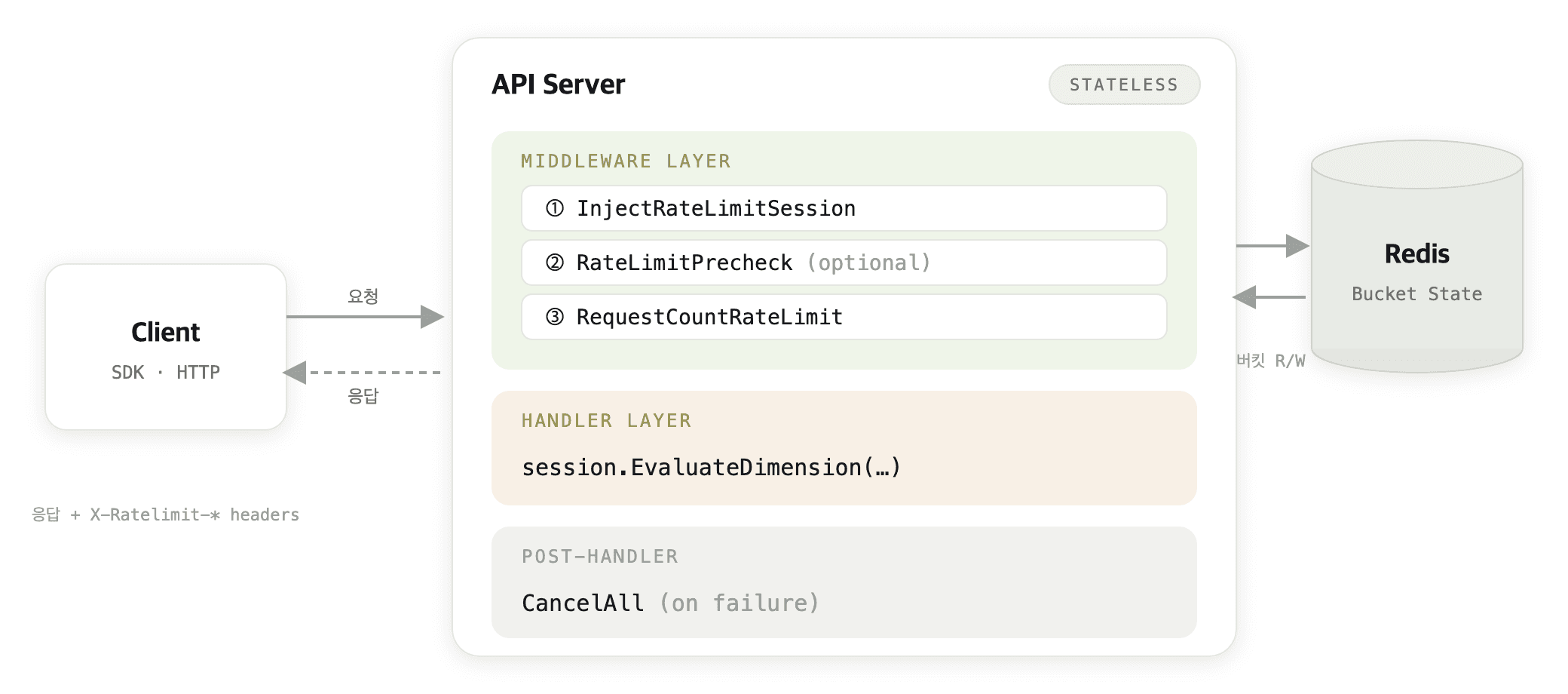
API 서버는 무상태(stateless)입니다. 모든 버킷 상태는 Redis에 저장되기 때문에 API 인스턴스를 수평 확장해도 레이트 리미팅이 일관되게 동작합니다.
핵심 추상화
전략 인터페이스(Strategy interface): 레이트 리미팅 알고리즘의 추상화입니다. Run()으로 소비하고 Cancel()로 되돌립니다. 현재는 고정 버킷(fixed bucket)만 구현되어 있지만, 다른 알고리즘(슬라이딩 윈도우 등)도 이 인터페이스를 구현하면 교체할 수 있습니다.
type Strategy interface { Name() string Run(ctx context.Context, request Request) (Result, error) Cancel(ctx context.Context, request Request) (Result, error
세션(Session): 요청 생명주기를 관리합니다. Context에 주입되어 핸들러 어디서든 접근 가능하고, 성공한 모든 소비를 추적하다가 필요시 일괄 취소합니다.
규칙 집합(RuleSet): 인메모리 규칙 인덱스입니다. DB에서 주기적으로 갱신하고, RuleKey(TargetGroup + RuleGroup + Dimension) 기준으로 O(1) 조회를 제공합니다.
Lua 스크립트: 원자적 토큰 버킷
레이트 리미터에서 가장 까다로운 부분이 동시성입니다. 여러 API 인스턴스가 동시에 같은 버킷에 접근하기 때문입니다.
저희는 Redis Lua 스크립트로 해결했습니다. Lua 스크립트는 Redis 내부에서 단일 원자적 연산(atomic operation)으로 실행되기 때문에 경합 조건(race condition)이 없습니다.
핵심 흐름은 다음과 같습니다.
flowchart TD A([요청: amount]) --> Atomic subgraph Atomic["Redis"] direction TB B[경과 시간만큼 토큰 리필] --> C[리필분으로 debt 우선 상환<br/>남은 분으로 consumed 감소] C --> D{debt가 아직 남았나?} D -- 예: 직전 초과로 잠김 --> DENY[거절] D -- 아니오 --> E{consumed + amount ≤ limit?} E -- 예 --> ALLOW[허용] E -- 아니오 --> F{overshoot 허용?} F -- 예 --> LOCK[허용 후 잠금<br/>초과분을 debt로 기록] F -- 아니오 --> DENY end ALLOW --> R([상태 저장 · 결과 반환]) LOCK --> R DENY --> R
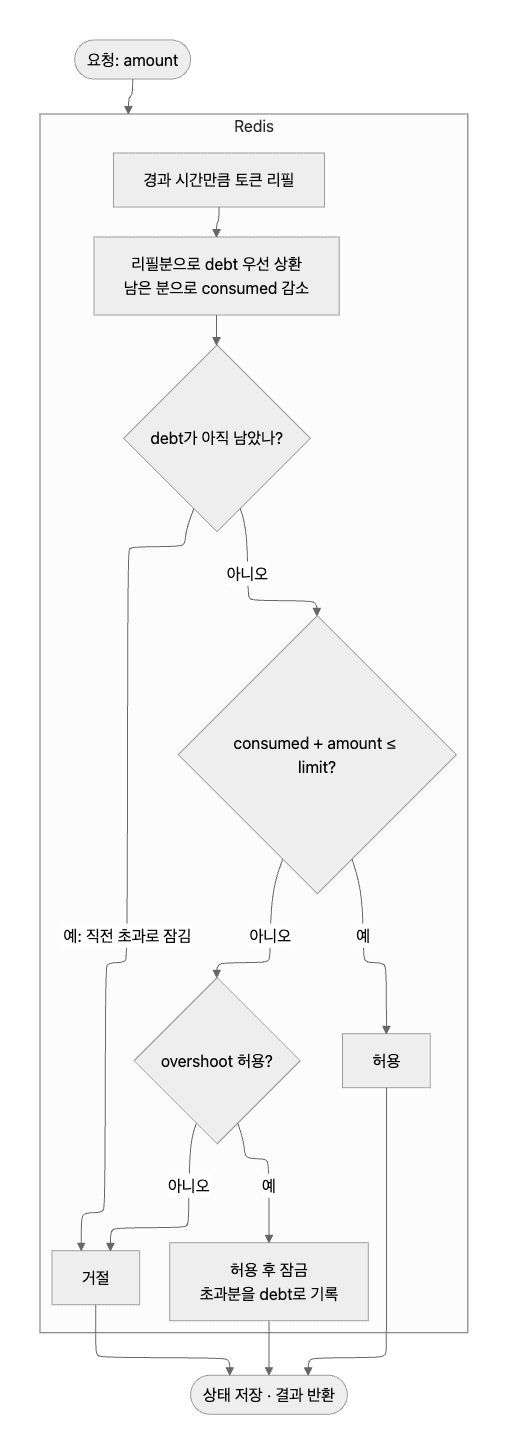
Redis MULTI/EXEC도 검토했지만, Lua가 조건 분기와 계산 로직을 하나의 원자적 연산 안에서 처리할 수 있어 훨씬 유연했습니다.
미들웨어 구성
세 가지 미들웨어가 역할을 나누어 동작합니다.
InjectRateLimitSessionMiddleware: 세션을 생성하고 request context에 주입합니다. 자체적으로는 아무 차원도 평가하지 않습니다. 핸들러가 끝난 뒤에 에러/4xx 여부를 확인해 취소를 결정하는 역할입니다.
RequestCountRateLimitMiddleware: request_count 차원만 선제 평가합니다. 세션이 있으면 세션을 통해, 없으면 자체적으로 규칙을 조회해서 처리합니다. 거절 시 429를 즉시 반환하고, 통과 시에는 실패 시 롤백할 수 있도록 헤더를 설정합니다.
RateLimitPrecheckMiddleware: 비용이 큰 차원(output_token_count 등)에 대한 사전 확인입니다. 특정 차원에 대해 모든 규칙이 debt 없는 상황인지 확인한 후 핸들러로 진행합니다. 이미 한도가 찬 상태에서 비싼 연산을 시작하는 것을 미리 막아주는 것입니다.
—————————————————————————————————
운영하면서 배운 것들
1. 레이트 리밋이 아니었던 것들
레이트 리미터를 운영하면서 가장 자주 마주친 혼란은, 정작 레이트 리밋 시스템이 아닌 것들이 레이트 리밋으로 오해받는다는 점이었습니다. TwelveLabs API에서 사용자의 요청을 막는 메커니즘은 세 가지가 있고, 그 셋의 구현은 전혀 다릅니다.
메커니즘 | 묻는 질문 | 시간 축 | 풀리는 조건 |
|---|---|---|---|
레이트 리밋(rate limit) | 단위 시간당 요청 량이 과다한가? | 있음 (분/시/일) | 시간 |
플랜 쿼터(plan quota) | 플랜이 허용하는 총량(예: 누적 인덱싱 영상 시간)을 넘었는가? | 없음 | 플랜 업그레이드 |
동시성 캡(concurrency cap) | 동시에 처리 중인 작업이 너무 많은가? | 없음 (in-flight) | 앞 작업이 끝나면 |
겉으로는 다 "막혔다"지만, 사용자가 취해야 할 행동이 정반대입니다. 이를 정확히 구분하지 않으면 두 가지 문제가 발생할 수 있습니다.
첫째, 부정확한 에러 코드는 클라이언트의 부적절한 다음 행동을 야기합니다. 한때는 쿼터 초과도 검증 에러와 똑같이 400으로 반환해서, 두 가지 경우를 구분할 수가 없게 만들었습니다. 그러면 429로 바꾸면 될까요? 아닙니다 — 대부분의 SDK는 429를 자동 재시도하는데, 쿼터는 기다려도 안 풀리므로 절대 성공하지 않을 요청을 무한 재시도하는 폭주가 생깁니다. 그래서 쿼터 초과는 429가 아니라 422(Unprocessable Content)로 분리했습니다.(RFC 9110 - 15.5.21) 요청 형식은 멀쩡하지만 지금은 처리할 수 없다는 뜻이고, 자동 재시도 대상도 아니며, 레이트 리밋 지표(SLO)도 오염시키지 않습니다. 429는 "기다리면 풀린다"는 약속입니다. 그 약속을 지킬 수 없는 상황에서 429를 쓸 수 없었습니다.
둘째, 원인 진단이 어긋납니다. 한 고객이 "요청이 멈춘다"고 했는데, 알고 보니 레이트 리밋도 쿼터도 아니고 사용자별 동시 인덱싱 캡이었습니다. 수천 개 작업을 한꺼번에 넣었으나 동시성 캡이 제한적으로 설정되어 있어서 대기열이 하루 가까이 길어진 것이었죠. 모든 작업은 결국 성공했지만 체감은 "막힘"이었습니다.
다차원 레이트 리미터를 만들면서 정작 더 중요했던 건, 레이트 리밋이 책임지는 범위를 가시성 있게 명확히 긋는 것이었습니다.
2. Fail-open은 조용히 작동하면 안 됩니다
솔직히 저는 Fail-open을 설계에 넣으면서 "이러면 최악의 경우에도 안전하다"고만 생각했습니다. 레이트 리미터가 죽어도 서비스는 사니까요.
그런데 부하 테스트에서 함정을 봤습니다. Redis 레이트 리밋 조회가 3초를 넘기고 타임아웃이 나면, 설계대로 체크를 건너뛰고 요청을 통과시킵니다. 무서운 건 이 "건너뜀"이 E2E 테스트에서는 에러로도 잘 드러나지 않는다는 점입니다. 페일오픈은 본질적으로 조용히 실패합니다. 명시적인 지표가 없으면 "그 시간 동안 레이트 리미팅이 사실상 꺼져 있었다"는 사실 자체를 알 수가 없습니다.
여기서 배운 것은 분명합니다. 페일오픈은 장애를 흡수하는 동시에 장애를 숨기는 정책이라는 것입니다. 통과시키는 선택 자체는 맞지만, 통과시키고 있다는 사실을 알려주지 않으면 그사이의 남용에 무방비가 됩니다.
3. 레이트 리미팅 헤더의 UX
"어떤 차원 기준으로 헤더를 내려줄 것인가" 역시 까다로운 문제였습니다.
초기에는 단일 차원 헤더만 내려줬는데, 다차원으로 확장하면서 여러 버그가 생겼습니다. 429로 거절되었는데 x-ratelimit-duration-remaining이 0이 아니라 "140"으로 표시되거나, 특정 엔드포인트에서 헤더가 아예 빠지거나, 커스텀 규칙이 헤더에 제대로 반영되지 않는 문제들이었습니다.
결국 저희는 가장 짧은 시간 윈도우의 규칙을 기준으로 기본 헤더를 내려주되, 모든 차원의 상태를 함께 내려주는 다차원 헤더를 추가했습니다. 사용자 입장에서 연속 요청 시 가장 먼저 마주하는 제약은 짧은 윈도우이기 때문입니다.
헤더는 "맞으면 아무도 모르고, 틀리면 바로 티 나는" 영역입니다. QA 과정에서 차원별, 엔드포인트별 헤더 값 검증을 체계적으로 하지 않으면 이상한 값이 프로덕션에 나갑니다.
4. Deny 메시지의 명확성
초기에는 429 응답에 "Too many requests"만 내려줬는데, 고객 문의가 쏟아졌습니다. "내가 뭘 초과한 건지 모르겠다", "embed video를 요청한 적이 없는데 429가 왔다", "에러 메시지가 이상하게 보인다" 등 다양한 형태의 혼란이 있었습니다.
특히 다차원 레이트 리미팅에서는 어떤 차원이 걸렸는지를 명확히 전달하지 않으면 유저가 원인을 파악할 수 없습니다. "request count 때문인지, duration 때문인지, output token 때문인지"를 알아야 대응할 수 있기 때문입니다.
차원과 시간 윈도우를 명확하게 전달하도록 바꾸니 문의가 눈에 띄게 줄었습니다. 실제 응답 메시지는 다음과 같은 형식입니다.
괄호 안에 어떤 한도·시간 윈도우에 걸렸는지(60 Requests/1 minute)가, 끝에 언제 풀리는지(after ...)가 한 줄에 함께 담깁니다 — 차원이 다르면 단위도 그에 맞게 바뀝니다. 나아가 대시보드에서 레이트 리미팅 에러 로그를 직접 확인할 수 있는 기능도 추가했습니다.
5. 엔터프라이즈 커스텀 규칙의 운영 부담
"배포 없이 DB에 규칙 하나 추가하면 끝"이라고 설계했는데, 운영하다 보니 규칙 관리 자체가 부담이 되었습니다.
엔터프라이즈 고객이 늘어나면서 커스텀 규칙 추가/변경 요청이 지속적으로 발생하였습니다. "이 고객은 duration 한도를 5000시간/일로 올려주세요", "이 계정은 다음 주까지만 한시적으로 올려주세요" 같은 요청들입니다. 규칙 적용은 빠르지만, 누가 어떤 규칙을 쓰고 있는지 추적하고, 만료된 한시적 규칙을 정리하는 것은 수동으로 이루어졌습니다.
이 경험에서 배운 것은 두 가지입니다.
Field Engineering 팀이 고객의 레이트 리미팅 상태를 직접 확인할 수 있는 도구가 필요하다는 점 — 매번 엔지니어에게 문의하는 것은 스케일이 나지 않습니다.
자주 한도에 걸리는 고객을 선제적으로 알 수 있는 시스템이 필요하다는 점 — 고객이 불만을 제기하기 전에 먼저 알아야 합니다.
—————————————————————————————————
앞으로
레이트 리미팅은 한 번 만들고 끝나는 것이 아니라, 서비스가 성장하면서 같이 진화하는 시스템입니다. 양적으로도 질적으로도, 스케일이 증가하면 모든 것이 깨지기 시작합니다. 새로운 API가 추가되면 새로운 차원이 필요할 수 있고, 트래픽 패턴이 바뀌면 리필(refill) 전략도 조정이 필요합니다. 저희도 계속 배우고 고쳐나가는 중입니다.
돌아보면 레이트 리미팅은 고전적인 문제입니다. 하지만 요청 하나의 비용이 수백 배씩 차이 나는 영상 AI에서는, 익숙한 문제도 다시 풀어야 했습니다. 한정된 리소스를 가지고 공정성과 안정성을 어떻게 동시 충족시킬 수 있을 것인가. 저희가 매일 부딪혀 푸는 문제들은 이런 디테일까지 고려되어야 합니다.
이 글이 비슷한 문제를 고민하고 계신 분들에게 조금이라도 도움이 되었으면 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]

들어가며
API 레이트 리미팅(rate limiting)이라고 하면 보통 규모(scale)의 문제를 떠올립니다. 트래픽이 몰려도 분산 환경에서 카운터를 정확하고 빠르게 세는 것 — 어려움은 거기에 있다고들 하고, 실제로 많은 경우 그렇습니다.
저희도 처음엔 간단하게 접근했습니다. 초기 TwelveLabs API는 엔드포인트별로 "초당 N건, 시간당 M건" 같은 단순한 요청 수 제한만 두고 있었거든요.
그런데 영상 AI에서는 진짜 난제가 다른 곳에 숨어 있었습니다. 10초 길이의 숏폼 영상을 분석하는 요청과 2시간 길이의 영화를 분석하는 요청이 있다고 가정해 보겠습니다. 둘 다 시스템상으로는 '1건'의 요청이지만, 소비되는 컴퓨팅 자원은 수백 배 차이가 날 수도 있습니다. 즉, 단순히 요청의 개수만 세는 방식은 더 이상 공정하지 않았습니다.
측정 가능한 형태로 부하를 분산할 수 없다면, 자연스럽게 뒤에 있는 ML 서비스 역시 위험에 노출될 가능성이 생깁니다. 레이트 리밋의 진짜 목적은 한 사용자의 과도한 워크로드가 GPU 추론 같은 공유 자원을 잠식해, 다른 모든 사용자의 요청까지 느려지거나 실패하게 만드는 'Noisy Neighbor' 상황을 막는 것이었습니다. 실제로 한 고객의 워크로드가 폭주하면서 다운스트림 서비스를 과부하 시켜, 그 고객과 무관한 사용자들에게까지 장애가 번지는 아찔한 경험을 하기도 했습니다.
TwelveLabs API는 영상 인덱싱, 검색, 영상 정보 추출, 임베딩(embedding) 등 다양한 엔드포인트를 제공하며, 각각의 비용 구조가 전부 다릅니다. Search는 인덱스 스캔 비용이 주인 반면, Indexing/Embedding은 영상 길이에 따른 벡터 추출 비용이 지배적입니다. Analyze 엔드포인트는 모델이 뱉어내는 출력 토큰(output token) 수에 따라 다시 한번 비용이 비례하여 증가합니다.
하나의 잣대로 이 모든 것을 제한하는 건 무리가 있었습니다.
이 글에서는 저희가 이러한 문제를 해결하기 위해 '다차원 레이트 리미터'를 설계하고 구현하며 내린 결정들을 공유하려 합니다.
—————————————————————————————————
문제 정의
비용 비대칭
TwelveLabs API의 각 엔드포인트는 리소스를 소모하는 형태가 완전히 다릅니다.
Operation | 주요 비용 요소 |
|---|---|
Search | 요청 수 (request count) |
Indexing / Embedding | 요청 수 + 미디어 길이 (duration) |
Analyze | 요청 수 + 미디어 길이 + 출력 토큰 수 (output tokens) |
요청 수 제한만으로는 Heavy 유저의 리소스 독점을 막을 수 없었습니다. 유저 A가 숏폼 형태의 짧은 영상 100개를 인덱싱하고, 유저 B가 2시간짜리 영상 5개를 인덱싱한다고 해봅시다. 요청 수 기준으로는 A가 20배 더 많이 쓴 것이지만, 실제 리소스 소비는 B가 훨씬 클 수 있습니다.
엔터프라이즈 온보딩 속도
비즈니스가 성장하면서 전용 한도(Dedicated Limit)를 요구하는 엔터프라이즈 고객이 빠르게 늘어났습니다. 엔터프라이즈 고객이 온보딩하는 경우에는, 요청에 따라 전용 한도를 빠르게 적용해야 하는 경우가 많습니다. 운영을 더 쉽고 빠르게 하기 위해서는 코드 배포 없이 DB에 규칙을 하나 추가하는 것과 같은 간단한 방법이 필요했습니다.
결론적으로 저희에게 필요한 것은 요청 수(request count), 영상 길이(duration), 출력 토큰(output token)의 세 축을 동시에 제어할 수 있는 시스템이었습니다.
—————————————————————————————————
핵심 설계 결정들
1. 다차원 제한(Multi-dimensional rate limit): 차원(dimension)을 1급 개념으로
가장 먼저 정해야 했던 것은 "여러 종류의 비용을 어떤 방식으로 표현할 것인가"였습니다.
저희의 선택은 비용의 종류 자체를 1급 개념(first-class)으로 끌어올리는 것이었습니다. 서로 다른 비용 축을 각각 독립된 차원으로 정의하고, 이를 규칙 모델의 정식 필드로 새겨 넣었습니다.
const ( DimensionRequestCount Dimension = "request_count" DimensionDuration Dimension = "duration" DimensionOutputTokenCount Dimension = "output_token_count"
차원은 단순한 enum 값이 아니라 규칙(rule)의 정식 속성입니다. 규칙은 자신이 어떤 차원을 제한하는지를 알고 있고, 조회 키에도 이 차원 이름이 포함됩니다. 그래서 각 차원은 완전히 독립적으로 규칙을 가질 수 있습니다.
같은 차원에 여러 시간 윈도우가 공존할 수도 있습니다 — 예를 들어 요청 수에 "분당 60건"과 "일일 1,000건" 규칙이 동시에 적용되는 식입니다. 두 규칙 모두 통과해야 요청이 허용됩니다.
차원을 도입하면서 ‘무엇을 셀 것인가’를 하나의 일관된 모델로 정리했습니다. 기존에는 요청 횟수(request count) 하나만 셌다면, 이제는 요청 수·길이(초)·출력 토큰을 아우르는, 차원별로 ‘측정 가능한 숫자’라는 같은 형태가 된 셈입니다.
비용 축을 이러한 방식으로 분리하면 두 가지 장점을 얻을 수 있습니다. 첫째, 확장이 단순 더하기로 끝납니다. 입력 토근 수 같이 새로운 비용 축이 필요해지면, 기존 로직을 건드릴 필요 없이 새로운 차원을 하나 더 정의해 주기만 하면 됩니다. 둘째, 운영과 커뮤니케이션 측면 모두에서 직관적입니다. 특정 차단이 일어났을 때 어떤 축에서 제한이 발생했는지를 바로 파악할 수 있기 때문에, "분당 요청 수 초과"처럼 차단 사유가 사람이 쉽게 이해할 수 있는 형태로 표현됩니다.
2. 세션 기반 평가와 롤백 전략
차원을 분리하고 나니 또 다른 난관이 기다리고 있었습니다. 하나의 요청 안에서 각 차원의 비용이 확정되는 시점이 제각각 다르다는 점이었습니다.
'요청 수'는 요청이 들어오는 시점에 바로 알 수 있습니다. 항상 1이기 때문입니다. 하지만 '출력 토큰(output token) 수'는 실제 연산 작업이 끝나야만 비로소 알 수 있습니다. 영상 분석에 소요되는 시간(Duration)도 마찬가지로, 실제 영상을 분석하기 전까지는 정확한 소비량을 알 수 없습니다.
하나의 API 요청 안에서 여러 차원이 서로 다른 시점에 평가되는 구조이므로, 이것을 하나의 생명주기로 묶어야 일관된 롤백이 가능했습니다.
이를 해결하기 위해 저희는 요청마다 고유한 세션(session)을 열어서, 각 차원을 순차적으로 평가하고, 요청이 실패하면 소비한 할당량을 취소하는 구조를 만들었습니다.
세션 내부에서는 성공한 모든 평가 기록을 별도의 자료구조로 추적합니다. 취소가 필요해지면 이 세션에 기록된 목록을 역순으로 순회하면서 각각의 소비를 되돌립니다.
[요청 실패 시] 세션에 기록된 성공 평가를 역순 순회 └─ 각 디멘션의 소비량을 환불(refund) · 별도 goroutine · 비동기(non-blocking) · 원 요청 context와 무관하게 끝까지 실행
3. 규칙 우선순위와 실시간 반영
레이트 리미팅 규칙의 우선순위를 어떻게 결정할 것인가도 중요한 설계 포인트였습니다.
저희는 다차원 레이트 리미터의 도입과 함께 티어를 세분화하며 3단계 우선순위를 도입했습니다.
💡 잠깐, 여기서 티어(rate tier)란?
전용 한도를 받는 엔터프라이즈 고객을 제외하면, 대부분의 사용자는 '티어'(rate tier) 단위로 관리됩니다. 티어는 미리 정의된 한도 묶음으로, 저희 시스템에서는 Free Tier와 함께 Tier 1·2·3을 미리 구분해 두었습니다. 각 티어에 어떤 한도를 줄지는 가격·플랜 같은 비즈니스 결정에서 내려오고, 그 값들을 하나의 프리셋으로 정의하기 때문에, "이 사용자의 한도가 얼마인가"는 사실상 "이 사용자가 어느 티어인가"의 문제가 됩니다.
정리하면 한도는 두 층으로 정해집니다 — 기본은 티어, 엔터프라이즈 같은 예외는 그 위에 얹는 커스텀 규칙. 뒤에 나오는 다이어그램의 한도 값이나 "규칙 우선순위" 이야기는 모두 이 티어 구조를 전제로 합니다.
핵심 기능 중 하나는 "코드 배포 없이 즉시 적용"이 가능하다는 것입니다. 엔터프라이즈 고객이 온보딩되면 백오피스를 통해 owner-specific 규칙 하나만 추가하면 됩니다. 티어 기반 규칙도 마찬가지로, 유저가 플랜을 업그레이드하면 별도 배포 없이 새 티어의 규칙이 적용됩니다.
규칙은 인메모리 캐시(in-memory cache)에 인덱싱되어 있어 조회에 대한 시간복잡도는 O(1)입니다. 주기적으로 DB에서 갱신해 최신 상태를 유지합니다.
한 가지 더 말씀을 드리자면, 티어는 사용자의 직전 달 사용량에 따라 자동으로 변경됩니다. 그래서 규칙 조회는 "이 사용자가 지금 어느 티어인가"를 런타임에 반영해야 하고, 급격한 한도 감소로 인해 사용자가 예상치 못한 서비스 거부를 맞이하지 않게 유예 기간(grace period)을 둡니다.
그 외 설계 레이어들
- 소비량을 카운터로 (Consumed, not Remaining)
버킷의 카운터는 소비할 때마다 값을 깎는 게 아니라 쌓는 쪽으로 구현했습니다. 버킷에는 사용량(consumed)만 저장하고, 허용 여부는 읽는 시점에 consumed + amount ≤ limit로 판단합니다.
잔여량(remaining)을 저장해두고 깎아 나가는 방식과 결과는 같지만, 운영 관점에서는 전혀 다릅니다.
운영 중 한도 변경의 복잡성을 없앱니다.
limit은 저장된 값이 아니라 비교 시점에 적용되는 정책 값이라, 운영 중 한도를 변경할 필요성이 생겼을 때 (i.e, 100 → 200), 올리는 즉시 반영됩니다. 깎는 방식은 한도가 이미 각 키에 녹아 있어서, 한도를 바꾸는 순간 이미 누적된remaining을 어떻게 재계산할지가 문제가 됩니다.초기화가 단순합니다. 새 키는 0(= 키 없음)에서 시작하면 끝입니다. 깎는 방식은 키를 만들 때 한도 값으로 seed해야 하고, 그러려면 그 시점의 한도를 알아야 해서 결국 위 문제와 다시 엮입니다.
결국 한도는 규칙(데이터)에만 존재하고, 버킷은 소비량만 셉니다. 앞서 말한 “코드 배포 없이 한도를 즉시 바꾼다”가 가능한 것도 이 구조 덕분입니다.
- 첫 요청 시 초기화 (Lazy Initialization)
버킷 초기화 전략도 고민이었습니다. 모든 유저의 버킷을 미리 만들어 두는 것이 개념적으로 단순할 수 있지만, 저희는 **지연 초기화(lazy initialization)**를 선택했습니다.
버킷이 Redis에 아직 없으면 consumed=0으로 초기화한 뒤 첫 소비를 시도합니다.
이유는 단순합니다. 전체 키의 개수는 유저 수 × 차원 수 × 규칙 수로 계산됩니다. 즉, 서비스가 확장할수록 키가 폭발적으로 늘어나게 되는 구조입니다. 사전 할당은 Redis 메모리와 운영 복잡도 모두에서 비현실적이었습니다. 게다가 lazy init은 단순히 키 수를 줄이는 것을 넘어, 실제로 요청을 보내는 활성 사용자에 대해서만 키를 만듭니다. 또한 버킷마다 TTL을 걸어 일정 시간이 지나면 비활성 사용자의 메모리를 자동으로 회수할 수 있게끔 하였습니다.
- 장애 시 허용 정책 (Fail-Open)
규칙 조회 실패, Redis 장애, 전략 실행 에러 등 다양한 장애 상황에 대한 대비 정책도 필요했습니다. 저희는 모두 로그를 남기고 통과시키는 fail-open 정책을 선택했습니다.
res, err := s.rateLimiter.RunStrategy(ruleCtx, req, rl.Strategy) if err != nil { logger.Error(ctx, fmt.Errorf("ratelimit strategy failed: %w", err)) metrics.Incr("ratelimit.fail_open", tags...) continue // Fail-open on error
레이트 리미터는 방어 장치이지 핵심 비즈니스 로직이 아닙니다. 레이트 리미터가 죽어서 서비스 전체가 멈추는 건 더 나쁜 결과이기 때문입니다. 레이트 리미터가 단일 장애점으로 작동해서는 안됩니다.
물론 여기에도 위험은 존재합니다. 페일오픈 중에는 레이트 리미팅이 사실상 없는 상태이므로 남용 가능성이 있습니다. 다만 이 점은 모니터링과 알림(alerting)으로 보완하고 있습니다.
- 초과 허용 vs 즉시 거절
마지막으로, 한도를 초과하는 요청을 어떻게 처리할 것인지에 대한 고민이 필요했습니다.
저희는 차원에 따라 다른 정책을 적용합니다.
request_count: 즉시 거절(hard deny) — 초과 즉시 거절duration,output_token_count: 허용 후 잠금(allow-and-lock) — 약간의 초과를 허용하되, 그 초과분을 부채(debt)로 기록하고 상환 전까지 후속 요청을 차단
비용 예측이 가능한지 여부가 이 두 정책을 나누는 기준이 됩니다.
요청 수는 항상 한 개씩 증가합니다. 새 요청을 처리하기 전에 즉각적으로 요청의 차단 여부에 대한 판단이 가능합니다. 하지만 duration이나 출력 토큰은 요청의 처리 중, 혹은 처리가 끝난 이후에야 실제 소비량을 알 수 있습니다. 이 경우에는 필요한 경우 약간의 부채를 허용하도록 구성하였습니다.
부채 메커니즘은 이렇게 동작합니다.
단, 부채가 한도의 일정 비율을 초과하면 초과분도 거절합니다. 극단적인 남용을 방지하기 위한 안전장치입니다.
—————————————————————————————————
구현
전체 구조
API 서버는 무상태(stateless)입니다. 모든 버킷 상태는 Redis에 저장되기 때문에 API 인스턴스를 수평 확장해도 레이트 리미팅이 일관되게 동작합니다.
핵심 추상화
전략 인터페이스(Strategy interface): 레이트 리미팅 알고리즘의 추상화입니다. Run()으로 소비하고 Cancel()로 되돌립니다. 현재는 고정 버킷(fixed bucket)만 구현되어 있지만, 다른 알고리즘(슬라이딩 윈도우 등)도 이 인터페이스를 구현하면 교체할 수 있습니다.
type Strategy interface { Name() string Run(ctx context.Context, request Request) (Result, error) Cancel(ctx context.Context, request Request) (Result, error
세션(Session): 요청 생명주기를 관리합니다. Context에 주입되어 핸들러 어디서든 접근 가능하고, 성공한 모든 소비를 추적하다가 필요시 일괄 취소합니다.
규칙 집합(RuleSet): 인메모리 규칙 인덱스입니다. DB에서 주기적으로 갱신하고, RuleKey(TargetGroup + RuleGroup + Dimension) 기준으로 O(1) 조회를 제공합니다.
Lua 스크립트: 원자적 토큰 버킷
레이트 리미터에서 가장 까다로운 부분이 동시성입니다. 여러 API 인스턴스가 동시에 같은 버킷에 접근하기 때문입니다.
저희는 Redis Lua 스크립트로 해결했습니다. Lua 스크립트는 Redis 내부에서 단일 원자적 연산(atomic operation)으로 실행되기 때문에 경합 조건(race condition)이 없습니다.
핵심 흐름은 다음과 같습니다.
flowchart TD A([요청: amount]) --> Atomic subgraph Atomic["Redis"] direction TB B[경과 시간만큼 토큰 리필] --> C[리필분으로 debt 우선 상환<br/>남은 분으로 consumed 감소] C --> D{debt가 아직 남았나?} D -- 예: 직전 초과로 잠김 --> DENY[거절] D -- 아니오 --> E{consumed + amount ≤ limit?} E -- 예 --> ALLOW[허용] E -- 아니오 --> F{overshoot 허용?} F -- 예 --> LOCK[허용 후 잠금<br/>초과분을 debt로 기록] F -- 아니오 --> DENY end ALLOW --> R([상태 저장 · 결과 반환]) LOCK --> R DENY --> R
Redis MULTI/EXEC도 검토했지만, Lua가 조건 분기와 계산 로직을 하나의 원자적 연산 안에서 처리할 수 있어 훨씬 유연했습니다.
미들웨어 구성
세 가지 미들웨어가 역할을 나누어 동작합니다.
InjectRateLimitSessionMiddleware: 세션을 생성하고 request context에 주입합니다. 자체적으로는 아무 차원도 평가하지 않습니다. 핸들러가 끝난 뒤에 에러/4xx 여부를 확인해 취소를 결정하는 역할입니다.
RequestCountRateLimitMiddleware: request_count 차원만 선제 평가합니다. 세션이 있으면 세션을 통해, 없으면 자체적으로 규칙을 조회해서 처리합니다. 거절 시 429를 즉시 반환하고, 통과 시에는 실패 시 롤백할 수 있도록 헤더를 설정합니다.
RateLimitPrecheckMiddleware: 비용이 큰 차원(output_token_count 등)에 대한 사전 확인입니다. 특정 차원에 대해 모든 규칙이 debt 없는 상황인지 확인한 후 핸들러로 진행합니다. 이미 한도가 찬 상태에서 비싼 연산을 시작하는 것을 미리 막아주는 것입니다.
—————————————————————————————————
운영하면서 배운 것들
1. 레이트 리밋이 아니었던 것들
레이트 리미터를 운영하면서 가장 자주 마주친 혼란은, 정작 레이트 리밋 시스템이 아닌 것들이 레이트 리밋으로 오해받는다는 점이었습니다. TwelveLabs API에서 사용자의 요청을 막는 메커니즘은 세 가지가 있고, 그 셋의 구현은 전혀 다릅니다.
메커니즘 | 묻는 질문 | 시간 축 | 풀리는 조건 |
|---|---|---|---|
레이트 리밋(rate limit) | 단위 시간당 요청 량이 과다한가? | 있음 (분/시/일) | 시간 |
플랜 쿼터(plan quota) | 플랜이 허용하는 총량(예: 누적 인덱싱 영상 시간)을 넘었는가? | 없음 | 플랜 업그레이드 |
동시성 캡(concurrency cap) | 동시에 처리 중인 작업이 너무 많은가? | 없음 (in-flight) | 앞 작업이 끝나면 |
겉으로는 다 "막혔다"지만, 사용자가 취해야 할 행동이 정반대입니다. 이를 정확히 구분하지 않으면 두 가지 문제가 발생할 수 있습니다.
첫째, 부정확한 에러 코드는 클라이언트의 부적절한 다음 행동을 야기합니다. 한때는 쿼터 초과도 검증 에러와 똑같이 400으로 반환해서, 두 가지 경우를 구분할 수가 없게 만들었습니다. 그러면 429로 바꾸면 될까요? 아닙니다 — 대부분의 SDK는 429를 자동 재시도하는데, 쿼터는 기다려도 안 풀리므로 절대 성공하지 않을 요청을 무한 재시도하는 폭주가 생깁니다. 그래서 쿼터 초과는 429가 아니라 422(Unprocessable Content)로 분리했습니다.(RFC 9110 - 15.5.21) 요청 형식은 멀쩡하지만 지금은 처리할 수 없다는 뜻이고, 자동 재시도 대상도 아니며, 레이트 리밋 지표(SLO)도 오염시키지 않습니다. 429는 "기다리면 풀린다"는 약속입니다. 그 약속을 지킬 수 없는 상황에서 429를 쓸 수 없었습니다.
둘째, 원인 진단이 어긋납니다. 한 고객이 "요청이 멈춘다"고 했는데, 알고 보니 레이트 리밋도 쿼터도 아니고 사용자별 동시 인덱싱 캡이었습니다. 수천 개 작업을 한꺼번에 넣었으나 동시성 캡이 제한적으로 설정되어 있어서 대기열이 하루 가까이 길어진 것이었죠. 모든 작업은 결국 성공했지만 체감은 "막힘"이었습니다.
다차원 레이트 리미터를 만들면서 정작 더 중요했던 건, 레이트 리밋이 책임지는 범위를 가시성 있게 명확히 긋는 것이었습니다.
2. Fail-open은 조용히 작동하면 안 됩니다
솔직히 저는 Fail-open을 설계에 넣으면서 "이러면 최악의 경우에도 안전하다"고만 생각했습니다. 레이트 리미터가 죽어도 서비스는 사니까요.
그런데 부하 테스트에서 함정을 봤습니다. Redis 레이트 리밋 조회가 3초를 넘기고 타임아웃이 나면, 설계대로 체크를 건너뛰고 요청을 통과시킵니다. 무서운 건 이 "건너뜀"이 E2E 테스트에서는 에러로도 잘 드러나지 않는다는 점입니다. 페일오픈은 본질적으로 조용히 실패합니다. 명시적인 지표가 없으면 "그 시간 동안 레이트 리미팅이 사실상 꺼져 있었다"는 사실 자체를 알 수가 없습니다.
여기서 배운 것은 분명합니다. 페일오픈은 장애를 흡수하는 동시에 장애를 숨기는 정책이라는 것입니다. 통과시키는 선택 자체는 맞지만, 통과시키고 있다는 사실을 알려주지 않으면 그사이의 남용에 무방비가 됩니다.
3. 레이트 리미팅 헤더의 UX
"어떤 차원 기준으로 헤더를 내려줄 것인가" 역시 까다로운 문제였습니다.
초기에는 단일 차원 헤더만 내려줬는데, 다차원으로 확장하면서 여러 버그가 생겼습니다. 429로 거절되었는데 x-ratelimit-duration-remaining이 0이 아니라 "140"으로 표시되거나, 특정 엔드포인트에서 헤더가 아예 빠지거나, 커스텀 규칙이 헤더에 제대로 반영되지 않는 문제들이었습니다.
결국 저희는 가장 짧은 시간 윈도우의 규칙을 기준으로 기본 헤더를 내려주되, 모든 차원의 상태를 함께 내려주는 다차원 헤더를 추가했습니다. 사용자 입장에서 연속 요청 시 가장 먼저 마주하는 제약은 짧은 윈도우이기 때문입니다.
헤더는 "맞으면 아무도 모르고, 틀리면 바로 티 나는" 영역입니다. QA 과정에서 차원별, 엔드포인트별 헤더 값 검증을 체계적으로 하지 않으면 이상한 값이 프로덕션에 나갑니다.
4. Deny 메시지의 명확성
초기에는 429 응답에 "Too many requests"만 내려줬는데, 고객 문의가 쏟아졌습니다. "내가 뭘 초과한 건지 모르겠다", "embed video를 요청한 적이 없는데 429가 왔다", "에러 메시지가 이상하게 보인다" 등 다양한 형태의 혼란이 있었습니다.
특히 다차원 레이트 리미팅에서는 어떤 차원이 걸렸는지를 명확히 전달하지 않으면 유저가 원인을 파악할 수 없습니다. "request count 때문인지, duration 때문인지, output token 때문인지"를 알아야 대응할 수 있기 때문입니다.
차원과 시간 윈도우를 명확하게 전달하도록 바꾸니 문의가 눈에 띄게 줄었습니다. 실제 응답 메시지는 다음과 같은 형식입니다.
괄호 안에 어떤 한도·시간 윈도우에 걸렸는지(60 Requests/1 minute)가, 끝에 언제 풀리는지(after ...)가 한 줄에 함께 담깁니다 — 차원이 다르면 단위도 그에 맞게 바뀝니다. 나아가 대시보드에서 레이트 리미팅 에러 로그를 직접 확인할 수 있는 기능도 추가했습니다.
5. 엔터프라이즈 커스텀 규칙의 운영 부담
"배포 없이 DB에 규칙 하나 추가하면 끝"이라고 설계했는데, 운영하다 보니 규칙 관리 자체가 부담이 되었습니다.
엔터프라이즈 고객이 늘어나면서 커스텀 규칙 추가/변경 요청이 지속적으로 발생하였습니다. "이 고객은 duration 한도를 5000시간/일로 올려주세요", "이 계정은 다음 주까지만 한시적으로 올려주세요" 같은 요청들입니다. 규칙 적용은 빠르지만, 누가 어떤 규칙을 쓰고 있는지 추적하고, 만료된 한시적 규칙을 정리하는 것은 수동으로 이루어졌습니다.
이 경험에서 배운 것은 두 가지입니다.
Field Engineering 팀이 고객의 레이트 리미팅 상태를 직접 확인할 수 있는 도구가 필요하다는 점 — 매번 엔지니어에게 문의하는 것은 스케일이 나지 않습니다.
자주 한도에 걸리는 고객을 선제적으로 알 수 있는 시스템이 필요하다는 점 — 고객이 불만을 제기하기 전에 먼저 알아야 합니다.
—————————————————————————————————
앞으로
레이트 리미팅은 한 번 만들고 끝나는 것이 아니라, 서비스가 성장하면서 같이 진화하는 시스템입니다. 양적으로도 질적으로도, 스케일이 증가하면 모든 것이 깨지기 시작합니다. 새로운 API가 추가되면 새로운 차원이 필요할 수 있고, 트래픽 패턴이 바뀌면 리필(refill) 전략도 조정이 필요합니다. 저희도 계속 배우고 고쳐나가는 중입니다.
돌아보면 레이트 리미팅은 고전적인 문제입니다. 하지만 요청 하나의 비용이 수백 배씩 차이 나는 영상 AI에서는, 익숙한 문제도 다시 풀어야 했습니다. 한정된 리소스를 가지고 공정성과 안정성을 어떻게 동시 충족시킬 수 있을 것인가. 저희가 매일 부딪혀 푸는 문제들은 이런 디테일까지 고려되어야 합니다.
이 글이 비슷한 문제를 고민하고 계신 분들에게 조금이라도 도움이 되었으면 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]
들어가며
API 레이트 리미팅(rate limiting)이라고 하면 보통 규모(scale)의 문제를 떠올립니다. 트래픽이 몰려도 분산 환경에서 카운터를 정확하고 빠르게 세는 것 — 어려움은 거기에 있다고들 하고, 실제로 많은 경우 그렇습니다.
저희도 처음엔 간단하게 접근했습니다. 초기 TwelveLabs API는 엔드포인트별로 "초당 N건, 시간당 M건" 같은 단순한 요청 수 제한만 두고 있었거든요.
그런데 영상 AI에서는 진짜 난제가 다른 곳에 숨어 있었습니다. 10초 길이의 숏폼 영상을 분석하는 요청과 2시간 길이의 영화를 분석하는 요청이 있다고 가정해 보겠습니다. 둘 다 시스템상으로는 '1건'의 요청이지만, 소비되는 컴퓨팅 자원은 수백 배 차이가 날 수도 있습니다. 즉, 단순히 요청의 개수만 세는 방식은 더 이상 공정하지 않았습니다.
측정 가능한 형태로 부하를 분산할 수 없다면, 자연스럽게 뒤에 있는 ML 서비스 역시 위험에 노출될 가능성이 생깁니다. 레이트 리밋의 진짜 목적은 한 사용자의 과도한 워크로드가 GPU 추론 같은 공유 자원을 잠식해, 다른 모든 사용자의 요청까지 느려지거나 실패하게 만드는 'Noisy Neighbor' 상황을 막는 것이었습니다. 실제로 한 고객의 워크로드가 폭주하면서 다운스트림 서비스를 과부하 시켜, 그 고객과 무관한 사용자들에게까지 장애가 번지는 아찔한 경험을 하기도 했습니다.
TwelveLabs API는 영상 인덱싱, 검색, 영상 정보 추출, 임베딩(embedding) 등 다양한 엔드포인트를 제공하며, 각각의 비용 구조가 전부 다릅니다. Search는 인덱스 스캔 비용이 주인 반면, Indexing/Embedding은 영상 길이에 따른 벡터 추출 비용이 지배적입니다. Analyze 엔드포인트는 모델이 뱉어내는 출력 토큰(output token) 수에 따라 다시 한번 비용이 비례하여 증가합니다.
하나의 잣대로 이 모든 것을 제한하는 건 무리가 있었습니다.
이 글에서는 저희가 이러한 문제를 해결하기 위해 '다차원 레이트 리미터'를 설계하고 구현하며 내린 결정들을 공유하려 합니다.
—————————————————————————————————
문제 정의
비용 비대칭
TwelveLabs API의 각 엔드포인트는 리소스를 소모하는 형태가 완전히 다릅니다.
Operation | 주요 비용 요소 |
|---|---|
Search | 요청 수 (request count) |
Indexing / Embedding | 요청 수 + 미디어 길이 (duration) |
Analyze | 요청 수 + 미디어 길이 + 출력 토큰 수 (output tokens) |
요청 수 제한만으로는 Heavy 유저의 리소스 독점을 막을 수 없었습니다. 유저 A가 숏폼 형태의 짧은 영상 100개를 인덱싱하고, 유저 B가 2시간짜리 영상 5개를 인덱싱한다고 해봅시다. 요청 수 기준으로는 A가 20배 더 많이 쓴 것이지만, 실제 리소스 소비는 B가 훨씬 클 수 있습니다.
엔터프라이즈 온보딩 속도
비즈니스가 성장하면서 전용 한도(Dedicated Limit)를 요구하는 엔터프라이즈 고객이 빠르게 늘어났습니다. 엔터프라이즈 고객이 온보딩하는 경우에는, 요청에 따라 전용 한도를 빠르게 적용해야 하는 경우가 많습니다. 운영을 더 쉽고 빠르게 하기 위해서는 코드 배포 없이 DB에 규칙을 하나 추가하는 것과 같은 간단한 방법이 필요했습니다.
결론적으로 저희에게 필요한 것은 요청 수(request count), 영상 길이(duration), 출력 토큰(output token)의 세 축을 동시에 제어할 수 있는 시스템이었습니다.
—————————————————————————————————
핵심 설계 결정들
1. 다차원 제한(Multi-dimensional rate limit): 차원(dimension)을 1급 개념으로
가장 먼저 정해야 했던 것은 "여러 종류의 비용을 어떤 방식으로 표현할 것인가"였습니다.
저희의 선택은 비용의 종류 자체를 1급 개념(first-class)으로 끌어올리는 것이었습니다. 서로 다른 비용 축을 각각 독립된 차원으로 정의하고, 이를 규칙 모델의 정식 필드로 새겨 넣었습니다.
const ( DimensionRequestCount Dimension = "request_count" DimensionDuration Dimension = "duration" DimensionOutputTokenCount Dimension = "output_token_count"
차원은 단순한 enum 값이 아니라 규칙(rule)의 정식 속성입니다. 규칙은 자신이 어떤 차원을 제한하는지를 알고 있고, 조회 키에도 이 차원 이름이 포함됩니다. 그래서 각 차원은 완전히 독립적으로 규칙을 가질 수 있습니다.
같은 차원에 여러 시간 윈도우가 공존할 수도 있습니다 — 예를 들어 요청 수에 "분당 60건"과 "일일 1,000건" 규칙이 동시에 적용되는 식입니다. 두 규칙 모두 통과해야 요청이 허용됩니다.
차원을 도입하면서 ‘무엇을 셀 것인가’를 하나의 일관된 모델로 정리했습니다. 기존에는 요청 횟수(request count) 하나만 셌다면, 이제는 요청 수·길이(초)·출력 토큰을 아우르는, 차원별로 ‘측정 가능한 숫자’라는 같은 형태가 된 셈입니다.
비용 축을 이러한 방식으로 분리하면 두 가지 장점을 얻을 수 있습니다. 첫째, 확장이 단순 더하기로 끝납니다. 입력 토근 수 같이 새로운 비용 축이 필요해지면, 기존 로직을 건드릴 필요 없이 새로운 차원을 하나 더 정의해 주기만 하면 됩니다. 둘째, 운영과 커뮤니케이션 측면 모두에서 직관적입니다. 특정 차단이 일어났을 때 어떤 축에서 제한이 발생했는지를 바로 파악할 수 있기 때문에, "분당 요청 수 초과"처럼 차단 사유가 사람이 쉽게 이해할 수 있는 형태로 표현됩니다.
2. 세션 기반 평가와 롤백 전략
차원을 분리하고 나니 또 다른 난관이 기다리고 있었습니다. 하나의 요청 안에서 각 차원의 비용이 확정되는 시점이 제각각 다르다는 점이었습니다.
'요청 수'는 요청이 들어오는 시점에 바로 알 수 있습니다. 항상 1이기 때문입니다. 하지만 '출력 토큰(output token) 수'는 실제 연산 작업이 끝나야만 비로소 알 수 있습니다. 영상 분석에 소요되는 시간(Duration)도 마찬가지로, 실제 영상을 분석하기 전까지는 정확한 소비량을 알 수 없습니다.
하나의 API 요청 안에서 여러 차원이 서로 다른 시점에 평가되는 구조이므로, 이것을 하나의 생명주기로 묶어야 일관된 롤백이 가능했습니다.
이를 해결하기 위해 저희는 요청마다 고유한 세션(session)을 열어서, 각 차원을 순차적으로 평가하고, 요청이 실패하면 소비한 할당량을 취소하는 구조를 만들었습니다.
세션 내부에서는 성공한 모든 평가 기록을 별도의 자료구조로 추적합니다. 취소가 필요해지면 이 세션에 기록된 목록을 역순으로 순회하면서 각각의 소비를 되돌립니다.
[요청 실패 시] 세션에 기록된 성공 평가를 역순 순회 └─ 각 디멘션의 소비량을 환불(refund) · 별도 goroutine · 비동기(non-blocking) · 원 요청 context와 무관하게 끝까지 실행
3. 규칙 우선순위와 실시간 반영
레이트 리미팅 규칙의 우선순위를 어떻게 결정할 것인가도 중요한 설계 포인트였습니다.
저희는 다차원 레이트 리미터의 도입과 함께 티어를 세분화하며 3단계 우선순위를 도입했습니다.
💡 잠깐, 여기서 티어(rate tier)란?
전용 한도를 받는 엔터프라이즈 고객을 제외하면, 대부분의 사용자는 '티어'(rate tier) 단위로 관리됩니다. 티어는 미리 정의된 한도 묶음으로, 저희 시스템에서는 Free Tier와 함께 Tier 1·2·3을 미리 구분해 두었습니다. 각 티어에 어떤 한도를 줄지는 가격·플랜 같은 비즈니스 결정에서 내려오고, 그 값들을 하나의 프리셋으로 정의하기 때문에, "이 사용자의 한도가 얼마인가"는 사실상 "이 사용자가 어느 티어인가"의 문제가 됩니다.
정리하면 한도는 두 층으로 정해집니다 — 기본은 티어, 엔터프라이즈 같은 예외는 그 위에 얹는 커스텀 규칙. 뒤에 나오는 다이어그램의 한도 값이나 "규칙 우선순위" 이야기는 모두 이 티어 구조를 전제로 합니다.
핵심 기능 중 하나는 "코드 배포 없이 즉시 적용"이 가능하다는 것입니다. 엔터프라이즈 고객이 온보딩되면 백오피스를 통해 owner-specific 규칙 하나만 추가하면 됩니다. 티어 기반 규칙도 마찬가지로, 유저가 플랜을 업그레이드하면 별도 배포 없이 새 티어의 규칙이 적용됩니다.
규칙은 인메모리 캐시(in-memory cache)에 인덱싱되어 있어 조회에 대한 시간복잡도는 O(1)입니다. 주기적으로 DB에서 갱신해 최신 상태를 유지합니다.
한 가지 더 말씀을 드리자면, 티어는 사용자의 직전 달 사용량에 따라 자동으로 변경됩니다. 그래서 규칙 조회는 "이 사용자가 지금 어느 티어인가"를 런타임에 반영해야 하고, 급격한 한도 감소로 인해 사용자가 예상치 못한 서비스 거부를 맞이하지 않게 유예 기간(grace period)을 둡니다.
그 외 설계 레이어들
- 소비량을 카운터로 (Consumed, not Remaining)
버킷의 카운터는 소비할 때마다 값을 깎는 게 아니라 쌓는 쪽으로 구현했습니다. 버킷에는 사용량(consumed)만 저장하고, 허용 여부는 읽는 시점에 consumed + amount ≤ limit로 판단합니다.
잔여량(remaining)을 저장해두고 깎아 나가는 방식과 결과는 같지만, 운영 관점에서는 전혀 다릅니다.
운영 중 한도 변경의 복잡성을 없앱니다.
limit은 저장된 값이 아니라 비교 시점에 적용되는 정책 값이라, 운영 중 한도를 변경할 필요성이 생겼을 때 (i.e, 100 → 200), 올리는 즉시 반영됩니다. 깎는 방식은 한도가 이미 각 키에 녹아 있어서, 한도를 바꾸는 순간 이미 누적된remaining을 어떻게 재계산할지가 문제가 됩니다.초기화가 단순합니다. 새 키는 0(= 키 없음)에서 시작하면 끝입니다. 깎는 방식은 키를 만들 때 한도 값으로 seed해야 하고, 그러려면 그 시점의 한도를 알아야 해서 결국 위 문제와 다시 엮입니다.
결국 한도는 규칙(데이터)에만 존재하고, 버킷은 소비량만 셉니다. 앞서 말한 “코드 배포 없이 한도를 즉시 바꾼다”가 가능한 것도 이 구조 덕분입니다.
- 첫 요청 시 초기화 (Lazy Initialization)
버킷 초기화 전략도 고민이었습니다. 모든 유저의 버킷을 미리 만들어 두는 것이 개념적으로 단순할 수 있지만, 저희는 **지연 초기화(lazy initialization)**를 선택했습니다.
버킷이 Redis에 아직 없으면 consumed=0으로 초기화한 뒤 첫 소비를 시도합니다.
이유는 단순합니다. 전체 키의 개수는 유저 수 × 차원 수 × 규칙 수로 계산됩니다. 즉, 서비스가 확장할수록 키가 폭발적으로 늘어나게 되는 구조입니다. 사전 할당은 Redis 메모리와 운영 복잡도 모두에서 비현실적이었습니다. 게다가 lazy init은 단순히 키 수를 줄이는 것을 넘어, 실제로 요청을 보내는 활성 사용자에 대해서만 키를 만듭니다. 또한 버킷마다 TTL을 걸어 일정 시간이 지나면 비활성 사용자의 메모리를 자동으로 회수할 수 있게끔 하였습니다.
- 장애 시 허용 정책 (Fail-Open)
규칙 조회 실패, Redis 장애, 전략 실행 에러 등 다양한 장애 상황에 대한 대비 정책도 필요했습니다. 저희는 모두 로그를 남기고 통과시키는 fail-open 정책을 선택했습니다.
res, err := s.rateLimiter.RunStrategy(ruleCtx, req, rl.Strategy) if err != nil { logger.Error(ctx, fmt.Errorf("ratelimit strategy failed: %w", err)) metrics.Incr("ratelimit.fail_open", tags...) continue // Fail-open on error
레이트 리미터는 방어 장치이지 핵심 비즈니스 로직이 아닙니다. 레이트 리미터가 죽어서 서비스 전체가 멈추는 건 더 나쁜 결과이기 때문입니다. 레이트 리미터가 단일 장애점으로 작동해서는 안됩니다.
물론 여기에도 위험은 존재합니다. 페일오픈 중에는 레이트 리미팅이 사실상 없는 상태이므로 남용 가능성이 있습니다. 다만 이 점은 모니터링과 알림(alerting)으로 보완하고 있습니다.
- 초과 허용 vs 즉시 거절
마지막으로, 한도를 초과하는 요청을 어떻게 처리할 것인지에 대한 고민이 필요했습니다.
저희는 차원에 따라 다른 정책을 적용합니다.
request_count: 즉시 거절(hard deny) — 초과 즉시 거절duration,output_token_count: 허용 후 잠금(allow-and-lock) — 약간의 초과를 허용하되, 그 초과분을 부채(debt)로 기록하고 상환 전까지 후속 요청을 차단
비용 예측이 가능한지 여부가 이 두 정책을 나누는 기준이 됩니다.
요청 수는 항상 한 개씩 증가합니다. 새 요청을 처리하기 전에 즉각적으로 요청의 차단 여부에 대한 판단이 가능합니다. 하지만 duration이나 출력 토큰은 요청의 처리 중, 혹은 처리가 끝난 이후에야 실제 소비량을 알 수 있습니다. 이 경우에는 필요한 경우 약간의 부채를 허용하도록 구성하였습니다.
부채 메커니즘은 이렇게 동작합니다.
단, 부채가 한도의 일정 비율을 초과하면 초과분도 거절합니다. 극단적인 남용을 방지하기 위한 안전장치입니다.
—————————————————————————————————
구현
전체 구조
API 서버는 무상태(stateless)입니다. 모든 버킷 상태는 Redis에 저장되기 때문에 API 인스턴스를 수평 확장해도 레이트 리미팅이 일관되게 동작합니다.
핵심 추상화
전략 인터페이스(Strategy interface): 레이트 리미팅 알고리즘의 추상화입니다. Run()으로 소비하고 Cancel()로 되돌립니다. 현재는 고정 버킷(fixed bucket)만 구현되어 있지만, 다른 알고리즘(슬라이딩 윈도우 등)도 이 인터페이스를 구현하면 교체할 수 있습니다.
type Strategy interface { Name() string Run(ctx context.Context, request Request) (Result, error) Cancel(ctx context.Context, request Request) (Result, error
세션(Session): 요청 생명주기를 관리합니다. Context에 주입되어 핸들러 어디서든 접근 가능하고, 성공한 모든 소비를 추적하다가 필요시 일괄 취소합니다.
규칙 집합(RuleSet): 인메모리 규칙 인덱스입니다. DB에서 주기적으로 갱신하고, RuleKey(TargetGroup + RuleGroup + Dimension) 기준으로 O(1) 조회를 제공합니다.
Lua 스크립트: 원자적 토큰 버킷
레이트 리미터에서 가장 까다로운 부분이 동시성입니다. 여러 API 인스턴스가 동시에 같은 버킷에 접근하기 때문입니다.
저희는 Redis Lua 스크립트로 해결했습니다. Lua 스크립트는 Redis 내부에서 단일 원자적 연산(atomic operation)으로 실행되기 때문에 경합 조건(race condition)이 없습니다.
핵심 흐름은 다음과 같습니다.
flowchart TD A([요청: amount]) --> Atomic subgraph Atomic["Redis"] direction TB B[경과 시간만큼 토큰 리필] --> C[리필분으로 debt 우선 상환<br/>남은 분으로 consumed 감소] C --> D{debt가 아직 남았나?} D -- 예: 직전 초과로 잠김 --> DENY[거절] D -- 아니오 --> E{consumed + amount ≤ limit?} E -- 예 --> ALLOW[허용] E -- 아니오 --> F{overshoot 허용?} F -- 예 --> LOCK[허용 후 잠금<br/>초과분을 debt로 기록] F -- 아니오 --> DENY end ALLOW --> R([상태 저장 · 결과 반환]) LOCK --> R DENY --> R
Redis MULTI/EXEC도 검토했지만, Lua가 조건 분기와 계산 로직을 하나의 원자적 연산 안에서 처리할 수 있어 훨씬 유연했습니다.
미들웨어 구성
세 가지 미들웨어가 역할을 나누어 동작합니다.
InjectRateLimitSessionMiddleware: 세션을 생성하고 request context에 주입합니다. 자체적으로는 아무 차원도 평가하지 않습니다. 핸들러가 끝난 뒤에 에러/4xx 여부를 확인해 취소를 결정하는 역할입니다.
RequestCountRateLimitMiddleware: request_count 차원만 선제 평가합니다. 세션이 있으면 세션을 통해, 없으면 자체적으로 규칙을 조회해서 처리합니다. 거절 시 429를 즉시 반환하고, 통과 시에는 실패 시 롤백할 수 있도록 헤더를 설정합니다.
RateLimitPrecheckMiddleware: 비용이 큰 차원(output_token_count 등)에 대한 사전 확인입니다. 특정 차원에 대해 모든 규칙이 debt 없는 상황인지 확인한 후 핸들러로 진행합니다. 이미 한도가 찬 상태에서 비싼 연산을 시작하는 것을 미리 막아주는 것입니다.
—————————————————————————————————
운영하면서 배운 것들
1. 레이트 리밋이 아니었던 것들
레이트 리미터를 운영하면서 가장 자주 마주친 혼란은, 정작 레이트 리밋 시스템이 아닌 것들이 레이트 리밋으로 오해받는다는 점이었습니다. TwelveLabs API에서 사용자의 요청을 막는 메커니즘은 세 가지가 있고, 그 셋의 구현은 전혀 다릅니다.
메커니즘 | 묻는 질문 | 시간 축 | 풀리는 조건 |
|---|---|---|---|
레이트 리밋(rate limit) | 단위 시간당 요청 량이 과다한가? | 있음 (분/시/일) | 시간 |
플랜 쿼터(plan quota) | 플랜이 허용하는 총량(예: 누적 인덱싱 영상 시간)을 넘었는가? | 없음 | 플랜 업그레이드 |
동시성 캡(concurrency cap) | 동시에 처리 중인 작업이 너무 많은가? | 없음 (in-flight) | 앞 작업이 끝나면 |
겉으로는 다 "막혔다"지만, 사용자가 취해야 할 행동이 정반대입니다. 이를 정확히 구분하지 않으면 두 가지 문제가 발생할 수 있습니다.
첫째, 부정확한 에러 코드는 클라이언트의 부적절한 다음 행동을 야기합니다. 한때는 쿼터 초과도 검증 에러와 똑같이 400으로 반환해서, 두 가지 경우를 구분할 수가 없게 만들었습니다. 그러면 429로 바꾸면 될까요? 아닙니다 — 대부분의 SDK는 429를 자동 재시도하는데, 쿼터는 기다려도 안 풀리므로 절대 성공하지 않을 요청을 무한 재시도하는 폭주가 생깁니다. 그래서 쿼터 초과는 429가 아니라 422(Unprocessable Content)로 분리했습니다.(RFC 9110 - 15.5.21) 요청 형식은 멀쩡하지만 지금은 처리할 수 없다는 뜻이고, 자동 재시도 대상도 아니며, 레이트 리밋 지표(SLO)도 오염시키지 않습니다. 429는 "기다리면 풀린다"는 약속입니다. 그 약속을 지킬 수 없는 상황에서 429를 쓸 수 없었습니다.
둘째, 원인 진단이 어긋납니다. 한 고객이 "요청이 멈춘다"고 했는데, 알고 보니 레이트 리밋도 쿼터도 아니고 사용자별 동시 인덱싱 캡이었습니다. 수천 개 작업을 한꺼번에 넣었으나 동시성 캡이 제한적으로 설정되어 있어서 대기열이 하루 가까이 길어진 것이었죠. 모든 작업은 결국 성공했지만 체감은 "막힘"이었습니다.
다차원 레이트 리미터를 만들면서 정작 더 중요했던 건, 레이트 리밋이 책임지는 범위를 가시성 있게 명확히 긋는 것이었습니다.
2. Fail-open은 조용히 작동하면 안 됩니다
솔직히 저는 Fail-open을 설계에 넣으면서 "이러면 최악의 경우에도 안전하다"고만 생각했습니다. 레이트 리미터가 죽어도 서비스는 사니까요.
그런데 부하 테스트에서 함정을 봤습니다. Redis 레이트 리밋 조회가 3초를 넘기고 타임아웃이 나면, 설계대로 체크를 건너뛰고 요청을 통과시킵니다. 무서운 건 이 "건너뜀"이 E2E 테스트에서는 에러로도 잘 드러나지 않는다는 점입니다. 페일오픈은 본질적으로 조용히 실패합니다. 명시적인 지표가 없으면 "그 시간 동안 레이트 리미팅이 사실상 꺼져 있었다"는 사실 자체를 알 수가 없습니다.
여기서 배운 것은 분명합니다. 페일오픈은 장애를 흡수하는 동시에 장애를 숨기는 정책이라는 것입니다. 통과시키는 선택 자체는 맞지만, 통과시키고 있다는 사실을 알려주지 않으면 그사이의 남용에 무방비가 됩니다.
3. 레이트 리미팅 헤더의 UX
"어떤 차원 기준으로 헤더를 내려줄 것인가" 역시 까다로운 문제였습니다.
초기에는 단일 차원 헤더만 내려줬는데, 다차원으로 확장하면서 여러 버그가 생겼습니다. 429로 거절되었는데 x-ratelimit-duration-remaining이 0이 아니라 "140"으로 표시되거나, 특정 엔드포인트에서 헤더가 아예 빠지거나, 커스텀 규칙이 헤더에 제대로 반영되지 않는 문제들이었습니다.
결국 저희는 가장 짧은 시간 윈도우의 규칙을 기준으로 기본 헤더를 내려주되, 모든 차원의 상태를 함께 내려주는 다차원 헤더를 추가했습니다. 사용자 입장에서 연속 요청 시 가장 먼저 마주하는 제약은 짧은 윈도우이기 때문입니다.
헤더는 "맞으면 아무도 모르고, 틀리면 바로 티 나는" 영역입니다. QA 과정에서 차원별, 엔드포인트별 헤더 값 검증을 체계적으로 하지 않으면 이상한 값이 프로덕션에 나갑니다.
4. Deny 메시지의 명확성
초기에는 429 응답에 "Too many requests"만 내려줬는데, 고객 문의가 쏟아졌습니다. "내가 뭘 초과한 건지 모르겠다", "embed video를 요청한 적이 없는데 429가 왔다", "에러 메시지가 이상하게 보인다" 등 다양한 형태의 혼란이 있었습니다.
특히 다차원 레이트 리미팅에서는 어떤 차원이 걸렸는지를 명확히 전달하지 않으면 유저가 원인을 파악할 수 없습니다. "request count 때문인지, duration 때문인지, output token 때문인지"를 알아야 대응할 수 있기 때문입니다.
차원과 시간 윈도우를 명확하게 전달하도록 바꾸니 문의가 눈에 띄게 줄었습니다. 실제 응답 메시지는 다음과 같은 형식입니다.
괄호 안에 어떤 한도·시간 윈도우에 걸렸는지(60 Requests/1 minute)가, 끝에 언제 풀리는지(after ...)가 한 줄에 함께 담깁니다 — 차원이 다르면 단위도 그에 맞게 바뀝니다. 나아가 대시보드에서 레이트 리미팅 에러 로그를 직접 확인할 수 있는 기능도 추가했습니다.
5. 엔터프라이즈 커스텀 규칙의 운영 부담
"배포 없이 DB에 규칙 하나 추가하면 끝"이라고 설계했는데, 운영하다 보니 규칙 관리 자체가 부담이 되었습니다.
엔터프라이즈 고객이 늘어나면서 커스텀 규칙 추가/변경 요청이 지속적으로 발생하였습니다. "이 고객은 duration 한도를 5000시간/일로 올려주세요", "이 계정은 다음 주까지만 한시적으로 올려주세요" 같은 요청들입니다. 규칙 적용은 빠르지만, 누가 어떤 규칙을 쓰고 있는지 추적하고, 만료된 한시적 규칙을 정리하는 것은 수동으로 이루어졌습니다.
이 경험에서 배운 것은 두 가지입니다.
Field Engineering 팀이 고객의 레이트 리미팅 상태를 직접 확인할 수 있는 도구가 필요하다는 점 — 매번 엔지니어에게 문의하는 것은 스케일이 나지 않습니다.
자주 한도에 걸리는 고객을 선제적으로 알 수 있는 시스템이 필요하다는 점 — 고객이 불만을 제기하기 전에 먼저 알아야 합니다.
—————————————————————————————————
앞으로
레이트 리미팅은 한 번 만들고 끝나는 것이 아니라, 서비스가 성장하면서 같이 진화하는 시스템입니다. 양적으로도 질적으로도, 스케일이 증가하면 모든 것이 깨지기 시작합니다. 새로운 API가 추가되면 새로운 차원이 필요할 수 있고, 트래픽 패턴이 바뀌면 리필(refill) 전략도 조정이 필요합니다. 저희도 계속 배우고 고쳐나가는 중입니다.
돌아보면 레이트 리미팅은 고전적인 문제입니다. 하지만 요청 하나의 비용이 수백 배씩 차이 나는 영상 AI에서는, 익숙한 문제도 다시 풀어야 했습니다. 한정된 리소스를 가지고 공정성과 안정성을 어떻게 동시 충족시킬 수 있을 것인가. 저희가 매일 부딪혀 푸는 문제들은 이런 디테일까지 고려되어야 합니다.
이 글이 비슷한 문제를 고민하고 계신 분들에게 조금이라도 도움이 되었으면 합니다.
팀과 여정을 함께할 분들을 찾고 있습니다 → [TwelveLabs Careers]
Related articles





Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved