" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Company
From Microservices Mesh to Streamlined Layers: Why We Rebuilt Our Internal Video Indexing System

Stu Stewart, Abraham Jo, SJ Kim, Paritosh Mohan
Twelve Labs rebuilt its video indexing platform from a microservices mesh into a layered system after Indexing 2.0 stopped scaling — not in raw compute, but in engineering throughput, deployment portability, and the ability for new contributors to reason about the system end to end.
Twelve Labs rebuilt its video indexing platform from a microservices mesh into a layered system after Indexing 2.0 stopped scaling — not in raw compute, but in engineering throughput, deployment portability, and the ability for new contributors to reason about the system end to end.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Feb 5, 2026
10 Minutes
Copy link to article
Introduction — Indexing is where video becomes usable
Video is a uniquely punishing input for production systems. It’s high bandwidth, long-lived, and multimodal—pixels, audio, speech, motion, and timing all matter. More importantly, the “unit of work” isn’t a single inference call. Indexing is an end-to-end transformation: take an opaque blob of video and turn it into structured representations that downstream systems can query reliably.
That boundary layer—indexing—is where video becomes usable.
As TwelveLabs grew, indexing moved from “the thing that runs in the background” to a core piece of infrastructure that every product surface depends on. Search and generation don’t just consume model outputs; they consume the indexing system’s guarantees: what gets processed, how consistently, how debuggably, and how deployably.
And that’s where we hit the breaking point.
Our earlier indexing platform (internally, “Indexing 2.0”) wasn’t failing in the obvious ways. It could process videos. It powered real workloads. But its architecture carried assumptions that became limiting as our team and deployment needs expanded: coordination costs rose, infrastructure coupling hardened, and the system became harder for new engineers to reason about end-to-end.
Indexing 3.0 is our response—but it’s not a “version upgrade” in the product sense. It’s an architectural reframe: from a microservices mesh that implicitly depended on a specific operating environment, to a layered system designed to scale engineering throughput and run across multiple deployment shapes.
In this post, we’ll walk through the thinking behind Indexing 3.0: what stopped scaling in the previous approach, what actually drove the rebuild, and how the “mesh → layers” model became the organizing idea for everything that followed.
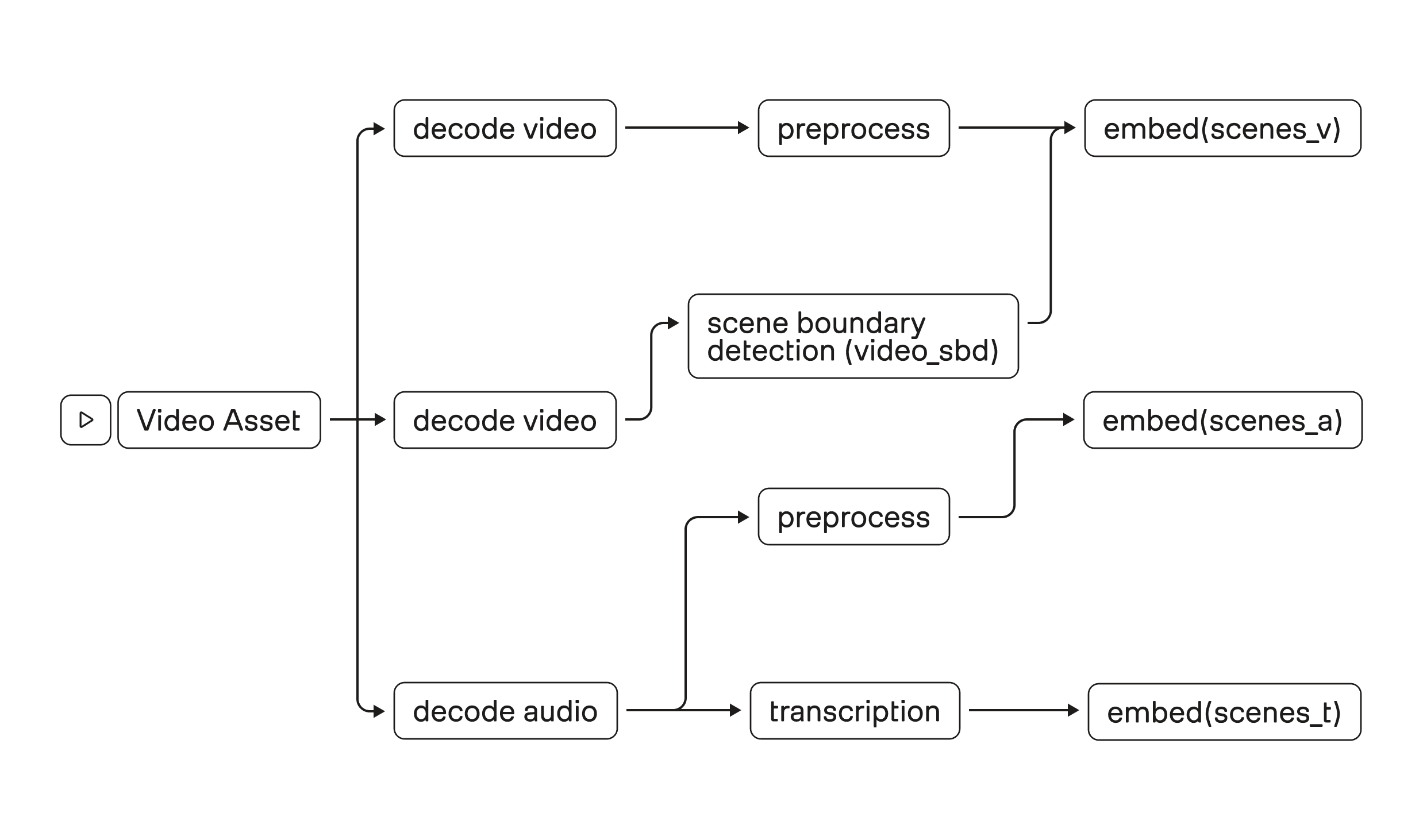
Figure 1. High-level embedding flow: decode video/audio, detect scene boundaries, then embed visual, audio, and transcript segments.
1 - The real breaking point: why our earlier indexing system stopped scaling
Before Indexing 3.0, TwelveLabs operated an earlier generation of our video indexing platform—what we’ll refer to here simply as Indexing 2.0. Like many early-stage production ML platforms, it was designed to solve a very real problem at the time: reliably transforming raw video into usable representations at scale.
And by that definition, it worked.
It powered real workloads, supported multiple model capabilities, and enabled core product surfaces. But as the company grew, a different kind of pressure surfaced—one that had less to do with model quality and more to do with how the system behaved operationally and how it scaled as an organization.
A useful way to see why is to look at what indexing actually has to do end-to-end. It’s a coordinated flow that turns a video asset into cached representations that downstream systems (search and text generation) can use repeatedly.
1.1 - When microservices stop feeling modular
Over time, the Indexing 2.0 platform evolved into a distributed collection of services, each responsible for a specific part of the indexing process. On paper, that decomposition looked clean and modular. In practice, it introduced a form of complexity that compounded with every change.
A small feature update often required touching multiple services. Releases had to be coordinated. Debugging required reconstructing behavior across boundaries instead of reasoning about a single flow. What initially felt flexible slowly became rigid—not because any one service was poorly designed, but because the system as a whole had too many moving parts.
One additional multiplier here was runtime and language boundaries. Some components written in Golang naturally lived closer to production plumbing, while others written in Python lived closer to ML workflows—and the interface between them wasn’t always clean. Crossing that boundary repeatedly (data formats, error propagation, tracing/observability, retries, deployment artifacts) made the “distributed modularity” feel less like separation of concerns and more like separation of context.
At a certain point, the cost of coordination overtook the benefits of decomposition.
1.2 - Infrastructure and scaling assumptions become visible in the worst case scenario
A deeper issue emerged as the system matured: application behavior became coupled to infrastructure behavior.
One example was a scaling pattern that is extremely flexible but can become operationally expensive: spinning up resources per video. That design can be a reasonable default when workloads skew toward longer jobs and when isolation is valuable. Each video becomes a self-contained unit of scheduling and execution.
But the workload reality changes as products mature.
When workloads include a high proportion of very short videos, per-video orchestration overhead starts to dominate:
scheduling and startup costs become a larger fraction of end-to-end time,
scaling down cleanly becomes harder (resource churn and minimum footprints),
and you can end up paying “setup tax” repeatedly for work that finishes quickly.
In other words, a pattern optimized for flexibility at the unit-of-video granularity can behave poorly when the unit of work gets small. This isn’t a “bug,” it’s a mismatch between execution granularity and workload distribution—and it’s exactly the kind of mismatch that only reveals itself after a system hits real product scale.
1.3 - The human scalability ceiling
Perhaps the most telling signal was not an outage or a performance regression, but a people problem.
As the team grew, fewer engineers were able to comfortably reason about the full indexing flow. Understanding how a change propagated through the system required deep, accumulated context. Onboarding became slower. Contributions clustered around a small set of specialists.
Indexing 2.0 had reached a point where it could scale compute, but not contributors. That’s the inflection point we associate with “stopped scaling”: the system continues to run, but it becomes increasingly hard to evolve—especially when product requirements shift (deployment environments diversify, workloads change shape, new model capabilities arrive).
For our ML Infrastructure team at TwelveLabs, this was the moment we realized that incremental improvements would no longer be enough. To move forward, we needed to rethink indexing not as a collection of services, but as a coherent, portable system that could scale teams, deployments, and future capabilities together.
That realization set the stage for Indexing 3.0.
2 - What actually drove Indexing 3.0
Once we accepted that the bottleneck was organizational and operational—not just computational—we had to get precise about what we were optimizing for next.
Indexing 3.0 is our name for the architectural response. It isn’t a “version upgrade” in the product sense. It’s a deliberate rebuild designed around new constraints: more teams shipping in parallel, more deployment environments, and workload shapes (like short video) that stress different parts of the system.
Three drivers emerged clearly—and in a different priority order than we initially expected.
2.1 - Scaling engineering throughput, not just compute
The primary driver behind Indexing 3.0 was maintainability, but not in the abstract sense of “clean code.”
What mattered was engineering throughput: how many people could make changes confidently, how quickly new contributors could form a mental model of the system, and how safely teams could work in parallel without stepping on each other.
This is where the earlier polyglot / multi-service shape mattered. Even when each component was individually understandable, the interfaces were where complexity accumulated: data contracts, serialization, failure semantics, tracing, deployment packaging. Indexing 3.0 explicitly treats reducing those boundaries as a first-class lever for velocity.
2.2 - Packaging and deployment became first-order constraints
A second, business-critical driver followed closely behind: deployment flexibility.
As TwelveLabs expanded into new environments, it became clear that assumptions baked into the earlier system no longer held. Some environments offered full orchestration platforms. Others allowed only minimal container execution. Treating these as edge cases would have limited where the product could realistically ship.
This forced a shift in perspective:
Instead of “how do we deploy this system?”, we asked: what does the system assume about where it runs?
Indexing 3.0 is designed so deployment shape becomes a variable, not a defining feature of the architecture.
This matters because indexing isn’t a standalone service—it’s the substrate beneath multiple downstream products. Since we offer two video foundation models (Marengo and Pegasus) with different capabilities, the same indexed representations can power retrieval-style workloads (search) and reasoning-style workloads (analysis). Portability expands what products can exist and where they can ship.
2.3 - Cost as a structural outcome, not a tuning exercise
Cost was an important consideration, but notably, it was not the starting point.
In earlier iterations, cost optimizations had largely taken the form of incremental tuning—adjusting resource usage, tweaking configurations, or reacting to specific bottlenecks. Indexing 3.0 took a different approach.
The team recognized that many cost issues were symptoms of deeper structural choices: too many always-on components, inefficient coordination between stages, and architectures that made it difficult to right-size resources independently.
Rather than chasing isolated savings, Indexing 3.0 aimed to create an architecture where efficiency emerged naturally from simpler execution paths, clearer scaling boundaries, and more flexible deployment models.
2.4 - A change in what “success” meant
Taken together, these drivers led to a subtle but important shift in how success was defined.
Indexing 3.0 would not be judged primarily by raw performance numbers or by how novel the architecture looked on paper. It would be judged by whether it enabled:
Faster onboarding and safer contributions,
Parallel development without constant coordination,
Consistent behavior across environments,
The ability to evolve without repeated rewrites.
In the next section, we’ll look at how this shift in priorities led to a fundamentally different way of thinking about the indexing architecture itself.
3 - The architectural reframe: from “microservices mesh” to “streamlined layers”
Once the drivers behind Indexing 3.0 were clear, the next step was to confront a harder truth: the existing architecture was optimized for a different set of assumptions than the ones the business now faced.
What needed to change was not a single component, but the shape of the system itself.
3.1 - The problem with the “microservices mesh”
The earlier indexing platform followed a pattern that will be familiar to many teams: break the system into many small services, connect them through orchestration and routing layers, and let the infrastructure manage execution.
Over time, this created what we now think of as a microservices mesh.
work flows sideways as much as forward,
coordination logic spreads across services and control-plane interactions,
and understanding “what happens to a request” requires global context.
This approach has advantages early on. It allows teams to move independently and scale components in isolation. But as the indexing system grows—and especially as workloads become more heterogeneous—those advantages erode.
Even at a high level, indexing involves decoding, segmentation, embedding, and persistence steps that must compose correctly. When each step is its own service boundary, the system becomes harder to debug, harder to package, and harder to evolve.
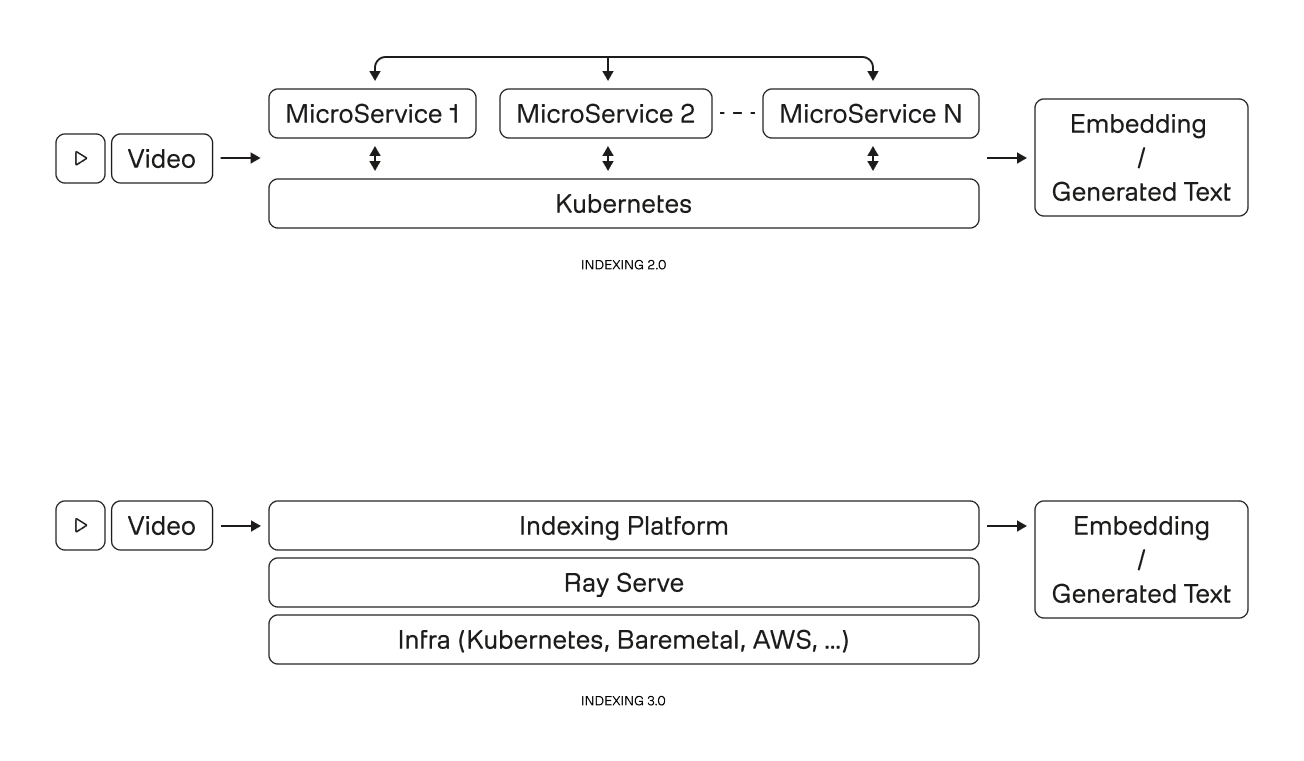
Figure 2. Indexing architecture shift: from a Kubernetes-coupled microservices mesh (2.0) to a layered platform with a unified execution layer (3.0).
3.2 - A different question: what should be layered, and what should not?
Indexing 3.0 began with a different framing.
Instead of asking how to decompose the system into smaller services, we asked:
Which responsibilities actually need to be distributed, and which need to stay conceptually unified?
That led to a layered mental model, illustrated in the “mesh vs layers” diagram above:
At the top sits the indexing platform itself—the logic that understands how video should be processed, how work is sequenced, and what constitutes a completed result.
In the middle is a unifying execution and orchestration layer (Ray Serve in our case) - responsible for scaling, scheduling, and fault handling without leaking infrastructure details upward.
At the bottom is the infrastructure layer—the compute substrate (Kubernetes, Baremetal, AWS, etc.)—which is treated as interchangeable rather than defining.
The shift is not “fewer boxes.” It’s clean directionality: work flows down through layers; infrastructure concerns don’t leak upward.
3.3 - Make it concrete: the indexing 3.0 data flow
Why is a layered architecture fits the shape of the indexing works?
The diagram below shows indexing as three reusable primitives that power the product surfaces people actually interact with:
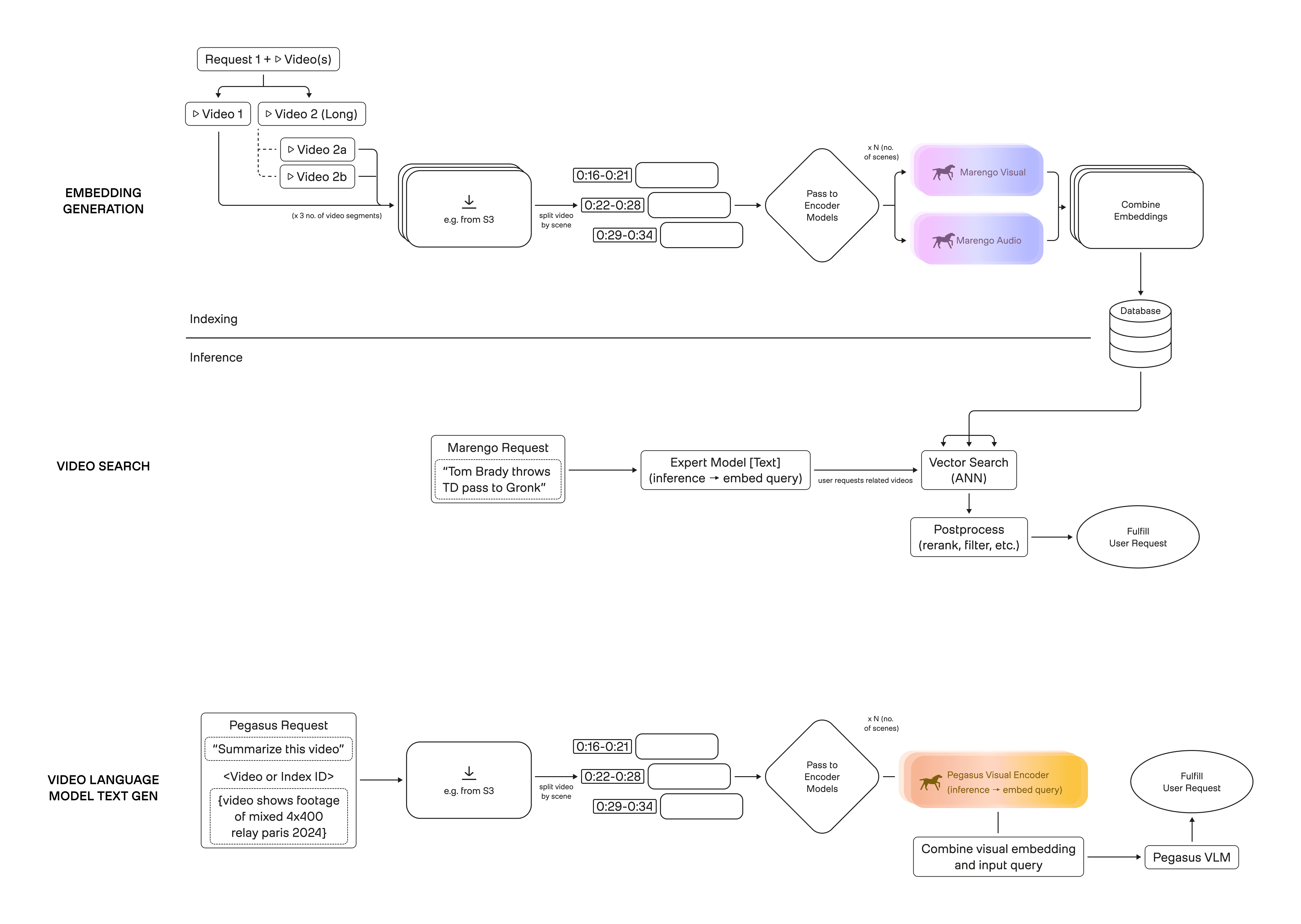
Figure 3. Three primitives powered by the same index: embedding generation → storage, text-to-video search via vector retrieval, and video-language generation via cached embeddings.
(1) Embedding generation (turn video into reusable representations)
At a high level, indexing starts by taking one request with one or more videos and turning each video into embeddings that can be reused across many downstream calls.
Conceptually, the flow is:
Video(s) → download
Split into logical segments (e.g., scenes; the point is “time becomes addressable”)
Pass segments to encoder models
Produce multimodal embeddings (e.g., visual + audio)
Combine + persist embeddings (and minimal metadata) into a database
This is the core “video → index” transformation. Everything else in the system is downstream reuse of these cached representations.
(2) Video search (turn a text query into retrieval over the index)
Search becomes straightforward once the index exists:
Text query → embed the query (in the same representation space as the video embeddings)
Vector search over stored embeddings to retrieve candidate matches
Post-process results (rerank, filter, apply simple constraints)
Return relevant clips/moments
The important point here is architectural: search is not “video processing” every time. It is retrieval over precomputed representations, plus lightweight post-processing.
(3) Video-language generation (reuse embeddings as context for a VLM)
Generation follows a similar reuse pattern, but routes the retrieved/cached representations into a decoder:
Request (prompt + video or index reference)
If embeddings exist, reuse them; otherwise, run the same embedding generation flow
Combine visual embeddings + the user’s input
Decode to text (video-language model)
Return the response
The key takeaway is that indexing is the shared substrate. Embedding generation produces reusable “addresses” into video. Search consumes those addresses via retrieval. Generation consumes them as context for reasoning.
That’s why the layered architecture matters. If you treat indexing as a collection of microservices stitched together by infrastructure, you pay coordination costs repeatedly across all three product paths. If you treat it as a coherent application flow running atop an execution layer and a swappable infrastructure substrate, you can evolve the shared substrate once—and every downstream surface benefits.
3.4 - Why layering changed everything
This reframe had several compounding effects.
First, it restored local reasoning. Engineers could understand and modify indexing behavior by looking at one place, rather than reconstructing intent from interactions across services.
Second, it made deployment a property of the bottom layer—not a constraint on the entire system. Swapping infrastructure no longer implied rewriting application logic.
Third, it aligned the architecture with how video workloads actually behave. Indexing is not a set of loosely related requests—it is a coordinated, end-to-end transformation. Treating it as such reduced the accidental complexity introduced by over-decomposition.
Most importantly, this shift changed what it meant to “scale” the system. Scaling no longer meant adding more services or more orchestration logic. It meant scaling the clarity of the system itself—so more people, more environments, and more future capabilities could be supported without compounding fragility.
In Part 2, we’ll dive into the design choices that made this layered model real in practice: consolidation, packaging, the trade-offs of a unifying execution layer, migration strategy, and supporting multiple deployment environments without fragmentation.
Introduction — Indexing is where video becomes usable
Video is a uniquely punishing input for production systems. It’s high bandwidth, long-lived, and multimodal—pixels, audio, speech, motion, and timing all matter. More importantly, the “unit of work” isn’t a single inference call. Indexing is an end-to-end transformation: take an opaque blob of video and turn it into structured representations that downstream systems can query reliably.
That boundary layer—indexing—is where video becomes usable.
As TwelveLabs grew, indexing moved from “the thing that runs in the background” to a core piece of infrastructure that every product surface depends on. Search and generation don’t just consume model outputs; they consume the indexing system’s guarantees: what gets processed, how consistently, how debuggably, and how deployably.
And that’s where we hit the breaking point.
Our earlier indexing platform (internally, “Indexing 2.0”) wasn’t failing in the obvious ways. It could process videos. It powered real workloads. But its architecture carried assumptions that became limiting as our team and deployment needs expanded: coordination costs rose, infrastructure coupling hardened, and the system became harder for new engineers to reason about end-to-end.
Indexing 3.0 is our response—but it’s not a “version upgrade” in the product sense. It’s an architectural reframe: from a microservices mesh that implicitly depended on a specific operating environment, to a layered system designed to scale engineering throughput and run across multiple deployment shapes.
In this post, we’ll walk through the thinking behind Indexing 3.0: what stopped scaling in the previous approach, what actually drove the rebuild, and how the “mesh → layers” model became the organizing idea for everything that followed.
Figure 1. High-level embedding flow: decode video/audio, detect scene boundaries, then embed visual, audio, and transcript segments.
1 - The real breaking point: why our earlier indexing system stopped scaling
Before Indexing 3.0, TwelveLabs operated an earlier generation of our video indexing platform—what we’ll refer to here simply as Indexing 2.0. Like many early-stage production ML platforms, it was designed to solve a very real problem at the time: reliably transforming raw video into usable representations at scale.
And by that definition, it worked.
It powered real workloads, supported multiple model capabilities, and enabled core product surfaces. But as the company grew, a different kind of pressure surfaced—one that had less to do with model quality and more to do with how the system behaved operationally and how it scaled as an organization.
A useful way to see why is to look at what indexing actually has to do end-to-end. It’s a coordinated flow that turns a video asset into cached representations that downstream systems (search and text generation) can use repeatedly.
1.1 - When microservices stop feeling modular
Over time, the Indexing 2.0 platform evolved into a distributed collection of services, each responsible for a specific part of the indexing process. On paper, that decomposition looked clean and modular. In practice, it introduced a form of complexity that compounded with every change.
A small feature update often required touching multiple services. Releases had to be coordinated. Debugging required reconstructing behavior across boundaries instead of reasoning about a single flow. What initially felt flexible slowly became rigid—not because any one service was poorly designed, but because the system as a whole had too many moving parts.
One additional multiplier here was runtime and language boundaries. Some components written in Golang naturally lived closer to production plumbing, while others written in Python lived closer to ML workflows—and the interface between them wasn’t always clean. Crossing that boundary repeatedly (data formats, error propagation, tracing/observability, retries, deployment artifacts) made the “distributed modularity” feel less like separation of concerns and more like separation of context.
At a certain point, the cost of coordination overtook the benefits of decomposition.
1.2 - Infrastructure and scaling assumptions become visible in the worst case scenario
A deeper issue emerged as the system matured: application behavior became coupled to infrastructure behavior.
One example was a scaling pattern that is extremely flexible but can become operationally expensive: spinning up resources per video. That design can be a reasonable default when workloads skew toward longer jobs and when isolation is valuable. Each video becomes a self-contained unit of scheduling and execution.
But the workload reality changes as products mature.
When workloads include a high proportion of very short videos, per-video orchestration overhead starts to dominate:
scheduling and startup costs become a larger fraction of end-to-end time,
scaling down cleanly becomes harder (resource churn and minimum footprints),
and you can end up paying “setup tax” repeatedly for work that finishes quickly.
In other words, a pattern optimized for flexibility at the unit-of-video granularity can behave poorly when the unit of work gets small. This isn’t a “bug,” it’s a mismatch between execution granularity and workload distribution—and it’s exactly the kind of mismatch that only reveals itself after a system hits real product scale.
1.3 - The human scalability ceiling
Perhaps the most telling signal was not an outage or a performance regression, but a people problem.
As the team grew, fewer engineers were able to comfortably reason about the full indexing flow. Understanding how a change propagated through the system required deep, accumulated context. Onboarding became slower. Contributions clustered around a small set of specialists.
Indexing 2.0 had reached a point where it could scale compute, but not contributors. That’s the inflection point we associate with “stopped scaling”: the system continues to run, but it becomes increasingly hard to evolve—especially when product requirements shift (deployment environments diversify, workloads change shape, new model capabilities arrive).
For our ML Infrastructure team at TwelveLabs, this was the moment we realized that incremental improvements would no longer be enough. To move forward, we needed to rethink indexing not as a collection of services, but as a coherent, portable system that could scale teams, deployments, and future capabilities together.
That realization set the stage for Indexing 3.0.
2 - What actually drove Indexing 3.0
Once we accepted that the bottleneck was organizational and operational—not just computational—we had to get precise about what we were optimizing for next.
Indexing 3.0 is our name for the architectural response. It isn’t a “version upgrade” in the product sense. It’s a deliberate rebuild designed around new constraints: more teams shipping in parallel, more deployment environments, and workload shapes (like short video) that stress different parts of the system.
Three drivers emerged clearly—and in a different priority order than we initially expected.
2.1 - Scaling engineering throughput, not just compute
The primary driver behind Indexing 3.0 was maintainability, but not in the abstract sense of “clean code.”
What mattered was engineering throughput: how many people could make changes confidently, how quickly new contributors could form a mental model of the system, and how safely teams could work in parallel without stepping on each other.
This is where the earlier polyglot / multi-service shape mattered. Even when each component was individually understandable, the interfaces were where complexity accumulated: data contracts, serialization, failure semantics, tracing, deployment packaging. Indexing 3.0 explicitly treats reducing those boundaries as a first-class lever for velocity.
2.2 - Packaging and deployment became first-order constraints
A second, business-critical driver followed closely behind: deployment flexibility.
As TwelveLabs expanded into new environments, it became clear that assumptions baked into the earlier system no longer held. Some environments offered full orchestration platforms. Others allowed only minimal container execution. Treating these as edge cases would have limited where the product could realistically ship.
This forced a shift in perspective:
Instead of “how do we deploy this system?”, we asked: what does the system assume about where it runs?
Indexing 3.0 is designed so deployment shape becomes a variable, not a defining feature of the architecture.
This matters because indexing isn’t a standalone service—it’s the substrate beneath multiple downstream products. Since we offer two video foundation models (Marengo and Pegasus) with different capabilities, the same indexed representations can power retrieval-style workloads (search) and reasoning-style workloads (analysis). Portability expands what products can exist and where they can ship.
2.3 - Cost as a structural outcome, not a tuning exercise
Cost was an important consideration, but notably, it was not the starting point.
In earlier iterations, cost optimizations had largely taken the form of incremental tuning—adjusting resource usage, tweaking configurations, or reacting to specific bottlenecks. Indexing 3.0 took a different approach.
The team recognized that many cost issues were symptoms of deeper structural choices: too many always-on components, inefficient coordination between stages, and architectures that made it difficult to right-size resources independently.
Rather than chasing isolated savings, Indexing 3.0 aimed to create an architecture where efficiency emerged naturally from simpler execution paths, clearer scaling boundaries, and more flexible deployment models.
2.4 - A change in what “success” meant
Taken together, these drivers led to a subtle but important shift in how success was defined.
Indexing 3.0 would not be judged primarily by raw performance numbers or by how novel the architecture looked on paper. It would be judged by whether it enabled:
Faster onboarding and safer contributions,
Parallel development without constant coordination,
Consistent behavior across environments,
The ability to evolve without repeated rewrites.
In the next section, we’ll look at how this shift in priorities led to a fundamentally different way of thinking about the indexing architecture itself.
3 - The architectural reframe: from “microservices mesh” to “streamlined layers”
Once the drivers behind Indexing 3.0 were clear, the next step was to confront a harder truth: the existing architecture was optimized for a different set of assumptions than the ones the business now faced.
What needed to change was not a single component, but the shape of the system itself.
3.1 - The problem with the “microservices mesh”
The earlier indexing platform followed a pattern that will be familiar to many teams: break the system into many small services, connect them through orchestration and routing layers, and let the infrastructure manage execution.
Over time, this created what we now think of as a microservices mesh.
work flows sideways as much as forward,
coordination logic spreads across services and control-plane interactions,
and understanding “what happens to a request” requires global context.
This approach has advantages early on. It allows teams to move independently and scale components in isolation. But as the indexing system grows—and especially as workloads become more heterogeneous—those advantages erode.
Even at a high level, indexing involves decoding, segmentation, embedding, and persistence steps that must compose correctly. When each step is its own service boundary, the system becomes harder to debug, harder to package, and harder to evolve.
Figure 2. Indexing architecture shift: from a Kubernetes-coupled microservices mesh (2.0) to a layered platform with a unified execution layer (3.0).
3.2 - A different question: what should be layered, and what should not?
Indexing 3.0 began with a different framing.
Instead of asking how to decompose the system into smaller services, we asked:
Which responsibilities actually need to be distributed, and which need to stay conceptually unified?
That led to a layered mental model, illustrated in the “mesh vs layers” diagram above:
At the top sits the indexing platform itself—the logic that understands how video should be processed, how work is sequenced, and what constitutes a completed result.
In the middle is a unifying execution and orchestration layer (Ray Serve in our case) - responsible for scaling, scheduling, and fault handling without leaking infrastructure details upward.
At the bottom is the infrastructure layer—the compute substrate (Kubernetes, Baremetal, AWS, etc.)—which is treated as interchangeable rather than defining.
The shift is not “fewer boxes.” It’s clean directionality: work flows down through layers; infrastructure concerns don’t leak upward.
3.3 - Make it concrete: the indexing 3.0 data flow
Why is a layered architecture fits the shape of the indexing works?
The diagram below shows indexing as three reusable primitives that power the product surfaces people actually interact with:
Figure 3. Three primitives powered by the same index: embedding generation → storage, text-to-video search via vector retrieval, and video-language generation via cached embeddings.
(1) Embedding generation (turn video into reusable representations)
At a high level, indexing starts by taking one request with one or more videos and turning each video into embeddings that can be reused across many downstream calls.
Conceptually, the flow is:
Video(s) → download
Split into logical segments (e.g., scenes; the point is “time becomes addressable”)
Pass segments to encoder models
Produce multimodal embeddings (e.g., visual + audio)
Combine + persist embeddings (and minimal metadata) into a database
This is the core “video → index” transformation. Everything else in the system is downstream reuse of these cached representations.
(2) Video search (turn a text query into retrieval over the index)
Search becomes straightforward once the index exists:
Text query → embed the query (in the same representation space as the video embeddings)
Vector search over stored embeddings to retrieve candidate matches
Post-process results (rerank, filter, apply simple constraints)
Return relevant clips/moments
The important point here is architectural: search is not “video processing” every time. It is retrieval over precomputed representations, plus lightweight post-processing.
(3) Video-language generation (reuse embeddings as context for a VLM)
Generation follows a similar reuse pattern, but routes the retrieved/cached representations into a decoder:
Request (prompt + video or index reference)
If embeddings exist, reuse them; otherwise, run the same embedding generation flow
Combine visual embeddings + the user’s input
Decode to text (video-language model)
Return the response
The key takeaway is that indexing is the shared substrate. Embedding generation produces reusable “addresses” into video. Search consumes those addresses via retrieval. Generation consumes them as context for reasoning.
That’s why the layered architecture matters. If you treat indexing as a collection of microservices stitched together by infrastructure, you pay coordination costs repeatedly across all three product paths. If you treat it as a coherent application flow running atop an execution layer and a swappable infrastructure substrate, you can evolve the shared substrate once—and every downstream surface benefits.
3.4 - Why layering changed everything
This reframe had several compounding effects.
First, it restored local reasoning. Engineers could understand and modify indexing behavior by looking at one place, rather than reconstructing intent from interactions across services.
Second, it made deployment a property of the bottom layer—not a constraint on the entire system. Swapping infrastructure no longer implied rewriting application logic.
Third, it aligned the architecture with how video workloads actually behave. Indexing is not a set of loosely related requests—it is a coordinated, end-to-end transformation. Treating it as such reduced the accidental complexity introduced by over-decomposition.
Most importantly, this shift changed what it meant to “scale” the system. Scaling no longer meant adding more services or more orchestration logic. It meant scaling the clarity of the system itself—so more people, more environments, and more future capabilities could be supported without compounding fragility.
In Part 2, we’ll dive into the design choices that made this layered model real in practice: consolidation, packaging, the trade-offs of a unifying execution layer, migration strategy, and supporting multiple deployment environments without fragmentation.
Introduction — Indexing is where video becomes usable
Video is a uniquely punishing input for production systems. It’s high bandwidth, long-lived, and multimodal—pixels, audio, speech, motion, and timing all matter. More importantly, the “unit of work” isn’t a single inference call. Indexing is an end-to-end transformation: take an opaque blob of video and turn it into structured representations that downstream systems can query reliably.
That boundary layer—indexing—is where video becomes usable.
As TwelveLabs grew, indexing moved from “the thing that runs in the background” to a core piece of infrastructure that every product surface depends on. Search and generation don’t just consume model outputs; they consume the indexing system’s guarantees: what gets processed, how consistently, how debuggably, and how deployably.
And that’s where we hit the breaking point.
Our earlier indexing platform (internally, “Indexing 2.0”) wasn’t failing in the obvious ways. It could process videos. It powered real workloads. But its architecture carried assumptions that became limiting as our team and deployment needs expanded: coordination costs rose, infrastructure coupling hardened, and the system became harder for new engineers to reason about end-to-end.
Indexing 3.0 is our response—but it’s not a “version upgrade” in the product sense. It’s an architectural reframe: from a microservices mesh that implicitly depended on a specific operating environment, to a layered system designed to scale engineering throughput and run across multiple deployment shapes.
In this post, we’ll walk through the thinking behind Indexing 3.0: what stopped scaling in the previous approach, what actually drove the rebuild, and how the “mesh → layers” model became the organizing idea for everything that followed.
Figure 1. High-level embedding flow: decode video/audio, detect scene boundaries, then embed visual, audio, and transcript segments.
1 - The real breaking point: why our earlier indexing system stopped scaling
Before Indexing 3.0, TwelveLabs operated an earlier generation of our video indexing platform—what we’ll refer to here simply as Indexing 2.0. Like many early-stage production ML platforms, it was designed to solve a very real problem at the time: reliably transforming raw video into usable representations at scale.
And by that definition, it worked.
It powered real workloads, supported multiple model capabilities, and enabled core product surfaces. But as the company grew, a different kind of pressure surfaced—one that had less to do with model quality and more to do with how the system behaved operationally and how it scaled as an organization.
A useful way to see why is to look at what indexing actually has to do end-to-end. It’s a coordinated flow that turns a video asset into cached representations that downstream systems (search and text generation) can use repeatedly.
1.1 - When microservices stop feeling modular
Over time, the Indexing 2.0 platform evolved into a distributed collection of services, each responsible for a specific part of the indexing process. On paper, that decomposition looked clean and modular. In practice, it introduced a form of complexity that compounded with every change.
A small feature update often required touching multiple services. Releases had to be coordinated. Debugging required reconstructing behavior across boundaries instead of reasoning about a single flow. What initially felt flexible slowly became rigid—not because any one service was poorly designed, but because the system as a whole had too many moving parts.
One additional multiplier here was runtime and language boundaries. Some components written in Golang naturally lived closer to production plumbing, while others written in Python lived closer to ML workflows—and the interface between them wasn’t always clean. Crossing that boundary repeatedly (data formats, error propagation, tracing/observability, retries, deployment artifacts) made the “distributed modularity” feel less like separation of concerns and more like separation of context.
At a certain point, the cost of coordination overtook the benefits of decomposition.
1.2 - Infrastructure and scaling assumptions become visible in the worst case scenario
A deeper issue emerged as the system matured: application behavior became coupled to infrastructure behavior.
One example was a scaling pattern that is extremely flexible but can become operationally expensive: spinning up resources per video. That design can be a reasonable default when workloads skew toward longer jobs and when isolation is valuable. Each video becomes a self-contained unit of scheduling and execution.
But the workload reality changes as products mature.
When workloads include a high proportion of very short videos, per-video orchestration overhead starts to dominate:
scheduling and startup costs become a larger fraction of end-to-end time,
scaling down cleanly becomes harder (resource churn and minimum footprints),
and you can end up paying “setup tax” repeatedly for work that finishes quickly.
In other words, a pattern optimized for flexibility at the unit-of-video granularity can behave poorly when the unit of work gets small. This isn’t a “bug,” it’s a mismatch between execution granularity and workload distribution—and it’s exactly the kind of mismatch that only reveals itself after a system hits real product scale.
1.3 - The human scalability ceiling
Perhaps the most telling signal was not an outage or a performance regression, but a people problem.
As the team grew, fewer engineers were able to comfortably reason about the full indexing flow. Understanding how a change propagated through the system required deep, accumulated context. Onboarding became slower. Contributions clustered around a small set of specialists.
Indexing 2.0 had reached a point where it could scale compute, but not contributors. That’s the inflection point we associate with “stopped scaling”: the system continues to run, but it becomes increasingly hard to evolve—especially when product requirements shift (deployment environments diversify, workloads change shape, new model capabilities arrive).
For our ML Infrastructure team at TwelveLabs, this was the moment we realized that incremental improvements would no longer be enough. To move forward, we needed to rethink indexing not as a collection of services, but as a coherent, portable system that could scale teams, deployments, and future capabilities together.
That realization set the stage for Indexing 3.0.
2 - What actually drove Indexing 3.0
Once we accepted that the bottleneck was organizational and operational—not just computational—we had to get precise about what we were optimizing for next.
Indexing 3.0 is our name for the architectural response. It isn’t a “version upgrade” in the product sense. It’s a deliberate rebuild designed around new constraints: more teams shipping in parallel, more deployment environments, and workload shapes (like short video) that stress different parts of the system.
Three drivers emerged clearly—and in a different priority order than we initially expected.
2.1 - Scaling engineering throughput, not just compute
The primary driver behind Indexing 3.0 was maintainability, but not in the abstract sense of “clean code.”
What mattered was engineering throughput: how many people could make changes confidently, how quickly new contributors could form a mental model of the system, and how safely teams could work in parallel without stepping on each other.
This is where the earlier polyglot / multi-service shape mattered. Even when each component was individually understandable, the interfaces were where complexity accumulated: data contracts, serialization, failure semantics, tracing, deployment packaging. Indexing 3.0 explicitly treats reducing those boundaries as a first-class lever for velocity.
2.2 - Packaging and deployment became first-order constraints
A second, business-critical driver followed closely behind: deployment flexibility.
As TwelveLabs expanded into new environments, it became clear that assumptions baked into the earlier system no longer held. Some environments offered full orchestration platforms. Others allowed only minimal container execution. Treating these as edge cases would have limited where the product could realistically ship.
This forced a shift in perspective:
Instead of “how do we deploy this system?”, we asked: what does the system assume about where it runs?
Indexing 3.0 is designed so deployment shape becomes a variable, not a defining feature of the architecture.
This matters because indexing isn’t a standalone service—it’s the substrate beneath multiple downstream products. Since we offer two video foundation models (Marengo and Pegasus) with different capabilities, the same indexed representations can power retrieval-style workloads (search) and reasoning-style workloads (analysis). Portability expands what products can exist and where they can ship.
2.3 - Cost as a structural outcome, not a tuning exercise
Cost was an important consideration, but notably, it was not the starting point.
In earlier iterations, cost optimizations had largely taken the form of incremental tuning—adjusting resource usage, tweaking configurations, or reacting to specific bottlenecks. Indexing 3.0 took a different approach.
The team recognized that many cost issues were symptoms of deeper structural choices: too many always-on components, inefficient coordination between stages, and architectures that made it difficult to right-size resources independently.
Rather than chasing isolated savings, Indexing 3.0 aimed to create an architecture where efficiency emerged naturally from simpler execution paths, clearer scaling boundaries, and more flexible deployment models.
2.4 - A change in what “success” meant
Taken together, these drivers led to a subtle but important shift in how success was defined.
Indexing 3.0 would not be judged primarily by raw performance numbers or by how novel the architecture looked on paper. It would be judged by whether it enabled:
Faster onboarding and safer contributions,
Parallel development without constant coordination,
Consistent behavior across environments,
The ability to evolve without repeated rewrites.
In the next section, we’ll look at how this shift in priorities led to a fundamentally different way of thinking about the indexing architecture itself.
3 - The architectural reframe: from “microservices mesh” to “streamlined layers”
Once the drivers behind Indexing 3.0 were clear, the next step was to confront a harder truth: the existing architecture was optimized for a different set of assumptions than the ones the business now faced.
What needed to change was not a single component, but the shape of the system itself.
3.1 - The problem with the “microservices mesh”
The earlier indexing platform followed a pattern that will be familiar to many teams: break the system into many small services, connect them through orchestration and routing layers, and let the infrastructure manage execution.
Over time, this created what we now think of as a microservices mesh.
work flows sideways as much as forward,
coordination logic spreads across services and control-plane interactions,
and understanding “what happens to a request” requires global context.
This approach has advantages early on. It allows teams to move independently and scale components in isolation. But as the indexing system grows—and especially as workloads become more heterogeneous—those advantages erode.
Even at a high level, indexing involves decoding, segmentation, embedding, and persistence steps that must compose correctly. When each step is its own service boundary, the system becomes harder to debug, harder to package, and harder to evolve.
Figure 2. Indexing architecture shift: from a Kubernetes-coupled microservices mesh (2.0) to a layered platform with a unified execution layer (3.0).
3.2 - A different question: what should be layered, and what should not?
Indexing 3.0 began with a different framing.
Instead of asking how to decompose the system into smaller services, we asked:
Which responsibilities actually need to be distributed, and which need to stay conceptually unified?
That led to a layered mental model, illustrated in the “mesh vs layers” diagram above:
At the top sits the indexing platform itself—the logic that understands how video should be processed, how work is sequenced, and what constitutes a completed result.
In the middle is a unifying execution and orchestration layer (Ray Serve in our case) - responsible for scaling, scheduling, and fault handling without leaking infrastructure details upward.
At the bottom is the infrastructure layer—the compute substrate (Kubernetes, Baremetal, AWS, etc.)—which is treated as interchangeable rather than defining.
The shift is not “fewer boxes.” It’s clean directionality: work flows down through layers; infrastructure concerns don’t leak upward.
3.3 - Make it concrete: the indexing 3.0 data flow
Why is a layered architecture fits the shape of the indexing works?
The diagram below shows indexing as three reusable primitives that power the product surfaces people actually interact with:
Figure 3. Three primitives powered by the same index: embedding generation → storage, text-to-video search via vector retrieval, and video-language generation via cached embeddings.
(1) Embedding generation (turn video into reusable representations)
At a high level, indexing starts by taking one request with one or more videos and turning each video into embeddings that can be reused across many downstream calls.
Conceptually, the flow is:
Video(s) → download
Split into logical segments (e.g., scenes; the point is “time becomes addressable”)
Pass segments to encoder models
Produce multimodal embeddings (e.g., visual + audio)
Combine + persist embeddings (and minimal metadata) into a database
This is the core “video → index” transformation. Everything else in the system is downstream reuse of these cached representations.
(2) Video search (turn a text query into retrieval over the index)
Search becomes straightforward once the index exists:
Text query → embed the query (in the same representation space as the video embeddings)
Vector search over stored embeddings to retrieve candidate matches
Post-process results (rerank, filter, apply simple constraints)
Return relevant clips/moments
The important point here is architectural: search is not “video processing” every time. It is retrieval over precomputed representations, plus lightweight post-processing.
(3) Video-language generation (reuse embeddings as context for a VLM)
Generation follows a similar reuse pattern, but routes the retrieved/cached representations into a decoder:
Request (prompt + video or index reference)
If embeddings exist, reuse them; otherwise, run the same embedding generation flow
Combine visual embeddings + the user’s input
Decode to text (video-language model)
Return the response
The key takeaway is that indexing is the shared substrate. Embedding generation produces reusable “addresses” into video. Search consumes those addresses via retrieval. Generation consumes them as context for reasoning.
That’s why the layered architecture matters. If you treat indexing as a collection of microservices stitched together by infrastructure, you pay coordination costs repeatedly across all three product paths. If you treat it as a coherent application flow running atop an execution layer and a swappable infrastructure substrate, you can evolve the shared substrate once—and every downstream surface benefits.
3.4 - Why layering changed everything
This reframe had several compounding effects.
First, it restored local reasoning. Engineers could understand and modify indexing behavior by looking at one place, rather than reconstructing intent from interactions across services.
Second, it made deployment a property of the bottom layer—not a constraint on the entire system. Swapping infrastructure no longer implied rewriting application logic.
Third, it aligned the architecture with how video workloads actually behave. Indexing is not a set of loosely related requests—it is a coordinated, end-to-end transformation. Treating it as such reduced the accidental complexity introduced by over-decomposition.
Most importantly, this shift changed what it meant to “scale” the system. Scaling no longer meant adding more services or more orchestration logic. It meant scaling the clarity of the system itself—so more people, more environments, and more future capabilities could be supported without compounding fragility.
In Part 2, we’ll dive into the design choices that made this layered model real in practice: consolidation, packaging, the trade-offs of a unifying execution layer, migration strategy, and supporting multiple deployment environments without fragmentation.
Related articles




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved