" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)
" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Company
Video Advertising Still Does Not Read the Room: The Case for Owning Your Video Intelligence Layer

Thomas Koch
Most streaming ad decisions still happen around the video, not inside it. This post explains why publishers need to own the video intelligence layer that turns scenes, context, and brand suitability into decisionable advertising signals. It also shows how TwelveLabs helps connect video-native understanding to real ad-tech workflows, from IAB taxonomy mapping to FreeWheel-compatible payloads.
Most streaming ad decisions still happen around the video, not inside it. This post explains why publishers need to own the video intelligence layer that turns scenes, context, and brand suitability into decisionable advertising signals. It also shows how TwelveLabs helps connect video-native understanding to real ad-tech workflows, from IAB taxonomy mapping to FreeWheel-compatible payloads.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Jun 18, 2026
16 Minutes
Copy link to article
There is a new category of adtech vendor building real businesses on a compelling premise: let us analyze your video, classify scenes, score brand suitability, and tell you where, when and what ad to serve. The pitch is intuitive. Contextual targeting works. Scene-level intelligence matters. Advertisers want safer and more relevant placements. Consumers are receptive to ads that fund their favorite programming, so long as they resonate and will not disrupt the experience.
Yet most streaming ad decisions still happen around the video, not inside it. An ad server knows campaign rules, frequency caps, targeting parameters, and available demand. But the actual moment where an ad appears is treated like an empty slot in a stream: meaning unread, and context unused. This is the gap that contextual advertising is meant to close.
The problem is neither the use case, nor a shared desire to make contextual advertising work. It is the infrastructure we built to deliver upon its promise.
The Shift: From Selling Inventory to Selling Moments
Premium video advertising has always sold attention. The next step is selling context with proof.
That matters because two streams can look identical to an ad server while being completely different to a viewer:
A cooking show can contain a family meal, a tense elimination, a humorous mistake, a luxury kitchen reveal, or a quiet emotional exchange.
A sports broadcast can contain routine play, luxury fashion in the tunnel, a controversial call, a comeback, a player injury, and championship-defining moments.
A news program can contain breaking violence, market analysis, weather coverage, an interview, or a human-interest segment.
Those moments should not carry the same ad logic. Scene-level intelligence allows publishers to create packages around what buyers actually care about:
Brand-safe news segments that should not be over-blocked
High-energy sports moments suitable for auto, beverage, and retail advertisers
Calm lifestyle environments suitable for finance, travel, wellness, and CPG
Family-safe scenes across mixed programming
Multilingual inventory that can be understood and monetized consistently across regions
Break points that respect the viewer experience rather than interrupting narrative tension
This is not better tagging. It is a new way to make video inventory addressable.
The goal is not to replace the ad stack. The goal is to give the ad stack better intelligence.
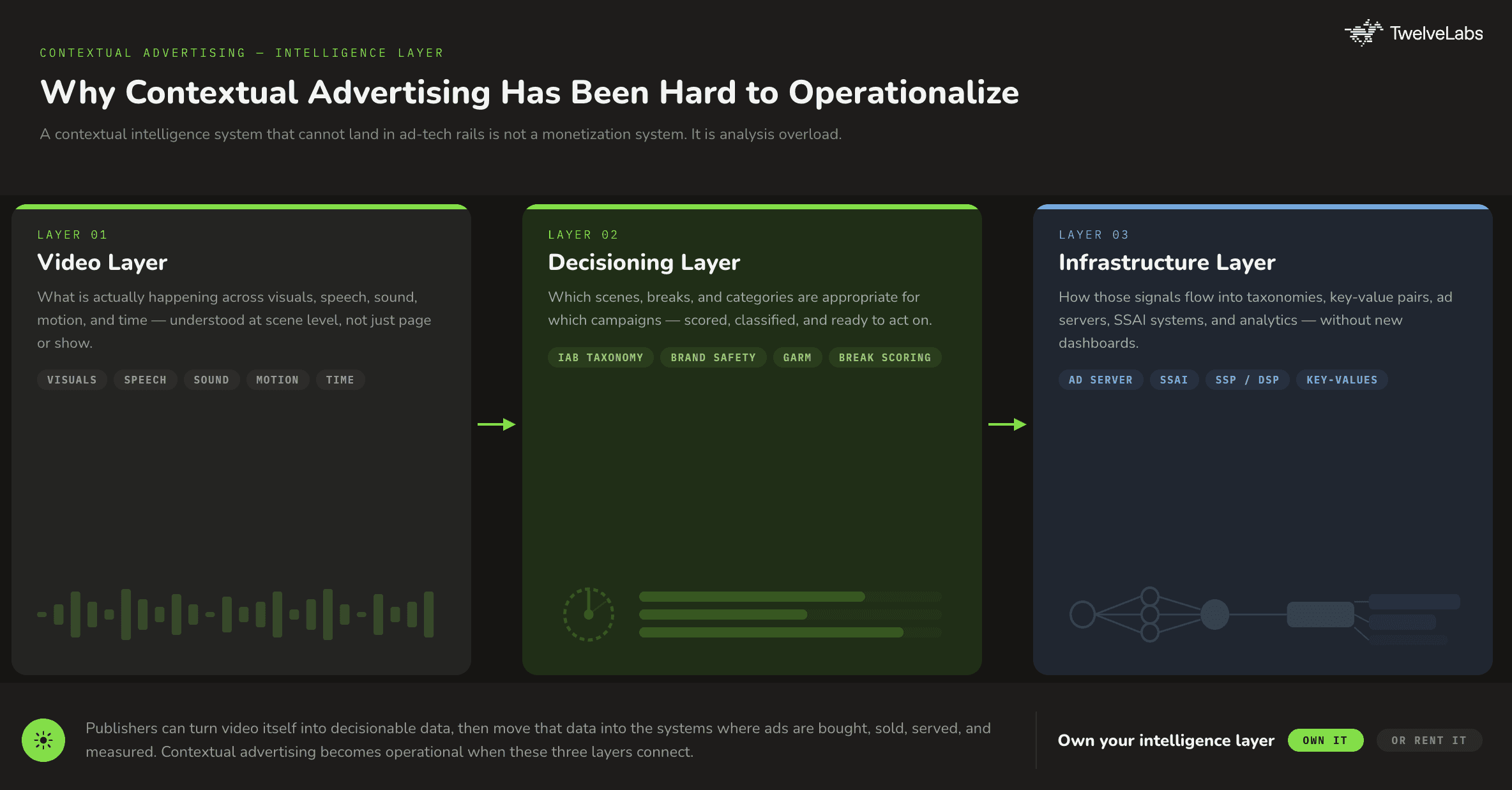
Why Contextual Advertising Has Been Hard to Operationalize
For years, the promise of more relevant and less intrusive advertising has been suggested as an obvious path forward. The commercial logic is clear: advertisers want safer and more engaging placements, publishers want higher yield and fill rates. Consumers are more receptive to ads that fund their favorite programs, so long as they respect the moments they are watching.
In practice, most contextual advertising conversations remain abstract because the workflow is hard to visualize:
Where does the context come from?
How is a scene scored?
Who defines suitability?
How does the signal reach and inform the Ad Server, SSAI, SSP, or DSP?
How do these systems avoid creating more dashboards that ad operations and media buying teams have to monitor and decision on?
These are not secondary questions. They are the product itself.
A contextual intelligence system that cannot land in real ad-tech rails is not a monetization system. It is analysis.
The commercial opportunity is to connect three layers that have historically been separate:
The video layer: what is actually happening across visuals, speech, sound, motion, and time
The decisioning layer: which scenes, breaks, and categories are appropriate for which campaigns
The ad infrastructure layer: how those signals flow into taxonomies, key-value pairs, ad servers, SSAI systems, and analytics environments
When those layers connect, contextual advertising becomes operational. Publishers can package inventory more precisely. Buyers can trust the placement logic. Partners can build on top of a repeatable intelligence layer instead of negotiating one-off metadata projects.
The Intermediary Tax
When a streaming publisher integrates a third-party contextual intelligence vendor, the transaction looks simple on the surface. You pipe your video into their platform. They return signals. The vendor facilitates decisioning on those signals downstream.
What is actually happening is more expensive than it looks.
The content you produced or licensed leaves your storage infrastructure. A single hour of broadcast-quality content can exceed 50GB before processing. Egressing that data at scale is a meaningful recurring infrastructure cost. That cost compounds on top of the per-CPM or SaaS licensing fee you are paying to process your content and generate usable signals. Three costs: one to move your data, one to enrich it, and one to bear risk.
You do not own and control the methodology. Classification rules, suitability thresholds, and segment definitions that determine how your inventory is priced and packaged are first calibrated for a median advertiser. Not your content, not your buyers, not your market position. Each time you want to adjust those rules, the vendor must be notified and a service request fulfilled. The flexibility that AI should deliver is gated behind a vendor relationship: custom rule sets, configurable packaging, and direct iteration.
There are costs that do not appear on your invoice. When you egress video to a third party, you lose control of what happens to it. Your content now resides on infrastructure you do not own, governed by privacy policies and data handling agreements you did not write. Most content agreements do not contemplate this. Many explicitly prohibit it. In the event of a vendor breach or improper data use, the compliance exposure lands on you.
The Multimodal Claim That Needs Unpacking
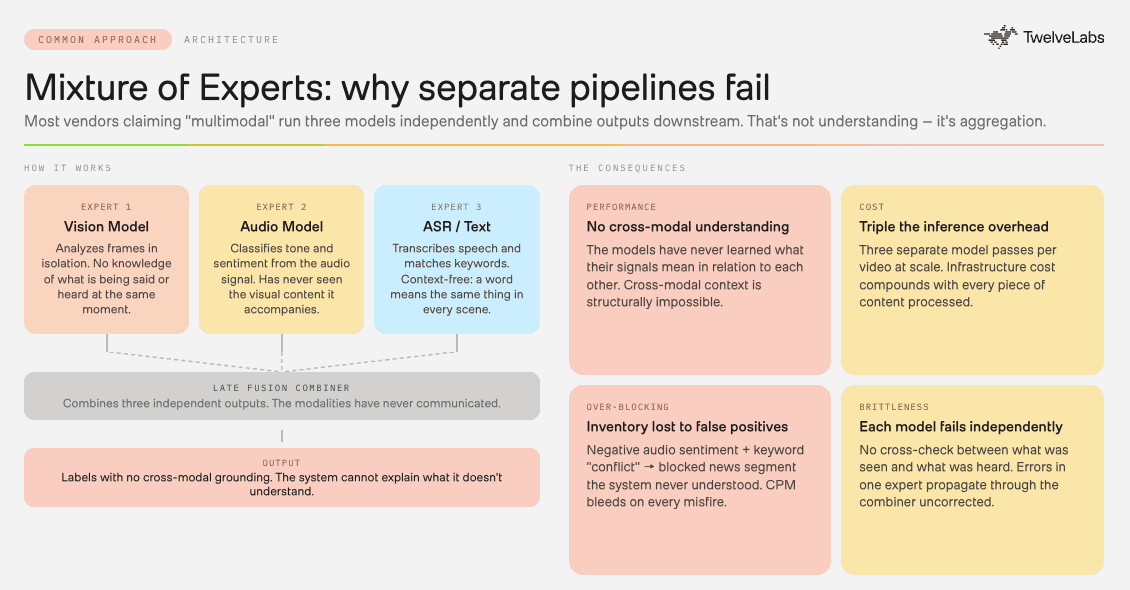
Not all contextual AI is built the same way, and the difference matters in production.
Many vendors claiming multimodal approaches use a “Mixture of Experts” (MoE) framework by weighting and combining text analysis, image classification, and audio processing into a content signal. That is real engineering work which produces usable outputs. But a system that processes each modality of video separately and combines them downstream has never learned what those modalities mean in relation to each other, losing the plot and incurring explosive costs of multiple processing pipelines beneath the hood.
The system learns what a frame looks like. It produces a transcript of what it hears. But it has not learned how background music changes the emotional register of a scene, or how quiet visuals with rising audio tension create a different brand context than the same visual with peaceful sound. Cross-modal understanding only emerges from joint model training. Most vendors claiming multimodal capability are not running jointly-trained models.
This gap shows up in practice. A system that scores negative audio sentiment and detects the word "conflict" in a transcript will produce a brand safety flag on a news segment it does not understand. A jointly-trained model that reads the full scene can make the contextual judgment a human editor would make. That distinction is the difference between over-blocked news inventory and CPM points left on the table.
What a Production-Ready Contextual System Has to Do

A working contextual advertising system needs to satisfy both technical and commercial requirements.
It has to understand video beyond transcripts and thumbnails. Video is a temporal signal. Meaning emerges from the relationship between what is seen, what is heard, what changes, and when it changes. A sampled frame may detect an object. A transcript may capture a keyword. Neither is enough to determine whether a scene is suitable for a specific advertiser.
It has to produce configurable scores, not just labels. Suitability is not universal. A pharmaceutical advertiser, a beer brand, an auto advertiser, and a financial institution all have different tolerance thresholds. Publishers need the ability to tune rules by category, buyer, region, and content type.
It has to integrate with industry standards. The IAB Content Taxonomy exists to provide a common language for describing content, including contextual targeting and brand safety. IAB Tech Lab lists contextual targeting and brand safety as typical uses of the taxonomy. A contextual system has to map into that language, not invent a private ontology that ad systems cannot use.
It has to land in ad-serving workflows. AWS Elemental MediaTailor, for example, describes contextual signals as part of extending ad requests in personalized ad workflows. FreeWheel positions its publisher tools around helping media sellers control and monetize premium video inventory. Contextual intelligence becomes commercially useful when it can feed these systems, not sit beside them.
It has to be auditable. When a buyer asks why an ad was included or excluded, the publisher needs a defensible answer tied to scene evidence, taxonomy mapping, safety rules, and scoring logic.
The architecture of the system is the difference between AI-generated metadata and contextual ad intelligence.

A Working Blueprint: Scene Intelligence to Ad Decisioning
Our recent tutorial on building a contextual ad insertion engine shows what this looks like in practice: The application uses Pegasus 1.5 for structured scene intelligence, Marengo 3.0 for multimodal embeddings, Databricks Delta Lake for enterprise analytics, and FreeWheel/OpenRTB-compatible payload generation for integration with existing ad servers.
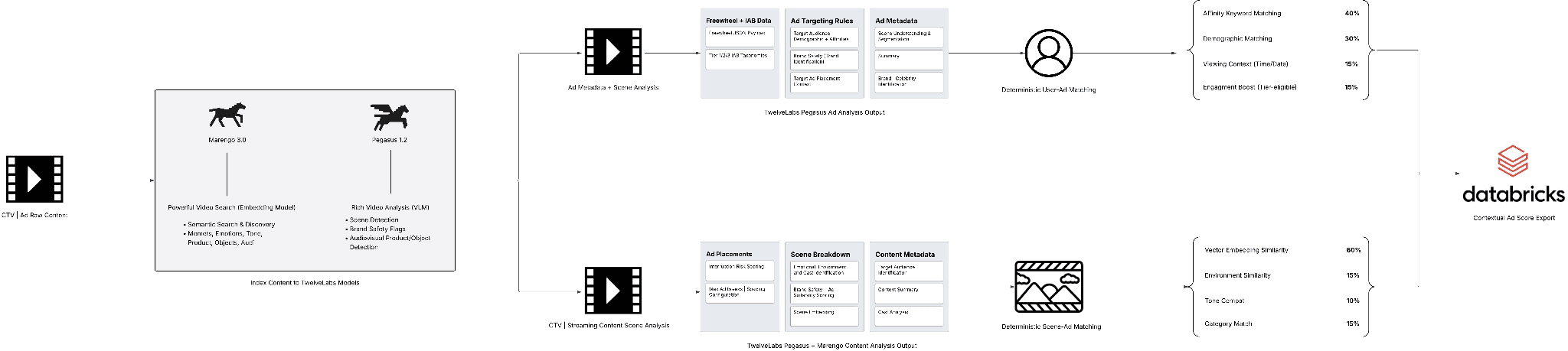
The architecture is important because it makes contextual advertising visible as a workflow.
Pegasus analyzes each scene and produces structured metadata: sentiment, tone, environment, cast, brand safety flags, and targeting recommendations.
Marengo encodes both content scenes and ad creatives into the same 512-dimensional embedding space, enabling visual similarity matching between what is on screen in the content and what appears in the ad creative.
The engine then combines model-derived context with deterministic business logic.
At a high level:
totalScore = adAffinity * sceneFit sceneFit = suitableMatch * 0.15 + environmentFit * 0.15 + toneCompat * 0.10 + contextMatch * 0
That weighting matters. Marengo’s embedding similarity drives most of the score because the best contextual match comes from the actual scene-ad relationship. Pegasus-derived structured signals preserve controllability for brand suitability, environment, tone, and policy rules. Our tutorial makes this explicit: the remaining signals give policy and content safety teams deterministic guardrails.
This is the practical middle ground publishers need. Not a black box. Not a brittle rules engine. A configurable scoring layer that combines video-native intelligence with commercial constraints.
Why Publishers Should Own Their Video Intelligence Layer
There will always be a role for ad-tech platforms, SSPs, ad servers, SSAI providers, brand safety vendors, and workflow partners. The question is not whether publishers should build everything themselves. The question is whether the core understanding of their own content should be rented from someone else.
When a publisher depends entirely on a third-party contextual vendor, the vendor controls more than a feature. It controls the methodology that determines how inventory is classified, packaged, blocked, priced, and explained to buyers.
That creates four commercial constraints.
First, content may need to leave the publisher’s environment for processing, creating infrastructure cost, governance questions, and contractual risk.
Second, classifications are often calibrated around a vendor’s generalized taxonomy rather than the publisher’s inventory and buyer relationships.
Third, changes to suitability rules often require vendor services work rather than direct iteration by the publisher’s product, data, or ad operations teams.
Fourth, the intelligence does not compound inside the publisher’s own infrastructure. Each new analysis enriches the vendor’s platform more than the publisher’s own operating layer.
Owning the intelligence layer changes that. Publishers can encode their video libraries once, persist embeddings, define their own contextual segments, test different suitability logic, integrate outputs into ad servers, and build repeatable packaging strategies across VOD, FAST, live, sports, news, and international libraries. The value transitions from a vendor report to a flexible, monetizable asset to drive engagement, CPM lift, and fill rate.
Where This Matters First

The first wave of adoption will not be generic. It will concentrate in places where better scene intelligence directly affects yield, safety, or workflow cost.
FAST channels: FAST operators need to create more value from large libraries without adding manual programming overhead. Contextual intelligence can help identify better ad breaks, package inventory by scene context, support category exclusions, and improve the ad experience without requiring every asset to be manually reviewed.
Premium VOD libraries: Large catalogs often contain valuable scenes that are invisible to title-level metadata. Scene intelligence makes it possible to create packages around mood, setting, talent presence, objects, topics, themes, and brand-safe environments.
Live sports and event programming: Sports monetization depends on timing. The same ad can feel appropriate after a celebration and jarring during an injury review. Video-native models can reason across motion, audio, and crowd energy to support better ad break and sponsorship decisions.
News and current affairs: News has suffered from blunt blocking. The word "conflict" in a transcript should not automatically make an entire segment unsuitable. Publishers need models that can distinguish reporting, analysis, weather, market commentary, and genuinely unsafe adjacency.
These are not speculative use cases. They are the places where ad sales, ad ops, product, and technology teams already feel the limitations of current metadata.
The Partner Opportunity
For adtech and media technology partners, the opportunity is not to compete with publishers for content understanding. It is to build better products on top of a stronger foundation: A contextual SaaS vendor may already know how to deliver signals into the right systems. An SSP may already understand supply packaging. A SSAI platform may already own the insertion workflow. A data platform may already govern downstream analytics.
TwelveLabs strengthens those systems by providing the video intelligence layer underneath them: Marengo serves as the multimodal encoder, turning video, audio, text, and visual context into a searchable representation. Pegasus serves as the reasoning layer, converting that representation into structured outputs that downstream systems can use.
For partners, that means:
Better contextual signal quality
More configurable suitability logic
Cleaner taxonomy mapping
Stronger explainability for buyers
Faster product development without building video foundation models from scratch
The result is not another closed ad-tech platform. It is infrastructure that lets the ecosystem build more precise advertising products.
The Conversation Publishers Should Be Having Now
At StreamTV show, the conversation has centered on streaming growth, FAST monetization, advertising innovation, and technology infrastructure. At Cannes Lion Festival, it will center on brands, agencies, creativity, media quality, and the role AI should play in advertising.
Those conversations often happen in different rooms. Contextual advertising connects them.
Publishers should be asking:
Is my contextual AI vendor natively multimodal, and do they provide academic benchmarking for video understanding tasks?
Can we explain why an ad appeared in this moment?
Can we package inventory by what happens inside the video, not just by title or genre?
Can we reduce blunt blocking without compromising brand safety?
Can we tune suitability rules by advertiser category, region, and content type — without a vendor service request?
Can we send context into the ad systems we already use?
Can our contextual intelligence improve over time, inside our own environment?
Can partners build on our intelligence layer without taking control of it?
The organizations that answer yes will have a different kind of leverage with buyers: They will not simply sell impressions. They will sell understood moments.
Contextual Advertising Is an Infrastructure Decision
The future of contextual advertising will not be defined by who has the most polished dashboard. It will be defined by who owns the representation of video that every downstream decision depends on:
If the video remains opaque, advertising remains approximate.
If the video becomes queryable, contextual, and decisionable, every ad break becomes more valuable.
That is the role TwelveLabs plays: We help publishers and partners turn video into an intelligence layer that can support search, retrieval, suitability, ad decisioning, analytics, and automation. Marengo encodes the content. Pegasus reasons across it. The outputs can be mapped to taxonomies, scored against business rules, delivered into ad systems, and audited by the teams responsible for revenue and trust.
Contextual advertising is no longer just a targeting tactic. It is a test of whether media companies can turn their most valuable asset, video, into infrastructure.
The publishers who do that first will not just monetize more inventory. They will define what premium video advertising feels like next.
See the contextual ad engine in action: Explore our technical tutorial to understand how TwelveLabs turns scene intelligence into IAB-compliant, FreeWheel-compatible ad decisioning workflows.
For publishers and partners: Talk to us about piloting contextual ad intelligence across FAST, VOD, sports, news, and premium streaming inventory at sales@twelvelabs.io.
There is a new category of adtech vendor building real businesses on a compelling premise: let us analyze your video, classify scenes, score brand suitability, and tell you where, when and what ad to serve. The pitch is intuitive. Contextual targeting works. Scene-level intelligence matters. Advertisers want safer and more relevant placements. Consumers are receptive to ads that fund their favorite programming, so long as they resonate and will not disrupt the experience.
Yet most streaming ad decisions still happen around the video, not inside it. An ad server knows campaign rules, frequency caps, targeting parameters, and available demand. But the actual moment where an ad appears is treated like an empty slot in a stream: meaning unread, and context unused. This is the gap that contextual advertising is meant to close.
The problem is neither the use case, nor a shared desire to make contextual advertising work. It is the infrastructure we built to deliver upon its promise.
The Shift: From Selling Inventory to Selling Moments
Premium video advertising has always sold attention. The next step is selling context with proof.
That matters because two streams can look identical to an ad server while being completely different to a viewer:
A cooking show can contain a family meal, a tense elimination, a humorous mistake, a luxury kitchen reveal, or a quiet emotional exchange.
A sports broadcast can contain routine play, luxury fashion in the tunnel, a controversial call, a comeback, a player injury, and championship-defining moments.
A news program can contain breaking violence, market analysis, weather coverage, an interview, or a human-interest segment.
Those moments should not carry the same ad logic. Scene-level intelligence allows publishers to create packages around what buyers actually care about:
Brand-safe news segments that should not be over-blocked
High-energy sports moments suitable for auto, beverage, and retail advertisers
Calm lifestyle environments suitable for finance, travel, wellness, and CPG
Family-safe scenes across mixed programming
Multilingual inventory that can be understood and monetized consistently across regions
Break points that respect the viewer experience rather than interrupting narrative tension
This is not better tagging. It is a new way to make video inventory addressable.
The goal is not to replace the ad stack. The goal is to give the ad stack better intelligence.
Why Contextual Advertising Has Been Hard to Operationalize
For years, the promise of more relevant and less intrusive advertising has been suggested as an obvious path forward. The commercial logic is clear: advertisers want safer and more engaging placements, publishers want higher yield and fill rates. Consumers are more receptive to ads that fund their favorite programs, so long as they respect the moments they are watching.
In practice, most contextual advertising conversations remain abstract because the workflow is hard to visualize:
Where does the context come from?
How is a scene scored?
Who defines suitability?
How does the signal reach and inform the Ad Server, SSAI, SSP, or DSP?
How do these systems avoid creating more dashboards that ad operations and media buying teams have to monitor and decision on?
These are not secondary questions. They are the product itself.
A contextual intelligence system that cannot land in real ad-tech rails is not a monetization system. It is analysis.
The commercial opportunity is to connect three layers that have historically been separate:
The video layer: what is actually happening across visuals, speech, sound, motion, and time
The decisioning layer: which scenes, breaks, and categories are appropriate for which campaigns
The ad infrastructure layer: how those signals flow into taxonomies, key-value pairs, ad servers, SSAI systems, and analytics environments
When those layers connect, contextual advertising becomes operational. Publishers can package inventory more precisely. Buyers can trust the placement logic. Partners can build on top of a repeatable intelligence layer instead of negotiating one-off metadata projects.
The Intermediary Tax
When a streaming publisher integrates a third-party contextual intelligence vendor, the transaction looks simple on the surface. You pipe your video into their platform. They return signals. The vendor facilitates decisioning on those signals downstream.
What is actually happening is more expensive than it looks.
The content you produced or licensed leaves your storage infrastructure. A single hour of broadcast-quality content can exceed 50GB before processing. Egressing that data at scale is a meaningful recurring infrastructure cost. That cost compounds on top of the per-CPM or SaaS licensing fee you are paying to process your content and generate usable signals. Three costs: one to move your data, one to enrich it, and one to bear risk.
You do not own and control the methodology. Classification rules, suitability thresholds, and segment definitions that determine how your inventory is priced and packaged are first calibrated for a median advertiser. Not your content, not your buyers, not your market position. Each time you want to adjust those rules, the vendor must be notified and a service request fulfilled. The flexibility that AI should deliver is gated behind a vendor relationship: custom rule sets, configurable packaging, and direct iteration.
There are costs that do not appear on your invoice. When you egress video to a third party, you lose control of what happens to it. Your content now resides on infrastructure you do not own, governed by privacy policies and data handling agreements you did not write. Most content agreements do not contemplate this. Many explicitly prohibit it. In the event of a vendor breach or improper data use, the compliance exposure lands on you.
The Multimodal Claim That Needs Unpacking
Not all contextual AI is built the same way, and the difference matters in production.
Many vendors claiming multimodal approaches use a “Mixture of Experts” (MoE) framework by weighting and combining text analysis, image classification, and audio processing into a content signal. That is real engineering work which produces usable outputs. But a system that processes each modality of video separately and combines them downstream has never learned what those modalities mean in relation to each other, losing the plot and incurring explosive costs of multiple processing pipelines beneath the hood.
The system learns what a frame looks like. It produces a transcript of what it hears. But it has not learned how background music changes the emotional register of a scene, or how quiet visuals with rising audio tension create a different brand context than the same visual with peaceful sound. Cross-modal understanding only emerges from joint model training. Most vendors claiming multimodal capability are not running jointly-trained models.
This gap shows up in practice. A system that scores negative audio sentiment and detects the word "conflict" in a transcript will produce a brand safety flag on a news segment it does not understand. A jointly-trained model that reads the full scene can make the contextual judgment a human editor would make. That distinction is the difference between over-blocked news inventory and CPM points left on the table.
What a Production-Ready Contextual System Has to Do
A working contextual advertising system needs to satisfy both technical and commercial requirements.
It has to understand video beyond transcripts and thumbnails. Video is a temporal signal. Meaning emerges from the relationship between what is seen, what is heard, what changes, and when it changes. A sampled frame may detect an object. A transcript may capture a keyword. Neither is enough to determine whether a scene is suitable for a specific advertiser.
It has to produce configurable scores, not just labels. Suitability is not universal. A pharmaceutical advertiser, a beer brand, an auto advertiser, and a financial institution all have different tolerance thresholds. Publishers need the ability to tune rules by category, buyer, region, and content type.
It has to integrate with industry standards. The IAB Content Taxonomy exists to provide a common language for describing content, including contextual targeting and brand safety. IAB Tech Lab lists contextual targeting and brand safety as typical uses of the taxonomy. A contextual system has to map into that language, not invent a private ontology that ad systems cannot use.
It has to land in ad-serving workflows. AWS Elemental MediaTailor, for example, describes contextual signals as part of extending ad requests in personalized ad workflows. FreeWheel positions its publisher tools around helping media sellers control and monetize premium video inventory. Contextual intelligence becomes commercially useful when it can feed these systems, not sit beside them.
It has to be auditable. When a buyer asks why an ad was included or excluded, the publisher needs a defensible answer tied to scene evidence, taxonomy mapping, safety rules, and scoring logic.
The architecture of the system is the difference between AI-generated metadata and contextual ad intelligence.
A Working Blueprint: Scene Intelligence to Ad Decisioning
Our recent tutorial on building a contextual ad insertion engine shows what this looks like in practice: The application uses Pegasus 1.5 for structured scene intelligence, Marengo 3.0 for multimodal embeddings, Databricks Delta Lake for enterprise analytics, and FreeWheel/OpenRTB-compatible payload generation for integration with existing ad servers.
The architecture is important because it makes contextual advertising visible as a workflow.
Pegasus analyzes each scene and produces structured metadata: sentiment, tone, environment, cast, brand safety flags, and targeting recommendations.
Marengo encodes both content scenes and ad creatives into the same 512-dimensional embedding space, enabling visual similarity matching between what is on screen in the content and what appears in the ad creative.
The engine then combines model-derived context with deterministic business logic.
At a high level:
totalScore = adAffinity * sceneFit sceneFit = suitableMatch * 0.15 + environmentFit * 0.15 + toneCompat * 0.10 + contextMatch * 0
That weighting matters. Marengo’s embedding similarity drives most of the score because the best contextual match comes from the actual scene-ad relationship. Pegasus-derived structured signals preserve controllability for brand suitability, environment, tone, and policy rules. Our tutorial makes this explicit: the remaining signals give policy and content safety teams deterministic guardrails.
This is the practical middle ground publishers need. Not a black box. Not a brittle rules engine. A configurable scoring layer that combines video-native intelligence with commercial constraints.
Why Publishers Should Own Their Video Intelligence Layer
There will always be a role for ad-tech platforms, SSPs, ad servers, SSAI providers, brand safety vendors, and workflow partners. The question is not whether publishers should build everything themselves. The question is whether the core understanding of their own content should be rented from someone else.
When a publisher depends entirely on a third-party contextual vendor, the vendor controls more than a feature. It controls the methodology that determines how inventory is classified, packaged, blocked, priced, and explained to buyers.
That creates four commercial constraints.
First, content may need to leave the publisher’s environment for processing, creating infrastructure cost, governance questions, and contractual risk.
Second, classifications are often calibrated around a vendor’s generalized taxonomy rather than the publisher’s inventory and buyer relationships.
Third, changes to suitability rules often require vendor services work rather than direct iteration by the publisher’s product, data, or ad operations teams.
Fourth, the intelligence does not compound inside the publisher’s own infrastructure. Each new analysis enriches the vendor’s platform more than the publisher’s own operating layer.
Owning the intelligence layer changes that. Publishers can encode their video libraries once, persist embeddings, define their own contextual segments, test different suitability logic, integrate outputs into ad servers, and build repeatable packaging strategies across VOD, FAST, live, sports, news, and international libraries. The value transitions from a vendor report to a flexible, monetizable asset to drive engagement, CPM lift, and fill rate.
Where This Matters First
The first wave of adoption will not be generic. It will concentrate in places where better scene intelligence directly affects yield, safety, or workflow cost.
FAST channels: FAST operators need to create more value from large libraries without adding manual programming overhead. Contextual intelligence can help identify better ad breaks, package inventory by scene context, support category exclusions, and improve the ad experience without requiring every asset to be manually reviewed.
Premium VOD libraries: Large catalogs often contain valuable scenes that are invisible to title-level metadata. Scene intelligence makes it possible to create packages around mood, setting, talent presence, objects, topics, themes, and brand-safe environments.
Live sports and event programming: Sports monetization depends on timing. The same ad can feel appropriate after a celebration and jarring during an injury review. Video-native models can reason across motion, audio, and crowd energy to support better ad break and sponsorship decisions.
News and current affairs: News has suffered from blunt blocking. The word "conflict" in a transcript should not automatically make an entire segment unsuitable. Publishers need models that can distinguish reporting, analysis, weather, market commentary, and genuinely unsafe adjacency.
These are not speculative use cases. They are the places where ad sales, ad ops, product, and technology teams already feel the limitations of current metadata.
The Partner Opportunity
For adtech and media technology partners, the opportunity is not to compete with publishers for content understanding. It is to build better products on top of a stronger foundation: A contextual SaaS vendor may already know how to deliver signals into the right systems. An SSP may already understand supply packaging. A SSAI platform may already own the insertion workflow. A data platform may already govern downstream analytics.
TwelveLabs strengthens those systems by providing the video intelligence layer underneath them: Marengo serves as the multimodal encoder, turning video, audio, text, and visual context into a searchable representation. Pegasus serves as the reasoning layer, converting that representation into structured outputs that downstream systems can use.
For partners, that means:
Better contextual signal quality
More configurable suitability logic
Cleaner taxonomy mapping
Stronger explainability for buyers
Faster product development without building video foundation models from scratch
The result is not another closed ad-tech platform. It is infrastructure that lets the ecosystem build more precise advertising products.
The Conversation Publishers Should Be Having Now
At StreamTV show, the conversation has centered on streaming growth, FAST monetization, advertising innovation, and technology infrastructure. At Cannes Lion Festival, it will center on brands, agencies, creativity, media quality, and the role AI should play in advertising.
Those conversations often happen in different rooms. Contextual advertising connects them.
Publishers should be asking:
Is my contextual AI vendor natively multimodal, and do they provide academic benchmarking for video understanding tasks?
Can we explain why an ad appeared in this moment?
Can we package inventory by what happens inside the video, not just by title or genre?
Can we reduce blunt blocking without compromising brand safety?
Can we tune suitability rules by advertiser category, region, and content type — without a vendor service request?
Can we send context into the ad systems we already use?
Can our contextual intelligence improve over time, inside our own environment?
Can partners build on our intelligence layer without taking control of it?
The organizations that answer yes will have a different kind of leverage with buyers: They will not simply sell impressions. They will sell understood moments.
Contextual Advertising Is an Infrastructure Decision
The future of contextual advertising will not be defined by who has the most polished dashboard. It will be defined by who owns the representation of video that every downstream decision depends on:
If the video remains opaque, advertising remains approximate.
If the video becomes queryable, contextual, and decisionable, every ad break becomes more valuable.
That is the role TwelveLabs plays: We help publishers and partners turn video into an intelligence layer that can support search, retrieval, suitability, ad decisioning, analytics, and automation. Marengo encodes the content. Pegasus reasons across it. The outputs can be mapped to taxonomies, scored against business rules, delivered into ad systems, and audited by the teams responsible for revenue and trust.
Contextual advertising is no longer just a targeting tactic. It is a test of whether media companies can turn their most valuable asset, video, into infrastructure.
The publishers who do that first will not just monetize more inventory. They will define what premium video advertising feels like next.
See the contextual ad engine in action: Explore our technical tutorial to understand how TwelveLabs turns scene intelligence into IAB-compliant, FreeWheel-compatible ad decisioning workflows.
For publishers and partners: Talk to us about piloting contextual ad intelligence across FAST, VOD, sports, news, and premium streaming inventory at sales@twelvelabs.io.
There is a new category of adtech vendor building real businesses on a compelling premise: let us analyze your video, classify scenes, score brand suitability, and tell you where, when and what ad to serve. The pitch is intuitive. Contextual targeting works. Scene-level intelligence matters. Advertisers want safer and more relevant placements. Consumers are receptive to ads that fund their favorite programming, so long as they resonate and will not disrupt the experience.
Yet most streaming ad decisions still happen around the video, not inside it. An ad server knows campaign rules, frequency caps, targeting parameters, and available demand. But the actual moment where an ad appears is treated like an empty slot in a stream: meaning unread, and context unused. This is the gap that contextual advertising is meant to close.
The problem is neither the use case, nor a shared desire to make contextual advertising work. It is the infrastructure we built to deliver upon its promise.
The Shift: From Selling Inventory to Selling Moments
Premium video advertising has always sold attention. The next step is selling context with proof.
That matters because two streams can look identical to an ad server while being completely different to a viewer:
A cooking show can contain a family meal, a tense elimination, a humorous mistake, a luxury kitchen reveal, or a quiet emotional exchange.
A sports broadcast can contain routine play, luxury fashion in the tunnel, a controversial call, a comeback, a player injury, and championship-defining moments.
A news program can contain breaking violence, market analysis, weather coverage, an interview, or a human-interest segment.
Those moments should not carry the same ad logic. Scene-level intelligence allows publishers to create packages around what buyers actually care about:
Brand-safe news segments that should not be over-blocked
High-energy sports moments suitable for auto, beverage, and retail advertisers
Calm lifestyle environments suitable for finance, travel, wellness, and CPG
Family-safe scenes across mixed programming
Multilingual inventory that can be understood and monetized consistently across regions
Break points that respect the viewer experience rather than interrupting narrative tension
This is not better tagging. It is a new way to make video inventory addressable.
The goal is not to replace the ad stack. The goal is to give the ad stack better intelligence.
Why Contextual Advertising Has Been Hard to Operationalize
For years, the promise of more relevant and less intrusive advertising has been suggested as an obvious path forward. The commercial logic is clear: advertisers want safer and more engaging placements, publishers want higher yield and fill rates. Consumers are more receptive to ads that fund their favorite programs, so long as they respect the moments they are watching.
In practice, most contextual advertising conversations remain abstract because the workflow is hard to visualize:
Where does the context come from?
How is a scene scored?
Who defines suitability?
How does the signal reach and inform the Ad Server, SSAI, SSP, or DSP?
How do these systems avoid creating more dashboards that ad operations and media buying teams have to monitor and decision on?
These are not secondary questions. They are the product itself.
A contextual intelligence system that cannot land in real ad-tech rails is not a monetization system. It is analysis.
The commercial opportunity is to connect three layers that have historically been separate:
The video layer: what is actually happening across visuals, speech, sound, motion, and time
The decisioning layer: which scenes, breaks, and categories are appropriate for which campaigns
The ad infrastructure layer: how those signals flow into taxonomies, key-value pairs, ad servers, SSAI systems, and analytics environments
When those layers connect, contextual advertising becomes operational. Publishers can package inventory more precisely. Buyers can trust the placement logic. Partners can build on top of a repeatable intelligence layer instead of negotiating one-off metadata projects.
The Intermediary Tax
When a streaming publisher integrates a third-party contextual intelligence vendor, the transaction looks simple on the surface. You pipe your video into their platform. They return signals. The vendor facilitates decisioning on those signals downstream.
What is actually happening is more expensive than it looks.
The content you produced or licensed leaves your storage infrastructure. A single hour of broadcast-quality content can exceed 50GB before processing. Egressing that data at scale is a meaningful recurring infrastructure cost. That cost compounds on top of the per-CPM or SaaS licensing fee you are paying to process your content and generate usable signals. Three costs: one to move your data, one to enrich it, and one to bear risk.
You do not own and control the methodology. Classification rules, suitability thresholds, and segment definitions that determine how your inventory is priced and packaged are first calibrated for a median advertiser. Not your content, not your buyers, not your market position. Each time you want to adjust those rules, the vendor must be notified and a service request fulfilled. The flexibility that AI should deliver is gated behind a vendor relationship: custom rule sets, configurable packaging, and direct iteration.
There are costs that do not appear on your invoice. When you egress video to a third party, you lose control of what happens to it. Your content now resides on infrastructure you do not own, governed by privacy policies and data handling agreements you did not write. Most content agreements do not contemplate this. Many explicitly prohibit it. In the event of a vendor breach or improper data use, the compliance exposure lands on you.
The Multimodal Claim That Needs Unpacking
Not all contextual AI is built the same way, and the difference matters in production.
Many vendors claiming multimodal approaches use a “Mixture of Experts” (MoE) framework by weighting and combining text analysis, image classification, and audio processing into a content signal. That is real engineering work which produces usable outputs. But a system that processes each modality of video separately and combines them downstream has never learned what those modalities mean in relation to each other, losing the plot and incurring explosive costs of multiple processing pipelines beneath the hood.
The system learns what a frame looks like. It produces a transcript of what it hears. But it has not learned how background music changes the emotional register of a scene, or how quiet visuals with rising audio tension create a different brand context than the same visual with peaceful sound. Cross-modal understanding only emerges from joint model training. Most vendors claiming multimodal capability are not running jointly-trained models.
This gap shows up in practice. A system that scores negative audio sentiment and detects the word "conflict" in a transcript will produce a brand safety flag on a news segment it does not understand. A jointly-trained model that reads the full scene can make the contextual judgment a human editor would make. That distinction is the difference between over-blocked news inventory and CPM points left on the table.
What a Production-Ready Contextual System Has to Do
A working contextual advertising system needs to satisfy both technical and commercial requirements.
It has to understand video beyond transcripts and thumbnails. Video is a temporal signal. Meaning emerges from the relationship between what is seen, what is heard, what changes, and when it changes. A sampled frame may detect an object. A transcript may capture a keyword. Neither is enough to determine whether a scene is suitable for a specific advertiser.
It has to produce configurable scores, not just labels. Suitability is not universal. A pharmaceutical advertiser, a beer brand, an auto advertiser, and a financial institution all have different tolerance thresholds. Publishers need the ability to tune rules by category, buyer, region, and content type.
It has to integrate with industry standards. The IAB Content Taxonomy exists to provide a common language for describing content, including contextual targeting and brand safety. IAB Tech Lab lists contextual targeting and brand safety as typical uses of the taxonomy. A contextual system has to map into that language, not invent a private ontology that ad systems cannot use.
It has to land in ad-serving workflows. AWS Elemental MediaTailor, for example, describes contextual signals as part of extending ad requests in personalized ad workflows. FreeWheel positions its publisher tools around helping media sellers control and monetize premium video inventory. Contextual intelligence becomes commercially useful when it can feed these systems, not sit beside them.
It has to be auditable. When a buyer asks why an ad was included or excluded, the publisher needs a defensible answer tied to scene evidence, taxonomy mapping, safety rules, and scoring logic.
The architecture of the system is the difference between AI-generated metadata and contextual ad intelligence.
A Working Blueprint: Scene Intelligence to Ad Decisioning
Our recent tutorial on building a contextual ad insertion engine shows what this looks like in practice: The application uses Pegasus 1.5 for structured scene intelligence, Marengo 3.0 for multimodal embeddings, Databricks Delta Lake for enterprise analytics, and FreeWheel/OpenRTB-compatible payload generation for integration with existing ad servers.
The architecture is important because it makes contextual advertising visible as a workflow.
Pegasus analyzes each scene and produces structured metadata: sentiment, tone, environment, cast, brand safety flags, and targeting recommendations.
Marengo encodes both content scenes and ad creatives into the same 512-dimensional embedding space, enabling visual similarity matching between what is on screen in the content and what appears in the ad creative.
The engine then combines model-derived context with deterministic business logic.
At a high level:
totalScore = adAffinity * sceneFit sceneFit = suitableMatch * 0.15 + environmentFit * 0.15 + toneCompat * 0.10 + contextMatch * 0
That weighting matters. Marengo’s embedding similarity drives most of the score because the best contextual match comes from the actual scene-ad relationship. Pegasus-derived structured signals preserve controllability for brand suitability, environment, tone, and policy rules. Our tutorial makes this explicit: the remaining signals give policy and content safety teams deterministic guardrails.
This is the practical middle ground publishers need. Not a black box. Not a brittle rules engine. A configurable scoring layer that combines video-native intelligence with commercial constraints.
Why Publishers Should Own Their Video Intelligence Layer
There will always be a role for ad-tech platforms, SSPs, ad servers, SSAI providers, brand safety vendors, and workflow partners. The question is not whether publishers should build everything themselves. The question is whether the core understanding of their own content should be rented from someone else.
When a publisher depends entirely on a third-party contextual vendor, the vendor controls more than a feature. It controls the methodology that determines how inventory is classified, packaged, blocked, priced, and explained to buyers.
That creates four commercial constraints.
First, content may need to leave the publisher’s environment for processing, creating infrastructure cost, governance questions, and contractual risk.
Second, classifications are often calibrated around a vendor’s generalized taxonomy rather than the publisher’s inventory and buyer relationships.
Third, changes to suitability rules often require vendor services work rather than direct iteration by the publisher’s product, data, or ad operations teams.
Fourth, the intelligence does not compound inside the publisher’s own infrastructure. Each new analysis enriches the vendor’s platform more than the publisher’s own operating layer.
Owning the intelligence layer changes that. Publishers can encode their video libraries once, persist embeddings, define their own contextual segments, test different suitability logic, integrate outputs into ad servers, and build repeatable packaging strategies across VOD, FAST, live, sports, news, and international libraries. The value transitions from a vendor report to a flexible, monetizable asset to drive engagement, CPM lift, and fill rate.
Where This Matters First
The first wave of adoption will not be generic. It will concentrate in places where better scene intelligence directly affects yield, safety, or workflow cost.
FAST channels: FAST operators need to create more value from large libraries without adding manual programming overhead. Contextual intelligence can help identify better ad breaks, package inventory by scene context, support category exclusions, and improve the ad experience without requiring every asset to be manually reviewed.
Premium VOD libraries: Large catalogs often contain valuable scenes that are invisible to title-level metadata. Scene intelligence makes it possible to create packages around mood, setting, talent presence, objects, topics, themes, and brand-safe environments.
Live sports and event programming: Sports monetization depends on timing. The same ad can feel appropriate after a celebration and jarring during an injury review. Video-native models can reason across motion, audio, and crowd energy to support better ad break and sponsorship decisions.
News and current affairs: News has suffered from blunt blocking. The word "conflict" in a transcript should not automatically make an entire segment unsuitable. Publishers need models that can distinguish reporting, analysis, weather, market commentary, and genuinely unsafe adjacency.
These are not speculative use cases. They are the places where ad sales, ad ops, product, and technology teams already feel the limitations of current metadata.
The Partner Opportunity
For adtech and media technology partners, the opportunity is not to compete with publishers for content understanding. It is to build better products on top of a stronger foundation: A contextual SaaS vendor may already know how to deliver signals into the right systems. An SSP may already understand supply packaging. A SSAI platform may already own the insertion workflow. A data platform may already govern downstream analytics.
TwelveLabs strengthens those systems by providing the video intelligence layer underneath them: Marengo serves as the multimodal encoder, turning video, audio, text, and visual context into a searchable representation. Pegasus serves as the reasoning layer, converting that representation into structured outputs that downstream systems can use.
For partners, that means:
Better contextual signal quality
More configurable suitability logic
Cleaner taxonomy mapping
Stronger explainability for buyers
Faster product development without building video foundation models from scratch
The result is not another closed ad-tech platform. It is infrastructure that lets the ecosystem build more precise advertising products.
The Conversation Publishers Should Be Having Now
At StreamTV show, the conversation has centered on streaming growth, FAST monetization, advertising innovation, and technology infrastructure. At Cannes Lion Festival, it will center on brands, agencies, creativity, media quality, and the role AI should play in advertising.
Those conversations often happen in different rooms. Contextual advertising connects them.
Publishers should be asking:
Is my contextual AI vendor natively multimodal, and do they provide academic benchmarking for video understanding tasks?
Can we explain why an ad appeared in this moment?
Can we package inventory by what happens inside the video, not just by title or genre?
Can we reduce blunt blocking without compromising brand safety?
Can we tune suitability rules by advertiser category, region, and content type — without a vendor service request?
Can we send context into the ad systems we already use?
Can our contextual intelligence improve over time, inside our own environment?
Can partners build on our intelligence layer without taking control of it?
The organizations that answer yes will have a different kind of leverage with buyers: They will not simply sell impressions. They will sell understood moments.
Contextual Advertising Is an Infrastructure Decision
The future of contextual advertising will not be defined by who has the most polished dashboard. It will be defined by who owns the representation of video that every downstream decision depends on:
If the video remains opaque, advertising remains approximate.
If the video becomes queryable, contextual, and decisionable, every ad break becomes more valuable.
That is the role TwelveLabs plays: We help publishers and partners turn video into an intelligence layer that can support search, retrieval, suitability, ad decisioning, analytics, and automation. Marengo encodes the content. Pegasus reasons across it. The outputs can be mapped to taxonomies, scored against business rules, delivered into ad systems, and audited by the teams responsible for revenue and trust.
Contextual advertising is no longer just a targeting tactic. It is a test of whether media companies can turn their most valuable asset, video, into infrastructure.
The publishers who do that first will not just monetize more inventory. They will define what premium video advertising feels like next.
See the contextual ad engine in action: Explore our technical tutorial to understand how TwelveLabs turns scene intelligence into IAB-compliant, FreeWheel-compatible ad decisioning workflows.
For publishers and partners: Talk to us about piloting contextual ad intelligence across FAST, VOD, sports, news, and premium streaming inventory at sales@twelvelabs.io.
Related articles





Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved