" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
Twelve Labs와 함께 올림픽 비디오 분류 애플리케이션 구축하기

흐리시케시 야다브(Hrishikesh Yadav)
이 튜토리얼에서는 별도의 모델 학습 없이도 Twelve Labs의 Classification API와 Marengo 2.6을 활용해 스트림릿(Streamlit) 인터페이스에서 스포츠 영상을 미리 정의된 클래스 또는 사용자 지정 클래스로 자동 분류하는 '올림픽 비디오 클립 분류 애플리케이션'을 구축하는 과정을 단계별로 알아봅니다.
이 튜토리얼에서는 별도의 모델 학습 없이도 Twelve Labs의 Classification API와 Marengo 2.6을 활용해 스트림릿(Streamlit) 인터페이스에서 스포츠 영상을 미리 정의된 클래스 또는 사용자 지정 클래스로 자동 분류하는 '올림픽 비디오 클립 분류 애플리케이션'을 구축하는 과정을 단계별로 알아봅니다.

In this article
No headings found on page
뉴스레터 구독하기
뉴스레터 구독하기
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
영상 이해 분야의 최신 기술 업데이트, 튜토리얼 및 인사이트를 받아보세요.
AI로 영상을 검색하고, 분석하고, 탐색하세요.
2024. 9. 3.
15분
링크 복사하기
올림픽 동영상 영상을 정리하는 것만으로 금메달을 따는 꿈을 꾸어본 적이 있으신가요? 🥇 이제 그 시상대 위에 설 수 있는 기회가 왔습니다!
올림픽 동영상 클립 분류 애플리케이션은 스포츠 영상 분류라는 번거롭고 시간이 많이 걸리는 과정을 간소화하기 위해 설계되었습니다. Twelve Labs의 Marengo 2.6 임베딩 모델을 통해, 이 앱은 비디오 클립 내의 올림픽 스포츠 종목을 빠르게 분류해 냅니다.
화면 상의 텍스트, 음성 대화, 시각 요소를 모두 분석하여 동영상 클립을 손쉽게 카테고리별로 정렬합니다. 본 튜토리얼에서는 연구자, 스포츠 마니아, 방송사 관계자가 올림픽 콘텐츠를 다루는 방식을 완전히 혁신할 Streamlit 애플리케이션 구축 과정을 단계별로 안내합니다. 사용자가 직접 정의한 카테고리에 따라 동영상을 분류하는 앱을 구현하는 방법을 배우게 되며, 상세한 앱 시연 동영상은 아래에서 확인하실 수 있습니다.
애플리케이션 데모는 여기서 직접 실행해 볼 수 있습니다: 올림픽 분류 앱 데모. 또한, 이 Replit 템플릿을 통해 코드를 직접 작동시켜 볼 수도 있습니다.
사전 준비 단계
Twelve Labs Playground에 가입하고 API 키를 생성하세요.
노트북과 본 애플리케이션의 소스 코드가 포함된 GitHub 저장소를 확인하세요.
본 Streamlit 애플리케이션은 Python, HTML, JavaScript를 사용합니다.
애플리케이션 작동 원리
이 섹션에서는 올림픽 비디오 클립 분류를 위한 애플리케이션 파이프라인의 전체적인 흐름을 설명합니다.
이 애플리케이션은 다양한 활용 시나리오를 가진 분류 검색 엔진을 기반으로 개발되었습니다. 여기서는 올림픽 스포츠 동영상 클립을 분류하고 필요한 부분만 검색해 내는 작업에 집중합니다. 가장 핵심적인 첫 단계를 바로 인덱스(Index)를 생성하는 것입니다.
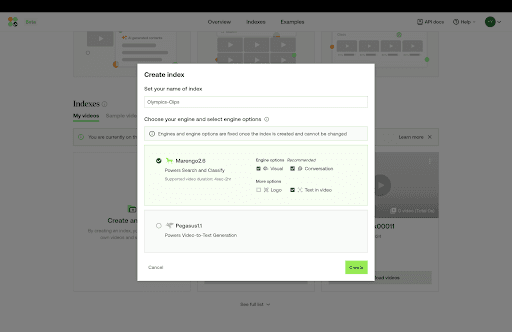
시작하려면 Twelve Labs Playground에 접속하세요.
새 인덱스(New Index)를 생성하고 비디오 인덱싱 및 분류 작업에 최적화된
Marengo 2.6 (Embedding Engine)을 선택합니다.분류하고자 하는 모든 스포츠 비디오를 해당 인덱스에 업로드하고 나면 다음 단계로 진행할 수 있습니다.
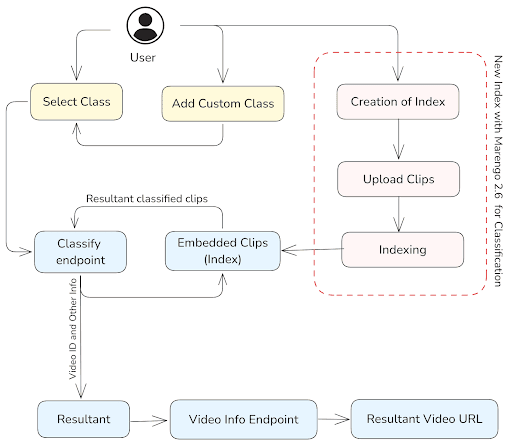
아래 섹션에서는 생성된 Index ID를 연동하고 실제로 구현하는 과정을 구체적으로 설명합니다. 먼저 전체적인 애플리케이션 워크플로우를 요약해 드립니다.
사용자는 다중 선택(Multi-select) 메뉴에서 시청하고자 하는 스포츠 카테고리를 직접 선택하거나, 본인만의 맞춤 클래스(Custom class)를 새로 정의하여 추가할 수 있습니다.
선택된 클래스는 해당 인덱스 내의 비디오 클립을 검색하고 분류하기 위해
INDEX ID및 기타 옵션(예:include_clips등)과 함께 classify 엔드포인트로 전송됩니다.API 응답 데이터에는 비디오 ID, 매칭된 클래스 이름, 신뢰도(Confidence Level), 시작 및 종료 시간, 썸네일 URL 등이 함께 포함됩니다.
검색 및 분류 결과로 반환된 비디오 ID의 실제 비디오 스트리밍 URL을 가져오기 위해 비디오 상세 정보 엔드포인트에 전송 요청을 수행하게 됩니다.
기본 준비 사항
Twelve Labs Playground에서 계정을 생성하고 인덱스를 만들어 줍니다.
분류 작업에 가장 적합한 엔진인 Marengo 2.6 (Embedding Engine)을 설정해 줍니다. 이 엔진은 높은 수준의 비디오 검색 및 비디오 분류 성능을 발휘하여 뛰어난 비디오 이해도의 강력한 기반을 제공합니다.
분류할 올림픽 스포츠 동영상을 업로드하세요. 테스트용 영상이 필요하시다면 본 가이드에서 제공하는 샘플 클립인 스포츠 비디오 클립을 다운로드하여 활용해 보세요.
Twelve Labs Playground 대시보드에서 고유 API 키를 복사합니다.
올림픽 클립을 새로 생성해 둔 인덱스 화면에 들어가면 웹 브라우저 주소창에서 고유 인덱스 ID를 확인할 수 있습니다: https://playground.twelvelabs.io/indexes/{index_id}.
메인 애플리케이션 파일과 같은 경로에 API Key와 INDEX_ID 값을 기술한 .env 파일을 생성해 설정해 둡니다.
여기까지 모든 준비 작업이 완료되었다면, 본격적으로 실제 애플리케이션 개발 단계로 넘어가 보겠습니다!
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here INDEX_ID=your_index_id_here
분류 기능 상세 가이드
1 - 라이브러리 임포트, 검증 및 클라이언트 개발 설정
가장 먼저 필요한 라이브러리를 임포트하고 올바른 실행 환경 조성을 위한 환경 변수를 세팅해 줍니다. 다음과 같이 작성합니다.
import os import requests import glob import requests from twelvelabs import TwelveLabs from twelvelabs.models.task import Task import dotenv API_KEY=os.getenv("Twelvelabs_API") API_URL=os.getenv("API_URL") INDEX_ID=os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # URL of the /indexes endpoint INDEXES_URL = f"{API_URL}/indexes" # Setting headers variables default_header = { "x-api-key": API_KEY }
의존성 라이브러리를 성공적으로 가셔왔고, 환경 변수가 정확하게 로드되었으며 대시보드 크리덴셜을 사용해 올바른 API 클라이언트 초기화가 구성되었습니다. 또한, 인덱스에 접근하기 위한 베이스 URL과 API 요청을 위한 기본 헤더 설정도 완료되었습니다.
기초 뼈대가 든든하게 갖춰졌으므로, 이제 인덱스 제어 및 보다 정밀한 스포츠 비디오 분류 작업에 착수해 보겠습니다.
2 - 분류 클래스 그룹 설정하기
올림픽 스포츠 영상 클립들을 체계적으로 분류하는 데 사용할 기본 클래스(카테고리명 및 관련 프롬프트 조합) 목록은 다음과 같습니다.
# Categories for the classification of the Olympics Sports CLASSES = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] }, { "name": "AthleticEvents", "prompts": [ "track and field", "marathon running", "long jump competition", "javelin throw", "high jump event" ] }, { "name": "GymnasticsEvents", "prompts": [ "artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance" ] }, { "name": "CombatSports", "prompts": [ "boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel" ] }, { "name": "TeamSports", "prompts": [ "basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition" ] }, { "name": "CyclingSports", "prompts": [ "road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial" ] }, { "name": "RacquetSports", "prompts": [ "tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match" ] }, { "name": "RowingAndSailing", "prompts": [ "rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition" ] } ]
3 - 특정 인덱스 내 검색된 모든 동영상을 분류하는 유틸리티 함수
# Utility function def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} clips={cl.clips.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASSES, include_clips=True )
실제 분류를 트리거하기 위해 client.classify.index() 메소드를 노출해 호출합니다. 사전에 설정해 둔 INDEX_ID 값과 함께 비디오 내 시각 정보(options=["visual"])를 참조하도록 구성하고 메타데이터로 각 타임스탬프 기반 Clip 상세 내역도 응답에 반환받도록 처리합니다. 분류 타겟 배열로는 구성해둔 CLASSES를 제공합니다.
print_page(result) 헬프 메소드는 이러한 반환 결과들을 가독성 높은 출력 형식으로 나타내어 줍니다. 비디오 루프를 돌며 video_id를 출력하고, 매칭된 분류명 가각의 스코어 점수, 해당 스포츠가 재생된 전체 듀레이션 비율(Duration Ratio), 그리고 개별 비디오 클립 데이터들의 구조화된 상태 리스트를 프린트해 결과를 명확히 확인하도록 돕습니다.
4 - 정돈된 형태로 분류 스코어 결과를 표출해 주는 출력 핸들러 작성
print_classification_result() 헬퍼는 Twelve Labs API의 최종 비디오 감별 결과 구조 데이터를 사람이 인지하기 가장 쉬운 형태로 가시화합니다. 각 비디오 소스를 반복 순회하며 대상 ID, 감지된 최종 카테고리 정보 및 매칭 점수를 시각적으로 정리합니다. 또한 각 클래스별 신뢰 점수와 구간 점유 비중을 정밀하게 추출하며, 각 비디오 내부에서 발견된 가장 연관성이 우수한 상위 5개의 세부 클립 목록을 우선 정렬해 각각 시작/끝 시점, 그리고 매칭 유도가 이뤄진 CLASSES 프롬프트를 깔끔하게 화면에 찍어 줍니다. 5개 이상의 상세 검출 클립이 더 존재하면 생략 카운팅도 알려줍니다.
def print_classification_result(result) -> None: for video_data in result.data: print(f"Video ID: {video_data.video_id}") print("=" * 50) for class_data in video_data.classes: print(f" Class: {class_data.name}") print(f" Score: {class_data.score:.2f}") print(f" Duration Ratio: {class_data.duration_ratio:.2f}") print(" Clips:") sorted_clips = sorted(class_data.clips, key=lambda x: x.score, reverse=True) for i, clip in enumerate(sorted_clips[:5], 1): # Print top 5 clips print(f" {i}. Score: {clip.score:.2f}") print(f" Start: {clip.start:.2f}s, End: {clip.end:.2f}s") print(f" Prompt: {clip.prompt}") if len(sorted_clips) > 5: print(f" ... and {len(sorted_clips) - 5} more clips") print("-" * 40) print("\n") print(f"Total results: {result.page_info.total_results}") print(f"Page expires at: {result.page_info.page_expired_at}") print(f"Next page token: {result.page_info.next_page_token}")
위의 실행 결과 예시는 다음과 같습니다 -
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
5 - 인덱스 내 전체 동영상에서 특정 스포츠 종류만 정밀 구분하기
특정 클래스 전용 필터 적용 테스트를 위해, 전체 업로드 파일 중 오직 "수상 스포츠(AquaticSports)" 관련 콘텐츠만 콕 집어내는 분류를 예시로 보겠습니다. 절차는 매우 직관적입니다. 타겟 클래스명과 매핑 프롬프트 범주를 단독 지정해 API 호출을 던진 후, 결과만 걸러서 관측해 봅니다.
이렇듯 목적이 명료하게 좁혀진 검사는 해당 스포츠가 등장한 핵심 영상을 찾는 데 한층 더 정확하고 고품질의 감별 성과를 보장합니다. 간이 디버깅용 도구인 print_page()가 분류된 원시 결과를 요약하여 출력해 줍니다.
CLASS = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] } ] def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} detailed_scores={cl.detailed_scores.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASS, include_clips=True, show_detailed_score=True ) print_classification_result(result)
위 코드의 실행 결과 데이터를 보면 지정된 대상 CLASS인 수상 스포츠 검사 범주에 명확하게 들어맞는 올림픽 비디오들이 나열됩니다.
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
Twelve Labs 공식 SDK를 사용하여 분류 엔드포인트를 효과적으로 다루고 조율하는 방법을 마스터하셨으니, 이제 실사용자를 위한 어진 가독성을 갖춘 Streamlit 전체 애플리케이션 프레젠테이션 설계 단계로 넘어가 보겠습니다.
Streamlit 기반 웹 애플리케이션 구축
본 시스템의 웹 프로토타입 구현 환경으로는 심플한 설정과 놀라운 초고속 MVP 도출 생산성을 자랑하는 Streamlit을 낙점했습니다. 단 몇 줄의 직관적인 코드로 뛰어난 대화형 인터랙티브 웹 포털 화면을 찍어낼 수 있어 비디오 인공지능 분류 결과를 깔끔하게 보여주기 가장 안성맞춤입니다. Twelve Labs SDK와 연동하면 단 수 분 이내에 근사한 웹 GUI를 만들 수 있습니다.
Streamlit 실행에 앞서 개발 가상 환경이 제대로 켜져 있는지 체크한 주 아래 쉘 명령어를 기동해 의존성 모듈 설치를 진행합니다.
pip install streamlit
보다 다양한 프레임워크 핵심 팁을 보시려면, 공식 Streamlit 설명서 웹사이트를 확인하세요.
프로젝트 구성을 위해 다음과 같이 디렉터리와 파일을 레이아웃하여 소스를 생성합니다.
. ├── .env ├── app.py ├── requirements.txt └── .gitignore
이 중 프로젝트 의존 패키지를 서술할 requirements.txt의 내용물은 아래와 같습니다.
streamlit twelvelabs requests python-dotenv
이 짧은 몇 줄의 환경 추가로 스포츠 영상 분류기를 돌려줄 백앤드 구조 준비가 완료되었습니다.
메인 실행파일인 app.py에는 핵심적인 제어 기능 블록들이 명쾌하게 탑재됩니다.
get_initial_classes(): 시스템에 사전에 장착될 올림픽 전용 스포츠 카테고리를 자동 맵핑합니다.get_custom_classes()및add_custom_class(): 사용자 임의로 더 유연하게 탐지 필터를 개량/확장해 맞춤 타겟을 올릴 수 있게 지원하는 조력 함수입니다.classify_videos(): 입력받은 분석 기준 배열을 기반으로 인공지능이 추론을 시작하도록 Twelve Labs API 서버와 원활히 교신합니다.get_video_urls(): 정확히 일치하거나 분류된 대상 고유 Video ID들로부터 실시간 영상 주소를 조회하여 리턴합니다.render_video(): 사용자 웹 브라우저에서 끊김에 대처 가능한 HLS.js 플러그인 연동 HTML5 플레이어 쉘을 동적 마운트합니다.
# Import Necessary Dependencies import streamlit as st from twelvelabs import TwelveLabs import requests import os from dotenv import load_dotenv load_dotenv() # Get the API Key from the Dashboard - https://playground.twelvelabs.io/dashboard/api-key API_KEY = os.getenv("API_KEY") # Create the INDEX ID as specified in the README.md and get the INDEX_ID INDEX_ID = os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # Background Setting of the Application page_element = """ <style> [data-testid="stAppViewContainer"] { background-image: url("https://wallpapercave.com/wp/wp3589963.jpg"); background-size: cover; } [data-testid="stHeader"] { background-color: rgba(0,0,0,0); } [data-testid="stToolbar"] { right: 2rem; background-image: url(""); background-size: cover; } </style> """ st.markdown(page_element, unsafe_allow_html=True) # Classes to classify the video into, there are categories name and # the prompts which specifc finds that factor to label that category @st.cache_data def get_initial_classes(): return [ {"name": "AquaticSports", "prompts": ["swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming"]}, {"name": "AthleticEvents", "prompts": ["track and field", "marathon running", "long jump competition", "javelin throw", "high jump event"]}, {"name": "GymnasticsEvents", "prompts": ["artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance"]}, {"name": "CombatSports", "prompts": ["boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel"]}, {"name": "TeamSports", "prompts": ["basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition"]}, {"name": "CyclingSports", "prompts": ["road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial"]}, {"name": "RacquetSports", "prompts": ["tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match"]}, {"name": "RowingAndSailing", "prompts": ["rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition"]} ] # Session State for the custom classes def get_custom_classes(): if 'custom_classes' not in st.session_state: st.session_state.custom_classes = [] return st.session_state.custom_classes # Utitlity Function to add the custom classes in app def add_custom_class(name, prompts): custom_classes = get_custom_classes() custom_classes.append({"name": name, "prompts": prompts}) st.session_state.custom_classes = custom_classes st.session_state.new_class_added = True # Utitlity Function to classify all the videos in the specified Index def classify_videos(selected_classes): return client.classify.index( index_id=INDEX_ID, options=["visual"], classes=selected_classes, include_clips=True ) # To get the video urls from the resultant video id def get_video_urls(video_ids): base_url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{{}}" headers = {"x-api-key": API_KEY, "Content-Type": "application/json"} video_urls = {} for video_id in video_ids: try: response = requests.get(base_url.format(video_id), headers=headers) response.raise_for_status() data = response.json() if 'hls' in data and 'video_url' in data['hls']: video_urls[video_id] = data['hls']['video_url'] else: st.warning(f"No video URL found for video ID: {video_id}") except requests.exceptions.RequestException as e: st.error(f"Failed to get data for video ID: {video_id}. Error: {str(e)}") return video_urls # Utitlity Function to Render the Video by the resultant video url def render_video(video_url): hls_player = f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <div style="width: 100%; border-radius: 10px; overflow: hidden; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);"> <video id="video" controls style="width: 100%; height: auto;"></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """ st.components.v1.html(hls_player, height=300)
get_initial_classes() 정적 메서드는 변경되지 않을 올림픽 전역 운동 종목 대상을 전달합니다. Streamlit은 똑똑하게 이 데이터를 즉각 캐싱 처리해, 시스템 구동 중 한 번만 이 구조체 평가가 일어나도록 제어하여 응답 성능을 비약적으로 보전합니다. 캐시 데이터 로드로 부하를 줄일 수 있습니다.
정적인 get_initial_classes()가 캐싱 보전을 사용하는 반면, 사용자가 상호작용하는 get_custom_classes()는 유동적인 업데이트 보전을 위해 의도적으로 캐싱 처리에서 제외됩니다. 수동 제작 분류군 정보는 동적으로 더해지거나 고쳐져야만 하기 때문입니다.
get_video_urls()는 일련의 매칭 동영상 ID들을 접수 후, Twelve Labs REST API를 반복 질의하여 HLS 비디오 스트리밍 주소 목록으로 깔끔하게 변환 출력하는 임무를 성실히 해내며 전송 실패 등 각종 에러 안전망을 제공합니다.
render_video() 또한 뛰어난 하위 범용 웹브라우저 재생 방식을 보증하고자 HLS.js 플러그인 랩퍼 소스를 동적 생성한 후 네이티브 미디어를 실행하지 못하는 단말 환경에서도 훌륭히 재생되도록 돕습니다.
classify_videos()는 마침내 수합 완료된 관조하려 한 관심 분류군 필터 조합을 바탕으로 본 Twelve Labs 인덱스 대상 분류 작업을 실행합니다. 오직 영상의 시각적 행동과 상황(Visual)의 매칭 신호 분석에 타겟을 둡니다.
# Main Function def main(): # Basic Markdown Setup for the Application st.markdown(""" <style> .big-font { font-size: 40px !important; font-weight: bold; color: #000000; text-align: center; margin-bottom: 30px; } .subheader { font-size: 24px; font-weight: bold; color: #424242; margin-top: 20px; margin-bottom: 10px; } .stButton>button { width: 100%; } .video-info { background-color: #f0f0f0; border-radius: 10px; padding: 15px; margin-bottom: 20px; } .custom-box { background-color: #f9f9f9; border-radius: 10px; padding: 20px; margin-bottom: 20px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } .stTabs [data-baseweb="tab-list"] { gap: 24px; } .stTabs [data-baseweb="tab"] { height: 50px; white-space: pre-wrap; background-color: #f0f2f6; border-radius: 4px 4px 0px 0px; gap: 1px; padding-top: 10px; padding-bottom: 10px; } .stTabs [data-baseweb="tab-list"] button[aria-selected="true"] { background-color: #e8eaed; } </style> """, unsafe_allow_html=True) st.markdown('<p class="big-font">Olympics Classification w/t Twelve Labs</p>', unsafe_allow_html=True) # Updation of the classes CLASSES = get_initial_classes() + get_custom_classes() # Nav Tabs Creation tab1, tab2 = st.tabs(["Select Classes", "Add Custom Class"]) with tab1: st.markdown('<p class="subheader">Select Classes</p>', unsafe_allow_html=True) with st.container(): class_names = [cls["name"] for cls in CLASSES] # Multiselect option from the CLASSES selected_classes = st.multiselect("Choose one or more Olympic sports categories:", class_names) if st.button("Classify Videos", key="classify_button"): if selected_classes: with st.spinner("Classifying videos..."): selected_classes_with_prompts = [cls for cls in CLASSES if cls["name"] in selected_classes] res = classify_videos(selected_classes_with_prompts) video_ids = [data.video_id for data in res.data] # Retrieving the video urls from the resultant video which matches to the selected CLASSES video_urls = get_video_urls(video_ids) st.markdown('<p class="subheader">Classified Videos</p>', unsafe_allow_html=True) # Iterating over to showcase the information for every resulatant video for i, video_data in enumerate(res.data, 1): video_id = video_data.video_id video_url = video_urls.get(video_id, "URL not found") st.markdown(f"### Video {i}") st.markdown('<div class="video-info">', unsafe_allow_html=True) st.markdown(f"**Video ID:** {video_id}") for class_data in video_data.classes: st.markdown(f""" **Class:** {class_data.name} - Score: {class_data.score:.2f} - Duration Ratio: {class_data.duration_ratio:.2f} """) if video_url != "URL not found": render_video(video_url) else: st.warning("Video URL not available. Unable to render video.") st.markdown("---") st.success(f"Total videos classified: {len(res.data)}") else: st.warning("Please select at least one class.") st.markdown('</div>', unsafe_allow_html=True) # Nav Tab for the addition of the Custom Classes to select from with tab2: st.markdown('<p class="subheader">Add Custom Class</p>', unsafe_allow_html=True) with st.container(): custom_class_name = st.text_input("Enter custom class name") custom_class_prompts = st.text_input("Enter custom class prompts (comma-separated)") if st.button("Add Custom Class"): if custom_class_name and custom_class_prompts: add_custom_class(custom_class_name, custom_class_prompts.split(',')) st.success(f"Custom class '{custom_class_name}' added successfully!") st.experimental_rerun() else: st.warning("Please enter both class name and prompts.") st.markdown('</div>', unsafe_allow_html=True) if st.session_state.get('new_class_added', False): st.session_state.new_class_added = False st.experimental_rerun() if __name__ == "__main__": main()
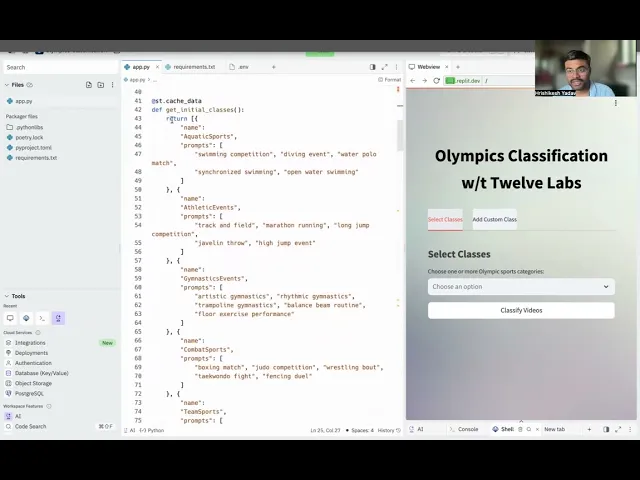
이 애플리케이션의 메인 엔트리 포인트(Main function)는 인터페이스 레이아웃 구성과 매끄러운 반응형 CSS 연동, 제어 핸들러 호출 순서를 잡는데 주력합니다. 사용자는 "Add Custom Class" 탭에서 추가 전용 맞춤 타겟 입력을 받아 수시로 유동적인 추론 범주 확장을 도모할 수 있으며, 준비된 "Select Classes" 탭을 열어 신속한 비디오 분류 가동 범위 정렬을 시도해 볼 수 있습니다.
이제 준비된 사용자가 실제 "Classify Videos" 버튼을 정식 누르면 애플리케이션은 즉시 아래 조치를 실행합니다.
사용자가 선택 보전한 목적 클래스들을 정밀 매칭합니다.
전용 헬퍼 함수(
classify_videos())를 통해 Twelve Labs 클라우드로 질의 검사를 수행합니다.추출 검출된 개별 결과 비디오 고유 HLS 미디어 주소 목록을 즉각 다시 받아옵니다.
신뢰도 지표를 깔끔이 표출하며 미디어를 브라우저 상에 한눈에 재생해 시현합니다.
훌륭히 빌드되어 완성된 비디오 포털의 최종 모습 -

영역을 탐색하기 위한 아이디어 추천
본 튜토리얼을 기반으로 파이프라인과 비디오 인지 성능을 습득하셨다면, 일상이나 비즈니스 내 다양한 분야에 직접 이를 접목하여 새로운 프로젝트를 기획해 보실 수 있습니다. 여기 몇 가지 영감을 제공해 드립니다.
🔍 멀티모달 비디오 검색 포털: 테라바이트급 동영상 라이브러리 속에서 누구나 특정 대화나 인물 행동, 상황만을 지정해 연관 씬을 초단위로 짚어낼 수 있는 커스텀 검색기를 구축할 수 있습니다.
🎥 모니터링 이벤트 감지 분석기: 감시용 카메라 피드 데이터 스트림을 가동하고 이상 상황이나 고유 행동 패턴 등을 똑똑히 잡아내 분류하는 도구를 설계합니다.
💃 모션 및 안무 댄스 코칭 시스템: 트렌디한 챌린지 댄스 영상들에서 시그니처 댄스 동작이나 구체적인 안무 스타일만을 고유 분류하고 지도하는 기제를 구현합니다.
마치며
본 블로그의 핵심 타겟은 올림픽이라는 친숙한 소스를 통해 Twelve Labs 분류 AI 모델을 직접 작동시키며 비디오 분류 엔진의 파이프라인 개발 방법을 아주 현실적이고 알기 쉽게 풀어내는 것이었습니다. 튜토리얼을 즐겁게 수행해 주셔서 기쁩니다. 여러분이 해결해 나갈 다음 세대 비디오 어플리케이션 발상과 더욱 탁월해질 다양한 경험적 개선안들을 한시바삐 만나보고 싶습니다!
올림픽 동영상 영상을 정리하는 것만으로 금메달을 따는 꿈을 꾸어본 적이 있으신가요? 🥇 이제 그 시상대 위에 설 수 있는 기회가 왔습니다!
올림픽 동영상 클립 분류 애플리케이션은 스포츠 영상 분류라는 번거롭고 시간이 많이 걸리는 과정을 간소화하기 위해 설계되었습니다. Twelve Labs의 Marengo 2.6 임베딩 모델을 통해, 이 앱은 비디오 클립 내의 올림픽 스포츠 종목을 빠르게 분류해 냅니다.
화면 상의 텍스트, 음성 대화, 시각 요소를 모두 분석하여 동영상 클립을 손쉽게 카테고리별로 정렬합니다. 본 튜토리얼에서는 연구자, 스포츠 마니아, 방송사 관계자가 올림픽 콘텐츠를 다루는 방식을 완전히 혁신할 Streamlit 애플리케이션 구축 과정을 단계별로 안내합니다. 사용자가 직접 정의한 카테고리에 따라 동영상을 분류하는 앱을 구현하는 방법을 배우게 되며, 상세한 앱 시연 동영상은 아래에서 확인하실 수 있습니다.
애플리케이션 데모는 여기서 직접 실행해 볼 수 있습니다: 올림픽 분류 앱 데모. 또한, 이 Replit 템플릿을 통해 코드를 직접 작동시켜 볼 수도 있습니다.
사전 준비 단계
Twelve Labs Playground에 가입하고 API 키를 생성하세요.
노트북과 본 애플리케이션의 소스 코드가 포함된 GitHub 저장소를 확인하세요.
본 Streamlit 애플리케이션은 Python, HTML, JavaScript를 사용합니다.
애플리케이션 작동 원리
이 섹션에서는 올림픽 비디오 클립 분류를 위한 애플리케이션 파이프라인의 전체적인 흐름을 설명합니다.
이 애플리케이션은 다양한 활용 시나리오를 가진 분류 검색 엔진을 기반으로 개발되었습니다. 여기서는 올림픽 스포츠 동영상 클립을 분류하고 필요한 부분만 검색해 내는 작업에 집중합니다. 가장 핵심적인 첫 단계를 바로 인덱스(Index)를 생성하는 것입니다.
시작하려면 Twelve Labs Playground에 접속하세요.
새 인덱스(New Index)를 생성하고 비디오 인덱싱 및 분류 작업에 최적화된
Marengo 2.6 (Embedding Engine)을 선택합니다.분류하고자 하는 모든 스포츠 비디오를 해당 인덱스에 업로드하고 나면 다음 단계로 진행할 수 있습니다.
아래 섹션에서는 생성된 Index ID를 연동하고 실제로 구현하는 과정을 구체적으로 설명합니다. 먼저 전체적인 애플리케이션 워크플로우를 요약해 드립니다.
사용자는 다중 선택(Multi-select) 메뉴에서 시청하고자 하는 스포츠 카테고리를 직접 선택하거나, 본인만의 맞춤 클래스(Custom class)를 새로 정의하여 추가할 수 있습니다.
선택된 클래스는 해당 인덱스 내의 비디오 클립을 검색하고 분류하기 위해
INDEX ID및 기타 옵션(예:include_clips등)과 함께 classify 엔드포인트로 전송됩니다.API 응답 데이터에는 비디오 ID, 매칭된 클래스 이름, 신뢰도(Confidence Level), 시작 및 종료 시간, 썸네일 URL 등이 함께 포함됩니다.
검색 및 분류 결과로 반환된 비디오 ID의 실제 비디오 스트리밍 URL을 가져오기 위해 비디오 상세 정보 엔드포인트에 전송 요청을 수행하게 됩니다.
기본 준비 사항
Twelve Labs Playground에서 계정을 생성하고 인덱스를 만들어 줍니다.
분류 작업에 가장 적합한 엔진인 Marengo 2.6 (Embedding Engine)을 설정해 줍니다. 이 엔진은 높은 수준의 비디오 검색 및 비디오 분류 성능을 발휘하여 뛰어난 비디오 이해도의 강력한 기반을 제공합니다.
분류할 올림픽 스포츠 동영상을 업로드하세요. 테스트용 영상이 필요하시다면 본 가이드에서 제공하는 샘플 클립인 스포츠 비디오 클립을 다운로드하여 활용해 보세요.
Twelve Labs Playground 대시보드에서 고유 API 키를 복사합니다.
올림픽 클립을 새로 생성해 둔 인덱스 화면에 들어가면 웹 브라우저 주소창에서 고유 인덱스 ID를 확인할 수 있습니다: https://playground.twelvelabs.io/indexes/{index_id}.
메인 애플리케이션 파일과 같은 경로에 API Key와 INDEX_ID 값을 기술한 .env 파일을 생성해 설정해 둡니다.
여기까지 모든 준비 작업이 완료되었다면, 본격적으로 실제 애플리케이션 개발 단계로 넘어가 보겠습니다!
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here INDEX_ID=your_index_id_here
분류 기능 상세 가이드
1 - 라이브러리 임포트, 검증 및 클라이언트 개발 설정
가장 먼저 필요한 라이브러리를 임포트하고 올바른 실행 환경 조성을 위한 환경 변수를 세팅해 줍니다. 다음과 같이 작성합니다.
import os import requests import glob import requests from twelvelabs import TwelveLabs from twelvelabs.models.task import Task import dotenv API_KEY=os.getenv("Twelvelabs_API") API_URL=os.getenv("API_URL") INDEX_ID=os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # URL of the /indexes endpoint INDEXES_URL = f"{API_URL}/indexes" # Setting headers variables default_header = { "x-api-key": API_KEY }
의존성 라이브러리를 성공적으로 가셔왔고, 환경 변수가 정확하게 로드되었으며 대시보드 크리덴셜을 사용해 올바른 API 클라이언트 초기화가 구성되었습니다. 또한, 인덱스에 접근하기 위한 베이스 URL과 API 요청을 위한 기본 헤더 설정도 완료되었습니다.
기초 뼈대가 든든하게 갖춰졌으므로, 이제 인덱스 제어 및 보다 정밀한 스포츠 비디오 분류 작업에 착수해 보겠습니다.
2 - 분류 클래스 그룹 설정하기
올림픽 스포츠 영상 클립들을 체계적으로 분류하는 데 사용할 기본 클래스(카테고리명 및 관련 프롬프트 조합) 목록은 다음과 같습니다.
# Categories for the classification of the Olympics Sports CLASSES = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] }, { "name": "AthleticEvents", "prompts": [ "track and field", "marathon running", "long jump competition", "javelin throw", "high jump event" ] }, { "name": "GymnasticsEvents", "prompts": [ "artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance" ] }, { "name": "CombatSports", "prompts": [ "boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel" ] }, { "name": "TeamSports", "prompts": [ "basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition" ] }, { "name": "CyclingSports", "prompts": [ "road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial" ] }, { "name": "RacquetSports", "prompts": [ "tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match" ] }, { "name": "RowingAndSailing", "prompts": [ "rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition" ] } ]
3 - 특정 인덱스 내 검색된 모든 동영상을 분류하는 유틸리티 함수
# Utility function def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} clips={cl.clips.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASSES, include_clips=True )
실제 분류를 트리거하기 위해 client.classify.index() 메소드를 노출해 호출합니다. 사전에 설정해 둔 INDEX_ID 값과 함께 비디오 내 시각 정보(options=["visual"])를 참조하도록 구성하고 메타데이터로 각 타임스탬프 기반 Clip 상세 내역도 응답에 반환받도록 처리합니다. 분류 타겟 배열로는 구성해둔 CLASSES를 제공합니다.
print_page(result) 헬프 메소드는 이러한 반환 결과들을 가독성 높은 출력 형식으로 나타내어 줍니다. 비디오 루프를 돌며 video_id를 출력하고, 매칭된 분류명 가각의 스코어 점수, 해당 스포츠가 재생된 전체 듀레이션 비율(Duration Ratio), 그리고 개별 비디오 클립 데이터들의 구조화된 상태 리스트를 프린트해 결과를 명확히 확인하도록 돕습니다.
4 - 정돈된 형태로 분류 스코어 결과를 표출해 주는 출력 핸들러 작성
print_classification_result() 헬퍼는 Twelve Labs API의 최종 비디오 감별 결과 구조 데이터를 사람이 인지하기 가장 쉬운 형태로 가시화합니다. 각 비디오 소스를 반복 순회하며 대상 ID, 감지된 최종 카테고리 정보 및 매칭 점수를 시각적으로 정리합니다. 또한 각 클래스별 신뢰 점수와 구간 점유 비중을 정밀하게 추출하며, 각 비디오 내부에서 발견된 가장 연관성이 우수한 상위 5개의 세부 클립 목록을 우선 정렬해 각각 시작/끝 시점, 그리고 매칭 유도가 이뤄진 CLASSES 프롬프트를 깔끔하게 화면에 찍어 줍니다. 5개 이상의 상세 검출 클립이 더 존재하면 생략 카운팅도 알려줍니다.
def print_classification_result(result) -> None: for video_data in result.data: print(f"Video ID: {video_data.video_id}") print("=" * 50) for class_data in video_data.classes: print(f" Class: {class_data.name}") print(f" Score: {class_data.score:.2f}") print(f" Duration Ratio: {class_data.duration_ratio:.2f}") print(" Clips:") sorted_clips = sorted(class_data.clips, key=lambda x: x.score, reverse=True) for i, clip in enumerate(sorted_clips[:5], 1): # Print top 5 clips print(f" {i}. Score: {clip.score:.2f}") print(f" Start: {clip.start:.2f}s, End: {clip.end:.2f}s") print(f" Prompt: {clip.prompt}") if len(sorted_clips) > 5: print(f" ... and {len(sorted_clips) - 5} more clips") print("-" * 40) print("\n") print(f"Total results: {result.page_info.total_results}") print(f"Page expires at: {result.page_info.page_expired_at}") print(f"Next page token: {result.page_info.next_page_token}")
위의 실행 결과 예시는 다음과 같습니다 -
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
5 - 인덱스 내 전체 동영상에서 특정 스포츠 종류만 정밀 구분하기
특정 클래스 전용 필터 적용 테스트를 위해, 전체 업로드 파일 중 오직 "수상 스포츠(AquaticSports)" 관련 콘텐츠만 콕 집어내는 분류를 예시로 보겠습니다. 절차는 매우 직관적입니다. 타겟 클래스명과 매핑 프롬프트 범주를 단독 지정해 API 호출을 던진 후, 결과만 걸러서 관측해 봅니다.
이렇듯 목적이 명료하게 좁혀진 검사는 해당 스포츠가 등장한 핵심 영상을 찾는 데 한층 더 정확하고 고품질의 감별 성과를 보장합니다. 간이 디버깅용 도구인 print_page()가 분류된 원시 결과를 요약하여 출력해 줍니다.
CLASS = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] } ] def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} detailed_scores={cl.detailed_scores.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASS, include_clips=True, show_detailed_score=True ) print_classification_result(result)
위 코드의 실행 결과 데이터를 보면 지정된 대상 CLASS인 수상 스포츠 검사 범주에 명확하게 들어맞는 올림픽 비디오들이 나열됩니다.
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
Twelve Labs 공식 SDK를 사용하여 분류 엔드포인트를 효과적으로 다루고 조율하는 방법을 마스터하셨으니, 이제 실사용자를 위한 어진 가독성을 갖춘 Streamlit 전체 애플리케이션 프레젠테이션 설계 단계로 넘어가 보겠습니다.
Streamlit 기반 웹 애플리케이션 구축
본 시스템의 웹 프로토타입 구현 환경으로는 심플한 설정과 놀라운 초고속 MVP 도출 생산성을 자랑하는 Streamlit을 낙점했습니다. 단 몇 줄의 직관적인 코드로 뛰어난 대화형 인터랙티브 웹 포털 화면을 찍어낼 수 있어 비디오 인공지능 분류 결과를 깔끔하게 보여주기 가장 안성맞춤입니다. Twelve Labs SDK와 연동하면 단 수 분 이내에 근사한 웹 GUI를 만들 수 있습니다.
Streamlit 실행에 앞서 개발 가상 환경이 제대로 켜져 있는지 체크한 주 아래 쉘 명령어를 기동해 의존성 모듈 설치를 진행합니다.
pip install streamlit
보다 다양한 프레임워크 핵심 팁을 보시려면, 공식 Streamlit 설명서 웹사이트를 확인하세요.
프로젝트 구성을 위해 다음과 같이 디렉터리와 파일을 레이아웃하여 소스를 생성합니다.
. ├── .env ├── app.py ├── requirements.txt └── .gitignore
이 중 프로젝트 의존 패키지를 서술할 requirements.txt의 내용물은 아래와 같습니다.
streamlit twelvelabs requests python-dotenv
이 짧은 몇 줄의 환경 추가로 스포츠 영상 분류기를 돌려줄 백앤드 구조 준비가 완료되었습니다.
메인 실행파일인 app.py에는 핵심적인 제어 기능 블록들이 명쾌하게 탑재됩니다.
get_initial_classes(): 시스템에 사전에 장착될 올림픽 전용 스포츠 카테고리를 자동 맵핑합니다.get_custom_classes()및add_custom_class(): 사용자 임의로 더 유연하게 탐지 필터를 개량/확장해 맞춤 타겟을 올릴 수 있게 지원하는 조력 함수입니다.classify_videos(): 입력받은 분석 기준 배열을 기반으로 인공지능이 추론을 시작하도록 Twelve Labs API 서버와 원활히 교신합니다.get_video_urls(): 정확히 일치하거나 분류된 대상 고유 Video ID들로부터 실시간 영상 주소를 조회하여 리턴합니다.render_video(): 사용자 웹 브라우저에서 끊김에 대처 가능한 HLS.js 플러그인 연동 HTML5 플레이어 쉘을 동적 마운트합니다.
# Import Necessary Dependencies import streamlit as st from twelvelabs import TwelveLabs import requests import os from dotenv import load_dotenv load_dotenv() # Get the API Key from the Dashboard - https://playground.twelvelabs.io/dashboard/api-key API_KEY = os.getenv("API_KEY") # Create the INDEX ID as specified in the README.md and get the INDEX_ID INDEX_ID = os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # Background Setting of the Application page_element = """ <style> [data-testid="stAppViewContainer"] { background-image: url("https://wallpapercave.com/wp/wp3589963.jpg"); background-size: cover; } [data-testid="stHeader"] { background-color: rgba(0,0,0,0); } [data-testid="stToolbar"] { right: 2rem; background-image: url(""); background-size: cover; } </style> """ st.markdown(page_element, unsafe_allow_html=True) # Classes to classify the video into, there are categories name and # the prompts which specifc finds that factor to label that category @st.cache_data def get_initial_classes(): return [ {"name": "AquaticSports", "prompts": ["swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming"]}, {"name": "AthleticEvents", "prompts": ["track and field", "marathon running", "long jump competition", "javelin throw", "high jump event"]}, {"name": "GymnasticsEvents", "prompts": ["artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance"]}, {"name": "CombatSports", "prompts": ["boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel"]}, {"name": "TeamSports", "prompts": ["basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition"]}, {"name": "CyclingSports", "prompts": ["road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial"]}, {"name": "RacquetSports", "prompts": ["tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match"]}, {"name": "RowingAndSailing", "prompts": ["rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition"]} ] # Session State for the custom classes def get_custom_classes(): if 'custom_classes' not in st.session_state: st.session_state.custom_classes = [] return st.session_state.custom_classes # Utitlity Function to add the custom classes in app def add_custom_class(name, prompts): custom_classes = get_custom_classes() custom_classes.append({"name": name, "prompts": prompts}) st.session_state.custom_classes = custom_classes st.session_state.new_class_added = True # Utitlity Function to classify all the videos in the specified Index def classify_videos(selected_classes): return client.classify.index( index_id=INDEX_ID, options=["visual"], classes=selected_classes, include_clips=True ) # To get the video urls from the resultant video id def get_video_urls(video_ids): base_url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{{}}" headers = {"x-api-key": API_KEY, "Content-Type": "application/json"} video_urls = {} for video_id in video_ids: try: response = requests.get(base_url.format(video_id), headers=headers) response.raise_for_status() data = response.json() if 'hls' in data and 'video_url' in data['hls']: video_urls[video_id] = data['hls']['video_url'] else: st.warning(f"No video URL found for video ID: {video_id}") except requests.exceptions.RequestException as e: st.error(f"Failed to get data for video ID: {video_id}. Error: {str(e)}") return video_urls # Utitlity Function to Render the Video by the resultant video url def render_video(video_url): hls_player = f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <div style="width: 100%; border-radius: 10px; overflow: hidden; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);"> <video id="video" controls style="width: 100%; height: auto;"></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """ st.components.v1.html(hls_player, height=300)
get_initial_classes() 정적 메서드는 변경되지 않을 올림픽 전역 운동 종목 대상을 전달합니다. Streamlit은 똑똑하게 이 데이터를 즉각 캐싱 처리해, 시스템 구동 중 한 번만 이 구조체 평가가 일어나도록 제어하여 응답 성능을 비약적으로 보전합니다. 캐시 데이터 로드로 부하를 줄일 수 있습니다.
정적인 get_initial_classes()가 캐싱 보전을 사용하는 반면, 사용자가 상호작용하는 get_custom_classes()는 유동적인 업데이트 보전을 위해 의도적으로 캐싱 처리에서 제외됩니다. 수동 제작 분류군 정보는 동적으로 더해지거나 고쳐져야만 하기 때문입니다.
get_video_urls()는 일련의 매칭 동영상 ID들을 접수 후, Twelve Labs REST API를 반복 질의하여 HLS 비디오 스트리밍 주소 목록으로 깔끔하게 변환 출력하는 임무를 성실히 해내며 전송 실패 등 각종 에러 안전망을 제공합니다.
render_video() 또한 뛰어난 하위 범용 웹브라우저 재생 방식을 보증하고자 HLS.js 플러그인 랩퍼 소스를 동적 생성한 후 네이티브 미디어를 실행하지 못하는 단말 환경에서도 훌륭히 재생되도록 돕습니다.
classify_videos()는 마침내 수합 완료된 관조하려 한 관심 분류군 필터 조합을 바탕으로 본 Twelve Labs 인덱스 대상 분류 작업을 실행합니다. 오직 영상의 시각적 행동과 상황(Visual)의 매칭 신호 분석에 타겟을 둡니다.
# Main Function def main(): # Basic Markdown Setup for the Application st.markdown(""" <style> .big-font { font-size: 40px !important; font-weight: bold; color: #000000; text-align: center; margin-bottom: 30px; } .subheader { font-size: 24px; font-weight: bold; color: #424242; margin-top: 20px; margin-bottom: 10px; } .stButton>button { width: 100%; } .video-info { background-color: #f0f0f0; border-radius: 10px; padding: 15px; margin-bottom: 20px; } .custom-box { background-color: #f9f9f9; border-radius: 10px; padding: 20px; margin-bottom: 20px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } .stTabs [data-baseweb="tab-list"] { gap: 24px; } .stTabs [data-baseweb="tab"] { height: 50px; white-space: pre-wrap; background-color: #f0f2f6; border-radius: 4px 4px 0px 0px; gap: 1px; padding-top: 10px; padding-bottom: 10px; } .stTabs [data-baseweb="tab-list"] button[aria-selected="true"] { background-color: #e8eaed; } </style> """, unsafe_allow_html=True) st.markdown('<p class="big-font">Olympics Classification w/t Twelve Labs</p>', unsafe_allow_html=True) # Updation of the classes CLASSES = get_initial_classes() + get_custom_classes() # Nav Tabs Creation tab1, tab2 = st.tabs(["Select Classes", "Add Custom Class"]) with tab1: st.markdown('<p class="subheader">Select Classes</p>', unsafe_allow_html=True) with st.container(): class_names = [cls["name"] for cls in CLASSES] # Multiselect option from the CLASSES selected_classes = st.multiselect("Choose one or more Olympic sports categories:", class_names) if st.button("Classify Videos", key="classify_button"): if selected_classes: with st.spinner("Classifying videos..."): selected_classes_with_prompts = [cls for cls in CLASSES if cls["name"] in selected_classes] res = classify_videos(selected_classes_with_prompts) video_ids = [data.video_id for data in res.data] # Retrieving the video urls from the resultant video which matches to the selected CLASSES video_urls = get_video_urls(video_ids) st.markdown('<p class="subheader">Classified Videos</p>', unsafe_allow_html=True) # Iterating over to showcase the information for every resulatant video for i, video_data in enumerate(res.data, 1): video_id = video_data.video_id video_url = video_urls.get(video_id, "URL not found") st.markdown(f"### Video {i}") st.markdown('<div class="video-info">', unsafe_allow_html=True) st.markdown(f"**Video ID:** {video_id}") for class_data in video_data.classes: st.markdown(f""" **Class:** {class_data.name} - Score: {class_data.score:.2f} - Duration Ratio: {class_data.duration_ratio:.2f} """) if video_url != "URL not found": render_video(video_url) else: st.warning("Video URL not available. Unable to render video.") st.markdown("---") st.success(f"Total videos classified: {len(res.data)}") else: st.warning("Please select at least one class.") st.markdown('</div>', unsafe_allow_html=True) # Nav Tab for the addition of the Custom Classes to select from with tab2: st.markdown('<p class="subheader">Add Custom Class</p>', unsafe_allow_html=True) with st.container(): custom_class_name = st.text_input("Enter custom class name") custom_class_prompts = st.text_input("Enter custom class prompts (comma-separated)") if st.button("Add Custom Class"): if custom_class_name and custom_class_prompts: add_custom_class(custom_class_name, custom_class_prompts.split(',')) st.success(f"Custom class '{custom_class_name}' added successfully!") st.experimental_rerun() else: st.warning("Please enter both class name and prompts.") st.markdown('</div>', unsafe_allow_html=True) if st.session_state.get('new_class_added', False): st.session_state.new_class_added = False st.experimental_rerun() if __name__ == "__main__": main()
이 애플리케이션의 메인 엔트리 포인트(Main function)는 인터페이스 레이아웃 구성과 매끄러운 반응형 CSS 연동, 제어 핸들러 호출 순서를 잡는데 주력합니다. 사용자는 "Add Custom Class" 탭에서 추가 전용 맞춤 타겟 입력을 받아 수시로 유동적인 추론 범주 확장을 도모할 수 있으며, 준비된 "Select Classes" 탭을 열어 신속한 비디오 분류 가동 범위 정렬을 시도해 볼 수 있습니다.
이제 준비된 사용자가 실제 "Classify Videos" 버튼을 정식 누르면 애플리케이션은 즉시 아래 조치를 실행합니다.
사용자가 선택 보전한 목적 클래스들을 정밀 매칭합니다.
전용 헬퍼 함수(
classify_videos())를 통해 Twelve Labs 클라우드로 질의 검사를 수행합니다.추출 검출된 개별 결과 비디오 고유 HLS 미디어 주소 목록을 즉각 다시 받아옵니다.
신뢰도 지표를 깔끔이 표출하며 미디어를 브라우저 상에 한눈에 재생해 시현합니다.
훌륭히 빌드되어 완성된 비디오 포털의 최종 모습 -
영역을 탐색하기 위한 아이디어 추천
본 튜토리얼을 기반으로 파이프라인과 비디오 인지 성능을 습득하셨다면, 일상이나 비즈니스 내 다양한 분야에 직접 이를 접목하여 새로운 프로젝트를 기획해 보실 수 있습니다. 여기 몇 가지 영감을 제공해 드립니다.
🔍 멀티모달 비디오 검색 포털: 테라바이트급 동영상 라이브러리 속에서 누구나 특정 대화나 인물 행동, 상황만을 지정해 연관 씬을 초단위로 짚어낼 수 있는 커스텀 검색기를 구축할 수 있습니다.
🎥 모니터링 이벤트 감지 분석기: 감시용 카메라 피드 데이터 스트림을 가동하고 이상 상황이나 고유 행동 패턴 등을 똑똑히 잡아내 분류하는 도구를 설계합니다.
💃 모션 및 안무 댄스 코칭 시스템: 트렌디한 챌린지 댄스 영상들에서 시그니처 댄스 동작이나 구체적인 안무 스타일만을 고유 분류하고 지도하는 기제를 구현합니다.
마치며
본 블로그의 핵심 타겟은 올림픽이라는 친숙한 소스를 통해 Twelve Labs 분류 AI 모델을 직접 작동시키며 비디오 분류 엔진의 파이프라인 개발 방법을 아주 현실적이고 알기 쉽게 풀어내는 것이었습니다. 튜토리얼을 즐겁게 수행해 주셔서 기쁩니다. 여러분이 해결해 나갈 다음 세대 비디오 어플리케이션 발상과 더욱 탁월해질 다양한 경험적 개선안들을 한시바삐 만나보고 싶습니다!
올림픽 동영상 영상을 정리하는 것만으로 금메달을 따는 꿈을 꾸어본 적이 있으신가요? 🥇 이제 그 시상대 위에 설 수 있는 기회가 왔습니다!
올림픽 동영상 클립 분류 애플리케이션은 스포츠 영상 분류라는 번거롭고 시간이 많이 걸리는 과정을 간소화하기 위해 설계되었습니다. Twelve Labs의 Marengo 2.6 임베딩 모델을 통해, 이 앱은 비디오 클립 내의 올림픽 스포츠 종목을 빠르게 분류해 냅니다.
화면 상의 텍스트, 음성 대화, 시각 요소를 모두 분석하여 동영상 클립을 손쉽게 카테고리별로 정렬합니다. 본 튜토리얼에서는 연구자, 스포츠 마니아, 방송사 관계자가 올림픽 콘텐츠를 다루는 방식을 완전히 혁신할 Streamlit 애플리케이션 구축 과정을 단계별로 안내합니다. 사용자가 직접 정의한 카테고리에 따라 동영상을 분류하는 앱을 구현하는 방법을 배우게 되며, 상세한 앱 시연 동영상은 아래에서 확인하실 수 있습니다.
애플리케이션 데모는 여기서 직접 실행해 볼 수 있습니다: 올림픽 분류 앱 데모. 또한, 이 Replit 템플릿을 통해 코드를 직접 작동시켜 볼 수도 있습니다.
사전 준비 단계
Twelve Labs Playground에 가입하고 API 키를 생성하세요.
노트북과 본 애플리케이션의 소스 코드가 포함된 GitHub 저장소를 확인하세요.
본 Streamlit 애플리케이션은 Python, HTML, JavaScript를 사용합니다.
애플리케이션 작동 원리
이 섹션에서는 올림픽 비디오 클립 분류를 위한 애플리케이션 파이프라인의 전체적인 흐름을 설명합니다.
이 애플리케이션은 다양한 활용 시나리오를 가진 분류 검색 엔진을 기반으로 개발되었습니다. 여기서는 올림픽 스포츠 동영상 클립을 분류하고 필요한 부분만 검색해 내는 작업에 집중합니다. 가장 핵심적인 첫 단계를 바로 인덱스(Index)를 생성하는 것입니다.
시작하려면 Twelve Labs Playground에 접속하세요.
새 인덱스(New Index)를 생성하고 비디오 인덱싱 및 분류 작업에 최적화된
Marengo 2.6 (Embedding Engine)을 선택합니다.분류하고자 하는 모든 스포츠 비디오를 해당 인덱스에 업로드하고 나면 다음 단계로 진행할 수 있습니다.
아래 섹션에서는 생성된 Index ID를 연동하고 실제로 구현하는 과정을 구체적으로 설명합니다. 먼저 전체적인 애플리케이션 워크플로우를 요약해 드립니다.
사용자는 다중 선택(Multi-select) 메뉴에서 시청하고자 하는 스포츠 카테고리를 직접 선택하거나, 본인만의 맞춤 클래스(Custom class)를 새로 정의하여 추가할 수 있습니다.
선택된 클래스는 해당 인덱스 내의 비디오 클립을 검색하고 분류하기 위해
INDEX ID및 기타 옵션(예:include_clips등)과 함께 classify 엔드포인트로 전송됩니다.API 응답 데이터에는 비디오 ID, 매칭된 클래스 이름, 신뢰도(Confidence Level), 시작 및 종료 시간, 썸네일 URL 등이 함께 포함됩니다.
검색 및 분류 결과로 반환된 비디오 ID의 실제 비디오 스트리밍 URL을 가져오기 위해 비디오 상세 정보 엔드포인트에 전송 요청을 수행하게 됩니다.
기본 준비 사항
Twelve Labs Playground에서 계정을 생성하고 인덱스를 만들어 줍니다.
분류 작업에 가장 적합한 엔진인 Marengo 2.6 (Embedding Engine)을 설정해 줍니다. 이 엔진은 높은 수준의 비디오 검색 및 비디오 분류 성능을 발휘하여 뛰어난 비디오 이해도의 강력한 기반을 제공합니다.
분류할 올림픽 스포츠 동영상을 업로드하세요. 테스트용 영상이 필요하시다면 본 가이드에서 제공하는 샘플 클립인 스포츠 비디오 클립을 다운로드하여 활용해 보세요.
Twelve Labs Playground 대시보드에서 고유 API 키를 복사합니다.
올림픽 클립을 새로 생성해 둔 인덱스 화면에 들어가면 웹 브라우저 주소창에서 고유 인덱스 ID를 확인할 수 있습니다: https://playground.twelvelabs.io/indexes/{index_id}.
메인 애플리케이션 파일과 같은 경로에 API Key와 INDEX_ID 값을 기술한 .env 파일을 생성해 설정해 둡니다.
여기까지 모든 준비 작업이 완료되었다면, 본격적으로 실제 애플리케이션 개발 단계로 넘어가 보겠습니다!
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here INDEX_ID=your_index_id_here
분류 기능 상세 가이드
1 - 라이브러리 임포트, 검증 및 클라이언트 개발 설정
가장 먼저 필요한 라이브러리를 임포트하고 올바른 실행 환경 조성을 위한 환경 변수를 세팅해 줍니다. 다음과 같이 작성합니다.
import os import requests import glob import requests from twelvelabs import TwelveLabs from twelvelabs.models.task import Task import dotenv API_KEY=os.getenv("Twelvelabs_API") API_URL=os.getenv("API_URL") INDEX_ID=os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # URL of the /indexes endpoint INDEXES_URL = f"{API_URL}/indexes" # Setting headers variables default_header = { "x-api-key": API_KEY }
의존성 라이브러리를 성공적으로 가셔왔고, 환경 변수가 정확하게 로드되었으며 대시보드 크리덴셜을 사용해 올바른 API 클라이언트 초기화가 구성되었습니다. 또한, 인덱스에 접근하기 위한 베이스 URL과 API 요청을 위한 기본 헤더 설정도 완료되었습니다.
기초 뼈대가 든든하게 갖춰졌으므로, 이제 인덱스 제어 및 보다 정밀한 스포츠 비디오 분류 작업에 착수해 보겠습니다.
2 - 분류 클래스 그룹 설정하기
올림픽 스포츠 영상 클립들을 체계적으로 분류하는 데 사용할 기본 클래스(카테고리명 및 관련 프롬프트 조합) 목록은 다음과 같습니다.
# Categories for the classification of the Olympics Sports CLASSES = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] }, { "name": "AthleticEvents", "prompts": [ "track and field", "marathon running", "long jump competition", "javelin throw", "high jump event" ] }, { "name": "GymnasticsEvents", "prompts": [ "artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance" ] }, { "name": "CombatSports", "prompts": [ "boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel" ] }, { "name": "TeamSports", "prompts": [ "basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition" ] }, { "name": "CyclingSports", "prompts": [ "road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial" ] }, { "name": "RacquetSports", "prompts": [ "tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match" ] }, { "name": "RowingAndSailing", "prompts": [ "rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition" ] } ]
3 - 특정 인덱스 내 검색된 모든 동영상을 분류하는 유틸리티 함수
# Utility function def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} clips={cl.clips.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASSES, include_clips=True )
실제 분류를 트리거하기 위해 client.classify.index() 메소드를 노출해 호출합니다. 사전에 설정해 둔 INDEX_ID 값과 함께 비디오 내 시각 정보(options=["visual"])를 참조하도록 구성하고 메타데이터로 각 타임스탬프 기반 Clip 상세 내역도 응답에 반환받도록 처리합니다. 분류 타겟 배열로는 구성해둔 CLASSES를 제공합니다.
print_page(result) 헬프 메소드는 이러한 반환 결과들을 가독성 높은 출력 형식으로 나타내어 줍니다. 비디오 루프를 돌며 video_id를 출력하고, 매칭된 분류명 가각의 스코어 점수, 해당 스포츠가 재생된 전체 듀레이션 비율(Duration Ratio), 그리고 개별 비디오 클립 데이터들의 구조화된 상태 리스트를 프린트해 결과를 명확히 확인하도록 돕습니다.
4 - 정돈된 형태로 분류 스코어 결과를 표출해 주는 출력 핸들러 작성
print_classification_result() 헬퍼는 Twelve Labs API의 최종 비디오 감별 결과 구조 데이터를 사람이 인지하기 가장 쉬운 형태로 가시화합니다. 각 비디오 소스를 반복 순회하며 대상 ID, 감지된 최종 카테고리 정보 및 매칭 점수를 시각적으로 정리합니다. 또한 각 클래스별 신뢰 점수와 구간 점유 비중을 정밀하게 추출하며, 각 비디오 내부에서 발견된 가장 연관성이 우수한 상위 5개의 세부 클립 목록을 우선 정렬해 각각 시작/끝 시점, 그리고 매칭 유도가 이뤄진 CLASSES 프롬프트를 깔끔하게 화면에 찍어 줍니다. 5개 이상의 상세 검출 클립이 더 존재하면 생략 카운팅도 알려줍니다.
def print_classification_result(result) -> None: for video_data in result.data: print(f"Video ID: {video_data.video_id}") print("=" * 50) for class_data in video_data.classes: print(f" Class: {class_data.name}") print(f" Score: {class_data.score:.2f}") print(f" Duration Ratio: {class_data.duration_ratio:.2f}") print(" Clips:") sorted_clips = sorted(class_data.clips, key=lambda x: x.score, reverse=True) for i, clip in enumerate(sorted_clips[:5], 1): # Print top 5 clips print(f" {i}. Score: {clip.score:.2f}") print(f" Start: {clip.start:.2f}s, End: {clip.end:.2f}s") print(f" Prompt: {clip.prompt}") if len(sorted_clips) > 5: print(f" ... and {len(sorted_clips) - 5} more clips") print("-" * 40) print("\n") print(f"Total results: {result.page_info.total_results}") print(f"Page expires at: {result.page_info.page_expired_at}") print(f"Next page token: {result.page_info.next_page_token}")
위의 실행 결과 예시는 다음과 같습니다 -
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
5 - 인덱스 내 전체 동영상에서 특정 스포츠 종류만 정밀 구분하기
특정 클래스 전용 필터 적용 테스트를 위해, 전체 업로드 파일 중 오직 "수상 스포츠(AquaticSports)" 관련 콘텐츠만 콕 집어내는 분류를 예시로 보겠습니다. 절차는 매우 직관적입니다. 타겟 클래스명과 매핑 프롬프트 범주를 단독 지정해 API 호출을 던진 후, 결과만 걸러서 관측해 봅니다.
이렇듯 목적이 명료하게 좁혀진 검사는 해당 스포츠가 등장한 핵심 영상을 찾는 데 한층 더 정확하고 고품질의 감별 성과를 보장합니다. 간이 디버깅용 도구인 print_page()가 분류된 원시 결과를 요약하여 출력해 줍니다.
CLASS = [ { "name": "AquaticSports", "prompts": [ "swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming" ] } ] def print_page(page): for data in page: print(f"video_id={data.video_id}") for cl in data.classes: print( f" name={cl.name} score={cl.score} duration_ratio={cl.duration_ratio} detailed_scores={cl.detailed_scores.model_dump_json(indent=2)}" ) result = client.classify.index( index_id=INDEX_ID, options=["visual"], classes=CLASS, include_clips=True, show_detailed_score=True ) print_classification_result(result)
위 코드의 실행 결과 데이터를 보면 지정된 대상 CLASS인 수상 스포츠 검사 범주에 명확하게 들어맞는 올림픽 비디오들이 나열됩니다.
Video ID: 66c9b03be53394f4aaed82c1 ================================================== Class: AquaticSports Score: 96.08 Duration Ratio: 0.90 Clips: 1. Score: 85.74 Start: 19.30s, End: 42.00s Prompt: water polo match 2. Score: 85.38 Start: 56.30s, End: 160.41s Prompt: water polo match 3. Score: 85.25 Start: 19.30s, End: 124.07s Prompt: synchronized swimming 4. Score: 85.13 Start: 0.00s, End: 24.83s Prompt: swimming competition 5. Score: 85.08 Start: 124.10s, End: 160.41s Prompt: synchronized swimming ... and 19 more clips
Twelve Labs 공식 SDK를 사용하여 분류 엔드포인트를 효과적으로 다루고 조율하는 방법을 마스터하셨으니, 이제 실사용자를 위한 어진 가독성을 갖춘 Streamlit 전체 애플리케이션 프레젠테이션 설계 단계로 넘어가 보겠습니다.
Streamlit 기반 웹 애플리케이션 구축
본 시스템의 웹 프로토타입 구현 환경으로는 심플한 설정과 놀라운 초고속 MVP 도출 생산성을 자랑하는 Streamlit을 낙점했습니다. 단 몇 줄의 직관적인 코드로 뛰어난 대화형 인터랙티브 웹 포털 화면을 찍어낼 수 있어 비디오 인공지능 분류 결과를 깔끔하게 보여주기 가장 안성맞춤입니다. Twelve Labs SDK와 연동하면 단 수 분 이내에 근사한 웹 GUI를 만들 수 있습니다.
Streamlit 실행에 앞서 개발 가상 환경이 제대로 켜져 있는지 체크한 주 아래 쉘 명령어를 기동해 의존성 모듈 설치를 진행합니다.
pip install streamlit
보다 다양한 프레임워크 핵심 팁을 보시려면, 공식 Streamlit 설명서 웹사이트를 확인하세요.
프로젝트 구성을 위해 다음과 같이 디렉터리와 파일을 레이아웃하여 소스를 생성합니다.
. ├── .env ├── app.py ├── requirements.txt └── .gitignore
이 중 프로젝트 의존 패키지를 서술할 requirements.txt의 내용물은 아래와 같습니다.
streamlit twelvelabs requests python-dotenv
이 짧은 몇 줄의 환경 추가로 스포츠 영상 분류기를 돌려줄 백앤드 구조 준비가 완료되었습니다.
메인 실행파일인 app.py에는 핵심적인 제어 기능 블록들이 명쾌하게 탑재됩니다.
get_initial_classes(): 시스템에 사전에 장착될 올림픽 전용 스포츠 카테고리를 자동 맵핑합니다.get_custom_classes()및add_custom_class(): 사용자 임의로 더 유연하게 탐지 필터를 개량/확장해 맞춤 타겟을 올릴 수 있게 지원하는 조력 함수입니다.classify_videos(): 입력받은 분석 기준 배열을 기반으로 인공지능이 추론을 시작하도록 Twelve Labs API 서버와 원활히 교신합니다.get_video_urls(): 정확히 일치하거나 분류된 대상 고유 Video ID들로부터 실시간 영상 주소를 조회하여 리턴합니다.render_video(): 사용자 웹 브라우저에서 끊김에 대처 가능한 HLS.js 플러그인 연동 HTML5 플레이어 쉘을 동적 마운트합니다.
# Import Necessary Dependencies import streamlit as st from twelvelabs import TwelveLabs import requests import os from dotenv import load_dotenv load_dotenv() # Get the API Key from the Dashboard - https://playground.twelvelabs.io/dashboard/api-key API_KEY = os.getenv("API_KEY") # Create the INDEX ID as specified in the README.md and get the INDEX_ID INDEX_ID = os.getenv("INDEX_ID") client = TwelveLabs(api_key=API_KEY) # Background Setting of the Application page_element = """ <style> [data-testid="stAppViewContainer"] { background-image: url("https://wallpapercave.com/wp/wp3589963.jpg"); background-size: cover; } [data-testid="stHeader"] { background-color: rgba(0,0,0,0); } [data-testid="stToolbar"] { right: 2rem; background-image: url(""); background-size: cover; } </style> """ st.markdown(page_element, unsafe_allow_html=True) # Classes to classify the video into, there are categories name and # the prompts which specifc finds that factor to label that category @st.cache_data def get_initial_classes(): return [ {"name": "AquaticSports", "prompts": ["swimming competition", "diving event", "water polo match", "synchronized swimming", "open water swimming"]}, {"name": "AthleticEvents", "prompts": ["track and field", "marathon running", "long jump competition", "javelin throw", "high jump event"]}, {"name": "GymnasticsEvents", "prompts": ["artistic gymnastics", "rhythmic gymnastics", "trampoline gymnastics", "balance beam routine", "floor exercise performance"]}, {"name": "CombatSports", "prompts": ["boxing match", "judo competition", "wrestling bout", "taekwondo fight", "fencing duel"]}, {"name": "TeamSports", "prompts": ["basketball game", "volleyball match", "football (soccer) match", "handball game", "field hockey competition"]}, {"name": "CyclingSports", "prompts": ["road cycling race", "track cycling event", "mountain bike competition", "BMX racing", "cycling time trial"]}, {"name": "RacquetSports", "prompts": ["tennis match", "badminton game", "table tennis competition", "squash game", "tennis doubles match"]}, {"name": "RowingAndSailing", "prompts": ["rowing competition", "sailing race", "canoe sprint", "kayak event", "windsurfing competition"]} ] # Session State for the custom classes def get_custom_classes(): if 'custom_classes' not in st.session_state: st.session_state.custom_classes = [] return st.session_state.custom_classes # Utitlity Function to add the custom classes in app def add_custom_class(name, prompts): custom_classes = get_custom_classes() custom_classes.append({"name": name, "prompts": prompts}) st.session_state.custom_classes = custom_classes st.session_state.new_class_added = True # Utitlity Function to classify all the videos in the specified Index def classify_videos(selected_classes): return client.classify.index( index_id=INDEX_ID, options=["visual"], classes=selected_classes, include_clips=True ) # To get the video urls from the resultant video id def get_video_urls(video_ids): base_url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{{}}" headers = {"x-api-key": API_KEY, "Content-Type": "application/json"} video_urls = {} for video_id in video_ids: try: response = requests.get(base_url.format(video_id), headers=headers) response.raise_for_status() data = response.json() if 'hls' in data and 'video_url' in data['hls']: video_urls[video_id] = data['hls']['video_url'] else: st.warning(f"No video URL found for video ID: {video_id}") except requests.exceptions.RequestException as e: st.error(f"Failed to get data for video ID: {video_id}. Error: {str(e)}") return video_urls # Utitlity Function to Render the Video by the resultant video url def render_video(video_url): hls_player = f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <div style="width: 100%; border-radius: 10px; overflow: hidden; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);"> <video id="video" controls style="width: 100%; height: auto;"></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """ st.components.v1.html(hls_player, height=300)
get_initial_classes() 정적 메서드는 변경되지 않을 올림픽 전역 운동 종목 대상을 전달합니다. Streamlit은 똑똑하게 이 데이터를 즉각 캐싱 처리해, 시스템 구동 중 한 번만 이 구조체 평가가 일어나도록 제어하여 응답 성능을 비약적으로 보전합니다. 캐시 데이터 로드로 부하를 줄일 수 있습니다.
정적인 get_initial_classes()가 캐싱 보전을 사용하는 반면, 사용자가 상호작용하는 get_custom_classes()는 유동적인 업데이트 보전을 위해 의도적으로 캐싱 처리에서 제외됩니다. 수동 제작 분류군 정보는 동적으로 더해지거나 고쳐져야만 하기 때문입니다.
get_video_urls()는 일련의 매칭 동영상 ID들을 접수 후, Twelve Labs REST API를 반복 질의하여 HLS 비디오 스트리밍 주소 목록으로 깔끔하게 변환 출력하는 임무를 성실히 해내며 전송 실패 등 각종 에러 안전망을 제공합니다.
render_video() 또한 뛰어난 하위 범용 웹브라우저 재생 방식을 보증하고자 HLS.js 플러그인 랩퍼 소스를 동적 생성한 후 네이티브 미디어를 실행하지 못하는 단말 환경에서도 훌륭히 재생되도록 돕습니다.
classify_videos()는 마침내 수합 완료된 관조하려 한 관심 분류군 필터 조합을 바탕으로 본 Twelve Labs 인덱스 대상 분류 작업을 실행합니다. 오직 영상의 시각적 행동과 상황(Visual)의 매칭 신호 분석에 타겟을 둡니다.
# Main Function def main(): # Basic Markdown Setup for the Application st.markdown(""" <style> .big-font { font-size: 40px !important; font-weight: bold; color: #000000; text-align: center; margin-bottom: 30px; } .subheader { font-size: 24px; font-weight: bold; color: #424242; margin-top: 20px; margin-bottom: 10px; } .stButton>button { width: 100%; } .video-info { background-color: #f0f0f0; border-radius: 10px; padding: 15px; margin-bottom: 20px; } .custom-box { background-color: #f9f9f9; border-radius: 10px; padding: 20px; margin-bottom: 20px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } .stTabs [data-baseweb="tab-list"] { gap: 24px; } .stTabs [data-baseweb="tab"] { height: 50px; white-space: pre-wrap; background-color: #f0f2f6; border-radius: 4px 4px 0px 0px; gap: 1px; padding-top: 10px; padding-bottom: 10px; } .stTabs [data-baseweb="tab-list"] button[aria-selected="true"] { background-color: #e8eaed; } </style> """, unsafe_allow_html=True) st.markdown('<p class="big-font">Olympics Classification w/t Twelve Labs</p>', unsafe_allow_html=True) # Updation of the classes CLASSES = get_initial_classes() + get_custom_classes() # Nav Tabs Creation tab1, tab2 = st.tabs(["Select Classes", "Add Custom Class"]) with tab1: st.markdown('<p class="subheader">Select Classes</p>', unsafe_allow_html=True) with st.container(): class_names = [cls["name"] for cls in CLASSES] # Multiselect option from the CLASSES selected_classes = st.multiselect("Choose one or more Olympic sports categories:", class_names) if st.button("Classify Videos", key="classify_button"): if selected_classes: with st.spinner("Classifying videos..."): selected_classes_with_prompts = [cls for cls in CLASSES if cls["name"] in selected_classes] res = classify_videos(selected_classes_with_prompts) video_ids = [data.video_id for data in res.data] # Retrieving the video urls from the resultant video which matches to the selected CLASSES video_urls = get_video_urls(video_ids) st.markdown('<p class="subheader">Classified Videos</p>', unsafe_allow_html=True) # Iterating over to showcase the information for every resulatant video for i, video_data in enumerate(res.data, 1): video_id = video_data.video_id video_url = video_urls.get(video_id, "URL not found") st.markdown(f"### Video {i}") st.markdown('<div class="video-info">', unsafe_allow_html=True) st.markdown(f"**Video ID:** {video_id}") for class_data in video_data.classes: st.markdown(f""" **Class:** {class_data.name} - Score: {class_data.score:.2f} - Duration Ratio: {class_data.duration_ratio:.2f} """) if video_url != "URL not found": render_video(video_url) else: st.warning("Video URL not available. Unable to render video.") st.markdown("---") st.success(f"Total videos classified: {len(res.data)}") else: st.warning("Please select at least one class.") st.markdown('</div>', unsafe_allow_html=True) # Nav Tab for the addition of the Custom Classes to select from with tab2: st.markdown('<p class="subheader">Add Custom Class</p>', unsafe_allow_html=True) with st.container(): custom_class_name = st.text_input("Enter custom class name") custom_class_prompts = st.text_input("Enter custom class prompts (comma-separated)") if st.button("Add Custom Class"): if custom_class_name and custom_class_prompts: add_custom_class(custom_class_name, custom_class_prompts.split(',')) st.success(f"Custom class '{custom_class_name}' added successfully!") st.experimental_rerun() else: st.warning("Please enter both class name and prompts.") st.markdown('</div>', unsafe_allow_html=True) if st.session_state.get('new_class_added', False): st.session_state.new_class_added = False st.experimental_rerun() if __name__ == "__main__": main()
이 애플리케이션의 메인 엔트리 포인트(Main function)는 인터페이스 레이아웃 구성과 매끄러운 반응형 CSS 연동, 제어 핸들러 호출 순서를 잡는데 주력합니다. 사용자는 "Add Custom Class" 탭에서 추가 전용 맞춤 타겟 입력을 받아 수시로 유동적인 추론 범주 확장을 도모할 수 있으며, 준비된 "Select Classes" 탭을 열어 신속한 비디오 분류 가동 범위 정렬을 시도해 볼 수 있습니다.
이제 준비된 사용자가 실제 "Classify Videos" 버튼을 정식 누르면 애플리케이션은 즉시 아래 조치를 실행합니다.
사용자가 선택 보전한 목적 클래스들을 정밀 매칭합니다.
전용 헬퍼 함수(
classify_videos())를 통해 Twelve Labs 클라우드로 질의 검사를 수행합니다.추출 검출된 개별 결과 비디오 고유 HLS 미디어 주소 목록을 즉각 다시 받아옵니다.
신뢰도 지표를 깔끔이 표출하며 미디어를 브라우저 상에 한눈에 재생해 시현합니다.
훌륭히 빌드되어 완성된 비디오 포털의 최종 모습 -
영역을 탐색하기 위한 아이디어 추천
본 튜토리얼을 기반으로 파이프라인과 비디오 인지 성능을 습득하셨다면, 일상이나 비즈니스 내 다양한 분야에 직접 이를 접목하여 새로운 프로젝트를 기획해 보실 수 있습니다. 여기 몇 가지 영감을 제공해 드립니다.
🔍 멀티모달 비디오 검색 포털: 테라바이트급 동영상 라이브러리 속에서 누구나 특정 대화나 인물 행동, 상황만을 지정해 연관 씬을 초단위로 짚어낼 수 있는 커스텀 검색기를 구축할 수 있습니다.
🎥 모니터링 이벤트 감지 분석기: 감시용 카메라 피드 데이터 스트림을 가동하고 이상 상황이나 고유 행동 패턴 등을 똑똑히 잡아내 분류하는 도구를 설계합니다.
💃 모션 및 안무 댄스 코칭 시스템: 트렌디한 챌린지 댄스 영상들에서 시그니처 댄스 동작이나 구체적인 안무 스타일만을 고유 분류하고 지도하는 기제를 구현합니다.
마치며
본 블로그의 핵심 타겟은 올림픽이라는 친숙한 소스를 통해 Twelve Labs 분류 AI 모델을 직접 작동시키며 비디오 분류 엔진의 파이프라인 개발 방법을 아주 현실적이고 알기 쉽게 풀어내는 것이었습니다. 튜토리얼을 즐겁게 수행해 주셔서 기쁩니다. 여러분이 해결해 나갈 다음 세대 비디오 어플리케이션 발상과 더욱 탁월해질 다양한 경험적 개선안들을 한시바삐 만나보고 싶습니다!








