" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Product
Building a Memory Layer for Video Intelligence

James Le
Video intelligence is evolving from understanding individual clips to reasoning across entire collections. This shift requires a memory layer that preserves entities, events, timelines, relationships, and evidence so agents and applications can build on video, not just search it. In this post, we explore why video memory is different, why search alone is insufficient, and how concepts like context graphs and knowledge stores can make video collections queryable, inspectable, and programmable.
Video intelligence is evolving from understanding individual clips to reasoning across entire collections. This shift requires a memory layer that preserves entities, events, timelines, relationships, and evidence so agents and applications can build on video, not just search it. In this post, we explore why video memory is different, why search alone is insufficient, and how concepts like context graphs and knowledge stores can make video collections queryable, inspectable, and programmable.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
May 29, 2026
17 Minutes
Copy link to article
TLDR: Video Intelligence Needs Memory, Not Just Search
Video intelligence is moving from single-clip understanding to corpus-level reasoning. The hardest product questions are no longer only "what is in this video?", but "what does this collection know?"
Search remains foundational. It finds relevant moments. But search alone does not preserve entities, relationships, timelines, evidence, or reusable context across a video library.
A video memory layer turns raw video into durable primitives: moments, entities, appearances, relationships, summaries, metadata, and grounded references.
The right mental model is a context graph for video: not necessarily a specific graph database, but an inspectable representation of how moments, people, objects, places, timestamps, and intent connect across a corpus.
This is the product thesis behind Jockey: to make video collections queryable, inspectable, and programmable for developers and enterprises.
The Next Bottleneck Is Continuity
The first wave of video understanding made individual clips easier to search, summarize, and analyze. That was a necessary breakthrough. Current multimodal foundation models (like TwelveLabs Marengo and Pegasus) increasingly support video and long-context inputs, but benchmarks such as LongVideoBench and Video-MME show that long-video reasoning remains a distinct evaluation problem, not merely a solved model interface problem.
But production systems rarely stop at one file. Real applications operate over archives, back catalogs, training libraries, ad inventories, content repositories, evidence collections, and operational footage. The unit of work is not always a clip. It is often a corpus. MVU-Eval is the strongest citation for this shift. It argues that existing evaluation benchmarks have been limited to single-video understanding and overlook multi-video understanding in real-world scenarios such as sports analytics and autonomous systems.
That changes the problem:
A media team does not just want "clips of a player celebrating." They want the best moments across seasons, connected to opponents, dates, commentators, camera angles, surrounding plays, and source timestamps.
A compliance team does not just want "possible issue." They need every relevant moment, how it was phrased, where it appeared, and the exact evidence a reviewer can inspect.
A product team does not just want "show me demos." They want a digest of themes, recurring objections, spokesperson appearances, and the sequence of clips that support a narrative.
These are not just retrieval tasks. They are memory tasks that require continuity. Letta’s agent-stack writing frames memory as a core requirement for agents that need state across interactions, while Mem0 and Memori both argue that effective long-horizon agent behavior depends on persistent, structured memory rather than repeatedly loading raw context.
The system must preserve what it has already understood, connect that understanding across many assets, and make it available for future questions. Without that layer, every query starts over. The application may find useful clips, but it does not build a durable model of the collection. Zep describes enterprise agent memory as dynamic knowledge integration across conversations and business data, with temporal knowledge graphs maintaining historical relationships.
That is the gap a video memory layer is meant to close.
Search can surface relevant moments. Memory gives applications and agents a persistent representation of entities, events, timelines, relationships, and evidence across the whole library.
Search helps answer "where is something like this?" Memory helps answer "what does this collection know, and how do we know it?"
Why Video Memory Is Different
Memory for video is not the same as memory for text.
Text can be chunked, embedded, summarized, and retrieved with relatively clean boundaries. Video is messier. Its meaning is temporal, multimodal, dense, ambiguous, and evidence-sensitive.
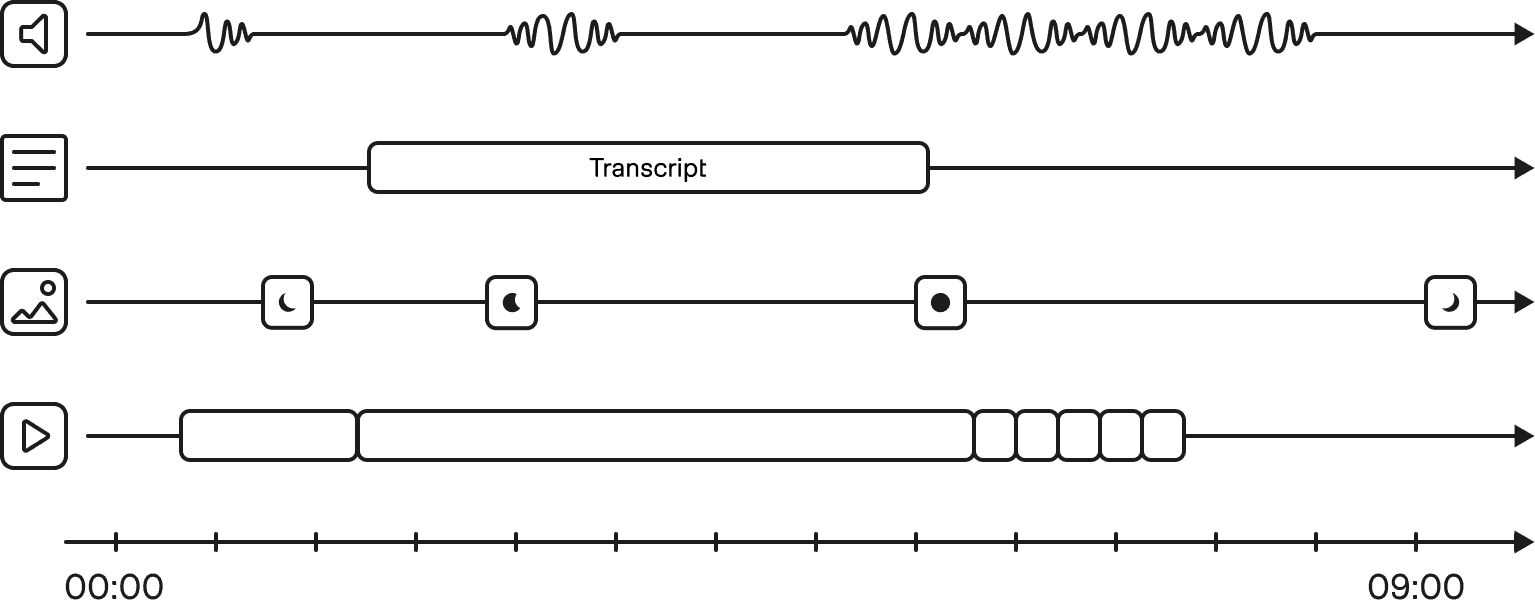
Figure 1: Video is a multi-layer timeline, not a flat document
1 - Video is Temporal
Meaning lives in sequence: buildup and aftermath, action and reaction, cause and consequence. A single frame rarely tells the full story. A neutral expression can mean very different things depending on the shots around it. A product placement can be positive, negative, incidental, or central depending on the surrounding moment. A sports clip can be meaningless without the play before it and the reaction after it.
LongVideoBench frames long-form video understanding as retrieving and reasoning over detailed multimodal information from long inputs, with videos up to an hour long and questions requiring referred-context reasoning. RAVU explicitly argues that long videos challenge LMMs because they lack explicit memory and retrieval mechanisms, then proposes a spatiotemporal graph to track entities and actions across time.
