
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)

Research
Every Video Revolution Evolved What Stories We Could Tell

Ryan Khurana
Each wave of video technology — from film reels to tape to digital editing — didn't just speed up production but unlocked entirely new narrative forms, and AI video understanding is doing the same by removing the human bandwidth constraint that made multi-perspective storytelling, semantic editorial search, and ambient production economically impossible.
Each wave of video technology — from film reels to tape to digital editing — didn't just speed up production but unlocked entirely new narrative forms, and AI video understanding is doing the same by removing the human bandwidth constraint that made multi-perspective storytelling, semantic editorial search, and ambient production economically impossible.

In this article
No headings found on page
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Oct 16, 2025
10 Minutes
Copy link to article
Marshall McLuhan famously observed that "it is the framework which changes with each new technology and not just the picture within the frame." In video production, this insight has proven prophetic—each technological leap hasn't merely sped up production; it's revealed entirely new forms of storytelling that were hiding in plain sight, waiting for the right tools to make them possible.
Today, we're witnessing another fundamental shift. But unlike past revolutions that imposed new constraints, AI video understanding removes the oldest bottleneck of all: human bandwidth for comprehending footage. This isn't about faster workflows—it's about stories that were theoretically possible but economically impossible finally becoming viable.
The Pattern: New Tech → New Bottleneck → New Content Grammar
1950s-1960s: When Film Reels Dictated Story Structure
In early days of television Lucille Ball and Desi Arnaz pioneered what has become the standard for sitcoms since, I Love Lucy. The show’s three-camera setup, live audiences, and real-time 35mm film shooting were staples for decades. The narrative structure of the show was dictated by the fact that film reels held only about 11 minutes of footage, forcing writers to structure scenes around reel changes. The high cost of film stock meant episodes were shot almost in real-time—Desilu Productions could film a 22-minute episode in just 60 minutes of shooting.
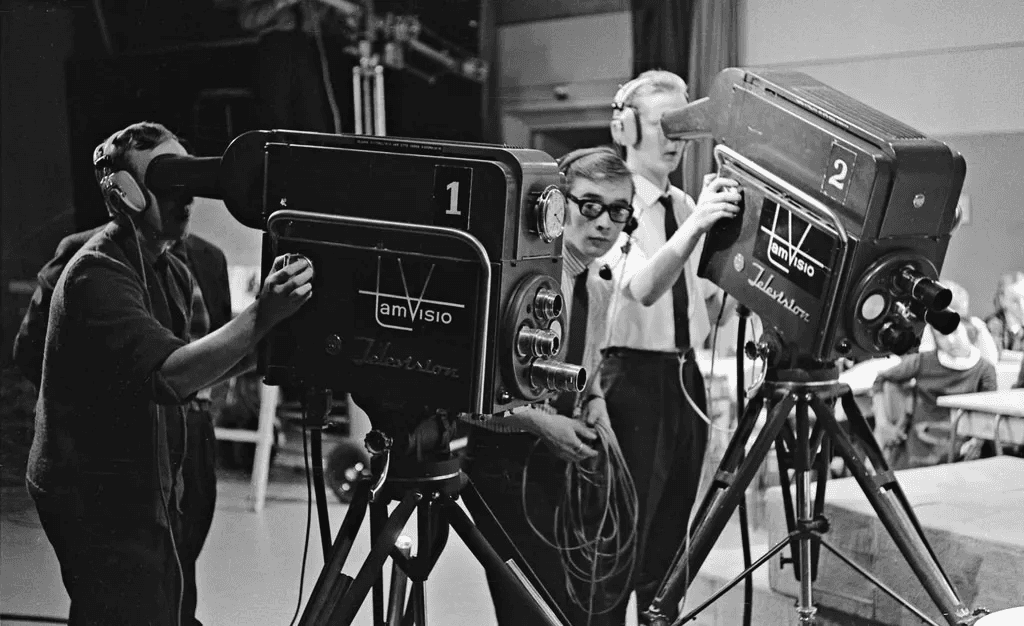
Source: https://picryl.com/media/filming-a-television-program-at-frenckells-studio-in-tampere-121965-1b5285
The result? Tightly scripted, theater-like performances with minimal editing. Networks saw so little value in recordings that 60-70% of the BBC's output from the 1950s-1970s was simply erased. Content was ephemeral by design.
The three camera format that I Love Lucy pioneered is still a mainstay of sitcoms, while the three act structure for narratives that film reel and projector limitations imposed remain the conventional standard for all narratives. The successive revolutions in technology did not do away with prior forms of creative expression, they made it so that other forms could also flourish.
1970s-1980s: The Tape Revolution Creates Live TV and 24-Hour Formats
Magnetic tape shattered television's theatrical constraints. Suddenly filming more got a lot cheaper, and the cameras themselves could become smaller too. Sony's U-matic format in 1974 enabled portable video, shrinking the time from shooting to broadcast from hours to minutes. Suddenly, "breaking news" became a format. "Live from the scene" became a genre. Instant replays became a sports necessity.
The pipe became the program. Twenty-four-hour news wasn't just more news—it was a fundamentally different beast, built on the assumption that cameras could be anywhere, anytime.
Meanwhile, Betacam in 1982 fused camera and recorder into a single unit, making field production even more nimble. The Quantel Paintbox (1981) turned TV into "graphic space"—essential for MTV's aesthetic and modern sports broadcasting.

Source: https://commons.wikimedia.org/wiki/File:Sony_Betacam_SP_with_Fujinon_lense_20080830.jpg
And crucially, VCRs and the 1984 Betamax decision legalized time-shifting. Audiences could now own time itself, creating entirely new markets for home video and fundamentally altering rerun economics.
1990s-2000s: Digital Archives Unlock Self-Referential Storytelling
The introduction of Avid's non-linear editing system in 1989 completed the transition from physical to digital. Suddenly, footage could be stored infinitely, searched instantly, and remixed endlessly. Archives transformed from worthless to valuable—old episodes found new life in reruns, DVD sets, and streaming libraries. "Clip shows" proliferated in the '90s and 2000s, mining past episodes for best-of compilations.
This technological shift birthed new content forms. Shows like Lost (2004-2010) could weave together multiple timelines—flashbacks, flash-forwards, and parallel realities—with precision impossible in linear editing. 24 (2001-2010) pioneered real-time storytelling with split screens showing simultaneous action across locations. The Wire (2002-2008) built season-long narrative arcs that referenced minute details from episodes aired years earlier. These weren't just faster ways to tell stories—they were narrative architectures that couldn't exist without random-access editing. Avid gave storytellers the ability to treat time itself as a malleable narrative element.

Source: https://commons.wikimedia.org/wiki/File:المونتاج_التلفزيوني_الخطي.jpg
It’s difficult to overstate the transformational impact that Non-Linear Editing had on video content. Stanley Kubrick famously noted that editing is the unique contribution of the language of film that distinguishes it from other arts. In the era of linear editing however the Director could exert total control over the process. Non-Linear Editing creating a technical craft that established and expanded the art of editing into its own creative discipline. The editor rather than an executor of the Director’s vision could now add his or her own unique style and creative flair into the process.
2000s-2010s: Cheap Cameras Create Reality TV's "Found" Narratives
When digital cameras became affordable, producers could deploy dozens of cameras rolling continuously. Reality TV exploded—but the real innovation wasn't in filming; it was in post-production. Shows like The Bachelor might shoot hundreds of hours for a single episode, but it’s the armies of loggers and story producers mining footage to "find" the narrative after filming wrapped that make it compelling.
The bottleneck shifted from camera costs to human review time. But this constraint created a new art form: stories crafted in hindsight from authentic moments, giving viewers "reality" that was actually carefully constructed editorial storytelling.
2010s-2020s: Smartphones and Personalization Enable a Content Explosion
When billions gained pocket cameras via smartphones, platforms like Instagram and TikTok emerged with mobile native formats: vertical, ephemeral, ultra-short. The constraint of small screens and short attention spans birthed new grammars—jump cuts, duets, challenges—optimized for algorithmic distribution rather than linear programming.
The rise of internet media consumption has also given rise to more proactive content recommendations personalized to each user. Netflix began not only showing recommended movies and shows to each user but personalizing the visuals for each piece of content to increase engagement. TikTok’s FYP created a watch-time driven loop that rapidly fit content to personal taste. These recommendation engines that leveraged metadata, transcripts, and visual content provided the consumer validation for the value of video understanding models that now sit to once again transform content.
The Current Revolution: From Decomposition to Comprehension
Here's what makes AI video understanding fundamentally different: Previous approaches decomposed video into constituent parts—transcript, objects, frames—then attempted to reconstruct meaning. This is like trying to understand a symphony by analyzing each instrument in isolation.
Video-native models comprehend the interplay between visual, temporal, and contextual elements simultaneously. They capture emergent properties that only exist in the interaction—the comedy in juxtaposition, the tension in timing, the meaning in movement.
Take for example this sequence from Shaun of the Dead which is equal parts horror and comedy. Shaun’s routine actions in the foreground and the zombie outbreak in the background are both portrayed with seriousness, but that juxtaposition creates the comedy. The humor doesn't exist in the visuals alone (mundane actions), the audio alone (ordinary sounds), or the narrative alone (getting ready for work).
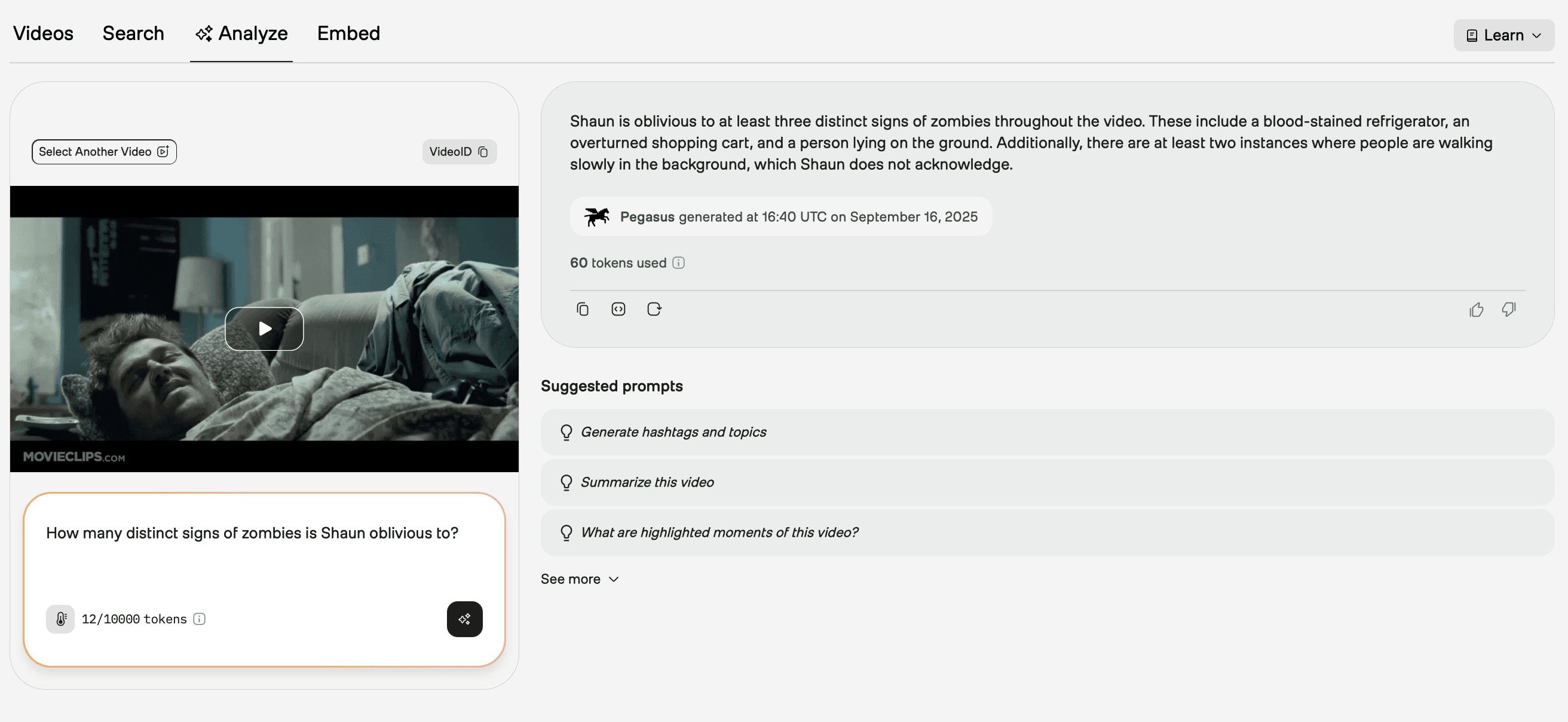
TwelveLabs’ Pegasus model was able to identify that Shaun’s unawareness contrasts the clear signs of a zombie outbreak around him. What traditional approaches to video analysis that segmented video components lost as a consequence of focusing on the measurable, video understanding models retrieves.
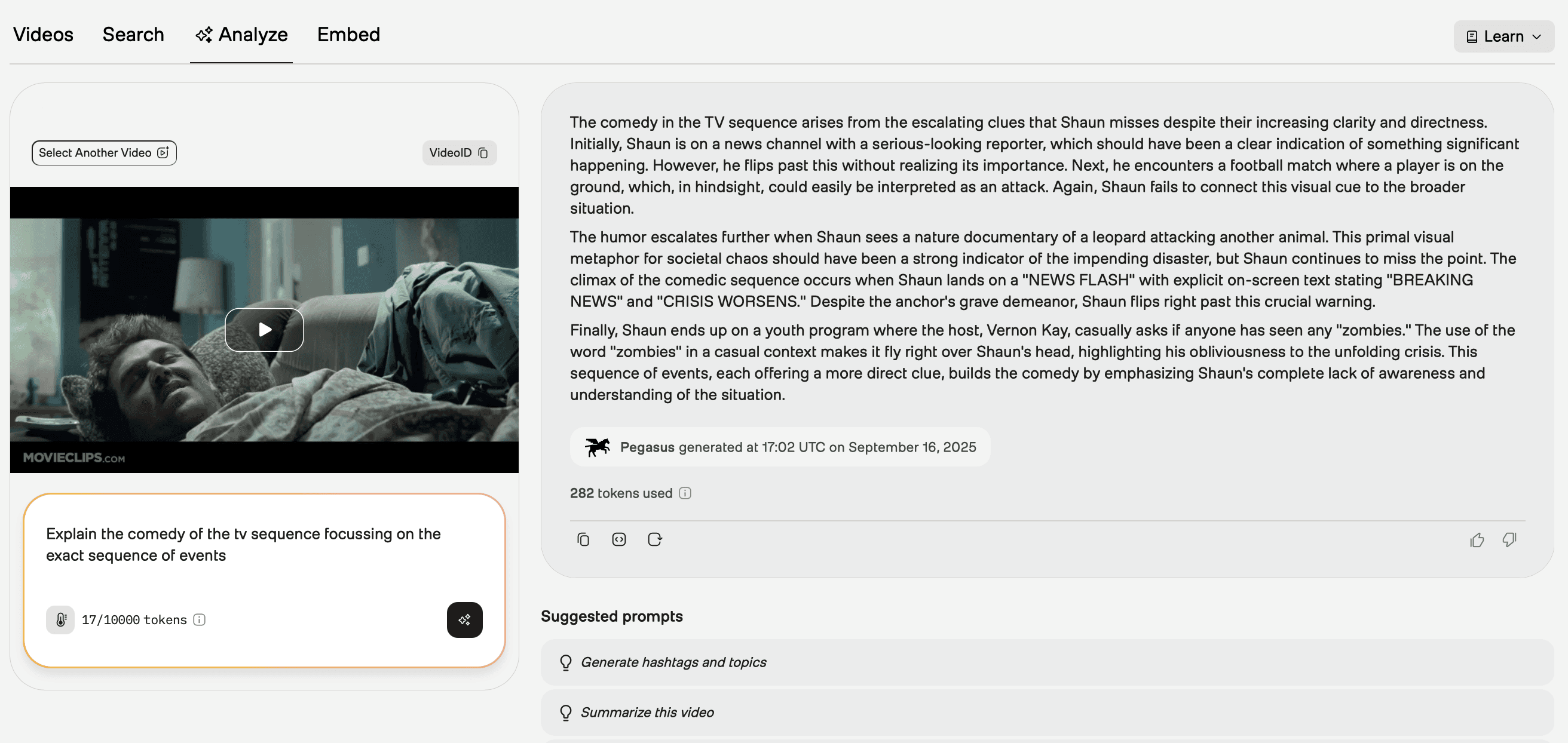
This is demonstrated most clearly in the ability to explain the humor of the TV sequence where Shaun rapidly flips channels while being warned of the zombie apocalypse. It understood that there was valuable content that appeared in each channel that Shaun failed to acknowledge. While it missed some subtleties (like coherent warnings across channel flips), it grasped something more fundamental, that there was something “off” about what was happening that made it funny.
This isn't incremental improvement. It's the difference between a system that can identify "person" and "zombie" and one that understands their relationship creates comedy.
We are still in the early days of video understanding and while the models continue to improve, another key innovation lies in the creativity of those early adopters who build narrative formats around previously non-existent capabilities.
Previous revolutions imposed constraints that forced innovation. AI understanding removes the human bandwidth constraint that made certain formats economically impossible. Here's what becomes viable:
Multi-Perspective Narratives:
When Netflix released Arrested Development Season 4 in 2013, each episode followed a single character through the same time period. The experiment was bold—viewers could theoretically watch in any order and piece together the larger story. But audiences didn’t react well to the new format.
Netflix spent millions re-editing the entire season into chronological order for "Season 4 Remix: Fateful Consequences." This required editors to manually track every scene's temporal position, identify narrative dependencies, and rebuild 15 episodes into 22. The cost? Hundreds of hours of editorial work plus Mitch Hurwitz's direct involvement to maintain coherence.

Source: https://www.reddit.com/r/arresteddevelopment/comments/1g5y0k/arrested_development_season_4_timeline_warning/ (The complexity of mapping the character specific timeline back to chronological order for Arrested Development S4)
With video understanding, the two formats could become interchangeable. During production, video understanding could analyze dailies in real-time, flagging which character perspectives still need coverage for specific story beats. Storyboards could be drafted with multiple narrative paths in mind. Post-production could test dozens of arrangements—chronological, character-focused, thematic—without manual reconstruction. Most importantly, the speed of enables audiences to choose their viewing experience, with the system ensuring narrative coherence regardless of path chosen.
The same story truly becomes multiple stories, each valid and complete.
Micro-Pattern Discovery:
Streaming services spend billions figuring out exactly what content to recommend to the user, yet can’t seem to crack why instead of watching something new millions go to rewatch The Office for the fiftieth time. They know you completed nine seasons of a "workplace comedy" featuring "Steve Carell" with tags like "mockumentary" and "ensemble cast." What they can't capture: why you actually connected with it.
Instead of relying on titles, transcripts, and metadata tags alone to identify what’s worth recommending, the video itself can be the source of truth. The meaning and relationships inside of a video carry more information that until now were difficult to extract. For example, it may not be a certain actor that draws attention, but only when they are playing a particular type of character or have scenes where they get to show off their comedic skills. These nuances, invisible to metadata, become retrievable with video understanding.
This more in-depth understanding can create entirely new paths of content recommendation that aren’t based on intrusive data collection to create a person specific graph but rather letting the relationship between content and viewing habits themselves present the best recommendations.
Marengo's embeddings capture what we call the "fingerprint" of content—not just objects and actions, but the interplay between visual elements, audio cues, and temporal dynamics. This granular understanding means content creators can finally understand WHY audiences connect with specific moments, empowering them to craft more resonant stories rather than chasing algorithmic trends.
Ambient Production:
Love Island films contestants 24/7 with 80 robotic cameras and multiple studio cameras, capturing approximately 168 hours of footage weekly. To transform this into six hour-long episodes per week, the show employs 400 crew members working in shifts around the clock. Thirty editors and twenty producers work across different departments—story teams compile individual moments into scenes, stitch teams assemble scenes into acts, and executive producers determine running orders in real-time. The entire operation runs on a 24-hour turnaround, with Monday's drama airing by Tuesday night.
Nathan Fielder's The Rehearsal pushed ambient capture into new territory by creating controlled environments that became uncontrollably rich with story. The Alligator Lounge replica was so meticulously detailed that it functioned less like a set and more like a story-generation engine. Fielder intended to control specific narratives, but the environments took on lives of their own—extras developed real relationships, background actors created their own dramas, the fake became real. The controlled world became less controlled, generating more authentic (actually who knows with that show…) narratives than planned scenarios.
With video understanding, this abundance becomes manageable. Instead of armies of loggers making binary decisions about what to mark, AI could generate "smart dailies" that understand narrative potential. Not just "argument at 2:47 AM" but "emerging tension between X and Y characters." The system could track relationship dynamics across weeks, identify patterns invisible to exhausted loggers, and surface the slow-burn stories that current production misses.
Whole shows can be designed around this capability, expanding upon the successful format of Love Island for a fraction of the cost with a less intensive production process. Instead of pre-selecting "main characters" and hoping they generate drama, productions could cast wider nets and let stories emerge organically from the environment. The narrative becomes truly discovered rather than manufactured, found in the ambient capture rather than forced through producer intervention.
Semantic Editorial:
The Last Dance documentary required editors to review over 10,000 hours of archival footage. The production hired a team of assistant editors who spent months creating detailed logs with keywords, descriptions, and timecodes. Even with this massive investment, editors still missed relevant moments because human logging can't capture every nuance.
Current text-based editing tools like Adobe Premiere's transcription feature let editors search dialogue, but can't understand visual storytelling. An editor looking for "tension between Jordan and teammates" must rely on someone having logged those subjective moments or combing through the footage themselves.
Video understanding transforms this from keyword search to semantic query. An editor could ask: "Find moments where Jordan is physically isolated from teammates," or "Show me reaction shots where players avoid eye contact after Jordan speaks." The system understands not just objects and actions but relationships and emotions.
For The Last Dance, this could have revealed subtle dynamics no logger would catch—patterns of body language across seasons, evolving team dynamics visible in spacing and positioning, unspoken tensions that only become apparent when viewed systematically. The value of archives for narrative archeology explodes.
Infinite Versioning:
In the global, digital world there is rarely just one true version of a show or movie. Some content gets internationalized for different markets, reflecting taste in certain pace, cultural context, or product presence. Others get safety adapted for theatres, airlines, and kid-friendly versions of the merc’ with the mouth. Each version required manual re-editing, costing hundreds of thousands per market.
Video understanding enables dynamic versioning at scale. Instead of creating fixed alternative edits, productions could define parameters—pacing preferences, content thresholds, cultural emphasis—and generate versions in real-time. A Japanese version of Squid Game could emphasize different character moments than the American version, based on actual viewing patterns rather than assumptions.
More radically, versions could adapt to individual viewers. Not through invasive data collection, but by understanding how viewing patterns correlate with content fingerprints. The same source material becomes thousands of potential experiences, each maintaining narrative integrity while optimizing for resonance.
The Bottom Line
As machines get better at understanding video, human creativity becomes more important, not less. When you can search thousands of hours for "moments of hope emerging from despair," the differentiator isn't finding footage—it's knowing what’s worth looking for.
Template-based AI tools force content into predetermined boxes. Video understanding does the opposite—it reveals what's already there, waiting to be discovered. It handles the overwhelming mechanical burden of comprehension, then hands clean, organized possibilities to human creators for final alchemy.
We're still in the early days. Current models struggle with abstract humor, cultural nuance, and conceptual metaphor. They understand that something is happening but not always why it matters. Yet even these imperfect capabilities cross a threshold that enables genuinely new creative forms.
History shows artists don't wait for perfect tools—they exploit imperfect ones in unexpected ways. The question isn't whether video understanding has arrived complete. It's whether current capabilities, with all their limitations, enable stories we couldn't tell before.
The answer is yes.
At TwelveLabs, we're not building tools that tell stories. We're building infrastructure that empowers storytellers to discover stories that were always there, waiting for the right technology to make them visible.
The framework is changing. What picture will you create within it?
Ready to explore what's possible when video understanding meets your content? Learn more about our video understanding APIs or see our models in action.
Marshall McLuhan famously observed that "it is the framework which changes with each new technology and not just the picture within the frame." In video production, this insight has proven prophetic—each technological leap hasn't merely sped up production; it's revealed entirely new forms of storytelling that were hiding in plain sight, waiting for the right tools to make them possible.
Today, we're witnessing another fundamental shift. But unlike past revolutions that imposed new constraints, AI video understanding removes the oldest bottleneck of all: human bandwidth for comprehending footage. This isn't about faster workflows—it's about stories that were theoretically possible but economically impossible finally becoming viable.
The Pattern: New Tech → New Bottleneck → New Content Grammar
1950s-1960s: When Film Reels Dictated Story Structure
In early days of television Lucille Ball and Desi Arnaz pioneered what has become the standard for sitcoms since, I Love Lucy. The show’s three-camera setup, live audiences, and real-time 35mm film shooting were staples for decades. The narrative structure of the show was dictated by the fact that film reels held only about 11 minutes of footage, forcing writers to structure scenes around reel changes. The high cost of film stock meant episodes were shot almost in real-time—Desilu Productions could film a 22-minute episode in just 60 minutes of shooting.
Source: https://picryl.com/media/filming-a-television-program-at-frenckells-studio-in-tampere-121965-1b5285
The result? Tightly scripted, theater-like performances with minimal editing. Networks saw so little value in recordings that 60-70% of the BBC's output from the 1950s-1970s was simply erased. Content was ephemeral by design.
The three camera format that I Love Lucy pioneered is still a mainstay of sitcoms, while the three act structure for narratives that film reel and projector limitations imposed remain the conventional standard for all narratives. The successive revolutions in technology did not do away with prior forms of creative expression, they made it so that other forms could also flourish.
1970s-1980s: The Tape Revolution Creates Live TV and 24-Hour Formats
Magnetic tape shattered television's theatrical constraints. Suddenly filming more got a lot cheaper, and the cameras themselves could become smaller too. Sony's U-matic format in 1974 enabled portable video, shrinking the time from shooting to broadcast from hours to minutes. Suddenly, "breaking news" became a format. "Live from the scene" became a genre. Instant replays became a sports necessity.
The pipe became the program. Twenty-four-hour news wasn't just more news—it was a fundamentally different beast, built on the assumption that cameras could be anywhere, anytime.
Meanwhile, Betacam in 1982 fused camera and recorder into a single unit, making field production even more nimble. The Quantel Paintbox (1981) turned TV into "graphic space"—essential for MTV's aesthetic and modern sports broadcasting.
Source: https://commons.wikimedia.org/wiki/File:Sony_Betacam_SP_with_Fujinon_lense_20080830.jpg
And crucially, VCRs and the 1984 Betamax decision legalized time-shifting. Audiences could now own time itself, creating entirely new markets for home video and fundamentally altering rerun economics.
1990s-2000s: Digital Archives Unlock Self-Referential Storytelling
The introduction of Avid's non-linear editing system in 1989 completed the transition from physical to digital. Suddenly, footage could be stored infinitely, searched instantly, and remixed endlessly. Archives transformed from worthless to valuable—old episodes found new life in reruns, DVD sets, and streaming libraries. "Clip shows" proliferated in the '90s and 2000s, mining past episodes for best-of compilations.
This technological shift birthed new content forms. Shows like Lost (2004-2010) could weave together multiple timelines—flashbacks, flash-forwards, and parallel realities—with precision impossible in linear editing. 24 (2001-2010) pioneered real-time storytelling with split screens showing simultaneous action across locations. The Wire (2002-2008) built season-long narrative arcs that referenced minute details from episodes aired years earlier. These weren't just faster ways to tell stories—they were narrative architectures that couldn't exist without random-access editing. Avid gave storytellers the ability to treat time itself as a malleable narrative element.
Source: https://commons.wikimedia.org/wiki/File:المونتاج_التلفزيوني_الخطي.jpg
It’s difficult to overstate the transformational impact that Non-Linear Editing had on video content. Stanley Kubrick famously noted that editing is the unique contribution of the language of film that distinguishes it from other arts. In the era of linear editing however the Director could exert total control over the process. Non-Linear Editing creating a technical craft that established and expanded the art of editing into its own creative discipline. The editor rather than an executor of the Director’s vision could now add his or her own unique style and creative flair into the process.
2000s-2010s: Cheap Cameras Create Reality TV's "Found" Narratives
When digital cameras became affordable, producers could deploy dozens of cameras rolling continuously. Reality TV exploded—but the real innovation wasn't in filming; it was in post-production. Shows like The Bachelor might shoot hundreds of hours for a single episode, but it’s the armies of loggers and story producers mining footage to "find" the narrative after filming wrapped that make it compelling.
The bottleneck shifted from camera costs to human review time. But this constraint created a new art form: stories crafted in hindsight from authentic moments, giving viewers "reality" that was actually carefully constructed editorial storytelling.
2010s-2020s: Smartphones and Personalization Enable a Content Explosion
When billions gained pocket cameras via smartphones, platforms like Instagram and TikTok emerged with mobile native formats: vertical, ephemeral, ultra-short. The constraint of small screens and short attention spans birthed new grammars—jump cuts, duets, challenges—optimized for algorithmic distribution rather than linear programming.
The rise of internet media consumption has also given rise to more proactive content recommendations personalized to each user. Netflix began not only showing recommended movies and shows to each user but personalizing the visuals for each piece of content to increase engagement. TikTok’s FYP created a watch-time driven loop that rapidly fit content to personal taste. These recommendation engines that leveraged metadata, transcripts, and visual content provided the consumer validation for the value of video understanding models that now sit to once again transform content.
The Current Revolution: From Decomposition to Comprehension
Here's what makes AI video understanding fundamentally different: Previous approaches decomposed video into constituent parts—transcript, objects, frames—then attempted to reconstruct meaning. This is like trying to understand a symphony by analyzing each instrument in isolation.
Video-native models comprehend the interplay between visual, temporal, and contextual elements simultaneously. They capture emergent properties that only exist in the interaction—the comedy in juxtaposition, the tension in timing, the meaning in movement.
Take for example this sequence from Shaun of the Dead which is equal parts horror and comedy. Shaun’s routine actions in the foreground and the zombie outbreak in the background are both portrayed with seriousness, but that juxtaposition creates the comedy. The humor doesn't exist in the visuals alone (mundane actions), the audio alone (ordinary sounds), or the narrative alone (getting ready for work).
TwelveLabs’ Pegasus model was able to identify that Shaun’s unawareness contrasts the clear signs of a zombie outbreak around him. What traditional approaches to video analysis that segmented video components lost as a consequence of focusing on the measurable, video understanding models retrieves.
This is demonstrated most clearly in the ability to explain the humor of the TV sequence where Shaun rapidly flips channels while being warned of the zombie apocalypse. It understood that there was valuable content that appeared in each channel that Shaun failed to acknowledge. While it missed some subtleties (like coherent warnings across channel flips), it grasped something more fundamental, that there was something “off” about what was happening that made it funny.
This isn't incremental improvement. It's the difference between a system that can identify "person" and "zombie" and one that understands their relationship creates comedy.
We are still in the early days of video understanding and while the models continue to improve, another key innovation lies in the creativity of those early adopters who build narrative formats around previously non-existent capabilities.
Previous revolutions imposed constraints that forced innovation. AI understanding removes the human bandwidth constraint that made certain formats economically impossible. Here's what becomes viable:
Multi-Perspective Narratives:
When Netflix released Arrested Development Season 4 in 2013, each episode followed a single character through the same time period. The experiment was bold—viewers could theoretically watch in any order and piece together the larger story. But audiences didn’t react well to the new format.
Netflix spent millions re-editing the entire season into chronological order for "Season 4 Remix: Fateful Consequences." This required editors to manually track every scene's temporal position, identify narrative dependencies, and rebuild 15 episodes into 22. The cost? Hundreds of hours of editorial work plus Mitch Hurwitz's direct involvement to maintain coherence.
Source: https://www.reddit.com/r/arresteddevelopment/comments/1g5y0k/arrested_development_season_4_timeline_warning/ (The complexity of mapping the character specific timeline back to chronological order for Arrested Development S4)
With video understanding, the two formats could become interchangeable. During production, video understanding could analyze dailies in real-time, flagging which character perspectives still need coverage for specific story beats. Storyboards could be drafted with multiple narrative paths in mind. Post-production could test dozens of arrangements—chronological, character-focused, thematic—without manual reconstruction. Most importantly, the speed of enables audiences to choose their viewing experience, with the system ensuring narrative coherence regardless of path chosen.
The same story truly becomes multiple stories, each valid and complete.
Micro-Pattern Discovery:
Streaming services spend billions figuring out exactly what content to recommend to the user, yet can’t seem to crack why instead of watching something new millions go to rewatch The Office for the fiftieth time. They know you completed nine seasons of a "workplace comedy" featuring "Steve Carell" with tags like "mockumentary" and "ensemble cast." What they can't capture: why you actually connected with it.
Instead of relying on titles, transcripts, and metadata tags alone to identify what’s worth recommending, the video itself can be the source of truth. The meaning and relationships inside of a video carry more information that until now were difficult to extract. For example, it may not be a certain actor that draws attention, but only when they are playing a particular type of character or have scenes where they get to show off their comedic skills. These nuances, invisible to metadata, become retrievable with video understanding.
This more in-depth understanding can create entirely new paths of content recommendation that aren’t based on intrusive data collection to create a person specific graph but rather letting the relationship between content and viewing habits themselves present the best recommendations.
Marengo's embeddings capture what we call the "fingerprint" of content—not just objects and actions, but the interplay between visual elements, audio cues, and temporal dynamics. This granular understanding means content creators can finally understand WHY audiences connect with specific moments, empowering them to craft more resonant stories rather than chasing algorithmic trends.
Ambient Production:
Love Island films contestants 24/7 with 80 robotic cameras and multiple studio cameras, capturing approximately 168 hours of footage weekly. To transform this into six hour-long episodes per week, the show employs 400 crew members working in shifts around the clock. Thirty editors and twenty producers work across different departments—story teams compile individual moments into scenes, stitch teams assemble scenes into acts, and executive producers determine running orders in real-time. The entire operation runs on a 24-hour turnaround, with Monday's drama airing by Tuesday night.
Nathan Fielder's The Rehearsal pushed ambient capture into new territory by creating controlled environments that became uncontrollably rich with story. The Alligator Lounge replica was so meticulously detailed that it functioned less like a set and more like a story-generation engine. Fielder intended to control specific narratives, but the environments took on lives of their own—extras developed real relationships, background actors created their own dramas, the fake became real. The controlled world became less controlled, generating more authentic (actually who knows with that show…) narratives than planned scenarios.
With video understanding, this abundance becomes manageable. Instead of armies of loggers making binary decisions about what to mark, AI could generate "smart dailies" that understand narrative potential. Not just "argument at 2:47 AM" but "emerging tension between X and Y characters." The system could track relationship dynamics across weeks, identify patterns invisible to exhausted loggers, and surface the slow-burn stories that current production misses.
Whole shows can be designed around this capability, expanding upon the successful format of Love Island for a fraction of the cost with a less intensive production process. Instead of pre-selecting "main characters" and hoping they generate drama, productions could cast wider nets and let stories emerge organically from the environment. The narrative becomes truly discovered rather than manufactured, found in the ambient capture rather than forced through producer intervention.
Semantic Editorial:
The Last Dance documentary required editors to review over 10,000 hours of archival footage. The production hired a team of assistant editors who spent months creating detailed logs with keywords, descriptions, and timecodes. Even with this massive investment, editors still missed relevant moments because human logging can't capture every nuance.
Current text-based editing tools like Adobe Premiere's transcription feature let editors search dialogue, but can't understand visual storytelling. An editor looking for "tension between Jordan and teammates" must rely on someone having logged those subjective moments or combing through the footage themselves.
Video understanding transforms this from keyword search to semantic query. An editor could ask: "Find moments where Jordan is physically isolated from teammates," or "Show me reaction shots where players avoid eye contact after Jordan speaks." The system understands not just objects and actions but relationships and emotions.
For The Last Dance, this could have revealed subtle dynamics no logger would catch—patterns of body language across seasons, evolving team dynamics visible in spacing and positioning, unspoken tensions that only become apparent when viewed systematically. The value of archives for narrative archeology explodes.
Infinite Versioning:
In the global, digital world there is rarely just one true version of a show or movie. Some content gets internationalized for different markets, reflecting taste in certain pace, cultural context, or product presence. Others get safety adapted for theatres, airlines, and kid-friendly versions of the merc’ with the mouth. Each version required manual re-editing, costing hundreds of thousands per market.
Video understanding enables dynamic versioning at scale. Instead of creating fixed alternative edits, productions could define parameters—pacing preferences, content thresholds, cultural emphasis—and generate versions in real-time. A Japanese version of Squid Game could emphasize different character moments than the American version, based on actual viewing patterns rather than assumptions.
More radically, versions could adapt to individual viewers. Not through invasive data collection, but by understanding how viewing patterns correlate with content fingerprints. The same source material becomes thousands of potential experiences, each maintaining narrative integrity while optimizing for resonance.
The Bottom Line
As machines get better at understanding video, human creativity becomes more important, not less. When you can search thousands of hours for "moments of hope emerging from despair," the differentiator isn't finding footage—it's knowing what’s worth looking for.
Template-based AI tools force content into predetermined boxes. Video understanding does the opposite—it reveals what's already there, waiting to be discovered. It handles the overwhelming mechanical burden of comprehension, then hands clean, organized possibilities to human creators for final alchemy.
We're still in the early days. Current models struggle with abstract humor, cultural nuance, and conceptual metaphor. They understand that something is happening but not always why it matters. Yet even these imperfect capabilities cross a threshold that enables genuinely new creative forms.
History shows artists don't wait for perfect tools—they exploit imperfect ones in unexpected ways. The question isn't whether video understanding has arrived complete. It's whether current capabilities, with all their limitations, enable stories we couldn't tell before.
The answer is yes.
At TwelveLabs, we're not building tools that tell stories. We're building infrastructure that empowers storytellers to discover stories that were always there, waiting for the right technology to make them visible.
The framework is changing. What picture will you create within it?
Ready to explore what's possible when video understanding meets your content? Learn more about our video understanding APIs or see our models in action.




Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
©
2026
TwelveLabs, Inc. All Rights Reserved