2 - Video is Multimodal
Evidence can come from visuals, speech, music, sound effects, OCR, captions, camera motion, metadata, and external context. A scene might matter because a logo is visible, a person says a specific phrase, the crowd reacts, a timestamp places it in a sequence, or attached metadata identifies the camera, campaign, or event.
Well-known benchmarks such as Video-MME evaluate video understanding across temporal duration and modalities beyond frames, including subtitles and audio. Frontier model interfaces like Marengo now explicitly treat video, audio, images, and text as supported inputs.
3 - Video is Dense
A few minutes of footage can contain many shots, people, objects, actions, overlays, scene changes, and spoken claims. The useful signal is not evenly distributed. Some moments carry the whole meaning of a clip. Others are filler, transition, repetition, or noise.
VideoAgent supports this point well: it emphasizes that long-form video understanding requires reasoning over long multimodal sequences and proposes an agentic approach that iteratively identifies and compiles crucial information rather than processing every frame equally.
4 - Video is Ambiguous
A person may be unnamed. A brand may be partially visible. A location may be implied rather than spoken. The same entity may reappear under different lighting, clothing, angles, or resolutions. Identity is often established across time, not in a single instant.
RAVU represents spatial and temporal relationships between entities and uses that graph as long-term memory to track objects and actions across time. VideoRAG preserves cross-video semantic relationships through graph-based grounding and multimodal retrieval.
5 - Video is Evidence-Sensitive
If a system says "this brand appears in a negative context" or "this clip supports the product launch story," the answer is not useful unless it can point back to the exact video evidence. For enterprise workflows, a claim without a reference is not intelligence. It is an opinion.
This is why larger context windows alone do not solve video. Frontier multimodal models are increasingly capable of accepting long, multimodal inputs, including video, audio, images, and text. But long-video benchmarks still show that retrieving and reasoning over detailed temporal and multimodal evidence remains challenging, especially as videos grow longer or span multiple files.
More context helps, but video intelligence needs more than a bigger prompt. It needs a representation layer that decides what to preserve, how to connect it, and how to retrieve it later.
Search Finds Moments. Memory Preserves Meaning.

Figure 2: Candidate moments vs reusable understanding
Search is still essential. It is how builders recover relevant moments from a large corpus. A strong video search system should understand visual content, speech, text on screen, audio, and semantic similarity. Without search, a video library remains opaque.
But search gives you candidates, not continuity. This is the same limitation that has pushed the broader AI infrastructure ecosystem from retrieval alone toward memory, graph, and context-engineering systems. Standard RAG can struggle with global questions over a corpus, and agent-memory systems increasingly treat persistent state as a structured representation rather than a larger prompt. GraphRAG is the best analogy from text corpora: it was motivated by the observation that standard RAG struggles with global questions over a whole corpus. Letta and Zep make the same point in agent-memory terms, where static retrieval is not equivalent to persistent state.
"Find clips of people cooking" is a search task. "Across this cooking archive, what techniques recur most often, who demonstrates them, and which moments best illustrate each technique?" is a memory task.
"Find the logo" is search. "Where does this brand appear across campaigns, what scenes surround it, and how does the tone change over time?" is memory.
"Find a dramatic moment" is search. "Assemble a coherent sequence of moments that supports a story arc, with timestamps and rationale" is memory.
VideoRAG, RAVU, and AdaVideoRAG make this distinction concrete for video: retrieval alone is not the endpoint. These systems combine retrieval with multimodal context, graph representations, intent classification, or multi-step reasoning to answer complex questions over long video.
The distinction matters because applications need reusable state. A search result is often useful for the immediate query. A memory layer should be useful across many queries, many users, and many workflows. It should allow the system to ask follow-up questions, compare new results against prior understanding, generate structured outputs, and explain why a result was selected. Mem0 and Memori both frame agent memory as a persistent layer that improves multi-session behavior and reduces the cost of repeatedly injecting large raw contexts.
Search says, "Here are relevant clips." Memory says, "Here is what we know about this collection, here is how the pieces relate, and here is the evidence behind each claim."
That shift is what makes video usable as infrastructure.
The Context Graph As A Systems Concept
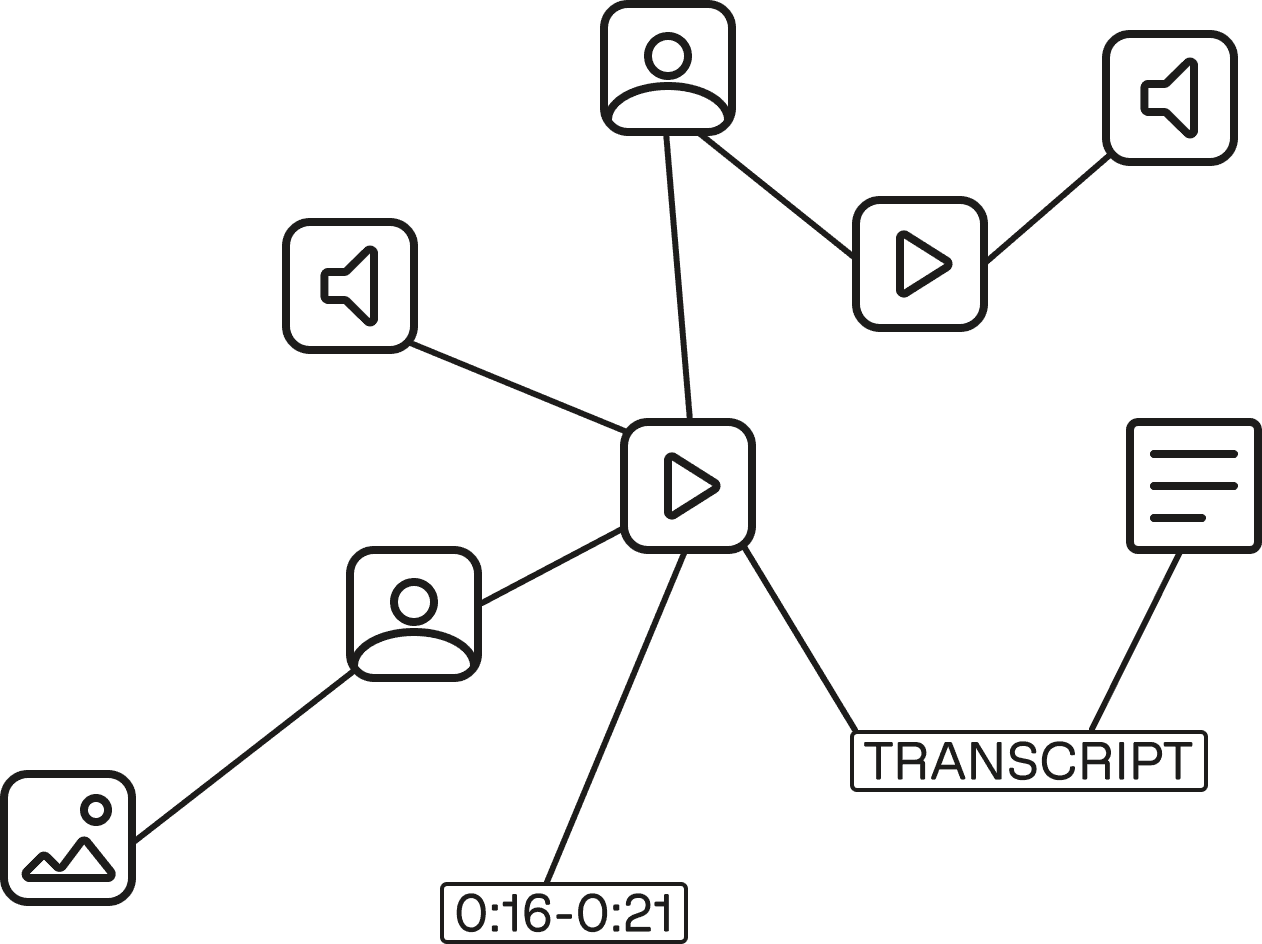
Figure 3: The video context graph
A useful mental model for video memory is the context graph.
By context graph, I do not mean a requirement to use a specific graph database. I mean a systems concept: a durable, queryable representation that connects moments, entities, events, timestamps, metadata, and evidence across a collection.
An index helps answer "where might this be?" A context graph helps answer "what does this collection contain, how are its pieces connected, and what evidence supports that understanding?"
For video, that representation needs to preserve several kinds of knowledge.
It needs time-bounded moments: clips, scenes, shots, segments, or other spans with start and end times. It needs entities: people, characters, places, objects, brands, concepts, and domain-specific subjects. It needs appearances: where and when entities show up. It needs relationships: who is associated with what, which moments belong together, what happened before or after, and which evidence supports a conclusion.
It also needs corpus-level context. A single video may show one customer testimonial. A library may reveal recurring objections, common emotions, seasonal patterns, visual motifs, or gaps in coverage. A single training clip may show one procedure. A corpus may reveal which procedures are common, which mistakes recur, and where the best examples live.
Finally, it needs intent. The same footage should be remembered differently depending on the application. A marketing workflow cares about brand presence, emotional tone, product usage, creator style, and campaign relevance. A media workflow cares about story beats, characters, locations, usable takes, and editorial structure. A compliance workflow cares about claims, disclosures, prohibited content, and review evidence. A training workflow cares about concepts, procedures, mistakes, demonstrations, and outcomes.
There is no universal memory of a video library that is optimal for every product. A useful memory layer must be shaped by what the builder is trying to do. ContextWeaver argues that retrieval-based memory systems can miss causal and logical structure needed for multi-step reasoning, then organizes traces into dependency graphs for future context selection.
The 5 Principles For Building A Video Memory Layer
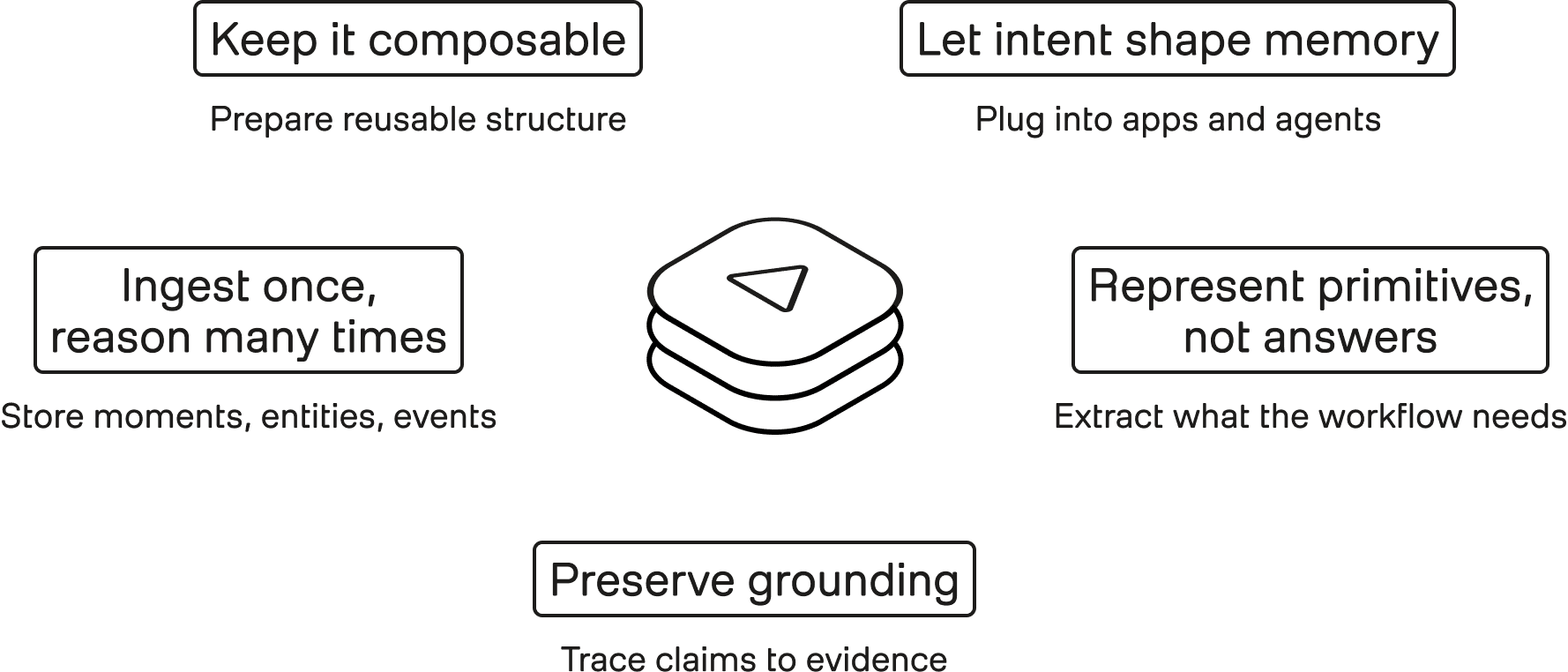
Figure 4: Five design constraints around the memory layer
1. Ingest Once, Reason Many Times
Video understanding is expensive because the input is large, temporal, and multimodal. Re-understanding the same corpus from scratch for every query is wasteful and inconsistent.
A strong memory layer moves expensive understanding work into a preparation step. During ingestion, the system should extract reusable structure from the corpus: summaries, moments, entities, relationships, metadata, and references. At query time, the application can retrieve and reason over that prepared memory instead of repeatedly scanning the same footage.
This does not mean every answer becomes instant or every task becomes simple. It means the system stops treating every question as a fresh encounter with raw media.
For developers, this is the same mental model that makes databases valuable. You do not repeatedly parse the entire source of truth every time an application needs an answer. You prepare, index, structure, and query.
Video needs the same discipline.
2. Store Primitives, Not Just Answers
A summary is useful, but it is not enough. If the system only stores summaries, every downstream product inherits the limits of those summaries.
Video memory should store primitives that can be reused across workflows: time-bounded moments, entities, appearances, relationships, topics, themes, timelines, and grounded references.
Those primitives compose.
An entity appearance can support search, organization, rights review, recommendation, and content assembly.
A moment with a timestamp can support a highlight reel, an audit trail, a training module, or a structured citation.
A corpus-level theme can support browsing, planning, reporting, and follow-up questions.
The goal is not to precompute every possible answer. The goal is to create a reusable substrate from which many answers can be built.
3. Ground Every Claim
Video memory must be inspectable.
If an application says a clip supports a claim, it should show the source.
If it says a person appeared across several assets, it should show where.
If it proposes a sequence, it should provide timestamps and rationale.
If it organizes a library by theme, the user should be able to inspect the evidence behind each grouping.
Grounding is not just a safety feature. It is a product feature. Provenance standards make the same point in more formal terms: trust depends on knowing which entities, activities, and people produced a claim, how it was derived, and whether the supporting evidence can be inspected.
It helps developers debug. It helps users trust. It helps reviewers verify. It lets downstream systems render not just an answer, but a path back to the source material.
This matters especially for video because verification is otherwise slow. A text answer can often be scanned quickly. A video claim may require opening a clip, scrubbing to the right moment, checking the visual, listening to the audio, and comparing it against surrounding context. A memory layer should reduce that burden, not add to it.
4. Let Intent Shape Memory
This aligns with the broader shift from prompt engineering to context engineering: the system should assemble the right information, tools, and format for the task. For video specifically, adaptive approaches such as AdaVideoRAG select retrieval strategies based on query complexity, balancing cost, latency, and reasoning depth.
The same video can mean different things to different applications:
A shot of a person holding a drink might be irrelevant to one product and central to another.
A background logo might be noise in a sports workflow and critical in a brand safety workflow.
A moment of hesitation might be filler in a transcript summary and the most important signal in a sales-training library.
That is why video memory should be configurable. Builders should be able to tell the system what matters for their domain: which entities to track, which attributes to extract, which moments to preserve, which relationships matter, and what kind of output their application needs.
This is where memory becomes more than generic metadata extraction. It becomes application-shaped knowledge.
The best video systems will not ask developers to accept a fixed interpretation of their media. They will let developers shape what the system remembers.
5. Keep The Memory Layer Composable
Developers do not need another closed vertical agent for every use case. They need infrastructure that can plug into the systems they are already building.
A video memory layer should be API-first. It should work with search, agents, dashboards, review tools, content management systems, labeling workflows, and enterprise applications. It should support natural language, structured outputs, and references that downstream software can use. This is also consistent with agent infrastructure trends: MCP standardizes how assistants connect to external data and tools, while agent frameworks and APIs increasingly expose durable execution, memory, tool use, tracing, and structured outputs as first-class building blocks.
This separation matters. The memory layer should not try to be the editor, the compliance product, the training platform, and the content management system all at once. It should provide the durable video understanding those products need.
That is how video intelligence becomes programmable.
What This Unlocks For Builders
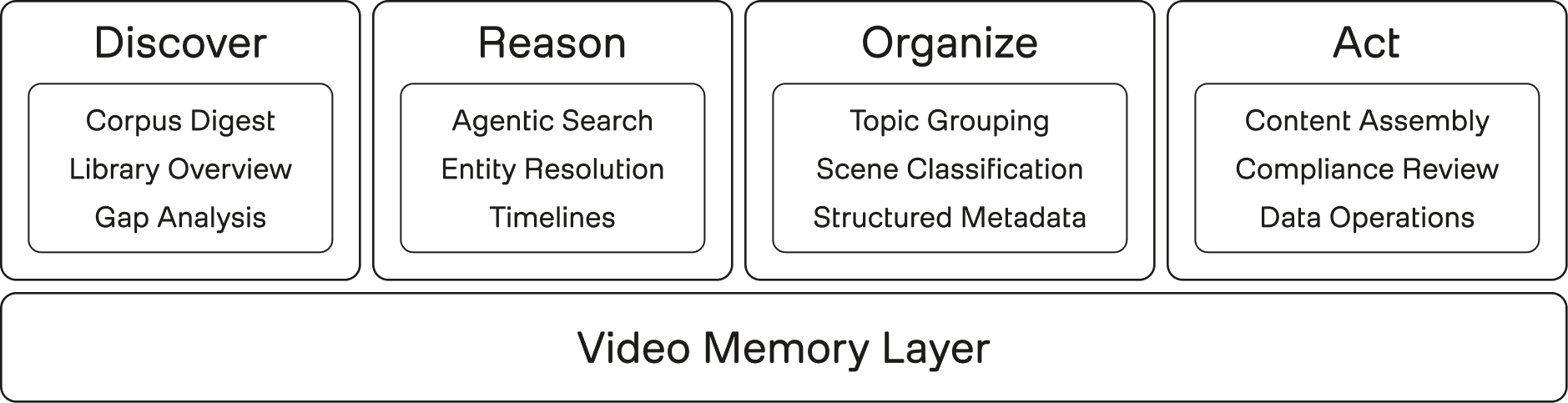
Figure 5: Builder workflow fan-out
Once a video corpus has memory, the product surface changes.
Developers can build corpus digest experiences that summarize what is in a library: topics, formats, entities, themes, patterns, gaps, and unusual moments. This gives users a starting point before they know what to search for.
They can build agentic search experiences that go beyond one retrieval call. The application can search, inspect, compare, refine, and return grounded references rather than a flat list of clips.
They can build entity-centric workflows: show where a person, object, brand, place, or concept appears across the collection, how often it appears, what surrounds it, and which moments matter most.
They can build timelines. Instead of isolated results, the application can reconstruct an event, campaign, narrative, or workflow over time.
They can build organization systems that group videos by topic, scene type, quality, format, use case, audience, risk, or domain-specific taxonomy.
They can build content assembly tools that identify candidate moments, sequence them, and hand a human editor a better starting point.
They can build compliance and review workflows where every finding links back to evidence.
They can build data operations tools that accelerate labeling, enrichment, dataset QA, and corpus understanding.
In each case, the memory layer does not replace the human or the application. It gives them a better substrate to work from.
Jockey And The Productization Of Video Memory
This is the thesis behind Jockey, our effort to productize the memory layer for video intelligence: a video cognition engine that helps developers and enterprises turn video collections into queryable, inspectable, programmable intelligence.
The product concepts are intentionally infrastructure-oriented:
Knowledge stores provide durable, queryable memory for a collection.
Configurable ingestion lets builders shape what the system extracts for a given application.
Corpus digest gives users an overview of what exists in the library.
Entity resolution connects recurring people, places, objects, brands, and concepts across content.
Agentic search retrieves, reasons, and returns grounded references.
A Responses API gives developers a way to ask questions and receive natural-language or structured outputs from that memory.
The important point is not that Jockey is a single end-user workflow. It is not trying to be the final editing interface, the compliance product, or the content management system. It is the video cognition infrastructure beneath those applications.
The next generation of video intelligence will not be defined only by bigger multimodal models or better search indexes. Those will matter. But the real product shift is turning video collections into durable memory: grounded, inspectable, intent-shaped, and reusable across applications.
Search finds moments. Memory makes those moments mean something across the corpus. Jockey is TwelveLabs' effort to build that layer.
Sign up for Jockey private beta access here: https://forms.gle/88pNBNdhY7JjfYXY7
TLDR: Video Intelligence Needs Memory, Not Just Search
Video intelligence is moving from single-clip understanding to corpus-level reasoning. The hardest product questions are no longer only "what is in this video?", but "what does this collection know?"
Search remains foundational. It finds relevant moments. But search alone does not preserve entities, relationships, timelines, evidence, or reusable context across a video library.
A video memory layer turns raw video into durable primitives: moments, entities, appearances, relationships, summaries, metadata, and grounded references.
The right mental model is a context graph for video: not necessarily a specific graph database, but an inspectable representation of how moments, people, objects, places, timestamps, and intent connect across a corpus.
This is the product thesis behind Jockey: to make video collections queryable, inspectable, and programmable for developers and enterprises.
The Next Bottleneck Is Continuity
The first wave of video understanding made individual clips easier to search, summarize, and analyze. That was a necessary breakthrough. Current multimodal foundation models (like TwelveLabs Marengo and Pegasus) increasingly support video and long-context inputs, but benchmarks such as LongVideoBench and Video-MME show that long-video reasoning remains a distinct evaluation problem, not merely a solved model interface problem.
But production systems rarely stop at one file. Real applications operate over archives, back catalogs, training libraries, ad inventories, content repositories, evidence collections, and operational footage. The unit of work is not always a clip. It is often a corpus. MVU-Eval is the strongest citation for this shift. It argues that existing evaluation benchmarks have been limited to single-video understanding and overlook multi-video understanding in real-world scenarios such as sports analytics and autonomous systems.
That changes the problem:
A media team does not just want "clips of a player celebrating." They want the best moments across seasons, connected to opponents, dates, commentators, camera angles, surrounding plays, and source timestamps.
A compliance team does not just want "possible issue." They need every relevant moment, how it was phrased, where it appeared, and the exact evidence a reviewer can inspect.
A product team does not just want "show me demos." They want a digest of themes, recurring objections, spokesperson appearances, and the sequence of clips that support a narrative.
These are not just retrieval tasks. They are memory tasks that require continuity. Letta’s agent-stack writing frames memory as a core requirement for agents that need state across interactions, while Mem0 and Memori both argue that effective long-horizon agent behavior depends on persistent, structured memory rather than repeatedly loading raw context.
The system must preserve what it has already understood, connect that understanding across many assets, and make it available for future questions. Without that layer, every query starts over. The application may find useful clips, but it does not build a durable model of the collection. Zep describes enterprise agent memory as dynamic knowledge integration across conversations and business data, with temporal knowledge graphs maintaining historical relationships.
That is the gap a video memory layer is meant to close.
Search can surface relevant moments. Memory gives applications and agents a persistent representation of entities, events, timelines, relationships, and evidence across the whole library.
Search helps answer "where is something like this?" Memory helps answer "what does this collection know, and how do we know it?"
Why Video Memory Is Different
Memory for video is not the same as memory for text.
Text can be chunked, embedded, summarized, and retrieved with relatively clean boundaries. Video is messier. Its meaning is temporal, multimodal, dense, ambiguous, and evidence-sensitive.
Figure 1: Video is a multi-layer timeline, not a flat document
1 - Video is Temporal
Meaning lives in sequence: buildup and aftermath, action and reaction, cause and consequence. A single frame rarely tells the full story. A neutral expression can mean very different things depending on the shots around it. A product placement can be positive, negative, incidental, or central depending on the surrounding moment. A sports clip can be meaningless without the play before it and the reaction after it.
LongVideoBench frames long-form video understanding as retrieving and reasoning over detailed multimodal information from long inputs, with videos up to an hour long and questions requiring referred-context reasoning. RAVU explicitly argues that long videos challenge LMMs because they lack explicit memory and retrieval mechanisms, then proposes a spatiotemporal graph to track entities and actions across time.
2 - Video is Multimodal
Evidence can come from visuals, speech, music, sound effects, OCR, captions, camera motion, metadata, and external context. A scene might matter because a logo is visible, a person says a specific phrase, the crowd reacts, a timestamp places it in a sequence, or attached metadata identifies the camera, campaign, or event.
Well-known benchmarks such as Video-MME evaluate video understanding across temporal duration and modalities beyond frames, including subtitles and audio. Frontier model interfaces like Marengo now explicitly treat video, audio, images, and text as supported inputs.
3 - Video is Dense
A few minutes of footage can contain many shots, people, objects, actions, overlays, scene changes, and spoken claims. The useful signal is not evenly distributed. Some moments carry the whole meaning of a clip. Others are filler, transition, repetition, or noise.
VideoAgent supports this point well: it emphasizes that long-form video understanding requires reasoning over long multimodal sequences and proposes an agentic approach that iteratively identifies and compiles crucial information rather than processing every frame equally.
4 - Video is Ambiguous
A person may be unnamed. A brand may be partially visible. A location may be implied rather than spoken. The same entity may reappear under different lighting, clothing, angles, or resolutions. Identity is often established across time, not in a single instant.
RAVU represents spatial and temporal relationships between entities and uses that graph as long-term memory to track objects and actions across time. VideoRAG preserves cross-video semantic relationships through graph-based grounding and multimodal retrieval.
5 - Video is Evidence-Sensitive
If a system says "this brand appears in a negative context" or "this clip supports the product launch story," the answer is not useful unless it can point back to the exact video evidence. For enterprise workflows, a claim without a reference is not intelligence. It is an opinion.
This is why larger context windows alone do not solve video. Frontier multimodal models are increasingly capable of accepting long, multimodal inputs, including video, audio, images, and text. But long-video benchmarks still show that retrieving and reasoning over detailed temporal and multimodal evidence remains challenging, especially as videos grow longer or span multiple files.
More context helps, but video intelligence needs more than a bigger prompt. It needs a representation layer that decides what to preserve, how to connect it, and how to retrieve it later.
Search Finds Moments. Memory Preserves Meaning.
Figure 2: Candidate moments vs reusable understanding
Search is still essential. It is how builders recover relevant moments from a large corpus. A strong video search system should understand visual content, speech, text on screen, audio, and semantic similarity. Without search, a video library remains opaque.
But search gives you candidates, not continuity. This is the same limitation that has pushed the broader AI infrastructure ecosystem from retrieval alone toward memory, graph, and context-engineering systems. Standard RAG can struggle with global questions over a corpus, and agent-memory systems increasingly treat persistent state as a structured representation rather than a larger prompt. GraphRAG is the best analogy from text corpora: it was motivated by the observation that standard RAG struggles with global questions over a whole corpus. Letta and Zep make the same point in agent-memory terms, where static retrieval is not equivalent to persistent state.
"Find clips of people cooking" is a search task. "Across this cooking archive, what techniques recur most often, who demonstrates them, and which moments best illustrate each technique?" is a memory task.
"Find the logo" is search. "Where does this brand appear across campaigns, what scenes surround it, and how does the tone change over time?" is memory.
"Find a dramatic moment" is search. "Assemble a coherent sequence of moments that supports a story arc, with timestamps and rationale" is memory.
VideoRAG, RAVU, and AdaVideoRAG make this distinction concrete for video: retrieval alone is not the endpoint. These systems combine retrieval with multimodal context, graph representations, intent classification, or multi-step reasoning to answer complex questions over long video.
The distinction matters because applications need reusable state. A search result is often useful for the immediate query. A memory layer should be useful across many queries, many users, and many workflows. It should allow the system to ask follow-up questions, compare new results against prior understanding, generate structured outputs, and explain why a result was selected. Mem0 and Memori both frame agent memory as a persistent layer that improves multi-session behavior and reduces the cost of repeatedly injecting large raw contexts.
Search says, "Here are relevant clips." Memory says, "Here is what we know about this collection, here is how the pieces relate, and here is the evidence behind each claim."
That shift is what makes video usable as infrastructure.
The Context Graph As A Systems Concept
Figure 3: The video context graph
A useful mental model for video memory is the context graph.
By context graph, I do not mean a requirement to use a specific graph database. I mean a systems concept: a durable, queryable representation that connects moments, entities, events, timestamps, metadata, and evidence across a collection.
An index helps answer "where might this be?" A context graph helps answer "what does this collection contain, how are its pieces connected, and what evidence supports that understanding?"
For video, that representation needs to preserve several kinds of knowledge.
It needs time-bounded moments: clips, scenes, shots, segments, or other spans with start and end times. It needs entities: people, characters, places, objects, brands, concepts, and domain-specific subjects. It needs appearances: where and when entities show up. It needs relationships: who is associated with what, which moments belong together, what happened before or after, and which evidence supports a conclusion.
It also needs corpus-level context. A single video may show one customer testimonial. A library may reveal recurring objections, common emotions, seasonal patterns, visual motifs, or gaps in coverage. A single training clip may show one procedure. A corpus may reveal which procedures are common, which mistakes recur, and where the best examples live.
Finally, it needs intent. The same footage should be remembered differently depending on the application. A marketing workflow cares about brand presence, emotional tone, product usage, creator style, and campaign relevance. A media workflow cares about story beats, characters, locations, usable takes, and editorial structure. A compliance workflow cares about claims, disclosures, prohibited content, and review evidence. A training workflow cares about concepts, procedures, mistakes, demonstrations, and outcomes.
There is no universal memory of a video library that is optimal for every product. A useful memory layer must be shaped by what the builder is trying to do. ContextWeaver argues that retrieval-based memory systems can miss causal and logical structure needed for multi-step reasoning, then organizes traces into dependency graphs for future context selection.
The 5 Principles For Building A Video Memory Layer
Figure 4: Five design constraints around the memory layer
1. Ingest Once, Reason Many Times
Video understanding is expensive because the input is large, temporal, and multimodal. Re-understanding the same corpus from scratch for every query is wasteful and inconsistent.
A strong memory layer moves expensive understanding work into a preparation step. During ingestion, the system should extract reusable structure from the corpus: summaries, moments, entities, relationships, metadata, and references. At query time, the application can retrieve and reason over that prepared memory instead of repeatedly scanning the same footage.
This does not mean every answer becomes instant or every task becomes simple. It means the system stops treating every question as a fresh encounter with raw media.
For developers, this is the same mental model that makes databases valuable. You do not repeatedly parse the entire source of truth every time an application needs an answer. You prepare, index, structure, and query.
Video needs the same discipline.
2. Store Primitives, Not Just Answers
A summary is useful, but it is not enough. If the system only stores summaries, every downstream product inherits the limits of those summaries.
Video memory should store primitives that can be reused across workflows: time-bounded moments, entities, appearances, relationships, topics, themes, timelines, and grounded references.
Those primitives compose.
An entity appearance can support search, organization, rights review, recommendation, and content assembly.
A moment with a timestamp can support a highlight reel, an audit trail, a training module, or a structured citation.
A corpus-level theme can support browsing, planning, reporting, and follow-up questions.
The goal is not to precompute every possible answer. The goal is to create a reusable substrate from which many answers can be built.
3. Ground Every Claim
Video memory must be inspectable.
If an application says a clip supports a claim, it should show the source.
If it says a person appeared across several assets, it should show where.
If it proposes a sequence, it should provide timestamps and rationale.
If it organizes a library by theme, the user should be able to inspect the evidence behind each grouping.
Grounding is not just a safety feature. It is a product feature. Provenance standards make the same point in more formal terms: trust depends on knowing which entities, activities, and people produced a claim, how it was derived, and whether the supporting evidence can be inspected.
It helps developers debug. It helps users trust. It helps reviewers verify. It lets downstream systems render not just an answer, but a path back to the source material.
This matters especially for video because verification is otherwise slow. A text answer can often be scanned quickly. A video claim may require opening a clip, scrubbing to the right moment, checking the visual, listening to the audio, and comparing it against surrounding context. A memory layer should reduce that burden, not add to it.
4. Let Intent Shape Memory
This aligns with the broader shift from prompt engineering to context engineering: the system should assemble the right information, tools, and format for the task. For video specifically, adaptive approaches such as AdaVideoRAG select retrieval strategies based on query complexity, balancing cost, latency, and reasoning depth.
The same video can mean different things to different applications:
A shot of a person holding a drink might be irrelevant to one product and central to another.
A background logo might be noise in a sports workflow and critical in a brand safety workflow.
A moment of hesitation might be filler in a transcript summary and the most important signal in a sales-training library.
That is why video memory should be configurable. Builders should be able to tell the system what matters for their domain: which entities to track, which attributes to extract, which moments to preserve, which relationships matter, and what kind of output their application needs.
This is where memory becomes more than generic metadata extraction. It becomes application-shaped knowledge.
The best video systems will not ask developers to accept a fixed interpretation of their media. They will let developers shape what the system remembers.
5. Keep The Memory Layer Composable
Developers do not need another closed vertical agent for every use case. They need infrastructure that can plug into the systems they are already building.
A video memory layer should be API-first. It should work with search, agents, dashboards, review tools, content management systems, labeling workflows, and enterprise applications. It should support natural language, structured outputs, and references that downstream software can use. This is also consistent with agent infrastructure trends: MCP standardizes how assistants connect to external data and tools, while agent frameworks and APIs increasingly expose durable execution, memory, tool use, tracing, and structured outputs as first-class building blocks.
This separation matters. The memory layer should not try to be the editor, the compliance product, the training platform, and the content management system all at once. It should provide the durable video understanding those products need.
That is how video intelligence becomes programmable.
What This Unlocks For Builders
Figure 5: Builder workflow fan-out
Once a video corpus has memory, the product surface changes.
Developers can build corpus digest experiences that summarize what is in a library: topics, formats, entities, themes, patterns, gaps, and unusual moments. This gives users a starting point before they know what to search for.
They can build agentic search experiences that go beyond one retrieval call. The application can search, inspect, compare, refine, and return grounded references rather than a flat list of clips.
They can build entity-centric workflows: show where a person, object, brand, place, or concept appears across the collection, how often it appears, what surrounds it, and which moments matter most.
They can build timelines. Instead of isolated results, the application can reconstruct an event, campaign, narrative, or workflow over time.
They can build organization systems that group videos by topic, scene type, quality, format, use case, audience, risk, or domain-specific taxonomy.
They can build content assembly tools that identify candidate moments, sequence them, and hand a human editor a better starting point.
They can build compliance and review workflows where every finding links back to evidence.
They can build data operations tools that accelerate labeling, enrichment, dataset QA, and corpus understanding.
In each case, the memory layer does not replace the human or the application. It gives them a better substrate to work from.
Jockey And The Productization Of Video Memory
This is the thesis behind Jockey, our effort to productize the memory layer for video intelligence: a video cognition engine that helps developers and enterprises turn video collections into queryable, inspectable, programmable intelligence.
The product concepts are intentionally infrastructure-oriented:
Knowledge stores provide durable, queryable memory for a collection.
Configurable ingestion lets builders shape what the system extracts for a given application.
Corpus digest gives users an overview of what exists in the library.
Entity resolution connects recurring people, places, objects, brands, and concepts across content.
Agentic search retrieves, reasons, and returns grounded references.
A Responses API gives developers a way to ask questions and receive natural-language or structured outputs from that memory.
The important point is not that Jockey is a single end-user workflow. It is not trying to be the final editing interface, the compliance product, or the content management system. It is the video cognition infrastructure beneath those applications.
The next generation of video intelligence will not be defined only by bigger multimodal models or better search indexes. Those will matter. But the real product shift is turning video collections into durable memory: grounded, inspectable, intent-shaped, and reusable across applications.
Search finds moments. Memory makes those moments mean something across the corpus. Jockey is TwelveLabs' effort to build that layer.
Sign up for Jockey private beta access here: https://forms.gle/88pNBNdhY7JjfYXY7
TLDR: Video Intelligence Needs Memory, Not Just Search
Video intelligence is moving from single-clip understanding to corpus-level reasoning. The hardest product questions are no longer only "what is in this video?", but "what does this collection know?"
Search remains foundational. It finds relevant moments. But search alone does not preserve entities, relationships, timelines, evidence, or reusable context across a video library.
A video memory layer turns raw video into durable primitives: moments, entities, appearances, relationships, summaries, metadata, and grounded references.
The right mental model is a context graph for video: not necessarily a specific graph database, but an inspectable representation of how moments, people, objects, places, timestamps, and intent connect across a corpus.
This is the product thesis behind Jockey: to make video collections queryable, inspectable, and programmable for developers and enterprises.
The Next Bottleneck Is Continuity
The first wave of video understanding made individual clips easier to search, summarize, and analyze. That was a necessary breakthrough. Current multimodal foundation models (like TwelveLabs Marengo and Pegasus) increasingly support video and long-context inputs, but benchmarks such as LongVideoBench and Video-MME show that long-video reasoning remains a distinct evaluation problem, not merely a solved model interface problem.
But production systems rarely stop at one file. Real applications operate over archives, back catalogs, training libraries, ad inventories, content repositories, evidence collections, and operational footage. The unit of work is not always a clip. It is often a corpus. MVU-Eval is the strongest citation for this shift. It argues that existing evaluation benchmarks have been limited to single-video understanding and overlook multi-video understanding in real-world scenarios such as sports analytics and autonomous systems.
That changes the problem:
A media team does not just want "clips of a player celebrating." They want the best moments across seasons, connected to opponents, dates, commentators, camera angles, surrounding plays, and source timestamps.
A compliance team does not just want "possible issue." They need every relevant moment, how it was phrased, where it appeared, and the exact evidence a reviewer can inspect.
A product team does not just want "show me demos." They want a digest of themes, recurring objections, spokesperson appearances, and the sequence of clips that support a narrative.
These are not just retrieval tasks. They are memory tasks that require continuity. Letta’s agent-stack writing frames memory as a core requirement for agents that need state across interactions, while Mem0 and Memori both argue that effective long-horizon agent behavior depends on persistent, structured memory rather than repeatedly loading raw context.
The system must preserve what it has already understood, connect that understanding across many assets, and make it available for future questions. Without that layer, every query starts over. The application may find useful clips, but it does not build a durable model of the collection. Zep describes enterprise agent memory as dynamic knowledge integration across conversations and business data, with temporal knowledge graphs maintaining historical relationships.
That is the gap a video memory layer is meant to close.
Search can surface relevant moments. Memory gives applications and agents a persistent representation of entities, events, timelines, relationships, and evidence across the whole library.
Search helps answer "where is something like this?" Memory helps answer "what does this collection know, and how do we know it?"
Why Video Memory Is Different
Memory for video is not the same as memory for text.
Text can be chunked, embedded, summarized, and retrieved with relatively clean boundaries. Video is messier. Its meaning is temporal, multimodal, dense, ambiguous, and evidence-sensitive.
Figure 1: Video is a multi-layer timeline, not a flat document
1 - Video is Temporal
Meaning lives in sequence: buildup and aftermath, action and reaction, cause and consequence. A single frame rarely tells the full story. A neutral expression can mean very different things depending on the shots around it. A product placement can be positive, negative, incidental, or central depending on the surrounding moment. A sports clip can be meaningless without the play before it and the reaction after it.
LongVideoBench frames long-form video understanding as retrieving and reasoning over detailed multimodal information from long inputs, with videos up to an hour long and questions requiring referred-context reasoning. RAVU explicitly argues that long videos challenge LMMs because they lack explicit memory and retrieval mechanisms, then proposes a spatiotemporal graph to track entities and actions across time.
2 - Video is Multimodal
Evidence can come from visuals, speech, music, sound effects, OCR, captions, camera motion, metadata, and external context. A scene might matter because a logo is visible, a person says a specific phrase, the crowd reacts, a timestamp places it in a sequence, or attached metadata identifies the camera, campaign, or event.
Well-known benchmarks such as Video-MME evaluate video understanding across temporal duration and modalities beyond frames, including subtitles and audio. Frontier model interfaces like Marengo now explicitly treat video, audio, images, and text as supported inputs.
3 - Video is Dense
A few minutes of footage can contain many shots, people, objects, actions, overlays, scene changes, and spoken claims. The useful signal is not evenly distributed. Some moments carry the whole meaning of a clip. Others are filler, transition, repetition, or noise.
VideoAgent supports this point well: it emphasizes that long-form video understanding requires reasoning over long multimodal sequences and proposes an agentic approach that iteratively identifies and compiles crucial information rather than processing every frame equally.
4 - Video is Ambiguous
A person may be unnamed. A brand may be partially visible. A location may be implied rather than spoken. The same entity may reappear under different lighting, clothing, angles, or resolutions. Identity is often established across time, not in a single instant.
RAVU represents spatial and temporal relationships between entities and uses that graph as long-term memory to track objects and actions across time. VideoRAG preserves cross-video semantic relationships through graph-based grounding and multimodal retrieval.
5 - Video is Evidence-Sensitive
If a system says "this brand appears in a negative context" or "this clip supports the product launch story," the answer is not useful unless it can point back to the exact video evidence. For enterprise workflows, a claim without a reference is not intelligence. It is an opinion.
This is why larger context windows alone do not solve video. Frontier multimodal models are increasingly capable of accepting long, multimodal inputs, including video, audio, images, and text. But long-video benchmarks still show that retrieving and reasoning over detailed temporal and multimodal evidence remains challenging, especially as videos grow longer or span multiple files.
More context helps, but video intelligence needs more than a bigger prompt. It needs a representation layer that decides what to preserve, how to connect it, and how to retrieve it later.
Search Finds Moments. Memory Preserves Meaning.
Figure 2: Candidate moments vs reusable understanding
Search is still essential. It is how builders recover relevant moments from a large corpus. A strong video search system should understand visual content, speech, text on screen, audio, and semantic similarity. Without search, a video library remains opaque.
But search gives you candidates, not continuity. This is the same limitation that has pushed the broader AI infrastructure ecosystem from retrieval alone toward memory, graph, and context-engineering systems. Standard RAG can struggle with global questions over a corpus, and agent-memory systems increasingly treat persistent state as a structured representation rather than a larger prompt. GraphRAG is the best analogy from text corpora: it was motivated by the observation that standard RAG struggles with global questions over a whole corpus. Letta and Zep make the same point in agent-memory terms, where static retrieval is not equivalent to persistent state.
"Find clips of people cooking" is a search task. "Across this cooking archive, what techniques recur most often, who demonstrates them, and which moments best illustrate each technique?" is a memory task.
"Find the logo" is search. "Where does this brand appear across campaigns, what scenes surround it, and how does the tone change over time?" is memory.
"Find a dramatic moment" is search. "Assemble a coherent sequence of moments that supports a story arc, with timestamps and rationale" is memory.
VideoRAG, RAVU, and AdaVideoRAG make this distinction concrete for video: retrieval alone is not the endpoint. These systems combine retrieval with multimodal context, graph representations, intent classification, or multi-step reasoning to answer complex questions over long video.
The distinction matters because applications need reusable state. A search result is often useful for the immediate query. A memory layer should be useful across many queries, many users, and many workflows. It should allow the system to ask follow-up questions, compare new results against prior understanding, generate structured outputs, and explain why a result was selected. Mem0 and Memori both frame agent memory as a persistent layer that improves multi-session behavior and reduces the cost of repeatedly injecting large raw contexts.
Search says, "Here are relevant clips." Memory says, "Here is what we know about this collection, here is how the pieces relate, and here is the evidence behind each claim."
That shift is what makes video usable as infrastructure.
The Context Graph As A Systems Concept
Figure 3: The video context graph
A useful mental model for video memory is the context graph.
By context graph, I do not mean a requirement to use a specific graph database. I mean a systems concept: a durable, queryable representation that connects moments, entities, events, timestamps, metadata, and evidence across a collection.
An index helps answer "where might this be?" A context graph helps answer "what does this collection contain, how are its pieces connected, and what evidence supports that understanding?"
For video, that representation needs to preserve several kinds of knowledge.
It needs time-bounded moments: clips, scenes, shots, segments, or other spans with start and end times. It needs entities: people, characters, places, objects, brands, concepts, and domain-specific subjects. It needs appearances: where and when entities show up. It needs relationships: who is associated with what, which moments belong together, what happened before or after, and which evidence supports a conclusion.
It also needs corpus-level context. A single video may show one customer testimonial. A library may reveal recurring objections, common emotions, seasonal patterns, visual motifs, or gaps in coverage. A single training clip may show one procedure. A corpus may reveal which procedures are common, which mistakes recur, and where the best examples live.
Finally, it needs intent. The same footage should be remembered differently depending on the application. A marketing workflow cares about brand presence, emotional tone, product usage, creator style, and campaign relevance. A media workflow cares about story beats, characters, locations, usable takes, and editorial structure. A compliance workflow cares about claims, disclosures, prohibited content, and review evidence. A training workflow cares about concepts, procedures, mistakes, demonstrations, and outcomes.
There is no universal memory of a video library that is optimal for every product. A useful memory layer must be shaped by what the builder is trying to do. ContextWeaver argues that retrieval-based memory systems can miss causal and logical structure needed for multi-step reasoning, then organizes traces into dependency graphs for future context selection.
The 5 Principles For Building A Video Memory Layer
Figure 4: Five design constraints around the memory layer
1. Ingest Once, Reason Many Times
Video understanding is expensive because the input is large, temporal, and multimodal. Re-understanding the same corpus from scratch for every query is wasteful and inconsistent.
A strong memory layer moves expensive understanding work into a preparation step. During ingestion, the system should extract reusable structure from the corpus: summaries, moments, entities, relationships, metadata, and references. At query time, the application can retrieve and reason over that prepared memory instead of repeatedly scanning the same footage.
This does not mean every answer becomes instant or every task becomes simple. It means the system stops treating every question as a fresh encounter with raw media.
For developers, this is the same mental model that makes databases valuable. You do not repeatedly parse the entire source of truth every time an application needs an answer. You prepare, index, structure, and query.
Video needs the same discipline.
2. Store Primitives, Not Just Answers
A summary is useful, but it is not enough. If the system only stores summaries, every downstream product inherits the limits of those summaries.
Video memory should store primitives that can be reused across workflows: time-bounded moments, entities, appearances, relationships, topics, themes, timelines, and grounded references.
Those primitives compose.
An entity appearance can support search, organization, rights review, recommendation, and content assembly.
A moment with a timestamp can support a highlight reel, an audit trail, a training module, or a structured citation.
A corpus-level theme can support browsing, planning, reporting, and follow-up questions.
The goal is not to precompute every possible answer. The goal is to create a reusable substrate from which many answers can be built.
3. Ground Every Claim
Video memory must be inspectable.
If an application says a clip supports a claim, it should show the source.
If it says a person appeared across several assets, it should show where.
If it proposes a sequence, it should provide timestamps and rationale.
If it organizes a library by theme, the user should be able to inspect the evidence behind each grouping.
Grounding is not just a safety feature. It is a product feature. Provenance standards make the same point in more formal terms: trust depends on knowing which entities, activities, and people produced a claim, how it was derived, and whether the supporting evidence can be inspected.
It helps developers debug. It helps users trust. It helps reviewers verify. It lets downstream systems render not just an answer, but a path back to the source material.
This matters especially for video because verification is otherwise slow. A text answer can often be scanned quickly. A video claim may require opening a clip, scrubbing to the right moment, checking the visual, listening to the audio, and comparing it against surrounding context. A memory layer should reduce that burden, not add to it.
4. Let Intent Shape Memory
This aligns with the broader shift from prompt engineering to context engineering: the system should assemble the right information, tools, and format for the task. For video specifically, adaptive approaches such as AdaVideoRAG select retrieval strategies based on query complexity, balancing cost, latency, and reasoning depth.
The same video can mean different things to different applications:
A shot of a person holding a drink might be irrelevant to one product and central to another.
A background logo might be noise in a sports workflow and critical in a brand safety workflow.
A moment of hesitation might be filler in a transcript summary and the most important signal in a sales-training library.
That is why video memory should be configurable. Builders should be able to tell the system what matters for their domain: which entities to track, which attributes to extract, which moments to preserve, which relationships matter, and what kind of output their application needs.
This is where memory becomes more than generic metadata extraction. It becomes application-shaped knowledge.
The best video systems will not ask developers to accept a fixed interpretation of their media. They will let developers shape what the system remembers.
5. Keep The Memory Layer Composable
Developers do not need another closed vertical agent for every use case. They need infrastructure that can plug into the systems they are already building.
A video memory layer should be API-first. It should work with search, agents, dashboards, review tools, content management systems, labeling workflows, and enterprise applications. It should support natural language, structured outputs, and references that downstream software can use. This is also consistent with agent infrastructure trends: MCP standardizes how assistants connect to external data and tools, while agent frameworks and APIs increasingly expose durable execution, memory, tool use, tracing, and structured outputs as first-class building blocks.
This separation matters. The memory layer should not try to be the editor, the compliance product, the training platform, and the content management system all at once. It should provide the durable video understanding those products need.
That is how video intelligence becomes programmable.
What This Unlocks For Builders
Figure 5: Builder workflow fan-out
Once a video corpus has memory, the product surface changes.
Developers can build corpus digest experiences that summarize what is in a library: topics, formats, entities, themes, patterns, gaps, and unusual moments. This gives users a starting point before they know what to search for.
They can build agentic search experiences that go beyond one retrieval call. The application can search, inspect, compare, refine, and return grounded references rather than a flat list of clips.
They can build entity-centric workflows: show where a person, object, brand, place, or concept appears across the collection, how often it appears, what surrounds it, and which moments matter most.
They can build timelines. Instead of isolated results, the application can reconstruct an event, campaign, narrative, or workflow over time.
They can build organization systems that group videos by topic, scene type, quality, format, use case, audience, risk, or domain-specific taxonomy.
They can build content assembly tools that identify candidate moments, sequence them, and hand a human editor a better starting point.
They can build compliance and review workflows where every finding links back to evidence.
They can build data operations tools that accelerate labeling, enrichment, dataset QA, and corpus understanding.
In each case, the memory layer does not replace the human or the application. It gives them a better substrate to work from.
Jockey And The Productization Of Video Memory
This is the thesis behind Jockey, our effort to productize the memory layer for video intelligence: a video cognition engine that helps developers and enterprises turn video collections into queryable, inspectable, programmable intelligence.
The product concepts are intentionally infrastructure-oriented:
Knowledge stores provide durable, queryable memory for a collection.
Configurable ingestion lets builders shape what the system extracts for a given application.
Corpus digest gives users an overview of what exists in the library.
Entity resolution connects recurring people, places, objects, brands, and concepts across content.
Agentic search retrieves, reasons, and returns grounded references.
A Responses API gives developers a way to ask questions and receive natural-language or structured outputs from that memory.
The important point is not that Jockey is a single end-user workflow. It is not trying to be the final editing interface, the compliance product, or the content management system. It is the video cognition infrastructure beneath those applications.
The next generation of video intelligence will not be defined only by bigger multimodal models or better search indexes. Those will matter. But the real product shift is turning video collections into durable memory: grounded, inspectable, intent-shaped, and reusable across applications.
Search finds moments. Memory makes those moments mean something across the corpus. Jockey is TwelveLabs' effort to build that layer.
Sign up for Jockey private beta access here: https://forms.gle/88pNBNdhY7JjfYXY7
Related articles




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved